Die Bedeutung von Performance - fileVO Rechnerarchitekturen / Performance A. Steininger 2 Überblick...
36
VO Rechnerarchitekturen / Performance A. Steininger 1 Die Bedeutung von Performance
-
Upload
trinhtuong -
Category
Documents
-
view
224 -
download
0
Transcript of Die Bedeutung von Performance - fileVO Rechnerarchitekturen / Performance A. Steininger 2 Überblick...

VO Rechnerarchitekturen / PerformanceA. Steininger
1
Die Bedeutung von
Performance

VO Rechnerarchitekturen / PerformanceA. Steininger
2
Überblick
verstehenPERFORMANCE richtig bestimmen
angeben
– Entscheidungen bei Kauf, Design, Optimierung– optimale Nutzung der HW bei Programmierung– besseres Verständnis für Rechnerarchitekturen
VO Rechnerarchitekturen / PerformanceA. Steininger
3
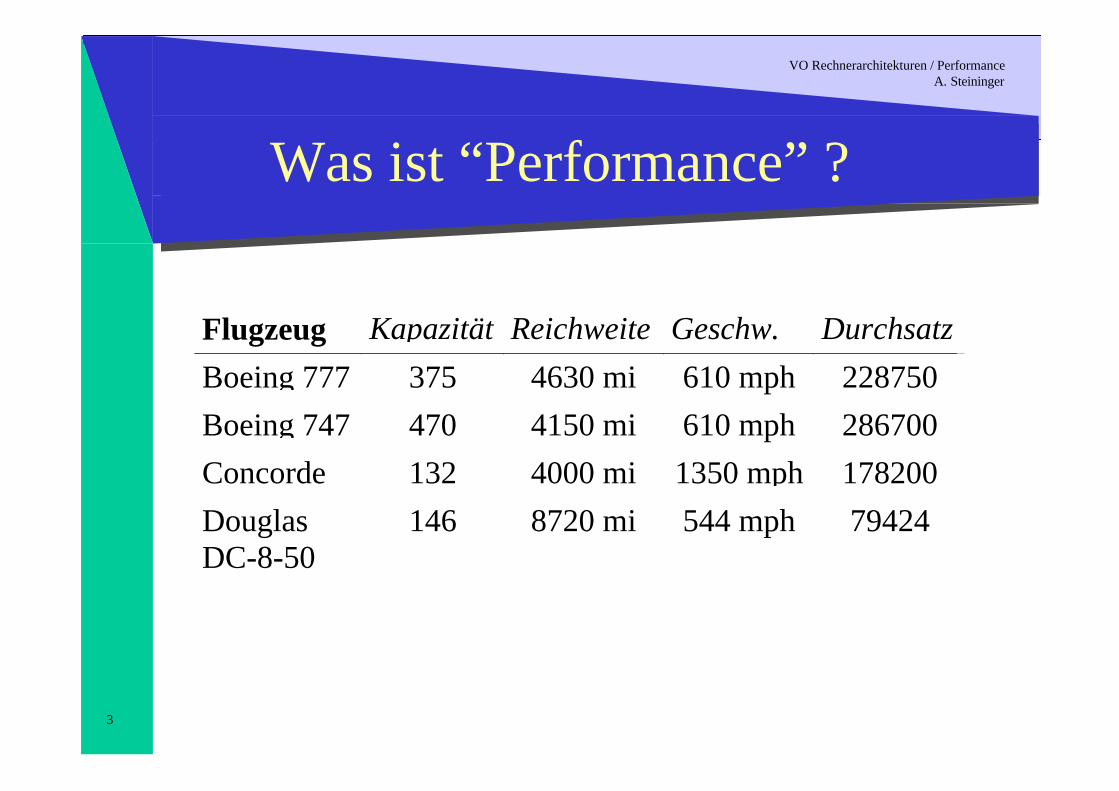
Was ist “Performance” ?
Flugzeug Kapazität Reichweite Geschw. DurchsatzBoeing 777 375 4630 mi 610 mph 228750Boeing 747 470 4150 mi 610 mph 286700Concorde 132 4000 mi 1350 mph 178200DouglasDC-8-50
146 8720 mi 544 mph 79424

VO Rechnerarchitekturen / PerformanceA. Steininger
4
Kenngrößen für Performance
• Antwortzeit (incl. Wartezeit)
– gesamt (incl. Periph.)
• Ausführungszeit – CPU-time (incl. OS)– user CPU-time
• Durchsatz
– Was verbessert ein schnellerer / 2. Prozessor?

VO Rechnerarchitekturen / PerformanceA. Steininger
5
Durchsatz vs. Antwortzeit
Beispiel Schilift:zwei Sessel alle 15 sFahrtzeit 10 min
– Durchsatz in Personen/h = – Zeitaufwand für eine Bergfahrt = /– Verbesserung durch Vierersessel ?

VO Rechnerarchitekturen / PerformanceA. Steininger
6
Definition von Performance
“relative” Performance:
PerformanceAusführungszeitX
X
=1
PerformancePerformance
AusführungszeitAusführungszeit
nX
Y
Y
X
= =

VO Rechnerarchitekturen / PerformanceA. Steininger
7
Beispiel: Relative Performance
Rechner A benötigt für ein Programm 10 s, Rechner B für das selbe Programm 15 s.
Rechner A ist also 15/10 = 1,5 mal (50%)schneller als Rechner B

VO Rechnerarchitekturen / PerformanceA. Steininger
8
Taktzyklen statt Echtzeit
Ausführungszeit = benötigte * Takt-für ein Programm Taktschritte periode
Ausführungszeit = benötigte / Takt-für ein Programm Taktschritte rate
• Wodurch kann daher Performance verbessert werden ?

VO Rechnerarchitekturen / PerformanceA. Steininger
9
Beispiel: Performance-Steigerung
Rechner A hat 400MHz Takt. Unser Lieblingsprogramm benötigt dort 10s. Wir helfen einem Computerdesigner beim Bau eines Rechners, der das Programm in 6s abarbeiten kann. Der Designer meint, man könne die Taktrate wesentlich erhöhen, wenn man zuläßt, daß der neue Rechner B um 20% mehr Taktzyklen zur Abarbeitung des Programmes benötigt. Welche Taktrate muß daher erreicht werden?

VO Rechnerarchitekturen / PerformanceA. Steininger
10
CPI: “Clocks per instruction”
Wieviele Taktschritte benötigt ein Programm?
– Nicht jeder Maschinenbefehl kann in einemTaktschritt abgearbeitet werden:
• Multiplikation, Division,• Gleitkomma-Arithmetik• Speicherzugriffe
– Angabe einer “mittleren” Anzahl von Taktschritten je Befehl: CPI
VO Rechnerarchitekturen / PerformanceA. Steininger
11
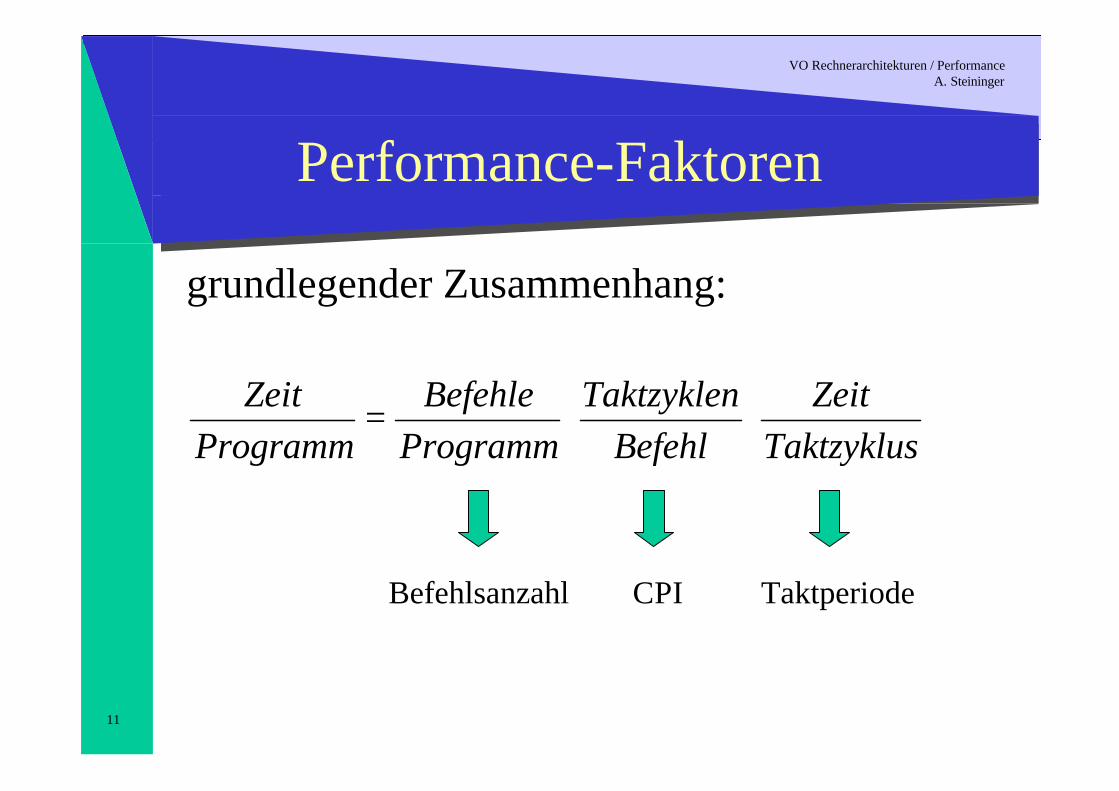
Performance-Faktoren
grundlegender Zusammenhang:
Befehlsanzahl CPI Taktperiode
ZeitProgramm
BefehleProgramm
TaktzyklenBefehl
ZeitTaktzyklus
= ⋅ ⋅

VO Rechnerarchitekturen / PerformanceA. Steininger
12
Performance-Optimierung
• höhere Taktrate (Technologie, Implementierg.)
• geringere CPI (Organisation, Compiler)
• weniger Befehle pro Applikation bzw. Befehle mit geringerer CPI (Compiler)
– einseitige Verbesserung eines Faktors ist selten möglich, meist sind Kompromisse erforderlich

VO Rechnerarchitekturen / PerformanceA. Steininger
13
Beispiel: Performance-Vergleich
• Prozessor A: – Taktzyklus = 1ns– CPI = 2.0 für Programm X
• Prozessor B: – Taktzyklus = 2ns
– CPI = 1.2 für Programm X– gleicher Befehlssatz wie A
Welcher Prozessor ist schneller, um wieviel ?

VO Rechnerarchitekturen / PerformanceA. Steininger
14
Berechnung der CPI
gewichteter Mittelwert aller individuellenCPIs der Befehle im Programm:
Befehle der Klasse i mit CPIi kommen im betrachteten Programm Ci mal vor
CPICPI C
C
i ii
n
ii
n=⋅
=
=
∑
∑
( )1
1

VO Rechnerarchitekturen / PerformanceA. Steininger
15
Beispiel: CPI-Berechnung
• Prozessor:
• Compiler:
Welcher Code ist schneller ?
Befehlsklasse A B CCPI 1 2 3
Häufigkeit der KlasseCode A B C
X 2 1 2Y 4 1 1

VO Rechnerarchitekturen / PerformanceA. Steininger
16
Der ideale Benchmark
• Echtes Anwenderprogrammunbestechlich aber anwenderabhängig
• Einfaches Programmeinfach nachvollziehbar aber “betrugsanfällig”
• SPEC (System Performance Evaluation Cooperative)
allgemein akzeptierter Kompromiß
VO Rechnerarchitekturen / PerformanceA. Steininger
17
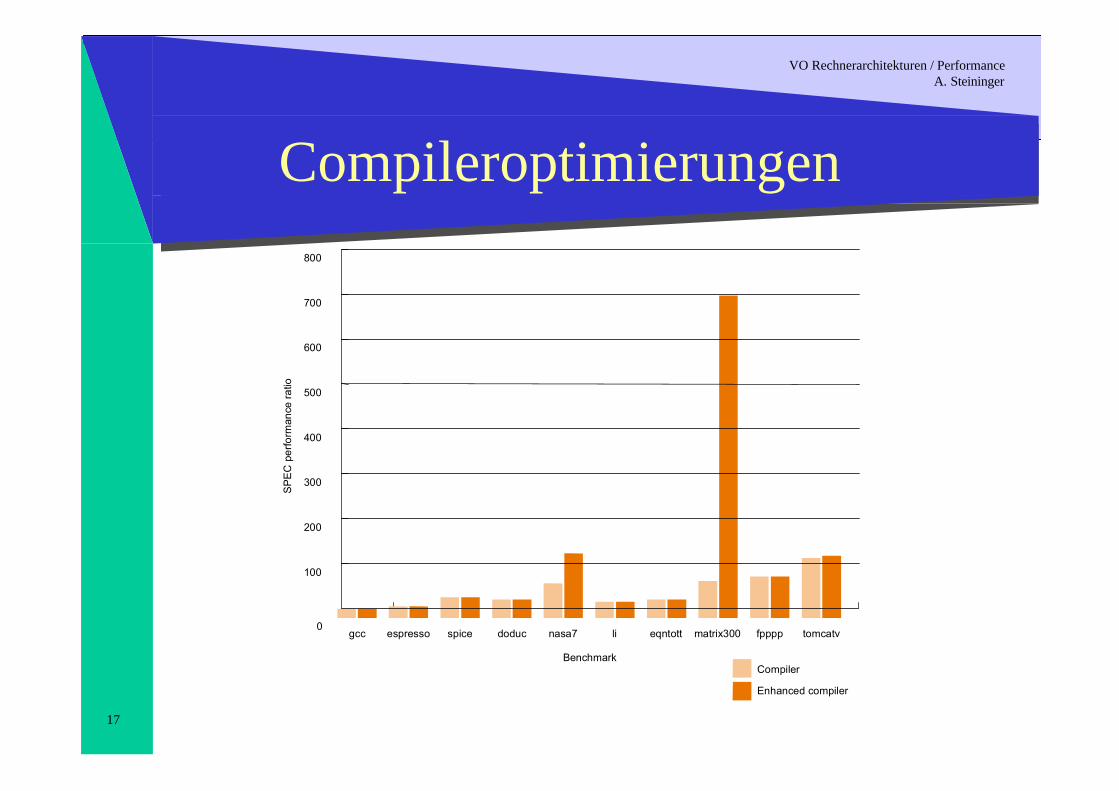
Compileroptimierungen
0
100
200
300
400
500
600
700
800
tomcatvfppppmatrix300eqntottlinasa7doducspiceespressogcc
BenchmarkCompiler
Enhanced compiler
SP
EC
per
form
ance
rat
io
VO Rechnerarchitekturen / PerformanceA. Steininger
18
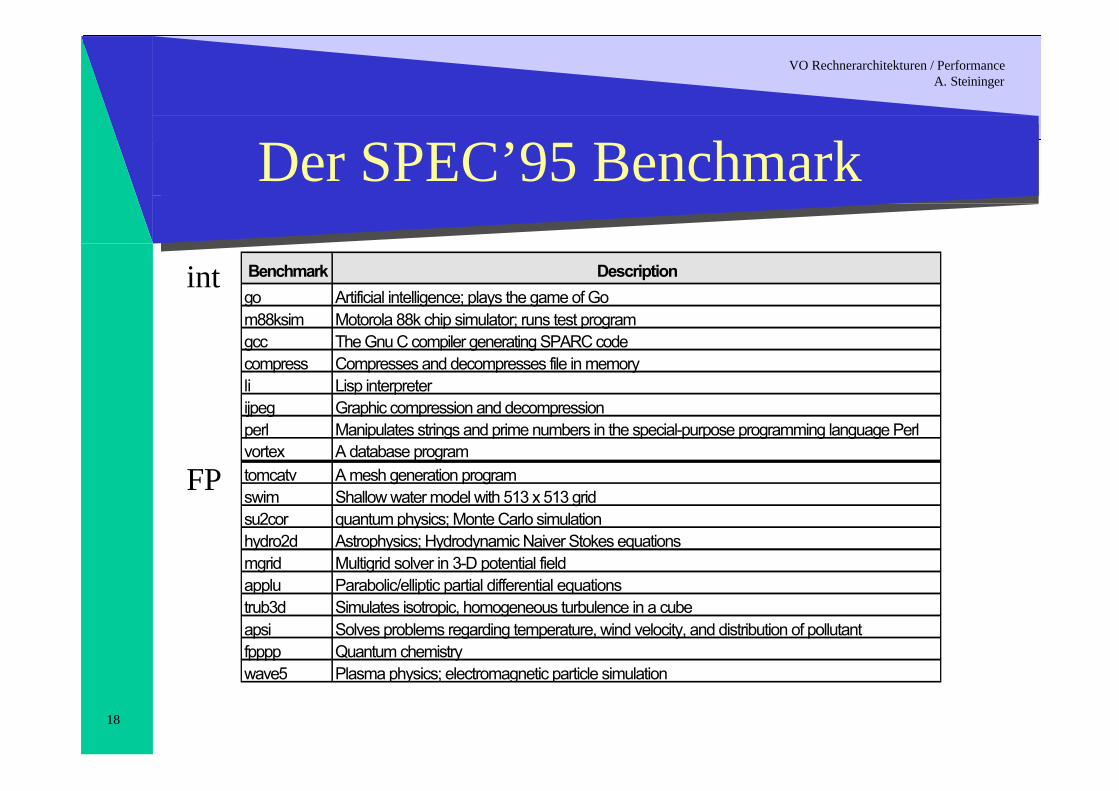
Der SPEC’95 Benchmark
Benchmark Description
go Artificial intelligence; plays the game of Gom88ksim Motorola 88k chip simulator; runs test programgcc The Gnu C compiler generating SPARC codecompress Compresses and decompresses file in memoryli Lisp interpreterijpeg Graphic compression and decompressionperl Manipulates strings and prime numbers in the special-purpose programming language Perlvortex A database programtomcatv A mesh generation programswim Shallow water model with 513 x 513 gridsu2cor quantum physics; Monte Carlo simulationhydro2d Astrophysics; Hydrodynamic Naiver Stokes equationsmgrid Multigrid solver in 3-D potential fieldapplu Parabolic/elliptic partial differential equationstrub3d Simulates isotropic, homogeneous turbulence in a cubeapsi Solves problems regarding temperature, wind velocity, and distribution of pollutantfpppp Quantum chemistrywave5 Plasma physics; electromagnetic particle simulation
int
FP
VO Rechnerarchitekturen / PerformanceA. Steininger
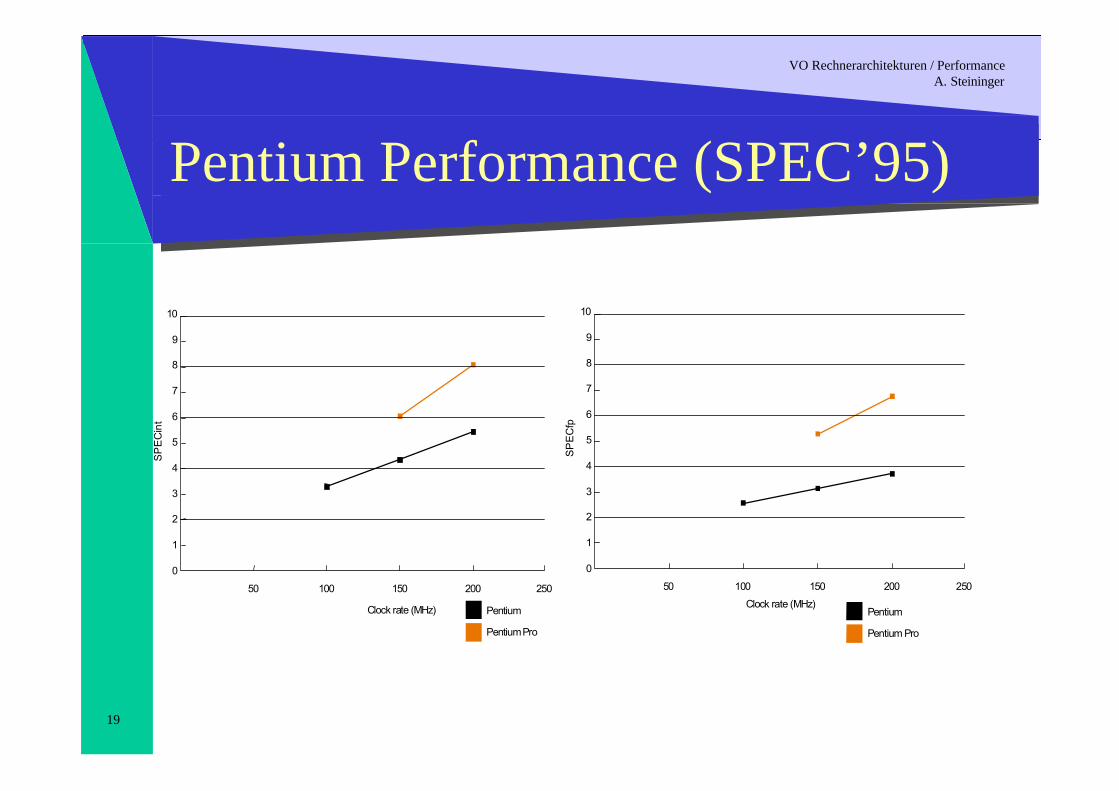
19
Pentium Performance (SPEC’95)
Clock rate (MHz)
SP
EC
int
2
0
4
6
8
3
1
5
7
9
10
200 25015010050
Pentium
Pentium Pro
PentiumClock rate (MHz)
SP
EC
fp
Pentium Pro
2
0
4
6
8
3
1
5
7
9
10
200 25015010050

VO Rechnerarchitekturen / PerformanceA. Steininger
20
“Gesamt”-Performance
• Beispiel:
=> Der einfachste Weg zur Zusammenfassung mehrerer Einzelmessungen ist das arithmetische Mittel der nicht normierten (!)
Ausführungszeiten:
Computer A Computer BProg 1 1 s 10 sProg 2 1000 s 100 sSumme 1001 s 110 s
1
1nTi
i
n
⋅=∑

VO Rechnerarchitekturen / PerformanceA. Steininger
21
Beispiel: Teiloptimierung
Die Ausführungszeit eines Programms beträgt100 s, davon entfallen 80 s auf Multiplikations-befehle.Um wieviel muß die Multiplikation beschleunigt werden, damit das Programm
(a) 4 mal schneller und(b) 5 mal schneller läuft?

VO Rechnerarchitekturen / PerformanceA. Steininger
22
Amdahl’sches Gesetz
Optimierte Ausführungszeitoptimierter Zeitanteil
Verbesserungsfaktorrestl. Zeitanteil= +
Konsequenz:
Optimiere den häufigsten Fall !

VO Rechnerarchitekturen / PerformanceA. Steininger
23
Beispiel: Amdahl’sches Gesetz
Ein Rechner benötigt in einer Applikation 30% der Ausführungszeit für FP-Multiplikation und 8% FP-Division. Bei einem Redesign stellen sich die beiden folgenden Designalternativen:– FP division 8-fach beschleunigen oder– FP-Multiplikation 2-fach beschleunigen.
Welche Variante ist günstiger ?

VO Rechnerarchitekturen / PerformanceA. Steininger
24
Verbreitete Performance-Maße
– native: “million instructions per second”
MIPS – peak: MIPS für Code mit min CPI– relative: bezogen auf Referenzrechner
MOPS = “million operations per second”
MFLOPS = “million FP operations per second”
Whetstone, Dhrystone,... synthet. Benchmarks
Linpack, Livermore,... Kernel-Benchmarks

VO Rechnerarchitekturen / PerformanceA. Steininger
25
Beispiel: Native MIPS
Zwei unterschiedliche Compiler generieren für die gleiche Applikation folgende Befehlssequenzen:
Welcher Code ist schneller, wie sind die entsprechenden native MIPS bei 500MHz Prozessortakt?
Häufigkeit d. BefehlsklassenCode von 1 CPI 2 CPI 3 CPICompiler 1 5*109 1*109 1*109
Compiler 2 10*109 1*109 1*109

VO Rechnerarchitekturen / PerformanceA. Steininger
26
Der Kostenaspekt
• Zielgruppe für das Produkt ?– High-performance-Designs (supercomputer)– Ausgewogene Designs (PC, Workstation)– Low-cost-Designs (Nintendo, “Embedded”)
• weitere Kostenfaktoren:Entwicklung & Test, Packaging, Peripherie, Time-to-market

VO Rechnerarchitekturen / PerformanceA. Steininger
27
Zusammenfassung
• Erfassung von Performance ist eine wichtige Aufgabe• Zeit ist das objektivste Performance-Maß• Performance ist abhängig vom gewählten Programm• Reale Applikationen sind die besten Benchmarks• Performance-optimierung erfolgt im Spannungsfeld
zwischen Taktrate, CPI und Befehlsanzahl• Herstellerangaben über Performance sind oft verzerrt• Optimiere den häufigsten Fall (Amdahl’sches Gesetz)• Ein Trade-off zwischen Kosten und Performance ist nötig

VO Rechnerarchitekturen / PerformanceA. Steininger
28
B1: Preis/Leistung
Vergleichen Sie die Performance von zwei Rechnersystemen
S1 ATS 90.000S2 ATS 145.000
Folgende Ergebnisse wurden gemessen:
Programm Laufzeit auf S1 Laufzeit auf S21 11 s 5 s2 4 s 4 s

VO Rechnerarchitekturen / PerformanceA. Steininger
29
B1: Preis/Leistung
a) Welches System ist kostengünstiger (Preis / Leistung), wenn Programm 1 und Programm 2 je einmal ausgeführt werden? Um wieviel (in Prozent)?
b) Programm 1 verbringt 30% der Rechenzeit mit Integer Befehlen, 47% mit Load und Store Befehlen und 23% mit anderen Befehlen. Eine neue Version von S1 ist bei gleichen Kosten bei Integer Befehlen doppelt so schnell und bei Loadund Store Befehlen um 60% schneller. Welches der beiden Systeme ist kostengünstiger (Preis / Leistung), wenn nur Programm 1 ausgeführt wird?

VO Rechnerarchitekturen / PerformanceA. Steininger
30
L1: Preis/Leistung
a) PL1/PL2 = (90000*(11+4))/(145000*(5+4))=1.034
S2 ist kostengünstiger um 3.4%.
b) Laufzeit = 11s: 30% = 3.3s, 47% = 5.17s, 23% = 2.53s. Neue Laufzeit: 3.3s/2+5.17s/1.6+2.53s = 7.41s.PL1/PL2 = (90000*7.41)/(145000*5) = 0.92
S1 ist kostengünstiger.

VO Rechnerarchitekturen / PerformanceA. Steininger
31
B2: Performance-ISA
Von einem Instruktionssatz gibt es die Implementierung M1 und M2. Es gibt vier Klassen von Instruktionen in diesem Instruktionssatz:
K lasse C P I M 1[50M H z]
C P I M 2[75 M H z]
Häufigkeit
A 1.4 2 40%B 2 1.7 43%C 5.2 4 11%D 1 8 6%

VO Rechnerarchitekturen / PerformanceA. Steininger
32
B2: Performance-ISA
Aufgabenstellung:
a) Geben Sie die Peak MIPS für beide Implementierungen an!
b) Bei welcher Taktfrequenz hätte Maschine M1 dieselbe PeakPerformance wie die Maschine M2?
c) Berechnen Sie für die gegebene Instruktionsmischung die durchschnittliche Performance in MIPS (für beide Maschinen).

VO Rechnerarchitekturen / PerformanceA. Steininger
33
L2: Performance-ISA
a) PM1 = 50PM2 = 75/1,7 = 44,11
b) 44,11 MHz
c) M1 = 50/(1,4*0,4+2*0,43+5,2*0,11+1*0,06) = 24,37M2 = 75/(2*0,4+1,7*0,43+4*0,11+8*0,06) = 30,6

VO Rechnerarchitekturen / PerformanceA. Steininger
34
B3: Performance
VLSI Design Technologies produziert den Prozessor E1822. Für die nächste, leistungsstärkere Serie, den E1822-RA, werden 3 Experten beauftragt, eine neue Architektur zu entwerfen. Das Referenzprogramm besteht aus folgenden Teilen:
Teil 1 Rechne_Fließkomma() 20%Teil 2 Rechne_ALU() 18%Teil 3 Steuere() 20%Teil 4 Speichern() 20%Teil 5 Interrupts, OS Service Rest

VO Rechnerarchitekturen / PerformanceA. Steininger
35
B3: Performance
Die drei Experten (A,B,C) kommen mit Architekturvorschlägen, diefolgende Auswirkungen auf die Programmteile haben:
Teil A B C1 Faktor 2 schneller 30% langsamer Faktor 4 schneller2 Faktor 1.2 langsamer Faktor 4 schneller 20% langsamer3 bleibt gleich Faktor 2 schneller 30% schneller4 20% schneller gleich 25% langsamer5 Faktor 2.3 langsamer Faktor 3 schneller Faktor 1.2 langsamer
Der Konzernchef beauftragt Sie, in einer Vergleichsstudie die Beschleunigung durch die 3 Methoden als Faktor gegenüberzustellen. Angenommen, man könnte die beiden besten Lösungen so miteinanderkombinieren, daß die jeweils effektivere Optimierungsmaßnahme zur Wirkung kommt. Welche Beschleunigung würde man erzielen?

VO Rechnerarchitekturen / PerformanceA. Steininger
36
L3: Performance
Speedup A: 1/(0.2/2+0.18*1.2+0.2+0.2/1.2+0.22*2.3) = 1/1.18 = 0.841=> Programm wird langsamer
Speedup B: 1/(0.2*1.3+0.18/4+0.2/2+0.2+0.22/3) = 1.474Speedup C: 1/(0.2/4+0.18*1.2+0.2/1.3+0.2*1.25+0.22*1.2) = 1.0708
Kombination von B und C => D.
Speedup D: 1/(0.2/4+0.18/4+0.2/2+0.2+0.22/3) = 2.135
Die beiden Methoden vereint sind besser als das Produkt von Beschleunigung(B) und Beschleunigung(C)!