Computerorientierte Mathematik I - Private...
329
Computerorientierte Mathematik I mit Java Rolf H. M ¨ ohring Technische Universit¨ at Berlin Institut f ¨ ur Mathematik Wintersemester 2004/05
Transcript of Computerorientierte Mathematik I - Private...

Computerorientierte Mathematik Imit Java
Rolf H. Mohring
Technische Universitat BerlinInstitut fur Mathematik
Wintersemester 2004/05

ii

Vorbemerkungen
Die Computerorientierte Mathematik stellt die Informatikgrundausbildung an der TU Berlin fur dieStudiengangeTechno- und WirtschaftsmathematiksowieInformationstechnik im Maschinenwe-sendar. Zugleich bildet sie das Bindeglied zwischen Informatik und Mathematik. Diesaußert sich vorallem in der Auswahl der Themen und der algorithmischen Fragen, die in der Veranstaltung behandeltwerden.
Die Veranstaltung streckt sichuber zwei Semester und vermittelt den Stoff in insgesamt 8 Semes-terwochenstunden Vorlesung und 8 SemesterwochenstundenUbung. Die Vorlesung umfasst folgendePunkte
- Grundlagen des Entwurfs und der Analyse von Algorithmen
- Standardalgorithmen und Datenstrukturen
- Grundlagen von prozeduralen und objektorientierten Programmiersprachen, insbesondere Java
- Einfuhrung in Aufbau und Funktionsweise von Rechnern (einschließlich Schaltkreistheorie)
- Aspekte der Rechnernutzung in der Mathematik: Zahlendarstellung, Computerarithmetik, grund-legende Algorithmen der Diskreten und der Numerischen Mathematik
Die Ubung vertieft diesen Stoff in praktischen und theoretischen Aufgaben. Der praktische Teil enthalteine Einfuhrung in die Rechnerbenutzung an UNIX-Workstations und das Erlernen der Programmier-sprache Java. Sie untergliedert sich in folgende Punkte:
- Einfuhrung in die Rechnerbenutzung
- Einfuhrung in die Programmiersprache Java
- Einuben von Techniken fur das Erstellen und Testen von Programmen und Algorithmen
- Realisierung von Algorithmen auf dem Rechner
- Besprechung derUbungsaufgaben
- PraktischeUbungen am Rechner
Es werden keinerlei Vorkenntnisse aus dem Bereich der Informatik vorausgesetzt. Hinsichtlich derMathematik sind Kenntnisse im Umfang der Schulmathematik ausreichend.
iii

iv VORBEMERKUNGEN

Inhaltsverzeichnis
Vorbemerkungen iii
Inhaltsverzeichnis v
1 Einleitung 1
1.1 Computer und Algorithmen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Programmiersprachen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Algorithmen versus Programmiersprachen. . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Probleme, Algorithmen, Programme 11
2.1 Temperatur Umrechnung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.1 Das Problem:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.2 Der Algorithmus:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.3 Das Programm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Einkommensteuerberechnung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Das Problem. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.2 Der Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2.3 Das Programm. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3 Primzahl. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3.1 Das Problem. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3.2 Der Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3 Ausdrucke, Anweisungen, Kontrollstrukturen 31
v

vi INHALTSVERZEICHNIS
3.1 Variablen und Objekte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2 Ausdrucke . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.1 Ausdrucke, genaue Erklarung . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.2 Ausdrucke und einfache Anweisungen. . . . . . . . . . . . . . . . . . . . . 36
3.2.3 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.3 Definitionen und Deklarationen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.4 Strukturierte Anweisungen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4.1 Zusammengesetzte Anweisung, Verkettung. . . . . . . . . . . . . . . . . . 39
3.4.2 Selektion, Bedingte Anweisung. . . . . . . . . . . . . . . . . . . . . . . . 44
3.4.3 Wiederholung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.4.4 Machtigkeit von Kontrollstrukturen. . . . . . . . . . . . . . . . . . . . . . 53
3.5 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4 Syntax und Semantik von Programmiersprachen 57
4.1 Backus Naur Form. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.2 Erweiterte Backus Naur Form. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.3 Syntaxgraphen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.4 Syntax versus Semantik. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.5 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5 Objekte, Typen, Datenstrukturen 69
5.1 Datentypen und Operationen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2 Strukturierte Datentypen (Datenstrukturen). . . . . . . . . . . . . . . . . . . . . . 72
5.3 Arrays . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.3.1 Arrays in Java. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.3.2 Mehrdimensionale Arrays. . . . . . . . . . . . . . . . . . . . . . . . . . . 77
5.4 Strings. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.4.1 Strings in Java. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.4.2 Manipulation von Strings: ein erster Ansatz. . . . . . . . . . . . . . . . . . 80
5.4.3 Manipulation von Strings mit der Klasse StringTokenizer und Exception Hand-ling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.5 Records. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.6 Listen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89

INHALTSVERZEICHNIS vii
5.6.1 Einschub: Javadoc. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.6.2 Eine Klasse fur Listen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.7 Stacks. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .101
5.8 Queues (Warteschlangen). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .111
5.9 Zusammenfassung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .112
5.10 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .114
6 Algorithmen auf Arrays 115
6.1 Suchen einer Komponente vorgegebenen Wertes. . . . . . . . . . . . . . . . . . . . 115
6.1.1 Sequentielle Suche. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .115
6.1.2 Binare Suche. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .116
6.2 Lineare Gleichungssysteme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .119
6.2.1 Vektoren und Matrizen. . . . . . . . . . . . . . . . . . . . . . . . . . . . .119
6.2.2 Ein Produktionsmodell. . . . . . . . . . . . . . . . . . . . . . . . . . . . .127
6.2.3 Das Gaußsche Eliminationsverfahren. . . . . . . . . . . . . . . . . . . . . 130
6.2.4 Wahl des Pivotelements. . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
6.2.5 Eine Java Klasse zur Losung linearer Gleichungssysteme. . . . . . . . . . . 140
6.3 Kurzeste Wege in gerichteten Graphen. . . . . . . . . . . . . . . . . . . . . . . . . 160
6.3.1 Graphen und Wege. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .160
6.3.2 Zwei konkrete Anwendungen. . . . . . . . . . . . . . . . . . . . . . . . . 162
6.3.3 Die Bellman Gleichungen. . . . . . . . . . . . . . . . . . . . . . . . . . . 166
6.3.4 Der Einfluss negativer Zykel. . . . . . . . . . . . . . . . . . . . . . . . . . 169
6.3.5 Der Bellman-Ford Algorithmus. . . . . . . . . . . . . . . . . . . . . . . . 170
6.3.6 Die Ermittlung negativer Zykel. . . . . . . . . . . . . . . . . . . . . . . . 175
6.3.7 Die Ermittlung kurzester Wege. . . . . . . . . . . . . . . . . . . . . . . . . 176
6.4 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .178
7 Abstraktion von Methoden und Daten 181
7.1 Funktionale (Prozedurale) Abstraktion. . . . . . . . . . . . . . . . . . . . . . . . . 181
7.1.1 Funktionen und Prozeduren. . . . . . . . . . . . . . . . . . . . . . . . . . 181
7.1.2 Parameter und Datenfluss. . . . . . . . . . . . . . . . . . . . . . . . . . . 182
7.1.3 Gultigkeitsbereiche von Identifiern (Scope). . . . . . . . . . . . . . . . . . 187
7.1.4 Abarbeitung von Funktionsaufrufen. . . . . . . . . . . . . . . . . . . . . . 190

viii INHALTSVERZEICHNIS
7.1.5 Der Run-Time-Stack. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .192
7.2 Modulare Abstraktion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .197
7.3 Abstraktion durch Klassen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .198
7.3.1 Definition von Klassen. . . . . . . . . . . . . . . . . . . . . . . . . . . . .198
7.3.2 Static-Felder und Methoden. . . . . . . . . . . . . . . . . . . . . . . . . 201
7.3.3 Unterklassen und Vererbung. . . . . . . . . . . . . . . . . . . . . . . . . . 201
7.3.4 Packages. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .204
7.3.5 Sichtbarkeit von Klassen, Methoden und Feldern. . . . . . . . . . . . . . . 204
7.3.6 Weitere Modifizierer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .205
7.3.7 Interfaces. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .206
7.3.8 Klassen in Klassen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .208
7.3.9 Implementationen des Interface ActionListener. . . . . . . . . . . . . . . . 208
7.3.10 Der Lebenszyklus von Objekten. . . . . . . . . . . . . . . . . . . . . . . . 212
7.4 Beispiele von Klassen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .212
7.4.1 Bruchrechnung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .212
7.4.2 Erzeugung von Zufallszahlen. . . . . . . . . . . . . . . . . . . . . . . . . . 217
7.5 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .224
8 Rekursion 225
8.1 Beispiele fur Rekursive Algorithmen. . . . . . . . . . . . . . . . . . . . . . . . . . 228
8.1.1 Berechnung des ggT. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .228
8.1.2 Die Turme von Hanoi . . . . . . . . . . . . . . . . . . . . . . . . . . . . .229
8.1.3 Die Ackermann Funktion. . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
8.1.4 Ulams Funktion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .235
8.2 Wo Rekursion zu vermeiden ist. . . . . . . . . . . . . . . . . . . . . . . . . . . . .236
8.2.1 Berechnung der Fakultat . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
8.2.2 Berechnung des großten gemeinsamen Teilers. . . . . . . . . . . . . . . . . 237
8.2.3 Die Turme von Hanoi . . . . . . . . . . . . . . . . . . . . . . . . . . . . .237
8.2.4 Berechnung der Fibonacci-Zahlen. . . . . . . . . . . . . . . . . . . . . . . 237
8.2.5 Zusammenfassung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .239
8.3 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .239
9 Die Analyse von Algorithmen 241

INHALTSVERZEICHNIS ix
9.1 Analysearten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .242
9.2 Die Asymptotische Notation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .243
9.2.1 Obere Schranken. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .243
9.2.2 Untere Schranken. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .246
9.3 A posteriori Analyse, Laufzeitmessungen. . . . . . . . . . . . . . . . . . . . . . . 247
9.4 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .248
10 Sortieren in Arrays 249
10.1 Direkte Methoden. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .250
10.1.1 Sortieren durch Austauschen: Bubblesort. . . . . . . . . . . . . . . . . . . 250
10.1.2 Sortieren durch direktes Auswahlen: Selection Sort. . . . . . . . . . . . . . 252
10.1.3 Sortieren durch direktes Einfugen: Insertion Sort. . . . . . . . . . . . . . . 254
10.2 Mergesort. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .256
10.2.1 Mischen sortierter Arrays. . . . . . . . . . . . . . . . . . . . . . . . . . . 256
10.2.2 Sortieren durch rekursives Mischen: Mergesort. . . . . . . . . . . . . . . . 259
10.2.3 Die Analyse von Mergesort. . . . . . . . . . . . . . . . . . . . . . . . . . 260
10.3 Beschleunigung durch Aufteilung: Divide and Conquer. . . . . . . . . . . . . . . . 263
10.3.1 Aufteilungs-Beschleunigungs-Satze . . . . . . . . . . . . . . . . . . . . . . 263
10.3.2 Multiplikation von Dualzahlen. . . . . . . . . . . . . . . . . . . . . . . . . 267
10.4 Quicksort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .269
10.4.1 Der Algorithmus. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .269
10.4.2 Der Rekursionsaufwand von Quicksort. . . . . . . . . . . . . . . . . . . . 273
10.4.3 Der Worst Case Aufwand von Quicksort. . . . . . . . . . . . . . . . . . . . 274
10.4.4 Der mittlere Aufwand von Quicksort. . . . . . . . . . . . . . . . . . . . . . 274
10.5 Heapsort. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .279
10.5.1 Die Grobstruktur von Heapsort. . . . . . . . . . . . . . . . . . . . . . . . . 279
10.5.2 Die Implementation des Heaps. . . . . . . . . . . . . . . . . . . . . . . . . 280
10.5.3 Die Implementation von Heapsort. . . . . . . . . . . . . . . . . . . . . . . 284
10.5.4 Die Analyse von Heapsort. . . . . . . . . . . . . . . . . . . . . . . . . . . 286
10.6 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .289
11 Untere Komplexitatsschranken fur das Sortieren 291
11.1 Das Entscheidungsbaum-Modell. . . . . . . . . . . . . . . . . . . . . . . . . . . . 292

x INHALTSVERZEICHNIS
11.2 Analyse des Entscheidungsbaums. . . . . . . . . . . . . . . . . . . . . . . . . . . 293
11.3 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .296
12 Zahlendarstellungen und Rechnerarithmetik 297
12.1 Zahlensysteme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .297
12.2 Darstellung ganzer Zahlen im Rechner. . . . . . . . . . . . . . . . . . . . . . . . . 300
12.2.1 Die Vorzeichen-Betrag Darstellung. . . . . . . . . . . . . . . . . . . . . . 300
12.2.2 Komplement-Darstellungen. . . . . . . . . . . . . . . . . . . . . . . . . . 301
12.3 Darstellung reeller Zahlen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .304
12.3.1 Festkommazahlen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .305
12.3.2 Gleitkommazahlen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .306
12.3.3 Genauigkeit von Gleitkommadarstellungen. . . . . . . . . . . . . . . . . . 309
12.3.4 Der Einfluss von Algorithmen auf die numerische Genauigkeit. . . . . . . . 310
12.4 Literaturhinweise. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .311
Literaturverzeichnis 313
Index 316

Kapitel 1
Einleitung
1.1 Computer und Algorithmen
Wir leben im Zeitalter der Computerrevolution. Sie hat vergleichbare Auswirkungen fur die Gesell-schafts- und Sozialordnung wie die Industrielle Revolution. War die Industrielle Revolution im We-sentlichen eine Steigerung der korperlichen Krafte des Menschen, so ist die Computerrevolution eineSteigerung der geistigen Krafte, eine Verstarkung des menschlichen Gehirns.
Die Bedeutung des Computers hat zurInformatik(Computer Science) als neue wissenschaftliche Dis-ziplin gefuhrt. Sie behandelt alle Aspekte des Computereinsatzes und der Rechnerentwicklung.
Wenn man sich einmal fragt, was einen Computer so revolutionar macht, so kann man in ersterNaherung zur Beantwortung dieser Frage sagen, dass ein Computer eine Maschine ist, die geistigeRoutinearbeiten durchfuhrt, indem sie einfache Operationen (Basisoperationen) mit hoher Geschwin-digkeit ausfuhrt. Ein Beispiel ist etwa das Suchen eines Namens in einer Liste oder das Sortieren einerMenge von Namen in alphabetischer Reihenfolge.
Dies bedeutet, dass ein Computer naturlich nur solche Aufgaben erledigen kann, die durch solcheeinfachen Operationen beschreibbar sind. Außerdem muss man dem Computer mitteilen konnen, wiedie Aufgabe durchzufuhren ist. Eine solche Beschreibung der Aufgabe fur den Computer nennt manAlgorithmus.
Ein Algorithmus ist also eineHandlungsvorschrift, und keine Problembeschreibung. Etwas genauer:
Ein Algorithmusist eine prazise, das heisst in einer festgelegten Sprache abgefasste, endliche Be-schreibung eines allgemeinen Verfahrens unter Verwendung ausfuhrbarer elementarer Verarbeitungs-schritte zur Losung einer gestellten Aufgabe.
In der Informatik muss man diese umgangssprachliche Beschreibung weiter prazisieren durch die An-gabe eines geeigneten Modells fur den Computer (Maschinenmodell) und die Angabe der moglichenelementaren Schritte (d. h. der Angabe einer Programmiersprache). Mogliche Modelle in der Infor-matik sind die Turing-Maschine, die Random-Access-Maschine (RAM) und viele andere. Diese Ma-
Version vom 21. Januar 2005
1

2 KAPITEL 1. EINLEITUNG
schinenmodelle werden genauer in der Theorie der Berechenbarkeit untersucht. Es hat sich gezeigt,dass alle gangigen Maschinenmodelle zueinanderaquivalent sind in dem Sinne, dass man das eineModell durch das andere simulieren kann. Man kann also eine Turingmaschine so programmieren,dass sie eine RAM darstellt und umgekehrt.
Die konkrete Ausfuhrung bzw. Abarbeitung des Algorithmus nennt man einenProzess. Die Einheit,die den Prozess ausfuhrt heißtProzessor. Ein Prozess besitzt zu jedem Zeitpunkt einenZustand, derden aktuellen Stand der Ausfuhrung angibt.
Man beachte, dass ein Prozessor nicht nur ein Computer, sondern auch ein Mensch oder ein Geratsein kann.
Beispiel:
Prozess Algorithmus Typische Schritte im AlgorithmusPullover stricken Strickmuster 2 rechts, 2 linksModellflugzeug bauen Montageanleitung leime Teil A an Flugel BKuchen backen Backrezept 3 Eier unter ruhrenBeethovensonate spielenNotenblatt einzelne Noten
Ein Computer ist also nichts anderes als ein spezieller Prozessor. Ein gangiger Computer hat dreiHauptkomponenten wie sie Abbildung1.1zeigt.
Ein-, Ausgabe-gerate
-
Zentraleinheit
CPU
-
Speicher(memory)
(3) (1) (2)
Abbildung 1.1: Hauptkomponenten eines Computers.
Es sind:
1. Die Zentraleinheit(CPU oderCentral Processing Unit). Sie fuhrt die Basisoperationen aus.
2. DerSpeicher(Memory). Er enthalt
• die auszufuhrenden Operationen des Algorithmus,
• die Information (Datenbzw.Objekte), auf der die Operationen wirken (wesentliches Kenn-zeichen desvon-Neumann Rechners).
3. Die Ein-Ausgabegerate (Input and Output Devices), uber die der Algorithmus und die Daten,die in den Hauptspeicher gebracht werden unduber die der Computer die Ergebnisse seinerTatigkeit mitteilt.
Diese Komponenten bilden dieHardware. Das sind die physikalischen Einheiten, aus denen sichein Computer zusammensetzt. Im Rahmen der Vorlesung werden Ihnen die Computer sowohl alstheoretisches Modell in der Vorlesung, als auch als praktische Hardware begegnen. Die praktische

1.1. COMPUTER UND ALGORITHMEN 3
Hardware wird durch UNIX-Workstations oder Linux PCs dargestellt. Die typischen Schritte in denAlgorithmen fur diese Computer sind Statements der Programmiersprache Java, die Sie im Rahmender Veranstaltung erlernen werden. In theoretischer Hinsicht wird in der Vorlesung ein idealisiertesRechnermodell (ahnlich zu einer RAM) betrachtet, das Java-Statements verarbeiten kann, aber idea-lisiert in der Hinsicht ist, dass vorab keine Beschrankungen durch Wortlange, großte zu verarbeitendeZahl usw. angenommen werden. Sie spielen erst bei konkreten Implementationen eine Rolle.
Kommen wir zuruck zur Frage, was denn den Computer denn so revolutionar macht, und fragen nachkennzeichnenden Merkmale hervorheben. Dann ergeben sich:
1. Geschwindigkeit
Selbst komplexe Algorithmen mit vielen Basisoperationen konnen schnell ausgefuhrt werden.Man beachte jedoch, dass trotz hoher Computergeschwindigkeit Aufgaben bleiben, die zu zei-tintensiv sind, um durchfuhrbar zu sein (z. B. die Bestimmung einer Gewinnstrategie beimSchachspielen). Im Rahmen der Komplexitatstheorie wird der Schwierigkeitsgrad von Proble-men untersucht, den sie fur die Behandlung auf dem Computer darstellen.
2. Zuverl assigkeit
Die Wahrscheinlichkeit fur elektronische Fehler sindaußerst gering. Meist sind Absturze oderInkorrektheiten in Programmen auf Programmierfehler oder logische Fehler zuruckzufuhren.In einem gewissen Sinne ist ein Computer also ein billiger und gehorsamer Diener. Er fuhrtblindlings Befehle aus und wiederholt sie, wenn notig, beliebig oft ohne Beschwerde. DieseStarke ist aber zugleich auch eine Schwache, da die Anweisungen blindlings ausgefuhrt werden,egal ob sie nun den beabsichtigten Ablauf korrekt beschreiben oder nicht.
3. Speicher
Ein Rechner kann riesige Informationsmengen speichern und schnell darauf zugreifen, da seineSpeichertechnik den beliebigen Zugriff (Random Access) gestattet. Hier besteht ein großer Un-terschied zum menschlichen Gehirn, das in der Regel assoziativ arbeitet, d. h. beim Auffindenvon Informationen wird nicht auf die Adresse der Information zuruckgegriffen, sondern manbenutzt die Assoziation mit anderen Informationen (“Eselsbrucken”).
4. Kosten
Die Kosten der Computer sind in vielen Bereichen niedrig im Vergleich zuaquivalenter mensch-licher Arbeit.
5. Vernetzung
Die Vernetzung von Computern (insbesondere im Internet) eroffnet vollig neuartige und schnel-le Moglichkeiten zur Kommunikation und zum Zugang zu Information aus vielfaltigen Quellen.
Die Punkte 1.–5. werden deutlich, wenn man sich ein modernesFlugreservierungssystemvorstellt,bei dem parallel in vielen Landern Reiseburos auf zentrale Dateien Buchungen und Stornierungenvornehmen. Man stelle sich einmal vor, wie man das ohne Computer realisieren musste.

4 KAPITEL 1. EINLEITUNG
1.2 Programmiersprachen
Die Ausfuhrung eines Algorithmus auf einem Prozessor setzt voraus, dass der Prozessor den Algo-rithmusinterpretierenkonnen muss, d. h. er muss
• verstehen, was jeder Schritt bedeutet und
• die jeweilige Operation ausfuhren konnen.
Dies ist erreichbar durch dieschrittweise Verfeinerung(ein wichtiges Instrument fur die Program-miermethodik) bis hin auf das Verstandnisniveau des Prozessors. So kann z. B. bei der Anleitung zumStricken die Anweisung “2 links-2 rechts” Teil der Verfeinerung der Anweisung “Zopfmuster” sein.
Bei Computern als Prozessor muss der Algorithmus in einer Programmiersprache ausgedruckt wer-den. Die Schritte im Algorithmus heißen dannAnweisungoderBefehl(statement). Ihr Detailliertheits-grad und ihre konkrete Formulierung ist abhangig von der verwendeten Programmiersprache.
Bei den einfachsten Sprachen (Maschinensprachen) kann jede Anweisung direkt vom Computer in-terpretiert werden. Dies bedeutet, dass Anweisungen jeweils nur kleine Teile des Algorithmus aus-drucken und man lange Programme fur komplexe Aufgaben schreiben muss. Die Programmierung inder Maschinensprache ist also langwierig und muhsam und dadurch auch fehleranfallig.
Zur Vereinfachung der Programmierung wurden andere Sprachen entwickelt, die sogenanntenhoherenProgrammiersprachen. Sie sind komfortabler, da eine Anweisung bereits einen großeren Algorith-musteil abdecken kann, was wiederum die Erstellung vom Programmen erleichtert.
Programme in hoheren Programmiersprachen konnen nicht direkt durch die CPU eines Computersinterpretiert werden. Der gangige Weg, dies zu erreichen besteht darin, Programme aus hoheren Pro-grammiersprachen in die Maschinensprachen zuubersetzen, bevor sie ausgefuhrt werden (evtl.ubermehrere Zwischensprachen). DieseUbersetzung kann selbst wiederum von einem Computer aus-gefuhrt werden und ist damit ein automatisierter Teil der schrittweisen Verfeinerung, vgl. Abbildung1.2.
Der Ubergang zwischen Problem- und Maschinen-orientierten Sprachen ist fließend. So weist bei-spielsweise die Programmiersprache C einerseits den Sprachumfang und die Notation einer hoherenProgrammiersprache auf, verfugt aber andererseitsuber viele Eigenschaften einer Assemblersprachefur eine maschinennahe Programmierung. Am Maschinen-orientierten Ende der Skala ist die auf vie-len Rechnern vorhandene so genannteMikroprogrammierungzu erwahnen, mit deren Hilfe elemen-tare Algorithmen zwischen der Ebene der internen Maschinendarstellung und der Assemblerebenerealisiert werden konnen. Wir verdeutlichen dies anhand eines sehr einfachen Beispiels. Die Additionzweier Zahlena undb und die Zuweisung des Ergebnisses an eine Variablec kann in einer Program-miersprache folgendermaßen formuliert sein:
c = a+b
Die Notationahnelt der von der Mathematik her bekannten Formelschreibweise und ist unmittelbarverstandlich. Die Formulierung in einer Assemblersprache konnte wie folgt aussehen:

1.2. PROGRAMMIERSPRACHEN 5
Algorithmus
Programmierung (Codierung)
?
Programm in hohererProgrammiersprache
automatisierteUbersetzung
?
Programm inMaschinensprache
Interpretation durch CPU (Decodierung)
?gewunschter Ablauf wird ausgefuhrt
Hauptthemader
Vorlesung
Abbildung 1.2: Ubersetzung von Programmen.
MOVE R1,a (holea aus dem Speicher und schreibea in das Register R1)MOVE R2,b (holeb aus dem Speicher und schreibeb in das Register R2)ADD R2,R1 (addiere den Inhalt von Register R1 zum Inhalt von Register R2)MOVE c,R2 (schreibe den Inhalt von Register R2 unter dem Namen
c in den Speicher)
Zusatzlich zur eigentlichen Additionsoperation mussen nun noch die Lese- und Schreiboperationenauf dem Speicher berucksichtigt werden. Fur alle Assembleroperationen sind sehr genaue Kenntnisseuber die Organisation des verwendeten Rechners erforderlich, etwa die Funktionsweise, Anzahl undBenennung der Register. Fur den nur am Ergebnisc interessierten Programmierer ist weder von Inter-esse, welche Speicheroperationen erforderlich sind, noch, was denn ein Registeruberhaupt ist. Schondieses extrem einfache Beispiel zeigt die Unubersichtlichkeit von Assemblerprogrammen.
Auf der Ebene der Mikroprogrammierung konnen die Schritte der Assemblerprogramme weiter zer-legt werden. Dies kann bis hinunter zu Operationen auf einzelnen Bits gehen. Die Mikroprogrammie-rung erlaubt die Programmierung auch der kleinsten Teilfunktionen eines Rechners.
Auf der untersten Maschinenebene erhalt man nur noch intern verschlusselte Darstellungen, mit denennur noch sehr geduldige und bis ins kleinste mit “ihrem” Rechner vertraute Spezialisten umgehenkonnen. Ein fiktives Beispiel fur einen Maschinencode konnte lauten:

6 KAPITEL 1. EINLEITUNG
0000 0111 0110 1011 1001 1111 1010 0010 1110 1010 10100101 1110 1010 0101 0100 0101 0100 0010 1010 1010 11110001 1010 1010 1010 1011 0101 0101 0101 0101 0101 01011010 1010 1010 1010 1010 1010 1010 1010 1010 1010 1001
Am anderen Ende der Skala gibt es verschiedene Versucheuber die hoheren Programmiersprachenhinaus in Richtung auf die Problemformulierung in naturlicher Sprache.
Bei derUbersetzung von einer hoheren Programmiersprache in die Maschinensprache unterscheidetman zwischeninterpretierenundkompilieren. Beim Interpretieren wird
• jede Anweisung einzelnubersetzt,
• vor derUbersetzung der nachsten Anweisung zunachst die vorige Anweisung ausgefuhrt,
• bei jedem Lauf des Programms wieder neuubersetzt.
Beim Kompilieren wird
• das Programm als ganzesubersetzt durch den sogenanntenCompiler. Ein Compiler ist also einProgramm, das ein anderes Programm aus dem Quelltext (source code) in maschinenlesbareFormubersetzt (object code).
• Der object code steht dann in Maschinensprache fur jeden Aufruf zur Verfugung.
Die auf den ersten Personal Computern verfugbare Programmiersprache BASIC wurde speziell imHinblick auf Interpretation entworfen. Im allgemeinen sind interpretierte Sprachen “strukturschwa-cher”, haben jedoch den Vorteil, dass man Programme sehr schnell zum Laufen bekommt.
Kompilieren erfordert mehr Speicherplatz als interpretieren. Die Fehlersuche ist im Allgemeinen muh-samer, dafur laufen kompilierte Programme jedoch wesentlich schneller.
Die im Rahmen der Vorlesung gelehrte Programmiersprache Java wird sowohlkompiliert wie inter-pretiert, allerdings auf verschiedenen Niveaus. Der Programmtext wird vom Java-Compiler in eineZwischensprache, denJava Bytecodekompiliert. Dieser wird dann durch dieJava Virtual Machine(JVM) interpretiert und ausgefuhrt. Dadurch muss nur die JVM fur verschiedene Rechnerarchitektu-ren (Windows, Unix, Macintosh ...) angepasst werden. Der einmal kompilierte Code kann dann aufallen Architekturen ausgefuhrt werden.
Diese Systemunabhangigkeit macht Java zur WWW-Sprache par excellence und fuhrt zur Zeit auchzu eigenstandigen systemunabhangigen Applikationen (z. B. Burosoftware in Java).
Bei derUbersetzung eines Programms erfolgt stets eine Syntaxanalyse. Dabei erlaubt die Interpretati-on die Suche einfacher Fehler, wahrend die Kompilation meistens eine weitergehende Syntaxanalyseund auch eine partielleUberprufung der Semantik erlaubt.
Es gibt eine ganze Hierarchie von Programmiersprachen, die von einfachen Sprachen (Maschinen-sprache)uber mittleres Niveau (FORTRAN, BASIC) bis zu hohem Niveau reichen (Pascal, C, C++,Java).

1.3. ALGORITHMEN VERSUS PROGRAMMIERSPRACHEN 7
Diese Sammlung von Programmen auf einem Rechner nennt man dieSoftware. Auch bei der Softwaregibt es eine Hierarchie, die am unteren Ende mit der Hardware verknupft ist: dieSoftware-Hardware-Hierarchie(vgl. Abbildung1.3).
Anwendungssoftwarez. B. Textverarbeitung, Statistik-paket
Systemsoftwarez. B. Betriebssystem, Editor,Compiler, Eclipse
Computerhardwarez. B. CPU, Speicher, Ein-, Aus-gabegerate
Programmier-
umgebung
Abbildung 1.3: Die Software-Hardware Hierarchie.
Auf der mittleren Ebene ist dasBetriebssystem(operating system) besonders wichtig. Es dient der
• Verwaltung und Steuerung der Ein-Ausgabe-Einheiten, z. B. Drucker,
• Speicherung von Informationen (z. B. auf Diskette),
• Unterstutzung der gleichzeitigen Benutzung von Computern durch mehrere Benutzer,
• Bereitstellung von Kommandooberflachen (Shells) fur die Benutzer zur Kommunikation mitdem Rechner (Start von Programmen, Kopieren von Files usw.).
In der Vorlesung wird als Betriebssystem UNIX verwendet. Eine Einfuhrung in UNIX wird in derUbung gegeben.
1.3 Algorithmen versus Programmiersprachen
Wie wir gesehen haben, erfordert die Durchfuhrung eines Prozesses auf einem Computer, dass
• ein Algorithmus entworfen wird, der beschreibt, wie der Prozess auszufuhren ist,
• der Algorithmus als Programm in einer geeigneten Programmiersprache ausgedruckt wird,
• der Computer das Programm ausfuhrt.

8 KAPITEL 1. EINLEITUNG
Die Rolle von Algorithmen ist grundlegend. Ohne Algorithmus gibt es kein Programm und ohneProgramm gibt es nichts auszufuhren.
Algorithmen sind unabhangig von einer konkreten Programmiersprache und einem konkreten Com-putertyp, auf denen sie ausgefuhrt werden. Ein wesentlicher Teil der Vorlesung besteht darin, denEntwurf von Algorithmen unabhangig von der “Tagestechnologie” zu entwerfen und zu studieren.Dabei spielt naturlich dieModellierungundMathematisierungder zugrunde liegenden Anwendungeine wichtige Rolle.
Uberspitzt gesagt sind Algorithmen wichtiger als Computer und Programmiersprachen. Programmier-sprachen sind nur Mittel zum Zweck, um Algorithmen in Form von Prozessen auszufuhren. Naturlichsind auch Computer und Programmiersprachen wichtig, da sie z. B. die Ausfuhrgeschwindigkeit einesProgramms und den Aufwand zur Erstellung des Programms bestimmen, aber sie sind letztlich nurMittel zur effektiveren Darstellung und Ausfuhrung von Algorithmen.
Wegen dieser grundlegenden Bedeutung von Algorithmen gibt es viele Gebiete der AngewandtenMathematik und der Informatik, die sich mit Algorithmen beschaftigen. Dies sind z. B.
– Entwurf (Design) von Algorithmen Dies ist im allgemeinen eine schwierige Tatigkeit, die vielKreativitat und Einsicht erfordert (es gibt keinen Algorithmus zum Entwurf von Algorithmen).Dieses Thema ist ein wesentlicher Gegenstand der Vorlesung.
– BerechenbarkeitGibt es Prozesse, fur die kein Algorithmus existiert? Die Antwort auf dieseFrage und das Studium dessen, was Berechenbarkeit ist, d. h. auf einem Algorithmus ausfuhrbarist oder nicht, ist Gegenstand dieses Gebietes.
– Komplexit at von Algorithmen Dieses Gebiet befasst sich mit der Untersuchung des Aufwandsan Laufzeit und Speicherplatz und der Ermittlung in Form von unteren Komplexitatsschrankenfur Problemklassen und der Entwicklung von “schnellen” Algorithmen zu ihrer Losung. ImRahmen der Vorlesung wird dies bereits an einfachen Beispielen (Sortieren) erlautert.
– Korrektheit von Algorithmen Hier werden Methoden entwickelt um nachzuweisen, dass einAlgorithmus korrekt arbeitet. Diese Methoden sind teilweise wieder automatisierbar (automati-sches Beweisen!).
1.4 Literaturhinweise
Neuere einfuhrende Werke, die die gesamte Informatik oder zumindest große Teile davon behandeln, sind[AU92, Bro04, GL02, GS04]. Die hier gegebene Einleitung lehnt sich an [GL02] an. Speziell fur die theoreti-sche Informatik sei auf die umfangreichen Handbucher [vL90a, vL90b] verwiesen.
Im Hinblick auf denEntwurf und die Analyse von Algorithmensind in den letzten Jahren eine ganze Reihe guterLehrbucher erschienen. Besonders empfehlenswert ist [CLRS01], weitere gute Bucher sind [Meh88, Mei98,OW02, Sed03] und die neu aufgelegten Klassiker [Knu97, Knu98a, Knu98b].
Die zunehmende Bedeutung von Java spiegelt sich zur Zeit in einer Flut von BuchernuberJava und objektori-entiertes Programmierenwieder.

1.4. LITERATURHINWEISE 9
Fur Anfanger geeignet und besonders ausfuhrlich und anschaulich ist [DD01]. Fur Umsattler von einer anderenProgrammiersprache nach Java ist [Fla02] zu empfehlen. Die Bucher [Kuh99] und [Job02] behandeln Java vom“ubergeordneten” Standpunkt und beleuchten die Syntax in vielen Einzelheiten. Sehr empfehlenswert ist dassowohl als Buch als auch online verfugbare Tutorial [CW98]. Ein weiteres online Tutorial ist [Kru02]. Einegelungene Verbindung von Datenstrukturen, Standardalgorithmen und Java bringen [GT04], wobei jedoch JavaKenntnisse vorausgesetzt werden, [Pre00], das ebenfalls online verfugbar ist, und [SS02].
Die Analyse von Algorithmen verlangt Grundkenntnisse aus derDiskreten Mathematik(vor allem aus der Kom-binatorik und der Graphentheorie). Die notigen Techniken sind u. a. in [CLRS01] enthalten. Weiterfuhrende,empfehlenswerte Bucher sind [Aig04, GR03, Wii87].

10 KAPITEL 1. EINLEITUNG

Kapitel 2
Probleme, Algorithmen, Programme:Einige Beispiele
2.1 Temperatur Umrechnung
2.1.1 Das Problem:
Temperaturangaben in Fahrenheit sollen in Celsius umgerechnet werden.
2.1.2 Der Algorithmus:
Dafur nutzt man den Zusammenhang zwischen beiden Temperaturskalen. Beide Skalen haben eineaquidistante Unterteilung mit folgenden Entsprechungen1:
0 Grad Fahrenheit ∼= −1779 Grad Celsius,
100 Grad Fahrenheit∼= 3779 Grad Celsius.
Hieraus lasst sich die TemperaturC in Celsius als affin-lineare Funktion der TemperaturF in Fahren-heit berechnen, vgl. Abbildung2.1:
C =59(F−32) .
Dies resultiert in den folgenden Algorithmus.
1 Der anekdotischenuberlieferung zufolge kamen diese auf folgende Weise zustande. Fahrenheit wollte eines Tages eine“normierte” Temperaturskala entwickeln. Es war gerade Winter und ziemlich kalt (namlich−177
9 Grad Celsius). Da er sichkeine kaltere Temperatur vorstellen konnte, normierte er diese zu 0. Anschließend wollte er die normale Korpertemperaturdes Menschen zu 100 normieren. Da er aber an diesem Tage leichtes Fieber hatte, wurden daraus 377
9 Grad Celsius.
Version vom 21. Januar 2005
11

12 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
- C
−17,78 0 50 10037,78
- F
0 32 100 212
Abbildung 2.1: Die Celsius- und Fahrenheitskala.
Algorithmus 2.1 (Temperatur Umrechnung)1. Einlesen vonF2. Umrechnung inC3. Ausgabe vonC
2.1.3 Das Programm
Wir sehen uns jetzt ein zugehoriges Java Programm an. Dieses erzeugt ein Applet, das in Abbil-dung2.2 im Applet Launcher auf meinem Macintosh Rechner dargestellt ist.
Abbildung 2.2: Das Temperatur Applet.
Zunachst der Programmtext:
Programm 2.1 Temperatur.java//Temperatur.java (1)// (1)// Transforms Fahrenheit to Celsius (1)import java.awt.*; (2)import java.applet.Applet; (3)import java.awt.event.ActionListener; (3)import java.awt.event.ActionEvent; (3)
public class Temperatur extends Applet (4)

2.1. TEMPERATUR UMRECHNUNG 13
(5)// variables for the problemdouble fahrenheit, celsius; (6)
// objects for the graphical user interfaceLabel inputPrompt, outputPrompt1, outputPrompt2; (7)TextField input, output; (7)
// setup the graphical user interface components// and initialize labels and text fieldspublic void init() (8)
// define labels and textfieldsinputPrompt = new Label("Geben Sie eine Temperatur " (9)
+ "in Fahrenheit an und drucken Sie Return."); (9)outputPrompt1 = new Label("Die Temperatur in " (9)
+ "Celsius betragt"); (9)outputPrompt2 = new Label(" Grad."); (9)
input = new TextField(10); (10)input.addActionListener(new ActionListener() (11)
public void actionPerformed(ActionEvent e) (11)calculateTemperature(); (11)
(11)); // action will be on input field (11)
output = new TextField( 10 ); (12)output.setEditable( false ); (13)
// disable editing in output field (13)
// add labels and textfields to the appletadd(inputPrompt); (14)add(input); (14)add(outputPrompt1); (14)add(output); (14)add(outputPrompt2); (14)
// process user’s action on the input text fieldpublic void calculateTemperature() (15)
// get input numberfahrenheit = Double.parseDouble(input.getText()); (16)
// calculate celsius and round it to 1/100 degreescelsius = 5.0 / 9 * (fahrenheit - 32); (17)

14 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
// use Math class for roundcelsius = Math.round(celsius * 100); (18)celsius = celsius / 100.0; (19)
// show result in textfield outputoutput.setText(Double.toString(celsius)); (20)
(21) (22)
Wir erlautern jetzt die Bedeutung der einzelnen Anweisungen gemaß der Nummerierung am rechtenRand.
(1) Alles nach// bis zum Ende einer Zeile ist Kommentar. Die Kommentare enthalten den Namendes Programms (Temperatur.java) und Informationen daruber, was das Programm tut.
Kommentare sollten auf Englisch sein, man weiß nie, wer das Programm einmal verwendenmuss.
(2) – (3) Das Programm benutzt Teile der von SUN entwickelten Bibliothek fur Java. Die benotigtenTeile mussen dem Compiler perimport-Anweisung mitgeteilt werden. Durch die Zeileimportjava.awt.* in (2) werden alle Bibliotheksdateien geladen, die zumawt, demabstractwindowtoolkit gehoren. Die Import-Anweisungen (3) laden dieApplet-Klasse, und zwei Klassen zurVerarbeitung von Aktionen (ActionListener undActionEvent).
Jede Klasse besteht grob gesprochen aus einer Kollektion von gleich gearteten Daten und Me-thoden, die auf diesen Daten arbeiten. Inzwischen gibt es Tausende von verfugbaren Klassen inJava, und die Klassenbibliothek wird laufend erweitert. Eine Beschreibung aller jeweils in Javaverfugbaren Klassen findet man unter http://java.sun.com/j2se/1.4.2/docs/index.html.
(4) Deklariert das HauptprogrammTemperatur. Jedes Hauptprogramm ist in Java selber eineKlasse, was durch das Schlusselwortclass zum Ausdruck gebracht wird.Temperatur er-weitert (Schlusselwortextends) die vordefinierte KlasseApplet. Dies bedeutet, dass daslauffahige ProgrammTemperatur alsAppletzur Verfugung steht, alsouber das WWW gela-den und mit Appletviewern oder HTML-Browsern ausgefuhrt werden kann, vgl. Abbildung2.2und Abbildung2.3.2
Das Schlusselwortpublic bringt zum Ausdruck, dass die Klasse Temperatur auch von anderenKlassen benutzt werden darf. Alle durchimport geladenen Klassen sind ebenfallspublic,d. h. die von ihnen bereit gestellten Methoden konnen vonTemperatur benutzt werden.
(5) – (22) Die geschweiften Klammern. . . enthalten denBlockder KlasseTemperatur. In ihmwird festgelegt, was die Klasse leisten soll.
(6) Definiert dieVariablencelsius, fahrenheit vomDatentypdouble. Dieser bezeichnet Gleit-kommazahlen doppelter Prazision (daher die Bezeichnungdouble), also im Rechner darstell-bare reelle Zahlen mit großer Genauigkeit.
2Man kann naturlich auch in Java eigenstandige Programme schreiben; hierauf wird in denUbungen naher eingegangen.

2.1. TEMPERATUR UMRECHNUNG 15
celsius, fahrenheit konnen also reelle Werte annehmen, aber keine anderen wie z. B. Buch-staben oder Strings.
Die Bezeichnercelsius undfahrenheit sindmnemonischgewahlt, d. h. aus den Namen lasstsich leicht auf die Bedeutung schließen. Man sollte stets mnemonische Bezeichner verwenden.
(7) Deklariert die Objekte fur das graphische User Interface, drei Label und zwei Textfelder. Labelsind Strings von Zeichen, und Textfelder sind rechteckige einzeilige Felder, die Text enthaltenkonnen.
(8) Leitet die Definition derpublic Methodeinit() an. Diese wird automatisch beim Start desApplets durch den Browser oder Appletviewer aufgerufen. Die Klammern() bedeuten, dassdie Methode keinen Input erwartet. Das Schlusselwortvoid gibt an, dass die Methode kei-nen Outputwert erzeugt. Der Block der Methode wird wieder durch geschweifte Klammernbegrenzt.
(9) Definiert die Anfangseigenschaften der Labels. Fur jedes in (7) deklarierte Label wird durch
new Label (...)
ein neues Objekt vom Typ Label erzeugt und mit dem in den Klammern angegebenen String in-itialisiert. Die Quotes". . ." dienen als Begrenzer eines Strings, das+ konkateniert zwei Stringszu einem.
(10) Hierdurch wird ein neues Textfeld der Lange 10 (d. h. fur 10 sichtbare Zeichen) eingerichtet undder Variableninput zugewiesen. Dieses Textfeld ist jetzt unter dem Nameninput ansprechbar.
(11) Diese (spater naher erklarten3) Anweisungen bewirken, dass das Textfeldinput Aktionenauslosen kann. Dies geschieht durch das Drucken der<Return> Taste. Der dem Textfeld hin-zugefugteActionListener startet beim Drucken der<Return> Taste die Methode mit demvorgeschriebenen NamenactionPerformed, die wiederum die von uns weiter unten in demZeilen (15) – (20) definierte MethodecalculateTemperature() startet.
(12) Richtet analog zu (10) das Textfeldoutput ein.
(13) Nutzt die MethodesetEditable() der KlasseTextField, um output nicht-editierbar zumachen.
(14) Hier werden durch die Methodeadd() der KlasseApplet alle Labels und Textfelder dem App-let hinzugefugt. Da keine weiteren Layoutanweisungen erfolgen, werden sie auf der verfugbarenAppletflache zeilenweise zentriert angeordnet. Dabei sind mehrere Komponenten pro Zeilemoglich.
(15) Leitet die Definition derpublic MethodecalculateTemperature() ein, die die eigentlicheRechnung und die Ein- und Ausgabe erledigt.
3 Hier wird eine anonyme Klasse definiert, die das InterfaceActionListener prazisiert, vgl. Kapitel7.3.8.

16 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
(16) Zunachst wird die ininput angegebene Zahl der Variablenfahrenheit zugewiesen. Dieserfolgt durch zwei ineinander geschachtelte Methoden. Die ininput eingegebene Zahl istzunachst nur ein String. Dieser wird durch
input.getText()
eingelesen, anschließend durch die MethodeparseDouble() der KlasseDouble, also durchDouble.parseDouble() zu einerdouble Variablen konvertiert. Dieser Wert wird derdoubleVariablenfahrenheit zugewiesen.
Man konnte die Zeile (16)aquivalent auch in die folgenden Anweisungen zerlegen:
String str = input.getText(); // erzeugt String strdouble temp = Double.parseDouble(str);
// erzeugt double temp aus strfahrenheit = temp; // weist den Wert von temp
// der Variablen fahrenheit zu
(17) Ist eineZuweisung. Der Wert desAusdruck(5.0 / 9) * (fahrenheit - 32) wird berech-net und der Variablencelsius zugewiesen. Da/ sowohl die ganzzahlige Division mit Rest, alsauch die reellwertige Division bezeichnet, muss man (z. B. durch Angabe von5.0 statt5) demCompiler klar machen, dass hier die reellwertige Division gemeint ist. Beachte:5 / 9 ergibtden Wert0, aber5.0 / 9 den Wert0.5555555555555556.
Hier findet die eigentliche Umrechnung statt. Alle anderen Anweisungen im Programm bezie-hen sich auf das User-Interface und die Ein- und Ausgabe.
(18) – (19) Um viele Nachkommastellen bei der Ausgabe zu vermeiden, wird das Ergebnis auf 2Nachkommastellen gerundet. Dies geschieht durch Verwendung der Methoderound() derKlasseMath, die viele mathematische Standardfunktionen bereitstellt.round() rundet einedouble Zahl auf die nachstliegende ganze Zahl.
(20) Zeigt das Resultat im Ausgabefeldoutput. Die MethodetoString() der KlasseDoublewandelt dendouble Wertcelsius in einen String um, der dann mit der MethodesetText()der KlasseTextField fur das Textfeldoutput benutzt wird.
Wir haben im ProgrammTemperatur.java einige wichtige Begriffe kennen gelernt:Variable, Zu-weisung, Klasse, Methode.
EineVariableist (in erster Naherung) ein Name (Platzhalter) fur Objekte (Daten) eines Typs, z. B. desTyps “reelle Zahl”.
Sie belegt im Speicher einen bestimmten (dem Benutzer unbekannten) Speicherplatz, dessen Großevom vereinbarten Typ des Objekts abhangt. Dieser Speicherplatz ist unter dem Namen der Variablenansprechbar.
EineZuweisungaktualisiert den Wert (Inhalt) des Speicherplatzes.

2.1. TEMPERATUR UMRECHNUNG 17
Beispiel 2.1 Die Deklaration
double fahrenheit, celsius;
erzeugt im Speicher die (automatisch mit 0 initialisierten) Objekte
celsius 0
fahrenheit 0 .
Die Eingabe von 95 bewirkt folgendes. Durch
fahrenheit = Double.parseDouble(input.getText());
wird der Variablenfahrenheit der eingelesene Wert zugewiesen.
celsius 0
fahrenheit 95.0
Die Zuweisung
celsius = (5.0 / 9) * (fahrenheit - 32)
bewirkt die Auswertung des Ausdrucks(5.0 / 9) * (fahrenheit - 32) zu
(5.0/9)∗ (95−32) =59·63= 35
und die Zuweisung an die Variablecelsius.
celsius 35.0
fahrenheit 95.0
Man beachte: Ein Ausdruck hat einenWert. Eine Zuweisung hat einenEffekt.
EineKlassebesteht aus Variablen (auchKomponentenoderDatenfeldergenannt) undMethoden(auchFunktionengenannt). In Klassen sollen gleichartige Daten zusammengefasst werden und alle Me-thoden, sie zu verarbeiten, bereitgestellt werden. Die Komponenten und Methoden konnen durchdas Schlusselwortpublic auch anderen Klassen zur Verfugung gestellt werden, bzw. durch dasSchlusselwortprivate außerhalb der Klasse verboten werden. Der Zugriff auf einepublic Methodeoder Komponente einer anderen Klasse erfolgt durch den “.”, wie in
Double.parseDouble() oderMath.round()
Klassen sind in Java auch Datentypen, man kann also Variable dieses Typs definieren, wie z. B.
TextField input;
Eine solche Variable wird auch alsInstanzder Klasse oder Objekt bezeichnet. Instanzen (Objekte)konnen die Methoden und Komponenten der Klasse benutzen. Der Zugriff geschieht wieder mit dem“.” wie in
18 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
input.getText()
Methodeneiner Klasse sind in anderen Programmiersprachen alsFunktionenbekannt. Sie konnen einoder mehrere Argumente eines bestimmten Typsubergeben bekommen wie in
Math.round(celsius * 100)
und liefern Werte einesRuckgabetyps, beiMath.round vom Typlong, der fur (lange) ganze Zahlensteht. Argumenttypen und Ruckgabetyp mussen in der Deklaration vereinbart werden, furMath.roundist diese in der KlasseMath gegeben durch
long round(double a)
Dabei stehta fur den zuubergebenden Wert vom Typdouble.
Diese Bemerkungen sind nur eine sehr oberflachliche Einfuhrung in Methoden und Klassen. Sie wer-den wesentlich detaillierter in Kapitel7 behandelt.
Das ProgrammTemperatur.java wird4 durch den Befehl
javac Temperatur.java
kompiliert. Dies erzeugt die DateiTemperatur.class, die das Java Programm als Byte-Code enthalt,sowie eine HilfsklasseTemperatur$1.class 5.
In dieser Form kann esuber das Internet durch Browser aus html-Seiten geladen und ausgefuhrtwerden, siehe Abbildung2.3.
Abbildung 2.3: Darstellung des Applet”Temperatur“ im Internet Explorer.
Dafur benotigt man eine html-Datei, die das Laden auslost. Sie kann wie folgt aussehen.
DateistartApplet.html
<title>Temperatur</title>
4in meiner Unix shell5 Diese zweite.class Datei ruhrt von der anonymen Klasse her, die denActionListener prazisiert.

2.2. EINKOMMENSTEUERBERECHNUNG 19
<hr><applet codebase=. code="Temperatur.class" width=550 height=70></applet><hr><a href="Temperatur.java">The source.</a>
codebase gibt das directory an, in dem dercode Temperatur.class zu finden ist.codebase=.bedeutet also, dass sich dieser in der gleichen directory wieTemperatur.html befindet. Durchwidth=550 undheight=70 werden die Weite und Hohe des Applets (gemessen in Pixel) festgelegt.Diese Werte konnen im Applet selbst6 bzw. im Appletviewer durch Veranderung der Fenstergroße, indem das Applet angezeigt wird, verandert werden. Abbildung2.4zeigt eine verkleinerte DarstellungdurchAnderung der Fenstergroße im Appletviewer. Sie zeigt deutlich, das die Objekte zeilenweisezentriert auf das Applet gelegt werden.
Abbildung 2.4: Darstellung des Applet”Temperatur“ bei Veranderung der Fenstergroße im Applet-
viewer.
Durch Laden der html-DateistartApplet.html in einen html-Browser (z. B. Internet Explorer)oder einen Appletviewer steht dann das Applet ausfuhrbar zur Verfugung.
2.2 Einkommensteuerberechnung
2.2.1 Das Problem
In einem (hypothetischen) Steuermodell sind EinkommensteuernSin Abhangigkeit des zu versteuern-den EinkommensE zu zahlen. Das Steuermodell verwendet den sogenannten Stufen- oder Scheiben-tarif, in dem das EinkommenE in Scheiben unterteilt wird, die mit unterschiedlichen Satzen besteuertwerden. Hier sind es 3 Scheiben:
E ≤ 20.000e 0e Steuer20.000< E ≤ 60.000 20% vonE−20.000E > 60.000e 8.000+40% vonE−60.000
6durch die AnweisungsetSize( x, y ) in der Methodeinit()

20 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
2.2.2 Der Algorithmus
Aus dem Scheibentarif ergibt sich die EinkommensteuerSals stuckweise lineare, monoton steigendeFunktion vonE, vgl. Abbildung2.5.
-
EinkommenE in Te
0 20 40 60 80 100
6 SteuerS in Te
8
24
!
!!!!!!!!
!!!!
Abbildung 2.5: Die Einkommensteuer Kurve.
Dies resultiert in den folgenden Algorithmus.
Algorithmus 2.2 (Steuer Berechnung)1. Einlesen vonE2. Berechnung vonS3. Ausgabe vonS
2.2.3 Das Programm
Ein entsprechendes Java Programm ist:
Programm 2.2 Steuer.java// Steuer.java//// calculates taxes depending on the income in a// piecewise linear fashionimport java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class Steuer extends Applet
// constants for tax calculationfinal double noTaxBound = 20000, lowRate = .2,

2.2. EINKOMMENSTEUERBERECHNUNG 21
lowTaxBound = 60000, highRate = .4;
double income, tax;
// setup the graphical user interface components// and initialize labels and text fieldsLabel inputPrompt, outputString;TextField input;Panel p1, p2; // use subdivision of applet into 2 panels
// for better layout
public void init() //set layout for applet so that eveything is left alligned
setLayout(new FlowLayout(FlowLayout.LEFT));
p1 = new Panel();p2 = new Panel();
// define layout and color for panel p1p1.setLayout(new FlowLayout(FlowLayout.LEFT));p1.setBackground(Color.pink);
inputPrompt = new Label("Geben Sie das zu versteuernde "+ "Einkommen an und drucken Sie Return. EURO");
input = new TextField(10);input.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e) calculateTax();
); // action will be on input field
p1.add(inputPrompt); // put prompt on panelp1.add(input); // put input on panel
// same for panel p2p2.setLayout(new FlowLayout(FlowLayout.LEFT));p2.setBackground(Color.yellow);
// this time we write the output into a labeloutputString = new Label("Es sind " + tax
+ " EURO Steuern zu zahlen. Ihr Finanzamt. ");p2.add(outputString);
// add panels to the applet

22 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
add(p1);add(p2);
// process user’s action on the input text fieldpublic void calculateTax()
income = Double.parseDouble(input.getText());
if (income <= noTaxBound) // no taxtax = 0;
else if (income <= lowTaxBound) // low rate appliestax = lowRate * (income - noTaxBound);
else tax = lowRate * (lowTaxBound - noTaxBound)
// low rate applies+ highRate * (income - lowTaxBound);
// high rate applies
// round to Pfennigtax = Math.round(tax * 100) / 100.0;
outputString.setText("Es sind " + tax+ " EURO Steuern zu zahlen. Ihr Finanzamt.");
outputString.invalidate();// marks outputString for updating when it changes
validate(); // tells applet to check for invalidations// and update layout if necessary
Das entspechende Applet ist in Abbildung2.6dargestellt.
Hier sehen wir zusatzlich:
• Die Definition von Konstanten.
• Die if -Anweisung.
• Panels
• Layout-Anweisungen

2.2. EINKOMMENSTEUERBERECHNUNG 23
Abbildung 2.6: Das Steuer Applet.
Konstanten sollte man immeruber Bezeichner ansprechen, da man so ihre Werte bei einer moglichenAnderung nur an einer Stelleandern muss.7 Konstanten werden in Javauber das Schlusselwortfinalgekennzeichnet.8 Sie mussen bei der Definition initialisiert werden.
Als Bezeichner(Identifikator) fur Klassen, Methoden, Variablen, Kanstanten usw. kommen in Javabestimmte Strings in Frage. Allgemein bestehen Strings aus 16-bit Unicode Zeichen. Diese Zeichensind bei den ersten 128 Zeichen mit dem ASCII-Zeichensatz und mit den ersten 256 Zeichen mit demISO8859-1 (Latin 1) Zeichensatz vertraglich. Bei 16 Bit sind insgesamt ca. 34000 Zeichen darstellbar,so dass auch Zeichensatze exotischer Sprachen (athiopisch, Bengali, Tamil. . .) darstellbar sind.
Als Bezeichner kommen solche Strings in Frage, die mit einem Unicode-Buchstaben beginnen undnur aus Unicode-Buchstaben und Unicode-Ziffern bestehen. Zulassig sind also
input_1, Mohring,
nicht jedoch
3-Felder, no Tax Bound.
Die if -Anweisung (if -statement) hat in Java die Form
if (Bedingung) Anweisung1 else Anweisung2
wobei derelse-Teil fehlen kann. Dabei istBedingungein logischer Ausdruck. Logische Ausdruckesind in Java vom Typboolean und konnen die Wertetrue undfalse fur die beiden Wahrheitswertewahr undfalschannehmen.
Ist im if -statement der Wert vonBedingunggleichtrue, so wirdAnweisung1 ausgefuhrt, ansonsten(Bedingungist “false”) Anweisung2 (bzw. nichts, falls derelse-Teil fehlt).
Anweisung1 bzw. Anweisung2 konnen wiederif -statements sein, wodurch eine Verschachtelung wieim obigen Programm auftritt.
Die KlassePanel (ausjava.awt) stellt eine Moglichkeit dar, die Oberflache eines Applets zu un-tergliedern. In unserem Fall werden zwei Panelsp1 und p2 definiert. Fur beide Panels wird mitsetLayout() ein Layout festgelegt, namlich ein linksbundiges Flowlayout. Ohne Layout Spezifi-
7Ein Negativbeispiel war die Umstellung der Postleitzahlen; die Anzahl der Zeichen hierfur war meist nie als Konstantedeklariert worden, was einen immensen Umstellungsaufwand erforderte und ganze Programmsysteme lahmlegte.
8Genau genommen sind Konstanten in Java Variable, deren Wert nicht mehr geandert werden darf.

24 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
zierung wird daszentrierte Flowlayout genommen (wie inTemperatur.java). Daruber hinauswerden mit der MethodesetBackground() Farben fur diese Panels definiert. Die Argumente dieserMethode sind Konstanten der Klasse Color, werden also (Zugriff auf Komponenten!) mitColor.pinkangesprochen.
Auch das gesamte Applet verwendet ein linksbundiges Flowlayout. Die Layoutanweisungen sindnicht absolut, sondernandern sich mit der Große des Applets. Das linksbundige Flowlayout schreibtnur vor, dass die Komponenten in der Reihenfolge deradd() Befehle Zeile fur Zeile eingefugt wer-den.
Die Ausgabe erfolgt diesmaluber ein LabeloutputString, das ininit() eingerichtet und in-itialisiert wird, und in calculateTax() mit der MethodesetText() aktualisiert wird. Um dieLange dem veranderten Text anzupassen, wird das ObjektoutputString zunachst durch die An-weisungoutputString.invalidate() als “verandert” markiert, und mit dem Aufruf der Methodevalidate() fur das Applet wird dieses angewiesen,outputString zu aktualisieren.
2.3 Primzahl
2.3.1 Das Problem
Zu einer gegebenen naturlichen Zahln∈ N, n > 0 soll die kleinste Primzahlp bestimmt werden, diegroßer alsn ist.9
2.3.2 Der Algorithmus
Der Algorithmus zur Losung dieses Problems basiert auf der folgenden Idee.
Prufe die Zahlenn+ 1,n+ 2,n+ 3, . . ., ob sie durch eine kleinere naturliche Zahlk > 1 ohne Restteilbar ist. Die erste Zahlz, die das nicht ist, ist die gesuchte Primzahl.
Algorithmus 2.3 (Primzahl)Lese die Zahln einSetzez := nWiederhole
Erhohez um 1uberprufe obz Primzahl ist
bisz Primzahl istGebez aus
Der Test, obz eine Primzahl ist, geschieht nach folgender Idee:
9 N bezeichnet die Menge der naturlichen Zahlen 0,1,2, . . .

2.3. PRIMZAHL 25
Teile z durch alle Zahlenk = 2,3, . . . (bis k · k > z) und prufe ob der Rest 0 ist. Ist dies fur eink derFall, so istz keine Primzahl, andernfalls (d. h. keines derk teilt z ohne Rest) istz eine Primzahl.
Diese Idee fuhrt zu dem folgenden Algorithmus. Hierin istteilerGefundeneine sogenannteBoolescheVariable, also eine Variable, die nur die Wertewahroderfalschannimmt. Die geschweiften Klammern. . . enthalten Kommentare.
Algorithmus 2.4 (Primzahltest)Setzek := 2SetzeteilerGefunden:= falschnoch kein Teiler gefundenSolange(teilerGefunden= falsch) und(k ·k≤ z) fuhre aus
Teilez ganzzahlig durchk. Seirestder entstehende RestFallsrest= 0 so setzeteilerGefunden:= wahrSetzek := k+1
z ist Primzahl fallsteilergefunden= falschbeim Austritt aus der Schleife
Algorithmus2.3und2.4werden jetzt in ein Java Programm umgesetzt.
Programm 2.3 Primzahl.java// Primzahl.java//// input: natural number n// output: smallest prime number p with p > n//// method: apply prime test to n+1, n+2, ... until prime is found,// prime testing of z is done by testing numbers k = 2 ... with// k * k <= z if they are factors of z//
import java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class Primzahl extends Applet Label inputPrompt; // declare LabelTextField input, output; // declare textfields for input and output
int n, // the input integer read from terminalz, // candidate for the prime, set to n+1, n+2 etc.k; // possible divisor of z
boolean divisorFound; // Boolean, indicates that a divisor// k of z has been found

26 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
// setup the graphical user interface components// and initialize labels and text fieldspublic void init()
// set layoutsetLayout(new FlowLayout(FlowLayout.LEFT));
inputPrompt = new Label("Geben Sie die Zahl n ein "+ "und drucken Sie Return.");
input = new TextField(10);input.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e) // call method for finding next primefindPrime();
); // action will be on input field
// output will be text in a fieldoutput = new TextField(60);output.setEditable(false);output.setBackground(Color.yellow);
add(inputPrompt); // put prompt on appletadd(input); // put input on appletadd(output); // put output on applet
// function for finding next prime numberpublic void findPrime()
// get input numbern = Integer.parseInt(input.getText());z = n;do
z++;k = 2;divisorFound = false;
// so far no divisor of z has been foundwhile (!divisorFound && k*k <= z)
// check if k is a divisor of zif (z % k == 0)
divisorFound = true;k++;
//end while

2.3. PRIMZAHL 27
while (divisorFound);
// define the output stringString str = "Die nachstgroßere Primzahl nach "
+ n + " ist " + z + ’.’;
// put the sting into the output fieldoutput.setText( str );
Das entsprechende Applet ist in Abbildung2.7dargestellt.
Abbildung 2.7: Das Primzahl Applet.
Neu sind hier folgende Konstrukte fur Schleifen:
while (Fortsetzungsbedingung) Anweisung
bzw.
do Anweisungwhile (Fortsetzungsbedingung)
Im ersten Fall wirdAnweisungso oft ausgefuhrt, wieFortsetzungsbedingunggilt. Diese Bedingungwird vor jedem Eintritt in die Schleifeuberpruft. Evtl. wird die Schleife also auch kein mal durchlau-fen.
Im zweiten Fall erfolgt dieUberprufung der Fortsetzungsbedingungnachjeder Abarbeitung vonAn-weisung. Anweisungwird also mindestens einmal ausgefuhrt.
Neu sind ferner folgende Operatoren:! logische Negation&& logisches und% Rest bei ganzzahliger Division,8 % 3 ergibt2
Bei der Ausgabe wird zunachst der Stringstr-durch Konkatenation von Zeichenketten und Wertenvon Variablen erzeugt. Dieser wird dann als String im Textfeldoutput ausgegeben.
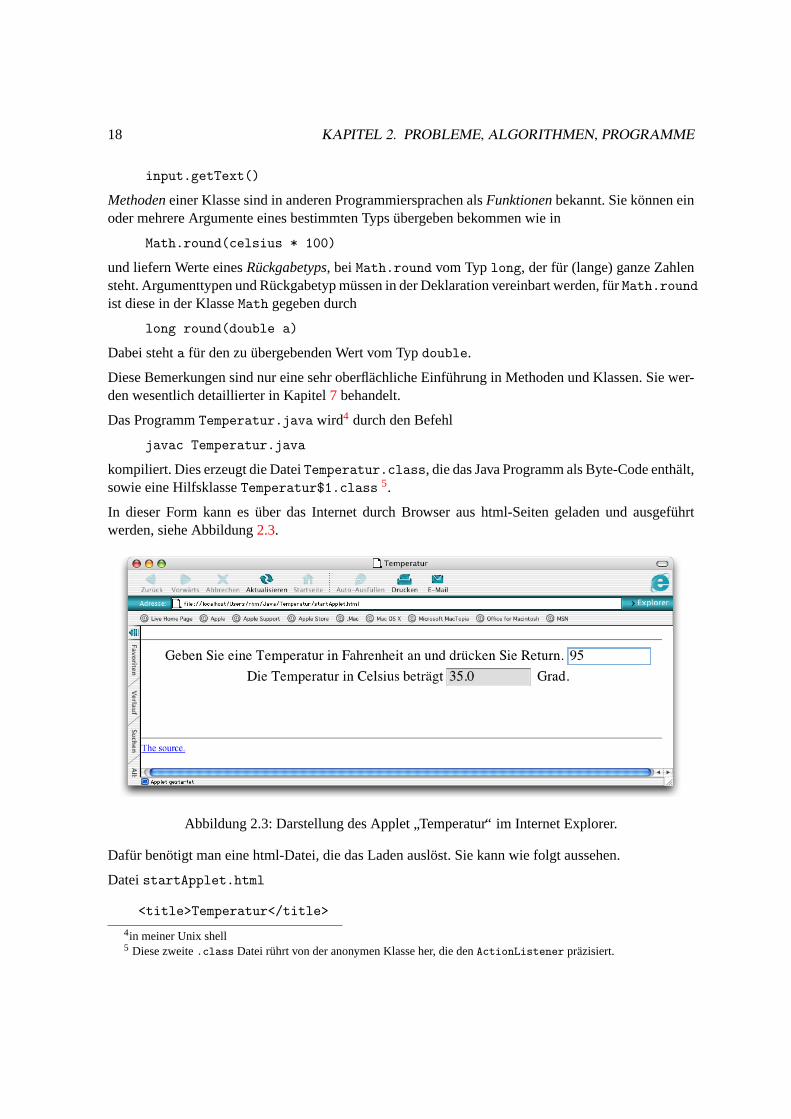
Betrachten wir das Programm fur das Zahlenbeispieln= 50. Tabelle2.1dokumentiert die Veranderungder Werte der Variablenn, z, k, divisorFound wahrend des Programmablaufs (von oben nach un-ten).
28 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
Tabelle 2.1: Werte der Variablen in Programm2.3
n z k divisorFound Aktion im Programm0 0 0 false Default Initialisierung bei Definition50 0 0 false nach Einlesen inn50 50 0 false nachz = n50 51 0 false nachz++50 51 2 false nachk = 250 51 2 false nachdivisorFound = false50 51 2 false Eintritt in while-Schleife
z % k = 51 % 26= 050 51 3 false nachk++
neuer Eintritt inwhile-Schleifez % k = 51 % 3= 0
50 51 3 true “then” statement ausgefuhrt50 51 4 true nachk++
kein neuer Eintritt inwhile-Schleifeneuer Eintritt indo-Schleife
50 52 4 true nachz++50 52 2 true nachk = 250 52 2 false nachdivisorFound = false50 52 2 false Eintritt in while-Schleife
z % k = 52 % 2= 050 52 2 true “then” statement ausgefuhrt50 52 3 true nachk++
kein neuer Eintritt inwhile-Schleifeneuer Eintritt indo-Schleife
50 53 3 true nachz++50 53 2 true nachk = 250 53 2 false nachdivisorFound = false50 53 2 false Eintritt in while-Schleife
z % k = 53 % 26= 050 53 3 false nachk++50 53 3 false neuer Eintritt inwhile-Schleife
z % k = 53 % 36= 050 53 4 false nachk++50 53 4 false neuer Eintritt inwhile-Schleife
z % k = 53 % 46= 050 53 5 false nachk++50 53 5 false neuer Eintritt inwhile-Schleife
z % k = 53 % 56= 0

2.3. PRIMZAHL 29
n z k divisorFound Aktion im Programm50 53 6 false nachk++50 53 6 false neuer Eintritt inwhile-Schleife
z % k = 53 % 66= 050 53 7 false nachk++50 53 7 false neuer Eintritt inwhile-Schleife
z % k = 53 % 76= 050 53 8 false nachk++50 53 8 false k*k = 8∗8 > 53
⇒ kein neuer Eintritt inwhile-SchleifedivisorFound hat Wertfalse⇒ kein neuer Eintritt indo-Schleife⇒ z= 53 ausgegeben
Die Korrektheit des Programms folgt aus den Voruberlegungen10:
- Die while-Schleife testet alle in Frage kommenden naturlichen Zahlenk≤ √z ob sie Teilervonz sind.
- Die do-Schleife terminiert mit einemz, fur das kein Teiler gefunden wurde.
- Da es zu jeder Zahln eine Primzahlp mit p > n gibt, terminiert auch diedo-Schleife nachendlich vielen Schritten (keine Endlosschleife).
Der Algorithmus kann auf verschiedene Weisen verbessert und schneller gemacht werden.
1. Die if-Anweisung
if (z % k == 0) divisorFound = true;
kann ersetzt werden durch die (allerdings schwer lesbare) Zuweisung
divisorFound = (z % k == 0);
Dabei istz % k == 0 ein Boolescher Ausdruck, dessen Wert der VariablendivisorFoundzugewiesen wird.
2. Es kommen nur ungerade Zahlen als Primzahlen in Frage. Daher kann man als ersten Wert vonz die erste ungerade Zahl> n nehmen und dann stetsz um 2 erhohen.
3. Daz ungerade gewahlt wird, kommen nur ungerade Zahlenk als Teiler vonz in Frage.
Der Einbau dieserAnderungen (Anfang und Ende wie in Programm2.3):
10 Dabei wird vorausgesetzt, dass nur naturliche Zahlen eingegeben werden. Fur andere typzulassige Eingaben wie zumBeispiel negative ganze Zahlen wird nichts ausgesagt. Solche Eingaben konnte man naturlich durch entsprechende Fallun-terscheidungen “abfangen”.

30 KAPITEL 2. PROBLEME, ALGORITHMEN, PROGRAMME
. . .if (n % 2 == 0) z = n - 1; else z = n;
// this makes z + 2 smallest odd number > ndo
z += 2;k = 3;divisorFound = false;while (!divisorFound && k*k <= z)
divisorFound = (z % k == 0);k += 2;
\\endwhile while (divisorFound);. . .
Dabei istk += 2 aquivalent zuk = k + 2.
4. Eine andere Verbesserung besteht darin, in derwhile-Schleife eine unnotige Erhohung derVariablenk zu vermeiden. Dies kann erreicht werden durch:
if (z % k == 0) divisorFound = true;
else k += 2;
2.4 Literaturhinweise
Die Beispiele sind [OSW83] entnommen. Dort finden sich insgesamt 100 Beispielaufgaben fur einfache Pro-gramme und zugehorige Losungsalgorithmen (allerdings in Pascal).
Weitere Beispiele fur einfache Java Programme findet man in [DD01, CW98, Kru02].

Kapitel 3
Ausdrucke, Anweisungen,Kontrollstrukturen
Wir behandeln nunubersichtsartig diewichtigsten Sprachelementein (hoheren) Programmiersprachenfur die Formulierung von Algorithmen.
3.1 Variablen und Objekte
Ausdrucke beinhaltenublicherweise Variable, auf deren Wert bei der Auswertung zugegriffen wird.In Java gibt es zwei unterschiedliche Arten von Variablen (bzw. Datentypen) namlichStandardtypenundReferenztypen.
Die Standardtypensind die “eingebauten” Typen1
boolean 1 Bitchar 16 Bit ganze Zahl ohne Vorzeichen
entspricht dem Zahlenwert eines Unicode-Zeichenbyte 8 Bit ganze Zahl mit Vorzeichenshort 16 Bit ganze Zahl mit Vorzeichenint 32 Bit ganze Zahl mit Vorzeichenlong 64 Bit ganze Zahl mit Vorzeichenfloat 32 Bit Fließkommazahldouble 64 Bit Fließkommazahl
Bei diesen Typen wird unter dem Namen der Variablen stets derWertangesprochen. In der Sequenz
int a = 1;
1Auf die rechnerinterne Darstellung der auftretenden Zahlen wird genauer in Kapitel12eingegangen.
Version vom 21. Januar 2005
31

32 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
int b = 2;a = a + b;
wird also ina + b auf die Werte 1 und 2 zugegriffen.
Alle anderen Typen in Java sindReferenztypen. Hierzu gehoren
• Klassentypen
• Schnittstellentypen
• Arraytypen
Wir behandeln zunachst nur die Klassentypen. Jede Klasse stellt einen Datentyp dar. Die Werte vonVariablen eines Klassentyps heißen in JavaObjekte. In
TextField input, output;
werden zwei Variablen der KlasseTextField deklariert.
Bei Referenztypen wird unter dem Namen der Variablen nicht derWert (also das Objekt), sonderndie Adresse(Referenz) angesprochen, an der das Objekt im Speicher abgelegt ist. Man braucht daherMethoden, um
• die Objekte im Speicher zu erzeugen,
• die Werte/Daten einzugeben,
• auf die Werte/Daten zuzugreifen.
Die Erzeugung der Objekte erfolgt (bis auf wenige Ausnahmen) mit dernew-Anweisung und demAufruf einesKonstruktors. In
output = new TextField (10);
ist TextField(10) ein Konstruktor (von mehreren) der KlasseTextField, der ein Textfeld mit 10Zeichen konstruiert und im Speicher einrichtet. Ein anderer Konstruktor ist z. B.
output = new TextField("Coma I", 10);
der das Textfeld gleich mit dem StringComa I belegt und eine Lange von 10 Zeichen vereinbart.Jede Klasse verfugt ublicherweiseuber mehrere Konstruktoren fur Objekte, darunter einenDefault-Konstruktorohne Argumente.
Die Eingabe von Daten erfolgt dann z. B.uber die MethodesetText() wie in
output.setText("Hallo!");

3.1. VARIABLEN UND OBJEKTE 33
Der Zugriff auf Daten entsprechenduber die MethodegetText()
output.getText();
Ausnahmen gibt es bei der KlasseString (als Zugestandnis an C-Programmierer). Hier ist neben derJava-konformen Konstruktion
String str = new String("Hallo");
auch die direkte Zuweisung moglich
String str = "Hallo";
Ferner wird unter dem Namen einer Variablen vom TypString in Ausdrucken stets der Wert (alsoder String selbst) angesprochen.
Fur alle Standardtypen gibt es in Java korrespondierende Klassen (sogenannte Wrapper-Classes), etwaInteger fur int, Double fur double usw. Die Sequenz
int a = 64;Integer A = new Integer(a);
erzeugt ein Integer Objekt mit Wert vona (also 64). Durch
int b = A.intValue();
wird derint-Variablenb der Wert des ObjektesA zugewiesen, auf den mit der MethodeintValue()zugegriffen wird. Vollig falsch und nicht Typ-vertraglich ware hier die Zuweisung
int b = A;
da unterA dieAdressevonA, aber nicht der Wert angesprochen wird.
Zur Illustration des Unterschiedes zwischen Adresse (Referenz) und Wert betrachte man folgendeDeklaration:
TextField input, output;String str = new String("Hallo!");
Hierfur werden im Speicher Platze fur drei Referenzen angelegt. Die ersten beiden werden mitnullinitialisiert, wahrend die dritte eine Referenz auf den StringHallo enthalt. Dabei steht die Konstantenull fur die “leere” Adresse. Im allgemeinen nehmen Referenzen naturlich weniger Speicherplatz alsdie eigentlichen Daten ein. Dies wird durch die unterschiedliche Große der Speicherplatze angedeutet.Die Referenz vonstr auf die eigentlichen Daten (denWert) wird durch den Pfeil dargestellt.

34 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
input null
output null
str r - Hallo!
Durch
input = new TextField(str, 10);output = new TextField("Wie geht’s?", 10);str = "Gut!";
werden zwei neueTextField-Objekte mit Adresseninput und output erzeugt, die die WerteHallo! bzw.Wie geht’s? haben. Ferner wird der Variablenstr der neue WertGut! zugewiesen.Es ergibt sich folgendes Speicherbild:
input r - Hallo!
output r - Wie geht’s?
str r - Gut!
Durch die Zuweisunginput = output wird input dieAdressevonoutput (nicht der Wert!) zuge-ordnet. Danach werden unterinput undoutput dasselbeTextField-Objekt mit WertWie geht’s?angesprochen. Das Objekt mit WertHallo! kann jedoch nicht mehr (mitinput) angesprochen wer-den. Es entsteht folgendes Speicherbild:
input rPPPPPPq Hallo!
output r - Wie geht’s?
str r - Gut!
Um in input denselben Wert wie inoutput abzuspeichern, muss man die MethodengetText() undsetText() verwenden:
input.setText(output.getText());
Den Unterschied zwischen Referenz und Wert zeigt auch folgendes Codefragment.
Integer intA = new Integer(10);Integer intB = new Integer(10);String compare = (intA == intB) + " " + intA.equals(intB);
Zunachst werden zwei verschiedene Integer ObjekteintA undintB mit demselben Wert10 erzeugt.Der Boolesche Ausdruck(intA == intB) vergleicht die Referenzen vonintA undintB, wahrend

3.2. AUSDRUCKE 35
intA.equals(intB) mittels der Methodeequals() der KlasseInteger die Werte vonintA undintB vergleicht. Der Stringcompare bekommt also den Werttrue false zugewiesen.2
3.2 Ausdrucke
Ein Ausdruckist grob gesprochen eine Formel oder Rechenregel, die stets einen Wert (Resultat) spe-zifiziert. Der Ausdruck besteht ausOperatorenundOperanden.
Beispiele fur Operanden sind Konstanten, Variablen, Funktionen; Beispiele fur Operatoren sind diearithmetischen Operatoren+ - * / und die logischen Operatoren! && || (nicht, und, oder). Ope-ratoren sind immer in Zusammenhang mit zugehorigen Wertebereichen(im ProgrammiersprachenJargon:DatentypenoderTypen) zu sehen, z. B. ganze Zahlen oder Gleitkommazahlen. Sie werdendaher in Zusammenhang mit Datentypen in Kapitel5 noch eingehender diskutiert.
Beispiele fur Ausdrucke in Java sind:
a > b logischer Ausdrucka * b / c != c + d * e logischer Ausdruck(a + b) * 3 / 2 arithmetischer Ausdruck
Habena,. . .,e die Werte 1,2, . . . ,6, so liefern die Ausdrucke die Wertefalse, true, bzw.4.
Der Vorrang von Operatoren ist im Zweifelsfall durch Klammern zu regeln. Bei gleichwertigen Ope-ratoren erfolgt die Auswertung von links nach rechts.
3.2.1 Ausdrucke, genaue Erklarung
In Java unterscheidet man wie in Clvaluesundrvalues. Beide sind Ausdrucke, jedoch konnenlvaluesin Zuweisungen nur links vom Zuweisungszeichen= stehen. Genauer:lvaluesbezeichnen alles, wasInhalt einer Speicheradresse ist (also insbesondere Variablen, wahrendrvaluesallgemein den Werteines Ausdrucks bezeichnet.
Ein Ausdruck hat ganz allgemein 3 Eigenschaften:
• EinenWertoderRuckgabewert, der sich durch vollstandige Auswertung des Ausdrucks ergibt.
• EinenTyp, namlich den Typ seines Wertes. Bei Funktionsaufrufen ist dies der Typ des Ruckgabe-wertes (Ruckgabetyp).
• EinenEffekt. Darunter versteht man einen Effekt auf Speicherinhalte. Ergibt sich dieser nichtaus der Zuweisung eines Wertes an einen lvalue, so nennt man dies einenSeiteneffekt.3 Sei-teneffekte entstehen vor allem bei Funktionsaufrufen (Anderung von Parametern oder globalenVariablen), aber auch bei vielen Operatoren.
2Eine einzige Ausnahme von der Unterscheidung zwischen Adresse und Wert gibt es bei Strings, vgl. Abschnitt5.4.3Manchmal wird auch die Zuweisung an einen lvalue als Seiteneffekt bezeichnet.

36 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
3.2.2 Ausdrucke und einfache Anweisungen
Eine wichtige Regel in der C-Programmierung (und damit auch in Java) ist: Ein Ausdruck wird zueiner(einfachen) Anweisungdurch Anfugen eines Semikolons. In diesem Fall wird der Ruckgabewertunterdruckt, und Zuweisungen an lvalues und ggf. Seiteneffekte sind die einzigen Effekte.
Weitereeinfache Anweisungensind: Aufruf einervoid-Funktion oder eine Definition, jeweils abge-schlossen durch ein Semikolon. Dieleere Anweisungbesteht nur aus einem Semikolon.
3.2.3 Beispiele
1. a = b
Dies ist einZuweisungsausdruckmit demZuweisungsoperator=. Dabei wird dem lvaluea (dereinen Speicherplatz bezeichnet) der Wert des rvalueb zugewiesen. Es wird also ein Speicherin-halt verandert; dies zahlt aber nicht als Seiteneffekt, da es eine Zuweisung an einen lvalue ist.Der Wert des Ausdrucks ist der Wert, der der linken Seite zugewiesen wird. DerTyp ist derTyp der linken Seite.
Die einfache Anweisung
a = b;
weist alsoa den Wert vonb zu. Der Wert des Ausdrucksa = b, alsob, wird unterdruckt.
2. c += b = a
+= ist ein Zuweisungsoperator mit folgender Bedeutung:x += y ist aquivalent zux = x +y. In dem Ausdruckc += b = a ist c der lvalue undb = a der rvalue. Die Auswertung desrvalue weistb (alsSeiteneffekt!) den Wert vona zu. Der Wert des rvalues ist der Wert vona.Zu diesem wird der Wert vonc addiert. (wegen des+= Operators) und die Summe dem lvaluec zugewiesen. Ein Beispiel mit konkreten Werten:
a) vorher a 1b 5c 2
b) nachher a 1b 1 ← Seiteneffekt!c 3
Solche Seiteneffekte sind zwar moglich, aber sollten tunlichst vermieden werden, da sie zuunlesbaren Programmen fuhren. Die Zuweisungen
b = a; c += b;
leisten dasselbe und sind klarer.
3. Zuweisungen in logischen Ausdrucken
Ein deutliches Beispiel fur die Eigenschaften von Ausdrucken ist

3.3. DEFINITIONEN UND DEKLARATIONEN 37
if ((a = b) > c) c = a;
fur int Variablena,b,c. Die Zuweisunga = b liefert einen Wert (namlich den vonb). Ist die-ser großer als der Wert vonc, so wirdc = a ausgefuhrt. Durch die Auswertung des Ausdrucksa = b wird als Seiteneffekta der Wert vonb zugewiesen.
4. Der Inkrementoperator++ (entsprechend--)
Er kann alsPrafix (++a) oderPostfix(a++) auf einen arithmetischen Ausdrucka angewendetwerden. Ista ein lvalue, so wird der Wert vona um 1 erhoht. Der Wert vona++ ist der Wertvona; der Wert von++a ist der Wert vona plus 1. Also:
a++; bedeutet: erst benutzen, dann erhohen++a; bedeutet: erst erhohen, dann benutzen
Ein Beispiel mit Wertena == 2 undb == 4:
a = b++; weista den Wert4 zu und erhoht als Seiteneffekt den Wert vonb auf5.a = ++b; weista den Wert5 zu und erhoht als Seiteneffekt den Wert vonb auf5.a++; weista den Wert von3 zu, dies ist kein Seiteneffekt, daa ein lvalue ist.++a; weista den Wert von3 zu, dies ist kein Seiteneffekt, daa ein lvalue ist.
3.3 Definitionen und Deklarationen
In Java unterscheidet man zwischenDeklarationundDefinition. Deklarationenfuhren Identifier einund assoziieren mit ihnen Typen, so dass der Compiler aufgrund dieser Deklaration die Typver-traglichkeit uberprufen kann (type checking). In Java erfolgt dabei automatisch eine Default-Initia-lisierung.
Definitionensind Deklarationen, die zugleich (bei Variablen und Konstanten) den Identifiern Spei-cherplatz zuordnen oder (bei Funktionen) den Rumpf der Funktion auffuhren. Jeder Identifier mussdeklariert sein, bevor er benutzt werden kann. Beispiele sind:
int a; deklariertdie Integer Variablea.double x = 3.14; definiertdie Gleitkomma Variablex und
initialisiert sie zu 3.14.int Square(int x) definiertdie Funktionf (x) = x2. In den...
return x*x; Klammern steht der Funktionsrumpf.int Square(int x); deklarierteine Funktion Square. Dem Compiler
sind dadurch Name, Ruckgabetyp undArgumenttyp bekannt.
Weitere Beispiele werden in Kapitel7.1.3diskutiert.

38 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
3.4 Strukturierte Anweisungen
Neben den einfachen Anweisungen gibt es diestrukturierten Anweisungen:
• zusammengesetzte Anweisung (Verbundanweisung)
• bedingte Anweisung
• wiederholende Anweisung
und daraus abgeleitete Anweisungen (z. B. die selektive Anweisung). Sie werden mit den nach-folgend beschriebenenKontrollstrukturengebildet, die in allen hoheren Programmiersprachen exis-tieren. Sie heißen Kontrollstrukturen, da mit ihnen
”kontrolliert“ wird, wie Programme intern in
Abhangigkeit von Bedingungen gesteuert werden, d. h., je nach Bedingung unterschiedliche An-weisungen ausfuhren, teilweise auch wiederholt. Man sagt auch, die Kontrollstrukturen legen den
”Programmfluss“ fest. Neben den Kontrollstrukturen bilden Methoden und Klassen weitere wichtige
Bausteine zum Steuern und Strukturieren von Programmen. AUf sie wird ausfuhrlich in Kapitel7eingegengen.
Fur die Kontrollstrukturen werden wir neben einer umgangsprachlichen Beschreibung und einem Bei-spiel drei programmiersprachenunabhangige Darstellungen angeben, und zwar als:
• Pseudocode,
• Struktogramm,
• Flussdiagramm.
Danach wird auf die entsprechende Realisierung der Kontrollstrukturen in Java eingegangen.
Struktogramme(auchNassi-Shneiderman-flowchartsgenannt) undFlussdiagrammesind graphischeBeschreibungen von Algorithmen unter Verwendung der genannten Kontrollstrukturen.
Pseudocodeleistet das gleiche in einer an Pascal orientierten, mit normalem Text durchsetzten Be-schreibung. Die folgende Tabelle stellt die PseudocodeAquivalente bereits eingefuhrter Java Kon-strukte zusammen.
Pseudocode Java Bedeutung:= = Zuweisung= == Test auf Gleichheit6= != Test auf Ungleichheitnot ! logisches nichtand && logisches undor || logisches oder. . . /*...*/ bzw.//... Kommentare

3.4. STRUKTURIERTE ANWEISUNGEN 39
3.4.1 Zusammengesetzte Anweisung, Verkettung
Die zusammengesetzte Anweisung(compound statement) besteht in der Hintereinanderschaltung (Ver-kettung) von Anweisungen (einfachen oder strukturierten)M1, . . . ,Mt , die in der gegebenen Reihen-folge sequentiell abgearbeitet werden.
Beispiel 3.1 (Hypothekberechnung)Es ist der monatliche Betrag a zu berechnen, der zur Ablosungeiner Annuitatshypothek in Hohe von b EURO bei einer Laufzeit von n Jahren und jahrlicher Verzin-sung zum Zinssatz von z % anfallt.
Dazu stellen wir folgendeUberlegung an. Der Betragb wachst inn Jahren bei der angegebenenVerzinsung aufb · (1+z)n, falls keine Ruckzahlungen erfolgen. Die monatlichen Zahlungen vonamussen, wenn sie zum selben Zinssatz verzinst werden, nachn Jahren auf den selben Betrag vonb· (1+z)n fuhren. Durch Gleichsetzung beider Betrage lasst sicha berechnen.
Sehen wir uns an, wie sich die monatlichen Zahlungen verzinsen. Im ersten Jahr wird 12a “angespart”.Dieser Betrag wird allerdings erst ab dem zweiten Jahr verzinst.4 Er wachst also nachn Jahren auf12a(1+z)n−1 EURO. Entsprechend ergeben die Zahlungen im zweiten Jahr am Ende 12a(1+z)n−2
EURO, usw. Insgesamt ist der Wert aller Zahlungen nachn Jahren auf
12a· (1+z)n−1 +12a· (1+z)n−2 + . . .+12a
angewachsen. Die Gleichsetzung der Betrage ergibt dann:
b· (1+z)n = 12a· (1+z)n−1 +12a· (1+z)n−2 + . . .+12a
= 12a[(1+z)n−1 + . . .+(1+z)1 +(1+z)0]
= 12a(1+z)n−1(1+z)−1
= 12a(1+z)n−1
z
Hieraus folgt
a =b12· (1+z)n ·z(1+z)n−1
Dies resultiert in folgenden Algorithmus zur Berechnung vona.
Algorithmus 3.1 (Hypothek Abtrag)
4Dies ist eine gerichtlich umstrittene Praxis vieler Banken. An sich mussten die Zahlungen bereits—wie beiSparguthaben—fur Teile eines Jahres verzinst werden. Die entsprechende Rechnung bleibt alsUbunguberlassen.

40 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
M1 Leseb ein (in EURO)M2 Lesez ein (in %)M3 Lesen ein (in Jahren)M4 Berechner := 1+zM5 BerechneR := rn
M6 Berechnea := (b/12)(R·z)/(R−1)M7 Gebea aus
Die Verkettung erlaubt keine Verzweigung. Sie hat daher (ohne Verwendung weiterer Kontrollstruktu-ren) nur einen beschrankten Anwendungsbereich. Viele sogenannte “programmierbare” Taschenrech-ner der ersten Generation waren nur so programmierbar.
DerPseudocodefur die Verkettung lautet:
beginM1;M2;...Mt ;
end
DasStruktogramm fur die Verkettung ist in Abbildung3.1angegeben, dasFlussdiagramm in Ab-bildung3.2.
M1
M2...
Mt
Abbildung 3.1: Struktogramm der Verkettung.
−→ M1 −→ M2 −→ . . .−→ Mt −→
Abbildung 3.2: Flussdiagramm der Verkettung.
In Java werden zusammengesetzte Anweisungen durch geschweifte Klammern dargestellt:
M1;M2;...Mt;

3.4. STRUKTURIERTE ANWEISUNGEN 41
Ein Beispiel fur ein Java Programm mit nur einer zusammengesetzten Anweisung ist Programm2.1(Temperatur.java). Hier folgt ein weiteres fur die Hypothekberechnung.
Programm 3.1 Hypothek.java// Hypothek.java//// calculates monthly mortgage rateimport java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class Hypothek extends Applet
double amount, // total amountratePerMonth, // monthly rateinterestRate, // interest rate in %interestFactor, // 1 + interest ratepower; // interestFactor^period
int period; // number of years
Label amountPrompt,interestRatePrompt,periodPrompt,startPrompt; // declare Labels
TextField amountField,interestRateField,periodField; // declare textfields for input
// setup the graphical user interface components// and initialize labels and text fieldspublic void init()
setLayout(new FlowLayout(FlowLayout.LEFT));setFont(new Font("Times", Font.PLAIN, 14));
amountPrompt = new Label("Geben sie den Gesamtbetrag "+ "des Darlehens in EURO an:");
amountField = new TextField(10);amountField.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)calculateMortgage();
);

42 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
interestRatePrompt = new Label("Geben Sie den Zinssatz "+ "in % an:");
interestRateField = new TextField(10);interestRateField.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)calculateMortgage();
);
periodPrompt = new Label("Geben Sie die Laufzeit "+ "in Jahren an:");
periodField = new TextField(10);periodField.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)calculateMortgage();
);
startPrompt = new Label("Drucken Sie Return "+ "zum Start der Berechnung.");
add(amountPrompt);add(amountField);add(interestRatePrompt);add(interestRateField);add(periodPrompt);add(periodField);add(startPrompt);
// display the result as graphicspublic void paint(Graphics g)
g.drawString("Ihre monatliche Rate betraegt EURO "+ ratePerMonth, 15, 150);
g.drawString("fur EURO " + amount + " bei " + period+ " Jahren und " + interestRate+ " % Zinsen.", 15, 170);
// process user’s action on the input text fieldspublic void calculateMortgage()
// get input numbersamount = Double.parseDouble(amountField.getText());

3.4. STRUKTURIERTE ANWEISUNGEN 43
interestRate = Double.parseDouble(interestRateField.getText());
period = Integer.parseInt(periodField.getText());
interestFactor = (100 + interestRate) / 100;power = Math.pow(interestFactor, period);ratePerMonth = (amount / 12) * power
* (interestFactor - 1)/(power - 1);
// round to CentratePerMonth = (Math.round(ratePerMonth * 100)) / 100.0;
repaint(); // calls method paint for the whole applet
Hier wird die Funktionpow() aus der KlasseMath fur die Potenzierung verwendet.pow(a,b) be-rechnet den Wertab und gibt ihn als Ruckgabewert zuruck.
Um die Berechnung in jedem Eingabefeld auslosen zu konnen, wird an jedes Eingabefeld ein Action-Listener hinzugefugt, der in allen Fallen dieselbe MethodecalculateMortgage() aufruft.
Ferner nutzen wir die Graphikmoglichkeiten von Java zur Ausgabe. Die Anweisungrepaint() ver-anlasst das Applet, sich selbst als Graphikobjekt zu sehen und die Methodepaint() fur sich selbstauf zu rufen. In ihr wird die MethodedrawString(str, x, y) verwendet, die den Stringstr ander Position(x,y) zeichnet. Dabei sindx,y int-Variablen, die die Anzahl der Pixel von der linkenoberen Ecke der Appletflache angeben (nach rechts bzgl.x und nach unten bzgl.y. Das fertige Appletist in Abbildung3.3dargestellt.
Abbildung 3.3: Das Hypothek Applet.

44 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
3.4.2 Selektion, Bedingte Anweisung
Die Selektion ermoglicht das Ansteuern einer Alternative in Abhangigkeit von Daten. Der Prototypder Selektion ist die if-Anweisung.
Die if-Anweisung
DerPseudocodefur die if-Anweisung lautet:
if Bthen S1
elseS2
Dabei istBein Boolescher Ausdruck und sindS1,S2 beliebige Anweisungen (insb. wieder strukturierteAnweisungen). Der Prozessor berechnet den Wahrheitswert (true bzw. false) von B und steuert inAbhangigkeit davonS1 bzw.S2 an. Derelse-Teil darf fehlen.
Beispiel 3.2 (Betrag)Der Betrag|a−b| der Differenz a−b zweier reeller Zahlen a,b ist zu berech-nen.
Eine Losung in Pseudocode lautet:
if a > bthen berechne a−belseberechne b−a
DasStruktogramm der if-Anweisung ist in Abbildung3.4 dargestellt, dasFlussdiagramm in Ab-bildung3.5.
HHHHHH
B
true false
S1 S2
XXXXXXXXXXXX
Btrue
S1
Abbildung 3.4: Struktogramm der if-Anweisung.
In Java wird die if-Anweisung folgendermaßen gebildet:
if (B) B1 else B2
Auch hier darf derelse-Teil fehlen. Die Codekonvention schlagt vor, if und else Teile immer mit... zu klammern und dabei folgendes Einruckmuster zu verwenden:

3.4. STRUKTURIERTE ANWEISUNGEN 45
S1 S2
?HHH
HHH
B
? ?
+ −
?
S1
?HHH
HHH
B
?
+
−
?
Abbildung 3.5: Flussdiagramm der if-Anweisung.
if (B1) Anweisungen
else if (B2) Anweisungen
else (B1) Anweisungen
Die selektive Anweisung
Sollen mehr als die zwei Falle true und false unterschieden werden, so ist dies mit derselektivenAnweisungoderSelektionmoglich.
Diese lasst sich als “geschachtelte” Variante der if-Anweisung auffassen. Sind etwac1, . . .cn die Wer-te, die der AusdruckB annehmen kann, und soll beim Wertci die AnweisungSi ausgefuhrt werden,so lasst sich die entsprechende Selektion wie folgt in Pseudocode realisieren:
if B = c1
then S1
else ifB = c2
then S2
else if. . ....
else ifB = cn
then Sn
Hierfur existiert inPseudocodedie folgende Kurzform:
caseB ofc1 : S1;c2 : S2;

46 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
...cn : Sn;end
Das zugehorigeStruktogramm ist in Abbildung3.6dargestellt, dasFlussdiagrammin Abbildung3.7.
S1S2
Sn
aaaaaaaaaaaaaaaaaaaaaaaaaaaaa
B
c1
c2
cn. . .
Abbildung 3.6: Struktogramm der Selektion.
B
S1 S2 Sn. . .
? ?
PPPP
PPPP
P
?
c1 c2 cn
?
rAbbildung 3.7: Flussdiagramm der Selektion.
In Java existiert dafur dieswitch-Anweisung, sieheUbung.
Bei ineinandergeschachteltenif-Anweisungen kann es wegen fehlenderelse Teile zu Unklarheitenbei der Zuordnung derelse zu denif kommen. Falls dies nicht durch Klammerung mit...geregelt wird, bezieht sich ein “hangendes”else immer auf das letzteif, auf das eine Zuordnungmoglich ist. Bei
if (Bedingung1) Anweisung1

3.4. STRUKTURIERTE ANWEISUNGEN 47
if (Bedingung2) Anweisung2else Anweisung3
bezieht sich daselse also auf das zweiteif.
3.4.3 Wiederholung
Die Wiederholung ermoglicht die wiederholte Durchfuhrung einer Anweisung (meist mit verandertenWerten von Variablen). Die Haufigkeit der Wiederholung wird dabei durch eine Boolesche Bedingungkontrolliert. Der Prototyp der Selektion ist die while-Anweisung.
Die while-Anweisung
DerPseudocodefur die while-Anweisung lautet:
while B do S
Dabei istB ein Boolescher Ausdruck und istS eine beliebige Anweisung (insb. wieder eine struk-turierte Anweisung). Der Prozessor berechnet den Wahrheitswert (true bzw. false) von B vor jederAusfuhrung vonS. Ist B = trueso wirdSausgefuhrt, sonst nicht.
Falls der Wahrheitswert vonB immer true bleibt, so wirdSstets wieder ausgefuhrt. Man gerat dannin eine sog.Endlosschleife. Sie stellt bei Anfangern einen haufig gemachten Programmierfehler dar.
DasStruktogramm der while-Anweisung ist in Abbildung3.8 dargestellt, dasFlussdiagramm inAbbildung3.9.
B
S
Abbildung 3.8: Struktogramm der while-Anweisung.
In Java wird diewhile-Anweisung wie folgt gebildet:
while ( B ) S
Die Codekonvention schlagt folgende einruckende Schreibweise vor:
while (B) AnweisungenS

48 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
S
?HHH
HHH
B
?
?+
−
Abbildung 3.9: Flussdiagramm der while-Anweisung.
Beispiel 3.3 (Großter gemeinsamer Teiler)Fur zwei positive naturliche Zahlen x,y ist der großtegemeinsame Teiler ggT(x,y) zu berechnen.
Der großte gemeinsame Teiler von zwei positiven naturlichen Zahlenx undy ist die großte naturlicheZahl, diex undy teilt. So istggT(12,16) = 4 undggT(12,17) = 1.
Zur Berechnung desggT nutzen wir folgende mathematische Aussage:
Lemma 3.1 Sind a,b∈ N und ist a> b > 0, so ist
ggT(a,b) = ggT(a−b,b).
Beweis:Zeige:
1. Ist c ein Teiler vona undb, so auch vona−b undb.
2. Ist c ein Teiler vona−b undb, so auch vona undb.
Aus 1. und 2. folgt:a,b und a−b,b haben dieselben Teiler, und damit auch denselbengroßtenge-meinsamen Teiler.
zu 1: Seic ein Teiler vona undb. Dann existierenk1,k2 ∈N mit k1 ·c= a undk2 ·c= b. Hieraus folgt:
a−b = k1 ·c−k2 ·c = (k1−k2) ·c
Da a > b, ist k1− k2 > 0. Also ista−b ein Vielfaches vonc und somitc ein Teiler vona−b. Da cnach Annahme auch ein Teiler vonb ist, istc ein Teiler vona−b undb. Also gilt 1.
zu 2: Seic ein Teiler vona−b undb. Dann existierenl1, l2 ∈N mit l1 ·c= a−b undl2 ·c= b. Hierausfolgt:
a = (a−b)+b = l1 ·c+ l2 ·c = (l1 + l2) ·cAlso ist c ein Teiler vona. Dac nach Annahme auch ein Teiler vonb ist, istc ein Teiler vona undb.Also gilt 2.
Dies fuhrt zu folgendem Algorithmus zur Berechnung vonggT(x,y) (in Pseudocode).

3.4. STRUKTURIERTE ANWEISUNGEN 49
Algorithmus 3.2 (Großter gemeinsamer Teiler)a := x; b := y;while a 6= b do
if a > b then a := a−belse b := b−a;
ggT(a,b) = ggT(x,y)ggT(x,y) = a = bggT(x,y) := a;
Wir uberlegen uns zunachst, dass dieser Algorithmus korrekt arbeitet.
Satz 3.1 Algorithmus3.2 berechnet fur zwei beliebige positive naturliche Zahlen x,y ihren großtengemeinsamen Teiler.
Beweis: Lemma3.1 garantiert, dass am Ende der if-Anweisung bei jedem Durchlauf der while-Schleife die BedingungggT(a,b) = ggT(x,y) gilt.
Daa oderb in jedem Durchlauf der while-Schleife um mindestens 1 kleiner wird unda undb positivbleiben, kann die while-Schleife hochstens maxx,y mal durchlaufen werden. Also terminiert diewhile-Schleife.
Beim Austritt aus der while-Schleife gilta = b, alsoggT(a,b) = a = b. Zusammen mit der oben ge-zeigten GleichheitggT(a,b) = ggT(x,y) folgt die Behauptung.
Ein Zahlenbeispiel: Fur x = 28, y = 12 ergeben sich folgende Werte fur a undb.
a: 28→ 16 → 4 → 4 → 4b: 12 → 12 → 12→ 8 → 4
Nach dem 4. Schleifendurchlauf ista = b = 4, und der Algorithmus terminiert mitggT(28,12) = 4.
Ein entsprechendes Java Programm lautet:
Programm 3.2 GGT.java// GGT.java//// calculates gratest common divisor gcd(x,y)// of natural numbers x and yimport java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class GGT extends Applet

50 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
int x, y, a, b, gcd; // natural numbers
Label xPrompt,yPrompt,startPrompt; // declare Labels
String message; // declare String for ResultTextField xField,
yField; // declare textfields for input
// setup the graphical user interface components// and initialize labels and text fieldspublic void init()
setLayout(new FlowLayout(FlowLayout.LEFT));setFont(new Font("Times", Font.PLAIN, 14));setSize(380, 150);
xPrompt = new Label("Geben sie eine naturliche Zahl "+ "x > 0 ein:");
xField = new TextField("24", 10);xField.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)compute_gcd();
);
yPrompt = new Label("Geben Sie eine naturliche "+ "Zahl y > 0 ein:");
yField = new TextField("36", 10);yField.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)compute_gcd();
);
startPrompt = new Label("Drucken Sie Return zum "+ "Start der Berechnung.");
add(xPrompt);add(xField);add(yPrompt);add(yField);add(startPrompt);

3.4. STRUKTURIERTE ANWEISUNGEN 51
message = "Der ggT von 24 und 36 ist 12.";
// display the result as graphicspublic void paint(Graphics g)
g.drawString(message, 15, 130);
// process user’s action on the input text fieldspublic void compute_gcd()
// get input numbersx = Integer.valueOf(xField.getText()).intValue();y = Integer.valueOf(yField.getText()).intValue();
if (x <= 0 || y <= 0) message = "Bitte nur positive ganze Zahlen "
+ "eingeben!"; else
a = x;b = y;while (a != b)
if (a > b) a = a - b;
else b = b - a;
// gcd(x,y) == amessage = "Der ggT von " + x + " und " + y
+ " ist " + a + ".";
repaint();
Man beachte, dass unzulassige Eingaben von ganzen Zahlen (0 oder negative Zahlen) durch den Be-nutzer im Programm abgefangen werden. Dies ist notwendig, da das Programm sonst in eine Endlos-schleife gerat. Das fertige Applet ist in Abbildung3.10dargestellt.

52 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
Abbildung 3.10: Das GGT Applet.
Varianten der while-Anweisung
Bei der while-Anweisung wirdS nie ausgefuhrt, wennB bereits zu Anfang den Wertfalsehat. Oftmochte man jedoch die AnweisungSmindestens einmal (unabhangig vonB) ausfuhren. Dies ist mitder while-Anweisung wie folgt moglich:
S;while B do S
Da dies haufig vorkommt, gibt es hierfur dierepeat-Anweisungals eigene Kontrollstruktur.
repeatSwhile B
oder,aquivalent dazu,
repeatSuntil not B
Der Prozessor fuhrt erstSaus, dann wirdB gepruft (post checkingim Gegensatz zupre checkingbeider while-Anweisung). FallsB noch erfullt ist, so wirdSerneut ausgefuhrt.
DasStruktogramm der repeat-Anweisung ist in Abbildung3.11dargestellt, dasFlussdiagramm inAbbildung3.12.
In Java gibt es hierfur diedo-while-Anweisung:
doS
while ( B );
Laut Codekonvention soll sie wie folgt geschrieben werden:
do AnweisungenS
while (B);

3.4. STRUKTURIERTE ANWEISUNGEN 53
not B
S
Abbildung 3.11: Struktogramm der repeat-Anweisung.
S
?
HHH
HHH
B
?
-
+
−
?
Abbildung 3.12: Flussdiagramm der repeat-Anweisung
Manchmal muss man einefeste Anzahlvon Wiederholungen (Iterationen) vonSmachen (z. B.n mal).Dies kann realisiert werden durch die Mitfuhrung einerKontrollvariablen z, dienicht in Svorkommt.Diese wirdublicherweise alsZahler bezeichnet.
z := n;while z> 0 do
z := z−1;S
Kurzform:
repeatS ntimes
DasStruktogramm hierfur ist in Abbildung3.13dargestellt.
In Java gibt es dafur dasfor-statement als eigene Kontrollstruktur, sieheUbung.
3.4.4 Machtigkeit von Kontrollstrukturen
Mit den eingefuhrten Kontrollstrukturen Verkettung, Selektion und Wiederholung kann alles berech-net werden, was im intuitiven Sinne berechenbar ist. Der Nachweis hiervon wird in der Theorie derBerechenbarkeit gefuhrt.

54 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
n times
S
Abbildung 3.13: Struktogramm dern-maligen Wiederholung.
Tatsachlich lasst sich dies bereits mit weniger Kontrollstrukturen erreichen, z. B. reichen die Verket-tung und die while-Schleife bereits aus. (Ubung: hierdurch ist die if-Anweisung simulierbar). Verket-tung und Iteration (n-malige Wiederholung) reichen jedoch nicht aus. Man braucht die Moglichkeit,beliebige Boolesche AusdruckeB als Abbruchbedingung zu wahlen.
Die gleiche Machtigkeit erreicht man alternativ auch mit der Verkettung, der Selektion und dergoto-Anweisung. Die goto-Anweisung ermoglicht es, zu beliebigen Stellen im Programm zu “springen”.In alteren Programmiersprachen (Basic, Fortran) und in Assembler gehoren goto-Anweisungen zumStandard, in moderneren Sprachen sind sie verpont, da die Programme durch sie meist unstrukturiertwerden und schwer zu verstehen und zuuberprufen sind.
In Java gibt es kein goto Statement, jedoch sind Sprunge partiell mit den”abgeschwachten“ goto
Anweisungenbreak undcontinue erlaubt, bei denen auch Sprungstellen definiert werden konnen.Wir erlautern hier nur zwei spezielle Situationen um aus geschachteltenif- oderwhile-Anweisungenheraus zu springen. Hierbei sind keine selbst definierten Sprungstellen erforderlich.
Zum Verlassen von Schleifen “in der Mitte” gibt es die Anweisungenbreak und continue. Diewhile Anweisung wird dann zu
while (true) ...if (!Fortsetzungsbedingung) break;...
bzw. zu
while ( Fortsetzungsbedingung)...if (!Bedingung) continue;weitere Anweisungen
Im ersten Fall wird diewhile-Schleife ganz verlassen, im zweiten Fall werden die “weiteren Anwei-sungen” ubersprungen und erfolgt der nachste Durchlauf derwhile-Schleife.

3.5. LITERATURHINWEISE 55
break kann auch in derif- bzw.switch-Anweisung auftreten, vgl.Ubung.
Zum Abschluss geben wir in den Abbildungen3.14und3.15die verbesserte Version des Algorithmuszur Berechnung der nachst großeren Primzahl zu einer gegebenen Zahl (vgl. Kapitel2.3) in Form vonStruktogrammen an.
Lese Zahln ein
Durchlaufe alle ungeraden Zahlenz> n der Reihe nach
k kein Teiler vonz undk ·k≤ z
Teste alle ungeraden Zahlenk abk = 3 bisk ·k≤ zob sie Teiler vonz sind
kein Teiler vonz gefunden
Gebez aus
Abbildung 3.14: Struktogramm des Primzahl-Algorithmus (Grobversion).
``````
``````
`````
XXXXX
XXXXXX
XXX
Lese Zahln ein
true falsen gerade
z := n−1 z := n
z := z+2
k := 3
divisorFound:= false
(divisorFound= false) and (k ·k≤ z)
true falsez modulok = 0
divisorFound:= true k := k+2
divisorFound= false
Gebez aus
Abbildung 3.15: Struktogramm des Primzahl-Algorithmus (Feinversion).
3.5 Literaturhinweise
Kontrollstrukturen werden in nahezu allen Buchernuber Programmiersprachen behandelt. Geschichtliche Hin-weise zur Entstehung der Kontrollstrukturen und Vergleiche zwischen verschiedenen Programmierstilen undSprachen finden sich in [Hor84].

56 KAPITEL 3. AUSDRUCKE, ANWEISUNGEN, KONTROLLSTRUKTUREN
Bzgl. Java verweisen wir auf [CW98, DD01, Kuh99].
Die Behandlung von Kontrollstrukturen, Ausdrucken, Typechecking usw. durch Compiler ist ausfuhrlich in[ASU86] dargestellt.
Eine Einfuhrung in die Theorie der Formalen Sprachen ist in [Wii87] enthalten. Tiefer geht [HU79].

Kapitel 4
Syntax und Semantik vonProgrammiersprachen
Unter derSyntaxeiner Sprache versteht man die Menge der grammatischen Regeln, nach denen ausdenSymbolen(auchTerminalsymbolegenannt) einer Sprache korrekte Ausdrucke gebildet werden.
In Java sind die Symbole:
Schlusselworter : if, while, return, int, . . .Zeichen : a . . . z, A . . . Z, 0 . . . 9, a, u, ~n, . . . (Unicode Zeichen)Sonderzeichen : /, %, (, ), , , +, -, *, &&, ++, ==, . . .
Zur Darstellung der Syntaxregeln von Programmiersprachen gibt es standardisierte Beschreibungsar-ten:
• Backus Naur Form (BNF) bzw. erweiterte Backus-Naur-Form (EBNF)1
• Syntaxdiagramme
Beide Arten stellen Beschreibungsmittel fur folgende Konstrukte zur Verfugung:
- Option
- Alternative (Vereinigung)
- (begrenzte) Wiederholung
- Konkatenation (Produkt)
1so benannt nach Backus und Naur, zwei Informatikern, die in den 60ger Jahren maßgeblich an der Entwicklung vonALGOL 60, der ersten strukturierten Programmiersprache, mitwirkten.
Version vom 21. Januar 2005
57

58 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
4.1 Backus Naur Form
Zur Darstellung der genannten Konstrukte werden sogenannteMetazeichenverwendet:
Option durch [. . .]Alternativen durch . . . | . . . | . . . | . . .Wiederholung durch . . .Konkatenation durch Aneinanderreihung
Zusatzlich zu den Terminalsymbolen verwendet man Begriffe, die noch nicht erklart sind. Diese hei-ßenNonterminalsymboleodersyntaktische Variable. Sie werden in< .. . > geschrieben und durch::= definiert.
Beispiel 4.1 (Identifier in Java)<identifier> ::= <Unicode-Buchstabe><Unicode-Buchstabe> |<Unicode-Ziffer><Unicode-Buchstabe>::= |A|B|C| . . . |a|b| . . . |a|o| . . . |~n| . . . | |<Unicode-Ziffer> ::= 0|1|2|3|4|5|6|7|8|9
Nach diesen Regeln korrekt geformte Identifier sind:a1, a very long identifier.
Nicht korrekt sind:1a, x-11, a*.
Neben derSyntax, die die Regeln zur korrekten Bildung festlegt, gibt es dieSemantik. Sie legt dieBedeutungder korrekt gebildeten Ausdrucke fest. Dies geschieht meist durch zusatzliche Regeln, dienichts mit der Syntax zu tun haben. Fur Identifier sind dies folgende Regeln:
- Groß- und Kleinschreibweise werden unterschieden (an jeder Position)
- Schlusselworte konnen keine Identifier sein.
Beispiel 4.2 (if statement in Java)<if statement> ::= if (<Bedingung>) <statement> else <statement><Bedingung> ::= <Ausdruck der einenboolean-Wert liefert><statement> ::= <einfache oder zusammengesetzte Anweisung>
Wir verzichten auf die weitere Erklarung der syntaktischen Variablen<Ausdruck der einenboolean-Wert liefert><einfache oder zusammengesetzte Anweisung>.
Sie ergibt sich aus Kapitel3.
Das folgende Beispiel ist ausfuhrlicher und erklart alle syntaktischen Variablen bis hinunter zu Ter-minalsymbolen.
Beispiel 4.3 (Ganze Zahl (Integer-Literal) in Java)<integer literal> ::= <Zahlenwert> [<Typsuffix>]

4.1. BACKUS NAUR FORM 59
<Zahlenwert> ::= <Dezimalwert> |<Oktalwert> | <Hexadezimalwert><Typsuffix> ::= l|L<Dezimalwert> ::= 0 |<erste Dezimalziffer> <Dezimalziffer><erste Dezimalziffer> ::= 1|2|3|4|5|6|7|8|9<Dezimalziffer> ::= 0 |<erste Dezimalziffer><Oktalwert> ::= <Oktalprafix><Oktalziffer> <Oktalziffer><Oktalprafix> ::= 0<Oktalziffer> ::= 0|1|2|3|4|5|6|7<Hexadezimalwert> ::= <Hexadezimalprafix><Hexadezimalziffer>
<Hexadezimalziffer><Hexadezimalprafix> ::= 0x|0X<Hexadezimalziffer> ::= 0|1|2|3|4|5|6|7|8|9|a|A|b|B|c|C|d|D|e|E|f|F
Die Bedeutungder nach diesensyntaktischenRegeln geformten Integer-Literale ergibt sich aus denfolgendensemantischenZusatzregeln.
• Prafix 0 bedeutet Oktaldarstellung, d. h. zur Basis 8 mit den Ziffern0,1,. . .,7. Das Literal045hat also den Dezimalwert 5·80 +4·81 = 37.
• Prafix0x oder0X bedeutet Hexadezimaldarstellung, d. h. zur Basis 16 mit den Ziffern0,. . .,9,A,B,C,D,E,F,die den Zahlenwerten 0,1, . . . ,15 entsprechen. Dabei konnen stattA. . .F auch die Kleinbuchsta-bena. . .f genommen werden. Dem Literal0x2fA entspricht also die Dezimalzahl(A ·160 +F ·161 +2·162) = (10·160 +15·161 +2·162) = 762.
• Der Typsuffix bezieht sich auf den Java Typlong zur Darstellung ganzer Zahlen. Standardmaßigwerden ganze Zahlen alsint Zahlen mit 32 Bit im sogenannten Zweierkomplement2 darge-stellt, so dass Werte zwischen−231 =−2147483648 und 231−1 = 2147483647 moglich sind.Bei long werden (wiederum im Zweierkomplement) 64 Bit zur Darstellung verwendet.3
• Liegt der Zahlenwert eines Literals außerhalb des durch 32 bzw. 64 Bit begrenzten darstellbarenBereiches, so soll beim Kompilieren eine Fehlermeldung erfolgen4.
Beispiele fur korrekt geformte integer-literals sind:13, 0, 000, 0x0fL, 0xDaDaCafe.
Beispiele fur nicht korrekt geformte integer-literals sind:039, f17, 0-3. Die ersten beiden sind sinn-los, das letzte Beispiel ist ein Ausdruck, der den Wert -3 liefert.
Man beachte, dass das Vorzeichen nicht zum Integer-Literal gehort. Es ist vielmehr ein einstelligerOperator, der auf ein Literal angewendet wird. Die Literale selbst geben also nur die moglichen Ab-solutbetrage an.
2vgl. hierzu Kapitel12.3Daneben existieren noch die Typenbyte undshort mit 8 bzw. 16 Bit.4Laut Java-Spezifikation. Allerdings wird dies nicht von allen Compilern beachtet und gemaß der 2-
Komplementdarstellung eine falsche Zahl berechnet, vgl. Kapitel12.

60 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
Der darstellbare Bereich wird in den KlassenInteger undLong dokumentiert. InInteger werdenu. a. die KonstantenInteger.MAX VALUE undInteger.MIN VALUE zu0x7fffffff und0x80000000definiert, deren Dezimalwerte die oben genannten Werte 231−1= 2147483647 und 231= 2147483648sind. Der letzte Wert darf nur mit dem unaren Operator- auftreten, sonst soll wie beimUberlauf einKompilierfehler erfolgen.
Die “kompakte” Notation der BNF erlaubt es, die Syntax der Programmiersprache Java auf wenigenSeiten darzustellen, vgl. z. B. [Kuh99]. Viele Bucher enthalten abgewandelte Formen der BNF, vondenen zwei im folgenden erlautert werden.
4.2 Erweiterte Backus Naur Form
Die erweiterte Backus Naur Form (extended Backus Naur FormoderEBNF) sieht einige vereinfa-chende Schreibweisen vor:
. . .k` (mindestens mal, hochstensk mal). . .∗` (mindestens mal, sonst beliebig oft)
Dann kann[. . .] durch. . .10 ausgedruckt werden. So lassen sich etwa in Beispiel4.3einige Syntax-regeln einfacher formulieren:
< integer literal> ::= < Zahlenwert> < Typsuffix>10< Oktalwert> ::= < Oktalprafix> < Oktalziffer>∗1
4.3 Syntaxgraphen
Die BNF ist nur eine von vielen Moglichkeiten zur Darstellung von Syntaxregeln. Eine graphischorientierte Darstellungsform sind die sogenanntenSyntaxgraphenoderSyntaxdiagramme. Die ver-wendeten Metasymbole sind in Abbildung4.1dargestellt. Dabei sindA,B,C Nicht-Terminalsymboleunda,b,c Terminalsymbole.
Als Beispiel sind hier der Syntaxgraph der if Anweisung (Abbildung4.2) und Teile des Syntaxgraphenfur die integer literals (Abbildung4.3) aufgefuhrt.
Als ein weiteres Beispiel betrachten wirkorrekte Klammerausdrucke. Sie sind wichtig fur die korrekteDarstellung von arithmetischen und logischen Ausdrucken [(,) Klammern], und zur Bildung korrek-ter Java Programme [, Klammern]. Der Compiler muss in der Lage sein, Klammerausdrucke aufKorrektheit zuuberprufen und “korrespondierende” Klammerpaare zu finden, etwa:
(()()) korrekt(() nicht korrekt nicht korrekt
4.3. SYNTAXGRAPHEN 61
- A -
Nichtterminalsymbole
- a -
Terminalsymbole
- A - B -
Konkatenation
-
-
-
A
B
-6? -
Alternative
A
-
-6
Option
A
-6
Wiederholung
Abbildung 4.1: Metasymbole von Syntaxgraphen.
- if -
( - Bedingung - ) - Anweisung - -
else - Anweisung
Abbildung 4.2: Syntaxgraph der if-Anweisung.
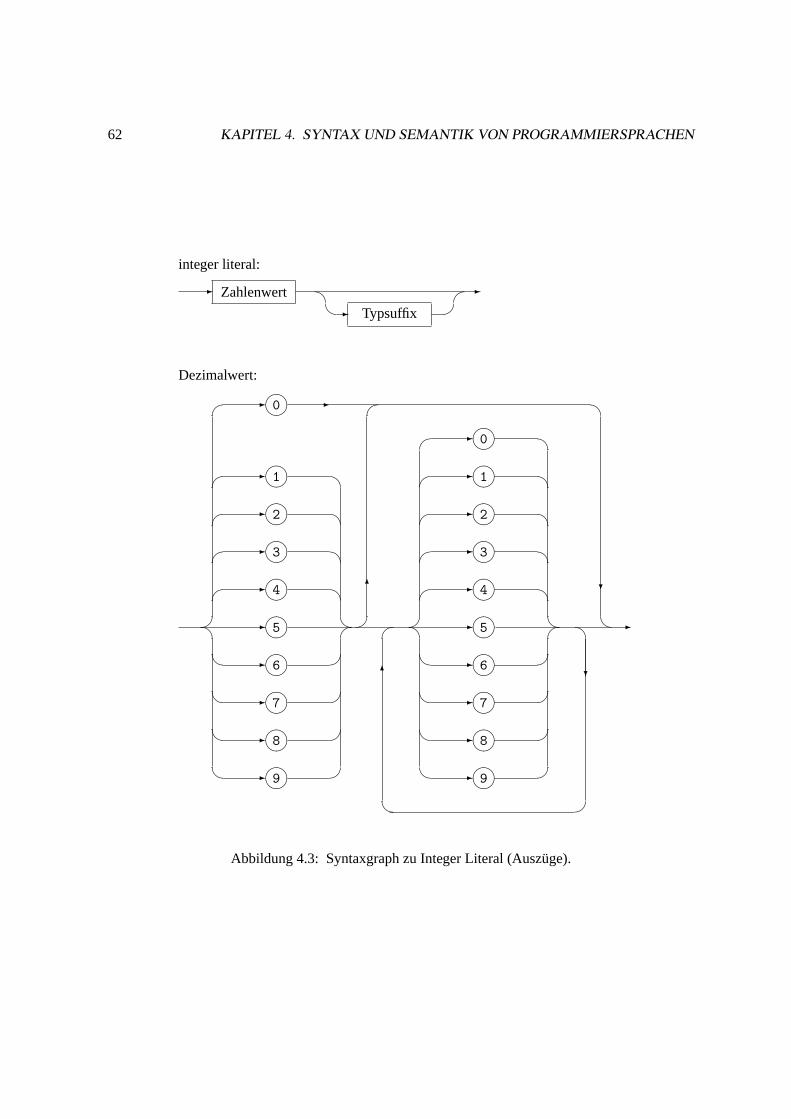
62 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
integer literal:
- Zahlenwert -- Typsuffix
Dezimalwert:
0
1
2
3
4
5
6
7
8
9
-
-
-
-
-
-
-
-
-
1
2
3
4
5
6
7
8
9
-
-
-
-
-
-
-
-
0 - -
- - - 6
?
?
6
Abbildung 4.3: Syntaxgraph zu Integer Literal (Auszuge).

4.3. SYNTAXGRAPHEN 63
Zur Erstellung eines Syntaxdiagrammsuberlegt man sich, wie man korrekte Klammerausdrucke auseinfacheren (d. h. mit weniger Klammern) zusammensetzen kann.
Es bezeichnenA,B im weiteren immer korrekte Klammerausdrucke. Dann gilt bzgl. der Zusammen-setzung von Klammerausdrucken:
– Der einfachste korrekte Klammerausdruck istA = ().
– Man kann korrekte Klammerausdrucke hintereinander schreiben und erhalt einen neuen korrek-ten Klammerausdruck.
A,B korrekt ⇒ ABkorrekt
Beispiel:A = (),B = (()) ⇒ AB= ()(())
– Man kann einen korrekten KlammerausdruckA wieder klammern und erhalt einen neuen kor-rekten Klammerausdruck.
A korrekt ⇒ (A) korrekt
Beispiel:A = ()()⇒ (A) = (()())
Satz 4.1 Jeder korrekte Klammerausdruck mit mehr als 2 Klammern kann mit einer dieser Moglichkeitenaus kleineren konstruiert werden.
Beweis:Sei A ein korrekter Klammerausdruck mit mehr als 2 Klammern. Dann gehort zur erstenKlammer auf( eine entsprechende Klammer zu).
Ist dies die letzte Klammer inA, so istA von der Form(B) wobeiB wieder ein korrekter Klammer-ausdruck ist (da sonstA nicht korrekt ware).
Ist die “Klammer zu” nicht die letzte Klammer inA, so seiB der Teilausdruck vom Anfang vonAbis einschließlich dieser Klammer, undC der Rest. Dann sindB undC korrekte Klammerausdrucke(sonst wareA nicht korrekt).
Die Fallunterscheidung zeigt also:A = (B) oderA = BC, wobeiB bzw.B,C kurzere korrekte Klam-merausdrucke alsA sind. Also trifft eine der beiden Regeln zu.
Nach Satz4.1ist ein korrekter Klammerausdrucke entweder der einfachste Ausdruck(), oder er lasstsich durch zwei Regeln aus einfacheren korrekten Ausdrucken aufbauen. Daraus ergibt sich das inAbbildung4.4dargestellte Syntaxdiagramm zur Bildung korrekter Klammerausdrucke.
Man beachte, dass das Syntaxdiagrammrekursivdefiniert ist, d. h. die syntaktische Variable “korrekterKlammerausdruck” kommt auf der rechten Seite ihrer Definition wieder vor (und entspricht dannkleinerenkorrekten Ausdrucken wie im Beweis von Satz4.1.
Als letztes Beispiel fur Syntaxdiagramme behandeln wir dieNotation beim Schach(ausfuhrliche No-tation). Beispiele fur Zuge in dieser Notation sind:

64 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
- korrekter Klammerausdruck - korrekter Klammerausdruck -
- ( - korrekter Klammerausdruck -
)
6
6
Abbildung 4.4: Syntaxgraph fur korrekte Klammerausdrucke.
Sg1–f3 Bewegung eines Springerse2–e4 Bewegung eines BauernTa1xa4 Schlagen (x)
Ta1–a8+ Schach (+)Th1–h7++ Matt (++)
0–0 kurze Rochade0–0–0 lange Rochade
a7–a8D Umwandlung in eine Damee4xd3 e.p. “en passent” schlagen (nur bei Bauern)
Das Syntaxdiagramm eines Zuges ist in den Abbildungen4.5und4.6dargestellt.
4.4 Syntax versus Semantik
Man stellt in den vorangegangenen Beispielen deutlich einen Unterschied fest zwischen derSyntax(also den Regeln, die festlegen, wie die Ausdrucke gebildet werden) und derSemantik(also der Be-deutung der Ausdrucke).
So ist der Schachzug Ta1–b2 syntaktisch (nach den gegebenen Regeln) korrekt aber semantisch sinn-los, da Turme nicht so ziehen durfen.
Man konnte diese Zugregeln fur Figuren noch durch ausgefeiltere Syntaxregeln formulieren, wie z. B.in Abbildung 4.7. Dann wird zwar Ta1-b2 als syntaktisch falsch erkannt, aber von dem syntaktischkorrektem Zug Ta1-a4 kann erst aus der Spielsituation heraus (d. h. “zur Laufzeit”) entschieden wer-den, ob er semantisch korrekt ist. (Es konnte ja auf a2 noch eine eigene Figur stehen.)
Diese fließende Grenze zwischen Syntax und Semantik tritt in allen formalen Systemen, insbesondereauch in Programmiersprachen auf.
In Programmiersprachen wird die syntaktische Korrektheit des Programmtextes bei der Programmubersetzungin Maschinensprache vom Interpreter bzw. Compiler getestet. Das setzt voraus, dass die Syntaxana-lyse ohne Bezug auf die Semantik der Ausdrucke moglich ist. Ist dies moglich, so spricht man (inder Theorie der formalen Sprachen) vonkontextfreienSprachen. Programmiersprachen sind nur inTeilen kontextfrei (z. B. korrekte Klammerausdrucke oder integer-literal), in anderen aber nicht (z. B.Korrespondenz zwischen formalen und aktuellen Parametern bei Funktionen, vgl. Kapitel7.1).
Syntaktisch korrekte Ausdrucke konnen semantisch sinnlos sein, wie das Beispiel der Turmzuge zeig-te. Dies gilt auch fur die Umgangssprache. So sind die Anweisungen
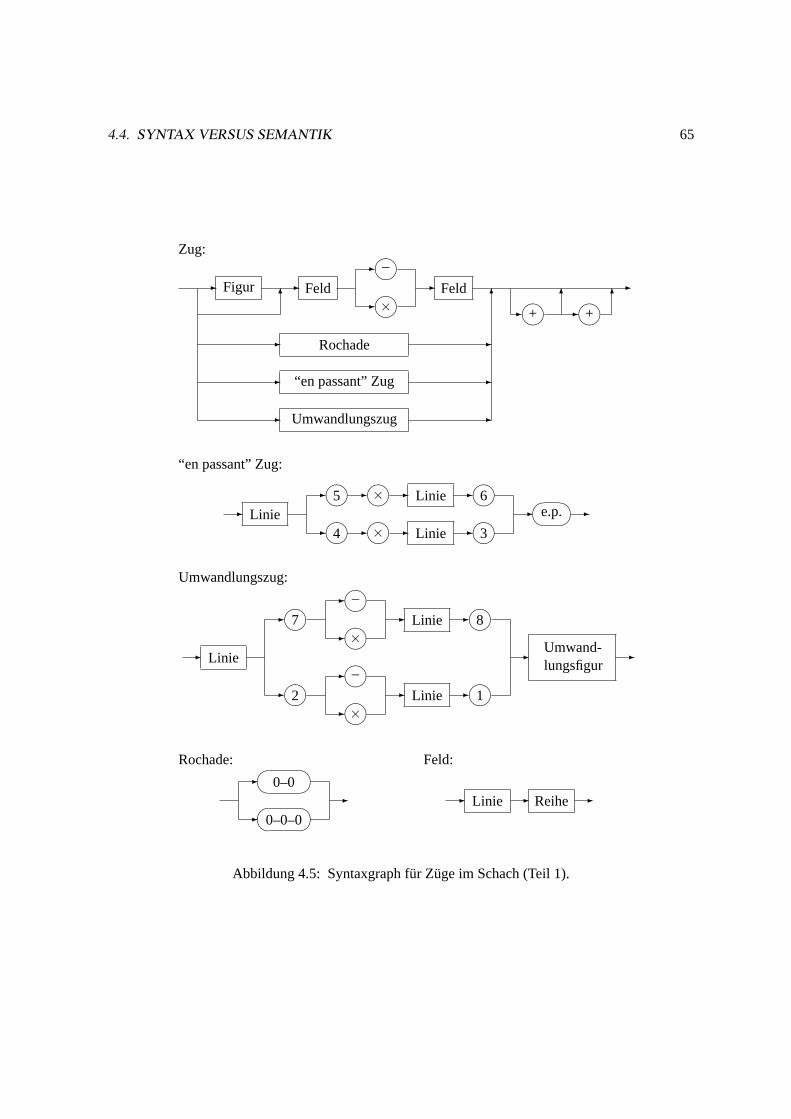
4.4. SYNTAX VERSUS SEMANTIK 65
Zug:
- Figur - Feld
-
-
–
×
- Feld -
- + -
6 +
66 6
- -Rochade
- -“en passant” Zug
- -Umwandlungszug
“en passant” Zug:
- Linie
-
-
5
4
-
-
×
×
-
-
Linie
Linie
-
-
6
3
- e.p. -
Umwandlungszug:
- Linie -
-
-
7
2
-
-
-
-
–
–
×
×
-
-
Linie
Linie
-
-
8
1
Umwand-lungsfigur
-
Feld:
- Linie - Reihe -
Rochade:-
-
0–0 0–0–0
-
Abbildung 4.5: Syntaxgraph fur Zuge im Schach (Teil 1).
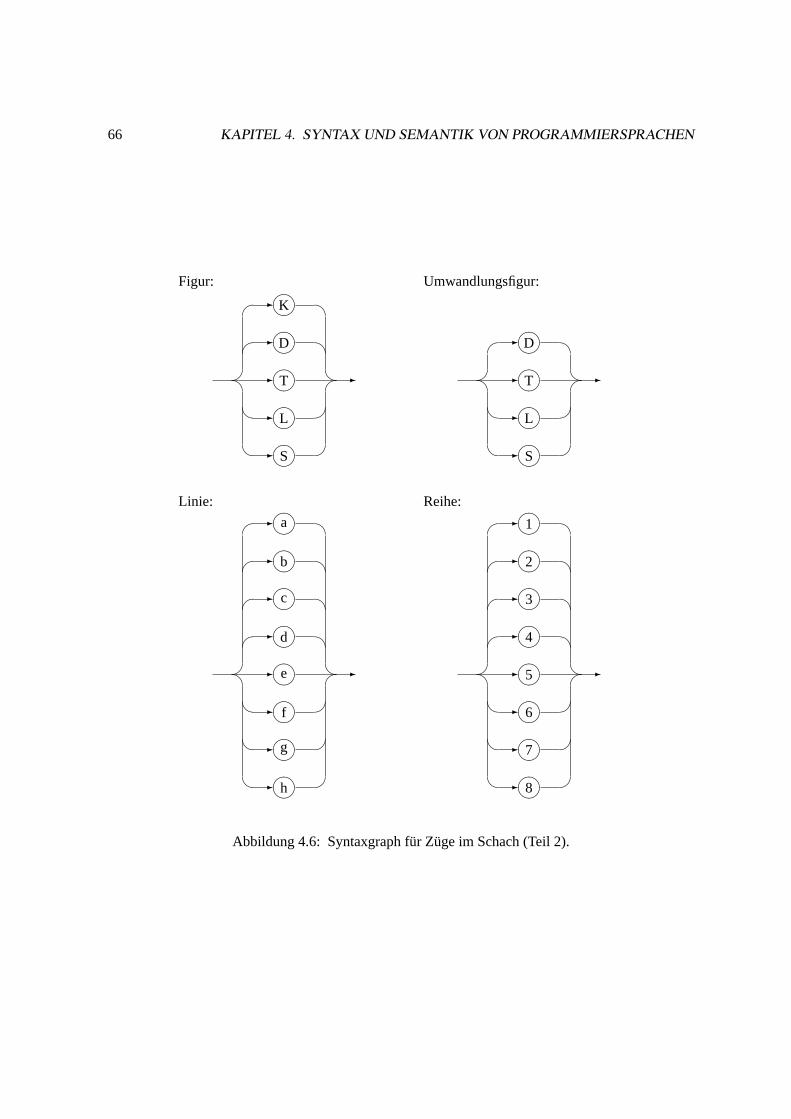
66 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
Figur:
K
D
T
L
S
-
-
-
-
- -
Umwandlungsfigur:
D
T
L
S
-
-
-
- -
Linie:
a
b
c
d
e
f
g
h
-
-
-
-
-
-
-
- -
Reihe:
1
2
3
4
5
6
7
8
-
-
-
-
-
-
-
- -
Abbildung 4.6: Syntaxgraph fur Zuge im Schach (Teil 2).

4.4. SYNTAX VERSUS SEMANTIK 67
T -
-
-
-
a
b
h
Linie
-
-
-
Reihe
Reihe
Reihe
qqq
-
-
-
-
-
-
-
-
–
–
–
×
×
×
-
-
-
a
b
h
-
-
6- Reihe - q q q
1
8
qqq-
-
-
-
–
–
×
×
-
-
Linie
Linie
-
-
1
8
-
-
6
Abbildung 4.7: Ein detaillierterer Syntaxgraph fur Turmzuge.
Schreibe den Namen des 1. Monats im Jahr.Schreibe den Namen des 13. Monats im Jahr.
beide syntaktisch korrekt, die zweite ist jedoch semantisch sinnlos.
Semantikfehler konnen durch einen Prozessor nur aufgedeckt werden, falls er genugenduber dieObjekte, auf die der Algorithmus Bezug nimmt, weiß. Auch dann sind sie meist schwer auffindbar,wenn sie in versteckter Form vorkommen, wie etwa in den folgenden Anweisungen:
Wahlen aus1, . . . ,13.Schreibe den Namen desn-ten Monats im Jahr.
Die hier auftretende Unstimmigkeit ist ein Ergebnis der Algorithmusausfuhrung, daher schwer ausdem Text der Anweisung (dem “Programmtext”) zu ermitteln.
Zur Ausfuhrung von Anweisungen in einem Programm muss ein Prozessor Folgendes konnen:
1. die Symbole verstehen, die der Algorithmusschritt enthalt (dies ist die Stufe zum Finden derSyntaxfehler),
2. jedem Schritt eine Bedeutung zuordnen in Form von auszufuhrenden Operationen (dies ist dieStufe zum Finden mancher Semantikfehler),
3. die Operationen ausfuhren (manche Semantikfehler konnen erst hier festgestellt werden).
Neben den Syntax- und Semantikfehlern gibt es dieLogikfehler. Das Programm beschreibt den gewunschten

68 KAPITEL 4. SYNTAX UND SEMANTIK VON PROGRAMMIERSPRACHEN
Ablauf nicht, ist aber syntaktisch und semantisch korrekt. Ein Beispiel:
Berechne den Umfang durch Multiplikation des Radius mitπ.
ist syntaktisch und semantisch korrekt, aber falsch.
Bei Programmiersprachen bilden die Syntaxdiagramme die Basis fur die Syntaxanalyse durch denCompiler. Auch hier sind die Grenzen zwischen Syntax und Semantik fließend:
– Ist 1/0 syntaktisch oder semantisch (oder nur pragmatisch) unzulassig?5
– Ist a := 0, b := 1/a zulassig?6
– Ist a+b syntaktisch zulassig, wenna alsdouble Variable undb alsint Variable definiert ist?7
4.5 Literaturhinweise
Eine leicht verstandliche Einfuhrung in formale Sprachen gibt [Wii87]. Zur Vertiefung sei auf [HU79] verwie-sen.
[Kuh99] enthalt eine vollstandige Beschreibung der Syntax von Java mittels BNF. [ASU86] geht ausfuhrlichauf die Verwendung von Syntaxregeln in Compilern ein.
5In Java ist dies syntaktisch zulassig, aber zur Laufzeit erfolgt beiint und double Variablen die FehlermeldungArithmeticException: / by zero.
6In Java ist dies syntaktisch zulassig. Zur Laufzeit erfolgt bei int Variablen die FehlermeldungArithmeticException: / by zero, wahrend beidouble Variablen b den in der KlasseDouble definierten WertInfinity bekommt.
7Dies ist in Java zulassig. Das Ergebnis ist vom Typdouble.

Kapitel 5
Objekte, Typen, Datenstrukturen:Einf uhrung und Beispiele
5.1 Datentypen und Operationen
Die Syntax einer algorithmischen Sprache beschreibt die formalen Regeln, mit denen ein Algorithmusformuliert werden kann. Sie erklart jedoch nicht die Bedeutung der Daten und Operationen, die ineinem in einer bestimmten algorithmischen Sprache geschriebenen Algorithmus zulassig sind. Diesist ein Problem der Semantik.
Fur Daten eines vorgegebenen Typs ergibt sich die Semantik aus den moglichenWertenund denzugelassenenOperationenauf diesen Werten. Beide zusammen bilden einen Typ oder Datentyp.
Definition: EinDatentyp(kurzTyp) besteht aus
• demWertebereich(domain) des Typs
• einer Menge vonOperationen(Methoden) auf diesen Werten
Jede Programmiersprache verfugt uber eingebaute (Standard) Datentypen. Andere mussen als soge-nannteabstrakteoderselbst definierteDatentypen mit den Ausdrucksmitteln der Programmiersprachedefiniert werden.
Beispiel 5.1 (Der Java Typint)Wertebereich: Die endliche Teilmenge
Nmin,Nmin+1,Nmin+2, . . . ,0,1,2, . . . ,Nmax
der ganzen Zahlen, wobei Nmin =−231 und Nmax = 231−1 ist.Version vom 21. Januar 2005
69

70 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Operationen: = Zuweisung+ Addition- Subtraktion* Multiplikation/ Ganzzahlige Division% Rest bei ganzzahliger Division== Test auf Gleichheit, Ergebnis ist vom Typboolean!= Test auf Ungleichheit, Ergebnis ist vom Typbooleanund viele andere mehr (vgl.Ubung).
Beispiel 5.2 (Ein selbstdefinierter Typ Fraction)Wertebereich: Alle Bruche der Form r= p/q wobei p und qint Werte sind und q> 0 ist.
Operationen:Fraction(a,b) Erzeuge den Bruch r aus gegebenenint Zahlen a,btoString() Schreibe den Bruch r in der Form “p/q”doubleValue() Berechne den entsprechendendouble Wertsimplify() Reduziere r auf die Form p/q, so dass p und q teilerfremd sindgetNumerator() Gebe den Zahler (numerator) zuruckgetDenominator() Gebe den Nenner (denominator) zuruckmultiply(s) Multipliziere Bruch mit Bruch sequals(s) Teste, ob Bruch= s ist (2/4 = 1/2)
Der Typ Fraction ist in Java nicht vorhanden, kann aber (uberKlassen, vgl. Kapitel7.4.1) implemen-tiert werden.
Wir werden jedoch bereits in unserem Pseudocode die Schreibweise (und Ausdrucksweise) der JavaKlassenubernehmen. toString(),. . ., equals() sind Methoden der Klasse Fraction.
Die Deklaration von Variablen vom Typ Fraction erfolgt gemaß
Fractionr,s;
Man nennt dannr,s Instanzen(Objekte) der Klasse. Auf die zugehorigen Objektmethoden wird mit
r.toString();
usw. zugegriffen. Diese Anweisung bewirkt das Schreiben des Bruchesr als String in der Forma/b.
Die Erzeugung (auchInstantiierunggenannt) erfolgt wie bei Objektenublich mit new.
Fractionr = new Fraction(3,4);
bedeutet also die Erzeugung der Variablen (des Objektes)r vom Typ Fraction mit dem Wert 3/4.
In Java sind also folgende Anweisungen denkbar (bei Umsetzung obiger Methoden):

5.1. DATENTYPEN UND OPERATIONEN 71
Fraction r = new Fraction(3, 4) // r := 3/4Fraction s = new Fraction(4, 8); // x := 4/8s.simplify(); // s= 1/2r.multiply(s); // r := r ·s= 3
4 ·12 = 3
8if(r.equals(s)) ... // Test auf Gleichheit
Beispiel 5.3 (Skatkarte)Wertebereich:=Karo 7, . . . ,Karo Ass, . . . ,Kreuz 7, . . . ,Kreuz Ass, d. h. 32 Werte, die die Spielkar-ten im Skat Spiel darstellen.
Funktionen:farbe() Gibt die Farbe (Kreuz, Pik, HerzoderKaro) einer Karte anwert() Gibt den Wert (7,. . .,10, Bube, Dame, KonigoderAss)
einer Karte anSkatkarte() Konstruktor, zieht eine zufallige KarteSkatkarte(f,w) Konstruktor, erzeugt eine Karte mit Farbe f und Wert w
Dann weist die Sequenz
Skatkartekarte= new Skatkarte();w = karte.wert();
der Variablenw den Wert einer zufalligen Skatkarte zu.
Auch dieser Typ ist in Java nicht vorhanden, konnte aberahnlich wie der Typ Fraction als Klasseimplementiert werden.
Wichtig ist die Unterscheidung zwischen (abstrakten)Datentypenund Implementationen(z. B. inJava) solcher Datentypen.Algorithmenentwicklung basiert nur auf abstrakten Datentypen. Die Um-setzung abstrakter Datentypen in eine Implementation erfolgt entweder erst danach, oder ist unnotig,da bereits Implementationen existieren, die man verwenden kann (Wiederverwendbarkeit wird geradevon Java besonders unterstutzt).
Datentypen sind extrem wichtig fur dieCompilierung, da der Compiler dann
• beim Compilieren allen definierten Objekten den erforderlichen Speicherplatz zuweisen kann,
• die Typinformation zurUberprufung der Zulassigkeit von Programmstatements benutzen kann(syntaktisch und partiell auch semantisch),
• den Typ des Wertes eines Ausdrucks bereits (weitgehend) ermitteln kann, ohne den Rechen-prozess durchfuhren zu mussen (zum Beispiel ist die Multiplikation einerint Zahl mit einerdouble Zahl vom Typdouble, siehe unten.).

72 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Dies setzt voraus, dassder Datentyp jedes Identifiers im Programm deklariert bzw. definiert wirdunddamit “zur Compilierzeit” bekannt ist. Diese Eigenschaft kennzeichnetstatisch getypteSprachen wieC++, Pascal und Java.
Bei der Typuberprufung (type checking) unterscheidet man zwischenstrikter Typuberprufungwiein Pascal undnicht strikter Typuberprufungwie in Java. Bei strikter Typuberprufung ist das “Mischen”von Typen stark eingeschrankt. In Java sind Typumwandlungen nur explizit durch das sogenanntecastingodertype castingmoglich. Besonders wichtig wird die Typumwandlung im Zusammenhangmit der Vererbung bei Klassen, vgl. Abschnitt7.3.3.
Ist intVar eineint Variable undfloatVar einefloat Variable, so bedeutet:
intVar = (int) floatVar;
eine Zuweisung mit expliziter Typumwandlung.
Ein Beispiel liefert die Division. Da/ bei ganzen Zahlen die ganzzahlige Division bezeichnet, hat5/8 den ganzzahligen Wert0 und5.0/8 den gebrochenen Wert0.625. Statt5.0/8 kann man auch(double) 5 / (double) 8 schreiben, was vor allem fur Ausdrucke wie(double) x / (double)y wichtig ist, in denenx, y ganzzahlige Werte annehmen, man aber die reelle Division meint.
Bei offensichtlichen Operationen wie
floatVar = floatVar * intVar;
findet eine implizite Typumwandlung(float) intVar statt.
In Pseudocodewerden Typvereinbarungen in der Form
TypName identifier;
geschrieben.
Java stelltelementare Datentypenmit zugehorigen Operationen bereit fur
• ganze Zahlen:int, long, short, byte.
• Gleitkommazahlen:float, double.
• Zeichen:char.
• Wahrheitswerte:boolean
Die genaue Behandlung dieser Datentypen erfolgt in derUbung.
5.2 Strukturierte Datentypen (Datenstrukturen)
Die bisherigen Beispiele waren Beispiele fur einfache (unstrukturierteoderprimitive) Datentypen.

5.2. STRUKTURIERTE DATENTYPEN (DATENSTRUKTUREN) 73
Neben einfachen Datentypen gibt es sogenanntezusammengesetzteoderstrukturierte Datentypen. Siesetzen sich aus bereits eingefuhrten Datentypen gemaß bestimmterStrukturierungsmerkmalezusam-men. Stehen die Strukturierungsmerkmale im Vordergrund (und nicht der Typ der “Grunddaten”), soredet man vonDatenstrukturen.
Strukturierte Typen oder Datenstrukturen haben (nebenWertebereichundOperationen)
• Komponenten-Daten, die atomar oder wieder strukturiert sein konnen
• Regeln, die das Zusammenwirken der Komponenten zur gesamten Struktur definieren.
Programmiersprachen haben i. a. nur wenige Datenstrukturen als eingebaute Typen (alle haben z. B.Arrays). Die meisten muss der Programmierer selber implementieren, wobei ihm Java machtige Kon-struktionsmoglichkeiten (vor allemKlassenundVererbung) bereitstellt.
Wir behandeln zunachst die wichtigsten Datenstrukturen ausabstrakter Sicht. Die Implementation inJava wird erst jeweils dann erfolgen, wenn die notigen Konstruktionsmoglichkeiten besprochen sind.
Abbildung5.1gibt eine hierarchischeUbersichtuber einige der wichtigsten Datenstrukturen.
Array Record
Liste Stack
Queue
HomogeneKomponenten
HeterogeneKomponenten
Allgemein Last-InFirst-out
First-InFirst-Out
Direkter Zugriff
@@@
Sequentieller Zugriffhhhh
hhhhhhh
hhh
HHH
HH
``````
`````
Linear
XXXXX
XXXXX
Nichtlinear
@@@ Set
Datenstrukturen
Abbildung 5.1: Klassifikation einiger wichtiger Datenstrukturen.
Eine lineare Datenstrukturhat (bei mindestens 2 Komponenten) eineOrdnungauf den Komponentenmit folgenden Eigenschaften:
• Es gibt eine eindeutige erste Komponente.
• Es gibt eine eindeutige letzte Komponente.
• Jede Komponente (außer der ersten) hat einen eindeutigen Vorganger.
• Jede Komponente (außer der letzten) hat einen eindeutigen Nachfolger.

74 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Direkter Zugriff (auchrandom accessgenannt) bedeutet, dass man auf jede beliebige Komponentezugreifen kann, ohne vorher auf andere Komponenten zugreifen zu mussen. Beispiele sind:
– Ein Regalbrett mit Buchern; auf jedes Buch kann direkt zugegriffen werden.
– CDs mit direkter Ansteuerung von Musikstucken.
Sequentieller Zugriffbedeutet, dass man auf diei-te Komponente nur zugreifen kann, nachdem manvorher auf die Komponenten 1,2, . . . , i−1 zugegriffen hat. Beispiele sind:
– Ein Stapel von Buchern; um dasi-te zu nehmen, mussen erst diei−1 obersten entfernt werden.
– Musikstucke auf einem Tonband.
5.3 Arrays
DasArray ist die verbreitetste Datenstruktur; in einigen Programmiersprachen (Fortran, Basic, Algol60) sogar die einzige.
Kennzeichen der Datenstruktur Array sind:
• feste Komponentenzahl (die in Java erst zur Laufzeit festgelegt werden muss),
• direkter Zugriff auf Komponenten mittelsIndizes,
• homogener Grundtyp,
• Indizes konnen berechnet werden.
Ist k die Anzahl der Komponenten undA der Wertebereich des Grundtyps, so ist derWertebereich Xdes Arraysdas kartesische ProduktA× . . .×A (k-fach).
Die k Komponenten haben in der Regel ganze Zahlen (meist 0,1, . . . ,k−1) als Index. Mathematischentspricht alsoX den Vektoren der Langek mit Komponenten ausA, d. h.
X = (a0,a1, . . . ,ak−1) | ai ∈ A, i = 0, . . . ,k−1
Zu denOperationenauf Arrays gehoren (abstrakt formuliert):
value(a, i) Ermittelt den Wert der Komponente eines Arraysa mit Index i, also denWert der(i +1)-ten Komponente. Ista = (a0, . . . ,ak−1), so liefertvalue(a, i) den Wertai .
store(i,v) Weist der Komponente vona mit Index i den Wertv zu. Danach istai = v.a := b Zuweisung von Arrays. Danach giltai = bi , i = 0, . . . ,k−1.a = b Test auf Gleichheit. Liefert den Werttruegenau dann, wennai = bi fur
i = 0, . . . ,k−1.

5.3. ARRAYS 75
5.3.1 Arrays in Java
In Java existiert bereits ein eingebauter Array Typ alsReferenztyp. Durch die Anweisung
int[] x = new int[10]; (auchint x[] = ...)
wird ein Array mit 10 Komponenten mit Komponententypint definiert, das unter dem Namenxansprechbar ist. Die Komponenten haben die Indizes0,1,...,9. In Java sind0,1,...,n-1 dieeinzig moglichen Indizes eines Arrays mitn Komponenten.
Arraytypen in Java sind Referenztypen. Arrayvariable (x in obiger Anweisung) verweisen daher aufArray-Objekte, die wieublich mitnew erzeugt werden. Diese Objekte verfugenuber ein Feldlength,das die Anzahl der Komponenten angibt. Hierauf wird (wie immer bei Objekten) mit dem. zugegrif-fen, alsox.length.1
Der Operationvalue(a,i)entspricht in Java derFeldzugriff gemaß der Syntax
<Feldzugriff>::=<Referenzausdruck>[<Ausdruck>]
Dabei wird der Referenzausdruck zuerst ausgewertet und liefert die Referenz (Adresse) des Arrays.Der Ausdruck in den Klammern[. . .] muss einenint Wert liefern, der den Index der Komponenteberechnet. Zur Laufzeit wird in Java automatischuberpruft, ob der berechnete Index wirklich imvereinbarten Bereich des Arrays liegt. Ist dies nicht der Fall, so erfolgt eine Exception-Meldung durchdie Laufzeitumgebung (ArrayIndexOutOfBoundsException).
Durch
a = x[3];
wird also der Variablena der Wert der 4-ten Komponente vonx zugewiesen. Entsprechend wird durch
x[i] = v;
der(i +1)-ten Komponente vonx der Wert vonv zugewiesen.
Bei der Deklaration von Arrays kann eine Initialisierung ohne Benutzung vonnew vorgenommenwerden, wie in
int[] x = 1, 2, 3, 4 ;
Zuweisung und Test auf Gleichheit existieren nicht in Java, konnen aber einfachuberfor Schleifenrealisiert werden. So initialisiert
int n = 10;int[] x = new int[n];int[] y;for (int i = 0; i < x.length; i++) x[i] = i*i;
das Arrayx mit den Werten
00
11
42
93
164
255
366
497
648
819
1Aber nichtx.length(), dalength keineMethodeist.

76 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
y ist zunachst undefiniert. Die Zuweisungy = x ist zwar zulassig, weist aber nury die Adresse vonxzu. Beide Variablen zeigen dann auf dasselbe Array. Will man iny eine Kopie anlegen, so muss mandies entweder selber realisieren oder spezielle Methoden wieclone() verwenden.
Bei dem demint Array x lasst sich einfach eine Kopie mit einerfor-Schleife herstellen:
y = new int[n];for (int i = 0; i < n; i++) y[i] = x[i];
Diese einfache Art geht jedoch nicht mehr bei Objekten als Grundtyp, da durch die Zuweisungy[i]= x[i] nur die Referenzen zugewiesen wurden und nicht die Werte. Hier hilft die Methodeclone(),uber die die meisten Referenztypen (darunter Arraytypen) verfugen.2 Ist etwa
String[] stringArr = "Hallo!", "Wie gehts?", "Gut.";
ein Array aus drei Strings, so lasst sich mit der Anweisung
String[] copyOfstringArr = (String[]) stringArr.clone();
eine”echte“ Kopie vonstringArr herstellen. Die AnweisungstringArr.clone() kopiert den
vom Array stringArr belegten Speicherinhalt in ein allgemeines Objekt, das mit der Castanwei-sung(String[]) auf den richtigen Typ (Array von Strings) gecastet werden muss. Jetzt sprechenstringArr undcopyOfstringArr verschiedene Speicherbereiche an und konnen unabhangig von-einander geandert und verwendet werden.
Als kompliziertes Beispiel fur den Komponentenzugriff gemaß der Regel
<Feldzugriff>::=<Referenzausdruck>[<Ausdruck>]
betrachten wir das Fragment
int[] x = 1, 2, 3, 4,y = 5, 6, 7, 8,z;
y[x [0]] = 9; // ergibt y[1] == 9(z = y)[(y = x)[0] + y[1]] = 0;
In der letzten Zeile wird zunachst der Referenzausdruck(z = y) ausgewertet. Er ist ein Zuweisungs-ausdruck, der den Wert vony, also die Adresse vony ergibt, wobei diese als Seiteneffektz zugewiesenwird. Hiernach wird unterz also das Arrayy angesprochen!
In der Auswertung von[<Ausdruck>] geschiehtAhnliches mit dem Referenzausdrucky = x. Da-her wird(y = x)[0] zu x[0], also zu1 ausgewertet, und der gesamte Ausdruck in[...] zu 1 +x[1] = 1 + 2 = 3. Als Seiteneffekt zeigty jetzt aufx.
Die gesamte Zeile bewirkt also eine Zuweisung anz[3], so dassy undz (einschließlich derAnderungvony und der beiden Seiteneffekte) am Ende die Werte
2Genauer: alle Typen, die das InterfaceClonable implementieren, vgl. Abschnitt7.3.7.

5.3. ARRAYS 77
y 10
21
32
43
z 50
91
72
03
haben.
5.3.2 Mehrdimensionale Arrays
Der Komponententyp eines Arrays kann naturlich wieder ein strukturierter Typ sein. Insbesonderesind so Arrays von Arrays moglich. So deklariert
double[][] table = new double[5][10];
ein Arraytable mit 5 Komponenten, wobei jede Komponente wiederum ein Array mit 10 Kompo-nenten vom Grundtypdouble ist.3
table ist ein Beispiel eines2-dimensionalen Arrays. Man stellt es sich am besten so vor:
table
table[4]
table[3]
table[2]
table[1]
table[0]
table[4][5]
table[i] greift dann auf die(i + 1) Komponente vontable zu (also das Arraytable[i]), undtable[i][j] auf die( j +1)-te Komponente des Arraystable[i].
Ein zweidimensionales Array kann aus Arraysunterschiedlicher Langebestehen. So erzeugt
int[][] table = new int[5][]; // 5 Zeilenfor (int i = 0; i < table.length; i++)
int[] tmp = new int[i+1];for (int j = 0; j < tmp.length; j++)
tmp[j] = i+j; // initialisiere tmp[j]table[i] = tmp;
das Array
3Bei der Stellung der Klammern[][] sind auchdouble[] table[] bzw.double table[][] zulassig.

78 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
table
40
51
62
73
84
3 4 5 6
2 3 4
1 2
0
Dies ist moglich, da Arraytypen Referenztypen sind. Der Komponententyp des Arraystable ist derReferenztypint [], und dieser kann Referenzen aufint-Arrays unterschiedlicher Lange haben.
Das Array im Beispiel ließe sich auch durch direkte Initialisierung erzeugen:
int[][] table = 0 , 1, 2 , 2, 3, 4 , 3, 4, 5, 6 , 4, 5, 6, 7, 8
;
Als abschließenden Beispiel dieser Einfuhrung von Arrays betrachten wir das Umdrehen eines Arrays.
Beispiel 5.4 (Umdrehen eines Arrays)Ein 1-dimensionales Array mit nint Komponenten soll um-gedreht werden.
4 1 3 2 −→ 2 3 1 4
int[] vector = new int[n];// Initialisierung der Komponentenint temp; // Hilfsvariableint limit = vector.length/2; // obere Grenze in der for Schleifefor (int i = 0; i < limit; i++)
temp = vector[i];vector[i] = vector[n-1-i]; // Zugriff auf Komponente n-1-ivector[n-1-i] = temp; // Zuweisung an Komponente n-1-i
Hier wird in vector[n-1-i] der Indexn-1-i berechnet und dann auf die entsprechende Kompo-nente vonvector zugegriffen bzw. ihr etwas zugewiesen.
Eine andere Implementation (unter voller Ausnutzung der Moglichkeiten vonfor-Schleifen) ist:
for (int i = -1, j = vector.length; ++i < --j;)temp = vector[i];vector[i] = vector[j];vector[j] = temp;

5.4. STRINGS 79
5.4 Strings
Strings sind Zeichenketten. Sie sind extrem wichtig fur die EDV, werden aber sehr unterschiedlich inden verschiedenen Programmiersprachen behandelt.
Kennzeichen der Datenstruktur String sind:
• variable Komponentenzahl,
• Komponenten sind homogen vom Typchar,
• direkter Zugriff auf Komponenten,
• typische Stringoperationen wie:
– Verkettung,
– Finden von Substrings,
– Vergleich bezuglich lexikographischer Ordnung,
– Einfugen/Lesen von Zeichen an bestimmter Stelle.
Der Wertebereichvon Strings ist die Menge der Zeichenketten auschar Zeichen (einschließlich derleeren Zeichenkette).
5.4.1 Strings in Java
In Java gibt es zwei Klassen fur Strings,String undStringBuffer.
Die KlasseString hat als Objekte Zeichenketten, die sich nach der Erzeugung nichtandern. Sie istspeziell optimiert fur die Verwaltung konstanter Zeichenketten.
Die KlasseStringBuffer hat als Objekte Zeichenketten, die sich im Verlauf des Programmsandernkonnen (kurzer werden, wachsen, Teilstringsandern,. . .). Beispielsweise werden Operationen ausdieser Klasse zur Implementation des “+” Operators der KlasseString verwendet.
Im Gegensatz zu C oder C++ sind Strings in Java keine Arrays vonchar.
char[] string = ’H’, ’a’, ’l’, ’l’, ’o’ ;
ist nicht dasselbe wie
String str = "Hallo";
Allerdings gibt es in der Syntax viele Zugestandnisse an C-Programmierer, zum Beispiel die Zuwei-sung
String str = "Hallo!";

80 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
die gleichzeitig neben der Java-konformen Erzeugung mitnew existiert:4
String str = new String("Hallo!");
Es gibt viele Methoden fur Strings, die fur alle gangigen Stringoperationen ausreichen. Man schauesich dafur die KlassenString undStringBuffer in der Java-Dokumentation an. Als Beispiel fuhrenwir drei Konstruktoren der KlasseString auf.
public String(); // konstruiert den leeren Stringpublic String(String value); // konstruiert einen String mit Wertvaluepublic String(char[] value); // wandelt einchar-Array in einen String um.
5.4.2 Manipulation von Strings: ein erster Ansatz
Als Beispiel fur den Umgang mit Arrays und Strings betrachten wir zwei Java Programme fur dasEinlesen einer Folge von Zahlen aus einer TextArea in ein Array. Das erste Programm macht sehrspezielle Annahmenuber die gegebene Zahlenfolge, und fangt noch keine Fehler ab, die aus derVerletzung dieser Annahmen resultieren. Das zweite Programm nutzt die Werkzeuge der Java KlasseStringTokenizer und beinhaltet einException Handlingfur den Umgang mit Fehlern.
Gegeben ist in beiden Fallen eine Folge vonint-Zahlenn,a0,a1, . . . ,am, die durch die sogenanntenwhite space, d. h. ein oder mehrere Leerzeichen (blanks), Tabulatoren und Zeilenumbruche getrenntsind, etwa
4 10 20 3040 50
Die erste Zahl gibt die Lange des Arrays an, in das die Zahlena0,a1, . . . ,an−1 aus der Folge eingelesenwerden sollen. Daher mussm≥ n− 1 sein. Ferner wird vorausgesetzt, dass außerint-Zahlen undwhite space keine anderen Strings in der TextArea stehen.
Im ersten ProgrammStringDemo wird zusatzlich angenommen, dass nach jeder Zahl ein Leerzei-chen’’ steht. Dieses Leerzeichen wird als Trennsymbol verwendet, um das Ende einerint-Zahl zuerkennen.
StringDemo verwendet Methoden der KlassenString undStringBuffer, u. a.
4Tatachlich gibt es zwischen beiden Arten der Erzeugung einen diffizilen Unterschied. Zwei mitnew erzeugte Stringsstr1, str2 mit gleichem WertHallo! haben (wie bei Referenztypen zu erwarten) unterschiedliche Adressen. Dagegenergeben Zuweisungen
String str1 = "Hallo!";
...
String str2 = "Hallo!";
desselben Strings an verschiedene Variable auch dieselbe Adresse, da der Compileruberpruft, ob es die StringkonstanteHallo! bereits gibt und sie dann wiederverwendet. Wenn man also stets diese Art Erzeugung (ohnenew) verwendet, lasstsich Gleichheit von Strings auch mit(str1 == str2) uberprufen (weiteres Zugestandnis an C-Programmierer), wahrendallgemein bei Objekten mit== nur Gleichheit der Adressen gepruft wird. Gleichheit der Werte muss man mit der Methodeequals() uberprufen, alsostr1.equals(str2).

5.4. STRINGS 81
trim() // Wegschneiden von white space vor und nach dem StringcharAt(pos) // Gibt das Zeichen an Positionpos zuruckgetChars(pos1, pos2, charArray, begin)
// Kopiert Zeichen des Strings vonpos1 bispos2 - 1// in daschar-Array charArray ab Indexbegin
aus der KlasseString, und
append(str) // Hangt den Stringstr an dasStringBuffer-Objekt antoString() // Konvertiert einStringBuffer-Objekt in einString-Objekt
aus der KlasseStringBuffer.
Programm 5.1 StringDemo.java// StringDemo.java//// Demonstrates use of the classes Strings and StringBuffer// together with arrays//// A string of integer numbers in which each number is terminated by a blank// is converted into an array of integers//// Assumptions:// input is a sequence of numbers n, a0, a1, a2 ...// n specifies the length of an array// a0, a1, ... are the array entries (must be at least n)// numbers are terminated by a blank with possibly more white space// between them (return, tab or newline)//// Take care! You will get exceptions if these assumptions are violated.
import java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class StringDemo extends Applet
TextArea input, output;Button startBtn;
int[] vec;
// setup the graphical user interface components

82 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
public void init() //set layoutsetLayout(new FlowLayout(FlowLayout.LEFT));// set fontsetFont(new Font("Times", Font.PLAIN, 24));
input = new TextArea("4 10 20 30 40 ", 5, 30);add(input); // put input on applet
startBtn = new Button("Start");startBtn.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runDemo();
);add(startBtn);
output = new TextArea(10, 30);output.setEditable(false);add(output);
// process user’s action on the input text areapublic void runDemo()
String inputStr = input.getText();String str, currStr;
int n; // will be the first number in the text area// it determines the length of vec
// delete leading and trailing white space,// but preserve blank after last numbercurrStr = new String(inputStr.trim() + " ");// find first blank that terminates the string// representing the first numberint pos = 0;while (currStr.charAt(pos) != ’ ’)
pos++;// chars 0 to pos-1 contain first number// copy these chars and convert them to an intchar[] charArr = new char[pos];currStr.getChars(0, pos, charArr, 0);str = new String(charArr);

5.4. STRINGS 83
n = Integer.valueOf(str).intValue();
// delete these chars by copying// the rest of the stringcharArr = new char[currStr.length() - pos];currStr.getChars(pos, currStr.length(), charArr, 0);currStr = new String(charArr);
// define the array of the right length nvec = new int[n];
// read the n numbers into the arrayfor (int i = 0; i < n; i++)
// delete leading white spacecurrStr = new String(currStr.trim() + " ");// find first blankpos = 0;while (currStr.charAt(pos) != ’ ’)
pos++;// chars 0 to pos-1 contain first number// copy these chars and convert them to an intcharArr = new char[pos];currStr.getChars(0, pos, charArr, 0);str = new String(charArr);vec[i] = Integer.valueOf(str).intValue();
// delete these chars by copying// the rest of the stringcharArr = new char[currStr.length() - pos];currStr.getChars(pos, currStr.length(), charArr, 0);currStr = new String(charArr);
// Construct the output string in a StringBuffer objectStringBuffer outputBuf = new StringBuffer();for (int i = 0; i < vec.length; i++)
outputBuf.append(i + ": "+ Integer.toString(vec[i]) + "\n");
// show string str in outputoutput.setText(outputBuf.toString());

84 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
5.4.3 Manipulation von Strings mit der Klasse StringTokenizer und Exception Hand-ling
Das bessere Programm nutzt die Java-KlasseStringTokenizer. Diese Klasse hat einen Konstruk-tor StringTokenizer(str), der den Stringstr in die durch white space getrennten Teile zerlegt,die sogenanntenTokens.5 Die Klasse verfugt ebenfallsuber sehr machtige Methoden, um mit diesenTokens umzugehen, etwa
hasMoreTokens() // liefert Werttrue, falls noch weitere Tokens existierennextToken() // liefert das nachste Token als String zuruck.
// Dieses gilt dann als “verbraucht”countTokens() // gibt die Anzahl der Tokens alsint-Wert zuruck
Um mogliche Fehler abzufangen, verwenden wir dasException-Handlingmit try undcatch. Sie hatdie folgende Syntax (Darstellung gemaß Codekonvention):6
try statements
catch(Exceptionklasse1 Exceptionvariable1 ) Statements fur Exceptionbehandlung
... catch(Exceptionklassek Exceptionvariablek )
Statements fur Exceptionbehandlung
Falls notig, kann einfinally Block angehangt werden.
finally weitere Anweisungen fur Exceptionbehandlung
Tritt bei Abarbeitung destry Blocks eine Exception auf, so wird in den zugehorigencatch Blockgesprungen und dieser durchgefuhrt. Anschließend wird der optionalefinally Block durchgefuhrtund danach der umgebende Programmtext weiter abgearbeitet.
Um Exceptions mittry undcatch abfangen zu konnen, muss man in selbsr geschriebenen Metho-den auch dafur sorgen, dass Exceptions erzeugt werden. Dies geschieht mit derthrow Anweisungim Rumpf der Methode. Im Kopf der Methode wird zusatzlich durchthrows ExceptionKlassedemCompiler kenntlich gemacht, dass die Methode Ausnahmen erzeugen kann, die in anderen Programm-teilen mittry undcatch abgefangen werden konnen. Als Beispiel betrachten wir die Berechnungdes großten gemeinsamen Teilers als Methode:
5Auch andere Trennzeichen als white space sind moglich; siehe die Java Dokumentation.6Zur vollstandigen Syntax siehe die Java Dokumentation.

5.4. STRINGS 85
int ggT(int a, int b) throws IllegalArgumentException if ((a <= 0) || (b <= 0))
throw new IllegalArgumentException("No negative numbers allowed.");
// insert code for computing the ggT
Hierin istIllegalArgumentException eine in Jave bereits vorhandene Klasse, aus der in dernew-Anweisungnew IllegalArgumentException("No negative numbers") ein Konstruktor ver-wendet wird, dem man Strings als Argumenteubergeben kann. Diese Strings konnen in einercatch-Anweisung entsprechen fur Fehlermeldungen verwendet werden.
Wird diethrow-Anweisung ausgefuhrt, so wird die Methode danach beendet und der Rest des Rump-fes nicht ausgefuhrt.
In unserem Beispiel fur Strings konnen drei Typen von Exceptions auftreten, die ebenfalls in Java alsKlassen vorhanden sind:
NumberFormatException Der gelesene String stellt keineint-Zahl darNoSuchElementException Das erste oder nachste Token existiert nichtNegativeArraySizeException Die erste gelesene Zahl ist negativ
Sie werden entsprechend abgefangen und in Mitteilungen an den Benutzer umgesetzt. Um den Typder Exception zu ermitteln, reicht es, den entsprechenden Fehler beim Ablauf zu erzeugen und dieMeldung der Laufzeitumgebung auf dem Bildschirm zu studieren.7
Programm 5.2 StringTokenizerDemo.java// StringTokenizerDemo.java//// Demonstrates use of the classes String and StringTokenizer// together with arrays//// A string of integer numbers that are separated by white space// is converted into an array of integers//// Assumptions:// input is a sequence of numbers n, a0, a1, a2 ...// n specifies the length of an array// a0, a1, ... are the array entries, there must be at least n// numbers are separated by white space//// now we do exception handling
7Unter Unix/Linux die Shell, in der der Appletviewer gestartet wurde.

86 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
import java.awt.*;import java.applet.Applet;import java.util.*; // for class StringTokenizerimport java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class StringTokenizerDemo extends Applet
TextArea input, output;Button startBtn;
int[] vec;
// setup the graphical user interface componentspublic void init()
//set layoutsetLayout(new FlowLayout(FlowLayout.LEFT));//set FontsetFont(new Font("Times", Font.PLAIN, 24));
input = new TextArea("4 10 20 30 40 ", 5, 30);add(input); // put input on applet
startBtn = new Button("Start");startBtn.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runDemo();
);add(startBtn);
output = new TextArea(10, 30);add(output);
// process user’s action on the input text fieldpublic void runDemo()
output.setText("");String inputStr = input.getText();String str = "";StringTokenizer inputTokens = new StringTokenizer(inputStr);
try int n; // will be the first number that determines

5.4. STRINGS 87
// the length of vec
str = inputTokens.nextToken();// throws NoSuchElementException// if there is no next token
n = Integer.valueOf(str).intValue();
// define the array of the right length nvec = new int[n];// throws NegativeArraySizeException// if str is a negative int
// read the n numbers into the arrayfor (int i = 0; i < n; i++)
str = inputTokens.nextToken();// throws NoSuchElementException// if there is no next tokenvec[i] = Integer.valueOf(str).intValue();// throws NumberFormatException// if str is not an int
// Construct the output string in a StringBuffer objectStringBuffer outputBuf = new StringBuffer();for (int i = 0; i < vec.length; i++)
outputBuf.append(i + ": "+ Integer.toString(vec[i]) + "\n");
output.setText(outputBuf.toString());
catch (NoSuchElementException e) output.setText("Zu wenige Zahlen eingegeben!.");
catch (NumberFormatException e) output.setText("Bitte nur ganze Zahlen eingeben.");
catch (NegativeArraySizeException e) output.setText("Die erste Zahl muss "
+ "eine positive ganze Zahl sein.");

88 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
5.5 Records
Kennzeichen der DatenstrukturRecordsind:
• feste Komponentenzahl,
• direkter Zugriff auf Komponenten mittelsNamen,
• heterogene Komponententypen, dafur keine Berechnung von Indizes.
Die Komponenten von Records heißen auchFelder, oderDatenfelder. Record Typen werden in derPseudosprache wie folgt deklariert
type StudentRec =recordString name;String adresse;Integer matrikelnr;String fach;
end record
Selektion von Komponenten findet mit dem Punkt (.) statt.
StudentRec student;student.matrikelnr := 127538;
In Java gibt es keine eigene Datenstruktur Record, sie kann jedoch alsSpezialfall einer Klasseaufge-fasst werden. Klassen enthalten zusatzlich zu den Datenfeldern Konstruktoren und Methoden (Ope-rationen), die auf den Datenfeldern operieren. Detailsuber Klassen werden in Kapitel7.3behandelt.Eine rudimentare Klasse fur Studenten konnte wie folgt aussehen:
public class Student public String name;public String adresse;public int matrikelnr;public String fach;public int fachsemester;// Konstruktor fuer Neueinschreibungpublic Student(String aktName, String aktAdr, int aktMatrNr,
String aktFach) name = aktName;adresse = aktAdr;matrikelnr = aktMatrNr;fach = aktFach;fachsemester = 1;

5.6. LISTEN 89
public void changeAddress(String newAdr)adresse = newAdr;
// weitere Konstruktoren und Methoden
Eine typische Verwenung der Klasse Student ist ein Array, dessen Komponenten Studenten sind, etwaalle Studenten der Coma:
Student[] comaTeilnehmer = new Student[200];comaTeilnehmer[27] = new Student("Hans Meier", "unbekannt", 20307, "TWM");
5.6 Listen
Eine Liste ist eine lineare Datenstruktur. Ihre Komponenten werdenItemsoderListenelementege-nannt. Das erste Element heißtAnfangoderKopf (head) der Liste, das letzte Element heißtEnde(tail). Kennzeichen der Datenstruktur Liste sind:
• veranderliche Lange (Listen konnenwachsenundschrumpfen),
• homogene Komponenten (elementar oder strukturiert),
• sequentieller Zugriff auf Komponenten durch einen (impliziten)Listenzeiger, der stets auf einbestimmtes Element der Liste zeigt, und nur immer ein Listenelement vor oder zuruck gesetztwerden kann8.
Ein Beispiel sind Guterwaggons eines Zuges an einer Verladestation (= Listenzeiger), die nur einenWaggon zur Zeit beladen kann. Listen werden immer dann angewendet, wenn man an beliebigenStellen noch Elemente einfugen oder loschen mochte. So sind in der Textverarbeitung Zeilen Listenvon Wortern, Paragraphen Listen von Zeilen, Kapitel Listen von Paragraphen usw.
Typische Listenoperationen sind das Einfugen in eine Liste, der sequentielleUbergang zum nachstenElement, das Loschen eines Elementes usw. Wir werden sie nachstehend alsJava MethodeneinerKlasseLinkedList wiedergeben, die ihrerseits auf der KlasseListNode fur Listenelemente beruht.Dies greift dem spater eingefuhrten Klassenkonzept von Java vor (vgl. Kapitel7.3). Der hier gewonne-ne Vorteil ist, dass diese Methoden bereits genutzt werden konnen, ohne ihre Implementationsdetailszu kennen.
5.6.1 Einschub: Javadoc
Wir verwenden außerdem eine weitere, wichtige Methode um Java-Code zu dokumentieren. Nebenden Kommentar-Zeichen
8sowie auf die Stelle hinter dem letzten Element, wodurch der Zustand “end of list” gekennzeichnet wird.

90 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
// alles ab hier bis Ende der Zeile ist Kommentar/* ... */ alles zwischen/* und*/ ist Kommentar
gibt es in Java die zusatzlichen Kommentar-Klammern
/** ... */
Sie wirken wie/* und*/, aber dienen als Input fur das Dokumentationsprogrammjavadoc. Ruftman dieses Programm mit
javadoc *.java
auf, so erstellt es fur jede.java Datei der momentanen Directory eine entsprechende.html Datei, inder Informationen abgelegt werden, die aus den/** ... */ Kommentaren und den Deklarationenvon Klassen, Methoden, Konstruktoren, Feldern usw. gewonnen werden. Dazu mussen die Kommen-tare den Deklarationen vorausgehen und sie sinnvoll dokumentieren. Zusatzlich erstelltjavadoc inder Dateitree.html eine Einordnung der eigenen Klassen in die Klassenhierarchie von Java (durchdie man sich dann auch per html-Browser bewegen kann), in der DateiAllNames.html einen Indexaller Klassen, Methoden, Konstruktoren, Feldern usw. aus den analysierten.java Dateien und nochvieles, vieles mehr.
Dieses Dokumentationswerkzeug ist sehr machtig und bietet einen guten Zugriff auf Klassen, dieKlassenhierarchie, und die Methoden einer Klasse. Die/** ... */ Kommentare konnen mit html-Formatierungsbefehlen angereichert werden, wie etwa
<code> ... </code> erzeugt Schreibmaschinentext
Außerdem sind spezielle tags verwendbar um die html-Seiten entsprechend zu strukturieren, z. B.:
@see fur Verweise@author Nennung des Autors@version Versionsnummer@param Erlauterung der Parameter@return Erlauterung der Ruckgabe von Methoden@exception Erlauterung von Ausnahmen
Als Beispiel schaue man sich die folgenden, entsprechend dokumentierten DateienListNode undLinkedList.java an. Ausschnitte der vonjavadoc ausLinkedList.java erzeugten html-DateiLinkedList.html sind in Abbildung5.2 und Abbildung5.3 in Browsersicht dargestellt. WeitereInformationenuberjavadoc erhalt man in der Javadokumentation oder mitman javadoc in denUnix/Linux Manual Pages.
5.6.2 Eine Klasse fur Listen
Programm 5.3 ListNode.java

5.6. LISTEN 91
Abbildung 5.2: Anfang der vonjavadoc erzeugten DateiLinkedList.html.
/*** A generic class for list nodes.* A list node consists of a data component and a link to the next list node*/public class ListNode
/*** data component is of the general type Object*/private Object data;

92 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Abbildung 5.3: Methodenteil der vonjavadoc erzeugten DateiLinkedList.html.
/*** next points to the next list node*/private ListNode next;
/*** Construct a list node containing a specified object

5.6. LISTEN 93
* @param o the object for the list node*/public ListNode(Object o)
data = o;next = null; // leave next uninitialized
/*** Return the data in this node.* @return the data of this node.*/public Object getData()
return data;
/*** Set the data of the node.* @param o the data object for the node.*/public void setData(Object o)
data = o;
/*** Return the next node.* @return the reference to the next node.*/public ListNode getNext()
return next;
/*** Set the next node.* @param n the next node.*/public void setNext(ListNode n)
next = n;
Programm 5.4 LinkedList.javaimport java.util.NoSuchElementException;
/**

94 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
* The <code>LinkedList</code> class implements a dynamically growable* list of objects. <code>LinkedList</code> administers a cursor to* point to the active list node.** @see ListNode** Each list is a collection of ListNodes along with an* implicit list cursor in the range 1..n+1, where n is* the current length of the list*/public class LinkedList
/*** a list pointer to the first node*/private ListNode firstNode;
/*** a list pointer to the current node*/private ListNode currNode;
/*** a list pointer to node preceding the current node*/private ListNode prevNode;
/*** Constructs an empty list.**/public LinkedList()
firstNode = prevNode = currNode = null;
/*** Tests if this list has no entries.** @return <code>true</code> if the list is empty; <code>false</code>* otherwise*/public boolean isEmpty()
return (firstNode == null);

5.6. LISTEN 95
/*** Set the list cursor to the first list element.*/public void reset()
currNode = firstNode;prevNode = null;
/*** Test if the list cursor stands behind the last element of the list.** @return <code>true</code> if the cursor stands behind the last* element of the list; <code>false</code> otherwise*/public boolean endOfList()
return (currNode == null);
/*** Advance the list cursor to the next list node* Throws <code>NoSuchElementException</code> if* <code>endOfList() == true</code>*/public void advance() throws NoSuchElementException
if(endOfList()) throw new NoSuchElementException(
"No further list node.");prevNode = currNode;currNode = currNode.getNext();
/*** Return the value of the current node.* Throws <code>NoSuchElementException</code> if* there is no current node*/public Object currentData() throws NoSuchElementException
if(currNode == null) throw new NoSuchElementException(
"No current list node.");return currNode.getData();

96 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
/*** Inserts a new list node before the current node.* If the list is empty insert at front.* The cursor points to the new list node.** @param someData the object to be added.*/public void insertBefore(Object someData)
ListNode newNode = new ListNode(someData);if (isEmpty())
firstNode = currNode = newNode; else
newNode.setNext(currNode);currNode = newNode;if (prevNode != null)
prevNode.setNext(newNode); else
firstNode = newNode;
/*** Inserts a new list node after the current node. The cursor points* to the new list node.* Throws <code>NoSuchElementException</code> if* there is no current node** @param someData the object to be added.*/public void insertAfter(Object someData) throws NoSuchElementException
ListNode newNode = new ListNode(someData);if (isEmpty())
firstNode = currNode = newNode; else
if (currNode == null) throw new NoSuchElementException(
"Cursor not on a valid element.");newNode.setNext(currNode.getNext());currNode.setNext(newNode);prevNode = currNode;

5.6. LISTEN 97
currNode = newNode;
/*** Delete the current node from the list.* Throws <code>NoSuchElementException</code> if* there is no current node*/public void delete() throws NoSuchElementException
if (currNode == null) throw new NoSuchElementException(
"No element for deletion.");if (currNode == firstNode)
firstNode = currNode = currNode.getNext(); else
currNode = currNode.getNext();prevNode.setNext(currNode);
Als Demonstration der Listenoperationen behandeln wir folgendes Beispiel.
Beispiel 5.5 (Einlesen eines Strings in eine Liste)Es sollen folgende Aktionen ausgefuhrt werden:
– Einlesen eines Strings in eine Liste vonchar,
– Ausgabe der Liste auf dem Bildschirm,
– Loschen des Anfangs der Liste bis zu einem vorgegebenen Zeichen (ergibt die leere Liste, fallsdas Zeichen nicht vorkommt),
– Ausgabe der gekurzten Liste.
Dies leistet das nachstehende Java Applet. Es verwendet als Datenteildata der ListenelementeCharacter-Objekte, da ja nur Objekte in Listenknoten erlaubt sind. Dazu mussen mit
Ch = new Character(ch);
einzelnechar-Zeichench in entsprechende “Wrapperobjekte”Ch der KlasseCharacter eingepacktwerden. Um die allgemeinen Datenobjekte der Liste dann wieder alsCharacter-Objekte behandelnzu konnen, ist ein Casting erforderlich. Die Anweisungen

98 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Ch = (Character) stringList.currentData();ch = Ch.charValue();
packen das im aktuellen Listenknoten enthaltenechar-Zeichen aus und weisen es der Variablenchzu.
Programm 5.5 List-Demo.java/** List-Demo.java** Represents strings as list of char and manipulates them*/import java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public class ListDemo extends Applet String str;StringBuffer strBuf;char ch;Character Ch, Cha; // needed as subclass of Object
// setup the graphical user interface components// and initialize labels and text fieldsLabel inputPrompt1, inputPrompt2;TextField input1, input2, output1, output2;Panel p1, p2, p3, p4, p5;
public void init() //set layoutsetLayout(new GridLayout(5, 1));//set FontsetFont(new Font("Times", Font.PLAIN, 24));
p1 = new Panel();p2 = new Panel();p3 = new Panel();p4 = new Panel();p5 = new Panel();
p1.setLayout(new FlowLayout(FlowLayout.LEFT));inputPrompt1 = new Label("Schreiben Sie einen String "

5.6. LISTEN 99
+ "und beenden Sie ihn mit Return.");p1.add(inputPrompt1);
p2.setLayout(new FlowLayout(FlowLayout.LEFT));input1 = new TextField("Hello World", 40);input1.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runDemo();
);p2.add(input1);
p3.setLayout(new FlowLayout(FlowLayout.LEFT));output1 = new TextField("Der String ist: Hello World", 40);p3.add(output1);output1.setEditable(false);
p4.setLayout(new FlowLayout(FlowLayout.LEFT));inputPrompt2 = new Label("Geben Sie das Zeichen an, "
+ "bis zu dem geloscht wird:");p4.add(inputPrompt2);input2 = new TextField("W", 1);input2.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runDemo();
);p4.add(input2);
p5.setLayout(new FlowLayout(FlowLayout.LEFT));output2 = new TextField("Gekurzter String: World", 40);p5.add(output2);output2.setEditable(false);
add(p1);add(p2);add(p3);add(p4);add(p5);
// process user’s actionpublic void runDemo()

100 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
// list for representing stringLinkedList stringList = new LinkedList();// read input stringstr = input1.getText();
// represent str as a list of Character// use length() and charAt() methods of class Stringfor (int i = 0; i < str.length(); i++)
ch = str.charAt(i); // get the charCh = new Character(ch); // convert it to a
// Character objectstringList.insertAfter(Ch); // insert it in the list
// use list methods to write string in first output fieldif (stringList.isEmpty())
output1.setText("Der String ist leer."); else
stringList.reset();strBuf = new StringBuffer();while (! stringList.endOfList())
// cast Object to CharacterCh = (Character) stringList.currentData();// convert Character to char chch = Ch.charValue();// append ch to strBufstrBuf.append(ch);stringList.advance();
output1.setText("Der String ist: "
+ strBuf.toString());
// read char until which will be deletedch = input2.getText().charAt(0);
if (! stringList.isEmpty()) // nothing to do otherwisestringList.reset();while (((Character) stringList.currentData())
.charValue() != ch) stringList.delete();// leave while loop if stringList is emptyif (stringList.isEmpty()) break;

5.7. STACKS 101
// write remaining string in second output fieldif (stringList.isEmpty())
output2.setText("Die gekurzte Liste ist leer."); else
strBuf = new StringBuffer();while (! stringList.endOfList())
Ch = (Character) stringList.currentData();ch = Ch.charValue();strBuf.append(ch);stringList.advance();
output2.setText("Gekuerzte Liste: "
+ strBuf.toString());
5.7 Stacks
Stacks sind eine eingeschrankte Form von Listen, bei denen das Einfugen und Loschen nur am Kopf(genannttop) moglich ist. Als Liste gesehen kann der Listenzeiger also nur auf das erste Elementzeigen. Ein Beispiel ist ein Bucherstapel in einem engen Karton, man hat immer nur auf das obereBuch Zugriff. Man nennt daher Stacks auch Last-In, First-Out oderLIFO Listen.
Wie bei Listen sehen wir uns die Stack Operationen ausgedruckt als Methoden einer Java Klasse an.9
Programm 5.6 Stack.Javaimport java.util.NoSuchElementException;
/*** The <code>Stack</code> class implements a Stack* of objects.** @see ListNode*/public class Stack
/*** a list pointer to the first node*/private ListNode top;
9Es gibt in Java eine eigene KlasseStack im Packagejava.util, die auf der KlasseVector basiert. Aus didaktischenGrunden verwenden wir hier eine eigene Klasse.

102 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
/*** Constructs an empty stack.**/public Stack()
top = null;
/*** Tests if this stack has no entries.** @return <code>true</code> if the stack is empty;* <code>false</code> otherwise*/public boolean isEmpty()
return (top == null);
/*** Return the value of the top node.*/public Object top() throws NoSuchElementException
if (top == null) throw new NoSuchElementException("No top node.");
return top.getData();
/*** Inserts a new stack node at the top with <code>someData</code>* as data** @param someData the data object of the new node*/public void push(Object someData)
ListNode newNode = new ListNode(someData);if (isEmpty())
top = newNode; else
newNode.setNext(top);top = newNode;

5.7. STACKS 103
/*** Delete the top node from the stack.*/public void pop() throws NoSuchElementException
if (top == null) throw new NoSuchElementException("No element "
+ "for deletion.");top = top.getNext();
Diese Klasse verwaltet wieder Objekte der allgemeinen KlasseObject. Betrachten wir die dreiChar-Objekte.
Character A = new Character(’a’);Character B = new Character(’b’);Character C = new Character(’c’);
So erzeugt die Folge der Java Anweisungen
Stack myStack = new Stack();myStack.push(A);myStack.push(B);myStack.push(C);StringBuffer strBuf = new StringBuffer();while(! myStack.isEmpty())
strBuf.append((Character) myStack.top());myStack.pop();
String str = strBuf.toString();
die folgende Folge von Belegungen der Instanzmystack:
leer a ba
c
ba
ba
a leer Top
Nach Abarbeitung derwhile-Schleife hatstr den Wertcba.
Stacks sind fundamental fur viele Aufgabenstellungen der Informatik, z. B.
• Laufzeitverwaltung von Funktions- und Prozeduraufrufen,

104 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
• Realisierung von Rekursion,
• Auswertung von Ausdrucken in Postfixnotation, z. B. in HP-Taschenrechnern, etwa
Eingabe: abc+*
Stackfolge: leer a ba
c
ba
c+ba
(c+b)*a Top
Beispiel 5.6 (Erkennung von korrekten Klammerausdrucken)Klammerausdrucke sind auf Korrektheit zuuberprufen und einander entsprechende Klammern sindzu paaren.
So ist z. B.(()()))() nicht korrekt, aber korrekt. Die entsprechende Paarung des zweitenAusdrucks ist
Dies geschieht mit dem folgenden Algorithmus.
Algorithmus 5.1 (Erkennung von korrekten Klammerausdrucken)1. Lese die Folge der Klammern von links nach rechts.2. Falls “(”, so pushe diese auf den Stack.3. Falls “)” so poppe eine “(” vom Stack, erklare diese als zur momentan gelesenen “)”
gehorig.4. Erklare den Klammerausdruck als korrekt, falls der Stack am Ende leer ist,
jedoch zwischendurch nie vom leeren Stack gepoppt wird.
Als konkretes Beispiel betrachten wir(1 (2 (3 )4 (5 )6 )7 (8 )9 )10, wobei die Klammern zur besserenIdentifizierung mit Indizes versehen sind. Dann ergibt sich in Algorithmus5.1 die in Abbildung5.4dargestellte Stackfolge.
Sie zeigt, dass der Ausdruck korrekt ist mit der folgenden Klammerung:
(1 (2 (3 )4 (5 )6 )7 (8 )9 )10 Bei dem Beispiel(1 )2 )3 (4 )5 ergibt sich die Stackfolge

5.7. STACKS 105
0 1 2 3 4 5 6 7 8 9 10
leer (1 (2 (3 (2 (5 (2 (1 (8 (1 leer
(1 (2 (1 (2 (1 (1
(1 (1
⇓ ⇓ ⇓ ⇓ ⇓Paar Paar Paar Paar Paar(3 )4 (5 )6 (2 )7 (8 )9 (1 )10
Abbildung 5.4: Ein Beispiel zu Algorithmus5.1.
0 1 2 3
leer (1 leer Error
Also wird (1 )2 )3 (4 )5 als nicht-korrekter Klammerausdruck erkannt.
Satz 5.1 (Erkennung korrekter Klammerausdrucke) Algorithmus 5.1 erkennt genau die korrektenKlammerausdrucke als korrekt und identifiziert zueinander gehorende Klammerpaare richtig.
Beweis:Der Beweis wird durch Induktion nach der Anzahlk der Klammern im Ausdruck gefuhrt.
Induktionsanfang: k = 2. Offenbar wird beik = 2 Klammern genau() als korrekt erkannt, und dieKlammerkorrespondenz hergestellt.
Induktionsvoraussetzung: Die Methode arbeitet fur alle Klammerausdrucke der Lange< k korrekt(k > 2).
Induktionsschluss auf die Lange k:
1. Ist A ein korrekter Klammerausdruck, so sind die Stack Bedingungen erfullt und korrespondie-rende Klammern werden richtig ermittelt.
SeiA korrekt mit der Langek > 2. Dann gibt es aufgrund der Syntax fur korrekte Klammeraus-drucke (vgl.4.1) 2 Falle: a)A = B ·C oder b)A = (B), wobeiB,C kurzere korrekte Klammer-ausdrucke sind, auf die dann die Induktionsvoraussetzung zutrifft.
a) Da aufB,C die Induktionsvoraussetzung zutrifft, werden sie als korrekt erkannt und wer-den die zugehorigen Korrespondenzen richtig ermittelt.
Die Stackfolge fur A ergibt sich als Konkatenation der Stackfolgen vonB undC. Alsogelten auch inA die Stack Bedingungen.
Da der Stack am Ende vonB leer ist, konnen auch innerhalb vonA Klammern ausB nurmit Klammern ausB korrespondieren. Diese Korrespondenzen werden nach Induktions-voraussetzung richtig erkannt. Das gilt entsprechend auch fur C.
b) Da aufB die Induktionsvoraussetzung zutrifft, wirdB als korrekt erkannt und werden diezugehorigen Korrespondenzen richtig ermittelt. Dies bedeutet, dass sich inA die außeren

106 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Klammern entsprechen mussen, da alle Klammern inB bereits fur die Korrespondenzeninnerhalb vonB “verbraucht” werden.
Die Stackfolge fur A ergibt sich also aus der Stackfolge vonB durch Anhangen der ersten“(” von A als unterste Komponente des Stacks. Also gelten auch inA die Stack Bedingun-gen.
Da der Stack am Ende vonB genau noch die erste “(” von A enthalt, werden dieaußerenKlammern als korrespondierend erkannt. Da innerhalb vonB stets die erste “(” von A alsunterste Komponente im Stack enthalten ist, werden die Korrespondenzen innerhalb vonB auch nach Induktionsvoraussetzung richtig erkannt.
Abbildung5.5 illustriert die Stackfolgen fur die beiden auftretenden Falle.
2. Sind die Stack Bedingungen erfullt, so istA ein korrekter Klammerausdruck.
Betrachte die erste Stelle, an der der Stack nach der zugehorigen Push/Pop Operation leer ist.Es gibt 2 Falle: a)` < k oder b)` = k.
a) Aus ` < k folgt, dass sichA zerlegen lasst in einen ersten TeilB := a1a2 . . .a` und einenzweiten TeilC := a`+1 . . .ak; ai ∈ (,). Da die Stack Bedingungen inA erfullt sind, sindsie nach der Wahl von auch inB undC erfullt, und die Induktionsvoraussetzung trifftwegen < k aufB undC zu. Also sindB undC korrekt, und damit nach den SyntaxregelnauchA = BC.
b) Aus ` = k folgt, dass in der Stackfolge die zuerst gelesene “(” von A bis zum Schluss aufdem Stack bleibt. Da die Stack Bedingungen erfullt sind, muss die letzte Klammer vonAeine “)” sein, die dann mit der ersten Klammer korrespondiert. Also istA von der FormA = (B).Die Stackfolge vonB ist dann gleich der Stackfolge vonA ohne die erste Klammer “(”von A. Also folgt, dass auch die Stack Bedingungen fur B erfullt sind. DaB kurzer alsAist, istB nach Induktionsvoraussetzung korrekt, und damit nach den Syntaxregeln auchA.
Aus 1 und 2 folgt die Behauptung.
Wir betrachten jetzt eine Implementation von Algorithmus5.1fur Strings, der außer den Klammern(und) auch andere Zeichen enthalten kann. Der Test auf korrekte Klammern bezieht sich auf( und).
Dazu verwenden wir ein Hilfsarray
partner : Array vonint
Am Ende sollpartner[i] die zum Zeichen an Positioni im String zugehorige Klammer angeben.Dabei soll gelten (mitk > 0):
partner[i] :=
k charAt(k) und charAt(i) bilden ein Paar(..) oder
charAt(i) und charAt(k) bilden ein Paar(..),−1 charAt(i) 6= (,).

5.7. STACKS 107Fall a)
leer (B1
p p p leer (C1
p p p leer
Stackfolge fur B Stackfolge fur C
Fall b)
leer (1 (2
(1
p p p (1 leer
Stackfolge fur B mit (1 als zusatzlicher,
unterer Komponente
Abbildung 5.5: Die Stackfolgen aus dem Beweis von Satz5.1.
Fur den String((a+b)(-1))/(2+c) ergibt sich
10 5 -1 -1 -1 1 9 -1 -1 6 0 -1 16 -1 -1 -1 120 2 4 6 8 10 12 14 16
als Belegung fur das Arraypartner.
Um diese Belegung vonpartner zu erreichen wird statt der “(” in einem Stack jeweils die Positioni im String abgespeichert, d. h. man definiert den benotigten Stack als Stack vonInteger Objekten.
Abbildung5.6 zeigt ein Struktogramm fur die Verfeinerung von Algorithmus5.1 mit diesen Daten-strukturen. Eine Implementierung in Java gibt Programm5.7.
Programm 5.7 StackDemo.javaimport java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
/*** reads string of parantheses and other chars* uses stack to check for correct parantheses rules* @see Stack.java*/public class StackDemo extends Applet
// setup the graphical user interface components// and initialize labels and text fields

108 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
``````
``````
`````
XXXXXX
XXXXX
hh
hhhhhhh
hhhhhhh
hhhhhhh
hhhhhhh
h
Gebepartner ausDer Ausdruckist korrekt
Fehlermeldung: Der Ausdruck ist anStellei-1 inkorrekt
true falsekorrekt and s.isEmpty()
i := i+1
partner[m] := i
partner[i] := m
s.pop()entferne “(”
m := s.top()merke Position der“(” in der Variablenmkorrekt := false
es kann bei “)”nicht vom Stack ge-poppt werden
s.push(i)merke die Positionder “(” im Stack
true falses.isEmpty()
’(’
’)’
str.charAt(i)
i < n and korrekt
korrekt := true Boolesche Variable; bleibttrue bis festgestellt wird, dassstr nicht korrekt ist
i := 0 Initialisierung der ZahlvariablenDefiniere den Stacks Einrichten des leeren StacksInitialisiere das Arraypartner zu-1,...,-1
Ermittle die Langen des gegebenen Stringsstr
Abbildung 5.6: Struktogramm fur Algorithmus5.1.
Label inputPrompt;TextField input;TextArea output;
public void init() //set layoutsetLayout(new FlowLayout(FlowLayout.LEFT));setFont(new Font("Times", Font.PLAIN, 24));Font fixedWidthFont = new Font("Courier", Font.PLAIN, 24);

5.7. STACKS 109
inputPrompt = new Label("Schreiben Sie einen String und "+ "beenden Sie ihn mit Return.");
add(inputPrompt);
input = new TextField("((a+b)-(c-d))/(x-y)", 50);input.setFont(fixedWidthFont);input.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runDemo();
);add(input);
output = new TextArea(10, 50);output.setFont(fixedWidthFont);add(output);
public void runDemo() String str;StringBuffer outputBuf = new StringBuffer();Integer intObj;
// read the stringstr = input.getText();
// define partner and initialize to -1 ... -1int[] partner = new int[str.length()];int i;for (i = 0; i < str.length(); i++)
partner[i] = -1;
// define Stack object intStackStack checkStack = new Stack();
// main loop, use stack for checking correctnessi = 0;boolean correct = true;int m;while (i < str.length() && correct)
switch (str.charAt(i))

110 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
case ’(’ : intObj = new Integer(i);// remember position i of ’(’ on stackcheckStack.push(intObj);break;
case ’)’ :
if (checkStack.isEmpty()) // no corresponding ’(’correct = false;
else // corresponding ’(’ is in position mintObj = (Integer) checkStack.top();m = intObj.intValue();// remove the position of ’(’checkStack.pop();// positions i and m have// coresponding ’(’ and ’)’partner[i] = m;partner[m] = i;
break;
default : // neither ’(’ nor ’)’ at position i
; // nothing to do,// partner[i] is already -1
//end switchi++;
//end while: if not correct, then at// position i-1 (counting from 0)
// output correct pairs or report errorif (correct && checkStack.isEmpty())
// correct paranthesises// output correct pairsoutputBuf.append("Der String ist korrekt mit "
+ "folgender Klammerung:\n");outputBuf.append(str);
i = 0;while (true)
// look for next ’(’while (str.charAt(i) != ’(’

5.8. QUEUES (WARTESCHLANGEN) 111
&& i < str.length() - 1) i++;
// leave while loop if at end of strif (i == str.length() - 1) break;// newline on current ’(’outputBuf.append(’\n’);// indent until current ’(’for (m = 0; m < i ; m++)
outputBuf.append(’ ’);//end for// write current ’(’outputBuf.append(str.charAt(i));for (m = i + 1; m < partner[i] ; m++)
// indent until corresponding ’)’outputBuf.append(’ ’);
//end for// write corresponding ’)’outputBuf.append(str.charAt(partner[i]));i++; // increase i for next while loop
//end while else
outputBuf.append("Die Klammerung ist an Position "+ i + " nicht korrekt.\n");
// indicate the wrong positionoutputBuf.append(str + ’\n’);// indent until wrong positionfor (m = 0; m < i - 1; m++)
outputBuf.append(’ ’);//end for// write ’!’ at wrong positionoutputBuf.append(’!’);
output.setText(outputBuf.toString());
5.8 Queues (Warteschlangen)
Queues sind wie Stacks eingeschrankte Listen, bei denen dasEinfugennur am Ende (rear odertail)und dasLoschennur am Kopf (front oderhead) moglich ist. Sie bilden also die geeignete Datenstruk-tur fur das, was man im taglichen Leben unter “Warteschlange” versteht. Man nennt daher Queues

112 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
auch First-In, First-Out oderFIFO Listen.
Wie bei Stacks drucken wir dieOperationenals Methoden einer Java-KlasseQueue aus. Die Imple-mentation bleibt zunachst offen.10
/*** Tests if this queue has no entries.** @return <code>true</code> if the queue is empty; <code>false</code>* otherwise*/abstract public boolean isEmpty();
/*** Return the value of the current node.*/abstract public Object front() throws NoSuchElementException;
/*** Inserts a new queue node at the rear.** @param <code>someData</code> the object to be added.*/abstract public void enqeue(Object someData);
/*** Delete the front node from the list.*/abstract public void dequeue() throws NoSuchElementException;
Queues haben viele Anwendungen, z. B. in Rechnerbetriebssystemen (Verwaltung wartender Jobs,Pufferung von Ein/Ausgabe) und bei der Simulation von “Wartesituationen” in vielen Algorithmenund Modellen betrieblicher Ablaufe (Abfertigung an Bankschaltern u. a.)
5.9 Zusammenfassung
Die diskutierten Beispiele von Datenstrukturen zeigen:
• Datentypen und zugehorige Operationen bilden eine Einheit und konnen nicht getrennt gesehenwerden.
10In Java nennt man solche Methodenabstrakt und kennzeichnet sie durch das Schlusselwortabstract, vgl. Ab-schnitt7.3.5.

5.9. ZUSAMMENFASSUNG 113
• Die Semantik ergibt sich erst durch den Wertebereich und die Operationen (mit den zugehorigenAxiomen)
Es gibt verschiedene Methoden, um Datentypen zu definieren:
a) Die konstruktive Methode
Hierzu gehort die Definition von Arrays in Java. Die Definition “hoherer” Datentypen erfolgtaus bereits eingefuhrten Datentypen nach folgendem Muster.
einfache Datentypen niedrigste Stufe, z. B.int| ↑
Konstruktor Selektor↓ |
strukturierte Objekte 1. Stufe z. B.int[] vec; // Vektoren| ↑
Konstruktor Selektor↓ |
strukturierte Objekte 2. Stufe z. B.double[][] table; // Matrizen| ↑
Konstruktor Selektor↓ |
...
Aus der Mathematik ist diesefortgesetzte Abstraktionz. B. von Mengen bekannt:
Elemente einer Grundmenge↓ ↑
Mengen von Elementen (Menge)↓ ↑
Mengen von Mengen (Potenzmenge)
b) Die axiomatische Methode
Beispiele hierzu sind die Datenstrukturen Liste, Stack, Queue. Die Definition geschieht implizitDefinition mittels Operationen und deren Eigenschaften in Form von Axiomen.
Auch diese Methode ist in der Mathematik gebrauchlich, z. B.
– Peano Axiome fur naturliche Zahlen
– Inzidenzbeziehungen in der Geometrie usw.
Die Vorteile der axiomatischen Methode ist die Abstraktion von der Implementation (Imple-mentationsdetails sind unwesentlich). Dies erlaubt eine genauere Spezifikation und leichtereKorrekheitsbeweise. Ein (leichter) Nachteil besteht darin, dass i. a. verschiedene Interpretatio-nen (Modelle) einer abstrakten Datenstruktur moglich sind. Daher ist dieUbereinstimmung vonModell und Spezifikation i. a. nicht leichtuberprufbar, insbesondere fur ungeubte Benutzer.

114 KAPITEL 5. OBJEKTE, TYPEN, DATENSTRUKTUREN
Zusammenfassend lasst sich feststellen, dass die konstruktive Methode sich bereits als Implementa-tionsvorschrift verstehen lasst, wahrend die axiomatische Methode wesentlich mehr Freiheitsgradeerlaubt.
5.10 Literaturhinweise
Datenstrukturen werden in nahezu allen Buchernuber Entwurf und Analyse von Algorithmen behandelt. IhreRealisierung in Java wird ausfuhrlich in [GT04] erlautert.
Die hier gegebene Darstellung lehnt sich an [HR94] an. Dort wird im Gegensatz zu den meisten Buchernausfuhrlich auf die Umsetzung von der abstrakten Spezifikation zu Programmen eingegangen, allerdings inC++. Die hier gegebenen Definitionen bzw. Deklarationen der Java Funktionen fur Listen, Stack und Queuessind eine leichte Modifikation der dort gegebenen Darstellung in C++.

Kapitel 6
Algorithmen auf Arrays
Wir behandeln jetzt drei Aufgabenstellungen mit zunehmendem Schwierigkeitsgrad, deren Losung zuAlgorithmen auf Arrays fuhrt:
• Suchen eines Wertes in einem Array,
• Losung linearer Gleichungssysteme,
• Berechnung kurzester Wege in Graphen.
6.1 Suchen einer Komponente vorgegebenen Wertes
Hier handelt es sich um folgendes Basisproblem in Arrays:
Gegeben: Ein Array mitn ganzen Zahlen, eine ganze Zahlx.
Gesucht: Der Indexi einer Komponente mit Wertx (falls vorhanden).
6.1.1 Sequentielle Suche
Eine einfache Losung dieses Problems basiert auf folgender Idee. Durchlaufe die Komponenten desArrayssequentiellbis die aktuelle Komponentei den Wertx enthalt. Gebe danni aus. Istx in keinerKomponente, gebe−1 aus.
Diese Methode heißtsequentielle Suche. Sie erfordert im schlimmsten Falln Vergleiche bis der Indexi gefunden ist, bzw. festgestellt wird, dass keine Komponente den Wertx hat.
Eine Java Methode hierfur ist:
Programm 6.1 sequentialSearch
Version vom 21. Januar 2005
115

116 KAPITEL 6. ALGORITHMEN AUF ARRAYS
/*** searches for an element in an int array* by sequential search** @param a the int array* @param x the int to search for* @return the index of the first component containing <code>x</code>* or <code>-1</code> if <code>x</code> is not in the array*/public int sequentialSearch(int[] a, int x)
int k = 0; // variable to hold the index or -1while (k < a.length)
if (a[k] == x) return k; // found x
k++;
return -1;
Beim i-ten Wiedereintritt in diefor Schleife gilt dieZusicherung(Assertion)
i < n unda[0], . . . ,a[i−1] 6= x
Beim Austritt aus der Schleife gilt
a[i] = x oderi = a.length
Ist i = n, so istx nicht im Array.
DieseUberlegungen zeigen die Korrektheit des Algorithmus. Zusicherungen bei Schleifen nennt manauchSchleifeninvarianten. Sie spielen bei Korrektheitsbeweisen eine wichtige Rolle.
6.1.2 Binare Suche
Liegt das Arraya in sortierter Form vor (mitn= a.length), gilt alsoa[0]≤ a[1]≤ . . .≤ a[n−1], so lasstsich die Suche wesentlich beschleunigen durch die Verwendung derbinaren SucheoderBisection.
Die Idee der binaren Suche ist wie folgt:
– Wahle den mittleren Indexi und vergleichex unda[i].
– Ist a[i] = x, so ist der Indexi gefunden.
– Ist a[i] < x, so kannx nur in der “linken Halfte” von a, d. h. ina[0] . . .a[i−1] sein. Wende dasVerfahren auf die linke Halfte an.

6.1. SUCHEN EINER KOMPONENTE VORGEGEBENEN WERTES 117
– Ist a[i] > x, so kannx nur in der “rechten Halfte” vona, d. h. ina[i +1] . . .a[n−1] sein. Wendedas Verfahren auf die rechte Halfte an.
– Verfahre so weiter bisx gefunden, oder der noch zu durchsuchende Teil, in demx sein konnte,leer ist.
Als Beispiel betrachten wira mit den Werten
3 5 6 8 10 12 13 160 1 2 3 4 5 6 7
undx = 10. Zuerst wirdi in der Mitte gewahlt, etwai = 3. Dann ista[i] = 8 < x = 10, und es wird inder rechten Halfte vona weitergesucht.
10 12 13 164 5 6 7
i wird wieder in der Mitte gewahlt, etwai = 5. Dann ista[i] = 12> x = 10, und es wird in der linkenHalfte des verbleibenden Arrays weiter gesucht, also in
104
Die einzig verbleibende Wahl voni = 4 findet dann den gesuchten Wert. Ware jetztx 6= a[i], so stellteman an dieser Stelle fest dassx nicht im Array enthalten sein kann.
Eine Java Methode hierfur ist:
Programm 6.2 binarySearch/*** searches for an element in an int array* by binary search** @param a the int array* @param x the int to search for* @return the index of the first component containing <code>x</code>* or <code>-1</code> if <code>x</code> is not in the array*/public int binarySearch(int[] a, int x)
int k; // variable to hold the index or -1int i, j; // lower and upper array boundsi = 0; // initial array boundsj = a.length - 1; // initial array boundswhile (i <= j)
k = (i + j) / 2; // choose k in the middleif (a[k] == x)
return k; // found x

118 KAPITEL 6. ALGORITHMEN AUF ARRAYS
if (x > a[k])
i = k + 1; else
j = k - 1; // update bounds
return -1;
Vor jedem Eintritt in die Schleife gilt (fallsx im Array ist) die Invariante
a[i] < x≤ a[ j] und 0≤ i ≤ j ≤ n−1.
Da in jedem Schleifendurchlaufi erhoht oderj erniedrigt wird, terminiert das Programm mita[k] = xoderi > j. Im ersten Fall wird der richtige Indexk zuruckgegeben. Im zweiten Fall (also beii > j) istder Bereich, in demx sein konnte, wegen der Schleifeninvariante leer und es wird−1 zuruckgegeben.
Also arbeitet der Algorithmus korrekt. Bezuglich der notigen Anzahl von Vergleichen ergibt sich:
Satz 6.1 (Aufwand der binaren Suche) Fur die Anzahl C(n) von Vergleichen bei der binaren Suchein einem Array mit n Komponenten gilt1 C(n)≤ blognc+1.
Beweis:Der Beweis erfolgt durch vollstandige Induktion nachn.
Induktionsanfang: Ist n = 1, so ist nur 1 Vergleich erforderlich. Also stimmt die Behauptung wegenblog1c+1 = 0+1 = 1.
Induktionsvoraussetzung: Die Behauptung sei richtig fur alle Arrays der Lange< n,n≥ 2.
Schluss auf n: Nach dem ersten Vergleich mita[k] muss nur in einer der Halften weitergesucht werden.Beide Halften haben eine Lange≤ bn/2c und erfordern daher nach Induktionsvoraussetzung
C(bn/2c)≤ blog(bn/2c)c+1
Vergleiche. Insgesamt sind dann 1+C(bn/2c) Vergleiche erforderlich. Einsetzen ergibt:
C(n) ≤ 1+C(bn/2c)≤ 1+ blog(bn/2c)c+1
≤ 1+ log(n/2)+1
= 1+ log(n/2)+ log2
= 1+ log((n/2) ·2)= 1+ logn
da bn/2c ≤ n/2
da log(a·b) = loga+ logb
1 logn bedeutet hier (wie stets in der Informatik) den Logarithmus vonn zur Basis 2.dae ist a nach oben gerundet,bacist a nach unten gerundet, alsod5,2e= 6 undb5,2c= 5.

6.2. LINEARE GLEICHUNGSSYSTEME 119
Also istC(n)≤ 1+ logn. DaC(n) ganzzahlig ist, folgtC(n)≤ b1+ lognc= blognc+1.
Es sind also wesentlich weniger Vergleiche notig als bei der sequentiellen Suche. Bein= 1.000.000≈220 = 1048576 reichenC(n) = 20 Vergleiche bei der binaren Suche aus, wahrend die sequentielleSuche 1.000.000 Vergleiche braucht.
6.2 Lineare Gleichungssysteme
6.2.1 Vektoren und Matrizen
Ein n-dimensionaler Vektor(genauer:Spaltenvektor) mit Elementen aus einer MengeI ist einn-Tupel
x =
x1
x2...
xn
mit xi ∈ I , i = 1, . . . ,n.
Die Menge aller solchen Vektoren wird mitVn(I) bezeichnet. Meist istI = R, d. h.Vn(I) = Vn(R).Dafur schreibt man auch kurzRn.
Einem×n-Matrix mit Elementen aus einer MengeI ist eine Zusammenfassung
A =
a11 a12 . . . a1 j . . . a1n
a21 a22 . . . a2 j . . . a2n...
......
ai1 ai2 . . . ai j . . . ain...
...am1 am2 . . . am j . . . amn
von m·n Elementen ausI . Mm,n(I) bezeichnet die Menge allerm×n-Matrizen von Elementen ausI .Meist ist I = R oderI ⊆ R.
Jede Spalte vonA bildet einen VektorA· j , den sogenanntenSpaltenvektor( j = 1, . . . ,n); analog bildetjede ZeileAi· einenZeilenvektor(i = 1, . . . ,m).
Offensichtlich lassen sich Vektoren und Matrizen in Java durch 1- bzw. 2-dimensionale Arrays dar-stellen.
double[] vector = new double[n];double[][] matrix = new double[m][n];
definieren entsprechende Array-Objekte.
Matrizen und Vektoren konnen wie folgt miteinander multipliziert werden:

120 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Multiplikation einer m×n-Matrix A mit einem n-Vektor x: a11 . . . a1n...
...am1 . . . amn
x1
...xn
=
a11x1 + a12x2 + · · · + a1nxn
a21x1 + a22x2 + · · · + a2nxn
. . . . . . . . . . . . . . . . . . . . . . . . . .am1x1 + am2x2 + · · · + amnxn
Beispiele:
1. Multiplikation einer 2×3 Matrix mit einem 3-Vektor. Ergebnis ist ein 2-Vektor.(1 2 12 0 −1
)·
10−1
=(
1·1 + 2·0 + 1· (−1)2·1 + 0·0 + −1· (−1)
)=(
03
)
2. Multiplikation einer 1×3 Matrix mit einem 3-Vektor. Ergebnis ist eine Zahl.
(1 2 1
)·
10−1
= 1·1 + 2·0 + 1· (−1) = 0
Multiplikation einer m× p-Matrix A mit einer p×n-Matrix B:a11 . . . a1p...
...ai1 . . . aip...
...am1 . . . amp
b11 . . . b1 j . . . b1n
......
...bp1 . . . bp j . . . bpn
=
c11 . . . c1n...
...cm1 . . . cmn
mit
ci j = ai1b1 j +ai2b2 j + · · ·+aipbp j
=p
∑k=1
aikbk j
Die Formel zur Berechnung vonci j zeigt, dassci j aus deri-ten Zeile vonA und der j-ten Spalte vonB gebildet wird. Die illustriert Abbildung6.1.
Beispiele:
1. Multiplikation einer 2×3 Matrix mit einer 3×3 Matrix. Ergebnis ist eine 2×3 Matrix.(1 2 12 0 −1
) 2 1 3−1 0 01 1 0
=
(1·2+2· (−1)+1·1 , 1·1+2·0+1·1 , 1·3+0+02·2+0·0+(−1) ·1 , 2·1+0·0+(−1) ·1 , 2·3+0+0
)=
(1 2 33 1 6
)

6.2. LINEARE GLEICHUNGSSYSTEME 121
118 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Multiplikation einer m× p-Matrix A mit einer p× n-Matrix B:
a11 . . . a1p...
...ai1 . . . aip...
...am1 . . . amp
b11 . . . b1j . . . b1n...
......
bp1 . . . bpj . . . bpn
= c11 . . . c1n...
...cm1 . . . cmn
mit
cij = ai1b1j + ai2b2j + · · · + aipbpj
=p∑k=1
aikbkj
Die Formel zur Berechnung von cij zeigt, daß cij aus der i-ten Zeile von A und der j-tenSpalte von B gebildet wird. Die illustriert Abbildung 6.1.
· =i
j
ij
Abbildung 6.1: Schema der Matrixmultiplikation.
Beispiele:
1. Multiplikation einer 2×3 Matrix mit einer 3×3 Matrix. Ergebnis ist eine 2×3 Matrix.
1 2 12 0 −1
) 2 1 3−1 0 01 1 0
=
1 · 2 + 2 · (−1) + 1 · 1 , 1 · 1 + 2 · 0 + 1 · 1 , 1 · 3 + 0 + 02 · 2 + 0 · 0 + (−1) · 1 , 2 · 1 + 0 · 0 + (−1) · 1 , 2 · 3 + 0 + 0
)
=
1 2 33 1 6
)
Abbildung 6.1: Schema der Matrixmultiplikation.
2. Multiplikation einer 1×3 Matrix mit einem 3-Vektor. Ergebnis ist eine Zahl.
(1,2,1
) 201
= 1·2+2·0+1·1 = 3
3. Multiplikation eines 3 Vektors mit einer 1×3 Matrix. Ergebnis ist eine 3×3 Matrix. 201
( 1,2,1)
=
2·1 2·2 2·10·1 0·2 0·11·1 1·2 1·1
=
2 4 20 0 01 2 1
Diese Beispiele zeigen, dass die Matrixmultiplikation die Multiplikation von Matrizen mit Vektorenals Spezialfall enthalt. Stellt man sich dien Spalten derp× n-Matrix B als p-SpaltenvektorenB· j ,j = 1, . . . ,n, vor, so gilt
A·B = A·(B·1, . . . ,B·n
)=
(A·B·1, . . . ,A·B·n
).
In Java lasst sich die Matrizenmultiplikation folgendermaßen realisieren:
double[][] a = new double[m][p]; // Array fur Matrix Adouble[][] b = new double[p][n]; // Array fur Matrix Bdouble[][] c = new double[m][n]; // Array fur Ergebnismatrix Cint i, j, k;
// multiplicationfor (i = 0; i < m; i++)

122 KAPITEL 6. ALGORITHMEN AUF ARRAYS
for (j = 0; j < n; j++) c[i][j] = 0;for (k = 0; k < p; k++)
c[i][j] += a[i][k] * b[k][j];//end for k
//endfor j//endfor i
Wir bauen diese Multiplication jetzt in eine KlasseMatrix fur Matrizen ein. Jedes Matrix Objekthat die drei (privaten) Feldermatrix (fur die Eintrage),numberOfRows undnumberOfColumns (furAnzahl der Zeilen und Spalten). In den Methoden und Konstruktoren der KlasseMatrix verwendenwir die Variable mit dem reservierten Namenthis. Sie bezeichnet eine implizite Referenz auf dasObjekt, das gerade im Konstruktor konstruiert wird bzw. eine Methode fur sich aufruft. Sinda, bObjekte der KlasseMatrix, und ruft a die Methodea.multiply(b) fur sich auf, so bezeichnetalsothis im Rumpf vonmultiply() die Referenz auf das Objekta. Diese implizite Referenz kannnur innerhalb der Klassedurch die Variablethis angesprochen werden. Mehr dazu findet sich inKapitel 7.3.
Programm 6.3 Matriximport java.lang.IllegalArgumentException;import java.lang.ArrayIndexOutOfBoundsException;
/*** This is a class for rectangular double matrices*/public class Matrix
/*** the private representation of a matrix is a* 2-dimensional double array*/private double[][] matrix;
/*** number of rows* is 0 for empty matrix*/private int numberOfRows;
/*** number of columns* is 0 for empty matrix*/private int numberOfColumns;

6.2. LINEARE GLEICHUNGSSYSTEME 123
/*** default constructor, creates empty matrix*/public Matrix()
matrix = null;numberOfRows = 0;numberOfColumns = 0;
/*** constructor, constructs a matrix with prescribed number* of rows and columns and all entries equal to zero** Throws <code>IllegalArgumentException</code> if* <code>m</code> or <code>n</code> is negative** @param m the number of rows* @param n thenumber of columns*/public Matrix(int m, int n) throws IllegalArgumentException
if ((m <= 0) || (n <= 0)) throw new IllegalArgumentException("Anzahl der "
+ "Zeilen und Spalten muss positiv sein.");// this is a reference to the matrix to be constructed// we could also say matrix = new double[m][n] etc.,// but we use this to make the reference clearthis.matrix = new double[m][n];this.numberOfRows = m;this.numberOfColumns = n;
/*** @return the number of rows of this matrix*/public int getNumberOfRows()
// here this refers to the object that applies the method// i.e., in myMatrix.getNumberofRows(), this refers to myMatrix// we could also say return numberOfRows,// but we use this to make the reference clearreturn this.numberOfRows;
/**

124 KAPITEL 6. ALGORITHMEN AUF ARRAYS
* @return the number of coulumns of this matrix*/public int getNumberOfColumns()
return this.numberOfColumns;
/*** returns the entry at a matrix position** Throws <code>IllegalArgumentException</code> if* <code>i</code> or <code>j</code> is negative** Throws <code>ArrayIndexOutOfBoundsException</code> if* <code>i</code> or <code>j</code> is too big** @param i the row index* @param j the colum index* @return the entry in row i and column j*/public double getEntry(int i, int j) throws
IllegalArgumentException,ArrayIndexOutOfBoundsException
if ((i < 0) || (j < 0)) throw new IllegalArgumentException("Negative Indizes");
if (this.matrix == null)
throw new IllegalArgumentException("Matrix ist leer.");if ((i > this.getNumberOfRows()) ||
(j > this.getNumberOfColumns())) throw new ArrayIndexOutOfBoundsException(
"Index zu groß.");return this.matrix[i][j];
/*** sets the entry at position (i,j) of this matrix** Throws <code>IllegalArgumentException</code> if* <code>i</code> or <code>j</code> is negative or* if this matrix is empty** Throws <code>ArrayIndexOutOfBoundsException</code> if

6.2. LINEARE GLEICHUNGSSYSTEME 125
* <code>i</code> or <code>j</code> is too big** @param i the row index* @param j the colum index* @param x the value of the entry*/public void setEntry(int i, int j, double x) throws
IllegalArgumentException,ArrayIndexOutOfBoundsException
if ((i < 0) || (j < 0)) throw new IllegalArgumentException("Negative Indizes");
if (this.matrix == null)
throw new IllegalArgumentException("Matrix ist leer.");if ((i > this.getNumberOfRows()) ||
(j > this.getNumberOfColumns())) throw new ArrayIndexOutOfBoundsException(
"Index zu groß.");this.matrix[i][j] = x;
/*** multiplies this matrix with another matrix** Throws <code>IllegalArgumentException</code> if* dimensions are not compatible or* if this matrix is empty** @param m the other matrix*/public void multiply(Matrix m) throws IllegalArgumentException
if (this.getNumberOfColumns() != m.getNumberOfRows()) throw new IllegalArgumentException("Falsche "
+ "Dimensionen");if (this.matrix == null)
throw new IllegalArgumentException("Multiplikation "+ "mit leerer Matrix.");
// array for resultdouble[][] c = new double[this.getNumberOfRows()]

126 KAPITEL 6. ALGORITHMEN AUF ARRAYS
[m.getNumberOfColumns()];int i, j, k;
// multiplicationfor (i = 0; i < this.getNumberOfRows(); i++)
for (j = 0; j < m.getNumberOfColumns(); j++) c[i][j] = 0;for (k = 0; k <
this.getNumberOfColumns(); k++)c[i][j] += this.matrix[i][k]
* m.getEntry(i, j);//end for k
//endfor j//endfor i// store the result in this matrix,// update this column numberthis.matrix = c;this.numberOfColumns = m.getNumberOfColumns();
Wie ublich werden jetzt Matrizen mit
Matrix a = new Matrix(10, 15);
erzeugt. Mit Anweisungen der Form
a.setEntry(2, 1, 3.14);
werden Komponenten gesetzt, und zwei Matrizena undb werden mit
a.multiply(b);
miteinander multipliziert, wobei dann das Ergebnis in der Matrixa steht.
Die algebraische Struktur der Menge der Matrizen (Rechenstruktur!) wird in derLinearen Algebraausfuhrlich behandelt.
Wir werden im weiteren die Kurzschreibweisen
A·x bzw.Ax fur die Matrix-Vektor Multiplikation, undA·B bzw.AB fur die Matrizenmultiplikation
verwenden (geeignete “Abmessungen” vorausgesetzt).

6.2. LINEARE GLEICHUNGSSYSTEME 127
6.2.2 Ein Produktionsmodell
Ein Betrieb verarbeitet an ProduktionsstatteP1 die RohstoffeR1 . . . ,Rn zu ZwischenproduktenZ1, . . .Zp,die dann an der ProduktionsstatteP2 zu EndproduktenE1, . . . ,Em weiterverarbeitet werden. Der Be-darf an Rohstoffen fur die Zwischenprodukte ist durch Tabelle6.1gegeben, d. h. zur Produktion einerEinheit vonZi werdenbi j Einheiten vonRj benotigt, j = 1, . . . ,n.
Tabelle 6.1: Rohstoffbedarf fur Zwischenprodukte.
R1 R2 . . . Rn
Z1 b11 b12 . . . b1n...Zi bi1 bi2 . . . bin...
Zp bp1 bp2 . . . bpn
Ebenso ist der Bedarf an Zwischenprodukten fur die Endprodukte durch Tabelle6.2gegeben.
Tabelle 6.2: Zwischenproduktbedarf fur Endprodukte.
Z1 Z2 . . . Zp
E1 a11 a12 . . . a1p...
Ei ai1 ai2 . . . aip...
Em am1 am2 . . . amp
Diese beiden Tabellen definieren MatrizenA undB gemaß
A := (ai j ) i=1,...,mj=1,...,p
, B := (bi j ) i=1,...,pj=1,...,n
Dann ergibt sich der Bedarfci j an RohstoffRj fur die Produktion einer Einheit von EndproduktEi zu
ci j = ai1b1 j +ai2b2 j + · · ·+aipbp j .
Bezeichnet man die Matrix derci j alsC, alsoC := (ci j ) i=1,...,mj=1,...,n
, so ergibt sichC also durch Multiplika-
tion der MatrizenA undB, d. h.C = A·B .
C heißtRohstoffbedarfsmatrix.

128 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Diese Daten sollen jetzt zum Einkauf der benotigten Rohstoffe fur eine vorgegebene Produktion vonyi Einheiten von EndproduktEi (i = 1, . . . ,m) genutzt werden.
Gegeben ist also derProduktionsvektor
y =
y1
y2...
ym
Die benotigte Mengezj des ZwischenproduktsZ j an ProduktionsstatteP1 ergibt sich zu
zj = y1 ·a1 j +y2 ·a2 j + · · ·+ym ·am j
= (y1, . . . ,ym)
a1 j
a2 j...
am j
= (a1 j ,a2 j , . . . ,am j)
y1...
ym
Bezeichnet
z=
z1...
zp
denBedarfsvektoran Zwischenprodukten, so gilt also
z= ATy . 2
Hieraus ergibt sich der Bedarfx j an RohstoffRj wie folgt:
x j = z1 ·b1 j +z2b2 j + · · ·+zp ·bp j
= (z1, . . . ,zp)
b1 j...
bp j
= (b1 j , . . . ,bp j)
z1...
zp
= BT· j ·z .
Also gilt fur den Bedarfsvektorx
x =
x1...
xn
= BT ·z= BTATy .
2 AT ist die zuA transponierteMatrix AT = (aTi j ) mit aT
i j = a ji . Sie ergibt sich ausA durch Spiegeln an der Hauptdiago-nalen.

6.2. LINEARE GLEICHUNGSSYSTEME 129
Dieser Bedarfsvektor lasst sich naturlich auch direktuber die RohstoffbedarfsmatrixC = A ·B ermit-teln:
x j = Bedarf anRj fur alleEi zusammen bei Produktionsvektory
= y1c1 j +y2c2 j + · · ·+ymcm j
= (y1,y2, . . . ,ym)
c1 j
c2 j...
cm j
= (c1 j , . . . ,cm j)
y1
y2...
ym
= CT
· j ·y .
Also ist
x = CT ·y = BT ·AT ·y . 3
Jetzt betrachten wir die umgekehrte Fragestellung. Es sind nur bestimmte Mengen von Rohstoffenverfugbar, die durch einen Rohstoffvektor
r =
r1...rn
beschrieben werden. Gesucht ist ein Produktionsvektor
y =
y1...
ym
,
der die bezuglich r mogliche Produktion angibt.
Die obige Matrizengleichung liefertCTy = r, d. h. daslineare Gleichungssystem
c11y1 + c21y2 + . . . + cm1ym = r1
c12y1 + c22y2 + . . . + cm2ym = r2
. . .c1ny1 + c2ny2 + . . . + cnmym = rn
mit n Gleichungenundm Unbekannten.4
3 Es gilt allgemein bezuglich der Transponierung(A·B)T = BTAT (Ubung). Daher hatte man die obige Gleichung auchaus dieser Regel direkt ableiten konnen.
4 Es handelt sich hier um ein spezielles lineares Gleichungssystem innicht ublicherSchreibweise, die daraus resultiert,dass die transponierte MatrixCT verwendet wird.

130 KAPITEL 6. ALGORITHMEN AUF ARRAYS
6.2.3 Das Gaußsche Eliminationsverfahren
Wir betrachten jetzt lineare Gleichungssysteme in allgemeiner Form (und Schreibweise). Das System
a11x1 + a12x2 + . . .+ a1nxn = b1
a21x1 + a22x2 + . . .+ a2nxn = b2
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .am1x1 +am2x2 + . . .+amnxn = bm
heißtlineares Gleichungssystemmit mGleichungen in denn Variablenx1, . . . ,xn. In Matrizenschreib-weise schreibt sich dieses System kurz als
Ax= b
mit
A =
a11 . . . a1n
am1 . . . amn
, x =
x1...
xn
, b =
b1...
bm
.
A wird Koeffizientenmatrixdes Gleichungssystems genannt, undb heißtrechte Seitedes Gleichungs-systems.
Ein Vektor
x =
x1...
xn
mit Ax= bheißtLosungdes linearen Gleichungssystems. Die Menge aller Losungen wirdLosungsraumdes Gleichungssystem genannt.
Wir werden jetzt einen einfachen Algorithmus zur Losung linearer Gleichungssysteme entwickeln,das sogenannteGaußsche Eliminationsverfahren. Dazu benotigen wir zunachst einige Hilfsaussagenuber Umformungen des Gleichungssystems, die den Losungsraum unverandert lassen.
Lemma 6.1 Die Addition bzw. Subtraktion des Vielfachen einer Gleichung zu einer anderenandertden Losungsraum nicht.
Beweis:Addiere dasc-fache derk-ten Gleichung zuri-ten. Es entsteht das GleichungssystemAx= b:
a11x1 + . . .+ a1nxn = b1
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .(ai1 +c·ak1)x1 + . . .+(ain +c·akn)xn = bi +c·bk
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .a11x1 + . . .+ a1nxn = bn
Sei x Losung vonAx= b. Dann erfullt x auch alle Gleichungen vonAx= b (außer evtl. deri-ten), dadiese inAx= b unverandert sind.

6.2. LINEARE GLEICHUNGSSYSTEME 131
Wir zeigen nun, dass ¯x auch diei-te Gleichung vonAx= b erfullt und daher auch eine Losung vonAx= b ist.
Da x eine Losung vonAx= b ist, gilt (die i-te Gleichung hingeschrieben):
(ai1 +cak1)x1 + · · ·+(ain +c·akn)xn = bi +c·bk .
Die linke Seite ist gleich
(ai1x1 + · · ·+ainxn)+c(ak1x1 + · · ·+aknxn) .
Nun ist(ak1x1 + · · ·+aknxn) = bk, dax diek-te Gleichung vonAx= b lost. Also folgt:
bi +c·bk = ai1x1 + · · ·+ainxn +c·bk
oderbi = ai1x1 + · · ·+ainxn ,
d. h. x lost auch diei-te Gleichung vonAx= b. Also ist jede Losung vonAx = b auch eine LosungvonAx= b.
Die Umkehrung folgt entsprechend.
Lemma 6.2 Die Multiplikation einer Gleichung mit einer Konstanten6= 0 andert den Losungsraumnicht.
Beweis:Der Beweis erfolgt analog zu Lemma6.1.
Die Operationen “Addition des Vielfachen einer Zeile zu einer anderen” und “Multiplikation einerZeile mit einer Konstanten” heißen auchelementare Umformungen.
Lemma 6.3 Das Vertauschen von Zeilen (Umnummerieren der Gleichungen) und Spalten (Umnum-merieren der Variablen)andern den Losungsraum (bis auf Umnummerieren der Koordinaten) nicht.
Beweis:Klar.
Satz 6.2 Das Gleichungssystem Ax= b kann durch elementare Umformungen und gegebenenfalls
Zeilen und Spaltenvertauschungen so umgeformt werden, dass die erweiterte Matrix(A... b) die in
Abbildung6.2dargestellteDreiecksformhat, d. h.
aii 6= 0 fur i = 1, . . . ,k, ai j = 0 fur i > 1 und i< j .

132 KAPITEL 6. ALGORITHMEN AUF ARRAYS
a11... b1
0... ai j
......
......
...... akk
... bk
0 0 . . . 0 0... bk+1
0 0 . . . 0 0... bm
Abbildung 6.2: Dreiecksform der erweiterten Matrix.
Bevor wir Satz6.2beweisen, rechnen wir zunachst einige Beispiele durch.
Beispiel 6.11. m≤ n
x1 + x2 − x3 = 2x1 + x3 = −1
Die erweiterte Matrix(A...b) hat die Form 1 1 −1
... 2
1 0 1... −1
.
Die Subtraktion der ersten Zeile von der zweiten ergibt 1 1 −1... 2
0 −1 2... −3
,
wodurch die Dreiecksform erreicht ist.
2. m> nx1 + x2 = 1x1 − x2 = 0x1 + 2x2 = 2
Die erweiterte Matrix(A...b) hat die Form
1 1... 1
1 −1... 0
1 2... 2
.

6.2. LINEARE GLEICHUNGSSYSTEME 133
Die Subtraktion der ersten Zeile von der zweiten und der dritten ergibt1 1
... 1
0 −2... −1
0 1... 1
,
und die Addition des12-fachen der zweiten Zeile zu der dritten1 1
... 1
0 −2... −1
0 0... 1/2
,
wodurch die Dreiecksform erreicht ist.
Beweis: (von Satz6.2) Der Beweis erfolgt durch die Angabe eines Algorithmus (im Struktogramm)und den Nachweis seiner Korrektheit. Das Struktogramm ist in Abbildung6.3 angegeben. Die Kor-rektheit des Algorithmus basiert auf der folgendenSchleifeninvariante:
Die erweiterte Matrix hat bei jedem Eintritt in die Schleife die in Abbildung6.4dargestellteForm.
Dies folgt direkt aus der Tatsache, dass die Addition in den ersten Stellen 1, . . . , i−1 nur 0+0 ergibtund diei-te Spalte beimi-ten Durchlauf unterhalb von Zeilei zu Null gemacht wird.
Also verlasst man die Schleife mitk = minn,m oderk < minn,m undA = 0.
Der obige Algorithmus wird auch alsGaußsches Eliminationsverfahrenzur Losung linearer Glei-chungssysteme bezeichnet. Seine Nutzung zur Losung linearer Gleichungssysteme beruht auf demfolgenden Satz:
Satz 6.3 (Losungskriterien fur lineare Gleichungssysteme)Sei Ax= b gegeben, und seien(A... b)
und k die durch das Gaußsche Eliminationsverfahren gelieferten Großen. Dann gilt:
a) Ax= b hat genau dann (mindestens) eine Losung wennbi = 0 fur alle i > k (falls k< m).
b) In diesem Falle erhalt man alle Losungen, indem man (fur k < n) xk+1,xk+2, . . . ,xn beliebigwahlt und die anderen Variablen x1, . . . ,xk aus der Dreiecksform
a11x1 + a12x2 + · · ·+ a1kxk = b1− (a1,k+1xk+1 + · · ·+ a1,nxn)a22x2 + · · ·+ a2kxk = b2− (a2,k+1xk+1 + · · ·+ a2,nxn)
...
akkxk = bk− (ak,k+1xk+1 + · · ·+ ak,nxn)
durch sukzessives Ausrechnen von xk,xk−1, . . . ,x1 “von unten nach oben” erhalt.

134 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Lasse von(A...b) die Zeile und Spalte mit Indexi−1 weg. Bezeich-
ne die entstehende Matrix wieder mit(A... b).
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhtrue
i ≤minn,m
i := i +1
Addiere zu allen Zeilen mit a`i 6= 0 ein geeignetes Vielfaches,so dass ˜a`i + c · aii = 0 gilt. Dann istc = − a`i
aii. Dies nennt man
PivotoperationoderPivotisierung.
AndereA durch Zeilen- und Spaltenpermutationen bis ˜aii 6= 0 gilt.Das gewahlte Element heißtPivotelementin Zeile i.
A 6= 0 (Nullmatrix)and i ≤minn,m
Setze(A... b) := (A
...b) und i := 1
Abbildung 6.3: Struktogramm des Gauß-Eliminationsverfahrens.
6.2. LINEARE GLEICHUNGSSYSTEME 127
Lasse von (A... b) die Zeile und Spalte mit Index i − 1 weg.
Bezeichne die entstehende Matrix wieder mit (A... b).
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!!
!
true
i ≤ minn,m
i := i + 1
Addiere zu allen Zeilen ! mit a!i #= 0 ein geeignetes Vielfaches,so daß a!i + c · aii = 0 gilt. Dann ist c = − a!i
aii. Dies nennt
man Pivotoperation oder Pivotisierung .
Andere A durch Zeilen- und Spaltenpermutationen bis aii #= 0gilt. Das gewahlte Element heißt Pivotelement in Zeile i.
A #= 0 (Nullmatrix) and i ≤ minn,m
Setze (A... b) := (A
... b) und i := 1
Abbildung 6.3: Struktogramm des Gauß-Eliminationsverfahrens.
A
#= 0
b0
#= 0
#= 0
. . .
aii
Abbildung 6.4: Die Schleifeninvariante im Beweis zu Satz 6.2.Abbildung 6.4: Die Schleifeninvariante im Beweis zu Satz6.2.

6.2. LINEARE GLEICHUNGSSYSTEME 135
c) Dies sind bereitsalleLosungen von Ax= b.
Man nenntk auch denRangder MatrixA. Aussage a) bedeutet dann, dassAx= b genau dann losbar
ist, wenn der Rang vonA gleich dem Rang der erweiterten Matrix(A...b) ist.
Aussage b) und c) bedeuten, dass der Losungsraum ein(n−k)-dimensionaler affiner Raumist. Diesbedeutet grob gesagt folgendes:
– Der Losungsraum des zugehorigenhomogenenSystemsAx = 0 ist ein(n− k)-dimensionalerVektorraumL.
– Man erhalt alle Losungenx desinhomogenenSystemsAx= b als Kombinationx= x+y, wobeix irgendeine fest gewahlte Losung vonAx= b ist, undy alle Losungen vonAx= 0 durchlauft.
Genauer werden diese Zusammenhange in derLinearen Algebrain einem allgemeineren Rahmenuntersucht.
Beispiel 6.2 (Fortsetzung von Beispiel6.1)1. Das Gleichungssystem ist losbar, dak = 2 = m. Man erhalt
x1 x2 x3... b
. . . . . . . . . . . . . . . . . . .
1 1 −1... 2
0 −1 2... −3
.
Man kannx3 beliebig wahlen (z. B.x3 = c) und erhalt
x1 +x2 = 2+c
−x2 = −3−2c
Hieraus ergibt sichx2 = 3+2c, und dann aus der ersten Gleichung
x1 = −x2 +2+c
= −(3+2c)+2+c
= −1−c .
Also ist der Losungsraum
−1−c3+2c
c
| c∈R1 beliebig ein 1-dimensionaler affiner Raum.
2. Das Gleichungssystem ist nicht losbar, dak = 2 < m undb3 = 12 6= 0.
Beweis: (von Satz6.3)
zu a)

136 KAPITEL 6. ALGORITHMEN AUF ARRAYS
1. Die Bedingungbi = 0 fur i > k ist notwendig fur die Losbarkeit:
Der Gauß-Algorithmus lasst wegen Lemma6.1–6.3 den Losungsraum unverandert. Istbi 6= 0fur ein i > k, so lautet diei-te Gleichung vonAx= b
0·x1 + · · ·+0·xn = bi 6= 0
Dies ist fur keinx erfullt.
2. Die Bedingungbi = 0 fur alle i > k ist auch hinreichend fur die Losbarkeit:
Man kann aufgrund der Bedingung b) eine Losung wie folgt ausrechnen: Fur beliebig, aber festgewahlte Werte vonxk+1, . . . ,xn ist
d` := a`,k+1xk+1 + a`,k+2xk+2 · · ·+ a`,nxn ,
` = 1, . . . ,m, eine Konstante. Dann ergibt sich (wegen ¯akk 6= 0)
xk =1
akk[bk− (ak,k+1xk+1 + · · ·+ ak,nxn)︸ ︷︷ ︸
Konstantedk
] .
Sindxk,xk−1, . . . ,x`+1 bereits berechnet, so ergibt sichx` (wegen ¯a`` 6= 0) als
x` =1
a``[b`− (a`,`+1x`+1 + · · ·+ a`,kxk)−d`] .
Also folgt a) und auch b).
zu c) Zeige:Jede Losung lasst sich gemaß b) gewinnen.
Sei
x =
x1...
xn
eine Losung. Wahle dann in b)xk+1 := xk+1, . . . ,xn := xn. Dann sind (wie die Formel oben fur xl zeigt)x1,x2, . . . ,xk eindeutig bestimmt durch die Wahl vonx j = x j ( j = k+1, . . . ,n). Also mussxi = xi furi = 1, . . . ,k sein.
6.2.4 Wahl des Pivotelements
Im Gauß-Algorithmus wurde die Auswahl der Pivotelemente offen—d. h. beliebig—gelassen. Ausnumerischen Grunden sind jedoch bestimmte Pivotelemente vorzuziehen.

6.2. LINEARE GLEICHUNGSSYSTEME 137
Beispiel 6.3 (Ungunstige Wahl des Pivotelementes)Das lineare Gleichungssystem
0,000100x1 +x2 = 1
x1 +x2 = 2
soll mit 3-stelliger Arithmetik5 gelost werden.
Die Gauß-Elimination ergibt (Zeile 1 mit 10000 multiplizieren und von Zeile 2 abziehen):
x1(1−10000·0,000100)︸ ︷︷ ︸=:a
+x2(1−10000)︸ ︷︷ ︸=:b
= 2−10000︸ ︷︷ ︸=:c
In 3-stelliger Arithmetik ergeben sich folgende Werte fur a,b,c (; steht fur das Runden):
a = 1−10000·0,000100= 1−1 = 0
b = 1−10000=−9999=−0,9999·104
; −0,100·105 =−10000
c = 2−10000=−9998=−0,9998·104
; −0,100·105 =−10000
Das transformierte Gleichungssystem in 3-stelliger Arithmetik lautet dann
0,000100x1 +x2 = 1
−10000x2 = −10000
Hieraus ergibt sich dieangenaherteLosung
x1 = 0,000 x2 = 1,000.
Die exakteLosung ist jedochx1 = 1,00010 x2 = 0,99990,
was bedeutet, das die angenaherte Losung fur x1 auf Basis der 3-stelligen Arithmetik unvertretbarschlecht ist.
Die Ursache liegt darin, dassa11 = 0,000100 ein zu kleines Pivotelement im Verhaltnis zua21 = 1ist. Will man dies vermeiden, so kann man (z. B. durch Zeilenvertauschung) nach einem großerenPivotelement suchen. Im Beispiel ergibt die Zeilenvertauschung
x1 +x2 = 2
0,000100x1 +x2 = 1
5 Dies bedeutet, dass nur 3 Nachkommastellen in der normalisierten Gleitkommadarstellung (vgl. Kapitel12) einer Zahldargestellt werden konnen. Die darstellbaren Zahlen haben also die Form 0,x1x2x3 ·10e mit xi ∈ 0,1, . . . ,9, x1 6= 0 undeganzzahlig. Bei mehr Nachkommastellen wird entsprechend gerundet.

138 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Die Gauß-Elimination ergibt
x1(0,000100−0,000100)︸ ︷︷ ︸=:a
+x2(1−0,000100)︸ ︷︷ ︸=:b
= 1−0,000200︸ ︷︷ ︸=:c
mit folgenden Werten fur a,b,c in 3-stelliger Arithmetik:
a = 0,000100−0,000100= 0
b = 1−0,000100= 0,9999= 0,9999·100
; 0,100·101 = 1
c = 1−0,000200= 0,9998=−0,9998·100
; 0,100·101 = 1
Das transformierte Gleichungssystem in 3-stelliger Arithmetik lautet dann
x1 +x2 = 2
x2 = 1 ,
woraus sich die angenaherte Losungx1 = x2 = 1 ergibt, die die exakte Losung fur eine 3-stelligeArithmetik sehr gut approximiert.
Dies Beispiel zeigt, dass man das Gaußsche Eliminationsverfahren nicht einfach “naiv” anwendendarf, sondern sich Gedankenuber die numerische Genauigkeit machen muss.
Dies geschieht durch die Suche nach geeigneten Pivotelementen, die sogenanntePivotstrategie. Esgibt zweiStandard-Pivotstrategien, diepartielleund dietotalePivotsuche.
Bei derpartiellen Pivotsuchesucht man das Pivotelement in der jeweiligen Spalte nach folgenderRegel (vgl. Abbildung6.5):
Permutiere in Schritti diejenige Zeile (unter den Zeilen= i, . . . ,m) mit großtem absolutemWert |a`i | an diei-te Stelle.
20 KAPITEL 1. ALGORITHMEN AUF ARRAYS
i
...i
!Vertauschung
|a!i| = maxj=i,...,m
|aji|
Abbildung 1.5: Schema der partiellen Pivotsuche.
Vergleiche, d. h. quadratisch in m viele.
Bei der totalen Pivotsuche sucht man das Pivotelement in der gesamten verbleibenden Rest-matrix nach folgender Regel (vgl. Abbildung ??):
Permutiere in Schritt i die verbleibenden Zeilen und Spalten bis an Stelle (i, i) derEintrag mit dem großten Absolutbetrag steht.
Spaltenpermutation
i
iZeilenpermutation
großter Absolutbetrag
Abbildung 1.6: Schema der totalen Pivotsuche.
Hierdurch ergibt sich in Schritt i der Gauß Elimination ein zusatzlicher Suchaufwand von(m − i)(n − i) Vergleichen, also insgesamt uber alle Schritte
m∑i=1
(m − i)(n − i) = (m − 1)(n − 1) + (m − 2)(n − 2) + · · · + 1
≤ (n − 1)2 + (n − 2)2 + · · · + 1 = nn − 1
3(n −
1
2)
Vergleiche, d. h. kubisch in m viele.
In der Numerischen Mathematik werden weitere Methoden zum Erreichen numerischer Ge-nauigkeit und zum Abschatzen des maximalen Fehlers untersucht.
Abbildung 6.5: Schema der partiellen Pivotsuche.

6.2. LINEARE GLEICHUNGSSYSTEME 139
Hierdurch ergibt sich in Schritti der Gauß-Elimination ein zusatzlicher Suchaufwand vonm− i Ver-gleichen, also insgesamtuber alle Schritte
m
∑i=1
(m− i) = (m−1)+(m−2)+ · · ·+1
=m(m−1)
2
Vergleiche, d. h.quadratischin m viele.
Bei der totalen Pivotsuchesucht man das Pivotelement in der gesamten verbleibenden Restmatrixnach folgender Regel (vgl. Abbildung6.6):
Permutiere in Schritti die verbleibenden Zeilen und Spalten bis an Stelle(i, i) der Eintragmit dem großten Absolutbetrag steht.
20 KAPITEL 1. ALGORITHMEN AUF ARRAYS
i
...i
!Vertauschung
|a!i| = maxj=i,...,m
|aji|
Abbildung 1.5: Schema der partiellen Pivotsuche.
Vergleiche, d. h. quadratisch in m viele.
Bei der totalen Pivotsuche sucht man das Pivotelement in der gesamten verbleibenden Rest-matrix nach folgender Regel (vgl. Abbildung ??):
Permutiere in Schritt i die verbleibenden Zeilen und Spalten bis an Stelle (i, i) derEintrag mit dem großten Absolutbetrag steht.
Spaltenpermutation
i
iZeilenpermutation
großter Absolutbetrag
Abbildung 1.6: Schema der totalen Pivotsuche.
Hierdurch ergibt sich in Schritt i der Gauß Elimination ein zusatzlicher Suchaufwand von(m − i)(n − i) Vergleichen, also insgesamt uber alle Schritte
m∑i=1
(m − i)(n − i) = (m − 1)(n − 1) + (m − 2)(n − 2) + · · · + 1
≤ (n − 1)2 + (n − 2)2 + · · · + 1 = nn − 1
3(n −
1
2)
Vergleiche, d. h. kubisch in m viele.
In der Numerischen Mathematik werden weitere Methoden zum Erreichen numerischer Ge-nauigkeit und zum Abschatzen des maximalen Fehlers untersucht.
Abbildung 6.6: Schema der totalen Pivotsuche.
Hierdurch ergibt sich in Schritti der Gauß Elimination ein zusatzlicher Suchaufwand von(m− i)(n−i) Vergleichen, also insgesamtuber alle Schritte
m
∑i=1
(m− i)(n− i) = (m−1)(n−1)+(m−2)(n−2)+ · · ·+1
Vergleiche. Wenn wir der Einfachheit halberm = n annehmen (quadratische Matrizen), so ergebensich
(m−1)2 +(m−2)2 + · · ·+1 = mm−1
3(m− 1
2)
viele Vergleiche, alsokubischin m viele.
In derNumerischen Mathematikwerden weitere Methoden zum Erreichen numerischer Genauigkeitund zum Abschatzen des maximalen Fehlers untersucht.

140 KAPITEL 6. ALGORITHMEN AUF ARRAYS
6.2.5 Eine Java Klasse zur Losung linearer Gleichungssysteme
Wir geben nun ein Java Programm fur die Losung linearer Gleichungssysteme mittels Gauß-Eliminationan. Dazu implementieren wir eine KlasseLinearEquation, deren Objekte lineare Gleichungssyste-me sind. Zu denpublic Methoden dieser Klasse gehoren
solveByTotalPivotSearch() undsolveWithoutPivotSearch(),
die die entsprechende Variante der Gauß-Elimination des letzten Abschnitts zur Losung verwenden.Ein ObjectlinEq dieser Klasse kann sich also durch die Anweisung
linEq.solveByTotalPivotSearch();
selbst losen. Die Losbarkeit wird in demprivate Feld solvable abgespeichert, auf das mit derpublicMethodeisSolvable() zugegriffen werden kann. Ist das System losbar (alsolinEq.isSolvable()== true), so wird eine Losung in demprivate Feldsolution abgespeichert, auf die mitgetSolution()zugegriffen werden kann.
Einejavadoc Ubersicht allerpublic Konstruktoren und Methoden (es gibt keinepublic Felder)der KlasseLinearEquation ist in Abbildung6.7angegeben, genauere Informationen enthalten Ab-bildung6.8und Abbildung6.9.
Bei der Pivotsuche werden Vertauschungen von Zeilen und Spalten nicht tatsachlich durchgefuhrt(dies wurde zu viel Rechenzeit erfordern), sondern man merkt sich die Indexvertauschungen in zweiHilfsarrays, namlich
int[] row; // Zeilenindexint[] col; // Spaltenindex
Ist durch
double[][] a;
die Koeffizientenmatrix definiert, so ista[row[i]][col[j]] also das “aktuelle” Element an derStelle(i, j); entsprechend sindx[col[j]] undb[row[i]] die aktuellen Elemente fur
double[] x; // Variabledouble[] b; // rechte Seite
Die Arraysrow und col werden beim Aufruf des KonstruktorsLinearEquation(double[][],double[]) entsprechend zurow[i] = i undcol[j] = j initialisiert.
Neben der KlasseLinearEquation werden noch die Hilfsklassen
MatrixPosition undDimensionException
benotigt. Sie sind am Ende von Programm6.4aufgefuhrt.

6.2. LINEARE GLEICHUNGSSYSTEME 141
Abbildung 6.7:javadoc Summary der KlasseLinearEquation.
Programm 6.4 Java Klassen zum Losen linearer Gleichungssysteme
/*** class for systems of linear equations*/public class LinearEquation
/*** will be true if system is solvable

142 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Abbildung 6.8: Konstruktoren der KlasseLinearEquation.
*/private boolean solvable;
/*** will be true if solvability has been checked*/private boolean solved;
/*** the rank of the coefficient matrix*/private int rank;
/*** the matrix of coefficients*/private double[][] coeff;
/*** the right hand side*/private double[] rhs;

6.2. LINEARE GLEICHUNGSSYSTEME 143
Abbildung 6.9: Die wichtigsten Methoden der KlasseLinearEquation.
/*** encodes row permutations, row i is at position row[i]*/private int[] row;
/*** encodes column permutations, column j is at position col[j]*/private int[] col;
/**

144 KAPITEL 6. ALGORITHMEN AUF ARRAYS
* holds the solution vector*/private double[] solution;
/*** is true if system is in triangular form*/private boolean triangular;
/*** default constructor*/public LinearEquation()
solvable = false;solved = false;triangular = false;rank = 0;solution = null;coeff = null;rhs = null;row = null;col = null;
/*** constructs object with given coeff matrix and rhs* and initializes row and col** @param a the matrix to which the coeff matrix is set* @param b the rhs to which the rhs is set*/public LinearEquation(double[][] a, double[] b)
throws NullPointerException, DimensionException if (a == null || b == null)
throw new NullPointerException("zugewiesener Array "+ "ist null");
if (a.length != b.length)
throw new DimensionException("unvertragliche "+ "Dimension");
coeff = a;rhs = b;

6.2. LINEARE GLEICHUNGSSYSTEME 145
row = new int[coeff.length];for (int i = 0; i < coeff.length; i++) row[i] = i;col = new int[coeff[0].length];for (int j = 0; j < coeff[0].length; j++) col[j] = j;rank = 0;solution = null;solved = false;solvable = false;triangular = false;
/*** tests if system has been tested for solvability** @return true if a solutioan has already been computed*/public boolean isSolved()
return solved;
/*** brings system into triangular form with choice of pivot method* @exception NullPointerException* @exception DimensionException*/private void triangularForm(int method) throws NullPointerException
if (coeff == null || rhs == null) throw new NullPointerException();
int m = coeff.length;int n = coeff[0].length;
int i, j, k; // countersint pivotRow = 0; // row index of pivot elementint pivotCol = 0; // column index of pivot elementdouble pivot; // value of pivot element
// main loop, transformation to triangle formk = -1; // denotes current position on diagonalboolean exitLoop = false;

146 KAPITEL 6. ALGORITHMEN AUF ARRAYS
while (! exitLoop) k++;
// pivot search for entry in remaining matrix// (depends on chosen method in switch)// store position in pivotRow, pivotCol
MatrixPosition pivotPos = new MatrixPosition(0, 0);MatrixPosition currPos = new MatrixPosition(k, k);
switch (method) case 0 :
pivotPos = nonZeroPivotSearch(k);break;
case 1 :pivotPos = totalPivotSearch(k);break;
pivotRow = pivotPos.rowPos;pivotCol = pivotPos.colPos;pivot = coeff[row[pivotRow]][col[pivotCol]];
// permute rows and colums to get this entry onto// the diagonalpermutePivot(pivotPos, currPos);
// test conditions for exiting loop// after this iteration// reasons are: Math.abs(pivot) == 0// k == m - 1 : no more rows// k == n - 1 : no more columsif ((Math.abs(pivot) == 0) ||( k == m - 1)
|| (k == n - 1)) exitLoop = true;
// update rankif (Math.abs(pivot) > 0)
rank++;
// pivoting only if Math.abs(pivot) > 0// and k < m - 1if ((Math.abs(pivot) > 0) && (k < m - 1))

6.2. LINEARE GLEICHUNGSSYSTEME 147
pivotOperation(k);
//end whiletriangular = true;
/*** method for total pivot search** @param k search starts at entry (k,k)* @return the position of the found pivot element*/
private MatrixPosition totalPivotSearch(int k)double max = 0;int i, j, pivotRow = k, pivotCol = k;double absValue;for (i = k; i < coeff.length; i++)
for (j = k; j < coeff[0].length; j++)
// compute absolute value of// current entry in absValueabsValue = Math.abs(coeff[row[i]][col[j]]);
// compare absValue with value max// found so farif (max < absValue)
// remember new value and positionmax = absValue;pivotRow = i;pivotCol = j;
//end if//end for j
//end for kreturn new MatrixPosition(pivotRow, pivotCol);
/*** method for trivial pivot search, searches for non-zero entry** @param k search starts at entry (k,k)* @return the position of the found pivot element*/private MatrixPosition nonZeroPivotSearch(int k)

148 KAPITEL 6. ALGORITHMEN AUF ARRAYS
int i, j;double absValue;for (i = k; i < coeff.length; i++)
for (j = k; j < coeff[0].length; j++)
// compute absolute value of// current entry in absValueabsValue = Math.abs(coeff[row[i]][col[j]]);
// check if absValue is non-zeroif (absValue > 0) // found a pivot element
return new MatrixPosition(i, j);//end if
//end for j//end for kreturn new MatrixPosition(k, k);
/*** permutes two matrix rows and two matrix columns** @param pos1 the fist position for the permutation* @param pos2 the second position for the permutation*/private void permutePivot(MatrixPosition pos1, MatrixPosition pos2)
int r1 = pos1.rowPos; int c1 = pos1.colPos;int r2 = pos2.rowPos; int c2 = pos2.colPos;int index;index = row[r2]; row[r2] = row[r1]; row[r1] = index;index = col[c2]; col[c2] = col[c1]; col[c1] = index;
/*** performs a pivot operation** @param k pivoting takes place below (k,k)*/private void pivotOperation(int k)
double pivot = coeff[row[k]][col[k]];for (int i = k + 1; i < coeff.length; i++)
// compute factordouble q = coeff[row[i]][col[k]] / (double) pivot;
// modify entry a[i,k], i > k

6.2. LINEARE GLEICHUNGSSYSTEME 149
coeff[row[i]][col[k]] = 0;
// modify entries a[i,j], i > k fixed, j = k+1...n-1for (int j = k + 1; j < coeff[0].length; j++)
coeff[row[i]][col[j]] = coeff[row[i]][col[j]]- coeff[row[k]][col[j]] * q;
//end for j
// modify right-hand-siderhs[row[i]] = rhs[row[i]] - rhs[row[k]] * q;
//end for k
/*** solves linear system with the chosen method* @param method the pivot search method*/private void solve(int method) throws NullPointerException
if (solved) return; // solution exists
if (! triangular)
triangularForm(method);if (! isSolvable(method))
return;
int n = coeff[0].length;double[] x = new double[n];
// set x[rank] = ... = x[n-1] = 0if (rank < n)
for (int j = rank; j < n ; j++) x[col[j]] = 0;
//end if
// compute x[rank-1]x[col[rank-1]] = rhs[row[rank-1]]
/ (double) coeff[row[rank-1]][col[rank-1]];
// compute remaining x[i] backwards

150 KAPITEL 6. ALGORITHMEN AUF ARRAYS
for (int i = rank - 2; i >= 0; i--) x[col[i]] = rhs[row[i]];for (int j = i + 1; j <= rank-1; j++)
x[col[i]] = x[col[i]]- coeff[row[i]][col[j]] * x[col[j]];
//end for jx[col[i]] = x[col[i]]
/ (double) coeff[row[i]][col[i]];//end for i
solution = x;solved = true;
/*** solves linar system by total pivot search*/public void solveByTotalPivotSearch() throws NullPointerException
solve(1);
/*** solves linar system without pivot search*/public void solveWithoutPivotSearch() throws NullPointerException
solve(0);
/*** checks solvability of linar system with the chosen method* @param method the pivot search method* @return true if linear system in solvable*/private boolean isSolvable(int method) throws NullPointerException
if (solved) return solvable;
if (! triangular)
triangularForm(method);for (int i = rank; i < rhs.length; i++)
if (Math.abs(rhs[row[i]]) > 0) solvable = false;return false; // not solvable

6.2. LINEARE GLEICHUNGSSYSTEME 151
// end if// end forsolvable = true;return true;
/*** checks if a solved system is solvable* @return true if linear system is solved and solvable*/public boolean isSolvable()
return solvable && solved;
/*** returns the solution* @return <code>double</code> array representing a solution*/public double[] getSolution()
return solution;
/*** returns current matrix (A|b) as String* @return String representing current matrix*/public String equationsToString() throws NullPointerException
if ((coeff == null) || (rhs == null)|| (row == null) || (col == null))
throw new NullPointerException();
StringBuffer strBuf = new StringBuffer();String str = " ";for (int j = 0; j < coeff[0].length; j++)
str = str + col[j] + " ";strBuf.append(str + "\n");for (int i = 0; i < coeff.length; i++)
str = "" + row[i] + ":";for (int j = 0; j < coeff[0].length; j++)
str = str + " " + coeff[row[i]][col[j]];str = str + " " + rhs[row[i]];

152 KAPITEL 6. ALGORITHMEN AUF ARRAYS
strBuf.append(str + "\n");return strBuf.toString();
/*** returns solution as String* @return string representing solution vector*/public String solutionToString() throws NullPointerException
if (solution == null) throw new NullPointerException();
StringBuffer strBuf = new StringBuffer();for (int j = 0; j < solution.length; j++)
strBuf.append("x_" + j + " = " + solution[j] + "\n");
return strBuf.toString();
/*** class for matrix positions*/public class MatrixPosition
int rowPos;int colPos;
/*** Constructor* @param i the row position* @param j the column position*/MatrixPosition(int i, int j)
rowPos = i;colPos = j;
/*** class for dimension exceptions*/

6.2. LINEARE GLEICHUNGSSYSTEME 153
import java.lang.*; // for class Exception
public class DimensionException extends Exception
/*** Constructs a <code>DimensionException</code>* with no detail message.*/public DimensionException()
super();
/*** Constructs a <code>DimensionException</code> with the* specified detail message.** @param s the detail message.*/public DimensionException(String s)
super(s);
Das AppletGauss.java verwendet diese Klassen zur Implementation eines interaktiven Losers furlineare Gleichungssysteme. Das Layout ist in Abbildung6.10dargestellt.
Programm 6.5 Gauss.java/*** Gauss.java** demonstrates the use of Gauss’ algorithms for solving linear equations** Assumptions:* Input is per row, row i contains coefficients a_ij and* the righthandside b_j as last number,* missing a_ij are interpreted as 0* numbers in a row are separated by white space*/import java.awt.*;import java.applet.Applet;import java.util.*; // for class StringTokenizerimport java.awt.event.ActionListener;import java.awt.event.ActionEvent;
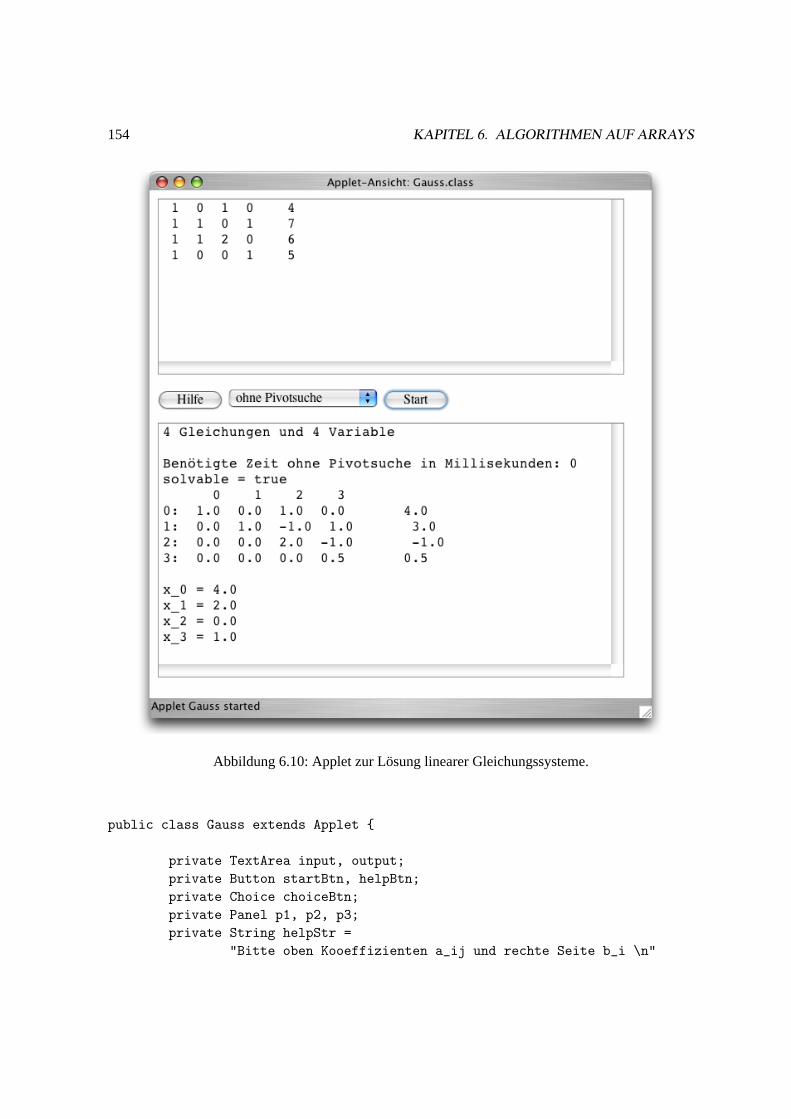
154 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Abbildung 6.10: Applet zur Losung linearer Gleichungssysteme.
public class Gauss extends Applet
private TextArea input, output;private Button startBtn, helpBtn;private Choice choiceBtn;private Panel p1, p2, p3;private String helpStr =
"Bitte oben Kooeffizienten a_ij und rechte Seite b_i \n"

6.2. LINEARE GLEICHUNGSSYSTEME 155
+ "zeilenweise eingeben.\n"+ "Die letze Zahl der Zeile i ist die rechte Seite b_i,\n"+ "die Zahlen davor als a_i1, a_i2, ...\n"+ "Fehlende a_ij in Zeile i werden als 0 interpretiert.\n"+ "Das eingegebene Gleichungssystem wird mit \n"+ "der gewahlten Pivotsuche gelost. \nDabei wird die Zeit "+ "gemessen und ausgegeben.\n";
public LinearEquation linEq = new LinearEquation();
// setup the graphical user interface componentspublic void init()
setLayout(new FlowLayout(FlowLayout.LEFT));setFont(new Font("Times", Font.PLAIN, 12));Font courier = new Font("Courier", Font.PLAIN, 12);
p1 = new Panel();p2 = new Panel();p3 = new Panel();
p1.setLayout(new FlowLayout(FlowLayout.LEFT));
input = new TextArea(" 1 0 1 0 4 \n"+ " 1 1 0 1 7 \n"+ " 1 1 2 0 6 \n"+ " 1 0 0 1 5 ", 10, 60);
input.setFont(courier);p1.add(input); // put input on panel
p2.setLayout(new FlowLayout(FlowLayout.LEFT));
helpBtn = new Button(" Hilfe ");helpBtn.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)showHelp();
);p2.add(helpBtn);
choiceBtn = new Choice();choiceBtn.addItem("ohne Pivotsuche");choiceBtn.addItem("mit totaler Pivotsuche");p2.add(choiceBtn);

156 KAPITEL 6. ALGORITHMEN AUF ARRAYS
startBtn = new Button(" Start ");startBtn.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)runGauss();
);p2.add(startBtn);
p3.setLayout(new FlowLayout(FlowLayout.LEFT));output = new TextArea(helpStr, 15, 60);output.setFont(courier);p3.add(output);
add(p1);add(p2);add(p3);
/*** reads numbers from input to arrays a and b and to precision*/private void initialize() throws NumberFormatException,
NoSuchElementException, DimensionException,NullPointerException
String inputStr = input.getText();
// divide input into linesStringTokenizer inputLines = new StringTokenizer(inputStr,
"\n\r");
// get the number of rowsif (! inputLines.hasMoreTokens())
throw new NoSuchElementException();int m = inputLines.countTokens();
StringBuffer strBuf = new StringBuffer();strBuf.append(m + " Gleichungen");
// define array of m lines of tokensStringTokenizer[] line = new StringTokenizer[m];for (int i = 0; i < m; i++)
line[i] = new StringTokenizer(inputLines.nextToken());

6.2. LINEARE GLEICHUNGSSYSTEME 157
// get the number of columns including bint n = 0;for (int i = 0; i < m; i++)
if (line[i].countTokens() < 2) throw new NoSuchElementException();
if (line[i].countTokens() - 1 > n)
n = line[i].countTokens() - 1;
strBuf.append(" und " + n + " Variable\n");
// initialize linEqdouble[][] a = new double[m][n];double[] b = new double[m];for (int i = 0; i < m; i++)
int j;int k = line[i].countTokens() - 1;// that many coeffs on line ifor (j = 0; j < k; j++)
a[i][j] = Double.parseDouble(line[i].nextToken());
for (j = k; j < n; j++)
a[i][j] = 0;b[i] = Double.parseDouble(line[i].nextToken());
linEq = new LinearEquation(a, b);
// write info in output fieldoutput.setText(strBuf.toString());
/*** displays help text*/public void showHelp()
output.setText(helpStr);

158 KAPITEL 6. ALGORITHMEN AUF ARRAYS
/*** solves system of linear equations by Gaussian elimination** @see <code>LinearEquationSolver</code>*/public void runGauss()
try output.setText("Rechne ...\n");initialize();
int choice = choiceBtn.getSelectedIndex();String choiceStr = choiceBtn.getSelectedItem();
long startTime = System.currentTimeMillis();switch (choice) case 0 :
linEq.solveWithoutPivotSearch();break;
case 1 :linEq.solveByTotalPivotSearch();break;
long endTime = System.currentTimeMillis();long runTime = endTime - startTime;
// Construct the output string in a// StringBuffer objectStringBuffer outputBuf = new StringBuffer();outputBuf.append("Benotigte Zeit "
+ choiceStr + " in Millisekunden: "+ Long.toString(runTime) + "\n");
outputBuf.append("solvable = " + linEq.isSolvable()+ "\n");
outputBuf.append(linEq.equationsToString() + "\n");if (linEq.isSolvable())
outputBuf.append(linEq.solutionToString());output.append("\n" + outputBuf.toString());
catch (NoSuchElementException exp) output.append("\nJede Zeile muss mindestens "
+ "2 Zahlen enthalten.");

6.2. LINEARE GLEICHUNGSSYSTEME 159
catch (NumberFormatException exp) output.append("\nNur double Zahlen eingeben.");
catch (DimensionException exp) output.append(exp.toString());
catch (Exception exp) // other exceptionsoutput.append(exp.toString());

160 KAPITEL 6. ALGORITHMEN AUF ARRAYS
6.3 Kurzeste Wege in gerichteten Graphen
6.3.1 Graphen und Wege
Ein gerichteter GraphoderDigraph (directed graph) ist ein PaarG = (V,E) bestehend aus
– Der MengeV derKnoten. Bei uns ist meistV = 1,2, . . . ,n oder (in Implementationen)V =0,1, . . . ,n−1.
– Der MengeE der (gerichteten) KantenoderBogenzwischen Knoten. Bei uns istE ⊆V×V \(i, i)|i ∈V; e= (i, j) bedeutet, dass die Kanteevom Knoteni zum Knotenj gerichtet ist.
Beispiel 6.4 G = (V,E) mit V = 1,2,3,4,5 und
E = (1,2),(1,3),(2,3),(2,4),(3,5),(4,1),(4,3),(5,4)
ist ein Graph mit 5 Knoten und 8 gerichteten Kanten. Er ist in Abbildung6.11dargestellt.
6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 151
6.3 Kurzeste Wege in gerichteten Graphen
6.3.1 Graphen und Wege
Ein gerichteter Graph oder Digraph (directed graph) ist ein Paar G = (V,E) bestehend aus
– Der Menge V der Knoten. Bei uns ist meist V = 1, 2, . . . , n oder (in Implementatio-nen) V = 0, 1, . . . , n− 1.
– Der Menge E der (gerichteten) Kanten oder Bogen zwischen Knoten. Bei uns istE ⊆ V × V \ (i, i)|i ∈ V ; e = (i, j) bedeutet, daß die Kante e vom Knoten i zumKnoten j gerichtet ist.
Beispiel 6.4 G = (V,E) mit V = 1, 2, 3, 4, 5 und
E = (1, 2), (1, 3), (2, 3), (2, 4), (3, 5), (4, 1), (4, 3), (5, 4)
ist ein Graph mit 5 Knoten und 8 gerichteten Kanten. Er ist in Abbildung 6.11 dargestellt.
1
2 4
53
Abbildung 6.11: Zeichnung des Graphen aus Beispiel 6.11.
Graphen haben viele Anwendungen. Sie eignen sich zur Beschreibung von
– Verbindungen zwischen Orten in einem Netzwerk (Straßennetz, U-Bahnnetz,. . .),
– Hierarchien,
– Syntax- und Flußdiagrammen,
– Arbeitsablaufen,
und vielem anderen mehr.
In solchen Anwendungen haben die Kanten (i, j) des Graphen meist eine Bewertung , die jenach Anwendung als Lange oder Entfernung von i nach j (Straßennetz), Kosten (Arbeitsab-lauf) oder ahnlich interpretiert wird.
Abbildung 6.11: Zeichnung des Graphen aus Beispiel6.11.
Graphen haben viele Anwendungen. Sie eignen sich zur Beschreibung von
– Verbindungen zwischen Orten in einem Netzwerk (Straßennetz, U-Bahnnetz,. . .),
– Hierarchien,
– Syntax- und Flussdiagrammen,
– Arbeitsablaufen,
und vielem anderen mehr.
In solchen Anwendungen haben die Kanten(i, j) des Graphen meist eineBewertung, die je nach An-wendung als Lange oder Entfernung voni nach j (Straßennetz), Kosten (Arbeitsablauf) oderahnlichinterpretiert wird.

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 161
Ein solcherbewerteter Graphist beschreibbar durch eine MatrixA = (ai j )i, j=1,...,n mit
ai j =
Bewertung (Lange) von Kante(i, j) falls (i, j) ∈ E,0 falls i = j,∞ sonst.
Wir nennenA die Bewertungsmatrix des GraphenG. Zur Abspeicherung vonA im Rechner wird statt∞ eine sehr große ZahlM (z. B.M := n·max(i, j)∈E |ai j |+1) verwendet.6
Beispiel 6.5 (Fortsetzung von Beispiel6.4) Fur den Graphen aus Beispiel6.4 legen wir die in Ab-bildung6.12links neben den Kanten angegebenen Kantenbewertungen fest. Die zugehorige MatrixAist rechts daneben angegeben.
152 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Ein solcher bewerteter Graph ist beschreibbar durch eine Matrix A = (aij)i,j=1,...,n mit
aij =
Bewertung (Lange) von Kante (i, j) falls (i, j) ∈ E,0 falls i = j,∞ sonst.
Wir nennen A die Bewertungsmatrix des Graphen G. Zur Abspeicherung von A im Rechnerwird statt ∞ eine sehr große Zahl M (z. B. M := n ·max(i,j)∈E |aij |+ 1) verwendet.
6
Beispiel 6.5 (Fortsetzung von Beispiel 6.4) Fur den Graphen aus Beispiel 6.4 legen wirdie in Abbildung 6.12 links neben den Kanten angegebenen Kantenbewertungen fest. Diezugehorige Matrix A ist rechts daneben angegeben.
1
2 4
53
−1
3
2 10
1
−1
2
⇒ A =
0 −1 2 ∞ ∞∞ 0 2 3 ∞∞ ∞ 0 ∞ 1−1 ∞ 0 0 ∞∞ ∞ ∞ 1 0
Abbildung 6.12: Bewerteter Graph aus Beispiel 6.12.
Falls nur der Graph G beschrieben werden soll (d. h. ohne Kantenbewertungen), so reichtauch die Matrix
A = (aij) mit aij =
1 (i, j) ∈ E,0 sonst.
Diese Matrix heißt Adjazenzmatrix des Graphen G. In ihr ist durch Zugriff auf aij in kon-stanter Zeit (d. h. unabhangig von der Große des Graphen) feststellbar, ob i und j durcheine Kante verbunden sind. Dafur benotigt man jedoch quadratischen Speicherplatz (n × nMatrix).
Es sind auch andere Datenstrukturen zur Speicherung von Graphen moglich, z. B. fur jedenKnoten i eine Liste der Knoten j, die mit i durch eine Kante (i, j) verbunden sind. Diesebenotigen weniger Platz, erfordern jedoch mehr Zeit, um festzustellen, ob (i, j) ∈ E ist odernicht, da Listen nur sequentiellen Zugriff erlauben.
Bei manchen Anwendungen spielen die Richtungen der Kanten keine Rolle. In diesem Fallist mit einer Kante (i, j) auch die Kante (j, i) im Graphen, und beide haben dieselbe Bewer-tung. In der Darstellung des Graphen wird dann statt der beiden gerichteten Kanten eine
6Wir werden hier nur diese einfache, aber viel Speicherplatz verbrauchende Datenstruktur verwenden. Eineoft benutzte Alternative besteht in einem Array von Listen. Dabei entsprechen die Indices der Komponentenden Knoten des Graphen, und die Komponente i enthalt eine Liste aller Knoten j, zu denen von i aus eineKante (i, j) existiert.
Abbildung 6.12: Bewerteter Graph aus Beispiel6.12.
Falls nur der GraphG beschrieben werden soll (d. h. ohne Kantenbewertungen), so reicht auch dieMatrix
A = (ai j ) mit ai j =
1 (i, j) ∈ E,0 sonst.
Diese Matrix heißtAdjazenzmatrixdes GraphenG. In ihr ist durch Zugriff aufai j in konstanter Zeit(d. h. unabhangig von der Große des Graphen) feststellbar, obi und j durch eine Kante verbundensind. Dafur benotigt man jedoch quadratischen Speicherplatz (n×n Matrix).
Es sind auch andere Datenstrukturen zur Speicherung von Graphen moglich, z. B. fur jeden Knoteni eine Liste der Knotenj, die mit i durch eine Kante(i, j) verbunden sind. Diese benotigen weni-ger Platz, erfordern jedoch mehr Zeit, um festzustellen, ob(i, j) ∈ E ist oder nicht, da Listen nursequentiellen Zugriff erlauben.
Bei manchen Anwendungen spielen die Richtungen der Kanten keine Rolle. In diesem Fall ist miteiner Kante(i, j) auch die Kante( j, i) im Graphen, und beide haben dieselbe Bewertung. In derDarstellung des Graphen wird dann statt der beiden gerichteten Kanten eine ungerichtete gezeichnet,
6Wir werden hier nur diese einfache, aber viel Speicherplatz verbrauchende Datenstruktur verwenden. Eine oft benutzteAlternative besteht in einem Array von Listen. Dabei entsprechen die Indices der Komponenten den Knoten des Graphen,und die Komponentei enthalt eine Liste aller Knotenj, zu denen voni aus eine Kante(i, j) existiert.

162 KAPITEL 6. ALGORITHMEN AUF ARRAYS
alsoz z
stattz
zRI . Man spricht dann vonungerichtetenKanten. Ein Graph
mit nur ungerichteten Kanten heißtungerichteter Graph.
Im folgenden werden wir die Kantenbewertung als Entfernung interpretieren, bzgl. der wir kurzesteWege zwischen je zwei Knoten berechnen wollen.
Ein Wegvon i nach j ist eine endliche Folge von Knoten und Kanten
i = i1,(i1, i2), i2,(i2, i3), . . . , ik−1,(ik−1, ik), ik = j .
i1 -
i2 - i3 - p p p
i`p pp pp pp pp pp pp pp p p - ik−1 -
ik
Dabei sind Knotenwiederholungen zugelassen, und auch dertriviale Weg, der nur aus einem Knotenbesteht (man “geht” dann voni nachi, indem man ini bleibt).
Ein Weg heißtelementar, wenn keine Knotenwiederholungen auftreten. Ein Weg voni nach j heißtZykel, falls i = j gilt. Die Lange eines Wegesist die Summe der Entfernungen der Kanten auf demWeg. Die Lange des trivialen Weges ist 0. Ein Weg voni nach j heißtkurzester Weg, falls alle anderenWege voni nach j eine mindestens ebenso große Lange haben.
Unser Ziel ist nun die Berechnung der kurzesten Weglangenui j zwischen je zwei Knoteni, j (mitui j = ∞ falls kein Weg voni nach j existiert) sowie zugehoriger kurzester Wege.
6.3.2 Zwei konkrete Anwendungen
Als erste Anwendung betrachten wir den Ausschnitt aus dem BVG-Netz von Berlin in Abbildung6.13. Dieses Netz wird in Abbildung6.14als bewerteter ungerichteter Graph wiedergegeben, da jedeKante in beiden Richtungen “bereist” werden kann, und die Reisezeit fur beide Richtungen gleich ist.Die Bewertung einer Kante ist fur beide Richtungen gleich und entspricht der mittleren Reisezeit inMinuten (ohne Umsteigezeiten und Wartezeiten).
Die BewertungsmatrixA dieses Graphen ist in Tabelle6.3 angegeben. Als kurzester Weg von derYorkstraße zum Mathematikgebaude ergibt sich
Yo−→ Be−→ Zoo−→ ER−→MA
mit der Lange 5+5+2+5 = 17 Minuten.
Umsteige- und Wartezeiten konnen berucksichtigt werden, indem man die Stationen “aufblaht” zumehreren Knoten, die den verschiedenen Linien entsprechen, und den Kanten dazwischen die Umsteige-und Wartezeiten zuordnet bzw. die Kantenbewertungen um diese Werte vergroßert. Dies ist in Abbil-dung6.15fur die Station Zoologischer Garten ausgefuhrt.
Bei Entfernungen als Kantenbewertungen treten nur nicht-negative Zahlen auf. Oft sind jedoch auchnegative Kantenbewertungen sinnvoll, wie die folgende Anwendung desDevisentauscheszeigt.
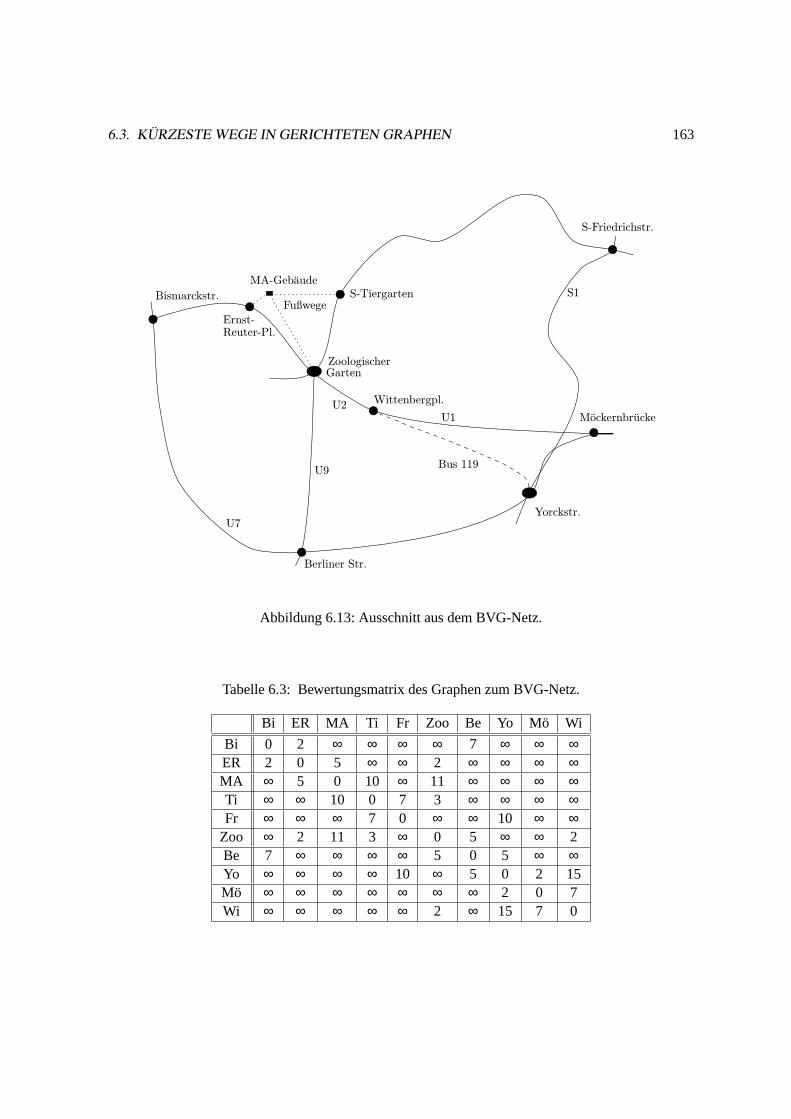
6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 163
154 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Yorckstr.
ZoologischerGarten
Ernst-Reuter-Pl.
Bismarckstr.
MA-GebaudeS-Tiergarten
S-Friedrichstr.
S1
Mockernbrucke
U7
U9
U1U2 Wittenbergpl.
Bus 119
Berliner Str.
Fußwege
Abbildung 6.13: Ausschnitt aus dem BVG-Netz.
Tabelle 6.3: Bewertungsmatrix des Graphen zum BVG-Netz.
Bi ER MA Ti Fr Zoo Be Yo Mo Wi
Bi 0 2 ∞ ∞ ∞ ∞ 7 ∞ ∞ ∞ER 2 0 5 ∞ ∞ 2 ∞ ∞ ∞ ∞MA ∞ 5 0 10 ∞ 11 ∞ ∞ ∞ ∞Ti ∞ ∞ 10 0 7 3 ∞ ∞ ∞ ∞Fr ∞ ∞ ∞ 7 0 ∞ ∞ 10 ∞ ∞Zoo ∞ 2 11 3 ∞ 0 5 ∞ ∞ 2Be 7 ∞ ∞ ∞ ∞ 5 0 5 ∞ ∞Yo ∞ ∞ ∞ ∞ 10 ∞ 5 0 2 15Mo ∞ ∞ ∞ ∞ ∞ ∞ ∞ 2 0 7Wi ∞ ∞ ∞ ∞ ∞ 2 ∞ 15 7 0
Abbildung 6.13: Ausschnitt aus dem BVG-Netz.
Tabelle 6.3: Bewertungsmatrix des Graphen zum BVG-Netz.
Bi ER MA Ti Fr Zoo Be Yo Mo Wi
Bi 0 2 ∞ ∞ ∞ ∞ 7 ∞ ∞ ∞ER 2 0 5 ∞ ∞ 2 ∞ ∞ ∞ ∞MA ∞ 5 0 10 ∞ 11 ∞ ∞ ∞ ∞Ti ∞ ∞ 10 0 7 3 ∞ ∞ ∞ ∞Fr ∞ ∞ ∞ 7 0 ∞ ∞ 10 ∞ ∞
Zoo ∞ 2 11 3 ∞ 0 5 ∞ ∞ 2Be 7 ∞ ∞ ∞ ∞ 5 0 5 ∞ ∞Yo ∞ ∞ ∞ ∞ 10 ∞ 5 0 2 15Mo ∞ ∞ ∞ ∞ ∞ ∞ ∞ 2 0 7Wi ∞ ∞ ∞ ∞ ∞ 2 ∞ 15 7 0
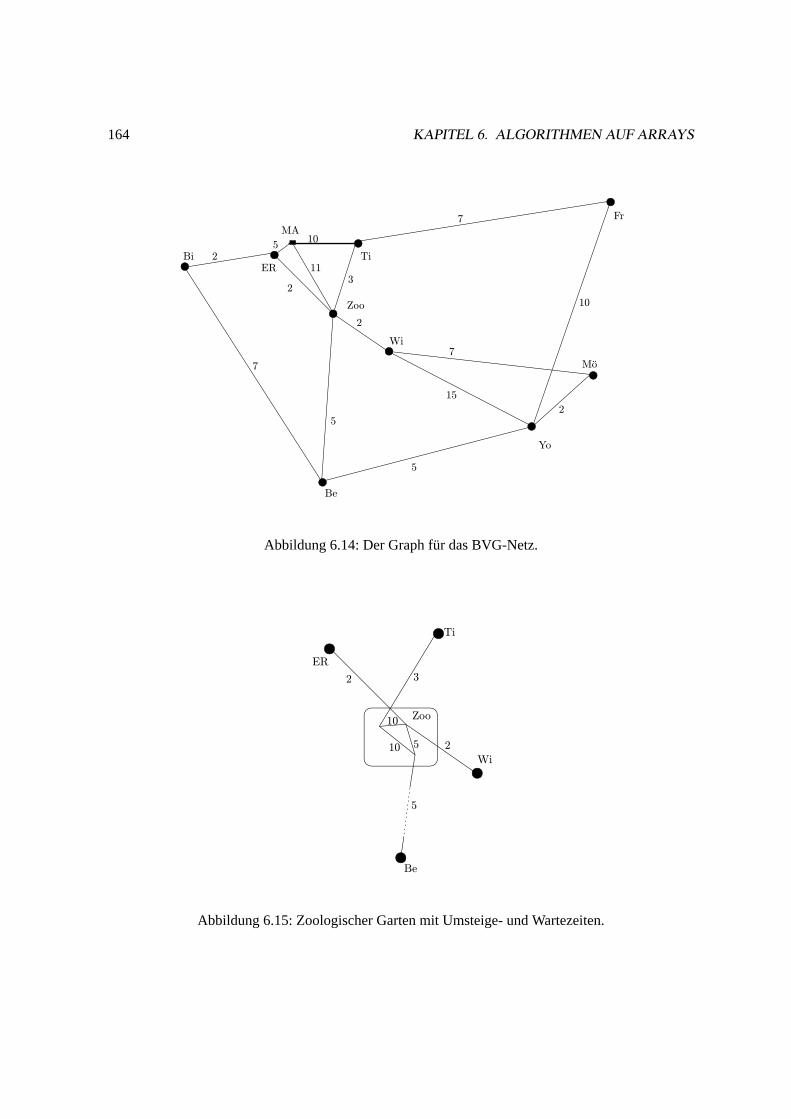
164 KAPITEL 6. ALGORITHMEN AUF ARRAYS
6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 155
Be
Wi
Mo
Zoo
Yo
ER
Fr
Bi
7
7
2
5
MA
10
Ti
15
5
2
113
105
2
2
7
Abbildung 6.14: Der Graph fur das BVG-Netz.
Wi
10
5
2
5
Be
3
Zoo
210
Ti
ER
Abbildung 6.15: Zoologischer Garten mit Umsteige- und Wartezeiten.
Abbildung 6.14: Der Graph fur das BVG-Netz.
6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 155
Be
Wi
Mo
Zoo
Yo
ER
Fr
Bi
7
7
2
5
MA
10
Ti
15
5
2
113
105
2
2
7
Abbildung 6.14: Der Graph fur das BVG-Netz.
Wi
10
5
2
5
Be
3
Zoo
210
Ti
ER
Abbildung 6.15: Zoologischer Garten mit Umsteige- und Wartezeiten.Abbildung 6.15: Zoologischer Garten mit Umsteige- und Wartezeiten.

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 165
Gegeben ist ein gerichteter Graph, bei dem die Knoten Devisenborsen darstellen und eine Kante(i, j)dem Tausch von Wahrungi in die “Zielwahrung” j entspricht. Die Bewertung der Kante(i, j) gibtden Preis (Kurs) fur eine Einheit der Zielwahrung j bzgl. der Wahrungi an. Daher haben beideKantenrichtungen unterschiedliche Werte. Ein Beispiel ist in Abbildung6.16angegeben (Kurse vomNovember 1998).
Abbildung 6.16: Ein Graph fur den Devisentausch (Kurse November 2003).
In dieser Anwendung mochte man fur gegebene “Heimatwahrung” i und Zielwahrung j eine Um-tauschfolge (also einen Weg) bestimmen, so dass das Produkt der Bewertungen entlang des Weges(also der Preis fur eine Einheit der Zielwahrung) moglichst klein wird.
Die Problem lasst sich folgendermaßen auf ein Kurzeste-Wege Problem transformieren. Ersetze dieKantenbewertungai j der Kante(i, j) durch logai j . Dann ist (nach den Logarithmengesetzen) dasProdukt entlang eines Weges gleich der Summe der Logarithmen der Kanten. Man erhalt also einKurzestes Wege Problem mit ¯ai j := logai j als Bewertung der Kanten. Dabei konnen negative Bewer-tungen ¯ai j auftreten, namlich genau dann, wennai j < 1 ist.
Als Konsequenz negativer Kantenbewertungen konnen auch Zykel negativer Lange auftreten. Diesemachen, wie wir sehen werden, bei der Berechnung kurzester Wege Schwierigkeiten. Beim Devisen-tausch haben sie jedoch eine besondere Bedeutung: Sie entsprechen einem Gewinn bringenden Zykel,auf dem man durch Umtausch seinen Einsatz vermehren kann. Im Graphen aus Abbildung6.16exis-tiert ein solcher Zykel, vgl. Abbildung6.17. Der Tausch entlang des Zykels ermoglicht den Kauf einerDM fur 2,79·0,51·0,61= 0,9960 DM, also eine Vermehrung des eingesetzten Kapitals um den Faktor1/0,9960' 1,004161.
Solche Zykel konnen tatsachlich bei Devisengeschaften vorkommen, allerdings nur kurzfristig, dasich Kurse dauernd aufgrund von Angebot und Nachfrageandern. Die Rechner der Devisenhandlerbemerken solche Zykel sofort und ordern entsprechend bis die steigende Nachfrage durch das Steigender Preise den Faktor wieder großer als 1 werden lasst.

166 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Abbildung 6.17: Ein gewinnbringender Zykel beim Devisentausch.
6.3.3 Die Bellman Gleichungen
Wir werden jetzt eine Methode kennen lernen, mit der man die kurzesten Weglangen (und auch diekurzesten Wege selbst) zwischen je 2 Knoten iterativ berechnen kann (sofern sie existieren). DieGrundidee basiert darauf, die Anzahl der Kanten auf den betrachteten Wegen in jeder Iteration um 1zu vergroßern. Dazu definieren wir fur i, j ∈V undm∈ N die Große
u(m)i j :=
Lange eines kurzesten Weges voni nach jmit hochstensm Kanten, falls dieser existiert,∞ falls kein solcher Weg existiert.
Diese Große ist wohldefiniert, da es fur festesm nur endlich viele Wege mit hochstensm Kantenzwischeni und j gibt, und somit unter diesen endlich vielen auch einen kurzesten.
In Beispiel??ergeben sich fur i = 1 und j = 5 folgende Werte:
u(1)15 = ∞, u(2)
15 = 3, u(3)15 = 2, u(4)
15 = 2, u(5)15 = 2 .
Allgemein gilt:
Lemma 6.4 Fur festes i und j und m≥ 2 ist
u(1)i j ≥ u(2)
i j ≥ . . .≥ u(m)i j ≥ u(m+1)
i j .
Beweis:BeimUbergang vonmaufm+1 vergroßert sich die Menge der Wege unter denen man einenkurzesten Weg ermittelt. Daher giltu(m)
i j ≥ u(m+1)i j .
Die u(m)i j lassen sich durch Rekursionsgleichungen berechnen, die im folgenden Satz6.4 angegeben
sind. Sie besagen anschaulich, dass sich die kurzeste Lange eines Weges voni nach j mit hochstens

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 167
m+1 Kanten aufspalten lasst in die kurzeste Lange eines Weges mit hochstensmKanten voni bis zueinem Knotenk und die Langeak j der Kante(k, j). Die Minimumsbildung in der Rekursionsgleichungdient dem Finden des richtigen Knotenk.
Im Beweis dieses Satzes spielt dasPrinzip der optimalen Substruktureine wichtige Rolle. Es besagtin diesem Fall, das ein kurzester Weg zwischen zwei Knoten sich aus kurzesten Teilwegen zusammensetzt. Kurz: jeder Teilweg eines kurzesten Weges ist selber ein kurzester Weg zwischen den Endpunk-ten des Teilweges. Abbildung6.18veranschaulicht dieses Prinzip. Es gilt in verschiedenen Bereichender Mathematik und gibt immer Anlass zu Algorithmen, die
”große“ optimale Strukturen aus optima-
len Teilstrukturen zusammen setzen.
i jr s
kürzester Weg von i nach j
!
r s
kürzester Weg von r nach s
Abbildung 6.18: Das Prinzip der optimalen Substruktur bei kurzesten Wegen.
Satz 6.4 (Bellman Gleichungen)Die u(m)i j erfullen die folgenden Rekursionsgleichungen (die sog.
Bellman Gleichungen).
u(1)i j = ai j , u(m+1)
i j = mink=1,...,n
[u(m)ik +ak j] fur m≥ 1 .
Beweis:Fur m= 1 kommen nur Wege mit hochstens einer Kante in Frage. Fur i 6= j also gerade dieLange der Kante(i, j), falls diese existiert, bzw.∞ andernfalls. Fur i = j kommt nur der triviale Weg
mit 0 Kanten in Frage. Also gilt in allen Fallenu(1)i j = ai j .
Betrachte nunu(m+1)i j . Wir zeigen zunachst
u(m+1)i j ≥ min
k=1,...,n[u(m)
ik +ak j] . (6.1)
Diese Ungleichung ist trivialerweise erfullt, falls u(m+1)i j = ∞ ist, also kein Weg voni nach j mit
hochstensm+1 Kanten existiert.
Also nehmen wir an, dass ein solcher Weg existiert. Sei dannW ein kurzester Weg voni nach j mithochstensm+1 Kanten (dieser existiert, da wegen der Beschrankung auf maximalm+1 Kanten nurendlich viele Wege in Frage kommen). Wir unterscheiden den Fall, dassW keine bzw. mindestenseine Kante enthalt.
(1) W habe mindestens eine Kante, etwa

168 KAPITEL 6. ALGORITHMEN AUF ARRAYS
W := i -
i1 - i2 - p p p -
ip ?ppp- - p p p -
` - j
Dann hatW die Langeu(m+1)i j . (Dabei kannW einen Zykel enthalten oder auchi = j sein, so dass der
ganze Weg einen Zykel bildet.)
Das Anfangsstuck
W′ := i -
i1 - i2 - p p p -
ip ?ppp- - p p p -
`
vonW ist ein kurzester Weg voni nach` mit hochstensm Kanten; denn gabe es einen kurzeren, sowurde man durch Anhangen der Kante(`, j) anW′ einen kurzeren Weg mit hochstensm+1 Kantenvon i nach j erhalten, im Widerspruch zur Annahme, dassW ein kurzester Weg voni nach j ist.
Also ist die Lange vonW′ gleichu(m)i` und somit die Lange vonW gleich
u(m+1)i j = u(m)
i` +a` j ≥ mink=1,...,n
[u(m)ik +ak j] ,
da` bei der Minimumsbildung vorkommt. Also ist Ungleichung (6.1) erfullt.
(2) HatW keine Kanten, so isti = j undW besteht nur aus dem einzigen Knoteni = j. Dann ist seineLangeu(m+1)
ii = 0. Aus Lemma6.4folgt u(m+1)ii ≤ u(m)
ii ≤ u(1)ii = aii = 0 und somitu(m)
ii = 0. Also gilt
u(m+1)ii = u(m)
ii +aii ≥ mink=1,...,n
[u(m)ik +ak j] ,
da i bei der Minimumsbildung vorkommt. Folglich gilt Ungleichung (6.1) auch in diesem Fall.
Jetzt zeigen wir umgekehrt die Ungleichung
u(m+1)i j ≤ min
k=1,...,n[u(m)
ik +ak j] . (6.2)
Diese Gleichung ist wieder trivialerweise erfullt, falls die rechte Seite∞ ist. Ist sie endlich, so seirder Index, fur den das Minimum angenommen werde, d. h.
mink=1,...,n
[u(m)ik +ak j] = u(m)
ir +ar j .
Dabei unterscheiden wir die Falle r 6= j bzw. r = j.
(1) Seir 6= j. Dau(m)ir +ar j < ∞, sindu(m)
ir < ∞ undar j < ∞. Also existiert ein kurzester Weg
W = i -
j1 - j2 - p p p -
jq ?ppp- - p p p -
r
von i nachr mit hochstensm Kanten und Langeu(m)ir und es existiert wegenr 6= j und ar j < ∞ im
Graphen die Kante(r, j). Der WegW kann Zykel enthalten und es kann auchi = r sein (dann hatWentweder 0 Kanten oder der gesamte WegW bildet einen Zykel). Das folgende Argument gilt fur alldiese Falle.
Da die Kante(r, j) existiert, ist

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 169
W′ := i -
j1 - j2 - p p p -
jq ?ppp- - p p p -
r - j
ein Weg voni nach j mit hochstensm+1 Kanten und seine Lange istu(m)ir +ar j . Diese kann naturlich
nicht kleiner als die kurzeste Lange eines Weges voni nach j mit hochstensm+1 Kanten sein, d. h.
u(m)ir +ar j ≥ u(m+1)
i j .
Also gilt Ungleichung (6.2).
(2) r = j. Dann ist
mink=1,...,n
[u(m)ik +ak j] = u(m)
i j +a j j = u(m)i j ≥ u(m+1)
i j
wegena j j = 0 und Lemma6.4.
Aus den Ungleichungen (6.1) und (6.2) folgt die Behauptung.
6.3.4 Der Einfluss negativer Zykel
Es stellt sich nun die Frage, wie groß man die Anzahlm der Kanten maximal wahlen muss, umkurzesteWeglangen zu berechnen. Hier gibt es Schwierigkeiten falls der Graph Zykel negativer Lange(kurz:negative Zykel) enthalt. In diesem Fall konnen die Wege mit hochstensmKanten einen solchenZykel (sogar mehrfach) enthalten, so dass das Ergebnisu(m)
i j keinemelementarenWeg (also einemohne Knotenwiederholungen) mehr entspricht, wie das folgende Beispiel zeigt.
Beispiel 6.6 (Der Einfluss negativer Zykel)Betrachte den Graph aus Abbildung6.19. Um die kurzesteWeglange von 1 nachn zu berechnen, mussenm := n−1 Kanten berucksichtigt werden. Dann gibtzwaru(m)
1n die richtige kurzeste Weglange an, aber die Werteu(m)1 j sind fur j = 2, . . . ,n−2 ungleich der
kurzesten Lange eineselementarenWeges von 1 nachj (die 0 betragt). Zum Beispiel ergibt sich furj = 4
u(3)14 = u(4)
14 = 0, u(5)14 = u(6)
14 =−1, u(7)14 = u(8)
14 =−2, . . . ,u(n−1)14 =−
⌊n−3
2
⌋.
Die Ursache ist naturlich der negative Zykel 2−→ 3−→ 2 der Lange−1.
1 -
0 2 -
0 3
?
−1
-0
4 -0
p p p -0
n
Abbildung 6.19: Ein Graph mit einem Zykel negativer Lange.

170 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Wir untersuchen daher zunachst den Fall, dass der gegebene GraphG keine negativen Zykel hat. Dieslasst immer noch negative Kantenbewertungen zu, nur durfen sich diese nicht entlang eines Zykels zueiner negativen Zahl summieren.
Lemma 6.5 Hat G keinen negativen Zykel und gibt es einen Weg von i nach j, so existiert ein kurzesterWeg von i nach j, der elementar ist.
Beweis: Da G keine negativen Zykel enthalt, kann die Wegnahme von Zykel aus einem Weg dieWeglange hochstens verkurzen. Also kann man sich bei der Suche nach kurzesten Wegen auf elemen-tare Wege beschranken. Da es nur endlich viele elementare Wege voni nach j gibt, existiert hierunterauch ein kurzester.
Wir definieren nun
ui j :=
Lange eines kurzesten elementaren Weges voni nach jfalls kein Weg voni nach j existiert,∞ falls ein Weg voni nach j existiert.
Dann gilt (vgl. Lemma6.4):
Satz 6.5 Hat G keine negativen Zykel, so ist fur festes i und j
u(1)i j ≥ u(2)
i j ≥ . . .≥ u(n−1)i j = ui j .
Die Bellman Gleichungen berechnen also in n−2 Iterationen die kurzesten Weglangen ui j .
Beweis:Da G keine negativen Zykel hat, folgt aus Lemma6.5, dassu(m)i j nie kleiner alsui j werden
kann. Elementare Wege konnen bein Knoten hochstensn−1 Kanten haben. Die Monotonieeigen-schaft deru(m)
i j aus Lemma6.4ergibt dann die Behauptung.
6.3.5 Der Bellman-Ford Algorithmus
Satz6.5lasst sich direkt in den folgenden Algorithmus umsetzen, der nach seinen EntdeckernBellman-Ford Algorithmusgenannt wird. Wir geben ihn direkt als Java Methode an, die aus der Entfernungsma-trix A des Graphen die MatrixU der kurzesten Weglangen ermittelt und zuruck gibt. Dabei speichertu dieu(m)
i j ab und dienttemp zur Berechnung deru(m+1)i j fur festesi.
Programm 6.6 bellmanpublic double[][] bellman(double[][] a)

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 171
int n = a.length; // number of nodesdouble[][] u = new double[n][n];// initialize ufor (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) u[i][j] = a[i][j];
// main loopfor (int m = 2; m < n; m++)
for (int i = 0; i < n; i++) double[] tmp = new double[n]; // tmp array// for calculating min... in Bellman equationfor (int j = 0; j < n; j++)
// save current distance from i to jtmp[j] = u[i][j];for (int k = 0; k < n; k++)
if (tmp[j] > u[i][k] + a[k][j]) tmp[j] = u[i][k] + a[k][j];
// end for k
// end for j// store tmp in u[i]for ( int j = 0; j < n; j++ )
u[i][j] = tmp[j];
// endfor i// endfor mreturn u;
Die Korrektheit des Bellman-Ford Algorithmus folgt direkt aus Satz6.5und den Bellman Gleichun-gen (Satz6.4). Fur den Aufwanduberlegt man sich aus der Schachtelung der Schleifen:
Satz 6.6 Der Bellman-Ford Algorithmus in der Version von Programm6.6 benotigt (n−2) ·n ·n ·nVergleiche und hochstens(n− 2) · n · (n(1+ n) + 1) Zuweisungen, d. h. seine Laufzeit liegt in derGroßenordnung von n4 Operationen.
Ist man nur an denui j interessiert, nicht jedoch an denu(m)i j (d. h. den kurzesten Weglangen mit
hochstensmKanten), so kann man wegen der Monotonieeigenschaft deru(m)i j in u[i,j] direkt jedes-
mal den Wert vontemp[j] abspeichern. Dann gilt nach derm-ten Iteration deraußeren Schleife
u(m)i j ≥ u[i,j] = u(m+`)
i j ≥ ui j

172 KAPITEL 6. ALGORITHMEN AUF ARRAYS
fur ein` mit 0≤ `≤ n−1−m. Dies liegt daran, dass kurzere Weglangen mit einer Kante mehr direktin u[i,j] abgespeichert werden und fur weitere Rechnungen schon benutzt werden.
Dies hat im Programm den Vorteil, dass die Zwischenspeicherung intemp uberflussig wird und da-durch weniger Zuweisungen notig sind. Dafur wird in derm-ten Iteration jedoch nichtu(m)
i j berechnet,
sondern ein Wert zwischenu(m)i j undu(n−1)
i j = ui j .
Der Algorithmus vereinfacht sich dann zu
Programm 6.7 bellmanShortpublic double[][] bellmanShort(double[][] a)
int n = a.length; // number of nodesdouble[][] u = new double[n][n];for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) u[i][j] = a[i][j];
for ( int m = 2; m < n; m++ )
for ( int i = 0; i < n; i++ ) for ( int j = 0; j < n; j++ )
for ( int k = 0; k < n; k++ ) if ( u[i][j] > u[i][k] + a[k][j] )
u[i][j] = u[i][k] + a[k][j];
return u;
Dieser Algorithmus hat allerdings immer noch eine Laufzeit von der Großenordnungn4. Tatsachlichgibt es, wenn man nur an denui j interessiert ist, andere einfache Algorithmen, deren Laufzeit von derGroßenordnungn3 ist, vgl. die Literaturhinweise am Ende des Kapitels.
Beispiel 6.7 (Fortsetzung von Beispiel ??)Fur den Graphen aus Beispiel?? sollen die kurzestenWeglangen mit dem Bellman-Ford Algorithmus berechnet werden (in der Version von Programm6.6).
Dabei bezeichnetU (m) die Matrix (u(m)i j )i, j=1,...,n undU die Matrix (ui j )i, j=1,...,n. Gemaß Satz6.4 ist
U (1) = A =
0 −1 2 ∞ ∞∞ 0 2 3 ∞∞ ∞ 0 ∞ 1−1 ∞ 0 0 ∞∞ ∞ ∞ 1 0

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 173
Dann ergibt sichu(2)11 aus den Bellman Gleichungen gemaß
u(2)11 = min
k=1,...,n[u(1)
1k +ak1]
= min[0+0, −1+∞, 2+∞, ∞−1, ∞+∞] = 0 .
Dies entspricht einerVerknupfungder ersten Zeile vonU (1) mit der ersten Spalte vonA. Diese Ver-knupfung, wir wollen sie mit “⊗” bezeichnen, ist gerade die rechte Seite der Bellman Gleichungen,also
U (1)1· ⊗A·1 = (0, −1, 2, ∞, ∞)⊗
0∞∞−1∞
= mink=1,...,n
[u(1)k +ak1] .
Entsprechend ist
u(2)12 = U (1)
1· ⊗A·2 = (0, −1, 2, ∞, ∞)⊗
−10∞∞∞
= min[0−1, −1+0, 2+∞, ∞+∞, ∞+∞] =−1 ,
u(2)13 = U (1)
1· ⊗A·3 = (0, −1, 2, ∞, ∞)⊗
2200∞
= min[0+2, −1+2, 2+0, ∞+0, ∞+∞] = 1 .
Hier wurde gegenuberu(1)13 = 2 eine kurzere Weglangeuber 2 Kanten ermittelt. Weiterhin ist
u(2)14 = U (1)
1· ⊗A·4 = (0, −1, 2, ∞, ∞)⊗
∞3∞01
= min[0+∞, −1+3, 2+∞, ∞+0, ∞+1] = 2 ,
u(2)15 = U (1)
1· ⊗A·5 = (0, −1, 2, ∞, ∞)⊗
∞∞1∞0
= min[0+∞, −1+∞, 2+1, ∞+∞, ∞+0] = 3 .

174 KAPITEL 6. ALGORITHMEN AUF ARRAYS
Also ist die erste Zeile vonU (2) gleich(0,−1, 1, 2, 3). Die anderenu(2)i j berechnen sich entsprechend,
z. B.
u(2)21 = U (1)
2· ⊗A·1 = (∞, 0, 2, 3, ∞)⊗
0∞∞−1∞
= min[∞+0, 0+∞, 2+∞, 3−1, ∞+∞] = 2 .
Insgesamt erhalt man
U (2) =
0 −1 1 2 32 0 2 3 3∞ ∞ 0 2 1−1 −2 0 0 1
0 ∞ 1 1 0
und schließlich
U = U (4) =
0 −1 1 2 22 0 2 3 31 0 0 2 1−1 −2 0 0 1
0 −1 1 1 0
.
Das Beispiel zeigt, dass die Bellman Gleichungen eine starke Analogie zur Matrixmultiplikation auf-weisen. Bei der MatrixmultiplikationC := A·B ist der Eintragci j der ErgebnismatrixC gegeben als
ci j =n
∑k=1
[aik ·bk j] .
Hier ist “·” die innereund “+” die außereOperation.
In den Bellman GleichungenC := A⊗B ist der Eintragci j der ErgebnismatrixC gegeben als
ci j = mink=1,...,n
[aik +bk j] ,
also mit “+” als innererund “min” alsaußererOperation.
Speziell istU (1) = AU (2) = U (1)⊗A = A⊗AU (3) = U (2)⊗A = A⊗A⊗A
...U (n−1) = U (n−2)⊗A = A⊗·· ·⊗A︸ ︷︷ ︸
n−1 mal
=: An−1 .

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 175
Die Analogie zwischen Matrixmultiplikation und Bellman Gleichungen wird besonders deutlich,wenn man sich nur dafur interessiert, obi und j mit einem Weg mit hochstensm Kanten verbun-den sind oder nicht. Dann kannu(m)
i j als Boolesche Variable definiert werden, d. h.
u(m)i j =
true es gibt einen Weg voni nach j mit hochstensm Kanten,false sonst.
Ausgehend vonA = (ai j ) mit
ai j =
true falls (i, j) ∈ Efalse sonst
erhalt manu(m+1)
i j = [u(m)i1 ∧a1 j ]∨ [u(m)
i2 ∧a2 j ]∨ . . .∨ [u(m)in ∧an j]
was genau der Matrixmultiplikation entspricht(∧ entspricht·,∨ entspricht+).
6.3.6 Die Ermittlung negativer Zykel
Fur die Berechnung der kurzesten Weglangenui j hat es sich als notwendig erwiesen, dass der GraphG keine negativen Zykel enthalt. Es stellt sich daher die Frage, wie man die Gultigkeit dieser Voraus-setzung effizientuberprufen kann.
Satz 6.7 (Test auf negative Zykel)Die folgenden Aussagen sindaquivalent:
1. Der Graph G enthalt einen negativen Zykel.
2. Der Graph G enthalt einen elementaren negativen Zykel.
3. Es gibt einen Knoten i mit u(n)ii < 0
Insbesondere kann die Existenz negativer Zykel durchUberprufen der Diagonalelemente in U(n) fest-gestellt bzw. ausgeschlossen werden.
Beweis:(1)⇒ (2): SeiZ ein negativer Zykel inG. Ist Z nicht bereits elementar, so durchlaufe manvon einem beliebigen Startknoten ausZ solange, bis der erste Knoten zum zweiten Mal erreicht wird.Sei i dieser Knoten. Dann zerfallt Z in den elementaren ZykelZ1 von i nach i und den RestZ2,der ebenfalls ein Zykel ist, aber nicht notwendigerweise elementar. Die Lange vonZ ist gleich derSumme der Langen vonZ1 undZ2. Also mussZ1 oderZ2 negativ sein. Ist esZ1, so ist ein elementarernegativer Zykel gefunden. Ist esZ2, so muss dasselbe Argument ggf. wiederholt werden. Da derGraphG endlich ist, endet man nach einer endlichen Anzahl von Anwendungen dieses Argumentesbei einem negativen elementaren Zykel.
(2)⇒ (3): Sei Z ein elementarer negativer Zykel inG und i ein Knoten inZ. Da Z elementar ist,enthalt Z hochstensn Kanten (sonst wurde ein Knoten doppelt vorkommen). Also gilt
u(n)ii ≤ Lange(Z) < 0,

176 KAPITEL 6. ALGORITHMEN AUF ARRAYS
daZ einen Weg voni nachi mit hochstensn Kanten bildet.
(3)⇒ (1): Seiu(n)ii < 0. Nach Definition vonu(n)
ii existiert dann ein Weg voni nachi (also ein Zykel
Z) mit hochstensn Kanten, dessen Lange gleichu(n)ii ist. Also istZ ein negativer Zykel (der trotz der
Beschrankung aufn Kanten nicht elementar zu sein braucht).
Es existieren also genau dann negative Zykel, sobald einu(m)ii < 0 wird fur 1≤ m≤ n. Da dies bei
der Berechnung vonu(m)ii festgestellt werden kann, kann man abbrechen, sobald dies zum ersten-
mal eintritt, und eine entsprechende Fehlermeldung ausgeben. Der einzige Mehraufwand (neben derUberprufung) besteht in einer zusatzlichen Iteration. Diese wird notwendig, da bein Knoten ein ele-mentarer Zykel maximaln Kanten haben kann (vgl. die zweite Richtung des Beweises).
6.3.7 Die Ermittlung kurzester Wege
Bisher haben wir nur die kurzestenWeglangen ui j berechnet. Naturlich mochte man auch einen zu-gehorigen kurzesten Weg ermitteln.
Dazu nutzt man die folgende, im Beweis von Satz6.4durchgefuhrteUberlegung aus: Bei der Berech-nung der Bellman Gleichungenu(m+1)
i j = mink[u(m)ik + ak j] entspricht (im Fallu(m+1)
i j < ∞) der Indexk0, fur den das Minimum angenommen wird, einem Knotenk0, so dass(k0, j) die letzte Kante aufeinem kurzesten Weg voni nach j ist. Merkt man sich also im Bellman-Ford Algorithmus jeweilsdiesen Index, so lasst sich aus dieser Information ein kurzester Weg rekonstruieren.
Die Realisierung im Programm erfolgt durch einn×n Array
int[][] tree;
mit der Initialisierung
tree[i][j] :=
i falls (i, j) ∈ E-1 sonst
.
In jedem Durchlauf deraußeren Schleife des Algorithmus wird danntree[i][j] der Wertk zuge-wiesen, wenn beiu[i][j] eineAnderung auftritt und das zugehorige Minimum beik angenommenwird.
Der Algorithmus (in der Version von Programm6.7) wird dann zu7:
Programm 6.8 bellmanTreepublic double[][] bellmanTree( double[][] a )
int n = a.length; // number of nodes
7In dieser Variante wird nur dietree-Matrix zuruckgegeben. Naturlich wurde man entweder eine geeignete Ergebnis-Klasse definieren, die die Ruckgabe vonu undtree gleichzeitig erlaubt, oder analog zur Losung linearer Gleichungssyste-me in Abschnitt6.2.5Graphen als Objekte ansehen, die entsprechende Felderu undtree aktualisieren.

6.3. KURZESTE WEGE IN GERICHTETEN GRAPHEN 177
double[][] u = new double[n][n];for ( int i = 0; i < n; i++ )
for ( int j = 0; j < n; j++ ) u[i][j] = a[i][j];for ( int m = 2; m < n; m++ )
for ( int i = 0; i < n; i++ )for ( int j = 0; j < n; j++ )
for ( int k = 0; k < n; k++ )if ( u[i][j] > u[i][k] + a[k][j] )
u[i][j] = u[i][k] + a[k][j];tree[i][j] = k;
return tree;
Das Arraytree enthalt nach Ausfuhrung der Methode die Informationuber die kurzesten Wege (fallskeine negativen Zykel gefunden wurden). Um dies genauer zu erlautern, brauchen wir den Begriff desgerichteten Baums.
Ein gerichteter Baumist ein DigraphT = (V,E) mit folgenden Eigenschaften:
– Es gibt genau einen Knotenr, in dem keine Kante endet (dieWurzelvonT).
– Zu jedem Knoteni 6= r gibt es genau einen Weg von der Wurzelr zu i.
Dies bedeutet, dass keine zwei Wege in den gleichen Knoten einmunden. Der Graph kann sich ausge-hend von der Wurzel also nur verzweigen. Daher kommt auch der NameBaum.
Satz 6.8 Hat G keine negativen Zykel, so ist bei Termination von Programm6.8 fur jeden Knoten ider Graph Ti := (V,Ei) mit der Knotenmenge V= 0, . . . ,n−1 und der Kantenmenge
Ei = (tree[i][j],j) | j = 0,1, . . . ,n−1; tree[i][j] 6=−1
ein gerichteter Baum mit i als Wurzel.
Ein Weg von i nach j in Ti ist ein kurzester Weg von i nach j in G. Ti heißt daher auchKurzester-Wege-Baumzum Knoten i.
Beweis:Jeder Knotenj 6= i hat inTi (wenn er voni aus inGerreichbar ist) genau einen Vorgangerknoten,namlichtree[i][j]. Also konnen inTi keine zwei Kanten in einem Knoten zusammentreffen. Da-her existiert zu jedem Knotenj, der voni aus inG erreichbar ist, ein eindeutiger Weg voni nach jin Ti . DaG keinen negativen Zykel hat, hati keinen Vorgangerknoten. Also bildetTi einen Baum mitWurzel i.
Sei i = i0, i1, . . . , i`+1 = j die Folge der Knoten auf dem Weg voni nach j in Ti . Dann ist
i` = tree[i][ j], i`−1 = tree[i][i`], . . . , i = tree[i][i2] .

178 KAPITEL 6. ALGORITHMEN AUF ARRAYS
i -
ai,i1 i1 -
ai1,i2 i2 -
ai2,i3
p p p -ai`−1,i`
i` -ai`, j
j
Da die Werte im Arraytree gerade bei der Minimumsbildung aktualisiert werden, folgt
ui j = ui,i` +ai`, j
ui,i` = ui,i`−1 +ai`−1,i`
...
ui,i2 = ui,i1 +ai1,i2
ui,i1 = ai,i1 .
Daher istui j = ai,i1 +ai1,i2 + . . .+ai`−1, j und somit der Weg inTi ein kurzester Weg voni nachj in G.
Beispiel 6.8 (Fortsetzung von Beispiel ??)Fur den Graphen aus Beispiel??erhalt man
tree =
−1 1 2 2 34 −1 2 2 34 1 −1 5 34 1 4 −1 34 1 4 5 −1
.
Als E1 ergibt sich aus der ersten Zeile vontree die Kantenmenge
E1 = (1,2),(2,3),(2,4),(3,5) ,
und somit der in Abbildung6.20dargestellte Kurzeste-Wege BaumT1. Die Kanten ausE1 entsprechenfolgenden Bellman Gleichungen:
u(4)11 = 0
u(4)12 = u(3)
11 +a12 k = 1 j = 2
u(4)13 = u(3)
12 +a23 k = 2 j = 3
u(4)14 = u(3)
12 +a24 k = 2 j = 4
u(4)15 = u(3)
13 +a35 k = 3 j = 5
6.4 Literaturhinweise
Suchverfahren in Arrays werden in nahezu allen Buchernuber Entwurf und Analyse von Algorithmen behan-delt. Besonders ausfuhrlich gehen [Knu98b, Meh88, OW02] hierauf ein.
Die Losung linearer Gleichungssysteme ist Gegenstand aller Bucheruber lineare Algebra. Ein empfehlenswer-tes Buch, das lineare Algebra und Numerik verbindet, ist [GMW91].
Die Berechnung kurzester Wege findet sich sowohl in Buchernuber Entwurf und Analyse von Algorithmen(z. B. in [CLRS01, OW02]), als auch in Buchernuber Graphenalgorithmen und/oder kombinatorische Optimie-rung (etwa [Jun94]). Eine sehr gute Darstellung verschiedener kurzeste Wegealgorithmen gibt [Tar83].

6.4. LITERATURHINWEISE 179
1>−1
2
?
2
-3
3 -1
4
5
Abbildung 6.20: Der Kurzeste-Wege Baum zum Knoten 1 in Beispiel6.8.

180 KAPITEL 6. ALGORITHMEN AUF ARRAYS

Kapitel 7
Abstraktion von Methoden und Daten
7.1 Funktionale (Prozedurale) Abstraktion
Funktionale Abstraktion erlaubt die “Auslagerung” haufig auftretenderahnlicher oder gleicher Pro-grammteile auf eigene “Untereinheiten” des Hauptprogramms. Diese Untereinheiten oderUnterpro-grammeexistieren in allen Programmiersprachen unter verschiedenen Namen: procedures, functions,subroutines. In Java sind alle Unterprogramme Funktionen, egal ob sie Werte zuruckgeben oder nicht.Die Java-interne Bezeichnung fur Funktion istMethode.
Funktionen sind ein Werkzeug zur Abstraktion, da man ihr Input-Output Verhalten (was tut die Funk-tion) von ihrer Implementation (wie tut sie es) trennen kann. Sie bilden daher ein Werkzeug sowohl furdenAlgorithmenentwurf(Aufteilung des Algorithmus in “kleine” Einheiten die alle Funktionen sind)als auch fur die Schaffungwiederverwendbarer Software(gut implementierte Funktionen konnen inunterschiedlichen Aufgabenbereichen eingesetzt werden).
In beiden Fallen ist alles, was der Programmierer braucht, dieSpezifikationder Funktion (d. h. eineBeschreibung dessen, was die Funktion tut). Die Implementation selbst ist fur ihn irrelevant, sofernsie die Spezifikation erfullt.
Beispiele sind mathematische Funktionen wiesqrt(x) (berechnet√
x) oderpow(x,n) (berechnetxn), Funktionen zur Handhabung von Strings und viele andere mehr. In allen Fallen interessiert nurdas Verhalten, aber nicht die Implementation.
7.1.1 Funktionen und Prozeduren
Funktionen fallen in zwei Kategorien, solche die einen einzelnen Funktionswert zuruckgeben (in Pas-cal “functions”) und solche, die keinen Wert zuruckgeben (in Pascal “procedures”).
In Java hat jede Funktion einen Ruckgabetyp, der in der Definition der Funktion angegeben werden
Version vom 21. Januar 2005
181

182 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
muss. Die allgemeine Definition hat die Form1
Ruckgabetyp FunktionsName(formale Parameterliste)
Funktionsrumpf
Dabei gelten folgende semantische Regeln:
• Ist der Ruckgabetypvoid, so wird kein Wert zuruckgegeben (wie bei einer Pascal Prozedur).
• Ist der Ruckgabetyp verschieden vonvoid, so wird pro Aufruf genau ein Wert vom Ruckgabetypmit einerreturn Anweisung im Rumpf zuruckgegeben.2
• Als Ruckgabetyp sind alle Typen erlaubt.
• Die formale Parameterliste ist optional. Falls vorhanden, so besteht sie aus einer durch Kommasgetrennten Folge
De f1,De f2, . . . ,De fk
von Variablendeklarationen ohne Initialisierungen. Jede DefinitionDe fi definiert genau eineVariable.
Der Aufruf einer Methode erfolgt mit”Werten“ fur die formalen Parameter. Diese Werte werdenaktu-
elle ParameteroderAufrufparametergenannt. Sie mussen naturlich typvertraglich mit den formalenParametern sein und auch in derselben Anzahl und Reihenfolge auftreten.
7.1.2 Parameter und Datenfluss
DerDatenflussbezeichnet die Art des Datenaustausches zwischen der Funktion und dem sie aufrufen-den Programm. Fur jeden Parameter in der formalen Parameterliste gibt es dabei drei Moglichkeiten
• Fluss nurin die Funktion,
• Fluss nurausder Funktion heraus,
• Fluss sowohlin die Funktion, als auchausder Funktion heraus.
Die Arten des Datenflusses sind geeignet zu kommentieren (zum Beispiel mit den@param und@returnVerweisen in denjavadoc Kommentaren). Zur Realisierung dieses Datenflusses stehen in Program-miersprachen verschiedene Methoden zurParameterubergabezur Verfugung:
• Call by value (Wertparameter).
1Modifizierer wie public, private usw. werden in Abschnitt7.3.5behandelt.2Einzige Ausnahme: Einethrow Anweisung zur Erzeugung einer Exception beendet die Abarbeitung einer Funktion
und gibt eine Exception zuruck.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 183
• Call by reference (Variabler Parameter).
Call by value (Wertparameter): Eine Kopie des aktuellen Parameters wird beim Aufruf an dieFunktion ubergeben. Die Funktion arbeitet mit der Kopie undandert den aktuellen Parameter desaufrufenden Programms nicht.
Beispiel 7.1 (Berechnung der Fakultat) Fur eine naturliche Zahln > 0 ist
n! := 1·2·3· . . . ·n
zu berechnen. Dies leistet die folgende Java Funktion.
int factorial (int n) int product = 1;for (int i = 2; i <= n; i++) product *= i;return product;
factorial ist also eine Funktion mit einem Wertparametern, die einen Wert zuruck gibt. Schema-tisch ist dies in Abbildung7.1 dargestellt. Der Datenfluss erfolgt nurin die Funktionuber den Wert-parametern. Eine solche Funktion entspricht am ehesten der in der Mathematikublichen Vorstellungeiner Funktion.
nby value
?
( )
Funktionswert
Abbildung 7.1: Datenfluss bei der Funktionfactorial.
Das aufrufende Programm kann diese Funktion in beliebigen Ausdrucken verwenden, z. B. in
x = factorial(5*a) + b;
Beim Aufruf wird 5*a berechnet und dem Parametern zugewiesen, der im Rumpf vonfactorialwie eine Variable verwendet wird. Diereturn Anweisung gibt den Funktionswert zuruck, und dieserwird der Variablenx zugewiesen.
Call by reference (Variabler Parameter): Die Adressedes aktuellen Parameters wird beim Aufrufan die Funktionubergeben. Die Funktion arbeitet im Rumpf auf dem Speicherplatz des aktuellenParameters und kann (aber muss nicht) diesen dadurch modifizieren.

184 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
Diese Art der Parameterubergabe ist in Java nicht moglich (aber z. B. in Pascal und C++). In Javawerden grundsatzlich alle Parameter durch call by valueubergeben. Da jedoch alle Datentypen außerden elementarenReferenztypensind, lasst sich der call by reference durch einencall by value miteinem Referenztypweitgehend simulieren.3
Fur den Datenfluss nurausder Funktion heraus betrachten wir folgendes Beispiel.
Beispiel 7.2 (Initialisierung eines Arrays) Ein Array ist mit den ersten Quadratzahlen zu initialisie-ren. Dies leistet folgende Funktion
void initializeWithSquares(int[] vec) for (int i = 0; i < vec.length; i++)
vec[i] = i*i;
Die Anweisungen
int[] myArray = new int[7];initializeWithSquares(myArray);System.out.println(myArray[3]);
bewirken die Initialisierung des ArraysmyArray mit 0, 1, 4, 9, 16, 25, 36, 49. Die Zahl9wird auf die Konsole geschrieben.
Die Funktion gibt keinen Wert zuruck. Schematisch ist dies in Abbildung7.2dargestellt. Der Daten-fluss erfolgt nurausder Funktion.4
Als Variante hiervon betrachten wir eine Funktion, die zu gegebener Zahln ein Array der erstennQuadratzahlen erzeugt und (die Referenz auf) das erzeugte Array als Funktionswert zuruck gibt.
int[] squareNumbers(int n) int[] vec = new int[n];for (int i = 0; i < vec.length; i++)
vec[i] = i*i;return vec;
3Gelegentlich wird dies falschlicherweise als call by reference bezeichnet. Ein call by reference beinhaltet jedoch eineautomatische Dereferenzierung, daher sind als Parameter nur lvalues (z. B. Variablennamen) erlaubt. Beim call by valuekonnen jedochrvalues als aktuelle Parameter(z. B. Ausdrucke)ubergeben werden, und genau dies geschieht in der An-weisung
initializeWithSquares(squareNumbers(n));
mit der FunktionsquareNumbers() von Seite184.4Zumindest im Wesentlichen. Naturlich fließt die Referenz auf das ArraymyArray undubermyArray.length auch die
Zahl der Komponenten als Information in die Funktion. Aber die Werte der Komponenten vonmyArray sind unerheblich.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 185
vec
6
( )
Abbildung 7.2: Datenfluss bei der FunktioninitializeWithSquares().
Der Funktionswert kann dann in Ausdrucken der Form
int[] myArray = squareNumbers(8);
verwendet werden, wodurch der ArrayvariablenmyArray das Array der ersten 8 Quadratzahlen (ge-nauer: die Referenz des in der FunktionsquareNumbers() erzeugten Arrays der ersten 8 Quadrat-zahlen) zugewiesen wird.
Der zugehorige Datenfluss ist in Abbildung7.3dargestellt.
n
?
( )
Array Referenz
Abbildung 7.3: Datenfluss bei der FunktionsquareNumbers().
Als Beispiel fur den Datenflussin eine undauseiner Funktion betrachten wir die Addition zweierVektoren.
Beispiel 7.3 (Addition von Vektoren) Zwei Arrays der Langen sollen komponentenweise addiertwerden und in einem Ergebnisarray zuruckgegeben werden. Dies leistet folgende Funktion
/*** Adds array a to array b and stores the result in c* PRE: All arrays have the same length*/void arrayAdd(int[] a, int[] b, int[] c)
for (int i = 0; i < a.length; i++) c[i] = a[i] + b[i];

186 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
Die Anweisungen
int[] vec1 = 1, 2, 3, 4, vec2 = 4, 3, 2, 1, sum = new int[4];arrayAdd(vec1, vec2, sum);
bewirken dann, dasssum == 5, 5, 5, 5 gilt.
Der Datenfluss der Funktion ist in Abbildung7.4dargestellt.
a b c
? ?
6
( )
Abbildung 7.4: Datenfluss bei der FunktionarrayAdd().
Naturlich ware es analog zur FunktionsquareNumbers auch moglich gewesen, das Ergebnis alsFunktionswert zuruckzugeben.
Die Ruckgabe interessierender Großen als Funktionswert ist prinzipiell immer moglich, da man eigeneKlassen fur die interessierenden Großen definieren kann und eine Referenz auf ein Objekt dieserKlasse zuruckgeben kann. Dies illustriert das folgende Beispiel.
Beispiel 7.4 (Minimale und maximale Komponente eines Arrays)In einem Array von ganzen Zah-len sollen der minimale und der maximale Wert ermittelt und zuruckgegeben werden. Um 2 Wertezuruckgeben zu konnen, definieren wir eine entsprechende KlasseIntPair.
public class IntPairpublic int first;public int second;public IntPair(int x, int y) // constructor
first = x;second = y;
Der zu dieser Klasse gehorige Datentyp wird in der FunktionarrayMinMax als Ruckgabetyp benutzt.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 187
IntPair arrayMinMax(int[] vec)int min, max;min = max = vec[0];for (int i = 0; i < vec.length; i++)
if (vec[i] < min) min = vec[i];
if (vec[i] > max)
max = vec[i];
IntPair pair = new IntPair(min, max);return pair;
Die Anweisungen
int[] vector = 10, 20, 3, 17, 9 ;IntPair xy = arrayMinMax(vector);
im aufrufenden Programmteil bewirken dann, dassxy.first == 3 undxy.second == 20 gilt.
7.1.3 Gultigkeitsbereiche von Identifiern (Scope)
In Unterprogrammen konnen Identifier verwendet werden, die auch in anderen Programmteilen oderUnterprogrammen auftreten. Dies geschieht zwangslaufig, wenn Programme von mehreren Personenentwickelt werden oder Fremdsoftware benutzt wird. Jede Programmiersprache braucht daher Re-geln, die festlegen, welcher Identifier wann gemeint ist, und wie lange ein ihm eventuell zugeordneterSpeicherplatz mit dem Identifier angesprochen wird.
In Java werden solcheGultigkeitsbereicheoderScopes(wie auch in Pascal) durch denProgrammtextfestgelegt. Man spricht daher auch vonstatischen Scoperegeln.5 Man unterscheidet in Java zwischenKlassenscope(class scope) undBlockscope(block scope).
Der Klassenscopeist der Bereich zwischen den Klammern..., die den Programmtext der Klassebegrenzen. In ihm sind alle Identifier vonclass members, also Variablen (Feldern) und Funktionen(Methoden) der Klasse bekannt, und zwar unabhangig davon, wo sie in der Klasse definiert werden.6
Identifier mit Klassenscope sind außerdem in allen Unterklassen der Klasse, in der sie deklariert wer-den, bekannt.
Der Blockscopewird durch die Blocke definiert. Dies sind strukturierte Anweisungen einschließlichdurch... geklammerter Programmteile alscompound statement. Stellt man sich alle Blocke als mit
5Andere Programmiersprachen wie LISP oder APL verwendendynamischeScoperegeln, bei der die Hierarchie derAufrufe zur Laufzeit festlegt, welcher Identifier gemeint ist.
6Man benotigt also keine forward-Deklaration wie in Pascal oder Funktionsprototypen wie in C++.

188 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
... geklammert vor, so bilden die Blocke in einem korrekten Programm einenkorrekten Klammer-ausdruck. Also liegen wegen Satz4.1je 2 Blocke entweder disjunkt hintereinander im Programmtext,oder einer ist vollstandig im anderen enthalten.
. . .︸ ︷︷ ︸Block 1
. . . . . .︸ ︷︷ ︸Block 2
bzw. . . . . . .︸ ︷︷ ︸Block 1
. . .
︸ ︷︷ ︸Block 2
Der Scope eines Identifiers, der innerhalb eines Blocks definiert wurde (man nennt daslokal definiert),ist der gesamte Block ab der Definition.
. . . . . .De f . . . . . . . . . . . . . . . . . . . . .︸ ︷︷ ︸Scope vonDef
. . .
Identifier (einer Klasse oder eines Blockes) bleiben in allen in der Klasse oder dem Block direkt oderindirekt enthaltenen Blocke gultig, sofern keineUberdeckungdurch Neudefinition in einem “tieferen”Block auftritt.
Neudefinition eines Identifiers (mit vollig anderer Bedeutung!) in anderen Blocken ist beschranktmoglich. Erfolgt die Neudefinition in einem BlockB1, der innerhalb eines BlocksB2 liegt, in dem derIdentifier bereits definiert war, so trittUberdeckungauf. Der Scope der ersten, “außeren” Definitionwird vom Scope der zweiten, “inneren” Definitionuberdeckt.
. . . . . .De f . . . . . .︸ ︷︷ ︸Def
Neude f. . . . . . . . .︸ ︷︷ ︸Neudef
. . . . . . . . .︸ ︷︷ ︸Def
. . .
Eine solcheUberdeckung durch Neudefinition ist in Java nur fur Identifier mit Klassenscope moglich(also Klassenvariable oder Funktionen), nicht jedoch fur Identifier mit Blockscope7. Man benotigt dieNeudefinition bei der Vererbung, muss sie also bei Identifiern mit Klassenscope erlauben. Ansonstenwird Uberdeckung durch Neudefinition in Java jedoch verboten und fuhrt zu einem Compiler-Fehler.
Formale Parameter in Funktionsdefinitionen haben als Scope den gesamtenaußersten Block der Funk-tion. Sie unterliegen den Blockscope Regeln.
Funktionen konnen (im Gegensatz zu Pascal) nicht geschachtelt werden. Allerdings ist es moglich,Klassen zu schachteln (vgl. Abschnitt7.3.3).
Das Programmfragment
for (int i = 0; i < n; i++) ...
while (i < 10)
i++;...
7im Gegensatz zu vielen anderen Programmiersprachen wie C++ oder Pascal.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 189
ist also nur korrekt, wenni eine Klassenvariable ist, wahrend das Fragment
for (int i = 0; i < n; i++) for (int i = 0; i < n; i++)
...
falsch ist, dai in der erstenfor-Schleife durchi in der zweitenfor-Schleife unzulassiguberdecktwird. Dagegen ist
... ... int a; ... ... double a; ...
erlaubt, da dieint-Variablea am Ende ihres Blockes ihre Gultigkeit verliert, also nicht durch diedouble-Variablea uberdeckt wird.
Das folgende Beispiel demonstriert den Unterschied zwischen statischen und dynamischen Scope-regeln.
Beispiel 7.5 (Statische versus dynamische Scoperegeln)Im Programmfragment
public class Test extends Applet // other variablesint a;
void P() System.out.println(a);
void Q() double a;a = 3.14;P();
public void init() a = 1;Q();
wird der Identifiera zweimal definiert, als Klassenvariable vom Typint, und als lokaledoubleVariable inQ(). Die lokale Neudefinitionenuberdeckt die Klassenvariablea innerhalb des BlockesvonQ().

190 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
In init() wird der Klassenvariablena der Wert 1 zugewiesen. Der Aufruf vonP() innerhalb vonQ() bezieht sich ebenfalls auf die Klassenvariablea, da sie im Block vonP() Gultigkeit hat. DasProgramm gibt also1 aus.
Bei Verwendung derdynamischen Scoperegeln(LISP, APL) wurde der Scope aus der Aufrufhierarchieermittelt. init() ruft Q() auf, undQ() ruft P() auf. Daher wurdeP() auf die inQ() definiertedouble-Variablea zugreifen und 3.14 ausgeben.
Aus den Scope Regeln ergibt sich, dass jede Funktion auf Klassenvariable (auchglobale Variablegenannt) zugreifen kann und ihre Werte verwenden bzw.andern kann. Dies stellt eine zusatzlicheForm des Datenflusses dar (neben Parametern und Funktionswert). Da diese Art des Datenflusses nichtaus der Parameterliste ersichtlich ist, sollte die Verwendung globaler Variablen stets gut dokumentiertwerden, sofern sie nach außenpublic sind.
Funktionen werden außer durch Namen auch durch ihre Parameterlisten unterschieden (abernichtdurch den Ruckgabetyp!). Es konnen also in einem Scopebereich mehrere Funktionen den gleichenNamen haben, sofern sie sich in ihren Parameterlisten (Anzahl, Typ, Reihenfolge der Typen) unter-scheiden.
7.1.4 Abarbeitung von Funktionsaufrufen
Der Aufruf einer Funktion erfolgt mit den sogenanntenaktuellen Parametern, die mit den in derDefinition der Funktion aufgefuhrten formalen Parametern typkompatibel sein mussen.
Bei Wertparametern darf der aktuelle Parameter ein Ausdruck sein, bei variablen Parametern muss eseine Variable sein.
Beim Aufruf der Funktion werden Speicherplatze fur die formalen Parameter angelegt, die unter denNamen dieser Parameter im Rumpf der Funktion angesprochen werden. Wertparameter werden ausge-wertet und ihr Wert in den Speicherplatz des zugehorigen formalen Parameters kopiert. Bei variablenParametern wird die Referenz (Adresse) derubergebenen Variablen ermittelt und im Speicherplatzdes zugehorigen formalen Parameters abgelegt. Im Rumpf arbeitet man dann bei Nennung diesesParameters stets auf dem Speicherplatz derubergebenen Variablen.
Da es in Java nur Wertparameter gibt, kann zwar eine Referenz auf ein Objekt als Wertubergebenwerden, aber man arbeitetnicht automatisch auf dem Speicherplatz desubergebenen Objektes. DasObjekt kann naturlich verandert werden, aber dazu benotigt man die fur das Objekt verfugbaren Me-thoden.
Durch einreturn-Statement wird ein Wert zuruckgegeben und die Abarbeitung der Funktion been-det. Ansonsten (beivoid-Funktionen) endet die Abarbeitung der Funktion mit der Ausfuhrung desRumpfes oder einerreturn Anweisung ohne Ruckgabe eines Wertes.
Nach Abarbeitung der Funktion werden alle Speicherplatze fur formale Parameter, lokale Variablenusw. geloscht, und im aufrufenden Programm wird an der Stelle nach dem Aufruf der Funktion wei-tergemacht. Da bei variablen Parametern auf dem Speicherplatz des aktuellen Parameters gearbeitetwurde, bleiben im Funktionsrumpf vorgenommeneAnderungen erhalten.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 191
Beispiel 7.6 (Fortsetzung von Beispiel7.3) Betrachte den AufrufarrayAdd(vec1, vec2, sum)auf Seite185.
Vor dem Aufruf ist die Situation im Speicher wie folgt (wobei Referenzen als Pfeile dargestellt wer-den).
vec1 r- 1 2 3 4
vec2 r- 4 3 2 1
sum r- 0 0 0 0
Unmittelbar nach der Parameterubergabe ergibt sich folgendes Bild im Speicher.
vec1 r- 1 2 3 4
vec2 r- 4 3 2 1
sum r- 0 0 0 0
a r6
b r6
c r6
Bei den Zuweisungenc[i] = a[i] + b [i] wird also das Arraysum verandert. Nach Abarbeitungder Funktion werden die fur die formalen Parameter angelegten Speicherplatze wieder freigegebenund man erhalt folgende Situation im Speicher.
vec1 r- 1 2 3 4
vec2 r- 4 3 2 1
sum r- 5 5 5 5
Wird bei der Abarbeitung einer Funktion ein neues Objekt mitnew erzeugt, so steht dieses auchnach Abarbeitung der Funktion zur Verfugung (sofern die Referenz auf diese Objekte im aufrufendenProgrammsegment noch bekannt ist).
Dies geschieht z. B. beim Aufruf der FunktionsquareNumbers() in
int[] myArray = squareNumbers(8);
wobei das im Funktionsrumpf erzeugte Arrayuber die Zuweisung der zuruckgegebenen Referenz jetztuber die ArrayreferenzvariablemyArray ansprechbar ist.
Dies liegt daran, dass durchnew erzeugter Speicherplatz in einem gesonderten Bereich (dem soge-nanntenHeap) angelegt wird, der getrennt von dem Bereich ist, in dem lokale Variable von Funktionenangelegt werden (dem sogenanntenStack).

192 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
7.1.5 Der Run-Time-Stack
Wir sehen uns jetzt die Organisation der Speicherplatzverwaltung beim Ein- und Austritt in Scope-blocke etwas genauer an.
Jeder Scopeblock hat zur Laufzeit ein sogenanntesEnvironmentin Form einesActivation Recordmit
1. Eintragen fur lokale Identifier (inklusive formale Parameter bei Funktionen),
2. Pointern aufclass-Identifier bzw. Identifier ausubergeordneten Blocken, die nicht im momen-tanen Block neu definiert werden,
3. der Adresse der Anweisung imubergeordneten Block, mit der nach Verlassen des Blocks wei-tergemacht wird (Rucksprungadresse).
Beim Eintritt in den Scopeblock werden diese Records mit den entsprechenden Eintragen auf einemStack, dem sogenanntenRun-Time-Stack, abgelegt.
Die Adressen innerhalb eines Activation Records ergeben sich dann durch die Anfangsadresse desRecords plus dem jeweiligen Offset innerhalb des Records, der zur Compilierzeit bekannt ist.
Zur Einrichtung der Pointer auf Identifier ausubergeordneten Blocks gibt es mehrere Moglichkeiten.Eine gangige besteht in der Einrichtung eines Zeigers (static pointer), der auf den Record des nachstenScopeblocks in der statischen Hierarchie zeigt. Dadurch kann der definierende Scopeblock eines Iden-tifiers uber eine Kette von Pointern erreicht werden.
Neben diesem Run-Time-Stack ist zur Analyse der Aufrufe von Funktionen bzw. des Ein- und Aus-tritts in Scopeblocke der sogenannteAufrufbaumvon Bedeutung, der dieAufrufhierarchiezur Laufzeitdarstellt. In Zusammenhang mit der Rekursion (Kapitel8) wird er auchRekursionsbaumgenannt.
Beide Begriffe sollen nun an folgendem Beispiel erlautert werden.
Beispiel 7.7 (Aufrufbaum und Run-Time-Stack) Betrachte die Applet Klasse in Abbildung7.5.Die Scopeblocke sind mitA (Klassenscope) undB–D (Blocke aufgrund von Methoden bzw. com-pound statements) gekennzeichnet. Dabei wird die Methodeinit() zuerst aufgerufen.
Der Aufrufbaum hat die in Abbildung7.6 angegebene Gestalt.8 (Durch rekursive Aufrufe kann derAufrufbaum im Prinzip unendlich groß werden.)
Wir sehen uns jetzt den Run-Time-Stack an. In BlockA werden alle Klassenvariablen und Funktionendefiniert, alsodouble x,y, int z; und die Funktionenf(), g(), undinit(). Diese werden nichtauf dem Run-Time-Stack, sondern als globale Großen in einen anderen Bereich des Speichers, demsogenanntenHeapabgelegt, vgl. Abbildung7.7.
Beim Aufruf von init() werden keine lokalen Großen definiert. Im Activation Record wird nurdie Rucksprungadresse der static Pointer abgelegt. Da noch keinubergeordneter Block existiert, fin-
8Die Wurzel ist dabei der oberste Knoten, und alle gerichteten Kanten verlaufen von “hoheren” zu “tieferen” Kno-ten. Daher verzichtet man bei derart dargestellten Baumen auf die Angabe der Kantenrichtung durch Pfeile wie sonst beigerichteten Graphenublich.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 193
class RunTimeStack extends Applet double x = 1, y = 2;int z = 3;
void f(double a) int i = 4;...x = x + i*a;System.out.println("B: a = " + a + ", x = " + x
+ ", y = " + y);...
void g(int x) int y = 5;...
double i = 6;...f(x);System.out.println("D: i = " + i
+ ", y = " + y + ", x = " + x);...
...int i = 7;f(y);System.out.println("C: i = " + i + ", y = "
+ y + ", x = " + x);...
void init() ...g(z)System.out.println("E: x = " + x + ", y = "
+ y + ", z = " + z);...
D
C
A
B
E
Abbildung 7.5: Ein Programm mit seinen Scopes.

194 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
B ← Aufruf von f() in D
D B ← Eintritt in Block D und Aufruf vonf() in C
C
@@@
← Aufruf von g() in init()
E ← Aufruf von init()
Abbildung 7.6: Der Aufrufbaum zum Programm aus Abbildung7.5.
HEAP x double Wert 1y double Wert 2z int Wert 3f functiong functioninit function
Abbildung 7.7: Der Heap zum Programm aus Abbildung7.5.

7.1. FUNKTIONALE (PROZEDURALE) ABSTRAKTION 195
det man alleubergeordneten Identifier im Heap (gekennzeichnet durch HEAP im Stack), vgl. Abbil-dung7.8.
Der Aufruf g(z) in init() bewirkt den Eintritt in den BlockC und die Parameteridentifikation vonx(definiert inC) mit z (global definiert). Da noch keinubergeordneter Block existiert, erubrigt sich dieEinrichtung eines static Pointers. Alleubergeordneten Identifier findet man im Heap (gekennzeichnetdurch HEAP im Stack), vgl. Abbildung7.8.
Rucksprungadresse 1static pointer: HEAP
E
Rucksprungadresse 1static pointer: HEAP
E
x int (Wert 3 vonz)y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
Abbildung 7.8: Der Stack nach dem Aufruf voninit() (links) undg(z) in init() (rechts).
Abbildung7.9beschreibt den Run-Time-Stack beim Eintritt in den ScopeblockD aus BlockC (links)und beim Eintritt in den ScopeblockB aus BlockD (rechts).
Rucksprungadresse 1static pointer: HEAP
E
x int (Wert 3 vonz)y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
i double (Wert 6)
Rucksprungadresse 3static pointer:
D r
a double (Wert 3 vonx)i int (Wert 4)Rucksprungadresse 4static pointer: HEAP
B
i double (Wert 6)
Rucksprungadresse 3static pointer:
D rx int (Wert 3 vonz)
y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
Rucksprungadresse 1static pointer: HEAP
E
Abbildung 7.9: Der Stack beim Eintritt in den ScopeblockD ausC (links) und inB ausD (rechts).
Im Statementx = x + i*a in Block B ist also mitx die Klassenvariablex und nicht die anfubergebene Variablex gemeint, da der static pointer auf den Heap zeigt. Also wirdx + i*a zu1+4∗3 = 13 ausgewertet.
Nach Abarbeitung des BlocksB wird der entsprechende Activation Record auf dem Stack geloscht.Die Rucksprungadresse 3 gibt an, wo im Programm weitergemacht wird. Die dann entstehende Situa-

196 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
tion ist in Abbildung7.10links angegeben, die nach Abarbeitung von BlockD rechts.
Rucksprungadresse 1static pointer: HEAP
E
x int (Wert 3 vonz)y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
i double (Wert 6)
Rucksprungadresse 3static pointer:
D r
x int (Wert 3 vonz)y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
Rucksprungadresse 1static pointer: HEAP
E
Abbildung 7.10: Der Stack nach dem Austritt aus ScopeblockB (links) und ausD (rechts).
Die Situation beim Eintritt in BlockB aus BlockC ist in Abbildung7.11angegeben. Jetzt wirdx +i*a zu 13+ 4∗ 5 = 33 ausgewertet. Danach werdenB, C und E abgearbeitet und die zugehorigenActivation Records geloscht.
Rucksprungadresse 1static pointer: HEAP
E
i int (neu im Scope, Wert 7)x int (Wert 3 vony)y int (Wert 5)Rucksprungadresse 2static pointer: HEAP
C
a double (Wert 5 vony)i int (Wert 4)Rucksprungadresse 5static pointer: HEAP
B
Abbildung 7.11: Der Stack nach dem Eintritt in ScopeblockB ausC.
Das Programm schreibt gemaß der Abarbeitung der Scopeblocke in der ReihenfolgeB – D – B – C –E mit denprintln Anweisungen die Zeilen
B: a = 3.0, x = 13.0, y = 2.0D: i = 6.0, y = 5, x = 3B: a = 5.0, x = 33.0, y = 2.0C: i = 7, y = 5, x = 3E: x = 33.0, y = 2.0, z = 3

7.2. MODULARE ABSTRAKTION 197
auf den Bildschirm. Sie geben die Werte der gerade sichtbaren Variablen im jeweiligen Block andieser Stelle an.
Aus den Regeln der Abarbeitung von Scopeblocken ergibt sich bezuglich des Aufrufbaumes und desStacks folgender Satz.
Satz 7.1 (Eigenschaften des Run-Time-Stack und des Aufrufbaumes)1. Der Aufrufbaum wird in der Reihenfolge LRW (linker Teilbaum vor rechter Teilbaum vor Wur-
zel) abgearbeitet.
2. Die maximale Anzahl von Activation Records auf dem Run-Time-Stack, die ein Maß fur dieGroße des zur Laufzeit beanspruchten Speicherplatzes darstellt, ist gleich der Hohe des Aufruf-baumes+ 1.9
Im Zusammenhang mit der Rekursion (Kapitel8) nennt man die Zahl
Hohe(Aufrufbaum)+1
auch dieRekursionstiefe.
7.2 Modulare Abstraktion
Die durch Funktionen gewonnene Abstraktion beschrankt sich weitgehend auf das Input-Output Ver-halten von Programmteilen, also auf denDatenfluss. Oft mochte man jedoch weiter gehen und auchganze Datenstrukturen mit mehreren zugehorigen Variablen, Funktionen und Typen abstrahieren, sowie bei den in Kapitel5 besprochenen Datenstrukturen.
Dies geschieht in vielen Programmiersprachen in sogenanntenModulen. Sie stellen Verallgemei-nerungen von Funktionen dar, indem sie eine Kollektion miteinander zusammenhangender Objekte(z. B. mehrere Funktionen, Typen, Konstanten, Variable) zu einerseparat compilierten Einheitzu-sammenfasst. Dies ist schematisch in Abbildung7.12dargestellt.
Funktion f
Anweisungenlokale Variablelokale Variable. . .
Modul M
Modul VariableModul VariableFunktionFunktionFunktion. . .
Abbildung 7.12: Funktion versus Modul.
Module sind so konzipiert, dass andere Module oder Programme Teile oder das Modul als Ganzesnutzen konnen. Man nennt die NutzerKlientendes genutzten Moduls.
9Die Hohe eines Baumes ist die maximale Kantenzahl auf einem Weg von der Wurzel bis zu einem Blatt.

198 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
Beispiele fur Module sind Bibliotheken in C oder Implementationen von abstrakten Datentypen. Mo-dule werden meist beschrieben durch eineSpezifikation, die das Verhalten und die Eigenschaften desModuls festlegt. Diese wird getrennt von derImplementation, die die zugehorigen Programme enthalt.
Die Spezifikation ist deroffentliche(public) Teil des Moduls. Klienten konnen (oder sollten) nur diedort deklarierten Begriffe nutzen.10 Im privaten (private) Teil sind die Rumpfe der Funktionen undzusatzliche private Variable enthalten, die nach außen verborgen bleiben (sollten). Man spricht daherauch vonEinkapselung(encapsulation).
Wirksame encapsulation setzt voraus, dass die Programmiersprache getrennte Kompilation von Pro-grammteilen erlaubt oder Konstrukte ermoglicht, die Daten als privat erklaren.
Getrennte Compilierung hat viele Vorteile:
1. Module sind wiederverwendbar (reusable, off-the-shelf components).
2. Module konnen beiAnderung rekompiliert werden, ohne die Klienten rekompilieren zu mussen.
3. Klienten konnen geandert werden, ohne das Modulandern zu mussen.
4. Module konnen nur als Objektcode zur Verfugung gestellt werden, so dass Details der Imple-mentation verborgen bleiben (encapsulation).
7.3 Abstraktion durch Klassen
Java bietet ein eigenes Konstrukt zur Abstraktion von Datentypen mit den zugehorigen Operationen:Klassen. EineKlasse(class) ist ein durch den Programmierer definierter strukturierter Typ. SeineKomponenten heißenclass members. Dies konnen Variablen, Funktionen und auch wieder Klassensein. In der Java Terminologie werden sieKlassenvariablenoderFelder, Methodenbzw. innere Klas-sengenannt. Da Klassen Typen sind, kann man Variable dieses Typs definieren. Jedes Objekt hatdann (im Prinzip11) als Komponenten alle Felder und Methoden der Klasse (und aller Oberklassen,von denen sie abgeleitet wird, vgl. Abschnitt7.3.3.
7.3.1 Definition von Klassen
Wir betrachten zunachst die eingeschrankte Definition
class KlassenNameDef1;Def2;
...Defr ;
10Sprachabhangig kann auch der Zugriff aufprivate Daten moglich sein. Er sollte jedoch unterbleiben.11Ausnahmen sind alsstatic deklarierte Felder und Methoden, vgl. dazu Abschnitt7.3.2.

7.3. ABSTRAKTION DURCH KLASSEN 199
Dabei istclassdas Schlusselwort, das die Klassendefinition einleitet, undDef1, . . . ,Defr sind Defini-tionen von Variablen (Feldernder Klasse), Funktionen (Methodender Klasse) oder inneren Klassen,vgl. Abschnitt7.3.8.
Unter den Methoden sindKonstruktorenvon besonderer Bedeutung. Sie haben immer denselben Na-men wie die Klasse und folgende Form
KlassenName(formale Parameterliste). . .
Es gibt weder einen expliziten Ruckgabetyp, noch das Schlusselwortvoid. Im gewissen Sinne ist derName des Konstruktors der Ruckgabetyp.
In der Regel haben Klassen mehrere Konstruktoren mit verschiedenen Parameterlisten. Der Aufrufeines Konstruktors erfolgt mitnew. Er erzeugt ein neues Objekt der Klasse und gibt eine Referenz aufdieses Objekt als Wert zuruck.
Wir betrachten diese Begriffe an einer Variation der auf Seite186definierten KlasseIntPair.
Programm 7.1 IntPairclass IntPair
int first;int second;
IntPair(int x, int y) first = x; second = y;
int sum() return first + second;
Diese Klasse hat 2 Felderfirst undsecond, eine Methodesum und einen KonstruktorIntPair.
Durch
IntPair xy = new IntPair(3, 7);
wird ein neues Objekt dieser Klasse erzeugt, dessen Felderfirst und second die Werte 3 und 7haben.
Der Zugriff eines Objektes auf seine Felder und Methoden erfolgt durch den. gemaßobject.feldbzw.object.methode().
xy.first = -4;
andert also den Wert vonfirst zu -4,

200 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
xy.second = xy.sum();
andert den Wert vonsecond zum Ergebnis des Aufrufes vonsum() fur das Objektxy, also zu−4+7 = 3.
Der Zugriff eines Objektes auf eine Methodeubergibt der Methode implizit eine Referenz auf das Ob-jekt als ersten Parameter. Diese implizite Referenz kanninnerhalb der Klassedurch die Variable mitdem reservierten Namenthis angesprochen werden. Die Definition vonsum in der KlasseIntPairhatte also auch als
int sum() return this.first + this.second;
geschrieben werden konnen. Außerhalb der Klasse des Objektes ist dies jedoch nicht moglich.
Die Verwendung vonthis gehort zur Namenskonvention von Java, insbesondere in Konstruktoren.Dort sollen nach Konvention die Parameter, mit denen Felder gesetzt werden, dieselben Bezeichnerwie die Feldnamen bekommen. Die Unterscheidung zwischen Parametern und Feldern ist dann nurmit this moglich. Bei Befolgung der Namenskonvention wird der Konstruktor der KlasseIntPairzu
IntPair(int first, int second) this.first = first;this.second = second;
Klassen konnen auch ohne die Definition von Konstruktoren geschrieben werden. Dann verfugen sieautomatischuber den sogenanntenleeren KonstruktoroderDefault Konstruktor, der keine Argumentehat. Dies gilt jedoch nicht mehr, sobald ein Konstruktor definiert wird. Da Default Konstruktoren furdie Vererbung (vgl. Abschnitt??) immens wichtig sind, sollte man Klassen, die Konstruktoren haben,immer zusatzlich mit einem Default Konstruktor ausstatten.
In der KlasseIntPair ware folgender Default Konstruktor sinnvoll, der das Paar (0,0) erzeugt.
public IntPair() first = 0;second = 0;
Oft ist auch einCopy Konstruktor sinnvoll. Ein solcher Konstruktor erstellt eine identische Kopiedes ihmubergebenen Objektes derselben Klasse. Wir erlautern es an der KlasseIntPair:
public IntPair(IntPair xy) first = xy.first;second = xy.second;

7.3. ABSTRAKTION DURCH KLASSEN 201
Statt eines Copy Konstruktors kann man auch das Interface Cloneable implementieren, siehe Ab-schnitt7.3.7.
7.3.2 Static-Felder und Methoden
In manchen Situationen mochte man Felder oder Methoden fur dieKlasse als Ganzesanlegen. Diesist z. B. sinnvoll bei der Definition von Konstanten, die fur alle Objekte der Klasse gleich sind, oderMethoden, die unabhangig von den Objekten der Klasse sind.
Dies kann erreicht werden durch Verwendung des Modifizierersstatic vor der Definition.
In der KlasseInteger wird etwa der maximale WertMAX VALUE definiert als12
public static final int MAX_VALUE = Ox7fffffff;
Ebenso sind in der KlasseMath von mathematischen Funktionen alle Methoden alsstatic definiert,etwa
public static native double sin(double a);
fur die Sinus-Funktion.
static Methoden und Felder konnen nicht auf Instanzen der Klasse zugreifen. Die Benutzung vonstatic Methoden und Feldern innerhalb der Klasse geschiehtuber ihre Namen, außerhalb konnensie (sofern sichtbar) durch Nennung des Klassennamens und den. angesprochen werden, also etwa
myColor = Color.orange;
fur diestatic Konstanteorange der KlasseColor, und
x = Math.max(y, z);
fur diestatic Funktionmax der KlasseMath.
Der etwas seltsame Namestatic ist historisch bedingt und meint den Gegensatz zudynamic. Iden-tifier ohne den Zusatzstatic sind automatischdynamic. Fur sie wird Speicherplatz bei Betreten desScopeblocks eingerichtet (vgl. Abschnitt7.1.5) und nach Verlassen des Scopeblocks wieder vernich-tet. Bei alsstatic deklarierten Identifiern bleibt dieser Speicherplatz auch zwischen Verlassen underneutem Wiedereintritt in den Scopeblock erhalten. Sie sind in diesem Sinne nicht
”dynamic“.
7.3.3 Unterklassen und Vererbung
Klassen konnen andere Klassenerweitern. Die neue, erweiterte Klasse heißt Unterklasse oder Sub-klasse, die vorgegebene Klasse heißt Oberklasse. Man sagt auch, dass die Unterklasse von der Ober-klasseabgeleitetwird. Die Syntax hierfur ist
12Ox7fffffff ist Hexadezimalnotation, vgl. Beispiel4.3. Die entsprechende Dezimalzahl ist 2.147.483.647= 231−1.

202 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
class NameUnterklasseextends NameOberklasse...
Die Unterklasse hat dabei Zugriff auf alle Felder und Methoden der Oberklasse, diese werden”ge-
erbt“. Die Unterklasse darf Methoden und Felder der Oberklasse neu definieren und zusatzliche Me-thoden und Felder einfuhren.
Hierdurch entstehen ganze Hierarchien von Klassen13. Die Java Bibliothek liefert viele Beispielehierfur. Wir haben dieses Prinzip schon in der Applet-Programmierung verwendet, alle Klassen warenErweiterungen der OberklasseApplet.
Alle Klassen von Objekten sind in Java Unterklassen der KlasseObject. Dadurch lassen sich Daten-strukturen fur Objekte sehr allgemein definieren, vgl. die Beispiele Stack und Liste in Abschnitt5.7und Abschnitt5.7.
Fur den Zugriff auf Felder und Methoden der Oberklasse dient die Referenzsuper. Entsprechendkonnen Konstruktoren der Superklasse mitsuper(...) und den entsprechenden aktuellen Parame-tern angesprochen werden. Hierzu ein Beispiel14:
Die Klasse
class Square double width;
Square(double width) this.width = width;
double area() return width * width;
wird erweitert durch die Klasse
class Rectangle extends Square double height;
Rectangle(double width, double height) super(width);this.height = height;
13In Java 1.1.4 gab es 21 Pakete mit 503 vordefinierten Klassen und ca. 5000 Methoden, in Java 1.3 gab es bereits 76Pakete mit 1841 Klassen und ca. 20000 Methoden. Wieviele gibt es in Java 1.4?
14das auch zeigt, dass die logische Hierarchie (Quadrat ist “Unterklasse” von Rechteck) nicht mit der Vererbungshierar-chieubereinstimmen muss. Bei der Vererbung bedeutet Spezialisierung immer Hinzufugen bzw.Uberschreiben von Feldernund Methoden.

7.3. ABSTRAKTION DURCH KLASSEN 203
double area() return width * height;
Im KonstruktorRectangle wird mit super(width) der Konstruktor vonSquare aufgerufen, ei-ne Zuweisungsuper.width = width statt dieses Aufrufes resultiert (da kein expliziter Konstruk-toraufruf der KlasseSquare erfolgt) in einen impliziten Aufruf vonsuper(), alsoSquare(). Einsolcher Konstruktor existiert aber nicht in der KlasseSquare, so dass der Compiler einen Fehlermeldet.15
Die Methodearea() wird in der KlasseRectangle uberschrieben. Fur beide Klassen steht daherderselbe Name fur die (unterschiedliche!) Berechnung der Flache zur Verfugung.
Um jetzt (z. B. in einer umfangreichen Graphik) verschiedene Quadrate und Rechtecke abzuspeichern,kann man ein Array
Square[] vec = new Square[n];
definieren. Da jedesrectangle Objekt durch die Vererbung auch vom TypSquare ist, konnengleichzeitigRechtecke und Quadrate im Array verwaltet werden, also etwa
vec[0] = new Square(1);vec[1] = new Rectangle(2, 3);
Der Durchlauf
for (int i = 0; i < vec.length; i++) System.out.println(vec[i].area());
schreibt dann nacheinander die Flache der Rechtecke und Quadrate auf den Bildschirm. Dabei wirdautomatisch die richtigearea() Methode gewahlt!
Will man als Programmierer die Klasse eines Objektes ermitteln, so geht dies mit der MethodegetClass() der KlasseObject. Diese Methode liefert eine Referenz auf ein Objekt der KlasseClass zuruck, das u. a. den Namen der Klasse des betrachteten Objektes enthalt, und zwar mit dempackage Prafix der Klasse (vgl. Abschnitt7.3.4).
Object o = new Object();String str = o.getClass().getName();
weist also der Variablenstr den Wert"java.lang.Object" zu. Im obigen Beispiel schreibt dieAnweisung
15Es ist daher guter Programmierstil, jede Klasse mit einem parameterlosen Defaultkonstruktor zu versehen.

204 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
for (int i = 0; i < 2; i++) System.out.println(vec[i].getClass().getName());
nacheinanderSquare undRectangle auf den Bildschirm. Derpackage Prafix entfallt hier, da dieKlassenSquare undRectangle keinem Package angehoren.
7.3.4 Packages
Ein Programm in Java ist eine Menge von Dateien der FormKlassenname.java, wobei Klassenna-me.javagenau den Programmtext der KlasseKlassennameenthalt16. Die Funktionsweise des Pro-gramms wird durch die Interaktion der Klassen (Verwendung der Methoden aus einer anderen Klasse,Vererbung, usw.) festgelegt.
Um Klassen zuahnlich gelagerten Aufgaben zusammenfassen zu konnen, gibt es die Moglichkeit zurDefinition vonPaketen(packages). Ein package ist eine Menge von Klassen in einem gemeinsamenVerzeichnis. Der Pfad zu diesem Directory stimmt mit der Bezeichnung des packagesuberein. Daspackagejava.lang liegt (in einem UNIX System) in einem Verzeichnis.../java/lang relativ zuden durch die Environment VariableCLASSPATH festgelegten Verzeichnis-Pfaden.
Das Herstellen eigener Packages geschieht mit der Anweisung
package PackageName;
vor jeder Klassendefinition des Packages, also z. B. mit
package java.awt;public class TextField extends TextComponent
...
bei der Definition der KlasseTextField des Paketesjava.awt.
7.3.5 Sichtbarkeit von Klassen, Methoden und Feldern
Damit Klassen in einem Java Programm interagieren konnen, muss dieSichtbarkeitder Namen nachaußen festgelegt werden. Gutes Softwaredesign macht nur ausgewahlte, wohluberlegte Methodennach außen sichtbar, verbirgt aber alle Methoden und Felder, die nur als interne Hilfsmittel dienen.
Zur Regelung der Sichtbarkeit zwischen Klassen dienen dieModifiziererpublic, protected undprivate, die der Definition vorangestellt werden. Dabei darf nur einer dieser Modifizierer auftreten.Sie haben folgende Bedeutung.
Sichtbarkeitsmodifizierer fur Felder und Methoden:16bis auf zusatzliche Klassen, die nach außen nicht sichtbar sind, vgl. Abschnitt7.3.8.

7.3. ABSTRAKTION DURCH KLASSEN 205
public Feld istuberall sichtbar (Klasse muss ebenfalls public sein).leer Default, Feld ist in dem Package sichtbar.protected Wie Default,unddas Feld ist auch in den Subklassen anderer
Packages sichtbar, die aus dieser Klasse abgeleitet wurden(protected ist also de factowenigergeschutzt als der Default!).
private Feld ist nur in dieser Klasse sichtbar.
Klassen haben als Sichtbarkeitsmodifizierer nur
public Klasse ist in anderen Packages sichtbar.leer Default, Klasse ist in dem Package sichtbar.
7.3.6 Weitere Modifizierer
Fur Felder einer Klasse wird die Art der Verwendung durch folgende Modifizierer festgelegt:
static Eins pro Klasse, nicht eins pro Objekt (vgl. Abschnitt7.3.2).final Wert kann nicht verandert werden.transient Solche Felder werden nicht mit dem Objekt abgespeichert.
Reserviert fur zukunftige Verwendung.volatile Diese Daten konnen an verschiedene Steuerthreadsubergeben werden,
so dass das Laufzeitsystem Lesen und Beschreiben solcher Feldersynchronisieren muss.
Bei Methoden unterscheidet man
final Kann nichtuberschrieben werden.static Eine pro Klasse, nicht eine fur jedes Objekt.abstract Mussuberschrieben werden (um einen Nutzen zu haben).native Nicht in Java geschrieben (kein Rumpf, sonst aber normal und
vererbbar, statisch usw.). Der Rumpf wird in einer anderen Sprachegeschrieben. Hierzu dient das JNI (Java Native Interface),das in einer eigenen JNI-Specification festgelegt ist.
synchronized Es kann in dieser Methode jeweils nur ein Thread ausgefuhrt werden.Der Zugriff auf diese Methode wirduberwacht (vgl. Threads in derUbung).
Bei Klassen gibt es schließlich
final Klasse kann nicht erweitert werden.abstract Klasse muss erweitert werden, wobei alle abstrakten Methodenuberschrieben
werden mussen.
Sinnvolle Kombinationen dieser Modifizierer wie

206 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
native private static ...
sind moglich.
7.3.7 Interfaces
Java sieht keine Mehrfachvererbung vor, so dass eine Klasse nureineandere erweitern kann. Um den-noch Methoden aus weiteren Klassen benutzen zu konnen, stellt Java Interfaces bereit. EinInterfacewird wie eine Klasse definiert
Modifiziererinterface InterfaceName...
und kann mehrere andere Interfaces erweitern. Im Gegensatz zu Klassen haben Interfaceskeine Kon-struktoren, sondern nur statische Konstanten und abstrakte Methoden. Bei den Methoden wird alsolediglich der Methodenkopf angegeben und mit einem Semikolon beendet.
Klassen konnen Interfacesuber das Schlusselwortimplements nutzen, und zwar mehrere Interfacesgleichzeitig.
class myClass extends Appletimplements ActionListener ...
Dies bedeutet, dass die Methodennamen aus dem Interface zur Verfugung stehen, die Methoden aberalle noch in der Klasse implementiert werden mussen, d. h. die Methodenkopfe werden mit einemRumpf versehen.
Interfaces schreiben also Namen und Parameterlisten fur Methoden vor, die Implementation mussjedoch in der Klasse erfolgen.
Wir erlautern dies am Beispiel der KlasseStack aus Abschnitt5.7.
/*** The <code>StackInterface</code> defines an interface* for a stack of objects.** @see ListNode*/public interface StackInterface
/*** Tests if this stack has no entries.** @return <code>true</code> if the stack is empty;* <code>false</code> otherwise*/boolean isEmpty();

7.3. ABSTRAKTION DURCH KLASSEN 207
/*** Return the value of the current node.* @throws NoSuchElementException*/Object top() throws NoSuchElementException;
/*** Inserts a new stack node at the top.** @param <code>someData</code> the object to be added.*/void push(Object someData);
/*** Delete the current node from the list.* @throws NoSuchElementException*/void pop() throws NoSuchElementException;
Man beachte, dass die Methoden eines Interfaces implizitpublic undabstract (sofern nichtfinal)sind. Diese Modifizierer brauchen also nicht hinzugefugt werden.
Die Implementation des Stacks auf Seite101) mit diesem Interface geschieht dann wie folgt:
public class Stack implements StackInterface // Hinzufugen von Feldern fur die Implementation// Implementation der Methoden// Hinzufugen von Konstruktoren
Die Klassenbibliothek von Java macht ausfuhrlich von Interfaces Gebrauch. Ein bereits genanntesBeispiel ist das InterfaceActionListener (vgl. Abschnitt7.3.8, andere sindCloneable, ComparableundRunnable. Diese definieren die Methodenclone() (vgl. Abschnitt6), compareTo() (fur Ver-gleiche von Objekten) undrun() (fur nebenlaufige Prozesse in Form von Threads).
Wir geben ein Beispiel fur Cloneable mit der KlasseIntPair aus Abschnitt7.3.1:
import java.lang.Cloneable;
class IntPair implements Cloneable ...
public Object clone()

208 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
return new IntPair(this.first, this.second);
Die uberschriebene Methodeclone() gibt ein allgemeines Objekt zuruck und muss daher mit castingverwendet werden:
IntPair p = new IntPair(1,2);IntPair q = (IntPair) p.clone();
7.3.8 Klassen in Klassen
Klassen konnen als Komponenten außer Datenfeldern und Methoden auch Klassen haben. Sie werdenwie Datenfelder oder Methodenuber den. angesprochen und konnen Modifizierer haben. Sind sienichtstatic, so werden sieinnere Klassengenannt.
Klassen konnen ferner (wie lokale Variable) lokal in Methoden verwendet werden. Sie heißen dannlokale Klassen. Sie werden wie gewohnliche Klassen deklariert.
Bezuglich der Sichtbarkeit von Klassen in Klassen gelten die gleichen Scope-Regeln wie beim Klas-senscope bzw. Blockscope. Zusatzlich konnen Komponentenklassen, die public sind, von anderenKlassen importiert und genutzt werden.
Mussen lokale Klassen nichtuber einen Klassennamen angesprochen werden, so kann man sie alsanonyme Klassendirekt nach der Angabe einer Oberklasse oder eines Interfaces definieren, ohnesie zu benennen. Wir haben hiervon bereits regen Gebrauch bei den ActionListenern gemacht, sieheAbschnitt7.3.9.
7.3.9 Implementationen des Interface ActionListener
Wir erlautern jetzt Varianten der Implementation des InterfaceActionListener. Zur Illustrationbenutzen wir das AppletTemperatur (Abschnitt2.1).
Die dort benutzten Anweisungen
TextField input = new TextField(10);input.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e) // perform the actioncalculateTemperature();
);
zur Anbindung eines ActionListeners lassen sich jetzt wie folgt erklaren.
ActionListener ist ein Interface, das als einzige Methode die abstrakte Methode

7.3. ABSTRAKTION DURCH KLASSEN 209
public void actionPerformed(ActionEvent e);
enthalt. Die Methode
public void addActionListener(ActionListener l) ...
der KlasseTextField verlangt die Angabe einesActionListener-Objektesl. Dieses geschiehtmit new ActionListener(). Da ActionListener ein Interface ist, braucht man eine Klasse, die“implements ActionListener” durchfuhrt, d. h. die MethodeactionPerformed(ActionEvent)definiert.
Genau dies leistet die anonyme Klasse
public void actionPerformed(ActionEvent e)
// perform the actioncalculateTemperature();
Naturlich konnte man den ActionListener auch in einer eigenen Klasse implementieren, oder durchdas Applet implementieren lassen. Wir betrachten zunachst eine Implementation als innere Klasse:
public class Temperatur extends Applet ...
public void init() ...TextField input = new TetField(10);input.addActionListener(new MyActionListener());...
class MyActionListener extends ActionListener public void actionPerformed(ActionEvent e)
// perform the actioncalculateTemperature();
public void calculateTemperature() ...

210 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
Hier istMyActionListener als innere Klasse auf Klassenniveau definiert, unterliegt also dem Klas-senscope und kann daher an beliebiger Stelle definiert werden. Es ware auch moglich, sie als lokaleKlasse direkt innerhalb der Methodeinit() zu definieren; dann wurde sie jedoch dem Blocksco-pe unterliegen und muss vor der Anweisunginput.addActionListener(...) erfolgen, da sonstMyActionListener() nicht bekannt ist.
Die Anweisung
new MyActionListener()
ruft den Default Konstruktor der inneren KlasseMyActionListener auf. Dieser musste nicht defi-niert werden, da Klassen ohne Definition von Konstruktoren automatischuber den Default Konstruk-tor verfugen.
Naturlich ist auch die Implementation des Interface ActionListener als eigene (nicht innere) KlasseMyActionListener moglich. Dann ist jedoch der Informationstransfer schwieriger zu gestalten. Dadie MethodeactionPerformed() in der KlasseMyActionListener angesiedelt ist, muss man demeinem Konstruktor der KlasseMyActionListener zumindest die TextFieldsinput undoutput desAppletsTemperatur ubergeben, damit die MethodeactionPerformed() auf sie zugreifen kann.Wir l osen dies, indem wir das gesamte AppletTemperatur ubergeben.
Innerhalb der KlasseTemperatur erfolgt die Anbindung des ActionListener an das TextFieldinputmit der Anweisung
input.addActionListener(new MyActionListener(this));
die einen Konstruktor der KlasseMyActionListener aufruft, dem ein Objekt der KlasseTemperaturubergeben werden kann. Die KlasseMyActionListener sieht dann folgendermaßen aus.
import java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
class MyActionListener implements ActionListener
private Temperatur tempApplet;
public MyActionListener(Temperatur tempApplet) this.tempApplet = tempApplet;
public void actionPerformed(ActionEvent e) // perform the actioncalculateTemperature();

7.3. ABSTRAKTION DURCH KLASSEN 211
// process user’s action on the input text fieldpublic void calculateTemperature()
// get input numberdouble fahrenheit =
Double.parseDouble(tempApplet.input.getText());
// calculate celsius and round it to 1/100 degreesdouble celsius = 5.0 / 9 * (fahrenheit - 32);// use Math class for roundcelsius = Math.round(celsius * 100);celsius = celsius / 100.0;
// show result in textfield outputtempApplet.output.setText(Double.toString(celsius));
Die MethodecalculateTemperature() ist jetzt in dieser Klasse, die Klasse Temperatur enthalt nurdie Methodeinit() und auch nicht mehr die Variablendouble undfahrenheit.
Zum Abschluss betrachten wir die Implementation desActionListener durch das AppletTemperaturselbst. Dann muss die KlasseTemperatur das InterfaceActionListener implementieren und daherdie MethodeactionPerformed() definieren.
public class Temperatur extends Applet implements ActionListener ...
public void init() ...input = new TextField(10);// register this applet as ActionListener for// TextField inputinput.addActionListener(this);...
// duties of this Applet as ActionListenerpublic void actionPerformed(ActionEvent e)
// body of method calculateTemperature()

212 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
7.3.10 Der Lebenszyklus von Objekten
Objekte werden durch Aufruf von Konstruktoren von Klassen mitnew erzeugt und auf dem Heapangelegt, unterliegen also nicht der Speicherverwaltung auf dem Run-Time-Stack. Hierdurch ist esmoglich, auch innerhalb von Methoden Objekte zu erzeugen und sie z. B. durch Ruckgabe einerReferenz (wie insquareNumbers auf Seite184) an den aufrufenden Programmteil zuubergeben.
Objekte bleiben so lange erhalten, wie es eine Referenz auf sie gibt. Das Java Run-Time-Environmentuberwacht dies und stellt den Speicherplatz, der durch ein nicht mehr referenziertes Objekt belegtwird, wieder zur Verfugung. Dieser Automatismus erlaubt jedoch keinen Einfluss auf denZeitpunktder Ruckgabe.
Die Uberwachung und Ruckgabe nicht mehr referenzierter Objekte bezeichnet man in allen Program-miersprachen alsGarbage Collection. Java hat also eine eingebaute Garbage Collection, um die sichder Programmierer nicht kummern muss.
Der Nachteil dieses Automatismus besteht in gewissen Einbußen an Laufzeit, die zudem zeitlich un-kontrollierbar auftreten konnen. Hat man jedoch gerade mal Zeit fur die Garbage Collection, so kannman sie mit der Methode
System.gc();
starten.
7.4 Beispiele von Klassen
7.4.1 Bruchrechnung
Die folgende KlasseFraction (vgl. auch Abschnitt5.2) stellt Datenstrukturen und Methoden zumRechnen mit Bruchen zur Verfugung.
import java.lang.Cloneable;
/*** The <code>Fraction</code> class implements fractions.* Each fraction is a pair numerator/denominator of longs* in simplified form, i.e. gcd(numerator,denominator) = 1*/public class Fraction implements Cloneable
/*** the numerator*/private long num;

7.4. BEISPIELE VON KLASSEN 213
/*** the denominator. It is always > 0*/private long denom;
/*** Default constructor, constructs 0 as fraction 0/1*/public Fraction()
num = 0;denom = 1;
/*** Constructs Fraction object from a long* @param a yields the fraction a/1*/public Fraction(long a)
num = a;denom = 1;
/*** Constructor with two long argument num and denom,* constructs the fraction num/denom and simplifies it.* @param num the numerator* @param denom the denominator* Throws <code>ArithmeticException</code> if* <code>denom == 0</code>*/public Fraction(long num, long denom) throws ArithmeticException
if (denom == 0) throw new ArithmeticException("Division by zero in constructor" );
else this.num = num;this.denom = denom;this.simplify();
/*** simplifies this fraction*/private void simplify()

214 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
if (num == 0) this.num = 0;this.denom = 1;
else long gcd = gcd(this.num, this.denom);this.num = this.num/gcd;this.denom = this.denom/gcd;if ( this.denom < 0 )
this.num = -this.num;this.denom = -this.denom;
/*** Calculates the greatest common divisor of |a| and |b|* @param a* @param b* @return the greatest common divisor of* |<code>a</code>| and |<code>b</code>|*/private static long gcd(long a, long b) throws ArithmeticException
if ( a == 0 || b == 0 ) throw new ArithmeticException("Zero argument in gcd calculation");
a = Math.abs(a);b = Math.abs(b);while (a != b)
if (a > b) a = a - b;else b = b - a;
return a;
/*** Returns a string representation of this fraction.* @return fraction in the form "num/denum"*/public String toString()
return Long.toString(this.num) + "/"+ Long.toString(this.denom);
/*** Returns the double value of this fraction.

7.4. BEISPIELE VON KLASSEN 215
* @return num/denum*/public double doubleValue()
return (double) this.num / (double) this.denom;
/*** Checks equality with other fraction r.* @param r the fraction to be compared with* @return <code>true</code> if this fraction equals <code>r</code>.*/public boolean equals(Fraction r)
return (this.num == r.num) && (this.denom == r.denom);
/*** Get the nominator of this fraction* @return the numerator of this fraction*/public long getNumerator()
return num;
/*** Get the denominator of this fraction* @return the denominator of this fraction*/public long getDenominator()
return denom;
/*** Multiplies this fraction with other fraction r and* simplifies the result.* @param r the fraction to be multiplied with.*/public void multiply(Fraction r)
this.num = this.num * r.num;this.denom = this.denom * r.denom;this.simplify();
/*** Adds fraction r to this fraction and

216 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
* simplifies result.* @param r the fraction to be added.*/public void add(Fraction r)
// use a/b + c/d = (ad + cb)/bd and simplify()this.num = this.num * r.denom + r.num * this.denom;this.denom = this.denom * r.denom;this.simplify();
/*** clones this fraction by implementing Cloneable*/public Object clone()
return new Fraction(this.num, this.denom);
Die Folge
System.out.println( "Demo der Klasse Fraction:" );Fraction r, s, t;r = new Fraction(3, 8);s = new Fraction(1, 6);double x = r.doubleValue();System.out.println( "Wert von " + r.toString() + " ist " + x );t = (Fraction) r.clone();t.add(s);System.out.println(r.toString() + " + "
+ s.toString() + " = " + t.toString());r = new Fraction(3, 4);t = (Fraction) r.clone();t.multiply(s);System.out.println(r.toString() + " * "
+ s.toString() + " = " + t.toString());System.out.println(r.toString() + " == " + s.toString()
+ " ergibt " + r.equals(s));
von Anweisungen schreibt dann
Demo der Klasse Fraction:Wert von 3/8 ist 0.3753/8 + 1/6 = 13/24

7.4. BEISPIELE VON KLASSEN 217
3/4 * 1/6 = 1/83/4 == 1/6 ergibt false
auf den Bildschirm.
7.4.2 Erzeugung von Zufallszahlen
Zufallszahlen sind ein Standardwerkzeug fur die Simulation vieler technischer Ablaufe. Die Aufgabeeines Zufallszahlengenerators ist es, wiederholt (d. h. in der Regel sehr lange Folgen von) Zahlen imInterval[0,1] zu generieren, die den Charakter zufalliger Ziehungen haben.17
Erfahrungen (undUberlegungen der Wahrscheinlichkeitstheorie) zeigen, dass sich mit der Funktion
f (x) = (a·x) modm
mit a = 16807 undm= 231−1 “gute” Zufallszahlen generieren lassen. Man startet mit beliebigemx0 ∈ 0,1, . . . ,m−1 (der sogenanntenseed) und erzeugt gemaßxn+1 = f (xn) eine Folge
x0,x1,x2, . . . ,xn,xn+1, . . .
von Zahlen aus0,1, . . . ,m−1. Die zugehorige Folge
x′n :=xn
m, n = 0,1,2, . . .
liefert dann “Zufallszahlen” im Interval[0,1].
Diese Folge ist naturlich bei festem Startwertx0 alles andere als zufallig, da man alle Werte berechnenkann. Außerdem wird irgendwann ein Wertxr zum zweiten mal auftreten und die Folge wird sich vonda ab wiederholen. Man spricht daher auch vonPseudozufallszahlen. Dennoch verhalten sich langeAnfangsstucke dieser Folge angenahert zufallig, so dass man sie in Simulationen gut nutzen kann.
Die unten stehende Klasse implementiert Generatoren fur Zufallszahlen als Objekte einer KlasseRandomNumber. Die Konstruktoren dieser Klasse erlauben entweder das Setzen der Startzahlx0, odereinen “zufalligen” Start, indemx0 als Systemzeit genommen wird. Als Methoden haben die Objek-te das Erzeugen der nachsten Zufallszahl aus dem Intervall[0,1] mit nextDoubleRand(), bzw. mitnextIntRand(int,int) das Erzeugen einer zufalligen gleichverteilten ganzen Zahl aus dem Be-reichlo,lo+1 . . . ,hi.
/*** The <code>RandomNumber</code> class offers facilities* for pseudorandom number generation.* <p>* An instance of this class is used to generate a stream of* pseudorandom numbers. The class uses a long seed, which is
17 Genauer, im Intervall[0,1] gleichverteilt sind. Teilt man also[0,1] in n gleichlange Teilintervalle und erzeugt manN n2 Zufallszahlen, so sollten in jedes Teilintervall ungefahr gleich viele (also∼ N/n) Zufallszahlen fallen.

218 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
* modified using a linear congruential formula. See <ul>* <li>Donald Knuth, <i>The Art of Computer Programming,* Volume 2</i>, Section 3.2.1. for general information about* random number gerneration and* <li>S. Park and K. Miller, Random number generators: Good* ones are hard to find, <i>Comm. ACM</i> 31 (1988) 1192-1201* for the specific one implemented here.* </ul>* @see java.util.Random* @see java.lang.Math#random()*/public class RandomNumber
private static final long MULTIPLIER = 16807;private static final long MODULUS = 2147483647;// Quotient of MODULUS / MULTIPLIERprivate static final long QUOT = 127773;// Remainder of MODULUS / MULTIPLIERprivate static final long REM = 2836;
/*** The current seed of the generator.*/private long currentSeed;
/*** Constructs a RandomNumber object and initializes it* with <code>System.currentTimeMillis()</code>*/public RandomNumber()
currentSeed = System.currentTimeMillis() % MODULUS;
/*** Constructs a RandomNumber object and initializes it* with the value <code>seed</code>* @param seed A value that permits a controlled* setting of the start seed.*/public RandomNumber(long seed)
currentSeed = Math.abs(seed) % MODULUS;
/**

7.4. BEISPIELE VON KLASSEN 219
* Generates the next random number in the interval [0,1]* @return The next random number in [0,1].*/public double nextDoubleRand()
long temp = MULTIPLIER*(currentSeed%QUOT) -REM*(currentSeed/QUOT);
currentSeed = (temp > 0) ? temp : temp + MODULUS;return (double) currentSeed / (double) MODULUS;
/*** Generates a random int value between the given limits.* @param lo The lower bound.* @param hi The upper bound.* @return An integer value in lo,...,hi* @throws InvalidOperationException if lo > hi*/public int nextIntRand(int lo, int hi)
throws InvalidOperationException if (lo > hi)
throw new InvalidOperationException("invalid range: " + lo + " > " + hi);
return (int) (nextDoubleRand() * (hi - lo + 1) + lo);
Die Implementation nutztcurrentSeed als Variable, die die momentane Zufallszahl enthalt. DieDefinition dieser Variablen alsprivate sorgt dafur, dass diese Variable nur innerhalb der Klassebenutzt werden kann.
Die Formelxk+1 = xk ·a modn wird hier zu
currentSeed = (currentSeed * MULTIPLIER) % MODULUS
Die modulo Berechnung wird, um einenUberlauf beicurrentSeed * MULTIPLIER zu verhindern,zerlegt in
MULTIPLIER * (currentSeed % QUOT) - REM * (currentSeed/QUOT);
wobei QUOT = MODULUS / MULTIPLIER und REM = MODULUS % MULTIPLIER ist. Zum Resultatmuss, falls es nicht positiv ist, nochMODULUS hinzu addiert werden, um es in den gewunschten Bereich
0≤ currentSeed≤ MODULUS−1
zu bringen18 (dies geschieht als bedingte Anweisung).
18Beweis alsUbung.

220 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
Die MethodenextIntRand() nutzt die Tatsache, dass bei der Konvertierung vondouble zu intnach unten gerundet wird. Es gilt also
0≤ nextDoubleRand() < 1
⇒ 0≤ nextDoubleRand() * (hi - lo + 1 ) < hi−lo+1
⇒ lo≤ nextDoubleRand() * (hi - lo + 1 ) < hi+1
⇒ lo≤ (int)(nextDoubleRand() * (hi - lo + 1) + lo) < hi+1
⇒ lo≤ (int)(nextDoubleRand() * (hi - lo + 1) + lo)≤ hi
Die Gleichverteilung der Zufallszahlen auf[0,1] ubersetzt sich daher auf die Gleichverteilung auflo,lo + 1, . . . ,hi.Eine mogliche Verwendung der KlasseRandomNumber zeigt das folgende Applet, das die Gute derZufallszahlen fur die Simulation eines Wurfelspiels testet. Dabei wird 360000 mal mit zwei Wurfelngewurfelt. Fur jeden Wurf wird die Summe der Augenzahlen ermittelt.Uber diese Summe wird eineStatistik gefuhrt und ausgegeben.
Programm 7.2 RollDice.Java/*** This class investigates the odds for rolling* two dice by randomly generating such rolls* and calculating the sum of their values*/import java.awt.*;import java.applet.Applet;import java.awt.event.ActionListener;import java.awt.event.ActionEvent;
public final class RollDice extends Applet
Label seedPrompt, no_rollsPrompt, progressMsg;TextField seedFld, no_rollsFld;TextArea output;
final static int MAX_VALUE = 6; // number of sides of the dicestatic int rolls; // number of rollsstatic long[] rollCount = new long[2 * MAX_VALUE + 1];
// rollCount[i] == number of times// that i was obtained as sum of the two dice
static long seed; // seed for random number generator
public void init() setLayout(new FlowLayout(FlowLayout.LEFT));

7.4. BEISPIELE VON KLASSEN 221
setFont(new Font("Times", Font.PLAIN, 24));Font courier = new Font("Courier", Font.PLAIN, 24);
no_rollsPrompt = new Label("Bitte Anzahl der Wurfe eingeben: ");
add(no_rollsPrompt);
no_rollsFld = new TextField("360000", 10);add(no_rollsFld);no_rollsFld.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)rollDice();
);
seedPrompt = new Label("Bitte Startzahl fur die Zufallszahlen eingeben: ");
add(seedPrompt);
seedFld = new TextField("0", 10);add(seedFld);seedFld.addActionListener(new ActionListener()
public void actionPerformed(ActionEvent e)rollDice();
);
output = new TextArea(12, 30);output.setFont(courier);add(output);
public void rollDice() try
output.setText("");
// get seedseed = Long.parseLong(seedFld.getText());// may throw NumberFormatExceptionrolls = Integer.parseInt(no_rollsFld.getText());
// get no of rolls// may throw NumberFormatExceptionif (rolls < 0)
output.setText("Anzahl der Wurfe "

222 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
+ "muss positiv sein");return;
for (int i = 0; i <= 2 * MAX_VALUE; i++) rollCount[i] = 0;
RandomNumber dice1, dice2 ; // the two dice// make them different by different seedsif (seed != 0)
dice1 = new RandomNumber(seed);dice2 = new RandomNumber(
seed*seed + 77*seed + 113); else
dice1 = new RandomNumber();dice2 = new RandomNumber(
System.currentTimeMillis() + 10000);
// throw the dice rolls many timesfor (int i = 0; i < rolls; i++)
rollCount[dice1.nextIntRand(1, MAX_VALUE)+ dice2.nextIntRand(1, MAX_VALUE)]++;
// generate the output nicely formattedString outputStr = format(rollCount);output.setText(outputStr);
catch (NumberFormatException e) output.setText("Bitte nur ganze Zahlen eingeben.");
private static String format(long[] rollCount) // generate the 3 colums of out put as 3 arrays of Strings// first column are the indices of rollCountString[] index = new String[rollCount.length];for (int i = 0; i < rollCount.length; i++)
index[i] = Integer.toString(i);// second column are the counts, ie. rollCount itselfString[] count = new String[rollCount.length];for (int i = 0; i < rollCount.length; i++)

7.4. BEISPIELE VON KLASSEN 223
count[i] = Long.toString(rollCount[i]);// third column are the normalized frequencies// with decimal pointString[] frequency = new String[rollCount.length];for (int i = 0; i < rollCount.length; i++)
long freq = (long) ((rollCount[i] / (double) rolls)* 10000);StringBuffer strBuf = new StringBuffer();strBuf.append(freq / 100 + "."); // decimal point
if (freq % 100 == 0) strBuf.append("00");else if (freq % 100 < 10) strBuf.append("0"
+ freq % 100);else strBuf.append(freq % 100);
frequency[i] = strBuf.toString();
// determine maximum Stringlength of every// column for indentationint maxIndex = maxLength(index);int maxCount = maxLength(count);int maxFreq = maxLength(frequency);
// generate the rows of the outputStringBuffer outputBuf = new StringBuffer();
outputBuf.append("sum count frequency\n");for (int i = 2; i < rollCount.length; i++)
// first columnoutputBuf.append(indent(maxIndex, index[i]) + ": ");// now the number of times that i is rolledoutputBuf.append(indent(maxCount, count[i]) + " ");// now the frequenciesoutputBuf.append(indent(maxFreq, frequency[i])
+ " %");if (i < rollCount.length - 1) outputBuf.append("\n");
return outputBuf.toString();
private static int maxLength(String[] arr) int max = arr[0].length();for (int i = 1; i < arr.length; i++)
if (max < arr[i].length()) max = arr[i].length();

224 KAPITEL 7. ABSTRAKTION VON METHODEN UND DATEN
return max;
private static String indent(int max, String str) StringBuffer strBuf = new StringBuffer();for (int i = 0; i < max - str.length(); i++)
strBuf.append(" ");strBuf.append(str);return strBuf.toString();
Der folgende Output furrolls= 360.000 zeigt, dass der Zufallszahlengenerator eine sehr gleichmaßigeVerteilung liefert. Jede Augenzahli = 2,3, . . . ,12 erscheint mit der zu erwartenden Haufigkeit von(i−1) ·10000 fur i = 2, . . . ,7 bzw.(12− i +1) ·10000 fur i = 8,9, . . . ,12.
sum count frequency2: 9942 2.76 %3: 19899 5.52 %4: 29768 8.26 %5: 39745 11.04 %6: 50104 13.91 %7: 60243 16.73 %8: 50225 13.95 %9: 40202 11.16 %10: 29888 8.30 %11: 19920 5.53 %12: 10064 2.79 %
7.5 Literaturhinweise
Die hier gegebene Darstellung lehnt sich stark an [HR94] an. Dies gilt insbesondere fur den Zufallszahlenge-nerator und die KlasseFraction.
Zufallsgeneratoren und Methoden zum Testen des Zufallsverhaltens werden ausfuhrlich in [Knu98a] behandelt.Der hier implementierte Generator geht auf [PM88] zuruck.
Weitere Beispiele fur Klassen und eine ausfuhrliche Beschreibung aller (hier nicht aufgefuhrten) Feinheitenund Variationen von Klassen in Java finden sich in [Kuh99].

Kapitel 8
Rekursion
Ein Objekt heißtrekursiv, wenn es sich selbst als Teil enthalt oder mit Hilfe von sich selbst definiertist. Rekursion kommt nicht nur in der Mathematik, sondern auch im taglichen Leben vor. Wer hatetwa noch nie Bilder gesehen, die sich selbst enthalten?
214 KAPITEL 8. REKURSION
Abbildung 8.1: Rekursion im Bild.
!!!!!!
""
""
""T1
!!!!
""
""T2
=⇒
!!!!!!
""
""
""T1
!!!!
""
""T2
!w
##
##
$$
$$
Abbildung 8.2: Rekursion bei binaren Baumen.! !!##! !$$
!!## !$$
!!##
!##
!!##
!$$
! !$$
!##
! !$$
!$$
Abbildung 8.3: Die nichtleeren binaren Baume mit hochstens 3 Knoten.
Zur Illustration beweisen wir die Aquivalenz der Definitionen bei binaren Baumen. Als Bewei-stechnik verwenden wir vollstandige Induktion, die bei der Rekursion als “Standardtechnik”angesehen werden kann.
Satz 8.1 Ein nicht-leerer Digraph T ist genau dann ein binarer Baum (im Sinne der Defini-tion gerichteter Baume auf Seite 168), wenn er aus einer Wurzel w und zwei (moglicherweiseleeren) Teilbaumen T1 und T2 besteht, die ihrerseits binar sind.
Beweis: ⇒ (durch vollstandige Induktion nach der Knotenzahl n von T ):
Abbildung 8.1: Rekursion im Bild
Rekursion kommt speziell in mathematischen Definitionen zur Geltung. Bekannte Beispiele sind dienaturlichen Zahlen, Baumstrukturen und gewisse Funktionen:
1. Naturliche Zahlen
Die MengeN der naturlichen Zahlen kann wie folgt rekursiv definiert werden.
– 0∈ N.
– Ist n∈ N, so auch derNachfolger n+1 vonn.
– N ist die kleinste Menge mit diesen Eigenschaften.
2. Binare Baume
Version vom 21. Januar 2005
225

226 KAPITEL 8. REKURSION
Binare Baumesind gerichtete Baume (vgl. Seite177), bei denen jeder Knoten Anfangspunktvon hochstens zwei Kanten ist. Die Menge der binaren Baume kann wie folgt rekursiv definiertwerden (siehe Satz8.1).
– Der leere Baum ohne Knoten ist ein binarer Baum (genannt derleere Baum).
– Sind T1 und T2 binare Baume, so ist auch der Graph bestehend aus einer Wurzelw undden TeilbaumenT1 undT2 ein binarer Baum, vgl. Abbildung8.2. Ist einer der Teilbaumeleer, so fehlt die zu ihm fuhrende Kante.
– Dies sind alle binaren Baume.
AAAAAAT1
AAAAT2
=⇒
AAAAAAT1
AAAAT2
rw
@@
@@
Abbildung 8.2: Rekursion bei binaren Baumen.
Die nicht leeren binaren Baume mit hochstens 3 Knoten sind in Abbildung8.3dargestellt.r rr r r@@ rr r@@ rrrrrr@@
r r@@rr r@@ r@@
Abbildung 8.3: Die nicht-leeren binaren Baume mit hochstens 3 Knoten.
3. Die Fakultatn! einer naturlichen Zahln kann rekursiv definiert werden als
n! =
1, falls n = 0n· (n−1)! , falls n > 0
Zur Illustration beweisen wir dieAquivalenz der Definitionen bei binaren Baumen. Als Beweistechnikverwenden wir vollstandige Induktion, die bei der Rekursion als “Standardtechnik” angesehen werdenkann.
Satz 8.1 Ein nicht-leerer Digraph T ist genau dann ein binarer Baum (im Sinne der Definition gerich-teter Baume auf Seite177), wenn er aus einer Wurzel w und zwei (moglicherweise leeren) TeilbaumenT1 und T2 besteht, die ihrerseits binar sind.
Beweis:”⇒“ (durch vollstandige Induktion nach der Knotenzahln vonT):

227
Induktionsanfang n= 1: Ist n = 1, so bestehtT nur aus der Wurzelw und den leeren TeilbaumenT1
undT2.
Induktionsschlussauf n > 1 Knoten: Seiw die Wurzel vonT. Wegenn > 1 hatT mindestens einennicht-leeren Teilbaum, etwaT1. Zu zeigen ist, dassT1 die rekursive Definition erfullt, d. h. aus einerWurzel und zwei binaren Teilbaumen besteht. Dies folgt sofort aus der Induktionsvorausetzung, daT1 weniger alsn Knoten hat. Fur den evtl. vorhandenen nicht-leeren zweiten TeilbaumT2 geht derBeweis analog.
”⇐“ (durch vollstandige Induktion nach der Knotenzahln vonT):
T erfulle die rekursive Definition. Zu zeigen ist:
1. T hat eine Wurzelw.
2. In jeden Knotenv 6= w geht genau eine Kante hinein.
3. Jeder Knotenv 6= w ist auf einem gerichteten Weg vonw aus erreichbar.
4. Von jedem Knoten gehen maximal 2 Kanten aus.
Induktionsanfang n= 1: Dann sind 1.–4. trivialerweise erfullt.
Induktionsschlussaufn > 1 Knoten: DaT die rekursive Definition erfullt, bestehtT aus einer Wurzelw und ein oder zwei nicht-leeren binaren TeilbaumenT1 undT2. Also ist 1. erfullt und gilt 4. fur w. SeiT1 nicht-leer undw1 die Wurzel vonT1. Auf T1 trifft die Induktionsvoraussetzung zu, d. h. 1.–4. geltenfur T1. Dies folgt ebenso fur T2, falls T2 nicht-leer ist. Also gilt 2. in ganzT, da 2. in den Teilbaumengilt und in ihren Wurzelnw1 bzw.w2 genau eine Kante endet. Entsprechend folgen 3. und 4.
Das Wesentliche der Rekursion ist die Moglichkeit, eineunendlicheMenge von Objekten durch eineendlicheAussage zu definieren. Auf die gleiche Art kann eine unendliche Zahl von Berechnungendurch ein endliches rekursives Programm beschrieben werden, ohne dass das Programm expliziteSchleifen enthalt. Rekursive Algorithmen sind hauptsachlich dort angebracht, wo das Problem, dieFunktion oder die Datenstruktur bereits rekursiv definiert ist.
Ein notwendiges und hinreichendes Werkzeug zur Darstellung rekursiver Programme sind Funktionen(also in Java Methoden), die sich selbst oder gegenseitig aufrufen konnen. Enthalt eine Funktionf() einen expliziten Aufruf ihrer selbst, so heißtf() direkt rekursiv; enthalt f() einen Aufruf einerzweiten Funktiong(), die dann ihrerseitsf() (direkt oder indirekt) aufruft, so heißtf() indirektrekursiv. Das Vorhandensein von Rekursion muss daher nicht direkt aus der Funktion ersichtlich sein.
Wie Wiederholungsanweisungen bergen auch rekursive Funktionen die Gefahr nicht abbrechenderAusfuhrung und verlangen daher die Betrachtung des Problems derTerminierung. Grundlegend istdaher die Bedingung, dass der rekursive Aufruf einer Funktion von einer BedingungB abhangt, dieirgendwann nicht mehr erfullt ist.

228 KAPITEL 8. REKURSION
8.1 Beispiele fur Rekursive Algorithmen
Zur Beachtung vorab: manchmal sollte man aus Komplexitatsgrunden statt Rekursion lieber Iterationverwenden. Hierauf wird in Kapitel8.2ausfuhrlich eingegangen.
8.1.1 Berechnung des ggT
Die Berechnung desggT erfolgte in Beispiel3.3 iterativ durch einewhile-Schleife. Aufgrund desdort gezeigten Lemma3.1gilt auch die folgende rekursive Darstellung desggT fur naturliche Zahlenx≥ y≥ 1.
ggT(x,y) =
y, falls x mody = 0ggT(y,x mody) , falls y > 0
Diese rekursive Darstellung fuhrt direkt zu der folgenden rekursiven Java Methode.
Programm 8.1 ggT rekursivint ggT(int a, int b)
// assume x, y >= 1int max = Math.max(a, b);int min = Math.min(a, b);int remainder = max % min;if (remainder == 0)
return min; else
return ggT(min, remainder);
Der Aufrufbaum (Rekursionsbaum) ist in Abbildung8.4 angegeben. Er entartet hier zur Liste, dakeine Verzweigung bei den Aufrufen auftritt.
Die Rekursionstiefe ist die Hohe des Rekursionsbaums plus 1, also 5. Der Run-Time Stack enthaltdaher beim “tiefsten” Aufruf 5 Activation Records, die in Abbildung8.5dargestellt sind.
Wir werden jetzt die Korrektheit des Programms beweisen und die maximale Rekursionstiefe abschatzen.Bei der Korrektheit unterscheiden wir zwischenpartieller Korrektheit(beim Terminieren des rekursi-ven Algorithmus liegt das korrekte Resultat vor) undtotaler Korrektheit(bei jedem Aufruf terminiertdie Abarbeitung mit dem korrekten Resultat).
Satz 8.2 Das Programm8.1 berechnet den großten gemeinsamen Teiler korrekt. IstggT(a,b) einAufruf des Programms und ist M:= maxa,b, so gilt fur die Rekursionstiefe (und die Gesamtzahlder Aufrufe) RggT(a,b):
RggT(a,b)≤ 1+2· logM

8.1. BEISPIELE FUR REKURSIVE ALGORITHMEN 229
ggT(4,2)
ggT(6,4)
ggT(10,6)
ggT(76,10)
ggT(76,238)
Abbildung 8.4: Der Rekursionsbaum von Programm8.1.
Beweis:Seia > b und seit := a div b undr := a modb. Dann gilt:
a = t ·b+ r ≥ b+ r (dat ≥ 1)> r + r (dab > r)
Also ist r < a2. Somit wird in der Paarfolge(a,b), (b, r), (r, ·) usw., die beim rekursiven Aufruf von
ggT(a,b) entsteht, das großere der beiden Elementea,b nach zwei Aufrufen mehr als halbiert. Alsokann es hochstens 1+2· logM Aufrufe geben.
Der Algorithmus terminiert also bei jedem Aufruf (sogar schnell). Die Korrektheit des dann geliefer-ten Ergebnisses folgt aus Lemma3.1, da ja die Operationa modb auf die fortgesetzte Subtraktionzuruckgefuhrt werden kann. Diet-malige Anwendung von Lemma3.1aufa = t ·b+ r ergibt namlichgeradeggT(a,b) = ggT(b, r).
8.1.2 Die Turme von Hanoi
Dieses Problem geht auf eine hinterindische Sage zuruck: In einem im Dschungel verborgenen hinter-indischen Tempel sind Monche seit Beginn der Zeitrechnung damit beschaftigt, einen Stapel von 50goldenen Scheiben mit nach oben hin abnehmendem Durchmesser, die durch einen goldenen Pfeilerin der Mitte zusammengehalten werden, durch sukzessive Bewegungen jeweils einer einzigen Scheibeauf einen anderen goldenen Pfeiler umzuschichten. Dabei durfen sie einen dritten Pfeiler als Hilfspfei-ler benutzen, mussen aber darauf achten, dass niemals eine Scheibe mit großerem Durchmesser aufeine mit kleinerem Durchmesser zu liegen kommt. Eine Losung fur 3 Scheiben ist in Abbildung8.6dargestellt.
Die Sage berichtet, dass das Ende der Welt gekommen ist, wenn die Monche ihre Aufgabe beendethaben.

230 KAPITEL 8. REKURSION
a = 4b = 2max = 4min = 2remainder = 0Rucksprungadresse 5static pointer: HEAP
a = 6b = 4max = 6min = 4remainder = 2Rucksprungadresse 4static pointer: HEAP
a = 10b = 6max = 10min = 6remainder = 4Rucksprungadresse 3static pointer: HEAP
a = 76b = 10max = 76min = 10remainder = 6Rucksprungadresse 2static pointer: HEAP
a = 76b = 238max = 238min = 76remainder = 10Rucksprungadresse 1static pointer: HEAP
1. Aufruf ⇒ Aufruf ggT(76,10)
⇒ Aufruf ggT(10,6)
⇒ Aufruf ggT(6,4)
⇒ Aufruf ggT(4,2)
⇒ return 2
Abbildung 8.5: Der Run-Time-Stack von Programm8.1.
Wir wollen uns nun ganz allgemeinuberlegen, wie mann Scheiben abnehmender Große von einemPfeileri auf einen Pfeilerj (1≤ i, j ≤ 3, i 6= j) entsprechend der angegebenen Vorschrift umschichtenkann.
Sei k der dritte zur Verfugung stehende Hilfspfeiler. Dann kann man das Problem,n Scheiben vom

8.1. BEISPIELE FUR REKURSIVE ALGORITHMEN 231
8.1. BEISPIELE FUR REKURSIVE ALGORITHMEN 219
Abbildung 8.6: Umschichten von 3 Scheiben.
vom Pfeiler i zum Pfeiler j mit Hilfe des Pfeilers k umzuschichten, folgendermaßen losen:
Man schichtet die obersten n− 1 Scheiben vom Pfeiler i zum Pfeiler k mit Hilfe des Pfeilersj; dann bringt man die auf dem Pfeiler i verbliebene einzige (anfangs unterste) Scheibe (alseinzige Scheibe) auf den Pfeiler j. Nun ist der Pfeiler i frei und man kann die n− 1 Scheibenvom Pfeiler k auf den Pfeiler j mit Hilfe des Pfeilers i umschichten. Dies ist in Abbildung 8.7dargestellt.
Wir definieren nun eine Methode move() so, daß der Aufruf move(n,i,j,k) die Zugfolge aus-gibt, mit der n Scheiben vom Pfeiler i zum Pfeiler j mit Hilfe des Pfeilers k so umgeschichtetwerden, daß niemals eine großere auf eine kleinere Scheibe zu liegen kommt.
Der oben erlauterte rekursive Zusammenhang zwischen move(n,...) und move(n-1,...)fuhrt dann zu folgender Methode:
String move( int numberOfDisks, int origin, int destination, int auxPile ) if ( numberOfDisks <= 0 ) return ""; // no moves to return
StringBuffer moves = new StringBuffer();
Abbildung 8.6: Umschichten von 3 Scheiben.
Pfeiler i zum Pfeilerj mit Hilfe des Pfeilersk umzuschichten, folgendermaßen losen:
Man schichtet die oberstenn−1 Scheiben vom Pfeileri zum Pfeilerk mit Hilfe des Pfeilersj; dannbringt man die auf dem Pfeileri verbliebene einzige (anfangs unterste) Scheibe (als einzige Scheibe)auf den Pfeilerj. Nun ist der Pfeileri frei und man kann dien−1 Scheiben vom Pfeilerk auf denPfeiler j mit Hilfe des Pfeilersi umschichten. Dies ist in Abbildung8.7dargestellt.
Wir definieren nun eine MethodegetMoves() so, dass der AufrufgetMoves(n,i,j,k) die Zugfol-ge ausgibt, mit dern Scheiben vom Pfeileri zum Pfeilerj mit Hilfe des Pfeilersk so umgeschichtetwerden, dass niemals eine großere auf eine kleinere Scheibe zu liegen kommt.
Der oben erlauterte rekursive Zusammenhang zwischengetMoves(n,...) undgetMoves(n-1,...)fuhrt dann zu folgender Methode:
String getMoves(int numberOfDisks, int origin, int destination, int auxPile)if (numberOfDisks <= 0) return ""; // no moves to return
StringBuffer moves = new StringBuffer();

232 KAPITEL 8. REKURSION
220 KAPITEL 8. REKURSION
n
i j k i j k
n− 1
n− 1
n
Abbildung 8.7: Umschichten von n Scheiben.
// move numberOfDisks - 1 smallest disks from origin to auxPile// with destination as auxiliary filemoves.append( move( numberOfDisks - 1, origin, auxPile, destination) );
// write the move of the largest disk on coutmoves.append( origin + " --> " + destination + "\n" );
// move the numberOfDisks - 1 smallest disks from auxPile// to destination with origin as auxiliary file// (the largest disk on destination does not interfere)moves.append( move( numberOfDisks - 1, auxPile, destination, origin) );
return moves.toString();
Diese Methode gibt bei Aufruf von move(3,1,2,3) folgende Zugfolge zuruck:
1 --> 21 --> 32 --> 31 --> 23 --> 13 --> 21 --> 2
Die rekursive Losung ist hier besonders elegant, da der Rekursionsansatz einfach ist, wahrend
Abbildung 8.7: Umschichten vonn Scheiben.
// move the numberOfDisks - 1 smallest disks// from origin to auxPile// with destination as auxiliary pilemoves.append(getMoves(numberOfDisks - 1, origin,
auxPile, destination));
// append the move of the largest disk to StringBuffer movesmoves.append(origin + " --> " + destination + "\n");
// move the numberOfDisks - 1 smallest disks from auxPile// to destination with origin as auxiliary file// (the largest disk on destination does not interfere)moves.append(getMoves(numberOfDisks - 1, auxPile,
destination, origin));
return moves.toString();
Diese Methode gibt bei Aufruf vongetMoves(3,1,2,3) folgende Zugfolge zuruck:
1 --> 21 --> 32 --> 31 --> 23 --> 13 --> 2

8.1. BEISPIELE FUR REKURSIVE ALGORITHMEN 233
1 --> 2
Die rekursive Losung ist hier besonders elegant, da der Rekursionsansatz einfach ist, wahrend dieHerleitung einer iterativen Losung (die der Angabe einer expliziten “Strategie” zum Bewegen derScheiben gleichkommt) wesentlich schwieriger ist (vgl.Ubung).
Der Rekursionsbaum fur den Aufruf vongetMoves(3,1,2,3) ist in Abbildung8.8 dargestellt. Erhat die Hohe 3. Also hat der Aufruf die Rekursionstiefe 4. Die Zahlen an den Aufrufen geben dieReihenfolge der Aufrufe an. Die zugehorige Belegung des Run-Time-Stack ist in Abbildung8.9wie-dergegeben. Sie entspricht dem Durchlauf des Baumes in WLR-Ordnung (erst die Wurzel, dann linkerTeilbaum nach derselben Regel, dann rechter Teilbaum nach derselben Regel).
getM(1,1,2,3) getM(1,2,3,1) getM(1,3,1,2) getM(1,1,2,3)
g(0,..) g(0,..) g(0,..) g(0,..) g(0,..) g(0,..) g(0,..) g(0,..)
getM(2,1,3,2) getM(2,3,2,1)
getM(3,1,2,3)
AAA
AAA
AAA
AAA
@@@
@@@
PPPP
PPPP
P
1
2 9
3 6 10 13
4 5 7 8 11 12 14 15
Abbildung 8.8: Rekursionsbaum zu den Turmen von Hanoi. Aus Platzgrunden istgetMoves(...)mit getM(...) oderg(...) abgekurzt.
leer 1 2 3 4 3 5 3 2 6 7 6 8 6 2 1 9 10 11 usw.1 2 3 2 3 2 1 2 6 2 6 2 1 1 9 10
1 2 1 2 1 1 2 1 2 1 1 91 1 1 1 1
Abbildung 8.9: Der Run-Time-Stack zugetMoves(3,1,2,3). Die Zahlen sind die Nummern derAufrufe aus Abbildung8.8
Allgemein gilt:
Satz 8.3 Beim Aufruf vonmove(n,1,2,3) ist die Rekursionstiefe R(n) = n+ 1, die Gesamtanzahlder rekursiven Aufrufe T(n) = 2n+1−1, und die Anzahl der Zuge Z(n) = 2n−1.
Beweis:Der Beweis erfolgt durch Induktion nach der Anzahln der Scheiben. Dabei ist der Indukti-onsanfang fur n = 0 undn = 1 klar.

234 KAPITEL 8. REKURSION
Zum Schluss aufn > 1 betrachten wir die Arbeitsweise vonmove(). Es wird zweimalmove( n -1, ...) aufgerufen und ein zusatzlicher Zug"origin --> destination" hinzugefugt. Auf diebeiden Aufrufemove( n - 1, ...) trifft die Induktionsvoraussetzung bzgl.n−1 zu. Also gilt:
R(n) = 1+R(n−1) = 1+n ,
T(n) = 1+2·T(n−1) = 1+2(2n−1+1−1) = 2n+1−1 ,
Z(n) = 1+2·Z(n−1) = 1+2(2n−1−1) = 2n−1 .
8.1.3 Die Ackermann Funktion
Als Beispiel fur eine rekursive Funktionsdefinition komplexerer Art betrachten wir das Beispiel derAckermann Funktiona(m,n), die als Extrapolation der Folge immer starker wachsenden FunktionenSumme, Produkt, Potenz,. . . aufgefasst werden kann. Sie ist wie folgt definiert.
a(m,n) =
n+1, falls m= 0a(m−1,1) , falls m> 0, n = 0a(m−1,a(m,n−1)) , falls m,n > 0
Auch diese Definition lasst sich unmittelbar in eine Java Methodeubersetzen:
int a(int m, int n) // assume m >= 0 and n >= 0if (m == 0) return n+1;else if (n == 0) return a(m-1,1);else return a(m-1,a(m,n-1));
Fur die MethodeA ist es bereits viel schwieriger zu sehen, wie (und dassuberhaupt) jede Berechnungnach endlich vielen Schritten terminiert. Dies ist zwar der Fall, wie Satz8.4zeigt, aber in der Praxisscheitert die Berechnung bereits fur relativ kleine Argumente an der riesigen Rekursionstiefe.
Die Ackermann Funktion wachst sehr stark, und zwar, wie in derTheorie der rekursiven Funktionenoder derBerechenbarkeitgezeigt wird, starker als jede sogenannteprimitiv rekursiveFunktion (dassind Funktionen mit einem “einfachen” Rekursionsschema). Es gilt z. B. (vgl.Ubung):
a(0,n) > n a(3,n) > 2n
a(1,n) > n+1 a(4,n) > 22··2
n mala(2,n) > 2n a(5,4) > 1010000

8.1. BEISPIELE FUR REKURSIVE ALGORITHMEN 235
So erfordert bereits die Ausrechnung vona(1,3) “per Hand” folgenden Aufwand:
a(1,3) = a(0,a(1,2))= a(0,a(0,a(1,1)))= a(0,a(0,a(0,a(1,0))))= a(0,a(0,a(0,a(0,1))))= a(0,a(0,a(0,2)))= a(0,a(0,3))= a(0,4)= 5
Satz 8.4 Fur alle m,n∈ N terminiert der Aufruf a(m,n) nach endlich vielen Schritten.
Beweis:Der Beweis erfolgt durch zwei ineinander geschachtelte Induktionenuberm (außere Induk-tion) und, bei festemm, ubern (innere Induktion).
Induktionsanfang(m= 0): Dann erfolgt unabhangig vonn nur ein Aufruf. Also wird terminiert.
Induktionsvoraussetzung: Die Behauptung sei richtig fur allek mit 0≤ k < m, und fur allen, d. h. derAufruf a(k,n) terminiert nach endlich vielen Schritten.
Schluss auf mdurch Induktionubern (innere Induktion):
Induktionsanfang(n = 0): Dann wird fur a(m,0) der Wert vona(m−1,1) zuruckgegeben. Hierfurterminiert der Algorithmus nach Induktionsvorausetzung deraußeren Induktion.
Induktionsvoraussetzung: Der Aufruf a(m, `) terminiert fur (festes)m und alle` < n.
Schluss auf n: Der Aufruf von a(m,n) erzeugt den Aufruf vona(m− 1,a(m,n− 1). Nach innererInduktionsvoraussetzung terminiert der Aufrufa(m,n−1) und liefert eine Zahlk. Dies erzeugt denAufruf a(m−1,k), der nachaußerer Induktionsvorausetzung terminiert.
8.1.4 Ulams Funktion
Diese Funktion wurde mehrfach von Mathematikern untersucht (Klam, Collatz, Kakutani, vgl. [LV92]).Sie stellt ein Beispiel fur einen einfachen Algorithmus dar, fur den bis heute nicht bekannt ist, ob erbei allen Eingaben terminiert.
Der Algorithmus erzeugt, ausgehend von einer naturlichen Zahla0 > 0, eine Folge von Zahlena0,a1, . . . ,an, . . .gemaß der Vorschrift
an+1 =
an/2, falls an gerade ist,3an +1, sonst,
und bricht ab, sobaldan = 1 gilt.

236 KAPITEL 8. REKURSION
Zum Beispiel fuhrt a0 = 3 zur Folge 3, 10, 5, 16, 8, 4, 2, 1. Es ist offen, ob der Algorithmus beibeliebigen Input stets zum Abbruch fuhrt, d. h. ob dieLange der Folgeimmer endlich ist.
Wir kleiden dies in eine rekursive Funktion. Seia∈ N,a > 0
ulam(a) :=
0, falls a = 1,1+ulam(a/2) , falls a gerade,a≥ 2,1+ulam(3a+1) , falls a ungerade,a≥ 2.
Offenbar berechnetulam(a) gerade die Lange der Folge mita0 = a.
Obwohl wir nicht wissen, ob diese Funktion fur jede naturliche Zahl als Input einen Funktionswertliefert, ist die Definition als Java Methode naturlich zulassig. Es ist jedoch die (zumindest theoretische)Moglichkeit nicht auszuschließen, dass ein Aufruf der Funktionulam fur bestimmte Argumente einenicht abbrechende Folge von rekursiven Aufrufen in Gang setzt. Dies ist zugleich ein Beispiel fur denFall, dass eine formal zulassige Funktionsdefinition nicht auch inhaltlich vernunftig sein muss. Mansollte sich stets vergewissern, ob der durch eine Funktionsdefinition beschriebene Berechnungsprozessfur beliebige Argumente abbricht, also auch fur solche, an die man vielleicht zunachst nicht gedachthat.
8.2 Wo Rekursion zu vermeiden ist
Rekursive Algorithmen eignen sich besonders, wenn das zugrunde liegende Problem oder die zu be-handelnden Daten rekursiv definiert sind. Das bedeutet aber nicht, dass eine solche rekursive Definiti-on eine Garantie dafur bietet, dass ein rekursiver Algorithmus der beste Weg zur Losung des Problemsist.
Der Aufwand bei rekursiven Aufrufen wird im wesentlichen durch denAufrufbaum(Rekursions-baum) bestimmt. Seine Hohe plus 1 ist dieRekursionstiefe. Sie bestimmt diemaximale Große desRun-Time-Stacks, der durch den ersten Aufruf verursacht wird, und bestimmt damit den benotigtenSpeicherplatz.
Die Gesamtanzahl der Knoten im Aufrufbaum bestimmt dieAnzahl aller rekursiven Aufrufe. Sie istein Maß fur die benotigteLaufzeit.
Als Generalregelsollte man daher Rekursion immer dann vermeiden, wenn der benotigte Speicher-platz (also die Rekursionstiefe) oder die benotigte Laufzeit (also die Anzahl der Knoten des Rekursi-onsbaums) zu groß werden. Wir erlautern dies an einigen Beispielen.
8.2.1 Berechnung der Fakultat
Die Implementation der Fakultatsfunktion gemaß der rekursiven Definition
f ak(n) :=
1, falls n = 0,n· f ak(n−1) , falls n > 0,

8.2. WO REKURSION ZU VERMEIDEN IST 237
fuhrt zur Rekursionstiefen+1, die deutlich zu groß ist. Der Rekursionsbaum entartet zudem zu einerListe (keine Verzweigungen), was meist ein Zeichen dafur ist, dass es auch einen einfachen iterativenAlgorithmus gibt (vgl. Beispiel7.1).
8.2.2 Berechnung des großten gemeinsamen Teilers
Der rekursive Algorithmus in Kapitel8.1.1fuhrt nach Satz8.2 zu einer Rekursionstiefe von 1+ 2 ·logmaxn,m. Dies ist akzeptabel. Allerdings ist der Rekursionsbaum wieder eine Liste, so dass manauch einen iterativen Algorithmus verwenden konnte (vgl. Algorithmus3.2).
8.2.3 Die Turme von Hanoi
Die Rekursionstiefe ist bein Scheibenn+ 1, und die Gesamtanzahl der Aufrufe ist 2n+1− 1. Dieserscheint sehr groß, ist es aber im Verhaltnis zu der Zahl der auszugebenden Zuge nicht. Eine iterativeLosung ware vorzuziehen, wenn sie denn einfach zu finden ware. Die rekursive Struktur des Problemslegt jedoch die Verwendung der Rekursion nahe.
8.2.4 Berechnung der Fibonacci-Zahlen
Die Folge f0, f1, f2, . . . derFibonacci-Zahlenwachst nach dem Gesetz
f0 := 0, f1 := 1,fn+1 := fn + fn−1 fur n > 0.
Sie stellen eine schnell wachsende Folge von Zahlen dar, die das Wachstum einer Population von sichschnell vermehrenden Lebewesen (Bakterien, Kaninchen) modelliert. Istfn die Anzahl der “Neuge-burten” in Perioden, und reproduzieren sich in einer Periode genau die in den beiden vorherigenPerioden “geborenen” Mitglieder (“gebarfahiges Alter”) so entsteht die Folge der Fibonacci-Zahlenals Folge der Geburtenzahlen.
Die rekursive Definition fuhrt auf folgende rekursive Methode:
int fib(int n) if (n == 0) return 0;else if (n == 1) return 1;else return fib(n-1) + fib(n-2);
Beim Aufruf vonfib(5) ergibt sich der in Abbildung8.10dargestellte Rekursionsbaum.
Beim Aufruf vonfib(n) ist also die Rekursionstiefen, und fur die GesamtanzahlTf ib(n) der rekur-siven Aufrufe gilt

238 KAPITEL 8. REKURSION
fib(2) fib(1) fib(1) fib(0) fib(1) fib(0)
fib(1) fib(0)
fib(3) fib(2) fib(2) fib(1)
fib(4) fib(3)
fib(5)
((((((((
(
hhhhhhhh
h
XXXXXX
XXXXXX
HHH
HHH
HHH
HHH
Abbildung 8.10: Rekursionsbaum zu der Fibonacci-Folge.
Satz 8.5 Tf ib(n) wachst mindestens exponentiell. Genauer gilt
Tf ib(n)≥ 2bn/2c fur n≥ 2.
Beweis:Dies beweist man durch vollstandige Induktion wie folgt:
Induktionsanfang:n = 0 : Tf ib(0) = 1, 2b0/2c = 20 = 1n = 1 : Tf ib(1) = 1, 2b1/2c = 20 = 1
Schluss von n auf n+1:
Tf ib(n+1) ≥ 2·Tf ib(n−1)
≥ 2·2b(n−1)/2c
= 2b(n+1)/2c .
Die erste Ungleichung folgt aus der Tatsache, dassf ib(n−1) zweimal aufgerufen wird; die zweitefolgt aus der Induktionsvoraussetzung.
Der Aufwand ist alsoahnlich wie bei den Turmen von Hanoi. Wahrend jedoch bei den Turmen vonHanoi stets andere Teilprobleme in den rekursiven Aufrufen berechnet werden, tauchen hierdieselbenTeilproblemewiederholt auf.
Eine solcheMehrfachberechnung identischer Teilproblemesollte man unbedingt vermeiden. Bei denFibonacci-Zahlen geht dies durch folgende iterative Variante.
Der letzteelse Teil in fib wird dabei ersetzt durch
int fib(int n) // assume n >= 0if (n == 0) return 0;

8.3. LITERATURHINWEISE 239
if (n == 1) return 1;int currentFib = 1, prevFib = 0;for ( int i = 1; i < n; i++ )
currentFib = currentFib + prevFib;prevFib = currentFib - prevFib;
return currentFib;
Dabei spielen die VariablencurrentFib und prevFib die Rolle von fn und fn−1, die in beidenZuweisungen zufn+1 = fn + fn−1 und fn = fn+1− fn−1 aktualisiert werden.
Man vergleiche einmal die Laufzeit beider Varianten fur Zahlenn abn = 35.
8.2.5 Zusammenfassung
Die Folgerung aus diesenUberlegungen ist, dass man auf die Verwendung von Rekursion immer dannverzichten sollte, wenn es eine offensichtliche Losung mit Iteration gibt. Das bedeutet aber nicht, dassRekursion um jeden Preis zu umgehen ist. Es gibt viele gute Anwendungen fur Rekursion, wie diefolgenden Kapitel zeigen werden.
Die Tatsache, dass Implementationen von rekursiven Funktionen auf nicht-rekursiven Maschinen exis-tieren, beweist, dass gegebenenfalls jedes rekursive Programm in ein rein iteratives umgeformt werdenkann. Dies verlangt jedoch das explizite Verwalten eines Rekursions-Stacks. Durch diese Operatio-nen wird das Grundprinzip eines Programms oft so sehr verschleiert, dass es schwer zu verstehen ist.Zusammenfassend lasst sich sagen, dass Algorithmen, die ihrem Wesen nach eher rekursiv als iterativsind, tatsachlich als rekursive Funktionen formuliert werden sollten.
8.3 Literaturhinweise
Die hier gegebene Darstellung lehnt sich in Teilen an [Wir86] an. Von dort ist auch Abbildung 8.1 entnommen.
Die Darstellung der Turme von Hanoi folgt [OW82].
Der Artikel [LV92] gibt vertiefende Informationen (und Berechnungen) zu Ulams Funktion.
Weitere Beispiele fur Rekursion finden sich in nahezu allen Buchernuber Algorithmen und Datenstrukturen.

240 KAPITEL 8. REKURSION

Kapitel 9
Die Analyse von Algorithmen
Ziel der Analyse ist dieEffizienzuntersuchungund dieEntwicklung effizienterer Algorithmen.
Die Analyse soll zunachst rechnerunabhangig durchgefuhrt werden. Man braucht also ein geeignetesRechnermodell.
Die Annahmenuber das Rechnermodell konnen wichtige Konsequenzen haben in Bezug auf die Fra-ge, wieviel Zeit man zur Losung eines Problems braucht. Es existieren zwar formale Rechnermodelle(z. B. Turingmaschinen oder Maschinen mitwahlfreiemSpeicherzugriff (random access machines)),wir werden jedoch fast immer einen “ganz gewohnlichen Rechner” zugrunde legen. Damit ist ge-meint, dass Befehle eines Programms zeitlich nacheinander (sequentiell) ausgefuhrt werden, und dassdie Kosten eines Algorithmus im wesentlichen abhangen von der Anzahl der erforderlichen Opera-tionen. Wir nehmen an, dass ein sogenanntes RAM (Random Access Memory) zur Verfugung steht,also ein Speicher mit wahlfreiem Zugriff. Mit diesem Speicher ist es moglich, jede beliebige Variableeines unstrukturierten Datentyps (alsoint, double usw. und ebenso unstrukturierte Komponenteneines strukturierten Datentyps mit random access (also Arraykomponenten und Felder von Objekten)in einer fest vorgegebenen Zeitspanne zu speichern bzw. auszulesen.
Bei der Analyse von Algorithmen besteht die erste Aufgabe darin festzustellen, welche Operatio-nen verwendet werden und wie hoch ihre relative Kosten sind. Typische Operationen sind z. B. dievier Grundrechenarten Addition, Subtraktion, Multiplikation und Division, angewendet auf ganzeZahlen. Andere elementare Operationen sind arithmetische Operationen mit Gleitkommazahlen, Ver-gleichsbefehle, Wertzuweisungen an Variablen und ggf. Funktionsaufrufe. Elementare Operationenbenotigen typischerweise nie mehr als eine gewisse feste Zeitspanne zur Ausfuhrung; wir sagen, dassihre Ausfuhrungszeit durch eine Konstante beschrankt ist. Dies trifft nicht mehr zu fur strukturierteDaten, z. B. fur Vergleich von Strings, die abhangig von der Lange der Strings ist, oder die Suche desmaximalen Elementes in einem Array.
Version vom 21. Januar 2005
241

242 KAPITEL 9. DIE ANALYSE VON ALGORITHMEN
9.1 Analysearten
Man unterscheidet folgende Arten der Analyse.
• A priori Analyse (rechnerunabhangig)
– worst-case Komplexitat: Dies ist eine obere Schranke fur die Ausfuhrungszeit (in Formvon Anzahl der auszufuhrenden Operationen) in Abhangigkeit der Große des Inputs, ge-messen in relevanten Parametern (z. B. die Anzahl der zu sortierenden Objekte, Stellen-zahl von Zahlen, etc.)
– Mittlere Komplexitat: Dies ist eine obere Schranke fur die mittlere Ausfuhrungszeit beigewissen (Wahrscheinlichkeits-) Annahmenuber das Auftreten der Problemdaten
– Untere Komplexitatsschranken: Hierunter versteht man die Ermittlung unterer Schrankenfur die (worst-case oder mittlere) Ausfuhrungszeit.
Im Idealfall liegen obere und und untere Schranke “dicht” zusammen. Dies ist meist jedoch sehrschwer zu erreichen. Hierfur hat sich eine eigene Disziplin, dieKomplexitatstheorieentwickelt.
• A posteriori Analyse(rechnerabhangig)
Hierunter versteht man das Testen einerImplementationdes Algorithmus an hinreichend großenDatensatzen, so dass “alle” Verhaltensweisen des Algorithmus auftreten. Man erstellt dann eineSammlung statistischer Datenuber Ziel- und Speicherbedarf in Abhangigkeit des Datenmateri-als.
Als Beispiel betrachten wir drei Programmsegmente
(a) (b) (c)x = x+y; for (i=0; i<n; i++) for (i=0; i<n; i++)
x = x+y; for (j=0; j<n; j++)x = x+y;
In allen Fallen nehmen wir an, dass die Anweisungx = x+y in keiner anderen Schleife steht als in denhier gezeigten. Daher ist im Segment(a) die Haufigkeit dieser Anweisung 1. Im Segment(b) ist sien,und im Segment(c) ist sien2. Diese Haufigkeiten 1, n, n2 unterscheiden sich um Großenordnungen.Der Begriff “Großenordnung” ist uns allen vertraut; so unterscheiden sich z. B. Gehen, Autofahrenund Fliegen durch verschiedene Großenordnungen bzgl. der Entfernung, die ein Mensch in einer Stun-de zurucklegen kann. Im Zusammenhang mit der Algorithmenanalyse bezieht sich die Großenordnungeiner Anweisung auf die Haufigkeit ihrer Ausfuhrung, wahrend die Großenordnung eines Algorith-mus sich auf die Summe der Haufigkeit aller seiner Anweisungen bezieht.
Die a priori Analyse beschaftigt sich hauptsachlich mit der Bestimmung von Großenordnungen.Glucklicherweise gibt es eine bequeme mathematische Notation, die diesem Begriff entspricht.

9.2. DIE ASYMPTOTISCHE NOTATION 243
9.2 Die Asymptotische Notation
Bei der a priori Analyse der Rechenzeit werden alle Faktoren außer acht gelassen, die von der Ma-schine oder der Programmiersprache abhangig sind. Man konzentriert sich ganz auf die Bestimmungder Großenordnung der Haufigkeit von Anweisungen. Es gibt mehrere Arten der mathematischenNotation, die sich hierfur anbieten. Eine davon ist dieO-Notation:
9.2.1 Obere Schranken
Seig : N→ N. Dann bezeichnet
O(g) := f : N→ N | ∃ c > 0 und∃ n0 ∈ N mit f (n)≤ c·g(n) ∀n≥ n0
die Menge aller Funktionenf : N→ N, fur die zwei positive (i. A. vonf abhangige) Konstantenc ∈ R und n0 ∈ N existieren, so dass fur alle n≥ n0 die Ungleichungf (n) ≤ c · g(n) gilt. Gehorteine Funktionf : N→ N zu dieser Menge, so schreibt manf ∈ O(g) (gesprochen:
”f ist von der
Großenordnung großOh von g“). Andere gebrauchliche Schreibweisen hierfur sind f = O(g) bzw.auch f (n) ∈O(g(n)) und f (n) = O(g(n)).1
Nehmen wir an, wir ermitteln die Rechenzeitf (n) fur einen bestimmten Algorithmus. Die Variablenkann z. B. die Anzahl der Ein- und Ausgabewerte sein, ihre Summe, oder auch die Große eines dieserWerte. Daf (n) maschinenabhangig ist, genugt eine a posteriori Analyse nicht. jedoch kann man mitHilfe einer a priori Analyse eing(n) bestimmen, so dassf (n) = O(g(n)).
Wenn wir sagen, dass ein Algorithmus eine RechenzeitO(g(n)) hat, dann meinen wir damit Folgen-des: Wenn der Algorithmus auf unterschiedlichen Computern mit den gleichen Datensatzen lauft, unddiese die Großen haben, dann werden die resultierenden Laufzeiten immer kleiner sein als eine Kon-stante malg(n). Bei der Suche nach der Großenordnung vonf (n) werden wir darum bemuht sein, das
”kleinste“ g(n) zu finden, so dassf (n) ∈O(g(n)) gilt.
Ist f (n) z. B. ein Polynom, so gilt:
Satz 9.1 Fur ein Polynom f(n) = amnm+ . . .+a1n+a0 vom Grade m gilt: f(n) ∈O(nm).
Beweis:Wir benutzen die Definition vonf (n) und eine einfache Ungleichung:
f (n) ≤ |am|nm+ . . .+ |a1|n+ |a0|
= (|am|+|am−1|
n+ . . .+
|a0|nm )nm
≤ (|am|+ . . .+ |a0|)nm fur n≥ 1.
Setzt manc = |am|+ . . .+ |a0| undn0 = 1, so folgt unmittelbar die Behauptung.
1In der Analysis wirdO(g) fur reelle Funktioneng eingefuhrt. Da uns hier nur Laufzeitfunktionen interessieren, be-schranken wir uns auf Funktionenf : N→ N.

244 KAPITEL 9. DIE ANALYSE VON ALGORITHMEN
Die asymptotischeO-Notation vernachlassigt Konstanten und Terme niedriger Ordnung (wie z. B. dieTermeaknk mit k < m im Polynom). Dafur gibt es zwei gute Grunde:
– Fur großen ist die Großenordnung allein maßgebend. Z. B. ist bei 104 · n und n2 die ersteLaufzeit fur großen (n≥ 104) zu bevorzugen.
– Konstanten und Terme niedrigerer Ordnung hangen von vielen Faktoren ab, z. B. der gewahltenSprache oder der verwendeten Maschine, und sind daher meist nicht maschinenunabhangig.
Um Großenordnungen unterscheiden zu konnen, gibt es dieo-Notation (lies: klein oh Notation). Seig : N→ N. Dann bezeichnet
o(g) := f : N→ N | ∀ c > 0 ∃ n0 ∈ N mit f (n) < c·g(n) ∀n≥ n0
die Menge aller Funktionenf : N→N, fur die zu jeder positiven Konstantenc∈R einn0∈N existiert,so dass fur alle n ≥ n0 die Ungleichungf (n) < c · g(n)gilt . Gehort eine Funktionf : N → N zudieser Menge, so schreibt manf ∈ o(g) (gesprochen:
”f ist klein oh von g“). Andere gebrauchliche
Schreibweisen hierfur sind analog zurO-Notation f = o(g) bzw. auchf (n) ∈ o(g(n)) und f (n) =o(g(n)). Man sagt dann auch, dassf von (echt) kleinerer Großenordnungalsg ist.
Die gangigsten Großenordnungen fur Rechenzeiten sind:
O(1) < O(logn) < O(n) < O(nlogn) < O(n2)< O(nk) fur k∈ N fest,k≥ 3
< O(nlogn) < O(2n)
Dabei bedeutetO( f (n)) < O(g(n)), dassf (n) = o(g(n)), f (n) also von kleinerer Großenordnung alsg(n) ist.
Um den Unterschied dieser Großenordnungen zuuberprufen, ziehen wir ein nutzliches Kriterium derAnalysis heran:
Lemma 9.1 Seien f,g : N→ N. Dann gilt
f (n) ∈ o(g(n)) ⇐⇒ limn→∞
f (n)g(n)
= 0.
Beweis:⇒: Seiε > 0 beliebig. Daf (n) ∈ o(g(n)) existiert zuε ein n0 ∈ N mit f (n) < g(n) fur allen≥ n0. Hieraus folgt f (n)
g(n) < ε fur allen≥ n0 . Da ε beliebig ist, gilt limn→∞f (n)g(n) = 0.
⇐: Es gelte limn→∞f (n)g(n) = 0. Dann gibt es zu jedemc > 0 ein n0 ∈ N mit f (n)
g(n) < c fur allen≥ n0 .
Also ist f (n) < c·g(n) fur allen≥ n0. Da dies fur allec > 0 gilt, folgt f (n) ∈ o(g(n)).

9.2. DIE ASYMPTOTISCHE NOTATION 245
Die Uberprufung von limn→∞f (n)g(n) = 0 fuhrt meist auf Ausdrucke der Form∞
∞ , deren Konvergenz mitder
”Regel von de L’Hopital“uberpruft werden kann:
limn→∞
f (n)g(n)
= limn→∞
dd n f (n)d
d ng(n)
sofern der Limes der rechten Seite existiert. Dieses Kriterium kann bei Bedarf naturlich iterativ ange-wendet werden.
Wir erlautern es exemplarisch an zwei Fallen:
1. logn∈ o(n), da
limn→∞
dd n logn
dd nn
= limn→∞
dd n
lnnln2
dd nn
= limn→∞
1ln2 ·
1n
1= lim
n→∞
1nln2
= 0.
2. nk ∈ o(2n) fur festesk, da
limn→∞
dd nnk
dd n2n
= limn→∞
knk−1
(ln2)2n = . . . = limn→∞
k!(ln2)k2n = 0.
Betrachten wir noch einmal die oben aufgefuhrten gangigen Großenordnungen
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(nk) < O(nlogn) < O(2n).
O(1) bedeutet, dass die Anzahl der Ausfuhrungen elementarer Operationen unabhangig von der Großedes Inputs durch eine Konstante beschrankt ist. Die ersten sechs Großenordnungen haben eine wich-tige Eigenschaft gemeinsam: sie sind durch ein Polynom beschrankt. (Sprechweisen:polynomial be-schrankt, polynomial, schnell, effizient). O(n), O(n2) undO(n3) sind selbst Polynome, die man—bzgl.ihrer Grade—linear, quadratischundkubischnennt.
Es gibt jedoch keine ganze Zahlm, so dassnm eine Schranke fur 2n darstellt, d. h. 2n 6∈O(nm) fur jedefeste ganze Zahlm. Die Großenordnung von 2n ist O(2n), dank ∈ o(2n).
Man sagt, dass ein Algorithmus mit der SchrankeO(2n) einenexponentiellenZeitbedarf hat. Fur großen ist der Unterschied zwischen Algorithmen mit exponentiellem bzw. durch ein Polynom begrenztemZeitbedarf ganz betrachtlich. Es ist eine große Leistung, einen Algorithmus zu finden, der statt einesexponentiellen einen durch ein Polynom begrenzten Zeitbedarf hat.
Tabelle9.1 zeigt, wie die Rechenzeiten der sechs typischen Funktionen anwachsen, wobei die Kon-stante gleich 1 gesetzt wurde. Wie man feststellt, zeigen die Zeiten vom TypO(n) und O(nlogn)ein wesentlich schwacheres Wachstum als die anderen. Fur sehr große Datenmengen ist dies oft daseinzig noch verkraftbare Wachstum.
Folgendes Beispiel verdeutlicht den drastischen Unterschied zwischen polynomialem und exponenti-ellem Wachstum. Es zeigt, dass selbst enorme Fortschritte in der Rechnergeschwindigkeit bei expo-nentiellen Laufzeitfunktionen hoffnungslos versagen.

246 KAPITEL 9. DIE ANALYSE VON ALGORITHMEN
Tabelle 9.1: Wachstum verschiedener Großenordnungen.
logn n nlogn n2 n3 2n
0 1 0 1 1 21 2 2 4 8 42 4 8 16 64 163 9 24 64 512 2564 16 64 256 4096 655365 32 160 1024 32768 4294967296
Beispiel 9.1 (Vergleich der Großenordnungen polynomial/exponentiell) Sei f (n) dieLaufzeitfunktion fur ein Problem, und sein0 die Problemgroße, die man mit der jetzigen Technologiein einer bestimmten Zeitspannet losen kann. (Z. B. Berechnen kurzester Wege in einem Graphen mitn Knoten,t = 60 Minuten. Dann istn0 die Große der Graphen, fur die in einer Stunde die kurzestenWege berechnet werden konnen.)
Wir stellen jetzt die Frage, wien0 wachst, wenn die Rechner 100 mal so schnell werden. Sei dazun?
die Problemgroße, die man auf den schnelleren Rechnern in der gleichen Zeitspannet losen kann.
Offenbar erfullt n0 die Gleichungf (n0) = t bei der alten Technologie, undf (n0) = t/100 bei derneuen Technologie. Dan? bei der neuen Technologief (n?) = t erfullt, ergibt sich
f (n?) = 100· f (n0) .
Ist die Laufzeitfunktionf (n) polynomial, etwaf (n) = nk, k fest, so folgt
nk? = 100·nk
0 , alson? = k√
100·n0 ,
d. h., man kann jetzt eine um denFaktor k√
100 großere Probleme in derselben Zeit losen.
Ist dagegen die Laufzeitfunktionf (n) exponentiell, etwaf (n) = 2n, so folgt
2n? = 100·2n0 , alson? = n0 + log(100)≤ n0 +7,
d. h., man kann jetzt nur eine um denadditivenTerm log(100) großere Probleme in derselben Zeitlosen. Der Fortschritt macht sich also kaum bemerkbar.
9.2.2 Untere Schranken
Die O-Notation dient der BeschreibungobererSchranken. Großenordnungen fur untereSchrankenwerden mit derΩ-Notation ausgedruckt, die analog zurO-Notation definiert wird.
Seig : N→ N. Dann bezeichnet
Ω(g) := f : N→ N | ∃ c > 0 und∃ n0 ∈ N mit f (n)≥ c·g(n) ∀n≥ n0

9.3. A POSTERIORI ANALYSE, LAUFZEITMESSUNGEN 247
die Menge aller Funktionenf : N→N, fur die zwei positive (i. A. vonf abhangige) Konstantenc∈Rundn0 ∈ N existieren, so dass fur allen≥ n0 die Ungleichungf (n)≥ c·g(n) gilt.
Manchmal kommt es vor, dass fur die Laufzeit f (n) eines Algorithmus gilt:f (n) = Ω(g(n)) undf (n) = O(g(n)). Dafur benutzen wir folgende Schreibweise.
Seig : N→ N. Dann istΘ(g) := O(g)∩Ω(g)
die Menge aller Funktionenf : N→ N fur die f ∈ O(g) und f ∈ Ω(g) gilt. Es ist also f ∈ Θ(g)(gelesen:
”f ist in Theta vong“), wenn es positive Konstantec1,c2 ∈ R undn0 ∈ N gibt, so dass fur
allen≥ n0 gilt: c1 ·g(n)≤ f (n)≤ c2 ·g(n).
Beispiel 9.2 (Sequentielle Suche)Sei f (n) die maximale Anzahl von Vergleichen bei der sequenti-ellen Suche in einem unsortierten Array mitn Komponenten (vgl. Kapitel6.1.1). Dann ist f (n) =O(n), da man je mitn Vergleichen auskommt. Andererseits muss man aber auch jede Komponen-te uberprufen, denn ihr Wert konnte ja der gesuchte Wert sein. Also istf (n) = Ω(n) und damitf (n) = Θ(n).
Beispiel 9.3 (Matrizenmultiplikation) Bei der Matrixmultiplikation vonn×n Matrizen ergibt sichdie Berechnung eines Eintragsci j von C = A ·B gemaß ci j= ∑n
k=1aik · bk j (vgl. Kapitel 6.2.1. Sieerfordert alson Multiplikation undn−1 Additionen.
Insgesamt sind fur ganzC alson2 Eintrageci j zu berechnen, und somitn2(n+ n−1) = 2n3−n2 =O(n3) arithmetische Operationen insgesamt auszufuhren..
Da jeder Algorithmus fur die Matrixmultiplikationn2 Eintrage berechnen muss, folgt andererseits,dass jeder Algorithmus zur Matrixmultiplikation von zwein×nMatrizenΩ(n2) Operationen benotigt.
Es klafft zwischenΩ(n2) undO(n3) also noch eine”Komplexitatslucke“.2
9.3 A posteriori Analyse, Laufzeitmessungen
Nehmen wir an, wir haben ein Programm zur Losung eines Problems entworfen, kodiert, als kor-rekt bewiesen und am Rechner die Fehlersuche erfolgreich durchgefuhrt. Wie konnen wir ein Leis-tungsprofil erstellen, welches exakt den Rechenzeit- und Speicherbedarf dieses Programms angibt?Um exakte Zeiten zu erhalten, muss unser Computeruber eine Uhr verfugen, von der die Zeit perProgramm abgelesen werden kann. Mit dieser Moglichkeit der Zeitmessung konnen viele Faktorender Programmausfuhrunguberpruft werden. Der wichtigste Test eines Programms besteht darin, zuzeigen, dass die fruhere Analyse bzgl. der Großenordnung richtig war. Mit Hilfe der tatsachlich ge-messenen Zeiten sollten wir in der Lage sein, die exakte Laufzeitfunktion in Abhangigkeit von derbenutzten Programmiersprache und dem Rechner zu bestimmen.
Zur Zeitmessung existieren UNIX-utilities wie/bin/time3 aber auch Java Methoden wie die Me-thode
2 Die schnellsten bekannten Algorithmen zur Matrixmultiplikation kommen mitO(n2,376) Operationen aus.3vgl. die entsprechenden Manual pages durch Aufruf vonman time.

248 KAPITEL 9. DIE ANALYSE VON ALGORITHMEN
public static native long System.currentTimeMillis()
der KlasseSystem. Sie gibt die aktuelle Zeit seit dem 1. Januar 1970 (UCT) in Millisekunden alslong-Wert zuruck. Dadurch lassen sich einfach Zeitmessungen durchfuhren wie in der folgendenFunktion fur die rekursive Berechnung der Fibonacci-Zahlen (vgl. Abschnitt8.2.4):
/*** measures time for the recursive calculation of the Fibonacci* numbers* @param <code>n</code> the argument for the Fibonacci number* @return the time in milliseconds for the calculation of the* <code>n</code>-th Fibonacci number*/long fibonacciTime( int n )
long start = System.currentTimeMillis();fib( 40 ); // no assignment since we don’t need the valuelong end = System.currentTimeMillis();return end - start;
9.4 Literaturhinweise
Eine gute Einfuhrung in asymptotische Notation mit vielen Beispielen und Abschatzungstechniken findet sichin [CLRS01].

Kapitel 10
Sortieren in Arrays
Sortieralgorithmen gehoren zu den am haufigsten angewendeten Algorithmen in der Datenverarbei-tung. Man hatte daher bereits fruh ein großes Interesse an der Entwicklung moglichst effizienter Sor-tieralgorithmen. Zu diesem Thema gibt es umfangreiche Literatur, nahezu jedes Buchuber Algo-rithmen und Datenstrukturen beschaftigt sich mit Sortieralgorithmen, da sie besonders geeignet sind,Anfangern Programmiermethodik, Entwurf von Algorithmen und Aufwandsanalyse zu lehren.
Wir erlautern die Sortieralgorithmen vor folgendem Hintergrund. Gegeben ist ein DatentypItem.
public class Item int key;// data components and methods
Objekte dieses Typs sind “Karteikarten”, z. B. aus einer Studentenkartei. Jede Karteikarte enthaltneben den Daten (data components) einen Schlussel (key) vom Typint, z. B. die Matrikelnummer,nach denen sortiert oder gesucht werden kann. Die gesamte Kartei wird durch ein Arrayvec mitGrundtypItem dargestellt. Wir reden daher im weiteren auch vonKomponentenoderElementenstattKarteikarten.
Die Wahl vonint als Schlusseltyp ist willkurlich. Hier kann jeder andere Typ verwendet werden,fur den eine vollstandige Ordnungsrelation definiert ist, also zwischen je zwei Wertena,b genau eineder Relationena < b, a = b, a > b gilt. Dies konnen z. B. auch Strings mit der lexikographischenOrdnung sein (Meier< Mueller), nur musste dann der “eingebaute” Vergleich “<” von ganzen Zahlendurch eine selbstdefinierte Funktion zum Vergleich von Strings ersetzt werden.1
1Dies kann mit dem InterfaceComparable (vgl. Abschnitt 7.3.7) realisiert werden. Die KlasseItem muss da-zu die Methode public int compareTo(Object o) implementieren. Dabei ist das Itemx kleiner als odergleich dem Itemy wenn x.compareTo((Object)y) <= 0 gilt. Alle Sortieralgorithmen nutzen dann die Abfragex.compareTo((Object)y) <= 0 fur den Vergleich vonx undy.
Version vom 21. Januar 2005
249

250 KAPITEL 10. SORTIEREN IN ARRAYS
10.1 Direkte Methoden
Direkt bedeutet: Sortieren der Komponenten “am Ort”. Ein typisches Beispiel dafur ist Bubblesort.
10.1.1 Sortieren durch Austauschen: Bubblesort
Bubblesort durchlauft das Array mehrmals von hinten nach vorn und lasst durch paarweise Vergleichedas kleinste Element der restlichen Menge zum linken Ende des Arrays wandern. Stellt man sichdas Array senkrecht angeordnet vor, und die Elemente als Blasen, so steigt bei jedem Durchlaufdurch das Array eine Blase auf die ihrem Gewicht (Schlusselwert) entsprechende Hohe auf (vgl.Abbildung10.1)
j vec[j].key i=1 2 3 4 5 6 7
0 63 12 12 12 12 12 12 121 24 63 18 18 18 18 18 182 12 24 63 24 24 24 24 243 53 18 24 63 35 35 35 354 72 53 35 35 63 44 44 445 18 72 53 44 44 63 53 536 44 35 72 53 53 53 63 637 35 44 44 72 72 72 72 72
Abbildung 10.1: Phasen bei Bubblesort.
Informell lasst sich Bubblesort wie folgt beschreiben:
1. Gegeben istvec[] mit n Komponenten.
2. Das Arrayvec wird n−1 mal von hinten nach vorn durchlaufen. Ein Durchlauf heißtPhase.
3. Phasei lauft von Komponentej = n− 1 bis j = i und vergleicht jeweilsvec[j].key mitvec[j-1].key. Ist vec[j-1].key > vec[j].key so werdenvec[j-1] und vec[j] ge-tauscht.
Die Korrektheitdes Algorithmus ergibt sich direkt aus folgenderSchleifeninvarianten, die nach jederPhase gilt:
Am Ende der Phasei ist vec[i-1].key der i-kleinste Schlussel invec und es gilt:vec[0].key ≤ vec[1].key ≤ . . . ≤ vec[i-1].key ≤ vec[j].key fur j = i, i +1, . . . ,n−1.
(10.1)
Dies ist klar fur die 1. Phase. Nimmt man die Richtigkeit fur Phasei an (Induktionsvoraussetzung), sofindet Phasei +1 das kleinste Element invec[i]...vec[n-1] und bringt es durch ggf. fortgesetzteAustauschoperationen an die Positioni. Also gilt die Invariante auch nach Phasei (Induktionsschluss).Fur i = n−1 folgt sofort die Korrektheit des Algorithmus.

10.1. DIREKTE METHODEN 251
Dies resultiert in die folgende Java Methode.
/*** Sorts with bubblesort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void bubbleSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();
int n = vec.length;Item temp;int bottom; // bottom for each passfor (bottom = 1; bottom < n; bottom++)
for (int i = n-1; i >= bottom; i--) if (vec[i-1].key > vec[i].key)
temp = vec[i-1];vec[i-1] = vec[i];vec[i] = temp;
Wir berechnen nun den Worst Case Aufwand von Bubblesort nach derAnzahl der Vergleiche. Dazubetrachten wir die Vergleiche pro Phase. Sein die Anzahl der Komponenten des Arrays.
Phase 1 : n−1 VergleichePhase 2 : n−2 Vergleiche
. . .Phasei : n− i Vergleiche
. . .Phasen−1 : 1 Vergleich
Also gilt fur die AnzahlC(n) der Vergleiche bein Komponenten
C(n) = 1+2+ . . .+(n−2)+(n−1) =n−1
∑i=1
i =n(n−1)
2.
Folglich istC(n) ∈O(n2). Da die Vergleiche unabhangig von der Eingabe durchgefuhrt werden (auchbei einem bereits sortierten Array) gilt:C(n) = n(n−1)
2 ≥ n2
3 fur n≥ 3, alsoC(n) ∈ Ω(n2) und damitC(n) ∈Θ(n2).

252 KAPITEL 10. SORTIEREN IN ARRAYS
Offensichtlich kann dieser Algorithmus verbessert werden, wenn man sich merkt, ob in einer Phaseuberhaupt ein Austausch stattgefunden hat. Findet kein Austausch statt, so ist das Array sortiert undman kann abbrechen.
Eine weitere Verbesserung besteht darin, sich in einer Phase die Position (Index)k des letzten Austau-sches zu merken. In den darauf folgenden Phasen mussenvec[0]...vec[k] nicht mehruberpruftwerden.
Schließlich kann man noch die Phasen abwechselnd von hinten nach vorn und von vorn nach hintenlaufen lassen (Shakersort), um Asymmetrie zwischen “leichten” Elementen (gehen gleich ganz nachoben) und “schweren” Elementen (sinken jeweils nur um eine Position ab) zu durchbrechen.
Diese Verbesserungen bewirken aber nur eine Verringerung der mittleren Anzahl der Vergleiche. Furden Worst Case lassen sich stets (Ubung) Beispiele finden, dieC(n) = n(n−1)
2 Vergleiche benotigen.Es gilt also:
Satz 10.1Bubblesort erfordertΘ(n2) Vergleiche im Worst Case.
Neben der AnzahlC(n) der Vergleiche ist fur die Laufzeit auch dieAnzahl A(n) der Zuweisungen(As-signments) von Arraykomponenten von großer Bedeutung, da sie außer den Schlusseln noch weitere(ggf. große) Datenmengen enthalten.
Offenbar kann jeder Vergleich einen Austausch und damit 3 Zuweisungen verursachen. Es gilt alsoA(n)≤ 3·C(n). Beispiele zeigen, dassA(n) = 3·C(n) vorkommt. Also folgt:
Satz 10.2Bubblesort erfordertΘ(n2) Zuweisungen im Worst Case.
10.1.2 Sortieren durch direktes Auswahlen: Selection Sort
Wir geben zunachst eine informelle Beschreibung:
1. Gegeben istvec[] mit n Komponenten.
2. Das Arrayvec wird n−1 mal von vorn nach hinten durchlaufen. Ein Durchlauf heißtPhase(pass).
3. Phasebottom sucht den IndexminIndx einer Komponente mit kleinstem Schlusselwert imBereich
vec[bottom], vec[bottom+1],...,vec[n-1],
mittels sequentieller Suche, und tauscht diese Komponente an die Stellebottom. Es werdenalsovec[bottom] undvec[minIndx] vertauscht.
Die Korrektheit basiert hier auf derselben Invarianten wie bei Bubblesort. Es folgt eine Java Methode:

10.1. DIREKTE METHODEN 253
/*** Sorts with selectionsort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void selectionSort(Item vec[])
throws NullPointerException if (vec == null) throw new NullPointerException();
int minIndx; // Index of smallest key in each passint bottom; // bottom for each passint i;Item temp;int n = vec.length;
for (bottom = 0; bottom < n-1; bottom++) // INVARIANT (prior to test):// All vec[bottom+1..n-1] are >= vec[bottom]// && vec[0..bottom] are in ascending order// && bottom >= 0
minIndx = bottom;for (i = bottom+1; i < n; i++)
// INVARIANT (prior to test):// vec[minIndx] <= all// vec[0..i-1]// && i >= bottom+1
if (vec[i].key < vec[minIndx].key) minIndx = i;
temp = vec[bottom];vec[bottom] = vec[minIndx];vec[minIndx] = temp;
Fur das Beispiel aus Abbildung10.1ergeben sich die in Abbildung10.2dargestellten Zustande nachden einzelnen Phasen
Fur die AnzahlC(n) der Vergleiche ergibt sich analog zu Bubblesort:
C(n) =n−1
∑i=1
(n− i) =n(n−1)
2,
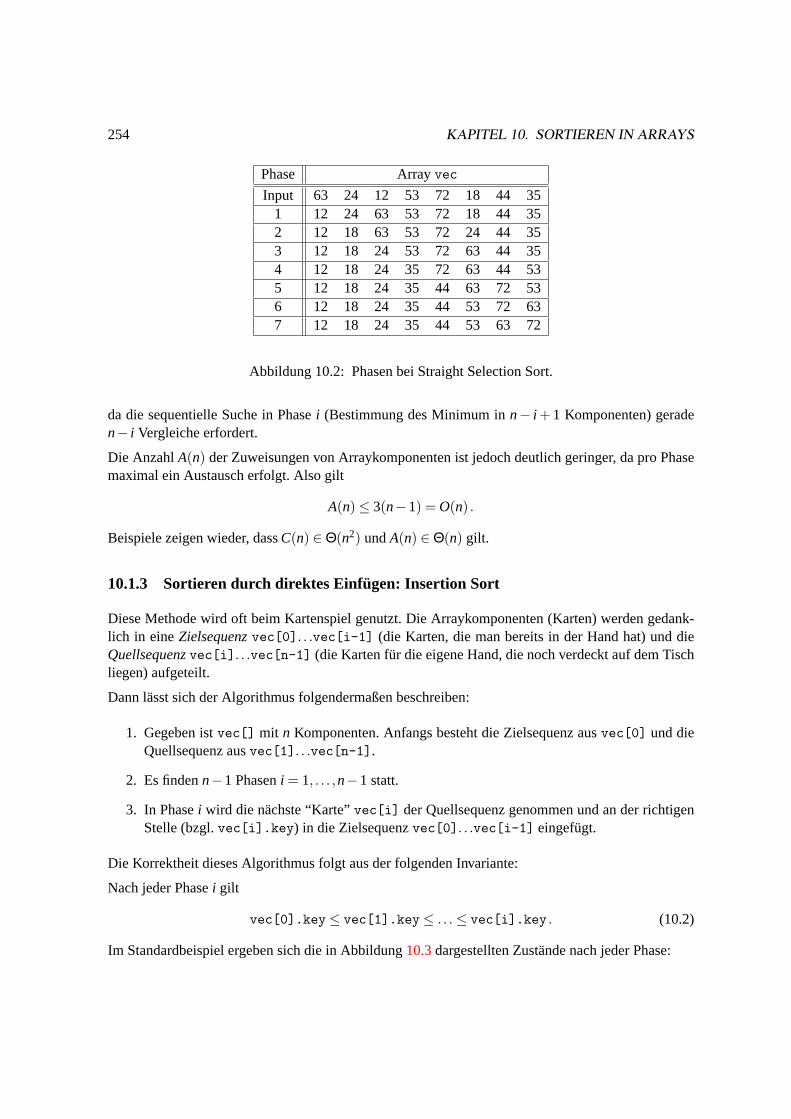
254 KAPITEL 10. SORTIEREN IN ARRAYS
Phase Array vec
Input 63 24 12 53 72 18 44 351 12 24 63 53 72 18 44 352 12 18 63 53 72 24 44 353 12 18 24 53 72 63 44 354 12 18 24 35 72 63 44 535 12 18 24 35 44 63 72 536 12 18 24 35 44 53 72 637 12 18 24 35 44 53 63 72
Abbildung 10.2: Phasen bei Straight Selection Sort.
da die sequentielle Suche in Phasei (Bestimmung des Minimum inn− i + 1 Komponenten) geraden− i Vergleiche erfordert.
Die AnzahlA(n) der Zuweisungen von Arraykomponenten ist jedoch deutlich geringer, da pro Phasemaximal ein Austausch erfolgt. Also gilt
A(n)≤ 3(n−1) = O(n) .
Beispiele zeigen wieder, dassC(n) ∈Θ(n2) undA(n) ∈Θ(n) gilt.
10.1.3 Sortieren durch direktes Einfugen: Insertion Sort
Diese Methode wird oft beim Kartenspiel genutzt. Die Arraykomponenten (Karten) werden gedank-lich in eineZielsequenzvec[0]. . .vec[i-1] (die Karten, die man bereits in der Hand hat) und dieQuellsequenzvec[i]. . .vec[n-1] (die Karten fur die eigene Hand, die noch verdeckt auf dem Tischliegen) aufgeteilt.
Dann lasst sich der Algorithmus folgendermaßen beschreiben:
1. Gegeben istvec[] mit n Komponenten. Anfangs besteht die Zielsequenz ausvec[0] und dieQuellsequenz ausvec[1]. . .vec[n-1].
2. Es findenn−1 Phaseni = 1, . . . ,n−1 statt.
3. In Phasei wird die nachste “Karte”vec[i] der Quellsequenz genommen und an der richtigenStelle (bzgl.vec[i].key) in die Zielsequenzvec[0]. . .vec[i-1] eingefugt.
Die Korrektheit dieses Algorithmus folgt aus der folgenden Invariante:
Nach jeder Phasei gilt
vec[0].key≤ vec[1].key≤ . . .≤ vec[i].key . (10.2)
Im Standardbeispiel ergeben sich die in Abbildung10.3dargestellten Zustande nach jeder Phase:

10.1. DIREKTE METHODEN 255
Phase Array vec
Input 63 24 12 53 72 18 44 351 24 63 12 53 72 18 44 352 12 24 63 53 72 18 44 353 12 24 53 63 72 18 44 354 12 24 53 63 72 18 44 355 12 18 24 53 63 72 44 356 12 18 24 44 53 63 72 357 12 18 24 35 44 53 63 72
Abbildung 10.3: Phasen bei Insertion Sort.
Die Anzahl der Vergleiche hangt davon ab, wie das Einfugen in die Zielsequenz durchgefuhrt wird.Beisequentieller Sucheder Stelle (von links nach rechts) ergeben sich im Worst Case folgende Zahlen:
Phase 1 : 1 VergleichPhase 2 : 2 Vergleiche
. . .Phasen−1 : n−1 Vergleiche
In diesem Fall ist wiederumC(n) = n(n−1)2 ∈O(n2).
Da die Zielsequenz bereits aufsteigend sortiert ist, lasst sich statt der sequentiellen Suche diebinareSucheverwenden. Phasei erfordert dann (Zieldatei enthalt i Elemente) gemaß Satz6.1 hochstensblogic+1 Vergleiche. Also gilt dann:
C(n) ≤n−1
∑i=1
(blogic+1)
≤n−1
∑i=1
(log(n−1)+1) = (n−1)(log(n−1)+1)
= (n−1) log(n−1)+(n−1) = O(nlogn)
Bezuglich der ZahlA(n) der Zuweisungen von Arraykomponenten ist in beiden Varianten (sequentiel-le oder binare Suche) eine Verschiebung der Komponenten der Quelldatei rechts von der Einfugestellek um jeweils eine Stelle erforderlich, im schlimmsten Fall(k = 0) also i Verschiebungen in Phasei.Dies lasst sich miti +1 Zuweisungen realisieren:
temp = vec[i];for (j = i-1; j >= 0; j++) vec[j+1] = vec[j];vec[0] = temp;
Also ist
A(n) ≤n−1
∑i=1
(i +1) =n
∑i=2
i = (n
∑i=1
i)−1
= n(n+1)2 −1∈O(n2) .

256 KAPITEL 10. SORTIEREN IN ARRAYS
Das Beispiel des absteigend sortierten Arrays zeigt, dass dieser Fall auch eintritt, alsoA(n) ∈ Ω(n2)gilt.
Straight Insertion (mit binarer Suche) ist also bezuglich der Anzahl der Vergleiche sehr gut(O(nlogn)),aber bezuglich der Anzahl der Zuweisungen schlecht(Ω(n2)).
Die hier vorgestellten direkten Methoden sind mit ihrer Worst Case Laufzeit vonΘ(n2) als sehr auf-wendig einzustufen. Wir werden im Rest des Kapitels drei “intelligentere” Sortiermethoden kennenlernen, die im Mittel, und teilweise auch im Worst Case, mitO(nlogn) Vergleichen und Zuweisungenauskommen.
10.2 Mergesort
Mergesort teilt das zu sortierende Array in zwei gleichgroße Teilfolgen (Unterschied hochstens eineKomponente), sortiert diese (durch rekursive Anwendung von Mergesort auf die beiden Teile) undmischtdie dann sortierten Teile zusammen.
10.2.1 Mischen sortierter Arrays
Wir betrachten daher zunachst dasMischenvon zwei bereits sortierten Arrays. Seien dazuvec1[]undvec2[] bereits sortierte Arrays der Langembzw.n mit Komponenten vom TypItem. Diese sindin das Arrayvec[] der Langem+n zu verschmelzen.
Dazu durchlaufen wirvec1 undvec2 von links nach rechts mit zwei Indexzeigerni undj wie folgt:
1. Initialisierung:i = 0; j = 0; k= 0;
2. Wiederhole Schritt 3 bisi = m oderj = n.
3. Falls vec1[i].key < vec2[j].key, so kopierevec1[i] an die Positionk von vec underhohei undk um 1.
Andernfalls kopierevec2[j] an die Positionk vonvec und erhohej undk um 1.
4. Ist i = m undj < n, soubertrage die restlichen Komponenten vonvec2 nachvec.
5. Ist j = n undi < m, soubertrage die restlichen Komponenten vonvec1 nachvec.
Bei jedem Wiedereintritt in die Schleife 3 gilt die Invariante
vec[0].key ≤ . . .≤ vec[k-1].keyvec[k-1].key ≤ vec1[i].key ≤ . . .≤ vec1[m-1].keyvec[k-1].key ≤ vec2[j].key ≤ . . .≤ vec2[n-1].key
(10.3)
Hieraus folgt sofort, dassvec am Ende aufsteigend sortiert ist.
Als Beispiel betrachten wir die Arrays:

10.2. MERGESORT 257
vec1: 12 24 53 63 vec2: 18 35 44 72
Die dazugehorige Folge der Werte voni,j,k undvec bei jedem Wiedereintritt in die Schleife 3 istin Abbildung10.4angegeben. Am Ende dieser Schleife isti = 4 und Schritt 4 des Algorithmus wirdausgefuhrt, d. h. der “Rest” vonvec2, also die 72, wird nachvec ubertragen.
i j k vec
1 0 1 12 - - - - - - -1 1 2 12 18 - - - - - -2 1 3 12 18 24 - - - - -2 2 4 12 18 24 35 - - - -2 3 5 12 18 24 35 44 - - -3 3 6 12 18 24 35 44 53 - -4 3 7 12 18 24 35 44 53 63 -
Abbildung 10.4: Phasen bei Merge.
SeiC(m,n) die maximale Anzahl von Schlusselvergleichen undA(m,n) die maximale Anzahl vonZuweisungen von Komponenten beim Mischen.
Vergleiche treten nur in der Schleife 3 auf, und zwar genau einer pro Durchlauf. Da die Schleifemaximalm+n−1 mal durchlaufen wird, gilt
C(m,n)≤m+n−1.
Zuweisungen treten genaun+mmal auf, da jede Komponente vonvec einen Wert bekommt. Also ist
A(m,n) = m+n.
Wir geben nun eine Java Methode fur dieses Verfahren an, und zwar in der (spater benotigten) Version,dass zwei benachbarte, bereits sortierte Teilbereiche eines Arraysvec gemischt werden und dann indemselbenBereich vonvec aufsteigend sortiert gemischt stehen.
Wir verlangen also folgendes Input/Output Verhalten:
Input: vec
6
left6
middle6
right
mit den sortierten Bereichenvec[left]. . .vec[middle] undvec[middle+1]. . .vec[right].
Output: vec
6
left6
right
mit dem aufsteigend sortierten Bereichvec[left]. . .vec[right].
Dazu werden zunachst die beiden sortierten Bereiche auf lokale Arraysvec1 undvec2 kopiert, diedann in den entsprechenden Bereich vonvec zuruckgemischt werden.

258 KAPITEL 10. SORTIEREN IN ARRAYS
Programm 10.1 merge/*** merges two sorted adjacent ranges of an array* @param vec the array in which this happens* @param left start of the first range* @param middle end of the first range* @param right end of the second range*/private static void merge(Item[] vec, int left, int middle, int right)
int i, j;int m = middle - left + 1; // length of first array regionint n = right - middle; // length of second array region
// make copies of array regions to be merged// (only the references to the items)Item[] copy1 = new Item[m];Item[] copy2 = new Item[n];for (i = 0; i < m; i++) copy1[i] = vec[left + i];for (j = 0; j < n; j++) copy2[j] = vec[middle + 1 + j];
i = 0; j = 0;// merge copy1 and copy2 into vec[left...right]while (i < m && j < n)
if (copy1[i].key < copy2[j].key) vec[left+i+j] = copy1[i];i++;
else vec[left+i+j] = copy2[j];j++;
//endif//endwhileif (j == n) // second array region is completely handled,
// so copy rest of first regionwhile (i < m)
vec[left+i+j] = copy1[i];i++;
// if (i == m) do nothing,// rest of second region is already in place

10.2. MERGESORT 259
10.2.2 Sortieren durch rekursives Mischen: Mergesort
Mit dieser Methodemerge() ergibt sich dann sehr einfach folgende rekursive Variante von Mergesort.
Programm 10.2 mergeSort/*** Sorts with mergesort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void mergeSort(Item vec[])
throws NullPointerException if (vec == null) throw new NullPointerException();mergeSort(vec, 0, vec.length - 1);
/*** sorts array by mergesort in a certain range* @param <code>vec</code> the array in which this happens* @param <code>first</code> start of the range* @param <code>last</code> end of the range*/private static void mergeSort(Item[] vec, int first, int last)
if (first == last) return;// devide vec into 2 equal partsint middle = (first + last) / 2;mergeSort(vec, first, middle); // sort the first partmergeSort(vec, middle+1, last); // sort the second partmerge(vec, first, middle, last); // merge the 2 sorted parts
Die public MethodemergeSort(Item[]) bekommt nur das Arrayubergeben und ruft dieprivateMethodemergeSort(Item[], int, int) in den Grenzen0 undvec.length-1 des Arraysvecauf.
Die Korrektheit vonmergeSort(Item[], int, int) ergibt sich sofort durch vollstandige Indukti-on nach der Anzahln = last - first + 1 der zu sortierenden Komponenten.
Ist n= 1, alsolast=first (Induktionsanfang), so wird im Rumpf vonmergeSort() nichts gemachtund das Arrayvec ist nach Abarbeitung vonmergeSort() trivialerweise im Bereichfirst. . .lastsortiert.
Ist n > 1, so sindfirst. . .middle und middle+1. . .last Bereiche mit weniger alsn Elementen,die also nach Induktionsvoraussetzung durch die AufrufemergeSort(vec, first, middle) und

260 KAPITEL 10. SORTIEREN IN ARRAYS
mergeSort(vec, middle+1, last) korrekt sortiert werden. Die Korrektheit vonmerge() ergibtdann die Korrektheit von mergeSort.
Fur das Standardbeispiel
a 63 24 12 53 72 18 44 35
ergibt der AufrufmergeSort(a,0,7) dann den in Abbildung10.5dargestellten Ablauf. Dabei be-schreiben die Einrucktiefe die Aufrufhierarchie (Rekursionsbaum), und die Kasten die bereits sortier-ten Teile des Arrays.
mergeSort(a,0,7) 63 24 12 53 72 18 44 35mergeSort(a,0,3) 63 24 12 53 72 18 44 35mergeSort(a,0,1) 63 24 12 53 72 18 44 35mergeSort(a,0,0) 63 24 12 53 72 18 44 35mergeSort(a,1,1) 63 24 12 53 72 18 44 35merge(a,0,0,1) 24 63 12 53 72 18 44 35
mergeSort(a,2,3) 24 63 12 53 72 18 44 35mergeSort(a,2,2) 24 63 12 53 72 18 44 35mergeSort(a,3,3) 24 63 12 53 72 18 44 35merge(a,2,2,3) 24 63 12 53 72 18 44 35
merge(a,0,1,3) 12 24 53 63 72 18 44 35mergeSort(a,4,7) 12 24 53 63 72 18 44 35mergeSort(a,4,5) 12 24 53 63 72 18 44 35mergeSort(a,4,4) 12 24 53 63 72 18 44 35mergeSort(a,5,5) 12 24 53 63 72 18 44 35merge(a,4,4,5) 12 24 53 63 18 72 44 35
mergeSort(a,6,7) 12 24 53 63 18 72 44 35mergeSort(a,6,6) 12 24 53 63 18 72 44 35mergeSort(a,7,7) 12 24 53 63 18 72 44 35merge(a,6,6,7) 12 24 53 63 18 72 35 44
merge(a,4,5,7) 12 24 53 63 18 35 44 72merge(a,0,3,7) 12 18 24 35 44 53 63 72
Abbildung 10.5: Die Rekursion beimergeSort().
10.2.3 Die Analyse von Mergesort
Wir ermitteln nun den Worst Case AufwandC(n) fur die Anzahl der Vergleiche undA(n) fur dieAnzahl der Zuweisungen vonmergeSort() beim Sortieren eines Arrays mitn Komponenten.

10.2. MERGESORT 261
Aus dem rekursiven Aufbau des Algorithmus ergeben sich sofort die folgenden Rekursionsgleichun-gen fur C(n).
C(2) = 1 C(2n) = 2·C(n)+C(n,n) fur n > 1
In Worten: Das Sortieren eines 2-elementigen Arrays erfordert einen Vergleich. Das Sortieren einesArrays der Lange 2n erfordert den Aufwand fur das Sortieren von 2 Arrays der Langen (rekursiveAufrufe von mergeSort() fur die beiden Teile), also 2·C(n), plus den AufwandC(n,n) fur dasMischen (Aufruf vonmerge()).
DaC(n,n) = 2n−1, ist also
C(2) = 1 C(2n) = 2·C(n)+2n−1 fur n > 1. (10.4)
Um diese Rekursionsgleichung zu losen, betrachten wir zunachst den Fall, dassn eine Zweierpotenzist, etwan = 2q. Dann istn genauq mal durch 2 ohne Rest teilbar und wir erhalten durch mehrfacheAnwendung der Rekursionsgleichung
C(n) = 2·C(n2)+2· n
2−1
= 2·C(n2)+n−1 1 mal angewendet
= 2(
2·C(n4)+2· n
4−1)
+n−1
= 4·C(n4)+2n−3 2 mal angewendet
= 4(
2·C(n8)+2· n
8−1)
+2n−3
= 8·C(n8)+3n−7 3 mal angewendet
. . . (insgesamtq−1 mal anwenden)
= 2q−1 ·C(2)+(q−1)n− (2q−1−1)
Wegenn = 2q undC(2) = 1 folgt hieraus
C(2q) = (q−1)2q +1.
Wir verifizieren diese eher intuitive Vorgehensweise durch einen formalen Beweis mit vollstandigerInduktion.2
Lemma 10.1 Ist n= 2q, so hat die Rekursionsgleichung10.4die Losung C(2q) = (q−1)2q +1.
Beweis: Der Beweis erfolgt durch vollstandige Induktion nachq. Ist q = 1, so istC(21) = 1 und(q− 1)2q + 1 = 1 (Induktionsanfang). Also sei die Behauptung richtig fur 2r mit 1 ≤ r ≤ q. Wir
2Eine Alternative ist die Verifikation durchEinsetzender “vermuteten” FormelC(2q) = (q−1)2q+1 in die Rekursions-gleichung und Nachrechnen der Gleichung. Dies fuhrt auf die gleichen Beweisschritte.

262 KAPITEL 10. SORTIEREN IN ARRAYS
schließen jetzt aufq+1:
C(2q+1) = 2·C(2q)+2·2q−1 Rekursionsgleichung
= 2· [(q−1)2q +1]+2·2q−1 Induktionsvoraussetzung
= (q−1)2q+1 +2+qq+1−1
= q·2q+1 +1,
was zu zeigen war.
Bezuglich der AnzahlA(n) der Zuweisungen von Arraykomponenten ergibt sich ganz analog:
A(2n) = 2·A(n)+ Zuweisungen inmerge()
In merge() werden zunachst die Teile vonvec nachvec1 undvec2 kopiert. Dies erfordert 2n Zu-weisungen. Fur das Mergen sind dann wiederA(n,n) = 2n Zuweisungen erforderlich. Also ergibt sichfolgende Rekursionsgleichung:
A(2) = 4 A(2n) = 2·A(n)+4·n fur n > 1 (10.5)
Der gleiche Losungsansatz liefert fur n = 2q
A(n) = 2q2q .
Wir betrachten nun den Fall, dassn keine Zweierpotenz ist. Dann unterscheiden sich die jeweiligenTeilarrays um maximal 1, vgl. Abbildung10.6.
0 1 2 3 4 5
@@
0 1 2
@@
3 4 5
@@
0 1
@@
3 4
@@
2 5
0 1 3 4
Abbildung 10.6: Rekursionsbaum vonmergeSort() fur n = 6.
Dies fuhrt dazu, dass im zugehorigen Rekursionsbaum nicht alle Zweige bis auf die unterste Ebenereichen. Vervollstandigt man (gedanklich) den Rekursionsbaum bis auf die unterste Ebene, so wurde

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 263
dies dem Rekursionsbaum fur ein Array der Langen′ entsprechen, wobein′ die nachstgroßere Zwei-erpotenz nachn ist, alson′ = min2r | 2r ≥ n, r = 1,2, . . ..Sei 2q dieses Minimum. Dann ist 2q−1 < n≤ 2q = n′, alson′ = 2·2q−1 < 2n sowieq−1 < logn≤ q.Also ist (wegen der Vervollstandigung):
C(n) ≤ C(n′) = C(2q) = (q−1)2q +1
< (logn) ·n′+1 < (logn) ·2n+1
= 2nlogn+1 = O(nlogn) .
Entsprechend folgt
A(n) ≤ A(n′) = A(2q) = (q+1)2q
< (logn+2)n′ < (logn+2)2n
= 2nlogn+4n = O(nlogn) .
Wir erhalten also
Satz 10.3mergeSort() sortiert ein Array mit n Komponenten mit O(nlogn) Vergleichen und Zu-weisungen.
Betrachten wir zum Abschluss noch den Rekursionsaufwand und die Rekursionstiefe. Fur n = 2q
ist die Rekursionstiefe geradeq = logn, fur beliebigen ergibt sich aus der soeben durchgefuhrtenVervollstandigungsuberlegung
logn′ < log(2n) = logn+1
als Schranke fur die Rekursionstiefe.
Die Anzahl der rekursiven Aufrufe ergibt sich als Summe entlang der Schichten des Rekursionsbaumszu
q
∑i=0
2i = 2q+1−1 = 2n′−1 < 4n−1 = O(n) .
Rekursionsaufwand und Rekursionstiefe halten sich also in vernunftigen Grenzen.
10.3 Beschleunigung durch Aufteilung: Divide and Conquer
Mergesort ist ein typisches Beispiel fur die sogenannte”Beschleunigung durch Aufteilung“. Dieses
Prinzip tritt oft bei der Konzeption von Algorithmen auf. Daher hat man Interesse an einer allgemeinenAussageuber die Laufzeit in solchen Situationen.
10.3.1 Aufteilungs-Beschleunigungs-Satze
Gegeben ist ein Problem der Großea·n mit der Laufzeitf (a·n). Dieses zerlegt man inb Teilproblemeder Großen mit Laufzeit f (n) pro Teilproblem, alsob · f (n) fur alle Teilprobleme zusammen. Ist die

264 KAPITEL 10. SORTIEREN IN ARRAYS
Laufzeit fur das Aufteilen und das Zusammenfugen der Teillosungen durchc ·n beschrankt, so ergibtsich die folgende Rekursionsgleichung und der
Satz 10.4 (Aufteilungs-Beschleunigungs-Satz)Seien a> 0, b, c naturliche Zahlen und sei folgendeRekursionsgleichung gegeben:
f (1) ≤ ca
f (a·n) ≤ b· f (n)+c·n fur n > 1
Dann gilt:
f (n) ∈
O(n) , falls a> bO(n· log2n) , falls a= bO(nloga b) , falls a< b
Beweis:: Fur n = aq gilt
f (n)≤ ca
nq
∑i=0
(ba
)i
Dies zeigt man durch Induktionuberq. Fur q = 0 ist die Summe 1 und daherf (1)≤ ca.
Die Behauptung sei nun fur q gezeigt. Dann ergibt sich im Induktionsschluss aufq+1:
f (aq+1) = f (a·aq)≤ b· f (aq)+c·aq (Rekursionsformel)
= b· ca·aq
q
∑i=0
(ba
)i
+c·aq (Induktionsvoraussetzung)
=ca
aq+1ba
q
∑i=0
(ba
)i
+ca·aq+1
=ca
aq+1q
∑i=0
(ba
)i+1
+ca
aq+1
=ca
aq+1
(q+1
∑i=1
(ba
)i
+1
)
=ca
aq+1q+1
∑i=0
(ba
)i
.
Also ist
f (n)≤ ca
nloga n
∑i=0
(ba
)i
.
Wir betrachten jetzt 3 Falle:

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 265
1. a > b: Dann istba < 1 und daher
loga n
∑i=0
(ba
)i
<∞
∑i=0
(ba
)i
=a
a−b,
da die geometrische Reihe∑∞i=0
(ba
)iwegenb
a < 1 gegenk1 := 11− b
a= a
a−b konvergiert. Also ist
f (n) <c·k1
an ⇒ f (n) ∈O(n) .
2. a = b: Dann ist
f (n)≤ ca
nloga n
∑i=0
1 =ca
n(logan+1) =ca
nlogan+ca
n.
Fur n≥ a ist logan≥ 1 und daher
f (n) ≤ ca
nlogan+ca
nlogan =2ca
nlogan
= (2ca· loga2) ·nlog2n∈O(nlog2n) .
3. a < b: Dann ist
f (n) ≤ ca·n
loga n
∑i=0
(ba
)i
=ca
aqq
∑i=0
(ba
)i
dan = aq
=ca
q
∑i=0
biaq−i =ca
q
∑i=0
bq−iai
=ca
bqq
∑i=0
(ab
)i<
ca
bq∞
∑i=0
(ab
)i.
∑∞i=0
(ab
)iist wie in Fall 1 eine geometrische Reihe mit Wertk2 = b
b−a. Also ist
f (n) <ck2
abq =
ck2
abloga n =
c·k2
anloga b ∈O(nlogab) .
Hier wurde ausgenutzt, dassbloga n = (aloga b)loga n = (aloga n)loga b = nloga b.
Die Verallgemeinerung vonn = aq auf beliebigen folgt analog zu der Verallgemeinerung auf beliebi-gen bei Mergesort.
Offenbar ist der Fall 2 gerade der auf Mergesort zutreffende Fall.
Der Aufteilungs-Beschleunigungssatz wurde hier nur in einer speziellen Form bewiesen, um den Be-weis einfacher zu halten. Wir geben nachstehend eine allgemeinere Version an und verweisen fur denBeweis auf [CLRS01].

266 KAPITEL 10. SORTIEREN IN ARRAYS
Satz 10.5 (Aufteilungs-Beschleunigungs-Satz, Allgemeine Version)Seien a> 0und b> 0naturlicheZahlen und sei die folgende Rekursionsgleichung gegeben:
f (a·n) = b· f (n)+g(n) .
Dann hat f(n) folgendes asymptotisches Wachstum:
1. Ist g(n) = O(nloga b−ε) fur eine Konstanteε > 0, so ist f(n) = Θ(nloga b).
2. Ist g(n) = Θ(nloga b), so ist f(n) = Θ(nloga b · logn)
3. Ist g(n) = Ω(nloga b+ε) fur eine Konstanteε > 0, und ist b·g(na) ≤ c ·g(n) fur eine Konstante
c < 1 und alle n≥ n0 (c,n0 geeignet gewahlt), so ist f(n) = Θ(g(n)).
Die Unterscheidung erfolgt hier also nach dem Wachstum vong(n) im Verhaltnis zunloga b. Ist g(n)deutlich kleinerals nloga b (Fall 1), so bestimmtnloga b das Wachstum vonf (n). Hat g(n) dasselbeWachstum wienloga b (Fall 2), so kommt im Wachstum vonf (n) ein logn Faktor dazu. Ist schließlichg(n) deutlich großerals nloga b und gilt die zusatzliche
”Regularitatsbedingung“ aus 3., so bestimmt
g(n) allein die Großenordnung vonf (n).
Deutlich kleinerbzw.deutlich großerbedeutet dabei jeweils mindestens um einen polynomialen Fak-tor nε .
Beispiel 10.1
1. f (3n) = 9 f (n)+n
Hier ergibt sich aus der einfachen Version des Satzes (Fall 3)f (n) = O(nlog3 9) = O(n2). Inder allgemeinen Version trifft Fall 1 zu, dag(n) ∈ O(nloga b−1) (also ε = 1), und man erhaltf (n) = Θ(nloga b) = Θ(n2).
2. f (32n) = f (n)+1
Hier ist g(n) = 1 undnlog3/2 1 = n0 = 1. Also trifft Fall 2 der allgemeinen Version zu, und manerhalt f (n) = Θ(logn).
3. f (4n) = 3 f (n)+nlogn
Hier istg(n) = nlogn undnloga b = nlog4 3 = O(n0,793). Also istg(n) = Ω(nloga b+ε) mit ε = 0,2.Es wurde also Fall 3. zutreffen, falls wir die Regularitatsbedingung fur g(n) zeigen konnen. Esist b · f (n
a) = 3 ·(
n4
)· log
(n4
)< 3
4nlogn, so dass die Regularitatsbedingung mitc = 34 gilt. Also
folgt f (n) = Θ(nlogn).
4. f (2n) = 2 f (n)+nlogn
Diese Rekursionsgleichung fallt nicht unter das allgemeine Schema, dag(n) = nlogn zwarasymptotisch großer alsnloga b = n ist, aber nicht um einen Faktornε . Dieser Fall fallt also indie
”Lucke“ zwischen Fall 2. und 3.

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 267
10.3.2 Multiplikation von Dualzahlen
Als weitere Anwendung betrachten wir dieMultiplikation von zwei n-stelligen Dualzahlen. Die tra-ditionelle Methode erfordertΘ(n2) Bit Operationen. Durch Aufteilung und Beschleunigung erreichtmanO(nlog3) = O(n1,59) Operationen. Dies ist nutzlich bei der Implementation der Multiplikationbeliebig langer Dualzahlen, z. B. in Programmpaketen, die mit den Standardlong oderint Zahlennicht auskommen.
Seienx,y zwein-stellige Dualzahlen, wobein eine Zweierpotenz sei. Wir teilenx,y in zwei n2-stellige
Zahlen wie folgt:
x = a b
y = c d
Dann ist
xy = (a2n2 +b)(c2
n2 +d)
= ac2n +(ad+bc)2n2 +bd.
Man hat die Multiplikation also auf 4 Multiplikationen vonn2-stelligen Zahlen und einige Additionenund Shifts (Multiplikationen mit 2
n2 bzw. 2n), die nur linearen Aufwand erfordern) zuruckgefuhrt.
Dies fuhrt zur Rekursionsgleichung
T(n) = 4·T(n2)+c0 ·n,
mit der LosungT(n) = Θ(n2), also ohne Gewinn gegenuber der traditionellen Methode.
Die Anweisungen
u := (a+b)(c+d)v := ac
w := bd
z := v2n +(u−v−w)2n2 +w
fuhren jedoch zur Berechnung vonz= xymit 3 Multiplikation von Zahlen der Langen2 bzw. n
2 +1, dabeia+b bzw.c+d ein Ubertrag auf die
(n2 +1
)-te Position entstehen konnte.
Ignorieren wir diesenUbertrag, so erhalt man
T(n) = 3T(n
2
)+c1n
mit der gewunschten LosungT(n) = Θ(nlog2 3).
Um denUbertrag zu berucksichtigen, schreiben wira+b undc+d in der Form
a+b = α a
c+d = γ c

268 KAPITEL 10. SORTIEREN IN ARRAYS
alsoa+b = α2n2 + a, c+d = γ2
n2 + c mit den fuhrenden Bitsα,γ und denn
2-stelligen Resten ¯a, c.
Dann ist(a+b)(c+d) = αγ2n +(αa+ γ c)2
n2 + ac.
Hierin tritt nureinProdukt vonn2-stelligen Zahlen auf (namlichac). Der Rest sind Shifts bzw. lineare
Operationen aufn2-stelligen Zahlen (z. B.αa).
Daher erhalt man insgesamt die Rekursionsgleichung
T(n) = 3T(n
2
)+c2n,
wobeic2n folgenden Aufwand enthalt:
– Additionena+b, c+d : 2· n2
– Produktαγ : 1– Shift vonαγ auf αγ2n : n– Produkteαa,γ c: 2· n
2– Addition αa+ γ c: n
2 +1– Shift vonαa,γ c um n
2 Stellen: n2
– Shift vonv aufv2n: n– Additionu−v−w: 2(n
2 +1)– Shift vonu−v−w um n
2 Stellen: n2
– Addition zuz: 2n
Dieser Aufwand addiert sich zu 8,5 n+ 2≤ 9n fur n≥ 2. Also kannc2 als 9 angenommen werden.Als Losung erhalt man nach dem Aufteilung-Beschleunigungs-Satz
T(n) = Θ(nlog3) = Θ(n1,59) .
Der”Trick“ bestand also darin, auf Kosten zusatzlicher Additionen und Shifts, eine
”teure“ Multipli-
kation von n2-stelligen Zahlen einzusparen. Die rekursive Anwendung dieses Tricks ergibt dann die
Beschleunigung vonΘ(n2) aufΘ(n1,59). Fur die normale Computerarithmetik (n= 32) zahlt sich die-ser Trick nicht aus, jedoch bedeutet er fur Computerarithmetiken mit beliebigstelligen Dualzahlen,die meist softwaremaßig realisiert werden, eine wichtige Beschleunigung.
Das Verfahren lasst sich naturlich auch im Dezimalsystem anwenden. Wir geben ein Beispiel furn = 4:
x = 4217 y = 5236
Dann ist
a = 42, b = 17 unda+b = 59;
c = 52, d = 36 undc+d = 88.

10.4. QUICKSORT 269
Es folgt
u = (a+b)(c+d) = 59·88= 5192
v = ac= 42·52= 2184
w = bd = 17·36= 612
xy = v·104 +(u−v−w) ·102 +w
= 2184·104 +2396·102 +612
= 21.840.000+239.600+612
= 22.080.212
Auf ahnliche Weise wie die Multiplikation von Zahlen lasst sich auch die Multiplikation (großer)n×nMatrizen beschleunigen, vgl. [CLRS01] Hier erhalt man die Rekursionsgleichung
T(2n) = 7·T(n)+14n2
mit der Losung (gemaß Satz10.5) Θ(nlog7) = Θ(n2,81), also eine Beschleunigung gegenuber der nor-malen Methode mit dem AufwandΘ(n3). Hier lassen sich noch weitere Beschleunigungen erzielen.Der momentane “Rekord” steht beiO(n2,39), vgl. [CW87].
10.4 Quicksort
Quicksort basiert (im Gegensatz zu Mergesort) aufvariabler Aufteilung des Eingabearrays. Es wurde1962 von Hoare entwickelt. Es benotigt zwar im Worst CaseΩ(n2) Vergleiche, im Mittel jedoch nurO(nlogn) Vergleiche, und ist aufgrund empirischer Vergleiche allen anderenO(nlogn) Sortierverfah-renuberlegen.
10.4.1 Der Algorithmus
Wir geben zunachst eine Grobbeschreibung von Quicksort an.
1. Gegeben istvec[] mit n Komponenten.
2. Wahle eine beliebige Komponentevec[pivot].
3. Zerlege das Arrayvec in zwei Teilbereichevec[0]. . .vec[k-1] undvec[k+1]. . .vec[n-1]mit
a) vec[i].key≤ vec[pivot].key fur i = 0, . . . ,k−1
b) vec[k].key = vec[pivot].key
c) vec[j].key > vec[pivot].key fur j = k+1, . . . ,n−1.
4. Sofern ein Teilbereich aus mehr als einer Komponente besteht, so wende Quicksort rekursiv aufihn an.

270 KAPITEL 10. SORTIEREN IN ARRAYS
Die Korrektheit des Algorithmus folgt leicht durch vollstandige Induktion. Die Aufteilung erzeugtArrays kleinerer Lange, die nach Induktionsvoraussetzung durch die Aufrufe von Quicksort in Schritt4. korrekt sortiert werden. Die Eigenschaften 3a)–3c) ergeben dann die Korrektheit fur das gesamteArray.
Im Standardbeispiel ergibt sich, falls man stets die mittlere Komponente wahlt (gekennzeichnet durch*) die in Abbildung 10.7 dargestellte Folge von Zustanden (jeweils nach der Aufteilung). Die um-rahmten Bereiche geben die aufzuteilenden Bereiche an.
Input 63 24 12 53* 72 18 44 351. Aufteilung 18 24 12* 35 44 53 72* 632. Aufteilung 12 24 18* 35 44 53 63 723. Aufteilung 12 18 24 35* 44 53 63 72Output 12 18 24 35 44 53 63 72
Abbildung 10.7: Phasen bei Quicksort.
Wir betrachten nun die Durchfuhrung der Aufteilung im Detail. Da sie rekursiv auf stets andere Teiledes Arraysvec angewendet wird, betrachten wir einen Bereich vonloBound bishiBound.
Grobbeschreibung der Aufteilung
1. Gegeben istvec und der Bereich zwischenloBound undhiBound.
2. Wahle eine Komponentevec[pivot].
3. Tauschevec[pivot] mit vec[loBound].
4. Setze IndexzeigerloSwap aufloBound+1 undhiSwap aufhiBound.
5. SolangeloSwap < hiSwap wiederhole:
5.1 Inkrementiere ggf.loSwap solange, bisvec[loSwap].key > vec[loBound].key.
5.2 Dekrementiere ggf.hiSwap solange, bisvec[hiSwap].key≤ vec[loBound].key.
5.3 FallsloSwap < hiSwap, so vertauschevec[loSwap] undvec[hiSwap], und inkremen-tiere bzw. dekrementiereloSwap undhiSwap um jeweils 1.
6. Tauschevec[loBound] undvec[hiSwap].
Abbildung 10.8 illustriert diese Aufteilung. und h geben die jeweilige Position vonloSwap undhiSwap an,∗ das gewahltevec[pivot] Element.
Bei jedem Eintritt in die Schleife 5 gilt die Invariante:
vec[i].key≤ vec[pivot].key fur i = loBound . . .loSwap−1,vec[j].key > vec[pivot].key fur j = hiSwap+1 . . .hiBound,loSwap < hiSwap⇒ vec[loSwap-1].key≤ vec[pivot].key≤
≤ vec[hiSwap+1].key.
(10.6)

10.4. QUICKSORT 271
Input 63 24 12 53 72 18 44 35Schritt 2 63 24 12 53* 72 18 44 35Schritt 3 53* 24 12 63 72 18 44 35Schritt 4 53* 24 12 63 72 18 44 35h
Am Ende von 5.1 53* 24 12 63` 72 18 44 35h
Am Ende von 5.2 53* 24 12 63` 72 18 44 35h
Schritt 5.3 53* 24 12 35 72 18 44h 63Am Ende von 5.1 53* 24 12 35 72` 18 44h 63Am Ende von 5.2 53* 24 12 35 72` 18 44h 63Schritt 5.3 53* 24 12 35 44 18`h 72 63Schritt 6 18 24 12 35 44 53* 72 63
Abbildung 10.8: Die Aufteilung bei Quicksort im Detail.
Beim Austritt gilt zusatzlich
loSwap≥ hiSwap, vec[hiSwap].key≤ vec[pivot].key, (10.7)
so dass der Tausch in Schritt 6 die “Pivot”-Komponente genau an die richtige Stelle tauscht.
Lemma 10.2 Enthalt der aufzuteilende Bereich m Komponenten, so ist die Anzahl der Vergleiche vonKomponenten fur die Aufteilung m−1.
Beweis: Da loSwap und hiSwap nach einem Austausch inkrementiert bzw. dekrementiert werden,wird jedes anderen Elemente genau einmal mit dem Pivotelement verglichen. Dies ergibtm−1 Ver-gleiche.
Es folgt eine Java Methode dieses Algorithmus.
Programm 10.3 quickSort/*** Sorts with quicksort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void quickSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();quickSort(vec, 0, vec.length - 1);

272 KAPITEL 10. SORTIEREN IN ARRAYS
/*** sorts array by quicksort in a certain range* @param vec the array in which this happens* @param loBound start of the range* @param hiBound end of the range*/private static void quickSort(Item[] vec, int loBound, int hiBound)
int loSwap, hiSwap;int pivotKey, pivotIndex;Item temp, pivotItem;
if (hiBound - loBound == 1) // Two items to sortif (vec[loBound].key > vec[hiBound].key)
temp = vec[loBound];vec[loBound] = vec[hiBound];vec[hiBound] = temp;
return;
pivotIndex = (loBound + hiBound) / 2; // 3 or more items to sortpivotItem = vec[pivotIndex];vec[pivotIndex] = vec[loBound];vec[loBound] = pivotItem;pivotKey = pivotItem.key;loSwap = loBound + 1;hiSwap = hiBound;do
while (loSwap <= hiSwap && vec[loSwap].key <= pivotKey)// INVARIANT (prior to test):// All vec[loBound+1..loSwap-1]// are <= pivot && loSwap <= hiSwap+1
loSwap++;while (vec[hiSwap].key > pivotKey)
// INVARIANT (prior to test):// All vec[hiSwap+1..hiBound]// are > pivot && hiSwap >= loSwap-1
hiSwap--;if (loSwap < hiSwap)
temp = vec[loSwap];vec[loSwap] = vec[hiSwap];vec[hiSwap] = temp;loSwap++;hiSwap--;

10.4. QUICKSORT 273
// INVARIANT: All vec[loBound..loSwap-1] are <= pivot// && All vec[hiSwap+1..hiBound] are > pivot// && (loSwap < hiSwap) -->// vec[loSwap] <= pivot < vec[hiSwap]// && (loSwap >= hiSwap) --> vec[hiSwap] <= pivot// && loBound <= loSwap <= hiSwap+1 <= hiBound+1
while (loSwap < hiSwap);vec[loBound] = vec[hiSwap];vec[hiSwap] = pivotItem;
if (loBound < hiSwap-1) // 2 or more items in 1st subvecquickSort(vec, loBound, hiSwap-1);
if (hiSwap+1 < hiBound) // 2 or more items in 2nd subvecquickSort(vec, hiSwap+1, hiBound);
10.4.2 Der Rekursionsaufwand von Quicksort
Da die Aufteilung (im Unterschied zur Mergesort) variabel ist, hat der Rekursionsbaum bei Quick-sort i. a. Teilbaume unterschiedlicher Hohe. Im Standardbeispiel ergibt sich der in Abbildung10.9dargestellte Baum.
QuickSort(vec,2,4)
QuickSort(vec,1,4)
QuickSort(vec,0,4)
QuickSort(vec,0,7)
QuickSort(vec,6,7)
PPPP
PPP
Abbildung 10.9: Rekursionsbaum zu Quicksort.
Man sieht, dass der Baum am tiefsten wird, wenn als Vergleichselement jeweils das kleinste odergroßte Element des aufzuteilenden Bereiches gewahlt wird. In diesem Fall entartet der Rekursions-baum zu einer Liste (keine Verzweigungen). DieRekursionstiefekann also bis zun−1 betragen.
Wir zeigen durch Induktion, dass auch die AnzahlR(n) der rekursiven Aufrufe bei einem Arraybereichder Langen hochstensn−1 betragt.
Fur n = 1 erfolgt kein Aufruf, also giltR(1) = 0 (Induktionsanfang). Fur n > 1 bewirkt der ersteAufruf eine Aufteilung in Bereiche mitn1 und n2 Komponenten, wobein1 + n2 = n−1 gilt, da die

274 KAPITEL 10. SORTIEREN IN ARRAYS
Vergleichskomponente weg fallt. Also sindn1,n2 < n und man erhalt
R(n) = 1+R(n1)+R(n2)≤ 1+(n1−1)+(n2−1) (Induktionsvoraussetzung)
= n1 +n2−1
< n−1.
Also istR(n)≤ n−1.
10.4.3 Der Worst Case Aufwand von Quicksort
Vergleiche von Schlusseln treten bei Quicksort nur bei den Aufteilungen auf. Dabei muss jeder andereSchlussel mit dem Vergleichsschlussel verglichen werden, also erfolgen bei einem Bereich vonnKomponenten mindestens (und mit Lemma10.2sogar genau)n−1 Vergleiche.
Wird nun jeweils der großte bzw. kleinste Schlusselwert als Vergleichsschlussel gewahlt, so verklei-nert sich der Bereich jeweils nur um ein Element und man erhalt:
(n−1)+(n−2)+ . . .+2+1 =n(n−1)
2Vergleiche.
Also gilt fur die Worst Case AnzahlC(n) von Vergleichen:
C(n) = Ω(n2) .
10.4.4 Der mittlere Aufwand von Quicksort
Quicksort ist also im Worst Case schlecht. Erfahrungsgemaß ist Quicksort aber sehr schnell im Ver-gleich zu anderenΩ(n2) Sortierverfahren wie Bubblesort. Dies liegt daran, dass der Worst Case nurbei wenigen Eingabefolgen auftritt.
Man wird daher Quicksort gerechter, wenn man nicht den Worst Case betrachtet, sondern den Auf-wand uber alle moglichen Eingabefolgenmittelt, also denmittleren AufwandC(n) bei Gleichver-teilung allern! Reihenfolgen der Schlussel 1,2, . . . ,n betrachtet. Gleichverteilung bedeutet hier, dassjede Reihenfolge (Permutation) der Werte 1, . . . ,n mit dem gleichen Gewicht (namlich 1) in das Mitteleingeht.3
Als Vergleichsbeispiel betrachten wir das Wurfeln mit einem Wurfel mit den Augenzahlen 1,2, . . . ,6.Dann ergibt sich die mittlere Augenzahl bei Gleichverteilung zu1+2+3+...+6
6 = 3,5. Die mittlereSchrittlange beim Mensch-argere-dich-nicht betragt also 3,5; der Worst Case (bzgl. Weiterkommen)jedoch nur 1.
Fur n = 3 ergeben sich bei Quicksort 3!= 6 Permutationen, namlich 123, 132, 213, 231, 312, 321.Die Anzahl der Vergleiche pro Permutation betragt (gemaß der Implementation in Programm10.3)
3In der Terminologie der Wahrscheinlichkeitstheorie sagt man, dass jede Reihenfolge mit der gleichen Wahrscheinlich-keit 1/n! auftritt (daher der NameGleichverteilung), und man nenntC(n) auch dieerwartete Anzahl der Vergleiche.

10.4. QUICKSORT 275
2, 4, 4, 4, 4, 2. Der mittlere Aufwand betragt also2+4+4+4+4+23! = 10
3 Vergleiche gegenuber demWorst Case von 4 Vergleichen.
SeiΠ die Menge aller Permutationen von 1, . . . ,n. Fur π ∈ Π seiC(π) die Anzahl von Vergleichen,die Quicksort benotigt, umπ zu sortieren. Dann ist
C(n) =1n! ∑
π∈ΠC(π) .
Wir werden jetztC(n) nach oben abschatzen. Dafur teilen wir die MengeΠ aller Permutationen in dieMengenΠ1,Π2, . . . ,Πn, wobei
Πk = π ∈Π | das Vergleichselement hat den Wertk .
Fur n = 3 ergibt sichΠ1 = 213,312, Π2 = 123,321 undΠ3 = 132,231.In Πk ist das Vergleichselement fest vorgeschrieben, die anderen Komponenten konnen jedoch in jederReihenfolge auftreten. Also ist
|Πk|= (n−1)! f ur k = 1, . . . ,n.
Fur alleπ ∈Πk ergibt die erste Aufteilung in Quicksort die Teilarrays bestehend aus einer Permutationπ1 von 1,2, . . . ,k−1 und einer Permutationπ2 von k+1, . . . ,n (da ja das Vergleichselement geradekist).
Z(π) sei die Anzahl der Vergleiche mit derπ in die Teileπ1 und π2 zerlegt wird. Dann ist fur alleπ ∈Πk
C(π) = Z(π)+C(π1)+C(π2) .
Dabei istZ(π)≤ 2n (in der Implementation in Programm10.3, vgl. Lemma10.2). Summiertuber alleπ ∈Πk, so ergibt sich wegen|Πk|= (n−1)!:
∑π∈Πk
C(π) = ∑π∈Πk
[Z(π)+C(π1)+C(π2)] = ∑π∈Πk
Z(π)︸ ︷︷ ︸=:S1
+ ∑π∈Πk
C(π1)︸ ︷︷ ︸=:S2
+ ∑π∈Πk
C(π2)︸ ︷︷ ︸=:S3
Hierin ist wegen Lemma10.2S1≤ ∑
π∈Πk
n = n(n−1)! = n! .
Wennπ alle Permutationen ausΠk durchlauft, entstehen beiπ1 alle Permutationen von 1, . . . ,k−1,und zwar jede(n−1)!/(k−1)! mal, daΠk ja insgesamt(n−1)! Permutationen enthalt, und wegender Arbeitsweise des Aufteilungsalgorithmus (und der Gleichverteilung der Permutationen inΠk jedePermutation von 1, . . . ,k−1 gleich haufig entsteht. Also ist
S2 =(n−1)!(k−1)! ∑
π1Permutation von 1,...,k−1
C(π1)
= (n−1)! C(k−1) .

276 KAPITEL 10. SORTIEREN IN ARRAYS
Entsprechend folgtS3 = (n−1)! C(n−k) .
Durch Zusammensetzen aller Gleichungen bzw. Ungleichungen ergibt sich
C(n) =1n! ∑
π∈ΠC(π)
=1n!
n
∑k=1
∑π∈Πk
C(π) =1n!
n
∑k=1
(S1 +S2 +S3)
≤ 1n!
n
∑k=1
(n! +(n−1)! C(k−1)+(n−1)! C(n−k))
=n!n!
n
∑k=1
1+(n−1)!
n!
n
∑k=1
C(k−1)+(n−1)!
n!
n
∑k=1
C(n−k)
= n+1n
n−1
∑k=0
C(k)+1n
n−1
∑k=0
C(k)
= n+2n
n−1
∑k=0
C(k) .
Wir haben damit eine Rekursionsgleichung fur C(n) gefunden. Beachtet man noch die Anfangswerte
C(0) = C(1) = 0, C(2) = 1
so ist
C(n)≤ n+2n
n−1
∑k=2
C(k) fur n≥ 2.
Lemma 10.3 Fur die Losung r(n) der Rekursionsgleichung
r(n) = n+2n
n−1
∑k=2
r(k) fur n≥ 2
mit den Anfangswerten r(0) = r(1) = 0, r(2) = 1 gilt fur alle n≥ 2
r(n)≤ 2nlnn. 4
Beweis:Der Beweis erfolgt durch vollstandige Induktion nachn mit dem Ansatzr(n)≤ 2nlnn, wobeidie Konstantec wahrend des Beweises ermittelt wird.
Induktionsanfang: Fur n = 2 ist r(2) = 1. Andererseits istc·2ln2≈ c·1,39. Also gilt der Induktions-anfang fur c≥ 1.
Induktionsvoraussetzung: Die Behauptung gelte fur 2,3, . . . ,n−1.
4ln = logen (naturlicher Logarithmus).
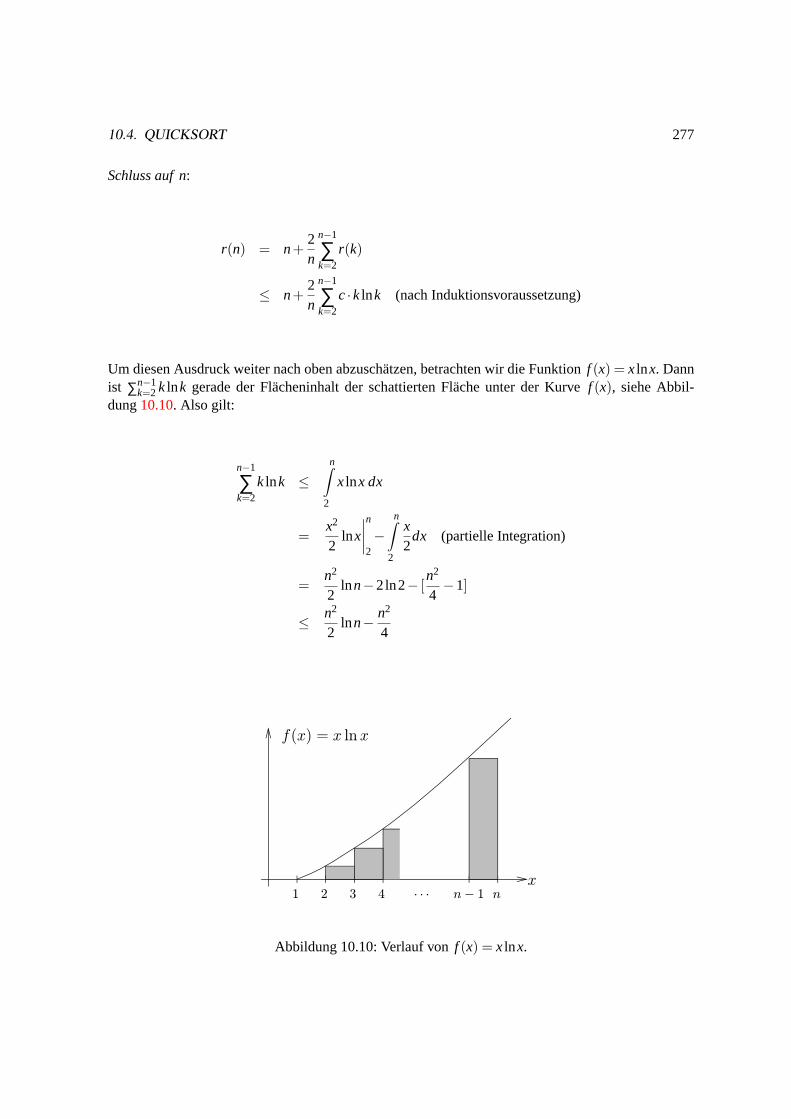
10.4. QUICKSORT 277
Schluss auf n:
r(n) = n+2n
n−1
∑k=2
r(k)
≤ n+2n
n−1
∑k=2
c·k lnk (nach Induktionsvoraussetzung)
Um diesen Ausdruck weiter nach oben abzuschatzen, betrachten wir die Funktionf (x) = xlnx. Dannist ∑n−1
k=2 k lnk gerade der Flacheninhalt der schattierten Flache unter der Kurvef (x), siehe Abbil-dung10.10. Also gilt:
n−1
∑k=2
k lnk ≤n∫
2
xlnx dx
=x2
2lnx
∣∣∣∣n2−
n∫2
x2
dx (partielle Integration)
=n2
2lnn−2ln2− [
n2
4−1]
≤ n2
2lnn− n2
4
266 KAPITEL 10. SORTIEREN IN ARRAYS
x
f(x) = x lnx
1 2 3 4 n· · · n− 1
Abbildung 10.10: Verlauf von f(x) = x lnx.
= c · n lnn+ 2n−2c
4n︸ ︷︷ ︸
=:R(n)
≤ c · n lnn falls R(n) ≤ 0 .
Nun ist
R(n) = 2n−c
2n
≤ 0 fur c ≥ 4 .
Aus dem Lemma folgt:
Satz 10.6 Fur die mittlere Anzahl C(n) der Vergleiche zum Sortieren eines n-elementigenArrays mit Quicksort gilt
C(n) ∈ O(n logn) .
Beweis: Aus C(n) ≤ r(n) und Lemma 10.3 folgt
C(n) ≤ 4 · n lnn = 4 · n ·logn
log e=4
log en logn
fur alle n ≥ 2.
Also ist C(n) ∈ O(n logn) mit der O-Konstanten 4 log e ≈ 2,77.
Abbildung 10.10: Verlauf vonf (x) = xlnx.

278 KAPITEL 10. SORTIEREN IN ARRAYS
Hieraus folgt
r(n) ≤ n+2n
n−1
∑k=2
c·k · lnk = n+2cn
n−1
∑k=2
k lnk
≤ n+2cn
(n2
2lnn− n2
4
)= n+
2c2
nlnn− 2c4
n
= c·nlnn+n− c2
n︸ ︷︷ ︸=:R(n)
≤ c·nlnn falls R(n)≤ 0.
Nun ist
R(n) = n− c2
n
≤ 0 fur c≥ 2.
Aus dem Lemma folgt:
Satz 10.6Fur die mittlere AnzahlC(n) der Vergleiche zum Sortieren eines n-elementigen Arrays mitQuicksort gilt
C(n) ∈O(nlogn) .
Beweis:AusC(n)≤ r(n) und Lemma10.3folgt
C(n)≤ 2·nlnn = 2·n· lognloge
=2
logenlogn
fur allen≥ 2.
Also istC(n) ∈O(nlogn) mit derO-Konstanten 2loge ≈ 1,386.
Entsprechend kann man fur die mittlere AnzahlA(n) von Zuweisungen beweisen (Ubung)
A(n) = O(nlogn).
Quicksort arbeitet also im Mittel beweisbar sehr schnell, und dies wird auch in allen Laufzeituntersu-chungen bestatigt. Quicksort ist der Sortieralgorithmus, den man verwenden sollte.

10.5. HEAPSORT 279
10.5 Heapsort
Heapsort basiert im Gegensatz zu Mergesort und Quicksort nicht auf dem Prinzip der Aufteilung,sondern nutzt eine spezielle Datenstruktur (denHeap), mit der wiederholt auf das großte Elementeines Arrays zugegriffen wird. Esahnelt damit eher einem verbesserten Selection Sort.
10.5.1 Die Grobstruktur von Heapsort
Ein Heap(auchPriority Queuegenannt) ist eine abstrakte Datenstruktur mit folgenden Kennzeichen:
Wertebereich: Eine Menge von Werten des (homogenen) Komponententyps. Alle Komponenten be-sitzen einen Wert (Schlussel).
Operationen:
1. Einfugen einer Komponente.
2. Zugriff auf die Komponente mit dem großten Wert.
3. Entfernen der Komponente mit dem großten Wert.
4. Anderung des Wertes einer Komponente.
Statt des großten Wertes wird auch oft der kleinste Wert in 2. und 3. genommen.
Bei der Anwendung in Heapsort sind die Komponenten vonvec die Elemente des Heaps, und dieSchlusselvec[i].key sind die Werte. Dann arbeitet Heapsort nach folgender Idee:
Grobstruktur von Heapsort
1. Gegeben sei das Arrayvec[] mit n Komponenten.
2. Initialisiere den Heap mit den Komponenten vonvec.
3. for i := n−1 downto 0 do
3.1 Greife auf das großte Element des Heaps zu.
3.2 Weise diesen Wert der Arraykomponentevec[i] zu.
3.3 Entferne das großte Element aus dem Heap.
Die Korrektheit des Algorithmus ist offensichtlich, und auch dieAhnlichkeit zu Selection Sort. Um zueinem schnellen Algorithmus zu kommen, muss man den Heap so implementieren, dass die benotigtenOperationen schnell ausgefuhrt werden konnen.
In Heapsort sind dies die Operationen 2 (in Schritt 3.1) und 3 (in Schritt 3.3), die jeweilsn malnacheinander ausgefuhrt werden. Hinzu kommt das Initialisieren des Heaps in Schritt 2.
Wir brauchen offenbar nicht alle Heapoperationen (4 wird nicht benotigt) und die anderen Opera-tionen nur in bestimmter Reihenfolge (Einfugen nur bei der Initialisierung, Zugriff und Entfernen

280 KAPITEL 10. SORTIEREN IN ARRAYS
stets nacheinander). Daher werden wir keinen allgemeinen Heap verwenden (vgl. dazu [CLRS01]),sondern die benotigten Heapoperationen direkt im Arrayvec implementieren, und zwar so, dass gilt:
Worst Case-Aufwand der hier gewahlten Heap Implementation
• Initialisierung inO(n).
• Zugriff auf das großte Element inO(1).
• Entfernen des großten Elements inO(logn).
Dabei werden sowohl Vergleiche als auch Zuweisungen von Arraykomponenten berucksichtigt. Hierausfolgt sofort:
Satz 10.7Der Worst Case Aufwand zum Sortieren eines n-elementigen Arrays mit Heapsort betragtO(nlogn).
10.5.2 Die Implementation des Heaps
Die Grundidee besteht darin, sich das Arrayvec als binaren Baum vorzustellen, wobei die Kompo-nenten der Reihe nach in die Schichten 0,1,2. . . von links nach rechts angeordnet werden.
Fur das Standardbeispiel
vec = 630
241
122
533
724
185
446
357
ergibt sich so der in Abbildung10.11dargestellte Baum.
357
533
724@@
185
446@@
241
122H
HH630
Abbildung 10.11: Array als Heap.
Fur einen Knotenv in einem binaren Baum bezeichnet man die vonv ausuber eine gerichtete Kanteerreichbaren Knoten alsSohneund nenntv denVaterdieser Sohne. Bei 2 Sohnen unterscheidet man(bzgl. einer gegebenen Darstellung) zwischenlinkemundrechtemSohn.
Mit diesen Bezeichnungen gelten fur den Baum zu einem Heap folgende Eigenschaften:

10.5. HEAPSORT 281
Lemma 10.4
a) vec[0] ist die Wurzel des Baumes.
b) Der linke Sohn vonvec[i] (falls vorhanden) istvec[2i+1].
c) Der rechte Sohn vonvec[i] (falls vorhanden) istvec[2i+2].
d) Nur Knotenvec[i] mit i≤⌊
n2
⌋haben Sohne.
Beweis:Ubung.
Wir sagen, dassvec dieHeapeigenschaft(heap ordering) erfullt, wenn fur i = 0, . . . ,n−1 gilt:
vec[i].key ≥ vec[2i+1].key falls 2i +1 < nvec[i].key ≥ vec[2i+2].key falls 2i +2 < n
Fur jeden Knotenvec[i] mit einem oder zwei Sohnen ist also derkey-Wert der Sohne nicht großerals der des Vaters.
Hieraus ergibt sich direkt:
Lemma 10.5 Erfullt vec die Heapeigenschaft, so gilt:
a) vec[0].key ist der großte auftretende Schlusselwert.
b) Entlang jeden Weges von einem Blatt zu der Wurzel sind die Schlusselwerte aufsteigend sortiert.
Erfullt vec die Heapeigenschaft, so kann also auf die großte Komponentevec[0] in O(1) Zeit zuge-griffen werden. Wenn wir sie entfernen, so haben beide Teilbaume noch die Heapeigenschaft. Wennwir dann ein neues Element an die Wurzel stellen (einfugen), so mussen wir die Heapeigenschaftwieder herstellen.
Dazu verwenden wir die Funktionheapify(). Sie setzt voraus, dass die Heapeigenschaft bereits imBereichvec[top+1]. . .vec[bottom] gilt, fugtvec[top] hinzu und ordnet die Komponenten so um,dass hinterher die Heapordnung im Bereichvec[top]. . .vec[bottom] gilt. Dazu werden folgendeSchritte ausgefuhrt:
1. Ermittle den großeren der beiden Sohne (child) von top (falls keine Sohne existieren, so istdie Heapeigenschaft trivialerweise erfullt, falls nur ein Sohn existiert, so nehme diesen).
2. Vergleichevec[child] mit vec[top]. Fallsvec[child].key > vec[top].key so tauschevec[top] undvec[child].
3. Wendeheapify() rekursiv aufchild an.

282 KAPITEL 10. SORTIEREN IN ARRAYS
Die Korrektheitvonheapify() sieht man wie folgt:
Seienr und s die Sohne vontop und seienb = vec[r], c = vec[s] und a = vec[top] die zu-gehorigenkey-Werte. In den dazugehorigen Teilbaumen (siehe Abbildung10.12gilt nach Vorausset-zung die Heapeigenschaft. O. B. d. A. seir der großere Sohn (alsob≥ c) undb > a. Dann werdendie Inhalte der Komponententop undr getauscht. Nach dem Tausch istb = vec[top].key > a,cund somit die Heapeigenschaft intop erfullt. Im rechten Teilbaum gilt sie unverandert. Im linkenTeilbaum konnte sie verletzt sein, weshalb der rekursive Aufruf vonheapify() fur r notig wird (undper Induktionsannahme die Herstellung der Heapeigenschaft in diesem Teilbaum sichert).
br
csHH
HHatop
AAAA
AAAA
- ar
csHH
HHbtop
AAAA
AAAA
Abbildung 10.12: Zur Korrektheit vonheapify()
Als Beispiel betrachten wir in Abbildung10.13 das Einfugen von 27 als Wurzel in einen Baum,dessen Teilbaume beide die Heapeigenschaft erfullen. Durchgezogene Linien bedeuten dabei, dassdie Heapeigenschaft erfullt ist, gepunktete Linien den durchheapify() durchgefuhrten Vergleichmit den Sohnen.
Es folgt eine Java Implementation vonheapify():
Programm 10.4 heapify/*** establishes heap property in a certain range* @param vec the array in which this happens* @param top start of the range* @param bottom end of the range*/private static void heapify(Item[] vec, int top, int bottom)
Item temp;int child;
if (2*top+1 > bottom) return; // nothing to do
if (2*top+2 > bottom) // vec[2*top+1] is only child of vec[top]child = 2*top+1;
else // 2 sons, determine bigger oneif (vec[2*top+1].key > vec[2*top+2].key)
child = 2*top+1;

10.5. HEAPSORT 283
357
533
244@@
185
126@@
631
p p p p p p p p442
pppppppp270 -
357
533
p p p p244
pppp185
126@@
271
442HH
H630
-
357
p p p p273
244@@
185
126@@
531
442HHH
630 -
277
353
244@@
185
126@@
531
442H
HH630
Abbildung 10.13: Ein Beispiel fur heapify().
else child = 2*top+2;
//endif
// check if exchange is necessaryif (vec[top].key < vec[child].key)
temp = vec[top];vec[top] = vec[child];vec[child] = temp;// recursive call for possible further exchangesheapify(vec, child, bottom);
//endif
heapify() lasst sich nun einfach zum Herstellen der Heapeigenschaft im gesamten Arrayvec nut-zen, indem man das Array von hinten nach vorn durchlauft und in jeder Komponentei (die Sohnehat)heapify(vec,i,n-1) aufruft. Vor dem Aufruf erfullt vec[i+1]. . .[n-1] bereits die Heapei-genschaft, und der Aufruf stellt die Heapeigenschaft fur vec[i]. . .vec[n-1] her.
Eine Java Implementation lautet:

284 KAPITEL 10. SORTIEREN IN ARRAYS
Programm 10.5 createHeap/*** turns array into a heap* @param vec the array to which this happens*/private static void createHeap(Item[] vec)
for (int i = vec.length/2 - 1; i >= 0; i--) heapify(vec, i, vec.length - 1);
Im Standardbeispiel ergeben sich die in Abbildung10.14dargestellten Zustande nach jedem Durch-lauf der Schleife. Dabei deuten durchgezogene Linien bereits hergestellte Heapbedingungen an.
10.5.3 Die Implementation von Heapsort
Mit heapify() undcreateHeap() lasst sich Heapsort jetzt einfach implementieren:
Programm 10.6 heapSort/*** sorts array by heapsort in a certain range* @param vec the array in which this happens*/public static void heapSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();
Item temp;int last;int n = vec.length;
createHeap(vec);for (last = n-1; last > 0; last--)
// exchange top component with// current last component of vectemp = vec[0];vec[0] = vec[last];vec[last] = temp;// call Heapify to to reestablish heap propertyheapify(vec, 0, last-1);
//endfor
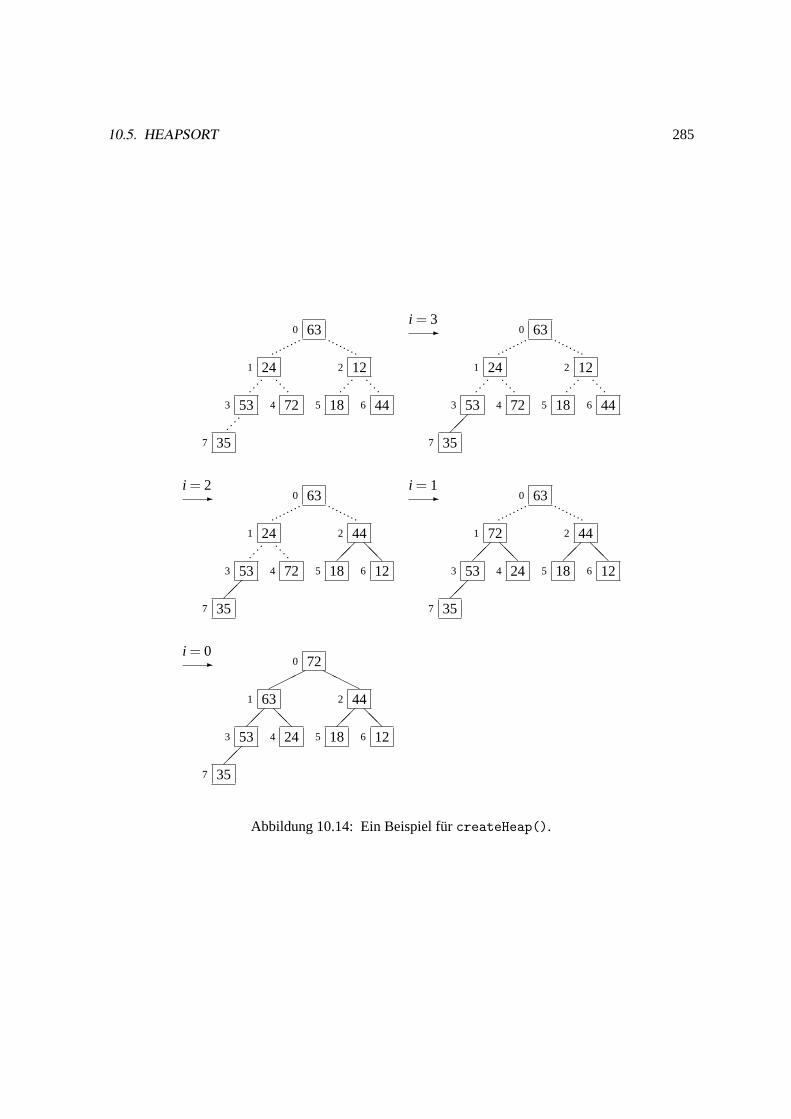
10.5. HEAPSORT 285
357
p p p p533
p p p p724
pppp185
p p p p446
pppp241
p p p p p p p p122
pppppppp630 -i = 3
357
533
p p p p724
pppp185
p p p p446
pppp241
p p p p p p p p122
pppppppp630
-i = 2
357
533
p p p p724
pppp185
126@@
241
p p p p p p p p442
pppppppp630 -i = 1
357
533
244@@
185
126@@
721
p p p p p p p p442
pppppppp630
-i = 0
357
533
244@@
185
126@@
631
442HH
H720
Abbildung 10.14: Ein Beispiel fur createHeap().

286 KAPITEL 10. SORTIEREN IN ARRAYS
Die Komponentenvec[0]. . .vec[last] bilden also den aktuellen Heap (mit jeweiligem großtenElementvec[0]), und die Komponentenvec[last+1]. . .vec[n-1] den bereits sortierten Teil desArrays.
Im Standardbeispiel ergeben sich jeweils beim Eintritt in diefor-Schleife die in Abbildung10.15dargestellten Heaps. Die noch verbundenen Komponenten des Arrays stellen den jeweiligen Heapvec[0]. . .vec[last] dar, die Aktionen vonheapify() werden nicht mehr dargestellt.
10.5.4 Die Analyse von Heapsort
Zur Vorbereitung der Analyse betrachten wir die Interpretation des Arrays als Baum genauer:
Da die Komponenten des Arrays schichtweise im Baum angeordnet sind, hat er die Eigenschaft, dassalle Schichteni bis auf eventuell die letztevoll sind, d. h. 2i Knoten enthalten. Ein solcher Baum heißtvoller (binarer) Baum.
Lemma 10.6 Sei T ein voller binarer Baum mit n Knoten. Sei h die Hohe von T. Dann gilt:
a) 2h≤ n≤ 2h+1−1
b) h≤ blognc
Beweis: In T sind alle Schichten voll bis eventuell auf die letzte. Also sind in Schichti fur i =0, . . . ,h−1 genau 2i Knoten, und in Schichthzwischen 1 und 2h Knoten (vergleiche Abbildung10.16).Also ist (
h−1
∑i=0
2i
)+1≤ n≤
h
∑i=0
2i .
Wegen∑ki=02i = 2k+1−1 ergibt sich
2h≤ n≤ 2h+1−1,
also a). Aus 2h≤ n folgt h≤ logn und somith≤ blognc, dah eine ganze Zahl ist.
Betrachten wir jetzt den Aufwand fur einen Aufruf vonheapify() einschließlich der dadurch er-zeugten weiteren rekursiven Aufrufe.
Bei jedem Aufruf, bei dem ein Austausch erfolgt, “sinkt” das betrachtete Element um eine Stufe nachunten im Baum. Die Anzahl der Folgeaufrufe durch Rekursion ist also durch die Anzahl der Schichtenunterhalb der Ausgangsstufe des Elements beschrankt.
Diese Beobachtung ist der Kern der folgenden Abschatzung. Wir bezeichnen dieUberprufung undggf. Herstellung der Heapeigenschaft fur einen Knoten mit seinen Sohnen als einePrufaktion.
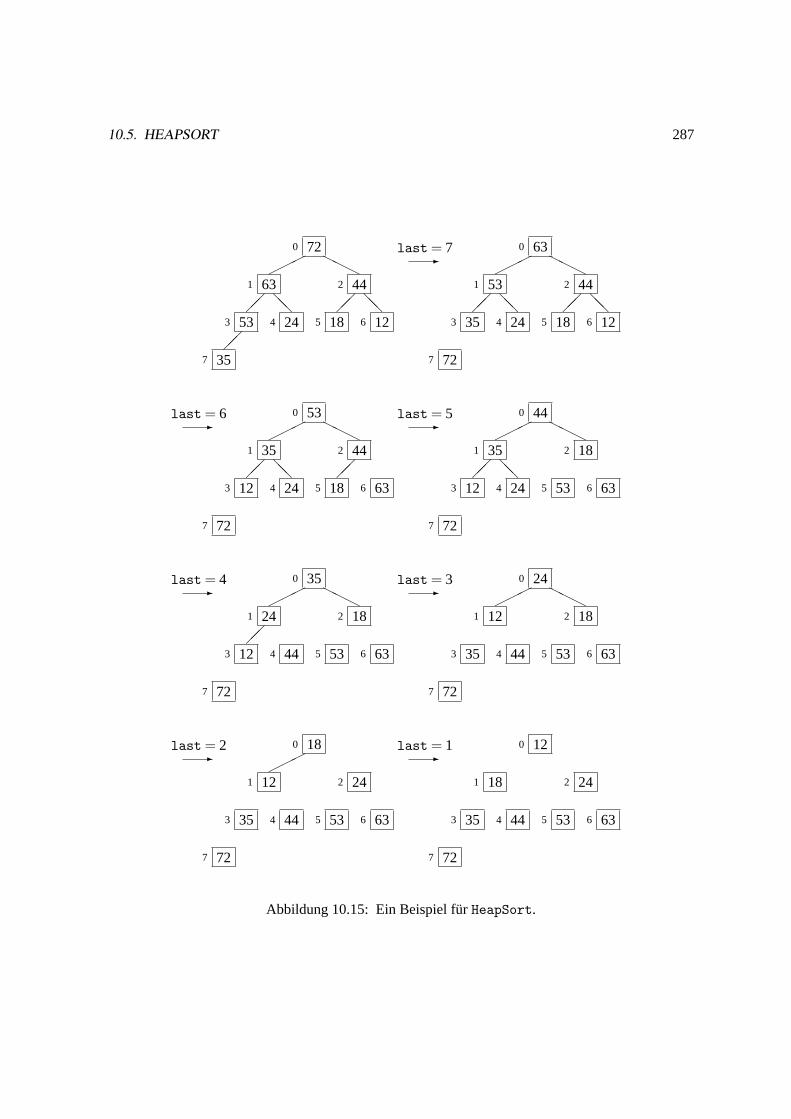
10.5. HEAPSORT 287
357
533
244@@
185
126@@
631
442HH
H720
-last = 7
727
353
244@@
185
126@@
531
442HH
H630
-last = 6
727
123
244@@
185
636
351
442HHH
530-
last = 5
727
123
244@@
535 636
351
182H
HH440
-last = 4
727
123
444 535 636
241
182HH
H350
-last = 3
727
353 444 535 636
121
182HH
H240
-last = 2
727
353 444 535 636
121
242
180-
last = 1
727
353 444 535 636
181 242
120
Abbildung 10.15: Ein Beispiel fur HeapSort.

288 KAPITEL 10. SORTIEREN IN ARRAYS
u uAA u Schichth = 3
u u@@ u u@@ Schicht 2 22 Knoten
u uQQQ Schicht 1 21 Knoten
Schicht 0 20 Knotenu
Abbildung 10.16: Ein voller Baum.
Lemma 10.7 Fur die Anzahl P1(n) der Prufaktionen beim Herstellen der Heapeigenschaft in einemn-elementigen Array gilt
P1(n)≤ 2n.
Beweis:Wir betrachten (wie increateHeap()) die Schichten von unten nach oben. Da die Anzahlder Prufaktionen nach der angestellten Voruberlegung durch die Anzahl der Schichten unterhalb desKnotens beschrankt ist, folgt:
Schichth: keine PrufaktionenSchichth−1: hochstens 1 Prufaktionen pro Knoten der SchichtSchichth−2: hochstens 2 Prufaktionen pro Knoten der Schicht
. . .Schichth− i: hochstensi Prufaktionen pro Knoten der Schicht
. . .Schicht 0: hochstensh Prufaktionen.
Also ist
P1(n) ≤ 2h−1 ·1+2h−2 ·2+ . . .+2h−i · i + . . .+20 ·h
=h
∑i=1
2h−i · i =h
∑i=1
2h
2i i = 2hh
∑i=1
i2i
≤ 2n, da 2h≤ n und∞
∑i=1
i2i = 2.
Die AnzahlP2(n) der Prufaktionen inHeapSort (außerhalb voncreateHeap()) ergibt sich analog.Im i-ten Durchlauf derfor-Schleife wirdheapify() fur die Komponente mit Index 0 und den Heapmit n− i Komponenten aufgerufen, dessen Hohe nach Lemma10.6hochstens log(n− i) ist. Also folgt
P2(n)≤n−2
∑i=1
log(n− i)≤n−1
∑i=1
logn = (n−1) logn.

10.6. LITERATURHINWEISE 289
Pro Prufaktion erfolgen 2 Vergleiche und maximal 3 Zuweisungen (1 Austausch). Hinzu kommenjeweils 3 Zuweisungen (1 Austausch) in derfor-Schleife vonHeapSort. Hieraus folgt:
Satz 10.8Fur die Anzahl C(n) der Vergleiche und die Anzahl A(n) der Zuweisungen bei Heapsortgilt:
C(n) = O(nlogn), A(n) = O(nlogn) .
Beweis:Nachrechnen ergibt:
C(n) ≤ 2·P1(n)+2·P2(n)≤ 4n+2nlogn
≤ 3nlogn fur n≥ 16,
A(n) ≤ 3·P1(n)+3· (n−1)+3·P2(n)≤ 9n+3nlogn
≤ 5nlogn fur n≥ 23.
10.6 Literaturhinweise
Sortieralgorithmen werden in allen Buchernuber Algorithmen und Datenstrukturen behandelt, vom Klassiker[Knu98b] bis zu [CLRS01]. Die Implementationen der Algorithmen lehnt sich zum Teil an [HR94] an.
Die allgemeine Version des Aufteilungs-Beschleunigungssatzes ist aus [CLRS01]. Dort finden sich auch wei-tere Details zur Beschleunigung der Matrixmultiplikation. Die Anwendung auf die Multiplikationn-stelligerDualzahlen ist aus [AHU83].

290 KAPITEL 10. SORTIEREN IN ARRAYS

Kapitel 11
Untere Komplexitatsschranken fur dasSortieren
Die besten bisher kennen gelernten Sortierverfahren fur Arrays haben einen Aufwand vonO(nlogn)im Worst Case (Mergesort, Heapsort), bzw. im Average Case (Quicksort).
Es stellt sich nun die Frage, ob es noch bessere Sortierverfahren geben kann. Dies kann tatsachlichder Fall sein, wenn man zusatzliche Informationenuber die Schlusselmenge hat, wie das VerfahrenBucketsortin Coma II zeigt. Fur eine große Klasse von Algorithmen, die alle in Kapitel10behandeltenAlgorithmen umfasst, ist dies jedoch nicht der Fall.
Um dies zu zeigen, benotigen wir noch einen Begriff. Ein Algorithmus heißtdeterministisch, wenn derAblauf des Algorithmus nur vom Input abhangt (und nicht etwa von im Algorithmus ausgefuhrten Zu-fallsexperimenten wie bei sogenanntenrandomisiertenAlgorithmen). Dies bedeutet beim Sortieren,dass bei gleicher Eingabe in verschiedenen Laufen des Algorithmus dieselbe Folge von Vergleichenangestellt wird. Mit diesem Begriff gilt dann:
Satz 11.1 (Untere Schranken fur das Sortieren mit Vergleichen) Jeder deterministische Sortieral-gorithmus, der auf paarweisen Vergleichen von Schlusseln basiert, braucht zum Sortieren eines n-elementigen Arrays sowohl im Worst Case, als auch im Mittel (bei Gleichverteilung)Ω(nlogn) Ver-gleiche.
Dieser Satz zeigt also, dass Mergesort, Heapsort und Quicksort bzgl. der Großenordnungoptimalsind,und dass Laufzeitunterschiede hochstens derO-Konstanten zuzuschreiben sind.
Man beachte den Unterschied zu den bisher gemachtenO(. . .) Abschatzungen fur ein Problem. Diesehaben wir dadurch erhalten, dass ein konkreter Algorithmus, der das Problem lost, analysiert wurde.Die im Satz formulierteΩ(. . .) Abschatzung bezieht sich jedoch aufalle moglichenSortierverfahren(bekannte und unbekannte). Sie macht also eine Aussageuber eineKlasse von Algorithmenstattubereinen konkreten Algorithmus und ist damit von ganz anderer Natur.
Version vom 21. Januar 2005
291

292 KAPITEL 11. UNTERE KOMPLEXITATSSCHRANKEN FUR DAS SORTIEREN
11.1 Das Entscheidungsbaum-Modell
Zum Beweis des Satzes werden wir die Tatsache nutzen, dass jeder deterministische Sortieralgorith-mus, der nur auf paarweisen Vergleichen von Schlusseln basiert, durch einenEntscheidungsbaumwiefolgt beschrieben werden kann.
• Innere Knoten des Entscheidungsbaums sind Vergleiche im Algorithmus.
• Ein Weg von der Wurzel bis zu einem Blatt entspricht im Algorithmus der Folge der angestelltenVergleiche. Dabei wird vereinbart, dass beim Weitergehen nachlinks bzw. rechtsder letzteVergleich richtig bzw. falsch ist.
• Blatter des Baumes stellen die Permutationen des Eingabe-Array dar, die zu der zu der angestell-ten Folge von Vergleichen fuhren. Bein zu sortierenden Elementen sind diesn! Permutationen.
Als Beispiel betrachten wir einen Ausschnitt des Entscheidungsbaums fur das Sortieren vonw1, w2,w3, w4 mit Mergesort. Es erfolgt also zunachst die Aufteilung in die Teilfolgenw1,w2 und w3,w4.Diese werden dann sortiert und gemischt. Es entsteht der in Abbildung11.1dargestellte Baum.
w1 < w2 Vergleich fur 1. Teilfolge
jaHHHH
HHH
nein
w3 < w4 w3 < w4 Vergleich fur 2. Teilfolge
ja@@@@
nein
ja@@@@
nein
w1 < w3 w1 < w4 w2 < w3 w2 < w4 1. Vergleich beim Mischenpppppp p p p p p p pppppp @@@@
neinpppppp p p p p p p pppppp p p p p p p
w1 < w3 2. Vergleich beim Mischen
jaHHHH
HHH
nein
w2 < w3 w4 w3 w1 w2...
ja@@@@
nein
w4 w1 w2 w3 w4 w1 w3 w2 Permutationen
Abbildung 11.1: Der Entscheidungsbaum fur Mergesort.
Satz 11.2Jeder deterministische Sortieralgorithmus, der auf paarweisen Vergleichen basiert, erzeugteinen solchen Entscheidungsbaum T.

11.2. ANALYSE DES ENTSCHEIDUNGSBAUMS 293
Beweis:Da der Algorithmus deterministisch ist, hat er fur jede Eingabefolge denselbenerstenVer-gleich zwischen Arraykomponenten. Dieser bildet dieWurzeldes Entscheidungsbaums. In Abhangig-keit vom Ausgang des Vergleichs (“<” oder “>”) ist der nachste Vergleich wiederum eindeutig be-stimmt. Die Fortsetzung dieser Argumentation liefert fur jede Eingabefolge eine endliche Folge vonVergleichen, die einem Weg von der Wurzel bis zu einem Blatt (Permutation, die diese Folge vonVergleichen verursacht) entspricht.
Wir uberlegen nun, wie wir den Worst Case bzw. Average Case AufwandC(n) bzw.C(n) des Algo-rithmus im BaumT ablesen konnen. Sei dazuh(v) die Hohe des Knotenv im BaumT, h(T) die HohevonT, undH(T) := ∑v Blatth(v) die sogenannteBlatterhohensummevonT.
Lemma 11.1 Sei T der Entscheidungsbaum fur den Algorithmus A und C(n) bzw.C(n) die WorstCase bzw. Average Case (bei Gleichverteilung) Anzahl von Vergleichen bei n zu sortierenden Kompo-nenten. Dann gilt:
a) C(n) = maxv Blatt
h(v) = h(T),
b) C(n) = 1n! ∑
v Blatt von T
h(v) =1n!
H(T).
Beweis:Die Anzahl der Vergleiche, um zu einer sortierten Ausgabev zu kommen, ist geradeh(v).Also folgt a) direkt. Da wir Gleichverteilung dern! verschiedenen Eingabereihenfolgen (und damitAusgabereihenfolgen) annehmen, folgt b).
11.2 Analyse des Entscheidungsbaums
Die Abschatzung vonC(n) bzw.C(n) nach unten reduziert sich also auf die Abschatzung der Hohebzw. der Blatterhohensumme eines binaren Baumes mitn! Bl attern nach unten. Dazu zeigen wirfolgendes Lemma.
Lemma 11.2 Sei T ein binarer Baum mit b Blattern. Dann gilt:
a) h(T)≥ logb
b) H(T)≥ b· logb
Beweis:Der Beweis wird in beiden Fallen durch vollstandige Induktion nach der Hoheh(T) von Tgefuhrt.

294 KAPITEL 11. UNTERE KOMPLEXITATSSCHRANKEN FUR DAS SORTIEREN
Ist h(T) = 0, so bestehtT nur aus der Wurzel, die zugleich ein Blatt ist. Also istb = 1 und logb =0 = h(T). Entsprechend istH(T) = ∑v Blatth(v) = 0 undb· logb = 0.
Es gelten nun a), b) fur h(T) = 0,1, . . . ,h−1 (Induktionsvoraussetzung).
Zum Schluss aufh betrachte man die beiden TeilbaumeT1 undT2 von T, wobei einer leer sein kann,vgl. Abbildung11.2
T u
HHHHHH
T1
AAAAAAAAA
T2
AAAAAA
h1
h2
︸ ︷︷ ︸b1
︸ ︷︷ ︸b2
Abbildung 11.2: Teilbaume im Beweis von Lemma11.2
Jeder der Teilbaume hat eine geringere Hohe alsh, also trifft aufT1 undT2 die Induktionsvorausset-zung zu. Seibi die Anzahl der Blatter undhi die Hohe vonTi (i = 1,2), und sei o. B. d. A.b1 ≥ b2.Dann gilt:
h(T) = 1+maxh1,h2 ≥ 1+h1
≥ 1+ logb1 (Induktionsvoraussetzung)
= log2+ logb1 = log(2·b1)≥ log(b1 +b2) (dab1≥ b2)
= logb.
Dies beweist a). im Fall b) giltH(T) = b+H(T1)+H(T2) ,
da inT jedes Blatt gegenuberT1 undT2 eine um 1 großere Hohe hat. AufT1 undT2 ist die Indukti-onsvoraussetzung anwendbar und es folgt
H(T) ≥ b+b1 logb1 +b2 logb2 (Induktionsvoraussetzung)
= b+b1 logb1 +(b−b1) log(b−b1) .
Da wir nicht genau wissen, wie großb1 ist, fassen wir die rechte Seite als Funktion vonx = b1 aufund suchen ihr Minimum.
Also ist
H(T) ≥ b+ minx∈[1,b]
(xlogx+(b−x) log(b−x)) .

11.2. ANALYSE DES ENTSCHEIDUNGSBAUMS 295
Die Funktion f (x) := xlogx+ (b− x) log(b− x) hat auf dem Interval[1,b] in etwa den in Abbil-dung11.3dargestellten Verlauf.
11.2. ANALYSE DES ENTSCHEIDUNGSBAUMS 283
Die Funktion f(x) := x log x + (b − x) log(b − x) hat auf dem Interval [1, b] in etwa den inAbbildung 11.3 dargestellten Verlauf.
1 2 3 bb/2
Abbildung 11.3: Verlauf der Funktion f(x) := x log x+ (b− x) log(b− x).
Eine Kurvendiskussion zeigt, daß f(x) das Minimum auf [1, b] bei x = b/2 annimmt (Ubung).Damit ist
H(T ) ≥ b+b
2logb
2+ (b−
b
2) log(b−
b
2)
= b+ b logb
2= b+ b(log b− log 2)
= b+ b(log b− 1) = b log b .
Fur die endgultige Abschatzung benotigen wir noch eine Abschatzung von n! nach unten. Esist1
n! = n(n− 1) · · · 2 · 1 ≥ n(n− 1) · · · #n/2$︸ ︷︷ ︸!n/2"+1 Faktoren
≥ #n/2$!n/2"+1 ≥ (n/2)n/2 .
Nach diesen Vorbereitungen kommen wir jetzt zum
Beweis von Satz 11.1: Sei T der Entscheidungsbaum zum gegebenen SortieralgorithmusA. Bei einem Inputarray der Lange n hat T n! Blatter. Es folgt
C(n) = h(T ) ≥ logn!
≥ log((n/2)n/2
)=n
2logn
2=n
2log n−
n
2
=n
3log n+
n
6log n−
n
21Eine genauere Abschatzung ergibt sich aus der Stirlingschen Formel n! =
√2πn(ne )
n(1 + Θ( 1n )), speziell√2πn(ne )
n ≤ n! ≤√2πn(ne )
n+(1/12n).
Abbildung 11.3: Verlauf der Funktionf (x) := xlogx+(b−x) log(b−x).
Eine Kurvendiskussion zeigt, dassf (x) das Minimum auf[1,b] beix = b/2 annimmt (Ubung). Damitist
H(T) ≥ b+b2
logb2
+(b− b2) log(b− b
2)
= b+blogb2
= b+b(logb− log2)
= b+b(logb−1) = blogb.
Fur die endgultige untere Schranke benotigen wir noch eine Abschatzung vonn! nach unten. Es ist1
n! = n(n−1) · · ·2·1≥ n(n−1) · · · dn/2e︸ ︷︷ ︸bn/2c+1 Faktoren
≥ dn/2ebn/2c+1≥ (n/2)n/2 .
Nach diesen Vorbereitungen kommen wir jetzt zum
Beweis von Satz11.1: SeiT der Entscheidungsbaum zum gegebenen SortieralgorithmusA. Bei einemInputarray der Langen hatT n! Bl atter. Es folgt
C(n) = h(T)≥ logn!
≥ log((n/2)n/2
)=
n2
logn2
=n2
logn− n2
=n3
logn+n6
logn− n2
≥ n3
logn furn6
logn≥ n2, alson≥ 8
= Ω(nlogn).1Eine genauere Abschatzung ergibt sich aus der Stirlingschen Formeln! =
√2πn( n
e)n(1+Θ( 1n)), speziell
√2πn( n
e)n≤n! ≤
√2πn( n
e)n+(1/12n).

296 KAPITEL 11. UNTERE KOMPLEXITATSSCHRANKEN FUR DAS SORTIEREN
Entsprechend ist
C(n) =1n!
H(T)≥ 1n!
(n! logn!) = logn!
= Ω(nlogn) (wie oben).
Dieses Ergebnis, bzw. genauer die Ungleichungen
C(n)≥ logn! , C(n)≥ logn!
werden auch alsinformations-theoretische Schrankefur das Sortieren bezeichnet. Sie lassen sich an-schaulich folgendermaßen interpretieren. Jeder Sortieralgorithmus muss zwischenn! Moglichkeiten(den sortierten Reihenfolgen) unterscheiden und muss daher logn! Bits an Information sammeln. EinVergleich ergibt hochstens ein Bit Information. Oder, anders formuliert: Jeder Vergleich teilt die Men-ge der kommenden Permutationen in zwei Teilmengen, die MengeΠ+ der Permutationen, die wei-terhin als gesuchte Permutation in Frage kommen, und die MengeΠ− der Permutationen, die nichtzum gemachten Vergleich passen. Die MengeΠ+ wird dann weiter durch Vergleiche unterteilt. Manist am Ziel, wenn nur noch eine Permutation (die gesuchte Sortierung)ubrig bleibt. Dazu braucht man(sukkzessive Halbierung, vgl. binare Suche in Abschnitt6.1.2) mindestens logn! Vergleiche.
11.3 Literaturhinweise
Untere Schranken fur Sortieralgorithmen werden in [CLRS01, Meh88, OW02] behandelt.
[Meh88] geht auch ausfuhrlich auf Erweiterungen solcher Schrankenresultate ein und zeigt unter anderem, dassdurchRandomisierung, also die zufallsgesteuerte Wahl der Vergleiche, keine Beschleunigung moglich ist. Dieerwartete Anzahl der Vergleiche betragt immer nochΩ(nlogn).

Kapitel 12
Zahlendarstellungen undRechnerarithmetik
12.1 Zahlensysteme
Die Darstellung von Zahlen (ganz allgemein von Daten) basieren auf sogenanntenZahlensystemen.Diese wiederum nutzen Zeichen eines sogenanntenAlphabetszu ihrer Darstellung.
Ist b > 1 eine beliebige naturliche Zahl, so heißt die MengeΣb := 0,1, . . . ,b−1 dasAlphabetdesb-adischen Zahlensystems.
Beispiel 12.11. Dem Dezimalsystem liegt das AlphabetΣ10 = 0,1,2, . . . ,9 zugrunde. Worteuber diesem
Alphabet sind etwa 123, 734, 7806. Feste Wortlange, etwan = 4, erreicht man durch “fuhrendeNullen”: 0123, 0734, 7806.
2. Σ2 = 0,1: Dual- oder BinaralphabetΣ8 = 0,1,2,3,4,5,6,7: OktalalphabetΣ16 = 0, . . . ,9,A, . . . ,F: Hexadezimalalphabet
Man beachte, dassΣ16 streng genommen das Alphabet0, . . . ,15 bezeichnet; anstelle der “Zif-fern” 10, 11 usw. werden jedoch generell, d. h. in allen AlphabetenΣb mit b > 9, “neue” Sym-boleA,B usw. (hier alsoA, . . . ,F) verwendet.
Diese Basenb = 2,8 bzw. 16 spielen in der Informatik eine besondere Rolle.
3. Alte Basen sindb = 12 (Dutzend) undb = 60 (Zeitrechnung).
Naturliche Zahlen konnen in jedemb-adischen Zahlensystem dargestellt werden:
Version vom 21. Januar 2005
297

298 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Satz 12.1 (b-adische Darstellung naturlicher Zahlen) Sei b∈N mit b> 1. Dann ist jede naturlicheZahl z mit0≤ z≤ bn−1 (und n∈ N) eindeutig als Wort der Lange nuberΣb darstellbar durch
z=n−1
∑i=0
zibi
mit zi ∈ Σb fur i = 0, . . . ,n−1. Als vereinfachende Schreibweise ist dabei auch folgendesublich (“Zif-fernschreibweise”)
z= (zn−1zn−2 . . .z1z0)b .
Beweis:Der Beweis erfolgt durch Induktion nachz.
Induktionsanfang: z< b hat eine eindeutige Darstellung mitz0 = z undzi = 0 sonst.
Induktionsvoraussetzung: Die Behauptung sei richtig fur alle Zahlen 0,1, . . . ,z−1.
Schluss auf z≥ b: Es istz= (z div b) ·b+(z mod b). Daz′ := z div b < z ist, hatz′ nach Induktions-voraussetzung die (eindeutige) Darstellung
z′ = (z′n−1z′n−2 . . .z′1z′0)
mit z′n−1 = 0, daz′ ·b≤ z≤ bn−1. Also ist(zn−1, . . . ,z0) mit zn−1 := z′n−2, zn−2 := z′n−3, . . . ,z1 := z′0undz0 := z mod b einen-stellige Darstellung vonz in Σb.
Angenommen, es gibt zwei verschiedene solche Darstellungen vonz, etwa
z= (z1n−1, . . . ,z
10)b = (z2
n−1, . . . ,z20)b .
Sei dann der großte Index mitz1` 6= z2
` , o. B. d. A.z1` > z2
` . Dann mussen die niedrigwertigen Stellenz2`−1, . . . ,z
20 eine Einheit der hoherwertigen Stelle “wettmachen”.
Nun hat aber der großte durch niedrigwertige Stellen erreichbare Wert die Form
(b−1)b0 +(b−1)b1 + · · ·+(b−1)b`−1 = (b−1)(b0 +b1 + · · ·+b`−1)
= (b−1)b`−1b−1
= b`−1 < b`.
Da 1·b` gerade eine Einheit der hoherwertigen Stelle ist, kann diese Einheit nicht “wettgemacht”werden. Also ergibt sich ein Widerspruch, d. h. beide Darstellungen mussen gleich sein.
Aus dem Beweis erhalt man direkt einen Algorithmus zur Umwandlung in dieb-adische Darstellung:
Algorithmus 12.1for i := 0 to n−1 do zi := 0;i := 0;while z> 0 do

12.1. ZAHLENSYSTEME 299
beginzi := z mod b;z := z div b;i := i +1;
end
Als Beispiel betrachten wir die Umwandlung vonz= (364)10 in eine Oktalzahl:
364 = 45·8+445 = 5·8+55 = 0·8+5
⇒ z= (554)8
Voraussetzung dieser Umwandlung ist also, dass diemod unddiv Operation im Ausgangszahlensys-tem implementiert ist.
Die Umkehrungb-adisch nach dezimal ist einfach und folgt dem Horner-Schema fur die Multiplika-tion von Polynomen:
Algorithmus 12.2z := 0for i := n−1 downto 0 do z := z∗b+zi
So ergibt(0554)8 den Dezimalwert((0·8+5) ·8+5) ·8+4 = 364.
Korollar 12.1 (Dualdarstellung naturlicher Zahlen) Sei n∈N. Dann ist jede naturliche Zahl z mit0≤ z≤ 2n−1 eindeutig darstellbar in der Form
z=n−1
∑i=0
zi2i
mit zi ∈ Σ2 = 0,1 (i = 0, . . . ,n−1).
So ist zum Beispiel(364)10 = (101101100)2.
ZwischenΣ2,Σ8 und Σ16 bestehen besonders einfache Umwandlungsalgorithmen. Dies liegt daran,dass eine Zifferzi ∈ Σ8 bzw. Σ16 gerade inΣ2 durch Worter der Lange 3 bzw. 4 dargestellt werdenkann. Man kann daher die UmwandlungenΣ2↔ Σ8 undΣ2↔ Σ16 ziffernweise vornehmen. Ein Bei-spiel ist:
(364)10 = (101101100)2 = (101︸︷︷︸(5)8
101︸︷︷︸(5)8
100︸︷︷︸(4)8
)2 = (554)8 = (0001︸︷︷︸(1)16
0110︸︷︷︸(6)16
1100︸︷︷︸(12)16
)2 = (16C)16
b-adische Zahlensysteme sind jedoch nicht die einzige Moglichkeit zur Zahlendarstellung, wie fol-gender Satz zeigt.

300 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Satz 12.2 (Polyadische Darstellung naturlicher Zahlen) Es sei(bn)n∈N eine Folge naturlicher Zah-len mit bn > 1 fur alle n∈N. Dann gibt es fur jede naturliche Zahl z genau eine Darstellung der Form
z=N
∑i=0
zi
i−1
∏j=0
b j = z0 +z1b0 +z2b1b0 + . . .+zNbN−1 · . . . ·b0
mit 0≤ zi < bi fur i = 0, . . . ,N.
Beweis:Ubung.
Nimmt man als Folge der Zahlen(bn)n∈N etwa die Primzahlen 2,3,5, . . ., so hat 364 die Darstellung(1,5,0,2,0), da 364= 0· (1)+2· (2)+0· (2·3)+5· (2·3·5)+1· (2·3·5·7).
12.2 Darstellung ganzer Zahlen im Rechner
12.2.1 Die Vorzeichen-Betrag Darstellung
Dies ist die im Alltag verwendete Darstellung. Hat man Worter der Langen (n Bit) zur Darstellungzur Verfugung, wird das linkeste Bit fur das Vorzeichen verwendet (0= +, 1=−), und die restlichenBits fur den Betrag der Zahl.
Bei n = 3 lassen sich also die in Tabelle12.1angegebenen Zahlen darstellen. Da die 0 zwei Darstel-lungen hat, konnen so 2n−1 Zahlen dargestellt werden.
Tabelle 12.1: 3-stellige Dualzahlen in Vorzeichen-Betrag Darstellung.
Bitmuster Dezimalwert000 0001 1101 2011 3100 −0101 −1110 −2111 −3
Diese “naturliche” Darstellung ist auf Rechnern vollig unublich. Der Grund liegt darin, dass hardwa-remaßig nur Addierwerke (plus Zusatzlogik) verwendet werden. Daher verwendet man Darstellungen,in denen die Subtraktion sehr einfach auf die Addition zuruckgefuhrt werden kann. Dies ist bei derVorzeichen-Betrag Darstellung nicht der Fall. Wir haben daher in der Schule alle fur die Addition undSubtraktion verschiedene Algorithmen gelernt.

12.2. DARSTELLUNG GANZER ZAHLEN IM RECHNER 301
12.2.2 Komplement-Darstellungen
Komplement-Darstellungen erlauben eine einfache Ruckfuhrung der Subtraktion auf die Addition.
Seix = (xn−1, . . . ,x0)b einen-stelligeb-adische Zahl. Das(b−1)-Komplement Kb−1(x) von x erhaltman, indem man stellenweise das “Komplement”(b−1)−xi zuxi bildet.
Beispiel: K9((325)10) = (674)10
K1((10110)2) = (01001)2
Dasb-Komplementvon x erhalt man, indem man dasKb−1-Komplement bildet und 1 dazu addiert,d. h.
Kb(x) = Kb−1(x)+1.
Beispiel: K10((325)10) = (674)10+(1)10 = (675)10
K2((10110)2) = (01001)2 +(1)2 = (01010)2
Speziell im Dualsystem nennt manKb−1 = K1 dasEinerkomplementundKb = K2 dasZweierkomple-ment, im Dezimalsystem spricht man beiKb−1 = K9 vom Neunerkomplementund beiKb = K10 vomZehnerkomplement.
Offenbar gilt:
Lemma 12.1 Fur jede n-stellige b-adische Zahl x gilt:
a) x+Kb(x) = bn,
b) x+Kb−1(x) = bn−1 = (b−1,b−1, . . . ,b−1)b,
c) Kb−1(Kb−1(x)) = x, Kb(Kb(x)) = x.
Beweis:Nach Definition des(b−1)-Komplements ist
x+Kb−1(x) = (b−1,b−1, . . . ,b−1)b
=n−1
∑i=0
(b−1)bi = (b−1)n−1
∑i=0
bi
= (b−1)bn−1b−1
= bn−1.
Also gilt b). a) folgt ausKb(x) = Kb−1(x)+1. c) folgt aus a) und b).

302 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Aussage a) bedeutet anschaulich, dass sich dasb-Komplement vonx bei n Stellen stets als Differenzvon x zu bn ergibt. Im Dezimalsystem mitn = 3 Stellen ergibt sich so fur x = 374K10(x) = 1000−374= 626.
Komplemente lassen sich nun wie folgt zur Darstellung ganzer Zahlen verwenden. Wir betrachtenzunachst das meistens verwendete Zweierkomplement (bzw. allgemein dasb-Komplement).
Sein die zur Verfugung stehende Wortlange. Imb-Komplement werden diebn Zahlenx mit −dbn
2 e ≤x≤ dbn
2 e− 1 dargestellt. Dieser Bereich heißt derdarstellbare Bereich. Zahlen aus diesem Bereichwerden wie folgt dargestellt:
• nicht-negative Zahlen durch ihreb-adische Darstellung,
• negative Zahlenx durch dasb-Komplement ihres Betrages|x|.
Bezeichnen wir mit(x)Kb = (xn−1, . . . ,x0)Kb = die Ziffern vonx in derb-Komplement-Darstellung, sogilt also:
(x)Kb =
(x)b falls x≥ 0,(Kb(|x|))b falls x < 0.
(12.1)
Man beachte, dass man das Vorzeichen der inb-Komplement-Darstellung gegebenen Zahlx an derZiffer xn−1 ablesen kann.
Wir betrachten einige Beispiele:
1. Dezimalsystem,n= 2. Der darstellbare Bereich ist−50≤ x≤ 49. Konkrete Darstellungen sind:
Zahl Darstellung43 43−13 87−27 7338 38
2. Dualsystem,n = 3. Der darstellbare Bereich ist in Tabelle12.2angegeben.
Man beachte die Darstellung vonx = −4. |x| hat das Bitmuster(100)2. Daraus ergibt sichK2((100)2) = K1((100)2)+(1)2 = (011)2 +(1)2 = (100)2.
Wir betrachten jetzt die Addition von Zahlen in dieser Darstellung. Dazu bezeichne(x)Kb ⊕ (y)Kb
die ziffernweise Addition der Darstellungen vonx undy, wobei ein eventuellerUbertrag auf dien+1-Stelle zwar zur Interpretation des Ergebnisses genutzt werden kann, aber in der Darstellung desErgebnisses verloren geht. Man rechnet also modulobn.
Satz 12.3Seien x,y n-stellige Zahlen in b-Komplement-Darstellung, und sei x+ y im darstellbarenBereich. Dann gilt:
x+y = (x)Kb⊕ (y)Kb .

12.2. DARSTELLUNG GANZER ZAHLEN IM RECHNER 303
Tabelle 12.2: 3-stellige Dualzahlen in Zweier-Komplement-Darstellung.
Bitmuster Dezimalwert000 0001 1010 2011 3100 −4101 −3110 −2111 −1
Beweis:Sindx,y≥ 0, so ist(x)Kb⊕ (y)Kb = (x)b +(y)b modbn = x+y modbn. Ein Ubertrag an derhochsten Stelle entspricht im Binarsystem einem Verlassen des darstellbaren Bereiches (Uberlauf).
Sindx,y < 0 so ist nach Definition und Lemma12.1
(x)Kb⊕ (y)Kb = (Kb(|x|))b +(Kb(|y|))b modbn
= Kb(|x|)+Kb(|y|) modbn
= bn−|x|+bn−|y|modbn
= −(|x|+ |y|) modbn
= x+y.
Ist x≥ 0 undy < 0, so ist entsprechend
(x)Kb⊕ (y)Kb = (x)b +(Kb(|y|))b modbn
= x+Kb(|y|) modbn
= x+bn−|y|modbn
= x−|y|= x+y.
Betrachten wir einige Beispiele im 2-stelligen Dezimalsystem. Dann istn = 2 und−50≤ x≤ 49 derBereich der darstellbaren Zahlen. Es folgt:
27+12 = (27)K10⊕ (12)K10 = (39)K10 = 3927+(−15) = (27)K10⊕ (85)K10 = (12)K10 = 1227+(−34) = (27)K10⊕ (66)K10 = (93)K10 = −7(−27)+(−21) = (73)K10⊕ (79)K10 = (52)K10 = −48
Die Ruckfuhrung der Subtraktion auf die Addition beruht dann einfach auf der Gleichungx− y =x+(−y):

304 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Satz 12.4Seien x,y n-stellige Zahlen in b-Komplement-Darstellung, und sei x− y im darstellbarenBereich. Dann gilt:
x−y = (x)Kb⊕ (Kb(y))Kb .
Beweis:Nach Lemma12.1 ist y+ Kb(y) = bn. Also ist−y = Kb(y)− bn. Daraus folgt wegen dermodulobn Rechnung:
(−y)Kb = (Kb(y))Kb .
Also istx−y = x+(−y) = (x)Kb⊕ (−y)Kb = (x)Kb⊕ (Kb(y))Kb .
Betrachten wir wieder einige Beispiele im 2-stelligen Dezimalsystem.
37−28 = (37)K10⊕ (K10(28))K10 = (37)K10⊕ (72)K10 = (9)K10 = 937−48 = (37)K10⊕ (K10(48))K10 = (37)K10⊕ (52)K10 = (89)K10 = −11−12−24 = (88)K10⊕ (K10(24))K10 = (88)K10⊕ (76)K10 = (64)K10 = −36
Dies beweist die Ruckfuhrung der Subtraktion auf die Addition. Naturlich muss dabei (wie bereits beider Addition) ein eventuellerUberlauf bzw. Unterlauf (Verlassen des dargestellten Bereiches) durchden Rechner oder durch den Programmierer abgefangen werden. Geschieht dies nicht, so werden dieentstehenden Bitmuster als Zahlen aus dem dargestellten Bereich interpretiert, was zu vollig falschenErgebnissen fuhrt.
So ist z. B. bein-stelliger Dualzahlarithmetik die großte darstellbare Zahlxmax = (011. . .1)2, undxmax+1 erzeugt das Bitmuster(100. . .0), was als−2n interpretiert wird.
Die darstellbaren Zahlen kann man sich beimb-Komplement ringformig angeordnet vorstellen, wobeidie großte positive und kleinste negative Zahl benachbart sind. Fur b = 2 undn = 3 ergibt sich der inAbbildung12.1dargestellte Ring.1
Durchlauft man den Ring im Uhrzeigersinn, so ergibt sich die jeweils nachste Zahl durch Additionvon 1 (und Weglassen desUbertrags beimUbergang von 111 zu 000), umgekehrt entspricht die Sub-traktion von jeweils 1 dem Durchlauf entgegen dem Uhrzeigersinn. In dieser Interpretation sind dieUberlauffehler ganz naturlich erklarbar. Sie werden auch durch die gangigen Java Laufzeitumgebun-gen nicht abgefangen.
12.3 Darstellung reeller Zahlen
Bei der Darstellung von reellen Zahlen unterscheidet man zwei Moglichkeiten,Festkommadarstellung(fixed point representation) undGleitkommadarstellung(floating point representation).
1Der genaue mathematische Hintergrund hierfur wird in der Algebra geliefert. Der Bereich−2n−1≤ x≤ 2n−1−1 bildeteinen sogenanntenRestklassenringmodulo 2n−1.

12.3. DARSTELLUNG REELLER ZAHLEN 30512.3. DARSTELLUNG REELLER ZAHLEN 293
0
1
111
3
−4
−1
011
001
−3
−1 −2 2 010 +1
100
000
110
101
Abbildung 12.1: Ringdarstellung der Binarzahlen im Zweierkomplement.
12.3 Darstellung reeller Zahlen
Bei der Darstellung von reellen Zahlen unterscheidet man zwei Moglichkeiten, Festkomma-darstellung (fixed point representation) und Gleitkommadarstellung (floating point represen-tation).
12.3.1 Festkommazahlen
Bei der Festkommadarstellung wird bei vorgegebener Stellenzahl n eine feste Stelle als ersteNachkommastelle vereinbart. Festkommazahlen im b-adischen System haben also die Dar-stellung
x = (xk−1xk−2 · · · x0.y1y2 · · · yn−k)b
mit k Vorkomma- und n− k Nachkommastellen. Der Zahlenwert von x ergibt sich zu
x =k−1∑i=0
xi +n−k∑j=1
yjb−j .
Beispiele sind:
(271.314)10 = 271, 314
(101.011)2 = 1 · 22 + 0 · 21 + 1 · 20 + 0 · 2−1 + 1 · 2−2 + 1 · 2−3
= 4 + 1 +1
4+1
8= 5, 375
Fur manche Anwendungen reicht es vollig aus, mit Festkommazahlen zu rechnen, z. B. beiokonomischen Anwendungen (DM Betrage). In diesen Bereichen eingesetzte Programmier-sprachen wie COBOL stellen daher reelle Zahlen als Festkommazahlen dar.
Abbildung 12.1: Ringdarstellung der Binarzahlen im Zweierkomplement.
12.3.1 Festkommazahlen
Bei der Festkommadarstellung wird bei vorgegebener Stellenzahln eine feste Stelle als erste Nach-kommastelle vereinbart. Festkommazahlen imb-adischen System haben also die Darstellung
x = (xk−1xk−2 · · ·x0.y1y2 · · ·yn−k)b
mit k Vorkomma- undn−k Nachkommastellen. Der Zahlenwert vonx ergibt sich zu
x =k−1
∑i=0
xibi +
n−k
∑j=1
y jb− j .
Beispiele sind:
(271.314)10 = 271,314
(101.011)2 = 1·22 +0·21 +1·20 +0·2−1 +1·2−2 +1·2−3
= 4+1+14
+18
= 5,375
Fur manche Anwendungen reicht es vollig aus, mit Festkommazahlen zu rechnen, z. B. beiokonomischenAnwendungen (EURO Betrage). In diesen Bereichen eingesetzte Programmiersprachen wie COBOLstellen daher reelle Zahlen als Festkommazahlen dar.
Im Gegensatz zur Darstellung von ganzen Zahlen konnen bereits bei der Konvertierung von Dezimal-zahlen inb-adische Zahlensysteme mitb 6= 10 Probleme auftreten. So ist etwa die Dezimalzahl 0,8als binare Festkommazahl nur unendlich-periodisch als
0.810 = 0.11001100110011001100110011001100110011001100110011. . .2
darstellbar.

306 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Der große Nachteil der Festkommazahlen besteht jedoch darin, dass (wie auch bei ganzen Zahlen) derBereich der darstellbaren Zahlen nach oben und unten stark beschrankt ist, und die Genauigkeit (derAbstand zwischen zwei benachbarten Zahlen)uberall gleich ist.
Dies fuhrt zu großen Ungenauigkeiten bei wissenschaftlichen Rechnungen. Liegt etwa ein Rechen-ergebnisx zwischen der kleinsten(z1) und der zweitkleinsten(z2) positiven darstellbaren Zahl (etwax = z2− z1
2 ), so mussx zur internen Darstellung auf eine der beiden Zahlenz1,z2 gerundet werden.Der dabei entstehende relative Fehler ist (bei Rundung aufz1)
x−z1
x=
12z132z1
=13
,
also ungefahr 33%. Dies ist fur wissenschaftlich-numerische Rechnungen vollig inakzeptabel. Ausdiesem Grunde verwendet man fur solche Rechnungen die Gleitkommadarstellung.
12.3.2 Gleitkommazahlen
Gleitkommazahlen haben die Form
z=±m·b±e.
Dabei heißtm Mantisseunde Exponent, b ist dieBasisfur den Exponenten. Die Basis der Mantissekann dabei von der Basisb des Exponenten verschieden sein.2 Wir werden hier jedoch die gleicheBasisb voraussetzen. Beispiele sind:
−213,78 = −2.1378·102
0,000031 = 0.31·10−4 = 3.1·10−5
(1101.011)2 = 1.101011·23
Die Beispiele zeigen, dass die Gleitkommadarstellung nicht eindeutig ist, da ein”Austausch“ zwi-
schen Vorkommastellen und Exponent moglich ist. UmEindeutigkeitfur die rechnerinterne Darstel-lung zu bekommen, verwendet man dienormalisierte Gleitkommadarstellung. Diese verlangt eineMantisse der Form
m= 0.m1m2 · · ·mt mit m1 6= 0,
oder,aquivalent dazu
1≤m1 < b .
Bei der rechnerinternen Darstellung muss festgelegt werden, wieviele Stellen fur die Mantisse, undwieviele fur den Exponenten zur Verfugung stehen. Dies resultiert in die MengeF der auf dem Rech-ner darstellbarenMaschinenzahlen. Wir kennzeichnenF durch
F = F(b, t,emin,emax),
2Oft wird fur die Mantisse die Basis 2 und fur b eine Potenz von 2 gewahlt, z. B. 26 = 64.

12.3. DARSTELLUNG REELLER ZAHLEN 307
wobeib die Basis (von Mantisse und Exponent),t die Anzahl der Stellen der Nachkommastellen derMantisse undemin≤ e≤ emax der Bereich des Exponenten ist. Es sind dann alle Zahlenx der Form
x =±.m1 . . .mt ·be mit emin≤ e≤ emax
darstellbar.
Beispiel 12.2Fur F = F(2,3,−1,1) ergeben sich folgende nichtnegative Zahlen, der Große nachgeordnet.
0.000·20 = 0 = 00.100·2−1 = (1/2) ·1/2 = 4/160.101·2−1 = (1/2+1/8) ·1/2 = 5/160.110·2−1 = (1/2+1/4) ·1/2 = 6/160.111·2−1 = (1/2+1/4+1/8) ·1/2 = 7/160.100·20 = (1/2) ·1 = 8/160.101·20 = (1/2+1/8) ·1 = 10/160.110·20 = (1/2+1/4) ·1 = 12/160.111·20 = (1/2+1/4+1/8) ·1 = 14/160.100·21 = (1/2) ·2 = 16/160.101·21 = (1/2+1/8) ·2 = 20/160.110·21 = (1/2+1/4) ·2 = 24/160.111·21 = (1/2+1/4+1/8) ·2 = 28/16
Auf der Zahlengeraden ergibt sich die in Abbildung12.2dargestellte Verteilung.
-
0 14
516
38
716
12
58
34
78 1 5
432
74
Abbildung 12.2: Nichtnegative Gleitkommazahlen ausF(2,3,−1,1).
Man sieht, dass der Abstand zwischen benachbarten Zahlen mit der Große der Zahlen wachst. Fernererkennt man eine relativ große “Lucke” zwischen der 0 und der kleinsten positiven Zahlpmin. Sieergibt sich aus der Normalisierungsbedingung und ist deutlich großer als der Abstand zur zweitgroßtenpositiven Zahl.
Der Grund dafur ist die erwunschte Kontrolle desRundungsfehlers, der dadurch entsteht, dass Nicht-Maschinenzahlen durch Maschinenzahlen dargestellt werden mussen. Solche Fehler entstehen durchKonvertierung(Eingabe einer Nicht-Maschinenzahl, z. B.x = (1.2)10 ; 0.101·21 = 5/4) oder durchRundung von Zwischenergebnissenauf eine Maschinenzahl (z. B. 0.100·21+0.110·2−1 = 1+3/8;
3/2 = 0.110·21). Der dabei entstehende Fehler wird im nachsten Abschnitt analysiert.
Da bei der Basisb = 2 das erste Bit der Mantisse wegen der Normalisierungsbedingung eindeutigfestliegt (m1 = 1), wird es oft nicht explizit dargestellt (hidden bit). In diesem Fall werden dietMantissenbits zur Darstellung vonm2 . . .mt+1 genutzt, d. h. man erreicht eine hohere Genauigkeit.Allerdings muss dann die Null besonders dargestellt werden, z. B. als Mantisse 0 mit Exponentemin−1.

308 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
Zur Darstellung der Exponenten verwendet man oft dieExzess- oderBias-Darstellung. Die Exponen-ten werden dabei durch Addition des Exzesses|emin|+1 in den Bereich 1. . .emin +emax+1 transfor-miert. Dies erleichtert den Vergleich von Exponenten.
Als konkretes Beispiel betrachten wir die Darstellung vondouble Zahlen in Java. Sie folgt dem soge-nannten IEEE 754 Standard3, der sich als de facto Standard fur numerische Rechnungen durchgesetzthat.
Fur die gesamte Zahl stehen 64 Bit zur Verfugung, davon 52 fur die Mantisse (in hidden bit Dar-stellung), 11 fur den Exponenten und 1 fur das Vorzeichen. Die Basis fur Mantisse und Exponentist 2. Mantissen werden in der Formm1.m2 . . .mt+1 (dem sogenanntensignificand) dargestellt, wobeim1 als hidden bit den Wert 1 hat. Der Bereich fur die Exponenten ergibt sich durchemin = −1022undemax = 1023. Auf den 11 Bit fur den Exponentene wird gemaß der Exzess-Darstellung der Werte′ = e+ |emin|+1 dargestellt, so dass sich der wirkliche Exponent alse= e′−1023 ergibt.
Die Zahl 0 wird dann durch das Bitmuster 000. . .000 reprasentiert, also durch die Zahl+1.000. . .000·2emin−1. Ein positiverUberlauf (POSITIVE INFINITY) erzeugt beim Exponenten das Bitmuster 11111111111,entspricht also 21024. Entsprechend stellt das Bitmuster 00000000000 im Exponenten mit einem po-sitiven Signifikanden einen Underflow dar (kleiner als die kleinste darstellbare normalisierte Zahl)4.Als maximale darstellbare Zahl ergibt sich somit 1.7976931348623157·10308, und als kleinste (nor-malisierte) darstellbare positive Zahl 2.2250738585072014·10−308.
Die Bitmuster vondouble Zahlen lassen sich mit der Methode
public static native long doubleToLongBits( double value )
der KlasseDouble erzeugen und (bis auf fuhrende Nullen) mit der Methode
String toBinaryString( long y )
darstellen. Als konkretes Beispiel ergibt sich die genaue Belegung der Bits fur die Zahl 10 zu
Vorzeichen+︷︸︸︷0 10000000010︸ ︷︷ ︸
Exponent 3=1026−1023
Significand 1.25︷ ︸︸ ︷0100000000000000000000000000000000000000000000000000
Entsprechend ergibt sich fur die Zahl−0.8 das (gerundete) Bitmuster
Vorzeichen−︷︸︸︷1 01111111110︸ ︷︷ ︸
Exponent−1=1022−1023
Significand 1.59999999999999...︷ ︸︸ ︷1001100110011001100110011001100110011001100110011010
3IEEE (vgl. http://www.ieee.org) steht fur The Institute of Electrical and Electronic Engineers, das alsuberkuppelndes Organ fur viele Vereine fur unterschiedliche Ingenieurwissenschaften fungiert.
4Hier werden im IEEE Standard noch weitere Unterscheidungen getroffen (denormalized), die in Java jedoch alle zumWert NaN (not a number) fuhren. Dadurch sind die Moglichkeiten fur adaquate numerische Abhilfen in Java beschrankt,so dass bei hohen Anforderungen an die numerische Genauigkeit besser andere Programmiersprachen (C, C++, Fortran)verwendet werden sollten.

12.3. DARSTELLUNG REELLER ZAHLEN 309
12.3.3 Genauigkeit von Gleitkommadarstellungen
Wie bereits erlautert, erzwingt der begrenzte Vorrat von Maschinenzahlen bei der Konvertierung oderDarstellung von Zwischenergebnissen dieRundungauf Maschinenzahlen und dadurch Rundungsfeh-ler.
Den maximalen relativen Rundungsfehler nennt man die (relative)Rechnergenauigkeit. Die Stellender Mantisse nennt man diesignifikanten Stellen, einet-stellige Mantisse bezeichnet man auch alst-stellige Arithmetik.
Wir berechnen jetzt die Rechnergenauigkeit fur F = F(b, t,emin,emax). Dabei betrachten wir zunachstden relativen RundungsfehlerµC, der durch Abschneiden (Chopping) nicht signifikanter Stellen ent-steht. Dies entspricht dem Runden zur betragskleineren Maschinenzahl.
Seix > pmin undxc ∈M die durch Abschneiden entstehende Zahl. Dann ist
µC =x−xc
x=
0.x1x2 . . .xtxt+1xt+2 . . . ·be−0.x1 . . .xt ·be
x
=0.0. . .0xt+1xt+2 . . . ·be
x=
0.xt+1xt+2 . . . ·b−t ·be
x
<b−t ·be
xda 0.xt+1xt+2 . . . < b0 = 1
≤ b−t ·be
1b ·be
dax > 0.x1 ·be≥ 1b
be wegen der Normalisierung
= b−t ·b =1
bt−1 .
Der relative RundungsfehlerµR ist offenbar hochstens halb so groß wie der relative Abschneidefehler.Also ergibt sich dierelative RechnergenauigkeitµR als
µR =12
µC =12· 1bt−1 .
Diese Zahl ist die wichtigste Große bei Genauigkeitsbetrachtungen fur ein Gleitkommasystem undGrundlage aller Fehlerabschatzungen in derNumerischen Mathematik.
Die Genauigkeit bezieht sich auf die Zahlt von signifikanten Stellen zur Basisb. Die entsprechendeZahls von signifikanten Stellen im Dezimalsystem erhalt man durch Auflosung der Gleichung
µR =12
1bt−1 =
12
110s−1
nachs. Dies ergibts= b1+(t−1) log10bc .
Umgekehrt berechnet mant aus einer gewunschten Anzahls von dezimalen Stellen gemaß
t = b1+(s−1) log10bc .
Bzgl. des in Java verwendeten IEEE Standards mitb = 2 undt = 53 (hidden bit!) ergeben sichs= 16signifikante Dezimalstellen.

310 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK
12.3.4 Der Einfluss von Algorithmen auf die numerische Genauigkeit
In Kapitel 6.2.4 haben wir bereits ein Beispiel fur die Auswirkung von Rundungsfehlern bei derLosung linearer Gleichungssysteme mit dem Gauß-Algorithmus kennen gelernt. Hier folgt ein weite-res Beispiel fur dieLosung quadratischer Gleichungen.
Die quadratische Gleichungax2 +bx+c = 0 hat die Losungen
x1,2 =−b±
√b2−4ac
2a.
Diese lassen sich nach dieser Formel berechnen durch
d := sqrt(sqr(b)−4ac);x1 := (d−b)/(2a);x2 := −(b+d)/(2a);
wobeisqrt(x) =√
x undsqr(b) = b2 als verfugbare Funktionen vorausgesetzt werden.
Ein numerisches Beispiel mit den Wertena= 1, b=−200 undc= 1, ausgefuhrt mit einer4-stelligendezimalen Arithmetik(d. h. 4 Stellen fur die Mantisse) ergibt folgende Resultate.
d = sqrt(sqr(−0.2000·103)−4)= sqrt( 0.4000·105−0.4000·101︸ ︷︷ ︸
0.4000·105 in 4-stelliger Arithmetik
)
= 0.2000·103
Hieraus folgt
x1 = (0.2000·103− (−0.2000·103))/(0.2000·101)= (0.4000·103)/(0.2000·101)= 0.2000·103
= 200,
x2 = −(0.2000·103 +(−0.2000·103))/(0.2000·101)= 0/(0.2000·101)= 0.
Die exakten Werte mit 4-stelliger Arithmetik lauten jedoch
x1 = 200 undx2 = 0.005.
Die 4-stellige Rechnerarithmetik hat die relative RechnergenauigkeitµR = 12 ·
1104−1 = 0,0005. Die
Abweichung des errechneten Ergebnisses (0 anstelle des exakten Wertes 0,005) muss daher als volliginakzeptabel betrachtet werden. Das Ergebnisx2 = 0 ist schlicht falsch.

12.4. LITERATURHINWEISE 311
Eine Losungsmethode, die die Gefahren der Gleitkomma-Arithmetik berucksichtigt, beruht auf derBeziehung
x1 ·x2 =ca
(Vieta).
Es wird jetzt lediglich eine Losung mit derublichen Formel berechnet, und zwar die mit demgroßtenAbsolutwert. Die zweite Losung errechnet man dann aus der Formel von Vieta. Dies ergibt das Pro-grammstuck:
d := sqrt(sqr(b)−4ac);if b≥ 0 then x1 :=−(b+d)/(2a)
else x1 := (d−b)/(2a);x2 := c/(x1 ·a);
Im Beispiel fuhrt dies zu den Werten
d = 0.2000·103 (wie oben),
x1 = (d−b)/(2a) = 200 (wie oben),
x2 = 1/200= 0.005.
Dies ist ein Beispiel fur den haufigen Fall, dass dieublichen mathematischen “Losungsmethoden”nicht unbesehenubernommen werden konnen, wenn mit wirklichen Rechnern gearbeitet werden soll.Die Numerik ist der Zweig der Mathematik, der sich mit der Entwicklung von Losungsmethodenbefasst, die die Tucken der Gleitkommaarithmetik berucksichtigen.
12.4 Literaturhinweise
Kapitel 12.1und 12.2 folgen [OV98]. Das Beispiel der Losung quadratischer Gleichungen in Kapitel12.3.4stammt aus [Wir78].
Als Einstieg in die Methoden der numerischen Mathematik sei auf [Ric93, Van85] verwiesen.

312 KAPITEL 12. ZAHLENDARSTELLUNGEN UND RECHNERARITHMETIK

Literaturverzeichnis
[AHU83] Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman.Data Structures and Algorith-mus. Addison-Wesley, Reading, NY, 1983.10.6
[Aig04] Martin Aigner.Diskrete Mathematik. Vieweg, Wiesbaden/Braunschweig, 2004. 5. Aufla-ge. 1.4
[ASU86] Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman.Compilers, Principles, Techniques, andTools. Addison-Wesley, Reading, NY, 1986.3.5, 4.5
[AU92] Alfred V. Aho and Jeffrey D. Ullman.Foundations of Computer Science. W. H. Freemanand Company, New York, 1992.1.4
[Bro04] J. Glenn Brookshear.Computer Science: An Overview. Prentice Hall, Englewood Cliffs,NJ, 8th edition, 2004.1.4
[CLRS01] Thomas H. Cormen, Charles E. Leiserson, Ronald R. Rivest, and Clifford Stein.Introduc-tion to Algorithms. The MIT Press, Cambridge, MA, second edition, 2001.1.4, 6.4, 9.4,10.3.1, 10.3.2, 10.5.1, 10.6, 11.3
[CW87] D. Coppersmith and S. Winograd. Matrix multiplication via arithmetic progression. InProc. 19th Ann. Symp. on Comp., pages 1–6, 1987.10.3.2
[CW98] Mary Campione and Cathy Walrath.The Java Tutorial: Object-Oriented Programmingfor the Internet. Addison-Wesley, Reading, NY, second edition, 1998. Also availableunder http://java.sun.com/docs/books/tutorial.1.4, 2.4, 3.5
[DD01] Harvey M. Deitel and Paul J. Deitel.Java: How to Program. Prentice Hall, EnglewoodCliffs, NJ, 4th edition, 2001.1.4, 2.4, 3.5
[Fla02] David Flanagan.Java in a Nutshell. Deutsche Ausgabe fur Java 1.4. O’Reilly & Associa-tes, Sebastopol, CA, 2002.1.4
[GL02] Les Goldschlager and Andrew Lister.Informatik – Eine moderne Einfuhrung. Carl HanserVerlag, Munchen, third edition, 2002.1.4
[GMW91] Philip E. Gill, Walter Murray, and Margaret H. Wright.Numerical Linear Algebra andOptimization, volume 1. Addison-Wesley, Reading, NY, 1991.6.4
313

314 LITERATURVERZEICHNIS
[GR03] Ralph P. Grimaldi and David J. Rothman.Discrete and Combinatorial Mathematics: AnApplied Introduction. Addison-Wesley, Reading, NY, 5th edition, 2003.1.4
[GS04] Heinz-Peter Gumm and Manfred Sommer.Einfuhrung in die Informatik. OldenbourgVerlag, Munchen, 2004. 5. Auflage.1.4
[GT04] Michael T. Goodrich and Roberto Tamassia.Data Structures and Algorithms in Java.John Wiley & Sons, New York, 3rd edition, 2004.1.4, 5.10
[Hor84] E. Horowitz. Fundaments of Programming Languages. Springer-Verlag, Berlin, 1984.Second Edition.3.5
[HR94] Mark R. Headington and David D. Riley.Data Abstraction and Structures Using C++.D. C. Heath and Company, Lexington, MA, 1994.5.10, 7.5, 10.6
[HU79] John E. Hopcroft and Jeffrey D. Ullman.Introduction to Automata Theory, Languages,and Computation. Addison-Wesley, Reading, NY, 1979.3.5, 4.5
[Job02] Fritz Jobst.Programmieren in Java. Carl Hanser Verlag, Munchen, 2002. 4. erweiterteAuflage. 1.4
[Jun94] Dieter Jungnickel.Graphen, Netzwerke und Algorithmen. BI Wissenschaftsverlag, Mann-heim, 1994. 3. Auflage.6.4
[Knu97] Donald. E. Knuth. The Art of Computer Programming, volume 1 Fundamental Algo-rithms. Addison-Wesley, Reading, NY, third edition, 1997.1.4
[Knu98a] Donald. E. Knuth.The Art of Computer Programming, volume 2 Seminumerical Algo-rithms. Addison-Wesley, Reading, NY, third edition, 1998.1.4, 7.5
[Knu98b] Donald. E. Knuth.The Art of Computer Programming, volume 3 Sorting and Searching.Addison-Wesley, Reading, NY, second edition, 1998.1.4, 6.4, 10.6
[Kr u02] Guido Kruger. Handbuch der Java Programmierung. Addison-Wesley, Reading, NY, 3.auflage edition, 2002.1.4, 2.4
[Kuh99] Ralf Kuhnel. Die Java 1.2 Fibel. Addison-Wesley Longman, Amsterdam, 1999. 3.Auflage. 1.4, 3.5, 4.1, 4.5, 7.5
[LV92] G. T. Leavens and M. Vermeulen. The 3+x problem.Computers Math. Appl., 24:79–99,1992. 8.1.4, 8.3
[Meh88] Kurt Mehlhorn. Datenstrukturen und effiziente Algorithmen, Band I: Sortieren und Su-chen. Teubner Verlag, Stuttgart, 1988.1.4, 6.4, 11.3
[Mei98] Christoph Meinel.Effiziente Algorithmen. Carl Hanser Verlag, Munchen, 1998.1.4
[OSW83] Thomas Ottmann, Michael Schrapp, and Peter Widmayer.PASCAL in 100 Beispielen.Teubner Verlag, Stuttgart, 1983.2.4

LITERATURVERZEICHNIS 315
[OV98] Walter Oberschelp and Gottfried Vossen.Rechneraufbau und Rechnerstrukturen. Olden-burg Verlag, Munchen, 7 edition, 1998.12.4
[OW82] T. Ottmann and P. Widmayer.Programmierung mit PASCAL. Teubner Verlag, Stuttgart,1982. 8.3
[OW02] Thomas Ottmann and Peter Widmayer.Algorithmen und Datenstrukturen. SpektrumAkademischer Verlag, 2002. 4. Auflage.1.4, 6.4, 11.3
[PM88] S. Park and K. Miller. Random number generators: Good ones are hard to find.Comm.ACM, 31:1192–1201, 1988.7.5
[Pre00] Bruno R. Preiss.Data Structures and Algorithms with Object-Oriented Design Patternsin Java. John Wiley & Sons, New York, 2000.1.4
[Ric93] John R. Rice.Numerical Methods, Software and Analysis. Academic Press, New York,second edition, 1993.12.4
[Sed03] Robert Sedgewick.Algorithms in Java. Addison-Wesley, Reading, NY, 3rd edition, 2003.1.4
[SS02] Gunter Saake and Kai-Uwe Sattler.Algorithmen und Datenstrukturen: eine Einfurung mitJava. dpunkt.verlag, Heidelberg, 2002.1.4
[Tar83] Robert Endre Tarjan.Data Structures and Network Algorithms. CBMS-NSF RegionalConference Series in Applied Mathematics. SIAM, Philadelphia, PA, 1983.6.4
[Van85] R. Vandergraft. Introduction to Numerical Computation. Academic Press, New York,1985. 12.4
[vL90a] Jan van Leeuwen, editor.Handbook of Theoretical Computer Science, A: Algorithms andComplexity Theory. North-Holland, Amsterdam, 1990.1.4
[vL90b] Jan van Leeuwen, editor.Handbook of Theoretical Computer Science, B: Formal Modelsand Semantics. North-Holland, Amsterdam, 1990.1.4
[Wii87] Stephen A. Wiitala. Discrete Mathematics: A Unified Approach. Mc Graw-Hill, NewYork, 1987. 1.4, 3.5, 4.5
[Wir78] N. Wirth. Systematisches Programmieren. Teubner Verlag, Stuttgart, 1978.12.4
[Wir86] N. Wirth. Algorithmen und Datenstrukturen. Teubner Verlag, Stuttgart, 1986.8.3

Index
abstract,205Ackermann Funktion,234Activation Record,192Adjazenzmatrix,161aktueller Parameter,182Algorithmus,1, 8
deterministischer,291randomisierter,291
Analysea posteriori,242, 247a priori,242von Algorithmen,242
Analyse von Algorithmen,241anonyme Klasse,208Applet,14
Gauss,153GGT,49Hypothek,41ListDemo,98Primzahl,25RollDice,220StackDemo,107Steuer,20StringDemo,81StringTokenizerDemo,85Temperatur,12
Array, 74Assembler,4asymptotische Notation,243Aufrufbaum,192Aufteilungs-Beschleunigungs-Satz
allgemeiner,265Aufteilungs-Beschleunigungss-Satz
spezieller,264
Ausdruck,17, 35awt,14
Backus Naur Form,58Bellman Gleichungen,167
als Matrixmultiplikation,174Berechenbarkeit,8Betriebssystem,7bewerteter Graph,161Bewertungsmatrix,161Bezeichner,23binare Suche,116Binarer Baum,225Blockscope,187Bogen,160Bubblesort,250
Call by reference,183Call by value,183clone(),76, 208Cloneable,207Comparable,207Computer,2Computerorientierte Mathematik,iiiCopy Konstruktor,200
Datenfluss,182Datenstruktur,73Datentyp,17, 69
Fraction,70Default Konstruktor,200Definition,37Deklaration,37Devisentausch,162Digraph,160
316

INDEX 317
direkter Zugriff,74do while Anweisung,27, 52Dreiecksform,131
einfache Anweisung,36elementare Umformung,131elementarer Weg,162Entscheidungsbaum,292Entwurf von Algorithmen,8Erkennung korrekter Klammerausdrucke,104Ermittlung kurzester Wege,176Ermittlung negativer Zykel,175Exception-Handling,84Exponent,306Extended Backus Naur Form,60
Feldzugriff,75Festkommazahl,305Fibonacci Zahlen,237final, 205Flowlayout,24formaler Parameter,182Funktion,18, 181Funktionsaufruf,190
Garbage Collection,212Gaußsches Eliminationsverfahren,133gerichteter Baum,177getClass(),203ggT,48Gleitkommazahl,306
Genauigkeit,309normalisiert,306
goto Anweisung,54Graph,160
hohere Programmiersprache,4Hardware,2Heap,279Heapeigenschaft,281Heapsort,279
Analyse,286Hexadezimaldarstellung,59html-Datei,18Hypothekberechnung,39
if Anweisung,23, 44, 58Implementation des ActionListener,208innere Klasse,208Insertion Sort,254Integer-Literal,58Interface,206Interpretieren,6
Java,6Java Bytecode,6Java Dokumentation,89Java Virtual Machine,6Java-Compiler,6javadoc,89
kurzester Weg,162Kurzester-Wege-Baum,177Kante,160Klasse,14, 17, 198
Fraction,212LinearEquation,141LinkedList,93ListNode,90Matrix, 122RandomNumber,217Stack,101
Klassenscope,187Klassentyp,32Knoten,160Kommentar,14Kompilieren,6Komplement-Darstellung,301
(b-1)-Komplement,301b-Komplement,301
Komplexitatmittlere,242worst case,242
Komplexitat von Algorithmen,8Konstante,23Konstruktor,32korrekter Klammerausdruck,63Korrektheit von Algorithmen,8
L’Hopital, 245Losungsraum,130

318 INDEX
lineare Datenstruktur,73lineares Gleichungssystem,130
Koeffizientenmatrix,130rechte Seite,130
Liste,89lokale Klasse,208lvalue,35
Mantisse,306Maschinensprache,4Matrix, 119Matrixmultiplikation,120mehrdimensionales Array,77Mergesort,256
Analyse,260Methode,18
bellman(),170bellmanShort(),172binare Suche,117bubbleSort(),251createHeap(),283heapify(),282merge(),258mergeSort(),259quickSort(),271selectionSort(),252
Methode:heapSort(),284Modifizierer,204Multiplikation von Dualzahlen,267
native,205negativer Zykel,169Nonterminalsymbol,58
Oberklasse,201Oktaldarstellung,59
Package,204Pivotelement
Wahl des,136Pivotsuche
partielle,138totale,139
Prinzip der optimalen Substruktur,167Priority Queue,279
private,204Produktionsmodell,127Programmiersprache,4protected,204Prozess,2Pseudocode,38public,204
Queue,111Quicksort,269
mittlerer Aufwand,274Rekursionsaufwand,273Worst Case Aufwand,274
Rucksprungadresse,192Rechnergenauigkeit,309Rechnermodell,3, 241Record,88Referenztyp,32Rekursion,225Rekursionstiefe,197Run-Time-Stack,192Rundungsfehler,309Runnable,207rvalue,35
Schrankenobere,243untere,246
Scope,187Scopeblock,192Seiteneffekt,35Selection Sort,252selektive Anweisung,45Semantik,58sequentielle Suche,115sequentieller Zugriff,74Software-Hardware-Hierarchie,7Sortieren
Algorithmen,249Bubblesort,250direkte Methoden,250Heapsort,279Insertion Sort,254Mergesort,256

INDEX 319
Quicksort,269Selection Sort,252untere Schranken,291
Stack,101StackInterface,206Standardtyp,31static Feld,201static Methode,201statische Scoperegeln,187String,79StringBuffer,79StringTokenizer,84strukturierter Datentyp,73super,202synchronized,205Syntax,57Syntaxdiagramm,60Syntaxgraph,60
Terminalsymbol,58this,122, 200transient,205Turme von Hanoi,229Typuberprufung,72
Uberdeckung,188Ubersetzung,4Ulams Funktion,235Unicode,23Unterklasse,201
Variable,16Varuabler Parameter,183Vektor,119Vererbung,202volatile,205
Warteschlange,111Weg,162Weglange,162Wertparameter,183while Anweisung,27, 47Wrapper-Klasse,33
Zahlensystem,297
b-adisch,297Komplement-Darstellung,301polyadisch,299
Zufallszahlen,217zusammengesetzte Anweisung,39Zuweisung,16Zykel, 162