
Apache solr
40
Apache Solr Oberseminar, 12.06.2015 Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen Péter Király, [email protected]
-
Upload
kiraly-peter -
Category
Software
-
view
109 -
download
1
Transcript of Apache solr

Apache Solr
Oberseminar, 12.06.2015Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen Péter Király, [email protected]

What is Apache Solr?
Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene
2
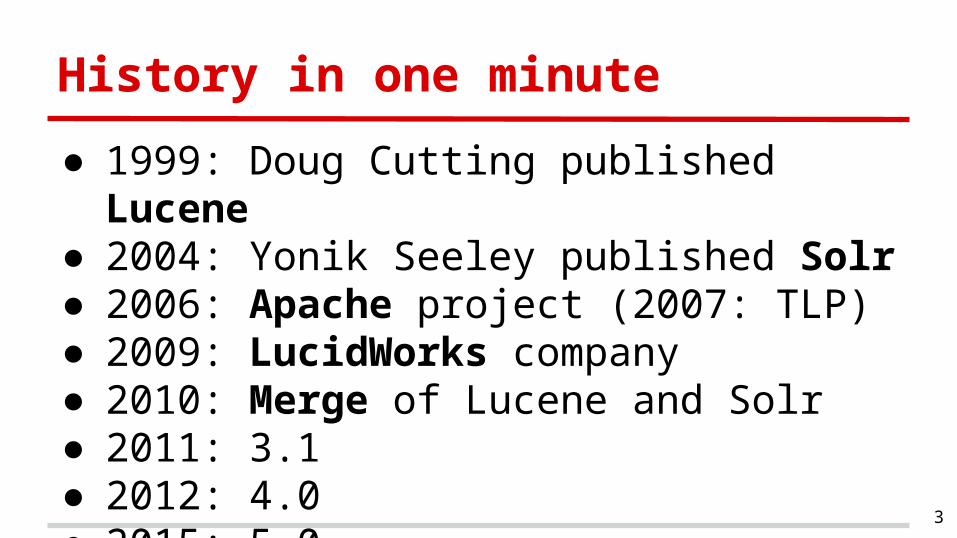
● 1999: Doug Cutting published Lucene● 2004: Yonik Seeley published Solr● 2006: Apache project (2007: TLP)● 2009: LucidWorks company● 2010: Merge of Lucene and Solr● 2011: 3.1● 2012: 4.0● 2015: 5.0
History in one minute
3

“Sister” projects
● Nutch: web scale search engine● Tika: document parser● Hadoop: distributes storage and data
processing● Elasticsearch: alternative to Solr● forks/ports of Lucene● client libraries and tools (Luke index viewer)
4

Main features I
● Faceted navigation● Hit highlighting● Query language● Schema-less mode and Schema REST API● JSON, XML, PHP, Ruby, Python, XSLT,
Velocity and custom Java binary outputs● HTML administration interface
5

Main features II
● Replication to other Solr servers● Distributed search through sharding● Search results clustering based on Carrot2● Extensible through plugins● Relevance boosting via functions● Caching - queries, filters, and documents● Embeddable in a Java Application
6

Main features III
● Geo-spatial search, including multiple points per documents and polygons
● Automated management of large clusters through ZooKeeper
● Function queries● Field Collapsing and grouping● Auto-suggest
7
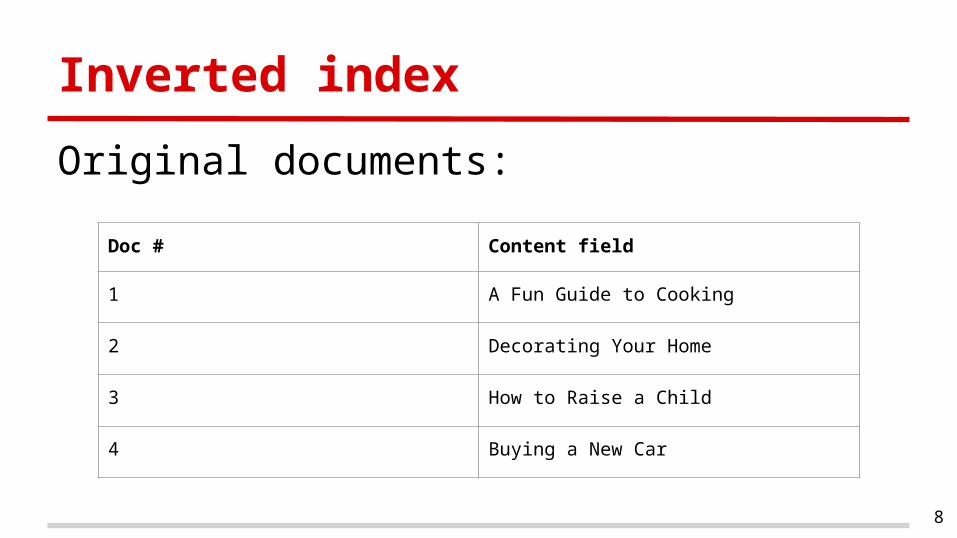
Inverted index
Original documents:
Doc # Content field
1 A Fun Guide to Cooking
2 Decorating Your Home
3 How to Raise a Child
4 Buying a New Car
8
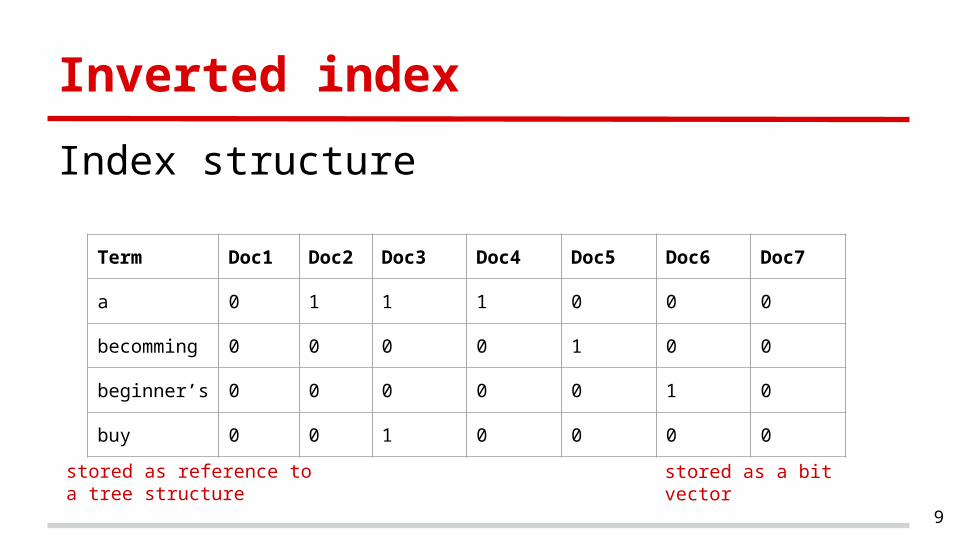
Inverted index
Index structure
Term Doc1 Doc2 Doc3 Doc4 Doc5 Doc6 Doc7
a 0 1 1 1 0 0 0
becomming 0 0 0 0 1 0 0
beginner’s 0 0 0 0 0 1 0
buy 0 0 1 0 0 0 0
stored as a bit vectorstored as reference to a tree structure
9

Indexing
Document ~ RDBM recordFields (key-value structure):● types (text, numeric, date, point, custom)● indexed, stored, multiple, required● field name patterns (prefixes, suffixes, such
as *_tx)● special fields (identifier, _version_)
10
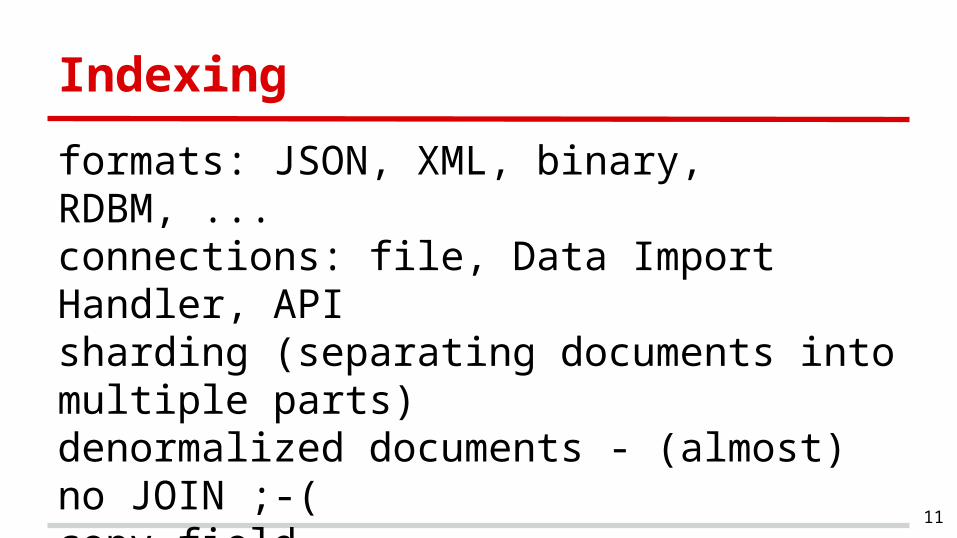
Indexing
formats: JSON, XML, binary, RDBM, ...connections: file, Data Import Handler, APIsharding (separating documents into multiple parts)denormalized documents - (almost) no JOIN ;-(copy fieldcatch all field (contains everything)
11

A document example (XML)
<doc> <field name="id">F8V7067-APL-KIT</field> string <field name="name">Belkin Mobile Power Cord for iPod w/ Dock</field> text <field name="cat">electronics</field> <field name="cat">connector</field> multivalue <field name="price">19.95</field> float <field name="inStock">false</field> boolean <field name="store">45.18014,-93.87741</field> geo point <field name="manufacturedate_dt">2005-08-01T16:30:25Z</field> date</doc>
12
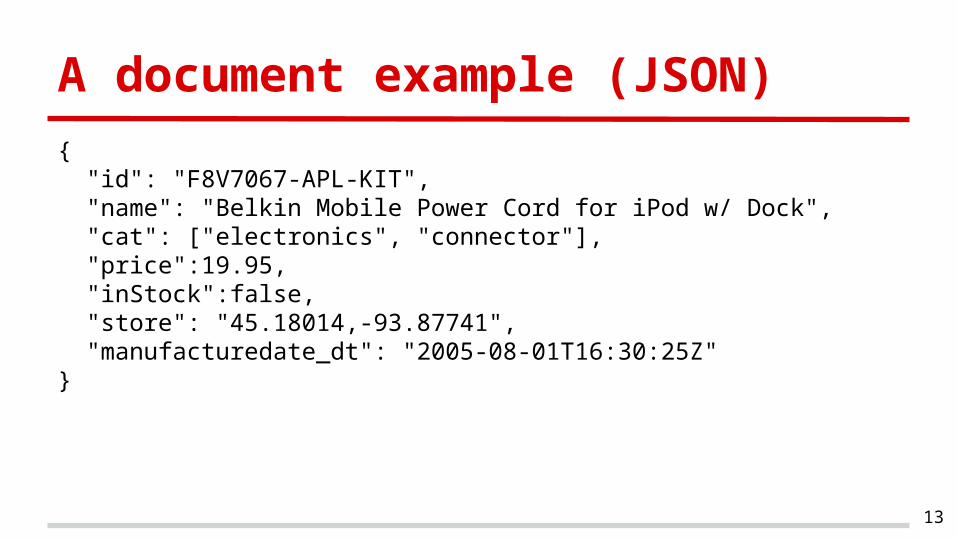
A document example (JSON)
{ "id": "F8V7067-APL-KIT", "name": "Belkin Mobile Power Cord for iPod w/ Dock", "cat": ["electronics", "connector"], "price":19.95, "inStock":false, "store": "45.18014,-93.87741", "manufacturedate_dt": "2005-08-01T16:30:25Z"}
13
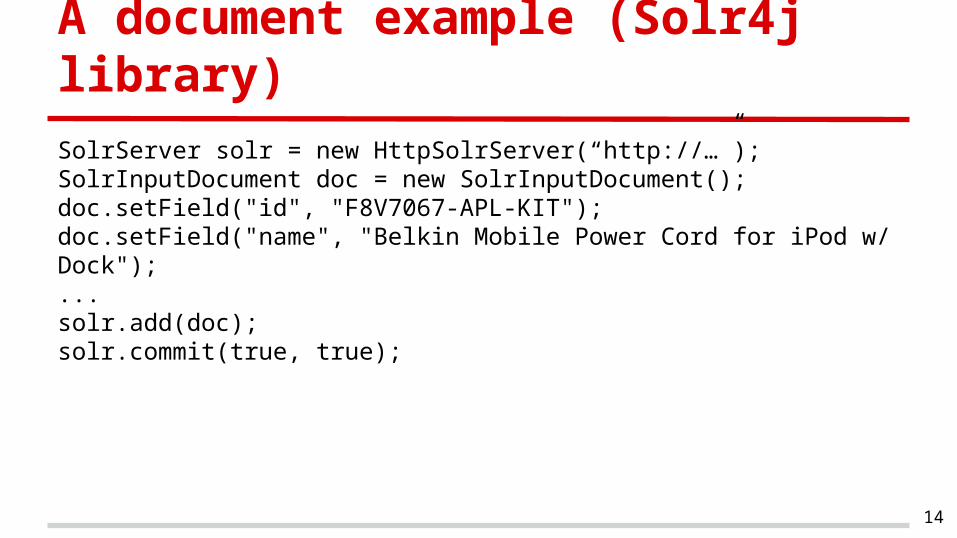
A document example (Solr4j library)
SolrServer solr = new HttpSolrServer(“http://…”);SolrInputDocument doc = new SolrInputDocument();doc.setField("id", "F8V7067-APL-KIT");doc.setField("name", "Belkin Mobile Power Cord for iPod w/ Dock");...solr.add(doc);solr.commit(true, true);
14

Text analysis chain
1) character filters — preprocess textpattern replace, ASCII folding, HTML stripping2) tokenizers — split text into smaller unitswhitespace, lowercase, word delim., standard3) token filters — examine/modify/eliminatestemming, lowercase, stop words,
15

Text analysis chain
<fieldType name="my-text-type" class="solr.TextField"> <analyzer type="index"> <charFilter class="solr.MappingCharFilterFactory" mapping="mapping-FoldToASCII.txt" /> <tokenizer class="solr.WhitespaceTokenizerFactory" /> <filter class="solr.StopFilterFactory" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer></fieldType>
16

Text analysis result
#Yummm :) Drinking a latte at Caffé Grecco in SF’s historic North Beach…Learning text analysis “#yumm”, “drink”, “latte”, “caffe”, “grecco”, “sf”/”san francisco”, “historic” “north” “beach”“learn”, “text”, “analysis”
stem
min
g
syno
nym
inje
ctio
n
stop
wor
d
17

Performing queries
1) user enters a query (+ specifies other components)
2) query handler3) analysis (use similar as in indexing)4) run search5) adding components6) serialization (XML, JSON etc.)
18

Lucene query language
● *:* (→ everything)● gwdg● name:gwdg● name:admin*● h?ld (→ hold, held)● name:administrator~ (→ —tor, —tion)● name:Gesellschaft~0.6 (similarity measure)
19

Lucene query language
● name:Max AND name:Planck● name:Max OR name:Planck● name:Max NOT name:Planck● name:”Max Planck”● name:(“Max Planck” OR Gesselschaft)● “Max Planck”~3 (within 3 words) → so “Planck Max”, “Max Ludwig Planck”
20
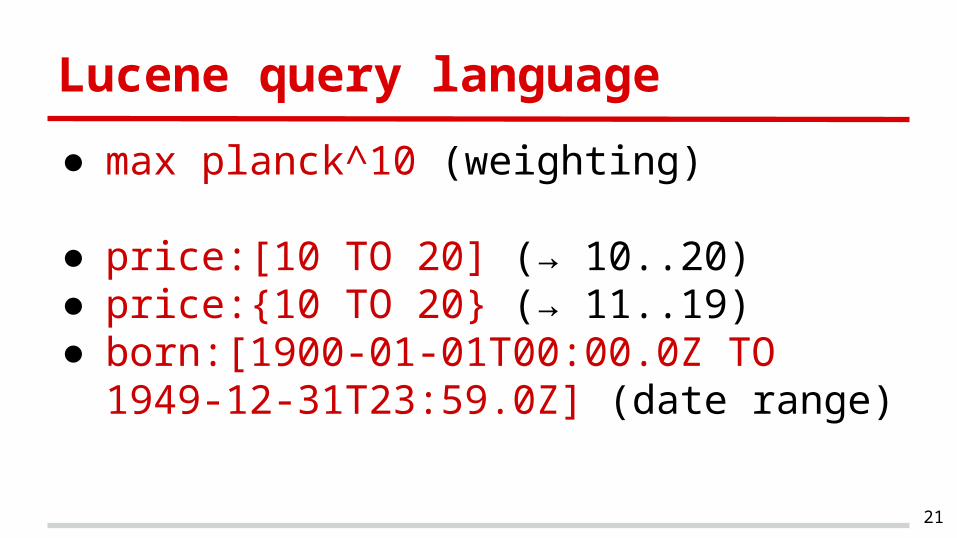
Lucene query language
● max planck^10 (weighting)
● price:[10 TO 20] (→ 10..20)● price:{10 TO 20} (→ 11..19)● born:[1900-01-01T00:00.0Z TO 1949-12-
31T23:59.0Z] (date range)
21
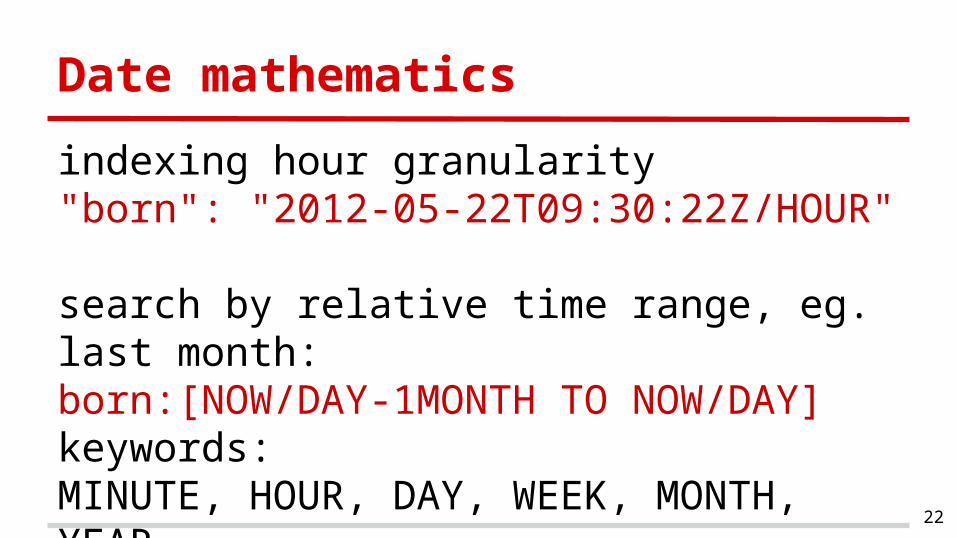
Date mathematics
indexing hour granularity"born": "2012-05-22T09:30:22Z/HOUR"
search by relative time range, eg. last month:born:[NOW/DAY-1MONTH TO NOW/DAY]keywords:MINUTE, HOUR, DAY, WEEK, MONTH, YEAR
22
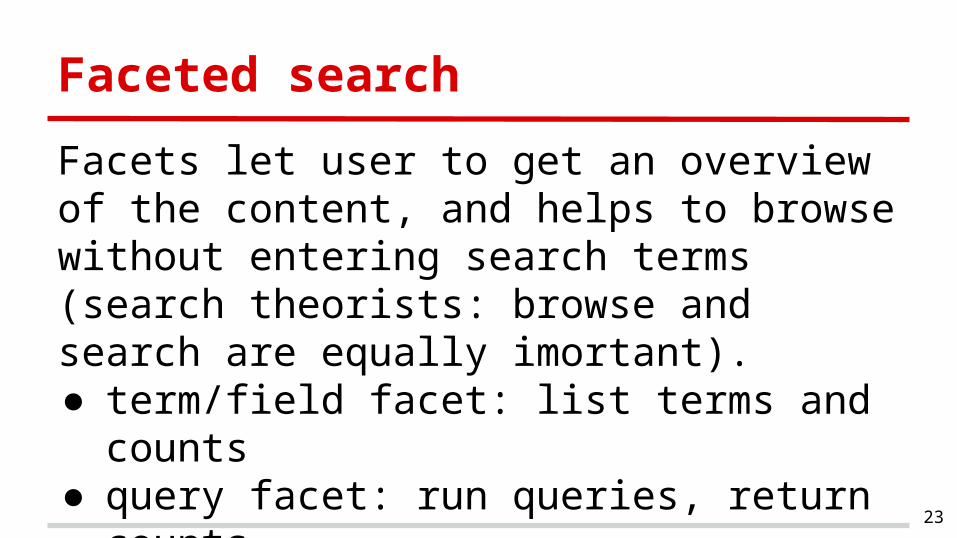
Faceted search
Facets let user to get an overview of the content, and helps to browse without entering search terms (search theorists: browse and search are equally imortant).● term/field facet: list terms and counts● query facet: run queries, return counts● range facet: split range into pieces
23
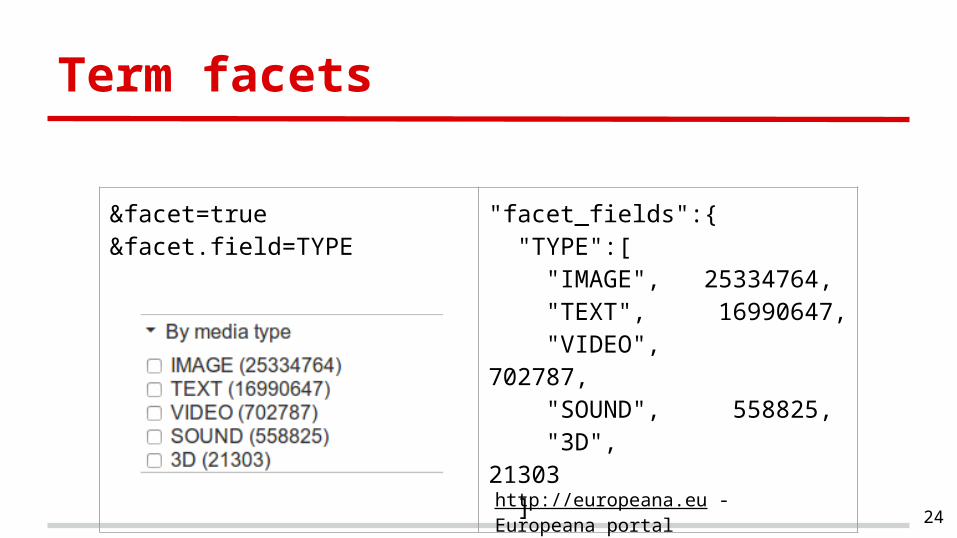
Term facets
&facet=true&facet.field=TYPE
"facet_fields":{ "TYPE":[ "IMAGE", 25334764, "TEXT", 16990647, "VIDEO", 702787, "SOUND", 558825, "3D", 21303 ]
http://europeana.eu - Europeana portal24

Term facet
Additional parameters:● limit, offset → for pagination● sort (by index or count) → alphabetically or frequency● mincount → filter less frequent terms● missing → number of documents miss this field● prefix → such as “http” to display URLs only● f.[facet name].facet.[parameter] → overwrites generals
25
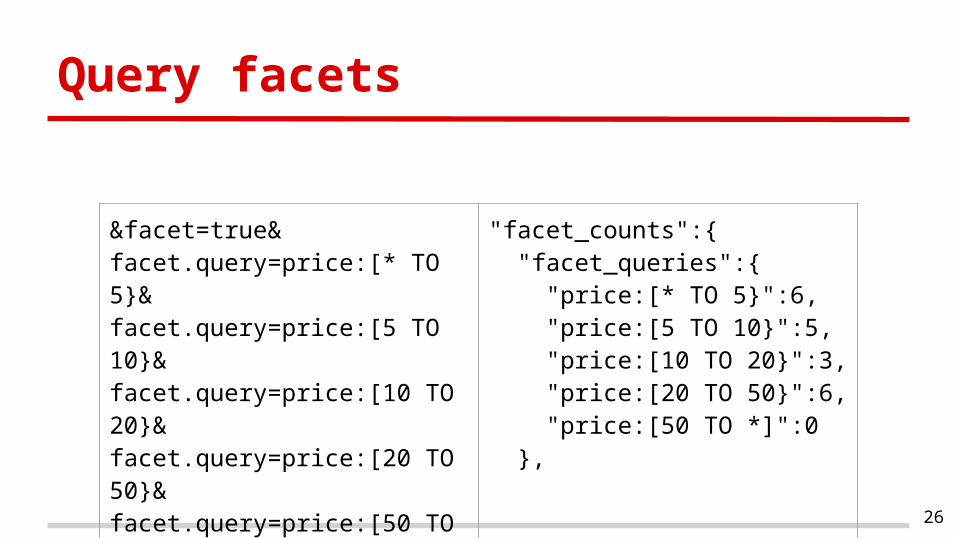
Query facets
&facet=true&facet.query=price:[* TO 5}&facet.query=price:[5 TO 10}&facet.query=price:[10 TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *]
"facet_counts":{ "facet_queries":{ "price:[* TO 5}":6, "price:[5 TO 10}":5, "price:[10 TO 20}":3, "price:[20 TO 50}":6, "price:[50 TO *]":0 },
26

Query facets (zooming)
From centuries to years
http://pcu.bage.es/ Catálogo Colectivo de las Bibliotecas de la Administración General del Estado
27
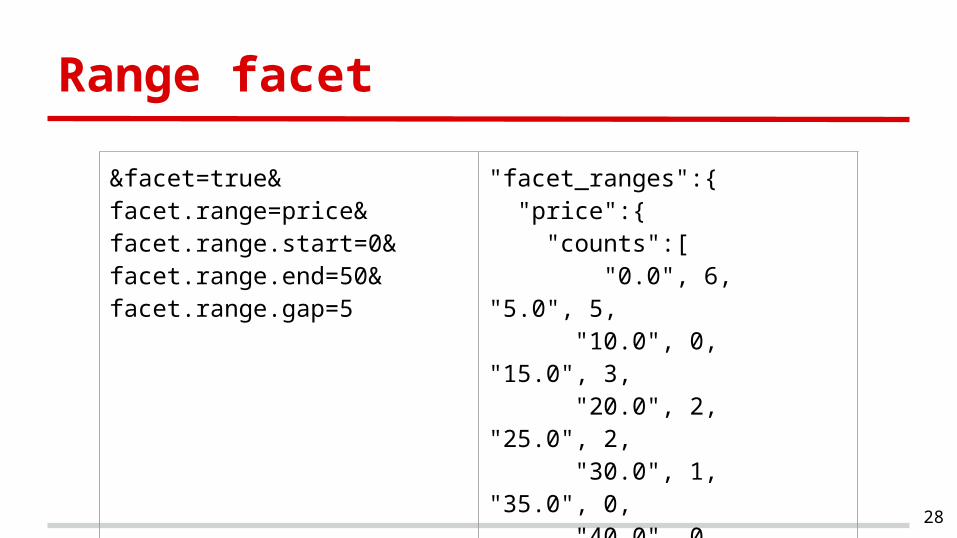
Range facet
&facet=true&facet.range=price&facet.range.start=0&facet.range.end=50&facet.range.gap=5
"facet_ranges":{ "price":{ "counts":[ "0.0", 6, "5.0", 5, "10.0", 0, "15.0", 3, "20.0", 2, "25.0", 2, "30.0", 1, "35.0", 0, "40.0", 0, "45.0", 1 ], "gap":5.0,"start":0.0,"end":50.0}}}}
28

Hit highlighting
?...&hl=true&hl.fl=name&hl.simple.pre=<em>&hl.simple.post=</em>
"highlighting": { "SP2514N": { ←ID "name": ["<em>SpinPoint P120 </em> SP2514N - hard drive - 250 GB - ATA-133"]}
29
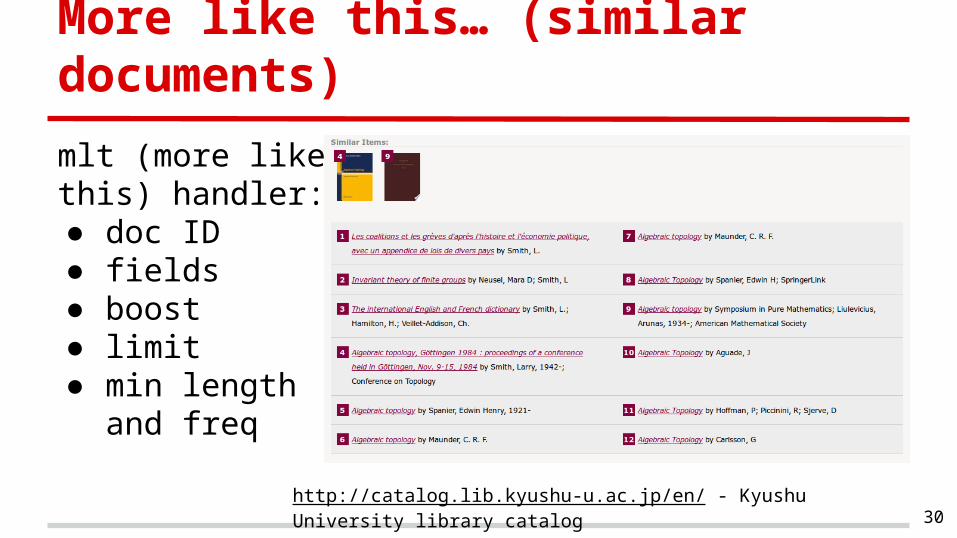
More like this… (similar documents)
mlt (more like this) handler:● doc ID● fields● boost● limit● min length and
freq
http://catalog.lib.kyushu-u.ac.jp/en/ - Kyushu University library catalog30
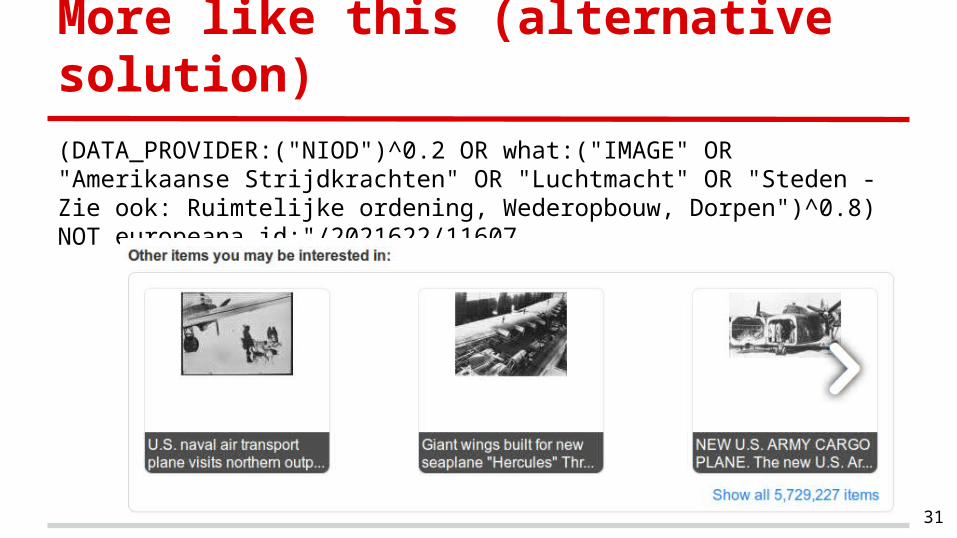
More like this (alternative solution)
(DATA_PROVIDER:("NIOD")^0.2 OR what:("IMAGE" OR "Amerikaanse Strijdkrachten" OR "Luchtmacht" OR "Steden - Zie ook: Ruimtelijke ordening, Wederopbouw, Dorpen")^0.8) NOT europeana_id:"/2021622/11607
31
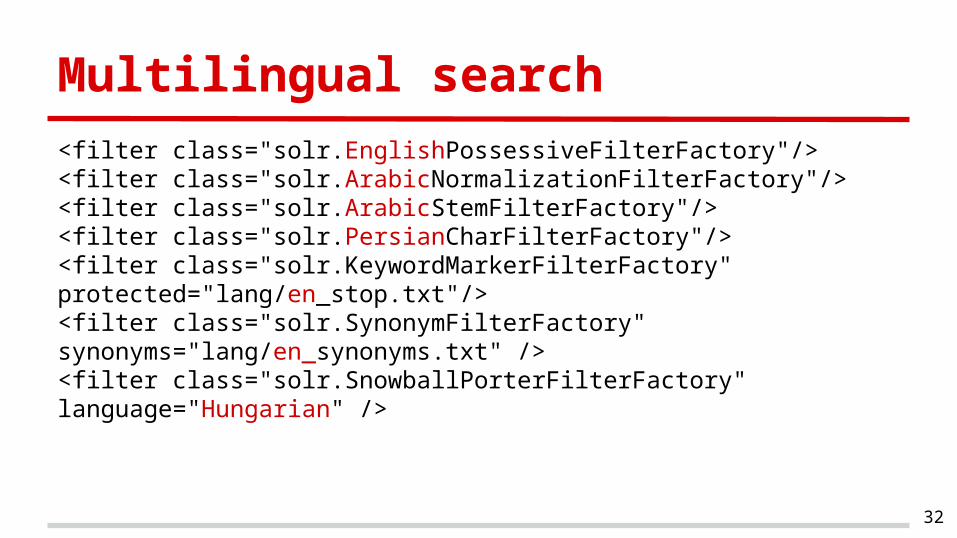
Multilingual search
<filter class="solr.EnglishPossessiveFilterFactory"/><filter class="solr.ArabicNormalizationFilterFactory"/><filter class="solr.ArabicStemFilterFactory"/><filter class="solr.PersianCharFilterFactory"/><filter class="solr.KeywordMarkerFilterFactory" protected="lang/en_stop.txt"/><filter class="solr.SynonymFilterFactory" synonyms="lang/en_synonyms.txt" /><filter class="solr.SnowballPorterFilterFactory" language="Hungarian" />
32
Multilingual search strategies
● Separate fields by language→ title_en:horse OR title_de:horse OR title_hu:horse
● Separate collections (core, shard) per languageall core has language settings and same field names→ /select?shards=.../english,.../spanish,.../french &q=title:horse
● All language in one field (from Solr 5.0)→ title:(es|escuela OR en,es,de|school OR school)
33
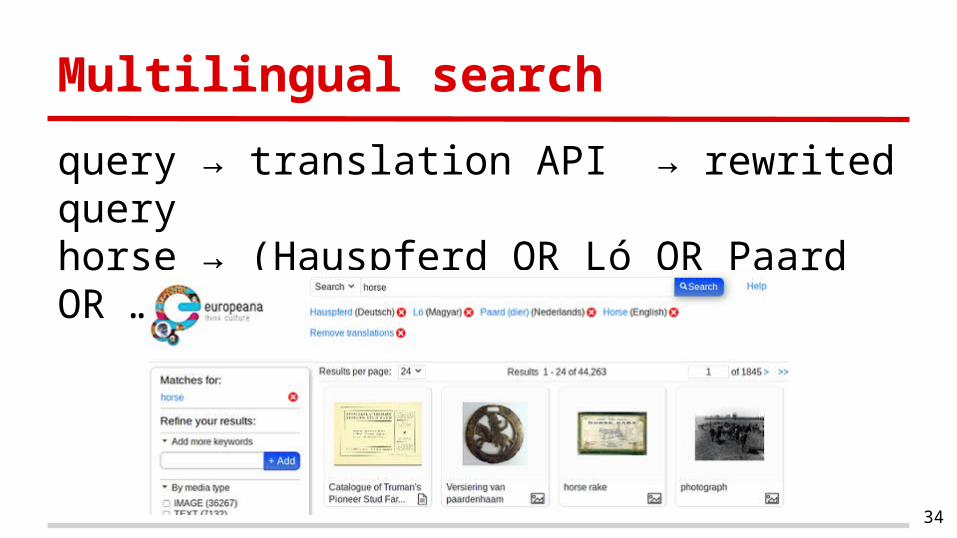
Multilingual search
query → translation API → rewrited queryhorse → (Hauspferd OR Ló OR Paard OR …)
34

Relevancy
The most important concepts:
● Term frequency (tf) - how often a particular term appears in a matching document
● Inverse document frequency (idf) - how “rare” a search term is, inverse of the document frequency (how many total documents the search term appears within)
● field normalization factor (field norm) - a combination of factors describing the importance of a particular field on a per-document basis
35

Relevancy
score(q,d) = Σ (tf(t in d) × idf(t)2 × t.getBoost() ×
norm(t,d)) × coord(q,d) × queryNorm(q)wheret = term; d = document; q = query; f = fieldtf(t in d) = num. of term occurrences in document1/2
norm(t,d) = d.getBoost() × lengthNorm(f) × f.getBoost()idf(t) = 1 + log (numDocs / (docFreq +1))coord(q,d) = numTermsInDocumentFromQuery / numTermsInQueryqueryNorm(q) = 1 / (sumOfSquaredWeights1/2)sumOfSquaredWeights = q.getBoost()2 × Σ(idf(t) × t.getBoost())2
see: Solr in Action, p. 6736

Debug
?...&debug=true..."debug":{ "rawquerystring":"hard drive", "querystring":"hard drive", "parsedquery":"text:hard text:drive", "parsedquery_toString":"text:hard text:drive",
37
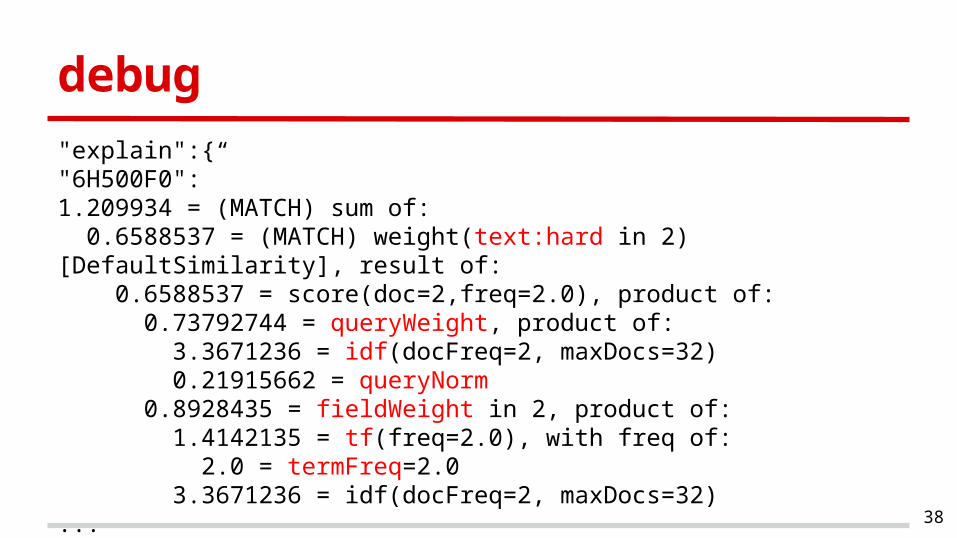
debug
"explain":{"6H500F0":”1.209934 = (MATCH) sum of: 0.6588537 = (MATCH) weight(text:hard in 2) [DefaultSimilarity], result of: 0.6588537 = score(doc=2,freq=2.0), product of: 0.73792744 = queryWeight, product of: 3.3671236 = idf(docFreq=2, maxDocs=32) 0.21915662 = queryNorm 0.8928435 = fieldWeight in 2, product of: 1.4142135 = tf(freq=2.0), with freq of: 2.0 = termFreq=2.0 3.3671236 = idf(docFreq=2, maxDocs=32)...
38

References
● http://lucene.apache.org/solr/● Grainger & Potter: Solr in Action● https://lucidworks.com/blog/● http://blog.sematext.com/● http://solr.pl/● https://www.packtpub.com/all?search=solr● http://www.slideshare.net/treygrainger
39

Happy searching!
40










![Apache Solr - DBIS EPubdbis.eprints.uni-ulm.de/1134/1/AusarbeitungMohring1203.pdf · Highlighting oua], Boosting [Foua] und Filter oua][F bieten alle Vier. Sphinx ist der einzige](https://static.fdokument.com/doc/165x107/5e00e30001b7fd3f5974457b/apache-solr-dbis-highlighting-oua-boosting-foua-und-filter-ouaf-bieten-alle.jpg)







