
Bachelor Arbeit: Software zur automatischen Zuordnung von ... · Microsoft Access und Oracle...
81
Transcript of Bachelor Arbeit: Software zur automatischen Zuordnung von ... · Microsoft Access und Oracle...

Fachbereich Elektrotechnik und Informatik
Studiengang Angewandte Informatik
Bachelorarbeitzur Erlangung des akademischen Grades Bachelor of Science
Software zur automatischen Zuordnung von ähnlichen
Datenbank-Schemata inklusive Datenmigration und
Testdatenerzeugung
Karl Glatz
13. März 2009
Betreuer
Prof. Dr. Martin HulinHochschule Ravensburg-Weingarten
Dr. Michael KeckeisenTWT GmbH - Neuhausen

Karl Glatz:
Software zur automatischen Zuordnung von ähnlichenDatenbank-Schemata inklusive Datenmigration und Testdaten-erzeugung
BachelorarbeitHochschule Ravensburg-Weingarten
Bearbeitungszeitraum: 15. Dezember 2008 - 14. März 2009

Eidesstattliche Versicherung
Ich versichere an Eides statt durch meine Unterschrift, dass ich die vorliegende Ba-chelorarbeit mit dem Thema �Software zur automatischen Zuordnung von ähnlichenDatenbank-Schemata inklusive Datenmigration und Testdatenerzeugung� ohne fremdeHilfe verfasst und nur die angegebenen Quellen und Hilfsmittel benutzt habe. Wörtlichoder dem Sinn nach anderen Werken entnommene Stellen sind unter Angabe der Quel-len kenntlich gemacht. Diese Arbeit hat in gleicher oder ähnlicher Form noch keinerPrüfungsbehörde vorgelegen.
Neuhausen auf den Fildern, 13.03.2009Karl Glatz
I


Inhaltsverzeichnis
Abbildungsverzeichnis VII
Tabellenverzeichnis IX
Abkürzungsverzeichnis X
1 Einleitung 11.1 Problemstellung und Motivation . . . . . . . . . . . . . . . . . . . . . . 11.2 Zielde�nition und Vorgehensweise . . . . . . . . . . . . . . . . . . . . . 21.3 Projektmanagement . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Anforderungen 42.1 Grundlagen und Begri�e . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Datenbanksysteme . . . . . . . . . . . . . . . . . . . . . . . . . 42.1.2 Elemente eines relationalen Datenbanksystems . . . . . . . . . . 42.1.3 Beziehungen und Normalformen . . . . . . . . . . . . . . . . . . 52.1.4 Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Anforderungen an die Datenmigration . . . . . . . . . . . . . . . . . . 72.2.1 Änderung am Datenbankmodell . . . . . . . . . . . . . . . . . . 82.2.2 Heterogenität . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.3 Strukturelle und semantische Heterogenität . . . . . . . . . . . . 102.2.4 Zuordnung von Tabellen und Spalten . . . . . . . . . . . . . . . 112.2.5 �Er�nden� von Werten . . . . . . . . . . . . . . . . . . . . . . . 122.2.6 Komplexe Zuordnungen . . . . . . . . . . . . . . . . . . . . . . 122.2.7 Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Anforderungen an Testdaten . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Analyse bestehender Lösungsansätze 163.1 Theoretische Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.1 Dynamische Schemaevolution . . . . . . . . . . . . . . . . . . . 163.1.2 Schemaintegration . . . . . . . . . . . . . . . . . . . . . . . . . 163.1.3 Schema Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . 173.1.4 Schema Matching . . . . . . . . . . . . . . . . . . . . . . . . . . 183.1.5 SchemaSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 Produkte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.2.1 Oracle SQL Developer (Version 1.5.1) . . . . . . . . . . . . . . . 203.2.2 IBM Clio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2.3 Altova MapForce (Enterprise 2009) . . . . . . . . . . . . . . . . 223.2.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . 22
III

4 Ansatz 244.1 Voraussetzungen für eine Datenmigration . . . . . . . . . . . . . . . . . 244.2 Schema Zuordnung im Detail . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.1 Konstante Werte . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2.2 SQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 Erkennen von Ähnlichkeiten zwischen Schemaelementen . . . . . . . . . 274.3.1 Vergleich von Namen . . . . . . . . . . . . . . . . . . . . . . . . 274.3.2 Vergleich der Struktureigenschaften . . . . . . . . . . . . . . . . 284.3.3 Optimierungsmöglichkeiten . . . . . . . . . . . . . . . . . . . . . 28
4.4 Erzeugen von Testdaten . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5 Software-Entwurf 315.1 Technologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.1.1 Die Datenbank Abstraktion JDBC . . . . . . . . . . . . . . . . 315.1.2 JDBC und ODBC . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.2 Generelle Aspekte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2.1 Sprache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2.2 Metadaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.3 Allgemeine Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.4 Datenbankzugri� . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.5 Datenmodell (Meta Modell) . . . . . . . . . . . . . . . . . . . . . . . . 36
5.5.1 Modellerweiterung für die Datenmigration . . . . . . . . . . . . 375.5.2 Modellerweiterung für die Testdatenerzeugung . . . . . . . . . . 38
5.6 Logik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.7 Ober�äche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
6 Implementierung 436.1 Allgemeiner Ablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.2 Migration: Zuordnung von Tabellen und Spalten . . . . . . . . . . . . . 43
6.2.1 De�nition alternativer Inhalte . . . . . . . . . . . . . . . . . . . 436.2.2 Editierabstand . . . . . . . . . . . . . . . . . . . . . . . . . . . 456.2.3 Bewertungskriterien und Gewichtung . . . . . . . . . . . . . . . 466.2.4 Realisierung der automatischen Zuordnung . . . . . . . . . . . . 47
6.3 Datenbankoperationen . . . . . . . . . . . . . . . . . . . . . . . . . . . 476.3.1 Abhängigkeiten zwischen Tabellen durch Beziehungen . . . . . . 476.3.2 Oracle: Sequenzen und Trigger . . . . . . . . . . . . . . . . . . 48
6.4 Migrationsvorgang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506.5 Testdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 526.6 Speichern und Laden von Projekten . . . . . . . . . . . . . . . . . . . . 536.7 Einschränkungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
7 Test 567.1 Test der Datenmigration . . . . . . . . . . . . . . . . . . . . . . . . . . 56
7.1.1 Schema A (MS Access XP) . . . . . . . . . . . . . . . . . . . . . 567.1.2 Schema B (Oracle 10g) . . . . . . . . . . . . . . . . . . . . . . . 577.1.3 Kon�guration . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
7.2 Testdaten erzeugen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
IV

8 Schlussbetrachtung 618.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 618.2 Ergebnisse dieser Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . 618.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 628.4 Danksagungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
Literaturverzeichnis A
Anhang C
V


Abbildungsverzeichnis
1.1 Typischer Entwicklungsablauf (stark vereinfacht) . . . . . . . . . . . . 1
2.1 Begri�e einer relationalen Datenbank; Quelle: [Wik09b] . . . . . . . . . 52.2 Entity-Relationship-Diagramm in Chen-Notation . . . . . . . . . . . . 62.3 Darstellung einer Datentransformation; Quelle: [Nau06b] . . . . . . . . 82.4 Beispiel: Zuordnung von Tabellen und Spalten . . . . . . . . . . . . . . 112.5 Gegenüberstellung zweier ähnlicher Schemata mit unterschiedlichen Be-
ziehungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.6 Beispielhafte Darstellung einer nicht trivialen Zuordnung (Datensicht) . 14
3.1 Mehrwertige Korrespondenzen (1:1, N:1, 1:N) . . . . . . . . . . . . . . 173.2 Höherstu�ge Korrespondenzen (gestrichelt); Quelle: [LN07a] . . . . . . 183.3 Schema Matching Klassi�kation nach [RB01] . . . . . . . . . . . . . . . 193.4 SQL Developer MS Access Export . . . . . . . . . . . . . . . . . . . . . 203.5 Oracle SQL Developer Startbildschirm . . . . . . . . . . . . . . . . . . 213.7 Altova MapForce Screenshot; Quelle: Altova Webseite . . . . . . . . . . 223.6 IBM Clio; Quelle: [IBM] . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1 Ansatz der Zuordnung von Schemaelementen . . . . . . . . . . . . . . . 254.2 SQL Befehl Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.3 Beziehungen zwischen Testdaten (Beispiel) . . . . . . . . . . . . . . . . 30
5.1 JDBC: Vereinfachter Aufbau . . . . . . . . . . . . . . . . . . . . . . . . 325.2 Schichtenmodell der Komponenten . . . . . . . . . . . . . . . . . . . . 345.3 Datenbank und Plugin Interfaces (UML) . . . . . . . . . . . . . . . . . 355.4 Basis Datenmodell der Anwendung . . . . . . . . . . . . . . . . . . . . 375.5 Erweiterung des Datenmodells (Migration) . . . . . . . . . . . . . . . . 385.6 Kompletter Entwurf des Datenmodells . . . . . . . . . . . . . . . . . . 405.7 Klassen der Logik Komponente . . . . . . . . . . . . . . . . . . . . . . 415.8 Simpler Ober�ächen Entwurf . . . . . . . . . . . . . . . . . . . . . . . 42
6.1 Allgemeiner Ablauf als Aktivitätsdiagramm . . . . . . . . . . . . . . . 446.2 Beziehungen zwischen Tabellen als Graph . . . . . . . . . . . . . . . . 486.3 Trigger und Sequenz im Verbindungsdialog . . . . . . . . . . . . . . . . 496.4 Migrationsvorgang Sequenzdiagramm . . . . . . . . . . . . . . . . . . . 506.5 Arbeitsweise von buildNextRow() . . . . . . . . . . . . . . . . . . . . . 516.6 Ermittlung der Voreinstellungen für Testdaten . . . . . . . . . . . . . . 55
7.1 Quellschema (Schema A) [MS Access] . . . . . . . . . . . . . . . . . . . 567.2 Zielschema (Schema B) [Oracle Designer] . . . . . . . . . . . . . . . . . 57
VII

7.3 Screenshot der Kon�guration des Migrationsprojektes . . . . . . . . . . 597.4 Migration: Tabelle �XY_FZG_TYPEN� Kon�guration . . . . . . . . . 597.5 Testdaten Einstellungen . . . . . . . . . . . . . . . . . . . . . . . . . . 607.6 Testdaten: Ausschnitt der generierten Daten . . . . . . . . . . . . . . . 60
VIII

Tabellenverzeichnis
1.1 Zeitplan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 Kardinalitäten, Beispiele und deren Abbildung in der DB . . . . . . . . 7
4.1 Quellen für Testdatenerzeugung . . . . . . . . . . . . . . . . . . . . . . 29
5.1 Vergleich der Technologien . . . . . . . . . . . . . . . . . . . . . . . . . 31
6.1 Bewertungstabelle für Ähnlichkeiten zwischen Schemaelementen . . . . 466.2 Beispiel: Bewertung der Ähnlichkeit von Spalten . . . . . . . . . . . . . 46
IX

X

Abkürzungsverzeichnis
DB . . . . . . . . gängige Abkürzung für Datenbank
DBMS . . . . Database Management System � Datenbankverwaltungssystem
DDL . . . . . . Data De�nition Language - Teil der Datenbanksprache, der zur Verwal-tung der Elemente der Datenbank dient
GUI . . . . . . . Graphical User Interface � Eine gra�sche Benutzerober�äche
JDBC . . . . Java Database Connectivity � Datenbank Abstraktion von Java
JDK . . . . . . Java Development Kit � Java Paket zur Entwicklung von Java Program-men
MFC . . . . . . Microsoft Foundation Classes � Bibliothek um Ober�ächen für Windowszu erstellen
MS . . . . . . . . gängige Abkürzung für Microsoft
ODBC . . . . Open Database Connectivity � Eine standardisierte Datenbankschnitt-stelle
ORM . . . . . Object-Relational Mapping -Objektrelationale Abbildung
RDBMS . . Relational Database Management System � Relationales Datenbanksys-tem
SQL . . . . . . . Structured Query Language � Datenbanksprache zur De�nition, Abfrageund Manipulation von Daten in relationalen Datenbanken
UML . . . . . Uni�ed Modeling Language � eine von der Object Management Group(OMG) entwickelte und standardisierte Sprache für die Modellierung vonSoftware und anderen Systemen
XI


1 Einleitung
1.1 Problemstellung und Motivation
Zu den Aufgabenbereichen vieler IT-Unternehmen zählt die Entwicklung datenbank-gestützter Software. Dabei ist die Datenbank ein Bestandteil des gesamten Software-Systems. Sie dient zur Speicherung und Verwaltung der Daten.
Es besteht die Anforderung, das Software-System stetig weiterzuentwickeln sowie miterweiterter Funktionalität zu versehen. Dies kann zur Folge haben, dass eine komplet-te Umstellung des Systems erfolgen muss. Soll diese Umstellung bei einem Systemerfolgen, das sich im produktiven Einsatz be�ndet, muss gewährleistet werden, dassdie bestehenden Daten problemlos in das neue System migriert werden können. Zuroptimalen Anbindung des neuen Systems kann der Einsatz eines anderen Datenbank-produkts nötig sein. Abbildung 1.1 verdeutlicht den zeitlichen Zusammenhang.
( a l t e s ) P r o d u k t i v s y s t e m
Z e i t
E n t w i c k l u n g d e s n e u e n S y s t e m
B e n u t z e r
D a t e n e i n g a b e
n e u e s S y s t e m
D a t e n e i n g a b e
U m s t e l l u n g s -p h a s e
Abbildung 1.1: Typischer Entwicklungsablauf (stark vereinfacht)
Viele, der auf dem Markt verfügbaren Produkte zur Migration von Datenbanken er-lauben nur eine komplette Übertragung der Datenbank. Dies schlieÿt das Schema1 derDatenbank mit ein. Die Neuentwicklung des Systems erfordert eine Anpassung desSchemas. Um alle Daten aus dem alten in das neue System zu übernehmen muss dieÜbertragung während der Umstellungsphase erfolgen. Die Unterschiede der Schemata,die zu diesem Zeitpunkt gegeben sind, müssen bei der Umstellung besonderes beachtetwerden.
Ein weiteres Problem stellt die Geheimhaltung der Daten dar. Externe Unternehmenerlauben nur eingeschränkten Zugri� auf sensible Daten aus dem Produktivsystem.1Struktur der Daten; Begri� wird in Abschnitt 2.1.4 erläutert.
1

1 Einleitung
Aus diesem Grund dürfen Daten von externen Unternehmen nicht für alle beteiligtenEntwickler sichtbar sein. Auf Testläufe während der Entwicklung kann jedoch in keinemFall verzichtet werden. Das manuelle Eintragen von Testdaten verursacht enormenAufwand und erhöht somit die Kosten. Deswegen ist es notwendig diesen Prozess zuvereinfachen.
1.2 Zielde�nition und Vorgehensweise
Ziel dieser Bachelorarbeit ist eine prototypische Softwarelösung, mit der sich folgendeAufgaben möglichst einfach lösen lassen:
• Migration von Daten zwischen zwei heterogenen Datenbanken am Beispiel vonMicrosoft Access und Oracle
• Teilautomatische Erzeugung von Testdaten am Beispiel einer Oracle Datenbank
Neben diesen primären Zielen soll eine Basis für zukünftige Datenmigrationen geschaf-fen werden. Daher spielt die Modularität des Programms eine wichtige Rolle.
Da die Migration von Daten ein komplexer Prozess ist und nicht jeder beliebige Fallabgedeckt werden kann, wird in Kapitel 2 genau dargelegt, welche Anforderungen er-füllt werden müssen. In diesem Zusammenhang werden theoretische und begri�icheGrundlagen erläutert. Anschlieÿend wird eine Analyse bestehender Ansätze durchge-führt (3). Neben theoretischen Ansätzen wird auch überprüft, welche Möglichkeitenaktuelle Produkte bieten um diesen Anforderungen gerecht zu werden.
Der Ansatz zur Lösung der bestehenden Probleme unter Beachtung der gegebenen An-forderungen wird in Kapitel 4 beschrieben. Das Kapitel 5 zeigt einen grundlegendenEntwurf für die angestrebten Lösung. Basierend auf diesem Entwurf wird die Imple-mentierung der Anwendung im Detail beschrieben (6). Um eine Veri�kation für diekorrekte Funktionalität der entworfenen Anwendung zu bekommen wurde ein praxis-naher Test entworfen (7). Zum Abschluss wird eine Zusammenfassung der Ergebnissedieser Bachelorarbeit erstellt sowie ein Ausblick auf künftige Weiterentwicklungen ge-geben (8).
1.3 Projektmanagement
Die Projektplanung ist ein wichtiger Baustein für den Erfolg eines Projektes. Da diesesProjekt Teil einer Bachelorarbeit ist, wird mit einer 7 Tage Woche gerechnet. Diegenaue Dauer einer Aufgabe kann im Voraus nicht bestimmt werden, deshalb ist esnotwendig zusätzlich einen Pu�er festzulegen. Der Zeitplan ist vor allem wichtig, weiler es ermöglicht, zeitliche Probleme während des Projektes früh zu erkennen.
2

1.3 Projektmanagement
Aufgabe Zeit (Tage)
Analyse der Anforderungen, Machbarkeitsstudie 2Erarbeiten der theoretischen Grundlagen 4Recherche bestehender Lösungen 2Projektplanung 2Erarbeiten des Lösungsansatzes 3Entwurf der Software-Architektur 5Entwicklungs- und Testumgebung einrichten 1Programmierung grundlegender Funktionen 11Programmierung der Migration 14Programmierung der Testdatenerzeugung 8Dokumentation (Quellcode, Bachelorarbeit) 24Projektabschluss 2
Benötigte Zeit 78Verfügbare Zeit (12 Wochen) 84Pu�er 6
Tabelle 1.1: Zeitplan
Das Testen des Quellcodes erfolgt kontinuierlich während der Programmierung und istdeshalb in den Zeitangaben der Programmieraufgaben enthalten.
3

2 Anforderungen
In diesem Kapitel werden zunächst die Grundlagen und Begri�ichkeiten (2.1) vorge-stellt. Weiterhin werden die Anforderungen an das System (2.2, 2.3) de�niert und durchentsprechende Beispiele erläutert.
2.1 Grundlagen und Begri�e
2.1.1 Datenbanksysteme
Implizit wird bei Datenbanken meist von den weit verbreiteten relationalen Datenbank-systemen (RDBMS) ausgegangen. Diese Arbeit beschränkt sich in diesem Zusammen-hang auf relationale Datenbanksysteme, die SQL1 unterstützen.
Ein Datenbanksystem hat die Aufgabe, Daten möglichst e�zient dauerhaft zu spei-chern. Ebenso soll es die Verwaltung der Daten vereinfachen. Relationale Datenbank-systeme nutzen das relationale Datenmodell. Es besteht aus den nachfolgend erläu-terten Elementen und bietet dem Nutzer eine logische, mengenorientierte Abfrage derDaten.
Alle Betrachtungen werden so allgemein wie möglich gehalten. Spezi�sche Beispieleund Implementierungen erfolgen mit Microsoft Access XP und Oracle 10g.
2.1.2 Elemente eines relationalen Datenbanksystems
Aus Benutzersicht besteht ein relationales Datenbanksystem aus Tabellen und Spalten.Jedoch unterscheidet sich ein Datenbanksystem im Detail enorm von einer Tabellenkalkulations-Software.
In Tabellen sind die Spalten (auch als Attribute oder Felder bekannt) de�niert. EineDatenbank beinhaltet in der Regel mehrere Tabellen.
Eine Spalte besitzt neben einem Namen immer auch einen Datentyp. Sie kann also nurbestimmte Daten aufnehmen. Beispiele hierfür sind die Datentypen Number (Zah-len) und Varchar (Text). Datentypen sind sowohl für die interne Speicherung derDaten durch das Datenbanksystem, als auch für die Datenbank-Benutzer wichtig. Diephysikalische Datenspeicherung auf dem Datenträger kann je nach Datentyp durchdas Datenbanksystem optimiert werden. Dem Anwender nutzen sie bei der Eingabe
1Abfragespache für Datenbanken
4

2.1 Grundlagen und Begri�e
A1RWert
... An
Relationsname/Tabellenname
Attribute/Felder/Spalten
Relationenschema
Tupel/Zeilen
Relation/Tabelle
Abbildung 2.1: Begri�e einer relationalen Datenbank; Quelle: [Wik09b]
von Daten. Bei einem fehlerhaften Eintrag aufgrund eines falschen Datentyps wird einFehler angezeigt.
Als Zeilen (oder auch Tupel) bezeichnet man die eigentlichen Datensätze. Eine Zeileenthält für jede Spalte einen Wert. Soll eine Spalte mit keinem Wert belegt werden, soist der Inhalt NULL2.
Abbildung 2.1 zeigt beispielhaft eine Tabelle mit Beschriftung der Begri�e. Für dieElemente einer Datenbank gibt es verschiedene Begri�e, welche nahezu gleichbedeutendsind. Diese Arbeit beschränkt sich auf folgende deutsche Begri�e: Datenbank, Tabelle,Spalte und Zeile.
Relationale Datenbanksysteme bieten dem Nutzer viele weitere Vorteile gegenüber derSpeicherung als Datei auf einem Datenträger. Dazu zählen neben Mehrbenutzerfähig-keit und Transaktionen auch Datensicherheit und Datenintegrität.
Zur Datensicherheit zählt sowohl der Schutz vor Datenverlust, als auch vor unerlaubtemZugri� durch Dritte. Die Datenintegrität wird durch Regeln (Constraints) erreicht.Diese geben vor, welche Daten wie geändert werden dürfen. Wichtigste Regel für dieDatenintegrität ist der Fremdschlüssel (Foreign Key Constraint).
2.1.3 Beziehungen und Normalformen
Beziehungen zwischen Daten werden in einem relationalen Datenbanksystem mit Hilfevon Schlüsselspalten realisiert.
Primärschlüssel sind Schlüssel, die einen Datensatz (Zeile) eindeutig identi�zieren.
Fremdschlüssel sind Schlüssel, die in eine Tabelle eingetragen werden, um eine Ver-bindung des Datensatzes zu einem anderen Datensatz herzustellen. Die Werte dieserSpalte identi�zieren den verknüpften Datensatz eindeutig.
Modelliert werden Beziehungen oft in so genannten Entity-Relationship (ER) Diagram-men (siehe Abbildung 2.2). Diese Notation ermöglicht eine abstrahierte Sicht: Tabellen
2Besonderer Wert der für �kein Inhalt� steht.
5

2 Anforderungen
v e r g i b t
A u f t r a g
K u n d e
M i t a r b e i t e r
a r b e i t e t a n
Abbildung 2.2: Entity-Relationship-Diagramm in Chen-Notation
werden als Entitäten, Spalten als Attribute einer Entität dargestellt. Eine Entität kann,anders als Tabellen, direkte Beziehungen zu anderen Entitäten besitzen. Die Art derBeziehung wird mit einer Kardinalität festgelegt. Die Kardinalität gibt den Grad derBeziehung an. Sie bestimmt, wie viele Elemente mit einem Element dieser Entitätverknüpft sein können.
Diese Darstellung kann, wie in Tabelle 2.1 erklärt, in Tabellen mit Primär3- und Fremd-schlüsseln umgewandelt werden.
Normalformen
Unter Normalisierung versteht man eine schrittweise Zerlegung von einer Tabelle inmehrere Tabellen auf der Grundlage funktionaler Abhängigkeiten. Das Ziel ist die Ver-meidung von Redundanzen und Anomalien. Auch die Steigerung der Konsistenz kanneine Motivation zur Normalisierung sein.
Daten in relationalen Datenbanksystemen liegen üblicherweise in der dritten Normal-form (3NF) vor. Diese Normalform bietet für die Praxis den gröÿten Nutzen. Für einedetailliertere Erklärung der Normalformen muss auf [Kel98] verwiesen werden.
Daten in der dritten Normalform müssen bei einer Abfrage aus mehreren Tabellenzusammengesetzt werden. Weil dies zu Geschwindigkeitseinbuÿen führt, wird zur Op-timierung für bestimmte Anwendungen teilweise auf Normalisierung verzichtet.
3Statt eines Primärschlüssels kann auch ein eindeutiger Schlüssel (�unique key�) genutzt werden.1Kardinalität2Theoretisch ist es möglich, dass so eine Person mehrere Personalausweise besitzt. Dies lässt sichjedoch über eine Einschränkung der Fremdschlüsselspalte verhindern (Unique Constraint).
6
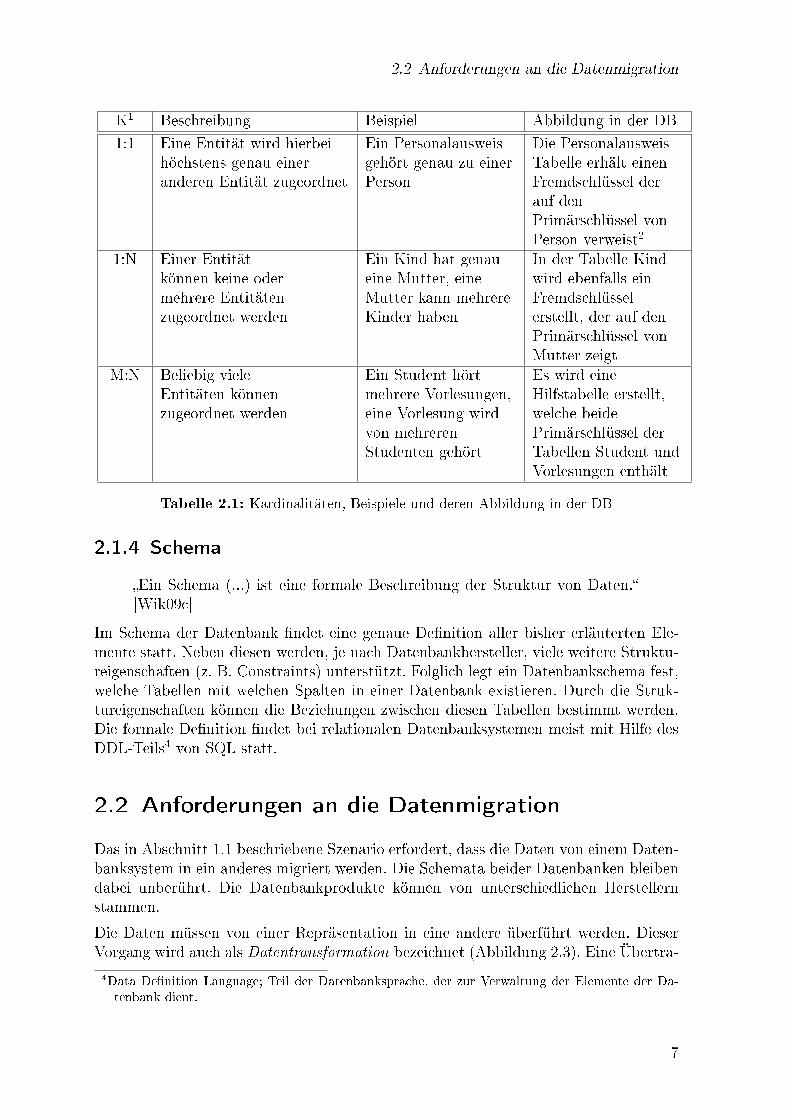
2.2 Anforderungen an die Datenmigration
K1 Beschreibung Beispiel Abbildung in der DB
1:1 Eine Entität wird hierbeihöchstens genau eineranderen Entität zugeordnet
Ein Personalausweisgehört genau zu einerPerson
Die PersonalausweisTabelle erhält einenFremdschlüssel derauf denPrimärschlüssel vonPerson verweist2
1:N Einer Entitätkönnen keine odermehrere Entitätenzugeordnet werden
Ein Kind hat genaueine Mutter, eineMutter kann mehrereKinder haben
In der Tabelle Kindwird ebenfalls einFremdschlüsselerstellt, der auf denPrimärschlüssel vonMutter zeigt
M:N Beliebig vieleEntitäten könnenzugeordnet werden
Ein Student hörtmehrere Vorlesungen,eine Vorlesung wirdvon mehrerenStudenten gehört
Es wird eineHilfstabelle erstellt,welche beidePrimärschlüssel derTabellen Student undVorlesungen enthält
Tabelle 2.1: Kardinalitäten, Beispiele und deren Abbildung in der DB
2.1.4 Schema
�Ein Schema (...) ist eine formale Beschreibung der Struktur von Daten.�[Wik09c]
Im Schema der Datenbank �ndet eine genaue De�nition aller bisher erläuterten Ele-mente statt. Neben diesen werden, je nach Datenbankhersteller, viele weitere Struktu-reigenschaften (z. B. Constraints) unterstützt. Folglich legt ein Datenbankschema fest,welche Tabellen mit welchen Spalten in einer Datenbank existieren. Durch die Struk-tureigenschaften können die Beziehungen zwischen diesen Tabellen bestimmt werden.Die formale De�nition �ndet bei relationalen Datenbanksystemen meist mit Hilfe desDDL-Teils4 von SQL statt.
2.2 Anforderungen an die Datenmigration
Das in Abschnitt 1.1 beschriebene Szenario erfordert, dass die Daten von einem Daten-banksystem in ein anderes migriert werden. Die Schemata beider Datenbanken bleibendabei unberührt. Die Datenbankprodukte können von unterschiedlichen Herstellernstammen.
Die Daten müssen von einer Repräsentation in eine andere überführt werden. DieserVorgang wird auch als Datentransformation bezeichnet (Abbildung 2.3). Eine Übertra-
4Data De�nition Language; Teil der Datenbanksprache, der zur Verwaltung der Elemente der Da-tenbank dient.
7

2 Anforderungen
ZielschemaQuellschema
TransformationsanfrageQuelldaten Zieldaten
Mapping ZielschemaQuellschema
TransformationsanfrageQuelldaten Zieldaten
Mapping
Abbildung 2.3: Darstellung einer Datentransformation; Quelle: [Nau06b]
gung zwischen zwei ähnlichen Schemata hat den Vorteil, dass sich die Repräsentationder Daten nicht fundamental unterscheidet. Änderungen am Schema werden nur danngemacht, wenn dies absolut erforderlich ist.
Der gesamte Vorgang wird in dieser Arbeit als Datenmigration bezeichnet.
Der weitere Verlauf des Abschnitts führt von den Gründen zur Änderung eines Sche-mas über die daraus resultierende Heterogenität hin zur konkreten Anforderung. DieAnforderungen werden zum besseren Verständnis anhand von Beispielen erklärt.
2.2.1 Änderung am Datenbankmodell
Bei der Modellierung der Datenbank wird ein Teil der Realität in einem Modell abge-bildet. Aus diesem Modell ergibt sich das Schema der Datenbank. Im professionellenUmfeld erfolgt dabei zunächst eine Analyse des Prozesses. Dabei handelt es sich um einBeobachten und Dokumentieren der Wirklichkeit. Aus dieser Analyse werden Schlüssegezogen, welche wiederum zu einer Annahme führen.
Beispiel:
BeobachtungEs ist kein Semester bekannt, in dem ein Student an derHS-Weingarten eine Vorlesung gehalten hat.
Annahme Studenten halten keine Vorlesungen.
SchlussfolgerungDas Modell muss keine �hält� Beziehung zwischen Student undVorlesung vorsehen.
Ist ein bestimmter Fall in der Vergangenheit nie eingetreten, so kann nicht automatischdavon ausgegangen werden, dass dies in Zukunft nicht doch geschehen wird. Um einModell jedoch möglichst e�zient und simpel zu gestalten, müssen solche Annahmenund Schlussfolgerungen gemacht werden.
Ändern sich die Gegebenheiten, muss das Modell angepasst werden. Im beschriebenenBeispiel wird hierzu eine �hält� Beziehung zwischen Student und Vorlesung hergestellt.
8

2.2 Anforderungen an die Datenmigration
Dieses simple Beispiel zeigt, warum sich in einem Modell die Beziehungen verändernkönnen. Durch komplexe Anforderungen an eine Softwarelösung können die Änderun-gen des Schemas wesentlich stärker ausfallen.
Technische Gründe
Ein weiterer Grund zur Änderung eines Schemas ist die Optimierung auf eine Anwen-dung.
Beispiel : Moderne Softwaresysteme setzen immer häu�ger Objektorientierung ein. UmDaten aus einer relationalen Datenbank möglichst einfach in die Objektorientierungeinzubinden, wird oft eine objektrelationale Abbildung (ORM) eingesetzt. Um denProzess der Abbildung von relationalen Daten auf Objekte zu vereinfachen, gibt esunterschiedliche Software, die den Entwickler unterstützt. Je nach Konzept und Artdieser Software kann es nötig sein, das Schema entsprechend anzupassen.
Grobe Entwurfsfehler im Schema der Quelldatenbank können ebenfalls eine Motivationzur Änderung sein.
2.2.2 Heterogenität
Aus den Änderungen am Datenbankmodell entstehen Unterschiede zwischen den Sche-mata der Datenbanken. Diese Unterschiede werden im Buch Informationsintegrationvon Ulf Lesser und Felix Naumann [LN07b] als Heterogenität wie folgt de�niert:
Zwei Informationssysteme, die nicht exakt die gleichen Methoden, Modelleund Strukturen zum Zugri� auf Ihre Daten anbieten, werden als heterogenbezeichnet.
Da die Heterogenität zwischen Informationssystemen auf vielen verschiedenen Ebenenbestehen kann, wird im Folgenden nur auf die für die Datenmigration wichtigen Aspekteeingegangen. Für die Betrachtung wird die De�nition der Arten von Heterogenität aus[LN07b] verwendet.
Da diese Arbeit nur relationale Datenbanksysteme betrachtet, ist eine gewisse techni-sche Homogenität gewährleistet. Dennoch gilt es, die technischen Unterschiede zwischeneinzelnen Datenbankprodukten zu beseitigen. Des Weiteren ist auch keine Datenmo-dellheterogenität gegeben. Das liegt daran, dass alle relationalen Datenbanksystemedas relationale Datenmodell nutzen.
Syntaktische Heterogenität liegt vor, wenn die Darstellung derselben Daten in den Da-tenbanksystemen unterschiedlich ist. Das ist bei verschiedenen Datenbankproduktenvon unterschiedlichen Herstellern oft der Fall (Stichwort: Datentypen). Die syntak-tische Heterogenität lässt sich jedoch durch Konvertierung der Daten relativ leichtüberwinden.
Das Verändern eines Schemas der Datenbank kann zu struktureller und semantischerHeterogenität führen.
9

2 Anforderungen
2.2.3 Strukturelle und semantische Heterogenität
Unter diesen zwei Begri�en werden alle Unterschiede, die das Schema und die darinverwendeten Namen und Konzepte betre�en, zusammengefasst. Im Folgenden wirdkurz erklärt, wie sich diese Unterschiede klassi�zieren lassen.
�Strukturelle Heterogenität liegt vor, wenn zwei Schemata unterschiedlichsind, obwohl sie den gleichen Ausschnitt aus der realen Welt erfassen.�[LN07b]
Durch Veränderungen am Schema kann eine strukturelle Heterogenität zwischen demveränderten Schema und dessen Ursprungsschema entstehen. Einige Gründe zur Ände-rung wurden bereits in den vorhergehenden Abschnitten aufgezeigt. Dazu gehört nebender Umsetzung eines konzeptionellen Modells in ein Schema auch die Optimierung aufeine bestimmte Anwendung.
Die schematische Heterogenität ist ein Spezialfall der strukturellen Heterogenität. Sieliegt vor, wenn verschiedene Elemente des Datenmodells (also Tabellen, Spalten oderWerte) zur Modellierung genutzt werden. Abbildung 2.4 zeigt ein solches Beispiel: Inder Quelldatenbank ist das Auto als Tabelle modelliert, die Art des Fahrzeuges istdurch den Namen der Tabelle klar de�niert. In der Zieldatenbank hingegen ist die Artdes Fahrzeuges erst durch den Wert der Spalte FZG_TYP de�niert. Ebenso wäre eineModellierung als Spalte denkbar, je eine Spalte pro Fahrzeugtyp. Als Datentyp könnteman hierfür Boolean (wahr/falsch) nutzen.
Die Schemaelemente besitzen Namen, welche zunächst lediglich Zeichenketten sind. EinMensch kann jedoch deuten, welche Information sich hinter einem Element be�ndet.Dies ist möglich, da der Mensch neben dem vorhandenen Wissen über das Schemazusätzliches Weltwissen besitzt.
�Semantische Heterogenität liegt vor, wenn die Elemente verschiedener Sche-mata sich intensional überlappen� [LN07b]
Um die De�nition besser zu verstehen, werden die Begri�e Intension und Extensionde�niert. Die Intension eines Elements beschreibt deren Konzept. Als Extension ver-steht man alle Objekte dieses Konzepts in der realen Welt. Beispiel: Die Intension desTabellennamens �Produkt� ist �alle Erzeugnisse die verkauft werden�. Die Extensionhingegen ist die Menge aller jemals hergestellten Produkte. Die konkrete Extension derTabelle �Produkt� sind alle zu einem Zeitpunkt darin enthaltenen Zeilen. SemantischeKon�ikte treten auf, wenn der Zusammenhang zwischen Namen und Konzepten in denSystemen verschieden ist.
Es gibt drei Arten von semantischen Kon�ikten. Ein Synonym liegt vor, wenn zweiNamen die unterschiedlich sind, die gleiche Intension haben. Homonyme sind hingegenzwei gleiche Namen mit unterschiedlicher Intension. Beispiel hierfür ist das Wort �Kiwi�- es beschreibt sowohl eine Frucht als auch einen Vogel.
Die dritte Art ist das Hyperonym. Es beschreibt einen Kon�ikt, bei dem ein Name einOberbegri� des zweiten Namens ist. Ein Beispiel ist in Abbildung 2.4 zu sehen. DerTabellenname �Fahrzeuge�5 schlieÿt die Intension und Extension des Tabellennamens�Autos� mit ein. In der Realität treten auch Mischungen dieser Arten auf.5Eigentlich: �XY_FAHRZEUGE�
10

2.2 Anforderungen an die Datenmigration
AutosAutoIdNamePSKaufdatumTueren
XY_FAHRZEUGEFZG_IDFZG_NAMEFZG_PSFZG_DATUMFZG_TUEREN
FZT_ID FZT_NAME
1 Auto
2 LKW
Quelldatenbank Zieldatenbank
Konstante: 1XY_FZG_TYPEN
Personen XY_PERSONEN
Auftraege XY_AUFTRAEGE
Zu geringe Ähnlichkeit → manuelle Zuordnung
Tabellen
Spalten
FremdschlüsselFZG_TYP
Abbildung 2.4: Beispiel: Zuordnung von Tabellen und Spalten
Die häu�gsten semantischen Kon�ikte bei einer Datenmigration sind Synonyme. Na-men von Tabellen werden oft aus technischen Gründen oder wegen einer Namens-konvention anders benannt. Die Reihenfolge der Spalten unterscheidet sich ebenfallshäu�g.
Die Übergänge zwischen struktureller und semantischer Heterogenität sind �ieÿend.Daher kann nicht immer genau unterschieden werden, ob die vorliegende Di�erenz vonsemantischer oder struktureller Natur ist.
Um ein sinnvolles Ergebnis bei der Übertragung von Daten zu erreichen, ist es nötig,dass die Unterschiede zwischen den Schemata der Datenbanken nicht zu groÿ sind.
2.2.4 Zuordnung von Tabellen und Spalten
Der intuitive Ansatz zur Überwindung der entstandenen Heterogenität ist eine Zuord-nung der Schemaelemente. Im Folgenden soll anhand von Beispielen gezeigt werden,warum diese Zuordnungen nötig sind.
Die Zuordnung von Tabellen- und Spalten aus Quell- und Zieldatenbank ist deshalbeine zentrale Aufgabe der Datenmigration. Hierbei muss der Anwender der Softwarejederzeit die volle Kontrolle über die Zuordnung haben. Ähnlichkeiten zwischen den
11

2 Anforderungen
Namen der Tabellen und Spalten sollte die Software jedoch automatisch erkennen. DieAbbildung 2.4 zeigt eine direkte Zuordnung von Tabellen und den enthaltenen Spalten.Ähnlichkeiten zwischen den Namen der Elemente sind hervorgehoben dargestellt (fettgedruckte Buchstaben).
2.2.5 �Er�nden� von Werten
Aufgrund einer unterschiedlichen Struktur der Schemata ist eine direkte Zuordnung derSpalten nicht immer möglich. Kann eine Spalte aus der Zieldatenbank keiner Spalte inder Quelldatenbank zugeordnet werden, ist es notwendig, den Inhalt für diese Spaltefestzulegen. Dies gilt vor allem für Spalten, die nicht leer gelassen werden dürfen (notnullable6).
Die einfachste Möglichkeit ist das Einfügen eines konstanten Werts wie in Abbildung2.4 dargestellt. Der Typ des Fahrzeuges wird statisch angegeben.
In diesem Beispiel wird ein weiteres Problem sichtbar: Angenommen, es gibt eine wei-tere Tabelle in der Quelldatenbank, die Fahrzeuge enthält, z. B. LKWs. Diese sollebenfalls in die �XY_FAHRZEUGE�-Tabelle der Zieldatenbank übertragen werden.Dazu wird die LkwId (Primärschlüssel von LKWs) der Spalte �FZG_ID� zugeordnet.Beim Übertragen der Daten kann es vorkommen, dass die Werte der Spalte �FZG_ID�nicht mehr eindeutig sind. Dies liegt daran, dass die Menge der Werte aus Auto-Id und LkwId überlappen können. Weil �FZG_ID� der Primärschlüssel der Tabelle�XY_FAHRZEUGE� ist, führt dies zu einem Fehler.
Dieses Problem lässt sich jedoch bedingt lösen. Vorausgesetzt, �FZG_ID� wird nichtals Fremdschlüssel in einer anderen Tabelle genutzt, können neue, eindeutige Werteerzeugt werden.
Hierbei handelt es sich um eine Generalisierung7 der Tabelle: Mehrere Tabellen derQuelldatenbank werden zu einer Tabelle in der Zieldatenbank zusammengefasst.
2.2.6 Komplexe Zuordnungen
Wenn sich zwei Schemata unterscheiden, ist es möglich, dass eine Zuordnung von Ta-bellen zwischen den Datenbanken nicht direkt angegeben werden kann. Abbildung 2.5zeigt zwei Schemata, die sich strukturell unterscheiden. Anders als im vorherigen Bei-spiel lässt sich diese Zuordnung nicht mit einem konstanten Wert lösen. Das liegt daran,dass die Daten der Quelldatenbank übernommen werden müssen. Das folgende Beispielsoll diese Problematik verdeutlichen.
Beispiel: Angenommen eine Firma produziert Reinigungs- und Kosmetikartikel. Beider Modellierung der Datenbank wurde festgelegt, dass ein Produkt immer genau voneinem Typ sein kann. Die Typen sind in Klassen unterteilt (Abbildung 2.5 linker Teil).
6Als �not nullable� bezeichnet man Spalten, die ausgefüllt werden müssen, daher keinen NULL-Wertenthalten dürfen.
7Verallgemeinerung
12

2.3 Anforderungen an Testdaten
Produkte
Typen
Klassen
ProduktIdNameErstellDatumTypId
TypIdNameBeschreibungKlasseId
KlasseIdNameBeschreibung
XY_KLASSEN (DBMT_TEST)
KLA_ID
KLA_NAME
KLA_BESCHREIBUNG
XY_TYPEN (DBMT_TEST)
TYP_ID
TYP_NAME
TYP_BESCHREIBUNG
XY_PRODUKTE (DBMT_TEST)
PRO_TYP_ID
PRO_ID
PRO_NAME
PRO_BESCHREIBUNG
PRO_DATUM
PRO_KLA_ID
PROD_XKN_FK
PR
OD
_XT
N_F
K
Quelldatenbank Zieldatenbank
Abbildung 2.5: Gegenüberstellung zweier ähnlicher Schemata mit unterschiedlichen Bezie-hungen
Diese Einteilung hat sich in der Praxis aufgrund der In�exibilität nicht bewährt. DieFirma produziert auch Produkte, deren Typ zwar gleich ist, die jedoch in einer anderenKlasse geführt werden sollen. Ein Beispiel hierfür ist Shampoo. Neben Produkten fürdie Reinigung (z. B. Teppichshampoo) gibt es auch Produkte für die Körperp�ege(Haarshampoo). Aus diesem Grund wurde das Schema der neuen Datenbank geändert(Abbildung 2.5 rechter Teil).
In Abbildung 2.6 ist diese Situation in der Datenansicht dargestellt.
2.2.7 Datentypen
Verschiedene Datenbanksysteme nutzen unterschiedliche Datentypen. Datenbanken fürEndbenutzer, wie Microsoft Access, haben viele, sehr spezielle Datentypen, wie bei-spielsweise Hyperlink. Beim Übertragen solcher Daten kann es zum Verlust von In-formationen kommen. Da bei der Migration möglichst wenige Informationen verlorengehen sollten, ist es notwendig, diese Daten zu konvertieren.
Unterschiedliche Datentypen in den Datenbankprodukten sind ein Beispiel für syntak-tische Heterogenität.
2.3 Anforderungen an Testdaten
Das Testen von Anwendungen ist eine der wichtigsten Maÿnahmen, um qualitativ hoch-wertige Software zu schreiben. Um datenbankgestützte Anwendungen testen zu können,ist es notwendig, dass die Datenbank Daten enthält.
13

2 Anforderungen
Quelldatenbank Zieldatenbank
KLA_ID KLA_NAME
1 Reinigung
2 Körperpflege
3 Kosmetik
XY_KLASSEN
TYP_ID TYP_NAME
101 Waschmittel
102 Shampoo
103 Haargel
XY_TYPENTypId Name KlassseId
101 Waschmittel 1102 Shampoo 2103 Haargel 3
Typen
ID NAME TYP_ID KLASSE_ID
1002 Sho... 103 31003 Ult.... 103 31004 Weis... 101 19008 K... 102 1
XY_PRODUKTE2
PId 1 Name TypId
1002 Shockwave 103
1003 Ultra XL 103
1004 Weisser ... 101
Produkte
KlasseId Name ...
1 Reinigung
2 Körperpflege
3 Kosmetik
Klassen
1:1
1 ProduktId2 Tabellen Präfix „PRO_“ aus Platzgründen entfernt Beziehungen innerhalb des Schema
Neuer Datensatz, nachder Übertragung eingefügt
Abbildung 2.6: Beispielhafte Darstellung einer nicht trivialen Zuordnung (Datensicht)
Stehen einem Entwickler nur sehr wenige oder gar keine nutzbaren Daten zur Verfü-gung, müssen diese erzeugt werden. Der einfachste Ansatz ist das manuelle Eintragender Daten mit Hilfe eines allgemeinen Datenbankwerkzeugs.
Eine Schwierigkeit beim manuellen Eintragen von Daten sind Beziehungen. Damit dieTestdaten einer gewissen Integrität entsprechen, müssen die Beziehungen eingehaltenwerden. Deshalb muss der Entwickler Werte aus der verknüpften Tabelle auslesen undin die aktuelle Tabelle eintragen. Dieser Prozess lässt sich mit normalem SQL nichtzufriedenstellend automatisieren.
Ebenso wichtig, wie die Beziehungen, sind fortlaufende, eindeutige Nummerierungenvon Elementen. Viele Datenbanken bieten zwar eine Generierung solcher Werte an, diesmuss jedoch im Schema der Datenbank de�niert werden. Die Funktion kann daher nurgenutzt werden, wenn die Generierung auch im produktiven Betrieb erwünscht ist.
Soll die Geschwindigkeit einer Anwendung beim Umgang mit vielen Datensätzen getes-tet werden, so ist es faktisch unmöglich, all diese Datensätze von Hand einzutragen. Bei
14

2.3 Anforderungen an Testdaten
solchen Tests ist der Inhalt einzelner Spalten, wie z. B. Namen, weniger von Bedeutung.Wichtig sind vor allem korrekte Beziehungen zwischen den Daten.
Um Testdaten zu erzeugen, müssen Datenquellen existieren. Diese können beispielswei-se über einen Generator erzeugt werden oder in einer Datei hinterlegt sein.
15

3 Analyse bestehender
Lösungsansätze
In diesem Kapitel werden relevante theoretische Ansätze und Produkte, die zur Pro-blemlösung beitragen könnten, betrachtet.
3.1 Theoretische Ansätze
In diesem Abschnitt werden Techniken aus Wissenschaft und Forschung vorgestellt.Hierbei wird untersucht, welche Ansätze sich für die Datenmigration eignen. Vieledieser Techniken stammen aus dem Gebiet der Informationsintegration.
3.1.1 Dynamische Schemaevolution
Schemaevolution ist die wissenschaftliche Bezeichnung eines Gebietes, das sich mitVoraussetzungen, Auswirkungen und Durchführbarkeit bei Änderungen an bestehen-den Datenbank-Schemata beschäftigt. Datenbankhersteller wie IBM und Oracle habeninzwischen diesen Bedarf erkannt und bieten dem Kunden bedienbare Werkzeuge an[Geb05].
Obwohl die dynamische Schemaevolution ein interessanter Ansatz ist, kann sie dasProblem, welches durch die Neuentwicklung eines bereits im produktiven Einsatz be-�ndlichen Systems entsteht, nicht lösen. Vor allem deshalb nicht, weil bei der Neu-entwicklung selten das gleiche Datenbankprodukt zum Einsatz kommt (bspw. Oraclestatt Microsoft Access). Des Weiteren sind die Änderungen am Schema durch das bis-herige Softwaresystem beschränkt. Bestimmte Änderungen können zum Verlust derFunktionsfähigkeit des Systems führen.
Das in Abschnitt 1.1 beschriebene Szenario kann durchaus als eine Art Schemaevolutionbetrachtet werden. Jedoch nicht als dynamische Schemaevolution.
3.1.2 Schemaintegration
Die Schemaintegration beschreibt das Zusammenfügen von Informationen aus meh-reren Schemata. Meist wird von verschiedenen Quellschemata in ein globales Schemaintegriert.
16

3.1 Theoretische Ansätze
Man unterscheidet generell zwei Arten der Schemaintegration. Werden die Daten tat-sächlich in eine Datenbank übertragen, spricht man von der materialisierten Integrati-on. Sind die Daten hingegen nur bei Abruf kombiniert, handelt es sich um eine virtuelleIntegration. Die materialisierte Integration bildet die Grundlage für sogenannte DataWarehouses1.
Die Datenmigration kann nicht als Schemaintegration betrachtet werden. Trotzdemgibt es einige Überschneidungen mit diesem Thema. Die Schemaintegration nutzt bei-spielsweise ebenfalls Techniken wie Schema Mapping und Schema Matching.
3.1.3 Schema Mapping
Einige der Eigenschaften und Probleme von �Schema Mapping� wurden schon in denAnforderungen dargestellt (Abschnitt 2.2.4). Die folgende Betrachtung ist jedoch for-maler und stützt sich auf die Arbeiten in [LN07a]. Das Schema Mapping beschränktsich nicht auf ein bestimmtes Datenmodell. Diese Beschreibung geht jedoch von rela-tionalen Datenbanken als Quelle und Ziel der Daten aus.
Der Begri� Schema Mapping (oder Schema-Abbildung) beschreibt im Prinzip zwei Din-ge. Zunächst versteht man unter Schema Mapping eine Menge von Korrespondenzenzwischen Schemaelementen. Auÿerdem wird damit auch ein komplexer Prozess be-schrieben. Dieser Prozess erzeugt, ausgehend von den Korrespondenzen, Vorschriftenzur Datentransformation.
Wertkorrespondenzen
Wertkorrespondenzen sind die wesentlichen Elemente des Schema Mapping. Eine Wert-korrespondenz gibt an, wie Werte einer oder mehrer Zielspalten aus einer oder mehrerenQuellspalten erzeugt werden.
Nachname
VornameNachname
VornameNachname
Name
Name
Name
concat()
extract()
Abbildung 3.1: Mehrwertige Korresponden-zen (1:1, N:1, 1:N)
Als einfache Korrespondenzen bezeichnetman solche, die eine Spalte genau eineranderen Spalte zuweisen. Somit werdendie Daten aus der einen Spalte in die an-dere übertragen (1:1). Bei mehrwertigenKorrespondenzen werden mehrere Spal-ten genau einer Spalte zugeordnet (N:1).Oder in umgekehrter Reihenfolge: EineSpalte wird mehreren anderen Spalten zu-geordnet (1:N). Die Aufteilung bzw. Ver-einigung übernimmt eine Funktion. Bei1:N Korrespondenzen bildet diese Funktion die Werte der einen Spalte auf mehrereWerte der zugeordneten Spalten ab. Abbildung 3.1 zeigt ein simples Beispiel mit demNamen einer Person.
In Abbildung 3.2 (links) wird das Geschlecht einer Person durch die Tabellennamen�Frauen� und �Männer� angegeben. Die Tabelle �Personen� hingegen gibt das Ge-
1Zentrale Sammlung von Daten die meist aus unterschiedlichen Quellen zusammengesetzt sind.
17

3 Analyse bestehender Lösungsansätze
Personen name adresse geschlecht
Frauen name adresse
Männer name adresse
'w'
'm'
Personen name adresse geschlecht
Personen name adresse geschlecht
Frauen name adresse
Männer name adresse
= 'w'
= 'm'
Abbildung 3.2: Höherstu�ge Korrespondenzen (gestrichelt); Quelle: [LN07a]
schlecht über die Spalte �geschlecht� an. Derselbe Sachverhalt wird hier mit verschiede-nen Elementen des Datenmodells dargestellt (Tabellenname vs. Wert einer Spalte). Diegestrichelten Pfeile symbolisieren eine höherstu�ge Wertkorrespondenz. Der rechte Teilder Abbildung zeigt genau das Gegenteil. Hier werden aus der Information der Spalte�geschlecht� die Daten jeweils in �Frauen� und �Männer� aufgeteilt. Die höherstu�genWertkorrespondenzen können zur Überwindung der hier beschriebenen, schematischenHeterogenität eingesetzt werden (siehe Abschnitt 2.2.3).
Logisches Mapping
Im Schema Mapping Prozess wird durch Interpretation aus den Wertkorrespondenzenein logisches Mapping erzeugt. Aus diesem können die Datenbankanfragen generiertwerden. Die Interpretation der Korrespondenzen ist dabei nicht immer eindeutig. Jenach Algorithmus unterscheidet sich diese.
Wie in den Anforderungen (Abschnitt 2.2) bereits angedeutet, ist eine Form des SchemaMapping für die entstehende Softwarelösung nötig.
3.1.4 Schema Matching
Das Schema Matching beschäftigt sich mit der automatischen Zuordnung von Ele-menten verschiedener Schemata. Dabei geht es um das Erkennen von Ähnlichkeitenzwischen Schemata. Diese Erkenntnisse werden herangezogen um eine (vorläu�ge) Zu-ordnung zu erzeugen.
Das Au�nden von Ähnlichkeiten zwischen zwei Schemata kann basieren auf:
• Namen der Schemaelemente (label-based)
• In der Datenbank eingetragene Daten (instance-based)
• Struktur des Schemas (structure-based)
• Mischformen
18

3.1 Theoretische Ansätze
Allgemeiner Algorithmus ([Nau06a])• Gegeben sind zwei Schemata (oder Tabellen) mit den Mengen der Tabellen (bzw.
Spalten) A und B
• Kernidee:
◦ Bilde Kreuzprodukt aller Attributea aus A und B
◦ Für jedes Paar berechne Ähnlichkeit
� z. B. bzgl. Attributnamen
� z. B. bzgl. gespeicherter Daten
◦ Wähle ein Matching aus
� Ähnlichste Paare bis Schwellwert
� Nebenbedingungen
aHierbei sind sowohl Tabellen, als auch Spalten gemeint. Je nachdem ob zwei Schemata oder zweiTabellen verglichen werden.
S c h e m a M a t c h i n g A n s ä t z e
I n d i v i d u e l l e A n s ä t z e K o m b i n i e r t e A n s ä t z e
S c h e m a - b a s i e r t
N a m e n ( L i n g u i s t i s c h )
I n s t a n z - b a s i e r t
S t r u k t u r -b a s i e r t
Inha l t ( L i n g u i s t i s c h )
S t r u k t u r - b a s i e r t
D u p l i k a t -b a s i e r t
H y b r i d Z u s a m m e n g e s e t z t
M a n u e l l A u t o m a t i s c h
Abbildung 3.3: Schema Matching Klassi�kation nach [RB01]
In Abbildung 3.3 ist eine allgemeine Klassi�kation dargestellt. Die gelb hervorgehobe-nen Elemente sind relevant für die Datenmigration. Neben dem Vergleich von Namender Schemaelemente (wie Tabelle- und Spalte) ist es ebenso sinnvoll, die Struktur desSchemas mit zu berücksichtigen. Hierzu zählen auÿer Datentypen auch weitere Eigen-schaften (Constraints) der Spalten, wie Fremd- und Primärschlüssel. Da das Zielschemain der Regel keine Daten enthält, ist ein instanzbasierter Vergleich schlicht unmöglich.
3.1.5 SchemaSQL
Bei SchemaSQL handelt es sich um eine Erweiterung von SQL. Während SQL nurdie Abfrage von Daten erlaubt, ist mit SchemaSQL auch der Zugri� auf Metadaten
19

3 Analyse bestehender Lösungsansätze
möglich. Des Weiteren kann die Sprache auf mehreren Datenbanken agieren, dahergehört sie zur Gattung der Multidatenbanksprachen. Es wird nur der lesende Zugri�unterstützt. Aufgrund der Eigenschaften von SchemaSQL kann es zur Überwindungschematischer Heterogenität genutzt werden.
Laut [Mau05] existiert keine fertig gestellte Implementierung von SchemaSQL. In die-sem Dokument �nden sich auch Beispiele, die die Verwendung von SchemaSQL erklä-ren.
3.2 Produkte
Das Prüfen der am Markt be�ndlichen Produkte ist notwendig, um zu verhindern, dasseine Anwendung entsteht, die es in dieser Form bereits gibt. Die Analyse soll ebensozeigen, welche Ansätze zur Datenmigration und Testdatenerzeugung bereits umgesetztwurden. Aufgrund der Fülle von Anwendungen werden hier nur einige Produkte vor-gestellt.
Im Folgenden wird analysiert, in wie weit sich diese Lösungen für die Datenmigration,wie in Kapitel 2 (Abschnitt 2.2) beschrieben, eignen.
3.2.1 Oracle SQL Developer (Version 1.5.1)
Beim Oracle SQL Developer handelt es sich um ein universelles Werkzeug zur Abfrageund Verwaltung von Datenbanken. Neben Oracles eigenen Datenbanksystemen werdenauch andere Produkte wie Microsoft Access oder MySQL unterstützt. Die Hauptfunk-tionen sind jedoch für Oracle und deren Technologien (z. B. PL/SQL) ausgelegt.
Abbildung 3.4: SQL Developer MS AccessExport
Der SQL Developer enthält eine Migra-tionsunterstützung, welche die Aufgabendes inzwischen nicht mehr weiterentwi-ckelten Oracle Migration Workbench er-setzt. Diese Migration bietet eine voll-ständige Übertragung von Schema undDaten. Da MS Access per JDBC-ODBCnur begrenzt Zugri� auf Metadaten lie-fert (der SQL Developer nutzt JDBC),wird der Export aus Access mit Hilfe ei-nes VBA2-Makros realisiert. Dieses er-zeugt eine XML Datei, die Schema undDaten enthält. Der SQL Developer kanndiese Datei in eine Oracle Datenbank um-
wandeln.
Dieser Ansatz zur Migration ist nur für eine initiale Migration sinnvoll. Eine Daten-migration im Sinne der Anforderungen lässt sich mit dem SQL Developer nicht durch-führen.2Visual Basic for Applications; Skriptsprache von Microsoft für Anwendungen
20
3.2 Produkte
Abbildung 3.5: Oracle SQL Developer Startbildschirm
3.2.2 IBM Clio
Clio ist ein Forschungsprojekt des �IBM Almaden Research Center� und der �Universi-ty of Toronto - Department of Computer Science�. Leider lässt sich die Software nichteinfach herunterladen und testen. Verfügbare Informationen ([IBM, LN07a, Nau06b])zeigen jedoch, dass dieses Projekt über die im Rahmen dieser Bachelorarbeit beschrie-bene Problematik hinausgeht. Es werden beispielsweise auch XML Schemata unter-stützt. Clio stellt ein universelles Zuordnungs- und Transformationswerkzeug dar. Überdie Unterstützung von Datenbankprodukten ist wenig bekannt, sicher ist jedoch, dassDB2 von IBM unterstützt wird. Regeln für die Zuordnung werden in einem proprie-tären Format angegeben und später in eines der Ausgabeformate XSL, XQuery oderSQL umgewandelt. Die Schema Matching Fähigkeiten von Clio setzen primär eineninstanzbasierten Vergleich ein. Dieser ist jedoch für die Datenmigration völlig ungeeig-net.
21

3 Analyse bestehender Lösungsansätze
3.2.3 Altova MapForce (Enterprise 2009)
Altova MapForce Enterprise 2009 ist ein kommerzielles Produkt der Firma Altova.MapForce bietet eine sehr übersichtliche und leicht verständliche Ober�äche. Der Zu-gri� auf Datenbanken erfolgt über ODBC. Die Software eignet sich besonders gut, umZuordnungen zwischen zwei oder mehreren Datenbanken (oder XML Daten) herzu-stellen. Eine Zuordnung der Elemente (Schema Matching) anhand ihres Namens istmöglich, jedoch nur auf Spaltenebene. Ebenso beschränkt sich diese Zuordnung aufidentische Namen; eine Ähnlichkeitsanalyse �ndet nicht statt.
Abbildung 3.7: Altova MapForce Screenshot; Quelle: Altova Webseite
3.2.4 Zusammenfassung
Diese Produkte zeigen interessante Ansätze. Neben den ausgefeilten Ober�ächen sindauch weitere Datenquellen wie XML oder Microsoft Excel möglich.
Trotzdem wird keines der untersuchten Produkte den Anforderungen aus Kapitel 2gerecht. Einige der genannten Aufgaben können mit dem ein oder anderen Programmerfüllt werden. Dennoch kann, gerade im Bezug auf die automatische Zuordnung vonSchemaelementen, keines der Produkte überzeugen. Auch das Erzeugen von Testdatenwird nicht unterstützt.
22
3.2 Produkte
Abbildung 3.6: IBM Clio; Quelle: [IBM]
23

4 Ansatz
Dieses Kapitel beschreibt den Lösungsansatz für die in Kapitel 2 dargelegten Problemeund Anforderungen.
Die im Rahmen dieser Bachelorarbeit entstandene prototypische Softwarelösung decktdie Bereiche der Datenmigration und Testdatenerzeugung ab. Die Übertragung derDaten wird direkt ausgeführt. Auf eine Ausgabe von Transformationsregeln in Spra-chen wie SQL wird verzichtet. Es wird zwischen den zwei Projekttypen Migration undTestdaten unterschieden.
Daten in der Datenbank
Für beide Projekttypen ist es notwendig, dass die Zieldatenbank völlig leer ist. Des-halb muss die Anwendung alle vorhandenen Inhalte aus der Datenbank löschen. DieserVorgang ist nur dann erfolgreich, wenn die Reihenfolge der Löschung den referentiellenIntegritätsbedingungen nicht widerspricht. Auch für das Eintragen von Daten muss dieReihenfolge stets beachtet werden. Die genaue Problematik und deren Lösung wird inKapitel 6 erklärt.
4.1 Voraussetzungen für eine Datenmigration
Es wird nur eine Datenmigration mit genau einer Quell- sowie genau einer Zieldaten-bank unterstützt. Ebenso müssen die Datentypen von Quell- und Zielspalte kompati-bel sein. Vor allem darf der Datentyp der Zielspalte keine stärkeren Einschränkungenhinsichtlich der Länge haben, als die Quellspalte erlaubt. Die Umsetzung der Konver-tierung von Datentypen ist in Kapitel 6 (Abschnitt 6.4) erklärt.
4.2 Schema Zuordnung im Detail
Das Zuordnen von Elementen der Schemata ist nötig, um strukturelle und semantischeHeterogenität zu überwinden. Anders als es im Schema Mapping (Abschnitt 3.1.3) er-klärt ist, nutzt dieser Ansatz keine De�nition von Korrespondenzen, sondern ermöglichtes, direkt ein logisches Mapping vorzunehmen. Der Vorteil dabei ist, dass die komplexeInterpretation der Korrespondenzen entfällt.
Der folgende praktische Ansatz kann nur einen Teil aller denkbarer Unterschiede über-brücken. Im weiteren Verlauf dieser Arbeit wird dargestellt, welche Einschränkungendurch den Ansatz bzw. die Implementierung bestehen.
24

4.2 Schema Zuordnung im Detail
Initialer Ansatz
Die Zuordnung von Schemaelementen �ndet zunächst auf Tabellenebene statt. EineTabelle der Quelldatenbank wird genau einer Tabelle der Zieldatenbank zugeordnet.Anschlieÿend erfolgt eine Zuordnung der Spalten. Diese Zuordnung beschränkt sichauf die Spalten der de�nierten Quelltabelle. Kann keine sinnvolle Zuordnung für eineTabelle gefunden werden, so besteht die Möglichkeit, diese Tabelle nicht zuzuordnen.Abbildung 4.1 verdeutlicht diesen Ansatz.
AutoAutoIdNamePSKaufdatumTueren
XY_FAHRZEUGFZG_IDFZG_NAMEFZG_PSFZG_DATUMFZG_TUEREN
QuelldatenbankZieldatenbank
FZG_TYP Menge aller auswählbarer
Spalten für XY_FAHRZEUG
Tabellen Zuordnung
Abbildung 4.1: Ansatz der Zuordnung von Schemaelementen
Erweiterung
Mit dieser Art der direkten Zuordnung (1:1) lassen sich nur Namen und Anordnung derSpalten bzw. Tabellen überbrücken. Daher sind für komplexere Unterschiede folgendeMöglichkeiten vorgesehen:
Konstante Ein konstanter Wert der in die Zielspalte eingetragen wird.
SQL Ein SQL-Skript, das auf der Quelldatenbank ausgeführt wird. Das Ergebnis bildetden Wert für die Zielspalte.
Mit diesen indirekten Zuordnungen sollen sowohl mehrwertige Korrespondenzen wieauch höherstu�ge Korrespondenzen (vgl. Abschnitt 3.1.3) ermöglicht werden.
4.2.1 Konstante Werte
Wie bereits in den Anforderungen (Abschnitt 2.2.4) erklärt, führen bestimmte Un-terschiede zwischen Quell- und Zieldatenbank dazu, dass eine direkte Zuordnung vonElementen nicht möglich ist. Für diesen Zweck gibt es die Möglichkeit, einen konstantenWert für diese Spalte anzugeben.
Ist eine Spalte als eindeutig beschrieben (�unique constraint�), müssen sich die Werteder Zeilen voneinander unterscheiden. Um dies zu erreichen, wird ein Zähler eingeführt.
25

4 Ansatz
Der Zähler beginnt bei einem bestimmten Startwert und erhöht die Zahl für jede Zeileum eins. Da ein Zähler nie den gleichen Wert liefert, ist er eigentlich keine Konstante.Trotzdem werden Zähler in dieser Ausarbeitung zu den konstanten Werten gezählt, dasie nicht von den Daten der Quelldatenbank selbst abhängen.
Die Angabe eines NULL-Werts ist ebenfalls möglich.
4.2.2 SQL
Zuordnungen, wie in Abbildung 2.6 auf Seite 14 dargestellt, lassen sich auf mehrereArten lösen. In dem angegebenen Beispiel könnten die zwei Tabellen der Quelldaten-bank mit einem Join1 in der Abfrage verbunden werden. Das Resultat dieser Abfragelieÿe sich dann den Tabellen der Zieldatenbank zuordnen.
Mit einer SQL Abfrage auf der Quelldatenbank lässt sich dieser Strukturunterschiedebenfalls überbrücken. Diese Methode bietet aufgrund des Sprachumfangs von SQL we-sentlich gröÿere Flexibilität. Des Weiteren steht der volle Funktionsumfang der Quell-datenbank zur Verfügung.
Statt einer Zuordnung für eine Spalte wird der SQL Befehl angegeben. Dieser Befehlsollte nur ein einziges Ergebnis liefern (eine Spalte, eine Zeile). Ist die Rückgabe mehr-zeilig oder es werden mehrere Spalten abgefragt, so wird immer nur der Wert aus Spalte1, Zeile 1 genutzt.
Beispiel
Dieses Beispiel bezieht sich auf die Problematik aus Abschnitt 2.2.6. In der folgendenAbbildung wird verdeutlicht, wie sich die Daten für die �XY_PRODUKTE� Tabellezusammensetzen. Der Pfeil von Produkte zu �XY_PRODUKTE� zeigt eine Zuordnungzwischen diesen Tabellen an.
TypId Name KlassseId
101 Waschmittel 1
102 Shampoo 2103 Haargel 3
Typen
PId 1 Name TypId
1002 Shockwave 103
1003 Ultra XL 103
1004 Weisser ... 101
Produkte
ID 1003
NAME Weisser...
TYP_ID 103
KLASSE_ID 3
XY_PRODUKTE
Daten einer Zeile
Abbildung 4.2: SQL Befehl Beispiel
Diese Zusammensetzung kann mit folgendem SQL Befehl für die Spalte �PRO_KLASSE_ID�der Zieltabelle �XY_PRODUKTE� erreicht werden:1Ein Join bewirkt bei der Abfrage mit SQL den Verbund von mehreren Tabellen über (Schlüssel-)Spalten.
26

4.3 Erkennen von Ähnlichkeiten zwischen Schemaelementen
SELECT Klasse Id FROM Typen WHERE TypId=103;
Dieser Befehl würde immer 3 zurück liefern. Um das Ergebnis von der aktuellen Zeileabhängig zu machen, müssen Parameter angegeben werden.
SELECT Klasse Id FROM Typen WHERE TypId={#TypId#};
{#TypId#} wird hierbei durch den Wert der Spalte TypId der aktuellen Zeile2 ersetzt.
Für jede Zeile einer Spalte, in der ein SQL Befehl angegeben ist, muss eine Abfragean die Quelldatenbank gestellt werden. Da Abfragen auf einer Datenbank Zeit kosten,ist der Nachteil dieser Vorgehensweise eindeutig die hohe Anzahl an Abfragen. DerMigrationsprozess ist meist nicht zeitkritisch, deshalb kann dieser Performance-Nachteilvernachlässigt werden.
4.3 Erkennen von Ähnlichkeiten zwischenSchemaelementen
Das Erkennen von Ähnlichkeiten zwischen den Schemaelementen basiert auf folgendenMethoden:
• Vergleich von Namen der Elemente (Tabelle, Spalte)
• Vergleich der strukturellen Eigenschaften der Elemente
Die Vergleiche erfolgen immer auf der Ebene des Elements. Jede Tabelle aus der Zielda-tenbank wird mit jeder Tabelle der Quelldatenbank verglichen. Dieser Vergleich führtzu einer Bewertung der Ähnlichkeit zweier Elemente. Die Spalten werden verglichen,sobald eine Zuordnung zwischen zwei Tabellen besteht.
Aus den Bewertungen der Ähnlichkeit resultiert eine sortierte Liste mit Elementen proElement der Zieldatenbank. Ziel ist es, den Aufwand für das Zuordnen von ähnlichenbzw. gleichen Namen zu minimieren.
4.3.1 Vergleich von Namen
Der Vergleich von Namen basiert auf einer Ähnlichkeitsanalyse der Zeichenketten. Hier-für gibt es mehrere Algorithmen, die unterschiedliche Ansätze verfolgen. In [Nav01]werden diese Methoden ausführlich beschrieben.
Der Editierabstand zwischen Elementen ist eine einfache und dennoch e�ektive Metho-de die Ähnlichkeit zwischen Namen festzustellen. Aus diesem Grund wird der Algo-rithmus für die Anwendung genutzt.
Der Editierabstand gibt letztlich an, wie viele Buchstaben mindestens geändert werdenmüssen, um aus einer Zeichenfolge A die Zeichenfolge B zu erzeugen. Dabei können dieOperationen �löschen�, �einfügen�, �tre�er� (Buchstaben sind gleich) sowie �ersetzen�
2Zeile die übertragen wird
27

4 Ansatz
auftreten. Im einfachsten Fall werden alle Operationen, auÿer �tre�er�, mit virtuellenKosten von 1 berechnet. Das Ergebnis ist die Anzahl der nötigen Operationen. Jegeringer diese Anzahl, desto ähnlicher sind die Zeichenketten.
Diese Vorgehensweise ist nur dann sinnvoll, wenn es sich tatsächlich um sehr ähnlicheZeichenfolgen handelt. Das Erkennen der Ähnlichkeit zwischen �Produkte� und �Pro-dukt� ist ein solcher Fall. Die Methode kann jedoch keine Ähnlichkeit zwischen ��lm�und �movie� feststellen. Auch Abkürzungen zählen zu den Fällen bei denen der Editier-abstand keine sinnvollen Ergebnisse liefern kann. In Abschnitt 4.3.3 �nden sich einigeAnsätze zur Optimierung der Einschränkungen dieses Vergleichs.
4.3.2 Vergleich der Struktureigenschaften
Ein Vergleich der strukturellen Eigenschaften ist vor allem bei Spalten sinnvoll. Zwarbesitzen Tabellen auch strukturelle Eigenschaften, wie z. B. die Anzahl der enthaltenenSpalten. Diese Eigenschaften sind häu�ger verschieden zwischen Quell- und Zieltabelle,als die Eigenschaften der Spalten.
Eine Spalte besitzt mehrere Eigenschaften. Ausgehend davon, dass diese Eigenschaftendie Möglichkeiten im Bezug auf den Inhalt der Spalte einschränken, werden sie auchals Einschränkungen (Constraints) bezeichnet.
Sind bestimmte Eigenschaften zweier Spalten identisch, erhöht sich die Wahrschein-lichkeit, dass diese Spalten korrespondieren.
Folgende Eigenschaften werden ausgewertet.
Beide Spalten ...
• ... sind Primärschlüssel ihrer Tabelle
• ... sind als Fremdschlüssel deklariert
• ... haben einen identischen Datentyp de�niert
• ... haben einen kompatiblen Datentyp
• ... dürfen leer sein (nullable) / ... dürfen nicht leer sein (not nullable)
Die Übereinstimmung dieser Eigenschaften �ieÿt zusätzlich in die Bewertung der Ähn-lichkeit von Spalten mit ein.
4.3.3 Optimierungsmöglichkeiten
Folgende Überlegungen zur Optimierung der automatischen Zuordnung sind aufgrundder begrenzten Zeit für die Implementierung nicht Teil des Prototypen.
Ausschluss bereits zugeordneter Schemaelemente
Eine Tabelle der Quelldatenbank, die bereits einer Tabelle der Zieldatenbank zugeord-net ist, wird wahrscheinlich nicht noch einer Tabelle der Zieldatenbank zugeordnet.Daher wäre es sinnvoll, noch nicht zugeordnete Tabellen zu bevorzugen.
28

4.4 Erzeugen von Testdaten
Ein möglicher Nebene�ekt tritt ein, wenn eine Tabelle falsch zugeordnet ist. Bei derSuche nach einer passenden Tabelle wird diese dann benachteiligt, obwohl sie vielleichtdie beste Bewertung hätte. Daher ist fraglich, ob diese Optimierung immer zu besserenErgebnissen führt.
Prä�x Erkennung
Bei Datenbanken erfreuen sich Prä�xe für Tabellen und Spalten groÿer Beliebtheit.Hierfür gibt es je nach Datenbankprodukt und Firma unterschiedliche Konventionen.
Beispiele:
• Eine Tabelle die Produkte heiÿen soll, wird als �XY_PRODUKTE� angelegt.�XY_� ist hierbei das Prä�x
• Die Spalte für einen Namen wird in der Tabelle als �PRO_NAME� angelegt.�PRO_� ist hierbei das Prä�x
Solche Prä�xe können dazu führen, dass die Ähnlichkeit zwischen Quell- und Ziel-element verfälscht wird. Daher könnte das Erkennen und Entfernen von Prä�xen zubesseren Ergebnissen führen.
4.4 Erzeugen von Testdaten
Um die Testdaten so anonym wie möglich zu gestalten, werden die Daten durch dieAngabe von Vorschriften erzeugt. Diese enthalten keine wirklichen Daten, sondern nurInformationen darüber, wie Daten generiert werden sollen. Tabelle 4.1 listet die mögli-chen Datenquellen auf. Bis auf die Quelle �Datei� handelt es sich rein um Vorschriftenzur Erzeugung von Daten. Welche Daten in einer Datei enthalten sind, steht dem An-wender natürlich frei.
Quelle Beschreibung
Zähler Ein Zähler, der bei Startwert beginnt und pro Zeile um eins erhöht wirdKonstante Ein konstanter Wert, der in jede Zeile eingetragen wirdDatei Datei mit Inhalten für diese SpalteZufall Es wird eine zufällige Zeichenfolge erstelltKein Inhalt In diese Spalte wird kein Inhalt bzw. der Standardinhalt3eingefügt
Tabelle 4.1: Quellen für Testdatenerzeugung
Diese Angaben sind alle �pro Spalte� zu verstehen. Es wird für jede Spalte eine Vor-schrift angegeben.
Die Daten in der Datei unterliegen keiner eigenen Struktur. Eine Zeile repräsentiertgenau einen Datensatz. Das hat den Vorteil, dass eine Datei für mehrere Spalten genutztwerden kann.3Viele Datenbanken erlauben es, einen Standardinhalt für eine Spalte zu de�nieren. Dieser wirdimmer dann eingefügt, wenn keine Daten für diese Spalte angegeben wurden.
29

4 Ansatz
Beziehungen
Bei der Generierung von Testdaten ist es besonders wichtig, dass eine korrekte Be-ziehung zwischen den Daten entsteht. Daher werden die Beziehungen automatisch er-zeugt. Die Software kann Beziehungen der Datenbank anhand von Fremdschlüssel-De�nitionen feststellen.
In eine Spalte, die als Fremdschlüssel dient, müssen korrekte Werte eingetragen werden.Hierfür werden die Werte der verknüpften Tabelle ausgelesen und in die Fremdschlüssel-Spalte eingetragen. Sind in der verknüpften Tabelle keine weiteren Datensätze mehrvorhanden, beginnt die nächste Referenz wieder beim ersten Datensatz. In Abbildung4.3 ist dies beispielhaft dargestellt.
KLA_ID KLA_NAME
1 Reinigung
2 Körperpflege
3 Kosmetik
XY_KLASSENTYP_ID TYP_NAME
101 Waschmittel
102 Shampoo
103 Haargel
XY_TYPEN
ID NAME TYP_ID KLASSE_ID
1 Prod 1 101 12 Prod 2 102 23 Prod 3 103 34 Prod 4 101 1
XY_PRODUKTE1
1 Tabellen Präfix „PRO_“ aus Platzgründen entfernt
Da alle Datensätze in XY_KLASSEN aufgebraucht wurden, wird wieder auf denersten Eintrag referenziert.
Abbildung 4.3: Beziehungen zwischen Testdaten (Beispiel)
30

5 Software-Entwurf
Der Software-Entwurf ist ein grundlegender Baustein für die Entwicklung einer Soft-ware. In dieser Phase werden Schnittstellen und Konzepte erarbeitet, die eine Basis fürdie Implementierung scha�en. Im Folgenden wird auf wichtige Aspekte des Entwurfseingegangen.
5.1 Technologie
Java .NET C++/MFC C++/Qtplattformunabhängig ja teilweise nein ja1
Lizenzkosten keine keine keine ja2
Kosten für Entwicklungsumgebung keine ja ja keineDatenbank Zugri�stechnik JDBC ADO.NET ODBC/ADO QSQLTreiber für Oracle ja ja ja jaTreiber für MS Access ja3 ja ja ja3
weitere Datenbankprodukte viele viele viele wenige
Tabelle 5.1: Vergleich der Technologien
Tabelle 5.1 zeigt einen Vergleich zwischen den Technologien, Java, .NET, C++ mitMFC und C++ mit Qt. Alle aufgelisteten Technologien bieten einen ähnlichen Funkti-onsumfang. Daher eigenen sie sich prinzipiell zur Erstellung der angestrebten Softwa-relösung.
Aufgrund der Plattformunabhängigkeit und den entfallenden Kosten für Lizenz undEntwicklungsumgebung, �el meine Wahl auf Java als Basistechnologie. Die weitrei-chende Unterstützung von Datenbanken in Java ist für die Aufgabe besonders wichtig.
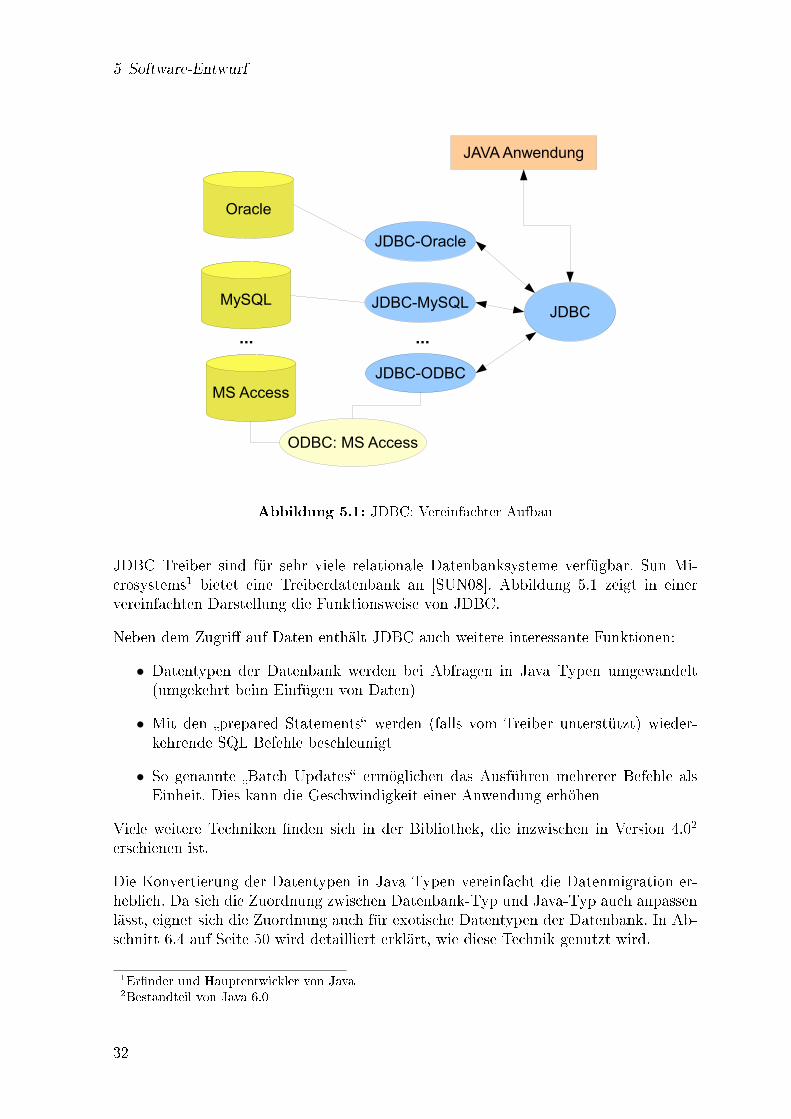
5.1.1 Die Datenbank Abstraktion JDBC
JDBC ist eine Technologie, die Datenbankzugri�e unabhängig von dem darunterlie-genden Datenbanksystem ermöglicht. Sie ist Teil der Java Plattform, der Kern dieserTechnologie ist ihr Treibersystem. Für jedes unterstützte Datenbankprodukt muss einTreiber vorliegen.
1Für jede Plattfrom muss eine Binärdatei erzeugt werden2Für kommerzielle Entwicklung3Über eine ODBC Brücke
31
5 Software-Entwurf
JDBC-Oracle
JDBC-MySQL
JDBC-ODBC
ODBC: MS Access
JDBC
JAVA Anwendung
Oracle
MySQL
MS Access
......
Abbildung 5.1: JDBC: Vereinfachter Aufbau
JDBC Treiber sind für sehr viele relationale Datenbanksysteme verfügbar. Sun Mi-crosystems1 bietet eine Treiberdatenbank an [SUN08]. Abbildung 5.1 zeigt in einervereinfachten Darstellung die Funktionsweise von JDBC.
Neben dem Zugri� auf Daten enthält JDBC auch weitere interessante Funktionen:
• Datentypen der Datenbank werden bei Abfragen in Java Typen umgewandelt(umgekehrt beim Einfügen von Daten)
• Mit den �prepared Statements� werden (falls vom Treiber unterstützt) wieder-kehrende SQL Befehle beschleunigt
• So genannte �Batch Updates� ermöglichen das Ausführen mehrerer Befehle alsEinheit. Dies kann die Geschwindigkeit einer Anwendung erhöhen
Viele weitere Techniken �nden sich in der Bibliothek, die inzwischen in Version 4.02
erschienen ist.
Die Konvertierung der Datentypen in Java Typen vereinfacht die Datenmigration er-heblich. Da sich die Zuordnung zwischen Datenbank-Typ und Java-Typ auch anpassenlässt, eignet sich die Zuordnung auch für exotische Datentypen der Datenbank. In Ab-schnitt 6.4 auf Seite 50 wird detailliert erklärt, wie diese Technik genutzt wird.
1Er�nder und Hauptentwickler von Java2Bestandteil von Java 6.0
32

5.2 Generelle Aspekte
5.1.2 JDBC und ODBC
Ähnlich wie JDBC ist ODBC eine Technologie um einheitlich auf Datenbanken zuzu-greifen. Im Gegensatz zu JDBC nutzt ODBC jedoch nicht die Java Plattform, sondernist in Microsoft Windows integriert3. Inzwischen bieten viele Hersteller sowohl ODBCals auch JDBC Treiber an. Als JDBC von SUN entwickelt wurde, war dies noch nichtder Fall. Für manche Datenbanken existiert nach wie vor kein JDBC Treiber, daher istder direkte Zugri� nicht immer möglich.
Um die Anzahl der Unterstützten Datenbanken zu erhöhen, ist der Zugri� von JDBCauf ODBC Datenquellen möglich. Der �JdbcOdbc� Treiber setzt Anfragen, die überdas JDBC-API gemacht werden, in ODBC Aufrufe um. Da beide Abstraktionsebenenjeweils nur einen Teil der Funktionen des DBMS unterstützten, kann es zu Einschrän-kungen kommen. MS Access bietet beispielsweise über ODBC keinen Zugri� auf dieDe�nitionen von Fremdschlüsseln an.
Diese JDBC-ODBC Brücke kommt auch beim Zugri� auf Microsoft Access Datenban-ken zum Einsatz.
5.2 Generelle Aspekte
5.2.1 Sprache
Aufgrund der internationalen Ausrichtung der TWT GmbH wird sowohl die Ober-�äche als auch der gesamte Quellcode und dessen Kommentare in englischer Spracheverfasst. Da die Anwendung hauptsächlich für Entwickler gedacht ist, werden Englisch-Kenntnisse vorausgesetzt.
Aus diesem Grund sind auch Diagramme und Ausschnitte des Quellcodes teilweise inenglischer Sprache.
5.2.2 Metadaten
�Als Metadaten oder Metainformationen bezeichnet man allgemein Daten,die Informationen über andere Daten enthalten.� [Wik09a]
Datenbanken enthalten eine ganze Reihe von Metadaten, z. B.:
• Tabellennamen
• Spaltennamen
• Datentyp einer Spalte
• Primär- und Fremdschlüssel-Spalten
• weitere Eigenschaften einer Spalte (Constraints)
3Mit �unixODBC� existiert allerdings auch eine Umsetzung für andere Betriebssysteme
33

5 Software-Entwurf
Die Sprache SQL erfordert die Angabe von Tabellen- und Spaltennamen. Um Datenin die Datenbank einzutragen, muss die Anwendung deshalb wissen, welche Elementein der Datenbank existieren. Sollen die Datenbanken nicht manuell analysiert werden,müssen diese Daten ausgelesen werden.
Der Zugri� auf diese Daten ist je nach Hersteller der Datenbank unterschiedlich. JDBCmacht als Abstraktionsschicht eine Schnittmenge der Metadaten zugänglich. Daten dieüber JDBC nicht abgefragt werden können, oder im JDBC Treiber nicht implemen-tiert wurden, sind bei vielen Datenbanksystemen über so genannte Systemtabellen perSQL-Abfrage zugänglich. Metadaten sind für Datenmigration und Testdatenerzeugungvon elementarer Bedeutung. Ohne diese Informationen können weder Testdaten er-zeugt, noch Daten migriert werden. Deshalb spielen Metadaten für die Architektur derSoftware eine zentrale Rolle.
5.3 Allgemeine Architektur
Die Allgemeine Architektur legt fest, in welche Teile das Softwaresystem aufgeteilt ist.Im weiteren Verlauf der Abschnitte werden der Aufbau und die Aufgaben der einzelnenKomponenten erklärt.
Die Anwendung ist in vier Komponenten aufgeteilt:
1. Gra�sche Ober�äche
2. Logik
3. Meta Modell (Datenmodell)
4. Datenbankzugri� (DB Zugri�)
Diese Aufteilung in Komponenten erhöht die Wiederverwendbarkeit der Software. Sokann beispielsweise zusätzlich zur gra�schen Ober�äche auch eine KonsolenbasierteAnwendung entwickelt werden, ohne die anderen Komponenten zu verändern.
G r a f i s c h e O b e r f l ä c h e ( G U I )
L o g i k M e t a M o d e l l
D B Z u g r i f f
D a t e n b a n k ( e n )
B e n u t z e r
Abbildung 5.2: Schichtenmodell der Komponenten
34

5.4 Datenbankzugri�
Abbildung 5.2 auf der vorherigen Seite zeigt die gra�sche Darstellung der Komponentenim Schichtenmodell. Die Pfeile zwischen den einzelnen Schichten zeigen deren Verwen-dung an. Diese Verbindungen sind als �kennt� bzw. �nutzt� Verbindungen zu verstehen.Weitere Vor- und Nachteile einer Schichtenarchitektur �nden sich in [Sta02].
5.4 Datenbankzugri�
Die Datenbankzugri�sschicht kümmert sich um den Zugang zur Datenbank. Hierzuzählt neben dem Verbindungsaufbau auch jede weitere Aktion, die auf einer Datenbankausgeführt wird.
Wie bereits in den Abschnitten (5.1.1 und 5.2.2) erklärt, ermöglicht JDBC einen ein-heitlichen Zugri� auf Datenbanken. Dennoch gibt es Fälle, in denen nützt die Abstrak-tion von JDBC nichts. Ein Beispiel ist der syntaktische Unterschied der SQL Dialekteeinzelner Datenbankprodukte.
Ein Fall aus dieser Kategorie sind Bezeichner (z. B. Namen von Tabellen und Spalten)die Leerzeichen enthalten. Der ANSI Standard SQL-92 sieht hierfür doppelte Anfüh-rungszeichen (") vor [ANS92]. Datenbankhersteller halten sich jedoch nicht immer andiesen Standard. Daher werden bei vielen Datenbanksystemen doppelte Anführungs-zeichen so behandelt wie einfache Anführungszeichen ('). Microsoft nutzt bei seinenProdukten (Access und SQL Server) eckige Klammern, um in SQL-Abfragen Bezeich-ner mit Leerzeichen zu ermöglichen:
SELECT ∗ FORM [ Meine Tabe l l e ] ;
Um solchen Fällen gerecht zu werden, nutzt die Anwendung ein Plugin-System, beidem für jedes unterstütze Datenbankprodukt ein Plugin existieren muss.
+ getDBInfos()
+ getTables()
+ getColumns()
+ getImportedKeys()
+ getPrimaryKeys()
+ getTriggers()
«interface »
IMetaData
JDBCMetaData
+ mofifyDBConnectionData()
+ createMetaDataObject()
+ createDBActions()
+ getPluginLabel()
+ getPluginFields()
«interface »
IDBPlugin
+ beforeDataInsert()
+ afterDataInsert()
+ deleteTable()
+ getData()
+ executeSimpleQuery()
+ getRowCount()
«interface »
IDBActions
DBActionsDefault
Abbildung 5.3: Datenbank und Plugin Interfaces (UML)
35

5 Software-Entwurf
Abbildung 5.3 zeigt die Schnittstellen (Interfaces) IMetaData, IDBPlugin und ID-BActions. Diese werden von einem Plugin implementiert. Dabei ist es zwingend not-wendig, dass ein Plugin die IDBPlugin-Schnittstelle implementiert. In der MethodecreateDBActions() wird die Plugin-spezi�sche Implementierung des IDBActions In-terfaces erzeugt und zurückgeliefert. Dasselbe gilt für createMetaDataObject(), je-doch für eine Implementierung von IMetaData.
Als Alternative zur kompletten Implementierung der Interfaces gibt es je eine Standard-Implementierung: JDBCMetaData und DBActionsDefault. Die Standard-Implementierungennutzen nur Methoden von JDBC sowie gängige SQL Befehle.
Das Beispiel der Tabellennamen bei Microsoft Access lässt sich somit sehr einfach lösen.
Plugin Beispiel (Java)
public class MSAccessMetaData extends JDBCMetaData{
// ( . . . )public List<ColumnData> getColumns ( S t r ing tableName ){
// f i x f o r ms−acces s t a b l e names wi th space " "i f ( tableName . indexOf ( " " ) != −1 ){
tableName = " [ " + tableName + " ] " ;}return super . getColumns ( tableName ) ;
}// ( . . . )
}
Dieser Quellcode-Ausschnitt zeigt die Flexibilität der Architektur. Es wird nur der Pa-rameter tableName verändert. Die eigentliche Arbeit �ndet trotzdem in der Standard-Implementierung JDBCMetaData statt. Auf diese Weise werden Redundanzen verhin-dert, was zu einer höheren Qualität des Codes führen kann. Dadurch wird ebenfalls derWartungsaufwand verringert.
5.5 Datenmodell (Meta Modell)
In der objektorientierten Programmierung werden die realen Gegebenheiten auf Klas-sen abgebildet. Das Datenmodell dient zur Speicherung und Verwaltung von Daten,mit denen das Programm zur Laufzeit arbeitet.
Für die Anwendung wurde ein vom Standard abweichendes Datenmodell entwickelt.Es enthält nicht wie üblich Informationen, die in einer Datenbank gespeichert sind,sondern Informationen über eine Datenbank. Aus diesem Grund wird es auch als MetaModell bezeichnet.
36

5.5 Datenmodell (Meta Modell)
Relationship
DataBase
Column
Table
1..* - realtions
1
- fkColumn
1 - pkColumn
1..* - tables
columns
1- table
1..*
Abbildung 5.4: Basis Datenmodell der Anwendung
Die zentralen Elemente des Datenmodells sind in Abbildung 5.4 dargestellt. Im Fol-genden werden die abgebildeten Klassen kurz erklärt:
DataBase Repräsentiert eine Datenbank und Informationen über diese. Eine Daten-bank enthält mehrere Tabellen. Die Verbindung zwischen Tabelle und Datenbankist eine Komposition, da eine Tabelle ein Teil einer Datenbank ist.
Table Tabelle der Datenbank; besitzt neben ihrem Namen eine Verbindung zu allenSpalten.
Column Eine Spalte: Sie kennt die ihr zugeordnete Tabelle (�gehört� somit immergenau zu einer Tabelle); enthält Namen, Datentyp und weitere Informationen(Constraints usw.).
Relationship Beziehungen in der Datenbank auf Basis der Schlüssel-Spalten, model-liert über zwei Verbindungen zu Column.
Dieses Klassenmodell repräsentiert ein möglichst generisches Abbild einer Datenbank.Es enthält jedoch keinerlei Informationen über die Datenmigration oder das Erzeugenvon Testdaten.
Um dieses Modell mit Daten aus einer realen Datenbank zu füllen, ist die Datenbank-zugri�sschicht vorgesehen.
5.5.1 Modellerweiterung für die Datenmigration
Die Datenmigration erfordert eine Zuordnung zwischen den Schemaelementen. Dasinitiale Modell (Abbildung 5.4) enthält alle gesammelten Informationen über die Da-tenbank selbst (Tabellen, Spalten usw.). Um festzulegen, welche Tabellen und Spaltenaus Quell- und Zieldatenbank einander zugeordnet werden, erfolgt eine Erweiterungdes Modells.
37
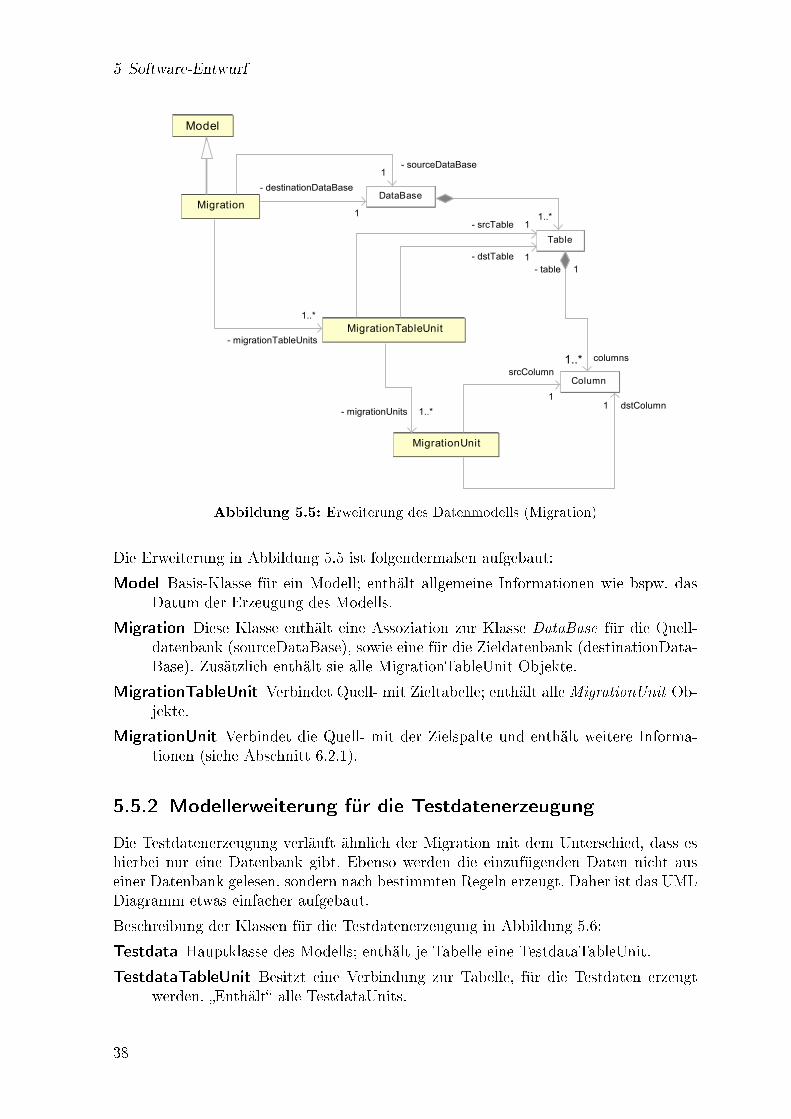
5 Software-Entwurf
DataBase
Column
Table
MigrationUnit
MigrationTableUnit
Migration
Model
+ ownedEnd
- tablesSortedByReference1..*
- table 1
columns
+ ownedEnd
srcColumn
1
+ ownedEnd
dstColumn1
+ ownedEnd
- dstTable 1
+ ownedEnd
- srcTable 1
+ ownedEnd
- migrationUnits 1..*
+ ownedEnd
1..*
- migrationTableUnits
+ ownedEnd
1- sourceDataBase
+ ownedEnd1
- destinationDataBase
1..*
Abbildung 5.5: Erweiterung des Datenmodells (Migration)
Die Erweiterung in Abbildung 5.5 ist folgendermaÿen aufgebaut:
Model Basis-Klasse für ein Modell; enthält allgemeine Informationen wie bspw. dasDatum der Erzeugung des Modells.
Migration Diese Klasse enthält eine Assoziation zur Klasse DataBase für die Quell-datenbank (sourceDataBase), sowie eine für die Zieldatenbank (destinationData-Base). Zusätzlich enthält sie alle MigrationTableUnit Objekte.
MigrationTableUnit Verbindet Quell- mit Zieltabelle; enthält alle MigrationUnit Ob-jekte.
MigrationUnit Verbindet die Quell- mit der Zielspalte und enthält weitere Informa-tionen (siehe Abschnitt 6.2.1).
5.5.2 Modellerweiterung für die Testdatenerzeugung
Die Testdatenerzeugung verläuft ähnlich der Migration mit dem Unterschied, dass eshierbei nur eine Datenbank gibt. Ebenso werden die einzufügenden Daten nicht auseiner Datenbank gelesen, sondern nach bestimmten Regeln erzeugt. Daher ist das UMLDiagramm etwas einfacher aufgebaut.
Beschreibung der Klassen für die Testdatenerzeugung in Abbildung 5.6:
Testdata Hauptklasse des Modells; enthält je Tabelle eine TestdataTableUnit.
TestdataTableUnit Besitzt eine Verbindung zur Tabelle, für die Testdaten erzeugtwerden. �Enthält� alle TestdataUnits.
38

5.6 Logik
TestdataUnit Alle, für das Erzeugen von Testdaten nötigen Informationen werdenhier gespeichert. �Kennt� die Spalte, für die Testdaten generiert werden.
Die Verbindung zwischen TestdataUnit und Column mit dem Namen relationPkColumnbildet Beziehungen innerhalb des Schemas der Datenbank ab. Dies verhindert denSuchvorgang nach Verbindungen in den Relationship Objekten.
5.6 Logik
Die Logik Komponente ist strukturell in �Tasks� aufgeteilt. Es gibt einenMigrationTasksowie einen TestdataTask. Wie der Name andeutet, sind diese Klassen für alle Aktionen,die mit der jeweiligen Aufgabe zusammenhängen, zuständig. MetaHelper greift aufMethoden des IMetaData Interfaces zurück und fasst für beide Aufgaben nützlicheMethoden zusammen. Die Klasse MetaData bietet einen höherstu�gen (high-level) undsomit vereinfachten Zugri� auf die Metadaten der Datenbank. In Abbildung 5.7 sinddie Klassen und ihre Assoziationen sowie Vererbungshierarchien dargestellt.
Die Klassen MigrateTable und GenerateTestdataTable sind für das zeilenweise Über-tragen bzw. Erzeugen von Daten zuständig.
5.7 Ober�äche
Für die Darstellung einer Datenbank gibt es unterschiedliche Ansätze. Nachfolgendwerden kurz einige Ansätze vorgestellt.
Flach
Die Speicherung von Daten in relationalen Datenbanksystemen wird als ��ach� be-zeichnet. Es gibt genau drei Ebenen: Datenbank→ Tabelle→ Spalte. Die Beziehungenzwischen den Daten werden über Werte hergestellt.
Die einfachste Möglichkeit ist daher eine ähnliche Darstellung wie sie in vielen Program-men zur Datenbankadministration genutzt wird (SQL Developer, phpMyAdmin). DieTabellen einer Datenbank werden als Liste im linken Teil der Ober�äche dargestellt.Spalten sind pro ausgewählter Tabelle rechts sichtbar.
Hierarchisch
Eine hierarchische Ansicht zeigt neben den Elementen der Tabelle auch deren Bezie-hungen innerhalb der Datenbank. Übliche Darstellungen sind Bäume, wie sie auchbei Dateisystem-Ansichten zum Einsatz kommen. Bei komplexen Schemata kann diesschnell unübersichtlich werden. Es bietet jedoch den Vorteil, dass unterschiedliche Be-ziehungen in Quell- und Zieldatenbank schneller erkannt werden.
Gra�sch
Eine mögliche gra�sche Darstellung ist bei Altovas MapForce zu sehen (Abbildung 3.7auf Seite 22). Die Beziehungen innerhalb einer Tabelle werden hierarchisch als Baum
39
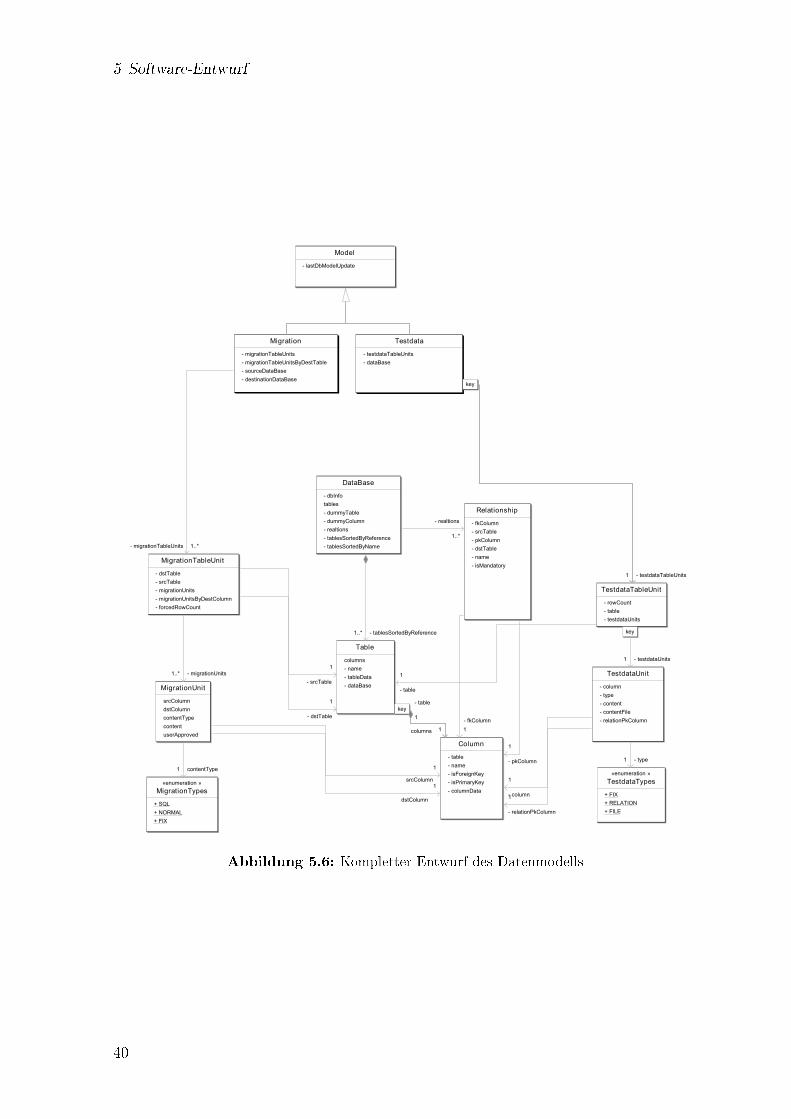
5 Software-Entwurf
- column
- type
- content
- contentFile
- relationPkColumn
TestdataUnit
- lastDbModelUpdate
Model
- migrationTableUnits
- migrationTableUnitsByDestTable
- sourceDataBase
- destinationDataBase
Migration
- testdataTableUnits
- dataBase
Testdata
+ FIX
+ RELATION
+ FILE
«enumeration »
TestdataTypes
- fkColumn
- srcTable
- pkColumn
- dstTable
- name
- isMandatory
Relationship
- dstTable
- srcTable
- migrationUnits
- migrationUnitsByDestColumn
- forcedRowCount
MigrationTableUnit
- table
- name
- isForeignKey
- isPrimaryKey
- columnData
Column
+ SQL
+ NORMAL
+ FIX
«enumeration »
MigrationTypes
srcColumn
dstColumn
contentType
content
userApproved
MigrationUnit
- rowCount
- table
- testdataUnits
TestdataTableUnit
columns
- name
- tableData
- dataBase
Table
- dbInfo
tables
- dummyTable
- dummyColumn
- realtions
- tablesSortedByReference
- tablesSortedByName
DataBase
- column
1
- type1
- testdataUnits1
key
- relationPkColumn
1
- migrationTableUnits 1..*
key
- testdataTableUnits1
- fkColumn
1
- pkColumn
1
- realtions
1..*
- srcTable
1
- dstTable
1
- migrationUnits1..*
columns 1
key
1
- table
dstColumn
1srcColumn
1contentType1
- tablesSortedByReference1..*
1
- table
Abbildung 5.6: Kompletter Entwurf des Datenmodells
40
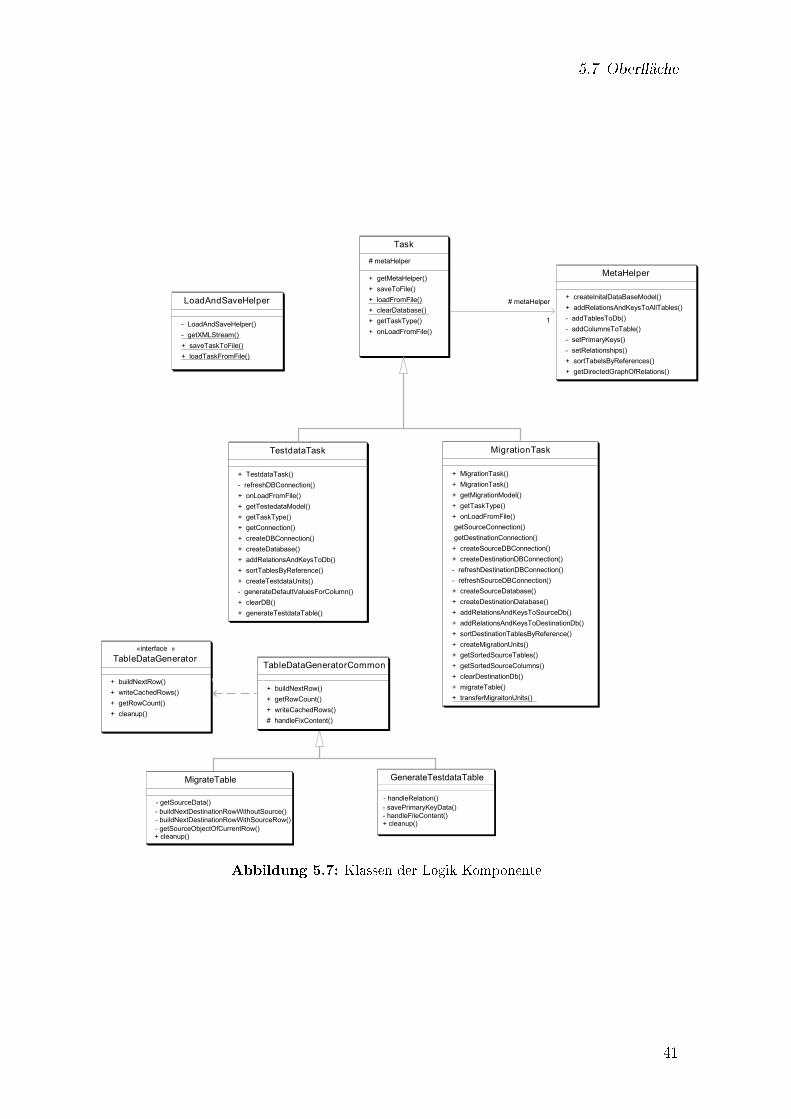
5.7 Ober�äche
- LoadAndSaveHelper()
- getXMLStream()
+ saveTaskToFile()
+ loadTaskFromFile()
LoadAndSaveHelper
+ buildNextRow()
+ writeCachedRows()
+ getRowCount()
+ cleanup()
«interface »
TableDataGenerator
+ buildNextRow()
+ getRowCount()
+ writeCachedRows()
# handleFixContent()
TableDataGeneratorCommon
+ TestdataTask()
- refreshDBConnection()
+ onLoadFromFile()
+ getTestedataModel()
+ getTaskType()
+ getConnection()
+ createDBConnection()
+ createDatabase()
+ addRelationsAndKeysToDb()
+ sortTablesByReference()
+ createTestdataUnits()
- generateDefaultValuesForColumn()
+ clearDB()
+ generateTestdataTable()
TestdataTask
+ MigrationTask()
+ MigrationTask()
+ getMigrationModel()
+ getTaskType()
+ onLoadFromFile()
getSourceConnection()
getDestinationConnection()
+ createSourceDBConnection()
+ createDestinationDBConnection()
- refreshDestinationDBConnection()
- refreshSourceDBConnection()
+ createSourceDatabase()
+ createDestinationDatabase()
+ addRelationsAndKeysToSourceDb()
+ addRelationsAndKeysToDestinationDb()
+ sortDestinationTablesByReference()
+ createMigrationUnits()
+ getSortedSourceTables()
+ getSortedSourceColumns()
+ clearDestinationDb()
+ migrateTable()
+ transferMigraitonUnits()
MigrationTask
# metaHelper
+ getMetaHelper()
+ saveToFile()
+ loadFromFile()
+ clearDatabase()
+ getTaskType()
+ onLoadFromFile()
Task
+ createInitalDataBaseModel()
+ addRelationsAndKeysToAllTables()
- addTablesToDb()
- addColumnsToTable()
- setPrimaryKeys()
- setRelationships()
+ sortTabelsByReferences()
+ getDirectedGraphOfRelations()
MetaHelper
«AutoDetected »
1
# metaHelper
columns
MigrateTable
- getSourceData()- buildNextDestinationRowWithoutSource()- buildNextDestinationRowWithSourceRow()- getSourceObjectOfCurrentRow()+ cleanup()
GenerateTestdataTable
- handleRelation()- savePrimaryKeyData()- handleFileContent()+ cleanup()
Abbildung 5.7: Klassen der Logik Komponente
41

5 Software-Entwurf
Tabelle 1Tabelle 2
...
Tabelle n
...
Spalte 1
Spalte n
Tabelle1 [Einstellungen]
[Spalten Einstellungen]
[Spalten Einstellungen]
Abbildung 5.8: Simpler Ober�ächen Entwurf
veranschaulicht. Die Zuordnungen zwischen den Schemata sind als Pfeile dargestellt.Der Aufwand für die Implementierung einer solchen gra�schen Darstellung ist enormhoch. Daher ist eine solche Ober�äche keine Option für die prototypische Softwarelö-sung dieser Arbeit.
Entwurf
Die Ober�äche der Anwendung ist zur eigentlichen Lösung der Aufgabe nur von niedri-ger Priorität. Im Prototyp wird, aufgrund der begrenzten Zeit für die Implementierung,eine ��ache� Darstellung mit einfachen GUI-Objekten genutzt. Die Modularität der An-wendung erlaubt es jedoch, zu einem späteren Zeitpunkt die Ober�äche auszubauenoder weitere Ansichten hinzuzufügen.
Abbildung 5.8 zeigt einen Entwurf dieser Ober�äche. Dieser Entwurf ist Zieldatenbankorientiert: Tabellen und Spalten stammen aus der Zieldatenbank. Die als �Einstellun-gen� zusammengefassten Blöcke sind z. B. Auswahlboxen für Tabellen und Spalten derQuelldatenbank. Diese Darstellung lässt sich mit einfachen GUI-Elementen umsetzen.
42

6 Implementierung
Dieses Kapitel beschreibt die Implementierung der Anwendung. Zunächst werden dieAbläufe der Anwendung erklärt. Anschlieÿend folgt eine Beschreibung einzelner, wich-tiger Teile dieser Abläufe.
6.1 Allgemeiner Ablauf
In Abbildung 6.1 auf der nächsten Seite wird anhand des Projekttyps Migration darge-stellt, wie die Aktivitäten vom Programmstart bis zum Einstellungsdialog (SetupPanel)verlaufen. Die Kommentare im Diagramm zeigen die entsprechenden Klassen zu denAktionen an.
Zunächst �ndet die Auswahl des Projekttyps statt. Nach der Eingabe der Daten zumAufbau einer Verbindung zu den Datenbanken wird der Analyseprozess angestoÿen.Dabei werden nach und nach alle nötigen Informationen über die Datenbank mit Hilfeder Datenbankzugri�sschicht abgefragt. Schlieÿlich wird aus diesen Informationen derEinstellungsdialog erzeugt. Der Anwender hat die Möglichkeit, alle Kon�gurationender Migration bzw. Testdatenerzeugung im Einstellungsdialog vorzunehmen.
Der Projekttyp Testdaten verläuft sehr ähnlich. Mit dem Unterschied, dass nur eineDatenbank analysiert wird.
6.2 Migration: Zuordnung von Tabellen und Spalten
Nachdem, wie im vorherigen Abschnitt erläutert, die Ober�äche für die Migrationerzeugt wurde, �ndet die Zuordnung der Tabellen und Spalten statt. Die direkte Zu-ordnung ist, wie im Entwurf zu sehen, über Assoziationen zwischen den Klassen desMeta Modells realisiert. Die Ober�äche bietet hierfür eine nach Ähnlichkeit sortier-te Liste von Tabellen der Quelldatenbank. Für Spalten der Quelltabelle wird dieselbeVorgehensweise genutzt.
6.2.1 De�nition alternativer Inhalte
Gemäÿ dem Ansatz aus Kapitel 4 wird nachfolgend die technische Umsetzung der De-�nition von nicht direkten Zuordnungen erklärt. Dazu wird eine sehr einfache Spracheeingesetzt. Die alternativen Inhalte werden in denMigrationUnit-Objekten gespeichert.
43
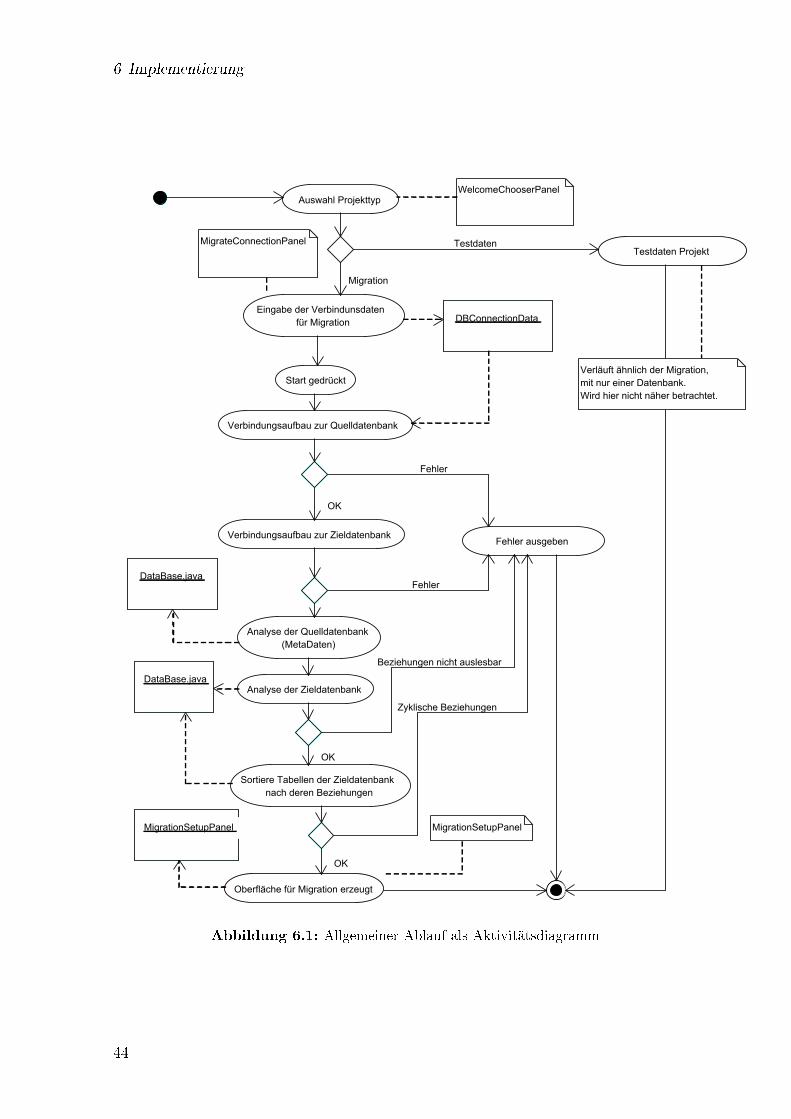
6 Implementierung
Auswahl Projekttyp
Eingabe der Verbindunsdatenfür Migration
Testdaten Projekt
WelcomeChooserPanel
Verbindungsaufbau zur Quelldatenbank
Start gedrückt
Fehler ausgeben
MigrateConnectionPanel
Fehler
Verbindungsaufbau zur Zieldatenbank
OK
DBConnectionData
Migration
Testdaten
Oberfläche für Migration erzeugt
MigrationSetupPanel
Fehler
Analyse der Quelldatenbank(MetaDaten)
Analyse der Zieldatenbank
Sortiere Tabellen der Zieldatenbanknach deren Beziehungen
OK
Beziehungen nicht auslesbar
OK
Zyklische Beziehungen
DataBase.java
DataBase.java
MigrationSetupPanel
Verläuft ähnlich der Migration,mit nur einer Datenbank.Wird hier nicht näher betrachtet.
Abbildung 6.1: Allgemeiner Ablauf als Aktivitätsdiagramm
44

6.2 Migration: Zuordnung von Tabellen und Spalten
FIX (Konstante Werte)
Unter der Bezeichnung �FIX� werden konstante Werte und Zähler, sowie weitere Pa-rameter zusammengefasst. Diese Bezeichnung �ndet sich auch in der Ober�äche derAnwendung wieder. Folgende Parameter lassen sich in dieses Feld eintragen:
{#countN#} Dieser Parameter wird durch eine Zahl ersetzt. Diese Zahlbeginnt bei N und wird je Zeile um eins erhöht.
{#null#} Der NULL-Wert wird in diese Spalte eingetragen.
{#date-now#} Die Spalte wird mit dem Datum zum Zeitpunkt der Eintragungversehen.
SQL Parameter
Damit ein SQL-Befehl von der aktuellen Zeile abhängen kann, müssen die Werte die-ser Zeile für den WHERE Teil der Abfrage zur Verfügung stehen. Dafür ist folgendeSchreibweise vorgesehen.
{#ColumName#} ColumName muss ein korrekter Name einer Spalte derQuelltabelle sein. Dieser Ausdruck wird dann durch den Wert,den diese Spalte in der aktuellen Zeile hat, ersetzt.
Keine Quelltabelle
Die Anzahl der Zeilen der Zieltabelle wird normalerweise durch die Zeilen der Quellta-belle bestimmt. Ist jedoch keine Quelltabelle bestimmt (�� No Table�), fehlt die Anzahlder Zeilen. Um trotzdem Daten in diese Tabelle schreiben zu können, kann die Anzahlder Zeilen festgelegt werden. So können FIX- oder SQL-Werte verarbeitet werden. BeiSQL-Befehlen stehen dann natürlich keine Parameter zur Verfügung.
6.2.2 Editierabstand
Die Ähnlichkeit von Namen wird, wie in Abschnitt 4.3 auf Seite 27 beschrieben, mitdem Editierabstand (auch als Levestin-Distanz bekannt) ermittelt. Unterschiede durchGroÿ- und Kleinschreibung beein�ussen das Ergebnis nicht (vorheriges Ausführen vonString.toLowerCase()).
Der eingesetzte Algorithmus zur Berechnung der Levestin-Distanz ist eine einfache Im-plementierung. Es wird eine Matrix mit der Gröÿe (n + 1)x(m + 1) erzeugt. Wobeim und n die Längen von Zeichenkette A und Zeichenkette B sind. Der Speicherver-brauch ist somit ebenfallsO(m∗n). Da die Namen der Schemaelemente in Datenbankennicht beliebig lang sind, bleibt der Speicherverbrauch im Rahmen. Eine verständlicheErklärung der Implementierung �ndet sich in [Sul09].
Der wesentlich komplexere Hirschberg-Algorithmus ermöglicht eine Berechnung desEditierabstands mit linearem Verbrauch von Speicherplatz (O(n)) [All99].
45
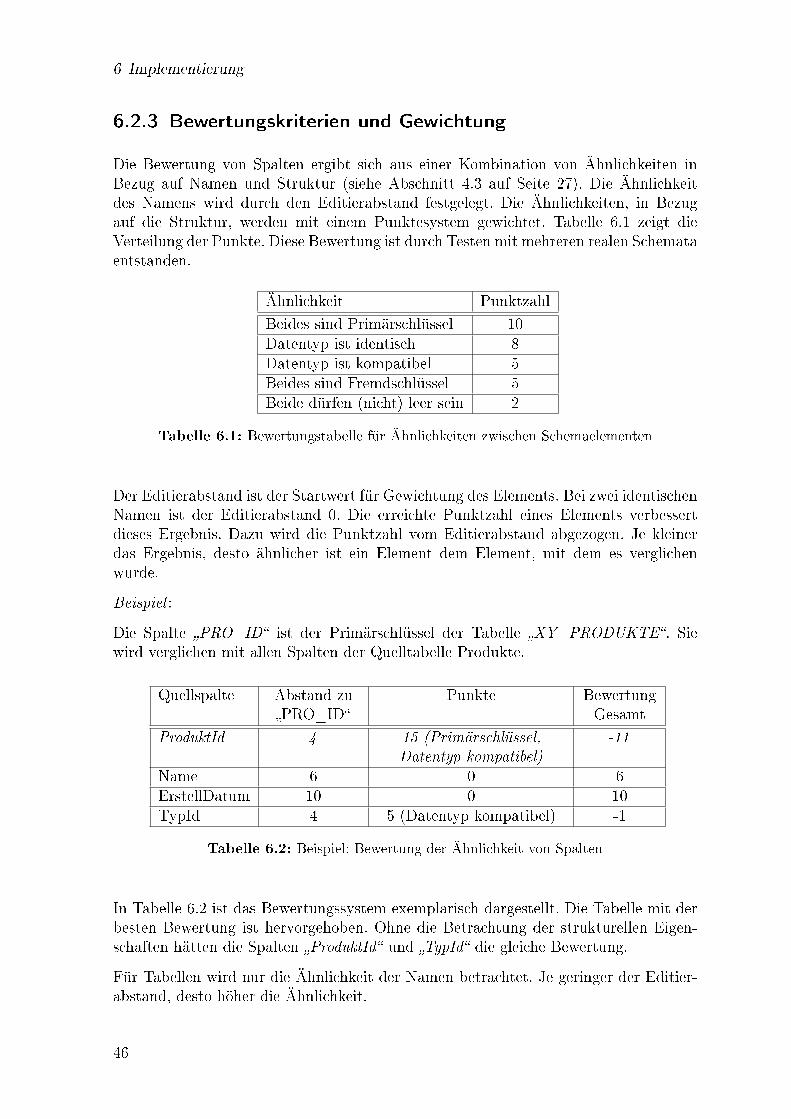
6 Implementierung
6.2.3 Bewertungskriterien und Gewichtung
Die Bewertung von Spalten ergibt sich aus einer Kombination von Ähnlichkeiten inBezug auf Namen und Struktur (siehe Abschnitt 4.3 auf Seite 27). Die Ähnlichkeitdes Namens wird durch den Editierabstand festgelegt. Die Ähnlichkeiten, in Bezugauf die Struktur, werden mit einem Punktesystem gewichtet. Tabelle 6.1 zeigt dieVerteilung der Punkte. Diese Bewertung ist durch Testen mit mehreren realen Schemataentstanden.
Ähnlichkeit Punktzahl
Beides sind Primärschlüssel 10Datentyp ist identisch 8Datentyp ist kompatibel 5Beides sind Fremdschlüssel 5Beide dürfen (nicht) leer sein 2
Tabelle 6.1: Bewertungstabelle für Ähnlichkeiten zwischen Schemaelementen
Der Editierabstand ist der Startwert für Gewichtung des Elements. Bei zwei identischenNamen ist der Editierabstand 0. Die erreichte Punktzahl eines Elements verbessertdieses Ergebnis. Dazu wird die Punktzahl vom Editierabstand abgezogen. Je kleinerdas Ergebnis, desto ähnlicher ist ein Element dem Element, mit dem es verglichenwurde.
Beispiel :
Die Spalte �PRO_ID� ist der Primärschlüssel der Tabelle �XY_PRODUKTE�. Siewird verglichen mit allen Spalten der Quelltabelle Produkte.
Quellspalte Abstand zu�PRO_ID�
Punkte BewertungGesamt
ProduktId 4 15 (Primärschlüssel,Datentyp kompatibel)
-11
Name 6 0 6ErstellDatum 10 0 10TypId 4 5 (Datentyp kompatibel) -1
Tabelle 6.2: Beispiel: Bewertung der Ähnlichkeit von Spalten
In Tabelle 6.2 ist das Bewertungssystem exemplarisch dargestellt. Die Tabelle mit derbesten Bewertung ist hervorgehoben. Ohne die Betrachtung der strukturellen Eigen-schaften hätten die Spalten �ProduktId� und �TypId� die gleiche Bewertung.
Für Tabellen wird nur die Ähnlichkeit der Namen betrachtet. Je geringer der Editier-abstand, desto höher die Ähnlichkeit.
46

6.3 Datenbankoperationen
6.2.4 Realisierung der automatischen Zuordnung
Bei der Generierung der Ober�äche für die Migration (Klasse MigrationSetupPanel)wird die Analyse der Ähnlichkeiten angestoÿen. Zunächst werden die Ähnlichkeiten derTabellen mittels der Methode getSortedSourceTables() der Klasse MigrationTaskberechnet.
Wenn sich die Quelltabelle ändert, wird die Ähnlichkeit der Spalten neu berechnet.Dafür zuständig ist die Methode getSortedSourceColumns().
Diese Methoden liefern jeweils die nach Ähnlichkeit sortierte Liste. Standardmäÿig wirdin der Ober�äche der erste Eintrag dieser Liste ausgewählt.
6.3 Datenbankoperationen
6.3.1 Abhängigkeiten zwischen Tabellen durch Beziehungen
Durch die De�nition von Beziehungen zwischen Tabellen entstehen Abhängigkeiten.Dies wirkt sich sowohl beim Eintragen als auch beim Löschen von Daten aus. Fügtman einen Datensatz in die Datenbank ein, wird überprüft ob es den verknüpftenDatensatz bereits gibt (referentielle Integrität). Falls nicht, tritt ein Fehler auf. BeimLöschen wird überprüft, ob ein Datensatz noch von einer anderen Tabelle genutztwird. Ist dies der Fall, kann der zu löschende Datensatz nicht entfernt werden. DieseÜberprüfungen verhindern eine inkonsistente Datenbank.
Einige Datenbanken bieten Regeln für das Löschen von Datensätzen an. Es gibt bei-spielsweise eine Option, um alle verknüpften Datensätze ebenfalls zu löschen (On De-lete: CASCADE). Diese Regel gilt nur für das Löschen, nicht für das Anlegen vonDatensätzen. Des Weiteren aktivieren Datenbankentwickler dieses Verhalten nur dann,wenn es explizit erwünscht ist. Eine falsche Handhabung dieser Regel kann zu Daten-verlust führen.
Datenmigration und Testdatenerzeugung erfordern, dass die Zieldatenbank zunächstgeleert wird. Anschlieÿend werden Daten in die Datenbank eingetragen. Für beideVorgänge ist es notwendig, die Reihenfolge der Lösch- und Anlegevorgänge so zu ge-stalten, dass es nicht zu Fehlern aufgrund der Integritätsprüfungen kommt. Das Löschenerfordert genau die gegenteilige Reihenfolge wie das Anlegen von Datensätzen.
Um dieses Problem zu lösen, könnte man dem Anwender das Sortieren der Tabellenanbieten. Hierbei muss der Anwender jedoch genau wissen, welche Tabelle mit welcheranderen Tabelle verbunden ist. Dies kann bei Mehrfachverbindungen durchaus sehrkomplex sein.
Nach einer genaueren Analyse zeigt sich, dass sich diese Abhängigkeiten in einem ge-richteten Graphen darstellen lassen. Hierzu bildet man aus den Tabellen Knoten underzeugt aus jeder Beziehung eine Kante. Die verknüpfte Spalte (meist der Primärschlüs-sel) bildet die ausgehende Kante und die Fremdschlüssel-Spalte die eingehende Kante.Abbildung 6.2 zeigt einen gerichteten Graphen.
47

6 Implementierung
��������
����������
�������� �����
������ ��
����������
������ ����
������������
�����������
����������
�������
Abbildung 6.2: Beziehungen zwischen Tabellen als Graph
Topologische Sortierung
Die topologische Sortierung ist ein bekannter Algorithmus zur Bestimmung der Rei-henfolge von Dingen bei einer vorgegebenen Abhängigkeit.
Ausgehend von der Darstellung im Graphen, werden zunächst alle eingehenden Kan-ten (Pfeilspitzen die zum Knoten führen) für jeden Knoten gezählt. Die Knoten, diekeine eingehenden Kanten besitzen, werden entfernt. Durch das Entfernen von Knotenenstehen weitere Knoten ohne eingehende Kante. Diese werden ebenfalls entfernt. DerVorgang wird solange wiederholt, bis keine Knoten mehr im Graphen vorhanden sind.Die entfernten Konten werden nicht gelöscht, sondern in einer Liste gespeichert. DieReihenfolge dieser Liste gibt die topologische Sortierung an.
Im Beispiel in Abbildung 6.2 würden also zunächst �XY_KLASSEN�, �XY_TYPEN�,�XY_PERSONEN� und �XY_FZG_TYPEN� entfernt werden. Anschlieÿend besitzenauch �XY_PRODUKTE�, �XY_KUNDE� und �XY_FAHRZEUGE� keine eingehen-den Kanten mehr, daher werden auch diese aus dem Graphen entfernt. Das Entfernenwird solange wiederholt, bis auch �XY_AUFTRAGSZEILE� nicht mehr im Graphenenthalten ist.
Eine topologische Sortierung kann nur dann erfolgen, wenn der Graph keine Zyklenenthält. Da Zyklen im Schema der Datenbank nur in sehr speziellen Fällen überhauptSinn ergeben, stellt die Beschränkung auf zyklenfreie Schemata keinen wesentlichenNachteil dar.
6.3.2 Oracle: Sequenzen und Trigger
Die Hersteller von Datenbanksystemen haben sich für die Aufgabe der Generierungvon eindeutigen Werten sehr unterschiedliche Lösungen überlegt. Im Folgenden soll
48

6.3 Datenbankoperationen
am Beispiel von Oracle gezeigt werden, wie solche Techniken zu einem Problem für dieDatenmigration werden können.
Oracle Datenbanken bieten zwar relativ gute Unterstützung für die Generierung vonSchlüsseln, erfordern jedoch viel Aufwand. Der Datenbankentwickler nutzt die Me-chanismen Sequenz (Sequence) und Trigger um einen Primärschlüssel automatisch zuerzeugen. Sequenzen sind Zähler, die immer eine eindeutige Zahl liefern. Selbst dann,wenn zwei Anfragen nahezu gleichzeitig eine Nummer anfordern. Daher bilden Sequen-zen die Basis für die Generierung der Schlüssel.
Ein Trigger ist eine Funktion mit der, je nach De�nition, zu bestimmten ZeitpunktenÄnderungen an der Datenbank vorgenommen werden können. Für Schlüsselspalteneignet sich ein Trigger mit dem Ereignis (Event) �ON INSERT�. Dieses Ereignis trittimmer dann ein, wenn Daten in diese Tabelle eingetragen werden. Bei der Generierungvon Schlüsseln kann auch auf Trigger verzichtet werden, dann muss die Sequenz beijedem INSERT mit angegeben werden.
Abbildung 6.3: Trigger und Sequenz im Verbindungsdialog
Der Migrationsvorgang überträgt alle Daten (also auch Primärschlüssel) von der Quell-datenbank. Deshalb muss in das Verhalten der Trigger eingegri�en werden. Ansonstenist es möglich, dass der Trigger, trotz der Angabe von Daten für eine Spalte, einengenerierten Schlüssel einträgt. Dadurch werden die Daten unter Umständen unbrauch-bar.
Trigger
Vor dem Eintragen von Daten in die Datenbank werden deshalb diese Trigger abgeschal-tet. Es kann nicht festgestellt werden, welche Trigger für die Generierung von Schlüsselngenutzt werden. Die meisten Datenbankentwickler halten sich jedoch an vorgegebeneNamenskonvention. Um diese Namen festzulegen, gibt es im Verbindungsdialog dieFelder �Trigger� und �Sequence� (siehe Abbildung 6.3).
Der Parameter {#p#} wird durch den Prä�x der Spaltennamen der Tabelle ersetzt. DasAktivieren und Deaktivieren des Triggers �ndet in den, für solche Zwecke vorgesehe-nen, Methoden beforeDataInsert() und afterDataInsert() (Interface IDBActions)statt. Wie der Name vermuten lässt, werden diese Methoden immer direkt vor bzw.direkt nach dem Einfügen von Daten in die Datenbank aufgerufen.
Sequenzen
In einer Sequenz wird der nächste Wert, den ein Element erhalten soll, gespeichert.Daher ist für jede Primärschlüssel-Spalte eine Sequenz de�niert. Nach einer Daten-migration kann es vorkommen, dass die Primärschlüssel-Spalte bereits einen gröÿeren
49

6 Implementierung
Wert als den nächsten Wert der Sequenz enthält. Ist dies der Fall, wird es irgendwannzu einer Kollision der Werte kommen.
Um dies zu verhindern, kann die Sequenz angepasst werden. Es �ndet nur dann eineAnpassung statt, wenn der nächste Wert gröÿer ist, als der gröÿte Wert, den die Spalteenthält. Der gröÿte Wert einer Spalte wird mit der SQL-Funktion MAX() ermittelt. DieAnpassung wird vor der Aktivierung des Triggers in afterDataInsert() durchgeführt.
6.4 Migrationsvorgang
Der Migrationsvorgang beginnt, nachdem der Anwender alle Einstellungen im Einstel-lungsdialog vorgenommen hat. Diese Einstellungen be�nden sich in den Objekten, derim Entwurf gezeigten Klassen (MigrationUnit etc.).
Interaction
loop destinationTables
loop[buildNextRow() == true]
Anwender
GUIApp
RunMigration
MigrateTable
MigrationTask IDBActions
Starte Migraton
runMigration
migrateTable(tableUnit)
writeCachedRows()
setObjects()
buildNextRow()
Abbildung 6.4: Migrationsvorgang Sequenzdiagramm
Abbildung 6.4 stellt den sequenziellen Ablauf der Migration dar. Ausgehend von denEinstellungen werden die Objekte abgearbeitet.
Für jedes der MigrationTableUnit Objekte wird ein MigrateTable Objekt erzeugt.Bei der Erzeugung werden die Daten aus der Quelltabelle abgefragt. Die Anzahl der
50

6.4 Migrationsvorgang
Zeilen der Quelltabelle wird ermittelt. Ist dieser Tabelle keine Quelltabelle zugeord-net, wird auf die Angabe der Zeilen vom Anwender zurückgegri�en. Die MethodebuildNextRow() liest jeweils eine Zeile aus der Quelldatenbank und wendet die in Mi-grationTableUnit hinterlegten Regeln an. In Abbildung 6.5 ist die Arbeitsweise dieserMethode dargestellt. Zur besseren Übersicht wurde auf eine Fehlerbehandlung verzich-tet und einige Abläufe sind zusammengefasst.
Die Methode buildNextRow() erzeugt eine Zeile für die Zieltabelle im Speicher. DerRückgabewert ist true, solange es in der Quelltabelle noch weitere Zeilen gibt oder diede�nierte Anzahl der Zeilen noch nicht erschöpft ist.
Eine Zeile für Zieltabelle erzeugen
Inhaltstyp bestimmen
MigrateTable.buildNextRow()
Daten zwischenspeichern
Ersetzte Parameter in SQLBefehl
SQL
SQL Befehl auf Quelldatenbankausführen
Informationen zur Spalteauslesen
FIX Parameterverarbeiten
FIX
Weitere Spalten vorhanden
NORMAL
Alle Spalten verarbeitet
Nächste Zeile der Quelltabelleauswählen
Quelltabelle angegebenKeine Quelltabelle
Zeilenanzahl = 0
Zähler fürZeilenanzahl anpassen
Definierte Zeilenanzahl > 0
Daten aus der Zeile fürdiese Spalte auslesen
Rückgabe: false
Rückgabe: true
Keine weiteren Zeilen vorhanden
Weitere Zeilen vorhanden
Nur wenn Quelltabelleangegeben wurde
Abbildung 6.5: Arbeitsweise von buildNextRow()
Die MigrateTable Klasse implementiert das TableDataGenerator Interface. Die Ver-wendung dieses Interfaces ist wie folgt:
1 MigarteTable mt ;2 // ( . . . )3 // c rea t e rows in memory4 while (mt . bui ldNextDestinationRow ( ) ) ;5 // wr i t e rows to d e s t i n a t i on db6 mt . wr i teDest inat ionsRows ( ) ;
Der Aufbau der Methoden ermöglicht es, nach einer bestimmten Anzahl an Zeilen denSchreibvorgang auszuführen. So kann dem Benutzer stets eine Statusmeldung zurück-gegeben werden.
51

6 Implementierung
Datentypen
Für SQL gibt es viele unterschiedliche Datentypen. Der JDBC Treiber setzt diese Da-tentypen zunächst in Typen des SQL Standards um. Diese richten sich nach den De-�nitionen für Datentypen des X/Open Konsortium (heute: The Open Group). DieserStandard vergibt für jeden Datentyp eine Zahl (Integer). Zu �nden sind die Typen inder Klasse java.sql.Types.
Neben dieser Typde�nition werden die Daten beim Abfragen und Eintragen in dieDatenbank in Java Typen umgewandelt. Der SQL-Typ Varchar wird hierbei in einjava.lang.String Objekt umgewandelt. Mit der Methode getObject() (InterfaceResultSet) besteht die Möglichkeit, jegliche Daten aus der Datenbank in ein Java-Objekt zu speichern. Der eigentliche Datentyp kann vom Programmierer zu einem spä-teren Zeitpunkt (z. B. mit instanceof) ermittelt werden. Fügt man mit setObject()(Interface Statement) Daten in die Datenbank ein, wird vor dem Einfügen ermittelt,welchen Datentyp diese Daten tatsächlich besitzen. Genau erläutert werden diese Tech-niken in [SUN99].
Je nach JDBC Treiber können auch exotische Datentypen verarbeitet werden. Dafürstellen die Treiber-Hersteller eigene Klassen zur Verfügung. Auch die Zuordnung vonDatenbank-Typ zu Java-Typ kann angepasst werden.
Die Konvertierung zwischen den Datentypen wird im Prototyp den Methoden vonJDBC überlassen.
6.5 Testdaten
Die Einstellungen für Testdaten sind ähnlich aufgebaut wie die der Migration. Beieinem Testdaten-Projekt gibt es folgende Typen:
FIX Aufgrund der gemeinsamen Implementierung sind diese identisch mit den kon-stanten Werten der Migration.
FILE Inhalte für eine Spalte in einer Datei. Jede Zeile repräsentiert einen Datensatz.
RELATION Beziehung innerhalb des Schemas.
Für die Beziehungen wurde die Vorgehensweise bereits im Ansatz erklärt. Der Inhalts-typ FILE verhält sich analog. Beide beginnen erneut beim ersten Datensatz, sollte dasEnde der Datei bzw. Tabelle erreicht worden sein.
Der Prototyp sieht keine Möglichkeit vor Zufallsdaten zu erzeugen. Die Längenbe-schränkungen der Spalten müssen vom Anwender bei der De�nition von Inhalten be-achtet werden.
Voreinstellungen
Um dem Anwender das Eintragen von Vorschriften zur Erzeugung der Testdaten zuerleichtern, werden je nach Datentyp und Länge der Spalte, Voreinstellungen getro�en.Dies geschieht für alle Spalten für die keine Beziehung erkannt wurde. Abbildung 6.6
52

6.6 Speichern und Laden von Projekten
zeigt den Ablauf der Generierung dieser Voreinstellungen. Diese Voreinstellungen sollendem Anwender die Arbeit erleichtern.
Ablauf der Testdatenerzeugung
Der Ablauf für die Testdatenerzeugung ist analog zu dem der Migration zu verstehen.Das TabelDataGenerator Interface wird für die Testdaten implementiert in Generate-TestdataTable.
6.6 Speichern und Laden von Projekten
Das Speichern und Laden ist sehr nützlich, wenn ein Anwender nicht alle Einstellungenam Stück erledigen kann. Besonders bei groÿen Datenbanken wäre die komfortableNutzung der Software ohne diese Funktion unmöglich.
Zum Speichern wird das im Entwurf erläuterte Meta Modell genutzt. Zusätzlich �ndensich noch die Verbindungsinformationen der Datenbanken in der Datei. Um die Objektepersistent auf einen Datenträger zu speichern, wird XStream [XSt09] genutzt. Dabeihandelt es sich um eine Java Bibliothek, die Java Objekte in einen XML Datenstromumwandelt (Serialisierung). Eine Wiederherstellung dieser Objekte anhand eines XMLDatenstromes ist ebenfalls möglich.
Da die Zuordnungen zwischen den Spalten über Assoziationen im Meta Modell reali-siert sind, wird das gesamte Modell eines Projektes gespeichert. Dies beinhaltet alleTabellen und Spalten sowie deren Eigenschaften. Lädt ein Anwender das Projekt zu ei-nem späteren Zeitpunkt, ist es möglich, dass sich die Datenbanken in der Zwischenzeitverändert haben.
Metadaten Update
Um Änderungen an den Datenbanken für das Programm sichtbar zu machen, müssendie Datenbanken erneut analysiert werden. Da im Analyseprozess alle Objekte neuerzeugt werden, bestehen für die Zuordnungen auch keine Assoziationen mehr. Deshalbgibt es eine Methode, die Assoziationen von einem bestehenden Modell in ein anderesModell überträgt. Dabei werden alle Zuordnungen anhand der Namen der Elemente inAssoziationen umgewandelt.
Das erneute Analysieren und Übertragen von Zuordnungen eines Modells muss vomAnwender mit der Schalt�äche �Reanalyze DB� angestoÿen werden. Dies ist im Proto-typen nur für den Projekttyp Migration implementiert.
6.7 Einschränkungen
Gründe für einige Einschränkungen sind teilweise bereits im Ansatz (Kapitel 4) begrün-det. In diesem Abschnitt werden Einschränkungen des Ansatzes sowie der Implemen-tierung zusammengefasst. Ebenso wird kurz auf Möglichkeiten zur Umgehung dieserEinschränkungen eingegangen.
53

6 Implementierung
Zyklen im Datenbankschema
Wie bereits Abschnitt 6.3.1 genau erklärt, dürfen sowohl in der Zieldatenbank als auchin der Datenbank für Testdaten keine zyklischen Beziehungen enthalten sein.
Da diese Zyklen durch optionale Beziehungen entstehen können, ist das manuelle Sor-tieren der Tabellen durch den Anwender eine Möglichkeit, diese Einschränkung zuumgehen.
Mehrwertige Korrespondenzen (N:1)
Die Implementierung erzeugt momentan für jede Tabelle der Zieldatenbank ein Migration-TableUnit-Objekt, welches wiederum alle Spalten als MigrationUnit-Objekte enthält.Aufgrund dieser Einschränkung ist es nicht möglich, mehrere Tabellen der Quelldaten-bank zu einer Tabelle in der Zieldatenbank zusammenzufassen.
Dies betri�t ebenso die höherstu�gen Korrespondenzen. Es lässt sich nur der Fall lösen,in dem eine Tabelle auf zwei oder mehr Tabellen aufgeteilt wird (Abbildung 3.2 rechts).
Theoretisch sollte sich die Anwendung so erweitern lassen, dass mehrere Tabellen derQuelldatenbank Daten für eine Tabelle der Zieldatenbank liefern können. Das Modellmüsste hierfür nur geringfügig geändert werden. Die Verarbeitung der gesammeltenZuordnungen (MigrateTable) hingegen würde gröÿere Änderungen nach sich ziehen.
Beziehungen zwischen Testdaten
Die Beziehungen zwischen den Testdaten können nur dann korrekt erzeugt werden,wenn es sich um Fremdschlüssel zu Primärschlüssel Beziehungen handelt. Viele Da-tenbankprodukte erlauben auch Beziehungen von Fremdschlüssel-Spalten zu Spaltendie nicht Primärschlüssel sind. Diese Spalten müssen dann eindeutig sein (�unique keycolumn�). Dieser Fall wird noch nicht berücksichtigt.
Datenbankprodukte
Die Migration funktioniert nur dann, wenn Microsoft Access (Version: XP) als Quelleund Oracle (Version: 10g) als Ziel genutzt wird. Eine Erzeugung von Testdaten ist nurmit Oracle möglich. Aufgrund der Plugin-Architektur lässt sich dies natürlich erweitern.Dennoch soll hier vermerkt sein, dass Tests nur für diese Produkte in der angegebenenKonstellation getätigt wurden.
Microsoft Access erlaubt keinen Zugri� auf Informationen zu den Beziehungen zwischenTabellen über ODBC. Aus diesem Grund ist es weder möglich, das �MS Access� Pluginals Ziel für die Datenmigration zu nutzen, noch mit einer Access Datenbank Testdatenzu generieren. Eine Möglichkeit, dies zu umgehen, wäre ein Ansatz, wie ihn der OracleSQL Developer (Abschnitt 3.2.1) nutzt. Dieser exportiert Informationen über Accessmit einem VBA-Makro. Darüber können sich auch die Informationen über Beziehun-gen der Datenbank ermitteln lassen. Im Prototyp ist diese Funktionalität jedoch nichtimplementiert.
54
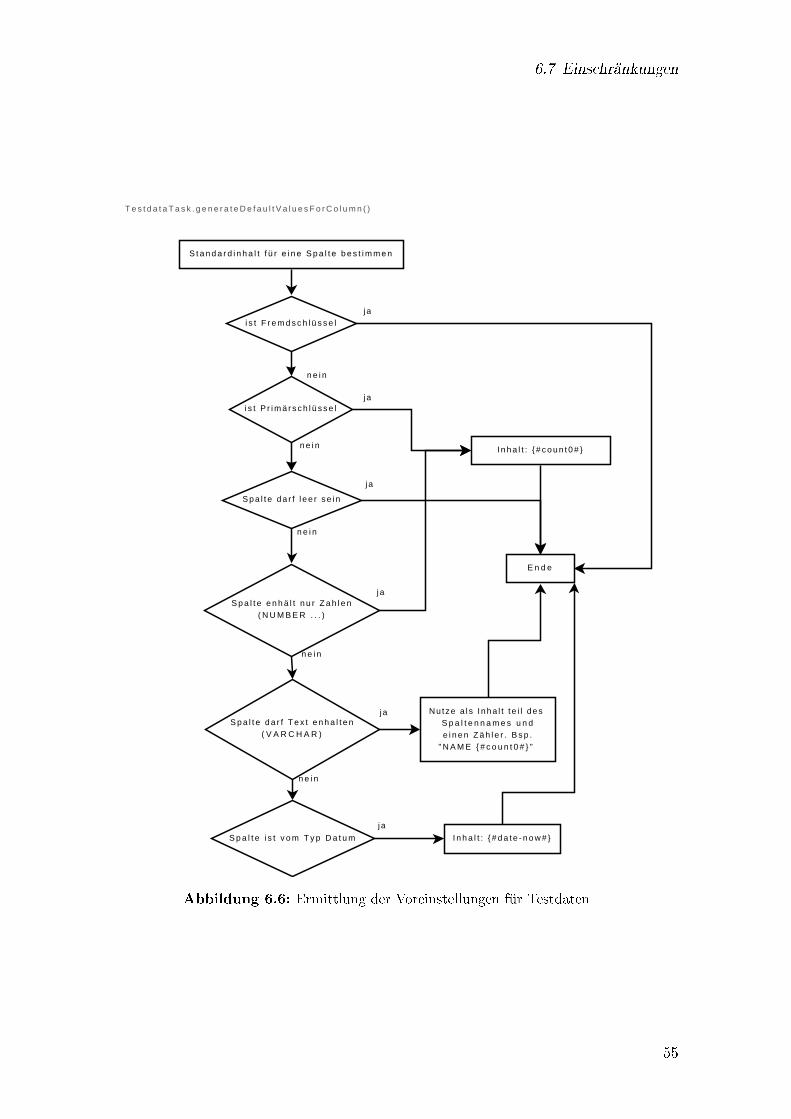
6.7 Einschränkungen
S t a n d a r d i n h a l t f ü r e i n e S p a l t e b e s t i m m e n
T e s t d a t a T a s k . g e n e r a t e D e f a u l t V a l u e s F o r C o l u m n ( )
i s t F r e m d s c h l ü s s e l
i s t P r i m ä r s c h l ü s s e l
E n d e
ja
n e i n
I n h a l t : { # c o u n t 0 # }
ja
S p a l t e d a r f l e e r s e i n
ja
S p a l t e d a r f T e x t e n h a l t e n( V A R C H A R )
n e i n
n e i n
S p a l t e e n h ä l t n u r Z a h l e n( N U M B E R . . . )
j a
n e i n
Nu tze a l s I nha l t t e i l des S p a l t e n n a m e s u n de i n e n Z ä h l e r . B s p .
" N A M E { # c o u n t 0 # } "
S p a l t e i s t v o m T y p D a t u m
ja
n e i n
I n h a l t : { # d a t e - n o w # }
ja
Abbildung 6.6: Ermittlung der Voreinstellungen für Testdaten
55

7 Test
7.1 Test der Datenmigration
In diesem Abschnitt �ndet sich die Dokumentation eines Tests der Datenmigration vonMicrosoft Access XP nach Oracle 10g. Der praktische Testfall zeigt die Möglichkeitender Software. Die verwendeten Schemata sind frei erfunden, beziehen sich jedoch aufdie Beispiele dieser Arbeit.
7.1.1 Schema A (MS Access XP)
Mitarbeiter
Personen
Kunden
Produkte
Typen
Klassen
Autos
Aufträge
Auftragszeile
MitarbeiterIdPersonIdEintrittsDatumAutoIdPersonId
NameStrassePLZOrt
KundenIdPersonId
ProduktIdNameErstellDatumTypId
TypIdNameBeschreibungKlasseId
KlasseIdNameBeschreibung
AutoIdMarkeNamePSKaufdatumTueren
AuftragIdKundenIdMitarbeiterIdDatumNotiz AuftragsZeileId
ProduktIdAuftragIdMengePreis
Abbildung 7.1: Quellschema (Schema A) [MS Access]
56
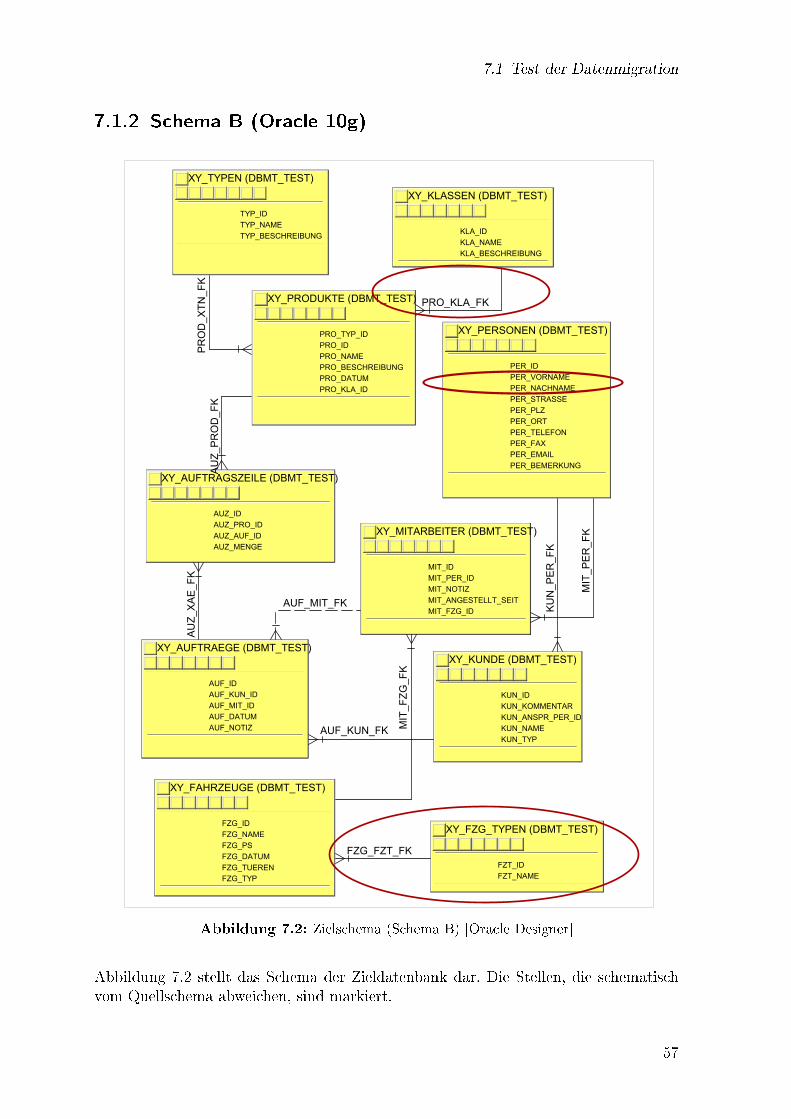
7.1 Test der Datenmigration
7.1.2 Schema B (Oracle 10g)
XY_FZG_TYPEN (DBMT_TEST)
FZT_ID
FZT_NAME
XY_FAHRZEUGE (DBMT_TEST)
FZG_ID
FZG_NAME
FZG_PS
FZG_DATUM
FZG_TUEREN
FZG_TYP
XY_PERSONEN (DBMT_TEST)
PER_ID
PER_VORNAME
PER_NACHNAME
PER_STRASSE
PER_PLZ
PER_ORT
PER_TELEFON
PER_FAX
PER_EMAIL
PER_BEMERKUNG
XY_KUNDE (DBMT_TEST)
KUN_ID
KUN_KOMMENTAR
KUN_ANSPR_PER_ID
KUN_NAME
KUN_TYP
XY_AUFTRAGSZEILE (DBMT_TEST)
AUZ_ID
AUZ_PRO_ID
AUZ_AUF_ID
AUZ_MENGE
XY_AUFTRAEGE (DBMT_TEST)
AUF_ID
AUF_KUN_ID
AUF_MIT_ID
AUF_DATUM
AUF_NOTIZ
XY_KLASSEN (DBMT_TEST)
KLA_ID
KLA_NAME
KLA_BESCHREIBUNG
XY_TYPEN (DBMT_TEST)
TYP_ID
TYP_NAME
TYP_BESCHREIBUNG
XY_PRODUKTE (DBMT_TEST)
PRO_TYP_ID
PRO_ID
PRO_NAME
PRO_BESCHREIBUNG
PRO_DATUM
PRO_KLA_ID
XY_MITARBEITER (DBMT_TEST)
MIT_ID
MIT_PER_ID
MIT_NOTIZ
MIT_ANGESTELLT_SEIT
MIT_FZG_ID
PRO_KLA_FK
PR
OD
_XT
N_F
KA
UZ
_PR
OD
_FK
AU
Z_X
AE
_FK
AUF_MIT_FK
AUF_KUN_FK
MIT
_PE
R_F
K
FZG_FZT_FK
MIT
_FZ
G_F
K
KU
N_P
ER
_FK
Abbildung 7.2: Zielschema (Schema B) [Oracle Designer]
Abbildung 7.2 stellt das Schema der Zieldatenbank dar. Die Stellen, die schematischvom Quellschema abweichen, sind markiert.
57

7 Test
7.1.3 Kon�guration
Die folgende Tabelle zeigt die Einstellungen der nicht direkten Zuordnungen.
Tabelle Spalte Einstellung
XY_FAHRZEUGE FZG_TYP FIX: 1XY_FZG_TYPEN FZT_ID FIX: 1
FZT_NAME FIX: �Auto�XY_PRODUKTE PRO_KLA_ID SQL:
SELECT Klasse IdFROM TypenWHERE TypId={#TypId#};
XY_PERSONEN PER_VORNAME SQL:
SELECT Mid ( [ Personen ] ! [ Name] , 1 , InStr ( 1 , [ Personen ] ! [Name ] , ' ' ) ) AS Vorname FROMPersonen WHERE PersonId={#
PersonId#};
XY_PERSONEN PER_NACHNAME SQL:
SELECT Mid ( [ Personen ] ! [ Name ] ,InSt r ( 1 , [ Personen ] ! [ Name ] , ' ' )+1) AS Nachname FROMPersonen WHERE PersonId={#PersonId#};
Weil es für die Tabelle �XY_FZG_TYPEN� in der Quelldatenbank kein pendant gibt,wird ihr keine Tabelle zugeordnet. Eine feste Anzahl an Zeilen wird de�niert (1). DieAngaben in �PER_VORNAME� und �PER_NACHNAME� teilen die Namen der Spal-te �Name� in Vor- und Nachname anhand des Leerzeichens auf. Hierzu werden Accessspezi�sche SQL-Erweiterungen genutzt. Abbildung 7.3 und 7.4 zeigen Ausschnitte derOber�äche.
7.2 Testdaten erzeugen
Für die Testdatenerzeugung wird ebenfalls das �Schema B� (Abbildung 7.2) genutzt.In Abbildungen 7.5 ist der Einstellungsdialog für das Testdatenprojekt sichtbar. Ab-bildung 7.6 zeigt einen Ausschnitt der generierten Daten.
58
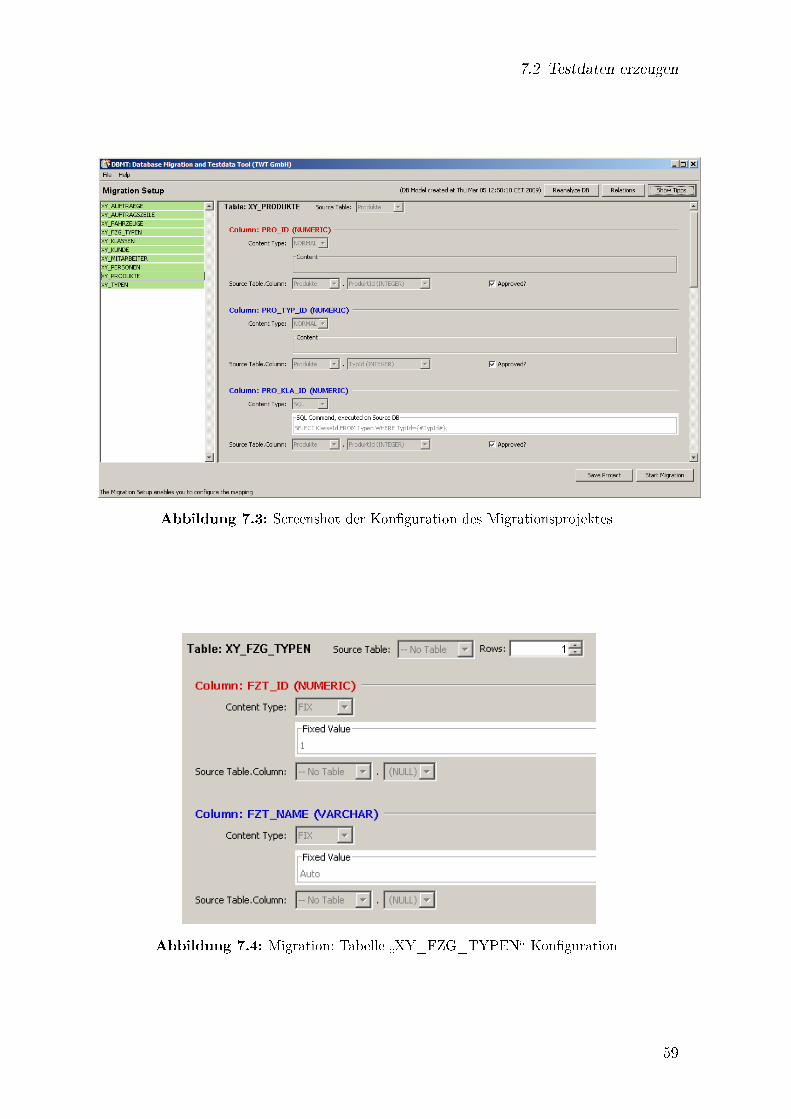
7.2 Testdaten erzeugen
Abbildung 7.3: Screenshot der Kon�guration des Migrationsprojektes
Abbildung 7.4: Migration: Tabelle �XY_FZG_TYPEN� Kon�guration
59
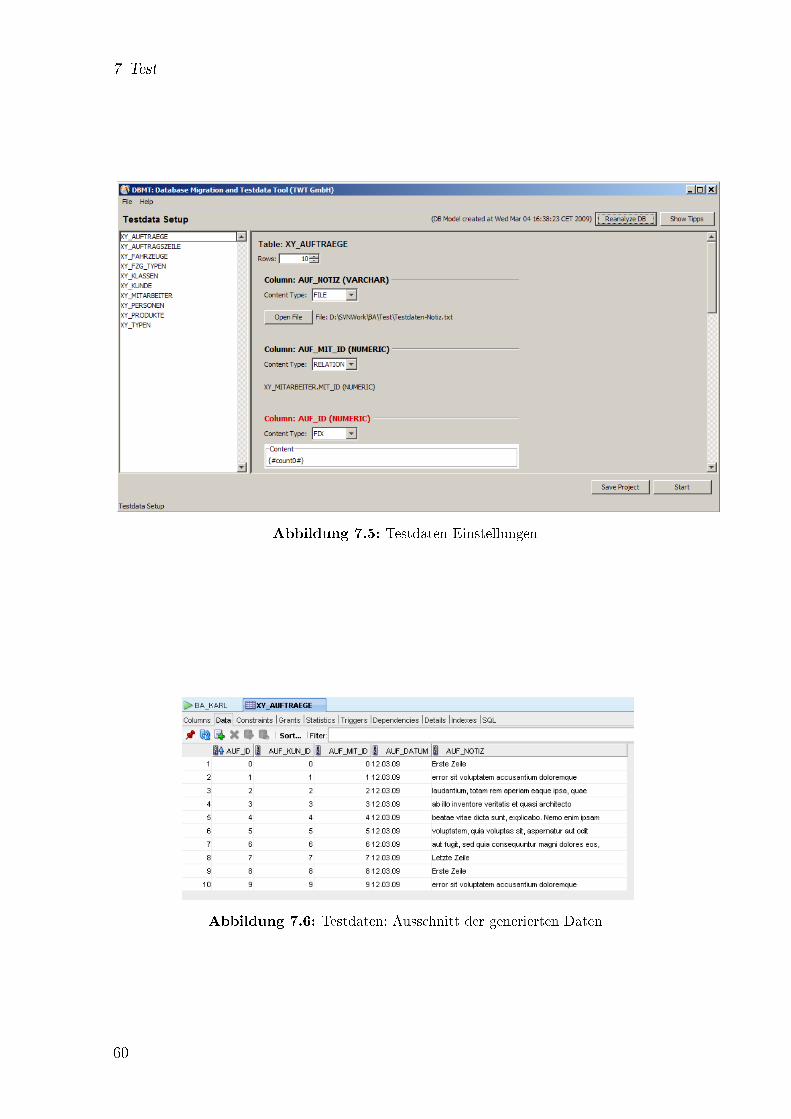
7 Test
Abbildung 7.5: Testdaten Einstellungen
Abbildung 7.6: Testdaten: Ausschnitt der generierten Daten
60

8 Schlussbetrachtung
8.1 Zusammenfassung
Das Ziel dieser Arbeit war es, eine Softwarelösung für die Aufgabe der Migration vonDaten zwischen heterogenen Datenbanken zu erstellen. Ebenfalls sollte das Erzeugenvon Testdaten möglich sein. Die Schwierigkeit der Migration lag darin, dass die Sche-mata der Quell- und Zieldatenbank sich unterscheiden können. Die Aufgabenstellungsah weiterhin vor, dass eine Zuordnung auf Basis von Ähnlichkeiten zwischen Schema-elementen automatisch erfolgen muss.
Zunächst habe ich mich eingehend mit den möglichen Unterschieden der Schemata undden Auswirkungen auf die Migration beschäftigt. Daraus ergaben sich die Anforderun-gen an die Anwendung. Im nächsten Schritt wurden theoretische Lösungen analysiertund Produkte auf ihre Tauglichkeit überprüft. Diese Überprüfung ergab, dass keinesder getesteten Produkte exakt den Anforderungen entsprach. Bei der Analyse konntenjedoch wertvolle Informationen über den gesamten Prozess gesammelt werden.
Aus den Anforderungen habe ich einen Ansatz zur Lösung der beschriebenen Themenerarbeitet. Dieser Ansatz wurde so gestaltet, dass eine praxistaugliche Softwarelösungin der verfügbaren Zeit entwickelt werden konnte. Der Ansatz zur Migration basiertauf verschiedenen Techniken, die in der Wissenschaft unter den Begri�en �SchemaMapping� und �Schema Matching� bekannt sind.
Der Ansatz wurde in Java implementiert und nutzt die Datenbankabstraktion JDBC.Mit der entstandenen Anwendung lässt sich die Aufgabe einer Migration von Datenzwischen zwei ähnlichen Schemata lösen. Zu den unterstützten Datenbanksystemenzählen Oracle 10g und Microsoft Access XP (eingeschränkt). Die Modularität der ent-wickelten Softwarearchitektur erlaubt es, mit wenig Programmieraufwand weitere Da-tenbanksysteme zu unterstützen. Die Anwendung unterstützt den Anwender bei derAuswahl passender Zuordnungen und erlaubt es, alternative Inhalte anzugeben. DieseInhalte können entweder aus der Quelldatenbank per SQL abgefragt werden, oder siesind konstant angegeben. Durch die Angabe von Regeln ist es möglich, völlig anonymeTestdaten zu erzeugen. Vor allem durch das Verknüpfen von Datensätzen wird demAnwender viel Arbeit erspart.
8.2 Ergebnisse dieser Arbeit
In dieser Bachelorarbeit konnte ich mein im Studium erlerntes Wissen in einem realenProjekt anwenden und vertiefen. Neben den alltäglichen administrativen Aufgaben an
61

8 Schlussbetrachtung
Datenbanken habe ich mich eingehender mit den Eigenschaften eines Schemas befasst.Vor allem habe ich sehr viel über die in der Praxis immer wiederkehrende Aufgabe derMigration gelernt.
Beim Entwurf und der Implementierung des Softwareprojekts konnte ich viele der imStudium erlernten Methoden in die Praxis umsetzen. Aufgrund der Aufgabe konnte ichselbständig an dem Projekt arbeiten. Dabei war ich erstmals für den gesamten Ablaufeines realen Projekts, von der Planung bis zur Umsetzung, verantwortlich. Deshalbmusste ich nicht nur meine fachlichen Fähigkeiten unter Beweis stellen, sondern wurdeauch mit Planung und Management konfrontiert.
Hilfreich war es, über Ansprechpartner zu verfügen, die bereits erfolgreich Softwarefür den Produktiveinsatz entworfen und entwickelt haben. Ein weiterer Vorteil für dasEntwickeln einer praxistauglichen Lösung war es, dass ich jederzeit meine Ergebnissemit einer realen Datenbank aus einem Kundenprojekt testen konnte.
Trotz der in Kapitel 6 beschriebenen Einschränkungen der Softwarelösung hat der Pro-totyp Produktcharakter. Die Anwendung wird in verschiedenen Bereichen der TWTGmbH bereits aktiv eingesetzt. Daher schätze ich das Projekt insgesamt als sehr er-folgreich ein.
8.3 Ausblick
Die entstandene Software bietet dem Anwender bereits ein Werkzeug zur Datenmigra-tion und Testdatenerstellung. Selbstverständlich gibt es Raum für Verbesserungen, diedie Nutzung der Software vereinfachen oder neue Funktionalitäten hinzufügen.
Die Ober�äche der Migration ist aus Zeitgründen eher spärlich ausgefallen. Diese könn-te um eine gra�sche Darstellung erweitert werden. Die automatische Zuordnung könnteum weitere Techniken, wie die Erkennung von Abkürzungen oder das Übersetzen vonBegri�en aus anderen Sprachen, erweitert werden. Die Einschränkung, dass mehre-re Tabellen nicht als Quelle einer Zieltabelle genutzt werden können, sollte in einerzukünftigen Version behoben werden.
Für die Testdatenerzeugung ist eine Erweiterung um ein Kommandozeilen-Interfacedenkbar. Damit könnten Testdaten im Build-Prozess1 einer Anwendung erzeugt undfür anschlieÿende Unit-Tests2 genutzt werden. Eine Generierung von SQL-Skripten zurNutzung in anderen Anwendungen könnte neue Anwendungsfelder ermöglichen. EinZufallsgenerator für Testdaten könnte für bestimmte Zwecke sinnvoll sein. Neben derGenerierung von Daten wäre es auch möglich, bestehende Daten zu anonymisieren(Obfuscation).
Die Erweiterung der modularen Datenbankzugri�sschicht um neue Datenbankproduk-te, wie Microsoft SQL Server oder MySQL, bietet sich ebenfalls an.
Ob all diese Änderungen ihren Weg in die Anwendung �nden werden, ist nicht abschlie-ÿend geklärt. Viele Aufgaben lassen sich bereits mit dem Prototyp zufriedenstellendlösen. Ich würde mich jedoch freuen, weiterhin an dem Projekt arbeiten zu können.1Prozess der Softwareentwicklung, bei dem Quellcode in ein auslieferbares Format umgewandelt wird.2Ein beliebtes Testverfahren in der Softwareentwicklung.
62

8.4 Danksagungen
8.4 Danksagungen
An dieser Stelle möchte ich mich zunächst bei meinem Betreuer an der Hochschu-le Ravensburg-Weingarten, Prof. Dr. rer. nat. Martin Hulin für seine Unterstützungbedanken.
Diese Arbeit ist am Standort Neuhausen der TWT GmbH entstanden. Dafür möchteich mich besonders bei meinem zweiten Betreuer, Dr. Michael Keckeisen, bedanken.Ebenso danke ich Dipl. Inf. Harald Lö�er und Dipl. Inf. Benjamin Jung für ihre Un-terstützung und Kompetenz in Datenbank und Software-Engineering Themen. MeinenDank möchte ich auch allen anderen Mitarbeitern der TWT GmbH aussprechen, diestets ein o�enes Ohr für meine Fragen hatten.
Vor allem jedoch bedanke ich mich bei meinen Eltern, die mir mein Studium erstermöglicht haben.
63


Literaturverzeichnis
[All99] L. Allison. Hirschberg's algorithm. http://www.csse.monash.edu.au/
~lloyd/tildeAlgDS/Dynamic/Hirsch/, 1999. [24.02.2009].
[ANS92] ANSI. ISO/IEC 9075:1992, Database Language SQL. http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt, 1992. (5.2).
[Geb05] Jáno Gebelein. Problemseminar Schema Evolution: Schema Evoluti-on in kommerziellen DBS (dynamische Schema-Evolution). http://
dbs.uni-leipzig.de/html/seminararbeiten/semWS0506/arbeit2.pdf,Dezember 2005. Seite 3.
[IBM] IBM. IBM Almaden Research Center - Schema Mapping Management Sys-tem. http://www.almaden.ibm.com/cs/projects/criollo/. [19.01.2009].
[Kel98] Andreas Kelz. Der königsweg: Normalisierung. http://v.hdm-stuttgart.de/~riekert/lehre/db-kelz/chap4.htm, 1998. [15.01.2009].
[LN07a] Ulf Lesser and Felix Naumann. Informationsintegration. dpunkt.Verlag,2007. Seite 123-143.
[LN07b] Ulf Lesser and Felix Naumann. Informationsintegration. dpunkt.Verlag,2007. Seite 58-78.
[Mau05] D. Mauter. SchemaSQL - Eine Erweiterung. http://www2.informatik.
hu-berlin.de/mac/lehre/WS04/Ausarbeitungen/SchemaSQL.pdf, 2005.Seite 14.
[Nau06a] Felix Naumann. Hauptseminar Schema Matching. http://www2.
informatik.hu-berlin.de/mac/lehre/SS06/SE_SchemaMatching_Einf%
FChrung.pdf, 2006. Seite 7.
[Nau06b] Felix Naumann. Informationsintegration Schema Mapping. http:
//www2.informatik.hu-berlin.de/mac/lehre/WS05/VLInfoInt/
InfoInt_15_SchemaMapping.pdf, Januar 2006.
[Nav01] Gonzalo Navarro. A guided tour to approximate string matching. 33(1):31�88, 2001.
[RB01] E. Rahm and P. Bernstein. A Survey of Approaches to Automatic SchemaMatching. The VLDB Journal, 10(4):334�350, 2001.
[Sta02] Gernot Starke. E�ektive Software-Architekturen. HANSER, 2002. Seite98-100.
[Sul09] Carsten Sulzberger. Wie funktioniert der Levenshtein-Algorithmus...? http:
//levenshtein.de/, 2009. [10.01.2009].
A

Literaturverzeichnis
[SUN99] SUN. Mapping SQL and Java Types. http://java.sun.com/j2se/1.5.0/docs/guide/jdbc/getstart/mapping.html, 1999. [12.02.2009].
[SUN08] SUN. JDBC Drivers � Sun, Java JDBC Data Access API. http://
developers.sun.com/product/jdbc/drivers, 2008. [20.12.2008].
[Wik09a] Wikipedia. Metadaten. http://de.wikipedia.org/w/index.php?title=
Metadaten&oldid=55290339, 2009. [19.01.2009].
[Wik09b] Wikipedia. Relationale Datenbank. http://de.wikipedia.org/w/index.
php?title=Relationale_Datenbank&oldid=55171932, 2009. [25.01.2009].
[Wik09c] Wikipedia. Schema (Informatik). http://de.wikipedia.org/w/index.
php?title=Schema_(Informatik)&oldid=55718905, 2009. [25.01.2009].
[XSt09] XStream. Two Minute Tutorial. http://xstream.codehaus.org/
tutorial.html, 2009. [08.01.2009].
B

Anhang
CD-ROM
Auf der beigelegten CD-ROM be�ndet sich die Bachelorarbeit als PDF-Dokument. Zu-sätzlich sind die Internetquellen im Verzeichnis �Literatur� gespeichert. Unter �Quell-code� be�ndet sich der gesamte Quellcode der Software. Das Verzeichnis �Test� enthältdie MS Access Datei der Testdatenbank sowie ein SQL-Skript zum Erstellen der OracleDatenbank. Eine ausführbare Datei der Anwendung be�ndet sich in �Programm�.
C


















