
Einführung in das Arbeiten mit STATA und Daten des Sozio ... · 1 1. Einleitung Dieses Skript...
31
Einführung in das Arbeiten mit STATA und Daten des Sozio-oekonomischen Panels (SOEP) Skript zum Seminar von Tobias Graf Stefanie Hoherz Universität Bielefeld Fakultät für Soziologie Postfach 100131 33501 Bielefeld Email: [email protected] [email protected] 2. April 2009
Transcript of Einführung in das Arbeiten mit STATA und Daten des Sozio ... · 1 1. Einleitung Dieses Skript...

Einführung in das Arbeiten mit STATA und Daten des
Sozio-oekonomischen Panels (SOEP)
Skript zum Seminar von
Tobias Graf
Stefanie Hoherz
Universität Bielefeld Fakultät für Soziologie
Postfach 100131 33501 Bielefeld
Email: [email protected] [email protected]
2. April 2009

Inhalt
1. Einleitung..............................................................................................................................................1 2. Einführung in das Arbeiten mit SOEP-Daten................................................................................1
2.1 Was ist das SOEP .........................................................................................................................1 2.2 Themenbereiche............................................................................................................................2 2.3 Analysemöglichkeiten...................................................................................................................3 2.4 SOEPinfo.......................................................................................................................................4 2.5 Dokumentation .............................................................................................................................4 2.6 Variablennamen und Datensätze................................................................................................4
3. Einführung in das Arbeiten mit STATA .........................................................................................6 3.1 Die Struktur ...................................................................................................................................6 3.2 Arbeiten mit do-files und log-files..............................................................................................8 3.3 Syntaxschreiben.............................................................................................................................9 3.4 Das Datenfenster ........................................................................................................................10 3.5 Grundlegende Befehle................................................................................................................10 3.5.1 Häufigkeitstabellen ..................................................................................................................12 3.5.2 Wichtige Befehlspräfixe ..........................................................................................................12 3.5.3 Befehlsbedingungen ................................................................................................................12 3.6 Erstellen und Verändern von Variablen..................................................................................13 3.6.1 Generate, replace und recode ................................................................................................13 3.6.2 Löschen .....................................................................................................................................15 3.6.3 Vergabe von Labels................................................................................................................15 3.6.4 Rationale Operatoren (Dummy-Variablen) .........................................................................16 3.7 Weitere Befehlspräfixe ...............................................................................................................16 3.8 Mergen..........................................................................................................................................17 3.9 Kippen des Datensatzes.............................................................................................................21 3.10 Der Umgang mit fehlenden Werten (Missings) ...................................................................24 3.11 Gewichtung ...............................................................................................................................24 3.12 Gruppieren von Daten.............................................................................................................25 3.13 Schleifen (loops)........................................................................................................................26 3.14 Grafiken .....................................................................................................................................28 Überblick über wichtige Literatur und Homepages: ......................................................................0

1
1. Einleitung Dieses Skript wurde zur Unterstützung des Seminars „Einführung in das Arbeiten mit STATA und Daten des Sozio-oekonomischen Panels (SOEP)“ an der Univarsität Bielefeld erstellt. Es gibt eine kurze Einführung in die Benutzung des Statistikprogramms STATA, jedoch nur im Bezug auf Funktionen, die für die Bearbeitung von SOEP-Datensätzen relevant sind. Ausführlichere und allgemeine Informationen für die Benutzung von STATA findet man in verschiedenen Handbüchern und auf der Seite www.stata.com. Es werden die aktuelle STATA-Version 10.0 und die SOEP-Daten bis 2007 (Welle X) verwendet. Diese Einführung in STATA beschränkt sich auf das Schreiben der Syntaxen, es können zwar (ähnlich wie bei SPSS) alle Funktionen über das Menü aufgerufen werden, doch hier steht das Erlernen der Programmiersprache im Vordergrund. Wir haben uns vorwiegend an dem Buch: „U. Kohler und F. Kreuter (2008): Datenanalyse mit STATA. Allgemeine Konzepte der Datenanalyse und ihre praktische Anwendung, München: Oldenbourg Wissenschaftsverlag.“ orientiert.
2. Einführung in das Arbeiten mit SOEP-Daten
2.1 Was ist das SOEP Das SOEP ist eine seit 1984 laufende jährliche Befragung von Deutschen, Ausländern und Zuwanderern in den alten und neuen Bundesländern. Es handelt sich um eine für die gesamte Bundesrepublik repräsentative Wiederholungsbefragung von Personen und Haushalten. Es gab neben der Erweiterung der Befragung im Jahr 1990 auf das Gebiet der ehemaligen DDR, auch für die Erfassung des gesellschaftlichen Wandels mehrere Stichproben in den Jahren 1994, 1995, 1998, 2000, 2002 und 2006, die in die laufende Erhebung integriert wurden. Insgesamt haben bereits 61545 Personen aus über 26000 Haushalten teilgenommen. Die Stichprobe umfasste im Erhebungsjahr 2007 ca. 11.000 Haushalte mit mehr als 21.000 Personen. Das Sozio-oekonomische Panel (SOEP) ist ein Survey, der für die sozial- und wirtschaftswissenschaftliche Grundlagenforschung Mikrodaten bereitstellt. Die vom Deutschen Institut für Wirtschaftsforschung (DIW) durchgeführte Studie befragt möglichst alle Personen eines Haushaltes, die mindestens 17 Jahre alt sind. Seit dem Befragungsjahr 2000 werden zusätzlich von Jugendlichen im Alter von 16 bis 17 Jahren jugendspezifische Biographiedaten erhoben. Seit 2003 beantworten Mütter von Neugeborenen Fragen nach zentralen Indikatoren, die für die Entwicklungsprozesse von Kindern eine hohe Erklärungskraft aufweisen und seit 2005 werden auch die Eltern von zwei- und dreijährigen Kindern besonders befragt. Ab 2008 werden auch die Eltern fünf- und sechsjähriger Kinder besonders befragt und ab 2010 zudem die Eltern älterer Kinder sowie die Kinder selbst, bevor diese mit dem 17. Lebensjahr zu regulären Befragungspersonen werden. Zudem werden über den Haushaltsvorstand (in Vertretung aller Haushaltsmitglieder) Informationen über den gesamten Haushalt erfasst. Erwachsene Haushaltsmitglieder und verzogene Haushalte werden auch nach einem Aus- oder Wegzug weiterverfolgt sowie zugezogene neue Haushaltsmitglieder mit befragt. Die Informationen werden sowohl durch herkömmliche Fragen in einjährigen Abständen, als auch über Kalendarien oder Retrospektivbefragungen monatsgenau erfasst.1
1 Für weitere Informationen siehe http://www.diw.de/deutsch/soep/26628.html

2
2.2 Themenbereiche Die SOEP-Daten enthalten Informationen über die Personen, den Haushalt in dem sie leben, ihre objektiven Lebensbedingungen, aber auch Persönlichkeitsmerkmale, Wertvorstellungen, Risikoeinstellungen und über dynamische Abhängigkeiten zwischen allen Bereichen und deren Veränderungen. Die Themen im SOEP sind sehr vielfältig. Kontinuierlich liefert es Informationen über Erwerbs- und Familienbiographien, Erwerbsbeteiligung und berufliche Mobilität, Einkommensverläufe, Kinderbetreuung und Bildungsbeteiligung, Persönlichkeitsmerkmale, körperliche und mentale Gesundheit, die Haushaltszusammensetzung, Wohnsituation, gesellschaftliche Partizipation und Zeitverwendung sowie Lebenszufriedenheit. Zudem werden in jährlich wechselnden Schwerpunktthemen Informationen über die Familie und soziale Dienste, Weiterbildung und Qualifikation, Soziale Sicherung sowie Energie- und Umweltverhalten gesammelt. Über die Jahre wurden verschiedene Teilstichproben integriert: Sample A - Grundstichprobe Bundesbürger 1984 (4500 Haushalte) Sample B - Ausländer 1984 (1500 Haushalte) HV mit türkischer, griechischer, jugoslawischer, spanischer oder italienischer Staatsangehörigkeit Sample C - Ost 1990 (2000 Haushalte) Sample D1 und D2 – Immigranten1995 (500 Haushalte) HH mit Personen, die in den Jahren 1984-1995 zugewandert sind Sample E – Auffrischungsstichprobe 1998 (1000 Haushalte) methodische Sonderstichprobe Sample F – Innovationsstichprobe 2000 (6000 Haushalte) Stichprobe zur Erhebung innovativer Erhebungskonzepte Sample G – Hocheinkommensbezieher 2002 (1200 Haushalte) Sample H – Haushalte in Deutschland 2006 (1000 Haushalte) Ergänzung zu E

3
Aufgrund der unterschiedlichen Ziehungswahrscheinlichkeit der Teilstichproben ist es deshalb unbedingt erforderlich, dass die Daten gewichtet werden. D.h. die jeweiligen Beobachtungen in den einzelnen Teilstichproben repräsentieren unterschiedlich viele Personen und Haushalte in der jeweiligen Grundgesamtheit. Für die Gewichtung gibt es im SOEP eigene Datensätze, in denen die Gewichtungsfaktoren enthalten sind.
2.3 Analysemöglichkeiten Durch sein Längsschnittdesign (Panelcharakter) bietet das SOEP besondere Analysemöglichkeiten. Eine besondere Möglichkeit ist, dass der Haushaltskontext betrachtet werden kann, da alle erwachsenen Haushaltsmitglieder befragt werden, die auch miteinander verknüpft werden können. Zudem werden zusätzlich Informationen über die Kinder der Befragungspersonen erhoben. Weiterhin gibt es die Möglichkeit regionaler Vergleiche und die Nutzung von kleinräumigen Kontextindikatoren. Besonders erwähnenswert ist die überproportionale Ausländerstichprobe (gegenwärtig die größte Wiederholungsbefragung bei Ausländern in der Bundesrepublik Deutschland; die Stichprobe umfasst Haushalte mit einem Haushaltsvorstand türkischer, spanischer, italienischer, griechischer oder ehemals jugoslawischer Nationalität) und die Erhebung von Zuwanderung (gegenwärtig die einzige methodisch zuverlässige Stichprobe von Zuwanderern, die von 1984 bis 1995 nach Westdeutschland gekommen sind). Ein Problem von allen Panelstudien ist, dass nicht zu allen Zeitpunkten Informationen der Befragten erhoben werden können. Einige Befragte möchten nicht mehr teilnehmen, ziehen weg, sterben und andere sind einfach nicht mehr auffindbar. Das SOEP zeichnet sich jedoch durch eine geringe Panelmortalität aus. Beispielsweise beteiligten sich 1984 in der ersten Welle im SOEP-West 5.921 Haushalte mit 12.245 erfolgreich befragten Personen an der Erhebung; nach 23 Wellen im Jahre 2007 sind es noch 3.337 Haushalte mit 5.963 Personen. Im Jahr 2000 wurde eine generelle Auffrischungsstichprobe eingeführt. Zudem werden auch Personen weiterverfolgt, die z.B. durch eine Scheidung den Haushalt verlassen oder Personen mit aufgenommen, die in den Haushalt neu hineinkommen. So muss beachtet werden, dass die Fallzahlen der unterschiedlichen Erhebungswellen variieren. 2
2 Ausführlichere Darstellungen unter: http://www.diw.de/documents/publikationen/73/88913/diw_datadoc_2008-039.pdf

4
Ein wichtiger Vorteil von Paneldaten ist, dass der Einfluss von institutioneller Veränderung auf individuelles Verhalten erfassbar wird. Weiterhin können Lebensverläufe von Individuen, ihren Partnern, Eltern oder Kindern über eine weite Spanne verfolgt werden und intergenerationale Analysen werden möglich. Intentionen und tatsächliche Verhaltensauswirkungen werden über die Zeit beobachtbar. Ein weiterer wichtiger Vorteil ist die hohe Reichweite statistischer Modellierungen, die durch die wiederholte Messung von Zusammenhängen entsteht. Ein großer Vorteil sind die Fallzahlen. Auch seltene Ereignisse haben hohe Fallzahlen, wenn sie über die Jahre zusammen genommen werden. Ein entscheidender Vorteil des SOEP ist, dass es international vergleichbar ist und mit großen Panels aus anderen Ländern zusammenarbeitet (z.B: BHPS). Nachteile, die genannt werden müssen, sind jedoch die Panelmortalität, selektive Ausfälle, Lerneffekte, die Abnahme der Teilnahmemotivation über die Zeit und demographisch bedingte Veränderung der Grundgesamtheit, die kontrolliert werden müssen.
2.4 SOEPinfo Das interaktive Programm SOEPinfo enthält eine Übersicht über alle Variablen, Datensätze sowie Fragebögen des SOEP und bietet darüber hinaus Programmierhilfen für die Datenverarbeitung an. Aufzurufen unter: http://panel.gsoep.de/soepinfo2007/.
2.5 Dokumentation Alles Wissenswerte zur Struktur und Daten des SOEP steht ausführlich im Desktop Companion (DTC). Es ist aus vielerlei Artikeln, Diskussionspapieren, und Seminar-Handouts entstanden und dokumentiert alles was man beachten sollte. Das DTC findet man auf der SOEP- Homepage: http://www.diw.de/deutsch/soep/26628.html unter → Service & Documentation oder direkt unter http://www.diw.de/documents/dokumentenarchiv/17/38951/dtc.354256.pdf .
2.6 Variablennamen und Datensätze Das SOEP ist eine Längsschnittserhebung mit Paneldaten. D.h. es werden immer wieder die gleichen Personen befragt. Die Informationen der Personen werden in unterschiedlichen Dateien abgespeichert. Da die Personen jährlich befragt werden, gibt es für jedes Jahr eigene Datensätze. Das SOEP gibt es inzwischen seit 25 Jahren, diese Daten benötigen natürlich viel Speicherplatz und sind nicht mehr ganz übersichtlich, sodass dieses Format seine Vorteile hat. Die Informationen der verschiednen Erhebungsjahre sind in einem Datensatz mit dem jeweiligen Buchstaben des Jahres enthalten. Die Datensätze mit den Informationen der ersten Befragung 1984 sind unter dem Buchstaben A zu finden, die zweite Erhebung bekam den Buchstaben B (1985), bis heute sind wir beim Buchstaben X für das Jahr 2007 angelangt. Das SOEP ist ein Haushalts-Panel, was bedeudet, dass alle Personen eines Haushaltes befragt werden und zusätzlich werden auch Informationen über den Haushalt als Ganzes erhoben. Diese Informationen sind für alle Personen des jeweiligen Haushaltes dieselben. Es gibt somit verschiedene Personendatensätze, hier sind Variablen mit Personeninformationen gespeichert ($p, $pgen)3. Der normale Personendatensatz der ersten Welle heißt ap.dta, der Personendatensatz der zweiten welle bp.dta usw., die generierten Datensätze heißen für die ersten beiden Wellen apgen.dta und bpgen.dta usw.. Außerdem gibt es Haushaltsdatensätze, in
3 Dies Zeichen $ steht für die jeweilige Wellen-Buchstaben: ap.dta, bp.dta, cp.dta, dp.dta…wp.dta, xp.dta.

5
denen die Haushaltsinformationen gespeichert sind ($h, $hgen). Der Buchstabe h nach dem jeweiligen Buchstaben der Welle steht für Haushaltsdatensatz, p für Personendatensatz. Die Bezeichnung gen steht für bereits generierte Datensätze. Es gibt zudem Datensätze mit Spell-Daten (biomarsy); Gewichtungen (phrf, hhrf) Kinder und Elterninformationen ($kind, bioparen) oder Kalendarien (sozkalen, $pkal). Besonders wichtige Datensätze sind ppfad.dta und hpfad.dta. Sie enthalten wellenübergreifende Personenbasisinfos bzw. Haushaltsinfos und bilden die Grundlage für das Zusammenspielen der verschiedenen Datensätze (Haushalts- und Personeninformationen). Die grundlegenden Datensätze mit denen man beginnen sollte, um einen Einstieg zu finden, sind ppfad.dta, $p.dta, $pgen.dta, $h.dta und $hgen.dta. Da diese Datensätze alle einzeln vorliegen, müssen sie zunächst zusammengespielt werden. Dies geschieht über ppfad.dta, da hier alle grundlegenden Informationen aller Wellen enthalten sind. In den anderen Datensätzen sind die spezifischen Informationen der einzelnen Wellen enthalten und müssen für das Arbeiten im Längsschnitt ebenfalls miteinander verknüpft werden. Wie dieses Verknüpfen von Datensätzen funktioniert, wird im Kapitel „3.16 Mergen“ beschrieben. Das erste Zeichen eines Variablennamens entsprechen ähnlich der Datensätze häufig der jeweiligen Welle: z.B. A der Welle 1984, B der Welle 1985, X der Welle 2007. Das zweite Zeichen gibt an, ob es sich um Personendaten, Haushaltsdaten, Daten von Jugendlichen oder Kindern handelt: z.B. P steht für Personendaten und H für Haushaltsdaten. Die darauf folgende Zahl entspricht der Nummer im Fragebogen. Variablen, die ohne Zahl enden, wurden häufig schon überarbeitet: z.B. apsbil, bpsbil, cpsbil. Einige Variablen enden mit der jeweiligen Jahreszahl: z.B. egp84, egp85, egp86 oder emplst05, emplst06, emplst07 und sind auch bereits überarbeitet vorhanden. Die Identifikation der Personen und Haushalte findet über bestimmte Variablen statt: persnr (Personennummer), hhnr (Haushaltsnummer), $hhnr (die wellenspezifische Haushaltsnummer). So können die Personen einem Haushalt zugeordnet werden.

6
3. Einführung in das Arbeiten mit STATA
3.1 Die Struktur
Nach dem Öffnen von STATA erscheinen vier Fenster. Zum einen das Results-Fenster. Hier erscheinen die eingegebene Syntax, die Resultate der Berechnungen und Fehlermeldungen. Zum anderen das Command-Fenster (unterhalb des Results-Fensters), welches zur Eingabe von Befehlen verwendet wird. Weiterhin gibt es das Review-Fenster, das die letzten eingegeben Befehle sowie Fehlermeldungen dokumentiert. Durch anklicken des Befehls erscheint dieser im Command-Fenster. Schließlich gibt es das Variables-Fenster, in dem alle Variablen des aktuell geöffneten Datensatzes aufgelistet sind sowie ihre genaue Bezeichnung. Auch die Variablen erscheinen durch anklicken im Command-Fenster. Außerdem gibt es eine Menü- und eine Button-Leiste. Fast alle Funktionen dieser Leisten können auch in Befehlen ausgedrückt werden. Da durch das Syntaxschreiben alle Vorgänge dokumentiert werden und so auch wiederholbar sowie besser nachvollziehbar sind, ist dieses Arbeiten von Vorteil. Hier steht zwar das Erlernen der Programmiersprache im Vordergrund, jedoch für das (in STATA sehr umfangreiche) Erstellen von Graphiken sollte auch das Ausprobieren über die Menü-Leiste stattfinden. STATA liest den gesamten Datensatz in den Arbeitsspeicher. Deshalb muss je nach Größe des Datensatzes ausreichend Arbeitsspeicher bereitgestellt werden. Standardmäßig ist 1.00 MB für die Daten reserviert. Um den Speicherplatz zu erhöhen schreibt man den Befehl set mem 100m . Da diese Erhöhung nur auf die aktuelle Sitzung beschränkt ist, gibt es die Möglichkeit mit set mem 200m, permanently den Speicher permanent zu erhöhen und erspart sich somit die erneute Eingabe zu Beginn jeder Sitzung.

7
Alle STATA-Befehle haben eine einheitliche Grundstruktur: [prefix varlist:] command [varlist] [if exp] [in range] [, options] In jedem STATA-Kommando muss ein Befehl command enthalten sein, da so die Form der Analyse oder Datenbearbeitung bestimmt wird. Nach dem Befehl kommt eine bestimmte Variable oder mehrere Variablen [varlist], auf die sich der Befehl bezieht. Die if-Bedingung [if exp] steht am Ende des eigentlichen Befehls und führt den Befehl nur für die Fälle aus, für die die angegebene Bedingung wahr ist. Die in-Bedingung [in range] zeigt an, auf welche Fälle der Befehl angewendet werden soll. Optionen [, options] stehen am Ende eines Kommandos, nach einem Komma. Hier können auch mehrere Optionen aufgelistet werden. Über Befehls-Präfixe [prefix varlist:] wie [by varlist:] oder [bysort varlist:] werden die Befehle für die unterschiedlichen Ausprägungen der genannten Variable oder Variablen getrennt durchgeführt. Nur nach einigen Befehls-Präfixe und der Variable folgt ein Doppelpunkt.4 Für das Arbeiten mit STATA sollte beachtet werden, dass das Programm häufig keine Umlaute sowie ß erkennt und deshalb auf diese insgesamt verzichtet werden sollte. Weiterhin muss bei STATA die Groß- und Kleinschreibung beachtet werden. Es ist üblich alle Variablennamen klein zu schreiben. Zudem dürfen keine Leerzeichen in Datei- oder Verzeichnisnamen stehen, außer die Namen sind in Anführungszeichen gesetzt. Fast alle Befehle können durch einen bis drei Buchstaben abgekürzt werden. Um Beispiele und Informationen zu bestimmten Befehlen oder Kommandos zu bekommen, kann man den Befehl help und den gesuchten Befehl oder das gesuchte Kommando eingeben. STATA gibt nun einen Überblick über alle Funktionen und zeigt Beispiele auf. Stichworte kann man mit dem Befehl search suchen. Der Search-Befehl kann auch mit ,all ergänzt werden und dann wird in allen Quellen (in Hilfefunktion, Online-Hilfe, FAQs, der Homepage, im STATA-Journal etc.) gesucht. Die Suche nach Programmerweiterungen (ado-files) oder anderen Informationen zu STATA im Internet funktioniert über findit. Ado-files sind von Benutzern selbst geschriebene Programmerweiterungen. Einige ado-files werden auf der STATA-Homepage zur Verfügung gestellt: http://www.stata.com. Die Befehle können in das Command-Fenster eingegeben und mit Enter bestätigt werden. Mit den Tasten: Bild▼ und Bild▲ kann man alle eingegebenen Befehle durchklicken. Um sich den Datensatz oder einzelne Variablen anzuschauen sowie Befehle und Funktionen auszuprobieren ist dieses Arbeiten gut geeignet und verschafft einen schnellen Überblick. Für die Datenaufbereitung und Auswertungen ist es jedoch sinnvoll mit einer Syntax zu arbeiten, da kurze, komplizierte oder sehr lange Befehlszeilen abgespeichert werden. Diese können dann später einfach geändert, ergänzt und umgestellt werden. Alle Arbeitsprozesse können genau nachvollzogen werden und durch dies das Arbeiten erheblich erleichtert. Programmabläufe können in do-files erstellt und aufgerufen werden. Die Dokumentation der Sitzung wird in log-files aufgezeichnet.
4 Siehe in STATA: help prefix

8
3.2 Arbeiten mit do-files und log-files
Um einen Do-file-Editor zu öffnen, klickt man im Menü auf das Das Symbol mit dem Schreibblock (Button 8) oder verwendet den Befehl doedit. Es öffnet sich ein Texteditor. In der neusten STATA-Version 10.0 können mehrere do-files nebeneinander aufgerufen werden.
In der oberen Leiste findet man verschiedene Buttons. Die Syntax wird mit einem der beiden rechten Buttons oder dem Befehl do ausgeführt und STATA arbeitet alle Befehle in dieser Datei ab. Um den Befehl do zu verwenden, muss ich jedoch die Syntax vorher abspeichern und den Namen hinter den do-Befehl schreiben. So kann ein do-file ausgeführt werden, ohne den Do-file-Editor zu öffnen. Der Do-file-Editor dokumentiert alle Befehle und es kann nachvollzogen werden, wie einzelne Variablen und letztendlich der gesamte Datensatz entstanden ist. Der Button ganz rechts arbeitet die Syntax ab, die auch im Results-Fenster erscheint, der Run-Button links daneben läuft im Hintergrund und die Syntax erscheint nicht im Results-Fenster. Klickt man auf einen der Buttons wird die gesamte Syntax abgearbeitet; markiert man nur einen Teil, arbeitet STATA nur diesen ab.5 Ein weiteres wichtiges Hilfsinstrument zu Dokumentation ist der log-file. Hier wird nicht nur die Aufbereitung der Daten dokumentiert, sondern auch die Berechnungen und Ergebnisse, also alle Inhalte des Results-Fensters. Um den Output zu speichern, muss STATA eine Datei genannt werden, in die der Output geschrieben werden soll. Mit dem Befehl log using Laufwerk:/Ordner/Name.log wird der Output gespeichert. Er kann mit view Laufwer:/Ordner/Name.log aufgerufen werden. Ein log-file kann mit einem beliebigen Text-Editor angesehen werden. Beachtet werden muss, dass Grafiken nicht im log-file gespeichert werden.
5 Do-files entsprechen den Syntax-files bei SPSS.

9
3.3 Syntaxschreiben Es ist sinnvoll eine Syntax mit einer Beschreibung des Vorhabens zu beginnen. Kommentare und Beschreibungen werden in Sternchen ** gesetzt. Beginnt eine Zeile mit Sternchen wird sie als Kommentar betrachtet. Setzt man vor und hinter die Sternchen ein Slash können die Kommentare innerhalb der Syntax stehen, die durchlaufen soll. Diese Funktion ist auch für Kommentare gedacht, die über mehrere Zeilen ausgedehnt sind. Ein Slash mit Stern öffnet den Kommentar und ein Stern mit Slash schließt ihn auch wieder. Es könnte beispielsweise so aussehen: ******** Kommentar oder /***************** Kommentar Kommentar Kommentar ***************/ Syntax /*Kommentar*/ Beachtet werden muss hierbei jedoch, dass der geöffnete Kommentar auch wieder geschlossen wird, damit nicht die gesamte Syntax als Kommentar verstanden wird. Der do-file sollte immer einen einheitlichen Kopf haben. Dieser Kopf besteht aus sechs Zeilen. Die Befehle sollten immer wieder verwendet werden, die Namen der Files sind variabel. clear set more off set memory 200m capture log close log using Laufwerk:/Ordner/Name.log, replace use Laufwerk:/Ordner/Daten.dta, clear Der Befehl clear steht am Anfang und schließt alle geöffneten Datensätze. Dies ist zwar bei der ersten Sitzung nicht notwendig, da bisher noch kein Datensatz verwendet wurde, doch wenn immer der gleiche Kopf verwendet werden soll, ist es für spätere Sitzungen sinnvoll. Damit der Output ohne Unterbrechung durchläuft, verwendet man den Befehl set more off. Setz man diesen Befehl nicht, stoppt die Ergebnisausgabe sobald der Bildschirm komplett mit Zeichen ausgefüllt ist. Darauf folgt die Setzung des Speichers (siehe oben). Der Befehl capture log close schließt alle offenen log-files. Wie bereits beschrieben wird ein log-file erstellt, der alles dokumentiert. Hinter dem Namen steht: , replace , so wird der log immer wieder überschrieben. Dies hat den Sinn, dass nicht bei jedem Durchlauf der Syntax ein neuer log-file-Name vergeben werden muss. Ändert man den Namen nicht, fordert STATA einen neuen Namen, da es den erstellten Namen bereits gibt. Beachtet werden muss, dass für eine neue Syntax auch ein neuer log-file-Name vergeben wird. Es ist sinnvoll den log-file und do-file ähnliche Namen zu geben, damit sie später zuordenbar sind sowie sie in einen gemeinsamen Ordner zu speichern. Neben einen einheitlichen Kopf ist es auch ratsam einen einheitlichen Schluss zu verwenden: save Laufwerk:/Ordner/Name.dta, replace log close clear exit Save speichert den Datensatz unter den genannten Namen, der nach dem Befehl steht und replace ersetzt diesen, wenn er bereits vorhanden ist. So werden Korrekturen ohne

10
Unterbrechung im Datensatz gespeichert. Möchte man sie dokumentieren speichert man unter neuen Namen. Der Befehl log close schließt den log-file und speichert die Ergebnisse. Erst durch diesen Befehl wird der log-file abgespeichert und kann aufgerufen werden. Clear schließt den geöffneten Datensatz und exit beendet STATA. STATA-Datensätze werden als .dta gespeichert.
3.4 Das Datenfenster Das Datenfenster kann zum einen über die Symbole der „Tabelle“ bzw. „Tabelle mit Lupe“ neben dem Do-File-Symbol geöffnet werden oder über die Befehle edit und browse. Die Befehle sind sich ähnlich, doch mit browse können die Daten nur betrachtet werden. Mit edit ist es möglich die Daten zu bearbeiten und neue Daten zu importieren. Der SOEP-Datensatz ist sehr umfangreich und unübersichtlich, deshalb können an den Befehl browse eine Variablenliste oder bestimmte Bedingungen angehängt werden. Somit stehen nur bestimmte Fälle oder nur bestimmte Ausprägungen im Fenster.
3.5 Grundlegende Befehle Die SOEP-Datensätze sind keine einfachen Datensätze. Um einen Überblick und einen ersten Eindruck zu bekommen, kann man die Daten mit list auflisten. Hier wird jede einzelne Person mit ihren Eigenschaften aufgelistet. Einige Personen haben Missings . für diese Personen gibt es in dieser Welle keine Informationen. Zusätzlich gibt es im SOEP-Datensatz weitere Missings, die mit einem Minus gekennzeichnet sind. Es gibt drei Missing Codes: -1 = keine Angabe -2 = trifft nicht zu -3 = Antwort unplausibel Da die Auflistung bei großen Datensätzen sehr umfangreich ist, sollte man nicht alle Fälle anzeigen lassen. Um eine Auflistung zu unterbrechen muss man ein q für quit eingeben und die Ausgabe wird bei - -more — unterbrochen. Um dennoch einen Überblick zu bekommen, kann man die Auslistung auf bestimmte Variablen begrenzen, z.B.: list VAR1 VAR2 VAR3. Möchte man sich alle Werte nur ein paar Personen anschauen, kann man dies beispielsweise mit: list in . So kann man die Auflistung auf bestimmte Beobachtungen begrenzen: list in 1 (nur die erste Beobachtung), list in 1/20 (die ersten 20) etc. Die in-Bedingung kann auch bei anderen Befehlen angewendet werden und diese somit begrenzen. Da sie immer der Variablenliste folgt, richtet sich STATA danach, wie sortiert ist. Für das Arbeiten mit dem SOEP-Datensatz ist das Sortieren sehr wichtig. Der Befehl lautet: sort VAR1 sort VAR1 VAR2 VAR3 Sortiert werden kann nach allen Variablen im Datensatz. Beachtet werden muss dabei aber, dass der Datensatz auch Missings enthält, die entweder im Minusbereich beginnen oder den Wert ∞ haben und mit dem einfachen sort-Befehl immer aufsteigend sortiert wird. Die Ausprägungen sind dann immer so sortiert: -3 -2 -1 0 1 123 12345656 . (Missings)

11
Weiterhin kann der Datensatz auch absteigend sortiert werden. Der Befehl gsort sortiert Variablen ab- oder aufsteigend, wenn man vor die Variable ein „-„ setzt wird absteigend sortiert, sonst aufsteigend. Beispielsweise: gsort persnr –hhnr . Eine Übersicht über den Datensatz erhält man auch mit den Befehlen describe oder codebook. Codebook listet alle Variablen untereinander auf, mit Ausprägungen, Häufigkeiten, Missings, und dem Range. Describe zeigt Allgemeines über den Datensatz, z.B. den Namen, die Anzahl der Beobachtungen und der Variablen, die Größe und Ausschöpfung des Speicherplatzes und das Erstellungsdatum des Datensatzes. Darunter folgt die Liste der Variablen, ihr Format, eine kurze Beschreibung und der Name der Variable, nach der sortiert wurde. Mit dem Befehl summarize wird das arithmetische Mittel berechnet. Zudem werden die Beobachtungen, die Standartabweichung sowie der größte und kleinste Wert angezeigt. Dem Befehl folgt die Variablenliste. Für eine detaillierte Betrachtung fügt man dem summarize-Befehl die Ergänzung , detail bei. Über den Befehl sum labgro07, detail werden neben dem Mittelwert, kleinsten und größten Ausprägungen, Zahl der Beobachtungen, Aufteilung in Perzentile, die Varianz, Schiefe etc. angegeben. Lässt man die Variablenliste weg, werden alle Variablen des Datensatzes aufgezeigt. So erhält man einen guten Überblick über den Datensatz und kann kontrollieren, wie sich Variablen oder der Datensatz insgesamt nach der Bearbeitung verändert hat. Für eine Auflistungen der Variablen des Datensatzes kann man ,separator(2) anhängen und unterteilt somit die Variablen in selbst definierte Abschnitte: sum persnr hhnr xhhnr xpsbil xpbbil01 xpbbil02 labgro07 egp07 emplst07 , separator(3). Missings, die auf Punkt . gesetzt sind, werden hier nicht mit aufgeführt was an den Beobachtungen deutlich wird. Häufigkeitsverteilungen werden mit tabulate erstellt und zeigen die absoluten Häufigkeiten, prozentuale Häufigkeiten und die kumulierten relativen Häufigkeiten an. Setzt man nur eine Variable hinter den Befehl wird nur die Häufigkeitsverteilung aufgezeigt. Um eine Häufigkeitstabelle zu erhalten müssen zwei Variablen nach dem Befehl stehen. Auch hier werden die Missings nicht angezeigt und aus den Berechnungen ausgeschlossen. Möchte man auch die Zahl der Missings erfahren, setzt man hinter die Variablenliste ,missing. Um sich die Häufigkeiten einer Variablenliste einzeln anzeigen zu lassen verwendet man den Befehl tab1 und fügt die Variablenliste an. Somit werden eindimensionale Häufigkeitstabellen für alle Variablen der Liste erstellt. Auffällig ist jedoch, dass die Nummernlabels der verschiedenen Ausprägungen nicht aufgeführt werden. Wenn man die Ausprägungen mit den jeweiligen Nummernlabels angezeigt bekommen will, muss man folgenden Befehl eingeben: numlabel _all, add. Jetzt werden die Ausprägungen aller Variablen mit Nummern versehen. Möchte man nur einzelne Variable mit Nummernlabels angezeigt bekommen, setzt man den Namen der Variable an die Stelle von _all. Um Variablen im Datensatz an eine bestimmte Position zu setzten, verwendet man die Befehle order, aorder und move. Mit order und der anschließenden Variablenliste setzt man die genannten Variablen an den Beginn des Datensatzes. Der Befehl aorder sortiert alle Variablen nach dem Alphabet, was besonders beim Arbeiten mit SOEP-Daten sehr nützlich sein kann. Move setzt eine Variable (VAR1) an die Stelle einer anderen (VAR2): move VAR1 VAR2. Diese Befehle sind beim Erstellen von Variablen nützlich, da man auch in großen Datensätzen nicht den Überblick verliert, zugleich die neue Variable im Daten-Editor leicht findet und sie so überprüfen kann.

12
3.5.1 Häufigkeitstabellen Erstellen von Häufigkeitstabellen mit tab. Dieser Befehl für zweidimensionale Häufigkeitstabellen zeigt die Verteilung einer Variable für unterschiedliche Ausprägungen an. Um sich die Spalten- und Zeilenhäufigkeiten anzeigen zu lassen, setzt man hinter den Befehl zum Erstellen der Kreuztabelle , column row. Die Option column zeigt die Verteilung der Zeilenvariable unter der Bedingung der Spaltenvariable und row sind die Anteile für die Bedingungen der Zeilenvariable: tab VAR1 VAR2, col row. Es gibt zudem das Möglichkeit mehrere zweidimensionale Häufigkeitstabellen mit jeder möglichen Kombination mit dem Befehl tab2 VAR1 VAR2 VAR3 zu erstellen. Da Häufigkeitstabellen in STATA auf zwei Variablen begrenzt sind, können sie zusätzlich nach Variablenausprägungen mit dem Befehls-Präfix by unterschieden werden. Siehe unten. Verwendet man die Ergänzung , all, dann erhält man zusätzlich den Chi-Quadrat, den p-Wert, den Chi-Quadrat Likelihood Ratio, Cramer´s V, Gamma und Kendall´s tau-b. Diese können jedoch auch einzeln aufgerufen werden mit: tab VAR1 VAR2, V tab VAR1 VAR2, chi2 tab VAR1 VAR2, V chi2 gamma etc., siehe help tabulate.
3.5.2 Wichtige Befehlspräfixe Es kann mit by nach den Ausprägungen einer einzelnen Variable unterschieden werden, oder: indem man eine Variablenliste vor das by setzt, werden alle Ausprägungen aller Variablen miteinander kombiniert und dafür der Befehl ausgeführt. So können beispielsweise dreidimensionale Häufigkeitstabellen erzeugt werden: by VAR1: tab VAR2 VAR3. Hier muss jedoch vorher sortiert werden: sort VAR1. Möchte man dies umgehen verwendet man einen der beiden folgenden Befehle: by VAR1, sort: tab VAR2 VAR3, col row. Oder mit dem Befehls-Präfix bysort, der by entspricht: bysort VAR1: tab VAR2 VAR3, col row.
3.5.3 Befehlsbedingungen Mit if können Befehle auf bestimmte Beobachtungen beschränkt werden. Ein Kommando wird nur dann ausgeführt, wenn die Bedingung, die bei if definiert wurde, zutrifft. Eine if-Bedingung ist prinzipiell bei fast jedem Befehl möglich. Die if-Bedingung wird immer mit verschiedenen Vergleichsoperatoren verwendet. Vergleichsoperatoren sind: == (gleich); > (größer); < (kleiner); >= (größer gleich); <= (kleiner gleich); ~= (ungleich). Dies würde in einem Befehl folgendermaßen aussehen: tab VAR1 if VAR2==1 | VAR3==4 sum VAR1 if VAR2>=5 & VAR3~=. Ausprägungen einer bereits bestehenden Variable werden immer mit doppelten Gleichheitszeichen == angegeben. Erstellt man eine Variable neu und gibt ihr verschiedene Ausprägungen verwendet man das einfache Gleichheitszeichen =. Siehe auch Punkt 3.6 „Erstellen und Verändern von Variablen“.

13
Mit in wird der Bereich angezeigt, für den der Befehl verwendet werden soll. In steht in Verbindung mit einer Zahl oder einem Zahlenbereich, der durch einen Slash angezeigt wird: list in 1 oder list in 1/20. Es wird hier nur der erste Fall und beim zweiten Beispiel der 1. bis 20. Fall aufgelistet. Auch in ist prinzipiell bei fast jedem Befehl möglich.
3.6 Erstellen und Verändern von Variablen Um mit den Variablen Analysen durchführen zu können, müssen sie aufbereitet und auch neue Variablen erstellt werden. Besonders mit so großen Datensätzen wie dem SOEP und beim Arbeiten im Längsschnitt ist dies der aufwendigste Teil der Arbeit. Wichtig ist zunächst, dass beim Verändern bestehender Variablen nie die Ursprungsvariable verändert wird, sondern eine kopierte Version dieser. Beim Erstellen von Variablen sollte viel mit dem tabulate-Befehl gearbeitet werden, um die Ursprungsvariable und die neu erstellet Variable immer vergleichen und überprüfen zu können.
3.6.1 Generate, replace und recode Um eine neue Variable zu erstellen, verwendet man den Befehl generate. Mit diesem Befehl kann man keine bereits bestehenden Variablen erstellen, und somit auch keine vorhandenen Variablen überschreiben. Dem Befehl folgt der Name der Variable, die neu erstellt werden soll, dann ein Gleichheitszeichen und dann ein Ausdruck, mit dessen Ergebnis die angegebene Variable gefüllt wird. Für den Namen dürfen 32 Zeichen bestehend aus Buchstaben, Zahlen und Unterstriche verwendet werden. Zu beachten ist, dass Variablennamen nicht mit Zahlen beginnen dürfen und sollten auch nicht mit einem Unterstrich beginnen, da diese Variablen von STATA-Programmierern für interne System-Variablen verwendet werden. Man sollte bei höchstens acht Zeichen bleiben, da die Variablennamen häufig geschrieben werden müssen, nur so in SPSS oder andere Programme übertragen und in älteren STATA-Versionen verwendet werden können. Zudem sollte der Name aus mindestens zwei Zeichen bestehen, um nicht mit einem Befehl verwechselt zu werden. Beim Erstellen der neuen Variable verwendet man das einfache Gleichheitszeichen = , aber um dann bestimme Ausprägungen anzeigen zu lassen oder zu verwenden, muss man immer das doppelte Gleichheitszeichen == setzen!!! Es ist zu unterscheiden zwischen a) Variablen mit selbst erstelltem Inhalt z.B. auch mit eigenen Berechnungen oder mathematischen Funktionen: gen VAR1=1 gen VAR2= VAR3/100 gen age2007= wave-gebjahr b) Variable mit dem Inhalt einer anderen Variable: gen VAR1= VAR2 c) Variable mit der Bedingung der Ausprägung einer anderen Variable: gen VAR1= 1 if VAR2==1 d) Variable mit Bedingungen der Ausprägungen mehrerer Variablen: gen VAR1= 1 if VAR2==1 & VAR3==1 Um Ausprägungen einer bestehenden Variable zu verändern, verwendet man replace. So kann keine neue Variable erstellt werden, aber der Inhalt einer bestehenden Variable verändert sich, so dass hier nicht mit Ursprungsvariablen gearbeitet werden sollte. Auch hier folgt dem

14
Befehlsnamen dem Name der zu verändernden Variable, dann das einfache Gleichheitszeichen und ein Ausdruck, mit dessen Ergebnis die Variable gefüllt wird: replace VAR1 =2. Mit replace können auch neue Ausprägungen zu den bestehenden Ausprägungen der Variable hinzugefügt werden. Auch hier kann der Befehl mit Bedingungen anderer Variablen verknüpft werden: replace VAR1=0 if VAR2 == 4 replace VAR1=1 if VAR2 == 1 replace VAR1=2 if VAR2 ==3 & VAR3 ==5 replace VAR1=3 if VAR2 ==2 & VAR3 ==4 & VAR4==1 Damit man bestehende Variablen nicht überschreiben muss, verwendet man beide Befehle in Kombination: gen VAR1=0 replace VAR1 =1 if VAR2==1 replace VAR1 =2 if VAR2==2 Wenn man eine Neue Variable erstellt, die Bedingungen anderer Variablen enthalten soll, erstellt man zunächst eine Variable mit dem Inhalt Null. So kann man leicht überprüfen, welche Beobachtungen schon in einer der definierten Kategorien enthalten sind. Man behält auch bei komplizierten Variablen den Überblick, was bereits definiert wurde. Nachdem alles überprüft wurde, kann man die Null mit Missing ersetzen. Für ein UND bzw. and wird in STATA das & -Zeichen verwendet. Für Oder bzw. or verwendet man das | -Zeichen. Wenn man beide Zeichen kombiniert, müssen sie in Klammern gesetzt werden, da die &-Verbindung vorgezogen wird: replace VAR1 =1 if (VAR2==1 | VAR2==2) & (VAR3==1 | VAR3==2 ). Für das Umkodieren von Variablen verwendet man den Befehl recode. So können Nummernlabels verändert oder mehrere Werte zusammengefasst werden: recode VAR1 (1=2) (2=1). um Werte zusammenzufassen, kann man folgendermaßen vorgehen: recode VAR1 (min/400=1) (401/500=2) (501/max=3). Beachtet werden muss hier unbedingt, dass Missings als größter Wert - also unendlich ∞ - zählen!!! Um die bestehende Variable nicht zu überschreiben, könnte ich wie bei replace vorgehen und eine neue Variable generieren: gen VAR2= VAR1 recode VAR2 (-1=.) (1=1) (2=2) (3=4) (4=4) (5=.) (6=.) (7=.) Dies kann man auch mit der generate-Funktion verkürzen. Die generate-Funktion erzeugt neue Variablen, die die umkodierten Ursprungsvariablen enthalten. Der Variablenname wird innerhalb einer Klammer der generate-Option geschrieben. Zwischen dem Befehl und der Klammer darf aber kein Leerzeichen sein: recode VAR1 (-1=.) (1=1) (2=2) (3=4) (7=.), gen(VAR2). Der Befehl egen ist eine Erweiterung des generate-Befehls. Die Zahl der egen-Befehle wächst ständig, da sie vom Benutzer selbst programmiert werden können. Mit egen kann man Variablen erstellen, die eine bestimmte Funktion enthalten. Dieser Befehl ist breit anwendbar, eine Übersicht gibt help egen und hier sollen nur einige Beispiele demonstriert werden. Um den Mittelwert einer Variable zu erhalten, kann man so vorgehen: egen VAR2=mean(VAR1). In der VAR2 steht nun der Mittelwert der VAR1. Möchte man den Median, verwendet man egen VAR2=median(VAR1). Um Werte aus verschiedenen Variablen aufzuaddieren kann man die Funktion rsum verwenden: egen VAR1=rsum(VAR2 VAR3 VAR4). So werden die Werte der definierten Variablen (VAR2, VAR3 und VAR4) zusammengezählt. Mit der Funktion group(VAR) werden alle Beobachtungen, die die gleiche Ausprägung der definierten Variable haben mit der gleichen Nummer versehen. Setzt man in die Klammern mehrere Variablen werden die Kombinationen durchgezählt: group(VAR1 VAR2). Mit der Funktion total(VAR) wird die Summe der Beobachtungen auf alle übertragen.

15
3.6.2 Löschen Um Variablen oder Beobachtungen aus dem Datensatz zu löschen, verwendet man drop. Die gelöschten Variablen drop VAR1 VAR2 VAR3 kommen im Datensatz dann nicht mehr vor. Verbindet man den drop-Befehl mit einer if Bedingung, dann werden ganze Personen gelöscht, für die die Aussage wahr ist!!! D.h. wenn ich z.B. die Missings aus einer Variable lösche: drop if VAR == - 1, dann sind alle Personen gelöscht, die hier nichts angeben wollten und somit auch alle anderen Informationen dieser Personen. Um bestimmte Variablen aus einem Datensatz auszuwählen, verwendet man den Befehl keep. Es sind dann nur noch, die nach dem Befehl definierten Variablen im Datensatz enthalten: keep VAR1 VAR2 VAR3.
3.6.3 Vergabe von Labels Einige Variablen im Datensatz oder auch selbst erstellte Variablen haben keinen Namen. Damit man direkt den Inhalt erkennt, ist es sinnvoll allen Variablen, die man häufig verwendet, einen Namen zu geben. Einen Namen vergibt man mit label variable VAR1 „Name der Variable“. In die Anführungszeichen wird der neue Name der VAR1 eingesetzt, der von nun an immer aufgezeigt werden soll. Erstellt man Variablen neu, haben sie immer nur Nummernlabels, auch wenn der Inhalt einer anderen Variablen komplett übernommen wurde. Die Benennung der Labels kann aus bis zu 80 Zeichen bestehen. Das Beschriften erfolgt mit Hilfe von Containern, die nur 32 Zeichen enthalten dürfen. Die Container müssen auch benannt werden und können auch unter dem gewählten Namen mehrfach für andere Variablen verwendet werden. label define Containername 1“ja“ 2“nein“ 3“vielleicht“ Nach dem Befehl wird der Container mit einem beliebigen Namen benannt (der nur einmal verwendet werden darf) und dieser wird dann mit Labels versehen, die in Anführungszeichen gesetzt werden. Zu beachten ist dabei, dass zwischen den Nummernlabels und den Anführungszeichen kein Leerzeichen stehen darf. Die Anführungszeichen sind nicht notwendig, wenn keine Leerzeichen in den Labels enthalten sind. Um den Container nun mit einer Variable oder mehreren Variablen zu verknüpfen verwendet man den Befehl label value, daran schließt der Name der Variable an und der Name des Containers: label value VAR1 Containername. Bei STATA werden jedoch immer nur die Wertelabels angezeigt, möchte man die Nummernlabels auch angezeigt bekommen, muss man erneut den Befehl numlabel VAR1, add verwenden (der Befehl wurde bereits oben beschrieben). Eine weitere Möglichkeit den Container mit einer Variable zu verknüpfen, ist ihn beim Erstellen einer neuen Variable mit Doppelpunkt in den Befehl zu integrieren. Nach dem neuen Variablennamen kommt ein Doppelpunkt und dann der Name des Containers: gen VAR1:Containername=VAR2. Um eine Übersicht über bereits vorhandene Container zu bekommen, die man eventuell verwenden könnte, nutzt man den Befehl label list bzw. für den Container einer bestimmten Variable label list VAR1. Möchte man einen Labelnamen wieder löschen, verwendet man label drop „VAR1“ oder label drop „Container“. Im ersten Beispiel werden die Labels der Ausprägungen der Variable 1 gelöscht und im zweiten Beispiel der Container mit den Labels. Möchte man einen bestehenden Namen einer Variable verändern, verwendet man den Befehl rename. Nach dem Befehl folgt der Name der Variable, die verändert werden soll und dann der neue Name: rename VAR1 VAR2. Der Name der alten Variable wird gelöscht. Besonders für das Arbeiten im Längsschnitt ist es sinnvoll den Variablen gleich zu Beginn einen neuen

16
systematischen Namen zu geben. Beginnt man mit einem Querschnittsdatensatz, der später ins Long-Format gekippt werden soll, müssen alle Variablen mit der jeweiligen Jahreszahl enden. So ist es ratsam die Variablen (hier z.B. Schulbildung) für alle Jahre gleich zu benennen: rename vpsbil in schulbild2005 rename wpsbil in schulbild2006 rename xpsbil in schulbild2007 Weiterhin gibt es die Möglichkeit Anfänge von Variablen mit renpfix umzubenennen. Zunächst kommt der Befehl, dann der Teil der Variablen, der umbenannt werden soll und dann der neue Variablenteil: renpfix p h. Hier werden alle p´s in den Namen mit h´s ersetzt. Man muss jedoch beachten, dass diese Änderungen an allen Variablen des Datensatzes vorgenommen werden. Möchte man z.B. die oben neu benannten Schulbildungsvariablen wieder umbenennen und nicht drei Mal den rename-Befehl verwenden, könnte man mit renpfix schulbild sb viel Schreibarbeit sparen. Die oben benannten Variablen heißen nun nicht mehr schulbild2005, schulbild2006 und schulbild2007, sondern sb2005, sb2006 und sb2007.
3.6.4 Rationale Operatoren (Dummy-Variablen) Die Verwendung von rationalen Operatoren ist wichtig, um ordinale Variablen für metrische Verfahren messbar zu machen. Sie sind immer mit 0 und 1 codiert, d.h. sie können wahr(1) oder falsch(0) sein. Sie werden Dummy-Variablen genannt und aus ordinalen Variablen erstellt. Es wird für jede Ausprägung ein Dummy erstellt. Jeweils eine Ausprägung ist wahr, die anderen zusammengenommen zählen als falsch. Zu beachten ist dabei, dass die Variablen, aus denen die Dummies erstellt werden, keine numerischen Missings enthalten, da diese sonst als Referenz und Ausprägung miteinbezogen werden. Die Dummy-Variablen können einzeln über gen, recode oder replace erstellt werden oder es wird ein spezieller Befehl zum Erstellen dieser Variablen verwendet: tab VAR1, gen(VAR2_). Aus der Variable1 wurden nun mehrere Variablen2_ erstellt, die den Ausprägungen der Variable1 entsprechen. D.h. wenn die Variable1 drei Ausprägungen hatte, bekommen die Variablen VAR2_1, VAR2_2 und VAR2_3 jeweils eine Ausprägung, die auf 1 gesetzt wird und die Beobachtungen der beiden anderen Fälle sind zusammen in der Ausprägung 0. Für das Arbeiten mit so erstellten Dummy-Variablen im Längsschnitt sollte man beachten, dass die Dummy-Variablen erst im Long-Format erstellen werden. Möchte man den Datensatz kippen, dürfen Variablen nicht mit einer anderen Zahl außer der Jahreszahl enden. Für diesen Fall kann man aber auch die Dummy-Variablen vorher umbenennen. Dummy-Variablen können auch direkt bei der Berechnung mit xi erstellt werden. Siehe unten.
3.7 Weitere Befehlspräfixe Neben den häufig verwendeten Befehlspräfixen by und bysort gibt es auch andere relevante Präfixe, siehe help prefix. Zwei davon sind quietly und noisily. Beide Präfixe stehen vor einem Befehl mit Doppelpunkt getrennt und geben an, ob der Output angezeigt werden soll oder nicht: quietly: gen VAR1=VAR2. Das Präfix quietly ist z.B. beim Arbeiten mit sehr aufwendigen Schleifen zeitsparend und hilfreich. Weiterhin gibt es das Präfix xi. Damit lassen sich ganz einfach Dummy-Variablen (rationale Operatoren) für Modelle bilden. Möchte man eine Regression rechnen verwendet man xi: regress i.VAR1 VAR2 i.VAR3 und für die Variablen mit i. vor dem Namen werden automatisch Dummy-Variablen gebildet. Als Referenzkategorie wird automatisch immer die niedrigste Ausprägung verwendet. Besonders geeignet und zeitsparend ist der Befehl zum

17
Erstellen von Interaktionseffekten. Um Interaktionseffekte zu bilden setzt man vor die Variablen i. und multipliziert sie miteinander: xi: regress i.VAR1*i.VAR2 VAR3 VAR4 etc.. Beachtet werden muss aber hierbei, dass es sich nicht um metrische Variablen handelt.
3.8 Mergen Im SOEP sind die Informationen der Befragungspersonen in unterschiedliche Datensätze verteilt. Um Analysen vornehmen zu können, müssen die Daten zunächst zusammengespielt – in STATA-Sprache: gemergt – werden. Der Befehl merge verknüpft die Beobachtungen eines Datensatzes, der im Arbeitsspeicher geladen ist, mit den Beobachtungen des Datensatzes oder der Datensätze, die auf der Festplatte gespeichert sind. Es handelt sich hier um einen sehr einfachen Befehl, dennoch muss beim Mergen einiges unbedingt beachtet werden. Zunächst ist es wichtig die verwendeten Datensätze zu sortieren, damit später auch die gewünschten Beobachtungen in der richtigen Reihenfolge an die bestehenden Beobachtungen gespielt werden. Das Mergen sollte bei SOEP-Daten immer über zwei ID-Variablen, die Schlüsselvariablen – bei Personendaten besser drei ID-Variablen - erfolgen und muss deshalb auch nach diesen Variablen sortiert werden. Für Personendaten verwendet man zunächst die Peronen-ID (persnr), dann folgt die Haushalts-ID (hhnr) und die wellspezifische Haushalts-ID ($hhnr). Welche Variablen für die Identifikation relevant sind, hängt vom jeweiligen Datensatz ab. In Personendatensätzen sind immer die persnr, hhnr und die wellenspezifische hhnr ($hhnr, hhnrakt) enthalten. Um ganz sicher zu gehen, kann man zum Mergen auch diese drei Variablen verwenden, was auch das Zusammenspielen mit Haushaltsdaten erleichtert. In Haushaltsdaten sind nur die hhnr und die wellenspezifische hhnr ($hhnr) enthalten. Da Personen beispielsweise auch neue Haushalte gründen können oder in neue Haushalte hineinheiraten, sich scheiden lassen und wegziehen, kann sich die $hhnr jährlich ändern und muss aktualisiert werden. Für die Zuordnung wird außerdem die Ursprungshaushaltsnummer hhnr verwendet. sort persnr hhnr Als erstes öffnet man die Master-Datei (ppfad.dta) sie enthält alle Basisinformationen der Personen. use Laufwerk:/Ordner/ppfad.dta, clear sort persnr hhnr Da man meist nicht alle Variablen aus diesem Datensatz verwenden will, nimmt man hier relevante Variablen mit dem Befehl keep heraus und speichert den Pfad neu ab (verwendet diesen dann als Master-Datei). Hier werden die wellenspezifischen Haushaltsnummern der Wellen W und X ausgewählt. Besonders wichtig sind die Netto-Variablen. Sie enthalten die Information, ob jemand an der Befragung teilgenommen hat oder nicht. Man kann hierfür die $netto-Variable oder die $netold-Variable verwenden, erstere enthält ausdifferenziertere Informationen. keep persnr hhnr whhnr xhhnr sex gebjahr vnetold wnetold xnetold save Laufwerk:/Ordner/meinpfad.dta, replace

18
Aus den Haushalts- und Personendatensätzen der Wellen W und X möchte ich auch nur bestimmte Informationen verwenden. Deshalb öffne ich diese, nehme relevante Informationen heraus, sortiere neu und speicher den Datensatz ab. use Laufwerk:/Ordner/wpgen.dta, clear keep persnr hhnr whhnr labgro06 wpsbil wpbbil01 egp06 nation06 sort persnr hhnr whhnr save Laufwerk:/Ordner/dat_welle_wp.dta, replace use Laufwerk:/Ordner/xpgen.dta, clear keep persnr hhnr xhhnr labgro07 xpsbil xpbbil01 egp07 nation07 sort persnr hhnr xhhnr save Laufwerk:/Ordner/dat_welle_xp.dta, replace use Laufwerk:/Ordner/whgen.dta, clear keep hhnr whhnr hinc06 sort hhnr whhnr save Laufwerk:/Ordner/dat_welle_wh.dta, replace use Laufwerk:/Ordner/xhgen.dta, clear keep hhnr xhhnr hinc07 sort hhnr xhhnr save Laufwerk:/Ordner/dat_welle_xh.dta, replace Die gerade neue erstellte Master-Datei “meinpfad” wird nun zum Mergen geöffnet. Daran anschließend erfolgt der merge-Befehl. Über die beiden ID-Variablen (Schlüsselvariablen) werden nun die gewünschten Datensätze angespielt. use Laufwerk:/Ordner/meinpfad.dta, clear sort persnr hhnr whhnr merge persnr hhnr vhhnr using Laufwerk:/Ordner/dat_welle_wp.dta Nach dem merge-Befehl wird eine Variable erstellt “_merge”. Diese enthält die Information, in welcher Form die Datensätze zusammengespielt wurden. Sie kann bis zu drei Ausprägungen annehmen: Beobachtungen mit dem Wert 1 sind Beobachtungen, die nur in der Master-Datei enthalten sind. Beobachtungen mit dem Wert 2 sind nur in der Using-Datei enthalten und Beobachtungen mit dem Wert 3 sind die Beobachtungen, die in beiden enthalten sind. Möchte man nun nur Personen, die auch in beiden Dateien enthalten sind, wählt man diese einfach mit keep aus. Man kann hinter den merge-Befehl auch ,nokeep setzen und erhält auch über diese Möglichkeit nur Beobachtungen, die in der Master-Datei enthalten sind. Somit wird ausgeschlossen, dass über den angespielten Datensatz neue Beobachtungen hinzukommen. Anschließend muss die Variable gelöscht werden, da beim erneuten Mergen eine neue _merge-Variable erstellt wird. tab _merge keep if _merge~=2 drop _merge sort persnr hhnr xhhnr Wichtig ist das Sortieren nach der Beendigung des ersten merge-Befehls!!!

19
Da wir nun Informationen aus einer anderen Welle anspielen wollen, muss auch anders sortiert werden. Es wird jetzt nach persnr, hhnr und whhnr sortiert und auch über diese Schlüsselvariablen gemergt. Das selbe Vorgehen bei Welle X. merge persnr hhnr xhhnr using Laufwerk:/Ordner/dat_welle_xp.dta tab _merge keep if _merge~=2 drop _merge sort hhnr whhnr Um nun die Haushaltsinformationen anzuspielen, muss neu sortiert werden. In den Haushaltsdatensätzen ist die persnr nicht mehr enthalten!!! STATA spielt die Haushaltsdaten jeder Person des jeweiligen Haushaltes zu, d.h. teilt sie auf die Haushaltsmitglieder auf. merge hhnr whhnr using Laufwerk:/Ordner/dat_welle_wh.dta, nokeep tab _merge drop _merge sort hhnr xhhnr merge hhnr xhhnr using Laufwerk:/Ordner/dat_welle_xh.dta, nokeep tab _merge drop _merge sort persnr hhnr xhhnr keep if wnetold==1 | xnetold==1 save Laufwerk:/Ordner/datensatzname.dta, replace Abschließend wird wieder nach persnr hhnr $hhnr sortiert und neu abgespeichert!!! Um die Personen auszuwählen, die auch an der Befragung teilgenommen haben, verwendet man die Netto-Variablen der Wellen. Möchte man einen unbalced Panel verwendet man ein Oder | . So sind alle Personen enthalten, die an einer der drei Wellen oder an zwei oder allen Wellen teilgenommen haben. Möchte man einen balced Panel, verwendet man ein & und hat nur noch Personen, die an allen drei Wellen teilgenommen haben. Die & und | - Verknüpfungen können natürlich auch kombiniert werden, sollten dann aber in Klammern stehen. In der folgenden Abbildung sieht man einen bereits zusammengespielten Gesamtdatensatz, der die (oben definierten) Informationen aus den unterschiedlichen SOEP-Datensätzen enthält.

20
21
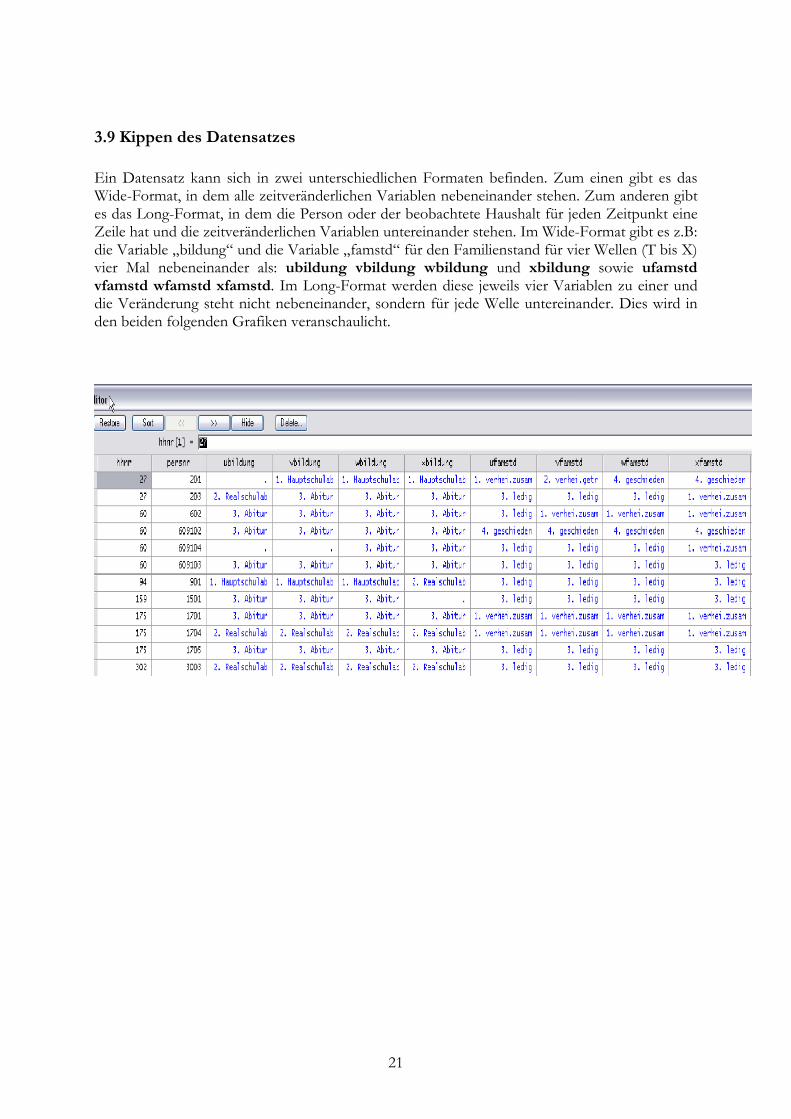
3.9 Kippen des Datensatzes Ein Datensatz kann sich in zwei unterschiedlichen Formaten befinden. Zum einen gibt es das Wide-Format, in dem alle zeitveränderlichen Variablen nebeneinander stehen. Zum anderen gibt es das Long-Format, in dem die Person oder der beobachtete Haushalt für jeden Zeitpunkt eine Zeile hat und die zeitveränderlichen Variablen untereinander stehen. Im Wide-Format gibt es z.B: die Variable „bildung“ und die Variable „famstd“ für den Familienstand für vier Wellen (T bis X) vier Mal nebeneinander als: ubildung vbildung wbildung und xbildung sowie ufamstd vfamstd wfamstd xfamstd. Im Long-Format werden diese jeweils vier Variablen zu einer und die Veränderung steht nicht nebeneinander, sondern für jede Welle untereinander. Dies wird in den beiden folgenden Grafiken veranschaulicht.

22
In der ersten Abbildung sehen wir, dass Person 1 mit der persnr 201 zunächst in Welle U (2004) noch keinen Schulabschluss hat. In der darauf folgenden Welle V (2005) hat diese Person 201 einen Hauptschulabschluss gemacht. Beim Familienstand in Welle U (2004) ist die Person noch verheiratet und lebt mit dem Partner zusammen. In der Welle V und W (2005 und 2006) ist sie verheiratet, aber getrennt lebend und in Welle X (2007) dann geschieden. Im Long-Format in der zweiten Abbildung gibt es die Variablen „bildung“ und „famstd“ nicht mehr vier Mal nebeneinander, sondern nur noch einmal. Die Zeitpunkte stehen nun untereinander, so dass es auch die Variable „persnr“ vier Mal gibt. In der Variable „welle“ sind die Jahre enthalten. Die Person 201 steht nun vier Mal untereinander und zwar für die Wellen 2004, 2005, 2006 und 2007. Auch hier lässt sich die Veränderung feststellen. In Welle 2004 hat die Person noch keinen

23
Schulabschluss, sondern erhält den Hauptschulabschluss erst in Welle 2005. Der Familienstand ist (wie oben) in Welle 2004 „verheiratet und zusammenlebend“, in Welle 2005 und 2006 „verheiratet und getrennt lebend“ und in Welle 2007 „geschieden“. Dies lässt sich auch bei den anderen Personen im Datensatz vergleichen. Jede Person in den Ausschnitten ist nun vier Mal enthalten und hat Informationen in vier Wellen, die sich über die Zeit verändern können. Doch wie bekommt man einen Long-Format-Datensatz? Bevor man einen Wide-Format-Datensatz in Long-Format kippen kann, müssen zunächst alle zeitveränderlichen Variablen umbenannt werden. Beim kippen in das Long-Format muss die jeweilige Variable den Zeitpunkten zugeordnet werden. Dies funktioniert aber nur, wenn die Variablen den jeweiligen Wellen über die Jahreszahl zugeordnet werden können. Deshalb muss am Ende des neuen Variablennamens immer die Jahreszahl der Welle stehen. Alle Variablen, die keine Jahreszahl am Ende haben und zeitveränderlich sind (also nicht die persnr, die hhnr, Geschlecht oder Geburtsjahr etc.) müssen mit rename oder renpfix (siehe 3.6.3) umbenannt werden. Weiterhin sollten alle bisher erstellten Hilfsvariablen und nicht mehr benötigten Ursprungsvariablen aus dem Datensatz gelöscht werden. Da das Kippen je nach Zahl der Variablen und Wellen im Datensatz viel Zeit und Speicherplatz in Anspruch nimmt, sollte der Datensatz so klein wie nötig sein. Der STATA-Befehl zum Kippen des Datensatzes ist reshape. Mit reshape long kann man einen Wide-Format-Datensatz ins Long-Format kippen und mit reshape wide einen Long-Format-Datensatz ins Wide-Format. Bevor man den Datensatz kippt, sollte man zunächst mit sum kontrollieren, dass keine Längsschnitts-Variablen mit spezifischen Welleninformationen im Datensatz enthalten sind. Außerdem sollte kontrolliert werden, dass auch alle Variablen in allen Wellen vorhanden sind, damit die Personen in dieser Variable der Welle nicht nur Missings bekommen. Nun muss man im Befehl definieren, welcher Teil des Variablennamens der eigentliche Name ist und welcher Teil die Jahreszahl, also die Welleninformation. Nach dem Befehl folgt dann der Teil des Variablennamens, der sich auf die beobachtete Eigenschaft bezieht, d.h. der tatsächliche Name der Variable: reshape long VAR1 VAR2 VAR3, i(ID) j(wave) Hinter den letzten Variablennamen muss nun ein Komma gesetzt werden, dann folgt die Identifikation der zu beobachtenden Individuen bzw. Einheiten mit i(ID). In die Klammer kommt die Identifikationsvariable, also die ID – hier die persnr. Anschließend muss die Variable benannt werden, in der die Zeitinformationen gespeichert werden Diese Variable wird von STATA selbst erstellt und enthält alle Jahre, die vorher mit den Variablennamen verbunden waren. Der Name für die „Wellen-Variable“ muss innerhalb der Option j( ) angegeben werden (wenn man keinen Namen vergibt, nennt STATA die Variable _j). Für einen Datensatz mit den Längsschnitt-Variablen „bildung“ und „famstd“ sieht der Befehl so aus: reshape long bildung famstd, i(persnr) j(welle) Anschließend definiere ich, dass es sich umeinen Paneldatensatz handelt: tsset ID year. So weiß STATA automatisch, dass er jeder ID(persnr) die Jahre aus der Variable „welle“ zuordnen muss. Es wird eine nicht sichtbare Verknüpfung zwischen den Variablen erstellt. Für unser Beispiel mit: tsset persnr welle Der tsset-Befehl definiert den Datensatz als Paneldaatensatz. Siehe: help tsset. Damit es kein Paneldatensatz mehr ist, muss der Befehl tsset, clear verwendet werden. Hat man den Datensatz einmal in ein neues Format gebracht, kann er leicht wieder in das andere Format umgewandelt werden: reshape wide bzw. reshape long.

24
3.10 Der Umgang mit fehlenden Werten (Missings) Das Umcodieren von Missings kann mit generate und replace geschehen. So können einerseits numerische Missing-Codes (-1 = keine Angab, -2 = trifft nicht zu, -3 = Antwort unplausibel, im SOEP-Datensatz) auf Punkt gesetzt werden und gehen dann auch nicht in Berechnungen ein, andererseits können Missings auch zu Zahlen umgewandelt werden. Ist eine Ausprägung auf Missing gesetzt, d.h. auf . hat sie den Wert unendlich ∞ und dieser wird als gültiger Wert verstanden. In STATA gibt es 26 verschiedene Missing-Codes: .a .b .c …. Für jede neue Umcodierung wird ein neuer Buchstabe hinter den Punkt . gesetzt, um später die Definition der Missings wieder aufheben zu können. Auch bei Umcodierungen von Missings kann eine if-Bedingung sehr nützlich sein. Arbeite ich beispielsweise mit Variablen wie Einkommen, die im SOEP Werte enthalten, die eigentlich nicht möglich sind oder mein Ergebnis zu sehr verfälschen würden (wie ein Bruttomonatslohn von 4,23 Euro oder 120000 Euro), kann ich Werte ausschließen, die über oder unter einer bestimmten Grenze liegen: replace VAR1=.c if VAR1<=10 | VAR1>=120000 . Außerdem gibt es den Befehl mvdecode. Hier werden Variablen einer Variablenliste Missings nach einer bestimmten Regel zugewiesen. Die Regel steht innerhalb der Option mv( ). Der verwendete Missingcode kann der normale Punkt . oder der spezifizierte .a oder .b etc. sein: mvdecode VAR1 VAR2 VAR3, mv(-1=.a). Um in allen Variablen des Datensatzes die Missings zu entfernen verwendet man anstelle der Variablen: mvdecode _all, mv(-2=.b). Die Aufhebung der Definition des Missings erfolgt über den Befehl: mvencode _all, mv(.b=-2). Die Umkehrung funktioniert aber nur, wenn die Umcodierung nur für einen Wert gemacht wurde. Eine Umcodierung für mehrere Werte kann nicht gemacht werden!!! Auch deshalb sollten nur Kopien der Originalvariablen umkodiert werden. Um mehrere numerische Missings in einfache Missings umzuwandeln, ist es möglich den Befehl etwas abzukürzen: mvdecode _all, mv (-3 -2 -1). So werden für alle Variablen des Datensatzes die -3, -2 und die -1 auf . gesetzt. Wichtig ist dabei ist außerdem, dass STATA die Missings als unendlich große Werte behandelt, was bei der Erstellung von Variablen mit den Zeichen > oder < unbedingt beachtet werden muss!!!
3.11 Gewichtung Da die unterschiedlichen Stichproben im SOEP überrepräsentiert sind muss man für deskriptive Analysen gewichten. Man soll aber nicht nur für das Arbeiten im Querschnitt gewichten, sondern auch bei Längsschnittsberechnungen. Es gibt bei STATA drei verschiedene Arten der Gewichtung: Frequency-Weights, Analytic-Weights und Sampling-Weights. Die Gewichtung wird nach dem Befehl und der Variablenliste in eckige Klammern gesetzt: tab VAR1 [aweight=VAR2] oder tab VAR1 [fweight=VAR2] oder tab VAR1 [pweight=VAR2]. Vor dem Gewichten sollte jedoch die Gewichtungsvariable (hier VAR2) gerundet werden, da nicht alle Gewichtungen ohne gerundete Werte, d.h. mit Dezimalstellen funktionieren. Die Gewichtungsvariablen im SOEP haben aber Dezimalstellen und müssen immer vorher gerundet werden. Dies ist mit dem Befehl round möglich, der die Variable in Klammern hinter dem Befehl rundet: gen VAR2=round(VAR1). Die VAR2 enthält nun die gerundeten Werte der VAR1.

25
Die Gewichtung im Längsschnitt mit SOEP-Daten ist etwas komplizierter. Hier verwendet man nur den Gewichtungsfaktor des Basisjahres, d.h. der ersten Welle. Für die darauf folgenden Jahre verwendet man die jeweiligen Bleibewahrscheinlichkeiten des Jahres. Die Bleibewahrscheinlichkeiten werden mit dem Gewichtungsfaktor des Basisjahres multipliziert und man erhält einen Längsschnittsgewichtungsfaktor. Im SOEP sind die Bleibewahrscheinlichkeiten und die Gewichtungsfaktoren aller Wellen in einem Datensatz abgespeichert, so muss man nicht erst alle Gewichtungsfaktoren der einzelnen Wellen zusammenspielen. Es gibt Gewichtungsfaktoren für unterschiedliche Daten, die in einzelnen Datensätzen abgespeichert sind. Alle Personenhochrechnungsfaktoren und -Bleibewahrscheinlichkeiten der unterschiedlichen Wellen sind im Datensatz phrf.dta abgelegt. Die Hochrechnungsfaktoren und Bleibewahrscheinlichkeiten des Haushaltes der einzelnen Wellen sind im Datensatz hhrf.dta gespeichert. Ein Längsschnittsgewicht erhält man wie folgt: gen lgewicht=$phrf*$pbleib*$pbleib*$pbleib etc..6 Anschließend wird die erstellte Variable lgewicht in den Gewichtungs-Befehl integriert: tab VAR1[fweight=lgewicht].
3.12 Gruppieren von Daten Beim Gruppieren von Daten werden ähnliche Ausprägungen zusammengefasst. Hier muss man jedoch beachten, dass dabei ein Informationsverlust stattfindet. Das Gruppieren von Daten verwendet man, um eine Variable übersichtlicher zu gestalten oder in bestimmte sinnvolle Gruppen einzuteilen. Beispielsweise die Variable „Einkommen“ enthält zu viele Ausprägungen um in Häufigkeitsauszählungen einen guten Überblick zu bekommen oder sie in dieser Form für Häufigkeitstabellen zu verwenden. Hier soll mit verschiedenen Möglichkeiten gezeigt werden, wie man das Einkommen gruppieren kann. Natürlich muss immer zwischen kontinuierlichen(Einkommen) und kategorialen(Bundesland) Variablen unterschieden werden. Zunächst gibt es die Möglichkeit die Variable mit recode umzucodieren. So lässt sich z.B. die Variable Einkommen in zwei Gruppen einteilen: recode labgro07 (min/2000=1) (2000.01/max=2). Hier wurde einfach vom niedrigsten Wert (min) bis zu 2000 Euro in eine Gruppe gefasst und 2000 bis zum maximalen Wert (max) in eine Gruppe. Möchte man einen Wertebereich mit bis definieren, verwendet man den Slash /. Möchte man eine Verteilung so gruppieren, dass jede Gruppe gleich viele Beobachtungen erhält, verwendet man den Befehl xtile. Z.B: gruppiert man Einkommen mit gleich vielen Beobachtungen mit: xtile VAR1= labgro07, nquantiles(4). Nun werden vier Gruppen mit genau gleich vielen Fallzahlen erstellt. Natürlich besteht auch die Möglichkeit in unterschiedlich viele Gruppen zu unterteilen (5), (6) etc. Um eine Gruppierung mit gleicher Intervallbreite vorzunehmen, kann man eine spezielle Form des recode-Befehls verwenden. Hier gibt man die Intervalle, welche man haben möchte, vorher in Klammern an (wieder am Beispiel des Einkommens): gen VAR1 = recode(labgro07, 1000,2000,3000,17000). Es wurde nun eine neue Variable erstellt, die 4 Gruppen hat. In der ersten Gruppe sind alle Personen mit einem Einkommen bis 1000 Euro, in der zweiten bis 2000 Euro, in der dritten Gruppe bis 3000 Euro und eine Gruppe mit einem Einkommen bis 17000 Euro. Es ist wichtig, vorher die maximale Größe zu bestimmen und die letzte Gruppe immer bis zum maximalen Wert zu definieren. Ein weiterer Befehl ist autocode. Mit diesem Befehl wird ein Intervall von min bis max in n-gleiche Teile (Intervalle) geteilt. Hinter autocode in die Klammer kommt als erstes die Variable, die gruppiert werden soll; danach folgt die Anzahl der Intervalle (hier z.B. 12); der kleinste Wert
6 Das $-Zeichen steht für die jeweilig verwendete Welle im SOEP, z.B.: Welle A entspricht dem Hochrechnungsfaktor aphrf und die Wellen B, C, D und E den Bleibewahrscheinlichkeiten bbleib cbleib dbleib ebleib.

26
und dann der größte Wert, der in der Variable enthalten ist: gen VAR1= autocode(labgro07,12,0,17000).
3.13 Schleifen (loops) Es gibt in STATA mehrere Formen von Schleifen. Diese sind besonders für das Arbeiten im Längsschnitt sehr hilfreich und zeitsparend.
a) Die foreach-Schleife Die foreach-Schleife wiederholt den angegebenen Befehl für jede aufgelistete Variable, Zahl oder jedes aufgelistete Jahr. Sie führt einen Befehl so oft aus, bis die Bedingung erfüllt ist. Es gibt eine Vielzahl an foreach-Schleifen, da man sie mit jedem Befehl logisch kombinieren kann. Alle Schleifen können für einzelne Befehle oder für ganze Serien von Befehlen verwendet werden. Die foreach-Schleife besteht immer aus mindestens drei Zeilen. Die erste Zeile enthält den Befehl sowie den Listentyp und öffnet die Schleife mit der öffnenden Klammer {. Foreach ist der Schleifen-Befehl, darauf folgt der Element-Name, der selbst benannt werden muss (jeder Name ist möglich, sollte aber sinnvoll sein und für diese Art von Schleifen immer verwendet werden, was das Arbeiten mit Schleifen vereinfacht). Danach wird der Listen-Typ definiert, z.B. eine Variablenliste, Nummernliste, Zahlen- oder Buchstabenliste. Anschließend wird die Liste aufgeführt und mit der geöffneten Klammer { die Schleife geöffnet. foreach X of varlist VAR1 VAR2 VAR3 { oder foreach nummer of numlist 1 2 3 4 5 6 { oder foreach X in 1984 1985 1986 { Die zweite Zeile der Schleife enthält das Kommando bzw. die Kommandos. Die Befehle können aufeinander bezogen werden. Der Element-Name, der in der ersten Zeile festgelegt wurde, wird in den folgenden Befehlen immer in den entsprechenden Anführungsstrichen gesetzt, damit STATA diesen als Element-Name identifiziert und nicht als Variable o.ä.. Das öffnende Anführungszeichen muss das Zeichen neben der ß-Taste sein, das schließende Anführungszeichen muss das Zeichen auf der #-Taste sein! tab `X’ VAR oder gen VAR`nummer’= `nummer’+VAR2 Geschlossen wird die Schleife mit der schließenden Klammer } . STATA startet die Schleife indem der Platzhalter `X’ durch die vorher aufgezählten Namen der Liste ersetzt wird. Da es ein Befehl in mehreren Stufen ist, kann man Fehler, die bereits

27
eingegeben wurden, nicht wieder rückgängig machen. Um von Neuem anzufangen, muss die Schleife - egal in welchem Stadium - wieder geschlossen werden. Es gibt verschiedene Listen-Typen: of newlist für neue Variablen, of varlist für Variablenlisten, of numlist für Nummernlisten, in für beliebige Listen. Der Listen-Typ of newlist wird verwendet, um neue Variablen zu generieren. Neue Variablen kann man zwar auch mit of numlist oder der beliebigen Liste generieren, doch hier wird vorher geprüft, ob zulässige Variablennamen verwendet wurden. Der Listen- Typ of numlist wird verwendet, um Veränderungen für alle aufgezählten Zahlen oder Nummern vorzunehmen, wird jedoch für Panelanalysen eher selten verwendet. Häufig Verwendung finden die in-Listen. Sie stehen immer in Verbindung mit einem in und sind durch ein Lehrzeichen getrennt. Die Liste kann eine Aufzählung von Buchstaben, Nummern und Worten sein. Für das Arbeiten mit Paneldaten ist häufig auch die Setzung von einem local year notwendig. So kann dieses als das Ausgangsjahr verwendet und z.B. Berechnungen mit diesem durchgeführt werden. Die Schleife funktioniert aber nur, wenn ich auch alle Jahre hintereinander aufsteigend verwende: local year =2005 foreach X in v w x { rename `X’psbil psbil`year’ rename `X’netto netto`year’ local year =`year’ +1 } Zudem kann die foreach-Schleife auch erweitert werden. Dafür müssen mehrere Nummern- oder Variablenlisten erstellt werden, die dann mit einer Klammer { abgeschlossen werden. Der Befehl innerhalb der letzten Klammer wird dann für jede Kombination der verschiedenen Listen erfüllt: foreach x in 1984 1985 1986 1987{ foreach y in 2000 2001 2002 { Dabei darf man nicht vergessen zwei schließende Klammern zu verwenden.
b) Die forvalues-Schleife Eine weitere Form ist die forvalues-Schleife. Diese hat keine zusätzlichen Funktionen zur foreach-Schleife, ist aber schneller im Abarbeiten von Nummernlisten. Die Struktur ist ähnlich der foreach-Schleife, nur wird hinter dem Befehl ein = gesetzt und der Zahlenbereich definiert. Der Zahlenbereich ist ein ganzer Bereich von Zahlen und nicht einzelne Ziffern, z.B.: 1(1)10 für alle ganzen Zahlen zwischen 1 und 10 oder 1/10 für 1 bis 10. Dies sieht folgendermaßen aus: forvalues X=1/10 { tab VAR`X’ replaceVAR`X’= 1 if VAR2 ==1 } Auch diese Schleife wird mit den geschwungenen { } Klammern geöffnet und geschlossen.

28
3.14 Grafiken In der Version 10.0 ist es möglich mit einem Grafik-Editor zu arbeiten. Es lassen sich auf diese Weise leichter Grafiken erstellen. Die Optionen der Grafik-Funktionen in STATA sind sehr umfangreich, so dass man schnell den Überblick verlieren kann. Die unterschiedlichen Optionen der Grafik-Befehle können hier nicht dargestellt werden. Grafiken kann man mit graph save C:/Ordner/name speichern. Geöffnet wird sie mit graph use C:/Ordner/name . Eine ausführliche Darstellung ist unter help graph und bei Kohler/Kreuter (2008) zu finden. Hier aber einige Beispiele: Ein Histogramm erstelle ich mit histogram VAR1. Ein Streudiagramm mit zwei Variablen erstelle ich mit: graph twoway (scatter VAR1 VAR2). Ein Liniendiagramm mit line VAR1 VAR2. Ein Punktdiagramm mit graph dot VAR1 VAR2. Ein Tortendiagramm mit graph pie VAR1 VAR2 VAR3.

Überblick über wichtige Literatur und Homepages: Acock, A. C. (2006) A Gentle Introduction to Stata. College Station, Texas: Stata Press. Hamilton, L. C. (2006): Statistics with Stata (Updated for Version 9). Brooks/Cole. Kohler, U./Kreuter, F. (2008): Datenanalyse mit Stata. Allgemeine Konzepte der Datenanalyse und ihre praktische Anwendung. München/Wien: Oldenbourg. Stata Corp. (2008): Getting Started with Stata for Windows. Release 10. College Station, Stata Corp. STATA-Homepage: http://www.stata.com Hier häufig gestellte Fragen: http://www.stata.com/support/faqs/ Lernhilfen http://www.stata.com/links/resources1.html Lernhilfen der UCLA: http://www.ats.ucla.edu/stat/stata/ Datensätze zum Kohler/Kreuter-Buch: http:/stata-press.com/data/kkd.html


















