
8. Wiederherstellung und Datensicherheitsattler/hal/dbimpl-7.pdf · 8. Wiederherstellung und...
23
8. Wiederherstellung und Datensicherheit ■ Einführung in Recovery ■ Recovery-Komponenten eines DBMSs ■ Fehlerklassen ■ Recovery-Klassen und Strategien VL Datenbank-Implementierungstechniken – 9–1 Einführung in Recovery ■ Datensicherung ohne Intervention garantieren → automatische Wiederherstellung eines konsistenten DB-Zustands nach einem Fehler ■ je nach Fehlerart müssen unterschiedliche Behandlungsstrategien ausgeführt werden ■ Transaktions-Manager/Scheduler wahren die Isolation- und Konsistenzeigenschaft einer Transaktion ■ Recovery-Komponenten sichern die Atomaritäts- und Dauerhaftigkeitseigenschaft einer Transaktion VL Datenbank-Implementierungstechniken – 9–2 Beteiligte Systemkomponenten T 1 T 2 T n Log restart read, write, commit, abort Log-Puffer ... Archiv Log- Archiv read, write, commit, abort read write write read read write write read read write fetch flush (z.B. Platte) Stabiler Speicher Scheduler (SC) Manager (TM) Transaktions Manager (RM) DB-Puffer DB DB- Flüchtiger Speicher ... Puffer Manager (PM) Speicher-Manager (SM) Recovery VL Datenbank-Implementierungstechniken – 9–3
Transcript of 8. Wiederherstellung und Datensicherheitsattler/hal/dbimpl-7.pdf · 8. Wiederherstellung und...

8. Wiederherstellung und Datensicherheit
■ Einführung in Recovery
■ Recovery-Komponenten eines DBMSs
■ Fehlerklassen
■ Recovery-Klassen und Strategien
VL Datenbank-Implementierungstechniken – 9–1
Einführung in Recovery
■ Datensicherung ohne Intervention garantieren→ automatische Wiederherstellung eines konsistentenDB-Zustands nach einem Fehler
■ je nach Fehlerart müssen unterschiedlicheBehandlungsstrategien ausgeführt werden
■ Transaktions-Manager/Scheduler wahren die Isolation-und Konsistenzeigenschaft einer Transaktion
■ Recovery-Komponenten sichern die Atomaritäts- undDauerhaftigkeitseigenschaft einer Transaktion
VL Datenbank-Implementierungstechniken – 9–2
Beteiligte Systemkomponenten
T 1 T 2 T n
Log
restartread, write,commit, abort
Log-Puffer
...
Archiv
Log-Archiv
read, write,commit, abort
read
write
write
read read
write
writeread
readwrite
fetchflush
(z.B. Platte)Stabiler Speicher
Scheduler (SC)
Manager (TM)Transaktions
Manager (RM)
DB-Puffer
DB
DB-
FlüchtigerSpeicher
...
PufferManager (PM)
Speicher-Manager (SM)
Recovery
VL Datenbank-Implementierungstechniken – 9–3

Recovery-Komponenten I
Speicher-Manager (SM):
■ bildet Schnittstelle zwischen flüchtigem und stabilenSpeicher
■ umfaßt Recovery-Manager und Puffer-Manager
Recovery-Manager (RM): sorgt dafür, daß
1. alle Änderungen einer „committed“ Transaktion auchtatsächlich im stabilen Speicher sind
2. keine Änderungen von aktiven oder abgebrochenenTransaktionen im stabilen Speicher sind
3. nach einem Fehler die DB in einen konsistenten Zustandgebracht wird→ zum Restart benötigte Daten müssengesichert werden
VL Datenbank-Implementierungstechniken – 9–4
Recovery-Komponenten II
Puffer-Manager (PM)/ Cache-Manager (CM):
■ verwaltet den Puffer (DB- und Log-Puffer)→ holt Daten (Seiten) vom stabilen Speicher in den
Puffer→ schreibt Daten (Seiten) vom Puffer in den stabilen
Speicher→ ersetzt Daten (Seiten) im Falle eines „Pufferüberlaufs“
VL Datenbank-Implementierungstechniken – 9–5
Fehlerklassifikation
Fehlerklassifikation
1. Transaktionsfehler
2. Systemfehler
3. Mediafehler
→ unterschiedliche Recovery-Maßnahmen je nach Fehlerart
VL Datenbank-Implementierungstechniken – 9–6

Transaktionsfehler
■ Transaktionsfehler◆ haben den Abbruch der jeweiligen Transaktion zur
Folge◆ haben keinen Einfluß auf den Rest des Systems→ auch: lokaler Fehler
■ Typische Transaktionsfehler:
1. Fehler im Anwendungsprogramm2. Transaktionsabbruch explizit durch den Benutzer3. Transaktionsabbruch durch das System
■ Behandlung:
→ „Isoliertes“ Zurücksetzen aller Änderungen derabgebrochenen Transaktionen
VL Datenbank-Implementierungstechniken – 9–7
Systemfehler
■ Systemfehler◆ Folge: Zuerstörung der Daten im Hauptspeicher◆ betreffen jedoch nicht den Hintergrundspeicher
■ Typische Systemfehler:
1. DBMS-Fehler2. Betriebssystemfehler3. Hardware-Fehler
■ Behandlung:
→ Zurücksetzen der von nicht beendetenTransaktionen in die DB eingebrachten Änderungen
→ Nachvollziehen der von abgeschlossenenTransaktionen nicht in die DB eingebrachtenÄnderungen VL Datenbank-Implementierungstechniken – 9–8
Mediafehler
■ Mediafehler◆ ziehen den Verlust von stabilen Datenbankbankdaten
nach sich
■ Häufige Ursachen:1. „Head-Crashes“2. Controller-Fehler3. Naturgewalten wie Feuer oder Erdbeben
■ Maßnahmen:
→ DB-Archiv auf anderen „Medien“
VL Datenbank-Implementierungstechniken – 9–9
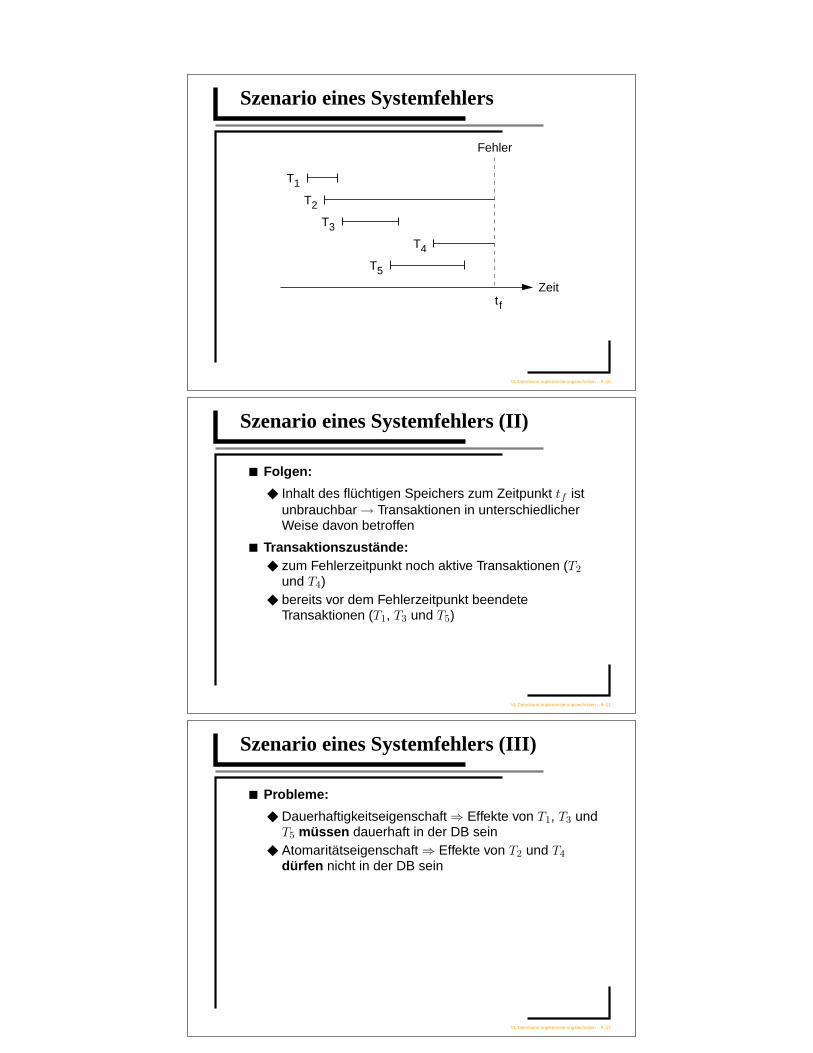
Szenario eines Systemfehlers
1T
2T
3T
4T
5T
tZeit
Fehler
f
VL Datenbank-Implementierungstechniken – 9–10
Szenario eines Systemfehlers (II)
■ Folgen:
◆ Inhalt des flüchtigen Speichers zum Zeitpunkt tf istunbrauchbar→ Transaktionen in unterschiedlicherWeise davon betroffen
■ Transaktionszustände:◆ zum Fehlerzeitpunkt noch aktive Transaktionen (T2
und T4)◆ bereits vor dem Fehlerzeitpunkt beendete
Transaktionen (T1, T3 und T5)
VL Datenbank-Implementierungstechniken – 9–11
Szenario eines Systemfehlers (III)
■ Probleme:
◆ Dauerhaftigkeitseigenschaft⇒ Effekte von T1, T3 undT5 müssen dauerhaft in der DB sein
◆ Atomaritätseigenschaft⇒ Effekte von T2 und T4
dürfen nicht in der DB sein
VL Datenbank-Implementierungstechniken – 9–12

Recovery-Klassen
■ R1-Recovery (lokales Zurücksetzen – TransactionUNDO):nach Transakationsfehler werden die entsprechendenTransaktionen isoliert zurückgesetzt
■ R2-Recovery (partielles Wiederholen – PartialREDO):nach Systemfehler besteht ein konsistenter Zielzustandaus allen bis zum Fehler abgeschlossenenTransaktionen⇒ alle Änderungen abgeschlossener Transaktionen,deren Daten beim Systemfehler noch im Puffer waren,nachvollziehen und in die DB schreiben
VL Datenbank-Implementierungstechniken – 9–13
Recovery-Klassen (II)
■ R3-Recovery (globales Zurücksetzen – GlobalUNDO):nach Systemfehler soll der Zielzustand keineAuswirkungen nicht beendeter Transaktionen enthalten⇒ Spuren sämtlicher zum Fehlerzeitpunkt aktiverTransaktionen aus der DB entfernen
■ R4-Recovery (globales Wiederholen – Global REDO):nach Defekt auf einem nichtflüchtigen Externspeicherwird eine Archivkopie auf den Datenträger kopiert⇒ alle Änderungen der nach der letzten Erstellung derArchivkopie beendeten Transaktionen nachvollziehenund in die DB schreiben
VL Datenbank-Implementierungstechniken – 9–14
Protokollierungsarten
■ Log-Buch
■ physische versus logische Protokollierung
■ Sicherungspunkte
VL Datenbank-Implementierungstechniken – 9–15

Prinzipieller Aufbau eines Log-Buchs
Schritt T1 T2 Log
1 lock A (T1, begin)2 read A3 A := A− 14 write A (T1, A, 10, 9)5 lock B6 unlock A7 lock A (T2, begin)8 read A9 A := A× 210 read B11 write A (T2, A, 9, 18)12 commit (T2, commit)13 unlock A14 B := B/A ↓ (T1, abort)
VL Datenbank-Implementierungstechniken – 9–16
Prinzipieller Aufbau eines Log-Buchs II
A hat zu zu Anfang den Wert 10Vor dem ersten Schritt wird (T1, begin) eingetragen
Vor Schritt 4 folgt (T1, A, 10, 9)Vor Schritt 7 beginnt T2 mit (T2, begin)Vor Schritt 11 wird (T2, A, 9, 18) eingetragenVor Schritt 12 folgt Abschluß von T2: (T2, commit)Nach Schritt 14 wird Abbruch (T1, abort) geschrieben
VL Datenbank-Implementierungstechniken – 9–17
Einträge im Log
[ LSN, TA, PageID, Redo, Undo, PrevLSN ]
■ LSN: Log-Sequence-Number, eindeutige undaufsteigende Durchnumerierung der Log-Einträge
■ TA: Transaktionskennung
■ PageID: Seitennummer
■ Redo: REDO-Information
■ Undo: UNDO-Information
■ PrevLSN: Verweis auf den vorherigen Eintrag der selbenTransaktion
VL Datenbank-Implementierungstechniken – 9–18

Einträge im Log – Beispiel
[ #1, T1, BOT ][ #2, T1, PA, A=A+1, A=A-1, #1 ][ #3, T2, BOT ][ #4, T2, PA, A=A×2, A=A/2, #3 ][ #5, T2, commit, #4 ][ #6, T1, abort, #2 ]
VL Datenbank-Implementierungstechniken – 9–19
Physisches Protokollieren
■ ganze physische Speichereinheiten (d.h. Seiten)
■ vor dem Einlagern Seite gesondert als Before-Imagespeichern
Vorteil:
■ Protokoll- bzw. Recovery-Komponenten sind sehreinfach zu realisieren
VL Datenbank-Implementierungstechniken – 9–20
Physisches Protokollieren (II)
Nachteile:
1. Protokollinformationen können nicht gepuffert werden→hoher E/A-Aufwand
2. Seitenprotokollierung erfordert das Sperren ganzerSeiten
3. Protokollinformationen über Änderungen in denZugriffspfaden, Tabellen, Ketten, etc. müssen zusätzlichgehalten werden
VL Datenbank-Implementierungstechniken – 9–21

Logisches Protokollieren
■ alle ausgeführten höheren Operation werden imLog-Buch erfaßt→ anhand dieser Informationen können dieDML-Anweisungen (und deren Invers-Operationen)nachvollzogen werden
Vorteil:
■ Auswirkungen der Änderungsoperationen einerTransaktion auf die Speicherungsstrukturen müssennicht protokolliert werden→ es genügt Änderungsoperationen und die aktuellenParameter zu notieren
VL Datenbank-Implementierungstechniken – 9–22
Logisches Protokollieren (II)
Nachteile:
1. Probleme bei der R1/R3-Recovery→ inverseDML-Operationen sind oftmals nicht (trivial) berechenbar
2. DB muß in einem speicherkonsistenten Zustand sein,um als Ausgangspunkt für die Recovery dienen zukönnen
VL Datenbank-Implementierungstechniken – 9–23
Szenario
Systemfehler nach einem Sicherungspunkt
1T
2T
3T
4T
5T
Sicherungspunkt
ttsZeit
Fehler
f
VL Datenbank-Implementierungstechniken – 9–24

Physisches vs. logisches Protokollieren
Phys. Protokollieren Log. Protokollieren
T1 In ts wurden alle bis dahin angefallenen Änderungen über-nommen (keine Wiederholung von T1 notwendig)
T2 Partielles Zurücksetzen vonT2 mit Hilfe der Before-Images
Ausführung bis ts protokollier-ter inverser DML-Befehle inumgekehrter Reihenfolge bisBOT
T3 Partielles Wiederholen von T3mit Hilfe der After-Images
Ausführung nach ts protokol-lierter Original-DML-Befehlebis Commit
T4 Alle Effekte von T4 mit Wiederherstellung des Zustandszum Zeitpunkt ts implizit entfernt (keine weiteren Maßnah-men erforderlich)
T5 Durch Wiederherstellen des Zustands zum Zeitpunkt ts ver-schwinden alle Auswirkungen von T5 (T5 komplett wieder-holen)
VL Datenbank-Implementierungstechniken – 9–25
Das WAL-Prinzip
Write Ahead Log
■ vor commit einer Transaktion Ausschreiben allerzugehörigen Log-Einträge(notwendig für Durchführung von REDO)
■ vor dem Auslagern einer modifizierten Seite Schreibenaller zugehörigen Log-Einträge in das Log-Archiv(ermöglicht UNDO bei abgebrochenen Transaktionen)
VL Datenbank-Implementierungstechniken – 9–26
Sicherungspunkte (SP)
■ Sicherungspunkte (engl. checkpoints)◆ werden im normalen Betrieb der DB angelegt, um bei
der Recovery Zeit/Kosten zu sparen
■ Arten:
1. Transaktionskonsistente Sicherungspunkte2. Aktionskonsistente Sicherungspunkte3. Unscharfe Sicherungspunkte
VL Datenbank-Implementierungstechniken – 9–27

Transaktionskonsistente SP
■ alle Änderungen werden in einem Moment, in dem keineSchreibbefehle aktiv sind, vom Puffer in die DBgeschrieben
Ablauf:
1. Sicherungspunkt angemelden
2. neu ankommende Transaktionen müssen warten
3. aktive Transaktionen werden zu Ende geführt
4. sobald alle aktiven Transaktionen beendet wurden,werden alle geänderten Seiten auf die Platte gezwungen
VL Datenbank-Implementierungstechniken – 9–28
Transaktionskonsistente SP (II)
■ Kennzeichen:◆ spätere R2-Recovery braucht keine Veränderungen
vor diesem Punkt mehr zu berücksichtigen◆ Nachteil: läßt Benutzer unter Umständen lange
warten
VL Datenbank-Implementierungstechniken – 9–29
Transaktionskonsistente SP (III)
1T
2T
3T
4T
Anm
eldu
ng
Sich
erun
gspu
nkt
Zeit
VL Datenbank-Implementierungstechniken – 9–30

Aktionskonsistente Sicherungspunkte
■ periodisches Blockieren aller aktiven Transaktionenblockiert und Schreiben der bis dahin geänderten Seitenin die DB
■ Änderungen der abgebrochenen Transaktionen (bzgl.des letzten Sicherungspunkts) werden im nächstenSicherungspunkt behandelt
VL Datenbank-Implementierungstechniken – 9–31
Aktionskonsistente Sicherungspunkte (II)
Kennzeichen:
■ beim Restart muß weniger geleistet werden, da◆ alle bis zum letzten Sicherungspunkt erfolgreich
abgeschlossenen Transaktionen gesichert sind unddamit keine Redo-Phase notwendig ist
◆ alle abgebrochenen Transaktionen mit demZurücksetzen ungültig gemacht wurden
■ Nachteil: läßt Benutzer unter Umständen lange warten
VL Datenbank-Implementierungstechniken – 9–32
Aktionskonsistente Sicherungspunkte (III)
1T
2T
3T
4T
Zeit
PeriodischeSicherungspunkte
VL Datenbank-Implementierungstechniken – 9–33

Unscharfe (fuzzy) Sicherungspunkte
■ es werden nur die Seiten auf die Platte gezwungen, dievor dem letzten Checkpoint nicht ausgeschriebenwurden
Kennzeichen:
■ vermeidet Performance-Verlust durch Unterbrechen bzw.Blockieren von Transaktionen
■ garantiert jeweils den vorletzten konsistenten Zustandder DB
VL Datenbank-Implementierungstechniken – 9–34
Recovery-Strategien
■ Seitenersetzungsstrategien
■ Propagierungsstrategien
■ Einbringstrategien
■ Konkrete Recovery-Strategien
VL Datenbank-Implementierungstechniken – 9–35
Seitenersetzungsstrategien
■ UNDO (steal):◆ jederzeit dürfen noch nicht freigegebene Seiten
auslagert werden→ benötigt das Write-Ahead-Logging-Protokoll→ Sicherung von Protokollinformationen bevorSeitenauslagerung
■ NO-UNDO (¬steal):◆ kein Auslagern von geänderten Seiten vor dem
Commit einer Transaktion erlaubt→ vermeidet das Zurücksetzen von Transaktionen→ vereinfacht den Abbruch einer Transaktion→ hat Probleme, wenn keine der im Puffer modifizierten
Seiten ausgelagert werden dürfen
VL Datenbank-Implementierungstechniken – 9–36

Propagierungsstrategien
■ NO-REDO (force):◆ beim Commit werden alle geänderten Seiten in die
DB eingebracht
■ REDO (¬force):◆ nach dem Commit können geänderte Seiten im
Puffer verbleiben, ohne explizit auf dem stabilenSpeicher gesichert werden→ Redo-Protokollinformationen im stabilen Speicherabgelegt
VL Datenbank-Implementierungstechniken – 9–37
Propagierungsstrategien (II)
Vergleich:
■ REDO-Variante ist im allgemeinen besser, weil
→ sie den großen E/A-Aufwand beim Commit und damitschlechte Antwortzeiten vermeidet
→ sie durch den Einsatz von Sicherungspunktenverbessert werden kann
VL Datenbank-Implementierungstechniken – 9–38
Einbringstrategien
■ Direkte Zuordnung (¬atomar = update-in-place):◆ jede Seite im Puffer ist genau einer Seite in der DB
zugeordnet→ Puffer-Seite wird beim Auslagern auf die
entsprechende DB-Seite kopiert→ der alte Zustand geht verloren⇒ erfordert physisches Protokollieren
■ Indirekte Zuordnung (atomar):◆ für jede Puffer-Seite ist im stabilen Speicher ein
Twin-Block reserviert→ Puffer-Seite wird jeweils auf den „‘älteren“ Twin-Block
ausgelagert→ selbst bei einem Fehler bleibt der letzte konsistente
Zustand erhalten VL Datenbank-Implementierungstechniken – 9–39

Einbringstrategien (II)
Nachteil (der indirekten Zuordnung):
1. doppelter Speicherplatzbedarf
2. Seitentabellen für die zur Abbildung zwischen flüchtigenund stabilen Speicher passen nicht in den Hauptspeicher
VL Datenbank-Implementierungstechniken – 9–40
Konkrete Recovery-Strategien
Kombination der Seitenersetzungs- undPropagierungsstrategien ergeben die möglichenRecoverystrategien:
1. UNDO/REDO
2. UNDO/NO-REDO
3. NO-UNDO/REDO
4. NO-UNDO/NO-REDO
VL Datenbank-Implementierungstechniken – 9–41
Recovery-Strategien im Überblick
PropagierungSeitenersetzung force ¬ force
¬ steal kein REDO REDO
kein UNDO kein UNDO
steal kein REDO REDO
UNDO UNDO
VL Datenbank-Implementierungstechniken – 9–42

UNDO/REDO
■ jederzeit dürfen geänderte Seiten auslagert werden
■ update-in-place erlaubt
■ WAL und Propagierung sind mit Sicherungspunktenverkoppelt
Vorteil:
■ maximiert die Effizienz bei normalen Betrieb auf Kostender Effizienz bei der Recovery
Nachteile:
■ After-Images brauchen viel Platz
■ großer E/A-Overhead, wenn die Seiten von den meistenTransaktionen nur geringfügig geändert werden
VL Datenbank-Implementierungstechniken – 9–43
UNDO/NO-REDO
■ alle geänderten Seiten werden spätestens beimCommit in die DB geschrieben
■ vermeidet partielles Redo→ keine After-Images benötigt
■ speichert Redo Einträge auf Archivmedium für globalesRedo
■ legt Undo Einträge (Before-Images) in der temporärenLogdatei ab
VL Datenbank-Implementierungstechniken – 9–44
UNDO/NO-REDO (2)
Vorteile:
■ läßt sich gut mit einem Multi-Versionen-Schedulerkombinieren, da die Multiversionen als Before-Imagesgenutzt werden können
■ keine After-Images notwendig
Nachteile:
■ geänderte „Hot-Spot“-Seiten müssen nach jedemCommit in die DB geschrieben werden→ hoherE/A-Aufwand
■ Verwaltungskosten für die Before-Images
VL Datenbank-Implementierungstechniken – 9–45

NO-UNDO/REDO
■ alle Änderungen werden bis mindestens zum Commitim Puffer gehalten→ DB enthält nur „committed“ Seiten
Vorteile:
■ Commit ist schnell und billig
■ keine Before-Images nötig
■ hohe Durchsatzrate, da wenig E/A bei normalem Betrieb
Nachteile:
■ großer Puffer nötig
■ nach Absturz ist die DB konsistent, aber alt→ muß beimNeustart anhand von After-Images aktualisiert werden
VL Datenbank-Implementierungstechniken – 9–46
NO-UNDO/NO-REDO
■ um NO-UNDO/NO-REDO zu garantieren, müssen alleÄnderungen einer Transaktion beim Commit atomar indie DB geschrieben werden
■ Änderungen werden zunächst auf Kopien geschrieben
■ Kopien werden über Directories verwaltet, wobei einZeiger auf die letzte „committed“ Kopie zeigt
■ beim Commit wird der Zeiger auf die neue Kopie gelenktund somit alle Änderungen atomar propagiert
VL Datenbank-Implementierungstechniken – 9–47
NO-UNDO/NO-REDO (II)
Vorteil:
■ kein Abbrechen und Wiederholen von Transaktionennotwendig
Nachteile:
■ Halten von Directories→ häufiger indirekter Zugriff darauf ist sehr teuer
■ Platzbedarf für die Versionen→ Finden von „uncommitted“ Versionen
VL Datenbank-Implementierungstechniken – 9–48

Recovery-Strategien im Vergleich
Eigenschaft Strategie
UNDO UNDO NO-UNDO NO-UNDO
REDO NO-REDO REDO NO-REDO
Zeitpunkt jederzeit spätestens nach dem beim Commit
der Auslagerung beim Commit Commit
Before-Images√ √ − −
After-Images√ − √ −
WAL-Protokoll√ − − −
VL Datenbank-Implementierungstechniken – 9–49
Wiederanlauf im Fehlerfall
2. Redo aller Änderungen (Winner und Loser)
3. Undo aller Loser-Änderungen
1. Analyse (Ermittlung der Winner und Loser)
Log
Systemfehler
VL Datenbank-Implementierungstechniken – 9–50
REDO-Protokoll
commit-Punkt einer Transaktion:
■ Für jedes A, das mit neuem Wert a von T belegt wird,wird (T,A, a) in das Log geschrieben
■ Eintrag (T, commit) wird an das Log angehängt
■ Alle Seiten des Log werden auf den stabilen Speichergeschrieben (Transaktion „committed“)
■ (T,A, a)-Änderungen werden in der Datenbank (oder nurim Puffer) durchgeführt
VL Datenbank-Implementierungstechniken – 9–51

REDO-Protokoll (II)
Untersuchung des Log-Buchs:
■ Datenbank wird in den letztmöglichen konsistentenZustand zurückgesetzt
■ Alle zur Zeit gesetzten Sperren werden aufgehoben
VL Datenbank-Implementierungstechniken – 9–52
REDO-Protokoll (III)
Recovery-Algorithmus:
■ Log wird rückwärts durchlaufen
■ Alle (T, commit)-Einträge werden notiert; dieseTransaktionen werden als erfolgreich („Winner“) markiert
■ Für jede erfolgreiche Transaktion T werden alle(T,A, a)-Einträge gesucht und a in die Datenbankgeschrieben
■ Transaktionen ohne (T, commit) oder mit (T, abort)werden als „Loser“ ignoriert ; Warnung an denBenutzer: „T not committed!“ oder ein automatischesrestart
VL Datenbank-Implementierungstechniken – 9–53
Das ARIES-Verfahren
Recovery in drei Phasen:
1. Analysephase
2. Redo-Phase„history repeating“
3. Undo-PhaseKompensation der zum Fehlerzeitpunkt aktivenTransaktionen
VL Datenbank-Implementierungstechniken – 9–54

Vorgehensweise in ARIES am Beispiel
LSN Log-Eintrag
10 update: T1 schreibt Seite P5
20 update: T2 schreibt Seite P3
30 commit: T2
40 EOT: T2
50 update: T3 schreibt Seite P1
60 update: T3 schreibt Seite P3
× Systemfehler→ restart
VL Datenbank-Implementierungstechniken – 9–55
Vorgehensweise in ARIES am Beispiel (II)
■ Analysephase: T1 und T3 aktiv→ Undo
◆ T2 Commit→ Resultate nach Recovery auf stabilemSpeicher
◆ P1, P3 und P5 potentielle „Dirty-Pages“
■ Redo-Phase: „history repeating“Änderungen von T1 und T3 wiederholt
■ Undo-Phase:Änderungen von T1 und T3 in umgekehrter Reihenfolgerückgängig machen: Log-Einträge 60, 50 und dann 10werden kompensiert
VL Datenbank-Implementierungstechniken – 9–56
ARIES: Notwendige Datenstrukturen
■ Transaktionsliste: Informationen über alle laufendenTransaktionen◆ für jede Transaktion Log-Sequenz-Nummer lastLSN:
letzter Log-Eintrag der von dieser Transaktiongeschrieben
■ Dirty-Page-Liste: Einträge über „Dirty-Pages“
◆ Seiten mit Änderungen, die nicht bereits auf denstabilen Speicher „gerettet“ wurden
◆ recoveryLSN: Log-Eintrag, der die Seite in denZustand „dirty“ bewegt hat
Log-Buch: prevLSN zum Verketten der Einträge einerTransaktion rückwärts in der Zeit; lastLSN ist Kopf dieserVerkettung
VL Datenbank-Implementierungstechniken – 9–57

Phasen des Wiederanlaufs
Start der ältesten aktivenTransaktion
Erste möglicherweise Checkpoint Ende des
Änderungverlorengegangene Logs
Analyse
Redo
Undo
VL Datenbank-Implementierungstechniken – 9–58
Phasen des Wiederanlaufs (II)
1. Analysephase■ Log wird vorwärts beginnend mit dem letzten
Sicherungspunkt analysiert■ Analysephase findet Dirty-Pages und aktive
Transaktionen■ firstLSN: älteste recoveryLSN aller Dirty-Pages→
Anfangspunkt der Redo-Phase
2. Redo-Phase■ „history repeating“: Wiederholung aller Änderungen■ Redo auf Seiten-Ebene■ Für Redo kein Logging notwendig!
VL Datenbank-Implementierungstechniken – 9–59
Phasen des Wiederanlaufs (III)
3. Undo-Phase■ Undo für logische Operationen■ Logisches Undo besonders hilfreich bei
Index-Operationen (da dort Probleme mit demZusammenspiel mit den erfolgreichen Transaktionenauftreten würden)
■ Im Log-Buch werden Undo-Schritte alsKompensations-Log-Einträge CLR protolliert
■ CLR enthält UndoNxtLSN als Verweis auf nächsteUndo-Operation der bearbeiteten Transaktion
VL Datenbank-Implementierungstechniken – 9–60

Einsatz der CLR
SchreibeSeite 1
LSN: 10
CLR fürLSN 30
40
Schreibe SchreibeSeite 1 Seite 1
CLR fürLSN 20
50
Restart
CLR fürLSN 10
60
Restart
20 30
Undo! Undo! Undo!
Log
VL Datenbank-Implementierungstechniken – 9–61
Schattenspeicherverfahren
Schattenspeicherverfahren für Recovery statt oderzusätzlich zu Logs Puffer
■ Kopien auf dem stabilem Speicher halten→Schattenspeicher
■ Seitenzuordnungstabelle→ logische Seitenadressen
■ Umschalten zwischen den Seitentabellen atomar→ boole’sche Variable als kleinstmöglicher kritischerSpeicherinhalt
VL Datenbank-Implementierungstechniken – 9–62
Schattenspeicherkonzept
p
Schatten ~j
q
r
aktuelles j
Schalter
iV0:
V1:
physische Seiten
virtuelle Seiten (−tabellen)
j
ji
VL Datenbank-Implementierungstechniken – 9–63

Vorteile des Schattenspeicher-Verfahren
■ Führen eines Logs ist überflüssig, so daß der laufendeBetrieb effizienter erfolgen kann
■ Beim Wiederanlauf der Datenbank ist kein REDO
notwendig
■ Rücksetzen auf den letzten konsistentenDatenbankzustand ist sehr billige Operation
VL Datenbank-Implementierungstechniken – 9–64
Nachteile bei Schattenspeicher
■ Durch viele Kopien von Schattenseiten entsteht‘"Datenmüll“ auf der Platte
■ Seiten zu einer Relation werden durch die Erstellung vonKopien, die bei Transaktionsende zu Originalen werden,über die ganze Platte verteilt ; Relation kann nichtmehr als sequentielle Folge von Blöcken effizient mitPrefetching-Strategien gelesen werden
■ Bei sehr großen Datenbanken werden Hilfstabellen zurUmsetzung der Seitenadressen so groß, daß sie selber(teilweise) auf den Sekundärspeicher ausgelagertwerden
VL Datenbank-Implementierungstechniken – 9–65
Backup-Strategien
■ Backup der gesamten Datenbank◆ sehr aufwendig◆ während des laufenden Betriebs ohne kaum
Einschränkungen möglich
■ Backup der Änderungen seit dem letztem Backup(inkrementelles Backup)◆ jeweils Backup der neuen Daten seit dem letztem
(auch inkrementellen) Backup◆ u.U. Aufbau einer langen Kette von inkrementellen
Backups, die bei Verlust der Datenbank bearbeitetwerden muß, um aktuellen Stand derverlorengegangenen Datenbank wiederherzustellen
VL Datenbank-Implementierungstechniken – 9–66

Backup-Strategien (II)
■ Inkrementelles Backup mit mehreren Ebenen◆ mehrere Backup-Ebenen legen fest, welchen Umfang
die Daten haben, für die Sicherung erfolgt◆ Basis-Ebene 0 sichert die komplette Datenbank◆ Backup geht zeitlich jeweils zum vorherigen Backup
einer kleineren Stufe zurück◆ je höher die Ebene, desto kürzer ist das Endstück der
Datenbank-Historie, für die das Backup erfolgt◆ Kette wiederherzustellender inkrementeller Backups
ist durch die Anzahl der Ebenen begrenzt
VL Datenbank-Implementierungstechniken – 9–67
Multi-level inkrementelles Backup
Level 0 1 1 2 2 1 2 2
Zeit
VL Datenbank-Implementierungstechniken – 9–68


















