
ADS: Algorithmen und Datenstrukturen 1 - Teil 13 · Invertierte Listen Nutzung vor allem zur...
29
ADS: Algorithmen und Datenstrukturen 1 Teil 13 Prof. Peter F. Stadler & Dr. Christian H¨ oner zu Siederdissen Bioinformatik/IZBI Institut f¨ ur Informatik & Interdisziplin¨ ares Zentrum f¨ ur Bioinformatik Universit¨ at Leipzig 16. Januar 2017 [Letzte Aktualisierung: 16/01/2017, 18:08] 1 / 23
Transcript of ADS: Algorithmen und Datenstrukturen 1 - Teil 13 · Invertierte Listen Nutzung vor allem zur...

ADS: Algorithmen und Datenstrukturen 1Teil 13
Prof. Peter F. Stadler & Dr. Christian Honer zu Siederdissen
Bioinformatik/IZBIInstitut fur Informatik
& Interdisziplinares Zentrum fur BioinformatikUniversitat Leipzig
16. Januar 2017[Letzte Aktualisierung: 16/01/2017, 18:08]
1 / 23

Statische Suchverfahren
Annahme: weitgehend statische Texte / Dokumente
derselbe Text wird haufig fur unterschiedliche Muster durchsucht
Beschleunigung der Suche durch Indexierung (Suchindex)Vorgehensweise bei
Information Retrieval-Systemen zur Verwaltung vonDokumentkollektionen
Volltext-Datenbanksystemen
Web-Suchmaschinen etc.
Indexvarianten
(Prafix-) B*-Baume
Tries, z.B. Radix oder PATRICIA Tries
Suffix-Baume
Invertierte Listen
Signatur-Dateien
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 2 / 23

Invertierte Listen
Nutzung vor allem zur Textsuche in Dokumentkollektionen
nicht nur ein Text/Sequenz, sondern beliebig viele Texte / Dokumente
Suche nach bestimmten Wortern/Schlusselbegriffen/Deskriptoren, nichtnach beliebigen Zeichenketten
Begriffe werden ggf. auf Stammform reduziert; Elimination so genannter“Stopp-Worter” (der, die, das, ist, er ...)
klassische Aufgabenstellung des Information Retrieval
Invertierung: Verzeichnis (Index) aller Vorkommen von Schlusselbegriffen
lexikographisch sortierte Liste der vorkommenden Schlusselbegriffe
pro Eintrag (Begriff) Liste der Dokumente (Verweise/Zeiger), die Begriffenthalten
eventuell zusatzliche Information pro Dokument wie Haufigkeit desAuftretens oder Position der Vorkommen
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 3 / 23

Invertierte Liste: Beispiel
Dies ist ein Text. Der Text hat viele Worter. Worter bestehen aus ...
Begriff Vorkommen
bestehen 53Dies 1Text 14, 24viele 33Worter 38, 46
Zugriffskosten werden durch Datenstruktur zur Verwaltung der invertiertenListe bestimmt, z.B. B∗-Baum, Hash-Verfahren.
Effiziente Realisierung uber (indirekten) B*-Baum - variabel langeVerweis/Zeigerlisten pro Schlussel auf Blattebene
Boolesche Operationen: Verknupfung von Zeigerlisten
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 4 / 23

Signatur-Dateien
Alternative zu invertierten Listen: Einsatz von Signaturen
zu jedem Dokument/Textfragment: Bitvektor fixer Lange (=Signatur)
Signatur wird aus Begriffen generiert durch Hash-Funktion s
OR-Verknupfung der Bitvektoren aller im Dokument/Fragmentvorkommenden Begriffe ergibt Dokument- bzw. Fragment-Signatur
Signaturen aller Dokumente/Fragmente werden entweder sequentielloder in einem speziellen Signaturbaum gespeichert.
Suche
Hashfunktion s angewandt auf Suchbegriff liefert Anfragesignatur
mehrere Suchbegriffe konnen einfach zu einer Anfragesignaturkombiniert werden (OR, AND, NOT-Verknupfung der Bitvektoren)
da Signatur nicht eindeutig, muss bei ermittelten Dokumenten /Fragmenten gepruft werden, ob tatsachlich ein Treffer vorliegt
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 5 / 23

Approximative Suche / Ahnlichkeitssuche
Erfordert Maß fur die Ahnlichkeit zwischen Zeichenketten s1 und s2,z.B.
Hamming-Distanz: Anzahl der Mismatches zwischen s1 und s2 (nursinnvoll wenn s1 und s2 die gleiche Lange haben)
Editierdistanz: Kosten zum Editieren von s1, um s2 zu erhalten(Einfuge-, Losch-, Ersetzungsoperationen)
Beispiels1 AGCAA AGCACACA
s2 ACCTA ACACACTA
Hamming distance 2 6
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 6 / 23

k-Mismatch-Suchproblem
Gesucht werden alle Vorkommen eines Musters in einem Text, so daßhochstens an k der m Stellen des Musters ein Mismatch vorliegt, d.h.Hamming-Distanz ≤ k ist.
Exakte Stringsuche ergibt sich als Spezialfall mit k = 0
Naiver Such-Algorithmus kann fur k-Mismatch-Problem leicht angepasstwerden
for(i=1 .. n-m+1) {
z=0;
for (j=1 .. m)
if( t[i+j-1]!=q[j] ) z=z+1; /* mismatch */
if (z<=k)
print("Treffer in ",i," mit ",z,"Mismatches");
}
Auch effizientere Suchalgorithmen (KMP, BM, . . . ) konnen angepasstwerden
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 7 / 23

Suchen in sublinearer Zeit?
>gi|15896971|ref|NC 002754.1| Sulfolobus solfataricus
GTATACTCTTCTTCCCTATACATTGTCGCAGCAAGCTTAGTTTCTTTAGCCTC
TTATAATCTTAATAGCAAGGAGACATATGATAGAGTATTTCTATATGATTCCT
CTTTATTGTCGCACTAAACTTCACTGCAATATTTTTAGAGTTAATAAGAGCAC
ACTGAAAGAAGTGCCAAGGTTACGGGGGAGGTCATGGGATGATAACTGAATTT
AGAAGAACATTTAAGCCATGTAAAGGAAGAGAATACGATATATGTAACAGATT
AGAGTAAGATATGAGAGTGAATACAAGGAGCTTGCAATCTCTCAGGTTTACGC
GGGACATATTGCATCTCGGTCTTGAAAGCGTATTAAAAGGGAACTTTAATGCA
TCTGAGAGAAATTAACGTCGGAGGTAAAGTTTATAAAATTAAAGGAAGAGCCG
GACAACGGGAAGAGTATTGTAATTGAGATAAAAACTTCTAGAAGTGATAAAGG
ATAAAATGCAGCTACAGATATATTTATGGTTATTTAGTGCAGAAAAAGGTATA
AGATAGGATAGCTGAGTATGAAATAAACGAACCTTTAGATGAAGCAACAATAG
ACAATAATGTTACAAAACTCACCTAGATTCAACTGGGAATGTAAATATTGCAT
CAGCTAAACTAACCTAAAATTAAAATCTCTCATCGATATAATTAAATTGTGCA
CCACAATAGCTGGGAGTGACAGTGGAGGAGGTGCTGGATTACAGGCTGATCTA
AGGAGTTTTTGGTACAACAATAATAACCGGTTTAACAGCACAGAATACAAGAA
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 8 / 23

zu losende Probleme
Probleme:
einen Text der Lange m in O(m) in einem Text der Lange n finden
alle k Treffer in O(m + k) Zeit
longest common substring in Θ(n1 + n2)
alle k maximalen Paare in O(n + k)
Generell: oft “sublineare” Suche
n “gross”: 109 Buchstaben
m “klein”: 102.5 Buchstaben
“kleine” Suchanfragen oft wiederholt
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 9 / 23

Losungsansatze
Textsuche (KMP): zu langsam wenn Anzahl der Suchanfragen k gross(O(k(m + n)))
Suffix Baume
Suffix Arrays
Den grossen Text vorverarbeiten (als Suffixbaum) um spater schnellsuchen zu konnen
Jeder Substring ist Prefix eines Suffixes
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 10 / 23

Definition: Suffixbaum
Ein Suffixbaum T fur den Eingabestring S = s1 . . . sn$, n ≥ 1ist ein gewurzelter Baum
s1 . . . sn 6= $
T hat n + 1 Blatter
jeder innere Knoten hat mindestens zwei Kinder
jede Kante hat als Label ein Infix von S
alle von einem Knoten ausgehende Kanten beginnen mitverschiedenen Buchstaben im Label
jeder Pfad von der Wurzel zu einem Blatt beschreibt ein Suffix von S
alle diese Pfade zusammen beschreiben alle Suffixe von S
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 11 / 23

Alle Suffixe eines Strings
Gegeben: S = babab$
$ kommt sonst nicht im String S vor
wie lassen sich nun “schnell” alle Vorkommenvon ba finden?
Alle Suffixe:
babab$
abab$
bab$
ab$
b$
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 12 / 23

Naive Konstruktion des Suffix-Baumes “wotd”
1 von der Wurzel bis zum Knoten u haben wir das Label u
2 Knoten u: R(u) = {s|us ist suffix von S}3 fur alle Buchstaben c ∈ Σ finde Untermenge an Suffixen die mit c
beginnen: G (u, c) = {w ∈ Σ∗|cw ∈ R(u)}4 1 |G (u, c)| = 1: Blattkante mit cw .
2 sonst finde langstes gemeinsames Prefix lcp(ucv), und setzeKantenlabel auf cv
5 wiederhole rekursiv (mit ucv als neuem u) bis nur noch Blattererstellt werden
Σ ist das Alphabet, Σ∗ alle Strings uber Σ (auch der leere String)
(u.a.) Giegerich, Kurtz, Stoye, 2003, efficient implementation of lazy suffixtrees
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 13 / 23
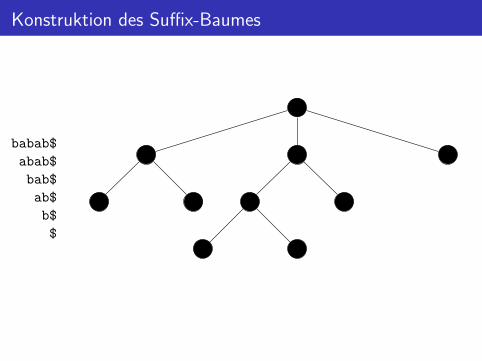
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$b
$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23

Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$
b a
$b
a
$b
$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23
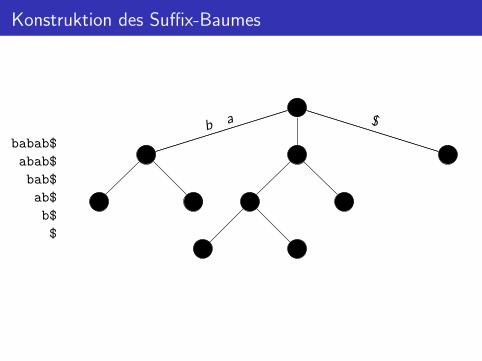
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$b
$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23
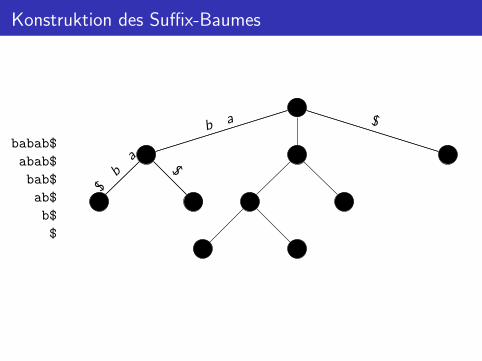
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$
b$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23
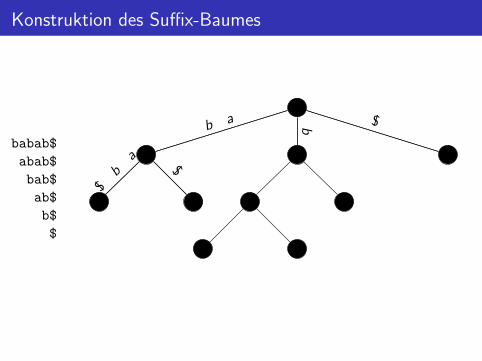
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$b
$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23
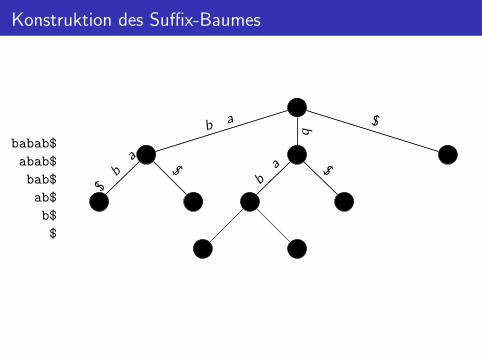
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$b
$
ba
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23
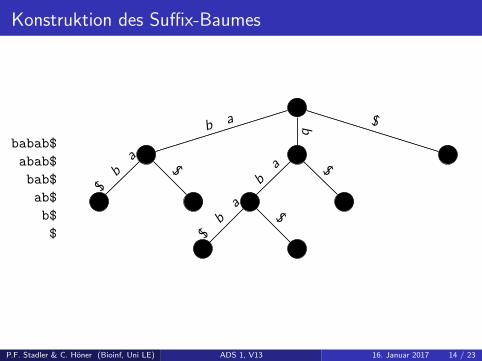
Konstruktion des Suffix-Baumes
babab$
abab$
bab$
ab$
b$
$
$b a
$b
a
$b
$
ba
$b
a$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 14 / 23

Hinweise
$ macht jedes Suffix einzigartig (“welches ab ist gemeint”)
kein Suffix soll Prefix eines anderen Suffixes sein
jedes Suffix beschreibt einen vollstandigen Pfad zu einem Blatt
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 15 / 23

Laufzeit
O(n) innere Knoten
O(n) Blatter
pro Knoten: O(n) fur G (u, c)
lcp amortisiert: O(n2)
insgesamt: O(n2)
aber:
erwartete Laufzeit: O(n log n)
wotdlazy (Giegerich, et al) baut nur die Teile des Baumes auf diebenotigt werden: beschranken sich die Suchen auf einen kleinenTeilbaum, wird nur dieser gebaut
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 16 / 23

Optimierungen / Speicherverbrauch
Kantenlabel nicht als String (“ab”) sondern als Paar (i,j) S [i . . . j ]speichern
12 bytes pro Character
Suffixbaume haben grossen Overhead!
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 17 / 23

Algorithmus: Textsuche
Starte Suche bei der Wurzel
1 gegeben Suchmuster Q = q1 . . . qm2 finde Kantenlabel das mit q1 beginnt, dies sei L = l1 . . . lk ; sonst:
Muster nicht im Text3 1 m ≤ k und Q = L[1 . . .m]: Muster gefunden
2 m ≥ k und Q[1 . . . k] = L: rekursiv weitermachen mit Q[k + 1 . . .m]als neues Q
3 “Mismatch”: Muster nicht im Text
4 falls Muster gefunden: folge allen Pfaden zu Blattern um die Anzahlund Position aller (!) Matches zu bekommen
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 18 / 23
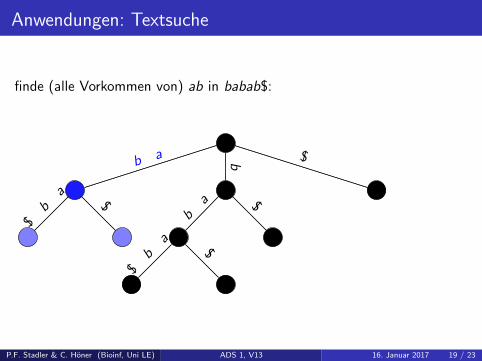
Anwendungen: Textsuche
finde (alle Vorkommen von) ab in babab$:
$b
$
ba
$b
a
$
b a
$b
a
$
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 19 / 23

Langster Substring der k-mal auftaucht
1 pre-order: folge allen Pfaden von der Wurzel zu den Blattern, schreibean jeden Knoten die Lange des Gesamtlabels bis dorthin
2 post-order: schreibe an jeden Knoten die Anzahl der Blatter imTeilbaum
3 finde Knoten mit k Blattern im Teilbaum (filtern), der das langsteGesamtlabel hat (maximieren)
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 20 / 23
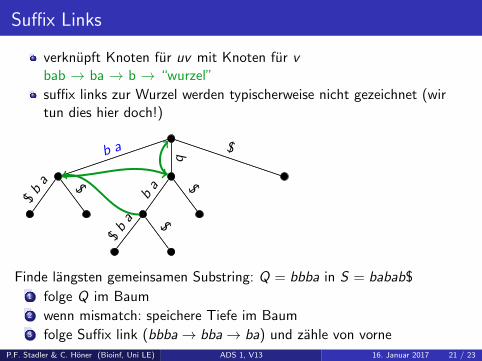
Suffix Links
verknupft Knoten fur uv mit Knoten fur vbab → ba → b → “wurzel”
suffix links zur Wurzel werden typischerweise nicht gezeichnet (wirtun dies hier doch!)
$b$
ba
$ba $
b a
$ba $
Finde langsten gemeinsamen Substring: Q = bbba in S = babab$1 folge Q im Baum2 wenn mismatch: speichere Tiefe im Baum3 folge Suffix link (bbba→ bba→ ba) und zahle von vorne
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 21 / 23

Generalisierter Suffix-Baum
Ein Baum T mit mehreren Strings
S = S1S2 . . . Sk = s11 . . . s1n1$1 . . . $k−1sk1 . . . sknk $k
Konstruktion wie gehabt
Wofur?
finde alle Si in denen Q auftaucht und wo
finde langsten String der in min. l Strings existiert
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 22 / 23

Zusammenfassung
Trie fur alle Suffixe eines Strings S
Einfaches Suchen, Zahlen, und andere Abfragen
hoher Speicherverbrauch
langsame O(n2), “einfache” oder schnelle O(n), aber komplexereKonstruktion (Ukkonens Algorithmus)
Erweiterbar fur mehrere Strings
40 Jahre alt und immer noch aktiv beforscht!
P.F. Stadler & C. Honer (Bioinf, Uni LE) ADS 1, V13 16. Januar 2017 23 / 23


















