
A P2P-Based Infrastructure for Censorship-Resistant … · Abstract...
62
Diplomarbeit A P2P-Based Infrastructure for Censorship-Resistant Web Access Taner Aydin September 26, 2011 Technische Universität Berlin Fakultät IV Institut für Softwaretechnik und Theoretische Informatik Professur Security in Telecommunications Betreuender Hochschullehrer: Prof. Dr. Jean-Pierre Seifert Betreuender Mitarbeiter: Dipl.-Ing. Benjamin Michéle
Transcript of A P2P-Based Infrastructure for Censorship-Resistant … · Abstract...

Diplomarbeit
A P2P-Based Infrastructure forCensorship-Resistant Web Access
Taner Aydin
September 26, 2011
Technische Universität BerlinFakultät IV
Institut für Softwaretechnik und Theoretische InformatikProfessur Security in Telecommunications
Betreuender Hochschullehrer: Prof. Dr. Jean-Pierre SeifertBetreuender Mitarbeiter: Dipl.-Ing. Benjamin Michéle


ErklärungHiermit erkläre ich, dass ich diese Arbeit selbstständig erstellt und keine anderen als dieangegebenen Hilfsmittel benutzt habe.
Berlin, den September 26, 2011
Taner Aydin


AcknowledgementsFirst of alI I would like to thank Prof. Seifert for letting me write this thesis at hisinstitute. I also thank Benjamin Michéle for providing me with the possibility to workon such an exciting and also challenging topic, for developing the idea of this thesistogether and for really helping out with ideas when I was struggling with problems.Thanks also to Dmitry Nedospasov who assisted me with technical issues of testingenvironments, and to my friends and family who always took their time to help me testthe prototype.But, most of all, I thank you, Mareike, for all your caring support and for your
patience.


AbstractInternet censorship is getting more and more established today. Censorshipcontradicts the human right to freedom of opinion and expression. Therecent national debate in Germany and other member states of the EuropeanUnion emphasizes that the legitimate wish to ban Internet content thatis against national law, can quickly turn into a direction that jeopardizesour right to censorship-free Internet usage. In many countries the latteris already taking place. Oppressive regimes consider Internet censorshipas an effective measure to keep citizens away from politically, culturally orreligiously undesired content. This is done to the extent that even web sitesthat are considered useful in most parts of the world can be completelycensored.
It is therefore of great importance to provide tools for suppressed Internetusers around the world which enable them to access censored web sites. Suchcensorship circumvention tools have difficult tasks to solve. First of all,they have to circumvent Internet censorship reliably – they have to providecensorship-resistant Internet access. At the same time, they have to beblocking-resistant, which means the tool itself should not be blockable bya censor. Besides this, the tool needs to prevent censors from identifyingactive users in the network.Current tools that can also circumvent censorship are mostly from the field
of anonymity systems. In most cases, they are not specifically designed withblocking resistance in mind. This makes them useless if a censor alreadyknows about the tools and blocks them.This thesis proposes WebBuddy, a tool that helps users circumvent Inter-
net censorship. It incorporates anonymity mechanisms of current systemsand is also designed to be blocking-resistant. WebBuddy creates a networkof users that relay connections to web sites for other users of the system.One focus of WebBuddy is to make its usage as seamless as possible forusers. It is therefore integrated directly in the user’s browser.
VII

KurzzusammenfassungDie Anwendung von Internet-Zensur hat sich in den letzten Jahren im-mer mehr etabliert. Diese Zensur widerspricht jedoch dem Menschenrechtauf Meinungsfreiheit und freie Meinungsäußerung. Die vergangene politis-che Debatte in Deutschland, aber auch in anderen Teilen der EuropäischenUnion, hat deutlich gemacht, dass der Wunsch nach mehr Kontrolle im Inter-net seitens der Politik groß ist. Der legitime Gedanke strafrechtlich beden-kliches Material aus dem Internet zu verbannen kann jedoch schnell zu derIdee eines staatlich kontrollierten Zensursystems führen und damit die freieNutzung des Internets stark gefährden. Solche Zensursysteme existieren invielen Ländern weltweit schon. Totalitäre Staaten nutzen die Zensur umdamit politische, kulturelle und religiös unerwünschte Inhalte aus dem In-ternet unzugänglich zu machen. Diese Zensur führt sogar so weit, dass derZugang zu ganzen Webseiten komplett gesperrt werden – Seiten die in denmeisten Orten der Welt als nützlich, legitim und wertvoll erachtet werden.Es werden somit dringend Mittel benötigt mit denen unterdrückte In-
ternetnutzer zensierte Webseiten wieder erreichen können. Solche Zensur-Umgehungs-Tools müssen schwierige Aufgaben meistern. Als erstes müssensie auf verlässliche Art und Weise die Zensur eines Zensursystems umgehenkönnen. Gleichzeitig müssen sie auch resistent sein gegen mögliche Versucheeines Regimes das Tool selbst oder den Zugang zu diesem zu blockieren. DesWeiteren müssen sie ausreichende Anonymität für den Nutzer gewährleis-ten, da dieser sonst allein durch die Benutzung des Tools potentiell negativeAufmerksamkeit auf sich ziehen könnte.Aktuell eingesetzte Tools für die Umgehung von Zensur stammen meist aus
dem Feld der Anonymitätssysteme. Meistens sind diese Systeme jedoch nichtin Hinblick auf eine mögliche Blockierung gestaltet worden. Somit werdensie unbrauchbar für die Umgehung der Zensur sobald ein Zensursystem vondiesen weiß.In dieser Diplomarbeit wird WebBuddy vorgestellt, ein Tool das In-
ternetnutzern hilft die Zensur in ihrem Land zu umgehen. Es nutztAnonymisierungstechniken aktueller Systeme, ist aber auch resistent gegenBlockversuche. WebBuddy erzeugt ein Netzwerk von Nutzern die in derFolge füreinander den Zugang zu Webseiten ermöglichen. Ein Hauptaugen-merk von WebBuddy liegt darin die Benutzung so nahtlos und einfach wiemöglich zu gestalten. Deshalb wird WebBuddy direkt in den Browser desNutzers integriert.
VIII

Contents
1 Introduction 1
2 Background 52.1 HTTP Proxy Servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 HTTPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 SSL Tunneling Through Web Proxy Servers . . . . . . . . . . . . . . . . 52.4 Public-Key Cryptography . . . . . . . . . . . . . . . . . . . . . . . . . . 62.5 Mix Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.6 Onion Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.7 Peer-to-Peer Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.7.1 Kademlia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.7.2 BitTorrent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.7.3 BitTorrent Mainline DHT . . . . . . . . . . . . . . . . . . . . . . 10
2.8 Censorship Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.8.1 IP-Based . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.8.2 Keyword-Based . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.8.3 DNS-Based . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Related Work 153.1 Non-P2P-Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Tor (The Onion Router) . . . . . . . . . . . . . . . . . . . . . . . 153.1.2 Private Web Search . . . . . . . . . . . . . . . . . . . . . . . . . 163.1.3 GoogleSharing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 P2P-Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2.1 Crowds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2.2 MorphMix & Tarzan . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Design 214.1 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.1.1 Censorship Resistance and Blocking Resistance . . . . . . . . . . 214.1.2 Anonymity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.1.3 Ease of Use . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.1.4 Scalability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2 Concepts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.2.1 Peer-to-Peer Proxying . . . . . . . . . . . . . . . . . . . . . . . . 224.2.2 URL Whitelists . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.2.3 Low Bandwith and Rate Limiting . . . . . . . . . . . . . . . . . 234.2.4 Country-Based Selection . . . . . . . . . . . . . . . . . . . . . . . 23
IX

Contents
4.2.5 HTTPS Only . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.2.6 HTTPS Onion Routing . . . . . . . . . . . . . . . . . . . . . . . 244.2.7 Browser Add-On . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2.8 BitTorrent DHT . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.3 Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.3.1 Browser Add-On . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.3.2 Lookup System . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.3.3 WebBuddy-Manager . . . . . . . . . . . . . . . . . . . . . . . . . 284.3.4 Local-Proxy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.3.5 Remote-Proxy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5 Implementation 315.1 Ruby as Main Language . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.2 DHT Component . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.3 Firefox Add-On . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.4 Remote-Proxy Implementation . . . . . . . . . . . . . . . . . . . . . . . 335.5 Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.6 WebBuddy Prototype . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6 Evaluation 376.1 Censorship and Blocking Resistance . . . . . . . . . . . . . . . . . . . . 376.2 Ease of Use . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396.3 Anonymity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396.4 Scalability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396.5 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
7 Conclusion 43
Glossary 45
Bibliography 47
X

List of Figures
2.1 Proxy Servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 SSL tunneling through a proxy server . . . . . . . . . . . . . . . . . . . 72.3 Onion-Routing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4.1 HTTPS onion routing with two WebBuddy proxies . . . . . . . . . . . . 264.2 WebBuddy architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.1 WebBuddy Firefox add-on . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2 WebBuddy tunnel, open . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.3 WebBuddy tunnel, send . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.4 WebBuddy tunnel, close . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
XI


1 Introduction
The right to freedom of opinion and expression is a universal human right. It is declaredin article 19 by the United Nations General Assembly in the Universal Declaration ofHuman Rights [19]. Not only is it part of this declaration but also many other nationalor supranational declarations, e.g., the European Union’s Convention for the Protectionof Human Rights and Fundamental Freedoms [42]. The right to freedom of opinion andexpression states that every human has the freedom to speak freely, without any formof censorship or consequences and to seek and access information freely without theinformation being censored. In practice these rights are of course limited in such a waythat they don’t collide with any other rights. For instance, hate speech is not coveredunder the freedom of opinion and expression.The different possible interpretations of the limits of freedom of opinion and expression
can lead to various forms of the right. Most democratic countries allow their citizens tomake use of it to the greatest extent possible. Some other democratic countries limit itaccording to their own values and standards. Turkey, for instance, although having aparliamentary democracy, is very keen about restricting freedom of expression when itcomes to insults against the founder of the Republic of Turkey, Mustafa Kemal Atatürk.A law to this end was issued in 1951, which ultimately led to a censorship of the wholewww.youtube.com web site in Turkey for most of the time during the last 4 years. Thereason for this were some videos available on the platform that were seen as an insultto Atatürk [35].There are also countries where the freedom of expression is limited to an extent where
it gets questionable if such a right even exists anymore. Those countries try to limitfreedom of expression for various reasons but mostly political ones. In such oppressiveenvironments the Internet is a dangerous medium for regimes as it enables their citizensto communicate, inform and organize themselves very quickly. A recent example for thiscould be observed in the Arab Spring where citizens used social media sites like Twitteror Facebook to share information about ongoing demonstrations [36].Internet censorship is not a new phenomenon. In many countries the Internet has
been censored for many years now. The most famous example for country-wide Inter-net censorship is the Great Firewall of China [54] (the official name is Golden ShieldProject), which is the system used by the Peoples’s Republic of China. The systemcensors Internet access by blocking complete web sites or blocking connections thattransmit undesired keywords. Frequent media coverage of the Great Firewall of Chinacan lead to the impression that such a sophisticated system is only being used in China.On the contrary, there are many countries that strongly restrict Internet usage by cen-soring. The organization Reporters Without Borders just recently published its reportwith “Internet Enemies”, a list of the most restrictive countries concerning Internetaccess [59]. In the category “Under Surveillance” they also list some more countries
1

1 Introduction
that are heavily surveilling Internet usage, including Australia, France or South Korea.Techniques for censoring can differ between countries but their goal is always the same:to block undesired Internet usage.Undesired web content ranges from famous examples like Google Search, Wikipedia,
WikiLeaks, blogging services like Blogger, Facebook, Twitter or YouTube to smallerweb sites the government does not want their citizens to know about. For instance,Google has agreements with countries on their local censorship policies and ensures tocensor unwanted search keywords themselves. This practice is not specific to China orother countries known to censor heavily. In fact this happens for every country [5]. Thereason for this is that a globally acting company like Google still has to comply withlocal laws. Since laws and the values they are based on can be quite different aroundthe world, this consequently leads to conflicts.In March 2010, Google publicly announced not to censor search keywords for China
anymore. They shut down www.google.cn and instead redirected every user of it totheir Hong Kong Google Search site www.google.co.hk, where Google is not bound tothe censoring rules for the rest of China. This again led the Chinese government tocensor the connections from mainland China to the Hong Kong site [34]. News coverageof the whole topic was also censored [50].Another country that caused a lot of publicity with the topic of Internet censoring
is Iran. Social media web sites like Facebook, Twitter or even the recently startedGoogle+ are blocked and only available with specific measures taken by users [37].Although it may seem that this censorship system is not as sophisticated as the onedeployed in China, the Iranian government is very keen about extending censorshipeven to the extent that citizens only get access to a national intranet instead of thewhole Internet [43].Censorship in Pakistan got quite public when in 2008 Pakistan Telecom tried to cen-
sor YouTube by BGP prefix hijacking, a technique in which the ISP’s networks claimthat the IP address of www.youtube.com belongs to their own networks and conse-quently packets meant for YouTube are not routed correctly anymore. While this reallyachieved the desired censorship of YouTube in Pakistan, the false routing informationwas propagated around, so that the networks of ISPs around the world “believed” thebogus routing information and YouTube became inaccessible for a few hours [40].The easiest way for an oppressed citizen to circumvent such censorship is to use proxy
servers. By doing this the user does not directly connect to a web site but instead to aproxy with a different IP address. By now, censorship systems worldwide have movedto block such proxy servers, too. In addition to that, unencrypted content via plainHTTP can be blocked pretty easily. Users also have to trust the proxy provider. Usingsimple open proxies therefore is not reliable.Existing approaches in the field of anonymity systems can also help with censorship
circumvention because of their nature of using one or multiple proxies. While someof them are of theoretical use only, others are deployed and in real use. Anonymityin oppressive regimes can be a dangerous task to master. If the tool fails to achieveits promise and breaks, it can endanger the user by compromising the identity to theoppressor. Since existing anonymity tools focus on the anonymity properties and assumea strong attacker in their threat model, they are well suited for this purpose.
2

Only focusing on strong anonymity for the user neglects strong blocking resistancethough. A major problem of those tools is that the tool itself can get blocked by a censor.So these tools have to be redesigned or adjusted to be blocking-resistant afterwards.This thesis introduces WebBuddy, a peer-to-peer based infrastructure for censorship-
resistant web access. WebBuddy’s main focus is on enabling users to circumvent censor-ship of universally useful and important web sites that are very helpful for informationretrieval; web sites like Google Search, Wikipedia, etc. The design concepts of Web-Buddy aim to achieve strong censorship resistance. This means that web sites that areblocked by the currently most sophisticated censorship systems can be accessed again.The results of current censorship methods is incorporated into the design of WebBuddy.But not less importantly, the infrastructure of WebBuddy aims to be blocking-resistant,too. WebBuddy also makes use of the same anonymization techniques as used in othersuccessful anonymity networks in order to provide anonymity.In WebBuddy, every participant is both a user and a proxy in the whole WebBuddy
network of proxies. Thus, participants from different parts of the world help each otherto circumvent their local censorship and become web buddies.In order to circumvent sophisticated censorship systems WebBuddy uses HTTPS only.
This means that the web site being accessed has to support it. This seems like a drasticlimitation, but the aim of WebBuddy is to access certain universally accepted web sitesaround the world that provide HTTPS access. Google Search for example was launchedin its HTTPS version under https://encrypted.google.com. In the future, otherweb sites could follow this example [29, 31]. By default, WebBuddy relays the HTTPSGoogle web site. The user can add more sites to the list of supported web sites asdescribed later (see 4.2.2).In order to be blocking-resistant, WebBuddy uses a peer-to-peer proxying scheme,
meaning everyone can use anyone’s proxy services. This is in contrast to other toolswhere there is a limited set of proxy servers with static IP addresses.Some of the already existing tools can be quite demanding regarding installation
and usage. WebBuddy tries to facilitate the usage and make it seamless for the user.Therefore, the tool is deployed as an add-on for the browser, so the only thing a userhas to do is to install the add-on and use it right away.This thesis is structured in the following way: Chapter 2 describes and briefly explains
the used technologies and prerequisites of WebBuddy. This chapter also contains alisting of censorship methods used. Chapter 3 describes already existing projects andtools that are similar to, but different from WebBuddy. Chapter 4 declares the goalsof WebBuddy and explains the concepts and design choices used to accomplish them.Chapter 5 describes implementation choices and details. Finally, Chapter 6 evaluatesif the declared goals are accomplished and which parts require further work. This isfollowed by a short conclusion in Chapter 7.
3


2 Background
This chapter describes concepts and technologies WebBuddy uses. Basic terminology isalso explained here.
2.1 HTTP Proxy ServersMost censorship circumvention tools are based on the usage of – often multiple – proxyservers. The basic functionality of a proxy server is quite simple. The proxy serveraccepts connections from a client. The latter wants to connect to a final server some-where. The proxy server acts on behalf of the client and represents it towards the server.Traffic from both client and final server is forwarded in both directions by the proxyserver (see Figure 2.1).A very simple example of a proxy server is an HTTP proxy server, often used in
networks where many users share the same Internet connection, e.g., in companies oruniversities. The HTTP proxy server receives the HTTP requests from the clients andfilters HTTP headers, caches responses and also anonymizes the actual user, since thefinal server only recognizes the proxy server speaking to it. This, in fact, is the verybasic idea behind anonymizing and censorship circumvention tools. How this concretelyhelps in these tools will be described in detail in Chapter 4.
2.2 HTTPS
HTTPS is a synonym for HTTP over SSL/TLS. This means SSL/TLS (in the follow-ing SSL) is used to establish a secure connection between client and server and HTTPrequests and responses are sent over this SSL connection. In order to establish such aconnection, both parties must exchange SSL handshake information which also includescertificates. With certificates each side can prove their authenticity to their communi-cation partner, although it is common that only the server authenticates itself to theclient. Clients usually do not authenticate themselves to a server.
2.3 SSL Tunneling Through Web Proxy ServersUsing an HTTP proxy server means that the proxy acts on behalf of the client. If aclient wants to connect to an HTTPS server, the proxy could establish its own HTTPSconnection to the server, including SSL handshake and verifying server authenticity. Theproxy now could provide its own certificate to the client. If used this way, a client wouldnever see the actual certificate of the original server and would not have true end-to-endencryption. Rather, there would be two encrypted connections with the proxy in the
5

2 Background
Internet
Proxy Server
Clients
Figure 2.1: Clients communicate through the proxy server with the Internet. The proxyserver represents each client towards others in the Internet.
middle. The proxy would know all about the content sent to the web server. However,this is not what SSL actually is intended for: establishing an end-to-end encryptedcommunication channel.There is an HTTP method besides GET, POST and all the others, that is specifically
intended for the described scenario: CONNECT. With CONNECT the proxy server isinstructed to not interfere in the following SSL connection establishment. The clientand server establish their own end-to-end encrypted connection, while the original serverstill only sees the proxy server connecting to it (see Figure 2.3).
2.4 Public-Key CryptographyPublic-key cryptography solves the problem when two parties want to communicatesecurely with one another but have not agreed on a shared key for encryption before.The cryptography here works asymmetrically, meaning that there are two keys: publickey and private key. The public key is distributed publicly, anyone can have it. Theprivate key is kept secret and is only stored locally on the user’s machine the keypair belongs to. Both keys of the key pair are inverse to each other. So any messageencrypted with the public key can only be decrypted with the private key and viceversa. If user Alice wants to send Bob some encrypted message only Bob is supposedto read, Alice encrypts the message by Bob’s public key. After this, only Bob, who hasthe corresponding private key, can decrypt the message. A widely known algorithm forasymmetric cryptography is RSA [46].
6

2.5 Mix Networks
Proxy Server Web Server(encrypted.google.com)
send"CONNECT encrypted.google.com:443 HTTP/1.1" open TCP connection
Client
(a) The client instructs the proxy server to open a connection to the web server.
Proxy Server Web Server(encrypted.google.com)
sendSSL handshake data for web server
forwarddata from web server
forwarddata from client
sendSSL handshake data to client
(1) (2)
(3)(4)
Client
(b) SSL handshake data is forwarded in both directions by the proxy without interfering. The webserver still recognizes the proxy server as its communication partner.
Figure 2.2: SSL tunneling through a proxy server
2.5 Mix NetworksThe concept of anonymous data traffic from a sender to a receiver reaches back to1981, when David L. Chaum first described this concept [21] for emails. A sender doesnot send data directly to the receiver but instead through a chain of proxies whichare called mixes. These mixes are responsible for different tasks before relaying thereceived data further. For instance, a mix collects data from different senders and onlysends them out in a batch, so that an attacker monitoring both sides cannot correlateincoming and outgoing data. Data is also reordered to make correlation more difficult.Chaum’s mix network concept also describes how public-key cryptography is used toensure that the sender of data stays anonymous against the final recipient. Mix networksare supposed to anonymize users in a high latency way, meaning that data being sentcan be delayed arbitrarily, due to the batch processing, for example. Therefore mixnetworks are very suitable for scenarios were communication happens asynchronously,such as electronic mail, which is also the originally described use case by Chaum. Todaythere are different applications of the mix networks concept. Anonymizing web surfing,for instance, demands low latency behavior of the network. Anonymity networks likeTor [27] or JAP [8] leave out the batch processing part because it conflicts with the lowlatency aspect of such systems. Tor is described in more detail in 3.1.1.
7

2 Background
2.6 Onion Routing
Onion routing [32] is an application of the concept of mix networks [21] for low latencynetworks. Tor – also being the most famous example for this – uses onion routing forits purposes. The idea is to add several layers of encryption to the actual data beforesending it through a previously built chain of proxies. This is done in a way that theserver cannot deduce where the data is really coming from because each proxy withinthe chain only knows its adjacent neighbors.For example, a client wants to connect to a web site via a chain of three proxies. The
initial data the client has to encrypt is the destination address of the web server andthe payload data it wants to send to the web site. First of all the client encrypts thedata (destination + payload) with the public key of the last proxy in the chain. Thisencrypted data gets concatenated with the plain text destination address of the thirdproxy. This combined data then gets encrypted again with the public key of the secondproxy server. Again the destination address of the second server is concatenated withthis and the whole packet gets encrypted one last time with the public key of the firstproxy server (see Figure 2.3).The first proxy receives this multiply encrypted packet first. It can decrypt the
outermost layer with its corresponding private key and recognizes a destination address– the one of the second proxy server – and an encrypted packet that it cannot readbecause it is encrypted with the public key of the second proxy server. It forwards thisencrypted packet to the second proxy server, which in turn follows the same procedureand the packet reaches the third proxy server. The third proxy server decrypts the lastencrypted packet with its corresponding key and finally delivers the original data to thedestination web server.The implication of this procedure is anonymity for the user. All proxies in the chain
receive and process data without knowing the true origin of this data. Except for thefinal proxy, a proxy does not know its position in the chain. The final proxy server,often called exit node, can recognize that it is the exit node because it has to contactthe web server. It is important to note that each proxy only has knowledge about thedirect sender of the data and the following recipient which the proxy sends the data to.Assuming the operators of the proxies do not work together the true origin of the datatherefore remains secret.The length of the chain plays an important role here: a chain length of one (only
one proxy server) obviously does not help with anonymity. A chain length of twowould already suffice to ensure that the client cannot be correlated to a web serveraccess anymore. As mentioned before, this only works if the proxies are operated byindependent parties that do not work together. In order to reduce the probability ofthis scenario, often a chain length of three ore more proxies is used.
2.7 Peer-to-Peer NetworksWebBuddy uses a completely decentralized peer-to-peer network to find its buddies.How this works in detail is described in Chapter 4. There are several proposed peer-
8

2.7 Peer-to-Peer Networks
data K1K2K3
K1: Public key of first proxy
K2: Public key of second proxy
K3: Public key of third proxy
Figure 2.3: Initial data is encrypted by three1 layers. First, with the key of the lastproxy, then with the key of the second and at last with the key of the first.Each recipient can only decrypt off one layer until the last proxy extractsthe original data.
to-peer protocols and some of them are also in real use in active networks. A popularexample is Kademlia.
2.7.1 KademliaKademlia [38] is the name of a peer-to-peer system for key-value storage and lookup. Itis a robust and fast system that allows finding participants of the peer-to-peer networkin logarithmic time. It does not use any centralized elements and therefore is a purepeer-to-peer protocol. It uses the concept of distributed hash tables (DHT) to do so.The original Kademlia protocol was adopted by two very commonly used file sharingapplications: aMule [1] and BitTorrent. The development of aMule proved to be not soactive anymore, whereas with BitTorrent the situation is quite the opposite. This madeBitTorrent the better choice for WebBuddy.In Kademlia the participants are called nodes. In practice the DHT in Kademlia is
a globally distributed storage for < key, value > pairs. Each key has an ID which isa 160-bit SHA-1 hash. Also every participating node in the DHT has an ID from thesame space of IDs. A node is “responsible” for storing values to a key ID if its ownID is “close enough” to this key ID. The closeness is determined by a distance metric
1 The example uses three proxy servers and therefore three layers of encryption. The number of usedproxies can be set arbitrarily.
9

2 Background
function. In this case it is a simple bitwise XOR of both the node and the key ID. Thelower the result value the closer they are.Nodes keep their information about other nodes from the DHT in routing tables.
These are built in a way that a node knows many other nodes from his close ID neighbor-hood but only few distant nodes. Those few distant nodes each act like a representativefor a certain ID range and each of those representatives knows its respective neighbor-hood the best. So when a node starts to look for another node that is responsible for acertain key ID, it queries the nodes in its own routing table that are the closest to thekey ID. If one of those queried nodes is already the right one the search is successfullyfinished. If not, the queried node responds with a list of nodes from its own routingtable that are the closest to the key ID. Since each node along this search path knowsits neighborhood in more detail than the nodes before, this search scheme converges andfinally yields a result.
2.7.2 BitTorrentBitTorrent is the most popular file sharing network today. Files shared with BitTorrentare called torrents. To download a torrent the user first has to download a torrentfile that contains information about the torrent and where to actually get it. Theoriginal BitTorrent system uses trackers [22] for finding other peers involved in down-and uploading a certain torrent. These are basically web servers that keep track of peerIP addresses and can be queried for those.Today most of the modern BitTorrent clients also implement trackerless lookup sys-
tems as an additional way to find other peers. One of those is an implementation ofKademlia (see 2.7.1). In BitTorrent terms it is often just called DHT. In order for DHTto work for the BitTorrent file sharing network, the different BitTorrent clients have toto use a compatible DHT protocol. Not every BitTorrent client does so. The originalBitTorrent client – having the same name BitTorrent [2] – proposes a DHT specifica-tion [3] for the clients. Most of the clients use this “mainline” DHT implementation.Vuze [14], another popular client, uses an incompatible implementation, for example.For WebBuddy’s prototype the mainline DHT implementation was chosen because ithas a big user base and thus a stable network.
2.7.3 BitTorrent Mainline DHTThe BitTorrent DHT is based on Kademlia. As described, a DHT stores < key, value >pairs in a distributed fashion. BitTorrent uses this distributed storage for managinginformation about torrents. Each torrent has its unique ID which is again a 160-bit SHA1hash. This is the key part of the DHT. The value part is a list of contact information (IPaddress and port number) for peers that are involved in a certain torrent. Therefore,if queried for a torrent ID, the BitTorrent DHT finally returns a list of peer contactinformation.BitTorrent’s DHT protocol, like the original Kademlia protocol, describes four remote
procedure calls (RPC): ping, find_node, get_peers, announce_peer. Whereas the
10

2.8 Censorship Methods
first two are used for maintenance and updates of the routing tables of a node, the lasttwo are those of interest here.
get_peers is used for finding BitTorrent peers that are involved in a specific torrent.One of its arguments is the torrent ID looked for. The response to get_peers eithercontains a list of peer contact information including the IP addresses and ports of thesearched peers, or it contains a list of DHT nodes that are closer to the ID and whichhave to be queried with the same method further.
announce_peer is invoked by a DHT node if it wants to announce to the DHT thatit is involved in a torrent itself. Its arguments contain the torrent ID that the nodeis involved in, the node’s own ID and the TCP port of the BitTorrent client that iscontrolling the DHT node.
2.8 Censorship MethodsThere are several ways to censor the Internet. One of the most sophisticated examplesof Internet censoring can be found in the People’s Republic of China [59]. The GreatFirewall of China also serves as the most analyzed censorship system and thereforeprovides a lot of information on how censoring is done. Organizationally, censoring isdone by the government instructing the ISPs of the country to apply filter techniques intheir border gateway routers (routers that handle the connections between China andthe rest of the world). Most of the filter techniques require updates of what is to befiltered. This leads to dissimilarities in which web sites are reachable from which partof the country because sometimes it can take a while for updates to propagate acrossall ISPs. Technically, censoring is done by a few different methods. An analysis of theGreat Firewall of China extracts the most common ones [60]. The following descriptionsare therefore based on it.
2.8.1 IP-BasedThe most obvious approach to censor certain web sites is to block the IP addresses ofthe web servers they are hosted on. The censors put those IP addresses on blacklistswhich are then propagated to the different ISPs. An ISP seeing one of its users tryingto connect to one of those blacklisted IP addresses can simply drop the connection. Forthe user this seems as if the original destination is not reachable. The browser shows aconnection error.Although this sounds like quite an easy censoring method it implies that all content
on the same server is blocked. Depending on how “forbidden” the content of the website is for the censor, this collateral damage is nevertheless tolerated in some cases.Apart from censoring web sites directly, censors started to block the counter measures
to censorship, too. For instance, proxy services are blocked on IP address basis. Thisalso started to affect the Tor servers, for example. The creators of Tor stated thatthe Chinese Government started to block the IP addresses of all Tor servers. Theseare publicly available from directory servers. The directory servers are getting blocked,too [25].
11

2 Background
Another IP-based method is BGP prefix hijacking used for IP address impersonation.This method of censoring uses the core structure of the Internet. The Internet consists ofautonomous systems (AS) [51] that are connected with each other. Each AS maintainsrouting tables that contain information about which other ASs own certain IP addressprefixes. BGP [52] is used for communication between the different ASs. An AS isusually controlled by one or more network operators. If these network operators getinstructed by their respective governments to route Internet traffic incorrectly in orderto censor, whole web sites can be made unreachable. Packets from a user surfing tohttp://www.youtube.com for example would not be routed to YouTube anymore butinstead to some other computer claiming to have the IP address of YouTube or to nocomputer at all. Forging routing information in this way on the BGP level is known asBGP prefix hijacking [41]. This kind of attack can have unforeseen consequences. Sinceneighboring ASs can get polluted with false routing information they start to routeincorrectly, too. This can lead to the scenario of users worldwide not being able toreach certain web sites anymore. There are already some counter measures to preventsuch attack scenarios [20].
2.8.2 Keyword-BasedWhile the IP-based method can cause too much collateral damage, this method allowsthe censor more fine grained control over what is blocked. Connections to undesirableservers are first allowed by the censor, but the data is analyzed for occurrences of certainundesired keywords. Whenever one of those is found in the URL or also in the HTMLof the web site, the censor — sitting in the middle between client and server — sendsTCP reset packets in both directions causing the connection between client and serverto terminate. This is done either in the border gateway routers or via dedicated proxyservers trough which Internet traffic is routed [24]. The proxy server approach is mostlycombined with IP-based filtering to a hybrid system: connection attempts to suspiciousIP addresses are routed through a proxy server which then can apply keyword or URLfiltering. Using only a government level proxy server would not scale and therefore isunrealistic, as long as the government does not restrict Internet speed for the population.Whenever a connection gets filtered, the user sees a browser error, not being able todetermine if it is a temporary error or a permanent blockage.
2.8.3 DNS-BasedAnother method of filtering is the manipulation of DNS responses. DNS servers can bequeried by a client to obtain the IP address corresponding to the domain of the website the user wants to connect to. The default DNS server is normally provided by theuser’s ISP, which means the ISP can control the DNS responses it sends back to theuser. Whenever the user tries to find out an IP address to a domain that is consideredundesirable by the censor, the ISP intentionally responds with incorrect IP addresses.This way the web site gets unreachable for the user unless he knows the IP address ofthe web site already.
12

2.8 Censorship Methods
A user could obtain publicly available DNS servers outside of his country and usethem as primary DNS server. In this case the censor has another method to counterthis: he blocks traffic to DNS servers outside of the country and only allows connectionsto DNS servers inside, which are under his control. This is a drastic measure, but couldbe taken in theory.
13


3 Related Work
There are already some approaches that can and sometimes do provide censorship cir-cumvention. Most of these have anonymity and privacy as their main goal but sometimesthe techniques for anonymity can be used as they provide censorship circumvention, too.Some of the relevant approaches are practically used, some of them are more theoreticalresearch projects. They can be categorized in two categories: Non-P2P-Systems andP2P-Systems.
3.1 Non-P2P-SystemsIn Non-P2P-Systems there are participants with different roles. Almost always thiscomes down to a client-server model: the infrastructure consists of the servers andclients use this infrastructure.
3.1.1 Tor (The Onion Router)Tor is an anonymity system [27] which is actively deployed and in use today. To achieveits functionality it uses different proxy servers (Tor servers) which constitute the Tornetwork. After a user installs the Tor client he can use it as a general TCP proxyserver. The user can configure his browser to use the local Tor client as a proxy for allconnections. When starting, the Tor client builds a so called circuit of Tor servers: threeTor servers are chosen from a public directory of all Tor servers and are used to build achain of these that is based on onion routing. Each Tor server only knows its adjacentneighbor. Assuming the operators of the different Tor servers are not collaborating theuser cannot be tracked by an individual Tor server or the destination server the userwants to reach. The last server of the circuit is called exit node. It’s the one that knowsthe content of the data transmission if it is not encrypted otherwise. It is also the onethat appears as the originating client for the destination server.Because of how Tor works it also serves as a circumvention tool for blocked web
sites. The user connects to proxies and not directly to a web site. Still the design andarchitecture of Tor has some disadvantages when it comes to blocking resistance. Theseare addressed by the creators of Tor separately and they are trying to improve thisaspect [25].While Tor focuses on anonymity first and tries to improve the blocking resistance flaws
with additions to the architecture, WebBuddy is designed to be blocking-resistant in thefirst place but also provides anonymity by the same mechanisms Tor uses. The problemin Tor’s design primarily lies in the relatively small set of Tor servers – approximately2500 by the time of writing [12] – that are also publicly available in a directory. Anadversary can easily get the list of IP addresses of those servers and block connections
15

3 Related Work
to all of them. The Tor network would become unreachable for a user in consequence.The creators of Tor are trying to address this by adding the possibility for clients tobecome a bridge to the Tor network [25]. But this relies on voluntary Tor client usersas they have to activate that they want to serve as a bridge to the network. WebBuddy,in contrast, considers all participants as proxies. This leads to a potentially bigger setof concurrently active proxies. Also, their IP addresses are mostly short-lived dynamicIP addresses due to common ISP policies.A further problem with Tor servers comes from the exit nodes. Since the exit nodes
transmit the data from the user to the destination server and this data can be unen-crypted (plain HTTP for example), to someone monitoring this connection it seems thatthe exit node is responsible for the data. In the case of illegal activities the exit node canthus be made legally responsible for the content. The legal situation of this scenario isin a gray area for many countries. That is why Tor servers can choose if they also wantto serve as an exit node or if they only want to be “used in the middle”. Tor aims tobe a general tool for all TCP connections. WebBuddy instead focuses on web sites andonly transmit HTTPS data. Therefore, the content is always encrypted on the wholeway between the user and destination server. In Tor the exit node may log unencryptedHTTP data and compromise the anonymity of the user.Another problem with Tor is performance. Data routed trough the Tor network takes
a lot more time than a direct connection. Although a significant delay is natural andobvious – the data is routed trough a circuit of not necessarily locally close servers –the speed of data transmission is also limited by the capacity of the network. With only2500 active servers it is difficult to serve a large number of users. WebBuddy insteaduses every participant as a proxy and should therefore scale better. Also, the content ofWebBuddy is restricted to web sites whereas with Tor a user could even do file sharingover it.The usability of Tor improved over the years. At first users had to download and
configure the Tor client to use it. Additionally, they had to configure there systemnetwork or browser network preferences to use the Tor client. Nowadays, there are Torbrowser bundles that deliver everything preconfigured and working together in a singlebundle. This bundle idea is also applied in WebBuddy as described later on (cf. Section4.2.7).
3.1.2 Private Web SearchBefore Tor browser bundles were introduced by The Tor Project another group alreadyhad the idea of integrating all components in a bundle to enable users to privately usesearch engines like Google Search. This approach was called Private Web Search [47]and resembles a lot the concept of WebBuddy. The tool itself was built as a browseradd-on for Firefox – just as in WebBuddy. But internally Private Web Search uses aTor client to route its traffic. Additional features include the filtering of HTTP headerinformation and sensitive HTML content. This is done so that the user does not leakany personal information. The tool also helps with censorship resistance for the samereasons like with Tor. The authors describe that, as a result of using Tor to route traffic,Private Web Search is much slower than a direct connection.
16

3.2 P2P-Systems
3.1.3 GoogleSharingGoogleSharing, like Private Web Search, is a Firefox browser add-on that uses a specialanonymizing system [6] so that users can use Google services without Google being ableto track the particular users and build profiles of their search habits. This works bymixing up the “identities” of participating users. So every time a user issues a searchrequest, for example, he uses another identity from the set of participants. Google-Sharing’s goal is to provide anonymity from Google. In a way it could also be usedas a censorship circumvention tool that specifically helps reaching Google Search, sincethe users do not connect directly to Google. But if analyzed further, it turns out tobe useless as a circumvention tool because GoogleSharing always connects to one andthe same proxy server provided by the creators. Thus, GoogleSharing itself could beblocked easily.
3.2 P2P-SystemsP2P-Systems do not distinguish between participants. Each one of them has the sametask: they serve their functionality to other clients and at the same time are clientsthemselves.
3.2.1 CrowdsCrowds is an anonymity system that enables users to surf web sites anonymously [44].Again, the main goal is anonymity and not censorship resistance. The way Crowdsworks also resembles WebBuddy a lot. Each node (participant) of the system is bothserver and client, meaning that each node forwards data on behalf of others. At firstthe initial user randomly chooses another node from the “crowd” of nodes to which heforwards his data. The receiving node decides with a certain probability if it forwardsthe data to another node that it chooses itself or if it delivers the data to the destinationserver. Although this results in some valuable anonymity properties, the tool is uselessfor censorship resistance. Each node receives the complete data packet in plain text,so each node on the whole path knows the IP address of the destination server to bereached. An adversary could put a lot of his own nodes in the system. Since eachnode knows the IP address of the destination server, a malicious node can easily denyforwarding the packet at all and therefore jam the system.
3.2.2 MorphMix & TarzanMorphMix [45] and Tarzan [30] are peer-to-peer based anonymity systems from 2002.Their concepts are very similar to those of WebBuddy and their censorship resistancepotential is more promising than in Crowds.MorphMix also is a system where each node serves as both a client to the system and a
proxy server to other clients. During startup the client gets a set of known participatingnodes and their IP addresses and public keys. After this it builds a chain of thosenodes using the same mechanism of layered encryption as in Tor and also WebBuddy
17

3 Related Work
(cf. Section 2.6). The lookup of other nodes can happen in several ways. The authorsexplain that they intentionally do not use a peer-to-peer based lookup system such asChord [49] which is quite similar to Kademlia [38]. The latter is used in WebBuddy.They argue that it would impose too much overhead for their tool. To join the network aclient only needs one existing and active node (bootstrap node). From there it can querythis node for further known nodes. They propose three strategies for finding a bootstrapnode. The first is to use the local cache of the client to find out if the already knownnodes are still active and use one of them as a bootstrap node. A second strategyinvolves nodes that are known to be always online. BitTorrent DHT, as describedearlier (cf. Section 2.7.3), uses this same strategy for the first time bootstrap. Anotherstrategy they describe would be the use of “information servers” which resemble muchthe functionality of BitTorrent trackers: They keep track of the nodes that are part ofthe network and can be queried for a list of them. In the description of the authors ofMorphMix it is said that those servers only know about a percentage of all active nodesand if queried for nodes they only give out portions of those lists in a random fashion.In Tarzan also every node is both server and client. The client also builds a chain
of nodes just in the same way. Tarzan differs from MorphMix mainly in how nodediscovery is described. As in MorphMix they use their own peer-to-peer network, whereeach participating node starts with knowing only a few nodes. The difference is thatnodes share their known nodes with each other through a kind of gossip protocol [7].Many of the described aspects work almost the same way in WebBuddy. The peer-
to-peer proxying works principally the same way. Also the client chooses all of theproxies for the chain by itself. Both MorphMix and Tarzan use peer-to-peer lookupmechanisms to find out about other nodes. Since the goal of a peer-to-peer network isthat every node can learn about any other node, it can be very easy for an adversary tojust participate in the network and try to get to know all nodes and simply put their IPaddresses on blacklists. Still this task can be very imprecise because of high fluctuationsof active users of the network. WebBuddy’s approach is to use a well established peer-to-peer network for that purpose. Assuming that the adversary would not block thewhole network at once because of the resulting collateral damage, WebBuddy clientscan work side by side with nodes that are not affiliated with WebBuddy at all. Thismakes it more difficult for an adversary to get and block the WebBuddy IP addresses.The fact that fluctuation of nodes in the peer-to-peer network is high and the DHT onlydelivers a maximum number of known WebBuddy nodes when queried, makes it evenmore difficult for the adversary (cf. Section 4.3.2).Tarzan and MorphMix are both general TCP proxy systems. Although both claim
high anonymity properties, the user’s privacy can still be compromised through inter-cepted plain text data on the application layer level (e.g. HTTP). There are still websites that do not use HTTPS login sites, for example. WebBuddy, in contrast, onlyrelays HTTPS data, so this cannot happen.When using HTTPS only the content of data transmission is not revealed. There-
fore, a user of the system who is serving as an exit node does not have to fear legalconsequences if other users use his Internet connection for transmitting illegal content.Another difference in WebBuddy is how the tool is actually used. MorphMix is a
proxy server written in Java, Tarzan is a proxy server written in C++. Both have to be
18

3.2 P2P-Systems
run as a separate program on the system. Applications have to be configured to use theproxy service of those tools. WebBuddy instead is fully integrated as a browser add-on.Consequently there is no need for configuration and even the most amateur user shouldbe able to use it.Despite their theoretical and conceptual resemblance, both MorphMix and Tarzan
were research projects that do not seem to be in real use nowadays.
19


4 Design
In this section the design of WebBuddy will be described. First of all the goals ofWebBuddy will be laid out. This will be followed by a detailed description of its conceptsand finally the architecture of the tool is shown.
4.1 GoalsWebBuddy has similar goals to anonymity systems that are already used but makescensorship resistance and blocking resistance as important as the anonymity property.Ease of use and scalability are goals that are also very important for reasons statedbelow.
4.1.1 Censorship Resistance and Blocking ResistanceThe main goal of WebBuddy is to provide a tool for censorship-resistant access toHTTPS web sites that are considered useful and important. Internet search engines likeGoogle Search or web sites like Wikipedia are examples for these. WebBuddy shouldenable every user around the world to access this kind of sites even if they are censoredby the government.Still, this functionality is not enough. WebBuddy should provide a high availability for
its service and should therefore be blocking-resistant itself, so that an adversary cannotblock the service of the tool and make it useless. In addition to that, WebBuddy shouldalso be downloadable in a blocking-resistant way. If the download is easily blockable,WebBuddy is useless for its purpose.In contrary to Tor, for example, which is a TCP proxy and therefore is more general-
ized in its approach, WebBuddy specializes in being an HTTPS proxy since it is a toolfor accessing web sites only. The reason for proxying only HTTPS – instead of HTTPalso – is described later in the concepts part (cf. Section 4.2.5).
4.1.2 AnonymityAnonymity tools like Tor mainly focus on the anonymity aspect and achieve censorshipcircumvention as a “side effect”. In WebBuddy the main goal is censorship resistanceand blocking resistance, but since anonymity plays a very important role in restrictiveand censoring environments, WebBuddy should not compromise any of its users byrevealing there activity with the WebBuddy network. Anonymity is therefore also partof the design.
21

4 Design
4.1.3 Ease of UseAnother important goal is that WebBuddy should be very easy to install and use.WebBuddy relies on large numbers of users in order to provide its availability, scalabilityand anonymity. The easier it is to install and use, the more people are going to use it.WebBuddy should demand no knowledge about proxies or network settings from theuser. It should be downloadable with the usually easy mechanisms of browser add-oninstallations. After the installation the user should just hit a button to start and stopit. This should lower the knowledge prerequisites to a minimum.
4.1.4 ScalabilityAn enormously positive effect of using a peer-to-peer system is scalability. In a peer-to-peer system lookups and relaying scale very well with a growing number of users.WebBuddy depends on a big amount of users to provide its properties. A system wherethe lookup and relaying is achieved through a centralized system would not scale andmake attracting more users difficult.
4.2 ConceptsThis part describes the basic concepts used in WebBuddy to achieve the declared goals.Some of them are already used with other tools described earlier. Some of them arespecific and new in WebBuddy.
4.2.1 Peer-to-Peer ProxyingThe main difference in WebBuddy, in contrast to Tor for example, is that every partici-pant is using the tool’s service and at the same time providing the service of the tool forothers. This is sort of a peer-to-peer proxying approach where every user is the same,whereas in Tor there are servers which provide the services of Tor and the users whichmerely use these services. This peer-to-peer proxying was also described in MorphMixand Tarzan (see 3.2.2).One advantage of this is that WebBuddy does not use proxies with static IP addresses,
since most Internet users get a dynamically assigned IP address at least every 24 hoursby their ISP. Consequently, the IP address of all available proxies (WebBuddy clients)changes frequently. This increases the difficulty for an adversary to maintain an IPaddress blacklist of all proxies in order to block them.Another advantage is the scalability of WebBuddy. In Tor there are approximately
2500 Tor servers [12] and many more clients (approximately between 150,000 and200,000) [33]. This can lead to performance problems when the amount of users isspiking or just increasing with time. In WebBuddy every participant is both client andserver. There is no separation between server, exit nodes or clients, which should makethe system more scalable for large user numbers.TheWebBuddy client automatically finds other WebBuddy users (web buddies) during
startup. It checks their availability and builds a tunnel (chain) of web buddies. After this
22

4.2 Concepts
it sends all its data through this tunnel to access the destination server of the web sitethe user wants to connect to. The length of the tunnel is configurable with a minimum oftwo. The minimum is necessary for the anonymity functionality. Anonymity is realizedthrough HTTPS Onion Routing and is described in Section 4.2.6.In order to make the Internet usage more stable for the user, WebBuddy not only
builds one tunnel but several tunnels at a time. If one of these tunnels fails to work,WebBuddy automatically switches to another working one. Additionally, tunnels arechanged frequently to increase anonymity.
4.2.2 URL WhitelistsWebBuddy provides its user the possibility to access certain universally accepted websites such as Google Search. There are two whitelists: One indicates the web sites theuser wants to reach through the WebBuddy network (outgoing URLs). The secondindicates the web sites the user wants to allow other web buddies to reach through hisclient (incoming URLs). Each user of WebBuddy can add preferred web sites to thesewhitelists.The restriction by whitelists is necessary. If there was no restriction on which sites
can be accessed, a user could not control if his proxying service is misused for illegalactivities. This potential fear of the user could increase the barrier to use the tool atall, thus conflicting with the goal of a large number of active users.There are two whitelists because an oppressed user may want to use web sites which
he himself is not able to provide for others. The access to a forbidden website alonecould be dangerous for an oppressed user.
4.2.3 Low Bandwith and Rate LimitingWebBuddy’s main functionality is to enable users to access blocked web sites. In general,fetching information from such sites does not lead to very high traffic volumes. One ofTor’s performance problems for instance is based on the fact that some users use Torto do anonymous file sharing and by that push the Tor servers to their capacity limits.Tor works as a general TCP proxy, which makes this possible. WebBuddy allows usersto choose which web sites can be accessed via their computer (cf. Section 4.2.2). Auser can also choose how much of his bandwidth he wants to share with the WebBuddynetwork. This way a user can avoid that his Internet connection is rendered unusablefor his own needs.
4.2.4 Country-Based SelectionWebBuddy uses a geolocation database to determine where potentially found web bud-dies reside. Depending on the user’s own country, web buddies are chosen for the tunnelin a way that at least the entry and the exit node of the tunnel are not in the samecountry. Not choosing the last node in the same country is obvious: if the user lives ina country where a certain web site is censored, the same restriction applies for others inthe country, meaning that they cannot serve as exit node. But also the first web buddyin the tunnel should not be in the same country. This reduces the probability that a
23

4 Design
web buddy being run by the censoring government from inside the country is picked.Otherwise the censor could find out that a user is illegally running WebBuddy.Apart from that, WebBuddy maintains a “country blacklist” meaning that the most
restrictive and oppressive countries cannot serve as the exit web buddy at all. Althoughthis sounds discriminating it has the purpose of not endangering censored citizens. Theircomputers could be used to try to access web sites that could make them suspicious totheir censoring government. Additionally, the clients of censored citizens potentiallycannot reach web sites and this makes them not a good choice for an exit web buddy.Of course it is hard to decide which country has censored access to certain web sitesand which not. Although censoring happens everywhere around the world, WebBuddysolves this issue very plainly by just putting those countries on the blacklist that areregarded as real “Internet enemies” [59]. If the exit node is not on the blacklist but stilldoes not connect to a web site properly, WebBuddy recognizes this and chooses one ofthe other prebuilt tunnels to route the traffic.
4.2.5 HTTPS OnlyAnother method of censorship is keyword filtering. The adversary scans an unencryptedconnection for certain keywords and resets the connection to both sides if a forbiddenkeyword is detected. By using HTTPS the connection is encrypted and the adversarytherefore cannot scan for keywords anymore. Using HTTPS only also helps with thefact that even the exit node cannot recognize the content sent to the web site, whichimproves the anonymity properties of WebBuddy.
4.2.6 HTTPS Onion RoutingThe principle behind HTTPS onion routing is – as the name suggests – onion routing (cf.Section 2.6). The difference is in using the inherent SSL usage of HTTPS for encryptioninstead of manually encrypting the packets. It is only made possible through the HTTPCONNECT method described in Section 2.3.The HTTP CONNECT method allows a client to establish an end-to-end encrypted
communication channel via a proxy server. The proxy server cannot manipulate or readthe data at all and merely forwards it back and forth. The destination server howeverstill sees the proxy server as its communication partner.After having found enough web buddies for the tunnel, it is built using the following
method: First of all an HTTPS connection is established to the first web buddy ofthe tunnel (WB1). The data sent through this connection can only be read by WB1.Using this encrypted channel the client sends an HTTP CONNECT with the destinationaddress of the second web buddy of the tunnel (WB2) to WB1. WB1 recognizes theCONNECT method and allows an end-to-end connection establishment between theclient and WB2 (Figure 4.2.6).The client can now use WB2 to send its connection attempt to the destination server,
again via CONNECT – for instance, “CONNECT encrypted.google.com HTTP/1.1”.The data sent to WB2 is end-to-end encrypted between the client and WB2, but the datais proxied through WB1. Therefore WB2 recognizes only WB1 as the communication
24

4.2 Concepts
partner, so it does not know that the packet originates from the client (like in theusual onion routing). Also, since the communication between client and WB2 cannotbe eavesdropped by WB1, WB1 cannot know where the client really wants to connectto.This HTTPS onion routing provides the anonymity functionality of WebBuddy. There
have to be a minimum of two web buddies in the tunnel but this number can be increasedarbitrarily by the user. The longer the tunnel the more anonymity is provided becausethe chance of an adversary controlling all nodes or most of the nodes of the tunnel –which helps him with correlation attacks [39] – decreases. Of course this also increasesthe connection overhead and will therefore slow down the connection.
4.2.7 Browser Add-OnThe reason for using a browser add-on is quite obvious. WebBuddy is used to accessblocked web sites. There should be no unnecessary step for the user to install a secondarysoftware which has be to run in the background and has to be maintained separately.Browser add-ons are usually easy to install and with a minimalistic interface also easyto use.Being a browser add-on also helps making the distribution of WebBuddy blocking-
resistant. It is important to make it difficult for an adversary to block the download ofthe tool. Making WebBuddy available as a separate program on a public and dedicatedweb site provides a censor the easy possibility to block the web site completely. Bywrapping the core functionality in a browser add-on the usual browser add-on distribu-tion channels can be utilized. In the prototype implementation Firefox [9] is used as thebrowser of choice. The add-on installation site of Firefox has the advantage of being anHTTPS site. This means while a user connects to it, the censor cannot recognize thedata being transferred, only that a connection is made. The add-on being downloadedwould remain secret. To block the whole add-ons site would be a last option for a censorbut is improbable as the collateral damage would be very high.
4.2.8 BitTorrent DHTWebBuddy clients announce to the DHT that they offer a WebBuddy torrent via theannounce_peer method. All WebBuddy clients use this WebBuddy torrent. If one webbuddy wants to find another it just queries the DHT with get_peers for this torrent andgets returned some of the available web buddy IP addresses. The amount of returnedweb buddies to a query is not a fixed list but rather depends on some parameters of theBitTorrent DHT (cf. Section 4.3.2).An advantage of using an already existing peer-to-peer network is that it already
has a large number of participating nodes. The estimated number of active nodes inBitTorrent DHT is over one million [23]. If the network is not attacked otherwise [28]it should provide high availability, so the lookup mechanism for other web buddies ishighly available, too.The fact that WebBuddy users appear as regular BitTorrent participants in the net-
work might also prove helpful. If WebBuddy would use its own separate network with
25

4 Design
establish SSL connection
Client Proxy 1 Proxy 2
(a) Client establishes SSL connection with Proxy 1. After completion this channel is SSL encryptedbetween Client and Proxy 1 (SSL<Client,Proxy1>).
open TCP connection
SSL<Client, Proxy1>
send "CONNECT Proxy2:port..."
Client Proxy 1 Proxy 2
(b) Client sends an “HTTP CONNECT Proxy2...” to Proxy 1. Proxy 1 opens connection to Proxy 2.
SSL<Client, Proxy1>send SSL handshake for proxy 2
forward data send SSL handshake for client
forward data
Client Proxy 1 Proxy 2
(c) SSL handshake data between client and Proxy 2 is routed through Proxy 1.
data
Client Proxy 1 Proxy 2
data
SSL<Client, Proxy1>SSL<Client, Proxy2> SSL<Client, Proxy2>
(d) Client established SSL connection to Proxy 2 within SSL connection to Proxy 1(SSL<Client,Proxy2>).
Figure 4.1: HTTPS onion routing with two WebBuddy proxies
26

4.3 Architecture
Browser
Addon
Browser sideCore side
communicatecommunicatecommunicate
Local-Proxy
WebBuddy-Manager
DHT-Client Remote-Proxy
starts
Tunnel 1 Tunnel 2 ...
Figure 4.2: WebBuddy architecture
its own protocol it would be easy to just block the whole WebBuddy peer-to-peer net-work. Using the BitTorrent DHT the adversary has to put more effort in finding thespecial nodes which are web buddies and block them. Of course an alternative couldbe to block the whole BitTorrent DHT network. Despite the difficulty of blocking thewhole network, this would also mean high collateral damage.
4.3 ArchitectureThis part describes the different components of WebBuddy and how they work together.The basic architecture is quite simple. The browser add-on is the only user interfaceand simply a starter for an external Ruby program. This Ruby program is the actualWebBuddy core program. It consists of a few components which are shown in theirinteraction in Figure 4.2. The functionality of those will be described in the followingparts.
4.3.1 Browser Add-OnThe prototype implementation uses a Firefox add-on. It is mainly a wrapper for thecore functionality and provides some preference elements for the user. It is reduced toa minimum in order to make it as easy as possible to use. Since it is only a startup
27

4 Design
wrapper the core module can be extracted easily and built into other add-ons for differentbrowsers in the future.Through the preferences pane users can change the local proxy port, which is the port
the browser connects to when it is supposed to use WebBuddy instead of a direct con-nection to a web site. The remote proxy port can also be changed. This is the TCP porton which the WebBuddy client listens publicly and provides its service as a WebBuddyproxy. This port number is also used for the UDP port for DHT communication.The user can also specify the number of hops a web buddy tunnel should be built of.
The default is two – which is also the minimum – meaning that two web buddies arebetween the client and the destination server.One last preference deals with the two URL whitelists. Each URL the user adds to
the outgoing URLs will be reached through other WebBuddy clients. Each URL theuser puts into the incoming URLs can be reached by other WebBuddy clients throughthe user.
4.3.2 Lookup SystemThe lookup system is the part of WebBuddy where other web buddies can actually befound. It consists of a minimal DHT client that uses the mainline DHT protocol ofBitTorrent.On starting up WebBuddy for the first time, it has to bootstrap into the DHT network
since it does not know any nodes of the DHT until then. This is done by using bootstrapnodes that are provided by the Transmission BitTorrent client. In principle this could beany node of the DHT. When WebBuddy is started the next time it uses the last knownnodes from the last session in order to speed up bootstrapping. After WebBuddy isbootstrapped correctly it issues a search for the WebBuddy torrent and at the same timeannounces to the network that itself supposedly offers this torrent. Each WebBuddyclient follows this procedure. By doing this, web buddies find each other.Since a torrent ID is a 160-bit SHA1 hash, and our WebBuddy torrent uses a prede-
fined hash that is is randomly chosen, it is highly improbable to “collide” with otherlegitimate BitTorrent IDs in the DHT.Nodes in the DHT only store up to a maximum of 2048 known peers for a certain
torrent. This means that a client asking a node for a list of peers only gets 2048peer addresses at maximum. This seems like a large number and can even be higher,depending on if there is more than one node responsible for the ID and on how distincttheir lists are to each other. Still, this factor helps with blocking resistance as anadversary cannot learn the whole list of active WebBuddy users at once, assuming therewill be much more web buddies active in the network and a high churn of nodes.
4.3.3 WebBuddy-ManagerThis is the core component that manages the other components of the application. Aslong as it is active it ensures that a WebBuddy connection is usable or at least is beingestablished. The WebBuddy-Manager issues the request for web buddies to the lookupsystem. As soon as the lookup system finds some web buddies it makes their contact
28

4.3 Architecture
information (IP address and port number) available to the WebBuddy-Manager. Withenough web buddies found, the WebBuddy-Manager starts a Local Proxy and handsover the web buddy addresses.
4.3.4 Local-ProxyThe Local-Proxy listens on a local TCP port for incoming connections from the browserand takes care of the proxying for the user for all the web sites that are supposedto be redirected through WebBuddy (that are on the outgoing URLs whitelist). It isalso responsible for building the tunnels of web buddies and preparing the packets forrouting (cf. Section 5.5). As long as there are enough buddies multiple tunnels are builtconcurrently. These can be used to process multiple browser connections in parallel.But this depends on how the web site deals with connections coming from differentclients. Also, if one tunnel breaks, the other tunnels help out, so that after the shortstartup time of WebBuddy there is alway a connection to use for the browser.
4.3.5 Remote-ProxyThe Remote-Proxy is built of a simple HTTP proxy with an SSL server in front of it.A client of the Remote-Proxy has to connect to it via SSL. The Remote-Proxy is alsoresponsible for the correct routing of packets. When a client connects to it, it is ableto recognize if it is used at the end of a tunnel (exit node) or somewhere else in thetunnel (intermediate node). In the latter case it cannot tell where exactly in the tunnelit is used. If it is used as an intermediate node it just forwards data back and forthin the established tunnel. If it is the exit node it has to process routing informationpreviously added to the packets by the client’s Local-Proxy. How this routing exactlyworks is described in detail in Section 5.5.
29


5 Implementation
In this chapter details of the prototype implementation of WebBuddy are described. Theused technologies are explained in detail. At the end the current state of the prototypeis described and which parts will need to be added in the future.
5.1 Ruby as Main Language
In order to speed up the implementation process for the prototype, Ruby [11] wasused as the main language. It is probably not the wisest choice when it comes toperformance (Ruby is an interpreted language), but the effective performance impactcould be analyzed in the future. The advantages are reduced lines of code and garbagecollection [53], which helps to reduce memory bugs.The components WebBuddy-Manager, Remote-Proxy and Local-Proxy are the Ruby
part of WebBuddy. Their functionality is described in Section 4.3.
5.2 DHT ComponentThe DHT component of WebBuddy is written in C language. The reason for this is thatWebBuddy uses exactly the same DHT implementation as the Transmission BitTorrentclient which is written in C. The basic implementation consists of one file named dht.c.With the Transmission source code comes a sample program which implements a verybasic client to the DHT network. This basic client implementation was taken andadapted to the needs of WebBuddy. By doing this, WebBuddy is maximally compatibleto the Transmission DHT. Future versions of WebBuddy could reimplement the DHTcode completely in Ruby. But it is reasonable to leave the network code in a compiledlanguage to get as much performance as possible. In the prototype implementation theDHT code runs as a separate process that is started and stopped from within the Rubyprogram. This can be changed in future versions where the Ruby program directlycalls C code. The standard Ruby interpreter is basically built on C and is able to callnative C code. The separate DHT process receives signals from the Ruby program. Forexample, the POSIX signal SIGUSR2 is used to instruct the DHT process to look fornew web buddies.
5.3 Firefox Add-OnFirefox add-on logic is programmed with JavaScript or C++, although there are someother language bindings, but these are the mainly supported languages. XUL [16] isused for designing the user interface of the add-on. Firefox is written in C++ and is very
31

5 Implementation
Figure 5.1: WebBuddy Firefox add-on: The minimal UI consists of only two buttonsin the lower right corner. One for starting WebBuddy, one for configuringparameters.
modular. It is based on a cross-platform component model (XPCOM [17]). This meansthat the browser consists of different components that serve different functionalities.These components can be accessed through interfaces which are written in a language-independent manner using XPIDL [18] (cross platform interface definition language).The components of Firefox communicate with each other through these interfaces. Thesesame interfaces can be used by JavaScript to call component functionality. JavaScriptcan also be used to create such components. This is how the WebBuddy add-on is built.A small WebBuddy component was developed in JavaScript. This component over-
rides the proxying behavior of Firefox so that Firefox implicitly uses a certain proxy fordefined URLs. Connections to other URLs are made directly. This way the user doesnot have to bother with Firefox’s proxy settings at all. The WebBuddy component usesthe network component of Firefox for the task of networking.The UI of WebBuddy is created with XUL which is the interface language of all
Mozilla applications. There are two buttons in the lower right corner of the browser.One for starting and stopping WebBuddy and a second for the preferences pane. Thebuttons and preferences logic is also written in JavaScript and is responsible for invokingand configuring the WebBuddy core.
32

5.4 Remote-Proxy Implementation
5.4 Remote-Proxy ImplementationThe Remote-Proxy handles the main functionality of WebBuddy: relaying connectionsfor other users. It consists of three parts. The first part is a Ruby SSL server whichaccepts SSL connections on a TCP port that the user defines as his public relay port inthe preferences pane of the add-on. On Unix/Linux systems Ruby’s SSL implementationuses the OpenSSL [10] libraries of the operating system. Each Remote-Proxy uses a self-signed SSL certificate to authenticate itself to its user.The Ruby SSL server decrypts received data implicitly and forwards the plain text
data to the second part, which is an HTTP proxy server. The HTTP proxy server usedin WebBuddy is taken from the Ruby standard library WEBrick [15].The third part is the “glue” logic between the two former. This part is responsible
for opening and closing parallel connections to the web proxy server in the mannerdescribed in Section 5.5.
5.5 RoutingOnce a tunnel of web buddies is established, all data from the initiating client is directedback and forth through it. In practice, the Local-Proxy of a WebBuddy client listensfor connections from the browser. The browser can send its data to the local proxy portas soon as the connection between both has been established. The Local-Proxy dealswith sending the received packets through the tunnel.Even for a single web site, like https://encrypted.google.com, a modern browser
does not just open one connection to fetch data from the web server but several. This isdone to fetch multiple objects from the web server in parallel. Sometimes connections areeven made to other servers, e.g. because certificates have to be checked for their statususing OCSP[56]. But WebBuddy redirects the data through one single tunnel. Thereare two solutions to this. The simplest would be to keep the local proxy single-threadedand allow only one connection at a time. Besides resulting in poor performance, thisapproach may not work at all for some sites, because for these sites the browser has tofetch certain objects first before it can proceed fetching the main content of the web site.Usually a browser fetches all of the objects in parallel. As soon as the required objectsare loaded the rest of the objects can be loaded, too. It appears that by using a singleconnection approach the whole process of web site loading can reach a deadlock, since thebrowser does not necessarily order the parallel connections. If the browser connectionfor handling required objects is processed after the connection for handling “unrequired”objects, the loading of the site deadlocks. Therefore, WebBuddy’s implementation usesthe other alternative.In WebBuddy the Local-Proxy works multi-threaded and the tunnel multiplexes par-
allel connections. In order for this to work data packets have to be extended withadditional information before they are sent through the tunnel. Also, packets have tobe treated inversely at the other end of the tunnel.The Local-Proxy listens on a port for connection attempts. When the browser opens a
connection to the Local-Proxy, the Local-Proxy first generates a random 4 byte header.
33

5 Implementation
This header is prepended by the Local-Proxy to every data packet that the browseris sending over this connection. Before the browser is sending any data over the firstconnection the Local-Proxy sends an instruction packet for the Remote-Proxy at theend of the tunnel. This packet consists of the string OPEN, prepended with the previouslygenerated header for this connection. This packet gets sent through the tunnel whereeach intermediate Remote-Proxy just forwards the data, but the exit Remote-Proxyrecognizes the instruction and opens a connection to its internal HTTP web proxy.The Remote-Proxy stores this correspondence between 4 byte header and HTTP proxyconnection as long as the connection stays active. After both connections on both sidesof the tunnel are established they are corresponding. The browser now can send itsdata over this connection. Whenever the browser or the destination web server closethe stream or shut down the connection, this correspondence of connections gets deletedand connections are closed on both sides. If the shutdown happens on the browser side,the Local-Proxy realizes this and sends an instruction packet CLOSE with the specificheader for this connection to the Remote-Proxy. The Remote-Proxy then shuts downthe corresponding connection to its HTTP proxy. The same procedure is taken whenthe shutdown takes place on the Remote-Proxy side: The Remote-Proxy sends a CLOSEinstruction to the Local-Proxy which closes the corresponding connection. Figures 5.2,5.3 and 5.4 illustrate an open, send and close scenario.
5.6 WebBuddy Prototype
The prototype of WebBuddy for this thesis is written to work on both Linux (32-Bitand 64-Bit) and Mac OS X with Firefox versions 3.5 to 6. C Binaries are alreadyprecompiled for these platforms. To run the Ruby code, a current Ruby interpreterhas to be installed on the system (version 1.8.7 or the newer 1.9.2). Also the usedgems (Ruby modules) have to be installed first. These Ruby-specific circumstanceswill change in future versions where all necessary parts will be packaged in a nativeexecutable application, so users downloading the Firefox add-on will not have to dealwith this themselves.Another part that will be added in the future is the automatic port configuration
of the user’s firewall. In the current prototype the user first has to open the relayport number of WebBuddy both as a TCP and UDP port in the firewall. There areseveral techniques to overcome this [55, 58, 57], but they are not yet implemented inthe prototype.The prototype also only uses one tunnel. The multiple tunnel approach to ensure
availability of the connections should be added easily though. The Local-Proxy compo-nent would need to be adjusted to this requirement.The URL whitelist functionality is rudimentary in the prototype implementation. It
only allows the user to enter outgoing URLs. A list of incoming URLs is not possibleyet, since an appropriate method for URL whitelist propagation has to be developedfirst (cf. Section 6.5).A last missing part in the prototype implementation is the rate limiting which enables
the user to limit the bandwidth that is used by his Internet connection for WebBuddy.
34
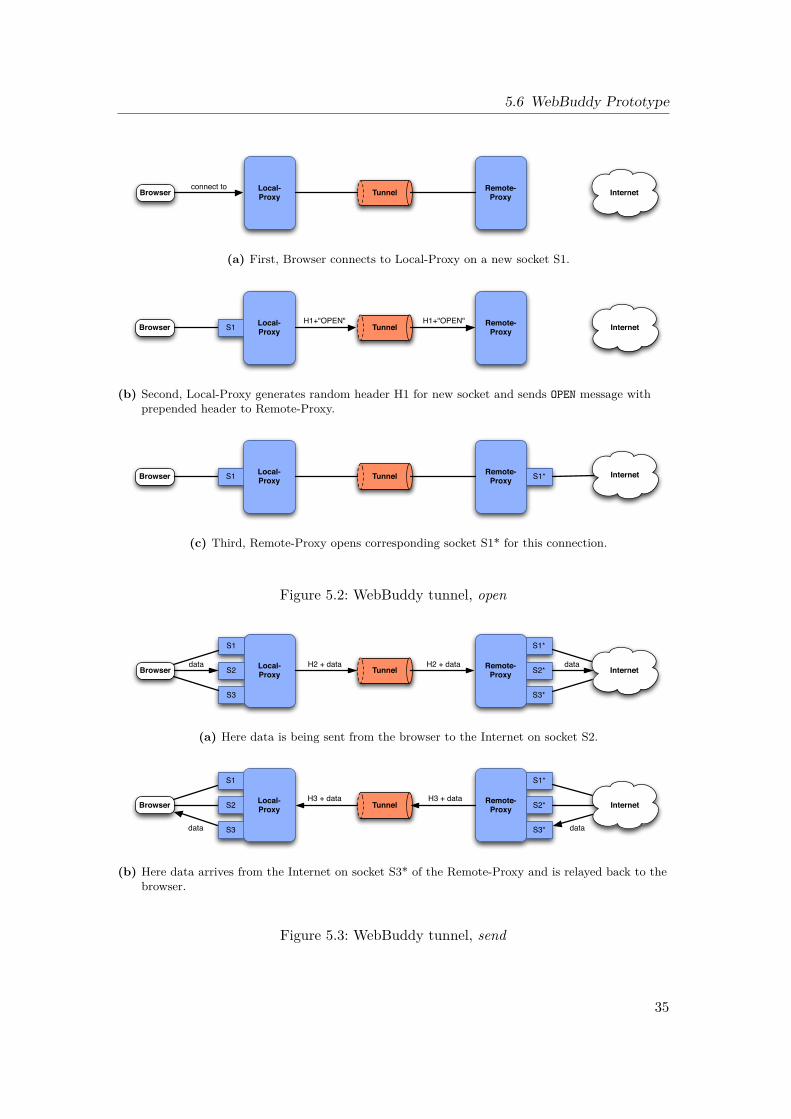
5.6 WebBuddy Prototype
connect toTunnelBrowser Local-
ProxyRemote-Proxy Internet
(a) First, Browser connects to Local-Proxy on a new socket S1.
TunnelBrowser Local-ProxyS1 Remote-
ProxyH1+"OPEN" H1+"OPEN"
Internet
(b) Second, Local-Proxy generates random header H1 for new socket and sends OPEN message withprepended header to Remote-Proxy.
TunnelBrowser Local-ProxyS1 Remote-
Proxy S1* Internet
(c) Third, Remote-Proxy opens corresponding socket S1* for this connection.
Figure 5.2: WebBuddy tunnel, open
dataTunnelBrowser Local-
Proxy
S1
S2
S3
Remote-Proxy
S1*
S2*
S3*
InternetH2 + data H2 + data data
(a) Here data is being sent from the browser to the Internet on socket S2.
TunnelBrowser Local-Proxy
S1
S2 Remote-Proxy
S1*
S2*
S3*
H3 + data H3 + dataInternet
S3 datadata
(b) Here data arrives from the Internet on socket S3* of the Remote-Proxy and is relayed back to thebrowser.
Figure 5.3: WebBuddy tunnel, send
35
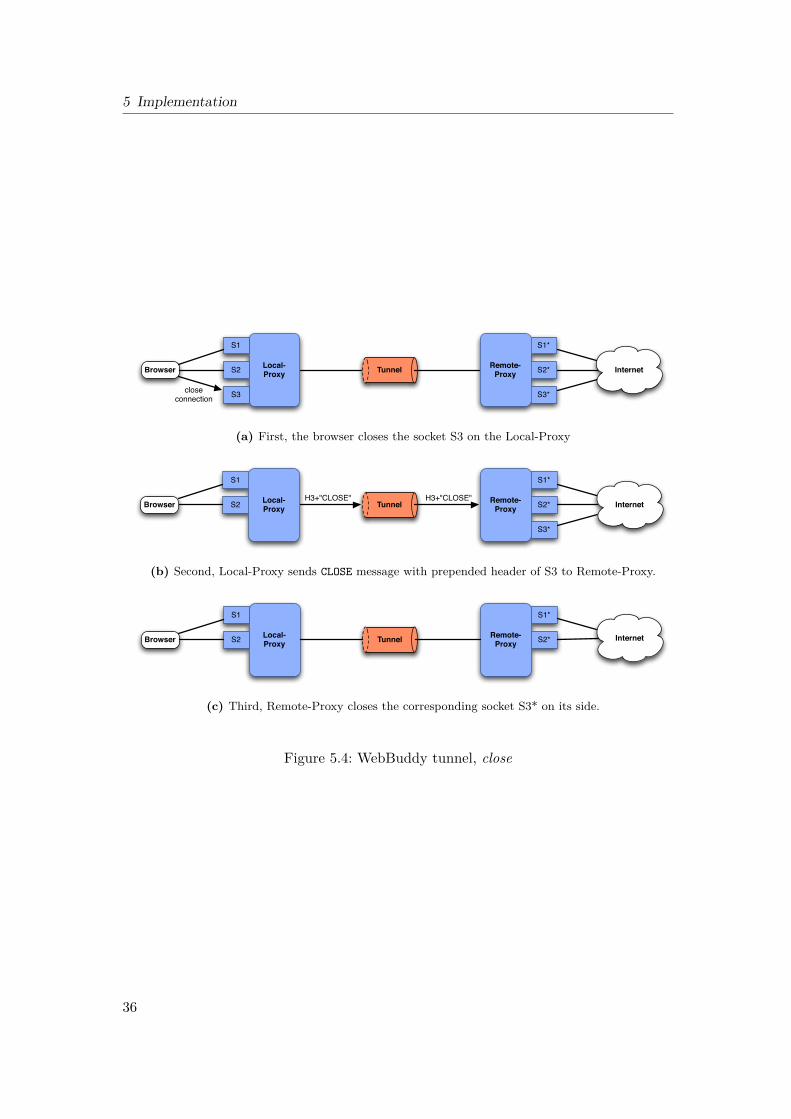
5 Implementation
close connection
TunnelBrowser Local-Proxy
S1
S2
S3
Remote-Proxy
S1*
S2*
S3*
Internet
(a) First, the browser closes the socket S3 on the Local-Proxy
TunnelBrowser Local-Proxy
S1
S2 Remote-Proxy
S1*
S2*
S3*
H3+"CLOSE" H3+"CLOSE"Internet
(b) Second, Local-Proxy sends CLOSE message with prepended header of S3 to Remote-Proxy.
TunnelBrowser Local-Proxy
S1
S2 Remote-Proxy
S1*
S2* Internet
(c) Third, Remote-Proxy closes the corresponding socket S3* on its side.
Figure 5.4: WebBuddy tunnel, close
36

6 Evaluation
WebBuddy’s main goal is to enable users to access web sites in a censorship-resistantway and at the same time to be blocking-resistant itself. Many of the tools described inChapter 3 suffer from being blockable very easily, based on the fact that some of theminitially were not even created with censorship resistance or blocking resistance in mind.In the following, WebBuddy is evaluated concerning the different censorship methodsused in global Internet filtering as described in Section 2.8. At the end of this chapterit is described where WebBuddy’s current concept still has weaknesses and what can bedone to counter these.
6.1 Censorship and Blocking ResistanceIP-Based Censorship Web sites that are blocked on an IP address basis can be reachedagain with WebBuddy. WebBuddy users send their data indirectly through other Web-Buddy users. Therefore an ISP that is monitoring connection attempts in order to droppackets destined for a specific undesired IP address, cannot do so. The only traffic thatcan be seen goes to the IP address of a WebBuddy user. Since all connections to webbuddies are encrypted with SSL and the IP address of the destination server the clientwants to reach is only sent over these encrypted channels, it is not possible for the ISPto retrieve this information.Since WebBuddy can be used by anybody, the censor could participate and launch
malicious nodes in the WebBuddy network. These malicious nodes could be used totry to break the proxying by ignoring instructions to establish a connection to anotherproxy or a server. To counter this a WebBuddy client always chooses its web buddiesfor the tunnel by itself and therefore can determine good nodes it wants to use. Whensearching for other web buddies, a geolocation database is used to reveal the web buddies’locations and countries respectively. This information is used by a WebBuddy client toavoid choosing web buddies for its tunnel that reside in the same country. Even if thedatabase returns incorrect countries or the adversary spoofs his IP address (he couldalso use a legitimate one from outside of the country), WebBuddy still works: If a nodein the tunnel refuses to work the tunnel is discarded and the WebBuddy client usesanother tunnel.
Keyword-Based Censorship In the case of URL filtering an ISP scans the URL inthe HTTP request of the user for certain undesired keywords. This is possible becauseHTTP data is submitted in plain text over the underlying TCP connection. If not in theURL keywords, the ISP can also scan the content of a web site for keywords. WebBuddyis designed from the ground up to use SSL encryption for all of its proxy connections.
37

6 Evaluation
Additionally, it only does HTTPS proxying. In a regular HTTPS connection betweena client and server someone monitoring the connection can only recognize that clientand server are communicating but the actual contents are encrypted. Every web buddyin a tunnel serves merely to forward encrypted data to his direct successor, data whichis otherwise undecipherable for it, too. When data reaches the exit web buddy it isthe only one to know the actual destination of the data. Even this last part of theconnection, going from exit web buddy to actual server, is SSL encrypted between theclient and the destination server. Thus, even if the exit web buddy was malicious, it stillcould not filter any keywords, neither on the content of the web site nor in the URL.The path part of a URL is sent via HTTP after the SSL connection is established andis therefore part of the encrypted data, too.
DNS-Based Censorship Generally, when a user surfs to a web site, the browser dealswith DNS lookup. The browser queries the system’s DNS server for the IP addressof the domain the user just entered in the browser’s address bar. After getting theresponse it connects to that IP address via TCP and issues the necessary HTTP requeststo the web server. In the case of WebBuddy, the client side must not perform DNSqueries anymore. Whenever web buddies are fetched, their IP addresses are alreadyknown. The WebBuddy client directly connects to those IP addresses. After tunnelestablishment the client attempts to connect to the destination SSL web server. Thedata travels through the tunnel and finally reaches the exit web buddy. The exit webbuddy receives an instruction such as CONNECT encrypted.google.com:443 HTTP/1.1.It is the task of this exit web buddy to do DNS lookup of the domain name received.Since WebBuddy chooses an exit node that lies outside of the censoring country, thisDNS lookup should not be manipulated by the client’s censor. Therefore, DNS-basedcensorship by responding with incorrect IP addresses or by blocking non-national DNSserver IP addresses completely does not work anymore.
Blocking Resistance As happened with Tor, an adversary can try to get all the IPaddresses of available proxy servers in order to block them with IP based blockingmechanisms. In WebBuddy, IP addresses of participants are mostly short-lived anddynamic. Also there can be many participants active in the network. Every user isintentionally also a proxy server for others. From analysis of the Great Firewall ofChina it can also be seen that updates of to be filtered content have to propagate toall ISPs in the country first. They again have to apply the new rules. So it takes sometime to update the final lists. During this time the dynamic IP addresses can easilyhave changed and the filtering would hit the wrong targets. Censoring is still possible ifthis risk is tolerated by the censor or, as the censorship system gets more sophisticated,this process could be automated to the extent where updating lists just takes seconds.WebBuddy’s usage of DHT helps with the latter aspect. A client querying the DHTdoes not get the whole list of available and active web buddies. Instead it only sees aportion of those (cf. Section 4.3.2). Also, a client cannot perform an arbitrary numberof queries per second. DHT nodes implement a rate limiting based on token buckets,which allows them to only answer about 4 messages per second [13].
38

6.2 Ease of Use
Another very simple mechanism of blocking tools is to block the access to the downloadof these. WebBuddy solves this problem by relying on the availability of the Firefoxadd-on site [4]. This site is an HTTPS web site, meaning that a censor monitoring theconnection between client and this site is not able to detect which add-on is actuallydownloaded by the user. Of course, if the censor is willing to block connections toFirefox’s add-on site completely, this approach breaks. But as long as Firefox and itsadd-ons are not completely forbidden in the country it solves the problem of availabilityfor downloads of WebBuddy.
6.2 Ease of UseUsing a browser add-on for enabling users to surf blocked web sites is the most obviousand easy way to implement such a tool. The Firefox browser especially gets its popularitythrough its extensibility with add-ons. Most Firefox users should be familiar with theadd-on installation procedure. Therefore installation of WebBuddy is simplified as muchas possible.After installation the user does not have to configure anything to use WebBuddy. The
predefined settings are sufficient to get WebBuddy started right after the installation(the prototype implementation still requires some prerequisites, which will be addressedin future versions, cf. Section 5.6).All the user has to do is click the button in the lower right corner of the browser that
reads “Start WebBuddy”. WebBuddy takes some time to be ready. During this timethe user can still use the browser as usual. After WebBuddy started successfully and atunnel is ready, the add-on signals this to the user and it can be used right away.
6.3 AnonymityAnonymity is achieved through the HTTPS onion routing of WebBuddy. As describedin Sections 2.6 and 4.2.6, the onion routing ensures that the destination server cannotknow where the packet is originating from. Also, proxies within the tunnel only knowtheir direct neighbors in the tunnel. Therefore, WebBuddy provides the same basicanonymity mechanism as in anonymity systems such as Tor. This is true as long as themajority of nodes in the network is not controlled by an adversary. An adversary couldlaunch many malicious nodes into the network, which increases the probability that abuilt tunnel only consists of those. In this case anonymity breaks and the adversarycan deduce which client is connecting to which web site. Assuming that the count ofgood nodes will be high, the adversary would have to put a lot of malicious nodes inthe network to achieve this.
6.4 ScalabilityTwo parts of WebBuddy have to be scalable: the lookup system to find web buddiesand the relaying through web buddies itself. Since WebBuddy uses the BitTorrentDHT which implements the Kademlia protocol, this part scales well with increasing
39

6 Evaluation
numbers of users [38]. The relaying scalability is also better than in systems withdedicated servers. WebBuddy uses every participant as a proxy. So with increasingnumbers of users there are also increasing numbers of proxies. This should not lead tothe performance issues Tor suffers from because of a small number of proxies comparedto the number of users. However, this aspect of scalability has to be tested when thenetwork is in real use with large numbers of users.
6.5 Future WorkPropagation of URL Whitelist Information One unsolved issue in the prototypeimplementation is how WebBuddy clients propagate the information about their URLwhitelists to the network so that clients can choose the right web buddy as exit webbuddy for the tunnel. One approach for this could be to encode the information in thetorrent ID a client announces. By hashing a URL a client could use this hash as thetorrent ID. This means that a client announces as many torrent IDs as it has URLs inits whitelist. If a client looks for a web buddy to help it reach a certain URL, the clienthashes the URL and looks for this hash in the DHT. It should find the available webbuddies willing to act as an exit node for a particular URL.While this approach seems very elegant, it contains the potential disadvantage of
fragmenting the WebBuddy network. It has to be analyzed further how much theperformance and availability of the WebBuddy network is negatively affected by that.
P2P Reputation Systems In the case that an adversary launches many maliciousnodes into the WebBuddy network it can pollute the network to a degree that thetunnel building could be broken: Since WebBuddy chooses the web buddies randomly– with the constraint of them being outside of the country for the entry and exit webbuddy – finding enough buddies for the tunnel to work could take some time underthis attack scenario. Whenever WebBuddy finds other web buddies refusing to do theirtasks it should memorize those and avoid them for a certain amount of time. Insteadof locally blacklisting such nodes, WebBuddy could also use some kind of reputationsystem that helps picking those web buddies that really work. There is some researchin this direction [26, 48].
Malicious Collector Nodes The DHT network is quite tolerant in respect to whatusers are doing in it as long as they stick to the protocol. Normally a BitTorrent clientchooses its own node ID for the DHT randomly and keeps it for an arbitrarily longperiod of time. But there is no check if the ID is really chosen randomly. This results inone attack scenario for the blocking resistance of WebBuddy: An adversary could choosethe predefined torrent ID, which is public, as its node ID for the DHT. By doing this,the adversary node gets “responsible” for knowing all the nodes that participate in thepredefined torrent ID and thus gets updated anytime some new web buddy announcesitself. Thus, the adversary can just wait and get all the web buddies in order to blocktheir IP addresses.
40

6.5 Future Work
To counter this attack scenario one would have to place a significant amount of goodnodes in the DHT that can somehow be verified. Details of this have to be elaboratedon in the future.
Certificates WebBuddy proxies use self signed certificates for HTTPS. In order toensure that a proxy is really authentic, one would need a trustable certificate server orat least a certificate chain. An idea for a future implementation is using a certificateserver. WebBuddy clients would query the certificate server for issuing them a certificatewhich they can use to authenticate themselves towards other users. Using a singleinstance certificate server creates a problem of course. Access to this certificate servercould be blocked for users in restrictive countries. But if the server remains reachablefrom outside at least users in “free” countries can still get their certificate and theyare the ones that serve as the proxies for restricted citizens anyway. One last problemcould also be that some more aggressively acting countries could try DDOS attacks onthe certificate server. New WebBuddy clients would not get certificates as long as theserver is down. But at least the already existing WebBuddy clients can still serve. AWebBuddy client only has to reach the certificate server once it is started and againwhen its IP address has changed (ideally every 24 hours only). Redundancy in thecertificate server infrastructure can also help to counteract possible DDOS attacks. Forinstance, there could be several certificate servers distributed around the world.Another problem arises when restricted users try to connect to a proxy. During the
SSL handshake, which happens in plain text, an eavesdropper of that connection canrecognize the certificate as a WebBuddy certificate and block the connection immediatelyby resetting it. Also the adversary could blacklist the IP address of the proxy.An idea to solve this is to make the WebBuddy certificate as “unsuspicious” as pos-
sible. How this can be done has to be worked out in the future.
41


7 Conclusion
Tools that are explicitly intended for circumventing Internet censorship are quite rarelydeployed. Currently deployed systems that can be used for censorship circumventionfocus on anonymity. Censorship circumvention is a byproduct. Additionally, they arenot designed from scratch to be blocking-resistant, which is an essential aspect of sucha tool.WebBuddy is an easy to install and, above all, easy to use tool to address those issues.
Its concept is not to be a tool for everything, but to specialize in helping Internet usersaround the world to be able to access universally accepted web sites for informationretrieval and communication. The internal concepts introduced in this thesis shouldhelp in attracting a lot of users so the whole network of WebBuddy users grows andconsequently every user benefits from it. The hardest part about such a tool is to designit to be blocking-resistant itself. WebBuddy addresses this with concepts like peer-to-peer proxying, strong usage of SSL and integration into a well established peer-to-peersystem. But still, those concepts rely on the assumption that an adversary is not willingto break most of the Internet connections for the country, not to speak of an adversarythat restricts Internet access completely.In this respect this thesis also shows where there are possible weaknesses in blocking
resistance of WebBuddy and introduces some ideas of how to deal with those issues infuture versions (cf. Section 6.5).In the end, censors and creators of censorship circumvention tools are in an arms
race: Whenever a tool helps citizens to circumvent censorship, either the tool itself isblocked or it is analyzed to counter the circumvention with new censoring techniques.This means that it is never about creating a perfect, unbreakable tool, but to keep upwith the pace of censoring around the world and develop new mechanisms against it.WebBuddy is one contribution to this.
43


Glossary
BGP Border Gateway Protocol
ISP Internet Service Provider
IP Internet Protocol
HTTP Hyper Text Transfer Protocol
HTTPS Hyper Text Transfer Protocol Secure
SSL Secure Sockets Layer
TLS Transport Layer Security
DHT Distributed Hash Table
SHA-1 Secure Hash Algorithm 1
RPC Remote Procedure Call
TCP Transmission Control Protocol
URL Uniform Resource Locator
HTML Hyper Text Markup Language
DNS Domain Name System
AS Autonomous System
POSIX Portable Operating System Interface for Unix
DDOS Distributed Denial of Service
45


Bibliography
[1] aMule - All-Platform P2P client based on eMule. http://www.amule.org/. 9
[2] BitTorrent. http://www.bittorrent.com/intl/de/. 10
[3] BitTorrent DHT protocol. http://www.bittorrent.org/beps/bep_0005.html.10
[4] Firefox Add-ons. https://addons.mozilla.org/. 39
[5] Google transparency report. http://www.google.com/transparencyreport/governmentrequests/. 2
[6] GoogleSharing. http://www.googlesharing.net/. 17
[7] Gossip protocol. http://en.wikipedia.org/wiki/Gossip_protocol. 18
[8] JAP. http://anon.inf.tu-dresden.de/JAPTechBgPaper.pdf. 7
[9] Mozilla Firefox. http://www.mozilla.org/de/firefox/. 25
[10] OpenSSL. http://www.openssl.org/. 33
[11] Ruby programming language. http://www.ruby-lang.org/. 31
[12] Tor servers - IP list. http://proxy.org/tor.shtml. 15, 22
[13] Transmission DHT implementation. https://trac.transmissionbt.com/browser/trunk/third-party/dht/dht.c. 38
[14] Vuze. http://www.vuze.com/. 10
[15] WEBrick HTTP proxy server. http://ruby-doc.org/stdlib-1.8.7/libdoc/webrick/rdoc/files/webrick_rb.html. 33
[16] XML user interface language. https://developer.mozilla.org/En/XUL. 31
[17] XPCOM. https://developer.mozilla.org/en/XPCOM. 32
[18] XPIDL. https://developer.mozilla.org/en/XPIDL. 32
[19] United Nations General Assembly. Universal declaration of human rights. http://www.un.org/en/documents/udhr/, 1948. 1
[20] K. Butler, T. Farley, P. Mcdaniel, and J. Rexford. A survey of BGP security issuesand solutions. AT&T Labs Research, 2008. 12
47

Bibliography
[21] D.L. Chaum. Untraceable electronic mail, return addresses, and digitalpseudonyms. Communications of the ACM, 24(2):84–90, 1981. 7, 8
[22] Bram Cohen. The BitTorrent protocol specification. http://www.bittorrent.org/beps/bep_0003.html, 2008. 10
[23] S.A. Crosby and D.S. Wallach. An analysis of BitTorrent’s two Kademlia-basedDHTs. department of Computer Science, Rice University, Houston, Texas, USA,2007. 25
[24] R. Deibert. Access denied: the practice and policy of global Internet filtering. TheMIT Press, 2008. 12
[25] R. Dingledine and N. Mathewson. Design of a blocking-resistant anonymity system.The Tor Project, Technical Report, 2006. 11, 15, 16
[26] R. Dingledine, N. Mathewson, and P. Syverson. Reputation in P2P anonymitysystems. In Proceedings of Workshop on Economics of Peer-to-Peer Systems, June.Citeseer, 2003. 40
[27] Roger Dingledine, Nick Mathewson, and Paul Syverson. Tor: the second-generationonion router. In Proceedings of the 13th conference on USENIX Security Sympo-sium - Volume 13, SSYM’04, pages 21–21, Berkeley, CA, USA, 2004. USENIXAssociation. 7, 15
[28] J. Douceur. The sybil attack. Peer-to-peer Systems, pages 251–260, 2002. 25
[29] Clint Ecker and Kurt Mackey. HTTPS is great: here’s why everyone needs touse it (so we can too). http://arstechnica.com/business/news/2011/03/https-is-great-here-is-why-everyone-needs-to-use-it-so-ars-can-too.ars, March 2011. 3
[30] M.J. Freedman and R. Morris. Tarzan: A peer-to-peer anonymizing network layer.In Proceedings of the 9th ACM Conference on Computer and Communications Secu-rity, pages 193–206. ACM, 2002. 17
[31] Scott Gilbertson. HTTPS is more secure, so why isn’t theweb using it? http://arstechnica.com/web/news/2011/03/https-is-more-secure-so-why-isnt-the-web-using-it.ars, March 2011. 3
[32] D. Goldschlag, M. Reed, and P. Syverson. Hiding routing information. In Infor-mation Hiding, pages 137–150. Springer, 1996. 8
[33] S. Hahn and K. Loesing. Privacy-preserving ways to estimate the number of Torusers. 2010. 22
[34] Miguel Helft and Michael Wines. Google faces fallout as china reacts to siteshift. http://www.nytimes.com/2010/03/24/technology/24google.html?hp,March 2010. 2
48

Bibliography
[35] Nico Hines. YouTube banned in Turkey after video insults. http://www.timesonline.co.uk/tol/news/world/europe/article1483840.ece, March2007. 1
[36] Philip N. Howard. The arab spring’s cascad-ing effects. http://www.miller-mccune.com/politics/the-cascading-effects-of-the-arab-spring-28575/, February 2011. 1
[37] Christian Klaß. Iran blockiert Google+. http://www.golem.de/1107/84878.html, July 2011. 2
[38] P. Maymounkov and D. Mazieres. Kademlia: A peer-to-peer information systembased on the xor metric. Peer-to-Peer Systems, pages 53–65, 2002. 9, 18, 40
[39] S.J. Murdoch and G. Danezis. Low-cost traffic analysis of tor. In Security andPrivacy, 2005 IEEE Symposium on, pages 183–195. IEEE, 2005. 25
[40] BBC news. Pakistan lifts the ban on YouTube. http://news.bbc.co.uk/2/hi/7262071.stm, February 2008. 2
[41] O. Nordström and C. Dovrolis. Beware of BGP attacks. ACM SIGCOMM Com-puter Communication Review, 34(2):1–8, 2004. 12
[42] Council of Europe. Convention for the protection of human rights and fundamentalfreedoms, 1950. 1
[43] Werner Pluta. Iran startet landesweites Kommunikationsnetz im August. http://www.golem.de/1107/84724.html, July 2011. 2
[44] Michael K. Reiter and Aviel D. Rubin. Crowds: anonymity for web transactions.ACM Trans. Inf. Syst. Secur., 1:66–92, November 1998. 17
[45] M. Rennhard and B. Plattner. Introducing MorphMix: peer-to-peer based anony-mous internet usage with collusion detection. In Proceedings of the 2002 ACMworkshop on Privacy in the Electronic Society, pages 91–102. ACM, 2002. 17
[46] R.L. Rivest, A. Shamir, and L. Adleman. A method for obtaining digital signaturesand public-key cryptosystems. Communications of the ACM, 21(2):120–126, 1978.6
[47] Felipe Saint-Jean, Aaron Johnson, Dan Boneh, and Joan Feigenbaum. Private websearch. In Proceedings of the 2007 ACM workshop on Privacy in electronic society,WPES ’07, pages 84–90, New York, NY, USA, 2007. ACM. 16
[48] S. Song, K. Hwang, R. Zhou, and Y.K. Kwok. Trusted P2P transactions with fuzzyreputation aggregation. Internet Computing, IEEE, 9(6):24–34, 2005. 40
[49] I. Stoica, R. Morris, D. Karger, M.F. Kaashoek, and H. Balakrishnan. Chord: Ascalable peer-to-peer lookup service for Internet applications. ACM SIGCOMMComputer Communication Review, 31(4):149–160, 2001. 18
49

Bibliography
[50] China Digital Times. The ministry of truth limits reporting on Google in China.http://chinadigitaltimes.net/2010/03/23/, March 2010. 2
[51] Wikipedia. Autonomous system (Internet) — wikipedia, the free encyclopedia,2011. [Online; accessed 21-August-2011]. 12
[52] Wikipedia. Border gateway protocol — wikipedia, the free encyclopedia, 2011.[Online; accessed 21-August-2011]. 12
[53] Wikipedia. Garbage collection (computer science) — wikipedia, the free encyclo-pedia, 2011. [Online; accessed 22-August-2011]. 31
[54] Wikipedia. Great Firewall of China — wikipedia, the free encyclopedia, 2011.[Online; accessed 25-August-2011]. 1
[55] Wikipedia. NAT port mapping protocol — wikipedia, the free encyclopedia, 2011.[Online; accessed 23-August-2011]. 34
[56] Wikipedia. Online certificate status protocol — wikipedia, the free encyclopedia,2011. [Online; accessed 25-September-2011]. 33
[57] Wikipedia. STUN — wikipedia, the free encyclopedia, 2011. [Online; accessed23-August-2011]. 34
[58] Wikipedia. Universal plug and play — wikipedia, the free encyclopedia, 2011.[Online; accessed 23-August-2011]. 34
[59] Reporters without Borders. Internet Enemies. Technical report, Reporters withoutBorders, March 2011. 1, 11, 24
[60] J. Zittrain and B. Edelman. Internet filtering in China. Internet Computing, IEEE,7(2):70–77, 2003. 11
50


















