
Datenbanksysteme II - db.inf.uni-tuebingen.de · Selektionskriterium day < 8/9/2002 " rname =...
62
Datenbanksysteme II Architektur und Implementierung von Datenbanksystemen Winter 2009/10 Melanie Herschel Willhelm-Schickard-Institut für Informatik 1
Transcript of Datenbanksysteme II - db.inf.uni-tuebingen.de · Selektionskriterium day < 8/9/2002 " rname =...

Datenbanksysteme IIArchitektur und Implementierung von Datenbanksystemen
Winter 2009/10
Melanie HerschelWillhelm-Schickard-Institut für Informatik
1

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
2

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Überblick
•Neben der Sortierung gibt es noch weitere Operatoren, die für die Evaluation einer relationalen Anfrage relevant sind (z.B.Selektion, Projektion, Join).
•Für einen dieser logischen Operatoren kann es verschiedene Implementierungsvarianten, sogenannte physische Operatoren geben.
•Physische Operatoren nutzen gezielt physische Eigenschaften ihrer Eingabe und des Systemsstatus aus:
•Indizes über die Eingabedaten,
•Sortierung der Eingabedaten,
•Größe der Eingabedaten,
•Verfügbarer Speicher im Bufferpool,
•Bufferpool Ersetzungsstrategieen,
•...
•In diesem Kapitel besprechen wir physische Operatoren und analysieren deren Kosten
(approximiert durch Anzahl I/O Operationen). Die Wahl der optimalen Variante ist Aufgabe des Anfrageoptimierers (siehe Kapitel 9).
3

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ÜberblickKlassifizierung der Algorithmen
Die Algorithmen für verschiedenste Operatoren basieren auf drei wesentlichen Techniken, nach denen wir die Algorithmen klassifizieren können.
1.Indexing
• Ist eine Selektion oder eine Join-Bedingung angegeben, können wir Indizes verwenden um nur die Tupel zu betrachten, die die Bedingung erfüllen.
2.Iteration
• Betrachte (alle) Tupel einer Eingabetabelle nacheinander, um die Operation durchzuführen. Existiert ein Index, der alle nötigen Attribute enthält, reicht es, alle Dateneinträge zu scannen (index-only-evaluation).
3.Partitionierung
• Indem wir Tupel nach einem bestimmten Attribut partitionieren, können wir oft eine Operation in mehrere, günstigere Operationen aufteilen. Sortieren und Hashing sind zwei vielseitig genutzte Partitionierungstechniken.
4

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ÜberblickZugriffspfad (Access Path)
•Ein Zugriffspfad (access path) beschreibt eine Methode, Daten einer Eingabetabelle abzurufen.
•Ein Zugriffspfad besteht entweder (1) aus einem Datei-Scan oder (2) aus einem Index und einer zusätzlichen Selektionsbedingung (matching selection condition).
•Der Input jedes relationalen Operators besteht aus einer oder mehrerer Tabellen, und der verwendete Zugriffspfad repräsentiert einen wesentlichen Anteil der Gesamtkosten des Operators.
5
Beispiele für Zugriffspfade
Gegeben folgende Anfrage: SELECT pnr, gehalt
FROM Angestellte
WHERE pnr = 50
AND gehalt > 5000
•Existiert ein Hash-Index über pnr, so besteht der Zugriffspfad aus dem Hash-Index und der Bedingung pnr = 50.
•Da eine weitere Bedingung existiert, die nicht durch den Index überprüft werden kann (gehalt > 5000) müssen wir die durch den Index ermittelten Tupel überprürfen.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ÜberblickSelektivität eines Zugriffspfads
•Die Selektivität eines Zugriffspfads ist die Anzahl Seiten (Index-Seiten + Daten-Seiten), die gelesen werden wenn wir den entsprechenden Zugriffspfad verwenden.
•Der selektivste Zugriffspfad ist der Zugriffspfad mit der geringsten Selektivität, also der Zugriffspfad, der am wenigsten Seiten lesen muss.
6
Beispiele für die Selektivität eines Zugriffspfades
Gegeben folgende Anfrage:
SELECT gehalt
FROM Angestellte
WHERE gehalt > 5000
•Angenommen, es existiert ein B+ Baumindex über <gehalt>.
•Zugriffspfad 1: Index. Angenommen, die Höhe des Index ist 3, so benötigen wir 3 Seitenzugriffe, ehe wir das erste Tupel finden und eventuelle mehr, um den Gehaltsbereich zu ermitteln. ! Selektivität zwischen 3 und 3 + N - 1 (N Anzahl Seiten des Sequence Sets)
•Zugriffspfad 2: Scan der Datendatei bestehend aus M Seiten ! Selektivität M >> N
•Zugriffspfad 3: Scan des Sequence Sets ! N

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ÜberblickDurchgängiges Beispiel
7
Matrosen und Hotelbuchungen
Beispielschema:
Sailors(sid:integer, sname:string, rating:integer, age:real)
•Jedes Tupel der Sailors-Tabelle ist 50 Bytes lang.
•Eine Seite kann 80 Sailors-Tupel fassen.
•Die Sailors-Tabelle benötigt 500 Seiten insgesamt.
Reservations(sid:integer, bid:integer, day:dates, rname:string)
•Jedes Tupel der Reservations Tabelle ist 40 Bytes lang.
•Eine Seite kann 100 Reservations-Tupel fassen.
•Die Reservations-Tabelle benötigt 1000 Seiten insgesamt.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
8
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
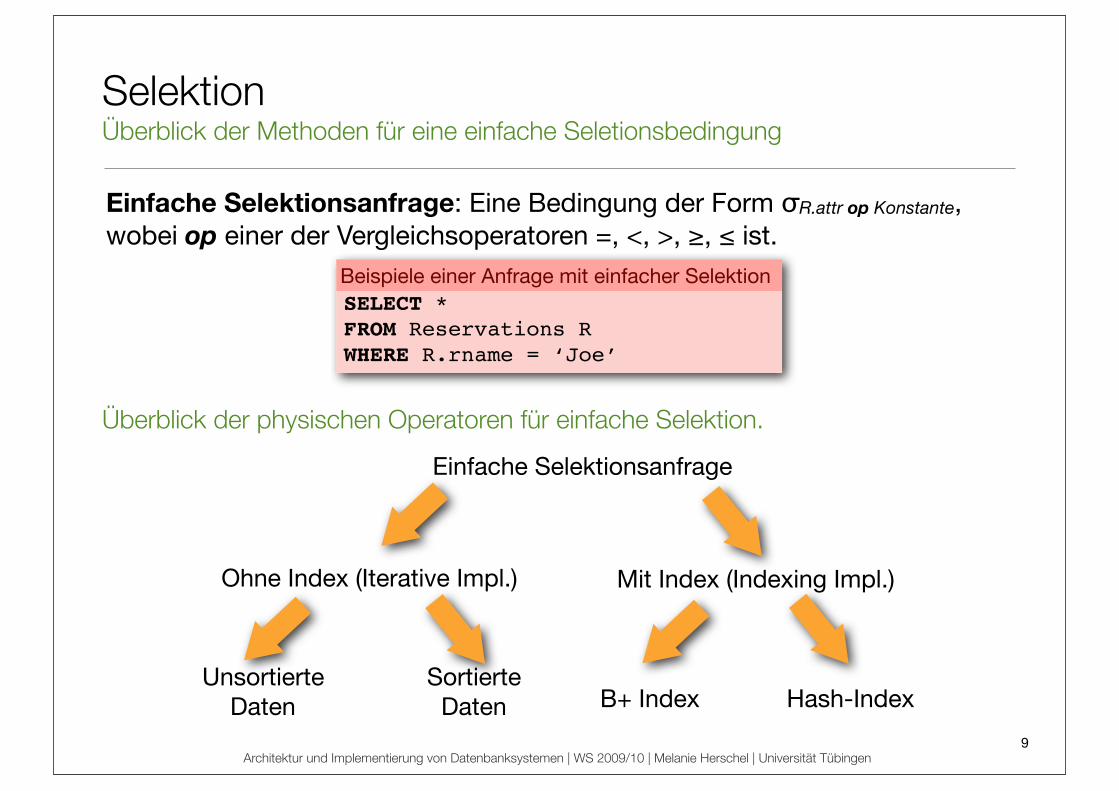
SelektionÜberblick der Methoden für eine einfache Seletionsbedingung
9
Einfache Selektionsanfrage: Eine Bedingung der Form !R.attr op Konstante, wobei op einer der Vergleichsoperatoren =, <, >, !, " ist.
Einfache Selektionsanfrage
Ohne Index (Iterative Impl.) Mit Index (Indexing Impl.)
UnsortierteDaten
SortierteDaten B+ Index Hash-Index
Überblick der physischen Operatoren für einfache Selektion.
Beispiele einer Anfrage mit einfacher SelektionSELECT *
FROM Reservations R
WHERE R.rname = ‘Joe’
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
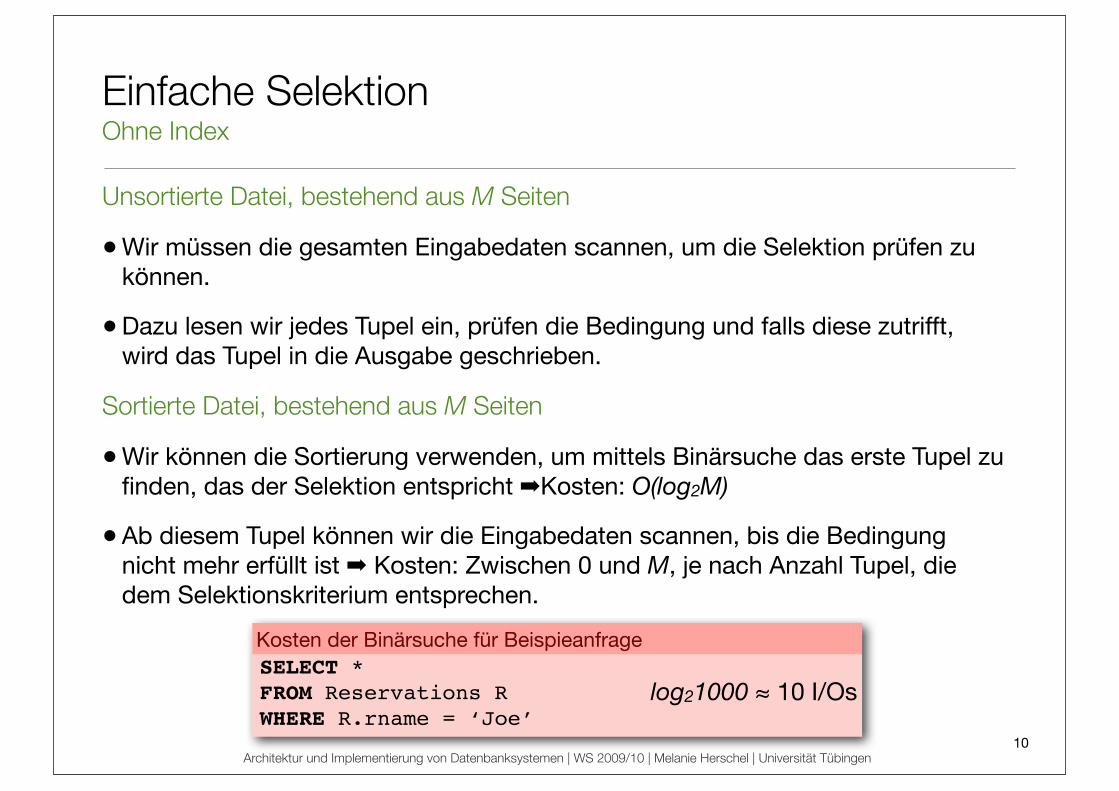
Einfache SelektionOhne Index
10
Unsortierte Datei, bestehend aus M Seiten
• Wir müssen die gesamten Eingabedaten scannen, um die Selektion prüfen zu können.
• Dazu lesen wir jedes Tupel ein, prüfen die Bedingung und falls diese zutrifft, wird das Tupel in die Ausgabe geschrieben.
Sortierte Datei, bestehend aus M Seiten
• Wir können die Sortierung verwenden, um mittels Binärsuche das erste Tupel zu finden, das der Selektion entspricht !Kosten: O(log2M)
• Ab diesem Tupel können wir die Eingabedaten scannen, bis die Bedingung nicht mehr erfüllt ist ! Kosten: Zwischen 0 und M, je nach Anzahl Tupel, die dem Selektionskriterium entsprechen.
Kosten der Binärsuche für BeispieanfrageSELECT *
FROM Reservations R
WHERE R.rname = ‘Joe’
log21000 ! 10 I/Os

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Einfache SelektionB+ Index
11
•Existiert ein clustered B+ Index, so bietet dieser den besten Zugriffspfad, wenn der Vergleichsoperator op nicht Gleichheit ist (hier sind Hash-basierte Indizes besser).
• Ist der B+ Index unclustered, so hängen die Kosten von der Anzahl Tupel ab, die dem Selektionskriterium entsprechen.
•Verwendung des Index:
•Verwende den Index, um erstes Tupel zu finden, das Selektionskriterium entspricht.Kosten: 2 - 3 I/Os (Höhe des Baumes).
•Finde alle weiteren Tupel durch Scan der Dateneinträge im Index, bis Selektionskriterium nicht mehr erfüllt ist.
•Verwendet der Index die Dateneintragsvariante (1), so entsprechen die Dateneinträge bereits den Tupeln, die wir ausgeben.
•Verwendet der Index Dateneintragsvarianten (2) oder (3), müssen wir die Tupel aus der Daten-Datei lesen ! im schlimmsten Fall ein Disk I/O pro Tupel, das ausgegeben wird. Sortieren wir relevante Dateneinträge nach ihrer page-id, können diese I/O Kosten reduziert werden.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Einfache SelektionB+ Index
12
Beispiel
Selektion der Form rname < ‘C%’
10% der Reservations-Tabelle entsprechen Selektionskriterium ! Entspricht 10,000 Tupeln auf 100 Seiten.
Gibt es einen clustered B+ Index mit Schlüssel <rname>, können wir alle Tupel der Ausgabe in nur ca. 100 I/O Operationen ermitteln.
Verwenden wir einen unclustered B+ Index mit Schlüssel <rname>, benötigen wir im worst case 10,000 I/O Operationen. Sortieren wir nach page-ids, so stellen wir sicher, dass keine Seite mehrfach gelesen wird, allerdings sind die Daten vermutlich über mehr als 100 Seiten sortiert.
!Die Verwendung eines unclustered Index für Bereichsanfragen kann teurer sein als einfacher Scan der Datei (in unserem Fall nur 1,000 Seiten).

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Einfache SelektionHash-Index
13
•Existiert ein Hash-Index und entspricht op der Gleichheit (=) verwendet der optimale
Zugriffspfad den Hash-Index.
•Die Kosten hierfür sind 1 - 2 I/O Operationen um den entsprechenden Bucket zu ermitteln, plus die Kosten, die qualifizierenden Tupel aus der Daten-Datei zu ermitteln. Hier hängen die Kosten von der Anzahl qualifizierender Tupel ab.
Kosten der Selektion bei vorhandenem Hash-Index
SELECT *
FROM Reservations R
WHERE R.rname = ‘Joe’
•Annahme: unclustered Hash-Index über <rname>.
•100 Tupel entsprechen dem Selektionskriterium.
•Bufferpool mit 10 Seiten.
•Kosten, korrekten Bucket zu ermitteln: 1 - 2 I/Os.
•Kosten, Tupel zu ermitteln: 1 - 100 I/Os, je nachVerteilung der Daten (sind die 100 Tupel auf 5 Seiten verteilt, dann 5 I/O).

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Allgemeine SelektionConjunctive Normal Form (CNF)
14
•Bisher: einfache Prädikate der Form !R.attr op Konstante(R).
•Jetzt: komplexere Prädikate, die Terme mit boolschen Operatoren AND (!) und OR (")
verbinden. Dabei hat ein Term die Form Attribut op Konstante oder Attribut1 op Attribut2.
Conjunctive Normal Form (CNF)
•Eine Conjunct ist eine Oder-Verknüpfung einzelner Terme.
conjunct = t1 " t2 " ... " tn
•Ein Prädikat in CNF ist eine Und-Verknüpfung von Conjuncts.
cnf = conjunct1 ! conjunct2 ! ... ! conjunctn
Beispiel einer komplexen AnfrageSELECT *
FROM Reservations R
WHERE R.rname = ‘Joe’
AND R.bid = 5
!R.name=‘Joe’ ! R.bid=5(R)

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Allgemeine SelektionKonjunktive Anfragen (ohne Disjunktion)
15
Ein Peädikat, das keinem Index entspricht kann ggf. in “kleinere” Prädikate aufgeteilt werden, die existierenden Indizes entsprechen.
Beispiel
Gegeben sei eine Selektion !p!q(R) für die es keinen entsprechenden Index gibt, jedoch für p und q einzeln schon.
!Der Optimieren kann entscheiden, mehrerer Indizes zu verwenden und die Ergebnisse zusammenzuführen, indem wir die Schnittmenge der jeweiligen
Ergebnismengen bilden (Gleichheit zweier Tupel über rid bestimmt, daher #rid).
R !p!q
R!’p
!’q
#rid
Anfrageplan 1
kein Index verwendbar
Anfrageplan 2
2 Indizes verwendbar
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Allgemeine SelektionKonjunktive Anfragen (ohne Disjunktion)
16
Verwendungen mehrerer Indizes gegeben eine Anfrage ohne Disjunktion
Gegeben: Selektionskriterium day < 8/9/2002 ! bid = 5 ! sid = 3Ein Hash-Index über <bid, sid> und ein B+ Baumindex über <day>.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Allgemeine SelektionMit Disjunktion
17
• Nehmen wir an, eines der Conjuncts ist eine Disjunktion von Termen.
!Benötigt mindestens einer der Terme einen Datei-Scan, so benötigt die separate Evaluation dieses Conjuncts einen Datei-Scan.
• Existiert für jeden Term ein Index, so können wir das Prädikat wieder aufteilen und die Ergebnisse der Teilanfragen mittels $rid wiedervereinen.
Beispiel
Gegeben sei eine Selektion !p"q(R) für die es keinen entsprechenden Index gibt, jedoch für p und q einzeln schon.
R !p"q
R!’p
!’q
$rid
Anfrageplan 1
kein Index verwendbar
Anfrageplan 2
2 Indizes verwendbar

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Allgemeine SelektionMit Disjunktion
18
Verwendungen mehrerer Indizes gegeben eine Anfrage mit Disjunktion
Gegeben: Selektionskriterium day < 8/9/2002 " rname = ‘Joe’Ein Hash-Index über <rname> und ein B+ Baumindex über <day>.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
20

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionAllgemeiner Ansatz
21
Projektion (#l) verändert jedes Tupel der Eingaberelation, indem es alle Attribute bis auf die in der Liste l angegebenen Attribute entfernt.
Allgemeiner Ansatz zur Implementierung der Projektion, gegeben #A,B
A B C
1 2 3
1 2 4
2 5 3
3 7 1
A B
1 2
1 2
2 5
3 7
A B
1 2
2 5
3 7
(1) Entferne nicht-projezierte Attribute
(hier C)
(2) Entferne ggf.doppelte Tupel
(SQL: DISTINCT)
2 Partitionierungsalgorithmen:
• Projektion basierend auf Sortierung
• Projektion basierend auf Hashing

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionBasierend auf Sortierung
22
Projektion mit Sortierung, Variante 1
1. Scan Eingabetabelle R und produziere eine Menge von Tupeln, die nur die gewünschten Attribute enthält.
2. Sortiere diese Menge von Tupeln in lexikographischer Reihenfolge. Der Sortierschlüssel besteht dabei aus allen Attributen.
3. Scan des sortierten Ergebnisses. Dabei vergleichen wir adjazente
Tupel und verwerfen Duplikate.
Kosten mit temporärer Tabelle nach jedem Schritt
Einlesen von R:
M
Schreiben temp. Tabelle:
T = O(M)
Sortierung:O(T log T)
Duplikateliminierung:T (Anzahl gelesener
Seiten)
Kosten insgesamt:
O(M log M)
Beispielhafte Kostenrechnung:Projektion über Reservations.
Reservations-Tabelle hat 1,000 Seiten ! M = 1,000 I/Os
Jedes Tupel ist nach entfernen von Attributen nur 10 Byte groß!T = 250 I/Os
Gegeben 20 Seiten im Buffer, können wir Daten in 2 Passes sortieren ! 2 * 2 * 250 = 1000 I/Os
Scan von 250 Seiten!250 I/Os
Kosten insgesamt: 2500 I/Os

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionBasierend auf Sortierung
23
Projektion mit Sortierung, Variante 2
1. Führe Pass 0 des externen Sortieralgorithmus (siehe Kapitel 6) aus. Bevor Tupel dabei zu einem Run hinzugefügt werden, entferne
überflüssige Attribute.
2. Wir entfernen Duplikate während der für die Sortierung verbleibenden Merge-Passes.
Kosten mit temporärer Tabelle nach jedem Schritt
Kosten für Pass 0:
M + T
Kosten der Merge-Passes:
T * #Merge Passes
Kosten insgesamt:
M + T * #Merge-Passes
Beispielhafte Kostenrechnung:Projektion über Reservations.
Reservations-Tabelle hat 1,000 Seiten, nach Projektion nur 250.
Kosten für Pass 0:! M + T = 1,250 I/Os
Gegeben 20 Seiten im Buffer, können wir Daten in einem Merge-Pass sortieren ! 250 I/Os
Kosten insgesamt: 1500 I/Os

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionBasierend auf Hashing
24
• Hat das DBMS für die Ausführung von "l(R) eine große Anzahl, sagen wir B Seiten, im Buffer zur Verfügung, kann hashbasierte Projektion in betracht gezogen werden.
• 2 Phasen
(1) Partitionierung
(2) Entfernung von Duplikaten
Hashbasierte Projektion "l(R) - Partitionierungsphase
1.Alloziiere B Seiten des Buffers. Eine dieser B Seiten ist der Input-Buffer, während die verbleibenden B - 1 Seiten als Hash-Buckets genutzt werden.
2.Lese die Datei R seitenweise in den Input-Buffer. Für jedes eingelesene Tupel t, entferne alle Attribute, die nicht in der Liste l auftauchen.
3.Für jedes Tupel, berechne h1(t) = h(t) mod (B - 1), wobei h(t) auf allen Attributen in l basiert. Speichere t im Hash-Bucket h1(t) (schreibe Bucket auf Platte wenn dieser voll ist).

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionBasierend auf Hashing
25
1
2
B-1
Input-Buffer Hash-BucketsEingabedatei
(auf Festplatte)Partitionen
(auf Festplatte)Buffer Pool
h
... ... ...
• Nach der Partitionierung ist das Entfernen von Duplikaten nur noch innerhalb einer
Partition, also eines Buckets nötig, denn zwei identische Records werden garantiert auf den gleichen Bucket gehasht.
t = t‘ ⇒ h1(t) = h1(t’)

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
ProjektionBasierend auf Hashing
26
Hashbasierte Projektion "l(R) - Entfernen von Duplikaten
1.Lese jede Partition seitenweise ein. Wenn möglich, bearbeite mehrere Partitionen parallel.
2.Auf jedes Record wenden wir eine Hashfunktion h2 $ h1 an, die wieder alle Attribute in l berücksichtigt.
3.Kollidieren zwei Records unter Anwendung von h2, so überprüfe, of t = t’. Wenn ja, entferne t’.
4.Wurde die gesamte Partition eingelesen, werden alle Hash-Buckets der Ausgabedatei angehängt.
Was passiert bei großen Partitionen?

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
27

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Join Operator
28
Der Join Operator fasst ein Kreuzprodukt (%) und eine anschließende Selektion (!p) zusammen. Wir betrachten zunächst nur Equijoin , d. h. p
beinhaltet nur Bedingungen mit Gleichheit als Vergleichsoperator.
Beispiel einer Join AnfrageSELECT *
FROM Reservations R, Sailors S
WHERE R.sid = S.sid
Evaluation ofRelational Operators
Torsten Grust
Relational QueryEnginesOperator Selection
Selection (!)Selectivity
Conjunctive Predicates
Disjunctive Predicates
Projection (")
Join (!")Nested Loops Join
Block Nested Loops Join
Index Nested Loops Join
Sort-Merge Join
Hash Join
Operator PipeliningVolcano Iterator Model
8.30
The Join Operator (!")
The join operator !"p is actually a short-hand for a combinationof cross product ! and selection !p.
Join vs. Cartesian product
R S
!"p "
R S
!
!p
One way to implement !"p is to follow this equivalence:
1 Enumerate and concatenate all records in the cross productof r1 and r2.
2 Then pick those that satisfy p.
More advanced algorithms try to avoid the obvious inefficiency inStep 1 (the size of the intermediate result is |R| · |S|).
R S
!"p !
R S
"
!p
Join-Implementierungen, die wir besprechen:
• Nested Loops Join (NPJ)
• 3 Varianten: Naive NLJ, Block NLJ, Index NLJ
• Sort-Merge Join
• Hash-Join

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Naive Nested Loops Join
29
Der Naive Nested Loops Join implementiert die Kombination des Kreuzprodukts (%) und der anschließenden Selektion (!p).
Naiver Nested Loops Join
function nljoin(R, S, p)
foreach Tupel r & R do
foreach Tupel s & S do
/* 〈r,s〉 beschreibt die Konkatenation von r und s */
if 〈r,s〉 erfüllt p then
Gebe 〈r,s〉 aus ;
Anzahl der zu verarbeitenden Tupel
%
(4,000,000,000 Tupel)
!R.sid = S.sid
(z.B. 100,000 Tupel)
Reservations
100,000 Tupel
Sailors
40,000 Tupel
Sei NR und NS die Anzahl Seiten von R und S, und sei pR und pS die Anzahl Tupel pro Seite in R und S.
Die Anzahl Leseoperationen für den naiven NLJ ist NR + pR %NR %NS
(Scan von R und Lesen aller Seiten von S für jedes Tupel in R).

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Naive Nested Loops JoinI/O Kosten
30
Kosten für den naiven Ansatz
•Der naive NLJ benötigt nur drei freie Seiten im Buffer (zwei Input-Buffer und ein Output-Buffer).
•Die Anzahl Leseoperationen ist enorm:
• In unserem Beispiel ist pR = 100, pS = 80, NR = 1000, NS = 500.
!1000 + 100 % 1000 % 500 = 5 % 107 Leseoperationen.
•Nehmen wir an, eine Leseoperation benötigt 10ms, so müssten wir 140 Stunden warten, bis alle Daten gelesen wären! (Kosten für Schreiboperationen ignorieren wir in diesem Kapitel).
Kosten, wenn kleinere Relation der äußeren Relation entspricht

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Naive Nested Loops JoinVerbesserte Variante
31
Verbesserung des naiven NLJ
•Seitenweises einlesen der beiden Tabellen R und S.
• In diesem Fall wir jede Seite der äußeren Relation R nur einmal gelesen.
•Jede Seite der inneren Relation S wird nur einmal proSeite in R gelesen).
!Anzahl Leseoperationen verringert sich aufNR + NR %NS
seitenweiser Nested Loops Join
function nljoin++(R, S, p)
foreach Seite Pr & R do
foreach Seite Ps & S do
nljoin(PR, PS, p);
I/O Kosten nach Verbesserung und kleineren Tabelle als äußere Tabelle
NS = 500NR = 1000! 500 + 500 % 1000 = 500 + 5%105
! 1.4 Stunden Laufzeit

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Blocked Nested Loops Join
32
Grundidee (bei genügend Bufferplatz, um R in den Buffer zu lesen)
•Wir verwenden mehr als nur drei Seiten im Buffer.
•Hat Buffer B freie Seiten, so verwenden wir B - 2 Seiten zum Lesen von R, einen Input-Buffer zum Lesen von S, und einen Output-Buffer.
•Wir lesen R in den Buffer ein.
•Wir lesen S seitenweise ein.
•Ist PS die im Input-Buffer von S liegende Seite, so schreiben wir !p (NR # PS) seitenweise in den Output-Buffer.
•Passt R in B - 2 Seiten, so benötigen wir nur NR + NS I/O Operationen.
Allgemeiner Ansatz (R passt nicht komplett in den Buffer, der B Seiten zur Verfügung stellt)
•Lese Blöcke der Größe B - 2 der äußeren Relation R ein. Sei BR ein Block von R.
•Wir können nun !p ( BR # PS) seitenweise in den Output schreiben.
•Insgesamt benötigen wir somit nur NR + NS %⎡NR / (B - 2)⎤I/O Operationen.
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
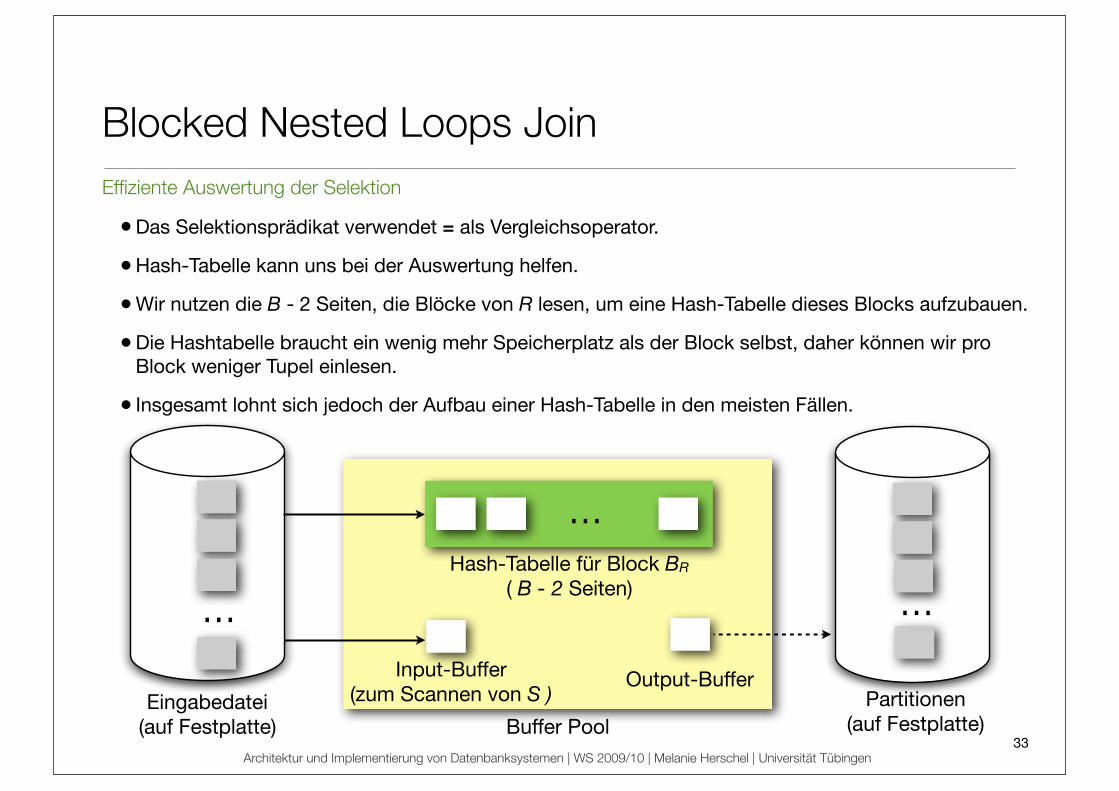
Blocked Nested Loops Join
33
Effiziente Auswertung der Selektion
• Das Selektionsprädikat verwendet = als Vergleichsoperator.
• Hash-Tabelle kann uns bei der Auswertung helfen.
• Wir nutzen die B - 2 Seiten, die Blöcke von R lesen, um eine Hash-Tabelle dieses Blocks aufzubauen.
• Die Hashtabelle braucht ein wenig mehr Speicherplatz als der Block selbst, daher können wir pro Block weniger Tupel einlesen.
• Insgesamt lohnt sich jedoch der Aufbau einer Hash-Tabelle in den meisten Fällen.
Input-Buffer(zum Scannen von S )
Output-BufferEingabedatei
(auf Festplatte)Partitionen
(auf Festplatte)Buffer Pool
... ...Hash-Tabelle für Block BR
( B - 2 Seiten)
...
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
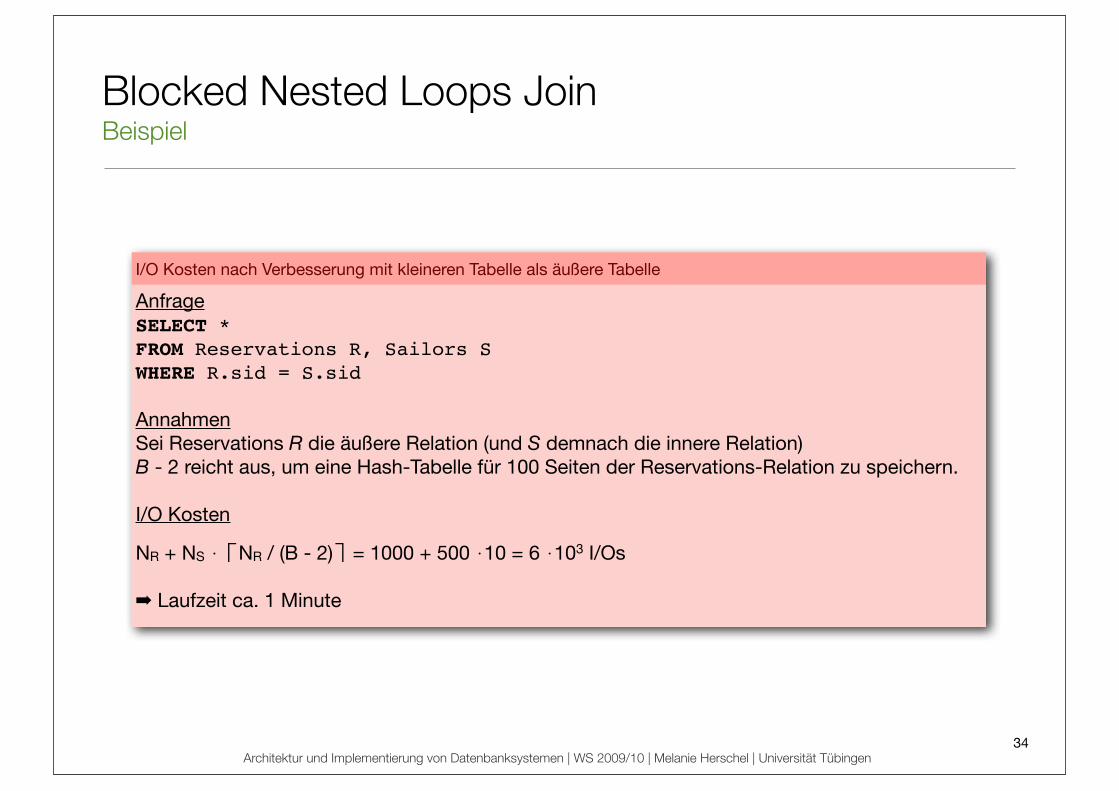
Blocked Nested Loops JoinBeispiel
34
I/O Kosten nach Verbesserung mit kleineren Tabelle als äußere Tabelle
AnfrageSELECT *
FROM Reservations R, Sailors S
WHERE R.sid = S.sid
AnnahmenSei Reservations R die äußere Relation (und S demnach die innere Relation)B - 2 reicht aus, um eine Hash-Tabelle für 100 Seiten der Reservations-Relation zu speichern.
I/O Kosten
NR + NS %⎡NR / (B - 2)⎤= 1000 + 500 %10 = 6 %103 I/Os
! Laufzeit ca. 1 Minute

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Index Nested Loops Join
35
•Bisher haben alle Varianten des NLJ das Kreuzprodukt enumeriert.
•Der Index NLJ vermeidet dies, indem er nur Tupel der äußeren Relation R mit Tupeln der gleichen Partition in der inneren Relation S kombiniert.
•Dies ist durch einen Index über die Join-Attribute der inneren Relation S möglich.
•Wir verwenden im Folgenden die Notation ri für das i-te Attribut der Relation R.
Index Nested Loops Join
function indexnljoin(R, S, p)
foreach Tupel r & R do
foreach Tupel s & S where ri == sj do
Gebe 〈r,s〉 aus ;
Hier verwenden wir den Index über <sj>, um nur die Tupel zu identifizieren, wo sj = ri

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Index Nested Loops JoinI/O Kosten
36
•Es ist weiterhin ein Scan von R nötig, der das Lesen von NR Seiten benötigt.
•Die Kosten, die entsprechenden Tupel aus S zu lesen, hängen von der Art des Index ab, den wir verwenden.
•Für jedes Tupel der Relation R setzten sich die Kosten wie folgt zusammen:
(1)Finden entsprechender Dateneinträge in der Index-Datei
•B+ Index über <sj>: Kosten entsprechen Höhe des Baumes (2 - 4 I/Os)
•Hash-Index über <sj>: Kosten entsprechen Anzahl I/Os, um richtigen Bucket zu finden (1 - 2 I/Os)
(2)Finden der korrekten Tupel in der Daten-Datei
•Clustered Index: typischerweise 1 I/O pro Tupel r & R
•Unclustered Index: bis zu 1 I/O pro Tuple s & S

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Index Nested Loops JoinBeispiel
37
I/O Kosten des Index Nesteld Loops Join
AnfrageSELECT *
FROM Reservations R, Sailors S
WHERE R.sid = S.sid
AnnahmenUnclustered Hash-basierter Index über Reserves.sid, der Dateneintragsvariante (2) nutzt.
I/O Kosten
Sailors ist die äußere Relation ! Scan von NS = 500 I/Os nötig.Insgesamt haben wir 80 x 500 = 40,000 Sailor-Tupel.Für jeden Sailor können wir in 1 - 2 I/Os entsprechende Reservations bestimmen (im Schnitt typischerweise 1.2 I/Os).
! Bisherige Kosten: 500 + 40,000 x 1.2 = 48,500 I/Os.
Zusätzlich müssen wir Tupel, die den Daten-Enträgen im Index entsprechen, bestimmen. Nehmen wir an, die Anzahl Reservations pro Sailor sei konstant ! 2.5 Reservations pro Sailor.Im schlimmsten Fall müssen wir daher für jedes der 2.5 Reservations-Tupel 1 I/O durchführen.
! Zusätzliche Kosten: 40,000 x 2.5 = 100,000 I/Os
! Kosten insgesamt: 48,500 + 100,000 = 148,400 I/Os (ca. 25 Minuten).

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Nested Loops JoinZusammenfassung
38
NLJ-Variante Theoretische Kosten Beispielkosten
Naive NLJ NR + pR %NR %NS 140 Stunden
Improved Naive NLJ
NR + NR %NS 1.4 Stunden
Blocked NLJ NR + NS %⎡NR / (B - 2)⎤ 1 Minute
Index NLJ Je nach Index25 Minuten(worst case)

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
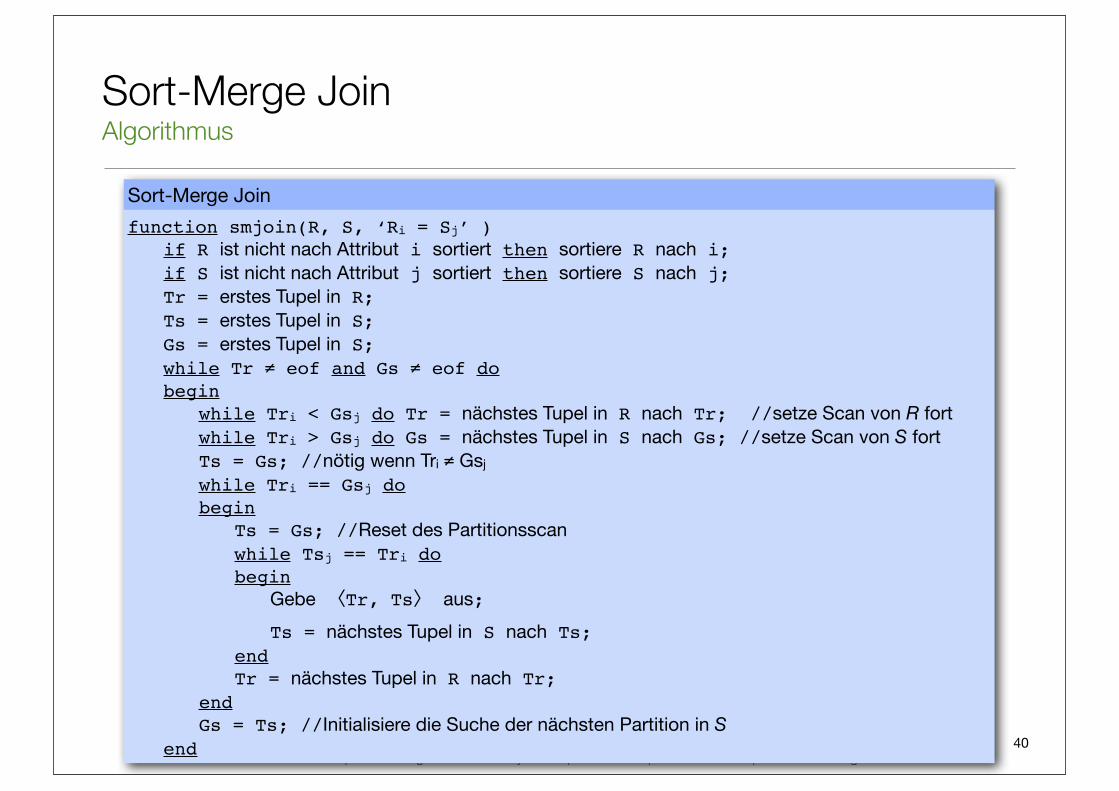
Sort-Merge Join
39
•Grundidee: sortiere R und S nach Join-Attributen und nutze die Sortierung, um nur Tupel, die der Join-Bedingung entsprechen, zu enumerieren.
•Nur nützlich bei Equijoin.
Beispiel zur Funktionsweise von Sort-Merge Join (Join-Bedingung ist Reservations.sid = Sailor.sid)
sid sname rating age
22 dustin 7 45.0
28 yuppy 9 35.0
31 lubber 8 55.5
36 lubber 6 36.0
44 guppy 5 35.0
58 rusty 10 35.0
sid bid day rname
28 103 12/04/96 guppy
28 103 11/03/96 yuppy
31 101 10/10/96 dustin
31 103 10/12/96 lubber
31 101 10/11/96 lubber
58 103 11/12/96 dustin
Sailors Reservations
Nach sid sortiert Nach sid sortiert
Tr Ts
22 < 2828 == 28 ! Ausgabe31 == 31 ! Ausgabe
x 2x 3
36 < 5844 < 58
58 == 58 ! Ausgabe x 1
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Sort-Merge JoinAlgorithmus
40
Sort-Merge Join
function smjoin(R, S, ‘Ri = Sj’ )
if R ist nicht nach Attribut i sortiert then sortiere R nach i;if S ist nicht nach Attribut j sortiert then sortiere S nach j;Tr = erstes Tupel in R;Ts = erstes Tupel in S;Gs = erstes Tupel in S;while Tr # eof and Gs # eof do
begin
while Tri < Gsj do Tr = nächstes Tupel in R nach Tr; //setze Scan von R fortwhile Tri > Gsj do Gs = nächstes Tupel in S nach Gs; //setze Scan von S fortTs = Gs; //nötig wenn Tri # Gsj
while Tri == Gsj do
begin
Ts = Gs; //Reset des Partitionsscanwhile Tsj == Tri do
begin
Gebe 〈Tr, Ts〉 aus;
Ts = nächstes Tupel in S nach Ts;end
Tr = nächstes Tupel in R nach Tr;end
Gs = Ts; //Initialisiere die Suche der nächsten Partition in Send

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Sort-Merge JoinI/O Kosten
41
•Im Allgemeinen müssen wir Tupel einer inneren Partition so oft scannen, wie es Tupel der gleichen Partition in der äußeren Relation gibt.
•Kosten zum Sortieren von R uns S sind jeweis O(Nr log Nr) und O(Ns log Ns)
•Kosten der Mergephase: Nr + Ns, wenn keine der S-Partitionen mehrmals gescannt werden muss.
•Der Worst Case tritt ein, wenn wir S so oft scannen müssen, wie es Tupel in R gibt. Dies tritt nur dann auf, wenn alle Werte beider Join-Attribute identisch sind. Dieser Fall ist äußerst selten.
•In der Praxis sind die Kosten der Mergephase oft Nr + Ns, da dieser Fall eintritt sobald eines der Join-Attribute eindeutige Werte enthält. Dies ist z.B. bei den sehr häufig auftretenden Joins über Primärschlüssel und Fremdschlüssel der Fall.
Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
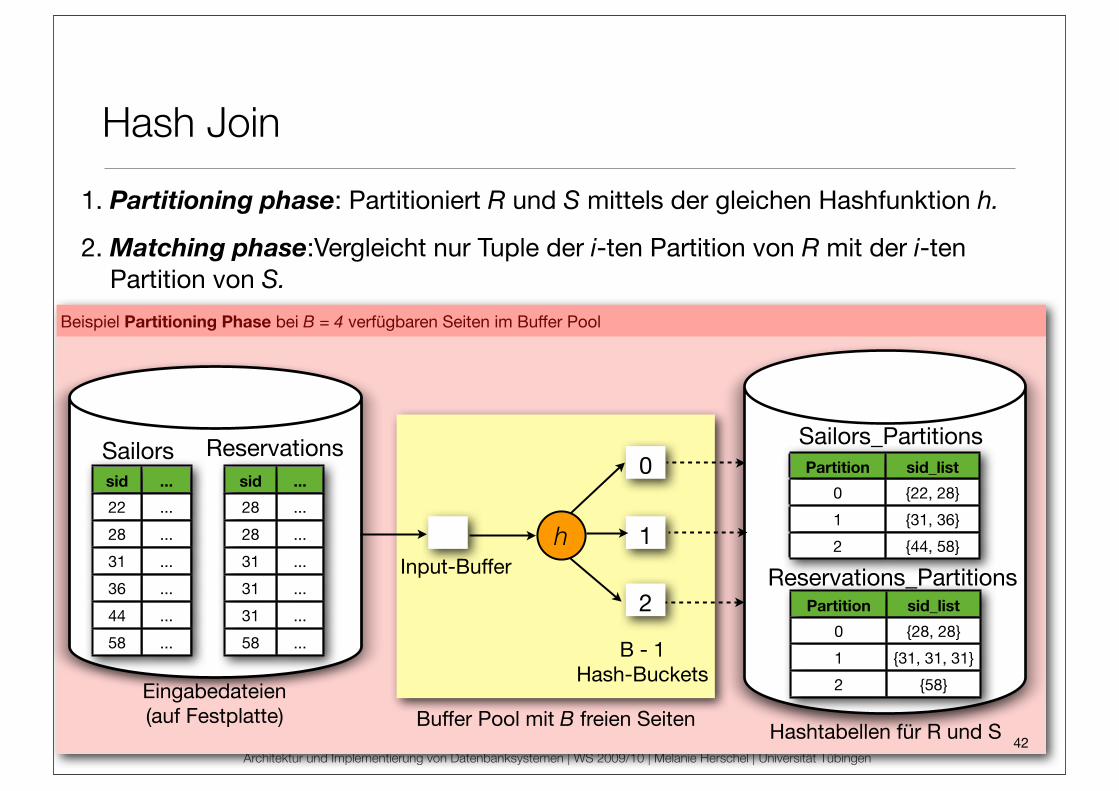
Beispiel Partitioning Phase bei B = 4 verfügbaren Seiten im Buffer Pool
Hash Join
42
1. Partitioning phase: Partitioniert R und S mittels der gleichen Hashfunktion h.
2. Matching phase:Vergleicht nur Tuple der i-ten Partition von R mit der i-ten Partition von S.
sid ...
22 ...
28 ...
31 ...
36 ...
44 ...
58 ...
sid ...
28 ...
28 ...
31 ...
31 ...
31 ...
58 ...
Sailors Reservations
Eingabedateien(auf Festplatte) Buffer Pool mit B freien Seiten
0
Input-Buffer
B - 1Hash-Buckets
1
2
h
Sailors_Partitions
Reservations_Partitions
Partition sid_list
0 {22, 28}
1 {31, 36}
2 {44, 58}
Partition sid_list
0 {28, 28}
1 {31, 31, 31}
2 {58}
Hashtabellen für R und S

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen 43
Beispiel Matching Phase bei B = 4 verfügbaren Seiten im Buffer Pool
Hash Join
1. Partitioning phase: Partitioniert R und S mittels der gleichen Hashfunktion h
2. Matching phase:Vergleicht nur Tuple der i-ten Partition von R mit der i-ten Partition von S.
Sailors_Partitions
Reservations_Partitions
Partition sid_list
0 {22, 28}
1 {31, 36}
2 {44, 58}
Partition sid_list
0 {28, 28}
1 {31, 31, 31}
2 {58}
Hashtabellen für R und S Buffer Pool mit B freien Seiten
Input-Buffer(zum Scannen
einer Partition PSi )
Hash-Tabelle für Partition PRi
( B - 2 Seiten, mit h2 $ h gehasht)
Output-Buffer
Join-Ergebnis
sidS ... sidR ...
28 ... 28 ...
28 ... 28 ...
31 ... 31 ...
31 ... 31 ...
31 ... 31 ...
58 ... 58 ...
Join Part. 0
Join Part. 1
Join Part. 2
{22, 28}
{28, 28}

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Hash JoinI/O Kosten
44
1.Partitioning Phase benötigt einmaliges Lesen und Schreiben von R und S! 2 (NR + NS)
2.Matching Phase
• Nehmen wir an, dass jede Partition in den zur Verfügung stehenden Hauptspeicher passt, d.h., es tritt kein partition overflow auf.
• In diesem Fall muss jede Partition (von R wie auch von S) nur einmal gelesen werden.
! (NR + NS)
!Gesamtkosten: 3 (NR + NS)
Kosten anhand unseres Sailor-Reservation Beispiels

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Hash JoinAlgorithmus
45
Hash Join
function hjoin(R, S, ‘Ri = Sj’ )
//Partition Phaseforeach Tuple r & R do
Lese r und schreibe h(ri) in Output-Buffer; //Output auf Platte geschrieben wenn Buffer vollforeach tuple s & S do
Lese s und schreibe h(sj) in Output-Buffer; //Output auf Platte geschrieben wenn Buffer voll
//Matching Phasefor l = 1, ..., k do
begin
//initialisiere Hashtabelle im Hauptspeicher für R-Partitionforeach Tupel r & Partition PRl do
Lese r und füge es in Hauptspeicher-Hashtabelle mittels h2(ri) ein;
//Scan der entsprechenden S-Partition und Ausgabe matchender Tupelforeach Tupel s & Partition PSl do
begin
Lese s und identifiziere matchende R-Partition mittels h2(sj);Für alle Tupelpaare, für die sj == ri gilt, gebe 〈r,s〉 aus;
end
end

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Hash JoinSpeicheranforderungen
46
• Annahme: jede Partition passt in den zur Verfügung stehenden Hauptspeicher.
• Maximieren der Anzahl Partitionen, um Chancen zu erhöhen, dass eine Partition in den Hauptspeicher passt.
• In der Partitioning Phase von R (und S) benötigen wir für k Partitionen k Input-Buffer ! Gegeben B Buffer Seiten, ist die maximale Anzahl Partitionen k = B - 1.
• Angenommen, jede Partition ist gleich groß, so ist die Größe einer Partition von R gleich PR = NR / (B - 1).
• Eine Hashtabelle für eine Partition der Größe PR benötigt ein wenig mehr Speicherplatz. Sei f der Faktor (genannt fudge factor), um den die Hashtabelle größer ist.
• Während der Matching Phase soll jede Partition von R in den dafür vorgesehenen Hauptspeicher passen. Daher benötigen wir einen Input-Buffer der Größe B > (f % NR) / (B - 1). Zusätzlich benötigen wir noch einen Input-Buffer für S und einen Output-Buffer.
• Aus diesen Betrachtungen ergibt sich, dass B > $(f % NR)

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Hash JoinHandhabung von Partition Overflows
47
• Tatsächlich ist es unwahrscheinlich, ,dass alle Partitionen gleich groß sind. Daher benötigen wir in Wirklichkeit B > (f % PMax,R) + 2, wobei PMax,R die Anzahl Seiten der größten Partition beschreibt.
• Was passiert, wenn nicht genügend Hauptspeicher zur Verfügung steht und somit ein Partition Overflow eintritt?
!Ähnlich wie bei hashbasierter Projektion können wir rekursiv Hashfunktionen zum Partitionieren aufrufen, bis die Partitionen klein genug sind.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Hash Join vs. Block Nested Loops Join
48
• Fall 1: Die komplette Hashtabelle der kleineren Relation R passt in den Hauptspeicher ! die I/O Kosten beider Algorithmen sind identisch (NR + NS).
• Fall 2: Sind beide Relationen R und S größer als ihre entsprechenden Input-Buffer, unterscheiden sich beide Algorithmen wie folgt.
• Block NLJ benötigt für jeden Block von R einen Scan über S.
• Hash Join benötigt für jede Partition von R einen Scan über die entsprechende Partition von S.
PR0
PR1
PR2
PR3
PS0 PS1 PS2 PS3
Partitionenvon R
Partitionen von S
verglichene Partitionen beiBlock NLJ
verglichene Partitionen beiHash Join

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
49

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Mengen-Operatoren
50
• Wir betrachten die Mengenoperatoren R # S, R # S, R $ S, R % S. Wir nehmen im Folgenden an, dass R und S selbst Mengen sind, die keine Duplikate enthalten.
• Aus Implementierungssicht sind die Schnittmenge (#) und das Kreuzprodukt (%) Spezialfälle von Join.
• Die Schnittmenge entspricht einem Equijoin über alle Attribute von R und S.
• Das Kreuzprodukt entspricht einem Join ohne Joinbedingung p.
• Für die Vereinigung ($) und die Mengendifferenz (&) ist das wesentliche Konzept die Duplikateliminierung. Wie wir bei der Implementierung der Projektion bereits gesehen haben, können wir dies mittels Sortierung oder Hashing bewerkstelligen.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Vereinigung und MengendifferenzBasierend auf Sortierung
51
Vereinigung
1.Sortiere R, indem der Sortierschlüssel aus allen Attributen der Relation R besteht.
2.Sortiere S analog.
3.Scanne die sortierten Relationen R und S parallel und führe diese zusammen indem Duplikate entfernt werden.
Verbesserung durch zusammenlegen der Sortierungs- und Merge-Phase
Mengendifferenz
1.Sortiere R und S (Schritt 1 und 2 der Vereinigung).
2.Scanne die sortierten Relationen R und S parallel und gebe nur Tupel von R aus, die nicht in S vorkommen.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Vereinigung und MengendifferenzBasierend auf Hashing
52
Vereinigung
1.Partitioniere R und S basierend auf einer Hashfunktion h.
2.Für jede Partition l
a.Baue eine Hashtabelle im Hauptspeicher für Sl auf. Verwende dabei eine Hashfunktion h2 & h.
b.Scanne Rl. Für jedes Tupel, suche nach entsprechendem Tupel in Sl. Ist das Tupel in der Hashtabelle, verwerfe es, ansonsten füge es der Tabelle hinzu.
c.Schreibe die Hashtabelle auf die Festplatte und leere den Buffer für die nächste Iteration.
Mengendifferenz
1.Partitioniere R und S basierend auf einer Hashfunktion h.
2.Für jede Partition l
a.Baue eine Hashtabelle im Hauptspeicher für Sl auf. Verwende dabei eine Hashfunktion h2 & h.
b.Scanne Rl. Für jedes Tupel, suche nach entsprechenden Tupeln in Sl. Ist das Tupel nicht in der Hashtabelle, so schreibe es in die Ausgabe.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
53

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Aggregation
54
Beispiel einer Anfrage mit Aggregation
SELECT AVG(S.age)
FROM Sailors S
Beispiel einer Anfrage mit Aggregation und Gruppierung
SELECT AVG(S.age)
FROM Sailors S
GROUP BY Rating
• Um eine Aggregation zu berechnen, wird die Eingabetabelle R gescannt und während des Scans wird laufende Information gespeichert um das Endergebnis zu berechnen ! O(NR) I/Os
• Wird zusätzlich gruppiert (GROUP BY Klausel), gibt es drei Varianten.
• Variante 1: Sortierung von R und Speichern der laufenden Information für jede Gruppe. ! O(NR log NR) I/Os
• Variante 2: Hashing über Gruppierungs-Attribut ! O(NR) I/Os
• Variante 3: Verwendung eines B+ Index, wenn index-only-evaluation möglich
! O(LR) I/Os, wobei LR Anzahl Seiten auf der Blattebene des Index.
Aggregations-
Operator
Laufende Information, die
beim Scan gespeichert wird
SUM Summe gelesener Werte
AVGSumme und Anzahl
gelesener Werte
COUNT Anzahl gelesener Werte
MIN Kleinster gelesener Wert
MAX Größter gelesener Wert

Architektur und Implementierung von Datenbanksystemen | WS 2009/10Melanie Herschel | Universität Tübingen
Kapitel 7Evaluation Relationaler Operatoren
• Überblick
• Selektion
• Projektion
• Join
• Mengen-Operatoren
• Aggregation
• Operator Pipelining
55

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Bearbeitung allgemeiner Anfragen
56
• Bisher haben wir angenommen, dass jeder Datenbankoperator Dateinen als Eingabe liest und Dateien als Ausgabe schreibt.
· · ·
· · ·!"
file1
!
file2
"
file3
· · ·
filen
!
• Die Verwendung des Sekundärspeichers als Kommunikationskanal führt zu häufigem Disk I/O.
• Zusätzlich führt dies zu langen Antwortzeiten, denn
• Ein Operator kann keine Berechnungen beginnen, bevor der vorangehende Operator nicht alle Eingabedaten verarbeitet hat und die Ausgabedatei nicht vollständig geschrieben (materialisiert) wurde.
• Effektiv werden alle Operatoren hintereinander ausgeführt.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Pipelined Evaluation
57
• Alternativ kann ein Operator sein Ergebnis direkt an den nächsten Operator
weitergeben (ohne dieses in einer Datei zu materialisieren).
! Operator muss nicht auf die Fertigstellung einer Datei warten, er kann stattdessen sofort Tupel einlesen und seine Ausgabe sofort weiter propagieren.
! Ergebnisse können so früh wie möglich berechnet werden, d.h. sobald genügend Eingabedaten vorhanden sind um Ausgabetupel zu berechnen.
• Diese Idee wird als Pipelining bezeichnet.
• Die Granularität der weitergegebenen Information kann die Laufzeit beeinflussen:
• Kleinere Informationseinheiten verringern die Antwortzeit des Systems.
• Größere Informationseinheiten können die Effektivität von Caches verbessern.
• Kommerzielle Systeme verwenden in der Regel Tupel als
Informationseinheit.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Das Volcano Iterator Modell
58
• Das Interface zur Operatorevaluation in RDBMS wird open-next-close-
interface oder Volcano Iterator Modell genannt.
• Jeder Operator implementiert die folgenden Funktionen:
• open(): Initialisiere den internen Status eines Operators.
• next(): Berechne das nächste Ergebnistupel und gebe dieses aus. Wurde bereits das gesamte Ergebnis berechnet, gebe eof zurück.
• close(): Gebe alle alloziierten Resourcen wieder frei (typischerweise nachdem alle Tuple verarbeitet wurden).
• Jeder Bearbeitungsstatus wird in einer Operartorinstanz selbst gespeichert.
• Operatoren müssen Tupel via next() produzieren, dann pausieren, und später ihre Arbeit im nächsten next() Aufruf wieder aufnehmen.
Weitherführende Literatur
Goetz Graefe. Volcano—An Extensibel and Parallel Query Evaluation System. Trans. Knowl. Data Eng. vol. 6, no. 1, February 1994.

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Volcano-Style Anfragebearbeitung
59
Beispiel eines pipelined Anfrageplans
Bespielanfrage:
Der Anfrageprozessor bearbeitet die Beispielanfrage wie folgt:
1. Der gesamte Anfrageplan wir zunächst zurückgesetzt, indem die open() Methode des Wurzeloperators (hier !q) aufgerufen wird.
2. Der Aufruf von open() wird durch den Plan weitergeleitet, sodass am Ende jeder Operator initialisiert ist.
3. Die Kontrolle wird an den Anfrageprozessor zurückgegeben.
4. Dieser ruft nun die next() Methode des Wurzeloperators auf.
5. Auch der Aufruf der next() Methode wird von jedem Operator an seine Kindoperatoren weitergegeben, falls nötig.
6. Sobald ein Ergebnistupel produziert wurde, geht die Kontrolle wieder an den Anfrageprozessor. Dieser ruft entweder next() (Schritt 4) auf, oder close(), falls eof zurückgegeben wurde.
Evaluation ofRelational Operators
Torsten Grust
Relational QueryEnginesOperator Selection
Selection (!)Selectivity
Conjunctive Predicates
Disjunctive Predicates
Projection (")
Join (!")Nested Loops Join
Block Nested Loops Join
Index Nested Loops Join
Sort-Merge Join
Hash Join
Operator PipeliningVolcano Iterator Model
8.52
Volcano-Style Pipelined Evaluation
Example (Pipelined query plan)
R1 !! scan""!!!!!"p !!!l !!"q !!
R2 !! scan##""""
• Given a query plan like the one shown above, queryevaluation is driven by the query processor like this (just likein the Unix shell):
1 The whole plan is initially reset by calling open () onthe root operator, i.e., "q.open ().
2 The open () call is forwarded through the plan by theoperators themselves (see ".open () on slide 54).
3 Control returns to the query processor.4 The root is requested to produce its next result record,
i.e., the call "q.next () is made.5 Operators forward the next () request as needed. As
soon as the next result record is produced, controlreturns to the query processor again.
Anfrageevaluation einer Anfrage q durch den Anfrageprozessor
function eval(q)
q.open();
r " q.next();
while r # eof do
begin
output(r);
r " q.next();
end
q.close();

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Volcano-Style Selektion
60
Volcano-style Interface für !P(R)
function open()
R.open();
function close()
R.close();
function next();
while (r " R.next()) # eof do
if p(r) then return r;
return eof;

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Volcano-Style Nested Loops Join
61
Eine Volcano-Style Implementierung von R JoinP S

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Blockierende Operatoren
62
• Pipelining reduziert sowohl den Speicherbedarf als auch die Antwortzeit, da jedes Tupel sofort propagiert wird.
• Leider unterstützen nicht alle Operatoren dieses Pipelining-Prinzip. Solche Operatoren nennen wir blockierende Operatoren (blocking operators).
• Blockierende Operatoren konsumieren ihre gesamte Eingabe, bevor sie ihre Ausgabe produzieren können.
• In diesen Fällen werden die Daten tatsächlich auf der Festplatte materialisiert.
Welche, in der Vorlesung besprochenen Operatoren sind blockierende Operatoren?

Architektur und Implementierung von Datenbanksystemen | WS 2009/10 | Melanie Herschel | Universität Tübingen
Zusammenfassung
63
Logische vs. physische Operatoren
•Für einen logischen Operator existieren im Allgemeinen mehrere Implementierungen.
•Je nach Systemstatus variiert potentiell der Zugriffspfads mit der geringsten Selektivität.
Implementierung relationaler Operatoren
•Selektion, Projektion, Join, Mengen-Operatoren, Aggregation.
•Wesentliche Techniken: Iterative Ansätze, Sortierung und Hashing (Partitionierung), Verwendung vorhandener Indizes.
Operator Pipelining
•Eine relationale Anfrage kann als Graph relationaler Operatoren dargestellt werden.
•Wir sparen uns wenn möglich das Anlegen temporärer Dateien, indem wir Tupel direkt von einem Operator zum nächsten weitergeben (Volcano Iterator Modell).
•Einige Operatoren sind blockierend und lassen kein Pipelining zu.

















![Übung Datenbanksysteme I Relationale Algebra - hpi.de · Thorsten Papenbrock | Übung Datenbanksysteme I – Relationale Algebra 5 Modellnummer Prozessorgeschwindigkeit [MHz] Festplattengröße](https://static.fdokument.com/doc/165x107/5d670d8088c9931d358b8071/uebung-datenbanksysteme-i-relationale-algebra-hpide-thorsten-papenbrock-.jpg)
