
Data Warehousing und Data Mining - · PDF fileUlf Leser: Data Warehousing und Data Mining 2 ....
49
Ulf Leser Wissensmanagement in der Bioinformatik Einführung in Data Mining Data Warehousing und Data Mining
Transcript of Data Warehousing und Data Mining - · PDF fileUlf Leser: Data Warehousing und Data Mining 2 ....

Ulf Leser
Wissensmanagement in der Bioinformatik
Einführung in Data Mining
Data Warehousing und
Data Mining

Ulf Leser: Data Warehousing und Data Mining 2
Wo sind wir?
• Einleitung & Motivation • Architektur • Modellierung von Daten im DWH • Umsetzung des multidimensionalen Datenmodells • Extraction, Transformation & Load (ETL) • Physische und logische Optimierung • Materialisierte Sichten • Data Mining
– Klassifikation – Warenkorbanalyse – Clustering

Ulf Leser: Data Warehousing und Data Mining 3
Inhalt dieser Vorlesung
• Was ist Data Mining? • Typische Problemstellungen & Anwendungen • Datenaufbereitung und Exploration • Data Mining Tools

Ulf Leser: Data Warehousing und Data Mining 4
Beispiel
• Welches Risiko schätzen wir für eine Person von 45 Jahren mit 4000 Euro Einkommen?
• Vorhersage aufgrund bisheriger Erfahrungen
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen 2 30 2000 Getilgt 3 35 1500 Ausgefallen 4 40 2800 Getilgt 5 50 3000 Getilgt 6 60 1900 Ausgefallen
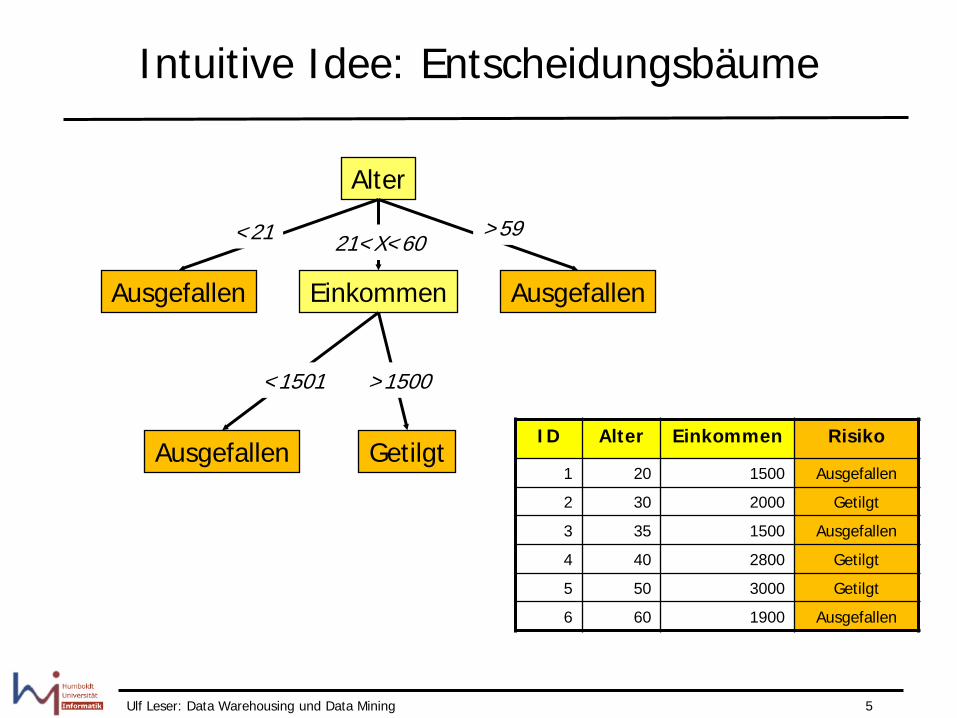
Ulf Leser: Data Warehousing und Data Mining 5
Intuitive Idee: Entscheidungsbäume
Alter
Ausgefallen Ausgefallen Einkommen
<21 >59 21<X<60
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen
2 30 2000 Getilgt
3 35 1500 Ausgefallen
4 40 2800 Getilgt
5 50 3000 Getilgt
6 60 1900 Ausgefallen
<1501
Ausgefallen Getilgt
>1500
Ulf Leser: Data Warehousing und Data Mining 6
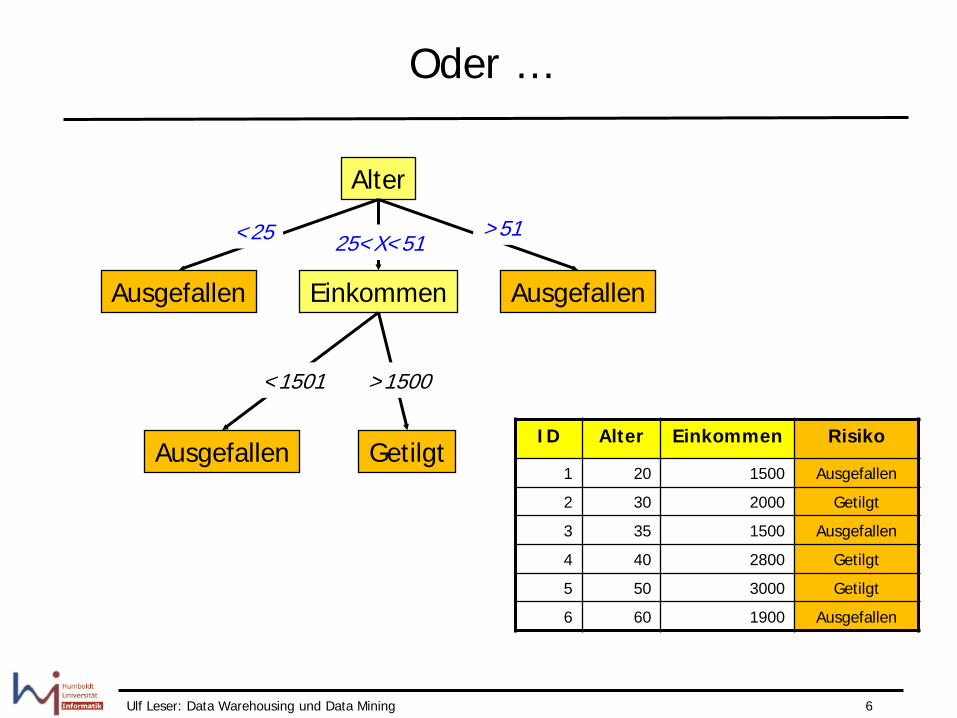
Oder …
Alter
Ausgefallen Ausgefallen Einkommen
<25 >51 25<X<51
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen
2 30 2000 Getilgt
3 35 1500 Ausgefallen
4 40 2800 Getilgt
5 50 3000 Getilgt
6 60 1900 Ausgefallen
<1501
Ausgefallen Getilgt
>1500
Ulf Leser: Data Warehousing und Data Mining 7
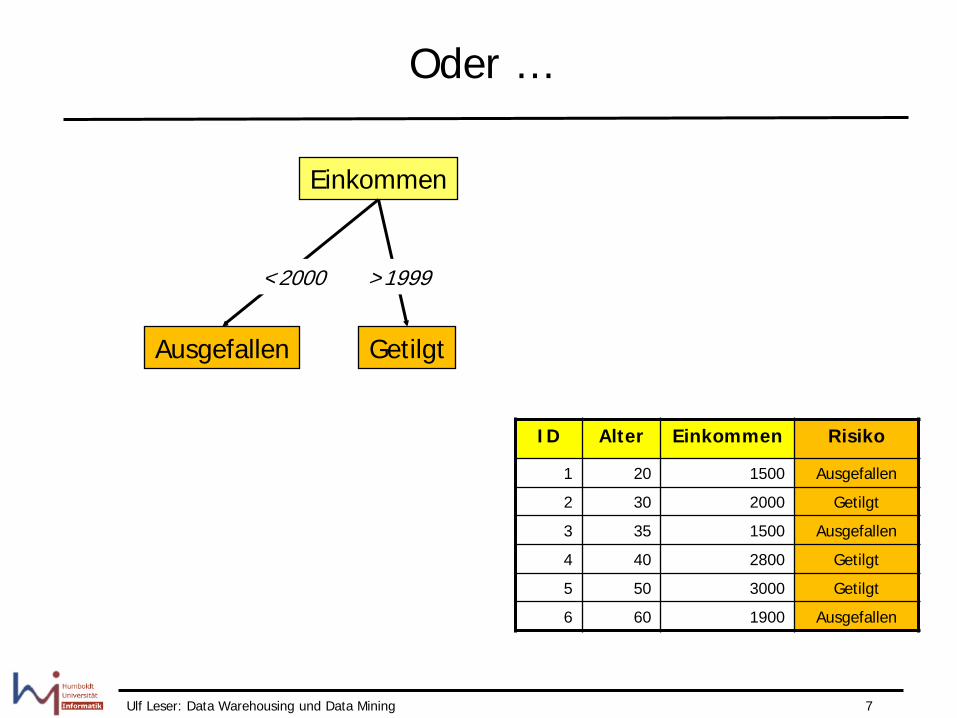
Oder …
Einkommen
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen
2 30 2000 Getilgt
3 35 1500 Ausgefallen
4 40 2800 Getilgt
5 50 3000 Getilgt
6 60 1900 Ausgefallen
<2000
Ausgefallen Getilgt
>1999

Ulf Leser: Data Warehousing und Data Mining 8
Was nun?
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen
2 30 2000 Getilgt
3 35 1500 Ausgefallen
4 40 2800 Getilgt
5 50 3000 Getilgt
6 60 1900 Ausgefallen
7 20 1500 Getilgt
Alter
Ausgefallen Einkommen
<25 >51 25<X<51
<1501
Ausgefallen Getilgt
>1500

Ulf Leser: Data Warehousing und Data Mining 9
Was nun?
ID Alter Einkommen Risiko
1 20 1500 Ausgefallen
2 30 2000 Getilgt
3 35 1500 Ausgefallen
4 40 2800 Getilgt
5 50 3000 Getilgt
6 60 1900 Ausgefallen
7 20 1500 Getilgt
50% Ausgefallen 50% Getilgt
Alter
Ausgefallen Einkommen
<25 >51 25<X<51
<1501
Ausgefallen Getilgt
>1500

Ulf Leser: Data Warehousing und Data Mining 10
Lernen von Entscheidungsbäumen
• In welcher Reihenfolge sollen Attribute verwendet werden?
• Wie viele Splits pro Attribut? • Wie sollen die Grenzen gewählt werden? • Was tun bei widersprüchlichen Daten? • Was tun bei 50.000.000 Datensätzen? • …

Ulf Leser: Data Warehousing und Data Mining 11
Traditionelle Analysemethode
• Manuell ausgeführte statistische Analyse • Eher wenige Datensätze, eher wenig Attribute • Formulieren von Hypothesen und deren Überprüfung
– „Hypothesis-driven“ – „Wie viele Kunden über 45 mit einem Einkommen unter 2000
Euro hatten einen Kreditausfall?“ – Hypothesen werden vor der Datenanalyse formuliert
• DWH: Man überlegt sich mögliche Zusammenhänge und überprüft sie durch Formulieren der entsprechenden (SQL-)Anfrage

Ulf Leser: Data Warehousing und Data Mining 12
Data Mining
• „We are drowning in data and starving for knowledge“ – „Was machen Kunden eigentlich auf meiner Webseite?“
• Riesige Datenberge – Business: Weblogs, Telefonate, Einkäufe, Börsendaten, … – Forschung: Astronomie, Teilchenphysik, Bioinformatik, … – Jeder: Nachrichten, Blogs, Webseiten, Fotos, … – Millionen oder Milliarden von Datensätzen – Hochdimensionale Daten mit Hunderten von Attributen
• Formulierung von Hypothesen schwierig: Es gibt zu viele • „Data-Driven“: Automatische Generierung und Prüfung
von Hypothesen – Vorsicht: Irgendwas findet man immer
Ulf Leser: Data Warehousing und Data Mining 13
Bei welchen Telefonkunden besteht der Verdacht eines Betrugs?
Zu welcher Klasse gehört dieser Stern?
Welche Assoziationen bestehen zwischen den in einem Supermarkt gekauften Waren?
Beispiele
Welche Kunden erreiche ich mit welcher Werbung am Besten?
DWH

Ulf Leser: Data Warehousing und Data Mining 14
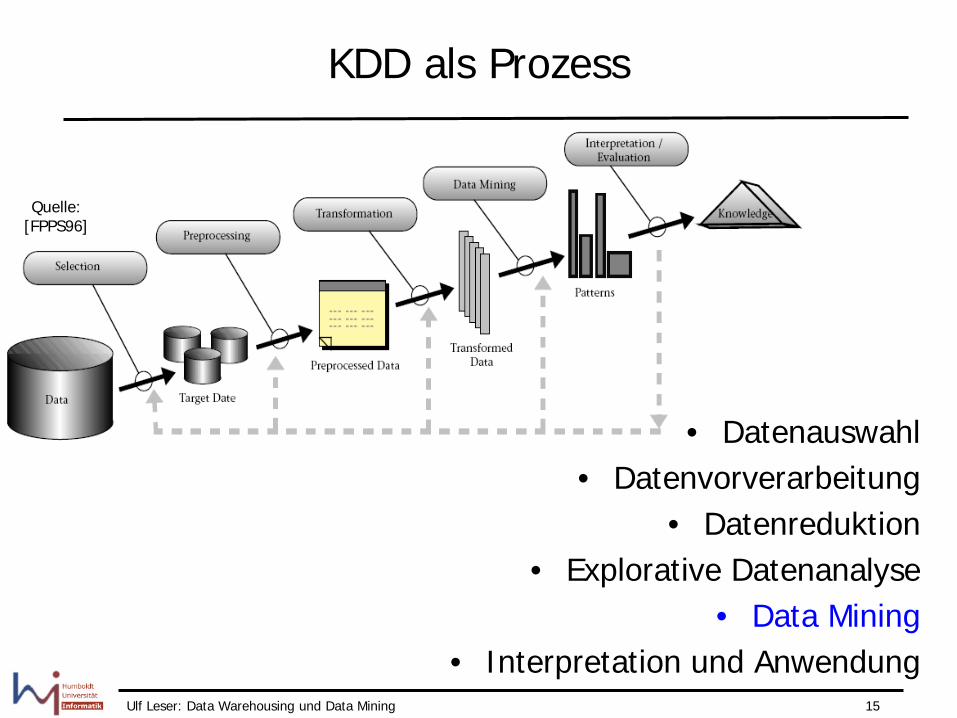
Knowledge Discovery in Databases [FPSS96]
• “KDD is the non-trivial process of identifying valid, novel, useful and ultimately understandable patterns in data" – Valid: Muster sind im statistischen Sinne valide
• Signifikant = wahrscheinlich nicht durch Zufall erzeugt
– Novel: Bisher unbekannt – Useful: Man kann damit Wertschöpfung erzielen – Understandable: Benutzer verstehen die Muster (und die Daten)
• Viel Interpretationsspielraum
Ulf Leser: Data Warehousing und Data Mining 15
KDD als Prozess
• Datenauswahl • Datenvorverarbeitung
• Datenreduktion • Explorative Datenanalyse
• Data Mining • Interpretation und Anwendung
Quelle: [FPPS96]

Ulf Leser: Data Warehousing und Data Mining 16
Begriffe
• KDD, Data Mining, Machine Learning, Business Intelligence, Artificial Intelligence
• BI umfasst alle Techniken, die dem Business helfen und auf Datenanalyse betonen – Klassisch: OLAP, heute auch Data Mining und ML
• KDD heute praktisch synonym zu Data Mining • Machine Learning: Bestimmte Formen des DM ohne den
Datenmanagementaspekt – ML ist praktisch immer main memory bound und will pre-
processing gerne ignorieren
• ML ist ein Teilgebiet des AI – Aber heute fast synonym

Ulf Leser: Data Warehousing und Data Mining 17
Inhalt dieser Vorlesung
• Was ist Data Mining? • Typische Problemstellungen
– Klassifikation – Clustering – Assoziationsregeln
• Datenaufbereitung und Exploration • Data Mining Tools

Ulf Leser: Data Warehousing und Data Mining 18
Eingabe
• Eine Menge O={o1, o2,… ,on} von Objekten • Jedes Objekt oi wird beschrieben durch Werte für eine
Menge von Attributen A={a1, a2,… ,am} – Heißen auch Dimensionen oder Feature
• Attributwerte können kategorial oder kontinuierlich sein • Attributwerte können geordnet, halbgeordnet,
ungeordnet sein

Ulf Leser: Data Warehousing und Data Mining 19
Drei klassische DM Aufgaben
• Klassifikation – Gegeben eine Menge von Objekten und eine Menge von Klassen – Welcher Klasse gehören die unklassifizierten Objekte an? – Beispiel: Fraud-Detection bei Kreditkarten
• Clustering – Gegeben eine Menge von Objekten – Gibt es Gruppen (Cluster) ähnlicher Objekte? – Beispiel: Segmentierung von Kunden
• Assoziationsregeln – Geg. Menge von jeweils gemeinsam durchgeführten Aktionen – Welche Aktionen kommen besonders häufig zusammen vor? – Beispiel: Welche Produkte werden häufig gemeinsam gekauft?
Ulf Leser: Data Warehousing und Data Mining 20
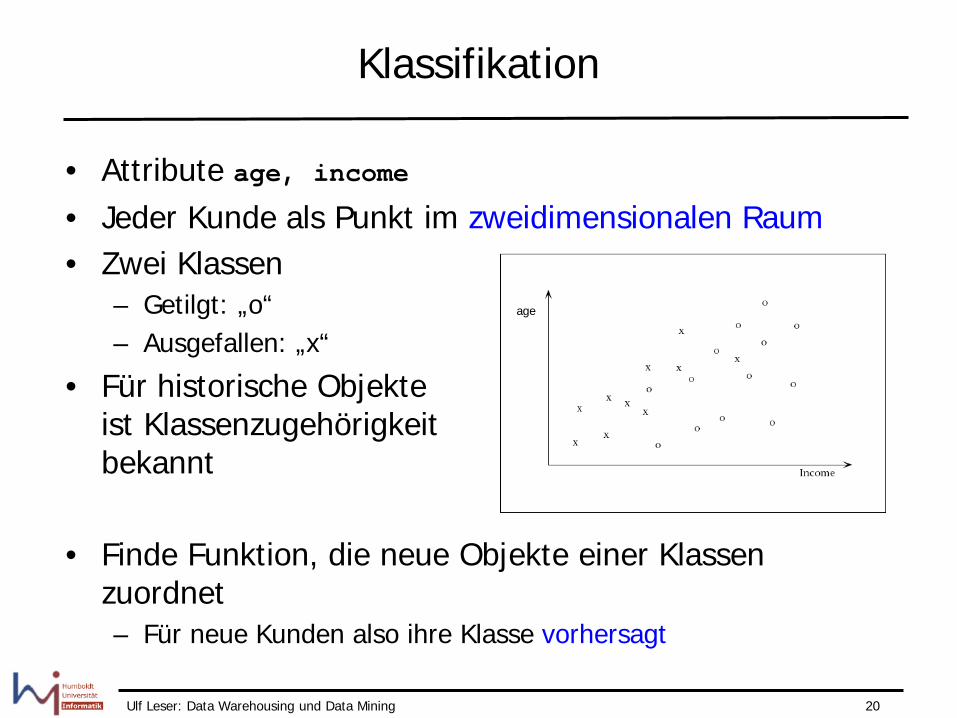
Klassifikation
• Attribute age, income • Jeder Kunde als Punkt im zweidimensionalen Raum • Zwei Klassen
– Getilgt: „o“ – Ausgefallen: „x“
• Für historische Objekte ist Klassenzugehörigkeit bekannt
• Finde Funktion, die neue Objekte einer Klassen zuordnet – Für neue Kunden also ihre Klasse vorhersagt
age

Ulf Leser: Data Warehousing und Data Mining 21
Lineare Trennung
• Berechnung der Trennfunktion, die den Fehler minimiert – Komplexere Funktionen als lineare sind möglich
• Geht nur bei numerischen Attributen
Quelle: [FPPS96]
Age

Ulf Leser: Data Warehousing und Data Mining 22
Overfitting
• Overfitting – Modell ist perfekt für Trainingsdaten – Aber sehr wahrscheinlich schlecht für andere Daten

Ulf Leser: Data Warehousing und Data Mining 23
Hierarchische Aufteilung
• Verwendung lokaler Trennfunktionen • Siehe Entscheidungsbäume
Ulf Leser: Data Warehousing und Data Mining 24
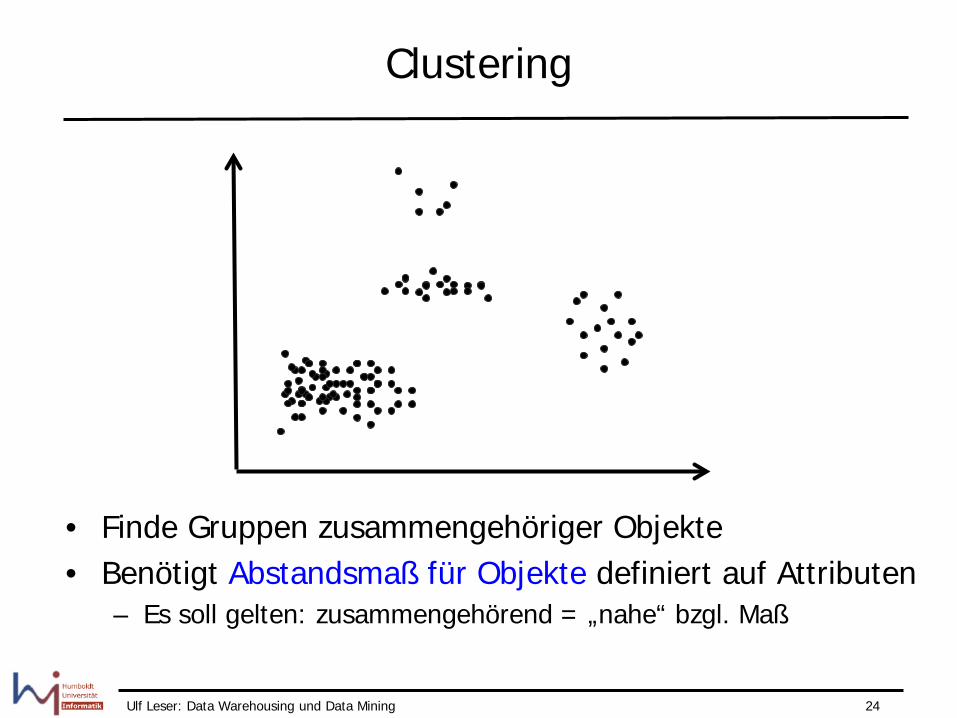
Clustering
• Finde Gruppen zusammengehöriger Objekte • Benötigt Abstandsmaß für Objekte definiert auf Attributen
– Es soll gelten: zusammengehörend = „nahe“ bzgl. Maß
Ulf Leser: Data Warehousing und Data Mining 25
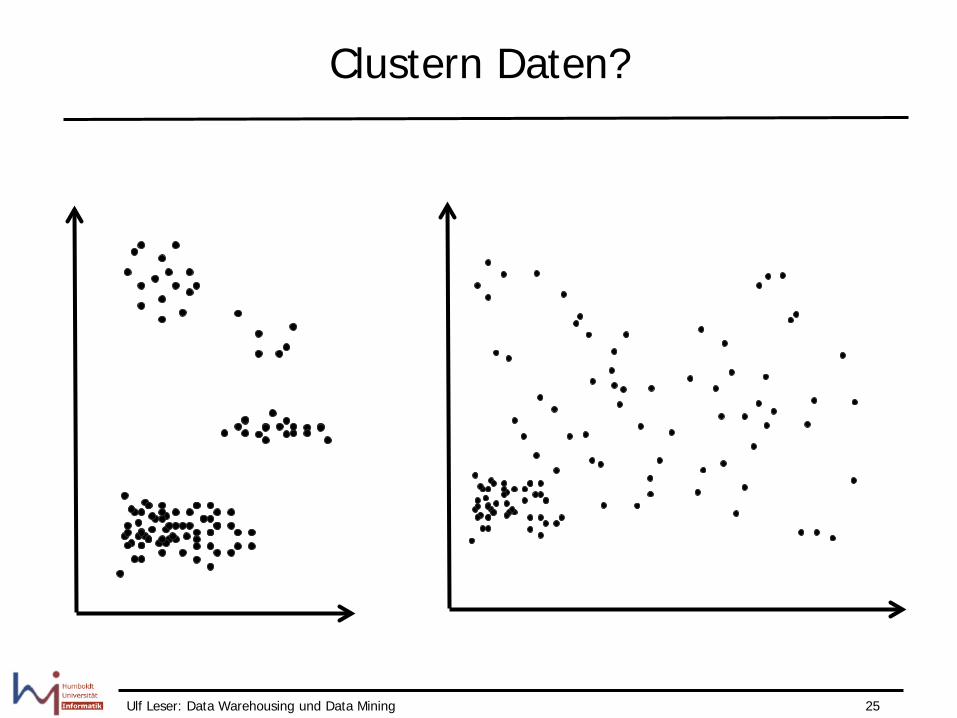
Clustern Daten?

Ulf Leser: Data Warehousing und Data Mining 26
Nicht immer einfach
• Problem schlechter definiert als Klassifikation – Wie groß sollen die Cluster ein? – Welche Form dürfen die Cluster haben? – Wie viele Cluster erwartet man? – Müssen alle Punkte geclustert werden? – Dürfen sich Cluster überlappen? – …
Quelle: [ES00]
Ulf Leser: Data Warehousing und Data Mining 27
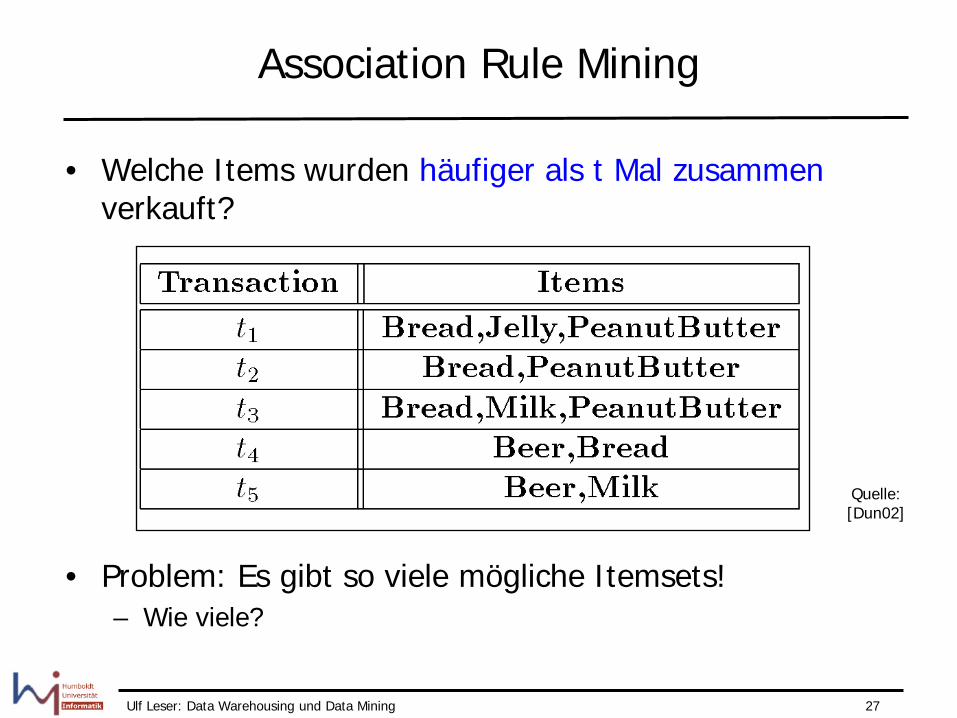
Association Rule Mining
• Welche Items wurden häufiger als t Mal zusammen verkauft?
• Problem: Es gibt so viele mögliche Itemsets! – Wie viele?
Quelle: [Dun02]
Ulf Leser: Data Warehousing und Data Mining 28
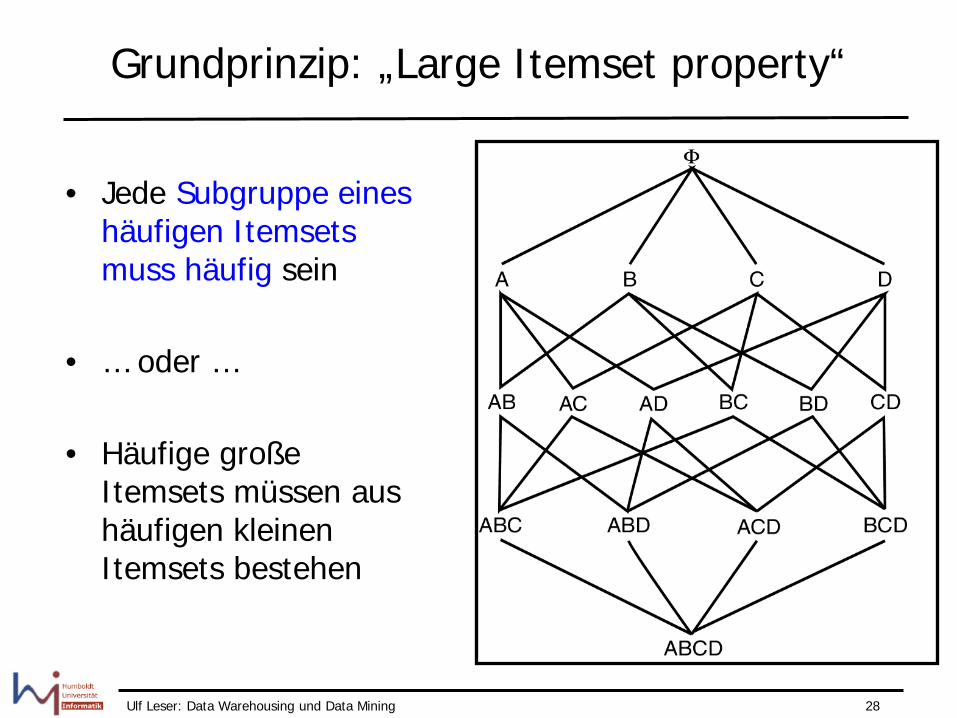
Grundprinzip: „Large Itemset property“
• Jede Subgruppe eines häufigen Itemsets muss häufig sein
• … oder …
• Häufige große Itemsets müssen aus häufigen kleinen Itemsets bestehen

Ulf Leser: Data Warehousing und Data Mining 29
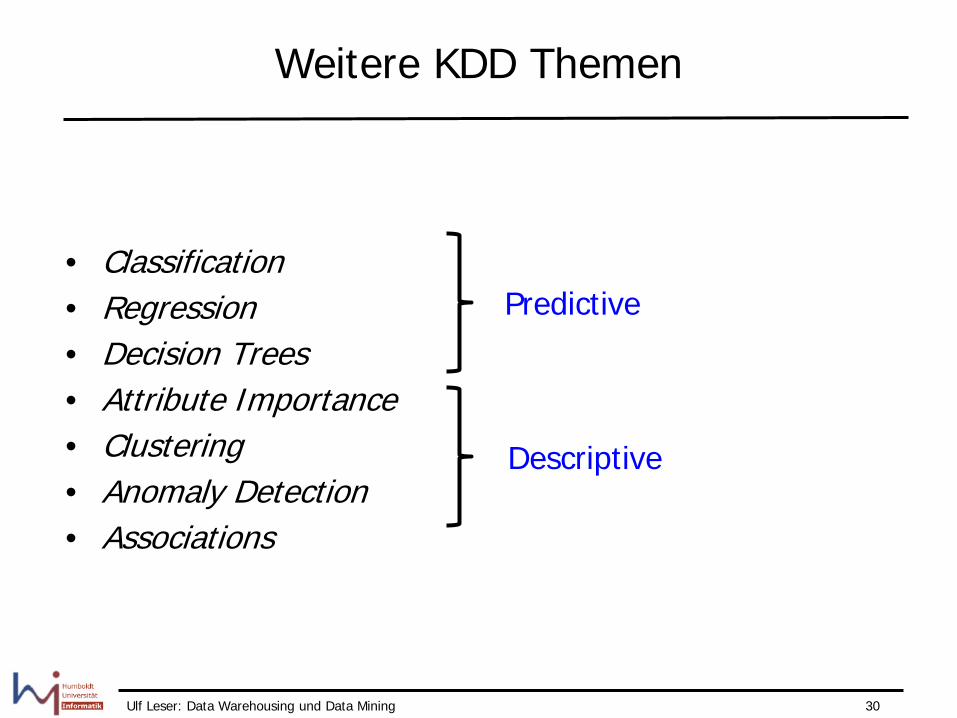
Weitere KDD Themen
• Oracle Advanced Analytics Whitepaper, 2014
– Predict customer behavior (Classification) – Predict or estimate a continuous value (Regression) – Find profiles of targeted people or items (Decision Trees) – Identify most important factor (Attribute Importance) – Segment a population (Clustering) – Find fraudulent or “rare events” (Anomaly Detection) – Determine co-occurring items in a “baskets” (Associations)
• Recommendation engines
Ulf Leser: Data Warehousing und Data Mining 30
Weitere KDD Themen
• Classification • Regression • Decision Trees • Attribute Importance • Clustering • Anomaly Detection • Associations
Predictive
Descriptive

Ulf Leser: Data Warehousing und Data Mining 31
KDD auf anderen Datentypen
• Text-Mining: Clustering und Klassifikation von Texten – Patentanalyse; Sentimentanalyse; Marktbeobachtung; gezieltes
Verschicken von Post; …
• Web-Mining – Welche Webseiten werden häufig in einer bestimmten
Reihenfolge besucht? Wann werden interaktive Elemente benutzt? Wie kommen Kunden mit meiner Webseite klar? …
• Spatial Mining – Wo soll der nächste Supermarkt hin? Hat der Wohnort Einfluss
auf Kreditwürdigkeit? Sind Cluster räumlich homogen? …
• Graph-Mining – Struktur sozialer Netzwerke, Web als Graph, biologische
Netzwerke, …
• …

Ulf Leser: Data Warehousing und Data Mining 32
Inhalt dieser Vorlesung
• Was ist Data Mining? • Typische Problemstellungen • Datenaufbereitung und Exploration • Data Mining Tools

Ulf Leser: Data Warehousing und Data Mining 33
Datenaufbereitung
• Preprocessing: Herstellung einer homogenen, vollständigen und bereinigten Datenbasis – Alles aus ETL: Transformation, Plausibilität, Umrechnung, … – Viele DM Verfahren reagieren empfindlich auf Ausreißer,
fehlende Werte, Datenfehler etc. – Ersetzung von fehlenden Werten durch Schätzen, Extrapolation – Diskretisierung von Werten (Binning)
• Z.B. Einteilung des Einkommens von Kunden in 5 Bereiche • Glättet Ausreißer, reduziert die Zahl verschiedener Werte

Ulf Leser: Data Warehousing und Data Mining 34
Binning: Equi-Width Histograms
0
500
1000
1500
2000
2500
3000
3500
40 47 54 61 68 75 82 89 96 103
110
117
Normal distributionEqui-width
• Zahl der Bins festlegen und Raum äquidistant aufteilen • Bins enthalten unterschiedlich viele Objekte • Bei Ausreissern (z.B. ein falscher, viel zu großer Wert) sind viele
Bins leer, weil der „Raum“ falsch abgeschätzt wird • Berechnung durch einen Scan
Ulf Leser: Data Warehousing und Data Mining 35
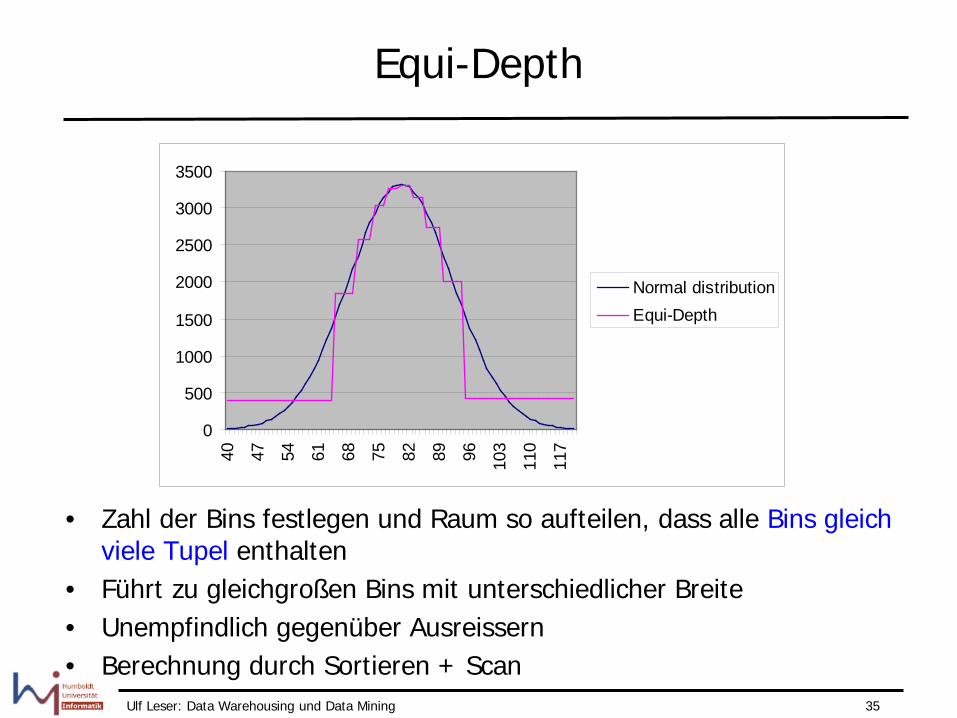
Equi-Depth
0
500
1000
1500
2000
2500
3000
3500
40 47 54 61 68 75 82 89 96 103
110
117
Normal distributionEqui-Depth
• Zahl der Bins festlegen und Raum so aufteilen, dass alle Bins gleich viele Tupel enthalten
• Führt zu gleichgroßen Bins mit unterschiedlicher Breite • Unempfindlich gegenüber Ausreissern • Berechnung durch Sortieren + Scan

Ulf Leser: Data Warehousing und Data Mining 36
Explorative (deskriptive) Datenanalyse
• Ziel: „Gefühl“ für die Daten bekommen – Welche Werte sind wie häufig? – Unterliegen die Werte einer bestimmten Verteilung? – Sind zwei (oder mehr) Attributwerte stark korreliert?
• Bei 2.000.000.000 Tupeln nicht einfach • Vorbereitung zur Auswahl des Data Mining Verfahrens • Hier: Nur ganz einfache statistische Kennwerte
– Und deren Berechnung im DWH
Ulf Leser: Data Warehousing und Data Mining 37
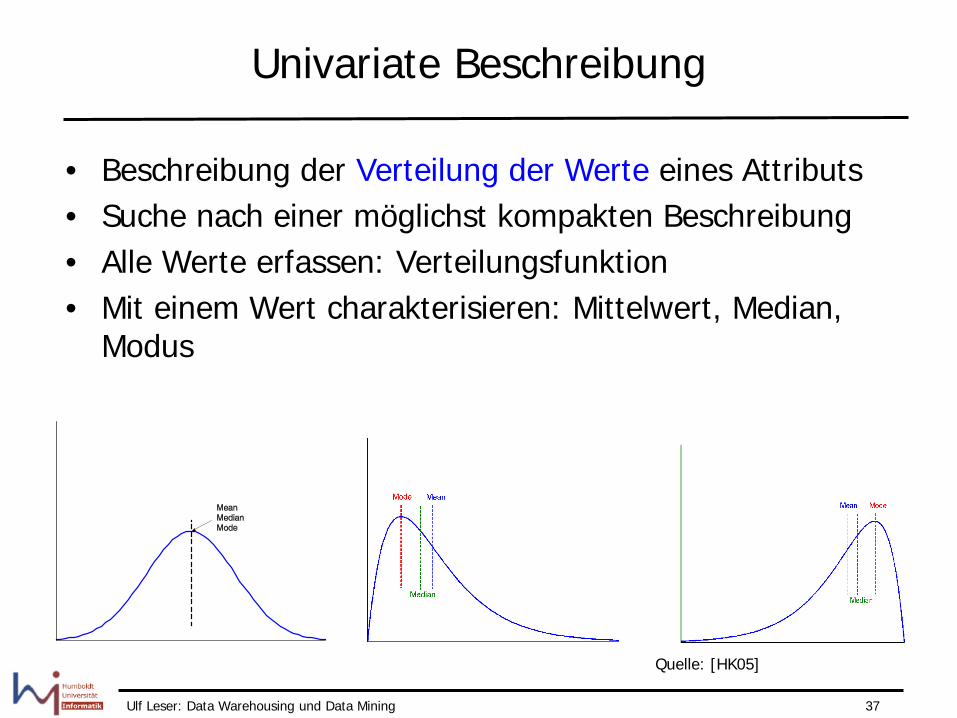
Univariate Beschreibung
• Beschreibung der Verteilung der Werte eines Attributs • Suche nach einer möglichst kompakten Beschreibung • Alle Werte erfassen: Verteilungsfunktion • Mit einem Wert charakterisieren: Mittelwert, Median,
Modus
Quelle: [HK05]

Ulf Leser: Data Warehousing und Data Mining 38
• Sehr viele Daten sind normalverteilt • Zwei Werte: Mittelwert und Varianz
– [μ–σ, μ+σ]: Ca. 68% der Datenpunkte – [μ–2σ, μ+2σ]: Ca. 95% der Datenpunkte – [μ–3σ, μ+3σ]: >99% der Datenpunkte
• Testen z.B. mit Shapiro-Wilk-Test
Normalverteilte Daten
Ulf Leser: Data Warehousing und Data Mining 39
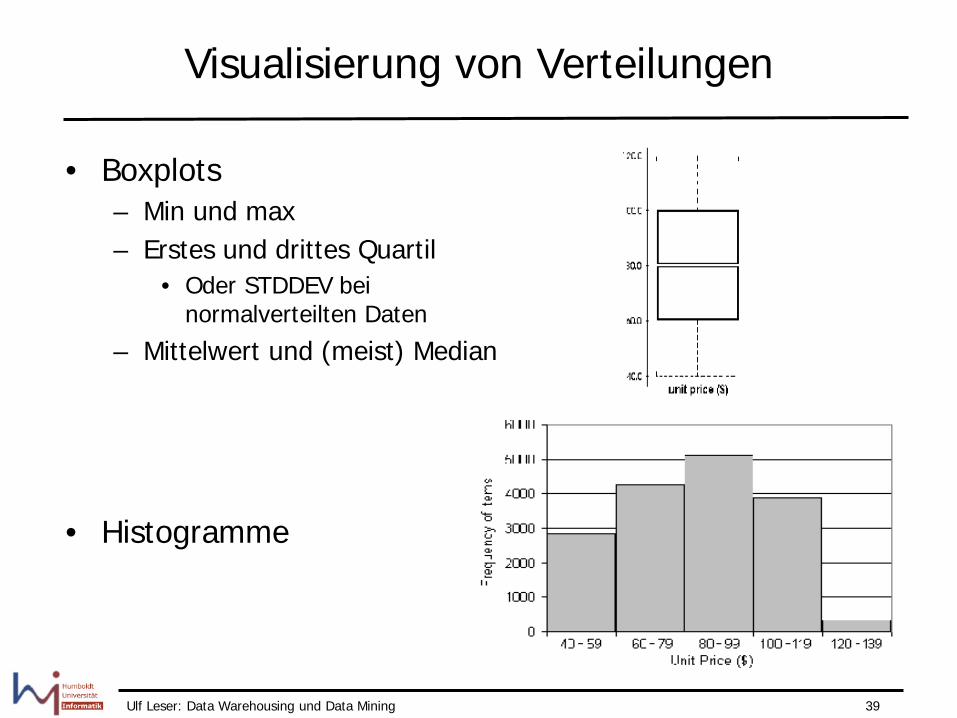
Visualisierung von Verteilungen
• Boxplots – Min und max – Erstes und drittes Quartil
• Oder STDDEV bei normalverteilten Daten
– Mittelwert und (meist) Median
• Histogramme

Ulf Leser: Data Warehousing und Data Mining 40
SQL
• Standard SQL: avg, stddev, median, quartile • Wie findet man den mode eines Attributs t.a?
SELECT a, cnt FROM (SELECT a, count(a) cnt FROM t GROUP BY a ORDER BY count(a) DESC) WHERE ROWNUM=1;
SELECT a, count(a) cnt FROM t GROUP BY a ORDER BY count(a) DESC) FETCH FIRST ROW ONLY;

Ulf Leser: Data Warehousing und Data Mining 41
Multivariate Beschreibung
• Betrachtung der gemeinsamen Verteilungen zweier oder mehr Attribute
• Einfachsten Fall: Statistische Unabhängigkeit – P(a|b)=p(a), p(b|a)=p(b), p(a ∧ b) = p(a)*p(b) – Dann reichen univariate Beschreibungen – Visuell erkennbar z.B. im Scatter-Plot
Ulf Leser: Data Warehousing und Data Mining 42
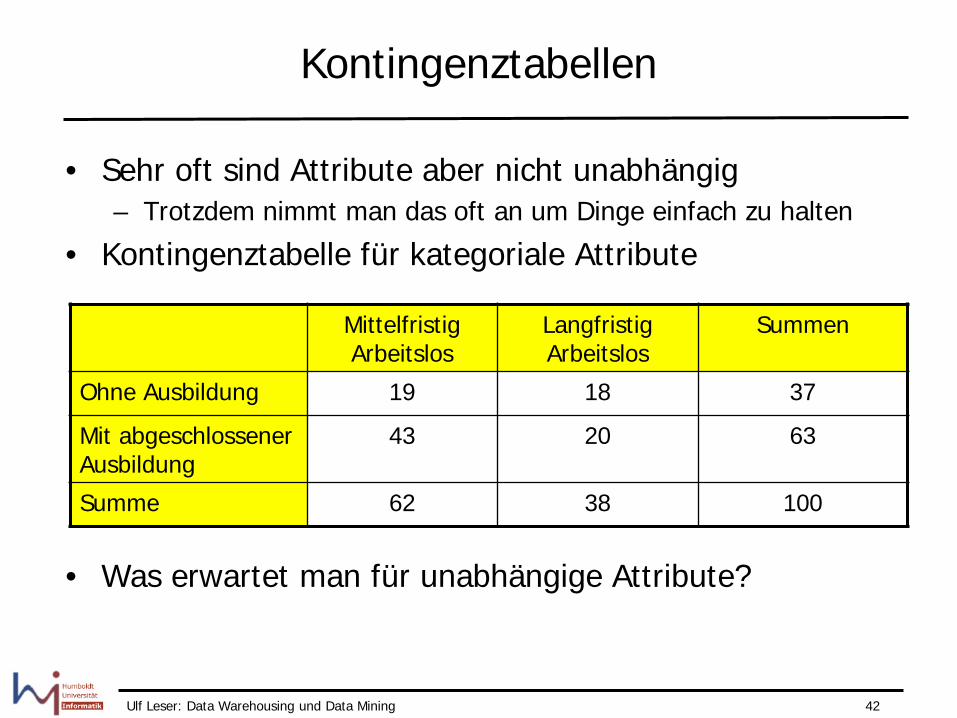
Kontingenztabellen
• Sehr oft sind Attribute aber nicht unabhängig – Trotzdem nimmt man das oft an um Dinge einfach zu halten
• Kontingenztabelle für kategoriale Attribute
• Was erwartet man für unabhängige Attribute?
Mittelfristig Arbeitslos
Langfristig Arbeitslos
Summen
Ohne Ausbildung 19 18 37
Mit abgeschlossener Ausbildung
43 20 63
Summe 62 38 100

Ulf Leser: Data Warehousing und Data Mining 43
Kontingenztabellen
• Sehr oft sind Attribute aber nicht unabhängig – Trotzdem nimmt man das oft an um Dinge einfach zu halten
• Kontingenztabelle für kategoriale Attribute
• Tests auf Unabhängigkeit, z.B. Chi-quadrat
Mittelfristig Arbeitslos
Langfristig Arbeitslos
Summen
Ohne Ausbildung 19 / 22 18 / 14 37
Mit abgeschlossener Ausbildung
43 / 39 20 / 24 63
Summe 62 38 100
Ulf Leser: Data Warehousing und Data Mining 44
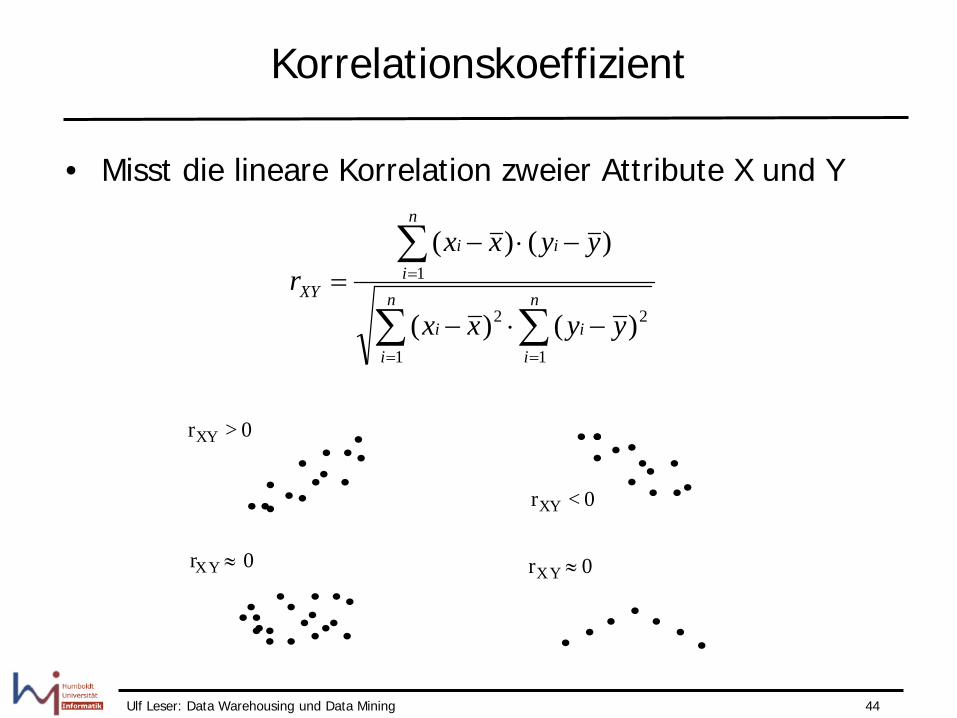
Korrelationskoeffizient
.........
. ....rXY > 0
rXY < 0..
...... . ...
.
.... .... . .. . .... .. .rXY ≈ 0
. . . . . . .rXY ≈ 0
• Misst die lineare Korrelation zweier Attribute X und Y
∑ ∑
∑
= =
=
−⋅−
−⋅−=
n
i
n
iii
n
iii
XY
yyxx
yyxxr
1 1
22
1
)()(
)()(

Ulf Leser: Data Warehousing und Data Mining 45
SQL
• Berechnung Kontingenztabelle für Attribute t.a und t.b?
• Berechnung des Korrelationskoeffizienten für t.a und t.b?
SELECT a,b,count(*) FROM t GROUP BY cube(a,b);
SELECT up/sqrt(down) FROM (SELECT sum((a-ma)*(b-mb)) up FROM t, (SELECT avg(a) ma, avg(b) mb FROM t) tm), (SELECT sum(sqr(a-ma))*sum(sqr(b-mb)) down FROM t, (SELECT avg(a) ma, avg(b) mb FROM t) tm);
∑ ∑
∑
= =
=
−⋅−
−⋅−=
n
i
n
iii
n
iii
XY
yyxx
yyxxr
1 1
22
1
)()(
)()(

Ulf Leser: Data Warehousing und Data Mining 46
Inhalt dieser Vorlesung
• Was ist Data Mining? • Typische Problemstellungen • Datenaufbereitung und Exploration • Data Mining Tools

Ulf Leser: Data Warehousing und Data Mining 47
Data Mining Software
• Viele Open Source Machine Learning Bibliotheken
– Meistens nicht auf Datenbanken ausgelegt – Files – Weka, SciKitLearn, RapidMiner, …
• Spezielle Verfahren haben oft spezielle Tools – SVMLight, TensorFlow, Keras, NLTK, Mahout, …
• Kommerzielle Tools – SPSS, EXCEL, MatLab, KNIME, …
• Erweiterungen von Datenbankherstellern – Oracle Data Mining, SQL Server Analysis Services, DB2
Intelligent Miner

Ulf Leser: Data Warehousing und Data Mining 48
Literatur
• Han, J. and Kamber, M. (2006). "Data Mining. Concepts and Techniques", Morgan Kaufmann.
• Alpar, P. and Niedereichholz, J., Eds. (2000). "Data Mining im praktischen Einsatz". Braunschweig/Wiesbaden, Vieweg Verlagsgesellschaft.
• Dunham, A. M. H. (2002). "Data Mining". New Jersey, Pearson Education Inc.
• Ester, M. and Sander, J. (2000). "Knowledge Discovery in Databases". Berlin, Springer.
• Fayyad, U. M., Piatetsky-Shapiro, G. and Smyth, P. (1996). "From Data Mining to Knowledge Discovery in Databases." AI Magazine 17(3): 37-54.
• Ganti, V., Gehrke, J. and Ramakrishnan, R. (1999). "Mining Very Large Databases." IEEE Computer: 38-45.

Ulf Leser: Data Warehousing und Data Mining 49
Selbsttest
• Nennen Sie einige deskriptive und einige prediktive Data
Mining Verfahren • KDD is a analytics process to find patterns in data that
are …(a) (b) … • Wenden Sie ein Equi-Depth Binning auf folgenden Daten
an für 5 bins • Wie wird eine Normalverteilung charakterisiert? • Vermuten Sie bei den folgenden Beispieldaten, ob Sie
einer Normalverteilung unterliegen oder nicht


















