
4. Nicht-Probabilistische Retrievalmodelle · 4. Nicht-ProbabilistischeRetrievalmodelle 12...
73
4. Nicht-Probabilistische Retrievalmodelle 1 4. Nicht-Probabilistische Retrievalmodelle Norbert Fuhr
Transcript of 4. Nicht-Probabilistische Retrievalmodelle · 4. Nicht-ProbabilistischeRetrievalmodelle 12...

4. Nicht-Probabilistische Retrievalmodelle 1
4. Nicht-Probabilistische Retrievalmodelle
Norbert Fuhr
4. Nicht-Probabilistische Retrievalmodelle 2
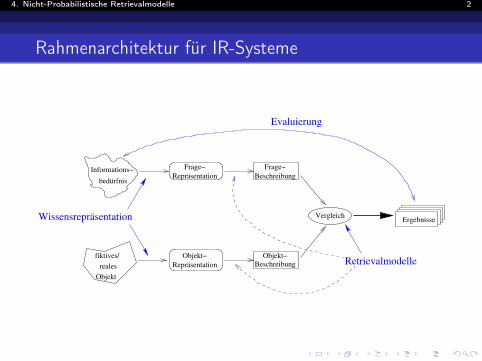
Rahmenarchitektur für IR-Systeme
Repräsentation
Objekt
Objekt−
Repräsentation
Frage− Frage−
Beschreibung
Beschreibung
VergleichErgebnisse
Retrievalmodelle
Evaluierung
Wissensrepräsentation
Objekt−
Informations−
bedürfnis
reales
fiktives/

Notationen

4. Nicht-Probabilistische Retrievalmodelle 4Notationen
Notationen
DD
rel.
judg.
α
αQ βQ
Dβ
ρIR
DQ
DD
Q
D
Q
R
qk ∈ Q: Anfrage/Info-bed.qk ∈ Q Anfragerepräs.
qDk ∈ QD : Anfragebeschr.
R: Relevanzskala
dm ∈ D: Dokumentdm ∈ D Dokumentrepräs.
dDm ∈ DD : Dokumentbeschr.
%: RetrievalfunktionIR Retrievalwert
T = {t1, . . . , tn}: IndexierungsvokabulardDm : ~dm = (dm1 , . . . , dmn): Dokument-Beschreibung als Menge von
Indexierungsgewichten

4. Nicht-Probabilistische Retrievalmodelle 4Notationen
Notationen
DD
rel.
judg.
α
αQ βQ
Dβ
ρIR
DQ
DD
Q
D
Q
R
qk ∈ Q: Anfrage/Info-bed.qk ∈ Q Anfragerepräs.
qDk ∈ QD : Anfragebeschr.
R: Relevanzskala
dm ∈ D: Dokumentdm ∈ D Dokumentrepräs.
dDm ∈ DD : Dokumentbeschr.
%: RetrievalfunktionIR Retrievalwert
T = {t1, . . . , tn}: IndexierungsvokabulardDm : ~dm = (dm1 , . . . , dmn): Dokument-Beschreibung als Menge von
Indexierungsgewichten

Überblick über die Modelle

4. Nicht-Probabilistische Retrievalmodelle 6Überblick über die Modelle
Überblick über die Modelle
Boolesches RetrievalFuzzy-RetrievalVektorraummodellProbabilistisches (Relevanz-orientiertes) Retrieval(Statistisches) Sprachmodell

4. Nicht-Probabilistische Retrievalmodelle 7Überblick über die Modelle
Eigenschaften von Modellen
Bool. Fuzzy Vektor Prob. Sprachmod..theoretische Boolesche Fuzzy- Vektorraum- Wahrsch.- Statist.Basis Logik Logik Modell Theorie Sprachmod.Bezug zur (x) x (x)Retrievalqual.gewichtete x x x xIndexierunggewichtete (x) x x xFragetermeFragestruktur:– linear x x x– boolesch x x (x) (x)

Boolesches Retrieval

4. Nicht-Probabilistische Retrievalmodelle 9Boolesches Retrieval
Boolesches Retrieval
Historisch als erstes Retrievalmodell entwickelt und eingesetzt(Dokument-Beschreibungen auf Magnetbändern!)
Dokumenten-Beschreibungen DD :ungewichtete Indexierung, d.h. dD
m = ~dm mit dmi ε{0, 1} füri = 1, . . . , n
boolesches Retrieval liefert nur Zweiteilung der Dokumente in„gefundene“ (% = 1) und „nicht gefundene“ (% = 0) Dokumente

4. Nicht-Probabilistische Retrievalmodelle 9Boolesches Retrieval
Boolesches Retrieval
Historisch als erstes Retrievalmodell entwickelt und eingesetzt(Dokument-Beschreibungen auf Magnetbändern!)
Dokumenten-Beschreibungen DD :ungewichtete Indexierung, d.h. dD
m = ~dm mit dmi ε{0, 1} füri = 1, . . . , n
boolesches Retrieval liefert nur Zweiteilung der Dokumente in„gefundene“ (% = 1) und „nicht gefundene“ (% = 0) Dokumente

4. Nicht-Probabilistische Retrievalmodelle 9Boolesches Retrieval
Boolesches Retrieval
Historisch als erstes Retrievalmodell entwickelt und eingesetzt(Dokument-Beschreibungen auf Magnetbändern!)
Dokumenten-Beschreibungen DD :ungewichtete Indexierung, d.h. dD
m = ~dm mit dmi ε{0, 1} füri = 1, . . . , n
boolesches Retrieval liefert nur Zweiteilung der Dokumente in„gefundene“ (% = 1) und „nicht gefundene“ (% = 0) Dokumente
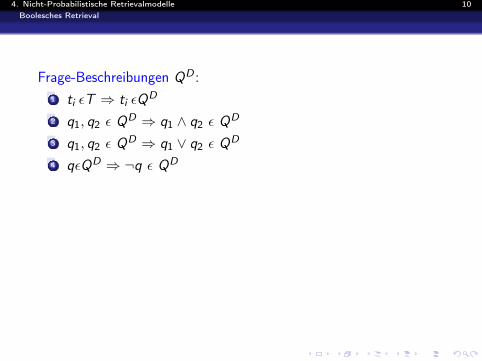
4. Nicht-Probabilistische Retrievalmodelle 10Boolesches Retrieval
Frage-Beschreibungen QD :1 ti εT ⇒ ti εQD
2 q1, q2 ε QD ⇒ q1 ∧ q2 ε QD
3 q1, q2 ε QD ⇒ q1 ∨ q2 ε QD
4 qεQD ⇒ ¬q ε QD
Retrievalfunktion %(q, dm):1 t1 εT ⇒ %(ti , ~dm) = dmi
2 %(q1 ∧ q2, ~dm) = min(%(q1, ~dm), %(q2, ~dm))
3 %(q1 ∨ q2, ~dm) = max(%(q1, ~dm), %(q2, ~dm))
4 %(¬q, ~dm) = 1− %(q, ~dm)

4. Nicht-Probabilistische Retrievalmodelle 10Boolesches Retrieval
Frage-Beschreibungen QD :1 ti εT ⇒ ti εQD
2 q1, q2 ε QD ⇒ q1 ∧ q2 ε QD
3 q1, q2 ε QD ⇒ q1 ∨ q2 ε QD
4 qεQD ⇒ ¬q ε QD
Retrievalfunktion %(q, dm):1 t1 εT ⇒ %(ti , ~dm) = dmi
2 %(q1 ∧ q2, ~dm) = min(%(q1, ~dm), %(q2, ~dm))
3 %(q1 ∨ q2, ~dm) = max(%(q1, ~dm), %(q2, ~dm))
4 %(¬q, ~dm) = 1− %(q, ~dm)

4. Nicht-Probabilistische Retrievalmodelle 11Boolesches Retrieval
Mächtigkeit der booleschen Anfragesprache:
jede beliebige Dokumentenmenge kann selektiert werden(Voraussetzung: alle Dokumente besitzen unterschiedlicheIndexierungen)
Konstruktion der booleschen Frageformulierung qk zu einervorgegebenen Dokumentenmenge Dk :
dQm = xm1 ∧ . . . ∧ xmnmit
xmi =
{ti falls dmi = 1¬ti sonst
qk =∨
dj εDk
dQj

4. Nicht-Probabilistische Retrievalmodelle 11Boolesches Retrieval
Mächtigkeit der booleschen Anfragesprache:
jede beliebige Dokumentenmenge kann selektiert werden(Voraussetzung: alle Dokumente besitzen unterschiedlicheIndexierungen)
Konstruktion der booleschen Frageformulierung qk zu einervorgegebenen Dokumentenmenge Dk :
dQm = xm1 ∧ . . . ∧ xmnmit
xmi =
{ti falls dmi = 1¬ti sonst
qk =∨
dj εDk
dQj

4. Nicht-Probabilistische Retrievalmodelle 12Boolesches Retrieval
Beispiel-Recherche
“The side effects of drugs on memory or cognitive abilities, notrelated to aging”
1. 19248 DRUGS2. 2412 DRUGS in TI3. 2560 AGING4. 19119 DRUG not AGING5. 2349 #2 and #46. 9305 MEMORY7. 6 #5 and (DRUG near4 MEMORY)8. 22091 COGNITIVE9. 16 #5 and (DRUG near4 COGNITIVE)
10. 22 #7 or #911. 2023 SIDE-EFFECTS-DRUG in DE12. 0 #11 and #10

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren
2 Keine Ordung der Antwortmenge nach mehr oder wenigerrelevanten Dokumenten
3 Keine Möglichkeit zur Gewichtung von Fragetermen odergewichteter Indexierung
4 Trennung gefunden / nicht gefunden zu streng:Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten
3 Keine Möglichkeit zur Gewichtung von Fragetermen odergewichteter Indexierung
4 Trennung gefunden / nicht gefunden zu streng:Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung
4 Trennung gefunden / nicht gefunden zu streng:Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung4 Trennung gefunden / nicht gefunden zu streng:
Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung4 Trennung gefunden / nicht gefunden zu streng:
Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich
6 schlechte RetrievalqualitätTrotzdem weiterhin Einsatz bei
Patentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung4 Trennung gefunden / nicht gefunden zu streng:
Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung4 Trennung gefunden / nicht gefunden zu streng:
Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

4. Nicht-Probabilistische Retrievalmodelle 13Boolesches Retrieval
Nachteile des booleschen Retrieval
1 Größe der Antwortmenge ist schwierig zu kontrollieren2 Keine Ordung der Antwortmenge nach mehr oder weniger
relevanten Dokumenten3 Keine Möglichkeit zur Gewichtung von Fragetermen oder
gewichteter Indexierung4 Trennung gefunden / nicht gefunden zu streng:
Zu q = t1 ∧ t2 ∧ t3 werden Dokumente mit zwei gefundenenTermen genauso zurückgewiesen wie solche mit 0Analog für q = t1 ∨ t2 ∨ t3 keine Unterteilung der gefundenenDokumente
5 Erstellung der Frageformulierung sehr umständlich6 schlechte Retrievalqualität
Trotzdem weiterhin Einsatz beiPatentretrieval (professionelle Rechercheure)Rechtsstreitigkeiten (Spezif. offenzulegender Dokumente)

Fuzzy-Retrieval
4. Nicht-Probabilistische Retrievalmodelle 15Fuzzy-Retrieval
Fuzzy-Retrieval
Teilweise Überwindung der Nachteile des booleschen Retrieval
Dokumenten-Beschreibungen:Erweiterung auf gewichtete Indexierung, d.h. dmi ε[0, 1]Frage-Beschreibungen, Retrievalfunktion:wie beim booleschen RetrievalRetrievalfunktion liefert jetzt Werte %(qD
k ,~dm)ε[0, 1]
→ Ranking der Antwortmenge

4. Nicht-Probabilistische Retrievalmodelle 15Fuzzy-Retrieval
Fuzzy-Retrieval
Teilweise Überwindung der Nachteile des booleschen RetrievalDokumenten-Beschreibungen:Erweiterung auf gewichtete Indexierung, d.h. dmi ε[0, 1]
Frage-Beschreibungen, Retrievalfunktion:wie beim booleschen RetrievalRetrievalfunktion liefert jetzt Werte %(qD
k ,~dm)ε[0, 1]
→ Ranking der Antwortmenge

4. Nicht-Probabilistische Retrievalmodelle 15Fuzzy-Retrieval
Fuzzy-Retrieval
Teilweise Überwindung der Nachteile des booleschen RetrievalDokumenten-Beschreibungen:Erweiterung auf gewichtete Indexierung, d.h. dmi ε[0, 1]Frage-Beschreibungen, Retrievalfunktion:wie beim booleschen Retrieval
Retrievalfunktion liefert jetzt Werte %(qDk ,~dm)ε[0, 1]
→ Ranking der Antwortmenge

4. Nicht-Probabilistische Retrievalmodelle 15Fuzzy-Retrieval
Fuzzy-Retrieval
Teilweise Überwindung der Nachteile des booleschen RetrievalDokumenten-Beschreibungen:Erweiterung auf gewichtete Indexierung, d.h. dmi ε[0, 1]Frage-Beschreibungen, Retrievalfunktion:wie beim booleschen RetrievalRetrievalfunktion liefert jetzt Werte %(qD
k ,~dm)ε[0, 1]
→ Ranking der Antwortmenge

4. Nicht-Probabilistische Retrievalmodelle 15Fuzzy-Retrieval
Fuzzy-Retrieval
Teilweise Überwindung der Nachteile des booleschen RetrievalDokumenten-Beschreibungen:Erweiterung auf gewichtete Indexierung, d.h. dmi ε[0, 1]Frage-Beschreibungen, Retrievalfunktion:wie beim booleschen RetrievalRetrievalfunktion liefert jetzt Werte %(qD
k ,~dm)ε[0, 1]
→ Ranking der Antwortmenge

4. Nicht-Probabilistische Retrievalmodelle 16Fuzzy-Retrieval
Problematische Definition der Retrievalfunktion
ρ
ρ
0.6 1
0.6
1
10.6
0.6
1
(t1 & t2, d)=0.6
(t1 | t2, d)=0.6
t2 t2
t1 t1
T = {t1, t2}q = t1 ∧ t2
~d1 = (0.6, 0.6) , ~d2 = (0.59, 0.99)
%(q, ~d1) = 0.6 , %(q, ~d2) = 0.59

4. Nicht-Probabilistische Retrievalmodelle 17Fuzzy-Retrieval
Andere Definitionen der Fuzzy-Operatoren
ρ
ρ
(t1 & t2, d)=0.6
(t1 | t2, d)=0.6
0.6 1
0.6
1
10.6
0.6
1
t2 t2
t1 t1
überwinden Nachteile der Standard-Definition,
aber verletzen Gesetze der Booleschen Algebra:(z.B. %(((t1 ∨ t2) ∧ t3), d) 6= %(((t1 ∧ t3) ∨ (t2 ∧ t3)), d))

4. Nicht-Probabilistische Retrievalmodelle 17Fuzzy-Retrieval
Andere Definitionen der Fuzzy-Operatoren
ρ
ρ
(t1 & t2, d)=0.6
(t1 | t2, d)=0.6
0.6 1
0.6
1
10.6
0.6
1
t2 t2
t1 t1
überwinden Nachteile der Standard-Definition,aber verletzen Gesetze der Booleschen Algebra:(z.B. %(((t1 ∨ t2) ∧ t3), d) 6= %(((t1 ∧ t3) ∨ (t2 ∧ t3)), d))
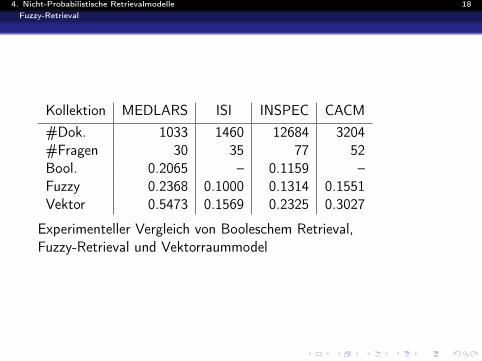
4. Nicht-Probabilistische Retrievalmodelle 18Fuzzy-Retrieval
Kollektion MEDLARS ISI INSPEC CACM#Dok. 1033 1460 12684 3204#Fragen 30 35 77 52Bool. 0.2065 – 0.1159 –Fuzzy 0.2368 0.1000 0.1314 0.1551Vektor 0.5473 0.1569 0.2325 0.3027
Experimenteller Vergleich von Booleschem Retrieval,Fuzzy-Retrieval und Vektorraummodel

4. Nicht-Probabilistische Retrievalmodelle 19Fuzzy-Retrieval
Beurteilung des Fuzzy-Retrieval
+ Generalisierung des booleschen Retrieval für gewichteteIndexierung → Ranking
– keine Fragetermgewichtung– schlechte Retrievalqualität– Erstellung der Frageformulierung sehr umständlich

Das Vektorraummodell
DefinitionRetrievalfunktionCoordination Level MatchDokumenten-IndexierungRelevance Feedback

4. Nicht-Probabilistische Retrievalmodelle 21Das VektorraummodellDefinition
Das VektorraummodellDefinition
zuerst entstanden im Rahmen der Arbeiten zu SMART(experimentelles Retrievalsystem von G. Salton und Mitarbeitern(Harvard/Cornell), seit 1961)
Dokumente und Fragen als Punkte in einem orthonormalenVektorraum, der durch die Terme aufgespannt wirdorthonormaler Vektorraum:
alle Term-Vektoren orthogonal (und damit auch linearunabhängig)alle Term-Vektoren normiert
Dokument-Beschreibung: ähnlich wie Fuzzy-RetrievaldDm = ~dm mit dmi εIR für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki εIR für i = 1, . . . , n

4. Nicht-Probabilistische Retrievalmodelle 21Das VektorraummodellDefinition
Das VektorraummodellDefinition
zuerst entstanden im Rahmen der Arbeiten zu SMART(experimentelles Retrievalsystem von G. Salton und Mitarbeitern(Harvard/Cornell), seit 1961)Dokumente und Fragen als Punkte in einem orthonormalenVektorraum, der durch die Terme aufgespannt wird
orthonormaler Vektorraum:alle Term-Vektoren orthogonal (und damit auch linearunabhängig)alle Term-Vektoren normiert
Dokument-Beschreibung: ähnlich wie Fuzzy-RetrievaldDm = ~dm mit dmi εIR für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki εIR für i = 1, . . . , n

4. Nicht-Probabilistische Retrievalmodelle 21Das VektorraummodellDefinition
Das VektorraummodellDefinition
zuerst entstanden im Rahmen der Arbeiten zu SMART(experimentelles Retrievalsystem von G. Salton und Mitarbeitern(Harvard/Cornell), seit 1961)Dokumente und Fragen als Punkte in einem orthonormalenVektorraum, der durch die Terme aufgespannt wirdorthonormaler Vektorraum:
alle Term-Vektoren orthogonal (und damit auch linearunabhängig)alle Term-Vektoren normiert
Dokument-Beschreibung: ähnlich wie Fuzzy-RetrievaldDm = ~dm mit dmi εIR für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki εIR für i = 1, . . . , n

4. Nicht-Probabilistische Retrievalmodelle 21Das VektorraummodellDefinition
Das VektorraummodellDefinition
zuerst entstanden im Rahmen der Arbeiten zu SMART(experimentelles Retrievalsystem von G. Salton und Mitarbeitern(Harvard/Cornell), seit 1961)Dokumente und Fragen als Punkte in einem orthonormalenVektorraum, der durch die Terme aufgespannt wirdorthonormaler Vektorraum:
alle Term-Vektoren orthogonal (und damit auch linearunabhängig)alle Term-Vektoren normiert
Dokument-Beschreibung: ähnlich wie Fuzzy-RetrievaldDm = ~dm mit dmi εIR für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki εIR für i = 1, . . . , n

4. Nicht-Probabilistische Retrievalmodelle 21Das VektorraummodellDefinition
Das VektorraummodellDefinition
zuerst entstanden im Rahmen der Arbeiten zu SMART(experimentelles Retrievalsystem von G. Salton und Mitarbeitern(Harvard/Cornell), seit 1961)Dokumente und Fragen als Punkte in einem orthonormalenVektorraum, der durch die Terme aufgespannt wirdorthonormaler Vektorraum:
alle Term-Vektoren orthogonal (und damit auch linearunabhängig)alle Term-Vektoren normiert
Dokument-Beschreibung: ähnlich wie Fuzzy-RetrievaldDm = ~dm mit dmi εIR für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki εIR für i = 1, . . . , n

4. Nicht-Probabilistische Retrievalmodelle 22Das VektorraummodellRetrievalfunktion
Retrievalfunktion
Vektor-Ähnlichkeitsmaße, z.B. CosinusMeistens: Skalarprodukt%(~qk , ~dm) = ~qk · ~dm =
∑ti∈T qki · dmi
t
t
1
2
q
d
d
1
2

4. Nicht-Probabilistische Retrievalmodelle 23Das VektorraummodellRetrievalfunktion
Beispiel-Frage:“retrieval experiments with weighted indexing”
term qki d1i d2i d3i d4i
retrieval 1 0.33 0.33 0.25 0.25experiment 1 0.33 0.33 0.25 0.25weight 1 0.25index 1 0.25 0.25XML 0.33method 0.33binary 0.25RSV 0.66 0.66 0.75 1.00

4. Nicht-Probabilistische Retrievalmodelle 24Das VektorraummodellCoordination Level Match
Coordination Level Match
Vereinfachung des Vektorraummodells:nur binäre Frage- und Dokumenttermgewichtung
Dokument-Beschreibung: wie Boolesches RetrievaldDm = ~dm mit dmi ε{0, 1} für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki ε{0, 1} für i = 1, . . . , n
Retrievalfunktion:Skalarprodukt
%(~qk , ~dm) = ~qk · ~dm = |qTk ∩ dT
m |

4. Nicht-Probabilistische Retrievalmodelle 24Das VektorraummodellCoordination Level Match
Coordination Level Match
Vereinfachung des Vektorraummodells:nur binäre Frage- und DokumenttermgewichtungDokument-Beschreibung: wie Boolesches RetrievaldDm = ~dm mit dmi ε{0, 1} für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki ε{0, 1} für i = 1, . . . , n
Retrievalfunktion:Skalarprodukt
%(~qk , ~dm) = ~qk · ~dm = |qTk ∩ dT
m |

4. Nicht-Probabilistische Retrievalmodelle 24Das VektorraummodellCoordination Level Match
Coordination Level Match
Vereinfachung des Vektorraummodells:nur binäre Frage- und DokumenttermgewichtungDokument-Beschreibung: wie Boolesches RetrievaldDm = ~dm mit dmi ε{0, 1} für i = 1, . . . , n
Frage-Beschreibung:qQk = ~qk mit qki ε{0, 1} für i = 1, . . . , n
Retrievalfunktion:Skalarprodukt
%(~qk , ~dm) = ~qk · ~dm = |qTk ∩ dT
m |

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektionhäufiger der Term im Dokumentkürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektionhäufiger der Term im Dokumentkürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektionhäufiger der Term im Dokumentkürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektion
häufiger der Term im Dokumentkürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektionhäufiger der Term im Dokument
kürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 25Das VektorraummodellDokumenten-Indexierung
Dokumenten-Indexierung
Vektorraum-Modell liefert keine Aussagen darüber, wie dieDokumenten-Indexierung zu berechnen ist!
(Dokumenten-)Indexierung im Vektoraummodell:heuristische Formeln zur Berechnung der Indexierungsgewichtezugrundeliegende Dokumenten-Repräsentation: Multi-Menge (Bag)von Termen
Heuristiken:Indexierungsgewicht umso höher, je . . .
seltener der Term in der Kollektionhäufiger der Term im Dokumentkürzer das Dokument

4. Nicht-Probabilistische Retrievalmodelle 26Das VektorraummodellDokumenten-Indexierung
dTm Menge der in dm vorkommenden Termslm Dokumentlänge (# laufende Wörter in dm)al durchschnittliche Dokumentlänge in D
tfmi : Vorkommenshäufigkeit (Vkh) von ti in dm.ni : # Dokumente, in denen ti vorkommt.N: # Dokumente in der Kollektion
inverse Dokumenthäufigkeit (idf):
idfi =log N
ni
N + 1
normalisierte Vorkommenshäufigkeit:
ntfi =tfmi
tfmi + 0.5+ 1.5 lmal
Indexierungsgewicht tfidf:
wmi = ntfi · idfi

4. Nicht-Probabilistische Retrievalmodelle 26Das VektorraummodellDokumenten-Indexierung
dTm Menge der in dm vorkommenden Termslm Dokumentlänge (# laufende Wörter in dm)al durchschnittliche Dokumentlänge in D
tfmi : Vorkommenshäufigkeit (Vkh) von ti in dm.ni : # Dokumente, in denen ti vorkommt.N: # Dokumente in der Kollektion
inverse Dokumenthäufigkeit (idf):
idfi =log N
ni
N + 1normalisierte Vorkommenshäufigkeit:
ntfi =tfmi
tfmi + 0.5+ 1.5 lmal
Indexierungsgewicht tfidf:
wmi = ntfi · idfi

4. Nicht-Probabilistische Retrievalmodelle 26Das VektorraummodellDokumenten-Indexierung
dTm Menge der in dm vorkommenden Termslm Dokumentlänge (# laufende Wörter in dm)al durchschnittliche Dokumentlänge in D
tfmi : Vorkommenshäufigkeit (Vkh) von ti in dm.ni : # Dokumente, in denen ti vorkommt.N: # Dokumente in der Kollektion
inverse Dokumenthäufigkeit (idf):
idfi =log N
ni
N + 1normalisierte Vorkommenshäufigkeit:
ntfi =tfmi
tfmi + 0.5+ 1.5 lmal
Indexierungsgewicht tfidf:
wmi = ntfi · idfi
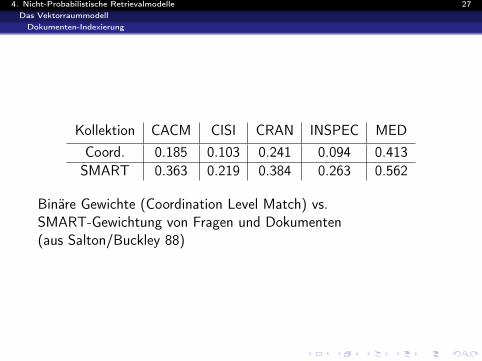
4. Nicht-Probabilistische Retrievalmodelle 27Das VektorraummodellDokumenten-Indexierung
Kollektion CACM CISI CRAN INSPEC MEDCoord. 0.185 0.103 0.241 0.094 0.413SMART 0.363 0.219 0.384 0.263 0.562
Binäre Gewichte (Coordination Level Match) vs.SMART-Gewichtung von Fragen und Dokumenten(aus Salton/Buckley 88)

4. Nicht-Probabilistische Retrievalmodelle 28Das VektorraummodellRelevance Feedback
Relevance Feedbackiteratives Retrieval:
objectrepresentation
queryrepresentation
results
object
comparison
objectdescription
querydescription
information
need
fictive/ real−world

4. Nicht-Probabilistische Retrievalmodelle 29Das VektorraummodellRelevance Feedback
Relevance Feedback im VRM
Ziel: Modifikation des Fragevektors
o
X Xo
o: relevant
X: irrelevant
XX X
XX
XXX
XXo
o
oo
o
X
X XXo
oXX X
X
oo
XX X
oXXX
oX

4. Nicht-Probabilistische Retrievalmodelle 30Das VektorraummodellRelevance Feedback
Bestimmung des optimalen Fragevektors
DR : relevante DokumenteDN : irrelevante Dokumente
Idee:wähle Fragevektor ~q so, dass Differenz der RSVs zwischenrelevanten und irrelevanten Dokumenten maximal wird:
∑(dk ,dl )∈DR×DN
~q ~dk − ~q~dl!= max
mit der Nebenbedingungn∑
i=1
q2i = c
Extremwertproblem mit Randbedingung→ Lagrange-Multiplikator einsetzen

4. Nicht-Probabilistische Retrievalmodelle 30Das VektorraummodellRelevance Feedback
Bestimmung des optimalen Fragevektors
DR : relevante DokumenteDN : irrelevante Dokumente
Idee:wähle Fragevektor ~q so, dass Differenz der RSVs zwischenrelevanten und irrelevanten Dokumenten maximal wird:
∑(dk ,dl )∈DR×DN
~q ~dk − ~q~dl!= max
mit der Nebenbedingungn∑
i=1
q2i = c
Extremwertproblem mit Randbedingung→ Lagrange-Multiplikator einsetzen

4. Nicht-Probabilistische Retrievalmodelle 30Das VektorraummodellRelevance Feedback
Bestimmung des optimalen Fragevektors
DR : relevante DokumenteDN : irrelevante Dokumente
Idee:wähle Fragevektor ~q so, dass Differenz der RSVs zwischenrelevanten und irrelevanten Dokumenten maximal wird:
∑(dk ,dl )∈DR×DN
~q ~dk − ~q~dl!= max
mit der Nebenbedingungn∑
i=1
q2i = c
Extremwertproblem mit Randbedingung→ Lagrange-Multiplikator einsetzen

4. Nicht-Probabilistische Retrievalmodelle 31Das VektorraummodellRelevance Feedback
F = λ
(n∑
i=1
q2i − c
)+
∑(dk ,dl )∈DR×DN
n∑i=1
qidki − qidli
∂F∂qi
= 2λqi +∑
(dk ,dl )∈DR×DN
dki − dli!= 0
qi = − 12λ
∑(dk ,dl )∈DR×DN
dki − dli
~q = − 12λ
∑(dk ,dl )∈DR×DN
~dk − ~dl
= − 12λ
|DN |∑
dk∈DR
~dk − |DR |∑
dl∈DN
~dl
= −|D
N ||DR |2λ
1|DR |
∑dk∈DR
~dk −1|DN |
∑dl∈DN
~dl

4. Nicht-Probabilistische Retrievalmodelle 32Das VektorraummodellRelevance Feedback
Optimaler Fragevektor
~q = −|DN ||DR |2λ
1|DR |
∑dk∈DR
~dk −1|DN |
∑dl∈DN
~dl
wähle c so, dass |DN ||DR |/2λ = −1:
~q =1|DR |
∑dk∈DR
~dk −1|DN |
∑dl∈DN
~dl
=̂ Verbindungsvektor der Zentroiden der relevanten / irrelevantenDokumente

4. Nicht-Probabilistische Retrievalmodelle 33Das VektorraummodellRelevance Feedback
−
−
−
−
−
−
+
+
+
+
+
+
+
−
− +
+
t
t
1
2
unterschiedliche Gewichtung positiver und negativer Beispiele:
−
−
−
−
−
−
+
+
+
+
+
+
+
−
− +
+

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:
1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:
1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:1 Retrieval mit Fragevektor ~qk vom Benutzer
2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung
3 Berechnung eines verbesserten Fragevektors ~qk′ aufgrund der
Feedback-Daten4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor
5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 34Das VektorraummodellRelevance Feedback
Rocchio-Algorithmus
unterschiedliche Gewichtung positiver und negativer BeispieleBerücksichtigung der ursprünglichen Anfrage
~qk′ = ~qk + α
1|DR
k |∑
dj εDRk
~dj − β1|DN
k |∑
dj εDNk
~dj
α, β — positive Konstanten, heuristisch festzulegen (z.B.α = 0.75, β = 0.25)
Vorgehensweise:1 Retrieval mit Fragevektor ~qk vom Benutzer2 Relevanzbeurteilung der obersten Dokumente der Rangordnung3 Berechnung eines verbesserten Fragevektors ~qk
′ aufgrund derFeedback-Daten
4 Retrieval mit dem verbesserten Vektor5 Evtl. Wiederholung der Schritte 2-4

4. Nicht-Probabilistische Retrievalmodelle 35Das VektorraummodellRelevance Feedback
Beurteilung des Vektorraummodells
+ einfaches Modell, insbes. für den Benutzer+ unmittelbar anwendbar auf neue Kollektionen+ gute Retrievalqualität– sehr viele heuristische Komponenten– kein Bezug zur Retrievalqualität
(Optimalität von Relevance Feedback?)– Dokumentrepräsentation kann schlecht erweitert werden


















