
Datenbanken in der Bioinformatik -...
29
Sommersemester 2012 Dr. Toralf Kirsten, Anika Groß http://dbs.uni-leipzig.de Universität Leipzig Institut für Informatik Datenbanken in der Bioinformatik Kapitel 2 Überblick Klassifizierung von BioDB
Transcript of Datenbanken in der Bioinformatik -...

Sommersemester 2012
Dr. Toralf Kirsten, Anika Großhttp://dbs.uni-leipzig.de
Universität LeipzigInstitut für Informatik
Datenbanken in der Bioinformatik
Kapitel 2
Überblick
Klassifizierung von BioDB

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Vorläufiges Inhaltsverzeichnis
1. Grundlagen
2. Klassifizierung von BioDB, Überblick
3. Sequenzierung und Genexpressionsanalyse
4. Datenmodelle und Anfragesprachen
5. Modellierungsalternativen
6. Versionierung von Datenbeständen
7. Annotationen
8. Datenintegration: Ansätze und Systeme
9. Datenmanagement in der Cloud

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Lernziele
� Wiedergabe von � Allgemeinen Problemfeldern im Gebiet der
Bioinformatik
� Typischen Anforderungen an Informations-systeme in der Bioinformatik
� Klassifikation von Datenquellen und Systemen� Kriterien & Ausprägungen
� Ausgewählte Beispiele

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Gliederung
� Motivation und historische Entwicklung
� Allgemeine Anforderungen an Bioinformationssysteme
� Klassifikation von Bioinformationssystemen� Merkmale, Ausprägungen und Beispiele

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Motivation
� Abspeicherung von Genom-, Protein- und Stoffwechselinformationen in konsistenter und effizienter Art und Weise
� Unterstützung von biowissenschaftlichen Anfragen und Analysen
� Beispiel: Insulin
� Identifizieren Sie die Insulin mRNA und Proteinsequenz für Mensch, Huhn und Schwein!
� In welche Stoffwechselwege ist Insulin eingebunden?
� Auf welchem Chromosom liegt (das Gen für) Insulin im Menschen?
� Gibt es eine Krankheit, die auf einer Mutation in Insulin beruht?
� Integration verschiedener Datenarten
� Experimentelle Rohdaten (z.B. Bitmaps bei Genexpressionsdaten)
� Aufbereitete Experimentdaten (z.B. Gen- oder Proteinsequenz)
� Textuelle Kommentare (Annotationen)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Historische Entwicklung
� Alle (großen) öffentlichen Bio-Datenbanken entstanden aus Büchern� Sammlungen bekannter Daten einer Art: DNA, Proteinsequenz,
Proteinstruktur� Jährliches / quartalsweises Erscheinen� Buch → Band → CD → FTP → WWW
� Anfangs Verwendung von flachen, textorientierten Datenmodellen� Viele Beschreibungen in freier Textform� Für Menschen konzipiert, nicht für Weiterverarbeitung durch
Computer� Datenbank = Menge ähnlich strukturierter "Entries"
� Entry-"Modell"� Entry: Menge von Feldern (Attribute, Lines) zu einem Bio-Objekt
(z.B. zu einem Protein)� Von nahezu allen Bio-Datenbanken verwendet� Kein Datenmodell im engeren Sinn (wie z.B. RM, OO)� Keine deklarativen Konsistenzbedingungen,
kein Klassen- oder Objektbegriff

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
„Eine Seite – Ein Objekt“� Beispiel Swiss-Prot
� Zum Entry-Modell mehr in Kapitel 4
Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Modeltechnische Entwicklung
Aspekt Entwicklung
Sukzessive Übernahme von DB-Techniken

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Bio-Daten: Historische Entwicklung
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005
Protein structures (11000)
DNA sequences(5000000)
Genomes (25)
Publications (1100000)
Pe
rce
nt
rela
tive
to
19
99
DNAstructure
determined
Firstprotein structure
FastDNA sequencing
Firstviral
genome
Start of thehuman genome project
Firstprokaryotic
genome
Firsteukaryotic
genome
First genomeof a multicellular
organism
Human genome
D. D. FrishmanFrishman , 2001, 2001Protein structures (11000)
DNA sequences(5000000)
Genomes (25)
Publications (1100000)
Pe
rce
nt
rela
tive
to
19
99
DNAstructure
determined
Firstprotein structure
FastDNA sequencing
Firstviral
genome
Start of thehuman genome project
Firstprokaryotic
genome
Firsteukaryotic
genome
First genomeof a multicellular
organism
Human genome
D. D. FrishmanFrishman , 2001, 2001
Paradigmenwechsel bzgl. Publikationen

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Bio-Datenquellen: Übersicht
� Weltweit große Menge an Datenquellen online verfügbar
� Derzeit 1230 bei NAR gelistet
G. R. Cochrane et al.: The 2010 NAR Database Issue and online Database Collection. Nucl. Acids. Res. 2010 DB Issue

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Hohe Vernetzung der Datenquellen

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Anforderungen
� Verwaltung biologischer Daten
� Verfügbarkeit und Flexibilität
� Datenqualität
� Integration und Datenaustausch
� Querying und Analyse

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Verwaltung biologischer Daten
� Unterschiedliche Datenarten
� unstruktruiert, z.B. das Bild eines Genexpressionschips
� strukturiert, z.B. Nucleotidsequenz, Proteinsequenz
� semistrukturiert, z.B. Annotationen
� Bio-Datenbanken ohne Experimentdaten im Bereich 1–200 GB
� Uniprot: Swiss-Prot + TrEMBL: >15 GB� EMBL = European Molecular Biology Laboratory; TrEMBL =
Proteinsequenz-Datenbank von EMBL (als Ergänzung zu Swiss-Prot)
� Mit Experimentdaten deutlich größere Datenmengen
� TIFF eines Genexpressionschips: ca. 50 MB
� Rohspektrum eines MS-Experimentes� MS = Massenspektrometer / Massenspektrometrie
� Tracefiles von Sequenziermaschinen
� Bilder von 2D-Gel-Elektrophorese-Experimenten

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Verfügbarkeit und Flexibilität
� Meist freier Zugriff und Download - „share data“� Selten direkter SQL Zugriff, oft Dumps zum Download� Web-basierte Nutzerschnittstellen
� Zugriff auf Server über verschiedene Clients(Java, CGI, Perl, PHP, ...)
� Forschungsfragen ändern sich ständig (regelmäßig neue Versionen)� Andere wissenschaftliche Fragestellungen
→ Andere Daten, andere Queries� Design muss Wartbarkeit und Flexibilität in Vordergrund stellen
� Schemaänderungen, Einbringung neuer Datentypen, Optimierung auf neue Anforderungen
� Bio-Datenbanken meist Teil eines Forschungsprojekts� Datenbeschaffung (LIMS), Datenarchivierung, Datenanalyse
� Integration mit selbstentwickelten Analyse-Algorithmen nötig� Algorithmen für Ähnlichkeitssuche/Alignments bzgl. Genen und
Proteinen (Blast/Fasta), Motif-Suche, Gensuche …

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Datenqualität
� Experimente erzeugen (fast) immer unscharfe Daten
� Arbeit mit lebenden Organismen
� Zugrundeliegende Mechanismen größtenteils unverstanden
� Fehleranfällige Techniken: Bilderkennung, Statistische/heuristische Algorithmen, ...
� Starke Redundanz
� Ungewollt: PIR - SwissProt, KEGG - Reactome
� Gewollt: spezies-spezifische Daten
� Manche Quellen kopieren von anderen (z.B. Ensembl)
� Kopieren und Überarbeiten von Daten → Inkonsistenzen (c/p error)
� Eine junge Wissenschaft: viele (falsche) Daten und Veröffentlichungen� Viele verschiedene (konkurrierende) Arbeitsgruppen
� Herkunft der Daten sollte (auch bei Ableitungen) ermittelbar sein
� Automatisch berechnete Daten oder „curated“ (=„redaktionell betreut“)� Falsch-Positiv-Rate bei High-Throughput Experimenten
� Curator: liest, fasst zusammen ..
� Probleme: Konsistenz, Vollständigkeit, Qualtätssicherung, Objektivität,…

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Integration
� Viele Daten machen erst Sinn im Kontext� (Teil-)Sequenz: Genkontext, Regulationskontext, Homologie� Protein: Welcher Organismus?, Strukturkontext, Domänen� Expression: Regulationskontext, Phänotypen, Krankheitsverläufe, ...
� Integration von Bio-Daten aus externen Quellen = offenes Problem� Die meisten Datenbanken sind "nur" integriert im Sinne einer
Verlinkung z.B. Verlinkung Ensembl ↔ Swiss-Prot ↔ OMIM� Typische Bio-Anfragen implizieren bereits Zugriffe auf mehrere
Datenquellen� Beispiel: Insulin
� Identifizieren Sie die Insulin mRNA und Proteinsequenz für Mensch, Huhn und Schwein (DB: NCBI-Entrez, GeneCards, UCSC Genome Browser, NCBI-GenBank (für Nucleotide), NCBI-GenBank (für Proteine)
� In welchem Stoffwechselweg ist Insulin eingebunden? (DB: KEGG)
� Auf welchem Chromosom liegt Insulin beim Mensch? (DB: NCBI-Entrez, NCBI-OMIM, GeneCards)
� Gibt es eine Krankheit, die auf einer Mutation in Insulin beruht? (DB: NCBI-OMIM)
� Integration im Sinne eines globalen Schemas oft nicht vorhanden

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Austauschformate
� Verschiedene Austauschformate� FASTA, EMBL Format
� ASN.1 (Sequenzen + Annotationen)
� MAGE (Experimentannotation bei Expressionsexperimenten)
� http://www.ebi.ac.uk/help/formats.html
� Export üblicherweise in Flat Files
� XML zunehmend von Bedeutung
� DTD’s definiert für verschiedene Projekte, z.B.� GAME: Genome Annotation Markup Elements
� BIOML: BIOpolymer Markup Language
� BSML: Bioinformatic Sequence Markup Language

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Querying und Analyse
� Bio-Daten werden im Allgemeinen für komplexe Weiterverarbeitungen genutzt
� Querying-Anforderungen� Vordefinierte (parametrisierbare) Masken für häufige
Anfragetypen� Möglichkeit, Ad-hoc-Queries komfortabel zusammen stellen
zu können (z.B. über grafisches Interface)� Interface mit voller Query-Komplexität
(für sog. "Power User")� Unterstützung von Unschärfe bei unstrukturierten
oder semi-strukturierten Daten� Analyse-Anforderungen
� Integration mittels Data Warehouse-Ansätzen (multidimensionale Anfragen, Aggregation)
� Integration von Statistik und Data Mining Tools

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifizierungsmerkmale
� Klassifizierung nach� Inhalt
� Verfügbarkeit
� Datenhaltungssystem
� Externer Datengewinnung
� Datenqualität
� Art der Integration
� Zugriffsmethoden

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifizierung nach Inhalt
� Organismus, Gewebe, Chromosome, ...� Typen der abgespeicherten Bio-Objekte: Sequenzen, Strukturen, Motifs, ...
� (kurze) Sequenz von Sekundär-Struktur-Elementen mit im Allg. spezifischer biologischer Funktion
Primär-Datenbanken
Sekundär-Datenbanken
Tertiär-Datenbanken
� Grenze vor allem zw. Sekundär- und Tertiärdatenbanken oft fließend
Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
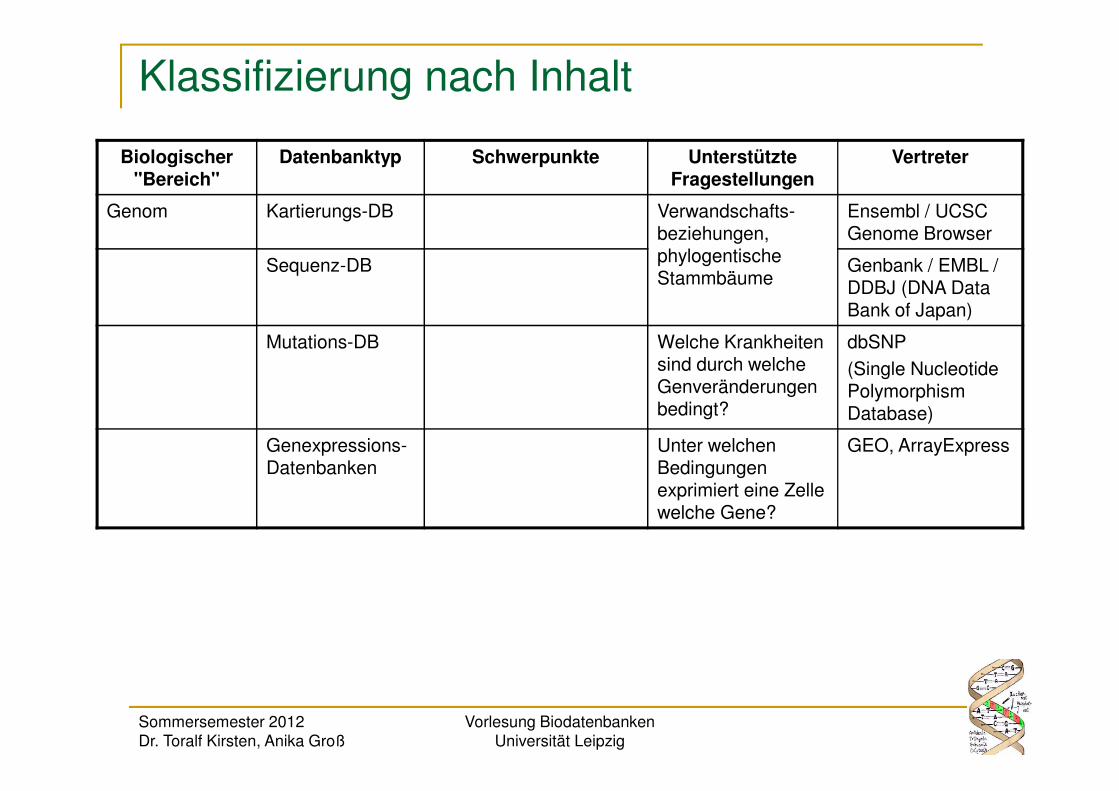
Klassifizierung nach Inhalt
Biologischer "Bereich"
Datenbanktyp Schwerpunkte Unterstützte Fragestellungen
Vertreter
Genom Kartierungs-DB Verwandschafts-beziehungen, phylogentische Stammbäume
Ensembl / UCSC Genome Browser
Sequenz-DB Genbank / EMBL / DDBJ (DNA Data Bank of Japan)
Mutations-DB Welche Krankheiten sind durch welche Genveränderungen bedingt?
dbSNP
(Single Nucleotide Polymorphism Database)
Genexpressions-Datenbanken
Unter welchen Bedingungen exprimiert eine Zelle welche Gene?
GEO, ArrayExpress

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Inhalt
Biologischer "Bereich"
Datenbanktyp Schwerpunkte Unterstützte Fragestellungen
Vertreter
Proteine Proteinsequenz-Datenbanken
Proteindesign (z.B. für neue Medikamente)
PDB
Proteinstruktur-Datenbanken
Genbank / EMBL / DDBJ (DNA Data Bank of Japan)
Protein-Domain/ family
Welche Proteingruppe ist für bestimmte Stoffwechstelprozesse (z.B. Blutgerinnnung) zuständig?
PFAM (Protein families database of alignments and HMMs)
Stoffwechsel Pathway-Datenbanken
Welche Stoffwechstelprozesse werden von welchen Proteinen (Enzymen) gesteuert. Welche (Abfall-)Produkte entstehen dabei
KEGG (Kyoto Encyclopedia of Genes and Genomes)
Publikationen MedLine
PubMed

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Verfügbarkeit
� Öffentliche Datenbanken� Lange bestehend, international organisiert
� Referenzdatenbanken, öffentliche Archive (Genbank, Swiss-Prot, PIR, PDB, ...)
� Nicht-öffentliche Datenbanken� Projektbezogene ("One-Shot")-Datenbanken von
Forschungsgruppen (hochaktuell für kurze Zeit; existieren oft nur bis zur Veröffentlichung der Ergebnisse)
� Kommerzielle Datenbanken von Bio-Firmen (z.B. Celera)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Datenhaltungssystem
� Verwendetes Speichersystem� Flat-Files
� Proprietäre Systeme (ACeDB, Icarus/SRS)
� Relationale DBMS
� Objektorientierte/Objektrelationale DBMS
� XML Datenbanken (Tamino, eXists, …)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Art der Datengewinnung
� "Passiv"� Alle Daten werden von externen Forschungsgruppen und
Institutionen eingebracht ("submittet")� Sinn: Archivierung, ID-Vergabe und "roher" Zugriff� Auf freiwilliger Basis, oder Verpflichtung durch Geldgeber,
Journale ("Publikation nur, wenn Daten eingebracht werden") etc.� Beispiele: Genbank/EMBL, PDB, ...
� "Aktiv"� Relevante (öffentlich zugängliche) Datenquellen werden
regelmäßig abgegriffen (z.B. Online-Abstracts bei Bio-Journalen)� Sinn: Integration, Veredlung, Vollständigkeit� Ermöglicht zentralen Zugriff ohne Verpflichtung� Beispiele: Swiss-Prot, Protein Information Resource, ...
� Mischformen: GDB (nicht mehr aktiv)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Datenqualität (Curation)
� Ansatz 1: (Externer) Einbringer ist "Datenherr" (z.B. Genbank, ArrayExpress)� Im nachhinein keine (inhaltlichen) Veränderungen an einmal eingebrachten
Daten� Vorteil: Urheber klar, hohe Datenstabilität; Nachteil: keine globale
Verantwortlichkeit, übergreifende Datenqualität schwierig zu sichern� Ansatz 2: Zentrale Nachbearbeitung/Kontrolle der Daten
(z.B. Swiss-Prot, MIPS)� Munich Information Center for Protein Sequences� Daten werden laufend verbessert� Hoher (manueller) Aufwand, da Automatisierung nur eingeschränkt möglich� Vorteil: Höhere Datenqualität; Nachteil: Urheber weniger klar, hohe Volatilität
� Redundanz� Ansatz 1: Alles aufnehmen, auch wenn teilweise redundant zu bisherigen
Einträgen� Ansatz 2: Entfernen gleicher oder sehr "ähnlicher" Einträge� Beispiel Swiss-Prot: Redundanzminimierung durch (menschliche) Editoren
(sicher, aber teuer)� Beispiel UniGene: Redundanzminimierung durch Algorithmen (ökonomisch,
aber mit Unsicherheiten behaftet)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Klassifikation nach Art der Integration
� Ansatz 1: Virtuelle Integration (über Links)� "lockerer Verbund" zwischen Datenquellen, deren Objekte
durch Verweise miteinander verbunden sind
� Häufigste Integrationsart in Bio-Datenbanken
� Ansatz 2: Materialisierte Integration� Daten werden kopiert und zentral aufbereitet
� Data Warehouse-Ansatz
� Beide Ansätze mit oder ohne globales Schema
� Manuelle versus automatische Integration� Automatische Integration anhand def. Kriterien (Ensembl)
� Manuelle Integration anhand Wissen des Editors (Swiss-Prot)

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Beispiel virtuelle Integration
� DBGET: Retrieval System für breite Palette von Bio-Datenbanken

Sommersemester 2012Dr. Toralf Kirsten, Anika Groß
Vorlesung BiodatenbankenUniversität Leipzig
Beispiel materialisierte Integration: GeWare
Experimental data•Raw chip intensities•Expression matrix
Data warehouse
External annotations•Netaffx data•Gene ontology (GO)•LocusLink
Experiment annota-tions•experiment, sample, …•MIAME
Source systems Analysis
Core data warehouse•multidimensional data model (star schema)
Tight integration•Special UDF‘s•DB procedures
Loose integration•Export•Download
Transparent integration•Use of API's•Insightful ArrayAnalyzer•OLAP Tools
DWH
uniform w
eb-b
ased
interface
Quelle: Do, H.H., Kirsten, T., Rahm, E.: Comparative Evaluation of Microarray-based Gene Expression Databases. Proc. 10. Fachtagung
Datenbanksysteme für Business, Technologie und Web (BTW 2003), Leipzig, Feb. 2003

















