
Clustering - About us ... | E-Commercedieter/teaching/dm08-clustering.pdf · Clustering 188.646,...
68
Clustering Clustering 188.646, Data Mining, 2 VO 188.646, Data Mining, 2 VO Sommersemester Sommersemester 2008 2008 Dieter Merkl e-Commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Transcript of Clustering - About us ... | E-Commercedieter/teaching/dm08-clustering.pdf · Clustering 188.646,...

ClusteringClustering188.646, Data Mining, 2 VO188.646, Data Mining, 2 VO
Sommersemester Sommersemester 20082008
Dieter Merkle-Commerce Arbeitsgruppe
Institut für Softwaretechnik und Interaktive SystemeTechnische Universität Wien
www.ec.tuwien.ac.at/~dieter/

2
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

3
Clustering
• Zielsetzung: Daten zu “natürlichen” Gruppen(Clusters) zusammenfassen
• Es gibt kein zur Gruppierung ausgezeichnetesAttribut
• Eigenschaften von Gruppen:• disjunkt vs überlappend• deterministisch vs probabilistisch• hierarchisch vs. flach
4
Clustering
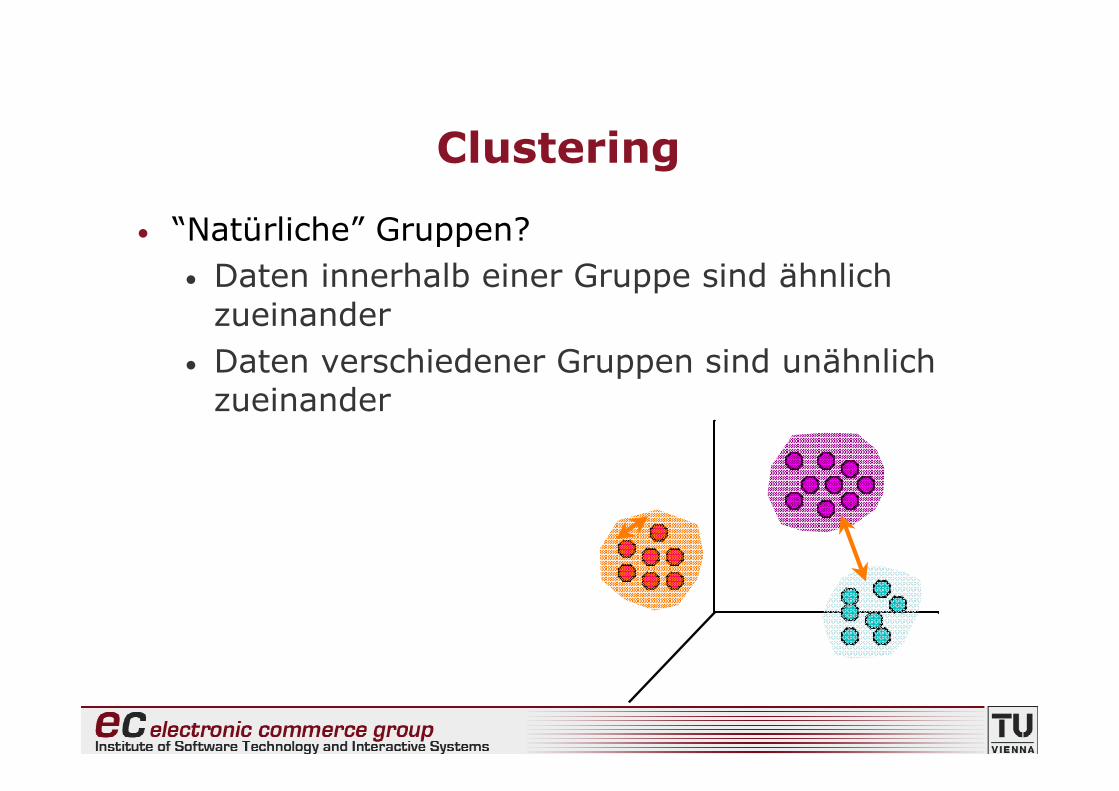
• “Natürliche” Gruppen?• Daten innerhalb einer Gruppe sind ähnlich
zueinander• Daten verschiedener Gruppen sind unähnlich
zueinander
5
Clustering
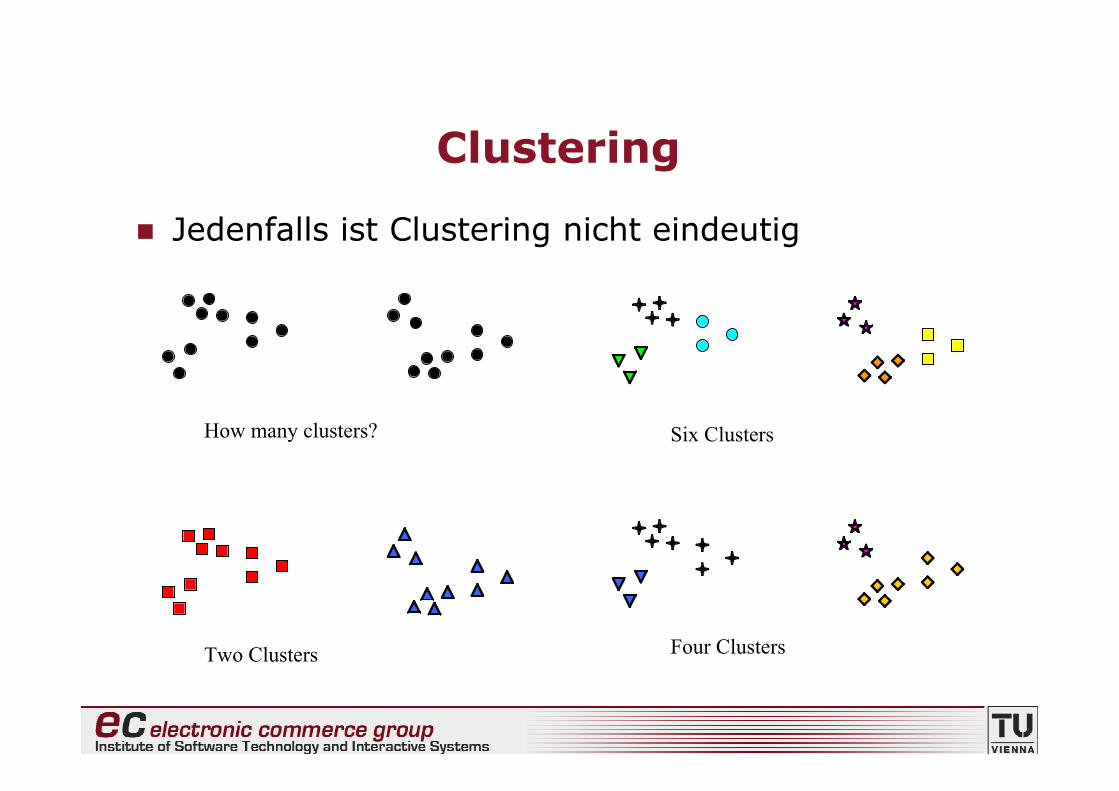
Jedenfalls ist Clustering nicht eindeutig
How many clusters? Six Clusters
Two Clusters Four Clusters

6
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

7
K-Means: Algorithmus
• Produziert K disjunkte Cluster• K ist vordefiniert• Jeder Cluster wird durch seinen “Mittelpunkt”
(Centroid) definiert• Sehr einfaches Verfahren

8
K-Means: Diskussion
• K-Means minimiert Distanzfunktion• Ergebnis hängt von der Wahl der ursprünglichen
Clusterzentren ab• Gefahr der Konvergenz zu lokalem Minimum
• Wiederholte Ausführung mit unterschiedlichenStartkonfigurationen
ursprüngliche Clusterzentren
Datenpunkte

9
K-Means: Diskussion
• K-Means minimiert Distanzfunktion• Ergebnis hängt von der Wahl der ursprünglichen
Clusterzentren ab• Gefahr der Konvergenz zu lokalem Minimum
• Wiederholte Ausführung mit unterschiedlichenStartkonfigurationen
ursprüngliche Clusterzentren
Datenpunkte
10
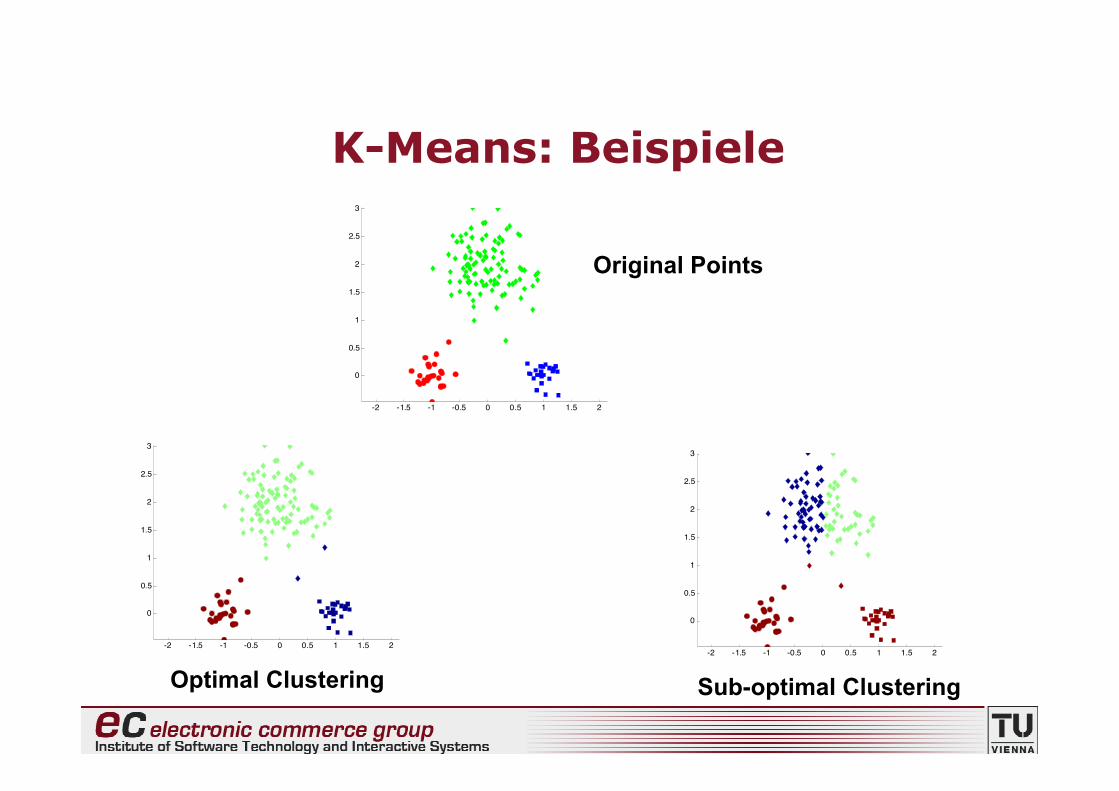
K-Means: Beispiele
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2
0
0.5
1
1.5
2
2.5
3
x
y
Original Points
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2
0
0.5
1
1.5
2
2.5
3
x
y
Optimal Clustering-2 -1.5 -1 -0.5 0 0.5 1 1.5 2
0
0.5
1
1.5
2
2.5
3
x
y
Sub-optimal Clustering
11
K-Means: Beispiele

12
K-Means: Evaluierung
Sum of Squared Errors
Für jeden Cluster Ci werden die quadriertenAbstände der Datenpunkte x zum Cluster-Centroiden mi aufsummiert
Von unterschiedlichen Ergebnissen, kann jenesmit dem geringeren SSE gewählt werden
Grössere K neigen zu geringeren SSEs(Aber warum muss das nicht immer so sein?)
∑∑= ∈
=K
i Cxi
i
xmdistSSE1
2 ),(

13
K-Means: Diskussion
• K-Means kann auch leere Cluster erzeugen :-(• Warum?• Strategien dagegen?• Auswahl der Centroiden:
• Datenpunkt, der am meisten zum SSE beiträgt• Datenpunkt aus dem Cluster mit dem höchsten
SSE

14
K-Means: Pre- & Post-Processing
• Pre-Processing• Normalisierung• Ausreisser eliminieren
• Post-Processing• “Kleine” Cluster eliminieren (Ausreisser?)• Teilen von Clustern mit hohem SSE• Zusammenfassen von ähnlichen Clustern mit
geringem SSE

15
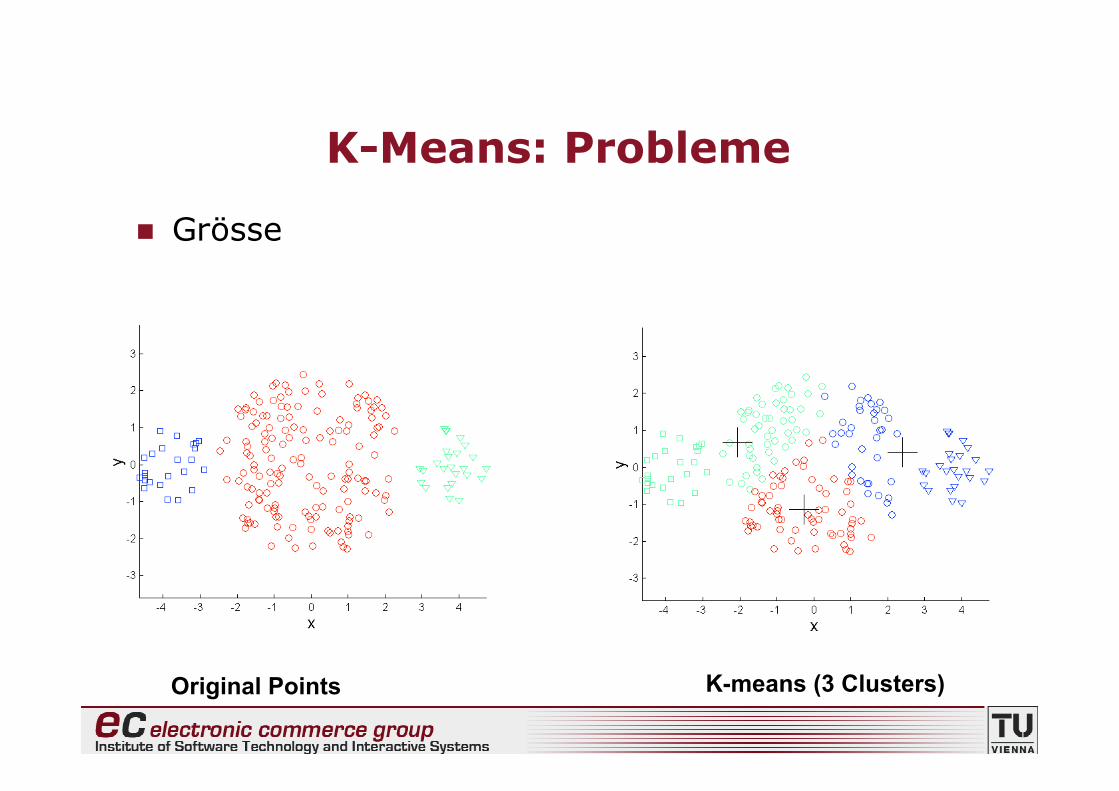
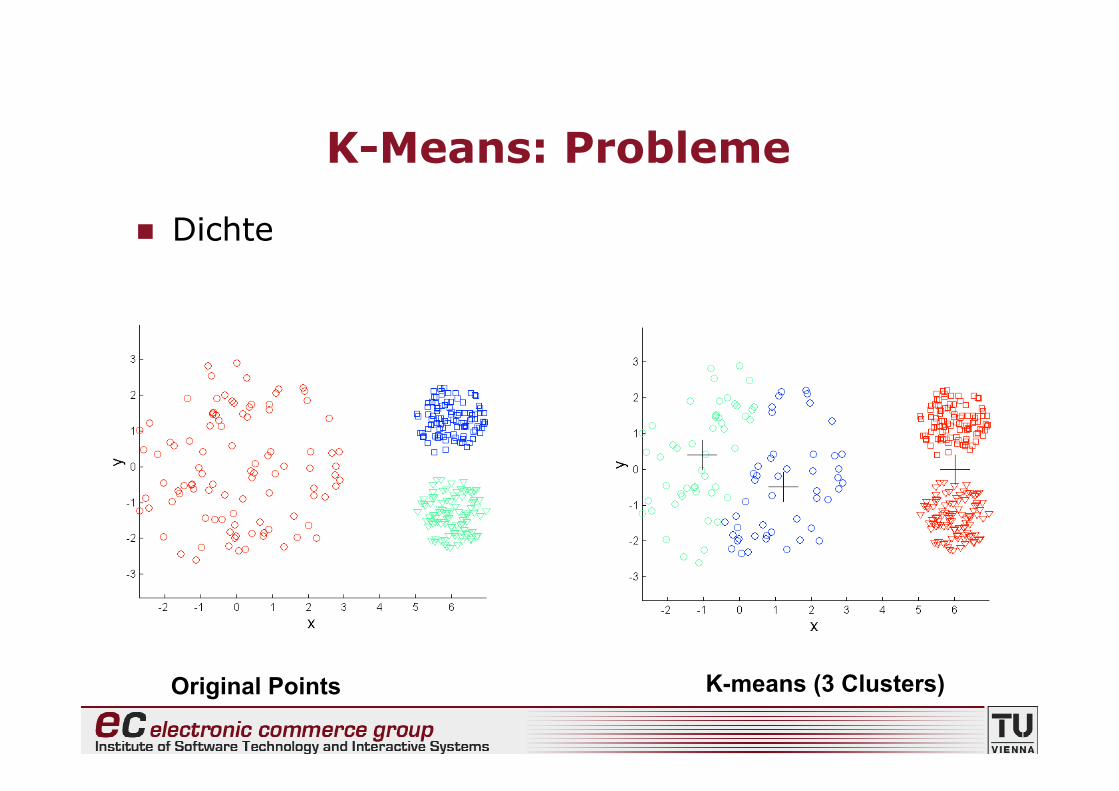
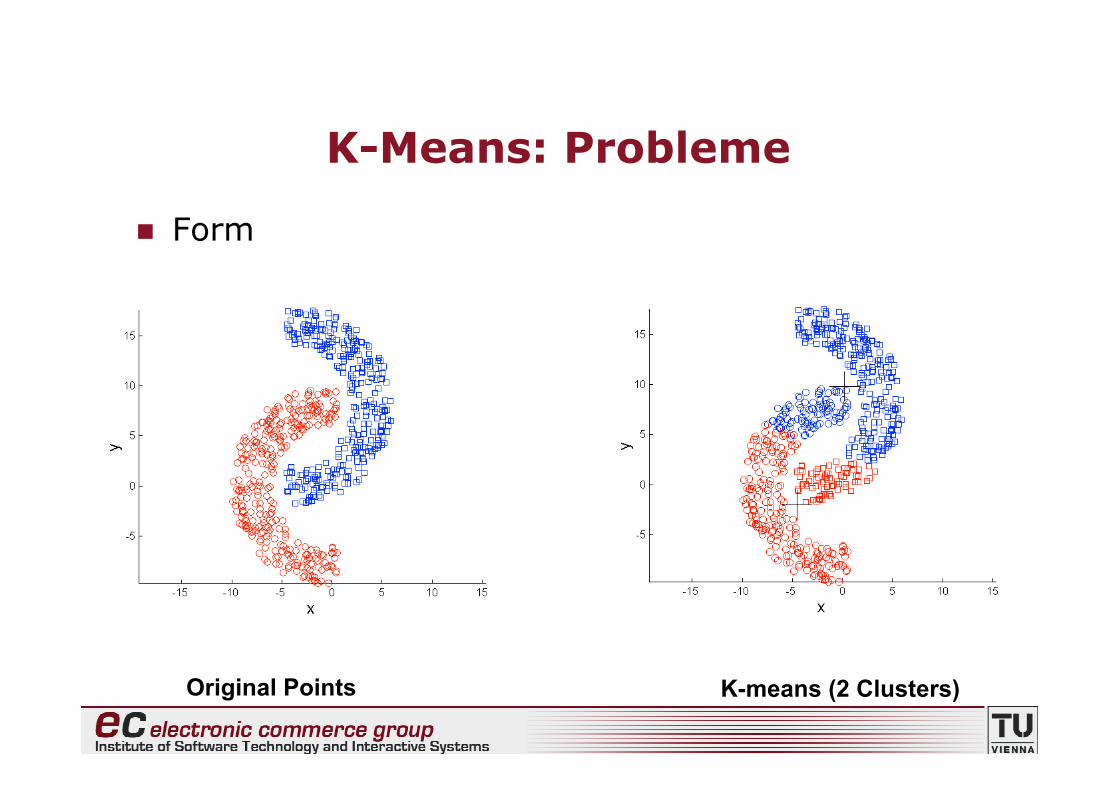
K-Means: Probleme
• K-Means hat “Probleme”, wenn Gruppen• unterschiedliche Grössen haben• unterschiedliche Dichten haben• abweichen von “Kugelform”
• K-Means ist “ziemlich anfällig” auf Ausreisser
16
K-Means: Probleme
Grösse
Original Points K-means (3 Clusters)
17
K-Means: Probleme
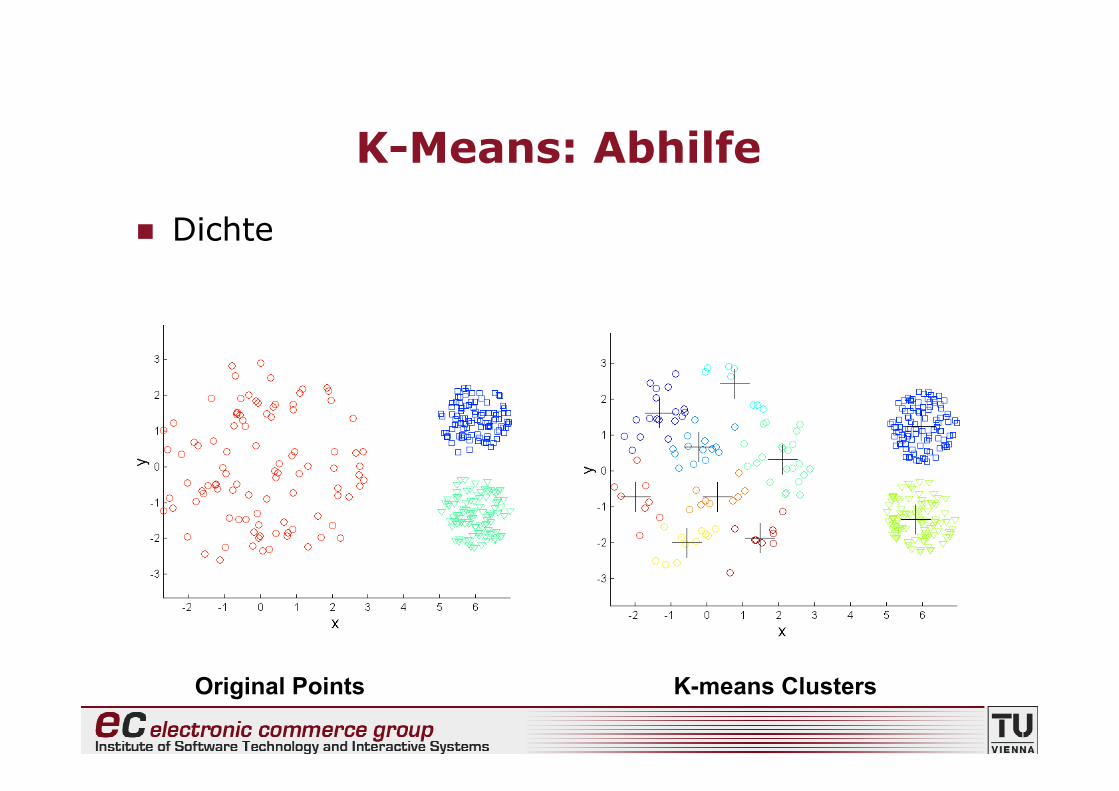
Dichte
Original Points K-means (3 Clusters)
18
K-Means: Probleme
Form
Original Points K-means (2 Clusters)

19
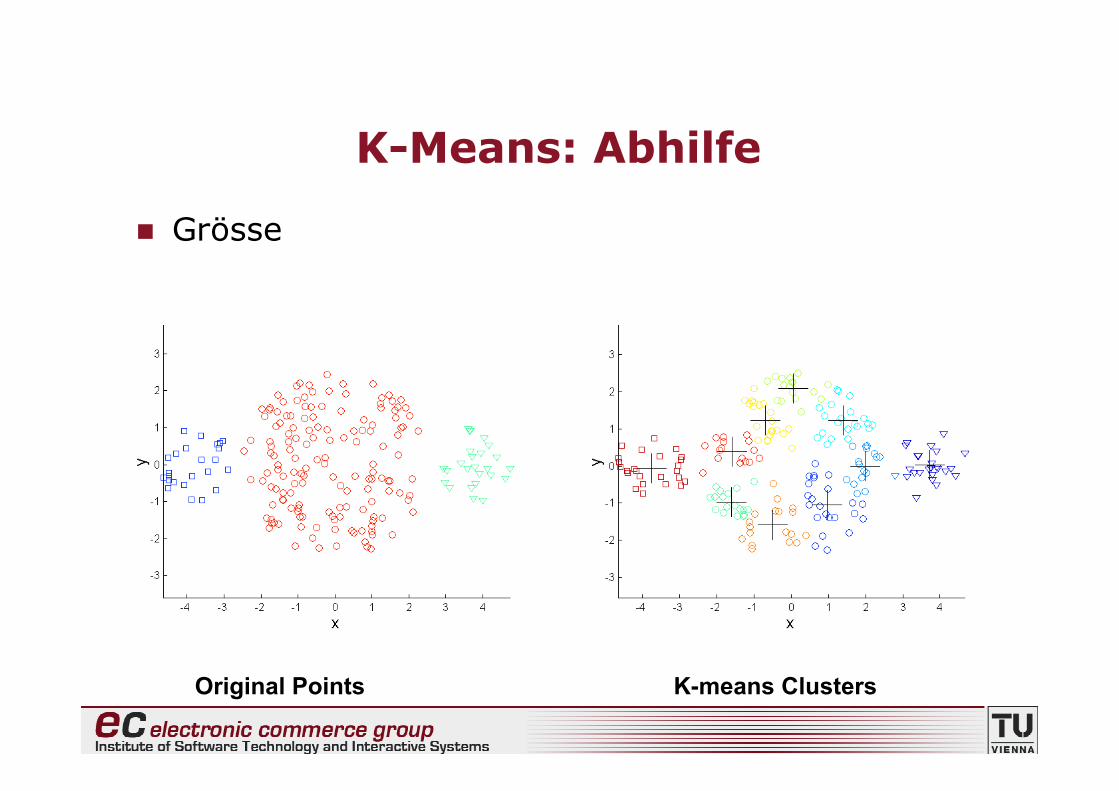
K-Means: Probleme
• Abhilfe?• Mehr und dafür kleinere Cluster :-)• ... und diese dann zu grösseren zusammensetzen
20
K-Means: Abhilfe
Grösse
Original Points K-means Clusters
21
K-Means: Abhilfe
Dichte
Original Points K-means Clusters

22
K-Means: Abhilfe
Form
Original Points K-means Clusters

23
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

24
Hierarchisches Clustering
• Agglomerative Verfahren (Bottom-Up)• Start mit den individuellen Datenpunkten• In jedem Schritt werden die “ähnlichsten”
Datenpunkte zu einem Clusterzusammengefasst
• Divisive Verfahren (Top-Down)• Start mit einem Cluster, der alle Datenpunkte
beinhaltet• In jedem Schritt werden Cluster geteilt
• Zentrale Bedeutung kommt der Wahl der Distanz-bzw Ähnlichkeitsfunktion zu

25
Agglomerative Verfahren
• Berechnung der Proximitätsmatrix• Jeder Datenpunkt ist ein Cluster• Repeat
• Zusammenfassen der beiden ähnlichstenCluster
• Berechnung der Proximitätsmatrix• Until alle Datenpunkte sind in einem Cluster

26
Agglomerative Verfahren
• Berechnung der Proximitätsmatrix hat zentraleBedeutung
• Unterschiedliche Verfahren zur Berechnung derÄhnlichkeit zwischen Clustern

27
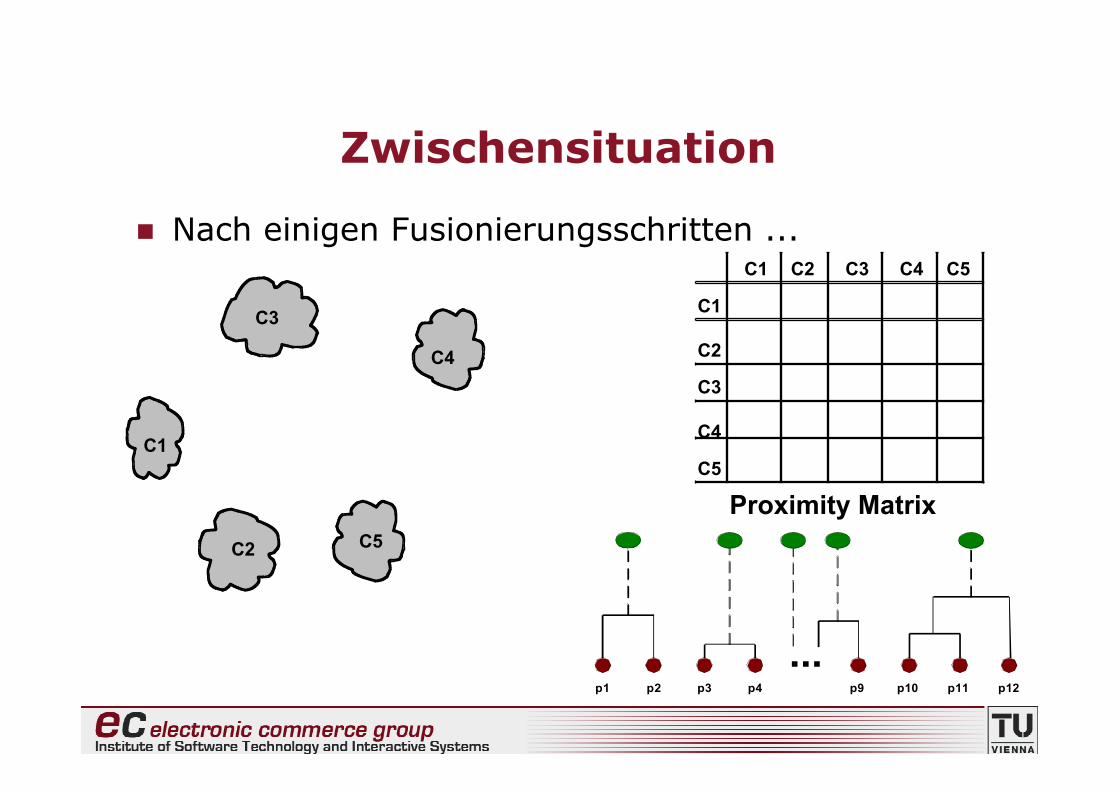
Ausgangssituation
Jeder Datenpunkt entspricht einem Cluster
p1
p3
p5
p4
p2
p1 p2 p3 p4 p5 . . .
.
.
. Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
28
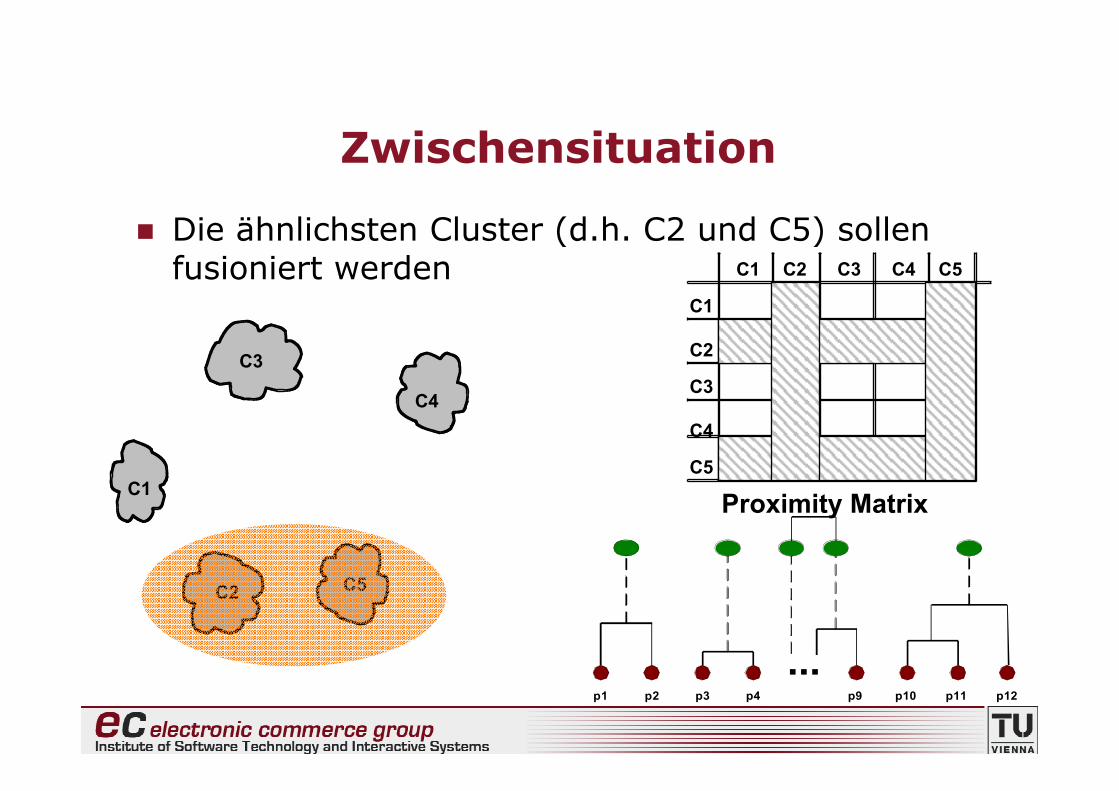
Zwischensituation
Nach einigen Fusionierungsschritten ...
C1
C4
C2 C5
C3
C2C1
C1
C3
C5
C4
C2
C3 C4 C5
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
29
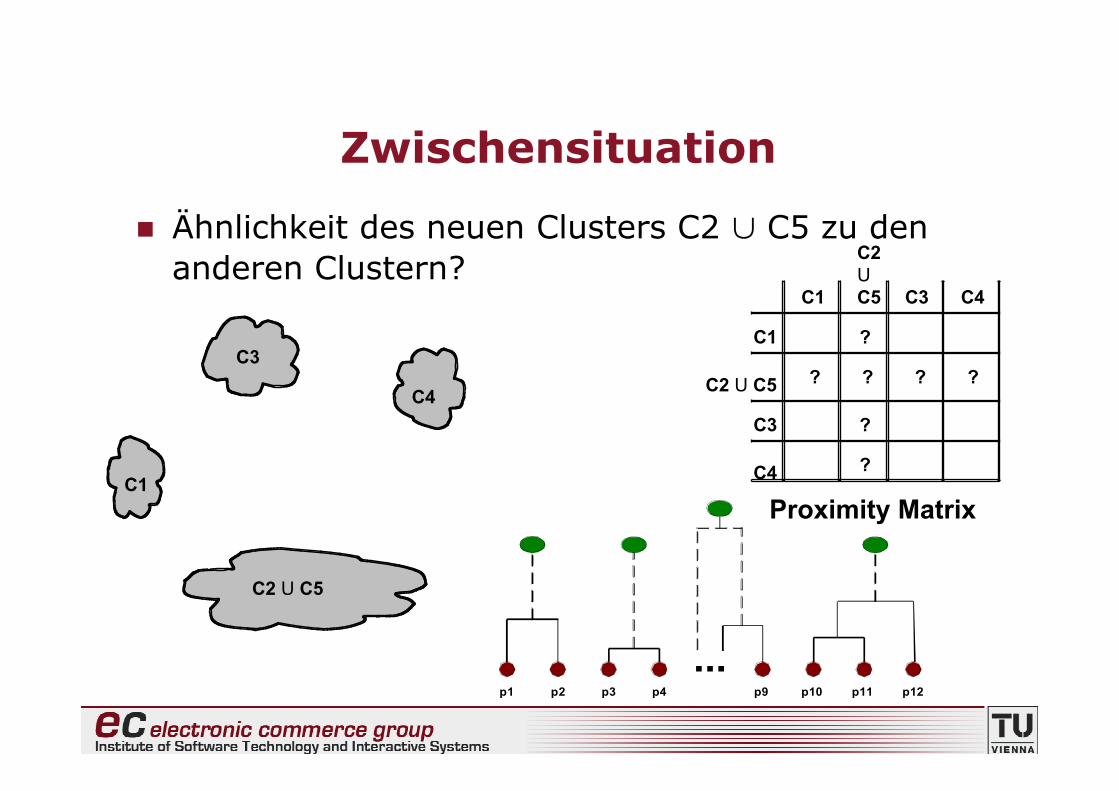
Zwischensituation
Die ähnlichsten Cluster (d.h. C2 und C5) sollenfusioniert werden
C1
C4
C2 C5
C3
C2C1
C1
C3
C5
C4
C2
C3 C4 C5
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
30
Zwischensituation
Ähnlichkeit des neuen Clusters C2 ∪ C5 zu denanderen Clustern?
C1
C4
C2 U C5
C3? ? ? ?
?
?
?
C2UC5C1
C1
C3
C4
C2 U C5
C3 C4
Proximity Matrix
...p1 p2 p3 p4 p9 p10 p11 p12
31
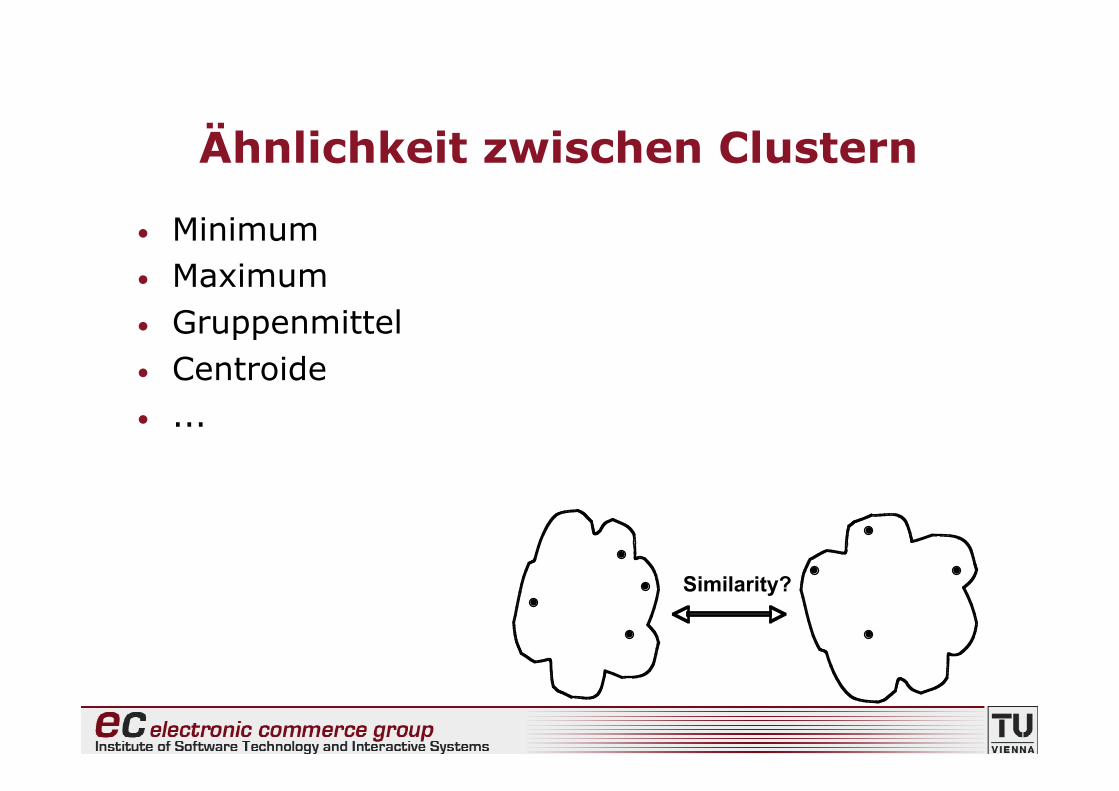
Ähnlichkeit zwischen Clustern
• Minimum• Maximum• Gruppenmittel• Centroide• ...
Similarity?
32
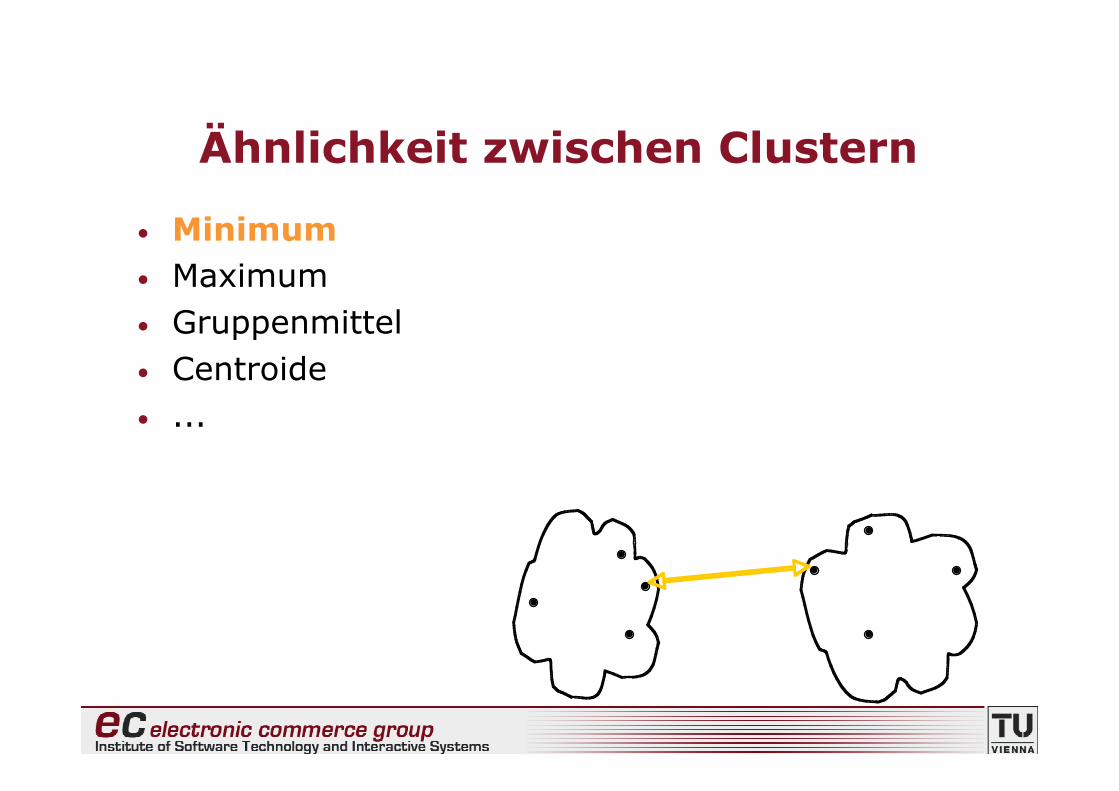
Ähnlichkeit zwischen Clustern
• Minimum• Maximum• Gruppenmittel• Centroide• ...
33
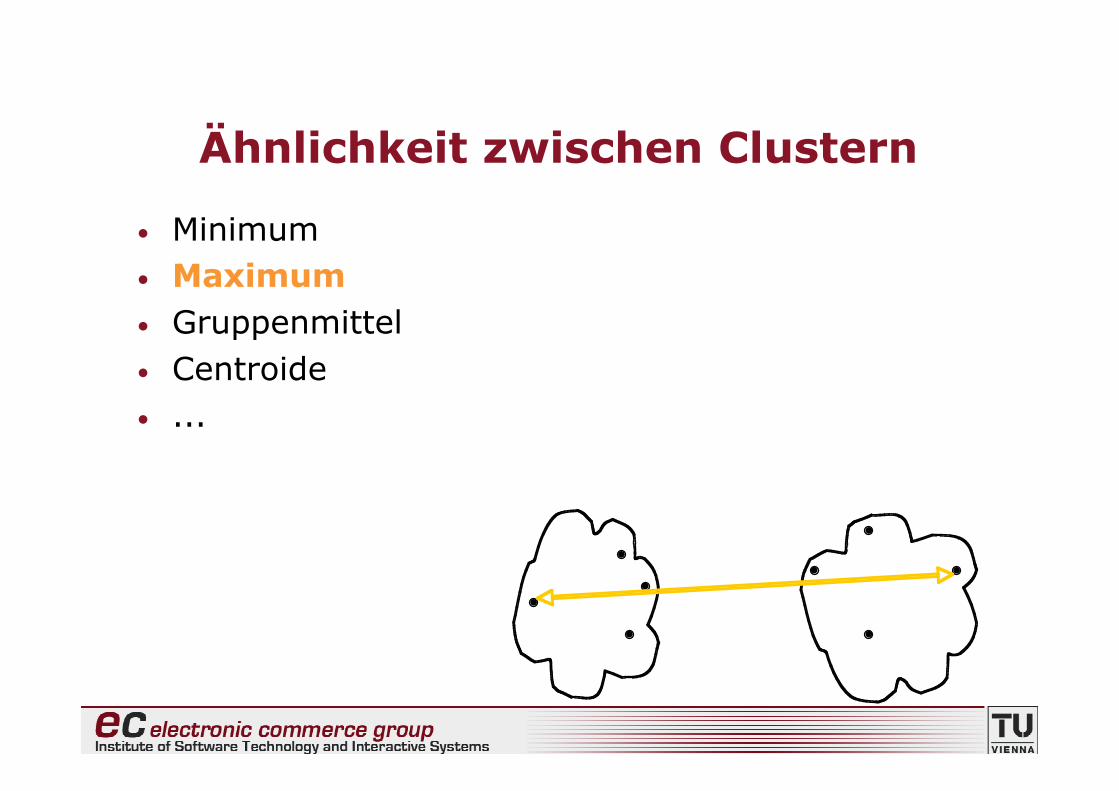
Ähnlichkeit zwischen Clustern
• Minimum• Maximum• Gruppenmittel• Centroide• ...
34
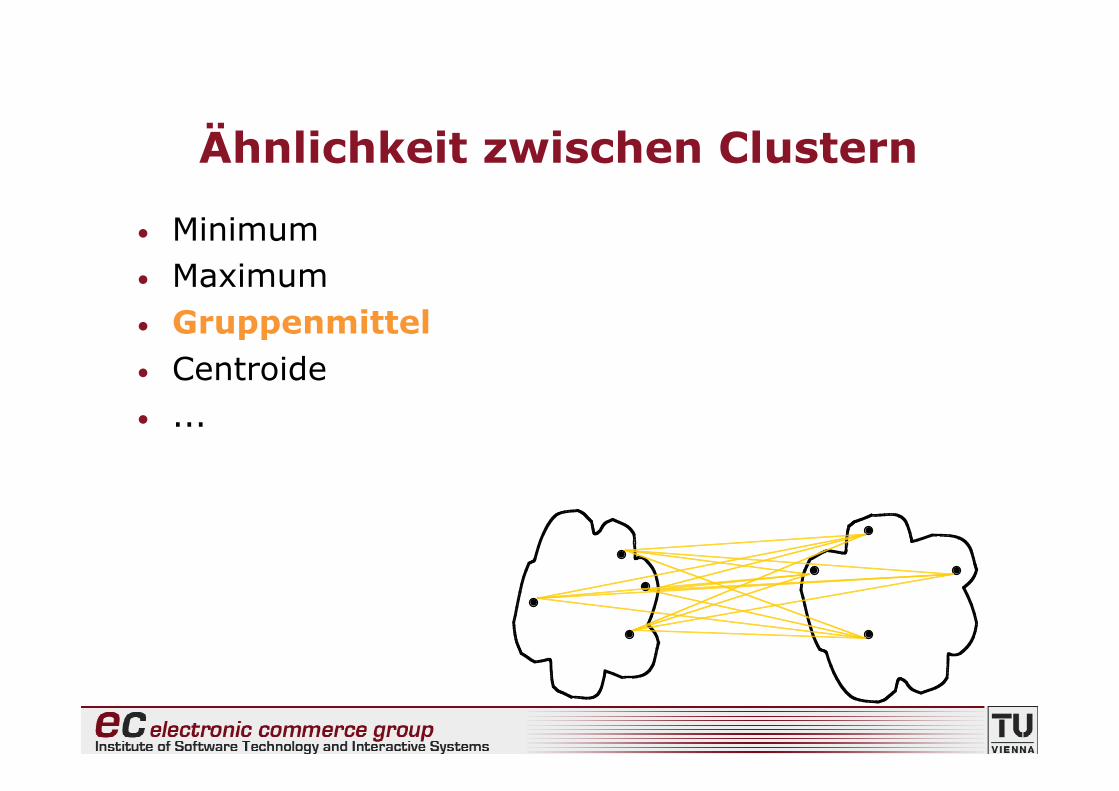
Ähnlichkeit zwischen Clustern
• Minimum• Maximum• Gruppenmittel• Centroide• ...
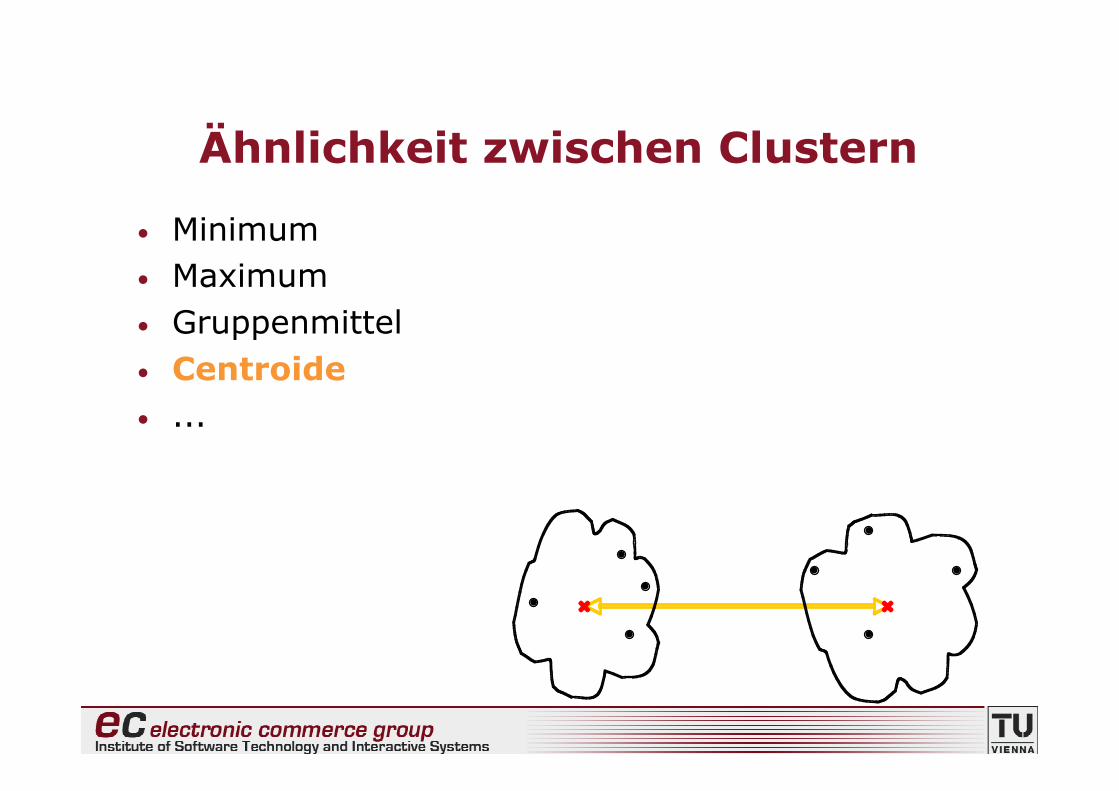
35
Ähnlichkeit zwischen Clustern
• Minimum• Maximum• Gruppenmittel• Centroide• ...
× ×

36
Minimum: Single Linkage
Ähnlichkeit zweier Cluster entspricht derÄhnlichkeit der ähnlichsten Datenpunkte
I1 I2 I3 I4 I5I1 1.00 0.90 0.10 0.65 0.20I2 0.90 1.00 0.70 0.60 0.50I3 0.10 0.70 1.00 0.40 0.30I4 0.65 0.60 0.40 1.00 0.80I5 0.20 0.50 0.30 0.80 1.00
1 2 3 4 5

37
Maximum: Complete Linkage
Ähnlichkeit zweier Cluster entspricht derÄhnlichkeit der unähnlichsten Datenpunkte
I1 I2 I3 I4 I5I1 1.00 0.90 0.10 0.65 0.20I2 0.90 1.00 0.70 0.60 0.50I3 0.10 0.70 1.00 0.40 0.30I4 0.65 0.60 0.40 1.00 0.80I5 0.20 0.50 0.30 0.80 1.00 1 2 3 4 5

38
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

39
Neuronale Netze
• artificial neural networks are massively parallelinterconnected structures consisting of simple(usually) adaptive processing units in hierarchicalorganization
• artificial neural networks are “trained” based onexample presentations to exhibit a particularbehavior (as opposed to “programmed”)

40
Neuronale Netze
(1)Establishment of new connections(2)Removal of existing connections(3)Adaptation of weights assigned to connection(4)Insertion of new units(5)Removal of existing units
• (1) - (3) are most commonly used• (1) and (2) are special cases of (3)

41
Competitive Learning
• Network architecture• k competitive units• each unit is assigned a n-dimensional weight
vector

42
Competitive Learning
• Training process
(1)random selection of an input pattern(2)computation of each unit’s activation(3)selection of the unit with the highest
activation (“winner”)(4)adaptation of the weight vector of the winner
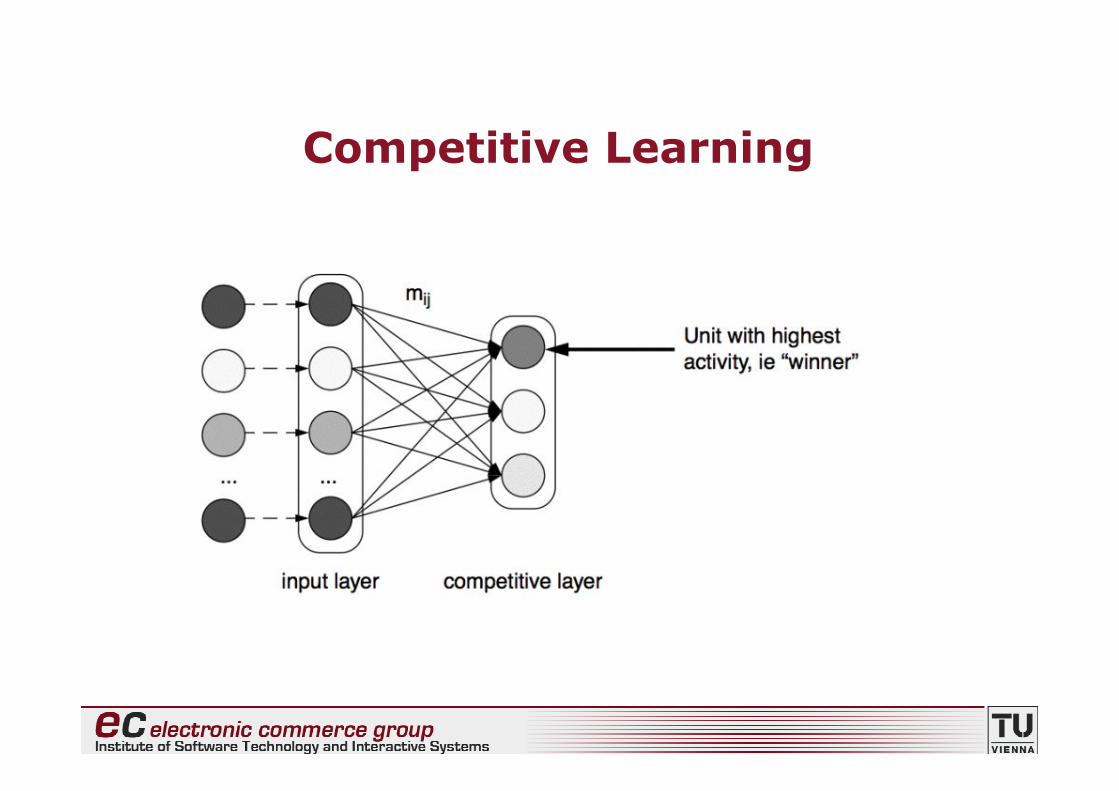
43
Competitive Learning
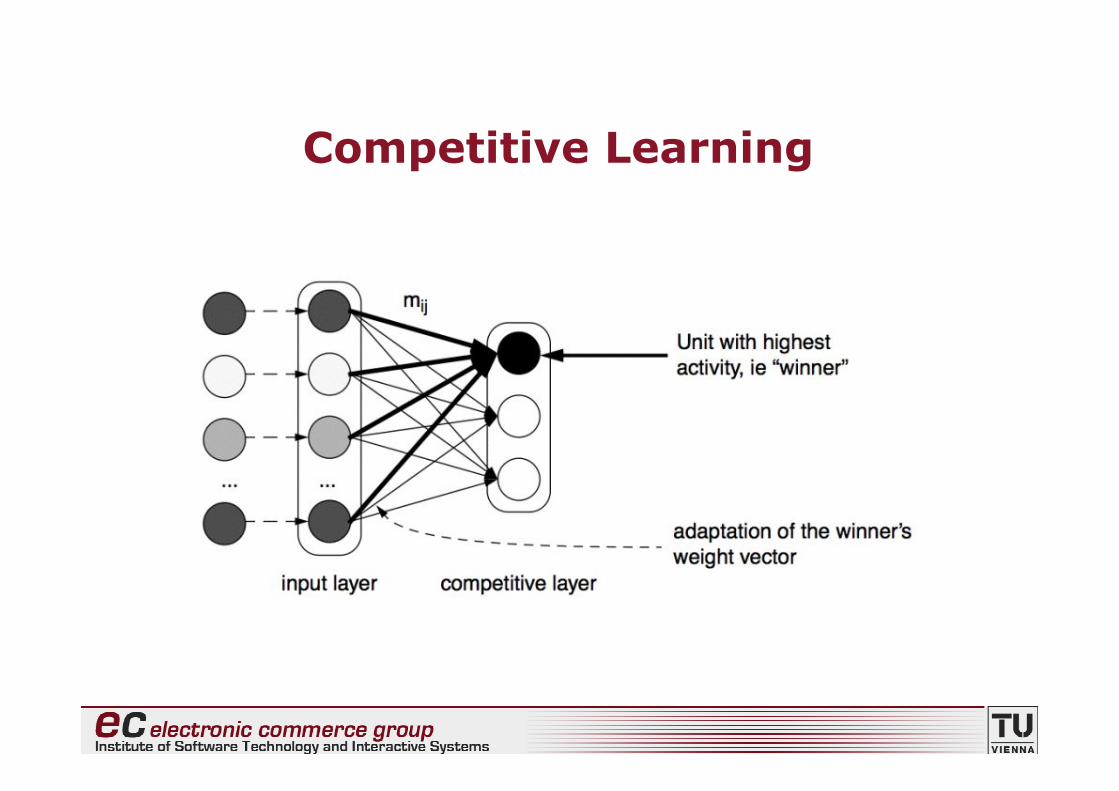
44
Competitive Learning

45
Self-Organizing Map
• Network architecture• Layer of input units
Propagate input pattern onto output units• Layer of output units
Arranged according to some topology (usually2-dimensional grid)

46
Self-Organizing Map
• Training process
(1)Initialization of weight vectors (e.g. random)(2)Random selection of input pattern(3)Computation of activation (e.g. Euclidean
distance between input and weight vector)(4)Selection of “winner”(5)Adaptation of weight vectors (“winner” and
neighbors)
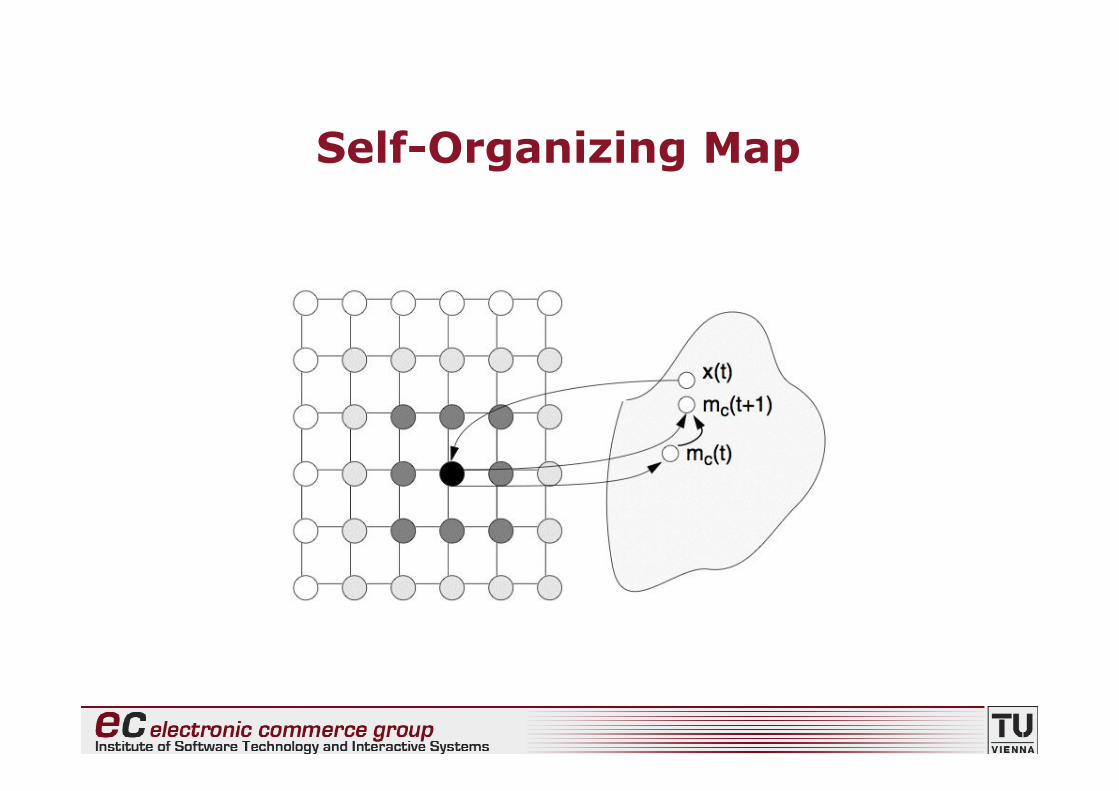
47
Self-Organizing Map
48
Self-Organizing Map

49
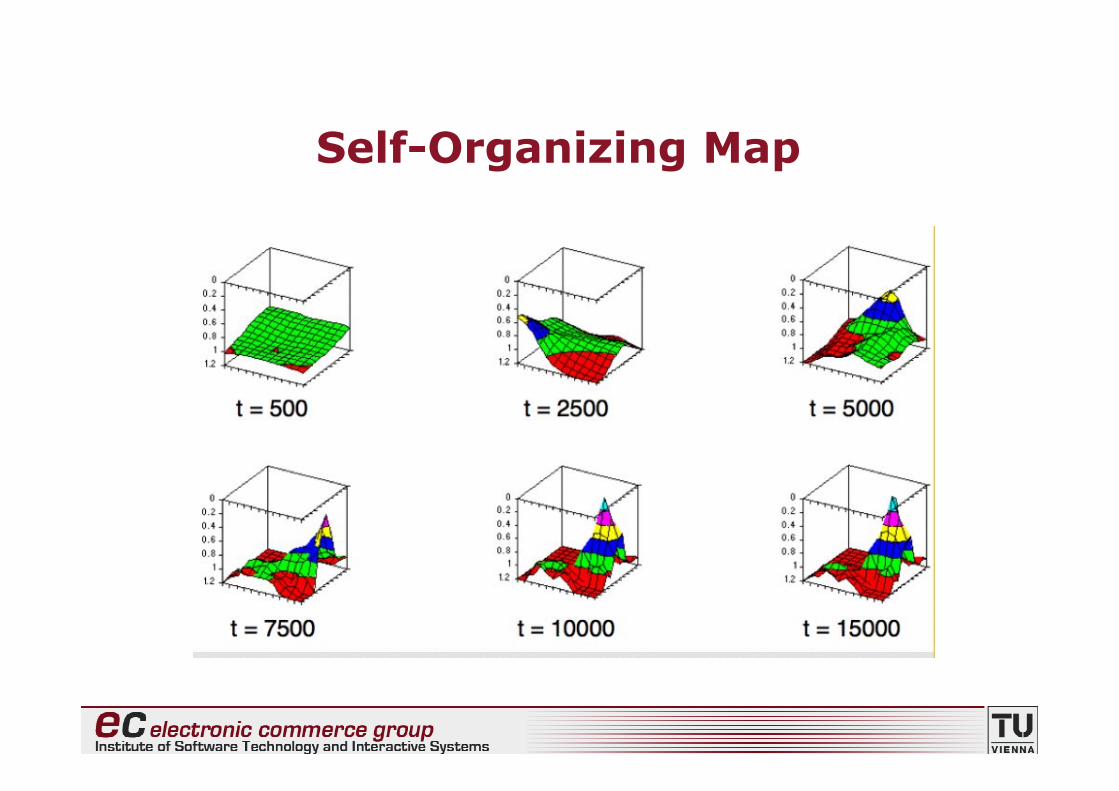
Self-Organizing Map
• Das Ergebnis von Self-Organizing Maps ist eine“räumliche” Anordnung der Datenpunkte (alsoeine Art “Datenlandkarte”)
• Dabei werden “ähnliche” Datenpunkte vonbenachbarten Bereichen der Karte repräsentiert
• Self-Organizing Maps werden daher(a) zur Visualisierung; und(b) zur Datenkompression verwendet

50
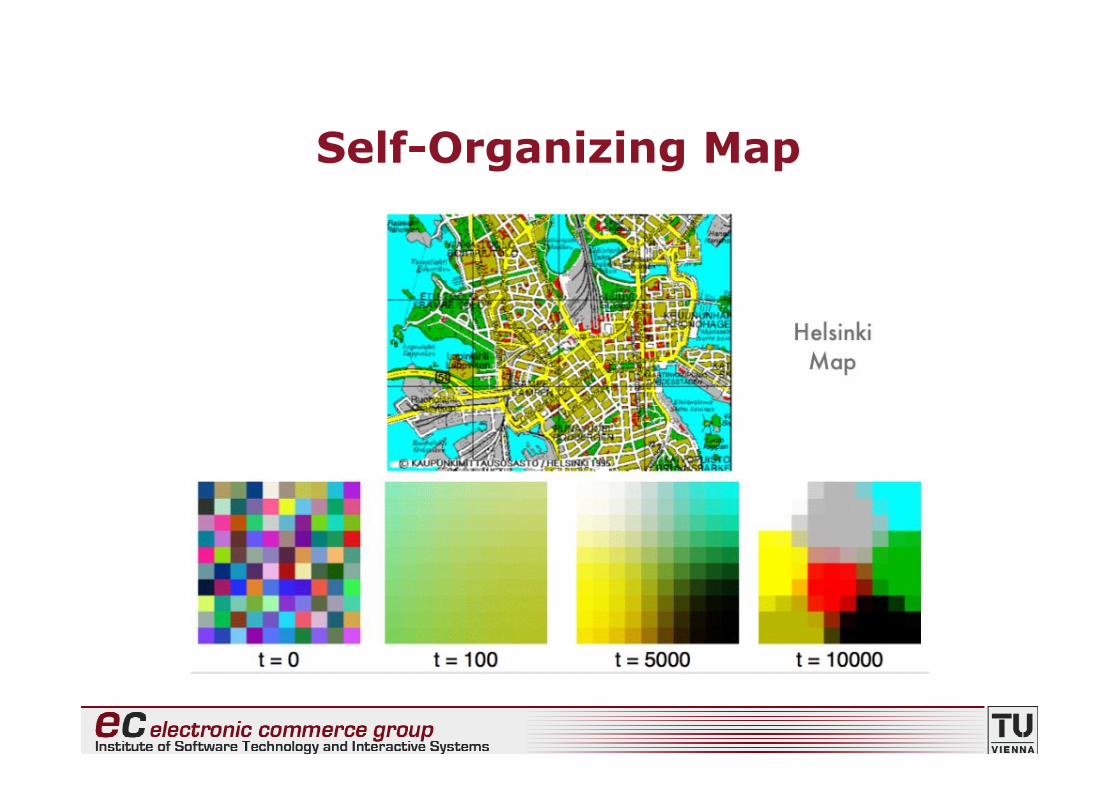
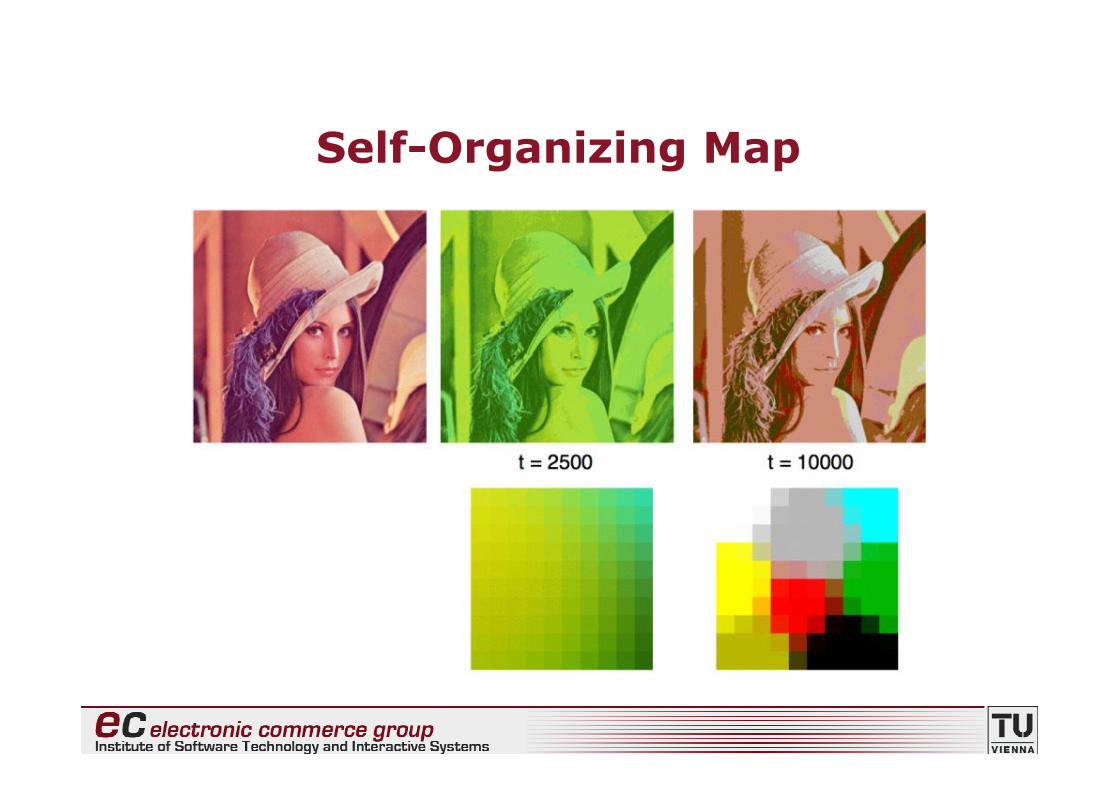
Self-Organizing Map
• In den beiden folgenden Beispielen sind dieDatenpunkte einzelne Pixel eines Bildes
• Die Pixel werden dabei durch 3-dimensionaleVektoren der RGB-Werte der Bildpunkterepräsentiert
• Zufällige Initialisierung der Gewichtsvektoren derSelf-Organizing Map
• Nach dem Training: räumlich verlaufendeAnordnung der Farbwerte des Bildes

51
Self-Organizing Map
52
Self-Organizing Map

53
Self-Organizing Map

54
Self-Organizing Map
55
Self-Organizing Map

56
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

57
Cluster Validierung
• Im Fall von (überwachter) Klassifikation stehenVerfahren zur Validierung zur Verfügung (z.B.Accuracy, Recall, Precision, ...)
• Im Fall von (unüberwachtem) Clustering ist dieValidierung nicht ganz so “geradlinig”
• Wie kann man entscheiden• welches Ergebnis bzw Verfahren “besser” ist• ob “sinnvolle” Cluster gefunden wurden

58
Cluster Validierung
• Externe Faktoren• “externe” Klassenlabels sind verfügbar• Grad der Übereinstimmung der externen
Labels mit dem Ergebnis des Clustering; z.B.Entropie
• Interne Faktoren• Clusterqualität ohne Rückgriff auf externe
Information; z.B. Sum of Squared Error

59
Cluster Validierung
• Validierung über Korrelation zwischenProximitätsmatrix und Clustermatrix
• Clustermatrix• Quadratische Matrix der Datenpunkte• 1, wenn die beiden entsprechenden
Datenpunkte zum gleichen Cluster gehören;sonst 0
• Hohe Korrelation ≈ gutes Clustering

60
Cluster Validierung
• Cluster Cohesion• Misst, wie ähnlich die Datenpunkte eines
Clusters zueinander sind
• Cluster Separation• Misst, wie unterschiedlich die einzelnen Cluster
zueinander sind

61
Cluster Validierung
• Silhouette Coefficient (s)• kombiniert Cluster Cohesion und Cluster
Separation• Für einen Datenpunkt i:
a = average distance to other points in clusterb = min(average distance to points in otherclusters)s = 1- a/b (wenn a < b)[ s = b/a - 1 (wenn a >= b, sollte aber eher dieAusnahme sein) ]

62
Cluster Validierung
• Silhouette Coefficient• Wert zwischen 0 und 1• je näher an 1 desto besser• Durch Summieren und Mitteln kann man Werte
für Cluster berechnen

63
Cluster Validierung
• “The validation of clustering structures is themost difficult and frustrating part of clusteranalysis.Without a strong effort in this direction, clusteranalysis will remain a black art accessible only tothose true believers who have experience andgreat courage.”
[A. K. Jain and R. C. Dubes. Algorithms for Clustering Data,Prentice Hall, 1988.]

64
Inhalt
• Ein paar grundlegende Gedanken• K-Means Clustering• Hierarchische Verfahren• Ganz was anderes: Self-Organizing Maps• Cluster Validierung• Zusammenfassung

65
Zusammenfassung
• Clustering soll Zusammenhänge zwischen Datenverdeutlichen
• Clustering soll Daten zu “natürlichen” Gruppenzusammenfassen
• Clusterverfahren liefern Ergebnisse inAbhängigkeit von Startkonfigurationen
• Es ist somit keine schlechte Idee, diese Verfahrenwiederholt anzuwenden - mit Variationen derStartkonfiguration

66
Quellen
• Einige Folien sind einem Foliensatz von
P.-N. Tan, M. Steinbach, V. Kumar:Introduction to Data Mining,University of Minnesota
nachempfunden.
• Das Original gibt es hier:http://www-users.cs.umn.edu/~kumar/dmbook/index.php

67
Soviel zu Clustering
• Danke!
• Fragen?

68
Doch noch was :-) One of the best techniques I've ever learned for breaking through inertia, stimulating ideas, and finding a direction
for a piece of writing is "clustering." I was introduced to clustering by Annapolis author and writing instructorLaura Oliver, and over the years I've used it to jump start everything from personal essays to corporate reports.Clustering is a powerful tool because it taps into the right brain, which drives creativity. Our right brain is wherefresh ideas and original insights are generated. The left brain, in contrast, is more logical and orderly. Both areessential to good writing, but if your left brain is too dominant when you start a piece, it inhibits the free flow ofthought. Clustering muffles the left brain for a time so the right brain can play freely. Here's how to do it.
1. Write a nucleus word or phrase on a clean piece of paper. I usually choose a word that I consider, loosely, to bemy topic. For example, if I'm writing a Mother's Day essay, "mother" would be a good nucleus word. If I'm writingan annual report for a client I might choose "service" or "business" or even a phrase like “improving our image."The nucleus word's purpose is to trigger associations. Emotionally charged words like "love," "loss," or "envy" areextremely effective, as are prepositions: "around," "beyond," "over," and so forth.
2. Circle the nucleus and let connections flow, writing down each new word or phrase that comes to mind, circling it,and connecting it with a line. to the, word that sparked it. Attach to the nucleus each word that seems like anentirely new direction. But don't get hung up on which words connect to what. The idea is to let thoughts runquickly without editing, censoring, or worrying about proper sequence.
3. Keep your hand moving all the time; do not stop. If you get stuck, keep circling words or thickening lines betweenthem. You can even doodle, but do not stop moving your pen. As long as your hand is occupied, jotting thoughtsand circling, your left brain—the "critic"—is occupied and thus is prevented from interfering with spontaneity andcreativity.
4. Cluster for three minutes or so—you'll probably fill the page. At some point you'll feel a mental shift or an "aha!"that suggests what you want to write about.
5. Continue adding to your cluster if you feel there is more to explore, but you can start writing anytime you want.Refer to your cluster to stimulate thoughts as you write, but don't feel you have to include in your pieceeverything that's in the cluster.
6. Write your piece without worrying about perfection. Get it all onto paper, and later, go back to polish using thelogical left brain.
[http://www.meadecomm.com/clustering.html]


















