Ein Dictionary Service für RDF Graphen -...
78
Fachbereich 4: Informatik Ein Dictionary Service für RDF Graphen Bachelorarbeit zur Erlangung des Grades eines Bachelor of Science im Studiengang Informatik vorgelegt von Torsten Schäfer Erstgutachter: Prof. Dr. Steffen Staab Institut für Web Science and Technologies Zweitgutachter: Martin Leinberger Institut für Web Science and Technologies Koblenz, im November 2016
Transcript of Ein Dictionary Service für RDF Graphen -...

Fachbereich 4: Informatik
Ein Dictionary Service für RDFGraphen
Bachelorarbeitzur Erlangung des Grades eines Bachelor of Science
im Studiengang Informatik
vorgelegt von
Torsten Schäfer
Erstgutachter: Prof. Dr. Steffen StaabInstitut für Web Science and Technologies
Zweitgutachter: Martin LeinbergerInstitut für Web Science and Technologies
Koblenz, im November 2016

Erklärung
Ich versichere, dass ich die vorliegende Arbeit selbständig verfasst undkeine anderen als die angegebenen Quellen und Hilfsmittel benutzt habe.
Ja Nein
Mit der Einstellung der Arbeit in die Bibliothek bin ich ein-verstanden.
� �
Der Veröffentlichung dieser Arbeit im Internet stimme ich zu. � �
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .(Ort, Datum) (Unterschrift)

Abstract Deutsch Das Koldfish Projekt der Universität Koblenz hat sich als
Ziel gesetzt Endbenutzer bei der Entwicklung von Applikationen gegen das Se-
mantic Web zu unterstützen, indem es als Middleware zwischen Semantic Web
und Applikation wiederkehrende Herausforderungen, wie etwa die Akquise und
Verwaltung von (freien) verknüpften Daten, übernimmt. Die Kernfunktionalität ist
dabei die Suche und Speicherung dieser in Form von RDF Graphen vorliegenden
Linked (open) Data und deren Zusammenfassung in einer einzigen großen Wis-
sensbasis. Ein besonderer Fokus liegt dabei auf der Skalierbarkeit des Dienstes für
große Datenmengen. Um dieses Vorhaben zu unterstützen ist ein Dictionary Serviceals Teilkomponente von Koldfish vorgesehen, der im Zuge dieser Arbeit entwickelt
und implementiert wird. Dieser ersetzt die meist sehr langen RDF Ausdrücke
durch sparsamere IDs, wodurch eine Reduktion der übermittelten Datengröße bei
der Kommunikation zwischen den Koldfish Komponenten sowie eine Kompressi-
on bei der Speicherung redundanter RDF Ausdrücke erreicht wird. Der Dictionary
Service sorgt für die Transformation, Speicherung und Rücktransformation dieser
RDF Ausdruck—ID Paare. Zusätzlich werden innerhalb der ID Metainformatio-
nen über den RDF Ausdruck gespeichert, die ohne Datenbankzugriff abrufbar
sind. Dabei werden Literale die Zahlen darstellen besonders behandelt, indem
eine Binärrepräsentation der Zahl als ID erfolgt. Des Weiteren werden eventu-
ell annotierte Datentypen von Literalen bei der Transformation erkannt und für
die spätere Abfrage seperat gespeichert. Außerdem stellt der Dictionary Service
eine Volltextsuche zur Verfügung, die es erlaubt mit flexiblen Ausdrücken nach
gespeicherten RDF Ausdrücken im Dictionary suchen zu können.

Abstract English The Koldfish project by the University of Koblenz aims at
the goal of supporting an end user in the development process of applications
against the Semantic Web. In form of a middleware between Semantic Web and
application Koldfish takes care of recurring challenges like data acquisition and
management of linked (open) data. The core function is searching and storing of
openly accessible linked data in form of RDF graphs and it’s compilation within
a single huge knowledge base. Special emphasis is given to the scalability of the
service for large amounts of data. To support this endeavor a Dictionary Servicecomponent is designated as part of Koldfish, which is to be developed and imple-
mented within this thesis. This service is replacing RDF expressions with more
memory efficient IDs, resulting in a reduction of data size for network communica-
tion within Koldfish as well as storage compression of redundant RDF expressions.
The Dictionary Service implements the transformation, storage and lookup of
these RDF expression—ID pairs. In addition IDs contain metainformation about
the corresponding RDF expressions, which can be accessed without the need of a
database query. RDF literals describing numbers are specially handled by using
the binary representation of the number as ID. Furthermore literals annotated
with datatypes are recognized during the transformation step and the datatype
is stored in a seperate database for later retrieval. Finally the Dictionary Service
supports a full-text search for flexible expression queries within the dictionary.

Inhaltsverzeichnis
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Kontext . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Grundlagen 42.1 Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 RDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 Koldfish . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Anforderungen 123.1 Anforderungsliste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1.1 Transformation von RDF Ausdrücken zu IDs . . . . . . . . . 12
3.1.2 Rücktransformation von IDs zu RDF Ausdrücken . . . . . . 13
3.1.3 Update von Dictionary Einträgen . . . . . . . . . . . . . . . 13
3.1.4 Domain Fragment zu IRI List . . . . . . . . . . . . . . . . . . 13
3.1.5 Domain Fragment zu ID List . . . . . . . . . . . . . . . . . . 14
3.1.6 Erkennung von Literalen . . . . . . . . . . . . . . . . . . . . 14
3.1.7 Volltextsuche für Literale . . . . . . . . . . . . . . . . . . . . 14
3.1.8 Binärrepräsentation von Zahlen . . . . . . . . . . . . . . . . 15
3.1.9 Löschen von Dictionary-Einträgen . . . . . . . . . . . . . . . 15
3.1.10 RDF Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.11 Volltextsuche für IRIs . . . . . . . . . . . . . . . . . . . . . . 16
3.1.12 Komprimierung für den Export von Listen . . . . . . . . . . 16
3.2 Technische Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . 17
i

INHALTSVERZEICHNIS ii
3.2.1 Domain Fragment Suche . . . . . . . . . . . . . . . . . . . . . 17
3.2.2 Volltextsuche . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.3 Metainformationen in IDs . . . . . . . . . . . . . . . . . . . . 19
4 Übersicht über bestehende Techniken und Systeme 204.1 Übliche Ansätze zur ID Vergabe . . . . . . . . . . . . . . . . . . . . . 20
4.1.1 Lineare ID Vergabe . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1.2 Lexikographische Sortierung . . . . . . . . . . . . . . . . . . 21
4.1.3 ID Vergabe durch Hashing . . . . . . . . . . . . . . . . . . . 22
4.2 Techniken zur Optimierung . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.1 Front Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.2 Multilevel Hashing . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.3 Trie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.4 Wavelet Tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2.5 Huffman Kodierung . . . . . . . . . . . . . . . . . . . . . . . 26
4.2.6 Prediction by Partial Matching . . . . . . . . . . . . . . . . . 27
4.3 Existierende Systeme . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3.1 HDT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3.2 RDFVault . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3.3 TripleBit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3.4 WaterFowl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.4 Vergleich mit den Anforderungen . . . . . . . . . . . . . . . . . . . . 33
5 Spezifikation der Implementation 365.1 Anwendungsfälle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.2 Programmablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Struktur des Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.3.1 Spezifikation API . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.3.2 Spezifikation Backend . . . . . . . . . . . . . . . . . . . . . . 47
6 Evaluation 496.1 Vergleich mit den Anforderungen . . . . . . . . . . . . . . . . . . . . 49
6.2 Bewertung der Performanz . . . . . . . . . . . . . . . . . . . . . . . 52
7 Fazit 557.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55

INHALTSVERZEICHNIS iii
7.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
A Funktionsspezifikation API 57
B Funktionsspezifikation Backend 61

Abbildungsverzeichnis
2.1 Linking open Data Cloud 2014 [SBJR]. . . . . . . . . . . . . . . . . . 5
2.2 Beispiel für einen RDF Graphen [W3C]. . . . . . . . . . . . . . . . . 7
2.3 Koldfish Komponentendiagramm [KOL]. . . . . . . . . . . . . . . . 10
3.1 Beispiel Domain Fragment Baum. . . . . . . . . . . . . . . . . . . . . 18
3.2 Beispiel Invertierter Index. . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1 Beispiel lineare ID Vergabe. . . . . . . . . . . . . . . . . . . . . . . . 21
4.2 Beispiel lexikographische ID Vergabe. . . . . . . . . . . . . . . . . . 21
4.3 Beispiel ID Vergabe mit Hash Funktion. . . . . . . . . . . . . . . . . 22
4.4 Beispiel Front Coding. . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.5 Multilevel Hash Tabelle [AI09, S.14]. . . . . . . . . . . . . . . . . . . 24
4.6 Beispiel Trie. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.7 Beispiel Wavelet Tree für „abracadabra“. . . . . . . . . . . . . . . . . 26
4.8 Beispiel Huffman Baum [WMB99, S.33]. . . . . . . . . . . . . . . . . 27
4.9 Beispiel PPM: Kontext-String „abracadabra“ und Wahrscheinlich-
keitsvorhersagung für die Zeichen „c“, „d“ und „t“ [CTW95]. . . . 28
4.10 HDT Kernkomponenten [FMPG+13]. . . . . . . . . . . . . . . . . . 30
4.11 TripleBit Dictionary [YLW+13]. . . . . . . . . . . . . . . . . . . . . . 31
4.12 WaterFowl Architektur [YLW+13]. . . . . . . . . . . . . . . . . . . . 32
5.1 Anwendungsfalldiagramm zum Koldfish Dictionary Modul. . . . . 37
5.2 Aktivitätsdiagramm nach Eintritt des Events einer neuen Transfor-
mationsanfrage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.3 Aktivitätsdiagramm für die Transformation eines RDF Ausdrucks
zu einer ID. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
iv

ABBILDUNGSVERZEICHNIS v
5.4 Aktivitätsdiagramm für das Hinzufügen eines RDF Ausdrucks zum
invertierten Index. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.5 Aktivitätsdiagramm nach Eintritt des Events einer neuen Überset-
zungsanfrage für eine ID. . . . . . . . . . . . . . . . . . . . . . . . . 41
5.6 Aktivitätsdiagramm nach Eintritt des Events einer Volltextsuchan-
frage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.7 Aktivitätsdiagramm nach Eintritt des Events einer Löschanfrage
für einen bereits bestehenden Dictionary Eintrag. . . . . . . . . . . 43
5.8 Black-Box-Sicht auf das Koldfish Dictionary Modul . . . . . . . . . 43
5.9 White-Box-Sicht zur API Komponente des Koldfish Dictionary Mo-
duls . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.10 White-Box-Sicht zur Backend Komponente des Koldfish Dictionary
Moduls . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47

Kapitel 1
Einleitung
1.1 Motivation
Die aktuelle Situation des Internets bietet dem Nutzer eine nahezu endlose Menge
an Informationen. Während dies ein enormes Potential birgt, stellt es den Nutzer
regelmäßig vor die Herausforderung, eine gewünschte spezifische Information
herauszufiltern. Ein beliebtes Werkzeug um dieses Problem zu lösen sind Such-
maschinen, die das Internet nach dem Vorkommen eines oder mehrerer Begriffe
durchsuchen und entsprechende Internetseiten, die diese Begriffe enthalten, zu-
rückgeben. Der Nutzer ist nun in der Lage unter aufwendigem Betrachten verschie-
dener vorgeschlagener Internetseiten die gewünschte Information zu erlangen.
Das Kernproblem an dieser Herangehensweise ist das fehlende Verständnis der
Maschine für die Bedeutung, die hinter der Anfrage des Menschen steht. Eine
mögliche Lösung ist das Semantic Web. Es sieht vor Daten in einer Form zu re-
präsentieren, die sowohl von Menschen als auch von Maschinen verstanden und
verarbeitet werden können. Dies wird durch sogenannte „semantische Statements“
erreicht, die Daten zueinander in Beziehung setzen um semantische Bedeutungen
zu speichern. Wikidata [WIKa], ein Projekt der Wikimedia Foundation, stellt 2016
fast 540 Millionen solcher semantischer Statements frei zur Verfügung [WIKb].
Diese gewaltige Menge an Daten benötigt jedoch gleichzeitig relativ viel Speicher-
platz. Insbesondere die Nutzung von Internationalized Resource Identifiers (IRIs)
zur eindeutigen Identifizierung von Daten trägt dazu bei. Ein gängiger Ansatz zur
effizienteren Speicherung ist die in den semantischen Statements vorkommenden
Ausdrücke durch kürzere IDs, wie beispielsweise Zahlen, zu ersetzen. Ein Dienst
1

1.2. KONTEXT 2
der die Transformation von Ausdrücken zu IDs, deren Speicherung und Verwal-
tung, sowie die Rücktransformation von IDs zu Ausdrücken übernimmt wird als
Dictionary Service bezeichnet.
1.2 Kontext
Bei der Verwendung der neugeschöpften Möglichkeiten des Semantic Webs, sieht
sich der Nutzer oftmals einer Reihe von Herausforderungen bezüglich des Findens
und Abrufens der gewünschten Daten, sowie bei der Sicherstellung von Quality
of Service Eigenschaften, gegenüber. Um die Nutzung der Daten zu vereinfachen
wurde an der Universität Koblenz das Koldfish Projekt ins Leben gerufen [KOL,
SLG+16]. Das Ziel von Koldfish ist es, eine Middleware anzubieten, die gängige
Funktionen bei der Programmierung von Anwendungen gegen das Semantic
Web zur Verfügung stellt. Dazu gehört ein Crawler, der frei zugängliche Semantic
Web Quellen durchläuft und gefundene semantische Statements für die spätere
Nutzung abspeichert. Auf diese Weise kann der Nutzer auf einer einzigen, großen
Wissensbasis arbeiten, die persistent zur Verfügung steht und ohne weiteres Zutun
des Nutzers stetig aktualisiert und erweitert wird.
1.3 Ziel der Arbeit
Ziel dieser Arbeit ist die Implementierung eines Dictionary Services, der bereit-
gestellte semantische Daten in eine komprimierte Form überführt. Dabei sollen
die einzelnen Ausdrücke semantischer Statements durch IDs ersetzt werden, mit
denen die verschiedenen Komponenten des Koldfish Projektes speichereffizienter
arbeiten können. Außerdem sollen zusätzliche Anforderungen im Rahmen des
Koldfish Projektes erfüllt werden, wie beispielsweise das Darstellen von Zahlen
in ihrer Binärrepräsentation und die Bereitstellung einer Volltextsuche für die
komprimierten Ausdrücke. Eine vollständige Spezifizierung der Anforderungen
erfolgt in Kapitel 3 „Anforderungen“.

1.4. AUFBAU DER ARBEIT 3
1.4 Aufbau der Arbeit
Zunächst werden in Kapitel 2 die nötigen Grundlagen behandelt. Dazu werden das
Semantic Web, Linked open Data, das Resource Description Framework (RDF) und
das Koldfish Projekt vorgestellt. Im Anschluss werden in Kapitel 3 Anforderungen
an den Dictionary Service spezifiziert und erläutert. Es folgt in Kapitel 4 eine
Analyse bisher bestehender verwandter Arbeiten. Hier werden bereits existierende
Systeme vorgestellt und mit den Anforderungen verglichen.
In Kapitel 5 folgt eine Beschreibung der eigenen Lösungsstrategie. Die Spezifi-
kation und Architektur der Implementation wird anhand von Modellen vorgestellt
und die einzelnen Funktionalitäten beschrieben. Das Ergebnis der Implementation
wird in Kapitel 6 evaluiert, indem es mit den Anforderungen verglichen wird
und anhand verschiedener Kriterien, wie beispielsweise Speichereffizienz und
Geschwindigkeit beurteilt wird.
Im Schlussteil in Kapitel 7 werden die Ergebnisse der Arbeit noch einmal
zusammengefasst und ein Ausblick gegeben, was in zukünftigen Arbeiten noch
ergänzt werden kann.

Kapitel 2
Grundlagen
Für ein besseres Verständnis der Arbeit ist es wichtig Begriffe wie das Semantic
Web und Linked Data voneinander abgrenzen zu können und zu wissen, wie das
Resource Description Framework (RDF) genutzt werden kann um diese Visionen
umzusetzen. Außerdem werden die verschiedenen Komponenten des Koldfish
Projektes vorgestellt, die mit dem Dictionary Service zusammenarbeiten.
2.1 Semantic Web
Ziel des Semantic Webs ist die Aufarbeitung des bestehenden Webs in ein Format
das von Maschinen gelesen und verarbeitet werden kann, um so die Informations-
flut des Internets besser zu handhaben. Ein Großteil der Daten im Internet liegt in
Fließtextform vor, was zwar für den Menschen gut lesbar, aber für eine Maschine
nur schwer zu filtern ist. Um eine bessere Verarbeitung der bereits bestehenden In-
formationen zu erreichen ist es notwendig, Daten um ihre semantische Bedeutung
und ihre Beziehungen zu anderen Daten aufzuwerten.
Für diese gewünschte Interoperabilität der Informationen müssen Daten in
einem standardisiertem Format vorliegen, weshalb sich das World Wide Web
Consortium (W3C) auf die Nutzung des Resource Description Framework (RDF)
als Datenmodell geeinigt hat, auf das in Abschnitt 2.2 näher eingegangen wird.
Linked (open) Data Linked Data ist ein von Sir Tim Berners-Lee angedachtes
Vorgehen, wie Daten im Internet strukturiert und veröffentlicht werden können,
4

2.1. SEMANTIC WEB 5
um das Semantic Web zu erreichen [BHBL09]. Dazu hat er eine Reihe von Prin-
zipien aufgestellt, deren Einhaltung diese Vision umsetzen [BL]: (1)“Use URIs
as names for things“, (2)“Use HTTP URIs so that people can look up those na-
mes“, (3)“When someone looks up a URI, provide useful information, using the
standards (RDF, SPARQL)“ und (4)“Include links to other URIs, so that they can
discover more things“. Diese Prinzipien besagen, dass zur Beschreibung eines
Gegenstandes im Internet eine URI als Name verwendet werden soll. Diese URIs
sollen mit Hilfe des HTTP-Protokolls über das Internet dereferenziert werden
können. Auf diese Weise sollen weitere Informationen über diesen Gegenstand ab-
rufbar sein. Bei der Angabe dieser Informationen ist es wichtig, dass Standards wie
beispielsweise RDF benutzt werden. Außerdem sollen Verlinkungen zu anderen
URIs eingebaut werden, um so eine Vernetzung der Daten zu erreichen.
Abbildung 2.1: Linking open Data Cloud 2014 [SBJR].
Ein Beispiel für eine solche Vernetzung der Daten bietet Linking Open Data, ein
Projekt, das unter offener Lizenz stehende Daten aus dem Semantic Web sammelt
und gemäß den oben beschriebenen Linked Data Prinzipien veröffentlicht. Ein
2014 veröffentlichtes Diagramm (siehe Abbildung 2.1) zeigt die in der LoD Cloud
veröffentlichten Datensätze und deren Verlinkungen. Im Zentrum der Cloud steht

2.2. RDF 6
DBPedia und enthält eine Sammlung strukturierter, aus Wikipedia extrahierter
Informationen. Zusammen mit FOAF (Friend of a Friend), einem Vokabular zur
Modellierung eines maschinenlesbaren Sozialen Netzwerkes und GeoNames,
einer Datenbank, die Millionen von geographischen Namen enthält, stellen sie die
größten Datensätze mit einer immensen Anzahl an Verlinkungen innerhalb der
LoD Cloud dar.
2.2 RDF
Das Ressource Description Framework ist ein W3C Standard zur Repräsentation
von Daten im Semantic Web. RDF trifft Aussagen über Ressourcen um Beziehun-
gen zwischen Daten herzustellen, die von Maschinen verarbeitet werden können.
Definition 1 (RDF Graph) Ein RDF Graph beschreibt eine Menge von RDF Tripeln.Jedes RDF Tripel besteht dabei aus drei Komponenten:
• Ein Subjekt, das entweder durch eine IRI oder ein Blank Node repräsentiert wird
• Ein Prädikat, das eine IRI sein muss
• Ein Objekt, das eine IRI, ein Blank Node oder ein Literal sein kann
Die durch IRIs, Blank Nodes und Literale beschriebenen Terme werden RDF Ausdrückegenannt.[RDFb]
RDF kann durch gerichtete Graphen dargestellt werden. Ein Beispiel dafür
befindet sich in Abbildung 2.2. In diesem Beispiel werden zwei einfache Aussagen
getroffen: „ex:Bachelorarbeit ex:hatTitel ’Dictionary Service für RDF Graphen’“
und „ex:Bachelorarbeit ex:hatAutor ex:Torsten“. Dabei ist „ex:Bachelorarbeit“
in beiden Fällen das Subjekt. „ex:hatTitel“ und „ex:hatAutor“ sind Prädikate.
„Dictionary Service für RDF Graphen“ und „ex:Torsten“ sind Objekte. Auf Grund
der Übersichtlichkeit wurden die IRIs an dieser Stelle mit dem Präfix „ex:“ anstelle
von „http://example.org/“ verkürzt.
Ressource Eine Ressource stellt eine Entität der physischen oder digitalen Welt
dar, über die eine Aussage getroffen werden soll. Sie kann entweder durch eine
IRI referenziert werden oder ihr wird durch ein Literal ein Wert zugewiesen.

2.2. RDF 7
Abbildung 2.2: Beispiel für einen RDF Graphen [W3C].
URI/IRI Uniform Resource Identifier (URI) werden als eindeutige Bezeichner
von Ressourcen verwendet. Sie bestehen aus fünf Teilen: Das Scheme definiert den
Kontext der URI, wie etwa die Verwendung des HTTP Protokolls, und endet mit
einem „:“. Authority bezeichnet die Instanz, unter deren Zuständigkeit die URI
fällt. Path ist neben Scheme die einzige verpflichtete Angabe. Der Pfad identifiziert
die Stelle an der die URI gefunden wird. Query und Fragment verfeinern den Pfad
durch Datenbankabfragen und weitere Referenzierungen innerhalb der Ressource.
Internationalized Resource Identifier (IRI) besitzen ein ähnliches Ziel und
Aufbau, erweitern URIs jedoch für die Nutzung im internationalen Raum durch
eine größere Spanne an erlaubten Unicode Zeichen.
Literal Literale werden verwendet um feste Werte wie etwa Strings und Zahlen
auszudrücken. Jedem Literal kann optional ein Datentyp zugewiesen werden,
der selbst durch eine IRI ausgedrückt wird und ein Mapping zwischen dem lexi-
kalischen Raum und dem Wert definiert. Wenn kein Datentyp angegeben wird,
wird „ http://www.w3.org/2001/XMLSchema#string“ als Datentyp angenom-
men. Literale können ebenfalls einen Language Tag aufweisen, dem der Datentyp
„http://www.w3.org/1999/02/22-rdf-syntax-ns#langString“ zugewiesen wird.
Blank Node Blank Nodes sind Bezeichner für Ressourcen, die nicht von IRIs
oder Literalen abgedeckt werden und nur im lokalen Kontext gültig sind. Für eine
globale Gültigkeit müssen Blank Nodes durch IRIs ersetzt werden.
Namespace Namespaces sorgen für die Eindeutigkeit von Objekten innerhalb
eines bestimmten Raumes. Zusätzlich können sie ein häufig genutztes Vokabular
definieren und erlauben Einsparungen durch die Verwendung von Präfixen für
längere und mehrfach vorkommende Textstrings. Bekannte Namespaces sind
beispielsweise „http://www.w3.org/1999/02/22-rdf-syntax-ns#“ von RDF und

2.2. RDF 8
„http://www.w3.org/2000/01/rdf-schema#“ von RDF Schema. Während Name-
spaces beliebig erstellt und verwendet werden können, bietet die Verwendung
von häufig genutzten und gut dokumentierten Namespaces den Vorteil klarer
Begriffsdefinitionen für eine bessere Vernetzung der Daten.
Serialisierungen Für die Umsetzung von RDF gibt es verschiedene Serialisie-
rungen. Zwei der Bekannteren sind dabei RDF/XML und Notation3 (N3). RD-
F/XML ist in Wirtschaft und Forschung weit verbreitet und wird häufig von Tools
und Programmiersprachen unterstützt. Aufgrund der XML-Baumstruktur enthält
es jedoch einen Overhead und ist für den Menschen vergleichsweise schwer lesbar.
N3 ist ein kompaktes Format mit hoher Lesbarkeit für den Menschen. In Listing
2.1 befindet sich ein Beispiel für die Schreibweise des vorherigen Beispielgraphen
2.2 in RDF/XML und in Listing 2.2 ein Beispiel für den selben Graphen in N3.
Listing 2.1: RDF/XML Beispiel.
<?xml vers ion ="1 .0"? >
<rdf :RDF
xmlns : rdf =" ht tp ://www. w3 . org/1999/02/22− rdf−sysntax−ns #"
xmlns : ex =" ht tp :// example . org/">
<rdf : Descr ip t ion
rdf : about =" ht tp :// example . org/ B a c h e l o r a r b e i t ">
<ex : h a t T i t e l >Dic t ionary S e r v i c e für RDF Graphen
</ex : h a t T i t e l >
<ex : hatAutor >
<rdf : Descr ip t ion
rdf : about =" ht tp :// example . org/Torsten " />
</ex : hatAutor >
</rdf : Descr ipt ion >
</rdf : RDF>
Zu Beginn jedes RDF-XML Dokuments steht, wie für XML üblich, zunächst die
verwendete XML Version. Anschließend müssen alle RDF-Daten in den Kontext
des rdf:RDF-Elementes gesetzt werden. Innerhalb des rdf:RDF Start-Tags werden
mit xmlns: Namensräume definiert. Jedes RDF/XML Dkoument erfordert die Fest-
legung von xmlns:rdf="http://www.w3.org/1999/02/22-rdf-sysntax-ns#" als Standard
Vokabular von RDF. Die Definition von ex="http://example.org/" ermöglicht die

2.3. KOLDFISH 9
Nutzung des Präfixes „ex“ anstelle der ausgeschriebenen Form „http://example.org/“im weiteren Verlauf des Dokumentes. rdf:Description öffnet den Beschreibungs-
Kontext einer Ressource, über die Aussagen getroffen werden sollen. In diesem
Beispiel wird der mit rdf:about gekennzeichneten IRI „http://example.org/Ba-
chelorarbeit“ das Prädikat „ex:hatTitel“ und das Objekt „Dictionary Service für
RDF Graphen“ zugeordnet, wobei die Anführungszeichen ein Literal signalisieren.
In diesem Fall wird direkt noch eine zweite Aussage über dieselbe IRI getroffen
und deshalb der End-Tag der <rdf:Description> verzögert. Die zweite Aussage
verwendet als Objekt diesmal eine IRI, anstelle eines Literals, über die weitere
Aussagen getroffen werden könnten.
Listing 2.2: N3 Beispiel.
@prefix ex : <http :// example . org / >.
<http :// example . org/Ba ch e l or ar be i t >
ex : h a t T i t e l " Dic t ionary S e r v i c e für RDF Graphen " ;
ex : hatAutor <http :// example . org/Torsten / >.
Im Gegensatz dazu beschränkt sich die N3 Serialisierung auf eine möglichst
kompakte Form der Darstellung. Nach der Festlegung von Präfixen durch @prefixwerden die Subjekt - Prädikat - Objekt Tripel einfach nacheinander aufgelistet. Da-
bei werden IRIs durch „<>“ und Literale durch Anführungszeichen gekennzeich-
net. Jedes Tripel wird durch einen Punkt geschlossen. Zur Abkürzung mehrerer
Eigenschaften zum selben Subjekt wird ein Semikolon verwendet.
2.3 Koldfish
Koldfish[KOL] steht als Middleware zwischen frei erreichbarer Linked open Data
und der Applikation eines Endnutzers, der mit semantischen Daten arbeiten möch-
te. Insgesamt setzt es sich aus sieben Modulen zusammen, die in Abbildung 2.3
veranschaulicht werden: Crawler, Data Access Module, Data Service, Provenance
Service, Schema Service, Quality Service und Dictionary Service.
Crawler Der Crawler durchsucht das Semantic Web und übergibt gefundene
RDF Daten an das Data Access Module.

2.3. KOLDFISH 10
Abbildung 2.3: Koldfish Komponentendiagramm [KOL].
Data Access Module Das Data Access Module empfängt die Daten vom Craw-
ler und leitet diese in kodierter Form weiter. Dafür stellt es Anfragen an das Dictio-
nary Module um RDF Ausdrücke durch IDs zu ersetzen. Außerdem dereferenziert
es IRIs in der LoD Cloud auf Anfrage des Data Services.
Data Service Der Data Service sorgt für die Speicherung der vom Crawler
gefundenen RDF-Daten und damit für die Persistenz des Services. Dies ermöglicht
im Folgenden die Auswahl zwischen der Verwendung aktueller Daten direkt aus
dem Netz oder Daten aus dem Cache des Data Services.
Provenance Service Der Provenance Service sammelt Informationen über die
Herkunft der gespeicherten Daten.
Schema Service Der Schema Service verarbeitet Schema basierte Datenbezie-
hungen zur Erweiterung des Datensatzes um relevante Daten, die auch außerhalb
des bisherigen Dateninputs liegen können.
Quality Service Der Quality Service dient der Überwachung der im Data Ser-
vice gespeicherten Daten. Er übeprüft beispielsweise die Einträge auf syntaktisches

2.3. KOLDFISH 11
Korrektheit, die Derefenzierbarkeit von IRIs und nicht mehr aktuell gültige Eigen-
schaften.
Dictionary Service Der Dictionary Service sorgt für Speicherkomprimierung,
indem es RDF Ausdrücke durch kürzere IDs ersetzt und diese auf Anfrage hin-
oder rücktransformiert.

Kapitel 3
Anforderungen
Das Ziel des Dictionary Moduls ist die Auslagerung der Kompression von Daten in
einen eigenen Service innerhalb des Koldfish Systems. Verschiedene Funktionalitä-
ten die innerhalb des Koldfish Projektes von dem Dictionary Service übernommen
werden können wurden als Anforderungen definiert.
3.1 Anforderungsliste
In einem Treffen der Mitglieder des Koldfish-Projektes am 24.02.2016 wurden
genaue Anforderungen an den Dictionary Webservice in Koldfish besprochen
und mit entsprechenden Prioritäten festgelegt. Dabei stellen Anforderungen mit
Priorität 1 die wichtigsten Kernfunktionalitäten dar.
3.1.1 Transformation von RDF Ausdrücken zu IDs
Priorität 1
Beschreibung Die RDF Ausdrücke IRI, Blank Node und Literale müssen auf
Anfrage zu IDs transformiert werden.
Erklärung Die Transformation von RDF Ausdrücken zu selbstvergebenen IDs
ist die Kernfunktionalität des Services und dient dazu den nötigen Speicherplatz
für die RDF Ausdrücke zu reduzieren. Eine Übersicht über mögliche Techniken
erfolgt in Abschnitt 4.1.
12

3.1. ANFORDERUNGSLISTE 13
3.1.2 Rücktransformation von IDs zu RDF Ausdrücken
Priorität 1
Beschreibung IDs müssen auf Anfrage zurück zu ihrer ursprünglichen Form
als IRI, Blank Node oder Literal transformiert werden.
Erklärung Die Vergebenen IDs müssen eindeutig und verlustfrei auf ihre ur-
sprüngliche Form zurückverweisen.
3.1.3 Update von Dictionary Einträgen
Priorität 1
Beschreibung Das Hinzufügen von neuen Dictionary Einträgen muss zur Lauf-
zeit des Programmes unterstützt werden.
Erklärung Das Sammeln und Speichern neuer RDF Tripel ist in Koldfish ein
fortlaufender Prozess. Das Dictionary Modul bekommt einen kontinuierlichen
Fluss neuer Daten übergeben, der beantwortet werden muss, ohne dass die kom-
pletten Daten im Vorfeld vorliegen.
3.1.4 Domain Fragment zu IRI List
Priorität 1
Beschreibung Auf Suchanfragen nach Domain Fragments muss mit einer Liste
der passenden IRIs geantwortet werden.
Erklärung Ein Domain Fragment ist entweder ein Schema, eine Top-Level-
Domain, oder eine Sub-Domain mit oder ohne IRI-Pfadfragment. IRI-Pfadfragmente
sind Teile des IRI-Pfades, die durch / voneinander getrennt werden. In dem Bei-
spiel http://www.uni-koblenz.de/west/studium sind folgende Domain Fragmente ent-
halten: http://, http://www., .de, http://www.uni-koblenz.de, http://www.uni-koblenz.de/west

3.1. ANFORDERUNGSLISTE 14
und http://www.uni-koblenz.de/west/studium. Auf die Suchanfrage nach einem Do-
main Fragment soll eine Liste sämtlicher IRIs ausgegeben werden, die dieses
bestimmte Domain Fragment beinhalten.
3.1.5 Domain Fragment zu ID List
Priorität 1
Beschreibung Auf Suchanfragen nach Domain Fragments muss mit einer Liste
der passenden IDs geantwortet werden.
Erklärung Auf die Suchanfrage nach einem Domain Fragment soll eine Lis-
te sämtlicher IDs ausgegeben werden, deren zugehörige IRIs dieses bestimmte
Domain Fragment beinhalten.
3.1.6 Erkennung von Literalen
Priorität 1
Beschreibung Bei der Transformation von RDF Ausdrücken zu IDs müssen
Literale erkannt und innerhalb der ID gekennzeichnet werden.
Erklärung Jede ID soll die Metainformation beinhalten, ob es sich bei dem zu-
gehörigen RDF Ausdruck um ein Literal handelt. Eine geeignete Kennzeichnung
innerhalb jeder ID muss eine Erkennung von Literalen ohne vorherige Rücktrans-
formation zum RDF Ausdruck ermöglichen.
3.1.7 Volltextsuche für Literale
Priorität 2
Beschreibung Der Service soll eine Volltextsuche für Literale ermöglichen.

3.1. ANFORDERUNGSLISTE 15
Erklärung Eine Volltextsuche für Literale soll es ermöglichen unabhängig von
spezifisch vorgefertigten Suchanfragen den Datensatz nach Literalen oder Teilwör-
tern davon zu durchsuchen, indem beispielsweise ein invertierter Index für alle
im Dictionary gespeicherten Ausdrücke erzeugt wird.
3.1.8 Binärrepräsentation von Zahlen
Priorität 3
Beschreibung Literale die ausschließlich eine Zahl enthalten sollen in Binärre-
präsentation dargestellt werden.
Erklärung Die Binärrepräsentation von Zahlen ermöglicht direkte Operationen
auf den Werten in ihrer ID-Form, ohne zuerst den Umweg über die Rücktransfor-
mation zum Literal machen zu müssen.
3.1.9 Löschen von Dictionary-Einträgen
Priorität 4
Beschreibung Einzelne Dictionary-Einträge können auf Anfrage nachträglich
gelöscht werden.
Erklärung Einzelne gespeicherte RDF Ausdrücke sollen zusammen mit den
ihnen zugewiesenen IDs auf Anfrage aus dem Dictionary gelöscht werden können.
3.1.10 RDF Datentypen
Priorität 5
Beschreibung RDF Datentypen können gesondert berücksichtigt werden.
Erklärung In [RDFa] werden 39 verschiedene Datentypen beschrieben, die
optional an Literale angehangen werden können. Bei der Transformation von
Literalen zu IDs sollen annotierte Datentypen erhalten bleiben und nachträglich
abgefragt werden können.

3.1. ANFORDERUNGSLISTE 16
3.1.11 Volltextsuche für IRIs
Priorität 5
Beschreibung Der Service kann eine Volltextsuche für IRIs unterstützen.
Erklärung Analog zu der in Abschnitt 3.1.6 beschriebenen Anforderung Volltext-suche für Literale, soll eine Volltextsuche für IRIs es ermöglichen unabhängig von
spezifisch vorgefertigten Suchanfragen den Datensatz nach IRIs oder Teilwörtern
davon zu durchsuchen.
3.1.12 Komprimierung für den Export von Listen
Priorität 6
Beschreibung Beim Exportieren von IRI- und ID-Listen können weitere Kom-
primierungstechniken verwendet werden.
Erklärung Bei Millionen von potentiellen Tripeln innerhalb der Linked open
Data Cloud kann das erstellte Dictionary sehr viel Speicher benötigen. Für den
Datenexport einzelner vollständig erstellter Listen können nachträglich zusätzliche
Techniken angewendet werden um die Daten weiter zu komprimieren.

3.2. TECHNISCHE UMSETZUNG 17
3.2 Technische Umsetzung
Eine Übersicht möglicher Techniken soll die Intention einiger der in Abschnitt 3.1
vorgestellten Anforderungen verdeutlichen. Eine vollständige Beschreibung der
Umsetzung aller Anforderungen erfolgt in Kapitel 5.
3.2.1 Domain Fragment Suche
Zur Speicherung des Dictionarys kann beispielsweise ein Domain Fragment Baum
aufgebaut werden. Dieser zerlegt IRIs in ihre einzelnen Bestandteile, angefan-
gen bei den Schemata (wie http und https) als Kinder der Wurzel. Es folgt eine
Auflistung der Top-Level-Domains und anschließend die verschiedenen Paylevel
Domains. In den inneren Knoten werden schließlich solange Domain Fragmente
hinzufügt, bis in den Blättern die vollständigen IRIs erreicht werden. Die Paylevel
Domain ist der Name, der in der DNS-Hierarchie an zweiter Stelle direkt unter
der jeweiligen Top-Level-Domain (beispielsweise .com) steht. Abbildung 3.1 ver-
anschaulicht einen Domain Fragment Baum, der die folgenden drei IRIs in ihre
Domain Fragmente aufgeteilt:
• http://www.uni-koblenz.de/west/team/ueber-uns/martin-leinberger
• http://www.uni-koblenz.de/west/team/ueber-uns/prof-dr-steffen-staab
• http://www.uni-koblenz.de/west/studium/scientific-thesis
http://www.uni-koblenz.de ist dabei in allen drei Fällen die Paylevel Domain.
Jeder Knoten inklusive seines Pfades stellt ein Domain Fragment dar. Den Knoten
martin-leinberger, prof-dr-steffen-staab und scientific-thesis müssen IDs zugewiesen
werden. Weiteren Knoten können zusätzliche IDs zugewiesen werden, um Such-
vorgänge zu beschleunigen.
Dieses Vorgehen verhindert Redundanzen bei der Speicherung von IRIs mit
gleichen Domain Fragmenten und ermöglicht die in Anforderung 2.1.4 und 2.1.5
geforderten Suchanfragen. Wird Anforderung 3.1.11 „Volltextsuche für IRIs“ um-
gesetzt wird der Domain Fragment Baum jedoch obsolet, da eine umgesetzte
Volltextsuche im Vergleich zu den zwei Anforderungen 2.1.4 und 2.1.5 flexiblere
Suchanfragen unterstützt.

3.2. TECHNISCHE UMSETZUNG 18
Abbildung 3.1: Beispiel Domain Fragment Baum.
3.2.2 Volltextsuche
Die zwei Anforderungen 2.1.7 und 2.1.11 fordern die Unterstützung einer Voll-
textsuche für Literale und IRIs. Das übliche Vorgehen dafür ist der Aufbau eines
invertierten Indexes über die gewünschten Dokumente, in diesem Fall die Menge
aller IRIs und Literale. Ein invertierter Index ordnet jedem Begriff innerhalb einer
Menge von Dokumenten einen Verweis auf die Dokumente, in denen dieser Begriff
vorkommt, zu [Wen03]. Ein Beispiel dafür befindet sich in Abbildung 3.2.
Während Literale vom Domain Fragment Baum, der im vorherigen Abschnitt
beschrieben wurde, nicht abgedeckt werden, hat die Umsetzung einer Volltextsu-
che für Literale eine hohe Priorität. Eine Volltextsuche für IRIs ersetzt die Strategie
des Domain Fragment Baumes, da sie flexibler ist als nur die Suche nach Domain
Fragmenten. Der Nachteil ist jedoch, dass die Umsetzung einer Volltextsuche zu-
sätzlich eine invertierter Index Struktur benötigt. Dies resultiert in einem erheblich
höheren Speicherverbrauch, da sämtliche IRIs einmal in dem Dictionary selbst
gespeichert werden und ein zusätzliches zweites Mal innerhalb des invertierten
Indexes.

3.2. TECHNISCHE UMSETZUNG 19
Abbildung 3.2: Beispiel Invertierter Index.
3.2.3 Metainformationen in IDs
Für die generierten IDs wurde der Datentyp Long ausgewählt. Dabei werden die
drei höchstwertigsten Bits für Metainformationen reserviert. Diese Metainformati-
on sind zum einen der RDF-Typ IRI / Blank Node oder Literal und zum anderen
ob das Literal eine Zahl ist oder nicht. Ein weiteres reserviertes Bit innerhalb der ID
weist auf die Existenz eines Datentyps hin. Die genaue Zuordnung wird daraufhin
in eine seperate Map von Literal-ID auf Datentyp ausgelagert.

Kapitel 4
Übersicht über bestehendeTechniken und Systeme
Im Hinblick auf die Entwicklung des Dictionary Services in Kapitel 5 ist es nötig
einen Überblick über gängige Grundtechniken, wie beispielsweise bei der Vergabe
von IDs, zu erlangen. Außerdem werden bereits bestehende Forschungsansätze
und Systeme, die Dictionary Systeme im Kontext von RDF verwenden, vorgestellt
und evaluiert inwiefern diese Ansätze für das Koldfish Projekt geeignet sind.
4.1 Übliche Ansätze zur ID Vergabe
Die Vergabe von IDs ist die Kernfunktionalität eines jeden Dictionary Services. Die
Umsetzung beeinflusst maßgeblich die Geschwindigkeit von Suchanfragen und
den Aufwand beim nachträglichen Hinzufügen von Einträgen. Für die Vergabe
von IDs gibt es mehrere Ansätze, die in der Praxis Anwendung finden.
4.1.1 Lineare ID Vergabe
Die einfachste Möglichkeit der ID Vergabe ist eine lineare Vergabe der IDs (siehe
Abbildung 4.1). Dabei wird dem ersten Wort die ID „1“ zugewiesen. Für jedes nach-
folgende Wort wird die ID des Vorgängers um Eins inkrementiert. Das Problem bei
diesem Ansatz ist das spätere Wiederfinden von Einträgen bei Datenbankabfragen
nach einzelnen IDs oder Wörtern (im Folgenden „Suchanfragen“ genannt) auf
die Liste mit der Aufwandsklasse O(n), da die gesamte Liste durchlaufen werden
20

4.1. ÜBLICHE ANSÄTZE ZUR ID VERGABE 21
muss. Durch die Realisierung mit assoziativen Arrays kann die Aufwandsklasse
von Suchanfragen auf O(1) reduziert werden.
Abbildung 4.1: Beispiel lineare ID Vergabe.
4.1.2 Lexikographische Sortierung
Bei der lexikographischen Sortierung werden sämtliche Ausdrücke in eine lexiko-
graphische Ordnung gebracht. Wörter werden also zunächst nach Anfangsbuch-
staben sortiert. Anschließend wird jede der Teillisten mit gleichem Anfangsbuch-
staben ebenfalls nach dem Folgebuchstaben sortiert. Dies wird solange fortgeführt,
bis jede Zeichenkette vollständig abgearbeitet wurde. Nach der Sortierung können
IDs linear vergeben werden. Dabei behählt die Liste der IDs ihre lexikographische
Eigenschaft bei. Dieses Vorgehen wird in Abbildung 4.2 veranschaulicht. Das
Verfahren ermöglicht eine Umwandlung von ID zu Ausdruck in O(1) während
die Transformation von Ausdruck zu ID mittels binärer Suche in O(log n) realisiert
werden kann. Das nachträgliche Hinzufügen von Einträgen ist mit hohem Auf-
wand verbunden, da die Erhaltung der lexikographischen Ordnung sichergestellt
werden muss.
Abbildung 4.2: Beispiel lexikographische ID Vergabe.

4.1. ÜBLICHE ANSÄTZE ZUR ID VERGABE 22
4.1.3 ID Vergabe durch Hashing
Beim Hashing werden IDs berechnet. Eine Hash Funktion h(x) sorgt dafür, dass
jedem eingegebenen Element deterministisch eine ID zugewiesen wird. Dieser
Vorgang wird in Abbildung 4.3 dargestellt. Die IDs und das jeweils zugehörige
Element werden in einer Hash Tabelle gespeichert. Die Größe der Tabelle hat Ein-
fluss auf die Speicherkompressionsrate. Eine zu geringe Menge an Tabellenslots
sorgt für Kollisionen bei der Vergabe von IDs. Gibt es viele freie Slots wird unnötig
Speicher verbraucht. Eine Hash Funktion heißt minimal perfekt, wenn sie für
einen Datensatz weder Kollisionen auslöst, noch freie Slots erzeugt. Die Effizienz
einer Hash Funktion ist jedoch für jeden Datensatz unterschiedlich, sodass eine all-
gemein perfekte Hash Funktion nicht existiert. Dementsprechend ist es notwendig
neben einer geeigneten Hash Funktion noch zusätzliche Strategien zur Kollisi-
onsbehandlung zu entwerfen. Eine Möglichkeit ist das Chaining. Hash Tabellen
Slots denen mehrere IDs zugewiesen werden beinhalten hier eine Linked List aller
kollidierenden IDs. Neue IDs werden als Kopf der Linked List hinzugefügt und
bei einer Anfrage auf eine ID muss im Fall einer Kollision neben der Berechnung
des richtigen Slots noch zusätzlich die enthaltene Linked List durchsucht werden
[CLRS09, S.257]. Das Problem dieser Strategie ist das Wiederfinden des Elementes
innerhalb der Liste, wofür die vergebene ID alleine jedoch nicht ausreicht. Eine
andere Möglichkeit ist eine Sondierungsstrategie. Hier wird bei einer Kollision die
Suche nach einem freien Slot fortgeführt, indem beispielsweise der nachfolgende
Slot (lineares Sondieren), oder in quadratisch wachsendem Abstand (quadratisches
Sondieren) Slots überprüft werden. Bei Kollisionsfreien Hashtabellen liegt die Auf-
wandsklasse für Suchanfragen bei O(1). Diese kann jedoch durch Kollisionen und
deren Behandlung im Worst-Case auf O(n) ansteigen.
Abbildung 4.3: Beispiel ID Vergabe mit Hash Funktion.

4.2. TECHNIKEN ZUR OPTIMIERUNG 23
4.2 Techniken zur Optimierung
Neben der Kernfunktionalität der ID Vergabe gibt es weitere Techniken und An-
sätze, die den Dictionary Service optimieren können, indem sie beispielsweise für
höhere Datenkompression sorgen oder die Eigenschaften verschiedener Daten-
strukturen ausnutzen.
4.2.1 Front Coding
Ein in vielen Dictionary Systemen verwendeter Ansatz ist eine lexikographische
Sortierung mit anschließendem Front Coding (siehe Abbildung 4.4). Es basiert
auf der Idee, dass in einer lexikographisch geordneten Liste von Wörtern aufein-
anderfolgende Wörter sich häufig ein gemeinsames Präfix teilen. Dieses Präfix
wird beim ersten Wort einmal ausgeschrieben und jedes weitere Vorkommen kann
durch ein sparsameres Kürzel ausgetauscht werden. [BF92] [WMB99, S.161]
Abbildung 4.4: Beispiel Front Coding.
4.2.2 Multilevel Hashing
Das Multilevel Hashing[AI09] kann die Geschwindigkeit von Suchanfragen auf
Hash Tabellen verbessern, indem mehrere Hashfunktionen in Reihe geschaltet wer-
den. Ein Beispiel für eine solche Multilevel Hashtabelle befindet sich in Abbildung
4.5.
In dem Kontext dieser Arbeit kann diese Idee genutzt werden, indem verschie-
dene Hashfunktionen auf die einzelnen Domain Fragmente einer IRI angewandt
werden. So könnte zunächst eine erste Hashfunktion auf die Paylevel Domain
angewandt werden, um eine grobe Einteilung zu erreichen und anschließend eine

4.2. TECHNIKEN ZUR OPTIMIERUNG 24
zweite Hashfunktion auf den restlichen Pfad der IRI. Eine solche Herangehenswei-
se kann die Anzahl an Kollisionen, die bei der Verwendung von Hashfunktionen
auf große Datenmengen praktisch unvermeidbar auftauchen, verringern und die
Geschwindigkeit von Suchanfragen auf die Hashtabellen erhöhen.
Abbildung 4.5: Multilevel Hash Tabelle [AI09, S.14].
4.2.3 Trie
Ein Trie ist eine Baumstruktur (siehe Abbildung 4.6) zur effizienten Speicherung
mehrerer Zeichenketten. Beginnend bei der Wurzel wird jeder ausgehenden Kante
ein einzelnes Zeichen zugewiesen. Die Zeichenkette eines Knotens kann durch die
Traversierung seines kompletten Pfades ausgehend von der Wurzel ausgelesen
werden. Diese Art der Speicherung entfernt sämtliche Redundanz von Präfixen.
Zur Reduzierung des Speicherbedarfs werden bei einem kompakten Trie Knoten
mit nur einer Ausgangskante zusammengefasst, solange dadurch keine Terminal-

4.2. TECHNIKEN ZUR OPTIMIERUNG 25
knoten entfernt werden.
Abbildung 4.6: Beispiel Trie.
4.2.4 Wavelet Tree
Bei einem Wavelet Tree (siehe Abbildung 4.7) oder auch Balanced Binary Tree
wird das Alphabet einer Zeichenfolge in der Wurzel zunächst in zwei gleich große
Teile aufgesplittet, denen jeweils Eins und Null zugewiesen wird. Diese Verteilung
von Einsen und Nullen wird dabei auf den Knoten angewendet, in dem die
Zeichen durch ihre jeweilige Zahl ausgetauscht werden. In den zwei entstehenden
Teilbäumen, die jeweils nur noch die Hälfte der Zeichen des ursprünglichen
Alphabets beinhalten, wird dieser Vorgang solange wiederholt, bis die Alphabete
aller entstandenen Teilsequenzen nur noch einzelne Buchstaben beinhalten. Für
das Arbeiten auf dem Wavelet Tree müssen drei Operationen umgesetzt werden:
Access gibt das Bit an einer gewünschten Position der Zeichensequenz aus. Rankzählt das Vorkommen der Zahlen Eins und Null innerhalb der ersten x Positionen.
Select sucht die Position des x-ten Vorkommens eines Bits. [Nav14]

4.2. TECHNIKEN ZUR OPTIMIERUNG 26
Abbildung 4.7: Beispiel Wavelet Tree für „abracadabra“.
4.2.5 Huffman Kodierung
Das Ziel eines Kodierungsalgorithmus ist eine Kompression von Daten auf Sym-
bolebene zu erreichen und steht damit auf einer anderen Ebene als Dictionarys,
die auf ganzen Zeichenketten arbeiten. Häufiger vorkommende Symbole wer-
den dabei mit kürzeren Bitsequenzen gespeichert und seltenere Symbole mit den
verbliebenen Bitsequenzen.
Der Huffman Algorithmus erzeugt eine Baumstruktur (siehe Abbildung 4.8),
indem im ersten Schritt (siehe Teil (a) der Abbildung) jedem vorkommendem
Zeichen der Ausgangsmenge ein Blatt mit dem Zeichen selbst und der Wahr-
scheinlichkeit seines Vorkommens erzeugt wird. Anschließend werden im zweiten
Schritt (siehe (b)) die zwei Knoten mit den niedrigsten Wahrscheinlichkeiten unter
einen neuen Knoten gestellt, der die kombinierte Wahrscheinlichkeit beider Zei-
chen enthält. Dieser Vorgang wird mehrfach wiederholt, wobei bereits angepasste
Kindknoten diesmal ignoriert werden. Sobald nur noch ein einzelner Knoten ohne
Elternknoten vorhanden ist, wird dieser als Wurzel mit der Gesamtwahrscheinlich-
keit von Eins etabliert. Der so erzeugte Baum wird nun an den zwei ausgehenden
Kanten jedes Elternknotens mit Null und Eins beschriftet und bildet so den ferti-
gen Huffman Baum (siehe (c)), an dem die Bitsequenzen der Huffman Kodierung

4.2. TECHNIKEN ZUR OPTIMIERUNG 27
für jedes Symbol durch Traversierung des Baumes von Wurzel zu Blatt abgelesen
werden kann. [WMB99]
In dem Fall dieser Arbeit können Kodierungsalgorithmen verwendet werden
um das Dictionary nachträglich zu komprimieren und somit für den Export zu
verkleinern (siehe Anforderung 3.1.12). Eine Komprimierung zur Laufzeit ist
aufgrund der dynamischen Daten jedoch nicht möglich.
Abbildung 4.8: Beispiel Huffman Baum [WMB99, S.33].
4.2.6 Prediction by Partial Matching
Prediction by Partial Matching (PPM) ist ein verlustfreier Datenkompressions-
ansatz für natürliche Sprachen, bei dem durch den Kontext bereits erfasster Da-
ten Vorhersagen für die Wahrscheinlichkeit des Vorkommens weiterer Symbole
des Stroms der Eingabesymbole getroffen werden. Der Unterschied zu anderen

4.2. TECHNIKEN ZUR OPTIMIERUNG 28
Kodierungsansätzen, wie beispielsweise der Huffman Kodierung besteht darin,
dass die Wahrscheinlichkeit des Vorkommens nicht auf der statischen Häufig-
keitsverteilung eines Symbols beruht, sondern abgearbeitete Symbole dynamisch
den Kontext anpassen und somit die folgende Analyse fortlaufend beeinflussen.
[CW84]
Abbildung 4.9: Beispiel PPM: Kontext-String „abracadabra“ und Wahr-scheinlichkeitsvorhersagung für die Zeichen „c“, „d“ und „t“ [CTW95].
In Abbildung 4.9 wird ein Beispiel für PPM anhand des Kontext-Strings „ab-
racadabra“ veranschaulicht. In diesem Fall wurde eine maximale Kontexttiefe
von Zwei gewählt. Die Kontexttiefe bestimmt die Anzahl der Zeichen die bei
der Vorhersage für das nächste folgende Zeichen als Kontext in Betracht gezogen
werden. Dadurch ergeben sich in der Tabelle vier mögliche Sequenzlängen. Die Ta-
bellenspalte „k = 2“ zeigt die sieben verschiedenen Sequenzen des Beispielstrings
an, die aus zwei Zeichen bestehen. Zusätzlich dazu wird die Häufigkeit ergänzt,

4.2. TECHNIKEN ZUR OPTIMIERUNG 29
mit der weitere Zeichen auf diese Zweiersequenzen folgen. „k = 1“ berechnet diese
Häufigkeit anhand eines Kontextes der nur aus einem Zeichen besteht. „k = 0“
beinhaltet die Häufigkeitsverteilung jedes einzelnen Zeichen des im bisherigen
Kontext verwendeten Alphabets. „k = -1“ zeigt die Wahrscheinlichkeit auf, dass
ein Zeichen des Alphabets folgt, das im bisherigen Kontext noch nicht vorgekom-
men ist. Für die Funktionsweise von PPM ist es außerdem notwendig für jede
Vorhersage einen Escape-Mechanismus einzubauen, falls ein Zeichen auftreten
sollte, das vom bisherigen Kontext noch nicht abgedeckt wird. Die Wahrscheinlich-
keit dafür wird durch die Anzahl unterschiedlicher Zeichen im aktuellen Kontext
bestimmt.
Im unteren Bereich der Abbildung 4.9 wird die Vorhersage für drei Zeichen
getroffen, die auf den String „abracadabra“ folgen könnten. Da die Kontexttiefe
in diesem Beispiel auf Zwei begrenzt ist, wird für die Berechnung die Sequenz
„ra“ betrachtet. Das Zeichen „c“ folgte in dem Kontext schon einmal der Sequenz
„ra“ und ermöglicht somit das direkte Ablesen der Wahrscheinlichkeit von 1/2
aus der Tabelle. Das Zeichen „d“ wird im Kontext der Tiefe Zwei nicht gefunden.
Deswegen wird der Escape-Mechanismus der Sequenz „ra“ verwendet und des-
sen Wahrscheinlichkeit von 1/2 notiert. Anschließend wird die nun reduzierte
Kontexttiefe „k = 1“ überprüft. Die Chance, dass auf ein „a“ ein „d“ folgt liegt bei
1/7. Daraus berechnet PPM die Gesamtwahrscheinlichkeit 1/2 ∗ 1/7 = 1/14. Da
ein „t“ in dem bisherigen Kontext noch nicht vorgekommen ist, müssen alle vier
Kontexttiefen durchlaufen werden. Dies sorgt für eine Gesamtwahrscheinlichkeit
von 1/2 ∗ 3/7 ∗ 5/16 ∗ 1/A, wobei A das gesamte Zeichenalphabet (in diesem Fall
256) ist.
Die notwendige Bitgröße für die Kodierung wird durch log2 der Gesamtwahr-
scheinlichkeit errechnet. Eine Optimierung des Ansatzes kann erreicht werden,
indem niedrigere Kontexttiefen bereits von höheren Kontexttiefen überprüfte Fälle
ausschließen. Ein Beispiel dafür ist die Reduzierung des Alphabets bei „k = -1“ von
256 auf 251, da die fünf Buchstaben „a, b, c, d, r“ von „k = 0“ bereits ausgeschlossen
wurden. [CTW95]

4.3. EXISTIERENDE SYSTEME 30
4.3 Existierende Systeme
Spätestens mit dem Aufkommen der Linked open Data Cloud ist die Komprimie-
rung von RDF-Daten eine absolute Notwendigkeit und somit Bestandteil einiger
Forschung geworden. Der Fokus dieser Ansätze divergiert dabei stark. Während
sich manche Arbeiten beispielsweise auf statische Daten beschränken um mög-
lichst hohe Kompressionsraten erreichen zu können, versuchen andere Ansätze
die Eigenschaften unterschiedlichster Datenstrukturen auszunutzen um auch mit
dynamischen Daten arbeiten zu können oder besonders effizient auf Anfragen
antworten zu können. Die für diese Arbeit relevantesten Forschungsansätze und
Systeme werden an dieser Stelle präsentiert.
4.3.1 HDT
Abbildung 4.10: HDT Kernkomponenten [FMPG+13].
HDT [HDT] steht für Header Dictionary Triples und ist ein Open Source Pro-
jekt für eine kompakte Datenstruktur von serialisierten RDF Daten. Abbildung
4.10 zeigt die drei Komponenten von HDT auf: Der Header stellt einfach erreich-
bare Metainformationen zu Datensätzen, wie etwa Herkunftsinformationen, zur
Verfügung. Dies ermöglicht es Nutzern grundlegende Informationen über einen
Datensatz zu erlangen, ohne diesen erst in kompletter Form laden zu müssen.
Das Dictionary ist ein Katalog aller im Datensatz vorkommenden RDF Terme und
einer dazugehörigen lexikographisch vergebenen ID. Der Triples Teil baut den
RDF Graphen mit den vom Dictionary erzeugten IDs in einer kompakteren Form
nach.

4.3. EXISTIERENDE SYSTEME 31
Das Dictionary von HDT verwendet Front Coding. Es teilt alle Terme in die
vier Gruppen Subjekt, Prädikat, Objekt und Subjekt+Objekt ein. Letztere Gruppe
ist notwendig da RDF Ressourcen gleichzeitig sowohl als Subjekt als auch als
Objekt vorkommen können. Anschließend werden die Gruppen jede für sich lexi-
kographisch sortiert. Dieser Ansatz setzt vorraus, dass von Begin an der komplette
Wortschatz des RDF Graphen vorliegt und bearbeitet werden kann.
4.3.2 RDFVault
Ein Ansatz der auf Tries aufbaut ist RDFVault [BRU+15]. RDFVault verwendet
die Speicheradresse von Terminalknoten als ID. Dadurch spart dieser Ansatz eine
normalerweise in Dictionary Systemen zusätzlich anfallende ID zu String Map,
indem der String anhand des Baumpfades der Speicheradresse rekonstruiert wird.
Durch die Nutzung von Speicheradressen als IDs unterstützt RDFVault je-
doch keine Persistenz. Jeder Programmneustart macht alle vorher vergebenen IDs
ungültig, da neue Speicheradressen verwendet werden.
4.3.3 TripleBit
Abbildung 4.11: TripleBit Dictionary [YLW+13].
Das Dictionary von TripleBit [YLW+13] verwendet einen Präfix Kompressions-
ansatz ähnlich zur Idee von Front Coding. Abbildung 4.11 veranschaulicht das

4.3. EXISTIERENDE SYSTEME 32
Vorgehen des Dictionarys. Dabei werden IRIs in einen Präfix und einen Suffix Part
geteilt. Die Trennung findet beim letzten Vorkommen eines „/“ statt. Anschließend
werden zwei Hashtabellen aufgebaut. Eine die jedem Präfix eine ID zuweist und
eine weitere, die Präfix ID mit Suffix zu einem neuen String aneinanderhängt und
diesem ebenfalls eine ID zuordnet. Zwei invertierte Tabellen sorgen für schnellere
Rücktransformationen. Außerdem verwendet TripleBit keine fixe Größe für In-
teger, sondern Integer mit variabler Größe, um so immer die minimal benötigte
Anzahl an Bytes für das Encoding zu verbrauchen und reserviert ein Bit für die
Unterscheidung zwischen Subjekt und Objekt einer ID.
4.3.4 WaterFowl
Abbildung 4.12: WaterFowl Architektur [YLW+13].
Aufbauend auf dem Ansatz von HDT setzt WaterFowl [CBRF14b] auf Suc-
cinct Data Structures (SDS) wie Wavelet Trees und Bit Maps um besonders große
Datensätze und Ontologien (Vokabulare für RDF) handhaben zu können. SDS
sorgen für nahezu optimale Kompressionsraten ohne die Notwendigkeit einer
Dekompression für Suchanfragen.
Abbildung 4.12 zeigt die Architektur von WaterFowl. WaterFowl setzt den

4.4. VERGLEICH MIT DEN ANFORDERUNGEN 33
Fokus auf die drei Bereiche Dictionary, Triple Storage und Query Processing. Das
Dictionary in WaterFowl teilt sich in zwei Bereiche. Der erste Bereich ist ein auf
Suffix Automaten und Tries aufbauendes Dictionary für die vorkommenden RDF
Ausdrücke. Der zweite Teil ist ein eigenes Dictionary für Ontologie Elemente, die
aus RDF Vokabularen, wie RDFS und OWL, generiert werden und Suchanfragen
auf deren Hierarchien ermöglicht.
4.4 Vergleich mit den Anforderungen
Die in Abschnitt 4.3 vorgestellten Systeme werden in Tabelle 4.1 der Anforderungs-
liste aus Abschnitt 3.1 gegenübergestellt.
HDT RDFVault TripleBit WaterFowlID Transformation 3 3 3 3
ID Rücktransformation 3 3 3 3
Update Dictionary Einträge 7 3 7 7
Domain Fragmente - 3 (3) -Erkennung Literale in ID 3 7 7 7
Volltextsuche Literale (3) 7 7 (3)Binärrepräsentation Zahlen 7 7 7 7
Löschen Dictionary Eintrag 7 3 7 7
RDF Datentypen 7 7 7 7
Volltextsuche IRIs (3) 7 7 (3)Komprimierung Export 3 7 7 7
Tabelle 4.1: Vergleich der verwandten Systeme aus 4.3 mit den Anforderun-gen aus 3.1.
HDT Wie alle an dieser Stelle betrachteten verwandten Systeme setzt HDT die
zwei Grundfunktionalitäten einer Dictionary-Komponente „Transformation von
IRIs, Blank Nodes und Literale in IDs“ und „Rücktransformation von IDs in die
ursprünglichen RDF-Ausdrücke“ um. Eine Trennung nach Subjekt, Prädikat, Ob-
jekt und Subjekt-Objekt wird auch bei der Vergabe der IDs getätigt, indem für jede
dieser vier Gruppen ein Wertebereiche festgelegt wird, in dem sich die jeweiligen
IDs befinden. Die Erstellung des Dictionarys von HDT basiert darauf, dass die
kompletten zu verarbeitenden Daten von Beginn an vorliegen und unterstützt

4.4. VERGLEICH MIT DEN ANFORDERUNGEN 34
somit keine dynamischen Änderungen. Am Ende liegt das komplette Dictionary
in einem einzelnen Stream von aneinander gehangenen und durch „ \“ getrennten
Strings vor. HDT Compress verwendet anschließend noch einen PPM (Prediction by
Partial Matching) Ansatz auf das Dictionary und eine Huffman Kodierung auf die
Tripel um die Daten noch weiter zu komprimieren. Präfix- oder auch komplette
Volltextsuchen können in HDT zusätzlich implementiert werden. [FMPG+13]
RDFVault RDFVault verwendet bei der ID Vergabe die Speicheradresse des
jeweiligen Knotens im Trie und setzt die Rücktransformation von IDs durch ei-
ne Bottom-Up Traversierung des Tries um. Eine Erkennung von Literalen durch
Betrachten der ID ist nicht möglich. Aufgrund der Beschaffenheit der Trie Daten-
struktur ist eine Suche anhand von Präfixen leicht durchführbar. Ein großes Ziel
von RDFVault ist die Unterstützung von dynamischen Daten. Das nachträgliche
Hinzufügen und Löschen von Dictionary-Einträgen ist daher eine notwendige
Funktionalität. Aufgrund des erhöhten Speicheraufwandes, den ein invertierter
Index mit sich bringt, wird auf eine Volltextsuche verzichtet. Eine nachträgliche
Komprimierung der Daten nach Aufbau des Tries macht keinen Sinn, da aufgrund
wechselnder Speicheradressen ein Export der Daten ausgeschlossen ist. [BRU+15]
TripleBit Die ID Vergabe und damit Erfüllung der Anforderungen Transforma-
tion und Rücktransformation von IDs und RDF-Ausdrücken wird bei TripleBit
durch Hashing umgesetzt. Durch die zusätzliche Trennung des Pfades von IRIs in
zwei Teile setzt TripleBit Domain Fragmente teilweise um. Für eine vollständige
Erfüllung dieser Anforderung müssten jedoch noch weitere Pfadtrennungen ein-
geführt werden, die sämtliche Teilfragmente einer IRI abdecken. Innerhalb der IDs
gibt ein reserviertes Bit zwar an, ob es sich um ein Subjekt oder ein Objekt handelt,
jedoch nicht ob es sich bei dem Objekt um ein Literal handelt. Dementsprechend
wird auch keine Sonderbehandlung von Literalen die nur aus Zahlen bestehen
von TripleBit realisiert. Während viel Aufwand für die Komprimierung der Spei-
cherung von Tripel und die Optimierung von Anfragen auf die Tripel betrieben
wird, wird das Dictionary von TripleBit weder nachträglich komprimiert, noch
wird eine stärkere Textsuche für die Ausdrücke des Dictionarys als die zwei Teile
Trennung der IRIs umgesetzt. [YLW+13]

4.4. VERGLEICH MIT DEN ANFORDERUNGEN 35
WaterFowl Je nach Datensatz verwendet WaterFowl als Dictionary Datenstruk-
tur Suffix Automaten (Directed Acyclic Word Graphs) oder Tries. Eine Kombinati-
on aus Präfix Baum und Suffix Automat kann eine nahezu komplette Volltextsuche
ermöglichen, wobei die nicht abgedeckten Ausnahmen in der Praxis keine relevan-
ten Suchanfragen darstellen. Zusätzlich zu dem Dictionary für die RDF Ausdrücke
der Tripel baut WaterFowl ein weiteres Dictionary für Ontologien auf. Dieses auf
zwei Hash Tabellen basierende Dictionary ist unabhängig von dem ersten Dictiona-
ry und beinhaltet ausschließlich Ontologie Elemente und dient der Unterstützung
von Ontologie Hierarchien. Keiner der beiden Dictionary Ansätze setzt jedoch auf
die Speicherung von erkennbaren Metainformationen in der ID Vergabe. Auch
können dieselben IDs für beide Dictionarys vergeben werden. Diese werden nur
anhand des Kontextes der Anfrage unterschieden.
Der starke Fokus auf Succinct Data Structures sorgt für hohe Kompressionsra-
ten der Daten und wurde gewählt um auf zusätzliche, nachträgliche Kompression
und die damit zusammenhängende Notwendigkeit einer Dekompression beim
Bearbeiten von Suchanfragen verzichten zu können. Ein nachträgliches Ändern
von Daten ist ein Ziel von WaterFowl, das bisher noch nicht umgesetzt wurde.
[CBRF14a]
Zusammenfassung Keines der betrachteten bestehenden Systeme erfüllt die
Anforderungen, die an den Dictionary Service des Koldfish Projektes gestellt
werden, in ausreichendem Maße. Ein großes Problem stellen dabei die dynamisch
übergebenen Daten dar. Die meisten Systeme, die eine Dictionary Komponente
verwenden, arbeiten ausschließlich auf statisch vorliegenden Daten, um durch
die Anwendung von Kompressionsalgorithmen möglichst kompakte Daten zu
erreichen. Daten werden in Koldfish jedoch fortlaufend an den Dictionary Service
übergeben, wodurch diese Art der Kompression erst bei Eintritt einer Export
Anfrage auf einen bestimmten Datensatz durchführbar ist. Auch die nötigen
Anpassungsmöglichkeiten bei der ID Transformation sind bei den bestehenden
Systemen nicht vorgesehen, wodurch die Darstellung von Metainformationen
über den RDF Ausdruck innerhalb der ID verhindert wird. Um die spezifischen
Anforderungen des Koldfish Projektes zu erfüllen wird daher in Kapitel 5 ein
neuer Dictionary Service entwickelt.

Kapitel 5
Spezifikation der Implementation
Anhand der Erkenntnisse der verwandten Forschungsansätze und Systeme aus
Kapitel 4 und den Anforderungen aus Kapitel 3 wurde eine Strategie für das
Dictionary Modul von Koldfish entwickelt.
5.1 Anwendungsfälle
Das Dictionary Modul hat innerhalb von Koldfish fünf Anwendungsfälle die im
Anwendungsfalldiagramm in Abbildung 5.1 veranschaulicht werden. Der erste
Fall ist eine neue Transformationsanfrage, die zum Beispiel vom Data Access
Module gestellt wird. Hierbei wird dem Dictionary Modul ein RDF Ausdruck
übergeben, der in eine ID transformiert werden soll, um eine Reduzierung des
Speicherbedarfs beim Speichern der Tripel zu erreichen. Damit mit den als IDs
gespeicherten Tripeln weitergearbeitet werden kann, müssen einzelne IDs auf
Anfrage wieder in ihre ursprüngliche Form zurücktransformiert werden. Eine
gestellte ID Übersetzungsanfrage des Data und des Schema Services muss dement-
sprechend mit dem korresponierenden RDF Ausdruck beantwortet werden. Es
kann passieren, dass manche RDF Ausdrücke mit der Zeit nicht mehr benötigt
werden, da sie beispielsweise veraltet sind und durch neue ersetzt wurden. Nicht
mehr verwendbare RDF Ausdrücke verbrauchen unnötigerweise Speicherplatz
und ID-Slots innerhalb der Hashtabellen und sollten daher wieder aus dem System
gelöscht werden können. Da stetig neue Daten in das Dictionary aufgenommen
werden ist es nicht praktikabel die Dictionary Einträge während der Laufzeit des
Systems mit Kodierungsalgorithmen weiter zu komprimieren. Für den Fall, dass
36

5.2. PROGRAMMABLAUF 37
Daten exportiert werden sollen, um etwa in ein anderes System integriert zu wer-
den oder extern gesichert werden sollen, ist diese Einschränkung jedoch für diese
statischen Daten nicht mehr zutreffend und eine weitere Komprimierung kann
umgesetzt werden. Der letzte Anwendungsfall ist eine Volltextsuche, die es dem
Nutzer und den anderen Koldfish Komponenten ermöglichen soll die Einträge
des Dictionarys nach beliebigen Wortbestandteilen durchsuchen zu können.
Data Service
Data Access Module
Schema Service
Nutzer
Neue Transformationsanfrage
ID Übersetzungsanfrage
Löschen von Dictionary Einträgen
Export von Listen
Volltextsuche
Abbildung 5.1: Anwendungsfalldiagramm zum Koldfish Dictionary Mo-dul.
5.2 Programmablauf
Der Programmablauf des Dictionary Moduls ist ereignisbasiert. Nach dem Start
wird auf Nachrichten der anderen Koldfish Komponenten gewartet, die eine der
Routinen zur Behandlung der fünf Anwendungsfälle anstoßen. Diese Nachrichten
werden gesammelt und nacheinander abgearbeitet. Um die Netzwerk Kommu-
nikation zu reduzieren können und sollten die Nachrichten mehrere Einträge
enthalten. Zur Übersichtlichkeit wird in den folgenden Diagrammen von einem
Eintrag ausgegangen.
5.2. PROGRAMMABLAUF 38
Überprüfe ob RDF Ausdruck bereits in
Datenbank vorhanden
Erkenne RDF-Typ
Antwort mit ID schicken
[nicht vorhanden] [vorhanden]
Setze Bit 1 = 1Setze Bit 2 = 0Setze Bit 3 = 0
Setze Bit 1 = 0
[Literal][IRI / Blank Node]
Erkenne ob Zahl
Setze Bit 2 = 0 Setze Bit 2 = 1
[Zahl] [keine Zahl]
Erkenne Datentyp
Setze Bit 3 = 1Setze Bit 3 = 0
[hat Datentyp][kein Datentyp]
Transformiere IDTransformiere ID
ID + Datentypspeichern
RDF Ausdruck + IDspeichern
Antwort mit ID schicken
RDF Ausdruck zum invertierten Index hinzufügen
RDF Ausdruck + IDspeichern
Antwort mit ID schicken
RDF Ausdruck zum invertierten Index hinzufügen
Transformiere ID
Abbildung 5.2: Aktivitätsdiagramm nach Eintritt des Events einer neuenTransformationsanfrage.

5.2. PROGRAMMABLAUF 39
Transformationsanfrage Abbildung 5.2 zeigt ein Aktivitätsdiagramm für die
Behandlung einer neuen Transformationsanfrage. Dabei wird zunächst überprüft
ob der übergebene RDF Ausdruck bereits in der Datenbank des Dictionarys vor-
handen ist. Ist dies der Fall wird direkt die zugehörige ID zurückgegeben, die
Anfrage aus der Queue gelöscht und mit dem nächsten Event fortgeführt oder auf
das Eintreten eines solchen gewartet.
Ist der RDF Ausdruck neu, so wird zunächst überprüft, ob es sich um eine
IRI, ein Blank Node oder ein Literal handelt. Dieser Fakt wird als erstes Bit der
ID festgehalten, wobei IRI und Blank Nodes eine Eins und Literale eine Null
zugewiesen bekommen. Für den Fall eines Literals wird zusätzlich überprüft, ob
es sich um eine Zahl handelt und dieser Umstand im zweiten Bit abgespeichert.
Ob das Literal einen Datentyp aufweist oder nicht wird im dritten Bit hinterlegt.
Da IRIs und Blank Nodes keine Zahlen sein können und nur Literale Datentypen
besitzen können, wird hier das zweite und dritte Bit auf 0 gesetzt. Nach dem
Setzen der ersten drei Bits wird die vollständige ID erzeugt. Diese wird zusammen
mit dem RDF Ausdruck in der Datenbank gespeichert und als Antwort an das
Koldfish Modul aus der Anfrage geschickt. Als letztes wird der RDF Ausdruck
zum invertierten Index hinzugefügt. Ist ein Datentyp vorhanden wird dieser
zusammen mit der zugehörigen ID in einer separaten Datenbank für Datentypen
gespeichert.
Der soeben beschriebene Schritt der vollständigen ID Erstellung wird in Abbil-
dung 5.3 näher veranschaulicht. Zunächst wird hier unterschieden, ob es sich bei
dem Ausdruck um eine Zahl handelt. Ist dies der Fall werden die ersten drei Bits
auf 0 gesetzt und die Zahl als ID verwendet um die gewünschte Binärrepräsenta-
tion für Zahlen zu erreichen. Komplexere Zahlendatentypen, wie beispielsweise
float, hingegen werden unter Angabe ihres Datentyps wie alle anderen Datentypen
gesondert betrachtet. Handelt es sich bei dem RDF Ausdruck um keine Zahl wird
diese mit Hilfe einer Hashfunktion umgewandelt und anschließend die ersten drei
Bits gemäß den bestimmten Metainformationen ersetzt. Dabei wird überprüft, ob
die berechnete ID eine Kollision mit bereits bestehenden IDs auslöst. Sollte dies
der Fall sein wird eine Kollisionsstrategie angewendet bis eine freie ID gefunden
wurde.
Das Hinzufügen eines neuen RDF Ausdrucks zum invertierten Index wird in
Abbildung 5.4 genauer dargestellt. Zur Umsetzung der Volltextsuche im Dictionary
Modul wird die Java Bibliothek Apache Lucene [LUC] verwendet. Zunächst wird
5.2. PROGRAMMABLAUF 40
Erkenne ob Zahl
Zahl als IDspeichern
Hashfunktion anwenden
Bits mit Metainformationen
ersetzen
[keine Zahl] [Zahl]
Auf Kollisionen überprüfen
Kollisionsstrategie anwenden
[Kollision]
[keine Kollision]
Abbildung 5.3: Aktivitätsdiagramm für die Transformation eines RDF Aus-drucks zu einer ID.
Erstelle/Lade Verzeichnis des
invertierten Indexes
Erzeuge Lucene IndexWriter
Füge RDF-Ausdruck der Eingabe als
neues Dokument dem Index hinzu
Erzeuge Lucene Analyzer
Schließe Lucene IndexWriter
Verwendet NGramTokenizer und
LowerCaseFilter
Abbildung 5.4: Aktivitätsdiagramm für das Hinzufügen eines RDF Aus-drucks zum invertierten Index.

5.2. PROGRAMMABLAUF 41
ein neues Verzeichnis für den invertierten Index angelegt, beziehungsweise das
bereits bestehende Verzeichnis geladen. Anschließend muss zum Schreiben neuer
Daten in den Index ein Lucene IndexWriter erzeugt werden. Damit die an die
Volltextsuche des Dictionary gestellten Anforderungen erfüllt werden, wird dem
IndexWriter ein modifizierter Lucene Analyzer übergeben. Diese Modifikationen
beinhalten das Hinzufügen eines NGramTokenizers, der den übergebenen RDF
Ausdruck in Tokens mit einer Mindest- und einer Maximallänge aufteilt. Die für
das Dictionary gewählten Werte sind dabei vier als Mindestlänge und zwanzig als
Maximallänge. Das sorgt dafür, dass jedes mögliche Teilwort des Ursprungswortes
das aus vier bis zwanzig Zeichen besteht als Token im Index gespeichert wird
und in späteren Suchanfragen gefunden werden kann. Eine weitere Anpassung ist
die Verwendung eines LowerCaseFilters, der dafür sorgt, dass alle gespeicherten
Tokens kleingeschrieben gespeichert werden. Nach Erzeugung des IndexWriterswird der RDF Ausdruck als neues Dokument zum Index hinzugefügt. Im letzten
Schritt wird der IndexWriter geschlossen.
Übersetzungsanfrage Der Ablauf einer Anfrage zur Rücktransformation einer
ID in ihren ursprünglichen RDF Ausdruck wird in Abbildung 5.5 dargestellt. Wird
die ID in der Datenbank gefunden wird als Antwort an das Modul, das die Anfrage
gestellt hat, der RDF Ausdruck zurückgegeben. Sollte die Suche kein Ergebnis
liefern wird Null zurückgegeben.
Suche nach ID in Datenbank
Antwort mit RDF Ausdruck
Antwort mit Null schicken
[ID gefunden] [ID nicht gefunden]
Abbildung 5.5: Aktivitätsdiagramm nach Eintritt des Events einer neuenÜbersetzungsanfrage für eine ID.

5.2. PROGRAMMABLAUF 42
Volltextsuche Bei der Volltextsuche (siehe Abbildung 5.6) wird der bei jeder
Transformationsanfrage angepasste invertierte Index nach dem übergebenen Aus-
druck durchsucht. Dafür wird der als String übergebene Ausdruck zunächst in
eine Lucene Query umgewandelt. Anschließend wird analog zum Lucene Index-Writer beim Hinzufügen eines Eintrages, ein Lucene IndexReader zum Auslesen
von Einträgen benötigt. Diesem IndexReader muss der gleiche Analyzer wie dem
IndexWriter zugewiesen werden, um korrekte Ergebnisse zu erhalten. Als Antwort
auf die an den IndexReader übergebene Query wird eine Liste aller RDF Ausdrücke,
die den gewünschten Ausdruck beinhalten, zurückgegeben. Sollte kein entspre-
chender Ausdruck gefunden werden, wird eine leere Liste zurückgegeben.
Suche nach Ausdruck im invertierten Index
Antwort mit Liste aller entsprechenden
RDF Ausdrücke
Antwort mit leerer Liste
[Ausdruck gefunden] [Ausdruck nicht gefunden]
Wandle String in Query um
Erzeuge IndexSearcher für
Index Directory
Abbildung 5.6: Aktivitätsdiagramm nach Eintritt des Events einer Volltext-suchanfrage.
Löschen von Dictionary Einträgen Wie in Abbildung 5.7 veranschaulicht,
besteht der Löschvorgang eines Dictionary Eintrages aus drei Schritten. Sofern der
übergebene Ausdruck oder die ID im Dictionary gefunden wurde, muss dieser
zum einen aus der Datenbank selbst, aber auch aus dem invertierten Index entfernt
werden, um im weiteren Programmablauf fehlerhafte Suchanfragen zu vermeiden.
Außerdem muss bei Literalen mit gesetztem Datentyp die ID aus der Datentyp
Datenbank gelöscht werden.
5.3. STRUKTUR DES SYSTEMS 43
Suche nach Ausdruck / ID in
Datenbank
Lösche ID aus Datentyp Datenbank
Überprüfe Bit 3
Lösche Eintrag aus Datenbank
Lösche Eintrag ausinvertiertem Index
[Eintrag gefunden] [Eintrag nicht gefunden]
[Bit 3 = 0]
[Bit 3 = 1]
Abbildung 5.7: Aktivitätsdiagramm nach Eintritt des Events einer Löschan-frage für einen bereits bestehenden Dictionary Eintrag.
5.3 Struktur des Systems
Abbildung 5.8 zeigt einen ersten Blick auf die Struktur des Dictionary Moduls.
Das Dictionary ist in die zwei Teilkomponenten API und Backend unterteilt. Die
API dient dabei als Schnittstelle zwischen den anderen Koldfish Modulen und
dem Dictionary. Nach einer ersten Initialisierung des Dictionary Backends reagiert
das Dictionary ausschließlich ereignisbasiert auf Anfragen der anderen Module.
Abbildung 5.8: Black-Box-Sicht auf das Koldfish Dictionary Modul

5.3. STRUKTUR DES SYSTEMS 44
ActiveMQ Die Kommunikation zwischen den Modulen von Koldfish wird
mit Apache ActiveMQ [Foua] umgesetzt. ActiveMQ ist eine Implementation der
Java Message Service API und ermöglicht eine asynchrone Kommunikation zwi-
schen den einzelnen Teilkomponenten. Dabei wird zwischen zwei möglichen
Umsetzungen unterschieden, die das Ziel einer Nachricht festlegen. In einer Queuewerden Nachrichten von einem Erzeuger genereriert und von einem Verbraucher
abgearbeitet. Der Verbraucher löscht nach Verarbeitung einer Nachricht diese
anschließend aus der Queue. Somit stehen Nachrichten für eventuelle weitere
Verbraucher nicht mehr zur Verfügung. In Topics gibt es Publisher, die Nachrichten
generieren und Subscriber, die Nachrichten empfangen. In diesem Fall ist es mög-
lich, dass die gleiche Nachricht von mehreren Subscribern empfangen wird. Das
Koldfish Dictionary arbeitet mit einer Queue um Anfragen der anderen Module
über die Dictionary API zu sammeln und nacheinander im Backend abzuarbeiten.
Antworten werden an das jeweilige Modul, das die Anfrage gestellt hat, gesendet.
Um die Anzahl an Nachrichten, die zwischen den Modulen gesendet werden, zu
reduzieren werden in einer Nachricht mehrere Einträge des gleichen Anfragetyps
auf einmal übertragen, beispielsweise als Liste von RDF Ausdrücken, oder als
Liste von IDs.
Maven Das Koldfish-Projekt verwendet das Build-Management Tool Apache
Maven [Foub]. Maven sorgt für eine standardisierte Verzeichnisstruktur und
verwaltet Abhängigkeiten zwischen den einzelnen Modulen, sowie zu anderen
Softwareprojekten. Für die Verwaltung dieser Abhängigkeiten und Strukturen
verwendet Maven POM-Dateien. Abbildung 5.1 zeigt Ausschnitte einer solchen
POM-Datei und zeigt wie das Dictionary Modul eine Abhängigkeit zu ActiveMQ
darstellt und sich in die zwei Teilmodule „API“ und „Backend“ aufteilt. Das Dic-
tionary ist dabei bereits selbst ein Teilmodul des Koldfish-Projektes und gibt daher
die übergeordnete POM-Datei des Gesamtprojektes als „parent“ an und kann so
deren Eigenschaften erben.
Listing 5.1: Beispiel für das Angeben von Abhängigkeiten und Strukturenmit Maven POM-Dateien
<parent >
<groupId>de . unikoblenz . west . koldf ish </groupId>
< a r t i f a c t I d >koldf ish </ a r t i f a c t I d >

5.3. STRUKTUR DES SYSTEMS 45
<version >0.0.1 </ version >
</parent >
<dependency>
<groupId>org . apache . activemq </groupId>
< a r t i f a c t I d >activemq−c l i e n t </ a r t i f a c t I d >
<version >\$ { activemq−vers ion }</ version >
</dependency>
<modules>
<module>api </module>
<module>backend</module>
</modules>
Datenbank Zur dauerhaften Speicherung der Daten verwendet das Dictionary
Modul den RocksDB Key-Value Store [ROC]. Zum einen werden alle transformier-
ten RDF Ausdrücke mit zugehöriger ID als Paare gespeichert. Um eine schnelle
Suche nach sowohl IDs als auch RDF Ausdrücken in der Datenbank zu gewähr-
leisten werden die Paare zweimal in die Datenbank übertragen. Einmal mit ID als
Schlüssel und RDF Ausdruck als Wert, und ein zweites Mal mit RDF Ausdruck
als Schlüssel und ID als Wert. Zum anderen werden Literale, die mit einem Da-
tentyp annotiert sind, in einer zweiten Datenbank gespeichert. Da die Suche nach
Datentypen nicht erforderlich ist, reicht es an dieser Stelle IDs als Schlüssel und
den jeweiligen Datentyp als Wert abzuspeichern.

5.3. STRUKTUR DES SYSTEMS 46
5.3.1 Spezifikation API
Das API Teilmodul spezifiziert Funktionen, die von außerhalb des Dictionary
Moduls sichtbar und aufrufbar sein müssen, um so die Funktionalitäten des
Dictionarys für die anderen Koldfish Module zugänglich zu machen. Abbildung
5.9 zeigt die Sicht innerhalb der API Komponente.
<<component>>
API+Dictionary()+transformRDF()+lookUpID()+hasDatatype()+getDatatype()+fullTextSearch()+removeEntry()+isLiteral()+isNumber()
-ActiveMQ Connection connection-ActiveMQ Session session-ActiveMQ Queue responseQueue-ActiveMQ Queue dictionaryInput-ActiveMQ Producer producer-ActiveMQ Consumer c
Dictionary -List<String> rdfAusdrücke
RDFListMessage
-List<Long> ids
IDListMessage
-long id
DATATYPEMessage
-String ausdruck
FULLTEXTMessage
-List<String> strings
STRINGListMessage
-String string
STRINGMessage
-long id
REMOVEMessage
Abbildung 5.9: White-Box-Sicht zur API Komponente des Koldfish Dictio-nary Moduls
Das Kernstück der API ist die Dictionary Klasse. Hier werden Funktionsaufrufe
für alle Anwendungsfälle des Dictionarys definiert, die von anderen Koldfish
Modulen aufgerufen werden können. Jeder Anwendungsfall, der einen Aufruf der
Backend Komponente erfordert, hat eine eigene Message Klasse zugeteilt, die zum
einen den Typ der Anfrage für das Backend ersichtlich macht und zum anderen die
jeweils notwendigen Übergabeparameter enthält. Die API ermöglicht Anfragen für
das Transformieren von RDF Ausdrücken zu IDs mit transformRDF(List<String>rdf), sowie deren Rücktransformation mit lookUpIDs(List<Long> ids). Wenn bei der
Erstellung einer ID der RDF Ausdruck mit einem Datentyp annotiert gewesen ist,
wird dieser in einer gesonderten Datenbank zusammen mit der ID gespeichert.
Mit getDatatype(long id) kann der entsprechende Eintrag abgerufen werden. Au-
ßerdem können mit fullTextSearch(String expression) Volltextsuchanfragen an die
im Dictionary gespeicherten RDF Ausdrücke gestellt werden. Sollte ein Eintrag
im Dictionary nicht mehr gewünscht sein kann dieser mit removeEntry(long id/ String rdf) aus den Datenbanken des Dictionarys und dem invertierten Index

5.3. STRUKTUR DES SYSTEMS 47
entfernt werden. Daneben existieren eine Reihe von Funktionen, die die in den ers-
ten Bits der IDs abgespeicherten Metainformationen überprüfen und ohne einen
Zugriff auf das Backend Informationen über den RDF Ausdruck hinter der ID
ermöglichen. Eine vollständige Beschreibung aller in Abbildung 5.9 dargestellten
API-Funktionen erfolgt im Anhang A.
5.3.2 Spezifikation Backend
Das Backend stellt den eigentlichen Funktionsumfang des Dictionary Moduls zur
Verfügung, nachdem entsprechende Anfragen der anderen Koldfish Module über
die API des Dictionarys gestellt wurden. Abbildung 5.10 zeigt die Sicht innerhalb
der Backend Komponente.
<<component>>
Backend
+main()
-ActiveMQ Connection connection-ActiveMQ Session session-ActiveMQ Queue dictionaryInput-ActiveMQ Producer producer-ActiveMQ Consumer consumer-ActiveMQ messageListener
Main
-long2bytes()-string2bytes()-asLong()-asString()-DB()-DBDatatype()+lookup()+datatypelookup()+dbkeystore()+dbtypestore()+dbWriteBatch()+dbDatatypeWriteBatch()+removeEntry()+removeDatatype()
-RocksDB db-RocksDB dbdatatype
RocksDBStorage+makeRDFNodes()+transformRDFNodes()-checkMetaBits()-hashCode()-canonicalize()-cutDatatypeString()-cutLiteralString()
TransformRDF
+lookUpIds()
LookUpID
+lookUpDatatype()
Datatypes +fullTextSearch()+addIndex()-addDocument()+removeIndex()
FullTextSearch
+removeEntry()
RemoveEntry
Abbildung 5.10: White-Box-Sicht zur Backend Komponente des KoldfishDictionary Moduls
Die main Methode des Backends enthält einen Message Listener, der nach Start
des Dictionary Backends permanent aktiv ist. Dieser empfängt die von der API
über ActiveMQ gesendeten Messages und verteilt anhand des jeweiligen Objekt-
Typs die nötigen Funktionsaufrufe an die verschiedenen Klassen des Backends.

5.3. STRUKTUR DES SYSTEMS 48
Jeder Anwendungsfall hat eine eigene Klasse, die die nötigen Schritte zur Abar-
beitung der Anfrage einleitet. Die meisten Anfragen erfordern eine Interaktion
mit einer oder beiden RocksDB Datenbanken, weswegen die Klasse RocksDB-Storage alle nötigen Funktionen enthält, um Daten in die zwei Datenbanken zu
übertragen oder daraus abzufragen. Fertige Antworten gehen stets zurück an
den Message Listener, der die entsprechenden Antworten wieder in Messages
verpackt und über ActiveMQ an die API zurücksendet. Die Klasse TransformRDFbehandelt Anfragen zur Transformation von RDF Ausdrücken zu IDs. Hier wird
zunächst die übergebene Liste an RDF Ausdrücken von Strings zu entsprechenden
Apache Jena Nodes umgewandelt, die den korrekten RDF-Typ (IRI/Blank Node
oder Literal) und eventuell annotierte Datentypen von Literalen berücksichtigen.
Die so erzeugten Jena Nodes werden an die Funktion transformRDF(List<Nodes>nodes) übergeben, die den Verlauf der Transformation von Bestimmung der Me-
tainformationen und Berechnung freier Hashwerte in der Klasse selbst, bis hin
zur Speicherung in den Datenbanken und dem invertiertem Index in den Klassen
RocksDBStorage und FullTextSearch dirigiert. Die Klassen LookUpId und Datatypesbehandeln Anfragen zum Nachschlagen von IDs oder den zu einer ID gehörenden
Datentyp und greifen auf die entsprechenden Funktionen der Klasse RocksDBSto-rage zu. Die Klasse FullTextSearch behandelt zum einen die von der Main Klasse
aufgerufenen Volltextsuchanfragen und enthält zum anderen Funktionen für das
Anlegen, sowie Entfernen von Einträgen im invertierten Index, welche von den
Klassen TransformRDF und RemoveEntry angestoßen werden. Eine vollständige
Beschreibung aller in Abbildung 5.10 dargestellten Backend-Funktionen erfolgt
im Anhang B.

Kapitel 6
Evaluation
Die in Kapitel 5 beschriebene Implementation eines Dictionary Services für das
Koldfish Projekt wird in diesem Kapitel evaluiert. Dies geschieht zum einen an-
hand der in Kapitel 3.1 beschriebenen Anforderungen und zum anderen durch
eine Bewertung anhand der Kriterien Speichereffizienz und Geschwindigkeit des
Dienstes.
6.1 Vergleich mit den Anforderungen
Tabelle 6.1 stellt die in Kapitel 3.1 beschriebenen Anforderungen dem im Lau-
fe dieser Arbeit entworfenen und implementierten Koldfish Dictionary Service
gegenüber.
ID Transformation Die Anforderung RDF Ausdrücke in IDs zu transformieren
wird vom Dictionary Modul erfüllt. Die API Funktion transformRDF() ermöglicht es
den anderen Koldfish Komponenten eine Liste mit RDF Ausdrücken als Strings zu
übergeben und als Antwort eine Liste mit neu generierten IDs zurückzubekommen.
Jede ID ist eine mittels Hashwert berechnete, einzigartige ID, deren höchsten drei
Bits Metainformationen über den RDF Ausdruck beinhalten. Die Zugehörigkeit
von RDF Ausdrücken und IDs werden in einer RocksDB Datenbank gespeichert.
ID Rücktransformation Die Anforderung vom Dictionary erzeugte IDs zu-
rück in ihren ursprünglichen RDF Ausdruck zu transformieren wird von der API
Funktion lookUpID() erfüllt. Die Funktion sucht in der RocksDB Datenbank nach
49

6.1. VERGLEICH MIT DEN ANFORDERUNGEN 50
Koldfish DictionaryID Transformation 3
ID Rücktransformation 3
Update Dictionary Einträge 3
Domain Fragmente -Erkennung Literale in ID 3
Volltextsuche Literale 3
Binärrepräsentation Zahlen 3
Löschen Dictionary Eintrag 3
RDF Datentypen 3
Volltextsuche IRIs 3
Komprimierung Export 7
Tabelle 6.1: Vergleich des Koldfish Dictionarys aus Kapitel 5 mit den Anfor-derungen aus Kapitel 3.1.
der ID und gibt, wenn diese gefunden wurde, den entsprechenden RDF Ausdruck
zurück.
Update von Dictionary Einträgen Das Hinzufügen von neuen Einträgen in
das Dictionary ist ein beliebig fortlaufender Prozess. Neue Transformationsanfra-
gen werden in einer ActiveMQ Queue gesammelt und nacheinander abgearbeitet.
Domain Fragmente Die Anforderung das Dictionary in Form eines Domain
Fragment Baumes zu speichern, um die Suche nach Domain Fragmenten von
IRIs zu ermöglichen wird durch die Erfüllung der Anforderung der Volltextsuche
nicht mehr benötigt. Die implementierte Volltextsuche ermöglicht die Suche nach
beliebigen Ausdrücken bei sowohl IRIs als auch Literalen und ist somit deutlich
flexibler.
Erkennung von Literalen in der ID Die vom Dictionary erzeugten IDs wei-
sen Metainformationen auf, anhand derer Literale von IRIs / Blank Nodes unter-
schieden werden können. Die API Funktionen isLiteral(), isNumber() und hasData-type() überprüfen die IDs auf die gesetzten Bits um Metainformationen abzufragen
ohne einen Datenbankzugriff zu erfordern.

6.1. VERGLEICH MIT DEN ANFORDERUNGEN 51
Volltextsuche für IRIs und Literale Das Dictionary setzt eine Volltextsuche
für IRIs und Literale um, indem ein invertierter Index erzeugt wird, der bei jeder
Transformationsanfrage um die neuen RDF Ausdrücke ergänzt wird. Aktuell
werden von der API Funktion fullTextSearch() beliebige Ausdrücke mit mindestens
vier Zeichen für die Suche akzeptiert. Suchbegriffe mit über 20 Zeichen werden auf
Teilbegriffe mit 20 Zeichen reduziert, die alle für sich erfolgreichen Ergebnisse als
Antwort liefern. Diese Limitierung wurde gewählt, um ein möglichst hohes Maß
an realistischen Suchanfragen abzudecken ohne Speicherplatz für unrealistische
Suchanfragen zu verbrauchen.
Binärrepräsentation von Zahlen RDF Ausdrücke die ausschließlich Zahlen
enthalten, ohne mit Datentypen annotiert zu sein, werden bei der ID Transformati-
on gesondert berücksichtigt und bekommen als ID ihren Zahlenwert zugewiesen.
Die Bitfolge für Metainformationen ist bei Zahlen „000“ (Literal, Zahl, kein Daten-
typ).
RDF Datentypen Bei der Transformation von RDF Ausdrücken werden even-
tuell annotierte Datentypen erkannt und als Paar ID - Datentyp in einer zweiten
RocksDB Datenbank gespeichert. Der zu einer ID gehörende Datentyp kann durch
die API Funktion getDatatype() abgefragt werden. Außerdem weisen IDs die auf
Datentyp annotierte RDF Ausdrücke verweisen ein entsprechend gesetztes Bit als
Metainformation in der ID auf.
Löschen von Dictionary Einträgen Die API Funktion removeEntry() ermög-
licht das nachträgliche Entfernen von RDF Ausdrücken und IDs. Bei einer Löschan-
frage wird die ID und der zugehörige RDF Ausdruck aus den Datenbanken ge-
löscht und vom invertierten Index entfernt.
Komprimierung für Export Die Anforderung eines Exports von Daten wird
nicht erfüllt. Zur Erfüllung dieser Anforderung ist es notwendig bestimmte Daten
gezielt aus dem Dictionary abfragen zu können und unter Anwendung geeigneter
Komprimierungsansätzen eine kompakte Liste für den Export bereitzustellen. In
der aktuellen Version des Dictionarys können die drei erzeugten Verzeichnisse
Index, Storage und StorageDatatypes ausschließlich komplett kopiert und an einem
neuen Ort mit dem Koldfish Dictionary weiterverwendet werden.

6.2. BEWERTUNG DER PERFORMANZ 52
Anzahl Einträge Format(NxE) Dauer(S) Storage(MB) Datatype(MB)10.000.000 10.000x1000 7683 334 95,81.000.000 1000x1000 651 53,6 24,11.000.000 4000x250 960 54,7 24,7100.000 100x1000 73 8,3 2,4100.000 400x250 102 8,3 2,4100.000 1000x100 199 8,4 2,510.000 10x1000 11,3 0,87 0,2610.000 40x250 12,6 0,87 0,2610.000 100x100 24,7 0,87 0,2610.000 1000x10 165 0,88 0,28
Tabelle 6.2: Testdurchläufe für Transformation von RDF Ausdrücken ohneinvertiertem Index
6.2 Bewertung der Performanz
Die Tabellen 6.2, 6.3 und 6.4 zeigen die Ergebnisse einer Reihe von Testdurchläufen,
die mit dem Koldfish Dictionary Service durchgeführt wurden. Das Testsystem
ist eine virtuelle Ubuntu Linux Maschine mit 2,4 GHz Prozessor und 1,5 GB
RAM, die auf einem Windows 7 Host System mit 2,4 GHz Dual Core Prozessor
und 4 GB RAM gestartet wird. Um die einzelnen Durchläufe besser vergleichen
zu können, wurden die Testdaten nach festen Mustern zufällig generiert. Jede
gesendete ActiveMQ Nachricht besteht dabei zur Hälfte aus IRIs, zu einem Viertel
aus Literalen und zu einem Viertel aus Literalen mit annotiertem Datentyp. Alle
Einträge sind dabei zehn Zeichen lange, zufallsgenerierte Strings, wobei IRIs
zusätzlich von „http://www.“ „.de“ umschlossen werden. Die drei wichtigsten
Kriterien, die in diesen Tests überprüft werden sind die Geschwindigkeit von
Transformationsanfragen, der Speicherverbrauch der zwei Datenbanken und des
invertierten Indexes und die Stabilität des Dienstes bei sehr großen Datenmengen.
Tabelle 6.2 zeigt verschiedene Testdurchläufe, die bei leerer Datenbank ohne
das Hinzufügen zum invertierten Index durchgeführt wurden. „Anzahl Einträge“
gibt dabei die Anzahl der RDF Ausdrücke an, die insgesamt in diesem Durch-
lauf getestet wurden. Die Spalte „Format“ gibt das Verhältnis zwischen Einträge
pro ActiveMQ Nachricht an. „10.000x1.000“ bedeudet, dass 10.000 ActiveMQ
Nachrichten mit jeweils 1.000 Einträgen gesendet wurden. Bei ausreichend vielen
Einträgen pro Nachricht skaliert die Dauer bei gleichbleibendem Format nahezu

6.2. BEWERTUNG DER PERFORMANZ 53
Anzahl Einträge Format(NxE) Dauer(S)1.000.000 1000x1000 748,5100.000 100x1000 18510.000 10x1000 27,210.000 40x250 32,510.000 100x100 57,8
Tabelle 6.3: Testdurchläufe für Transformation ohne invertiertem Index beivoller Datenbank (>10Millionen Einträge)
linear. Während „100x1.000“ Nachrichten 73 Sekunden beanspruchen brauchen
„1.000x1.000“ 651 Sekunden und „10.000x1.000“ 7683 Sekunden. Sind zu weni-
ge Einträge in einer Nachricht ist ActiveMQ ein Flaschenhals, der wie im Fall
„1.000x10“ gut zu sehen ist, die benötigte Zeit stark erhöht. RocksDB schafft es
den Speicherverbrauch bei größeren Daten zu komprimieren. Während 100.000
Einträge 8,3 MB Speicherplatz beanspruchen, steigt der Verbrauch bei einer zehn
mal höheren Menge nur um den Faktor 6,46 auf 53,6 MB an.
Wenn bereits über zehn Millionen Einträge in der Datenbank vorhanden sind,
nimmt die Dauer der Testdurchläufe, wie in Tabelle 6.3 dargestellt, deutlich zu.
Dies ist besonders bei den Testdurchläufen mit 10.000 Einträgen ausschlaggebend.
Hierbei erhöht sich die Dauer von 11,3 Sekunden auf 27,2 Sekunden. Ein Grund
hierfür ist die höhere Kollisionsanzahl bei der Berechnung eines freien Hashwertes.
Durch die Natur der zufällig generierten Testdaten ist nahezu jeder Eintrag ein
bisher unbekannter RDF Ausdruck der in eine neue ID umgewandelt werden
muss. Bei realen Daten würde jedoch bei gefüllter Datenbank ein erhöhter Anteil
bereits in der Datenbank vorliegen und dabei statt einer neuen Transformation
lediglich ein Nachschlagen in der Datenbank auslösen.
Tabelle 6.4 zeigt Testdurchläufe von Transformationen, die zusätzlich den in-
vertierten Index für die Volltextsuche aktualisieren. Dieser Vorgang erhöht nicht
nur drastisch die benötigte Dauer des Transformationsprozesses, sondern sorgt
zusätzlich auch noch für einen enorm erhöhten Speicherverbrauch. Dies erklärt
sich durch die hohe Anzahl an Teilwörtern, die aus jedem RDF Ausdruck ge-
neriert werden um den invertierten Index zu erstellen. Mit einer Erhöhung des
Minimalwertes bei der Tokengenerierung des Indexes von mindestens vier auf
mindestens sechs Zeichen konnte beispielsweise eine Erparnis von fast einem
Drittel des genutzten Speicherplatzes erreicht werden. Sowohl RocksDB als auch
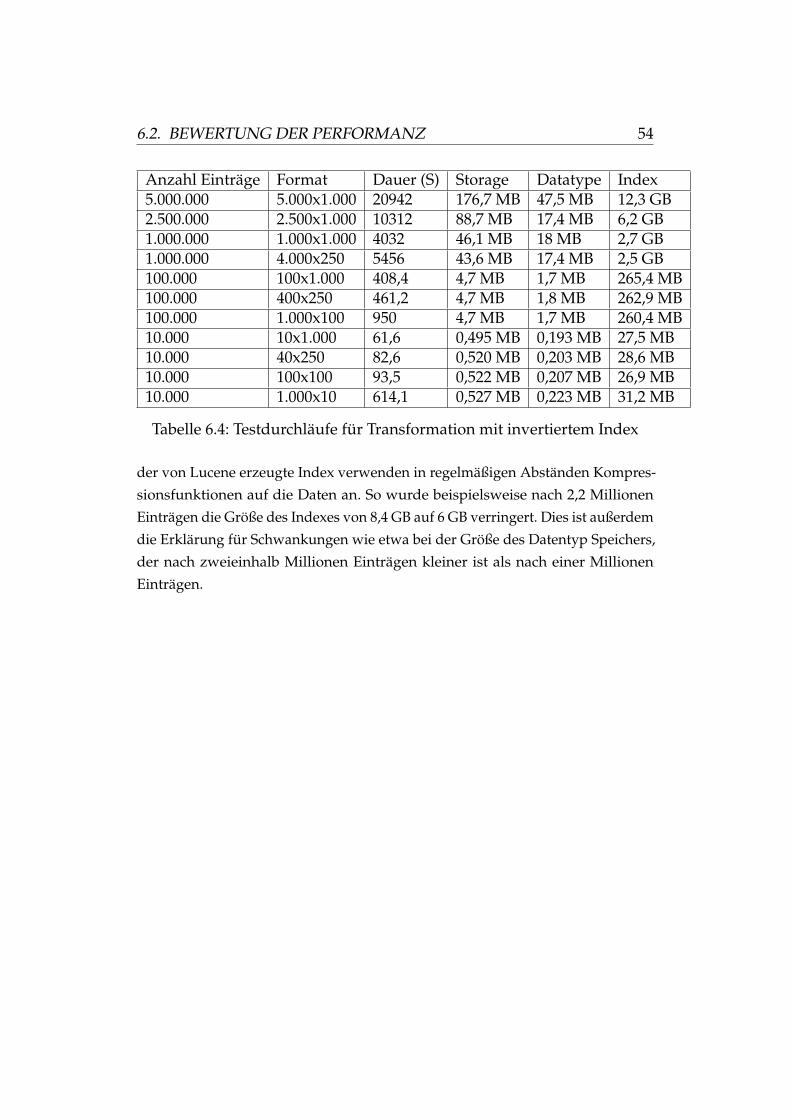
6.2. BEWERTUNG DER PERFORMANZ 54
Anzahl Einträge Format Dauer (S) Storage Datatype Index5.000.000 5.000x1.000 20942 176,7 MB 47,5 MB 12,3 GB2.500.000 2.500x1.000 10312 88,7 MB 17,4 MB 6,2 GB1.000.000 1.000x1.000 4032 46,1 MB 18 MB 2,7 GB1.000.000 4.000x250 5456 43,6 MB 17,4 MB 2,5 GB100.000 100x1.000 408,4 4,7 MB 1,7 MB 265,4 MB100.000 400x250 461,2 4,7 MB 1,8 MB 262,9 MB100.000 1.000x100 950 4,7 MB 1,7 MB 260,4 MB10.000 10x1.000 61,6 0,495 MB 0,193 MB 27,5 MB10.000 40x250 82,6 0,520 MB 0,203 MB 28,6 MB10.000 100x100 93,5 0,522 MB 0,207 MB 26,9 MB10.000 1.000x10 614,1 0,527 MB 0,223 MB 31,2 MB
Tabelle 6.4: Testdurchläufe für Transformation mit invertiertem Index
der von Lucene erzeugte Index verwenden in regelmäßigen Abständen Kompres-
sionsfunktionen auf die Daten an. So wurde beispielsweise nach 2,2 Millionen
Einträgen die Größe des Indexes von 8,4 GB auf 6 GB verringert. Dies ist außerdem
die Erklärung für Schwankungen wie etwa bei der Größe des Datentyp Speichers,
der nach zweieinhalb Millionen Einträgen kleiner ist als nach einer Millionen
Einträgen.

Kapitel 7
Fazit
Die Ergebnisse der Arbeit werden noch einmal zusammengefasst und in einem
Ausblick mögliche Ansatzpunkte für weiterführende Arbeiten an diesem Thema
gegeben.
7.1 Zusammenfassung
Der im Zuge dieser Arbeit entwickelte Dictionary Dienst bietet eine Reihe von
Funktionen für das Koldfish Projekt. Dazu gehört zunächst die Transformation
von RDF Ausdrücken zu IDs und deren Rücktransformation. Beim Speichern
dieser IDs werden Metainformationen über den RDF Ausdruck innerhalb der ID
festgelegt, die ohne einen Datenbankzugriff abgefragt werden können. Außerdem
werden eventuell annotierte Datentypen von Literalen berücksichtigt und für
eine spätere Abfrage in einer gesonderten Datenbank abgespeichert. Literale die
ausschließlich Zahlenwerte enthalten werden durch eine Binärrepräsentation der
Zahl innerhalb der ID dargestellt. Eine Volltextsuche ermöglicht das Durchsuchen
der im Dictionary gespeicherten Einträge für beliebige Ausdrücke mit mehr als
vier Zeichen. Zuletzt ist es möglich nicht mehr benötigte Einträge wieder aus den
zwei Datenbanken für die Speicherung von RDF Ausdruck - ID und ID - Datentyp
Paaren sowie dem invertierten Index für die Volltextsuche des Dictionarys zu
entfernen. Bis auf den Export von Daten in komprimierter Form konnten alle an
den Dienst gestellten Anforderungen erfüllt werden. Die Geschwindigkeit der
Transformation von RDF Ausdrücken ist dabei schnell genug, dass die Netzwerk-
kommunikation mit ActiveMQ der beschränkende Faktor ist. Der aktuelle Ansatz
55

7.2. AUSBLICK 56
der Volltextsuche ermöglicht sehr flexible Suchanfragen für beliebige Ausdrücke.
Der Speicherverbrauch und die Geschwindigkeit der Erzeugung des dafür benö-
tigten invertierten Indexes sind jedoch zu hoch. Für einen genaueren Einblick in
die Umsetzung des Dictionary Services befinden sich, neben der Beschreibung der
Implementation anhand von Modellen in Kapitel 5, vollständige Funktionsspezifi-
kationen für die API und das Backend der Dictionary Komponente im Anhang.
7.2 Ausblick
In zukünftigen Arbeiten kann der Dictionary Dienst noch in verschiedenen Be-
reichen verbessert werden. Eine mögliche Optimierung der Hashfunktion, bezie-
hungsweise der Kollisionsstrategie kann eine besser skalierende Geschwindigkeit
bei einer bereits mit mehreren Millionen Einträgen gefüllten Datenbank erreichen.
Außerdem sollte die Konfiguration der Volltextsuche mit Apache Lucene ange-
passt werden. Die Performancekosten und der erhöhte Speicherverbrauch, den die
von vier bis zwanzig Zeichen genaue Volltextsuche verursacht, ist für den Dictiona-
ry Service zu hoch. Ein möglicher Optimierungsansatz ist eine Tokengenerierung,
die sich ausschließlich auf realistische Suchanfragen beschränkt. Beispiele dafür
sind die Entfernung von Tokens, die Wortanteile wie „http://www.“ enthalten
oder Teilworte von Literalen die nur aus Zahlen bestehen. Alternativ kann die
zeichengenaue Volltextsuche durch eine Suche ersetzt werden, die beispielsweise
IRIs anhand der „/“ Symbole in vorgefertigte Suchworte auftrennt. Des Weiteren
kann die noch offene Anforderung des Datenexports umgesetzt werden. Dazu
notwendig ist die Generierung von Listen gewünschter Datensätze zum Beispiel
mittels der Volltextsuche und einer anschließenden Komprimierung mit Ansätzen
wie dem Front Coding oder der Huffman Kodierung. Weitere Ansatzpunkte sind
eine erhöhte Ausfallsicherheit des Dictionary Dienstes wie etwa bei Verlust der Ac-
tiveMQ Verbindung und eine Beschränkung von Löschanfragen auf ausgewählte
Komponenten um einen möglichen Missbrauch zu verhindern.

Anhang A
Funktionsspezifikation API
A.1 Dictionary()
Input: -
Output: -
Beschreibung: Konstruktor für eine neue Dictionary API Instanz. Baut die
Verbindung zum Koldfish ActiveMQ Server auf und erzeugt darin eine neue
Session mit einer InputQueue und einer ResponseQueue, sowie einem Producer
und einem Consumer.
A.2 transformRDF()
Input: Liste von RDF Ausdrücken (String). Literalen wird zusätzlich ein „ˆˆDa-
tentyp“ angehangen.
Output: Liste mit IDs (long) in der korrekten Reihenfolge zum Input.
Beschreibung: Fügt neue Transformationsanfragen für RDF Ausdrücke in IDs
in Form einer RDFListMessage der InputQueue hinzu. Im Verlauf der Abarbeitung
im Backend wird für jeden RDF Ausdruck der Eingabe eine eindeutige ID vom
Typ „long“ erzeugt. Jede ID speichert in den ersten drei Bits Metainformationen
ob es sich bei dem Ausdruck um eine IRI/Blank Node oder ein Literal handelt,
ob es eine Zahl ist und ob ein Datentyp vorhanden ist. Die Funktion wartet bis
57

58
eine Antwort zurückgeschickt wird und gibt dann eine Liste mit passenden IDs
zurück.
A.3 lookUpID()
Input: Liste mit IDs (long).
Output: Liste mit RDF Ausdrücken (String) in der korrekten Reihenfolge zum
Input.
Beschreibung: Fügt eine neue Übersetzungsanfrage für eine ID zurück in einen
RDF-Ausdruck in Form einer IDListMessage der InputQueue hinzu. Nach dem
Erhalt einer Antwort aus dem Backend wird eine Liste mit passenden RDF Aus-
drücken zurückgegeben.
A.4 fullTextSearch()
Input: Beliebiger Ausdruck (String).
Output: Liste mit zum Input passenden Ausdrücken (String).
Beschreibung: Fügt eine neue Volltextsuchanfrage für einen beliebigen Aus-
druck in Form einer FULLTEXTMessage der InputQueue hinzu. Im Zuge der Bear-
beitung wird ein invertierter Index nach dem Ausdruck überprüft und passende
Ergebnisse zurückgegeben.
A.5 isLiteral()
Input: ID (long).
Output: true / false (Boolean).
Beschreibung: Überprüft anhand des ersten Bits ob der zur ID gehörige RDF
Ausdruck ein Literal ist.

59
A.6 isNumber()
Input: ID (long).
Output: true / false (Boolean).
Beschreibung: Überprüft anhand des zweiten Bits ob der zur ID gehörige
RDF-Ausdruck eine Zahl ist.
A.7 hasDatatype()
Input: ID (long).
Output: true / false (Boolean).
Beschreibung: Überprüft anhand des dritten Bits ob der zur ID gehörige RDF
Ausdruck einen Datentyp hat.
A.8 getDatatype()
Input: ID (long).
Output: Datentyp (String).
Beschreibung: Überprüft mit hasDatatype() ob der zur ID gehörige RDF Aus-
druck einen Datentyp hat. Wenn ein Datentyp vorhanden ist wird eine DATATYPE-Message der InputQueue hinzugefügt. Bei deren Beantwortung wird eine Anfrage
mit der ID an die Datentyp Datenbank gestellt und das Resultat zurückgegeben.
A.9 removeEntry()
Input: ID (long) / RDF Ausdruck (String).
Output: -

60
Beschreibung: Fügt eine Löschanfrage in Form einer REMOVEMessage der
InputQueue hinzu. Die entsprechenden Werte ID, RDF Ausdruck und eventuell
vorhandener Datentyp werden aus den beiden Datenbanken sowie dem invertier-
tem Index entfernt.

Anhang B
Funktionsspezifikation Backend
B.1 main()
Input: -
Output: -
Beschreibung: Startet die Verbindung zum Koldfish ActiveMQ Server und
erzeugt darin eine neue Session mit der InputQueue, einem Producer und einem
Consumer. Außerdem wird ein MessageListener erzeugt, der die Anfragen der API
empfängt und an die entsprechende Stelle im Backend weiterleitet. Die Trennung
der einzelnen Anfragetypen geschieht anhand der verwendeten Messagetypen,
die als verschiedene Klassen in der API definiert werden. Die passenden Antwor-
ten werden ebenfalls als unterschiedliche Messagetypen über ActiveMQ an die
entsprechend wartenden Funktionen der API zurückgesendet.
B.2 makeRDFNodes()
Input: Liste mit RDF Ausdrücken (Strings).
Output: Liste mit RDF Ausdrücken (Apache Jena Nodes).
Beschreibung Die von der API übermittelten Strings werden je nach RDF-Typ
in Jena IRI oder Literal Nodes (mit Datentyp) transformiert. Dies entfernt die für
61

62
die ActiveMQ Übergabe notwendigen Anpassungen der Strings und stellt sicher,
dass ausschließlich korrekte Datentypen verwendet werden.
B.3 transformRDF()
Input: Liste mit RDF Ausdrücken (Jena Nodes).
Output: Liste mit IDs (long) in passender Reihenfolge.
Beschreibung: Für jeden Ausdruck der Input Liste wird eine Reihe von Funk-
tionen durchlaufen um eine fertige ID zu erzeugen. Zunächst wird überprüft,
ob der Ausdruck bereits in der Datenbank vorhanden ist und wenn ja, die ent-
sprechende ID der Ergebnisliste hinzugefügt. Handelt es sich um einen neuen
Ausdruck wird dieser je nach Typ zunächst in eine kanonische Form gebracht. An-
schließend werden mit checkMetaBits() die Metainformationen bestimmt. Darauf-
hin wird der Ausdruck mit den zugehörigen Bits an hashCode() weitergeleitet um
die fertige ID zu generieren. Sind alle Einträge abgearbeitet werden die erzeugten
(ID, RDF Ausdruck) sowie (RDF Ausdruck, ID) Paare in der ersten Datenbank und
(ID, Datentyp) Paare in der zweiten Datenbank gespeichert. Um zu verhindern,
dass innerhalb einer Anfrage nicht bereits belegte ID Slots verwendet werden, die
jedoch noch nicht an die Datenbank übertragen worden sind, wird eine zusätzliche
Map memory erstellt, die die bereits abgearbeiteten Paare der aktuellen Anfrage
beinhaltet. Am Ende wird eine Liste mit den fertigen IDs zurückgegeben.
B.4 checkMetaBits()
Input: RDF Ausdruck (Jena Node).
Output: Bitfolge (int).
Beschreibung An dieser Stelle werden die Metainformationen, die in der ID
gespeichert werden überprüft. Das erste Bit der ID gibt an, ob es sich um eine
IRI / Blank Node (1) oder ein Literal (0) handelt. Das zweite Bit bestimmt ob der
Ausdruck eine Zahl darstellt (Zahl = 0, keine Zahl = 1) und das dritte Bit gibt
Auskunft über einen eventuell angehängten Datentyp (Datentyp vorhanden = 1,
sonst 0). Da nicht mit einem Datentyp annotierte Literale automatisch als String

63
interpretiert werden, werden mit String annotierte Literale wie nicht annotierte
Literale behandelt. Die so erzeugte dreistellige Bitfolge wird zurückgegeben.
B.5 hashCode()
Input: RDF Ausdruck (Jena Node) + Bitfolge für Metainformationen (int) +
memory (Map <String, int>).
Output: ID (long).
Beschreibung Zunächst bestimmt die Funktion anhand der Bitfolge eine Bit
Maske die im weiteren Verlauf über die ID gelegt wird, um die Bits der Metain-
formationen zu setzen. Für den Fall, dass es sich bei dem Ausdruck um eine Zahl
handelt wird die Zahl selbst als ID verwendet. Dies ist möglich, da die gewählte
Bitfolge für Zahlen „000“ beträgt. Ist der Ausdruck keine Zahl wird eine Hash
Funktion aufgerufen, die einen Hashwert für den Ausdruck erstellt. Bei diesem
werden zunächst die ersten drei Bits auf Null gesetzt und diese anschließend mit
der vorher bestimmten Bit Maske auf die entsprechende Bitfolge gesetzt. Es folgt
eine Kollisionsüberprüfung mit den bereits in der Datenbank sowie der Memory-Map vorhandenen IDs. Wurde eine freie ID bestimmt wird diese zurückgegeben,
ansonsten wird an den darauffolgenden Stellen weiter nach einem freien Slot
gesucht.
B.6 lookUpID()
Input: Liste mit IDs (long).
Output: Liste mit passenden RDF Ausdrücken (String) in korrekter Reihenfolge.
Beschreibung: Stellt für jeden Listeneintrag eine Anfrage nach der ID an die
erste Datenbank und speichert die Ergebnisse in einer Liste, die anschließend
zurückgegeben wird.
B.7 lookUpDatatype()
Input: ID (long).

64
Output: Datentyp (String).
Beschreibung Stellt eine Datenbankanfrage nach der ID an die Datentyp Da-
tenbank.
B.8 fullTextSearch()
Input: Beliebiger Ausdruck (String).
Output: Liste mit passenden RDF Ausdrücken (String).
Beschreibung Sucht im invertierten Index nach dem angegebenen Ausdruck
und gibt eine Liste mit allen passenden Ausdrücken zurück.
B.9 removeEntry()
Input: ID (long).
Output: -
Beschreibung Entfernt die ID und den zugehörigen RDF Ausdruck aus beiden
Datenbanken sowie aus dem invertierten Index.
B.10 long2Bytes() / string2Bytes
Input: long / String.
Output: Byte.
Beschreibung Wandelt long oder String Werte zu Bytes um.
B.11 asLong() / asString()
Input: Byte.
Output: long / String.

65
Beschreibung Wandelt Bytes zurück zu ihrem long oder String Wert.
B.12 DB()
Input: -
Output: RocksDB Datenbank db.
Beschreibung Erzeugt, wenn nicht bereits vorhanden die Datenbank „db“, die
mit (ID, String) und (String, ID) Paaren gefüllt wird. Gibt db zurück.
B.13 DBDatatype()
Input: -
Output: RocksDB Datenbank dbdatatype.
Beschreibung Erzeugt, wenn nicht bereits vorhanden die Datenbank „dbdata-
types“, die mit (ID, Datentyp) Paaren gefüllt wird. Gibt dbdatatype zurück.
B.14 dbkeystore() / dbtypestore()
Input: (ID, RDF Ausdruck) / (ID, Datentyp).
Output: -
Beschreibung Wandelt das angegebene Paar mit long2bytes und string2bytes
in Byte um und speichert das transformierte Paar in der jeweiligen Datenbank.
B.15 dbWriteBatch() / dbDatatypeWriteBatch()
Input: Map<String, Long> / Map<Long, String>.
Output: -
Beschreibung Speichert mehrere Paare auf einmal in der jeweiligen Datenbank.

66
B.16 lookup()
Input: ID (long).
Output: RDF Ausdruck (String).
Beschreibung Sucht in der ersten Datenbank nach der ID, die zuvor mit long2bytes()
in Byte umgewandelt wurde. Der gefundene Wert wird mit asString() in einen
String umgewandelt und zurückgegeben.
B.17 datatypelookup()
Input: ID (long).
Output: Datentyp (String).
Beschreibung Sucht in der Datentyp Datenbank nach der ID, die zuvor mit
long2byte() in Byte umgewandelt wurde. Wurde ein Eintrag gefunden wird dieser
mit asString() in einen String umgewandelt und dieser zurückgegeben. Ansonsten
wird der Datentyp für Strings „http://www.w3.org/2001/XMLSchema#string“
zurückgegeben.
B.18 canonicalizeIRI() / cutLiteralString() / cutDatatypeString()
Input: RDF Ausdruck (String).
Output: kanonischer RDF Ausdruck(String).
Beschreibung Bringt IRIs / Literale / Literale mit Datentyp in ein einheitliches
Format.

Literaturverzeichnis
[AI09] A.T. Akinwale and F.T. Ibharalu. The usefulness of multilevel hash
tables with multiple hash functions in large databases, 2009.
[BF92] N. H. Bshouty and G. T. Falk. Compression of dictionaries via exten-
sions to front coding. In Computing and Information, 1992. Proceedings.ICCI ’92., Fourth International Conference on, pages 361–364, May 1992.
[BHBL09] Christian Bizer, Tom Heath, and Tim Berners-Lee. Linked da-
ta - the story so far. Special Issue on Linked Data, InternationalJournal on Semantic Web and Information Systems (IJSWIS), 2009.
http://linkeddata.org/docs/ijswis-special-issue.
[BL] Tim Berners-Lee. Linked data principles. htt-
ps://www.w3.org/DesignIssues/LinkedData.html letzter Zugriff
15.05.2016.
[BRU+15] Hamid R. Bazoobandi, Steven de Rooij, Jacopo Urbani, Anette ten
Teije, Frank van Harmelen, and Henri Bal. A compact in-memory
dictionary for rdf data. Chapter The Semantic Web. Latest Advancesand New Domains - Volume 9088 of the series Lecture Notes in ComputerScience pp 205-220, 21.05.2015.
[CBRF14a] Olivier Curé, Guillaume Blin, Dominique Revuz, and David Faye.
Waterfowl: a compact, self-indexed and inference-enabled rdf store.
2014.
[CBRF14b] Olivier Curé, Guillaume Blin, Dominique Revuz, and David Faye.
Waterfowl, a compact, self-indexed RDF store with inference-enabled
dictionaries. CoRR, abs/1401.5051, 2014.
67

LITERATURVERZEICHNIS 68
[CLRS09] Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rives, and Clif-
ford Stein. Introduction to Algorithms. The MIT Press, 2009.
[CTW95] J. G. Cleary, W. J. Teahan, and I. H. Witten. Unbounded length con-
texts for ppm. In Data Compression Conference, 1995. DCC ’95. Procee-dings, pages 52–61, 1995.
[CW84] J. Cleary and I. Witten. Data compression using adaptive coding
and partial string matching. IEEE Transactions on Communications,
32(4):396–402, 1984.
[FMPG+13] Javier D. Fernández, Miguel A. Martínez-Prieto, Claudio Gutiérrez,
Axel Polleres, and Mario Arias. Binary rdf representation for publica-
tion and exchange (hdt). Web Semantics: Science, Services and Agentson the World Wide Web, 19(0), 2013.
[Foua] The Apache Software Foundation. Apache activemq.
http://activemq.apache.org/ letzter Zugriff 16.10.2016.
[Foub] The Apache Software Foundation. Apache maven. htt-
ps://maven.apache.org/ letzter Zugriff 16.05.2016.
[HDT] Webseite hdt. http://www.rdfhdt.org/ letzter Zugriff 16.05.2016.
[KOL] Webseite koldfish. http://west.uni-
koblenz.de/de/forschung/forschungsprojekte/koldfish letzter
Zugriff 15.10.2016.
[LUC] Webseite apache lucene. https://lucene.apache.org/core letzter Zu-
griff 16.10.2016.
[Nav14] Gonzalo Navarro. Wavelet trees for all. Journal of Discrete Algorithms,
25:2–20, March 2014.
[RDFa] Webseite rdf 1.1 datatypes. https://www.w3.org/TR/rdf11-
concepts/#section-Datatypes letzter Zugriff 05.11.2016.
[RDFb] Webseite rdf 1.1 konzepte. https://www.w3.org/TR/rdf11-
concepts/#dfn-rdf-triple letzter Zugriff 05.11.2016.
[ROC] Webseite rocksdb. http://rocksdb.org/ letzter Zugriff 16.10.2016.

LITERATURVERZEICHNIS 69
[SBJR] Max Schmachtenberg, Christian Bizer, Anja Jentzsch, and Cyga-
niakm Richard. Linked open data cloud diagram 2014. http://lod-
cloud.net/ letzter Zugriff 15.05.2016.
[SLG+16] Stefan Scheglmann, Martin Leinberger, Thomas Gottron, Steffen
Staab, and Ralf Lämmel. Sepal - schema enhanced programming for
linked data. intern, 2016.
[W3C] W3C. Rdf/xml validator. https://www.w3.org/RDF/Validator/
letzter Zugriff 14.05.2016.
[Wen03] Michael Wenig. Entwicklung eines konzepts zur volltextsuche in se-
mantischen netzen, 2003. Diplomarbeit, Universität Stuttgart, Institut
für Parallele und Verteilte Systeme.
[WIKa] Webseite wikidata. https://www.wikidata.org/ letzter Zugriff
25.08.2016.
[WIKb] Wikidata rdf export statistiken august
2016. http://tools.wmflabs.org/wikidata-
exports/rdf/index.php?content=exports.php letzter Zugriff
25.08.2016.
[WMB99] Ian H. Witten, Alistair Moffat, and Timothy C. Bell. Managing Giga-bytes Compressing and Indexing Documents and Images. Morgan Kauf-
mann, 1999.
[YLW+13] Pingpeng Yuan, Pu Liu, Buwen Wu, Hai Jin, Wenya Zhang, and Ling
Liu. Triplebit: a fast and compact system for large scale rdf data.
Proceedings of the VLDB Endowment, Vol. 6, No. 7, 2013.