
Das relationale...
41
Das relationale Datenbankmodell Udo Kelter 27.11.2013 Zusammenfassung dieses Lehrmoduls Das relationale Datenbankmodell besteht im Kern aus Operationen wie der Selektion, der Projektion und diversen Verbundoperationen. Diese werden in der relationalen Algebra zusammengefaßt. Dieses Lehrmodul stellt diese Operationen vor. Vorab wird die statische Struktur einer relationalen Datenbank definiert. Aus der Vielzahl denkbarer Integrit¨ atsbedingungen werden hier nur Schl¨ usselbegriffe behandelt; wir unterscheiden u.a. Identifikations-, Super-, Fremd-, Prim¨ ar- und Sekund¨ arschl¨ ussel. Vorausgesetzte Lehrmodule: obligatorisch: – Datenverwaltungssysteme Stoffumfang in Vorlesungsdoppelstunden: 2.0 1
Transcript of Das relationale...

Das relationale Datenbankmodell
Udo Kelter
27.11.2013
Zusammenfassung dieses Lehrmoduls
Das relationale Datenbankmodell besteht im Kern aus Operationenwie der Selektion, der Projektion und diversen Verbundoperationen.Diese werden in der relationalen Algebra zusammengefaßt. DiesesLehrmodul stellt diese Operationen vor. Vorab wird die statischeStruktur einer relationalen Datenbank definiert. Aus der Vielzahldenkbarer Integritatsbedingungen werden hier nur Schlusselbegriffebehandelt; wir unterscheiden u.a. Identifikations-, Super-, Fremd-,Primar- und Sekundarschlussel.
Vorausgesetzte Lehrmodule:
obligatorisch: – Datenverwaltungssysteme
Stoffumfang in Vorlesungsdoppelstunden: 2.0
1

Das relationale Datenbankmodell 2
Inhaltsverzeichnis
1 Datenbankmodelle vs. reale Datenbanksprachen 3
2 Die Struktur relationaler Datenbanken 42.1 Tabellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Relationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Integritatsbedingungen . . . . . . . . . . . . . . . . . . . . . . 8
3 Die relationale Algebra 93.1 Die Selektion . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2 Die Projektion . . . . . . . . . . . . . . . . . . . . . . . . . . 113.3 Die Mengenoperationen . . . . . . . . . . . . . . . . . . . . . 123.4 Die Umbenennung . . . . . . . . . . . . . . . . . . . . . . . . 133.5 Das Kreuzprodukt . . . . . . . . . . . . . . . . . . . . . . . . 143.6 Verbundoperationen . . . . . . . . . . . . . . . . . . . . . . . 16
3.6.1 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . 163.6.2 Der naturliche Verbund . . . . . . . . . . . . . . . . . 193.6.3 Der Theta-Verbund . . . . . . . . . . . . . . . . . . . 223.6.4 Außere Verbunde . . . . . . . . . . . . . . . . . . . . . 23
3.7 Die Division . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.8 Relationale Vollstandigkeit . . . . . . . . . . . . . . . . . . . . 283.9 Ausdrucke in der relationalen Algebra . . . . . . . . . . . . . 29
4 Schlussel 304.1 Superschlussel und Identifizierungsschlussel . . . . . . . . . . 304.2 Primarschlussel . . . . . . . . . . . . . . . . . . . . . . . . . . 324.3 Fremdschlussel . . . . . . . . . . . . . . . . . . . . . . . . . . 344.4 Kriterien fur die Festlegung von Identifizierungs- und
Primarschlusseln . . . . . . . . . . . . . . . . . . . . . . . . . 354.5 Weitere Schlusselbegriffe . . . . . . . . . . . . . . . . . . . . . 36
Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Glossar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
c©2013 Udo Kelter Stand: 27.11.2013
Dieser Text darf fur nichtkommerzielle Nutzungen als Ganzes und unverandert in elektronischer odergedruckter Form beliebig weitergegeben werden und in WWW-Seiten, CDs und Datenbanken aufgenom-men werden. Jede andere Nutzung, insb. die Veranderung und Uberfuhrung in andere Formate, bedarfder expliziten Genehmigung. Die jeweils aktuellste Version ist uber http://kltr.de erreichbar.

Das relationale Datenbankmodell 3
Das relationale Datenbankmodell ist eines der drei “konventionellen”Datenbankmodelle und, gemessen am Entwicklungstempo der Infor-matik, schon uralt. Es geht auf Arbeiten von E.F. Codd am IBM SanJose Research Laboratory [Co70] zuruck. Seine Entwicklung wurdemaßgeblich von mehreren Prototypen relationaler DBMS beeinflußt,namentlich dem System R am IBM San Jose Research Laboratory, In-gres an der University of California at Berkeley und Query-by-Exampleam IBM T.J. Watson Research Center.
Im Laufe der Jahre wurden sehr umfangreiche formale Grundlagendes relationalen Datenbankmodells entwickelt. Ferner wurden vielfalti-ge Erweiterungen der ursprunglichen Konzepte vorgeschlagen.
In der Praxis ist das relationale Datenbankmodell heute dominie-rend. Eine Vielzahl kommerzieller oder kostenloser relationaler DBMSist verfugbar.
1 Datenbankmodelle vs. reale Datenbankspra-
chen
Das relationale Datenbankmodell legt zunachst nur zentrale, grundle-gende Konzepte fest (s. Begriff Datenbankmodell in [DVS]), namlichdie Struktur einer Datenbank und lesende Operationen auf dieserStruktur. Ein praktisch benutzbares System muß zusatzlich viele tech-nische Details festlegen, angefangen bei der Syntax entsprechenderSprachen und Bedienschnittstellen. Zum Vergleich: das Konzept einerwhile-Schleife wird von allen normalen imperativen Programmierspra-chen unterstutzt, die konkrete Syntax und technische Details konnenganz erheblich differieren (for (..,..,..) { .. } in C; WHILE ...
BEGIN ... END in Modula-2). Neben den Abfragen und Datenande-rungen mussen außerdem Funktionen bzw. Sprachkonstrukte zur De-finition konzeptueller und interner Schemata, Rechteverwaltung, Ad-ministration usw. angeboten werden; das relationale Datenbankmodelllegt diese Bereiche nicht fest. Ahnlich wie Programmiersprachen sinddaher die konkreten Abfragesprachen fur relationale Systeme außer-lich sehr verschieden und differieren auch außerhalb der grundlegenden
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 4
Konzepte in vielen technischen Details.Fur die Darstellung der grundlegenden Konzepte braucht man
naturlich dennoch Notationen, also eine Sprache. Die relationale Alge-bra und die relationalen Kalkule kann man in diesem Sinne als Spra-chen ansehen, die nur den Kern des relationalen Datenbankmodellsabdecken und von jeglichem storenden Ballast befreit sind.
2 Die Struktur relationaler Datenbanken
2.1 Tabellen
Die statische Struktur einer relationalen Datenbank kann man in-formell wie folgt definieren (eine prazisere Definition folgt spater):
1. Eine relationale Datenbank besteht aus mehreren Tabellen. JedeTabelle hat einen eindeutigen Namen.
2. Eine Tabelle hat eine Menge von Spalten.
3. Eine Spalte hat einen eindeutigen Namen, der im Tabellenkopfsteht, und einen zugeordneten Wertebereich. Statt von einer Spal-te reden wir auch von einem Attribut.
4. Der Rumpf (oder “Inhalt”) einer Tabelle enthalt eine Menge vonZeilen, d.h. Duplikate von Zeilen sind nicht erlaubt. Jede Zeileenthalt in jeder Spalte einen Wert entsprechend dem Wertebereichder Spalte.
Tabelle: kunden
Kundennummer Kundenname Wohnort Kreditlimit
177177 Meier, Anne Weidenau 2000.00177180 Budenbender, Christa Siegen 9000.00185432 Stotzel, Gyula Siegen 4000.00167425 Schneider, Peter Netphen 14000.00171876 Litt, Michael Siegen 0.00
Abbildung 1: Beispieltabelle
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 5
Als Beispiel betrachten wir eine Tabelle kunden , in der Daten uberdie Kunden eines Unternehmens verwaltet sein mogen (s. Bild 1). DieSpalte Kreditlimit gibt an, wieviele Waren dem Kunden auf Kreditgeliefert werden. Der Sinn der restlichen Spalten ist offensichtlich. DieWertebereiche der Spalten sind (von links nach rechts): 1. ganze Zahl,2. Text, 3. Text, 4. reelle Zahl. Uber Langenbeschrankungen der Texteoder die Genauigkeit der Zahlen machen wir uns an dieser Stelle keineGedanken.
Eine Zeile reprasentiert oft eine Entitat in der realen Welt, in unse-rem Beispiel reprasentiert jede Zeile einen Kunden. Wenn die Tabellezwei vollig gleiche Zeilen enthalten wurde, ware der gleiche Sachverhaltdoppelt reprasentiert; dies ware sinnlos, Duplikate von Zeilen werdendaher nicht erlaubt.
Die Spalten enthalten die Beschreibungsmerkmale der reprasentier-ten Entitat. Interessant ist hier die Beobachtung, daß die Reihenfolgeder Spalten unwesentlich ist, die folgende Tabelle ist zu der vorstehen-den offenbar aquivalent:
Tabelle: kunden
Wohnort Kundennummer Kundenname Kreditlimit
Weidenau 177177 Meier, Anne 2000.00Siegen 177180 Budenbender, Christa 9000.00. . . . . . . . . . . .
Eine Zeile konnen wir daher auch als eine Menge von Attributzu-weisungen auffassen, z.B. die erste Zeile als:
Kundennummer = 177177; Wohnort = Weidenau; Kundenname =”Meier, Anne”; Kreditlimit = 2000.00
Wahrend die Reihenfolge der Attribute aus einer konzeptuellenSichtweise irrelevant ist, ist sie fur die physische Speicherung i.a. rele-vant. Beide Sichtweisen mussen aber strikt getrennt werden; Daten-bankmodelle definieren nur konzeptuelle Aspekte, die physische Spei-cherung bleibt hier vollig außer Betracht.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 6
2.2 Relationen
Die Bezeichnung “relational” stammt vom mathematischen Begriff ei-ner Relation ab. Eine Relation ist in der Mathematik bekanntlichdefiniert als Teilmenge des Kreuzprodukts mehrerer Mengen, i.a.:
R ⊆ D1 × D2 × . . . × Dn
Ein Element einer Relation nennt man Tupel. Den Inhalt der letztenTabelle konnte man offenbar als folgende Relation ansehen:
kunden ⊆ string × integer × string × real
Tabellen werden oft als Relationen bezeichnet und umgekehrt, esgibt aber einen signifikanten Unterschied: Relationen haben kein Aqui-valent zum Tabellenkopf. Die “Spalten” einer Relation haben keinenNamen, sie sind nur anhand ihrer Position benennbar, und ihre Bedeu-tung muß durch eine separate Definition angegeben werden. Letzteresleistet ein Relationentyp.
Ein Relationentyp (auch als Relationenschema oder Relatio-nenformat bezeichnet) besteht aus:
– einem Namen, der innerhalb einer Datenbank eindeutig ist– einer Folge von Attributdefinitionen
Notieren werden wir Relationentypen nach folgendem Muster:
Relationentypname = ( . . . , Attributname, . . . )
wenn die Wertebereiche der Attribute schon anderweitig bekannt sindoder im Moment nicht interessieren, und als
Relationentypname = ( . . . , Attributname: Wertebereich; . . . )
wenn die Wertebereiche angegeben werden sollen. Als Wertebereicheder Attribute sind nur elementare Datentypen wie integer, real, date,string usw. zugelassen, nicht hingegen strukturierte Datentypen wieArrays, Tupel, Mengen usw. oder gar Relationen1.
Unsere erste Version der Kundentabelle fuhrt also zu folgendemRelationentyp:
1In erweiterten relationalen Modellen, die wir hier nicht behandeln, konnen At-tribute dagegen strukturierte Typen haben.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 7
Kunden = ( Kundennummer: integer;Kundenname: string;Wohnort: string;Kreditlimit: real )
Wir werden einen Relationentyp oft vereinfachend als Menge (undnicht Folge) von Attributen ansehen und die Schreibweisen A ∈ R bzw.R1 ⊆ R2 benutzen, um darzustellen, daß das Attribut A im Relatio-nentyp R vorkommt bzw. daß im Relationentyp R1 nur Attribute ausdem Relationentyp R2 vorkommen.
Da wir hier den Begriff Typ gebrauchen, sei ein Vergleich mitden Typen in Programmiersprachen gestattet: ein Relationentyp ent-spricht in etwa einem Datentyp, der als Menge von Objekten (oderRecords) mit den Attributen gemaß dem Relationentyp definiert ist.Eine Relation kann man in der Denkwelt von Programmiersprachenals Variable dieses Typs ansehen.
In Datenbanken ist die strikte Trennung zwischen Typ und Va-riable wenig sinnvoll, weil es zu jedem Relationentyp immer nur eineRelation gibt. Daher werden dort immer gleich Relationen definiert,ihr Typ wird nur implizit mitdefiniert und hat keinen Namen. Fur dieErklarung des relationalen Datenbankmodells werden wir allerdingswiederholt Relationentypen benotigen, so daß wir auf diesen Begriffnicht verzichten konnen.
Bzgl. der Schreibweisen werden wir die Konvention einhalten,
– Namen von Relationen klein zu schreiben,– Namen von Relationentypen und Attributmengen groß zu schrei-
ben.
Wenn wir festlegen, daß eine Relation r vom Relationentyp R seinsoll, ist wegen des Ruckgriffs auf den mathematischen Relationsbegriffimplizit klar,
– daß alle Tupel von r insofern korrekt sind, daß die Werte der ein-zelnen Attribute aus den passenden Wertebereichen stammen, und
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 8
– daß keine Tupel in r doppelt vorhanden sind (eine Relation ist eineMenge und keine Multimenge)2.
Wir werden i.f. Tabellen als Darstellung von Relationen benutzenund die beiden Begriffe in diesem Sinne synonym verwenden.
2.3 Integritatsbedingungen
Es gibt sehr viele Arten, Integritatsbedingungen in relationalen Daten-banken zu formulieren. Es ist Geschmackssache, wieviele davon manzum “Kern” des relationalen Datenbankmodells zahlt. Man kann dieIntegritatsbedingungen grob wie folgt einteilen:
– Dynamische Integritatsbedingungen schranken die erlaubtenZustandsubergange bei Anderungen der Daten ein. Beispielswei-se konnte bei einem Attribut Familienstand der Ubergang vonverheiratet nach ledig verboten sein. Dynamische Integritatsbedin-gungen werden wir nicht weiter betrachten.
– Statische Integritatsbedingungen schranken den erlaubten Zu-stand einer Datenbank weiter ein. Das bekannteste Beispiel sind(Identifizierungs-) Schlussel.
Integritatsbedingungen konnen allenfalls bei Anderungen an denDaten verletzt werden. Ein DBMS muß daher bei allen anderndenOperationen entsprechende Prufungen durchfuhren und die Operationggf. mit einem Fehlercode zuruckweisen.
Lesende Operationen sind dagegen uberhaupt nicht von Integritats-bedingungen betroffen: diese Operationen arbeiten auf beliebigen Da-tenbankinhalten, also erst recht auf der Teilmenge der “korrekten”Datenbankinhalte. Aus diesem Grunde sind Integritatsbedingungenfur die nachfolgende Diskussion der relationalen Algebra nicht erfor-derlich.
2Technisch ware es kein Problem, auch Multimengen zuzulassen. In der Pra-xis erspart man sich aus Performancegrunden oft die Eliminierung von Duplikaten.Wie schon erwahnt sind aber Duplikate von Tupeln i.a. nicht sinnvoll.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 9
3 Die relationale Algebra
Der Begriff Algebra stammt aus der Mathematik. Eine Algebra istdefiniert durch eine Wertemenge3 und i.a. mehrere Funktionen, diemit Werten dieser Menge arbeiten. Beispiele fur Algebren sind diereellen Zahlen oder Matrizen zusammen mit den diversen Rechenope-rationen. Die Funktionen konnen beliebig viele Argumente haben undliefern stets einen Wert aus der Wertemenge zuruck. Daher kann manFunktionsaufrufe schachteln und Ausdrucke konstruieren.
Die relationale Algebra ist eine ganz normale Algebra im vorste-henden Sinn. Als Werte benutzen wir beliebige Relationen. Daßdie entstehende Wertemenge recht groß ist und ganze Relationen alsArgumente oder Resultate etwas schwergewichtig erscheinen mogen,braucht uns nicht weiter zu storen.
Die relationale Algebra enthalt keine Operationen, mit denen manRelationen erzeugen bzw. loschen und in einer Relation Tupel einfugen,loschen oder verandern kann. Derartige Operationen mussen in rea-len Sprachen naturlich vorhanden sein. Die relationale Algebra kon-zentriert sich ausschließlich auf die “lesenden” Operationen und dieFrage, welche Daten man aus einer vorhandenen Datenbank extrahie-ren kann. Es wird vorausgesetzt, daß die Relationen der Datenbankschon irgendwie existieren und mit Tupeln gefullt worden sind. Ana-log gilt dies fur die Relationentypen, also das konzeptuelle Schema derDatenbank.
Die Operationen der relationalen Algebra entsprechen nicht un-zufallig den typischen Aufgaben, die beim Umgang mit Datenbankenin der Praxis auftreten. Wir stellen sie anschließend einzeln vor.
3.1 Die Selektion
Die Selektion erlaubt es, aus einer vorhandenen Relation r bestimmteTupel zu selektieren. Zuruckgeliefert wird eine neue Relation, die nur
3Dies gilt fur eine einsortige Algebra. Mehrsortige Algebren arbeiten mit meh-reren Wertemengen, die hier als Sorten bezeichnet werden.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 10
die Tupel enthalt, die das Selektionskriterium erfullen. Notiert wirddie Selektion ublicherweise in der Form
σBedingung(r )
Der griechische Buchstabe sigma (σ) erinnert an das S im Wort Selek-tion. Das Ergebnis einer Selektion hat den gleichen Relationentyp wiedie Argumentrelation.
Als Beispiel betrachten wir die Menge der Kunden aus der Rela-tion kunden in Bild 1, deren Kreditlimit großer als 5000 EUR ist.Folgender Ausdruck liefert eine Relation mit genau diesen Kunden:
σKreditlimit>5000.00 (kunden )
Die entstehende Tabelle ist
Tabelle: σKreditlimit>5000.00 (kunden )
Kundennummer Kundenname Wohnort Kreditlimit
177180 Budenbender, Christa Siegen 9000.00167425 Schneider, Peter Netphen 14000.00
Im vorstehenden Beispiel trat nur eine sehr einfache Selektions-bedingung auf, die den Wert eines Attributs mit einer Konstantenverglich. Neben > sind auch die Vergleichsoperatoren <, ≤, ≥, = und6= moglich. Ferner konnen so geformte elementare Bedingungen mitden Booleschen Operatoren (∧, ∨, ¬) und Klammern zu Ausdruckenzusammengesetzt werden. Die Bedingungen durfen sich naturlich nurauf solche Attribute beziehen, die im Typ der Argumentrelation vor-kommen.
Ubungsaufgabe: Zeigen Sie, daß die und-Verkupfung von zwei Be-dingungen durch eine Hintereinanderschaltung von zwei Selektionenmit den einzelnen Bedingungen ersetzt werden kann, daß also fur einebeliebige Relation r und Bedingungen B1 und B2 gilt:
σB1∧B2 (r ) = σB1 (σB2 (r )) = σB2 (σB1 (r ))
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 11
3.2 Die Projektion
Die Projektion lost das Problem, uberflussige Attribute in den Tupelneiner Relation zu entfernen. Man projiziert eine Relation auf die Attri-bute, die man noch beibehalten mochte. Notiert wird die Projektionublicherweise in der Form
πAttributmenge (r )
Der griechische Buchstabe pi (π) erinnert an das Wort Projektion.Als Beispiel betrachten wir wieder die Relation kunden in Bild
1. Wir mochten jetzt nur noch Kundenname und Wohnort haben, diebeiden anderen Attribute bzw. Spalten sollen “wegprojiziert” werden.Dies erreichen wir mit folgendem Ausdruck:
πKundenname,Wohnort (kunden )
Die entstehende Tabelle ist:
Tabelle: πKundenname,Wohnort (kunden )
Kundenname Wohnort
Meier, Anne WeidenauBudenbender, Christa SiegenStotzel, Gyula SiegenSchneider, Peter NetphenLitt, Michael Siegen
Das Ergebnis einer Projektion hat i.a. nicht den gleichen Relatio-nentyp wie die Argumentrelation4. Der Typ der Ergebnisrelation hatgenau die in der Projektion angegebenen Attribute.
Fur die formale Definition der Projektion benotigen wir folgendeneue Notation: Sei r eine Relation mit Relationentyp R , t ein Tupelin r , also t ∈ r , A ⊆ R eine nichtleere Teilmenge der Attribute inR . Dann bezeichnet t[A] das Tupel, das die Attributwerte fur die At-tribute in A gemaß t enthalt. Mit dieser Notation konnen wir dasErgebnis einer Projektion wie folgt definieren:
4Eine Ausnahme ist lediglich der wenig sinnvolle Sonderfall, daß man auf alleAttribute der Argumentrelation projiziert.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 12
πA (r) = { t[A] | t ∈ r }
Im vorigen Beispiel hat die Ergebnisrelation genausoviele Tupelwie die Argumentrelation. Dies ist nicht immer der Fall, wie folgendesBeispiel zeigt:
πWohnort (kunden )
Die entstehende Tabelle ist:
Tabelle: πWohnort (kunden )
Wohnort
WeidenauSiegenNetphen
Sie hat nur noch 3 Tupel, denn in der Spalte Wohnort treten nur3 verschiedene Werte auf. Man betrachte noch einmal die obige De-finition der Projektion: πA (r) ist als Menge, nicht als Multimengedefiniert. Zwei verschiedene Tupel t1, t2 ∈ R , t1 6= t2, konnen nach derProjektion gleich sein und fuhren daher nur zu einem einzigen Tupelin der Ergebnisrelation.
Ubungsaufgabe: Seien P , Q und R Relationentypen, r eine Rela-tion vom Typ R . Zeigen Sie, daß folgendes gilt:
P ⊆ Q ⊆ R ⇒ π P (π Q (r )) = π P (r )
3.3 Die Mengenoperationen
Da Relationen als Mengen von Tupeln definiert sind, sind automatischalle Mengenoperationen auf Relationen anwendbar. Voraussetzung istnaturlich, daß die beteiligten Relationen den gleichen Relationentyphaben.
Wenn also r1 und r2 Relationen vom Typ R sind, dann istr1 ∪ r2 die Vereinigungr1 ∩ r2 der Schnittr1 − r2 die Differenzvon r1 und r2 . Das Ergebnis hat wieder den Relationentyp R .
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 13
Als Beispiel betrachten wir wieder die Relation kunden in Bild 1.Wir suchen jetzt die Kunden, die in Weidenau wohnen oder ein Kre-ditlimit > 10000 haben. Hierzu definieren wir die Relation k1 wiefolgt:
k1 = σWohnort=“Weidenau′′ (kunden ) ∪ σKreditlimit>10000 (kunden )
Das Ergebnis ist:
Tabelle: k1
Kundennummer Kundenname Wohnort Kreditlimit
177177 Meier, Anne Weidenau 2000.00167425 Schneider, Peter Netphen 14000.00
Wir hatten dieses Ergebnis naturlich auch mit der folgenden Defi-nition erzielen konnen;
k1 = σWohnort=“Weidenau′′ ∨ Kreditlimit>10000 (kunden )
Ubungsaufgabe: Zeigen Sie, daß die oder-Verkupfung von zwei Be-dingungen durch eine Vereinigung von zwei Selektionen mit den ein-zelnen Bedingungen ersetzt werden kann, daß also fur eine beliebigeRelation r und Bedingungen B1 und B2 gilt:
σB1∨B2 (r ) = σB1 (r ) ∪ σB2 (r )
3.4 Die Umbenennung
Aus technischen Grunden benotigen wir fur die folgenden Operationeneine Hilfsoperation, mit der man Attribute umbenennen kann. Sei r
eine Relation vom Typ R und A ∈ R , B /∈ R . Dann ist
ρ A→ B (r )
eine Relation mit dem gleichen “Inhalt” wie r , aber mit einem Typ,bei dem das Attribut A in B umbenannt worden ist5. Der Buchsta-
5Diese Definition ist formal nicht sauber, sollte aber dennoch prazise verstandlichsein. Eine formal saubere Definition bedingt einen wesentlich hoheren notationellenAufwand; Tupel mussen dann als Abbildungen von Mengen von Attributnamen inMengen von Wertemengen definiert werden (wie z.B. in [Vo99]). Da dieser nota-
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 14
be rho (ρ) erinnert an rename. Der Typ der Ergebnisrelation ist, alsAttributmenge aufgefaßt, gleich (R − {A }) ∪ {B }.
Wir wenden die Umbenennungsoperation auch auf Relationenna-men an. Sei r eine Relation vom Typ R , s ein Name, der bisher keineRelation benennt, dann ist
ρ s (r )
eine Relation namens s mit Typ R und dem gleichen Inhalt wie r .
3.5 Das Kreuzprodukt
Eine sehr haufige praktische Aufgabe besteht darin, Tupel aus ver-schiedenen Relationen zu neuen Tupeln zu “verbinden”; Beispiele wer-den wir erst spater besprechen.
Das Verbinden von Einzelelementen zu einem Tupel ist durch dasmathematische Kreuzprodukt hinlanglich bekannt und wurde bereitsbeim Relationsbegriff ausgenutzt. Es liegt nahe, statt einzelner Wer-tebereiche auch ganze Relationen durch das mathematische Kreuzpro-dukt zu verbinden. Seien also r1 , . . . , rn Relationen, dann konnenwir folgendes mathematische Kreuzprodukt bilden:
r 1 × . . . × r n
Dies ist aber leider keine Relation im Sinne der relationalen Algebra:Ein Tupel in diesem Kreuzprodukt hat die Form
(t1, . . . , tn)
wobei ti ein Tupel aus Ri ist; als Elemente relationaler Tupel sindaber nur elementare Datentypen zugelassen. Wir hatten auch ein Pro-blem, den Relationentyp dieses Kreuzprodukts zu benennen.
Ein Losungsansatz besteht darin, die Tupel ti , ..., tn zu “konka-tenieren”, also ein einziges neues Tupel zu bilden. Diese Idee funktio-niert aber nur dann, wenn keine Attributnamen doppelt auftreten, al-so wenn die Typen der beteiligten Relationen paarweise disjunkt sind.
tionelle Aufwand keinen signifikanten Gewinn an Prazision bringt, andererseits derintuitiven Verstandlichkeit abtraglich ist, wird er hier vermieden.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 15
Unter dieser Annahme konnen wir das relationale Kreuzproduktfolgendermaßen definieren:
r 1 × . . . × r n = {< t1 | . . . | tn > | t i ∈ r i }
Darin ist < t1 | . . . | tn > die Konkatenation der einzelnen Tupel. DerTyp des Kreuzprodukts ist die Vereinigung der Ri , 1 ≤ i ≤ n.
Die Bildung eines Kreuzprodukts veranschaulicht Bild 2 am Bei-spiel zweier Relationen, die 3 bzw. 2 Tupel enthalten; der Aufbau derTupel interessiert hier nicht, der Inhalt ist mit “aa”, “bb” usw. nurangedeutet.
=Xcc
aaxx
yy
cc
cc
bb
bb
aaaa
yy
xx
yy
xx
yy
xx
bb
Abbildung 2: Beispiel eines Kreuzprodukts
Da jedes Tupel der ersten Relation mit jedem Tupel der zweitenkombiniert wird, gilt folgende Formel:
| r× s | = | r | ∗ | s |
Darin bezeichnet | r | die Anzahl der Tupel einer Relation r .Die “Lange” der Ergebnistupel (gemessen in der Zahl der Attri-
bute) ist gleich der Summe der Langen der Argumenttupel. Bei derKreuzproduktbildung entstehen also sehr viele und lange Tupel6.
Wir hatten unser relationales Kreuzprodukt bisher nur unter derAnnahme definieren konnen, daß die Typen der beteiligten Relatio-nen paarweise disjunkt sind; diese Annahme ist naturlich nicht immer
6Deshalb wird das Kreuzprodukt in der Praxis auch fast nie wirklich berechnet.Im Rahmen der Optimierung werden Kreuzprodukte, die in einer vorgegebenenAbfrage auftreten, praktisch immer zu Verbundoperationen umgeformt; letzterelassen sich meist effizient berechnen. Mit relationalen Abfragesprachen kann man(bzw. sollte man oft sogar) Abfragen formulieren, die auf den ersten Blick extremineffizient aussehen. Wir gehen hierauf in Abschnitt 3.9 noch naher ein.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 16
erfullt. Die Losung besteht darin, die Attribute, die in mehr als ei-ner Relation auftreten, automatisch umzubenennen, in dem wir dieden Relationsnamen getrennt durch einen Punkt voranstellen. Hier-zu mussen wir nachfolgende Restriktionen fur die Syntax von Nameneinfuhren:– Relationsnamen durfen keinen Punkt enthalten.– Ein Attribut kann einen lokalen oder globalen Namen haben. Ein
lokaler Name enthalt keinen Punkt. Ein globaler Name besteht auseinem Relationsnamen gefolgt von einem Punkt und einem lokalenAttributnamen.
– Ein Relation darf nicht zugleich ein Attribut mit einem globalenNamen der Form r.A und ein Attribut mit dem lokalen Namen A
haben.
Bei der Bildung von r 1 × . . .× r n somit immer dann, wenn ri einAttribut A und eine andere Relation rj, j 6= i, ein Attribut mit NamenA oder x.A hat, in ri das Attribut A zu ri.A umbenannt. D.h. wirfuhren innerhalb der Operationsausfuhrung und vor der eigentlichenBildung des Kreuzprodukts die Umbenennung
ρA→r.A (r)
durch. Unter der Annahme, daß alle auftretenden Relationsnamenverschieden sind, sind anschließend alle Attributnamen eindeutig.
Naturlich konnen die betroffenen Attribute auch explizit vor derBildung des Kreuzprodukts umbenannt werden, wenn die automati-sche (implizite) Umbenennung im Einzelfall unpassend ist.
Gelegentlich will man auch das Kreuzprodukt einer Relation mitsich selbst bilden. Dies verbieten wir hier und verlangen, daß in solchenFallen zunachst explizit eine der Relationen umbenannt wird, so daßletztlich alle involvierten Relationen eindeutige Namen bekommen.
3.6 Verbundoperationen
3.6.1 Beispiel
Wir betrachten nun das schon angekundigte Beispiel, bei dem Daten,die in verschiedenen Relationen stehen, zusammenzufuhren sind. Wir
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 17
fuhren hierzu eine weitere Relation lieferungen ein, die folgendenRelationentyp hat:
Lieferungen = ( Datum: date;Wert: real;Kundennummer: integer;Lager: string;Lieferadresse: string )
Ein Tupel dieses Typs zeigt an, daß am angegebenen Datum Waren imangegebenen Gesamtwert an den Kunden, der durch die Kundennummeridentifiziert wird, geliefert worden sind, und zwar vom angegebenenLager aus an die angegebene Lieferadresse. Der Inhalt der Relationlieferungen sei wie in Bild 3 angegeben.
Tabelle: lieferungen
Datum Wert Kundennummer Lager Lieferadresse
00-08-12 2730.00 167425 Mitte Bahnhofstr. 500-08-14 427.50 167425 Nord Luisenstr. 1300-08-02 1233.00 171876 West Bergstr. 33
Abbildung 3: Beispieltabelle fur Lieferungen
Wir wollen nun eine Relation erzeugen (und anzeigen oder aus-drucken), in der fur alle Lieferungen Datum, Wert und der Name desKunden angezeigt werden. Den Namen des Kunden mit einer gegebe-nen Kundennummer konnen wir anhand der Relation kunden heraus-finden. Wir konnen das gesuchte Resultat in mehreren Schritten wiefolgt konstruieren:
1. Wir mussen Daten aus verschiedenen Relationen in einzelnen Tu-peln zusammenbringen. Der einzige Operator, der dies leistet, istdas relationale Kreuzprodukt. Wir bilden also zuerst das Kreuz-produkt von lieferungen und kunden :
r1 = lieferungen × kunden
Dieser erste Schritt kann im Prinzip ein extrem großes Zwischen-ergebnis erzeugen. Dies braucht uns aber nicht zu storen, wie wir
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 18
spater sehen werden, wird dieses Zwischenergebnis infolge internerOptimierungen nicht wirklich erzeugt.
Die beiden Relationen haben das Attribut Kundennummer ge-meinsam. Gemaß der definierten Funktionsweise des Kreuzpro-dukts ist dieses Attribut automatisch in lieferungen.Kundennum-
mer bzw. kunden.Kundennummer umbenannt worden.
2. In r1 ist jedes Lieferungstupel mit jedem Kundentupel kombi-niert worden. Die meisten dieser Kombinationen sind fur unserenZweck unsinnig und daher uberflussig; wir interessieren uns nur furdie Kombinationen, bei denen lieferungen.Kundennummer undkunden.Kundennummer den gleichen Wert haben, denn nur hiersind die richtigen Kundendaten und Lieferungsdaten kombiniert.Wir bilden also
r2 = σ lieferungen.Kundennummer = kunden.Kundennummer (r1 )
3. In r2 sind die Spalten lieferungen.Kundennummer und kun-
den.Kundennummer identisch: dies war gerade die Selektionsbedin-gung. Eine der beiden Spalten ist offensichtlich entbehrlich undkann entfernt werden. Der lange Attributname der verbliebenenSpalte ist dann nicht mehr notwendig, wir konnen wieder den ur-sprunglichen Namen verwenden. Wir gehen nun so vor, daß wirzuerst eine der Spalten in den ursprunglichen Namen umbenennen:
r3 = ρlieferungen.Kundennummer→Kundennummer (r2 )
4. Die uberflussige Spalte mit dem langen Namen konnen wir nunentfernen, indem wir einfach auf die Vereinigung der beiden Rela-tionentypen projizieren:
r4 = πLieferungen ∪ Kunden (r3 )
5. Zum Schluß entfernen wir noch die nicht benotigten Attribute; ge-fragt war nur nach Datum, Wert und Kundennamen:
r5 = πDatum,Wert,Kundenname (r4 )
Unser Endresultat sieht folgendermaßen aus:
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 19
Tabelle: r5
Datum Wert Kundenname
00-08-12 2730.00 Schneider, Peter00-08-14 427.50 Schneider, Peter00-08-02 1233.00 Litt, Michael
3.6.2 Der naturliche Verbund
Das vorige Beispiel weist eine sehr haufig auftretende Problemstruk-tur auf: die Werte in der Spalte Kundennummer in der Relationlieferungen kann man als “Referenzen” auf Tupel in der Relati-on kunden ansehen7. Unsere Absicht war es, zu jedem Tupel inlieferungen die dort stehende Referenz auf ein Kundentupel zu ver-folgen und Daten aus diesem Kundentupel hinten an das Lieferungstu-pel anzuhangen – so hatte man es auch von Hand gemacht (s. auch Bild4). Letztlich verbinden wir solche Paare von je einem Lieferungstupelund einem Kundentupel, die im gemeinsamen Attribut Kundennummer
den gleichen Wert haben.
��������������������
����������������
..... .....
..... .....
177180
177180 177180
Abbildung 4: Auflosung einer “Referenz”
Der naturliche Verbund (natural join) verallgemeinert diesenVorgang; er faßt die obigen Schritte 1 bis 4 zu einer einzigen Ope-ration zusammen. Sie wird mit dem Zeichen ⋊⋉ notiert. Mit Hilfedes naturlichen Verbunds konnen wir das Beispiel in Abschnitt 3.6.1wesentlich einfacher losen, und zwar wie folgt:
7Die Denkweise in Referenzen unterstellt, daß die Kundennummern in der Re-lation kunden eindeutig sind, daß also eine bestimmte Kundennummer hochstenseinmal in der Spalte Kundennummer in der Relation kunden auftritt. Dies trifft inder Praxis auf fast alle Verbundbildungen zu, ist aber nicht zwingend erforderlich.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 20
πDatum,Wert,Kundenname (lieferungen ⋊⋉ kunden )
Definition: Gegeben seien zwei Relationen r und s mit den Rela-tionentypen R bzw. S .Sei V = R ∩ S die Menge der Verbundattribute. Es kann beliebigviele Verbundattribute geben, i.a. ist also V = {v1,...,vn}.Dann ist:
r ⋊⋉ s = π R ∪ S (ρ r.V→ V (σ r.V=s.V (r × s )))
Die Schreibweise σ r.V=s.V ist eine Kurzform von
σr.v1=s.v1 ∧ ...∧ r.vn=s.vn
Es werden also nur solche Tupel verbunden, die in allen Verbundattri-buten ubereinstimmen.
Die Schreibweise ρ r.V→ V (...) ist eine Kurzform fur
ρr.v1→v1(. . . (ρr.vn→vn(...)) . . .)
In dem Sonderfall, daß R und S disjunkt sind, also V die leereMenge ist, ist im obigen Ausdruck die Selektionsbedingung leer, d.h.die selektierten Tupel mussen keine Bedingung erfullen, es wird alsonichts weggefiltert. Bei V = ∅ bilden auch die darauf folgende Projekti-on und die Umbenennung ihre Argumente identisch ab, der naturlicheVerbund verhalt sich dann also wie das Kreuzprodukt.
Wie schon oben erwahnt ist es nicht zulassig, das Kreuzprodukteiner Relation mit sich selbst zu bilden, stattdessen muß wenigstenseine der Relationen vorher umbenannt werden. Dies gilt auch fur dennaturlichen Verbund. Wenn man dies tut, also z.B.
r ⋊⋉ ρ s (r )bildet, erhalt man als Ergebnis genau r (s. folgende Ubungsaufga-ben), d.h. ein Verbund einer Relation mit sich selbst ist uberflussig.
Ubungsaufgabe: Zeigen Sie, daß der naturliche Verbund eine kom-
mutative Operation ist, d.h. fur beliebige Relationen (oder besser ge-sagt Tabellen) r und s gilt:
r ⋊⋉ s = s ⋊⋉ r
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 21
Ubungsaufgabe: Zeigen Sie, daß der naturliche Verbund eine asso-ziative Operation ist, d.h. fur beliebige Relationen r , s und t gilt:
(r ⋊⋉ s ) ⋊⋉ t = r ⋊⋉ (s ⋊⋉ t )
Ubungsaufgabe: Zeigen Sie, daß im Sonderfall R = S der Verbundden Durchschnitt der beiden Relationen bildet, also:
R = S ⇒ r ⋊⋉ s = r ∩ s
Ubungsaufgabe: Berechnen Sie unter Nutzung des Ergebnisses dervorigen Ubungsaufgabe r ⋊⋉ ρ s (r ).
Verbundpartner. Ein sehr simpler Algorithmus zur Implementie-rung des Verbunds r ⋊⋉ s arbeitet wie folgt:
– man durchlauft alle Tupel t ∈ r ,
– fur jedes t durchlauft man alle Tupel u ∈ s , und
– fur die Tupel u, die zusammen mit t die Verbundbedingung erfullen,gibt man ein Ergebnistupel aus.
Das geschachtelte Durchlaufen beider Relationen entspricht der Bil-dung eines Kreuzprodukts. Jedes Ergebnistupel enthalt naturlich dieAttributwerte gemaß t und u.
Im Endeffekt realisiert man damit fur jedes t ∈ r eine lineare Su-che nach den Verbundpartnern von t in s . Verbundpartner von tsind diejenigen Tupel u ∈ s , fur die gilt: u [V] = t [V] . Diese Mengekonnen wir auch als Abfrage formulieren:
σ s.V =t[ V ](s )
Haufige Denkfehler. Das obige Beispiel, in dem wir den Verbundder Relationen lieferungen und kunden gebildet haben, enthaltMerkmale, die in der Praxis sehr haufig auftreten. Diese Merkmalewerden sehr leicht irrtumlich zu notwendigen Voraussetzungen erklartoder falsch interpretiert; die haufigsten Denkfehler in diesem Zusam-menhang sind:
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 22
1. Denkfehler: Im Beispiel und in ca. 99 % aller praktischen Fallehat man genau ein Verbundattribut. Dies wird oft falschlicherwei-se als Voraussetzung angesehen! Der Verbund ist fur beliebig vieleVerbundattribute definiert, auch fur V = ∅!
2. Denkfehler: Wenn keine Verbundattribute vorhanden sind, alsoV = ∅, dann findet ein Tupel in r scheinbar keine Verbundpartnerin s , also ist r ⋊⋉ s = ∅. Dies ist falsch.
Wenn V = ∅, dann ist die Menge der Verbundpartner von t,wie oben definiert, σ s. ∅=t[∅](s ). Darin verstehen wir s.∅ als “lee-res Tupel mit 0 Attributen”. Offensichtlich ist damit die Bedin-gung s.∅ = t[∅] fur jedes beliebige u erfullt, d.h. in Wirklichkeitsind fur ein beliebiges t ∈ r alle u ∈ s Verbundpartner, undr ⋊⋉ s = r × s .
3. Denkfehler: Im obigen Beispiel und in fast allen praktischen Fallenist das Verbundattribut in einer der beiden Relationen eindeutig.Dies haben wir auch unterstellt, als wir oben die Kundennummernin der Relation lieferungen als “Referenzen” auf genau ein Tupelin kunden interpretiert haben. Diese Eindeutigkeit ist aber nicht
notwendig. Wie schon bei der Definition des Begriffs Verbundpart-ner gesehen kann ein t ∈ r beliebig viele Verbundpartner in s
haben.
3.6.3 Der Theta-Verbund
Beim naturlichen Verbund wurden bei der Prufung, ob ein Paar vonTupeln verbunden werden soll,
– der Vergleichsoperator = benutzt, und– es wurde jeweils das gleiche Attribut in beiden Tupeln fur den Ver-
gleich herangezogen.
Dies wird beim Θ- (Theta-) Verbund dahingehend verallgemei-nert,
– daß irgendein Vergleichsoperator Θ ∈ {=, 6=, <,≤, >,≥} benutztwird und
– daß unterschiedliche Attribute in beiden Tupeln fur den Vergleichherangezogen werden.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 23
Wenn r und s Relationen vom Typ R bzw. S sind und A ∈ R und B
∈ S Attribute mit gleichem Wertebereich, dann ist ein Theta-Verbundwie folgt definiert:
r ⋊⋉r.AΘ s.B s := σr.AΘ s.B (r × s )
Man kann geteilter Meinung daruber sein, ob der Theta-Verbund vieleinbringt; eine wesentliche Ersparnis an Schreibarbeit und ein dement-sprechender Gewinn an Ubersichtlichkeit der Ausdrucke – die eingroßer Vorteil des naturlichen Verbundes sind – tritt hier jedenfallsnicht ein.
Ein Gleichheitsverbund (equi-join) ist ein Theta-Verbund mitdem Vergleichsoperator =.
3.6.4 Außere Verbunde
Wir betrachten noch einmal das Beispiel in Abschnitt 3.6.1 und neh-men an, in der Relation kunden sei das Tupel mit der Kundennummer167425 geloscht worden. Wenn wir jetzt wieder den Verbund
lieferungen ⋊⋉ kunden
bilden, wurden die beiden ersten Tupel in der Relation lieferungen
(s. Bild 3) keinen Verbundpartner mehr finden und dementsprechendherausfallen. Dies ist aber oft nicht erwunscht. Wenn der Kundenna-me nicht ermittelt werden kann, sollte der Sachverhalt, daß der Wertunbekannt ist, angezeigt werden, etwa in folgender Form:
Datum Wert Kunden-
nummer
Lieferadresse Kundenname
00-08-12 2730.00 167425 Bahnhofstr. 5 NULL00-08-14 427.50 167425 Luisenstr. 13 NULL00-08-02 1233.00 171876 Bergstr. 33 Litt, Michael
Der Text NULL soll einen Nullwert darstellen; dieser druckt aus,daß der tatsachliche Attributwert unbekannt ist.
In der vorstehenden Tabelle haben wir bei den Tupeln aus liefe-
rungen (also dem linken Verbundargument), die keinen Verbundpart-
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 24
ner gefunden haben, einen kunstlichen Verbundpartner benutzt. DieseArt von Verbund nennt man linken außeren Verbund.
Analog wird beim rechten außeren Verbund fur Tupel des rech-ten Verbundarguments ggf. ein kunstlicher Verbundpartner benutzt.Der außere Verbund ist die Vereinigung von linkem und rechtemaußeren Verbund.
3.7 Die Division
Das Kreuzprodukt ist in gewisser Weise vergleichbar mit einer Multi-plikation; im Kreuzprodukt r × s wird jedes Tupel aus r mit jedemTupel aus s kombiniert (s. auch Bild 2). Die relationale Division kannman sich als eine Art inverse Operation zum Kreuzprodukt vorstellen.
Hierzu betrachten wir das Beispiel in Bild 2 noch einmal genau-er. Jedes der Tupel “aa”, “bb” und “cc” der linken Relation fuhrt zueinem eigenen Abschnitt im Ergebnis (in Bild 2 jeweils durch einenkleinen Zwischenraum abgesetzt): die linken Halften der Tupel einesAbschnitts enthalten alle das gleiche, z.B. “aa”, die schattiert dar-gestellten rechten Halften bilden eine Kopie der rechten Argumentre-lation. Diese rechte Halfte eines Abschnitts wiederholt sich wie einStempelabdruck immer wieder.
Bei der Umkehrung der Kreuzproduktbildung suchen wir sozusa-gen nach Stempelabdrucken (s. Bild 5):
xxdd
=:yy
xx
cc
aa
yy
xx
zz
xx
yy
xxaaaa
bb
bb
cc
cczzcc
Abbildung 5: relationale Division
– Dividend ist eine Relation x vom Typ X ;
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 25
– Divisor ist eine Tupelmenge in einer Teilmenge der Spalten, aufge-faßt als Relation s vom Typ S (der “Stempel”);
– im Quotienten enthalten sind solche Tupel aus den restlichen Spal-ten von x , die mit allen Tupeln des Divisors kombiniert auftreten.
Im Beispiel in Bild 5 besteht der Stempel aus den Tupeln “xx”und “yy”. Fur “aa” ist ein kompletter Stempelabdruck vorhanden,fur “bb” und “dd” nur ein unvollstandiger, “bb” und “dd” sind dahernicht im Ergebnis enthalten. Die Tupel “bb/xx” und “dd/xx” tragensomit nicht zum Ergebnis bei, ebenfalls nicht das Tupel “bb/zz”, da“zz” nicht im Divisor auftritt. Die relationale Division ahnelt insofernder ganzzahligen Division ohne Rest. Wegen dieses Rests erhalt man,wenn man den Quotienten wieder mit dem Divisor multipliziert, i.a.nur noch eine Teilmenge des ursprunglichen Dividenden:
(x ÷ s ) × s ⊆ x
Formal definiert ist die Division wie folgt: Gegeben sei
– eine Relation x vom Typ X (der Dividend),– eine Relation s vom Typ S (der Divisor),
wobei ∅ 6= S und S ⊂ X sein muß. Sei R = X − S . Dann ist
x ÷ s = { t | t ∈ π R (x ) ∧ {t} × s ⊆ x }
Das Ergebnis ist eine Relation vom Typ R . Ein Tupel t ist genaudann im Ergebnis enthalten, wenn {t} × s ⊆ x , also wenn fur allet’ ∈ s gilt: < t | t′ >∈ x . Bildlich gesprochen enthalt das Ergebnisdiejenigen “linken Halften” von Tupeln aus x , die mit allen “rechtenHalften” aus s kombiniert in x auftreten.
Anwendungsbeispiel. Als Anwendungsbeispiel fur die Division be-trachten wir eine Relation konten , die Angaben zu den Konten einerBank enthalt und die folgenden Relationentyp hat:
Konten = ( Kontonummer: integer;Kundennummer: integer;Filialenname: string )
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 26
Der Filialenname gibt den Namen der Filiale an, bei der das Kontogefuhrt wird. Ein Kunde kann bei einer Filiale beliebig viele Kontenhaben. Gesucht sind nun die Kunden, die bei allen Filialen wenigstensein Konto haben. Fur die Losung unserer Aufgabe bilden wir zunachstdie Relation
kundeFiliale = πKundennummer,Filialenname (konten )
Diese enthalt genau dann ein Tupel < k, f >, wenn der Kunde k we-nigstens ein Konto in der Filiale f hat. Die Liste aller Filialen erhaltenwir als eine 1-spaltige Tabelle mittels:
filialen = πFilialenname (kundeFiliale )
Die Kunden, die in jeder Filiale ein Konto haben, erhalten wir nun-mehr durch:
kundeFiliale ÷ filialen
Das Typische an unserem Anwendungsbeispiel war, daß ein all-Quantor bei der Beschreibung der gesuchten Daten benutzt wurde(“Kunden, die bei allen Filialen ein Konto haben”). Fur derart spe-zifizierte Suchergebnisse kann man generell die Division einsetzen. Inden Selektionsbedingungen einer Selektion ist ein all-Quantor nichterlaubt; die Division bietet daher einen Ersatz. Ein Ersatz fur denExistenz-Quantor ist nicht notwendig, denn dieser wird implizit durchdie Selektion realisiert.
Berechnung von x ÷ s : x ÷ s kann direkt durch Ausnutzung derDefinition algorithmisch berechnet werden:
– Man bildet π R (x ) als die Menge der Kandidaten, die im Ergebnisenthalten sein konnten.
– Fur jedes t ∈ π R (x ) pruft man, ob {t} × s ⊆ x . Falls ja, kommtt in die Ergebnismenge.
Die Division ist aber auch, was man spontan vielleicht nicht erwar-ten wurde, zuruckfuhrbar auf die fruher definierten Operationen. Zuberechnen sei also x ÷ s . Sei R = X − S und
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 27
r = π R (x )
r enthalt alle “Kandidaten”, die im Ergebnis sein konnten. r ist i.a.eine Obermenge von x ÷ s , denn r kann Tupel enthalten, fur die{t} × s ⊆ x nicht gilt. Um diese Tupel (“durchgefallene Kandida-ten”) zu finden, benutzen wir einen Trick: Wir bilden zunachst dieRelation r × s . Sei nun
inv = (r × s ) − x
(r x s) x (r x s) − x
aaaa
bb
bb yy
xx
yy
xx aaaa
bb
bb zz
xx
yy
xx
bb yy
Abbildung 6: relationale Division
inv ist die Invertierung von x in r × s . Wir betrachten den Inhaltvon inv an einem Auszug unseres Beispiels aus Bild 5. Wir konnenhier 2 Falle unterscheiden, die in Bild 6 veranschaulicht sind:
1. Fur den Kandidaten t = “aa” sind alle Kombinationen mit denTupeln des Divisors in x vorhanden, und es gilt: {t} × s ⊆ x .
inv enthalt daher kein Tupel der Form “aa/...”, weil alle der-artigen Tupel aus r × s auch in x vorhanden sind und somitabgezogen wurden.
2. Fur den Kandidaten t = “bb” sind nicht alle Kombinationen mitden Tupeln des Divisors vorhanden, und es gilt: {t} × s 6⊆ x .
In inv bleibt daher wenigstens eine der fehlenden Kombinatio-nen ubrig. Wenn wir nun noch auf R projizieren, haben wir einen“durchgefallenen Kandidaten” gefunden.
Die Tupel in π R (inv ) sind somit gerade diejenigen, die in r zuvielsind. Unser Endresultat ist also
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 28
x ÷ s = r − π R (inv )
bzw. x ÷ s = π R (x ) − π R ((π R (x ) × s ) − x )
3.8 Relationale Vollstandigkeit
Wir haben inzwischen eine Reihe von Operationen mit Relationenkennengelernt und schon bei den relativ komplizierten Verbundope-rationen und der Division bemerkt, daß wir sie auf die einfacherenOperationen
σ, π, ρ,∪,−,×
zuruckfuhren konnten. Die Verbundoperationen und die Divisionmogen zwar die Formulierung mancher Abfragen erleichtern, sie er-weitern die Fahigkeiten der relationalen Algebra aber nicht wirklich,d.h. es gibt kein Suchproblem, das nur mit ihrer Hilfe losbar ware.Dieser Effekt ist auch bei diversen weiteren Operationen, die man sichnoch ausdenken kann, zu beobachten.
Hieraus schlußfolgert man, daß die Ausdruckskraft, die durch dievorstehende Operationenmenge erreicht wird, einerseits ausreichendfur eine große Klasse von Problemen, andererseits ein Minimum anAusdruckskraft ist, das von jeder Abfragesprache fur relationale Da-tenbanken erreicht werden sollte; solche Sprachen nennt man daherrelational vollstandig8.
Die Operationenmenge {σ, π, ρ,∪,−,×} ist ubrigens minimal indem Sinne, daß keine der Operationen auf die anderen zuruckfuhr-bar ist; jede echte Teilmenge ware nicht mehr relational vollstandig.Wir hatten alternativ statt des Kreuzprodukts zuerst den naturli-chen Verbund einfuhren konnen und hatten dann das Kreuzproduktauf den naturlichen Verbund zuruckgefuhrt; die Operationenmenge{σ, π, ρ,∪,−, ⋊⋉} ist also eine andere minimale, relational vollstandigeOperationenmenge.
8Diese Bezeichnung ist insofern irrefuhrend, als eine praxisgerechte Sprache vie-le uber die zentralen Abfrageoperationen hinausgehende Funktionen anbieten muß,s. Abschnitt 1. So gesehen sind die Operationen der relationalen Algebra ziemlichunvollstandig.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 29
3.9 Ausdrucke in der relationalen Algebra
Wie schon einleitend erwahnt setzen wir bei der relationalen Algebraeine existierende Datenbank, also ein konzeptuelles Schema und dazupassende existierende Relationen, voraus. Hierdurch ist eine Mengevon Namen von Relationen und Attributen vorgegeben. Diese Namenkonnen wir nun an passender Stelle in den Operationen der relatio-nalen Algebra einsetzen. Uberall dort, wo eine relationale Operationeine Relation als Argument benotigt, kann naturlich wiederum ein re-lationaler Ausdruck eingesetzt werden.
Syntaktisch korrekte Ausdrucke sind analog zu arithmetischen Aus-drucken in gangigen Programmiersprachen definiert. Details der Syn-taxdefinition und -prufung und Ubersetzung interessieren uns an dieserStelle nicht, und wir setzen i.f. syntaktisch korrekte Ausdrucke voraus.
Ausdrucke werden klassischerweise von innen nach außen ausge-wertet. Die entstehenden Zwischenresultate mussen gepuffert werden.Diese Zwischenresultate konnen, wenn Verbunde oder Kreuzprodukteauftreten, extrem groß werden, d.h. man kann erhebliche Performance-Probleme bekommen, wenn man einen relationalen Ausdruck in kano-nischer Weise auswertet.
Man kann das Ergebnis eines relationalen Ausdrucks oft effizienterberechnen als durch eine kanonische Auszuwertung; die Bestimmungeines effizienteren Rechenverfahrens bezeichnet man als Optimierung.Durch die Optimierung ist es vielfach moglich, auch außerlich “in-effiziente” Ausdrucke recht effizient auszuwerten. Die entscheidendeKonsequenz hieraus ist, daß man bei der Formulierung relationalerAbfragen zunachst keine Rucksicht auf Ineffizienz bei der kanonischenAuswertung nehmen sollte und sich stattdessen besser auf die inhaltli-
che Korrektkeit des Ausdrucks konzentieren sollte. Losungen, die klarund korrekt, aber “ineffizient” sind, sind vielfach kompakter und des-wegen leichter fur Optimierer behandelbar als “effiziente” komplizierte(und schlimmstenfalls inkorrekte) Losungen.
Wenn der Optimierer der Datenbank wider Erwarten doch keine ef-fiziente Ausfuhrung findet – Wunder wirken konnen Optimierer nicht,und nicht jedes DBMS hat einen guten Optimierer – , kann man in
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 30
einem zweiten Schritt immer noch versuchen, durch Umformung derAnfrage die eigentliche Arbeit des Optimierers doch selbst von Handzu erledigen.
4 Schlussel
Wir hatten schon in Abschnitt 2.3 Identifizierungsschlussel als einetypische Integritatsbedingung erwahnt; nachdem wir nun die Opera-tionen der relationalen Algebra kennen, konnen wir einige Schlussel-begriffe leichter exakt definieren.
4.1 Superschlussel und Identifizierungsschlussel
Wir betrachten noch einmal die Relation kunden in Bild 1. Von demAttribut Kundennummer verlangten wir schon fruher, daß es “eindeu-tig” sein sollte, m.a.W. daß zu jeder Kundennummer hochstens ein Tu-pel vorhanden sein sollte. Eine Kundennummer identifiziert also, so-fern vorhanden, genau ein Tupel. Formal laßt sich dies so ausdrucken:
kn ∈ πKundennummer (kunden) ⇒ | σKundennummer=kn (kunden) |= 1
Die vorstehende Bedingung ist aquivalent zu der folgenden kompak-teren Bedingung (Beweis: Ubungsaufgabe):
| πKundennummer (kunden) | = | kunden |
Das Attribut Wohnort hat diese Eigenschaft offensichtlich nicht. Eskonnte aber sein, daß die beiden Attribute Wohnort und Kundenname
zusammen die Identifizierungseigenschaft haben. Genereller kann einebeliebige Menge von Attributen zur Identifikation von Tupeln verwen-det werden. Eine derartige Menge von Attributen nennen wir einenSuperschlussel. Die formale Definition lautet:
Sei R ein Relationentyp, K ⊆ R eine Attributmenge. Wenn K einSuperschlussel fur R ist, dann gilt fur jede korrekte Relation r mitdem Relationentyp R stets folgendes:
| πK (r) | = | r |
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 31
Die Attribute in K nennen wir auch Schlusselattribute. Bildlich ge-sprochen gehen beim Projizieren auf einen Superschlussel keine Tupelverloren, weil eben keine Kombination der Werte der Schlusselattribu-te doppelt auftritt.
Der seltsam klingende Name Superschlussel ruhrt daher, daß dieAttributmenge gemaß der vorstehenden Definition auch “uberflussige”Attribute enthalten kann, die fur die Identifikation eigentlich nicht ge-braucht werden. Ein extremes Beispiel ist die Attributmenge R; R istimmer ein Superschlussel fur R , sofern die Relation eine Menge ist9.
Ein Identifizierungsschlussel ist eine minimale Menge von At-tributen, die Superschlussel ist.
Fur unsere Relation kunden sind {Kundennummer} und {Kundenna-me, Wohnort} Identifizierungsschlussel. Wenn zusatzlich die Personal-ausweisnummer zu jedem Kunden vorhanden ware, ware {Personal-ausweisnummer} ein weiterer Identifizierungsschlussel. Dieses Beispielzeigt, daß es fur einen Relationentyp mehrere Identifizierungsschlusselgeben kann.
Die Bezeichnung Schlussel wird meist als Synonym zu Identifi-zierungsschlussel verstanden. Unter einem Schlusselwert bei einemTupel t verstehen wir die Menge der Attributwerte von t bei den At-tributen des Identifizierungsschlussels.
Es sei noch einmal daran erinnert, daß Schlusseleigenschaften In-tegritatsbedingungen, also vom Anwender definierte Anforderungen
sind. Zu der Erkenntnis, daß eine Attributmenge K ein Identifi-zierungsschlussel ist, kommt man nicht etwa dadurch, daß man denZustand der Datenbank eine Zeitlang beobachtet und wahrenddessendauernd kontrolliert, ob die Identifizierungseigenschaft erfullt ist. Esist genau umgekehrt: die Identifizierungseigenschaft wird vorgegeben,und das DBMS hat dafur zu sorgen, daß unerwunschte Zustande ver-hindert werden.
Das DBMS muß bei jedem Einfugen eines neuen Tupels oder
9Manche DBMS erlauben Tupel-Duplikate, in solchen Fallen existiert kein ein-ziger Superschlussel.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 32
Andern eines vorhandenen Tupels fur jeden Identifizierungsschlusselprufen, ob der neue Schlusselwert schon in der Relation auftritt. DiesePrufung kann so implementiert werden, daß die ganze Relation line-ar durchsucht wird. Dies ist i.a. (außer bei kleinen Relationen) zuineffizient, daher muß fur einen Identifizierungsschlussel praktisch im-mer ein Verzeichnis angelegt werden, in dem die aktuell vorhandenenSchlusselwerte verzeichnet sind und das effizient durchsuchbar ist (z.B.als Baumstruktur oder Hash-Tabelle)10. Dieses Verzeichnis muß beiallen Datenanderungen entsprechend aktualisiert werden. Sofern ei-ne Relation mehrere Identifizierungsschlussel hat, muß fur jeden eineigenes Verzeichnis der vorhandenen Schlusselwerte angelegt werden.
Viele DBMS erlauben es, Relationen zu definieren, die keinen ein-zigen Identifizierungsschlussel haben. Eine derartige Relation kannTupelduplikate enthalten. Auch die Gesamtmenge aller Attribute bil-det hier keinen Schlussel, denn dann waren keine Duplikate erlaubt.
4.2 Primarschlussel
Die Verzeichnisse fur die Identifizierungsschlussel kosten Platz und Re-chenzeit, man wurde sie daher lieber vermeiden. Dies ist in der Tatbei vielen internen Speicherstrukturen moglich. Bei den folgenden An-nahmen und Implementierungsentscheidungen bekommt man die Ein-deutigkeitsprufung praktisch gratis:
1. jedes Tupel wird in einem Speichersatz gespeichert (vgl. [DBSA]),
2. die Relation wird in einem B*-Baum gespeichert,
3. der Identifizierungsschlussel ist einelementig (enthalt also nur einAttribut),
4. man verwendet die Schlusselwerte der Tupel als Schlusselwerte imB*-Baum.
Diese sehr effiziente Prufung der Schlusseleigenschaft ist aber nur beieinem einzigen Identifizierungsschlussel moglich. Wenn man mehrere
10Eine effiziente Suche wird z.B. auch durch die sortierte Speicherung nachdem Identifizierungsschlussel ermoglicht; allerdings machen hier Einfugungen undLoschungen Probleme. Derartige Implementierungstechniken sind kein Thema die-ses Lehrmoduls.
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 33
Identifizierungsschlussel hat, muß man fur die ubrigen nach wie vorseparate Verzeichnisse anlegen.
Als Primarschlussel bezeichnet man denjenigen Identifizierungs-schlussel, fur den die Moglichkeit der sehr effizienten Prufung derSchlusseleigenschaft ausgenutzt werden soll. Welche Implementie-rungstechniken hierzu verwendet werden, bleibt eine Entscheidung desDBMS-Herstellers.
Neben der Prufung der Schlusseleigenschaft ist naturlich bei einemPrimarschlussel auch die Suche nach dem Tupel, das einen bestimmtenWert bei diesem Attribut hat, besonders effizient moglich. DerartigeSuchvorgange sind z.B. bei der Verbundbildung notig (s. das Beispielin Abschnitt 3.6.1). Daher wird man, sofern mehrere Identifizierungs-schlussel vorhanden sind, denjenigen als Primarschlussel auswahlen,mit dem haufig Verbunde gebildet werden. In den meisten Fallenhat man aber ohnehin nur einen einzigen Identifizierungsschlussel, derdann automatisch als Primarschlussel zu wahlen ist.
Die vorstehenden Beobachtungen zeigen, daß die Festlegung desPrimarschlussels eine Implementierungsentscheidung ist, die fur diekonzeptionelle Struktur der Datenbank unerheblich ist. Im Sinne der3-Ebenen-Schema-Architektur (s. Abschnitt 5.2 in [DVS]) gehort dieFestlegung des Primarschlussels also zum internen Schema. Im Gegen-satz dazu gehoren Identifizierungsschlussel zum konzeptuellen Schema.
Leider wird zwischen den Ebenen oft nicht sauber getrennt. DieBezeichnung Schlussel wird vielfach auch als Synonym zu Primar-schlussel verstanden.
Eine wesentliche Ursache fur diese Vermischung von Begriffen liegtdarin, daß man beim Entwurf der konzeptuellen Schemata durchausRucksicht auf deren Implementierung nehmen muß; dies ist nicht ganzkonsistent mit der Idealvorstellung, wonach die konzeptuellen und im-plementierungsbezogenen Aspekte vollig getrennt voneinander auf denbeiden unteren Ebenen der 3-Ebenen-Schema-Architektur behandeltwerden konnen. Betrachten wir hierzu wieder das Beispiel in Bild1. Einer der Identifizierungsschlussel war {Kundenname, Wohnort}.Dieser Identifizierungsschlussel ist i.a. als Primarschlussel ungeeignet,
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 34
weil hier die internen Schlusselwerte als Konkatenation der beiden At-tributwerte gebildeten werden mußten und weil diese Zeichenkettenrelativ lang werden konnen. Aus Effizienzgrunden erlauben Imple-mentierungen von B*-Baumen und ahnlichen internen Strukturen ggf.nur relativ kurze Schlusselwerte fester Lange, z.B. ganze Zahlen mit 4oder 8 Bytes Lange oder Zeichenketten mit 8 Zeichen.
Sofern die “naturlichen” Identifizierungsschlussel alle als Primar-schlussel ungeeignet sind, muß man ein kunstliches Schlusselattributerfinden; hierauf gehen wir in Abschnitt 4.4 ausfuhrlicher ein.
4.3 Fremdschlussel
Identifizierungsschlussel einer Relation werden oft von einer anderenRelation aus “referenziert”. In unserer Relation lieferungen kamz.B. das Attribut Kundennummer vor, das Identifizierungsschlussel inkunden ist. Es sollte offensichtlich keine Lieferung geben, bei der dieKundennummer “ins Leere zeigt”, weil sie in kunden nicht auftritt.Die Abwesenheit solcher Datenfehler bezeichnet man auch als refe-rentielle Integritat. Formal formuliert fordern wir folgende Men-geninklusion:
πKundennummer (lieferungen) ⊆ πKundennummer (kunden)
Kundennummer bezeichnen wir als Fremdschlussel in der Relati-on lieferungen. Alle Werte, die im Attribut Kundennummer inlieferungen auftreten, mussen auch im Attribut Kundennummer inkunden auftreten.
Die allgemeine Definition ist: sei K eine Attributmenge, r eine Re-lation mit dem Relationentyp R, K ⊆ R, s eine andere Relation mitdem Relationentyp S und K ein Identifizierungsschlussel in S. Wenn K
Fremdschlussel in r (mit Bezug auf s) ist, dann gilt stets
πK (r) ⊆ πK (s)
Das DBMS muß hier verhindern,
1. daß Tupel in s, auf die noch Referenzen in r existieren, geloschtwerden, und
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 35
2. daß Tupel in r erzeugt werden, bei denen der Wert der Fremd-schlusselattribute kein Tupel in s referenziert.
Nullwerte sollten in Fremdschlusseln vermieden werden. Wenn mansie zulaßt, bedeutet ein Nullwert, daß unbekannt ist, welches andereTupel referenziert wird.
4.4 Kriterien fur die Festlegung von Identifizierungs-
und Primarschlusseln
Identifizierungsschlussel werden haufig als Fremdschlussel in anderenRelationen benutzt; hieraus ergeben sich mehrere Kriterien, die beider Festlegung von Identifizierungsschlusseln beachtet werden sollten:
– Konnen die Werte beim Eintragen immer sofort bestimmt werden?Man kann theoretisch auch Nullwerte bei Schlusselattributen zu-lassen, praktisch stort dies aber sehr. U.a. konnen keine Fremd-schlussel-Referenzen auf dieses Tupel in anderen erzeugt werden.
– Sind die Werte kurz und schreibbar? Dies betrifft wieder den Fall,daß in anderen Relationen Fremdschlussel-Referenzen von Handeingetragen werden mussen.
– Sind die Werte “sprechend”, d.h. ist den Systembenutzern intuitivverstandlich, welche reale Entitat durch ein Tupel dargestellt wird?Diese Anforderung steht oft im Widerspruch zu den beiden ersten.
Ein weiteres Kriterium betrifft die zeitliche Entwicklung des Daten-bankinhalts. Die aktuell in einem Identifizierungsschlussel auftreten-den Werte mussen naturlich eindeutig sein; zusatzlich kann es sinnvollsein, die Eindeutigkeit uber die Zeit hinweg zu verlangen. Beispiels-weise konnte Kundenname ein Identifizierungsschlussel sein und derzeiteine Kundin “Meier, Anna” vorhanden sein. Diese wird irgendwanngeloscht, und ein Jahr spater wird eine andere, neue Kundin eingetra-gen, die zufallig genauso heißt. Wenn man derartiges vermeiden will,durfen einmal benutzte Identifizierungsschlusselwerte nicht wiederver-wendet werden. Hierzu mußte ein Verzeichnis aller jemals verwendeten
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 36
Identifizierungsschlusselwerte gefuhrt werden, was sehr aufwendig undplatzraubend sein kann.
Die vorstehenden Anforderungen werden oft von “naturlichen”Identifizierungsschlusseln, die sich aus einer von Implementationsa-spekten unbeeinflußten Datenmodellierung ergeben, nicht erfullt. Bei-spielsweise sind textuelle Namen zwar oft gut verstandlich, aber zulang und wiederverwendbar.
Im Endergebnis entscheidet man sich daher oft dazu, ein kunstli-ches Schlusselattribut, meist eine laufende Nummer, zu erfinden. DasAttribut Kundennummer ist ein Beispiel hierfur, denn “von Natur aus”haben Kunden keine Nummer.
4.5 Weitere Schlusselbegriffe
Sofern mehrere Identifizierungsschlussel vorhanden sind, werden sieoft auch als Schlusselkandidaten bezeichnet. Jeder Identifizierungs-schlussel ist ein Kandidat dafur, Primarschlussel zu werden, nur einerschafft es. Diese Bezeichnung vermengt die konzeptuelle und interneBegriffs- und Denkwelt besonders stark, weshalb wir sie weitgehendvermeiden werden.
Ein Sortierschlussel (sort key) bestimmt die Reihenfolge, in derdie Speichersatze in einem DB-Segment gespeichert werden. Hier-durch kann die Verarbeitung kompletter Relationen beschleunigt wer-den. Ein Sortierschlussel muß nicht unbedingt identifizierend sein.
Ein Sekundarschlussel (secondary key) ist eine Menge von Attri-buten, fur die ein Sekundarindex vorhanden ist. Ein Sekundarschlusselist i.a. nicht identifizierend. Der Sekundarindex ist eine Datenstruk-tur, die jedem Sekundarschlusselwert eine Liste der Satze bzw. Tupelzuordnet, bei denen die entsprechenden Attributwerte auftreten. Bei-spielsweise konnte es sinnvoll sein, bei der Relation konten einen Se-kundarindex fur das Attribut Kundenname einzurichten; dies beschleu-nigt die Suche nach den Kunden mit einem bestimmten Namen erheb-lich.
Die folgende Tabelle stellt noch einmal alle Schlusselbegriffe zusam-
c©2013 Udo Kelter Stand: 27.11.2013
Das relationale Datenbankmodell 37
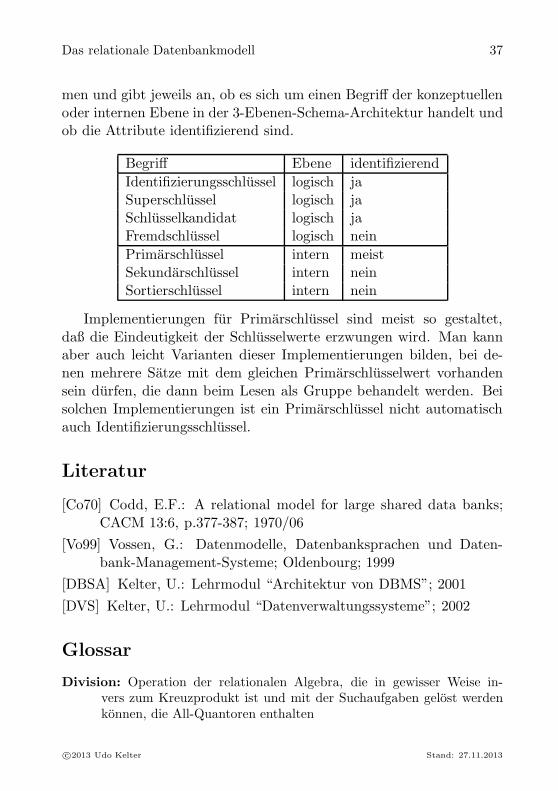
men und gibt jeweils an, ob es sich um einen Begriff der konzeptuellenoder internen Ebene in der 3-Ebenen-Schema-Architektur handelt undob die Attribute identifizierend sind.
Begriff Ebene identifizierend
Identifizierungsschlussel logisch jaSuperschlussel logisch jaSchlusselkandidat logisch jaFremdschlussel logisch nein
Primarschlussel intern meistSekundarschlussel intern neinSortierschlussel intern nein
Implementierungen fur Primarschlussel sind meist so gestaltet,daß die Eindeutigkeit der Schlusselwerte erzwungen wird. Man kannaber auch leicht Varianten dieser Implementierungen bilden, bei de-nen mehrere Satze mit dem gleichen Primarschlusselwert vorhandensein durfen, die dann beim Lesen als Gruppe behandelt werden. Beisolchen Implementierungen ist ein Primarschlussel nicht automatischauch Identifizierungsschlussel.
Literatur
[Co70] Codd, E.F.: A relational model for large shared data banks;CACM 13:6, p.377-387; 1970/06
[Vo99] Vossen, G.: Datenmodelle, Datenbanksprachen und Daten-bank-Management-Systeme; Oldenbourg; 1999
[DBSA] Kelter, U.: Lehrmodul “Architektur von DBMS”; 2001
[DVS] Kelter, U.: Lehrmodul “Datenverwaltungssysteme”; 2002
Glossar
Division: Operation der relationalen Algebra, die in gewisser Weise in-vers zum Kreuzprodukt ist und mit der Suchaufgaben gelost werdenkonnen, die All-Quantoren enthalten
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 38
Fremdschlussel: (Kontext: Attributmenge F in Relation R1 ist Fremd-schlussel auf eine Relation R2) Menge von Attributen, die Tupel ineiner anderen Relation identifizieren sollen; ist eine Integritatsbedin-gung, wonach die Projektion von R1 auf F komplett in der Projektionvon R2 auf F enthalten ist
Identifizierungsschlussel: minimale Menge von Attributen, die ein Super-schlussel ist
Primarschlussel: Attribut (-kombination), die der Primarindex un-terstutzt
Projektion: Operation der relationalen Algebra, mit der in den Tupeln ei-ner Eingaberelation Attribute entfernt werden konnen; entstehendeDuplikate werden eliminiert
relationale Algebra: Algebra mit den Kernfunktionen relationaler Daten-banksysteme im Bereich der Abfragedienste, insb. Selektion, Pro-jektion, Mengenoperationen, Kreuzprodukt, naturlicher bzw. Theta-Verbund und Division
Relationenschema: Namen und Typen der Attribute einer Relation; Syn-onyme: Relationentyp, Relationenformat
Schlussel: Oberbegriff fur mehrere spezielle Schlusselbegriffe; oft als Syn-onym fur Identifizierungsschlussel benutzt
Schlusselkandidat: Synonym fur Identifizierungsschlussel
Sekundarschlussel: Attribut (-kombination), fur die ein Sekundarindexvorhanden ist
Selektion: Operation der relationalen Algebra, mit der Tupel einer Einga-berelation anhand einer Bedingung selektiert werden konnen
Sortierschlussel: Attribut (-kombination), nach der intern sortiert gespei-chert wird
Spalte (column): einer Tabelle; Synonym: Attribut
Superschlussel: Menge von Attributen, deren Werte die Tupel einer Rela-tion eindeutig identifizieren
Tabelle (table): Hauptbestandteile einer relationalen Datenbank; wird oftals Synonym zu Relation benutzt
Verbund: Operation der relationalen Algebra, mit der die Tupel zweier Ein-gaberelationen paarweise verbunden werden, sofern sie eine Verbund-bedingung erfullen; beim Theta-Verbund wird die Verbundbedingungexplizit vorgegeben, beim Gleichheitsverbund werden Attribute der
c©2013 Udo Kelter Stand: 27.11.2013

Das relationale Datenbankmodell 39
zu verbindenden Tupel auf Gleichheit getestet, beim naturlichen Ver-bund werden nur Tupel verbunden, die in allen Attributen, die beidenRelationen gemeinsam sind, jeweils die gleichen Werte haben
Verbund, außerer: der linke (rechte) außere Verbund ist eine Variante dernormalen Verbunde, bei denen Tupel der linken (rechten) Eingabe-relation, die keinen Verbundpartner in der rechten (linken) Eingabe-relation finden, erganzt um Nullwerte bei den fehlenden Attributen,zum Ergebnis hinzugenommen werden; der beidseitige außere Verbundliefert die Vereinigung des rechten und linken außeren Verbunds
Zeile (row): einer Tabelle; Synonym: Tupel
c©2013 Udo Kelter Stand: 27.11.2013

Index
| .. |, 153-Ebenen-Schema-Architektur, 33,
36
Administration, 3Attribut, 4, 38
Reihenfolge, 5Wertebereich, 6Wertzuweisung, 5
B*-Baum, 32
Datenbank, 4Datenbankmodell
konventionelles, 3relationales, 3, 4
Datenbanksprache, 3Division, 23, 37Duplikate, 5, 7
equi-join, 22
Fremdschlussel, siehe Schlussel
Gleichheitsverbund, 22
Identifizierungsschlussel, siehe
Schlussel
Integritatsbedingung, 8dynamische, 8statische, 8Uberprufung, 8
Kalkul, siehe relationale Kalkule
Kreuzprodukt, 14, 20, 23
natural join, 19Notationskonventionen, 7
Nullwert, 23
Optimierung, 29
Primarschlussel, siehe Schlussel
Projektion, 11, 37
Rechteverwaltung, 3referentielle Integritat, 34Relation, 6relationale Algebra, 9, 37
außerer Verbund, 23Ausdrucke, 28
Auswertung, 29Differenz, 12Division, 23Gleichheitsverbund, 22Kreuzprodukt, 14naturlicher Verbund, 18Projektion, 11Schnitt, 12Theta-Verbund, 22Umbenennung, 13Vereinigung, 12
relationale Kalkule, 4relationale Vollstandigkeit, 28Relationenformat, 6Relationenschema, 6, 38Relationentyp, 6
als Menge von Attributen, 7
Schema, 3Schlussel, 29, 31, 33, 38
als Integritatsbedingungen, 31Fremdschlussel, 34, 36, 37Identifizierungsschlussel, 30, 37
Auswahlkriterien, 34
40

Das relationale Datenbankmodell 41
kunstlicher, 33Prufung, 31Wiederverwendung von
Schlusselwerten, 35Primarschlussel, 32, 33, 36, 37
Auswahl, 32Schlusselattribut, 30Schlusselkandidat, 36, 38Sekundarschlussel, 36, 38Sortierschlussel, 36, 38Superschlussel, 30, 36, 38
Schlusselkandidat, siehe Schlussel
Schlusselwert, 31secondary key, 36Sekundarschlussel, siehe Schlussel
Selektion, 9, 38Bedingung mit all-Quantor, 26
sort key, 36Sortierschlussel, siehe Schlussel
Spalte, 4, 38Superschlussel, siehe Schlussel
t[A], 11Tabelle, 4, 38Tupel, 6, 38
Umbenennung, 13
Verbund, 38außerer, 23, 38Gleichheits-, 22, 38naturlicher, 18, 38Theta-, 22, 38
Verbundattribute, 19Vollstandigkeit, 27
Zeile, 4, 38
c©2013 Udo Kelter Stand: 27.11.2013


















