
ASA Programmierhandbuch
506
Adaptive Server® Anywhere Handbuch für Programmierer Stand: Oktober 2002 Bestellnummer: 03946-01-0802-01
Transcript of ASA Programmierhandbuch

Adaptive Server® AnywhereHandbuch für Programmierer
Stand: Oktober 2002Bestellnummer: 03946-01-0802-01

Copyright © 1989–2002 Sybase, Inc. Teil-Copyright © 2002 iAnywhere Solutions, Inc. Alle Rechte vorbehalten.
Diese Publikation darf ohne vorheriges schriftliches Einverständnis der iAnywhere Solutions, Inc. weder ganz noch teilweise, weder elektronisch,mechanisch, manuell, optisch, noch auf sonst eine Weise reproduziert, übertragen oder übersetzt werden. iAnywhere Solutions, Inc ist eineTochtergesellschaft der Sybase Inc.
Sybase, das SYBASE-Logo, AccelaTrade, ADA Workbench, Adaptable Windowing Environment, Adaptive Component Architecture, AdaptiveServer, Adaptive Server Anywhere, Adaptive Server Enterprise, Adaptive Server Enterprise Monitor, Adaptive Server Enterprise Replication,Adaptive Server Everywhere, Adaptive Server IQ, Adaptive Warehouse, AnswerBase, Anywhere Studio, Application Manager, AppModeler,APT Workbench, APT-Build, APT-Edit, APT-Execute, APT-FORMS, APT-Library, APT-Translator, ASEP, Backup Server, BayCam, Bit-Wise,BizTracker, Certified PowerBuilder Developer, Certified SYBASE Professional, Certified SYBASE Professional (Logo), ClearConnect, ClientServices, Client-Library, CodeBank, Column Design, ComponentPack, Connection Manager, Convoy/DM, Copernicus, CSP, Data Pipeline, DataWorkbench, DataArchitect, Database Analyzer, DataExpress, DataServer, DataWindow, DB-Library, dbQueue, Developers Workbench, DirectConnect Anywhere, DirectConnect, Distribution Director, Dynamo, e-ADK, E-Anywhere, e-Biz Integrator, E-Whatever, EC-GATEWAY, ECMAP,ECRTP, eFulfillment Accelerator, Electronic Case Management, Embedded SQL, EMS, Enterprise Application Studio, Enterprise Client/Server,Enterprise Connect, Enterprise Data Studio, Enterprise Manager, Enterprise SQL Server Manager, Enterprise Work Architecture, Enterprise WorkDesigner, Enterprise Work Modeler, eProcurement Accelerator, eremote, Everything Works Better When Everything Works Together, EWA,Financial Fusion, Financial Fusion Server, First Impression, Formula One, Gateway Manager, GeoPoint, iAnywhere, iAnywhere Solutions,ImpactNow, Industry Warehouse Studio, InfoMaker, Information Anywhere, Information Everywhere, InformationConnect, InstaHelp, Intellidex,InternetBuilder, iremote, iScript, Jaguar CTS, jConnect for JDBC, KnowledgeBase, Logical Memory Manager, MainframeConnect, MaintenanceExpress, MAP, MDI Access Server, MDI Database Gateway, media.splash, MetaWorks, MethodSet, ML Query, MobiCATS, MySupport,Net-Gateway, Net-Library, New Era of Networks, Next Generation Learning, Next Generation Learning Studio, O DEVICE, OASiS, OASiS (logo),ObjectConnect, ObjectCycle, OmniConnect, OmniSQL Access Module, OmniSQL Toolkit, Open Biz, Open Business Interchange, Open Client,Open Client/Server, Open Client/Server Interfaces, Open ClientConnect, Open Gateway, Open Server, Open ServerConnect, Open Solutions,Optima++, Partnerships that Work, PB-Gen, PC APT Execute, PC DB-Net, PC Net Library, PhysicalArchitect, Pocket PowerBuilder,PocketBuilder, Power Through Knowledge, Power++, power.stop, PowerAMC, PowerBuilder, PowerBuilder Foundation Class Library,PowerDesigner, PowerDimensions, PowerDynamo, Powering the New Economy, PowerJ, PowerScript, PowerSite, PowerSocket, Powersoft,Powersoft Portfolio, Powersoft Professional, PowerStage, PowerStudio, PowerTips, PowerWare Desktop, PowerWare Enterprise, ProcessAnalyst,Rapport, Relational Beans, Replication Agent, Replication Driver, Replication Server, Replication Server Manager, Replication Toolkit, ReportWorkbench, Report-Execute, Resource Manager, RW-DisplayLib, RW-Library, S Designor, S-Designor, S.W.I.F.T. Message Format Libraries,SAFE, SAFE/PRO, SDF, Secure SQL Server, Secure SQL Toolset, Security Guardian, SKILS, smart.partners, smart.parts, smart.script,SQL Advantage, SQL Anywhere, SQL Anywhere Studio, SQL Code Checker, SQL Debug, SQL Edit, SQL Edit/TPU, SQL Everywhere,SQL Modeler, SQL Remote, SQL Server, SQL Server Manager, SQL Server SNMP SubAgent, SQL Server/CFT, SQL Server/DBM, SQL SMART,SQL Station, SQL Toolset, SQLJ, Stage III Engineering, Startup.Com, STEP, SupportNow, Sybase Central, Sybase Client/Server Interfaces, SybaseDevelopment Framework, Sybase Financial Server, Sybase Gateways, Sybase Learning Connection, Sybase MPP, Sybase SQL Desktop, SybaseSQL Lifecycle, Sybase SQL Workgroup, Sybase Synergy Program, Sybase User Workbench, Sybase Virtual Server Architecture, SybaseWare,Syber Financial, SyberAssist, SybMD, SyBooks, System 10, System 11, System XI (Logo), SystemTools, Tabular Data Stream, The EnterpriseClient/Server Company, The Extensible Software Platform, The Future Is Wide Open, The Learning Connection, The Model For Client/ServerSolutions, The Online Information Center, The Power of One, TradeForce, Transact-SQL, Translation Toolkit, Turning Imagination Into Reality,UltraLite, UNIBOM, Unilib, Uninull, Unisep, Unistring, URK Runtime Kit for UniCode, Viewer, Visual Components, VisualSpeller, VisualWriter,VQL, Warehouse Control Center, Warehouse Studio, Warehouse WORKS, WarehouseArchitect, Watcom, Watcom SQL, Watcom SQL Server,Web Deployment Kit, Web.PB, Web.SQL, WebSights, WebViewer, WorkGroup SQL Server, XA-Library, XA-Server und XP Server sind Markenvon Sybase, Inc. oder ihren Tochtergesellschaften.
Alle anderen Marken sind Eigentum ihrer jeweiligen Eigentümer.
Stand: Oktober 2002. Bestellnummer: 03946-01-0802-01.

iii
Inhalt
Über dieses Handbuch .................................................... viiDokumentation zu SQL Anywhere Studio ..............................viiiKonventionen in dieser Dokumentation ................................... xiAdaptive Server Anywhere-Beispieldatenbank.......................xivWenn Sie mehr wissen und uns Ihre Anregungenmitteilen möchten.................................................................... xv
1 Überblick über die Programmierschnittstelle .................. 1Die ODBC-Programmierschnittstelle ........................................2Die Programmierschnittstelle OLE DB......................................3Die Embedded SQL-Programmierschnittstelle .........................4Die JDBC-Programmierschnittstelle .........................................5Die Open Client-Programmierschnittstelle................................6
2 SQL in Anwendungen verwenden .................................... 9SQL-Anweisungen in Anwendungen ausführen .....................10Anweisungen vorbereiten .......................................................12Der Cursor...............................................................................15Mit Cursorn arbeiten................................................................20Cursortypen auswählen ..........................................................26Adaptive Server Anywhere-Cursor .........................................30Ergebnismengen beschreiben ................................................47Transaktionen in Anwendungen steuern ................................49
3 Einführung in Java für Datenbanken.............................. 53Einleitung ................................................................................54Fragen und Antworten zu Java in der Datenbank ..................57Ein Java-Seminar....................................................................64Die Laufzeitumgebung für Java in der Datenbank..................75Praktische Einführung: Eine Übung mit Java inder Datenbank.........................................................................84

iv
4 Java in der Datenbank benutzen .................................... 93Einleitung ................................................................................ 94Datenbank für Java aktivieren ................................................ 97Java-Klassen in einer Datenbank installieren....................... 103Spalten für die Aufnahme von Java-Objektenerstellen................................................................................. 109Java-Objekte einfügen, aktualisieren und löschen ............... 111Java-Objekte abfragen.......................................................... 117Java-Felder und Objekte vergleichen ................................... 119Besondere Funktionen von Java-Klassen in derDatenbank............................................................................. 123So werden Java-Objekte gespeichert................................... 130Java-Datenbankdesign ......................................................... 133Berechnete Spalten mit Java-Klassen verwenden ............... 137Speicher für Java konfigurieren ............................................ 140
5 Datenzugriff über JDBC ................................................ 143Überblick über JDBC ............................................................ 144jConnect-JDBC-Treiber verwenden...................................... 150JDBC-ODBC-Brücke verwenden.......................................... 155JDBC-Verbindungen herstellen ............................................ 157JDBC für den Zugriff auf Daten verwenden.......................... 165Verteilte Anwendungen erstellen .......................................... 174
6 Programmieren mit Embedded SQL ............................ 181Überblick ............................................................................... 182Beispielprogramme mit Embedded SQL .............................. 190Datentypen in Embedded SQL ............................................. 196Hostvariable benutzen .......................................................... 200SQL-Kommunikationsbereich (SQLCA) ............................... 208Daten abrufen ....................................................................... 214Statische und dynamische SQL............................................ 223Der SQL-Deskriptor-Bereich (SQLDA) ................................. 228Lange Werte senden und abfragen ...................................... 237Gespeicherte Prozeduren verwenden .................................. 243Programmiertechniken für Embedded SQL.......................... 247SQL-Präprozessor ................................................................ 249Referenz der Bibliotheksfunktion .......................................... 253Befehlszusammenfassung für Embedded SQL.................... 272
7 ODBC-Programmierung................................................ 277Einführung in ODBC ............................................................. 278ODBC-Anwendungen erstellen............................................. 280ODBC-Beispiele.................................................................... 285

v
ODBC-Handles .....................................................................287Verbindung mit einer Datenquelle herstellen........................290SQL-Anweisungen ausführen ...............................................294Mit Ergebnismengen arbeiten ...............................................299Gespeicherte Prozeduren aufrufen.......................................304Umgang mit Fehlern..............................................................306
8 Die DBTools-Schnittstelle ............................................. 311Einführung in die DBTools-Schnittstelle................................312DBTools-Schnittstelle verwenden.........................................314DBTools-Funktionen .............................................................323DBTools-Strukturen...............................................................335DBTools-Aufzählungstypen ..................................................367
9 Die OLE DB- und ADO-Programmierschnittstellen ..... 371Einführung zu OLE DB..........................................................372ADO-Programmierung mit Adaptive ServerAnywhere ..............................................................................374Unterstützte OLE DB-Schnittstellen......................................382
10 Die Open Client-Schnittstelle........................................ 389Was Sie für die Entwicklung von Open Client-Anwendungen brauchen .......................................................390Datentyp-Zuordnungen .........................................................391SQL in Open Client-Anwendungen verwenden ....................394Bekannte Open Client-Einschränkungen vonAdaptive Server Anywhere ...................................................398
11 Dreischichtige Datenverarbeitung und verteilteTransaktionen ................................................................ 399
Einleitung ..............................................................................400Dreischichtige Datenverarbeitungsarchitektur ......................401Verteilte Transaktionen verwenden ......................................405EAServer mit Adaptive Server Anywhereverwenden.............................................................................407
12 Deployment: Datenbanken und Anwendungen im Systembereitstellen ................................................................... 411
Systemeinführung - Überblick...............................................412Installationsverzeichnisse und Dateinamen..........................415InstallShield-Objekte und Vorlagen zumBereitstellen verwenden........................................................420

vi
Dialogfreie Installation für die Systemeinführung ................. 422Clientanwendungen im System bereitstellen........................ 426Tools zur Verwaltung bereitstellen........................................ 437Datenbankserver im System bereitstellen ............................ 438Eingebettete Datenbankanwendungen im Systembereitstellen........................................................................... 441
13 Fehlermeldungen des SQL-Präprozessors.................. 445Fehlermeldungen des SQL-Präprozessors,sortiert nach Fehlernummern................................................ 446SQLPP-Fehler....................................................................... 450
Index............................................................................... 467

vii
Über dieses Handbuch
In diesem Handbuch wird beschrieben, wie Datenbankanwendungen in denProgrammiersprachen C, C++ und Java aufgebaut und bereitgestellt werden.Benutzer von Programmen wie Visual Basic und PowerBuilder können derenProgrammierschnittstellen einsetzen.
Das Handbuch ist für Anwendungsentwickler bestimmt, die Programmeschreiben, welche direkt mit einer der Schnittstellen von Adaptive ServerAnywhere interagieren.
Sie brauchen das Handbuch nicht zu lesen, wenn Sie ein Entwicklungstoolwie PowerBuilder oder Visual Basic verwenden, die eine eigene Datenbank-Schnittstelle nach dem ODBC-Standard benutzen.
Gegenstand
Zielgruppe

viii
Dokumentation zu SQL Anywhere StudioDiese Dokumentation ist Teil der SQL Anywhere-Dokumentation. DieserAbschnitt enthält eine Liste der Handbücher und Hinweise zu ihrerVerwendung.
Dokumentation zu SQL Anywhere Studio
Die Dokumentation zu SQL Anywhere Studio besteht aus folgendenHandbüchern:
♦ SQL Anywhere Studio Erste Orientierung Dieses Handbuch enthälteinen Überblick über die Datenbankverwaltungs- undSynchronisationstechnologien von SQL Anywhere Studio. Es enthältpraktische Einführungen zu einzelnen Bestandteilen von SQL AnywhereStudio.
♦ Neues in SQL Anywhere Studio Dieses Handbuch richtet sich anBenutzer früherer Versionen dieser Software. Es enthält eine Liste neuerFunktionen in dieser und in früheren Versionen des Programms und eineBeschreibung der Upgrade-Prozeduren.
♦ Adaptive Server Anywhere Erste Schritte Dieses Handbuch richtetsich an Personen, die noch nicht mit relationalen Datenbanken bzw. mitAdaptive Server Anywhere gearbeitet haben. Es enthält eineKurzeinführung in das Datenbankverwaltungssystem Adaptive ServerAnywhere und einführende Hinweise zum Entwerfen und Aufbauen vonDatenbanken sowie zur Arbeit mit Datenbanken.
♦ Adaptive Server Anywhere Datenbankadministration DiesesHandbuch befasst sich mit der Ausführung, Verwaltung undKonfiguration von Datenbanken.
♦ Adaptive Server Anywhere SQL-Benutzerhandbuch In diesemHandbuch wird beschrieben, wie Datenbanken entworfen undeingerichtet, Daten importiert, exportiert, geändert bzw. abgerufen undgespeicherte Prozeduren und Trigger aufgebaut werden.
♦ Adaptive Server Anywhere SQL-Referenzhandbuch Dieses Handbuchist eine umfassende Referenz für die in Adaptive Server Anywhereverwendete SQL-Sprache. Auch die Adaptive Server Anywhere-Systemtabellen und Prozeduren werden darin beschrieben.

ix
♦ Adaptive Server Anywhere Handbuch für Programmierer In diesemHandbuch wird beschrieben, wie Datenbankanwendungen in denProgrammiersprachen C, C++ und Java aufgebaut und bereitgestelltwerden. Benutzer von Programmen wie Visual Basic und PowerBuilderkönnen deren Programmierschnittstellen einsetzen.
♦ Adaptive Server Anywhere Fehlermeldungen Dieses Handbuchenthält eine vollständige Liste der Fehlermeldungen in Adaptive ServerAnywhere sowie Diagnosehinweise.
♦ Adaptive Server Anywhere Ergänzung zu C2-SicherheitssystemenAdaptive Server Anywhere 7.0 wurde die Sicherheitseinstufung TCSEC(Trusted Computer System Evaluation Criteria) C2 der US-Regierungverliehen. Dieses Handbuch kann für den Personenkreis von Interessesein, der die aktuelle Version von Adaptive Server Anywhere in einerUmgebung ausführen möchte, die dem C2-Zertifikat entspricht. Nachder Zertifizierung hinzugefügte Sicherheitsfunktionen werden imHandbuch nicht erwähnt.
♦ MobiLink Benutzerhandbuch In diesem Handbuch werden alleAspekte des MobiLink-Datensynchronisationssystems für die mobileDatenverarbeitung erläutert. Mit diesem System können Daten voneinzelnen Oracle-, Sybase-, Microsoft- oder IBM-Datenbanken undvielen Adaptive Server Anywhere- bzw. UltraLite-Datenbankengemeinsam genutzt werden.
♦ SQL Remote Benutzerhandbuch In diesem Handbuch werden alleAspekte des SQL Remote-Datenreplikationssystems für mobileDatenverarbeitung beschrieben, das die gemeinsame Datennutzung voneiner einzelnen Adaptive Server Anywhere- bzw. Adaptive ServerEnterprise-Datenbank und vielen Adaptive Server Anywhere-Datenbanken über eine indirekte Verbindung wie etwa E-Mail oderDatenübertragung ermöglicht.
♦ UltraLite Benutzerhandbuch In diesem Handbuch wird beschrieben,wie Datenbankanwendungen für kleine Geräte wie Organizer mit derUltraLite-Bereitstellungstechnologie für Adaptive Server Anywhere-Datenbanken aufgebaut werden.
♦ UltraLite User’s Guide for PenRight! MobileBuilder (nur inenglischer Sprache verfügbar) Dieses Handbuch richtet sich anBenutzer des Entwicklungsprogramms PenRight! MobileBuilder. Hierwird beschrieben, wie die UltraLite-Technologie in der MobileBuilder-Programmierumgebung eingesetzt wird.
♦ SQL Anywhere Studio-Hilfe Dieses Handbuch ist nur online verfügbar.Es enthält die kontextsensitive Hilfe für Sybase Central, Interactive SQLund andere grafische Programme.

x
Zusätzlich zu dieser Dokumentation werden SQL Modeler und InfoMakermit eigener Dokumentation geliefert.
Dokumentationsformate
SQL Anywhere Studio umfasst Dokumentationen in folgenden Formaten:
♦ Online-Dokumentation Die Online-Dokumentation enthält dievollständige SQL Anywhere Studio-Dokumentation, einschließlich dergedruckten Handbücher und der kontextsensitiven Hilfe für dieSQL Anywhere-Dienstprogramme. Die Online-Dokumentation wird mitjeder Wartungsversion des Produkts aktualisiert. Dies ist dievollständigste und aktuellste Informationsquelle.
Wenn Sie unter Windows-Betriebssystemen auf die Online-Dokumentation zugreifen wollen, klicken Sie aufStart➤Programme➤Sybase SQL Anywhere 8➤Online-Dokumentation.Der Zugriff auf den Inhalt erfolgt über die HTML-Inhaltsangabe, denIndex und die Suchfunktion im linken Fensterausschnitt sowie überLinks und Menüs im rechten Fensterausschnitt.
Unter UNIX-Betriebssystemen geben Sie den folgenden Befehl in einerBefehlszeile ein, damit die Dokumentation aufgerufen wird:
dbbooks
♦ Ausdruckbare Handbücher Die SQL Anywhere-Handbücher werdenin Form von PDF-Dateien geliefert, die mit dem Adobe Acrobat Readereingesehen werden können.
Die PDF-Dateien finden sich auf der CD-ROM im Verzeichnispdf_docs. Während der Installation können Sie entscheiden, ob sieinstalliert werden sollen.
♦ Gedruckte Handbücher Die folgenden Handbücher finden Sie in derSQL Anywhere Studio-Box:
♦ SQL Anywhere Studio Erste Orientierung
♦ Adaptive Server Anywhere Erste Schritte
♦ SQL Anywhere Studio Kurzreferenz. Dieses Handbuch ist nur ingedruckter Form verfügbar.
Der gesamte Handbuchsatz kann als SQL Anywhere-Dokumentationüber den Sybase-Vertrieb bzw. den e-Shop - den Sybase-Online-Vertrieb - bezogen werden, und zwar unter der Adresse http://e-shop.sybase.com/cgi-bin/eshop.storefront/.

xi
Konventionen in dieser DokumentationIn diesem Abschnitt werden die Konventionen für die Schreibweise und dergrafische Aufbau beschrieben, der in dieser Dokumentation verwendet wird.
Syntaxkonventionen
Folgende Konventionen werden bei SQL-Syntaxbeispielen verwendet:
♦ Schlüsselwörter Alle SQL-Schlüsselwörter werden wie die WörterALTER TABLE im folgenden Beispiel angezeigt:
ALTER TABLE [ Eigentümer.]Tabellenname
♦ Platzhalter Elemente, die durch entsprechende Identifizierer oderAusdrücke ersetzt werden müssen, werden wie die Wörter Eigentümerund Tabellenname im folgenden Beispiel angezeigt:
ALTER TABLE [ Eigentümer.]Tabellenname
♦ Wiederholungen Listen mit sich wiederholenden Elementen werden miteinem Element der Liste, gefolgt von drei Punkten gezeigt, wie Spalten-Integritätsregel im folgenden Beispiel:
ADD Spaltendefinition [ Spalten-Integritätsregel, … ]
Ein oder mehrere Listenelemente sind zulässig. Wenn mehr als einElement angegeben wird, muss eine Trennung der Elemente durchKommas erfolgen.
♦ Fakultative Bestandteile Fakultative Bestandteile einer Anweisungwerden in eckige Klammern gesetzt.
RELEASE SAVEPOINT [ Savepoint-Name ]
Diese eckigen Klammern zeigen an, dass der Savepoint-Name fakultativist. Die eckigen Klammern werden nicht eingegeben.
♦ Optionen Wenn aus einer Liste kein oder nur ein Element ausgewähltwerden darf, werden die Elemente durch Senkrechtstriche voneinandergetrennt, und die komplette Liste wird in eckige Klammern gesetzt.
[ ASC | DESC ]
Sie können z.B. entweder ASC, DESC oder keines wählen. Die eckigenKlammern werden nicht eingegeben.
♦ Alternativen Wenn nur eine der vorhandenen Optionen gewählt werdendarf, werden die Alternativen in geschweifte Klammern gesetzt.
[ QUOTES { ON | OFF } ]

xii
Wenn die Option QUOTES ausgewählt wird, muss entweder ON oderOFF angegeben werden. Eckige und geschweifte Klammern sind nichteinzugeben.
♦ Eine oder mehrere Optionen Wenn Sie mehr als eine wählen, trennenSie die Eingaben durch Kommas.
{ CONNECT, DBA, RESOURCE }
Grafische Symbole
Folgende Symbole werden in dieser Dokumentation verwendet:

xiii
Symbol Bedeutung
Eine Clientanwendung
Ein Datenbankserver, wie etwa Sybase AdaptiveServer Anywhere oder Adaptive Server Enterprise
Eine UltraLite-Anwendung und der Datenbankserver.Bei UltraLite sind der Datenbankserver und dieAnwendung Teil des gleichen Prozesses.
Eine Datenbank. In einigen abstrakten Diagrammenkann dieses Symbol die Datenbank und gleichzeitigauch den Datenbankserver, der sie steuert,repräsentieren.
Replikations- oder Synchronisations-Middleware. MitHilfe derartiger Software können Daten in mehrerenDatenbanken gleichzeitig verwendet werden.Beispiele sind der MobiLink Synchronisationsserver,der SQL Remote-Nachrichtenagent und derReplication Agent (Log Transfer Manager), der inReplication Server eingesetzt wird.
Ein Sybase Replication Server
APIEine Programmierschnittstelle

xiv
Adaptive Server Anywhere-BeispieldatenbankViele der in der Dokumentation beschriebenen Beispiele verwenden dieAdaptive Server Anywhere-Beispieldatenbank.
Die Beispieldatenbank befindet sich in einer Datei mit dem Namenasademo.db im Installationsverzeichnis von SQL Anywhere.
Die Beispieldatenbank stellt ein kleines Unternehmen dar. Sie enthält interneInformationen über das Unternehmen wie Mitarbeiter (employees),Abteilungen (departments) und Finanzdaten (finances) sowieProduktinformationen (products) und Verkaufsinformationen (sales orders,customers, contacts). Alle Daten in der Datenbank sind frei erfunden.
In der nachstehend abgebildeten Strukturdarstellung werden die Tabellen derBeispieldatenbank und ihre Beziehungen zueinander erläutert.
id = id
id = prod_id
code = fin_code_id
emp_id = sales_rep
id = cust_id
code = code
dept_id = dept_idemp_id = dept_head_id
contactid <pk> integerlast_name char(15)first_name char(15)title char(2)street char(30)city char(20)state char(2)zip char(5)phone char(10)fax char(10)
customerid <pk> integerfname char(15)lname char(20)address char(35)city char(20)state char(2)zip char(10)phone char(12)company_name char(35)
sales_orderid <pk> integercust_id <fk> integerorder_date datefin_code_id <fk> char(2)region char(7)sales_rep <fk> integer
fin_codecode <pk> char(2)type char(10)description char(50)
fin_datayear <pk> char(4)quarter <pk> char(2)code <pk,fk> char(2)amount numeric(9)
productid <pk> integername char(15)description char(30)size char(18)color char(6)quantity integerunit_price numeric(15,2)
sales_order_itemsid <pk,fk> integerline_id <pk> smallintprod_id <fk> integerquantity integership_date date
employeeemp_id <pk> integermanager_id integeremp_fname char(20)emp_lname char(20)dept_id <fk> integerstreet char(40)city char(20)state char(4)zip_code char(9)phone char(10)status char(1)ss_number char(11)salary numeric(20,3)start_date datetermination_date datebirth_date datebene_health_ins char(1)bene_life_ins char(1)bene_day_care char(1)sex char(1)
departmentdept_id <pk> integerdept_name char(40)dept_head_id <fk> integer
asademo.db

xv
Wenn Sie mehr wissen und uns IhreAnregungen mitteilen möchten
Wir würden gerne Ihre Meinung kennen und sind an Ihren Vorschlägen undAnregungen zu dieser Dokumentation interessiert.
Sie können uns Ihre Anregungen zu dieser Dokumentation und der Softwareübermitteln, indem Sie Newsgroups nutzen, die zur Diskussion über SQLAnywhere-Technologien eingerichtet wurden. Sie finden diese Newsgroupsauf dem Newsserver forums.sybase.com.
Dazu gehören:
♦ sybase.public.sqlanywhere.general.
♦ sybase.public.sqlanywhere.linux.
♦ sybase.public.sqlanywhere.mobilink.
♦ sybase.public.sqlanywhere.product_futures_discussion.
♦ sybase.public.sqlanywhere.replication.
♦ sybase.public.sqlanywhere.ultralite.
Newsgroup-VerpflichtungsausschlussSybase ist weder verpflichtet, Lösungen, Informationen oder Ideen inseinen Newsgroups bereitzustellen, noch ist Sybase verpflichtet, mehrbereitzustellen als einen Systemadministrator, der den Service überwachtund seine Abwicklung sowie die Verfügbarkeit gewährleistet.
Die technischen Mitarbeiter von iAnywhere Solutions stehen, ebenso wieandere Mitarbeiter, für den Newsgroup-Service bereit, sofern sie Zeit dazuhaben. Sie stellen ihre Hilfe freiwillig zur Verfügung und sindmöglicherweise nicht regelmäßig verfügbar, um Lösungen undInformationen bereitzustellen. Ihre Einsatzfähigkeit ist abhängig von ihreraktuellen Arbeitsauslastung.

xvi

1
K A P I T E L 1
Überblick über dieProgrammierschnittstelle
Dieses Kapitel ist eine Einführung in die einzelnenProgrammierschnittstellen für Adaptive Server Anywhere. Alle Client-Anwendungen verwenden eine dieser Schnittstellen für die Kommunikationmit der Datenbank.
Thema Seite
Die ODBC-Programmierschnittstelle 2
Die Programmierschnittstelle OLE DB 3
Die Embedded SQL-Programmierschnittstelle 4
Die JDBC-Programmierschnittstelle 5
Die Open Client-Programmierschnittstelle 6
Über diesesKapitel
Inhalt

Die ODBC-Programmierschnittstelle
2
Die ODBC-ProgrammierschnittstelleODBC (Open Database Connectivity) ist eine Standardschnittstelle aufAufrufebene (Call Level Interface, CLI), die von Microsoft entwickeltwurde. Sie basiert auf der SQL Access Group CLI Spezifikation. ODBC-Anwendungen können mit jeder Datenquelle ausgeführt werden, die einenODBC-Treiber bereitstellt. Sie müssen ODBC verwenden, wenn IhreAnwendung auf andere Datenquellen portierbar sein soll, die mit ODBC-Treibern arbeiten. Auch wenn Sie die Arbeit mit einer API bevorzugen,sollten Sie ODBC verwenden.
ODBC ist eine Schnittstelle auf niedriger Ebene - etwa auf demselbenNiveau wie Embedded SQL. Fast alle Funktionen von Adaptive ServerAnywhere sind mit dieser Schnittstelle verfügbar. ODBC ist unter WindowsBetriebssystemen außer Windows CE als DLL verfügbar. Unter UNIX stehtder Treiber als Bibliothek zur Verfügung.
Die wichtigste Dokumentation für ODBC ist der Microsoft ODBC SoftwareDevelopment Kit. Das vorliegende Handbuch enthält einige zusätzlicheHinweise, die sich an Entwickler richten, die ODBC-Anwendungen fürAdaptive Server Anywhere bereitstellen.
$ ODBC wird im Abschnitt "ODBC-Programmierung" auf Seite 277beschrieben.

Kapitel 1 Überblick über die Programmierschnittstelle
3
Die Programmierschnittstelle OLE DBOLE DB ist eine Gruppe von Component Object Model-Schnittstellen(COM), die von Microsoft entwickelt wurden und Anwendungen einengleichförmigen Zugriff auf Daten bieten, die in unterschiedlichenInformationsquellen gespeichert sind, und darüber hinaus die Möglichkeitbieten, zusätzliche Datenbankdienste zu implementieren. Diese Schnittstellenunterstützen so viele DBMS-Funktionen, wie sie für die gemeinsameNutzung des Datenspeichers erforderlich sind.
ADO ist ein Objektmodell, das ermöglicht, über Programme und OLE DB-Systemschnittstellen auf eine große Anzahl von Datenquellen zuzugreifen,diese zu ändern und zu aktualisieren. ADO wurde ebenfalls von Microsoftentwickelt. Die meisten Entwickler, die die OLE DB-Programmierschnittstelle verwenden, tun dies in dem sie die ADO APIeinsetzen und nicht direkt die OLE DB API.
Adaptive Server Anywhere umfasst einen OLE DB-Provider für OLE DB-und ADO-Programmierer.
Die primäre Dokumentation für das Programmieren mit OLE DB und ADOist das Microsoft Developer Network. Das vorliegende Handbuch enthälteinige zusätzliche Hinweise, die sich an Entwickler richten, die OLE DB-und ADO-Anwendungen für Adaptive Server Anywhere bereitstellen.
$ Weitere Hinweise finden Sie unter "Die OLE DB- und ADO-Programmierschnittstellen" auf Seite 371

Die Embedded SQL-Programmierschnittstelle
4
Die Embedded SQL-ProgrammierschnittstelleEmbedded SQL ist ein System, in dem SQL-Befehle direkt in eine C- oderC++-Quelldatei eingebettet sind. Ein Präprozessor übersetzt dieseAnweisungen in Aufrufe einer Laufzeitbibliothek. Embedded SQL ist einISO/ANSI- und IBM-Standard.
Embedded SQL kann auf andere Datenbanken und andere Umgebungenportiert werden und ist in allen Betriebsumgebungen funktional äquivalent.Sie stellt alle im Produkt verfügbaren Funktionen bereit. Die Arbeit mitEmbedded SQL ist einfach und geradlinig, wenn auch eine gewisseEingewöhnung erforderlich ist, Embedded SQL Anweisungen (und nichtFunktionsaufrufe) in einem C-Programmcode zu verwenden.
$ Embedded SQL wird unter "Programmieren mit Embedded SQL" aufSeite 181 beschrieben.

Kapitel 1 Überblick über die Programmierschnittstelle
5
Die JDBC-ProgrammierschnittstelleJDBC ist eine Schnittstelle auf Aufrufebene für Java-Anwendungen. DerTreiber wurde von Sun Microsystems entwickelt und bietet Java-Programmierern eine einheitliche Schnittstelle zu einer Vielzahl vonrelationalen Datenbanken, sowie eine gemeinsame Basis, auf der Tools undSchnittstellen auf höherer Ebene aufgebaut werden können. JDBC ist jetztein Standardbestandteil von Java und wurde in den JDK aufgenommen.
SQL Anywhere enthält einen einen reinen Java-JDBC-Treiber namensSybase jConnect an. Dieser enthält außerdem einen JDBC-ODBC-Brücke.Beide werden im Abschnitt "Datenzugriff über JDBC" auf Seite 143beschrieben. Hinweise zur Auswahl eines Treibers finden Sie unter "JDBC-Treiber wählen" auf Seite 145.
Zusätzlich zum Einsatz von JDBC als clientseitigeAnwendungsprogrammierschnittstelle können Sie JDBC innerhalb desDatenbankservers verwenden, um Java-Daten in der Datenbank abzurufen.Aus diesem Grund wird JDBC als Teil von Java in derDatenbankdokumentation dokumentiert.
$ JDBC wird in diesem Handbuch nicht beschrieben. Eine Beschreibungdes JDBC-Treibers entnehmen Sie dem Kapitel "Datenzugriff über JDBC"auf Seite 143.

Die Open Client-Programmierschnittstelle
6
Die Open Client-ProgrammierschnittstelleSybase Open Client bietet Kundenanwendungen, Produkten vonDrittanbietern und anderen Sybase-Produkten die erforderlichenSchnittstellen zur Kommunikation mit dem Adaptive Server Anywhere undanderen Open Servern.
Der Einsatz der Open Client-Schnittstelle ist zu überlegen, wenn Ihnen dieKompatibilität von Adaptive Server Enterprise wichtig ist oder wenn Sieandere Sybase-Produkte verwenden, die die Open Client-Schnittstellebenötigen, zum Beispiel Replication Server.
$ Eine Beschreibung der Open Client-Schnittstelle entnehmen Sie demAbschnitt "Die Open Client-Schnittstelle" auf Seite 389.
$ Weitere Hinweise über die Open Client-Schnittstelle finden Sie unter"Adaptive Server Anywhere als Open Server" auf Seite 117 derDokumentation ASA Datenbankadministration.
Die Open Client-Architektur
Das Konzept "Open Client" kann man sich als System mit zweiKomponenten vorstellen: Programmierschnittstellen und Netzwerkdiensten.
Open Client bietet zwei Kern-Programmierschnittstellen für das Schreibenvon Clientanwendungen: DB-Library und Client-Library.
Die Open Client DB-Library bietet Unterstützung für ältere Open ClientAnwendungen und ist eine von der Client-Library vollständig getrennteProgrammierschnittstelle. DB-Bibliothek ist dokumentiert im Open ClientDB-Library/C Reference Manual, das zum Lieferumfang des ProduktsSybase Open Client gehört.
Client-Library-Programme sind auch von der CS-Library abhängig, dieRoutinen sowohl für den Einsatz in Client-Library- als auch Server-Library-Anwendungen bereitstellt. Client-Library-Anwendungen können auchRoutinen der Bulk-Library benutzen, um die Hochgeschwindigkeits-Datenübertragung zu erleichtern.
Die CS-Library und die Bulk-Library sind in Sybase Open Client enthalten.Dieses Produkt kann separat erworben werden.
Einsatzbereich desOpen Clients
Client-Library undDB-Library

Kapitel 1 Überblick über die Programmierschnittstelle
7
Open Client-Netzwerkdienste enthalten die Sybase Net-Library, die dieUnterstützung für bestimmte Netzwerkprotokolle wie TCP/IP und DECnetbereithält. Die Net-Library-Schnittstelle ist für Anwendungsprogrammiererunsichtbar. Auf manchen Plattformen benötigt eine Anwendung unterUmständen einen anderen Net-Library-Treiber für unterschiedliche System-Netzwerkkonfigurationen. Je nach Ihrer Hostplattform wird der Net-Library-Treiber entweder durch die Konfiguration der Sybase-Produkte des Systemsbestimmt, oder durch die Kompilierung und Verknüpfung Ihrer Programme.
$ Hinweise zur Treiberkonfiguration finden Sie in der DokumentationOpen Client/Server Configuration Guide.
$ Hinweise zum Aufbau von Client-Library-Programmen finden Sie inder Dokumentation Open Client/Server Programmer’s Supplement.
Netzwerkdienste

Die Open Client-Programmierschnittstelle
8

9
K A P I T E L 2
SQL in Anwendungen verwenden
Viele Aspekte der Entwicklung von Datenbankanwendungen hängen vomEntwicklungstool, von der Datenbank-Schnittstelle und von derProgrammiersprache ab. Einige Probleme und Grundsätze sind jedochallgemein gültig und wirken sich auf mehrere Aspekte der Entwicklung vonDatenbankanwendungen aus.
In diesem Kapitel werden einige Grundsätze und Techniken beschrieben, diefür die meisten oder alle Schnittstellen gelten. Außerdem enthält das KapitelVerweise auf weiterführende Informationen. Das Kapitel ist keine detaillierteAnweisung für die Programmierung mit einer bestimmten Schnittstelle.
Thema Seite
SQL-Anweisungen in Anwendungen ausführen 10
Anweisungen vorbereiten 12
Der Cursor 15
Mit Cursorn arbeiten 20
Cursortypen auswählen 26
Adaptive Server Anywhere-Cursor 30
Ergebnismengen beschreiben 47
Transaktionen in Anwendungen steuern 49
Über diesesKapitel
Inhalt

SQL-Anweisungen in Anwendungen ausführen
10
SQL-Anweisungen in Anwendungen ausführenWie Sie SQL-Anweisungen in Ihre Anwendung einbauen, hängt vomEntwicklungstool und der Programmierschnittstelle ab, die Sie verwenden.
♦ ODBC Wenn Sie direkt in die ODBC-Programmierschnittstelleschreiben, erscheinen Ihre SQL-Anweisungen in Funktionsaufrufen.Beispiel: Der folgende C-Funktionsaufruf führt eine DELETE-Anweisung aus:
SQLExecDirect( stmt, "DELETE FROM employee WHERE emp_id = 105", SQL_NTS );
♦ JDBC Wenn Sie die JDBC-Programmierschnittstelle verwenden,können Sie SQL-Anweisungen ausführen, indem Sie Methoden desStatement-Objekts aufrufen. Zum Beispiel:
stmt.executeUpdate( "DELETE FROM employee WHERE emp_id = 105" );
♦ Embedded SQL Wenn Sie Embedded SQL verwenden, erhalten dieSQL-Anweisungen der C-Sprachen das Schlüsselwort EXEC SQL alsPräfix. Der Code wird dann im Präprozessor verarbeitet, bevor erkompiliert wird. Zum Beispiel:
EXEC SQL EXECUTE IMMEDIATE ’DELETE FROM employee WHERE emp_id = 105’;
♦ Sybase Open Client Wenn Sie die Sybase Open Client- Schnittstelleverwenden, erscheinen Ihre SQL-Anweisungen in Funktionsaufrufen.Die folgenden beiden Aufrufe führen zum Beispiel eine DELETE-Anweisung aus:
ret = ct_command(cmd, CS_LANG_CMD, "DELETE FROM employee WHERE emp_id=105" CS_NULLTERM, CS_UNUSED);ret = ct_send(cmd);
♦ Anwendungs-Entwicklungstools Anwendungs-Entwicklungstools wiedie Mitglieder der Sybase Enterprise-Familie bieten ihre eigenen SQL-Objekte, die entweder ODBC (PowerBuilder) oder JDBC (Power J)verwenden.

Kapitel 2 SQL in Anwendungen verwenden
11
$ Genauere Hinweise zur Aufnahme von SQL-Anweisungen in IhreAnwendungen finden Sie in der Dokumentation Ihres Entwicklungstools.Wenn Sie ODBC oder JDBC verwenden, finden Sie weitere Hinweise imSoftware Development Kit für diese Schnittstellen.
$ Eine genaue Beschreibung der Programmierung mit Embedded SQLfinden Sie unter "Programmieren mit Embedded SQL" auf Seite 181.
Auf vielerlei Weise funktionieren gespeicherte Prozeduren und Trigger alsAnwendungen oder Teile von Anwendungen, die im Server laufen. Siekönnen viele der hier beschriebenen Techniken auch in gespeichertenProzeduren verwenden. Gespeicherte Prozeduren benutzen Anweisungen,die Embedded SQL sehr ähnlich sind.
$ Weitere Hinweise zu gespeicherten Prozeduren und Triggern finden Sieunter "Prozeduren, Trigger und Anweisungsfolgen verwenden" auf Seite 565der Dokumentation ASA SQL-Benutzerhandbuch.
Java-Klassen in der Datenbank können die JDBC-Schnittstelle genausobenutzen wie Java-Anwendungen dies außerhalb des Servers tun. In diesemKapitel werden einige Aspekte von JDBC beschrieben. Weitere Hinweisezur Arbeit mit JDBC finden Sie unter "Datenzugriff über JDBC" aufSeite 143.
Anwendungen imServer

Anweisungen vorbereiten
12
Anweisungen vorbereitenJedes Mal, wenn eine Anweisung an eine Datenbank geschickt wird, mussder Server die Anweisung zunächst vorbereiten. Zur Vorbereitung könnenfolgende Schritte gehören:
♦ Syntaktische Analyse der Anweisung und Umwandlung in eine interneForm.
♦ Prüfung der Richtigkeit aller Referenzen auf Datenbankobjekte, z.B.Prüfung, ob in der Abfrage genannte Spalten existieren.
♦ Optimierer für Abfragen veranlassen, einen Zugriffsplan zu erstellen,falls die Anweisung Joins oder Unterabfragen umfasst.
♦ Ausführung der Anweisung, nachdem alle diese Schritte durchgeführtwurden.
Wenn Sie dieselbe Anweisung immer wieder verwenden, etwa das Einfügenvon mehreren Zeilen in eine Tabelle, kommt es zu bedeutenden undunnötigen Overheads durch die wiederholte Vorbereitung der Anweisung.Um dies zu vermeiden, bieten einige Datenbank-Programmierschnittstelleneine Möglichkeit zur Verwendung von vorbereiteten Anweisungen. Einevorbereitete Anweisung ist eine Anweisung, die eine Reihe vonPlatzhaltern enthält. Wenn Sie die Anweisung ausführen wollen, müssen Sieden Platzhaltern nur Werte zuweisen, anstatt die gesamte Anweisung erneutvorzubereiten.
Der Einsatz von vorbereiteten Anweisungen ist besonders dann nützlich,wenn viele ähnliche Aktionen ausgeführt werden, wie etwa das Einfügen vonvielen Zeilen.
Im Allgemeinen erfordern vorbereitete Anweisungen die folgenden Schritte:
1 Anweisung vorbereiten In diesem Schritt versehen Sie die Anweisungim Allgemeinen mit einigen Platzhalter-Zeichen anstelle von Werten.
2 Wiederholtes Ausführen der vorbereiteten Anweisung In diesemSchritt liefern Sie Werte, die jedes Mal benutzt werden sollen, wenn dieAnweisung ausgeführt wird. Die Anweisung braucht nicht jedes Malvorbereitet zu werden.
3 Anweisung löschen In diesem Schritt geben Sie die Ressourcen frei,die für die vorbereitete Anweisung in Beschlag genommen wurden.Einige Programmierschnittstellen verarbeiten diesen Schritt automatisch.
DieWiederverwendungvon vorbereitetenAnweisungen kanndie Performanceverbessern

Kapitel 2 SQL in Anwendungen verwenden
13
Im Allgemeinen sollten Sie Anweisungen nicht vorbereiten, wenn sie nureinmal ausgeführt werden sollen. Bei getrennter Vorbereitung undDurchführung kommt es zu leichten Einbußen bei der Performance, undaußerdem werden dadurch unnötig komplizierte Schritte in die Anwendungeingefügt.
Bei manchen Schnittstellen müssen Sie allerdings eine Anweisungvorbereiten, um sie mit einem Cursor zu verbinden.
$ Hinweise zu Cursorn finden Sie unter "Der Cursor" auf Seite 15.
Die Aufrufe für die Vorbereitung und Ausführung von Anweisungen sindnicht Teil der SQL und unterscheiden sich daher je nach verwendeterSchnittstelle. Jede Programmierschnittstelle des Adaptive Server Anywherebietet eine Methode für die Verwendung von vorbereiteten Anweisungen.
So verwenden Sie vorbereitete Anweisungen
In diesem Abschnitt wird ein kurzer Überblick über die Verwendung vonvorbereiteten Anweisungen gegeben. Die allgemeine Vorgehensweise istidentisch, aber die Details unterscheiden sich je nach Schnittstelle. EinVergleich der Verwendung von vorbereiteten Anweisungen in den einzelnenSchnittstellen kann diesen Punkt vielleicht klarer darstellen.
v So verwenden Sie eine vorbereitete Anweisung (generisch):
1 Bereiten Sie die Anweisung vor.
2 Setzen Sie Bindungsparameter, die benutzt werden, um Werte in derAnweisung zu halten.
3 Weisen Sie den Bindungsparametern in der Anweisung Werte zu.
4 Führen Sie die Anweisung aus.
5 Wiederholen Sie nötigenfalls Schritte 3 und 4.
6 Löschen Sie die Anweisung, wenn Sie fertig sind. Dieser Schritt ist inJDBC nicht erforderlich, da der Abfalldatenmechanismus von JDBCdies erledigt.
v So verwenden Sie eine vorbereitete Anweisung (Embedded SQL):
1 Bereiten Sie die Anweisung mit dem Befehl EXEC SQL PREPARE vor.
2 Weisen Sie den Parametern in der Anweisung Werte zu.
3 Führen Sie die Anweisung mit dem Befehl EXE SQL EXECUTE aus.
Bereiten Sie keineAnweisungen vor,die nur einmalverwendet werden.

Anweisungen vorbereiten
14
4 Geben Sie die mit der Anweisung verbundenen Ressourcen frei, indemSie den Befehl EXEC SQL DROP benutzen.
v So verwenden Sie eine vorbereitete Anweisung (ODBC):
1 Bereiten Sie die Anweisung mit SQLPrepare vor.
2 Binden Sie die Anweisungsparameter mit SQLBindParameter.
3 Führen Sie die Anweisung mit SQLExecute aus.
4 Löschen Sie die Anweisung mit SQLFreeStmt.
$ Weitere Hinweise finden Sie unter "Vorbereitete Anweisungenausführen" auf Seite 297 und in der Dokumentation zum ODBC SDK.
v So verwenden Sie eine vorbereitete Anweisung (JDBC):
1 Bereiten Sie die Anweisung mit der Methode prepareStatement desVerbindungsobjekts vor. Daraus wird ein PreparedStatement-Objekterzeugt.
2 Setzen Sie die Anweisungsparameter mit den entsprechenden setType-Methoden des PreparedStatement-Objekts. Hier ist Type der Datentyp,der zugewiesen wird.
3 Führen Sie die Anweisung mit der geeigneten Methode für dasPreparedStatement-Objekt aus. Für Einfügungen, Aktualisierungen undLöschungen ist dies die Methode executeUpdate.
$ Weitere Hinweise zur Verwendung von vorbereitetenAnweisungen in JDBC finden Sie unter "Vorbereitete Anweisungen füreffizienteren Zugriff verwenden" auf Seite 171.
v So verwenden Sie eine vorbereitete Anweisung (Open Client):
1 Bereiten Sie die Anweisung mit der Funktion ct_dynamic mitCS_PREPARE als type-Parameter vor.
2 Setzen Sie die Anweisungsparameter ct_param.
3 Führen Sie die Anweisung mit ct_dynamic mit CS_EXECUTE alsTypparameter aus.
4 Geben Sie die mit der Anweisung verbundenen Ressourcen frei, indemSie ct_dynamic mit einem CS_DEALLOC-Typparameter verwenden.
Weitere Hinweise über die Verwendung von vorbereiteten Anweisungenin Open Client finden Sie unter "SQL in Open Client-Anwendungenverwenden" auf Seite 394.

Kapitel 2 SQL in Anwendungen verwenden
15
Der CursorWenn Sie eine Abfrage in einer Anwendung ausführen, besteht dieErgebnismenge aus einer Reihe von Zeilen. Im Allgemeinen wissen Sienicht, wie viele Zeilen die Anwendung empfangen wird, bevor die Abfrageausgeführt worden ist. Mit einem Cursor können Sie Ergebnismengen vonAbfragen in Anwendungen verarbeiten.
Wie Sie Cursor einsetzen, und welche Cursorarten verfügbar sind, hängt vonder Programmierschnittstelle ab, die Sie benutzen. JDBC 1.0 bietet nur eineBasisverarbeitung von Ergebnismengen, während ODBC und EmbeddedSQL über viele unterschiedliche Cursorarten verfügen. Mit einem Cursor inOpen Client kann man sich in einer Ergebnismenge nur vorwärts bewegen.
Sie können mit einem Cursor folgende Aufgaben innerhalb einerProgrammierschnittstelle durchführen:
♦ Die Ergebnisse einer Abfrage mittels Schleifen bearbeiten.
♦ Einfügungen, Aktualisierungen und Löschungen auf dendarunterliegenden Daten an einem beliebigen Punkt in einerErgebnismenge durchführen
Zusätzlich ermöglichen Ihnen einige Programmierschnittstellen dieVerwendung von Sonderfunktionen, um die Art zu optimieren, wieErgebnismengen an Ihre Anwendung zurückgegeben werden, wasbeträchtliche Performance-Vorteile für Ihre Anwendung bietet.
$ Weitere Hinweise zur den verfügbaren Cursorarten in den einzelnenProgrammierschnittstellen finden Sie unter "Cursorverfügbarkeit" aufSeite 26.
Was sind Cursor?
Ein Cursor ist ein Name, der einer Ergebnismenge zugeordnet ist. DieErgebnismenge erhalten Sie durch eine SELECT-Anweisung oder denAufruf einer gespeicherten Prozedur.
Ein Cursor ist ein Handle auf der Ergebnismenge. Zu jedem Zeitpunkt hatder Cursor eine genau definierte Position innerhalb der Ergebnismenge. Miteinem Cursor können Sie die Daten zeilenweise untersuchen undgegebenenfalls bearbeiten. In Adaptive Server Anywhere unterstützenCursor Vorwärts- und Rückwärts-Bewegungen durch die Abfrageergebnisse.
Cursor können an den folgenden Stellen positioniert werden:
♦ Vor der ersten Zeile der Ergebnismenge.
Cursorpositionen

Der Cursor
16
♦ Auf einer Zeile in der Ergebnismenge.
♦ Nach der letzten Zeile der Ergebnismenge.
Cursorposition und Ergebnismenge werden im Datenbankserveraufrechterhalten. Zeilen werden vom Client zur Anzeige oder Verarbeitungeinzeln oder in Gruppen abgerufen. Dem Client muss nicht die gesamteErgebnismenge übermittelt werden.
Vorteile der Cursorbenutzung
Sie müssen nicht unbedingt Cursor in Datenbankanwendungen verwenden,aber ihr Einsatz bietet eine Reihe von Vorteilen. Diese Vorteile beruhendarauf, dass die gesamte Ergebnismenge an den Client zur Ansicht undVerarbeitung übermittelt werden muss, wenn Sie keine Cursor verwenden:
♦ Clientseitiger Speicher Bei umfangreichen Ergebnismengen kann dasHalten der gesamten Ergebnismenge auf dem Client zu zusätzlichemSpeicherbedarf führen.

Kapitel 2 SQL in Anwendungen verwenden
17
♦ Antwortzeit Cursor können die ersten Zeilen liefern, bevor die gesamteErgebnismenge zusammengestellt wird. Wenn Sie keine Cursorverwenden, muss die gesamte Ergebnismenge übermittelt werden, bevoreine Zeile von Ihrer Anwendung angezeigt werden kann.
♦ Parallelitätskontrolle Wenn Sie Ihre Daten aktualisieren und keineCursor in Ihrer Anwendung verwenden, müssen Sie separate SQL-Anweisungen an den Datenbankserver senden, um die Änderungenanzuwenden. Dadurch können Probleme mit der Parallelität entstehen,falls sich die Ergebnismenge seit der Abfrage durch den Client geänderthat. Das wiederum kann möglicherweise zu Aktualisierungsverlustenführen.
Corsor sind wie Zeiger auf die darunter liegenden Daten und gebendadurch entsprechende Parallelitätsbeschränkungen für diedurchgeführten Änderungen vor.
Schritte der Cursorbenutzung
Die Verwendung eines Cursors in Embedded SQL unterscheidet sich von derVerwendung eines Cursors in anderen Schnittstellen.
v So verwenden Sie einen Cursor (Embedded SQL):
1 Bereiten Sie eine Anweisung vor.
Cursor verwenden üblicherweise einen Anweisungs-Handle statt einerZeichenfolge. Sie müssen eine Anweisung vorbereiten, damit ein Handleverfügbar ist.
$ Hinweise über das Vorbereiten einer Anweisung finden Sie unter"Anweisungen vorbereiten" auf Seite 12.
2 Deklarieren Sie den Cursor.
Jeder Cursor bezieht sich auf eine einzelne SELECT- oder CALL-Anweisung. Wenn Sie einen Cursor deklarieren, geben Sie den Namendes Cursors und die Anweisung an, auf die er sich bezieht.
$ Weitere Hinweise finden Sie unter "DECLARE CURSOR-Anweisung [ESQL] [GP]" auf Seite 412 der Dokumentation ASA SQL-Referenzhandbuch.
3 Öffnen Sie den Cursor.
$ Weitere Hinweise finden Sie unter "OPEN-Anweisung [ESQL][GP]" auf Seite 523 der Dokumentation ASA SQL-Referenzhandbuch.

Der Cursor
18
Bei der CALL-Anweisung wird durch das Öffnen des Cursors dieAbfrage bis zu dem Punkt ausgeführt, an dem die erste Zeile bezogenwerden kann.
4 Rufen Sie die Ergebnisse ab.
Obwohl eine einfache Abruf-Operation den Cursor in die nächste Zeileder Ergebnismenge bewegt, ermöglicht Adaptive Server Anywhere auchkompliziertere Bewegungen in der Ergebnismenge. Die verfügbarenAbruf-Operationen hängen davon ab, wie Sie den Cursor deklarieren.
$ Weitere Hinweise finden Sie unter "FETCH-Anweisung [ESQL][GP]" auf Seite 458 der Dokumentation ASA SQL-Referenzhandbuchund "Daten abrufen" auf Seite 214.
5 Schließen Sie den Cursor
Wenn Sie die Arbeit mit dem Cursor abgeschlossen haben, schließen Sieihn. Das löst etwaige Sperren auf den darunterliegenden Daten.
$ Weitere Hinweise finden Sie unter "CLOSE-Anweisung [ESQL][GP]" auf Seite 285 der Dokumentation ASA SQL-Referenzhandbuch.
6 Löschen Sie die Anweisung.
Um den Speicher freizugeben, der mit dem Cursor und der ihmzugeordneten Anweisung verbunden war, müssen Sie die Anweisungfreigeben.
$ Weitere Informationen finden Sie unter "DROP STATEMENT-Anweisung [ESQL]" auf Seite 439 der Dokumentation ASA SQL-Referenzhandbuch.
v So verwenden Sie einen Cursor (ODBC, JDBC, Open Client):
1 Bereiten Sie eine Anweisung vor und führen Sie sie aus:
Führen Sie eine Anweisung mit der normalen Methode für dieSchnittstelle aus. Sie können die Anweisung vorbereiten und dannausführen, oder die Anweisung direkt ausführen.
2 Überprüfen Sie, ob die Anweisung eine Ergebnismenge zurückgibt.
Ein Cursor wird implizit geöffnet, wenn eine Anweisung ausgeführtwird, die eine Ergebnismenge erstellt. Beim Öffnen eines Cursors wirder vor die erste Zeile der Ergebnismenge gesetzt.
3 Rufen Sie die Ergebnisse ab.
Obwohl eine einfache Abruf-Operation den Cursor in die nächste Zeileder Ergebnismenge bewegt, ermöglicht Adaptive Server Anywhere auchkompliziertere Bewegungen in der Ergebnismenge.

Kapitel 2 SQL in Anwendungen verwenden
19
4 Schließen Sie den Cursor
Wenn Sie die Arbeit mit dem Cursor abgeschlossen haben, schließen Sieihn, damit die ihm zugewiesenen Ressourcen freigegeben werden.
5 Geben Sie die Anweisung frei.
Wenn Sie eine vorbereitete Anweisung verwendet haben, geben Sie siefrei, um den benutzten Speicher wieder verfügbar zu machen.
In manchen Fällen kann die Interface-Bibliothek Performance-Optimierungen im Hintergrund durchführen (z.B. Prefetch von Ergebnissen),sodass diese Schritte in der Clientanwendung möglicherweise nicht denVorgängen in der Software entsprechen.
Prefetch von Zeilen

Mit Cursorn arbeiten
20
Mit Cursorn arbeitenIn diesem Abschnitt wird beschrieben, wie bestimmte Cursorvorgängeausgeführt werden.
Cursor positionieren
Wird ein Cursor geöffnet, ist er vor der ersten Zeile positioniert. Sie könnenden Cursor an eine absolute Position in Verhältnis zum Anfang oder zumEnde der Abfrageergebnisse positionieren oder ihn relativ zur aktuellenCursor-Position verschieben. Wie Sie im Einzelnen den Cursor verschiebenund welche Operationen möglich sind, hängt von derProgrammierschnittstelle ab.
Die Anzahl der Zeilenpositionen, die Sie mit einem Fetch-Vorgang abrufenkönnen, wird durch die Größe einer Ganzzahl bestimmt. Mit einem Fetch-Vorgang können Sie Zeilen bis zu Nummer 2147483646 abrufen, wobei essich um die größtmögliche Ganzzahl minus 1 handelt. Wenn Sie negativeWerte verwenden (Zeilen in Bezug auf das Ende), können Sie Fetch-Vorgänge nach unten bis zum kleinsten negativen Wert, der in einerGanzzahl möglich ist, plus 1 ausführen.
Sie können spezielle positionsbasierte Aktualisierungs- oderLöschungsoperationen verwenden, um die Zeile an der aktuellenCursorposition zu aktualisieren oder zu löschen. Ist der Cursor vor der erstenZeile oder nach der letzten Zeile positioniert, wird der Fehler No current rowof cursor zurückgeben.

Kapitel 2 SQL in Anwendungen verwenden
21
Probleme mit der CursorpositionierungEinfügungen und manche Aktualisierungsvorgänge mit nicht-empfindlichen Cursorn können Probleme mit der Positionierung vonCursorn verursachen. Adaptive Server Anywhere platziert eingefügteZeilen an unvorhersehbaren Positionen innerhalb eines Cursors, falls dieSELECT-Anweisung keine ORDER BY-Klausel hat. In einigen Fällenerscheint die eingefügte Zeile überhaupt nicht, bis der Cursor geschlossenund wieder geöffnet wurde.
Bei Adaptive Server Anywhere passiert dies, wenn eine Arbeitstabelleerstellt werden musste, um den Cursor zu öffnen (unter "Arbeitstabellen inder Abfrageverarbeitung verwenden" auf Seite 178 der DokumentationASA SQL-Benutzerhandbuch finden Sie eine diesbezüglicheBeschreibung).
Die UPDATE-Anweisung kann bewirken, dass sich eine Zeile im Cursorverschiebt. Das passiert, wenn der Cursor eine ORDER BY-Klausel hat,die einen vorhandenen Index benutzt (es wird keine Arbeitstabelleerstellt). Mit der Verwendung eines statisch abrollenden Cursors werdendiese Probleme vermieden, allerdings ist mehr Speicher undVerarbeitungsaufwand erforderlich.
Cursor beim Öffnen konfigurieren
Sie können die folgenden Aspekte des Cursorverhaltens konfigurieren, wennSie einen Cursor öffnen:
♦ Isolationsstufe Sie können die Isolationsstufen der Vorgänge für einenCursor explizit so setzen, dass sie von der aktuellen Isolationsstufe derTransaktion verschieden sind. Dazu stellen Sie dieISOLATION_LEVEL-Option ein.
$ Weitere Informationen finden Sie unter "ISOLATION_LEVEL-Option" auf Seite 637 der Dokumentation ASADatenbankadministration.
♦ Offen halten Standardmäßig werden Cursor in Embedded SQL am Endeeiner Transaktion geschlossen. Wenn Sie einen Cursor mit der WITHHOLD-Option öffnen, können Sie ihn offen halten, bis die Verbindungbeendet wird oder bis Sie ihn explizit schließen. ODBC, JDBC undOpen Client lassen Cursor beim Ende von Transaktionen standardmäßiggeöffnet.

Mit Cursorn arbeiten
22
Zeilen durch einen Cursor abrufen
Die einfachste Art, eine Ergebnismenge aus einer Abfrage mit einem Cursorzu verarbeiten, ist eine Schleife zum Absuchen aller Zeilen in derErgebnismenge, bis keine Zeilen mehr vorhanden sind.
v So führen Sie einen Schleifendurchlauf auf Zeilen einerErgebnismenge durch:
1 Deklarieren und öffnen Sie den Cursor (Embedded SQL), oder führenSie eine Anweisung aus, die eine Ergebnismenge zurückgibt (ODBC,JDBC, Open Client).
2 Setzen Sie die Fetch-Vorgänge für die nächste Zeile fort, bis der FehlerZeile nicht gefunden (Row Not Found) erscheint.
3 Schließen Sie den Cursor
Die Ausführung des zweiten Schrittes hängt davon ab, welche SchnittstelleSie verwenden. Zum Beispiel:
♦ ODBC SQLFetch, SQLExtendedFetch oder SQLFetchScrollverschieben den Cursor in die nächste Zeile und geben die Daten zurück.
$ Weitere Hinweise zur Verwendung eines Cursors in ODBC findenSie unter "Mit Ergebnismengen arbeiten" auf Seite 299.
♦ Embedded SQL Die FETCH-Anweisung führt dieselbe Operation aus.
$ Weitere Hinweise über die Verwendung von Cursorn in EmbeddedSQL finden Sie unter "Cursor in Embedded SQL verwenden" aufSeite 215.
♦ JDBC Die next-Methode des ResultSet-Objekts bewegt den Cursorweiter und gibt die Daten zurück.
$ Weitere Hinweise zur Verwendung des ResultSet-Objekts inJDBC finden Sie unter "Abfragen mit JDBC" auf Seite 169.
♦ Open Client Die ct_fetch-Funktion verschiebt den Cursor in die nächsteZeile und gibt die Daten zurück.
$ Weitere Hinweise zur Verwendung eines Cursors in Open Client-Anwendungen finden Sie unter "Cursor verwenden" auf Seite 395.
Mehrere Zeilen abrufen
In diesem Abschnitt wird besprochen, wie Sie mehrere Zeilen mit einemFetch-Vorgang abrufen können.

Kapitel 2 SQL in Anwendungen verwenden
23
Der mehrzeilige Abruf darf nicht mit dem Vorab-Abrufen von Zeilenverwechselt werden, was im nächsten Abschnitt beschrieben wird.Mehrzeilen-Abrufe werden von der Anwendung durchgeführt, während einVorab-Abrufen für die Anwendung nicht erkennbar ist und eine ähnlichePerformance-Steigerung bietet.
Einige Schnittstellen bieten Methoden zum gleichzeitigen Abrufen mehrererZeilen in die nächsten Felder eines Rasters. Im Allgemeinen gilt: Je wenigergetrennte Fetch-Vorgänge Sie ausführen, desto weniger einzelneAnforderungen muss der Server bewältigen, und desto besser wird diePerformance. Eine modifizierte FETCH-Anweisung, die mehrere Zeilenabruft, wird auch ein weiter Abruf genannt. Ein Cursor, der Mehrzeilen-Abrufe ausführt, wird manchmal auch als Block-Cursor (Blockcursor) oderfat cursor (Fetter Cursor) bezeichnet.
♦ In ODBC können Sie die Anzahl der Zeilen einstellen, die bei jedemAufruf von SQLFetchScroll oder SQLExtendedFetch zurückgegebenwerden, indem Sie das Attribut SQL_ROWSET_SIZE setzen.
♦ In Embedded SQL verwendet die FETCH-Anweisung eine ARRAY-Klausel, um die Anzahl der Zeilen zu steuern, die durch einen Fetch-Vorgang gleichzeitig abgerufen werden.
♦ Open Client und JDBC unterstützen mehrzeilige Fetch-Vorgänge nicht.Sie verwenden Prefetch-Vorgänge.
Fetch mit abrollendem Cursor
ODBC und Embedded SQL bieten Methoden für den Einsatz abrollenderbeziehungsweise dynamisch abrollender Cursortypen. Diese Methodenermöglichen das gleichzeitige Vorwärtsbewegen oder Rückwärtsbewegenüber mehrere Zeilen in einer Ergebnismenge.
Die JDBC- und Open Client-Schnittstellen unterstützen keine abrollendenCursor.
Prefetch-Vorgänge sind auf Vorgänge mit einem abrollenden Cursor nichtanwendbar. Zum Beispiel werden beim Abrufen einer Zeile inentgegengesetzter Richtung nicht mehrere vorherige Zeilen abgerufen.
Mehrzeilen-Fetch-Vorgänge
Mehrzeilen-Fetch-Vorgängeverwenden

Mit Cursorn arbeiten
24
Zeilen mit einen Cursor ändern
Cursor können mehr als nur Ergebnisse aus einer Abfrage lesen. Sie könnenauch Daten in der Datenbank verändern, während Sie einen Cursorverarbeiten. Diese Vorgänge werden im Allgemeinen als positionsbasierteoder positionierte Aktualisierungs- und Löschvorgänge oder PUT-Vorgänge(wenn es sich um ein INSERT handelt) bezeichnet.
Nicht alle Abfrage-Ergebnismengen ermöglichen positionsbasiertesAktualisieren oder Löschen. Wenn Sie eine Abfrage in einer nichtaktualisierbaren Ansicht ausführen, werden in den Basistabellen keineÄnderungen durchgeführt. Auch wenn die Abfrage einen Join enthält,müssen Sie angeben, aus welcher Tabelle Sie löschen wollen oder welcheSpalten Sie aktualisieren wollen, wenn Sie die Vorgänge ausführen.
Einfügungen durch einen Cursor können nur durchgeführt werden, wennnicht eingefügte Spalten in der Tabelle NULLWERTE zulassen oderStandardwerte haben.
ODBC, Embedded SQL und Open Client ermöglichen die Datenänderungmit einem Cursor, JDBC 1.1 hingegen nicht. Mit dem Open Client könnenSie Zeilen löschen und aktualisieren, aber Zeilen nur in einer Ein-Tabellenabfrage einfügen.
Wenn Sie ein positionsbasiertes Löschen durch einen Cursor versuchen, wirddie Tabelle, aus der Zeilen gelöscht werden, wie folgt festgelegt:
1 Wenn keine FROM-Klausel in der DELETE-Anweisung eingeschlossenist, muss der Cursor nur für eine Tabelle gesetzt sein.
2 Wenn der Cursor für eine Join-Abfrage (einschließlich zum Benutzeneiner Ansicht mit enthaltenem Join) gesetzt ist, muss die FROM-Klauselverwendet werden. Nur die aktuelle Zeile der angegebenen Tabelle wirdgelöscht. Die anderen Tabellen des Joins sind nicht betroffen.
3 Wenn eine FROM-Klausel enthalten ist und kein Tabelleneigentümerangegeben wurde, ist der Tabellenangabewert der erste, der zu denKorrelationsnamen passt.
$ Weitere Hinweise finden Sie unter "FROM-Klausel" auf Seite 467der Dokumentation ASA SQL-Referenzhandbuch.
4 Wenn ein Korrelationsname existiert, ist der Tabellenangabename mitdem Korrelationsnamen identifiziert.
5 Wenn ein Korrelationsname nicht vorhanden ist, muss derTabellenangabewert eindeutig als Tabellenname im Cursoridentifizierbar sein.
Aus welcherTabelle werdenZeilen gelöscht?

Kapitel 2 SQL in Anwendungen verwenden
25
6 Wenn eine FROM-Klausel enthalten ist und ein Tabelleneigentümerangegeben wurde, muss der Tabellenangabewert als Tabellenname imCursor eindeutig identifizierbar sein.
7 Die positionsbasierte DELETE-Anweisung kann für einen Cursorverwendet werden, der auf eine Ansicht geöffnet ist, solange die Ansichtaktualisierbar ist.
Cursorvorgänge abbrechen
Sie können eine Anforderung durch eine Schnittstellenfunktion abbrechen. InInteractive SQL können Sie eine Anforderung durch Klicken auf dieSchaltfläche "SQL-Anweisung unterbrechen" in der Symbolleiste abbrechen(oder durch den Befehl "Stop" im SQL-Menü).
Wenn Sie eine Anforderung abbrechen, die eine Cursoroperation durchführt,ist die Position des Cursors unbestimmt. Nach dem Abbrechen derAnforderung müssen Sie die absolute Position des Cursors ermitteln oder ihnschließen.

Cursortypen auswählen
26
Cursortypen auswählenDieser Abschnitt beschreibt Zuordnungen zwischen Adaptive ServerAnywhere-Cursorn und den Optionen, die Ihnen dieProgrammierschnittstellen bieten, die von Adaptive Server Anywhereunterstützt werden.
$ Hinweise zu Adaptive Server Anywhere-Cursorn finden Sie unter"Adaptive Server Anywhere-Cursor" auf Seite 30.
Cursorverfügbarkeit
Nicht alle Schnittstellen bieten Unterstützung für alle Cursortypen.
♦ ODBC und OLE DB (ADO) unterstützen alle Cursortypen.
$ Weitere Hinweise finden Sie unter "Mit Ergebnismengen arbeiten"auf Seite 299.
♦ Embedded SQL unterstützt alle Cursortypen.
♦ Für JDBC:
♦ jConnect 4.x stellt nur asensitive (nicht empfindliche) Cursor zurVerfügung.
♦ jConnect 5.x unterstützt alle Cursortypen, bei abrollbaren Cursornkommt es jedoch zu erheblichen Performance-Einbußen.
♦ Die JDBC-ODBC-Brücke unterstützt alle Cursortypen.
♦ Sybase Open Client unterstützt lediglich asensitive (nicht empfindliche)Cursor. Außerdem kommt es zu erheblichen Performance-Einbußen,wenn aktualisierbare, nicht eindeutige Cursor benutzt werden.
Cursoreigenschaften
Sie fordern einen Cursortyp entweder explizit oder implizit von derProgrammierschnittstelle an. Unterschiedliche Schnittstellenbibliothekenbieten eine unterschiedliche Auswahl von Cursortypen an. JDBC undODBC schreiben zum Beispiel unterschiedliche Cursortypen vor.
Jeder Cursortyp wird duch eine Reihe von Eigenschaften definiert:

Kapitel 2 SQL in Anwendungen verwenden
27
♦ Eindeutigkeit Wenn ein Cursor als eindeutig deklariert wird, zwingtdies die Abfrage, alle Spalten zurückzugeben, die für die eindeutigeIdentifizierung der einzelnen Zeilen erforderlich sind. Oft bedeutet dies,dass alle Spalten im Primärschlüssel zurückgegeben werden. Alleerforderlichen, aber nicht angegebenen Spalten werden derErgebnismenge hinzugefügt. Der Standardcursortyp ist "Nichteindeutig".
♦ Aktualisierbarkeit Ein als schreibgeschützt deklarierter Corsor kannnicht für eine positionierte Aktualisierung oder Löschung verwendetwerden. Der Standardcursortyp ist "Aktualisierbar".
♦ Abrollfähigkeit Sie können Cursor so deklarieren, dass Sie sichunterschiedlich verhalten, wenn Sie sich durch die Ergebnismengebewegen. Manche Cursor können nur die aktuelle oder die nächste Zeileabrufen. Andere können sich vorwärts und rückwärts in derErgebnismenge bewegen.
♦ Empfindlichkeit Änderungen an der Datenbank können durch einenCursor sichtbar sein, müssen es aber nicht.
Diese Eigenschaften haben möglicherweise signifikante Auswirkungen aufPerformance und Datenbankserver-Speicherzuordnung.
Adaptive Server Anywhere stellt Ihnen Cursor mit unterschiedlichenZusammensetzungen dieser Eigenschaften zur Verfügung. Wenn Sie einenCorsor eines gegebenen Typs anfordern, versucht Adaptive ServerAnywhere, diese Eigenschaften so gut wie möglich zuzuordnen. WieAdaptive Server Anywhere-Cursor den in den Programmierschnittstellenfestgelegten Cursorn im Einzelnen entsprechen, ist das Thema der folgendenAbschnitte.
Unter Umständen ist es nicht möglich, allen Eigenschaften zu entsprechen.Unempfindliche Cursor in Adaptive Server Anywhere zum Beispiel müssenschreibgeschützt sein, aus den weiter unten angeführten Gründen. Wenn IhreAnwendung einen aktualisierbaren unempfindlichen Cursor anfordert, wirdstatt dessen ein anderer Cursortyp (Wert-empfindlich) geliefert.
Adaptive Server Anywhere-Cursor anfordern
Wenn Sie einen Cursortyp von Ihrer Clientanwendung aus anfordern, liefertAdaptive Server Anywhere einen Cursor. Adaptive Server Anywhere-Cursorwerden nicht durch den in der Programmierschnittstelle festgelegten Typdefiniert, sondern durch die Empfindlichkeit der Ergebnismenge aufÄnderungen in den darunter liegenden Daten. Abhängig vom verlangtenCursortyp liefert Adaptive Server Anywhere einen Cursor mit einemVerhalten, das dem Typ entspricht.

Cursortypen auswählen
28
Die Empfindlichkeit der Adaptive Server Anywhere-Cursorn wirdentsprechend der Cursortyp-Anfrage des Clients gesetzt.
ODBC und OLE DB
Die nachstehende Tabelle beschreibt die Cursorempfindlichkeit, die beiverschiedenen abrollbaren ODBC-Cursortypen eingestellt wird.
Abrollbarer ODBC-Cursortyp Adaptive Server Anywhere-Cursor
STATIC Insensitive (Unempfindlich)
KEYSET Wertempfindlich
DYNAMIC Sensitiv (Empfindlich)
MIXED Wertempfindlich
$ Hinweise zu Adaptive Server Anywhere-Cursorn und ihrem Verhaltenfinden Sie unter "Adaptive Server Anywhere-Cursor" auf Seite 30. Hinweiseüber das Anfordern eines Cursortyps in ODBC finden Sie unter "Cursor-Eigenschaften wählen" auf Seite 299.
Wenn Sie einen STATIC-Cursor als aktualisierbar anfordern, wird stattdessen ein Wert-empfindlicher Cursor geliefert und eine Warnungausgegeben.
Wenn ein DYNAMIC- oder MIXED-Cursor angefordert wird und dieAbfrage nicht ohne Arbeitstabellen ausgeführt werden kann, wird stattdessen ein nicht-empfindlicher Cursor geliefert und eine Warnungausgegeben.
Embedded SQL
Um einen Cursor von einer Embedded SQL-Anwendung anzufordern, gebenSie den Cursortyp in der DECLARE-Anweisung an. Die nachstehendeTabelle beschreibt die Cursorempfindlichkeit, die als Antwort aufunterschiedliche Anforderungen eingestellt wird.
Cursortyp Adaptive Server Anywhere-Cursor
NO SCROLL Asensitiv (Nicht empfindlich)
DYNAMIC SCROLL Asensitive (Nicht empfindlich)
SCROLL Wertempfindlich
INSENSITIVE Insensitive (Unempfindlich)
SENSITIVE Sensitive (Empfindlich)
Ausnahmen

Kapitel 2 SQL in Anwendungen verwenden
29
Wenn Sie einen DYNAMIC SCROLL- oder NO SCROLL-Cursor alsUPDATABLE anfordern, wird ein empfindlicher oder wertempfindlicherCursor geliefert. Es ist nicht ausgemacht, welcher der Beiden geliefert wird.Diese Ungewissheit entspricht der Definition von nicht-empfindlichemVerhalten.
Wenn Sie einen INSENSITIVE-Cursor als UPDATABLE anfordern, wirdein wertempfindlicher Cursor geliefert.
Wenn Sie einen DYNAMIC SCROLL-Cursor anfordern, die PREFETCH-Datenbankoption auf OFF eingestellt ist und der Ausführungsplan derAbfrage keine Arbeitstabellen verlangt, wird möglicherweise einempfindlicher Cursor geliefert. Wieder entspricht diese Ungewissheit derDefinition von nicht-empfindlichem Verhalten.
JDBC
Es steht nur ein Typ von Cursorn für JDBC-Anwendungen zur Verfügung.Dies ist ein nicht-empfindlicher Cursor. In JDBC können Sie eineExecuteQuery-Anweisung ausführen, um einen Cursor zu öffnen.
Open Client
Es steht nur ein Typ von Cursorn für JDBC-Anwendungen zur Verfügung.Das ist ein nicht-empfindlicher Cursor.
Lesezeichen und Cursor
ODBC bietet Lesezeichen an bzw. Werte zum Identifizieren von Zeilen ineinem Cursor. Adaptive Server Anywhere unterstützt Lesezeichen für alleArten von Cursorn, mit Ausnahme von dynamischen Cursorn.
Block-Cursor
ODBC stellt einen Cursortyp namens Block-Cursor zur Verfügung. WennSie einen solchen Block-Cursor verwenden, können Sie SQLFetchScrolloder SQLExtendedFetch benutzen, um einen Zeilenblock und nicht eineeinzelne Zeile abzurufen. Block-Cursor verhalten sich genauso wieEmbedded SQL ARRAY-Abrufe.
Ausnahmen

Adaptive Server Anywhere-Cursor
30
Adaptive Server Anywhere-CursorSobald ein Cursor geöffnet ist, hat er eine zugeordnete Ergebnismenge. DerCursor bleibt eine Zeit lang geöffnet. Während dieser Zeit kann die demCursor zugeordnete Ergebnismenge geändert werden, entweder durch denCursor selbst oder, abhängig von den Anforderungen der Isolationsstufe,durch andere Transaktionen. Manche Cursor ermöglichen es, Änderungen anden darunter liegenden Daten sichtbar zu machen, während bei Anderendiese Änderungen nicht auszumachen sind. Das unterschiedliche Verhaltenvon Cursorn in Bezug auf Änderungen an den darunter liegenden Daten wirddie Empfindlichkeit des Cursors genannt.
Adaptive Server Anywhere stellt Cursor mit einer Vielzahl vonEmpfindlichkeitseigenschaften zur Verfügung. Dieser Abschnitt beschreibt,was Empfindlichkeit ist, sowie die Empfindlichkeitseigenschaften vonCursorn.
Dabei wird vorausgesetzt, dass Sie mit dem Abschnitt "Was sind Cursor?"auf Seite 15 vertraut sind.
Änderungen an den darunter liegenden Daten können sich folgendermaßenauf die Ergebnismenge eines Cursors auswirken:
♦ Mitgliedschaft Die Menge der Zeilen in der Ergebnismenge, die durchihre Primärschlüsselwerte gekennzeichnet sind.
♦ Reihenfolge Die Reihenfolge der Zeilen in der Ergebnismenge.
♦ Wert Die Werte der Zeilen in der Ergebnismenge.
Nehmen Sie zum Beispiel die folgende einfache Tabelle mit Mitarbeiterdaten(emp_id ist die Primärschlüsselspalte):
emp_id emp_lname
1 Whitney
2 Cobb
3 Chin
Ein Cursor auf der folgenden Abfrage gibt alle Ergebnisse aus der Tabelle inder Reihenfolge des Primärschlüssels zurück.
SELECT emp_id, emp_lnameFROM employeeORDER BY emp_id
Änderungen beiMitgliedschaft,Reihenfolge undWerten

Kapitel 2 SQL in Anwendungen verwenden
31
Die Mitgliedschaft der Ergebnismenge könnte durch das Hinzufügen einerneuen Zeile oder das Löschen einer Zeile geändert werden. Die Wertekönnten durch eine Namensänderung in der Tabelle geändert werden. DieReihenfolge könnte geändert werden, indem der Primärschlüssel einesMitarbeiters geändert wird.
Abhängig von den Anforderungen der Isolationsstufe können Mitgliedschaft,Reihenfolge und Werte der Ergebnismenge eines Cursors geändert werden,nachdem der Cursor geöffnet wurde. Es hängt vom Typ des verwendetenCursors ab, ob sich die Ergebnismenge, wie sie von der Anwendung gesehenwird, ändert, um diese Änderungen darzustellen.
Änderungen an den darunter liegenden Daten können durch den Cursorsichtbar oder unsichtbar sein. Eine sichtbare Änderung ist eine, die sich inder Ergebnismenge des Cursors wiederspiegelt. Änderungen an den darunterliegenden Daten, die nicht in der Ergebnismenge, wie sie vom Cursorgesehen wird, wiedergespiegelt werden, sind unsichtbar.
Überblick über die Cursor-Empfindlichkeit
Adaptive Server Anywhere-Cursor werden anhand ihrer Empfindlichkeitgegenüber Änderungen an den darunter liegenden Daten eingeteilt. ImBesonderen wird die Cursor-Empfindlichkeit anhand der Sichtbarkeit vonÄnderungen definiert.
♦ Unempfindliche Cursor Die Ergebnismenge ist unveränderlich, wennder Cursor geöffnet ist. Änderungen an den darunter liegenden Datensind nicht sichtbar.
$ Weitere Hinweise finden Sie unter "Unempfindliche Cursor" aufSeite 36.
♦ Empfindliche Cursor Die Ergebnismenge kann sich ändern, nachdemder Cursor geöffnet wurde. Alle Änderungen an den darunter liegendenDaten sind sichtbar.
$ Weitere Hinweise finden Sie unter "Empfindliche Cursor" aufSeite 37.
♦ Nicht-empfindliche Cursor Änderungen können in der Mitgliedschaft,der Reihenfolge oder den Werten der Ergebnismenge, wie sie durch denCursor gesehen wird, wiedergespiegelt werden, müssen es aber nicht.
$ Weitere Hinweise finden Sie unter "Nicht-empfindliche Cursor"auf Seite 39.
♦ Wert-empfindliche Cursor Änderungen in der Reihenfolge oder denWerten der darunter liegenden Daten sind sichtbar. Die Mitgliedschaftder Ergebnismenge ist unveränderlich, wenn der Cursor geöffnet ist.
Sichtbare undunsichtbareÄnderungen

Adaptive Server Anywhere-Cursor
32
$ Weitere Hinweise finden Sie unter "Wert-empfindliche Cursor" aufSeite 40.
Die unterschiedlichen Anforderungen an Cursor bewirken unterschiedlicheBeschränkungen bei der Ausführung, was sich wiederum auf diePerformance auswirkt. Weitere Hinweise finden Sie unter "Cursor-Empfindlichkeit und Performance" auf Seite 43.
Beispiel für Cursor-Empfindlichkeit: Eine gelöschte Zeile
Dieses Beispiel verwendet eine einfache Abfrage, um zu illustrieren, wieverschiedene Cursor auf eine Zeile in der Ergebnismenge reagieren, diegelöscht wird.
Es gibt die folgende Abfolge von Ereignissen:
1 Eine Anwendung öffnet einen Cursor auf der folgenden Abfrage auf derBeispieldatenbank.
SELECT emp_id, emp_lnameFROM employeeORDER BY emp_id
emp_id emp_lname
102 Whitney
105 Cobb
160 Breault
… …
2 Die Anwendung ruft die erste Zeile durch den Cursor ab (102).
3 Die Anwendung ruft die nächste Zeile durch den Cursor ab (105).
4 Eine weitere Anwendung löscht Mitarbeiter 102 (Whitney) und schreibtdie Änderung fest.
In dieser Situation hängen die Ergebnisse der Cursor-Aktionen von derCursor-Empfindlichkeit ab.
♦ Unempfindliche Cursor Das DELETE wird weder in der Mitgliedschaftnoch in den Werten der Ergebnissen, wie sie durch den Cursor gesehenwerden, wiedergespiegelt:

Kapitel 2 SQL in Anwendungen verwenden
33
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt die ursprüngliche Kopie der Zeile zurück(102).
Erste Zeile abrufen(absoluter Abruf)
Gibt die ursprüngliche Kopie der Zeile zurück(102).
Zweite Zeile abrufen(absoluter Abruf)
Gibt die ungeänderte Zeile zurück (105).
♦ Empfindliche Cursor Die Mitgliedschaft der Ergebnismenge hat sichinsofern geändert, dass jetzt Zeile 105 die erste Zeile in derErgebnismenge ist:
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt den Fehler Zeile nicht gefunden zurück. Esgibt keine vorherige Zeile.
Erste Zeile abrufen(absoluter Abruf)
Gibt Zeile 105 zurück.
Zweite Zeile abrufen(absoluter Abruf)
Gibt Zeile 160 zurück.
♦ Wert-empfindliche Cursor Die Mitgliedschaft der Ergebnismenge istunveränderlich, und daher ist Zeile 105 weiterhin die zweite Zeile in derErgebnismenge. Das DELETE wird in den Werten des Cursorswiedergespiegelt und erzeugt ein tatsächliches "Loch" in derErgebnismenge.
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt Keine aktuelle Cursorzeile zurück. Wovorher die erste Zeile war, steht jetzt im Cursoreine Lücke.
Erste Zeile abrufen(absoluter Abruf)
Gibt Keine aktuelle Cursorzeile zurück. Wovorher die erste Zeile war, steht jetzt im Cursoreine Lücke.
Zweite Zeile abrufen(absoluter Abruf)
Gibt Zeile 105 zurück.

Adaptive Server Anywhere-Cursor
34
♦ Nicht-empfindliche Cursor Die Mitgliedschaft und Werte derErgebnismenge sind in Bezug auf die Änderungen unbestimmt. DieAntwort auf einen Abruf der vorherigen Zeile, der ersten Zeile oder derzweiten Zeile hängt von der entsprechenden Optimierungsmethode fürdie Abfrage ab. Die Antwort hängt davon ab, ob die Methode dieErstellung einer Arbeitstabelle erfordert und ob die abgerufene Zeilevom Client vorab abgerufen wurde.
Der Vorteil von nicht-empfindlichen Cursorn liegt darin, dass für vieleAnwendungen die Empfindlichkeit unwichtig ist. Besonders wenn Sieeinen schreibgeschützten Vorwärts-Cursor verwenden, sind keine derdarunter liegenden Änderungen sichtbar. Auch wenn Sie auf einer hohenIsolationsstufe ausführen, sind darunter liegende Änderungen nichtzulässig.
Beispiel für Cursor-Empfindlichkeit: Eine aktualisierte Zeile
Dieses Beispiel verwendet eine einfache Abfrage, um zu illustrieren wieverschiedene Cursortypen auf eine Zeile in der Ergebnismenge reagieren, dieaktualisiert wird und dadurch die Reihenfolge in der Ergebnismengeverändert.
Es gibt die folgende Abfolge von Ereignissen:
1 Eine Anwendung öffnet einen Cursor auf der folgenden Abfrage auf derBeispieldatenbank.
SELECT emp_id, emp_lnameFROM employee
emp_id emp_lname
102 Whitney
105 Cobb
160 Breault
… …
2 Die Anwendung ruft die erste Zeile durch den Cursor ab (102).
3 Die Anwendung ruft die nächste Zeile durch den Cursor ab (105).
4 Eine weitere Transaktion aktualisiert die Mitarbeiter-ID des Mitarbeiters102 (Whitney) auf 165 und schreibt die Änderung fest.
In dieser Situation hängen die Ergebnisse der Cursor-Aktionen von derCursor-Empfindlichkeit ab.

Kapitel 2 SQL in Anwendungen verwenden
35
♦ Unempfindliche Cursor Das UPDATE wird weder in derMitgliedschaft noch in den Werten der Ergebnisse, wie sie durch denCursor gesehen werden, wiedergespiegelt:
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt die ursprüngliche Kopie der Zeile zurück(102).
Erste Zeile abrufen(absoluter Abruf)
Gibt die ursprüngliche Kopie der Zeile zurück(102).
Zweite Zeile abrufen(absoluter Abruf)
Gibt die ungeänderte Zeile zurück (105).
♦ Empfindliche Cursor Die Mitgliedschaft der Ergebnismenge hat sichinsofern geändert, dass jetzt Zeile 105 die erste Zeile in derErgebnismenge ist:
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt den Fehler Zeile nicht gefunden zurück.Die Mitgliedschaft der Ergebnismenge hat sichgeändert und 105 ist jetzt die erste Zeile. DerCursor wird auf die Position vor der ersten Zeileverschoben.
Erste Zeile abrufen(absoluter Abruf)
Gibt Zeile 105 zurück.
Zweite Zeile abrufen(absoluter Abruf)
Gibt Zeile 160 zurück.
Außerdem wird beim Abrufen durch einen empfindlichen Cursor dieWarnung SQLE_ROW_UPDATED_WARNING ausgegeben, wenn dieZeile seit dem letzten Lesen geändert wurde. Die Warnung wird nureinmal ausgegeben. Aufeinander folgende FETCH-Vorgänge fürdieselbe Zeile lösen keine Warnung aus.
Ähnlich gibt auch eine positionsbasierte UPDATE- oder DELETE-Anweisung durch den Cursor auf einer Zeile, die seit dem letzten Abrufgeändert wurde, die FehlermeldungSQLE_ROW_UPDATED_SINCE_READ aus. Eine Anwendung mussdas Abrufen einer Zeile nochmals durchführen, damit UPDATE oderDELETE bei einem empfindlichen Cursor funktionieren.
Eine Aktualisierung einer Spalte bewirkt die Warnung oder den Fehler,auch wenn die Spalte vom Cursor nicht referenziert wird. Beispiel: EinCursor auf einer Abfrage, der emp_lname zurückgibt, würde dieAktualisierung melden, auch wenn nur die Spalte salary geändertworden wäre.

Adaptive Server Anywhere-Cursor
36
♦ Wert-empfindliche Cursor Die Mitgliedschaft der Ergebnismenge istunveränderlich, und daher ist Zeile 105 weiterhin die zweite Zeile in derErgebnismenge. Das DELETE wird in den Werten des Cursorswiedergespiegelt und erzeugt ein tatsächliches "Loch" in derErgebnismenge.
Maßnahme Ergebnis
Vorherige Zeileabrufen
Gibt den Fehler Zeile nicht gefunden zurück.Die Mitgliedschaft der Ergebnismenge hat sichgeändert und 105 ist jetzt die erste Zeile. DerCursor wird über dem Loch positioniert: Erbefindet sich vor Zeile 105.
Erste Zeile abrufen(absoluter Abruf)
Gibt den Fehler Zeile nicht gefunden zurück.Die Mitgliedschaft der Ergebnismenge hat sichgeändert und 105 ist jetzt die erste Zeile. DerCursor wird über dem Loch positioniert: Erbefindet sich vor Zeile 105.
Zweite Zeile abrufen(absoluter Abruf)
Gibt Zeile 105 zurück.
♦ Nicht-empfindliche Cursor Die Mitgliedschaft und Werte derErgebnismenge sind in Bezug auf die Änderungen unbestimmt. DieAntwort auf einen Abruf der vorherigen Zeile, der ersten Zeile oder derzweiten Zeile hängt von der entsprechenden Optimierungsmethode fürdie Abfrage ab, ob die Methode die Erstellung einer Arbeitstabelleerfordert und ob die abgerufene Zeile vom Client vorab abgerufenwurde.
Keine Warnungen oder Fehler in MassenvorgängenWarnungs- und Fehlerbedingungen für Aktualisierungen kommen inMassenvorgängen nicht vor (Option -b für Datenbankserver).
Unempfindliche Cursor
Diese Cursor haben unempfindliche Mitgliedschaft, Reihenfolge und Werte.Keine Änderungen, die nach dem Öffnen des Cursors durchgeführt werden,sind sichbar.
Unempfindliche Cursor werden nur für schreibgeschützte Cursortypenverwendet.
Unempfindliche Cursor entsprechen der ISO/ANSI-Standarddefinition vonunempfindlichen Cursorn beziehungsweise den statischen ODBC-Cursorn.
Standards

Kapitel 2 SQL in Anwendungen verwenden
37
Schnittstelle Cursortyp Kommentar
ODBC, OLE DBund ADO
Static Wenn ein aktualisierbarer statischerCursor angefordert wird, wird stattdessen ein Wert-empfindlicher Cursorverwendet.
Embedded SQL INSENSITIVEoder NOSCROLL
JDBC Nicht unterstützt
Open Client Nicht unterstützt
Unempfindliche Cursor geben immer Zeilen zurück, die denAuswahlkriterien der Abfrage entsprechen, und zwar in der durch eineORDER BY-Klausel festgelegte Reihenfolge.
Die Ergebnismenge eines unempfindlichen Cursors wird vollständig alsArbeitstabelle materialisiert, wenn der Cursor geöffnet wird. Das hatfolgende Konsequenzen:
♦ Wenn die Ergebnismenge sehr umfangreich ist, sind die Festplatten- undSpeicheranforderungen zum Verwalten des Ergebnisses möglicherweisevon Bedeutung.
♦ Keine Zeile wird an die Anwendung zurückgegeben, bevor nicht diegesamte Ergebnismenge als eine Arbeitstabelle zusammengestellt ist.Bei komplexen Abfragen kann das zu einer Verzögerung führen, bevordie erste Zeile an die Anwendung zurückgegeben wird.
♦ Nachfolgende Zeilen können direkt von der Arbeitstabelle abgerufenwerden, und werden daher rasch ausgegeben. Die Client-Bibliothekkann mehrere Zeilen gleichzeitig vorab abrufen, was die Performanceweiter steigert.
♦ Unempfindliche Cursor sind von ROLLBACK oder ROLLBACK TOSAVEPOINT nicht betroffen.
Empfindliche Cursor
Diese Cursor haben empfindliche Mitgliedschaft, Reihenfolge und Werte.
Empfindliche Cursor können für schreibgeschützte oder aktualisierbareCursortypen verwendet werden.
Empfindliche Cursor entsprechen der ISO/ANSI-Standarddefinition vonempfindlichen Cursorn beziehungsweise den dynamischen ODBC-Cursorn.
Programmier-schnittstellen
Beschreibung
Standards

Adaptive Server Anywhere-Cursor
38
Schnittstelle Cursortyp Kommentar
ODBC, OLE DBund ADO
Dynamic
Embedded SQL SENSITIVE Wird auch als Antwort auf eine Anfragenach einem DYNAMIC SCROLL-Cursorgeliefert, wenn keine Arbeitstabelleerforderlich ist und PREFETCH auf OFFeingestellt ist.
Alle Änderungen sind durch den Cursor sichtbar, sowohl die Änderungendurch den Cursor als auch die durch andere Transaktionen. HöhereIsolationsstufen können auf Grund von Sperren manche Änderungenverbergen, die von anderen Transaktionen durchgeführt werden.
Alle Änderungen von Mitgliedschaft, Reihenfolge und Spaltenwerten desCursors sind sichtbar. Beispiel: Wenn ein empfindlicher Cursor einen Joinenthält und einer der Werte von einer der darunter liegenden Tabellegeändert wird, dann zeigen alle Ergebniszeilen, die aus dieser Basiszeilezusammengesetzt sind, den neuen Wert. Die Mitgliedschaft und Reihenfolgeder Ergebnismenge können sich bei jedem Abruf ändern.
Empfindliche Cursor geben immer Zeilen zurück, die den Auswahlkriteriender Abfrage entsprechen, und zwar in der durch eine ORDER BY-Klauselfestgelegte Reihenfolge. Aktualisierungen können sich auf dieMitgliedschaft, Reihenfolge und Werte der Ergebnismenge auswirken.
Die Anforderungen von empfindlichen Cursorn bewirken bei derImplementierung von empfindlichen Cursorn folgende Einschränkungen:
♦ Zeilen können nicht vorab abgerufen werden, weil die Änderungen ansolchen Zeilen durch den Cursor nicht sichtbar wären. Das kann sich aufdie Performance auswirken.
♦ Empfindliche Cursor müssen so implementiert werden, dass keineArbeitstabellen zusammengestellt werden, weil Änderungen an den inder Arbeitstabelle gespeicherten Zeilen durch den Cursor nicht sichtbarwären.
♦ Die Bedingung, keine Arbeitstabelle zu verwenden, schränkt dieAuswahl der Join-Methode durch den Optimierer ein und kann sichdaher auf die Performance auswirken.
♦ Bei einigen Abfragen ist es unvermeidlich, dass der Optimierer einenPlan erstellt, der eine Arbeitstabelle enthält, und somit keinenempfindlichen Cursor erlaubt.
Programmier-schnittstellen
Beschreibung

Kapitel 2 SQL in Anwendungen verwenden
39
Arbeitstabellen werden üblicherweise zum Sortieren und Gruppierenvon Zwischenergebnissen verwendet. Eine Arbeitstabelle ist zumSortieren nicht erforderlich, wenn auf die Zeilen durch einen Indexzugegriffen werden kann. Es ist nicht immer möglich vorherzusagen,welche Abfragen Arbeitstabellen verwenden, aber sie werden vonfolgenden Abfragen verwendet:
♦ UNION-Abfragen, auch wenn UNION ALL nicht unbedingtArbeitstabellen verwenden.
♦ Anweisungen mit einer ORDER BY-Klausel, wenn es keinen Indexauf der ORDER BY-Spalte gibt.
♦ Jede Abfrage, die mit einem Hash-Join optimiert ist.
♦ Viele Abfragen, die DISTINCT- oder GROUP BY-Klauselnbetreffen.
In diesen Fällen gibt Adaptive Server Anywhere entweder eineFehlermeldung an die Anwendung zurück, oder er ändert den Cursortypin einen nicht-empfindlichen Cursor und gibt eine Warnmeldung aus.
$ Weitere Hinweise zur Abfragenoptimierung und Verwendung vonArbeitstabellen finden Sie unter "Abfragen optimieren und ausführen"auf Seite 345 der Dokumentation ASA SQL-Benutzerhandbuch.
Nicht-empfindliche Cursor
Diese Cursor haben keine genau definierte Empfindlichkeit in ihrerMitgliedschaft, ihrer Reihenfolge oder ihren Werten. Die Flexibilität, die siein Bezug auf Empfindlichkeit haben, ermöglicht es, nicht-empfindlicheCursor für die Performance zu optimieren.
Nicht-empfindliche Cursor werden nur für schreibgeschützte Cursortypenverwendet.
Nicht-empfindliche Cursor entsprechen der ISO/ANSI-Standarddefinitionvon nicht-empfindlichen Cursorn beziehungsweise den ODBC-Cursorn mitunbestimmter Empfindlichkeit.
Schnittstelle Cursortyp
ODBC, OLE DB und ADO Unspecified sensitivity
Embedded SQL DYNAMIC SCROLL
Standards
Programmier-schnittstellen

Adaptive Server Anywhere-Cursor
40
Die Anforderung eines nicht-empfindlichen Cursors schränkt die Auswahlder Methoden kaum ein, die Adaptive Server Anywhere verwenden kann,um die Abfrage zu optimieren und Zeilen an die Anwendung zurückzugeben.Aus diesen Gründen erhalten Sie mit nicht-empfindlichen Cursorn die bestePerformance. Vor allem steht es dem Optimierer frei, jede Maßnahme zurMaterialisierung von Zwischenergebnissen, wie z.B. Arbeitstabellen,anzuwenden, und Zeilen können vom Client vorab abgerufen werden.
Adaptive Server Anywhere kann die Sichtbarkeit von Änderungen in dendarunter liegenden Basiszeilen nicht garantieren. Einige Änderung könnensichtbar sein, andere nicht. Die Mitgliedschaft und Reihenfolge können sichmit jedem Abruf ändern. Besonders Aktualisierungen in Basiszeilen könnendazu führen, dass nur einige der aktualisierten Spalten im Ergebnis desCursors wiedergespiegelt werden.
Nicht-empfindliche Cursor sind keine Garantie dafür, dass Zeilenzurückgegeben werden, die der Auswahl und Reihenfolge der Abfrageentsprechen. Die Zeilenmitgliedschaft steht zum Zeitpunkt des Öffnens desCursors fest, aber nachfolgende Änderungen an den darunter liegendenWerten werden in den Ergebnissen wiedergespiegelt.
Nicht-empfindliche Cursor geben immer Zeilen zurück, die den WHERE-und ORDER BY-Klauseln des Kunden zu dem Zeitpunkt entsprachen, andem die Cursor-Mitgliedschaft etabliert wurde. Wenn sich Spaltenwerte nachdem Öffnen des Cursors ändern, werden möglicherweise Zeilenzurückgegeben, die nicht mehr den WHERE- und ORDER BY-Klauselnentsprechen.
Wert-empfindliche Cursor
Diese Cursor sind in Bezug auf ihre Mitgliedschaft unempfindlich, dafür sindsie empfindlich, was die Reihenfolge und Werte der Ergebnismenge betrifft.
Wert-empfindliche Cursor können für schreibgeschützte oder aktualisierbareCursortypen verwendet werden.
Wert-empfindliche Cursor entsprechen keiner ISO/ANSI-Standarddefintion.Sie entsprechen den Schlüsselmengen-gesteuerten ODBC-Cursorn.
Schnittstelle Cursortyp
ODBC, OLE DB und ADO Schlüsselmengen-basiert
Embedded SQL SCROLL
JDBC Schlüsselmengen-basiert
Open Client Schlüsselmengen-basiert
Beschreibung
Standards
Programmier-schnittstellen

Kapitel 2 SQL in Anwendungen verwenden
41
Wenn eine Anwendung eine Zeile abruft, die aus einer darunter liegendengeänderten Basiszeile besteht, dann muss der Anwendung der aktualisierteWert sowie die SQL_ROW_UPDATED-Statusmeldung übermittelt werden.Wenn die Anwendung versucht, eine Zeile abzurufen, die aus einer darunterliegenden Basiszeile zusammengesetzt war, welche gelöscht worden ist,muss eine SQL_ROW_DELETED-Statusmeldung an die Anwendungübermittelt werden.
Eine Änderung am Primärschlüsselwert entfernt die Zeile aus derErgebnismenge (dies wird als Löschen, gefolgt von Einfügen, behandelt).Ein Sonderfall tritt auf, wenn eine Zeile in der Ergebnismenge gelöscht wird(durch den Cursor oder von auswärts), und eine neue Zeile mit demselbenSchlüsselwert eingefügt wird. Das führt dazu, dass die neue Zeile die alteZeile in der ursprünglichen Position ersetzt.
Es gibt keine Garantie, dass die Zeilen in der Ergebnismenge demReihenfolgen- oder Auswahlkriterium der Abfrage entsprechen. Da dieZeilenmitgliedschaft zum Zeitpunkt des Öffnens festgelegt wird, führennachfolgende Änderungen, durch die eine Zeile nicht mehr der WHERE-oder ORDER BY-Klausel entspricht, nicht dazu, dass sich die Mitgliedschaftoder Position einer Zeile ändert.
Alle Werte sind in Bezug auf Änderungen, die durch den Cursordurchgeführt werden,empfindlich. Die Empfindlichkeit der Mitgliedschaftgegenüber Änderungen, die durch den Cursor ausgeführt werden, wird durchdie ODBC-Option SQL_STATIC_SENSITIVITY gesteuert. Wenn dieseOption auf ON eingestellt ist, fügen Einfügungen durch den Cursor die Zeiledem Cursor hinzu. Ansonsten ist sie nicht in der Ergebnismenge enthalten.Löschungen durch den Cursor entfernen die Zeile aus der Ergebnismenge,wodurch ein Lücke vermieden wird, und geben die SQL_ROW_DELETED-Statusmeldung zurück.
Wert-empfindliche Cursor verwenden eine Schlüsselmengen-Tabelle. Wennder Cursor geöffnet wird, füllt Adaptive Server Anywhere eineArbeitstabelle mit Kenndaten für jede Zeile an, die zur Ergebnismengebeiträgt. Wenn Sie die Ergebnismenge durchblättern, wird dieSchlüsselmengen-Tabelle zur Identifizierung der Mitgliedschaft derErgebnismenge verwendet, aber die Daten werden, falls erforderlich, vonden darunter liegenden Tabellen bezogen.
Die Eigenschaft der festen Mitgliedschaft von Wert-empfindlichen Cursornermöglicht es Ihrer Anwendung, sich an die Zeilenpositionen innerhalb einesCursors erinnern, und stellt sicher, dass diese Positionen nicht geändertwerden. Weitere Hinweise finden Sie unter "Beispiel für Cursor-Empfindlichkeit: Eine gelöschte Zeile" auf Seite 32.
Beschreibung

Adaptive Server Anywhere-Cursor
42
♦ Wenn eine Zeile seit dem Öffnen des Cursors aktualisiertbeziehungsweise möglicherweise aktualisiert wurde, gibt AdaptiveServer Anywhere die Warnung SQLE_ROW_UPDATED_WARNINGzurück, wenn die Zeile abgerufen wird. Die Warnung wird nur einmalausgegeben: Ein weiteres Abrufen der Zeile generiert keineWarnmeldung.
Eine Aktualisierung einer beliebigen Spalte in der Zeile verursacht dieseWarnung sogar, wenn die aktualisierte Spalte nicht durch den Cursorreferenziert wird. Ein Cursor auf emp_lname und emp_fname würdebeispielsweise die Aktualisierung melden, selbst wenn nur die birthdate-Spalte geändert worden wäre. Diese Warn- und Fehlerbedingungen beiAktualisierung treten nicht im Massenoperationsmodus (Option -b fürDatenbankserver) auf, wenn die Zeilensperre deaktiviert ist. Siehe"Performance-Überlegungen beim Bewegen von Daten" auf Seite 470der Dokumentation ASA SQL-Benutzerhandbuch.
$ Weitere Hinweise finden Sie unter "Zeile wurde seit dem letztenLesen aktualisiert" auf Seite 324 der Dokumentation ASAFehlermeldungen
♦ Der Versuch, eine positionsbasierte UPDATE- oder DELETE-Anweisung auf einer Zeile auszuführen, die seit dem letzten Abrufgeändert wurde, gibt den SQLE_ROW_UPDATED_SINCE_READ-Fehler aus und bricht die Anweisung ab. Eine Anwendung muss dieZeile noch einmal mit FETCH ABRUFEN, bevor das UPDATE oderDELETE zugelassen wird.
Eine Aktualisierung einer beliebigen Spalte in der Zeile verursachtdiesen Fehler. Dies ist sogar dann der Fall, wenn die aktualisierte Spaltenicht durch den Cursor referenziert wird. Der Fehler tritt nicht imMassenvorgangsmodus auf.
$ Weitere Hinweise finden Sie unter "Zeile seit dem letzten Lesengeändert - Vorgang abgebrochen" auf Seite 323 der Dokumentation ASAFehlermeldungen.
♦ Wenn eine Zeile, entweder durch den Cursor oder durch eine andereTransaktion, nach dem Öffnen des Cursors gelöscht wurde, entsteht imCursor eine Lücke. Die Mitgliedschaft des Cursors steht fest, daher istdie Position einer Zeile reserviert, aber der DELETE-Vorgang wird imgeänderten Wert für die Zeile wiedergespiegelt. Wenn Sie die Zeile andieser Lücke abrufen, wird mit der Fehlermeldung Keine aktuelleCursorzeile (SQL state 24503) darauf hingewiesen, dass es keineaktuelle Zeile gibt, und der Cursor wird auf der Lücke belassen. Siekönnen Lücken vermeiden, indem Sie empfindliche Cursor verwenden,da sich deren Mitgliedschaft zusammen mit den Werten verändert.

Kapitel 2 SQL in Anwendungen verwenden
43
$ Weitere Hinweise finden Sie unter "Keine aktuelle Cursorzeile" aufSeite 207 der Dokumentation ASA Fehlermeldungen.
Sie können für Wert-empfindliche Cursor Zeilen nicht vorab abrufen. DieseEinschränkung kann sich manchmal auf die Performance auswirken.
Cursor-Empfindlichkeit und Performance
Es besteht eine Wechselwirkung zwischen Performance und anderen Cursor-Eigenschaften. Besonders wenn Sie einen Cursor aktualisierbar machen,führt das zu Beschränkungen der Abfrageverarbeitung und -zustellung, wasdie Performance vermindert. Auch können Anforderungen an die Cursor-Empfindlichkeit die Performance einschränken.
Um zu verstehen, wie sich die Aktualisierbarkeit und Empfindlichkeit vonCursorn auf die Performance auswirkt, ist es hilfreich zu wissen, wie dieErgebnisse, die durch einen Cursor sichtbar sind, von der Datenbank an dieClient-Anwendung übermittelt werden.
Im Einzelnen können Ergebnisse aus Performance-Gründen an zweidazwischengeschalteten Standorten gespeichert werden:
♦ Arbeitstabellen Sowohl Zwischen- als auch Endergebnisse können alsArbeitstabellen gespeichert werden. Wert-empfindliche Cursorverwenden eine Arbeitstabelle für Primärschlüsselwerte. Abfrage-Eigenschaften können ebenfalls dazu führen, dass der Optimierer inseinem gewählten Ausführungsplan Arbeitstabellen verwendet.
♦ Prefetch-Vorgang Der Client kann Zeilen vorab in einen clientseitigenPuffer abrufen, um separate Anfragen an der Datenbankserver für jedeZeile zu vermeiden.
Client-Anwendung
ODBC-Treiber in derNetzwerk-Bibliothek
Datenbank-Server
VorababgerufeneZeilen
Arbeits-tabelle
Die Empfindlichkeit und Aktualisierbarkeit beschränken die Verwendungvon zwischengeschalteten Standorten.

Adaptive Server Anywhere-Cursor
44
Einem aktualisierbaren Cursor ist es nicht gestattet, Arbeitstabellen zuverwenden oder mit PREFETCH Ergebnisse vorab abzurufen. Wäre diesmöglich, wäre er für verlorene Aktualisierungen anfällig. Dieses Problemwird im folgenden Beispiel erläutert:
1 Eine Anwendung öffnet auf der Beispieldatenbank in der folgendenAbfrage einen Cursor.
SELECT id, quantityFROM product
id quantity
300 28
301 54
302 75
… …
2 Die Anwendung ruft die Zeile mit id = 300 durch den Cursor ab.
3 Eine weitere Transaktion aktualisiert die Zeile mit der folgendenAnweisung:
UPDATE productSET quantity = quantity - 10WHERE id = 300
4 Die Anwendung aktualisiert die Zeile durch den Cursor auf einen Wertvon (quantity - 5 ).
5 Der korrekte Endwert für die Zeile sollte 13 sein. Wenn der Cursor dieZeile vorab abgerufen hätte, würde der neue Wert für die Zeile 23 lautenund die Aktualisierung der anderen Transaktion verloren gehen.
Ähnliche Einschränkungen sind maßgebend für die Empfindlichkeit. WeitereHinweise finden Sie unter den Beschreibungen der einzelnen Cursortypen.
Zeilen-Prefetch
Prefetch-Vorgänge und Mehrzeilen-Fetch-Vorgänge unterscheiden sichvoneinander. Prefetch-Vorgänge können ohne explizite Anweisungen aus derClientanwendung ausgeführt werden. Prefetch-Vorgänge rufen Zeilen ausdem Server in einen Puffer auf dem Client ab, machen diese Zeilen aber fürdie Clientanwendung erst verfügbar, wenn die entsprechende Zeile von derAnwendung abgerufen wird.

Kapitel 2 SQL in Anwendungen verwenden
45
Standardmäßig führt die Clientbibliothek von Adaptive Server AnywherePrefetch-Vorgänge für mehrere Zeilen aus, wenn eine Anwendung eineeinzelne Zeile abruft. Die Clientbibliothek von Adaptive Server Anywherespeichert die zusätzlichen Zeilen in einem Puffer.
Prefetch-Vorgänge verbessern die Performance durch die Reduktion desClient/Server-Verkehrs und erhöhen den Durchsatz, indem ohne separateAnforderung für einzelne Zeilen oder Zeilenblöcke viele Zeilen verfügbargemacht werden.
$ Weitere Hinweise zur Steuerung der Prefetch-Funktionen finden Sieunter "PREFETCH-Option" auf Seite 659 der Dokumentation ASADatenbankadministration.
♦ Durch die PREFETCH-Option wird gesteuert, ob Prefetch-Vorgängedurchgeführt werden oder nicht. Sie können die PREFETCH-Option füreine einzelne Verbindung auf ON oder OFF setzen. Standardmäßig wirdsie auf ON gesetzt.
♦ In Embedded SQL können Sie die PREFETCH-Vorgänge aufCursorbasis steuern, wenn Sie einen Cursor bei einem FETCH-Vorgangöffnen, indem Sie die BLOCK-Klausel verwenden.
Die Anwendung kann eine maximale Anzahl von Zeilen festlegen, die ineinem einzelnen FETCH-Vorgang vom Server enthalten sein dürfen,indem die BLOCK-Klausel angegeben wird. Beispiel: Wenn Sie 5Zeilen gleichzeitig abrufen und anzeigen, können Sie BLOCK 5verwenden. Wenn Sie BLOCK 0 festlegen, wird jeweils 1 Datensatzabgerufen, und ein FETCH RELATIVE 0 ruft die Zeile nochmals vomServer ab.
Obwohl Sie die PREFETCH-Vorgänge auch durch einenVerbindungsparameter für die Anwendung ausschalten können, ist eseffektiver, BLOCK=0 zu verwenden.
$ Weitere Hinweise finden Sie unter "PREFETCH-Option" aufSeite 659 der Dokumentation ASA Datenbankadministration.
♦ In Open Client können Sie das PREFETCH-Verhalten mit ct_cursorund CS_CURSOR_ROWS nach der Deklaration, aber vor dem Öffnendes Cursors steuern.
Cursor-Empfindlichkeit und Isolationsstufen
Sowohl Cursor-Empfindlichkeit als auch Isolationsstufen betreffen dasProblem der Parallelität, allerdings auf unterschiedliche Weise.
Prefetch-Funktionen auseiner Anwendungsteuern

Adaptive Server Anywhere-Cursor
46
Indem Sie eine Isolationsstufe für eine Transaktion auswählen (häufig aufder Verbindungsebene), legen Sie fest, wann Sperren auf Zeilen in derDatenbank plaziert werden. Sperren verhindern, dass andere Transaktionenauf die Werte in der Datanbank zugreifen oder sie verändern.
Indem Sie eine Cursor-Empfindlichkeit auswählen legen Sie fest, welcheÄnderungen für die Anwendung, die den Cursor verwendet, sichtbar sind.Indem Sie die Cursor-Empfindlichkeit einstellen legen Sie nicht fest, wannSperren auf Zeilen in der Datenbank gelegt werden, und Sie schränken auchnicht die Änderungen ein, die an der Datenbank selbst durchgeführt werden.

Kapitel 2 SQL in Anwendungen verwenden
47
Ergebnismengen beschreibenEinige Anwendungen bauen SQL-Anweisungen auf, die in der Anwendungnicht ausgeführt werden können. Anweisungen hängen manchmal von einerAntwort des Benutzers ab, sodass die Anwendung erst dann erfährt, welcheDaten abzurufen sind, z.B. wenn eine Berichtsanwendung dem Benutzer dieMöglichkeit gibt, die anzuzeigenden Spalten auszuwählen.
In einem solchen Fall benötigt die Anwendung eine Methode, umInformationen über die Art der Ergebnismenge selbst sowie den Inhalt derErgebnismenge zu erhalten. Die Informationen über die Art derErgebnismenge werden als Deskriptor bezeichnet. Sie identifizieren dieDatenstruktur einschließlich Anzahl und Typ der erwarteten Spalten. Wenndie Anwendung die Art der Ergebnismenge ermittelt hat, ist der Abruf desInhalts ein einfacher Vorgang.
Diese Ergebnismengen-Metadaten (Informationen über Art und Inhalt derDaten) werden mit Hilfe von Deskriptoren bearbeitet. Das Beziehen undVerwalten von Ergebnismengen-Metadaten wird als Beschreibenbezeichnet.
Da Cursor im Allgemeinen Ergebnismengen produzieren, sind Deskriptorenund Cursor eng verknüpft, obwohl manche Schnittstellen die Verwendungvon Deskriptoren vor dem Benutzer verbergen. Normalerweise gilt:Anweisungen, die Deskriptoren benötigen, sind entweder SELECT-Anweisungen oder gespeicherte Prozeduren, die Ergebnismengenzurückgeben.
Ein Deskriptor wird bei einem cursorbasierten Vorgang folgendermaßeneingesetzt:
1 Weisen Sie den Deskriptor zu. Dies kann implizit erfolgen, die expliziteZuweisung ist aber in manchen Schnittstellen zulässig.
2 Bereiten Sie die Anweisung vor.
3 Anweisung beschreiben. Wenn es sich bei der Anweisung um einegespeicherte Prozedur oder um eine Anweisungsfolge handelt und dieErgebnismenge nicht durch eine Ergebnisklausel in derProzedurdefinition definiert wird, sollte die Beschreibung nach demÖffnen des Cursors erscheinen.
4 Deklarieren Sie einen Cursor für die Anweisung und öffnen Sie ihn(Embedded SQL), oder führen Sie die Anweisung aus.
5 Beziehen Sie den Deskriptor und ändern Sie erforderlichenfalls denzugewiesenen Bereich . Dies erfolgt oft implizit.
6 Rufen Sie die Anweisungsergebnisse ab und und verarbeiten Sie sie.

Ergebnismengen beschreiben
48
7 Heben Sie die Zuweisung des Deskriptors auf.
8 Schließen Sie den Cursor.
9 Löschen Sie die Anweisung . Einige Schnittstellen führen diesautomatisch durch.
♦ In Embedded SQL enthält eine SQLDA-(SQL Descriptor Area) Strukturdie Deskriptor-Informationen.
$ Weitere Hinweise finden Sie unter "Der SQL-Deskriptor-Bereich(SQLDA)" auf Seite 228.
♦ In ODBC bietet ein Deskriptor-Handle, durch SQLAllocHandlezugewiesen, den Zugriff auf die Felder eines Deskriptors. Sie könnendiese Felder mit SQLSetDescRec, SQLSetDescField,SQLGetDescRec und SQLGetDescField verarbeiten.
Alternativ können Sie SQLDescribeCol und SQLColAttributesverwenden, um Spalteninformationen zu beziehen.
♦ In Open Client können Sie ct_dynamic für die Vorbereitung einerAnweisung und ct_describe zur Beschreibungder Ergebnismenge derAnweisung verwenden. Sie können aber auch ct_command benutzen,um eine SQL-Anweisung ohne vorherige Vorbereitung zu senden unddann ct_results benutzen, um die zurückgegebenen Zeilen nacheinanderzu verarbeiten. Dies ist die normalerweise benutzte Vorgehensweise beider Open Client-Anwendungsentwicklung.
♦ In JDBC bietet die Klasse java.SQL.ResultSetMetaDataInformationen über Ergebnismengen.
♦ Sie können auch Deskriptoren verwenden, um Daten an die Engine zusenden (z.B. mit der INSERT-Anweisung), aber dies ist eine andere Artvon Deskriptor als für die Ergebnismenge.
$ Weitere Hinweise zu Eingabe- und Ausgabeparametern für dieDESCRIBE-Anweisung finden Sie unter "DESCRIBE-Anweisung[ESQL]" auf Seite 426 der Dokumentation ASA SQL-Referenzhandbuch.
Hinweise zurImplementierung

Kapitel 2 SQL in Anwendungen verwenden
49
Transaktionen in Anwendungen steuernTransaktionen sind Zusammenstellungen einzelner SQL-Anweisungen.Entweder werden alle Anweisungen in der Transaktion ausgeführt oderkeine. In diesem Abschnitt werden einige Aspekte der Transaktionen inAnwendungen behandelt.
$ Weitere Hinweise zu Transaktionen entnehmen Sie dem Kapitel"Transaktionen und Isolationsstufen verwenden" auf Seite 99 derDokumentation ASA SQL-Benutzerhandbuch.
Automatisch oder manuell festschreiben
Datenbank-Programmierschnittstellen können entweder im manuellenFestschreibemodus (manual commit) oder im automatischenFestschreibemodus (autocommit) operieren.
♦ Manueller Festschreibemodus (manual commit) Operationen werdennur festgeschrieben, wenn Ihre Anwendung eine expliziteFestschreibungsoperation durchführt oder der Datenbankserver eineautomatische Festschreibung vollzieht, wie zum Beispiel beimAusführen einer ALTER TABLE-Anweisung oder andererDatendefinitionsanweisungen. Der manuelle Festschreibungsmoduswird manchmal auch verketteter Modus genannt.
Um in Ihren Anwendungen Transaktionen wie verschachtelteTransaktionen und Savepoints verwenden zu können, müssen Sie immanuellen Festschreibemodus operieren.
♦ Automatischer Festschreibemodus (autocommit) Jede Anweisungwird wie eine separate Transaktion behandelt. Die Wirkung ist dieselbe,wie wenn Sie eine COMMIT-Anweisung an das Ende jedes IhrerBefehle anhängen. Der automatische Festschreibungsmodus wirdmanchmal auch unverketteter Modus genannt.
Dieser Modus kann sich auf die Performance und das Verhalten IhrerAnwendung auswirken. Verwenden Sie ihn nicht, wenn Ihre AnwendungTransaktionsintegrität erfordert.
$ Hinweise über die Auswirkungen von AUTOCOMMIT auf diePerformance finden Sie unter "Autocommit-Modus ausschalten" aufSeite 166 der Dokumentation ASA SQL-Benutzerhandbuch.

Transaktionen in Anwendungen steuern
50
AUTOCOMMIT-Verhalten steuern
Wie Sie das Festschreibungsverhalten Ihrer Anwendung steuern hängt vonder verwendeten Programmierschnittstelle ab. Die Implementierung vonAUTOCOMMIT kann, abhängig von der Schnittstelle, clientseitig oderserverseitig stattfinden.
$ Weitere Hinweise finden Sie unter "Die AUTOCOMMIT-Implementierung" auf Seite 51.
v So steuern Sie den AUTOCOMMIT-Modus (ODBC):
♦ Standardmäßig arbeitet ODBC im AUTOCOMMIT-Modus. Die Art,wie Sie AUTOCOMMIT ausschalten, hängt davon ab, ob Sie ODBCdirekt verwenden, oder ein Anwendungsentwicklungstool einsetzen.Wenn Sie direkt über die ODBC-Schnittstelle programmieren, stellenSie das SQL_ATTR_AUTOCOMMIT-Verbindungsattribut ein.
v So steuern Sie den AUTOCOMMIT-Modus (JDBC):
♦ Standardmäßig arbeitet JDBC im AUTOCOMMIT-Modus. UmAUTOCOMMIT auszuschalten, verwenden Sie die setAutoCommit-Methode des Verbindungsobjekts:
conn.setAutoCommit( false );
v So steuern Sie den AUTOCOMMIT-Modus (Open Client):
♦ Standardmäßig operiert eine Verbindung, die durch Open Clienthergestellt wird, im AUTOCOMMIT-Modus. Sie können diesesVerhalten ändern, indem Sie die Datenbankoption CHAINED in IhrerAnwendung auf ON setzen, indem Sie eine Anweisung wie dieFolgende verwenden:
SET OPTION CHAINED=’ON’
v So steuern Sie den AUTOCOMMIT-Modus (Embedded SQL):
♦ Standardmäßig operieren Embedded SQL-Anwendungen im manuellenFestschreibemodus. Um AUTOCOMMIT einzuschalten, stellen Sie dieCHAINED-Datenbankoption auf OFF ein, indem Sie eine Anweisungwie die Folgende verwenden:
SET OPTION CHAINED=’OFF’

Kapitel 2 SQL in Anwendungen verwenden
51
Die AUTOCOMMIT-Implementierung
Der vorherige Abschnitt, "AUTOCOMMIT-Verhalten steuern" auf Seite 50,beschreibt, wie das AUTOCOMMIT-Verhalten von den einzelnen AdaptiveServer Anywhere-Programmierschnittstellen gesteuert werden kann.Abhängig von der verwendeten Schnittstelle und davon, wie Sie dasAUTOCOMMIT-Verhalten steuern, verhält sich der AUTOCOMMIT-Modus leicht unterschiedlich.
Der AUTOCOMMIT-Modus kann auf zwei Arten implementiert werden:
♦ Clientseitiges AUTOCOMMIT Wenn eine Anwendung AUTOCOMMITverwendet, sendet die Clientbibliothek eine COMMIT-Anweisung nachjeder ausgeführten SQL-Anweisung.
Adaptive Server Anywhere verwendet clientseitiges AUTOCOMMITfür ODBC- und OLE DB-Anwendungen.
♦ Serverseitiges AUTOCOMMIT Wenn eine AnwendungAUTOCOMMIT verwendet, gibt der Datenbankserver nach jeder SQL-Anweisung ein COMMIT aus. Dieses Verhalten wird, im Fall von JDBCimplizit, durch die CHAINED-Datenbankoption gesteuert.
Adaptive Server Anywhere verwendet serverseitiges AUTOCOMMITfür Embedded SQL-, JDBC- und Open Client-Anwendungen.
Es gibt einen Unterschied zwischen clientseitigem und serverseitigemAUTOCOMMIT im Fall von zusammengesetzten Anweisungen wiegespeicherten Prozeduren und Triggern. Für den Client ist eine gespeicherteProzedur eine einzelne Anweisung, und daher sendet AUTOCOMMIT eineeinzelne COMMIT-Anweisung, nachdem die gesamte Prozedur ausgeführtwurde. Aus der Perspektive des Datenbankservers kann die gespeicherteProzedur aus vielen SQL-Anweisungen bestehen, und daher gibt einserverseitiges AUTOCOMMIT ein COMMIT nach jeder SQL-Anweisunginnerhalb der Prozedur aus.
Clientseitige und serverseitige Implementierungen nichtvermischenSie sollten in Ihrer ODBC- oder OLE DB-Anwendung die Verwendungder CHAINED-Option nicht mit AUTOCOMMIT kombinieren.
Isolationsstufe steuern
Sie können die Isolationsstufe einer aktuellen Verbindung mit derDatenbankoption ISOLATION_LEVEL einstellen.

Transaktionen in Anwendungen steuern
52
Einige Schnittstellen, wie ODBC, ermöglichen das Setzen der Isolationsstufefür eine Verbindung beim Aufbau. Diese Isolationsstufe kann später mit derDatenbankoption ISOLATION_LEVEL zurückgesetzt werden.
Cursor und Transaktionen
Im Allgemeinen wird ein Cursor geschlossen, wenn ein COMMITausgeführt wird. Es gibt zwei Ausnahmen für dieses Verhalten.
♦ Die Datenbankoption CLOSE_ON_ENDTRANS ist auf OFF gesetzt.
♦ Ein Cursor wird mit WITH HOLD geöffnet, was der Standard bei OpenClient und JDBC ist.
Trifft einer dieser beiden Fälle zu, bleibt der Cursor bei COMMIT geöffnet.
Beim Zurücksetzen einer Transaktion wird der Cursor geschlossen, außerwenn er mit WITH HOLD geöffnet wurde. Dem Inhalt eines Cursors könnenSie nach einem Zurücksetzen nicht vertrauen.
Der projektierte ISO SQL3-Standard legt fest, dass bei einem Zurücksetzenalle Cursor geschlossen werden sollen. Sie können dieses Verhaltenerzwingen, indem Sie die OptionANSI_CLOSE_CURSORS_AT_ROLLBACK auf ON setzen.
Wenn eine Transaktion bis zu einem Savepoint zurückgesetzt wird undANSI_CLOSE_CURSORS_AT_ROLLBACK auf ON gesetzt ist, wird jedernach dem SAVEPOINT geöffnete Cursor geschlossen (sogar die Cursor, diemit WITH HOLD geöffnet wurden).
Sie können die Isolationsstufe für eine Verbindung während einerTransaktion setzen, indem Sie die Anweisung SET OPTION verwenden, umdie Option ISOLATION_LEVEL zu ändern. Diese Änderung wirkt sichjedoch nur auf geschlossene Cursor aus.
ROLLBACK undCursor
Savepoints
Cursor undIsolationsstufe

53
K A P I T E L 3
Einführung in Java für Datenbanken
In diesem Kapitel wird erklärt, warum es sinnvoll ist, Java in einerDatenbank zu verwenden.
Der Adaptive Server Anywhere ist eine Laufzeit-Umgebung für Java. Javabietet eine natürliche Erweiterung für SQL und verwandelt Adaptive ServerAnywhere in eine Plattform für Unternehmensanwendungen der nächstenGeneration.
Thema Seite
Einleitung 54
Fragen und Antworten zu Java in der Datenbank 57
Ein Java-Seminar 64
Die Laufzeitumgebung für Java in der Datenbank 75
Praktische Einführung: Eine Übung mit Java in der Datenbank 84
Über diesesKapitel
Inhalt

Einleitung
54
EinleitungAdaptive Server Anywhere ist eine Laufzeit-Umgebung für Java. Dasbedeutet, dass Java-Klassen im Datenbankserver ausgeführt werden können.Durch die Integration einer Laufzeit-Umgebung für Java-Klassen in denDatenbankserver werden neue, vielfältige Wege für die Verwaltung undSpeicherung von Daten und Logik eröffnet.
Java in der Datenbank bietet folgende Möglichkeiten:
♦ Sie können Java-Komponenten in den verschiedenen Schichten IhrerAnwendung verwenden (Client, mittlere Schicht oder Server) undüberall einsetzen, wo es für Sie am sinnvollsten ist. Adaptive ServerAnywhere wird damit zu einer Plattform für verteilteInformationsverarbeitung.
♦ Java bietet mehr Möglichkeiten als gespeicherte Prozeduren für dieIntegration von Logik in die Datenbank.
♦ Java-Klassen werden zu reichhaltigen, benutzerdefinierten Datentypen.
♦ Die Methoden der Java-Klassen bieten neue Funktionen für den Zugriffaus SQL.
♦ Java kann in der Datenbank benutzt werden, ohne dass die Integrität, dieSicherheit und die Robustheit der Datenbank verletzt werden.
Java in der Datenbank ist eine Komponente, die separat lizenziert werdenkann und vor der Installation bestellt werden muss. Die Bestellung kann mitder betreffenden Karte im SQL Anywhere Studio-Paket oder überhttp://www.sybase.com/detail?id=1015780 erfolgen.
Java in der Datenbank basiert auf den vorgeschlagenen Standards SQLJ Part1 und SQLJ Part 2. SQLJ Part 1 liefert Spezifikationen zum Aufrufen vonstatischen Java-Methoden als gespeicherte SQL-Prozeduren undbenutzerdefinierte Funktionen. SQLJ Part 2 bietet Spezifikationen für denEinsatz von Java-Klassen als in SQL geschriebene benutzerdefinierteDatentypen.
Hinweise zu Java in der Datenbank
Java ist eine relativ neue Programmiersprache, mit einer wachsenden, aberimmer noch limitierten Wissensbasis. Diese Dokumentation wurde für einbreites Spektrum von Java-Entwicklern geschrieben und unterstützt daheralle, von erfahrenen Entwicklern bis zu fachlich nicht vorgebildeten Lesern,die die Sprache, ihre Möglichkeiten, ihre Syntax und ihreEinsatzmöglichkeiten nicht kennen.
GetrenntlizenzierbareKomponente
Der SQLJ-Standard

Kapitel 3 Einführung in Java für Datenbanken
55
Leser, für die Java nichts Neues mehr ist, finden in diesem Kapitel wertvolleHinweise für den Einsatz von Java in einer Datenbank. Adaptive ServerAnywhere erweitert nicht nur die Möglichkeiten der Datenbank mit Java,sondern auch die Möglichkeiten von Java mit der Datenbank.
In der nachstehenden Tabelle finden Sie Hinweise zur Dokumentation zumThema Java in der Datenbank.
Titel Verwendung
"Einführung in Java fürDatenbanken" auf Seite 53(dieses Kapitel)
Java-Konzepte und Anwendungsmethoden inAdaptive Server Anywhere
"Java in der Datenbankbenutzen" auf Seite 93
Praktische Anleitung zum Einsatz von Java inder Datenbank
"Datenzugriff über JDBC" aufSeite 143
Zugriff auf Daten aus Java-Klassen,einschließlich verteilterInformationsverarbeitung
"Fehlersuche in derDatenbanklogik" aufSeite 635 der DokumentationASA SQL-Benutzerhandbuch
Testen und Fehlersuche von Java-Code für denEinsatz in der Datenbank
Adaptive Server AnywhereReferenzhandbuch
Das Referenzhandbuch enthält Informationenzu den SQL-Erweiterungen, die Java in derDatenbank unterstützen.
Referenzhandbuch für dieJava API von Sun
Online-Handbuch für Java API-Klassen, Felderund Methoden. Nur als Windows-Hilfedateiverfügbar.
Thinking in Java Thinking inJava by Bruce Eckel.
Online-Buch, mit dem man das Programmierenin Java lernen kann. Es wird im Adobe PDFFormat im UnterverzeichnisSamples\ASA\Java des Adaptive ServerAnywhere-Installationsverzeichnissesbereitgestellt.
Java-Dokumentation benutzen
Die folgende Tabelle ist ein Wegweiser für die Java-Dokumentationen, dieSie je nach Ihren Interessen und Vorkenntnissen benutzen können. DieTabelle ist nur als Richtlinie gedacht und soll Ihre Bemühungen, mehr überJava in der Datenbank zu lernen, unterstützen.
Java-Dokumentation

Einleitung
56
Gesuchtes Thema Textstelle
Sie benötigen eine Einführung inobjektorientiertes Programmieren
"Ein Java-Seminar" auf Seite 64
Thinking in Java von Bruce Eckel.
Sie benötigen eine Erklärung vonThemen wie instanziert, Feld undKlassenmethode.
"Ein Java-Seminar" auf Seite 64
Sie sind ein Java-Entwickler, der gleichmit der praktischen Arbeit beginnen will.
"Die Laufzeitumgebung für Java inder Datenbank" auf Seite 75
"Praktische Einführung: Eine Übungmit Java in der Datenbank" aufSeite 84
Sie wollen die Hauptmerkmale von Javain der Datenbank kennen lernen.
"Fragen und Antworten zu Java in derDatenbank" auf Seite 57
Sie wollen herausfinden, wie der Zugriffauf Daten aus Java erfolgt.
"Datenzugriff über JDBC" aufSeite 143
Sie wollen eine Datenbank für Javavorbereiten.
"Datenbank für Java aktivieren" aufSeite 97
Sie brauchen eine komplette Liste derunterstützten Java APIs.
"Java-Klassen-Datentypen" aufSeite 86 der Dokumentation ASASQL-Referenzhandbuch
Sie versuchen, eine Java API-Klasse zuverwenden und benötigen Java-Referenzinformationen.
Online-Handbuch für Java API-Klassen, Felder und Methoden (nurals Windows-Online-Hilfe)
Sie wollen ein Beispiel für verteilteInformationsverarbeitung sehen.
"Verteilte Anwendungen erstellen"auf Seite 174

Kapitel 3 Einführung in Java für Datenbanken
57
Fragen und Antworten zu Java in der DatenbankIn diesem Abschnitt werden die Hauptmerkmale von Java in der Datenbankbeschrieben.
Die wichtigsten Funktionen von Java in der Datenbank
Detaillierte Erläuterungen aller nachstehenden Punkte sind in den folgendenAbschnitten zu finden.
♦ Sie können Java auf dem Datenbankserver ausführen Eine interneJava Virtual Machine (VM) führt den Java-Code auf demDatenbankserver aus.
♦ Sie können Java aus SQL aufrufen Sie können Java-Funktionen(Methoden) aus SQL-Anweisungen ausführen. Java-Methoden bieteneine leistungsfähigere Sprache als in SQL geschriebene gespeicherteProzeduren, wenn Sie Ihrer Datenbank logische Elemente hinzufügenwollen.
♦ Sie können aus Java auf Daten zugreifen Ein interner JDBC-Treiberermöglicht den Zugriff auf Daten aus Java.
♦ Sie können die Fehlersuche für Java in der Datenbank vornehmenSie können den Sybase Java Debugger verwenden, um Ihre Java-Klassen in der Datenbank zu testen und auf Fehler zu durchsuchen.
♦ Sie können Java-Klassen als Datentypen verwenden Jede in einerDatenbank installierte Java-Klasse wird als Datentyp verfügbar, der füreine Spalte in einer Tabelle oder einer Variablen verwendet werdenkann.
♦ Sie können Java-Objekte in Tabellen speichern Eine Instanz einerJava-Klasse (ein Java-Objekt) kann als Wert in einer Tabelle gespeichertwerden. Java-Objekte können in eine Tabelle eingefügt, SELECT-Anweisungen in den Feldern und Methoden von in Tabellengespeicherten Objekten ausgeführt, und Java-Objekte aus einer Tabelleabgerufen werden.
Mit diesen Möglichkeiten wird Adaptive Server Anywhere zu einerobjekt-relationalen Datenbank, die Objekte unterstützt, gleichzeitig aberdie bestehenden relationalen Funktionen nicht beeinträchtigt.
♦ SQL wird bewahrt Der Einsatz von Java ändert das Verhaltenbestehender SQL-Anweisungen oder andere Aspekte des nicht mit Javaverbundenen Verhaltens der relationalen Datenbank nicht.

Fragen und Antworten zu Java in der Datenbank
58
Java-Instruktionen in der Datenbank speichern
Java ist eine objektorientierte Sprache, ihre Anweisungen (Quellcode)werden daher in Form von Klassen geliefert. Um Java in einer Datenbankauszuführen, schreiben Sie die Java-Instruktionen außerhalb der Datenbankin kompilierte Klassen (Bytecode), bei denen es sich um Binärdateien mitJava-Instruktionen handelt.
Sie installieren diese kompilierten Klassen dann in einer Datenbank. Nachder Installation können Sie diese Klassen im Datenbankserver ausführen.
Adaptive Server Anywhere ist eine Laufzeit-Umgebung für Java-Klassen,keine Java-Entwicklungsumgebung. Sie brauchen eine Java-Entwicklungsumgebung, wie Sybase PowerJ oder Java Development Kit vonSun Microsystems, um Java-Codes zu schreiben und zu kompilieren.
$ Weitere Hinweise finden Sie unter "Java-Klassen in einer Datenbankinstallieren" auf Seite 103.
Java in einer Datenbank ausführen
Adaptive Server Anywhere enthält eine Java Virtual Machine (VM), die inder Datenbankumgebung läuft. Die Sybase Java VM interpretiert kompilierteJava-Instruktionen und führt sie im Datenbankserver aus.
Zusätzlich zur VM wurde der SQL-Abfrageprozessor im Datenbankservererweitert, so dass er in der VM Aufrufe durchführen kann, um Java-Instruktionen auszuführen. Er kann auch Abfragen von der VM verarbeiten,um den Datenzugriff aus Java zu aktivieren.
Es gibt einen Unterschied zwischen dem Ausführen von Java-Codes miteiner Standard-VM wie Sun Java VM java.exe und dem Ausführen vonJava-Codes in einer Datenbank. Die Sun VM wird von einer Befehlszeile ausgestartet, während die Java VM von Adaptive Server Anywhere jederzeitverfügbar ist, um einen Java-Vorgang auszuführen, wenn dies als Teil derAusführung einer SQL-Anweisung erforderlich ist.
Auf den Sybase Java-Interpreter können Sie extern nicht zugreifen. Er wirdnur benutzt, wenn die Ausführung einer SQL-Anweisung einen Java-Vorgang erforderlich macht. Der Datenbankserver startet die VMautomatisch, wenn sie benötigt wird: Sie brauchen keine ausdrücklichenBedienungsmaßnahmen auszuführen, um die VM zu starten oder zu stoppen.
Unterschiede zueiner eigen-ständigen VM

Kapitel 3 Einführung in Java für Datenbanken
59
Vorteile von Java
Java bietet eine Reihe von Merkmalen, die für den Einsatz in Datenbankenbesonders gut geeignet sind:
♦ Präzise Fehlerprüfung bei der Kompilierung
♦ Integrierte Fehlerbehandlung mit einer gut definierten Methode für dieFehlerbehandlung
♦ Integrierte Sammlung von Abfalldaten (Speicher wird freigesetzt)
♦ Eliminierung vieler fehleranfälliger Programmiertechniken
♦ Leistungsfähige Sicherheitsfunktionen
♦ Java-Code wird interpretiert, daher werden keine Vorgänge ausgeführt,die von der VM nicht akzeptiert werden
Plattformen, die Java in der Datenbank unterstützen
Java in der Datenbank wird auf Windows CE nicht unterstützt. Wohl aberunter Windows-Betriebssystemen, UNIX und NetWare.
Java und SQL zusammen einsetzen
Ein Grundsatz für das Konzept von Java in der Datenbank besteht darin, dassdamit eine natürliche, offene Erweiterung für bestehende SQL-Funktionengegeben ist.
♦ Java-Vorgänge werden aus SQL aufgerufen Sybase hat den Bereichder SQL-Ausdrücke erweitert, sodass Eigenschaften und Methoden vonJava-Objekten einbezogen werden können und damit der Einbau vonJava-Vorgängen in eine SQL-Anweisung möglich ist.
♦ Java-Klassen werden Domänen Sie speichern Java-Klassen mitdenselben SQL-Anweisungen wie für normale SQL-Datentypen.
Sie können viele der Klassen verwenden, die Teil der Java API sind, so wiesie mit dem Java Development Kit von Sun Microsystems geliefert werden.Sie können auch Klassen verwenden, die von Java-Entwicklern erstellt undkompiliert wurden.

Fragen und Antworten zu Java in der Datenbank
60
Beschreibung der Java API
Die Java-Programmierschnittstelle (Java Application Programmer’sInterface, API) ist eine Gruppe von Klassen, die von Sun Microsystemserstellt wurde. Sie bietet eine Reihe von Basisfunktionen, die von Java-Entwicklern benutzt und erweitert werden können. Sie bilden den Kern allerEinsatzmöglichkeiten von Java.
Die Java API bietet aus sich heraus zahlreiche Möglichkeiten undFunktionen. Ein Großteil der Java API kann in jede Datenbank integriertwerden, die für die Arbeit mit Java-Programmcode eingerichtet wurde. Dazugehört die Mehrzahl der nicht-visuellen Klassen aus der Java API, dieEntwicklern, welche schon mit dem Java Development Kit (JDK) von SunMicrosystems arbeiten, bekannt sein dürften.
$ Weitere Hinweise über unterstützte Java-APIs finden Sie unter"Unterstützte Java-Pakete" auf Seite 87 der Dokumentation ASA SQL-Referenzhandbuch.
Zugriff auf Java aus SQL
Die Java API kann nicht nur in Klassen verwendet werden, sondern auch ingespeicherten Prozeduren und SQL-Anweisungen. Sie können die Java API-Klassen als Erweiterungen zu den verfügbaren Funktionen behandeln, dievon SQL zur Verfügung gestellt werden.
Beispiel: Die SQL-Funktion PI(*) gibt den Wert für pi zurück. Die Java API-Klasse java.lang.Math hat ein paralleles Feld namens PI, das denselbenWert zurückgibt. Die Klasse java.lang.Math hat aber auch ein Feld namensE, das die Basis von natürlichen Logarithmen zurückgibt, sowie eineMethode, die die Restoperation auf zwei Argumente gemäß dem StandardIEEE 754 durchführt.
Andere Bestandteile der Java API bieten weitere, zusätzliche Möglichkeiten.Beispiel: java.util.Stack generiert eine Warteschlange nach dem Last-In-First-Out-Prinzip, die eine Liste sortiert speichern kann,java.util.HashTable wird benutzt, um Werte Schlüsseln zuzuordnen,java.util.StringTokenizer unterteilt eine Zeichenfolge in einzelneWorteinheiten.
$ Weitere Hinweise finden Sie unter "Java-Objekte einfügen,aktualisieren und löschen" auf Seite 111.

Kapitel 3 Einführung in Java für Datenbanken
61
Unterstützte Java-Klassen
Die Datenbank unterstützt nicht alle Java API-Klassen. Einige Klassen,beispielsweise das Paket java.awt, das Bestandteile der Benutzerschnittstellefür Anwendungen enthält, ist in einem Datenbankserver nicht sinnvoll.Andere Klassen, einschließlich Teile der Klasse java.io, übernehmenSchreibfunktionen auf der Festplatte, was in einer Datenbankserver-Umgebung ebenfalls nicht unterstützt wird.
$ Weitere Hinweise über unterstützte und nicht unterstützte Klassenfinden Sie unter "Unterstützte Java-Pakete" auf Seite 87 der DokumentationASA SQL-Referenzhandbuch und "Nicht-unterstützte Java-Pakete undKlassen" auf Seite 88 der Dokumentation ASA SQL-Referenzhandbuch.
Eigene Java-Klassen in Datenbanken einsetzen
Sie können Ihre eigenen Java-Klassen in einer Datenbank installieren.Beispiel: Ein Entwickler könnte die benutzerdefinierte Klasse "Mitarbeiter"oder "Verpackung" konzipieren, in Java schreiben und mit einem Java-Compiler kompilieren.
Von einem Benutzer erstellte Java-Klassen können Informationen über denGegenstand der Klasse und Rechnerlogik enthalten. Nachdem sie in einerDatenbank installiert wurden, stellt Adaptive Server Anywhere diese Klassenin allen Teilen und Vorgängen der Datenbank zur Verfügung und führt ihreFunktionen (in der Form von Klassen- oder Instanzenmethoden) genausoschnell und einfach aus wie gespeicherte Prozeduren.
Java-Klassen und gespeicherte Prozeduren unterscheiden sichJava-Klassen unterscheiden sich von gespeicherten Prozeduren. Währendgespeicherte Prozeduren in SQL geschrieben sind, bieten Java-Klasseneine leistungsfähigere Sprache und können aus Clientanwendungen genauso leicht aufgerufen werden wie gespeicherte Prozeduren.
Wenn eine Java-Klasse in einer Datenbank installiert wird, steht sie als neueDomäne zur Verfügung. Eine Java-Klasse kann in jeder Situation verwendetwerden, in der integrierte SQL-Datentypen benutzt werden können: AlsSpaltentyp in einer Tabelle oder als Variablentyp.
Beispiel: Wenn eine Klasse namens Adresse in einer Datenbank installiertwurde, kann eine Spalte in einer Tabelle namens Adr den Typ Adressehaben, was bedeutet, dass nur auf der Klasse Adresse basierende Objekte alsZeilenwerte für diese Spalte gespeichert werden können.
$ Weitere Hinweise finden Sie unter "Java-Klassen in einer Datenbankinstallieren" auf Seite 103.

Fragen und Antworten zu Java in der Datenbank
62
Mit Java auf Daten zugreifen
Die JDBC-Schnittstelle ist ein Industriestandard, der speziell für den Zugriffauf Datenbanksysteme entwickelt wurde. Die JDBC-Klassen sollen folgendeAufgaben ermöglichen: Verbindung mit einer Datenbank, Anforderung vonDaten mit SQL-Anweisungen und Rücklieferung von Ergebnismengen, diein der Clientanwendung verarbeitet werden können.
Normalerweise werden die JDBC-Klassen von einer Clientanwendungverwendet, und der Datenbank-Systemlieferant stellt einen JDBC-Treiber zurVerfügung, mit dem JDBC-Klassen eine Verbindung herstellen können.
Sie können sich aus einer Clientanwendung mit Adaptive Server Anywhereüber JDBC verbinden, indem Sie jConnect oder eine JDBC/ODBC-Brückebenutzen. Adaptive Server Anywhere bietet auch einen internen JDBC-Treiber, der es in einer Datenbank installierten Java-Klassen ermöglicht,JDBC-Klassen zu verwenden, die SQL-Anweisungen ausführen.
$ Weitere Hinweise finden Sie unter "Datenzugriff über JDBC" aufSeite 143.
Klassen vom Client auf einen Server verschieben
Sie können Java-Klassen erstellen, die zwischen verschiedenen Ebenen einerUnternehmensanwendung verschoben werden können. Dieselbe Java-Klassekann in die Clientanwendung, eine mittlere Schicht oder die Datenbankintegriert werden - also an der Stelle, an der sie am sinnvollsten eingesetztwerden kann.
Eine Klasse, die Geschäftslogik, Daten oder eine Kombination von beidenenthält, kann auf jede Ebene des Unternehmenssystems, auch auf den Server,verschoben werden, so dass Sie die vorhandenen Ressourcen optimaleinsetzen können. Die Betreiber von unternehmensweiten Systemen könnendaher mit einer einzigen Programmiersprache in einer mehrschichtigenArchitektur mit bisher nie gekannter Flexibilität eigene Anwendungenentwickeln.
Verteilte Anwendungen erstellen
Sie können eine Anwendung erstellen, bei der einige Teile in der Datenbankarbeiten, andere auf dem Client-System. Sie können Java-Objekte vomServer an den Client übergeben und umgekehrt, genauso wie Sie SQL-Datenwie Zeichendaten und numerische Werte übergeben können.
$ Weitere Hinweise finden Sie unter "Verteilte Anwendungen erstellen"auf Seite 174.

Kapitel 3 Einführung in Java für Datenbanken
63
Einschränkungen für Java in der Datenbank
Adaptive Server Anywhere ist eine Laufzeit-Umgebung für Java-Klassen,keine Java-Entwicklungsumgebung.
Sie können folgende Aufgaben in einer Datenbank nicht durchführen:
♦ Klasse-Quelldaten bearbeiten (*.java-Dateien).
♦ Java-Klassen-Quelldateien kompilieren (*.java-Dateien).
♦ Java APIs ausführen, die nicht unterstützt werden, wie z.B. Applets undvisuelle Klassen
♦ Java-Methoden ausführen, die die Ausführung nativer Methodenvoraussetzen. Alle Benutzerklassen, die in einer Datenbank installiertsind, müssen 100% Java sein.
Die in Adaptive Server Anywhere benutzten Klassen müssen mit einemJava-Entwicklungstool geschrieben und kompiliert werden. Danach werdensie in einer Datenbank installiert, um dort getestet, auf Fehler geprüft undvom Endbenutzer benutzt zu werden.

Ein Java-Seminar
64
Ein Java-SeminarIn diesem Abschnitt werden die wichtigsten Java-Konzepte vorgestellt.Nachdem Sie sich diesen Abschnitt durchgelesen haben, sollten Sie in derLage sein, Java-Code zu prüfen, wie z.B. einfache Klassendefinitionen oderden Aufruf einer Methode, bzw. gegebenenfalls verstehen, warum etwaigeProbleme auftreten.
Java-BeispielverzeichnisAlle Klassen, die als Beispiele in diesem Dokument verwendet werden,sind im Verzeichnis mit den Java-Beispielen zu finden, nämlich imUnterverzeichnis Samples\ASA\Java zum Verzeichnis von AdaptiveServer Anywhere.
Zwei Dateien stehen für jedes Java-Klassen-Beispiel: Java-Quellcode undkompilierte Klasse. Sie können die kompilierte Version der Beispiele vonJava-Klassen in einer Datenbank sofort und ohne Änderung installieren.
Erklärung von Java-Klassen
Eine Java-Klasse kombiniert Daten und Funktionen: Die Möglichkeit zurSpeicherung von Informationen und die Fähigkeit zur Durchführung vonRechenvorgängen. Eine Klasse kann man als eine Entität, also eine abstrakteDarstellung von Dingen sehen.
Eine "Rechnungsklasse” könnte beispielsweise so entworfen werden, dasssie eine normale Rechnung imitiert, wie sie im täglichen Geschäftsverkehrverwendet wird. Eine Rechnung enthält bestimmte Informationen (z.B. dieverrechneten Artikel, die Rechnungsadresse, Rechnungsdatum, Zahlbetragund Fälligkeit) - dasselbe gilt für die Instanz einer Rechnungsklasse. Klassenspeichern Daten in Feldern.
Eine Klasse beschreibt nicht nur Daten, sondern kann auch Berechnungenvornehmen und logische Vorgänge durchführen. Die Rechnungsklassekönnte beispielsweise die Steuer für eine Liste von Rechnungsposten fürjedes Rechnungsobjekt errechnen und der Zwischensumme hinzufügen, umdamit die Gesamtrechnungssumme auszuwerfen, ohne dass ein Eingriff desBenutzers erforderlich wäre. Eine solche Klasse würde auch dafür sorgen,dass alle benötigten Informationselemente in die Rechnung eingefügtwerden, und könnte sogar automatisch anzeigen, ob die Zahlung fällig istoder schon teilweise geleistet wurde. Berechnungen und andere logischeVorgänge werden durch die Methoden einer Klasse ausgeführt.

Kapitel 3 Einführung in Java für Datenbanken
65
Der folgende Java-Code deklariert eine Klasse namens "Invoice". DieseKlassendeklaration würde in einer Datei namens Invoice.java gespeichert unddann mit einem Java-Compiler in eine Java-Klasse kompiliert.
Java-Klassen kompilierenBeim Kompilieren des Quellcodes für eine Java-Klasse wird eine neueDatei mit demselben Namen wie die Quelldatei erzeugt, jedoch mit eineranderen Erweiterung. Durch das Kompilieren von Invoice.java wird dabeieine Datei namens Invoice.class erstellt, die in einer Java-Anwendungverwendet und durch eine Java VM ausgeführt werden kann.
Das Sun JDK Tool für das Kompilieren der Klassendeklarationen istjavac.exe.
public class Invoice { // Bis jetzt kann diese Klasse nichts und hat auchkeine Daten}
Auf das Schlüsselwort class folgt der Name der Klasse. Es gibt einegeöffnete und eine geschlossene geschweifte Klammer. Alles, wasdazwischen liegt, also z.B. Felder und Methoden, wird zu einem Teil derKlasse.
Grundsätzlich gibt es keinen Java-Code außerhalb von Klassen. Sogar dieJava-Prozedur, die von einem Java-Interpreter automatisch ausgeführt wird,um andere Objekte zu erstellen - die Hauptmethode (main), die oft derBeginn Ihrer Anwendung ist - befindet sich selbst wieder innerhalb einerKlassendeklaration.
Unterklassen in Java
Sie können Klassen als Unterklassen (subclasses) anderer Klassendefinieren. Eine Klasse, die als Unterklasse einer anderen Klasse fungiert,kann die Felder und Methoden ihrer übergeordneten Klasse verwenden: Dieswird als Vererbung bezeichnet. Sie können zusätzliche Methoden undFelder definieren, die nur für die Unterklasse gelten, und die Bedeutung dergeerbten Felder und Methoden verändern.
Java ist eine Programmiersprache mit einer Einzelhierarchie. Das bedeutet,dass alle Klassen, die Sie erstellen oder benutzen, von einer Klasse erben.Das bedeutet weiterhin, dass die Klassen der niedrigsten Ebene (also in derHierarchie weiter oben angesiedelt) vorhanden sein müssen, bevor Klassender oberen Ebene benutzt werden können. Die Basisgruppe dererforderlichen Klassen für Java-Anwendungen wird als Laufzeit-Java-Klassen oder Java-API bezeichnet.
Beispiel

Ein Java-Seminar
66
Erklärung der Java-Objekte
Eine Klasse definiert, was ein Objekt tun kann, genauso wie einRechnungsformular festlegt, welche Informationen die Rechnung enthaltensollte.
Klassen enthalten keine spezifischen Informationen über Objekte. Vielmehrerstellt oder instanziert Ihre Anwendung Objekte auf Grundlage der Klasse(Vorlage), und die Objekte enthalten die Daten bzw. führen Berechnungenaus. Das instanzierte Objekt ist eine Instanz der Klasse. Beispiel: EinRechungsobjekt ist eine Instanz der Rechnungsklasse. Die Klasse definiert,was das Objekt leisten kann, aber das Objekt ist die Verwirklichung derKlasse, die erst Sinn und praktische Verwendbarkeit der Klasse ermöglicht.
Im Beispiel mit dem Rechnungsformular definiert es, was alle Rechnungenenthalten müssen, die auf diesem Rechnungsformular aufgebaut werden. Esgibt ein Formular und 0 bis unendlich viele Rechnungen, die aufgrund diesesFormulars erstellt werden. Das Formular enthält die Definition, aber dieRechnung beinhaltet dann den tatsächlichen Nutzen.
Das Rechnungsobjekt, das aus der Klasse erstellt wird, enthält die Daten,wird gespeichert, abgerufen, bearbeitet, und so weiter.
Genauso wie ein Rechnungsformular verwendet wird, um viele Rechnungenzu erstellen, wobei jede Rechnung in den Details von jeder anderenRechnung abweicht, so können aus einer Klasse viele Objekte abgeleitetwerden.
Eine Methode ist der Teil einer Klasse, der Arbeit leistet, eine Funktion, diefür die Klasse eine Berechnung durchführt oder mit anderen Objekteninteragiert. Methoden können Argumente aufnehmen und einen Wert an dieaufrufende Funktion zurückgeben. Wenn kein Rückgabewert benötigt wird,kann eine Methode void (leer) zurückgegeben werden. Klassen können jedebeliebige Anzahl von Methoden haben.
Ein Feld ist Teil einer Klasse, das Informationen enthält. Wenn ein Objektdes Typs JavaClass erstellt wird, enthalten die Felder in der JavaClass einenausschließlich für dieses Objekt bestimmten Zustand.
Klassenkonstruktoren
Sie erstellen ein Objekt, indem Sie einen Klassen-Konstruktor aufrufen. EinKonstruktor ist eine Methode mit den folgenden Eigenschaften:
♦ Eine Konstruktormethode hat denselben Namen wie die Klasse undkeinen deklarierten Datentyp. Beispiel: Ein einfacher Konstruktor fürdie Klasse "Produkt" würde wie folgt deklariert werden:
Produkt () {
Methoden undFelder

Kapitel 3 Einführung in Java für Datenbanken
67
...Konstruktorcode wird hier eingegeben...}
♦ Wenn Sie keine Konstruktormethode in Ihre Klassendefinitionaufnehmen, wird eine Standardmethode benutzt, die mit dem Java-Basisobjekt mitgeliefert wurde.
♦ Sie können mehr als einen Konstruktor für jede Klasse mitunterschiedlichen Argumenttypen- und Argumentzahlen liefern. BeimAufruf eines Konstruktors wird derjenige benutzt, der die richtigeArgumentzahl und die passenden Argumenttypen aufweist.
Erklärung von Feldern
Es gibt zwei Kategorien von Java-Feldern:
♦ Instanzfelder Jedes Objekt hat seine eigene Gruppe von Instanzfeldern,die bei der Erstellung des Objekts geschaffen wurden. Sie enthaltenInformationen, die speziell für diese Instanz gelten. Beispiel: Ein FeldlineItem1Description in der Klasse "Invoice" enthält die Beschreibungfür einen Rechnungsposten einer bestimmten Rechnung. Sie können aufInstanzfelder nur über eine Objektreferenz zugreifen.
♦ Klassenfelder Ein Klassenfeld enthält Informationen, die von einerbestimmten Instanz unabhängig sind. Ein Klassenfeld wird erstellt, wenndie Klasse zum ersten Mal geladen wird, und es werden keine weiterenInstanzen geschaffen, gleichgültig wie viele Objekte erzeugt werden.Auf Klassenfelder kann über den Klassennamen oder die Objektreferenzzugegriffen werden.
Um ein Feld in einer Klasse zu deklarieren, legen Sie seinen Typ fest undsetzen danach seinen Namen und ein Semikolon. Um ein Klassenfeld zuerstellen, benutzen Sie das Java-Schlüsselwort static in der Deklaration.Felder werden im Hauptteil einer Klasse, und nicht in einer Methodedeklariert. Die Deklaration einer Variablen in einer Methode macht sie zueinem Teil der Methode, nicht der Klasse.
Die folgende Deklaration der Klasse "Invoice" hat vier Felder, die denInformationen entsprechen, welche auf zwei Buchungszeilen in einerRechnung stehen könnten.
Beispiele

Ein Java-Seminar
68
public class Invoice {
// Felder einer Rechnung mit Rechnungsdaten public String lineItem1Description; public int lineItem1Cost;
public String lineItem2Description; public int lineItem2Cost;
}
Erklärung von Methoden
Es gibt zwei Kategorien von Java-Methoden:
♦ Instanzmethoden Eine totalSum-Methode in der Klasse "Invoice"muss die Steuer ausrechnen und hinzuaddieren, damit alle Kostenenthalten sind. Sie ist aber nur sinnvoll, wenn Sie im Zusammenhangmit einem Invoice-Objekt aufgerufen wird, bei dem die einzelnenRechnungsposten zusätzliche Steuer- oder Kostenposten enthalten. DieBerechnung kann nur für ein Objekt ausgeführt werden, da das Objektdie beiden Rechnungszeilen enthält, nicht die Klasse.
♦ Klassenmethoden Klassenmethoden (auch als statische Methodenbekannt) können aufgerufen werden, ohne dass erst ein Objekt erstelltwerden muss. Nur der Name der Klasse und der Methode sinderforderlich, um eine Klassenmethode aufzurufen.
Ähnlich wie bei Instanzmethoden akzeptieren die KlassenmethodenArgumente und Rückgabewerte. In der Regel führen Klassenmethodeneine Art von Dienstprogramm oder Informationsfunktion aus, die mitder Allgemeinfunktion der Klasse in Beziehung stehen.
Klassenmethoden können auf Instanzenfelder nicht zugreifen.
Um eine Methode zu deklarieren, geben Sie ihren Rückgabetyp, ihrenNamen und alle von ihr übernommenen Parameter an. Wie eineKlassendeklaration benutzt die Methode eine geöffnete und geschlossenegeschweifte Klammer, um den Hauptteil der Methode zu definieren, in dender Programmcode gesetzt wird.

Kapitel 3 Einführung in Java für Datenbanken
69
public class Invoice {
// Felderpublic String lineItem1Description; public double lineItem1Cost;
public String lineItem2Description; public double lineItem2Cost;
//Eine Methode public double totalSum() { double runningsum;
runningsum = lineItem1Cost +lineItem2Cost;
runningsum = runningsum * 1,16;
return runningsum; }}
Im Hauptteil der Methode totalSum wird eine Variable namens runningsumdeklariert. Sie wird zunächst verwendet, um die Zwischensumme der erstenund der zweiten Zeile aufzunehmen. Diese Zwischensumme wird dann mit16 Prozent (z.B. Mehrwertsteuer) multipliziert, um die Gesamtsumme zuerhalten.
Die lokale Variable (die im Hauptteil der Methode bekannt ist), wird dann andie aufrufende Funktion zurückgegeben. Wenn die Methode totalSumaufgerufen wird, gibt sie die Summe der zwei Zeilen plus die Steuer aufdiese Summe zurück.
Die Methode parseInt der Klasse java.lang.Integer, die mit AdaptiveServer Anywhere mitgeliefert wird, ist ein Beispiel für eine Klassenmethode.Wenn ihr ein Zeichenfolgenargument übergeben wird, gibt die MethodeparseInt eine Ganzzahl-Version der Zeichenfolge zurück.
Beispiel: Gegeben sei der Zeichenfolgenwert "1". Die Methode parseIntgibt den Ganzzahlwert 1 zurück, ohne eine Instanz der Klassejava.lang.Integer erstellen zu müssen. Das Beispiel wird im nachstehendenJava-Codefragment veranschaulicht:
String num = "1";int i = java.lang.Integer.parseInt( num );
Die folgende Version der Rechnungsklasse enthält nun eine Instanzmethodeund eine Klassenmethode. Die Klassenmethode namens rateOfTaxationgibt die Steuerrate zurück, die von der Klasse benutzt wird, um dieGesamtsumme der Rechnung zu kalkulieren.
Beispiel
Beispiel

Ein Java-Seminar
70
Dass die Methode rateOfTaxation zur Klassenmethode (und nicht zurInstanzmethode oder zu einem Feld) gemacht wurde, liegt darin, dass andereKlassen und Prozeduren den Wert benutzen können, der von dieser Methodezurückgegeben wird, ohne erst eine Instanz der Klasse erstellen zu müssen.Nur der Name der Klasse und der Methode sind erforderlich, um denSteuersatz auszugeben, der von dieser Klasse verwendet wird.
Dadurch dass der Steuersatz rateOfTaxation zu einer Methode, und nicht zueinem Feld gemacht wird, kann der Anwendungsentwickler den Steuersatzändern, ohne dass dies Auswirkungen auf Objekte, Anwendungen oderProzeduren hätte, die den Rückgabewert dieser Methode verwenden.Zukünftige Versionen der Klasse "Invoice" können den Rückgabewert derKlassenmethode rateOfTaxation auf einer komplizierteren Berechnungbasieren lassen, ohne dass andere Methoden beeinträchtigt werden, die denRückgabewert verwenden.
public class Invoice { // Felderpublic String lineItem1Description; public double lineItem1Cost; public String lineItem2Description; public double lineItem2Cost; // Eine Instanzenmethode public double totalSum() { double runningsum; double taxfactor = 1 + Invoice.rateOfTaxation();
runningsum = lineItem1Cost + lineItem2Cost; runningsum = runningsum * taxfactor;
return runningsum; } // Eine Klassenmethode public static double rateOfTaxation() { double rate; rate = .16;
return rate; }}
Objektorientierte und prozedurale Sprachen
Wenn Sie mehr Erfahrung mit prozeduralen Sprachen wie C oder derSprache für gespeicherte Prozeduren haben als mit objektorientiertenSprachen, finden Sie in diesem Abschnitt eine Erörterung der Ähnlichkeitenund Unterschiede zwischen prozeduralen und objektorientierten Sprachen.

Kapitel 3 Einführung in Java für Datenbanken
71
Die wichtigste strukturelle Einheit eines Codes in Java ist eine Klasse.
Eine Java-Klasse ist im Prinzip eine Sammlung von Prozeduren undVariablen, die gruppiert wurden, weil sie alle zu einer bestimmten,identifizierbaren Kategorie gehören.
Die Art und Weise, wie eine Klasse benutzt wird, unterscheidet aber dieobjektorientierten Sprachen von prozeduralen Sprachen. Eine in einerprozeduralen Sprache geschriebene Anwendung wird ausgeführt, indem sieeinmal in den Speicher geladen wird und eine genau vorgegebeneAbwicklungsfolge einhält.
In objektorientierten Sprachen wie Java wird eine Klasse wie eine Vorlagebenutzt: Eine Definition einer potenziellen Programmausführung. MehrereKopien der Klasse können je nach Anforderung erstellt und dynamischgeladen werden, wobei jede Instanz der Klasse eigene Daten, Werte undAblaufprozeduren enthalten kann. Jede geladene Klasse wird unabhängigvon anderen im Speicher geladenen Klassen behandelt und ausgeführt.
Eine Klasse, die zum Ausführen in den Speicher geladen wurde, wird alsinstanziert bezeichnet. Eine instanzierte Klasse wird "Objekt" genannt: Dabeihandelt es sich um eine Anwendung, die von der Klasse abgeleitet wurde, dievorbereitet wurde, um eindeutige Werte zu enthalten bzw. um zu bewirken,dass ihre Methoden unabhängig von anderen Klasseninstanzen ausgeführtwerden.
Ein Glossar der Java-Begriffe
Im folgenden Abschnitt werden einige Begriffe im Zusammenhang mit Java-Klassen erklärt. Dies ist natürlich keine erschöpfende Behandlung der Java-Sprache, sondern soll das Konzept der Java-Klassen in Adaptive ServerAnywhere vorstellen.
$ Weitere Hinweise über die Sprache Java finden Sie in der Online-Dokumentation Thinking in Java von Bruce Eckel. Sie gehört zumLieferumfang von Adaptive Server Anywhere, und Sie finden sie in derDatei Samples\ASA\Java\Tjava.pdf.
Ein Paket ist eine Gruppe von Klassen, die einen gemeinsamen Zweck odereine gemeinsame Kategorie haben. Ein Mitglied eines Pakets hat spezielleBerechtigungen für den Zugriff auf Daten und Methoden bei anderenMitgliedern des Pakets, und daher gibt es den Zugriffsmodifiziererprotected.
Java basiert aufKlassen
Pakete

Ein Java-Seminar
72
Ein Paket ist in Java das, was sonst unter einer Bibliothek oder Librarybekannt ist. Es handelt sich dabei um eine Sammlung von Klassen, die mitder import-Anweisung verfügbar gemacht werden können. Die folgendeJava-Anweisung importiert die Dienstprogramm-Bibliothek aus der Java-API:
import java.util.*
Pakete werden normalerweise in JAR-Dateien gespeichert, mit derErweiterung .jar oder .zip.
Ein Zugriffsmodifizierer (im Wesentlichen die Schlüsselwörter public,private oder protected vor jeder Deklaration) bestimmt die Sichtbarkeiteines Feldes, einer Methode oder einer Klasse für andere Java-Objekte.
♦ Mit public bezeichnete Klassen, Methoden oder Felder sind überallsichtbar.
♦ Mit private bezeichnete Klassen, Methoden oder Felder sind nur inMethoden sichtbar, die in dieser Klasse definiert wurden.
♦ Mit protected bezeichnete Methoden oder Felder sind für Methodensichtbar, die innerhalb dieser Klasse, in Unterklassen dieser Klassenoder in anderen Klassen des selben Pakets definiert wurden.
♦ Die Standardsichtbarkeit (Paket) bedeutet, dass die Methoden oderFelder innerhalb der Klasse oder für andere Klassen im Paket sichtbarsind.
Ein Konstruktor ist eine spezielle Methode einer Java-Klasse, dieaufgerufen wird, wenn eine Instanz der Klasse erstellt wird.
Klassen können ihre eigenen Konstruktoren definieren, darunter mehrfache,einander aufhebende Konstruktoren. Welcher Konstruktor verwendet wird,hängt davon ab, welche Argumente beim Versuch der Erstellung des Objektsverwendet wurden. Wenn der Typ, die Anzahl und die Reihenfolge derArgumente, die für die Erstellung einer Instanz der Klasse verwendetwerden, zu einem der Konstruktoren der Klasse passen, wird dieserKonstruktor verwendet, um das Objekt zu erstellen.
Die Abfalldatensammlung entfernt automatisch alle Objekte, für die keineReferenzen bestehen, mit Ausnahme der Objekte, die als Werte in einerTabelle gespeichert sind.
In Java gibt es keine Destruktorenmethode wie in C++. Java-Klassen könnenihre eigene Abschluss-Methode ("finalize") für das Aufräumen definieren,nachdem ein Objekt nach der Abfalldatensammlung entfernt wurde.
"Public" und"Private"
Konstruktoren
Sammlung derAbfalldaten

Kapitel 3 Einführung in Java für Datenbanken
73
Java-Klassen können nur von einer Klasse erben. Java benutzt Interfaces(Schnittstellen) anstelle von mehrfacher Vererbung. Eine Klasse kannmehrere Schnittstellen implementieren. Jede Schnittstelle definiert eineReihe von Methoden und Methodenprofilen, die von der Klasseimplementiert werden müssen, damit die Klasse kompiliert werden kann.
Eine Schnittstelle definiert, welche Methoden und statischen Felder dieKlasse deklarieren muss. Die Implementierung der Methoden und Felder, diein einer Schnittstelle deklariert werden, erfolgt in der Klasse, die dieSchnittstelle benutzt: Die Schnittstelle definiert, was die Klasse deklarierenmuss, und es obliegt der Klasse, festzulegen, wie die Implementierung vorsich geht.
Fehlerbehandlung in Java
Der Fehlerbehandlungscode ist in Java von der normalen Verarbeitunggetrennt.
Fehler generieren ein Ausnahmebedingungsobjekt, das den Fehler darstellt.Dies wird als throwing an exception (Ausnahmefehler auslösen) bezeichnet.Eine ausgelöste Ausnahmebedingung beendet ein Java-Programm, wenn sienicht in der Anwendung abgefangen und entsprechend verarbeitet wird.
Sowohl Java-API-Klassen, als auch benutzerdefinierte Klassen können einenAusnahmefehler auswerfen. Benutzer können ihre eigenen Ausnahmeklassenerstellen, die ihre eigenen benutzerdefinierten Klassen auswerfen können.
Wenn im Hauptteil der Methode, in der der Ausnahmefehler auftrat, keineAusnahmeroutine vorgesehen ist, wird die Suche nach einerAusnahmeroutine über den kompletten Aufrufstack fortgesetzt. Wenn dieSpitze des Aufrufstacks erreicht ist und noch immer keine Ausnahmeroutinegefunden wurde, wird die Standard-Ausnahmeroutine des Java-Interpretersaufgerufen und das Programm beendet.
In Adaptive Server Anywhere gilt: Wenn eine SQL-Anweisung eine Java-Methode aufruft, wird ein SQL-Fehler generiert.
Alle Fehler in Java werden aus zwei Arten von Fehlerklassen abgeleitet:Ausnahme (Exception) und Fehler (Error). Normalerweise werden Fehlervom Typ "Exception" durch Fehlerroutinen im Hauptteil der Methodeverarbeitet. Fehler vom Typ "Error" sind für interne Fehler undFehlerbedingungen wegen Ressourcenmangel im Java-Laufzeitsystemvorgesehen.
Ausnahmebedingungsfehler werden ausgeworfen und abgefangen. DieVerarbeitungsroutinen bei Ausnahmefehlern werden durch die Codeblöcketry, catch und finally gekennzeichnet.
Schnittstellen oderInterfaces
Fehlertypen inJava

Ein Java-Seminar
74
Ein try-Block führt einen Programmcode aus, der einen Fehler generierenkann. Ein catch-Block ist ein Codeteil, der ausgeführt wird, wenn ein Fehlerwährend der Ausführung eines try-Blocks generiert (ausgeworfen) wird.
Ein finally-Block definiert einen Codeblock, der unabhängig davonausgeführt wird, ob ein Fehler generiert und abgefangen wurde.Typischerweise wird er für Aufräumroutinen verwendet. Er wird für Codebenutzt, der unter keinen Umständen ausgelassen werden darf.
Ausnahmebedingungsfehler werden in zwei Typen unterteilt: Laufzeitfehlerund Nicht-Laufzeitfehler.
Fehler, die vom Laufzeitsystem generiert wurden, sind als impliziteAusnahmefehler bekannt, da sie nicht explizit als Teil jeder Klassen- oderMethodendeklaration verarbeitet werden müssen.
Beispiel: Der Ausnahmefehler "array out of bounds" kann auftreten, wennein Array benutzt wird, der Fehler muss aber nicht Teil der Deklaration derKlasse oder Methode sein, die dieses Array benutzen.
Alle anderen Ausnahmebedingungen sind explizit. Wenn die aufgerufeneMethode einen Ausnahmefehler auswerfen kann, muss der Fehler explizitvon der Klasse abgefangen werden, die die Auswurfmethode für den Fehlerbenutzt, oder diese Klasse muss explizit den Fehler selbst auswerfen, indemdie Ausnahmebedingung, die generiert werden könnte, in ihrerKlassendeklaration identifiziert wird. Im Wesentlichen heißt das: ExpliziteAusnahmebedingungen müssen explizit behandelt werden. Eine Methodemuss alle expliziten Fehler deklarieren, die sie auswirft, oder alle explizitenFehler abfangen, die möglicherweise ausgeworfen werden.
Nicht-Laufzeitfehler werden zum Kompilierungszeitpunkt geprüft.Laufzeitfehler werden normalerweise durch Programmierungsfehlerverursacht. Java erkennt viele dieser Fehler während der Kompilierung,bevor der Code ausgeführt wird.
Für jede Java-Methode wird ein alternativer Ausführungspfad definiert,sodass alle Java-Methoden abgeschlossen werden können, auch wenn dernormale Abschluss nicht möglich ist. Wenn der Typ des ausgeworfenenFehlers nicht erfasst ist, wird er an den nächsten Code-Block oder dienächste Methode im Stack weitergereicht.

Kapitel 3 Einführung in Java für Datenbanken
75
Die Laufzeitumgebung für Java in der DatenbankIn diesem Abschnitt wird die Sybase-Laufzeitumgebung für Javabeschrieben, und wie sie sich von einer Standard-Java-Laufzeitumgebungunterscheidet.
Unterstützte Versionen von Java und JDBC
Die Sybase Java VM bietet die Auswahl zwischen denProgrammierschnittstellen JDK 1.1, JDK 1.2, und JDK 1.3. Die tatsächlichgelieferte Version ist JDK 1.1.8. und 1.3.
Zwischen Version 1.0 des JDK und Version 1.1 wurden einige neue APIseingeführt. Außerdem wurden einige APIs entfernt. Die Verwendungbestimmter APIs wird nicht länger empfohlen, und die Unterstützung dieserAPIs könnte in kommenden Versionen nicht mehr gesichert sein.
Eine Java-Klassendatei, die nicht mehr empfohlene API verwendet, generiertbeim Kompilieren eine Warnung, kann aber auf einer Java Virtual Machineausgeführt werden, die gemäß den Standards der Version 1.1 programmiertwurde, wie z.B. der Sybase VM.
Der interne JDBC-Treiber unterstützt JDBC Version 2.
$ Weitere Hinweise zu den unterstützten JDK APIs finden Sie unter"Unterstützte Java-Pakete" auf Seite 87 der Dokumentation ASA SQL-Referenzhandbuch.
$ Hinweise zum Erstellen einer Datenbank, die Java unterstützt, findenSie unter "Datenbank für Java aktivieren" auf Seite 97.
Die Laufzeit-Java-Klassen
Die Laufzeit-Java-Klassen sind die Klassen der niedrigen Stufe, die für eineDatenbank verfügbar gemacht werden, wenn Sie erstellt oder für Javaaktiviert wird. Diese Klassen enthalten eine Teilmenge der Java-API. DieseKlassen sind Teil des Sun Java Development Kit.
Die Laufzeit-Klassen bieten Funktionen, auf denen Anwendungen aufbauenkönnen. Die Laufzeit-Klassen sind für Klassen in der Datenbank immerverfügbar.

Die Laufzeitumgebung für Java in der Datenbank
76
Sie können die Laufzeit-Java-Klassen in Ihre eigenen benutzerdefiniertenKlassen einbeziehen: Entweder, indem sie deren Funktionen erben oderindem Sie sie bei einer Berechnung oder einem Vorgang in einer Methodeverwenden.
Einige Java-API-Klassen, die in den Laufzeit-Java-Klassen enthalten sind:
♦ Primitive Java-Datentypen Alle "primitiven" (nativen) Datentypen inJava haben eine entsprechende Klasse. Um Objekte dieser Typen zuerstellen, haben die Klassen zusätzliche, oft sehr nützliche Funktionen.
Der Java-Datentyp int hat eine entsprechende Klasse injava.lang.Integer.
♦ Das Dienstprogramm-Paket Das Paket java.util.* enthält eine Reihevon sehr hilfreichen Klassen, deren Funktionen keine Entsprechung inden SQL-Funktionen haben, welche in Adaptive Server Anywhereverfügbar sind.
Zu diesen Klassen gehören:
♦ Hashtable Eine Zuordnung von Schlüsseln und Werten.
♦ StringTokenizer Diese Klasse zerlegt eine Zeichenfolge inEinzelwörter.
♦ Vector Diese Klasse enthält ein Array von Objekten, deren Größesich dynamisch ändern kann.
♦ Stack Diese Klasse enthält einen Last-in-First-out-Stack vonObjekten.
♦ JDBC für SQL-Vorgänge Das Paket java.SQL.* enthält die Klassen dievon Java-Objekten benötigt werden, um Daten mit SQL-Anweisungenaus der Datenbank zu extrahieren.
Anders als benutzerdefinierte Klassen werden die Laufzeitklassen in derDatenbank nicht gespeichert. Sie werden vielmehr im Unterverzeichnis javades Adaptive Server Anywhere-Installationsverzeichnisses gespeichert.
Benutzerdefinierte Klassen
Benutzerdefinierte Klassen werden in einer Datenbank mit der AnweisungINSTALL installiert. Nach ihrer Installation stehen sie anderen Klassen inder Datenbank zur Verfügung. Wenn es sich um öffentliche Klassen handelt,stehen Sie für SQL als Domänen zur Verfügung.
$ Hinweise zur Installation von Klassen finden Sie unter "Java-Klassen ineiner Datenbank installieren" auf Seite 103.
Beispiele

Kapitel 3 Einführung in Java für Datenbanken
77
Java-Methoden und Felder identifizieren
In SQL-Anweisungen identifiziert der Punkt Spalten von Tabellen, wie zumBeispiel in der folgenden Abfrage:
SELECT employee.emp_idFROM employee
Der Punkt kennzeichnet auch die Eigentümerschaft in qualifiziertenObjektnamen:
SELECT emp_idFROM DBA.employee
In Java ist der Punkt ein Operator, der die Methoden aufruft oder auf dieFelder einer Java-Klasse oder eines Java-Objekts zugreift. Er ist auch Teileines Bezeichners, der benutzt wird, um Klassennamen zu kennzeichnen,wie im voll qualifizierten Klassennamen java.util.Hashtable.
Im nachstehenden Java-Codefragment ist der Punkt in der ersten Zeile einBezeichner. In der zweiten Zeile des Programmcodes ist er ein Operator.
java.util.Random rnd = new java.util.Random();int i = rnd.nextInt();
In SQL kann der Punktoperator durch eine doppelte geschlossene spitzeKlammer (>>) ersetzt werden. Der Punktoperator ist für Java passender,kann aber bei bestehenden SQL-Namen zu Verwechslungen führen. DieVerwendung von >> beseitigt diese Zweideutigkeit.
>> in SQL ist nicht dasselbe wie >> in JavaDie doppelte geschlossene spitze Klammer wird nur in SQL-Anweisungen verwendet, wo sonst ein Java-Punktoperator erwartet wird.In einer Java-Klasse ist die doppelte geschlossene spitze Klammer keinErsatz für den Punktoperator und hat eine vollständig andere Bedeutungin ihrer Rolle als rechter Bitverschiebungs-Operator.
Die folgende SQL-Anweisungsfolge ist beispielsweise gültig:
CREATE VARIABLE rnd java.util.Random;SET rnd = NEW java.util.Random();SELECT rnd>>nextInt();
Das Ergebnis der SELECT-Anweisung ist eine zufallsgenerierte Ganzzahl.
Unter Verwendung der Variablen, die im vorhergehenden SQL-Beispielerstellt wurde, zeigt die folgende SQL-Anweisung die richtige Verwendungeiner Klassenmethode:
SELECT java.lang.Math>>abs( rnd>>nextInt() );
Der Punkt in SQL
Der Punkt in Java
Aufruf von Java-Methoden aus SQL

Die Laufzeitumgebung für Java in der Datenbank
78
Java berücksichtigt Groß/Kleinschreibung
Java-Syntax funktioniert so, wie Sie es von ihr erwarten, und SQL-Syntaxwird durch das Vorhandensein von Java-Klassen nicht verändert. Dies bleibtauch so, wenn dieselbe SQL-Anweisung sowohl Java, als auch SQL-Syntaxenthält. Dies ist eine einfache Feststellung, aber mit weit reichendenAuswirkungen.
Java berücksichtigt die Groß/Kleinschreibung. Die Java-Klasse FindOut istnicht dasselbe wie die Klasse Findout. SQL berücksichtigt die Groß-/Klein-schreibung bei Schlüsselwörtern und Bezeichnern nicht.
Die Berücksichtigung von Groß-/Kleinschreibung durch Java wird auchbeibehalten, wenn der Java-Code in eine SQL-Anweisung eingebettet ist, diedie Groß-/Kleinschreibung nicht berücksichtigt. Die Java-Teile derAnweisung müssen die Groß/Kleinschreibung berücksichtigen, auch wenndie Teile vor und nach der Java-Syntax ohne Berücksichtigung derSchreibweise programmiert werden können.
Beispielsweise werden die nachstehenden SQL-Anweisungen erfolgreichausgeführt, da die Schreibweise der Java-Objekte, Klassen und Operatorenrespektiert wird, auch wenn im restlichen Teil der SQL-Anweisung dieGroß-/Kleinschreibung nicht einheitlich ist.
SeLeCt java.lang.Math.random();
Wenn eine Java-Klasse als Datentyp für eine Spalte verwendet wird, erfolgtdies in Form eines benutzerdefinierten SQL-Datentyps. Trotzdem wird dieGroß/Kleinschreibung immer berücksichtigt. Diese Konvention verhindertZweideutigkeiten mit Java-Klassen, die sich nur durch die Groß-/Klein-schreibung voneinander unterscheiden.
Zeichenfolgen in Java und SQL
Mit Anführungszeichen werden Zeichenfolgenliterale in Javagekennzeichnet, wie im folgenden Java-Programmfragment gezeigt wird:
String str = "Dies ist eine Zeichenfolge"
In SQL werden Zeichenfolgen hingegen mit Apostrophen gekennzeichnet,und Anführungszeichen kennzeichnen einen Bezeichner, wie in derfolgenden SQL-Anweisung:
INSERT INTO TABLE DBA.t1VALUES( ’Hallo’ )
In Java-Quellcode müssen Sie immer Anführungszeichen verwenden, inSQL-Anweisungen hingegen Apostrophe.
Die folgenden SQL-Anweisungen sind beispielsweise gültig.
Datentypen

Kapitel 3 Einführung in Java für Datenbanken
79
CREATE VARIABLE str char(20);set str = new java.lang.String( ’Brandneues Objekt’ )
Das folgende Java-Codefragment ist auch gültig, wenn es in einer Java-Klasse verwendet wird.
String str = new java.lang.String( "Brandneues Objekt" );
Ausgabe in die Befehlszeile
Die Ausgabe in die Standardausgabe ist eine Technik für die schnellePrüfung von Variablenwerten und Ausführungsergebnissen an bestimmtenStellen im Programmcode. Bei Erkennung der Methode in der zweiten Zeiledes folgenden Java-Codefragments wird das Zeichenfolgenargument, dasvon der Methode akzeptiert wird, in die Standardausgabe geschrieben.
String str = "Hallo Welt";System.out.println( str );
In Adaptive Server Anywhere ist das Serverfenster die Standardausgabe, sodass die Zeichenfolge dort erscheint. Die Ausführung des oben angegebenenJava-Programmcodes in der Datenbank ist der folgenden SQL-Anweisunggleichwertig:
MESSAGE ’Hallo Welt’
Hauptmethode (main) verwenden
Wenn eine Klasse eine main-Methode enthält, die zur folgenden Deklarationpasst, wird sie von den meisten Java-Laufzeitumgebungen, wie zum Beispielvom Sun Java-Interpreter, automatisch ausgeführt. Normalerweise wird diesestatische Methode nur ausgeführt, wenn sie die Klasse ist, die vom Java-Interpreter aufgerufen wurde.
public static void main( String args[ ] ) { }
Die Hauptklasse ist eine nützliche Klasse für das Austesten der Funktionenvon Java-Objekten: Sie können immer sicher sein, dass diese Methode alserste aufgerufen wird, wenn Sie das Sun Java Laufzeitsystem starten.
In Adaptive Server Anywhere ist das Java-Laufzeitsystem jederzeitverfügbar. Die Funktionen der Objekte und Methoden können mit SQL-Anweisungen unmittelbar und dynamisch getestet werden. In vielerleiHinsicht ist diese Methode für das Testen von Java-Klassen-Funktionen vielflexibler.

Die Laufzeitumgebung für Java in der Datenbank
80
Bereich und Dauerhaftigkeit (Persistenz)
SQL-Variable sind nur so dauerhaft wie die Verbindung. Dies ist nichtanders als bei früheren Versionen von Adaptive Server Anywhere und wirdauch nicht davon berührt, ob die Variable eine Java-Klasse oder ein nativerSQL-Datentyp ist.
Die Dauerhaftigkeit (oder "Persistenz") von Java-Klassen entspricht der derTabellen in einer Datenbank: Tabellen existieren in einer Datenbank solange, bis sie gelöscht werden, gleichgültig ob sie Daten enthalten oderniemals benutzt werden. Java-Klassen, die in einer Datenbank installiertwurden, sind ähnlich: Man kann sie benutzen, bis sie explizit durch eineREMOVE-Anweisung entfernt werden.
$ Weitere Hinweise zum Entfernen von Klassen finden Sie unter"REMOVE-Anweisung" auf Seite 547 der Dokumentation ASA SQL-Referenzhandbuch.
Eine Klassenmethode in einer installierten Java-Klasse kann jederzeit auseiner SQL-Anweisung aufgerufen werden. Sie können die folgendeAnweisung überall ausführen, wo Sie SQL-Anweisungen ausführen können.
Select java.lang.Math.abs(-342)
Ein Java-Objekt ist nur in zwei Formen verfügbar: als Wert einer Variablenoder als Wert in einer Tabelle.
Java-Escapezeichen in SQL-Anweisungen
Im Java-Programmcode können Sie Escapezeichen verwenden, umbestimmte Sonderzeichen in Zeichenfolgen einzufügen. Ein Beispiel ist derfolgende Programmcode, der ein Zeichen für Neue Zeile und einTabulatorzeichen vor einem Satz einführt, der ein Apostroph enthält.
String str = "\n\t\Eine Zeichenfolge ist\’s, die mirfehlt";
Die Verwendung von Java-Escapezeichen ist im Adaptive Server Anywherenur erlaubt, wenn sie von Java-Klassen benutzt werden. Aus SQL müssenhingegen die Regeln befolgt werden, die für Zeichenfolgen in SQL gelten:
Beispiel: Um einen Zeichenfolgenwert an ein Feld zu übergeben, das eineSQL-Anweisung benutzt, kann folgende Anweisung benutzt werden, dasJava-Escapezeichen hingegen nicht.
set obj.str = ’\nDie Zeichenfolge ist’’s, die fehlte!’;
$ Weitere Hinweise über die Regeln für SQL-Zeichenfolgen finden Sieunter "Zeichenfolgen" auf Seite 10 der Dokumentation ASA SQL-Referenzhandbuch.

Kapitel 3 Einführung in Java für Datenbanken
81
Schlüsselwortkonflikte
SQL-Schlüsselwörter können im Konflikt mit Namen von Java-Klassen,einschließlich API-Klassen stehen. Dies tritt ein, wenn der Name einerKlasse, wie z.B. der Klasse "Date", die ein Teil des Pakets java.util.* ist,referenziert wird. SQL reserviert das Wort Date für den Einsatz alsSchlüsselwort, auch wenn es gleichzeitig der Name einer Java-Klasse ist.
Wenn solche Zweideutigkeiten auftreten, können Sie Anführungszeichenverwenden, um anzuzeigen, dass Sie das betreffende Wort nicht mehr als fürSQL reserviertes Wort verwenden. Beispiel: Die folgende SQL-Anweisungverursacht einen Fehler, da "Date" ein Schlüsselwort und seine Verwendungfür SQL reserviert ist.
-- Diese Anweisung ist unzulässigCREATE VARIABLE dt java.util.Date
Die folgenden beiden Anweisungen funktionieren hingegen richtig, weil dasWort "Date" in Anführungszeichen steht.
CREATE VARIABLE dt java.util."Date";SET dt = NEW java.util."Date"(1997, 11, 22, 16, 11, 01)
Die Variable dt enthält jetzt das Datum: November 22, 1997, 4:11 p.m.
Import-Anweisungen verwenden
Es ist allgemein üblich, in einer Java-Klassen-Deklaration eine Import-Anweisung für den Zugriff auf andere, externe Klassen einzubeziehen. Siekönnen importierte Klassen mit unqualifizierten Klassennamenreferenzieren.
Beispiel: Sie können die Stack-Klasse des Pakets java.util auf zwei Artenreferenzieren:
♦ Explizit mit dem Namen java.util.Stack
♦ Oder mit dem Namen Stack, und Einschluss der folgenden Import-Anweisung:
import java.util.*;
Eine von einer anderen Klasse explizit mit einem voll qualifizierten Namenoder implizit mit einer Import-Anweisung referenzierte Klasse mussebenfalls in der Datenbank installiert sein.
Die Klassen weiteroben in derHierarchie müssenebenfalls installiertsein.

Die Laufzeitumgebung für Java in der Datenbank
82
Die Import-Anweisung funktioniert in kompilierten Klassen wiebeabsichtigt. In der Laufzeitumgebung von Adaptive Server Anywhere gibtes allerdings keine der Import-Anweisung gleichwertige Anweisung. AlleKlassennamen, die in SQL-Anweisungen oder in gespeicherten Prozedurenverwendet werden, müssen voll qualifiziert sein. Beispiel: Um eine Variabledes Typs "Zeichenfolge" zu erstellen, wird diese Klasse mit dem vollqualifizierten Namen referenziert: java.lang.String.
CLASSPATH-Variable verwenden
Die Java-Laufzeitumgebung von Sun und der Sun JDK Java Compilerbenutzen die classpath-Umgebungsvariable, um Klassen zu ermitteln, die imJava-Programmcode angesprochen werden. Eine classpath-Variable stellteine Verbindung zwischen dem Java-Programmcode und dem tatsächlichenDateipfad oder dem URL der referenzierten Klassen her. Zum Beispielkönnen mit import java.io.* alle Klassen im Paket java.io ohne vollqualifizierten Namen referenziert werden. Nur der Klassenname ist imfolgenden Java-Code erforderlich, um Klassen aus dem Paket java.io zuverwenden. Die Umgebungsvariable classpath auf dem System, in dem dieJava-Klassendeklaration kompiliert werden soll, muss den Standort des Java-Verzeichnisses, also des Stammverzeichnisses des Pakets java.io, enthalten.
Die Umgebungsvariable classpath beeinträchtigt die Laufzeitumgebung vonAdaptive Server Anywhere für Java nicht während des Ausführens von Java-Vorgängen, da die Klassen in der Datenbank, und nicht in externen Dateienoder Archiven gespeichert sind.
Die Variable classpath kann jedoch verwendet werden, um den Standorteiner Datei während der Installation von Klassen zu ermitteln. Beispiel: Diefolgende Anweisung installiert eine benutzererstellte Java-Klasse in derDatenbank, gibt aber nur den Namen der Datei an, nicht ihren vollenSuchpfad plus Namen. (Beachten Sie, dass in dieser Anweisung keine Java-Vorgänge enthalten sind.)
INSTALL JAVA NEWFROM FILE ’Invoice.class’
Wenn die angegebene Datei in einem Verzeichnis oder in einer ZIP-Dateiliegt, die von der Umgebungsvariablen classpath definiert wurden, findetAdaptive Server Anywhere die Datei und installiert die Klasse.
CLASSPATHwährend derLaufzeit ignoriert
CLASSPATH zurInstallation vonKlassen

Kapitel 3 Einführung in Java für Datenbanken
83
Öffentliche Felder
Beim objektorientierten Programmieren ist es allgemein üblich,Klassenfelder als "private" zu definieren und ihre Werte nur über öffentlicheMethoden verfügbar zu machen.
Viele Beispiele, die in dieser Dokumentation verwendet werden, gebenFelder als "public" an, sodass die Beispiele kompakter und leichter zu lesensind. Die Verwendung öffentlicher Felder in Adaptive Server Anywherebietet Performancevorteile gegenüber der Verwendung öffentlicherMethoden.
Die in dieser Dokumentation allgemein eingehaltene Konvention bestehtdarin, dass eine benutzererstellte Java-Klasse, die für den Einsatz inAdaptive Server Anywhere gedacht ist, ihre Hauptwerte in ihren Feldernauswirft. Methoden enthalten Berechnungsautomation und Logik, die mitdiesen Feldern arbeiten.

Praktische Einführung: Eine Übung mit Java in der Datenbank
84
Praktische Einführung: Eine Übung mit Java inder Datenbank
Diese praktische Einführung soll die Grundlagen für den Aufruf von Java-Vorgängen mit Java-Klassen und Objekten über SQL-Anweisungenvermitteln. Es wird beschrieben, wie Java-Klassen in der Datenbankinstalliert werden. Darüber hinaus wird beschrieben, wie auf die Klasse undihre Mitglieder und Methoden von SQL-Anweisungen aus zugegriffen wird.In der praktischen Einführung wird die in "Ein Java-Seminar" auf Seite 64erstellte Klasse verwendet.
Die praktische Einführung geht davon aus, dass Java in der Datenbank-Software installiert wurde. Außerdem wird vorausgesetzt, dass Sie ein JavaDevelopment Kit (JDK) installiert haben, einschließlich dem Java Compiler(javac).
Quellcode und Anweisungsfolgen für dieses Beispiel finden Sie imVerzeichnis Samples\ASA\JavaInvoice in Ihrem SQL Anywhere-Verzeichnis.
Beispiel-Java-Klasse erstellen und kompilieren
Der erste Schritt besteht darin, den Java-Code zu schreiben und zukompilieren. Dies geschieht außerhalb der Datenbank.
v So wird die Klasse erstellt und kompiliert:
1 Erstellen Sie eine Datei mit dem Namen Invoice.java mit dem folgendenCode:
Anforderungen
Ressourcen

Kapitel 3 Einführung in Java für Datenbanken
85
public class Invoice {
// Felder public String lineItem1Description; public double lineItem1Cost;
public String lineItem2Description; public double lineItem2Cost;
// Eine Instanzmethode public double totalSum() { double runningsum; double taxfactor = 1 + Invoice.rateOfTaxation();
runningsum = lineItem1Cost + lineItem2Cost; runningsum = runningsum * taxfactor;
return runningsum; }
// Eine Klassenmethode public static double rateOfTaxation() { double rate; rate = .15;
return rate; }}
Den Quellcode für diese Klasse finden Sie in der DateiSamples\ASA\JavaInvoice\Invoice.java in Ihrem SQL Anywhere-Verzeichnis.
2 Kompilieren Sie die Datei, damit die Datei Invoice.class erstellt wird.
Führen Sie von der Befehlszeile im selben Verzeichnis wie Invoice.javaden folgenden Befehl aus.
javac *.java
Die Klasse ist jetzt kompiliert und kann in der Datenbank installiertwerden.
Beispiel-Java-Klasse installieren
Java-Klassen können erst verwendet werden, nachdem sie in einerDatenbank installiert wurden. Sie können Java-Klassen aus Sybase Centraloder Interactive SQL installieren. Dieser Abschnitt enthält Anweisungen fürbeide Möglichkeiten. Wählen Sie selbst.

Praktische Einführung: Eine Übung mit Java in der Datenbank
86
v So installieren Sie die Klasse in der Beispieldatenbank(Sybase Central):
1 Starten Sie Sybase Central und stellen Sie eine Verbindung zurBeispieldatenbank her.
2 Öffnen Sie den Ordner "Java-Objekte" und doppelklicken Sie auf "Java-Klasse hinzufügen". Der Assistent für die Erstellung von Java-Klassenwird angezeigt.
3 Klicken Sie auf die Schaltfläche "Durchsuchen" und wechseln Sie zurKlasse Invoice.class im Unterverzeichnis Samples\ASA\JavaInvoice inIhrem Installationsverzeichnis von SQL Anywhere.
4 Klicken Sie auf "Fertig stellen", damit der Assistent geschlossen wird.
v So installieren Sie die Klasse in der Beispieldatenbank(Interactive SQL):
1 Starten Sie Interactive SQL und stellen Sie eine Verbindung mit derBeispieldatenbank her.
2 Geben Sie im Fensterausschnitt "SQL-Anweisungen" in Interactive SQLden folgenden Befehl ein.
INSTALL JAVA NEWFROM FILE’Suchpfad\\samples\\ASA\\JavaInvoice\\Invoice.class’
wobei Suchpfad Ihr SQL Anywhere-Verzeichnis ist.
Die Klasse ist jetzt in der Beispieldatenbank installiert.
♦ Bis jetzt haben in der Datenbank keine Java-Vorgänge stattgefunden.Die Klasse wurde in der Datenbank installiert. Sie kann nun alsDatentyp einer Variablen oder Spalte in einer Tabelle verwendetwerden.
♦ In einer Klassendatei durchgeführte Änderungen werden nichtautomatisch auch in die Kopie der Klasse in der Datenbank übertragen.Sie müssen die Klassen neu installieren, wenn die Änderungenwiedergegeben werden sollen.
$ Weitere Hinweise zur Installation der Klassen und zur Aktualisierungeiner installierten Klasse finden Sie unter "Java-Klassen in einer Datenbankinstallieren" auf Seite 103.
Hinweise

Kapitel 3 Einführung in Java für Datenbanken
87
SQL-Variable vom Typ "Invoice" erstellen
In diesem Abschnitt wird eine SQL-Variable erstellt, die sich auf ein Java-Objekt vom Typ Invoice bezieht.
Berücksichtigung von Groß-/KleinschreibungJava berücksichtigt die Groß/Kleinschreibung, sodass die Teile dernachstehenden Beispiele, die Java-Syntax beinhalten, genausogeschrieben werden müssen wie gezeigt. Die SQL-Syntax wird mitGroßbuchstaben geschrieben.
1 Führen Sie von Interactive SQL aus die folgende Anweisung aus understellen Sie eine SQL-Variable mit dem Namen Inv vom Typ Invoice,wobei Invoice die Java-Klasse ist, die Sie in der Datenbank installierthaben:
CREATE VARIABLE Inv Invoice
Nach dem Erstellen einer Variablen kann ihr erst dann ein Wertzugewiesen werden, wenn Datentyp und deklarierter Datentyp identischsind oder wenn der Wert eine Unterklasse des deklarierten Datentyps ist.Im vorliegenden Fall kann die Variable Inv nur eine Referenz auf einObjekt des Typs Invoice oder eine Unterklasse von Invoice enthalten.
Anfangs ist die Variable Inv gleich NULL, weil kein Wert an sieweitergeleitet wurde.
2 Führen Sie die folgende Anweisung aus, damit der aktuelle Wert derVariablen Inv identifiziert wird.
select IfNull(Inv,’Kein Objekt referenziert’, 'Variable ist nicht null: enthält eineObjektreferenz')
Die Variable referenziert derzeit kein Objekt.
3 Weisen Sie Inv einen Wert zu.
Sie müssen die Klasse Invoice mit dem Schlüsselwort NEWinstanzieren.
SET Inv = NEW Invoice();
Die Variable Inv hat jetzt eine Referenz auf das Java-Objekt. ZurÜberprüfung können Sie die Anweisung aus Schritt 2 ausführen.
Die Variable Inv enthält eine Referenz auf ein Java-Objekt vom TypInvoice. Mit dieser Referenz können Sie auf viele Felder des Objektszugreifen oder eine ihrer Methoden aufrufen.

Praktische Einführung: Eine Übung mit Java in der Datenbank
88
Auf Felder und Methoden des Java-Objekts zugreifen
Wenn eine Variable (oder ein Spaltenwert in einer Tabelle) eine Referenz aufein Java-Objekt enthält, können den Feldern des Objekts Werte übergebenwerden, und ihre Methoden sind aufrufbar.
Beispiel: Eine Variable vom Typ "Invoice", die Sie im vorigen Abschnitterstellt haben, enthält eine Referenz auf ein Objekt Invoice und hat vierFelder, deren Werte durch SQL-Anweisungen festgelegt werden können.
v So greifen Sie auf die Felder des Objekts "Invoice" zu:
1 Führen Sie von Interactive SQL die folgenden SQL-Anweisungen aus,damit die Feldwerte für die Variable Inv gesetzt werden.
SET Inv.lineItem1Description = ’Gummistiefel’;
SET Inv.lineItem1Cost = ’79.99’;
SET Inv.lineItem2Description = ’Heugabel’;
SET Inv.lineItem2Cost = ’37.49’;
Jede der oben stehenden SQL-Anweisungen gibt einen Wert an ein Feldim Java-Objekt weiter, das durch Inv referenziert wird.
2 Führen Sie SELECT-Anweisungen mit der Variablen aus. Jedenachstehende SQL-Anweisung gibt den aktuellen Wert eines Feldes imJava-Objekt zurück, das von Inv referenziert wird.
SELECT Inv.lineItem1Description;
SELECT Inv.lineItem1Cost;
SELECT Inv.lineItem2Description;
SELECT Inv.lineItem2Cost;
3 Verwenden Sie ein Feld der Variablen Inv in einem SQL-Ausdruck.
Führen Sie die folgende SQL-Anweisung aus und lassen Sie die obigenSQL-Anweisungen ausführen.
SELECT * FROM PRODUCTWHERE unit_price < Inv.lineItem2Cost;
Zusätzlich zu den öffentlichen Feldern hat die Klasse Invoice eineInstanzmethode, die Sie aufrufen können.
v So rufen Sie die Methoden des Objekts "Invoice" auf:
♦ Führen Sie von Interactive SQL aus die folgende SQL-Anweisung aus,die die Methode totalSum() des Objekts aufruft, das von der VariablenInv referenziert wird. Sie gibt die Summe der beiden Kostenfelder plusder Steuer zurück.

Kapitel 3 Einführung in Java für Datenbanken
89
SELECT Inv.totalSum();
Hinter Methodennamen stehen immer Klammern, auch wenn sie keineArgumente annehmen. Nach Feldnamen stehen keine Klammern.
Die Methode totalSum() akzeptiert keine Argumente, sondern gibt einenWert zurück. Die Klammern werden verwendet, da eine Java-Operationaufgerufen wird, obwohl die Methode keine Argumente annimmt.
Bei Java in der Datenbank ist der direkte Feldzugriff schneller als der Aufrufvon Methoden. Für den Zugriff auf ein Feld ist der Aufruf der Java VM nichterforderlich, während für eine Methode die VM benötigt wird, um dieMethode auszuführen.
Wie in der am Anfang dieses Kapitels beschriebenen Invoice-Klassendefinition gezeigt, nutzt die totalSum-Instanzenmethode dieKlassenmethode rateOfTaxation.
Auf diese Klassenmethode kann direkt aus einer SQL-Anweisungzugegriffen werden.
SELECT Invoice.rateOfTaxation();
Beachten Sie, dass der Name der Klasse verwendet wird, und nicht der Nameeiner Variablen, die eine Referenz auf ein Invoice-Objekt enthält. Diesstimmt mit der Art überein, wie Java Klassenmethoden verarbeitet, auchwenn sie in SQL-Anweisungen verwendet werden. Eine Klassenmethodekann aufgerufen werden, auch wenn kein auf dieser Klasse basierendesObjekt instanziert wurde.
Klassenmethoden benötigen keine Instanz der Klasse, um richtig zufunktionieren, können aber immer noch für ein Objekt aufgerufen werden.Die folgende SQL-Anweisung bringt dieselben Ergebnisse wie die vorherausgeführte SQL-Anweisung.
SELECT Inv.rateOfTaxation();
Java-Objekte in Tabellen speichern
Wenn eine Klasse in einer Datenbank installiert wird, steht sie als neuerDatentyp zur Verfügung. Spalten in einer Tabelle können den Typ Javaclasshaben, wobei Javaclass der Name einer installierten öffentlichen Java-Klasseist. Dann können Sie ein Java-Objekt erstellen und es als Wert einer Spalte ineine Tabelle einfügen.
v So wird die Klasse "Invoice" in einer Tabelle verwendet:
1 Tabelle mit einer Spalte vom Typ Invoice erstellen.
Führen Sie von Interactive SQL die folgende SQL-Anweisung aus.
Methoden aufrufenund Felderreferenzieren

Praktische Einführung: Eine Übung mit Java in der Datenbank
90
CREATE TABLE T1 ( ID int, JCol Invoice);
Die Spalte namens JCol akzeptiert nur Objekte des Typs Invoice odereiner ihrer Unterklassen.
2 Führen Sie mit der Variablen Inv, die eine Referenz auf ein Java-Objektvom Typ Invoice enthält, die folgende SQL-Anweisung aus, damit derTabelle T1 eine Zeile hinzugefügt wird.
INSERT INTO T1VALUES( 1, Inv );
Sobald ein Objekt der Tabelle T1 hinzugefügt wurde, können SieAuswahlanweisungen benutzen, die die Felder und Methoden derObjekte in der Tabelle einbeziehen.
3 Führen Sie die folgende SQL-Anweisung aus, die den Wert des FeldesineItem1Description für alle Objekte in der Tabelle T1 zurück (derzeitsollte nur ein Objekt in der Tabelle sein).
SELECT ID, JCol.lineItem1DescriptionFROM T1;
Sie können ähnliche Auswahlanweisungen ausführen, die andere Felderund Methoden des Objekts einbeziehen.
4 Eine zweite Methode, ein Java-Objekt zu erstellen und einer Tabellehinzuzufügen, bezieht den folgenden Ausdruck ein, der immer ein Java-Objekt erstellt und ihm eine Referenz zurückgibt.
NEW Java-Klassenname()
5 Dieser Ausdruck kann auf verschiedene Arten benutzt werden.Beispielsweise wird mit der folgenden SQL-Anweisung ein Java-Objekterstellt und in die Tabelle T1 eingefügt.
INSERT INTO T1VALUES ( 2, NEW Invoice() );
6 Führen Sie die folgende SQL-Anweisung aus, damit geprüft wird, obdiese beiden Objekte als Werte der Spalte JCol in der Tabelle T1gespeichert wurden.
select id, JCol.totalSum()FROM t1
Die Ergebnisse der Spalte JCol (zweite von der oben genanntenAnweisung zurückgegebene Zeile) sollte 0 sein, da die Felder in diesemObjekt keine Werte haben und die Methode totalSum eine Berechnungdieser Felder ist.

Kapitel 3 Einführung in Java für Datenbanken
91
Objekt mit einer Abfrage zurückgeben
Außer auf Felder und Methoden zuzugreifen, können Sie mit einer Abfrageauch ein ganzes Objekt aus der Tabelle abrufen.
v So greifen Sie auf Invoice-Objekte zu, die in einer Tabellegespeichert sind:
♦ Führen Sie von Interactive SQL aus die folgenden Anweisungen aus,erstellen Sie eine neue Variable und übergeben Sie ihr einen Wert (Siekann nur eine Referenz auf ein Objekt vom Typ "Invoice" enthalten).Die an die Variable übergebene Objektreferenz wurde mit der TabelleT1 erstellt.
CREATE VARIABLE Inv2 Invoice;
set Inv2 = (select JCol from T1 where ID = 2);
SET Inv2.lineItem1Description = 'Süßigkeiten';
SET Inv2.lineItem2Description = 'Sicherheitsgurt';
Der Wert für das Feld lineItem1Description und lineItem2Descriptionwurde in der Variablen Inv2 geändert, jedoch nicht in der Tabelle, diedie Quelle für den Wert dieser Variablen war.
Dies ist konsistent mit der Art, in der SQL-Variable derzeit verarbeitetwerden: Die Variable Inv enthält eine Referenz auf ein Java-Objekt. DerWert in der Tabelle, die als Quelle für die Variablenreferenz diente, wirderst geändert, wenn eine UPDATE-Anweisung ausgeführt wird.

Praktische Einführung: Eine Übung mit Java in der Datenbank
92

93
K A P I T E L 4
Java in der Datenbank benutzen
In diesem Kapitel wird beschrieben, wie Sie Java-Klassen und Objekte IhrerDatenbank hinzufügen und wie Sie diese Objekte in einer relationalenDatenbank einsetzen.
Thema Seite
Einleitung 94
Datenbank für Java aktivieren 97
Java-Klassen in einer Datenbank installieren 103
Spalten für die Aufnahme von Java-Objekten erstellen 109
Java-Objekte einfügen, aktualisieren und löschen 111
Java-Objekte abfragen 117
Java-Felder und Objekte vergleichen 119
Besondere Funktionen von Java-Klassen in der Datenbank 123
So werden Java-Objekte gespeichert 130
Java-Datenbankdesign 133
Berechnete Spalten mit Java-Klassen verwenden 137
Speicher für Java konfigurieren 140
Vor den Beispielen in diesem Kapitel müssen Sie die DateiSamples\ASA\Java\jdemo.sql in Ihrem SQL Anywhere-Verzeichnisausführen.
$ Weitere Hinweise und vollständige Anweisungen finden Sie unter"Java-Beispiele einrichten" auf Seite 94.
Über diesesKapitel
Inhalt
Bevor Siebeginnen

Einleitung
94
EinleitungDieses Kapitel erläutert, wie Sie Aufgaben mit Java in der Datenbankausführen:
♦ Datenbank für Java aktivieren Sie müssen bestimmte Maßnahmentreffen, damit Ihre Datenbank für die Arbeit mit Java aktiviert wird.
♦ Java-Klassen installieren Sie müssen Java-Klassen in einer Datenbankinstallieren, damit sie für Aufgaben auf dem Server zur Verfügungstehen.
♦ Eigenschaften der Java-Spalten Dieser Abschnitt erläutert, wieSpalten mit Java-Klassen-Datentypen in das relationaleDatenbankmodell passen.
♦ Datenbankdesign für Java In diesem Abschnitt werden Tipps für dasDesign von Datenbanken gegeben, die Java-Klassen benutzen.
Java-Beispiele einrichten
Viele Beispiele in diesem Kapitel werden mit einer Gruppe von Klassen undTabellen ausgeführt, die der Beispieldatenbank hinzugefügt wurden. DieTabellen enthalten dieselben Daten wie Tabellen desselben Namens in derBeispieldatenbank, nur gehören sie einem Benutzer namens jdba. Siebenutzen Java-Klassen-Datentypen anstelle von einfachen relationalenTypen für die Daten. Das Beispiel finden Sie im UnterverzeichnisSamples\ASA\Java Ihres SQL Anywhere-Verzeichnisses.
Beispieltabellen sind nur für die praktische Einführung gedachtDie Beispieltabellen sollen unterschiedliche Java-Funktionen darstellen.Sie sind keinesfalls als Muster für das Design Ihrer Datenbank zuempfehlen. Überlegen Sie sich die konkreten Anforderungen in IhremDatenbanksystem, wenn Sie ermitteln wollen, an welchen Stellen Java-Datentypen und andere Java-Merkmale in die Datenbank eingebautwerden sollen.
Die Java-Beispiele werden in zwei Schritten eingerichtet:
1 Aktivieren Sie die Beispieldatenbank für Java.
2 Fügen Sie die Java-Beispielklassen und –tabellen hinzu.

Kapitel 4 Java in der Datenbank benutzen
95
v So wird die Beispieldatenbank für Java aktiviert:
1 Starten Sie Interactive SQL und stellen Sie eine Verbindung mit derBeispieldatenbank her.
2 Geben Sie im Fensterausschnitt "SQL-Anweisungen" in Interactive SQLdie folgende Anweisung ein.
ALTER DATABASE UPGRADE JAVA JDK ’1.3’
3 Schließen Sie Interactive SQL und die Beispieldatenbank.
Die Beispieldatenbank asademo.db muss zunächst heruntergefahrenwerden, damit Sie die Java-Funktionen benutzen können.
v So fügen Sie Java-Klassen und Tabellen der Beispieldatenbankhinzu:
1 Starten Sie Interactive SQL und stellen Sie eine Verbindung mit derBeispieldatenbank her.
2 Geben Sie im Fensterausschnitt "SQL-Anweisungen" in Interactive SQLdie folgende Anweisung ein:
READ "Suchpfad\\Samples\\ASA\\Java\\jdemo.sql"
wobei Suchpfad Ihr SQL Anywhere-Verzeichnis ist. Damit werden dieInstruktionen in der Befehlsdatei jdemo.sql ausgeführt. DieInstruktionen benötigen eventuell einige Zeit, bis sie abgeschlossen sind.
Sie können das Skript Samples\ASA\Java\jdemo.sql mit einem Texteditoröffnen. Es führt folgende Programmschritte aus:
1 Es installiert die Klasse JDBCExamples.
2 Es erstellt einen Benutzer namens JDBA mit dem Kennwort SQL undDBA-Berechtigung, und setzt den aktuellen Benutzer als JDBA ein.
3 Es installiert eine JAR-Datei namens asademo.jar. Diese Datei enthältdie Klassendefinitionen, die in den Tabellen verwendet werden.
4 Es erstellt die folgenden Tabellen unter der Benutzer-ID JDBA:
♦ product
♦ contact
♦ customer
♦ employee
♦ sales_order
♦ sales_order_items

Einleitung
96
Dies ist eine Teilmenge der Tabellen in der Beispieldatenbank.
5 Es fügt die Daten aus den Standardtabellen mit identischen Namen indie Java-Tabellen ein. Dieser Verfahrensschritt benutzt INSERT- undSELECT-Anweisungen. Dieser Schritt kann einige Zeit in Anspruchnehmen.
6 Es erstellt einige Indizes und Fremdschlüssel, um dem SchemaIntegritätsregeln hinzuzufügen.
Laufzeitumgebung für Java verwalten
Die Laufzeitumgebung für Java besteht aus folgenden Komponenten:
♦ Sybase Java Virtual Machine Die VM läuft im Datenbankserver,interpretiert kompilierte Java-Klassen und führt sie aus.
♦ Integrierte Java-Klassen Wenn Sie eine Datenbank erstellen, wird eineSerie von Java-Klassen für die Datenbank verfügbar. Für Java-Anwendungen in der Datenbank müssen diese Klassen fehlerfreifunktionieren.
Um eine Laufzeitumgebung für Java bereitzustellen, müssen Sie folgendeAufgaben durchführen:
♦ Datenbank für Java aktivieren Bei dieser Aufgabe müssen Sie dieVerfügbarkeit von integrierten Klassen und das Upgrade auf Standardsder Version 8 prüfen.
$ Weitere Hinweise finden Sie unter "Datenbank für Java aktivieren"auf Seite 97.
♦ Installieren Sie andere Klassen, die die Benutzer brauchen ImVerlauf dieser Aufgabe sorgen Sie dafür, dass andere Klassen als dieLaufzeitklassen installiert werden und auf dem letzten Stand sind.
$ Weitere Hinweise finden Sie unter "Java-Klassen in einerDatenbank installieren" auf Seite 103.
♦ Konfiguration des Servers Sie müssen Ihren Server so konfigurieren,dass der erforderliche Speicher für das Ausführen von Java-Aufgabenvorhanden ist.
$ Weitere Hinweise finden Sie unter "Speicher für Javakonfigurieren" auf Seite 140.
Sie können alle diese Aufgaben aus Sybase Central oder Interactive SQLausführen.
Aufgaben bei derVerwaltung vonJava
Tools zumVerwalten vonJava

Kapitel 4 Java in der Datenbank benutzen
97
Datenbank für Java aktivierenDie Adaptive Server Anywhere Laufzeitumgebung für Java benötigt eineJava VM und die Java-Laufzeitklassen von Sybase. Erst nachdem Sie eineDatenbank für Java aktiviert haben, können Sie sie mit Java-Laufzeitklassenbenutzen.
Java in der Datenbank ist eine separat lizenzierte Komponente vonSQL Anywhere Studio.
Neue Datenbanken sind standardmäßig nicht für Java aktiviertStandardmäßig ist eine Datenbank nicht für Java aktiviert, wenn Sie sie inAdaptive Server Anywhere neu erstellen.
Java ist eine Programmiersprache mit einer Einzelhierarchie. Das bedeutet,dass alle Klassen, die Sie erstellen oder benutzen, von einer Klasse erben.Das bedeutet weiterhin, dass die Klassen der niedrigsten Ebene (also in derHierarchie weiter oben angesiedelt) vorhanden sein müssen, bevor Klassender oberen Ebene benutzt werden können. Die Basisgruppe dererforderlichen Klassen für Java-Anwendungen wird als Laufzeit-Java-Klassen oder Java-API bezeichnet.
Durch das Bereitstellen einer Datenbank für Java werden in dieSystemtabellen zahlreiche Einträge eingefügt. Dies vergrößert die Datenbankund erfordert rund 200 KByte mehr Speicher zum Ausführen der Datenbank,auch wenn Sie keine Java-Funktionen verwenden.
Wenn Sie Java nicht verwenden werden und eine Umgebung mit begrenzterSpeicherkapazität haben, sollten Sie die Datenbank nicht für Java aktivieren.
Die Java-Laufzeitklassen für Sybase
Die Java-Laufzeitklassen für Sybase befinden sich auf der Festplatte, undnicht in der Datenbank wie andere Klassen. Die folgenden Dateien enthaltendie Java-Laufzeitklassen für Sybase. Sie werden im Unterverzeichnis JavaIhres SQL Anywhere-Verzeichnisses gespeichert.
♦ 1.1\classes.zip Diese Datei, lizenziert von Sun Microsystems, enthälteinen Teil der Java-Laufzeitklassen für JDK 1.1.8 von SunMicrosystems.
♦ 1.3\rt.jar Diese Datei, lizenziert von Sun Microsystems, enthält einenTeil der Java-Laufzeitklassen für JDK 1.3 von Sun Microsystems.
Java-Aktivierungder Datenbankmanchmal nichterforderlich

Datenbank für Java aktivieren
98
♦ asajdbc.zip Diese Datei enthält interne JDBC-Treiber-Klassen vonSybase für JDK 1.1.
♦ asajrt12.zip Diese Datei enthält interne JDBC-Treiber-Klassen vonSybase für JDK 1.2 und JDK 1.3.
Wenn Sie eine Datenbank für Java aktivieren, werden die Systemtabellen miteiner Liste verfügbarer Klassen aus den System-JAR-Dateien aktualisiert.Sie können dann die Klassenhierarchie aus Sybase Central durchsuchen, dieKlassen selbst aber sind in der Datenbank nicht vorhanden.
Die Datenbank speichert Laufzeit-Klassennamen unter folgenden JAR-Dateien:
♦ ASAJRT Klassennamen aus asajdbc.zip werden hier gespeichert.
♦ ASAJDBCDRV Klassennamen aus jdbcdrv.zip werden hier gespeichert.
♦ ASASystem Klassennamen aus classes.zip werden hier gespeichert.
Diese Laufzeitklassen enthalten die folgenden Pakete:
♦ java Die hier gespeicherten Pakete sind die unterstützten Java-Laufzeitklassen von Sun Microsystems.
$ Eine Liste der unterstützten Java-Laufzeitklassen finden Sie unter"Unterstützte Java-Pakete" auf Seite 87 der Dokumentation ASA SQL-Referenzhandbuch.
♦ com.sybase Die hier gespeicherten Pakete bieten serverseitige JDBC-Unterstützung.
♦ sun Sun Microsystems bietet die hier gespeicherten Pakete an.
♦ sybase.sql Die hier gespeicherten Pakete sind Teil der serverseitigenJDBC-Unterstützung von Sybase.
Vorsicht: Installieren Sie keine Klassen von einer anderenVersion des Sun JDKKlassen im Sun JDK haben identische Namen wie die Java-Laufzeitklassen für Sybase, die in jeder Datenbank installiert werdenmüssen, in denen Java-Vorgänge ausgeführt werden sollen.
Sie dürfen die Datei classes.zip, die mit Adaptive Server Anywheremitgeliefert wird, nicht ersetzen. Wenn Sie eine andere Version dieserKlassen verwenden, könnten sich daraus Kompatibilitätsprobleme mit derSybase Java Virtual Machine ergeben.
Eine Aktivierung einer Datenbank für Java dürfen Sie nur so vornehmen,wie dies in diesem Abschnitt beschrieben wird.
JAR-Dateien
Installierte Pakete

Kapitel 4 Java in der Datenbank benutzen
99
Methoden zur Java-Aktivierung einer Datenbank
Sie können Datenbanken bei der Erstellung, beim Upgrade oder zu einemspäteren Zeitpunkt in einem separaten Vorgang für Java aktivieren.
Sie können eine für Java aktivierte Datenbank wie folgt erstellen:
♦ Benutzen Sie die Anweisung CREATE DATABASE.
$ Hinweise zur Syntax finden Sie unter "CREATE DATABASE-Anweisung" auf Seite 298 der Dokumentation ASA SQL-Referenzhandbuch.
♦ Benutzen Sie das Dienstprogramm dbinit.
$ Hinweise finden Sie unter "Datenbank mit demBefehlszeilenprogramm ""dbinit"" erstellen" auf Seite 516 derDokumentation ASA Datenbankadministration.
♦ Sybase Central
$ Hinweise finden Sie unter "Datenbank erstellen" auf Seite 31 derDokumentation ASA SQL-Benutzerhandbuch.
Ein Upgrade einer Datenbank auf eine für Java aktivierte Datenbank derVersion 8 können Sie wie folgt durchführen:
♦ Benutzen Sie die Anweisung ALTER DATABASE.
$ Hinweise zur Syntax finden Sie unter "ALTER DATABASE-Anweisung" auf Seite 224 der Dokumentation ASA SQL-Referenzhandbuch.
♦ Benutzen Sie das Upgrade-Dienstprogramm dbupgrad.exe.
$ Hinweise finden Sie unter "Upgrade einer Datenbank mit demBefehlszeilenprogramm ""dbupgrad""" auf Seite 583 der DokumentationASA Datenbankadministration.
♦ Sybase Central.
$ Weitere Hinweise finden Sie unter "Datenbank für Java aktivieren"auf Seite 101.
Wenn Sie Java in der Datenbank nicht installieren, bleiben alleDatenbankvorgänge, die keine Java-Vorgänge einschließen, vollfunktionsfähig und laufen wie vorgesehen ab.
Datenbankenerstellen
Upgrade einerDatenbank

Datenbank für Java aktivieren
100
Neue Datenbanken und Java
Die Java-Laufzeitklassen für Sybase werden bei Adaptive Server Anywherestandardmäßig nicht jedesmal installiert, wenn Sie eine Datenbank erstellen.Die Installation dieser separat zu lizenzierenden Komponente ist fakultativund wird über die Methode gesteuert, mit der Sie die Datenbank erstellen.
Die SQL-Anweisung CREATE DATABASE hat eine Option namens JAVA.Wenn Sie die Datenbank für Java aktivieren wollen, setzen Sie diese Optionauf ON. Wenn Sie Java deaktivieren wollen, setzen Sie die Option auf OFF.Standardmäßig ist die Option auf OFF gesetzt.
Beispielsweise erstellt die folgende Anweisung eine Datei für eine Java-aktivierte Datenbank namens temp.db:
CREATE DATABASE ’c:\\sybase\\asa8\\temp’ JAVA ON
Die folgende Anweisung erstellt eine Datenbankdatei temp2.db, die Javanicht unterstützt:
CREATE DATABASE ’c:\\sybase\\asa8\\temp2’
Datenbanken können mit dem Dienstprogramm dbinit.exe erstellt werden.Das Dienstprogramm verfügt über Parameter, mit denen gesteuert wird, obdie Java-Laufzeitklassen in der neu installierten Datenbank installiertwerden. Standardmäßig werden diese Klassen nicht installiert.
Die gleichen Optionen sind verfügbar, wenn Sie eine Datenbank mit SybaseCentral erstellen.
Upgrade von Datenbanken und Java
Für vorhandene Datenbanken, die mit früheren Versionen der Softwareerstellt wurden, kann ein Upgrade durchgeführt werden, und zwar mit demDienstprogramm für den Datenbank-Upgrade oder mit der AnweisungALTER DATABASE.
Das Upgrade für Datenbanken auf den Standard von Adaptive ServerAnywhere Version 8 erfolgt mit dem Dienstprogramm dbupgrad.exe. DerParameter –jr verhindert die Installation der Java-Laufzeitklassen vonSybase.
$ Hinweise über die Bedingungen für das Einbeziehen von Java in dieUpgrade-Datenbank finden Sie unter "Upgrade einer Datenbank mit demBefehlszeilenprogramm ""dbupgrad""" auf Seite 583 der DokumentationASA Datenbankadministration.
CREATEDATABASE-Optionen
Dienstprogrammfür dieInitialisierung derDatenbank
Dienstprogrammfür das Datenbank-Upgrade

Kapitel 4 Java in der Datenbank benutzen
101
Datenbank für Java aktivieren
Wenn Sie eine Datenbank erstellt oder ein Upgrade einer Datenbankdurchgeführt, dabei aber die Option so gesetzt haben, dass die Datenbanknicht für Java aktiviert wurde, können Sie die erforderlichen Java-Klassenüber Sybase Central oder Interactive SQL auch zu einem späteren Zeitpunkthinzufügen.
v Um der Datenbank die Java-Laufzeitklassen für Sybasehinzuzufügen, gehen Sie wie folgt vor (Sybase Central):
1 Stellen Sie von Sybase Central aus als Benutzer mit DBA-Berechtigungeine Verbindung her.
2 Rechtsklicken Sie auf die Datenbank und wählen Sie "Upgrade einerDatenbank".
3 Klicken Sie auf der einführenden Seite des Assistenten auf "Weiter".
4 Wählen Sie die Datenbank, für die das Upgrade vorgenommen werdensoll, aus der Liste aus.
5 Sie können gegebenenfalls eine Sicherungskopie der Datenbank anlegenlassen. Klicken Sie auf "Weiter".
6 Falls erwünscht, kann jConnect-Metadaten-Unterstützung installiertwerden. Klicken Sie auf "Weiter"
7 Wählen Sie die Option "Java-Unterstützung installieren". Sie müssenaußerdem die Version des JDK festlegen, die installiert werden soll. DieStandardklassen sind JDK 1.3-Klassen. Für Version 7.x-Datenbankensind die Standardklassen JDK 1.1.8-Klassen.
8 Befolgen Sie die restlichen Anweisungen im Assistenten.
v Um die Java-Laufzeitklassen für Sybase der Datenbankhinzuzufügen, gehen Sie wie folgt vor (Interactive SQL):
1 Verbinden Sie sich mit der Datenbank aus Interactive SQL als Benutzermit DBA-Berechtigung.
2 Führen Sie folgende Anweisung aus:
ALTER DATABASE UPGRADE JAVA ON
$ Weitere Hinweise finden Sie unter "ALTER DATABASE-Anweisung" auf Seite 224 der Dokumentation ASA SQL-Referenzhandbuch.
3 Starten Sie die Datenbank neu, damit die Java-Unterstützung wirksamwird.

Datenbank für Java aktivieren
102
Mit Sybase Central eine Datenbank für Java aktivieren
Sie können Sybase Central für die Erstellung von Datenbanken überAssistenten benutzen. Während der Erstellung oder des Upgrades einerDatenbank fordert der Assistent Sie auf, auszuwählen, ob die Java-Laufzeitklassen für Sybase installiert werden. Standardmäßig ist dieseOption so gesetzt, dass die Datenbank für Java aktiviert wird.
Die Erstellung oder das Upgrade einer Datenbank werden in Sybase Centralwie folgt vorgenommen:
♦ Wählen Sie "Datenbank erstellen" aus dem Ordner "Dienstprogramme".
♦ Wählen Sie "Upgrade einer Datenbank" aus dem Ordner"Dienstprogramme", wenn Sie eine Datenbank von einer früherenVersion der Software auf eine Datenbank mit Java-Funktionen umstellenwollen.

Kapitel 4 Java in der Datenbank benutzen
103
Java-Klassen in einer Datenbank installierenBevor Sie eine Java-Klasse in einer Datenbank installieren, müssen Sie siekompilieren. Sie haben mehrere Methoden zur Auswahl, um Java-Klassen zuinstallieren:
♦ Einzelne Klasse Sie können eine einzelne Klasse in einer Datenbankaus einer kompilierten Klassendatei installieren. Klassendateien habennormalerweise die Erweiterung .class.
♦ JAR-Datei Sie können eine Serie von Klassen auf einmal installieren,wenn sie in einer komprimierten oder unkomprimierten JAR-Dateizusammengefasst sind. JAR-Dateien haben normalerweise dieErweiterung .jar oder .zip. Adaptive Server Anywhere unterstützt allekomprimierten JAR-Dateien, die mit dem SUN-JAR-Dienstprogramm,sowie anderen JAR-Kompressionsschemata, erstellt werden.
Dieser Abschnitt beschreibt, wie Java-Klassen installiert werden, nachdemSie sie kompiliert haben. Sie müssen über die DBA-Berechtigung verfügen,um eine Klasse oder eine JAR-Datei zu installieren.
Klasse erstellen
Die Details der einzelnen Schritte können zwar unterschiedlich sein, wennein Java-Entwicklungstool wie Sybase PowerJ verwendet wird, grundsätzlichsind aber für die Erstellung eigener Klassen die nachfolgend beschriebenenSchritte erforderlich.
v So erstellen Sie eine Klasse:
1 Definieren Sie Ihre Klasse Schreiben Sie den Java-Code, der IhreKlasse definiert. Wenn Sie den Sun Java SDK benutzen, können Sieeinen Texteditor verwenden. Wenn Sie ein Entwicklungstool wie SybasePowerJ benutzen, finden Sie entsprechende Anweisungen imEntwicklungstool.
Verwenden Sie nur unterstützte KlassenWenn Ihre Klasse Java-Laufzeitklassen benutzt, müssen Sie daraufachten, dass sie sich in der Liste der unterstützten Klassen befinden.Die Liste finden Sie unter "Unterstützte Java-Pakete" auf Seite 87 derDokumentation ASA SQL-Referenzhandbuch.
Benutzerklassen müssen 100% Java sein. Native Methoden sind nichtzulässig.

Java-Klassen in einer Datenbank installieren
104
2 Benennen und speichern Sie Ihre Klasse Speichern Sie IhreKlassendeklaration (Java-Code) in einer Datei mit der Erweiterung .java.Achten Sie darauf, dass der Name der Datei mit dem Namen der Klasseübereinstimmt, und dass die Groß-/Kleinschreibung beider Namenidentisch ist.
Beispiel: Eine Klasse namens "Dienstprogramm" muss in einer Dateinamens Dienstprogramm.java gespeichert werden.
3 Kompilieren Sie Ihre Klasse Mit diesem Schritt wird dieKlassendeklaration mit dem Java-Code in eine neue, eigene Dateiverwandelt, die Byte-Code enthält. Der Name der neuen Datei ist gleichlautend mit dem Namen der Java-Codedatei, hat aber die Erweiterung.class. Eine kompilierte Java-Klasse kann in einer Java-Laufzeitumgebung unabhängig von der Plattform ausgeführt werden, aufder sie kompiliert wurde. Auch das Betriebssystem der Java-Laufzeitumgebung spielt keine Rolle.
Der Sun JDK enthält den Java-Compiler Javac.exe.
Nur für Java aktivierte DatenbankenJede kompilierte Java-Klassendatei kann in einer Datenbankinstalliert werden. Java-Vorgänge, die eine installierte Klasseverwenden, können nur ausgeführt werden, wenn die Datenbank fürJava aktiviert wurde. Siehe unter "Datenbank für Java aktivieren" aufSeite 97.
Klasse installieren
Um Ihre Java-Klasse innerhalb der Datenbank verfügbar zu machen, könnenSie eine Klasse aus Sybase Central einrichten oder mit der AnweisungINSTALL aus Interactive SQL oder einer anderen Anwendung installieren.Sie müssen den Suchpfad und den Dateinamen der Klasse kennen, die Sieinstallieren wollen.
Sie brauchen die DBA-Berechtigung, um eine Klasse zu installieren.
v So installieren Sie eine Klasse (Sybase Central):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Öffnen Sie den Ordner "Java-Objekte" für die Datenbank.
3 Doppelklicken Sie auf "Java-Klasse hinzufügen".
4 Befolgen Sie die Anweisungen im Assistenten.

Kapitel 4 Java in der Datenbank benutzen
105
v So installieren Sie eine Klasse (Interactive SQL):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Führen Sie folgende Anweisung aus:
INSTALL JAVA NEWFROM FILE ’Suchpfad\\Klassenname.class’
Dabei gilt: Suchpfad ist das Verzeichnis, in dem die Klassendateigehalten wird, und Klassenname.class ist der Name der Klassendatei.
Der doppelte Rückstrich sorgt dafür, dass der Rückstrich nicht alsEscapezeichen behandelt wird.
Beispiel: Um eine Klasse zu installieren, die in einer Datei namensDienstprogramm.class im Verzeichnis c:\Quelle gehalten wird, geben Siefolgende Anweisung ein:
INSTALL JAVA NEW
FROM FILE ’c:\\Quelle\\Dienstprogramm.class’
Wenn Sie einen relativen Suchpfad verwenden, muss er zum aktuellenArbeitsverzeichnis des Datenbankservers relativ sein.
$ Weitere Hinweise finden Sie unter "INSTALL-Anweisung" aufSeite 504 der Dokumentation ASA SQL-Referenzhandbuch und unter"Java-Objekte, Klassen und JAR-Dateien löschen" auf Seite 116.
JAR-Datei installieren
Es ist sinnvoll und allgemein üblich, Gruppen von miteinander verwandtenKlassen in Paketen zu sammeln und diese Pakete in einer JAR-Dateizusammenzufassen. Informationen über JAR-Dateien und Pakete finden Sieim Online-Buch Thinking in Java oder anderer Literatur zum Thema Java-Programmierung.
Eine JAR-Datei wird auf dieselbe Weise installiert wie eine Klassendatei.Eine JAR-Datei kann die Erweiterung JAR oder ZIP haben. Jede JAR-Dateimuss einen Namen in der Datenbank haben. Normalerweise benutzen Siedenselben Namen wie die JAR-Datei, ohne die Erweiterung. Beispiel: WennSie eine JAR-Datei namens meinejar.zip installieren, sollten Sie ihr imAllgemeinen den JAR-Namen meinejar geben.
$ Weitere Hinweise finden Sie unter "INSTALL-Anweisung" aufSeite 504 der Dokumentation ASA SQL-Referenzhandbuch und "Java-Objekte, Klassen und JAR-Dateien löschen" auf Seite 116.

Java-Klassen in einer Datenbank installieren
106
v So installieren Sie eine JAR-Datei (Sybase Central):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Öffnen Sie den Ordner "Java-Objekte" für die Datenbank.
3 Doppelklicken Sie auf "JAR-Datei hinzufügen".
4 Befolgen Sie die Anweisungen im Assistenten.
v So installieren Sie eine JAR-Datei (Interactive SQL):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Geben Sie folgende Anweisung ein:
INSTALL JAVA NEWJAR ’jarname’FROM FILE ’Suchpfad\\JarName.jar’
Klassen und JAR-Dateien aktualisieren
Sie können Klassen und JAR-Dateien mit Sybase Central oder durch dieEingabe einer INSTALL-Anweisung in Interactive SQL bzw. einer anderenClientanwendung installieren.
Um eine Klasse oder eine JAR-Datei zu installieren, müssen Sie DBA-Berechtigung haben und über eine neuere Version der kompilierten Klasseoder JAR-Datei in einer Datei auf der Festplatte verfügen.
Es kann sein, dass Instanzen einer Java-Klasse in Form von Java-Objekten inIhrer Datenbank oder als Werte in einer Spalte gespeichert sind, die dieKlasse als Datentyp verwendet.
Trotz der Aktualisierung der Klasse bleiben diese alten Werte weiterhinverfügbar, auch wenn die Felder und Methoden, die in den Tabellengespeichert werden, mit der neuen Klassendefinition inkompatibel sind.
Alle neu eingefügten Zeilen müssen allerdings mit der neuen Definitionkompatibel sein.
Die neue Definition wird nur von Verbindungen benutzt, die nach derInstallation der Klasse eingerichtet wurden, oder die die Klasse zum erstenMal nach der Installation der Klasse verwenden. Wenn die Virtual Machinedie Klassendefinition lädt, bleibt diese im Speicher, bis die Verbindunggeschlossen wird.
Bestehende Java-Objekte undaktualisierteKlassen
GültigkeitaktualisierterKlassen

Kapitel 4 Java in der Datenbank benutzen
107
Wenn Sie eine Java-Klasse oder auf einer Klasse basierende Objekte in deraktuellen Verbindung benutzt haben, müssen Sie die Verbindung trennenund wieder aufnehmen, damit die neue Klassendefinition wirksam wird.
$ Um zu verstehen, wie aktualisierte Klassen wirksam werden, müssenSie mehr über die Arbeitsweise der Virtual Machine wissen. Hinweise dazufinden Sie unter "Speicher für Java konfigurieren" auf Seite 140.
Java-Objekte können die aktualisierte Klassendefinition verwenden, weil siein serialisierter Form gespeichert werden. Das benutzteSerialisierungsformat ist speziell für die Datenbank entworfen und entsprichtnicht dem Serialisierungsformat von Sun Microsystems. Die interne SybaseVM führt alle Serialisierungen und Deserialisierungen durch, sodass dadurchkeine Kompatibilitätsprobleme entstehen.
v So aktualisieren Sie eine Klasse oder JAR-Datei (Sybase Central):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Öffnen Sie den Ordner "Java-Objekte".
3 Suchen Sie die Klasse oder JAR-Datei, die Sie aktualisieren wollen.
4 Rechtsklicken Sie auf die Klasse oder JAR-Datei und wählen Sie"Aktualisieren" aus dem Einblendmenü.
5 In dem nun eingeblendeten Dialogfeld geben Sie den Namen und denStandort der Klasse oder JAR-Datei ein, die Sie aktualisieren wollen. Siekönnen mit "Durchsuchen" danach suchen.
TippSie können eine Java-Klasse oder JAR-Datei auch aktualisieren, indemSie im Register "Allgemein" ihres Eigenschaftsfensters auf "Jetztaktualisieren" klicken.
v So aktualisieren Sie eine Klasse oder JAR-Datei (Interactive SQL):
1 Stellen Sie mit DBA-Berechtigung eine Verbindung mit einerDatenbank her.
2 Führen Sie folgende Anweisung aus:
INSTALL JAVA UPDATE[ JAR ’jarname’ ]FROM FILE ’Dateiname’
Wenn Sie eine JAR-Datei aktualisieren, müssen Sie den Nameneingeben, unter dem die JAR in der Datenbank bekannt ist.
In serialisierterForm gespeicherteObjekte

Java-Klassen in einer Datenbank installieren
108
$ Weitere Hinweise finden Sie unter "INSTALL-Anweisung" aufSeite 504 der Dokumentation ASA SQL-Referenzhandbuch.

Kapitel 4 Java in der Datenbank benutzen
109
Spalten für die Aufnahme von Java-Objektenerstellen
Dieser Abschnitt erläutert, wie Spalten mit Datentypen der Java-Klassen indie standardmäßige SQL-Struktur passen.
Spalten mit Java-Datentypen erstellen
Sie können jede installierte Java-Klasse als Datentyp benutzen. Sie müsseneinen voll qualifizierten Namen für den Datentyp verwenden.
Beispiel: Die folgende Anweisung CREATE TABLE enthält Spalten derJava-Datentypen asademo.Name und asademo.ContactInfo. Hier sindName und ContactInfo Klassen im Paket asademo.
CREATE TABLE jdba.customer(
id integer NOT NULL,company_name CHAR(35) NOT NULL,JName asademo.Name NOT NULL,JContactInfo asademo.ContactInfo NOT NULL,PRIMARY KEY (id)
)
Anders als bei SQL-Datentypen berücksichtigen Java-Datentypen die Groß-/Kleinschreibung. Sie müssen die Datentypen immer in der richtigenSchreibweise eingeben.
Standardwerte und NULLWERTE in Java-Spalten verwenden
Sie können Standardwerte für Java-Spalten verwenden, und Java-Spaltenkönnen NULLWERTE enthalten.
Java-Spalten und Standardwerte Spalten können als Standardwert jedeFunktion mit dem richtigen Datentyp oder einen beliebigen voreingestelltenStandardwert enthalten. Sie können jede Funktion mit dem richtigenDatentyp (d.h. derselben Klasse wie die Spalte) als Standardwert für Java-Spalten verwenden.
Java-Spalten und NULLWERTE Java-Spalten können NULLWERTEzulassen. Wenn für eine nullwertfähige Spalte mit einem Java-Datentyp keinStandardwert gesetzt ist, enthält die Spalte NULL.
Berücksichtigungvon Groß-/Klein-schreibung

Spalten für die Aufnahme von Java-Objekten erstellen
110
Wenn ein Java-Wert nicht gesetzt ist, hat er den Java-NULLWERT. DieserJava-NULLWERT ist dem SQL-NULLWERT zugeordnet, und Sie könnendaher die Suchbedingungen IS NULL und IS NOT NULL für diese Werteverwenden. Beispiel: Wenn die Beschreibung des Java-Objekts "product" ineiner Spalte namens JProd nicht gesetzt wurde, können Sie alle Produkte mitNicht-Nullwerten für die Beschreibung wie folgt abrufen:
SELECT *FROM productWHERE JProd>>description IS NULL

Kapitel 4 Java in der Datenbank benutzen
111
Java-Objekte einfügen, aktualisieren undlöschen
In diesem Abschnitt wird beschrieben, wie Standard-SQL-Anweisungen fürdie Datenverarbeitung auf Java-Spalten angewendet werden.
In diesem Abschnitt werden die einzelnen Punkte mit konkreten Beispielenillustriert, die auf der Tabelle Product der Beispieldatenbank und einerKlasse namens Product basieren. Als Erstes sollten Sie sich die DateiSamples\ASA\Java\asademo\Product.java in Ihrem SQL Anywhere-Verzeichnis ansehen.
Die Beispiele in diesem Abschnitt setzen voraus, dass Sie die Java-Tabellender Beispieldatenbank hinzugefügt haben und als Benutzer jDBA mit demKennwort SQL verbunden sind.
$ Weitere Hinweise finden Sie unter "Java-Beispiele einrichten" aufSeite 94.
Eine Beispielklasse
In diesem Abschnitt wird eine Klasse beschrieben, die in Beispielen allerfolgenden Abschnitte verwendet wird.
Die Klassendefinition Product im VerzeichnisSamples\ASA\Java\asademo\Product.java in Ihrem SQL Anywhere-Verzeichnis wird teilweise im Folgenden dargestellt (zum besserenVerständnis werden die Kommentarzeilen, die in der Originaldatei inEnglisch sind, hier in deutscher Übersetzung wiedergegeben):
package asademo;
public class Product implements java.io.Serializable {
// "public"-Felder public String name ; public String description ; public String size ; public String color; public int quantity ; public java.math.BigDecimal unit_price ;
// Standard-Konstruktor Product () {
unit_price = new java.math.BigDecimal( 10.00 );name = "Unknown";size = "One size fits all";
Java-Beispiel-Tabellen erstellen

Java-Objekte einfügen, aktualisieren und löschen
112
}
// Konstruktor mit allen verfügbaren Argumenten Product ( String inColor,
String inDescription, String inName, int inQuantity, String inSize, java.math.BigDecimal inUnit_price ) {
color = inColor; description = inDescription; name = inName; quantity = inQuantity; size = inSize; unit_price=inUnit_price; }
public String toString() { return size + " " + name + ": " + unit_price.toString(); }
♦ Die Klasse Product hat einige öffentliche Felder, die einigen Spaltender Tabelle DBA.Product entsprechen, die in dieser Klasse gesammeltwerden sollen.
♦ Die Methode toString wird der Einfachheit halber bereitgestellt. WennSie einen Objektnamen in eine Auswahlliste einbeziehen, wird dieMethode toString ausgeführt, und ihre Rückgabezeichenfolgen werdenangezeigt.
♦ Einige Methoden sind vorgesehen, um die Felder zu setzen undabzurufen. Es ist beim objektorientierten Programmieren auch allgemeinüblich, solche Methoden zu verwenden, und nicht die Felder direkt zuadressieren. Für die praktische Einführung wurden die Felder zureinfacheren Durchführung als "öffentliche" Felder zugänglich gemacht.
Java-Objekte einfügen
Wenn Sie eine Zeile in eine Tabelle EINFÜGEN, die eine Java-Spalte hat,müssen Sie ein Java-Objekt in die Java-Spalte einfügen.
Sie können ein Java-Objekt auf zwei Arten einfügen: aus SQL oder mitJDBC aus anderen Java-Klassen, die in der Datenbank ausgeführt werden.
Hinweise

Kapitel 4 Java in der Datenbank benutzen
113
Java-Objekte aus SQL einfügen
Sie können ein Java-Objekt mit einem Konstruktor einfügen oder SQL-Variable verwenden, um ein Java-Objekt aufzubauen, bevor Sie es einfügen.
Wenn Sie einen Wert in eine Spalte einfügen, die einen Java-Klassen-Datentyp hat, fügen Sie ein Java-Objekt ein. Um ein Objekt mit den richtigenEigenschaften einzufügen, muss das neue Objekt die richtigen Werte füröffentliche Felder haben, und Methoden, die private Felder setzen, müssenaufgerufen werden.
v So fügen Sie ein Java-Objekt ein:
♦ INSERT: Verwenden Sie die INSERT-Anweisung, um eine neueInstanz der Klasse "Product" in die Tabelle product einzufügen:
INSERTINTO product ( ID, JProd )VALUES ( 702, NEW asademo.Product() )
Sie können dieses Beispiel in der Beispieldatenbank als Benutzer jdbaausführen, nachdem Sie das Skript jdemo.sql ausgeführt haben.
Das Schlüsselwort NEW ruft den Standard-Konstruktor für die KlasseProduct im Paket asademo auf.
Sie können die Werte der Felder des Objekts in einer SQL-Variablen derrichtigen Klasse auch individuell setzen, und nicht durch den Konstruktor.
v So fügen Sie ein Java-Objekt mit SQL-Variablen ein:
1 Erstellen Sie eine SQL-Variable der Java-Klassentypen:
CREATE VARIABLE ProductVar asademo.Product
2 Weisen Sie der Variablen ein neues Objekt zu, indem Sie denKlassenkonstruktor verwenden:
SET ProductVar = NEW asademo.Product()
3 Weisen Sie den Feldern des Objekts Werte zu, wo solche erforderlichsind:
SET ProductVar>>color = ’Black’;SET ProductVar>>description = ’Steel tipped boots’;SET ProductVar>>name = ’Work boots’;SET ProductVar>>quantity = 40;SET ProductVar>>size = ’Extra Large’;SET ProductVar>>unit_price = 79.99;
4 Fügen Sie die Variable in die Tabelle ein:
INSERTINTO Product ( id, JProd )
Objekt mit einemKonstruktoreinfügen
Objekt aus einerSQL-Variableneinfügen

Java-Objekte einfügen, aktualisieren und löschen
114
VALUES ( 800, ProductVar )
5 Prüfen Sie, ob der Wert eingefügt wurde:
SELECT *FROM productWHERE id=800
6 Machen Sie die Änderungen rückgängig, die Sie in dieser Übungvorgenommen haben:
ROLLBACK
Die Verwendung von SQL-Variablen ist typisch für gespeicherte Prozedurenund andere Verwendungsmöglichkeiten von SQL zum Einbau vonprogrammierter Logik in die Datenbank. Java ist die leistungsfähigereSprache für solche Aufgaben. Sie können die serverseitigen Java-Klassengemeinsam mit JDBC verwenden, um Objekte in Tabellen einzufügen.
Objekt aus Java einfügen
Sie können ein Objekt mit einer vorbereiteten Anweisung von JDBCeinfügen.
Eine vorbereitete Anweisung benutzt Platzhalter für Variable. Sie könnendann die Methode setObject des Objekts PreparedStatement benutzen.
Sie können vorbereitete Anweisungen verwenden, um Objekte vonclientseitiger oder serverseitiger JDBC einzufügen.
$ Weitere Hinweise über die Verwendung von vorbereitetenAnweisungen für Objekte finden Sie unter "Objekte einfügen und abrufen"auf Seite 172.
Java-Objekt aktualisieren
Java-Spaltenwerte können mit einer der folgenden Methoden aktualisiertwerden:
♦ Gesamtes Objekt aktualisieren
♦ Einige der Felder im Objekt aktualisieren
Für die Aktualisierung des Objekts gehen Sie fast genauso vor wie für dasEinfügen:
♦ Aus SQL können Sie einen Konstruktor verwenden, um das Objekt aufein neues Objekt zu aktualisieren, wenn der Konstruktor es erstellt. Siekönnen dann einzelne Felder aktualisieren, wenn Sie dies benötigen.
Gesamtes Objektaktualisieren

Kapitel 4 Java in der Datenbank benutzen
115
♦ Aus SQL können Sie eine SQL-Variable verwenden, um das benötigteObjekt aufzunehmen, und dann die Zeile aktualisieren, damit dieVariable darin eingefügt wird.
♦ Aus JDBC können Sie eine vorbereitete Anweisung und die MethodePreparedStatement.setObject verwenden.
Einzelne Felder eines Objekts haben Datentypen, die SQL-Datentypenentsprechen. Dabei verwenden Sie die Zuordnung von SQL- zu Java-Datentypen laut der Beschreibung unter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95 der Dokumentation ASA SQL-Referenzhandbuch.
Sie können einzelne Felder mit einer Standard-UPDATE-Anweisungaktualisieren:
UPDATE ProductSET JProd.unit_price = 16.00WHERE ID = 302
In der ersten Version von Java in der Datenbank musste eine spezielleFunktion (EVALUATE) verwendet werden, um Aktualisierungenvorzunehmen. Dies ist nicht mehr erforderlich.
Damit ein Java-Feld aktualisiert werden kann, muss der Java-Typ des Feldeseinem SQL-Typ zugeordnet sein: Der Ausdruck auf der rechten Seite derSET-Klausel muss mit diesem Typ übereinstimmen. Sie müssen eventuelldie CAST-Funktion verwenden, um die Datentypen entsprechendeinzuordnen.
$ Hinweise zur Datentypzuordnung zwischen Java und SQL finden Sieunter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95 derDokumentation ASA SQL-Referenzhandbuch.
Bei der Java-Programmmierung ist es allgemein üblich, Felder nicht direktanzusprechen, sondern Methoden zu benutzen, um die Werte zu holen und zusetzen. Außerdem ist es allgemein üblich, dass diese Methoden voidzurückgeben. Sie können in SQL set-Methoden verwenden, um eine Spaltezu aktualisieren:
UPDATE jdba.ProductSET JProd.setName( ’Tank Top’)WHERE id=302
Der Einsatz von Methoden anstelle der direkten Ansprache des Feldes istlangsamer, da die Java VM laufen muss.
$ Weitere Hinweise finden Sie unter "Rückgabewert von Methoden, die"void" zurückgeben" auf Seite 125.
Felder des Objektsaktualisieren
set-Methodenverwenden

Java-Objekte einfügen, aktualisieren und löschen
116
Java-Objekte, Klassen und JAR-Dateien löschen
Das Löschen von Zeilen mit Java-Objekten unterscheidet sich nicht vomLöschen anderer Zeilen. Die WHERE-Klausel in der DELETE-Anweisungkann Java-Objekte oder Java-Felder und Methoden enthalten.
$ Weitere Hinweise finden Sie unter "DELETE-Anweisung" aufSeite 422 der Dokumentation ASA SQL-Referenzhandbuch.
Mit Sybase Central können Sie auch eine ganze Java-Klasse oder JAR-Dateilöschen.
v So löchen Sie eine Java-Klasse oder JAR-Datei (Sybase Central):
1 Öffnen Sie den Ordner "Java-Objekte".
2 Suchen Sie die Klasse oder JAR-Datei, die Sie löschen wollen.
3 Rechtsklicken Sie auf die Klasse oder JAR-Datei und wählen Sie"Löschen" aus dem Einblendmenü.
$ Siehe auch:
♦ "Klasse installieren" auf Seite 104
♦ "JAR-Datei installieren" auf Seite 105

Kapitel 4 Java in der Datenbank benutzen
117
Java-Objekte abfragenJava-Spaltenwerte können mit einer der folgenden Methoden abgefragtwerden:
♦ Gesamtes Objekt abfragen
♦ Einige der Felder im Objekt abfragen
Aus SQL können Sie eine Variable des geeigneten Typs erstellen und denWert aus dem Objekt in diese Variable auswählen. Vor allem aber werdenSie das ganze Objekt in einer Java-Anwendung brauchen.
Sie können ein Objekt in eine serverseitige Java-Klasse abrufen, indem Siedie Methode getObject des ResultSet einer Abfrage verwenden. Sie könnenauch ein Objekt in eine clientseitige Java-Anwendung abrufen.
$ Wie Objekte mit JDBC abgerufen werden, finden Sie unter "Abfragenmit JDBC" auf Seite 169.
Einzelne Felder eines Objekts haben Datentypen, die SQL-Datentypenentsprechen. Dabei verwenden Sie die Zuordnung von SQL- zu Java-Datentypen laut der Beschreibung unter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95 der Dokumentation ASA SQL-Referenzhandbuch.
♦ Sie können einzelne Felder abrufen, indem Sie sie in die Auswahllisteeiner Abfrage einschließen, wie dies im folgenden einfachen Beispielbeschrieben wird.
SELECT JProd>>unit_priceFROM productWHERE ID = 400
♦ Wenn Sie Methoden verwenden, um die Werte Ihrer Felder zu setzenund abzurufen, wie es beim objektorientierten Programmieren allgemeinüblich ist, können Sie eine Methode getField in Ihre Abfrageeinbeziehen.
SELECT JProd>>getName()FROM ProductWHERE ID = 401
$ Informationen über die Verwendung von Objekten in der WHERE-Klausel und andere Hinweise zum Vergleich von Objekten finden Sie unter"Java-Felder und Objekte vergleichen" auf Seite 119.
Gesamtes Objektabfragen
Felder des Objektsabrufen

Java-Objekte abfragen
118
Performance-TippDas direkte Abrufen eines Feldes ist schneller als der Aufruf einerMethode, die das Feld abruft, da für den Aufruf der Methode die Java VMgestartet werden muss.
Sie können den Spaltennamen in einer Abfrage-Auswahlliste auflisten, wiein der folgenden Abfrage:
SELECT JProdFROM jdba.product
Die Abfrage gibt die Sun-Serialisierung des Objekts an die Clientanwendungzurück.
Wenn Sie in Interactive SQL eine Abfrage ausführen, die ein Objekt abruft,wird der Rückgabewert der toString-Methode des Objekts angezeigt. Für dieKlasse "Product" listet die Methode toString in einer Zeichenfolge dieGröße, den Namen und den Stückpreis des Objekts auf. Die Ergebnisse derAbfrage lauten wie folgt:
JProd
Small Tee Shirt: 9.00
Medium Tee Shirt: 14.00
One size fits all Tee Shirt: 14.00
One size fits all Baseball Cap: 9.00
One size fits all Baseball Cap: 10.00
One size fits all Visor: 7.00
One size fits all Visor: 7.00
Large Sweatshirt: 24.00
Large Sweatshirt: 24.00
Medium Shorts: 15.00
Die Ergebnisse derAnweisungSELECTSpaltenname

Kapitel 4 Java in der Datenbank benutzen
119
Java-Felder und Objekte vergleichenÖffentliche Java-Klassen sind Domänen, die viel umfangreichere Funktionenbieten als herkömmliche SQL-Domänen. In diesem Zusammenhang ergibtsich die Frage, wie sich Java-Spalten in einer relationalen Datenbank imVergleich zu traditionellen SQL-Datentypen verhalten.
Die Frage des Vergleichs von Objekten hat Auswirkungen insbesondere infolgenden Bereichen:
♦ Abfragen mit einer ORDER BY Klausel, einer GROUP BY Klausel,einem DISTINCT Schlüsselwort oder mit einer Aggregatfunktion
♦ Anweisungen, die Gleichheits- oder Ungleichheits-Vergleichsbedingungen verwenden
♦ Indizes und eindeutige Spalten
♦ Primär- und Fremdschlüsselspalten
Sortieren von Zeilen in einer Abfrage oder in einem Index setzt voraus, dassdie Werte in jeder Zeile miteinander verglichen werden. Wenn Sie eine Java-Spalte haben, können Sie Vergleiche in der folgenden Weise ausführen:
♦ Vergleich über ein öffentliches Feld Sie können über ein öffentlichesFeld genauso einen Vergleich vornehmen wie über eine normale Zeile.Beispielsweise könnten Sie folgende Abfrage ausführen:
SELECT name, JProd.unit_priceFROM ProductORDER BY JProd.unit_price
Diese Art des Vergleichs kann in Abfragen verwendet werden, ist aberfür Indizes und Schlüsselspalten nicht anwendbar.
♦ Vergleich mit einer "compareTo"-Methode Java-Objekte, die einecompareTo-Methode implementiert haben, können verglichen werden.Die Klasse "Product", auf der die Spalte JProd basiert, hat einecompareTo-Methode, die Objekte auf Grundlage des Feldes unit_pricemiteinander vergleicht. Damit wird folgende Abfrage ermöglicht:
SELECT name, JProd.unit_priceFROM ProductORDER BY JProd
Der benötigte Vergleich für die ORDER BY Klausel erfolgt automatischbasierend auf der Methode compareTo.
Art des Vergleichsvon Java-Objekten

Java-Felder und Objekte vergleichen
120
Java-Objekte vergleichen
Um zwei Objekte desselben Typs zu vergleichen, müssen Sie einecompareTo-Methode implementieren:
♦ Damit Spalten mit Java-Datentypen als Primärschlüssel, Indizes odereindeutige Spalten verwendet werden können, muss die Spaltenklasseeine compareTo-Methode implementieren.
♦ Um die Klauseln ORDER BY, GROUP BY oder DISTINCT in einerAbfrage verwenden zu können, müssen die Werte der Spalte verglichenwerden. Die Spaltenklasse muss eine compareTo-Methode haben,damit alle diese Klauseln gültig sind.
♦ Funktionen, die Vergleiche verwenden, wie MAX und MIN, können nurmit einer Java-Klasse benutzt werden, die eine compareTo-Methodehat.
Die compareTo-Methode muss folgende Eigenschaften haben:
♦ Bereich Die Methode muss extern sichtbar und daher eine öffentlicheMethode sein.
♦ Argumente Die Methode übernimmt ein einzelnes Argument, das einObjekt des aktuellen Typs ist. Das aktuelle Objekt wird mit demgelieferten Objekt verglichen. Beispiel: Product.compareTo hatfolgendes Argument:
compareTo( Produkt AnderesProdukt )
Die Methode vergleicht das Objekt AnderesProdukt vom Typ"Produkt" mit dem aktuellen Objekt.
♦ Rückgabewerte Die Methode "compareTo" muss einen int-Datentypmit folgenden Bedeutungen zurückgeben:
♦ Negative Ganzzahl Das aktuelle Objekt ist geringer als dasgelieferte Objekt. Es wird empfohlen, dass Sie für diesen Fall -1zurückgeben, um die Kompatibilität mit "compareTo"-Methoden inBasis-Java-Klassen zu gewährleisten.
♦ Ziffer Null Das aktuelle Objekt hat denselben Wert wie dasgelieferte Objekt.
♦ Positive Ganzzahl Das aktuelle Objekt ist größer als das gelieferteObjekt. Es wird empfohlen, dass Sie für diesen Fall 1 zurückgeben,um die Kompatibilität mit "compareTo"-Methoden in Basis-Java-Klassen zu gewährleisten.
Die Klasse Product, die mit den Beispielklassen in der Beispieldatenbankinstalliert wird, hat eine compareTo-Methode der folgenden Art:
Anforderungen der"compareTo"-Methode
Beispiel

Kapitel 4 Java in der Datenbank benutzen
121
public int compareTo( Product anotherProduct ) { // Erst auf Basis des Preises vergleichen // und dann auf Basis von toString() int lVal = unit_price.intValue(); int rVal = anotherProduct.unit_price.intValue(); if ( lVal > rVal ) { return 1; } else if (lVal < rVal ) { return -1; } else { return toString().compareTo(anotherProduct.toString() );{ } } }
Diese Methode vergleicht den Einheitspreis jedes Objekts. Wenn dieEinheitspreise identisch sind, werden die Namen verglichen (mit Java-Zeichenfolgenvergleichen, nicht mit Datenbank-Zeichenfolgenvergleichen).Nur wenn der Einheitspreis und der Name gleich sind, werden die beidenObjekte beim Vergleich als identisch angesehen.
Wenn Sie eine Java-Spalte in die Auswahlliste einbeziehen und in InteractiveSQL ausführen, wird der Wert der Methode toString zurückgegeben. WennSie Spalten vergleichen, wird die Methode compareTo verwendet. Wenn dieMethoden toString und compareTo nicht konsistent implementiert sind,kann es zu unvorhergesehenen Ergebnissen kommen, wie DISTINCT-Abfragen, die augenscheinlich Duplikat-Zeilen zurückgeben.
Als Beispiel nehmen wir an, dass die Klasse "Product" in derBeispieldatenbank eine Methode toString hat, die den Produktnamenzurückgibt, und eine Methode compareTo, die auf dem Preis basiert. Diefolgende, in Interactive SQL eingegebene Abfrage würde in diesem FallDoppelwerte ausgeben:
SELECT DISTINCT JProdFROM product
JProd
Tee Shirt
Tee Shirt
Baseball Cap
Visor
Sweatshirt
Shorts
Methoden"toString" und"compareTo"kompatibelmachen

Java-Felder und Objekte vergleichen
122
Hier wird der angezeigte Rückgabewert durch toString festgelegt. DasDISTINCT-Schlüsselwort eliminiert Duplikate, wie von compareTofestgelegt. Da hier eine Implementierung der Methoden vorliegt, die dieBeziehungen untereinander nicht berücksichtigt, sieht es so aus, als würdenDuplikatzeilen zurückgegeben.

Kapitel 4 Java in der Datenbank benutzen
123
Besondere Funktionen von Java-Klassen in derDatenbank
In diesem Abschnitt werden besondere Funktionen von Java-Klassenbeschrieben, die in einer Datenbank eingesetzt werden.
Unterstützte Klassen
Sie können nicht alle Klassen aus dem JDK verwenden. Die Java-Laufzeitklassen, die für den Einsatz in einem Datenbankserver verfügbarsind, gehören zu einer Teilmenge der Java-API.
$ Weitere Hinweise über unterstützte Pakete finden Sie unter"Unterstützte Java-Pakete" auf Seite 87 der Dokumentation ASA SQL-Referenzhandbuch.
Hauptmethode (main) verwenden
Sie starten Java-Anwendungen (außerhalb der Datenbank), indem Sie dieJava VM mit einer Klasse ausführen, die eine main-Methode hat.
Zum Beispiel hat die Klasse JDBCExamples in der DateiSamples\ASA\Java\JDBCExamples.java in Ihrem SQL Anywhere-Verzeichnis eine Hauptmethode (main). Wenn Sie die Klasse von derBefehlszeile aus mit einem Befehl wie dem folgenden ausführen, wird dieHauptmethode (main) ausgeführt:
java JDBCExamples
$ Hinweise über das Ausführen der Klasse JDBCExamples finden Sieunter "JDBC-Verbindungen herstellen" auf Seite 157.
v So wird die Hauptmethode (main) einer Klasse von SQL ausaufgerufen:
1 Deklarieren Sie die Methode mit einem Array von Zeichenfolgen alsArgument.
public static void main( java.lang.String[] args ){...}
2 Rufen Sie die Methode main mit der CALL-Anweisung auf.

Besondere Funktionen von Java-Klassen in der Datenbank
124
Jedes Mitglied des Arrays von Zeichenfolgen muss den Datentyp CHARoder VARCHAR haben oder muss ein Literal sein.
Die folgende Klasse enthält eine main-Methode, die die Argumente inumgekehrter Reihenfolge ausgibt:
public class ReverseWrite { public static void main( String[] args ){ int i: for( i = args.length; i > 0 ; i-- ){ System.out.print( args[ i-1 ] ); } }}
Sie können diese Methode aus SQL wie folgt ausführen:
call ReverseWrite.main( ’ one’, ’ two’, ’three’ )
Das Datenbankserver-Fenster zeigt die Ausgabe:
three two one
Threads in Java-Anwendungen verwenden
Sie können mehrere Threads in einer Java-Anwendung benutzen, indem SieFunktionen des Pakets java.lang.Thread einsetzen. Jeder Java-Thread ist einEngine-Thread und wird aus der Menge der zulässigen Threads gemäß derOption -gn des Datenbankservers bezogen.
Sie können Threads in Java-Anwendungen synchronisieren, vorläufigaussetzen, wieder aufnehmen, unterbrechen oder stoppen.
$ Hinweise zu Datenbankserver-Threads finden Sie unter "–gn-Serveroption" auf Seite 158 der Dokumentation ASADatenbankadministration.
Alle Aufrufe zum serverseitigen JDBC-Treiber sind serialisiert, sodass nurein Thread jeweils JDBC ausführt.
Fehler "Prozedur nicht gefunden"
Wenn Sie eine falsche Anzahl von Argumenten für den Aufruf einer Java-Methode eingeben oder einen falschen Datentyp verwenden, antwortet derServer mit der Fehlermeldung Prozedur nicht gefunden. Prüfen Sie in diesemFall Anzahl und Typ der Argumente.
Beispiel
Serialisierung vonJDBC-Aufrufen

Kapitel 4 Java in der Datenbank benutzen
125
$ Eine Liste der Datentypkonvertierungen zwischen SQL und Java findenSie unter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95 derDokumentation ASA SQL-Referenzhandbuch.
Rückgabewert von Methoden, die "void" zurückgeben
Sie können Java-Methoden in SQL-Anweisungen überall dort verwenden,wo Sie einen Ausdruck benutzen können. Sie müssen dafür Sorge tragen,dass der Rückgabe-Datentyp der Java-Methode zum entsprechenden SQL-Datentyp passt.
$ Weitere Hinweise über Zuordnungen von Java- und SQL-Datentypenfinden Sie unter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95der Dokumentation ASA SQL-Referenzhandbuch.
Wenn eine Methode jedoch eine leere Menge zurückgibt, wird der Wert thisan SQL zurückgegeben, d.h. das Objekt selbst. Die Funktion betrifft nurAufrufe, die von SQL aus ausgeführt werden, nicht von Java aus.
Diese Funktion ist besonders gut in UPDATE-Anweisungen einsetzbar, indenen set-Methoden in der Regel "void" zurückgeben. Sie können diefolgende UPDATE-Anweisung in der Beispieldatenbank benutzen:
update jdba.productset JProd = JProd.setName(’Tank Top’)where id=302
Die Methode setName gibt "void" und daher implizit das Objekt "Product"an SQL zurück.
Ergebnismengen aus Java-Methoden zurückgeben
Dieser Abschnitt beschreibt, wie Ergebnismengen aus Java-Methodenverfügbar gemacht werden. Sie müssen eine Java-Methode schreiben, dieeine Ergebnismenge an die aufrufende Umgebung zurückgibt, und dieseMethode in eine in SQL geschriebene gespeicherte Prozedur einbauen, dieals EXTERNAL NAME of LANGUAGE JAVA deklariert sein muss.
v So werden Ergebnismengen aus einer Java-Methodezurückgegeben:
1 Achten Sie darauf, dass die Java-Methode als öffentlich und statisch ineiner öffentlichen Klasse deklariert wird.
2 Für jede Ergebnismenge, die die Methode zurückgeben soll, muss dieMethode einen Parameter vom Typ java.sql.ResultSet[] haben. DieseErgebnismengen-Parameter müssen am Ende der Parameterliste stehen.

Besondere Funktionen von Java-Klassen in der Datenbank
126
3 In der Methode erstellen Sie erst eine Instanz von java.sql.ResultSetund ordnen sie dann einem der ResultSet[]-Parameter zu.
4 Erstellen Sie eine in SQL geschriebene gespeicherte Prozedur des TypsEXTERNAL NAME LANGUAGE JAVA. Dieser Prozedurtyp ist einMantel für eine Java-Methode. Sie können einen Cursor für dieErgebnismenge der SQL-Prozedur auf dieselbe Weise verwenden wiejede andere Prozedur, die Ergebnismengen zurückgibt.
$ Hinweise zur Syntax für gespeicherte Prozeduren, die als Mantelfür Java-Methoden verwendet werden, finden Sie unter "CREATEPROCEDURE-Anweisung" auf Seite 331 der Dokumentation ASA SQL-Referenzhandbuch.
Die folgende Beispielklasse hat eine einzige Methode, die eine Abfrageausführt und die Ergebnismenge an die aufrufende Umgebung zurückgibt.
import java.sql.*;
public class MyResultSet { public static void return_rset( ResultSet[] rset1 ) throws SQLException { Connection conn = DriverManager.getConnection( "jdbc:default:connection" ); Statement stmt = conn.createStatement(); ResultSet rset = stmt.executeQuery ( "SELECT CAST( JName.lastName " + "AS CHAR( 50 ) )" + "FROM jdba.contact " ); rset1[0] = rset; }}
Die Ergebnismenge wird in SQL mit der Anweisung CREATEPROCEDURE exponiert, womit die Anzahl der von der Prozedurzurückgegebenen Ergebnismengen und die Signatur der Java-Methodeangezeigt werden.
Eine Anweisung vom Typ CREATE PROCEDURE, die eine Ergebnismengeanzeigt, könnte wie folgt definiert werden:
CREATE PROCEDURE result_set() DYNAMIC RESULT SETS 1 EXTERNAL NAME ’MyResultSet.return_rset ([Ljava/sql/ResultSet;)V’ LANGUAGE JAVA
Ein Cursor kann für diese Prozedur genauso wie für andere ASA-Prozedurengeöffnet werden, die Ergebnismengen zurückgeben.
Beispiel

Kapitel 4 Java in der Datenbank benutzen
127
Die Zeichenfolge (Ljava/sql/ResultSet;)V ist eine Java-Methodensignatur,also eine kompakte Zeichendarstellung der Anzahl und der Typen derParameter und Rückgabewerte.
$ Weitere Hinweise zu Java-Methodensignaturen finden Sie unter"CREATE PROCEDURE-Anweisung" auf Seite 331 der DokumentationASA SQL-Referenzhandbuch.
Rückgabe von Werten aus Java über gespeicherte Prozeduren
Sie können gespeicherte Prozeduren, die mit EXTERNAL NAMELANGUAGE JAVA erstellt wurden, als Mantel für Java-Methodenverwenden. In diesem Abschnitt wird beschrieben, wie Sie Ihre Java-Methode so schreiben, dass OUT- oder INOUT-Parameter in dergespeicherten Prozedur benutzt werden können.
Java hat keine explizite Unterstützung für INOUT- oder OUT-Parameter.Anstelle dessen können Sie ein Array des Parameters verwenden. Beispiel:Um einen Ganzzahl-OUT-Parameter zu benutzen, erstellen Sie ein Array vongenau einer Ganzzahl:
public class TestClass { public static boolean testOut( int[] param ){ param[0] = 123; return true; }}
Die folgende Prozedur benutzt die testOut-Methode:
CREATE PROCEDURE sp_testOut ( OUT p INTEGER )EXTERNAL NAME ’TestClass/testOut ([I)Z’LANGUAGE JAVA
Die Zeichenfolge ([I)Z ist eine Java-Methodensignatur, die anzeigt, dass dieMethode einen einzelnen Parameter hat, der ein Array von Ganzzahlendarstellt und einen Boolschen Wert zurückgibt. Sie müssen die Methoden sodefinieren, damit der Methodenparameter, den Sie als OUT- oder INOUT-Parameter verwenden wollen, ein Array eines Java-Datentyps ist, der demSQL-Datentyp des OUT- oder INOUT-Parameters entspricht.
$ Hinweise zur Syntax, einschließlich der Methodensignatur, finden Sieunter "CREATE PROCEDURE-Anweisung" auf Seite 331 derDokumentation ASA SQL-Referenzhandbuch.
$ Weitere Hinweise finden Sie unter "Umwandlung von JAVA- in SQL-Datentypen" auf Seite 95 der Dokumentation ASA SQL-Referenzhandbuch.

Besondere Funktionen von Java-Klassen in der Datenbank
128
Sicherheits-Management für Java
Java bietet Sicherheits-Manager, die Sie zur Steuerung des Benutzerzugriffsauf vertrauliche Funktionen Ihrer Anwendungen, wie etwa Dateizugriff undNetzwerkzugriff, einsetzen können. Adaptive Server Anywhere bietet diefolgende Unterstützung für Java-Sicherheitsmanager in der Datenbank:
♦ Adaptive Server Anywhere liefert einen standardmäßigen Sicherheits-Manager.
♦ Sie können Ihren eigenen Sicherheitsmanager stellen.
$ Hinweise dazu finden Sie unter "Eigenen Sicherheits-Managerimplementieren" auf Seite 129.
Der standardmäßige Sicherheits-Manager ist die Klassecom.sybase.asa.jrt.SAGenericSecurityManager. Er führt die folgendenAufgaben durch:
1 Er prüft den Wert der Datenbankoption JAVA_INPUT_OUTPUT.
2 Er prüft, ob der Datenbankserver mit der Datenbankserveroption -sc imC2-Sicherheitsmodus gestartet wurde.
3 Falls die Verbindungseigenschaft auf OFF steht, wird damit der Zugriffauf Java-Datei-I/O-Funktionen deaktiviert.
4 Wenn der Datenbankserver im C2-Sicherheitsmodus läuft, wird derZugriff auf java.net-Pakete verwehrt.
5 Wenn der Sicherheits-Manager einen Benutzer am Zugriff auf eineFunktion hindert, wird eine java.lang.SecurityExceptionzurückgegeben.
$ Weitere Hinweise finden Sie unter "JAVA_INPUT_OUTPUT-Option"auf Seite 642 der Dokumentation ASA Datenbankadministration, und "–sc-Serveroption" auf Seite 167 der Dokumentation ASADatenbankadministration.
Die Java-Datei-I/O-Vorgänge werden über die DatenbankoptionJAVA_INPUT_OUTPUT gesteuert. Standardmäßig wird diese Option aufOFF gesetzt, sodass Datei-I/O-Vorgänge nicht zulässig sind.
v So wird der Dateizugriff mit dem standardmäßigen Sicherheits-Manager zugelassen:
♦ Setzen Sie die Option JAVA_INPUT_OUTPUT auf ON:
SET OPTION JAVA_INPUT_OUTPUT=’ON’
Der Standard-Sicherheits-Manager
Java-Datei-I/O-Vorgänge mit demstandardmäßigenSicherheits-Manager steuern

Kapitel 4 Java in der Datenbank benutzen
129
Eigenen Sicherheits-Manager implementieren
Ein eigener Sicherheits-Manager wird mit mehreren Schritten implementiert.
v So wird Ihr eigener Sicherheits-Manager verfügbar gemacht:
1 Implementieren Sie eine Klasse, die java.lang.SecurityManagererweitert.
Die Klasse SecurityManager umfasst eine Reihe von Methoden, dieprüfen, ob ein bestimmter Vorgang zulässig ist. Falls die Aktion zulässigist, kehrt die Methode stillschweigend zurück. Falls die Methode einenWert zurückgibt, wird eine SecurityException ausgegeben.
Sie müssen Methoden aufheben, die Aktionen mit stillschweigendzurückkehrenden Methoden steuern. Sie können dies durchImplementieren einer Methode public void erreichen.
2 Ordnen Sie Ihrem Sicherheits-Manager die betreffenden Benutzer zu.
Verwenden Sie die gespeicherten Systemprozedurenadd_user_security_manager, update_user_security_manager unddelete_user_security_manager, um einem Benutzer Sicherheits-Manager zuzuordnen. Wenn Sie z.B. die KlasseMeinSicherheitsManager einem Benutzer als Sicherheits-Managerzuordnen wollen, würden Sie den folgenden Befehl ausführen.
call dbo.add_user_security_manager( Benutzername, ’MeinSicherheitsManager’, NULL )
Mit der folgenden Klasse können Sie das Lesen aus Dateien zulassen, jedochdas Schreiben untersagen:
public class MeinSicherheitsManager extendsSecurityManager{ public void checkRead(FileDescriptor) {} public void checkRead(String) {} public void checkRead(String, Object) {}}
Die Methoden SecurityManager.checkWrite werden nicht aufgehoben undverhindern Schreibvorgänge in den Dateien. Die Methoden checkReadkehren stillschweigend zurück und lassen die Aktion zu.
Beispiel

So werden Java-Objekte gespeichert
130
So werden Java-Objekte gespeichertJava-Werte werden in serialisierter Form gespeichert. Das bedeutet, dassjede Zeile folgende Informationen enthält:
♦ Einen Versionsbezeichner
♦ Einen Bezeichner für die Klasse (oder Unterklasse), die gespeichert wird
♦ Die Werte von nicht-statischen, nicht-zeitweiligen Feldern in der Klasse
♦ Andere Overhead-Informationen
Die Klassendefinition wird nicht für jede Zeile gespeichert. Anstelle dessenenthält der Bezeichner eine Referenz auf die Klassendefinition, die nureinmal gehalten wird.
Sie können Java-Objekte verwenden, ohne im Detail zu wissen, wie dieseElemente zusammenwirken, aber die Art der Speicherung dieser Objekte hateinige Auswirkungen auf die Verarbeitungsleistung. Daher werden dieseInformationen hier etwas genauer ausgeführt.
♦ Plattenspeicher Der Overhead pro Zeile ist 10 bis 15 Byte. Falls dieKlasse nur über eine Variable verfügt, kann der erforderliche Overheaddem für die Variable ähneln. Falls die Klasse viele Variablen umfasst,kann der Overhead vernachlässigt werden.
♦ Performance Wenn Sie einen Java-Wert einfügen oder aktualisieren,muss die Java VM ihn serialisieren. Jedes Mal, wenn ein Java-Wert ineiner Abfrage abgerufen wird, muss er von der VM deserialisiertwerden. Dies kann bedeutende Performanceeinbußen verursachen.
Sie können die Performanceeinbußen für Abfragen vermeiden, indemSie berechnete Spalten verwenden.
♦ Indizieren Indizes auf Java-Spalten sind nicht sehr selektiv und bietennicht die Performancevorteile wie Indizes auf einfachen SQL-Datentypen.
♦ Serialisierung Wenn eine Klasse eine readObject- oder writeObject-Methode hat, wird diese beim Serialisieren oder Deserialisieren derInstanz aufgerufen. Der Einsatz einer readObject- oder writeObject-Methode kann sich auf die Performance auswirken, weil die Java VMaufgerufen wird.
Hinweise

Kapitel 4 Java in der Datenbank benutzen
131
Java-Objekte und Klassenversionen
Java-Objekte, die in der Datenbank gespeichert werden, sind beständig - d.h.sie bestehen, auch wenn kein Programmcode läuft. Das bedeutet, dass Siefolgende Aktionen ausführen können:
1 Installieren Sie eine Klasse.
2 Tabelle mit dieser Klasse als Datentyp für eine Spalte erstellen
3 Zeilen in die Tabelle einfügen
4 Neue Version der Klasse installieren
Funktionsweise der bestehenden Zeilen mit der neuen Version der Klasse
Adaptive Server Anywhere sieht eine Form der Evidenzhaltung vonKlassenversionen vor, die es ermöglicht, dass die neue Klasse mit den altenZeilen arbeiten kann. Die Regeln für den Zugriff auf diese älteren Wertelauten wie folgt:
♦ Wenn ein serialisierbares Feld in der alten Version der Klasse vorhandenist, aber in der neuen Version fehlt oder nicht serialisierbar ist, wird dasFeld ignoriert.
♦ Wenn ein serialisierbares Feld in der neuen Version der Klassevorhanden ist, aber in der alten Version fehlt oder nicht serialisierbarwar, wird das Feld auf einen Standardwert initialisiert. Der Standardwertist 0 für native Typen, "false" für Boolesche Werte, und "NULL" fürObjektreferenzen.
♦ Wenn eine Überklasse der alten Version vorhanden war, die nicht eineÜberklasse der neuen Version ist, werden die Daten für diese Überklasseignoriert.
♦ Wenn eine Überklasse der neuen Version vorhanden ist, die nicht eineÜberklasse der alten Version war, werden die Daten für dieseÜberklasse auf Standardwerte initialisiert.
♦ Wenn ein serialisierbares Feld zwischen der älteren Version und derneueren Version den Typ ändert, wird das Feld auf Standardwerteinitialisiert. Typenkonvertierungen werden nicht unterstützt - dies istkompatibel mit der Sun Microsystems-Serialisierung.
Ein serialisiertes Objekt ist nicht zugänglich, wenn die Klasse des Objektsoder eine ihrer Überklassen zu irgendeinem Zeitpunkt aus der Datenbankentfernt wurde. Dieses Verhalten ist kompatibel mit der Sun Microsystems-Serialisierung.
Zugriff auf Zeilen,wenn eine Klasseaktualisiert wird
UnzugänglicheObjekte

So werden Java-Objekte gespeichert
132
Diese Änderungen machen die Verschiebung von Objekten zwischenDatenbanken möglich, auch wenn die Versionen der Klassen voneinanderabweichen. Die Verschiebung über Datenbanken kann wie nachstehendbeschrieben erfolgen:
♦ Objekte werden in eine entfernte Datenbank verlegt.
♦ Eine Tabelle mit Objekten wird entladen und dann in eine andereDatenbank eingelesen.
♦ Eine Logdatei mit Objekten wird übersetzt und in einer anderenDatenbank angewendet.
Die Klassendefinition für jede Klasse wird durch die VM jeder Verbindunggeladen, wenn die Klasse zum ersten Mal benutzt wird.
Wenn Sie eine Klasse installieren, wird die VM auf Ihrer Verbindungimplizit gestartet. Daher haben Sie sofort Zugang zu der neuen Klasse.
Für andere Verbindungen als diejenige, die die INSTALL-Anweisungausführt, wird die neue Klasse das nächste Mal geladen, wenn die VM aufdie Klasse zugreift. Wenn die Klasse von einer VM bereits geladen ist, siehtdiese Verbindung die neue Klasse erst, wenn die VM für diese Verbindungneu gestartet wird (zum Beispiel mit STOP JAVA und START JAVA).
Objekte zwischenDatenbankenverschieben
Wann die neueKlasse benutztwird

Kapitel 4 Java in der Datenbank benutzen
133
Java-DatenbankdesignFür das Design Ihrer relationalen Datenbanken gibt es einen umfangreichentheoretischen und praktischen Erfahrungsschatz. Sie können Beschreibungenzum Design von Entitätsbeziehungen und andere Ansätze nicht nur ineinleitender Form (siehe "Planung Ihrer Datenbank" auf Seite 3 derDokumentation ASA SQL-Benutzerhandbuch), sondern auch in der Literaturfür fortgeschrittene Anwender finden.
Eine derartige Vielfalt ist für die Theorie und Praxis von objekt-relationalenDatenbanken nicht vorhanden, und dies gilt umso mehr für Java-relationaleDatenbanken. Im Folgenden finden Sie einige Vorschläge für den Einsatzvon Java zur Erweiterung des praktischen Einsatzes relationalerDatenbanken.
Entitäten und Attribute in relationalen und objektorientierten Daten
Beim Design relationaler Datenbanken beschreibt jede Tabelle eine Entität .Beispiel: In der Beispieldatenbank gibt es Tabellen mit dem NamenEmployee, Customer, Sales_order und Department. Die Attribute dieserEntitäten werden zu den Spalten der Tabelle: Adressen der Mitarbeiter,Kundennummern, Bestellnummern, und so weiter. Jede Zeile in der Tabellekann als getrennte Instanz der Entität bezeichnet werden - ein bestimmterMitarbeiter, eine Bestellung eine Abteilung.
Beim objektorientierten Programmieren beschreibt jede Klasse eine Entität,und die Methoden und Felder dieser Klasse beschreiben die Attribute derEntität. Jede Instanz der Klasse (jedes Objekt) enthält eine eigene Instanzder Entität.
Es scheint daher unnatürlich, dass relationale Spalten auf Java-Klassenbasieren. Eine natürlichere Entsprechung liegt zwischen Tabellen undKlassen vor.
Entitäten und Attribute in der realen Welt
Die Unterscheidung zwischen Entität und Attribut scheint klar, aber beinäherem Hinsehen zeigt sich, dass sie in der Praxis nicht ganz so eindeutigausfällt.
♦ Eine Adresse kann als Attribut eines Kunden gesehen werden, ist aberauch eine Entität, die als eigene Attribute die Straße, Stadt etc. hat.
♦ Ein Preis kann als Attribut eines Produkts gesehen werden, ist aber aucheine Entität mit den Attributen "Summe" und "Währung".

Java-Datenbankdesign
134
Der Sinn der objektrelationalen Datenbank ist genau in diesem Faktum zusuchen, nämlich dass es zwei Möglichkeiten gibt, Entitäten auszudrücken.Sie können einige Entitäten als Tabellen, und andere Entitäten als Klassen ineiner Tabelle ausdrücken. Im nächsten Abschnitt wird ein Beispiel erläutert.
Einschränkungen der relationalen Datenbanken
Stellen Sie sich ein Versicherungsunternehmen vor, das Überblick über seineKunden behalten will. Ein Kunde kann als Entität angesehen werden, sodasses sinnvoll ist, eine einzelne Tabelle zu entwerfen, in der alle Kunden derGesellschaft enthalten sind.
Nun werden aber von Versicherungsgesellschaften verschiedene Arten vonKunden betreut. Es gibt die Policeninhaber, die Begünstigten und Personen,die die Prämien zu bezahlen haben. Für alle diese Kundentypen benötigt dieVersicherungsgesellschaft verschiedene Informationen. Für denBegünstigten braucht sie eigentlich nicht viel mehr als die Adresse. Für denPoliceninhaber sind Informationen über den Gesundheitszustanderforderlich. Für den Prämienzahler braucht man zusätzlicheFinanzinformationen für die steuerlichen Aspekte.
Ist es besser, diese unterschiedlichen Kundentypen als unterschiedlicheEntitäten zu behandeln, oder als Attribut des Kunden? Bei beiden Ansätzengibt es Einschränkungen:
♦ Wenn für jeden Kundentyp eine eigene Tabelle eingerichtet wird, kanndas Datenbankdesign sehr unübersichtlich werden, und beim Abfragenvon Informationen zu allen Kunden müssen mehrere Tabellendurchsucht werden.
♦ Und wenn eine einzelne Kundentabelle verwendet wird, ist es nichteinfach, sicherzustellen, dass für jeden Kunden die richtigenInformationen eingegeben werden. Das Einrichten von Spalten, die füreinige Kunden nullwertfähig sind, für andere aber nicht, ermöglicht dierichtige Dateneingabe, erzwingt sie aber nicht. Es gibt in relationalenDatenbanken keine einfache Methode, das Standardverhalten an einAttribut der neuen Dateneingabe zu binden.
Mit Klassen bestimmte Einschränkungen relationaler Datenbankenüberwinden
Sie können eine einzelne Kundentabelle verwenden, wobei für einigeInformationen Java-Klassenspalten benutzt werden, um die Begrenzungenrelationaler Datenbanken zu überwinden.

Kapitel 4 Java in der Datenbank benutzen
135
Beispiel: Nehmen wir an, Sie brauchen für die Policeninhaber andereKontaktinformationen als für die Begünstigten. Sie können dieses Problemlösen, indem Sie eine Spalte definieren, die auf der KlasseKontaktinformation basiert. Dann definieren Sie Klassen mit den NamenPolicenhalterKontaktdaten und BegünstigterKontaktdaten, dieUnterklassen der Klasse Kontaktdaten sind. Indem Sie neue Kunden nachihrem Typ eingeben, können Sie sicherstellen, dass die richtigenInformationen eingegeben werden.
Abstraktionsebenen für relationale Daten
Daten in einer relationalen Datenbank können nach Zweck kategorisiertwerden. Welche Daten gehören in eine Java-Klasse, und welche solltenbesser in einer einfachen Datentyp-Spalte eingegeben werden?
♦ Spalten für die referenzielle Integrität Primärschlüsselspalten undFremdschlüsselspalten haben gemeinsame Identifizierungsnummern.Diese Identifizierungsnummern können als referenzielle Datenbezeichnet werden. Ihr Hauptzweck ist die Definition der Struktur derDatenbank und die Definition der Beziehungen zwischen Tabellen.
Referenzielle Daten gehören im Allgemeinen nicht in Java-Klassen.Obwohl Sie aus einer Java-Klassenspalte eine Primärschlüsselspaltemachen können, sind Ganzzahlen und andere einfache Datentypen fürdiesen Zweck besser geeignet.
♦ Indizierte Daten Spalten, die im Allgemeinen indiziert werden, werdenebenfalls nicht in Java-Klassen angelegt. Allerdings ist die Trennliniezwischen Daten, die indiziert werden sollen, und solchen, bei denen diesnicht erforderlich ist, eher unscharf.
Bei berechneten Spalten können Sie selektiv ein Java-Feld oder eineJava-Methode (bzw. auch einen anderen Ausdruck) indizieren. WennSie eine Java-Klassenspalte definieren und dann feststellen, dass essinnvoll wäre, sie auf ein Feld oder eine Methode dieser Spalte zuindizieren, können Sie berechnete Spalten verwenden, um aus diesemFeld oder dieser Methode eine eigene Spalte zu erstellen.
$ Weitere Hinweise finden Sie unter "Berechnete Spalten mit Java-Klassen verwenden" auf Seite 137.
♦ Beschreibende Daten In jeder Zeile gibt es im Allgemeinen auchbeschreibende Daten. Solche Daten werden für die referenzielleIntegrität nicht verwendet, meist nicht indiziert, aber häufig in Abfragenverwendet. Bei einer Mitarbeitertabelle können dies Daten wieEinstellungsdatum, Adresse, Vergünstigungen, Gehalt usw. sein. Fürdiese Daten kann es häufig von Vorteil sein, wenn sie in wenigerSpalten vom Typ Javaklasse kombiniert werden.

Java-Datenbankdesign
136
Java-Klassen sind für die Abstraktion auf einer Ebene zwischen der dereinzelnen relationalen Spalte und der relationalen Tabelle nützlich.

Kapitel 4 Java in der Datenbank benutzen
137
Berechnete Spalten mit Java-Klassenverwenden
Berechnete Spalten sind ein Merkmal, das entwickelt wurde, um das Designvon Java-Datenbanken einfacher zu gestalten, damit Java-Funktionen inbestehenden Datenbanken besser genutzt werden können, und um diePerformance von Java-Datentypen zu verbessern.
Eine berechnete Spalte ist eine Spalte, deren Werte aus anderen Spaltenausgewertet werden. Sie können in berechneten Spalten kein INSERT undkein UPDATE durchführen. Eine UPDATE-Anweisung, die versucht, denWert einer berechneten Spalte zu ändern, löst aber Trigger aus, die mit derSpalte verbunden sind.
Es gibt zwei Haupteinsatzgebiete für berechnete Spalten mit Java-Klassen:
♦ Java-Spalte aufgliedern Wenn Sie eine Spalte mit einem Java-Klassen-Datentyp erstellen, können Sie mit berechneten Spalten eines der Feldereiner Klasse indizieren. Sie können eine berechnete Spalte hinzufügen,die den Wert des Feldes enthält, und daher einen Index auf dieses Felderstellen.
♦ Java-Spalte einer relationalen Tabelle hinzufügen Wenn Sie einigeder Funktionen von Java-Klassen nutzen, aber in die bestehendeDatenbank so wenig wie möglich eingreifen wollen, können Sie Java-Spalten als berechnete Spalten hinzufügen, die ihre Werte aus anderenSpalten in der Tabelle beziehen.
Berechnete Spalten festlegen
Berechnete Spalten werden in den Anweisungen CREATE TABLE oderALTER TABLE deklariert.
Die folgende CREATE TABLE-Anweisung wird benutzt, um die Tabelleproduct in den Java-Beispieltabellen zu erstellen:
CREATE TABLE product( id INTEGER NOT NULL, JProd asademo.Product NOT NULL, name CHAR(15) COMPUTE ( JProd>>name ), PRIMARY KEY ("id"))
EinsatzbereichberechneterSpalten
Tabellen mitberechnetenSpalten erstellen

Berechnete Spalten mit Java-Klassen verwenden
138
Die folgende Anweisung ändert die Tabelle product, indem eine weitereberechnete Spalte hinzugefügt wird:
ALTER TABLE productADD inventory_Value INTEGER COMPUTE ( JProd.quantity * JProd.unit_price )
Sie können mit der Anweisung ALTER TABLE den Ausdruck ändern, der ineiner berechneten Spalte verwendet wird. Die folgende Anweisung ändertden Ausdruck, auf der eine berechnete Spalte basiert:
ALTER TABLE Tabellenname ALTER Spaltenname SET COMPUTE ( Ausdruck )
Die Spalte wird neu berechnet, wenn diese Anweisung ausgeführt wird.Wenn der neue Ausdruck ungültig ist, schlägt die ALTER TABLE-Anweisung fehl.
Die folgende Anweisung macht aus einer berechneten Spalte wieder einenormale Spalte.
ALTER TABLE Tabellenname ALTER Spaltenname DROP COMPUTE
Wenn Sie diese Anweisung ausführen, werden die Werte in der Spalte nichtverändert.
Berechnete Spalten einfügen und aktualisieren
Berechnete Spalten haben Auswirkungen auf die Gültigkeit von INSERTund UPDATE. Die Tabelle jdba.product in den Java-Beispieltabellen hateine berechnete Spalte (name), die wir zur Erläuterung dieses Problemfeldesheranziehen. Die Tabellendefinition lautet wie folgt:
CREATE TABLE "jdba"."product"(
"id" INTEGER NOT NULL,"JProd" asademo.Product NOT NULL,"name" CHAR(15) COMPUTE( JProd.name ),PRIMARY KEY ("id")
)
♦ Keine direkten Einfügungen oder Aktualisierungen Sie können ineine berechnete Spalte keinen Wert direkt einfügen. Die folgendeAnweisung schlägt mit der Fehlermeldung Duplikat beim Einfügen ineine Spalte fehl.
-- Falsche AnweisungINSERT INTO PRODUCT (id, name)VALUES( 3006, ’bad insert statement’ )
BerechneteSpalten zuTabellenhinzufügen
Ausdruck fürberechneteSpalten ändern

Kapitel 4 Java in der Datenbank benutzen
139
Eine UPDATE-Anweisung kann eine berechnete Spalte nicht direktaktualisieren.
♦ Auflisten von Spaltennamen Sie müssen in INSERT-Anweisungen fürTabellen mit berechneten Spalten immer die Spaltennamen angeben. Diefolgende Anweisung schlägt mit der Fehlermeldung Falsche Anzahl vonWerten für INSERT fehl:
-- Falsche AnweisungINSERT INTO PRODUCTVALUES( 3007,new asademo.Product() )
Anstelle dessen müssen Sie die Spalten wie folgt auflisten:
INSERT INTO PRODUCT( id, JProd )VALUES( 3007,new asademo.Product() )
♦ Trigger Sie können Trigger für eine berechnete Spalte definieren, damitein INSERT oder UPDATE in diesen Spalten den Trigger auslöst.
Zeitpunkt der Neuberechnung von Spalten
Die berechneten Spalten werden unter folgenden Bedingungen neuberechnet:
♦ Eine Spalte wird gelöscht, hinzugefügt oder umbenannt.
♦ Die Spalte wird umbenannt.
♦ Der Datentyp oder die COMPUTE-Klausel einer Spalte wird geändert.
♦ Eine Zeile wird eingefügt.
♦ Eine Zeile wird aktualisiert.
Berechnete Spalten werden nicht neu berechnet, wenn sie abgefragt werden.Wenn Sie einen Ausdruck verwenden, der zeitabhängig ist oder in andererWeise vom Status der Datenbank abhängt, bringt die berechnete Spaltemöglicherweise nicht das gewünschte Ergebnis.

Speicher für Java konfigurieren
140
Speicher für Java konfigurierenIn diesem Abschnitt wird beschrieben, welche Speichererfordernisse für Javain der Datenbank bestehen, und wie Sie Ihren Server so einrichten, dass dieseAnforderungen erfüllt werden.
Die Java VM benötigt viel Cachespeicher.
$ Hinweise zur Optimierung des Caches finden Sie unter "Performancedurch den Einsatz eines Cachespeichers steigern" auf Seite 170 derDokumentation ASA SQL-Benutzerhandbuch.
Die Java VM benutzt Speicher sowohl pro Datenbank, als auch proVerbindung.
♦ Der erforderliche Speicher für die Datenbank ist nicht auslagerbar: DieSeiten können nicht auf die Festplatte ausgelagert werden. Sie müssen inden Servercache passen. Dieser Typ des Speichers ist nicht für denServer vorgesehen, sondern für jede Datenbank. Wenn Sie dieCacheerfordernisse berechnen wollen, müssen Sie die Erfordernisse fürjede Datenbank zusammenzählen, die auf dem Server laufen soll.
♦ Der erforderliche Speicher pro Verbindung ist auslagerbar, aber nur alsEinheit. Der erforderliche Speicher für eine Verbindung ist entwederkomplett im Cache oder komplett in einer temporären Datei.
Speicherbelegung
Java in der Datenbank benötigt Speicher für verschiedene Zwecke:
♦ Wenn Java auf einem laufenden Server zum ersten Mal benutzt wird,holt das System die VM in den Speicher. Die VM braucht dort ca. 1,5MByte Platz. Dieser Speicherbedarf wird in den erforderlichen Speicherfür die Datenbank eingerechnet. Eine zusätzliche VM wird für jedeDatenbank geladen, die Java benutzt.
♦ Für jede Verbindung, die Java benutzt, wird eine neue Instanz der VMfür diese Verbindung geladen. Die neue Instanz benötigt ca. 200 KBytepro Verbindung.
♦ Jede in einer Java-Anwendung benutzte Klassendefinition wird in denSpeicher geladen. Sie wird im Datenbankspeicher untergebracht:Getrennte Kopien sind für die einzelnen Verbindungen nichterforderlich.
♦ Jede Verbindung benötigt eine arbeitende Gruppe von Java-Variablenund Anwendungs-Stack-Speicherplatz für Methodenargumente etc.).
Datenbank undVerbindung

Kapitel 4 Java in der Datenbank benutzen
141
Sie können die Speicherbelegung wie folgt steuern:
♦ Gesamtcachegröße setzen Sie müssen die Größe des Caches sosetzen, dass alle Erfordernisse des nicht auslagerbaren Speichers erfülltwerden.
Die Cachegröße wird mit der Befehlszeilenoption -c beim Serverstartgesetzt.
In vielen Fällen reicht eine Cachegröße von 8 MByte aus.
♦ Speicher für den Namensbereich setzen Der Java-Namensbereich istdie Maximalgröße der Datenbankspeichererfordernisse in Bytes.
Sie können diesen Wert mit der Option JAVA_NAMESPACE_SIZEsetzen. Diese Option ist global und kann nur von einem Benutzer mitDBA-Berechtigung gesetzt werden.
♦ Heap-Größe setzen Diese Option JAVA_HEAP_SIZE setzt dieMaximalgröße des pro Verbindung erforderlichen Speichers in Byte.
Diese Option kann für einzelne Verbindungen gesetzt werden, betrifftaber den für andere Benutzer verfügbaren Speicher und darf daher nurvon einem Benutzer mit DBA-Berechtigung verwendet werden.
Sie können nicht nur Speicherparameter für Java setzen, sondern auch dieVM entladen, wenn Java nicht benutzt wird, indem Sie die Anweisung STOPJAVA aufrufen. Nur ein Benutzer mit DBA-Berechtigung kann dieseAnweisung ausführen. Die Syntax ist einfach:
STOP JAVA
Die VM wird geladen, wenn ein Java-Vorgang ausgeführt wird. Wenn Siedie VM explizit laden wollen, damit sie für Java-Vorgänge bereit steht,können Sie folgende Anweisung ausführen:
START JAVA
Verwaltung desSpeichers
VM starten undstoppen

Speicher für Java konfigurieren
142

143
K A P I T E L 5
Datenzugriff über JDBC
In diesem Kapitel wird beschrieben, wie JDBC für den Zugriff auf Dateneingesetzt werden kann.
JDBC kann sowohl aus Clientanwendungen als auch innerhalb einerDatenbank eingesetzt werden. Java-Klassen, die JDBC verwenden, bieteneine leistungsstärkere Alternative zu gespeicherten Prozeduren in SQL fürdie Einbeziehung von Programmierlogik in die Datenbank.
Thema Seite
Überblick über JDBC 144
jConnect-JDBC-Treiber verwenden 150
JDBC-ODBC-Brücke verwenden 155
JDBC-Verbindungen herstellen 157
JDBC für den Zugriff auf Daten verwenden 165
Verteilte Anwendungen erstellen 174
Über diesesKapitel
Inhalt

Überblick über JDBC
144
Überblick über JDBCJDBC bietet eine SQL-Schnittstelle für Java-Anwendungen: Wenn Sie aufrelationale Daten von Java zugreifen wollen, tun Sie dies über JDBC-Aufrufe.
Dieses Kapitel ist keine detailgenaue Anleitung für die JDBC-Datenbankschnittstelle, sondern liefert einige einfache Beispiele zurEinführung von JDBC und zur Illustration, wie sie beim Client und in derDatenbank eingesetzt werden kann.
$ Die Beispiele veranschaulichen die unterschiedlichen Funktionen beimEinsatz von JDBC in Adaptive Server Anywhere. Weitere Hinweise zumProgrammieren von JDBC finden Sie in jedem beliebigen JDBC-Programmierhandbuch.
Sie können JDBC auf folgende Weise mit Adaptive Server Anywhereverwenden:
♦ JDBC auf dem Client Java-Clientanwendungen können JDBC-Aufrufein Adaptive Server Anywhere ausführen. Die Verbindung erfolgt übereinen JDBC-Treiber. SQL Anywhere Studio enthält zwei JDBC-Treiber:den jConnect-Treiber für Anwendungen in reinem Java sowie eineJDBC-ODBC-Brücke.
In diesem Kapitel bezieht sich der Ausdruck Clientanwendung sowohlauf Anwendungen, die auf dem Rechner des Benutzers laufen, als auchauf Mittelschicht-Anwendungsserver.
♦ JDBC in der Datenbank In einer Datenbank installierte Java-Klassenkönnen JDBC-Aufrufe ausführen, um mit Hilfe eines internen JDBC-Treibers auf Daten in der Datenbank zuzugreifen und diese zu ändern.
♦ Erforderliche Software Sie benötigen TCP/IP für den Sybase jConnect-Treiber.
Der Sybase jConnect Treiber kann abhängig von Ihrer Installation vonAdaptive Server Anywhere bereits verfügbar sein.
$ Weitere Hinweise den jConnect-Treiber und seinen Standort finden Sieunter "Die Dateien des jConnect-Treibers" auf Seite 150.
♦ Beispiel-Quellcode Quellcode für die Beispiele in diesem Kapitelfinden Sie in der Datei Samples\ASA\Java\JDBCExamples.java in IhremSQL Anywhere-Verzeichnis.
$ Hinweise zur Installation von Java-Beispielen, einschließlich derKlasse JDBCExamples, finden Sie unter "Java-Beispiele einrichten"auf Seite 94.
JDBC undAdaptive ServerAnywhere
JDBC-Ressourcen

Kapitel 5 Datenzugriff über JDBC
145
JDBC-Treiber wählen
Für Adaptive Server Anywhere werden zwei JDBC-Treiber bereitgestellt:
♦ jConnect Dieser Treiber ist eine 100% reine Java-Implementierungdes Treiber. Er kommuniziert mit Adaptive Server Anywhere über dasTDS-Client/Server-Protokoll.
♦ JDBC-ODBC-Brücke Dieser Treiber kommuniziert mit AdaptiveServer Anywhere über das Command Sequence-Client/Server-Protokoll.Sein Verhalten ist mit ODBC-, Embedded SQL- und OLE DB-Anwendungen konsistent.
Bei der Auswahl des geeigneten Treibers sollten die folgenden Faktorenbeachtet werden:
♦ Features Beide Treiber sind JDK 2-kompatibel. Die JDBC-ODBC-Brücke bietet vollständig abrollbare Cursor, die in jConnect nichtverfügbar sind.
♦ "Pure Java" Der jConnect-Treiber ist eine reine Java-Lösung. DieJDBC-ODBC-Brücke benötigt den Adaptive Server Anywhere ODBC-Treiber und ist keine reine Java-Lösung.
♦ Performance Die JDBC-ODBC-Brücke bietet bessere Performancefür die meisten Einsatzbereiche als der jConnect-Treiber.
♦ Kompatibilität Das vom jConnect-Treiber verwendete TDS-Protokollwird mit Adaptive Server Enterprise gemeinsam genutzt. Einige Aspektedes Verhaltens dieses Treibers werden durch das Protokoll bestimmt undsind so konfiguriert, dass die Kompatibilität mit Adaptive ServerEnterprise gewährleistet bleibt.
Beide Treiber sind für Windows 95/98/Me und Windows NT/2000/XP sowiedie unterstützten UNIX- und Linux-Betriebssystemen verfügbar. Sie sindnicht für NetWare oder Windows CE erhältlich.
JDBC-Programmstruktur
In JDBC-Anwendungen sind folgende Abläufe typisch:
1 Verbindungsobjekt erstellen Mit dem Aufruf der getConnection-Klassenmethode der Klasse DriverManager wird ein Connection-Objekt erstellt, das eine Verbindung mit einer Datenbank einrichtet.
2 Statement-Objekt erstellen Das Objekt Connection erstellt einStatement-Objekt.

Überblick über JDBC
146
3 SQL-Anweisung übergeben Eine SQL-Anweisung, die in derDatenbankumgebung ausgeführt werden soll, wird an das Statement-Objekt übergeben. Wenn die Anweisung eine Abfrage ist, wird durchdiese Aktion ein ResultSet-Objekt zurückgegeben.
Das ResultSet-Objekt enthält die von der SQL-Anweisungzurückgegebenen Daten, gibt jedoch jeweils nur eine Zeile aus (ähnlichwie die Arbeitsweise des Cursors).
4 Schleife über die Zeilen der Ergebnismenge Die next-Methode desObjekts ResultSet führt zwei Aktionen aus:
♦ Die aktuelle Zeile (die Zeile in der über das Objekt ResultSetausgegebenen Ergebnismenge), wird eine Zeile weitergeschoben.
♦ Ein Boolescher Wert wird zurückgegeben (TRUE/FALSE), derangibt, ob eine Zeile vorhanden ist, zu der weitergeschoben werdenkann.
5 Für jede Zeile Werte abrufen Für jede Zeile im ResultSet-Objektwerden Werte entweder mit dem Namen oder der Position der Spalteabgerufen. Sie können die Methode getDate verwenden, um den Werteiner Spalte in der aktuellen Zeile zu beziehen.
Java-Objekte können JDBC-Objekte verwenden, um mit einer Datenbank zuinteragieren und Daten für die eigene Verwendung abzurufen, und zwar fürdie eigene Verarbeitung oder für den Einsatz in anderen Abfragen.
JDBC-Funktionen in der Datenbank
Die Version von JDBC, die Sie von Java in der Datenbank benutzen können,wird von der JDK-Version bestimmt, die für die Datenbank eingerichtetwurde.
♦ Wenn Ihre Datenbank mit JDK 1.2 oder JDK 1.3 initialisiert wurde,können Sie die JDBC 2.0 API verwenden.
$ Hinweise zum Upgrade der Datenbanken auf JDK 1.2 oder JDK1.3 finden Sie unter "ALTER DATABASE-Anweisung" auf Seite 224der Dokumentation ASA SQL-Referenzhandbuch oder "Upgrade einerDatenbank mit dem Befehlszeilenprogramm ""dbupgrad""" aufSeite 583 der Dokumentation ASA Datenbankadministration.
♦ Falls Ihre Datenbank mit JDK 1.1 initialisiert wurde, können Sie dieFunktionen von JDBC 1.2 verwenden. Der interne JDBC-Treiber fürJDK 1.1 (asajdbc) stellt einige Funktionen von JDBC 2.0 vonserverseitigen Java-Anwendungen zur Verfügung, bietet aber keine volleJDBC 2.0-Unterstützung.

Kapitel 5 Datenzugriff über JDBC
147
$ Weitere Hinweise finden Sie unter "JDBC 2.0-Funktionen vonJDK 1.1-Datenbanken aus benutzen" auf Seite 147.
JDBC 2.0-Funktionen von JDK 1.1-Datenbanken aus benutzen
In diesem Abschnitt wird beschrieben, wie JDBC 2.0-Funktionen vonDatenbanken aus benutzt werden, die mit JDK 1.1 initialisiert wurden. Invielen Fällen ist es besser, Ihre Version von Java in der Datenbank auf 1.3umzustellen.
Bei Datenbanken, die mit JDK 1.1 initialisiert wurden, enthält das Paketsybase.sql.ASA Funktionen, die Teil von JDBC 2.0 sind. Um diese JDBC2.0-Funktionen verwenden zu können, müssen Sie Ihre JDBC-Objekte in dieentsprechenden Klassen im Paket sybase.sql.ASA und nicht im Paketjava.sql einbauen. Klassen, die als java.sql deklariert sind, bleiben auf dieJDBC 1.2-Funktionen beschränkt.
Die Klassen in sybase.sql.ASA sind:
JDBC-Klasse Interne Sybase-Treiberklasse
java.sql.Connection sybase.sql.ASA.SAConnection
java.sql.Statement sybase.sql.ASA.SAStatement
java.sql.PreparedStatement sybase.sql.ASA.SAPreparedStatement
java.sql.CallableStatement sybase.sql.ASA.SACallableStatement
java.sql.ResultSetMetaData sybase.sql.ASA.SAResultSetMetaData
java.sql.ResultSet sybase.sql.SAResultSet
java.sql.DatabaseMetaData sybase.sql.SADatabaseMetaData
Die folgende Funktion bietet ein ResultSetMetaData-Objekt für einevorbereitete Anweisung ohne das ResultSet oder das Ausführen derAnweisung nötig sind. Diese Funktion ist nicht Teil des Standards JDBC 1.2.
ResultSetMetaDatasybase.sql.ASA.SAPreparedStatement.describe()
Der folgende Code ruft die vorherige Zeile in einer Ergebnismenge ab, eineFunktion, die in JDBC 1.2 nicht unterstützt wird:
import java.sql.*;import sybase.sql.asa.*;ResultSet rs;// hier mehr Code( ( sybase.sql.asa.SAResultSet)rs ).previous();
Die folgenden Klassen sind Teil der Kernschnittstelle von JDBC 2.0, stehenaber im Paket sybase.sql.ASA nicht zur Verfügung:
Einschränkungenvon JDBC 2.0

Überblick über JDBC
148
♦ java.sql.Blob
♦ java.sql.Clob
♦ java.sql.Ref
♦ java.sql.Struct
♦ java.sql.Array
♦ java.sql.Map
Die folgenden Kernfunktionen von JDBC 2.0 sind im Paket sybase.sql.ASAnicht verfügbar:
Klasse insybase.sql.ASA
Fehlende Funktionen
SAConnection java.util.Map getTypeMap()
void setTypeMap( java.util.Map map )
SAPreparedStatement void setRef( int pidx, java.sql.Ref r )
void setBlob( int pidx, java.sql.Blob b )
void setClob( int pidx, java.sql.Clob c )
void setArray( int pidx, java.sql.Array a )
SACallableStatement Object getObject( pidx, java.util.Map map )
java.sql.Ref getRef( int pidx )
java.sql.Blob getBlob( int pidx )
java.sql.Clob getClob( int pidx )
java.sql.Array getArray( int pidx )
SAResultSet Object getObject( int cidx, java.util.Map map )
java.sql.Ref getRef( int cidx )
java.sql.Blob getBlob( int cidx )
java.sql.Clob getClob( int cidx )
java.sql.Array getArray( int cidx )
Object getObject( String cName, java.util.Map map )
java.sql.Ref getRef( String cName )
java.sql.Blob getBlob( String cName )
java.sql.Clob getClob( String cName )
java.sql.Array getArray( String cName )

Kapitel 5 Datenzugriff über JDBC
149
Unterschiede zwischen client- und serverseitigen JDBC-Verbindungen
Der Unterschied zwischen dem JDBC-Treiber auf dem Client bzw. auf demDatenbankserver liegt darin, dass eine Verbindung mit derDatenbankumgebung hergestellt wird.
♦ Clientseitig Beim clientseitigen JDBC-Treiber erfordert die Herstellungeiner Verbindung den Sybase jConnect JDBC- Treiber oder der JDBC-ODBC-Brücke von Adaptive Server Anywhere. Die Übergabe vonArgumenten an DriverManager.getConnection richtet die Verbindungein. Die Datenbankumgebung ist von der Perspektive derClientanwendung aus eine externe Anwendung.
♦ Serverseitig Wenn JDBC innerhalb des Datenbankservers eingesetztwird, ist bereits eine Verbindung vorhanden. Der Wertjdbc:default:connection wird an DriverManager.getConnectionübergeben, damit die JDBC-Anwendung die Möglichkeit erhält,innerhalb der aktuellen Benutzerverbindung zu arbeiten. Dies ist einschneller, effizienter und sicherer Vorgang, weil die Clientanwendungdie Sicherheitsprüfung der Datenbank zur Herstellung der Verbindungbereits bestanden hat. Benutzer-ID und Kennwort wurden angegebenund brauchen nicht noch einmal angegeben zu werden. Der interneJDBC-Treiber kann nur mit der Datenbank der aktuellen Verbindungeine Verbindung herstellen.
JDBC-Klassen können so geschrieben werden, dass sie auf der Client- undauf der Serverseite ausgeführt werden, indem Sie eine einzige bedingteAnweisung für die Angabe des URL verwenden. Eine externe Verbindungerfordert den Rechnernamen und die Portnummer, während die interneVerbindung jdbc:default:connection benötigt.

jConnect-JDBC-Treiber verwenden
150
jConnect-JDBC-Treiber verwendenWenn Sie JDBC von einer Clientanwendung oder einem Applet ausverwenden wollen, brauchen Sie den jConnect JDBC-Treiber, um eineVerbindung mit Datenbanken von Adaptive Server Anywhere herstellen zukönnen.
jConnect gehört zum Lieferumfang von SQL Anywhere Studio. Wenn SieAdaptive Server Anywhere als Teil eines anderen Paketes erhalten haben,besteht die Möglichkeit, dass jConnect nicht enthalten ist. Sie brauchenjConnect, um JDBC von Clientanwendungen aus einsetzen zu können. Siekönnen JDBC in der Datenbank ohne jConnect verwenden.
Die Dateien des jConnect-Treibers
Der jConnect JDBC-Treiber ist in einer Reihe von Verzeichnissen unterSybase\Shared installiert. Es werden zwei Versionen von jConnectbereitgestellt:
♦ jConnect 4.5 Diese Version von jConnect ist für die Entwicklung vonJDK 1.1-Anwendungen vorgesehen. jConnect 4.5 ist im VerzeichnisSybase\Shared\jConnect-4_5 installiert.
jConnect 4.5 wird als Gruppe von Klassen geliefert.
♦ jConnect 5.5 Diese Version von jConnect ist für die Entwicklung vonJDK 1.2-Anwendungen vorgesehen. jConnect 5.5 ist im VerzeichnisSybase\Shared\jConnect-5_5 installiert.
jConnect 5.5 wird als jar-Datei mit dem Namen jconn2.jar geliefert.
Beispiele in diesem Kapitel verwenden jConnect 5.5. Benutzer von jConnect4.5 müssen die entsprechenden Anpassungen vornehmen.
Damit Ihre Anwendung "jConnect" verwenden kann, müssen die jConnect-Klassen beim Kompilieren und Ausführen in die UmgebungsvariableCLASSPATH einbezogen sein, sodass der Java-Compiler und die Java-Machine die notwendigen Dateien ausfindig machen können.
Der folgende Befehl fügt den jConnect 5.5-Treiber in eine vorhandeneCLASSPATH-Umgebungsvariable ein, wobei Suchpfad Ihr Sybase\Shared–Verzeichnis ist.
set classpath=%classpath%;Suchpfad\jConnect-5_5\classes\jconn2.jar
Mit dem folgenden Befehl wird der jConnect 4.5-Treiber einer vorhandenenCLASSPATH-Umgebungsvariablen hinzugefügt:
set classpath=%classpath%;Suchpfad\jConnect-4_5\classes
CLASSPATH fürjConnect einrichten

Kapitel 5 Datenzugriff über JDBC
151
Die Klassen in jConnect befinden sich alle im Paket com.sybase.
Wenn Sie jConnect 5.5 verwenden, muss Ihre Anwendung auf Klassen incom.sybase.jdbc2.jdbc zugreifen. Sie müssen diese Klassen am Anfangeiner jeden Quelldatei importieren:
import com.sybase.jdbc2.jdbc.*
Wenn Sie jConnect 4.5 verwenden, befinden sich die Klassen incom.sybase.jdbc. Sie müssen diese Klassen am Anfang einer jedenQuelldatei importieren:
import com.sybase. jdbc.*
jConnect-Systemobjekte in einer Datenbank installieren
Wenn Sie mit jConnect auf Systemtabellendaten zugreifen wollen(Datenbank-Metadaten), müssen Sie die jConnect-Systemobjekte IhrerDatenbank hinzufügen.
Die jConnect-Systemobjekte werden standardmäßig jeder neuen Datenbankhinzugefügt. Sie können die jConnect-Objekte der Datenbank beim Erstellen,beim Upgrade oder zu einem späteren Zeitpunkt hinzufügen.
Sie können die jConnect-Systemobjekte über Sybase Central oder überInteractive SQL installieren.
v So fügen Sie jConnect-Systemobjekte einer Datenbank hinzu(Sybase Central):
1 Stellen Sie von Sybase Central aus als Benutzer mit DBA-Berechtigungeine Verbindung her.
2 Im linken Fensterausschnitt von Sybase Central rechtsklicken Sie aufdas Datenbanksymbol und wählen "jConnect Metadatenunterstützungneu installieren" aus dem Einblendmenü.
v So fügen Sie jConnect-Systemobjekte einer Datenbank hinzu(Interactive SQL):
♦ Stellen Sie über Interactive SQL als Benutzer mit DBA-Berechtigungeine Verbindung her und geben Sie im Ausschnitt für die Eingabe derSQL-Anweisungen folgenden Befehl ein:
read Suchpfad\scripts\jcatalog.sql
wobei Suchpfad Ihr SQL Anywhere-Verzeichnis ist.
jConnect-Klassenimportieren

jConnect-JDBC-Treiber verwenden
152
TippSie können die jConnect-Systemobjekte einer Datenbank auch über dieBefehlszeile hinzufügen: Die Eingabe bei der Eingabeaufforderung lautetwie folgt:
dbisql -c "uid=Benutzer;pwd=Kennwort"Suchpfad\scripts\jcatalog.sql
Dabei gilt: Benutzer und Kennwort gehören zu einem Benutzer mit DBA-Berechtigung, und Suchpfad ist Ihr SQL Anywhere-Verzeichnis.
jConnect-Treiber laden
Bevor Sie jConnect in Ihrer Anwendung benutzen können, müssen Sie dieTreiber laden, indem Sie folgende Anweisung eingeben.
Class.forName("com.sybase.jdbc2.jdbc.SybDriver").newInstance();
Mit der Methode newInstance werden Probleme in einigen Browsernvermieden.
Einem Server einen URL liefern
Um per jConnect eine Verbindung mit einer Datenbank herzustellen, müssenSie einen "Uniform Resource Locator" (URL) für die Datenbank angeben.Ein Beispiel finden Sie im Abschnitt "Von einer JDBC-Clientanwendung ausmit jConnect eine Verbindung herstellen" auf Seite 157 Die Anweisunglautet wie folgt:
StringBuffer temp = new StringBuffer();// jConnect-Treiber verwenden ...temp.append("jdbc:sybase:Tds:");// zur Verbindung mit angegebenem Rechnernamen...temp.append(_coninfo);// auf der Standard-Portnummer des ASA...temp.append(":2638");// und baue Verbindung auf.System.out.println(temp.toString());conn = DriverManager.getConnection(temp.toString() ,_props );
Der URL wird folgendermaßen zusammengesetzt:
jdbc:sybase:Tds:Rechnername:Portnummer
Die einzelnen Komponenten sind:

Kapitel 5 Datenzugriff über JDBC
153
♦ jdbc:sybase:Tds Der Sybase jConnect JDBC Treiber unterVerwendung des TDS-Anwendungsprotokolls
♦ Rechnername Die IP-Adresse oder der Name des Rechners, auf demder Server läuft. Wenn Sie eine Verbindung auf demselben Rechnerherstellen, können Sie localhost benutzen, also den aktuellen Rechner.
♦ Portnummer Die Portnummer, an der der Datenbankserver aufVerbindungsanforderungen wartet. Die Adaptive Server Anywherezugewiesene Portnummer ist 2638. Sie sollten diese Nummerverwenden, es sei denn, es gibt besondere Gründe, dies nicht zu tun.
Die Verbindungszeichenfolge darf nicht länger als 252 Zeichen sein.
Datenbank auf einem Server angeben
Jeder Adaptive Server Anywhere-Server kann mehrere Datenbankengleichzeitig laden. Der oben angegebene URL legt einen Server fest, nichtaber eine Datenbank. Der Verbindungsversuch wird mit derStandarddatenbank auf dem Server vorgenommen.
Sie können eine bestimmte Datenbank angeben, indem Sie die URL-Angabewie folgt erweitern:
jdbc:sybase:Tds:Rechnername:Portnummer?ServiceName=DBN
Das Fragezeichen, gefolgt von einer Reihe von Zuordnungen, ist einStandardverfahren, um einem URL Argumente zu liefern. Die Groß- undKleinschreibung von servicename wird nicht berücksichtigt, und vor bzw.nach dem =-Zeichen darf es keine Leerstellen geben. Der Parameter DBN istder Datenbankname.
Eine allgemeinere Methode ist die Eingabe zusätzlicherVerbindungsparameter wie Datenbankname oder Datenbankdatei mit demFeld RemotePWD: Setzen Sie RemotePWD als Eigenschaftsfeld mit derMethode setRemotePassword().
Nachstehend wird ein Beispielcode für die Verwendung dieses Feldesgezeigt.
sybDrvr = (SybDriver)Class.forName( "com.sybase.jdbc2.jdbc.SybDriver" ).newInstance();
props = new Properties();props.put( "User", "DBA" );props.put( "Password", "SQL" );sybDrvr.setRemotePassword(
null, "dbf=asademo.db", props );Connection con = DriverManager.getConnection(
"jdbc:sybase:Tds:localhost", props );
Mit dem ParameterServiceName
Mit dem ParameterRemotePWD

jConnect-JDBC-Treiber verwenden
154
Mit dem Parameter für die Datenbankdatei DBF können Sie mit jConnecteine Datenbank auf einem Server starten. Standardmäßig wird die Datenbankmit autostop=YES gestartet. Wenn Sie DBF oder DBN mit utility_dbeingeben, wird die Dienstprogramm-Datenbank automatisch gestartet.
$ Weitere Hinweise zur Dienstprogramm-Datenbank finden Sie unter"Die Dienstprogrammdatenbank verwenden" auf Seite 249 derDokumentation ASA Datenbankadministration.
Für jConnect-Verbindungen eingestellte Datenbankoptionen
Wenn sich eine Anwendung mit dem jConnect-Treiber mit der Datenbankverbindet, werden zwei gespeicherte Prozeduren aufgerufen:
1 sp_tsql_environment stellt einige Datenbankoptionen für dieKompatibilität mit Adaptive Server Enterprise ein.
2 Anschließend wird die Prozedur spt_mda aufgerufen, die einige andereOptionen einstellt. Insbesondere legt die Prozedur spt_mda dieEinstellung der Option QUOTED_IDENTIFIER fest. Zum Ändern desStandardverhaltens sollten Sie die Prozedur spt_mda ändern.

Kapitel 5 Datenzugriff über JDBC
155
JDBC-ODBC-Brücke verwendenDie JDBC-ODBC-Brücke bietet einen JDBC-Treiber, der eine besserePerformance sowie einige zusätzliche Funktionen im Vergleich zumjConnect JDBC-Treiber ausweist; die JDBC-ODBC-Brücke ist jedoch imGegensatz zum jConnect-Treiber keine reine Java-Lösung.
$ Hinweise zur Auswahl des JDBC-Treibers finden Sie unter "JDBC-Treiber wählen" auf Seite 145.
Die Java-Komponente der JDBC-ODBC-Brücke ist in der Datei jodbc.jarenthalten, die Sie im Unterverzeichnis Java der SQL Anywhere-Installationfinden. Unter Windows ist die systemeigene Komponente in der Dateidbjodbc8.dll im Unterverzeichnis win32 der SQL Anywhere-Installation zufinden; für UNIX und Linux befindet sich die systemeigene Komponente indbjodbc8.so. Die Komponente muss im Systempfad enthalten sein. WennAnwendungen mit diesem Treiber eingeführt werden, müssen auch dieODBC-Treiberdateien installiert werden.
Der folgende Code veranschaulicht, wie eine Verbindung mit der JDBC-ODBC-Brücke hergestellt wird:
String driver, url;Connection conn;
driver="ianywhere.ml.jdbcodbc.IDriver";url = "jdbc:odbc:dsn=ASA 8.0 Sample";Class.forName( driver );conn = DriverManager.getConnection( url );
Dieser Code weist folgende Besonderheiten auf:
♦ Da die Klassen mit Class.forName geladen werden, muss das Paket,das die JDBC-ODBC-Brücke enthält, nicht mit import-Anweisungenimportiert werden.
♦ jodbc.jar muss im Classpath enthalten sein, wenn Sie die Anwendungausführen.
♦ Der URL enthält jdbc:odbc:, gefolgt von einer standardmäßigenODBC-Verbindungszeichenfolge. Die Verbindungszeichenfolge ist inder Regel eine ODBC-Datenquelle; Sie können jedoch auch explizitdurch Strichpunkte getrennte, einzelne Verbindungszeichenfolgenzusätzlich zu oder an Stelle der Datenquelle verwenden. WeitereHinweise zu den Optionen, die Sie in einer Verbindungszeichenfolgeverwenden können, finden Sie unter "Verbindungsparameter" aufSeite 78 der Dokumentation ASA Datenbankadministration.
ErforderlicheDateien
Verbindungherstellen

JDBC-ODBC-Brücke verwenden
156
Falls Sie keine Datenquelle verwenden, sollen Sie den ODBC-Treiberangeben, indem Sie die Treiberoption zur Verbindungszeichenfolgehinzufügen:
url = "jdbc:odbc:";url += "driver=Adaptive Server Anywhere 8.0;...";
Unter UNIX verwendet die JDBC-ODBC-Brücke keine ODBC-Unicode-Bindungen oder -Aufrufe und nimmt keine Zeichensatzkonvertierungen vor.Das Senden von Nicht-ASCII-Daten über die Brücke führt zur Beschädigungder Daten.
Unter Windows verwendet die JDBC-ODBC-Brücke ODBC-Unicode-Bindungen und -Aufrufe, um Zeichensatzkonvertierungen vorzunehmen.
Zeichensätze

Kapitel 5 Datenzugriff über JDBC
157
JDBC-Verbindungen herstellenIn diesem Abschnitt werden Klassen vorgestellt, die von einer Java-Anwendung aus eine JDBC-Datenbankverbindung herstellen. In denBeispielen in diesem Abschnit werden jConnect (clientseitig) oder Java inder Datenbank (serverseitig) verwendet. Hinweise zur Herstellung vonVerbindungen mit der JDBC-ODBC-Brücken finden Sie unter"JDBC-ODBC-Brücke verwenden" auf Seite 155.
Von einer JDBC-Clientanwendung aus mit jConnect eineVerbindung herstellen
Wenn Sie von einer JDBC-Anwendung auf Datenbank-Systemtabellenzugreifen wollen (Datenbank-Metadaten), müssen Sie eine Reihe vonjConnect-Systemobjekten in Ihre Datenbank einfügen. Die internen JDBC-Treiberklassen und jConnect nutzen gemeinsam gespeicherte Prozeduren fürdie Unterstützung der Datenbank-Metadaten. Diese Prozeduren werden inallen Datenbanken standardmäßig installiert. Der Parameter dbinit -iverhindert die Installation.
$ Weitere Hinweise zum Hinzufügen von jConnect-Systemobjekten ineine Datenbank finden Sie unter "jConnect-JDBC-Treiber verwenden" aufSeite 150.
Die folgende, vollständige Java-Anwendung ist eineBefehlszeilenanwendung, die eine Verbindung mit einer laufendenDatenbank herstellt, eine Reihe von Daten auf der Befehlszeile ausgibt undbeendet wird.
Der erste Schritt einer beliebigen JDBC-Anwendung ist die Herstellung derVerbindung mit der Datenbank, wenn sie mit dieser arbeiten will.
$ Dieses Beispiel veranschaulicht eine externe Verbindung, bei der essich um eine reguläre Client/Server-Verbindung handelt. Hinweise zumErstellen einer internen Verbindung von Java-Klassen, die imDatenbankserver laufen, finden Sie unter "Verbindung von einerserverseitigen JDBC-Klasse herstellen" auf Seite 161.

JDBC-Verbindungen herstellen
158
Beispielcode für eine externe Verbindung
Es folgt ein Beispiel-Quellcode für die Methoden, die zum Herstellen einerVerbindung eingesetzt werden. Der Quellcode befindet sich in den Methodenmain und ASAConnect in der Datei JDBCExamples.java im VerzeichnisSamples\ASA\Java in Ihrem SQL Anywhere-Verzeichnis. (Die Kommentarewerden zum besseren Verständnis hier in deutscher Übersetzungwiedergegeben.)
import java.sql.*; // JDBCimport com.sybase.jdbc2.jdbc.*; // Sybase jConnectimport java.util.Properties; // Eigenschaftenimport sybase.sql.*; // Sybase Dienstprogrammeimport asademo.*; // Beispielklassenclasses
public class JDBCExamples{ private static Connection conn;
public static void main( String args[] ){ // Verbindung herstellen conn = null; String machineName = ( args.length == 1 ? args[0] :"localhost" ); ASAConnect( "DBA", "SQL", machineName ); if( conn!=null ) { System.out.println( "Connection successful" ); }else{ System.out.println( "Connection failed" ); }
try{ getObjectColumn(); getObjectColumnCastClass(); insertObject(); } catch( Exception e ){ System.out.println( "Error: " + e.getMessage() ); e.printStackTrace(); } }

Kapitel 5 Datenzugriff über JDBC
159
private static void ASAConnect( String userID, String password, String machineName ) {
// Mit einem Adaptive Server Anywhere verbinden String coninfo = new String( machineName );
Properties props = new Properties(); props.put( "user", userID ); props.put( "password", password ); props.put("DYNAMIC_PREPARE", "true");
// jConnect laden try { Class.forName( "com.sybase.jdbc2.jdbc.SybDriver").newInstance(); String dbURL = "jdbc:sybase:Tds:" + machineName + ":2638/?JCONNECT_VERSION=5"; System.out.println( dbURL ); conn = DriverManager.getConnection( dbURL , props); } catch ( Exception e ) { System.out.println( "Error: " + e.getMessage() ); e.printStackTrace(); } }
So funktioniert das Beispiel für eine externe Verbindung
Das Beispiel für eine externe Verbindung ist eine Java-Befehlszeilenanwendung.
Die Anwendung benötigt mehrere Bibliotheken. Deren Import erfolgt in denersten Zeilen von JDBCExamples.java:
♦ Das Paket java.sql enthält die JDBC-Klassen von Sun Microsystems,die für alle JDBC-Anwendungen erforderlich sind. Sie finden sie in derDatei classes.zip im Java-Unterverzeichnis.
♦ Der aus com.sybase.jdbc2.jdbc importierte Sybase jConnect JDBC-Treiber ist für alle Anwendungen erforderlich, die Verbindungen überjConnect herstellen.
♦ Die Anwendung benutzt eine Eigenschaftsliste (property list). DieKlasse java.util.Properties ist erforderlich, um mit Eigenschaftslistenarbeiten zu können. Sie finden sie in der Datei classes.zip im Java-Unterverzeichnis.
♦ Das Paket asademo enthält Klassen, die in einigen Beispielen verwendetwerden. Sie finden es in der Datei Samples\ASA\Java\asademo.jar.
Pakete importieren

JDBC-Verbindungen herstellen
160
Jede Java-Anwendung erfordert eine Klasse mit einer Methode mit demNamen main, die beim Programmstart aufgerufen wird. In diesem einfachenBeispiel ist JDBCExamples.main die einzige Methode in der Anwendung.
Die Methode JDBCExamples.main führt folgende Aufgaben aus:
1 Sie verarbeitet das Befehlszeilenargument und benutzt dabei denRechnernamen, wenn ein solcher übergeben wurde. Standardmäßig istder Name des Rechners localhost, der sich für den PersonalDatenbankserver eignet.
2 Sie ruft die Methode "ASAConnect" auf, damit eine Verbindunghergestellt wird.
3 Sie führt mehrere Methoden aus, die Daten in die Befehlszeile abrollen.
Die Methode JDBCExamples.ASAConnect führt folgende Aufgaben aus:
1 Sie stellt über Sybase jConnect eine Verbindung mit der laufendenStandarddatenbank her.
♦ Class.forName lädt jConnect. Mit der Methode newInstancewerden Probleme in einigen Browsern vermieden.
♦ Die StringBuffer-Anweisungen bauen aus der Literal-Zeichenfolgeund dem in der Befehlszeile angegebenen Rechnernamen eineVerbindungszeichenfolge auf.
♦ DriverManager.getConnection stellt mit derVerbindungszeichenfolge eine Verbindung her.
2 Sie gibt die Kontrolle an die aufrufende Methode zurück.
Beispiel für eine externe Verbindung
In diesem Abschnitt wird beschrieben, wie das Beispiel für eine externeVerbindung ausgeführt wird.
v So wird die Beispielanwendung für eine externe Verbindung erstelltund ausgeführt:
1 Öffnen Sie eine Befehlszeile.
2 Wechseln Sie in Ihr SQL Anywhere-Verzeichnis.
3 Wechseln Sie in das Unterverzeichnis Samples\ASA\Java.
4 Die Datenbank muss auf einem Datenbankserver geladen sein, der mitTCP/IP läuft. Einen solchen Server können Sie auf Ihrem lokalenRechner starten, indem Sie folgenden Befehl ausführen (vomUnterverzeichnis Samples\ASA\Java aus):
Die Methode"main"
Die Methode"ASAConnect"

Kapitel 5 Datenzugriff über JDBC
161
start dbeng8 ..\..\..\asademo
5 Führen Sie das Beispiel aus, indem Sie an der Eingabeaufforderungfolgenden Befehl eingeben:
java JDBCExamples
Wenn Sie dies mit einem Server ausprobieren wollen, der auf einemanderen Rechner läuft, müssen Sie den Namen dieses Rechnerseingeben. Der Standard ist localhost, wobei es sich um ein Alias für denNamen des aktuellen Rechners handelt.
6 Eine Liste von Personen und Produkten muss an derEingabeaufforderung angezeigt werden.
Wenn der Verbindungsversuch fehlschlägt, erscheint stattdessen eineFehlermeldung. Prüfen Sie, ob Sie alle erforderlichen Schritte ausgeführthaben. Prüfen Sie, ob Ihr CLASSPATH richtig eingestellt wurde. Einfalscher CLASSPATH führt dazu, dass eine Klasse nicht gefundenwerden kann.
$ Weitere Hinweise zur Verwendung von jConnect finden Sie unter"jConnect-JDBC-Treiber verwenden" auf Seite 150 sowie in der Online-Dokumentation für jConnect.
Verbindung von einer serverseitigen JDBC-Klasse herstellen
SQL-Anweisungen werden in JDBC mit Hilfe der MethodecreateStatement des Connection-Objekts aufgebaut. Auch Klassen, dieinnerhalb des Servers laufen, müssen eine Verbindung herstellen, damit einConnection-Objekt erstellt wird.
Eine Verbindung von einer serverseitigen JDBC-Klasse herzustellen isteinfacher, als eine externe Verbindung einzurichten. Da die serverseitigeKlasse von einem bereits verbundenen Benutzer ausgeführt wird, verwendetdie Klasse einfach die vorhandene Verbindung.
Beispielcode für eine serverseitige Verbindung
Nachstehend wird der Quellcode für das Beispiel gezeigt. Den Quellcodefinden Sie in der Methode InternalConnect inSamples\ASA\Java\JDBCExamples.java in Ihrem SQL Anywhere-Verzeichnis:
public static void InternalConnect() { try { conn =DriverManager.getConnection("jdbc:default:connection"); System.out.println("Hello World");

JDBC-Verbindungen herstellen
162
} catch ( Exception e ) { System.out.println("Error: " + e.getMessage()); e.printStackTrace(); } }}
So funktioniert das Beispiel für eine serverseitige Verbindung
In diesem einfachen Beispiel ist InternalConnect() die einzige Methode inder Anwendung.
Die Anwendung erfordert nur eine der Bibliotheken (JDBC), die in derersten Zeile der Klasse JDBCExamples.java importiert werden. Die anderenwerden für externe Verbindungen benötigt. Das Paket java.sql enthält dieJDBC-Klassen.
Die InternalConnect()-Methode führt folgende Aufgaben aus:
1 Sie stellt über die aktuelle Verbindung eine Verbindung mit derlaufenden Standarddatenbank her:
♦ DriverManager.getConnection stellt eine Verbindung unterVerwendung der Verbindungszeichenfolgejdbc:default:connection her.
2 Sie gibt an der aktuellen Standardausgabe, d.h. im Serverfenster, HelloWorld aus. System.out.println führt die Ausgabe aus.
3 Wenn bei dem Verbindungsversuch ein Fehler auftritt, erscheint eineFehlermeldung im Serverfenster, die Auskunft über die Stelle gibt, ander der Fehler aufgetreten ist.
Die Anweisungen try und catch bieten den Rahmen für dieFehlerbehandlung.
4 Beendet die Klasse
So wird das Beispiel für eine serverseitige Verbindung ausgeführt.
In diesem Abschnitt wird beschrieben, wie das Beispiel für eine serverseitigeVerbindung ausgeführt wird.

Kapitel 5 Datenzugriff über JDBC
163
v So wird die Beispielanwendung für eine interne Verbindung erstelltund ausgeführt:
1 Falls Sie es noch nicht getan haben, kompilieren Sie die DateiJDBCExamples.java. Wenn Sie das JDK verwenden, können Sie imVerzeichnis Samples\ASA\Java von einer Befehlszeile ausfolgendermaßen vorgehen:
javac JDBCExamples.java
2 Starten Sie einen Datenbankserver mit der Beispieldatenbank. Einensolchen Server können Sie auf Ihrem lokalen Rechner starten, indem Siefolgenden Befehl ausführen (vom Unterverzeichnis Samples\ASA\Javaaus):
start dbeng8 ..\..\..\asademo
In diesem Fall ist das TCP/IP-Netzwerkprotokoll nicht erforderlich, dajConnect nicht verwendet wird.
3 Installieren Sie die Klasse in der Beispieldatenbank. Wenn dieVerbindung mit der Beispieldatenbank hergestellt ist, können Sie vonInteractive SQL aus folgenden Befehl verwenden:
INSTALL JAVA NEWFROM FILE’Suchpfad\Samples\ASA\Java\JDBCExamples.class’
Dabei gilt: Suchpfad ist der Suchpfad zu Ihrem Installationsverzeichnis.
Es besteht außerdem die Möglichkeit, die Klasse mit Sybase Central zuinstallieren. Öffnen Sie den Ordner mit den Java-Objekten beivorhandener Verbindung mit der Datenbank und doppelklicken Sie auf"Java-Klasse hinzufügen". Befolgen Sie dann die Anweisungen imAssistenten.
4 Jetzt können Sie die Methode InternalConnect dieser Klasse aufrufen,als wenn Sie eine gespeicherte Prozedur aufrufen würden:
CALL JDBCExamples>>InternalConnect()
Beim ersten Aufruf einer Java-Klasse muss die Java Virtual Machinegestartet werden. Dies kann einige Sekunden dauern.
5 Auf dem Serverbildschirm muss Hello World erscheinen.

JDBC-Verbindungen herstellen
164
Hinweise zu JDBC-Verbindungen
♦ AutoCommit-Verhalten Die JDBC-Spezifikation erfordert, dassstandardmäßig nach jeder Datenänderungsanweisung ein COMMITausgeführt wird. Derzeit ist das serverseitige JDBC-Verhalten auf"Festschreiben" eingestellt. Sie können dieses Verhalten steuern, indemSie folgende Anweisung verwenden:
conn.setAutoCommit( false ) ;
Dabei gilt: conn ist das aktuelle Verbindungsobjekt.
♦ Standardwerte für die Verbindung Bei der serverseitigen JDBC erstelltnur der erste Aufruf von getConnection( "jdbc:default:connection" )eine neue Verbindung mit den Standardwerten. Nachfolgende Aufrufegeben einen Behälter der aktuellen Verbindung mit allen unverändertenVerbindungseigenschaften zurück. Wenn Sie AutoCommit in Ihrerursprünglichen Verbindung auf OFF setzen, geben alle nachfolgendengetConnection Aufrufe in demselben Java-Code eine Verbindung mitAutoCommit in Stellung OFF zurück.
Es kann sinnvoll sein, die Verbindungseigenschaften beim Schließen derVerbindung auf die Standardwerte zurücksetzen zu lassen, damitnachfolgende Verbindungen mit Standard-JDBC-Werten eingerichtetwerden. Verwenden Sie dafür den folgenden Programmcode:
Connection conn = DriverManager.getConnection("");boolean oldAutoCommit = conn.getAutoCommit();try { // Code hierher setzen}finally { conn.setAutoCommit( oldAutoCommit );}
Diese Hinweise gelten nicht nur für AutoCommit, sondern auch fürandere Verbindungseigenschaften wie TransactionIsolation undisReadOnly.

Kapitel 5 Datenzugriff über JDBC
165
JDBC für den Zugriff auf Daten verwendenJava-Anwendungen, die einige oder alle Klassen in der Datenbank enthalten,bieten einen erheblichen Vorteil gegenüber traditionellen in SQLgeschriebenen gespeicherten Prozeduren. Als Einführung kann es jedochhilfreich sein, Parallelen zu mit SQL geschriebenen gespeichertenProzeduren zu ziehen, um die Fähigkeiten von JDBC zu demonstrieren. Inden folgenden Beispielen werden Java-Klassen geschrieben, die eine Zeile indie Tabelle Department einfügen.
Wie auch bei anderen Schnittstellen können SQL-Anweisungen in JDBCentweder statisch oder dynamisch sein. Statische SQL-Anweisungenwerden in der Java-Anwendung aufgebaut und zur Datenbank gesandt. DerDatenbankserver analysiert die Anweisung syntaktisch, wählt einenAusführungsplan und führt die Anweisung aus. Syntaktische Analyse undAuswahl eines Ausführungsplans werden in der Folge als Vorbereitung derAnweisung bezeichnet.
Wenn eine ähnliche Anweisung häufig ausgeführt werden soll (z.B. vieleEinfügungen in eine Tabelle), kann dies zu erheblichem Overhead in derstatischen SQL führen, weil jedesmal der Vorbereitungsschritt ausgeführtwerden muss.
Im Gegensatz dazu enthält eine dynamische SQL-Anweisung Platzhalter.Die Anweisung wird einmal mit Hilfe dieser Platzhalter vorbereitet und kanndann mehrmals ausgeführt werden, ohne dass sie neuerlich vorbereitetwerden muss.
In diesem Abschnitt verwenden wir statische SQL. Dynamische SQL wirdweiter unten behandelt.
Vorbereitung der Beispiele
In diesem Abschnitt wird beschrieben, welche Vorbereitungsmaßnahmen fürdie Beispiele im restlichen Teil des Kapitels ergriffen werden müssen.
Die Codefragmente in diesem Abschnitt stammen aus der vollständigenKlasse Samples\ASA\Java\JDBCExamples.java.
v So wird die Klasse JDBCExamples installiert:
1 Wenn Sie dies noch nicht getan haben, installieren Sie die DateiJDBCExamples.class in der Beispieldatenbank. Wenn die Verbindungvon Interactive SQL mit der Beispieldatenbank hergestellt ist, könnenSie im Fensterausschnitt für die SQL-Anweisungen folgenden Befehlverwenden:
Beispielcode

JDBC für den Zugriff auf Daten verwenden
166
INSTALL JAVA NEWFROM FILE’Suchpfad\Samples\ASA\Java\JDBCExamples.class’
Dabei gilt: Suchpfad ist der Suchpfad zu Ihrem Installationsverzeichnis.
Es besteht außerdem die Möglichkeit, die Klasse mit Sybase Central zuinstallieren. Öffnen Sie den Ordner mit den Java-Objekten beivorhandener Verbindung mit der Datenbank und doppelklicken Sie auf"Java-Klasse hinzufügen". Befolgen Sie dann die Anweisungen imAssistenten.
Einfügen, Aktualisieren und Löschen mit JDBC
Das Objekt Statement führt statische SQL-Anweisungen aus. SQL-Anweisungen wie INSERT, UPDATE, DELETE, die keine Ergebnismengenzurückgeben, können Sie mit Hilfe der Methode executeUpdate des ObjektsStatement ausführen. Anweisungen wie CREATE TABLE und andereAnweisungen zur Datendefinition können auch mit executeUpdateausgeführt werden.
Das folgende Codefragment veranschaulicht, wie INSERT-Anweisungeninnerhalb von JDBC ausgeführt werden. Es benutzt eine interne Verbindung,die im Verbindungsobjekt conn definiert ist. Der Programmcode für dasEinfügen von Werten aus einer externen Anwendung mit JDBC benötigt eineandere Verbindung, ist aber ansonsten unverändert.
public static void InsertFixed() { // Gibt die aktuelle Verbindung zurück conn =DriverManager.getConnection("jdbc:default:connection"); // AutoCommit deaktivieren conn.setAutoCommit( false );
Statement stmt = conn.createStatement();
Integer IRows = new Integer( stmt.executeUpdate ("INSERT INTO Department (dept_id, dept_name )" + "VALUES (201, 'Eastern Sales')" ) );
// Anzahl von aktualisierten Zeilen ausgeben System.out.println(IRows.toString() + " rowinserted" ); }

Kapitel 5 Datenzugriff über JDBC
167
Quellcode verfügbarDieses Codefragment ist Teil der Methode InsertFixed der KlasseJDBCExamples, die sich im Unterverzeichnis Samples\ASA\Java IhresInstallationsverzeichnisses befindet.
♦ Die Methode setAutoCommit deaktiviert das AutoCommit-Verhalten,sodass Änderungen nur festgeschrieben werden, wenn eine expliziteCOMMIT-Anweisung ausgeführt wird.
♦ Die Methode executeUpdate gibt eine Ganzzahl zurück, die die Anzahlder Zeilen ausdrückt, die von dem Vorgang betroffen waren. In diesemFall würde ein erfolgreicher INSERT-Vorgang den Wert Eins (1)zurückgeben.
♦ Der Rückgabetyp "Ganzzahl" wird in ein Objekt Integer konvertiert.Die Klasse "Integer" ist ein Behälter für den grundlegenden Datentypint, der einige nützliche Methoden enthält, wie z.B. toString().
♦ Die Ganzzahl IRows wird in eine Zeichenfolge konvertiert, dieausgegeben werden muss. Die Ausgabe erfolgt im Serverfenster.
v So wird das Beispiel JDBC Insert ausgeführt:
1 Über Interactive SQL stellen Sie als Benutzer DBA eine Verbindung mitder Beispieldatenbank her.
2 Die Klasse JDBCExamples muss installiert sein. Sie wird gemeinsammit den anderen Java-Beispielklassen installiert.
$ Weitere Hinweise, wie Sie die Java-Beispiele installieren können,finden Sie unter "Java-Beispiele einrichten" auf Seite 94.
3 Rufen Sie die Methode wie folgt auf:
CALL JDBCExamples>>InsertFixed()
4 Vergewissern Sie sich, dass in die Tabelle Department eine zusätzlicheZeile eingefügt wurde.
SELECT *FROM department
Die Zeile 201 ist nicht festgeschrieben. Sie können eine ROLLBACK-Anweisung ausführen, um die Zeile zu entfernen.
In diesem Beispiel haben Sie gesehen, wie eine sehr einfache JDBC-Klasseerstellt wird. Die nächsten Beispiele bauen darauf auf.
Hinweise

JDBC für den Zugriff auf Daten verwenden
168
Argumente an Java-Methoden übergeben
Wir können die Methode InsertFixed erweitern, um zu veranschaulichen,wie Argumente an Java-Methoden übergeben werden.
Die folgende Methode verwendet Argumente, die im Aufruf als dieeinzufügenden Werte an die Methode übergeben werden:
public static void InsertArguments( String id, String name) {
try { conn = DriverManager.getConnection( "jdbc:default:connection" );
String sqlStr = "INSERT INTO Department "+ " ( dept_id, dept_name )"+ " VALUES (" + id + ", ’" + name + "’)";
// Anweisung ausführen Statement stmt = conn.createStatement(); Integer IRows = new Integer( stmt.executeUpdate(sqlStr.toString() ) );
// Anzahl von aktualisierten Zeilen ausgeben System.out.println(IRows.toString() + " rowinserted" ); } catch ( Exception e ) { System.out.println("Error: " + e.getMessage()); e.printStackTrace(); } }
♦ Die beiden Argumente sind "department ID" (eine Ganzzahl) und"department name" (eine Zeichenfolge). Hier werden beide Argumenteals Zeichenfolgen an die Methode übergeben, weil sie als Teil derZeichenfolge der SQL-Anweisung verwendet werden.
♦ INSERT ist eine statische Anweisung: Sie nimmt außer der SQL selbstkeine Parameter an.
♦ Wenn Sie eine falsche Anzahl oder einen falschen Typ von Argumentenangeben, erscheint die Fehlermeldung Prozedur nicht gefunden(Procedure Not Found).
v So wird die Java-Methode mit Argumenten verwendet:
1 Wenn Sie dies noch nicht getan haben, installieren Sie die DateiJDBCExamples.class in der Beispieldatenbank.
Hinweise

Kapitel 5 Datenzugriff über JDBC
169
2 Stellen Sie über Interactive SQL eine Verbindung zur Beispieldatenbankher und geben Sie folgenden Befehl ein:
call JDBCExamples>>InsertArguments( ’203’, ’NorthernSales’ )
3 Vergewissern Sie sich, dass in die Tabelle "Department" einezusätzliche Zeile eingefügt wurde.
SELECT *FROM Department
4 Setzen Sie die Änderungen zurück, damit die Datenbank unverändertbleibt:
ROLLBACK
Abfragen mit JDBC
Das Objekt Statement wird für die Ausführung von statischen Abfragen undfür Anweisungen eingesetzt, die keine Ergebnismengen zurückgeben. BeiAbfragen verwenden Sie die Methode executeQuery des ObjektsStatement. Dies führt zur Rückgabe der Ergebnismenge in einem ObjektResultSet.
Das folgende Codefragment veranschaulicht, wie Abfragen in JDBCbehandelt werden. Das Codefragment setzt den Gesamt-Bestandswert für einProdukt in eine Variable mit dem Namen Inventory. DieArtikelbezeichnung wird in der String-Variablen prodname abgelegt.Dieses Beispiel ist als Methode Query der Klasse JDBCExamplesverfügbar.
Es gilt die Voraussetzung, dass eine interne bzw. externe Verbindunghergestellt wurde, die sich im Verbindungsobjekt mit der Bezeichnung connbefindet.
public static int Query () {int max_price = 0; try{ conn = DriverManager.getConnection( "jdbc:default:connection" );
// Abfrage aufbauen String sqlStr = "SELECT id, unit_price "
+ "FROM product" ;
// Anweisung ausführen Statement stmt = conn.createStatement(); ResultSet result = stmt.executeQuery( sqlStr );
while( result.next() ) {

JDBC für den Zugriff auf Daten verwenden
170
int price = result.getInt(2);System.out.println( "Price is " + price );if( price > max_price ) { max_price = price ;}
} } catch( Exception e ) { System.out.println("Error: " + e.getMessage()); e.printStackTrace(); } return max_price; }
Wenn Sie die Klasse JDBCExamples in der Beispieldatenbank installierthaben, können Sie diese Methode mit folgender Anweisung in InteractiveSQL ausführen:
select JDBCExamples>>Query()
♦ Die Abfrage wählt Menge und Einheitspreis für alle Produkte mit demNamen prodname. Diese Ergebnisse werden in das Objekt ResultSetmit dem Namen result zurückgegeben.
♦ In der Ergebnismenge wird über jeder Zeile eine Schleife ausgeführt.Die Schleife verwendet die Methode next.
♦ Für jede Zeile wird der Wert jeder Spalte mit der Methode getInt in eineGanzzahlvariable abgerufen. ResultSet umfasst ebenfalls Methoden fürandere Datentypen, wie etwa getString, getDate und getBinaryString.
Das Argument für die Methode getInt ist eine Indexnummer für dieSpalte, beginnend mit 1.
Die Datentyp-Konvertierung von SQL auf Java wird gemäß denAngaben im folgenden Abschnitt erklärt: "Datentypkonvertierung vonSQL in Java" auf Seite 96 der Dokumentation ASA SQL-Referenzhandbuch.
♦ Adaptive Server Anywhere unterstützt bidirektional abrollende Cursor.JDBC bietet jedoch nur die Methode next, die dem Vorwärts-Abrollendurch die Ergebnismenge entspricht.
♦ Die Methode gibt der aufrufenden Umgebung den Wert max_pricezurück, und Interactive SQL zeigt ihn auf dem Register "Ergebnisse" imFenster "Ergebnisse" an.
Das Beispielausführen
Hinweise

Kapitel 5 Datenzugriff über JDBC
171
Vorbereitete Anweisungen für effizienteren Zugriff verwenden
Wenn Sie ein Statement-Interface verwenden, muss jede Anweisung, die Siean die Datenbank senden, syntaktisch analysiert werden. Außerdem ist einZugriffsplan zu generieren und die Anweisung auszuführen. Die Schritte vorder eigentlichen Ausführung werden als Vorbereitung der Anweisungbezeichnet.
Sie können Performance-Vorteile erzielen, wenn Sie diePreparedStatement-Schnittstelle verwenden. Damit haben Sie dieMöglichkeit, eine Anweisung mit Platzhaltern vorzubereiten, und dann beimAusführen der Anweisung diesen Platzhaltern Werte zuzuordnen.
Der Einsatz von vorbereiteten Anweisungen ist besonders dann nützlich,wenn viele ähnliche Aktionen ausgeführt werden, wie etwa das Einfügen vonvielen Zeilen.
$ Weitere Hinweise über vorbereitete Anweisungen finden Sie unter"Anweisungen vorbereiten" auf Seite 12.
Das folgende Beispiel zeigt, wie die Schnittstelle PreparedStatementbenutzt werden kann, obwohl das Einfügen einer einzelnen Zeile in derPraxis nicht mit vorbereiteten Anweisungen erfolgen sollte.
Die folgende Methode der Klasse JDBCExamples führt eine vorbereiteteAnweisung aus:
public static void JInsertPrepared(int id, String name)try { conn = DriverManager.getConnection( "jdbc:default:connection");
// INSERT-Anweisung erstellen // ? ist ein Platzhalterzeichen String sqlStr = "INSERT INTO Department "
+ "( dept_id, dept_name ) "+ "VALUES ( ? , ? )" ;
// Anweisung vorbereiten PreparedStatement stmt = conn.prepareStatement(sqlStr );
stmt.setInt(1, id); stmt.setString(2, name ); Integer IRows = new Integer( stmt.executeUpdate() );
// Anzahl von aktualisierten Zeilen ausgeben System.out.println(IRows.toString() + " rowinserted" ); }
Beispiel

JDBC für den Zugriff auf Daten verwenden
172
catch ( Exception e ) { System.out.println("Error: " + e.getMessage()); e.printStackTrace(); } }
Wenn Sie die Klasse JDBCExamples in der Beispieldatenbank installierthaben, können Sie das Beispiel mit folgender Anweisung ausführen:
call JDBCExamples>>InsertPrepared( 202, ’Eastern Sales’ )
Das Zeichenfolgenargument wird entsprechend den SQL-Regeln inApostrophe eingeschlossen. Wenn Sie diese Methode von einer Java-Anwendung aus aktiviert hätten, sind zur Begrenzung der ZeichenfolgeAnführungszeichen zu verwenden.
Objekte einfügen und abrufen
Als Schnittstelle für relationale Datenbanken ist JDBC für das Abrufen vontraditionellen SQL-Datentypen sowie für das Arbeiten mit diesen Typenkonzipiert. Adaptive Server Anywhere umfasst auch abstrakte Datentypen inForm von Java-Klassen. Die Art, wie Sie mit JDBC auf diese Java-Klassenzugreifen, hängt davon ab, ob Sie die Objekte einfügen oder abrufen.
$ Weitere Hinweise zum Abrufen und Setzen ganzer Objekte finden Sieunter "Verteilte Anwendungen erstellen" auf Seite 174.
Objekte abrufen
Auf folgende Art und Weise können Sie Objekte, deren Felder und derenMethoden abrufen:
♦ Auf Methoden und Felder zugreifen Java-Methoden und -Felderkönnen in die Auswahlliste einer Abfrage einbezogen werden. EineMethode oder ein Feld erscheint als eine Spalte in der Ergebnismenge.Sie können mit einer der standardmäßigen ResultSet-Methoden daraufzugreifen, wie etwa getInt oder getString.
♦ Objekt abrufen Wenn Sie eine Spalte mit einem Java-Klassen-Datentypin die Auswahlliste einer Abfrage einbeziehen, können Sie dieResultSet-Methode getObject verwenden, um das Objekt in die Java-Klasse abzurufen. Dann können Sie innerhalb der Java-Klasse auf dieMethoden und Felder des betreffenden Objekts zugreifen.
Das Beispielausführen

Kapitel 5 Datenzugriff über JDBC
173
Objekte einfügen
Von einer serverseitigen Java-Klasse aus können Sie die JDBC-MethodesetObject benutzen, um ein Objekt in eine Spalte mit Java-Klassen-Datentypeinzufügen.
Sie können Objekte mit einer vorbereiteten Anweisung einfügen. Dasfolgende Codefragment fügt z.B. ein Objekt vom Typ "MyJavaClass" in eineSpalte der Tabelle T ein:
java.sql.PreparedStatement ps = conn.prepareStatement("insert T values( ? )" );ps.setObject( 1, new MyJavaClass() );ps.executeUpdate();
Eine Alternative wäre, eine SQL-Variable einzurichten, die das Objektenthält, und dann die SQL-Variable in die Tabelle einzufügen.
Gemischte JDBC-Hinweise
♦ Zugriffsberechtigungen Wie auf alle Java-Klassen in der Datenbank,kann jeder beliebige Benutzer auch auf Klassen mit JDBC-Anweisungenzugreifen. Es gibt keine Entsprechung zur Anweisung GRANTEXECUTE, die die Berechtigung zum Ausführen von Prozeduren erteilt,und der Name einer Klasse braucht nicht mit dem Namen desEigentümers qualifiziert zu werden.
♦ Berechtigung zum Ausführen Java-Klassen werden mit denBerechtigungen der sie ausführenden Verbindung ausgeführt. DiesesVerhalten unterscheidet sich von dem der gespeicherten Prozeduren, diemit den Berechtigungen des Eigentümers ausgeführt werden.

Verteilte Anwendungen erstellen
174
Verteilte Anwendungen erstellenIn einer verteilten Anwendung laufen Teile der Anwendungslogik aufeinem Rechner, andere Teile auf einem anderen. In Adaptive ServerAnywhere können Sie verteilte Java-Anwendungen erstellen, bei denen einTeil der Logik auf dem Datenbankserver, und ein Teil auf dem Clientsystemläuft.
Adaptive Server Anywhere ist in der Lage, Java-Objekte mit einem externenJava-Client auszutauschen.
Die Schlüsselaufgabe für eine Clientanwendung in einer verteiltenAnwendung besteht darin, ein Java-Objekt von einer Datenbank abzurufen.In diesem Abschnitt wird beschrieben, wie dies geschieht.
In anderen Teilen dieses Kapitels haben wir beschrieben, wie mehrereAufgaben abgerufen werden, die in Beziehung mit abrufenden Objektenstehen, jedoch nicht mit dem Abrufen des Objekts selbst verwechselt werdensollten. Zum Beispiel:
♦ "Java-Objekte abfragen" auf Seite 117 Hier wird beschrieben, wie einObjekt in eine SQL-Variable abgerufen wird. Damit ist allerdings nochnicht das Problem gelöst, wie das Objekt in Ihre Java-Anwendunggelangt.
♦ "Java-Objekte abfragen" auf Seite 117 Hier wird auch beschrieben, wiedie öffentlichen Felder und der Rückgabewert von Java-Methodenabgerufen werden. Auch dies unterscheidet sich vom Abrufen einesObjekts in eine Java-Anwendung.
♦ "Objekte einfügen und abrufen" auf Seite 172 Hier wird beschrieben,wie Objekte in serverseitige Java-Klassen abgerufen werden. Auch diesunterscheidet sich vom Abrufen von Objekten in eine Clientanwendung.
Beim Aufbau einer verteilten Anwendung müssen mehrere Aufgaben erfülltwerden.
v So wird eine verteilte Anwendung aufgebaut:
1 Jede auf dem Server laufende Klasse muss die serialisierbareSchnittstelle implementieren. Dies ist sehr einfach.
2 Die clientseitige Anwendung muss die Klasse importieren, damit dasObjekt auf der Clientseite wieder aufgebaut werden kann.
3 Verwenden Sie die Methode sybase.sql.ASAUtils.toByteArray auf derServerseite, um das Objekt zu serialisieren. Dies ist nur für AdaptiveServer Anywhere Version 6.0.1 und älter erforderlich.
DazugehörigeAufgaben
Anforderungen fürverteilteAnwendungen

Kapitel 5 Datenzugriff über JDBC
175
4 Verwenden Sie die Methode sybase.sql.ASAUtils.fromByteArray aufder Clientseite, um das Objekt wieder aufzubauen. Dies ist nur fürAdaptive Server Anywhere Version 6.0.1 und älter erforderlich.
Diese Aufgaben werden in den folgenden Abschnitten beschrieben.
Serialisierbare Schnittstelle implementieren
Objekte werden in einer so genannten serialisierten Form vom Server aneine Clientanwendung übergeben. Das bedeutet, dass jede Zeile folgendeInformationen enthält:
♦ Einen Versionsbezeichner
♦ Einen Bezeichner für die Klasse (oder Unterklasse), die gespeichert wird
♦ Die Werte von nicht-statischen, nicht-zeitweiligen Feldern in der Klasse
♦ Andere Overhead-Informationen
Damit ein Objekt an eine Clientanwendung gesendet wird, muss zunächst dieserialisierbare Schnittstelle implementiert werden. Dies ist eine sehr einfacheAufgabe.
v So wird die serialisierbare Schnittstelle implementiert:
♦ Fügen Sie den Text implements java.io.Serializable in IhreKlassendefinition ein.
Zum Beispiel implementiert Samples\ASA\Java\asademo\Product.javadie serialisierbare Schnittstelle über die folgende Deklaration:
public class Product implements java.io.Serializable
Die Implementierung der serialisierbaren Schnittstelle besteht lediglichdarin, zu deklarieren, dass diese Klasse serialisiert werden kann.
Die serialisierbare Schnittstelle enthält weder Methoden noch Variable. DieSerialisierung eines Objekts besteht darin, dass es in einen Byte-Stromkonvertiert wird, wodurch es auf einer Platte gespeichert bzw. an eine andereJava-Anwendung gesendet werden und wieder aufgebaut bzw. deserialisiertwerden kann.
Ein Java-Objekt, das in einem Datenbankserver serialisiert, an eineClientanwendung gesendet und deserialisiert wurde, ist in jeder Hinsichtidentisch mit dem Original. Einige Variable in einem Objekt brauchen nicht,bzw. sollten aus Sicherheitsgründen nicht serialisiert werden. DieseVariablen werden wie in der folgenden Deklaration der Variablen mit Hilfedes Schlüsselworts transient deklariert:

Verteilte Anwendungen erstellen
176
transient String password;
Wenn ein Objekt mit dieser Variablen deserialisiert wird, enthält dieVariable immer ihren Standardwert Null.
Angepasste Serialisierung kann durch Hinzufügen der MethodenwriteObject() und readObject() zu Ihren Klassen erreicht werden.
$ Weitere Hinweise zur Serialisierung finden Sie im Java DevelopmentKit (JDK) von Sun Microsystems.
Klassen clientseitig importieren
Auf der Clientseite muss jede Klasse, die ein Objekt abruft, Zugriff auf diegeeignete Klassendefinition haben, damit sie das Objekt benutzen kann. Umdie Klasse Product verwenden zu können, die Teil des Pakets asademo ist,müssen Sie folgende Zeile in Ihre Anwendung einbeziehen:
import asademo.*
Die Datei asademo.jar muss in Ihren CLASSPATH einbezogen sein, damitdieses Paket gefunden werden kann.
Beispiel für eine verteilte Anwendung
Die Klasse JDBCExamples.java enthält drei Methoden als Beispiel für denverteilten Einsatz von Java. Sie werden alle von der Methode mainaufgerufen. Diese Methode wird im Verbindungsbeispiel im Abschnitt "Voneiner JDBC-Clientanwendung aus mit jConnect eine Verbindung herstellen"auf Seite 157 beschrieben und ist ein Beispiel für eine verteilte Anwendung.
So sieht die Methode getObjectColumn aus der Klasse JDBCExamples aus:
private static void getObjectColumn() throws Exception {// Rückgabe einer Ergebnismenge von einer Spalte mit// Java-Objekten asademo.ContactInfo ci; String name; String sComment ;
if ( conn != null ) { Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery( "SELECT JContactInfo FROM jdba.contact" );

Kapitel 5 Datenzugriff über JDBC
177
while ( rs.next() ) { ci = ( asademo.ContactInfo )rs.getObject(1); System.out.println( "\n\tStreet: " + ci.street + "City: " + ci.city + "\n\tState: " + ci.state + "Phone: " + ci.phone + "\n" ); } } }
Die getObject-Methode wird wie bei einem internen Java-Fall verwendet.
Ältere Methode
getObject und setObject empfohlenDie Methoden getObject und setObject machen eine expliziteSerialisierung und Deserialisierung überflüssig, die bei früherenVersionen der Software erforderlich waren. In diesem Abschnitt wird fürBenutzer, die den älteren Programmcode benutzen, die ältere Methodebeschrieben.
In diesem Abschnitt wird beschrieben, wie eines dieser Beispielefunktioniert. Für die anderen Beispiele können Sie sich den Code ansehen.
Dies ist die Methode serializeColumn einer alten Version der KlasseJDBCExamples.
private static void serializeColumn() throws Exception { Statement stmt; ResultSet rs; byte arrayb[]; asademo.ContactInfo ci; String name;
if ( conn != null ) { stmt = conn.createStatement(); rs = stmt.executeQuery( "SELECT sybase.sql.ASAUtils.toByteArray( JName.getName() )AS Name, sybase.sql.ASAUtils.toByteArray(jdba.contact.JContactInfo ) FROM jdba.contact" );
while ( rs.next() ) { arrayb = rs.getBytes("Name"); name = ( String)sybase.sql.ASAUtils.fromByteArray( arrayb ); arrayb = rs.getBytes(2);
Abfrageergebnisseserialisieren unddeserialisieren

Verteilte Anwendungen erstellen
178
ci =(asademo.ContactInfo)sybase.sql.ASAUtils.fromByteArray(arrayb ); System.out.println( "Name: " + name + "\n\tStreet: " + ci.street + "\n\tCity: " + ci.city + "\n\tState: " + ci.state + "\n\tPhone: " + ci.phone + "\n" ); } System.out.println( "\n\n" ); } }
Und so funktioniert die Methode:
1 Es ist bereits eine Verbindung vorhanden, wenn die Methode aufgerufenwird. Das Verbindungsobjekt wird geprüft, und wenn es vorhanden ist,wird der Code ausgeführt.
2 Eine SQL-Abfrage wird aufgebaut und ausgeführt. Die Abfrage lautetfolgendermaßen:
SELECTsybase.sql.ASAUtils.toByteArray( JName.getName() )AS Name,sybase.sql.ASAUtils.toByteArray(jdba.contact.JContactInfo ) FROM jdba.contact
Diese Anweisung führt eine Abfrage in der Tabelle jdba.contact aus. Sieruft Daten aus den Spalten JName und JContactInfo ab. Anstatteinfach nur die Spalten selbst bzw. eine Methode der Spalte abzurufen,wird die Funktion sybase.sql.ASAUtils.toByteArray verwendet.
3 Der Client führt eine Schleife über die Zeilen der Ergebnismenge aus.Für jede Zeile wird der Wert jeder Spalte in ein Objekt deserialisiert.
4 Die Ausgabe (System.out.println) zeigt, dass die Felder und Methodendes Objekts ebenso wie im Originalstatus eingesetzt werden können.
Sonstige Funktionen von verteilten Anwendungen
Es gibt zwei weitere Methoden in JDBCExamples.java, die verteilteInformatinosverarbeitung verwenden:
♦ serializeVariable Diese Methode erstellt ein natives Java-Objekt, dasvon einer SQL-Variablen auf dem Datenbankserver referenziert wird,und gibt es an die Clientanwendung zurück.

Kapitel 5 Datenzugriff über JDBC
179
♦ serializeColumnCastClass Diese Methode ähnelt der MethodeserializeColumn, veranschaulicht jedoch, wie Unterklassen wiederaufgebaut werden. Die abgefragte Spalte (JProd aus der Tabelleproduct) hat den Datentyp asademo.Product. Einige der Zeilen sindasademo.Hat, wobei es sich um eine Unterklasse der Klasse "Product"handelt. Die richtige Klasse wird clientseitig wieder aufgebaut.

Verteilte Anwendungen erstellen
180

181
K A P I T E L 6
Programmieren mit Embedded SQL
In diesem Kapitel wird beschrieben, wie die Embedded SQL-Schnittstelle zuAdaptive Server Anywhere verwendet wird.
Thema Seite
Überblick 182
Beispielprogramme mit Embedded SQL 190
Datentypen in Embedded SQL 196
Hostvariable benutzen 200
SQL-Kommunikationsbereich (SQLCA) 208
Daten abrufen 214
Statische und dynamische SQL 223
Der SQL-Deskriptor-Bereich (SQLDA) 228
Lange Werte senden und abfragen 237
Gespeicherte Prozeduren verwenden 243
Programmiertechniken für Embedded SQL 247
SQL-Präprozessor 249
Referenz der Bibliotheksfunktion 253
Befehlszusammenfassung für Embedded SQL 272
Über diesesKapitel
Inhalt

Überblick
182
ÜberblickEmbedded SQL ist eine Datenbank-Programmierschnittstelle für dieProgrammiersprachen C und C++. Es besteht aus SQL-Anweisungen, die inC- oder C++-Quellcode eingebettet sind. Die SQL-Anweisungen werden voneinem SQL-Präprozessor in C- oder C++-Quellcode konvertiert, die Sieanschließend kompilieren.
Während der Laufzeit verwenden Embedded SQL-Anwendungen eineAdaptive Server Anywhere-Schnittstellenbibliothek für dieKommunikation mit dem Datenbankserver. Die Schnittstellenbibliothek isteine dynamische Verknüpfungsbibliothek (dynamic link library - DLL) oder- auf den meisten Betriebssystemplattformen - eine gemeinsam genutzteBibliothek (shared library).
♦ Unter Windows-Betriebssystemen ist die Schnittstellenbibliothekdblib8.dll.
♦ Bei UNIX-Betriebssystemen heißt die Schnittstellenbibliothek je nachBetriebssystem libdblib8.so, libdblib8.sl oder libdblib8.a.
Adaptive Server Anywhere liefert zwei Arten von Embedded SQL.Statisches Embedded SQL ist einfacher zu verwenden, jedoch wenigerflexibel als dynamisches Embedded SQL. Diese beiden Arten werden indiesem Kapitel behandelt.
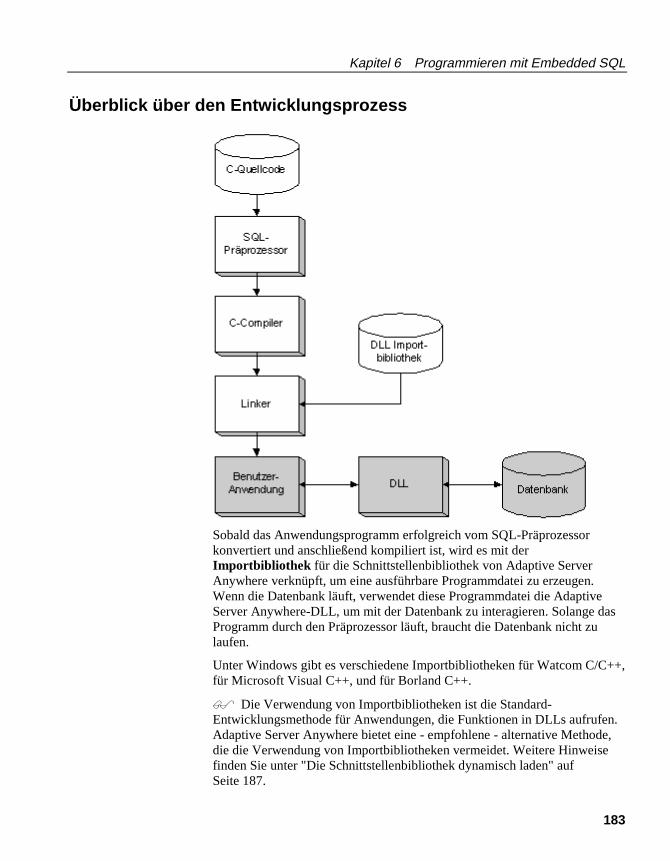
Kapitel 6 Programmieren mit Embedded SQL
183
Überblick über den Entwicklungsprozess
Sobald das Anwendungsprogramm erfolgreich vom SQL-Präprozessorkonvertiert und anschließend kompiliert ist, wird es mit derImportbibliothek für die Schnittstellenbibliothek von Adaptive ServerAnywhere verknüpft, um eine ausführbare Programmdatei zu erzeugen.Wenn die Datenbank läuft, verwendet diese Programmdatei die AdaptiveServer Anywhere-DLL, um mit der Datenbank zu interagieren. Solange dasProgramm durch den Präprozessor läuft, braucht die Datenbank nicht zulaufen.
Unter Windows gibt es verschiedene Importbibliotheken für Watcom C/C++,für Microsoft Visual C++, und für Borland C++.
$ Die Verwendung von Importbibliotheken ist die Standard-Entwicklungsmethode für Anwendungen, die Funktionen in DLLs aufrufen.Adaptive Server Anywhere bietet eine - empfohlene - alternative Methode,die die Verwendung von Importbibliotheken vermeidet. Weitere Hinweisefinden Sie unter "Die Schnittstellenbibliothek dynamisch laden" aufSeite 187.

Überblick
184
Den SQL-Präprozessor verwenden
Der SQL-Präprozessor ist eine Programmdatei namens sqlpp.exe.
Die SQLPP-Befehlszeile sieht wie folgt aus:
sqlpp [ Parameter ] SQL-Dateiname [ Ausgabedateiname ]
Der SQL-Präprozessor konvertiert ein C-Programm mit Embedded SQL,bevor der C- oder C++-Compiler ausgeführt wird. Der Präprozessorübersetzt die SQL-Anweisungen in C-/C++-Quellcode und schreibt denQuellcode in eine Ausgabedatei. Die normale Dateinamenerweiterung fürQuelldateien mit embedded SQL ist .sqc. Der voreingestellte Name für dieAusgabedatei ist der Name der SQL-Datei mit der Erweiterung .c. Falls derName der SQL-Datei bereits die Erweiterung .c hat, erhält die Ausgabedeiteistandardmäßig die Erweiterung .cc.
$ Eine vollständige Auflistung der Optionen finden Sie unter "SQL-Präprozessor" auf Seite 249.
Unterstützte Compiler
Der SQL-Präprozessor für C wird bisher in Verbindung mit folgendenCompilern benutzt:
Betriebssystem Compiler Version
Windows Watcom C/C++ 9.5 und höher
Windows Microsoft Visual C/C++ 1.0 und höher
Windows Borland C++ 4.5
Windows CE Microsoft Visual C/C++ 5.0
UNIX GNU oder nativerCompiler
NetWare Watcom C/C++ 10.6, 11
$ Anweisungen zur Erstellung von NetWare NLMs finden Sie unter"NetWare loadable Modules erstellen" auf Seite 188.
Header-Dateien für Embedded SQL
Alle Header-Dateien befinden sich nach der Installation von Adaptive ServerAnywhere im Unterverzeichnis h des Installationsverzeichnisses.
Befehlszeile

Kapitel 6 Programmieren mit Embedded SQL
185
Dateiname Beschreibung
sqlca.h Wichtigste Header-Datei, wird in alle Embedded SQL-Programme eingefügt. Die Datei fügt die Strukturdefinition fürden SQL-Kommunikationsbereich ein (SQL CommunicationArea - SQLCA), sowie Prototypen für alle Embedded SQL-Datenbankschnittstellenfunktionen.
sqlda.h SQL-Deskriptorbereich-Strukturdefinition, wird in EmbeddedSQL-Programme eingefügt, die dynamisches SQL benutzen
sqldef.h Definition der Datentypen für die Embedded SQL-Schnittstelle. Die Datei enthält auch Strukturdefinitionen undRückgabewerte, die gebraucht werden, um denDatenbankserver aus einem C-Programm zu starten.
sqlerr.h Definitionen für Fehlercodes, die im Feld sqlcode desSQLCA-Bereichs zurückgegeben werden
sqlstate.h Definitionen für ANSI/ISO SQL-Standardfehlerzustände, dieim Feld sqlstate des SQLCA-Bereichs zurückgegeben werden
pshpk1.h,pshpk2.h,poppk.h
Diese Header stellen sicher, dass das Strukturverdichten(structure packing) korrekt gehandhabt wird. Sie unterstützendie Compiler Watcom C/C++, Microsoft Visual C++, IBMVisual Age und Borland C/C++.
Importbibliotheken
Alle Importbibliotheken sind im Unterverzeichnis lib unter demInstallationsunterverzeichnis von Adaptive Server Anywhere installiert. DieWindows-Importbibliotheken sind zum Beispiel im Unterverzeichniswin32\lib abgelegt.
Betriebssystem Compiler Importbibliothek
Windows Watcom C/C++ dblibtw.lib
Windows Microsoft VisualC++
dblibtm.lib
Windows CE Microsoft VisualC++
dblib8.lib
NetWare Watcom C/C++ dblib8.lib
Solaris (nicht verketteteAnwendungen)
Alle Compiler libdblib8.so,libdbtasks8.so
Solaris (verketteteAnwendungen)
Alle Compiler libdblib8_r.so,libdbtasks8_r.so

Überblick
186
Die Bibliotheken libdbtasks8 werden von der Bibliothek libdblib8 aufgerufen.Einige Compiler ermitteln die Position von libdbtasks8 automatisch, währendSie dies für andere explizit angeben müssen.
Ein einfaches Beispiel
Es folgt ein sehr einfaches Beispiel für ein Embedded SQL-Programm.
#include <stdio.h>EXEC SQL INCLUDE SQLCA;main(){
db_init( &sqlca );EXEC SQL WHENEVER SQLERROR GOTO error;EXEC SQL CONNECT "DBA" IDENTIFIED BY "SQL";EXEC SQL UPDATE employee
SET emp_lname = ’Plankton’WHERE emp_id = 195;
EXEC SQL COMMIT WORK;EXEC SQL DISCONNECT;db_fini( &sqlca );return( 0 );
error:printf( "update unsuccessful -- sqlcode = %ld.n",
sqlca.sqlcode );db_fini( &sqlca );return( -1 );
}
Dieses Beispiel stellt eine Verbindung mit der Datenbank her, aktualisiertden Nachnamen des Angestellten mit der Nummer 195, schreibt dieÄnderung fest und beendet das Programm. Es gibt praktisch keineInteraktion zwischen dem SQL-Code und dem C-Code. C-Code wird indiesem Beispiel ausschließlich zur Ablaufsteuerung benutzt. Die AnweisungWHENEVER wird für Fehlerüberprüfung benutzt. Die Fehleraktion (indiesem Beispiel GOTO) wird nach jeder SQL-Anweisung ausgeführt, dieeinen Fehler verursacht.
$ Weitere Hinweise zum Abrufen von Daten finden Sie unter "Datenabrufen" auf Seite 214.

Kapitel 6 Programmieren mit Embedded SQL
187
Struktur von Embedded SQL-Programmen
In Embedded-SQL-Programmen sind SQL-Anweisungen in normalen C-oder C++-Code eingebettet. Alle Embedded SQL-Anweisungen beginnenmit den Worten EXEC SQL und enden mit einem Semikolon (;). NormaleKommentare der Sprache C sind innerhalb von Embedded SQL-Anweisungen erlaubt.
Der Quellcode eines C-Programms, das Embedded SQL benutzt, muss vorder ersten Embedded SQL-Anweisung in der Quelldatei folgende Anweisungenthalten:
EXEC SQL INCLUDE SQLCA;
Die erste Embedded SQL-Anweisung, die von dem C-Programm ausgeführtwird, muss eine CONNECT-Anweisung sein. Die CONNECT-Anweisungstellt eine Verbindung mit dem Datenbankserver her und spezifiziert dieBenutzer-ID für alle Anweisungen, die während der Verbindung ausgeführtwerden.
Die CONNECT-Anweisung muss als erste Embedded SQL-Anweisungausgeführt werden. Ausnahme: Einige Embedded SQL-Befehle erzeugenkeinen C-Code oder benötigen keine Verbindung mit der Datenbank. DieseBefehle sind daher vor der CONNECT-Anweisung erlaubt. Die wichtigstensind die INCLUDE-Anweisung und die WHENEVER-Anweisung für dieFehlerbehandlung.
Die Schnittstellenbibliothek dynamisch laden
Um Anwendungen zu entwickeln, die Funktionen aus DLLs aufrufen, ist esüblich, die Anwendung mit einer Importbibliothek zu verknüpfen, die dieerforderlichen Funktionsdefinitionen enthält.
Dieser Abschnitt beschreibt eine alternative Methode, um Anwendungen fürAdaptive Server Anywhere zu entwickeln. Die Adaptive Server AnywhereSchnittstellenbibliothek kann dynamisch geladen werden, ohne dass sie mitder Importbibliothek verknüpft werden muss, und zwar mit Hilfe des Modulsesqldll.c im Unterverzeichnis src Ihres Installationsverzeichnisses. Wirempfehlen, esqldll.c zu benutzen, denn diese Methode ist einfacheranzuwenden und findet die Schnittstellen-DLL zuverlässiger.

Überblick
188
v Um die Schnittstellen-DLL dynamisch zu laden, gehen Sie wie folgtvor:
1 Ihr Programm muss db_init_dll aufrufen, um die DLL zu laden, und esmuss db_fini_dll aufrufen, um die DLL wieder freizugeben. db_init_dllmuss vor jeder anderen Funktion der Datenbankschnittstelle aufgerufenwerden. Nach db_fini_dll kann keine Funktion derDatenbankschnittstelle mehr aufgerufen werden.
Sie müssen trotzdem die Bibliotheksfunktionen db_init und db_finiaufrufen.
2 Fügen Sie vor der Anweisung EXEC SQL INCLUDE SQLCA mit#include die Header-Datei esqldll.h ein, oder fügen Sie #include <sqlca.h> in Ihr Embedded SQL-Programm ein.
3 Ein SQL OS (Operating System - Betriebssystem)-Makro muss definiertwerden. Die Header-Datei sqlca.h, die mit esqdll.c eingefügt wird,versucht das passende Makro zu bestimmen und zu definieren. Beibestimmten Kombinationen von Betriebssystemen und Compilern kanndieser Versuch allerdings fehlschlagen. In diesem Fall müssen Sieentweder mit #define eine Definition am Beginn Ihrer Datei einfügen,oder die Definition mit einer Compiler-Option liefern.
Makro Unterstützte Plattformen
_SQL_OS_WINNT Alle Windows-Betriebssysteme
_SQL_OS_UNIX UNIX
_SQL_OS_UNIX NetWare
4 Kompilieren Sie esqldll.c.
5 Statt mit der Importbibliothek verknüpfen Sie Ihre Embedded SQL-Anwendung mit dem Objektmodul esqldll.obj.
Ein Beispielprogramm, aus dem ersichtlich ist, wie dieSchnittstellenbibliothek dynamisch geladen werden kann, finden Sie imUnterverzeichnis Samples\ASA\ESQLDynamicLoad in IhremSQL Anywhere-Verzeichnis. Der Quellcode befindet sich inSamples\ASA\ESQLDynamicLoad\sample.sqc.
NetWare loadable Modules erstellen
Sie müssen den Watcom C/C++-Compiler, Version 10.6 oder 11.0verwenden, um Embedded SQL-Programme als NetWare loadable Modules(NLM) zu kompilieren.
Beispiel

Kapitel 6 Programmieren mit Embedded SQL
189
v So erstellen Sie ein Embedded SQL-NLM:
1 Auf einem Windows-basierten System müssen Sie die Embedded SQL-Datei mit folgendem Befehl vorverarbeiten:
sqlpp -o NETWARE srcfile.sqc
Diese Anweisung erstellt eine Datei mit der Erweiterung .c.
2 Kompilieren Sie file.c mit dem Watcom-Compiler (10.6 oder 11.0) unterVerwendung der Option /bt=netware.
3 Verknüpfen Sie die sich ergebende Objektdatei mit Hilfe des Watcom-Linkers mit den folgenden Optionen:
FORMAT NOVELLMODULE dblib8OPTION CASEEXACTIMPORT @dblib8.impLIBRARY dblib8.lib
Die Dateien dblib8.imp und dblib8.lib werden mit Adaptive ServerAnywhere ausgeliefert und befinden sich im Verzeichnis nlm. Für dieZeilen IMPORT und LIBRARY ist eventuell der vollständige Suchpfadnotwendig.

Beispielprogramme mit Embedded SQL
190
Beispielprogramme mit Embedded SQLDie Embedded SQL-Beispiele sind Teil der Adaptive Server Anywhere-Installation. Sie werden im Unterverzeichnis Samples\ASA\C IhresVerzeichnisses SQL Anywhere gespeichert.
♦ Das Beispiel für statische Cursor Samples\ASA\C\cur.sqc zeigt dieVerwendung von statischen SQL-Anweisungen.
♦ Das Beispiel für dynamische Cursor und Embedded SQLSamples\ASA\C\dcur.sqc zeigt die Verwendung von dynamischen SQL-Anweisungen.
Um die Anzahl der Codezeilen zu verringern, die in denBeispielprogrammen cur und dcur (und dem odbc-Beispiel) mehrmalsvorkommen, sind die Mainlines und die Druckfunktionen in einer separatenDatei enthalten. Und zwar in mainch.c für zeichenbasierte Systeme und inmainwin.c für fensterbasierte Systeme.
Die Beispielprogramme liefern jeweils folgende drei Routinen, die von denMainlines aufgerufen werden.
♦ WSQLEX_Init Stellt eine Verbindung zur Datenbank her und öffnet denCursor
♦ WSQLEX_Process_Command Verarbeitet Benutzerbefehle undbedient den Cursor
♦ WSQLEX_Finish Schließt den Cursor und trennt die Verbindung zurDatenbank
Die Funktion der Mainline ist:
1 Die Routine WSQLEX_Init aufzurufen
2 Sie ist eine Schleife, die Befehle vom Benutzer abholt, undWSQL_Process_Command aufruft, bis der Benutzer das Programmbeendet
3 Die Routine WSQLEX_Finish aufzurufen
Die Verbindung mit der Datenbank wird mit dem Embedded SQL-BefehlCONNECT hergestellt, der die erforderliche Benutzer-ID und das Kennwortbereitstellt.
Zusätzlich zu diesen Beispielen können Sie als Teil von SQL AnywhereStudio weitere Programme und Quelldateien finden, die Eigenschaften desServers für bestimmte Betriebssystemplattformen veranschaulichen.

Kapitel 6 Programmieren mit Embedded SQL
191
Beispielprogramme erstellen
Dateien für den Aufbau der Beispielprogramme werden mit demBeispielcode geliefert.
♦ Bei Windows- und NetWare-Betriebssystemen mit Windows als Host-Betriebssystem, verwenden Sie makeall.bat zum Kompilieren derBeispielprogramme.
♦ Für UNIX verwenden Sie das Shell-Skript makeall.
♦ Für Windows CE verwenden Sie die dcur.dsp-Projektdatei für MicrosoftVisual C++.
Die Syntax des Befehls ist wie folgt:
makeall {Beispiel} {Plattform} {Compiler}
Der erste Parameter ist der Name des Beispielprogramms, das Siekompilieren wollen. Es ist eines der folgenden Programme:
♦ CUR Beispiel für statischen Cursor
♦ DCUR Beispiel für dynamischen Cursor
♦ ODBC Beispiel für ODBC
Der zweite Parameter ist die Zielplattform. Sie ist eines der folgendenProgramme:
♦ WINNT Für Windows kompilieren
♦ NETWARE Für NetWare NLM kompilieren
Der dritte Parameter ist der Compiler, mit dem das Programm kompiliertwerden soll. Der Compiler kann einer der folgenden sein:
♦ WC - Watcom C/C++
♦ MC Microsoft C
♦ BC Borland C
Beispielprogramme ausführen
Die ausführbaren Dateien befinden sich gemeinsam mit dem Quellcode imVerzeichnis Samples\ASA\C.
v So wird das Beispielprogramm für einen statischen Cursorausgeführt:
1 Starten Sie das Programm:

Beispielprogramme mit Embedded SQL
192
♦ Starten Sie die Personal Server Beispieldatenbank von AdaptiveServer Anywhere.
♦ Führen Sie die Datei Samples\ASA\C\curwnt.exe aus.
2 Befolgen Sie die Anweisungen auf dem Bildschirm.
Die verschiedenen Befehle verändern einen Datenbankcursor und gebenAbfrageergebnisse am Bildschirm aus. Geben Sie einfach denBuchstaben des Befehls ein, den Sie ausführen wollen. Bei einigenSystemen müssen Sie anschließend die Eingabetaste (ENTER) drücken,um den Befehl auszuführen.
v So wird das Beispielprogramm für einen dynamischen Cursorausgeführt:
1 Starten Sie das Programm:
♦ Führen Sie die Datei Samples\ASA\C\dcurwnt.exe aus.
2 Stellen Sie eine Verbindung zu einer Datenbank her:
♦ Alle Beispielprogramme haben eine Konsolen-Benutzeroberflächemit einer Eingabeaufforderung. Geben Sie die nachstehendeZeichenfolge ein, damit eine Verbindung mit der Beispieldatenbankhergestellt wird:
DSN=ASA 8.0 Sample
3 Wählen Sie eine Tabelle:
♦ Jedes einzelne Beispielprogramm fordert Sie auf, eine Tabelleanzugeben. Wählen Sie eine der Tabellen in der Beispieldatenbank.Sie können z.B. Customer oder Employee eingeben.
4 Befolgen Sie die Anweisungen auf dem Bildschirm.
Die verschiedenen Befehle verändern einen Datenbankcursor und gebenAbfrageergebnisse am Bildschirm aus. Geben Sie einfach denBuchstaben des Befehls ein, den Sie ausführen wollen. Bei einigenSystemen müssen Sie anschließend die Eingabetaste (ENTER) drücken,um den Befehl auszuführen.
Die Windows-Versionen der Beispielprogramme sind echte Windows-Programme. Um allerdings den Code für die Benutzeroberfläche nicht zukompliziert zu gestalten, wurden einige Vereinfachungen vorgenommen. ImBesonderen schreiben diese Programme auf WM_PAINT-Nachrichten hinnicht die Fenster neu, sondern nur die Eingabeaufforderung.
Windows Beispiele

Kapitel 6 Programmieren mit Embedded SQL
193
Beispiel für statischen Cursor
Dieses Beispiel zeigt die Verwendung von Cursorn. Der Cursor, der hierverwendet wurde, ruft bestimmte Informationen aus der Tabelle employee inder Beispieldatenbank ab. Der Cursor wird statisch deklariert, das heißt, dieSQL-Anweisung, die die Information abruft, ist im Quellprogrammenthalten. Dies ist ein gutes Beispiel, um zu lernen, wie Cursorfunktionieren. Das nächste Beispiel ("Beispiel für dynamischen Cursor" aufSeite 193) konvertiert dieses erste Beispiel und verwendet dynamische SQL-Anweisungen.
$ Wo der Quellcode zu finden ist und wie Sie dieses Beispielprogrammkompilieren, finden Sie unter "Beispielprogramme mit Embedded SQL" aufSeite 190.
Die open_cursor-Routine deklariert einen Cursor für den jeweiligen SQL-Befehl und öffnet ebenfalls den Cursor.
Die print-Routine druckt eine Seite mit Informationen. Sie führt pagesize-mal eine Schleife aus, die eine einzelne Zeile vom Cursor abruft und druckt.Beachten Sie, dass die Abrufroutine überprüft, ob eine Warnsituationvorliegt (wie Row not found), und gegebenenfalls die erforderlicheFehlermeldung ausgibt. Außerdem positioniert das Programm den Cursorneu in der Zeile vor derjenigen, die am Anfang der aktuellen Datenseiteausgegeben wurde.
Die Routinen move, top und bottom benutzen die geeignete Form derFETCH-Anweisung, um den Cursor zu positionieren. Beachten Sie bitte,dass diese Form der FETCH-Anweisung nicht tatsächlich die Daten abruft,die Anweisung positioniert lediglich den Cursor. Außerdem wurde eineallgemeine Routine namens move zur relativen Positionierungimplementiert, die abhängig vom Vorzeichen des Parameters den Cursor indie eine oder andere Richtung bewegt.
Beendet der Benutzer das Programm, wird der Cursor geschlossen und dieDatenbankverbindung getrennt. Der Cursor wird durch eine ROLLBACKWORK-Anweisung geschlossen und die Verbindung mit DISCONNECTgetrennt.
Beispiel für dynamischen Cursor
Dieses Beispiel veranschaulicht, wie Cursor für eine dynamische SQL-SELECT-Anweisung verwendet werden. Es ist eine leichte Änderung desvorangehenden Beispiels. Bitte sehen Sie sich das vorangehende "Beispielfür statischen Cursor" auf Seite 193 an, bevor Sie sich mit diesem Beispielbefassen.

Beispielprogramme mit Embedded SQL
194
$ Wo der Quellcode zu finden ist und wie Sie dieses Beispielprogrammkompilieren, finden Sie unter "Beispielprogramme mit Embedded SQL" aufSeite 190.
Das Programm dcur erlaubt dem Benutzer, mit dem n-Befehl eine Tabelleauszuwählen, die er anschauen möchte. Das Programm zeigt dann so vieleInformationen aus dieser Tabelle an, wie auf den Bildschirm passen.
Wenn dieses Programm ausgeführt wird, erwartet es eine Zeichenfolge fürdie Verbindung der Form:
uid=DBA;pwd=SQL;dbf=c:\Programme\Sybase\SQLAnywhere 8\asademo.db
Das C-Programm mit Embedded SQL befindet sich im UnterverzeichnisSamples\ASA\C Ihres SQL Anywhere-Installationsverzeichnisses.Abgesehen von den Funktionen connect, open_cursor und print gleicht dasProgramm weitgehend dem vorigen Beispiel.
Die Funktion connect benutzt die Embedded SQL-Schnittstellenfunktiondb_string_connect, um die Verbindung zur Datenbank herzustellen. DieseFunktion liefert die zusätzliche Funktionalität, um die Zeichenfolge für dieVerbindung zu unterstützen, die benutzt wird, um die Verbindung zurDatenbank herzustellen.
Die Routine open_cursor baut zuerst die SELECT-Anweisung auf:
SELECT * FROM Tabellenname
Wobei Tabellenname der Parameter ist, der an die Routine übergeben wird.Dann bereitet sie eine dynamische SQL-Anweisung mit Hilfe dieserZeichenfolge vor.
Der Embedded SQL-Befehl DESCRIBE wird benutzt, um die Ergebnisse derSELECT-Anweisung in die SQLDA-Struktur zu schreiben.
Größe der SQLDAZu Beginn wird die Größe der SQLDA geschätzt (3). Ist das nicht großgenug, wird die tatsächliche Größe der Auswahlliste, die vomDatenbankserver zurückgegeben wurde, benutzt, um eine SQLDA derrichtigen Größe zuzuweisen.
Die SQLDA-Struktur wird dann mit Puffern gefüllt, die Zeichenfolgenenthalten, die wiederum für das Ergebnis der Abfrage stehen. Die Routinefill_s_sqlda konvertiert alle Datentypen in der SQLDA in DT_STRINGund weist Puffer der passenden Größe zu.
Dann wird für diese Anweisung ein Cursor deklariert und geöffnet. Dieübrigen Routinen zum Bewegen und Schließen des Cursors sind die gleichenwie beim vorhergehenden Beispiel.

Kapitel 6 Programmieren mit Embedded SQL
195
Die fetch-Routine differiert leicht, sie schreibt die Ergebnisse in dieSQLDA-Struktur statt in eine Liste von Hostvariablen. Die print-Routine istleicht verändert, um Ergebnisse aus der SQLDA-Struktur bis zur vollenBildschirmbreite auszugeben. Die print-Routine benutzt auch dieNamenfelder des SQLDA-Bereichs, um Überschriften für die Spaltenauszugeben.
Beispiele für Dienste
Die Beispielprogramme cur.sqc und dcur.sqc werden optional als Diensteausgeführt, wenn sie für eine Windows-Version kompiliert werden, aufdenen Dienste laufen können.
Die beiden Dateien, die den Beispielcode für Windows-Dienste enthalten,sind die Quelldatei ntsvc.c und die Header-Datei ntsvc.h. Der Codeermöglicht es, das damit gelinkte ausführbare Programm entweder alsnormales Programm oder als Windows-Dienst auszuführen.
v Um eines der kompilierten Beispiele als Windows-Dienstauszuführen, gehen Sie wie folgt vor:
1 Starten Sie Sybase Central und öffnen Sie das Verzeichnis "Dienste".
2 Wählen Sie einen Diensttyp aus der Beispielanwendung aus und klickenSie auf "OK".
3 Geben Sie einen Dienstnamen in das entsprechende Feld ein.
4 Wählen Sie das Beispielprogramm (curwnt.exe oder dcurwnt.exe) ausdem Unterverzeichnis Samples\ASA|C im SQL Anywhere-Installationsverzeichnis.
5 Klicken Sie auf "OK", um den Dienst zu installieren.
6 Klicken Sie auf "Start" im Hauptfenster, um den Dienst zu starten.
Wird das Programm als Dienst ausgeführt, zeigt es, falls möglich, dienormale Benutzeroberfläche. Die Ausgabe wird in das Ereignisprotokoll derAnwendung geschrieben. Falls die Benutzeroberfläche nicht gestartet werdenkann, schreiben die Programme eine Seite in das Ereignisprotokoll derAnwendung und halten an.
Diese Beispiele wurden mit dem Watcom C/C++ 10.5-Compiler und demMicrosoft Visual C++-Compiler getestet.

Datentypen in Embedded SQL
196
Datentypen in Embedded SQLUm Informationen zwischen einem Programm und dem Datenbankserveraustauschen zu können, müssen alle Datenelemente einen Datentyp haben.Die Konstanten für Embedded SQL haben alle das Präfix DT_ und befindensich in der Header-Datei sqldef.h. Eine Hostvariable kann jeden derunterstützten Datentypen haben. Sie können diese Datentypen auch in einerSQLDA-Struktur benutzen, um Daten mit der Datenbank auszutauschen.
Sie können mit den DECL_-Makros in sqlca.h Variablen dieser Datentypendefinieren. Beispielsweise kann mit DECL_BIGINT eine Variable mit einemBIGINT-Wert deklariert werden.
Folgende Datentypen werden von der Embedded SQL-Programmierschnittstelle unterstützt:
♦ DT_BIT 8-Bit Ganzzahl mit Vorzeichen
♦ DT_SMALLINT 16-Bit-Ganzzahl mit Vorzeichen
♦ DT_UNSSMALLINT 16-Bit Ganzzahl ohne Vorzeichen
♦ DT_TINYINT 8-Bit Ganzzahl mit Vorzeichen
♦ DT_BIGINT 64-Bit Ganzzahl mit Vorzeichen
♦ DT_INT 32-Bit Ganzzahl mit Vorzeichen
♦ DT_UNSINT 16-Bit Ganzzahl ohne Vorzeichen
♦ DT_FLOAT 4-Byte-Gleitkommazahl
♦ DT_DOUBLE 8-Byte-Gleitkommazahl.
♦ DT_DECIMAL gepackte Dezimalzahl
typedef struct DECIMAL { char array[1];} DECIMAL;
♦ DT_STRING Mit Nullwert endende Zeichenfolge. Die Zeichenfolgewird mit Leerzeichen aufgefüllt, wenn bei der Initialisierung derDatenbank mit Leerzeichen aufgefüllte Zeichenfolgen verwendetwerden.
♦ DT_DATE Mit Nullwert endende Zeichenfolge, die ein gültiges Datumrepräsentiert
♦ DT_TIME Mit Nullwert endende Zeichenfolge, die eine gültigeZeitangabe repräsentiert
♦ DT_TIMESTAMP Mit Nullwert endende Zeichenfolge, die einengültigen Zeitstempel repräsentiert

Kapitel 6 Programmieren mit Embedded SQL
197
♦ DT_FIXCHAR Zeichenfolge mit fester Länge, mit Leerzeichen aufgefüllt
♦ DT_VARCHAR Zeichenfolge variabler Länge, mit einem 2-Byte-Längenfeld. Wenn Sie dem Datenbankserver Informationen liefern,müssen Sie das Längenfeld setzen. Wenn Sie Informationen vomDatenbankserver abholen, setzt der Datenbankserver das Längenfeld(nicht aufgefüllt).
typedef struct VARCHAR { unsigned short int len; char array[1];} VARCHAR;
♦ DT_LONGVARCHAR Lange Zeichendaten mit unterschiedlicher Länge.Das Makro definiert eine Struktur folgendermaßen:
#define DECL_LONGVARCHAR( size ) \ struct { a_sql_uint32 array_len; \ a_sql_uint32 stored_len; \ a_sql_uint32 untrunc_len; \ char array[size+1];\ }
Die DECL_LONGVARCHAR-Struktur kann mit Daten über 32 Kbyteverwendet werden. Umfangreiche Daten können auf einmal,beziehungsweise in Abschnitten abgerufen werden, und zwar mit derGET DATA-Anweisung. Sie können an den Server auf einmal,beziehungsweise in Abschnitten übermittelt werden, indem sie an eineDatenbankvariable mit der SET-Anweisung angehängt werden. DieDaten werden nicht mit Nullwert abgeschlossen.
$ Weitere Hinweise finden Sie unter "Lange Werte senden undabfragen" auf Seite 237.
♦ DT_BINARY Binärdaten variabler Länge mit einem 2-Byte-Längenfeld.Wenn Sie dem Datenbankserver Informationen liefern, müssen Sie dasLängenfeld setzen. Wenn Sie Informationen vom Datenbankserverabholen, setzt der Datenbankserver das Längenfeld.
typedef struct BINARY { unsigned short int len; char array[1];} BINARY;
♦ DT_LONGBINARY Lange Binärdaten. Das Makro definiert eine Strukturfolgendermaßen:
#define DECL_LONGBINARY( size ) \ struct { a_sql_uint32 array_len; \ a_sql_uint32 stored_len; \ a_sql_uint32 untrunc_len; \ char array[size]; \ }

Datentypen in Embedded SQL
198
Die DECL_ LONGBINARY -Struktur kann mit Daten über 32 Kbyteverwendet werden. Umfangreiche Daten können auf einmalbeziehungsweise in Abschnitten abgerufen werden, und zwar mit derGET DATA-Anweisung. Sie können an den Server auf einmal,beziehungsweise in Abschnitten übermittelt werden, indem sie an eineDatenbankvariable mit der SET-Anweisung angehängt werden.
$ Weitere Hinweise finden Sie unter "Lange Werte senden undabfragen" auf Seite 237.
♦ DT_TIMESTAMP_STRUCT SQLDATETIME-Struktur mit Feldern fürjeden Teil des Zeitstempels.
typedef struct sqldatetime {unsigned short year; /* z. B. 1999 */unsigned char month; /* 0-11 */unsigned char day_of_week; /* 0-6 0=Sonntag */unsigned short day_of_year; /* 0-365 */unsigned char day; /* 1-31 */unsigned char hour; /* 0-23 */unsigned char minute; /* 0-59 */unsigned char second; /* 0-59 */unsigned long microsecond; /* 0-999999 */
} SQLDATETIME;
Die SQLDATETIME-Struktur kann benutzt werden, um Felder vomTyp DATE, TIME und TIMESTAMP abzurufen (oder alles, was ineinen dieser Datentypen konvertiert werden kann). Anwendungen habenhäufig eigene Formate und einen eigenen Programmcode für Zeit undDatum. Der Abruf von Daten in dieser Struktur, erleichtert demProgrammierer den Umgang damit. Beachten Sie, dass Felder vom TypDATE, TIME und TIMESTAMP auch mit einem beliebigenZeichendatentyp abgerufen und aktualisiert werden können.
Wenn Sie eine SQLDATETIME-Struktur verwenden, um ein Datum,eine Zeit oder einen Zeitstempel in die Datenbank einzugeben, werdendie Untersätze day_of_year und day_of_week ignoriert.
$ Näheres finden Sie unter den DatenbankoptionenDATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT undDATE_ORDER in "Datenbankoptionen" auf Seite 597 derDokumentation ASA Datenbankadministration.
♦ DT_VARIABLE mit Nullwert abgeschlossene Zeichenfolge. DieZeichenfolge muss der Name einer SQL-Variablen sein, deren Wertvom Datenbankserver benutzt wird. Dieser Datentyp wird ausschließlichbenutzt, um Daten an den Datenbankserver zu liefern. Er kann nichtbenutzt werden, um Daten vom Datenbankserver abzurufen.

Kapitel 6 Programmieren mit Embedded SQL
199
Die Strukturen sind in der Datei sqlca.h festgelegt. Die DatentypenVARCHAR, BINARY und DECIMAL enthalten ein Array, das aus einemeinzigen Zeichen besteht und sind daher nicht geeignet, um Hostvariable zudeklarieren. Sie sind dagegen nützlich, um Variable dynamisch zuzuweisenoder Variable zu konvertieren (typecasting).
Die Embedded SQL-Schnittstelle bietet keine Datentypen, die denverschiedenen Datenbank-Datentypen von DATE und TIME entsprechen.Diese Datenbank-Datentypen werden alle entweder mit der StrukturSQLDATETIME oder mit Zeichenfolgen abgerufen und aktualisiert.
$ Weitere Hinweise finden Sie unter "GET DATA-Anweisung [ESQL]"auf Seite 471 der Dokumentation ASA SQL-Referenzhandbuch und "SET-Anweisung" auf Seite 572 der Dokumentation ASA SQL-Referenzhandbuch.
Datenbank-Datentypen DATEund TIME

Hostvariable benutzen
200
Hostvariable benutzenHostvariable sind C-Variable, die dem SQL-Präprozessor bekannt gemachtwerden. Hostvariable können benutzt werden, um Werte an denDatenbankserver zu übergeben oder um Werte vom Datenbankserverabzurufen.
Hostvariable sind recht einfach zu benutzen, aber sie unterliegen einigenEinschränkungen. Dynamische SQL ist eine allgemeinere Art, umInformationen mit dem Datenbankserver auszutauschen, mit Hilfe einerStruktur namens SQL-Deskriptor-Bereich (SQL Descriptor Area - SQLDA).Der SQL-Präprozessor erzeugt für jede einzelne Anweisung, in derHostvariablen verwendet werden, automatisch ein SQLDA.
$ Weitere Hinweise zu dynamischem SQL finden Sie unter "Statischeund dynamische SQL" auf Seite 223.
Hostvariable deklarieren
Hostvariable werden definiert, indem sie in einen Deklarationsabschnitteingefügt werden (declaration section). Wie in den Standards für IBM SAAund ANSI Embedded SQL beschrieben, werden Hostvariable definiert,indem eine normale C-Variable mit folgenden Zeilen eingeschlossen wird:
EXEC SQL BEGIN DECLARE SECTION;/* Deklarationen der C-Variablen */EXEC SQL END DECLARE SECTION;
Diese Hostvariable können dann an Stelle von konstanten Werten in jederSQL-Anweisung verwendet werden. Wenn der Datenbankserver den Befehlausführt, wird der Wert der Hostvariable benutzt. Beachten Sie, dassHostvariable nicht an Stelle von Tabellen- oder Spaltennamen verwendetwerden können: Dafür ist dynamisches SQL erforderlich. DerVariablenname hat in einer SQL-Anweisung einen Doppelpunkt (:) alsPräfix, um ihn von anderen Namen zu unterscheiden, die in der Anweisungerlaubt sind.
Ein standardmäßiger SQL-Präprozessor durchsucht nur den C-Programmcode, der innerhalb des Deklarationsabschnitts steht. TYPEDEF-Typen und –Strukturen sind also nicht zulässig. Variable können innerhalbdes DECLARE-Abschnitts initialisiert werden.
♦ Das folgende Beispiel zeigt den Gebrauch von Hostvariablen für einenINSERT-Befehl. Die Variablen werden von dem Programm belegt unddann in die Datenbank eingefügt:
Beispiel

Kapitel 6 Programmieren mit Embedded SQL
201
EXEC SQL BEGIN DECLARE SECTION;long employee_number;char employee_name[50];char employee_initials[8];char employee_phone[15];EXEC SQL END DECLARE SECTION;/* Das Programm belegt die Variablen mit passendenWerten*/*/EXEC SQL INSERT INTO EmployeeVALUES (:employee_number, :employee_name,:employee_initials, :employee_phone );
$ Ein größeres Beispiel finden Sie unter "Beispiel für statischenCursor" auf Seite 193.
C-Hostvariablentypen
Nur eine begrenzte Anzahl von C-Datentypen werden als Hostvariableunterstützt. Andererseits haben bestimmte Hostvariable keinenentsprechenden Datentyp in C.
In der Header-Datei sqlca.h festgelegte Makros können dazu verwendetwerden, Hostvariable folgenden Typs zu definieren: VARCHAR,FIXCHAR, BINARY, PACKED DECIMAL, LONG VARCHAR, LONGBINARY oder SQLDATETIME. Sie werden wie folgt benutzt:
EXEC SQL BEGIN DECLARE SECTION;DECL_VARCHAR( 10 ) v_varchar;DECL_FIXCHAR( 10 ) v_fixchar;DECL_LONGVARCHAR( 32678 ) v_longvarchar;DECL_BINARY( 4000 ) v_binary;DECL_LONGBINARY( 128000 ) v_longbinary;DECL_DECIMAL( 10, 2 ) v_packed_decimal;DECL_DATETIME v_datetime;EXEC SQL END DECLARE SECTION;
Der Präprozessor erkennt diese Makros innerhalb einesDeklarationsabschnitts und behandelt Variable ihrem Typ entsprechend.
Die folgende Tabelle zeigt die C-Variablentypen, die als Hostvariable erlaubtsind und die entsprechenden Datentypen der Embedded SQL-Schnittstelle.
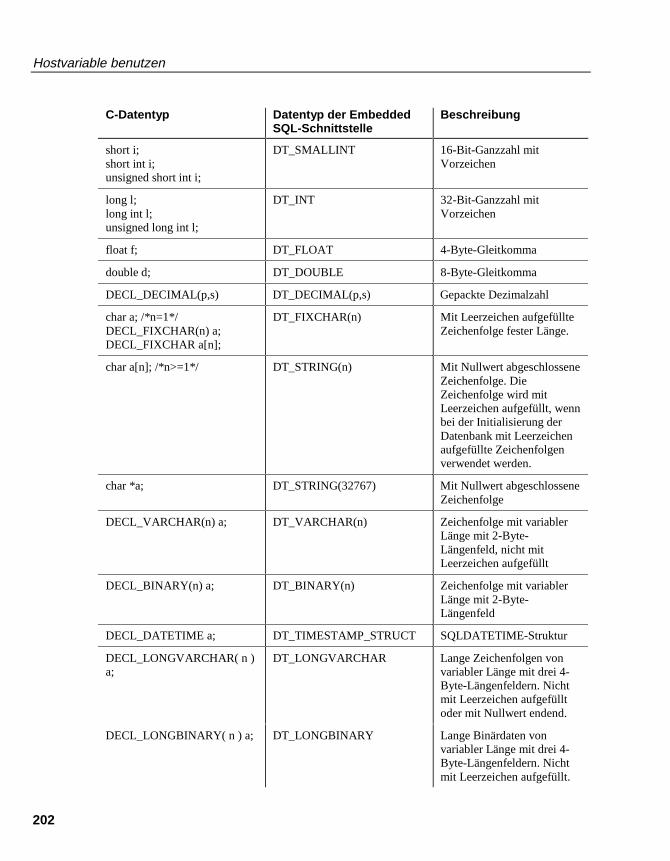
Hostvariable benutzen
202
C-Datentyp Datentyp der EmbeddedSQL-Schnittstelle
Beschreibung
short i;short int i;unsigned short int i;
DT_SMALLINT 16-Bit-Ganzzahl mitVorzeichen
long l;long int l;unsigned long int l;
DT_INT 32-Bit-Ganzzahl mitVorzeichen
float f; DT_FLOAT 4-Byte-Gleitkomma
double d; DT_DOUBLE 8-Byte-Gleitkomma
DECL_DECIMAL(p,s) DT_DECIMAL(p,s) Gepackte Dezimalzahl
char a; /*n=1*/DECL_FIXCHAR(n) a;DECL_FIXCHAR a[n];
DT_FIXCHAR(n) Mit Leerzeichen aufgefüllteZeichenfolge fester Länge.
char a[n]; /*n>=1*/ DT_STRING(n) Mit Nullwert abgeschlosseneZeichenfolge. DieZeichenfolge wird mitLeerzeichen aufgefüllt, wennbei der Initialisierung derDatenbank mit Leerzeichenaufgefüllte Zeichenfolgenverwendet werden.
char *a; DT_STRING(32767) Mit Nullwert abgeschlosseneZeichenfolge
DECL_VARCHAR(n) a; DT_VARCHAR(n) Zeichenfolge mit variablerLänge mit 2-Byte-Längenfeld, nicht mitLeerzeichen aufgefüllt
DECL_BINARY(n) a; DT_BINARY(n) Zeichenfolge mit variablerLänge mit 2-Byte-Längenfeld
DECL_DATETIME a; DT_TIMESTAMP_STRUCT SQLDATETIME-Struktur
DECL_LONGVARCHAR( n )a;
DT_LONGVARCHAR Lange Zeichenfolgen vonvariabler Länge mit drei 4-Byte-Längenfeldern. Nichtmit Leerzeichen aufgefülltoder mit Nullwert endend.
DECL_LONGBINARY( n ) a; DT_LONGBINARY Lange Binärdaten vonvariabler Länge mit drei 4-Byte-Längenfeldern. Nichtmit Leerzeichen aufgefüllt.

Kapitel 6 Programmieren mit Embedded SQL
203
Von einer Hostvariable, die als pointer to char (char *a) deklariert ist,nimmt die Datenbankschnittstelle an, dass sie 32.767 Bytes lang ist. JedeHostvariable vom Typ pointer to char, die benutzt wird, um Informationenvon der Datenbank abzurufen, muss auf einen Puffer zeigen, der groß genugist, um jeden Wert enthalten zu können, der möglicherweise von derDatenbank zurückkommen könnte.
Dies kann recht gefährlich sein, denn jemand könnte die Definition derSpalte in der Datenbank ändern, sodass sie größer wird als zu dem Zeitpunkt,als das Programm geschrieben wurde. Dies wiederum könnte zuunvorhersehbaren Speicherbelegungen und daraus resultierenden Problemenführen. Falls Sie einen 16-Bit-Compiler benutzen, könnten die erforderlichen32.767 Bytes einen Programm-Stack-Überlauf verursachen. Es ist dahervorzuziehen, ein deklariertes Array zu benutzen, auch als Parameter für eineFunktion, die einen pointer to char erwartet. So erkennt die PREPARE-Anweisung die Größe des Arrays.
Die Deklaration einer Hostvariablen kann im Allgemeinen überall dortstehen, wo auch eine C-Variablendeklaration stehen könnte. Das gilt auch fürden Parameterdeklarationsbereich einer C-Funktion. Die dort deklarierten C-Variablen haben ihre normalen Aufgaben (sie stehen innerhalb des Blockszur Verfügung, in dem sie definiert sind). Da aber der SQL-Präprozessor denC-Code nicht durchsucht, erkennt er keine C-Blöcke.
Für den SQL-Präprozessor sind Hostvariable globale Variable: zweiHostvariable können niemals den gleichen Namen haben.
Hostvariable benutzen
Hostvariable können unter folgenden Umständen benutzt werden:
♦ In SELECT-, INSERT-, UPDATE- und DELETE-Anweisungen sind sieüberall dort erlaubt, wo eine Zahlen- oder Zeichenfolgenkonstanteerlaubt sind.
♦ In der INTO-Klausel einer SELECT oder FETCH-Anweisung
♦ Hostvariable können auch in Embedded SQL-Befehlen benutzt werdenan Stelle eines Anweisungsnamens, eines Cursornamens oder einesOptionsnamens.
♦ Im Fall von CONNECT, DISCONNECT und SET CONNECT kanneine Hostvariable benutzt werden an Stelle einer Benutzer-ID, einesKennworts, eines Verbindungsnamens, einer Verbindungszeichenfolgeoder eines Datenbank-Umgebungsnamens.
Zeiger auf einZeichen (pointer tochar)
Gültigkeitsbereichvon Hostvariablen

Hostvariable benutzen
204
♦ Im Fall von SET OPTION und GET OPTION kann eine Hostvariablebenutzt werden an Stelle einer Benutzer-ID, eines Optionsnamens odereines Optionswerts.
♦ Hostvariable können nicht an Stelle eines Tabellennamens oder einesSpaltennamens in einer Anweisung benutzt werden.
♦ Folgendes ist gültiges Embedded SQL:
INCLUDE SQLCA;long SQLCODE;sub1() {
char SQLSTATE[6];exec SQL CREATE TABLE ...
}
♦ Folgendes ist nicht gültiges Embedded SQL:
INCLUDE SQLCA;sub1() {
char SQLSTATE[6];exec SQL CREATE TABLE ...
}sub2() {
exec SQL DROP TABLE...// Kein SQLSTATE im Gültigkeitsbereich dieser
Anweisung}
♦ SQLSTATE und SQLCODE sind besonders wichtig. Der ISO/ANSI-Standard verlangt, dass sie exakt wie folgt definiert werden:
long SQLCODE;char SQLSTATE[6];
Indikatorvariable
Indikatorvariable sind C-Variable, die zusätzliche Informationen liefern,wenn Sie Daten abrufen oder speichern. Indikatorvariable werden infolgenden Fällen benutzt:
♦ NULL-Werte Damit eine Anwendung mit NULL-Werten umgehen kann.
♦ Gekürzte Zeichenfolgen Damit eine Anwendung Fälle behandeln kann,in denen ein abgerufener Wert gekürzt werden muss, um in eineHostvariable zu passen.
♦ Konvertierungsfehler Für Fehlerinformationen
Beispiele

Kapitel 6 Programmieren mit Embedded SQL
205
Eine Indikatorvariable ist eine Hostvariable vom Typ short int, die in einerSQL-Anweisung unmittelbar auf eine normale Hostvariable folgt. In derfolgenden INSERT-Anweisung zum Beispiel ist :ind_phone eineIndikatorvariable:
EXEC SQL INSERT INTO EmployeeVALUES (:employee_number, :employee_name,:employee_initials, :employee_phone:ind_phone );
Indikatorvariable für die Behandlung von Nullwerten verwenden
In SQL-Daten repräsentiert NULL entweder ein unbekanntes Attribut odereine nicht anwendbare Information. NULL in SQL darf nicht verwechseltwerden mit der C-Konstante gleichen Namens (NULL). Die C-KonstanteNULL wird benutzt, um nicht initialisierte oder ungültige Zeiger zurepräsentieren.
In der Dokumentation zum Adaptive Server Anywhere bezieht sich eineErwähnung von NULL immer auf die Bedeutung, die es in einer SQL-Datenbank hat (wie oben definiert). Die gleichnamige C-Konstante wirddagegen als Null-Zeiger bezeichnet (Groß-/Kleinschreibung).
NULL kann nicht für einen Wert stehen, der dem für die Spalte definiertenTyp entspricht. Um einen NULL-Wert an die Datenbank zu übergeben oderNULL als Ergebnis von der Datenbank erhalten zu können, ist daher mehrals eine normale Hostvariable erforderlich. Indikatorvariable werden fürdiesen Zweck eingesetzt.
Eine INSERT-Anweisung könnte wie folgt eine Indikatorvariable einfügen:
EXEC SQL BEGIN DECLARE SECTION;short int employee_number;char employee_name[50];char employee_initials[6];char employee_phone[15];short int ind_phone;EXEC SQL END DECLARE SECTION;
/*Das Programm belegt empnum, empname,initials und homephone*/if( /* falls die Telefonnummer unbekannt ist */ ) {
ind_phone = -1;} else {
ind_phone = 0;}EXEC SQL INSERT INTO Employee
VALUES (:employee_number, :employee_name,:employee_initials, :employee_phone:ind_phone );
Indikatorvariableverwenden, umNULL einzufügen

Hostvariable benutzen
206
Hat die Indikatorvariable den Wert –1, wird NULL eingefügt. Hat sie denWert 0, wird der tatsächliche Wert von employee_phone eingefügt.
Indikatorvariable werden auch benutzt, um Daten von der Datenbankabzurufen. Sie werden verwendet, um anzuzeigen, dass ein NULL-Wertabgerufen wurde (der Indikator ist negativ). Falls ein NULL-Wert von derDatenbank abgerufen wird und keine Indikatorvariable zur Verfügung steht,wird ein Fehler erzeugt (SQLE_NO_INDICATOR). Fehler werden imnächsten Abschnitt erklärt.
Indikatorvariable für gekürzte Werte verwenden
Indikatorvariable zeigen an, ob irgendwelche abgerufenen Werte gekürztwurden, um in eine Hostvariable zu passen. So können Anwendungen mitdem Kürzen von Werten angemessen umgehen.
Falls ein Wert beim Abrufen gekürzt wurde, wird die Indikatorvariable miteinem positiven Wert belegt. Dieser Wert gibt die Länge an, den der aus derDatenbank abgerufene Wert vor dem Kürzen hatte. Ist die Länge desgekürzten Werts größer als 32.767, hat die Indikatorvariable den Wert32.767.
Indikatorwerte für Konvertierungsfehler verwenden
Als Voreinstellung ist die Datenbankoption CONVERSION_ERROR aufON gesetzt, jede fehlgeschlagene Datentypkonvertierung führt zu einemFehler und es wird keine Zeile zurückgegeben.
Sie können Indikatorvariable verwenden, um festzustellen, in welcher Spalteeine fehlgeschlagene Datentypkonvertierung auftrat. Wenn Sie dieDatenbankoption CONVERSION_ERROR auf OFF setzen, erzeugt jedefehlgeschlagene Datentypkonvertierung (statt eines Fehlers) die WarnungCANNOT_CONVERT. Hat die Spalte, in der der Konvertierungsfehlerauftrat, eine Indikatorvariable, wird diese Variable mit –2 belegt.
Wenn Sie beim Einfügen von Daten in die Datenbank die DatenbankoptionCONVERSION_ERROR auf OFF setzen, wird der Wert NULL eingefügt,falls eine fehlgeschlagene Konvertierung auftritt.
Zusammenfassung: Werte für Indikatorvariable
Folgende Tabelle bietet eine Zusammenfassung zum Gebrauch vonIndikatorvariablen.
Indikatorvariableverwenden, umNULL abzurufen

Kapitel 6 Programmieren mit Embedded SQL
207
Indikator-wert
Wert, an dieDatenbankübergeben
Wert von der Datenbank erhalten
> 0 Wert der Hostvariable Der abgerufene Wert wurde gekürzt -tatsächliche Länge in derIndikatorvariable
0 Wert der Hostvariable Entweder das Abrufen war erfolgreichoder CONVERSION_ERROR ist aufON gesetzt.
–1 Nullwert Ergebnis NULL
–2 Nullwert Konvertierungsfehler (nur wennCONVERSION_ERROR auf OFFgesetzt ist). SQLCODE gibt dieWarnung CANNOT_CONVERT aus.
< –2 Nullwert Ergebnis NULL
$ Weitere Informationen über das Abrufen von long-Werten finden Sieunter "GET DATA-Anweisung [ESQL]" auf Seite 471 der DokumentationASA SQL-Referenzhandbuch.

SQL-Kommunikationsbereich (SQLCA)
208
SQL-Kommunikationsbereich (SQLCA)Der SQL-Kommunikationsbereich (SQL Communication Area - SQLCA)ist ein Speicherbereich, der bei jeder Datenbankanforderung benutzt wird,um Statistiken und Fehlermeldungen von der Anwendung zumDatenbankserver zu übermitteln und umgekehrt. Der SQLCA-Bereich wirdals Handle für die Kommunikationsverbindung zwischen Anwendung undDatenbank benutzt. Er wird allen Datenbank-Bibliotheksfunktionenübergeben, die mit dem Datenbankserver kommunizieren müssen. Er wirdimplizit allen Embedded SQL-Anweisungen übergeben.
Eine globale SQLCA-Variable ist in der Schnittstellenbibliothek definiert.Der Präprozessor erzeugt eine externe Referenz auf die globale SQLCA-Variable und eine externe Referenz auf einen Zeiger auf die Variable. Dieexterne Referenz heißt sqlca und ist vom Typ SQLCA. Der Zeiger heißtsqlcaptr. Die globale Variable selbst wird in der Importbibliothek deklariert.
Der SQLCA-Bereich ist in der Header-Datei sqlca.h definiert, die imUnterverzeichnis h Ihres Installationsverzeichnisses enthalten ist.
Sie benutzen den SQLCA-Bereich, um auf einen bestimmten Fehlercode zutesten. Die Felder sqlcode und sqlstate enthalten Fehlercodes, falls eineAnforderung an die Datenbank einen Fehler hervorrief (siehe unten). EinigeC-Makros sind definiert, um die Felder sqlcode, sqlstate und einige weitereanzusprechen.
SQLCA-Felder
Die SQLCA-Felder haben folgende Bedeutung:
♦ sqlcaid 8-Byte Zeichenfeld, das die Zeichenfolge SQLCA enthält (zurIdentifizierung der SQLCA-Struktur). Dieses Feld unterstützt dieFehlersuche, wenn Sie Speicherinhalte untersuchen.
♦ sqlcabc Ganzzahl (long integer), die die Länge der SQLCA-Strukturenthält (136 Bytes)
♦ sqlcode Eine Ganzzahl ("long integer"), die den Fehlercode angibt,wenn die Datenbank einen Fehler bei einer Anforderung feststellt.Definitionen für die Fehlercodes befinden sich in der Header-Dateisqlerr.h. Bei einer erfolgreichen Operation ist der Fehlercode 0 (Null),bei einer Warnung ist er positiv und bei einem Fehler ist er negativ.
$ Eine vollständige Auflistung der Fehlercodes finden Sie unter"Datenbank-Fehlermeldungen" auf Seite 1 der Dokumentation ASAFehlermeldungen.
SQLCA-Bereichbietet Fehlercodes

Kapitel 6 Programmieren mit Embedded SQL
209
♦ sqlerrml Die Länge der Daten im Feld sqlerrmc
♦ sqlerrmc Kann eine oder mehrere Zeichenfolgen enthalten, die in eineFehlermeldung einzufügen sind. Einige Fehlermeldungen enthalten eineoder mehr Platzhalter-Zeichenfolgen (%1, %2, …), die durch dieZeichenfolge in diesem Feld ersetzt werden.
Wenn zum Beispiel ein Fehler Table Not Found erzeugt wird, enthältsqlerrmc den Tabellennamen, der dann an passender Stelle in dieFehlermeldung eingefügt wird.
$ Eine vollständige Auflistung der Fehlermeldungen finden Sie unter"Datenbank-Fehlermeldungen" auf Seite 1 der Dokumentation ASAFehlermeldungen.
♦ sqlerrp Reserviert
♦ sqlerrd Array von Ganzzahlen ("long integer")
♦ sqlwarn Reserviert
♦ sqlstate SQLSTATE-Statuswert. Der ANSI SQL-Standard (SQL-92)definiert einen neuen Rückgabewerttyp für SQL-Anweisungen,zusätzlich zu dem in früheren Standards definierten SQLCODE. DerWert von SQLSTATE ist immer eine fünf Zeichen lange mit 0 (Null)abgeschlossene Zeichenfolge, aufgeteilt in eine zwei Zeichen langeKlasse (die ersten zwei Zeichen) und eine drei Zeichen langeUnterklasse. Jedes Zeichen kann eine Ziffer von 0 bis 9 sein oder einGroßbuchstabe von A bis Z.
Jede Klasse oder Unterklasse, die mit 0 bis 4 oder A bis H beginnt, istdurch den SQL-Standard definiert. Andere Klassen und Unterklassensind durch die Implementierung definiert. Hat SQLSTATE den Wert'00000', ist kein Fehler und keine Warnung aufgetreten.
$ Weitere SQLSTATE-Werte finden Sie unter "Datenbank-Fehlermeldungen" auf Seite 1 der Dokumentation ASAFehlermeldungen.
Das Array sqlerror besteht aus folgenden Elementen:
♦ sqlerrd[1] (SQLIOCOUNT) Die Anzahl der Eingabe/Ausgabe-Vorgänge,die erforderlich waren, um einen Befehl auszuführen.
Die Datenbank beginnt diese Zählung nicht mit 0 (Null) für jedenBefehl. Ihr Programm kann diese Variable vor der Ausführung einerBefehlssequenz auf 0 (Null) setzen. Nach dem letzten Befehl zeigt derWert der Variablen die Gesamtzahl der Eingabe/Ausgabe-Vorgänge fürdie gesamte Befehlssequenz an.
♦ sqlerrd[2] (SQLCOUNT) Der Wert dieses Felds hängt davon ab, welcheAnweisung ausgeführt wurde.
sqlerror-Array

SQL-Kommunikationsbereich (SQLCA)
210
♦ INSERT-, UPDATE-, PUT und DELETE-Anweisungen Anzahl derZeilen, die von der Anweisung betroffen waren
Bei Cursor OPEN wird das Feld belegt entweder mit dertatsächlichen Anzahl der Zeilen im Cursor (ein Wert größer als odergleich 0) oder mit einer Schätzung der Anzahl (ein negative Zahl,deren absoluter Wert die Schätzung ist). Es wird sich um dietatsächliche Anzahl der Zeilen handeln, wenn der Datenbankserversie errechnen kann, ohne die Zeilen zu zählen. Die Datenbank kannauch so konfiguriert werden, dass sie immer die tatsächliche Anzahlder Zeilen liefert (mit der Option ROW_COUNT).
♦ FETCH Cursor-Anweisung Das Feld SQLCOUNT wird belegt,falls eine SQLE_NOTFOUND-Warnung zurückgegeben wird. Esenthält die Anzahl der Zeilen, um die eine FETCH RELATIVE-oder eine FETCH ABSOLUTE-Anweisung den Bereich dermöglichen Cursorpositionen überschritten hat. (Ein Cursor kannsich auf einer Zeile, vor der ersten Zeile oder nach der letzten Zeilebefinden.) Bei weiten Abrufen entspricht SQLCOUNT der Anzahlder tatsächlich abgerufenen Zeilen und ist kleiner oder gleich derAnzahl der angeforderten Zeilen. Während eines weiten Abrufswird SQLE_NOTFOUND nicht festgelegt.
$ Weitere Hinweise zu weiten Abrufen finden Sie unter "Mehrals eine Zeile auf einmal abrufen" auf Seite 218.
Der Wert ist 0 (Null), falls die Zeile nicht gefunden wurde, diePosition aber gültig ist, zum Beispiel wenn FETCH RELATIVE 1ausgeführt wird, und die Position ist auf der letzten Zeile einesCursors. Der Wert ist positiv, falls das Abrufen jenseits des Cursorsversucht wurde, und negativ, falls das Abrufen vor dem Anfang desCursors versucht wurde.
♦ GET DATA-Anweisung Das Feld SQLCOUNT enthält dietatsächliche Länge des Werts.
♦ DESCRIBE-Anweisung In der Klausel WITH VARIABLERESULT, die benutzt wird, um Prozeduren zu beschreiben, diemehr als ein Ergebnis haben können, wird SQLCOUNT auf einender folgenden Werte gesetzt:
♦ 0 Die Ergebnismenge kann sich ändern: der Prozeduraufrufsollte nach jeder OPEN-Anweisung neu beschrieben werden.
♦ 1 Die Ergebnismenge ist unveränderlich. Eine erneuteBeschreibung ist nicht erforderlich.
Im Fall eines Syntaxfehlers, SQLE_SYNTAX_ERROR, enthältdieses Feld die ungefähre Position des Zeichens innerhalb derBefehlszeichenfolge, wo der Fehler erkannt wurde.

Kapitel 6 Programmieren mit Embedded SQL
211
♦ sqlerrd[3] (SQLIOESTIMATE) Die geschätzte Anzahl derEingabe/Ausgabe-Vorgänge für den Abschluss des Befehls. Dieses Feldwird bei einem OPEN- oder EXPLAIN-Befehl belegt.
SQLCA-Verwaltung für Code mit mehreren Threads oder"reentrant"-Code
Sie können Embedded SQL-Anweisungen in Code mit mehreren Threadsoder reentrant-Code benutzen. Wenn Sie allerdings eine einfacheVerbindung benutzen, sind Sie auf eine aktive Anforderung pro Verbindungbeschränkt. In einer Applikation mit mehreren Threads sollten Sie esvermeiden, für alle Threads dieselbe Verbindung zur Datenbank benutzen,außer wenn Sie Semaphore für die Zugriffssteuerung benutzen.
Sie können ohne Einschränkung für jeden Thread, der die Datenbankbenutzen will, eine separate Verbindung öffnen. Der SQLCA-Bereich wirdvon der Laufzeitbibliothek benutzt, um zwischen den verschiedenen Thread-Kontexten zu unterscheiden. Daher braucht jeder Thread, der eineVerbindung zur Datenbank benötigt, seinen eigenen SQCLA-Bereich.
Jede einzelne Datenbankverbindung ist nur von einem einzelnen SQLCA-Bereich aus zugänglich, außer bei der Abbruchanweisung, die von einemseparaten Thread aus ausgegeben werden muss.
$ Hinweise zur Abbruchanforderung finden Sie unter "Anforderungs-Management implementieren" auf Seite 247.
Mehrere SQLCA-Bereiche benutzen
v Um mehrere SQLCA-Bereiche in Ihrer Anwendung zu benutzen,gehen Sie wie folgt vor:
1 Sie müssen für den SQL-Präprozessor den Befehlszeilenschalterbenutzen, der reentrant-Code erzeugt (-r). Der reentrant-Code ist etwasumfangreicher und etwas langsamer, weil keine statisch initialisiertenglobalen Variablen benutzt werden können. Diese Auswirkungen sindallerdings minimal.
2 Jeder SQLCA-Bereich, der in Ihrem Programm benutzt wird, muss miteinem Aufruf von db_init initialisiert und am Ende mit einem Aufrufvon db_fini wieder freigegeben werden.

SQL-Kommunikationsbereich (SQLCA)
212
VorsichtWird unter NetWare nicht db_fini für jedes db_init aufgerufen,kann das den Datenbankserver und den NetWare-Dateiserver zumAbsturz bringen.
3 Die Embedded SQL-Anweisung SET SQLCA ("SET SQLCA-Anweisung [ESQL]" auf Seite 588 der Dokumentation ASA SQL-Referenzhandbuch) wird verwendet, um den SQL-Präprozessoranzuweisen, einen anderen SQLCA-Bereich fürDatenbankanforderungen zu benutzen. Ein Beispiel ist die folgendeAnweisung: EXEC SQL SET SQLCA 'task_data->sqlca' wird zu Beginneines Programms oder in einer Header-Datei benutzt, um SQLCA-Referenzen so einzustellen, dass sie auf Task-spezifische Daten zeigen.Diese Anweisung erzeugt keinen Code und hat daher keinen Einfluss aufdie Performance. Sie ändert den Status innerhalb des Präprozessors,sodass jede Referenz auf den SQLCA-Bereich die angegebeneZeichenfolge benutzt.
$ Weitere Hinweise zum Erstellen von SQLCA-Bereichen finden Sieunter "SET SQLCA-Anweisung [ESQL]" auf Seite 588 der DokumentationASA SQL-Referenzhandbuch.
In welchen Fällen Sie mehrere SQLCA-Bereiche benutzen
Sie können die Unterstützung mehrfacher SQLCAs in jeder der unterstütztenEmbedded SQL-Umgebungen benutzen, sie ist jedoch nur für reentrant-Codeerforderlich.
Die folgende Aufstellung gibt einen Überblick über die Umgebungen, indenen mehrfache SQLCAs benutzt werden müssen:
♦ Anwendungen mit mehreren Threads Falls mehr als ein Threaddenselben SQLCA-Bereich benutzt, kann ein Kontextwechselverursachen, dass zum gleichen Zeitpunkt mehr als ein Thread auf denSQLCA-Bereich zugreift. Jeder Thread braucht seinen eigenen SQLCA-Bereich. Das kann auch geschehen, wenn Sie eine DLL haben, dieEmbedded SQL benutzt und die von mehr als einem Thread in IhrerAnwendung aufgerufen wird.

Kapitel 6 Programmieren mit Embedded SQL
213
♦ Dynamische Verknüpfungsbibliotheken (DLL) und gemeinsamgenutzte Bibliotheken Eine DLL hat nur ein Datensegment. Währendder Datenbankserver eine Anforderung von einer Anwendung bearbeitet,könnte er die Kontrolle an eine andere Anwendung übergeben, dieebenfalls eine Anforderung an den Datenbankserver richtet. Falls IhreDLL den globalen SQLCA-Bereich benutzt, greifen beideAnwendungen gleichzeitig darauf zu. Jede Windows-Anwendungbraucht ihren eigenen SQLCA-Bereich.
♦ Eine DLL mit einem Datensegment Eine DLL kann mit nur einemDatensegment erstellt werden oder mit einem Datensegment für jedeAnwendung. Falls Ihre DLL nur ein Datensegment hat, dürfen Sie ausdem gleichen Grund nicht den globalen SQLCA-Bereich benutzen, ausdem eine DLL den globalen SQLCA-Bereich nicht benutzen kann. JedeAnwendung braucht ihren eigenen SQLCA-Bereich.
Verbindungsverwaltung mit mehreren SQLCA-Bereichen
Sie müssen nicht mehrere SQLCA-Bereiche benutzen, um Verbindungen zumehr als einer Datenbank herzustellen oder um mehr als eine Verbindung zueiner einzelnen Datenbank zu halten.
Jeder SQLCA-Bereich kann eine namenlose Verbindung haben. JederSQLCA-Bereich hat eine aktive oder aktuelle Verbindung (siehe "SETCONNECTION-Anweisung [Interactive SQL]" auf Seite 578 derDokumentation ASA SQL-Referenzhandbuch). Alle Vorgänge, die sich aufeine angegebene Datenbankverbindung beziehen, müssen denselbenSQLCA-Bereich benutzen, der verwendet wurde, als die Verbindunggeöffnet wurde.
Datensatz sperrenVorgänge, die sich auf verschiedene Verbindungen beziehen, sind dennormalen Datensatz-Sperrmechanismen unterworfen und können sichgegenseitig blockieren oder möglicherweise zu einer Deadlock-Situationführen. Information über Sperrmechanismen finden Sie im Kapitel"Transaktionen und Isolationsstufen verwenden" auf Seite 99 derDokumentation ASA SQL-Benutzerhandbuch.

Daten abrufen
214
Daten abrufenIn Embedded SQL werden Daten mit der Anweisung SELECT abgerufen.Dabei werden zwei Fälle unterschieden:
♦ Die SELECT-Anweisung gibt mehr als eine Zeile zurück VerwendenSie eine INTO-Klausel, damit die zurückgegebenen Werte direktHostvariablen zugeordnet werden.
$ Hinweise dazu finden Sie unter "SELECT-Anweisungen, diehöchstens eine Zeile zurückgeben" auf Seite 214.
♦ Die SELECT-Anweisung kann mehrere Zeilen zurückgebenVerwenden Sie Cursor zur Verwaltung der Zeilen in der Ergebnismenge.
$ Weitere Hinweise finden Sie unter "Cursor in Embedded SQLverwenden" auf Seite 215.
$ LONG VARCHAR- und LONG BINARY-Datentypen werdenunterschiedlich zu anderen Datentypen behandelt. Weitere Hinweise findenSie unter "LONG-Daten abrufen" auf Seite 238.
SELECT-Anweisungen, die höchstens eine Zeile zurückgeben
Eine einzeilige Abfrage fragt höchstens eine Zeile von der Datenbank ab. Ineiner SELECT-Anweisung für eine einzeilige Abfrage befindet sich eineINTO-Klausel nach der Auswahlliste und vor der FROM-Klausel. DieINTO-Klausel enthält eine Liste der Hostvariablen, die die Werte derAuswahllisten-Elemente übernehmen sollen. Die Anzahl der Hostvariablenmuss mit der Anzahl der Auswahllisten-Elemente übereinstimmen. DieHostvariable können von Indikatorvariablen gefolgt sein, um NULL-Ergebnisse anzuzeigen.
Sobald die SELECT-Anweisung ausgeführt wird, ruft der Datenbankserverdie Ergebnisse ab und schreibt sie in die Hostvariable. Falls dieAbfrageergebnisse mehr als eine Zeile enthalten, gibt der Datenbankservereinen Fehler zurück.
Falls das Abfrageergebnis ist, dass keine Zeile ausgewählt ist, wird eine RowNot Found-Warnung zurückgeben. Fehler und Warnungen werden in derSQLCA-Struktur zurückgegeben, wie beschrieben in "SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
Folgendes Code-Fragment gibt zum Beispiel 1 zurück, falls eine Zeile derTabelle "employee" erfolgreich abgerufen wird, 0, falls die Zeile nichtexistiert, und –1, falls ein Fehler auftritt.
EXEC SQL BEGIN DECLARE SECTION;
Beispiel

Kapitel 6 Programmieren mit Embedded SQL
215
long emp_id;char name[41];char sex;char birthdate[15];short int ind_birthdate;
EXEC SQL END DECLARE SECTION;. . .int find_employee( long employee ){
emp_id = employee;EXEC SQL SELECT emp_fname ||
’ ’ || emp_lname, sex, birth_dateINTO :name, :sex,
:birthdate:ind_birthdateFROM "DBA".employeeWHERE emp_id = :emp_id;
if( SQLCODE == SQLE_NOTFOUND ) {return( 0 ); /* ’employee’ wurde nicht gefunden
*/} else if( SQLCODE < 0 ) {
return( -1 ); /* Fehler */} else {
return( 1 ); /* gefunden */}
}
Cursor in Embedded SQL verwenden
Ein Cursor wird benutzt, um Zeilen aus einer Abfrage abzurufen, diemehrere Zeilen in Ihrer Ergebnismenge hat. Ein Cursor ist ein Handle oderein Name (identifier) für die SQL-Abfrage und eine Position innerhalb derErgebnismenge.
$ Eine Einführung zu Cursorn finden Sie unter "Mit Cursorn arbeiten"auf Seite 20.
v So verwalten Sie einen Cursor in Embedded SQL:
1 Deklarieren Sie einen Cursor für eine bestimmte SELECT-Anweisungmit der DECLARE-Anweisung.
2 Öffnen Sie den Cursor mit der Anweisung OPEN.
3 Rufen Sie die Ergebnisse Zeile für Zeile aus dem Cursor ab mit derFETCH-Anweisung.
4 Wiederholen Sie das Abrufen der Zeilen, bis die Warnung Row NotFound zurückgegeben wird.

Daten abrufen
216
Fehler und Warnungen werden in der SQLCA-Struktur zurückgegeben,wie in "SQL-Kommunikationsbereich (SQLCA)" auf Seite 208beschrieben.
5 Schließen Sie den Cursor mit der CLOSE-Anweisung.
Als Voreinstellung werden Cursor automatisch am Ende der Transaktiongeschlossen (bei COMMIT oder ROLLBACK). Cursor, die mit einer WITHHOLD-Klausel geöffnet werden, bleiben für folgende Transaktionengeöffnet, bis sie explizit geschlossen werden.
Das folgende einfache Beispiel zeigt den Gebrauch von Cursorn:
void print_employees( void ){
EXEC SQL BEGIN DECLARE SECTION;char name[50];char sex;char birthdate[15];short int ind_birthdate;EXEC SQL END DECLARE SECTION;EXEC SQL DECLARE C1 CURSOR FOR
SELECTemp_fname || ’ ’ || emp_lname,sex, birth_date
FROM "DBA".employee;EXEC SQL OPEN C1;for( ;; ) {
EXEC SQL FETCH C1 INTO :name, :sex,:birthdate:ind_birthdate;
if( SQLCODE == SQLE_NOTFOUND ) {break;
} else if( SQLCODE < 0 ) {break;
}if( ind_birthdate < 0 ) {
strcpy( birthdate, "UNKNOWN" );}printf( "Name: %s Sex: %c Birthdate:
%s.n",name, sex, birthdate );}
EXEC SQL CLOSE C1;}
$ Vollständige Beispiele für Cursor finden Sie unter "Beispiel fürstatischen Cursor" auf Seite 193 und "Beispiel für dynamischen Cursor" aufSeite 193.
Ein Cursor wird an einer von drei Stellen positioniert:
♦ Auf einer Zeile
♦ Vor der ersten Zeile
Cursorpositionieren

Kapitel 6 Programmieren mit Embedded SQL
217
♦ Nach der letzten Zeile
Wird ein Cursor geöffnet, ist er vor der ersten Zeile positioniert. DieCursorposition kann mit dem FETCH-Befehl verschoben werden (siehe"FETCH-Anweisung [ESQL] [GP]" auf Seite 458 der Dokumentation ASASQL-Referenzhandbuch ). Er kann absolut positioniert werden, entwederbezogen auf den Anfang oder auf das Ende des Abfrageergebnisses. Er kannauch relativ zur aktuellen Cursorposition verschoben werden.
Mit speziellen positioned-Versionen der Anweisungen UPDATE undDELETE können Sie die Zeile an der aktuellen Cursor-Position aktualisierenoder löschen. Ist der Cursor vor der ersten Zeile oder nach der letzten Zeilepositioniert, wird der Fehler No Current Row of Cursor zurückgeben.
Die Anweisung PUT kann verwendet werden, um eine Zeile in einen Cursoreinzufügen.
Einfügungen und einige Aktualisierungen zu DYNAMIC SCROLL-Cursornkönnen Probleme bei der Cursorpositionierung verursachen. DerDatenbankserver platziert eingefügte Zeilen an unvorhersehbaren Positioneninnerhalb eines Cursors, falls die SELECT-Anweisung keine ORDER BY-Klausel hat. In einigen Fällen erscheint die eingefügte Zeile überhaupt nicht,bis der Cursor geschlossen und wieder geöffnet wurde.
Cursor-positionierungs-probleme

Daten abrufen
218
Bei Adaptive Server Anywhere tritt dies auf, wenn zum Öffnen einesCursors eine temporäre Tabelle erstellt werden musste.
$ Eine Beschreibung finden Sie unter "Arbeitstabellen in derAbfrageverarbeitung verwenden" auf Seite 178 der Dokumentation ASASQL-Benutzerhandbuch.
Die UPDATE-Anweisung kann bewirken, dass sich eine Zeile im Cursorverschiebt. Das passiert, wenn der Cursor eine ORDER BY-Klausel hat, dieeinen vorhandenen Index benutzt (es wird keine temporäre Tabelle erstellt).
Mehr als eine Zeile auf einmal abrufen
Die FETCH-Anweisung kann so modifiziert werden, dass sie mehr als eineZeile auf einmal abruft. Das kann die Performance verbessern. Man nenntdiese Methode mehrzeiliges Abrufen (wide fetch) oder auch Array-Abrufen (array fetch).
$ Der Adaptive Server Anywhere unterstützt auch mehrzeiliges Speichern(wide puts) und mehrzeiliges Einfügen (wide inserts). Hinweise dazu findenSie unter "PUT-Anweisung [ESQL]" auf Seite 538 der Dokumentation ASASQL-Referenzhandbuch und "EXECUTE-Anweisung [ESQL]" auf Seite 449der Dokumentation ASA SQL-Referenzhandbuch.
Um mehrzeiliges Abrufen (wide fetches) in Embedded SQL zu verwenden,fügen Sie die Abrufanweisung wie folgt in Ihren Code ein:
EXEC SQL FETCH . . . ARRAY nnn
Dabei ist ARRAY nnn das letzte Element der FETCH-Anweisung. DieAbrufanzahl nnn kann eine Hostvariable sein. Die Anzahl der Variablen imSQLDA-Bereich muss das Produkt aus nnn multipliziert mit der Anzahl derSpalten pro Zeile sein. Die erste Zeile wird in die SQLDA-Variablen von 0bis (Anzahl der Spalten pro Zeile)-1 geschrieben, und so fort.
Jede Spalte muss in jeder Zeile des SQLDA-Bereichs vom selben Typ sein,sonst wird der Fehler SQLDA_INCONSISTENT ausgegeben.
Der Server gibt in SQLCOUNT die Anzahl der Datensätze zurück, dieabgerufen wurden. Diese Anzahl ist immer größer als 0 (Null), außer wennein Fehler oder eine Warnung ausgegeben wird. Bei einem mehrzeiligenAbruf gibt ein SQLCOUNT von 1 ohne Fehlerzustand an, dass eine gültigeZeile abgerufen wurde.
Der folgende Beispielcode zeigt den Gebrauch von mehrzeiligen Abrufen(wide fetches). Sie können diesen Code auch insamples\ASA\esqlwidefetch\widefetch.sqc in Ihrem SQL Anywhere-Verzeichnis finden.
Beispiel

Kapitel 6 Programmieren mit Embedded SQL
219
#include <stdio.h>#include <stdlib.h>#include <string.h>#include "sqldef.h"EXEC SQL INCLUDE SQLCA;
EXEC SQL WHENEVER SQLERROR { PrintSQLError(); goto err; };
static void PrintSQLError()/*************************/{ char buffer[200];
printf( "SQL error %d -- %s\n", SQLCODE, sqlerror_message( &sqlca,
buffer, sizeof( buffer ) ) );
}
static SQLDA * PrepareSQLDA(a_sql_statement_numberstat0,unsigned width,unsigned *cols_per_row )
/*********************************************//* Einen SQLDA-Bereich für Abrufe von der von "stat0" definierten Anweisung zuordnen. "width"- Zeilen werden bei jeder FETCH-Anforderung abgerufen. Die Anzahl der Spalten wird "cols_per_row" zugeordnet. */{ int num_cols; unsigned row, col, offset; SQLDA * sqlda; EXEC SQL BEGIN DECLARE SECTION; a_sql_statement_number stat; EXEC SQL END DECLARE SECTION;
stat = stat0; sqlda = alloc_sqlda( 100 ); if( sqlda == NULL ) return( NULL ); EXEC SQL DESCRIBE :stat INTO sqlda; *cols_per_row = num_cols = sqlda->sqld; if( num_cols * width > sqlda->sqln ) { free_sqlda( sqlda ); sqlda = alloc_sqlda( num_cols * width ); if( sqlda == NULL ) return( NULL ); EXEC SQL DESCRIBE :stat INTO sqlda; } // Erste Zeile in SQLDA mit describe in // folgende (weite) Zeilen kopieren

Daten abrufen
220
sqlda->sqld = num_cols * width; offset = num_cols; for( row = 1; row < width; row++ ) { for( col = 0;
col < num_cols; col++, offset++ ) { sqlda->sqlvar[offset].sqltype =
sqlda->sqlvar[col].sqltype; sqlda->sqlvar[offset].sqllen =
sqlda->sqlvar[col].sqllen; // optional: beschriebenen Spaltennamen kopieren
memcpy( &sqlda->sqlvar[offset].sqlname, &sqlda->sqlvar[col].sqlname, sizeof( sqlda->sqlvar[0].sqlname )); } } fill_s_sqlda( sqlda, 40 ); return( sqlda );
err: return( NULL );}
static void PrintFetchedRows( SQLDA * sqlda, unsigned cols_per_row )
/******************************************//* Bereits durch weite Abrufe erhaltene Zeilen in SQLDAausgeben */{ long rows_fetched; int row, col, offset;
if( SQLCOUNT == 0 ) {rows_fetched = 1;
} else {rows_fetched = SQLCOUNT;
} printf( "Abgerufene %d Zeilen:\n", rows_fetched ); for( row = 0; row < rows_fetched; row++ ) {
for( col = 0; col < cols_per_row; col++ ) { offset = row * cols_per_row + col; printf( " \"%s\"",
(char *)sqlda->sqlvar[offset] .sqldata );
}printf( "\n" );
}}
static int DoQuery( char * query_str0, unsigned fetch_width0 )

Kapitel 6 Programmieren mit Embedded SQL
221
/*****************************************//* Wide Fetch "query_str0"-Auswahlanweisung * mit der Weite von "fetch_width0" Zeilen" */{ SQLDA * sqlda; unsigned cols_per_row; EXEC SQL BEGIN DECLARE SECTION; a_sql_statement_number stat; char * query_str; unsigned fetch_width; EXEC SQL END DECLARE SECTION;
query_str = query_str0; fetch_width = fetch_width0;
EXEC SQL PREPARE :stat FROM :query_str; EXEC SQL DECLARE QCURSOR CURSOR FOR :stat
FOR READ ONLY; EXEC SQL OPEN QCURSOR; sqlda = PrepareSQLDA( stat,
fetch_width, &cols_per_row );
if( sqlda == NULL ) { printf( "Fehler beim Zuweisen von SQLDA\n" ); return( SQLE_NO_MEMORY );} for( ;; ) { EXEC SQL FETCH QCURSOR INTO DESCRIPTOR sqlda
ARRAY :fetch_width; if( SQLCODE != SQLE_NOERROR ) break;
PrintFetchedRows( sqlda, cols_per_row ); } EXEC SQL CLOSE QCURSOR; EXEC SQL DROP STATEMENT :stat; free_filled_sqlda( sqlda );err: return( SQLCODE );}
void main( int argc, char *argv[] )/*********************************//* Optionales erstes Argument ist ’select’-Anweisung * optionales zweites Argument ist ’Fetch’-Weite */{ char *query_str =
"select emp_fname, emp_lname from employee"; unsigned fetch_width = 10;
if( argc > 1 ) {query_str = argv[1];if( argc > 2 ) { fetch_width = atoi( argv[2] );

Daten abrufen
222
if( fetch_width < 2 ) {fetch_width = 2;
}}
} db_init( &sqlca ); EXEC SQL CONNECT "dba" IDENTIFIED BY "sql";
DoQuery( query_str, fetch_width );
EXEC SQL DISCONNECT;err: db_fini( &sqlca );}
♦ Die Funktion PrepareSQLDA weist den SQLDA-Bereich mit Hilfe derFunktion alloc_sqlda einem Speicherbereich zu. So wird Platz fürIndikatorvariable ermöglicht, anstatt die Funktion alloc_sqlda_noind zuverwenden.
♦ Falls weniger als die angeforderte Anzahl von Zeilen, jedoch nicht Null,abgerufen wurden (zum Beispiel am Ende des Cursors), wird für dienicht abgerufenen SQLDA-Elemente jeweils NULL zurückgegeben,indem der entsprechende Indikatorwert gesetzt wird. Falls keineIndikatorvariable vorhanden ist, wird ein Fehler erzeugt(SQLE_NO_INDICATOR: keine Indikatorvariable für ein NULL-Ergebnis).
♦ Falls eine Zeile zurückgegeben wird, die aktualisiert wurde, und die eineWarnung SQLE_ROW_UPDATED_WARNING hervorgerufen hat,wird der Abruf in der Zeile angehalten, die die Warnung verursacht hat.Die Werte aller bis zu diesem Zeitpunkt abgearbeiteten Zeilen werdenzurückgegeben (einschließlich der Zeile, die die Warnung verursachthat). SQLCOUNT enthält die Anzahl der Zeilen, die abgerufen wurden,einschließlich der Zeile, die die Warnung verursacht hat. Alleverbleibenden SQLDA-Elemente werden mit NULL gekennzeichnet.
♦ Falls eine Zeile, die abgerufen werden soll, gelöscht oder gesperrt wurdeund so einen Fehler hervorruft (SQLE_NO_CURRENT_ROW oderSQLE_LOCKED), enthält SQLCOUNT die Anzahl der Zeilen, die vordem Fehler gelesen wurden. Dies schließt nicht die Zeile ein, die denFehler verursachte. Der SQLDA-Bereich enthält keine Werte für dieZeilen, denn bei Fehlern werden keine SQLDA-Werte zurückgegeben.Der Wert von SQLCOUNT kann verwendet werden, um den Cursor neuzu positionieren und, falls nötig, um die Zeilen zu lesen.
Hinweise zurVerwendung vonmehrzeiligenAbrufen (widefetches)

Kapitel 6 Programmieren mit Embedded SQL
223
Statische und dynamische SQLEs gibt zwei Möglichkeiten, SQL-Anweisungen in ein C-Programmeinzubetten:
♦ Statische Anweisungen
♦ Dynamische Anweisungen
Bis hier haben wir statische SQL erklärt. Dieser Abschnitt vergleichtstatische und dynamische SQL.
Statische SQL-Anweisungen
Alle Standard-SQL-Anweisungen zur Datenmanipulation undDatendefinition können in ein C-Programm eingebettet werden, indem mansie mit dem Präfix EXEC SQL versieht und das Kommando mit einemSemikolon (;) abschliesst. Diese Anweisungen werden als statischeAnweisungen bezeichnet.
Statische Anweisungen können Referenzen auf Hostvariable enthalten, wiein "Hostvariable benutzen" auf Seite 200 beschrieben. Alle Beispiele bis hierhaben statische Embedded SQL-Anweisungen benutzt.
Hostvariable können nur an Stelle von Zeichenfolgen- und numerischenKonstanten benutzt werden. Sie können nicht verwendet werden, umSpalten- oder Tabellennamen zu ersetzen; für diese Vorgänge sinddynamische Anweisungen erforderlich.
Dynamische SQL-Anweisungen
In C werden Zeichenfolgen in Zeichen-Arrays gespeichert. DynamischeAnweisungen werden in C-Zeichenfolgen konstruiert. Diese dynamischenAnweisungen können dann mit der PREPARE-Anweisung und derEXECUTE-Anweisung ausgeführt werden. Solche SQL-Anweisungenkönnen Hostvariable nicht in der gleichen Weise ansprechen wie statischeAnweisungen, denn auf C-Variable kann nicht über den Namen zugegriffenwerden, solange das C-Programm ausgeführt wird.

Statische und dynamische SQL
224
Um Informationen zwischen dynamischen SQL-Anweisungen und C-Variablen auszutauschen, wird eine Datenstruktur namens SQL-Deskriptorbereich (SQL Descriptor Area - SQLDA) verwendet. DieseStruktur wird vom SQL-Präprozessor erzeugt, wenn Sie beim EXECUTE-Befehl in der USING-Klausel eine Liste von Hostvariablen spezifizieren.Jeder Variablen entspricht jeweils ein Platzhalter in der vorbereitetenAnweisung, zugeordnet über die Position.
$ Informationen zum SQLDA-Bereich finden Sie unter "Der SQL-Deskriptor-Bereich (SQLDA)" auf Seite 228.
Ein Platzhalter wird in die Anweisung eingefügt, um anzuzeigen, wo aufHostvariable zugegriffen wird. Ein Platzhalter ist entweder ein Fragezeichen(?) oder eine Referenz auf eine Hostvariable wie in statischen Anweisungen(ein Hostvariablen-Name mit einem vorangestellten Doppelpunkt). Imletzteren Fall dient der Name der Hostvariable, der im Text der Anweisungbenutzt wird, nur als Platzhalter für eine Referenz auf den SQL-Deskriptorbereich.
Eine Hostvariable, mit der Informationen an die Datenbank übergebenwerden, wird eine Bindevariable genannt.
Zum Beispiel:
EXEC SQL BEGIN DECLARE SECTION;char comm[200];char address[30];char city[20];short int cityind;long empnum;
EXEC SQL END DECLARE SECTION;. . .
sprintf( comm, "update %s set address = :?,city = :?"
" where employee_number = :?",tablename );
EXEC SQL PREPARE S1 FROM :comm;EXEC SQL EXECUTE S1 USING :address, :city:cityind,:empnum;
Um diese Methode zu benutzen, muss der Programmierer wissen, wie vieleHostvariable in der Anweisung vorkommen. Normalerweise ist das nicht derFall. Daher können Sie Ihre eigene SQLDA-Struktur aufsetzen und diesenSQLDA-Bereich in der USING-Klausel des EXECUTE-Befehls angeben.
Die Anweisung DESCRIBE BIND VARIABLES gibt die Namen derHostvariablen zu den Bindevariablen zurück, die in einem Prepared-Statement gefunden wurden. Dies erleichtert es dem C-Programm, dieHostvariablen zu verwalten. Im Folgenden finden Sie die allgemeineMethode:
Beispiel

Kapitel 6 Programmieren mit Embedded SQL
225
EXEC SQL BEGIN DECLARE SECTION;char comm[200];
EXEC SQL END DECLARE SECTION;. . .sprintf( comm, "update %s set address = :address,
city = :city"" where employee_number = :empnum",tablename );
EXEC SQL PREPARE S1 FROM :comm;/* Nehmen Sie an, dass es nicht mehr als 10 Hostvariablegibt. Siehe nächstes Beispiel, falls Siekeine Grenze festlegen können */sqlda = alloc_sqlda( 10 );EXEC SQL DESCRIBE BIND VARIABLES FOR S1 USING DESCRIPTORsqlda;/* sqlda->sqld sagt Ihnen, wie viele Hostvariablegefunden wurden. *//* SQLDA_VARIABLE-Felder mit Werten belegen,die auf den name-Feldern in sqlda basieren.. . .EXEC SQL EXECUTE S1 USING DESCRIPTOR sqlda;free_sqlda( sqlda );
Der SQLDA-Bereich besteht aus einem Array von Variablendeskriptoren.Jeder Deskriptor beschreibt die Attribute der entsprechenden Variablen desC-Programms, oder die Stelle, an der die Datenbank Daten speichert odervon der sie Daten abruft:
♦ den Datentyp
♦ die Länge, falls type eine Zeichenfolge ist
♦ Gesamtstellen und Dezimalstellen, falls type ein nummerischerDatentyp ist
♦ Speicheradresse
♦ Indikatorvariable
$ Eine vollständige Beschreibung der SQLDA-Struktur finden Sie unter"Der SQL-Deskriptor-Bereich (SQLDA)" auf Seite 228
Die Indikatorvariable wird verwendet, um einen NULL-Wert an dieDatenbank zu übergeben, oder um einen NULL-Wert von der Datenbankabzurufen. Die Indikatorvariable wird auch vom Datenbankserver verwendet,um anzuzeigen, unter welchen Bedingungen Werte während einerDatenbankoperation gekürzt wurden. Die Indikatorvariable wird mit einempositiven Wert besetzt, wenn nicht genug Platz zur Verfügung stand, umeinen Wert von der Datenbank zu erhalten.
$ Weitere Hinweise finden Sie unter "Indikatorvariable" auf Seite 204.
SQLDA-Inhalt
Indikatorvariableund NULL

Statische und dynamische SQL
226
Die dynamische SELECT-Anweisung
Eine SELECT-Anweisung, die nur eine einzige Zeile zurückgibt, kanndynamisch vorbereitet werden, gefolgt von einer EXECUTE-Anweisung miteiner INTO-Klausel, um das einzeilige Ergebnis abzurufen. SELECT-Anweisungen, die mehrere Zeilen zurückgeben, werden dagegen mit Hilfevon dynamischen Cursorn verwaltet.
Mit dynamischen Cursorn werden Ergebnisse in eine Hostvariablen-Listegeschrieben, oder in einen SQLDA-Bereich, der mit der FETCH-Anweisungangegeben wird (FETCH INTO und FETCH USING DESCRIPTOR). Dadie Anzahl der Elemente in der Auswahlliste dem C-Programmierernormalerweise unbekannt ist, wird in der Regel der SQLDA-Bereich benutzt.Die Anweisung DESCRIBE SELECT LIST richtet einen SQLDA-Bereichein mit Typen für die Elemente der Auswahlliste. Der Platzbedarf für dieWerte wird dann mit der Funktion fill_sqlda() zugewiesen, die Informationwird mit der Anweisung FETCH USING DESCRIPTOR abgerufen.
Ein typisches Szenario sieht wie folgt aus:
EXEC SQL BEGIN DECLARE SECTION;char comm[200];
EXEC SQL END DECLARE SECTION;int actual_size;SQLDA * sqlda;
. . .sprintf( comm, "select * from %s", table_name );EXEC SQL PREPARE S1 FROM :comm;/* Anfaengliche Schaetzung von 10 Spalten im Ergebnis.Falls es
falsch ist, wird es gleich nach dem erstenDESCRIBE korrigiert, indem sqlda neu zugewiesen und DESCRIBE erneut ausgeführt wird. */
sqlda = alloc_sqlda( 10 );EXEC SQL DESCRIBE SELECT LIST FOR S1 USING DESCRIPTORsqlda;if( sqlda->sqld > sqlda->sqln ){
actual_size = sqlda->sqld;free_sqlda( sqlda );sqlda = alloc_sqlda( actual_size );EXEC SQL DESCRIBE SELECT LIST FOR S1
USING DESCRIPTOR sqlda;}fill_sqlda( sqlda );EXEC SQL DECLARE C1 CURSOR FOR S1;EXEC SQL OPEN C1;EXEC SQL WHENEVER NOTFOUND {break};for( ;; ){
EXEC SQL FETCH C1 USING DESCRIPTOR sqlda;/* Daten verarbeiten */

Kapitel 6 Programmieren mit Embedded SQL
227
}EXEC SQL CLOSE C1;EXEC SQL DROP STATEMENT S1;
Beenden Sie Anweisungen (drop), wenn sie nicht mehr gebraucht werden.So stellen Sie sicher, dass Anweisungen beendet werden, damit nichtunnötigerweise Ressourcen gebunden bleiben.
$ Ein vollständiges Beispiel für den Gebrauch von Cursorn für einedynamische Anweisung finden Sie unter "Beispiel für dynamischen Cursor"auf Seite 193.
$ Detaillierte Informationen zu den oben erwähnten Funktionen findenSie unter "Referenz der Bibliotheksfunktion" auf Seite 253.

Der SQL-Deskriptor-Bereich (SQLDA)
228
Der SQL-Deskriptor-Bereich (SQLDA)Der SQLDA-Bereich (SQL Descriptor Area) ist eine Schnittstellenstruktur,die für dynamische SQL-Anweisungen verwendet wird. Die Struktur tauschtInformationen über Hostvariable und Ergebnisse der SELECT-Anweisungmit der Datenbank aus. Der SQLDA-Bereich ist in der Header-Datei sqlda.hdefiniert.
$ In der Datenbank-Schnittstellenbibliothek oder DLL gibt esFunktionen, die Sie zur Verwaltung der SQLDA-Bereiche verwendenkönnen. Die Beschreibung dieser Funktionen finden Sie unter "Referenz derBibliotheksfunktion" auf Seite 253.
Wenn Hostvariable mit statischen SQL-Anweisungen verwendet werden,erzeugt der Präprozessor einen SQDLA-Bereich für diese Hostvariable. Wasdann mit der Datenbank ausgetauscht wird, ist tatsächlich dieser SQLDA-Bereich.
Die SQLDA-Header-Datei
Der Inhalt von sqlda.h ist der folgende:
#ifndef _SQLDA_H_INCLUDED#define _SQLDA_H_INCLUDED#define II_SQLDA
#include "sqlca.h"
#if defined( _SQL_PACK_STRUCTURES )#include "pshpk1.h"#endif
#define SQL_MAX_NAME_LEN 30
#define _sqldafar _sqlfar
typedef short int a_SQL_type;struct sqlname { short int length; /* Länge der Char-Daten */ char data[ SQL_MAX_NAME_LEN ]; /* Daten */};
struct sqlvar { /* Array der Deskriptoren der Variablen */ short int sqltype; /* Typ der Hostvariablen */ short int sqllen; /* Länge der Hostvariablen */ void _sqldafar *sqldata; /* Adresse der Variablen */ short int _sqldafar *sqlind; /* Indikatorvariablen-Zeiger */ struct sqlname sqlname;};

Kapitel 6 Programmieren mit Embedded SQL
229
struct sqlda{ unsigned char sqldaid[8]; /* Eye-catcher "SQLDA"*/ a_SQL_int32 sqldabc; /* Länge der sqlda-Struktur*/ short int sqln; /* Deskriptorgröße in Anzahl der Einträge */ short int sqld; /* Anzahl der von DESCRIBE gefundenen Variablen*/ struct sqlvar sqlvar[1]; /* Array der Variablendeskriptoren */};
#define SCALE(sqllen) ((sqllen)/256)#define PRECISION(sqllen) ((sqllen)&0xff)#define SET_PRECISION_SCALE(sqllen,precision,scale) \ sqllen = (scale)*256 + (precision)#define DECIMALSTORAGE(sqllen) (PRECISION(sqllen)/2 + 1)
typedef struct sqlda SQLDA;typedef struct sqlvar SQLVAR, SQLDA_VARIABLE;typedef struct sqlname SQLNAME, SQLDA_NAME;
#ifndef SQLDASIZE#define SQLDASIZE(n) ( sizeof( struct sqlda ) + \ (n-1) * sizeof( struct sqlvar) )#endif
#if defined( _SQL_PACK_STRUCTURES )#include "poppk.h"#endif
#endif
SQLDA-Felder
Die SQLDA-Felder haben folgende Bedeutung:
Feld Beschreibung
sqldaid Ein 8-Byte-Zeichenfeld, das die Zeichenfolge SQLDA zurIdentifizierung der SQLDA-Struktur enthält. Dieses Feldunterstützt die Fehlersuche, wenn Sie Speicherinhalte untersuchen.
sqldabc Eine Ganzzahl (long integer), die die Länge der SQLDA-Strukturenthält
sqln Die Anzahl der Variablendeskriptoren im Array sqlvar
sqld Die Anzahl der gültigen Variablendeskriptoren (die eineHostvariable beschreiben). Dieses Feld wird in der Regel von derDESCRIBE-Anweisung gesetzt, manchmal auch vomProgrammierer, wenn Daten an den Datenbankserver geliefertwerden.
sqlvar Ein Array, bestehend aus Deskriptoren vom Typ struct sqlvar,von denen jeder eine Hostvariable beschreibt

Der SQL-Deskriptor-Bereich (SQLDA)
230
SQLDA-Hostvariablen-Beschreibungen
Jede sqlvar-Struktur im SQLDA-Bereich beschreibt eine Hostvariable. DieFelder der sqlvar-Struktur haben folgende Bedeutung:
♦ sqltype Der Typ der Variable, die von diesem Deskriptor beschriebenwird (siehe "Datentypen in Embedded SQL" auf Seite 196)
Das "low order Bit" zeigt an, ob NULL-Werte erlaubt sind. GültigeTypen- und Konstantendefinitionen befinden sich in der Header-Dateisqldef.h.
Dieses Feld wird von der DESCRIBE-Anweisung belegt. Sie könnendieses Feld mit jedem Typ belegen, wenn Sie Daten an denDatenbankserver liefern oder Daten vom Datenbankserver abrufen.Erforderliche Typkonvertierungen erfolgen automatisch.
♦ sqllen Länge der Variable. Was der Wert dieser Variable tatsächlichbedeutet, hängt von den Informationen zum Typ ab und davon, wie derSQLDA-Bereich verwendet wird.
Für DECIMAL-Typen wird dieses Feld in zwei je 1 Byte lange Felderaufgeteilt. Das "high byte" repräsentiert die Anzahl der Gesamtstellenund das "low byte" die Anzahl der Dezimalstellen. Die Gesamtstellensind die Gesamtzahl der Ziffern. Die Dezimalstellen sind die Anzahl derZiffern nach dem Dezimalzeichen.
Bei LONG VARCHAR- und LONG BINARY-Datentypen wird dasarray_len-Feld der DT_LONGBINARY- und DT_LONGVARCHAR-Datentypstruktur anstelle des sqllen-Felds verwendet.
$ Weitere Informationen über das Längenfeld finden Sie unter"SQLDA sqllen-Feldwerte" auf Seite 232.
♦ sqldata Ein 4-Byte-Zeiger auf den Speicher, der von der Variable belegtwird. Dieser Speicherinhalt muss den Feldern sqltype und sqllenentsprechen.
$ Informationen über Speicherformate finden Sie unter "Datentypenin Embedded SQL" auf Seite 196.
Beim UPDATE- und INSERT-Befehl spielt diese Variable keine Rollefür den Vorgang, falls der sqldata-Zeiger ein Null-Zeiger ist. BeiFETCH werden keine Daten zurückgegeben, falls der sqldata-Zeigerein Null-Zeiger ist. In anderen Worten, die vom Zeiger sqldatazurückgegebene Spalte ist eine entbundene Spalte.

Kapitel 6 Programmieren mit Embedded SQL
231
Falls die DESCRIBE-Anweisung LONG NAMES benutzt, enthältdieses Feld den Langnamen der Ergebnismengen-Spalte. Falls dieDESCRIBE-Anweisung darüber hinaus eine DESCRIBE USERTYPES-Anweisung ist, dann enthält dieses Feld den Langnamen desbenutzerdefinierten Datentyps statt der Spalte. Ist der Typ ein einvordefinierter Datentyp, ist das Feld leer.
♦ sqlind Ein Zeiger auf den Indikatorwert. Ein Indikatorwert ist eineGanzzahl (short int). Ein negativer Indikatorwert zeigt einen NULL-Wert an. Ein positiver Indikatorwert bedeutet, dass diese Variable voneiner FETCH-Anweisung gekürzt wurde. Der Indikatorwert enthält dieLänge der Daten, bevor sie gekürzt wurden. Ein Wert von –2 zeigteinen Konvertierungsfehler an, wenn die DatenbankoptionCONVERSION_ERROR auf OFF gesetzt ist.
$ Weitere Hinweise finden Sie unter "Indikatorvariable" aufSeite 204.
Ist der sqlind-Zeiger ein Null-Zeiger, gehört keine Indikatorvariable zudieser Hostvariable.
Das sqlind-Feld wird auch in der DESCRIBE-Anweisung verwendet,um Parametertypen anzuzeigen. Ist der Datentyp benutzerdefiniert, wirddas Feld auf DT_HAS_USERTYPE_INFO gesetzt. In diesem Fallsollten Sie DESCRIBE USER TYPES ausführen, um Informationenüber den benutzerdefinierten Datentyp zu erhalten.
♦ sqlname Eine VARCHAR-Struktur, die einen Längen- und einenZeichenpuffer enthält. Sie ist mit einer DESCRIBE-Anweisung belegtund wird nur dafür benutzt. Dieses Feld hat verschiedene Bedeutungenfür zwei Formate der DESCRIBE-Anweisung:
♦ Auswahlliste (SELECT LIST) Der Namenpuffer ist belegt mit demSpaltentitel des entsprechenden Elements in der ausgewählten Liste.
♦ Bindevariable Der Namenpuffer ist belegt mit dem Namen derHostvariable, die als Bindevariable benutzt wurde, oder mit "?" fallseine namenlose Parametermarkierung verwendet wurde.
Handelt es sich um einen DESCRIBE SELECT LIST-Befehl, sind allevorhandenen Indikatorvariablen mit einer Markierung (flag) belegt, dieanzeigt, ob das Listenelement aktualisierbar ist. Weitere Informationenüber diese Markierung finden Sie in der Header-Datei sqldef.h.
Handelt es sich um eine DESCRIBE USER TYPES-Anweisung, dannenthält dieses Feld den Langnamen des benutzerdefinierten Datentyps anStelle der Spalte. Ist der Typ ein ein vordefinierter Datentyp, ist das Feldleer.

Der SQL-Deskriptor-Bereich (SQLDA)
232
SQLDA sqllen-Feldwerte
Die Feldlänge sqllen der sqlvar-Struktur in einem SQLDA-Bereich wird indrei verschiedenen Arten von Interaktionen mit dem Datenbankserververwendet.
♦ Werte beschreiben Mit der DESCRIBE-Anweisung erhalten SieInformationen über die Hostvariablen, die zum Speichern von Datenerforderlich sind, die von der Datenbank abgerufen wurden, oder überHostvariable, die zum Übergeben von Daten an die Datenbankerforderlich sind.
$ Siehe "Werte beschreiben" auf Seite 232.
♦ Werte abrufen Werte von der Datenbank abrufen.
$ Siehe "Werte abrufen" auf Seite 235.
♦ Werte senden Informationen an die Datenbank senden.
$ Siehe "Werte senden" auf Seite 234.
Diese Interaktionen werden in diesem Abschnitt behandelt.
Die folgenden Tabellen beschreiben detailliert jede dieser Interaktionen.Diese Tabellen enthalten die Schnittstellen-Konstantentypen (DT_-Typen),die in der Header-Datei sqldef.h zu finden sind. Es sind die Konstanten, diedas SQLDA-Feld sqltype belegen können.
$ Hinweise über sqltype-Feldwerte finden Sie unter "Datentypen inEmbedded SQL" auf Seite 196.
Auch in statischem SQL wird ein SQLDA-Bereich verwendet, er wirdallerdings vom SQL-Präprozessor erzeugt und vollständig belegt. In diesemFall zeigen die Tabellen die Entsprechungen zwischen den statischen C-Hostvariablentypen und den Schnittstellenkonstanten.
Werte beschreiben
Die folgende Tabelle zeigt die Werte der Strukturelemente sqllen undsqltype, die der DESCRIBE-Befehl für verschiedene Datenbanktypenzurückgibt (sowohl SELECT LIST als auch BIND VARIABLE DESCRIBE-Anweisungen). Im Fall eines benutzerdefinierten Datenbank-Datentyps wirdder zu Grunde liegende Datentyp beschrieben.
Ihr Programm kann entweder die Typen und Längen benutzen, dieDESCRIBE zurückgibt, oder es kann andere Typen benutzen. DerDatenbankserver wird jede erforderliche Typkonvertierung durchführen. DerSpeicherbereich, auf den das Feld sqldata zeigt, muss den Feldern sqltypeund sqllen entsprechen.

Kapitel 6 Programmieren mit Embedded SQL
233
$ Weitere Hinweise zu Embedded SQL-Datentypen finden Sie unter"Datentypen in Embedded SQL" auf Seite 196.
Datenbank-Feldtyp zurückgegebenerEmbedded SQL-Typ
von describezurückgegebeneLänge
BIGINT DT_BIGINT 8
BINARY(n) DT_BINARY n
BIT DT_BIT 1
CHAR(n) DT_FIXCHAR n
DATE DT_DATE die Länge derlängsten formatiertenZeichenfolge
DECIMAL(p,s) DT_DECIMAL das high byte desLängenfelds imSQLDA-Bereich aufp setzen, das lowbyte auf s
DOUBLE DT_DOUBLE 8
FLOAT DT_FLOAT 4
INT DT_INT 4
LONG BINARY DT_LONGBINARY 32767
LONG VARCHAR DT_LONGVARCHAR 32767
REAL DT_FLOAT 4
SMALLINT DT_SMALLINT 2
TIME DT_TIME die Länge derlängsten formatiertenZeichenfolge
TIMESTAMP DT_TIMESTAMP die Länge derlängsten formatiertenZeichenfolge
TINYINT DT_TINYINT 1
UNSIGNED BIGINT DT_UNSBIGINT 8
UNSIGNED INT DT_UNSINT 4
UNSIGNED SMALLINT DT_UNSSMALLINT 2
VARCHAR(n) DT_VARCHAR n

Der SQL-Deskriptor-Bereich (SQLDA)
234
Werte senden
Die folgende Tabelle zeigt, wie Sie die Länge eines Werts spezifizieren,wenn Sie im SQLDA-Bereich Daten an den Datenbankserver liefern.
In diesem Fall sind nur die in der Tabelle gezeigten Datentypen erlaubt. DieDatentypen DT_DATE, DT_TIME und DT_TIMESTAMP werden genau sobehandelt wie DT_STRING, wenn Informationen an die Datenbank geliefertwerden. Der Wert muss eine mit Nullwert abgeschlossene Zeichenfolge ineinem passenden Datumsformat sein.
Embedded SQL-Datentyp Programmaktion zur Einstellung derLänge
DT_BIGINT keine Aktion erforderlich
DT_BINARY(n) die Länge wird einem Feld in der StrukturBINARY entnommen
DT_BIT keine Aktion erforderlich
DT_DATE Länge durch das abschließende \0 bestimmt
DT_DECIMAL(p,s) das high byte des Längenfelds im SQLDA-Bereich auf p setzen, das low byte auf s
DT_DOUBLE keine Aktion erforderlich
DT_FIXCHAR(n) das Längenfeld im SQLDA-Bereichbestimmt die Länge der Zeichenfolge
DT_FLOAT keine Aktion erforderlich
DT_INT keine Aktion erforderlich
DT_LONGBINARY Längenfeld ignoriert. Siehe "LONG-Datensenden" auf Seite 240
DT_LONGVARCHAR Längenfeld ignoriert. Siehe "LONG-Datensenden" auf Seite 240
DT_SMALLINT keine Aktion erforderlich
DT_STRING Länge durch das abschließende \0 bestimmt
DT_TIME Länge durch das abschließende \0 bestimmt
DT_TIMESTAMP Länge durch das abschließende \0 bestimmt
DT_TIMESTAMP_STRUCT keine Aktion erforderlich

Kapitel 6 Programmieren mit Embedded SQL
235
Embedded SQL-Datentyp Programmaktion zur Einstellung derLänge
DT_UNSBIGINT keine Aktion erforderlich
DT_UNSINT keine Aktion erforderlich
DT_UNSSMALLINT keine Aktion erforderlich
DT_VARCHAR(n) die Länge wird einem Feld in der StrukturVARCHAR entnommen
DT_VARIABLE Länge durch das abschließende \0 bestimmt
Werte abrufen
Die folgende Tabelle zeigt die Werte des Längenfelds, wenn Sie Daten vonder Datenbank abrufen und den SQLDA-Bereich verwenden. Das Feldsqllen wird beim Abrufen von Daten nie geändert.
In diesem Fall sind nur die in der Tabelle gezeigten Datentypen erlaubt. DieDatentypen DT_DATE, DT_TIME und DT_TIMESTAMP werden genau sobehandelt wie DT_STRING, wenn Informationen von der Datenbankabgerufen werden. Der Wert wird als Zeichenfolge im aktuellenDatumsformat formatiert.
Embedded SQL-Datentyp
Auf welchen Wertmuss das Programmdas Längenfeld setzen,wenn es Daten von derDatenbank abruft?
Wie gibt die DatenbankLängeninformationenzurück, nachdem einWert abgerufenwurde?
DT_BIGINT keine Aktion erforderlich keine Aktion erforderlich
DT_BINARY(n) Maximale Länge derStruktur BINARY (n+2)
das Feld len der StrukturBINARY ist auf dietatsächliche Länge gesetzt
DT_BIT keine Aktion erforderlich keine Aktion erforderlich
DT_DATE Länge des Puffers \0 am Ende derZeichenfolge
DT_DECIMAL(p,s) Das "high byte" auf psetzen und das "low byte"auf s
keine Aktion erforderlich
DT_DOUBLE keine Aktion erforderlich keine Aktion erforderlich
DT_FIXCHAR(n) Länge des Puffers bis zur Länge des Puffersaufgefüllt mit Leerzeichen
DT_FLOAT keine Aktion erforderlich keine Aktion erforderlich

Der SQL-Deskriptor-Bereich (SQLDA)
236
Embedded SQL-Datentyp
Auf welchen Wertmuss das Programmdas Längenfeld setzen,wenn es Daten von derDatenbank abruft?
Wie gibt die DatenbankLängeninformationenzurück, nachdem einWert abgerufenwurde?
DT_INT keine Aktion erforderlich keine Aktion erforderlich
DT_LONGBINARY Länge-Feld ignoriert. Siehe"LONG-Daten abrufen"auf Seite 238
Länge-Feld ignoriert. Siehe"LONG-Daten abrufen"auf Seite 238
DT_LONGVARCHAR Länge-Feld ignoriert. Siehe"LONG-Daten abrufen"auf Seite 238
Länge-Feld ignoriert. Siehe"LONG-Daten abrufen"auf Seite 238
DT_SMALLINT keine Aktion erforderlich keine Aktion erforderlich
DT_STRING Länge des Puffers \0 am Ende derZeichenfolge
DT_TIME Länge des Puffers \0 am Ende derZeichenfolge
DT_TIMESTAMP Länge des Puffers \0 am Ende derZeichenfolge
DT_TIMESTAMP_STRUCT
keine Aktion erforderlich keine Aktion erforderlich
DT_UNSBIGINT keine Aktion erforderlich keine Aktion erforderlich
DT_UNSINT keine Aktion erforderlich keine Aktion erforderlich
DT_UNSSMALLINT keine Aktion erforderlich keine Aktion erforderlich
DT_VARCHAR(n) Maximale Länge derStruktur VARCHAR (n+2)
das Feld len der StrukturVARCHAR ist auf dietatsächliche Länge gesetzt

Kapitel 6 Programmieren mit Embedded SQL
237
Lange Werte senden und abfragenDie Methode zum Senden und Abrufen von LONG VARCHAR- und LONGBINARY-Werten in Embedded SQL-Anwendungen ist anders als bei denübrigen Datentypen. Sie können auch die Standard-SQLDA-Felderverwenden, allerdings sind diese auf 32-Kbyte-Daten beschränkt, da dieFelder, die die Informationen enthalten (sqldata, sqllen, sqlind), 16-Bit-Werte sind. Eine Änderung dieser Werte auf 32-Bit-Werte würdevorhandene Anwendungen zerstören.
Die Methode zur Beschreibung von LONG VARCHAR- und LONGBINARY-Werten ist dieselbe wie bei anderen Datentypen.
$ Hinweise über das Abrufen und Senden von Werten finden Sie unter"LONG-Daten abrufen" auf Seite 238 und "LONG-Daten senden" aufSeite 240.
Es werden separate Struktuten verwendet, um die zugeordneten,gespeicherten und ungekürzten Längen von LONG BINARY- und LONGVARCHAR-Datentypen aufzunehmen. Die statischen SQL-Datentypenwerden in sqlca.h folgendermaßen definiert:
#define DECL_LONGVARCHAR( size ) \ struct { a_sql_uint32 array_len; \ a_sql_uint32 stored_len; \ a_sql_uint32 untrunc_len; \ char array[size+1];\ }
#define DECL_LONGBINARY( size ) \ struct { a_sql_uint32 array_len; \ a_sql_uint32 stored_len; \ a_sql_uint32 untrunc_len; \ char array[size]; \ }
Bei dynamischem SQL ist das Einstellen des sqltype-Felds aufDT_LONGVARCHAR oder DT_LONGBINARY ausreichend. Diezugeordneten LONGBINARY- und LONGVARCHAR-Sturkturen sehenfolgendermaßen aus:
Verwendung vonstatischem SQL
Verwendung vondynamischem SQL

Lange Werte senden und abfragen
238
typedef struct LONGVARCHAR { a_sql_uint32 array_len; /* Anzahl der zugeordneten Byte im Array */ a_sql_uint32 stored_len; /* Anzahl der im Array gespeicherten Byte * (nie höher als array_len) */ a_sql_uint32 untrunc_len; /* Anzahl der Byte in nicht-gekürztem * Ausdruck(kann höher sein als array_len) */ char array[1]; /* die Daten */} LONGVARCHAR, LONGBINARY;
$ Hinweise darüber, wie Sie diese Funktion in Ihren Anwendungenimplementieren, finden Sie unter "LONG-Daten abrufen" auf Seite 238 und"LONG-Daten senden" auf Seite 240.
LONG-Daten abrufen
Dieser Abschnitt beschreibt, wie Sie LONG-Werte aus der Datenbankabrufen. Hintergrundinformationen finden Sie unter "Lange Werte sendenund abfragen" auf Seite 237.
Die Prozeduren unterscheiden sich abhängig davon, ob Sie statisches oderdynamisches SQL verwenden.
v So rufen Sie einen LONG VARCHAR- oder LONG BINARY-Wert ab(statisches SQL):
1 Deklarieren Sie eine Hostvariable vom Typ DECL_LONGVARCHARoder DECL_LONGBINARY, wie erforderlich.
2 Rufen Sie die Daten mit FETCH, GET DATA oder EXECUTE INTOab. Adaptive Server Anywhere stellt die folgenden Informationen ein:
♦ Indikatorvariable Die Indikatorvariable ist negativ, wenn der WertNULL ist, oder 0, wenn es keine Kürzung gibt; beziehungsweise diepositive ungekürzte Länge in Byte bis zu einem Höchstwert von32767.
$ Weitere Hinweise finden Sie unter "Indikatorvariable" aufSeite 204.
♦ stored_len Dieses DECL_LONGVARCHAR- oderDECL_LONGBINARY-Feld enthält die Anzahl von Byte, die indas Array abgerufen werden. Der Wert ist niemals größer alsarray_len.

Kapitel 6 Programmieren mit Embedded SQL
239
♦ untrunc_len Dieses DECL_LONGVARCHAR- oderDECL_LONGBINARY-Feld enthält die Anzahl von Byte, die vomDatenbankserver gehalten werden. Dieser Wert muss kleiner/gleichdem stored_len-Wert sein. Er wird auch gesetzt, wenn derDatenwert ungekürzt ist.
v So nehmen Sie einen Wert in eine LONGVARCHAR- oderLONGBINARY-Struktur auf (dynamisches SQL):
1 Stellen Sie das sqltype-Feld auf DT_LONGVARCHAR oderDT_LONGBINARY ein, wie erforderlich.
2 Stellen Sie das sqldata-Feld so ein, dass es auf die LONGVARCHAR-oder LONGBINARY-Struktur zeigt.
Sie können das LONGVARCHARSIZE( n )- oder LONGBINARYSIZE( n)-Makro verwenden, um die Gesamtanzahl der Bytes zu bestimmen, diezugeordnet werden müssen, um n-Byte von Daten im Array-Feldaufzunehmen.
3 Stellen Sie das array_len-Feld der LONGVARCHAR- oderLONGBINARY-Struktur auf die Anzahl der Bytes ein, die dem Array-Feld zugeordnet sind.
4 Rufen Sie die Daten mit FETCH, GET DATA oder EXECUTE INTOab. Adaptive Server Anywhere stellt die folgenden Informationen ein:
♦ * sqlind Dieses sqlda-Feld ist negativ, wenn der Wert NULL ist,oder 0, wenn es keine Kürzung gibt, beziehungsweise die positiveungekürzte Länge in Byte bis zu einem Höchstwert von 32767.
♦ stored_len Dieses LONGVARCHAR- oder LONGBINARY-Feldenthält die Anzahl von Byte, die in das Array abgerufen werden.Der Wert ist niemals größer als array_len.
♦ untrunc_len Dieses LONGVARCHAR- oder LONGBINARY-Feldenthält die Anzahl von Byte, die vom Datenbankserver gehaltenwerden. Dieser Wert muss kleiner/gleich dem stored_len-Wertsein. Er wird auch gesetzt, wenn der Datenwert ungekürzt ist.
Der folgende Codeabschnitt illustriert den Mechanismus, der zum Abrufenvon LONG VARCHAR-Daten mittels dynamischem Embedded SQLverwendet wird. Er dient nur zur Illustration und ist nicht für einetatsächliche Verwendung bestimmt.

Lange Werte senden und abfragen
240
#define DATA_LEN 128000void get_test_var()/*****************/{ LONGVARCHAR *longptr; SQLDA *sqlda; SQLVAR *sqlvar;
sqlda = alloc_sqlda( 1 ); longptr = (LONGVARCHAR *)malloc( LONGVARCHARSIZE( DATA_LEN ) ); if( sqlda == NULL || longptr == NULL ) { fatal_error( "Allocation failed" ); }
// longptr für Datenaufnahme initialisieren longptr->array_len = DATA_LEN;
// _ // (sqllen wird nicht mit DT_LONG-Typen verwendet) sqlda->sqld = 1; // 1 sqlvar verwenden sqlvar = &sqlda->sqlvar[0]; sqlvar->sqltype = DT_LONGVARCHAR; sqlvar->sqldata = longptr;
printf( "fetching test_var\n" ); EXEC SQL PREPARE select_stmt FROM 'SELECT test_var'; EXEC SQL EXECUTE select_stmt INTO DESCRIPTOR sqlda; EXEC SQL DROP STATEMENT select_stmt; printf( "stored_len: %d, untrunc_len: %d, 1st char: %c, last char: %c\n", longptr->stored_len, longptr->untrunc_len, longptr->array[0], longptr->array[DATA_LEN-1] ); free_sqlda( sqlda ); free( longptr );}
LONG-Daten senden
Dieser Abschnitt beschreibt, wie Sie LONG-Werte an die Datenbank vonEmbedded SQL-Anwendungen senden. Hintergrundinformationen finden Sieunter "Lange Werte senden und abfragen" auf Seite 237.
Die Prozeduren unterscheiden sich abhängig davon, ob Sie statisches oderdynamisches SQL verwenden.

Kapitel 6 Programmieren mit Embedded SQL
241
v So senden Sie einen LONG VARCHAR- oder LONG BINARY-Wert(statisches SQL):
1 Deklarieren Sie eine Hostvariable vom Typ DECL_LONGVARCHARoder DECL_LONGBINARY, wie erforderlich.
2 Wenn Sie NULL senden und eine Indikatorvariable verwenden, stellenSie die Indikatorvariable auf einen negativen Wert ein.
$ Weitere Hinweise finden Sie unter "Indikatorvariable" aufSeite 204.
3 Stellen Sie das stored_len-Feld der DECL_LONGVARCHAR- oderDECL_LONGBINARY-Struktur auf die Anzahl von Byte der Daten imArray-Feld ein.
4 Senden Sie die Daten, indem Sie den Corsor öffnen oder die Anweisungausführen.
Der folgende Codeabschnitt illustriert den Mechanismus, der zum Sendenvon LONG VARCHAR-Daten mittels statischem Embedded SQL verwendetwird. Er dient nur zur Illustration und ist nicht für eine tatsächlicheVerwendung bestimmt.
#define DATA_LEN 12800EXEC SQL BEGIN DECLARE SECTION;// SQLPP initialisiert longdata.array_lenDECL_LONGVARCHAR(128000) longdata;EXEC SQL END DECLARE SECTION;
void set_test_var()/*****************/{ // longdata für das Senden von Daten initialisieren memset( longdata.array, 'a', DATA_LEN ); longdata.stored_len = DATA_LEN;
printf( "Setting test_var to %d a's\n", DATA_LEN ); EXEC SQL SET test_var = :longdata;}
v So senden Sie einen Wert mittels einer LONGVARCHAR- oderLONGBINARY-Struktur (dynamisches SQL):
1 Stellen Sie das sqltype-Feld auf DT_LONGVARCHAR oderDT_LONGBINARY ein, wie erforderlich.
2 Wenn Sie NULL senden, stellen Sie * sqlind auf einen negativen Wertein.
3 Stellen Sie das sqldata-Feld so ein, dass es auf die LONGVARCHAR-oder LONGBINARY-Struktur zeigt.

Lange Werte senden und abfragen
242
Sie können das LONGVARCHARSIZE( n )- oder LONGBINARYSIZE( n)-Makro verwenden, um die Gesamtanzahl an Byte zu bestimmen, diezugeordnet werden müssen, um n-Byte von Daten im Array-Feldaufzunehmen.
4 Stellen Sie das array_len-Feld der LONGVARCHAR- oderLONGBINARY-Struktur auf die Anzahl an Byte ein, die dem Array-Feld zugeordnet sind.
5 Stellen Sie das stored_len-Feld der LONGVARCHAR- oderLONGBINARY-Struktur auf die Anzahl an Byte der Daten im Array-Feld ein. Dieser Wert darf nicht größer als array_len sein.
6 Senden Sie die Daten, indem Sie den Cursor öffnen oder die Anweisungausführen.

Kapitel 6 Programmieren mit Embedded SQL
243
Gespeicherte Prozeduren verwendenIn diesem Abschnitt wird die Verwendung von SQL-Prozeduren inEmbedded SQL beschrieben.
Einfache gespeicherte Prozeduren verwenden
Sie können gespeicherte Prozeduren in Embedded SQL erstellen undaufrufen.
Eine CREATE PROCEDURE-Anweisung kann wie jede andereDatendefinitions-Anweisung, z.B. CREATE TABLE, eingebettet werden.Sie können auch eine CALL-Anweisung einbetten, um eine gespeicherteProzedur auszuführen. Das folgende Code-Fragment veranschaulicht dasErstellen und Ausführen einer gespeicherten Prozedur in Embedded SQL
EXEC SQL CREATE PROCEDURE pettycash( IN amountDECIMAL(10,2) )
BEGINUPDATE accountSET balance = balance - amountWHERE name = ’bank’;
UPDATE accountSET balance = balance + amountWHERE name = ’pettycash expense’;
END;EXEC SQL CALL pettycash( 10.72 );
Wenn Sie Werte von Hostvariablen an eine gespeicherte Prozedurweitergeben oder die Ausgabevariable abrufen wollen, bereiten Sie eineCALL-Anweisung vor und führen Sie sie aus. Das folgende Code-Fragmentveranschaulicht die Verwendung von Hostvariablen. Sowohl die USING alsauch die INTO-Klausel werden in der EXECUTE-Anweisung benutzt.
EXEC SQL BEGIN DECLARE SECTION;double hv_expense;double hv_balance;
EXEC SQL END DECLARE SECTION;

Gespeicherte Prozeduren verwenden
244
// hier Code schreibenEXEC SQL CREATE PROCEDURE pettycash(
IN expense DECIMAL(10,2),OUT endbalance DECIMAL(10,2) )
BEGINUPDATE accountSET balance = balance - expenseWHERE name = ’bank’;
UPDATE accountSET balance = balance + expenseWHERE name = ’pettycash expense’;
SET endbalance = ( SELECT balance FROM account WHERE name = ’bank’ );
END;
EXEC SQL PREPARE S1 FROM ’CALL pettycash( ?, ? )’;EXEC SQL EXECUTE S1 USING :hv_expense INTO :hv_balance;
$ Weitere Hinweise finden Sie unter "EXECUTE-Anweisung [ESQL]"auf Seite 449 der Dokumentation ASA SQL-Referenzhandbuch und"PREPARE-Anweisung [ESQL]" auf Seite 533 der Dokumentation ASASQL-Referenzhandbuch.
Gespeicherte Prozeduren mit Ergebnismengen
Eine Datenbankprozedur kann auch eine SELECT-Anweisung enthalten. DieProzedur wird mit einer RESULT-Klausel deklariert, um Anzahl, Name undTypen der Spalten in der Ergebnismenge zu spezifizieren. Die Spalten einerErgebnismenge unterscheiden sich von den Ausgabeparametern. In einerProzedur mit Ergebnismenge kann die CALL-Anweisung an Stelle derSELECT-Anweisung in der Cursordeklaration verwendet werden:
EXEC SQL BEGIN DECLARE SECTION;char hv_name[100];
EXEC SQL END DECLARE SECTION;
EXEC SQL CREATE PROCEDURE female_employees()RESULT( name char(50) )BEGIN
SELECT emp_fname || emp_lname FROM employeeWHERE sex = ’f’;
END;
EXEC SQL PREPARE S1 FROM ’CALL female_employees()’;
EXEC SQL DECLARE C1 CURSOR FOR S1;EXEC SQL OPEN C1;for(;;) {

Kapitel 6 Programmieren mit Embedded SQL
245
EXEC SQL FETCH C1 INTO :hv_name;if( SQLCODE != SQLE_NOERROR ) break;printf( "%s\\n", hv_name );
}EXEC SQL CLOSE C1;
In diesem Beispiel wurde die Prozedur mit einer OPEN-Anweisung statteiner EXECUTE-Anweisung aufgerufen. Nach der OPEN-Anweisung wirddie Prozedur ausgeführt, bis sie eine SELECT-Anweisung erreicht. Zudiesem Zeitpunkt ist C1 ein Cursor für die SELECT-Anweisung innerhalbder Datenbankprozedur. Sie können alle Arten des FETCH-Befehlsverwenden (rückwärts und vorwärts scrollen) solange Sie sie benötigen. DieCLOSE-Anweisung beendet die Ausführung der Prozedur.
Nach der SELECT-Anweisung wird in der Prozedur keine weitereAnweisung ausgeführt. Um Anweisungen nach dem SELECT auszuführen,benutzen Sie den Befehl RESUME Cursorname. Der RESUME-Befehl gibtentweder die Warnung SQLE_PROCEDURE_COMPLETE zurück oderSQLE_NOERROR, und zeigt damit an, dass es noch einen weiteren Cursorgibt. Das folgende Beispiel zeigt eine zweifache Auswahlprozedur:
EXEC SQL CREATE PROCEDURE people()RESULT( name char(50) )BEGIN
SELECT emp_fname || emp_lnameFROM employee;
SELECT fname || lnameFROM customer;
END;
EXEC SQL PREPARE S1 FROM ’CALL people()’;
EXEC SQL DECLARE C1 CURSOR FOR S1;EXEC SQL OPEN C1;while( SQLCODE == SQLE_NOERROR ) {
for(;;) {EXEC SQL FETCH C1 INTO :hv_name;if( SQLCODE != SQLE_NOERROR ) break;printf( "%s\\n", hv_name );
}EXEC SQL RESUME C1;
}EXEC SQL CLOSE C1;
Diese Beispiele haben statische Cursor verwendet. Dynamische Cursorkönnen auch für die CALL-Anweisung verwendet werden.
$ Eine Beschreibung von dynamischen Cursorn finden Sie unter "Diedynamische SELECT-Anweisung" auf Seite 226.
DynamischeCursor für CALL-Anweisungen

Gespeicherte Prozeduren verwenden
246
Die DESCRIBE-Anweisung funktioniert ohne Einschränkung fürProzeduraufrufe. DESCRIBE OUTPUT erzeugt einen SQLDA-Bereich miteiner Beschreibung für jede Spalte der Ergebnismenge.
Hat die Prozedur keine Ergebnismenge, enthält der SQLDA-Bereich eineBeschreibung für jeden INOUT- oder OUT-Parameter der Prozedur. EineDESCRIBE INPUT-Anweisung erzeugt einen SQLDA-Bereich mit einerBeschreibung für jeden IN- oder INOUT-Parameter der Prozedur.
DESCRIBE ALL beschreibt IN-, INOUT-, OUT- und RESULT-Parameter.DESCRIBE ALL benutzt die Indikatorvariablen im SQLDA-Bereich, umzusätzliche Information zu liefern.
Die Bits für DT_PROCEDURE_IN und DT_PROCEDURE_OUT werden inden Indikatorvariablen gesetzt, wenn eine CALL-Anweisung beschriebenwird. DT_PROCEDURE_IN gibt einen IN- oder INOUT-Parameter an, undDT_PROCEDURE_OUT gibt einen INOUT- oder OUT-Parameter an. InRESULT-Spalten von Prozeduren sind beide Bits bereinigt.
Nach einem Beschreibungs-OUTPUT können diese Bits benutzt werden, umzwischen Anweisungen zu unterscheiden, die Ergebnismengen haben(müssen OPEN, FETCH, RESUME, CLOSE benutzen), und Anweisungen,die keine Ergebnismengen haben (müssen EXECUTE benutzen).
$ Eine vollständige Beschreibung finden Sie unter "DESCRIBE-Anweisung [ESQL]" auf Seite 426 der Dokumentation ASA SQL-Referenzhandbuch.
Haben Sie eine Prozedur, die mehrere Ergebnismengen zurückgibt, müssenSie sie nach jeder RESUME-Anweisung neu beschreiben, falls sich die Formder Ergebnismengen ändert.
Sie müssen den Cursor beschreiben, nicht die Anweisung, um die aktuellePosition des Cursors neu zu beschreiben.
DESCRIBE ALL
MehrfacheErgebnismengen

Kapitel 6 Programmieren mit Embedded SQL
247
Programmiertechniken für Embedded SQL´Dieser Abschnitt enthält eine Reihe von Tipps für Entwickler vonProgrammen mit Embedded SQL.
Anforderungs-Management implementieren
Das voreingestellte Verhalten der Schnittstellen-DLL für Anwendungenbeinhaltet es, zu warten, bis eine Anforderung an die Datenbank ausgeführtwurde und erst dann andere Funktionen auszuführen. Dieses Verhaltenkönnen Sie mit Hilfe der Funktionen für die Anforderungsverwaltungändern. Zum Beispiel ist bei Interactive SQL das Betriebssystem weiterhinaktiv, während Interactive SQL auf eine Antwort der Datenbank wartet undinzwischen andere Aufgaben ausführt.
Sie können eine Anwendung aktivieren, während eine Anforderung an dieDatenbank abgearbeitet wird, indem Sie eine Callback-Funktion zurVerfügung stellen. In dieser Callback-Funktion setzen Sie eine weitereDatenbankanforderung - keine db_cancel_request - ab. Sie können dieFunktion db_is_working in Ihren Message-Handlers verwenden, umfestzustellen, ob gerade eine Anforderung an die Datenbank abgearbeitetwird.
Die Funktion db_register_a_callback wird verwendet, um die Callback-Funktionen Ihrer Anwendung zu registrieren:
$ Weitere Hinweise finden Sie im Folgenden.
♦ "db_register_a_callback-Funktion" auf Seite 261
♦ "db_cancel_request-Funktion" auf Seite 257
♦ "db_is_working-Funktion" auf Seite 260
Sicherungsfunktionen
Die Funktion db_backup unterstützt online-Sicherungen in Anwendungenmit Embedded SQL. Das Sicherungsdienstprogramm setzt diese Funktionein. Sie brauchen nur dann ein Programm zu schreiben, das diese Funktionverwendet, falls Ihre Sicherungsanforderungen die Leistung desSicherungsdienstprogramms von Adaptive Server Anywhere übersteigen.

Programmiertechniken für Embedded SQL
248
BACKUP-Anweisung wird empfohlenObwohl diese Funktion ein Möglichkeit bietet, einer AnwendungSicherungsfunktionen hinzuzufügen, wird empfohlen, diese Aufgabe überdie BACKUP-Anweisung zu auszuführen. Weitere Hinweise finden Sieunter "BACKUP-Anweisung" auf Seite 268 der Dokumentation ASASQL-Referenzhandbuch.
$ Sie können mit der Funktion DBBackup der Datenbank-Tools auchdirekt auf das Sicherungsdienstprogramm zugreifen. Weitere Hinweise überdiese Funktion finden Sie im Abschnitt "DBBackup-Funktion" auf Seite 323.
$ Weitere Hinweise finden Sie unter "db_backup-Funktion" aufSeite 254.

Kapitel 6 Programmieren mit Embedded SQL
249
SQL-PräprozessorDer SQL-Präprozessor bearbeitet ein C- oder C++-Programm, dasEmbedded SQL-Code enthält, bevor der Compiler gestartet wird.
sqlpp [ Parameter ] SQL-Dateiname [ Ausgabedateiname ]
Parameter Beschreibung
–c"Schlüsselwort=Wert;..."
Referenzparameter für die Datenbankverbindungbereitstellen [UltraLite]
–d Bevorzugte Datengröße
–e Ebene Nicht-konforme SQL-Syntax als Fehler kennzeichnen
–f Das Schlüsselwort "far" in erzeugte statische Datenschreiben
-g UltraLite-Warnungen nicht anzeigen
–h Zeilenbreite Maximale Zeilenlänge der Ausgabe begrenzen
–k Benutzerdeklarationation von SQLCODE einfügen
-m Version Versionsnamen für generierte Synchronisationsskriptenangeben
–n Zeilennummern
–o Betriebssys Ziel-Betriebssystem.
–p Projekt UltraLite-Projektname
–q Stiller Modus: Keinen Vorspann ausgeben
–r Wieder-eintretender Code
–s Zeichenfolgenlänge Maximale Zeichenfolgenlänge für den Compiler
–w Ebene Nicht-konforme SQL-Syntax als Warnungkennzeichnen
–x Mehrbyte-SQL-Zeichenfolgen in Escapesequenzenumwandeln
–z Sequenz Sortierfolge angeben
"Überblick" auf Seite 182
Syntax
Siehe auch:

SQL-Präprozessor
250
Der SQL-Präprozessor bearbeitet ein C- oder C++-Programm, dasEmbedded SQL-Code enthält, bevor der Compiler gestartet wird. SQLPPübersetzt die SQL-Anweisungen in Eingabedatei in Quellcode der SpracheC, der in Ausgabedatei gelegt wird. Die normale Dateinamenerweiterung fürQuelldateien mit Embedded SQL ist .sqc. Der voreingestellte Name für dieAusgabedatei ist der Name der SQL-Datei mit der Erweiterung .c. Falls derName der SQL-Datei bereits die Erweiterung .c hat, erhält die Ausgabedateistandardmäßig die Erweiterung .cc.
–c Erforderlich, wenn Dateien, die Teil einer UltraLite-Anwendung sind, mitdem Präprozessor bearbeitet werden. Die Verbindungszeichenfolge mussdem SQL-Präprozessor Zugriff zum Lesen und Ändern IhrerReferenzdatenbank geben.
–d Code erzeugen, der die Größe des Datenbereichs reduziert.Datenstrukturen werden vor der Verwendung zur Ausführungszeit wiederbenutzt und initialisiert. Dies erhöht die Code-Größe.
–e Diese Option kennzeichnet Embedded SQL-Code, der nicht Teil einesbestimmten Sets von SQL/92 ist, als Fehler.
Die zulässigen Werte von Ebene und ihre Bedeutung sind wie folgt:
♦ e Kennzeichnet Syntax, die nicht Einstiegsebene-SQL/92-Syntax ist
♦ i Kennzeichnet Syntax, die nicht Zwischenebene-SQL/92-Syntax ist
♦ f Kennzeichnet Syntax, die nicht vollständige SQL/92-Syntax ist
♦ t Nicht-Standard-Hostvariablentypen markieren
♦ u Kennzeichnet Syntax, die nicht von UltraLite unterstützt wird
♦ w Lässt die gesamte unterstützte Syntax zu
-g Keine Warnungen im Hinblick auf die Erzeugung von UltraLite-Code
–h Begrenzt die maximale Länge von Ausgabezeilen durch sqlpp aufZeilenbreite. Das Fortsetzungszeichen ist ein Rückstrich (\) und derMindestwert von Zeilenbreite ist zehn.
–k Teilt dem Präprozessor mit, dass das zu kompilierende Programm eineBenutzerdeklaration von SQLCODE enthält
-m Geben Sie den Versionsnamen für die erzeugten Synchronisationsskriptsan. Die erzeugten Synchronisationsskripts können in einer MobiLink-konsolidierten Datenbank für einfache Synchronisation verwendet werden.
Beschreibung
Optionen

Kapitel 6 Programmieren mit Embedded SQL
251
–n Erzeugt Zeilennummerinformationen in der C-Datei. Diese umfassen#line-Direktiven an den betreffenden Stellen im erzeugten C-Code. Wennder von Ihnen verwendete Compiler die Anweisung #line unterstützt, lässtdiese Option den Compiler Fehler in Zeilennummern in der SQC-Dateiprotokollieren (der Datei mit Embedded SQL), und zwar im Gegensatz zumProtokollieren von Fehlern in Zeilennummern in der C-Datei, die vom SQL-Präprozessor erzeugt wird. Ebenso werden die #line-Anweisungen indirektvom Source Level Debugger verwendet, sodass Sie bei der Fehlersuchegleichzeitig die SQC-Quelldatei sehen können.
–o Geben Sie das Ziel-Betriebssystem an. Beachten Sie, dass diese Optionmit dem Betriebssystem übereinstimmen muss, auf dem das Programmausgeführt werden soll. In Ihrem Programm wird eine Referenz auf einbestimmtes Symbol erzeugt. Dieses Symbol ist in derSchnittstellenbibliothek definiert. Wenn Sie die falsche Betriebssystem-Spezifikation oder die falsche Bibliothek verwenden, wird vom Linker einFehler erkannt. Folgende Betriebssysteme werden unterstützt:
♦ WINDOWS Windows 95/98/Me, Windows CE
♦ WINNT Microsoft Windows NT/2000/XP
♦ NETWARE Novell NetWare
♦ UNIX UNIX
–p Kennzeichnet das UltraLite-Projekt, zu dem die Embedded SQL-Dateiengehören. Diese Option kann nur verwendet werden, wenn Dateien verarbeitetwerden, die Teil einer UltraLite-Anwendung sind.
–q Kein Banner drucken.
–r Weitere Hinweise zum reentrant-Code finden Sie unter "SQLCA-Verwaltung für Code mit mehreren Threads oder "reentrant"-Code" aufSeite 211.
–s Setzt die maximale Größe für Zeichenfolgen fest, die der Präprozessor indie C-Datei ausgibt. Zeichenfolgen, die länger als dieser Wert sind, werdenmit Hilfe einer Liste von Zeichen initialisiert (’a’,’b’,’c’ usw.). Die meisten C-Compiler sind in der Größe der Zeichenfolgenliterale begrenzt, die Siehandhaben können. Mit dieser Option wird die obere Grenze festgesetzt. DerStandardwert ist 500.
–w Diese Option kennzeichnet jeden Embedded SQL-Code als Warnung, dernicht Teil eines bestimmten Sets von SQL/92 ist.
Die zulässigen Werte von Ebene und ihre Bedeutung sind wie folgt:
♦ e Kennzeichnet Syntax, die nicht Einstiegsebene-SQL/92-Syntax ist

SQL-Präprozessor
252
♦ i Kennzeichnet Syntax, die nicht Zwischenebene-SQL/92-Syntax ist
♦ f Kennzeichnet Syntax, die nicht vollständige SQL/92-Syntax ist
♦ t Nicht-Standard-Hostvariablentypen markieren
♦ u Kennzeichnet Syntax, die nicht von UltraLite unterstützt wird
♦ w Lässt die gesamte unterstützte Syntax zu
–x Ändert Mehrbyte-Zeichenfolgen in Escape-Sequenzen, sodass sie vomCompiler verarbeitet werden können.
–z Mit dieser Option wird die Kollatierungssequenz angegeben. Um eineListe mit den empfohlenen Kollatierungssequenzen zu erhalten, geben Siedbinit –l an der Eingabeaufforderung ein.
Die Kollatierungssequenz hilft dem Präprozessor, die Zeichen zu verstehen,die im Quellcode oder Programm verwendet werden, z.B. bei derIdentifizierung von alphabetischen Zeichen, die für die Verwendung inBezeichnern geeignet sind. Wenn -z nicht angegeben wird, versucht derPräprozessor, auf Grund des Betriebssystems und der UmgebungsvariablenSQLLOCALE eine geeignete Kollatierung zu ermitteln.

Kapitel 6 Programmieren mit Embedded SQL
253
Referenz der BibliotheksfunktionDer SQL-Präprozessor erzeugt Funktionsaufrufe in derSchnittstellenbibliothek oder DLL. Zusätzlich zu den vom SQL-Präprozessorerzeugten Funktionsaufrufen wird dem Benutzer eine Gruppe vonBibliotheksfunktionen zur Verfügung gestellt, mit denen Datenbankvorgängeleichter ausgeführt werden können. Prototypen dieser Funktionen werdendurch den Befehl EXEC SQL INCLUDE SQLCA eingefügt.
Dieser Abschnitt enthält eine Referenzbeschreibung der verschiedenenFunktionen, geordnet nach Kategorien.
Die DLL-Eintrittspunkte sind gleich, abgesehen davon, dass die Prototypeneinen für DLLs passenden Zusatz haben.
Sie können die Eintrittspunkte auf portierbare Weise unter Verwendung von_esqlentry_ deklarieren, was in sqlca.h definiert ist. Es wird in den Wert__stdcall aufgelöst:
alloc_sqlda-Funktion
SQLDA *alloc_sqlda( unsigned numvar );
Diese Funktion weist einen SQLDA-Bereich mit Deskriptoren für dienumvar zu. Das Feld sqln des SQLDA-Bereichs wird mit der numvarinitialisiert. Den Indikatorvariablen wird Speicherplatz zugewiesen, dieIndikatorzeiger werden auf diesen Speicherplatz gesetzt und derIndikatorwert wird mit 0 (Null) initialisiert. Ein Null-Zeiger wirdzurückgegeben, falls kein Speicher zugewiesen werden konnte. Es wirdempfohlen, dass Sie diese Funktion an Stelle der Funktionalloc_sqlda_noind verwenden.
alloc_sqlda_noind-Funktion
SQLDA *alloc_sqlda_noind( unsigned numvar );
Diese Funktion weist einen SQLDA-Bereich mit Deskriptoren für dienumvar zu. Das Feld sqln des SQLDA-Bereichs wird mit der numvarinitialisiert. Den Indikatorvariablen wird kein Speicherplatz zugewiesen; dieIndikatorzeiger werden auf den Null-Zeiger gesetzt. Ein Null-Zeiger wirdzurückgegeben, falls kein Speicher zugewiesen werden konnte.
DLL-Eintrittspunkte
Prototyp
Beschreibung
Prototyp
Beschreibung

Referenz der Bibliotheksfunktion
254
db_backup-Funktion
void db_backup(SQLCA * sqlca,int op,int file_num,unsigned long page_num,SQLDA * sqlda);
Um die Sicherungsfunktionen benutzen zu können, müssen Sie mit einerBenutzer-ID mit DBA-Berechtigung oder mit REMOTE DBA-Berechtigung(SQL Remote) verbunden sein.
BACKUP-Anweisung wird empfohlenObwohl diese Funktion ein Möglichkeit bietet, einer AnwendungSicherungsfunktionen hinzuzufügen, wird empfohlen, diese Aufgabe überdie BACKUP-Anweisung zu auszuführen. Weitere Hinweise finden Sieunter "BACKUP-Anweisung" auf Seite 268 der Dokumentation ASASQL-Referenzhandbuch.
Welche Aktion ausgeführt wird, hängt vom Wert des Parameters op ab:
♦ DB_BACKUP_START Muß aufgerufen werden, bevor eine Sicherungbeginnen kann. Zu einem Zeitpunkt kann immer nur eine Sicherung aufeinem gegebenen Datenbankserver laufen. Datenbank-Checkpoints sinddeaktiviert, bis die Sicherung vollständig ist (db_backup wird mit demWert op für DB_BACKUP_END aufgerufen). Kann die Sicherung nichtstarten, wird der SQLCODE mit SQLE_BACKUP_NOT_STARTEDbelegt. Andernfalls wird das Feld SQLCOUNT des sqlca mit der Größeder Datenbankseiten belegt. (Sicherungen werden Seite für Seitedurchgeführt.)
Die Parameter file_num, page_num und sqlda werden nicht beachtet.
♦ DB_BACKUP_OPEN_FILE Öffnet die mit file_num angegebeneDatenbankdatei, sodass Seiten der angegebenen Datei mitDB_BACKUP_READ_PAGE gesichert werden können. GültigeDateinummern sind 0 (Null) bis DB_BACKUP_MAX_FILE für dieStamm-Datenbankdateien, DB_BACKUP_TRANS_LOG_FILE für dieTransaktionslogdatei und DB_BACKUP_WRITE_FILE für dieDatenbank-Write-Datei, falls sie existiert. Falls die angegebene Dateinicht existiert, wird SQLCODE mit SQLE_NOTFOUND belegt.Andernfalls enthält SQLCOUNT die Anzahl der Seiten in der Datei,SQLIOESTIMATE enthält einen 32-Bit-Wert (POSIX time_t), der dieZeit angibt, zu der die Datenbankdatei erstellt wurde, der Name derBetriebssystemdatei befindet sich im Feld sqlerrmc des SQLCA-Bereichs.
Prototyp
Zugriffs-Berechtigung
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
255
Die Parameter page_num und sqlda werden nicht beachtet.
♦ DB_BACKUP_READ_PAGE Eine Seite der Datenbankdatei lesen, diemit file_num angegeben wird. page_num sollte einen Wert von 0 bis 1weniger als die Seitenanzahl haben, die von einem erfolgreichen Aufrufvon db_backup mit dem Vorgang DB_BACKUP_OPEN_FILE inSQLCOUNT zurückgegeben wurde. Andernfalls wird SQLCODE mitSQLE_NOTFOUND belegt. Der sqlda-Deskriptor sollte mit einerVariablen vom Typ DT_BINARY eingerichtet werden, die auf einenPuffer zeigt. Der Puffer sollte groß genug sein, um Binärdaten in derGröße zu speichern, wie sie im Feld SQLCOUNT beim Aufruf vondb_backup mit dem Vorgang DB_BACKUP_START zurückgegebenwerden.
Die Daten in DT_BINARY enthalten eine 2 Byte lange Längenangabe,gefolgt von den eigentlichen Binärdaten, sodass der Puffer mindestens 2Byte länger sein muss als die Seitengröße.
Die Anwendung muss den Puffer speichernDieser Aufruf erzeugt eine der angegebenen Datenbankseiten imPuffer, aber es bleibt der Anwendung überlassen, den Pufferinhalt aufeinem Sicherungsdatenträger zu speichern.
♦ DB_BACKUP_READ_RENAME_LOG Die gleiche Aktion wie beiDB_BACKUP_READ_PAGE, außer dass nach der letzten Seite dasTransaktionslog zurückgegeben wurde; der Datenbankserver dasbestehende Transaktionslog umbenennt und ein ein neues startet
Falls der Datenbankserver nicht in der Lage ist, das Log zu diesemZeitpunkt umzubenennen (z.B. können in Datenbanken der Version 7.xoder älter unvollständige Transaktionen auftreten) tritt der FehlerSQLE_BACKUP_CANNOT_RENAME_LOG_YET auf. In diesem Fallbenutzen Sie nicht die zurückgegebene Seite, sondern erneuern Sie dieAnforderung, bis Sie SQLE_NOERROR erhalten und schreiben Siedann die Seite. Fahren Sie mit dem Lesen der Seiten fort, bis Sie denZustand SQLE_NOTFOUND erhalten.
Die FehlermeldungSQLE_BACKUP_CANNOT_RENAME_LOG_YET kann mehrereMale und für mehrere Seiten auftreten. In Ihrer Wiederholungsschleifesollten Sie eine Verzögerung einbauen, um den Server nicht mit zuvielen Anforderungen zu verlangsamen.
Erhalten Sie die Bedingung SQLE_NOTFOUND, wurde dasTransaktionslog erfolgreich gesichert und die Datei umbenannt. DerName der alten Transaktiondatei wird im Feld sqlerrmc des SQLCA-Bereichs zurückgegeben.

Referenz der Bibliotheksfunktion
256
Den Wert von sqlda->sqlvar[0].sqlind sollten Sie überprüfen,nachdem Sie db_backup aufgerufen haben. Ist dieser Wert größer als 0(Null), wurde die letzte Logseite geschrieben und die Logdatei wurdeumbenannt. Der neue Name befindet sich nach wie vor insqlca.sqlerrmc, aber der Wert von SQLCODE ist SQLE_NOERROR.
Danach sollten Sie db_backup nicht nochmals aufrufen, außer Siemöchten Dateien schließen und die Sicherung beenden. Falls Sie dastun, erhalten Sie eine zweite Kopie Ihrer gesicherten Logdatei undSQLE_NOTFOUND.
♦ DB_BACKUP_CLOSE_FILE Muss aufgerufen werden, wenn dieBearbeitung einer Datei abgeschlossen ist, um die mit file_numangegebene Datenbankdatei zu schließen.
Die Parameter page_num und sqlda werden nicht beachtet.
♦ DB_BACKUP_END Muß beim Beenden der Sicherung aufgerufenwerden. Keine andere Sicherung kann beginnen, bevor die letzte beendetwurde. Checkpoints werden wieder aktiviert.
Die Parameter file_num, page_num und sqlda werden nicht beachtet.
Das Programm dbbackup verwendet folgenden Algorithmus. Beachten Sie,dass es sich nicht um C-Code handelt, und dass keine Fehlerüberprüfungenthalten ist.
db_backup( ... DB_BACKUP_START ... )allocate page buffer based on page size in SQLCODEsqlda = alloc_sqlda( 1 )sqlda->sqld = 1;sqlda->sqlvar[0].sqltype = DT_BINARYsqlda->sqlvar[0].sqldata = allocated bufferfor file_num = 0 to DB_BACKUP_MAX_FILE db_backup( ... DB_BACKUP_OPEN_FILE, file_num ... ) if SQLCODE == SQLE_NO_ERROR /* Datei vorhanden */ num_pages = SQLCOUNT file_time = SQLE_IO_ESTIMATE open backup file with name from sqlca.sqlerrmc for page_num = 0 to num_pages - 1 db_backup( ... DB_BACKUP_READ_PAGE, file_num, page_num, sqlda ) write page buffer out to backup file next page_num close backup file db_backup( ... DB_BACKUP_CLOSE_FILE, file_num ... ) end ifnext file_numbackup up file DB_BACKUP_WRITE_FILE as abovebackup up file DB_BACKUP_TRANS_LOG_FILE as abovefree page buffer

Kapitel 6 Programmieren mit Embedded SQL
257
db_backup( ... DB_BACKUP_END ... )
db_cancel_request-Funktion
int db_cancel_request( SQLCA *sqlca );
Diese Funktion bricht die gerade aktive Anforderung an denDatenbankserver ab. Sie überprüft, ob die Anforderung an denDatenbankserver aktiv ist, bevor sie die Abbruchsanforderung sendet. Wenndie Funktion 1 zurückgibt, wurde die Abbruchsanforderung gesendet; wennsie 0 zurückgibt, wurde keine Anforderung gesendet.
Ein Rückgabewert ungleich 0 bedeutet nicht, dass die Anforderungabgebrochen wurde. Es gibt einige kritische zeitliche Überschneidungen,wenn sich die Abbruchsanforderung und die Antwort von der Datenbankoder vom Server überschneiden. In diesen Fällen findet einfach keinAbbruch statt, obwohl die Funktion weiterhin TRUE zurückgibt.
Die Funktion db_cancel_request kann asynchron aufgerufen werden. Dieseund die Funktion db_is_working sind die einzigen Funktionen in derSchnittstellenbibliothek der Datenbank, die asynchron aufgerufen werdenkönnen, weil sie einen SQLCA-Bereich benutzen, der schon von eineranderen Anforderung verwendet werden könnte.
Wenn Sie eine Anforderung abbrechen, die eine Cursoroperation durchführt,ist die Position des Cursors unbestimmt. Sie müssen den Cursor entwedermit seiner absoluten Position festlegen oder ihn nach dem Abbrechenschließen.
db_delete_file-Funktion
void db_delete_file(SQLCA * sqlca,char * filename );
Um die Sicherungsfunktionen benutzen zu können, müssen Sie mit einerBenutzer-ID mit DBA-Berechtigung oder mit REMOTE DBA-Berechtigung(SQL Remote) verbunden sein.
Die Funktion db_delete_file fordert vom Datenbankserver das Löschen derDatei namens filename an. Diese Funktion kann nach dem Sichern undUmbenennen des Transaktionslogs verwendet werden (siehe oben,DB_BACKUP_READ_RENAME_LOG in "db_backup-Funktion" aufSeite 254), um das alte Transaktionslog zu löschen. Sie müssen mit einerBenutzer-ID mit DBA-Berechtigung verbunden sein.
Prototyp
Beschreibung
Prototyp
Zugriffs-Berechtigung
Beschreibung

Referenz der Bibliotheksfunktion
258
db_find_engine-Funktion
unsigned short db_find_engine(SQLCA *sqlca,char *name );
Diese Funktion gibt eine kurze Ganzzahl ohne Vorzeichen zurück, dieStatusinformationen über den Datenbankserver namens name anzeigt. Fallskein Server mit dem angegebenen Namen gefunden werden kann, ist derRückgabewert 0 (Null). Ein Rückgabewert ungleich 0 bedeutet, dass derangegebene Server gerade läuft.
Jedes Bit des Rückgabewert enthält eine spezifische Information. DieHeader-Datei sqldef.h definiert Konstanten für diese Informationen. Falls einNull-Zeiger für name angegeben wird, gibt die Funktion Information überdie voreingestellte Datenbank zurück.
db_fini-Funktion
unsigned short db_fini( *sqlca );
Diese Funktion gibt Ressourcen frei, die von der Datenbankschnittstellebenutzt wurden. Nachdem Sie db_fini aufgerufen haben, sind keine weiterenBibliotheksaufrufe und keine weiteren Embedded SQL-Befehle erlaubt.Wenn während der Verarbeitung ein Fehler auftritt, wird der Fehlercode inSQLCA eingestellt und die Funktion gibt 0 zurück. Wenn es keine Fehlergegeben hat, wird ein Nicht-Nullwert zurückgegeben.
Sie müssen db_fini einmal für jeden benutzten SQLCA-Bereich aufrufen.
VorsichtWird unter NetWare nicht db_fini für jedes db_init aufgerufen, kann dasden Datenbankserver und den NetWare-Dateiserver zum Absturz bringen.
Hinweise über die Verwendung von db_fini in UltraLite-Anwendungenfinden Sie unter "db_fini-Funktion" auf Seite 247 der DokumentationUltraLite Benutzerhandbuch.
db_get_property-Funktion
unsigned int db_get_property(SQLCA * sqlca,a_db_property property,char * value_buffer,int value_buffer_size );
Prototyp
Beschreibung
Prototyp
Beschreibung
Siehe auch:
Prototyp

Kapitel 6 Programmieren mit Embedded SQL
259
Diese Funktion wird verwendet, um die Adressen der Server zu erhalten, zudenen derzeit eine Verbindung besteht. Sie wird vom Dienstprogrammdbping verwendet, um die Serveradresse auszudrucken.
Die Funktion kann auch benutzt werden, um den Wert derDatenbankeigenschaften zu erhalten. Datenbankeigenschaften können auchauf eine schnittstellenunabhängige Weise abgerufen werden, nämlich durchAusführen einer SELECT-Anweisung, siehe "Eigenschaften vonDatenbanken" auf Seite 690 der Dokumentation ASADatenbankadministration.
Es gelten die folgenden Argumente:
♦ a_db_property Ein enum mit dem WertDB_PROP_SERVER_ADDRESS. DB_PROP_SERVER_ADDRESSruft die Servernetzwerkadresse der derzeitigen Verbindung alsausdruckbare Zeichenfolge zurück. Gemeinsamer Speicher undNamedPipes-Protokolle geben immer die leere Zeichenfolge für dieAdresse zurück. TCP/IP- und SPX-Protokolle geben nicht-leereZeichenfolgeadressen zurück.
♦ value_buffer Dieses Argument wird mit dem Eigenschaftswert alsZeichenfolge mit einer abschließenden Null gefüllt.
♦ value_buffer_size Die maximale Länge der Zeichenfolge value_buffer,einschließlich des abschließenden Nullzeichens.
"Eigenschaften von Datenbanken" auf Seite 690 der Dokumentation ASADatenbankadministration
db_init-Funktion
unsigned short db_init( SQLCA *sqlca );
Diese Funktion initialisiert die Schnittstellenbibliothek der Datenbank. DieseFunktion muss aufgerufen werden, bevor ein anderer Bibliotheksaufruferfolgen kann und bevor ein Embedded SQL-Befehl ausgeführt wird. DieRessourcen, die die Schnittstellenbibliothek für Ihr Programm braucht,werden bei diesem Aufruf zugewiesen und initialisiert.
Geben Sie mit db_fini am Ende Ihres Programms die Ressourcen frei. Fallswährend der Prozessverarbeitung Fehler auftreten, werden sie im SQLCA-Bereich zurückgegeben und der Rückgabewert ist 0 (Null). Treten keineFehler auf, ist der Rückgabewert ungleich 0 (Null) und Sie können beginnen,Embedded SQL-Befehle und -Funktionen zu benutzen.
Beschreibung
Siehe auch:
Prototyp
Beschreibung

Referenz der Bibliotheksfunktion
260
In den meisten Fällen sollte diese Funktion nur einmal aufgerufen werden,um die Adresse der globalen Variable sqlca weiterzugeben, die in derHeader-Datei sqlca.h definiert ist. Falls Sie mit Embedded SQL eine DLLoder eine Anwendung schreiben, die mehrfache Threads hat, rufen Siedb_init einmal für jeden SQLCA-Bereich auf, der benutzt wird.
$ Weitere Hinweise finden Sie unter "SQLCA-Verwaltung für Code mitmehreren Threads oder "reentrant"-Code" auf Seite 211.
VorsichtWenn Sie unter NetWare db_fini nicht für jedes db_init aufrufen, kanndies einen Absturz des Datenbankservers und des NetWare-Dateiserversverursachen.
Hinweise über die Verwendung von db_init in UltraLite-Anwendungenfinden Sie unter "db_init-Funktion" auf Seite 247 der DokumentationUltraLite Benutzerhandbuch.
db_is_working-Funktion
unsigned db_is_working( SQLCA *sqlca );
Diese Funktion gibt 1 zurück, falls eine Datenbankanforderung IhrerAnwendung läuft, die den angegebenen sqlca benutzt. Sie gibt 0 (Null)zurück, falls keine Anwendung läuft, die den angegebenen sqlca benutzt.
Diese Funktion kann asynchron aufgerufen werden. Diese und die Funktiondb_cancel_request sind die einzigen Funktionen in derSchnittstellenbibliothek der Datenbank, die asynchron aufgerufen werdenkönnen, weil sie einen SQLCA-Bereich benutzen, der schon von eineranderen Anforderung verwendet werden könnte.
db_locate_servers-Funktion
unsigned int db_locate_servers(SQLCA *sqlca,SQL_CALLBACK_PARM callback_address,void *callback_user_data );
Bietet Zugriff auf die vom Befehlszeilen-Dienstprogramm dblocateangezeigten Daten und listet alle Adaptive Server Anywhere-Datenbankserver mit TCP/IP-Anschluss im lokalen Netzwerk auf.
Die Callback-Funktion muss folgende Syntax haben:
Siehe auch:
Prototyp
Beschreibung
Prototyp
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
261
int (*)( SQLCA *sqlca,a_server_address *server_addr,void *callback_user_data );
Die Callback-Funktion wird für jeden gefundenen Server ausgeführt. Wenndie Callback-Funktion den Wert 0 zurückgibt, stoppt db_locate_servers dieSuche nach Servern.
Die an die Callback-Funktion übergebenen Parameter sqlca undcallback_user_data sind dieselben Parameter, die an db_locate_serversübergeben werden. Der zweite Parameter ist ein Zeiger auf einea_server_address-Struktur. a_server_address wird mit folgenderDefinition in sqlca.h festgelegt:
typedef struct a_server_address { a_SQL_uint32 port_type; a_SQL_uint32 port_num; char *name; char *address;} a_server_address;
♦ port_type Ist hier immer PORT_TYPE_TCP (laut Definition 6 insqlca.h)
♦ port_num Ist die TCP-Portnummer, die der Server abhört
♦ name Zeigt auf einen Puffer, der den Servernamen enthält
♦ address Zeigt auf einen Puffer, der die IP-Adresse des Servers enthält
$ Weitere Hinweise finden Sie unter "Das Serverposition-Dienstprogramm" auf Seite 554 der Dokumentation ASADatenbankadministration.
db_register_a_callback-Funktion
void db_register_a_callback(SQLCA *sqlca,a_db_callback_index index,( SQL_CALLBACK_PARM ) callback );
Diese Funktion registriert Callback-Funktionen:
Falls Sie keine Callback-Funktion DB_CALLBACK_WAIT registrieren, istdie voreingestellte Reaktion, nichts zu tun. Ihre Anwendung ist blockiert,wartet auf die Antwort von der Datenbank und Windows zeigt den Cursor alsSanduhr an.
Um einen Callback zu löschen, übergeben Sie einen Null-Zeiger alscallback-Funktion.
Prototyp
Beschreibung

Referenz der Bibliotheksfunktion
262
Die folgenden Werte sind für den Parameter index erlaubt:
♦ DB_CALLBACK_DEBUG_MESSAGE Die bereitgestellte Funktion wirdfür jede Fehlersuchmeldung einmal aufgerufen. Ihr wird eine auf Nullendende Zeichenfolge übergeben, die den Text der Debug-Meldungenthält. Die Zeichenfolge enthält gewöhnlich eine Zeilenendmarke (\n)unmittelbar vor dem beendenden Nullwertzeichen. Der Prototyp derCallback-Funktion lautet folgendermaßen:
void SQL_CALLBACK debug_message_callback(SQLCA *sqlca,char * message_string );
♦ DB_CALLBACK_START Der Callback-Prototyp sieht wie folgt aus:
void SQL_CALLBACK start_callback( SQLCA *sqlca );
Diese Funktion wird unmittelbar vor dem Absenden einerDatenbankanforderung an den Server aufgerufen.DB_CALLBACK_START wird nur unter Windows verwendet.
♦ DB_CALLBACK_FINISH Der Callback-Prototyp sieht wie folgt aus:
void SQL_CALLBACK finish_callback( SQLCA * sqlca );
Diese Funktion wird aufgerufen, nachdem die Antwort auf eineDatenbankanforderung von der Schnittstellen-DLL empfangen wurde.DB_CALLBACK_FINISH wird nur unter Windows-Betriebssystemenverwendet.
♦ DB_CALLBACK_CONN_DROPPED Die Syntax sieht wie folgt aus:
void SQL_CALLBACK conn_dropped_callback (SQLCA *sqlca,char *conn_name );
Diese Funktion wird aufgerufen, wenn der Datenbankserver im Begriffist, die Verbindung aufgrund einer Zeitüberschreitung zu verlieren, voneiner DROP CONNECTION-Anweisung oder weil der Serverheruntergefahren wird. Der Verbindungsname conn_name wirdübergeben, sodass Sie zwischen den Verbindungen unterscheidenkönnen. Wenn die Verbindung nicht benannt war, hat sie den WertNULL.
♦ DB_CALLBACK_WAIT Der Callback-Prototyp sieht wie folgt aus:
void SQL_CALLBACK wait_callback( SQLCA *sqlca );
Diese Funktion wird wiederholt von der Schnittstellenbibliothekaufgerufen, während der Datenbankserver oder die Clientbibliothek mitdem Abarbeiten Ihrer Datenbankanforderung beschäftigt sind.
So würden Sie diesen Callback registrieren:

Kapitel 6 Programmieren mit Embedded SQL
263
db_register_a_callback( &sqlca, DBCALLBACK_WAIT, (SQL_CALLBACK_PARM)&db_wait_request );
♦ DB_CALLBACK_MESSAGE Diese Funktion ermöglicht es derAnwendung, Nachrichten vom Server zu verarbeiten, während sie eineAnforderung abarbeitet.
Der Callback-Prototyp sieht wie folgt aus:
void SQL_CALLBACK message_callback(SQLCA* sqlca,unsigned short msg_type,an_SQL_code code,unsigned length,char* msg);
Der msg_type-Parameter gibt an, wie wichtig die Nachricht ist undmehrere unterschiedliche Nachrichtentypen können unterschiedlichbehandelt werden. Die möglichen Nachrichtentypen sindMESSAGE_TYPE_INFO, MESSAGE_TYPE_WARNING,MESSAGE_TYPE_ACTION und MESSAGE_TYPE_STATUS. DieseKonstanten sind in sqldef.h definiert. Das code-Feld ist einIdentifizierer. Das Längen-Feld gibt an, wie lang die Nachricht ist. DieMeldung ist nicht mit Nullwert abgeschlossen.
Zum Beispiel zeigt die Interactive SQL Callback-Funktion STATUS-und INFO-Nachrichten in einem Nachrichtenfenster an, währendNachrichten vom Typ ACTION und WARNING in einem Dialogfenstererscheinen. Wenn eine Anwendung diese Callback-Funktion nichtregistriert, gibt es eine Standard-Callback-Funktion, die alle Nachrichtenin die Serverlogdatei schreibt (wenn der Debug-Modus eingestellt undeine Logdatei angegeben ist). Zusätzlich werden Nachrichten vom TypMESSAGE_TYPE_WARNING und MESSAGE_TYPE_ACTIONbetriebssystemabhängig auffälliger dargestellt.
db_start_database-Funktion
unsigned int db_start_database( SQLCA * sqlca, char * parms );
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine Semikolon-getrennteListe mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
Prototyp
Argumente

Referenz der Bibliotheksfunktion
264
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Diese Funktion startet eine Datenbank auf einem vorhandenen Server, fallsdie Datenbank nicht bereits läuft. Die Schritte, die zum Starten einerDatenbank ausgeführt werden, sind unter "Personal Server starten" aufSeite 88 der Dokumentation ASA Datenbankadministration beschrieben.
Der Rückgabewert ist wahr, falls die Datenbank bereits lief oder erfolgreichgestartet werden konnte. Informationen über Fehler werden im SQLCA-Bereich zurückgegeben.
Falls eine Benutzer-ID und ein Kennwort in den Parametern übergebenwurden, werden sie ignoriert.
$ Die Berechtigung zum Starten und Stoppen einer Datenbank wird in derServerbefehlszeile gesetzt. Weitere Hinweise finden Sie unter "DerDatenbankserver" auf Seite 134 der Dokumentation ASADatenbankadministration.
db_start_engine-Funktion
unsigned int db_start_engine( SQLCA * sqlca, char * parms );
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine durch Semikolonsgetrennte Liste mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Mit dieser Funktion wird der Datenbankserver gestartet, falls er nicht bereitsläuft. Die Schritte, die diese Funktion ausführt, sind dieselben, wie sie unter"Personal Server starten" auf Seite 88 der Dokumentation ASADatenbankadministration beschrieben sind.
Der Rückgabewert ist gültig, falls der Datenbankserver gefunden wurde oderfalls er erfolgreich gestartet werden konnte. Informationen über Fehlerwerden im SQLCA-Bereich zurückgegeben.
Beschreibung
Prototyp
Argumente
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
265
Der folgende Aufruf von db_start_engine startet den Datenbankserver undnennt ihn asademo, er lädt nicht die Datenbank, trotz des DBF-Verbindungsparameters:
db_start_engine( &sqlca, "DBF=c:\\asa8\\asademo.db;Start=dbeng8" );
Falls Sie nach dem Server auch eine Datenbank starten wollen, fügen Sie dieDatenbankdatei in den Verbindungsparameter START ein:
db_start_engine( &sqlca,"ENG=eng_name;START=dbeng8c:\\asa\\asademo.db" );
Dieser Aufruf startet den Server, nennt ihn eng_name und startet dieDatenbank asademo auf diesem Server.
Die Funktion db_start_engine versucht, eine Verbindung zu einem Serverherzustellen, bevor einer gestartet wird, um zu verhindern, dass ein Servergestartet wird, der bereits läuft.
Der Verbindungsparameter FORCESTART wird nur von der Funktiondb_start_engine verwendet. Wenn er auf YES gesetzt wird, wird nichtversucht, eine Verbindung zu einem Server herzustellen, bevor einergestartet wird. Dadurch kann das folgende Befehlspaar wie erwartet arbeiten:
1 Starten eines Datenbankservers mit dem Namen server_1:
start dbeng8 -n server_1 asademo.db
2 Der Start eines neuen Servers wird erzwungen und es wird eineVerbindung zu ihm hergestellt:
db_start_engine( &sqlda, "START=dbeng8 -n server_2 asademo.db;ForceStart=YES" )
Wenn FORCESTART nicht oder ohne ENG-Parameter verwendet wurde,hätte der zweite Befehl versucht, eine Verbindung zu server_1 herzustellen.Der Servername wird von der Funktion db_start_engine nicht vomParameter des START-Parameters ermittelt.
db_stop_database-Funktion
unsigned int db_stop_database( SQLCA * sqlca, char * parms );
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine durch Semikolonsgetrennte Liste mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
Prototyp
Argumente

Referenz der Bibliotheksfunktion
266
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Diese Funktion beendet die Datenbank namens DatabaseName auf demServer namens EngineName. Falls der EngineName nicht angegeben ist,bezieht sich die Funktion auf den voreingestellten Server.
Als Voreinstellung beendet diese Funktion eine Datenbank nicht, solangenoch eine Verbindung zu dieser Datenbank offen ist. Falls Unconditionalmit yes belegt ist, wird die Datenbank beendet, auch wenn nochVerbindungen offen sind.
Ist der Rückgabewert TRUE, sind keine Fehler aufgetreten.
$ Die Berechtigung zum Starten und Stoppen einer Datenbank wird in derServerbefehlszeile gesetzt. Weitere Hinweise finden Sie unter "DerDatenbankserver" auf Seite 134 der Dokumentation ASADatenbankadministration.
db_stop_engine-Funktion
unsigned int db_stop_engine( SQLCA * sqlca, char * parms );
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine durch Semikolonsgetrennte Liste mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Diese Funktion fährt den Datenbankserver herunter. Folgende Schrittewerden von dieser Funktion ausgeführt:
♦ Sie sucht den Datenbankserver, dessen Name dem Wert des ParametersEngineName entspricht. Falls EngineName nicht angegeben wurde,sucht sie nach dem voreingestellten lokalen Datenbankserver.
♦ Falls kein passender Server gefunden wird, schlägt die Funktion fehl.
♦ Die Funktion sendet eine Anforderung an den Server, alle Datenbankenzu finden und zu beenden.
♦ Sie entlädt den Datenbankserver.
Beschreibung
Prototyp
Argumente
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
267
Als Voreinstellung beendet diese Funktion einen Datenbankserver nicht,solange noch eine Verbindung zu dieser Datenbank offen ist. FallsUnconditional mit yes belegt ist, wird der Datenbankserver beendet, auchwenn noch Verbindungen offen sind.
Ein C-Programm kann diese Funktion nutzen anstatt DBSTOP aufzurufen.Ist der Rückgabewert TRUE, sind keine Fehler aufgetreten.
Die Verwendung von db_stop_engine hängt von den Berechtigungen ab, diemit der Serveroption -gk festgelegt wurden.
$ Weitere Hinweise finden Sie unter "–gk-Serveroption" auf Seite 157der Dokumentation ASA Datenbankadministration.
db_string_connect-Funktion
unsigned int db_string_connect( SQLCA * sqlca, char * parms );
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine durch Semikolonsgetrennte Liste mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Liefert zusätzliche Funktionalität über den Embedded SQL-BefehlCONNECT hinaus. Diese Funktion führt eine Verbindung aus, wobei derAlgorithmus verwendet wird, der in "Fehlerbehandlung bei Verbindungen"auf Seite 82 der Dokumentation ASA Datenbankadministration beschriebenwird.
Der Rückgabewert ist wahr (ungleich Null), falls eine Verbindungzustandekam, andernfalls ist er falsch (Null). Informationen über Fehler beimStarten des Servers, beim Starten der Datenbank oder beimVerbindungsaufbau werden im SQLCA-Bereich zurückgegeben.
db_string_disconnect-Funktion
unsigned int db_string_disconnect( SQLCA * sqlca, char * parms );
Prototyp
Argumente
Beschreibung
Prototyp

Referenz der Bibliotheksfunktion
268
sqlca Ein Zeiger auf eine SQLCA-Struktur. Hinweise dazu finden Sie unter"SQL-Kommunikationsbereich (SQLCA)" auf Seite 208.
parms Eine auf NULL endende Zeichenfolge, die eine durch Semikolonsgetrennte Liste mit Parametereinstellungen enhält, und zwar in der FormSTICHWORT=Wert. Zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\\db\\MeineDatenbank.db"
$ Eine Liste der Verbindungsparameter finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Diese Funktion trennt die Verbindung, die mit dem ParameterConnectionName angegeben wurde. Alle anderen Parameter werdenignoriert.
Falls der Parameter ConnectionName in der Zeichenfolge fehlt, wird dieunbenannte Verbindung getrennt. Dies entspricht dem Embedded SQL-Befehl DISCONNECT. Der Boolesche Rückgabewert ist wahr, falls eineVerbindung erfolgreich getrennt wurde. Informationen über Fehler werdenim SQLCA-Bereich zurückgegeben.
Diese Funktion fährt die Datenbank herunter, falls sie mit dem ParameterAutoStop=yes gestartet wurde, und falls keine anderen Verbindungen mitder Datenbank bestehen. Es beendet auch den Serverbetrieb, falls der Servermit dem Parameter AutoStop=yes gestartet wurde, und falls keine weitereDatenbank mehr auf dem Server läuft.
db_string_ping_server-Funktion
unsigned int db_string_ping_server(SQLCA * sqlca,char * connect_string,unsigned int connect_to_db );
connect_string ist eine normale Verbindungszeichenfolge, die eventuellServer- und Datenbankinformationen enthält.
Wenn connect_to_db nicht gleich Null (d.h. wahr) ist, dann versucht dieFunktion eine Verbindung zu einer Datenbank auf einem Server herzustellen.Es wird nur ein Wert ungleich Null (d.h. wahr) zurückgegeben, wenn dieVerbindungszeichenfolge ausreicht, um eine Verbindung zu einer benanntenDatenbank auf dem benannten Server herzustellen.
Argumente
Beschreibung
Prototyp
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
269
Wenn connect_to_db gleich Null ist, versucht die Funktion lediglich, diePosition eines Servers zu ermitteln. Es wird nur ein Wert ungleich Nullzurückgegeben, wenn die Verbindungszeichenfolge ausreicht, um diePosition eines Servers zu ermitteln. Es wird nicht versucht, eine Verbindungzur Datenbank herzustellen.
fill_s_sqlda-Funktion
struct sqlda * fill_s_sqlda(struct sqlda * sqlda,unsigned int maxlen );
Diese Funktion entspricht fill_sqlda,, abgesehen davon, dass sie alleDatentypen in sqlda in den Datentyp DT_STRING umwandelt. Es wirdgenügend Speicherplatz zugewiesen, um die eine Repräsentation desDatentyps als Zeichenfolge zu speichern, der ursprünglich im SQLDA-Bereich angegeben wurde, und zwar bis zu maximal maxlen Byte. DieLängenfelder im SQLDA-Bereich (sqllen) werden dementsprechendgeändert. Die Funktion gibt im Erfolgsfall sqlda zurück und den Null-Zeiger,falls nicht genügend Speicherplatz zur Verfügung stand.
fill_sqlda-Funktion
struct sqlda * fill_sqlda( struct sqlda * sqlda );
Diese Funktion weist alle Variable, die in den Deskriptoren von sqldabeschrieben sind, Speicherplatz zu und ordnet die Speicheradressen demFeld sqldata des entsprechenden Deskriptors zu. Es wird genügendSpeicherplatz zugewiesen für den im Deskriptor angegebenen Datenbanktypund die angegebene Länge. Die Funktion gibt im Erfolgsfall sqlda zurückund den Null-Zeiger, falls nicht genügend Speicherplatz zur Verfügungstand.
free_filled_sqlda-Funktion
void free_filled_sqlda( struct sqlda * sqlda );
Diese Funktion gibt den Speicherplatz frei, der einem sqldata-Zeiger unddem SQLDA-Bereich selbst zugewiesen war. Null-Zeiger werden nichtfreigegeben.
Durch Aufrufen dieser Funktion wird automatisch auch free_sqldaaufgerufen und alle Deskriptoren, die durch alloc_sqlda zugewiesen waren,freigegeben.
Prototyp
Beschreibung
Prototyp
Beschreibung
Prototyp
Beschreibung

Referenz der Bibliotheksfunktion
270
free_sqlda-Funktion
void free_sqlda( struct sqlda *sqlda );
Diese Funktion gibt Speicherplatz, der diesem sqlda zugewiesen wurde, undden Speicherplatz der Indikatorvariablen, der in fill_sqlda zugewiesenwurde, frei. Sie sollten den von den sqldata -Zeigern referenziertenSpeicherplatz nicht freigeben.
free_sqlda_noind-Funktion
void free_sqlda_noind( struct sqlda * sqlda );
Diese Funktion gibt den Speicherplatz frei, der dem sqlda zugewiesen war.Sie sollten den von den sqldata -Zeigern referenzierten Speicherplatz nichtfreigeben. Die Indikatorvariablen-Zeiger werden nicht beachtet.
"Eigenschaften von Datenbanken" auf Seite 690 der Dokumentation ASADatenbankadministration
"Das Ping-Dienstprogramm" auf Seite 550 der Dokumentation ASADatenbankadministration
sql_needs_quotes-Funktion
unsigned int sql_needs_quotes( SQLCA *sqlca, char *str );
Diese Funktion gibt einen Booleschen Wert zurück, der anzeigt, ob eineZeichenfolge mit Anführungszeichen eingeschlossen werden muss, wenn sieals SQL-Name (identifier) benutzt wird. Sie formuliert eine Anforderung anden Datenbankserver, um festzustellen, ob Anführungszeichen nötig sind.Die relevante Information wird im Feld sqlcode gespeichert.
Wir unterscheiden drei unterschiedliche Kombinationen von Rückgabewertund Code:
♦ return = FALSE, sqlcode = 0 In diesem Fall braucht die Zeichenfolgemit Sicherheit keine Anführungszeichen.
♦ return = TRUE In diesem Fall ist sqlcode immer mit SQLE_WARNINGbelegt und die Zeichenfolge braucht mit Sicherheit Anführungszeichen.
♦ return = FALSE Falls sqlcode mit etwas anderem alsSQLE_WARNING belegt ist, ist das Testergebnis unklar.
Prototyp
Beschreibung
Prototyp
Beschreibung
Prototyp
Beschreibung

Kapitel 6 Programmieren mit Embedded SQL
271
sqlda_storage-Funktion
unsigned long sqlda_storage( struct sqlda *sqlda, int varno );
Die Funktion gibt die Speichergröße zurück, die erforderlich wäre, um jedenmöglichen Wert der in sqlda->sqlvar[varno] beschriebenen Variable zuspeichern.
sqlda_string_length-Funktion
unsigned long sqlda_string_length( SQLDA *sqlda, int varno );
Diese Funktion gibt die Länge zurück, die eine C-Zeichenfolge (TypDT_STRING) haben müsste, um die Variable sqlda->sqlvar[varno]aufzunehmen (unabhängig vom Datentyp).
sqlerror_message-Funktion
char *sqlerror_message( SQLCA *sqlca, char * buffer, int max );
Diese Funktion gibt einen Zeiger auf eine Zeichenfolge zurück, die eineFehlermeldung enthält. Die Fehlermeldung enthält den Text für denFehlercode im SQLCA-Bereich. Wurde kein Fehler gemeldet, wird ein Null-Zeiger zurückgegeben. Die Fehlermeldung wird in dem gelieferten Puffergespeichert, falls erforderlich, gekürzt auf die Länge max.
Prototyp
Beschreibung
Prototyp
Beschreibung
Prototyp
Beschreibung

Befehlszusammenfassung für Embedded SQL
272
Befehlszusammenfassung für Embedded SQL
Alle Embedded SQL Anweisungen beginnen mit EXEC SQL undenden mit einem Semikolon (;).
Es gibt zwei Gruppen von Embedded SQL-Befehlen: Standard-SQL-Befehlewerden benutzt, indem sie einfach in ein C-Programm geschrieben werden,eingeschlossen von EXEC SQL und einem Semikolon (;). CONNECT,DELETE, SELECT, SET und UPDATE haben zusätzliche Formate, die nurin Embedded SQL zur Verfügung stehen. Die zusätzlichen Formate gehörenzur zweiten Gruppe der Embedded SQL-spezifischen Befehle.
$ Eine Beschreibung der Standard-SQL-Befehle finden Sie unter "SQL-Anweisungen" auf Seite 217 der Dokumentation ASA SQL-Referenzhandbuch.
Mehrere SQL-Befehle sind spezifisch für Embedded SQL und können nurinnerhalb eines C-Programms benutzt werden.
$ Weitere Hinweise über die Embedded SQL-Befehle finden Sie unter"SQL-Sprachelemente" auf Seite 3 der Dokumentation ASA SQL-Referenzhandbuch.
Standardmäßige Datenbearbeitung und Datendefinitions-Anweisungenkönnen von Embedded SQL-Anwendungen verwendet werden. Darüberhinaus gelten die folgenden Anweisungen speziell für die Programmierungvon Embedded SQL:
♦ ALLOCATE DESCRIPTOR Speicher für einen Deskriptor zuweisen
$ Siehe "ALLOCATE DESCRIPTOR-Anweisung [ESQL]" aufSeite 222 der Dokumentation ASA SQL-Referenzhandbuch
♦ CLOSE Einen Cursor schließen
$ Siehe "CLOSE-Anweisung [ESQL] [GP]" auf Seite 285 derDokumentation ASA SQL-Referenzhandbuch
♦ CONNECT Mit der Datenbank verbinden
$ Siehe "CONNECT-Anweisung [ESQL] [Interactive SQL]" aufSeite 292 der Dokumentation ASA SQL-Referenzhandbuch
♦ DEALLOCATE DESCRIPTOR Speicher freigeben, der für einenDeskriptor reserviert war
$ Siehe "DEALLOCATE DESCRIPTOR-Anweisung [ESQL]" aufSeite 410 der Dokumentation ASA SQL-Referenzhandbuch

Kapitel 6 Programmieren mit Embedded SQL
273
♦ Deklarationsabschnitt Hostvariable für die Kommunikation mit derDatenbank deklarieren
$ Siehe "Deklarationsabschnitt [ESQL]" auf Seite 421 derDokumentation ASA SQL-Referenzhandbuch
♦ DECLARE CURSOR Einen Cursor deklarieren
$ Siehe "DECLARE CURSOR-Anweisung [ESQL] [GP]" aufSeite 412 der Dokumentation ASA SQL-Referenzhandbuch
♦ DELETE (positioniert) Die Zeilen an der aktuellen Cursorpositionlöschen
$ Siehe "DELETE-Anweisung (positionsbasiert) [ESQL] [GP]" aufSeite 424 der Dokumentation ASA SQL-Referenzhandbuch
♦ DESCRIBE Die Hostvariable für eine bestimmte SQL-Anweisungdeklarieren
$ Siehe "DESCRIBE-Anweisung [ESQL]" auf Seite 426 derDokumentation ASA SQL-Referenzhandbuch
♦ DISCONNECT Die Verbindung mit dem Datenbankserver lösen
$ Siehe "DISCONNECT-Anweisung [ESQL] [Interactive SQL]" aufSeite 430 der Dokumentation ASA SQL-Referenzhandbuch
♦ DROP STATEMENT Ressourcen freigeben, die von einem Prepared-Statement benutzt werden
$ Siehe "DROP STATEMENT-Anweisung [ESQL]" auf Seite 439der Dokumentation ASA SQL-Referenzhandbuch
♦ EXECUTE Eine bestimmte SQL-Anweisung ausführen
$ Siehe "EXECUTE-Anweisung [ESQL]" auf Seite 449 derDokumentation ASA SQL-Referenzhandbuch
♦ EXPLAIN Die Strategie zur Optimierung eines bestimmten Cursorserklären
$ Siehe "EXPLAIN-Anweisung [ESQL]" auf Seite 456 derDokumentation ASA SQL-Referenzhandbuch
♦ FETCH Eine Zeile aus einem Cursor abrufen
$ Siehe "FETCH-Anweisung [ESQL] [GP]" auf Seite 458 derDokumentation ASA SQL-Referenzhandbuch
♦ GET DATA Lange Werte aus einem Cursor abrufen
$ Siehe "GET DATA-Anweisung [ESQL]" auf Seite 471 derDokumentation ASA SQL-Referenzhandbuch

Befehlszusammenfassung für Embedded SQL
274
♦ GET DESCRIPTOR Angaben zu einer Variablen in einen SQLDA-Bereich abrufen.
$ Siehe "GET DESCRIPTOR-Anweisung [ESQL]" auf Seite 473 derDokumentation ASA SQL-Referenzhandbuch
♦ GET OPTION Die Einstellung einer bestimmten Datenbankoptionabholen
$ Siehe "GET OPTION-Anweisung [ESQL]" auf Seite 475 derDokumentation ASA SQL-Referenzhandbuch
♦ INCLUDE Eine Datei ins SQL-Preprocessing einschließen
$ Siehe "INCLUDE-Anweisung [ESQL]" auf Seite 495 derDokumentation ASA SQL-Referenzhandbuch
♦ OPEN Einen Cursor öffnen
$ Siehe "OPEN-Anweisung [ESQL] [GP]" auf Seite 523 derDokumentation ASA SQL-Referenzhandbuch
♦ PREPARE Eine bestimmte SQL-Anweisung vorbereiten
$ Siehe "PREPARE-Anweisung [ESQL]" auf Seite 533 derDokumentation ASA SQL-Referenzhandbuch
♦ PUT Eine Zeile in einen Cursor einfügen
$ Siehe "PUT-Anweisung [ESQL]" auf Seite 538 der DokumentationASA SQL-Referenzhandbuch
♦ SET CONNECTION Die aktive Verbindung ändern
$ Siehe "SET CONNECTION-Anweisung [Interactive SQL]" aufSeite 578 der Dokumentation ASA SQL-Referenzhandbuch
♦ SET DESCRIPTOR Die Variablen in einem SQLDA-Bereichbeschreiben und Daten im SQLDA-Bereich ablegen
$ Siehe "SET DESCRIPTOR-Anweisung [ESQL]" auf Seite 579 derDokumentation ASA SQL-Referenzhandbuch
♦ SET SQLCA Einen anderen als den global voreingestellten SQLCA-Bereich benutzen
$ Siehe "SET SQLCA-Anweisung [ESQL]" auf Seite 588 derDokumentation ASA SQL-Referenzhandbuch
♦ UPDATE (positioniert) Die Zeile an der aktuellen Cursorpositionaktualisieren
$ Siehe "UPDATE-Anweisung (positionsbasiert) [ESQL] [GP]" aufSeite 626 der Dokumentation ASA SQL-Referenzhandbuch

Kapitel 6 Programmieren mit Embedded SQL
275
♦ WHENEVER Angeben, welche Aktionen bei Fehlern in SQL-Anweisungen erfolgen sollen
$ Siehe "WHENEVER-Anweisung [ESQL]" auf Seite 636 derDokumentation ASA SQL-Referenzhandbuch

Befehlszusammenfassung für Embedded SQL
276

277
K A P I T E L 7
ODBC-Programmierung
In diesem Kapitel finden Sie Hinweise zum Entwickeln von Anwendungen,die die ODBC-Programmierschnittstelle direkt aufrufen.
Die primäre Dokumentation für die Entwicklung von ODBC-Anwendungenist die Microsoft ODBC SDK Documentation, die als Teil des MicrosoftData Access Components (MDAC) SDK verfügbar ist. Dieses Kapitelenthält einführende Unterlagen sowie eine Beschreibung der spezifischenFunktionen für Adaptive Server Anywhere. Sie ist jedoch keine umfassendeAnleitung für die Entwicklung von ODBC-Anwendungen.
Einige Tools zur Entwicklung von Anwendungen, die bereits ODBCunterstützen, haben eine eigene Programmierschnittstelle, die die ODBC-Schnittstelle verbirgt. Dieses Kapitel richtet sich nicht an die Benutzer dieserTools.
Thema Seite
Einführung in ODBC 278
ODBC-Anwendungen erstellen 280
ODBC-Beispiele 285
ODBC-Handles 287
Verbindung mit einer Datenquelle herstellen 290
SQL-Anweisungen ausführen 294
Mit Ergebnismengen arbeiten 299
Gespeicherte Prozeduren aufrufen 304
Umgang mit Fehlern 306
Über diesesKapitel
Inhalt

Einführung in ODBC
278
Einführung in ODBCOpen Database Connectivity (ODBC) ist eine Programmierschnittstelle,die von der Microsoft Corporation als Standardschnittstelle für Datenbank-Managementsysteme in Windows-Betriebssystemen definiert wurde. ODBCist eine aufrufbasierte Schnittstelle.
Um ODBC-Anwendungen für Adaptive Server Anywhere zu entwickeln,brauchen Sie:
♦ Adaptive Server Anywhere.
♦ Einen C-Compiler, mit dem Sie Programme in IhrerBetriebssystemumgebung erstellen können
♦ Das Microsoft ODBC Software Development Kit. Sie finden es imMicrosoft Developer Network. Es umfasst Dokumentation und Tools,um ODBC-Anwendungen zu testen.
Adaptive Server Anywhere unterstützt die ODBC API außer unter Windowsauch unter UNIX und Windows CE. Die plattformunabhängige ODBC-Unterstützung erleichtert die Entwicklung portablerDatenbankanwendungen.
$ Weitere Informationen zur Auflistung von ODBC-Treibern in verteiltenTransaktionen finden Sie unter "Dreischichtige Datenverarbeitung undverteilte Transaktionen" auf Seite 399.
ODBC-Übereinstimmung
Adaptive Server Anywhere bietet Unterstützung für ODBC 3.52.
ODBC-Funktionen werden nach Kompatibilitätsstufen eingeordnet. EineFunktion ist entweder Kern, Stufe 1, oder Stufe 2, wobei Stufe 2 denStandard am besten unterstützt. Diese Funktionen sind aufgeführt in derDokumentation ODBC Programmer’s Reference, die von der MicrosoftCorporation als Teil des ODBC Software Development Kits bzw. von derMicrosoft Website unterhttp://msdn.microsoft.com/library/default.asp?url=/library/en-us/odbc/htm/odbcabout_this_manual.asp bezogen werden kann.
Der Adaptive Server Anywhere unterstützt die ODBC 3,52 Spezifikation.
♦ Kernübereinstimmung Der Adaptive Server Anywhere unterstützt alleKernfunktionen.
UnterstütztePlattformen
Stufen der ODBC-Unterstützung
Von AdaptiveServer AnywhereunterstützteFunktionen

Kapitel 7 ODBC-Programmierung
279
♦ Übereinstimmung mit Stufe 1 Adaptive Server Anywhere unterstütztalle Funktionen der Stufe 1, abgesehen von der asynchronen Ausführungvon ODBC-Funktionen.
Adaptive Server Anywhere unterstützt die gemeinsame Nutzung einerVerbindung durch mehrfache Threads. Die Anforderungen vonverschiedenen Threads werden von Adaptive Server Anywhereserialisiert.
♦ Übereinstimmung mit Stufe 2 Adaptive Server Anywhere unterstütztalle Funktionen der Stufe 2, mit Ausnahme der folgenden:
♦ Dreiteilige Namen von Tabellen und Ansichten. Dies ist aufAdaptive Server Anywhere nicht anwendbar.
♦ Asynchrone Ausführung von ODBC-Funktionen für bestimmteeinzelne Anweisungen
♦ Die Fähigkeit, Login-Anforderungen und SQL-Anforderungen nacheiner gegebenen Zeit abzubrechen (time out)
Anwendungen, die mit älteren Versionen von ODBC entwickelt wurden,sind weiter kompatibel mit Adaptive Server Anywhere und dem neuerenODBC-Treiber-Manager. Die neuen ODBC Funktionen stehen in den älterenAnwendungen nicht zur Verfügung.
Der ODBC-Treiber-Manager gehört zu der mit Adaptive Server Anywhereausgelieferten ODBC-Software. ODBC-Treiber-Manager Version 3 hat eineneue Schnittstelle für die Konfiguration von ODBC-Datenquellen.
ODBC-Rückwärts-Kompatibilität
Der ODBC-Treiber-Manager

ODBC-Anwendungen erstellen
280
ODBC-Anwendungen erstellenIn diesem Abschnitt wird beschrieben, wie einfache ODBC-Anwendungenkompiliert und gelinkt werden.
ODBC-Header-Datei einbeziehen
Jede C-Quelldatei, die ODBC-Funktionen aufruft, muss eineplattformspezifische ODBC-Header-Datei einbeziehen. Jedeplattformspezifische Header-Datei schließt die wichtigste ODBC-Header-Datei odbc.h ein, die alle Funktionen, Datentypen und Konstanten definiert,die erforderlich sind, um ein ODBC-Programm zu schreiben.
v So wird die ODBC-Header-Datei in eine C-Quelldatei einbezogen:
1 Fügen Sie eine Include-Zeile hinzu, die die betreffendeplattformspezifische Header-Datei referenziert. Folgende Zeilen müssenbenutzt werden:
Betriebssystem Include-Zeile
Windows #include "ntodbc.h"
UNIX #include "unixodbc.h"
Windows CE #include "ntodbc.h"
2 Fügen Sie das Verzeichnis, das die Header-Datei enthält, dem Include-Pfad Ihres Compilers hinzu.
Die plattformspezifischen Header-Dateien und odbc.h werden imUnterverzeichnis h Ihres SQL Anywhere-Verzeichnisses installiert.
ODBC-Anwendungen unter Windows verknüpfen
Dieser Abschnitt betrifft nicht Windows CE. Weitere Hinweise finden Sieunter "ODBC-Anwendungen unter Windows CE verknüpfen" auf Seite 281.
Wenn Sie Ihre Anwendung linken, müssen Sie diese mit der geeignetenImportbibliothekdatei verbinden. Damit ist der Zugriff auf die ODBC-Funktionen gewährleistet: Mit der Importbibliothek werden Eintrittspunktefür den ODBC Driver Manager odbc32.dll definiert. Der Treiber-Managerseinerseits lädt den Adaptive Server Anywhere-ODBC-Treiber dbodbc8.dll.

Kapitel 7 ODBC-Programmierung
281
Separate Importbibliotheken werden für Microsoft-, Watcom- und Borland-Compiler angeboten.
v So wird eine ODBC-Anwendung verknüpft (Windows):
♦ Fügen Sie das Verzeichnis mit der plattformspezifischenImportbibliothek der Liste der Bibliothekenverzeichnisse hinzu.
Die Importbibliotheken werden im Unterverzeichnis lib desVerzeichnisses mit den ausführbaren Dateien von Adaptive ServerAnywhere gespeichert und tragen die folgenden Bezeichnungen:
Betriebssystem Compiler Importbibliothek
Windows 95/98 undWindows NT
Microsoft odbc32.lib
Windows 95/98 undWindows NT
WatcomC/C++
wodbc32.lib
Windows 95/98 undWindows NT
Borland bodbc32.lib
Windows CE Microsoft dbodbc8.lib
ODBC-Anwendungen unter Windows CE verknüpfen
In Windows CE-Betriebssystemen gibt es keinen ODBC-Treiber-Manager.Mit der Importbibliothek (dbodbc8.lib) werden die Eintrittspunkte direkt inden Adaptive Server Anywhere-ODBC-Treiber dbodbc8.dll definiert.
Für die verschiedenen Chips, auf denen Windows CE verfügbar ist, werdenseparate Versionen dieser DLL zur Verfügung gestellt. Die Dateien befindensich in betriebssystemspezifischen Unterverzeichnissen des Verzeichnissesce in Ihrem SQL Anywhere-Verzeichnis. Zum Beispiel befindet sich derODBC-Treiber für Windows CE mit dem SH3-Chip an folgendemSpeicherort:
C:\Programme\Sybase\SQL Anywhere 8\ce\SH3
$ Eine Liste der unterstützten Versionen von Windows CE finden Sieunter "Erforderliche Systemausstattung für Adaptive Server Anywhere" aufSeite 31 der Dokumentation ASA Erste Schritte.
v So wird eine ODBC-Anwendung gelinkt (Windows CE):
1 Fügen Sie das Verzeichnis mit der plattformspezifischenImportbibliothek der Liste der Bibliothekenverzeichnisse hinzu.

ODBC-Anwendungen erstellen
282
Die Importbibliothek trägt den Namen dbodbc8.lib und ist an einembetriebssystemabhängigen Ort im Verzeichnis ce in IhremSQL Anywhere-Verzeichnis gespeichert. Zum Beispiel befindet sich dieImportbibliothek für Windows CE mit dem SH3-Chip an folgendemSpeicherort:
C:\Programme\Sybase\SQL Anywhere 8\ce\SH3\lib
2 Belegen Sie den Parameter DRIVER= in der Verbindungs-Zeichenfolge, die an die Funktion SQLDriverConnect weitergegebenwird.
szConnStrIn ="driver=BSSuchpfad\dbodbc8.dll;dbf=c:\asademo.db"
wobei BSSuchpfad der vollständige Suchpfad bis zum Chip-spezifischenUnterverzeichnis Ihres SQL Anywhere-Verzeichnisses auf demWindows CE-Gerät ist. Zum Beispiel:
\Programme\Sybase\SQL Anywhere 8\ce\SH3\lib
Das Beispielprogramm (odbc.c) verwendet eine Dateidatenquelle (FileDSN-Verbindungsparameter) mit dem Namen ASA 8.0 Sample.dsn. Sie könnenDateidatenquellen auf Ihrem Desktopsystem aus dem ODBC-Treiber-Manager erstellen und sie dann auf Ihr Windows CE-Gerät kopieren.
Adaptive Server Anywhere verwendet die Codierung UTF-8 ist; hierbeihandelt es sich um eine Mehrbyte-Zeichenkodierung, die für die Codierungvon Unicode verwendet werden kann.
Der Adaptive Server Anywhere ODBC-Treiber unterstützt entweder ASCII(8-Bit)-Zeichenfolgen oder Unicode (Wide Character)-Zeichenfolgen. DasUNICODE-Makro steuert, ob ODBC-Funktionen ASCII- oder Unicode-Zeichenfolgen erwarten. Wenn Ihre Anwendung mit dem definiertenUNICODE-Makro erstellt werden muss, Sie aber die ASCII ODBC-Funktionen nutzen möchten, müssen Sie ebenfalls dasSQL_NOUNICODEMAP-Makro definieren.
Die Beispieldatei Samples\ASA\C\odbc.c veranschaulicht, wie Sie dieUnicode ODBC-Funktionen anwenden.
ODBC-Anwendungen auf UNIX verknüpfen
Adaptive Server Anywhere umfasst keinen ODBC-Treiber-Manager, es gibtjedoch Treiber-Manager von Drittherstellern. In diesem Abschnitt wirdbeschrieben, wie ODBC-Anwendungen aufgebaut werden, die den ODBC-Treiber-Manager nicht verwenden.
Windows CE undUnicode

Kapitel 7 ODBC-Programmierung
283
Der ODBC-Treiber ist ein gemeinsam genutztes Objekt oder eine gemeinsamgenutzte Bibliothek. Separate Versionen der Adaptive Server Anywhere-ODBC-Treiber werden für Anwendungen mit einfachem sowie mit mehrerenThreads angeboten.
Die ODBC-Treiber sind folgende Dateien:
Betriebssystem Tread-Modell ODBC-Treiber
Solaris/Sparc Ein Thread dbodbc8.so (dbodbc8.so.1)
Solaris/Sparc Mehrere Threads dbodbc_r.so (dbodbc_r.so.1)
Die Bibliotheken sind mit einer Versionsnummer (in Klammern) alssymbolische Verknüpfungen mit der gemeinsam benutzten Bibliothekinstalliert.
v So wird eine ODBC-Anwendung gelinkt (UNIX):
1 Linken Sie Ihre Anwendung direkt mit dem geeigneten ODBC-Treiber.
2 Wenn Sie Ihre Anwendung bereitstellen, achten Sie darauf, dass dergeeignete ODBC-Treiber im Bibliotheks-Suchpfad des Benutzersystemsenthalten ist.
Wenn Adaptive Server Anywhere keinen ODBC-Treiber-Manager findet,verwendet er die Datei ~/.odbc.ini als Datenquelleninformation.
ODBC-Treiber-Manager unter UNIX
ODBC-Treiber-Manager für UNIX werden von Drittherstellern angeboten.Ein ODBC-Treiber-Manager beinhaltet die folgenden Dateien:
Betriebssystem Dateien
Solaris/Sparc libodbc.so (libodbc.so.1)
libodbcinst.so (libodbcinst.so.1)
Solaris/Sparc libodbc.so (libodbc.so.1)
libodbcinst.so (libodbcinst.so.1)
Wenn Sie eine Anwendung bereitstellen, die einen ODBC-Treiber-Managererfordert, und Sie keinen Treiber-Manager eines Drittanbieters benutzen,erstellen Sie symbolische Verknüpfungen für die gemeinsam genutztenBibliotheken libodbc und libodbcinst zum Adaptive Server Anywhere-ODBC-Treiber.
ODBC-Treiber
Datenquellen-information

ODBC-Anwendungen erstellen
284
Wenn ein ODBC-Treiber-Manager vorhanden ist, fragt der Adaptive ServerAnywhere diesen und nicht ~/.odbc.ini nach Datenquelleninformationen ab
Standard-ODBC-Anwendungen werden im Allgemeinen nicht direkt an denODBC-Treiber gelinkt. Statt dessen gehen ODBC-Funktionsaufrufe über denODBC-Treiber-Manager. Bei UNIX- und Windows CE-Betriebssystemenbezieht Adaptive Server Anywhere keinen ODBC-Treiber-Manager ein. Siekönnen weiterhin ODBC-Anwendungen erstellen, indem Sie sie direkt anden Adaptive Server Anywhere-ODBC-Treiber linken, jedoch können Siedann nur auf Adaptive Server Anywhere-Datenquellen zugreifen.

Kapitel 7 ODBC-Programmierung
285
ODBC-BeispieleMit Adaptive Server Anywhere werden mehrere Beispiele geliefert. DieBeispiele finden Sie im Unterverzeichnis Samples\ASA IhresSQL Anywhere-Verzeichnisses. Standardmäßig ist dies
C:\Programme\Sybase\SQL Anywhere 8\Samples\ASA
Die Beispiele in Verzeichnissen, die mit ODBC beginnen, veranschaulichenseparate und einfache ODBC-Aufgaben, wie etwa eine Verbindung mit einerDatenbank herstellen und Anweisungen ausführen. Ein vollständiges ODBC-Beispielprogramm finden Sie unter Samples\ASA\C\odbc.c. Das Programmführt dieselben Aktionen aus wie das Beispielprogramm für einendynamischen Cursor in Embedded SQL, das sich im gleichen Verzeichnisbefindet.
$ Eine Beschreibung des entsprechenden Embedded SQL-Programmsfinden Sie unter "Beispielprogramme mit Embedded SQL" auf Seite 190.
ODBC-Beispielprogramm erstellen
Das ODBC-Beispielprogramm in Samples\ASA\C umfasst eineStapelverarbeitungsdatei (Shell-Skript für UNIX), die eingesetzt werdenkann, um die Beispielanwendung zu kompilieren und zu linken.
v So wird das ODBC-Beispielprogramm erstellt
1 Öffnen Sie eine Befehlszeile und wechseln Sie in das UnterverzeichnisSamples\ASA\C Ihres SQL Anywhere-Verzeichnisses.
2 Führen Sie die Stapeldatei makeall oder das Shell-Skript aus.
Die Syntax des Befehls ist wie folgt:
makeall API Plattform Compiler
Die Parameter sind wie folgt:
♦ API Geben Sie odbc an, damit das ODBC-Beispiel kompiliert wirdund nicht eine Embedded SQL-Version der Anwendung.
♦ Plattform Geben Sie WINNT an wenn Sie für Windows-Betriebssystem kompilieren wollen.
♦ Compiler Geben Sie den Compiler an, mit dem das Programmkompiliert werden soll. Folgende Compiler sind möglich:
♦ WC - Watcom C/C++
♦ MC - Microsoft Visual C++

ODBC-Beispiele
286
♦ BC - Borland C++ Builder
ODBC-Beispielprogramm ausführen
Das Beispielprogramm odbc.c kann als Dienst laufen, wenn es für Windows-Versionen kompiliert wurde, die Dienste unterstützen.
Die beiden Dateien, die den Beispielcode für Windows-Dienste enthalten,sind die Quelldatei ntsvc.c und die Header-Datei ntsvc.h. Der Codeermöglicht es, das damit gelinkte ausführbare Programm entweder alsnormales Programm oder als Windows-Dienst auszuführen.
v So wird das ODBC-Beispiel ausgeführt:
1 Starten Sie das Programm:
♦ Führen Sie die Datei Samples\ASA\C\odbcwnt.exe aus.
2 Wählen Sie eine Tabelle:
♦ Wählen Sie eine der Tabellen in der Beispieldatenbank. Sie könnenz.B. Customer oder Employee eingeben.
v Um das ODBC-Beispiel als Windows-Dienst auszuführen, gehen Siewie folgt vor:
1 Starten Sie Sybase Central und öffnen Sie den Ordner "Dienste".
2 Klicken Sie auf "Dienst hinzufügen". Folgen Sie den Anweisungen, umdas Beispielprogramm den NT-Diensten hinzuzufügen.
3 Rechtsklicken Sie auf das Dienstsymbol und klicken Sie auf "Start", umden Dienst zu starten.
Wird das Programm als Dienst ausgeführt, zeigt es, falls dies möglich ist, dienormale Benutzeroberfläche. Es schreibt die Ausgabe in die Ereignisanzeigeunter der Rubrik "Anwendungen". Falls die Benutzeroberfläche nichtgestartet werden kann, schreibt das Programm eine Seite in dieEreignisanzeige und hält an.

Kapitel 7 ODBC-Programmierung
287
ODBC-HandlesODBC-Anwendungen verwenden eine kleine Anzahl von Handles, umgrundlegende Funktionen wie Datenbankverbindungen und SQL-Anweisungen zu definieren. Ein Handle ist ein 32-Bit-Wert.
Die folgenden Handles werden in nahezu allen ODBC-Anwendungeneingesetzt.
♦ Umgebung Das Umgebungs-Handle liefert einen globalen Kontext, indem auf Daten zugegriffen wird. Jede ODBC-Anwendung muss beimStart genau einen Umgebungs-Handle zuweisen und es bei Beendigungwieder freigeben.
Der folgende Code veranschaulicht, wie ein Umgebungs-Handlezugewiesen wird:
SQLHENV env;SQLRETURN rc;rc = SQLAllocHandle( SQL_HANDLE_ENV, SQL _NULL_HANDLE, &env );
♦ Verbindung Ein Verbindungs-Handle wird von einem ODBC-Treiberund einer Datenquelle angegeben. Eine Anwendung kann über mehrere,ihrer Umgebung zugeordnete Verbindungen verfügen. Ein Verbindungs-Handle zuzuweisen heißt nicht, eine Verbindung herzustellen. EinVerbindungs-Handle muss zunächst zugewiesen und dann verwendetwerden, wenn die Verbindung hergestellt ist.
Der folgende Code veranschaulicht, wie ein Verbindungs-Handlezugewiesen wird:
SQLHDBC dbc;SQLRETURN rc;rc = SQLAllocHandle( SQL_HANDLE_DBC, env, &dbc );
♦ Anweisung Ein Anweisungs-Handle bietet Zugriff auf eine SQL-Anweisung und damit verbundene Daten, wie etwa Ergebnisgruppenund Parameter. Jede Verbindung kann mehrere Anweisungen haben.Anweisungen werden sowohl für Cursorvorgänge (Daten abrufen) alsauch für die Ausführung einfacher Anweisungen benutzt (z.B. INSERT,UPDATE und DELETE).
Der folgende Code veranschaulicht, wie ein Anweisungs-Handlezugewiesen wird:
SQLHSTMT stmt;SQLRETURN rc;rc = SQLAllocHandle( SQL_HANDLE_STMT, dbc, &stmt );

ODBC-Handles
288
ODBC-Handles zuweisen
Die für ODBC-Programme erforderlichen Handle-Typen sind:
Element Handle-Typ
Umgebung SQLHENV
Verbindung SQLHDBC
Anweisung SQLHSTMT
Deskriptor SQLHDESC
v So wird ein ODBC-Handle verwendet:
1 Funktion SQLAllocHandle aufrufen.
SQLAllocHandle nimmt die folgenden Parameter an:
♦ Einen Bezeichner für den Typ des zuzuweisenden Elements
♦ Das Handle des übergeordneten Elements
♦ Einen Zeiger auf den Ort, an dem das Handle zugewiesen wird
$ Eine vollständige Beschreibung finden Sie unter SQLAllocHandlein der Microsoft-Dokumentation ODBC Programmer’s Reference.
2 Das Handle in nachfolgenden Funktionsaufrufen verwenden.
3 Das Objekt mit SQLFreeHandle freisetzen.
SQLFreeHandle nimmt die folgenden Parameter an:
♦ Einen Bezeichner für den Typ des freizusetzenden Elements
♦ Das Handle des freizusetzenden Elements
$ Eine vollständige Beschreibung finden Sie unter SQLFreeHandlein der Microsoft-Dokumentation ODBC Programmer's Reference.
Mit dem folgenden Codefragment wird ein Umgebungs-Handle zugewiesenund freigesetzt:
SQLHENV env;SQLRETURN retcode;retcode = SQLAllocHandle( SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env );if( retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO ) { // Erfolg: Hier den Anwendungscode}SQLFreeHandle( SQL_HANDLE_ENV, env );
$ Weitere Hinweise zu Rückgabecodes und Fehlerbehandlung finden Sieunter "Umgang mit Fehlern" auf Seite 306.
Beispiel

Kapitel 7 ODBC-Programmierung
289
Ein erstes ODBC-Beispiel
Es folgt ein einfaches ODBC-Programm, dass eine Verbindung mit derAdaptive Server Anywhere-Beispieldatenbank herstellt und diese sofortwieder trennt.
$ Dieses Beispiel finden Sie alsSamples\ASA\ODBCConnect\odbcconnect.cpp in Ihrem SQL Anywhere-Verzeichnis.
#include <stdio.h>#include "ntodbc.h"
int main(int argc, char* argv[]){ SQLHENV env; SQLHDBC dbc; SQLRETURN retcode;
retcode = SQLAllocHandle( SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env ); if (retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO) { printf( "env allocated\n" ); /* Umgebungsattribut ODBC-Version setzen */ retcode = SQLSetEnvAttr( env, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0); retcode = SQLAllocHandle( SQL_HANDLE_DBC, env, &dbc ); if (retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO) { printf( "dbc allocated\n" ); retcode = SQLConnect( dbc, (SQLCHAR*) "ASA 8.0 Sample", SQL_NTS, (SQLCHAR* ) "DBA", SQL_NTS, (SQLCHAR*) "SQL", SQL_NTS ); if (retcode == SQL_SUCCESS || retcode == SQL_SUCCESS_WITH_INFO) { printf( "Successfully connected\n" ); } SQLDisconnect( dbc ); } SQLFreeHandle( SQL_HANDLE_DBC, dbc ); } SQLFreeHandle( SQL_HANDLE_ENV, env ); return 0;}

Verbindung mit einer Datenquelle herstellen
290
Verbindung mit einer Datenquelle herstellenIn diesem Abschnitt wird beschrieben, wie ODBC-Funktionen zumHerstellen einer Verbindung mit einer Adaptive Server Anywhere-Datenbank eingesetzt werden.
Eine ODBC-Verbindungsfunktion wählen
ODBC bietet eine Reihe von Verbindungsfunktionen. Welche Sieverwenden, hängt davon ab, wie Ihre Anwendung bereitgestellt und benutztwerden soll:
♦ SQLConnect Die einfachste Verbindungsfunktion.
SQLConnect nimmt einen Datenquellennamen und eine fakultativeBenutzer-ID und ein fakultatives Benutzkennkennwort an. VerwendenSie SQLConnect, wenn Sie einen Datenquellennamen in IhrerAnwendung hartcodieren.
$ Weitere Hinweise finden Sie unter SQLConnect in der MicrosoftDokumentation ODBC Programmer’s Reference.
♦ SQLDriverConnect Stellt mit Hilfe einer Verbindungszeichenfolge eineVerbindung zu einer Datenquelle her.
Mit SQLDriverConnect kann die Anwendung Adaptive ServerAnywhere-spezifische Verbindungsdaten verwenden, die unabhängigvon der Datenquelle sind. Darüber hinaus können SieSQLDriverConnect benutzen, um anzufordern, dass der AdaptiveServer Anywhere-Treiber zur Eingabe von Verbindungsdaten auffordert.
SQLDriverConnect kann auch benutzt werden, um eine Verbindungherzustellen, ohne dass eine Datenquelle angegeben wird.
$ Weitere Hinweise finden Sie unter SQLDriverConnect in derMicrosoft Dokumentation ODBC Programmer’s Reference.
♦ SQLBrowseConnect Stellt wie SQLDriverConnect mit Hilfe einerVerbindungszeichenfolge eine Verbindung zu einer Datenquelle her.
Mit SQLBrowseConnect kann Ihre Anwendung eigene Dialogfelderaufbauen, die zur Eingabe von Verbindungsdaten auffordern und nachDatenquellen suchen, die von einem bestimmten Treiber verwendetwerden (in diesem Fall der Adaptive Server Anywhere-Treiber).
$ Weitere Hinweise finden Sie unter SQLBrowseConnect in derMicrosoft Dokumentation ODBC Programmer’s Reference.

Kapitel 7 ODBC-Programmierung
291
In den Beispielen in diesem Kapitel wird hauptsächlich SQLDriverConnectverwendet.
$ Eine vollständige Liste der Verbindungsparameter, die inVerbindungszeichenfolgen eingesetzt werden können, finden Sie unter"Verbindungsparameter" auf Seite 182 der Dokumentation ASADatenbankadministration.
Eine Verbindung herstellen
Ihre Anwendung muss eine Verbindung herstellen, bevor sieDatenbankvorgänge ausführen kann.
v So wird eine ODBC-Verbindung hergestellt:
1 ODBC-Umgebung zuweisen.
Zum Beispiel:
SQLHENV env;SQLRETURN retcode;retcode = SQLAllocHandle( SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env );
2 ODBC-Version deklarieren.
Wenn Sie deklarieren, dass die Anwendung ODBC Version 3 befolgensoll, werden SLQSTATE-Werte und einige andere versionsabhängigeFunktionen auf das entsprechende Verhalten eingestellt. Zum Beispiel:
retcode = SQLSetEnvAttr( env, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
3 Falls erforderlich, die Datenquelle oder Verbindungszeichenfolgezusammenstellen.
Je nach Ihrer Anweisung können Sie eine Datenquelle oderVerbindungszeichenfolge hartcodieren oder sie für erhöhte Flexibilitätextern speichern.
4 Ein ODBC-Verbindungselement zuweisen.
Zum Beispiel:
retcode = SQLAllocHandle( SQL_HANDLE_DBC, env, &dbc);
5 Diejenigen Verbindungsattribute festlegen, die vor dem Verbindeneingerichtet sein müssen.

Verbindung mit einer Datenquelle herstellen
292
Einige Verbindungsattribute müssen festgelegt werden, bevor eineVerbindung hergestellt wird, während andere vorher oder nachhereingerichtet werden können. Zum Beispiel:
retcode = SQLSetConnectAttr( dbc, SQL_AUTOCOMMIT, (SQLPOINTER)SQL_AUTOCOMMIT_OFF, 0);
$ Weitere Hinweise finden Sie unter "Verbindungsattributefestlegen" auf Seite 292.
6 ODBC-Verbindungsfunktion aufrufen.
Zum Beispiel:
if (retcode == SQL_SUCCESS || retcode ==SQL_SUCCESS_WITH_INFO) {
printf( "dbc allocated\n" );retcode = SQLConnect( dbc,
(SQLCHAR*) "ASA 8.0 Sample", SQL_NTS,(SQLCHAR* ) "DBA", SQL_NTS,(SQLCHAR*) "SQL", SQL_NTS );
if (retcode == SQL_SUCCESS|| retcode == SQL_SUCCESS_WITH_INFO){
// Verbindung erfolgreich hergestellt.
$ Ein vollständiges Beispiel finden Sie inSamples\ASA\ODBCConnect\odbcconnect.cpp in Ihrem SQL Anywhere-Verzeichnis.
♦ SQL_NTS Jede Zeichenfolge, die an ODBC übergeben wird, hat eineentsprechende Länge. Ist die Länge unbekannt, können Sie SQL_NTSals Argument verwenden, um anzuzeigen, dass es sich um einen NullTerminated String handelt, dessen Ende durch das Nullzeichengekennzeichnet ist (\0).
♦ SQLSetConnectAttr Voreingestellt arbeitet ODBC im Autocommit-Modus. Dieser Modus wird abgeschaltet, indem SQL_AUTOCOMMITauf "false" gesetzt wird.
$ Weitere Hinweise finden Sie unter "Verbindungsattributefestlegen" auf Seite 292.
Verbindungsattribute festlegen
Die Funktion SQLSetConnectAttr wird eingesetzt, um Verbindungsdetails zusteuern. Zum Beispiel deaktiviert die folgende Anweisung das ODBC-Autocommit-Verhalten.
retcode = SQLSetConnectAttr( dbc, SQL_AUTOCOMMIT, (SQLPOINTER)SQL_AUTOCOMMIT_OFF, 0 );
Hinweise

Kapitel 7 ODBC-Programmierung
293
$ Weitere Hinweise sowie eine Liste der Verbindungsattribute finden Sieunter SQLSetConnectAttr in der Microsoft Dokumentation ODBCProgrammer’s Reference .
Viele Aspekte der Verbindung können über die Verbindungsparametergesteuert werden. Hinweise finden Sie unter "Verbindungsparameter" aufSeite 78 der Dokumentation ASA Datenbankadministration.
Threads und Verbindungen in ODBC-Anwendungen
Sie können ODBC-Anwendungen mit mehreren Threads für Adaptive ServerAnywhere entwickeln. Es wird empfohlen, dass Sie für jeden Thread eineeigene Verbindung benutzen.
Sie können für mehrfache Threads eine einfache Verbindung benutzen. DerDatenbankserver erlaubt allerdings nicht mehr als eine aktive Anforderungfür eine Verbindung zur gleichen Zeit. Falls ein Thread eine Anweisungausführt, die lange braucht, müssen alle anderen Threads warten, bis dieAnforderung abgeschlossen ist.

SQL-Anweisungen ausführen
294
SQL-Anweisungen ausführenODBC umfasst mehrere Funktionen zum Ausführen von SQL-Anweisungen:
♦ Direkte Ausführung Adaptive Server Anywhere führt eine syntaktischeAnalyse der SQL-Anweisung durch, bereitet einen Zugriffsplan vor undführt die Anweisung aus. Das syntaktische Analysieren und dasVorbereiten des Zugriffsplans wird Vorbereitung der Anweisunggenannt.
♦ Vorbereitete Ausführung Die Vorbereitung der Anweisung erfolgtgetrennt von der Ausführung. Bei Anweisungen, die wiederholtausgeführt werden sollen wird damit vermieden, dass wiederholtvorbereitet werden muss. Damit wird die Performance verbessert.
$ Siehe "Vorbereitete Anweisungen ausführen" auf Seite 297.
Anweisungen direkt ausführen
Mit der Funktion SQLExecDirect wird eine SQL-Anweisung vorbereitetund ausgeführt. Die Anweisung kann auch Parameter enthalten.
Das folgende Codefragment veranschaulicht, wie eine Anweisung ohneParameter ausgeführt wird. Die Funktion SQLExecDirect nimmt einAnweisungs-Handle, eine SQL-Zeichenfolge und eine Länge bzw. einAbschlusszeichen an, falls ein Zeichenfolgeindikator mitNullabschlusszeichen erforderlich ist.
Das in diesem Abschnitt beschriebene Verfahren ist zwar einfach, aberunflexibel. Die Anweisung kann keine Benutzereingabe zur Änderung derAnweisung annehmen. Flexiblere Methoden zum Aufbau von Anweisungenfinden Sie unter "Anweisungen mit gebundenen Parametern ausführen" aufSeite 295.
v So wird eine SQL-Anweisung in einer ODBC-Anwendungausgeführt:
1 Der Anweisung mit SQLAllocHandle ein Handle zuweisen.
Mit der folgenden Anweisung wird z.B. bei einer Verbindung mit demHandle dbc ein Handle vom Typ SQL_HANDLE_STMT mit dem Namenstmt zugewiesen:
SQLAllocHandle( SQL_HANDLE_STMT, dbc, &stmt );
2 Funktion SQLExecDirect aufrufen und die Anweisung ausführen:

Kapitel 7 ODBC-Programmierung
295
Mit den folgenden Zeilen wird z.B. eine Anweisung deklariert undausgeführt. Die Deklaration von deletestmt würde normalerweise amAnfang der Funktion auftreten:
SQLCHAR deletestmt[ STMT_LEN ] = "DELETE FROM department WHERE dept_id = 201";SQLExecDirect( stmt, deletestmt, SQL_NTS) ;
$ Ein vollständiges Beispiel mit Fehlerprüfung finden Sie unterSamples\ASA\ODBCExecute\odbcexecute.cpp.
$ Weitere Hinweise zu SQLExecDirect finden Sie unter SQLExecDirectin der Microsoft-Dokumentation ODBC Programmer’s Reference.
Anweisungen mit gebundenen Parametern ausführen
In diesem Abschnitt wird beschrieben, wie eine SQL-Anweisung aufgebautund ausgeführt wird, bei der zum Festlegen der Werte vonAnweisungsparametern gebundene Parameter eingesetzt werden.
v So wird eine SQL-Anweisung mit gebundenen Parametern in einerODBC-Anwendung ausgeführt:
1 Der Anweisung mit SQLAllocHandle ein Handle zuweisen.
Mit der folgenden Anweisung wird z.B. bei einer Verbindung mit demHandle dbc ein Handle vom Typ SQL_HANDLE_STMT mit dem Namenstmt zugewiesen:
SQLAllocHandle( SQL_HANDLE_STMT, dbc, &stmt );
2 Anweisungsparameter mit SQLBindParameter binden.
Zum Beispiel werden mit den folgenden Zeilen Variable deklariert, dieWerte für Abteilungs-ID, Abteilungsname und Manager-ID, sowie dieAnweisungszeichenfolge selbst enthalten sollen. Als Nächstes werdenParameter an den ersten, zweiten und dritten Parameter einer Anweisunggebunden, die mit dem Anweisungs-Handle stmt ausgeführt wird.

SQL-Anweisungen ausführen
296
#defined DEPT_NAME_LEN 20SQLINTEGER cbDeptID = 0, cbDeptName = SQL_NTS, cbManagerID = 0;SQLCHAR deptname[ DEPT_NAME_LEN ];SQLSMALLINT deptID, managerID;SQLCHAR insertstmt[ STMT_LEN ] = "INSERT INTO department " "( dept_id, dept_name, dept_head_id )" "VALUES (?, ?, ?,)";SQLBindParameter( stmt, 1, SQL_PARAM_INPUT, SQL_C_SSHORT, SQL_INTEGER, 0, 0, &deptID, 0, &cbDeptID);SQLBindParameter( stmt, 2, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, DEPT_NAME_LEN, 0, deptname, 0,&cbDeptName);SQLBindParameter( stmt, 3, SQL_PARAM_INPUT, SQL_C_SSHORT, SQL_INTEGER, 0, 0, &managerID, 0, &cbManagerID);
3 Den Parametern Werte zuweisen.
Mit den folgenden Zeilen werden z.B. den Parametern im Fragment vonSchritt 2 Werte zugewiesen.
deptID = 201;strcpy( (char * ) deptname, "Sales East" );managerID = 902;
Im Allgemeinen werden diese Variablen als Reaktion auf eineBenutzerhandlung festgelegt.
4 Führen Sie die Anweisung mit SQLExecDirect aus.
Mit der folgenden Zeile wird z.B. eine Anweisungszeichenfolgeausgeführt, die sich in insertstmt im Anweisungs-Handle stmtbefindet.
SQLExecDirect( stmt, insertstmt, SQL_NTS) ;
Gebundene Parameter werden auch mit vorbereiteten Anweisungenverwendet, um die Performance von Anweisungen zu steigern, die mehr alseinmal ausgeführt werden sollen. Weitere Hinweise finden Sie unter"Vorbereitete Anweisungen ausführen" auf Seite 297.
$ Die obigen Codefragmente enthalten keine Fehlerprüfung. Einvollständiges Beispiel mit Fehlerprüfung finden Sie unterSamples\ASA\ODBCExecute\odbcexecute.cpp.
$ Weitere Hinweise zu SQLExecDirect finden Sie unter SQLExecDirectin der Microsoft-Dokumentation ODBC Programmer’s Reference.

Kapitel 7 ODBC-Programmierung
297
Vorbereitete Anweisungen ausführen
Vorbereitete Anweisungen bieten Performance-Vorteile bei häufig benutztenAnweisungen. ODBC bietet eine vollständige Menge von Funktionen fürvorbereitete Anweisungen.
$ Eine Einführung in vorbereitete Anweisungen finden Sie unter"Anweisungen vorbereiten" auf Seite 12.
v So wird eine vorbereitete Anweisung ausgeführt:
1 Die Anweisung mit SQLPrepare vorbereiten.
Das folgende Codefragment veranschaulicht z.B., wie eine INSERT-Anweisung vorbereitet wird:
SQLRETURN retcode;SQLHSTMT stmt;retcode = SQLPrepare( stmt, "INSERT INTO department ( dept_id, dept_name, dept_head_id ) VALUES (?, ?, ?,)", SQL_NTS);
In diesem Beispiel gilt:
♦ retcode Enthält einen Rückgabecode, der auf Erfolg oderFehlschlag des Vorgangs überprüft werden sollte
♦ stmt Liefert ein Handle zu der Anweisung, sodass sie späterreferenziert werden kann.
♦ ? Die Fragezeichen sind Platzhalter für Anweisungsparameter.
2 Mit SQLBindParameter Anweisungsparameter mit Werten belegen.
Der folgende Funktionsaufruf zum Beispiel belegt den Wert derVariablen dept_id:
SQLBindParameter( stmt, 1, SQL_PARAM_INPUT, SQL_C_SSHORT, SQL_INTEGER, 0, 0, &sDeptID, 0, &cbDeptID);
In diesem Beispiel gilt:
♦ stmt ist das Anweisungs-Handle

SQL-Anweisungen ausführen
298
♦ 1 zeigt an, dass dieser Aufruf den ersten Platzhalter mit einem Wertbelegt.
♦ SQL_PARAM_INPUT zeigt an, dass der Parameter eineEingabeanweisung ist.
♦ SQL_C_SHORT zeigt den C-Datentyp an, der in der Anwendungverwendet wird.
♦ SQL_INTEGER zeigt den SQL-Datentyp an, der in der Datenbankverwendet wird.
♦ Die nächsten beiden Parameter zeigen die Spaltengröße und dieAnzahl der Dezimalstellen an: beide sind mit 0 (Null) fürGanzzahlen belegt.
♦ &sDeptID ist ein Zeiger auf einen Puffer für den Parameterwert.
♦ 0 gibt die Länge des Puffers in Byte an.
♦ &cbDeptID ist ein Zeiger auf einen Puffer für die Länge desParameterwerts.
3 Die beiden anderen Parameter binden und sDeptId Werte zuordnen.
4 Die Anweisung ausführen:
retcode = SQLExecute( stmt);
Schritte 2 bis 4 können mehrfach ausgeführt werden.
5 Anweisung löschen.
Das Löschen der Anweisung setzt die der Anweisung zugewiesenenRessourcen frei. Anweisungen werden mit SQLFreeHandle gelöscht.
$ Ein vollständiges Beispiel mit Fehlerprüfung finden Sie unterSamples\ASA\ODBCPrepare\odbcprepare.cpp.
$ Weitere Hinweise zu SQLPrepare finden Sie unter SQLPrepare in derMicrosoft-Dokumentation ODBC Programmer’s Reference.

Kapitel 7 ODBC-Programmierung
299
Mit Ergebnismengen arbeitenODBC-Anwendungen verwenden Cursor zum Bearbeiten und Aktualisierenvon Ergebnismengen. Adaptive Server Anywhere bietet umfassendeUnterstützung für verschiedene Arten von Cursorn und Cursorvorgängen.
$ Eine Einführung zu Cursorn finden Sie unter "Mit Cursorn arbeiten"auf Seite 20.
Cursor-Eigenschaften wählen
ODBC-Funktionen, die Anweisungen ausführen und Ergebnismengenverarbeiten, verwenden für diese Aufgaben Cursor. Anwendungen öffnenimplizit einen Cursor, wenn sie eine Funktion SQLExecute oderSQLExecDirect ausführen.
Bei Anwendungen, die sich nur vorwärts durch eine Ergebnismengebewegen und sie nicht aktualisieren, ist das Cursor-Verhalten recht einfach.Standardmäßig erwarten ODBC-Anwendungen dieses Verhalten. ODBCdefiniert einen Nur-Lesen-Cursor, der nur vorwärts liest und Adaptive ServerAnywhere liefert einen Cursor, der für diesen Fall auf Performance optimiertist.
$ Ein einfaches Beispiel für einen nur vorwärts lesenden Cursor findenSie unter "Daten abrufen" auf Seite 300.
Bei Anwendungen, die sowohl vorwärts als auch rückwärts durch dieErgebnismenge blättern müssen, wie etwa Anwendungen mit grafischerBenutzeroberfläche, ist das Cursor-Verhalten komplexer. Wie reagiert dieAnwendung, wenn sie eine Zeile zurückgibt, die von einer anderenAnwendung aktualisiert wurde? ODBC definiert eine Reihe vonabrollenden Cursorn, damit Sie das gewünschte Verhalten in IhreAnwendung einbauen können. Adaptive Server Anywhere liefert einevollständige Gruppe von Cursorn, die mit den abrollenden ODBC-Cursortypen übereinstimmen.
Die erforderlichen Cursor-Merkmale werden mit der FunktionSQLSetStmtAttr gesetzt, die die Anweisungsattribute definiert. Sie müssenSQLSetStmtAttr aufrufen, bevor Sie eine Anweisung ausführen, die eineErgebnismenge erzeugt.
Viele Cursor-Merkmale können mit SQLSetStmtAttr festgelegt werden.Folgende Merkmale bestimmen den von Adaptive Server Anywheregelieferten Cursortyp:

Mit Ergebnismengen arbeiten
300
♦ SQL_ATTR_CURSOR_SCROLLABLE Für einen abrollenden Cursorauf SQL_SCROLLABLE setzen und auf SQL_NONSCROLLABLE fürVorwärts-Cursor. SQL_NONSCROLLABLE ist der Standardwert.
♦ SQL_ATTR_CONCURRENCY Auf einen der folgenden Werte setzen:
♦ SQL_CONCUR_READ_ONLY Aktualisierungen deaktivieren.SQL_CONCUR_READ_ONLY ist der Standardwert.
♦ SQL_CONCUR_LOCK Verwenden Sie die niedrigste Sperrstufe,die ausreicht, um eine Zeile zu aktualisieren.
♦ SQL_CONCUR_ROWVER Verwenden Sie optimistischeParallelitätssteuerung, bei der Zeilenversionen verglichen werden,wie z.B. SQLBase ROWID oder Sybase TIMESTAMP.
♦ SQL_CONCUR_VALUES Verwenden Sie optimistischeParallelitätssteuerung, bei der Werte verglichen werden.
$ Weitere Hinweise finden Sie unter SQLSetStmtAttr in der Microsoft-Dokumentation ODBC Programmer’s Reference.
Für das folgende Fragment ist ein abrollender Nur-Lesen-Cursorerforderlich:
SQLAllocHandle( SQL_HANDLE_STMT, dbc, &stmt );SQLSetStmtAttr( stmt, SQL_ATTR_CURSOR_SCROLLABLE,
SQL_SCROLLABLE, 0 );
Daten abrufen
Um Zeilen aus einer Datenbank abzurufen, führen Sie mit SQLExecute oderSQLExecDirect eine SELECT-Anweisung aus. Damit wird ein Cursor fürdie Anweisung geöffnet. Als Nächstes verwenden Sie SQLFetch oderSQLExtendedFetch, damit über den Cursor Zeilen abgerufen werden.Wenn eine Anwendung die Anweisung mit Hilfe von SQLFreeHandlefreigibt, wird der Cursor geschlossen.
Um Werte von einem Cursor abzurufen, kann die Anwendung entwederSQLBindCol oder SQLGetData verwenden. Falls Sie SQLBindColbenutzen, werden die Werte mit jedem Abruf (fetch) abgeholt. Falls SieSQLGetData benutzen, müssen Sie sie für jede Spalte nach jedem Abruf(fetch) aufrufen.
SQLGetData wird benutzt, um Werte in Teilen für Spalten wie LONGVARCHAR oder LONG BINARY einzulesen. Alternativ können Sie dasSQL_MAX_LENGTH-Anweisungsattribut auf einen Wert setzen, der großgenug ist, um den Wert für die gesamte Spalte aufzunehmen. DerStandardwert für SQL_ATTR_MAX_LENGTH ist 256 KByte.
Beispiel

Kapitel 7 ODBC-Programmierung
301
Mit dem folgenden Codefragment wird ein Cursor für eine Abfrage geöffnetund Daten über den Cursor abgerufen. Auf eine Fehlerüberprüfung wurdeverzichtet, um das Beispiel leichter lesbar zu halten. Das Fragment stammtaus dem vollständigen Beispiel Samples\ASA\ODBCSelect\odbcselect.cpp.
SQLINTEGER cbDeptID = 0, cbDeptName = SQL_NTS, cbManagerID = 0;SQLCHAR deptname[ DEPT_NAME_LEN ];SQLSMALLINT deptID, managerID;SQLHENV env;SQLHDBC dbc;SQLHSTMT stmt;SQLRETURN retcode;
SQLAllocHandle( SQL_HANDLE_ENV, SQL_NULL_HANDLE, &env );SQLSetEnvAttr( env, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);SQLAllocHandle( SQL_HANDLE_DBC, env, &dbc );SQLConnect( dbc,
(SQLCHAR*) "ASA 8.0 Sample", SQL_NTS,(SQLCHAR*) "DBA", SQL_NTS,(SQLCHAR*) "SQL", SQL_NTS );
SQLAllocHandle( SQL_HANDLE_STMT, dbc, &stmt );SQLBindCol( stmt, 1, SQL_C_SSHORT, &deptID, 0, &cbDeptID);SQLBindCol( stmt, 2, SQL_C_CHAR, deptname, sizeof(deptname),&cbDeptName);SQLBindCol( stmt, 3, SQL_C_SSHORT, &managerID, 0, &cbManagerID);
SQLExecDirect( stmt, (SQLCHAR * )"SELECT dept_id, dept_name, dept_head_id FROM DEPARTMENT "
"ORDER BY dept_id", SQL_NTS );while( ( retcode = SQLFetch( stmt ) ) != SQL_NO_DATA ){
printf( "%d %20s %d\n", deptID, deptname, managerID );}SQLFreeHandle( SQL_HANDLE_STMT, stmt );SQLDisconnect( dbc );SQLFreeHandle( SQL_HANDLE_DBC, dbc );SQLFreeHandle( SQL_HANDLE_ENV, env );
Die Anzahl der Zeilenpositionen, die Sie mit einem Fetch-Vorgang abrufenkönnen, wird durch die Größe einer Ganzzahl bestimmt. Mit einem Fetch-Vorgang können Sie Zeilen bis zu Nummer 2147483646 abrufen, wobei essich um die größtmögliche Ganzzahl minus 1 handelt. Wenn Sie negativeWerte verwenden (Zeilen in Bezug auf das Ende), können Sie Fetch-Vorgänge nach unten bis zum niedrigsten negativen Wert, der in einerGanzzahl möglich ist, plus 1 ausführen.

Mit Ergebnismengen arbeiten
302
Zeilen über einen Cursor aktualisieren und löschen
Im Dokument "Microsoft ODBC Programmer’s Reference" wird empfohlen,dass Sie SELECT ... FOR UPDATE benutzen, um anzuzeigen, dass eineAbfrage mit positionierten Vorgängen aktualisierbar ist. In Adaptive ServerAnywhere brauchen Sie die Klausel FOR UPDATE nicht zu benutzen:SELECT-Anweisungen können automatisch aktualisiert werden, sofern diefolgenden Bedingungen erfüllt sind:
♦ Die zu Grunde liegende Abfrage unterstützt Aktualisierungen.
Unter der Voraussetzung, dass eine Datenänderungsanweisung für dieSpalten im Ergebnis sinnvoll ist, kann also dieDatenänderungsanweisung im Cursor ausgeführt werden.
Die Datenbankoption ANSI_UPDATE_CONSTRAINTS schränkt denTyp aktualisierbarer Abfragen ein.
$ Weitere Hinweise finden Sie unter"ANSI_UPDATE_CONSTRAINTS" auf Seite 615 der DokumentationASA Datenbankadministration.
♦ Der Cursortyp unterstützt Aktualisierungen.
Wenn Sie einen Nur-Lese-Cursor verwenden, können Sie dieErgebnismenge nicht aktualisieren.
Es gibt in ODBC zwei Alternativen, um positionsbasierte Updates undpositionsbasiertes Löschen durchzuführen.
♦ Die Funktion SQLSetPos.
Abhängig von den angegebenen Parametern (SQL_POSITION,SQL_REFRESH, SQL_UPDATE, SQL_DELETE) legt SQLSetPos dieCursorposition fest und ermöglicht es der Anwendung, die Darstellungder Daten in der Ergebnismenge oder die Daten selbst zu aktualisierenoder die Daten zu löschen.
Diese Methode muss bei Adaptive Server Anywhere angewendetwerden.
♦ Mit Hilfe von SQLExecute positionsbasierte UPDATE- und DELETE-ANWEISUNGEN senden. Diese Methode darf nicht bei AdaptiveServer Anywhere angewendet werden.

Kapitel 7 ODBC-Programmierung
303
Bookmarks verwenden
ODBC bietet Bookmarks, die benutzt werden, um Zeilen in einem Cursor zuidentifizieren. Adaptive Server Anywhere unterstützt Lesezeichen(Bookmarks, Textmarken) für alle Arten von Cursorn, mit Ausnahme vondynamischen Cursorn.
Vor der ODBC-Version 3.0 konnte eine Datenbank nur angeben, ob sieBookmarks unterstützt oder nicht: Es gab keine Schnittstelle, die dieseInformationen für jeden Cursortyp bereitstellte. Der Datenbankserver hattekeine Möglichkeit, anzugeben, welche Typen von Cursor-Bookmarksunterstützt werden. Für ODBC 2-Anwendungen gibt Adaptive ServerAnywhere nur zurück, dass er Bookmarks unterstützt. ODBC wird Sie alsonicht an dem Versuch hindern, Bookmarks mit dynamischen Cursorn zubenutzen; Sie sollten diese Kombination allerdings vermeiden.

Gespeicherte Prozeduren aufrufen
304
Gespeicherte Prozeduren aufrufenIn diesem Abschnitt wird beschrieben, wie gespeicherte Prozedurenaufgerufen und die Ergebnisse in einer ODBC-Anwendung bearbeitetwerden.
$ Eine vollständige Beschreibung von gespeicherten Prozeduren undTriggern finden Sie unter "Prozeduren, Trigger und Anweisungsfolgenverwenden" auf Seite 565 der Dokumentation ASA SQL-Benutzerhandbuch.
Es gibt zwei Arten von Prozeduren: Prozeduren, die Ergebnismengenzurückgeben und solche, die keine zurückgeben. Sie könnenSQLNumResultCols verwenden, um den Unterschied festzustellen: dieAnzahl der Ergebnisspalten ist 0 (Null), falls die Prozedur keineErgebnismenge zurückgibt. Falls eine Ergebnismenge zurückgegeben wird,können Sie die Werte mit SQLFetch oder SQLExtendedFetch abrufen, wiebei jedem anderen Cursor.
Parameter müssen an Prozeduren mit Parametermarkierungen (Fragezeichen)übergeben werden. Verwenden Sie SQLBindParameter, um jederParametermarkierung einen Speicherbereich zuzuweisen: INPUT, OUTPUToder INOUT.
Um mehrfache Ergebnismengen verarbeiten zu können, muss ODBC denaktuell ausgeführten Cursor beschreiben, und nicht die von der Prozedurdefinierte Ergebnismenge. Deshalb bezeichnet ODBC die Spaltennamennicht immer so, wie sie in der RESULT-Klausel der gespeicherten Prozedurdefiniert sind. Um dieses Problem zu vermeiden, können Sie imErgebnismengencursor Ihrer Prozedur einen Spaltenalias verwenden.
Mit diesem Beispiel wird eine Prozedur erstellt und aufgerufen, die keineErgebnismenge zurückgibt. Die Prozedur übernimmt einen INOUT-Parameter und erhöht seinen Wert. Im Beispiel wird die Variable num_colden Wert 0 (Null) haben, denn die Prozedur gibt keine Ergebnismengezurück. Auf eine Fehlerüberprüfung wurde verzichtet, um das Beispielleichter lesbar zu halten.
HDBC dbc;HSTMT stmt;long i;SWORD num_col;
/* Prozedur erstellen */SQLAllocStmt( dbc, &stmt );SQLExecDirect( stmt,
"CREATE PROCEDURE Increment( INOUT a INT )" \" BEGIN" \
" SET a = a + 1" \" END", SQL_NTS );
Prozeduren undErgebnismengen
Beispiel

Kapitel 7 ODBC-Programmierung
305
/* Prozedur zur Erhöhung von 'i' aufrufen */i = 1;SQLBindParameter( stmt, 1, SQL_C_LONG, SQL_INTEGER, 0,
0, &i, NULL );SQLExecDirect( stmt, "CALL Increment( ? )",
SQL_NTS );SQLNumResultCols( stmt, &num_col );do_something( i );
Mit dem folgenden Beispiel wird eine Prozedur aufgerufen, die eineErgebnismenge zurückgibt. Im Beispiel hat die Variable num_col den Wert2, denn die Prozedur gibt eine Ergebnismenge mit zwei Spalten zurück. Aufeine Fehlerüberprüfung wurde auch hier verzichtet, um das Beispiel leichterlesbar zu halten.
HDBC dbc;HSTMT stmt;SWORD num_col;RETCODE retcode;char emp_id[ 10 ];char emp_lame[ 20 ];
/* Prozedur erstellen */SQLExecDirect( stmt,
"CREATE PROCEDURE employees()" \" RESULT( emp_id CHAR(10), emp_lname CHAR(20))"\" BEGIN" \" SELECT emp_id, emp_lame FROM employee" \" END", SQL_NTS );
/* Prozedur aufrufen - Ergebnisse ausgeben */SQLExecDirect( stmt, "CALL employees()", SQL_NTS );SQLNumResultCols( stmt, &num_col );SQLBindCol( stmt, 1, SQL_C_CHAR, &emp_id,
sizeof(emp_id), NULL );SQLBindCol( stmt, 2, SQL_C_CHAR, &emp_lname,
sizeof(emp_lname), NULL );
for( ;; ) {retcode = SQLFetch( stmt );if( retcode == SQL_NO_DATA_FOUND ) {
retcode = SQLMoreResults( stmt );if( retcode == SQL_NO_DATA_FOUND ) break;
} else {do_something( emp_id, emp_lname );
}}
Beispiel

Umgang mit Fehlern
306
Umgang mit FehlernFehler in ODBC werden mit dem Rückgabewert jedes einzelnen ODBC-Funktionsaufrufs und entweder mit der Funktion SQLError oder derFunktion SQLGetDiagRec gemeldet. Die Funktion SQLError wurde inODBC-Versionen bis Version 3 (ausschließlich Version 3) verwendet. AbVersion 3 wird die Funktion SQLError nicht mehr weiter entwickelt unddurch die Funktion SQLGetDiagRec ersetzt.
Jede ODBC-Funktion gibt einen SQLRETURN zurück, der einen derfolgenden Statuscodes annehmen kann:
Statuscode Beschreibung
SQL_SUCCESS Kein Fehler.
SQL_SUCCESS_WITH_INFO Die Funktion wurde vollständig ausgeführt, aberein Aufruf von SQLError zeigt eine Warnung an.
Der häufigste Grund für diesen Status ist, dass einWert zurückgegeben wurde, der für den von derAnwendung zur Verfügung gestellten Puffer zulang ist.
SQL_ERROR Die Funktion wurde wegen eines Fehlers nichtvollständig ausgeführt. Sie können SQLErrorausführen, um mehr Informationen über dasProblem zu erhalten.
SQL_INVALID_HANDLE Ein ungültiger Umgebungs-, Verbindungs- oderStatement-Handle wurden als Argumentübergeben.
Dies passiert häufig, wenn ein Handle benutztwird, nachdem es freigegeben wurde, oder fallsdas Handle ein Null-Zeiger ist.
SQL_NO_DATA_FOUND Keine Hinweise verfügbar.
Der häufigste Grund für diesen Staus ist, dass -beim Abrufen von einem Cursor - keine weiterenZeilen mehr in dem Cursor waren.
SQL_NEED_DATA Für einen Parameter werden Daten benötigt.
Dies ist eine erweiterte Funktion, die in derHilfedatei unter SQLParamData undSQLPutData beschrieben wird.

Kapitel 7 ODBC-Programmierung
307
Mit jeder Umgebung, jeder Verbindung und jedem Statement-Handle könnenein oder mehrere Fehler oder Warnungen verbunden sein. Jeder Aufruf vonSQLError oder SQLGetDiagRec gibt Hinweise für einen Fehler zurückund entfernt die Hinweise über diesen Fehler. Falls Sie SQLError oderSQLGetDiagRec nicht aufrufen, um alle Fehlermeldungen zu entfernen,werden die Fehlermeldungen beim nächsten Funktionsaufruf entfernt, derdas gleiche Handle als Parameter übergibt.
Jeder Aufruf von SQLError kann drei Handles für Umgebung, Verbindungund Anweisung übergeben. Der erste Aufruf benutzt SQL_NULL_HSTMT,um den mit einer Verbindung zusammenhängenden Fehler zu erhalten. Aufdie gleiche Weise gibt ein Aufruf mit SQL_NULL_DBC undSQL_NULL_HSTMT alle mit dem Umgebungshandle zusammenhängendenFehler zurück.
Jeder Aufruf von SQLGetDiagRec kann entweder ein Umgebungs-,Verbindungs- oder Anweisungshandle übergeben. Der erste Aufruf benutztSQL_HANDLE_DBC, um den mit einer Verbindung zusammenhängendenFehler zurückzugeben. Der zweite Aufruf benutzt SQL_HANDLE_STMT,um den mit der soeben ausgeführten Anweisung zusammenhängenden Fehlerzurückzugeben.
SQLError und SQLGetDiagRec geben SQL_SUCCESS zurück, falls einFehler zu melden ist (nicht SQL_ERROR), und SQL_NO_DATA_FOUND,falls keine weiteren Fehler zu melden sind.
Das folgende Programmfragment benutzt SQLError und gibtRückgabecodes zurück:
Beispiel 1

Umgang mit Fehlern
308
/* Erforderliche Variable deklarieren */SQLHDBC dbc;SQLHSTMT stmt;SQLRETURN retcode;UCHAR errmsg[100];/* Hier wurde Code ausgelassen */retcode = SQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt );if( retcode == SQL_ERROR ){
SQLError( env, dbc, SQL_NULL_HSTMT, NULL, NULL,errmsg, sizeof(errmsg), NULL );
/* Annahme: print_error ist definiert.print_error( "Failed SQLAllocStmt", errmsg );return;
}
/* Artikel für Auftrag 2015 löschen */retcode = SQLExecDirect( stmt, "delete from sales_order_items where id=2015", SQL_NTS );if( retcode == SQL_ERROR ) {
SQLError( env, dbc, stmt, NULL, NULL,errmsg, sizeof(errmsg), NULL );
/* Annahme: print_error ist definiert.print_error( "Elemente konnten nicht gelöscht
werden", errmsg );return;
Die Beispiele übergeben den Null-Zeiger für einige der Parameter vonSQLError. Die ODBC-Dokumentation enthält eine vollständigeBeschreibung von SQLError und all seinen Parametern.
Der folgende Auszug aus einem Beispielcode benutzt SQLGetDiagRec undRückgabecodes:
/* Erforderliche Variablen deklarieren */SQLHDBC dbc;SQLHSTMT stmt;SQLRETURN retcode;SQLSMALLINT errmsglen;SQLINTEGER errnative;UCHAR errmsg[255];UCHAR errstate[5];/* Hier wurde Code weggelassen */retcode = SQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt );if( retcode == SQL_ERROR ){ SQLGetDiagRec(SQL_HANDLE_DBC, dbc, 1, errstate, &errnative, errmsg, sizeof(errmsg), &errmsglen); /* Annahme: print_error ist definiert */ print_error( "Allocation failed", errstate,errnative, errmsg ); return;
Beispiel 2

Kapitel 7 ODBC-Programmierung
309
}/* Artikel für Auftrag 2015 löschen */
retcode = SQLExecDirect( stmt, "delete from sales_order_items where id=2015", SQL_NTS );if( retcode == SQL_ERROR ) { SQLGetDiagRec(SQL_HANDLE_STMT, stmt, recnum,errstate, &errnative, errmsg, sizeof(errmsg), &errmsglen); /* Annahme: print_error ist definiert*/ print_error("Failed to delete items", errstate,errnative, errmsg ); return;}

Umgang mit Fehlern
310

311
K A P I T E L 8
Die DBTools-Schnittstelle
In diesem Kapitel wird beschrieben, wie die DBTools-Bibliothek benutztwird, die zum Lieferumfang von Adaptive Server Anywhere gehört und C-oder C++-Anwendungen zusätzlich mit Funktionen derDatenbankverwaltung ausstattet.
Thema Seite
Einführung in die DBTools-Schnittstelle 312
DBTools-Schnittstelle verwenden 314
DBTools-Funktionen 323
DBTools-Strukturen 335
DBTools-Aufzählungstypen 367
Über diesesKapitel
Inhalt

Einführung in die DBTools-Schnittstelle
312
Einführung in die DBTools-SchnittstelleMit dem Sybase Adaptive Server Anywhere wird Sybase Central und eineSerie von Dienstprogrammen mitgeliefert, die für die Verwaltung vonDatenbanken verwendet werden können. Diese Dienstprogramme für dieDatenbankverwaltung übernehmen bestimmte Aufgaben, wie etwa dasSichern und Erstellen von Datenbanken, die Übersetzung vonTransaktionslogs in SQL, usw.
Alle Dienstprogramme für die Datenbankverwaltung benutzen einegemeinsame Bibliothek, die DBTools-Bibliothek. Sie wird für dieBetriebssysteme Windows Windows 95/98 und Windows NT mitgeliefert.Der Name der Bibliothek lautet dbtool8.dll.
Sie können Ihre eigenen Dienstprogramme für die Datenbankverwaltungentwickeln oder Funktionen der Datenbankverwaltung in Ihre Anwendungeneinbauen, indem Sie die DBTools-Bibliothek aufrufen. In diesem Kapitelwird die Schnittstelle zur DBTools-Bibliothek beschrieben. Wenn Sie diesesKapitel lesen, sollten Sie mit der Methode vertraut sein, mit der die vonIhnen benutzte Entwicklungsumgebung DLLs aufruft.
Die DBTools-Bibliothek hat Funktionen oder Eintrittspunkte für jedeseinzelne Dienstprogramm zur Datenbankverwaltung. Außerdem müssenFunktionen vor dem Aufruf anderer DBTools-Funktionen, sowie imAnschluss an die Verwendung anderer DBTools-Funktionen aufgerufenwerden.
Die Bibliothek dbtool8.dll wird für Windows CE geliefert, enthält aber nurProgrammeinstiegspunkte für DBToolsInit, DBToolsFini, DBRemoteSQLund DBSynchronizeLog. Andere Tools werden für Windows CE nichtbereitgestellt.
Die DBTools-Header-Datei, die mit dem Adaptive Server Anywheremitgeliefert wird, enthält eine Liste der Eintrittspunkte zur DBTools-Bibliothek und liefert die Strukturen, die benutzt werden, um Daten an dieBibliothek zu übergeben und von ihr zu beziehen. Die Datei dbtools.h wirdim Unterverzeichnis h im Installationsverzeichnis eingerichtet. In der Dateidbtools.h finden Sie die neuesten Informationen über die Eintrittspunkte unddie Strukturbestandteile.
Die Header-Datei dbtools.H enthält zwei andere Dateien:
♦ sqlca.h Diese Datei ist für die Auflösung diverser Makros, nicht fürSQLCA selbst, vorgesehen.
♦ dllapi.h Diese Datei definiert Präprozessor-Makros fürbetriebssystemabhängige und sprachenabhängige Makros.
UnterstütztePlattformen
Windows CE
Die dbtools.h-Header-Datei

Kapitel 8 Die DBTools-Schnittstelle
313
Die Header-Datei sqldef.h enthält außerdem Fehler-Rückgabewerte.

DBTools-Schnittstelle verwenden
314
DBTools-Schnittstelle verwendenDieser Abschnitt enthält einen Überblick über die Entwicklung vonAnwendungen, die die DBTools-Schnittstelle für die Verwaltung derDatenbanken verwenden.
Importbibliotheken verwenden
Damit die DBTools-Funktionen verwendet werden können, müssen Sie IhreAnwendung mit einer DBTools Importbibliothek verknüpfen, die dieerforderlichen Funktionsdefinitionen enthält.
Importbibliotheken sind Compiler-spezifisch und werden für Windows-Betriebssysteme mit Ausnahme von Windows CE geliefert.Importbibliotheken für die DBTools-Schnittstelle werden mit dem AdaptiveServer Anywhere mitgeliefert und können im Unterverzeichnis lib desjeweiligen Betriebssystemverzeichnisses im Installationsverzeichnisgefunden werden. Folgende DBTools-Importbibliotheken werden geliefert:
Compiler Bibliothek
Watcom win32\dbtlstw.lib
Microsoft win32\dbtlstM.lib
Borland win32\dbtlstB.lib
DBTools-Bibliothek starten und beenden
Bevor Sie andere DBTools-Funktionen verwenden, müssen Sie DBToolsInitaufrufen. Wenn Sie die DBTools DLL nicht mehr verwenden, müssen SieDBToolsFini aufrufen.
Die Funktionen DBToolsInit und DBToolsFini bezwecken hauptsächlich,der DBTools-DLL das Laden der Adaptive Server Anywhere Sprachen-DLLzu ermöglichen. Die Sprachen-DLL enthält lokalisierte Versionen allerFehlermeldungen und Bedieneraufforderungen, die DBTools internverwendet. Wenn DBToolsFini nicht aufgerufen wird, kann dieReferenznummer der Sprachen-DLL nicht heruntergezählt werden, sodassdiese DLL nicht entladen wird. Achten Sie daher immer darauf, dass zujedem Aufruf von DBToolsInit als Gegenstück DBToolsFini aufgerufenwird.
UnterstütztePlattformen

Kapitel 8 Die DBTools-Schnittstelle
315
Im folgenden Programmcodebeispiel wird gezeigt, wie DBTools aufgerufenund wieder bereinigt werden:
// Deklarationena_dbtools_info info;short ret;
//Initialisierung der a_dbtools_info-Strukturmemset( &info, 0, sizeof( a_dbtools_info) );info.errorrtn = (MSG_CALLBACK)MyErrorRtn;
// Initialisierung von DBToolsret = DBToolsInit( &info );if( ret != EXIT_OKAY ) {
// DLL-Initialisierung fehlgeschlagen…
}// einige DBTools-Routinen aufrufen. . .…// DBTools dll bereinigenDBToolsFini( &info );
DBTools-Funktionen aufrufen
Alle Tools werden aufgerufen, indem erst eine Struktur ausgefüllt und danneine Funktion (oder ein Eintrittspunkt) in der DBTools-DLL aufgerufenwird. Jeder Eintrittspunkt nimmt einen Zeiger zu einer bestimmten Strukturals Argument.
Im folgenden Beispiel wird gezeigt, wie die DBBackup-Funktion untereinem Windows-Betriebssystem verwendet wird.
// Initialisierung der Struktura_backup_db backup_info;memset( &backup_info, 0, sizeof( backup_info ) );
// Struktur ausfüllenbackup_info.version = DB_TOOLS_VERSION_NUMBER;backup_info.output_dir = "C:\BACKUP";backup_info.connectparms="uid=DBA;pwd=SQL;dbf=asademo.db";backup_info.startline = "dbeng8.EXE";backup_info.confirmrtn = (MSG_CALLBACK) ConfirmRtn ;backup_info.errorrtn = (MSG_CALLBACK) ErrorRtn ;backup_info.msgrtn = (MSG_CALLBACK) MessageRtn ;backup_info.statusrtn = (MSG_CALLBACK) StatusRtn ;backup_info.backup_database = TRUE;
// Sicherung startenDBBackup( &backup_info );

DBTools-Schnittstelle verwenden
316
$ Hinweise zu den Bestandteilen der DBTools-Strukturen finden Sieunter "DBTools-Strukturen" auf Seite 335.
Rückgabecodes der Softwarekomponenten
Alle Datenbanktools werden als Eintrittspunkt in einer DLL geliefert. DieseEintrittspunkte verwenden die folgenden Rückgabecodes:
Programmcode
Erklärung
0 Erfolg
1 Allgemeiner Ausfall
2 Ungültiges Dateiformat
3 Datei nicht gefunden, kann nicht geöffnet werden
4 Kein Speicher mehr
5 Beendet vom Benutzer
6 Fehlgeschlagene Kommunikationen
7 Erforderlicher Datenbankname fehlt
8 Falsches Client/Server-Protokoll
9 Keine Verbindung mit dem Datenbankserver möglich
10 Datenbankserver läuft nicht
11 Datenbankserver nicht gefunden
254 Stoppzeit erreicht
255 Ungültige Parameter in der Befehlszeile
Callback-Funktionen verwenden
Einige Elemente in der DBTools-Struktur sind vom TypMSG_CALLBACK. Es handelt sich dabei um Zeiger auf Callback-Funktionen.
Mit Callback-Funktionen können DBTools-Funktionen die Kontrolle derVerarbeitung an die aufrufende Anwendung des Benutzers zurückgeben. DieDBTools-Bibliothek benutzt Callback-Funktionen zur Verarbeitung vonNachrichten, die von den DBTools-Funktionen an den Benutzer gesandtwerden, für vier Zwecke:
Nutzung derCallback-Funktionen

Kapitel 8 Die DBTools-Schnittstelle
317
♦ Bestätigung Wird aufgerufen, wenn eine Aktion vom Benutzer bestätigtwerden muss. Falls zum Beispiel das Sicherungsverzeichnis nichtvorhanden ist, fragt die Tools-DLL, ob es erzeugt werden soll.
♦ Fehlermeldung Wird aufgerufen, um eine Nachricht zu bearbeiten,wenn ein Fehler auftritt, zum Beispiel, wenn ein Vorgang nichtgenügend Speicherplatz hat
♦ Informationsnachricht Wird aufgerufen, um den Benutzer zuinformieren, wie zum Beispiel eine Nachricht mit den Namen derTabelle, die gerade gesichert wird
♦ Statusinformation Wird aufgerufen, um den Status eines Vorgangsanzuzeigen, wie zum Beispiel, wie viel Prozent einer Tabelle entladensind
Sie können der Struktur direkt eine Callback-Routine zuordnen. Die folgendeAnweisung ist ein Beispiel für die Verwendung einer Sicherungsstruktur:
backup_info.errorrtn = (MSG_CALLBACK) MyFunction
MSG_CALLBACK ist in der Header-Datei dllapi.h definiert, die imAdaptive Server Anywhere enthalten ist. Tools-Routinen könnenNachrichten in die aufrufende Anwendung übergeben, die dann in derpassenden Benutzeroberfläche dargestellt werden sollten; das kann eineFensterumgebung sein, die Standardausgabe eines zeichenbasierten Systemsoder andere Benutzeroberflächen.
Im folgenden Beispiel fragt eine Routine den Benutzer nach einerBestätigung mit YES oder NO und gibt die Antwort des Benutzers zurück:
extern short _callback ConfirmRtn(char far * question )
{int ret;if( question != NULL ) {
ret = MessageBox( HwndParent, question,"Confirm", MB_ICONEXCLAMTION|MB_YESNO );
}return( 0 );
}
Im folgenden Beispiel zeigt eine Routine zur Behandlung einerFehlermeldung die Fehlermeldung in einer Meldungsbox an.
extern short _callback ErrorRtn(char far * errorstr )
{if( errorstr != NULL ) {
ret = MessageBox( HwndParent, errorstr,"Backup Error", MB_ICONSTOP|MB_OK );
}
Callback-Funktioneiner Strukturzuordnen
Beispiel für eineCallback-Funktionmit Bestätigung
Beispiel für eineCallback-Funktionmit Fehlermeldung

DBTools-Schnittstelle verwenden
318
return( 0 );}
Eine typische Implementierung einer Callback-Funktion, die eine Nachrichtam Bildschirm ausgibt:
extern short _callback MessageRtn(char far * errorstr )
{if( messagestr != NULL ) {OutputMessageToWindow( messagestr );}return( 0 );
}
Eine Status-Callback-Routine wird aufgerufen, wenn die Tools den Statuseines Vorgangs anzeigen müssen (zum Beispiel wie viel Prozent einerTabelle entladen sind). Im folgenden Beispiel sehen Sie eine typischeImplementierung, die lediglich die Nachricht am Bildschirm ausgibt:
extern short _callback StatusRtn(char far * statusstr )
{if( statusstr == NULL ) {
return FALSE;}OutputMessageToWindow( statustr );return TRUE;
}
Versionsnummern und Kompatibilität
Jede Struktur enthält ein Element, das die Versionsnummer angibt. Siesollten dieses Versionselement benutzen, um die Version der DBTools-Bibliothek zu speichern, für die Ihre Anwendung entwickelt wurde. Dieaktuelle Version der DBTools-Bibliothek ist als Konstante in der Header-Datei dbtools.h enthalten.
v Um einer Struktur die aktuelle Versionsnummer zuzuordnen, gehenSie wie folgt vor:
♦ Ordnen Sie die Versionskonstante dem Versionselement der Struktur zu,bevor Sie die DBTools-Funktion aufrufen. Die folgende Zeile ordnet dieaktuelle Version einer Sicherungsstruktur zu:
backup_info.version = DB_TOOLS_VERSION_NUMBER;
Beispiel für eineCallback-Funktionmit Nachricht
Beispiel für eineCallback-Funktionmit Statusmeldung

Kapitel 8 Die DBTools-Schnittstelle
319
Die Versionsnummer ermöglicht es der Anwendung, auch in Zukunft mitneueren Versionen der DBTools-Bibliothek weiterzuarbeiten. Die DBTools-Funktionen sorgen mit Hilfe der Versionsnummern, die von IhrerAnwendung zur Verfügung gestellt werden, dafür, dass Ihre Anwendungauch dann weiterarbeiten kann, wenn neue Elemente zur DBTools-Strukturhinzugefügt wurden.
Anwendungen arbeiten nicht mit älteren Versionen der DBTools-Bibliothekzusammen.
Bit-Felder benutzen
Viele DBTools-Strukturen benutzen Bit-Felder, um Boolesche Informationenkompakt zu speichern. Die Sicherungsstruktur zum Beispiel hat folgendeBit-Felder:
a_bit_field backup_database : 1;a_bit_field backup_logfile : 1;a_bit_field backup_writefile: 1;a_bit_field no_confirm : 1;a_bit_field quiet : 1;a_bit_field rename_log : 1;a_bit_field truncate_log : 1;a_bit_field rename_local_log: 1;
Jedes Bit-Feld ist ein Bit lang, angezeigt durch eine 1 rechts neben demDoppelpunkt in der Strukturdeklaration. Der hier verwendete Datentyp hängtvom Wert ab, der am Anfang von dbtools.h a_bit_field zugeordnet wurde,und ist abhängig vom Betriebssystem.
Sie ordnen dem Bit-Feld einen Wert von 0 (Null) oder 1 zu, um einenBooleschen Wert an die Struktur zu übergeben.
Ein Beispiel für DBTools
Dieses Beispiel sowie Hinweise zum Kompilieren finden Sie imUnterverzeichnis Samples\ASA\DBTools Ihres SQL Anywhere-Verzeichnisses. Das Beispielprogramm selbst istSamples\ASA\DBTools\main.c. Das Beispiel veranschaulicht, wie dieDBTools-Bibliothek zum Sichern der Datenbank eingesetzt werden kann.
# define WINNT
Kompatibilität

DBTools-Schnittstelle verwenden
320
#include <stdio.h>#include "windows.h"#include "string.h"#include "dbtools.h"
extern short _callback ConfirmCallBack(char far * str){if( MessageBox( NULL, str, "Backup",
MB_YESNO|MB_ICONQUESTION ) == IDYES ) {return 1;
}return 0;
}
extern short _callback MessageCallBack( char far * str){if( str != NULL ) {
fprintf( stdout, "%s", str );fprintf( stdout, "\n" );fflush( stdout );
}return 0;
}
extern short _callback StatusCallBack( char far * str ){if( str != NULL ) {
fprintf( stdout, "%s", str );fprintf( stdout, "\n" );fflush( stdout );
}return 0;
}
extern short _callback ErrorCallBack( char far * str ){if( str != NULL ) {
fprintf( stdout, "%s", str );fprintf( stdout, "\n" );fflush( stdout );
}return 0;
}
// Haupteintrittspunkt in das Programm.int main( int argc, char * argv[] ){
a_backup_db backup_info;a_dbtools_info dbtinfo;char dir_name[ _MAX_PATH + 1];char connect[ 256 ];HINSTANCE hinst;FARPROC dbbackup;FARPROC dbtoolsinit;FARPROC dbtoolsfini;

Kapitel 8 Die DBTools-Schnittstelle
321
// Immer mit 0 initialisieren, sodass neue Versionen// der Struktur kompatibel sind.memset( &backup_info, 0, sizeof( a_backup_db ) );backup_info.version = DB_TOOLS_VERSION_8_0_00;backup_info.quiet = 0;backup_info.no_confirm = 0;backup_info.confirmrtn =
(MSG_CALLBACK)ConfirmCallBack;backup_info.errorrtn = (MSG_CALLBACK)ErrorCallBack;backup_info.msgrtn = (MSG_CALLBACK)MessageCallBack;backup_info.statusrtn = (MSG_CALLBACK)StatusCallBack;
if( argc > 1 ) {strncpy( dir_name, argv[1], _MAX_PATH );
} else {// DBTools erwartet nicht den// nachgestellten Schraegstrichstrcpy( dir_name, "c:\\temp" );
}backup_info.output_dir = dir_name;
if( argc > 2 ) {strncpy( connect, argv[2], 255 );
} else {// Annahme: die Engine läuft bereits.strcpy( connect, "DSN=ASA 8.0 Sample" );
}backup_info.connectparms = connect;backup_info.startline = "";backup_info.quiet = 0;backup_info.no_confirm = 0;backup_info.backup_database = 1;backup_info.backup_logfile = 1;backup_info.backup_writefile = 1;backup_info.rename_log = 0;backup_info.truncate_log = 0;
hinst = LoadLibrary( "dbtool8.dll" );if( hinst == NULL ) {
// Fehlgeschlagenreturn 0;
}

DBTools-Schnittstelle verwenden
322
dbtinfo.errorrtn = (MSG_CALLBACK)ErrorCallBack;dbbackup = GetProcAddress( (HMODULE)hinst,
"_DBBackup@4" );dbtoolsinit = GetProcAddress( (HMODULE)hinst,
"_DBToolsInit@4" );dbtoolsfini = GetProcAddress( (HMODULE)hinst,
"_DBToolsFini@4" );(*dbtoolsinit)( &dbtinfo );(*dbbackup)( &backup_info );(*dbtoolsfini)( &dbtinfo );FreeLibrary( hinst );return 0;
}

Kapitel 8 Die DBTools-Schnittstelle
323
DBTools-FunktionenDieser Abschnitt beschreibt die Funktionen in der DBTools-Bibliothek. DieFunktionen sind alphabetisch aufgelistet.
DBBackup-Funktion
Datenbanksicherungs-Funktion. Diese Funktion wird von dem Befehlszeilen-Dienstprogramm dbbackup benutzt.
short DBBackup ( const a_backup_db * Sicherungsdatenbank );
Parameter Beschreibung
Sicherungs-datenbank
Zeiger auf eine "a_backup_db-Struktur" auf Seite 335
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
Die Funktion DBBackup verwaltet alle Datenbanksicherungs-Aufgaben.
$ Die Beschreibung dieser Aufgaben finden Sie unter "DasSicherungsdienstprogramm" auf Seite 484 der Dokumentation ASADatenbankadministration.
"a_backup_db-Struktur" auf Seite 335
DBChangeLogName-Funktion
Ändert den Namen der Transaktionslogdatei. Diese Funktion wird von demBefehlszeilen-Dienstprogramm dblog benutzt.
short DBChangeLogName ( const a_change_log * Änderungslog );
Parameter Beschreibung
Änderungslog Zeiger auf eine "a_change_log-Struktur" auf Seite 337
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
Die Option -t des Dienstprogramms dblog ändert den Namen desTransaktionslogs. DBChangeLogName liefert eine Programmierschnittstellezu dieser Funktion.
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung

DBTools-Funktionen
324
$ Eine Beschreibung des Dienstprogramms dblog finden Sie unter "DasTransaktionslog-Dienstprogramm" auf Seite 564 der Dokumentation ASADatenbankadministration.
"a_change_log-Struktur" auf Seite 337
DBChangeWriteFile-Funktion
Ändert eine Write-Datei, sodass sie auf eine andere Datenbankdatei zugreift.Diese Funktion wird von dem Dienstprogramm dbwrite benutzt, wenn dieOption -d angewendet wird.
short DBChangeWriteFile ( const a_writefile * Write-Datei );
Parameter Beschreibung
Write-Datei Zeiger auf eine "a_writefile-Struktur" auf Seite 364
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Write-Datei-Dienstprogramm und seineEigenschaften finden Sie unter "Das Write-Datei-Dienstprogramm" aufSeite 592 der Dokumentation ASA Datenbankadministration.
"DBCreateWriteFile-Funktion" auf Seite 326"DBStatusWriteFile-Funktion" auf Seite 329"a_writefile-Struktur" auf Seite 364
DBCollate-Funktion
Extrahiert eine Kollatierungssequenz aus einer Datenbank.
short DBCollate ( const a_db_collation * DB-Kollatierung );
Parameter Beschreibung
DB-Kollatierung Zeiger auf eine "a_db_collation-Struktur" auf Seite 344
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Kollatierungs-Dienstprogramm und seineEigenschaften finden Sie unter "Das Kollatierungs-Dienstprogramm" aufSeite 489 der Dokumentation ASA Datenbankadministration
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung

Kapitel 8 Die DBTools-Schnittstelle
325
"a_db_collation-Struktur" auf Seite 344
DBCompress-Funktion
Komprimiert eine Datenbankdatei. Diese Funktion wird von demDienstprogramm dbshrink benutzt.
short DBCompress ( const a_compress_db * Komprimierte_DB );
Parameter Beschreibung
Kompri-mierte_DB
Zeiger auf eine "a_compress_db-Struktur" auf Seite 339
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Komprimierungs-Dienstprogramm und seineEigenschaften finden Sie unter "Das Komprimierungs-Dienstprogramm" aufSeite 495 der Dokumentation ASA Datenbankadministration.
"a_compress_db-Struktur" auf Seite 339
DBCreate-Funktion
Erstellt eine Datenbank. Diese Funktion wird von dem Dienstprogrammdbinit benutzt.
short DBCreate ( const a_create_db * Erstellte_DB );
Parameter Beschreibung
Erstellte_DB Zeiger auf eine "a_create_db-Struktur" auf Seite 341
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Initialisierungsdienstprogramm finden Sie unter"Das Initialisierungs-Dienstprogramm" auf Seite 515 der DokumentationASA Datenbankadministration.
"a_create_db-Struktur" auf Seite 341
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch

DBTools-Funktionen
326
DBCreateWriteFile-Funktion
Erstellt eine Write-Datei. Diese Funktion wird von dem Dienstprogrammdbwrite benutzt, wenn die Option -c angewendet wird.
short DBCreateWriteFile ( const a_writefile * Write-Datei );
Parameter Beschreibung
Write-Datei Zeiger auf eine "a_writefile-Struktur" auf Seite 364
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Write-Datei-Dienstprogramm und seineEigenschaften finden Sie unter "Das Write-Datei-Dienstprogramm" aufSeite 592 der Dokumentation ASA Datenbankadministration.
"DBChangeWriteFile-Funktion" auf Seite 324"DBStatusWriteFile-Funktion" auf Seite 329"a_writefile-Struktur" auf Seite 364
DBCrypt-Funktion
Dient zum Verschlüsseln einer Datenbankdatei. Diese Funktion wird vondem Dienstprogramm dbinit benutzt, wenn die Option -e angewendet wird.
short DBCrypt ( const a_crypt_db * Verschlüsselte_DB );
Parameter Beschreibung
Verschlüs-selte_DB
Zeiger auf eine "a_crypt_db-Struktur" auf Seite 343
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Weitere Hinweise zum Verschlüsseln von Datenbanken finden Sieunter "Datenbank mit dem Befehlszeilenprogramm ""dbinit"" erstellen" aufSeite 516 der Dokumentation ASA Datenbankadministration.
"a_crypt_db-Struktur" auf Seite 343
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
327
DBErase-Funktion
Löscht eine Datenbankdatei und/oder ein Transaktionslog. Diese Funktionwird von dem Dienstprogramm dberase benutzt.
short DBErase ( const an_erase_db * Zu_löschende_DB );
Parameter Beschreibung
Zu_löschen-de_DB
Zeiger auf eine "an_erase_db-Struktur" auf Seite 349
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Lösch-Dienstprogramm und seineEigenschaften finden Sie unter "Das Dienstprogramm zum Löschen derDatenbank" auf Seite 508 der Dokumentation ASA Datenbankadministration.
"an_erase_db-Struktur" auf Seite 349
DBExpand-Funktion
Dekomprimiert eine Datenbankdatei. Diese Funktion wird von demDienstprogramm dbexpand benutzt.
short DBExpand ( const an_expand_db * Zu_expandierende_DB );
Parameter Beschreibung
Zu_expan-dierende_DB
Zeiger auf eine "an_expand_db-Struktur" auf Seite 350
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Dekomprimierungs-Dienstprogramm und seineEigenschaften finden Sie unter "Das Dekomprimierungs-Dienstprogramm"auf Seite 569 der Dokumentation ASA Datenbankadministration.
"an_expand_db-Struktur" auf Seite 350
DBInfo-Funktion
Gibt Informationen über eine Datenbankdatei zurück. Diese Funktion wirdvon dem Dienstprogramm dbinfo benutzt.
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion

DBTools-Funktionen
328
short DBInfo ( const a_db_info * DB-Info );
Parameter Beschreibung
DB-Info Zeiger auf eine "a_db_info-Struktur" auf Seite 345
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Informations-Dienstprogramm und seineEigenschaften finden Sie unter "Das Informations-Dienstprogramm" aufSeite 513 der Dokumentation ASA Datenbankadministration.
"DBInfoDump-Funktion" auf Seite 328"DBInfoFree-Funktion" auf Seite 328"a_db_info-Struktur" auf Seite 345
DBInfoDump-Funktion
Gibt Informationen über eine Datenbankdatei zurück. Diese Funktion wirdvon dem Dienstprogramm dbinfo benutzt, wenn die Option -u angewendetwird.
short DBInfoDump ( const a_db_info * DB-Info );
Parameter Beschreibung
DB-Info Zeiger auf eine "a_db_info-Struktur" auf Seite 345
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Informations-Dienstprogramm und seineEigenschaften finden Sie unter "Das Informations-Dienstprogramm" aufSeite 513 der Dokumentation ASA Datenbankadministration.
"DBInfo-Funktion" auf Seite 327"DBInfoFree-Funktion" auf Seite 328"a_db_info-Struktur" auf Seite 345
DBInfoFree-Funktion
Wird aufgerufen, um nach dem Aufruf der Funktion DBInfoDumpRessourcen freizugeben.
short DBInfoFree ( const a_db_info * DB-Info );
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp

Kapitel 8 Die DBTools-Schnittstelle
329
Parameter Beschreibung
DB-Info Zeiger auf eine "a_db_info-Struktur" auf Seite 345
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Informations-Dienstprogramm und seineEigenschaften finden Sie unter "Das Informations-Dienstprogramm" aufSeite 513 der Dokumentation ASA Datenbankadministration.
"DBInfo-Funktion" auf Seite 327"DBInfoDump-Funktion" auf Seite 328"a_db_info-Struktur" auf Seite 345
DBLicense-Funktion
Wird aufgerufen, um die Lizenzdaten des Datenbankservers zu ändern odermitzuteilen.
short DBLicense ( const a_db_lic_info * DB-Liz.-Info );
Parameter Beschreibung
DB-Liz.-Info Zeiger auf eine "a_dblic_info-Struktur" auf Seite 348
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Informations-Dienstprogramm und seineEigenschaften finden Sie unter "Das Informations-Dienstprogramm" aufSeite 513 der Dokumentation ASA Datenbankadministration.
"a_dblic_info-Struktur" auf Seite 348
DBStatusWriteFile-Funktion
Ruft den Status einer Write-Datei ab. Diese Funktion wird von demDienstprogramm dbwrite benutzt, wenn die Option -s angewendet wird.
short DBStatusWriteFile ( const a_writefile * Write-Datei );
Parameter Beschreibung
Write-Datei Zeiger auf eine "a_writefile-Struktur" auf Seite 364
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter

DBTools-Funktionen
330
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Write-Datei-Dienstprogramm und seineEigenschaften finden Sie unter "Das Write-Datei-Dienstprogramm" aufSeite 592 der Dokumentation ASA Datenbankadministration.
"DBChangeWriteFile-Funktion" auf Seite 324"DBCreateWriteFile-Funktion" auf Seite 326"a_writefile-Struktur" auf Seite 364
DBSynchronizeLog-Funktion
Synchronisiert eine Datenbank mit einem MobiLink Synchronisationsserver.
short DBSynchronizeLog( const a _sync_db * Synchronisierte_DB );
Parameter Beschreibung
Synchroni-sierte_DB
Zeiger auf eine "a_sync_db-Struktur" auf Seite 352
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Weitere Informationen über diese Features finden Sie unter"Synchronisation einleiten" auf Seite 149 der Dokumentation MobiLinkBenutzerhandbuch.
DBToolsFini-Funktion
Vermindert den Zähler und gibt Ressourcen frei, nachdem eine Anwendungdie DBTools-Bibliothek nicht mehr benötigt.
short DBToolsFini ( const a_dbtools_info * DBTools-Info );
Parameter Beschreibung
DBTools-Info Zeiger auf eine "a_dbtools_info-Struktur" auf Seite 349
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
Die Funktion DBToolsFini muss am Ende jeder Anwendung aufgerufenwerden, die die DBTools-Schnittstelle benutzt. Falls diese Funktion nichtaufgerufen wird, kann das zum Verlust von Speicherressourcen führen.
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung

Kapitel 8 Die DBTools-Schnittstelle
331
"DBToolsInit-Funktion" auf Seite 331"a_dbtools_info-Struktur" auf Seite 349
DBToolsInit-Funktion
Bereitet die DBTools-Bibliothek für die Benutzung vor.
short DBToolsInit t( const a_dbtools_info * DBTools-Info );
Parameter Beschreibung
DBTools-Info Zeiger auf eine "a_dbtools_info-Struktur" auf Seite 349
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
Der hauptsächliche Zweck der Funktion DBToolsInit ist es, die Sprach-DLLvon Adaptive Server Anywhere zu laden. Die Sprach-DLL enthält lokaleVersionen der Fehlermeldungen und Bedieneraufforderungen, die DBToolsintern verwendet.
Die Funktion DBToolsInit muss zu Beginn jeder Anwendung aufgerufenwerden, die die DBTools-Schnittstelle benutzt, bevor irgend eine andereDBTools-Funktion benutzt wird.
♦ Das folgende Code-Beispiel zeigt, wie man DBTools initialisiert undordnungsgemäß beendet:
a_dbtools_info info;short ret;
memset( &info, 0, sizeof( a_dbtools_info) );info.errorrtn = (MSG_CALLBACK)MakeProcInstance(
(FARPROC)MyErrorRtn, hInst );
// Initialisierung von DBToolsret = DBToolsInit( &info );if( ret != EXIT_OKAY ) {
// DLL-Initialisierung fehlgeschlagen…
}// einige DBTools-Routinen aufrufen. . .…// DBTools dll bereinigenDBToolsFini( &info );
"DBToolsFini-Funktion" auf Seite 330"a_dbtools_info-Struktur" auf Seite 349
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Beispiel
Siehe auch

DBTools-Funktionen
332
DBToolsVersion-Funktion
Gibt die Versionsnummer der DBTools-Bibliothek zurück.
short DBToolsVersion ( void );
Eine Ganzzahl (short integer), die die Versionsnummer der DBTools-Bibliothek angibt
Verwenden Sie die Funktion DBToolsVersion, um zu überprüfen, dass dieDBTools-Bibliothek nicht älter ist als diejenige, mit der Ihre Anwendungentwickelt wurde. Anwendungen können mit neueren Versionen vonDBTools laufen, nicht aber mit älteren Versionen.
"Versionsnummern und Kompatibilität" auf Seite 318
DBTranslateLog-Funktion
Übersetzt eine Transaktionslogdatei in SQL. Diese Funktion wird von demDienstprogramm dbtran benutzt.
short DBTranslateLog ( const a_translate_log * Zu_übersetzendes_Log );
Parameter Beschreibung
Zu_überset-zendes_Log
Zeiger auf eine "a_translate_log-Struktur" auf Seite 357
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Logkonvertierungs-Dienstprogramm finden Sieunter "Das Logkonvertierungs-Dienstprogramm" auf Seite 543 derDokumentation ASA Datenbankadministration.
"a_translate_log-Struktur" auf Seite 357
DBTruncateLog-Funktion
Kürzt eine Transaktionslogdatei. Diese Funktion wird von demDienstprogramm dbbackup benutzt.
short DBTruncateLog ( const a_truncate_log * Zu_kürzendes_Log );
Parameter Beschreibung
Zu_kürzen-des_Log
Zeiger auf eine "a_truncate_log-Struktur" auf Seite 358
Funktion
Prototyp
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter

Kapitel 8 Die DBTools-Schnittstelle
333
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Sicherungsdienstprogramm finden Sie unter"Das Sicherungsdienstprogramm" auf Seite 484 der Dokumentation ASADatenbankadministration
"a_truncate_log-Struktur" auf Seite 358
DBUnload-Funktion
Entlädt eine Datenbank. Diese Funktion wird von dem Dienstprogrammdbunload wie auch von dem Dienstprogramm dbxtract für SQL Remotebenutzt.
short DBUnload ( const an_unload_db * Zu_entladende_DB );
Parameter Beschreibung
Zu_entla-dende_DB
Zeiger auf eine "an_unload_db-Struktur" auf Seite 359
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Entladungs-Dienstprogramm finden Sie unter"Das Dienstprogramm UNLOAD zum Entladen der Datenbank" aufSeite 572 der Dokumentation ASA Datenbankadministration.
"an_unload_db-Struktur" auf Seite 359
DBUpgrade-Funktion
Installiert ein Upgrade für eine Datenbankdatei. Diese Funktion wird vondem Dienstprogramm dbupgrade benutzt.
short DBUpgrade ( const an_upgrade_db * DB_für_Upgrade );
Parameter Beschreibung
DB_für_Upgrade Zeiger auf eine "an_upgrade_db-Struktur" auf Seite 361
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert

DBTools-Funktionen
334
$ Informationen über das Upgrade-Dienstprogramm finden Sie unter"Das Upgrade-Dienstprogramm" auf Seite 582 der Dokumentation ASADatenbankadministration.
"an_upgrade_db-Struktur" auf Seite 361
DBValidate-Funktion
Validiert eine Datenbank oder Teile einer Datenbank. Diese Funktion wirdvon dem Dienstprogramm dbvalid benutzt.
short DBValidate ( const a_validate_db * Zu_validierende_DB );
Parameter Beschreibung
Zu_vali-dierende_DB
Zeiger auf eine "a_validate_db-Struktur" auf Seite 363
Ein Rückgabecode wie in "Rückgabecodes der Softwarekomponenten" aufSeite 316 beschrieben.
$ Informationen über das Validierungs-Dienstprogramm finden Sie unter"Das Validierungs-Dienstprogramm" auf Seite 588 der Dokumentation ASADatenbankadministration.
"a_validate_db-Struktur" auf Seite 363
Anwendung
Siehe auch
Funktion
Prototyp
Parameter
Rückgabewert
Anwendung
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
335
DBTools-StrukturenIn diesem Abschnitt sind die Strukturen aufgeführt, mit deren HilfeInformationen mit der DBTools-Bibliothek ausgetauscht werden. DieStrukturen sind alphabetisch aufgeführt.
Viele der Strukturelemente entsprechen Befehlszeilenoptionen desentsprechenden Dienstprogramms. Einige Strukturen zum Beispiel haben einElement namens "quiet", das mit den Werten 0 oder 1 belegt sein kann.Dieses Element entspricht der Befehlszeilenoption (-q) des Vorgangs"quiet", der von vielen Dienstprogrammen benutzt wird.
a_backup_db-Struktur
Enthält die Informationen, die gebraucht werden, um Sicherungsaufgabenmit der DBTools-Bibliothek auszuführen.
typedef struct a_backup_db {unsigned short version;const char * output_dir;const char * connectparms;const char * startline;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field backup_database: 1;a_bit_field backup_logfile : 1;a_bit_field backup_writefile : 1;a_bit_field no_confirm : 1;a_bit_field quiet : 1;a_bit_field rename_log : 1;a_bit_field truncate_log : 1;a_bit_field rename_local_log: 1;const char * hotlog_filename;char backup_interrupted;} a_backup_db;
Funktion
Syntax

DBTools-Strukturen
336
Mitglied Beschreibung
Version DBTools-Versionsnummer
output_dir Suchpfad des Ausgabeverzeichnisses. Zum Beispiel:
"c:\backup"
connectparms Parameter für die Verbindung zur Datenbank. Sie habendie Form von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\asa\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sieunter "Verbindungsparameter" auf Seite 78 derDokumentation ASA Datenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Dasfolgende Beispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
confirmrtn Callback-Routine für die Bestätigung einer Aktion
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einer Statusmeldung
backup_database Datenbankdatei sichern (1) oder nicht (0)
backup_logfile Transaktionslogdatei sichern (1) oder nicht (0)
backup_writefile Datenbank-Write-Datei sichern (1) oder nicht (0), fallseine Datenbank-Write-Datei benutzt wird
no_confirm Mit (0) oder ohne (1) Bestätigung arbeiten
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
rename_log Transaktionslog umbenennen
truncate_log Transaktionslog löschen
rename_local_log Lokale Sicherung des Transaktionslogs umbenennen
hotlog_filename Dateiname für die gerade benutzte Sicherungsdatei
backup_interrupted Gibt an, dass der Vorgang unterbrochen wurde
"DBBackup-Funktion" auf Seite 323$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
Parameter
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
337
a_change_log-Struktur
Enthält die Informationen, die gebraucht werden, um dblog-Aufgaben mitder DBTools-Bibliothek auszuführen.
typedef struct a_change_log {unsigned short version;const char * dbname;const char * logname;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;a_bit_field query_only : 1;a_bit_field quiet : 1;a_bit_field mirrorname_present : 1;a_bit_field change_mirrorname : 1;a_bit_field change_logname : 1;a_bit_field ignore_ltm_trunc : 1;a_bit_field ignore_remote_trunc : 1;a_bit_field set_generation_number : 1;a_bit_field ignore_dbsync_trunc : 1;const char * mirrorname;unsigned short generation_number;const char * key_file;char * zap_current_offset;char * sap_starting_offset;char * encryption_key;} a_change_log;
Mitglied Beschreibung
version DBTools-Versionsnummer
dbname Datenbankdateiname
logname Name der Transaktionslogdatei. Wenn dieser Wertgleich NULL gesetzt wird, gibt es kein Log
errorrtn Callback-Routine für die Behandlung einerFehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
query_only Name des Transaktionslogs anzeigen. 0: Änderung desLognamens erlauben
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
mirrorname_present Auf 1 setzen; zeigt an, dass die DBTools-Version neugenug ist, um das Feld mirrorname zu unterstützen
change_mirrorname Änderung des Namens der Logspiegeldatei erlauben
change_logname Änderung des Transaktionslognamens erlauben.
Funktion
Syntax
Parameter

DBTools-Strukturen
338
Mitglied Beschreibung
ignore_ltm_trunc Wird der Log Transfer Manager verwandt, wird diegleiche Funktion wie mit Funktion dbcc settrunc( ’ltm’,'gen_id', n ) des Replication Server ausgeführt:
$ Weitere Informationen finden Sie in derDokumentation zum Replication Server.
ignore_remote_trunc Für SQL Remote. Setzt den Ausgangspunkt für dieOption DELETE_OLD_LOGS zurück, der es erlaubt,ein Transaktionslog zu löschen, wenn es nicht längergebraucht wird.
set_generation_number Wird - falls der Log Transfer Manager benutzt wird -nach der Wiederherstellung einer Sicherung verwendet,um die Generierungsnummer zu setzen.
ignore_dbsync_trunc Wenn dbmlsync verwendet wird, wird hiermit derAusgangspunkt für die Option DELETE_OLD_LOGSzurückgesetzt, mit dem ein Transaktionslog gelöschtwerden kann, wenn es nicht mehr gebraucht wird.
mirrorname Der neue Name des Transaktionslogspiegels
generation_number Die neue Generationsnummer. Wird zusammen mitset_generation_number benutzt.
key_file Eine Datei mit dem Chiffrierschlüssel
zap_current_offset Aktuellen Ausgangspunkt auf den angegebenen Wertändern. Dies ist nur für das Zurücksetzen einesTransaktionslogs nach Entladen und Aktualisieren zurAbstimmung mit den Einstellungen für dbremote oderdbmlsync vorgesehen.
zap_starting_offset Ausgangspunkt auf den angegebenen Wert ändern.Dies ist nur für das Zurücksetzen einesTransaktionslogs nach Entladen und Aktualisieren zurAbstimmung mit den Einstellungen für dbremote oderdbmlsync vorgesehen.
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
"DBChangeLogName-Funktion" auf Seite 323$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
339
a_compress_db-Struktur
Enthält die Informationen, die gebraucht werden, umDatenbank-Komprimierungsaufgaben mit der DBTools-Bibliothekauszuführen.
typedef struct a_compress_db {unsigned short version;const char * dbname;const char * compress_name;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field display_free_pages : 1;a_bit_field quiet : 1;a_bit_field record_unchanged : 1;a_compress_stats * stats;MSG_CALLBACK confirmrtn;a_bit_field noconfirm : 1;const char * encryption_key} a_compress_db;
Mitglied Beschreibung
version DBTools-Versionsnummer
dbname Name der zu komprimierenden Datenbank
compress_name Dateiname der komprimierten Datenbank
errorrtn Callback-Routine für die Behandlung einerFehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einerStatusmeldung
display_free_pages Informationen über freie Seiten anzeigen
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
Funktion
Syntax
Parameter

DBTools-Strukturen
340
Mitglied Beschreibung
record_unchanged Auf 1 gesetzt. Zeigt an, dass die Struktura_compress_stats neu genug ist, um das Elementunchanged zu haben
a_compress_stats Zeiger auf eine Struktur vom Typ a_compress_stats. Wirdbelegt, wenn das Element nicht NULL ist und wenndisplay_free_pages nicht 0 (Null) ist
confirmrtn Callback-Routine für die Bestätigung einer Aktion
noconfirm Mit (0) oder ohne (1) Bestätigung arbeiten
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
"DBCompress-Funktion" auf Seite 325"a_compress_stats-Struktur" auf Seite 340$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_compress_stats-Struktur
Enthält statistische Informationen über komprimierte Datenbankdateien.
typedef struct a_compress_stats {a_stats_line tables;a_stats_line indices;a_stats_line other;a_stats_line free;a_stats_line total;a_sql_int32 free_pages;a_sql_int32 unchanged;} a_compress_stats;
Mitglied Beschreibung
tables Enthält Information zur Komprimierung von Tabellen
Indices Enthält Information zur Komprimierung von Indizes
Other Enthält weitere Information zur Komprimierung
Free Enthält Informationen über freien Speicherplatz
Total Enthält allgemeine Information zur Komprimierung
free_pages Enthält Informationen über freie Seiten
Unchanged Anzahl der Seiten, die der Komprimierungsalgorithmus nichtschrumpfen konnte
Siehe auch
Funktion
Syntax
Parameter

Kapitel 8 Die DBTools-Schnittstelle
341
"DBCompress-Funktion" auf Seite 325"a_compress_db-Struktur" auf Seite 339
a_create_db-Struktur
Enthält die Informationen, die gebraucht werden, um eine Datenbank mit derDBTools-Bibliothek zu erstellen.
typedef struct a_create_db {unsigned short version;const char * dbname;const char * logname;const char * startline;short page_size;const char * default_collation;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;short database_version;char verbose;a_bit_field blank_pad : 2;a_bit_field respect_case : 1;a_bit_field encrypt : 1;a_bit_field debug : 1;a_bit_field dbo_avail : 1;a_bit_field mirrorname_present : 1;a_bit_field avoid_view_collisions : 1;short collation_id;const char * dbo_username;const char * mirrorname;const char * encryption_dllname;a_bit_field java_classes : 1;a_bit_field jconnect : 1;const char * data_store_typeconst char * encryption_key;const char * encryption_algorithm;const char * jdK_version;} a_create_db;
Siehe auch
Funktion
Syntax

DBTools-Strukturen
342
Mitglied Beschreibung
version DBTools-Versionsnummer
dbname Datenbankdateiname
logname Neuer Transaktionslogname
startline Befehlszeile zum Starten der Datenbank-Engine. Dasfolgende Beispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
page_size Die Seitengröße der Datenbank
default_collation Die Kollatierung für die Datenbank
errorrtn Callback-Routine für die Behandlung einerFehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
database_version Die Versionsnummer der Datenbank
verbose Im ausführlichen Darstellungsmodus ausführen
blank_pad Leerzeichen in Zeichenfolgevergleichen beachten undentsprechende Indexinformationen speichern
respect_case Groß/Kleinschreibung in Zeichenfolgevergleichenbeachten und entsprechende Indexinformationenspeichern
encrypt Datenbank verschlüsseln
debug Reserviert
dbo_avail Auf 1 gesetzt. Der Benutzer dbo ist in dieser Datenbankverfügbar.
mirrorname_present Auf 1 setzen; zeigt an, dass die DBTools-Version neugenug ist, um das Feld mirrorname zu unterstützen
avoid_view_collisions Die Erzeugung der Watcom SQL-Kompatibilitäts-Ansichten SYS.SYSCOLUMNS undSYS.SYSINDEXES vermeiden
collation_id Kollatierungsname (identifier)
dbo_username Nicht mehr benutzt: auf NULL gesetzt
mirrorname Name des Transaktionslogspiegels
encryption_dllname Die zum Verschlüsseln der Datenbank verwendete DLL.
java_classes Für Java aktivierte Datenbank erstellen
Parameter

Kapitel 8 Die DBTools-Schnittstelle
343
Mitglied Beschreibung
jconnect Für jConnect erforderliche Systemprozedureneinbeziehen
data_store_type Reserviert NULL benutzen
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
encryption_algorithm AESoder MDSR eingeben.
jdk_version Einer der Werte für die Option dbinit -jdk.
"DBCreate-Funktion" auf Seite 325$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316 .
a_crypt_db-Struktur
Enthält die Informationen, die zum Verschlüsseln einer Datenbankdateiverwendet werden, die auch das dbinit-Dienstprogramm benutzt.
typedef struct a_crypt_db {const char _fd_ * dbname;const char _fd_ * dllname;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;char verbose;a_bit_field quiet : 1; a_bit_field debug : 1;} a_crypt_db;
Mitglied Beschreibung
dbname Datenbankdateiname
dllname Der Name der DLL, die für die Ausführung derVerschlüsselung verwendet wird
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einer Statusmeldung
verbose Im ausführlichen Darstellungsmodus ausführen
quiet Ohne Nachrichten arbeiten
debug Reserviert
Siehe auch
Funktion
Syntax
Parameter

DBTools-Strukturen
344
"DBCrypt-Funktion" auf Seite 326"Datenbank mit dem Befehlszeilenprogramm ""dbinit"" erstellen" auf
Seite 516 der Dokumentation ASA Datenbankadministration
a_db_collation-Struktur
Enthält die Informationen, die gebraucht werden, um mit der DBTools-Bibliothek eine Kollatierungssequenz aus der Datenbank zu extrahieren.
typedef struct a_db_collation {unsigned short version;const char * connectparms;const char * startline;const char * collation_label;const char * filename;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;a_bit_field include_empty : 1;a_bit_field hex_for_extended : 1;a_bit_field replace : 1;a_bit_field quiet : 1;const char * input_filename;const char _fd_ * mapping_filename;} a_db_collation;
Mitglied Beschreibung
version DBTools-Versionsnummer
connectparms Parameter für die Verbindung zur Datenbank. Sie habendie Form von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\asa\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sieunter "Verbindungsparameter" auf Seite 78 derDokumentation ASA Datenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Dasfolgende Beispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
confirmrtn Callback-Routine für die Bestätigung einer Aktion
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
Siehe auch
Funktion
Syntax
Parameter

Kapitel 8 Die DBTools-Schnittstelle
345
Mitglied Beschreibung
include_empty Leere Zuordnungen für Lücken in derKollatierungssequenz schreiben
hex_for_extended Zweiziffrige Hexadezimalzahlen benutzen, um high-value-Zeichen zu repräsentieren
replace Ohne Bestätigungsaktionen arbeiten
quiet Ohne Nachrichten arbeiten
input_filename Kollatierungsdefinition eingeben
mapping_filename Ausgabe von syscollationmapping
"DBCollate-Funktion" auf Seite 324$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_db_info-Struktur
Enthält die Informationen, die gebraucht werden, um dbinfo-Informationenmit der DBTools-Bibliothek zurückzugeben.
Siehe auch
Funktion

DBTools-Strukturen
346
typedef struct a_db_info {unsigned short version;MSG_CALLBACK errorrtn;const char * dbname;unsigned short dbbufsize;char * dbnamebuffer;unsigned short logbufsize;char * lognamebuffer;unsigned short wrtbufsize;char * wrtnamebuffer;a_bit_field quiet : 1;a_bit_field mirrorname_present : 1;a_sysinfo sysinfo;unsigned long free_pages;a_bit_field compressed : 1;const char * connectparms;const char * startline;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field page_usage : 1;a_table_info * totals;unsigned long file_size;unsigned long unused_pages;unsigned long other_pages;unsigned short mirrorbufsize;char * mirrornamebuffer;char * unused_field;char * collationnamebuffer;unsigned short collationnamebufsize;char * classesversionbuffer;unsigned short classesversionbufsize;} a_db_info;
Mitglied Beschreibung
version DBTools-Versionsnummer
errortrn Callback-Routine für die Behandlung einerFehlermeldung
dbname Datenbankdateiname
dbbufsize Länge des Elements dbnamebuffer
dbnamebuffer Datenbankdateiname
logbufsize Länge des Elements lognamebuffer
lognamebuffer Transaktionslog-Dateiname
wrtbufsize Länge des Elements wrtnamebuffer
wrtnamebuffer Name der Write-Datei
Syntax
Parameter

Kapitel 8 Die DBTools-Schnittstelle
347
Mitglied Beschreibung
quiet Ohne Bestätigungsnachrichten arbeiten
mirrorname_present Auf 1 setzen; zeigt an, dass die DBTools-Version neugenug ist, um das Feld mirrorname zu unterstützen
sysinfo Zeiger auf eine a_sysinfo-Struktur
free_pages Anzahl der freien Seiten
compressed 1 falls komprimiert, sonst 0
connectparms Parameter für die Verbindung zur Datenbank. Sie habendie Form von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\Programme\Sybase\SQL Anywhere 8\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sieunter "Verbindungsparameter" auf Seite 78 derDokumentation ASA Datenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Dasfolgende Beispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einerStatusmeldung
page_usage 1, um Auskunft zu geben über Seitennutzungs-Statistiken,sonst 0
totals Zeiger auf eine a_table_info-Struktur
file_size Größe der Datenbankdatei
unused_pages Anzahl der nicht genutzten Seiten
other_pages Anzahl der Seiten, die weder Tabellen- noch Indexseitensind
mirrorbufsize Länge des Elements mirrornamebuffer
mirrornamebuffer Name des Transaktionslogspiegels

DBTools-Strukturen
348
Mitglied Beschreibung
collationnamebuffer Name und Bezeichnung der Datenbankkollatierung(Maximum ist 128+1)
collationnamebufsize Länge des Elements collationnamebuffer
key_file Eine Datei mit dem Chiffrierschlüssel
classesversionbuffer Die JDK-Version der installierten Java-Klassen, wie z.B.1.1.3, 1.1.8, 1.3 oder eine leere Zeichenfolge, falls Java-Klassen nicht in der Datenbank installiert sind (diemaximale Größe beträgt 10+1)
classesversionbufsize Länge des Elements classesversionbuffer
"DBInfo-Funktion" auf Seite 327$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_dblic_info-Struktur
Enthält Angaben zu den Lizenzdaten. Sie dürfen diese Informationen nurgemäß Ihrem Lizenzvertrag benutzen.
typedef struct a_dblic_info {unsigned short version;char * exename;char * username;char * compname;char * platform_str;a_sql_int32 nodecount;a_sql_int32 conncount;a_license_type type;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;a_bit_field quiet : 1;a_bit_field query_only : 1;} a_dblic_info;
Mitglied Beschreibung
version DBTools-Versionsnummer
exename Name der ausführbaren Datei
username Benutzername für die Lizenz
compname Name des Unternehmens für die Lizenz
platform_str Betriebssystem: WinNT oder NLM oder UNIX
nodecount Anzahl der Knotenlizenzen.
Siehe auch
Funktion
Syntax
Parameter

Kapitel 8 Die DBTools-Schnittstelle
349
Mitglied Beschreibung
conncount Muss 1000000L sein
type Werte finden Sie unter lictype.h
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
query_only Wenn 1, nur die Lizenzinformationen anzeigen. Wenn 0,Änderung der Informationen zulassen.
a_dbtools_info-Struktur
Enthält die Informationen, die gebraucht werden, um die Arbeit mit derDBTools-Bibliothek zu beginnen und zu beenden.
typedef struct a_dbtools_info {MSG_CALLBACK errorrtn;} a_dbtools_info;
Mitglied Beschreibung
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
"DBToolsFini-Funktion" auf Seite 330"DBToolsInit-Funktion" auf Seite 331$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
an_erase_db-Struktur
Enthält die Informationen, die gebraucht werden, um eine Datenbank mit derDBTools-Bibliothek zu löschen.
Funktion
Syntax
Parameter
Siehe auch
Funktion

DBTools-Strukturen
350
typedef struct an_erase_db {unsigned short version;const char * dbname;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;a_bit_field quiet : 1;a_bit_field erase : 1;const char * encryption_key;} an_erase_db;
Mitglied Beschreibung
version DBTools-Versionsnummer
dbname Name der zu löschenden Datenbankdatei
confirmrtn Callback-Routine für die Bestätigung einer Aktion
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
erase Ohne Bestätigung löschen (1) oder mit Bestätigung (0)
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
"DBErase-Funktion" auf Seite 327$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
an_expand_db-Struktur
Enthält Informationen, die für die Datenbankdekomprimierung mit derDBTools-Bibliothek gebraucht werden.
Syntax
Parameter
Siehe auch
Funktion

Kapitel 8 Die DBTools-Schnittstelle
351
typedef struct an_expand_db {unsigned short version;const char * compress_name;const char * dbname;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field quiet : 1;MSG_CALLBACK confirmrtn;a_bit_field noconfirm : 1;const char * key_file;const char * encryption_key;} an_expand_db;
Mitglied Beschreibung
version DBTools-Versionsnummer
compress_name Name der komprimierten Datenbankdatei
dbname Datenbankdateiname
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einer Statusmeldung
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
confirmrtn Callback-Routine für die Bestätigung einer Aktion
noconfirm Mit (0) oder ohne (1) Bestätigung arbeiten
key_file Eine Datei mit dem Chiffrierschlüssel
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
"DBExpand-Funktion" auf Seite 327$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_name-Struktur
Enthält eine verkettete Liste von Namen. Wird von anderen Strukturenbenutzt, die Namenslisten erfordern.
Syntax
Parameter
Siehe auch
Funktion

DBTools-Strukturen
352
typedef struct a_name {struct a_name * next;char name[1];} a_name, * p_name;
Mitglied Beschreibung
next Zeiger auf eine next a_name-Struktur in der Liste
Name Der Name
p_name Zeiger auf die vorangehende a_name-Struktur
"a_translate_log-Struktur" auf Seite 357"a_validate_db-Struktur" auf Seite 363"an_unload_db-Struktur" auf Seite 359
a_stats_line-Struktur
Enthält Informationen, welche für die Komprimierung undDekomprimierung der Datenbank mit der DBTools-Bibliothek gebrauchtwerden.
typedef struct a_stats_line {long pages;long bytes;long compressed_bytes;} a_stats_line;
Mitglied Beschreibung
Pages Anzahl der Seiten
Bytes Anzahl der Bytes für die nicht komprimierte Datenbank
Compressed_bytes Anzahl der Bytes für die komprimierte Datenbank
"a_compress_stats-Struktur" auf Seite 340
a_sync_db-Struktur
Enthält Informationen, die für den Gebrauch des Dienstprogramms dbmlsyncmit der DBTools-Bibliothek benötigt werden.
Syntax
Parameter
Siehe auch
Funktion
Syntax
Parameter
Siehe auch
Funktion

Kapitel 8 Die DBTools-Schnittstelle
353
typedef struct a_sync_db {unsigned short version;char _fd_ * connectparms;char _fd_ * publication;const char _fd_ * offline_dir;char _fd_ * extended_options;char _fd_ * script_full_path;const char _fd_ * include_scan_range;const char _fd_ * raw_file;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK logrtn;
Syntax

DBTools-Strukturen
354
a_SQL_uint32 debug_dump_size;a_SQL_uint32 dl_insert_width;a_bit_field verbose : 1;a_bit_field debug : 1;a_bit_field debug_dump_hex : 1;a_bit_field debug_dump_char : 1;a_bit_field debug_page_offsets : 1;a_bit_field use_hex_offsets : 1;a_bit_field use_relative_offsets : 1;a_bit_field output_to_file : 1;a_bit_field output_to_mobile_link : 1;a_bit_field dl_use_put : 1;a_bit_field dl_use_upsert : 1;a_bit_field kill_other_connections : 1;a_bit_field retry_remote_behind : 1;a_bit_field ignore_debug_interrupt : 1;SET_WINDOW_TITLE_CALLBACK set_window_title_rtn;char * default_window_title;MSG_QUEUE_CALLBACK msgqueuertn;MSG_CALLBACK progress_msg_rtn;SET_PROGRESS_CALLBACK progress_index_rtn;char ** argv;char ** ce_argv;a_bit_field connectparms_allocated : 1;a_bit_field entered_dialog : 1;a_bit_field used_dialog_allocation : 1;a_bit_field ignore_scheduling : 1;a_bit_field ignore_hook_errors : 1;a_bit_field changing_pwd : 1;a_bit_field prompt_again : 1;a_bit_field retry_remote_ahead : 1;a_bit_field rename_log : 1;a_bit_field hide_conn_str : 1;a_bit_field hide_ml_pwd : 1;a_bit_field delay_ml_disconn : 1;a_SQL_uint32 dlg_launch_focus;char _fd_ * mlpassword;char _fd_ * new_mlpassword;char _fd_ * verify_mlpassword;a_SQL_uint32 pub_name_cnt;char ** pub_name_list;USAGE_CALLBACK usage_rtn;a_sql_uint32 hovering_frequency;a_bit_short ignore_hovering : 1;a_bit_short verbose_upload : 1;a_bit_short verbose_upload_data : 1;a_bit_short verbose_download : 1;a_bit_short verbose_download_data : 1;a_bit_short autoclose : 1;a_bit_short ping : 1;a_bit_short _unused : 9;

Kapitel 8 Die DBTools-Schnittstelle
355
char _fd_ * encryption_key;a_syncpub _fd_ * upload_defs;char _fd_ * log_file_name;char _fd_ * user_name;} a_sync_db;
Die Parameter entsprechen Funktionen, die über das Dienstprogrammdbmlsync zugänglich sind.
In der Header-Datei dbtools.h finden Sie weitere Kommentare.
$ Weitere Hinweise finden Sie unter "MobiLink-Synchronisationsclient"auf Seite 440 der Dokumentation MobiLink Benutzerhandbuch.
"DBSynchronizeLog-Funktion" auf Seite 330
a_syncpub-Struktur
Enthält Informationen, die für das Dienstprogramm dbmlsync benötigtwerden.
typedef struct a_syncpub { struct a_syncpub _fd_ * next; char _fd_ * pub_name; char _fd_ * ext_opt; a_bit_field alloced_by_dbsync: 1;} a_syncpub;
Mitglied Beschreibung
a_syncpub Zeiger auf den nächsten Knoten in der Liste, NULL fürden letzten Knoten
pub_name Für diesen –n-Parameter angegebenePublikationsnamen. Dies ist die exakte Zeichenfolgenach -n in der Befehlszeile.
ext_opt Erweiterte Optionen, die mit dem Parameter -euangegeben werden
encryption 1 falls die Datenbank verschlüsselt ist, 0 (Null) fallsnicht
alloced_by_dbsync FALSE, mit Ausnahme der von dbtool8.dll erstelltenKnoten
Parameter
Siehe auch:
Funktion
Syntax
Parameter

DBTools-Strukturen
356
a_sysinfo-Struktur
Enthält Informationen, die für den Gebrauch der Dienstprogramme dbinfound dbunload mit der DBTools-Bibliothek benötigt werden.
typedef struct a_sysinfo {a_bit_field valid_data : 1;a_bit_field blank_padding : 1;a_bit_field case_sensitivity : 1;a_bit_field encryption : 1;char default_collation[11];unsigned short page_size;} a_sysinfo;
Mitglied Beschreibung
valid_date Bit-Feld, das angibt, ob die folgenden Werte gesetzt sind
blank_padding 1 falls Auffüllen mit Leerzeichen in der Datenbank benutztwird, 0 (Null) falls nicht
case_sensitivity 1 falls die Datenbank Groß/Kleinschreibung beachtet, 0 (Null)falls nicht
encryption 1 falls die Datenbank verschlüsselt ist, 0 (Null) falls nicht
default_collation Die Kollatierungssequenz für die Datenbank
page_size Die Seitengröße für die Datenbank
"a_db_info-Struktur" auf Seite 345
a_table_info-Struktur
Enthält Informationen über eine Tabelle, die als Teil der a_db_info-Strukturgebraucht wird.
typedef struct a_table_info {struct a_table_info * next;unsigned short table_id;unsigned long table_pages;unsigned long index_pages;unsigned long table_used;unsigned long index_used;char * table_name;a_sql_uint32 table_used_pct;a_sql_uint32 index_used_pct;} a_table_info;
Funktion
Parameter
Siehe auch
Funktion
Syntax

Kapitel 8 Die DBTools-Schnittstelle
357
Mitglied Beschreibung
next Nächste Tabelle in der Liste
table_id ID-Nummer für diese Tabelle
table_pages Anzahl der Tabellenseiten
index_pages Anzahl der Indexseiten
table_used Anzahl der in den Tabellenseiten benutzten Bytes
index_used Anzahl der in den Indexseiten benutzten Bytes
table_name Name der Tabelle
table_used_pct Verwendung des Tabellenbereichs als Prozentsatz
index_used_pct Verwendung des Indexbereichs als Prozentsatz
"a_db_info-Struktur" auf Seite 345
a_translate_log-Struktur
Enthält Informationen, die für die Konvertierung des Transaktionslogs mitder DBTools-Bibliothek gebraucht werden.
typedef struct a_translate_log {unsigned short version;const char * logname;const char * sqlname;p_name userlist;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;char userlisttype;a_bit_field remove_rollback : 1;a_bit_field ansi_SQL : 1;a_bit_field since_checkpoint: 1;a_bit_field omit_comments : 1;a_bit_field replace : 1;a_bit_field debug : 1;a_bit_field include_trigger_trans : 1;a_bit_field comment_trigger_trans : 1;unsigned long since_time;const char _fd_ * reserved_1;
Parameter
Siehe auch
Funktion
Syntax

DBTools-Strukturen
358
const char _fd_ * reserved_2;a_sql_uint32 debug_dump_size;a_bit_field debug_sql_remote : 1;a_bit_field debug_dump_hex : 1;a_bit_field debug_dump_char : 1;a_bit_field debug_page_offsets : 1;a_bit_field reserved_3 : 1;a_bit_field use_hex_offsets : 1;a_bit_field use_relative_offsets : 1;a_bit_field include_audit : 1;a_bit_field chronological_order : 1;a_bit_field force_recovery : 1;a_bit_field include_subsets : 1;a_bit_field force_chaining : 1;a_sql_uint32 recovery_ops;a_sql_uint32 recovery_bytes;const char _fd_ * include_source_sets;const char _fd_ * include_destination_sets;const char _fd_ * include_scan_range;const char _fd_ * repserver_users;const char _fd_ * include_tables;const char _fd_ * include_publications;const char _fd_ * queueparms;a_bit_field generate_reciprocals :1;a_bit_field match_mode :1;const char _fd_ * match_pos;MSG_CALLBACK statusrtn;const char _fd_ * encryption_key;a_bit_field show_undo :1;const char _fd_ * logs_dir;} a_translate_log;
Die Parameter entsprechen Funktionen, die über das Dienstprogramm dbtranzugänglich sind.
In der Header-Datei dbtools.h finden Sie weitere Kommentare.
"DBTranslateLog-Funktion" auf Seite 332"a_name-Struktur" auf Seite 351"dbtran_userlist_type-Aufzählungstyp" auf Seite 368$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_truncate_log-Struktur
Enthält Informationen, die für das Kürzen des Transaktionslogs mit derDBTools-Bibliothek gebraucht werden.
Parameter
Siehe auch
Funktion

Kapitel 8 Die DBTools-Schnittstelle
359
typedef struct a_truncate_log {unsigned short version;const char * connectparms;const char * startline;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;a_bit_field quiet : 1;char truncate_interrupted;} a_truncate_log;
Mitglied Beschreibung
version DBTools-Versionsnummer
connectparms Parameter für die Verbindung zur Datenbank. Sie habendie Form von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\asa\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sieunter "Verbindungsparameter" auf Seite 78 derDokumentation ASA Datenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Dasfolgende Beispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
truncate_interrupted Gibt an, dass der Vorgang unterbrochen wurde
"DBTruncateLog-Funktion" auf Seite 332$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
an_unload_db-Struktur
Enthält die Informationen, die gebraucht werden, um eine Datenbank mit derDBTools-Bibliothek zu entladen oder um eine entfernte Datenbank für SQLRemote zu extrahieren. Die Felder, die vom SQL Remote-Extraktionsdienstprogramm dbxtract benutzt werden, sind gekennzeichnet.
Syntax
Parameter
Siehe auch
Funktion

DBTools-Strukturen
360
typedef struct an_unload_db {unsigned short version;const char * connectparms;const char * startline;const char * temp_dir;const char * reload_filename;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;MSG_CALLBACK confirmrtn;char unload_type;char verbose;a_bit_field unordered : 1;a_bit_field no_confirm : 1;a_bit_field use_internal_unload : 1;a_bit_field dbo_avail : 1;a_bit_field extract : 1;a_bit_field table_list_provided : 1;a_bit_field exclude_tables : 1;a_bit_field more_flag_bits_present : 1;a_sysinfo sysinfo;const char * remote_dir;const char * dbo_username;const char * subscriber_username;const char * publisher_address_type;const char * publisher_address;unsigned short isolation_level;a_bit_field start_subscriptions : 1;a_bit_field exclude_foreign_keys : 1;a_bit_field exclude_procedures : 1;a_bit_field exclude_triggers : 1;a_bit_field exclude_views : 1;a_bit_field isolation_set : 1;a_bit_field include_where_subscribe : 1;a_bit_field debug : 1;p_name table_list;a_bit_short escape_char_present : 1;a_bit_short view_iterations_present : 1;unsigned short view_iterations;
Syntax

Kapitel 8 Die DBTools-Schnittstelle
361
char escape_char;char _fd_ * reload_connectparms;char _fd_ * reload_db_filename;a_bit_field output_connections:1;char unload_interrupted;a_bit_field replace_db:1;const char _fd_ * locale;const char _fd_ * site_name;const char _fd_ * template_name;a_bit_field preserve_ids:1;a_bit_field exclude_hooks:1;char _fd_ * reload_db_logname;const char _fd_ * encryption_key;const char _fd_ * encryption_algorithm;a_bit_field syntax_version_7:1;a_bit_field remove_java:1;} an_unload_db;
Die Parameter entsprechen Funktionen, die über die Dienstprogrammedbunload und dbxtract und mlxtract zugänglich sind.
In der Header-Datei dbtools.h finden Sie weitere Kommentare.
"DBUnload-Funktion" auf Seite 333"a_name-Struktur" auf Seite 351"dbunload-Aufzählungstyp" auf Seite 368$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
an_upgrade_db-Struktur
Enthält die Informationen, die gebraucht werden, um eine Datenbank mit derDBTools-Bibliothek zu aktualisieren.
Parameter
Siehe auch
Funktion

DBTools-Strukturen
362
typedef struct an_upgrade_db {unsigned short version;const char * connectparms;const char * startline;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field quiet : 1;a_bit_field dbo_avail : 1;const char * dbo_username;a_bit_field java_classes : 1;a_bit_field jconnect : 1;a_bit_field remove_java : 1;a_bit_field java_switch_specified : 1;const char * jdk_version;} an_upgrade_db;
Mitglied Beschreibung
version DBTools-Versionsnummer
connectparms Parameter für die Verbindung zur Datenbank. Sie haben dieForm von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\asa\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sie unter"Verbindungsparameter" auf Seite 78 der Dokumentation ASADatenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Das folgendeBeispiel zeigt eine Startzeile:
"c:\asa\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn diesesElement NULL ist.
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einer Statusmeldung
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
dbo_avail Auf 1 gesetzt. Zeigt an, dass die DBTools-Version neu genugist, um das Feld dbo_mirrorname zu unterstützen
Syntax
Parameter

Kapitel 8 Die DBTools-Schnittstelle
363
Mitglied Beschreibung
dbo_username Der für den dbo zu benutzende Name
java_classes Datenbank umstellen, sodass sie Java enthält
jconnect Datenbank umstellen, sodass sie jConnect-Prozedurenakzeptiert
remove_java Datenbank umstellen, sodass die Java-Funktionen entferntwerden
jdk_version Einer der Werte für die Option dbinit -jdk
"DBUpgrade-Funktion" auf Seite 333$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
a_validate_db-Struktur
Enthält Informationen, die für Datenbankvalidierung mit der DBTools-Bibliothek gebraucht werden.
typedef struct a_validate_db {unsigned short version;const char * connectparms;const char * startline;p_name tables;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;MSG_CALLBACK statusrtn;a_bit_field quiet : 1;a_bit_field index : 1;a_validate_type type;} a_validate_db;
Siehe auch
Funktion
Syntax

DBTools-Strukturen
364
Mitglied Beschreibung
version DBTools-Versionsnummer
connectparms Parameter für die Verbindung zur Datenbank. Sie haben dieForm von Zeichenfolgen, zum Beispiel:
"UID=DBA;PWD=SQL;DBF=c:\asa\asademo.db"
$ Alle Zeichenfolgen für die Verbindung finden Sie unter"Verbindungsparameter" auf Seite 78 der Dokumentation ASADatenbankadministration
startline Befehlszeile zum Starten der Datenbank-Engine. Das folgendeBeispiel zeigt eine Startzeile:
"c:\Programme\Sybase\SA\win32\dbeng8.exe"
Die standardmäßige Startzeile wird benutzt, wenn dieses ElementNULL ist.
tables Zeiger auf eine verknüpfte Liste mit Tabellennamen
errorrtn Callback-Routine für die Behandlung einer Fehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
statusrtn Callback-Routine für die Behandlung einer Statusmeldung
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
index Indizes validieren
type Weitere Hinweise unter "a_validate_type-Aufzählungstyp" aufSeite 369
"DBValidate-Funktion" auf Seite 334"a_name-Struktur" auf Seite 351
$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-Funktionen verwenden" auf Seite 316.
a_writefile-Struktur
Enthält Informationen, die für die Verwaltung der Datenbank-Write-Dateimit der DBTools-Bibliothek gebraucht werden.
Parameter
Siehe auch
Funktion

Kapitel 8 Die DBTools-Schnittstelle
365
typedef struct a_writefile {unsigned short version;const char * writename;const char * wlogname;const char * dbname;const char * forcename;MSG_CALLBACK confirmrtn;MSG_CALLBACK errorrtn;MSG_CALLBACK msgrtn;char action;a_bit_field quiet : 1;a_bit_field erase : 1;a_bit_field force : 1;a_bit_field mirrorname_present : 1;const char * wlogmirrorname;a_bit_field make_log_and_mirror_names: 1;const char * encryption_key;} a_writefile;
Mitglied Beschreibung
version DBTools-Versionsnummer
writename Name der Write-Datei
wlogname Wird nur für die Erstellung von Write-Dateien benutzt
dbname Wird zum Ändern und Erstellen von Write-Dateienbenutzt
forcename Erzwungene Referenz auf einen Dateinamen
confirmrtn Callback-Routine für die Bestätigung einer Aktion. Wirdnur für die Erstellung einer Write-Datei benutzt
errorrtn Callback-Routine für die Behandlung einerFehlermeldung
msgrtn Callback-Routine für die Behandlung einerInformationsnachricht
action Reserviert für Sybase
quiet Ohne die Ausgabe von Nachrichten arbeiten (1) oderNachrichten ausgeben (0)
erase Wird nur für die Erstellung von Write-Dateien benutzt.Ohne Bestätigung löschen (1) oder mit Bestätigung (0)
Syntax
Parameter

DBTools-Strukturen
366
Mitglied Beschreibung
force Falls 1, Write-Datei zwingend auf die angegebene Dateizeigen lassen
mirrorname_present Wird nur für die Erstellung von Write-Dateien benutzt.Auf 1 setzen; zeigt an, dass die DBTools-Version neugenug ist, um das Feld mirrorname zu unterstützen
wlogmirrorname Name des Transaktionslogspiegels
make_log_and_mirror_names
Wenn auf TRUE, verwenden Sie die Werte in wlognameund wlogmirrorname benutzt zum Festlegen derDateinamen.
encryption_key Der Chiffrierschlüssel für die Datenbankdatei.
"DBChangeWriteFile-Funktion" auf Seite 324"DBCreateWriteFile-Funktion" auf Seite 326"DBStatusWriteFile-Funktion" auf Seite 329$ Weitere Hinweise zu Callback-Funktionen finden Sie unter "Callback-
Funktionen verwenden" auf Seite 316.
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
367
DBTools-AufzählungstypenDieser Abschnitt führt die Aufzählungstypen auf, die von der DBTools-Bibliothek benutzt werden. Die Aufzählungstypen sind alphabetischaufgeführt.
Verbosity (Ausführlichkeit)
Gibt die Ausführlichkeit der Ausgabe an.
enum {VB_QUIET,VB_NORMAL,VB_VERBOSE};
Wert Beschreibung
VB_QUIET Keine Ausgabe
VB_NORMAL Normale Ausgabemenge
VB_VERBOSE Ausgabe ausführlich darstellen, nützlich für dieFehlersuche
"a_create_db-Struktur" auf Seite 341"an_unload_db-Struktur" auf Seite 359
Auffüllen mit Leerzeichen
Wird in der Struktur "a_create_db" (siehe "a_create_db-Struktur" aufSeite 341) benutzt, um den Wert von blank_pad anzugeben.
enum {NO_BLANK_PADDING,BLANK_PADDING};
Wert Beschreibung
NO_BLANK_PADDING Benutzt kein Auffüllen mit Leerzeichen
BLANK_PADDING Benutzt Auffüllen mit Leerzeichen
"a_create_db-Struktur" auf Seite 341
Funktion
Syntax
Parameter
Siehe auch
Funktion
Syntax
Parameter
Siehe auch

DBTools-Aufzählungstypen
368
dbtran_userlist_type-Aufzählungstyp
Typ einer Benutzerliste, wie er unter "a_translate_log-Struktur" auf Seite 357beschrieben ist.
typedef enum dbtran_userlist_type {DBTRAN_INCLUDE_ALL,DBTRAN_INCLUDE_SOME,DBTRAN_EXCLUDE_SOME} dbtran_userlist_type;
Wert Beschreibung
DBTRAN_INCLUDE_ALL Alle Benutzervorgänge einschliessen
DBTRAN_INCLUDE_SOME Nur Vorgänge der in der Benutzerlisteaufgeführten Benutzer einschliessen
DBTRAN_EXCLUDE_SOME Vorgänge der in der Benutzerlisteaufgeführten Benutzer ausschliessen
"a_translate_log-Struktur" auf Seite 357
dbunload-Aufzählungstyp
Der Entladungstyp, der von der Struktur "an_unload-db" (siehe"an_unload_db-Struktur" auf Seite 359) benutzt wird.
enum {UNLOAD_ALL,UNLOAD_DATA_ONLY,UNLOAD_NO_DATA};
Wert Beschreibung
UNLOAD_ALL Sowohl Daten wie auch Schema entladen
UNLOAD_DATA_ONLY Daten entladen Schema nicht entladen.
UNLOAD_NO_DATA Nur Schema entladen
"an_unload_db-Struktur" auf Seite 359
Funktion
Syntax
Parameter
Siehe auch
Funktion
Syntax
Parameter
Siehe auch

Kapitel 8 Die DBTools-Schnittstelle
369
a_validate_type-Aufzählungstyp
Der ausgeführte Validierungstyp gemäß "a_validate_db-Struktur" aufSeite 363.
typedef enum {VALIDATE_NORMAL = 0,VALIDATE_DATA,VALIDATE_INDEX,VALIDATE_EXPRESS,VALIDATE_FULL} a_validate_type;
Wert Beschreibung
VALIDATE_NORMAL Nur mit der Standardprüfung validieren
VALIDATE_DATA Zusätzlich zur Standardprüfung mit der Datenprüfungvalidieren
VALIDATE_INDEX Zusätzlich zur Standardprüfung mit der Indexprüfungvalidieren
VALIDATE_EXPRESS Zusätzlich zur Standard- und Datenprüfung mit derExpressprüfung validieren
VALIDATE_FULL Zusätzlich zur Standardprüfung mit der Daten- undIndexprüfung validieren
"Datenbank mit dem Befehlszeilenprogramm ""dbvalid"" validieren" aufSeite 589 der Dokumentation ASA Datenbankadministration
"VALIDATE TABLE-Anweisung" auf Seite 632 der Dokumentation ASASQL-Referenzhandbuch
Funktion
Syntax
Parameter
Siehe auch

DBTools-Aufzählungstypen
370

371
K A P I T E L 9
Die OLE DB- und ADO-Programmierschnittstellen
In diesem Kapitel wird beschrieben, wie Sie die OLE DB-Schnittstelle zuAdaptive Server Anywhere verwenden.
Viele Anwendungen, welche die OLE DB-Schnittstelle verwenden, tun diesnicht direkt, sondern über das Microsoft ActiveX-Datenobjekt (ADO)-Programmierungsmodell. In diesem Kapitel wird auch die ADO-Programmierung mit Adaptive Server Anywhere beschrieben.
Thema Seite
Einführung zu OLE DB 372
ADO-Programmierung mit Adaptive Server Anywhere 374
Unterstützte OLE DB-Schnittstellen 382
Über diesesKapitel
Inhalt

Einführung zu OLE DB
372
Einführung zu OLE DBOLE DB ist ein Datenzugriffsmodell von Microsoft. Es verwendetComponent Object Model (COM)-Schnittstellen und, anders als bei ODBC,wird hier nicht vorausgesetzt, dass die Datenquelle einen SQL-Abfrageprozessor verwendet.
Adaptive Server Anywhere enthält einen OLE DB-Provider namensASAProv. Dieser Provider steht für aktuelle Windows- sowie fürWindows CE-Plattformen zur Verfügung.
Sie können auf Adaptive Server Anywhere auch über den Microsoft OLEDB Provider für ODBC (MSDASQL) zusammen mit dem ODBC-Treibervon Adaptive Server Anywhere zugreifen.
Die Verwendung des OLE DB-Providers von Adaptive Server Anywherebietet mehrere Vorteile:
♦ Einige Funktionen, wie z.B. die Aktualisierung über einen Cursor, sindbei Verwendung der OLE DB/ODBC Brücke nicht verfügbar.
♦ Wenn Sie Adaptive Server Anywhere OLE DB-Provider verwenden, istODBC für Ihre Entwicklung nicht erforderlich.
♦ Mit MSDASQL können OLE DB-Clients mit jedem ODBC-Treiberarbeiten, wobei jedoch nicht garantiert wird, dass Sie sämtlicheFunktionen jedes ODBC-Treibers nutzen können. Wenn Sie AdaptiveServer Anywhere-Provider verwenden, haben Sie Zugriff auf sämtlicheAdaptive Server Anywhere-Funktionen aus OLE DB-Programmierumgebungen.
Unterstützte Plattformen
Der Adaptive Server Anywhere OLE DB-Provider wurde so entwickelt, dasser mit OLE DB 2.5 und höher arbeitet. Für Windows CE und Nachfolgerwurde der OLE DB-Provider für ADOCE 3.0 und höher entwickelt.
ADOCE ist der Microsoft ADO für Windows CE SDK und bietetDatenbankfunktionen für Anwendungen, die mit den Windows CE Toolkitsfür Visual Basic 5.0 und Visual Basic 6.0 entwickelt wurden.
$ Eine Liste der unterstützten Plattformen finden Sie unter"Betriebssystemversionen" auf Seite 150 der Dokumentation SQL AnywhereStudio Erste Orientierung.

Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
373
Verteilte Transaktionen
Der OLE DB-Treiber kann in einer Umgebung mit verteilten Transaktionenals Ressourcen-Manager eingesetzt werden.
$ Weitere Hinweise finden Sie unter "Dreischichtige Datenverarbeitungund verteilte Transaktionen" auf Seite 399.

ADO-Programmierung mit Adaptive Server Anywhere
374
ADO-Programmierung mit Adaptive ServerAnywhere
Bei ADO (ActiveX-Datenobjekte) handelt es sich um einDatenzugriffsmodell, das über eine Automationsschnittstelle zugänglichwird, die es Clientanwendungen ermöglicht, die Methoden undEigenschaften von Objekten in Laufzeit zu erfassen, ohne das Objekt vorherzu kennen. Mit Hilfe von Automation können Skriptsprachen wie VisualBasic ein Standardmodell für Datenzugriffsobjekte verwenden. ADOverwendet OLE DB, um den Datenzugriff bereitzustellen.
Wenn Sie den Adaptive Server Anywhere OLE DB-Provider verwenden,haben Sie aus einer ADO-Programmierungsumgebung Zugriff auf sämtlicheAdaptive Server Anywhere-Funktionen.
In diesem Abschnitt wird beschrieben, wie grundlegende Aufgaben währendder Verwendung von ADO aus Visual Basic ausgeführt werden. Er stelltkeine vollständige Anleitung zur Programmierung mit ADO dar.
Codebeispiele aus diesem Abschnitt finden Sie in den folgenden Dateien:
Entwicklungs-Tool Beispiel
Microsoft Visual Basic6.0
Samples\ASA\VBSampler\vbsampler.vbp
Microsoft eMbeddedVisual Basic 3.0
Samples\ASA\ADOCE\OLEDB_PocketPC.ebp
$ Weitere Hinweise zur Programmierung in ADO finden Sie imHandbuch Ihres Entwicklungstools.
$ Detaillierte Erläuterungen zur Verwendung von ADO und VisualBasic, um auf Daten in einer Adaptive Server Anywhere-Datenbankzuzugreifen, finden Sie im Whitepaper "Accessing Data in Adaptive ServerAnywhere Using ADO and Visual Basic" unterhttp://www.sybase.com/detail?id=1017429.
Eine Datenbank mit einem Verbindungsobjekt verbinden
In diesem Abschnitt wird eine einfache Visual Basic-Routine beschrieben,die eine Verbindung zu einer Datenbank herstellt.

Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
375
Sie können diese Routine ausprobieren, indem Sie eine Befehlsschaltflächenamens Command1 in einer Maske platzieren und die Routine in ihr Click-Ereignis einfügen. Führen Sie das Programm aus und klicken Sie auf dieSchaltfläche, um eine Verbindung herzustellen und trennen Sie dieVerbindung dann.
Private Sub cmdTestConnection_Click() ’ Variable deklarieren Dim myConn As New ADODB.Connection Dim myCommand As New ADODB.Command Dim cAffected As Long
On Error GoTo HandleError
’ Verbindung herstellen myConn.Provider = "ASAProv" myConn.ConnectionString = _ "Data Source=ASA 8.0 Sample" myConn.Open MsgBox "Verbindung erfolgreich" myConn.Close Exit Sub
HandleError: MsgBox "Verbindung nicht erfolgreich" Exit SubEnd Sub
Das Beispiel führt die folgenden Aufgaben aus:
♦ Es deklariert die Variablen, die in der Routine verwendet werden.
♦ Es stellt mit Hilfe des OLE DB-Providers von Adaptive ServerAnywhere eine Verbindung zur Beispieldatenbank her.
♦ Es verwendet ein Befehlsobjekt zur Ausführung einer einfachenAnweisung, die eine Meldung im Fenster des Datenbankservers anzeigt.
♦ Es beendet die Verbindung.
Wenn der ASAProv-Provider installiert ist, registriert er sich selbst. DerRegistriervorgang umfasst auch die Registriereinträge in dem AbschnittCOM der Registry, sodass ADO die Position der DLL ermitteln kann, wennder ASAProv-Provider aufgerufen wird. Wenn Sie den Speicherort IhrerDLL ändern, müssen Sie sie neu registrieren.
v So registrieren Sie den OLE DB-Provider:
1 Öffnen Sie eine Befehlszeile.
Beispielcode
Hinweise

ADO-Programmierung mit Adaptive Server Anywhere
376
2 Wechseln Sie zu dem Verzeichnis, in dem der OLE DB-Providerinstalliert ist.
3 Geben Sie den folgenden Befehl ein, um den Provider zu registrieren:
regsvr32 dboledb8.dll
$ Weitere Hinweise, wie Sie mit OLE DB eine Verbindung zu einerDatenbank herstellen, finden Sie unter "Verbinden mit einer Datenbank überOLE DB" auf Seite 75 der Dokumentation ASA Datenbankadministration.
Anweisungen mit dem Befehlsobjekt ausführen
In diesem Abschnitt wird eine einfache Routine beschrieben, die eineeinfache SQL-Anweisung an die Datenbank sendet.
Sie können diese Routine ausprobieren, indem Sie eine Befehlsschaltflächenamens Command2 in einer Maske platzieren und die Routine in ihr Click-Ereignis einfügen. Führen Sie das Programm aus und klicken Sie auf dieSchaltfläche, um eine Verbindung herzustellen, eine Meldung im Fenster desDatenbankservers anzuzeigen, und trennen Sie die Verbindung dann.
Private Sub cmdUpdate_Click() ’ Variable deklarieren Dim myConn As New ADODB.Connection Dim myCommand As New ADODB.Command Dim cAffected As Long ’Verbindung herstellen myConn.Provider = "ASAProv" myConn.ConnectionString = _ "Data Source=ASA 8.0 Sample" myConn.Open
'Befehl ausführen myCommand.CommandText = _ "update customer set fname='Liz' where id=102" Set myCommand.ActiveConnection = myConn myCommand.Execute cAffected MsgBox CStr(cAffected) +
" rows affected.", vbInformation
myConn.CloseEnd Sub
Nachdem eine Verbindung hergestellt wurde, erstellt der Beispielcode einBefehlsobjekt und stellt die Eigenschaft CommandText auf eine Update-Anweisung und die Eigenschaft ActiveConnection auf die aktuelleVerbindung ein. Dann führt er die Update-Anweisung aus und zeigt dieAnzahl der von der Aktualisierung betroffenen Zeilen in einemMeldungsfeld an.
Beispielcode
Hinweise

Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
377
In diesem Beispiel wird die Aktualisierung an die Datenbank gesendet undfestgeschrieben, sobald sie ausgeführt wurde.
$ Weitere Hinweise zur Verwendung von Transaktionen in ADO findenSie unter "Transaktionen verwenden" auf Seite 381.
Sie können Aktualisierungen auch über einen Cursor ausführen.
$ Weitere Hinweise finden Sie unter "Daten mit einem Cursoraktualisieren" auf Seite 379.
Datenbank mit dem Recordset-Objekt abfragen
Das ADO-Recordset-Objekt stellt die Ergebnismenge einer Abfrage dar. Siekönnen es benutzen, um Daten aus einer Datenbank anzuzeigen.
Sie können diese Routine ausprobieren, indem Sie eine Befehlsschaltflächemit dem Namen cmdQuery in ein Formular einfügen und die Routine in ihrClick-Ereignis einfügen. Führen Sie das Programm aus und klicken Sie aufdie Schaltfläche, um eine Verbindung herzustellen, eine Meldung im Fensterdes Datenbankservers anzuzeigen, eine Abfrage auszuführen und die erstenZeilen in Meldungsfeldern anzuzeigen. Danach trennen Sie die Verbindung.
Beispielcode

ADO-Programmierung mit Adaptive Server Anywhere
378
Private Sub cmdQuery_Click()’ Variable deklarieren Dim myConn As New ADODB.Connection Dim myCommand As New ADODB.Command Dim myRS As New ADODB.Recordset
On Error GoTo ErrorHandler:
’ Verbindung herstellen myConn.Provider = "ASAProv" myConn.ConnectionString = _ "Data Source=ASA 8.0 Sample" myConn.CursorLocation = adUseServer myConn.Mode = adModeReadWrite myConn.IsolationLevel = adXactCursorStability myConn.Open
'Eine Abfrage ausführen Set myRS = New Recordset myRS.CacheSize = 50 myRS.Source = "Select * from customer" myRS.ActiveConnection = myConn myRS.CursorType = adOpenKeyset myRS.LockType = adLockOptimistic myRS.Open
'Durch die ersten Ergebnisse blättern myRS.MoveFirst For i = 1 To 5 MsgBox myRS.Fields("company_name"), vbInformation myRS.MoveNext Next
myRS.Close myConn.Close Exit SubErrorHandler: MsgBox Error(Err) Exit SubEnd Sub
Das Recordset-Objekt in diesem Beispiel enthält die Ergebnisse aus einerAbfrage der Tabelle Kunden. Die Schleife For blättert durch die erstenZeilen und zeigt den Wert company_name für jede Zeile an.
Hierbei handelt es sich um ein einfaches Beispiel für die Verwendung einesCursors aus ADO.
$ Weiterführende Beispiele für die Verwendung eines Cursors aus ADOfinden Sie unter "Mit dem Recordset-Objekt arbeiten" auf Seite 379.
Hinweise

Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
379
Mit dem Recordset-Objekt arbeiten
Bei der Arbeit mit Adaptive Server Anywhere stellt die ADO Recordseteinen Cursor dar. Sie können den Cursortyp auswählen, indem Sie eineCursorType-Eigenschaft des Recordset-Objekts deklarieren, bevor Sie dasRecordset öffnen. Die Auswahl des Cursortyps beeinflusst die Aktionen, dieSie am Recordset vornehmen können und hat Auswirkungen auf diePerformance.
Die von Adaptive Server Anywhere unterstützten Cursortypen werden in"Cursoreigenschaften" auf Seite 26 beschrieben. ADO hat seine eigeneNamenskonvention für Cursortypen.
Die verfügbaren Cursortypen, die entsprechenden Cursortypenkonstantenund die Adaptive Server Anywhere-Typen, denen sie entsprechen, sind hieraufgelistet:
ADO-Cursortyp ADO-Konstante Adaptive ServerAnywhere-Typ
DynamischerCursor
adOpenDynamic Dynamisch abrollenderCursor
Schlüsselgruppen-Cursor
adOpenKeyset Abrollender Cursor
Statischer Cursor adOpenStatic Unempfindlicher Cursor
Vorwärts-Cursor adOpenForwardOnly Nicht-abrollender Cursor
$ Weitere Hinweise zur Auswahl eines für Ihre Anwendung geeignetenCursortyps finden Sie unter "Cursortypen auswählen" auf Seite 26.
Der folgende Code legt den Cursortyp für ein ADO Recordset-Objekt fest:
Dim myRS As New ADODB.RecordsetmyRS.CursorType = adOpenDynamic
Daten mit einem Cursor aktualisieren
Mit dem Adaptive Server Anywhere OLE DB-Provider können Sie eineErgebnismenge über einen Cursor aktualisieren. Diese Funktion ist über denMSDASQL-Provider nicht verfügbar.
Sie können die Datenbank über einen Recordset aktualisieren.
Private Sub Command6_Click() Dim myConn As New ADODB.Connection Dim myRS As New ADODB.Recordset Dim SQLString As String
Cursortypen
Beispielcode
Recordsetsaktualisieren

ADO-Programmierung mit Adaptive Server Anywhere
380
’ Verbindung herstellen myConn.Provider = "ASAProv" myConn.ConnectionString = _ "Data Source=ASA 8.0 Sample" myConn.Open myConn.BeginTrans SQLString = "Select * from customer" myRS.Open SQLString, _
myConn, adOpenDynamic, adLockBatchOptimistic
If myRS.BOF And myRS.EOF Then MsgBox "Recordset ist leer!", _ 16, "Leeres Recordset" Else MsgBox "Cursor-Typ: " + _ CStr(myRS.CursorType), vbInformation myRS.MoveFirst For i = 1 To 3 MsgBox "Zeile: " + CStr(myRS.Fields("id")), _ vbInformation If i = 2 Then myRS.Update "City", "Toronto" myRS.UpdateBatch End If myRS.MoveNext Next i’ myRS.MovePrevious myRS.Close End If myConn.CommitTrans myConn.CloseEnd Sub
Wenn Sie die Einstellung adLockBatchOptimistic für das Recordsetverwenden, werden bei der myRS.Update-Methode keine Änderungen ander Datenbank selbst vorgenommen. Statt dessen wird eine lokale Kopie desRecordsets aktualisiert.
Die myRS.UpdateBatch-Methode nimmt die Aktualisierung amDatenbankserver vor, schreibt sie jedoch nicht fest, da sie sich innerhalbeiner Transaktion befindet. Wenn eine UpdateBatch-Methode vonaußerhalb einer Transaktion aufgerufen wurde, werden die Änderungenfestgeschrieben.
Die Methode myConn.CommitTrans schreibt die Änderungen fest. DasRecordset-Objekt wurde zwischenzeitlich geschlossen, sodass das Problem,ob die lokale Kopie der Daten geändert wurde oder nicht, nicht mehr besteht.
Hinweise

Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
381
Transaktionen verwenden
Standardmäßig werden sämtliche Änderungen, die Sie mit ADO an derDatenbank vornehmen, festgeschrieben, sobald sie ausgeführt werden.Hierzu gehören auch explizite Aktualisierungen und die UpdateBatch-Methode für einen Recordset. Im vorherigen Abschnitt wurde jedochgezeigt, dass Sie die Methoden BeginTrans und RollbackTrans oderCommitTrans auf das Connection-Objekt anwenden können, umTransaktionen zu benutzen.
Die Transaktions-Isolationsstufe wird als eine Eigenschaft desVerbindungsobjekts festgelegt. Die Eigenschaft IsolationLevel kann einender folgenden Werte annehmen:
ADO-Isolationsstufe Konstante ASA-Stufe
Unbekannt (Unspecified) adXactUnspecified Nicht anwendbar. Auf 0setzen
Chaos adXactChaos Nicht unterstützt. Auf 0setzen
Durchsuchen (Browse) adXactBrowse 0
Nicht festgeschriebeneLesevorgänge (Readuncommitted)
adXactReadUncommitted 0
Cursorstabilität (Cursorstability)
adXactCursorStability 1
FestgeschriebeneLesevorgänge (Readcommitted)
adXactReadCommitted 1
WiederholbareLesevorgänge (reatableread)
adXactRepeatableRead 2
Isoliert (Isolated) adXactIsolated 3
Serialisierbar(Serializable)
adXactSerializable 3
$ Weitere Hinweise zu Isolationsstufen finden Sie unter "Isolationsstufenund Konsistenz" auf Seite 105 der Dokumentation ASA SQL-Benutzerhandbuch.

Unterstützte OLE DB-Schnittstellen
382
Unterstützte OLE DB-SchnittstellenDie OLE DB API besteht aus einer Reihe von Schnittstellen. In derfolgenden Tabelle wird die Unterstützung für jede Schnittstelle im OLE DB-Treiber von Adaptive Server Anywhere beschrieben.
Schnittstelle Verwendung Einschränkungen
IAccessor Bindungen zwischenClientspeicher- undDatenspeicherwertendefinieren
DBACCESSOR_PASSBYREF nichtunterstützt
DBACCESSOR_OPTIMIZED nichtunterstützt
IAlterIndex
IAlterTable
Tabellen, Indizes undSpalten ändern
Nicht unterstützt
IChapteredRowset Mit einer segmentiertenZeilengruppe kann aufZeilen einer Zeilengruppein getrennten Kapitelnzugegriffen werden
Nicht unterstützt
Adaptive ServerAnywhere untersütztsegmentierteZeilengruppen nicht.
IColumnsInfo Einfache Informationen zuSpalten in einer Zeilen-gruppe erhalten
Nicht für CE
IColumnsRowset Informationen zuoptionalenMetadatenspalten in einerZeilengruppe und eineZeilengruppe von Spalten-Metadaten erhalten
Nicht für CE
ICommand SQL-Befehle ausführen Unterstützt keinenAufruf
ICommandProperties
GetProperties mitDBPROPSET_PROPERTIESINERRORum Eigenschaften zufinden, die nichtgesetzt werdenkonnten.
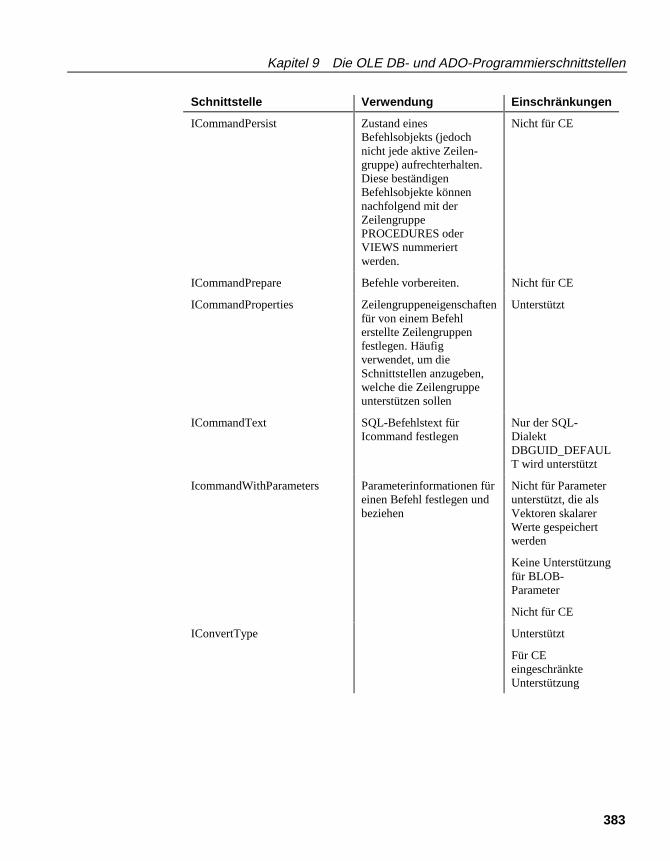
Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
383
Schnittstelle Verwendung Einschränkungen
ICommandPersist Zustand einesBefehlsobjekts (jedochnicht jede aktive Zeilen-gruppe) aufrechterhalten.Diese beständigenBefehlsobjekte könnennachfolgend mit derZeilengruppePROCEDURES oderVIEWS nummeriertwerden.
Nicht für CE
ICommandPrepare Befehle vorbereiten. Nicht für CE
ICommandProperties Zeilengruppeneigenschaftenfür von einem Befehlerstellte Zeilengruppenfestlegen. Häufigverwendet, um dieSchnittstellen anzugeben,welche die Zeilengruppeunterstützen sollen
Unterstützt
ICommandText SQL-Befehlstext fürIcommand festlegen
Nur der SQL-DialektDBGUID_DEFAULT wird unterstützt
IcommandWithParameters Parameterinformationen füreinen Befehl festlegen undbeziehen
Nicht für Parameterunterstützt, die alsVektoren skalarerWerte gespeichertwerden
Keine Unterstützungfür BLOB-Parameter
Nicht für CE
IConvertType Unterstützt
Für CEeingeschränkteUnterstützung

Unterstützte OLE DB-Schnittstellen
384
Schnittstelle Verwendung Einschränkungen
IDBAsynchNotify
IDBAsyncStatus
Asynchrone Verarbeitung
Client über Ereignisse inder asynchronenVerarbeitung bei derInitialisierung vonDatenquellen, demAnfüllen von Zeilen-gruppen, usw. informieren
Nicht unterstützt
IDBCreateCommand Befehle aus einer Sitzungerstellen
Unterstützt
IDBCreateSession Eine Sitzung aus einemDatenquellenobjekterstellen.
Unterstützt
IDBDataSourceAdmin Datenquellenobjekte, beidenen es sich um COM-Objekte handelt, die vonClients unterstützt werden,erstellen/zerstören/ändern.Diese Schnittstelle wirdnicht für die Verwaltungvon Datenspeichern(Datenbanken) verwendet.
Nicht unterstützt
IDBInfo Informationen überSchlüsselwörter suchen, diefür diesen Providereindeutig sind (d.h.Schlüsselwörter die nichtdem Standard-SQLentsprechen)
Außerdem Informationenzu Literalen, d.h. Sonder-zeichen, die in textlichübereinstimmendenAbfragen verwendetwerden, und andere Literal-Informationen suchen
Nicht für CE
IDBInitialize Datenquellenobjekte undAufzähler initialisieren.
Nicht für CE
IDBProperties Eigenschaften für einDatenquellenobjekt odereinen Aufzähler verwalten
Nicht für CE
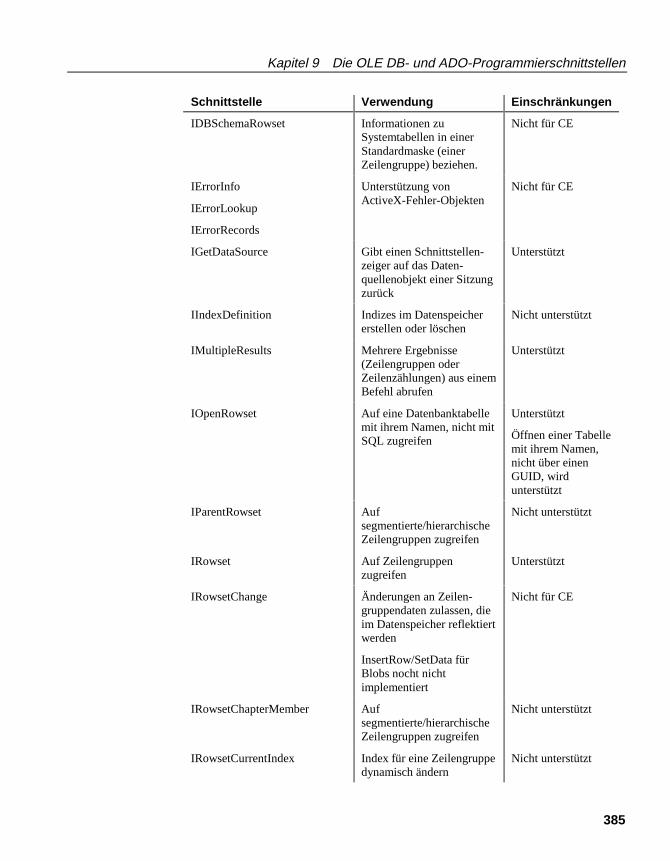
Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
385
Schnittstelle Verwendung Einschränkungen
IDBSchemaRowset Informationen zuSystemtabellen in einerStandardmaske (einerZeilengruppe) beziehen.
Nicht für CE
IErrorInfo
IErrorLookup
IErrorRecords
Unterstützung vonActiveX-Fehler-Objekten
Nicht für CE
IGetDataSource Gibt einen Schnittstellen-zeiger auf das Daten-quellenobjekt einer Sitzungzurück
Unterstützt
IIndexDefinition Indizes im Datenspeichererstellen oder löschen
Nicht unterstützt
IMultipleResults Mehrere Ergebnisse(Zeilengruppen oderZeilenzählungen) aus einemBefehl abrufen
Unterstützt
IOpenRowset Auf eine Datenbanktabellemit ihrem Namen, nicht mitSQL zugreifen
Unterstützt
Öffnen einer Tabellemit ihrem Namen,nicht über einenGUID, wirdunterstützt
IParentRowset Aufsegmentierte/hierarchischeZeilengruppen zugreifen
Nicht unterstützt
IRowset Auf Zeilengruppenzugreifen
Unterstützt
IRowsetChange Änderungen an Zeilen-gruppendaten zulassen, dieim Datenspeicher reflektiertwerden
InsertRow/SetData fürBlobs nocht nichtimplementiert
Nicht für CE
IRowsetChapterMember Aufsegmentierte/hierarchischeZeilengruppen zugreifen
Nicht unterstützt
IRowsetCurrentIndex Index für eine Zeilengruppedynamisch ändern
Nicht unterstützt
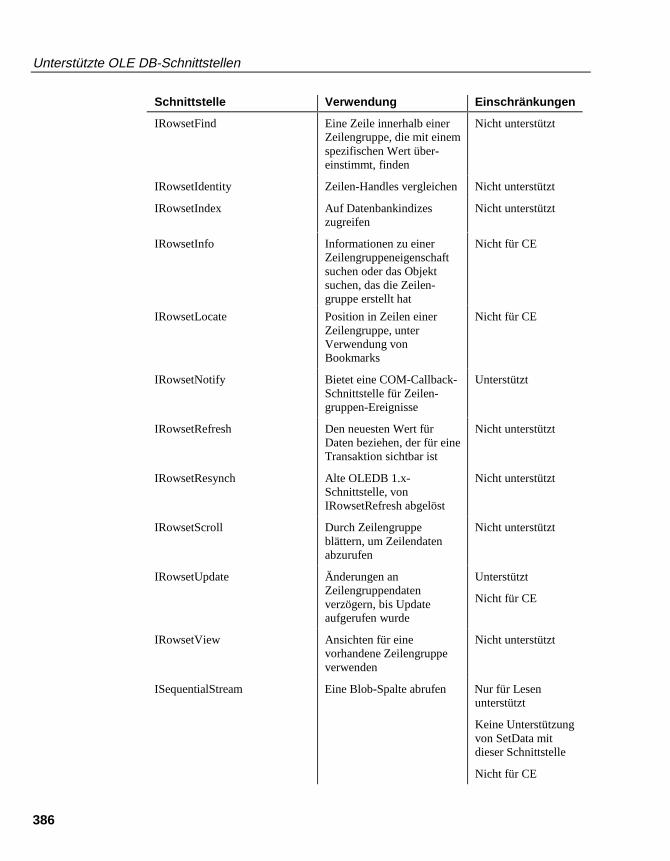
Unterstützte OLE DB-Schnittstellen
386
Schnittstelle Verwendung Einschränkungen
IRowsetFind Eine Zeile innerhalb einerZeilengruppe, die mit einemspezifischen Wert über-einstimmt, finden
Nicht unterstützt
IRowsetIdentity Zeilen-Handles vergleichen Nicht unterstützt
IRowsetIndex Auf Datenbankindizeszugreifen
Nicht unterstützt
IRowsetInfo Informationen zu einerZeilengruppeneigenschaftsuchen oder das Objektsuchen, das die Zeilen-gruppe erstellt hat
Nicht für CE
IRowsetLocate Position in Zeilen einerZeilengruppe, unterVerwendung vonBookmarks
Nicht für CE
IRowsetNotify Bietet eine COM-Callback-Schnittstelle für Zeilen-gruppen-Ereignisse
Unterstützt
IRowsetRefresh Den neuesten Wert fürDaten beziehen, der für eineTransaktion sichtbar ist
Nicht unterstützt
IRowsetResynch Alte OLEDB 1.x-Schnittstelle, vonIRowsetRefresh abgelöst
Nicht unterstützt
IRowsetScroll Durch Zeilengruppeblättern, um Zeilendatenabzurufen
Nicht unterstützt
IRowsetUpdate Änderungen anZeilengruppendatenverzögern, bis Updateaufgerufen wurde
Unterstützt
Nicht für CE
IRowsetView Ansichten für einevorhandene Zeilengruppeverwenden
Nicht unterstützt
ISequentialStream Eine Blob-Spalte abrufen Nur für Lesenunterstützt
Keine Unterstützungvon SetData mitdieser Schnittstelle
Nicht für CE
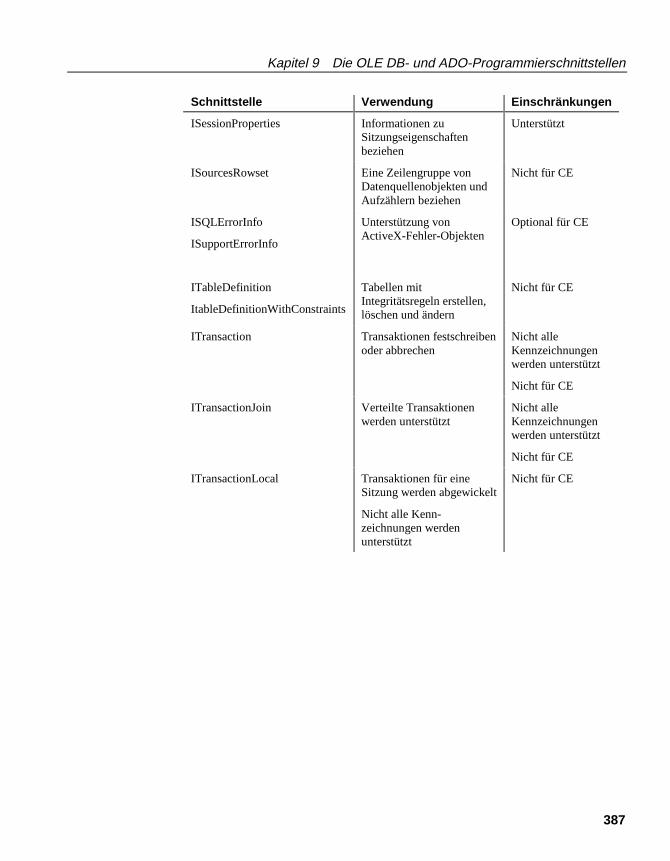
Kapitel 9 Die OLE DB- und ADO-Programmierschnittstellen
387
Schnittstelle Verwendung Einschränkungen
ISessionProperties Informationen zuSitzungseigenschaftenbeziehen
Unterstützt
ISourcesRowset Eine Zeilengruppe vonDatenquellenobjekten undAufzählern beziehen
Nicht für CE
ISQLErrorInfo
ISupportErrorInfo
Unterstützung vonActiveX-Fehler-Objekten
Optional für CE
ITableDefinition
ItableDefinitionWithConstraints
Tabellen mitIntegritätsregeln erstellen,löschen und ändern
Nicht für CE
ITransaction Transaktionen festschreibenoder abbrechen
Nicht alleKennzeichnungenwerden unterstützt
Nicht für CE
ITransactionJoin Verteilte Transaktionenwerden unterstützt
Nicht alleKennzeichnungenwerden unterstützt
Nicht für CE
ITransactionLocal Transaktionen für eineSitzung werden abgewickelt
Nicht alle Kenn-zeichnungen werdenunterstützt
Nicht für CE
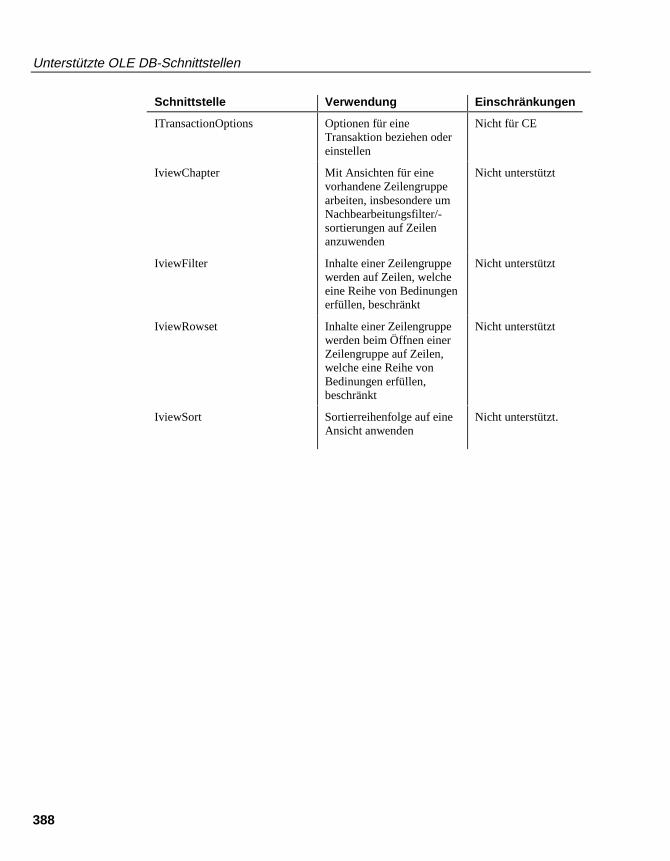
Unterstützte OLE DB-Schnittstellen
388
Schnittstelle Verwendung Einschränkungen
ITransactionOptions Optionen für eineTransaktion beziehen odereinstellen
Nicht für CE
IviewChapter Mit Ansichten für einevorhandene Zeilengruppearbeiten, insbesondere umNachbearbeitungsfilter/-sortierungen auf Zeilenanzuwenden
Nicht unterstützt
IviewFilter Inhalte einer Zeilengruppewerden auf Zeilen, welcheeine Reihe von Bedinungenerfüllen, beschränkt
Nicht unterstützt
IviewRowset Inhalte einer Zeilengruppewerden beim Öffnen einerZeilengruppe auf Zeilen,welche eine Reihe vonBedinungen erfüllen,beschränkt
Nicht unterstützt
IviewSort Sortierreihenfolge auf eineAnsicht anwenden
Nicht unterstützt.

389
K A P I T E L 1 0
Die Open Client-Schnittstelle
Dieses Kapitel beschreibt die Open Client-Programmierschnittstelle fürAdaptive Server Anywhere.
Die primäre Quelle für Informationen zur Open Client-Anwendungsentwicklung ist die Sybase Open Client-Dokumentation. DiesesKapitel beschreibt spezifische Funktionen für Adaptive Server Anywhere; esist jedoch keine umfassende Anleitung für die Anwendungsentwicklung mitOpen Client.
Thema Seite
Was Sie für die Entwicklung von Open Client-Anwendungenbrauchen 390
Datentyp-Zuordnungen 391
SQL in Open Client-Anwendungen verwenden 394
Bekannte Open Client-Einschränkungen von Adaptive ServerAnywhere 398
Über diesesKapitel
Inhalt

Was Sie für die Entwicklung von Open Client-Anwendungen brauchen
390
Was Sie für die Entwicklung von Open Client-Anwendungen brauchen
Um Open Client-Anwendungen auszuführen, müssen Sie Open Client-Komponenten auf dem Rechner installieren und konfigurieren, auf dem dieAnwendung laufen soll. Diese Komponenten sind eventuell bereits als TeilIhrer Installation anderer Sybase Produkte vorhanden; andernfalls könnenSie diese Bibliotheken wahlweise mit Adaptive Server Anywhereentsprechend den Bedingungen Ihres Lizenzvertrags installieren.
Open Client-Anwendungen benötigen keine Open Client-Komponenten aufdem Rechner, auf dem der Datenbankserver läuft.
Um Open Client-Anwendungen zu erstellen, benötigen Sie dieEntwicklungsversion von Open Client. Diese ist bei Sybase erhältlich.
Standardmäßig werden Adaptive Server Anywhere-Datenbanken ohneBerücksichtigung von Groß-/Kleinschreibung erstellt, während AdaptiveServer Enterprise-Datenbanken unter Berücksichtigung von Groß-/Kleinschreibung erstellt werden.
$ Weitere Hinweise zur Ausführung von Open Client-Anwendungen mitAdaptive Server Anywhere finden Sie unter "Adaptive Server Anywhere alsOpen Server" auf Seite 117 der Dokumentation ASADatenbankadministration.

Kapitel 10 Die Open Client-Schnittstelle
391
Datentyp-ZuordnungenOpen Client hat seine eigenen internen Datentypen, die in einigen Detailsvon den Datentypen abweichen, die in Adaptive Server Anywhere zurVerfügung stehen. Aus diesem Grunde ordnet Adaptive Server Anywhereintern einige Datentypen von Open Client-Anwendungen den in AdaptiveServer Anywhere zur Verfügung stehenden Datentypen zu.
Um Open Client Anwendungen zu erstellen, benötigen Sie dieEntwicklungsversion von Open Client. Um Open Client-Anwendungen zuverwenden, müssen die Open Client Laufzeitprogramme auf dem Computerinstalliert und konfiguriert sein, auf dem die Anwendung laufen soll.
Der Adaptive Server Anywhere Server benötigt zur Unterstützung von OpenClient-Anwendungen keine externe Kommunikations-Laufzeit.
Jeder Open Client-Datentyp wird dem entsprechenden Adaptive ServerAnywhere-Datentyp zugeordnet. Es werden alle Open Client-Datentypenunterstützt.
Die folgende Tabelle zeigt die Zuordnung von Datentypen, die in AdaptiveServer Anywhere unterstützt werden, und die keine direkte Entsprechung inOpen Client haben.
Adaptive Server Anywhere-Datentyp
Open Client-Datentyp
unsigned short int
unsigned int bigint
unsigned bigint bigint
date smalldatetime
time smalldatetime
serialization longbinary
java longbinary
string varchar
timestamp struct datetime
Adaptive ServerAnywhere-Datentypen ohnedirekteEntsprechung inOpen Client

Datentyp-Zuordnungen
392
Wertebereichseinschränkungen bei der Zuordnung von Datentypen
Einige Datentypen haben in Adaptive Server Anywhere andereWertebereiche als in Open Client. In solchen Fällen kann es zuÜberlauffehlern während der Abfrage oder des Einfügens von Datenkommen.
Die folgende Tabelle zeigt Open Client-Anwendungsdatentypen, die zwarAdaptive Server Anywhere-Datentypen zugeordnet werden können, aber nurmit einigen Einschränkungen im Wertebereich möglicher Werte.
In den meisten Fällen wird der Open Client-Datentyp einem Adaptive ServerAnywhere-Datentyp zugeordnet, der einen größeren Bereich möglicherWerte hat. Deshalb ist es möglich, einen Wert an Adaptive Server Anywherezu übergeben, der zwar akzeptiert und in einer Datenbank gespeichert wird,der aber zu groß ist, um von einer Open Client-Anwendung abgerufen zuwerden.
Datentyp Untere OpenClient-Grenze
Obere OpenClient-Grenze
Untere ASA-Grenze
Obere ASA-Grenze
MONEY –922 377 203 685477.5808
922 377 203 685477.5807
–1e15 + 0.0001 1e15 – 0.0001
SMALLMONEY –214 748.3648 214 748.3647 –214 748.3648 214 748.3647
DATETIME 1. Januar 1753 31. Dezember9999
1. Januar 0001 31. Dez. 9999
SMALLDATETIME 1. Januar 1900 Juni 2079 1. März 1600 31. Dez. 7910
Die Open Client-Datentypen MONEY und SMALLMONEY umfassen zumBeispiel nicht den gesamten numerischen Bereich der zu Grunde liegendenAdaptive Server Anywhere-Implementierung. Daher kann in einer Spalte inAdaptive Server Anywhere ein Wert enthalten sein, der die Grenzwerte desOpen Client Datentyps MONEY überschreitet. Ruft der Client einen solchenunzulässigen Wert mit Adaptive Server Anywhere ab, wird eineFehlermeldung erzeugt.
Die Implementierung des Open Client-Datentyps TIMESTAMP in AdaptiveServer Anywhere unterscheidet sich von der Implementierung in AdaptiveServer Enterprise. In Adaptive Server Anywhere wird der Wert auf demAdaptive Server Anywhere-Datentyp DATETIME zugeordnet. Dervoreingestellte Wert ist NULL in Adaptive Server Anywhere, der Wert kannalso uneindeutig sein. Im Gegensatz dazu stellt Adaptive Server Enterprisesicher, dass der Wert gleichförmig steigt und somit immer eindeutig ist.
Beispiel
Zeitstempel

Kapitel 10 Die Open Client-Schnittstelle
393
Der Adaptive Server Anywhere Datentyp TIMESTAMP umfasst Jahr,Monat, Tag, Stunde, Minute, Sekunde und Sekundenbruchteile. Außerdemhat der Datentyp DATETIME einen größeren Wertebereich als die OpenClient-Datentypen, die von Adaptive Server Anywhere zugeordnet werden.

SQL in Open Client-Anwendungen verwenden
394
SQL in Open Client-Anwendungen verwendenDieser Abschnitt bietet eine kurze Einführung in die Verwendung von SQLin Open Client-Anwendungen, mit einem Schwerpunkt auf Themen, die fürAdaptive Server Anywhere spezifisch sind.
$ Eine Einführung in die Konzepte finden Sie unter "SQL inAnwendungen verwenden" auf Seite 9. Eine vollständige Beschreibungfinden Sie in Ihrer Open Client-Dokumentation.
SQL Anweisungen ausführen
Sie senden SQL Anweisungen an eine Datenbank, indem Sie sie in die ClientLibrary Funktionsaufrufe einschließen. Die folgenden beiden Aufrufe führenzum Beispiel eine DELETE-Anweisung aus:
ret = ct_command(cmd, CS_LANG_CMD, "DELETE FROM employee WHERE emp_id=105" CS_NULLTERM, CS_UNUSED);ret = ct_send(cmd);
Die Funktion ct_command wird für viele verschiedene Zwecke eingesetzt.
Vorbereitete Anweisungen verwenden
Die Funktion ct_dynamic wird für die Verwaltung von vorbereitetenAnweisungen benutzt. Diese Funktion übernimmt den type-Parameter, derdie Aktion beschreibt, die Sie ausführen.
v Eine vorbereitete Anweisung in Open Client benutzen:
1 Bereiten Sie die Anweisung mit der Funktion ct_dynamic mitCS_PREPARE als type-Parameter vor.
2 Setzen Sie die Anweisungsparameter mit ct_param.
3 Führen Sie die Anweisung mit ct_dynamic mit CS_EXECUTE alstype-Parameter aus.
4 Geben Sie die mit der Anweisung verbundenen Ressourcen frei, indemSie ct_dynamic mit einem CS_DEALLOC-type-Parameterverwenden.

Kapitel 10 Die Open Client-Schnittstelle
395
$ Weitere Informationen über die Verwendung von vorbereitetenAnweisungen in Open Client finden Sie in der Open Client-Dokumentation.
Cursor verwenden
Die Funktion ct_cursor wird für die Verwaltung von Cursorn verwendet.Diese Funktion übernimmt den type-Parameter, der die Aktion beschreibt,die Sie ausführen.
Einige der Cursortypen, die Adaptive Server Anywhere unterstützt, stehen inder Open Client Schnittstelle nicht zur Verfügung. Sie können über OpenClient weder Scroll-Cursor, noch dynamische Scroll-Cursor, nochunempfindliche Cursor benutzen.
Eindeutigkeit und Aktualisierbarkeit sind zwei Eigenschaften von Cursorn.Cursor können eindeutig sein (unabhängig davon, ob sie von der Anwendungbenutzt wird oder nicht, hat jede Zeile einen Primärschlüssel oder eineEindeutigkeitsinformation) oder nicht eindeutig sein. Cursor könnenschreibgeschützt oder aktualisierbar sein. Ist ein Cursor aktualisierbar undnicht eindeutig, kann die Performance leiden, da in diesem Fall keine Zeilenvorab abgerufen werden können. Dies ist unabhängig von derCS_CURSOR_ROWS-Belegung (siehe unten).
Im Gegensatz zu anderen Schnittstellen wie Embedded SQL ordnet OpenClient einem Cursor eine SQL Anweisung als Zeichenfolge zu. EmbeddedSQL bereitet zuerst eine Anweisung vor, dann wird der Cursor mit Hilfe desStatement-Handles deklariert.
v Cursor in Open Client verwenden:
1 Um einen Cursor in Open Client zu deklarieren, verwenden Siect_cursor mit CS_CURSOR_DECLARE als type-Parameter.
2 Nachdem Sie einen Cursor deklariert haben, können Sie steuern, wieviele Zeilen vorab vom Client abgerufen werden, und zwar jedesmalwenn eine Zeile mit ct_cursor mit CS_CURSOR_ROWS als type-Parameter vom Server abgerufen wird.
Vorab abgerufene Zeilen clientseitig zu speichern, reduziert die Anzahlder Serveraufrufe. Dies verbessert sowohl den Gesamtdurchsatz als auchdie Fertigstellungszeit. Vorab abgerufene Zeilen werden nicht sofort andie Anwendung übergeben, sondern werden verwendungsbereit in einemclientseitigen Puffer zwischengespeichert.
UnterstützteCursortypen
Schritte bei derVerwendung vonCursorn

SQL in Open Client-Anwendungen verwenden
396
Die Einstellung der Datenbankoption PREFETCH steuert den Prefetch-Vorgang für andere Schnittstellen. Sie wird von Open ClientVerbindungen nicht beachtet. Die Einstellung CS_CURSOR_ROWSwird bei nicht eindeutigen, aktualisierbaren Cursorn nicht beachtet.
3 Um einen Cursor in Open Client zu öffnen, verwenden Sie ct_cursormit CS_CURSOR_OPEN als type-Parameter.
4 Um eine Zeile in der Anwendung abzurufen, verwenden Sie jeweilsct_fetch.
5 Um einen Cursor zu schließen, verwenden Sie ct_cursor mitCS_CURSOR_CLOSE.
6 In Open Client müssen Sie außerdem die Ressourcen freigeben, die anden Cursor gebunden waren. Verwenden Sie dafür ct_cursor mitCS_CURSOR_DEALLOC. Sie können auch CS_CURSOR_CLOSE mitdem zusätzlichen Parameter CS_DEALLOC benutzen, um dieseVorgänge in einem Schritt auszuführen.
Zeilen mit einen Cursor ändern
Mit Open Client können Sie Zeilen in einem Cursor löschen oderaktualisieren, sofern der Cursor für eine einzelne Tabelle gilt. Der Benutzermuss die Berechtigung zur Aktualisierung der Tabelle haben und der Cursormuss für Aktualisierung markiert sein.
v Zeilen durch einen Cursor verändern:
♦ Statt einen Abruf durchzuführen, können Sie die aktuelle Zeile imCursor mit ct_cursor und CS_CURSOR_DELETE löschen oder mitct_cursor und CS_CURSOR_UPDATE aktualisieren.
Sie können in Open Client-Anwendungen mit einem Cursor keine Zeileneinfügen.
Abfrageergebnisse in Open Client beschreiben
Open Client geht mit Ergebnismengen anders um als andere Adaptive ServerAnywhere-Schnittstellen.
In Embedded SQL und ODBC beschreiben Sie eine Abfrage oder einegespeicherte Prozedur, um die richtige Anzahl und Typen der Variablen zusetzen, die die Ergebnisse aufnehmen sollen. Die Beschreibung wird in derAnweisung selbst gegeben.

Kapitel 10 Die Open Client-Schnittstelle
397
In Open Client brauchen Sie eine Anweisung nicht zu beschreiben. Stattdessen kann jede Zeile, die vom Server zurückgegeben wird, eineBeschreibung Ihrer Inhalte enthalten. Falls Sie ct_command undct_send verwenden, um Anweisungen auszuführen, können Sie dieFunktion ct_results benutzen, um mit allen Aspekten derzurückgegebenen Zeilen umzugehen.
Falls Sie nicht nach dieser Zeile-für-Zeile-Methode vorgehen wollen, könnenSie ct_dynamic verwenden, um eine SQL Anweisung vorzubereiten undct_describe, um die Ergebnismenge zu beschreiben. Dies entsprichtmehr dem Beschreiben von SQL Anweisungen bei anderen Schnittstellen.

Bekannte Open Client-Einschränkungen von Adaptive Server Anywhere
398
Bekannte Open Client-Einschränkungen vonAdaptive Server Anywhere
Mit der Open Client-Schnittstelle können Sie eine Adaptive ServerAnywhere-Datenbank weitgehend wie eine Adaptive Server Enterprise-Datenbank verwenden. Es gibt allerdings einige Einschränkungen, unteranderem folgende:
♦ Commit Service Adaptive Server Anywhere unterstützt AdaptiveServer Enterprise Commit Service nicht.
♦ Funktionen Die Funktionen einer Client/Server-Verbindung bestimmen,welche Clientanforderungen und Serverantworten für diese Verbindungzulässig sind. Folgende Funktionen werden nicht unterstützt:
♦ CS_REG_NOTIF
♦ CS_CSR_ABS
♦ CS_CSR_FIRST
♦ CS_CSR_LAST
♦ CS_CSR_PREV
♦ CS_CSR_REL
♦ CS_DATA_BOUNDARY
♦ CS_DATA_SENSITIVITY
♦ CS_PROTO_DYNPROC
♦ CS_REQ_BCP
♦ Sicherheitsoptionen, wie SSL und verschlüsselte Kennwörter, werdennicht unterstützt.
♦ Open Client-Anwendungen können über TCP/IP oder, wenn verfügbar,über das Named Pipes-Protokoll des lokalen Systems eine Verbindungzu Adaptive Server Anywhere herstellen.
$ Weitere Hinweise zu Funktionen finden Sie in der DokumentationOpen Server Server-Library C Reference Manual (in englischerSprache).

399
K A P I T E L 1 1
Dreischichtige Datenverarbeitung undverteilte Transaktionen
In diesem Kapitel wird beschrieben, wie Adaptive Server Anywhere in einerdreischichtigen Umgebung mit einem Anwendungsserver verwendet wird.Der Schwerpunkt ist, wie Adaptive Server Anywhere in verteilteTransaktionen einbezogen werden kann.
Thema Seite
Einleitung 400
Dreischichtige Datenverarbeitungsarchitektur 401
Verteilte Transaktionen verwenden 405
EAServer mit Adaptive Server Anywhere verwenden 407
Über diesesKapitel
Inhalt

Einleitung
400
EinleitungSie können Adaptive Server Anywhere als Datenbankserver oder alsRessourcen-Manager einsetzen, der an verteilten Transaktionen teilnimmt,die von einem Transaktionsserver koordiniert werden.
Eine dreischichtige Umgebung, in der ein Anwendungsserver zwischenClientanwendung und einer Reihe von Ressourcen-Managern sitzt, ist eineübliche Umgebung für verteilte Transaktionen. Sybase EAServer und einigeandere Anwendungsserver sind ebenfalls Transaktionsserver.
Sybase EAServer und Microsoft Transaction Server verwenden beide denMicrosoft Distributed Transaction Coordinator (DTC) zum Koordinieren derTransaktionen. Adaptive Server Anywhere bietet Unterstützung für verteilteTransaktionen, die vom DTC-Service kontrolliert werden, sodass SieAdaptive Server Anywhere mit einem dieser Anwendungsserver oder einemanderen DTC-basierten Produkt verwenden können.
Wenn Sie Adaptive Server Anywhere in eine dreischichtige Umgebungintegrieren, muss der Großteil der Arbeit vom Anwendungsserver erledigtwerden. Dieses Kapitel ist eine Einführung in die Konzepte und dieArchitektur der dreischichtigen Datenverarbeitung sowie ein Überblick überdie relevanten Adaptive Server Anywhere-Funktionen. Es beschreibt nicht,wie Ihr Anwendungsserver für die Arbeit mit Adaptive Server Anywherekonfiguriert werden muss. Weitere Hinweise finden Sie in derAnwendungsserver-Dokumentation.

Kapitel 11 Dreischichtige Datenverarbeitung und verteilte Transaktionen
401
Dreischichtige DatenverarbeitungsarchitekturBei der dreistufigen Datenverarbeitung wird die Anwendungslogik auf einemAnwendungsserver wie einem Sybase EAServer gespeichert, der sichzwischen dem Ressourcen-Manager und der Clientanwendung befindet. Invielen Situationen kann ein einziger Anwendungsserver auf mehrereRessourcen-Manager zugreifen. Bei Internetanwendungen ist die Clientseitebrowserbasiert, und der Anwendungsserver ist im Allgemeinen eineWebserver-Erweiterung.
Anwendungs-Server
Sybase EAServer speichert die Anwendungslogik in Form vonKomponenten und stellt diese den Clientanwendungen zur Verfügung. Beiden Komponenten kann es sich um PowerBuilder-Komponenten, JavaBeansoder COM-Komponenten handeln.
$ Weitere Hinweise finden Sie in der Dokumentation zum SybaseEAServer.

Dreischichtige Datenverarbeitungsarchitektur
402
Verteilte Transaktionen in dreischichtiger Datenverarbeitung
Wenn Clientanwendungen oder Anwendungsserver mit einer einfachenTransaktionsverarbeitungs-Datenbank arbeiten, wie etwa Adaptive ServerAnywhere, wird außerhalb der Datenbank selbst keine Transaktionslogikbenötigt. Wenn jedoch mit mehreren Ressourcen-Managern gearbeitet wird,muss die Transaktionssteuerung die in die Transaktion einbezogenenRessourcen abdecken. Anwendungsserver bieten ihren ClientanwendungenTransaktionslogik, sodass Gruppen von Vorgängen in kleinsten Einheitenausgeführt werden.
Viele Transaktionsserver, einschließlich Sybase EAServer, verwenden denMicrosoft Distributed Transaction Coordinator (DTC), um denClientanwendungen Transaktionsdienste anzubieten. DTC verwendet OLE-Transaktionen, die ihrerseits das Protokoll Zwei-Phasen-Commit für dieKoordinierung von Transaktionen mit mehreren Ressourcen-Managernverwenden. Um die in diesem Kapitel beschriebenen Funktionen verwendenzu können, müssen Sie DTC installiert haben.
Adaptive Server Anywhere in verteilten Transaktionen
Adaptive Server Anywhere kann an von DTC koordinierten Transaktionenteilnehmen. Das bedeutet, dass Sie Adaptive Server Anywhere-Datenbankenin verteilten Transaktionen mit einem Transaktionsserver wie etwa SybaseEAServer oder Microsoft Transaction Server verwenden können. Außerdemkönnen Sie DTC direkt in Ihren Anwendungen zur Koordinierung vonTransaktionen über mehrere Ressourcen-Manager einsetzen.
Begriffe im Zusammenhang mit verteilten Transaktionen
In diesem Kapitel wird eine gewisse Vertrautheit mit verteiltenTransaktionen vorausgesetzt. Hinweise finden Sie in der Dokumentation zumTransaktionsserver. In diesem Abschnitt werden allgemein übliche Begriffebeschrieben.
♦ Ressourcen-Manager sind Dienste, die in eine Transaktioneinbezogene Daten verwalten.
Der Adaptive Server Anywhere-Datenbankserver kann in einerverteilten Transaktion als Ressourcen-Manager agieren, wenn über OLEDB oder ODBC darauf zugegriffen wird. Der ODBC-Treiber und derOLE DB-Provider agieren auf dem Client-System als Ressourcen-Manager-Proxys.

Kapitel 11 Dreischichtige Datenverarbeitung und verteilte Transaktionen
403
♦ Anstatt direkt mit dem Ressourcen-Manager, könnenAnwendungskomponenten mit Ressourcen-Verteilern kommunizieren,die ihrerseits Verbindungen oder Verbindungs-Pools zu den Ressourcen-Managern verwalten.
Adaptive Server Anywhere unterstützt zwei Ressourcen-Verteiler: denODBC-Treibermanager und OLE DB.
♦ Wenn eine Transaktionskomponente eine Datenbankverbindunganfordert (über einen Ressourcen-Manager), bezieht derAnwendungsserver alle Datenbankverbindungen ein, die an derTransaktion teilnehmen. DTC und der Ressourcen-Verteiler führen denEinbeziehungsvorgang aus.
Verteilte Transaktionen werden mit Zwei-Phasen-Commit verwaltet. Wenndie Arbeit der Transaktion abgeschlossen ist, fragt der Transaktions-Manager(DTC) alle in die Transaktion einbezogenen Ressourcen-Manager, ob siebereit sind, die Transaktion festzuschreiben. Diese Phase wird Vorbereitenzum Festschreiben genannt.
Wenn alle Ressourcen-Manager antworten, dass sie zum Festschreiben bereitsind, sendet DTC eine Anforderung zum Festschreiben an jeden einzelnenRessourcen-Manager und antwortet seinem Client, dass die Transaktionabgeschlossen ist. Wenn einer oder mehrere Ressourcen-Manager nichtantworten oder antworten, dass sie die Transaktion nicht festschreibenkönnen, wird die gesamte Arbeit der Transaktion über alle Ressourcen-Manager zurückgesetzt.
So verwenden Anwendungsserver DTC
Sybase EAServer und Microsoft Transaction Server sind beidesKomponentenserver. Die Anwendungslogik wird in Form von Komponentengespeichert und den Clientanwendungen zur Verfügung gestellt.
Jede Komponente hat ein Transaktionsattribut, das darauf hinweist, wie dieKomponente an Transaktionen teilnimmt. Der Anwendungsentwickler, derdie Komponente aufbaut, muss die Arbeit der Transaktion in dieKomponente einprogrammieren: Die Ressourcen-Manager-Verbindungen,die Vorgänge mit den Daten, für die jeder einzelne Ressourcen-Managerverantwortlich ist. Der Anwendungsentwickler braucht jedoch nicht dieTransaktionsverwaltungslogik in die Komponente einzubauen. Wenn dasTransaktionsattribut so gesetzt ist, dass darauf hingewiesen wird, dass dieKomponente eine Transaktionsverwaltung benötigt, verwendet EAServerDTC, um die Transaktion einzubeziehen und den Zwei-Phasen-Commit-Vorgang zu verwalten.
Zwei-Phasen-Commit

Dreischichtige Datenverarbeitungsarchitektur
404
Verteilte Transaktionsarchitektur
Das folgende Diagramm veranschaulicht die Architektur von verteiltenTransaktionen. In diesem Fall ist der Ressourcen-Manager-Proxy entwederODBC oder OLE DB.
DTCDTC
DTCRessourcen-
Manager-Proxy
Ressourcen-Manager-
Proxy
Anwendungs-Server
Client-System
Server-system 1
Server-system 2
In diesem Fall wird ein einzelner Ressourcen-Verteiler verwendet. DerAnwendungsserver fordert DTC auf, die Transaktion vorzubereiten. DTCund der Ressourcen-Verteiler beziehen jede einzelne Verbindung in dieTransaktion ein. Jeder einzelne Ressourcen-Manager muss sowohl mit DTCals auch mit der Datenbank in Kontakt stehen, damit die Arbeit ausgeführtwerden kann, und um DTC ggf. auf seinen Transaktionsstatus hinzuweisen.
Auf jedem System muss ein DTC-Dienst laufen, damit die verteiltenTransaktionen ausgeführt werden können. DTC-Dienste können vomSymbol "Dienste" in der Windows-Systemsteuerung aus kontrolliert werden.Der DTC-Dienst heißt MSDTC.
$ Weitere Hinweise finden Sie in der Dokumentation zu DTC bzw.EAServer.

Kapitel 11 Dreischichtige Datenverarbeitung und verteilte Transaktionen
405
Verteilte Transaktionen verwendenWenn Adaptive Server Anywhere in eine verteilte Transaktion einbezogenist, gibt er die Kontrolle an den Transaktionsserver weiter und AdaptiveServer Anywhere gewährleistet, dass keine implizite Transaktionsverwaltungausgeführt wird. Die folgenden Bedingungen werden automatisch vonAdaptive Server Anywhere auferlegt, wenn er an verteilten Transaktionenteilnimmt:
♦ Autocommit wird automatisch deaktiviert, wenn es verwendet wurde.
♦ Datendefinitions-Anweisungen (als Nebenwirkung festgeschrieben)werden während der verteilten Transaktionen deaktiviert.
♦ Ein explizites COMMIT oder ROLLBACK von der Anwendung direktan Adaptive Server Anywhere anstatt über den Transaktionskoordinatorführt zu einer Fehlermeldung. Die Transaktion wird jedoch nichtabgebrochen.
♦ Eine Verbindung kann jeweils nur an einer verteilten Transaktionteilnehmen.
♦ Zu dem Zeitpunkt, wenn die Verbindung in eine verteilte Transaktioneinbezogen wird, darf es keine nicht festgeschriebenen Vorgänge geben.
DTC-Isolationsstufen
DTC weist eine Reihe von Isolationsstufen auf, die der Anwendungsserverangibt. Diese Isolationsstufen entsprechen folgendermaßen denIsolationsstufen von Adaptive Server Anywhere:
DTC-Isolationsstufe Adaptive ServerAnywhere-Isolationsstufe
ISOLATIONLEVEL_UNSPECIFIED 0
ISOLATIONLEVEL_CHAOS 0
ISOLATIONLEVEL_READUNCOMMITTED 0
ISOLATIONLEVEL_BROWSE 0
ISOLATIONLEVEL_CURSORSTABILITY 1
ISOLATIONLEVEL_READCOMMITTED 1
ISOLATIONLEVEL_REPEATABLEREAD 2
ISOLATIONLEVEL_SERIALIZABLE 3
ISOLATIONLEVEL_ISOLATED 3

Verteilte Transaktionen verwenden
406
Wiederherstellung nach verteilten Transaktionen
Wenn der Datenbankserver einen Fehler aufweist, während nichtfestgeschriebene Vorgänge auf Ausführung warten, müssen diese Vorgängebeim Neustart entweder zurückgesetzt oder festgeschrieben werden, damitdie atomare Natur der Transaktion geschützt wird.
Wenn während der Wiederherstellung nicht festgeschriebene Vorgänge einerverteilten Transaktion gefunden werden, versucht der Datenbankserver eineVerbindung mit DTC herzustellen und fordert, wieder in die auf Ausführungwartenden bzw. in die zweifelhaften Transaktionen einbezogen zu werden.Wenn die Wiedereinbeziehung abgeschlossen ist, weist DTC denDatenbankserver an, die ausstehenden Vorgänge zurückzusetzen oderfestzuschreiben.
Wenn der Wiedereinbeziehungsvorgang fehlschlägt, kann Adaptive ServerAnywhere nicht wissen, ob die zweifelhaften Vorgänge festgeschrieben oderzurückgesetzt werden sollten, und die Wiederherstellung schlägt fehl. WennSie wollen, dass die Datenbank wieder in solch einem Status hergestellt wird,unabhängig vom unsicheren Status der Daten, können Sie dieWiederherstellung mit den folgenden Datenbankserveroptionen erzwingen:
♦ -tmf Wenn DTC nicht geladen werden kann, werden die ausstehendenVorgänge zurückgesetzt und die Wiederherstellung wird fortgesetzt.
$ Weitere Hinweise finden Sie unter "–tmf-Serveroption" aufSeite 169 der Dokumentation ASA Datenbankadministration.
♦ -tmt Wenn die Wiedereinbeziehung vor der angegebenen Zeit nichtgelingt, werden die ausstehenden Vorgänge zurückgesetzt und dieWiederherstellung wird fortgesetzt.
$ Weitere Hinweise finden Sie unter "–tmt-Serveroption" aufSeite 169 der Dokumentation ASA Datenbankadministration.

Kapitel 11 Dreischichtige Datenverarbeitung und verteilte Transaktionen
407
EAServer mit Adaptive Server Anywhereverwenden
Dieser Abschnitt bietet einen Überblick über die in EAServer 3.0 oder späterfür die Arbeit mit Adaptive Server Anywhere zu ergreifenden Maßnahmen.Weitere Hinweise finden Sie in der Dokumentation zum Sybase EAServer.
EA Server konfigurieren
Alle in einem Sybase EAServer installierten Komponenten nutzengemeinsam denselben Transaktionskoordinator.
EAServer 3.0 und später bieten eine Auswahl vonTransaktionskoordinatoren. Sie müssen DTC als Transaktionskoordinatorverwenden, wenn Sie Adaptive Server Anywhere in die Transaktioneneinbeziehen. In diesem Abschnitt wird beschrieben, wie EAServer 3.0 für dieBenutzung von DTC als Transaktionskoordinator konfiguriert wird.
Der Komponentenserver in EAServer trägt den Namen Jaguar.
v So wird ein EAServer für die Verwendung des Microsoft DTCTransaktionsmodells konfiguriert:
1 Vergewissern Sie sich, dass Ihr Jaguar-Server läuft.
Unter Windows läuft der Jaguar-Server normalerweise als Dienst. Wennder mit EAServer 3.0 installierte Jaguar-Server manuell gestartet werdensoll, wählen Sie Start➤Programme➤Sybase➤EAServer➤EAServer.
2 Starten Sie den Jaguar Manager.
Wählen Sie vom Windows DesktopStart➤Programme➤Sybase➤EAServer➤Jaguar Manager.
3 Stellen Sie vom Jaguar Manager aus eine Verbindung mit dem Jaguar-Server her.
Wählen Sie im Sybase Central-Menü Extras➤Verbinden➤JaguarManager. Geben Sie im Verbindungsdialog jagadmin alsBenutzernamen ein, lassen Sie das Kennwortfeld leer und geben Sie denHostnamen localhost ein. Klicken Sie auf OK, damit eine Verbindunghergestellt wird.
4 Legen Sie das Transaktionsmodell für den Jaguar-Server fest.

EAServer mit Adaptive Server Anywhere verwenden
408
Öffnen Sie im linken Fensterausschnitt den Ordner "Server".Rechtsklicken Sie im rechten Fensterausschnitt auf den Server, den Siekonfigurieren wollen und wählen Sie "Servereigenschaften" aus demMenü. Öffnen Sie das Register "Transaktionen" und wählen SieMicrosoft DTC als Transaktionsmodell. Klicken Sie auf OK, damit derVorgang abgeschlossen wird.
Komponenten-Transaktionsattribut festlegen
Im EAServer können Sie eine Komponente implementieren, die Vorgängemit mehr als einer Datenbank ausführt. Sie weisen dieser Komponente einTransaktionsattribut zu, das festlegt, wie sie an Transaktionen teilnimmt.Das Transaktionsattribut kann die folgenden Werte annehmen:
♦ Nicht unterstützt Die Methoden der Komponente werden nie als Teileiner Transaktion ausgeführt. Wird die Komponente von einer anderenKomponente aktiviert, die innerhalb einer Transaktion ausgeführt wird,dann wird die Arbeit der neuen Instanz außerhalb der vorhandenenTransaktion ausgeführt. Dies ist die Standardeinstellung.
♦ Unterstützt Transaktion Die Komponente kann im Kontext einerTransaktion ausgeführt werden, eine Verbindung ist jedoch nichterforderlich, um die Methoden der Komponente auszuführen. Wenn dieKomponente direkt von einem Basis-Clienten instanziert wird, beginntEAServer keine Transaktion. Wenn Komponente A von Komponente Binstanziert und Komponente B innerhalb einer Transaktion ausgeführtwird, führt das System die Komponente A in derselben Transaktion aus.
♦ Erfordert Transaktion Die Komponente wird immer in einerTransaktion ausgeführt. Wenn die Komponente direkt von einem Basis-Client instanziert wird, beginnt eine neue Transaktion. WennKomponente A von Komponente B aktiviert wird und B innerhalb einerTransaktion ausgeführt wird, führt das System A innerhalb derselbenTransaktion aus, wenn B nicht in einer Transaktion ausgeführt wird,führt das System A in einer neuen Transaktion aus.
♦ Erfordert neue Transaktion Wenn die Komponente instanziert wird,beginnt eine neue Transaktion. Wenn Komponente A von KomponenteB aktiviert wird und B innerhalb einer Transaktion ausgeführt wird,beginnt A einen neue Transaktion, die unabhängig ist vom Ergebnis derTransaktion B, wenn B nicht in einer Transaktion ausgeführt wird, führtdas System A in einer neuen Transaktion aus.

Kapitel 11 Dreischichtige Datenverarbeitung und verteilte Transaktionen
409
In der Beispielanwendung Sybase Virtual University, die mit EAServer alsSVU-Paket geliefert wird, führt die Methode enroll() der KomponenteSVUEnrollment zwei separate Vorgänge aus (reserviert einen Platz ineinem Kurs, fakturiert den Studenten für den Kurs). Diese beiden Vorgängemüssen als Einzel-Transaktionen behandelt werden.
Microsoft Transaction Server bietet dieselbe Gruppe von Attributwerten.
v So wird das Transaktionsattribut einer Komponente festgelegt:
1 Ermitteln Sie die Position der Komponente im Jaguar Manager.
Wenn Sie die Komponente SVUEnrollment in der Jaguar-Beispielanwendung suchen wollen, stellen Sie eine Verbindung mit demJaguar-Server her, öffnen Sie den Ordner "Pakete" und öffnen Sie dasSVU-Paket. Die Komponenten im Paket werden im rechtenFensterausschnitt aufgeführt.
2 Legen Sie das Transaktionsattribut für die gewünschte Komponente fest.
Rechtsklicken Sie auf die Komponente und klicken Sie auf"Komponenten-Eigenschaften" im Einblendmenü. Öffnen Sie dasRegister "Transaktion" und wählen Sie den Wert für dasTransaktionsattribut aus der Liste. Klicken Sie auf OK, damit derVorgang abgeschlossen wird.
Die Komponente SVUEnrollment ist bereits als "Erfordert Transaktion"markiert.
Wenn das Komponenten-Transaktionsattribut festgelegt ist, können SieAdaptive Server Anywhere-Vorgänge von der Komponente aus ausführenund sicher sein, dass die Transaktion auf der Ebene ausgeführt wird, die Sieangegeben haben.

EAServer mit Adaptive Server Anywhere verwenden
410

411
K A P I T E L 1 2
Deployment: Datenbanken undAnwendungen im System bereitstellen
In diesem Kapitel wird beschrieben, wie Komponenten von Adaptive ServerAnywhere für die allgemeine Nutzung im System bereitgestellt werdenkönnen. Beschrieben werden die erforderlichen Dateien für dieBereitstellung sowie Fragen im Zusammenhang mit der Adressierung undder Einstellung von Verbindungsparametern.
Prüfen Sie Ihre LizenzvereinbarungDie Weitergabe von Dateien wird durch die Lizenzvereinbarung geregelt.In diesem Kapitel enthaltene Ausführungen können die BestimmungenIhrer Lizenzvereinbarung weder aufheben noch ändern. Bevor Sie daherAnwendungen im System bereitstellen, prüfen Sie bitte IhreLizenzvereinbarung.
Thema Seite
Systemeinführung - Überblick 412
Installationsverzeichnisse und Dateinamen 415
InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden 420
Dialogfreie Installation für die Systemeinführung 422
Clientanwendungen im System bereitstellen 426
Tools zur Verwaltung bereitstellen 437
Datenbankserver im System bereitstellen 438
Eingebettete Datenbankanwendungen im System bereitstellen 441
Über diesesKapitel
Inhalt

Systemeinführung - Überblick
412
Systemeinführung - ÜberblickWenn Sie eine Datenbankanwendung fertig gestellt haben, müssen Sie dieAnwendung für Ihre Endbenutzer bereitstellen. Je nach der Art, wie IhreAnwendung Adaptive Server Anywhere verwendet (als eingebetteteDatenbank, im Client-/Servermodus usw.), müssen Sie Komponenten vonAdaptive Server Anywhere zusammen mit Ihrer Anwendung bereitstellen. Eskann außerdem erforderlich sein, Konfigurationsdaten bereitzustellen, wieetwa Datenquellennamen, damit die Anwendung mit Adaptive ServerAnywhere kommunizieren kann.
Prüfen Sie Ihre LizenzvereinbarungDie Weitergabe von Dateien wird durch die Lizenzvereinbarung mitSybase geregelt. In diesem Kapitel enthaltene Ausführungen können dieBestimmungen Ihrer Lizenzvereinbarung weder aufheben noch ändern.Bevor Sie daher Anwendungen im System bereitstellen, prüfen Sie bitteIhre Lizenzvereinbarung.
Folgende Bereiche der Systemeinführung werden in diesem Kapitelbesprochen:
♦ Ermittlung der erforderlichen Dateien je nach Anwendungsplattformund Plattformarchitektur
♦ Konfiguration der Clientanwendungen
Eine großer Teil des Kapitels befasst sich mit einzelnen Dateien und wo sieplatziert werden müssen. Es wird jedoch empfohlen, Adaptive ServerAnywhere-Komponenten unter Verwendung der Installshield-Objekte oderdialogfrei zu installieren. Hinweise finden Sie unter "InstallShield-Objekteund Vorlagen zum Bereitstellen verwenden" auf Seite 420 und "DialogfreieInstallation für die Systemeinführung" auf Seite 422.
Modelle für die Systemeinführung
Welche Dateien Sie bei der Systemeinführung bereitstellen müssen, hängtvom gewählten Modell ab. Nachstehend werden einige denkbare Modellebeschrieben:
♦ Clientbereitstellung Sie können nur die Clientkomponenten vonAdaptive Server Anywhere für die Endbenutzer bereitstellen, sodassdiese sich mit einem zentral untergebrachten Netzwerk-Datenbankserververbinden können.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
413
♦ Netzwerkserver bereitstellen Sie können Netzwerkserver inZweigstellen einrichten und dann Clients für alle Benutzer in diesenBüros bereitstellen.
♦ Eingebettete Datenbanken bereitstellen Sie können eine Datenbankbereitstellen, die mit einem Personal Datenbankserver läuft. In diesemFall müssen der Client und der Personal Server auf dem Rechner desEndbenutzers installiert werden.
♦ Bereitstellung über SQL Remote Die Bereitstellung einer SQLRemote-Anwendung ist eine Erweiterung des Modells der Bereitstellungeiner eingebetteten Datenbank.
♦ DBTools-Bereitstellung Sie können Interactive SQL, Sybase Centralund andere Tools zur Verwaltung bereitstellen.
Möglichkeiten zur Weitergabe von Dateien
Es gibt zwei Möglichkeiten, Adaptive Server Anywhere für den allgemeinenGebrauch verfügbar zu machen:
♦ Sie benutzen das Installationsprogramm von Adaptive ServerAnywhere Sie können das Setup-Programm den Endbenutzern zurVerfügung stellen. Wenn der Endbenutzer die richtigenInstallationsoptionen wählt, verfügt er garantiert über alle erforderlichenDateien.
Dies ist die einfachste Lösung für viele Fälle der Systemeinführung. Indiesem Fall müssen Sie den Endbenutzern nur noch eine Methode zurVerbindungsaufnahme mit dem Datenbankserver übergeben (z.B. eineODBC-Datenquelle).
$ Weitere Hinweise finden Sie unter "Dialogfreie Installation für dieSystemeinführung" auf Seite 422.
♦ Entwicklung Ihrer eigenen Installation Es kann Gründe dafür geben,dass Sie ein eigenes Installationsprogramm entwickeln wollen, dasDateien von Adaptive Server Anywhere enthält. Diese Option ist vielkomplizierter, und daher richtet sich der größte Teil dieses Kapitels anjene, die eigene Installationen entwickeln müssen.
Wenn Adaptive Server Anywhere bereits passend für den Servertyp unddas Betriebssystem der Clientanwendung installiert wurde, stehen dieerforderlichen Dateien in dem entsprechend benannten Unterverzeichnisbereit, das im Installationsverzeichnis von Adaptive Server Anywhereangelegt wurde.

Systemeinführung - Überblick
414
Wenn beispielsweise das Standard-Installationsverzeichnis gewähltwurde, enthält das Unterverzeichnis win32 im Installationsverzeichnisdie Dateien, die benötigt werden, um den Server unter Windows-Betriebssystemen zu betreiben.
Ebenso können Anwender von InstallShield Professional 5.5 und höherdie InstallShield-Vorlagenprojekte für SQL Anywhere Studioverwenden, um ihre eigenen Anwendungen bereitzustellen. Mit dieserFunktion erstellen Sie das Installationsprogramm für Ihre Anwendung,indem Sie das gesamte Vorlagenprojekt oder nur die für Ihre Installationrelevanten Teile verwenden.
Gleichgültig welche Option Sie wählen: Sie müssen sich dabei immer an dieBestimmungen Ihrer Lizenz halten.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
415
Installationsverzeichnisse und DateinamenDamit eine im System bereitgestellte Anwendung richtig funktioniert,müssen die Clientbibliotheken ermitteln können, wo die erforderlichenDateien untergebracht sind. Die bereitgestellten Dateien müssen in derselbenStruktur gespeichert werden wie in der Installation von Adaptive ServerAnywhere.
In der Praxis bedeutet das, dass auf einem PC die meisten Dateien in eineinziges Verzeichnis gehören. Unter Windows z.B. werden Dateien für denDatenbankserver und für den Client in nur einem Verzeichnis installiert,nämlich dem Unterverzeichnis win32 des Installationsverzeichnisses vonAdaptive Server Anywhere.
$ Eine vollständige Beschreibung der Standorte, an denen die Softwarenach Dateien sucht, finden Sie unter "Ermittlung des Dateienstandorts durchAdaptive Server Anywhere" auf Seite 228 der Dokumentation ASADatenbankadministration.
Anwendungen unter UNIX bereitstellen
Die Bereitstellung von Anwendungen unter UNIX unterscheidet sich von derauf PC üblichen in folgender Weise:
♦ Verzeichnisstruktur Bei UNIX-Installationen lautet dieVerzeichnisstruktur wie folgt:
Verzeichnis Inhalt
/opt/sybase/SYBSsa8/bin Programmdateien
/opt/sybase/SYBSsa8/lib Gemeinsame Objekte und Bibliotheken
/opt/sybase/SYBSsa8/res Textdateien
Auf AIX lautet das standardmäßige Stammverzeichnis/usr/lpp/sybase/SYBSsa8 an Stelle von /opt/sybase/SYBSsa8.
♦ Dateierweiterungen In den Tabellen dieses Kapitels werden diegemeinsamen Objekte mit der Erweiterung .so angeführt. Unter HP-UXlautet diese Erweiterung .sl.
Im Betriebssystem AIX haben gemeinsam genutzte Dateien, mit denensich Anwendungen verknüpfen müssen, die Erweiterung .a.

Installationsverzeichnisse und Dateinamen
416
♦ Symbolische Verknüpfungen Jedes gemeinsam genutzte Objekt ist alssymbolische Verknüpfung zu einer Datei gleichen Namens mit derzusätzlichen Erweiterung .1 (eins) installiert. Beispiel: Die Dateilibdblib8.so ist eine symbolische Verknüpfung zur Datei libdblib8.so.1 indemselben Verzeichnis.
Wenn Korrekturprogramme für die Installation von Adaptive ServerAnywhere erforderlich sind, werden sie mit der Erweiterung .2 geliefertund die symbolische Verknüpfung muss umgeleitet werden.
♦ Anwendungen mit und ohne Threads Die meisten gemeinsamgenutzten Objekte werden in zwei Formen geliefert, von denen eine mitden zusätzlichen Zeichen _r vor der Dateierweiterung versehen ist.Beispiel: Zusätzlich zu libdblib8.so gibt es eine Datei mit derBezeichnung libdblib8_r.so. In diesem Fall müssen Anwendungen mitThread mit dem gemeinsam genutzten Objekt _r verknüpft werden,Anwendungen ohne Thread hingegen mit dem gemeinsam genutztenObjekt ohne den Zusatz _r.
♦ Zeichensatzkonvertierung Wenn Sie die Zeichensatzkonvertierungdes Datenbankservers (Serveroption -ct) benutzen möchten, müssen diefolgenden Dateien hinzugefügt werden:
♦ libunic.so
♦ Verzeichnisstruktur charsets/
♦ asa.cvf
$ Eine Beschreibung der Standorte, an denen die Software nach Dateiensucht, finden Sie unter "Ermittlung des Dateienstandorts durch AdaptiveServer Anywhere" auf Seite 228 der Dokumentation ASADatenbankadministration.
Namenskonventionen für Dateien
Adaptive Server Anywhere benutzt einheitliche Konventionen, damit Sie dieSystemkomponenten leichter erkennen und zu Gruppen zusammenfassenkönnen.
Diese Konventionen sind wie folgt aufgebaut:
♦ Versionsnummer Die Versionsnummer von Adaptive Server Anywherewird im Dateinamen der Haupt-Serverkomponenten (.exe and .dllDateien) dargestellt.
Beispiel: Die Datei dbeng8.exe ist eine Programmdatei für Version 7.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
417
♦ Sprache Die in einer Sprachen-Ressourcebibliothek verwendeteSprache wird durch einen Sprachcode im Dateinamen angezeigt. Diezwei Zeichen vor der Versionsnummer weisen auf die in der Bibliothekverwendete Sprache hin. Zum Beispiel ist dblgen8.dll die Sprachen-Ressourcebibliothek für Englisch. Diese Codes aus zwei Buchstabensind im ISO-Standard 639 festgelegt.
$ Weitere Hinweise zur Sprachenkennzeichnung finden Sie unter"Näheres zur Sprache der Sprachumgebung" auf Seite 288 derDokumentation ASA Datenbankadministration.
Sie können das International Resources Deployment Kit, das DLLs für dieBereitstellung von Sprachressourcen enthält, gratis von der Sybase-Websiteherunterladen.
v So laden Sie das International Resources Deployment Kit von derSybase-Website herunter:
1 Öffnen Sie im Webbrowser den folgenden URL:
http://www.sybase.com/products/mobilewireless/anywhere/
2 Klicken Sie unterhalb der Überschrift "SQL Anywhere Studio" links aufder Seite auf "Downloads".
3 Klicken Sie unterhalb der Überschrift "Emergency Bug Fix/Updates"auf "Emergency Bug Fixes and Updates for SQL Anywhere Studio".
4 Melden Sie sich bei Ihrem Sybase-Netzkonto an.
Klicken Sie auf "Create a New Account", um ein Sybase-Netzkonto zuerstellen, falls Sie noch keines haben.
5 Aus der Liste der verfügbaren Downloads wählen Sie das InternationalResources Deployment Kit aus, das der verwendeten Plattform undVersion von Adaptive Server Anywhere entspricht.
$ Eine Liste der in Adaptive Server Anywhere verfügbaren Sprachenfinden Sie unter "Mitgelieferte Kollatierungen" auf Seite 295 derDokumentation ASA Datenbankadministration.
Die folgende Tabelle zeigt die Plattform und die Funktion der AdaptiveServer Anywhere-Dateien entsprechend ihrer Dateierweiterung. In AdaptiveServer Anywhere wurden, wo immer möglich, die Standard-Dateierweiterungen verwendet.
Andere Dateitypenerkennen
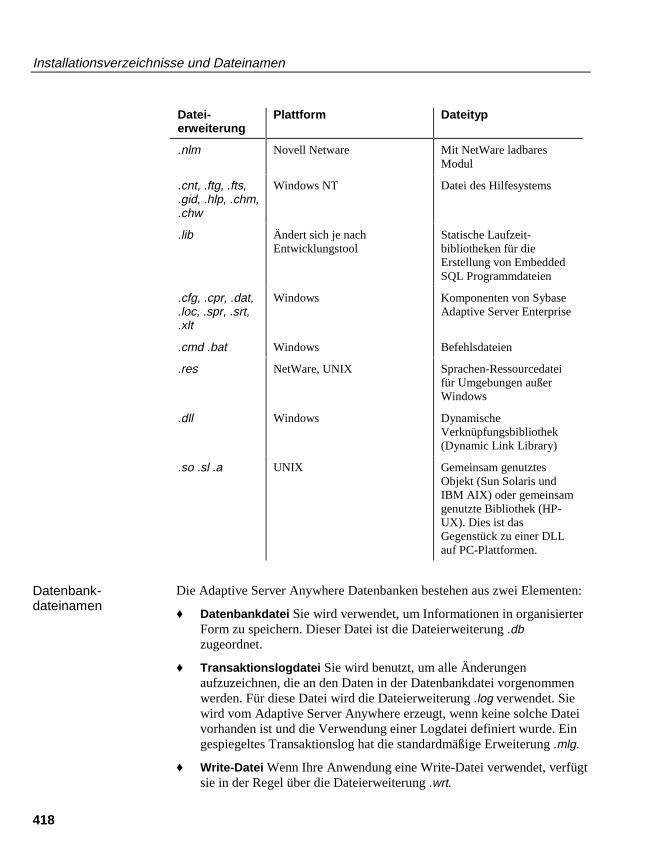
Installationsverzeichnisse und Dateinamen
418
Datei-erweiterung
Plattform Dateityp
.nlm Novell Netware Mit NetWare ladbaresModul
.cnt, .ftg, .fts,
.gid, .hlp, .chm,
.chw
Windows NT Datei des Hilfesystems
.lib Ändert sich je nachEntwicklungstool
Statische Laufzeit-bibliotheken für dieErstellung von EmbeddedSQL Programmdateien
.cfg, .cpr, .dat,
.loc, .spr, .srt,
.xlt
Windows Komponenten von SybaseAdaptive Server Enterprise
.cmd .bat Windows Befehlsdateien
.res NetWare, UNIX Sprachen-Ressourcedateifür Umgebungen außerWindows
.dll Windows DynamischeVerknüpfungsbibliothek(Dynamic Link Library)
.so .sl .a UNIX Gemeinsam genutztesObjekt (Sun Solaris undIBM AIX) oder gemeinsamgenutzte Bibliothek (HP-UX). Dies ist dasGegenstück zu einer DLLauf PC-Plattformen.
Die Adaptive Server Anywhere Datenbanken bestehen aus zwei Elementen:
♦ Datenbankdatei Sie wird verwendet, um Informationen in organisierterForm zu speichern. Dieser Datei ist die Dateierweiterung .dbzugeordnet.
♦ Transaktionslogdatei Sie wird benutzt, um alle Änderungenaufzuzeichnen, die an den Daten in der Datenbankdatei vorgenommenwerden. Für diese Datei wird die Dateierweiterung .log verwendet. Siewird vom Adaptive Server Anywhere erzeugt, wenn keine solche Dateivorhanden ist und die Verwendung einer Logdatei definiert wurde. Eingespiegeltes Transaktionslog hat die standardmäßige Erweiterung .mlg.
♦ Write-Datei Wenn Ihre Anwendung eine Write-Datei verwendet, verfügtsie in der Regel über die Dateierweiterung .wrt.
Datenbank-dateinamen

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
419
♦ Komprimierte Datenbankdatei Wenn Sie eine schreibgeschütztekomprimierte Datenbankdatei verwenden, hat sie normalerweise dieDateierweiterung .cdb.
Diese Dateien werden vom Datenbank-Managementsystem von AdaptiveServer Anywhere aktualisiert, gepflegt und verwaltet.

InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden
420
InstallShield-Objekte und Vorlagen zumBereitstellen verwenden
Wenn Sie InstallShield 6 oder höher verwenden, können Sie SQL AnywhereStudio InstallShield-Objekte in Ihr Installationsprogramm einbeziehen. DieObjekte zur Bereitstellung von Clients, Personal Datenbankservern,Netzwerkservern und Verwaltungstools finden Sie im Verzeichnisdeployment\Objects in Ihrem SQL Anywhere-Verzeichnis.
Anwender von InstallShield Professional 5.5 und höher können InstallShield-Vorlagenprojekte für SQL Anywhere Studio verwenden, um sich die Arbeitfür die Bereitstellung ihrer eigenen Anwendungen zu erleichtern. Vorlagenzum Bereitstellen eines Netzwerkservers, eines Personal Servers, Client-Schnittstellen und Verwaltungstools finden Sie im VerzeichnisSQL Anywhere 8\deployment\Templates.
Wenn Sie InstallShield 6 oder höher haben, sind die Objekte den Vorlagenvorzuziehen, weil sie einfacher zusammen mit anderen Komponenten in dieInstallation zu integrieren sind.
v So fügen Sie ein Vorlagenprojekt zu Ihrer InstallShield-IDE hinzu:
1 Starten Sie die InstallShield-IDE.
2 Wählen Sie Datei➤Öffnen.
3 Wechseln Sie zu Ihrer SQL Anywhere 7-Installation und insBereitstellungsverzeichnis.
Wechseln Sie zum Beispiel zu folgendem Verzeichnis:
C:\Programme\Sybase\SQL Anywhere 8\deployment.
4 Öffnen Sie die Vorlage, die dem Typ des Objekts entspricht, das Siebereitstellen wollen.
Sie können zwischen NetworkServer, PersonalServer, Client undJavaTools wählen.
5 Wählen Sie die Datei mit der Erweiterung .ipr.
Das Projekt wird in der InstallShield-IDE geöffnet. Im Projektbereichwird ein Symbol für die Vorlage angezeigt.
Die Vorlagen werden während der Installation geändert, sodass dieSuchpfade der einzelnen Dateien, die in allen .fgl-Dateien aufgelistetsind, auf die aktuelle Installation von ASA zeigen. Laden Sie einfach dieVorlage in die InstallShield-IDE, generieren Sie die Medien und dieVorlage wird unmittelbar ausgeführt.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
421
Wenn Sie die Medien generieren, sehen Sie Warnmeldungen über leereDateigruppen. Diese Warnungen werden durch leere Dateigruppenverursacht, die als Platzhalter für die Dateien Ihrer Anwendung in dieVorlage eingefügt wurden. Um diese Warnungen zu entfernen, könnenSie entweder die Dateien Ihrer Anwendung in die Dateigruppeneinfügen oder die Dateigruppen löschen oder umbenennen.
Hinweise:

Dialogfreie Installation für die Systemeinführung
422
Dialogfreie Installation für die SystemeinführungDialogfreie Installationen laufen ohne Eingriff von Seiten des Benutzers undohne dass der Benutzer erfährt, dass eine Installation ausgeführt wird. BeiWindows-Betriebssystemen können Sie das InstallShield-Setup-Programmvon Adaptive Server Anywhere so aufrufen, dass die Adaptive ServerAnywhere Installation dialogfrei verläuft. Dialogfreie Installationen werdenebenfalls vom Microsoft Systems Management Server verwendet (siehe"SMS-Installation" auf Seite 424).
Sie können eine dialogfreie Installation für alle Systemeinführungsmodelleverwenden, die in "Modelle für die Systemeinführung" auf Seite 412beschrieben wurden. Sie können zur Bereitstellung von MobiLink-Synchronisationsservern auch eine dialogfreie Installation verwenden.
So wird eine dialogfreie Installation eingerichtet
Die bei einer dialogfreien Installation verwendeten Installationsoptionenstammen aus einer Antwortdatei. Die Antwortdatei wird erstellt, indem dasSetup-Programm von Adaptive Server Anywhere mit der Option –rausgeführt wird. Eine dialogfreie Installation wird durch Ausführen vonSetup mit der Option –s ausgeführt.
Verwenden Sie keine DurchsuchungsfunktionenWenn Sie eine dialogfreie Installation erstellen, dürfen Sie dieSchaltflächen "Durchsuchen" nicht verwenden. Die Ergebnisse vonDurchsuchungsfunktionen können fehlerhaft sein.
v So wird eine dialogfreie Installation eingerichtet:
1 (Fakultativ) Entfernen Sie vorhandene Installationen von AdaptiveServer Anywhere.
2 Öffnen Sie eine Systembefehlszeile und wechseln Sie in das Verzeichnismit den Installations-Dateien (die setup.exe, setup.ins usw. enthalten).
3 Installieren Sie die Software im Modus "Record" (Aufzeichnen).
Geben Sie folgenden Befehl ein:
setup –r

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
423
Mit diesem Befehl wird das Setup-Programm von Adaptive ServerAnywhere ausgeführt und aus Ihrer Auswahl bei den Optionen eineAntwortdatei erstellt. Die Antwortdatei erhält den Namen setup.iss undbefindet sich im Windows-Verzeichnis. Diese Datei enthält dieAntworten, die Sie während der Installation in den Dialogfelderngegeben haben.
Wenn das Programm im Modus "Record" (Aufzeichnen) ausgeführtwird, schlägt es nicht vor, das Betriebssystem neu zu starten, auch wennein Neustart erforderlich ist.
4 Installieren Sie Adaptive Server Anywhere mit den Optionen undEinstellungen, die beim Bereitstellen von Adaptive Server Anywhereauf dem Computer des Endbenutzers für die Benutzung mit IhrerAnwendung eingerichtet werden sollen. Während der dialogfreienInstallation können Pfade aufgehoben werden.
Dialogfreie Installation ausführen
Ihr eigenes Installationsprogramm muss die dialogfreie Installation vonAdaptive Server Anywhere mit der Option –s aufrufen. In diesem Abschnittwird beschrieben, wie eine dialogfreie Installation verwendet wird.
v So wird eine dialogfreie Installation verwendet:
1 Fügen Sie den entsprechenden Befehl in Ihre Installationsprozedur ein,damit die dialogfreie Installation von Adaptive Server Anywhereausgeführt wird.
Wenn die Antwortdatei sich im Installations-Verzeichnis befindet,können Sie die dialogfreie Installation ausführen, indem Sie imVerzeichnis mit dem Installationsabbilds folgenden Befehl ausführen:
setup –s
Wenn sich die Antwortdatei anderswo befindet, müssen Sie den Pfadmit der Option –f1 angeben. In der folgenden Befehlszeile darf es keineLeerstelle zwischen f1 und dem Anführungszeichen geben.
setup –s –f1"c:\winnt\setup.iss"
Wenn die Installation von einem anderen InstallShield-Skript ausgeführtwerden soll, können Sie folgenden Befehl benutzen:
DoInstall("Pfad_des_ASA_Installationsabbilds\SETUP.INS",
"-s", WAIT );

Dialogfreie Installation für die Systemeinführung
424
Zum Aufheben der Pfade für das Adaptive Server Anywhere-Verzeichnis und für das gemeinsam genutzte Verzeichnis können SieOptionen benutzen:
setup TARGET_DIR=VerzeichnisnameSHARED_DIR=Gem_Verzeichnis –s
Die Argumente TARGET_DIR und SHARED_DIR müssen allenanderen Optionen vorangestellt werden.
2 Prüfen Sie, ob der Zielcomputer neu gestartet werden muss.
Setup erstellt eine Datei namens silent.log im Zielverzeichnis. DieseDatei enthält nur einen Abschnitt mit der Bezeichnung ResponseResultund der folgenden Zeile:
Reboot=Wert
Diese Zeile gibt an, ob der Zielcomputer neu gestartet werden muss,damit die Installation abgeschlossen wird. Mögliche Werte sind 0 bzw.1, mit folgender Bedeutung:
♦ Reboot=0 Neustart nicht erforderlich.
♦ Reboot=1 Die Option BATCH_INSTALL war während derInstallation aktiviert und der Zielcomputer muss neu gestartetwerden. Die Installationsprozedur, die die dialogfreie Installationaufgerufen hat, ist verantwortlich für die Prüfung des Eintrags"Reboot" und ggf. für den Neustart des Zielcomputers.
3 Prüfen Sie, ob das Setup ordnungsgemäß abgeschlossen wurde.
Setup erstellt eine Datei namens setup.log im Verzeichnis mit derAntwortdatei. Die Logdatei enthält einen Bericht über die dialogfreieInstallation. Der letzte Abschnitt dieser Datei heißt ResponseResult undenthält die folgende Zeile:
ResultCode=Wert
Diese Zeile gibt an, ob die Installation erforderlich war. Ein Nicht-Null-ResultCode gibt an, dass während der Installation ein Fehler aufgetretenist. Eine Beschreibung der Fehlercodes finden Sie in der Dokumentationzu InstallShield.
SMS-Installation
Microsoft System Management Server (SMS) erfordert eine dialogfreieInstallation, die den Zielcomputer nicht neu startet. Die dialogfreieInstallation von Adaptive Server Anywhere startet den Computer nicht neu.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
425
Ihr SMS-Distributionspaket müsste eine Antwortdatei, dasInstallationsabbild und die Paket-Definitionsdatei asa8.pdf enthalten (aufder Adaptive Server Anywhere-CD-ROM im Ordner \Extras). Die Setup-Befehlszeile in der PDF-Datei enthält die folgenden Optionen:
♦ Die Option –s für eine dialogfreie Installation
♦ Die Option –SMS zur Angabe, dass die Installation von SMS ausgelöstwird
♦ Die Option –m, damit eine MIF-Datei erzeugt wird. Die MIF-Datei wirdvon SMS verwendet um festzustellen, ob die Installation erfolgreichwar.

Clientanwendungen im System bereitstellen
426
Clientanwendungen im System bereitstellenUm eine Clientanwendung im System bereitzustellen, die mit einemNetzwerk-Datenbankserver betrieben wird, müssen Sie jedem Endbenutzerfolgende Elemente zur Verfügung stellen:
♦ Clientanwendung Die Anwendungssoftware selbst ist von derDatenbanksoftware unabhängig und wird hier nicht beschrieben.
♦ Datenbank-Interface-Dateien Die Clientanwendung benötigt dieDateien für die Datenbank-Schnittstelle, die sie benutzt (ODBC, JDBC,Embedded SQL oder Open Client).
♦ Verbindungsinformationen Jede Clientanwendung benötigtVerbindungsinformationen für die Datenbank.
Die erforderlichen Interface-Dateien und Verbindungsinformationen richtensich nach der Schnittstelle, die von Ihrer Anwendung benutzt wird. JedeSchnittstelle wird in den folgenden Abschnitten im Einzelnen beschrieben.
Die einfachste Methode zur Bereitstellung von Clients ist es, diemitgelieferten InstallShield-Objekte zu verwenden. Weitere Hinweise findenSie unter "InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden"auf Seite 420.
OLE DB- und ADO-Clients bereitstellen
Die einfachste Art, OLE DB-Clientbibliotheken bereitzustellen, ist es, dieInstallShield-Objekte und Vorlagen zu verwenden. Hinweise dazu finden Sieunter "InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden" aufSeite 420. Dieser Abschnitt beschreibt die Dateien, die Sie den Endbenutzernbereitstellen müssen, wenn Sie vorhaben, Ihre eigene Installation zuerstellen.
Jeder OLE DB-Clientrechner muss folgende Elemente aufweisen:
♦ Eine funktionierende OLE DB-Installation OLE DB-Dateien undAnweisungen für ihre Verteilung können bei der Microsoft Corporationbezogen werden. Sie werden hier nicht im Einzelnen beschrieben.
♦ Der Adaptive Server Anywhere OLE DB-Provider Die folgendeTabelle enthält die Dateien, die für den Adaptive Server Anywhere OLEDB-Provider erforderlich sind. Diese Dateien sollten in nur einemVerzeichnis abgelegt werden. Die Adaptive Server Anywhere-Installation platziert sie alle in das Betriebssystem-Unterverzeichnis desSQL Anywhere-Installationsverzeichnisses (zum Beispiel: win32).

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
427
Beschreibung Windows Windows CE
OLE DB-Treiberdatei dboledb8.dll dboledb8.dll
OLE DB-Treiberdatei dboledba8.dll dboledba8.dll
Sprachen-Ressourcebibliothek
dblgen8.dll dblgen8.dll
Dialogfeld "Verbinden" dbcon8.dll Nicht zutreffend
OLE DB-Provider benötigen viele Registrierungseinträge. Sie könnendiese erstellen, indem Sie die DLLs mit dem Dienstprogramm regsvr32unter Windows oder dem Dienstprogramm regsvrce unter Windows CEselbst registrieren.
$ Weitere Hinweise finden Sie unter "Datenbanken für Windows CEerstellen" auf Seite 300 der Dokumentation ASADatenbankadministration und "ODBC-Anwendungen unter WindowsCE verknüpfen" auf Seite 281.
ODBC-Clients im System bereitstellen
Die einfachste Art, ODBC-Clients bereitzustellen, ist es, die InstallShield-Objekte und Vorlagen zu verwenden. Hinweise dazu finden Sie unter"InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden" aufSeite 420.
Jeder ODBC-Clientrechner muss folgende Elemente aufweisen:
♦ Eine funktionierende ODBC-Installation ODBC-Dateien undAnweisungen für ihre Verteilung können bei der Microsoft Corporationbezogen werden. Sie werden hier nicht im Einzelnen beschrieben.
Microsoft liefert den ODBC-Treibermanager für Windows-Betriebssysteme. SQL Anywhere Studio enthält einen ODBC DriverManager für UNIX. Es gibt keinen ODBC-Treibermanager für WindowsCE.
ODBC-Anwendungen können ohne den Treibermanager laufen. AufPlattformen, für die ein ODBC-Treibermanager verfügbar ist, ist dasnicht zu empfehlen.

Clientanwendungen im System bereitstellen
428
Falls erforderlich ODBC aktualisierenDas SQL Anywhere Setup-Programm aktualisiert alte Installationender Microsoft Data Access-Komponenten, einschließlich ODBC.Wenn Sie Ihre eigene Anwendung bereitstellen, müssen Siesichergehen, dass die ODBC-Installation den Anforderungen IhrerAnwendung entspricht.
♦ Der ODBC-Treiber für Adaptive Server Anywhere Dies ist die Dateidbodbc8.dll mit ihren Zusatzdateien.
$ Weitere Hinweise finden Sie unter "Erforderliche Dateien für denODBC-Treiber" auf Seite 428.
♦ Verbindungsinformation Die Clientanwendung muss Zugriff auf dieDaten haben, aus denen sie die Informationen für die Verbindung mitdem Server bezieht. Diese Informationen sind normalerweise in derODBC-Datenquelle enthalten.
Erforderliche Dateien für den ODBC-Treiber
Die folgende Tabelle zeigt die Dateien, die für einen funktionierendenODBC-Treiber von Adaptive Server Anywhere erforderlich sind. DieseDateien sollten in nur einem Verzeichnis abgelegt werden. Die AdaptiveServer Anywhere-Installation platziert sie alle in das Betriebssystem-Unterverzeichnis des SQL Anywhere-Installationsverzeichnisses (zumBeispiel: win32).
Beschreibung Windows Windows CE UNIX
ODBC-Treiber dbodbc8.dll dbodbc8.dll libdbodbc8.solibdbtasks8.so
Sprachen-Ressourcebibliothek
dblgen8.dll dblgen8.dll dblgen8.res
Dialogfeld"Verbinden"
dbcon8.dll Nicht zutreffend Nicht zutreffend
♦ Der Endbenutzer muss über eine funktionierende ODBC-Installation miteinem Treibermanager verfügen. Anweisungen für die Bereitstellungvon ODBC finden Sie im Microsoft ODBC SDK.
♦ Das Dialogfeld "Verbinden" ist erforderlich, wenn die Endbenutzereigene Datenquellen erstellen sollen, bei der VerbindungsaufnahmeBenutzer-IDs und Kennwörter eingeben müssen oder wenn DasDialogfeld aus anderen Gründen angezeigt werden muss.
Hinweise

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
429
♦ Der ODBC-Übersetzer ist nur erforderlich, wenn Ihre Anwendung eineUmwandlung von OEM in ANSI durchführt.
$ Weitere Hinweise finden Sie unter "Datenbanken für Windows CEerstellen" auf Seite 300 der Dokumentation ASADatenbankadministration, und "ODBC-Anwendungen unter WindowsCE verknüpfen" auf Seite 281.
♦ Bei Anwendungen mit mehrfachen Threads unter UNIX benutzen Sielibdbodbc8_r.so und libdbtasks8_r.so.
ODBC-Treiber konfigurieren
Das Setup-Programm muss nicht nur die Dateien des ODBC-Treibers auf dieFestplatte kopieren, sondern auch eine Reihe von Einträgen in derRegistrierung vornehmen, damit der ODBC-Treiber richtig installiert wird.
Das Setup-Programm von Adaptive Server Anywhere führt Änderungen inder Systemregistrierung durch, um den ODBC-Treiber anzumelden und zukonfigurieren. Wenn Sie ein Setup-Programm für die Endbenutzer erstellen,müssen Sie dieselben Einstellungen vornehmen.
Sie können das Dienstprogramm regedit verwenden, um dieRegistrierungseinträge anzuzeigen.
Der ODBC-Treiber von Adaptive Server Anywhere wird im System durcheine Gruppe von Registrierungseinträgen im folgendenRegistrierungsschlüssel angemeldet:
HKEY_LOCAL_MACHINE\SOFTWARE\
ODBC\ODBCINST.INI\
Adaptive Server Anywhere 8.0
Folgende Werte werden gesetzt:
Name des Wertes Typ des Wertes Daten des Wertes
Driver Zeichenfolge Pfad\dbodbc8.dll
Setup Zeichenfolge Pfad\dbodbc8.dll
Es gibt auch einen Registrierungseintrag im folgenden Schlüssel:
HKEY_LOCAL_MACHINE\SOFTWARE\
ODBC\ODBCINST.INI\
ODBC Drivers
Windows

Clientanwendungen im System bereitstellen
430
Der Wert ist wie folgt:
Name des Wertes Typ desWertes
Daten des Wertes
Adaptive Server Anywhere 8.0 Zeichenfolge Installed
Wenn Sie einen ODBC-Treiber eines Drittanbieters auf einem anderenBetriebssystem als Windows verwenden, finden Sie in der Dokumentationdieses ODBC-Treibers Hinweise dazu, wie der ODBC-Treiber zukonfigurieren ist.
Verbindungsinformationen bereitstellen
Die Verbindungsinformationen für den ODBC-Client werden imAllgemeinen in Form einer ODBC-Datenquelle im System bereitgestellt. DieBereitstellung einer ODBC-Datenquelle erfolgt auf folgende Weise:
♦ Programmgesteuert Fügen Sie die Beschreibung für eine Datenquellein die Registrierung des Endbenutzers oder in die ODBC-Initialisierungsdateien ein.
♦ Manuell Übergeben Sie den Endbenutzern Anweisungen, damit sie aufihrem Rechner eine geeignete Datenquelle einrichten können.
Sie können eine Datenquelle manuell mit dem ODBC Administratorerstellen, indem Sie das Register Benutzer-DSN oder System-DSNverwenden. Der ODBC-Treiber von Adaptive Server Anywhere zeigtden Konfigurationsdialog für die Eingabe der Einstellungen an.Einstellungen für die Datenquelle enthalten den Standort derDatenbankdatei, den Namen des Datenbankservers sowie Startparameterund andere Optionen.
In diesem Abschnitt finden Sie die Informationen, die Sie für beide Ansätzebenötigen.
Es gibt drei Arten von Datenquellen: Benutzerdatenquellen,Systemdatenquellen und Dateidatenquellen.
Die Definitionen der Benutzerdatenquellen werden in der Registrierung imAbschnitt für den aktuell im System angemeldeten Benutzer gespeichert.Systemdatenquellen hingegen stehen allen Benutzern und Diensten vonWindows zur Verfügung, wobei die Dienste auch aktiv sind, wenn keinBenutzer angemeldet ist. Bei einer richtig konfigurierten Systemdatenquelle"MeineAnwendung" kann jeder Benutzer diese ODBC-Verbindungverwenden, indem er "DSN=MeineAnwendung" in der ODBC-Verbindungszeichenfolge eingibt.
ODBC-Treiber vonDrittanbietern
Arten vonDatenquellen

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
431
Dateidatenquellen werden nicht in der Registrierung gespeichert, sondern ineinem speziellen Verzeichnis. Eine Verbindungszeichenfolge muss einenFileDSN-Verbindungsparameter liefern, um eine Dateidatenquelle benutzenzu können.
Jede Benutzerdatenquelle ist im System über Registrierungseinträgeangemeldet.
Sie müssen eine Gruppe von Registrierungswerten in einem bestimmtenRegistrierungsschlüssel angeben. Für Benutzerdatenquellen ist der Schlüsselwie folgt:
HKEY_CURRENT_USER\SOFTWARE\
ODBC\ODBC.INI\
Benutzerdatenquellenname
Für Systemdatenquellen ist der Schlüssel wie folgt:
HKEY_LOCAL_MACHINE\SOFTWARE\
ODBC\ODBC.INI\
Systemdatenquellenname
Der Schlüssel enthält eine Gruppe von Registrierungswerten, die jeweilseinem Verbindungsparameter entsprechen. Zum Beispiel enthält derSchlüssel "ASA 8.0 Sample", der der Datenquelle der Beispieldatenbank vonASA 8.0 entspricht, folgende Einstellungen:
Name des Wertes Typ desWertes
Daten des Wertes
Autostop Zeichenfolge yes
DatabaseFile Zeichenfolge Pfad\asademo.db
Description Zeichenfolge Adaptive Server Anywhere Beispieldatenbank
Driver String Pfad\win32\dbodbc8.dll
PWD String sql
Start String Pfad\win32\dbeng8.exe -c 8m
UID String dba
In diesen Einträgen steht Pfad für das Installationsverzeichnis von AdaptiveServer Anywhere.
Außerdem müssen Sie die Datenquelle der Liste von Datenquellen in derRegistrierung hinzufügen. Für Benutzerdatenquellen benutzen Sie folgendenSchlüssel:
Registrierungs-einträge für dieDatenquelle

Clientanwendungen im System bereitstellen
432
HKEY_CURRENT_USER\SOFTWARE\
ODBC\ODBC.INI\
ODBC Data Sources
Für Systemdatenquellen benutzen Sie folgenden Schlüssel:
HKEY_LOCAL_MACHINE\SOFTWARE\
ODBC\ODBC.INI\
ODBC Data Sources
Der Wert verknüpft jede Datenquelle mit einem ODBC-Treiber. Der Namedes Wertes ist der Datenquellenname, und die Daten des Wertes sind derName des ODBC-Treibers. Beispiel: Die Benutzerdatenquelle, die vonAdaptive Server Anywhere installiert wird, heißt "ASA 8.0 Sample" und hatfolgenden Wert:
Name des Wertes Typ desWertes
Daten des Wertes
ASA 8.0 Sample Zeichenfolge Adaptive Server Anywhere 8.0
Vorsicht: ODBC-Einstellungen können leicht angezeigt werdenDie Konfiguration von Benutzerdatenquellen kann vertraulicheDatenbankeinstellungen enthalten, wie z.B. Benutzerkennungen undKennwörter. Diese Einstellungen werden in der Registrierung in reinerTextform gespeichert und können mit Registrierungseditoren vonWindows regedit.exe oder regedt32.exe angezeigt werden. Diese Editorensind in jedem Windows-System automatisch installiert. Sie könnenKennwörter verschlüsseln oder von Benutzern verlangen, sie bei derAufnahme der Verbindung einzugeben.
Sie können den Datenquellennamen in einem ODBC-Konfigurationseintragin folgender Weise definieren:
DSN=Benutzerdatenquellenname
Wenn ein DSN-Parameter in der Verbindungszeichenfolge geliefert wird,werden erst die aktuellen Definitionen von Benutzerdatenquellen in derRegistrierung durchsucht, dann die Systemdatenquellen. Dateidatenquellenwerden nur durchsucht, wenn "FileDSN" in der Zeichenfolge für die ODBC-Verbindung geliefert wird.
Die folgende Tabelle zeigt die Auswirkungen auf Benutzer und Entwickler,wenn eine Datenquelle vorhanden ist und in die Verbindungszeichenfolgeder Anwendung als Parameter DSN oder FileDSN einbezogen ist.
Erforderliche undfakultativeVerbindungs-parameter
Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
433
Datenquelle Eingabe in derVerbindungs-zeichenfolge
Eingabe durch denBenutzer
Enthält den ODBC-Treibernamen und –Speicherort, den Namender Datenbankdatei, desDatenbankservers, dieStartparameter sowieBenutzer-ID undKennwort
Keine zusätzlichenInformationen
Keine zusätzlichenInformationen
Enthält nur Namen undSpeicherort des ODBC-Treibers
Name der Datenbankdateioder des Datenbank-servers; fakultativ dieBenutzerkennung und dasKennwort
Benutzer-ID undKennwort, wenn nichtim DSN oder in derZeichenfolge für dieODBC-Verbindungangegeben.
Nicht vorhanden Der Name des zuverwendenden ODBC-Treibers in folgendemFormat:
Driver={ODBCTreibername}
Ebenfalls: Name derDatenbank, Datenbank-datei oder Datenbank-server; fakultativ andereVerbindungsparameterwie Benutzerkennung undKennwort
Benutzerkennung undKennwort, wenn nichtin der Zeichenfolge fürdie ODBC-Verbindunggeliefert
$ Weitere Hinweise zu ODBC-Verbindungen und Konfigurationen findenSie unter
♦ "Verbindung mit einer Datenbank herstellen" auf Seite 41 derDokumentation ASA Datenbankadministration.
♦ Open Database Connectivity (ODBC) SDK von Microsoft
Bereitstellen von Embedded SQL-Clients
Die einfachste Art, Embedded SQL-Clients bereitzustellen, ist es, dieInstallShield-Objekte und Vorlagen zu verwenden. Hinweise dazu finden Sieunter "InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden" aufSeite 420.

Clientanwendungen im System bereitstellen
434
Die Bereitstellung von Embedded SQL-Clients im System umfasst folgendeAufgaben:
♦ Installierte Dateien Jeder Clientrechner muss die erforderlichen Dateienfür eine Adaptive Server Anywhere Embedded SQL-Clientanwendungenthalten.
♦ Verbindungsinformation Die Clientanwendung muss Zugriff auf dieDaten haben, aus denen sie die Informationen für die Verbindung mitdem Server bezieht. Diese Informationen können in die ODBC-Datenquelle aufgenommen werden.
Dateien für Embedded SQL-Clients installieren
Die folgende Tabelle zeigt, welche Dateien für Embedded SQL Clientsbenötigt werden.
Beschreibung Windows UNIX
Schnittstellenbibliothek dblib8.dll libdblib8.so,libdbtasks8.so
Sprachen-Ressourcebibliothek
dblgen8.dll dblgen8.res
IPXNetzwerkkommunikation
dbipx8.dll Nicht zutreffend
Dialogfeld "Verbinden" dbcon8.dll Nicht zutreffend
♦ Die Netzwerkport-DLL ist nicht erforderlich, wenn der Client nur mitdem Personal Datenbankserver arbeitet.
♦ Wenn die Clientanwendung eine ODBC-Datenquelle benutzt, um dieVerbindungsparameter zu speichern, muss der Endbenutzer über einefunktionierende ODBC-Installation verfügen. Anweisungen für dieBereitstellung von ODBC finden Sie im Microsoft ODBC SDK.
$ Weitere Hinweise zur Bereitstellung von ODBC-Informationen imSystem finden Sie unter "ODBC-Clients im System bereitstellen" aufSeite 427.
♦ Das Dialogfeld "Verbindung" ist erforderlich, wenn die Endbenutzereigene Datenquellen erstellen, bei der Verbindungsaufnahme Benutzer-IDs und Kennwörter eingeben müssen oder wenn das Dialogfeld ausanderen Gründen angezeigt werden muss.
♦ Bei Anwendungen mit mehrfachen Threads unter UNIX benutzen Sielibdbodbc8_r.so und libdbtasks8_r.so.
Hinweise

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
435
Verbindungsinformationen
Verbindungsinformation Die Bereitstellung von Embedded SQL-Verbindungsinformationen erfolgt auf folgende Weise:
♦ Manuell Übergeben Sie den Endbenutzern Anweisungen, damit sie aufihrem Rechner eine geeignete Datenquelle einrichten können.
♦ Datei Übergeben Sie den Endbenutzern eine Datei, dieVerbindungsinformationen in einem Format enthält, das IhreAnwendung lesen kann.
♦ ODBC-Datenquelle Sie können die ODBC-Datenquelle verwenden, umdarin die Verbindungsinformationen zu speichern. In diesem Fallbenötigen Sie eine Teilgruppe der ODBC-Dateien von Microsoft.Hinweise finden Sie unter "ODBC-Clients im System bereitstellen" aufSeite 427.
♦ Hartcodiert Sie können Verbindungsinformationen in der Anwendungprogrammieren. Dies ist eine unflexible Methode, die beispielsweise beieinem Upgrade von Datenbanken umfassende Neuprogrammierungenerforderlich macht.
JDBC-Clients im System bereitstellen
Zusätzlich zur Java-Laufzeitumgebung (Java Runtime Environment) mussjeder JDBC-Client auch über den JDBC-Treiber jConnect von Sybase oderdie JDBC-ODBC-Brücke verfügen.
$ Hinweise zur Bereitstellung von jConnect finden Sie unterhttp://manuals.sybase.com/onlinebooks/group-jc/jcg0420e/ auf der Sybase-Website.
Zur Bereitstellung der JDBC-ODBC-Brücke müssen die folgenden Dateienmitgeliefert werden:
♦ jodbc.jar Diese muss sich im Classpath der Anwendung befinden.
♦ dbjodbc8.dll Diese muss sich im Systempfad befinden. In UNIX- oderLinux-Umgebungen ist die Datei eine gemeinsam genutzte Bibliothek(dbjodbc8.so).
♦ Die ODBC-Treiberdateien. Weitere Hinweise finden Sie unter"Erforderliche Dateien für den ODBC-Treiber" auf Seite 428.
Ihre Java-Anwendung benötigt einen URL, um sich mit der Datenbank zuverbinden. Dieser URL gibt den Treiber, den zu verwendenden Rechner undden Port an, auf dem der Datenbankserver auf Daten wartet.

Clientanwendungen im System bereitstellen
436
$ Weitere Hinweise zu URL finden Sie unter "Einem Server einen URLliefern" auf Seite 152.
Open Client-Anwendungen im System bereitstellen
Um Open Client-Anwendungen bereitzustellen, muss auf jedem RechnerSybase Open Client installiert sein. Sie müssen die Open Client-Softwaregetrennt bei Sybase erwerben. Sie enthält eigene Installationsanweisungen.
$ Verbindungsinformationen für Open Client-Clients sind in der Interface-Datei zu finden. Hinweise zur Interface-Datei finden Sie in der Open Client-Dokumentation und unter "Open Server konfigurieren" auf Seite 122 derDokumentation ASA Datenbankadministration.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
437
Tools zur Verwaltung bereitstellenAbhängig von Ihrer Lizenzvereinbarung können Sie eine Reihe vonVerwaltungstools wie Interactive SQL, Sybase Central und dasÜberwachungsdienstprogramm dbconsole bereitstellen.
Die einfachste Methode zur Bereitstellung von Verwaltungstools ist es, diemitgelieferten InstallShield-Objekte zu verwenden. Weitere Hinweise findenSie unter "InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden"auf Seite 420.
Wenn Ihre Kundenanwendung auf Rechnern mit begrenzten Ressourcenläuft, sollten Sie die C-Version von Interactive SQL (dbisqlc.exe) an Stelleder Standardversion bereitstellen (dbisql.exe und die dazugehörigen Java-Klassen).
Das dbisqlc-Programm erfordert die clientseitigen Embedded SQL-Standardbibliotheken.
$ Hinweise über die Systemanforderungen von Verwaltungstools findenSie unter "Systemvoraussetzungen für das Administrationstool" aufSeite 153 der Dokumentation SQL Anywhere Studio Erste Orientierung.
Interactive SQLbereitstellen

Datenbankserver im System bereitstellen
438
Datenbankserver im System bereitstellenSie können einen Datenbankserver im System bereitstellen, indem Sie dasSetup-Programm für das SQL Anywhere Studio den Endbenutzernübergeben. Wenn der Endbenutzer die richtigen Installationsoptionen wählt,verfügt er garantiert über alle erforderlichen Dateien.
Die einfachste Methode zur Bereitstellung eines Personal Datenbankserversoder eines Netzwerk-Datenbankserver ist es, die mitgelieferten InstallShield-Objekte zu verwenden. Weitere Hinweise finden Sie unter "InstallShield-Objekte und Vorlagen zum Bereitstellen verwenden" auf Seite 420.
Um einen Datenbankserver zu betreiben, müssen Sie eine Gruppe vonDateien installieren. Die Dateien werden in der folgenden Tabelle angeführt.Die Weitergabe dieser Dateien unterliegt den Bestimmungen derLizenzvereinbarung. Sie müssen vorher feststellen, ob Sie das Recht haben,die Dateien des Datenbankservers weiterzugeben.
Windows UNIX NetWare
dbeng8.exe dbeng8 Nicht zutreffend
dbsrv8.exe dbsrv8 dbsrv8.nlm
dbserv8.dll libdbserv8.so,libdbtasks8_r.so
Nicht zutreffend
dbserv8.dll dbserv8.so,libdbtasks8.so
Nicht zutreffend
dblgen8.dll oderdblgde8.dll
dblgen8.res dblgen8.res
dbjava8.dll (1) libdbjava8.so (1) dbjava8.nlm (1)
dbctrs8.dll Nicht zutreffend Nicht zutreffend
dbextf.dll (2) libdbextf.so (2) dbextf.nlm (2)
asajdbc.zip (1,3) asajdbc.zip (1,3) asajdbc.zip (1,3)
asajrt12.zip (1,3) asajrt12.zip (1,3) asajrt12.zip (1,3)
classes.zip (1,3) classes.zip (1,3) classes.zip (1,3)
dbmem.vxd (4) N/A N/A
libunic.dll libunic.so N/A
asa.cvf asa.cvf asa.cvf
Verzeichnis charsets\ charsets/ directory N/A
1. Nur erforderlich, wenn Sie Java in der Datenbank verwenden. Bei Datenbanken, die mit JDK1.1 initialisiert wurden, stellen Sie asajdbc.zip bereit. Bei Datenbanken, die mit JDK 1.2 oderJDK 1.3 initialisiert wurden, stellen Sie asajrt13.zip bereit.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
439
2. Nur erforderlich, wenn Sie erweiterte Systemprozeduren und Funktionen benutzen (xp_).3. So installieren, dass die Klassen in dieser Datei über die Umgebungsvariable CLASSPATHgefunden werden.4. Erforderlich auf Windows 95/98/Me, wenn die dynamische Cachebelegung verwendet wird.
♦ Je nach Konfiguration müssen Sie den Personal Datenbankserver(dbeng8) oder den Netzwerk-Datenbankserver (dbsrv8) im Systembereitstellen.
♦ Die Java DLL (dbjava8.dll) ist nur erforderlich, wenn derDatenbankserver die Funktionalität von Java in der Datenbankverwenden soll.
♦ Die Tabelle enthält keine Dateien, die für das Ausführung vonDienstprogrammen wie dbbackup erforderlich sind.
$ Hinweise zur Bereitstellung von Datenbank-Dienstprogrammen imSystem finden Sie unter "Tools zur Verwaltung bereitstellen" aufSeite 437.
♦ Die zip-Dateien sind nur für Anwendungen erforderlich, die Java in derDatenbank verwenden und werden an einem Standort in derUmgebungsvariable CLASSPATH auf dem Rechner des Benutzersinstalliert.
Datenbanken im System bereitstellen
Eine Datenbankdatei wird im System bereitgestellt, indem Sie dieDatenbankdatei auf der Festplatte des Endbenutzers installieren.
Wenn der Datenbankserver sauber herunterfährt, brauchen Sie mit derDatenbankdatei kein Transaktionslog bereitzustellen. Wenn der Endbenutzerdie Datenbank startet, wird ein neues Transaktionslog erstellt.
Für Anwendungen mit SQL Remote muss die Datenbank in einem ordentlichsynchronisierten Zustand erstellt werden und daher wird keinTransaktionslog benötigt. Sie können dafür das Extraktionsdienstprogrammverwenden.
Datenbanken auf schreibgeschützten Datenträgern bereitstellen
Sie können Datenbanken auf schreibgeschützten Datenträgern verteilen, wieetwa CD-ROM, sofern Sie sie im schreibgeschützten Modus oder mit einerWrite-Datei ausführen.
$ Weitere Hinweise zum Ausführen von Datenbanken imschreibgeschützten Modus finden Sie unter "–r-Serveroption" auf Seite 166der Dokumentation ASA Datenbankadministration.
Hinweise

Datenbankserver im System bereitstellen
440
Damit Änderungen an Adaptive Server Anywhere-Datenbankenvorgenommen werden können, die auf schreibgeschützten Datenträgerngeliefert werden, wie etwa CD-ROM, können Sie eine Write-Dateiverwenden. In der Write-Datei werden Änderungen gespeichert, die in einerschreibgeschützten Datenbank durchgeführt werden. Sie befindet sich aufeinem Datenträger, der Schreiben und Lesen zulässt, z.B. einer Festplatte.
In diesem Fall wird die Datenbankdatei auf der CD-ROM gespeichert, dieWrite-Datei hingegen auf der Festplatte. Die Verbindung wird mit der Write-Datei aufgenommen, die auf der Festplatte ein Transaktionslog führt.
$ Weitere Hinweise zu Write-Dateien finden Sie unter "Mit Write-Dateien arbeiten" auf Seite 247 der Dokumentation ASADatenbankadministration.

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
441
Eingebettete Datenbankanwendungen imSystem bereitstellen
In diesem Abschnitt finden Sie Informationen über die Bereitstellung voneingebetteten Datenbanken, bei denen die Anwendung und die Datenbankauf demselben Rechner untergebracht sind.
Eine eingebettete Datenbankanwendung enthält folgende Komponenten:
♦ Datenbankserver Der Adaptive Server Anywhere PersonalDatenbankserver.
$ Hinweise zur Bereitstellung von Datenbankservern finden Sieunter "Datenbankserver im System bereitstellen" auf Seite 438.
♦ SQL Remote Wenn Ihre Anwendung die Replikation mit SQL Remotebenutzt, müssen Sie das Deployment von SQL Remote Message Agentvornehmen.
♦ Die Datenbank Sie müssen eine Datenbankdatei im Systembereitstellen, die die von der Anwendung benutzten Daten aufnimmt.
Personal Server im System bereitstellen
Wenn Sie eine Anwendung im System bereitstellen, die den Personal Serverbenutzt, müssen Sie sowohl die Komponenten der Clientanwendungbereitstellen, als auch die Komponenten des Datenbankservers.
Die Sprachen-Ressourcebibliothek (dblgen8.dll) wird vom Client und vomServer gemeinsam genutzt. Sie brauchen nur ein Exemplar dieser Datei.
Es wird empfohlen, dass Sie die Installationsvorgaben von Adaptive ServerAnywhere einhalten und die Dateien für Client und Server in demselbenVerzeichnis installieren.
Beachten Sie, dass Sie die Java zip-Dateien und die Java-DLL bereitstellenmüssen, wenn Ihre Anwendung Java in der Datenbank benutzt.
Datenbank-Dienstprogramme bereitstellen
Wenn Sie Datenbank-Dienstprogramme (wie z.B. dbbackup.exe) gemeinsammit Ihrer Anwendung im System bereitstellen müssen, brauchen Sie dieProgrammdatei des Dienstprogramms mit folgenden zusätzlichen Dateien:
Eingebettete Datenbankanwendungen im System bereitstellen
442
Beschreibung Windows UNIX
Bibliothek der Datenbanktools Dbtool8.dll libdbtools8.so,libdbtasks8.so
Zusätzliche Bibliothek dbwtsp8.dll Libdbwtsp8.so
Sprachen-Ressourcebibliothek dblgen8.dll dblgen8.res
Verbindungsdialog (nur dbisqlc) dbcon8.dll
♦ Die Datenbanktools sind Embedded SQL-Anwendungen. Sie müssen diefür diese Anwendungen erforderlichen Dateien bereitstellen. Siehe dazudie Liste in "Bereitstellen von Embedded SQL-Clients" auf Seite 433.
♦ Bei Anwendungen mit mehrfachen Threads unter UNIX benutzen Sielibdbodbc8_r.so und libdbtasks8_r.so.
SQL Remote im System bereitstellen
Wenn Sie den Nachrichtenagenten von SQL Remote im System bereitstellen,müssen folgende Dateien installiert werden:
Beschreibung Windows UNIX
Nachrichtenagent dbremote.exe dbremote
Bibliothek der Datenbanktools dbtool8.dll libdbtools8.so,libdbtasks8.so
Zusätzliche Bibliothek dbwtsp8.dll libdbwtsp8.so
Sprachen-Ressourcebibliothek dblgen8.dll dblgen8.res
Bibliothek für VIM-Nachrichtenverbindungen1
dbvim8.dll
Bibliothek für SMTP-Nachrichtenverbindungen1
dbsmtp8.dll
Bibliothek für FILE-Nachrichtenverbindungen1
dbfile8.dll libdbfile8.so
Bibliothek für FTP-Nachrichtenverbindungen1
dbftp8.dll
Bibliothek für MAPI-Nachrichtenverbindungen1
dbmapi8.dll
Schnittstellenbibliothek dblib8.dll1 Stellen Sie nur die Bibliothek für die Nachrichtenverbindung bereit, die die Anwendungbenutzen wird.
Hinweise

Kapitel 12 Deployment: Datenbanken und Anwendungen im System bereitstellen
443
Es wird empfohlen, dass Sie die Installationsvorgaben von Adaptive ServerAnywhere einhalten und die Dateien für SQL Remote in demselbenVerzeichnis installieren wie Adaptive Server Anywhere.
Bei Anwendungen mit mehrfachen Threads unter UNIX benutzen Sielibdbodbc8_r.so und libdbtasks8_r.so.

Eingebettete Datenbankanwendungen im System bereitstellen
444

445
K A P I T E L 1 3
Fehlermeldungen des SQL-Präprozessors
In diesem Kapitel finden Sie eine Liste aller Fehler- und Warnmeldungen desSQL-Präprozessors.
Thema Seite
Fehlermeldungen des SQL-Präprozessors, sortiert nachFehlernummern 446
SQLPP-Fehler 450
Über diesesKapitel
Inhalt

Fehlermeldungen des SQL-Präprozessors, sortiert nach Fehlernummern
446
Fehlermeldungen des SQL-Präprozessors,sortiert nach Fehlernummern
Fehlernummer Meldung
2601 "Subskriptionswert %1 zu groß" aufSeite 464
2602 "Kombinierter Zeiger und Arrays fürHosttypen nicht zulässig" aufSeite 455
2603 "Nur eindimensionale Arrays werdenfür den 'char'-Typ unterstützt" aufSeite 463
2604 "VARCHAR-Typ muss eine Längehaben" auf Seite 454
2605 "Arrays von VARCHAR nichtunterstützt" auf Seite 454
2606 "VARCHAR-Hostvariable könnenkeine Zeiger sein" auf Seite 453
2607 "Initialisieren bei der VARCHAR-Hostvariablen nicht zulässig" aufSeite 459
2608 "FIXCHAR-Typ muss eine Längehaben" auf Seite 451
2609 "Arrays werden für FIXCHAR nichtunterstützt" auf Seite 454
2610 "Arrays dieses Typs werden nichtunterstützt" auf Seite 455
2611 "Beim Dezimaltyp muss die Anzahlder Dezimalstellen angegebenwerden" auf Seite 463
2612 "Dezimalzahlen-Arrays sind nichtzulässig" auf Seite 454
2613 "Unbekannter Hostvariablen-Typ"auf Seite 453
2614 "Ungültige Ganzzahl" auf Seite 460
2615 "'%1' Hostvariable muss ein C-Zeichenfolgentyp sein" auf Seite 450
Kapitel 13 Fehlermeldungen des SQL-Präprozessors
447
Fehlernummer Meldung
2617 "Das Symbol ’%1’ ist bereitsdefiniert" auf Seite 450
2618 "Ungültiger Typ für SQL-Anweisungsvariable" auf Seite 461
2619 "Include-Datei '%1' kann nichtgefunden werden" auf Seite 451
2620 "Hostvariable '%1' ist unbekannt" aufSeite 457
2621 "Indikatorvariable '%1' istunbekannt" auf Seite 459
2622 "Ungültiger Typ für Indikatorvariable'%1'" auf Seite 460
2623 "Ungültiger Hostvariablen-Typ auf'%1'" auf Seite 460
2625 "Hostvariable '%1' hat zweiverschiedene Definitionen" aufSeite 457
2626 "Anweisung '%1' wurde vorher nochnicht vorbereitet" auf Seite 463
2627 "Cursor '%1' wurde vorher noch nichtdeklariert" auf Seite 455
2628 "Unbekannte Anweisung '%1'" aufSeite 465
2629 "Hostvariable für diesen Cursor nichtzulässig" auf Seite 457
2630 "Hostvariable zweimal angegeben -bei 'Declare' und bei 'Open'" aufSeite 458
2631 "Host-Liste oder Using-Klausel für%1 muss angegeben werden" aufSeite 461
2633 "Keine INTO-Klausel in SELECT-Anweisung" auf Seite 462
2634 "Fehlerhafte SQL-Sprachensyntax -Dies ist eine '%1' Erweiterung" aufSeite 458
2635 "Fehlerhafte Embedded-SQL-Sprachensyntax - Dies ist eine '%1'Erweiterung" auf Seite 458
Fehlermeldungen des SQL-Präprozessors, sortiert nach Fehlernummern
448
Fehlernummer Meldung
2636 "Fehlerhafte Embedded-SQL-Syntax"auf Seite 458
2637 "Fehlendes schließendesAnführungszeichen für dieZeichenfolge" auf Seite 461
2639 "Token zu lang" auf Seite 464
2640 "'%1' Hostvariable muss einGanzzahltyp sein" auf Seite 450
2641 "SQLDA muss für DESCRIBEangegeben werden" auf Seite 462
2642 "Zwei SQLDAs für denselben Typangegeben (INTO oder USING)" aufSeite 453
2646 "Statische Cursor können nichtbeschrieben werden" auf Seite 455
2647 "Makros können nicht neu definiertwerden" auf Seite 453
2648 "Ungültige Arraydimension" aufSeite 453
2649 "Ungültiger Deskriptor-Index" aufSeite 459
2650 "Ungültiges Feld für SETDESCRIPTOR" auf Seite 460
2651 "Feld in SET DESCRIPTORAnweisung mehr als einmalverwendet" auf Seite 456
2652 "Datenwert muss eine Hostvariablesein" auf Seite 456
2660 "Into-Klausel in 'declare cursor' nichtzulässig - ignoriert" auf Seite 452
2661 "Nicht erkannte SQL-Syntax" aufSeite 465
2662 "Unbekannte SQL-Funktion '%1'" aufSeite 465
2663 "Falsche Anzahl von Parametern fürSQL-Funktion '%1'" auf Seite 466
2664 "Statische Anweisungsnamenfunktionieren nicht richtig, wenn von2 Threads benutzt" auf Seite 463
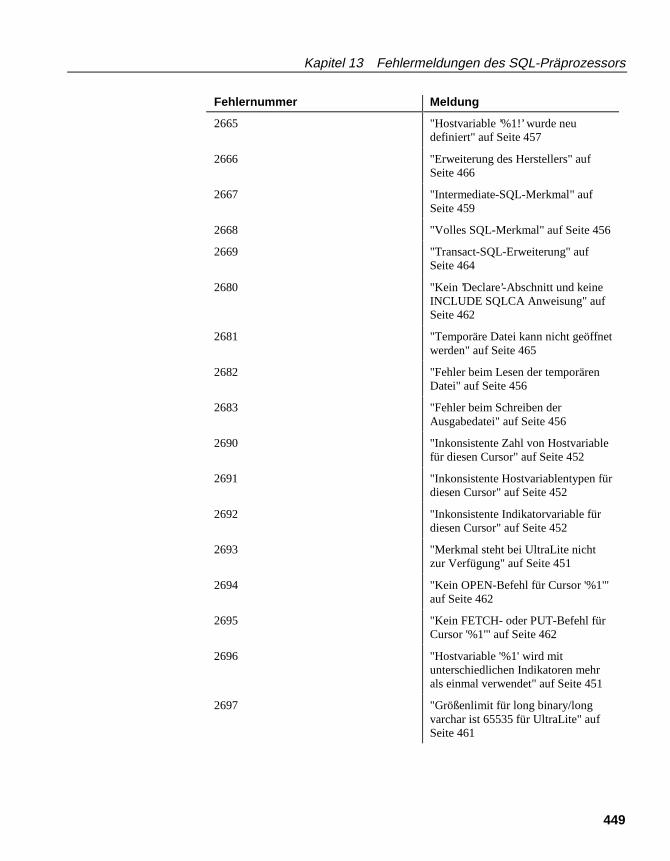
Kapitel 13 Fehlermeldungen des SQL-Präprozessors
449
Fehlernummer Meldung
2665 "Hostvariable ’%1!’ wurde neudefiniert" auf Seite 457
2666 "Erweiterung des Herstellers" aufSeite 466
2667 "Intermediate-SQL-Merkmal" aufSeite 459
2668 "Volles SQL-Merkmal" auf Seite 456
2669 "Transact-SQL-Erweiterung" aufSeite 464
2680 "Kein ’Declare’-Abschnitt und keineINCLUDE SQLCA Anweisung" aufSeite 462
2681 "Temporäre Datei kann nicht geöffnetwerden" auf Seite 465
2682 "Fehler beim Lesen der temporärenDatei" auf Seite 456
2683 "Fehler beim Schreiben derAusgabedatei" auf Seite 456
2690 "Inkonsistente Zahl von Hostvariablefür diesen Cursor" auf Seite 452
2691 "Inkonsistente Hostvariablentypen fürdiesen Cursor" auf Seite 452
2692 "Inkonsistente Indikatorvariable fürdiesen Cursor" auf Seite 452
2693 "Merkmal steht bei UltraLite nichtzur Verfügung" auf Seite 451
2694 "Kein OPEN-Befehl für Cursor '%1'"auf Seite 462
2695 "Kein FETCH- oder PUT-Befehl fürCursor '%1'" auf Seite 462
2696 "Hostvariable '%1' wird mitunterschiedlichen Indikatoren mehrals einmal verwendet" auf Seite 451
2697 "Größenlimit für long binary/longvarchar ist 65535 für UltraLite" aufSeite 461

SQLPP-Fehler
450
SQLPP-FehlerIn diesem Abschnitt finden Sie die Meldungen, die vom SQL-Präprozessorgeneriert werden. Die Meldungen können je nach Einstellung durch dieBefehlszeilenparameter Fehler-, Warnmeldungen oder beides sein.
$ Weitere Hinweise zum SQL-Präprozessor und zu seinenBefehlszeilenparametern finden Sie unter "SQL-Präprozessor" auf Seite 249.
’%1’ Hostvariable muss ein C-Zeichenfolgentyp sein
Fehlernummer Fehlertyp
2615 Fehler
Eine C-Zeichenfolge war in einer Embedded SQL-Anweisung erforderlich(für einen Cursornamen, Optionsnamen etc.), und der übergebene Wert warkeine C-Zeichenfolge.
’%1’ Hostvariable muss ein Ganzzahltyp sein
Fehlernummer Fehlertyp
2640 Fehler
Sie haben eine Hostvariable, die kein Ganzzahltyp ist, in einer Anweisungverwendet, in der nur Hostvariablen vom Ganzzahltyp zulässig sind.
Das Symbol ’%1’ ist bereits definiert
Fehlernummer Fehlertyp
2617 Fehler
Sie haben eine Hostvariable zweimal definiert.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
451
Include-Datei ’%1’ kann nicht gefunden werden
Fehlernummer Fehlertyp
2619 Fehler
Die angegebene Include-Datei wurde nicht gefunden. Beachten Sie, dass derPräprozessor die INCLUDE-Umgebungsvariable zur Suche nach Include-Dateien verwendet.
FIXCHAR-Typ muss eine Länge haben
Fehlernummer Fehlertyp
2608 Fehler
Sie haben den Makro DECL_FIXCHAR benutzt, um eine Hostvariable desTyps FIXCHAR zu deklarieren, aber keine Länge angegeben.
Merkmal steht bei UltraLite nicht zur Verfügung
Fehlernummer Fehlertyp
2693 Markierung (Warnung oder Fehler)
Sie haben eine Funktion benutzt, die von UltraLite nicht unterstützt wird.
Hostvariable ’%1’ wird mit unterschiedlichen Indikatoren mehr alseinmal verwendet
Fehlernummer Fehlertyp
2696 Fehler
Sie haben dieselbe Hostvariable mehrere Male mit unterschiedlichenIndikatorvariablen in derselben Anweisung verwendet. Dies wird nichtunterstützt.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
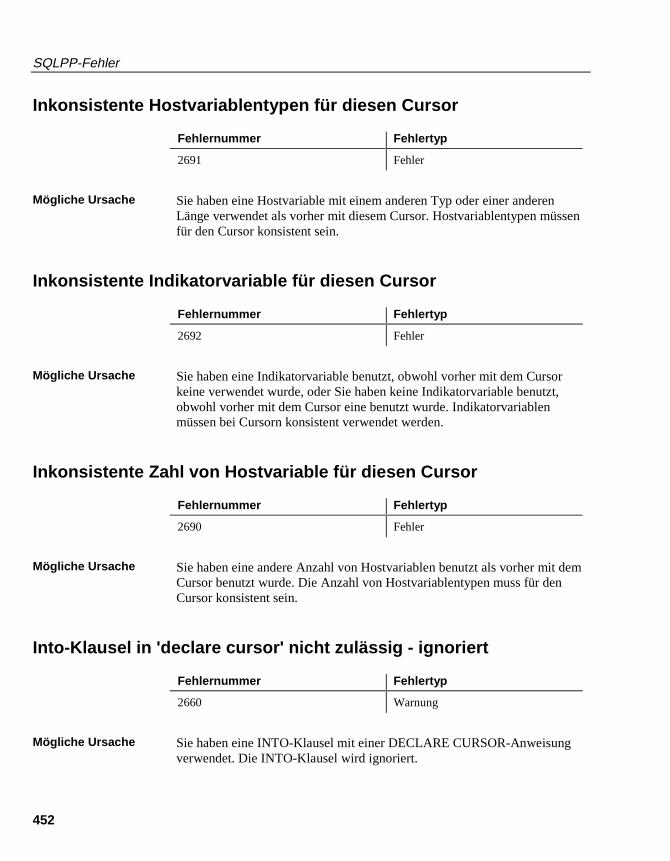
SQLPP-Fehler
452
Inkonsistente Hostvariablentypen für diesen Cursor
Fehlernummer Fehlertyp
2691 Fehler
Sie haben eine Hostvariable mit einem anderen Typ oder einer anderenLänge verwendet als vorher mit diesem Cursor. Hostvariablentypen müssenfür den Cursor konsistent sein.
Inkonsistente Indikatorvariable für diesen Cursor
Fehlernummer Fehlertyp
2692 Fehler
Sie haben eine Indikatorvariable benutzt, obwohl vorher mit dem Cursorkeine verwendet wurde, oder Sie haben keine Indikatorvariable benutzt,obwohl vorher mit dem Cursor eine benutzt wurde. Indikatorvariablenmüssen bei Cursorn konsistent verwendet werden.
Inkonsistente Zahl von Hostvariable für diesen Cursor
Fehlernummer Fehlertyp
2690 Fehler
Sie haben eine andere Anzahl von Hostvariablen benutzt als vorher mit demCursor benutzt wurde. Die Anzahl von Hostvariablentypen muss für denCursor konsistent sein.
Into-Klausel in 'declare cursor' nicht zulässig - ignoriert
Fehlernummer Fehlertyp
2660 Warnung
Sie haben eine INTO-Klausel mit einer DECLARE CURSOR-Anweisungverwendet. Die INTO-Klausel wird ignoriert.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
453
Ungültige Arraydimension
Fehlernummer Fehlertyp
2648 Fehler
Die Arraydimension der Variablen ist negativ.
Makros können nicht neu definiert werden
Fehlernummer Fehlertyp
2647 Fehler
Ein Präprozessor-Makro wurde zweimal definiert, möglicherweise in einerHeader-Datei.
Zwei SQLDAs für denselben Typ angegeben (INTO oder USING)
Fehlernummer Fehlertyp
2642 Fehler
Sie haben zwei INTO DESCRIPTOR- oder zwei USING DESCRIPTOR-Klauseln für diese Anweisung angegeben.
Unbekannter Hostvariablen-Typ
Fehlernummer Fehlertyp
2613 Fehler
Sie haben eine Hostvariable eines Typs angegeben, der vom SQL-Präprozessor nicht verstanden wird.
VARCHAR-Hostvariable können keine Zeiger sein
Fehlernummer Fehlertyp
2606 Fehler
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
454
Sie haben versucht, eine Hostvariable als Zeiger auf einen VARCHAR- oderBINARY-Typ zu deklarieren. Dies ist kein zulässiger Hostvariablentyp.
VARCHAR-Typ muss eine Länge haben
Fehlernummer Fehlertyp
2604 Fehler
Sie haben versucht, eine VARCHAR- oder BINARY-Hostvariable mit demDECL_VARCHAR- oder DECL_BINARY-Makro zu deklarieren, aberkeine Größe für das Array angegeben.
Arrays werden für FIXCHAR nicht unterstützt
Fehlernummer Fehlertyp
2609 Fehler
Sie haben versucht, eine Hostvariable als Array von FIXCHAR-Arrays zudeklarieren. Dies ist kein zulässiger Hostvariablentyp.
Arrays von VARCHAR nicht unterstützt
Fehlernummer Fehlertyp
2605 Fehler
Sie haben versucht, eine Hostvariable als Array von VARCHAR- oderBINARY-Arrays zu deklarieren. Dies ist kein zulässiger Hostvariablentyp.
Dezimalzahlen-Arrays sind nicht zulässig
Fehlernummer Fehlertyp
2612 Fehler
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
455
Sie haben versucht, eine Hostvariable als Array von DECIMAL-Arrays zudeklarieren. Ein dezimales Array ist kein zulässiger Hostvariablentyp.
Arrays dieses Typs werden nicht unterstützt
Fehlernummer Fehlertyp
2610 Fehler
Sie haben versucht, ein Hostvariablen-Array eines Typs zu deklarieren, dernicht unterstützt wird.
Statische Cursor können nicht beschrieben werden
Fehlernummer Fehlertyp
2646 Fehler
Sie haben einen statischen Cursor beschrieben. Beim Beschreiben einesCursors muss der Cursorname in einer Hostvariablen angegeben sein.
Kombinierter Zeiger und Arrays für Hosttypen nicht zulässig
Fehlernummer Fehlertyp
2602 Fehler
Sie haben ein Array von Zeigern als Hostvariable benutzt. Dies ist nichtzulässig.
Cursor ’%1’ wurde vorher noch nicht deklariert
Fehlernummer Fehlertyp
2627 Fehler
Ein Embedded SQL-Cursorname wurde benutzt (in FETCH, OPEN, CLOSEetc.), ohne vorher deklariert worden zu sein.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
456
Datenwert muss eine Hostvariable sein
Fehlernummer Fehlertyp
2652 Fehler
Die in der SET DESCRIPTOR-Anweisung benutzte Variable wurde nicht alsHostvariable deklariert.
Fehler beim Lesen der temporären Datei
Fehlernummer Fehlertyp
2682 Fehler
Beim Lesen aus einer temporären Datei ist ein Fehler aufgetreten.
Fehler beim Schreiben der Ausgabedatei
Fehlernummer Fehlertyp
2683 Fehler
Beim Schreiben in die Ausgabedatei ist ein Fehler aufgetreten.
Feld in SET DESCRIPTOR Anweisung mehr als einmal verwendet
Fehlernummer Fehlertyp
2651 Fehler
Dasselbe Schlüsselwort wurde mehr als einmal in einer einzigen SETDESCRIPTOR-Anweisung verwendet.
Volles SQL-Merkmal
Fehlernummer Fehlertyp
2668 Markierung (Warnung oder Fehler)
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
457
Sie haben eine volle SQL/92-Funktion verwendet und mit den Optionen -ee,-ei, -we oder -wi im Präprozessor verarbeitet.
Hostvariable ’%1!’ wurde neu definiert
Fehlernummer Fehlertyp
2665 Warnung
Sie haben dieselbe Hostvariable mit einem anderen Hosttyp neu definiert.Für den SQL-Präprozessor sind Hostvariable globale Variable: zweiHostvariable mit unterschiedlichen Typen können niemals den gleichenNamen haben.
Hostvariable ’%1’ hat zwei verschiedene Definitionen
Fehlernummer Fehlertyp
2625 Fehler
Dieselbe Hostvariable wurden in demselben Modul mit zwei verschiedenenTypen definiert. Beachten Sie, dass die Hostvariablen in einem C-Modulglobal sind.
Hostvariable ’%1’ ist unbekannt
Fehlernummer Fehlertyp
2620 Fehler
Sie haben eine Hostvariable in einer Anweisung benutzt, und dieseHostvariable wurde nicht in einem Declare-Abschnitt deklariert.
Hostvariable für diesen Cursor nicht zulässig
Fehlernummer Fehlertyp
2629 Fehler
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
458
Hostvariable sind in der Declare-Anweisung für den angegebenen Cursornicht zulässig. Wenn der Cursorname über eine Hostvariable übergebenwird, müssen Sie volle dynamische SQL verwenden und die Anweisungvorbereiten. Eine vorbereitete Anweisung kann Hostvariable aufweisen.
Hostvariable zweimal angegeben - bei ’Declare’ und bei ’Open’
Fehlernummer Fehlertyp
2630 Fehler
Sie haben Hostvariablen für einen Cursor in den Declare- und Open-Anweisungen angegeben. Im statischen Fall müssen Sie Hostvariable in derDeclare-Anweisung angeben. Im dynamischen Fall geben Sie sie in derOpen-Anweisung an.
Fehlerhafte Embedded-SQL-Sprachensyntax - Dies ist eine ’%1’Erweiterung
Fehlernummer Fehlertyp
2635 Fehler
Fehlerhafte Embedded-SQL-Syntax
Fehlernummer Fehlertyp
2636 Fehler
Eine Embedded SQL-spezifische Anweisung (OPEN, DECLARE, FETCHetc.) hat einen Syntaxfehler.
Fehlerhafte SQL-Sprachensyntax - Dies ist eine ’%1’ Erweiterung
Fehlernummer Fehlertyp
2634 Fehler
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
459
Indikatorvariable ’%1’ ist unbekannt
Fehlernummer Fehlertyp
2621 Fehler
Sie haben eine Indikatorvariable in einer Anweisung benutzt, und dieseIndikatorvariable wurde nicht in einem Declare-Abschnitt deklariert.
Initialisieren bei der VARCHAR-Hostvariablen nicht zulässig
Fehlernummer Fehlertyp
2607 Fehler
Sie können keinen C-Variablen-Initialisierer für eine Hostvariable des TypsVARCHAR oder BINARY angeben. Sie müssen diese Variable in regulätemausführbarem C-Code initialisieren.
Intermediate-SQL-Merkmal
Fehlernummer Fehlertyp
2667 Markierung (Warnung oder Fehler)
Sie haben eine Intermediate-SQL/92-Funktion verwendet und mit denOptionen -ee oder -we im Präprozessor verarbeitet.
Ungültiger Deskriptor-Index
Fehlernummer Fehlertyp
2649 Fehler
Sie haben weniger als eine Variable mit der Anweisung ALLOCATEDESCRIPTOR zugewiesen.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
460
Ungültiges Feld für SET DESCRIPTOR
Fehlernummer Fehlertyp
2650 Fehler
Ein ungültiges oder unbekanntes Schlüsselwort ist in einer SETDESCRIPTOR-Anweisung vorhanden. Schlüsselwörter können nur sein:TYPE, PRECISION, SCALE, LENGTH, INDICATOR oder DATA.
Ungültiger Hostvariablen-Typ auf '%1'
Fehlernummer Fehlertyp
2623 Fehler
Sie haben an einer Stelle, an der der Präprozessor eine Hostvariable vomZeichenfolgentyp erwartete, eine Hostvariable verwendet, die keinZeichenfolgentyp ist.
Ungültige Ganzzahl
Fehlernummer Fehlertyp
2614 Fehler
Eine Ganzzahl wurde in einer Embedded SQL-Anweisung (für einen Fetch-Offset oder einen Hostvariablen-Arrayindex, etc.) erwartet, und derPräprozessor konnte das übergebene Element nicht in eine Ganzzahlkonvertieren.
Ungültiger Typ für Indikatorvariable '%1'
Fehlernummer Fehlertyp
2622 Fehler
Indikatorvariable müssen den Typ "short int" haben. Sie haben eine Variableeines anderen Typs als Indikatorvariable verwendet.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
461
Ungültiger Typ für SQL-Anweisungsvariable
Fehlernummer Fehlertyp
2618 Fehler
Eine Hostvariable, die als Anweisungsbezeichner benutzt wird, muss vomTyp a_sql_statement_number sein. Sie haben versucht, eine Hostvariableeines anderen Typs als Anweisungsbezeichner zu benutzen.
Größenlimit für long binary/long varchar ist 65535 für UltraLite
Fehlernummer Fehlertyp
2697 Fehler
Bei der Verwendung von DECL_LONGBINARY oderDECL_LONGVARCHAR mit UltraLite ist die Obergrenze für das Array 64KByte.
Fehlendes schließendes Anführungszeichen für die Zeichenfolge
Fehlernummer Fehlertyp
2637 Fehler
Sie haben eine Zeichenfolgenkonstante in einer Embedded SQL-Anweisungeingegeben, aber es ist kein schließendes Anführungszeichen für dasZeilenende oder das Dateiende vorhanden.
Host-Liste oder Using-Klausel für %1 muss angegeben werden
Fehlernummer Fehlertyp
2631 Fehler
Die angegebene Anweisung benötigt die Angabe von Hostvariablen in einerHostvariablenliste oder aus einer SQLDA.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
462
SQLDA muss für DESCRIBE angegeben werden
Fehlernummer Fehlertyp
2641 Fehler
Kein FETCH- oder PUT-Befehl für Cursor '%1'
Fehlernummer Fehlertyp
2695 Fehler
Ein Cursor ist deklariert und geöffnet, wird aber nie verwendet.
Keine INTO-Klausel in SELECT-Anweisung
Fehlernummer Fehlertyp
2633 Fehler
Sie haben eine statische Embedded-SQL-SELECT-Anweisung angegeben,aber keine INTO-Klausel für die Ergebnisse festgelegt.
Kein OPEN-Befehl für Cursor '%1'
Fehlernummer Fehlertyp
2694 Fehler
Ein Cursor ist deklariert und möglicherweise benutzt, wird aber nie geöffnet.
Kein ’Declare’-Abschnitt und keine INCLUDE SQLCA Anweisung
Fehlernummer Fehlertyp
2680 Fehler
Die EXEC SQL INCLUDE SQLCA-Anweisung fehlt in der Quelldatei.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
463
Nur eindimensionale Arrays werden für den 'char'-Typ unterstützt
Fehlernummer Fehlertyp
2603 Fehler
Sie haben versucht, eine Hostvariable als Array von Zeichen-Arrays zudeklarieren. Dies ist kein zulässiger Hostvariablentyp.
Beim Dezimaltyp muss die Anzahl der Dezimalstellen angegebenwerden
Fehlernummer Fehlertyp
2611 Fehler
Sie müssen die Dezimalstellen angeben, wenn Sie eine gepackte dezimaleHostvariable mit dem Makro DECL_DECIMAL deklarieren. DieGesamtstellenanzahl ist fakultativ.
Anweisung ’%1’ wurde vorher noch nicht vorbereitet
Fehlernummer Fehlertyp
2626 Fehler
Ein Embedded SQL-Anweisungsname wurde benutzt (EXECUTE), ohnevorher vorbereitet worden zu sein.
Statische Anweisungsnamen funktionieren nicht richtig, wenn von2 Threads benutzt
Fehlernummer Fehlertyp
2664 Warnung
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
464
Sie haben einen statischen Anweisungsnamen benutzt und mit demWiedereintrittsparameter -r im Präprozessor verarbeitet. StatischeAnweisungsnamen bewirken, dass statische Variable generiert werden, dieaus der Datenbank einfließen. Wenn zwei Threads dieselbe Anweisungverwenden, kommt es wegen dieser Variablen zum Engpass. Benutzen Sieeine lokale Hostvariable als Anweisungsbezeichner, und nicht einenstatischen Namen.
Subskriptionswert %1 zu groß
Fehlernummer Fehlertyp
2601 Fehler
Sie haben versucht, eine Hostvariable zu indizieren, die in einem Array miteinem zu großen Wert für das Array liegt.
Token zu lang
Fehlernummer Fehlertyp
2639 Fehler
Der SQL-Präprozessor hat eine maximale Tokenlänge von 2 KByte. AlleToken über 2 KByte ergeben diesen Fehler. Für Konstantenzeichenfolgen inEmbedded SQL-Befehlen (Hauptursache für diesen Fehler) benutzen Sieeine Zeichenfolgenverkettung, um eine längere Zeichenfolge zuermöglichen.
Transact-SQL-Erweiterung
Fehlernummer Fehlertyp
2669 Markierung (Warnung oder Fehler)
Sie haben eine Sybase Transact-SQL-Funktion verwendet, die von SQL/92nicht definiert wurde, und mit den Parametern -ee, -ei, -ef, -we, -wi oder -wfim Präprozessor verarbeitet.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

Kapitel 13 Fehlermeldungen des SQL-Präprozessors
465
Temporäre Datei kann nicht geöffnet werden
Fehlernummer Fehlertyp
2681 Fehler
Beim Öffnen einer temporären Datei ist ein Fehler aufgetreten.
Unbekannte SQL-Funktion ’%1’
Fehlernummer Fehlertyp
2662 Warnung
Sie haben eine SQL-Funktion benutzt, die dem Präprozessor nicht bekanntist und die wahrscheinlich einen Fehler generieren wird, sobald dieAnweisung an die Datenbankengine geschickt wurde.
Unbekannte Anweisung ’%1’
Fehlernummer Fehlertyp
2628 Fehler
Sie haben versucht, eine Embedded SQL-Anweisung zu löschen, die nichtexistiert.
Nicht erkannte SQL-Syntax
Fehlernummer Fehlertyp
2661 Warnung
Sie haben eine SQL-Anweisung benutzt, die wahrscheinlich einenSyntaxfehler generieren wird, sobald sie an die Datenbankengine geschicktwurde.
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache
Mögliche Ursache

SQLPP-Fehler
466
Erweiterung des Herstellers
Fehlernummer Fehlertyp
2666 Markierung (Warnung oder Fehler)
Sie haben eine Adaptive Server Anywhere-Funktion verwendet, die vonSQL/92 nicht definiert wurde, und mit den Parametern -ee, -ei, -ef, -we, -wioder -wf im Präprozessor verarbeitet.
Falsche Anzahl von Parametern für SQL-Funktion '%1'
Fehlernummer Fehlertyp
2663 Warnung
Sie haben eine SQL-Funktion mit der falschen Anzahl von Parameternverwendet. Dies wird wahrscheinlich einen Fehler generieren, sobald dieAnweisung an die Datenbankengine gesendet wurde.
Mögliche Ursache
Mögliche Ursache

467
Index
>>>
Java in der Datenbank-Methoden, 77
Aa_backup_db, Struktur, 335
a_change_log, Struktur, 337
a_compress_db, Struktur, 339
a_compress_stats, Struktur, 340
a_create_db, Struktur, 341
a_crypt_db, Struktur, 343
a_db_collation, Struktur, 344
a_db_info, Struktur, 345
a_dblic_info, Struktur, 348
a_dbtools_info, Struktur, 349
a_name, Struktur, 351
a_stats_line, Struktur, 352
a_sync_db, Struktur, 352
a_syncpub, Struktur, 355
a_sysinfo, Struktur, 356
a_table_info, Struktur, 356
a_translate_log, Struktur, 357
a_truncate_log, Struktur, 358
a_validate_db, Struktur, 363
a_validate_type, Aufzählungstyp, 369
a_writefile, Struktur, 364
AbfragenADO-Recordset-Objekt, 377, 379einzelne Zeilen, 214Java in der Datenbank, 117JDBC, 169
Abrollbare CursorJDBC-Unterstützung, 145
Abrollender Cursor, 23
AbrufenObjekte, 174ODBC, 300SQLDA, 235
ActiveX-DatenobjekteInfo, 374
ADOAbfragen, 377, 379Aktualisierungen, 379Befehle, 376Befehlsobjekt, 376Cursor, 28, 379Cursortypen, 26Einführung in die Programmierung, 3Info, 374Recordset-Objekt, 377, 379SQL-Anweisungen in Anwendungen verwenden,
10Verbindungen, 374Verbindungsobjekt, 374
AggregatfunktionenJava in der Datenbank, Spalten, 120

A–A
468
AktualisierungenCursor, 379
alloc_sqlda, Funktion, 253
alloc_sqlda_noind, Funktion, 253
ALTER DATABASE, AnweisungJava in der Datenbank, 99, 100
an_erase_db, Struktur, 349
an_expand_db, Struktur, 350
an_unload_db, Struktur, 359
an_upgrade_db, Struktur, 361
Anforderungenabbrechen, 257Open Client-Anwendungen, 390
Anforderungen abbrechenEmbedded SQL, 247
AnforderungsverarbeitungEmbedded SQL, 247
AnführungszeichenJava in der Datenbank, 78
Angeführte BezeichnerSQL_needs_quotes-Funktion, 270
AnregungenDokumentation, xv
AntwortdateiDefinition, 422
AnweisungenCOMMIT, 52DELETE, positionsbasiert, 24INSERT, 12PUT, 24ROLLBACK, 52ROLLBACK TO SAVEPOINT, 52UPDATE, positionsbasiert, 24
Anweisungs-HandleODBC, 287
Anwendungenbereitstellen, 426Bereitstellung, 411SQL, 10
Anwendungen bereitstellenEmbedded SQL, 433
Anwendungen mit mehreren ThreadsODBC, 278, 293UNIX, 282
Anwendungen mit ThreadverarbeitungUNIX, 416
ArbeitstabellenCursor-Performance, 43
Array, AbrufeInfo, 218
ARRAY, KlauselFETCH-Anweisung, 218
asademo.db, DateiInfo, xiv
asajdbc.zipDatenbankserver bereitstellen, 438Laufzeitklassen, 97
ASAJDBCDRV, JAR-DateiInfo, 98
ASAJRT, JAR-DateiInfo, 98
asajrt12.zipLaufzeitklassen, 97
ASAJSystem, JAR-DateiInfo, 98
ASAProvOLE DB-Provider, 372
AssistentenJAR- und ZIP-Datei erstellen, 105Java-Klasse hinzufügen, 104Neue Java-Klasse erstellen, 85, 161Upgrade einer Datenbank, Assistent, 101
AttributeJava in der Datenbank, 133
Auffüllen mit Leerzeichen, 367
AufzählungstypenDBTools-Schnittstelle, 367
Ausführlichkeit, 367
AuslagerbarDefinition, 140
AusnahmenJava, 73

B–B
469
autocommitODBC, 289steuern, 50
AutoCommitJDBC, 164
Autocommit, ModusImplementierung, 51Transaktionen, 49
BBefehle
ADO-Befehlsobjekt, 376
BefehlsobjektADO, 376
BeispieldatenbankInfo über asademo.db, xivJava in der Datenbank, 94
BeispieleDBTools-Programm, 319Embedded SQL, 191Embedded SQL-Anwendungen, 190esqldll.c, 188ODBC, 285statische Cursor in Embedded SQL, 193Windows-Dienste, 286
Benutzerdefinierte KlassenJava in der Datenbank, 76
Berechnete SpaltenBegrenzungen, 139erstellen, 137INSERT-Anweisung, 138Java in der Datenbank, 137Neuberechnungen, 139Trigger, 138UPDATE-Anweisung, 138
BerechtigungenJDBC, 173
BereichJava, 72
BereitstellenAnwendungen, 426Datenbanken, 439Datenbanken auf CD-ROM, 439
Datenbankserver, 438dbconsole, Dienstprogramm, 437eingebettete Datenbanken, 441Embedded SQL, 433Interactive SQL, 437Java in der Datenbank, 438jConnect, 435JDBC-Clients, 435JDBC-ODBC-Brücke, 435ODBC, 427ODBC-Treiber, 428OLE DB-Provider, 426Open Client, 436Personal Datenbankserver, 441schreibgeschützte Datenbanken, 439SQL Remote, 442Sybase Central, 437Verwaltungstools, 437
BereitstellungDateistandorte, 415Datenbanken und Anwendungen, 411Info, 411InstallShield, 420Methoden, 412MobiLink-Synchronisationsserver, 422ohne Dialog, 422siehe auch Bereitstellung, Überblick, 412Write-Dateien, 418
BeschreibenErgebnismengen, 47
BeständigkeitJava in den Datenbankklassen, 80
BetriebssystemDateinamen, 417
BezeichnerAnführungszeichen nötig, 270
BibliothekenEmbedded SQL, 185
BibliotheksfunktionenEmbedded SQL, 253
BINARY, DatentypenEmbedded SQL, 201
BindevariableInfo, 223

C–C
470
Bindungsparametervorbereitete Anweisungen, 13
Bit-FelderVerwendung, 319
BLOBsEmbedded SQL, 237in Embedded SQL abrufen, 238in Embedded SQL senden, 240
Block-Cursor, 22ODBC, 29
BookmarksODBC-Cursor, 303
Borland C++Unterstützung, 184
Breite Ablagen, 218
BytecodeJava-Klassen, 58
CC, Programmiersprache
Datentypen, 201
CacheJava in der Datenbank, 140
CALL, Anweisungembedded SQL, 243
Callback, FunktionenEmbedded SQL, 247registrieren, 261
CallbacksDB_CALLBACK_DEBUG_MESSAGE, 262
Catch, BlockJava, 73
CD-ROMDatenbanken bereitstellen, 439
Chained, ModusImplementierung, 51steuern, 50Transaktionen, 49
CHAINED, OptionJDBC, 164
Class.forName, MethodejConnect laden, 152
classes.zipDatenbankserver bereitstellen, 438Laufzeitklassen, 97
CLASSPATH, Umgebungsvariableeinrichten, 160Info, 82Java in der Datenbank, 82jConnect, 150
Clientseitiges autocommitInfo, 51
CLOSE, AnweisungInfo, 215
com.sybase, PaketLaufzeitklassen., 97
COMMIT, AnweisungAutocommit-Modus, 49, 50Cursor, 52JDBC, 164
compareTo, MethodeObjektvergleiche, 120
Compilerunterstützte, 184
COMPUTE, KlauselCREATE TABLE, 137
CREATE DATABASE, AnweisungJava in der Datenbank, 99, 100
CREATE PROCEDURE, Anweisungembedded SQL-Syntax, 243
CS_CSR_ABS, 398
CS_CSR_FIRST, 398
CS_CSR_LAST, 398
CS_CSR_PREV, 398
CS_CSR_REL, 398
CS_DATA_BOUNDARY, 398
CS_DATA_SENSITIVITY, 398
CS_PROTO_DYNPROC, 398
CS_REG_NOTIF, 398

D–D
471
CS_REQ_BCP, 398
ct_command, FunktionOpen Client, 394, 396
CT_CURSOR, FunktionOpen Client, 395
ct_dynamic, FunktionOpen Client, 394
ct_results, FunktionOpen Client, 396
ct_send, FunktionOpen Client, 396
Cursor, 29abbrechen, 25, 257abrollende, 23ADO, 28aktualisieren, 379, 396aktualisieren und löschen, 24anfordern, 27Arbeitstabellen, 43Beispiel C-Code, 190beschreiben, 47DYNAMIC SCROLL, 21, 26, 39Dynamisch, 37eindeutig, 26Einführung, 15Embedded SQL, 28, 215empfindlich, 37Empfindlichkeit, 30, 31Empfindlichkeit, Beispiele, 32, 34Ergebnismengen, 15Fat, 22Fetch-Vorgänge für mehrere Zeilen, 22Fetch-Vorgänge für Zeilen, 20, 22gespeicherte Prozeduren, 244Info, 15Interna, 30Isolationsstufe (isolation level), 21löschen, 396Mitgliedschaft, 30nicht-empfindlich, 39NO SCROLL, 26, 36ODBC, 28, 299ODBC-Aktualisierungen, 302ODBC-Bookmarks, 303ODBC-Cursor-Merkmale wählen, 299ODBC-Ergebnismengen, 300ODBC-Löschungen, 302OLE DB, 28
Open Client, 395Performance, 43, 44Plattformen, 26positionieren, 20Reihenfolge, 30Savepoints, 52Schlüsselmengen-gesteuert, 40Schreibschutz, 26Schritt für Schritt, 17SCROLL, 26, 40sichtbare Änderungen, 31Statisch, 36Transaktionen, 52unbestimmte Empfindlichkeit, 39unempfindlich, 26, 36Verfügbarkeit, 26verwenden, 15, 20vorbereitete Anweisungen, 19Werte, 30wert-empfindlich, 40
Cursor positionierenFehlerbehandlung, 21
DJDBCExamples.java, 144
DateienNamenskonventionen, 416Standorte für die Bereitstellung, 415
DateinamenKonventionen, 416Sprache, 417Versionsnummer, 416
Daten abrufenEmbedded SQL, 214
DatenbankdesignJava in der Datenbank, 133
Datenbankeigenschaftendb_get_property-Funktion, 258
Datenbankenbereitstellen, 439Java in der Datenbank, 133Java-aktivieren, 97, 99, 101URL, 153

D–D
472
Datenbankoptionenfür jConnect eingestellt, 154
Datenbankserverbereitstellen, 438Funktionen, 267
Datenbank-Tools, Schnittstellea_backup_db-Struktur, 335a_change_log-Struktur, 337a_compress_db-Struktur, 339a_compress_stats-Struktur, 340a_create_db-Struktur, 341a_crypt_db-Struktur, 343a_db_collation-Struktur, 344a_db_info-Struktur, 345a_dblic_info-Struktur, 348a_dbtools_info-Struktur, 349a_name-Struktur, 351a_stats_line-Struktur, 352a_sync-db-Struktur, 352a_syncpub-Struktur, 355a_sysinfo-Struktur, 356a_table_info-Struktur, 356a_translate_log-Struktur, 357a_truncate_log-Struktur, 358a_validate_db-Struktur, 363a_validate_type-Aufzählungstypen, 369a_writefile-Struktur, 364an_erase_db-Struktur, 349an_expand_db-Struktur, 350an_unload_db-Struktur, 359an_upgrade_db-Struktur, 361Auffüllen mit Leerzeichen, 367Aufzählungstypen, 367Ausführlichkeit, 367DBBackup-Funktion, 323DBChangeLogName-Funktion, 323DBChangeWriteFile-Funktion, 324DBCollate-Funktion, 324DBCompress-Funktion, 325DBCreate-Funktion, 325DBCreateWriteFile-Funktion, 326DBCrypt-Funktion, 326DBErase-Funktion, 327DBExpand-Funktion, 327DBInfo, Funktion, 327DBInfoDump-Funktion, 328DBInfoFree-Funktion, 328DBLicense-Funktion, 329DBStatusWriteFile-Funktion, 329DBToolsFini-Funktion, 330
DBToolsInit-Funktion, 331DBToolsVersion-Funktion, 332dbtran_userlist_type-Aufzählungstyp, 368DBTranslateLog-Funktion, 332DBTruncateLog-Funktion, 332dbunload-Aufzählungstyp, 368DBUnload-Funktion, 333DBUpgrade-Funktion, 333DBValidate-Funktion, 334dbxtract, 333Info, 311
DatentypenBereiche, 392C-Datentypen, 201dynamische SQL, 228Embedded SQL, 196Hostvariable, 201Java in der Datenbank, 109Open Client, 391SQLDA, 230Zuordnung, 391
DatentypkonvertierungIndikatorvariable, 206
db_backup, FunktionInfo, 247, 254
DB_BACKUP_CLOSE_FILE, Parameter, 254
DB_BACKUP_END, Parameter, 254
DB_BACKUP_OPEN_FILE, Parameter, 254
DB_BACKUP_READ_PAGE, Parameter, 254
DB_BACKUP_READ_RENAME_LOG,Parameter, 254
DB_BACKUP_START, Parameter, 254
DB_CALLBACK_CONN_DROPPED, Callback-Parameter, 262
DB_CALLBACK_DEBUG_MESSAGE, Callback-Parameter, 262
DB_CALLBACK_FINISH, Callback-Parameter,262
DB_CALLBACK_MESSAGE, Callback-Parameter,263
DB_CALLBACK_START, Callback-Parameter,262

D–D
473
DB_CALLBACK_WAIT, Callback-Parameter, 262
db_cancel_request, Funktion, 257Anforderungsverwaltung, 247
db_delete_file, Funktion, 257
db_find_engine, Funktion, 258
db_fini, Funktion, 258
db_fini_dllaufrufen, 188
db_get_property, FunktionInfo, 258
db_init, Funktion, 259
db_init_dllaufrufen, 188
db_is_working, Funktion, 260Anforderungsverwaltung, 247
db_locate_servers, Funktion, 260
db_register_a_callback, Funktion, 261Anforderungsverwaltung, 247
db_start_database, FunktionInfo, 263
db_start_engine, FunktionInfo, 264
db_stop_database, FunktionInfo, 265
db_stop_engine, FunktionInfo, 266
db_string_connect, FunktionInfo, 267
db_string_disconnect, FunktionInfo, 267
db_string_ping_server, FunktionInfo, 268
DBBackup, Funktion, 323
DBChangeLogName, Funktion, 323
DBChangeWriteFile, Funktion, 324
DBCollate, Funktion, 324
DBCompress, Funktion, 325
dbcon8.dllDatenbank-Dienstprogramme bereitstellen, 441Embedded SQL-Clients bereitstellen, 434ODBC-Clients bereitstellen, 428OLE DB-Clients bereitstellen, 426
dbconsole, Dienstprogrammbereitstellen, 437
DBCreate, Funktion, 325
DBCreateWriteFile, Funktion, 326
DBCrypt, Funktion, 326
dbctrs8.dllDatenbankserver bereitstellen, 438
dbeng8Datenbankserver bereitstellen, 438
DBErase, Funktion, 327
DBExpand, Funktion, 327
dbextf.dllDatenbankserver bereitstellen, 438
dbfile.dllSQL Remote bereitstellen, 442
DBInfo, Funktion, 327
DBInfoDump, Funktion, 328
DBInfoFree, Funktion, 328
dbinit (Dienstprogramm)Java in der Datenbank, 99, 100
dbipx8.dllEmbedded SQL-Clients bereitstellen, 434ODBC-Clients bereitstellen, 428
dbjava8.dllDatenbankserver bereitstellen, 438
dblgen8.dllDatenbank-Dienstprogramme bereitstellen, 441Datenbankserver bereitstellen, 438Embedded SQL-Clients bereitstellen, 434ODBC-Clients bereitstellen, 428OLE DB-Clients bereitstellen, 426SQL Remote bereitstellen, 442
dblib8.dllEmbedded SQL-Clients bereitstellen, 434Schnittstellenbibliothek, 182

D–D
474
DBLicense, Funktion, 329
dbmapi.dllSQL Remote bereitstellen, 442
dbmlsync, (Dienstprogramm)C API für, 352eigenes schreiben, 352
dbodbc8.dllODBC-Clients bereitstellen, 428
dbodbc8.libWindows CE ODBC-Importbibliothek, 282
dbodbc8.soUNIX ODBC-Treiber, 283
dboledb8.dllOLE DB-Clients bereitstellen, 426
dboledba8.dllOLE DB-Clients bereitstellen, 426
dbremoteSQL Remote bereitstellen, 442
dbserv8.dllDatenbankserver bereitstellen, 438
dbsmtp.dllSQL Remote bereitstellen, 442
dbsrv8Datenbankserver bereitstellen, 438
DBStatusWriteFile, Funktion, 329
DBSynchronizeLog, Funktion, 330
dbtool8.dllDatenbank-Dienstprogramme bereitstellen, 441SQL Remote bereitstellen, 442Windows CE, 312
DBTools, Schnittstellebeenden, 314Einführung, 312Info, 311starten, 314Verwendung, 314
DBToolsFini, Funktion, 330
DBToolsInit, Funktion, 331
DBTools-SchnittstelleBeispielprogramm, 319DBTools-Funktionen aufrufen, 315Funktionen, 323
DBToolsVersion, Funktion, 332
dbtran_userlist_type, Aufzählungstyp, 368
DBTranslateLog, Funktion, 332
DBTruncateLog, Funktion, 332
dbunload, Aufzählungstyp, 368
dbunload, Dienstprogrammeigenes schreiben, 359Header-Datei, 359
DBUnload, Funktion, 333
dbupgrad (Dienstprogramm)Java in der Datenbank, 100
dbupgrad, (Dienstprogramm)Java in der Datenbank, 99
DBUpgrade, Funktion, 333
DBValidate, Funktion, 334
dbvim.dllSQL Remote bereitstellen, 442
dbwtsp8.dllDatenbank-Dienstprogramme bereitstellen, 441SQL Remote bereitstellen, 442
dbxtract, (Dienstprogramm)Datenbank-Tools-Schnittstelle, 333
dbxtract, Dienstprogrammeigenes schreiben, 359Header-Datei, 359
DECIMAL, DatentypEmbedded SQL, 201
DECL_BINARY, Makro, 201
DECL_DECIMAL, Makro, 201
DECL_FIXCHAR, Makro, 201
DECL_LONGBINARY, Makro, 201
DECL_LONGVARCHAR, Makro, 201
DECL_VARCHAR, Makro, 201

D–D
475
DECLARE, AnweisungInfo, 215
DeklarationsabschnittInfo, 200
DeklarierenEmbedded SQL-Datentypen, 196Hostvariable, 200
DELETE, AnweisungJava in der Datenbank-Objekte, 116positionsbasiert, 24
DESCRIBE, AnweisungInfo, 226mehrere Ergebnismengen, 246SQLDA-Felder, 230sqllen-Felder, 232sqltype-Feld, 232
DeskriptorenErgebnismengen beschreiben, 47
DestruktorenJava, 72
DiensteBeispielcode, 195, 286Windows, 286
Dienstprogrammebereitstellen, 441Datenbank-Dienstprogramme bereitstellen, 441SQL-Präprozessor, 249
DISTINCT, SchlüsselwortJava in der Datenbank, Spalten, 120
Distributed Transaction Coordinatordreischichtige Datenverarbeitung, 403
DLL-Eintrittspunkte, 253
DLLsmehrere SQLCAs, 212
DokumentationKonventionen, xi
Dokumentation zu SQL Anywhere Studio, viii
Dreischichtige DatenverarbeitungArchitektur, 401Distributed Transaction Coordinator, 403EAServer, 403Info, 399
Microsoft Transaction Server, 403Ressourcen-Manager, 402Ressourcen-Verteiler, 402verteilte Transaktionen, 402
DT_BIGINT Embedded SQL, Datentyp, 196
DT_BINARY Embedded SQL, Datentyp, 197
DT_BIT Embedded SQL, Datentyp, 196
DT_DATE Embedded SQL, Datentyp, 196
DT_DECIMAL Embedded SQL, Datentyp, 196
DT_DOUBLE Embedded SQL, Datentyp, 196
DT_FIXCHAR Embedded SQL, Datentyp, 197
DT_FLOAT Embedded SQL, Datentyp, 196
DT_INT Embedded SQL, Datentyp, 196
DT_LONGBINARY Embedded SQL, Datentyp,198
DT_LONGVARCHAR Embedded SQL, Datentyp,197
DT_SMALLINT Embedded SQL, Datentyp, 196
DT_STRING, Datentyp, 271
DT_TIME Embedded SQL, Datentyp, 196
DT_TIMESTAMP Embedded SQL, Datentyp, 197
DT_TIMESTAMP_STRUCT Embedded SQL,Datentyp, 198
DT_TINYINT Embedded SQL, Datentyp, 196
DT_UNSINT Embedded SQL, Datentyp, 196
DT_UNSSMALLINT Embedded SQL, Datentyp,196
DT_VARCHAR Embedded SQL, Datentyp, 197
DT_VARIABLE Embedded SQL, Datentyp, 198,199
DTCdreischichtige Datenverarbeitung, 403
DYNAMIC SCROLL, CursorEmbedded SQL, 28Fehlerbehandlung, 21Info, 26, 39

E–F
476
Dynamische CursorBeispiel, 193Info, 37ODBC, 28
Dynamische SQLInfo, 223SQLDA, 228
EEAServer
dreischichtige Datenverarbeitung, 403Komponenten-Transaktionsattribut, 408transaction coordinator, 407Verteilte Transaktionen, 407
Eigenschaftendb_get_property-Funktion, 258
Einbeziehungverteilte Transaktionen, 402
Eindeutige CursorInfo, 26
Eindeutige SpaltenJava in der Datenbank, Spalten, 120
Eingebettete Datenbankenbereitstellen, 441
EinstellenWerte mit SQLDA, 234
Embedded SQLautocommit-Modus, 49, 50Befehlszusammenfassung, 272Beispielprogramm, 186Berechtigungen, 251Cursor, 28, 190, 215Cursortypen, 26Daten abrufen, 214Dynamische Anweisungen, 223Dynamische Cursor, 193Einführung, 4Entwicklung, 182Funktionen, 253Header-Dateien, 184Hostvariable, 200Importbibliotheken, 185Info, 181Kompilieren- und Verknüpfen-Prozess, 183
SQL-Anweisungen, 10statische Anweisungen, 223Zeichenfolgen, 251Zeilennummern, 251
Empfindliche CursorBeispiele für Aktualisieren, 34Beispiele für Löschen, 32Einführung, 31Embedded SQL, 28Info, 37
EmpfindlichkeitBeispiele für Aktualisieren, 34Beispiele für Löschen, 32Cursor, 30, 31Isolationsstufen und, 45
EntitätenJava in der Datenbank, 133
ErgebnismengenADO-Recordset-Objekt, 377, 379Cursor, 15gespeicherte Prozeduren, 244Java in der Datenbank, Gespeicherte Prozeduren,
125Java in der Datenbank, Methoden, 125Metadaten, 47ODBC, 299, 304ODBC abrufen, 300Open Client, 396verwenden, 20
EscapezeichenJava in der Datenbank, 80SQL, 80
EXEC SQLEntwicklung in Embedded SQL, 187
EXECUTE, Anweisung, 223Gespeicherte Prozeduren in Embedded SQL, 243
executeQuery, MethodeInfo, 169
executeUpdate, JDBC-Methode, 14Info, 166
FFat Cursor, 22

G–G
477
Feedbackgeben, xv
FehlerCodes, 208SQLCODE, 208sqlcode SQLCA-Feld, 208
FehlerbehandlungCursor positionieren, 21Java, 73Java in der Datenbank, Methoden, 124ODBC, 306
FehlermeldungenEmbedded SQL-Funktion, 271
FelderInstanz, 67Java in der Datenbank, 66Klasse, 67private, 72protected, 72public, 72, 83
FestschreibenTransaktionen aus ODBC, 289
FetchODBC, 300
FETCH, Anweisungdynamische Abfragen, 226Info, 214, 215mehrzeilig, 218weit, 218
Fetch, Vorgängeabrollende Cursor, 23Beschränkungen, 20Cursor, 22Mehrere Zeilen, 22
fill_s_sqlda, FunktionInfo, 269
fill_sqlda, FunktionInfo, 269
Finally, BlockJava, 73
FIXCHAR, DatentypEmbedded SQL, 201
ForceStart, Verbindungsparameterdb_start_engine, 265
FormatJava in der Datenbank, Objekte, 130
free_filled, FunktionInfo, 269
free_sqlda, FunktionInfo, 270
free_sqlda_noind, FunktionInfo, 270
FunktionenDBTools, 323DBTools-Funktionen aufrufen, 315Embedded SQL, 253
GGemischte Cursor
ODBC, 28
Gespeicherte ProzedurenEmbedded SQL, 243Ergebnismengen, 244in dynamischem SQL ausführen, 243in dynamischem SQL erstellen, 243INOUT-Parameter und Java, 127Java in der Datenbank, 125OUT-Parameter und Java, 127
getConnection, MethodeInstanzen, 164
getObject, Methodeverwenden, 176
GleichheitJava in der Datenbank-Objekte, 119
GNU-CompilerUnterstützung, 184
GRANT, AnweisungJDBC, 173
Groß-/KleinschreibungJava in der Datenbank und SQL, 78Java in der Datenbank, Datentypen, 109
GROUP BY, KlauselJava in der Datenbank, Spalten, 120

H–I
478
HHandles
ODBC zuweisen, 288über ODBC, 287
Header-DateienEmbedded SQL, 184ODBC, 280
Heap-GrößeJava in der Datenbank, 141
HintergrundverarbeitungCallback-Funktionen, 247
HinzufügenJAR-Dateien, 105Klassen für Java in der Datenbank, 104
Hostvariablebenutzen, 203Datentypen, 201deklarieren, 200Info, 200SQLDA, 230
IImport, Anweisung
Java, 71Java in der Datenbank, 81jConnect, 151
ImportbibliothekenAlternativen, 187DBTools, 314Einführung, 183Embedded SQL, 185NetWare, 188ODBC, 280Windows CE ODBC, 282
INCLUDE, AnweisungSQLCA, 208
IndikatorvariableDatentypkonvertierung, 206Info, 204kürzen, 206NULL, 205SQLDA, 230Zusammenfassungen der Werte, 206
IndizesJava in der Datenbank, 120, 130, 137
INOUT, ParameterJava in der Datenbank, 127
INSERT, AnweisungJava in der Datenbank, 112JDBC, 166, 168mehrzeilig, 218Objekte, 172Performance, 12weit, 218
INSTALL, AnweisungEinführung, 76Klassenversionen, 132verwenden, 104, 105
Installationohne Dialog, 422
InstallationsprogrammeBereitstellung, 413
InstallierenJAR-Dateien in einer Datenbank, 105Java-Klassen in einer Datenbank, 103, 104
InstallShieldAdaptive Server Anywhere-Anwendungen
bereitstellen, 420Bereitstellung ohne Dialog, 422
Instanz, FelderInfo, 67
Instanz, MethodenInfo, 68
InstanzenJava-Klassen, 71
InstanziertDefinition, 71
Interactive SQLbereitstellen, 437
IsolationsstufenAnwendungen, 51Cursor, 21Cursorempfindlichkeit und, 45

J–J
479
JJaguar
EAServer, 407
JAR- und ZIP-Datei erstellenverwenden, 105
JAR, Dateienaktualisieren, 106hinzufügen, 105installieren, 103, 105Java, 71löschen, 116Versionen, 106
JavaCatch-Block, 73Destruktoren, 72Fehlerbehandlung, 73Finally-Block, 73JDBC, 144Klassen, 71Konstruktoren, 72Objekte abfragen, 174Schnittstellen, 73Try-Block, 73
Java 2unterstützte Versionen, 75
Java in der DatenbankAbfragen, 117API, 60, 75Beispiel-Tabellen, 94benutzen, 93bereitstellen, 438Beständigkeit, 80compareTo-Methode, 120Datenbankdesign, 133Datentypen, 109die Dokumentation verwenden, 55die wichtigsten Funktionen, 57eine Datenbank aktivieren, 99, 101einfügen, 112Einführung, 54, 64Escapezeichen, 80Fehler, Prozedur nicht gefunden, 124Felder, 66Fragen und Antworten, 57Heap-Größe, 141in der Datenbank aktivieren, 97Indizes, 120, 130
Klassen installieren, 103Klassen kompilieren, 65Klassen löschen, 116Klassenversionen, 131Laufzeitklassen, 97Laufzeitumgebung, 75, 96main-Methode, 79, 123Methoden, 66Namensbereich, 141NULL, 109Objekte, 66Objekte einfügen, 114Objekte entladen und wieder laden, 132Objekte replizieren, 132Objekte vergleichen, 119Performance, 130Praktische Einführung, 84Primärschlüssel, 120Sicherheitsmanagement, Info, 128Spalten aktualisieren, 115Spalten berechnen, 137Spalten erstellen, 109Speicherfragen, 140Speicherung, 130Standardwerte, 109unterstützte Klassen, 61unterstützte Plattformen, 59Überblick, 94Version, 75Virtual Machine, 57, 58, 141Werte aktualisieren, 114Zeilen löschen, 116
Java, Datentypenabrufen, 172einfügen, 172
Java, gespeicherte ProzedurenBeispiel, 126Info, 125
Java, PaketLaufzeitklassen., 97
JAVA_HEAP_SIZE, Option, 141
JAVA_NAMESPACE_SIZE, Optionverwenden, 141
Java-Klasse erstellen, Assistantverwenden, 85
Java-Klasse hinzufügen, Assistantverwenden, 104, 161

K–K
480
Java-KlassenHinzufügen, 104installieren, 104
Java-SicherheitsmanagementInfo, 129
jcatalog.sql, DateijConnect, 151
jConnectCLASSPATH, Umgebungsvariable, 150Einrichtung der Datenbank, 151gelieferte Versionen, 150Info, 150JDBC-Clients bereitstellen, 435JDBC-Treiber wählen, 145laden, 152Pakete, 151Systemobjekte, 151URL, 152Verbindungen, 157, 161
JDBCArten der Benutzung, 144AutoCommit, 164Autocommit-Modus, 49, 50Beispiele, 144Berechtigungen, 173Bespiele, 157clientseitig, 149Client-Verbindungen, 157Cursortypen, 26Datenzugriff, 165Einführung, 5Info, 144INSERT-Anweisung, 166, 168jConnect, 150JDBC-Clients bereitstellen, 435Laufzeitklassen, 97Nicht-Standardklassen, 146, 147SELECT-Anweisung, 169serverseitig, 149serverseitige Verbindungen, 161SQL-Anweisungen, 10Standardwerte für die Verbindung, 164Überblick über die Anwendungen, 145verbinden, 157Verbindung mit einer Datenbank, 153Verbindungen, 149, 157Verbindungscode, 158Version, 75, 146, 147Version 2.0-Funktionen, 146, 147
Voraussetzungen, 144vorbereitete Anweisungen, 171
JDBCExamples, KlasseInfo, 165
JDBC-ODBC-Brückeerforderliche Dateien, 155JDBC-Clients bereitstellen, 435JDBC-Treiber wählen, 145verbinden, 155verwenden, 155
JDBC-TreiberKompatibilität, 145Performance, 145wählen, 145
jdemo.sqlBeispieltabellen, 94
JDKDefinition, 60Version, 75, 97
KKapazitäten
unterstützte, 398
Klassenaktualisieren, 106als Datentypen, 109Beispiel, 111erstellen, 103importieren, 176Info, 64installieren, 103Instanzen, 71Java, 71kompilieren, 65Konstruktoren, 66Laufzeit, 75unterstützte, 61Versionen, 106
Klassen, FelderInfo, 67
Klassen, MethodenInfo, 68

L–M
481
KlauselnWITH HOLD, 21
Kompilieren und Verknüpfen, Prozess, 183
KomponentenTransaktionsattribut, 408
Konsolendienstprogrammbereitstellen, 437
KonstruktorenDaten einfügen, 113Info, 66Java, 72
KonventionenDateinamen, 416Dokumentation, xi
KonvertierungDatentypen, 206
Kürzenbei FETCH, 206FETCH-Anweisung, 206Indikatorvariable, 206
LLaufzeitklassen
Inhalt, 97installieren, 97
Laufzeitklassen, Java in der Datenbank, 75
LaufzeitumgebungJava in der Datenbank, 96
length, SQLDA-FeldInfo, 230, 232
Lesezeichen, 29
LONG BINARY, DatentypEmbedded SQL, 201, 237in Embedded SQL abrufen, 238in Embedded SQL senden, 240
LONG VARCHAR, DatentypEmbedded SQL, 201, 237in Embedded SQL abrufen, 238in Embedded SQL senden, 240
LöschenJAR-Dateien, 116Java-Klassen, 116
Mmain, Methode
Java in der Datenbank, 79, 123
Makros_SQL_OS_NETWARE, 188_SQL_OS_UNIX, 188_SQL_OS_WINNT, 188
manual commit, ModusImplementierung, 51steuern, 50Transaktionen, 49
MAX, FunktionJava in der Datenbank, Spalten, 120
Mehrere ErgebnismengenDESCRIBE-Anweisung, 246
Mehrere Threads in AnwendungenEmbedded SQL, 211Java in der Datenbank, 124
Mehrfache ErgebnismengenODBC, 304
Mehrzeilige AbfragenCursor, 215
Mehrzeilige Abrufe, 218
Mehrzeilige Einfügungen, 218
Mehrzeiliges Speichern, 218
MeldungenCallback, 263Server, 263
printlnJava in der Datenbank, 79
Methoden>>, 77deklarieren, 68Instanz, 68Java in der Datenbank, 66Klasse, 68private, 72

N–O
482
protected, 72public, 72Punktoperator, 77statisch, 68void-Rückgabewert, 125
Microsoft Transaction Serverdreischichtige Datenverarbeitung, 403
Microsoft Visual C++Unterstützung, 184
MIN, FunktionJava in der Datenbank, Spalten, 120
Mit Leerzeichen aufgefülltZeichenfolgen in Embedded SQL, 196
MitgliedschaftErgebnismengen, 30
mlxtract, Dienstprogrammeigenes schreiben, 359Header-Datei, 359
MobiLink, SynchronisationsserverBereitstellung, 422
MSDASQLOLE DB-Provider, 372
Nname, SQLDA-Feld
Info, 230
NamensbereichJava in der Datenbank, 141
NetWareEmbedded SQL-Programme, 188
Newsgroupstechnische Unterstützung, xv
Nicht-empfindlicher CursorBeispiele für Aktualisieren, 34Beispiele für Löschen, 32Einführung, 31Info, 39
NLMEmbedded SQL-Programme, 188
NO SCROLL, CursorEmbedded SQL, 28Info, 26, 36
ntodbc.hInfo, 280
NULLIndikatorvariable, 204Java in der Datenbank, 109
Nullabschlusszeichen für ZeichenfolgeEmbedded SQL-Datentyp, 196
NULLWERTdynamische SQL, 228
OObjekte
abfragen, 174abrufen, 172einfügen, 172entladen und wieder laden, 132Java in der Datenbank, 66Klassenversionen, 131Replikation, 132Speicherformat, 107Speicherung von Java in der Datenbank, 130Typen, 66
Objektorientierte ProgrammierungJava in der Datenbank, 70Stil, 83
ODBCAbwärts-Kompatibilität, 279Anwendungen mit mehreren Threads, 293Autocommit-Modus, 49, 50Beispielanwendung, 289Beispielprogramm, 285bereitstellen, 427Cursor, 28, 299Cursortypen, 26Datenquellen, 431Einführung, 278Einführung in die Programmierung, 2Ergebnismengen, 304Fehlerprüfung, 306gespeicherte Prozeduren, 304Handles, 287Header-Dateien, 280

P–P
483
Importbibliotheken, 280kein Treiber-Manager, 284Kompatibilität, 279linken, 280mehrfache Ergebnismengen, 304programmieren, 277Registrierungseinträge, 431SQL-Anweisungen, 10Treiber bereitstellen, 428UNIX-Entwicklung, 282, 284unterstützte Version, 278Übereinstimmung, 278vorbereitete Anweisungen, 297Windows CE, 281, 282
ODBC, TreiberUNIX, 283
odbc.hInfo, 280
ODBC-Einstellungenbereitstellen, 428, 430
OLE DBAdaptive Server Anywhere, 372Aktualisierungen, 379bereitstellen, 426Cursor, 28, 379Cursortypen, 26Einführung in die Programmierung, 3Info, 372ODBC und, 372Provider bereitstellen, 426unterstützte Plattformen, 372unterstützte Schnittstellen, 382
OLE, Transaktionendreischichtige Datenverarbeitung, 402
Online-SicherungenEmbedded SQL-Funktionen, 247
Open ClientAdaptive Server Anywhere-Einschränkungen,
398Anforderungen, 390autocommit-Modus, 49, 50Cursortypen, 26Datentypbereiche, 392Datentypen, 391Datentyp-Kompatibilität, 391Einführung, 6Open Client-Anwendungen bereitstellen, 436
SQL, 394SQL-Anweisungen, 10
OPEN, AnweisungInfo, 215
OpenClientEinschränkungen, 398Schnittstelle, 389
ORDER BY, KlauselJava in der Datenbank, Spalten, 120
OUT, ParameterJava in der Datenbank, 127
PPakete
installieren, 105Java, 71Java in der Datenbank, 81jConnect, 151
PerformanceCursor, 43, 44Java in der Datenbank, Werte, 130JDBC, 171JDBC-Treiber, 145vorbereitete Anweisungen, 12, 297
Personal Serverbereitstellen, 441
PlattenspeicherJava in der Datenbank, Werte, 130
PlattformenCursor, 26Java in der Datenbank, 59
Platzhalterdynamische SQL, 223
Positionsbasierte Lösch-Vorgänge, 24
Positionsbasierte UpdatesInfo, 21
Positionsbasierte Update-Vorgänge, 24
Präprozessorausführen, 184Info, 182

Q–R
484
PrefetchCursor, 44Cursor-Performance, 43
PREFETCH, OptionCursor, 44
Prefetch-Vorgängemehrere Zeilen abrufen, 22
PREPARE TRANSACTION, Anweisungund OpenClient, 398
PREPARE, Anweisung, 223
PreparedStatement, KlassesetObject-Methode, 114
PreparedStatement, SchnittstelleInfo, 171
prepareStatement, Methode, 14
PrimärschlüsselJava in der Datenbank, Spalten, 120
PrivateJava-Zugriff, 72
ProgrammeinstiegspunkteDBTools-Funktionen aufrufen, 315
ProgrammstrukturEmbedded SQL, 187
ProtectedJava, 71Java-Zugriff, 72
Prozedur nicht gefunden, FehlermeldungJava-Methoden, 168
ProzedurenEmbedded SQL, 243Ergebnismengen, 244ODBC, 304
PublicJava-Zugriff, 72
Public, FelderWichtiges, 83
Punkt-OperatorJava und SQL, 77
PUT, Anweisung, 24mehrzeilig, 218weit, 218
PUT, Vorgang, 24
QQUOTED_IDENTIFIER, Option
jConnect-Einstellung, 154
RRecordset-Objekt
ADO, 377, 379
Registrierungbereitstellen, 428, 430ODBC, 431
REMOTEPWDverwenden, 153
ReplikationJava in der Datenbank, Objekte, 132
Reservierte WörterSQL und Java in der Datenbank, 81
Ressourcen-Managerdreischichtige Datenverarbeitung, 402Info, 400
Ressourcen-Verteilerdreischichtige Datenverarbeitung, 402
ROLLBACK TO SAVEPOINT, AnweisungCursor, 52
ROLLBACK, AnweisungCursor, 52
rt.jarLaufzeitklassen, 97
Rückgabecodes, 316ODBC, 306
RückrufeDB_CALLBACK_CONN_DROPPED, 262DB_CALLBACK_FINISH, 262DB_CALLBACK_MESSAGE, 263DB_CALLBACK_START, 262DB_CALLBACK_WAIT, 262

S–S
485
SSavepoints
Cursor, 52
Schlüsselmengen-gesteuerte CursorInfo, 40ODBC, 28
SchlüsselwörterSQL und Java in der Datenbank, 81
SchnittstelleJava, 73
SchnittstellenbibliothekDateiname, 182dynamisch laden, 187Info, 182
Schreibgeschützte CursorInfo, 26
SchreibschutzDatenbanken bereitstellen, 439
SCROLL, CursorEmbedded SQL, 28Info, 26, 40
SecurityManager, KlasseInfo, 128, 129
SELECT, Anweisungdynamisch, 226einzelne Zeilen, 214Java in der Datenbank, 117JDBC, 169Objekte, 172
SerialisierungJava in der Datenbank, Objekte, 130Objekte, 175Objekte in Tabellen, 107verteilte Datenverarbeitung, 176
Serversuchen, 268
ServeradressenEmbedded SQL-Funktion, 258
setAutocommit, MethodeInfo, 164
setObject, Methodeverwenden, 176
Setup-Programmdialogfreie Installation, 422
SicherheitJava in der Datenbank, 128, 129
SicherungenDBBackup, DBTools-Funktion, 323DBTools-Beispiel, 319Embedded SQL-Funktionen, 247
Sichtbare ÄnderungenCursor, 31
SoftwareRückgabecode, 316
SortierenJava in der Datenbank-Objekte, 119
sp_tsql_environment, SystemprozedurOptionen für jConnect einstellen, 154
SpaltenJava in der Datenbank aktualisieren, 114Java in der Datenbank, Datentypen, 109
SpeicherJava in der Datenbank, 140
SpeicherungJava in der Datenbank, Objekte, 130
SprachenDateinamen, 417
Sprachen-DLLerhalten, 417
spt_mda, gespeicherte ProzedurOptionen für jConnect einstellen, 154
SQLADO-Anwendungen, 10Anwendungen, 10Embedded SQL-Anwendungen, 10JDBC-Anwendungen, 10ODBC-Anwendungen, 10Open Client-Anwendungen, 10
SQL Anywhere StudioDokumentation, viii
SQL Remotebereitstellen, 442Java in der Datenbank, Objekte, 132

S–S
486
SQL, KommunikationsbereichInfo, 208
SQL/92SQL-Präprozessor, 250
SQL_ATTR_MAX_LENGTH, AttributInfo, 300
SQL_CALLBACK, Typendeklaration, 261
SQL_CALLBACK_PARM, Typendeklaration, 261
SQL_ERRORODBC-Rückgabewert, 306
SQL_INVALID_HANDLEODBC-Rückgabewert, 306
SQL_NEED_DATAODBC-Rückgabewert, 306
sql_needs_quotes, FunktionInfo, 270
SQL_NO_DATA_FOUNDODBC-Rückgabewert, 306
SQL_SUCCESSODBC-Rückgabewert, 306
SQL_SUCCESS_WITH_INFOODBC-Rückgabewert, 306
SQL92SQL-Präprozessor, 250
SQLAllocHandle, ODBC-FunktionAnweisungen ausführen, 294Info, 287Parameter binden, 295verwenden, 288
SQL-Anweisungenausführen, 394
SQLBindCol, ODBC-FunktionInfo, 299, 300
SQLBindParameter, ODBC-Funktion, 14gespeicherte Prozeduren, 304Info, 295Vorbereitete Anweisungen, 297
SQLBrowseConnect, ODBC-FunktionInfo, 290
SQLCAändern, 211Felder, 208Info, 208Länge von, 208mehrere, 211, 212Threads, 211
sqlcabc SQLCA, FeldInfo, 208
sqlcaidSQLCA-Feld, 208
sqlcode SQLCA, FeldInfo, 208
SQLConnect, ODBC-FunktionInfo, 290
SQLCOUNTsqlerror SQLCA-Feldelement, 209
sqld, SQLDA-FeldInfo, 229
SQLDADeskriptoren, 48Felder, 229freigeben, 269füllen, 269Hostvariable, 230Info, 223, 228sqllen-Felder, 232Zeichenfolgen, 269zuweisen, 253
sqlda_storage, FunktionInfo, 271
sqlda_string_length, FunktionInfo, 271
sqldabc, SQLDA-FeldInfo, 229
sqldaif, SQLDA-FeldInfo, 229
sqldata, SQLDA-FeldInfo, 230
sqldef.hDatentypen, 196
SQLDriverConnect, ODBC-FunktionInfo, 290

S–S
487
sqlerrd SQLCA, FeldInfo, 209
sqlerrmc SQLCA, FeldInfo, 209
sqlerrml SQLCA, FeldInfo, 209
sqlerror SQLCA, FeldElemente, 209SQLCOUNT, 209SQLIOCOUNT, 209SQLIOESTIMATE, 211
SQLError, ODBC-FunktionInfo, 306
sqlerror_message, FunktionInfo, 271
sqlerrp SQLCA, FeldInfo, 209
SQLExecDirect, ODBC-Funktiongebundene Parameter, 295Info, 294
SQLExecute, ODBC-Funktion, 14
SQLExtendedFetch, ODBC-Funktiongespeicherte Prozeduren, 304Info, 300
SQLFetch, ODBC-Funktiongespeicherte Prozeduren, 304Info, 300
SQLFreeHandle, ODBC-Funktionverwenden, 288
SQLFreeStmt, ODBC-Funktion, 14
SQLGetData, ODBC-FunktionInfo, 299, 300
sqlind, SQLDA-FeldInfo, 230
SQLIOCOUNTsqlerror SQLCA-Feldelement, 209
SQLIOESTIMATEsqlerror SQLCA-Feldelement, 211
SQLJ, StandardsInfo, 54
sqllen, SQLDA-FeldDESCRIBE-Anweisung, 232Info, 230, 232Werte abrufen, 235Werte beschreiben, 232Werte senden, 234
sqlname, SQLDA-FeldInfo, 230
SQLNumResultCols, ODBC-Funktiongespeicherte Prozeduren, 304
SQLPPBefehlszeile, 249Info, 182
SQL-Präprozessorausführen, 184Befehlszeile, 249Info, 249
SQLPrepare, ODBC-Funktion, 14Info, 297
SQLRETURNTyp des ODBC-Rückgabewertes, 306
SQLSetConnectAttr, ODBC-FunktionInfo, 292
SQLSetPos, ODBC-FunktionInfo, 302
SQLSetStmtAttr, ODBC-FunktionCursor-Merkmale, 299
sqlstate SQLCA, FeldInfo, 209
SQLtransact, ODBC-FunktionInfo, 289
sqltype, SQLDA-FeldDESCRIBE-Anweisung, 232Info, 230
sqlvar, SQLDA-FeldInfo, 229, 230Inhalt, 230
sqlwarn SQLCA, FeldInfo, 209
StandardausgabeJava in der Datenbank, 79

T–U
488
StandardsSQLJ, 54
StandardwerteJava in der Datenbank, 109
START JAVA, Anweisungverwenden, 141
StartenDatenbanken unter Verwendung von jConnect,
153
Statische MethodenInfo, 68
Statische SQLInfo, 223
Statischer CursorInfo, 36ODBC, 28
STOP JAVA, Anweisungverwenden, 141
StrukturverdichtenHeader-Dateien, 184
sun, PaketLaufzeitklassen., 97
Sybase Centralbereitstellen, 437Datenbnak für Java aktivieren, 101JAR-Dateien hinzufügen, 105Java-Klassen hinzufügen, 104ZIP-Dateien hinzufügen, 105
sybase.sql, PaketLaufzeitklassen., 97
sybase.sql.ASA, PaketJDBC 2.0-Funktionen, 147
Sybase-Laufzeitklassen für JavaInfo, 97
Symbolein Handbüchern, xii
System Management ServerSystemeinführung, 424
SystemeinführungODBC-Einstellungen, 428, 430Registrierungseinstellungen, 428, 430System Management Server, 424
TTechnische Unterstützung
Newsgroups, xv
thisJava in der Datenbank, Methoden, 125
-gn, Option, 124
ThreadsEmbedded SQL, 211Java in der Datenbank, 124ODBC, 278ODBC-Anwendungen, 293UNIX-Entwicklung, 282
TIMESTAMP, DatentypKonvertierung, 392
Transaction coordinatorEAServer, 407
TransaktionenAnwendungsentwicklung, 49Autocommit-Modus, 49, 50Cursor, 52Isolationsstufe, 51ODBC, 289verteilt, 400, 405
TransaktionsattributKomponente, 408
Try, BlockJava, 73
TypenObjekte, 66
UUmgebungs-Handle
ODBC, 287
Unchained, ModusImplementierung, 51steuern, 50Transaktionen, 49
Unempfindliche CursorBeispiele für Aktualisieren, 34Beispiele für Löschen, 32Einführung, 31

Ü–V
489
Embedded SQL, 28Info, 36
Unempfindlicher CursorInfo, 26
UnicodeODBC, 281Windows CE, 281
UNIXAnwendungen mit mehreren Threads, 416Hinweise zu Bereitstellungsmethoden, 415ODBC, 282, 283ODBC-Anwendung, 284Verzeichnisstruktur, 415
unixodbc.hInfo, 280
Unterstützte PlattformenOLE DB, 372
UnterstützungNewsgroups, xv
UPDATE, AnweisungJava in der Datenbank, 114positionsbasiert, 24set-Methoden, 115
Upgrade einer Datenbank, AssistantDatenbank für Java aktivieren, 101
URLDatenbank, 153jConnect, 152
ÜÜberlauffehler
Datentyp-Konvertierung, 392
VVARCHAR, Datentyp
Embedded SQL, 201
Veraltete Java-KlassenInfo, 75
VerbindungenADO-Verbindungsobjekt, 374Funktionen, 267jConnect, 153jConnect-URL, 152JDBC, 149JDBC im Server, 161JDBC-Beispiel, 157, 161JDBC-Client-Anwendungen, 157JDBC-Standardwerte, 164ODBC, programmieren, 291ODBC-Attribute, 292ODBC-Funktionen, 290
Verbindungs-HandleODBC, 287
VerbindungsobjektADO, 374
VerfügbarkeitVerbindungen, 262
VerschlüsselungDBTools-Schnittstelle, 326
VersionJava in der Datenbank, 75JDBC, 75JDK, 75
VersionenKlassen, 131
VersionsnummerDateinamen, 416
Verteilte AnwendungenBeispiele, 176Info, 174Voraussetzungen, 174
Verteilte TransaktionenArchitektur, 402, 404dreischichtige Datenverarbeitung, 402EAServer, 407Einbeziehung, 402Info, 399, 400, 405Wiederherstellung, 406
VerzeichnisstrukturUNIX, 415
Visual C++Unterstützung, 184

W–
490
VMJava Virtual Machine, 58starten, 141stoppen, 141
voidJava in der Datenbank, Methoden, 66, 125
Vorbereitenzum Festschreiben, 403
Vorbereitete AnweisungenBindungsparameter, 13Cursor, 19Java in der Datenbank, Objekte, 114JDBC, 171löschen, 13ODBC, 297Open Client, 394verwenden, 12
WWatcom C/C++
Unterstützung, 184
Weite Abrufe, 22Info, 218
Weite Einfügungen, 218
Wert-empfindlicher CursorBeispiele für Aktualisieren, 34Beispiele für Löschen, 32Einführung, 31Info, 40
Wiederherstellungverteilte Transaktionen, 406
Windows CEdbtool8.dll, 312Java in der Datenbank nicht unterstützt, 59ODBC, 281, 282OLE DB, 372unterstützte Versionen, 372
Windows-DiensteBeispielcode, 195
WITH HOLD, KlauselCursor, 21
Write-Dateienbereitstellen, 418
ZZeichenfolgen, 251
Datentyp, 271DT_STRING wird mit Leerzeichen aufgefüllt,
196Java in der Datenbank, 78
ZeichensatzkonvertierungJDBC-ODBC-Brücke, 156
ZeilenlängeSQL-Präprozessor-Ausgabe, 250
ZeilennummernSQL-Präprozessor, 251
Zip, DateienJava, 71
ZugriffsmodifiziererJava, 72
Zwei-Phasen-Commitdreischichtige Datenverarbeitung, 402, 403und OpenClient, 398


















