
2.5.5. Aufgaben des Betriebssystems - · PDF filemehrere Unterordner, unter anderem der...
22
2.5.5. Aufgaben des Betriebssystems ■ Ein Betriebssystem ist ein Programm, das dem Benutzer und den Anwendungsprogrammen elementare Dienste bereitstellt. Der Nutzer eines Betriebssystems ist nicht notwendigerweise ein Programmierer, sondern möglicherweise jemand, der vom Funktionieren des Rechners keine Ahnung hat. Für einen solchen Benutzer präsentiert sich der Rechner über das Betriebssystem. Die Dienste, die es bereitstellt, sind das, was der Rechner in den Augen eines solchen Nutzers kann. Seitdem Rechner in viele Bereiche unseres Lebens Einzug gehalten haben, gibt es immer mehr Menschen, die mit einem Computer arbeiten müssen. Daher muss das Betriebssystem immer einfacher zu benutzen sein. Erst den graphischen Betriebssystemoberflächen ist es zu verdanken, dass heute jeder einen Rechner irgendwie bedienen kann und dass es auch leicht ist, mit einem bisher unbekannten Programm zu arbeiten, ohne vorher umfangreiche Handbücher zu wälzen. ■ Der Rechner mit seinen Peripheriegeräten stellt eine Fülle von Ressourcen zur Verfügung, auf die Benutzerprogramme zugreifen. Zu diesen Ressourcen gehören - CPU (Rechenzeit) - Hauptspeicher - Plattenspeicherplatz - interne Geräte (Erweiterungskarten) - externe Geräte (Drucker, Scanner, etc.) ■ Die Verwaltung dieser Ressourcen ist eine schwierige Aufgabe, da viele Benutzer und deren Programme auf diese Ressourcen gleichzeitig zugreifen wollen. Die zentralen Bestandteile eines Betriebssystems sind entsprechend der zentralen Aufgaben die - Dateiverwaltung - Prozessverwaltung - Speicherverwaltung
Transcript of 2.5.5. Aufgaben des Betriebssystems - · PDF filemehrere Unterordner, unter anderem der...

2.5.5. Aufgaben des Betriebssystems■ Ein Betriebssystem ist ein Programm, das dem Benutzer und den Anwendungsprogrammen elementare Dienste bereitstellt. Der
Nutzer eines Betriebssystems ist nicht notwendigerweise ein Programmierer, sondern möglicherweise jemand, der vom Funktionieren des Rechners keine Ahnung hat. Für einen solchen Benutzer präsentiert sich der Rechner über das Betriebssystem. Die Dienste, die es bereitstellt, sind das, was der Rechner in den Augen eines solchen Nutzers kann. Seitdem Rechner in viele Bereiche unseres Lebens Einzug gehalten haben, gibt es immer mehr Menschen, die mit einem Computer arbeiten müssen. Daher muss das Betriebssystem immer einfacher zu benutzen sein. Erst den graphischen Betriebssystemoberflächen ist es zu verdanken, dass heute jeder einen Rechner irgendwie bedienen kann und dass es auch leicht ist, mit einem bisher unbekannten Programm zu arbeiten, ohne vorher umfangreiche Handbücher zu wälzen.
■ Der Rechner mit seinen Peripheriegeräten stellt eine Fülle von Ressourcen zur Verfügung, auf die Benutzerprogramme zugreifen. Zu diesen Ressourcen gehören
- CPU (Rechenzeit)- Hauptspeicher- Plattenspeicherplatz- interne Geräte (Erweiterungskarten)- externe Geräte (Drucker, Scanner, etc.)
■ Die Verwaltung dieser Ressourcen ist eine schwierige Aufgabe, da viele Benutzer und deren Programme auf diese Ressourcen gleichzeitig zugreifen wollen. Die zentralen Bestandteile eines Betriebssystems sind entsprechend der zentralen Aufgaben die
- Dateiverwaltung- Prozessverwaltung- Speicherverwaltung
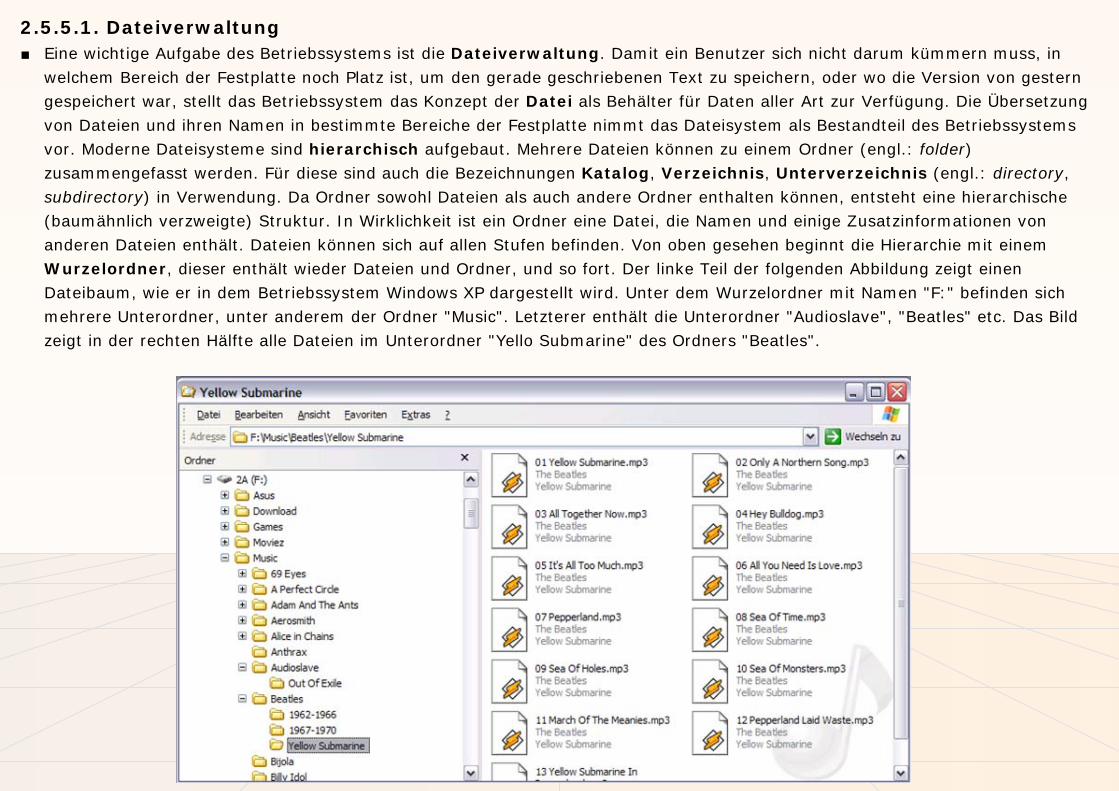
2.5.5.1. Dateiverwaltung■ Eine wichtige Aufgabe des Betriebssystems ist die Dateiverwaltung. Damit ein Benutzer sich nicht darum kümmern muss, in
welchem Bereich der Festplatte noch Platz ist, um den gerade geschriebenen Text zu speichern, oder wo die Version von gestern gespeichert war, stellt das Betriebssystem das Konzept der Datei als Behälter für Daten aller Art zur Verfügung. Die Übersetzung von Dateien und ihren Namen in bestimmte Bereiche der Festplatte nimmt das Dateisystem als Bestandteil des Betriebssystems vor. Moderne Dateisysteme sind hierarchisch aufgebaut. Mehrere Dateien können zu einem Ordner (engl.: folder) zusammengefasst werden. Für diese sind auch die Bezeichnungen Katalog, Verzeichnis, Unterverzeichnis (engl.: directory, subdirectory) in Verwendung. Da Ordner sowohl Dateien als auch andere Ordner enthalten können, entsteht eine hierarchische (baumähnlich verzweigte) Struktur. In Wirklichkeit ist ein Ordner eine Datei, die Namen und einige Zusatzinformationen von anderen Dateien enthält. Dateien können sich auf allen Stufen befinden. Von oben gesehen beginnt die Hierarchie mit einem Wurzelordner, dieser enthält wieder Dateien und Ordner, und so fort. Der linke Teil der folgenden Abbildung zeigt einen Dateibaum, wie er in dem Betriebssystem Windows XP dargestellt wird. Unter dem Wurzelordner mit Namen "F:" befinden sich mehrere Unterordner, unter anderem der Ordner "Music". Letzterer enthält die Unterordner "Audioslave", "Beatles" etc. Das Bild zeigt in der rechten Hälfte alle Dateien im Unterordner "Yello Submarine" des Ordners "Beatles".

■ Jede Datei erhält einen Namen, unter der sie gespeichert und wiedergefunden werden kann. Der Dateinamen ist im Prinzip beliebig, er kann sich aus Buchstaben Ziffern und einigen erlaubten Sonderzeichen zusammensetzen. Allerdings hat sich als Konvention etabliert, Dateinamen aus zwei Teilen, dem eigentlichen Namen und der Erweiterung, zu bilden. Ein Punkt"." trennt den Namen von der Erweiterung. Die vorige Abbildung zeigt z.B. die Datei "01 Yellow Submarine.mp3". Anhand des Namens macht man den Inhalt der Datei kenntlich, anhand der Erweiterung die Art des Inhaltes. Von Letzterem ist nämlich abhängig, mit welchem Programm die Datei geöffnet werden kann. In diesem Falle zeigt die Erweiterung ".mp3", dass es sich um eine Datei handelt, die z. B. mit dem Programm "WinAmp" geöffnet werden kann. Obwohl auch Dateinamen ohne Erweiterung möglich sind, ist es sinnvoll, sich an die Konventionen zu halten, da auch die Anwenderprogramme von diesem Normalfall (engl.: default) ausgehen. Ein Anwendungsprogramm wie z.B. Word wird beim ersten Abspeichern einer neuen Datei als default die Endung ".doc" vorgeben.
■ Es kann leicht vorkommen, dass zwei Dateien, die sich in verschiedenen Ordnern befinden, den gleichen Namen besitzen. Dies ist kein Problem, da das Betriebssystem eine Datei auch über ihre Lage im Dateisystem identifiziert. Diese Lage ist in einer baumartigen Struktur wie dem Dateisystem immer eindeutig durch den Pfad bestimmt, den man ausgehend von der Wurzel traversieren muss, um zu der gesuchten Datei zu gelangen. Den Pfad kennzeichnet man durch die Folge der dabei traversierten Unterverzeichnisse. Der Pfad zu dem Unterverzeichnis "Beatles" von "Music" in der vorigen Abbildung ist:
F:\Music\Beatles
■ Man erkennt, dass die einzelnen Unterordner durch das Trennzeichen "\" (backslash) getrennt wurden. In den Betriebssystemen der Unix-Familie (Linux, SunOs, BSD) wird stattdessen "/" (slash) verwendet. Der Pfad, zusammen mit dem Dateinamen (incl. Erweiterung), muss eine Datei eindeutig kennzeichnen. Die MP3-Datei aus unserem Beispiel hat also den vollständig qualifizierten Dateinamen
F:\Music\Beatles\Yellow Submarine\01 Yellow Submarine.mp3

■ Viele Speichergeräte arbeiten blockweise indem sie Daten als Blöcke oder Cluster fester Größe (je nach Dateisystem zwischen 512 Bytes und 64 KBytes) in Bereiche des Speichergeräts oder eines Datenträgers speichern. Die Hardware bietet somit dem System eine Folge von N Blöcken an, die eindeutig adressierbar sind. Das Betriebssystem verwaltet alle N Blöcke in einem Dateisystem und enthält Routinen zum Lesen und Schreiben von Blöcken für die jeweils verwendeten Gerätetypen, sogenannte Gerätetreiber. Das vom Betriebssystem verwaltete Dateisystem erspart es den Anwendern, sich um technische Details der Speichergeräte oder Datenträger kümmern zu müssen. Statt dessen kann eine abstraktere, objektorientierte Sicht verwendet werden. Für den Benutzer bietet das Speichergerät
- Dateien- Zugriffsmethoden zum Lesen und Schreiben von Daten
■ UNIX-basierte Betriebsysysteme verwalten ein systemweites Dateisystem, in dem alle Dateien auf allen angeschlossenen Geräten enthalten sind. MS-DOS und Windows verwalten für jedes Gerät einen unabhängigen Katalog. Ein systemweites Dateisystem hat Vorteile, wenn viele Festplatten vorhanden sind und der Benutzer gar nicht wissen will, auf welchen Geräten sich die Daten befinden. Es hat aber Nachteile, wenn Geräte mit auswechselbaren Datenträgern (z.B. Disketten) betrieben werden, da bei jedem Diskettenwechsel entsprechende Teile des Kataloges geändert werden müssen. In dieser Hinsicht ist ein Dateisystem mit einem unabhängigen Katalog pro Gerät vorteilhaft, ähnlich auch beim Betrieb von mehreren Festplatten, da der Anwender bestimmen kann, welche Daten wo gespeichert werden sollen. Beim Ausfall eines Laufwerkes sind nur die Dateien dieses Laufwerkes betroffen - nicht das gesamte Dateisystem. Wichtige Daten können zur Sicherheit auf mehreren Laufwerken gelagert werden.
--> Ein Cluster ist eine logische Zusammenfassung von Blöcken eines Datenträgers. "Cluster" ist ein Terminus im Windows-Sprachgebrauch, bei anderen Betriebssystemen ist der Terminus "Block" gebräuchlich. Beide Begriffe sind synonym zu verwenden, jedoch sind die Blöcke des Datenträgers und die des Dateissystems zu unterscheiden. Das Dateisystem kann im Allgemeinen nur vollständige Cluster adressieren, es ist nicht möglich, einzelne Datenträger-Blöcke oder gar einzelne Bytes innerhalb eines Clusters zu adressieren. Daher belegen Dateien auf einem Datenträger immer eine ganze Anzahl von Clustern. Je größer die Cluster sind, desto weniger Verwaltungsaufwand muss für große Dateien aufgewendet werden und desto geringer wird die statistische Fragmentierung einer Datei. Da für jede Datei im Mittel ein halber Cluster verschwendet wird, sind größere Cluster hierbei im Nachteil. Die maximal mögliche Anzahl von Clustern auf einem Datenträger variiert je nach Dateisystem. FAT32 unterstützt bis zu 232, NTFS 264 Cluster. Aus der maximalen Anzahl von Clustern und der gewählten Clustergröße –typischerweise zwischen 512 und 32 KByte – ergibt sich die maximale Größe eines Dateisystems. Bei einer Clustergröße von nur 512 Byte kann ein FAT32-Dateisystem beispielsweise bis zu 2200 Gigabyte (232 * 512) groß sein.

■ Das Dateisystem wird mit Hilfe von speziellen Dateien verwaltet, die Informationen über die Dateien enthalten. Diese werden Kataloge oder Dateiverzeichnisse (engl.: directory) genannt. Eine Katalogdatei enthält für jede Datei einen Eintrag mit Informationen über
- den Dateinamen, (dazu gehört ggf. auch die "Erweiterung" )- den Dateityp: Normaldatei oder Katalogdatei- die Länge der Datei in Bytes- die Blöcke, aus denen die Datei besteht, ggf. reicht ein Verweis auf den ersten Block- die Zugriffsrechte, d.h. welche Benutzer diese Datei lesen oder verändern dürfen- Passwörter zum Schutz der Datei vor unberechtigtem Zugriff- Statistikdaten wie die Zugriffshäufigkeit, das Datum der letzten Änderung, der Erstellung
■ Das Dateisystem bietet dem Anwenderprogramm mindestens folgende Operationen zur Verwaltung von Dateien:
- Neu: Anlegen einer noch leeren Datei in einem bestimmten Katalog- Löschen: Die Datei wird entfernt und damit unzugänglich- Kopieren: Dabei kann implizit eine neue Datei erzeugt oder eine bestehende überschrieben oder verlängert
werden- Umbenennen: Änderung des Dateinamens- Verschieben: Die Datei wird in einen anderen Katalog übertragen
■ Jede gefüllte Datei besteht aus einer Liste von ihr belegter Blöcke. Im Katalog finden sich Hinweise auf die Blöcke, aus denen die Dateien bestehen. Daneben muss das Dateisystem eine Pseudodatei verwalten, die aus allen nicht belegten (also noch verfügbaren) Blöcken eines Datenträger besteht. Eine weitere Pseudodatei besteht aus allen Blöcken, die als unzuverlässig gelten, weil ihre Bearbeitung zu Hardwareproblemen geführt hat. Unzuverlässige Blöcke werden nicht mehr für Dateien genutzt. Es gibt also:
- belegte Blöcke,- freie Blöcke,- unzuverlässige Blöcke.
--> Während der Bearbeitung der Dateien ändern sich diese Listen dynamisch.

■ Um eine Datei bearbeiten zu können, muss man sie vorher öffnen. Dabei wird eine Verbindung zwischen der Datei und ihrem Katalogeintrag, zwischen der Zugriffsmethode, mit der sie bearbeitet werden soll, und einem Anwenderprogramm, das dies veranlasst, hergestellt. Nach dem Bearbeiten muss die Datei wieder geschlossen werden. Wenn beispielsweise ein Anwender eine Textdatei editiert, dann muss das Betriebssystem aus dem Dateinamen die Liste der Blöcke bestimmen, in denen der Datei-Inhalt gespeichert ist. Meist ist dazu nur die Kenntnis des ersten Blockes notwendig. Dieser enthält dann einen Verweis auf den nächsten Block und so fort. Wird die editierte Datei gespeichert, so müssen möglicherweise neue Blöcke an die Liste angehängt werden, oder einige Blöcke können entfernt und der Liste der freien Blöcke übergeben werden.
Block 1 Block 2Datei = Block N...........
■ Das Betriebssystem muss also Operationen des Anwendungsprogrammes wie z.B. "Datei lesen" und "Datei speichern" umsetzen in elementarere Operationen, so genannte Systemaufrufe (engl.: system calls) welche die Hardware ausführen kann. Dazu gehören:
- Lesen eines oder mehrerer Blöcke- Schreiben eines oder mehrerer Blöcke
■ Die Systemaufrufe "Neu" oder "Löschen" führen lediglich dazu, dass Blöcke der Liste der freien Blöcke entnommen oder zurückgegeben werden. Der Inhalt der Blöcke muss nicht gelöscht werden. Aus diesem Grunde sind ist mit bestimmten Programmen auch möglich versehentlich gelöschte Dateien ganz oder teilweise wiederherzustellen, sobald man den ersten Block wiederfindet. Sind mittlerweile aber einige Blöcke in anderen Dateien wiederbenutzt worden, ist es zu spät.
■ Das Dateisystem verwaltet eine Datei als Folge von Blöcken. Eine Datei, die nur ein Byte enthält, verbraucht mindestens den Speicherplatz eines Blockes. Für ein Anwenderprogramm wie einen Texteditor besteht eine Datei aus einer Folge von Bytes. Der Texteditor muss in der Lage sein, ein bestimmtes Byte zu schreiben, zu löschen oder an einer bestimmten Stelle ein Byte einzufügen. Die Präsentation der Datei als eine solche Folge von Bytes obliegt dem Betriebssystem. Es stellt daher Systemaufrufe zur Verfügung, um Dateien byteweise zu lesen und zu schreiben. Selbst der Programmierer des Texteditors muss nichts von der blockweisen Organisation der Dateien wissen. Für ihn ist die Abbildung von der Bytefolge in die Blockfolge unsichtbar.

2.5.5.2. Prozessverwaltung■ Ein auf einem Rechner ablauffähiges oder im Ablauf befindliches Programm, zusammen mit all seinen benötigten Ressourcen wird
zusammenfassend als Prozess oder Task bezeichnet. Auf einem Rechner mit einer CPU ist es nicht wirklich möglich, dass mehrere Prozesse gleichzeitig laufen. Wenn man allerdings mehrere Prozesse abwechselnd immer für eine kurze Zeit (einige Millisekunden) arbeiten läßt, so entsteht der Eindruck, als würden diese Prozesse gleichzeitig laufen. Die zur Verfügung stehende Zeit wird in kurze Intervalle unterteilt. In jedem Intervall steht die CPU einem anderen Prozeß zur Verfügung. Dazwischen findet ein Taskwechsel statt, wobei der bisherige Prozess suspendiert und ein anderer Prozess (re-)aktiviert wird.
■ Ein Prozess kann sich, nachdem er gestartet wurde, in verschiedenen Zuständen befinden. Nach dem Start ist er zunächst bereitund wartet auf die Zuteilung eines virtuellen Prozessors, auf dem er ablaufen kann. Irgendwann wird er vom Betriebssystem zur Ausführung ausgewählt - er ist dann aktiv. Wenn er nach einer gewissen Zeitdauer nicht beendet ist, wird das Betriebssystem ihn unterbrechen (suspendieren), um einem anderen Prozess den Prozessor zuzuteilen. Unser Prozess ist dann erneut bereit. Es kann aber auch der Fall eintreten, dass der Prozess auf eine Ressource wartet - z. B. auf einen Drucker oder auf eine Dateioperation. Dann wird er blockiert und erst wieder als bereit eingestuft, falls das Signal kommt, dass seine benötigten Ressourcen bereitstehen. In der Zwischenzeit können die anderen Prozesse den Prozessor nutzen.
gestartet bereit aktiv beendet
suspendiert
--> Hat ein Rechner genau eine CPU, so ist höchstens ein Prozess zu jedem Zeitpunkt aktiv. Dieser wird als laufender Prozessbezeichnet.

Bestandteile eines Prozesses■ Ein Prozess ist eine Instanz eines in Ausführung befindlichen Programmes. Wenn er deaktiviert wird, müssen alle notwendigen
Informationen gespeichert werden, um ihn später im gleichen Zustand wieder reaktivieren zu können. Dazu gehören:
- sein Programmcode- sein im Arbeitsspeicher des Rechners befindlichen Daten- der Inhalt der CPU-Registern einschließlich des Befehlszählers- eine Tabelle aller geöffneten Dateien mit ihrem aktuellen Bearbeitungszustand
--> Wenn ein Prozess unterbrochen werden soll, muss der Inhalt der CPU-Register in den vorgesehenen Arbeitsbereich gerettet werden. Wenn ein wartender Prozess aktiviert werden soll, muss der Inhalt der Register, so wie er bei seiner letzten Unterbrechung gesichert wurde, wieder geladen werden.
ThreadsJeder Prozess besitzt seinen eigenen Speicherbereich. Demgegenüber sind Threads (engl.: thread = Faden) Prozesse, die keinen eigenen Speicherbereich besitzen. Man nennt sie daher auch leichtgewichtige Prozesse (engl.: lightweight process). Der Aufwand (der so genannte overhead) zur Erzeugung und Verwaltung von Threads ist deutlich geringer als bei Prozessen. Gewöhnlich laufen innerhalb eines Prozesses mehrere Threads ab, die den gemeinsamen Speicherbereich nutzen. Threads sind in den letzten Jahren immer beliebter geworden. Moderne Sprachen, darunter Java, haben Threads in die Sprache integriert.
Befehle
Daten
Speicher für Registerinhalte
Speicher für die Tabelle offener Dateien
Speicherabbild des Prozesses

Multitasking■ Für die Verwaltung der Prozesse hat das Betriebssystem verschiedene Möglichkeiten. Die einfachste Methode besteht darin,
Prozessen eine Priorität zuzuordnen und jeweils dem bereiten Prozess höchster Priorität die CPU zuzuordnen, bis dieser Prozess nicht mehr bereit ist oder ein anderer Prozess höherer Priorität rechenwillig wird. Eine allein durch Prioritäten gesteuerte Verwaltung begünstigt also den Prozess mit höchster Priorität. Zeitpunkt und Dauer der Ausführung von Prozessen geringerer Priorität sind nicht vorhersehbar. Diese Form des Multitasking ist das von älteren Windows-Versionen und Mac OS bis Version 9 bekannte kooperative Multitasking. Dabei ist es jedem Prozess selbst überlassen, wann er die Kontrolle an das Betriebssystem zurückgibt. Es hat den Nachteil, dass Programme, die nicht kooperieren, bzw. die Fehler enthalten, das gesamte System zum Stillstand bringen können. Diese Methode ist daher nur in einfachen Fällen möglich.
■ Eine bessere Methode besteht darin, die Zuteilung des Betriebsmittels CPU nicht allein von der Priorität eines Prozesses abhängig zu machen, sondern jedem bereiten Prozess per Zeitscheiben in regelmäßigen Abständen die CPU zuzuteilen. Diese Methode bezeichnet man als präemptives Multitasking. Das Betriebssystem führt eine neue CPU-Zuteilung durch, wenn der laufende Prozeß entweder
- eine bestimmte Zeit gerechnet hat, oder- wenn er auf ein Ereignis warten muss.
■ Ein solches Ereignis könnte die Ankunft einer Nachricht von einem anderen Prozess sein oder die Freigabe eines Betriebsmittels wie Laufwerk, Drucker, Modem, das der Prozess zur Weiterarbeit benötigt. Je nach System werden als Dauer einer Zeitscheibe 1 Millisekunde, 10 Millisekunden oder mehr gewählt.
■ Die meisten Betriebssysteme führen allerdings nur eine sehr einfache Zeitscheibenzuteilung für die bereiten Prozesse durch. Dieses Verfahren wird round robin (engl. für Kreislauf) genannt und besteht darin, alle Prozesse, die bereit sind, in einer zyklischen Liste anzuordnen. Die bereiten Prozesse kommen in einem bestimmten Turnus an die Reihe und erhalten jeweils eine Zeitscheibe. Prozesse, die nicht mehr bereit sind, werden aus der Liste entfernt, solche, die soeben bereit geworden sind, werden an einer bestimmten Stelle in der Liste eingehängt. Die Verwaltung der Prozesse erfolgt durch einen Teil des Betriebssystems, den sogenannten Scheduler, der selbst als einer der Prozesse betrieben wird, die in der Liste enthalten sind. Er wird einmal pro Rundendurchlauf aktiv und kann den Ablauf der anderen Prozesse planen.

2.5.5.3. Speicherverwaltung■ Eine der Aufgaben des Betriebssystems besteht in der Versorgung der Prozesse mit dem Betriebsmittel Arbeitsspeicher. Dabei
sollen die Prozesse vor gegenseitiger Beeinträchtigung durch fehlerhafte Adressierung gemeinsam benutzter Speicherbereiche geschützt werden Die wesentlichen Verfahren zur Speicherverwaltung, die im Folgenden beschrieben werden sollen, sind:
- Swapping- Paging
■ In den frühen Tagen des Computers waren Speicher klein und teuer. Traditionell löste man dieses Problem durch Verwendung eines Sekundärspeichers, z. B. einer Festplatte. Der Programmierer zerlegte das Programm in einzelne Segmente, die jeweils in den Speicher passten. Um das Programm auszuführen, wurde das erste Segment in den Hauptspeicher geladen und ausgeführt. War es abgearbeitet, las es das nächste Segment ein, rief das nächste Segment auf, usw. Der Programmierer war dafür verantwortlich, das Programm zu segmentieren und festzulegen, wo die einzelnen Segmente im Sekundärspeicher angeordnet werden sollen, und wie die Überlagerungen zwischen dem Haupt- und dem Sekundärspeicher zu transportieren sind. Im Allgemeinen musste er den gesamten Segmentierungsprozess ohne Unterstützung durch den Computer verwalten.
■ 1961 schlugen Forscher im britischen Manchester eine Methode zur automatischen Durchführung des Segmentierungsprozesses vor. Diese Methode, die man heute virtuellen Speicher (Virtual Memory) nennt, hatte den klaren Vorteil, dass sie den Programmierer von all diesen Verwaltungsaufgaben entlastete. Das Konzept basierte auf der Trennung von Adressraum und Speicherstellen. Man betrachte als Beispiel einen typischen Computer aus jener Zeit. Er hatte möglicherweise ein 16-Bit-Adressfeld in seinen Instruktionen und 4096 Speicherwörter. Auf diesem Computer konnte ein Programm 65.536 Speicherwörter adressieren. Der Grund, warum es genau 65.536 (216) 16-Bit-Adressen sind, ist, dass jede einem anderen Speicherwort entspricht. Man beachte, dass die Anzahl der adressierbaren Wörter nur von der Bitanzahl in einer Adresse abhängt und nichts mit der Anzahl der tatsächlich verfügbaren Speicherwörter zu tun hat. Der Adressraum bestand bei diesem Computer aus den Zahlen 0, 1, 2, ..., 65.535, weil das der Bereich der möglichen Adressen ist. Möglicherweise hatte der Computer aber auch weniger als 65.535 Speicherwörter.
--> Vor der Erfindung des virtuellen Speichers unterschied man zwischen den Adressen unter 4096 und denen bei oder über 4096. Diese beiden Teile galten als nützlicher bzw. unnützer Adressraum, weil die Adressen oberhalb von 4095 nicht den tatsächlichen Speicheradressen entsprachen. Man unterschied nicht zwischen Adressraum und Speicheradressen, weil die Hardware eine Eins-zu-Eins-Entsprechung der beiden Bereiche auferlegte.

■ Im Detail besagt das Konzept, den Adressraum und die Speicheradressen zu trennen, Folgendes: Zu einem beliebigen Zeitpunkt können 4096 Speicherwörter direkt adressiert werden, müssen aber nicht den Speicheradressen 0 bis 4095 entsprechen. Wir könnten dem Computer z. B. "sagen", dass ab jetzt das Speicherwort an Adresse 0 zu benutzen ist, wenn die Adresse 4096 referenziert wird. Bei einer Referenz auf Adresse 4097 ist das Speicherwort an Adresse 1 zu benutzen, bei einer Referenz auf Adresse 8191 das Speicherwort an Adresse 4095, usw. Anders ausgedrückt: Wir haben eine Abbildung des Adressraums auf die tatsächlichen Speicheradressen definiert, wie die folgende Abbildung zeigt:
■ Eine interessante Frage ist: Was passiert, wenn ein Programm, an eine Adresse zwischen 8192 und 12287 verzweigt? Auf einer Maschine ohne virtuellen Speicher würde das Programm einen Fehler verursachen und beendet werden. Auf Maschinen mit einem virtuellen Speicher würden folgende Schritte ablaufen:
1. Der Inhalt des Arbeitsspeichers wird auf Platte gespeichert.2. Die Wörter 8192 bis 12287 werden auf der Platte ausfindig gemacht.3. Die Wörter 8192 bis 12287 werden in den Arbeitsspeicher geladen.4. Die Adressabbildung wird so geändert, dass sie die Adressen 8192 bis 12287 auf die Speicherlokationen 0 bis 4095
abbildet.5. Die Ausführung wird fortgesetzt, als wäre nichts Ungewöhnliches passiert.
--> Diese Technik der automatischen Segmentierung nennt man Paging, und die Programmhappen, die von der Platte eingelesen werden, Seiten (Pages).
■ Wir nennen die Adressen, die das Programm referenzieren kann, den virtuellen Adressraum (Virtual Address Space) und die realen, festverdrahteten Speicheradressen den physikalischen Adressraum (Physical Address Space). Eine Speicherabbildung(Memory Map) oder Seitentabelle (Page Table) referenziert virtuelle auf physikalische Adressen. Wir gehen davon aus, dass auf der Platte ausreichend Platz vorhanden ist um den gesamten virtuellen Adressraum (oder zumindest den zu benutzenden Teil) zu speichern.
8191
04096
4K-Hauptspeicher
Adressraum
0
4095
Abbildung
Implementierung von Paging■ Eine wichtige Voraussetzung für einen virtuellen Speicher ist eine Platte, auf der das komplette Programm und alle Daten geführt
werden können. Konzeptionell ist es einfacher, sich die Kopie des Programms auf der Platte als Original und die hier und da in den Arbeitsspeicher überführten Teile als Kopien vorzustellen, und nicht umgekehrt. Natürlich ist es wichtig, das Original auf dem neuesten Stand zu halten. Wird die Kopie im Arbeitsspeicher geändert, sollten sich diese Änderungen (letztendlich) auch im Original widerspiegeln.
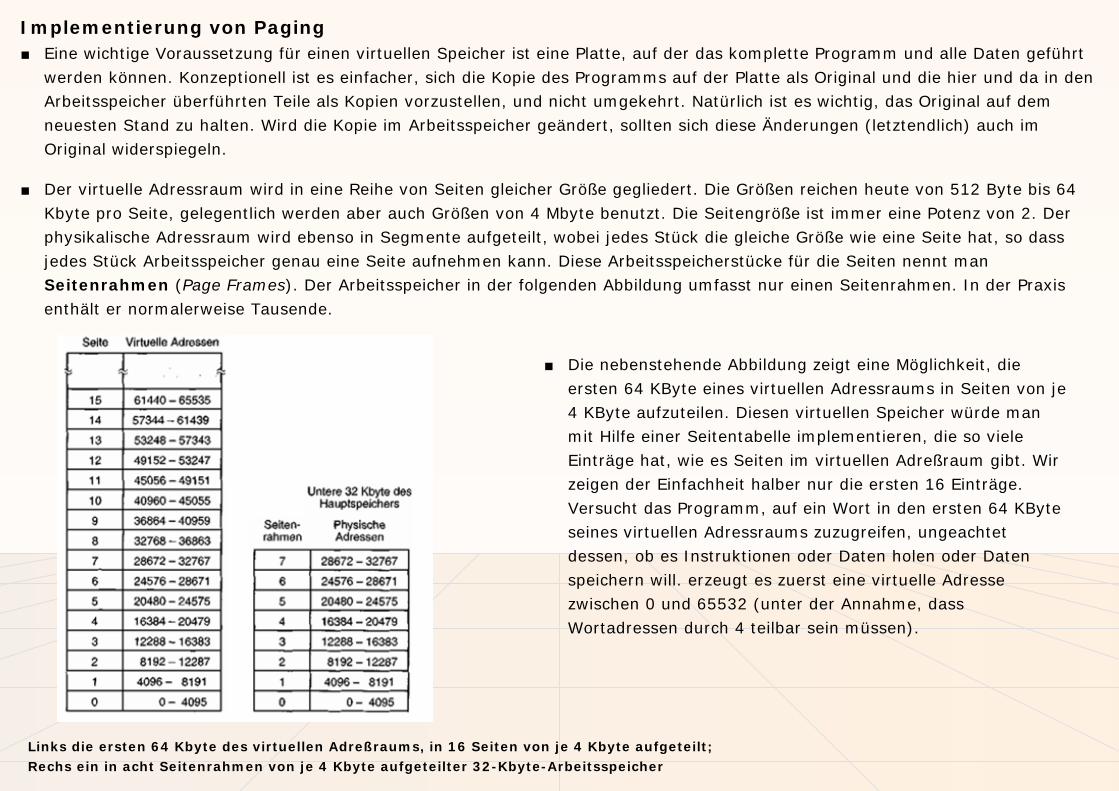
■ Der virtuelle Adressraum wird in eine Reihe von Seiten gleicher Größe gegliedert. Die Größen reichen heute von 512 Byte bis 64 Kbyte pro Seite, gelegentlich werden aber auch Größen von 4 Mbyte benutzt. Die Seitengröße ist immer eine Potenz von 2. Der physikalische Adressraum wird ebenso in Segmente aufgeteilt, wobei jedes Stück die gleiche Größe wie eine Seite hat, so dass jedes Stück Arbeitsspeicher genau eine Seite aufnehmen kann. Diese Arbeitsspeicherstücke für die Seiten nennt man Seitenrahmen (Page Frames). Der Arbeitsspeicher in der folgenden Abbildung umfasst nur einen Seitenrahmen. In der Praxis enthält er normalerweise Tausende.
■ Die nebenstehende Abbildung zeigt eine Möglichkeit, die ersten 64 KByte eines virtuellen Adressraums in Seiten von je 4 KByte aufzuteilen. Diesen virtuellen Speicher würde man mit Hilfe einer Seitentabelle implementieren, die so viele Einträge hat, wie es Seiten im virtuellen Adreßraum gibt. Wir zeigen der Einfachheit halber nur die ersten 16 Einträge. Versucht das Programm, auf ein Wort in den ersten 64 KByte seines virtuellen Adressraums zuzugreifen, ungeachtet dessen, ob es Instruktionen oder Daten holen oder Daten speichern will. erzeugt es zuerst eine virtuelle Adresse zwischen 0 und 65532 (unter der Annahme, dass Wortadressen durch 4 teilbar sein müssen).
Links die ersten 64 Kbyte des virtuellen Adreßraums, in 16 Seiten von je 4 Kbyte aufgeteilt;Rechs ein in acht Seitenrahmen von je 4 Kbyte aufgeteilter 32-Kbyte-Arbeitsspeicher

Seitenersetzung■ Eine referenzierte virtuelle Seite befindet sich nicht immer im Arbeitsspeicher, weil der Arbeitsspeicher nicht für alle virtuellen
Seiten Platz hat. Erfolgt eine Referenz auf eine Adresse einer Seite, die nicht im Arbeitsspeicher ist, nennt man das Seitenfehler(Page Fault). Nach Eintritt eines Seitenfehlers muss das Betriebssystem die erforderliche Seite von der Platte lesen, ihre neue physikalische Speicherstelle in die Seitentabelle eingeben und dann die Instruktion wiederholen, die den Seitenfehler verursacht hat. Ein Programm, das auf einer Maschine mit einem virtuellen Speicher läuft, kann man starten, ohne dass sich auch nur ein Programmteil im Arbeitsspeicher befindet. Die Seitentabelle muss lediglich entsprechend gesetzt werden, so dass sie darauf hinweist, dass sich jede einzelne virtuelle Seite nicht im Arbeits-, sondern im Sekundärspeicher befindet. Versucht die CPU, die erste Instruktion zu holen, ergeht sofort ein Seitenfehler, so dass die Seite mit der ersten Instruktion in den Speicher geladen und in die Seitentabelle eingetragen wird. Dann kann die erste Instruktion beginnen. Hat die erste Instruktion zwei Adressen und befinden sich beide Adressen auf verschiedenen Seiten, die sich ihrerseits beide von der Instruktionsseite unterscheiden, treten zwei oder mehr Seitenfehler ein, und zwei weitere Seiten werden herbeigeholt, bevor die Instruktion schließlich ausgeführt wird. Die nächste Instruktion kann wieder mehrere Seitenfehler verursachen, usw.
■ Im Idealfall kann man die Arbeitsmenge, die ein Programm vorwiegend nutzt, im Speicher halten, um Seitenfehler zu reduzieren. Programmierer wissen aber selten, welche Seiten sich in der Arbeitsmenge befinden. Deshalb muss das Betriebssystem diese Menge dynamisch feststellen. Fordert ein Programm eine Seite an, die sich nicht im Arbeitsspeicher befindet, muss die angeforderte Seite von der Platte geholt werden. Um für sie Platz zu schaffen, muss aber irgendeine andere Seite auf die Platte zurückgeschickt werden. Folglich benötigt man eine Methode, der die zu entfernende Seite bestimmt. Die meisten Betriebssysteme versuchen vorherzusagen, welche Seiten im Speicher dahingehend am wenigsten brauchbar sind, dass sie die geringste nachteilige Wirkung auf das laufende Programm haben.
■ Eine Möglichkeit hierfür ist es vorauszusagen, wann die nächste Referenz auf eine Seite erfolgt, und die Seite zu entfernen, deren vorhergesagte nächste Referenz am weitesten in der Zukunft liegt. Anders ausgedrückt: Statt eine Seite zu entfernen, die in Kürze wieder gebraucht wird, versucht man, eine auszuwählen, die über lange Zeit nicht gebraucht wird. Diese Methode heißt LRU(Least Recently Used).
■ Ein weitere Methode, FIFO (First-In First-Out), entfernt die jeweils zuletzt geladene Seite, unabhängig davon, wann diese Seite zuletzt angefordert wurde. Für jeden Seitenrahmen gibt es einen Zähler. Anfangs werden alle Zähler auf 0 gesetzt. Nach der Bearbeitung eines Seitenfehlers wird der Zähler der momentan im Speicher befindlichen Seite um eins erhöht, während der Zähler für die gerade eingebrachte Seite auf 0 gesetzt wird. Wird es nötig, eine Seite zu entfernen, wird die mit dem höchsten Zähler gewählt. Weil ihr Zähler der höchste ist, hat sie die höchste Zahl an Seitenfehlern. Das bedeutet, dass sie vor allen übrigen, im Speicher befindlichen Seiten geladen wurde und damit aller Wahrscheinlichkeit nach lange nicht mehr gebraucht wird.

Swapping■ Eine weitere Methode zur Speicherverwaltung in das so genannte Swapping. Hierbei befinden sich zu einem gegebenen Zeitpunkt
einige Segmentmengen im Speicher. Bei einer Referenz auf ein Segment, das sich momentan nicht im Speicher befindet, wird dieses geholt. Ist kein Platz dafür vorhanden, müssen eines oder mehrere Segmente zuerst auf die Platte ausgelagert werden. In dieser Hinischt ist das Swapping von Segmenten mit dem Paging vergleichbar: Segmente werden nach Bedarf geholt und ausgelagert.
■ Die Segmentierung wird beim Swapping aber anders als beim Paging implementiert. Swapping besitzt einen entscheidenden Nachteil: Seiten haben eine feste Größe, Swapping-Segmente nicht.
■ Die obige Abbildung zeigt das Beispiel eines physikalischen Speichers, der anfangs fünf Segmente enthält. Man betrachte, was passiert, wenn in (a) Segment 1 ausgelagert und das kleinere Segment 7 an seine Stelle gesetzt wird. Wir gelangen zu der Speicherkonfiguration von (b). Zwischen Segment 7 und Segment 2 liegt ein ungenutzter Bereich, also ein Loch. Dann wird Segment 4 durch Segment 5 (c) und Segment 3 durch Segment 6 ersetzt (d). Nachdem das System eine Weile lief, wird Speicher in Stücke aufgeteilt, von denen einige Segmente und andere Löcher enthalten. Dieses Phänomen nennt man externe Fragmentierung (External Fragmentation), weil außerhalb der Segmente in den dazwischenliegenden Löchern Platz verschwendet wird.

2.5.6. Das Betriebsssystem Unix■ Im Prinzip liefert das Betriebssystem eine hardwareunabhängige Schnittstelle zum Rechner. Dennoch sind Betriebssysteme von
den Stärken und Schwächen oder von besonderen Fähigkeiten spezieller CPUs beeinflusst. So sind Betriebssysteme wie MS-DOS, Windows 9x, Windows 2000 und Windows XP nur auf Rechnern einer Bauart (x86-Architektur) verfügbar, während andere Betriebssysteme wie UNIX und Windows NT auf vielen Hardware-Plattformen (darunter auch die x86-Architektur) verfügbar sind. Auf Workstations und im wissenschaftlichen Umfeld dominiert seit Anfang der achtziger Jahre das Betriebssystem UNIX. Auf PCs gewinnt der frei erhältliche UNIX-Abkömmling Linux immer mehr an Boden. Im Vergleich zu Windows ist es technisch ausgereifter, stabiler und schneller. Aufgrund der weiten Verbreitung von UNIX und Linux wollen wir exemplarisch den Umgang mit diesem Betriebssystem behandeln. Wir betrachten hier UNIX aus der Sicht eines Benutzers.
■ Das UNIX-Dateisystem ist als Baum organisiert. Die Dateisysteme der einzelnen Benutzer sind Unterbäume des globalen Dateibaumes. Die Wurzel dieses Baumes heißt root und wird mit einem Schrägstrich "/" (slash) abgekürzt. Die inneren Knoten sind Unterverzeichnisse, die Blätter sind die eigentlichen Dateien. In UNIX zählt man auch die Verzeichnisse zu den Dateien. Schließlich werden auch Geräte (Drucker, Terminals, Platten, Maus etc.) logisch wie Dateien behandelt. In die einem Bildschirm zugeordnete Datei kann man nur schreiben, von der zu einer Tastatur gehörenden Datei nur lesen. Löscht man diese Dateien, so kann man das zugehörige Gerät nicht mehr ansprechen. Diese Philosophie hat den Vorteil der Einfachheit. Wenn der Benutzer weiß, wie er ein Datum in eine Datei schreibt, so weiß er auch, wie er es druckt: Es wird einfach in die dem Drucker zugeordnete Datei geschrieben. Angesichts der zahlreichen Implementierungen von Unix kann man nur schwer über den Aufbau des Dateisystems Aussagen treffen, da sich alle in gewisser Weise unterscheiden. Allgemein läßt sich die folgende Struktur annehmen:
■ Für die Organisation des UNIX-Dateibaumes haben sich gewisse Konventionen eingebürgert. Einige Unterverzeichnisse haben eine spezielle Bedeutung:
bin : Systemdateien (binär) dev : Gerätedateien (devices) lib : Bibliotheken (libraries) usr : Benutzerdateien (user) etc : Sonstige Systemdateien

Zugriffsrechte■ Wie wir bereits gesehen haben, befindet sich unter den elementarsten Diensten jedes Betriebssystems die Dateiverwaltung.
Dateien müssen erzeugt, verändert, abgespeichert, umbenannt und gelöscht werden. Ferner muss der Zugang zu ihnen den anderen Benutzern des Rechners ermöglicht oder verweigert werden. Das UNIX-System hat für viele spätere Systeme in diesem Bereich Maßstäbe gesetzt und ist insbesondere auf Workstations zum de facto-Standard geworden.
■ UNIX ist ein Mehrbenutzersystem. Das Dateisystem jedes Benutzers ist ein Unterbaum des globalen Dateisystems, meist direkt unter dem Verzeichnis usr angehängt. Die Wurzel dieses Benutzer-Dateibaumes heißt auch home directory des Benutzers. Jede Datei hat einen owner. Wie der Name schon andeutet, besitzt dieser die Datei, kann also die Zugriffsrechte anderer Benutzer auf diese Datei vergeben. Jeder Benutzer kann auf beliebige Dateien in dem Dateibaum zugreifen, sofern ihm die notwendigen Zugriffsrechte gewährt werden. Auf diese Weise können Ressourcen des Systems gemeinsam genutzt werden.
■ Wie bereits erwähnt, hat jede Datei einen Besitzer (owner), welcher festlegen darf, wer welche Zugriffsberechtigung hat. Es gibt drei Arten des Zugriffs:
r : Lesezugriff (r = read)w : Schreibzugriff (w = write)x : Ausführung (x = execute)
Die Schreibberechtigung w schließt das Recht für Änderungen und das Löschen der Datei ein. Die Ausführungsberechtigung x ist nur für die Ausführung von Programmdateien und den Zugriff auf Verzeichnisse relevant. Die Benutzer werden in drei Klassen eingeteilt:
user : der Besitzer (owner) der Dateigroup : die Arbeitsgruppe, zu der der owner gehörtothers : alle anderen Benutzer des Systems
Für jede dieser Benutzerklassen können die drei Zugriffsarten jeweils erlaubt oder verweigert werden. Der Systemverwalter legt fest, zu welcher group der Benutzer gehört.

Unix-Shells■ Wenn ein Benutzer unter Unix Kommandos auf der Systemkonsole eingibt, werden diese vom Kommandointerpreter, einer so
genannten shell, an das Betriebssystem weiter gereicht. Dahinter steckt die Vorstellung, dass sich der Kommandointerpreter wie eine Schale (engl.: shell) um den Betriebssystemkern legt. Die Shell vermittelt zwischen den Wünschen des Benutzers und den Ressourcen des Betriebssystems. Sie nimmt Kommandos entgegen, analysiert diese und sorgt dafür, dass das Betriebssystem die gewünschten Aktionen ausführt. Nach einer abgeschlossenen Aktion wartet die Shell auf das nächste Kommando. Der UNIX-Benutzer hat verschiedene Shells zur Auswahl. Einige davon sind die Bourne-Shell, die Korn-Shell, die C-Shell oder die tc-Shell. Diese unterscheiden sich nur wenig, was die elementaren Kommandos betrifft. Stärker sind die Unterschiede erst hinsichtlich der Art ihrer Programmierbarkeit und des Komforts, den sie bieten. Der Benutzer kann durchaus mehrere Shells gleichzeitig benutzen. Durch das Kommando csh, öffnet er z. B. eine neue C-Shell.
Unix-Kommandos■ Auf der Kommandoebene unterscheidet sich UNIX nicht sehr von DOS. Für den geübten Benutzer erweist es sich aber als weit
mächtiger und flexibler. Für jedes Kommando existiert ein Eintrag im Online Manual, welcher mit dem Befehl
man <kommando>
abgerufen werden kann. Man erhält eine komplette Beschreibung des Befehls <kommando>. Füllt der Eintrag mehrere Seiten, so kann mit der Leertaste vorwärts und mit b (backward) rückwärts geblättert werden, q oder Ctrl-c brechen die Ausgabe ab. Als Beispiele versuche man:
man pwdman man
Wir können im Rahmen dieses Seminars nicht jedes Kommando einzeln besprechen. Im Folgenden einige wichtige Kommandos zur Dateiverwaltung:
cp Datei kopieren (copy) rmdir Verzeichnis löschen (remove directory) mv Datei umbenennen (move) ls Dateiliste anzeigen (list directory)rm Datei löschen (remove) cat Datei-Inhalt anzeigenmkdir neues Verzeichnis erstellen (make directory) lp Datei drucken (line-print)

Kommandooptionen■ Die meisten UNIX-Befehle können durch Optionen noch verändert und damit den Benutzeranforderungen angepasst werden.
Optionen werden in der Regel durch einen Buchstaben mit vorgestelltem Bindestrich (dash) gekennzeichnet. Man kann auch mehrere Optionen zu einer Zeichenkette zusammenfassen und mit vorgestelltem "-" dem Befehl anhängen. Die Syntax des Befehls ls, wird im Manual mit
ls [[Optionen] Dateien]
angegeben. Wie üblich sind die Teile in den eckigen Klammern optional. Ein Beispiel für die Benutzung des ls-Befehls ist:
ls -al *. dvi
Hier wird der ls-Befehl mit den Optionen -a (all) und -l (long) aufgerufen. Gemeint ist: "Liste in langer Form (d. h. mit Zusatzinformationen) die Dateien auf, deren Namen auf ". dvi" enden, und zwar alle (auch die versteckten)." Die wichtigsten Optionen des ls-Befehles sind im folgenden zusammengestellt:
-C (columns) Mehrspaltige Ausgabe.-c (creation date) Zeige Datei in der Reihenfolge ihrer Erzeugung.-d (directories) Zeige nur die Verzeichnisse.
Softlinks■ Statt eine Kopie einer Datei, die im UNIX-Dateisystem vorhanden ist, in das eigene Verzeichnis zu kopieren (und damit erneut
Speicherplatz zu verschwenden), kann man mit dem Befehl ln einen sogenannten Softlink erzeugen. Ein Softlink verhält sich logisch wie eine Datei, die Dateien liegen aber physikalisch in einem entfernten Verzeichnis. Die Befehle
ln Quelldatei Zieldateiund
cp Quelldatei Zieldatei
sind also weitestgehend äquivalent. Jede (physikalische) Datei hat die Anzahl der auf sie zeigenden Softlinks als Attribut. Sie kann physikalisch erst gelöscht werden, falls kein Softlink mehr vorhanden ist, der auf sie zeigt.

Standard-Eingabe/-Ausgabe■ Viele UNIX-Kommandos, die mit Eingabe und/oder Ausgabe arbeiten, erwarten, wenn nichts anderes vereinbart wird, die Eingabe
von der Tastatur und liefern die Ausgabe an den Bildschirm. Da sowohl Tastatur als auch Bildschirm als Dateien behandelt werden, kann man sie auch durch andere Dateien ersetzen. Man spricht von einer Umlenkung (redirection) von Standardeingabe und Standardausgabe. Die Umlenkung der Standardausgabe geschieht mit den Zeichen ">" (bzw. ">>") und die Umlenkung der Standardeingabe durch das Zeichen "<". In einem UNIX-Befehl bedeuten
> Datei Ersetze Standardausgabe durch Datei>> Datei Hänge Standardausgabe an Datei an< Datei Ersetze Standard-Input durch Datei
Beispielsweise kann man mit dem Kommando
ls -l *. tex >dokumente
eine Datei dokumente erzeugen, die die Liste aller Dateien mit Endung ". tex" enthält. Auf dem Bildschirm erscheint kein Zeichen, denn Standardausgabe ist jetzt die Datei dokumente. Erwartet ein UNIX-Kommando einen Text als Argument, so wird, falls dieser nicht angegeben wird, meist Standardeingabe angenommen. Das Folgende Kommando versendet eine E-Mail mit der Datei text.txtals Inhalt:
mail -s [email protected] < text.txt

Dateibearbeitung■ Die bisherigen Kommandos dienten im Wesentlichen der Navigation und Orientierung im UNIX-Dateisystem. Zur Verarbeitung und
Veränderung von Dateien gibt es eine Reihe von effektiven und vielseitigen Kommandos, von denen wir jetzt eine kleine Auswahl vorstellen. Wenn eine Ausgabe erzeugt wird, so geht diese immer zur Standardausgabe, also zum Terminal, wenn nichts anderes vereinbart wurde. Fehlt eine Eingabedatei, so wird die Eingabe von der Standardeingabe, also von der Tastatur, erwartet. Das Kommando
cat [options] [files]
konkateniert die angegebenen Dateien.
Beispiel:cat Kapitel.1 Kapitel.2 Kapitel.3 > Buch
fügt die Dateien zu einer neuen Datei Buch zusammen.
■ Das Kommando sort [options] [file] sortiert die Datei.
Beispiel: sort -u namelist > namelist.sortiert (Sortiere die Datei namelist, entferne Duplikate (-u = unique) und speichere das Ergebnis in namelist.sortiert)
■ Das Kommando wc [options] [file] zählt die Zeilen (-1 = lines), Worte (-w) und Buchstaben (-c = characters).
Beispiel: wc -wc romeo-julia (Zähle die Worte (-w) und Zeichen (-c) in romeo-julia)
■ Das Kommando chmod [options] mode filename setzt die Zugriffsberechtigungen (permissions) einer Datei für die verschiedenen Benutzerklassen u (user), g (group) und o (others). Die Attribute können sein: r (read), w (write) und x (execute).
Beispiel: chmod ug = rw meineDatei (Setze das Lese- und Schreibrecht für Benutzer und Gruppe)
■ Das Kommando grep [options] regexp [files] sucht in den angegebenen Dateien nach dem angegebenen regulären Ausdruck (Muster einer Zeichenkette) regexp.
Beispiel: grep -l Hugo * (Gib die Namen aller Dateien an, in denen das Wort Hugo vorkommt)
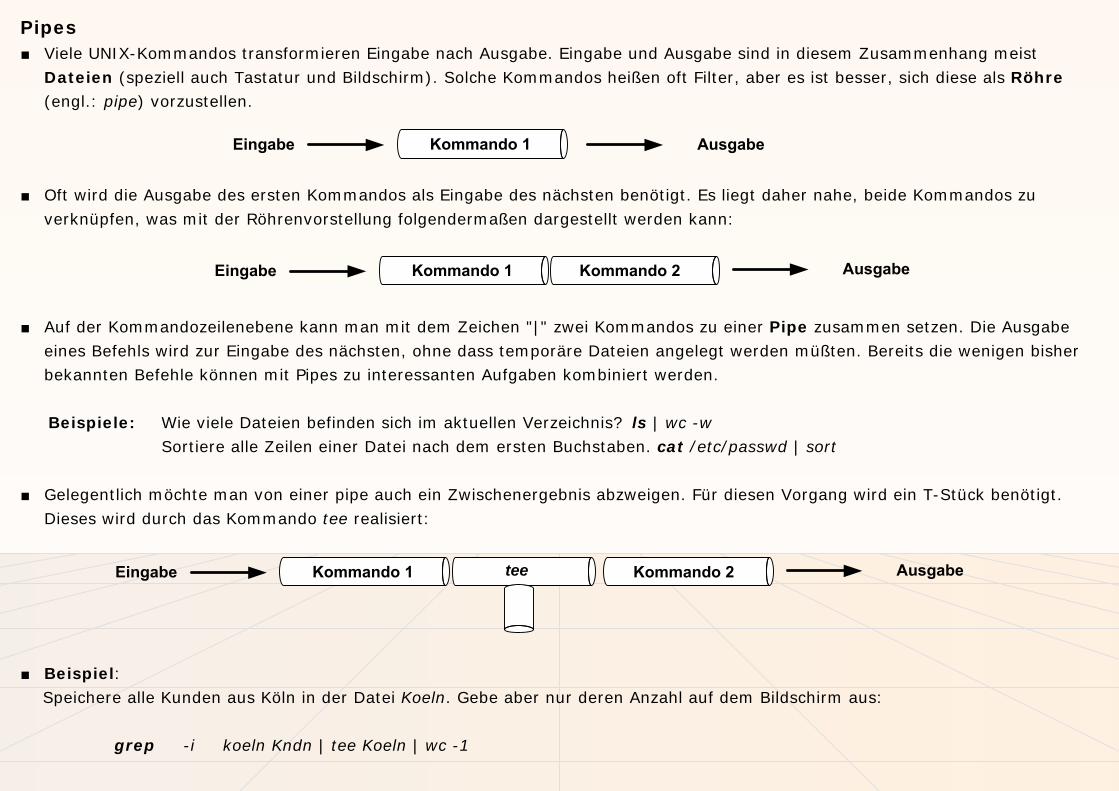
Pipes■ Viele UNIX-Kommandos transformieren Eingabe nach Ausgabe. Eingabe und Ausgabe sind in diesem Zusammenhang meist
Dateien (speziell auch Tastatur und Bildschirm). Solche Kommandos heißen oft Filter, aber es ist besser, sich diese als Röhre(engl.: pipe) vorzustellen.
Kommando 1Eingabe Ausgabe
■ Oft wird die Ausgabe des ersten Kommandos als Eingabe des nächsten benötigt. Es liegt daher nahe, beide Kommandos zu verknüpfen, was mit der Röhrenvorstellung folgendermaßen dargestellt werden kann:
Kommando 1Eingabe AusgabeKommando 2
■ Auf der Kommandozeilenebene kann man mit dem Zeichen "|" zwei Kommandos zu einer Pipe zusammen setzen. Die Ausgabe eines Befehls wird zur Eingabe des nächsten, ohne dass temporäre Dateien angelegt werden müßten. Bereits die wenigen bisher bekannten Befehle können mit Pipes zu interessanten Aufgaben kombiniert werden.
Beispiele: Wie viele Dateien befinden sich im aktuellen Verzeichnis? ls | wc -wSortiere alle Zeilen einer Datei nach dem ersten Buchstaben. cat /etc/passwd | sort
■ Gelegentlich möchte man von einer pipe auch ein Zwischenergebnis abzweigen. Für diesen Vorgang wird ein T-Stück benötigt. Dieses wird durch das Kommando tee realisiert:
Kommando 1Eingabe AusgabeKommando 2tee
■ Beispiel:Speichere alle Kunden aus Köln in der Datei Koeln. Gebe aber nur deren Anzahl auf dem Bildschirm aus:
grep -i koeln Kndn | tee Koeln | wc -1

Hausaufgaben
(1) Erläutern Sie den Unterschied zwischen Swapping und Paging.(2) Beschreiben Sie das Konzept der Pipes unter Unix.


















