
Big-Data-Analyse und NoSQL-Datenbanken
77
Datenbanken Big Data Johannes Schildgen 2015-03-13 [email protected] http://bit.ly/schildgen Analyse NoSQL- &
-
Upload
johannes-schildgen -
Category
Data & Analytics
-
view
136 -
download
0
Transcript of Big-Data-Analyse und NoSQL-Datenbanken

Datenbanken
Big Data
Johannes Schildgen2015-03-13
[email protected]://bit.ly/schildgen
AnalyseNoSQL-&

Seit Anbeginn der Zivilisation bis zumJahre 2003 haben die Menschen
fünf Exabytes an Daten produziert.
Seit Anbeginn der Zivilisation bis zumJahre 2003 haben die Menschen
fünf Exabytes an Daten produziert.
Mittlerweile produzieren wir fünf Exabytes alle zwei Tage.Mittlerweile produzieren wir fünf Exabytes alle zwei Tage.
Eric Schmidt – Executive Chairman, GoogleEric Schmidt.jpg, Author: Gisela Giardino, Wikimedia Commons, 12 April 2007, 20:24:40

Big Data = Groß ?

Big Data = Groß
Volume
6 Mrd. Mobiltelefone6 Mrd. Mobiltelefone
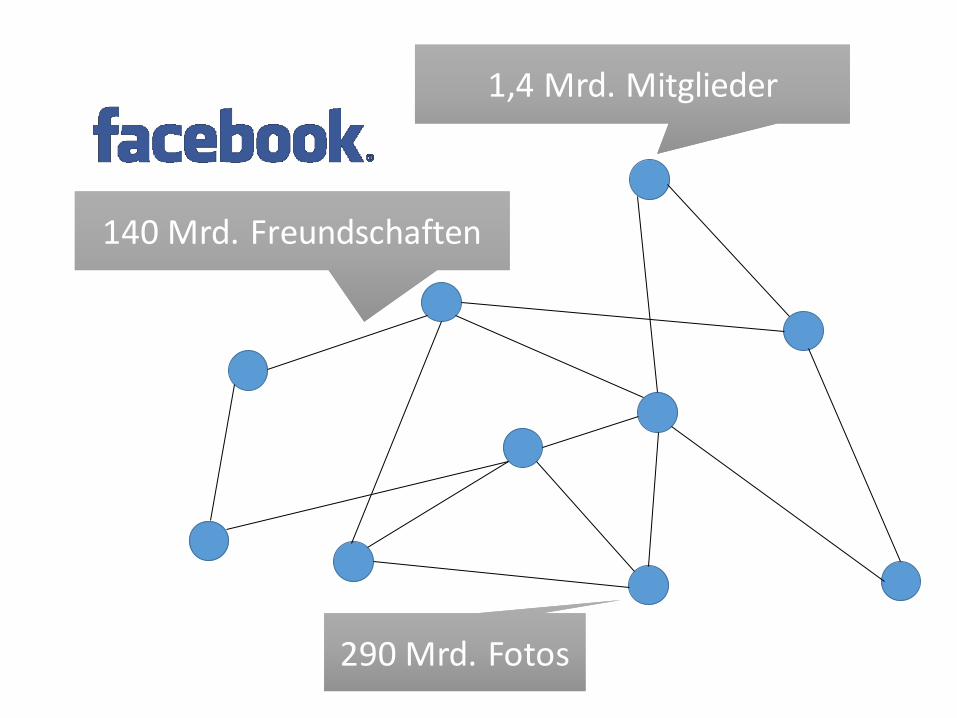
1,4 Mrd. Mitglieder1,4 Mrd. Mitglieder
140 Mrd. Freundschaften140 Mrd. Freundschaften
290 Mrd. Fotos290 Mrd. Fotos

Big Data = Schnell
Volume Velocity

500 Mio. Tweets / Tag500 Mio. Tweets / Tag 500 Mio. Kommentare / Minute500 Mio. Kommentare / Minute
48h Videos / Sekunde48h Videos / Sekunde
>100 Sensoren>100 Sensoren

Big Data = Heterogen
Volume Velocity Variety
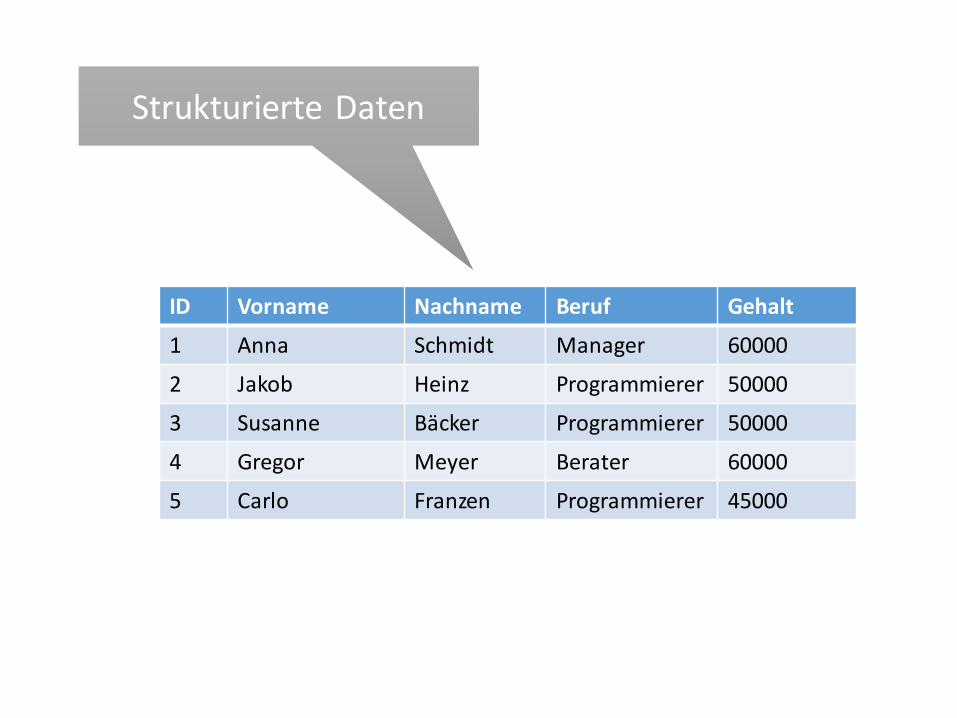
ID Vorname Nachname Beruf Gehalt
1 Anna Schmidt Manager 60000
2 Jakob Heinz Programmierer 50000
3 Susanne Bäcker Programmierer 50000
4 Gregor Meyer Berater 60000
5 Carlo Franzen Programmierer 45000
Strukturierte DatenStrukturierte Daten

{
_id: 883,
"Titel": "Notebook zu verkaufen",
"Preis": 400,
"Waehrung": "EURO",
"Verkaeufer": {
"Name": "Franzen",
"Vorname": "Carlo",
"maennlich": true,
"Hobbys": [ "Reiten", "Golfen", "Lesen" ],
"Alter": 42,
"Kinder": [],
"Partner": null
}
}
Semi-Strukturierte DatenSemi-Strukturierte Daten

„Hab heute nen schönen Tag zs. mit meiner Mutter in der Frankfurter Innenstadt verbracht, Pics folgen später.“
Unstrukturierte DatenUnstrukturierte Daten
Media DatenMedia Daten

Multi-Media DatenMulti-Media Daten
"datastreams": [
{
"name": "temperature",
"description": "Temperature"
"longitude": "2.363471",
"latitude": "48.917536",
"timezone": "+1",
„value": „19.2",
"unit": "Celsius"
}
SensordatenSensordaten

Big Data = Unklar
Volume Velocity Variety Veracity
Ich habe Elvis gesehenIch habe Elvis gesehen
Die Elbphilamonie wird 2016 eröffnetDie Elbphilamonie wird 2016 eröffnet
Merkel ist zurückgetretenMerkel ist zurückgetreten
Die Elbphilamobieöffnet 2015
Die Elbphilamobieöffnet 2015

Big-Data-Anwendungen
Empfehlungssysteme
• Clustering, Collaborative Filtering
Marketing
• Online-Werbung, Offline-Werbung
Prozessoptimierung
• Fertigung, Lagerhaltung, Personalplanung
Diagnosetools
• KFZ, Luft- und Raumfahrt
Forschung
• Klima, Rohstoffe, Krankheiten

Relationale Datenbanksysteme
ID Vorname Nachname Beruf Gehalt
1 Anna Schmidt Manager 60000
2 Jakob Heinz Programmierer 50000
3 Susanne Bäcker Programmierer 50000
4 Gregor Meyer Berater 60000
5 Carlo Franzen Programmierer 45000
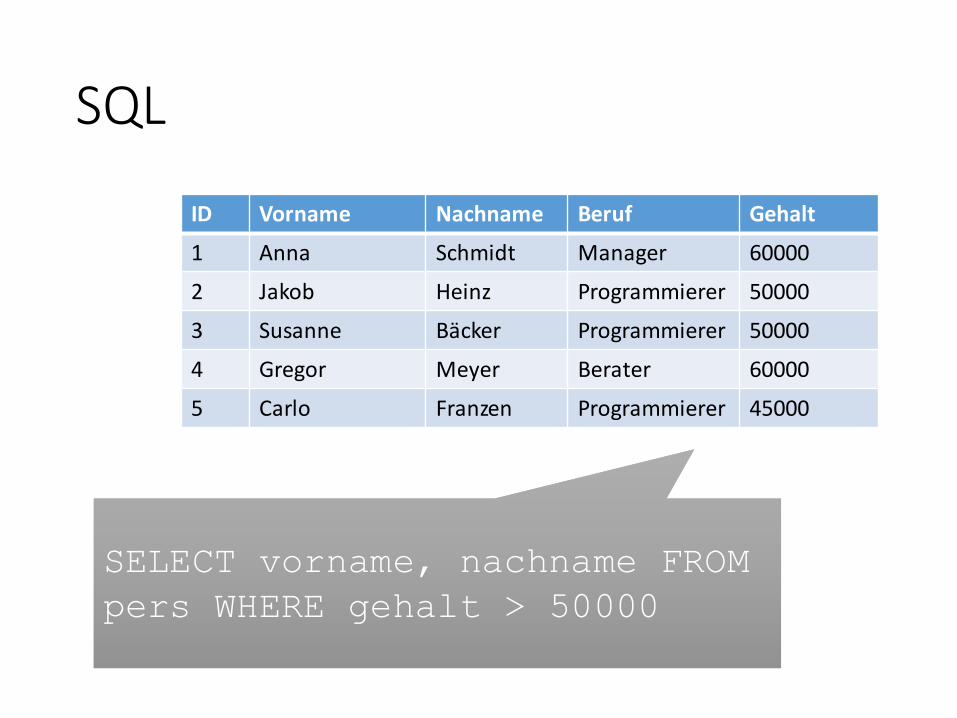
SQL
ID Vorname Nachname Beruf Gehalt
1 Anna Schmidt Manager 60000
2 Jakob Heinz Programmierer 50000
3 Susanne Bäcker Programmierer 50000
4 Gregor Meyer Berater 60000
5 Carlo Franzen Programmierer 45000
SELECT vorname, nachname FROM
pers WHERE gehalt > 50000
SELECT vorname, nachname FROM
pers WHERE gehalt > 50000

SQL: DDL*PrID Titel PrLeiter
100 Projekt X 5
101 DB-Projekt 1
CREATE TABLE proj (
PrID INT PRIMARY KEY,
Titel VARCHAR(100) NOT NULL,
PrLeiter INT REFERENCES pers(ID))
CREATE TABLE proj (
PrID INT PRIMARY KEY,
Titel VARCHAR(100) NOT NULL,
PrLeiter INT REFERENCES pers(ID))
* Data-Definition Language

SQL: Joins
ID Vorname Nachname Beruf Gehalt
1 Anna Schmidt Manager 60000
2 Jakob Heinz Programmierer 50000
3 Susanne Bäcker Programmierer 50000
4 Gregor Meyer Berater 60000
5 Carlo Franzen Programmierer 45000
SELECT proj.titel FROM pers, proj
WHERE proj.PrLeiter = pers.ID AND
pers.beruf = ‘Manager’
SELECT proj.titel FROM pers, proj
WHERE proj.PrLeiter = pers.ID AND
pers.beruf = ‘Manager’
PrID Titel PrLeiter
100 Projekt X 5
101 DB-Projekt 1

NoSQL-Datenbanken
Not Only SQLNot Only SQL
Alle Open-SourceAlle Open-Source
NoSQL-Datenbanken
Verteilte DatenbankVerteilte Datenbank => Lastverteilung,Hochverfügbarkeit,Verteilte Berechnungen
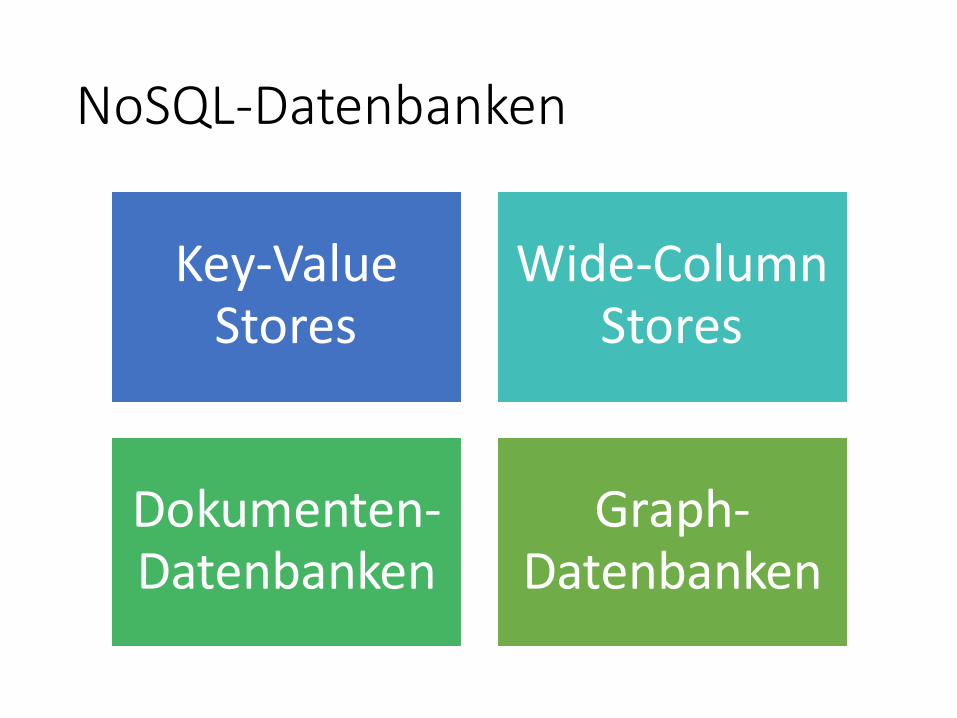
NoSQL-Datenbanken
Key-Value Stores
Wide-Column Stores
Dokumenten-Datenbanken
Graph-Datenbanken
NoSQL-Datenbanken
Key-Value Stores
Wide-ColumnStores
Dokumenten-Datenbanken
Graph-Datenbanken
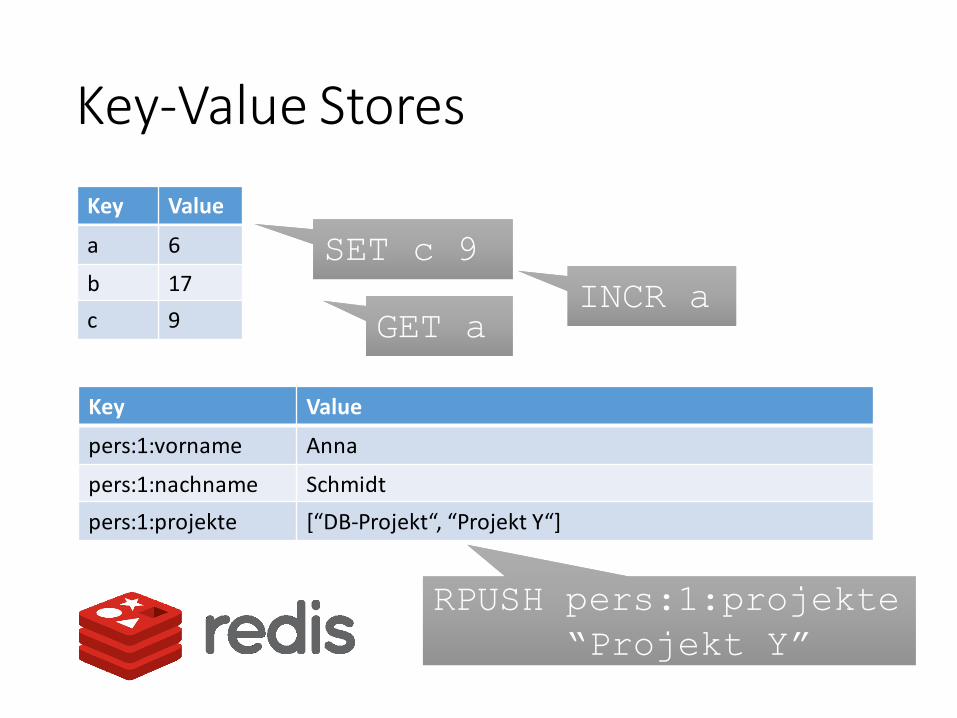
Key-Value Stores
Key Value
a 5
b 17
SET c 9SET c 9
c 9 GET aGET a
Key Value
pers:1:vorname Anna
pers:1:nachname Schmidt
pers:1:projekte [“DB-Projekt“]
INCR aINCR a
a 6
RPUSH pers:1:projekte
“Projekt Y”
RPUSH pers:1:projekte
“Projekt Y”
pers:1:projekte [“DB-Projekt“, “Projekt Y“]
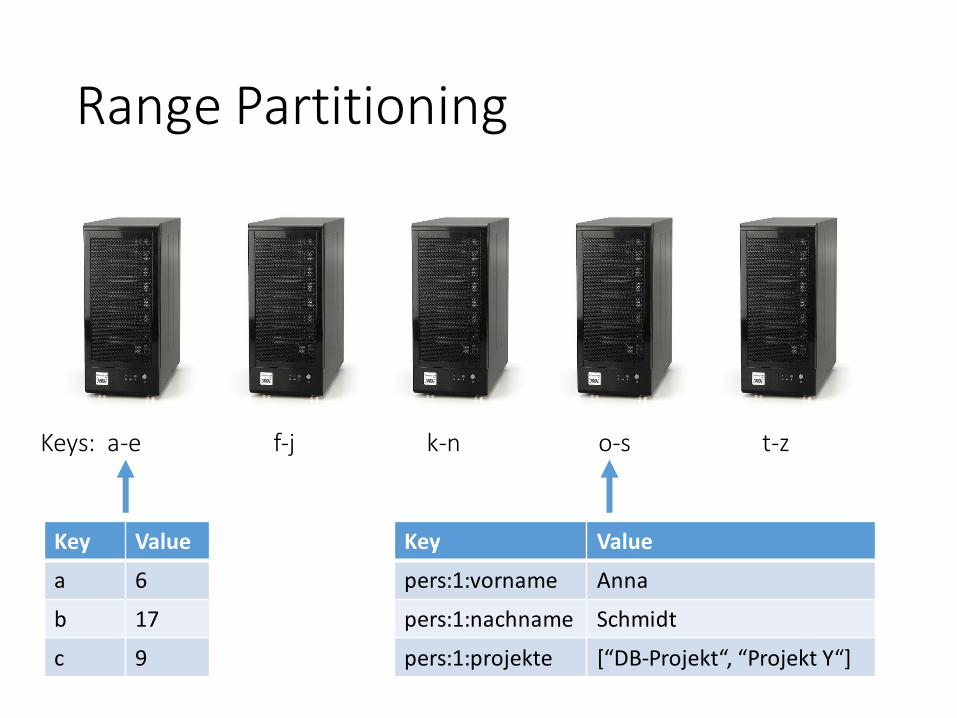
Range Partitioning
Keys: a-e f-j k-n o-s t-z
Key Value
a 6
b 17
c 9
Key Value
pers:1:vorname Anna
pers:1:nachname Schmidt
pers:1:projekte [“DB-Projekt“, “Projekt Y“]

Range Partitioning
Keys: a-pers:0 pers:1-pers:500 … ... …
Key Value
a 6
b 17
c 9
Key Value
pers:1:vorname Anna
pers:1:nachname Schmidt
pers:1:projekte [“DB-Projekt“, “Projekt Y“]
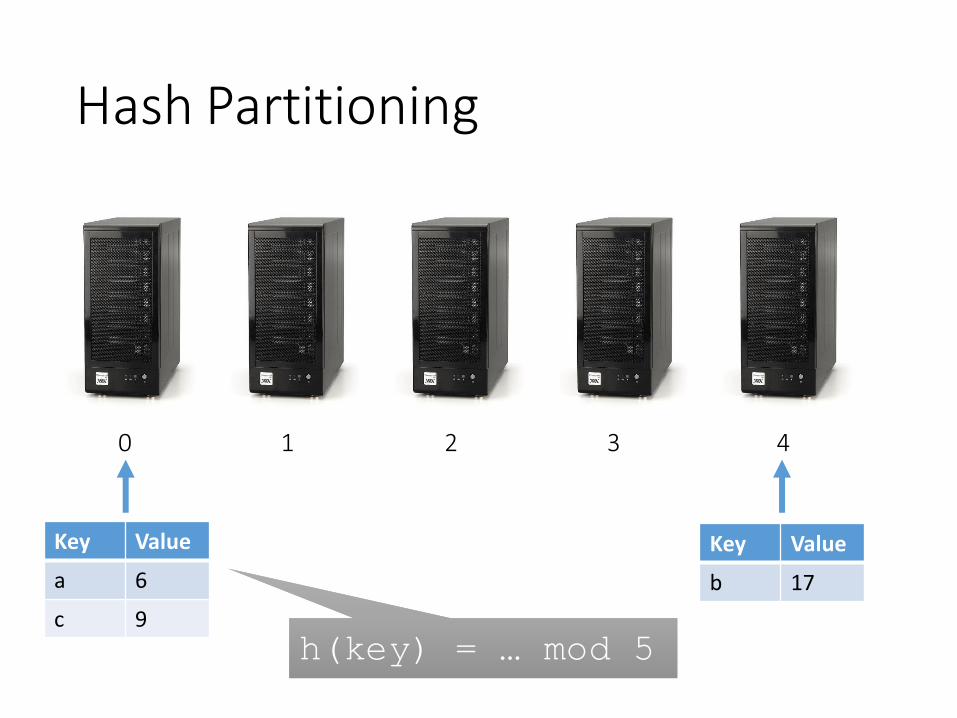
Hash Partitioning
0 1 2 3 4
Key Value
a 6
c 9
Key Value
b 17
h(key) = … mod 5h(key) = … mod 5
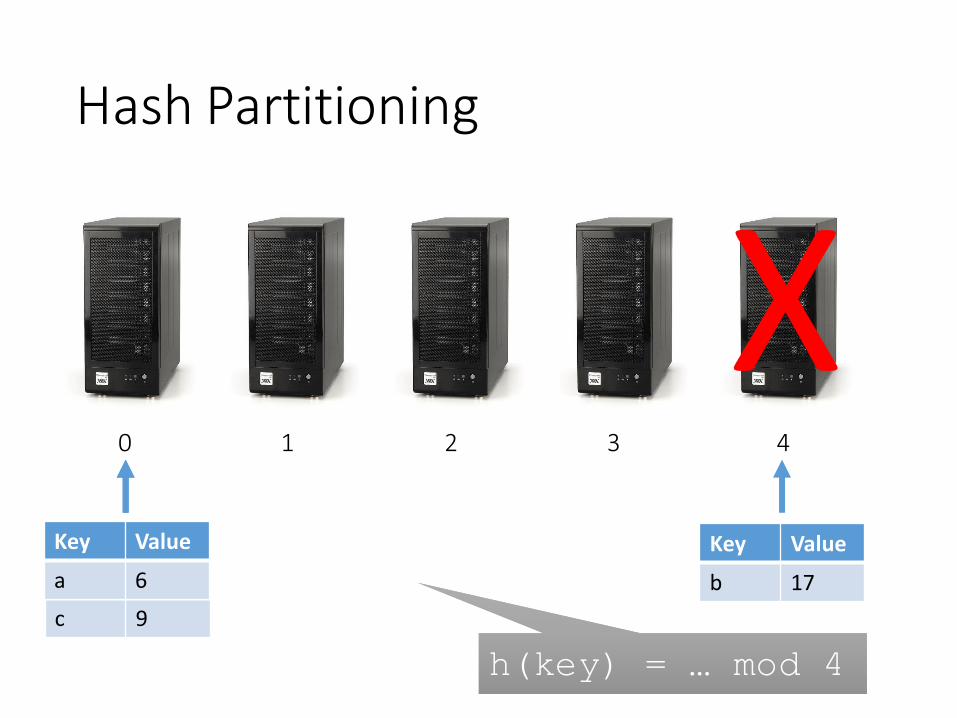
Key Value
c 9
Hash Partitioning
0 1 2 3 4
Key Value
a 6
Key Value
b 17
h(key) = … mod 4h(key) = … mod 4
X

Consistent Hashing
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Key Value
a 6
c 9
Key Value
b 17
h(key) = … mod 20h(key) = … mod 20

Consistent Hashing
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Key Value
a 6
c 9
Key Value
b 17
X
h(key) = … mod 20h(key) = … mod 20
16 17 18 19
NoSQL-Datenbanken
Key-Value Stores
Wide-Column Stores
Dokumenten-Datenbanken
Graph-Datenbanken
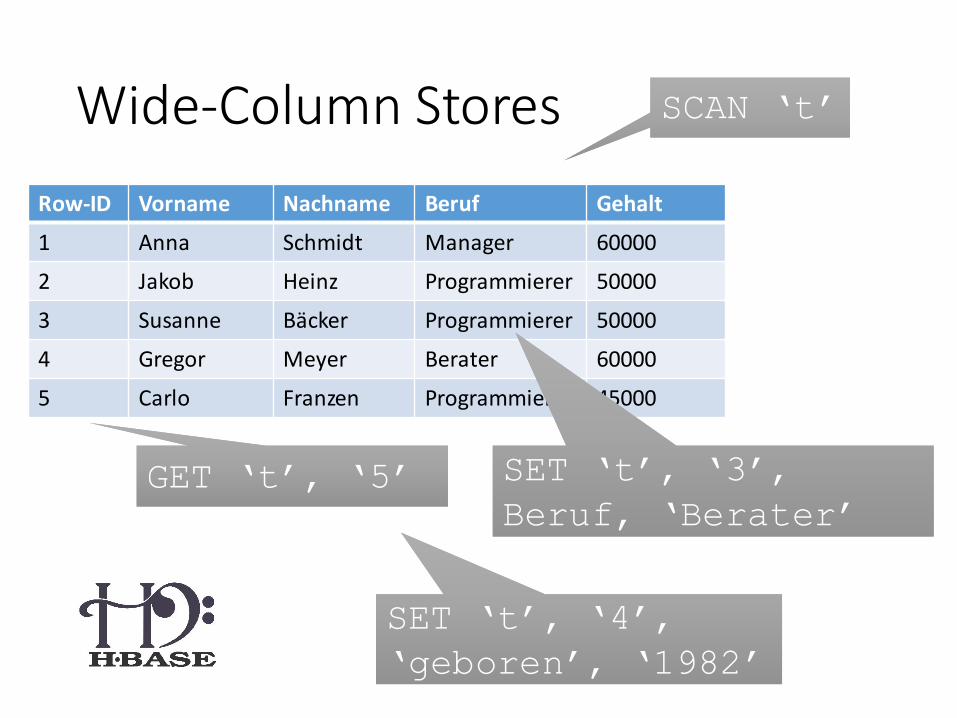
Wide-Column Stores SCAN ‘t’SCAN ‘t’
GET ‘t’, ‘5’GET ‘t’, ‘5’
SET ‘t’, ‘4’,
‘geboren’, ‘1982’
SET ‘t’, ‘4’,
‘geboren’, ‘1982’
Row-ID Vorname Nachname Beruf Gehalt
1 Anna Schmidt Manager 60000
2 Jakob Heinz Programmierer 50000
3 Susanne Bäcker Programmierer 50000
4 Gregor Meyer Berater 60000
5 Carlo Franzen Programmierer 45000
SET ‘t’, ‘3’,
Beruf, ‘Berater’
SET ‘t’, ‘3’,
Beruf, ‘Berater’
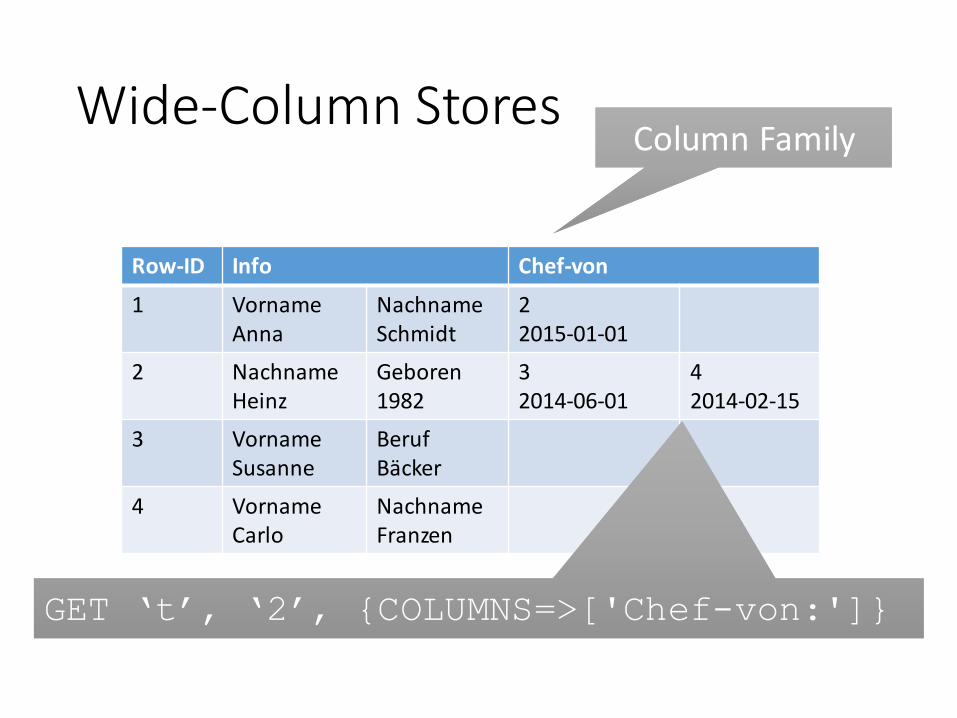
Wide-Column Stores
Row-ID Info Chef-von
1 VornameAnna
NachnameSchmidt
22015-01-01
2 NachnameHeinz
Geboren1982
32014-06-01
42014-02-15
3 VornameSusanne
BerufBäcker
4 VornameCarlo
NachnameFranzen
Column FamilyColumn Family
GET ‘t’, ‘2’, {COLUMNS=>['Chef-von:']}GET ‘t’, ‘2’, {COLUMNS=>['Chef-von:']}
NoSQL-Datenbanken
Key-Value Stores
Wide-Column Stores
Dokumenten-Datenbanken
Graph-Datenbanken

{
_id: 883,
"Titel": "Notebook zu verkaufen",
"Preis": 400,
"Waehrung": "EURO",
"Verkaeufer": {
"Name": "Franzen",
"Vorname": "Carlo",
"maennlich": true,
"Hobbys": [ "Reiten", "Golfen", "Lesen" ],
"Alter": 42,
"Kinder": [],
"Partner": null
}
}
Dokumenten-DatenbankenJSON-DokumentJSON-Dokument
db.prod.find()db.prod.find()
db.prod.find({Preis: {
$gt: 100} }, {Titel:1})
db.prod.find({Preis: {
$gt: 100} }, {Titel:1})
db.prod.insert({_id:
884, Titel:”xyz”})
db.prod.insert({_id:
884, Titel:”xyz”})
NoSQL-Datenbanken
Key-Value Stores
Wide-Column Stores
Dokumenten-Datenbanken
Graph-Datenbanken
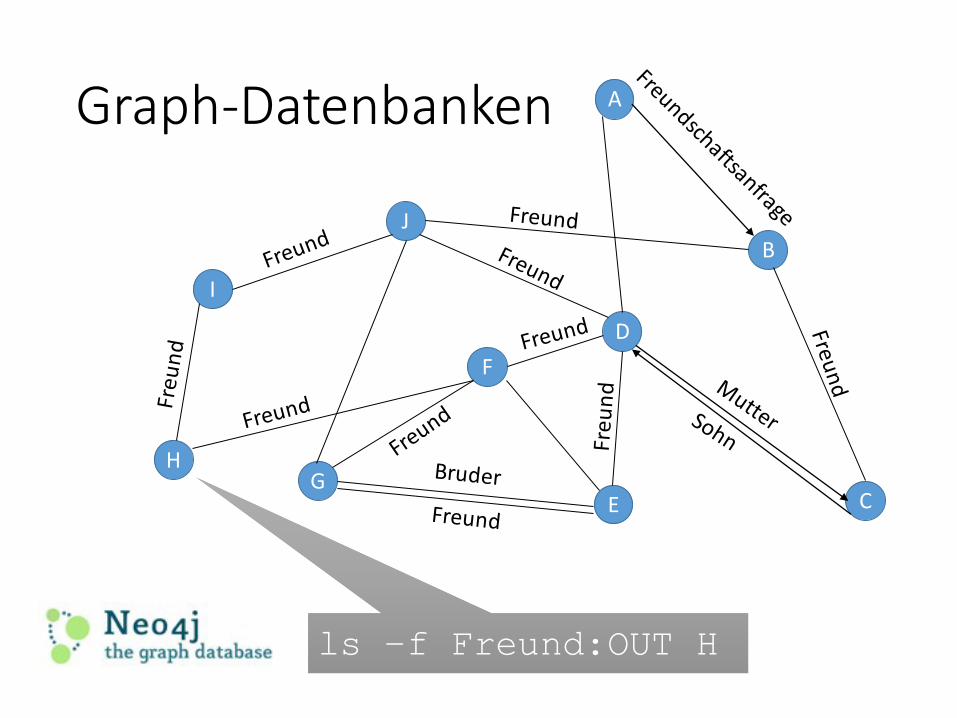
I
J
F
GH
D
A
B
CE
Graph-Datenbanken
ls –f Freund:OUT Hls –f Freund:OUT H
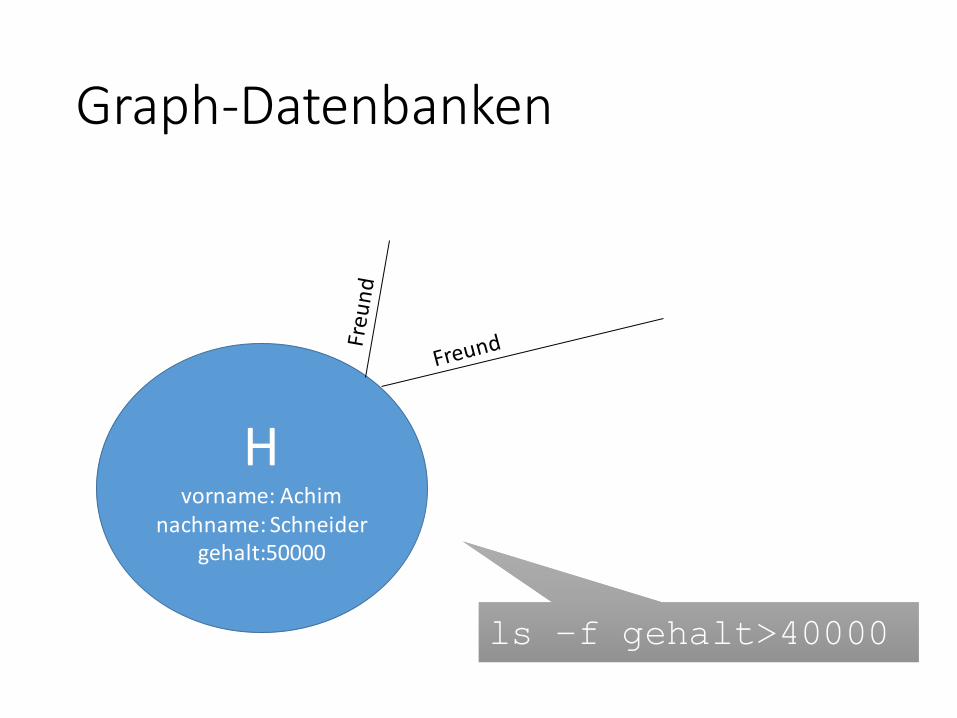
Graph-Datenbanken
Hvorname: Achim
nachname: Schneidergehalt:50000
ls –f gehalt>40000ls –f gehalt>40000
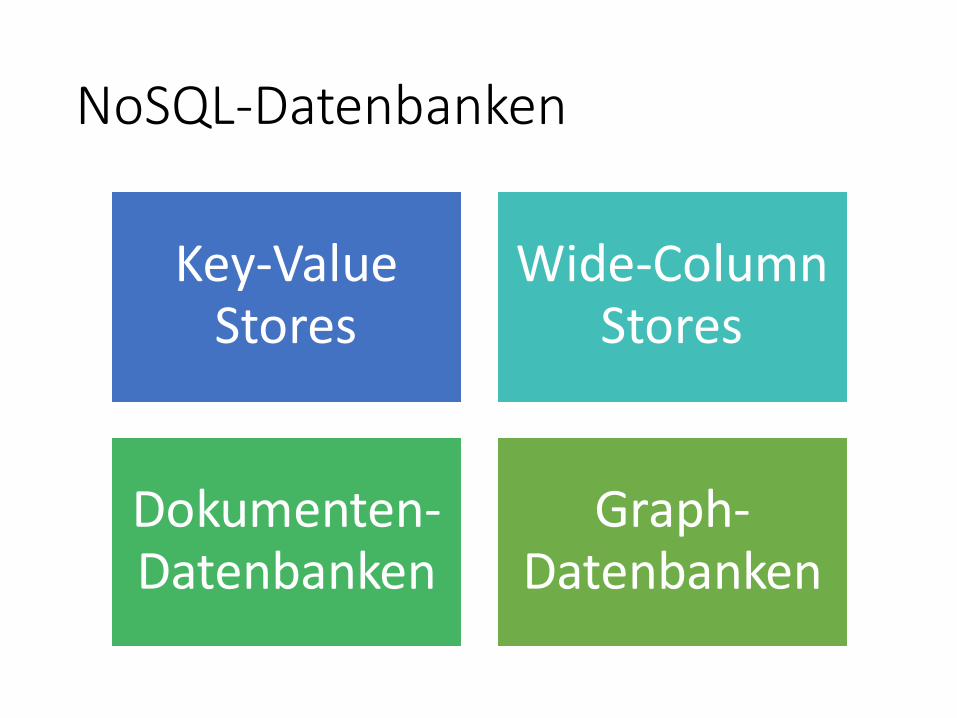
NoSQL-Datenbanken
Key-Value Stores
Wide-Column Stores
Dokumenten-Datenbanken
Graph-Datenbanken
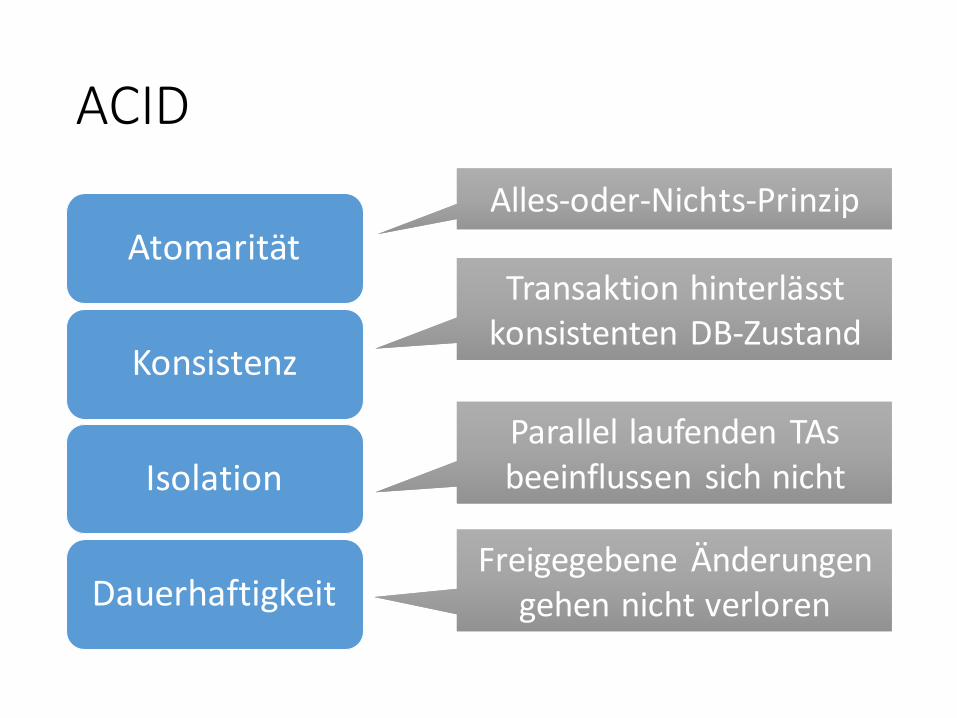
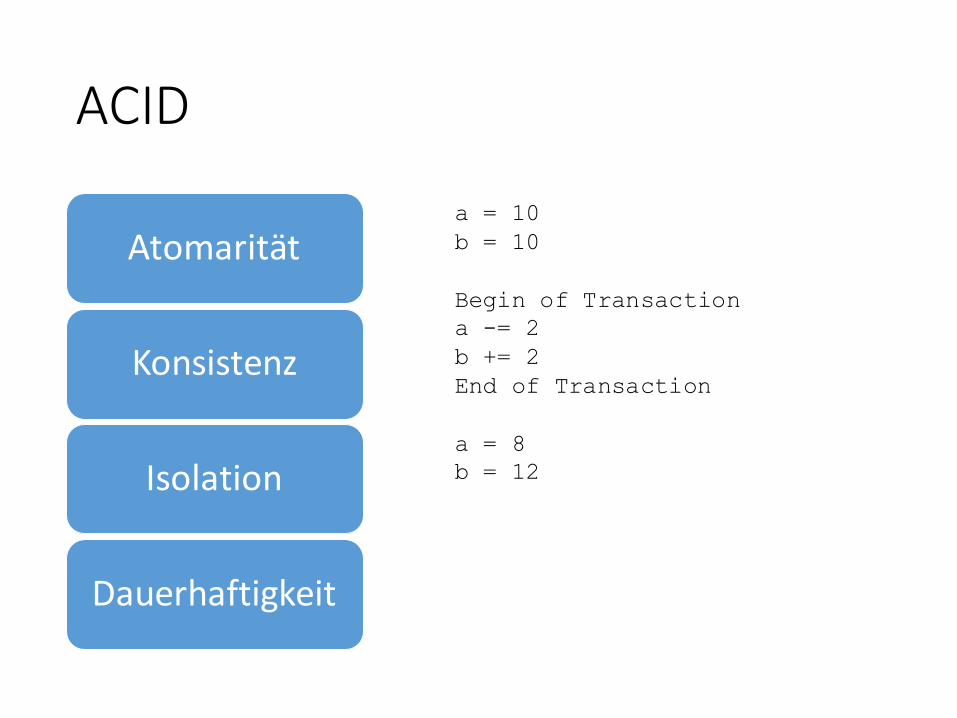
ACID
Atomarität
Konsistenz
Isolation
Dauerhaftigkeit
Alles-oder-Nichts-PrinzipAlles-oder-Nichts-Prinzip
Transaktion hinterlässtkonsistenten DB-Zustand
Transaktion hinterlässtkonsistenten DB-Zustand
Parallel laufenden TAs beeinflussen sich nichtParallel laufenden TAs beeinflussen sich nicht
Freigegebene Änderungengehen nicht verloren
Freigegebene Änderungengehen nicht verloren
ACID
Atomarität
Konsistenz
Isolation
Dauerhaftigkeit
a = 10
b = 10
Begin of Transaction
a -= 2
b += 2
End of Transaction
a = 8
b = 12
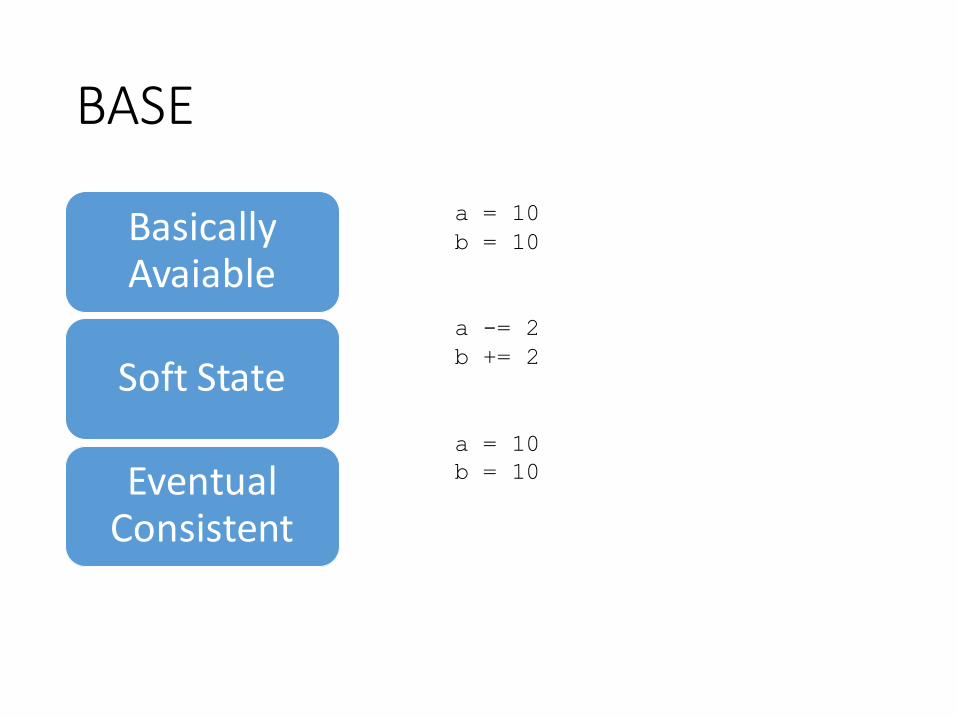
BASE
BasicallyAvaiable
Soft State
Eventual Consistent
a = 10
b = 10
a -= 2
b += 2
a = 10
b = 10
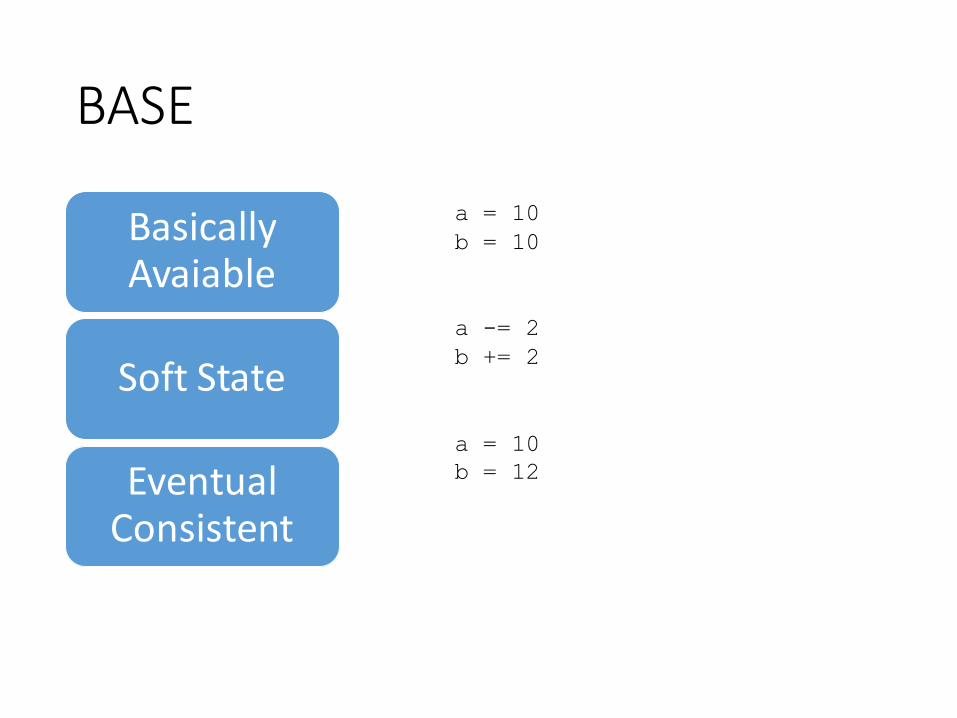
BASE
BasicallyAvaiable
Soft State
Eventual Consistent
a = 10
b = 10
a -= 2
b += 2
a = 10
b = 12
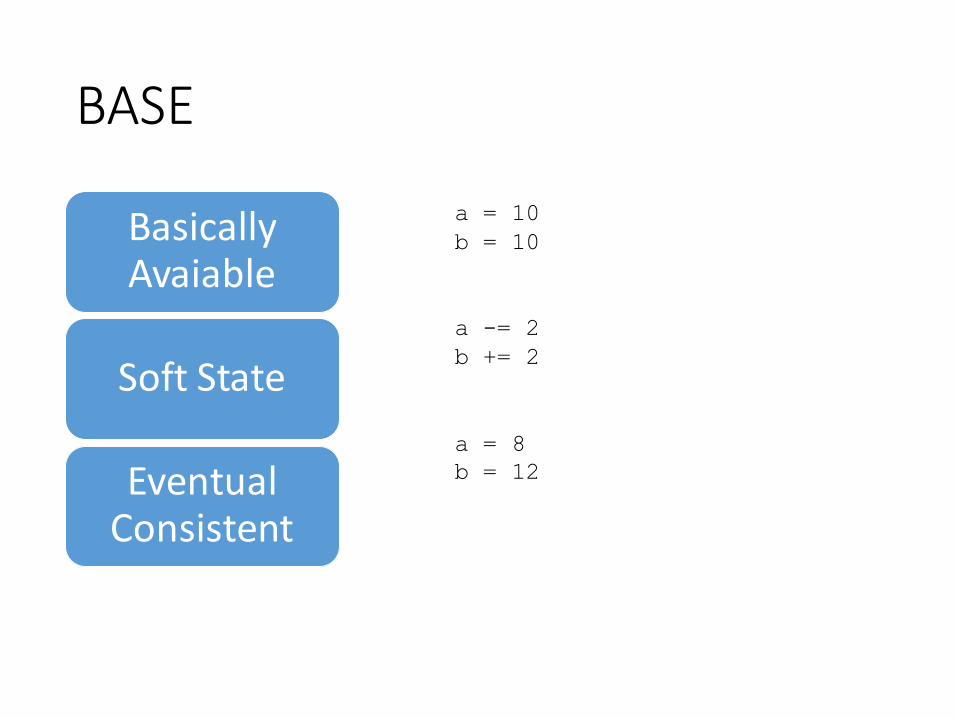
BASE
BasicallyAvaiable
Soft State
Eventual Consistent
a = 10
b = 10
a -= 2
b += 2
a = 8
b = 12
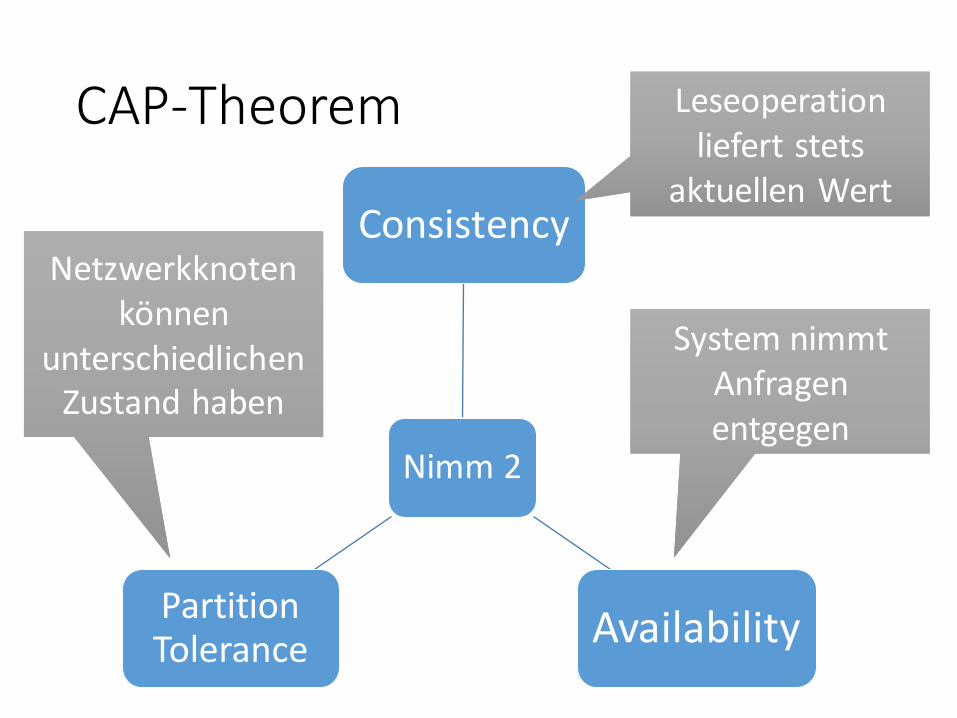
CAP-Theorem
Nimm 2
Consistency
AvailabilityPartition Tolerance
Leseoperationliefert stets
aktuellen Wert
Leseoperationliefert stets
aktuellen Wert
System nimmtAnfragenentgegen
System nimmtAnfragenentgegen
Netzwerkknotenkönnen
unterschiedlichenZustand haben
Netzwerkknotenkönnen
unterschiedlichenZustand haben

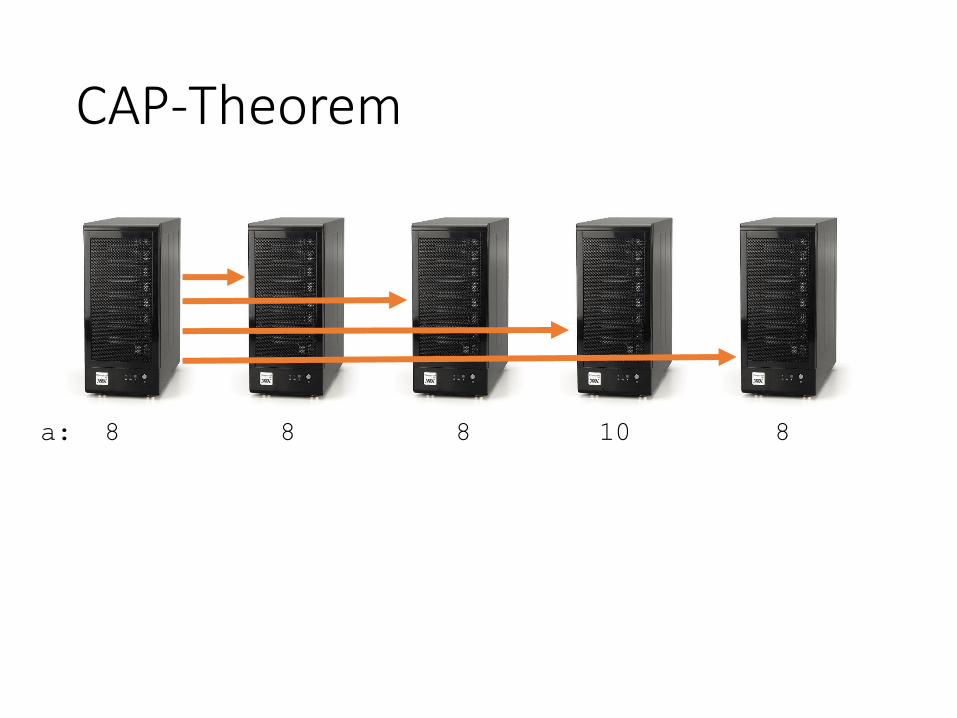
CAP-Theorem
a: 10 10 10 10 10
SET a 8SET a 8

CAP-Theorem
a: 8 10 10 10 10
CAP-Theorem
a: 8 8 8 10 8
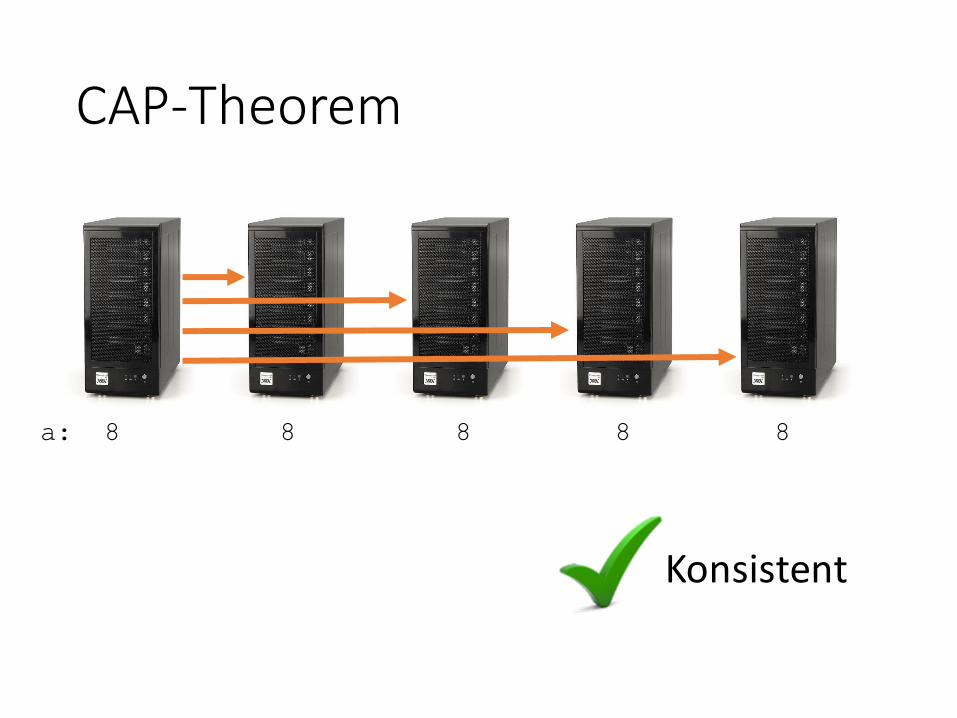
CAP-Theorem
a: 8 8 8 8 8
Konsistent
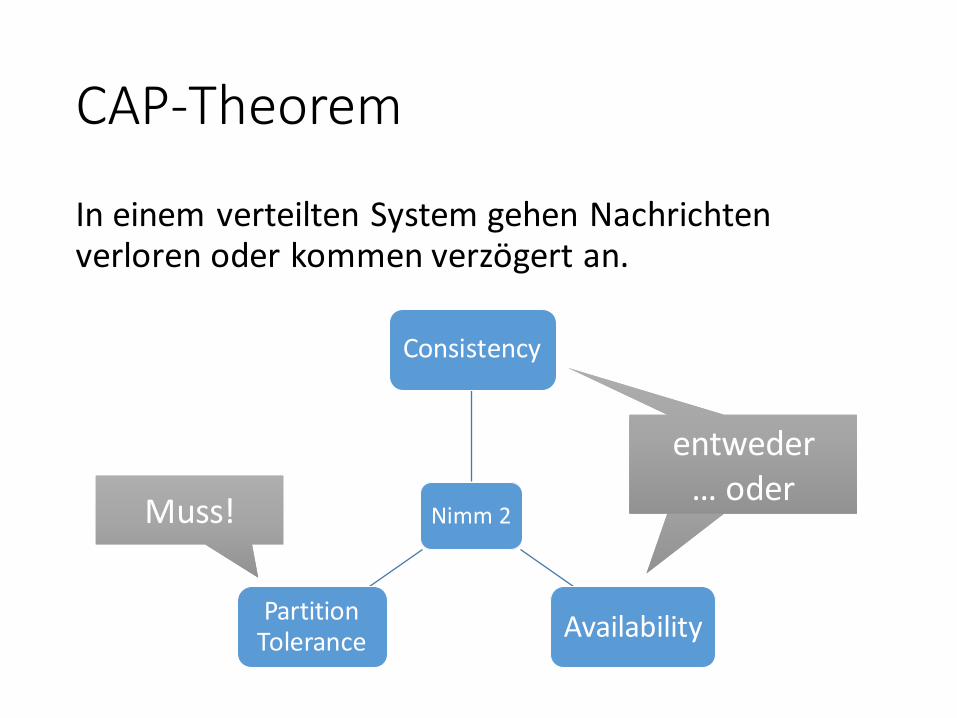
CAP-Theorem
In einem verteilten System gehen Nachrichten verloren oder kommen verzögert an.
Nimm 2
Consistency
AvailabilityPartition
Tolerance
Muss!Muss!
entweder… oder
entweder… oder
entweder… oder
entweder… oder
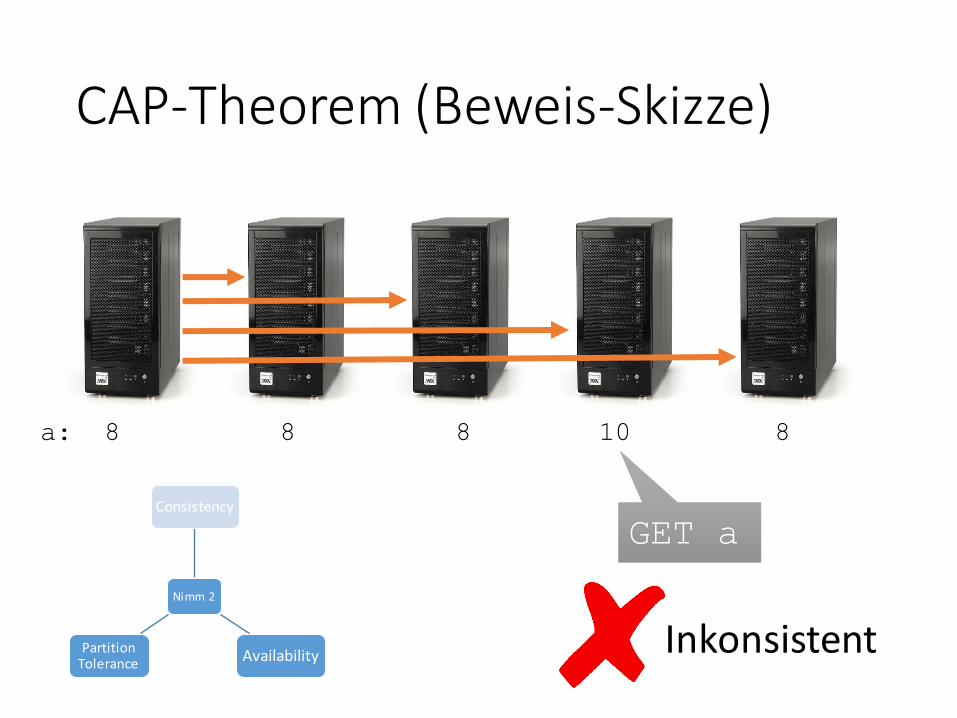
CAP-Theorem (Beweis-Skizze)
a: 8 8 8 10 8
GET aGET a
InkonsistentNimm 2
Consistency
AvailabilityPartition
Tolerance
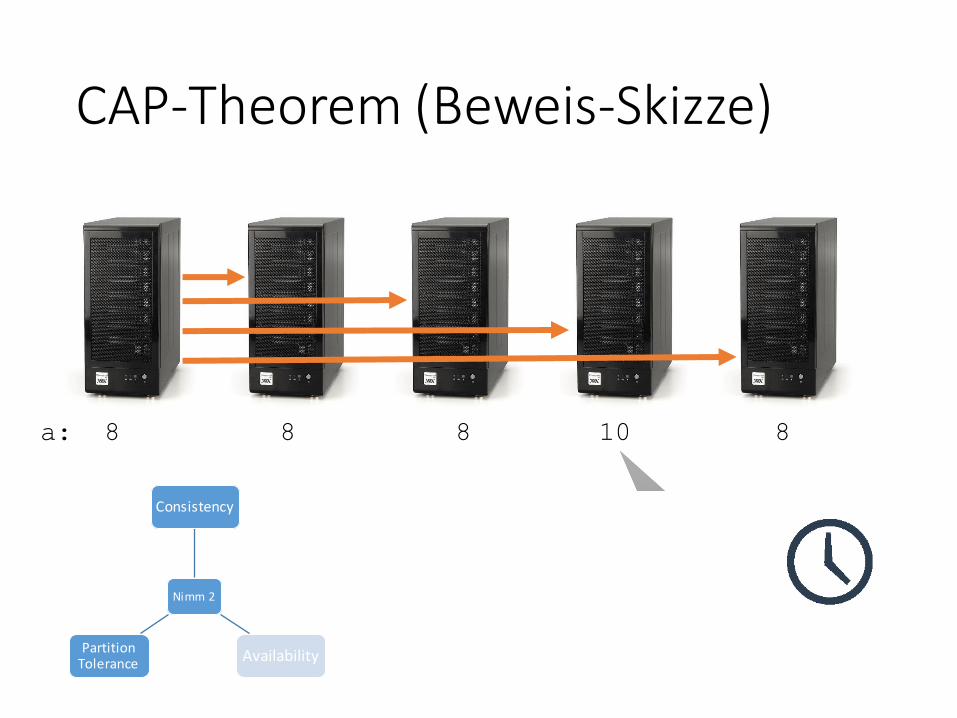
CAP-Theorem (Beweis-Skizze)
a: 8 8 8 10 8
GET aGET a
Nimm 2
Consistency
AvailabilityPartition
Tolerance
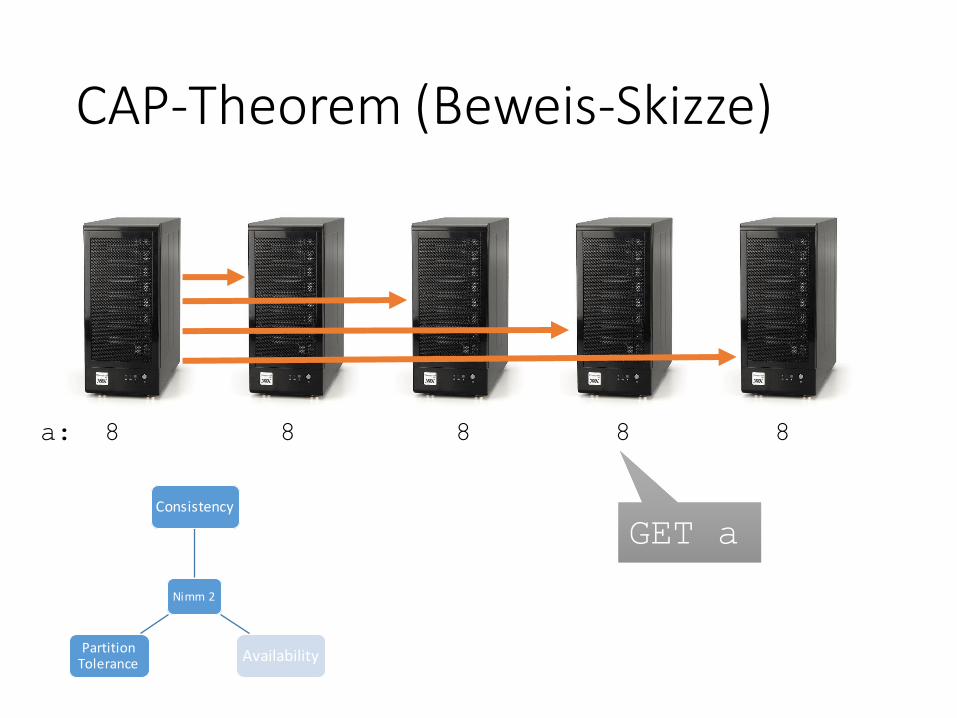
CAP-Theorem (Beweis-Skizze)
a: 8 8 8 8 8
GET aGET a
Nimm 2
Consistency
AvailabilityPartition
Tolerance

Strong Consistency
a: 10 10 10 10 10
SET a 8SET a 8 SET a 8SET a 8 SET a 8SET a 8 SET a 8SET a 8 SET a 8SET a 8
N = 5
W = 5
R = 1
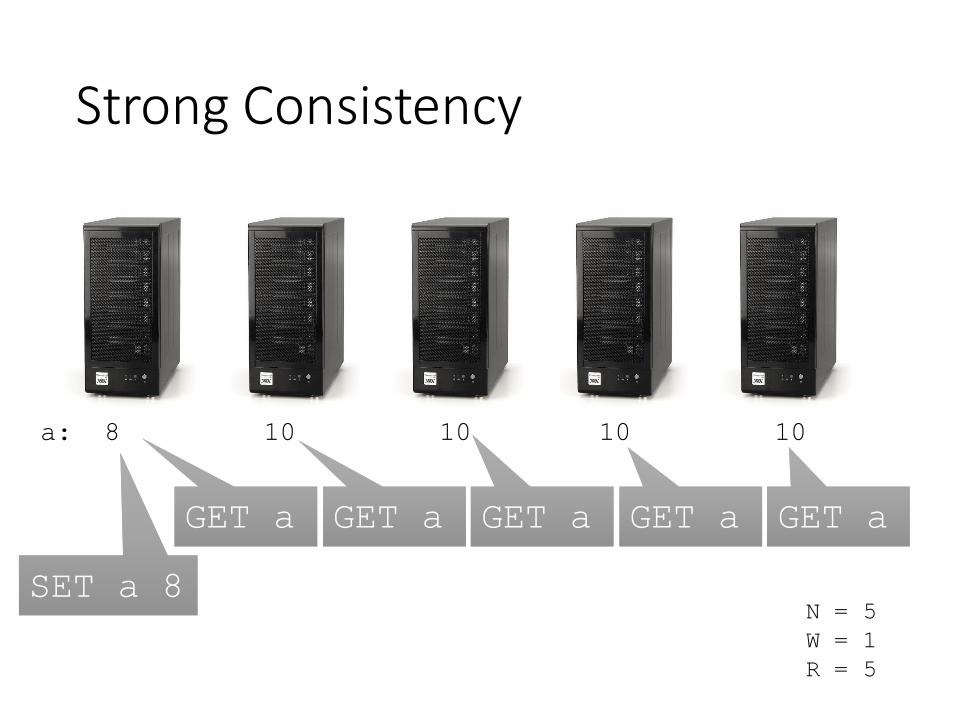
Strong Consistency
SET a 8SET a 8
GET aGET a GET aGET a GET aGET a GET aGET a GET aGET a
a: 8 10 10 10 10
N = 5
W = 1
R = 5

Strong Consistency: W+R>N
SET a 8SET a 8
GET aGET a GET aGET a GET aGET a
a: 8 8 8 10 10
N = 5
W = 3
R = 3
SET a 8SET a 8 SET a 8SET a 8

Eventual Consistency: W+R≤N
SET a 8SET a 8
GET aGET a GET aGET a GET aGET a
a: 8 8 10 10 10
N = 5
W = 2
R = 3
SET a 8SET a 8
Map Reduce
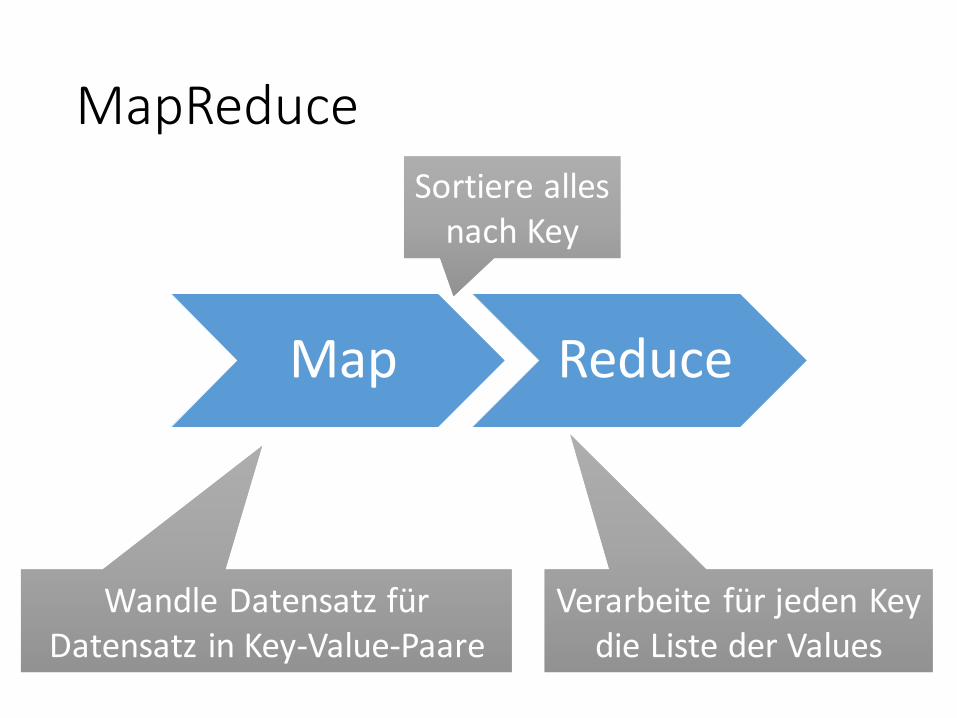
MapReduce
Wandle Datensatz fürDatensatz in Key-Value-Paare
Wandle Datensatz fürDatensatz in Key-Value-Paare
Sortiere allesnach Key
Sortiere allesnach Key
Verarbeite für jeden Key die Liste der Values
Verarbeite für jeden Key die Liste der Values

MapReduce
map(zeilennr, text):
for each word in text:
emit(word, 1)
reduce(word, values):
sum = 0
for each v in values:
sum = sum + v
emit(word, sum)
1: ich bin ich1: ich bin ich
(ich, 1)(ich, 1) (bin, 1)(bin, 1) (ich, 1)(ich, 1)
(ich, [1,1])(ich, [1,1])
(ich, 2)(ich, 2)
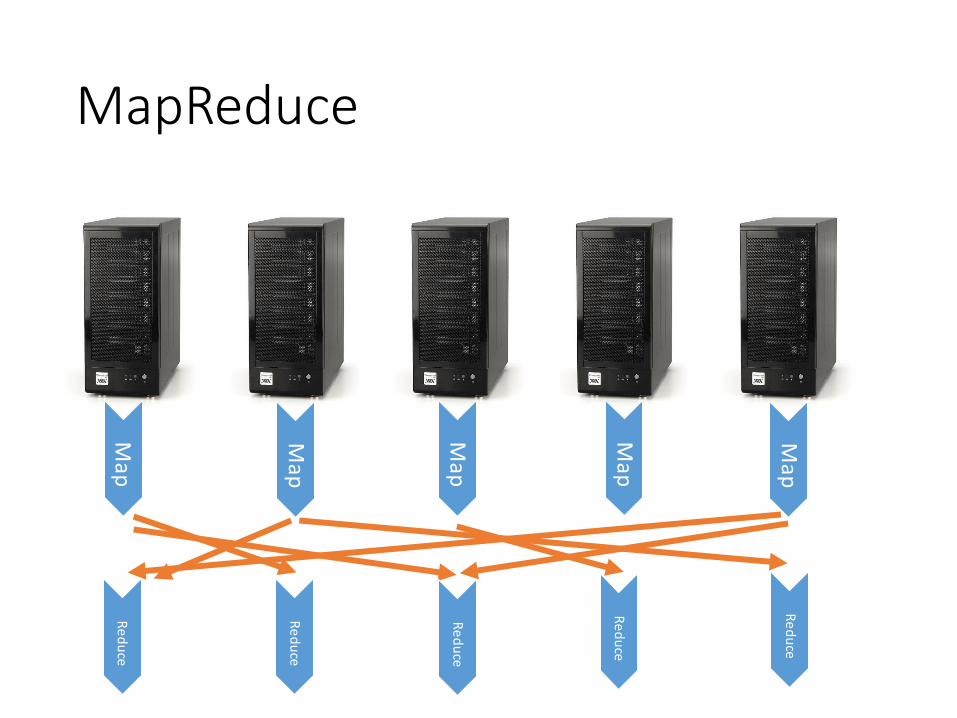
MapReduce
Map
Map
Map
Map
Ma
p
Re
du
ce
Re
du
ce
Re
du
ce
Re
du
ce
Re
du
ce

MapReduce
• Von Google
• Freie Implementierung: Apache Hadoop
• Eingabe-/Ausgabe-Formate:• HBase• MongoDB• HDFS (Hadoop Distributed File System)
• Höhere Sprachen• Hive (Generiert MapReduce aus SQL)• Pig• NotaQL
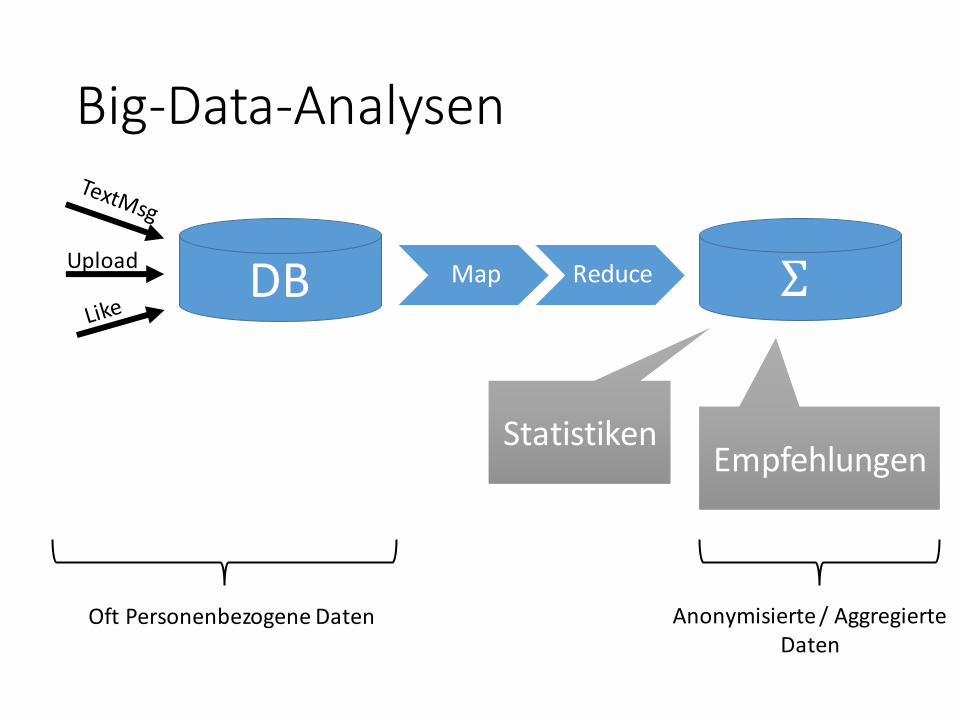
Big-Data-Analysen
DBUpload
Map Reduce Σ
StatistikenStatistikenEmpfehlungenEmpfehlungen
Oft Personenbezogene Daten Anonymisierte / Aggregierte Daten
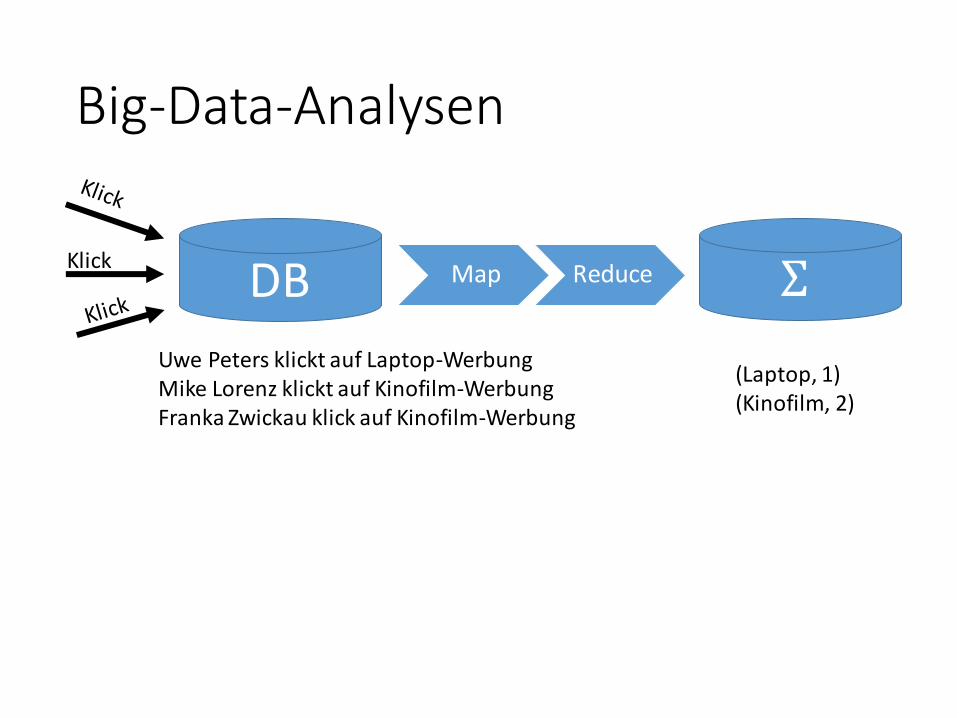
Big-Data-Analysen
DBKlick
Map Reduce Σ
Uwe Peters klickt auf Laptop-WerbungMike Lorenz klickt auf Kinofilm-WerbungFranka Zwickau klick auf Kinofilm-Werbung
(Laptop, 1)(Kinofilm, 2)

k-Anonymität
Ein sichtbares Ergebnis hat seinenUrsprung in mind. k DatensätzenEin sichtbares Ergebnis hat seinenUrsprung in mind. k Datensätzen
=> Verhindert, dass man auf die Datensätze rückschließen kann

k-Anonymität
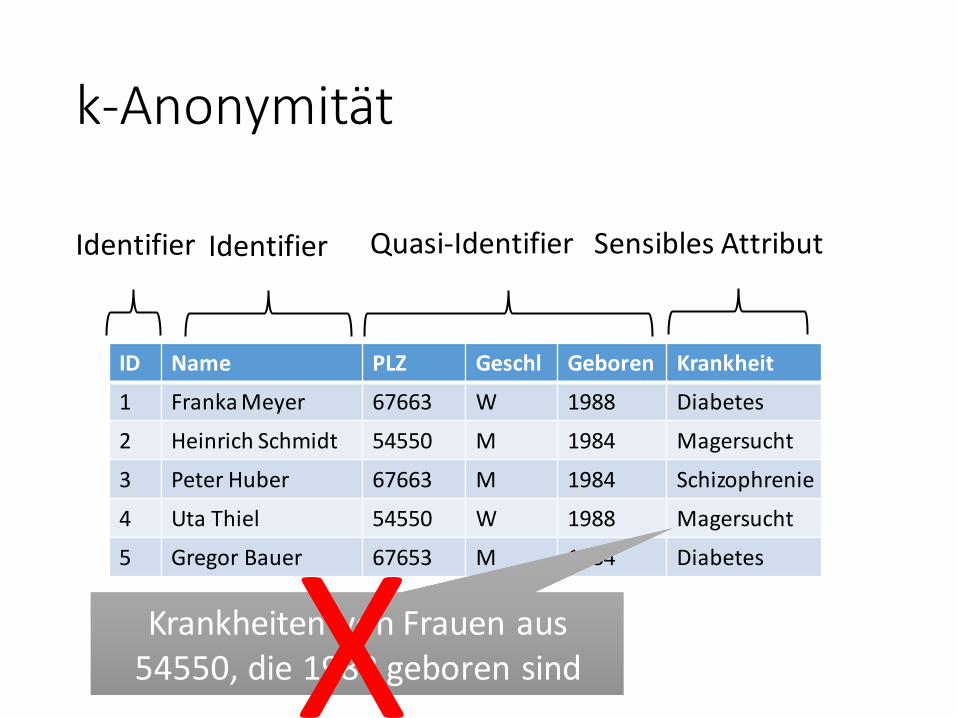
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
Identifier Quasi-Identifier Sensibles Attribut
Krankheit von Uta ThielKrankheit von Uta ThielX
Identifier
k-Anonymität
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
Krankheiten von Frauen aus54550, die 1988 geboren sindKrankheiten von Frauen aus
54550, die 1988 geboren sindX
Identifier Quasi-Identifier Sensibles AttributIdentifier

k-Anonymität
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
Krankheiten von Frauen, die 1988 geboren sind
Krankheiten von Frauen, die 1988 geboren sind
Identifier Quasi-Identifier Sensibles AttributIdentifier

k-Anonymität
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
Keine Anonymität bzgl. dieses Quasi-IdentifiersKeine Anonymität bzgl. dieses Quasi-Identifiers
Quasi-Identifier
k-Anonymität
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
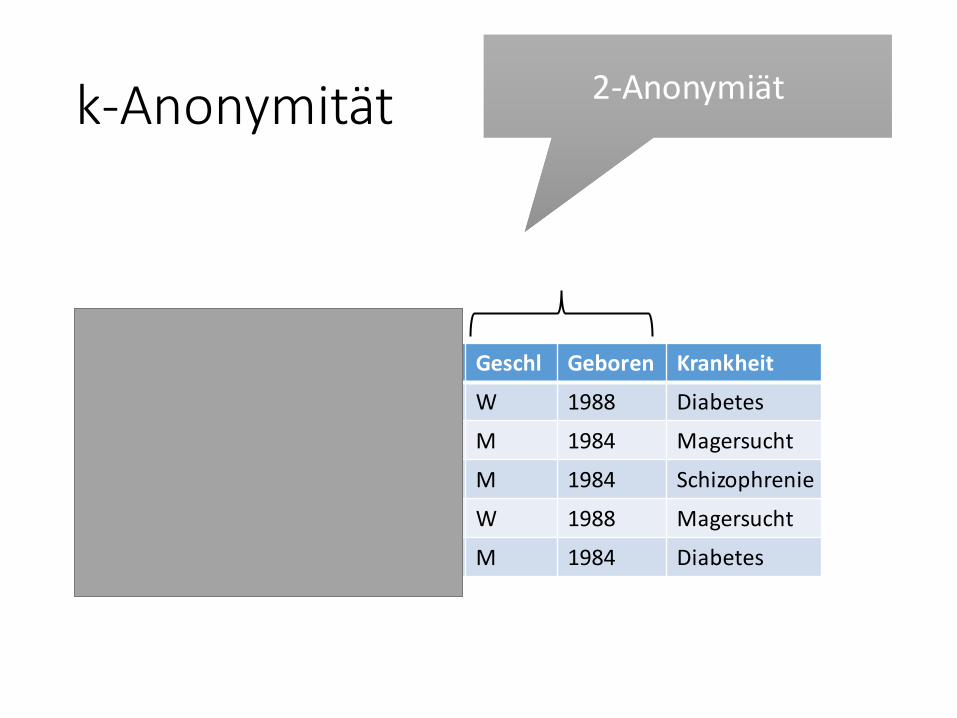
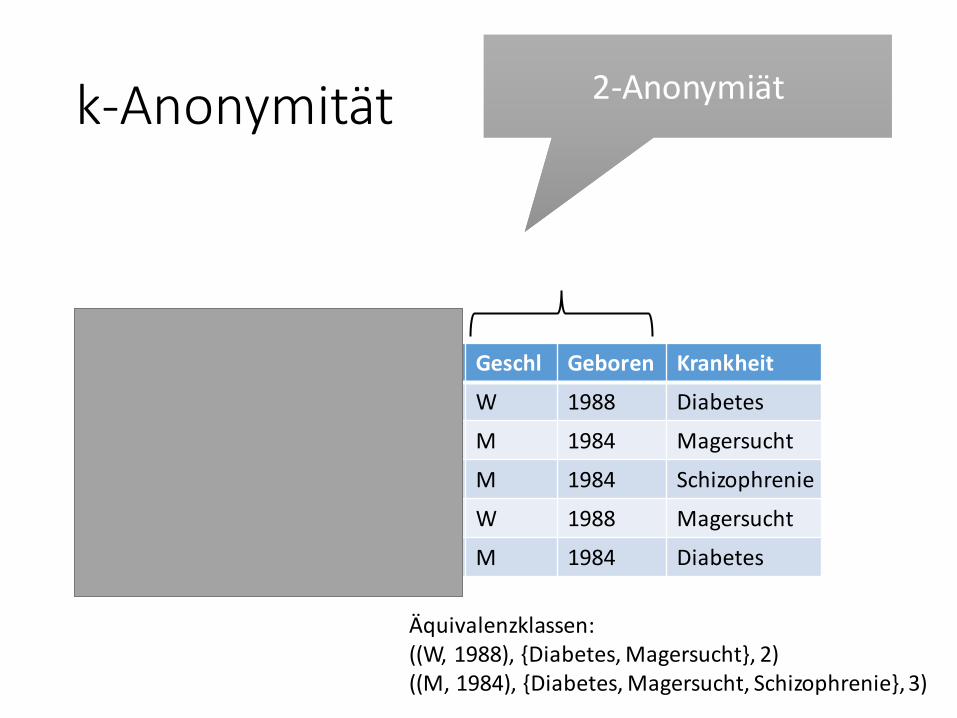
2-Anonymiät2-Anonymiät
k-Anonymität
ID Name PLZ Geschl Geboren Krankheit
1 Franka Meyer 67663 W 1988 Diabetes
2 Heinrich Schmidt 54550 M 1984 Magersucht
3 Peter Huber 67663 M 1984 Schizophrenie
4 Uta Thiel 54550 W 1988 Magersucht
5 Gregor Bauer 67653 M 1984 Diabetes
2-Anonymiät2-Anonymiät
Äquivalenzklassen:((W, 1988), {Diabetes, Magersucht}, 2)((M, 1984), {Diabetes, Magersucht, Schizophrenie}, 3)

k-Anonymität
ID Name PLZ Geschl Geboren Gehalt
1 Franka Meyer 67663 W 1988 50000
2 Heinrich Schmidt 54550 M 1984 40000
3 Peter Huber 67663 M 1984 50000
4 Uta Thiel 54550 W 1988 60000
5 Gregor Bauer 67653 M 1984 70000
2-Anonymiät2-Anonymiät
Äquivalenzklassen:((W, 1988), AVG: 55000, 2)((M, 1984), AVG: 50000, 3)

Zusammenfassung
• Big Data• Volume• Velocity• Variety• Veracity
• NoSQL• Key-Value-, Wide-Column-, Dokumenten-, Graph-DBs• BASE, CAP Theorem, Eventual Consistency
• MapReduce
• k-Anonymität

Quellen / Weitere Literatur
• NoSQL: Einstieg in die Welt nichtrelationaler Web 2.0 Datenbanken, Stefan Edlich, 2011
• http://nosql-database.org
• http://wwwlgis.informatik.uni-kl.de/cms/courses/distributeddatamanagement
• http://www.ipd.uni-karlsruhe.de/~buchmann/14SS-Datenschutz


















