
Darstellung von Instruktionen - userpages.uni-koblenz.deunikorn/lehre/gdra/ss12/03 MIPS... · MIPS...
33
Darstellung von Instruktionen Grundlagen der Rechnerarchitektur ‐ Assembler 21
Transcript of Darstellung von Instruktionen - userpages.uni-koblenz.deunikorn/lehre/gdra/ss12/03 MIPS... · MIPS...

Darstellung von Instruktionen
Grundlagen der Rechnerarchitektur ‐ Assembler 21
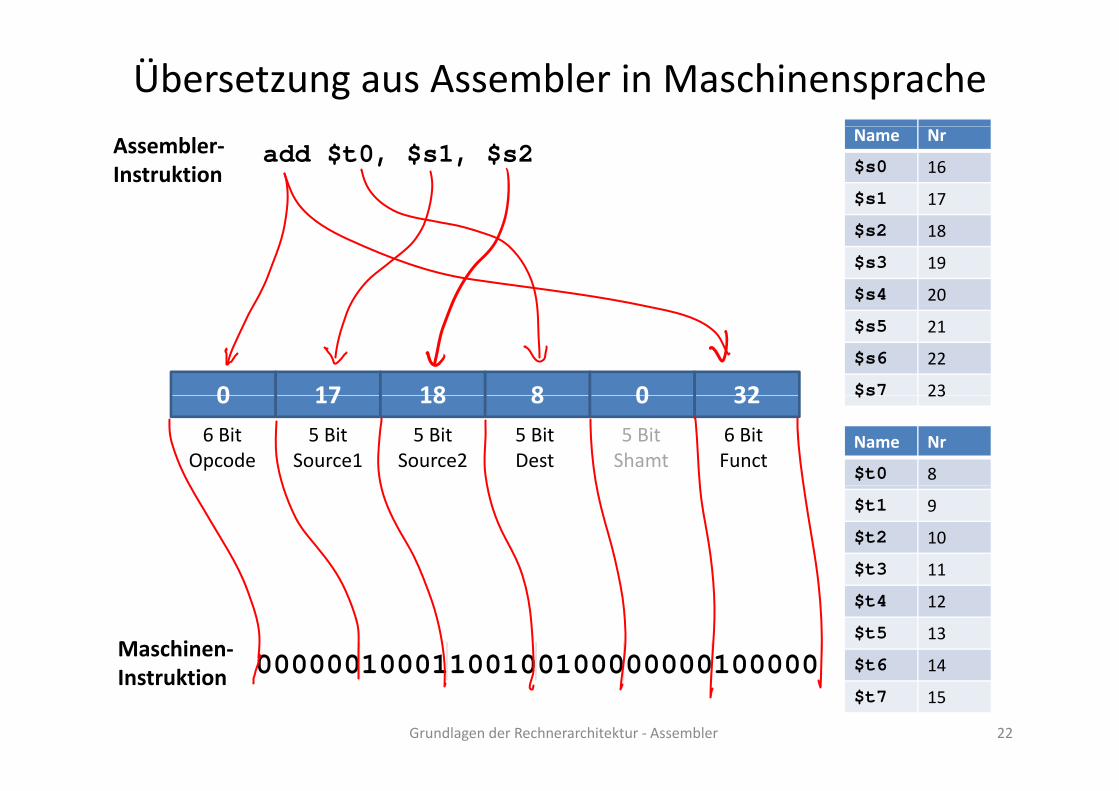
Übersetzung aus Assembler in Maschinensprache
add $t0, $s1, $s2Assembler‐Instruktion
Name Nr
$s0 16
$s1 17
$s2 18
$s3 19
$s4 20
0 17 18 8 0 32
$s5 21
$s6 22
$s7 230 17 18 8 0 32
6 BitOpcode
5 BitSource1
5 BitSource2
5 BitDest
5 BitShamt
6 BitFunct
Name Nr
$t0 8
$s 23
$t1 9
$t2 10
$t3 11
00000010001100100100000000100000Maschinen‐
$ 11
$t4 12
$t5 13
$t6 14
Grundlagen der Rechnerarchitektur ‐ Assembler 22
00000010001100100100000000100000Instruktion$t6 14
$t7 15
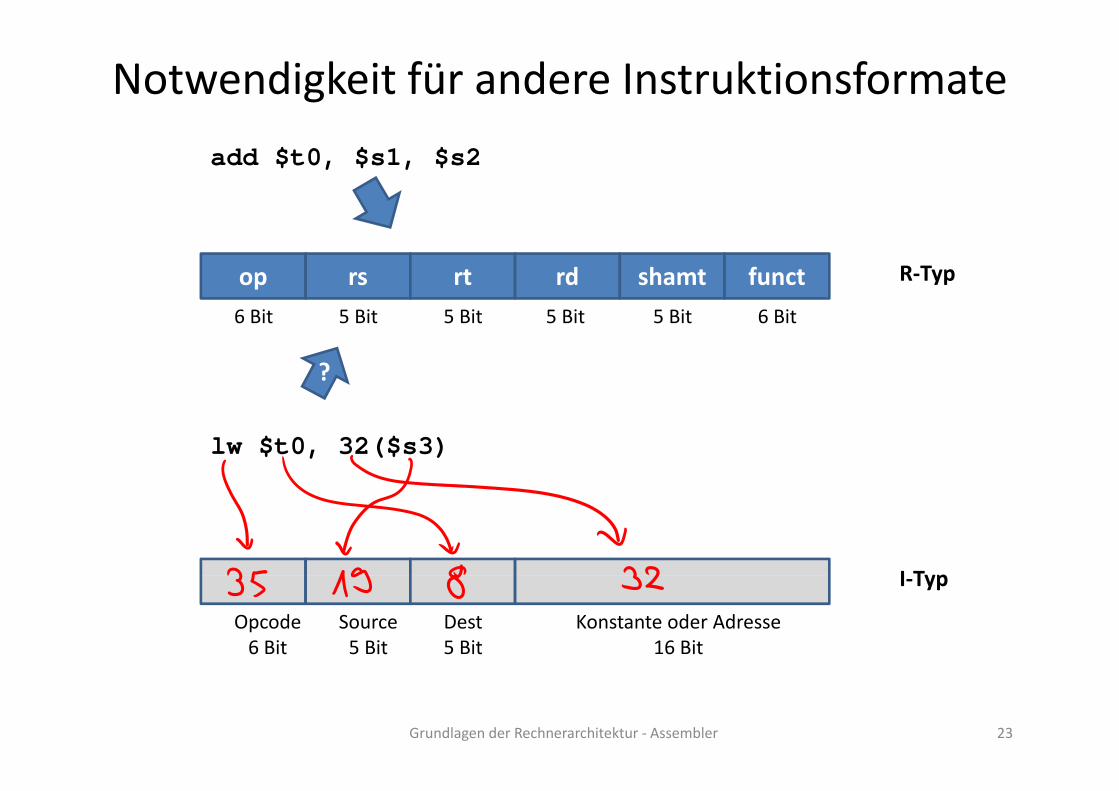
Notwendigkeit für andere Instruktionsformate
add $t0, $s1, $s2
op rs rt rd shamt funct R‐Typ
6 Bit 5 Bit 5 Bit 5 Bit 5 Bit 6 Bit
?
lw $t0, 32($s3)
I Typ
Opcode6 Bit
Source5 Bit
Dest5 Bit
Konstante oder Adresse16 Bit
I‐Typ
Grundlagen der Rechnerarchitektur ‐ Assembler 23
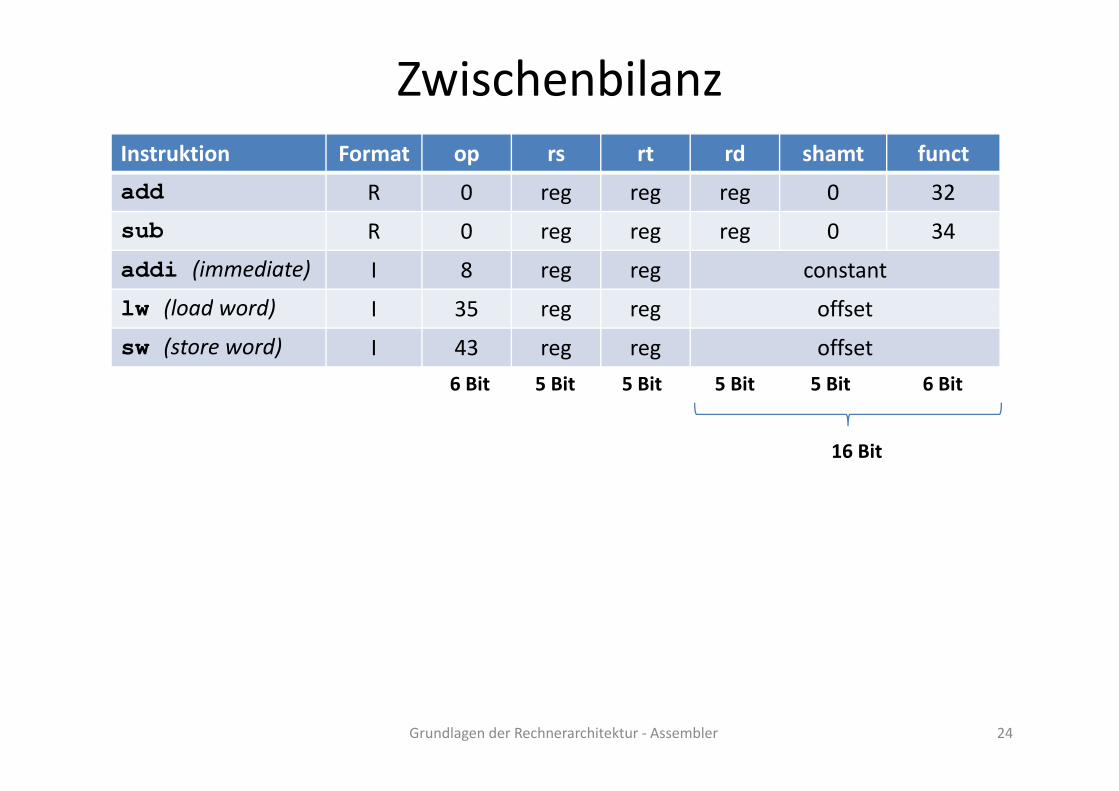
ZwischenbilanzInstruktion Format op rs rt rd shamt funct
add R 0 reg reg reg 0 32
sub R 0 reg reg reg 0 34
addi (immediate) I 8 reg reg constant
lw (load word) I 35 reg reg offsetlw (load word) I 35 reg reg offset
sw (store word) I 43 reg reg offset
6 Bit 5 Bit 5 Bit 5 Bit 5 Bit 6 Bit
16 Bit
Grundlagen der Rechnerarchitektur ‐ Assembler 24
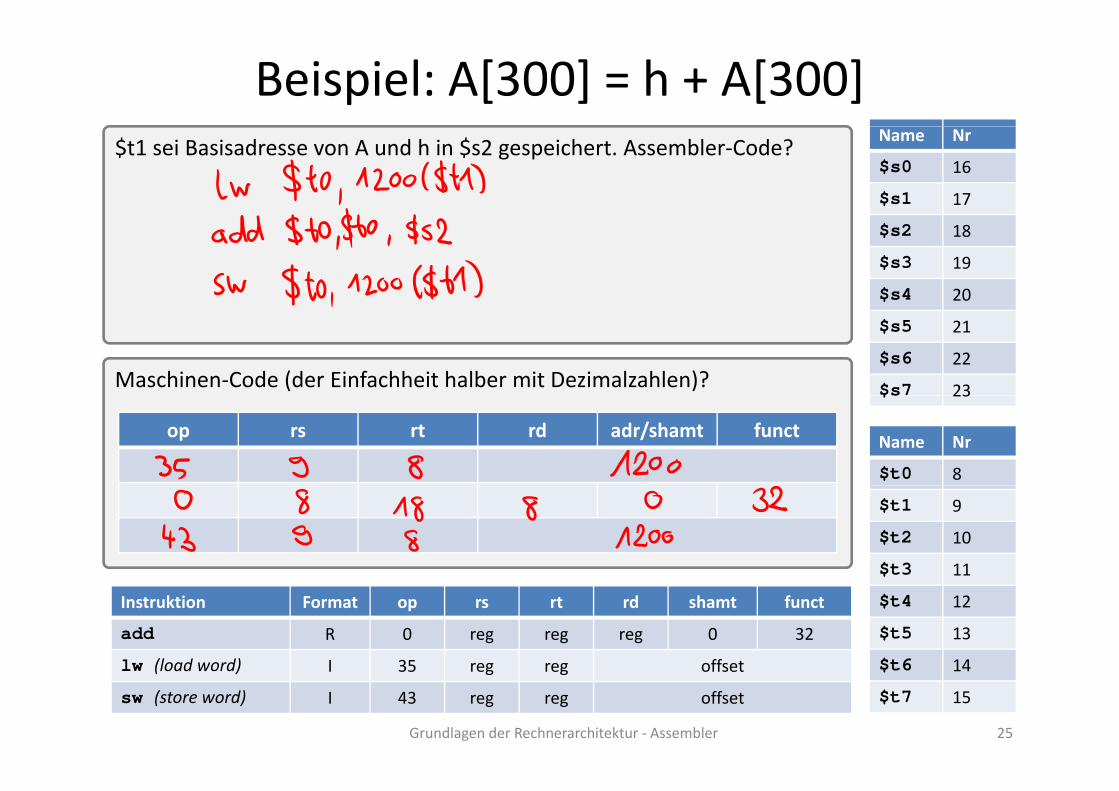
Beispiel: A[300] = h + A[300]$t1 sei Basisadresse von A und h in $s2 gespeichert. Assembler‐Code?
Name Nr
$s0 16
$s1 17
$s2 18
$s3 19
$s4 20
Maschinen‐Code (der Einfachheit halber mit Dezimalzahlen)?
$s5 21
$s6 22
$s7 23
op rs rt rd adr/shamt functName Nr
$t0 8
$s 23
$t1 9
$t2 10
$t3 11$ 11
$t4 12
$t5 13
$t6 14
Instruktion Format op rs rt rd shamt funct
add R 0 reg reg reg 0 32
lw (load word) I 35 reg reg offset
Grundlagen der Rechnerarchitektur ‐ Assembler 25
$t6 14
$t7 15
lw (load word) I 35 reg reg offset
sw (store word) I 43 reg reg offset

Logische Operationen
Grundlagen der Rechnerarchitektur ‐ Assembler 26

Logischer Links‐ und Rechts‐ShiftErinnerung: Logischer Shift. Beispiel:
Links‐Shift um 4 Stellen Rechts‐Shift um 4 Stellen
MIPS‐Shift‐Instruktionen sll und srl, sllv, srlv:, ,
sll $t2,$s0,4 # $t2 = $s0 << 4 Bitssrl $t2,$s0,7 # $t2 = $s0 >> 7 Bitssllv $t2,$s0,$s1 # $t2 = $s0 << $s1 Bitssrlv $t2,$s0,$s1 # $t2 = $s0 >> $s1 Bits
Beispiel: Maschineninstruktion für obige sll Assembler‐Instruktion:
R‐Typ0 0 16 10 4 0
6 BitO d
5 BitS 1
5 BitS 2
5 BitD t
5 BitSh t
5 BitF t
Grundlagen der Rechnerarchitektur ‐ Assembler 27
Opcode Source1 Source2 Dest Shamt Funct

Arithmetischer Rechts‐ShiftErinnerung: Arithmetischer Rechts‐Shift. Beispiel mit 8‐Bit:
0011 0000 1101 0111
Rechts‐Shift um 4 Stellen Rechts‐Shift um 3 Stellen
Arithmetischer Rechts‐Shift in MIPS:
sra $t2,$s0,4 # $t2 = $s0 arithmetisch# um 4 Bits geshiftet
srav $t2,$s0,$s1 # $t2 = $s0 arithmetisch# um $s1 Bits geshiftet
Grundlagen der Rechnerarchitektur ‐ Assembler 28
g
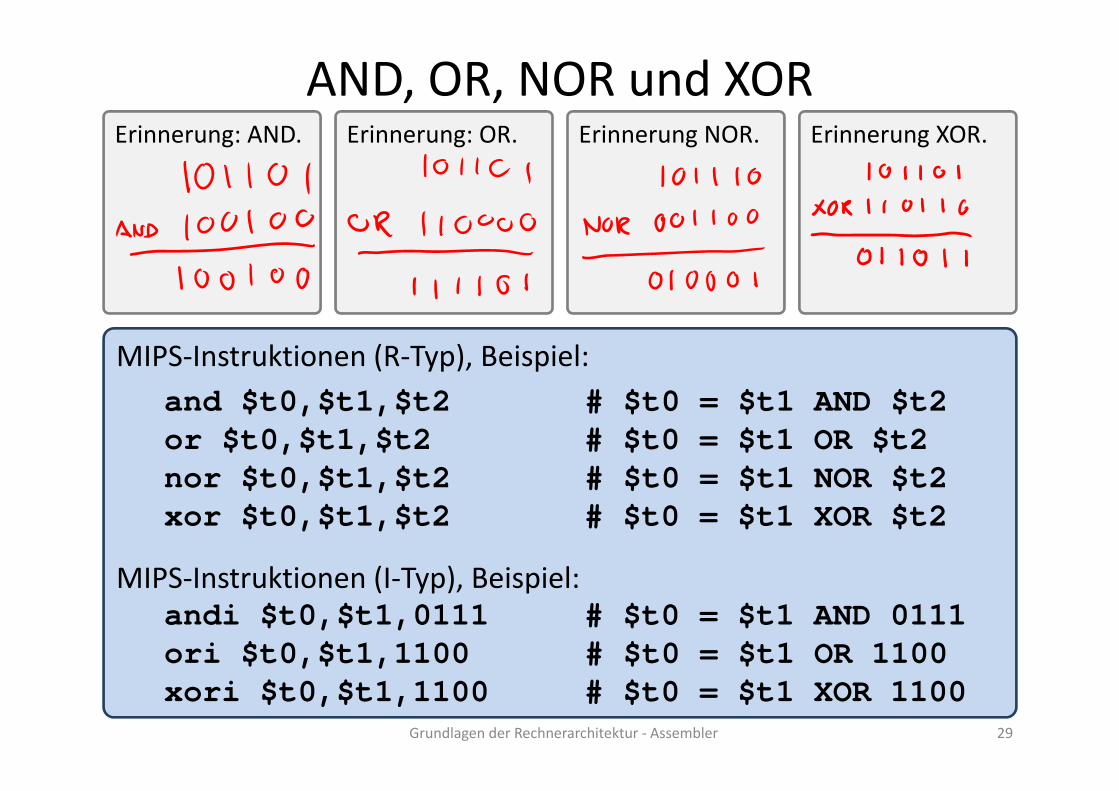
E i AND
AND, OR, NOR und XORE i OR E i NOR E i XORErinnerung: AND. Erinnerung: OR. Erinnerung NOR. Erinnerung XOR.
MIPS‐Instruktionen (R‐Typ), Beispiel:d $t0 $t1 $t2 # $t0 $t1 AND $t2and $t0,$t1,$t2 # $t0 = $t1 AND $t2
or $t0,$t1,$t2 # $t0 = $t1 OR $t2nor $t0,$t1,$t2 # $t0 = $t1 NOR $t2nor $t0,$t1,$t2 # $t0 $t1 NOR $t2xor $t0,$t1,$t2 # $t0 = $t1 XOR $t2
MIPS Instruktionen (I Typ) Beispiel:MIPS‐Instruktionen (I‐Typ), Beispiel:andi $t0,$t1,0111 # $t0 = $t1 AND 0111ori $t0,$t1,1100 # $t0 = $t1 OR 1100
Grundlagen der Rechnerarchitektur ‐ Assembler 29
$ ,$ , # $ $xori $t0,$t1,1100 # $t0 = $t1 XOR 1100

Es gibt gar kein NOT?!Erinnerung NOT (auf Folie zu Zweierkomplement kurz eingeführt):
Beobachtung:
Wie kann man also „NOT($t0)“ in MIPS realisieren?
Grundlagen der Rechnerarchitektur ‐ Assembler 30

Zusammenfassung der behandelten InstruktionenInstruktion Bedeutung
sll rd, rs, shamt Register rd = Register rs logisch links um den Wert shamt geshiftet.
sllv rd rt rs Register rd = Register rs logisch links um den in Register rs gespeicherten Wert
hift
sllv rd, rt, rs Register rd Register rs logisch links um den in Register rs gespeicherten Wert geshiftet.
srl rd, rs, shamt Register rd = Register rs logisch rechts um den Wert shamt geshiftet.
srlv rd rt rs Register rd Register rs logisch rechts um den in Register rs gespeicherten WertSh srlv rd, rt, rs Register rd = Register rs logisch rechts um den in Register rs gespeicherten Wert geshiftet.
sra rd, rs, shamt Register rd = Register rs arithmetisch rechts um den Wert shamt geshiftet.
srav rd, rt, rs Register rd = Register rs arithmetisch rechts um den in Register rsgespeicherten Wert geshiftet.
ng
and rd, rs, rt Register rd = Register rs AND Register rt.
Verknü
pfun or rd, rs, rt Register rd = Register rs AND Register rt.
nor rd, rs, rt Register rd = Register rs AND Register rt.
xor rd, rs, rt Register rd = Register rsAND Register rt.
Logische
V
xor rd, rs, rt Register rd Register rsAND Register rt.
andi rt, rs, imm Register rt = Register rs AND Konstante imm
ori rt, rs, imm Register rt = Register rs AND Konstante imm
Grundlagen der Rechnerarchitektur ‐ Assembler 31
L
xori rt, rs, imm Register rt = Register rs AND Konstante imm

Schwieriges QuizMIPS‐Assemblercode um folgende Funktion zu berechnen:
$ 1 di t 8 Bit 4 * NOT($ 1 AND $ 2)$s1 = die ersten 8 Bits von 4 * NOT($s1 AND $s2)
Tipp: wir brauchen d d ll
Grundlagen der Rechnerarchitektur ‐ Assembler 32
and, nor und sll

Weitere Arithmetik
Grundlagen der Rechnerarchitektur ‐ Assembler 33

Die speziellen Register lo und hiErinnerung: ganzzahliges Produkt von zwei n‐Bit‐Zahlen benötigt bis zu 2n Bits.
Eine MIPS‐Instruktion zur ganzzahligen Multiplikation von zwei Registern der Länge 32‐Bits benötigt damit ein Register der Länge g g g g g64 Bit, um das Ergebnis abzuspeichern.
MIPS hat für die ganzzahliges Multiplikation zwei spezielle RegisterMIPS hat für die ganzzahliges Multiplikation zwei spezielle Register, lo und hi, in denen das Ergebnis abgespeichert wird:
lo : Low‐Order‐Word des Produktshi : Hi‐Order‐Word des Produkts.
Zugriff auf lo und hi erfolgt mittels mflo und mfhi. Beispiel:mflo $s1 # lade Inhalt von lo nach $s1
Grundlagen der Rechnerarchitektur ‐ Assembler 34
mfhi $s2 # lade Inhalt von hi nach $s2

Ganzzahlige Multiplikation und DivisionGanzzahlige Multiplikation. Beispiel:mult $s1, $s2 # (hi,lo) = $s1 * $s2
Ganzzahlige Division. Beispiel:div $s1, $s2 # berechnet $s2 / $s1div $s1, $s2 # berechnet $s2 / $s1
# lo speichert den Quotienten# hi speichert den Rest
Register hi und lo können auch beschrieben werden. Beispiel:tl $ 1 # L d I h lt $ 1 h lmtlo $s1 # Lade Inhalt von $s1 nach lomthi $s2 # Lade Inhalt von $s2 nach hi
Das ist sinnvoll für madd und msub. Beispiele:madd $s1,$s2 # (hi,lo)=(hi,lo)+$s1*$s2
Grundlagen der Rechnerarchitektur ‐ Assembler 35
msub $s1,$s2 # (hi,lo)=(hi,lo)-$s1*$s2

Ganzzahlige Multiplikation ohne hi und loEs gibt eine weitere Instruktion, zur Multiplikaiton, die kein hi und loverwendet:
mul $s1 $s2 $s3 # $s1 die low order 32mul $s1, $s2, $s3 # $s1 = die low-order 32# Bits des Produkts von# $s2 und $s3.# $s2 und $s3.
Grundlagen der Rechnerarchitektur ‐ Assembler 36

Zwischenbilanz der MIPS‐Architektur
CPU
Memory
$0.
Registers
.
.
.$31
Neu$
ArithmeticUnit
MultiplyDivideUnit Divide
Lo Hi
Grundlagen der Rechnerarchitektur ‐ Assembler 37

Die speziellen Register $f01 bis $f31MIPS unterstützt mit einem separaten FPU‐Coprozessor Gleitkommaarithmetik auf Zahlen im IEEE 754‐Single‐Precision (32‐Bi ) d D bl P i i F (64 Bi )Bit) und Double‐Precision‐Format (64 Bit).
Die MIPS‐Floating‐Point‐Befehle nutzen die speziellen 32‐Bit‐Die MIPS Floating Point Befehle nutzen die speziellen 32 BitFloating‐Point‐Register (die Register des FPU‐Coprozessors):$f0, $f1, $f3, ..., $f31
Single‐Precision‐Zahlen können in jedem der Register gespeichert d ( l $f0 $f1 $f31)werden (also $f0, $f1, ..., $f31).
Double‐Precision‐Zahlen können nur in Paaren von aufeinanderDouble Precision Zahlen können nur in Paaren von aufeinander folgenden Registern ($f0,$f1), ($f2,$3), ..., ($f30,$f31) gespeichert werden. Zugriff erfolgt immer über die geradzahligen Register (also
Grundlagen der Rechnerarchitektur ‐ Assembler 38
$f0, $f2, ..., $f30).

Floating‐Point‐BefehleLaden/speichern von Daten in die Register $f0,...,$f31 am Beispiel:mtc1 $s1,$f3 # $f3 = $s1f 1 $ 1 $f3 # $ 1 $f3mfc1 $s1,$f3 # $s1 = $f3lwc1 $f3,8($s1) # $f3 = Memory[8+$s1]ldc1 $f2,8($s1) # ($f2,$f3) = Memory[8+$s1]ldc1 $f2,8($s1) # ($f2,$f3) Memory[8+$s1]swc1 $f3,8($s1) # Memory[8+$s1] = $f3sdc1 $f2,8($s1) # Memory[8+$s1] = ($f2,$f3)
Verschieben von Registerinhalten von $f0,...,$f31 am Beispiel:$f6 $f3 # $f6 $f3mov.s $f6,$f3 # $f6 = $f3
mov.d $s4,$f6 # ($f4,$f5) = ($f6,$f7)
Grundlagen der Rechnerarchitektur ‐ Assembler 39

Floating‐Point‐BefehleDie MIPS‐Single‐Precision‐Operationen am Beispiel:add.s $f1,$f2,$f3 # $f1 = $f2 + $f3
b $f1 $f2 $f3 # $f1 $f2 $f3sub.s $f1,$f2,$f3 # $f1 = $f2 - $f3mul.s $f1,$f2,$f3 # $f1 = $f2 * $f3div s $f1,$f2,$f3 # $f1 = $f2 / $f3div.s $f1,$f2,$f3 # $f1 $f2 / $f3
Die MIPS‐Double‐Precision‐Operationen am Beispiel:add.d $f2,$f4,$f6 # $f2 = $f4 + $f6sub.d $f2,$f4,$f6 # $f2 = $f4 - $f6l d $f2 $f4 $f6 # $f2 $f4 * $f6mul.d $f2,$f4,$f6 # $f2 = $f4 * $f6
div.d $f2,$f4,$f6 # $f2 = $f4 / $f6
Grundlagen der Rechnerarchitektur ‐ Assembler 40
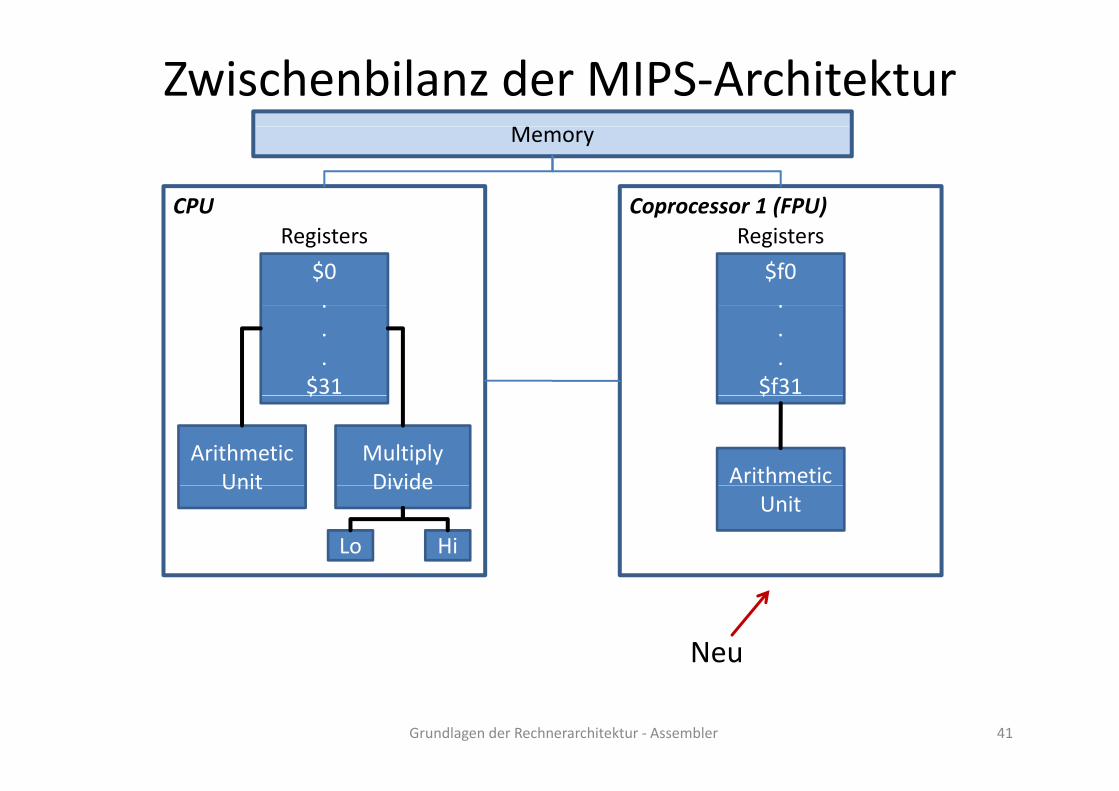
Zwischenbilanz der MIPS‐Architektur
CPU Coprocessor 1 (FPU)
Memory
p ( )
$0.
$f0.
RegistersRegisters
.
.
.$31
.
.
.$f31$
ArithmeticUnit
MultiplyDivide
$
ArithmeticUnit DivideUnit
Lo Hi
Neu
Grundlagen der Rechnerarchitektur ‐ Assembler 41

Arithmetische Operationen zusammengefasstInstruktion Beispiel BemerkungInstruktion Beispiel Bemerkung
mult, div,madd, msub
mult $s1, $s2 Ergebnis wir in den speziellen Registern lo und hi abgelegt.
nzzahlig add , sub add $s1, $s2, $s3 Operieren auf den 32 standard CPU‐Registern
addi addi $s1, $s2, 42 Ein Parameter ist eine Konstante
Gan
$ , $ ,
mflo, mfhi,mtlo, mthi
mflo $s1 ZumLaden und Speichern der Inhalte von lo‐ und hi‐Register
l l $ 1 $ 2 $ 3 $ 1 32 L d Bi $ 2 * $ 3mul mul $s1, $s2, $s3 $s1 = 32 Low‐order Bits von $s2 * $s3
add.s, sub.s, mul.s, div.s,
add.s $f0, $f1, $f2 Instruktionen arbeiten auf den speziellen Registern $f0,...,$f31. Single‐Precision.
omma add.d, sub.d,
mul.d, div.dadd.d $f0, $f1, $f2 Instruktionen arbeiten auf den speziellen Registern
($f0,$f1),...,($f30,$f31). Double‐Precision.
lwc1 swc1 lwc1 $f0 4($s1) Zum Laden und Speichern der Inhalte von
Gleitko lwc1, swc1,
ldc1, sdc1lwc1 $f0, 4($s1) Zum Laden und Speichern der Inhalte von
$f0,...,$f31 über den Speicher.
mfc1, mtc2 mtc1 $s1, $f0 Zum Laden und Speichern der Inhalte von $f0 $f31 üb di t d d CPU R i t
Grundlagen der Rechnerarchitektur ‐ Assembler 42
$f0,...,$f31 über die standard CPU‐Register.
mov.s, mov.d mov.s $f1, $f2 Verschieben der Inhalte von $f0,...,$f31

Einfaches QuizMIPS‐Assemblercode um die Eingabe in Single‐Precision aus Fahrenheit in Celsius umzurechnen:
$f0 = (5.0 / 9.0) * (Eingabe – 32.0)
Ti i b hTipp: wir brauchen:lwc1 zum laden unddiv.s, sub.s, mul.s
…
Inhalt (Word)
8 9 012 32.0
…
Adresse
0 Eingabe4 5.08 9.0A
Grundlagen der Rechnerarchitektur ‐ Assembler 43
Speicher

Branches und Jumps
Grundlagen der Rechnerarchitektur ‐ Assembler 44

Der Program‐Counter
CPU Coprocessor 1 (FPU)
Memory
p ( )
$0.
Registers Unsere bisherigen Assemblerprogrammewaren rein sequentiell. Beispiel:0x4000000 : addi $s0, $zero, 4.
.
.$31
0x4000000 : addi $s0, $zero, 40x4000004 : lw $s1, 0($s0)0x4000008 : lw $s2, 4($s0)0x400000c : add $s1, $s1, $s1$
ArithmeticUnit
MultiplyDivide
$ , $ , $0x4000010 : ...
Welche nächste Instruktion abgearbeitetUnit Divide
Lo HiPC
werden soll steht im Program‐Counter.
Zur Abarbeitung der nächsten Instruktion wirdder Program‐Counter von der CPU auf dienächste Instruktion gesetzt, d.h. $pc = $pc + 4.
$Der Program‐Counter ist ein
Grundlagen der Rechnerarchitektur ‐ Assembler 45
Zur Abarbeitung einer Instruktion zeigt der $pcschon auf die nachfolgende Instruktion.
weiteres Register, genannt $pc.
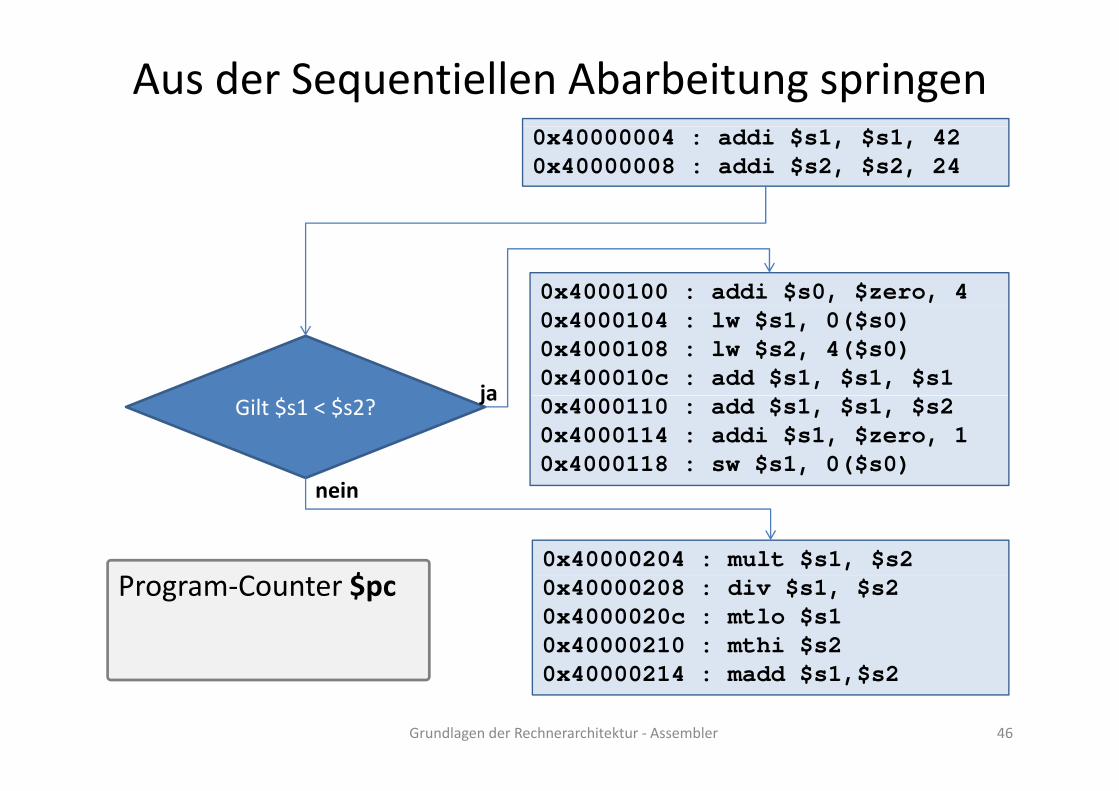
Aus der Sequentiellen Abarbeitung springen0x40000004 : addi $s1, $s1, 420x40000008 : addi $s2, $s2, 24
0x4000100 : addi $s0, $zero, 40x4000104 : lw $s1, 0($s0)0x4000108 : lw $s2, 4($s0)0x400010c : add $s1, $s1, $s1
ja 0x4000110 : add $s1, $s1, $s20x4000114 : addi $s1, $zero, 10x4000118 : sw $s1, 0($s0)
Gilt $s1 < $s2?ja
i
0x40000204 : mult $s1, $s2
nein
$ 0x40000208 : div $s1, $s2 0x4000020c : mtlo $s1 0x40000210 : mthi $s2
$ $
Program‐Counter $pc
Grundlagen der Rechnerarchitektur ‐ Assembler 46
0x40000214 : madd $s1,$s2

Bedingte Sprünge und unbedingte Sprünge
Start: ...beq register1 register2 Label3beq register1, register2, Label3...bne register1, register2, Label1g g...j Label2...
Label1: ...Ein Label (oder Sprungmarke zu deutsch) ist eine mit einem Namen markierte Stelle im Code an die man per Branch...
Label2: ......
Stelle im Code an die man per Branchbzw. Jump hin springen möchte.Assembler‐Syntax: „Name des Labels“
Label3: ...y „
gefolgt von einem „:“.
Grundlagen der Rechnerarchitektur ‐ Assembler 47

Formate für SprungbefehleBedingte Sprünge beq und bne haben das Format I‐Typ (Immediate):
$ $beq $s1, $s2, Label
4 18 17 Label I‐Typ4 18 17 Label
Opcode6 Bit
Source5 Bit
Dest5 Bit
Konstante oder Adresse16 Bit
yp
Unbedingter Sprung hat das Format J‐Typ (Jump‐Format):
j addr # Springe nach Adresse addr
2 addr
Opcode6 Bit
Adresse26 Bit
J‐Typ
Grundlagen der Rechnerarchitektur ‐ Assembler 48
6 Bit 26 Bit

Anwendungsbeispiel if‐then‐else
if (i == j) thenf = g + h;f = g + h;
elsef = g - h;g ;
Es sei f,…,j in $s0,…,$s4 gespeichert:
bne $s3,$s4,Else # gehe nach Else wenn i!=jadd $s0,$s1,$s2 # f = g + h (bei i!=j übersprungen)j Exit # gehe nach Exit
Else: sub $s0,$s1,$s2 # f = g – h (bei i!=j übersprungen)Exit:
Grundlagen der Rechnerarchitektur ‐ Assembler 49Bildquelle: David A. Patterson und John L. Hennessy, „Computer Organization and Design“, Fourth Edition, 2012

Anwendungsbeispiel while
while (safe[i] == k)i += 1;
Es sei i und k in $s3 und $s5 gespeichert und die Basis von safe sei $s6:
Loop: sll $t1,$s3,2 # Temp-Reg $t1 = i * 4add $t1,$t1,$s6 # $t1 = Adresse von safe[i]lw $t0,0($t1) # Temp-Reg $t0 = save[i]bne $t0,$s5,Exit # gehe nach Exit, wenn save[i]!=kaddi $s3,$s3,1 # i = i + 1
#j Loop # gehe wieder nach LoopExit:
safe[i]b0 b1 b2 b3 b4 b5 …
Grundlagen der Rechnerarchitektur ‐ Assembler 50

Test auf Größer und Kleiner?
slt $t0, $s3, $s4 # $t0 = 1 wenn $s3 < $s4
slti $t0, $s2, 10 # $t0 = 1 wenn $s2 < 10
Beispiel: springe nach Exit, wenn $s2 < 42
...slti $t0, $s2, 42bne $t0, $zero, Exit, ,...
Exit:
Grundlagen der Rechnerarchitektur ‐ Assembler 51

Signed und unsigned Vergleiche
Registerinhalt von $s0 sei:1111 1111 1111 1111 1111 1111 1111 11111111 1111 1111 1111 1111 1111 1111 1111
Registerinhalt von $s1 sei:0000 0000 0000 0000 0000 0000 0000 0001
W i t d W t $t0 h A füh d f l d Z ilWas ist der Wert von $t0 nach Ausführung der folgenden Zeile:slt $t0, $s0, $s1 # Signed-Vergleich $s0<$s1
Was ist der Wert von $t1 nach Ausführung der folgenden Zeile:sltu $t0, $s0, $s1 # Unsigned-Vergleich $s0<$s1
Grundlagen der Rechnerarchitektur ‐ Assembler 52

Beispiel: Test auf 0 <= $s0 < $s1 in einer Code‐ZeileUmständlicher Test in zwei Zeilen:
slti $t0, $s0, 0 # $t0=1 wenn $s0<0 sonst $t0=0bne $t0, $zero, OutOfBound # gehe nach OutOfBound wenn $t0!=0slt $t0, $s0, $s1 # $t0=1 wenn $s0<$s1 sonst $t0=0beq $t0, $zero, OutOfBound # gehe nach OutOfBound wenn $t0==0...OutOfBound:
Test in einer Zeile wenn $s1 immer größer oder gleich 0 ist?
Grundlagen der Rechnerarchitektur ‐ Assembler 53


















