
bjohanne/AI/2002/KI-2002-1FolieProSeite.pdf
367
Universität des Saarlandes FR 6.2 Informatik Stuhlsatzenhausweg, Geb. 36 66123 Saarbrücken Tel.: (0681) 302-5252/2363 Fax: (0681) 302-5341 E-mail: [email protected] WWW: http://www.dfki.de/~wahlster Wolfgang Wahlster Vorlesung im SS 2002 Einführung in die Methoden der Künstlichen Intelligenz
-
Upload
hoangkhanh -
Category
Documents
-
view
212 -
download
0
Transcript of bjohanne/AI/2002/KI-2002-1FolieProSeite.pdf

Universität des SaarlandesFR 6.2 Informatik
Stuhlsatzenhausweg, Geb. 3666123 Saarbrücken
Tel.: (0681) 302-5252/2363Fax: (0681) 302-5341
E-mail: [email protected]: http://www.dfki.de/~wahlster
Wolfgang Wahlster
Vorlesung im SS 2002
Einführung indie Methoden
der Künstlichen Intelligenz

2
KI, Kognitionswissenschaft und Intellektik
Die KI hat: ingenieurswissenschaftliche Ziele kognitionswissenschaftliche Ziele
KI
Ingenieurswissenschaften
Informatik
BiowissenschaftenPsychologie
PhilosophieLinguistik
Kognitions-wissenschaft

3
Kerngebiete und Anwendungsfelder der KI
Natürlich-sprachliche
Systeme
Natürlich-sprachliche
Systeme
Bild-verstehende
Systeme
Bild-verstehende
SystemeExperten-systeme
Experten-systeme RobotikRobotik
Multi-AgentenSysteme
Multi-AgentenSysteme
IntelligenteTutorielleSysteme
IntelligenteTutorielleSysteme
IntelligenteHilfe-
systeme
IntelligenteHilfe-
systeme
IntelligenteBenutzer-
schnittstellen
IntelligenteBenutzer-
schnittstellen
Subsymbolische VerarbeitungSignal-Symbol-Transformation
Wissensrepräsentation
Wissensverarbeitung- Suchen- Inferieren- Lernen
Wissenspräsentation
KI-Programmiermethoden
KI-Programmiersprachen
KI-
Wer
kzeu
ge
KI-
Har
dw
are

4
Die Notwendigkeit hybrider KI-Systeme
Hybrides KI-System
Symbolische Ebene
- Semantische Netze- Regelbasierte Verfahren- Constraintbasierte Techniken
Subsymbolische Ebene
- Neuronale Netze
- Genetische Algorithmen- Fuzzy Control
Fahrzeug gemäß Verkehrsregelnund Zielvorgabe lenkenwissensintensive höhere kognitiveProzesse mit Erklärungsmöglichkeitweniger zeit- und störkritischeVerarbeitung
Fahrzeug gemäß Verkehrsregelnund Zielvorgabe lenkenwissensintensive höhere kognitiveProzesse mit Erklärungsmöglichkeitweniger zeit- und störkritischeVerarbeitung
Beispiel: Autofahren
Fahrzeug auf der Fahrbahn halten
unbewußter senso-motorischerProzeß, keine Erklärungsmöglichkeit
sehr schnelle, robuste Verarbeitung
Fahrzeug auf der Fahrbahn halten
unbewußter senso-motorischerProzeß, keine Erklärungsmöglichkeit
sehr schnelle, robuste Verarbeitung
5
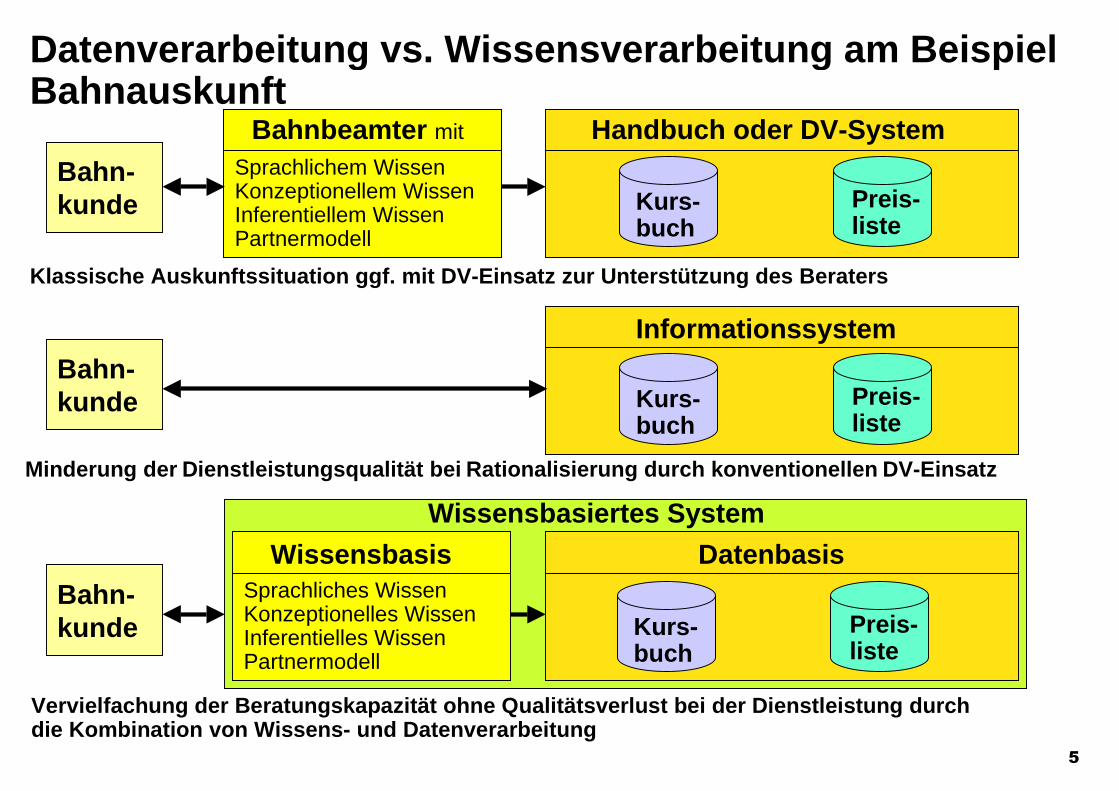
Datenverarbeitung vs. Wissensverarbeitung am BeispielBahnauskunft
Bahn-kunde
Minderung der Dienstleistungsqualität bei Rationalisierung durch konventionellen DV-Einsatz
Informationssystem
Kurs-buch
Preis-liste
Bahn-kunde
Bahnbeamter mit
Klassische Auskunftssituation ggf. mit DV-Einsatz zur Unterstützung des Beraters
Handbuch oder DV-System
Kurs-buch
Preis-liste
Sprachlichem WissenKonzeptionellem WissenInferentiellem WissenPartnermodell
Bahn- kunde
Vervielfachung der Beratungskapazität ohne Qualitätsverlust bei der Dienstleistung durchdie Kombination von Wissens- und Datenverarbeitung
Wissensbasiertes System
Wissensbasis Datenbasis
Kurs-buch
Preis-liste
Sprachliches WissenKonzeptionelles WissenInferentielles WissenPartnermodell

6
Die wichtigsten Unterschiede zwischenDatenverarbeitung und Wissensverarbeitung
Inhaltliche KriterienDatenverarbeitung Wissensverarbeitung
Automatisierung monotoner, klar strukturierterund wohldefinierter Informationsverarbeitungs-
prozesse
Automatisierung komplexer Informationsver-arbeitungsprozesse, die den intelligentenUmgang mit diffusem Wissen erfordern
Komplexität entsteht hauptsächlich durch denUmfang der Datenmenge
Bei formaler Ein-/Ausgabespezifikation ist prinzipiell die Möglichkeit eines Korrektheits-
beweises gegeben
Hauptsächlich Verarbeitung homogen strukturier-ter Massendaten (viele Instanzen, wenigTypen)
Nur der Programmierer, nicht das System selbstkann einen ausgeführten Verarbeitungsprozeß
erklären und rechtfertigen
Systementwickler schreibt mit Hilfe seines Wissens über den Anwendungsbereich ein
Programm
Zu automatisierende Verarbeitungsabläufe sindaus nichtautomatisierten Informations-
verarbeitungsprozessen bekannt
Komplexität entsteht hauptsächlich durch dieReichhaltigkeit der Wissensstruktur
Da die Verarbeitung durch Heuristiken unddiffuses Wissen gesteuert ist, sind
Korrektheitsbeweise nicht immer möglich
Verarbeitung heterogen strukturierter Wissens-einheiten (wenig Instanzen, viele Typen)
Das wissensbasierte System selbst kannprinzipiell einen ausgeführten Verarbeitungs-
prozeß erklären und rechtfertigen
Wissensträger transferiert sein Wissen über denAnwendungsbereich in ein wissensbasiertes
System
Zu automatisierende Verarbeitungsabläufesind kognitive Prozesse und daher nicht
direkt beobachtbar

7
Grundbegriffe der WissensrepräsentationWissen: Ansammlung von Kenntnissen, Erfahrungen und Problemlösemethoden, die denHintergrund für komplexe Informationsverarbeitungsprozesse bilden.
Wissensrepräsentation: Operationale sowie formale und damit computergerechte Darstellungvon Wissensinhalten.
Wissensrepräsentationssprache: Formale Sprache zur systematischenWissensrepräsentation.
Repräsentationskonstruktion: Teilmenge einer Wissensrepräsentationssprache.
Wissensbasis: Gesamtheit an Wissen, die einem KI-System zur Verfügung steht.
Metawissen: Wissen, das sich auf anderes Wissen innerhalb einer Wissensbasis bezieht.
Heterogene Wissensbasis: Wissensbasis, in der unterschiedliche Wissensrepräsenta-tionssprachen zur Codierung von Wissensquellen verwendet werden.
Multiple Repräsentation: Darstellung der gleichen Wissensinhalte in verschiedenenWissenseinheiten mit Hilfe unterschiedlicher Wissensrepräsentationssprachen.
Wissensbasis
Wissensquellen
Wissenseinheiten
8
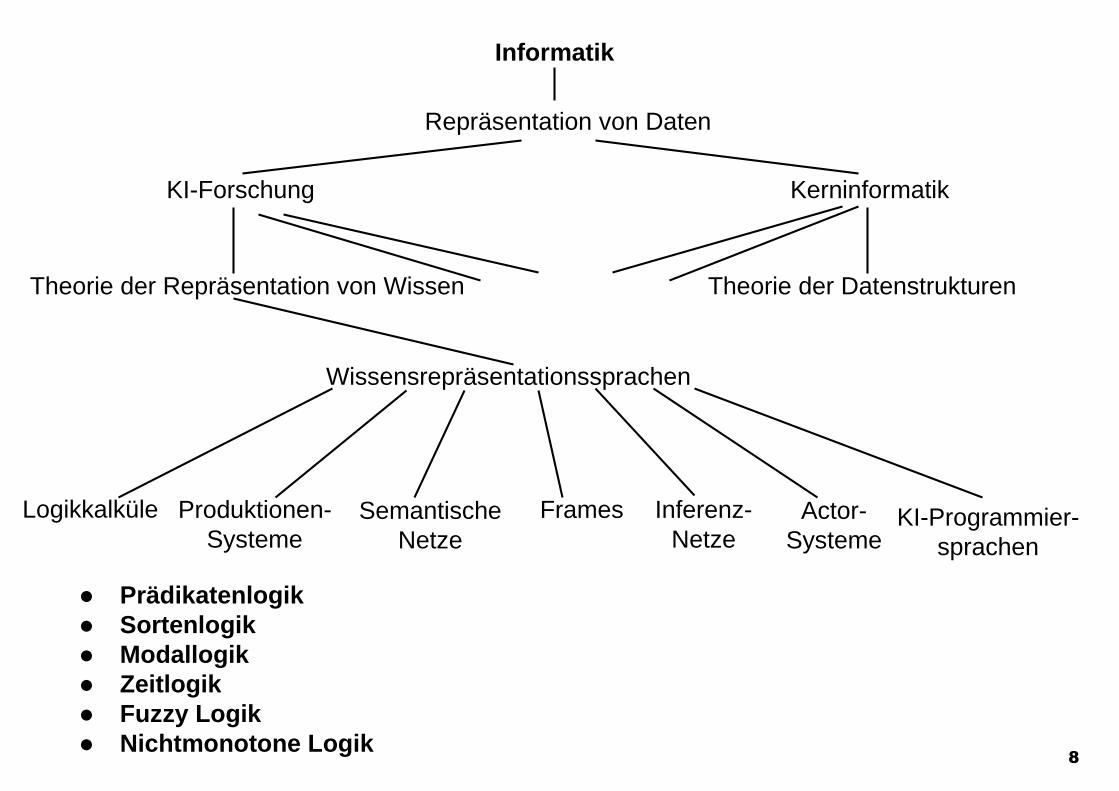
Informatik
Repräsentation von Daten
KI-Forschung Kerninformatik
Theorie der Repräsentation von Wissen Theorie der Datenstrukturen
Wissensrepräsentationssprachen
Logikkalküle Produktionen-Systeme
SemantischeNetze
Frames Inferenz-Netze
Actor-Systeme
KI-Programmier-sprachen
Prädikatenlogik Sortenlogik Modallogik Zeitlogik Fuzzy Logik Nichtmonotone Logik

9
Das Umfeld terminologischer Logiken
PrädikatenlogikPrädikatenlogik Thue SystemeThue Systeme PolymodaleLogiken
PolymodaleLogiken
ModelltheorieModelltheorie ReguläreSprachenReguläreSprachen
DynamischeLogiken
DynamischeLogiken
ConstraintSolving
ConstraintSolving
FeatureLogikenFeatureLogiken
Terminologische LogikenDie KL-ONE SprachfamilieTerminologische Logiken
Die KL-ONE Sprachfamilie
Feature Logiken
- Mengenwertige Features- Functional Uncertainty
Feature Logiken
- Mengenwertige Features- Functional Uncertainty
Komplexe Objekte
- Subtyp-Inferenz- Erfüllbarkeit
Komplexe Objekte
- Subtyp-Inferenz- Erfüllbarkeit
nach B. Nebel

10
Hybride, KL-ONE-basierte Systeme
TBox
Father = (and Man Parent)
TBox
Father = (and Man Parent)
ABox
Father(a)c x: Man(x) / ...
ABox
Father(a)c x: Man(x) / ...
Beispiele: KL-TWO, BACK, SB-ONE, KRIS, CLASSIC, LOOM, FACTS, RACER

11
Wissensrepräsentation mit Terminologischen LogikenTerminologische Logik = Konzeptsprachen = Termsubsumptionssprachen= KL-ONE (Knowledge Language) Derivate
Hauptziel: Repräsentation von terminologischem Wissen auf der Basisstrukturierter Vererbungsnetze
Konzepte und Taxonomien:
‚Konzept‘ als atomare Wissensenheit repräsentiert Klasse von Entitäten einerDiskurswelt
Konzept wird benannt nach den Elementen der Klasse graphisch dargestellt als Ellipse, die den Namen umrahmt
Ein Konzept, das eine Menge S repräsentiert, wird mit |C|S bezeichnet Wenn S 3 T, dann ist: |C|S Unterkonzept (Sub C) von |C|T
|C|T Oberkonzept (SuperC) von |C|S Diese Relation wird als: Konzeptsubsumption bezeichnet und
graphisch als dicker, gerichteter Pfeil von |C|S nach |C|T dargestellt
Man sagt: |C|T subsumiert |C|S|C|S spezialisiert |C|T

12
Konzepte und TaxonomienDie Konzeptsubsumption
ist transitiv :Falls |C|A subsumiert |C|B und |C|B subsumiert |C|C, dann gilt |C|A subsumiert |C|C.ist antisymmetrisch :Falls |C|A subsumiert |C|A‘ und |C|A‘ subsumiert |C|A, dann gilt |C|A = |C|A‘induziert eine partielle Ordnung über eine Menge von Konzepten führt graphisch zu einemgerichteten azyklischen Graph, dessen Kanten Subsumptionsrelationen entsprechen.
Jedes Netzwerk enthält als Wurzel ein allgemeinstes Oberkonzept THING, das immer alleanderen Konzepte eines Netzes autark subsumiert.Wenn ein neues Konzept in ein bestehendes Netzwerk aufgenommen werden soll, muß es ander richtigen Stelle in der Taxonomie plaziert werden.Regel:Das neue Konzept |C|A soll gleichzeitig die allgemeinsten Konzepte subsumieren, die wenigerallgemein sind als |C|Aund: es soll alle spezifischsten Konzepte spezialisieren, die weniger spezifisch sind als |C|ADieser Prozeß der Aufnahme eines neuen Konzeptes gemäß einer Regel wird alsKlassifikation bezeichnet, und wird von einem sogenannten Classifier durchgeführt.Die Reihenfolge der inkrementellen Aufnahme in ein zyklenfreies Netz hat keinen Einfluß aufdie Gestalt des Netzes.

13
Subsumptionsrelation in NIKL
Beachte: MICRO-COMPUTER spezialisiert DIGITAL-COMPUTER und ELECTRICAL-DEVICE.RADIO ist kein VEGETABLE, da diese Subsumptionsrelation nicht repräsentiert ist.
DEVICEDEVICE
THINGTHING
ELECTRICAL-DEVICE
ELECTRICAL-DEVICE
VEGETABLEVEGETABLE
MOUSE-TRAP
MOUSE-TRAP COMPUTING-
DEVICECOMPUTING-
DEVICE
RADIORADIO
SUPER-COMPUTER
SUPER-COMPUTER
MICRO-COMPUTER
MICRO-COMPUTER
WIND-TUNNELWIND-
TUNNEL
DIGITAL-COMPUTER
DIGITAL-COMPUTER
SLIDE-RULE
SLIDE-RULE
ANALOG-COMPUTERANALOG-
COMPUTER
14
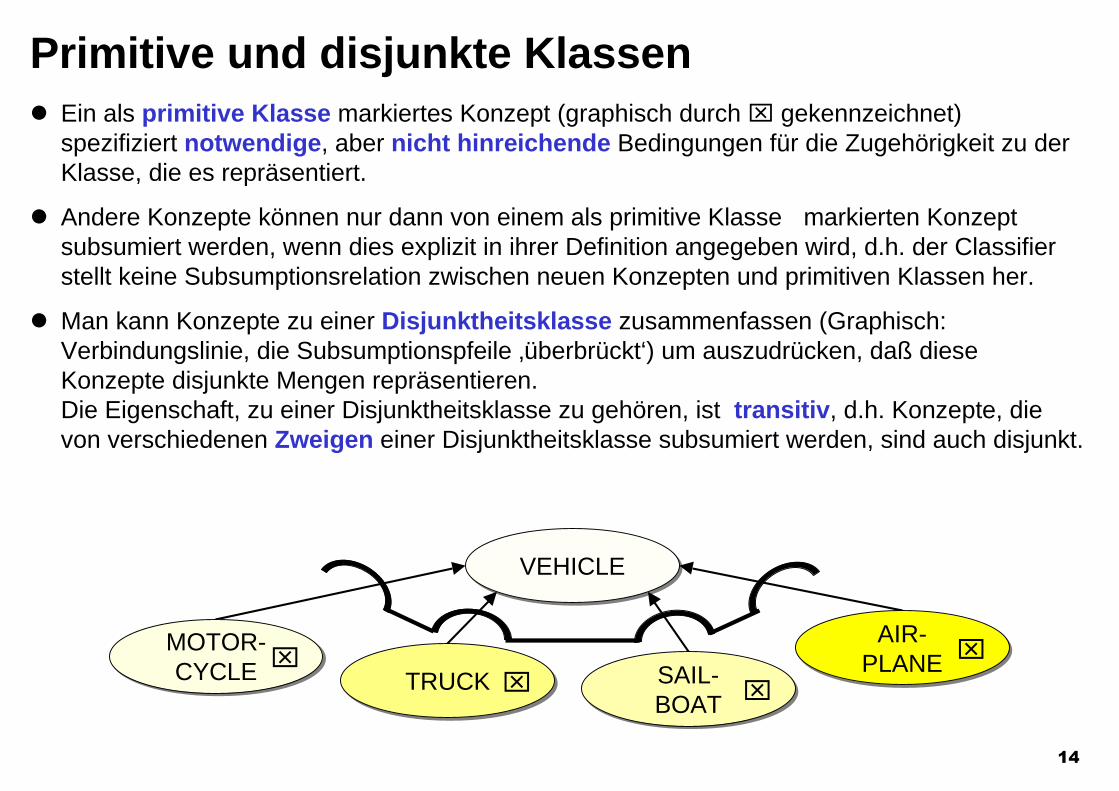
Primitive und disjunkte KlassenEin als primitive Klasse markiertes Konzept (graphisch durch ⌧ gekennzeichnet)spezifiziert notwendige, aber nicht hinreichende Bedingungen für die Zugehörigkeit zu derKlasse, die es repräsentiert.
Andere Konzepte können nur dann von einem als primitive Klasse markierten Konzeptsubsumiert werden, wenn dies explizit in ihrer Definition angegeben wird, d.h. der Classifierstellt keine Subsumptionsrelation zwischen neuen Konzepten und primitiven Klassen her.
Man kann Konzepte zu einer Disjunktheitsklasse zusammenfassen (Graphisch:Verbindungslinie, die Subsumptionspfeile ‚überbrückt‘) um auszudrücken, daß dieseKonzepte disjunkte Mengen repräsentieren.Die Eigenschaft, zu einer Disjunktheitsklasse zu gehören, ist transitiv, d.h. Konzepte, dievon verschiedenen Zweigen einer Disjunktheitsklasse subsumiert werden, sind auch disjunkt.
VEHICLEVEHICLE
MOTOR-CYCLE
MOTOR-CYCLE ⌧ TRUCKTRUCK ⌧ SAIL-
BOATSAIL-BOAT ⌧
AIR-PLANEAIR-
PLANE ⌧
15
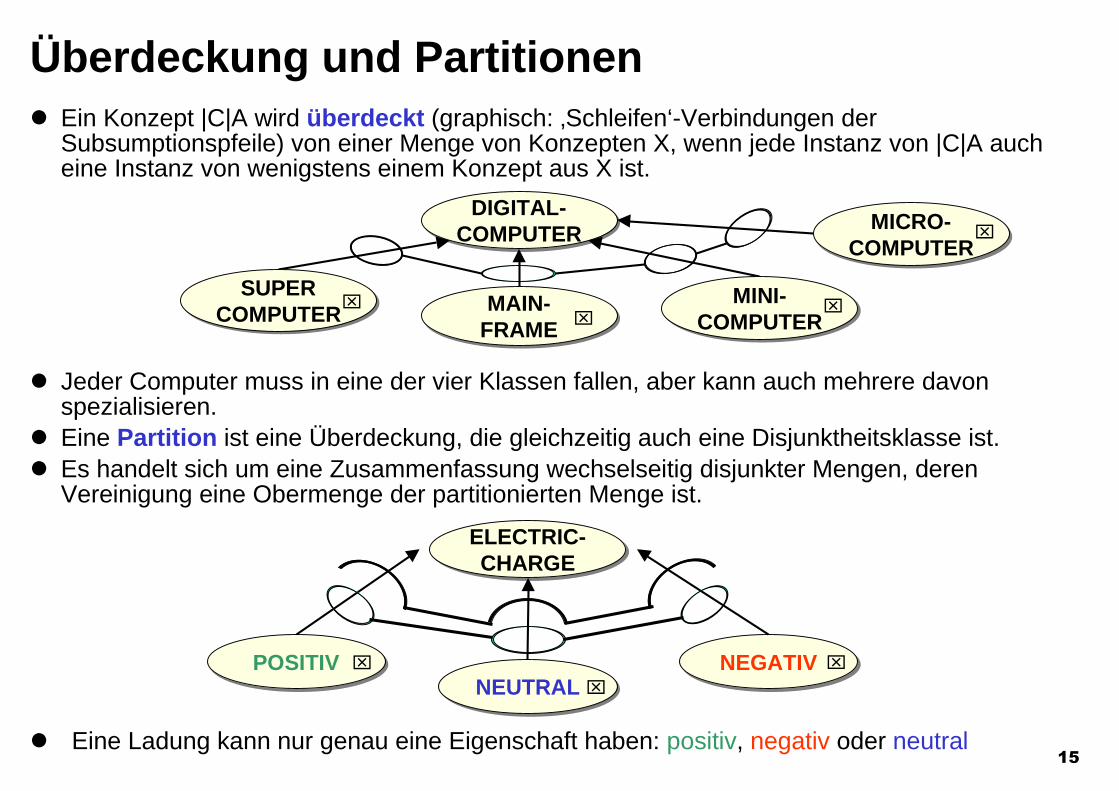
Überdeckung und PartitionenEin Konzept |C|A wird überdeckt (graphisch: ‚Schleifen‘-Verbindungen derSubsumptionspfeile) von einer Menge von Konzepten X, wenn jede Instanz von |C|A aucheine Instanz von wenigstens einem Konzept aus X ist.
Jeder Computer muss in eine der vier Klassen fallen, aber kann auch mehrere davonspezialisieren.Eine Partition ist eine Überdeckung, die gleichzeitig auch eine Disjunktheitsklasse ist.Es handelt sich um eine Zusammenfassung wechselseitig disjunkter Mengen, derenVereinigung eine Obermenge der partitionierten Menge ist.
Eine Ladung kann nur genau eine Eigenschaft haben: positiv, negativ oder neutral
NEUTRALNEUTRALNEGATIVNEGATIVPOSITIVPOSITIV
ELECTRIC-CHARGE
ELECTRIC-CHARGE
⌧⌧
⌧
MAIN-FRAMEMAIN-
FRAME
DIGITAL-COMPUTERDIGITAL-
COMPUTER
SUPERCOMPUTER
SUPERCOMPUTER
MINI-COMPUTER
MINI-COMPUTER
⌧⌧
⌧
MICRO-COMPUTER
MICRO-COMPUTER
⌧

16
Rollen und Rollenfüller• Eine Rolle definiert eine Beziehung zwischen zwei Konzepten.
Eine Rolle wird als zweistellige Relation graphisch durch ein umkreistes Quadratdargestellt.Vom Definitionsbereich der Rolle führt eine ungerichtete Kante zu Rollensymbol.Vom Rollensymbol führt eine gerichtete Kante zum Bildbereich der Rolle.
• Eine Instanz des Bildbereichs einer Rolle nennt Rollenfüller.
• ‚Alle Bewohner eines belebten Planeten sind Lebensformen.‘
• c x 2 INHABITED-PLANET(x) d y 2 LIFE-FORM(y) o INHABITANT(x,y)
• Die Rolle |R| INHABITANT repräsentiert eine Relation, die auf alle Unterkonzeptedes Definitionsbereiches vererbt wird.
• Eine allgemeine Methode zur Definition von Unterkonzepten ist die Restriktion des Bildbereichs der ererbten Rolle.
INHABITEDPLANET
INHABITEDPLANET
LIFE-FORMLIFE-FORM
⌧
⌧
INHABITANT

17
Rollentaxonomie• Wenn eine Rolle |R|A eine speziellere Relation repräsentiert als |R|B, dann nennen wir
|R|A Unterrolle (SubR) von |R|B und|R|B Oberrolle (SuperR) von |R|A.
• |R|A differenziert |R|B und |R|B verallgemeinert |R|A.
• Die allgemeinste Oberrolle ist MostGeneralRole. Sieht man diese Oberrolle als Konzept an(kann man für alle Rollen tun), so ergibt sich:
• Primitive Rollen sind Rollen, die ihre Oberrolle in einer Weise differenzieren, die dem Systemunzugänglich ist.
PET
RENT LEASE
RELATION
SPOUSE
LOVER
PARTNER
USE
FRIEND
THINGTHING
MostGeneralRoleMostGeneralRole
domain range
(1 1) (1 1)
18
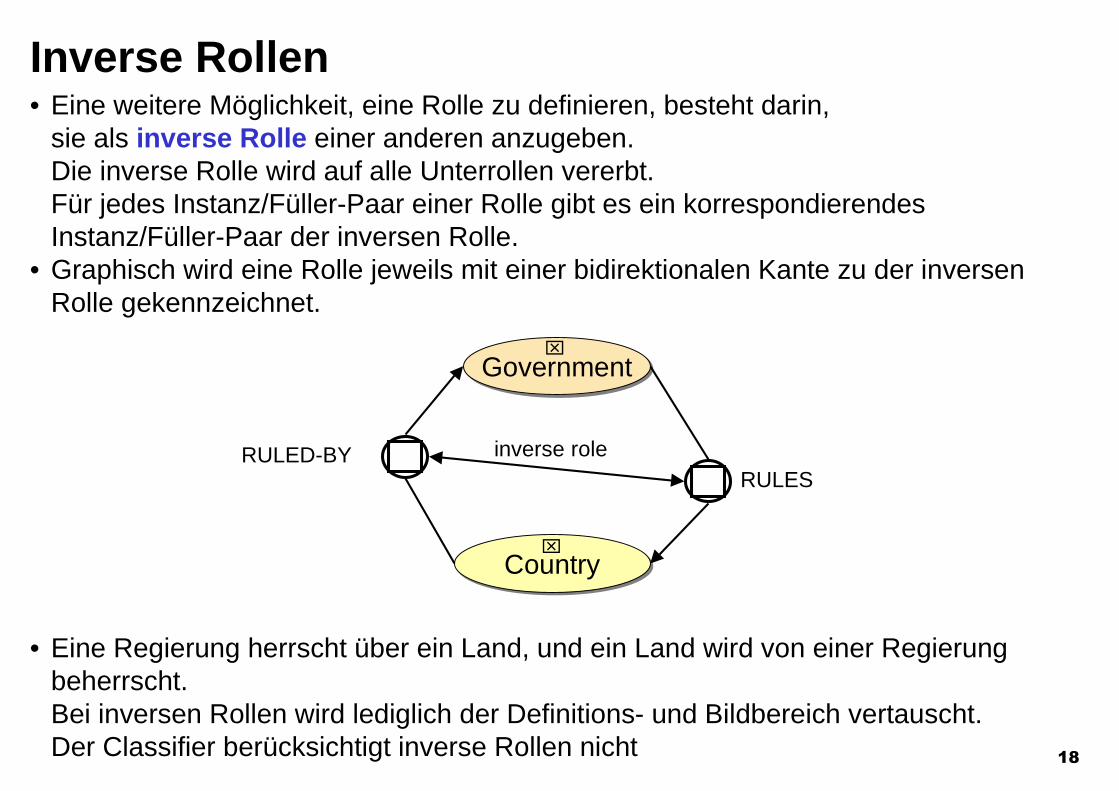
Inverse Rollen• Eine weitere Möglichkeit, eine Rolle zu definieren, besteht darin,
sie als inverse Rolle einer anderen anzugeben.Die inverse Rolle wird auf alle Unterrollen vererbt.Für jedes Instanz/Füller-Paar einer Rolle gibt es ein korrespondierendesInstanz/Füller-Paar der inversen Rolle.
• Graphisch wird eine Rolle jeweils mit einer bidirektionalen Kante zu der inversenRolle gekennzeichnet.
• Eine Regierung herrscht über ein Land, und ein Land wird von einer Regierungbeherrscht.Bei inversen Rollen wird lediglich der Definitions- und Bildbereich vertauscht.Der Classifier berücksichtigt inverse Rollen nicht
CountryCountry
GovernmentGovernment
RULED-BYRULES
inverse role
⌧
⌧
19
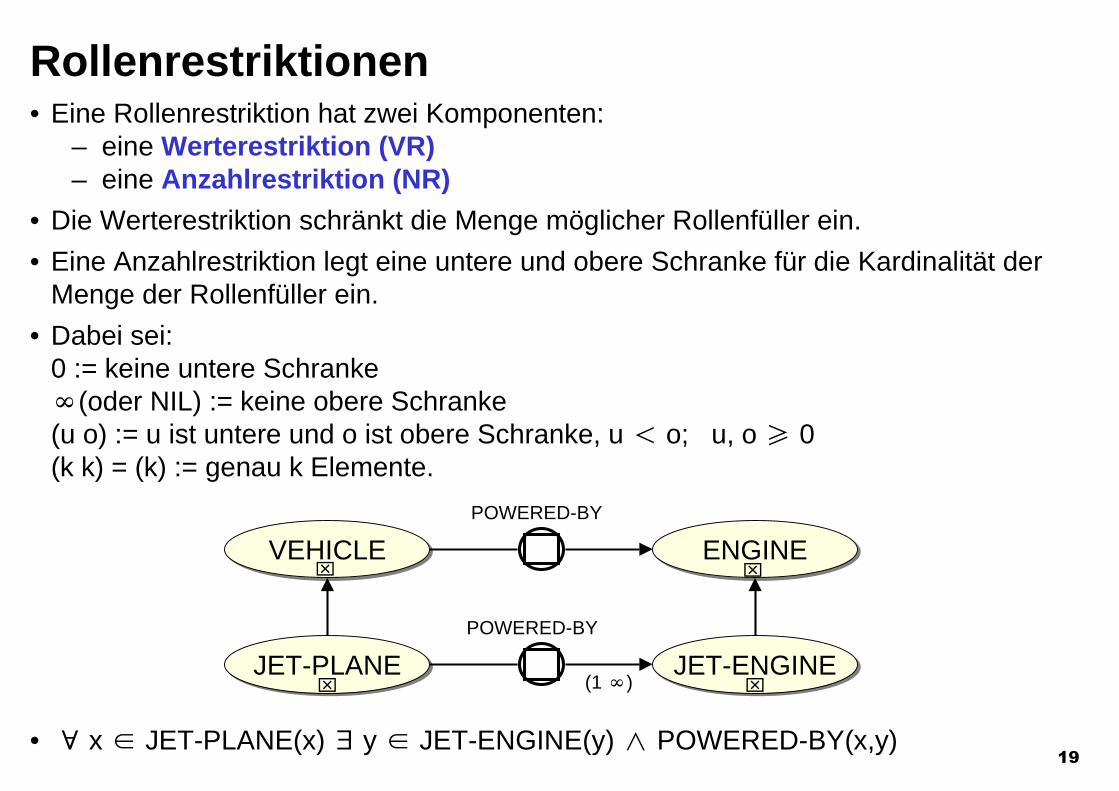
Rollenrestriktionen• Eine Rollenrestriktion hat zwei Komponenten:
– eine Werterestriktion (VR)– eine Anzahlrestriktion (NR)
• Die Werterestriktion schränkt die Menge möglicher Rollenfüller ein.
• Eine Anzahlrestriktion legt eine untere und obere Schranke für die Kardinalität derMenge der Rollenfüller ein.
• Dabei sei:0 := keine untere SchrankeN(oder NIL) := keine obere Schranke(u o) := u ist untere und o ist obere Schranke, u ! o; u, o P 0(k k) = (k) := genau k Elemente.
• c x 2 JET-PLANE(x) d y 2 JET-ENGINE(y) o POWERED-BY(x,y)
VEHICLEVEHICLE⌧
JET-PLANEJET-PLANE⌧
ENGINEENGINE⌧
JET-ENGINEJET-ENGINE⌧
POWERED-BY
POWERED-BY
(1 N)

20
Rollenbeziehungen• Um ein Konzept exakt zu definieren, ist es häufig notwendig, nicht nur isoliert für
einzelne Rollen Restriktionen zu formulieren, sondern auch Beziehungen zwischenden Rollenfüllermengen zweier Rollen bezüglich eines Konzeptes zu fordern.
• Dazu dienen Rollenbeziehungen (engl. oft role constraints oder role value maps),die aus zwei Rollenketten und einem Beschränkungstyp (Teilmenge, Obermenge,Gleichheit) bestehen.
• Eine Rollenkette ist eine Liste von Rollen, deren erstes Element mit dem Konzeptverbunden ist, für das die Rollenbeziehung definiert wird.
• Da jede Rolle in einer Rollenkette einer Relation entspricht, ergibt eine Rollenkette eine Komposition der Relationen. Der Definitionsbereich der komponierten Relationist das Konzept, für das die Rollenbeziehung definiert ist.
• Mit Rollenbeziehungen können also Relationen repräsentiert werden, dieverschiedene Konzepte, Rollen und Taxonomieebenen ‚überspannen‘.
• Graphisch wird ein Beschränkungstyp durch einen Rhombus dargestellt , der dasSymbol für die entsprechende Mengenbeziehung enthält.
• Von dem Rhombus gehen gestrichelte Linien aus, die den Rollenkettenentsprechen.

21
Beispiel für Rollenbeziehungen• Im folgenden Beispiel wird die Muttersprache einer Person als die Sprache definiert, welche
die Bewohner der Stadt sprechen, in der die Person geboren wurde.
• Rollenkette: MOTHER-TONGUE (PERSON) =• Rollenkette: SPEAK (RESIDENTS (LOCATION (BIRTH (PERSON))))
LANGUAGE⌧
PERSON⌧
(PERSON)⌧
CITY⌧
HOSPITAL⌧
=
LANGUAGE⌧
PERSON⌧
CITY⌧
HOSPITAL⌧
=
MOTHER-TONGUE BIRTH
LOCATION
RESIDENTS
SPEAK
LOCATIONRESIDENTSSPEAK
MOTHER-TONGUE BIRTH
Darstellung ohne Knotenkopie für Person:

22
ATOM-OR-IONATOM-OR-ION
THINGTHING
UNIT-OF-MATTERUNIT-OF-MATTER
Beispiel für eine Konzeptdefinition: das Wasserstoffatom
PARTICLEPARTICLE
HYDROGEN-ATOM
HYDROGEN-ATOM
NEUTRONNEUTRON
CHARGED-PARTICLE
CHARGED-PARTICLE
PROTONPROTON
ELECTRONELECTRON
CONTAINS-2
(0 N)
(1 N)
CONTAINS-1
CONTAINS-3(1 1)
CONTAINS-4
(1 1)

23
Definitionen für Wasserstoffatom(DEFCONCEPT UNIT-OF-MATTER PRIMITIVE (SPECIALIZES THING))
(DEFCONCEPT PARTICLE PRIMITIVE (SPECIALIZES UNIT-OF-MATTER))
(DEFCONCEPT NEUTRON PRIMITIVE (SPECIALIZES PARTICLE))
(DEFCONCEPT CHARGED-PARTICLE PRIMITIVE (SPECIALIZES PARTICLE))
(DEFCONCEPT ELECTRON PRIMITIVE (SPECIALIZES CHARGED-PARTICLE))
(DEFCONCEPT PROTON PRIMITIVE (SPECIALIZES CHARGED-PARTICLE))
(DEFCONCEPT CHARGE-DICHOTOMY (ELECTRON PROTON))
(DEFCONCEPT ATOM-OR-ION PRIMITIVE (SPECIALIZES UNIT-OF-MATTER)
(ROLE CONTAINS-1 (VRCONCEPT NEUTRON)
(MIN 0) (MAX NIL))
(ROLE CONTAINS-2 (VRCONCEPT CHARGED-PARTICLE)
(MIN 1) (MAX NIL)))
(DEFCONCEPT HYDROGEN-ATOM PRIMITIVE (SPECIALIZES ATOM-OR-ION)
(ROLE CONTAINS-3 (DIFFERENTIATES CONTAINS-2)
(VRCONCEPT ELECTRON (NUMBER 1))
(ROLE CONTAINS-4 (DIFFERENTIATES CONTAINS-2)
(VRCONCEPT PROTON) (NUMBER 1)))

24
Definition eines Kreises als Subkonzept von Ellipse
THINGTHING
MATHEMATICALOBJECT
MATHEMATICALOBJECT
⌧ LINE-
SEGMENT
⌧ LINE-
SEGMENT
⌧ CLOSED-CURVE
⌧ CLOSED-CURVE
⌧ ELLIPSE⌧
ELLIPSE
CIRCLECIRCLE
=
MINOR-AXIS
MAJOR-AXIS
MINOR-AXISMAJOR-AXIS
(1 1)
(1 1)
(1 1)(1 1)
(DEFCONCEPT MATHEMATICAL-OBJECT (SPECIALIZES THING))(DEFCONCEPT LINE-SEGMENT
PRIMITIVE (SPECIALIZES MATHEMATICAL-OBJECT))(DEFCONCEPT CLOSED-CURVE
PRIMITIVE (SPECIALIZES MATHEMATICAL-OBJECT))(DEFCONCEPT ELLIPSE
PRIMITIVE (SPECIALIZES CLOSED-CURVE)(ROLE MINOR-AXIS (VRCONCEPT LINE-SEGMENT) (NUMBER 1))(ROLE MAJOR-AXIS (VRCONCEPT LINE-SEGMENT) (NUMBER 1)))
(DEFCONCEPT CIRCLE (SPECIALIZES ELLIPSE) ( = (MINOR-AXIS) (MAJOR-AXIS)))

25
Automatische Klassifikation(DEFCONCEPT GROSSVATER
(SPECIALIZES MANN)(ROLE KIND (VR ELTERNTEIL) (MIN 1)))
ELTERNTEILELTERNTEIL
GROSSVATERGROSSVATER
ELTERNTEILELTERNTEIL
MENSCHMENSCH
GELDGELDMENSCHMENSCH
MANNMANN
MENSCHMENSCH
(DEFCONCEPT ELTERNTEIL(SPECIALIZES MENSCH)(ROLE KIND (MIN 1)))
SPECIALIZES-Kante
⌧
⌧
S
S
S
S
VR
VR
VR
RRRR
RR
RR
VR
P 1 KIND
P 1 KIND P 1 ENKEL
EINKOMMEN

26
Automatische Klassifikation(DEFCONCEPT GROSSVATER
(SPECIALIZES MANN)(ROLE KIND (VR ELTERNTEIL) (MIN 1)))
ELTERNTEILELTERNTEIL
GROSSVATERGROSSVATER
ELTERNTEILELTERNTEIL
MENSCHMENSCH
GELDGELDMENSCHMENSCH
MANNMANN
MENSCHMENSCH
(DEFCONCEPT ELTERNTEIL(SPECIALIZES MENSCH)(ROLE KIND (MIN 1)))
SPECIALIZES-KanteBerechneteSubsumptionsbeziehung
⌧
⌧
S
S
S
S
VR
VR
VR
RRRR
RR
RR
VR
P 1 KIND
P 1 KIND P 1 ENKEL
EINKOMMEN

27
Inferenzdienste in Konzeptsprachen
In der T-Box:
In der gesamten Wissenbasis (T-Box und A-Box):
Sind alle Konzepte verschieden oder stimmen welche überein? (Äquivalenz)
Welche Unterbegriffsbeziehungen bestehen? (Subsumption/Klassifikation)
Welche Rollen-Beziehungen gelten daher für die Begriffe? (Vererbung)
Ist ein definierter Begriff sinvoll oder ist die Klasse grundsätzlich leer? (Inkohärenz)
Haben zwei Klassen gemeinsame Instanzen oder nicht? (Disjunktheit)
Ist die WB konsistent? (Konsistenz)
Welche Klassen instantiiert ein gegebenes Objekt? (Instantiierung/Realisierung)
Welche der bekannten Elemente enthält eine vorgegebene Klasse? (Retrieval)
Welche (Rollen-)Beziehungen bestehen zwischen verschiedenen Objekten? (Vererbung)

28
InferenzdiensteT-Box:
Wissensbasis (WB):
Subsumption: cx LKW(x) 0 Transportfahrzeuge(x)?
Vererbung: cx Mutter_ohne_Söhne(x) 0 dy Kinder(x,y)
Inkohärenz: cx lGroßvater(x)? oder: ex. Interpretation I ~dx Großvater(x)?
Disjunktheit: l dx Vater(x) o Mutter(x)?
Konsistenz: existiert ein Modell der WB, d.h. ex. Interpretation I ~ WB?
Instantiierung/Realisierung: Güterzug(Z#521)?
bzw. Finde alle Konzepte C mit C(Z#521)!
Retrieval: Finde alle Objekte c mit Frau(c)!
Vererbung: Kinder(Karin,Eva)?

29
Eine formale Semantik von Konzeptsprachen
Warum?
Präzisierung der Bedeutung von Repräsentationskonstrukten Vergleichbarkeit mit anderen Formalismen Algorithmisierung Entscheidbarkeit und Komplexität
Wie?
Konzepte beziehen sich auf Mengen von Instanzen: Konzeptextension Rollen beschreiben Relationen zwischen diesen Instanzen: Rollenextension Konzeptbeschreibungen geben notwendige und hinreichende Bedingungenfür Instanzen an
Subsumption ist die notwendige Inklusion von Konzeptextensionen Inkonsistenz ist die notwendige Leerheit von Konzeptextensionen

30
Rollen, Konzepte und ihre InterpretationA: Menge von atomaren Konzepten (Variablen: A, B)S: Menge von atomaren Rollen (Variablen: S)
Interpretation: I Z 6D, 8%9I7 mit D beliebige Menge und Funktion:
A / 2D
S / 2D / 2D3
Die Interpretation wird induktiv definiert: 8R l R#9I Z $d → !8R9I(d) h 8R#9I(d)#%
8R-C9I Z $d → !8R9I(d) h 8C9I#%
8%9I:
8A9I heißt Konzeptextension8S9I heißt Rollenextension8S9I(d) heißt Rollenfüllermenge der Rolle S für d
R: Menge von RollenbeschreibungenR / S atomare Rolle - R l R# Rollenkonjunktion - R-C Rollenrestriktion

31
Terminologien, Modelle, Subsumption
Eine Interpretation I erfüllt eine solche Gleichung (symbolisch ~I):
~I A ^ C 5 8A9I Z 8C9I
~I A 8 C 5 8A9I 4 8C9I
~I S ^ R 5 8S9I(d) Z 8R9I(d) für alle d 2 D ~I S 8 R 5 8S9I(d) 4 8R9I(d) für alle d 2 D
def
def
def
def
I ist ein Modell von T gdw. I alle Gleichungen erfüllt.
Der intuitive Subsumptionsbegriff ergibt sich dann wie folgt:C wird von D in T subsumiert (C 7T D) gdw.
8C9I ⊆ 8D9I für alle Modelle I von T.
Eine Terminologie (T) ist eine Menge von Gleichungen und Ungleichungen derfolgenden Form (keine Doppeldefinitionen): A ^ C definiertes Konzept A 8 C primitives Konzept S ^ R definierte Rolle S 8 R primitive Rolle.
32
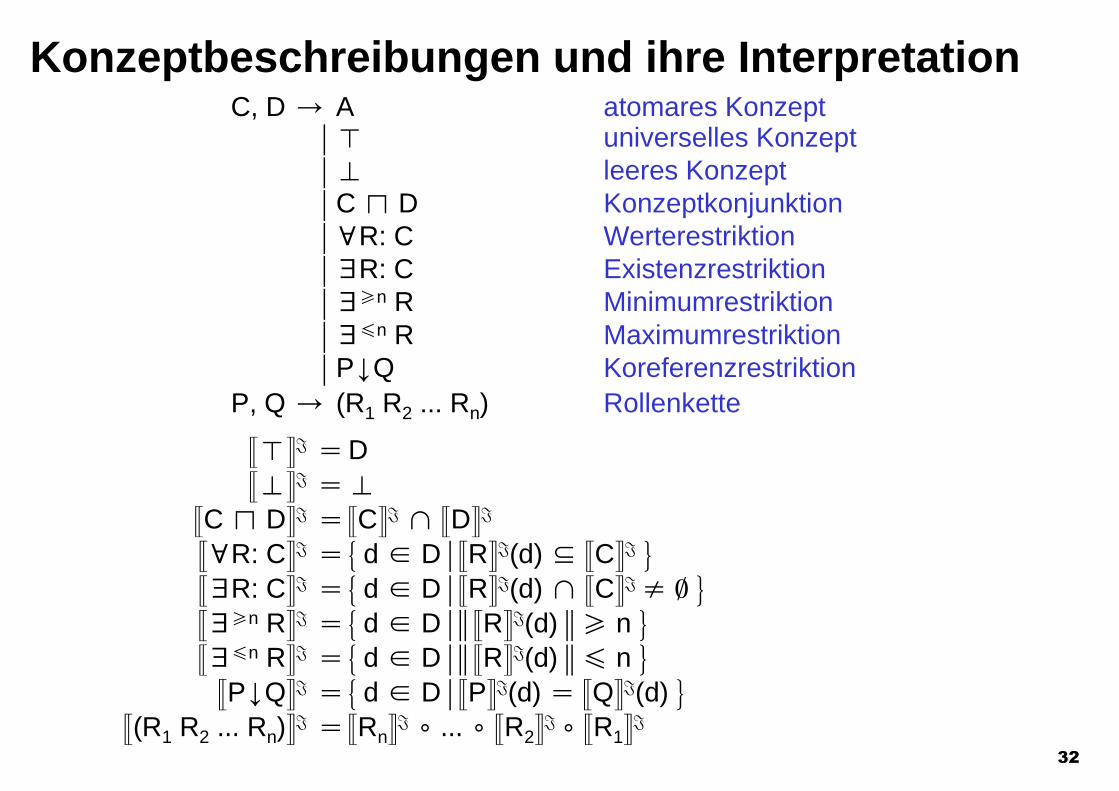
C, D / A atomares Konzept- u universelles Konzept- t leeres Konzept- C l D Konzeptkonjunktion- cR: C Werterestriktion- dR: C Existenzrestriktion- dPn R Minimumrestriktion- d#n R Maximumrestriktion- PYQ Koreferenzrestriktion
P, Q / (R1 R2 ... Rn) Rollenkette
Konzeptbeschreibungen und ihre Interpretation
8u9I Z D8t9I Z t
8C l D9I Z 8C9I h 8D9I
8cR: C9I Z & d 2 D - 8R9I(d) 4 8C9I (8dR: C9I Z & d 2 D - 8R9I(d) h 8C9I s \ (8dPn R9I Z & d 2 D - / 8R9I(d) / P n (8d#n R9I Z & d 2 D - / 8R9I(d) / # n (
8PYQ9I Z & d 2 D - 8P9I(d) Z 8Q9I(d) (8(R1 R2 ... Rn)9I Z 8Rn9I + ... + 8R29I + 8R19I

33
Konzeptbildende OperatorenAbstrakte Form: Konkrete From: Interpretation: Bezeichnung:
C, D / A A 3[A] Atomares Konzept| C l D (and C D) 3[C] h 3[D] Konzeptkonjunktion| C k D (or C D) 3[C] g 3[D] Konzeptdisjunktion| lC (not C) D \ 3[C] Konzeptnegation| cR : C (all R C) { d 2 D | 3[R](d) 4 3[C] } Wertrestriktion| dR (some R) { d 2 D | 3[R](d) s \ } Existenzrestriktion| Pn R (atleast n R) { d 2 D | | 3[R](d) | P n } Minimum-Zahlenrestriktion| #n R (atmost n R) { d 2 D | | 3[R](d) | # n } Maximum-Zahlenrestriktion| n R (exact n R) { d 2 D | | 3[R](d) | Z n } Exakte Zahlenrestriktion| (0nPn) R (optatleast n R) { d 2 D | 3[R](d) Z \ n | 3[R](d) | P n } (Opt.) Minimum-Zahlenrestriktion| dR: C (some R C) { d 2 D | 3[R](d) h 3[C] s \ } (Qual.) Existenzrestriktion| Pn R: C (atleast n R C) { d 2 D | | 3[R](d) h 3[C] | P n } (Qual.) Minimum-Zahlenrestriktion| #n R: C (atmost n R C) { d 2 D | | 3[R](d) h 3[C] | # n } (Qual.) Maximum-Zahlenrestriktion| Zn R: C (exact n R C) { d 2 D | | 3[R](d) h 3[C] | Z n } (Qual.) Exakte Zahlenrestriktion| RC Z SC (eq RC SC) { d 2 D | 3[RC](d) Z 3[SC](d) } Rollenketten-Gleichheit| RC s SC (neq RC SC) { d 2 D | 3[RC](d) s 3[SC](d) } Rollenketten-Ungleichheit| RC 4 SC (subset RC SC) { d 2 D | 3[RC](d) 4 3[SC](d) } Rollenketten-Teilmengenbeziehung| r : C (in r C ) { d 2 D | \ s 3[r](d) 4 3[C] } Attributrestriktion auf Konzept| r : i (is r i ) { d 2 D | 3[i](d) 2 3[r](d) } Attributrestriktion auf Individuum| rc Z sc (opteq rc sc ) { d 2 D | 3[rc](d) Z 3[sc](d) } (Opt.) Attributketten-Gleichheit| rc s sc (optneq rc sc ) { d 2 D | 3[rc](d) s 3[sc](d) } (Opt.) Attributketten-Ungleichheit| rc Z sc (eq rc sc ) { d 2 D | 3[rc](d) Z 3[sc](d) s \ } Attributketten-Gleichheit| rc s sc (neq rc sc ) { d 2 D | \ s 3[rc](d) s 3[sc](d) s \ } Attributketten-Ungleichheit| {i1 , i2 , . . . , in} (oneof i1 . . . in) { 3[i1], 3[i2], . . . , 3[in] } Aufzählung| datatype Abstrakter Datentyp| fn (apply fn) Aufruf externer Funktion
Y
Y

34
Vier Beschreibungsebenen für Wissensrepräsentations-sprachen
1) ImplementationsebeneObjektePointer
2) Logische Ebene:PrädikateQuantoren
3) Epistemologische EbeneVererbungsrelationenStrukturierungsprimitive
4) Ontologische EbenePrimitive KonzeptePrimitive Relationen

35
Beispiel für initiale Konzepttaxonomie: NIKL
PREDICATEDTHING
THING
RELATIONLISPDATA
CONSP
CHARACTERP
ATOM
ARRAYP
VECTORP
BIT_VECTORP
SECOND-PLACE
STRINGP
SYMBOLP
NULL
NUMBERP
2-PLACERELATION
ROLE-RELATION
INTEGERP
RATIONALP
COMPLEXP
FLOATPFIRST-PLACE
PLACESD
RANGE DOMAIN
⌧
⌧
⌧
⌧
⌧
⌧⌧
⌧
⌧
⌧
⌧⌧
⌧
⌧
⌧
⌧
⌧
⌧
⌧
⌧
⌧
⌧ ⌧
⌧
⌧

36
Zur Entwicklung semantischer Netzwerke Einfache semantische Netzwerke Quillian 1966 Semantische Netzwerke mit Kasusrahmen Simmons 1971
Norman/Rummelhart1972
konzeptuelle Dependenz-Netze Schank 1972(CD-Graphen)
partitionierte semantische Netze Hendrix 1977(LN2)
gerichtete rekursive Bewertungsknoten- Boley 1975Hypergraphen (DRLH)
prozedurale semantische Netze Levesque 1977(PSN)
Strukturierte Vererbungsnetze Brachmann 1978(SI-Netze, z.B. KL-ONE)

37
MUSIKINSTRUMENTmusical instrument
MOEBELpiece of furniture
FARBEcolour
SITZGELEGENHEITseating
SESSELarm-chair
ROTred
WEISSwhite
SCHWARZblack
KLAVIERpiano
TISCHtable
WASSERwater
GEGENSTANDobject
FESTsolid
DINGthing
AGGREGATZUSTANDstate
FLUESSIGKEITliquid
GETRAENKdrink
SAFTjuice
APFELSAFTapple juice
APFELSAFT 1
WEISSwhite
KLAVIER 1
SCHWARZblack
BEIN 1
BEIN 2
BEIN 3
BRAUNKAPUTTdamaged
BRAUNbrown
HEILintact
SESSEL 1
STUHLchair
KLAVIERSTUHLpiano-stool
BEINleg
FLUESSIGfluid
STUHL 1STUHL 2
KLAVIERSTUHL 1
Konzeptuelles semantisches Netz von HAM-RPM (v. Hahn, Wahlster)
Referentielles semantisches Netz von HAM-RPM
U
U
U
U
U
U
UU
UU
U U
E
U
U 0.7
VV
V
DD
E
U
TT
U
D 0.8
ISA
ISA
ISA
ISAISA
ISAISA
(ANZAHL:4) 0.8
(ANZAHL:4) 0
.7
REF
REFREF
HAP
REF
Frühe Semantische Netze in HAM-RPM

38
Framesprachen
ModellierungsprimitiveOKBC-Lite
Framesprachen
ModellierungsprimitiveOKBC-Lite
Konzeptsprachen/Terminologische Logiken
Formale SemantikSubsumption, Inferenzen
Konzeptsprachen/Terminologische Logiken
Formale SemantikSubsumption, Inferenzen
Websprachen
XML- und RDF-Syntax
Websprachen
XML- und RDF-Syntax
OILOIL
OIL führt drei Sprachfamilien zusammen

39
Drei Ebenen von Mark-up-Sprachen im Web
Inhalt : Struktur : Form = 1 : n : m
WWW-DokumentWWW-Dokument
Inhalt
Struktur
Form
OIL
XML
HTML

40
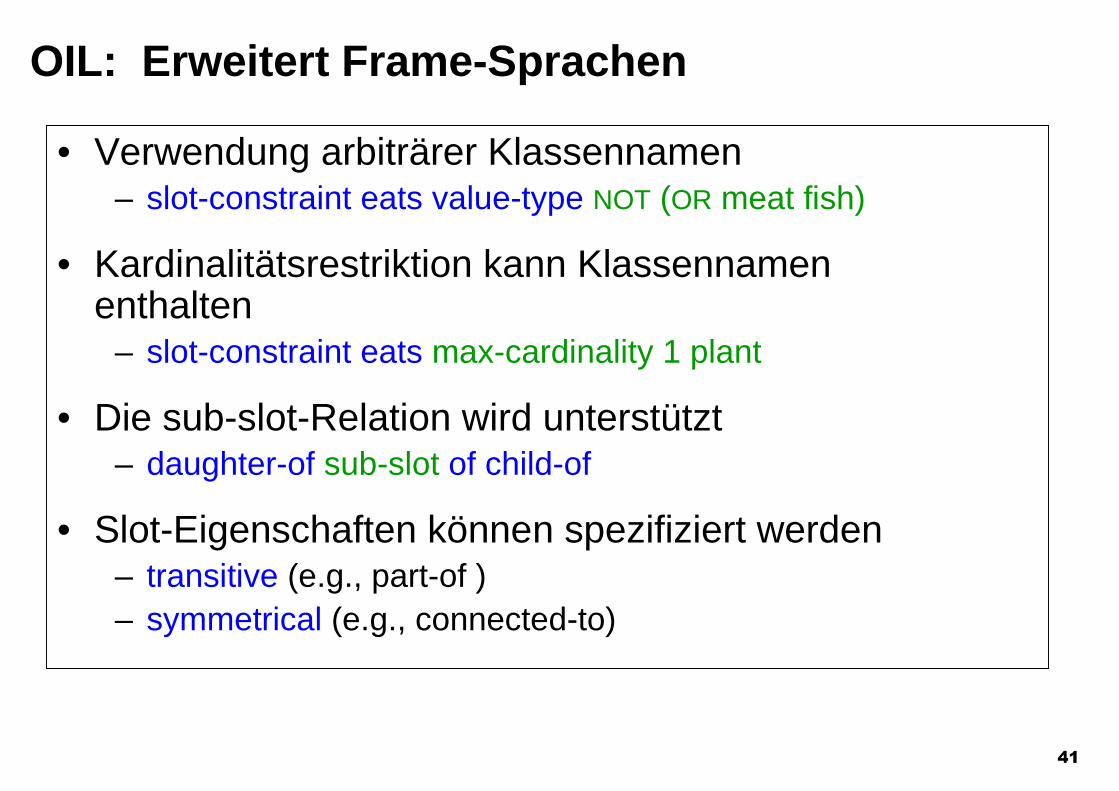
OIL: Erweitert Frame-Sprachen
• Klassen können primitiv sein (notwendigeBedingungen)– elephant 0 animal that has-colour grey
• oder definiert (notwendige und hinreichendeBedingungen)– vegetarian 5 person who eats meat nor fish
• Klassen sind als Slot-Constraints zugelassen– slot-constraint eats has-value meat
(eats some meat)– slot-constraint eats value-type meat
(eats only meat)
41
OIL: Erweitert Frame-Sprachen
• Verwendung arbiträrer Klassennamen– slot-constraint eats value-type NOT (OR meat fish)
• Kardinalitätsrestriktion kann Klassennamen enthalten
– slot-constraint eats max-cardinality 1 plant
• Die sub-slot-Relation wird unterstützt– daughter-of sub-slot of child-of
• Slot-Eigenschaften können spezifiziert werden– transitive (e.g., part-of )– symmetrical (e.g., connected-to)

42
OIL: Beispiel einer Ontologie für Drucker (Teil 1)class-def Productslot-def Price domain Productslot-def ManufacturedBy domain Productclass-def PrintingAndDigitalImagingProduct subclass-of Productclass-def HPProduct subclass-of Product slot-constraint ManufacturedBy has-value "Hewlett Packard"class-def Printer subclass-of PrintingAndDigitalImagingProductslot-def PrinterTechnology domain Printerslot-def Printing Speed domain Printerslot-def PrintingResolution domain Printerclass-def PrinterForPersonalUse subclass-of Printerclass-def HPPrinter subclass-of HPProduct and Printer

43
OIL: Beispiel einer Ontologie für Drucker (Teil 2)class-def LaserJetPrinter subclass-of Printer slot-constraint PrintingTechnology has-value "Laser Jet"class-def HPLaserJetPrinter subclass-of LaserJetPrinter and HPProductclass-def HPLaserJet1100Series subclass-of HPLaserJetPrinter and PrinterForPersonalUse slot-constraint PrintingSpeed has-value "8 ppm" slot-constraint PrintingResolution has-value "600 dpi"class-def HPLaserJet1100se subclass-of HPLaserJet1100Series slot-constraint Price has-value "$479"class-def HPLaserJet1100xi subclass-of HPLaserJet1100Series slot-constraint Price has-value "$399"

44
Einige Begriffe zur Repräsentation einerAktionssemantik in terminologischen Logiken
Aktionen ändern den Zustand der Welt.
Aktionsparameter:Objekte, die für Aktionen relevant sind,formale Objektparameter,Typ beschränkt auf Konzept,(Cup1 CUP)
Zustände:beschrieben mittels Attributen,durch Restriktion der Attributwerte oder‘Agreements‘ auf Attributketten,(Cup1.contents.temperature: HOT)(Cup1.position = Agent.hand.inside)
Vor/Nachbedingungen:Konjunktion von Zuständen

45
Aktionstypen
Atomare Aktionen:
nicht zerlegbar,
definiert durch Vor- und Nachbedingungen,
Vorbedingung muss erfüllt sein, damit Aktion ausgeführt werden kann,
Nachbedingung wird hergestellt, nachdem Aktion erfolgreich abgelaufen ist.
Aktionssequenzen:
Sequenz von Aktionen mit optionalen Einschränkungen bzgl. der Aktionsparameter der Teilaktionen

46
(defaction PUT-CUP-UNDER-WATEROUTLET(actpars ( (Cup1 CUP)
(Agent PERSON)(Duo1 ESPRESSO-MACHINE))
(before (Cup1.position = Agent.hand.inside))(after (Cup1.position = Duo1.wateroutlet.under))))
(defaction TURN-SWITCH-TO-ESPRESSO(actpars ( (EM1 ESPRESSO-MACHINE)
(Agent PERSON))(before (EM1.state: (and OFF READY)))(before (EM1.has-on/off-switch.position:
OFF-POSITION))(after (EM1.state: ON)
(EM1.has-on/off-switch.position:ESPRESSO-POSITION))))

47
(defaction MAKE-ESPRESSO(actpars ( (EM ESPRESSO-MACHINE)
(Agent PERSON)...)(sequence
(A1...)...
(A5 PUT-CUP-UNDER-WATEROUTLET)(A6 TURN-SWITCH-TO-ESPRESSO)
...)(constraints
(equal Agent (A5 Agent) (A6 Agent) ...)(equal EM (A5 Duo1) (A6 EM1) ...)
...)))

48
LIVING-OBJECT PHYSICAL-OBJECT
COMPOUND-PHYSICAL-OBJECT
LOCATION
(defaction PUT-CUP-UNDER-WATEROUTLET(actpars ((Agent PERSON)
(Duo1 ESPRESSO-MACHINE)) (Cup1 CUP))
(before (Cup1.position = Agent.hand.inside))
(after (Cup1.position = Duo1.wateroutlet.under))))
PERSON ESPRESSO-MACHINE WATEROUTLET CONTAINER
HAND
PART-OF-BODYwateroutlet
inside
CUP
part
under
position
CONCEPT
role

49
RATRAT
Plan
P1
P2
ActionActionActionActionAction
RAT
*TOP*
Phys. Obj. Beings
CupMachine
Human
KRIS
Duo
Aktionen
Konzepte
TBox WERKZEUGE ABox
RAT
KRIS
Objekte
Ereignisse
Take-Cup#5
Place-Cup#13
Turn-Switch#6
Switch#2
Cup#9
User#5
Aktions-SubsumptionAktions-Subsumption
AusführbarkeitstestAusführbarkeitstest
Plan InstantiierungPlan Instantiierung
SimulationSimulation
ZwischenzuständeZwischenzustände
RealisationRealisation
Konzept InstantiierungKonzept Instantiierung
KonsistenzKonsistenz KlassifikationKlassifikation
Konzept-SubsumptionKonzept-Subsumption

50
RAT: Services
• Feasibility Test: ist der Plan P generell ausführbar?
• Instantiierung: Erzeuge eine Planinstanz I mit den angegebenenParameterwerten.
• Applicability Test: Ist die Planinstanz I im aktuellen Weltzustandanwendbar?
• Simulation: Simuliere die Ausführung der Planinstanz I bis zu einerbestimmten Stelle innerhalb des Plans.
• Intermediate States: Berechne den Weltzustand an einerbestimmten Stelle des Plans.

51
Ausführbarkeitstest
• Gegeben: Aktionssequenz P = (A1 A2 A3)Gesucht: Globale Vor- und Nachbedingungen von P
• Algorithmus: (temporal projection) Propagieren der Bedingungen
• Berechnung der schwächsten (allgemeinsten) Vorbedingungund der stärksten (speziellsten) Nachbedingung

52
Instantiierung
• Bei der Instantiierung einer Aktionssequenz werden alleTeilaktioneninstantiiert. Dafür können für die formalen Aktionsparameter konkreteObjekte der KRIS-Abox angegeben werden.
• Danach kann mit Hilfe der gespeicherten ADD- und DELETE-Listeneine Simulation des Planablaufs auf verschiedenen Ebenendurchgeführt werden.
• Die KRIS-ABox repräsentiert dabei den jeweiligen aktuellenWeltzustand.

53
Subsumption
Subsumption zwischen Aktionen kann auf Subsumption zwischenVor- und Nachbedingungen reduziert werden.
Vier verschiedene Subsumptionsbeziehungen:
Goal Subsumption (z.B. plan retrieval)A 8a B 5 Post(A) 8 Post(B)
Abstraction Subsumption (z.B. hierarchical planning)A 8b B 5 Pre(A) 8 Pre(B) o Post(A) 8 Post(B)
Applicability Subsumption (z.B. plan optimization)A 8g B 5 Pre(B) 8 Pre(A) o Post(A) 8 Post(B)
o Par(A) 8 Par(B)
Action Parameter Subsumption (z.B. lexical choice)A 8d B 5 Par(A) 8 Par(B) o A 8b B

54
BREW-ESPRESSO
PREPARE-ESPRESSO-POWDER
REMOVE-COVER-OF-WATERCONTAINER
SCREW-IN-COVER-OF-WATERCONTAINER
PREPARE-WATER
PLACE-CUP-UNDER-OUTLET
TURN-MACHINE-ON
ESPRESSO-DROPS-INTO-CUP
TURN-MACHINE-OFF
LIFT-LID
INSTALL-COVER-OF-WATERCONTAINER
FILL-WATER-INTO-WATERCONTAINERPUT-IN-COVER-OF-WATERCONTAINER
LIFT-COVER-OF-WATERCONTAINER
UNSCREW-COVER-OF-WATERCONTAINER
INSTALL-FILTER-IN-HOLDER
FILL-FILTER-HOLDER
INSTALL-FILTER-HOLDER
action57543
TAKE-CUP
action57544
PRESS-BUTTON
PUT-FILTER-INTO-HOLDER
PUL-BACKWARD-CLIP-OF-FILTER
COMPRESS-ESPRESSO-POWDER
FILL-IN-ESPRESSO-POWDER
SCREW-FILTER-HOLDER
PLACE-FILTER-HOLDER

55
Action Sequence „Put_cup_under_drain“(defaction put_cup_under_drain
(actpars ((Agent USER) (Object CUP) (EM1 DUO5649))(sequence (A1 take_cup) (A2 put_down_cup))(constraints
(eq Agent (A1 Agent)) (eq Agent (A2 Agent)) (eq Object (A1 Object))(eq Object (A1 Object)) (eq EM1 (A2 EM1)))))
(defaction take_cup (actpars ((Agent USER) (Object CUP))
(before (is (Object position) LOCATION) (is (Agent has-hand contents) *BOTTOM*))
(after (eq (Object position) (Agent has-hand region-inside)) (eq (Agent has-hand contents) CUP))))
(defaction put_down_cup (actpars ((Agent USER) (Object CUP) (EM1 DUO5649))
(before (eq (Object position) (Agent has-hand region-inside)) (eq (Agent has-hand contents) Object) (is (EM1 has-drain occupied-by) *BOTTOM*))
(after (eq (Object position) (EM1 has-drain region-below)) (eq (EM1 has-drain occupied-by) Object) (is (Agent has-hand contents) *BOTTOM*))))

56
Ausführbarkeitstest Fortsetzung
Dabei:
Konsistenz aller Zwischenzustände
Prüfung der Anwendbarkeit für jede Teilaktion (ist Vorbe-dingung der Teilaktion allgemeiner als der aktuelle Weltzu-stand?)
Seiteneffekt:
Speicherung der ADD- und DELETE-Listen von Zustandsbe-schreibungen

57
Ausführbarkeitstest Fortsetzung• Abbildung der Anwendbarkeitstests in TL
‘Aktion A anwendbar in Weltzustand S‘/‘Vorbedingung von A subsumiert S‘
• Zustandsbeschreibung / Konzeptbeschreibung
(defaction . . . (actpars ((Cup1 CUP)) . . .) . . .))
(Cup1.position = Agent.hand.inside) /(and (all Cup1 CUP)
(equal (compose Cup1 position)(compose Agent hand inside)))
(Cup.contents.temperature: HOT) /(and (all Cup1 CUP)
(some (compose Cup1 contents temperature)HOT))
58
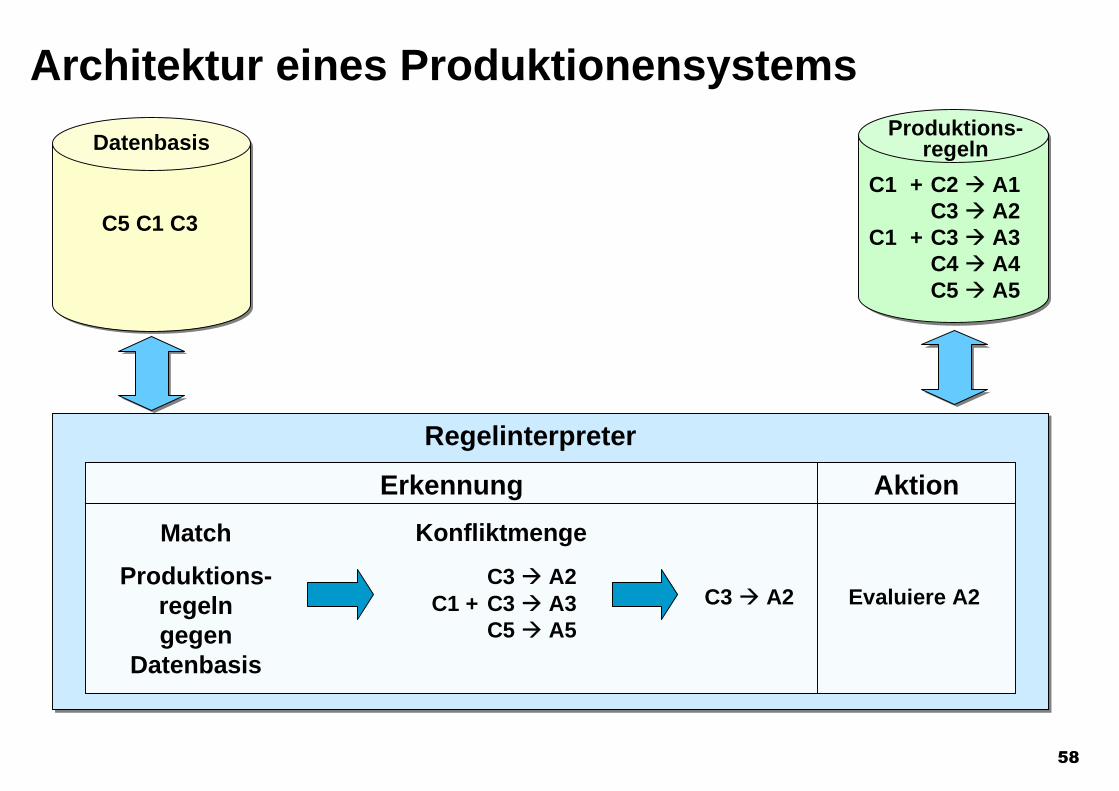
Architektur eines Produktionensystems
Datenbasis
C5 C1 C3
Produktions-regeln
C1 + C2 A1C3 A2
C1 + C3 A3C4 A4C5 A5
Regelinterpreter
Match
Produktions-regelngegen
Datenbasis
Erkennung Aktion
Konfliktmenge
C3 A2 C1 + C3 A3
C5 A5
C3 A2 Evaluiere A2

59
Entwicklung der ProduktionensystemePost1943
Markov1954
Chomsky1957
Newell/Simon1965

60
Produktionensystem für „P minus Q“
Datenbasis: (START) (P 5) (Q 3)
Variablen: X1 X2
Produktionsregeln:
R1: (START)
LÖSCHE ((START)), ERGÄNZE ((COUNT 0))
R2: (COUNT X1) & (P X2) & (Q X2))
DRUCKE (X1), STOP
R3: (COUNT X1) & (Q X2)
ERSETZE (X1, SUCC(X1), (COUNT X1)),
ERSETZE (X2, SUCC(X2), (Q X2))
DB1: (COUNT 0) (P 5) (Q 3) <R1>
DB2: (COUNT 1) (P 5) (Q 4) <R3>
DB3: (COUNT 2) (P 5) (Q 5) <R3>
“2“ <R2>

61
Das kanonische System von Emil Post alsVorläufer von ProduktionensystemenPostsche Systeme sind Ersetzungssysteme, die über einem endlichen Alphabet V definiert sind und aus
- einer endlichen Menge von Ersetzungsregeln und- einer endlichen Menge von Zeichenketten über V (Axiome)
bestehen.Beispiel: Erzeugung aller Palindrome (Zeichenketten, die in beiden
Leserichtungen gleich sind: ‘Reliefpfeiler‘, ‘Ein Neger mit Gazelle zagt im Regen nie‘) über einem Alphabet.
Alphabet: V = {a, b, c}Axiome: a, b, c, aa, bb, ccErsetzungsregeln: $ a$a
$ b$b$ c$c
$ kann durch beliebige Zeichenketten über V ersetzt werden.$ aca bacab cbacabc
Unterschiede zu Produktionensystemen:- Datenbasis (Arbeitsspeicher, Working Memory) besteht aus nicht weiter strukturierten
Symbolfolgen
- Rechte Regelseite enthält nur Ersetzungsvorschriften, aber keine Löschungen oderandere Operationen über der Datenbasis
- Konfliktauflösung bleibt ungeklärt (nicht-deterministische Auswahl der passenden Regel)

62
Grundbegriffe der Produktionensystemejede Produktion (Synonym: Inferenzregel)
besteht aus 2 Teilen:
A BPrämisse
AntezedensEvidenz
Wenn - TeilLinke Seite (LHS)
Bedingung
KonklusionKonsequenzHypotheseDann – TeilRechte Seite (RHS)Aktion
Die Produktionen werden über der Datenbasis (nicht: Datenbank!) ausgewertet, dieauch als ‚Arbeitsspeicher‘ (WM) oder bei Anwendung in der Kognitiven Psychologie als‚Kurzzeitgedächtnis‘ (STM) bezeichnet wird.
Es werden zwei Modi der Auswertung von Produktionen unterschieden:
A BDatengesteuertes Inferieren
Antezedens-orientiertes InferierenBottom-up InferierenIf-added Methoden
LHS-gesteuerte Verkettung
A BZielgesteuertes Inferieren
Konsequenz-orientiertes InferierenTop-down InferierenIf-needed Methoden
RHS-gesteuerte Verkettung
Vorwärtsverkettung Rückwärtsverkettung

63
Auswertungsmodi von ProduktionensystemenProblem
Rückwärtsverkettung Vorwärtsverkettung
anfängliches Wissen
... ...
... ...
Ein Problem P kann durch Vorwärtsverkettung (P) oder Rückwärtsverkettung (P) gelöst werden.Vorwärtsverkettung (X)
WM := anfängliches WissenUNTIL P ist gelöst oder keine Produktion kann mehr feuernDO:
(1) Bestimme die Menge K aller Regeln, deren Prämissen durch WM erfüllt sind(2) Wähle aus K aufgrund der Konfliktauflösungsstrategie eine Regel R aus(3) WM := Ergebnis der Auswertung von R über WM
Rückwärtsverkettung (X)WM := anfängliches WissenUNTIL P ist gelöst oder keine Produktion kann mehr feuernDO:
(1) Bestimme die Menge K aller Regeln, deren Konklusion mit P unifiziert werden kann(2) Wähle aus K aufgrund der Konfliktauflösungsstrategie eine Regel R aus(3) Falls die Prämisse von R nicht im WM steht, führe
Rückwärtsverkettung(Prämisse von R) ausFür Schritt (2) ist jeweils backtracking möglich

64
Kommutative ProduktionensystemeIn Ausnahmefällen können für Produktionensysteme unwiderrufliche Auswertungsmodiverwendet werden, bei denen kein backtracking notwendig ist.
Ein Produktionensystem heißt kommutativ, wenn es bzgl. jeder beliebigen Datenbasis Dfolgende Eigenschaften hat:
- Jede Produktion, die auf D anwendbar ist, ist auch noch auf alle Datenbasen anwendbar, die durch eine anwendbare Regel erzeugt werden.
- Wenn die Terminierungsbedingung für D erfüllt ist, ist sie auch noch für jede Datenbasis erfüllt, die durch eine auf D anwendbare Regel erzeugt wird.
- Die Datenbasis, die durch Anwendung einer beliebigen Folge von auf D anwend-baren Regeln auf D entsteht, ist invariant bzgl. Permutationen der Regelfolge.
Beispiel für ein kommutatives Produktionensystem:
Hier führt die Anwendung einer ‘ungünstigen Regel‘ nur zu einer Verlängerung desInferenzpfades, ohne jedoch die erfolgreiche Terminierung zu verhindern.
S11
R1
S3
R1
R2R2
SO S12 S2 SG
S13
R3
S1
R3
R2
R1
R2
R3
R3
R2
R3
R2
R1
R3
R1
R2
R3R1R1
R3
R1
R2

65
Dekomponierbare ProduktionensystemeEin Produktionensystem heißt dekomponierbar, wenn seine Datenbasis und dieTerminierungsbedingung dekomponierbar ist.
Die Datenbasis ist dekomponierbar, wenn sie in Komponenten zerlegt werden kann, die unabhängigvoneinander (prinzipiell parallel) vom Produktionensystem-Interpretierer bearbeitet werden können.
Die Terminierungsbedingungen ist dekomponierbar, wenn sie durch die Terminierungs-bedingungen über den Komponenten der dekomponierten Datenbasis ausgedrückt werden kann.
Beispiel: Datenbasis: (C,B,Z)Terminierungsbedingung: Datenbasis enthält nur M‘s
Produktionen: R1: C (D,L)R2: C (B,M)R3: B (M,M)R4: Z (B,B,M)
Dekomposition der Datenbasis: C,B,ZDekomposition der Terminierungsbedingungen: Jede dekomponierte Datenbasis führtnur zu M‘s
M
(C,B,Z)
(C) (B) (Z)
(D,L) (B,M) (M,M) (B,B,M)
(M,M)
D L B
M M M M M M
M M B M B
(M,M) (M,M)
R1 R2
R3
R3 R4
R3 R3

66
Vor- und Nachteile von ProduktionensystemenMächtigkeit der Repräsentations-
sprache
Mächtigkeit der Repräsentations-
spracheErweiterbarkeitErweiterbarkeit Statische Analyse
des KontrollflussesStatische Analyse des Kontrollflusses
Realisierungkomplexer
Kontrollstrukturen
Realisierungkomplexer
Kontrollstrukturen
Starkeingeschränkte
Syntax
Starkeingeschränkte
Syntax
Indirekte Regelinteraktion über
die Datenbasis
Programmieren durch Seiteneffekte
Indirekte Regelinteraktion über
die Datenbasis
Programmieren durch Seiteneffekte
Nachteile - - - -
Maschinelle Weiterverarbeitung
Maschinelle Weiterverarbeitung
ModulareWissensrepräsentation
ModulareWissensrepräsentation
Konsistenz-prüfung
Konsistenz-prüfung
Erklärungs-komponenteErklärungs-komponente WissenserwerbWissenserwerb FehlerkorrekturFehlerkorrektur
Merk-male
++Vorteile
++ + +

67
Zur Verwendung von Metaregeln in regelbasiertenSystemenMetawissen ist Wissen, das sich auf andere Wissenseinheiten in der Wissensbasis bezieht.Metaregeln beziehen sich auf die Form und den Inhalt von Produktionen, die in derWissensbasis gespeichert sind.
(1) Metaregeln zur KonfliktauflösungAngenommen in einem Expertensystem, das bei chemischen Verunreinigungen berät, gibt esfolgende Regeln:R1:Falls die Verunreinigung durch Schwefelsäure verursacht wurde, verwende Verfahren A.R2:Falls die Verunreinigung durch Schwefelsäure verursacht wurde, verwende Verfahren B.
Bei der Vorwärtsverkettung kann sich als Konfliktmenge {R1, R2} ergeben.Angenommen die Wissensbasis enthält folgende Information:
- Verfahren A ist teuer, Verfahren B ist billig- Verfahren A ist nicht gefährlich, Verfahren B ist gefährlich- R1 wurde von dem Experten Meyer eingegeben, R2 von dem Novizen Schulz
Metaregeln:R3:Bevorzuge Regeln, die billige Verfahren vorschlagen, gegenüber denen, die teure
Verfahren vorschlagen.R4:Bevorzuge Regeln, die weniger gefährliche Verfahren vorschlagen, gegenüber denen, die
gefährliche Verfahren vorschlagen.R5:Bevorzuge Regeln, die von Experten eingegeben wurden, gegenüber denen, die von
Novizen eingegeben wurden.

68
Konfliktauflösung mit Metaregeln(1) R4, R5: R1 vor R2(2) R3: R2 vor R1Die Entscheidung hängt ab:
- bei gemeinsamem Interpreter für Regeln und Metaregeln: Auswertungsreihenfolge- bei getrennten Interpretern für Metaregeln:
- bei zufälliger Auswahl: (1) wahrscheinlicher- bei ‘Mehrheitsentscheidung‘: (1)
Reflexive Verwendung von Metaregeln als Meta-Meta-Regeln- Angenommen die Wissensbasis enthält folgende Information:
R4 wurde vom Experten Meyer eingegeben,R3 vom Novizen SchulzR5: R4 vor R3: R1 vor R2
- Angenommen die Wissensbasis enthält die folgende Information:Die Anwendung von R3 ist gefährlich,die von R5 weniger gefährlich,die von R4 ungefährlich,R4: R4 vor R3, R5: R1 vor R2
Bei einem Konflikt zwischen Metaregeln wird ggf. wiederum eine Konfliktauflösungsstrategiebenötigt.
Ein infiniter Regreß wird dabei durch zufällige Wahl einer Produktion aus der Konfliktmenge aufeiner bestimmten Metaebene verhindert.
Mehr als 2 Metaebenen sind bisher in der Praxis nicht notwendig gewesen.
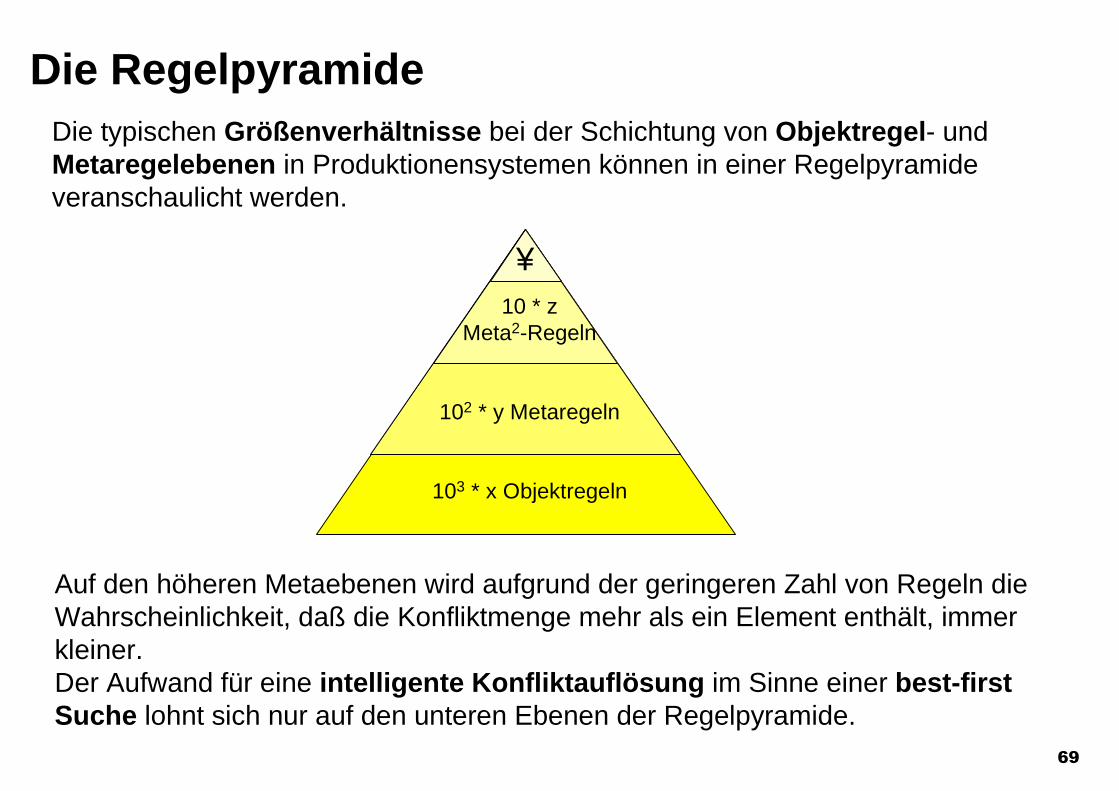
69
Die RegelpyramideDie typischen Größenverhältnisse bei der Schichtung von Objektregel- undMetaregelebenen in Produktionensystemen können in einer Regelpyramideveranschaulicht werden.
Auf den höheren Metaebenen wird aufgrund der geringeren Zahl von Regeln dieWahrscheinlichkeit, daß die Konfliktmenge mehr als ein Element enthält, immerkleiner.Der Aufwand für eine intelligente Konfliktauflösung im Sinne einer best-firstSuche lohnt sich nur auf den unteren Ebenen der Regelpyramide.
10 * zMeta2-Regeln
102 * y Metaregeln
103 * x Objektregeln

70
Konfliktauflösung aufgrund eines Prioritätenschemas für Regeln,Spezialisierungsrelationen zwischen Instantiierungen und Verweilzeiten im WM
WM ( (P S) (Q T) (P T) (R V) (Q S) (P V) ... (W V) (W T) )P1( (Q =X) (P =X) / ... )
I11 [ P1 ((Q T) (P T)) ]I12 [ P1 ((Q S) (P S)) ]
P2( (P S) (P =X) (W =X) / ... )I21 [ P2 ((P S) (P T) (W T)) ]I22 [ P2 ((P S) (P V) (W V)) ]
P3( (=X S) (=X =Y) (W =Y) (R =Y) (Q S) / ... )I3 [ P3 ((P S) (P V) (W V) (R V) (Q S)) ]
P4( (Q S) l(U S) (P =X) l(U V) l(U T) / ... )I41 [ P4 ((Q S) (P S)) ]I42 [ P4 ((Q S) (P T)) ]I43 [ P4 ((Q S) (P V)) ]
PO1 {I11 I12}PO2 {I11 I12 I3}SC1 {I21 I22 I3 I41 I42 I43}SC2 {I11 I21 I3 I42}SC3 {I11 I21 I3 I41 I42 I43}Rl {I12 I21 I22 I3 I41}R2 {I11 I12 I21 I22 I3 I41}R3 {I11}R4 {I11 I12 I41 I42 I43}R5 {I21}

71
Konfliktauflösungsstrategien
Im WM sind die Datenelemente von links nach rechts auf der Basis steigenderVerweildauer geordnet.
(P S) und (Q T) sind beim letzten Zyklus, (P T) und (R V) beim vorletzten Zyklus,(Q S) und (P V) vor 3 Zyklen und (W V) sowie (W T) vor 101 Zyklen im WMabgespeichert worden.
Die Produktionen sind in der Reihenfolge der Eingabe abgelegt. Variablen sindmit ‘=’ präfigiert.
(1) Konfliktauflösung aufgrund von Regelprioritäten- PO1: Totale Ordnung auf Regeln, z.B. Eingabereihenfolge.
Damit wird P1 selektiert.- PO2: Partielle Ordnung auf den Regeln, z.B. P1 dominiert P2, P3 dominiert P4.
Dann werden P1 und P3 selektiert.PO2 ist bei strukturierten Regelmengen relevant.

72
Konfliktauflösungsstrategien(2) Konfliktauflösung aufgrund von Spezialisierungsrelationen
zwischen Instantiierungen und Produktionen- SC1: S ist Spezialfall von Produktion A, falls
* S hat mindestens soviele Prämissen wie A und* zu jeder Prämisse in A, die Konstanten enthält, gibt es eine
entsprechende in S, die diese Konstanten als Teilmenge enthält, und* S und A sind nicht identisch
P4 ist damit Spezialfall von P1, so daß bei Instantiierung von P4 die Instantiierungenvon P1 ausgeschlossen sind. Zwischen P2, P3 und den anderen Produktionenbestehen keine Spezialisierungsbeziehungen im Sinne von SC1.
- SC2: S ist Spezialfall von Instantiierung A, falls S die Datenelemente von Aals eine echte Teilmenge enthält.Damit ist I3 Spezialfall von I12, I22, I41 und I43.
- SC3: Zusätzlich zu SC2 muß für Spezialfall noch gelten, daß die Produktionzu S mehr Prämissen hat als die zu A.Daher fallen I41 und I43 als Spezialfälle fort, da P4 und P3 die gleicheAnzahl von Prämissen haben.

73
Konfliktauflösungsstrategienaufgrund von Verweilzeiten im WM- R1: Ordnung aufgrund des Elementes einer lnstantiierung, das die kürzeste Verweilzeit
im WM hat, wobei die Zeit als Anzahl der Aktionen gemessen wird, die seit demEintrag ausgeführt wurden.
- R2: wie R1, wobei die Zeit als Anzahl der Interpreter-Zyklen gemessen wird, die seitdem letzten Eintrag ausgeführt wurden.
- R3: Geprüft werden die ältesten Elemente aller Instantiierungen. Es wird dann dieInstantiierung mit dem Element gewählt, die unter den ältesten die kürzesteVerweilzeit im Sinn von R1 hat.
- R4: Die Zeit wird wie in R2 gemessen. Geprüft werden wie in R3 die ältesten Elementealler Instantiierungen. Diejenigen, deren ältestes Element ≤100 Zyklen Verweilzeithat, werden gegenüber den Instantiierungen mit einer Verweilzeit von ≥101 Zyklenbevorzugt.
- R5: Die Zeit wird als Anzahl der ausgeführten Aktionen gemessen. Es werden dieElemente aller Instantiierungen verglichen. Zunächst werden die Elemente mit derkürzesten Verweilzeit verglichen. Bei Zeitgleichheit werden die Elemente mit dernächstkürzeren Verweilzeit betrachtet. Sobald eine Instantiierung gefunden wird,die ein Element mit kürzerer Verweildauer als die Vergleichselemente hat, wirddiese Instantiierung selektiert. Wenn beim sukzessiven Vergleich einigenInstantiierungen die Elemente ausgehen, so werden diese Instantiierungen nichtselektiert. Unter R5 sind also nur Instantiierungen mit identischen Elementen gleich.

74
Konfliktauflösungsstrategien
aufgrund eines Vergleichs der Instantiierungen in der Konfliktmenge mit vorherverwendeten Instantiierungen.
- D1: Es wird versucht, Produktionen am Feuern in zwei unmittelbar aufeinanderfolgendenZyklen zu hindern. Zwei Instantiierungen sind verschieden, wenn die dazugehörigenProduktionen verschieden sind. Es wird geprüft, ob vor einem Interpreter-Zyklus eineandere Instantiierung als die zur Wahl stehende gefeuert hat. Bei positivemVergleichsresultat wird die entsprechende Instantiierung bevorzugt.
- D2: Es wird versucht, Instantiierungen nicht mehr als einmal feuern zu lassen. ZweiInstantiierungen sind verschieden, wenn ihre Produktionen oder Datenelementeverschieden sind. Es wird die gesamte Feuerfolge betrachtet, wobeiInstantiierungen, die von allen bisher ausgeführten verschieden sind, bevorzugtwerden.
zufällige Wahl einer Instantiierung AD1 als letzte Entscheidungshilfe

75
Kombination von Konfliktauflösungsstrategien
WM ( (P S) (Q T) (P T) (R V) (Q S) (P V) ... (W V) (W T) )P1 ( (Q =X) (P =X) / ... )
I11 [ P1 ((Q T) (P T)) ]I12 [ P1 ((Q S) (P S)) ]
P2 ( (P S) (P =X) (W =X) / ... )I21 [ P2 ((P S) (P T) (W T)) ]I22 [ P2 ((P S) (P V) (W V)) ]
P3 ( (=X S) (=X =Y) (W =Y) (R =Y) (Q S) / ... )I3 [ P3 ((P S) (P V) (W V) (R V) (Q S)) ]
P4 ( (Q S) l(U S) (P =X) l(U V) l(U T) / ... )I41 [ P4 ((Q S) (P S)) ]I42 [ P4 ((Q S) (P T)) ]I43 [ P4 ((Q S) (P V)) ]
[D2] / R1 / SC2 / R3 {I3}[D2 ! R4] / Rl / SC2 {I12 I41}[D2 ! R4] / R5 {I12 I41}[D2 ! R4] / R5 / PO1 / AD1 {I12}
‘!’ die Strategien werden auf die gleiche Menge von Instantiierungen angewendet.Ergebnis ist der Durchschnitt der berechneten Teilmengen
‘/’ die rechte Strategie wird auf das Ergebnis der linken angewendet
‘[ ]’ alle Instantiierungen, die von der in Klammern angegebenen Strategie nichtpräferiert werden, sind von der weiteren Auswertung ausgeschlossen
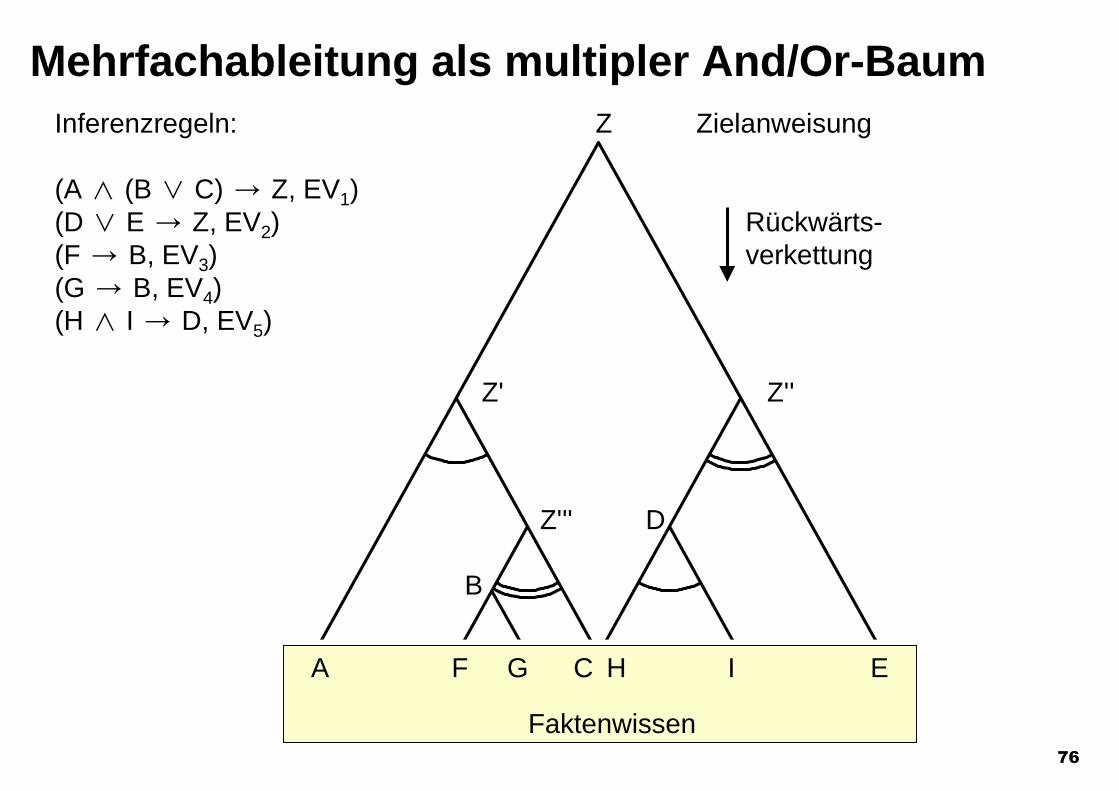
76
Mehrfachableitung als multipler And/Or-BaumInferenzregeln:
(A o (B n C) / Z, EV1)(D n E / Z, EV2)(F / B, EV3)(G / B, EV4) (H o I / D, EV5)
Z' Z''
DZ'''
Z
A F G C H I E
Faktenwissen
Rückwärts-verkettung
Zielanweisung
B

77
Die grundlegende Syntax von OPS5
<vector-element> | <av-element>({<value>}+)(<object>{^<attribute><value>}+)
1) Die Struktur von Elementen der Datenbasis
2) Die Struktur der Produktionsregeln
( P <rule-name> <antecedent> → <consequent> ){<condition>}+
<pattern> | -<pattern>(<object>{^<attribute><value>}+){<action>}+
(MAKE <object>{^<attribute><value>}+) |(MODIFY <pattern-number>{^<attribute><value>}+) |(REMOVE <pattern-number>) |(WRITE {<value>}+)
<rule> ::=<antecedent> ::=
<condition> ::=<pattern> ::=
<consequent> ::=<action> ::=
<element> ::=<vector-element> ::=
<av-element> ::=

78
Konfliktauflösungsstrategien im OPS5-Regelinterpreter
In OPS5 gibt es zwei Konfliktauflösungsstrategien, wobei in beiden mehrere Filterhintereinandergeschaltet sind: LEX und MEA.
LEX (voreingestellte Strategie)
Die Bezeichnung 'LEX' basiert auf der Tatsache, daß im zweiten Filter dielexikographische Ordnung eine wichtige Rolle spielt.
LEX eignet sich vor allem für kleine Regelmengen und Probleme, bei denen es nichtauf die Reihenfolge der Lösung von Teilaufgaben ankommt.
MEA
Die Bezeichnung ‘MEA’ soll an das Problemlöseverfahren der ‘Means Ends Analysis’erinnern.
Die Priorisierung der ersten Einzelbedingung eignet sich zur Steuerung des Systems,indem diese Bedingung jeweils das aktuelle Unterziel beschreibt.
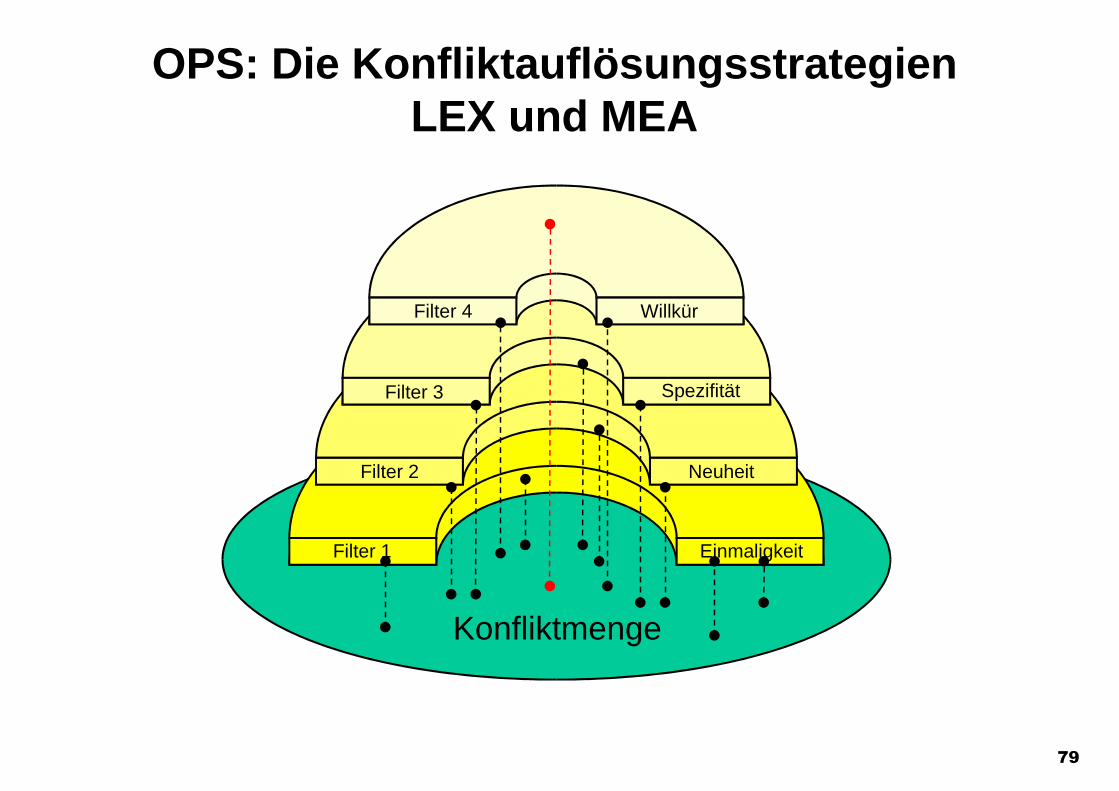
79
Konfliktmenge
EinmaligkeitFilter 1
NeuheitFilter 2
SpezifitätFilter 3
OPS: Die KonfliktauflösungsstrategienLEX und MEA
WillkürFilter 4
Konfliktmenge
Einmaligkeit
Neuheit
Spezifität
Willkür
Filter 1
Filter 2
Filter 3
Filter 4

80
OPS: Die KonfliktauflösungsstrategienLEX und MEA
Willkür
Spezifität
Einmaligkeit
Neuheit der Instantiierung
Neuheit der Arbeitsspeicherelemente,die die erste Einzelbedingung erfüllen
LEX MEA

81
Konfliktauflösungsstrategien im OPS5-Regelinterpreter
Einmaligkeit
Es werden alle Instantiierungen ausgefiltert, die bereits einmal gefeuert haben, aberseitdem noch immer in der Konfliktmenge sind, da ihr Bedingungsteil mit denselbenArbeitsspeicherelementen erfüllt blieb.
Diesem Filter liegt die Heuristik zugrunde, daß ein erneutes Feuern derselbenInstantiierungen nichts Neues bringen würde.
Neuheit
Diesem zweiten Filter liegt im wesentlichen eine Verweilzeitstrategie zugrunde, diediejenigen Instantiierungen bevorzugt, die auf möglichst jungen Datenelementen beruhen.
Dazu werden die Zeitstempel, die zu einer Instantiierung gehören, der Größe nach inabsteigender Reihenfolge geordnet und als Vektor aufgefaßt.
Der größte Vektor in dieser Ordnung entspricht der Instantiierung, die diesen Filterpassieren kann.

82
Konfliktauflösungsstrategien im OPS5-Regelinterpreter Neuheit (Fortsetzung)
Es ist möglich, daß verschiedene Instantiierungen denselben Vektor von Zeitstempelnhaben, so daß mehrere Instantiierungen diesen Filter passieren können.
Ist ein Vektor in einem anderen enthalten, so wird der längere Vektor als größer in dieserOrdnung angesehen. Dadurch wird neben einer Verweildauerstrategie auch eineSpezialfallstrategie realisiert.
Beispiel:
Eingabe in diese Filterstufe sei:
Regel_3 27 19 11 6Regel_1 27 19 11 6Regel_2 27 19 11Regel_7 27 19 11Regel_2 21 19 11Regel_4 17 12 13 6 2 1
Ausgabe des Filters:
Regel_3 27 19 11 6Regel_1 27 19 11 6

83
Konfliktauflösungsstrategien im OPS5-Regelinterpreter Spezifität
Alle Instantiierungen, die den Neuheitsfilter verlassen, werden mit der gleichen Menge vonArbeitsspeicherelementen gebildet. Der dritte Filter, dem diese Instantiierungen zugeleitetwerden, ist eine weitere Spezialfallstrategie.
Als Maß für die Spezifität wird die Anzahl der Tests von Variablen und Konstanten einesBedingungsteils verwendet.
Als ein Test zählt:Jede (mit einem Prädikat versehene) KonstanteJede Auswahl einer KonstantenJeder Vergleich mit einer gebundenen Variablen
Die Instantiierung der Regeln, die die maximale Anzahl an Tests durchführt, passiert denSpezifitätsfilter.
Willkür
Zuletzt wird eine willkürliche (aber nicht zufällige) Entscheidung für genau eineInstantiierung getroffen, so daß eine reproduzierbare und eindeutige Wahl getroffen wird.

84
Konfliktauflösungsstrategien im OPS5-Regelinterpreter
LEX-Algorithmus
1. Entferne alle Instantiierungen, die schon gefeuert haben.
2. Ordne die restlichen Instantiierungen entsprechend der Neuheit der an siegebundenen Elemente und wähle die größte Instantiierung gemäß dieser Ordnung.
3. Gibt es mehrere gleich große Instantiierungen gemäß voriger Ordnung, ordnediese nach der Zahl der Tests und wähle die größte Instantiierung gemäß dieserOrdnung.
4. Gibt es auch in dieser Ordnung mehrere gleich große Instantiierungen, wählewillkürlich eine der größten.

85
Konfliktauflösungsstrategien im OPS5-Regelinterpreter
MEA-Algorithmus
1. Entferne alle Instantiierungen, die schon gefeuert haben.
2. Ordne die restlichen Instantiierungen entsprechend der Neuheit der Elemente, diedie erste Einzelbedingung erfüllen und wähle die größte lnstantiierung gemäßdieser Ordnung.
3. Gibt es mehrere lnstantiierungen mit gleich neuem ersten Element, ordne dieseentsprechend der Neuheit aller an sie gebundenen Elemente und wähle die größteInstantiierung gemäß dieser Ordnung.
4. Gibt es mehrere gleich große Instantiierungen gemäß voriger Ordnung, ordnediese nach der Zahl der Tests und wähle die größte Instantiierung gemäß dieserOrdnung.
5. Gibt es auch in dieser Ordnung mehrere gleich große Instantiierungen, wählewillkürlich eine der größten.

86
Der RETE-Algorithmus in OPS5Eine naive Implementation des Erkennungs/Aktionszyklus, in der bei jedem Schleifen-durchlauf alle Elemente der Datenbasis mit den Bedingungsteilen aller Regeln ver-glichen werden, würde zu einem völlig indiskutablen Laufzeitverhalten bei großenRegelmengen führen.
Zwei grundlegende Ideen zur Effizienzsteigerung:
1) Einschränkung der zu überprüfenden Datenbasiseinträge:
Bei der Auswertung einer Regel wird jeweils nur ein kleiner Teil des Arbeitsspeichers verändert, und ein Mustervergleich mit den unveränderten Elementen ändert die Konfliktmenge nicht.
Man kann also die Ergebnisse einer Vergleichsphase speichern und beim nächsten Zyklus nur die Änderungen der Datenbasis daraufhin prüfen, ob sie zur Instantiierung neuer Regeln führen oder ob sie bestehende Instantiierungen aufheben.
2) Einschränkung der zu überprüfenden Bedingungen:
Da die Bedingungsteile der Regeln im allgemeinen nicht disjunkt sind, kann der Aufwand fürdie Erkennungsphase auch dadurch reduziert werden, daß gleichartige Tests nur einmal durchgeführt werden.
87
Der RETE-Algorithmus in OPS5Der RETE-Algorithmus erlaubt eine effiziente Implementierung der Mustervergleichsphase inProduktionensystemen.
Er erhält alle Änderungen der Datenbasis als Eingabe und berechnet die sich darausergebenden Änderungen der Konfliktmenge.
Die Regeln werden durch ein Netz aus Code-Stücken übersetzt, welche Bedingungsteilerepräsentieren (RETE = Netz im Lateinischen).
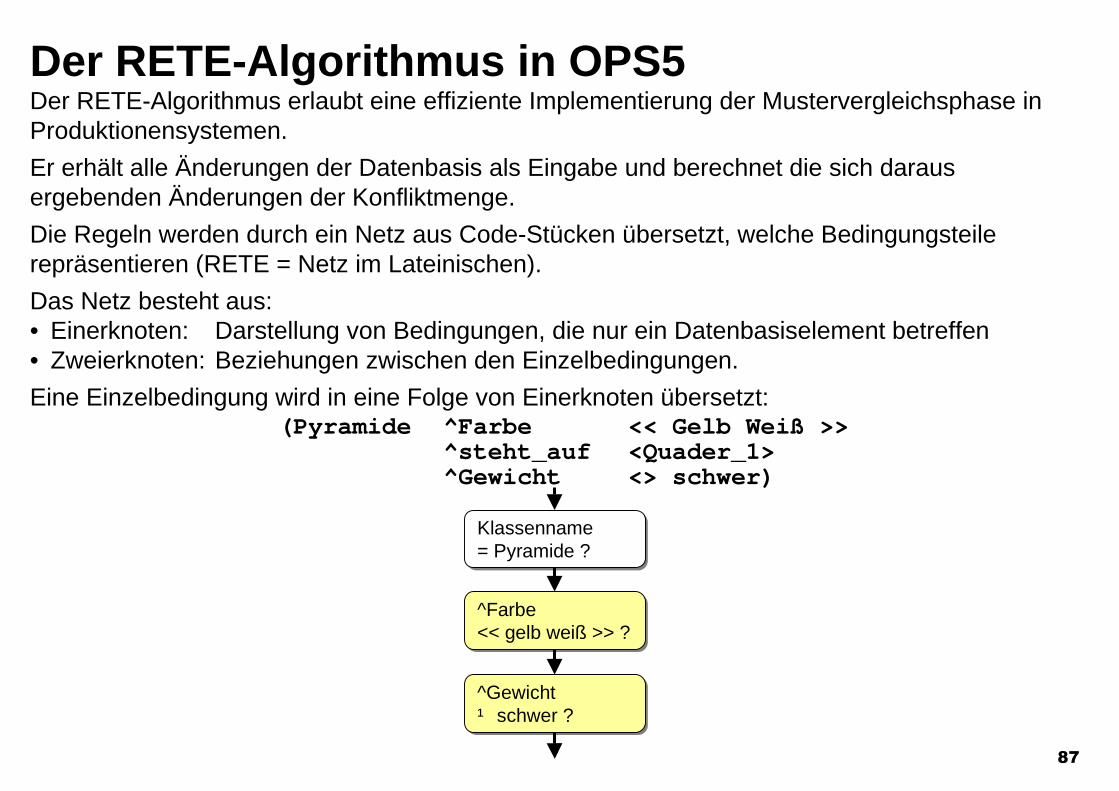
Das Netz besteht aus:• Einerknoten: Darstellung von Bedingungen, die nur ein Datenbasiselement betreffen• Zweierknoten: Beziehungen zwischen den Einzelbedingungen.
Eine Einzelbedingung wird in eine Folge von Einerknoten übersetzt:(Pyramide ^Farbe << Gelb Weiß >>
^steht_auf <Quader_1>^Gewicht <> schwer)
Klassenname= Pyramide ?Klassenname= Pyramide ?
^Farbe<< gelb weiß >> ?^Farbe<< gelb weiß >> ?
^Gewicht¹ schwer ?^Gewicht¹ schwer ?
88
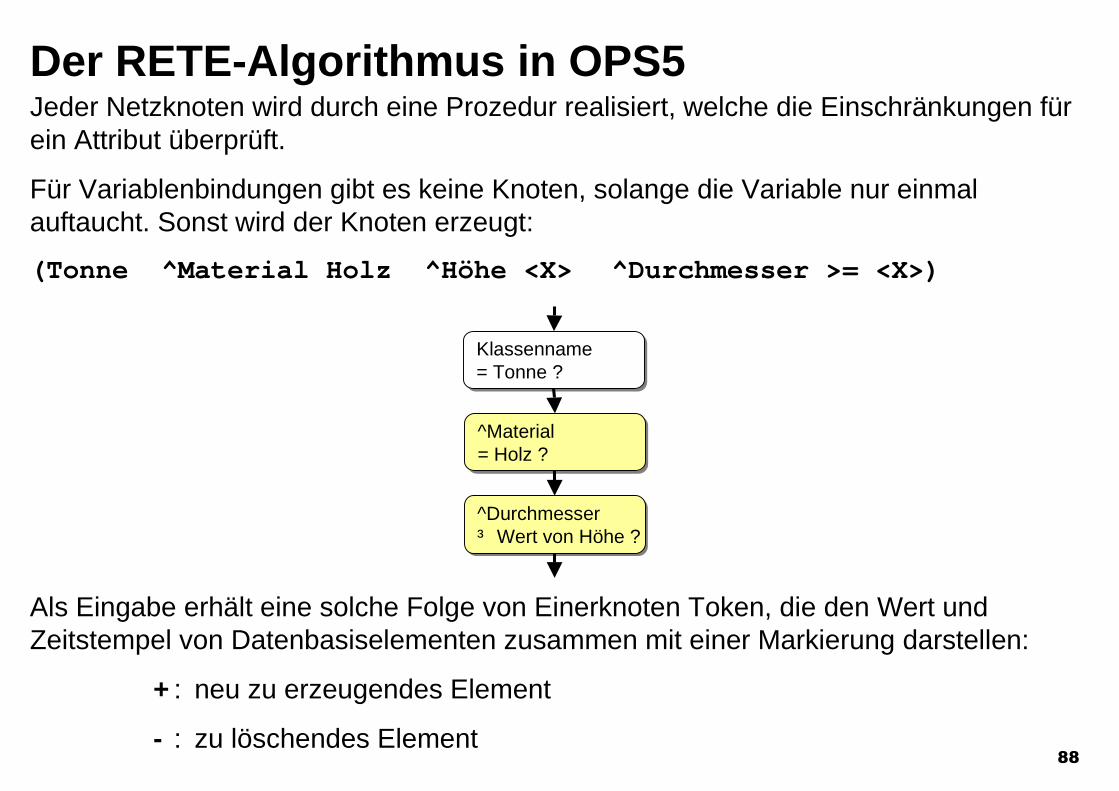
Der RETE-Algorithmus in OPS5Jeder Netzknoten wird durch eine Prozedur realisiert, welche die Einschränkungen fürein Attribut überprüft.
Für Variablenbindungen gibt es keine Knoten, solange die Variable nur einmalauftaucht. Sonst wird der Knoten erzeugt:
(Tonne ^Material Holz ^Höhe <X> ^Durchmesser >= <X>)
Klassenname= Tonne ?Klassenname= Tonne ?
^Material= Holz ?^Material= Holz ?
^Durchmesser³ Wert von Höhe ?^Durchmesser³ Wert von Höhe ?
Als Eingabe erhält eine solche Folge von Einerknoten Token, die den Wert undZeitstempel von Datenbasiselementen zusammen mit einer Markierung darstellen:
+ : neu zu erzeugendes Element
- : zu löschendes Element
89
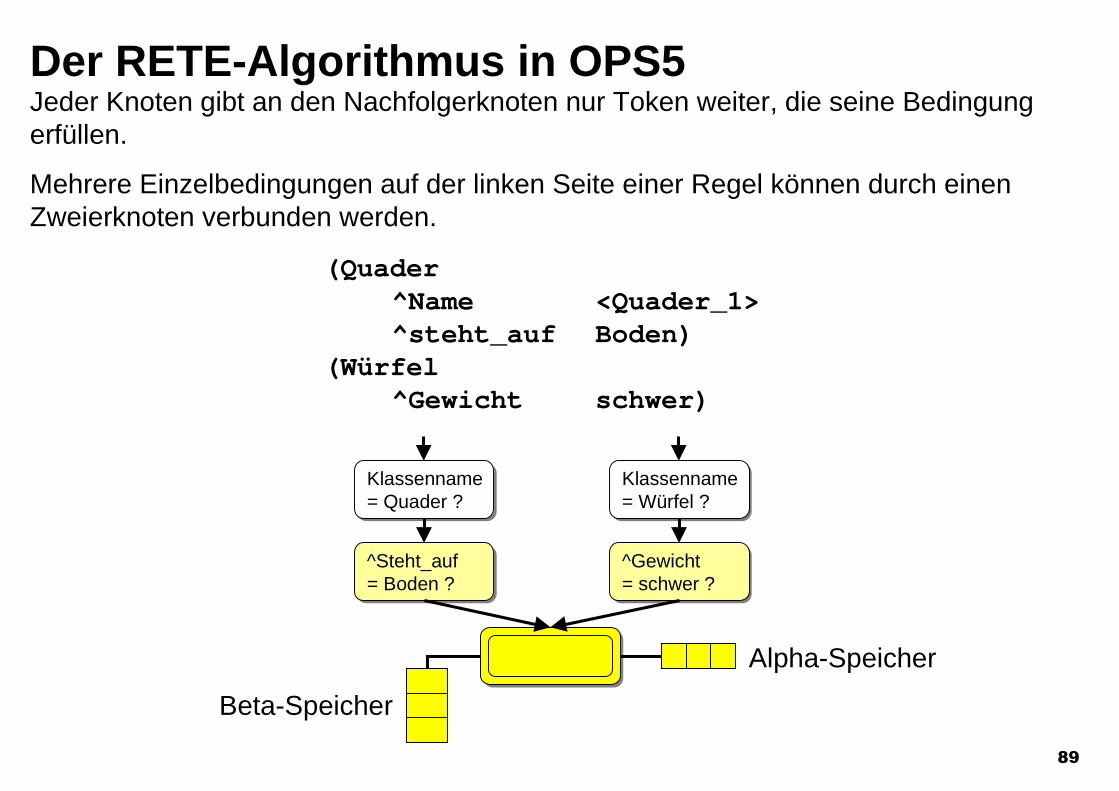
Der RETE-Algorithmus in OPS5Jeder Knoten gibt an den Nachfolgerknoten nur Token weiter, die seine Bedingungerfüllen.
Mehrere Einzelbedingungen auf der linken Seite einer Regel können durch einenZweierknoten verbunden werden.
(Quader^Name <Quader_1>^steht_auf Boden)
(Würfel^Gewicht schwer)
Klassenname= Quader ?Klassenname= Quader ?
^Steht_auf= Boden ?^Steht_auf= Boden ?
Klassenname= Würfel ?Klassenname= Würfel ?
^Gewicht= schwer ?^Gewicht= schwer ?
Alpha-Speicher
Beta-Speicher

90
Der RETE-Algorithmus in OPS5Ein Zweierknoten hat zwei Eingänge. Wenn der Bedingungsteil einer Regel mehr alszwei Klauseln umfaßt, werden weitere Zweierknoten gebildet, wobei je ein Eingangmit dem Ausgang eines vorangegangenen Zweierknotens verbunden wird.
Zweierknoten verwalten zwei Listen, in denen Token gespeichert werden können.
Im Alpha- und Betaspeicher werden die Ausgaben der beiden Vorgängerknotengespeichert.
Ist einer der beiden Vorgängerknoten ein Zweierknoten, so wird dessen Ausgabe imBetaspeicher abgelegt.
Wenn die beiden Eingänge eines Zweierknotes keine gemeinsamen Variablen haben,so liefert der Zweierknoten als Ergebnis das Kreuzprodukt seines Alpha- undBetaspeichers.
Wenn gemeinsame Variablen vorkommen, prüft der Zweierknoten, welche Elementeim Betaspeicher zusammenpassen, so daß eine konsistente Variablenbelegungentsteht.
Die Ausgabe des letzten Zweierknotens, der zu einer Regel gehört, stellt dieÄnderung der Konfliktmenge dar.

91
Der RETE-Algorithmus in OPS5Wird der Datenbasis ein neues Element hinzugefügt, so wandert dieses als Plus-Token durch das Netz, wobei ggf. die Alpha- und Betaspeicher aktualisiert werden.
Soll ein Element aus der Datenbasis gelöscht werden, so wandert dieses als Minus-Token durch das Netz, wobei die zugehörigen Einträge im Alpha- und Betaspeicherebenfalls gelöscht werden.
(P Suche_Pyramide(Quader
^Name <Quader_1>^steht_auf Boden )
(Würfel^Gewicht schwer)
(Pyramide^Farbe << Gelb Weiß >>^steht_auf <Quader_1>^Gewicht <> schwer)
--> (Aktionsteil))
Beispiel für die Verwendung von Alpha- und Betaspeicher
92
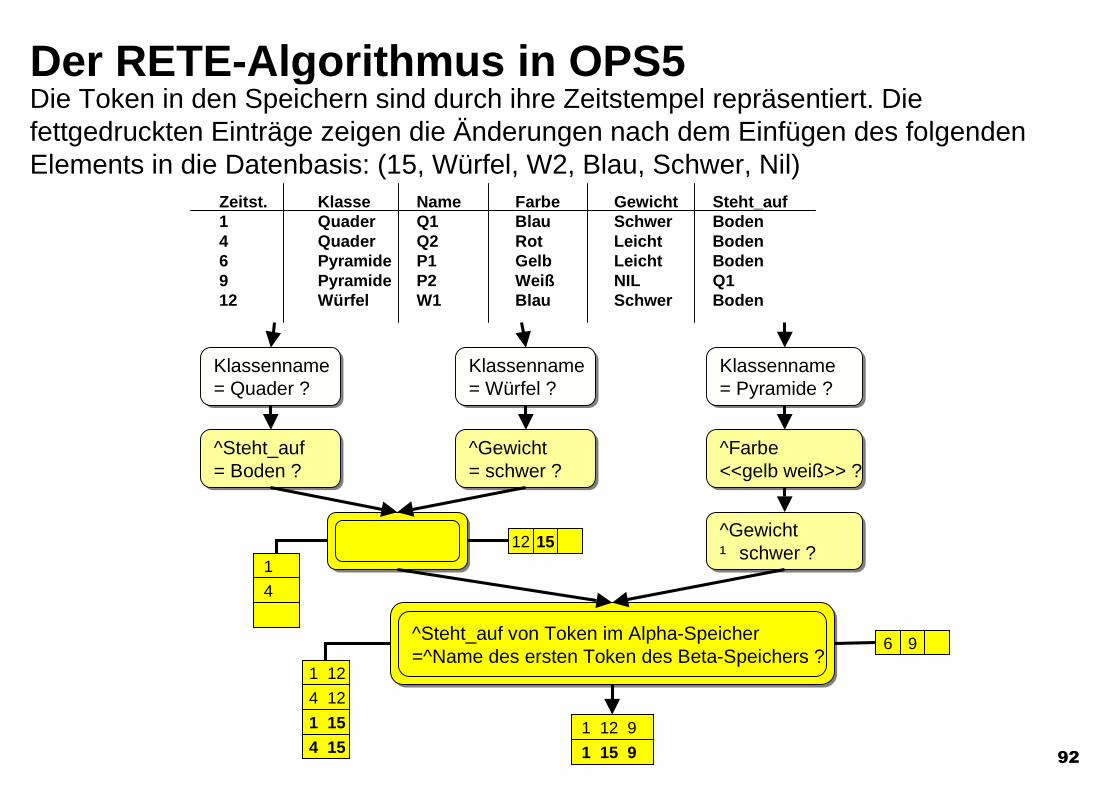
Der RETE-Algorithmus in OPS5Zeitst. Klasse Name Farbe Gewicht Steht_auf
Klassenname= Quader ?Klassenname= Quader ?
^Steht_auf= Boden ?^Steht_auf= Boden ?
Klassenname= Würfel ?Klassenname= Würfel ?
^Gewicht= schwer ?^Gewicht= schwer ?
Klassenname= Pyramide ?Klassenname= Pyramide ?
^Farbe<<gelb weiß>> ?^Farbe<<gelb weiß>> ?
^Gewicht¹ schwer ?^Gewicht¹ schwer ?
^Steht_auf von Token im Alpha-Speicher=^Name des ersten Token des Beta-Speichers ?
1 Quader Q1 Blau Schwer Boden
1
1
4 Quader Q2 Rot Leicht Boden
4
4
6 Pyramide P1 Gelb Leicht Boden
6
9 Pyramide P2 Weiß NIL Q1
9
1 9
12 Würfel W1 Blau Schwer Boden
12
1 12
4 12
1 12 9
15 Würfel W2 Blau Schwer Nil
1 15
1 15 94 15
15
(P Suche_Pyramide(Quader
^Name <Quader_1>^steht_auf Boden )
(Würfel^Gewicht schwer )
(Pyramide^Farbe << Gelb Weiß >>^steht_auf <Quader_1>^Gewicht <>schwer )
--> (Aktionsteil))
Die Token in den Speichern sind durch ihre Zeitstempel repräsentiert. Diefettgedruckten Einträge zeigen die Änderungen nach dem Einfügen des folgendenElements in die Datenbasis: (15, Würfel, W2, Blau, Schwer, Nil)
Zeitst. Klasse Name Farbe Gewicht Steht_auf1 Quader Q1 Blau Schwer Boden4 Quader Q2 Rot Leicht Boden6 Pyramide P1 Gelb Leicht Boden9 Pyramide P2 Weiß NIL Q112 Würfel W1 Blau Schwer Boden
Klassenname= Quader ?Klassenname= Quader ?
^Steht_auf= Boden ?^Steht_auf= Boden ?
Klassenname= Würfel ?Klassenname= Würfel ?
^Gewicht= schwer ?^Gewicht= schwer ?
12 15
1
4
Klassenname= Pyramide ?Klassenname= Pyramide ?
^Farbe<<gelb weiß>> ?^Farbe<<gelb weiß>> ?
^Gewicht¹ schwer ?^Gewicht¹ schwer ?
^Steht_auf von Token im Alpha-Speicher=^Name des ersten Token des Beta-Speichers ?
6 9
1 12 9
1 15 9
1 12
1 15
4 15
4 12

93
Der RETE-Algorithmus in OPS5Bisher hätte das Netz, das aus der Übersetzung einer Regel entsteht, so viele Ein-träge, wie die Regel Einzelbedingungen enthalten hat, und einen Ausgang, der dieInstantiierung der Regel liefert.Das Gesamtnetz für die Regelbasis bestünde aus einer Menge nebeneinanderliegen-der Einzelnetze.
Regel 1 Regel 2 Regel 3 Regel 4 Regel 5
Der RETE-Algorithmus verschmelzt nun gleiche Anfangsstücke von den Einzelnetzen.
Regel 1 Regel 2 Regel 3 Regel 4 Regel 5

94
Der RETE-Algorithmus in OPS5
(P Regenwarnung(Wettervorhersage
^Status aktuell^Quelle Rundfunknachrichten^Wetter Regen)
(Beobachtung^Art Dunkle-Wolken)
--> (WRITE |Es wird wohl Regen geben.| (CRLF)|Ich empfehle, einen Schirm mitzunehmen.|)
)
(P Ausflugsempfehlung(Wettervorhersage
^Status aktuell^Quelle Bauernregel^Wetter Sonnenschein)
(Datum^Wochentag Freitag^Monat << Juni Juli August September >>)
--> (WRITE |Das Wetter wird prima.| (CRLF)|Ich empfehle, dieses Wochenende| (CRLF)|ans Meer zu fahren.|)
)
Bei der Übersetzung werden die Bedingungen nicht umgeordnet, so daß trotz inhaltlicher Gleichheit fürdie folgenden Einzelbedingungen nur der Test auf den Klassennamen verschmolzen wird.
(Kiste ^Farbe blau ^Material Holz ^Größe <= 100 )(Kiste ^Material Holz ^Farbe blau ^Größe <= 100 )
Die folgenden beiden Regeln können für den Anfang ihrer ersten Bedingung ein gemeinsamesNetzstück benutzen.

95
Der RETE-Algorithmus in OPS5
Die Namen der verwendeten Variablen spielen für eine mögliche Verschmelzung keine Rolle, so daß z.B.folgende Einzelbedingungen auf eine Knotenfolge abgebildet werden:
(Kiste ^Höhe <H> ^Breite >= <H> ^Material Holz)(Kiste ^Höhe <Höhe> ^Breite >= <Höhe> ^Material Holz)
Klassenname= Wettervorhersage ?Klassenname= Wettervorhersage ?
^Status= aktuell ?^Status= aktuell ?
^Quelle= Rundfunknachricht ?^Quelle= Rundfunknachricht ?
^Wetter= Regen ?^Wetter= Regen ?
Klassenname= Beobachtung ?Klassenname= Beobachtung ?
^Art= Dunkle_Wolken ?^Art= Dunkle_Wolken ?
^Quelle= Bauernregel ?^Quelle= Bauernregel ?
^Wetter= Sonnenschein ?^Wetter= Sonnenschein ?
Klassenname= Datum ?Klassenname= Datum ?
^Wochentag= Freitag ?^Wochentag= Freitag ?
^Monat « Jun Jul Aug Sep » ?^Monat « Jun Jul Aug Sep » ?
Instantiierungen derRegel Regenwarnung
Instantiierungen der RegelAusflugsempfehlung
96
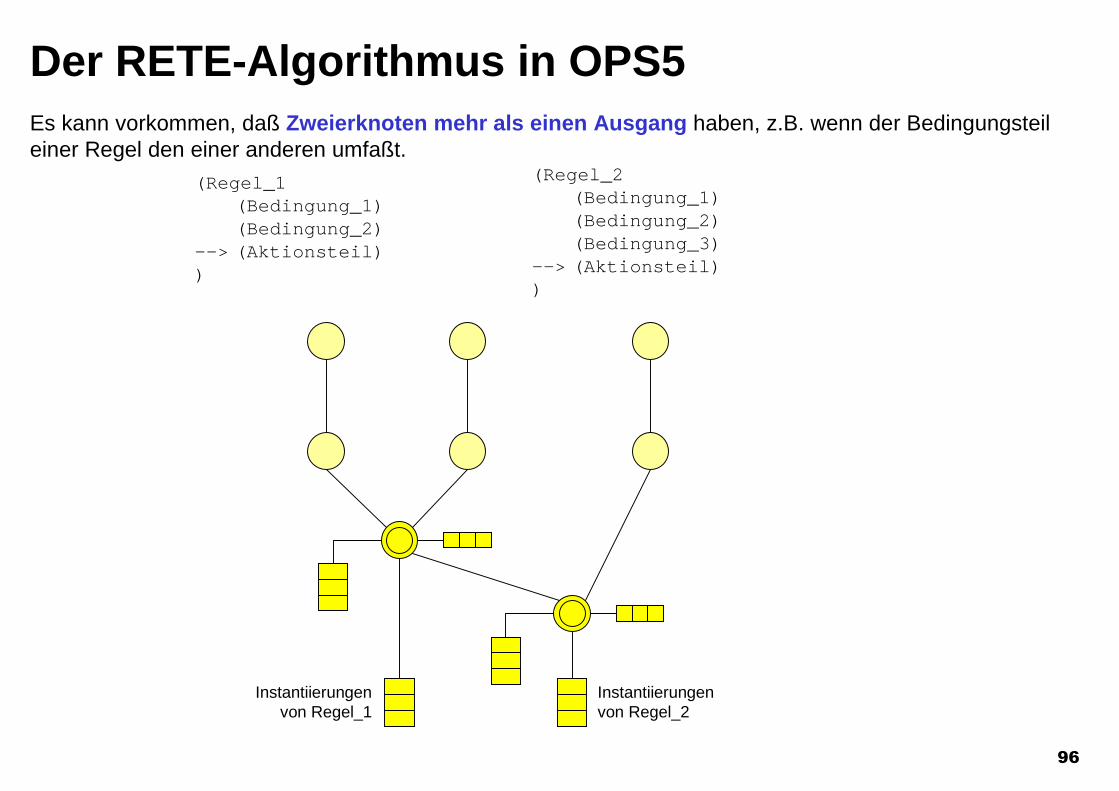
Es kann vorkommen, daß Zweierknoten mehr als einen Ausgang haben, z.B. wenn der Bedingungsteileiner Regel den einer anderen umfaßt.
Der RETE-Algorithmus in OPS5
(Regel_1(Bedingung_1)(Bedingung_2)
--> (Aktionsteil))
(Regel_2(Bedingung_1)(Bedingung_2)(Bedingung_3)
--> (Aktionsteil))
Instantiierungen von Regel_2
Instantiierungenvon Regel_1

97
Der RETE-Algorithmus in OPS5Zum Ändern eines Elementes in der Datenbasis wird ein Plus-Token und ein Minus-Token durch dasNetz geschickt, so daß das Ändern doppelt so aufwendig ist wie das Erzeugen oder Löschen einesElements.
Ein Nachteil des RETE-Algorithmus besteht darin, daß Regeln die zur Laufzeit neu erzeugt werden, nurauf diejenigen Elemente der Datenbasis reagieren, die nach der Regelerzeugung in die Datenbasiseingetragen wurden.
Die Kenntnis des RETE-Algorithmus ermöglicht eine effizientere Programmierung mitProduktionensystemen.
So sollte man versuchen, den Inhalt der einzelnen Alphaspeicher zu minimieren. Dies kann dadurchgeschehen, daß man die Bedingungen der Regeln so speziell wie möglich formuliert.
Beispiel: Regel, die zu allen Personen in der Datenbasis den Ort des Arbeitsplatzes ausgibt.
(P Ort_des_Arbeitsplatzes(Steuerelement
^Kontext Anfrage^Status aktiv)
(Person^Name <Name>^beschäftigt_bei <Arbeitgeber>)
(Firma^Name <Arbeitgeber>^Ort <gesuchter_0rt>)
--> (WRITE <Name> |arbeitet in| <gesuchter_Ort>))

98
Der RETE-Algorithmus in OPS5
Wenn wir zusätzlich wissen, daß Personen unter 16 und über 65 sowie Schüler undStudenten keinen Arbeitgeber haben, so können wir dadurch den Alphaspeicher kleinerhalten.
(P Ort_des_Arbeitsplatzes(Steuerelement
^Kontext Anfrage ^Status aktiv)
(Person^Name <Name>^Alter { >= 16 <= 65 }^Beruf { <> Schüler <> Student }^beschäftigt_bei <Arbeitgeber>)
(Firma^Name <Arbeitgeber>^Ort <gesuchter_Ort>)
--> (WRITE <Name> |arbeitet in| <gesuchter_Ort>))

99
Der RETE-Algorithmus in OPS5
Z3 10 Token
1000Tupel
10Inst.
D
Z2 10 Token
100Tupel
C
Z1 10 Token
10Tupel
BA
Der Inhalt des Betaspeichers läßt sichverkleinern, indem der davorliegendeZweierknoten nur eine Teilmenge des vonihm gebildeten Kreuzproduktes weitergibt.
Beispiel:(Bedingung_A <var_1>)(Bedingung_B <var_2>)(Bedingung_C <var_3>)(Bedingung_D <var_1> <var_2> <var_3>)
Die ersten drei Bedingungen sindvoneinander unabhängig, während zwischender vierten und den drei ersten eineAbhängigkeit besteht.Im Beispiel nehmen wir an, daß es zu jederder vier Bedingungen 10 passende Elementeder Datenbasis gibt. Die in der viertenBedingung formulierte Abhängigkeit soll zu 10verschiedenen Instantiierungen führen.
Hier muß im Knoten Z3 das aus 10.000Elementen bestehende Kreuzproduktuntersucht werden, wobei nur 10Instantiierungen übrig bleiben.

100
Der RETE-Algorithmus in OPS5
Z3’ 10 Token
10Tupel
10Inst.
C
Z2’ 10 Token
10Tupel
B
Z1’ 10 Token
10Tupel
AD
Durch eine Umstellung derEinzelbedingungen, bei der dieEinschränkungen möglichst früh ausgewertetwerden, kann der Aufwand in denZweierknoten erheblich reduziert werden.
(Bedingung_D <var_1> <var_2> <var_3>)(Bedingung_A <var_1>)(Bedingung_B <var_2>)(Bedingung_C <var_3>)

101
Beispiel einer OPS5-Produktion im Fertigungsplanungssystem FERPLAN
(p w18(goal ^lauf <u>
^status active^type legen^object Werkstück)
(Zähler ^lauf <u>^value1 <n>^value2 <m>^value3 <l>)
(Werkzeug ^lauf <u>^type <p>^pnr <l>)
(Werkzeug ^lauf <u>^type <s>^pnr <n>^schugi ja^empty ja)
Schutzgitter ^state open)-->
(write |Lege das Werkstück in | <s>)(remove 1)(modify 4 ^empty nein)(make goal ^lauf <u>
^status active^type schließen^object Schutzgitter)
)
Wenn ein aktives Zielexistiert, ein Werkstückin ein Werkzeug ‘s’ zu legen
‘Zähler’ so besetzt ist, daß
ein Werkzeug mit Namen ‘p’und Positionsnummer ‘l’ existiert,
ein nachfolgendes Werkzeugmit Namen ‘s’ undPositionsnummer ‘n’, zu dessenBedienung man ein Schutzgitterbenötigt,dieses geöffnet ist,dann
lösche das erreichte Ziel,ändere Wert des Attributsund erzeuge ein Ziel,das die Schließung desSchutzgitters veranlaßt

102
Erweiterung der Regelmenge durch Regeln
Zur Laufzeit können in OPS neue Regeln mit der Aktion BUILD generiert werden, z.B.um die Wissensbasis zu erweitern oder die Laufzeiteffizienz zu erhöhen.
Als Parameter werden ein eindeutiger Regelname, der Bedingungsteil, das Atom ‘-->’und der Aktionsteil der neuen Regel an BUILD übergeben.
Beispiel:
Falls die Datenbasis das Element (Endwert ^Wert 1986) enthält, wird folgende neueRegel erzeugt:
(P Regelbauer(Endwert ^Wert <x>)
--> (BUILD \\ (GENATOM)(Ergebnis ^Wert \\ <x> )--> (WRITE |Endwert erreicht| )
(HALT) )
(P G:372(Ergebnis ^Wert 1986 )
--> (WRITE |Endwert erreicht| )(HALT) )

103
Literatur zu ProduktionensystemenBrownston, L., Farrell, R., Kant, E., Martin, N.,:
Programming Expert Systems in OPS5. An Introduction to Rule-Based Programming.Reading: Addison-Wesley 1985.
Davis, R., King, J.:An Overview of Production Systems. In: Elcock, E.W., Michie, D. (eds): MachineIntelligence. New York: Wiley 1976, 300-331.
Davis, R.:Meta-Rules: Reasoning about Control. In: Artificial Intelligence, 15, 1980, 179-222.
Forgy, C.L.:RETE: A Fast Algorithm for the Many Pattern / Many Object Pattern Match Problem.In: Artificial Intelligence, 19, 1982, 17-37.
Krickhahn, R., Radig, B.:Die Wissensrepräsentationssprache OPS5. Sprachbeschreibung und Einführung indie regelorientierte Programmierung. Braunschweig: Vieweg 1987.
McDermott, J., Forgy, C.L.:Production System Conflict Resolution Strategies. In: Waterman, D.A., Hayes-Roth,F. (eds): Pattern-Directed Inference Systems. New York: Academic 1978.
104
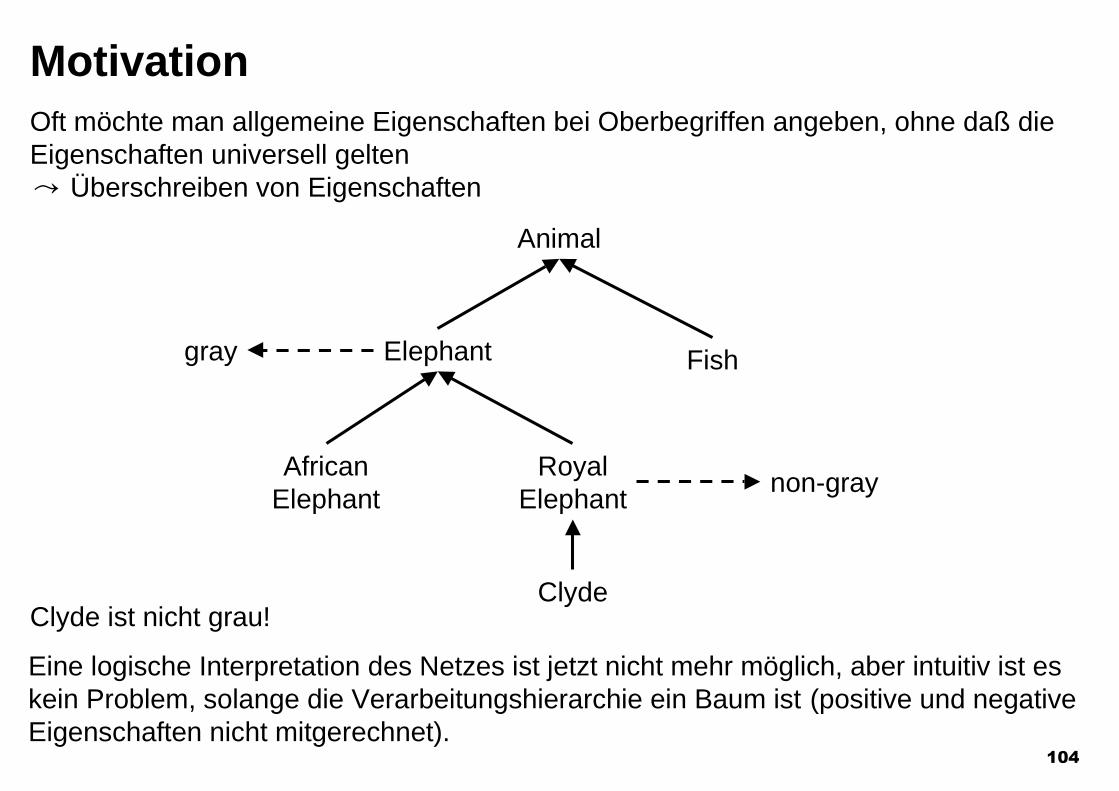
MotivationOft möchte man allgemeine Eigenschaften bei Oberbegriffen angeben, ohne daß dieEigenschaften universell gelten= Überschreiben von Eigenschaften
Animal
Elephant
Eine logische Interpretation des Netzes ist jetzt nicht mehr möglich, aber intuitiv ist eskein Problem, solange die Verarbeitungshierarchie ein Baum ist (positive und negativeEigenschaften nicht mitgerechnet).
Fish
AfricanElephant
RoyalElephant
ClydeClyde ist nicht grau!
gray
non-gray

105
Probleme
Clyde könnte grau oder nicht grau sein! Welche Schlussfolgerung ist „richtig“?
Animal
Elephant Fish
AfricanElephant
RoyalElephant
Clyde
gray
non-gray
Royal AfricanElephant

106
Bipolare VererbungsnetzeAzyklischer, gerichteter Graph. Knoten sind Begriffe (z.B. Elephant), Eigenschaften(z.B. gray) oder Individuen (Clyde).
Kanten sind positiv oder negativ (nicht strikt).
x/y positiv: x ist typischerweise yxKy negativ:x ist typischerweise nicht y
Quadruped
Mammal
Elephant Human
Clyde John
Biped
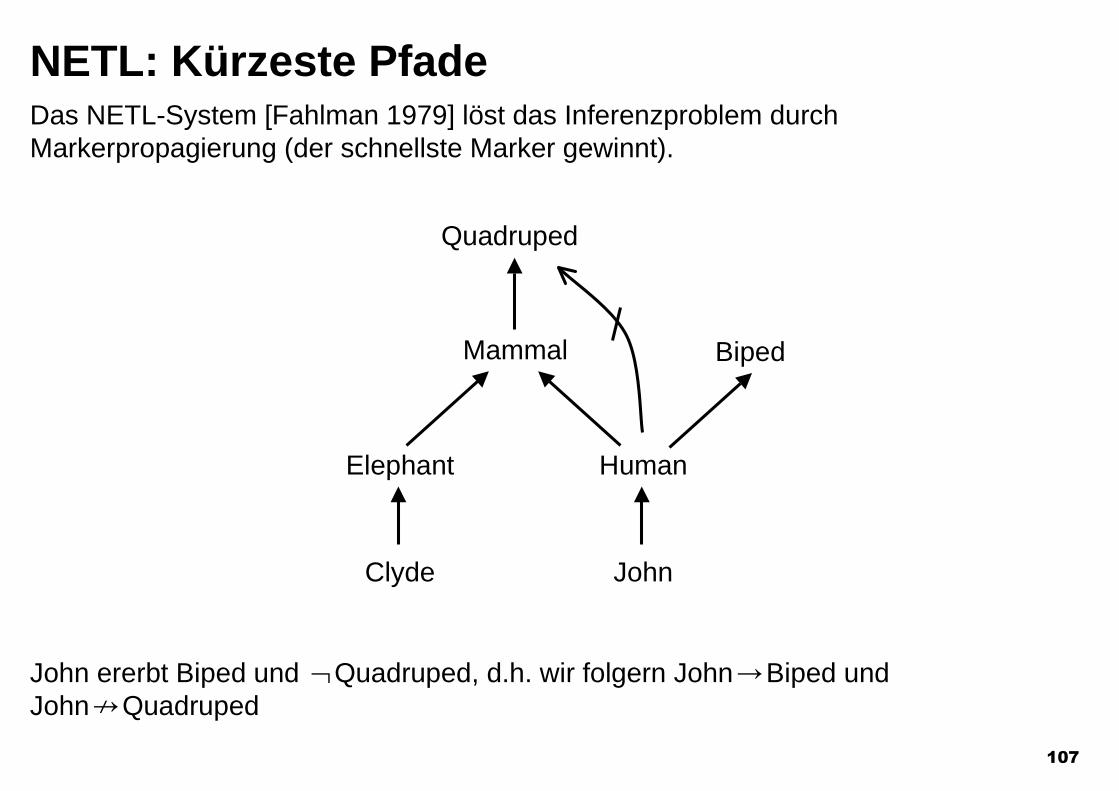
107
NETL: Kürzeste Pfade
Quadruped
Mammal
Elephant Human
Clyde John
Biped
Das NETL-System [Fahlman 1979] löst das Inferenzproblem durchMarkerpropagierung (der schnellste Marker gewinnt).
John ererbt Biped und lQuadruped, d.h. wir folgern John/Biped undJohnKQuadruped

108
Redundante Pfade
Quadruped
Mammal
Elephant Human
Clyde John
Biped
Jetzt ist lQuadruped und Quadruped in gleich vielen Schritten erreichbar.

109
Vererbungsstrategien und multiple Extensionen
Vererbung über kürzeste Pfade macht intuitiv keinen SinnAuch Vererbung bzgl. anderer prozeduraler Mechanismen (z.B.Tiefensuche, links zuerst) ist nicht intuitiv.
Konstruktion von Extensionen = Mengen von „zulässigen“ Pfaden(u.U. mehrere Extensionen)
= Wenn z.B. der PfadJohn/./Quadruped
in einer Extension ist, kann nicht auchJohn/.KQuadruped
in dieser Extension sein (und umgekehrt)

110
DefinitionenVererbungsnetz.
Ein Vererbungsnetz besteht aus einer Menge von Knoten N und einer Menge vonKanten G 4 N ! {0,1} ! Nwobei die 0/1-Werte Polarität heißen (0 = negativ = K, 1 = positiv = /).
Pfad.Ein Pfad ist eine Sequenz von Kanten von x0 nach x1 nach . xn-1 nach xn, wobeidie ersten n-1 Kanten positiv sind. Die Polarität eines Pfades ist die Polarität derletzten Kante.Schreibweise sZx0/./xi/./xn (oder .Kxn)
Folgerung.Ein Pfad sZx0/./xi/./xn (oder .Kxn) unterstützt die Folgerungx0/xn (oder x0Kxn).
Extension.Eine Extension ist dann eine Menge von Pfaden, die bestimmte Bedingungenerfüllt.
Folgerungsmenge.Die Folgerungsmenge ist die Menge der von einer Extension unterstütztenFolgerungen.

111
WiderspruchSei F eine beliebige (endliche) Menge von Pfaden.
Widerspruch.Ein Pfad s widerspricht einer Menge von Pfaden F , falls F einen Pfad mitdenselben Start- und Endpunkten aber entgegengesetzter Polarität enthält.
Pacifist(P)
Quaker(Q) Republican(R)
Nixon(N)
Sei FZ{N/Q/P}. Dann widerspricht sZN/RKP der Menge F.
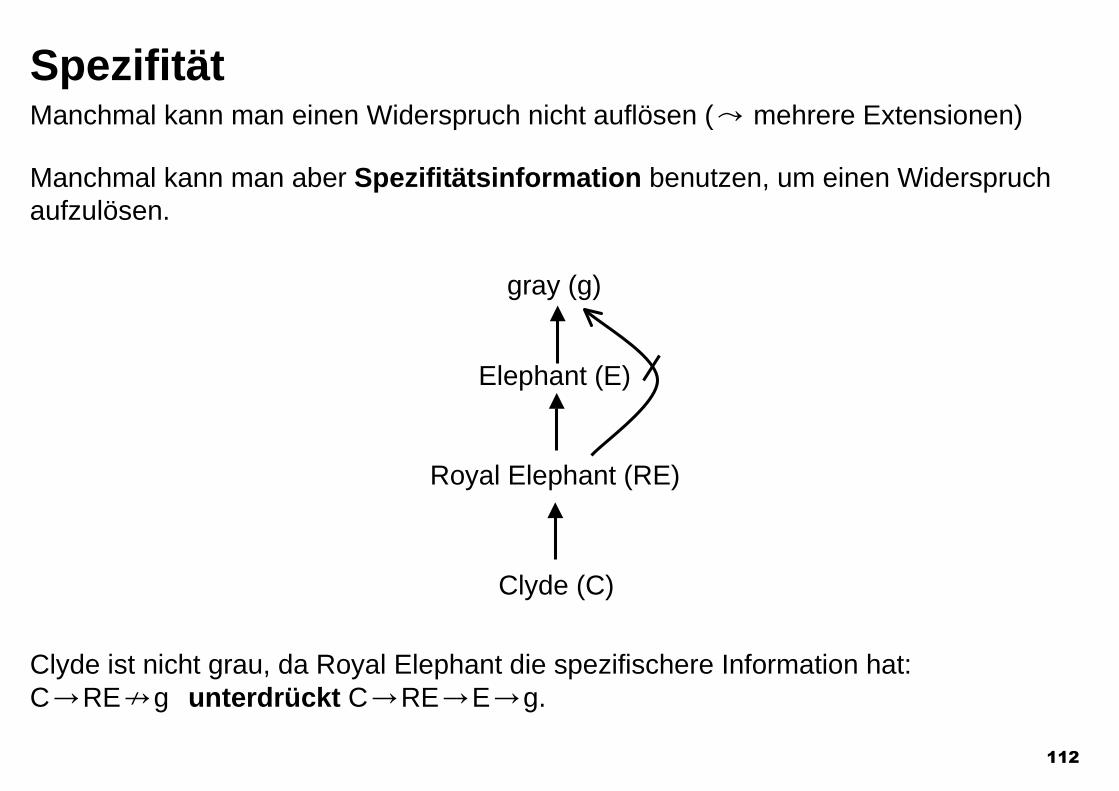
112
SpezifitätManchmal kann man einen Widerspruch nicht auflösen (= mehrere Extensionen)
Manchmal kann man aber Spezifitätsinformation benutzen, um einen Widerspruchaufzulösen.
Clyde (C)
Royal Elephant (RE)
Elephant (E)
gray (g)
Clyde ist nicht grau, da Royal Elephant die spezifischere Information hat:C/REKg unterdrückt C/RE/E/g.

113
Spezifität: Redundante Pfade
Clyde (C)
Royal Elephant (RE)
Elephant (E)
gray (g)
Die Kante C/E ist neu, aber redundant (wir wissen sowieso, dass C/RE/E).
Sollte der Pfad C/E/g unterdrückt werden?
Ja, da C/E redundant ist.

114
Alternativen:„A Clash of Intuitions“
[Touretzky et al, IJCAI-87]
Pfadunterdrückung.Es sind andere Möglichkeiten der Unterdrückung denkbar:auf-Pfad (on-path), nicht-auf-Pfad (off-path)
Vererbung.Alternative Formen der Konkatenierung:
abwärts/gekoppelt (downward/coupled) vs.aufwärts/entkoppelt (upward/decoupled)
Extensionen.Statt mehrerer Extensionen nur eine, die nur „unwidersprochene“ Pfadeenthält: leichtgläubig (credulous) vs. skeptisch (skeptical)

115
Pfadunterdrückung
Pfadunterdrückung (preemption).Ein Pfad sZx0/./xi/./xn(.Kxn), mit 0!i!n, wird in F unterdrückt,falls es einen Pfad g von x0 bis xi in F gibt, der bis xi-1 identisch mit s ist undeinen Teilpfad y0/./ym mit xi-1Zy0 und xiZym enthält, und es eine KanteyjKxn (yj/xn) in F gibt.
Beispiel: (Unterdrückung eines positiven Pfades)
xn
xn-1
xi
xi-1
x0
yj
xn
xn-1
xi
xi-1
x0
oder Zym
Zy0Zyj

116
Beispiel
Annahme FZG g {C/RE/E}
sZC/E/g wird von F unterdrückt, da
1. C/RE/E 2F2. REKg 2F
gray (g)
Elephant (E)
Royal Elephant (RE)
Clyde (C)

117
Pfadunterdrückung: Alternative Definition
Nicht-auf-Pfad Unterdrückung (off-path preemption).Ein Pfad sZx0/./xn-1/xn (xn-1Kxn) wird in F unterdrückt, falls es einen PfadgZx0/. /y/xn-1 gibt und yKxn (y/xn) eine Kante in F ist.
Beispiel:
xn
xn-1
x0
y

118
Pfadunterdrückung: off-path
Beispiel:
Gilt CKg in allen Extensionen?
Nein: C/AE/E/g ist nicht unterdrückt.
Aber: Die Information, daß AE’s g sind, ist nicht explizit gegeben. Stattdessen wird siedurch einen Knoten E ererbt, der auch auf dem Pfad C/RE/E/g liegt, welcherallerdings durch die spezifischere Information bei RE unterdrückt werden würde.
Deshalb: Sollte auch in diesem Fall die spezifischere Information bei RE Präzedenzhaben.
g
E
AE
C
RE

119
Konkatenierung
Konkatenierung.Ein Pfad s ist eine Konkatenierung von Pfaden in F gdw. g1, g2 2 F und g1 alleKanten von s bis auf die erste und g2 alle Kanten von s bis auf die letzte enthält.
xn
xn-1
xi-1
xn-1
xi-1
x0
xn
xn-1
xi-1
x0

120
Konkatenierung: Alternative Definition
Konkatenierung (aufwärts/entkoppelt).Ein Pfad s ist eine Konkatenierung von Pfaden in F gdw. g 2 F und g alle bis aufdie letzte Kante von s enthält und die letzte Kante von s in F ist.
xn
xn-1xn-1
x0
xn
xn-1
x0

121
Vererbbarkeit und Extension
Vererbbarkeit.Ein Pfad s ist in F, gdw.
• s eine Konkatenierung von Pfaden in F ist• s nicht F widerspricht• s nicht in F unterdrückt ist
Extension (credulous grounded extension).F ist eine Extension von G, gdw.
• G 4 F• für alle Pfade s, s 2 F – G gdw. s ist vererbbar in F.

122
Beispiel: Extension
Pacifist (P)
Nixon (N)
Republican (R)Quaker (Q)
1. G g {N/RKP}2. G g {N/Q/P}
Zwei Extensionen, eine mit NKP, eine mit N/P.

123
Vererbung
employed (e)
adult student (AS)
student (S)adult (A)
Jill (J)
Nach der angegebenen Definition gilt in jeder Extension, in der J/e (JKe) gilt,auch AS/e (ASKe). D.h. ein Wert für eine Unterklasse gilt auch in der Oberklasse(in ambigen Netzen).= Eigenschaften werden von oben nach unten vererbt.

124
Entkoppelte Vererbung: Beispiel
employed (e)
adult student (AS)
student (S)adult (A)
Jill (J)
Sei FZ{J/AS/A, AS/SKe, A/e}
Bei entkoppelter Vererbung können wir J/AS/A/e hinzunehmen -bei gekoppelter Vererbung nicht.

125
Beispiel: Extension
Clyde(C)
Royal Elephant (RE)
Elephant (E)
gray (g)
Konstruktion:1. G2. g {C/RE/E}3. g {RE/E/g} ? geht nicht: Widerspruch4. g {C/E/g} ? geht nicht: Unterdrückung5. g {C/REKg}6. Fertig.
Achtung: Mögliche Sackgasse: 1, 4, 3W, 5W, 2: nun ist 4 unterdrückt!

126
Beispiel: Extension (mögliche Sackgasse)
Clyde(C)
Royal Elephant (RE)
Elephant (E)
gray (g)
Konstruktion:1. G2. g {C/E/g} 3. g {RE/E/g} ? geht nicht: Widerspruch4. g {C/REKg} ? geht nicht: Widerspruch5. g {C/RE/E}6. {C/E/g} wird unterdrückt / Sackgasse

127
Multiple vs. eine Extension
Netze, die Ambiguitäten enthalten, führen zu mehreren Extensionen. Statt dessenkönnte man eine einzige Extension aufbauen, die nur Pfade enthält, denen nichtwidersprochen werden kann.
employed (e)
adult (A) student (S)
adult student (AS)
Jill (J)
F = G W {J/AS/S, J/AS/A}
D.h. wir folgern nichts über e.

128
Skeptische Extension
Grad eines Pfades.Der Grad eines Pfades von x nach y ist die Länge des längsten Pfades vonx und y (wobei die Polarität der Kanten ignoriert wird).
Skeptische Extension (skeptical grounded extension).F ist eine skeptische Extension von G gdw. F = fi, wobei fi wie folgtdefiniert ist:(a) f1 = G(b) fi+1 enthält alle Pfade aus fi und jeden Pfad s des Grades i+1
U∞
=1i
mit den folgenden Eigenschaften:
• s kann aus der Konkatenierung zweier Pfade aus fi gewonnenwerden.
• es gibt keinen Pfad in fi und keinen Pfad, der durch Vererbungaus fi gewonnen werden könnte, der dieselben Start- undEndpunkte wie s hat, aber entgegengesetzte Polarität besitzt.

129
Skeptisch vs. ideal skeptisch
Man könnte vermuten, dass skeptische Vererbung genau die Folgerungen unterstützt,die von allen „leichtgläubigen“ Extensionen unterstützt werden.
Gegenbeispiel:f
d
c
a
b
e
Die skeptische Extension unterstützt aKf, obwohl sie nicht in allen leichtgläubigenExtensionen unterstützt wird.

130
Probleme und AlgorithmenVererbung.
Berechne eine Folgerungsmenge – die Menge der Folgerungen, die von einerExtension unterstützt werden (im skeptischen Fall eindeutig).
Zielorientierte Vererbung.Prüfe, ob eine Folgerung in einer Extension liegt (im skeptischen Fall: in dereinzigen Extension).
Ideal-skeptische Vererbung.Prüfe, ob eine Folgerung in allen Extensionen liegt (im skeptischen Fall, dasselbewie oben, im leichtgläubigen Fall: ideal skeptisch).
/ Generiere eine Extension (bzw. alle), berechne Folgerungsmenge(n) (Start- undEndpunkte + Polarität), ..., fertig!
, Wieviele Folgerungsmengen gibt es? Wie groß können eine Folgerungsmenge undeine Extension werden?

131
Die FRAME-KonzeptionFrames sind:
• aus Erfahrungen abstrahierte, große Wissenseinheiten zur erwartungsgesteuertenErkennung von Objekten oder Ereignisfolgen
• größere Wissenseinheiten als Netzwerkknoten, Produktionen, logische Formeln
• Erwartungsrahmen, die zu konkreten Beschreibungen spezialisiert werden können
• Eine objektorientierte Wissensrepräsentationssprache
Frames dienen zur:
• Verarbeitung von Wissen in größeren Einheiten
• Erkennung durch partielle Instantiierung von Prototypen
• Fokussierung von Erkennungs- und Inferenzprozessen
• Unterstützung von Analogieschlüssen

132
FRAMES als DatenstrukturenFRAMES sindzusammengesetzte Datenstrukturen mit eindeutigen Namen, die aus einer Menge von innerhalb eines FRAMES eindeutig bezeichneten Attributen (engl. SLOTS)bestehen. Mit den Attributen sind Deskriptoren oder Attributwerte assoziiert. Mit denAttributen können auch Verweise auf andere Attribute assoziiert sein.
Typische Eigenschaften von FRAME-Systemen sind:
• FRAME-Vernetzung (z.B. AKO-, SELF-Attribute)
• verschiedene Vererbungsmechanismen in FRAME-Hierarchien
• Standardwertbelegungen (engl. DEFAULT VALUES) als Erwartungswerte
• objektbezogene Prozedurdefinitionen (engl. PROCEDURAL ATTACHMENT):IF-ADDED, IF-NEEDED
• partielle Instantiierung von Prototype-FRAMES
• mehrfache Sichten (engl. PERSPECTIVES) eines Objekt-FRAMES
• Meta-Merkmale zur Klassifikation von Deskriptoren (KRL) oder Attributen (AIMDS)
• FRAME-Wechselhinweise bei fehlgeschlagener Instantiierung

133
Zur Entwicklungder Wissensrepräsentationssprache ‘FRAMES‘1) Konzeption:
psychologische Grundlagen:- Gestaltpsychologie (Bartlett 1932, Wertheimer 1938)
als Schemata gespeicherte ‘ideale’ Typen unter den Perzeptionsstimuli als eine Art Ankerpunkt für die Wahrnehmung
- Prototypentheorie in der kognitiven Psychologie (Rosch 1973-)FRAMES als Wissensrepräsentationssprache:Minsky 1975, MITScripts zur Beschreibung stereotyper Erisfolgen:Schank/Abelson 1977, Yale
2) Realisierung in Softwaresystemen:
KRL (Bobrow/Winograd 1977, Xerox)FRL (Roberts/Goldstein 1977, MIT)AIMDS (Sridharan 1978, Rutgers Univ.)UNITS (Stefik 1980, Stanford Univ.)OBJTALK (Laubsch 1982, Univ. Stuttgart)auch in Expertensystem-Shells wie: KEE, ART, BABYLON, KNOWLEDGE CRAFTEntwurf beeinflußt von: SIMULA, CLU, SMALLTALK

134
FRAME REPRESENTATION LANGUAGE FRL1) Definition eines FRAMES mit FASSERT
(FASSERT MINSKY(NAME ($VALUE (|MARVIN MINSKY|)))(ADDRESS ($VALUE (|545 TECHNOLOGY SQUARE,
ROOM 821, CAMBRIDGE, MA 02139|)))(PUBLICATIONS ($VALUE (|A FRAMEWORK FOR REPRESENTATION
KNOWLEDGE|)))(INTERESTS ($VALUE (REPRESENTATION))))
2) Ergänzung des FRAMES mit FPUT(FPUT ‘MINSKY ‘INTERESTS ‘$VALUE ‘ROBOTICS ‘SOURCE: ‘RBR) (MINSKY
…(INTERESTS ($VALUE (REPRESENTATION) (ROBOTICS (SOURCE: RBR))))…)
3) Zugriff auf einen FRAME mit FGET(FGET ‘MINSKY ‘INTERESTS ‘$VALUE) (REPRESENTATION ROBOTICS)(FGET ‘MINSKY ‘INTERESTS ‘$VALUE ‘ROBOTICS ‘SOURCE:) (RBR)

135
FRAME REPRESENTATION LANGUAGE FRL
4) Löschen von Teilen eines FRAMES mit FREMOVE(FREMOVE ‘MINSKY ‘INTERESTS ‘$VALUE ‘ROBOTICS)
5) Vererbung über die AKO-Hierarchie:
(FASSERT MIT-AI(STREET ($VALUE (|545 TECHNOLOGY SQUARE|)))(CITY ($VALUE (|CAMBRIDGE|)))(STATE ($VALUE (|MA|)))(ZIP ($VALUE (|02139|))))
(FREMOVE ‘MINSKY ‘ADDRESS)
(FASSERT MINSKY(AKO ($VALUE (MIT-AI)))(OFFICE ($VALUE (821))))
(FGET ‘MINSKY ‘CITY ‘$VALUE) (|CAMBRIDGE|)

136
FRAME REPRESENTATION LANGUAGE FRL
6) Berechnung von Attributwerten
(FASSERT AI-WORLD…(ADDRESS ($VALUE (!GET-ADDRESS: FRAME)))…)
(FGET ‘MINSKY ‘ADDRESS ‘$VALUE)
7) Objektbezogene Prozedurdefinitionen:
(FPUT ‘MIT ‘INTERESTS ‘$IF-ADDED‘(PUSH :VALUE MASTER-LIST))
(FPUT ‘MIT ‘INTERESTS ‘$IF-REMOVED‘(POP :VALUE MASTER-LIST))
(FPUT ‘AI-WORLD ‘STREET ‘$IF-NEEDED‘(ASK-FOR-STREET :FRAME))

137
FRAME REPRESENTATION LANGUAGE FRL
8) Standartwertbelegungen mit der $DEFAULT-FACETTE
(FPUT ‘MIT-AI ‘OFFICE ‘$DEFAULT 817)
(FREMOVE ‘MINSKY ‘OFFICE)
(FGET ‘MINSKY ‘OFFICE ‘$VALUE) (817)
9) Wertrestriktionen in der $REQUIRE-FACETTE
(FASSERT AI-WORLD…(STATE ($REQUIRE ((OR
(MEMBER :VALUE STATE-ABBREVIATIONS)(MEMBER :VALUE STATES)))))
…)

138
FRAME REPRESENTATION LANGUAGE FRL10) Suchprozesse in einer FRAME-Wissensbasis
(FQUERY ‘?FRAME(CITY ($VALUE (|CAMBRIDGE|)))(INTERESTS ($VALUE ( ?INTEREST ))
($REQUIRE ((AKO? :VALUE‘NATURAL-LANGUAGE)))))
11) Zusammenfassung der FRAME-Syntax von FRL(FRAME1
(SLOT1 (FACET1 (DATUM1 (LABEL1 MESSAGE1 MESSAGE2… MESSAGE_N1)
… COMMENT_N2)(DATUM2 (LABEL1 MESSAGE1 …))… DATUM_N3)
(FACET2 (DATUM1 (LABEL1 MESSAGE1 MESSAGE2 …)))… FACET_N4))
(SLOT2 (FACET1 (DATUM1 (LABEL1 MESSAGE1 …)…)…)…)… SLOT_N5)

139
Leistungsfähige Deduktionssysteme(nach 20 Jahren Grundlagenforschung)• Aura (Automatic Reasoning Assistant, Wos et al., Argonne Nat. Lab.)
Haupterfolge:• Beweis eines offenen Theorems des Algebraikers Kaplansky aus dem Bereich der endlichen
Halbgruppen (2 Min. Rechenzeit) - angenommen in mathematischer Fachzeitschrift• Beweis eines offenen Problems aus dem Äquivalenzen-Kalkül angenommen in Fachzeitschrift für
Logik• BMTP (Boyer-Moore Theorem Proofer, Boyer/Moore, SRI)
Haupterfolg:• neuer Beweis für Unentscheidbarkeit des Halteproblems
• MKRP (Markgraf Karl Refutation Procedure, Siekmann/Deussen et al., Univ. Karlsruhe)Ziel: Alle Beweise des Buches ‘Halbgruppen und Automaten’ von Deussen automatisch erstellen.Arbeitet nach Connection-Graph-Verfahren (Kowalski)
Aufgaben von Deduktionssystemen:• Beweise und Gegenbeispiele finden• Modelle finden• Hypothesentest
Vielseitige Anwendungsmöglichkeiten:• Lösen offener mathematischer Probleme• Programmverifikation und -Synthese (LOPS, BIBEL, TU München)• VLSI-Entwurf• deduktive Datenbanksysteme• Inferenzkomponente in natürlich-sprachlichen Systemen, Expertensystemen

140
AussagenkalkülSätze der Sprache heißen Aussagen, aufgebaut aus• Aussagenvariablen {P, Q, R, S, T, ...}• Verknüpfungsoperationen (Junktoren) {l, o, n, ...}• Klammern {(,)}
z.B. “Wenn der Wind weht und die Sonne nicht scheint, ist es kalt.”P - der Wind wehtQ - die Sonne scheintR - es ist kalt(P o lQ) / Räquivalente Schreibweisen: l(P o lQ) n R oder lP n Q n R
Werden Wahrheitswerte {T, F} für Aussagenvariablen substituiert, so kann man nach den logischenVerknüpfungsregeln einen Wahrheitswert für die Aussage bestimmen.
Ist eine Aussage immer wahr, heißt sie Tautologie.
P Q R lP n Q n RF F F TF F T TF T F TF T T TT F F FT F T TT T F TT T T T

141
AussagenkalkülTypische Anwendung des Aussagenkalküls:• Gegeben Prämissen, d.h. Aussagen, deren Wahrheit zugesichert wird.• Gegeben Theorem, d.h. Aussage, deren Wahrheit behauptet wird.• Gesucht Beweis, d.h. Demonstration, dass Theorem aus Prämissen folgt.Formulierung im Aussagenkalkül:Ist (Prämisse1 o Prämisse2 o .) / Theorem eine Tautologie?
Beispiel:Prämissen:
Theorem: ‘Es muß geheizt werden.’P = Der Wind weht.Q = Die Sonne scheint.R = Es ist kalt.S = Es muß geheizt werden.
Prämisse1 = lP n Q n R Theorem = SPrämisse2 = lR n SPrämisse3 = lPPrämisse4 = lQ
1) ‘Wenn der Wind weht und die Sonne nicht scheint, ist es kalt.’2) ‘Wenn es kalt ist, muß geheizt werden.’3) ‘Der Wind weht.’4) ‘Die Sonne scheint nicht.’
Ist A = ((lP n Q n R) o (lR n S) o P o (lQ) / S) eine Tautologie?
Äquivalent: A = l(lP n Q n R) n l(lR n S) n lP n l(lQ) n S= (P o lQ o lR) n (R o lS) n lP n Q n S

142
1. Lösungsmethode: Wahrheitswerttabelle
Prüfe für alle Belegungen der Aussagevariablen, ob der Satz(Prämisse1 o Prämisse2 o .) / Theorem wahr ist.
(Beweis durch erschöpfende Fallunterscheidung)
Beispiel (s.o.)
P F F F F F F F F T T T T T T T T
Q F F F F T T T T F F F F T T T T
R F F T T F F T T F F T T F F T T
S F T F T F T F T F T F T F T F T
A T T T T T T T T T T T T T T T T
/ ‘Es muss geheizt werden.’
• Nachteil: Bei Sätzen mit n Aussagevariablen sind 2n Evaluierungen erforderlich.• Vorteil: simpler Algorithmus

143
2. Lösungsmethode: Wangs Algorithmus (Wang 1960)
Schreibe Prämissen und Theorem wie folgt: Prämisse1, Prämisse2, . / Theorem
Falls einer der durch Kommata getrennten Teilausdrücke links oder rechts negiert ist,überführe ihn unnegiert zur anderen Seite.
Falls der Hauptverknüpfungsoperator einer Aussage zur linken ‘o’ ist oder zur rechten ‘n’ ist,ersetze ihn durch Komma.
Falls der Hauptverknüpfungsoperator einer Aussage zur linken ‘n’ ist oder zur rechten ‘o’ ist,erzeuge daraus 2 Zeilen, jeweils nur mit einem der verknüpften Teilausdrücke.Alle Zeilen müssen bewiesen werden.
Falls links und rechts identische Aussagen auftreten, ist die Zeile bewiesen.
Falls eine Zeile keine Verknüpfungsoperatoren mehr enthält, und keine Aussagenvariablen sowohl linksals auch rechts auftritt, kann die Zeile nicht bewiesen werden.Belegt man alle Variablen links mit T und rechts mit F, so ist dies ein Gegenbeispiel für das Theorem.
R, lP n S / lQ, lR o S
R, lP / lQ, lR o S R, S / lQ, lR o S
P n Q, l(R o S), lQ, P n R / S, lP
P n Q, P n R, P / S, R o S, Q
P o Q, R o (lP n S) / lQ n lR
P, Q, R, lP n S / lQ, lR
Beispiele:
zu : zu :
zu :

144
2. Lösungsmethode: Wangs Algorithmus (Wang 1960)
Merke:
• eine Zeile L1, L2, L3 / R1, R2, R3 bedeutet logisch(L1 o L2 o L3) / (R1 n R2 n R3) oder lL1 n lL2 n lL3 n R1 n R2 n R3
• Tautologie 5 di, j: Li = Rj
• Bei m Verknüpfungsoperatoren in Prämissen und Theorem können bis zu 2m Zeilen entstehen.
(l(P o lQ) n R), (lR n S), P, lQ / S
(l(P o lQ) n R), (lR n S), P / S, Q
l(P o lQ), (lR n S), P / S, Q R, (lR n S), P / S, Q
(lR n S), P / S, Q, (P o lQ) R, lR, P / S, Q R, S, P / S, Q
R, P / S, Q, RlR, P / S, Q, (P o lQ) S, P / S, Q, (P o lQ)
lR, P / S, Q, P lR, P / S, Q, lQ
lR, P, Q / S, Q
Beispiel:
Alle Zeilen bewiesen / Theorem folgt aus den Prämissen.
bewiesen
bewiesenbewiesen
bewiesen
bewiesen

145
3. Lösungsmethode: Resolution im Aussagenkalkül(Robinson 1964)
Spezielle Schlussregel:(P n Q) o (lP n R) / Q n R
Vefahrensidee:Nimm an, das Theorem wäre falsch. Zeige, dass Prämissen und negiertes Theorem zueinem Widerspruch führen, d.h. nicht gemeinsam wahr sein können.
Prämisse1 o Prämisse2 o . o Negiertes Theorem / F
Bringe den Ausdruck
Prämisse1 o Prämisse2 o . o Negiertes Theorem
in die konjunktive Normalform. Die disjunktiven Teilausdrücke heißen Klauseln.
Wähle zwei Klauseln, in denen je die gleiche Aussagenvariable auftritt, in einer jedochnegiert.
Vereinige alle anderen Aussagenvariablen dieser Klauseln zu einer neuen Klausel und fügesie den anderen bei.
Das Theorem ist bewiesen, sobald eine leere Klausel abgeleitet werden kann.

146
3. Lösungsmethode: Resolution im Aussagenkalkül(Robinson 1964)
(lP n Q n R) o (lR n S) o P o lQ o lS
Finde Widerspruch in
NIL Leere Klausel
Negiertes Theorem
Q n S
lP n Q n S
S
Eigenschaften des Verfahrens:• Vollständig, d.h. findet Beweis für jedes Theorem, das aus den Prämissen folgt.• Entscheidbar, d.h. man erfährt in jedem Fall, ob das Theorem beweisbar ist. (Es gibt nur
endlich viele verschiedene Klauseln, die erzeugt werden können und damit endlich vieleResolutionsschritte.)
• Die Zahl der Klauseln kann sehr groß werden, Buchführung erforderlich.
Beispiel:

147
4. Lösungsmethode: die Konnektionsmethode (Bibel 1970)
{P, lP} nennt man eine KonnektionProblem: (lP n Q n R) o (lR n S) o P o lQ / S
Disjunktive Normalform:(P o lQ o lR) n (R o lS) n lP n Q n S
Mengennotation:{{P, lQ, lR}, {R, lS}, {lP}, {Q}, {S}}
Matrixnotation:
P
lQ
lR
R
lS
lP Q S
Einen Pfad durch eine Matrix erhält man bei ihrer horizontalen Traversierung, indemman aus jeder ihrer Spalten genau ein Literal auswählt und sie zu einer Mengezusammenfaßt.

148
4. Lösungsmethode: die Konnektionsmethode (Bibel 1970)
Satz: Eine Matrix repräsentiert eine gültige Formel genau dann, wenn jeder ihrerPfade eine Konnektion enthält.
Konnektionsableitung:
P
lQ
lR
R
lS
lP Q S
Pfade:
{P, R, lP, Q, S}, {P, lS, lP, Q, S}
{lQ, R, lP, Q, S}, {lQ, lS, lP, Q, S}
{lR, R, lP, Q, S}, {lR, lS, lP, Q, S}
Alle Pfade enthalten Konnektionen / Theorem bewiesen

149
Prädikatenkalkül 1. StufeAussagenkalkül ist beschränkt tauglich:
Aussagen sind nicht weiter in Nicht-Aussagen zerlegbar,z.B. Otto schläft
‘Subjekt‘ ‘Prädikat‘
All- und Existenzaussagen sind nicht möglich, z.B. es gibt Menschen, die alle Tiere hassen
Formale Sprache:Besteht aus Konstanten {OTTO, A1, 13, GELB, ...}
Variablen {x, y, z1, ...}Funktionen {f, g, h, Vater, PLUS, ...}Prädikatensymbolen {P, Q, R1, GROß, ...}Verknüpfungsoperatoren {o, n, l, /}Quantoren {d, c}Klammern, Kommata
<Term> := <Konstante> | <Variable> |<Funktion> (<Term> {, <Term>}*)
z.B. f(x), OTTO, g(OTTO), h(x, y), z)<Atomare Formel> := <Prädikat> | <Prädikat> (<Term> {, <Term>}*)
z.B. P(f(x)), GROß(OTTO), KLEINER(x, 7)

150
Prädikatenkalkül 1. Stufe
<Literal> := <atomare Formel> | l<atomare Formel>z.B.lQ(x), P(x, y), lGUT
<Quantor> := (d <Variable>) | (c <Variable>)z.B.(c x), (d z)
<quantorfreie Formel> := <Prädikat> |(l<qf Formel>) |(<qf Formel> o <qf Formel>) |
(<qf Formel> n <qf Formel>) |(<qf Formel> / <qf Formel>)
z.B.lP(g (x, y), Otto) o GROß(z) Q(z) o ((P(x, z) n R) n (R1 / R2))
<Formel> := {<Quantoren>}* <quantorenfreie Formel>z.B.(d x) (∃ y) (lGRÖßER(x, y) o lKLEINER(x, y))
(c z) (ALT(vater(z)) / ALT(mutter(z))
Zusätze: Alle Quantoren-Variablen einer Formel müssen verschieden sein.Nichtquantifizierte Variablen heißen „frei“, sonst „gebunden“,Formeln ohne freie Variablen heißen „Sätze“.
Im folgenden werden vorwiegend Sätze interessieren.

151
Interpretationbisher formale Sprache, keine SemantikBedeutungszuweisung (= Interpretation) durch Abbildung von
- Konstanten- Variablen- Funktionen- Prädikaten
in eine Diskurswelt (Domäne).
z.B.
GERADE
UNGERADE
minus1
plus1
3
4
5
A
f
P
Für die gezeigte Interpretation ist P(f(A)) wahr!
Variablen können alle Werte einer Diskurswelt annehmen/ häufig unendlich viele Interpretationen möglich!Eine Formel heißt gültig, wenn sie für alle Interpretationen wahr ist.Es gibt kein allgemeingültiges Verfahren zum Feststellen der Gültigkeit einerFormel: der Prädikatenkalkül ist unentscheidbar.Jedoch: es gibt ein Verfahren, welches gültige Formeln beweist(und bei ungültigen womöglich nicht terminiert)
Domäne

152
AbleitungsregelnAbleitungsregeln erzeugen aus Formeln neue Formeln
z.B. Modus PonensF1
o (F1 / F2)oder (F1 o (F1 / F2)) / F2
z.B. Spezialisierung(c x) (F(x)) / F(A) A Konstante
z.B. Resolution (s. Aussagenkalkül)(P1 n P2) o (lP1 n P3)
Ableiten einer Formel durch (wiederholtes) Anwenden von Ableitungsregeln heißtbeweisen.UnifizierenSubstitution von Termen für Variable, um identische Teilausdrücke in 2 Formeln zuerhalten.
z.B. P(A)P(x) / Q(x)
Spezialisierung unifiziertP(A) / Q(A)
Modus Ponens kann angewendet werdenQ(A)
/ F2
/ P2 n P3 (Resolvente)

153
Substitution von Termen für Variable erzeugt eine Substitutionsinstanz einesAusdrucks.Enthält eine Substitutionsinstanz keine Variable, so heißt sie Grundinstanz desAusdrucks.Ist die Substitutionsinstanz durch bloßes Umbenennen einer Variablen erzeugtworden, so heißt sie alphabetische Variante des Ausdrucks.Eine Substitution wird repräsentiert als Folge von geordneten Paaren.
s = {t1/v1, t2/v2, ., tn/vn}Term ti wird für alle Vorkommen von vi substituiert.z.B. F = P(x, f(y), A)
s = {z/x, B/y} / P(z, f(B), A) = FsNotation für Substitutionsinstanz von F mit s
Verknüpfung zweier Substitutionen:s1s2 = s3 enthält s1 mit Termen modifiziert durch s2, dazu alle Paare von s2
mit Variablen, die nicht unter den Variablen von s1 sind.z.B. {g(x,y)/z} {A/x, B/y, D/z} = {g(A,B)/z, A/x, B/y}Die Verknüpfung ist assoziativ: (s1s2)s3 = s1(s2s3)Es gilt auch: (Fs1)s2 = F(s1s2)
Unifikation

154
UnifikationEine Menge von Formeln {F1, F2, . Fn} heißt unifizierbar, wenn es eineSubstitution s gibt, die alle Fi gleich macht, d.h.
F1s = F2s = . = Fns
s heißt dann Unifizierer.
Man ist am allgemeinsten Unifizierer (Abk.: MGU) g interessiert, der keine‘überflüssigen’ Substitutionen vornimmt.
Ein Unifizierer g für {F1, F2, . Fn} ist genau dann der MGU, wenn es für alleUnifizierer s für die Menge von Ausdrücken {F1, F2, . Fn} eine Substitution rgibt, so daß s = gr,
z.B. {P(x,f(y),B), P(x,f(B),B)} wird unifiziert durchs = {A/s, B/y} oderg = {B/y} :: = MGU
Die Menge der Ausdrücke, ab denen zwei Ausdrücke nicht übereinstimmen,heißt Differenzmenge.

155
Unifikationsalgorithmus
w soll unifiziert werden, gesucht ist der MGU
1) K := 0, wK := w, sK := NIL
2) Wenn wK aus einzelnem Element bestehtdann: STOP; sK ist MGU für w.sonst: bilde Differenzmengen DK von wK.
3) Wenn es ein vK und tK in DK gibt, so daß vK eine Variable ist, dienicht in tK auftritt dann: GOTO 4sonst: w ist nicht unifizierbar.
4) sK+1 := sK{tK/vK} und wK+1 := wK{tK/vK}
5) K := K + 1; GOTO 2

156
UnifikationsalgorithmusBeispiel: Unifikation von w = {P(a, x, f(g(y))), P(z, f(z), f(u))}
1) K := 0, w0 := w, s0 := NIL
2) D0 := {a, z} z ist Variable, a ist Konstante
4) s1 := s0{a/z} = NIL{a/z} = {a/z}w1 := w0{a/z} = {P(a, x, f(g(y))), P(a, f(a), f(u))}
5) K := 1
2’) D1 := {x, f(a)} x ist Variable, f(a) ist Term ohne x
4’) s2 := s1{f(a)/x} = {a/z}{f(a)/x} = {a/z, f(a)/x}w2 := {P(a, f(a), f(g(y))), P(a, f(a), f(u))}
5’) K := 2
2’’) D2 := {f(g(y)), f(u)} u ist Variable, die nicht in g(y) auftritt
4’’) s3 := s2{g(y)/u} = {a/z, f(a)/x, g(y)/u}w3 := {P(a, f(a), f(g(y)))}
5’’) K := 3
2’’’) w3 besteht aus einzelnem Element, daher: s3 ist MGU; STOP

157
Unifikationsalgorithmus
Unifikationstheorem:
ist w eine nichtleere endliche Menge von unifizierbarenAusdrücken, dann hält der Unifikationsalgorithmusimmer und liefert den MGU.
In der allgemeineren Form der Unifikation werdenEigenschaften der Funktionen in den Termen gleichmitberücksichtigt.
So sind die beiden Terme 3 + 5 und x + 3 unifizierbarmit s = {5/x}, wenn man berücksichtigt, dass dieAddition kommutativ ist.

158
Rahmenprozedur zur Resolution inWiderlegungssystemen
(1) Klauseln := Basismenge
(2) Falls Klauseln NIL enthalten, ist der Beweis gefunden.
(3) Wähle zwei resolvierbare Klauseln Ki und Kj aus Klauseln
(4) Berechne eine Resolvente Rij aus Ki und Kj.
(5) Füge Rij in Klauseln ein;GOTO (2)

159
Strategien zur Auswahl resolvierbarer Klauseln1) Breitensuche
Ei = Klauseln der Ebene iR(Ei) = alle Resolventen mit der Eigenschaft:
- eine der beteiligten Klauseln stammt aus Ei
- die andere stammt aus Ej, j # iEi + 1 = R(Ei)Erzeuge zuerst alle Resolventen der jeweils niedrigeren Ebene.Vollständiges, aber sehr ineffizientes Verfahren.
2) Stützmengen-StrategieStützmenge = {Klauseln aus negiertem Theorem n Nachfolger davon}Satz: Wenn eine Widerlegung überhaupt möglich ist, so läßt sich ein
Widerlegungsgraph ableiten, wenn an einer Resolution stetsmindestens eine Klausel der Stützmenge beteiligt ist.
Diese Strategie führt zu einer Art Rückwärtsverkettung.
3) Linear-Input StrategieForderung: An jeder Resolution ist mindestens ein Element der Basismengebeteiligt.Es gibt Klauselmengen, die sich auf diese Weise nicht widerlegen lassen,obwohl die Widerlegung prinzipiell möglich ist.

160
NILNIL
lD(A)lD(A) L(A)L(A) ll(z) n lD(z)ll(z) n lD(z) lR(A)lR(A) ll(A)ll(A)L(A)L(A) ll(z) n lD(z)ll(z) n lD(z)
R(A)R(A)ll(z) n L(z)ll(z) n L(z) lR(y) n lD(y)lR(y) n lD(y) lL(A)lL(A)
l(A)l(A) ll(z) n R(z)ll(z) n R(z) D(A)D(A)lR(x) n L(x)lR(x) n L(x) lD(y) n lL(y)lD(y) n lL(y)
Beispiel für die Breitensuche bei der Resolution
... ...
...
Basismenge
Ebene 1
Ebene 2
Ebene 3

161
lD(A)lD(A) lI(A)lI(A) lD(A)lD(A)lD(A)lD(A)
L(A)L(A) L(A)L(A)ll(y) n lD(y)ll(y) n lD(y)
R(A)R(A)
ll(z) n L(z)ll(z) n L(z)
D(A)D(A)lR(x) n L(x)lR(x) n L(x) lD(y) n lL(y)lD(y) n lL(y)l(A)l(A)ll(z) n R(z)ll(z) n R(z)
Beispiel für die Stützmengen-Strategie
Basismenge
Ebene 1
Ebene 2
Ebene 3

162
Beispiel für die Linear-Input Strategie
Basismenge
Ebene 1
Ebene 2
Ebene 3 ll(A)ll(A)
R(A)R(A)
ll(z) n L(z) ll(z) n L(z)
lR(x) n lD(y)lR(x) n lD(y) lL(A)lL(A)
L(A)L(A) lR(A)lR(A)ll(z) n lD(z)ll(z) n lD(z)L(A)L(A) ll(y) n lD(y)ll(y) n lD(y)
D(A)D(A)lR(x) n L(x)lR(x) n L(x) lD(y) n lL(y)lD(y) n lL(y)ll(z) n R(z)ll(z) n R(z)l(A)l(A)
... ...

163
Strategien zur Auswahl resolvierbarer KlauselnBeispiel für eine nicht durch Linear-Input Strategie widerlegbare Klauselmenge:
Q(u) n P(A), lQ(w) n P(w), lQ(x) n lP(x), Q(y) n lP(y)
4) Vorfahr-Filter StrategieForderung: Jede Resolvente muß entweder
• einen direkten Vorgänger aus der Basismenge oder• einen direkten Vorgänger, der Vorfahre des anderen direkten
Vorgängers der Resolvente isthaben.
lQ(x) n lP(x)lQ(x) n lP(x) Q(y) n lP(y)Q(y) n lP(y)
lP(x)lP(x) lQ(w) n P(w)lQ(w) n P(w)
Q(u) n P(A)Q(u) n P(A)lQ(w)lQ(w)
P(A)P(A)
NILNIL

164
Strategien zur Auswahl resolvierbarer Klauseln5) Einzelelement-Bevorzugungsstrategie
Verfeinerung der Stützmengen-Strategie: Resolviere zuerst mit Klauseln, die nuraus einem Literal bestehen. Dabei wird die Resolvente stets kürzer als dieresolvierten Klauseln.
Beispiel(1) Jeder, der lesen kann, ist gebildet. (c x) (R(x) / L(x))(2) Delphine sind nicht gebildet. (c x) (D(x) / lL(x))(3) Es gibt intelligente Delphine. (d x) (D(x) o I(x))/(4) Es gibt jemanden, der intelligent ist und nicht lesen kann. (d x) (I(x) o lR(x))
Basismenge: lR(x) n L(x)lD(y) n lL(y)lD(A), I(A)lI(z) n R(z)
lI(z) n R(z)lI(z) n R(z) I(A)I(A)
lD(y) n lL(y)lD(y) n lL(y)
lR(x) n L(x)lR(x) n L(x)
D(A)D(A)
R(A)R(A)
L(A)L(A)
lD(A)lD(A)
NILNIL

165
1) Elimination von TautologienJede Klausel, die ein Literal und seine Negation (d.h. eine Tautologie) enthält, kannnicht zur Widerlegung beitragen und kann deshalb eliminiert werden.z.B. P(x) n B(y) n lB(y)
2) Partielle InterpretationDer Resolutionsmechanismus gilt für alle Interpretationen. Häufig ist in einerAnwendung eine bestimmte Interpretation beabsichtigt, d.h. Funktionen undPrädikate entsprechen bestimmten Prozeduren.Sobald diese in einer Grundinstanz verwendet werden, können sie evaluiertwerden.
z.B. ‘E(2,3)’ wird interpretiert als S-Ausdruck ‘(EQ 2 3)’.Dabei wird das Prädikatensymbol ‘E’ durch das LISP-Prädikat ‘EQ’ interpretiert unddie Konstanten ‘2’ und ‘3’ als die LISP-Atome ‘2’ und ‘3’.Die Evaluation durch den LISP-Interpretierer ergibt den Wahrheitswert F. Auf dieseWeise kann eine Klausel, die ‘E(2,3)’ enthält, vereinfacht werden.
Möglichkeiten zur Vereinfachung von KlauselmengenDie Zahl der neu generierten Klauseln kann dadurch beschränkt werden, dass dieVereinfachungsregeln auf die Klauseln angewandt werden, von denen bekannt ist,dass sie die Widerlegbarkeit der Klauselmenge nicht beeinflussen.

166
z.B. Vater(OTTO, KARL) läßt sich auswerten, wenn der Stammbaum der Familiebeispielsweise als Assertion (VATER OTTO KARL) ... in einer Wissensquelle desSystems zur Verfügung steht.
Falls ein Literal in einer Klausel zu T evaluiert, kann die gesamte Klausel eliminiertwerden.z.B. P(x) n E(2,2) n P(f(g(x)))
Falls ein Literal in einer Klausel zu F evaluiert, kann dieses Literal aus der Klauselentfernt werden.z.B. P(x) n Q(A) n E(2,3) wird vereinfacht zu: P(x) n Q(A)
3) Elimination subsumierter KlauselnEine Klausel {L} subsumiert eine Klausel {M}, wenn es eine Substitution s gibtderart, dass
{L}s 4 {M}Subsumierte Klauseln einer widerlegbaren Klauselmenge können eliminiert werden,ohne die Widerlegbarkeit zu beeinflussen.Durch diese Elimination kann häufig die Zahl der notwendigen Resolutionsschrittedeutlich reduziert werden.z.B. P(x) subsumiert P(y) n Q(z)
Q(y) subsumiert Q(A)P(x) n Q(A) subsumiert P(f(A)) n Q(A) n R(y)
Möglichkeiten zur Vereinfachung von Klauselmengen

167
Antwortextraktion aus Resolutionsbeweisen
Bisher: Es können nur Entscheidungsfragen beantwortet werden.z.B. Frage: Kann ich ein Buch über Affen und Löwen einsehen?
Antwortmöglichkeiten: Ja, Nein
Beantwortung von W-Fragen mit dem Greenschen Antwortprädikat
Faktenwissen: Wolfgang ist der Ehemann von Doris.Frage: Wer ist der Ehemann von Doris?
Es gibt ein x, das Ehemann von Doris ist.
(1) G(W,D)(2) (d x) G(x,D)
(C1) G(W,D)(C2) lG(x,D) {W/x}
(C1) + (C2): (C3) NIL
Um die Antwort ‘Wolfgang’ zu erhalten, muß die Variable x verfolgt werden.

168
Frage: Wie kann der Affe die Banane erreichen?Formalisierung:
P(x,y,z,s) Zustand s, Affe an Ort x, Banane an Ort y, Stuhl an Ort zR(s) Zustand, in dem Affe die Banane erreichtFunktionen:
walk(y,z,s) vom Zustand s geht Affe von y nach zcarry(y,z,s) Stuhl aus Zustand s von y nach z tragenclimb(s) Affe klettert im Zustand s auf Stuhl
Ausgangssituation:Affe sei an Ort A, Banane an Ort B, Stuhl an Ort C, Anfangszustand S1
Axiome:(c x)(c y)(c z)(c s) P(x,y,z,s) / P(z,y,z,walk(x,z,s))
Affe kann immer zu Stuhl gehen(c x)(c y)(c z)(c s) P(x,y,x,s) / P(y,y,y,carry(x,y,s))
falls Affe am Stuhl steht, kann er Stuhl zur Banane tragen(c s) P(B,B,B,s) / R(climb(s))
falls Affe mit Stuhl am Bananenplatz, kann er Banane erreichen
Ausgangssituation: P(A,B,C,S1)Frage: (c s) R(s) / ANS(s)
Automatisches Problemlösen mit dem Resolutionsverfahren
Beispiel: Das Affe-Banane-Problem: Affe, Banane, Stuhl, in einem Raum; Affe ist zu kurz, umBanane, die an der Decke hängt, zu erreichen; aber er kann auf den Stuhl klettern.

169
(C1) lP(x,y,z,s) n P(z,y,z,walk(x,z,s))(C2) lP(x,y,x,s) n P(y,y,y,carry(x,y,s))(C3) lP(B,B,B,s) n R(climb(s))(C4) lP(A,B,C,S1)(C5) lR(s) n ANS(s)
(C3) + (C5) Heuristik: gleich Antwortprädikat ins Spiel bringen(C6) lP(B,B,B,s) n ANS(climb(s)) {climb(s)/s}
(C6) + (C2) {B/y} {carry(x,B,s)/s}(C7) lP(x,B,x,s) n ANS(climb(carry(x,B,s)))(C7’) lP(z,B,z,s) n ANS(climb(carry(z,B,s))) Variablenumbenennung
(C7’) + (C1) {B/y} {walk(x,z,s)/s}(C8) lP(x,B,z,s) n ANS(climb(carry(z,B,(walk(x,z,s))))
(C8) + (C4) {A/x, C/z, S1/s}(C9) ANS(climb(carry(C,B,(walk(A,C,S1))))
Antwort: Zunächst geht der Affe zum Stuhl.Dann trägt er den Stuhl zur Banane.Schließlich klettert er auf den Stuhl.
Vollständigkeit der Resolution bei AntwortextraktionS1 sei die Menge der Klauseln, welche die Fakten repräsentieren. Frage: Finde Werte x1, ..., xn, so dass Q(x1, ..., xn) wahr ist.S2: lQ(x1, ..., xn) n ANS(x1, ..., xn)
Satz: Sei S = S1 n S2. Die Frage ist beantwortbar genau dann, wenn es eineDeduktion aus S gibt, welche die Antwortklausel erzeugt.

170
Default Reasoning - Motivation
• Das meiste, was wir über die Welt wissen, ist nur „fast immer“ wahr.
• Wir haben nie vollständiges Wissen über die Welt.
/ Ein Vogel fliegt typischerweise, soweit es nicht gerade ein Pinguin,Strauß, Kiwi, usw. ist. Mögliche Formalisierung:
cx: Vogel(x) o lPinguin(x) o lStrauß(x) ...0 Fliegt(x)
/ Probleme:
1) Können wir je „...“ vollständig angeben?2) Wir können nicht für irgendeinen Vogel schließen, dass er fliegen
kann, wenn wir nicht wissen, dass er kein Pinguin, kein Strauß,kein Kiwi und kein ... ist.

171
Lösungsansatz
/ Wir würden gern etwas wie „Vögel fliegen typischerweise“ haben.
• Möglichkeit: Zusätzliche (nicht-logische) Inferenzregeln:
Fliegt(x)Fliegt(x) :Vogel(x)
Intendierte Bedeutung:Wenn x ein Vogel ist, und die Annahme Fliegt(x) möglich ist ohne zuInkonsistenz zu führen, dann nehme Fliegt(x) an.
• Ausnahmen werden dann durch einfache Implikationen dargestellt:
cx: Pinguin(x) 0 lFliegt(x)cx: Strauß(x) 0 lFliegt(x)cx: Kiwi(x) 0 lFliegt(x)

172
Eigenschaften des Default Reasoning• Nicht-Monotonie
Nimm an, es gibt genau ein Default und sonst ist nichts bekannt. Dannkönnen wir B erschließen.Wenn der Fakt lA hinzukommt, kann B nicht mehr erschlossen werden!
BA:
• Nicht-Determinismus
Außerdem:Spouse(mary, tom), hometown(tom) = toronto,Employer(mary, univ), location(univ) = vancouver
/ Default-Regeln dienen zur Ergänzung von unvollständigen Theorien.Dabei können verschiedene Ergänzungen möglich sein: „MultipleExtensionen“ (leichtgläubige Strategie).
/ Man könnte auch den Schnitt über alle möglichen Extensionen nehmen(skeptische Strategie).
z )hometown(xz )hometown(x :z )location(y y),Employer(x
===∧
z )hometown(xz )hometown(x : z )hometown(y y)Spouse(x,
===∧

173
Weitere Beispiele• Default-Annahmen in Frames und semantischen Netzen.
Beispiel: Der Heimatort einer Person ist defaultmäßig Palo Alto.[Person UNIT Basic
.
.
.
<hometown {(a city) Palo Alto; DEFAULT}>... ]
y)hometown(xy)hometown(x :Person(x)
==
/ Aber beachte, dass wir keine Priorisierung im Sinne von Spezialisierung haben.
• Closed World Assumption. Für jede Basisrelation R in einer DB:)x,...,xR(
)x,...,xR(:
n1
n1
¬
¬
• Frame Default (als Ersatz für Frame-Axiome). Für jede Relation R mit einemSituationsargument s und Transitionsfunktion f:
s))f(x,R(x,s))f(x,R(x,:s)R(x,
/ Aber beachte das „Yale Shooting Problem“.

174
Formaler Rahmen• PL1 mit “w“ klassische Beweisbarkeit und Cn Konsequenzoperation. Wir
betrachten nur Mengen von abgeschlossenen Formeln.
• Defaultregeln
)x()x(),...,x(:)x(
mr
rrr
γα ββ
1
wobei Formeln mit freien Variablen sind.
o : Voraussetzung (prerequisite) / soll beweisbar sein
o : Begründung (justification) / konsistente Annahmen
o : Konsequenz (consequent)
Eine Defaultregel heißt abgeschlossen, wenn sie keine freien Variablen enthält.
)(),(),...,(),( xxxx m1
rrrr γα ββ x,...,xx n1=r
)(xrα
)x(),...,x(m
rrββ1
)x(r
γ
• Defaulttheorie: Ein Paar (D, W), wobei D eine abzählbare Menge vonDefaultregeln ist und W eine abzählbare Menge von PL1-Formeln ist.
• Abgeschlossene Defaulttheorie: Alle Defaultregeln sind abgeschlossen.
/ Im weiteren erstmal nur abgeschlossene Defaulttheorien.

175
Probleme mit der Default Logik:Fallunterscheidung in der Default Logik
Beispiel:
,
Von (Emu(Tweety) n Ostrich(Tweety)) können wir nicht auf lFly(Tweety) schließen.
)x(Fly)x(Fly:)x(Emu
¬¬
)x(Fly)x(Fly:)x(Ostrich
¬¬
Zwei Lösungen:
1) Entweder die Defaultregel zusammenfassen zu einem Default:
und zu den Fakten Emu(x) n Ostrich(x) 0 Big-Bird(x) hinzunehmen.
)x(Fly)x(Fly:)x(BirdBig
¬¬−
2) Wie eben, Defaults umformulieren:
,)x(Fly)x(Emu)x(Fly)x(Emu:
¬⇒¬⇒
)x(Fly)x(Ostrich)x(Fly)x(Ostrich:
¬⇒¬⇒

176
3) ; E
dann 2 E.
Extensionen von Defaulttheorien
Die Defaultregeln D erweitern die durch W gegebene PL1-Theorie: Extensionen von(D, W).
Wünschenswerte Eigenschaften einer Extension E von (D, W):
• Enthält die Fakten: W 4 E
• Ist deduktiv abgeschlossen: E = Cn(E)
• Alle anwendbaren Defaults wurden „gefeuert“:Falls
1) 2 D,
• E enthält nur die Fakten, die nach diesen Bedingungen in E sein müssen.
γ
ββα m,...,: 1
2) a 2 E,
m,..., β¬β¬ 1

177
Extensionen - Formal
Sei D = (D, W) eine abgeschlossene Defaulttheorie. Für jede Menge vonabgeschlossenen Formeln S sei G(S) die kleinste Menge, die folgendeBedingungen erfüllt:
D1: W 4 G(S),
D2: Cn(G(S)) = G(S),
D3: Falls
1) 2 D,
γ
ββα m,...,: 1
2) a 2 G(S) und
3) ; S,
dann 2 G(S).
m,..., β¬β¬ 1
Eine Menge von abgeschlossenen Formeln E ist eine Extension von D falls E = G(E).

178
1) , W = {B 0 lA o lC},
E1 = Cn(W W {A, C}), E2 = Cn(W W {B})
Beispiele
=
CC
BB
AA
D:
,:
,:
2) , W = \, E1 = Cn({lD, lF})
¬¬¬=
FE
ED
DC
D:
,:
,:
3) , W = \, E1 = Cn({lC}), E2 = Cn({lD})
¬¬=
CD
DC
D:
,:
4) , W = \,
E1 = Cn({lA}), E2 = Cn({A, dx P(x)})
¬¬
∃∃=
AA
AA
xP xxP xA
D:
,:
,:
)()(

179
Normale Defaults
Normale Defaults haben die Form:
Beachte: Alle unsere Beispiele hatten diese Form! Defaulttheorien, die nur normaleDefaults benutzen, heißen normale Defaulttheorien.
Normale Defaults haben sehr angenehme Eigenschaften.
Theorem: Normale Defaulttheorien haben immer mindestens eine Extension
Beweisskizze: Falls W inkonsistent, trivial. Ansonsten konstruiere:
E0 = WEi+1 = Cn(Ei) W Ti
wobei Ti eine maximale Menge ist mit(1) Ei W Ti ist konsistent und(2) wenn 2 Ti, dann ex. 2 D, a 2 Ei.Zu zeigen:
ββα :
ββα :
∉¬∈∈= EβEαDβ
βαβT ,,:| ii

180
Semi-normale Defaults
Neben den normalen Defaults haben die semi-normalen Defaults eine gewisseBedeutung:
Wichtig für interagierende Defaults:
, ,
besser:
Für sog. „geordnete Defaulttheorien“ gibt es eine Beweistheorie [Etherington 88].
Allerdings ist diese Art der Konfliktauflösung nicht sehr einfach, insbesondere wenndie Theorien größer werden.
γγ∧βα :
)x(Employed)x(Employed:)x(Adult
)x(Adult)x(Adult:)x(Dropout
)x(Employed)x(Employed:)x(Dropout
¬¬
)x(Employed)x(Dropout)x(Employed:)x(Adult ¬∧

181
Allgemeine Defaulttheorien
Die Beispiele am Anfang enthielten offene Defaults. Bisher haben wir aber nurabgeschlossene Defaults behandelt.
Wenn wir einen Default der Form haben, sollen die Variablen ja
mindestens für alle benennbaren Objekte stehen.
Problem: Implizite Einführung von Objekten: dx: P(x).
Lösung: Skolemisierung aller Formeln in W und D.
Interpretation: Ein offener Default steht für die rekursiv aufzählbare Mengevon geschlossenen Defaults, die durch Einsetzung mitGrundtermen entstehen. D.h. für jedes Objekt kann ein Defaultangewendet werden.
)x()x(:)x( rrr
γβα
Aber: Man kann keine universell quantifizierte Aussage ableiten. Z.B. und P(x) konsistent für jede Substitution von x. Trotzdem gibt es keinenDefaultbeweis für cx: P(x), falls es nicht schon aus W alleine ableitbar ist.
)()(:
xPxP

182
Temporale Projektion im Situationskalkül
Gegeben die Beschreibung einer Situation und einer Folge von Ereignissen:Welche Eigenschaften gelten, nachdem die Ereignisse stattgefunden haben?
Situationen: Si, s, ... (Intervalle, in denen sich nichts ändert).
Eigenschaften: awake, dead, f, ... (Situationen, in denen die Eigenschaft gilt)
Situationsaussagen: Holds(awake, Si), ...
Ereignisse: wakeup, shoot, e, ...
Resultate von Ereignissen sind wieder Situationen: Result(wakeup, S0), ...
Kausalgesetze: cs: Holds(awake, Result(wakeup, s)), ...

183
Das Frame-ProblemGegeben:
cs: Holds(awake, Result(wakeup, s))S1 = Result(wakeup, S0)S2 = Result(eat-breakfast, S1)
Gilt dann Holds(awake, S2)?
Hinzufügen von Frame-Axiomen. Aber
1) erfordert eine riesige Anzahl von Axiomen (|Eigenschaften| ! |Ereignisse|);
2) müssen diese Frame-Axiome ja auch gar nicht immer zutreffen.
/ Default: Holds(f, s) 0 Holds(f, Result(e, s)).
McCarthy´s Formulierung: Alle „normalen“ Fakten gelten nach „normalen“ Ereignissen:
cf, e, s: Holds(f, s) o lab(f, e, s) 0 Holds(f, Result(e, s))
„Minimierung“ des ab-Prädikats (/ Circumscription).
Gleiches Resultat mit DL: ),,(ab),,(ab:
sefsef
¬¬

184
Heuristische SuchverfahrenSuchprozesse sind ein wichtiger Bestandteil unterschiedlicher Problemlöseverfahren
z.B. Bestimmung der Konfliktmenge in ProduktionssystemenSuche nach resolvierbaren Klauseln in DeduktionssystemenSuche nach passendem Objektmodell bei der ObjekterkennungSuche in einem Lexikon nach der Grundform eines flektierten WortesSuche nach einem freien Weg für einen Roboter
Erster Schritt zur systematischen Suche: Formalisierung der Problemzustände in einemZustandsgraph.
Ein Suchschritt wird als Transformation eines Zustandes mit Hilfe eines Operatorsaufgefasst.
Meist liegt ein Zustandsgraph nur implizit vor, d.h. seine Knoten und Kanten werden erstwährend des Suchprozesses erzeugt.
Die Generierung von Nachfolgern eines Knotens wird als Expansion des Knotensbezeichnet.
Wichtige Suchverfahren in der KI sind:Algorithmus AAlgorithmus A*Minimax-VerfahrenAlpha-Beta-VerfahrenBidirektionale Suche

185
Algorithmus Graphsearchzur systematischen Suche eines Lösungsknoten in einem Zustandsgraphen
1) Liste neu enthält Startknoten S, Liste alt ist leer.
2) Falls neu leer ist, breche ohne Erfolg ab.
3) Wähle Knoten aus neu, nenne ihn K, entferne K aus neu, füge ihn zu althinzu.
4) Falls K Lösungsknoten ist, gib Lösungsweg mit Hilfe Zeigerkette von Knach S aus, breche ab.
5) Expandiere K, m enthalte alle Nachfolger, die nicht Vorfahren von K sind.
6) Alle Knoten aus m, die weder in neu noch in alt sind, erhalten einenZeiger auf K und werden zu neu hinzugefügt.Entscheide für alle Knoten aus m, die entweder in neu oder in alt sind, obihre Zeiger auf K gerichtet werden sollen.Entscheide für alle Nachfahren der Knoten in m, die bereits in alt sind, obihre Zeiger umgesetzt werden sollen.
7) Gehe nach 2)

186
StartknotenStartknoten
1 1
3 3
2 2
4 4 55
6 6
neualt
Suchgraph und Suchbaum vor Expansion von Knoten 1
Suchgraph und Suchbaum nach Expansion von Knoten 1

187
Eigenschaften von Graphsearch
A) Graphsearch entwickelt einen Zustandsbaum durch Vermeidenvon Duplikationen bis ein Lösungsknoten gefunden ist.
B) Die Kanten im Zustandsbaum sind durch Zeiger von jedem Knotenzu seinem Vorgänger repräsentiert.
C) Die Kanten des Zustandsgraphen können mit unterschiedlichenKosten markiert sein. Schritt (6) erlaubt es, Knoten so in den Baumaufzunehmen, dass sie von S auf dem kostengünstigsten (nichtnotwendigerweise kürzesten) Pfad erreicht werden.
D) In Schritt (3) sind verschiedene Auswahlkriterien möglich.

188
Variationen von Graphsearch (Michie/Ross 1970)
Erzeuge in Schritt (5) jeweils nur einen Nachfolger pro Durchlauf,setze K erst dann auf alt, wenn alle Nachfolger erzeugt sind.
Auf diese Weise können ggf. Expansionskosten eingespart werden(z.B. wenn der Lösungsknoten als Nachfolger eines Knotens Y erzeugtwird, bevor alle Nachfolger von Y generiert sind.)

189
Spezielle BaumsuchmethodenGraphsearch
Nicht-informierte Methoden‘blinde Suche‘:z.B. Breitensuche
Tiefensuche
Informierte Methoden – HeuristikenHeuristische Suche:z.B. Bewertungsfunktionen
A*-Algorithmus
BreitensucheAuswahlkriterium für Schritt (3) in Graphsearch: ‚Wähle Knoten geringster Tiefe.‘
- Breitensuche findet kürzesten Pfad zu einem Zielknoten (falls es einen gibt).
TiefensucheAuswahlkriterium für Schritt (3) in Graphsearch: ‚Wähle Knoten größter Tiefe.‘
- Tiefenbeschränkung notwendig (z.B. 8-er Puzzle: maximale Tiefe = 5)
BacktrackingEntspricht Tiefensuche , bei der jeweils ein Nachfolger generiert und nur ein Pfad (vomaktuellen Knoten zur Wurzel) gespeichert wird.
Eigenschaften Nicht-informierter Methoden:- einfache Kontrollstruktur- Expansion vieler Knoten
Verringerung des Aufwandes durch Berücksichtigung zusätzlicher Probleminformation –Informierte Methoden, Heuristische Suche

190
Suchbaum für 8-er Puzzle bei Tiefensuche2 8 31 6 47 5
1
2 8 31 47 6 5
182 8 31 6 47 5
2 8 31 6 4
7 5
2
2 8 36 4
1 7 5
3
8 32 6 41 7 5
4
8 32 6 41 7 5
5
8 32 6 41 7 5
68 6 32 41 7 5
7
2 8 36 41 7 5
8
2 8 31 4
7 6 5
19
8 32 1 47 6 5
20
8 32 1 47 6 5
21
8 32 1 47 6 5
228 1 32 47 6 5
23
2 8 36 41 7 5
122 8 36 7 41 5
152 36 8 41 7 5
9
2 36 8 41 7 5
102 36 8 41 7 5
112 86 4 31 7 5
132 8 36 4 51 7
142 8 36 7 4
1 5
162 8 36 7 41 5
17
2 31 8 47 6 5
28
2 8 37 1 4
6 5
24
2 8 37 1 46 5
25
2 8 37 46 1 5
262 8 37 1 46 5
27
2 31 8 47 6 5
29
1 2 38 4
7 6 5
30
1 2 38 47 6 5
311 2 37 8 4
6 5
2 8 31 47 6 5
2 31 8 47 6 5
Startknoten
Ziel-knoten

191
Suchbaum für 8-er Puzzle bei Breitensuche2 8 31 6 47 5
1
2 8 31 47 6 5
32 8 31 6 47 5
42 8 31 6 4
7 5
2
2 8 36 4
1 7 5
5
8 32 6 41 7 5
10
8 32 6 41 7 5
20
8 32 6 41 7 5
8 6 32 41 7 5
2 8 36 41 7 5
11
2 8 31 4
7 6 5
6
8 32 1 47 6 5
12
8 32 1 47 6 5
24
8 32 1 47 6 5
8 1 32 47 6 5
2 8 36 41 7 5
222 8 36 7 41 5
232 36 8 41 7 5
21
2 36 8 41 7 5
2 36 8 41 7 5
2 86 4 31 7 5
2 8 36 4 51 7
2 8 36 7 4
1 5
2 8 36 7 41 5
2 31 8 47 6 5
7
2 8 37 1 4
6 5
13
2 8 37 1 46 + 5
25
2 8 37 46 1 5
2 8 37 1 46 5
2 31 8 47 6 5
14
1 2 38 4
7 6 5
26
1 2 38 47 6 5
271 2 37 8 4
6 5
2 8 31 47 6 5
8
2 31 8 47 6 5
15
2 8 31 67 5 4
9
2 81 4 37 6 5
162 8 31 4 57 6
172 8 31 67 5 4
182 81 6 37 5 4
19
2 3 41 87 6 5
2 81 4 37 6 5
2 8 31 4 57 6
2 8 31 6
7 5 4
2 31 8 67 5 4
2 8 31 5 67 4
2 81 6 37 5 4
Startknoten
Ziel-knoten

192
Bewertungsfunktionen zur Steuerung der KnotenauswahlIn Schritt (3) von Graphsearch wird für einen Knoten K geprüft:„Wahrscheinlichkeit, daß K auf dem Lösungspfad liegt“, „Abstand von Lösung“, „Qualität derTeillösung“Ansatz: f(K) reellwertige Funktion, f(K1) ! f(K2) / K1 vor K2 untersuchen
Algorithmus AS Startknoten, K beliebiger Knoten, Ti Zielknoten, i = 1, 2, 3, ...
f(K) sei Kostenschätzung für günstigsten Pfad von S über K zu einem Zielknoten Ti.
Ki mit geringstem f(Ki)-Wert wird als nächster expandiert.
k(Ki, Kj) seien die tatsächlichen Kosten für günstigsten Pfad zwischen Ki und Kj (undefiniert, fallskein Pfad existiert).
h*(K) = mini k(K, Ti) Minimalkosten für Weg von K zu einem Zielknoten Ti (i = 1, 2, 3, ...)g*(K) = k(S,K) Minimalkosten für Weg von S nach Kf*(K) = g*(K) + h*(K) Minimalkosten für Lösungsweg über K
Zerlege f(K) in 2 Bestandteile: f(K) = g(K) + h(K)[ [
schätzt g*(K) schätzt h*(K)
Wahl für g(K): Summe der bisherigen Kantenkosten von S bis K / g(K) P g*(K)
Wahl für h(K): beliebige heuristische Funktion
Graphsearch mit dieser Bewertungsfunktion heißt Algorithmus A.
Sonderfall: g(K) = Tiefe von K, h = 0, Breitensuche ist ein Algorithmus A.

193
3210h
Endturm-gerüst
Türme von HanoiEs gibt 3 Turmgerüste und 64 gelochte Scheiben unterschiedlicher Größe.
Beginn:Alle Scheiben sind nach Größe geordnet auf dem ersten Turmgerüst.
Ziel:Turm auf 3. Turmgerüst transferieren.
Randbedingung:Nur jeweils eine Scheibe darf in einem Schritt bewegt werden.Keine Scheibe darf zwischenzeitlich auf einer kleineren Scheibe liegen.
Legenden:Einige Mönche in der Nähe von Hanoi arbeiten an dem Puzzle und wenn es fertig ist,ist das Weltende gekommen.
f(N) = Tiefe(N) + Endturmgerüstbewertung(N)

194
Zustandsgraph für den Turm von Hanoi
Zielh = 0f = 3
h = 1f = 4
h = 2f = 5
h = 2f = 3
h = 2f = 4
h = 3f = 5
h = 1f = 3
h = 3f = 4
Starth = 2f = 2
g = 1:
g = 2:
g = 3:
Start
Ziel

195
Algorithmus A*Ein Algorithmus A mit der Eigenschaft, dass gilt h(K) # h*(K), findet den optimalenLösungsweg. Ein solcher Algorithmus heißt A*.Da h(K) = 0 # h*(K) folgt: Breitensuche ist ein Algorithmus A*.
Def.: Ein Suchalgorithmus heißt zulässig, wenn er für alle Graphen den optimalenLösungsweg findet und damit terminiert, falls ein solcher existiert.
Es gilt: A* ist zulässig.h = 0 ergibt Zulässigkeit, aber führt zu ineffizienter Breitensuche.
h als größte obere Schranke von h* expandiert am wenigsten Knoten und garantiertZulässigkeit.
Oftmals: Zulässigkeit aufgeben, um härtere Probleme durch heuristische Verfahrenlösen zu können.
Bewertungsfunktionen zur Steuerung der Knotenauswahl

196
Die relative Gewichtung von g und h für f kann durch eine positive Zahl w gesteuertwerden: f(K) = g(K) + w h(K).
grosses w: betont die heuristische Komponentekleines w: führt zu einer Annäherung an eine Breitensuche
oft günstig: w umgekehrt proportional zur Tiefe der untersuchten Knoten variieren:bei geringer Suchtiefe: hauptsächlich gesteuert durch Heuristikbei großer Suchtiefe: stärker breitenorientiert, um Ziel nicht zu verfehlen.
Zusammenfassung:3 wichtige Einflussgrößen für die heuristische Stärke des Algorithmus A:
- Die Pfadkosten- Die Zahl der expandierten Knoten zum Finden des Lösungsweges- Der Aufwand zur Berechnung von h.
Bewertungsfunktionen zur Steuerung der Knotenauswahl

197
Fokussierung der Suchedurch h(N) = P(N) + 3S(N)
P(N): Summe der Abstände jederKachel von ihrem Zielfeld
S(N): Für alle Kacheln, die nicht inder Mitte liegen:Wert := 2, falls Kachel nichtneben ihrem richtigenNachfolger liegtWert := 0, sonst
Für Kacheln in der Mitte gilt:Wert := 1
1 38 2 47 6 5
P(N) = 2S(N) = 2 + 1
Bsp:

198
1. PenetranzP = L/TL = Länge des LösungspfadesT = Anzahl der insgesamt expandierten Knoten
‘Keine Lösung‘ 0 # P # 1 ‘Zielstrebig‘‘Buschiger Baum‘ ‘Schlanker Baum
2. Effektiver VerzweigungsfaktorB + B2 + ... + BL = TB(BL – 1)/(B – 1) = T
Keine explizite Lösung für BB P 1,B = 1: Es werden nur Knoten auf dem Lösungspfad expandiert.Kleines B: Schlanker Baum Großes B: Buschiger Baum
Merksatz: Mehr Wissen bedeutet weniger Suchaufwand.
Leistungsmaße

199
P zu L für verschiedene Werte von B
Pen
etra
nz P
Länge des Lösungspfades L
P = L/T
T := Gesamtzahlexpandierter Knoten
B := effektiverVerzweigungsfaktor

200
B zu T für verschiedene Werte von L
T = Gesamtzahl der expandierten Knoten
B =
effe
ktiv
er V
erzw
eigu
ngsf
akto
r
Für 8-er Puzzle mit f(N) = g(N) + P(N) + 3 S(N) ergibt sich B = 1.08.Bei 30-er Schrittlösung werden 120 Knoten expandiert.

201
Aufwandsreduktion durch Berücksichtigungzusätzlicher Probleminformation
vollständig00
Bet
riebs
mitt
elau
fwan
d
“Probleminformation”
Gesamtkosten
Aufwand fürSteuerungs-strategie
Expansionskosten
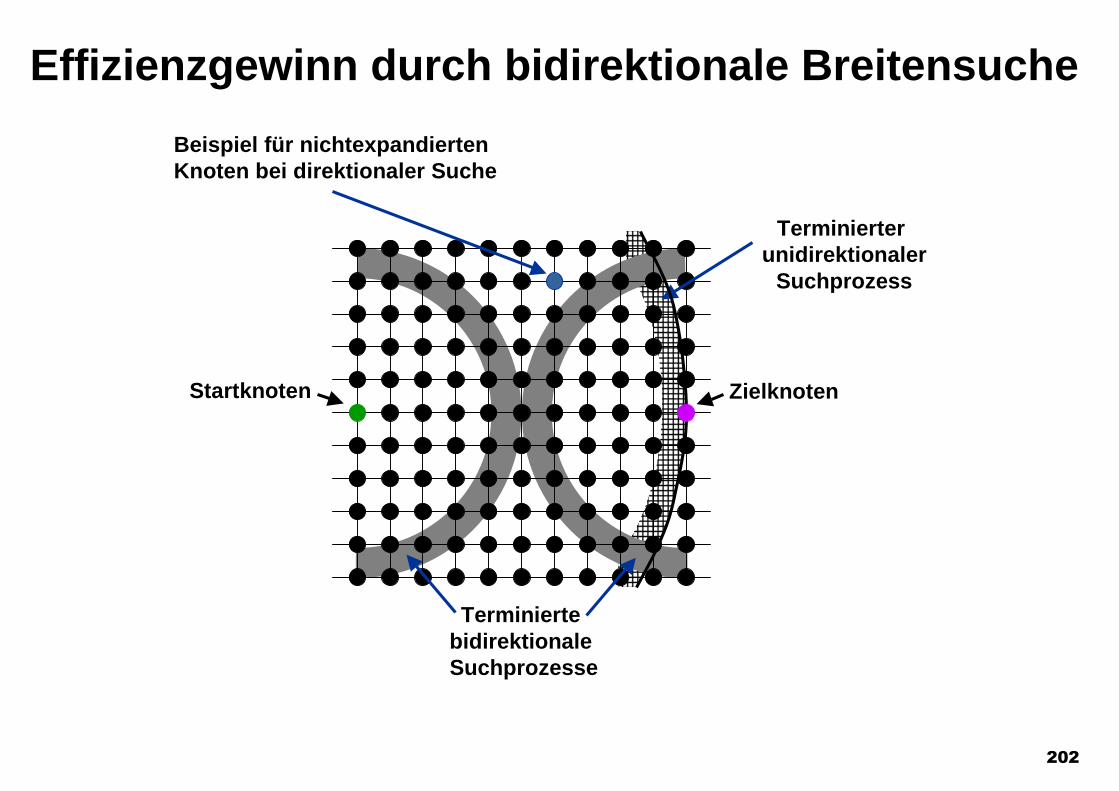
202
Effizienzgewinn durch bidirektionale Breitensuche
Startknoten
Terminierte bidirektionale Suchprozesse
Zielknoten
Terminierter unidirektionaler
Suchprozess
Beispiel für nichtexpandiertenKnoten bei direktionaler Suche

203
Effizienzverlust bei heuristischer bidirektionalerSuche mit ungünstiger Bewertungsfunktion
Startknoten Zielknoten
Rückwärtssuche
Vorwärtssuche

204
Das Minimax-Verfahren
z.B.: Schach, Verzweigungsfaktor: ca. 35,Züge pro Spieler: ca. 50;Suchgraph hätte also ca. 35100 Knoten.
daher: Zu Beginn eines Spiels ist sogar eine heuristische Suche nach einemvollständigen Lösungsweg aussichtslos.
Ziel der Suche daher:Bewertung des nächsten Handlungsschrittes
Allgemeines Vorgehen:Vorausschau und Bewertung einiger Züge, für die eine Expansion desSuchgraphen vorgenommen wird.
Bei Problemen, in denen nichtkooperative Aktoren beteiligt sind (klassisches Beispiel:Gesellschaftsspiele wie Schach, Go, Tic-Tac-Toe), ist der Suchgraph meist extremgroß.

205
Das Minimax-VerfahrenSpeziell Minimax:• Zwei Spieler Max und Min, statische Bewertungsfunktion für Knoten K des Suchgraphen sei
B(K), Knoten entspricht z.B. Brettposition bei Spielen.• Falls K Vorteil für Max: B(K) O 0 (Max sucht maximalen Wert)• Falls K Vorteil für Min: B(K) ! 0 (Min sucht minimalen Wert)• Bei ‘ausgeglichener‘ Position gilt: B(K) z 0
• Max soll als nächster agieren (wählt höchstbewerteten Knoten).• Expandiere Suchgraph bis zur Tiefe D = 2 N - 1, N P 2.• Bewerte alle Blätter mit der statischen Bewertungsfunktion B.• Verteile die Bewertungen nach folgendem Schema weiter zu den Vorgängern:
• Knoten der Tiefe D - 1 erhalten jeweils das Minimum der Bewertungen ihrer Nachfolger(‘Min-Zug’).
• Knoten der Tiefe D - 2 erhalten jeweils das Maximum der Bewertungen ihrer Nachfolger(‘Max-Zug’).
• Knoten der Tiefe 0 erhalten das Maximum.
Der Wechsel zwischen der Wahl von Knoten mit minimaler und maximaler Bewertung gab demMinimax-Verfahren seinen Namen.
Annahmen bei Minimax:• Die durch die Vorausschau erhaltene Bewertung der Nachfolger des Startknotens ist
zuverlässiger als die durch direkte Bewertung der Nachfolger mit B erhaltenen Hinweise.• Der jeweilige Gegenspieler entscheidet sich immer rational für den bestbewertesten Zug
nach dem Minimax-Verfahren.

206
Das Minimax-Verfahren am Beispiel von Tic-Tac-Toe
Statische Bewertungsfunktion:B(K) = <Anzahl der noch offenen, vollständigen Reihen und Spalten sowie Diagonalen für Max bei K> K
<Anzahl der noch offenen, vollständigen Reihen und Spalten sowie Diagonalen für Min>
Dadurch, dass Symmetrien bei der Expansion der Knoten berücksichtigt werdenkönnen (Drehung und Spiegelung am Gitter), bleibt der Verzweigungsfaktor zuBeginn klein.Später bleibt er durch die verringerte Zahl der noch offenen Gitterplätze klein.
Im Beispiel: Breitensuche bis alle Knoten der Tiefe 2 expandiert sind.
Nachteile:• Eine Zahl als Positionsbewertung ist wenig aussagekräftig; sie sagt nichts darüber
aus, wie sie entstanden ist.• Hoher Aufwand von Minimax:
• Alle möglichen Nachfolger werden erzeugt.• Für alle möglichen Pfade wird erst statische Bewertungsfunktion berechnet.

207
Das Minimax-Verfahren am Beispiel von Tic-Tac-Toe: erster Spielzug
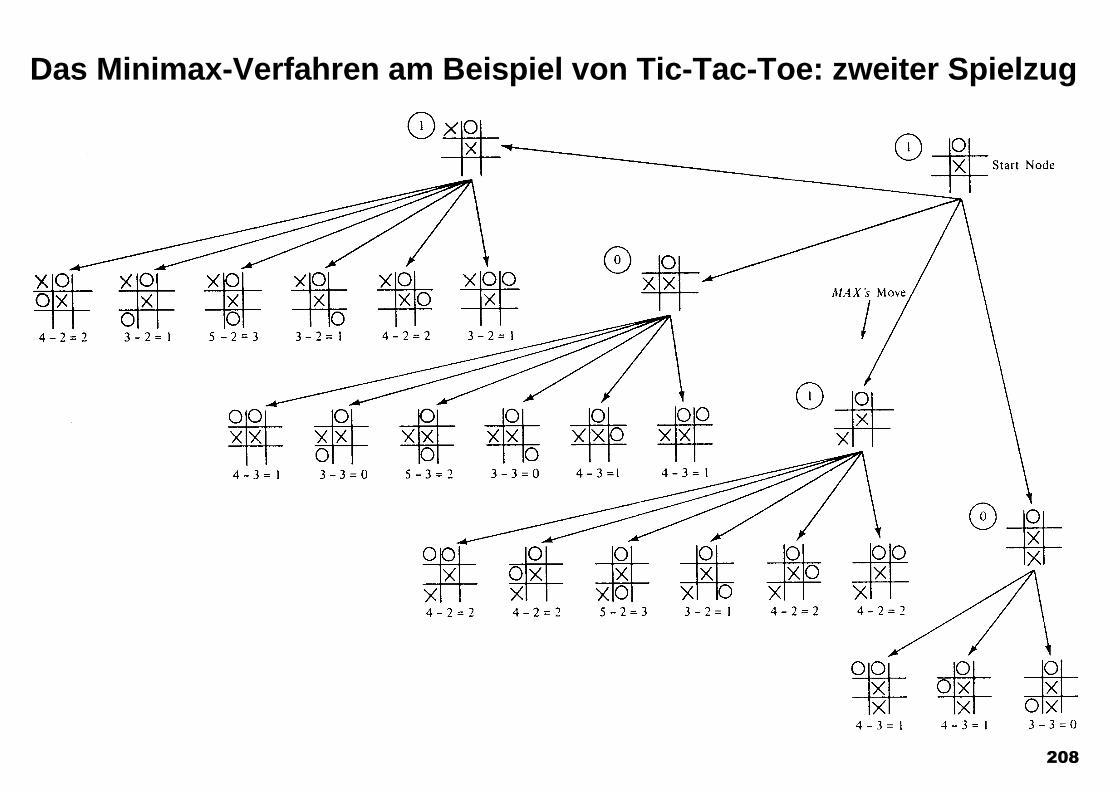
208
Das Minimax-Verfahren am Beispiel von Tic-Tac-Toe: zweiter Spielzug
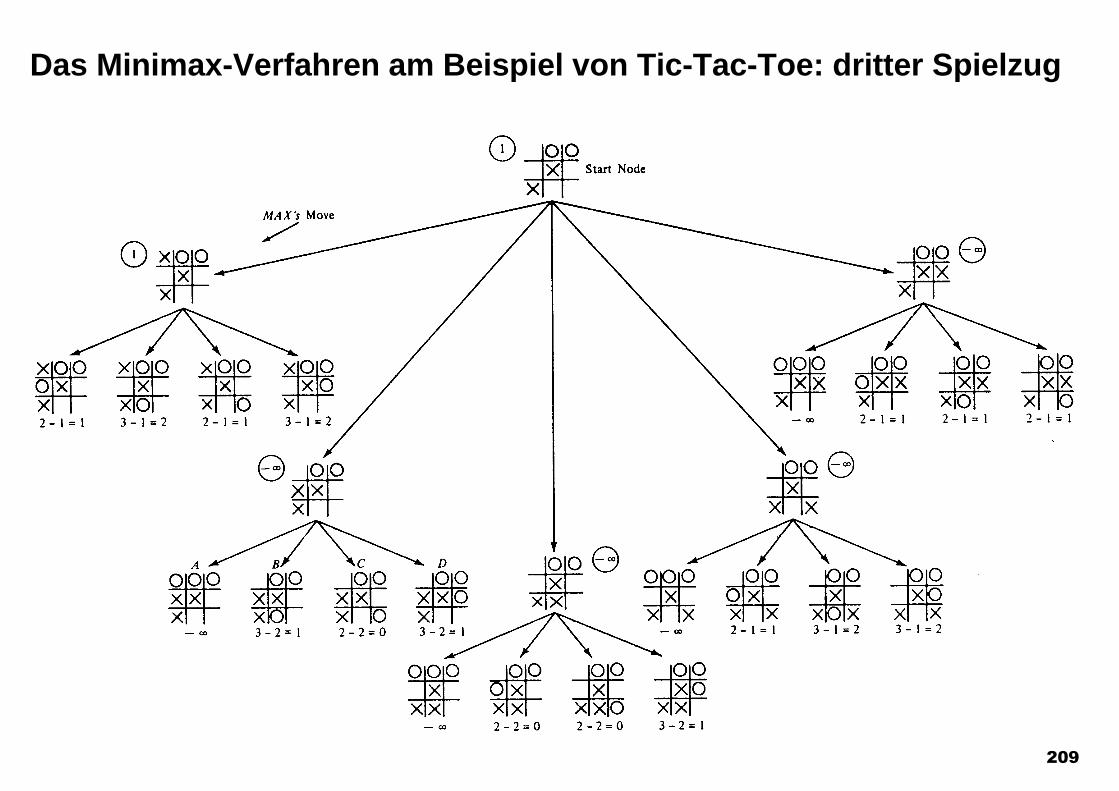
209
Das Minimax-Verfahren am Beispiel von Tic-Tac-Toe: dritter Spielzug

210
Das Alpha-Beta-Verfahren
Ausgangspunkt: Bei der Tiefensuche schon während der Expansion dieBewertungsfunktion auf Blätter anwenden und Werte nachMinimax-Verfahren nach oben verteilen.
Wenn im dritten Spielzug des Tic-Tac-Toe-Beispiels Knoten A erzeugt ist, lohnt essich nicht mehr B, C und D zu erzeugen, da Min auf jeden Fall A präferiert (bestermöglicher Zug für A).• Alpha-Wert eines Max-Knotens ist die jeweils größte geerbte Bewertung seiner
Nachfolger.• Beta-Wert eines Min-Knotens ist der jeweils kleinste geerbte Wert seiner Nachfolger.
2 Typen von Beschneidungen des Suchbaums:• Alpha-Schnitt: Suche wird abgebrochen an einem Min-Knoten,
dessen Beta-Wert # Alpha-Wert von irgendeinem seiner Max-Vorgänger.Der Beta-Wert bleibt der vererbte Wert des Min-Knotens, der gemäß Minimaxweiterverarbeitet wird.
• Beta-Schnitt: Suche wird abgebrochen an einem Max-Knoten,dessen Alpha-Wert P Beta-Wert von irgendeinem seiner Min-Vorgänger.Der Alpha-Wert bleibt der vererbte Wert des Max-Knotens.

211
Das Alpha-Beta-Verfahren
Die jeweilige Umsetzung der Alpha-Beta-Werte und die entsprechende Beschneidungdes Suchbaums wird als Alpha-Beta-Prozedur bezeichnet.
Die meisten Alpha-Beta-Schnitte würden erfolgen:• wenn Nachfolger von Max-Knoten in absteigender endgültiger Minimax-Bewertung• wenn Nachfolger von Min-Knoten in aufsteigender endgültiger Minimax-Bewertungentwickelt würden.
Wichtig:• Die Alpha-Werte von Max-Knoten können nicht kleiner werden.• Die Beta-Werte von Min-Knoten können nicht größer werden.
Während der Suche werden die Alpha- und Beta-Werte wie folgt berechnet:• Der Alpha-Wert eines Max-Knotens wird gleich gesetzt mit dem größten aktuellen
backed-up-Wert seiner Nachfolger.• Der Beta-Wert eines Min-Knotens wird gleich gesetzt mit dem kleinsten aktuellen
backed-up-Wert seiner Nachfolger.

212
Teil des ersten Spielzuges bei Tic-Tac-Toe mit Alpha und Beta

213
Beispiel für die Alpha-Beta-Prozedur

214
Plangenerierungsverfahren• Jede Roboter-Aktion besteht aus einer Folge primitiver Teilaktionen.• Eine Aktionsfolge kann sich auch verzweigen (Greifen mit zwei Armen:
Wechselwirkungen, Synchronisationsprobleme).• Bei außengesteuerten Aktionen: Teilfolgen hängen von sensorischer Information ab.
1969: STRIPS (Stanford Research Institute Problem Solver)
Repräsentation der Umwelt:nur Grundinstanzen prädikatenlogischer Literale
Planungsziele und -zwischenziele:Konjunktion von Literalen, alle Variablen existenzquantifiziert
Ein STRIPS-Operator besteht aus:• einem Bezeichner• Parametern (Variablen), die sich auf Objekte und Konzepte der Diskurswelt
beziehen• einer Vorbedingung (Precondition): Konjunktion von Literalen mit implizit
existenzquantifizierten Variablen• einer Liste zu löschender Assertionen (Delete-Liste)• einer hinzuzufügenden Formel (Add-Formel)

215
Plangenerierungsverfahren
Randbedingungen: Alle freien Variablen in der Add- undDelete-Liste müssen in der Vorbedingungenthalten sein.
Die gesamte Vorbedingung wird mit der Weltrepräsentationunifiziert und die dabei gewählte Substitution wird dann aufdie Delete-Liste und Add-Formel angewandt, wobeiGrundinstanzen entstehen.
Beispiel für STRIPS-Operator: pickup(x)
Precondition: ONTABLE(x) o HANDEMPTY o CLEAR(x) Delete-Liste: ONTABLE(x), HANDEMPTY, CLEAR(x) Add-Formula: HOLDING(x)

216
STRIPS-Operatoren als Produktionensystem mit Vorwärtsverkettung
Ausgangssituation in Blockwelt
Zielsituation in Blockwelt
1) pickup(x) P & D: ONTABLE(x), CLEAR(x), HANDEMPTY A: HOLDING(x)
2) putdown(x) P & D: HOLDING(x) A: ONTABLE(x), CLEAR(x), HANDEMPTY
3) stack(x,y) P & D: HOLDING(x), CLEAR(y) A: HANDEMPTY, ON(x,y), CLEAR(x)
4) unstack(x,y) P & D: HANDEMPTY, CLEAR(x), ON(x,y) A: HOLDING(x), CLEAR(y)
A
C
B
Roboterhand
CLEAR(B) ON(C,A) ONTABLE(A)CLEAR(C) HANDEMPTY ONTABLE(B)
A
C
B
GOAL: [ON(B,C) o ON(A,B)]

217
Zustandsraum für Stapelproblem

218
Dreieckstabellen zur Darstellung des Planungskontextes
• Tabelleneinträge in der Zeile links von einem Operator:Vorbedingungen des Operators
• Tabelleneinträge in der Spalte unter einem Operator:Literale der Add-Formel des Operators, welche von nachfolgenden Operatorenbenötigt werden oder Teil der Zielbeschreibung sind.
Der n-te Kern der Tabelle: Durchschnitt der n-ten Zeile und aller darunter liegendenZeilen mit allen Spalten, die links von der n-ten Spalte liegen.
Der n-te Kern enthält also alle Bedingungen, die erfüllt sein müssen, um den n-tenOperator und alle darauffolgenden Operatoren ausführen zu können, um dasPlanungsziel zu erreichen.
Die Kerne dienen zur Planüberwachung:Oft durch ungeplante Effekte: Plötzlich näher am oder weiter vom Ziel: Dann keineneue Plangenerierung notwendig, sondern nach jeder Ausführung einer Aktionerfüllten Kern mit maximalem n suchen: (Nur wenn kein Kern erfüllt ist, erfolgtNeuplanung)

219
Dreieckstabellen zur Darstellung des Planungskontextes
1) Beginne in der untersten Zeile, die Tabelle von links nach rechts zudurchsuchen nach einem Eintrag, der ein Literal enthält, das mit dergültigen Zustandsbeschreibung nicht unifiziert werden kann.
2) Falls kein Eintrag gefunden: Ziel erreicht,sonst: n = Nummer der Spalte in der Eintrag gefunden.
3) Gehe zur nächsthöheren Zeile und durchsuche diese bis Spalte n.
4) Falls vor Spalte n ein nicht unifizierbares Literal in Spalte m gefundenwird, setze n := m.
5) Falls in der n-ten Zeile von unten bis zur Spalte n alle Literale unifiziertwerden können: STOP,sonst: gehe nach 3)
Erfüllten Kern mit maximalem n suchen:

220
Darstellung eines Plans als Dreieckstabelle
0
1unstack(C,A)
2putdown(C)
3pickup(B)
4stack(B,C)
5pickup(A)
6stack(A,B)
HANDEMPTYCLEAR(C)ON(C,A)
ONTABLE(B)CLEAR(B)
ONTABLE(A)
HOLDING(C)
CLEAR(A)
HANDEMPTY
CLEAR(C) HOLDING(B)
HANDEMPTY
CLEAR(B)
ON(B,C)
HOLDING(A)
ON(A,B)
1
2
3
4
5
6
7Anzahl der
Teilaktionen + 1
4. Kern enthält alleVorbedingungen für
Teilplan
Zeile enthält jeweils Voraussetzungen für Aktion
Spalte enthält jeweils die durch dieAktion hinzugefügten Literale,welche für weitere Aktionen oderZiele benötigt werden.
Voraussetzungen für Aktion 1

221
Rückwärtsverkettung von STRIPS-Operatoren
Für effiziente Plangenerierung oft: Rückwärtsverkettung vom Planungsziel zurAusgangssituation
• Ausgehend von einem Zielausdruck wird ein Operator gewählt, dessen Add-Liste einLiteral enthält, das mit einem Literal des Zielausdrucks unifiziert werden kann.
• Eine neue Teilzielbeschreibung wird dadurch erzeugt, dass• die übrigen Literale des bearbeiteten Teilausdrucks einem Regressionsprozess
durch die Substitutionsinstanz des Operators unterworfen werden und• das Ergebnis des Regressionsprozesses mit der Substitutionsinstanz der
Vorbedingung des Operators konjunktiv verknüpft wird.
Regression eines Zielausdrucks:
G1´, G2´, ..., GN´ sind eine Regression von G1, G2, ..., GN durch die Instanz einesOperators OP, wenn die Anwendung von OP auf jede Zustandsbeschreibung,die mit G1´, G2´, ..., GN´ unifiziert werden kann, zu einer Zustandsmenge führt,die mit G1, G2, ..., GN unifiziert werden kann.

222
(1) goal: HOLDING(B)Substitutionsinstanz:
unstack(B,y)P & D: HANDEMPTY, CLEAR(B), ON(B,y)A: HOLDING(B), CLEAR(y)
A) Regression von HOLDING(B) = T (immer wahr nach Aktion)B) Regression von HANDEMPTY = F (immer falsch, direkt nach Aktion)C) Regression von ONTABLE(C) = ONTABLE(C) (keine Änderung durch Aktion)D) Regression von CLEAR(C) = T, falls y = C,
sonst: CLEAR(C)Daher werden 2 alternative Teilbeziehungen generiert: - eine mit P von unstack(B,C) - eine mit P von unstack(B,y) o (y s C)
E) Regression von CLEAR(B) = T, falls y = B, aber unstack(B,B) unmöglich
Beispiele für RegressionsprozesseOperator: unstack(x,y)
P & D: HANDEMPTY, CLEAR(x), ON(x,y)A: HOLDING(x), CLEAR(y)

223
Beispiele für Regressionsprozesse
(2) Substitutionsinstanz: unstack(x,B)
P & D: HANDEMPTY, CLEAR(x), ON(x,B)A: HOLDING(x), CLEAR(B)
Regression von CLEAR(C) = F, falls x = C, sonst: CLEAR(C)
d.h. Teilziel lautet: (x s C) o CLEAR(C)

224
Teil einer Rückwärtsverkettung bei der Plangenerierung
ON(B,C)
ON(A,B)
HOLDING(A)
CLEAR(B)
ON(B,C)
ONTABLE(A)CLEAR(A)HANDEMPTYON(B,C)CLEAR(B)
HANDEMPTYCLEAR(A)ON(A,B)ON(B,C)
Spezialisierungdes Originalziels
= unmögliche Ziele
pickup(A)
stack(A,B) stack(B,C)
stack(B,C) unstack(x,B) unstack(A,B)
HOLDING(B)
CLEAR(C)
ON(A,B)
HOLDING(B)CLEAR(C)HOLDING(A)
HANDEMPTYCLEAR(x)ON(x,B)(x s A)HOLDING(A)ON(B,C)

225
Fortsetzung der Rückwärtsverkettung
HANDEMPTYCLEAR(x)ON(x,A)ONTABLE(A)FON(B,C)CLEAR(B) (x s B)
HOLDING(A)ON(B,C)CLEAR(B)
HOLDING(B)CLEAR(C)ONTABLE(A)CLEAR(A)
HANDEMPTYCLEAR(x)ON(x,B)ONTABLE(A)CLEAR(A)(x s A)FON(B,C)
HOLDING(B)ONTABLE(A)CLEAR(A)ON(B,C)
HOLDING(x)ONTABLE(A)CLEAR(A)(x s A)ON(B,C)CLEAR(B)
ONTABLE(A)
CLEAR(A)
HANDEMPTY
ON(B,C)
CLEAR(B)
putdown(A)
putdown(A)
putdown(x)
putdown(B)unstack(x,B)
unstack(x,A)
stack(B,C)
Identisch mitVorgängerzustand
Nur X = B n X = C
DurchRegression vonHANDEMPTY
DurchRegression vonHANDEMPTY

226
Ende der Rückwärtsverkettung
HOLDING(B)
CLEAR(C)
ONTABLE(A)
CLEAR(A)
ONTABLE(B)
CLEAR(B)
HOLDING(C)
CLEAR(A)
ONTABLE(A)
HANDEMPTYCLEAR(C)ON(C,A)ONTABLE(B)CLEAR(B)ONTABLE(A)
Anfangssituation
HANDEMPTYCLEAR(B)ON(B,A)CLEAR(C)ONTABLE(A)
HOLDING(A)ONTABLE(B)CLEAR(B)CLEAR(C)
HANDEMPTYCLEAR(B)ON(B,C)CLEAR(A)ONTABLE(A)
Identisch zu einemVorgängerknoten
HOLDING(B)CLEAR(C)ONTABLE(A)CLEAR(A)
Identisch zu einemVorgängerknoten
HANDEMPTYCLEAR(C)ON(C,y)ONTABLE(B)CLEAR(B)(y s B)ONTABLE(A)CLEAR(A)(y s A)
HANDEMPTYCLEAR(C)ON(C,B)ONTABLE(B)ONTABLE(A)CLEAR(A)
HANDEMPTYCLEAR(B)ON(B,y)CLEAR(C)CLEAR(A)(y s C)(y s A)ONTABLE(A)
ONTABLE(B)
CLEAR(B)
HANDEMPTY
CLEAR(C)
CLEAR(A)
ONTABLE(A)
pickup(B)
putdown(A)
putdown(B)
putdown(C)
unstack(C,A)
putdown(x)
unstack(C,A)
unstack(C,y)
unstack(C,B)
unstack(B,C)
unstack(B,A)unstack(B,y)

227
Problem der redundanten Auswertung von Literalen in der Zielbeschreibung durch Mehrfach-auswertung derselben Zielkomponenten bei der Bearbeitung unterschiedlicher Subziele
Mögliche Lösung:Dekomposition der gesamten Zielbeschreibung mit sequentieller Bearbeitungder Zielkomponenten.
Beispiel (Ausgangssituation wie oben):
Interagierende Ziele
Fall 1: Zunächst ON(B,C) bearbeiten: pickup(B), stack(B,C) ergibt: ON(B,C), ON(C,A), ...Nachteile:
- Lösung von ON(A,B) wird schwieriger,- um ON(A,B) zu erreichen, muss ON(B,C) rückgängig gemacht werden.
Fall 2: Zunächst ON(A,B) bearbeiten: unstack(C,A), putdown(C), stack(A,B) ergibt:ON(A,B), CLEAR(C), ...Nachteile:
- Lösung von ON(B,C) wird schwieriger,- um ON(B,C) zu erreichen, muss ON(A,B) rückgängig gemacht werden.
ON(A,B) o ON(B,C)
ON(A,B) ON(B,C)

228
Interagierende Ziele
Die Lösung eines Ziels macht die unabhängig entwickelte Lösung eines anderen Zielswieder rückgängig.
In der Praxis der Plangenerierung sind interagierende Ziele selten. Daher Annahme inStrips zunächst: Zielkomponenten interagieren nicht. Falls dann doch Interaktionenauftreten, erfolgt Spezialbehandlung. Strips arbeitet mit Zielkeller, oberstesKellerelement = Fokus
Grundzüge des Strips-Verfahrens:
- Falls Fokus mit Weltrepräsentation unifizierbar, wird Substitution auf alleKellerelemente angewandt und Fokuselement gelöscht.
- Zusammengesetzte, ungelöste Ziele im Fokus werden zerlegt und die Literale derZielkomponenten werden im Keller über dem zusammengesetzten Ziel abgelegt.Durch Wiederauswertung des zusammengesetzten Ziels nach Einzelauswertung derZielkomponenten werden interagierende Ziele erkannt, und die rückgängiggemachten Zielkomponenten werden erneut aufgebaut.

229
Interagierende Ziele
Für das Ziel ON(A,B) Y ON(B,C) erzeugt Strips einen suboptimalen Plan:
unstack(C,A), putdown(C)pickup(A), stack(A,B), unstack(A,B), putdown(A)Umweg: ON(A,B)pickup(B), stack(B,C), pickup(A), stack(A,B)
- Falls im Fokus ein ungelöstes Literal A steht, sucht Strips einen Operator, dessenAdd-Liste ein Literal enthält, das mit A unifiziert werden kann. Der instantiierteOperator ersetzt dann A und die instantiierte Vorbedingung des Operators wird derneue Fokus.
- Falls der Fokus ein Operator ist, wird der Operator ausgeführt (vorher wurdeVorbedingung durch Unifikation mit Weltrepräsentation gelöscht) und danachgelöscht.

230
Rückwärtsverkettung in STRIPS - Teil 1) Planungsziel
Zerlegung eineszusammengesetzten Ziels
InstantiiereVorbedingungvonstack(C,B)
ON(x,y)in Add-Listevonstack(x,y)
Zerlegung
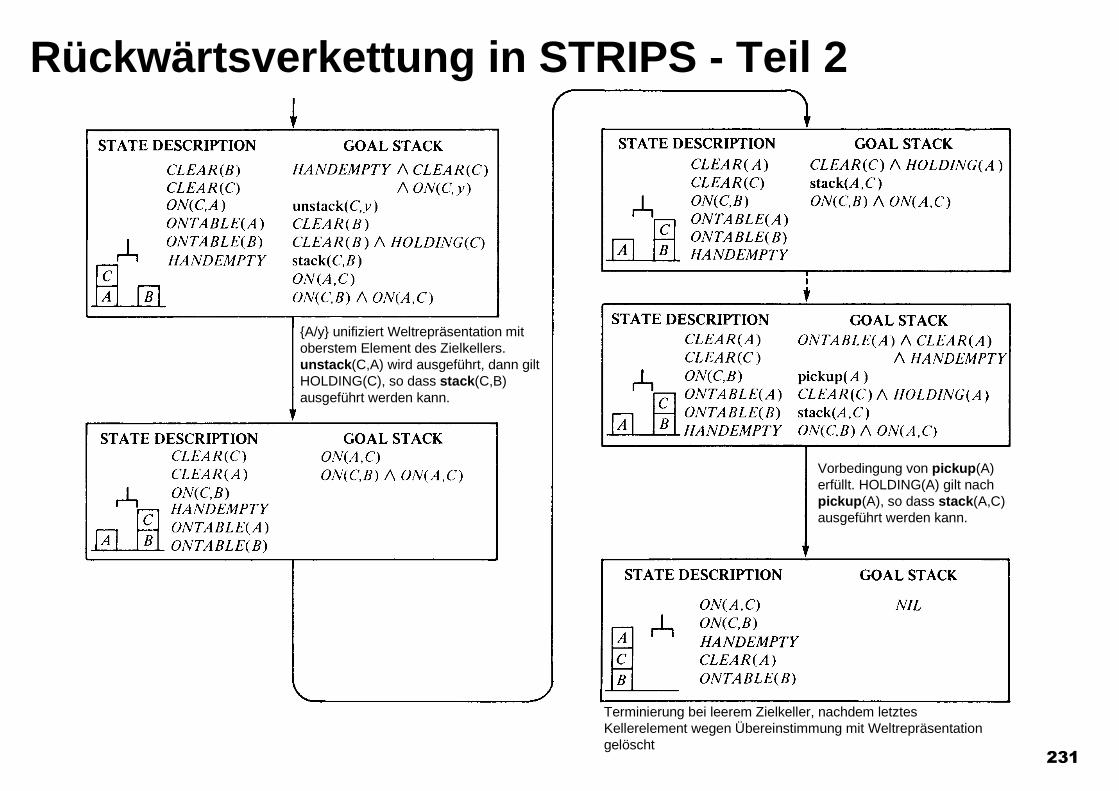
231
Terminierung bei leerem Zielkeller, nachdem letztesKellerelement wegen Übereinstimmung mit Weltrepräsentationgelöscht
Rückwärtsverkettung in STRIPS - Teil 2
{A/y} unifiziert Weltrepräsentation mitoberstem Element des Zielkellers.unstack(C,A) wird ausgeführt, dann giltHOLDING(C), so dass stack(C,B)ausgeführt werden kann.
Vorbedingung von pickup(A)erfüllt. HOLDING(A) gilt nachpickup(A), so dass stack(A,C)ausgeführt werden kann.

232
Die Kontrollstruktur des STRIPS-SystemsEntscheidungspunkte in STRIPS u. a.:- Reihenfolge von Zielkomponenten im Keller bei Zieldekomposition- Auswahl eines Operators, falls mehrere Operatoren zum Erreichen des fokussierten Ziels angewandt werden können
Der entstehende Planungsgraph kann mit den verschiedensten heuristischen Suchverfahrentraversiert werden. In die Bewertungsfunktion können z.B. die Länge des Zielkellers, derSchwierigkeitsgrad des fokussierten Ziels oder die Operatorkosten einfließen.
Beispiel für eine einfache, rekursive Version von STRIPS mit Backtracking: Sei S eine globale Variable, die mit der Bechreibung der Ausgangssituation initialisiert ist. Sei G das Planungsziel.
STRIPS(G) UNTIL S unifiziert mit G DO G::= eine Zielkomponente von G, die nicht mit S unifiziert werden kann
;hier ist Backtracking möglichF::= ein Operator, dessen Add-Liste ein Literal enthält, das mit G unifiziert werden kann
;hier ist Backtracking möglichP::= instantiierte Vorbedingung von FSTRIPS(P); RekursionS::= Resultat der Anwendung des instantiierten F auf S
OD

233
GPS (General Problem Solver) (Newell, Shaw, Simon 1960, CMU)
GPS war Vorläufer von STRIPS; entwickelt zur Simulation kognitiver Prozesse; Anwendung vonGPS wird auch als Mittel-Zweck-Analyse bezeichnet.
Auswahl der Operatoren durch Vergleich zwischen aktuellem Zustand der Planung undPlanungsziel: Berechnung einer DifferenzDie Operatoren sind in einer Differenztabelle verzeichnet, die diskursbereichsabhängig ist. Inder Differenztabelle sind die Operatoren geordnet nach Ihrer Relevanz für die Reduktionmöglicher Differenzen.
Rekursive Formulierung von GPS: Sei S eine globale Variable, die mit einer Beschreibung der Ausgangssituation initialisiert ist. Sei G das Planungsziel.
GPS(G) UNTIL S unifiziert mit G DO
D::= eine Differenz zwischen S und G ;hier ist Backtracking möglichF::= ein Operator, der relevant ist zur Reduktion von D ;hier ist Backtracking möglichP::= eine instantiierte Vorbedingung von FGPS(P); RekursionS::= Resultat der Anwendung des instantiierten F auf S
OD
STRIPS als Spezialfall von GPS: Differenz zwischen S und G in STRIPS: nicht mit S unifizierbare Zielkomponenten von G Zur Reduktion relevante Operatoren: Operatoren, deren Add-Liste G enthält.

234
Beispiel für Mittel-Zweck-Analyse mit GPS:Reiseplanung
Verkehrsmittel
+----D ! 1
-++--1 # D ! 100
--++-100 # D # 1000
----+D O 1000
GehenBusPKWDBFlugEntfernung in km
Differenztabelle:
Vorbedingung der Operatoren:Flug : sei am FlugzeugDB : sei am BahnhofPKW : sei am PKWBus : sei an der HaltestelleGehen : nil
Problem: Reise von Wohnung in Saarbrücken nach UC Berkeley
D O 1000 Flug sei am Flugzeug1 # D ! 100 PKW sei am PKWD ! 1 Gehen nil ;zum PKWD ! 1 Gehen nil ;zum Flugzeug1 # D ! 100 Bus sei an der Haltestelle
;hier wird PKW verworfen, da er in Saarbrücken steht und Flug zurück weiter vom Ziel abbringtD ! 1 Gehen nil ;zur HaltestelleD ! 1 Gehen nil ;UC Berkeley

235
Ein für STRIPS unlösbares Planungsproblem: Registeraustausch
Problem: Plan für Programm zumAustausch der Inhalte zweierRegister X, Y
CONT(X,A) bedeutet:Register X hat den Inhalt A
Operator:assign(U,R,T,S)
P: CONT(R,S) Y CONT(U,T)D: CONT(U,T) ; T geht also verlorenA: CONT(U,S)
U, R Register; T, S InhalteZ als zusätzliches Hilfsregister
Zieldekomposition
Wahl von ASSIGN(X,r,t,B)
Fehler: Verlust von A
{Y/r,A/t} undAnwendung vonassign(X,Y,A,B)
State Description Goal StackCONT(X,A) CONT(X,B) Y CONT(Y,A)CONT(Y,B)CONT(Z,0)
1
State Description Goal StackCONT(X,A) CONT(X,B)CONT(Y,B) CONT(Y,A)CONT(Z,0) CONT(X,B) Y CONT(Y,A)
2
State Description Goal StackCONT(X,A) CONT(r,B) Y CONT(X,t)CONT(Y,B) assign(X,r,t,B)CONZ(Z,0) CONT(Y,A)
CONT(X,B) Y CONT(Y,A)
3
State Description Goal StackCONT(X,B) CONT(Y,A)CONT(Y,B) CONT(X,B) Y CONT(Y,A)CONT(Z,0)
4

236
Planung bei Ziel-Interaktionen1) RSTRIPS (vgl. Warplan von Warren 1974 in Prolog), spezielle Art der Regressionsanalyse2) DCOMP (vgl. Sacerdoti 1975, Tate 1976): nichtlineare Planung
RSTRIPS verwendet im Zielkeller zusätzlich zu STRIPS die folgenden drei Markierungen:- senkrechte Klammer: Bereich der Zieldekomposition- waagerechte Linie: aktuelles Ziel- *-Markierung: gesicherte Ziele
Beispiel für die Plangenerierung mit RSTRIPS,zunächst ohne Zielinteraktion für das Ziel: ON(C,B) Y ON(A,C)Bis zur Anwendung des ersten Operators: gleicher Ablauf wie bei STRIPS.
Zusammengesetzte Vorbedingung kann unter {A/y} mit Weltrepräsentation unifiziert werden.Im Gegensatz zu STRIPS wird dann P nicht gestrichen.Waagerechte Linie unter HOLDING(C): Dieses Subziel wurde erreicht.Neuer Fokus: CLEAR(B)
HANDEMPTY Y CLEAR(C) Y ON(C,y)unstack(C,y)HOLDING(C)CLEAR(B)HOLDING(C) Y CLEAR (B)stack(C,B)ON(C,B)ON(A,C)ON(C,B) Y ON(A,C)

237
Planung bei Ziel-InteraktionenFalls waagerechte Linien durch Klammer läuft, gibt es oberhalb der Linie bereitserreichte Ziele. Diese werden durch die *-Markierung gesichert: Es wird in derKlammer kein Operator ausgeführt, der ein gesichertes Subziel falsifiziert oder löscht.
Ausführung von Operatoren in RSTRIPS unnötig: statt Aufbau neuerWeltrepräsentation erfolgt eine Regressionsanalyse für das zu lösende Teilziel durchalle Operatoren oberhalb der Markierung.Bsp.: Regression von CLEAR(B) durch unstack(C,A) ergibt CLEAR(B),
was bereits in Ausgangssituation gilt.Beide Vorbedingungen von stack(C,B) sind erfüllt: waagrechte Linie wird nach untenverschoben (d.h. Operator virtuell ausgeführt).ON(C,B) wird als gelöstes Subziel gesichert (*-Markierung).
HANDEMPTY CLEAR(C) ON(C,A)unstack(C,A)*HOLDING(C)
CLEAR(B)HOLDING(C) CLEAR (B)stack(C,B)ON(C,B)ON(A,C)ON(C,B) ON(A,C)
A B
C

238
Planung bei Ziel-InteraktionenDann wird Teilziel ON(A,C) bearbeitet und schließlich folgender Zielkeller aufgebaut:
Regressionsanalyse ergibt: P von pickup(A) erfüllt.Interaktionsanalyse bevor pickup angewandt wird:Sicherheitscheck – Falls Regression von ON(C,B) durch pickup(A) = F, dann wird Operatorblockiert.Hier ist Sicherheit von ON(C,B) gewährleistet: pickup(A) ausführenRegressionsanalyse für CLEAR(C) und ON(C,B) durch stack(A,C) verläuft positiv, so dassstack(A,C) ausgeführt werden kann.Terminierung: waagerechte Linie unterhalb des untersten Kellerelements
HANDEMPTY CLEAR(C) ON(C,A)unstack(C,A)HOLDING(C)CLEAR(B)HOLDING(C) CLEAR (B)stack(C,B)*ON(C,B)
HANDEMPTY CLEAR(A) ONTABLE (A)pickup(A)HOLDING(A)CLEAR(C)HOLDING(A) CLEAR (C)stack(A,C)ON(A,C)ON(C,B) ON(A,C)
A B
C
REGRESSION DURCHunstack(C,A)stack(C,B)

239
RSTRIPS bei interagierenden Zielen: ON(A,B) Y ON(B,C) als Beispiel
Sicherheitsbedingungen fürON(A,B) durch unstack(A,B)verletzt. ON(A,B) muss nur amEnde der senkrechten Klammergelten, temporäre Verletzungenkönnen toleriert werden.
Lösc
hung
nac
h In
tera
ktio
nsan
alys
e

240
RSTRIPS bei interagierenden Zielen: ON(A,B) Y ON(B,C) als Beispiel
Falls es Operatoren unterhalb der Linie aber vor Klammerende gibt, die ON(A,B)wieder herstellen, kann unstack(A,B) doch ausgeführt werden.
Hier ist dies durch pickup(B) und stack(B,C) aber nicht erreichbar.
störendes Teilziel: Das Teilziel, dessen Lösung einen Operator erfordert, der ein gesichertes Teilziel rückgängig machen würde.
Strategie zum Vermeiden der Verletzung von Sicherheitsbedingungen:Unterwirf das störende Teilziel einer Regressionsanalyse rückwärts durch dieSequenz der Operatoren im Zielkeller bis hin zu dem Operator, der das gesicherteTeilziel ergab und versuche das Ergebnis der Regression des störenden Teilzielsdirekt vor dem Operator zu erreichen.

241
ON(A,B) Y ON(B,C) als Beispiel
Im Beispiel:Regression von ON(B,C) durch stack(A,B) ergibt ON(B,C). Der verworfene Plan fürON(B,C) wird aus dem Zielkeller entfernt, und die waagerechte Linie wird wiederüber ON(B,C) platziert.
Sicherung, da Linie durch Klammer wandert
P ergänzt duchON(B,C)

242
ON(A,B) o ON(B,C) als Beispiel
neue
r S
ubpl
anfü
r O
N(B
,C)
zur Erreichung von HANDEMPTY, {A/x}
Es wird ein neuer Plan für ON(B,C)erzeugt, der allerdings durchputdown(A) das gesicherte ZielHOLDING(A) nicht nur temporärverletzt.

243
ON(A,B) o ON(B,C) als BeispielRSTRIPS unterwirft das störende Teilziel ON(B,C) einer weiteren Regression rückwärts, bisdurch pickup(A). Der verworfenen Plan zum Erreichen von ON(B,C) wird vom Zielkeller entferntund das ergänzte Literal ON(B,C) in der Vorbedingung von stack(A,B) wird gelöscht. Diewaagerechte Linie wird wieder über ON(B,C) platziert.
P ergänzt durch ON(B,C)

244
ON(A,B) o ON(B,C) als BeispielEs wird erneut ein anderer Subplan für ON(B,C) erzeugt, der wiederum mit pickup(B) dasgesicherte Ziel HANDEMPTY verletzt: allerdings nur temporär, da später stack(B,C) dieGültigkeit von HANDEMPTY sichert.
Jetzt können Fokus und Weltrepräsentation unifiziert werden und alle Operatoren im Zielkellerangewandt werden, so dass RSTRIPS terminiert. RSTRIPS findet einen kürzeren Plan alsSTRIPS (siehe oben):unstack(C,A), putdown(C), pickup(B), stack(B,C), pickup(A), stack(A,B).

245
Lösung des Registeraustauschproblems mit dem System RSTRIPS
Für RSTRIPS ergibt sich die erste Schwierigkeit, sobald CONT(r1,A) im Fokus ist.CONT(r1,A) kann unmöglich unifiziert werden, da nach assign(X,Y,A,B) A in keinemRegister mehr enthalten ist.
Wie bei der Verletzung gesicherter Ziele verwendet RSTRIPS bei unmöglichen Zieleneine Regressionsanalyse. Das unmögliche Ziel erfährt eine Regressionsanalyse durchden zuletzt angewandten Operator, um zu prüfen, ob es dann möglicherweiseerfüllbar ist.

246
Lösung des Registeraustauschproblems mit dem System RSTRIPS
Im Beispiel ergibt die Regressionsanalyse für CONT(r1,A) durch assign(X,Y,A,B) denWert: CONT(r1,A) o lEQUAL(r1,X), welcher der Vorbedingung von assign(X,Y,A,B)hinzugefügt wird.
Fokus von RSTRIPS ist jetzt CONT(r1,A), der zwar unter {X/r1} mit derAusgangssituation CONT(X,A) unifiziert werden könnte, aber das nächste Ziel mitlEQUAL(X,X) unmöglich machen würde.
Z:0 X:A Y:BCONT(r1,A)lEQUAL(r1,X)CONT(X,A)CONT(Y,B)CONT(X,A) o CONT(Y,B) o CONT(r1,A) o lEQUAL(r1,X)assign(X,Y,A,B)CONT(X,B)CONT(Y,t1)CONT(r1,A) o CONT(Y,t1)assign(Y,r1,t1,A)CONT(Y,A)CONT(X,B) o CONT(Y,A)

247
Z:0 X:A Y:B
CONT(r,A) CONT(X,A)CONT(r1,t) CONT(Z,0)CONT(r,A) o CONT(r1,t)assign(r1,r,t,A) assign(Z,X,0,A)CONT(r1,A) CONT(Z,A)lEQUAL(r1,X) lEQUAL(Z,A)=TCONT(X,A)CONT(Y,B)CONT(X,A) o CONT(Y,B) o CONT(r1,A) o lEQUAL(r1,X)assign(X,Y,A,B)CONT(X,B)CONT(Y,t1) CONT(Y,B)CONT(r1,A) o CONT(Y,t1)assign(Y,r1,t1,A) assign(Y,Z,B,A)CONT(Y,A)CONT(X,B) o CONT(Y,A)
Lösung des Registeraustauschproblems mit dem System RSTRIPSEs muss daher nochmals ein assign-Operator angewandt werden:
Im Gegensatz zu STRIPS findet RSTRIPS also einen Lösungsplan: assign(Z,X,0,A),assign(X,Y,A,B), assign(Y,Z,B,A).Eine allgemeinere Lösung für das Problem des Registeraustauschs umfasst nocheinen weiteren Operator genreg zur Erzeugung des Hilfsregisters Z. Dann würdeCONT(r1,t) zur Anwendung von genreg führen.
ok

248
DCOMP: Ein System zur Erzeugung nichtlinearer Pläne
DCOMP arbeitet in zwei Phasen:1) Die erste Phase erstellt eine vorläufige Lösung, in der mögliche Ziel-Interaktionen
unberücksichtigt bleiben.2) Die zweite Phase überarbeitet die tentative Lösung und versucht, die Interaktionen
zu beseitigen.
In DCOMP wird der Zielgraph als und/oder-Graph dargestellt. Falls keineInteraktionen festgestellt werden, können die verschiedenen Äste des und/oder-Graphen parallel ausgeführt werden. Dies ist z.B. für einen Roboter relevant, derseine Position ändern und dabei gleichzeitig seinen Arm bewegen kann.
Phase 1 von DCOMP erstellt einen und/oder-Graphen, dessen Blätter mit derAusgangssituation unifiziert werden können.
In Phase 2 sucht DCOMP nach Operatoren, welche in anderen Zweigen des Graphenbenötigte Vorbedingungen zerstören. Dies führt dann zu einer weiteren Beschränkungder partiellen Ordnung, die durch den und/oder-Graphen dargestellt wird. ImExtremfall führt Phase 2 zu einem linearen Plan.

249
Ergebnis der ersten Phase von DCOMP 1Join als virtueller Kompositionsoperator
Unifikation als Ausgangssituation
löscht HANDEMPTY als P von 2löscht HANDEMPTY als P von 4 Im Beispiel führt die erste Phase zu
zwei Operator-Sequenzen, die parallelausgeführt werden könnten:{unstack(C,A), stack(C,B)} und{unstack(C,A), pickup(A), stack(A,C)}.

250
Sei Cij das i-te Literal der Vorbedingung von Operator j.
Für jedes Cij bildet DCOMP zwei (möglicherweise leere) Mengen:
• Dij als die Menge der Operatoren, die Cij löschen und nicht Vorfahr von j sind(Deleters von Cij).
• Aij als die Menge der Operatoren, die Cij hinzufügen und nicht Vorfahr von j sind(Adders von Cij).
Die partielle Ordnung eines Plans weist keine Interaktion auf, falls für alle Cij
1) der Operator j vor allen Elementen von Dij auftritt oder2) es einen Operator k in Aij gibt, der vor j auftritt, und kein Element von Dij zwischen k
und j auftritt.
Nichtinteragierende partielle Ordnung
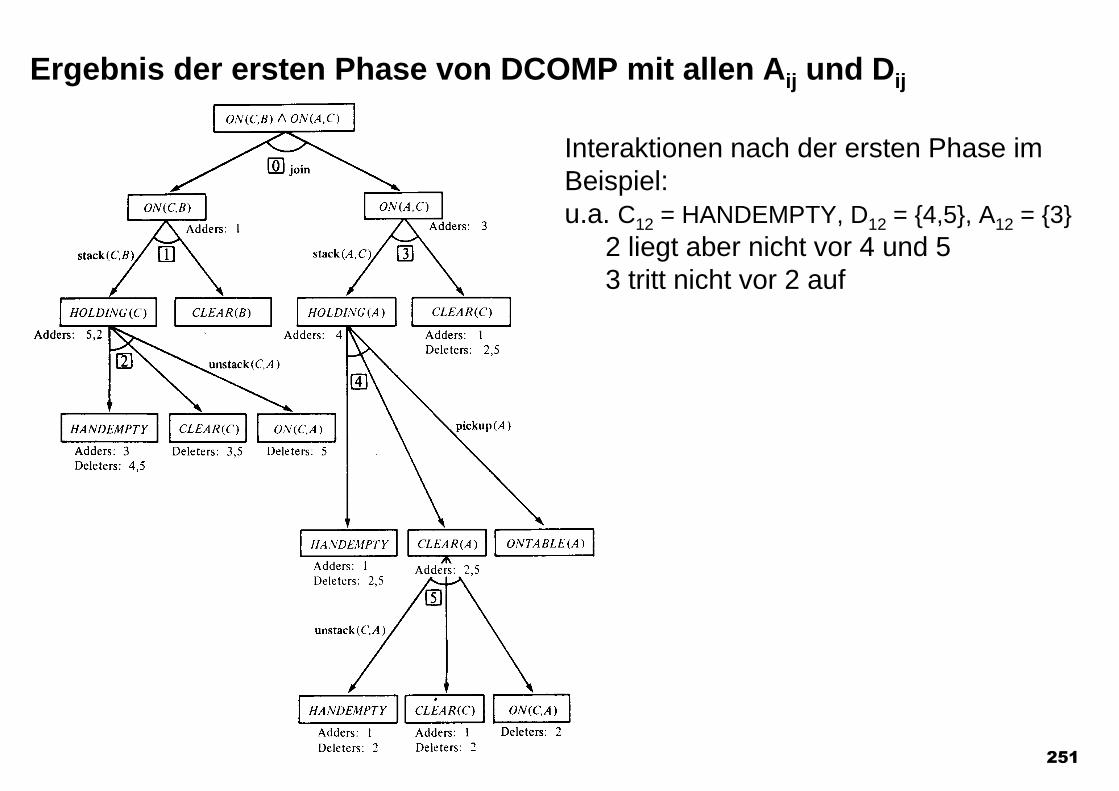
251
Ergebnis der ersten Phase von DCOMP mit allen Aij und Dij
Interaktionen nach der ersten Phase imBeispiel:u.a. C12 = HANDEMPTY, D12 = {4,5}, A12 = {3}
2 liegt aber nicht vor 4 und 53 tritt nicht vor 2 auf

252
Beseitigung von Interaktionen
Zwei Möglichkeiten, um in der zweiten Phase die aufgedeckten Interaktionen zubeseitigen:
1) Weitere Restriktionen in der Plansequenz, so dass eine der Bedingungen für denAusschluss von Interaktionen gilt.
2) Streichen eines Operators, dessen Effekt durch Umordnung von einem anderenAdder übernommen wird.
Beispiel:• 3 2 D22 für das Literal CLEAR(C). Wenn DCOMP 2 vor 3 ordnet, kann 3 aus D22
gestrichen werden.• 5 2 D14 für Literal HANDEMPTY, 4 ist bereits Vorfahr von 5, so dass die Ordnung
nicht mehr so eingeschränkt werden kann, dass 4 vor 5 liegt. Aber zwischen 5 und4 kann als Adder 1 eingeschoben werden.
Problem:Die zusätzlichen Ordnungsbedingungen müssen untereinander konsistent sein.Dies kann DCOMP nicht in allen Fällen gewährleisten.

253
Beseitigung von Interaktionen
Im Beispiel führt DCOMP folgende Operationen in der Phase 2 aus:
1) 2 vor 4 und Löschung von 5. 4 und 5 können dann als Deleter von 2 gestrichenwerden. Da 2 vor 3 liegt, kann auch 3 als Deleter von Literalen der Vorbedingungvon 2 gestrichen werden.
2) 1 vor 4. 1 stellt die Vorbedingungen wieder her, die 4 und 3 benötigen, die abervon 2 gestrichen werden.
1 2 A23 für CLEAR(C) und 1 2 A14 für HANDEMPTY2 2 D23 für CLEAR(C) und 2 2 D14 für HANDEMPTY
Insgesamt entsteht die totale Ordnung {2, 1, 4, 3}, d.h.die Plansequenz {unstack(C,A), stack(C,B), pickup(A), stack(A,C)}.

254
Plangenerierung für zweiarmige Roboter mit dem DCOMP-Verfahren
Die bisher verwendeten Operatoren werden mit einem weiteren Argument versehen,das angibt, ob Hand 1 oder Hand 2 die Aktion ausführt.
1) pickup(x,h)P&D: ONTABLE(x), CLEAR(x), HANDEMPTY(h)A: HOLDING(x,h)
2) putdown(x,h)P&D: HOLDING(x,h)A: ONTABLE(x), CLEAR(x), HANDEMPTY(h)
3) stack(x,y,h)P&D: HOLDING(x,h), CLEAR(y)A: HANDEMPTY(h), ON(x,y), CLEAR(x)
3) unstack(x,y,h)P&D: HANDEMPTY(h), CLEAR(x), ON(x,y)A: HOLDING(x,h), CLEAR(y)

255
Ergebnis der ersten DCOMP-Phase für Roboter mit zwei Händen
Der zweiarmige Roboter kannAktionen parallel ausführen,so dass ein partiellgeordneter Plan angemessenist.
Weniger Deleters als beieinarmigem Roboter
Phase 2:2 vor 4, Löschung von 5,2 vor 3

256
Ein partiell geordneter Plan füreinen zweiarmigen Roboter
Darstellung des Plans als prozedurales Netz
join*

257
Korrektur von fehlerhaften, approximativen Plänen
Falls in Phase 2 von DCOMP durch zusätzliche Ordnungsbedingungen Interaktionennicht beseitigt werden können, wird in einer dritten Phase versucht, den fehlerhaftenPlan (mit Löschungen von notwendigen Vorbedingungen) dadurch zu korrigieren,dass die gelöschten Bedingungen durch Einfügung zusätzlicher Planungsschrittewieder hergestellt werden. Die zusätzlichen Planungsschritte dürfen natürlich mit demzu korrigierenden Plan nicht interagieren.
CLEAR(A) o HANDEMPTY
CLEAR(A) HANDEMPTY
ON(C,A) CLEAR(C) HANDEMPTY
0
unstack(C,A) Keine Umordnung möglich;HANDEMPTY wird gelöscht
1Adders: 1 Deleters: 1
Ein Ergebnis der ersten Phase, das berücksichtigt werden muss.
join

258
Korrektur von fehlerhaften, approximativen PlänenZwischen 1 und 0 muss eine Ergänzung eingeschoben werden, die HANDEMPTY wiederherstellt.Die Vorbedingungen der Plan-Ergänzung sollen bei einer Regression durch 1 zu Bedingungenführen, die mit der Ausgangssituation unifizierbar sind (damit die Plan-Ergänzung ohne weitereBedingungen ausführbar ist) und CLEAR (A) soll bei Regression durch die Plan-Ergänzungunverändert bleiben, so dass die Wirkung von 1 erhalten bleibt.
Im Beispiel:putdown(x) bei Rückwärtsverkettung auf HANDEMPTY angewandt führt zum TeilzielHOLDING(x), Regression von HOLDING(x) durch unstack(C,A) ergibt unter {C/x} T.CLEAR(A) bleibt bei Regression durch putdown(C) erhalten.
CLEAR(A) o HANDEMPTY
CLEAR(A) o HOLDING(C)
ON(C,A) o CLEAR(C) o HANDEMPTY
korrigierter Plan
Berichtigung des fehlerhaften Plans
putdown(C)
unstack(C,A)

259
Ergebnis der ersten Phase mit interagierenden Zielen
Im allgemeinen Fall werden mehrereVorbedingungen von dem nochfehlerhaften Plan gelöscht. Dannbeginnt der Korrekturprozess an dergelöschten Vorbedingung, die amnächsten an der Ausgangssituationliegt und traversiert denPlanungsgraph, bis alle Interaktionenbeseitigt sind.

260
Erste Näherung des PlansZiel
*: Bedingungen, diein Näherung unerfülltbleiben
durch 3 gelöscht
durch 3 gelöscht
Ausgangssituation

261
Korrektur von fehlerhaften, approximativen Plänen
Phase 3 schiebt zunächst eine Ergänzung zwischen 3 und 5, um HANDEMPTY zuerhalten.
putdown(C) ist die angemessene Ergänzung.
Dann muss das gelöschte CLEAR(C) erwirkt werden. In diesem Fall ergibt dieRegressionsanalyse durch 5 CLEAR(C) und durch die Ergänzung putdown(C) ergibtsich T für CLEAR(C), so dass keine weitere Ergänzung mehr notwendig ist.
Der korrigierte Plan lautet also:unstack(C,A), putdown(C), pickup(B), stack(B,C), pickup(A), stack(A,B).
Für das allgemeine Problem der Korrektur nicht-linearer Pläne durch Einsetzungzusätzlicher Teilpläne sind noch keine Lösungen bekannt.

262
Hierarchische PlanungssystemeHäufig ist es sinnvoll, manche der Bedingungen des vorgegebenen Planungsziels und einigeder durch den Planungsprozess generierten Subziele zunächst als Details zu betrachten, derenLösung bis zu einem späteren Stadium der Planung zurückgestellt werden kann.
Beispiel: Ziel sei HausbauPlanung auf höchster Ebene: Fundament, Mauern, Fenster, ...Planung auf niedrigster Ebene: schrauben, bohren, ...
Bei der Planung nur auf einer Ebene kann der Plan so lang und komplex werden, dass diePlanungsverfahren scheitern.
Man führt daher mehrere Planungsebenen ein.
Auf jeder Ebene werden die üblichen Planungsverfahren wie STRIPS, RSTRIPS und DCOMPverwendet.
Auf jeder Planungsebene werden gewisse Bedingungen als Details angesehen und zunächstabsichtlich ‘übersehen‘.
Der auf einer höheren Ebene erstellte Plan muss dann bei Übergang zu detaillierterer Ebenedurch Einfügen zusätzlicher Operatoren verfeinert werden.
ABSTRIPS ist ein hierarchisches Planungssystem auf der Basis von STRIPS. Es wird eineHierarchie für die Literale der Vorbedingungen und der Delete-Liste aller Operatoren eingeführt,indem Wichtigkeitsbewertungen eingeführt werden.

263
Hierarchische Planungssysteme
Die Grobplanung ergibt also die Sequenz: stack(C,B), stack(A,C).Dabei entstehen teilweise inkonsistente Weltrepräsentationen wie der Endzustand mitONTABLE(A), ON(A,C), CLEAR(C).Die auf der ersten Ebene erzielte Plansequenz wird dann an die zweite Planungsebeneübergeben, auf der Bedingungen mit einem Wichtigkeitswert P 2 betrachtet werden.Die Plansequenz wird über der Zielbeschreibung jeweils mit den nun sichtbarenVorbedingungen im Zielkeller abgelegt.
Erste Ebene der Planung: Es wird nur mit Bedingungen gearbeitet, welche den höchstenWichtigkeitswert haben (im Beispiel: 3), alle anderenBedingungen bleiben unsichtbar.
• Beim Ziel ON(C,B) o ON(A,C) beginnt ABSTRIPS mit der Dekomposition desHauptziels, da beide ON-Literale mit 3 bewertet sind.
• Um ON(C,B) zu erreichen, wird der Operator stack(C,B) auf dem Zielkeller abgelegt,wobei beide Vorbedingungen des Operators entfallen, da ihr Wichtigkeitswert mit 2 zugering ist.
• stack(C,B) wird ausgeführt und bewirkt eine neue Weltrepräsentation, in der ON(C,B)ergänzt ist.
• Dann ist ON(A,C) im Fokus und führt zur Anwendung von stack(A,C). DieWeltrepräsentation wird um ON(A,C) ergänzt, der Zielkeller ist leer, so dass ABSTRIPSterminiert.

264
Hierarchische PlanungssystemeEs ergibt sich zu Beginn der zweiten Planungsstufe der folgende Zielkeller:
HOLDING(C) o CLEAR(B)stack(C,B)HOLDING(A) o CLEAR(C)stack(A,C)ON(C,B) o ON(A,C)
Daraus wird in der zweiten Planungsphase die Sequenzunstack(C,A), stack(C,B), pickup(A), stack(A,C) erzeugt.
Falls ABSTRIPS auf einer Ebene keine Lösung findet, wird ein Backtrackingprozessausgelöst und auf der darüberliegenden Ebene eine andere Lösung gesucht.
Auf der dritten Planungsebene (Wichtigkeitswert P 1) muß noch HANDEMPTYberücksichtigt werden.
Im Beispiel zeigt sich auf der dritten Ebene, dass die Lösung auf der zweiten Ebenealle Details bereits richtig behandelt.
Für komplexere Planungsprobleme ist ABSTRIPS effizienter als das einstufigeSTRIPS-Verfahren, da die Grobpläne den Suchraum auf den unterenPlanungsebenen stark einschränken.

265
Hierarchische Planungssysteme1) pickup(x)
2 2 1P&D: ONTABLE(x), CLEAR(x), HANDEMPTYA: HOLDING(x)
2) putdown(x)2
P&D: HOLDING(x)A: ONTABLE(x), CLEAR(x), HANDEMPTY
3) stack(x,y)2 2
P&D: HOLDING(x), CLEAR(y)A: HANDEMPTY, ON(x,y), CLEAR(x)
3) unstack(x,y)1 2 3
P&D: HANDEMPTY, CLEAR(x), ON(x,y)A: HOLDING(x), CLEAR(y)
Ein hoher Wert bedeutet, dass diese Bedingung besonders schwer erreichbar ist (z.B. ON(x,y)).Ein niedriger Wert bedeutet, dass diese Bedingung leicht zu erreichen ist (z.B. HANDEMPTY).
Bei der Anwendung eines Operators werden alle Literale der Add-Formel zurWeltrepräsentation hinzugefügt (unabhängig von der Wichtigkeitsbewertung).

266
Lösung auf erster Ebene für ABSTRIPS

267
Eine Variante von ABSTRIPS mit P-Vorbedingungen
P-Vorbedingungen eines Operators werden immer zurückgestellt bis auf die nächstePlanungsebene.
1) pickup(x)P&D: ONTABLE(x), CLEAR(x), P-HANDEMPTYA: HOLDING(x)
2) putdown(x)P&D: HOLDING(x)A: ONTABLE(x), CLEAR(x), HANDEMPTY
3) stack(x,y)P&D: P-HOLDING(x), CLEAR(y)A: HANDEMPTY, ON(x,y), CLEAR(x)
3) unstack(x,y)P&D: P-HANDEMPTY, CLEAR(x), ON(x,y)A: HOLDING(x), CLEAR(y)

268
STRIPS-Lösung mit P-Vorbedingungen auf der ersten Planungsebene

269
Wichtige Eigenschaften des Inferenzmodells
(1) Eine approximative Inferenzregel stellt eine abgeschwächteImplikation dar, jeder approximativen Inferenzregel wird daher einebestimmte Implikationsstärke zugeordnet.
(2) Oft sind die Prämissen einer approximativen Inferenzregel nur zueinem gewissen Grad erfüllt. Dies wird bei der Berechnung desEvidenzwertes für die Konklusion einer Inferenz berücksichtigt.
(3) Eine approximative Inferenzregel ist oft nur zu einem gewissen Gradanwendbar, weil in ihr enthaltene Sortenrestriktionen nur graduellerfüllt sind.
(4) Die Ergebnisse mehrerer voneinander unabhängiger Inferenzenkönnen sich in Mehrfachableitungen verstärken.

270
Das CF-Modell von MYCINDas Regelbewertungsmodell
Die Inferenzregeln in MYCIN werden durch 2 unterschiedliche Werte beurteilt:MB (measure of increased belief)MD (measure of increased disbelief)
MB[H,E] ist ein Maß (measure) für den, durch das Vorhandensein der Evidenz E bestärktenGlauben (belief) an das Zutreffen der Hypothese H.
MD[H,E] ist ein Maß für den, durch das Vorhandensein der Evidenz E abgeschwächtenGlauben an das Zutreffen der Hypothese H.
[ ]
<
=
≠∧≥−
−
=
)()|( für0
1)( für1
1)()()|( für)(1
)()|(
:,
HPEHP
HP
HPHPEHPHP
HPEHP
EHMB
[ ]
>
=
≠∧≤−
=
)()|( für0
0)( für1
0)()()|( für)(
)|()(
:,
HPEHP
HP
HPHPEHPHP
EHPHP
EHMD
Definition:

271
Beziehungen zwischen MB und MD
Forderungen an die Definitionen von MB und MD:
MB und MD sollen so definiert sein, dass eine positive (unterstützende)Evidenz für H keinen negativen Einfluss auf lH hat; d.h.vergrößert E den Glauben an ein Zutreffen von H, so hat dies keinenEinfluss auf den Glauben, dass H nicht zutrifft.Vergrößert umgekehrt E den Glauben an ein Zutreffen von lH, so hat dieskeinen Einfluss auf den Glauben, dass H zutrifft.
Das bedeutet formal:MB[H,E] O 0 0 MD[H,E] Z 0MD[H,E] O 0 0 MB[H,E] Z 0
Die Definitionen von MB und MD erfüllen diese Forderungen, wenn man fürdie beiden Extremfälle, dass die Hypothese H bereits a-priori als sicherzutreffend (P(H) = 1) oder als unmöglich (P(H) = 0) erachtet wird, folgendeVoraussetzungen macht:

272
1) a-priori P(H) Z 0 0 P(H8E) Z 0Hieraus folgt: MB[H,E] Z 0Interpretation: Wenn man sicher ist, dass H nicht zutrifft, kann keine Evidenz E
einen positiven Einfluss auf die Wahrscheinlichkeit von H erzielen.
2) a-priori P(H) Z 1 0 P(H8E) Z 1Hieraus folgt: MD[H,E] Z 0Interpretation: Wenn man sicher ist, dass H zutrifft, kann keine Evidenz E einen
negativen Einfluss auf die Wahrscheinlichkeit von H verüben.
Weiterhin lässt sich zeigen:MB[H,E] Z MD[lH,E]MD[H,E] Z MB[lH,E]
Dagegen gilt auf Wahrscheinlichkeitenniveau:P(H8E) Z x 5 P(lH8E) Z 1 K x
Jedoch ist im allgemeinen, d.h. für P(H8E) 2 ]0, 1[:MB[H,E] s 1 K MB[lH,E]MD[H,E] s 1 L MD[lH,E]
Beziehungen zwischen MB und MD

273
Die Bewertungsfunktion CFDie CF-Funktion (certainty factor) vereinigt die Information des MB- und MD-Wertesbei der Bewertung einer Regel. MB und MD sind so definiert, dass eine Evidenzniemals gleichzeitig positiven und negativen Einfluss auf eine Hypothese ausübenkann. Daher ist es möglich bei der Regelbewertung nur einen einzigen CF-Wert,anstatt eines MB- und MD-Wertes, einer Regel zuzuordnen, ohne Information zuverlieren.Diese Eigenschaft ist aus der folgenden Definition der CF-Funktion direkt ersichtlich.
Definition:
Folgerungen:
[ ][ ] ( ) ( ) ( )
( ) ( ) ( )[ ] ( ) ( ) ( )
=∨<−≠≠∧=
=∨>=
0| für,
10| für0
1| für,
:,
HPHPEHPEHMD
HPHPEHP
HPHPEHPEHMB
EHCF
[ ] [ ][ ] [ ]EHCFEHCF
EHCF
,,
1,1,
−=¬−∈
[ ] [ ][ ][ ] [ ][ ]EHCFEHMD
EHCFEHMB
,,0max,
,,0max,
−==
[ ] [ ] [ ]EHMDEHMBEHCF ,,:, −=

274
Sei eine mithilfe der CF-Funktion bewertete Regel der Form gegeben.
Interpretation der CF-Werte
Interpretation: Die Evidenz E vergrößert die Wahrscheinlichkeit für das Zutreffen derHypothese H. E ist positive (confirming) Evidenz für H.
Speziell:
Interpretation: Das Auftreten der Evidenz E ist hinreichend für das Zutreffen derHypothese H. E impliziert H. H trifft mit Sicherheit zu.
HE EHCF → ],[
[ ][ ] [ ]
( ) ( ) ( ) 1|
0,0,
1,0
=∨>⇔=∧>⇔
≤<
HPHPEHP
EHMDEHMB
EHCF
[ ][ ] [ ]
( ) 1|
0,1,
1,
=⇔=∧=⇔
=
EHP
EHMDEHMB
EHCF

275
Interpretation der CF-Werte
Interpretation: Das Ereignis E hat keinen Einfluss auf die Wahrscheinlichkeit für das Zutreffen von H. E ist keine Evidenz für H. E und H sindunabhängige Ereignisse.
[ ][ ] [ ]
( ) ( ) ( ) 10|
0,0,
0,
≠≠∧=⇔=∧=⇔
=
HPHPEHP
EHMDEHMB
EHCF
[ ][ ] [ ]
( ) ( ) ( ) 0|
0,0,
0,1
=∨<⇔>∧=⇔
<≤−
HPHPEHP
EHMDEHMB
EHCF
Interpretation: Die Evidenz E verringert die Wahrscheinlichkeit für das Zutreffen derHypothese H. E ist negative (disconfirming) Evidenz für H.
[ ][ ] [ ]
( ) 0|
1,0,
1,
=⇔=∧=⇔
−=
EHP
EHMDEHMB
EHCFSpeziell:
Interpretation: Die Beobachtung der Evidenz E schließt ein Zutreffen der HypotheseH mit Sicherheit aus. E impliziert lH.

276
Da die Anzahl der Hypothesen oft sehr groß ist, sind ihre a-priori Wahrscheinlichkeitenverschwindend klein.Formal: P(H) / 0
Sei E positive Evidenz für die Hypothese H.Formal: P(H8E) > P(H)
Dann folgt für den CF-Wert:
Bedeutung: Der CF-Wert der Hypothese H, unterstützt durch die Evidenz E, entspricht ungefähr der bedingten Wahrscheinlichkeit für H unter E.
)|()(1
)()|(],[ EHP
HPHPEHP
EHCF ≈−
−=
Interpretation der CF-Werte
Den Hypothesen aller Regeln von MYCIN sind MB- und MD-Werte zugeordnet, die zuAnfang des Dialogs (der Untersuchung) auf Null gesetzt sind. Werden nun ständigneue Evidenzen (Symptome) beobachtet, so werden die Regeln aktiviert, welchediese Evidenzen als Prämisse besitzen. Bei jeder Aktivierung („Feuern“) einer Regelwerden mithilfe des regeleigenen CF-Wertes die MB- und MD-Werte ihrer Hypotheseaktualisiert.

277
[ ]
[ ][ ] [ ]
[ ] [ ][ ][ ]
∧−
−+
∧
=∧
HEEEEHMD
HEHCFEHCFEHCFEHCF
HEEEEHMB
EEHCF
für Evidenzen negative und für,
ist für negativ andere
die und positiv Evidenz eine falls
,,,min1,,
für Evidenzen positive und für,
:,
2121
21
21
2121
21
H ist Konklusionsteil mehrerer feuernder Regeln
Ist (o.E.d.A.) E1 positive Evidenz für H und E2 negative Evidenz für H, so folgt:
[ ] [ ] [ ][ ] [ ][ ]21
2121 ,,,min1
,,:,
EHMDEHMBEHMDEHMB
EEHCF−
−=∧
Eine Hypothese H kann den Konklusionsteil mehrerer feuernder Regeln bilden. Das bedeutet,dass unterschiedliche Evidenzen E1, ..., En beobachtet wurden, die alle einen positiven odernegativen Einfluss auf H ausüben.Wiederum werden Approximationsregeln benötigt, um die MB- und MD-Werte solcherHypothesen zu berechnen.Die Evidenzen E1 und E2 seien beobachtet worden. Dadurch feuern die beiden Regeln
und
Approximation der kombinierten MB- und MD-Werte für HMB[H,E1 Y E2] = MB[H,E1] + MB[H,E2] - MB[H,E1] ) MB[H,E2]MD[H,E1 Y E2] = MD[H,E1] + MD[H,E2] - MD[H,E1] ) MD[H,E2]
[ ] HE EHCF → 2,2
[ ] HE EHCF → 1,1
Approximation des kombinierten CF-Wertes für H

278
Andererseits kann eine einzelne Evidenz E die Prämissen mehrerer Regeln bilden,falls E Einfluss auf mehrere Hypothesen H1, ..., Hn besitzt. Die Beobachtung von Ekann dann mehrere Regeln feuern. Man benötigt also Approximationsregeln, mitderen Hilfe man einen zusammengesetzten MB- und MD-Wert für konjunktiv bzw.disjunktiv verknüpfte Hypothesen bzgl. der Evidenz E berechnen kann.
Sei die Evidenz E gegeben, welche die beiden Regeln
und feuert.
Approximation der kombinierten MB- und MD-Werte bzgl. E
Konjunktive Verknüpfung der Hypothesen:MB[H1 Y H2,E] = min[MB[H1,E], MB[H2,E]]MD[H1 Y H2,E] = max[MD[H1,E], MD[H2,E]]
Disjunktive Verknüpfung der Hypothesen:MB[H1 Z H2,E] = max[MB[H1,E], MB[H2,E]]MD[H1 Z H2,E] = min[MD[H1,E], MD[H2,E]]
2],[ 2 HE EHCF →
E ist Prämisse mehrerer Regeln
[ ]1
,1 HE EHCF →

279
Es ist möglich, dass eine Evidenz E nicht mit Sicherheit vorhanden ist, sondern nurBeobachtungen E# gegeben sind, die mit einer gewissen Wahrscheinlichkeit für dasVorhandensein von E sprechen. Die Regel
kann also nicht „sicher“ feuern. Bei der Berechnung des MB- und MD-Wertes für Haus dem CF-Wert der Regel muss also die Unsicherheit bzgl. dem Vorhandensein vonE berücksichtigt werden. Dies kann durch Eingabe eines CF-Wertes für die Regel
geschehen.Man benötigt also eine Approximationsvorschrift für die Berechnung des MB- und MD-Wertes von H in der zusammengesetzten Regel
HEEHCF → ],[
HEE´EHCFE´ECF → → ],[],[
EE´E´ECF → ],[
E ist nicht mit Sicherheit vorhanden

280
Die Ergebniswerte sind die aktualisierten MB- und MD-Werte, aus denen am Ende derUntersuchung die endgültigen CF-Werte der Hypothese errechnet werden. Im Verlaufeiner Untersuchung können sowohl positive als auch negative Evidenzen bzgl. einerHypothese H auftreten. Die sequentielle Abarbeitung dieser Evidenzen führt zu einerschrittweisen Aktualisierung der MB- und MD-Werte der betroffenen Hypothese H. AmEnde der Untersuchung können also sowohl der MB-Wert, als auch der MD-Werteiner Hypothese verschieden von 0 sein.
MB[H,E#] := max[0, CF[H,E]] )max[0, CF[E,E#]] = MB[H,E] ) MB[E,E#]MD[H,E#] := max[0, -CF[H,E]] )max[0, CF[E,E#]] = MD[H,E] ) MB[E,E#]
Folgerung: CF[E,E#] % 0 0 MB[H,E#] = 0 Y MD[H,E#] = 0
Interpretation: Gibt es Argumente gegen ein Vorhandensein von E, so kann E nichtmehr als Evidenz fungieren.
Bemerkung: MB[H,E] und MD[H,E] sind die durch CF[H,E] gegebenen Belief- bzw.Disbeliefwerte, welche davon ausgehen, dass E mit Sicherheitvorhanden ist.
Approximation der zusammengesetzten MB- und MD-Werte
E ist nicht mit Sicherheit vorhanden

281
Eigenschaften der aktualisierten MB- und MD-Werte
Sei E+ (E-) die Summe aller bisher während der Untersuchung beobachteten positiven(negativen) Evidenzen bzgl. der Hypothese H, so gilt:
Grenzwerte:MB[H,E+] wächst gegen 1 mit jeder weiteren positiven Evidenz für H, die beobachtet
wird.Der Grenzwert 1 wird jedoch nur dann erreicht, wenn eine Evidenz auftritt,die schon für sich alleine, ohne Berücksichtigung der bisher beobachtetenpositiven Evidenz E+, die Hypothese H logisch impliziert.
MD[H,E-] wächst gegen 1 mit jeder weiteren negativen Evidenz für H, die beobachtetwird.Der Grenzwert 1 wird jedoch nur dann erreicht, wenn eine Evidenz auftritt,die schon für sich alleine, ohne Berücksichtigung der bisher beobachtetennegativen Evidenz E-, die Hypothese H mit Sicherheit verwirft.
Für die CF-Funktion gilt: CF[H,E-] % CF[H,E- Y E+] % CF[H,E+]

282
Logische Implikation (sicheres Bestätigen bzw. Verwerfen einer Hypothese):
MB[H,E+] = 1 0 MD[H,E-] = 0 0 CF[H,E+] = 1Interpretation: Falls es eine Evidenz gibt, die H logisch impliziert, so darf keine
Evidenz existieren, die gegen H spricht.
MD[H,E-] = 1 0 MB[H,E+] = 0 0 CF[H,E-] = -1Interpretation: Falls es eine Evidenz gibt, die H mit Sicherheit verwirft, so darf
keine Evidenz existieren, die für H spricht.
Kommutativität:Die zeitliche Reihenfolge mit der die einzelnen Evidenzen während der Untersuchungauftreten, hat keinen Einfluss auf die resultierenden MB- und MD-Werte bzw. denendgültigen CF-Wert der Hypothesen. Die Schreibweise E1 Y E2 induziere dieReihenfolge, dass zuerst E1, später E2 beobachtet werden. Wegen der Kommutativitätin der Abarbeitung der Evidenzen gilt:
MB[H,E1 Y E2] = MB[H,E2 Y E1]
MD[H,E1 Y E2] = MD[H,E2 Y E1]
CF[H,E1 Y E2] = CF[H,E2 Y E1]
Eigenschaften der aktualisierten MB- und MD-Werte

283
Eigenschaften der endgültigen CF-Werte
Mithilfe der aktualisierten MB- und MD-Werte werden die endgültigen CF-Werte derHypothesen berechnet.Diese CF-Werte stellen die gewünschten Untersuchungsergebnisse dar. Sie dienenals Auswahlkriterien bei der Selektion der am wahrscheinlichsten zutreffendenHypothesen (Diagnosen).
Sei E die Summe aller bisher während der Untersuchung beobachteten Evidenzenbzgl. der Hypothese H, so gilt für:
CF[H,E] > 0: Insgesamt gibt es mehr bzw. stärkere Evidenzen für ein Zutreffen von H.
CF[H,E] = 0: Die Summe der Evidenzen für ein Zutreffen von H sind genau gleichstark wie die Summe der Evidenzen gegen H, oder es gibt überhauptkeine Evidenzen für bzw. gegen H.
CF[H,E] < 0: Insgesamt gibt es mehr bzw. stärkere Evidenz für eine Ablehnung von H.
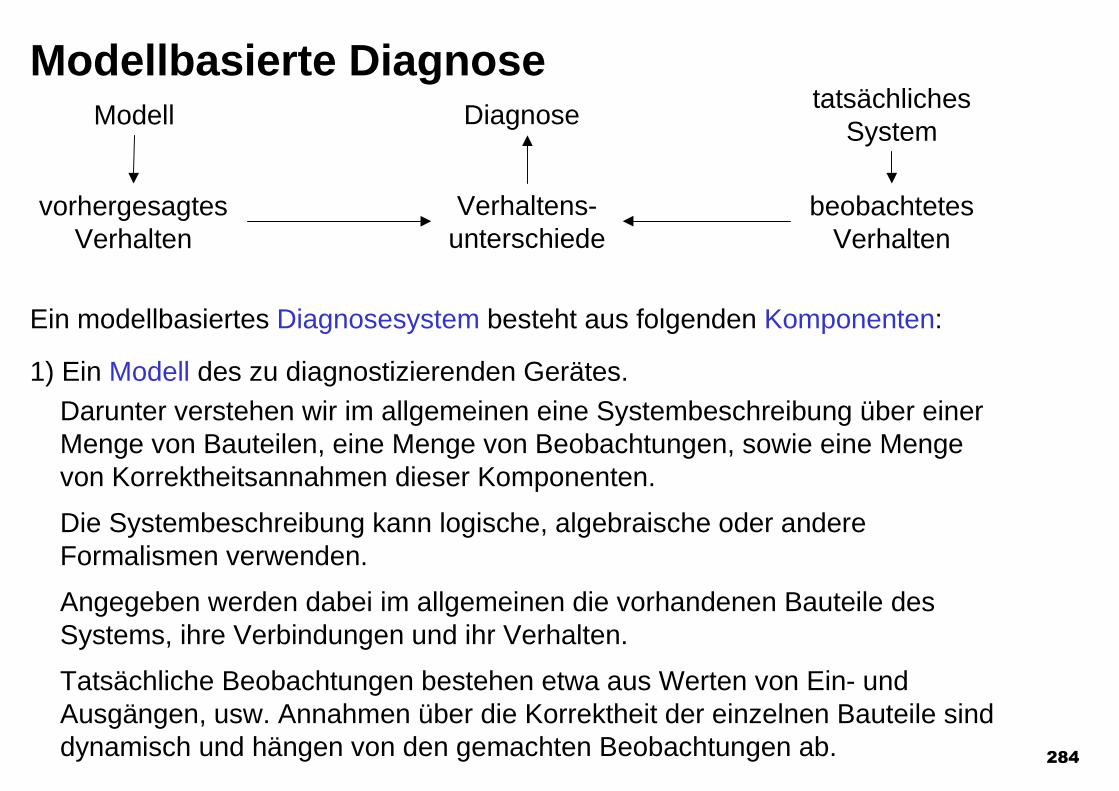
284
Modellbasierte DiagnoseModell Diagnose
tatsächlichesSystem
vorhergesagtesVerhalten
Verhaltens-unterschiede
beobachtetesVerhalten
Ein modellbasiertes Diagnosesystem besteht aus folgenden Komponenten:
1) Ein Modell des zu diagnostizierenden Gerätes. Darunter verstehen wir im allgemeinen eine Systembeschreibung über einer Menge von Bauteilen, eine Menge von Beobachtungen, sowie eine Menge von Korrektheitsannahmen dieser Komponenten.
Die Systembeschreibung kann logische, algebraische oder andere Formalismen verwenden.
Angegeben werden dabei im allgemeinen die vorhandenen Bauteile des Systems, ihre Verbindungen und ihr Verhalten.
Tatsächliche Beobachtungen bestehen etwa aus Werten von Ein- und Ausgängen, usw. Annahmen über die Korrektheit der einzelnen Bauteile sind dynamisch und hängen von den gemachten Beobachtungen ab.

285
Diagnosealgorithmus und Auswahl von optimalen Messpunkten
2) Ein Diagnosealgorithmus. Die Aufgabe dieses Algorithmus ist es, mögliche Diagnosen für eine bestimmte Konstellation von Beobachtungen zu finden, d.h. Mengen von fehlerhaften Bauteilen, die die gemachten Beobachtungen erklären.
Der Algorithmus versucht also, das durch die Beobachtungen inkonsistent gewordene Modell so zu verändern, dass es wieder konsistent wird. Dabei werden insbesondere die Annahmen über die Korrektheit der einzelnen Bauteile variiert.
Die Menge der schließlich als fehlerhaft angenommenen Bauteile wird als Diagnose bezeichnet.
3) Eine Prozedur zur Auswahl von optimalen Messpunkten. Diese Prozedur soll Messpunkte so auswählen, dass mit möglichst wenigen Messpunkten eine eindeutige Diagnose gefunden werden kann. Jeder zusätzlich gemessene Messpunkt erweitert die Systembeschreibung, worauf wieder der Diagnosealgorithmus aufgerufen wird.

286
GrundprinzipienIm folgenden wollen wir die Grundprinzipien der modellbasierten Diagnose an einemeinfachen elektronischen Schaltkreis beschreiben.Als Diagnosealgorithmus können wir ein einfaches Modellgenerierungssystemverwenden, das in Prolog implementiert ist und auf einem vorwärtsverkettendenMetainterpreter basiert.Auch das Verhalten des Schaltkreises wird durch (vorwärtsverkettende) Regelnbeschrieben.Als zu diagnostizierenden Schaltkreis verwenden wir den Schaltkreis, der nachfolgendbeschrieben ist.
m3
m2
m1
a3
b2
c2d3
e3
x6
y6
z6
f10
g12
Wobei mi Multiplizierer und aj Addierer sind.
a1
a2

287
type(M,multiplier) Y ok(M) Y val(in1(M), V1) Y val(in2(M), V2) Y V3 is V1 * V2
/ val(out(M), V3)type(M,multiplier) Y ok(M) Y val(out(M), V3) Y val(in2(M), V2) Y V1 is V3 O V2
/ val(in1(M), V1)type(M,multiplier) Y ok(M) Y val(out(M), V3) Y val(in1(M), V1) Y V2 is V3 O V1
/ val(in2(M), V2)type(A,adder) Y ok(A) Y val(in1(A), V1) Y val(in2(A), V2) Y V3 is V1 + V2
/ val(out(A), V3)type(A,adder) Y ok(A) Y val(out(A), V3) Y val(in2(A), V2) Y V1 is V3 – V2
/ val(in1(A), V1)type(A,adder) Y ok(A) Y val(out(A), V3) Y val(in1(A), V1) Y V2 is V3 – V1
/ val(in2(A), V2)
val(P, V1) Y val(P, V2) Y V1 s V2 / false.
conn(P1, P2) Y val(P1, V) / val(P2, V)conn(P1, P2) Y val(P2, Y) / val(P1, Y)

288
type(m1, multiplier). type(a1, adder).type(m2, multiplier). type(a2, adder).type(m3, multiplier).
conn(out(m1), in1(a1)). conn(in2(m1), in1(m3)).conn(out(m2), in2(a1)).conn(out(m2), in1(a2)).conn(out(m3), in2(a2)).
conn(a, in1(m1)). conn(x, out(m1)).conn(b, in1(m2)). conn(y, out(m2)).conn(c, in1(m3)). conn(z, out(m3)).conn(d, in2(m2)). conn(f, out(a1)).conn(e, in2(m3)). conn(g, out(a2)).
val(a, 3). val(f, 10).val(b, 2). val(g, 12).val(c, 2). val(x, 6).val(d, 3). val(y, 6).val(e, 3). val(z, 6).

289
Bedeutung der Prädikate1) ok(C) ist wahr, falls das Bauteil C korrekt funktioniert. Es ist falsch, wenn C fehlerhaft ist.
2) val(P,V) besagt, dass am Ein- oder Ausgang P der Wert V beobachtet wird. Falls verschiedene Werttypen (Spannung, Stromstärke) verwendet werden, kann dies durch Funktionssymbole ausgedrückt werden (z.B. val(spannung(in1(a), hoch))). Wir nehmen an, dass nur endlich viele verschiedene Werte an den Ein- und Ausgängen anliegen können. Eine neue Beobachtung wird durch ein neues val(P,V) Fakt dargestellt. Wenn z.B. f = 10 gemessen wird, stellen wir das durch val(f,10) dar.
3) conn(X,Y) beschreibt eine (bidirektionale) Verbindung zwischen Ein- und Ausgängen(X und Y) zweier Komponenten (z.B. conn(out(m1), in1(a1))). Außerdem wird dieses Prädikat verwendet, um Ein- oder Ausgänge mit den Namen entsprechender Messpunkte gleichzusetzen (z.B. conn(a, in1(m1))).
4) type(C,T) gibt an, welchen Typ T die Komponente C hat.
5) false gilt, wenn ein Widerspruch hergeleitet werden kann. In unserem Modell wird dieses Prädikat verwendet, um die Tatsache auszudrücken, dass in einem konsistenten Modell nur ein einziger Wert für einen Messpunkt existieren kann. Andernfalls stimmt ein Wert, der durch eine Beobachtung festgestellt wurde, nicht mit dem vorhergesagten Wert überein. Eine konsistente Theorie kann dann nur erzeugt werden, wenn man eine oder mehrere Komponenten als fehlerhaft annimmt (lok(C)) und ihr Verhalten dadurch unbestimmt wird.

290
Modellbasierte DiagnoseWenn alle Bauteile korrekt funktionieren, dann ist die Systembeschreibung inklusiveder gemachten Beobachtungen konsistent mit der Annahme, dass alle Bauteile inOrdnung sind (ok(ci)).
Falls wir false herleiten können, bedeutet das, dass beobachtete Werte nicht mitvorhergesagten Werten übereinstimmen.
Wir müssen daher für eine geeignete Menge von Bauteilen annehmen, dass sie defektsind. In unserem Modell drücken wir das durch lok(ci) aus.
Falls wir dann die strittigen Werte nicht mehr herleiten können und keinenWiderspruch mehr erhalten, haben wir ein konsistentes Modell. Diese Menge der alsdefekt angenommenen Bauteile ist dann ein möglicher Kandidat für eine Diagnose.
Im Extremfall können wir natürlich alle Bauteile als defekt annehmen, wodurch keineVorhersagen mehr gemacht werden können und daher auch false nicht hergeleitetwerden kann. Auch diese Menge aller Bauteile ist ein möglicher Kandidat für eineDiagnose.
Es ist aber sinnvoll, nur minimale Kandidaten als Diagnose zu bezeichnen, d.h.Kandidaten, die nicht Übermenge von anderen Kandidaten sind.

291
Modellbasierte Diagnose
Wir definieren daher eine Diagnose als minimalen Kandidaten, d.h. als minimaleMenge von defekten Bauteilen, die zu einem konsistenten Modell führen, in dem falsenicht hergeleitet werden kann.
Formal können wir das wie folgt definieren. Gegeben seien- SD, eine Systembeschreibung (ohne Beobachtung)- OBS, eine Menge von Beobachtungen- COMP, eine Menge von Bauteilen
Eine Diagnose für (SD, OBS, COMP) ist eine minimale Menge D von fehlerhaftenBauteilen, so dassSD W OBS W {lok(C)| C 2 D} W {ok(C)| C 2 COMP - D}
konsistent ist.
In unserem Beispiel ist eine mögliche Menge von Beobachtungen am Ende derModellbeschreibung angegeben. Eine Diagnose für diese Beobachtungen ist [a1].

292
Aufgaben des Diagnosesystems
Das modellbasierte Diagnosesystem hat daher zwei Aufgaben:
1) Diagnosen müssen berechnet und ausgegeben werden. Eine möglicheVorgangsweise ist die Ausgabe aller Diagnosen, nicht aber ihre Obermengen (dermöglichen Kandidaten). Die Diagnose wird beendet, falls nur mehr eine Diagnosemöglich ist, die deutlich wahrscheinlicher ist als die anderen Diagnosen (z. B. eineEinfachdiagnose und einige Mehrfachfehlerdiagnosen).
2) Es müssen Messpunkte vorgeschlagen werden, die möglichst gut zwischen denverschiedenen Diagnosen differenzieren. Das Ziel dabei ist, mit möglichstwenigen Messungen auf eine eindeutige Diagnose zu kommen.
Im Normalfall werden die Beobachtungen dem System nicht alle auf einmal mitgeteilt,sondern das System schlägt optimal Messungen basierend auf den bisherigenErgebnissen vor. Diese Messungen erweitern dann jeweils die Wissensbasis um neueBeobachtungen, die durch die val(P, V) Fakten dargestellt werden.

293
Messungen
Am Anfang messen wir eine Reihe von Werten, die noch keine Widersprücheerzeugen. Der Wert von a, d und e werde mit 3 gemessen, der von b und c mit 2.
Wir erhalten eine konsistente Menge von Fakten (für jeden Messpunkt erhalten wir nureinen Wert), auch wenn wir alle ok(C) Fakten als wahr annehmen. Wir können daherdaraus schließen, dass der Schaltkreis fehlerlos ist.
Messen wir zusätzlich am Punkt f den Wert 10, erhalten wir einen Widerspruch (falsekann hergeleitet werden), weil für f der Wert 12 vorhergesagt wird.
Um diese Vorhersage zu vermeiden, müssen wir eine der Komponenten m1, m2, a1
oder eine Obermenge davon als fehlerhaft ansehen.
Diagnosen sind daher [m1], [m2] und [a1].
Nach einer weiteren Messung (g = 12) können wir [m2] aus der Menge der potentiellenDiagnosen ausschließen.
Diagnosen sind daher [m1], [a1], [m2, m3] und [m2, a2].
Bei den Doppelfehlerdiagnosen kompensieren sich die Fehler der beiden Defektegegenseitig, so daß an g wieder der richtige Wert anliegt.

294
MessungenDie Beobachtung x = 6 schließlich führt uns zu der Diagnose, dass a1 die fehlerhafteKomponente sein muss, da es als einzige Einfachfehlerdiagnose übrigbleibt.
Zusätzliche Diagnosen sind [m2, m3] und [m2, a2].
Durch zusätzliche Messungen an y und z können noch beide Doppelfehlerdiagnosen mitBestimmtheit ausgeschlossen werden.
Dies ist jedoch im Normalfall nicht notwendig, da [a1] schon ohne Messungen eine deutlichhöhere Wahrscheinlichkeit als die anderen möglichen Diagnosen hat und daher schon vorhermit ausreichender Wahrscheinlichkeit als endgültige Diagnose betrachtet werden kann.
[[a1], [m2, m3], [m2, a2]]x = 6
[[m1], [a1], [m2, m3], [m2, a2]]g = 12
[[m1], [m2], [a1]]f = 10
[]:
DiagnosenMessung
Die nach den Messungen immer wieder erforderlichen Konsistenztests können durchgeführtwerden durch: Resolutionswiderlegungen, um Widersprüche herauszufinden oderModellgenerierung, um gültige Modelle zu finden, Constraint-Propagation Systeme, Truth-Maintenance-Systeme.

295
Beispiel: Drei Glühbirnen und eine Batterie
Drei Glühbirnen und eine Batterie
w1
w2
w5
w4
w3
w6
s b3b2b1
ok(C) Y type(C, bulb) Y val(port(C), +) / val(light(C), on).ok(C) Y type(C, bulb) Y val(port(C), 0) / val(light(C), off).ok(C) Y type(C, bulb) Y val(light(C), on) / val(port(C), +).ok(C) Y type(C, bulb) Y val(light(C), off) / val(port(C), 0).ok(C) Y type(C, supply) / val(port(C), +).
Nehmen wir nun an, dass die folgenden Beobachtungen gemacht wurden.val(light(b1), off).val(light(b2), off). val(light(b3), on).

296
Beispiel: Drei Glühbirnen und eine Batterie
Die minimalen Diagnosen, die gefunden werden, sind [b1,b2] und [s,b3]. Während dieerste Diagnose nicht überrascht, scheint die zweite Diagnose intuitiv falsch zu sein, dawir von defekten Glühbirnen nicht erwarten, dass sie brennen.
Um diese Diagnose ausschließen zu können, müssen wir zusätzlich zum korrektenVerhalten angeben, welches Verhalten unmöglich ist. Das ist notwendig, da dieBeschreibung des korrekten Verhaltens nicht den Fall ausschließt, dass eine Lampedefekt ist, aber trotzdem leuchtet.
type(C, bulb) Y val(light(C), on) Yval(port(C), 0) / false.
In unserem Fall kann dieses Axiom der physikalischen Unmöglichkeit in eines derphysikalischen Notwendigkeit umgeformt werden.
Wir verwenden dabei die Tatsache, dass das Licht einer Lampe nur die Werte on oderoff haben kann, und die Spannungsdifferenz entweder 0 oder + sein kann.

297
Beispiel: Drei Glühbirnen und eine Batterie
Die folgenden zwei Regeln subsumieren übrigens Teile unserer Beschreibung deskorrekten Verhaltens.
type(C, bulb) Y val(port(C), 0)/ val(light(C), off).
type(C, bulb) Y val(light(C), on)/ val(port(C), +).
Um unmögliches Verhalten auszuschließen, können auch Fehlermodelle eingeführtwerden, die den verschiedenen Fehlerzuständen außerdem nochWahrscheinlichkeiten zuordnen können.
Fehlermodelle erhöhen allerdings die Komplexität des Diagnoseprozesses imGegensatz zu den rein negativen Axiomen der physikalischen Unmöglichkeitbeträchtlich (weil die Fehlermodelle auch manchen nicht-minimalen Kandidatenausschließen).

298
Beispiel: ZentralheizungssystemBeispiel der Fehlfunktionsdiagnose eines Zentralheizungssystems in einem Haus.
Das System besteht u.a. aus einem Boiler, einem Thermostat in einem Raum, sowiemehreren Heizkörpern. Der Boiler enthält eine elektrische Wasserpumpe.

299
Beispiel: Zentralheizungssystem
Es gibt zahlreiche Fehlerarten in einem Zentralheizungssystem:
• zu geringer Wasserdruck• Wärmeverluste in Leitungen• Thermostat defekt• Stromversorgung für Boiler defekt• Brenner verschmutzt• Wasserleitungsbruch ...
Hier sollen nur zwei Fehlertypen betrachtet werden:
• Luft im Umlaufsystem• Pumpe defekt
Es gibt viele mögliche Beobachtungen im Heizungssystem, von denen einige sehreinfach, andere eher aufwendig sind (z.B. Geräuschprüfung vs.Wasserdurchlaufmessung)

300
Beispiel: Zentralheizungssystem
Wir betrachten hier nur sehr einfache Beobachtungen:
Die Pumpe erzeugt ein Geräusch, wenn sie arbeitet. Außerdem fließt dann auf dereinen Seite Wasser in die Pumpe und wird an der anderen Seite herausgedrückt.
Falls die Pumpe nicht arbeitet, hört man kein Geräusch und es fließt kein Wasser reinund raus.
Wenn ein Heizkörper korrekt arbeitet, hört man kein Geräusch. Die Wassermenge, dieaus dem Heizkörper zurückfließt, hängt dann von der Einstellung des Radiators undder Einlaufmenge ab.
Wenn man ein Blubbern hört, arbeitet er nicht korrekt. Dabei muss allerdings Wasserdurch den Radiator laufen.

301
Modellbeschreibung ZentralheizungssystemDie Modellbeschreibung umfasst 8 Komponenten:
radiatorcorrect RadNoise(t) = False, WaterOut(t + dt) = WaterIn(t) * RadControl(t)faulty RadNoise(t) = (WaterIn(t) > 0) Y (RadControl(t) > 0)
pumpcorrect WaterOut(t + dt) = PumpControl(t) * WaterIn(t), PumpNoise(t) = PumpControl(t)faulty WaterOut(t) = 0, PumpNoise(t) = False
pipecorrect Out(t + dt) = In(t)
joint1correct Out(t + dt) = In1(t) + In2(t)
joint2correct Out1(t + dt) = In1(t) / 2, Out2(t + dt) = In1(t) / 2
control circuitrycorrect Out(t + dt) = In(t)
cablecorrect Out(t) = In(t)
thermostatcorrect Out(t) = (Tset(t) > Tact(t))
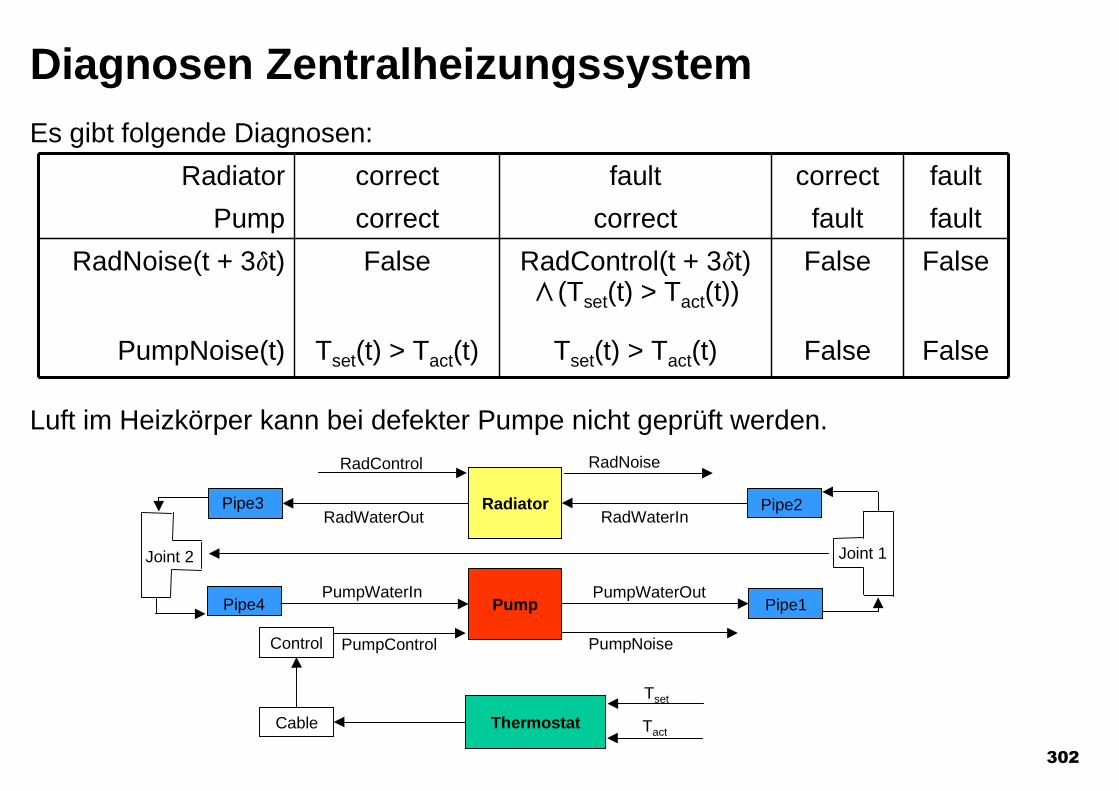
302
Diagnosen ZentralheizungssystemEs gibt folgende Diagnosen:
FalseFalseTset(t) > Tact(t)Tset(t) > Tact(t)PumpNoise(t)
FalseFalseRadControl(t + 3dt)Y(Tset(t) > Tact(t))
FalseRadNoise(t + 3dt)
faultfaultcorrectcorrectPump
faultcorrectfaultcorrectRadiator
Luft im Heizkörper kann bei defekter Pumpe nicht geprüft werden.
Radiator
Cable
Control
RadControl RadNoise
RadWaterOut RadWaterInPipe3
Pipe1
Pipe2
Pipe4
Joint 1Joint 2
PumpPumpWaterIn PumpWaterOut
Thermostat
Tset
Tact
PumpControl PumpNoise

303
Historisches
Die erste Publikation über modellbasierte Diagnosesysteme erschien erst 1982.Davis vom AI Labor des MIT berichtete über sein System HT (HardwareTroubleshooting).
Man spricht auch von Expertensystemen der zweiten Generation.
GDE (General Diagnostic Engine) wurde unter de Kleer ab 1986 bei XeroxPARC entwickelt.
Während HT nur Einfachfehler suchte, konnte GDE auch Mehrfachfehlerdiagnostizieren.
Die Komplexität des ursprünglichen GDE-Verfahrens war sehr hoch: beiKomponenten mit endlicher Wertemenge ist die Berechnung der kombiniertenFehlerannahmen NP-vollständig, bei unendlicher Wertemenge sogarunentscheidbar.

304
Modellbasierte Systeme vs. XPS der 1. Generation
Modellbasierte Systeme sollen gegenüber den Expertensystemen der erstenGeneration zwei Probleme überwinden:
• den Flaschenhals der Wissensakquisition• die mangelnde Robustheit
Die Wissensakquisition bei regel- und frame-basierten Systemen beruht aufInterviews mit Experten. Es wird nach Zusammenhängen zwischenBeobachtungen und Fehlern gesucht.
Da die Produktlebensdauer immer kürzer und die Fehlerhäufigkeit immergeringer wird, dauert der Aufbau eines Erfahrungsschatzes zu lange, um frühzu einem Wirkeinsatz des XPS zu kommen

305
Die mangelnde Robustheit klassischer Expertensysteme im Diagnosebereichberuht darauf, dass letztlich nur solche Fehler diagnostiziert werden können,die dem Experten bekannt waren.
Neuartige Fehler können bei einer direkten Assoziation zwischen Beobachtungund Diagnose nicht gefunden werden.
Fundamental für den Ansatz der Modellbasierten Diagnose ist die Trennungzwischen dem Modell eines Systems und der Diagnosekomponente, die überdem Modell arbeitet.
Das Wissen, wie eine Diagnose auszuführen ist, steckt nicht im Modell,sondern in der Diagnosekomponente – im Unterschied zur Vermischung inklassischen Expertensystemen.
Modellbasierte Systeme vs. XPS der 1. Generation

306
Aufgaben von Reason-Maintenance-SystemenEin nichtmonotones Schlussfolgerungssystem muss mit einer veränderlichenPrämissenmenge und Widersprüchen in der Menge der Überzeugungen umgehenkönnen.
Folgende Aufgaben sind zu erledigen:(1) Falls eine Prämisse zurückgezogen wird, ist zu untersuchen, ob von ihr aus
irgendeine Überzeugung abgeleitet wurde.(2) Falls eine Prämisse hinzugefügt wird, ist zu untersuchen, ob es Überzeugungen gibt,
die ausdrücklich vom Fehlen dieser Prämisse abhängen, d.h. ob die neue Prämisseirgendwelche Konsistenzannahmen verletzt.
(3) Falls ein Widerspruch festgestellt wird, ist zu untersuchen, wo der Ursprung diesesWiderspruchs liegt und ob weitere Inferenzen aus widersprüchlichen Überzeugungengezogen wurden.
Für (1) und (2) gäbe es eine einfache, aber unbefriedigende Lösung: Jedesmal, wenn sichdie Prämissenmenge ändert, werden alle abgeleiteten Überzeugungen verworfen und derInferenzprozeß erneut gestartet.
Zur effizienten Lösung der drei Aufgaben sind Reason-Maintenance-Systeme (RMS)entwickelt worden.
Die zentrale Idee von RMS ist, in einem Abhängigkeitsnetz (Dependenznetz) explizit zubeschreiben, wie die Überzeugungen voneinander abhängen.

307
Das Abhängigkeitsnetz in einem RMSEin Abhängigkeitsnetz DN besteht aus einer Menge von Knoten, die in zweiTeilmengen unterteilt ist:- die Menge der Überzeugungsknoten U- die Menge der Rechtfertigungsknoten REs werden drei Funktionen betrachtet, die jedem Rechtfertigungsknoten drei Mengenvon Überzeugungsknoten zuordnen:
IN-SET, OUT-SET, SUP-SET: R / 2U
DN wird dann als gerichteter Graph DN = (N,E) definiert:(i) N = U W R(ii) E 4 N ! N, definiert durch
(u,v) 2 E 5 u 2 U, v 2 R, u 2 (IN-SET(v) W OUT-SET(v)) oderu 2 R, v 2 U, v 2 SUP-SET(u).
Eine Kante verbindet also immer jeweils ein Element aus U und ein Element aus Rmiteinander, niemals zwei Elemente aus U oder zwei Elemente aus R.Ein Überzeugungsknoten kann durch mehrere Rechtfertigungsknoten unterstützt sein,d.h. es können von mehreren Knoten in R Kanten zum selben Knoten in U führen.
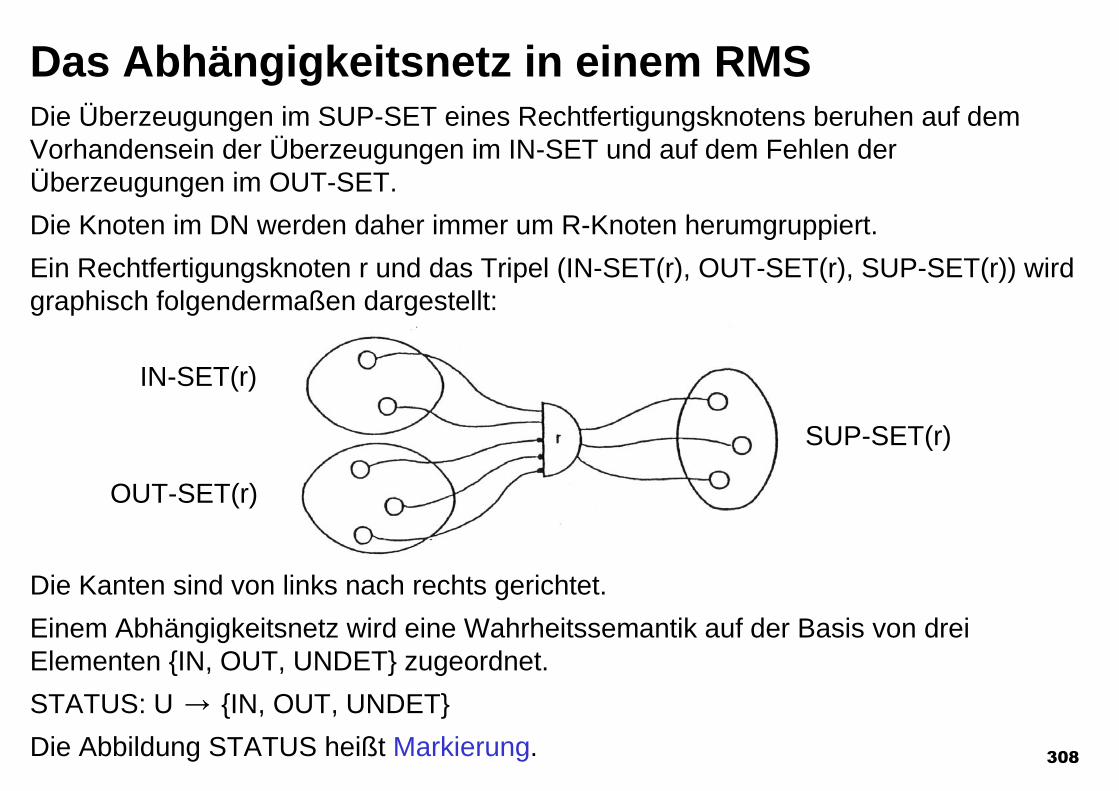
308
Das Abhängigkeitsnetz in einem RMSDie Überzeugungen im SUP-SET eines Rechtfertigungsknotens beruhen auf demVorhandensein der Überzeugungen im IN-SET und auf dem Fehlen derÜberzeugungen im OUT-SET.
Die Knoten im DN werden daher immer um R-Knoten herumgruppiert.
Ein Rechtfertigungsknoten r und das Tripel (IN-SET(r), OUT-SET(r), SUP-SET(r)) wirdgraphisch folgendermaßen dargestellt:
OUT-SET(r)
SUP-SET(r)
Die Kanten sind von links nach rechts gerichtet.
Einem Abhängigkeitsnetz wird eine Wahrheitssemantik auf der Basis von dreiElementen {IN, OUT, UNDET} zugeordnet.
STATUS: U / {IN, OUT, UNDET}
Die Abbildung STATUS heißt Markierung.
IN-SET(r)

309
Das Abhängigkeitsnetz in einem RMSDie Abbildung STATUS wir erweitert auf Rechtfertigungsknoten:
STATUS: R / {IN, OUT, UNDET}
mitIN, falls cu 2 IN-SET(r): STATUS(u) = IN und
cu 2 OUT-SET(r): STATUS(u) = OUTSTATUS(r) = OUT, falls du 2 IN-SET(r): STATUS(u) = OUT oder
du 2 OUT-SET(r): STATUS(u) = INUNDET, sonst
Ist STATUS(r) = IN für einen Rechtfertigungsknoten r, so heißt r gültig.
Eine Markierung heißt vollständig, wenn kein Knoten den Wert UNDET hat.
Eine Markierung heißt konsistent, wenn für jeden Überzeugungsknoten u gilt:STATUS(u) = IN 0 dr 2 R: [u 2 SUP-SET(r) Y STATUS(r) = IN]STATUS(u) = OUT 0 cr 2 R: [u 2 SUP-SET(r) 0 STATUS(r) = OUT]
Für eine konsistente und vollständige Markierung gelten Äquivalenzen statt derImplikationen.

310
Markierungstypen in Abhängigkeitsnetzen

311
Das Abhängigkeitsnetz in einem RMSEine Prämissen-Rechtfertigung ist eine Rechtfertigung mit leerem IN-SET und leeremOUT-SET (siehe r1).Sie wird immer als gültig angenommen, unabhängig von ihrer Markierung.Eine Prämisse ist eine Überzeugung, die eine Prämissen-Rechtfertigung hat (sieheu1).Eine Annahme-Rechtfertigung ist eine gültige Rechtfertigung mit nichtleerem OUT-SET (siehe r2).Eine Annahme ist eine Überzeugung, für die gilt, dass alle ihre gültigenRechtfertigungen Annahme-Rechtfertigungen sind (siehe u2).

312
Schleifen in AbhängigkeitsnetzenFalls das Netz eine Schleife enthält, ist eine Voraussetzung dafür, dass u IN ist, dieTatsache, dass u IN ist.Ein solcher Zusammenhang soll vermieden werden. Man fordert daher von einerMarkierung, dass sie wohlfundiert ist.
Sei rank: U W R / N eine Funktion, für die gilt:(i) cu 2 U: STATUS(u) = IN 0dr 2 R: u 2 SUP-SET(r) Y rank(r) ! rank(u)(ii) cr 2 R: STATUS(r) = IN 0cu 2 IN-SET(r): rank(u) ! rank(r)Dann heißt die Markierung STATUS wohlfundiert.

313
Unterstützungsbaum und UnterstützungsmengeIst eine Markierung vollständig, konsistent und wohlfundiert, so kann man zu jedemÜberzeugungsknoten u einen Unterstützungsbaum T(u) nach folgender Vorschrift konstruieren:
1) u ist die Wurzel von T(u).
2) Für jeden Knoten v in T(u) mit STATUS(v) = IN wird eine der unterstützendenRechtfertigungen, etwa r, mit rank(r) < rank(v) als Nachfolger in T(u) gewählt.
3) Für jede gültige Rechtfertigung r in T(u) werden alle Überzeugungsknotenv 2 (IN-SET(r) W OUT-SET(r)) als Nachfolger in T(u) aufgenommen,wobei für die v 2 IN-SET(r) gelten muss: rank(v) < rank(r).
Jedem Überzeugungsknoten u wird eine aktuelle Unterstützungsmenge AU(u) zugeordnet, diefolgendermaßen definiert ist:
1) Ist u IN und ist r eine gültige Rechtfertigung von u(d.h. u 2 SUP-SET(r) und STATUS(r) = IN), dann ist
AU(u) = IN-SET(r) W OUT-SET(r).
2) Sei u OUT und seien r1, ..., rk alle Rechtfertigungen von u.Alle diese Rechtfertigungen sind ungültig. Wähle für jedes ri (i = 1, ..., k)einen Überzeugungsknoten ui 2 IN-SET(ri), der OUT ist, odereinen Überzeugungsknoten ui 2 OUT-SET(ri), der IN ist. Setze
AU(u) = {u1, ..., uk}.
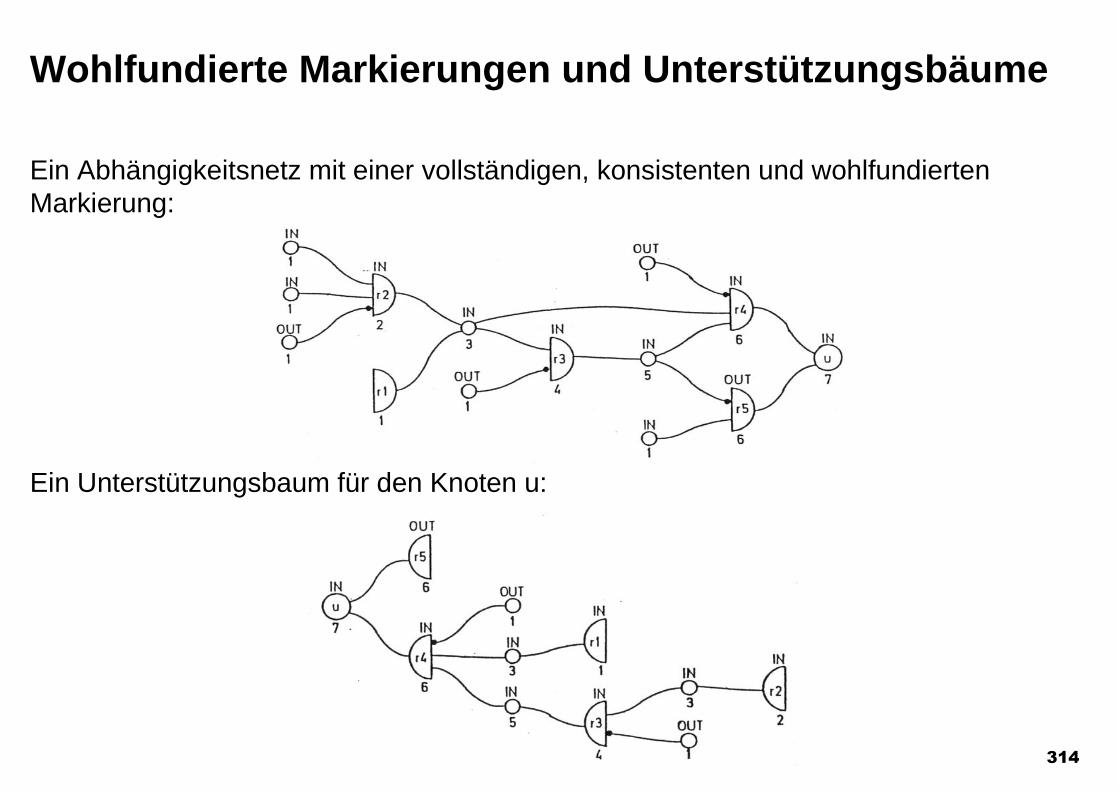
314
Wohlfundierte Markierungen und Unterstützungsbäume
Ein Abhängigkeitsnetz mit einer vollständigen, konsistenten und wohlfundiertenMarkierung:
Ein Unterstützungsbaum für den Knoten u:

315
Rückwirkungen und Begründungen
Ist DN = (N,E) das Abhängigkeitsnetz, so induziert die Definition der aktuellenUnterstützungsmengen einen Teilgraphen von DN,nämlich DN# = (N,E#), wobei zu E# nur noch die Kanten aus E gehören,die auf einem Pfad (der Länge 2) von AU(u) zu u führen, für jedes u 2 U.
Die Rückwirkungen RW(u) eines Überzeugungsknotens u ist die Menge allerÜberzeugungsknoten, die von u aus in DN# erreichbar sind, also
RW(u) = {v 2 U| es gibt einen Pfad von u nach v in DN#}.
Ein Unterstützungsbaum in DN# heißt aktueller Unterstützungsbaum.
Die Unterstützungsknoten in einem solchen aktuellen Unterstützungsbaum fürden Überzeugungsknoten u heißen Begründungen von u.
Aus der Sicht des RMS ist ein widersprüchlicher Überzeugungsknoten einer, derunter jeder Markierung die Marke OUT hat, also das Gegenstück zu einerPrämisse.
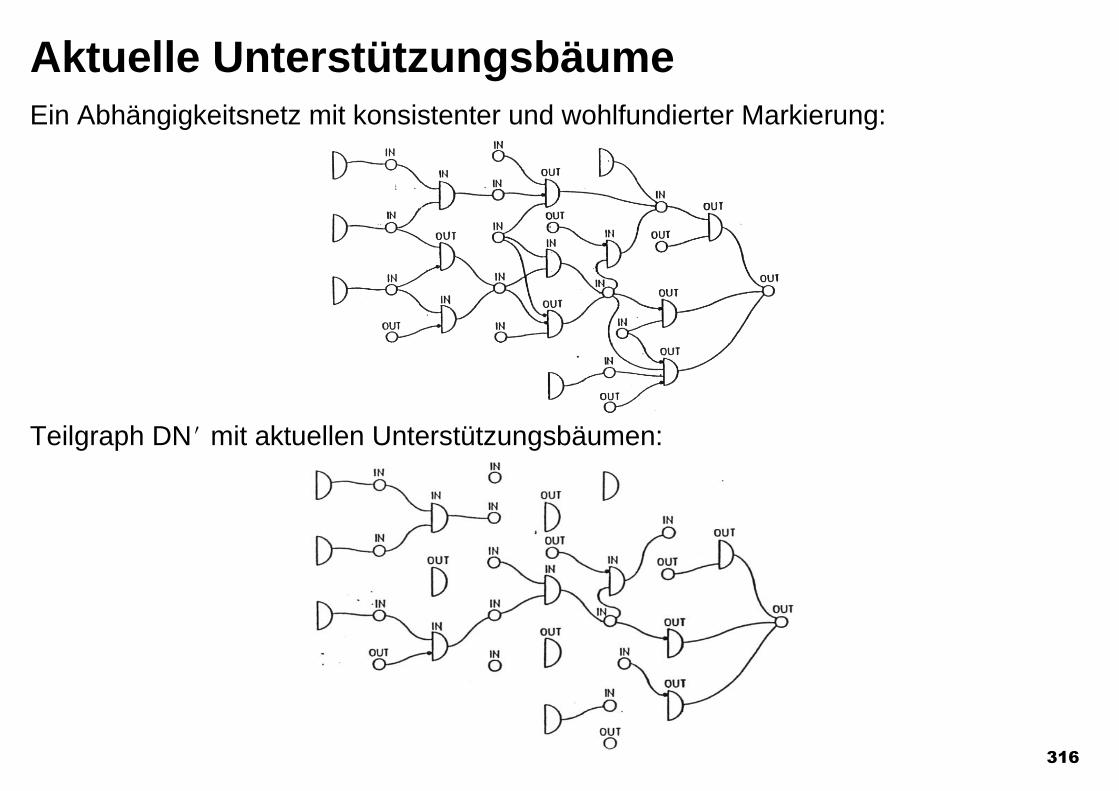
316
Aktuelle UnterstützungsbäumeEin Abhängigkeitsnetz mit konsistenter und wohlfundierter Markierung:
Teilgraph DN# mit aktuellen Unterstützungsbäumen:

317
Der RevisionsalgorithmusÜber das Entfernen und Hinzufügen von Prämissen hinaus kann der dem RMS übergeordneteProblemlöser auch andere Knoten kreieren. Diese werden ebenfalls in das Abhängigkeitsnetzeingebaut.
Das Hauptproblem für das RMS ist es, für das veränderte Netz eine neue konsistenteMarkierung zu bestimmen.
Dies geschieht in zwei Schritten:
1) Entfernen der aktuellen Markierung:Beginnend bei der Stelle, an der eine Änderung erfolgt ist, werden entlang der Kanten dieMarken der betroffenen Knoten auf UNDET gesetzt.
Ist u der geänderte Knoten, so kann man die Marken aller im Netz von u aus erreichbarenKnoten auf UNDET setzen, oder – effizienter – nur eine geeignete Auswahl. Eine solchebietet die Menge RW(u).
2) Bestimmen einer neuen Markierung:Durch Vorwärtspropagierung entlang der Kanten wird versucht, die mit UNDET markiertenKnoten mit anderen Marken zu versehen.
Hat ein solcher Überzeugungsknoten eine gültige Rechtfertigung, dann erhält er die MarkeIN, sind alle seine Rechtfertigungen ungültig, so erhält er die Marke OUT, entsprechend fürdie Rechtfertigungsknoten.
Man erreicht mit diesem Schritt nicht immer eine vollständige Markierung.

318
Die Behandlung von WidersprüchenEs bleibt noch die Lösung der dritten Aufgabe zu klären, nämlich die Behandlung vonWidersprüchen.
Das RMS selbst kann keine Widersprüche entdecken, da es ja den Inhalt derÜberzeugungen nicht kennt, vielmehr wird ihm vom Problemlöser mitgeteilt, welcherKnoten widersprüchlich ist.
Die Durchführung dieser Veränderung heißt abhängigkeitsgesteuertes Rücksetzen.
Dabei geht man von folgender Situation aus:
Ein Überzeugungsknoten ist als widersprüchlicher Knoten gekennzeichnet (dieseKennzeichnungen werden vom RMS intern verwaltet). Durch Hinzufügen von Knotenpassiert es, dass der widersprüchliche Knoten eine neue Rechtfertigung bekommt.Also hat er einen aktuellen Unterstützungsbaum.
In diesem werden die maximalen Annahmen identifiziert, etwa a1, ..., an und zu einerNogood-Menge NM zusammengefaßt, also NM = {a1, ..., an}.
Eine maximale Annahme ist eine Annahme, die so im Unterstützungsbaum liegt, dasszwischen ihr und der Wurzel des Baums keine andere Annahme liegt.
Ein Nogood-Knoten wird kreiert. Er ist ein Überzeugungsknoten und repräsentiert dieKonjunktion der maximalen Annahmen.

319
Die Behandlung von WidersprüchenSei nun u der widersprüchliche Knoten und S die Menge seiner Begründungen. DurchEntfernen der maximalen Annahmen und aller ihrer Rückwirkungen aus S erhält man dieMenge S#:
S# = S – [RW(a1) W ... W RW(an) W {a1, ..., an}]
S$ sei die Menge aller Rückwirkungen der Nogood-Menge in S, die mit IN markiert sind:S$ = { x | x 2 [(RW(a1) W ... W RW(an)) X S] und STATUS(x) = IN }
u selbst liegt in S$, aber in S$ liegen keine Annahmen, wegen der Definition der maximalenAnnahmen.Nun wird ein Rechtfertigungsknoten für den Nogood-Knoten auf folgende Weisekonstruiert:Sei T die Menge aller Überzeugungsknoten aus S#, die zur aktuellen Unterstützungs-menge AU(v) irgendeines Überzeugungsknotens v 2 S$ gehören.Dann gilt für den Rechtfertigungsknoten NGR des Nogood-Knotens:
IN-SET(NGR) = {v 2 T| STATUS(v) = IN}OUT-SET(NGR) = {v 2 T| STATUS(v) = OUT} = {}
Dass OUT-SET(NGR) leer ist, liegt wiederum an der Definition der maximalen Annahmen.Die maximalen Annahmen sind nicht in S# enthalten, also sind alle Überzeugungsknoten inS#, die zur aktuellen Unterstützungsmenge eines Knotens in S$ gehören können, keineAnnahmen, haben also ein leeres OUT-SET.

320
Die Behandlung von Widersprüchen
Nun wird eine der maximalen Annahmen als Schuldiger ausgewählt und„vernichtet“, indem man einen der Überzeugungsknoten im OUT-SET desSchuldigen mit einer gültigen Rechtfertigung r versieht, die folgendermaßendefiniert ist:
IN-SET(r) = (NM – {Schuldiger}) W {Nogood-Knoten}OUT-SET(r) = OUT-SET(r – Sch) – {Vernichtungsknoten}SUP-SET(r) = {Vernichtungsknoten}
Hierbei ist r – Sch die aktuelle, den Schuldigen unterstützende Rechtfertigungund der Vernichtungsknoten derjenige Knoten im OUT-SET von r – Sch, der fürdie Vernichtung des Schuldigen ausgewählt wurde.
Man geht also im Unterstützungsbaum des widersprüchlichen Überzeugungs-knotens zurück bis zur ersten Annahme in jedem Zweig. Das sind gerade diemaximalen Annahmen. Abgeleitete Überzeugungen werden dabei übergangen.

321
Die Behandlung von Widersprüchen
Mindestens eine der maximalen Annahmen war falsch und hat den Widerspruchverursacht. Angenommen, diese werde als Schuldiger ausgewählt.
Sie wird unschädlich gemacht, indem einer ihrer OUT-SET-Knoten eine gültigeRechtfertigung erhält. Dieser hängt von den übrigen maximalen Annahmen (imBeispiel u10) und von dem neukreierten Nogood-Knoten ab, dessen Inhalt diemaximalen Annahmen repräsentiert.
Dieser erhält eine sichere Unterstützung, also die Marke IN, durch diejenigenÜberzeugungen, die zur Unterstützung des widersprüchlichen Knotens beitragen,aber mit den maximalen Annahmen nichts zu tun haben (im Beispiel u3 und u9).
Das heißt, zum Ausschluss der als Schuldiger ausgewählten maximalenAnnahme werden praktisch alle übrigen Überzeugungen, die denwidersprüchlichen Knoten unterstützen, herangezogen, was zur Folge hat, dassdieser seine Unterstützung verliert.

322
Die Behandlung von WidersprüchenAktueller Unterstützungsbaum für widersprüchlichen Knoten u1.S = {u1, ..., u13}, S# = {u3, u5, ..., u9, u11, ..., u13},S$ = {u1, u4}, u11 ist nicht-maximale Annahme, T = {u3, u9},AU(u1) X S# = {u3}, AU(u4) X S# = {u9}

323
Die Behandlung von WidersprüchenVeränderter aktueller Unterstützungsbaum mit Nogood-Knoten u14,Schuldigem u2, Vernichtungsknoten u6 und neuer Markierung:

324
Was ist „Bildverstehen“?
Hauptproblemkreise:
• Zerlegen des Verstehensprozesses in geeignete Teilprozesse
• Repräsentationsformen für Zwischen- und Endresultate
• Identifizieren und Ausnutzen von physikalischen Gesetzmäßigkeiten
• Identifizieren, Repräsentieren und Ausnutzen von Erfahrung und Wissen
PhysikOptik
Zweck
Bedeutung
GefühleKontext
Konzepte
Erfahrung
Wissen
menschl.Sehvermögen
Bilder
= Die Bedeutung von Bildern mit Hilfe von exakt definierten Prozessen ermitteln

325
Bild 2Bild 3
Bildelemente, BereicheKanten, Markante Punkte
SzenenelementeObjektteile, 3D-Information
Bildinterpretation 1Objekte
1
2
3
4
6
5
Korresp
ondieren
de Bild
elem
ente
Differ
enzb
ilder
, Aner
ungsgeb
iete,
Optisch
er F
luss
Bild 114
13 12
11 10
9 7
17
18
Korresp
ondieren
de Sze
nenele
men
te
Beweg
te K
örper
Szenen
inte
rpre
tatio
n
Vorwissen, Weltmodell, Szenen- und Objektmodell
15
16
Zeit
8
19
Schematischer Aufbau eines bildverstehenden Systems

326
Prozesse in einem bildverstehenden System
1: Segmentierung, Zerlegung eines Bildes in geeignete Bildelemente, dabei Übergang von ikonischer zu symbolischer Repräsentation, wesentlicheDatenreduktion.
2: Deutung von Bildelementen als Szenenbestandteile, z.B. Interpretation einerHelligkeitsdiskontinuität als verdeckende Kontur. Übergang von 2D nach 3D.Identifizierung von Beleuchtungsphänomenen, z.B. Schatten.
3+4: Generieren von Objekthypothesen und Einzelbildinterpretationen.Prozess 3 bringt Szenenhinweise, Prozess 4 bringt Weltwissen, z.B. übertypische Objektformen, ein. Realisierbar durch Vergleich („Match“) einerunbekannten Beschreibung mit Modellbeschreibungen oder durchRelaxationstechniken. Gefahr kombinatorischer Explosion bei umfangreichemModellrepertoire.
5: Hypothesenverifikation. Prüfen, ob (vermutete) Objekt- oder Szenenansichtenin einem Bild vorliegen, ggf. Zurückweisung einer durch die Prozesse 3 und 4erzeugten Hypothese. Bewertungskriterium erforderlich.

327
Prozesse in einem bildverstehenden System
6: Rückprojektion eines (vermuteten) 3D-Objektes in die Bildebene.Hypothesenverifikation oder „Interpretationsgesteuerte Segmentierung“.
7+8: Aufbau einer Szeneninterpretation für die gesamte Bildfolge. Erzeugen vonBewegungshypothesen mit Hilfe von zeitspezifischen Modellen.
9: Generieren von Einzelbildhypothesen aus dem zeitlichen Kontext heraus.Wichtige Komponente für Szenen mit Bewegung: Sobald eineSzeneninterpretation vorliegt, können weitere Bilder vorwiegend Top-downinterpretiert werden.
10+11: Entsprechen den Prozessen 7 und 8 auf niedrigerer Repräsentationsebene.Aus zeitlich korrespondierenden Szenenelementen können volumetrischeObjektbeschreibungen abgeleitet werden.
12+13: Bewegungsanalyse durch Vergleich von Bildelementen, z.B. von Bereichenoder markanten Punkten, Korrespondenzproblem.
14: Bewegungsanalyse auf Pixelebene. Erzeugen von Differenzbildern,Änderungsgebieten, Masken für bewegte Objekte und dergleichen.Berechnungen von Verschiebungsvektorfeldern („optischer Fluß“).

328
15+16: Generieren und Verifizieren durch Bewegungshypothesen in 3D, auch mitHilfe von Modellwissen (Prozess 8).
17: 3D-Rekonstruktion einer Objektform durch verfolgen bewegterBildelemente (Bewegungsstereo). Ausnutzen der geometrischenAbbildungsgesetze für orthographische Projektionen bzw. perspektivischeProjektionen. Die photometrischen Abbildungsgesetze können aufähnliche Weise zur Formbestimmung herangezogen werden.
18: Rückprojektion von bewegten Szenenelementen, Prädikation vonTrajektorien.
19: Bewegungsgesteuerte Segmentierung. Aus Änderungsgebieten oder Diskontinuitäten im optischen Fluß können Objektgrenzen abgeleitetwerden. Steuerung höherer bewegungsspezifischer Prozesse, z.B. von Gruppierungsverfahren.
Prozesse in einem bildverstehenden System

329
4 Formen der Repräsentation von Bildmaterial
(A) ikonisch (B) segmentiert(C) geometrisch (D) relational

330
A1: Benachbarte Pixel gehören zu dem gleichen Objekt, falls es keinegegenteilige Evidenz gibt.Dies ist ein Kohärenzprinzip: Objekte sind meist zusammenhängende Einheiten,die nicht in beliebig kleinen Teilen in einer Szene verteilt sind (Problem: Ästeeines Baumes im Winter). A1 liegt vielen Segmentationsalgorithmen zugrunde.
A2: Ein Objektpunkt, der in einem gewissen Bild an einer bestimmten Stelleerkannt wird, ist im nächsten Bild ungefähr an der gleichen Stelle zu sehen.Prinzip der kontinuierlichen Veränderung: Objekte erscheinen oder verschwindennicht plötzlich und verändern auch ihre Gestalt, Farbe und Position nicht in einemZeitakt. A2 wird bei Bewegungsanalyse angenommen (Problem: Verdeckung,Verlassen des Bildausschnittes). Es wird z.B. mit A2 der optische Fluss (HORN)als Feld von Pixel-Verschiebungsvektoren aus lokalen Grauwertveränderungenberechnet. Außerdem dient A2 zur Auffindung korrespondierender Punkte inBildfolgen.
A3: Objekte sind feste Körper, falls es keine gegenteilige Evidenz gibt.A3 wird bei Bewegungsanalysen zur Rekonstruktion der 3D-Gestalt und zurTrajektorienbestimmung ausgenutzt.
Beispiele für Standardannahmen als Basisniedriger Bildverstehensprozesse

331
Beispiele für Standardannahmen als Basisniedriger BildverstehensprozesseA4: An Stellen mit geringer Helligkeitsvariation sind keine Objektgrenzen zu
erwarten.Dagegen werden Helligkeitsdiskontinuitäten meist als Hinweis auf Objektgrenzen gedeutet. Die Helligkeit hängt ab von:- der Beleuchtung- der Reflexivität (physikalische Eigenschaften der Objektoberfläche)- der Objektgeometrie (Oberflächenorientierung in Relation zu Lichtquelle und
Beobachterposition)- dem Sensor
Sensor kann künstlich konstant gehalten werden.Problem: Durch Zusammenfallen von Beleuchtungsdiskontinuitäten und
Objektgrenzen können ebenfalls geringe Helligkeitsunterschiede auftreten.
A5: Die Position der Lichtquellen und des Beobachters sind möglichst allgemein zu wählen, falls es keine gegenteilige Evidenz gibt.
Aus A5 folgt eine Reihe wichtiger anderer Annahmen: z.B. Eine Gerade im Bildentspricht einer Gerade in der beobachteten Szene, da eine gekrümmte Linienur unter speziellem Beobachterstandpunkt als gerade erscheint.

332
Bildverstehen bei StrichzeichnungenAusganspunkt: natürliches Bild bereits in Strichzeichnung umgesetzt
Arbeiten mit Bauklotz-Welten (Polyeder):- GUZMANN 1969 (einzelne Polyeder)- HUFFMANN, CLOWES 1971 (ohne Schatten, nur Tetraeder-Verzweigungen)- WALTZ 1975 (50 verschiedene Kantenmarkierungen)- KANADE 1978 (Origami-Welt, offene ‚Kästen‘)
Ziel: Erkennen der einzelnen Objekte, räumliche Relation zwischen den Teilen
Ziel wird erreicht durch Interpretation aller Linien im Bild
Beispiel für eine typische Szene:

333
Klassifikation von Linien und VerzweigungenPolyeder ohne Schatten weisen folgende Linientypen auf:1) Begrenzung (markiert durch ‚>‘ oder ‚<‘)2) innen
2.1) konvex (markiert durch ‚+‘)2.2) konkav (markiert durch ‚-‘)
Der Pfeil an der Objektbegrenzungslinie ist stets so gerichtet, dass er einer ‚Tour‘ um denObjektrand entspricht, bei der das Objekt jeweils möglichst rechts liegt.
Verstehen der physischen Gegebenheiten / Interpretation der LinienGrundidee für Verfahren:Umkehrung des Prozesses:
Interpretation der Linien / Bildverstehen
Vereinfachende Annahmen zunächst:- keine Schatten und Spalten- Alle Verzweigungen enstehen aus der Kreuzung von genau 3 Objektflächen.- allgemeiner Beobachterstandpunkt
+++
++
+-
Beispiel für eine Markierung eines L-förmigen Polyeders:
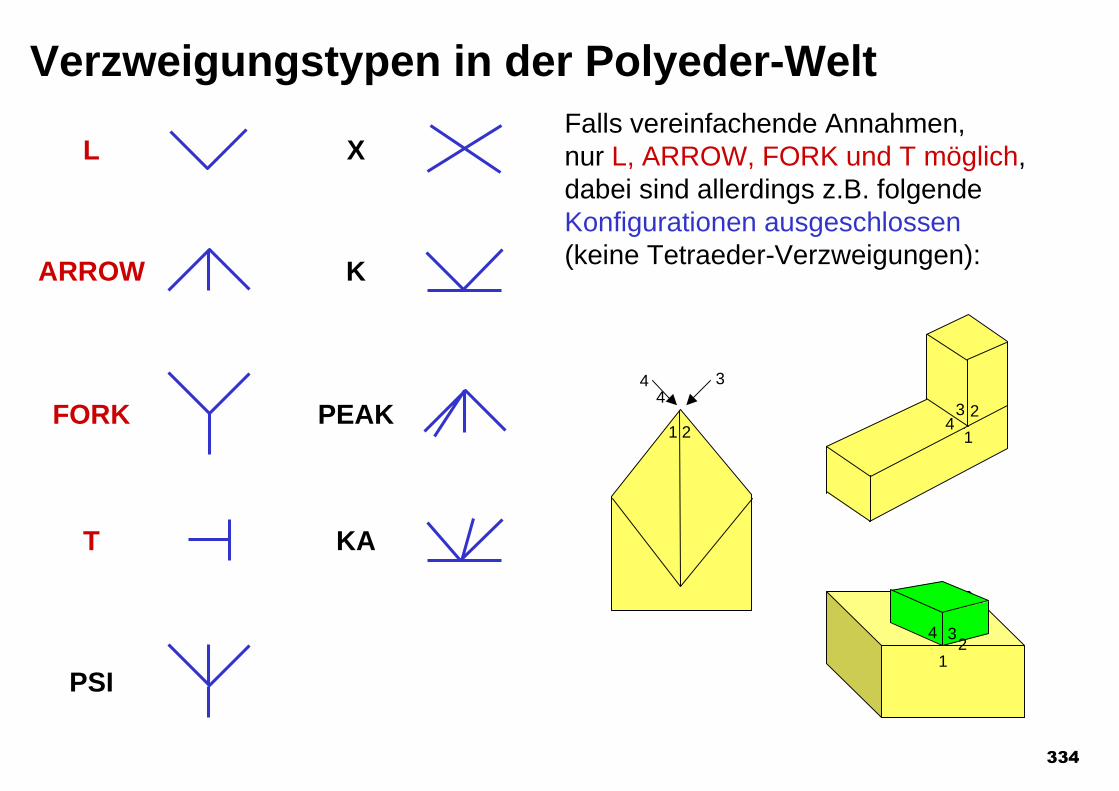
334
Verzweigungstypen in der Polyeder-WeltFalls vereinfachende Annahmen,nur L, ARROW, FORK und T möglich,dabei sind allerdings z.B. folgendeKonfigurationen ausgeschlossen(keine Tetraeder-Verzweigungen):
L X
ARROW K
FORK PEAK
T KA
PSI
1 2
344
2
1
34
12
34

335
Verzweigungstypen in der Polyeder-WeltBei folgender Konfiguration liegt kein allgemeiner Beobachterstandpunkt vor, da beigeringfügiger Bewegung des Beobachters andere Verzweigungstypen entstehen:
Wichtigste Einschränkung zunächst: nur Tetraeder-Verzweigungen.
Beispiele für Objekte mit Tetraeder-Verzweigungen (nur L, FORK, ARROW, T):

336
Verzweigungstypen der Polyeder-Welt
Bei 4 Linientypen gibt es 4²=16 Arten, ein L zu markierenund 4³=64 Arten FORK-, ARROW- und T-Verzweigungen zu markieren.
Obere Schranke: 208 MöglichkeitenDavon können nur 18 physisch auftreten.Es kann also die Methode der fortschreitenden Einschränkungen angewandt werden (wie beimPuzzle)
Beispiele für unmögliche Markierungen von Tetraeder-Verzweigungen:
Verfahren zum Auffinden der 18 physisch möglichenVerzweigungen: Jede Verzweigung aus allen möglichenBlickwinkeln ansehen und Markierungen anbringen.
3 Ebenen für eine Tetraeder-Verzweigung, also 8 OKTANTEN.
++
-
--

337
Verzweigungstypen der Polyeder-WeltAlle Möglichkeiten untersuchen, die 8 OKTANTEN mit Material zu füllen, und dannalle entsprechenden Verzweigungen von den ungefüllten OKTANTEN betrachten.
Bei 7 gefüllten OKTANTEN ergibt sich folgenderFORK (nur 1 Blickwinkel möglich)
Verzweigungsarten bei nur 1 gefüllten OKTANTEN:
-
--
L L R+ R
+L+ R
T+L R
T
L
T + +R
T

338
Verzweigungstypen der Polyeder-WeltSituationen, in denen nur 2, 4, oder 6 OKTANTEN gefüllt sind, widersprechen derAnnahme von Tetraeder-Verzweigungen.
Beispiel: 2 Fälle: Gegenüberliegend oder im Zentrum zusammenstoßend. Bei 2 gefüllten Oktanten: Jeweils 4 Flächen an einer Verzweigung.
3 gefüllte Oktanten ergeben 5 Sichten und je 3 neue L- und FORK-Typen
L R
++-
L R
R L+ +
-
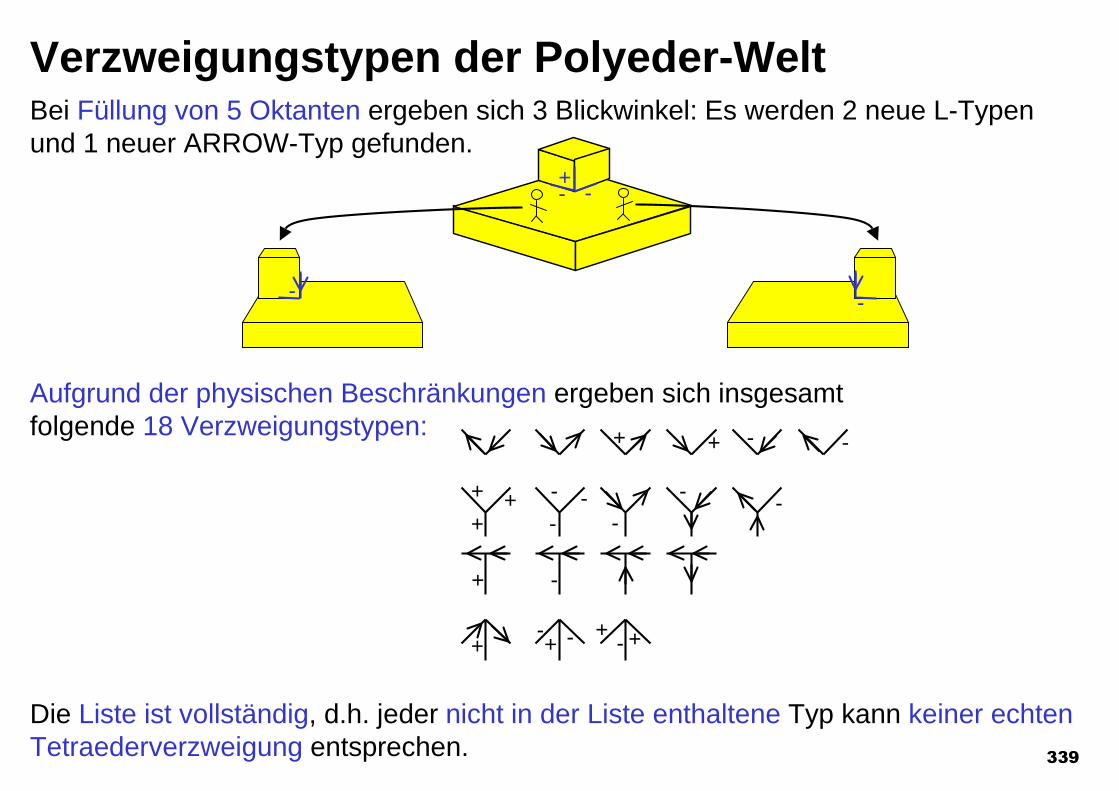
339
Verzweigungstypen der Polyeder-WeltBei Füllung von 5 Oktanten ergeben sich 3 Blickwinkel: Es werden 2 neue L-Typenund 1 neuer ARROW-Typ gefunden.
Aufgrund der physischen Beschränkungen ergeben sich insgesamtfolgende 18 Verzweigungstypen:
Die Liste ist vollständig, d.h. jeder nicht in der Liste enthaltene Typ kann keiner echtenTetraederverzweigung entsprechen.
- -
- -+
+ + - -
+ ++
- -- -
- -
+ -
+ +- - + +-

340
Bildverstehen als Suche nach korrekten Markierungenfür Verzweigungen3 auffällige Bedingungen:(A) An den Objektgrenzen gibt es nur ‚>‘-Markierungen, die einen Ring im Uhrzeigersinn bilden
müssen.(B) Es gibt nur einen Typ ARROW, der ‚>‘-Markierungen an der Pfeilspitze trägt. Der Schaft
diese Pfeiles muss mit ‚+‘ markiert sein.(C) Es gibt nur einen Typ FORK mit einer ‚+‘-Markierung. Für diesen Verzweigungstyp müssen
alle Linien mit ‚+‘ markiert sein.Beispiel für Markierungsverfahren:
1) Rand markieren2) Eckpunkte müssen ‚+‘ tragen nach (B)3) Bildmitte ‚+‘-FORK nach (C)
Zusätzlich zu (A)-(C): nur ein ARROW-Typ mit ‚+‘-Spitze: hat weitere ‚+‘ Spitze und ‚-‘-Schaft.(Dual für ‚+‘-Schaft)
+ +
+
+ +
+
+
+
+ + +
+
++
+
+ ++ +
-
+
-- -
-
--
-
-
+

341
Bildverstehen als Suche nach korrekten Markierungenfür VerzweigungenFalls der Markierungsprozess im Inneren eines Objektes beginnt, entstehen Mehrdeutigkeiten,die sich erst bei Erreichen des Objektrandes auflösen. Dies ist auch eine Erklärung fürAmbiguitäten bei der menschlichen Wahrnehmung.Beispiel (bei Konzentration auf das Bildzentrum: Sägeblätter in Reihe oder Treppe?)
Strichzeichnungen, die nicht mit einer konsistenten Markierung versehen werden können,entsprechen keinem realen Objekt (z.B. Z mit ‚-‘ oder ‚>‘-Markierung). Allerdings gibt esStrichzeichnungen, die konsistent markiert werden können und trotzdem keinem realen Objektentsprechen (planare Flächen A und B treffen an 2 verschiedenen Linien X, Y zusammen).
x
+
+ +? +z
+y
yx
A
B

342
Bildverstehen als Suche nach korrekten Markierungenfür VerzweigungenFalls Objekte vor einem Hintergrund (z.B. Tisch, Wand) dargestellt werden, entstehen leichtMehrdeutigkeiten.
Betrachten von Schatten löst Mehrdeutigkeiten in diesen Fällen. Das Einbeziehen von Schattenvereinfacht das Problem also, anstatt – wie vorher angenommen – es zu verkomplizieren.Beispiel (Spalten mit c gekennzeichnet)
Zeiger imSchatten-gebiet
cc c c c c
Beispiel: Welche Objekte liegenund welche hängen?
senkrecht festgeklebt auf dem Boden senkrecht festgeklebt

343
Bildverstehen als Suche nach korrekten Markierungenfür Verzweigungen
Die Linien-Typen können noch weiter verfeinert werden. Konkave Kante als Nahtzwischen Objekten wird weiter klassifiziert durch Auseinanderrücken der Objekte undAnalyse der Begrenzungslinie. Das gleiche gilt für Spalten.
- - -
- - -

344
Bildverstehen als Suche nach korrekten Markierungenfür Verzweigungen
Auf diese Weise kommt man zu folgenden 11 Arten von Linien:
all lines
real edges
interiors
boundaries
pseudo edges
shadows
cracks
convex
concave
c
----
c
+

345
Bildverstehen als Suche nach korrekten Markierungenfür VerzweigungenWeitere Einschränkungen ergeben sich durch Einbeziehen von Beleuchtungseffekten. Eswerden drei Möglichkeiten für Flächen eines Polyeders betrachtet:
Bei 3²=9 Beleuchtungskombinationen und 11 Linientypen entstehen max. 99 Möglichkeiten, vondenen lediglich rund 50 möglich sind (z.B. kein Beleuchtungswechsel an konkaver Kante).
Abschätzung der Markierungen
Verzweigungstyp kombinatorisch physisch %L 16 6 37.5FORK 64 5 7.8T 64 4 6.2ARROW 64 3 4.7
-I (illuminated): Fläche beleuchtet-S (shadowed): Schatten eines anderen
Objektes-SS (self-shadowed): Fläche des Objektes, die
nicht im Licht liegt SS
SI
I
I

346
Bildverstehen als Suche nach korrekten Markierungenfür VerzweigungenWaltz hat folgendes empirische Resultat erzielt:
Abschätzung der MarkierungenTyp kombinatorisch physisch %L 2.50 x103 80 3.20 x 100 %FORK 1.25 x105 500 4.0 x 10-1%T 1.25 x105 500 4.0 x 10-1%ARROW 1.25 x105 70 5.6 x 10-2%PSI 6.25 x106 300 4.8 x 10-3%K 6.25 x106 100 1.6 x 10-3%X 6.25 x106 100 1.6 x 10-3%MULTI 6.25 x106 100 1.6 x 10-3%PEAK 6.25 x106 10 1.6 x 10-4%KA 3.12 x108 30 9.6 x 10-6%
Auch für komplexe Szenen konvergiert der Markierungsprozess durch die Vielzahl derNebenbedingungen schnell. Sogar Szenen mit Beleuchtungskoinzidenzen, Objekten mitHohlräumen, nicht Tetraeder-Verzweigungen und speziellem Beobachterstandpunkt können mitdem Waltz-Verfahren markiert werden.Der Aufwand wächst nur linear mit der Zahl der Objekte in der Szene, da sich dieNebenbedingungen jeweils nur lokal auswirken.Problem: In einigen Fällen ergeben sich für eine Konfiguration mehrere Markierungen, falls
keine Schatten vorhanden sind.

347
Bildverstehen als Suche nach korrekten Markierungenfür Verzweigungen
Szenen, die mit dem Markierungsverfahren von Waltz bearbeitet werden können

348
Mehrdeutigkeit bei der Markierung ohne Schatten undLinienlängeFür die erste Konfiguration enstehen 3 verschiedene konsistente Markierungen, Davon scheintzunächst nur die erste plausibel zu sein. Wenn man den Quader aber zu einem Keil verformt(ohne Änderung von Verzweigungstypen), werden die Interpretationen mit den separierbarenBegrenzungslinien plausibel.
Problem: Das Modell ist noch zu abstrakt. Die Unterschiede zwischen den drei Konfigurationenkönnen durch die angegebene Taxonomie von Verzweigungen und Linien nicht erfasst werden.
++
+
++
+
++
+
-
-
-
-

349
Mehrdeutigkeit bei der Markierung ohne Schatten undLinienlänge
Schatten ergeben meist genügend Einschränkungen, die zueiner eindeutigen Markierung führen.
mehrdeutig eindeutig
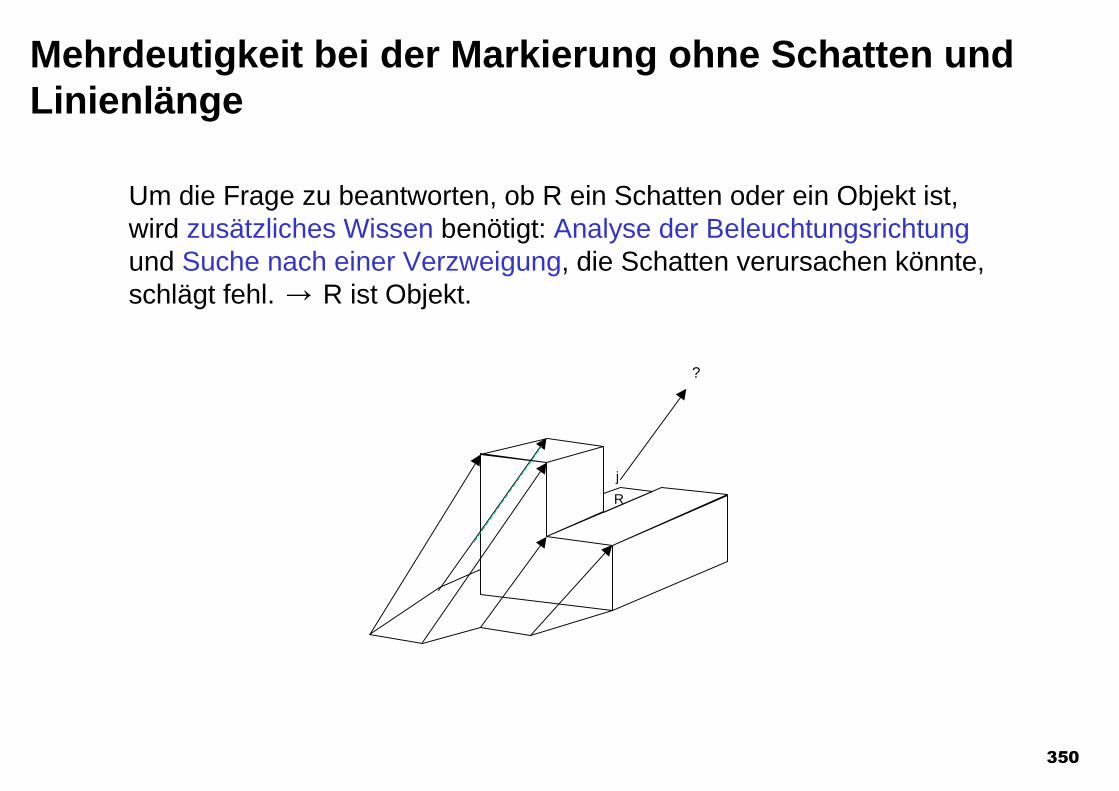
350
Mehrdeutigkeit bei der Markierung ohne Schatten undLinienlänge
Um die Frage zu beantworten, ob R ein Schatten oder ein Objekt ist,wird zusätzliches Wissen benötigt: Analyse der Beleuchtungsrichtungund Suche nach einer Verzweigung, die Schatten verursachen könnte,schlägt fehl. / R ist Objekt.
?
j
R

351
Mehrdeutigkeit bei der Markierung ohne Schatten undLinienlänge
Suchproblem bei Markierung: WelcheVerzweigung als nächste markieren?
Für A, B und C gibt es jeweils 2 FORK-Typen.
Prüfung von Verzweigungenin Reihenfolge lexikographi-scher Ordnung verursachtstarke Verzweigung
günstigere Reihen-folge der Markierung
B
E
G
D
A C
F
-
--
-
-
--

352
Der WALTZ-Algorithmus
Relaxationsmethode = Erreichen eines stabilen Gleichgewichts
Methode der fortschreitenden Einschränkungen
1) Wähle eine erste Verzweigung Vi (Heuristik: mit Begrenzungslinien) undspeichere auf Pi alle Verzweigungstypen, die gemäß ‚Verzweigungs-Lexikon‘ möglich sind.
2) Falls alle Verzweigungen bearbeitet wurden, Stop.
3) Wähle eine Verzweigung Vi+1, die eine Linie mit einer bereitsbearbeiteten Verzweigung Vj gemeinsam hat, und speichere auf Pi+1 dieVerzweigungen, die mit mindestens einem Element von Pj kompatibelsind.
4) Prüfe rekursiv für alle benachbarten Verzweigungen, ob sich durch Pi+1
weitere Einschränkungen für die jeweiligen Ps ergeben.
5) Falls alle benachbarten Verzweigungen bearbeitet sind und sich keineweiteren Änderungen der Ps mehr ergeben, setze i:=i+1, GOTO 2.

353
Der WALTZ-Algorithmus
+
4
2, 5
- +2
++
+
7
L
F
A2
A1
+-
+
1, 3, 6
-
-
+
1, 3
+
1, 3

354
Beispiel für die schnelle Konvergenz des Relaxationsverfahrens
13 2 34 1414 1 26 2015 5 - 7916 5 79 3317 4 15 1418 6 - 12319 6 123 2820 7 - 59321 7 593 4222 7 42 1823 6 28 1124 5 33 725 4 14 626 6 11 2227 7 18 128 5 7 129 4 6 1
Sch
ritt
Ver
zwei
gu
ng
vorh
er m
ög
lich
eA
lter
nat
iven
aktu
ell m
ög
lich
eA
lter
nat
iven
1 1 - 1232 1 123 763 2 - 794 2 79 525 1 76 326 3 - 3887 3 388 788 2 52 349 1 9 2610 4 - 7911 4 79 1512 3 78 20
15
16 14
1 2
3 4
5
67
89
11
18 19
10
12
13
17
20
30 6 2 131 3 20 232 2 14 233 1 20 234 8 - 7935 8 79 136 9 - 12337 9 123 238 10 - 59339 10 593 940 11 - 7941 11 79 742 10 9 843 12 - 59344 12 593 1245 11 7 546 10 8 6
47 9 2 148 13 - 59349 13 593 450 13 4 151 12 12 352 2 2 153 1 2 154 3 2 155 14 - 7956 14 79 157 15 - 12358 15 123 259 16 - 7960 16 79 561 16 5 162 15 2 163 17 - 123
64 17 123 565 17 5 166 12 3 167 11 5 268 18 - 3869 18 388 2070 18 20 471 10 6 472 11 2 173 19 - 139174 19 1391 575 19 5 176 20 - 12377 20 123 478 20 4 179 10 4 180 18 4 1

355
Auffinden von Linien in einem heterarchischenSystem (SHIRAI 1975)Beim Verfolgen von Linien wird heuristisches Wissen verwendet:
Zunächst werden die begrenzenden Linien gesucht (starker Kontrast zwischen Objekt undHintergrund). Es wird dann nach parallelen Linien gesucht (typisch bei Blöcken). Auch Wissenüber mögliche und erwartete Verzweigungen fließt in die Linienverfolgung ein.
Problem: Bei natürlichen Szenen ist unklar, ob schon bei den unteren Bildverarbeitungsebenenspezielles Weltwissen einfließen sollte.

356
Bayes’sche NetzeZur Behandlung und Repräsentation von unsicherem Wissen
• die Knoten des Netzes sind Zufallsvariablen
• Intuitive Bedeutung einer Kante von Knoten A zu Knoten B:A hat einen direkten Einfluss auf B.
• Jeder Knoten hat eine Tabelle mit bedingtenWahrscheinlichkeiten, die den Einfluss der Eltern auf denKnoten quantifizieren. P(xi|Parents(Xi))
• Im Graphen gibt es keine Zyklen / gerichteter, azyklischerGraph (DAG).
• diskrete Zufallsvariablen mit einer endlichen Anzahl vonZuständen. z. B.: die Variable Earthquake kann folgende Werteannehmen: {kein, schwach, mittel, stark}
Burglary
Alarm
Earthquake
JohnsCall MaryCall
erlaubt nicht erlaubt
Bayes’sche Regel:
( ) ( ) ( ) ( ) ( )APABPBPBAPBAP || ==∧Produktregel:
( ) ( ) ( )( )BP
APABPBAP
|| =
Bedingte Wahrscheinlichkeit: ( ) ( )( ) ( ) 0 ,| ≠∧= APAP
BAPABP
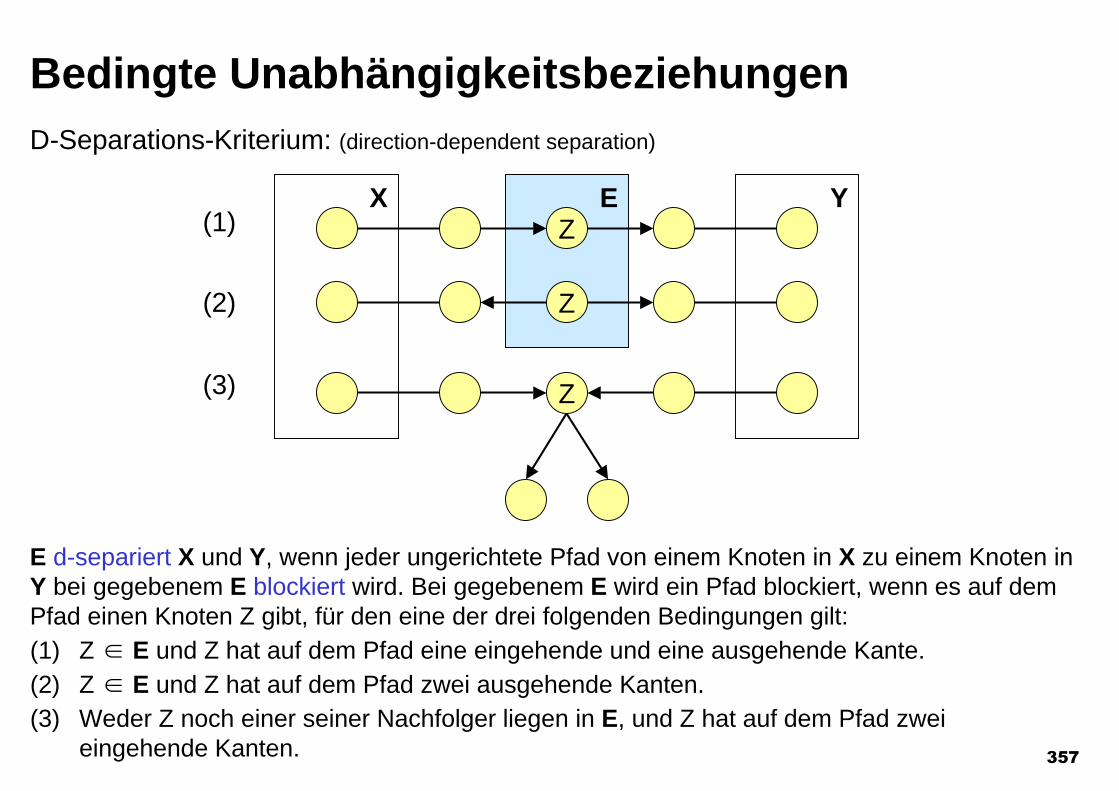
357
E d-separiert X und Y, wenn jeder ungerichtete Pfad von einem Knoten in X zu einem Knoten inY bei gegebenem E blockiert wird. Bei gegebenem E wird ein Pfad blockiert, wenn es auf demPfad einen Knoten Z gibt, für den eine der drei folgenden Bedingungen gilt:(1) Z 2 E und Z hat auf dem Pfad eine eingehende und eine ausgehende Kante.(2) Z 2 E und Z hat auf dem Pfad zwei ausgehende Kanten.(3) Weder Z noch einer seiner Nachfolger liegen in E, und Z hat auf dem Pfad zwei
eingehende Kanten.
Bedingte Unabhängigkeitsbeziehungen
X YEZ
Z
Z
(1)
(2)
(3)
D-Separations-Kriterium: (direction-dependent separation)

358
Bedingte Unabhängigkeitsbeziehungen
Batterie
ZündungRadio
Startet
Benzin
Fährt
Beispiel: Bayes’sches Netz, das einige Eigenschaften des elektrischen Systems und desMotors eines Autos beschreibt.
(1) Evidenz darüber, ob Zündung funktioniert / Benzin und Radio unabhängig voneinander(2) Zustand der Batterie bekannt / Benzin und Radio unabhängig voneinander(3) Keine Evidenz überhaupt / Benzin und Radio unabhängig voneinander
Evidenz darüber, ob Auto startet / Benzin und Radio abhängig voneinanderAuto startet nicht und Radio läuft 0erhöhte Evidenz, dass Benzin alle ist.

359
4 Arten von Inferenz
Q
E
E
Q
E
Q
E
Q E
Diagnostic Causal(Explaining Away)
Intercausal Mixed
• Diagnostische Inferenz (von den Auswirkungen zu den Ursachen)
• Kausale Inferenz (von den Ursachen zu den Auswirkungen)
• Interkausale Inferenz (zwischen Ursachen einer gemeinsamer Auswirkung)Die Gegenwart des einen macht das andere weniger wahrscheinlich. / Explaining Away.
• gemischte Inferenz (mehrere der obigen werden kombiniert)

360
4 Arten von Inferenz
DiagnostischeInferenz
P(Burglary|JohnCalls) = 0.016
KausaleInferenz
Anfangswahrscheinlichkeiten
P(JohnCalls|Burglary) = 0.86 P(MaryCalls|Burglary) = 0.67

361
4 Arten von Inferenz
Mixed
(Explaining Away)InterkausaleInferenz
P(Alarm|JohnCalls o lEarthquake) = 0.03(diagnostische und kausale Inferenz)
P(Burglary|JohnCalls o lEarthquake) = 0.017(interkausale und diagnostische Inferenz)
P(Burglary|Alarm) = 0.376 P(Burglary|Alarm o Earthquake) = 0.003

362
Beispielnetz• Struktur
• apriori- und bedingte Wahrscheinlichkeiten
A
B C
D EKoma Kopfschmerzen
GehirntumorCalciumspiegel
Krebsmetastasen
P(a,b,c,d,e) = P(a))P(b|a))P(c|a))P(d|b,c))P(e|c)
Krebsmetastasen (A: a1 = nein, a2 = ja)P(a): P(a1) = 0.80 P(a2) = 0.20
Calciumspiegel (B: b1 = normal, b2 = erhöht)P(b|a): P(b1|a1) = 0.80 P(b2|a1) = 0.20
P(b1|a2) = 0.20 P(b2|a2) = 0.80
Gehirntumor (C: c1 = nein, c2 = ja) P(c|a): P(c1|a1) = 0.95 P(c2|a1) = 0.05
P(c1|a2) = 0.80 P(c2|a2) = 0.20
Koma (D: d1 = nicht im Koma, d2 = komatös)P(d|b,c): P(d1|b1,c1) = 0.95 P(d2|b1,c1) = 0.05
P(d1|b1,c2) = 0.20 P(d2|b1,c2) = 0.80P(d1|b2,c1) = 0.20 P(d2|b2,c1) = 0.80P(d1|b2,c2) = 0.20 P(d2|b2,c2) = 0.80
Kopfschmerzen (E: e1 = keine, e2 = starke)P(e|c): P(e1|c1) = 0.40 P(e2|c1) = 0.60
P(e1|c2) = 0.20 P(e2|c2) = 0.80
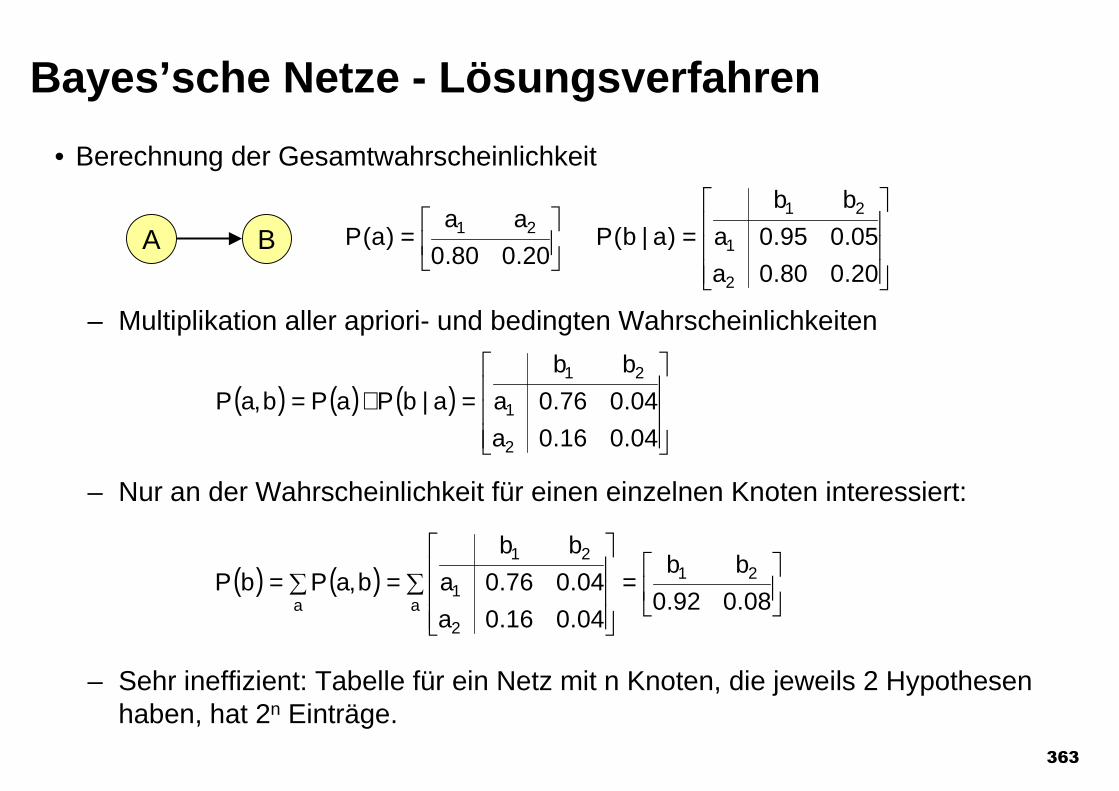
363
Bayes’sche Netze - Lösungsverfahren
• Berechnung der Gesamtwahrscheinlichkeit
– Multiplikation aller apriori- und bedingten Wahrscheinlichkeiten
– Nur an der Wahrscheinlichkeit für einen einzelnen Knoten interessiert:
– Sehr ineffizient: Tabelle für ein Netz mit n Knoten, die jeweils 2 Hypothesenhaben, hat 2n Einträge.
A B
=20.080.0
)( 21 aaaP
=
20.080.0
05.095.0)|(
2
1
21
a
a
bb
abP
( ) ( ) ( )
=∗=
04.016.0
04.076.0|,
2
1
21
a
a
bb
abPaPbaP
( ) ( )
=∑
=∑=
08.092.004.016.0
04.076.0, 21
2
1
21 bb
a
a
bb
baPbPaa

364
Bayes’sche Netze - Lösungsverfahren
Es existieren 3 Hauptklassen von Algorithmen, die mehrfach verknüpfteBayes’sche Netze lösen:
• Clustering MethodenDas mehrfach verknüpfte Netz wird in einen einfach verknüpften Polytreeumgewandelt, indem gewisse Knoten zu Megaknoten zusammengefügtwerden.
• Conditioning MethodenEs werden Variablen im Netz aufgebrochen, so daß ein Polytree entsteht.Dieser Polytree wird für jede mögliche Instantiierung der aufgebrochenenVariablen ausgewertet.
• Stochastic Simulation MethodenDas Netz wird dazu benutzt, eine große Anzahl von konkreten Modellen derDomäne zu erzeugen, die konsistent mit der Wahrscheinlichkeitsverteilungim Netz sind. Diese Verfahren sind approximativ.

365
Clustering Methoden
Cloudy
RainSprinkler
Wet Grass
Cloudy
Sprinkler+Rain
Wet Grass
( )
=5.05.0
FTCP ( )
=5.05.0
FTCP
( )
50.0
10.0
F
T
SPC ( )
20.0
80.0
F
T
RPC
( )
00.0
90.0
90.0
99.0
FF
TF
FT
TT
WPRS
( )
10.040.010.040.0
18.072.002.008.0
FFFTTFTT
F
T
CxRSP =+
( )
00.0
90.0
90.0
99.0
FF
FT
TF
TT
WPRS +
Problem: Auswahl der richtigen Megaknoten

366
Conditioning Methoden
+Cloudy
RainSprinkler
Wet Grass
+Cloudy -Cloudy
RainSprinkler
Wet Grass
-Cloudy
P(X|E) wird berechnet als gewichteter Durchschnitt über den Werten, die vonden einzelnen Polytrees berechnet werden.Problem: möglichst eine kleine Menge von Knoten bestimmen, die das Netz
aufspalten.
Anstatt eines komplexen Polytrees viele einfache Polytrees

367
Stochastic Simulation
Bestimmung der interessierenden Wahrscheinlichkeit durch Berechnung derFrequenz mit der die relevanten Ereignisse auftreten.Problem: benötigt viel Zeit, um akurate Wahrscheinlichkeiten für
unwahrscheinliche Ereignisse zu berechnen.
Wiederholt Simulationen über der durch das Bayes’sche Netz beschriebenen Welt
Cloudy
RainSprinkler
Wet Grass
Cloudy
RainSprinkler
Wet Grass
Cloudy
RainSprinkler
Wet Grass
Cloudy
RainSprinkler
Wet Grass
Cloudy
RainSprinkler
Wet Grass
Cloudy=T
Rain=TSprinkler=F
Wet Grass=T
Cloudy
RainSprinkler
Wet Grass


















