
Kapitel 11 Lernen, Gedächtnis und Amnesie Biologische Psychologie II Peter Walla.

Universität Potsdam Institut für Informatik
Lehrstuhl Maschinelles Lernen
Bayessches Lernen (II)
Christoph Sawade/Niels Landwehr
Dominik Lahmann
Tobias Scheffer

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Überblick
Wahrscheinlichkeiten, Erwartungswerte, Varianz
Grundkonzepte des Bayesschen Lernens
MAP-Hypothese und regularisierter Verlust
Bayesian Model Averaging
(Bayessche) Parameterschätzung für
Wahrscheinlichkeitsverteilungen
Bayessche Lineare Regression, Naive Bayes
2

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
3
Modellvorstellung beim Lernen
Wir wollen Modelle der Form aus Trainingsdaten
lernen.
Viele Verfahren des maschinellen Lernens basieren auf
probabilistischen Überlegungen.
Insbesondere: Modellvorstellung für Datengenerierungsprozess
Jemand hat echtes Modell f* nach A-Priori Verteilung
(„Prior“) p(f) gezogen
f* ist nicht bekannt, aber p(f) reflektiert Vorwissen (was sind
wahrscheinliche Modelle?)
Trainingseingaben xi werden gezogen (unabhängig von f*).
Klassenlabels yi werden nach gezogen.
Fragestellung Lernen: Gegeben L und p(f), was ist
wahrscheinlichstes „echte“ Modell?
→ Versuche, f* (ungefähr) zu rekonstruieren
*( | , )i ip y fx
( )y f x
1 1, ),..., ( , ){( }N NyL y xx

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Bayessche Regel:
Beweis einfach:
Wichtige Grundeinsicht für das maschinelle Lernen: Erlaubt
den Rückschluss auf Modellwahrscheinlichkeiten gegeben
Wahrscheinlichkeiten von Beobachtungen
Bayessche Regel
( | ) ( )( | )
( )
p Y X p Xp X Y
p Y
( , ) ( | ) ( )( | )
( ) ( )
p X Y p Y X p Xp X Y
p Y p Y
Definition bedingte
Verteilung Produktregel
Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
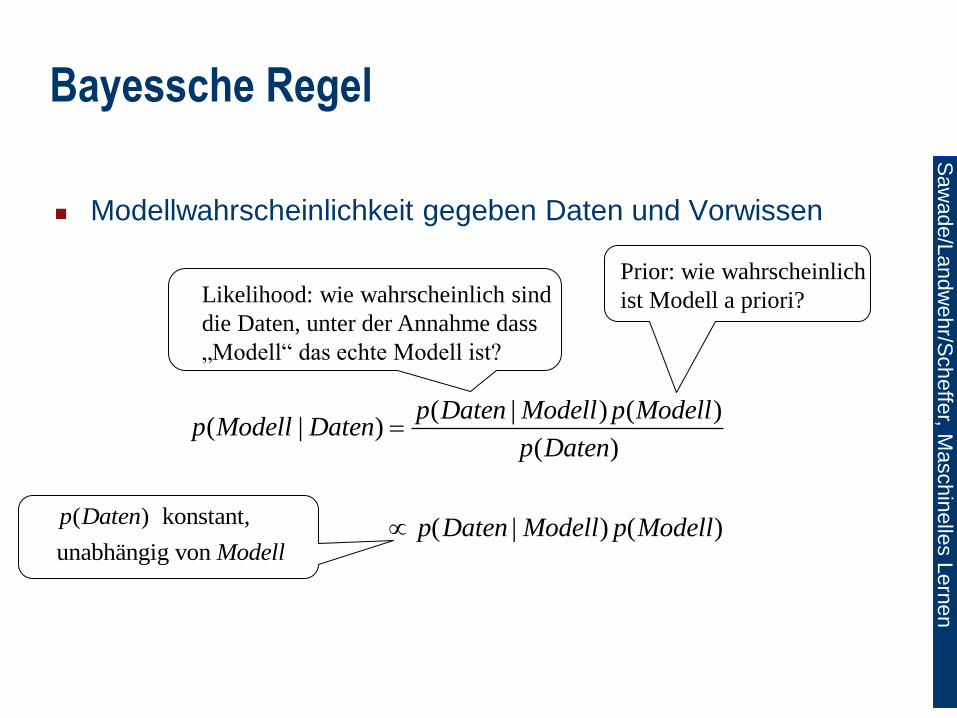
Modellwahrscheinlichkeit gegeben Daten und Vorwissen
Bayessche Regel
( | ) ( )( | )
( )
( | ) ( )
p Daten Modell p Modellp Modell Daten
p Daten
p Daten Modell p Modell
( ) konstant,
unabhängig von
p Daten
Modell
Likelihood: wie wahrscheinlich sind
die Daten, unter der Annahme dass
„Modell“ das echte Modell ist?
Prior: wie wahrscheinlich
ist Modell a priori?

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
6
Maximum-A-Posteriori-Hypothese
Wahrscheinlichstes Modell gegeben die Daten
arg max ( | )
( | ) ( )arg max
( )
arg max ( | ) ( )
arg max log ( | ) ( )
arg min log ( | ) log ( )
MAP f
f
f
f
f
f p f L
p L f p f
p L
p L f p f
p L f p f
P L f p f
w
w
w
w
w w
w w
w w
w w
w w
Log-Likelihood Log-Prior
w ( )fw
xParameter des Modells
Anwendung
Bayes‘sche Regel
Optimierungskriterium bestehend aus log-likelihood und log-prior
Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
7
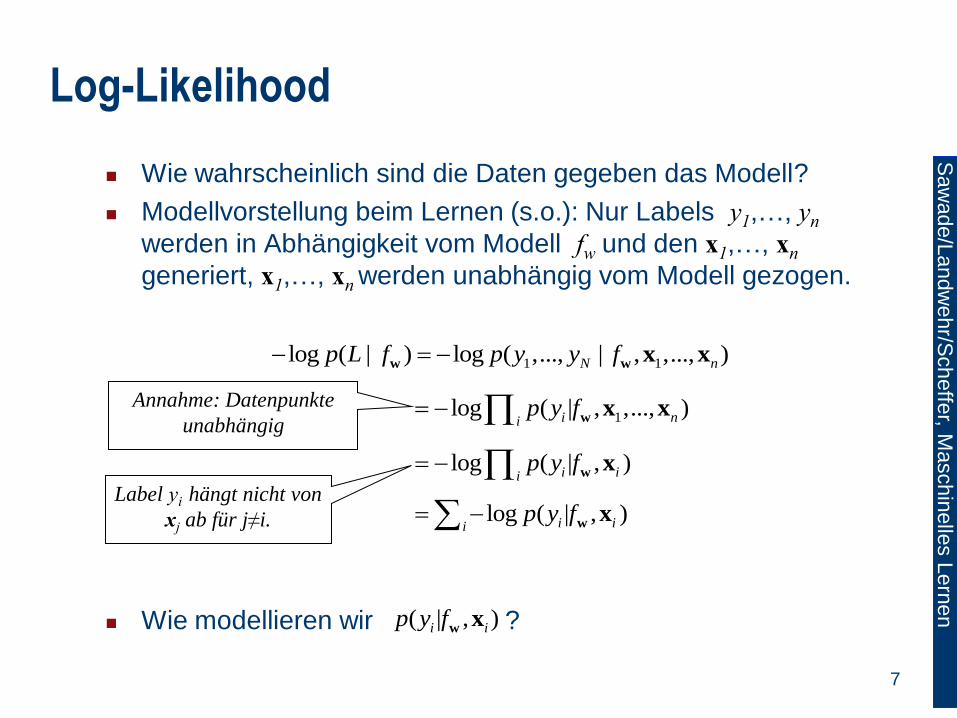
Log-Likelihood
Wie wahrscheinlich sind die Daten gegeben das Modell?
Modellvorstellung beim Lernen (s.o.): Nur Labels y1,…, yn
werden in Abhängigkeit vom Modell fw und den x1,…, xn
generiert, x1,…, xn werden unabhängig vom Modell gezogen.
Wie modellieren wir ?
1 1log ( | ) log ( ,..., | , ,..., )N np L f p y y f w w
x x
1log ( | , ,..., ) i nip y f
wx xAnnahme: Datenpunkte
unabhängig
Label yi hängt nicht von
xj ab für j≠i.
( | , )i ip y fw
x
log ( | , ) i iip y f
wx
log ( | , ) i iip y f
wx
Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
8
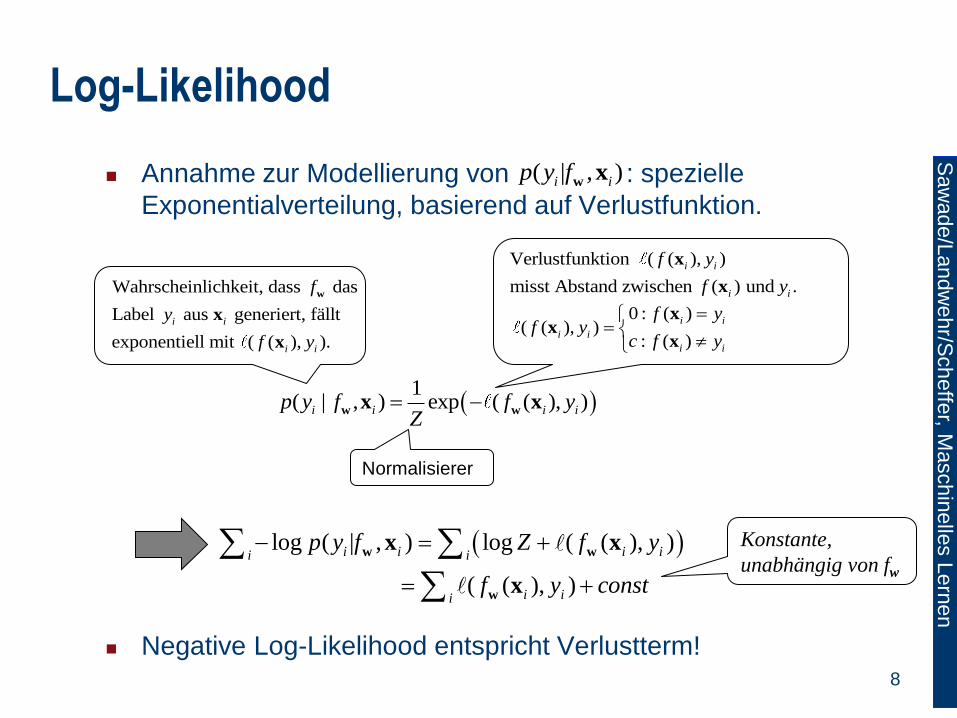
Log-Likelihood
Annahme zur Modellierung von : spezielle
Exponentialverteilung, basierend auf Verlustfunktion.
Negative Log-Likelihood entspricht Verlustterm!
log ( | , ) log (
( ), )
( ( ), )
i ii i i
ii
i
i
p y f Z f
f cony st
yw
w
wxx
x
1
( | , ) exp ( ( ), ) i i iip y f f yZ
ww x x
Normalisierer
Verlustfunktion ( ( ), )
misst Abstand zwischen ( ) u .nd
i i
i i
f y
f y
x
x
( | , )i ip y fw
x
Wahrscheinlichkeit, dass das
Label aus generiert, fällt
exponentiell mit ( ( ), ).
i i
i i
f
y
f y
w
x
x
0 : (( ( ),
:
))
( )
i
i
i i
i
i
ff y
c f
y
y
xx
x
Konstante,
unabhängig von fw

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
9
A-Priori-Wahrscheinlichkeit (Prior)
Annahme: Modellparameter normalverteilt mit Mittelwert
Wir bevorzugen Modelle mit kleinen Attributgewichten.
Negativer Log-Prior:
Negativer Log-Prior = Regularisierer!
2
2
2/2
)
( ) ( | ,
1 1exp | |
2 2
m
p f I
w w 0
w
21log ( ) | |
2p f const
ww
0
Konstante,
unabhängig von fw
mw1w
2w
( )p fw
0
0

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
10
A-Posteriori-Wahrscheinlichkeit (Posterior)
Wahrscheinlichstes Modell gegeben Vorwissen und
Daten.
ArgMin über regularisierte Verlustfunktion!
Rechtfertigung für Optimierungskriterium?
Wahrscheinlichste Hypothese (MAP-Hypothese).
2
arg max ( | )
arg min log ( | ) log ( )
arg min ( ( ), ) | |
MAP f
f
f i ii
f p f L
p L f p f
f y
w
w
w w
w w
w x w
1
2

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Überblick
Wahrscheinlichkeiten, Erwartungswerte, Varianz
Grundkonzepte des Bayesschen Lernens
MAP-Hypothese und regularisierter Verlust
Bayesian Model Averaging
(Bayessche) Parameterschätzung für
Wahrscheinlichkeitsverteilungen
Bayessche Lineare Regression, Naive Bayes
11

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
12
Lernen und Vorhersage
Bisher: Lernproblemstellung getrennt von Vorhersage
Lernen:
Vorhersage:
Wenn wir uns auf ein Modell festlegen müssen, ist MAP
Modell sinnvoll
Aber eigentliches Ziel ist Vorhersage einer Klasse!
Besser, sich nicht auf ein Modell festlegen - direkt nach
der optimalen Vorhersage suchen
arg max ( | )MAP ff p f L w w
( )
neue Testinstanz
MAPfx x
x
„Wahrscheinlichstes Modell
gegeben die Daten“
„Vorhersage des
MAP Modells“

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
13
Lernen und Vorhersage: Beispiel
Modellraum mit 4 Modellen:
Binäres Klassifikationsproblem,
Trainingdaten L
Wir haben a-posteriori-Wahrscheinlichkeiten berechnet
MAP Modell ist
1 2 3 4{ , , , }H f f f f
1( | ) 0.3p f L
2( | ) 0.25p f L
3( | ) 0.25p f L
4( | ) 0.2p f L
1 arg max ( | )if if p f L
{0,1}

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
14
Lernen und Vorhersage: Beispiel
Modelle probabilistische Klassifikatoren:
binäre Klassifikation:
Z.B Logistische Regression (lineares Modell):
( 1| , ) ( )Tp y x w w x1
( )1 exp( )
zz
Entscheidungsfunktionswert wTx
p(y
=1)
Parametervektorw
if
EntscheidungsfunktionswertTw x
„logistische
Regression“
( 1| , ) [0,1]ip y f x

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
15
Lernen und Vorhersage: Beispiel
Wir wollen neues Testbeispiel klassifizieren
Klassifikation mit MAP Modell :
Andererseits (Rechenregeln der Wahrscheinlichkeit!):
1( 1| , ) 0.6p y f x
x
1f
2( 1| , ) 0.1p y f x 4( 1| , ) 0.3p y f x
3( 1| , ) 0.2p y f x
1y
4
1
( 1| , ) ( 1, | , )i
i
p y L p y f L
x x
4
1
( 1| , ) ( | )i i
i
p y f p f L
x
0.6*0.3 0.1*0.25 0.2*0.25 0.3*0.2 0.315
Summenregel
Produktregel
4
1
( 1| , , ) ( | , )i i
i
p y f L p f L
x x
Unabhängigkeiten

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
16
Lernen und Vorhersage: Beispiel
Wenn Ziel Vorhersage ist, sollten wir
verwenden
Nicht auf ein Modell festlegen, solange noch
Unsicherheit über Modelle besteht
Grundidee des Bayesschen Lernens/Vorhersage!
( 1| , )p y L x

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
17
Bayessches Lernen und Vorhersage
Problemstellung Vorhersage
Gegeben:
Trainingsdaten L,
neue Testinstanz x.
Gesucht:
Verteilung über Labels y für gegebenes x:
Bayessche Vorhersage:
Minimiert Risiko einer falschen Vorhersage.
Heißt auch Bayes-optimale Entscheidung oder
Bayes-Hypothese.
* argmax ( | , )yy p y L x
( | , )p y Lx
Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
18
Bayessches Lernen und Vorhersage
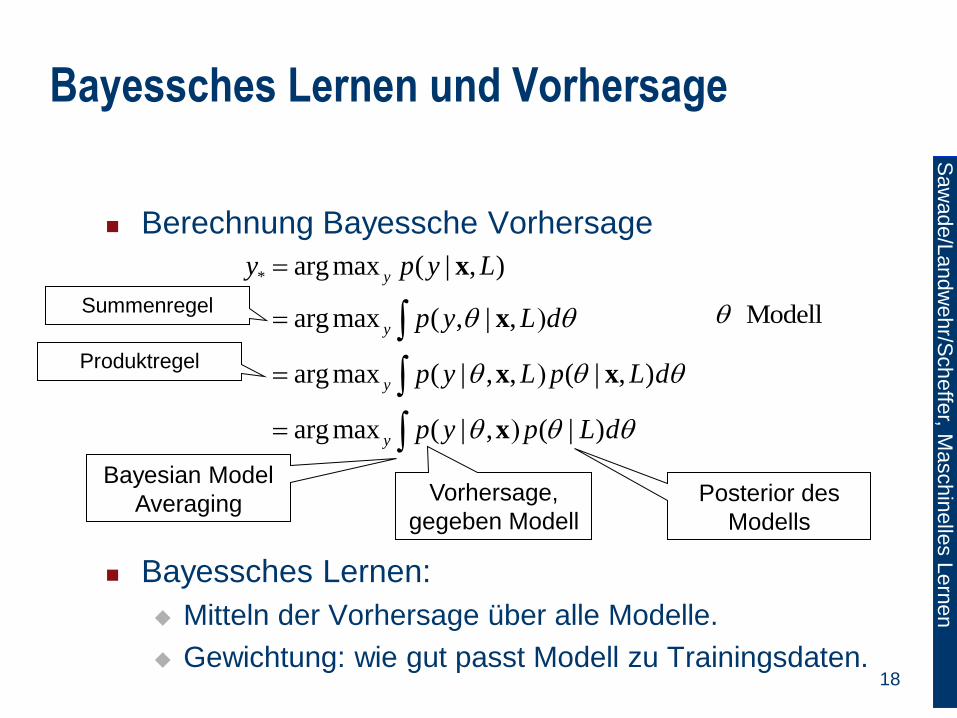
Berechnung Bayessche Vorhersage
Bayessches Lernen:
Mitteln der Vorhersage über alle Modelle.
Gewichtung: wie gut passt Modell zu Trainingsdaten.
* arg max ( | , )
arg max ( , | ,
arg max ( | , , ( | , )
arg max ( | , ( | )
y
y
y
y
y p y L
p y L d
p y L p L d
p y p L d
x
x
x x
x
Vorhersage,
gegeben Modell
Posterior des
Modells
Bayesian Model
Averaging
ModellSummenregel
Produktregel

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
19
Bayessches Lernen und Vorhersage
Bayessche Vorhersage praktikabel?
Bayesian Model Averaging: Mitteln über i.A. unendlich
viele Modelle
Wie berechnen? Nur manchmal praktikabel, geschlossene
Lösung.
Kontrast zu Entscheidungsbaumlernen:
Finde ein Modell, das gut zu den Daten passt.
Triff Vorhersagen für neue Instanzen basierend auf
diesem Modell.
Trennt zwischen Lernen eines Modells und Vorhersage.
* arg max ( | , )
arg max ( | , ( | )
y
y
y p y L
p y p L d
x
x

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Bayessches Lernen und Vorhersage
Wie Bayes-Hypothese ausrechnen?
Wir brauchen:
1) Wsk für Klassenlabel gegeben Modell,
* arg max ( | , )
arg max ( | , ( | )
y
y
y p y L
p y p L d
x
x
( | , )p y x
( 1| , ) ( ) Tp y x x
Folgt aus Modelldefinition:
z.B. linearer probabilistischer Klassifikator (logistische Regression)

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Bayessches Lernen und Vorhersage
Wie Bayes-Hypothese ausrechnen?
Wir brauchen:
2) Wsk für Modell gegeben Daten, a-posteriori-
Wahrscheinlichkeit
* arg max ( | , )
arg max ( | , ( | )
y
y
y p y L
p y p L d
x
x
( | )p L
→ Ausrechnen mit Bayes Regel
Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
22
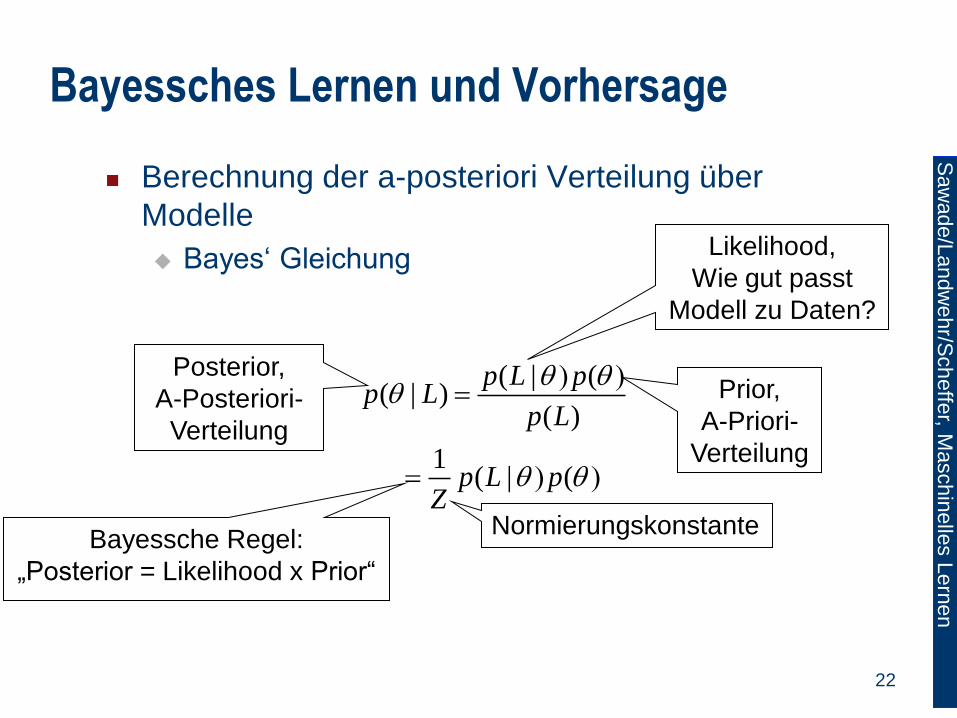
Bayessches Lernen und Vorhersage
Berechnung der a-posteriori Verteilung über
Modelle
Bayes‘ Gleichung
( | (
( | )( )
1( | (
p L pp L
p L
p L pZ
Posterior,
A-Posteriori-
Verteilung
Likelihood,
Wie gut passt
Modell zu Daten?
Prior,
A-Priori-
Verteilung
Bayessche Regel:
„Posterior = Likelihood x Prior“
Normierungskonstante

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
23
Bayessche Regel
Brauchen: Likelihood p(L | ).
Wie wahrscheinlich wären die Trainingsdaten, wenn
das richtige Modell wäre.
Wie gut passt Modell zu den Daten.
Typischerweise Unabhängigkeitsannahme:
11
1
( | ) (
( | ,
| ,..., )
,..
., ,
)
N
i i
N N
i
p L p y
p y
y
x
x x
Nur Labels y1,…, yn
werden in Abhängigkeit
vom Modell generiert
1 1{( , ),..., ( , )}N NL y y x x
Folgt aus Modelldefinition
(beispielsweise logistische
Regression)

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
24
Bayessche Regel
Brauchen: Prior p( ).
Wie wahrscheinlich ist Modell bevor wir
irgendwelche Trainingsdaten gesehen haben.
Annahmen über p( ) drücken datenunabhängiges
Vorwissen über Problem aus.
Beispiel lineare Modelle:

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
25
Bayessche Regel
Brauchen: Prior p( ).
Wie wahrscheinlich ist Modell bevor wir
irgendwelche Trainingsdaten gesehen haben.
Annahmen über p( ) drücken datenunabhängiges
Vorwissen über Problem aus.
Beispiel lineare Modelle:
möglichst niedrig
2| |

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
26
Bayessche Regel
Brauchen: Prior p( ).
Wie wahrscheinlich ist Modell bevor wir
irgendwelche Trainingsdaten gesehen haben.
Annahmen über p( ) drücken datenunabhängiges
Vorwissen über Problem aus.
Beispiel Entscheidungsbaumlernen:

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
27
Bayessche Regel
Brauchen: Prior p( ).
Wie wahrscheinlich ist Modell bevor wir
irgendwelche Trainingsdaten gesehen haben.
Annahmen über p( ) drücken datenunabhängiges
Vorwissen über Problem aus.
Beispiel Entscheidungsbaumlernen:
Kleine Bäume sind in vielen Fällen besser als
komplexe Bäume.
Algorithmen bevorzugen deshalb kleine Bäume.

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
28
Zusammenfassung Bayessche/MAP/ML-Hypothese
Um Risiko einer Fehlentscheidung zu minimieren: wähle
Bayessche Vorhersage
Problem: In vielen Fällen gibt es keine geschlossene
Lösung, Integration über alle Modelle unpraktikabel.
Maximum-A-Posteriori- (MAP-)Hypothese: wähle
Entspricht Entscheidungsbaumlernen.
Finde bestes Modell aus Daten,
Klassifiziere nur mit diesem Modell.
* arg max ( | , ) arg max ( | , ( | ) y yy p y L p y p L d x x
*
arg max ( | )
arg max ( | , )
MAP
y MAP
p L
y p y
x

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
29
Zusammenfassung Bayessche/MAP/ML-Hypothese
Um MAP-Hypothese zu bestimmen müssen wir Posterior (Likelihood x Prior) kennen.
Unmöglich, wenn kein Vorwissen (Prior) existiert.
Maximum-Likelihood- (ML-)Hypothese:
Berücksichtigt nur Beobachtungen in L, kein Vorwissen.
Problem der Überanpassung an Daten
*
arg max ( | )
arg max ( | ,
ML
y ML
p L
y p y
x

Saw
ade/L
andw
ehr/S
ch
effe
r, Maschin
elle
s L
ern
en
Überblick
Wahrscheinlichkeiten, Erwartungswerte, Varianz
Grundkonzepte des Bayesschen Lernens
(Bayes‘sche) Parameterschätzung für
Wahrscheinlichkeitsverteilungen
Bayes‘sche Lineare Regression, Naive Bayes
30

















