Informationsdarstellung, Sprachbeschreibung, Sprachverarbeitung - mit XML - Klaus Becker 2009.

Experimente, Evaluierung und Tools
Helmut Schmid
Centrum fur Informations- und SprachverarbeitungLudwig-Maximilians-Universitat Munchen
Stand: 10. Dezember 2019
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 1 / 172

Organisatorisches
Dienstag, 10-12 Uhr Raum 131Vorlesung:
I Vermittlung/Wiederholung der theoretischen GrundlagenI Gemeinsame Ausarbeitung der Details der Aufgabe
Mittwoch, 14-16 Uhr, Rechnerpool AntarktisUbungen: praktische Aufgaben zur
I Anwendung vorhandener WerkzeugeI Entwicklung eigener ProgrammeI Ort: Rechnerpool Antarktis
statt schriftlicher Prufung: Benotung der abgegebenen Aufgaben
Die Ubungen durfen zu zweit bearbeitet werden.
Wenn Sie nicht weiterkommen, bin ich da, um Ihnen zu helfen.
Alle wichtigen Informationen zu dem Kurs sind auf der Kursseiteverfugbar, die uber meine CIS-Homepage erreichbar ist.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 2 / 172
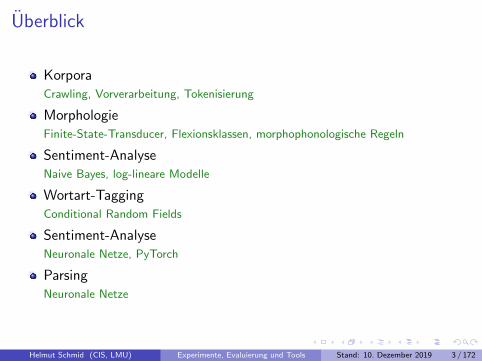
Uberblick
KorporaCrawling, Vorverarbeitung, Tokenisierung
MorphologieFinite-State-Transducer, Flexionsklassen, morphophonologische Regeln
Sentiment-AnalyseNaive Bayes, log-lineare Modelle
Wortart-TaggingConditional Random Fields
Sentiment-AnalyseNeuronale Netze, PyTorch
ParsingNeuronale Netze
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 3 / 172

Korpora
bilden die Grundlage der Forschung in der Computerlinguistik
Korpusquellen:
Bucher (z.B. Gutenberg-Archiv)
Zeitungen (Zeit, FAZ, TAZ)
WikipediaI großer Umfang (> 1,74 Milliarden Worter)I 264 Sprachen
soziale Medien (Twitter)I sehr großer UmfangI sehr aktuellI Tippfehler, Grammatikfehler, Slang, Abkurzungen
Parallelkorpora (EU, UN, kanadisches Parlament, Handbucher)
Vor ihrer Nutzung mussen die Korpora erst aufbereitet werden.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 4 / 172

Korpusaufbereitung
Schritte
Konvertierung von PDF-, DOC-, HTML-Dateien etc. in reineTextdateien
Entfernung von nicht-relevanten Teilen (Bilder, Tabellen etc.)
falls notig Konvertierung in Unicode (UTF8)
Tokenisierung (Zerlegung in Satze und Tokens)
linguistische Annotation (Wortart, Lemma, Parsebaum, Namen etc.)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 5 / 172
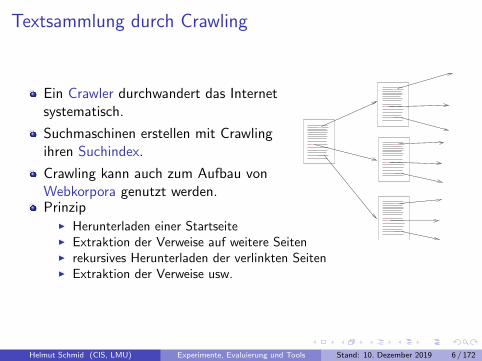
Textsammlung durch Crawling
Ein Crawler durchwandert das Internetsystematisch.
Suchmaschinen erstellen mit Crawlingihren Suchindex.
Crawling kann auch zum Aufbau vonWebkorpora genutzt werden.Prinzip
I Herunterladen einer StartseiteI Extraktion der Verweise auf weitere SeitenI rekursives Herunterladen der verlinkten SeitenI Extraktion der Verweise usw.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 6 / 172

Crawling-Werkzeuge
BootCat: komplexes Werkzeug zur Erstellung von Webkorpora,verwendet Suchmaschinenanfragen, um themenspezifische Seitenherunterzuladen
wget: Programm zum rekursiven Herunterladen von WebseitenBeispiel: wget -r -w 1 www.bbc.com
→ benutzt in Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 7 / 172

PDF, DOC und HTML
⇒TV-DuellTrump geht die Puste aus90 Minuten gegen Hillary Clinton sind zu viel fur Donald Trump.Nicht nur ahnungslos, auch unkonzentriert blamiert er sich vorMillionenpublikum. Ist die Wahl gelaufen?Ein Kommentar von Paul Middelhoff, Washington D.C.
Texte liegen oft formatiert vor.
Fur Korpora werden die reinen Texte benotigt.
Formatierte Texte mussen daher umgewandelt werden:I PDF-Dateien: pdftotext (Ergebnis nicht immer gut)I DOC-Dateien: mit Word, LibreOffice etc.I HTML-Datei: oft spezifische Losungen notwendig, um irrelevante Teile
der Seite (Werbung, Links etc.) auszufiltern (→ Aufgabe 1)I Spezialfall Bild: OCR
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 8 / 172

Textextraktion aus HTML-Seiten
...<div class=”article item ”><h1 class=”article-heading” itemprop=”headline”><span class=”article-heading kicker”>Kunstliche Intelligenz</span><spanclass=”visually-hidden”>: </span><spanclass=”article-heading title”>Watson, wir haben einProblem</span></h1></div><div class=”article item ”><div class=”summary” itemprop=”description”>Lesen, schreiben, zuhoren und verstehen – intelligente Maschinen konnen immermehr Dinge, die bisher nur Menschen konnten. Was bedeutet das fur unsereJobs? Und fur uns?</div><div class=”byline”>Von<span itemprop=”author” itemscopeitemtype=”http://schema.org/Person”><a href=”http://www.zeit.de/autoren/G/Lars Gaede” itemprop=”url”data-vars-url=”www.zeit.de/autoren/G/Lars Gaede”><span itemprop=”name”>Lars Gaede</span></a></span></div><div class=”metadata”>...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 9 / 172

Textextraktion aus HTML-Seiten
...<div class=”article item ”><h1 class=”article-heading” itemprop=”headline”><span class=”article-heading kicker”>Kunstliche Intelligenz</span><spanclass=”visually-hidden”>: </span><spanclass=”article-heading title”>Watson, wir haben einProblem</span></h1></div><div class=”article item ”><div class=”summary” itemprop=”description”>Lesen, schreiben, zuhoren und verstehen – intelligente Maschinen konnen immermehr Dinge, die bisher nur Menschen konnten. Was bedeutet das fur unsereJobs? Und fur uns?</div><div class=”byline”>Von<span itemprop=”author” itemscopeitemtype=”http://schema.org/Person”><a href=”http://www.zeit.de/autoren/G/Lars Gaede” itemprop=”url”data-vars-url=”www.zeit.de/autoren/G/Lars Gaede”><span itemprop=”name”>Lars Gaede</span></a></span></div><div class=”metadata”>...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 10 / 172

Zeichensatzkonvertierung
Texte konnen unterschiedlich kodiert sein: ISO-8859-1 (Latin1),Windows-1252 etc.
Ein Korpus sollte einen einheitlichen Zeichensatz verwenden
Unicode erlaubt die Darstellung (fast) aller Zeichen⇒ Umwandlung aller Texte nach Unicode (meist UTF8)
Linux-Werkzeuge fur ZeichensatzkonvertierungI recodeI iconv (ahnlich, aber andere Aufruf-Syntax)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 11 / 172

Zeichensatzkonvertierung
Anwendung von recode
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 12 / 172

Tokenisierung
Fur die Computerlinguistik sind der Satz und das Wort wichtigeEinheiten, da viele Werkzeuge auf Satzen und Wortern operieren.
Den ersten Schritt der linguistischen Annotation bildet daher dieTokenisierung = Zerlegung in Satze und Worter
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 13 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172
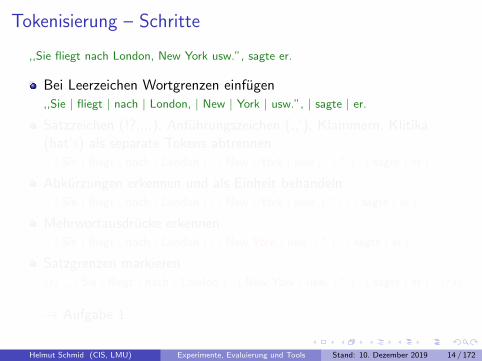
Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Tokenisierung – Schritte
,,Sie fliegt nach London, New York usw.”, sagte er.
Bei Leerzeichen Wortgrenzen einfugen,,Sie | fliegt | nach | London, | New | York | usw.”, | sagte | er.
Satzzeichen (!?.;:,), Anfuhrungszeichen (,,’), Klammern, Klitika(hat’s) als separate Tokens abtrennen,, | Sie | fliegt | nach | London | , | New | York | usw | . | ” | , | sagte | er | .
Abkurzungen erkennen und als Einheit behandeln,, | Sie | fliegt | nach | London | , | New | York | usw. | ” | , | sagte | er | .
Mehrwortausdrucke erkennen,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | .
Satzgrenzen markieren〈s〉 ,, | Sie | fliegt | nach | London | , | New York | usw. | ” | , | sagte | er | . 〈/s〉
→ Aufgabe 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 14 / 172

Wort-Segmentierung
Viele Sprachen markieren keine Wortgrenzen.
Chinesisch:
Japanisch:
Thai:
Koreanisch:
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 15 / 172

Wort-Segmentierung
Deutscher Satz ohne Leerzeichen: erbestellteinbierimgasthaus
Die bisherigen Tokenisierungsheuristiken funktionieren nicht, stattdessen
longest Match mit großen Wortlistenerbe | stellte | in | bier | im | gasthausWas ist hier schiefgegangen?
N-Gramm-Sprachmodelle zur Desambiguierunger | bestellt | ein | bier | im | gasthaus
Probleme mit unbekannten Worterner | bestellt | ein | bier | im | n | epo | m | u | k
Tagging-Ansatze r b e s t e l l t e i n b i e r i m g a s t h a u s
1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0
Es gibt keine allgemeingultige Definition von “Wort”(vgl. computer screen vs. Computerbildschirm)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 16 / 172

Wort-Segmentierung
Deutscher Satz ohne Leerzeichen: erbestellteinbierimgasthaus
Die bisherigen Tokenisierungsheuristiken funktionieren nicht, stattdessen
longest Match mit großen Wortlistenerbe | stellte | in | bier | im | gasthausWas ist hier schiefgegangen?
N-Gramm-Sprachmodelle zur Desambiguierunger | bestellt | ein | bier | im | gasthaus
Probleme mit unbekannten Worterner | bestellt | ein | bier | im | n | epo | m | u | k
Tagging-Ansatze r b e s t e l l t e i n b i e r i m g a s t h a u s
1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0
Es gibt keine allgemeingultige Definition von “Wort”(vgl. computer screen vs. Computerbildschirm)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 16 / 172

Wort-Segmentierung
Deutscher Satz ohne Leerzeichen: erbestellteinbierimgasthaus
Die bisherigen Tokenisierungsheuristiken funktionieren nicht, stattdessen
longest Match mit großen Wortlistenerbe | stellte | in | bier | im | gasthausWas ist hier schiefgegangen?
N-Gramm-Sprachmodelle zur Desambiguierunger | bestellt | ein | bier | im | gasthaus
Probleme mit unbekannten Worterner | bestellt | ein | bier | im | n | epo | m | u | k
Tagging-Ansatze r b e s t e l l t e i n b i e r i m g a s t h a u s
1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0
Es gibt keine allgemeingultige Definition von “Wort”(vgl. computer screen vs. Computerbildschirm)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 16 / 172

Wort-Segmentierung
Deutscher Satz ohne Leerzeichen: erbestellteinbierimgasthaus
Die bisherigen Tokenisierungsheuristiken funktionieren nicht, stattdessen
longest Match mit großen Wortlistenerbe | stellte | in | bier | im | gasthausWas ist hier schiefgegangen?
N-Gramm-Sprachmodelle zur Desambiguierunger | bestellt | ein | bier | im | gasthaus
Probleme mit unbekannten Worterner | bestellt | ein | bier | im | n | epo | m | u | k
Tagging-Ansatze r b e s t e l l t e i n b i e r i m g a s t h a u s
1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0
Es gibt keine allgemeingultige Definition von “Wort”(vgl. computer screen vs. Computerbildschirm)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 16 / 172

Wort-Segmentierung
Deutscher Satz ohne Leerzeichen: erbestellteinbierimgasthaus
Die bisherigen Tokenisierungsheuristiken funktionieren nicht, stattdessen
longest Match mit großen Wortlistenerbe | stellte | in | bier | im | gasthausWas ist hier schiefgegangen?
N-Gramm-Sprachmodelle zur Desambiguierunger | bestellt | ein | bier | im | gasthaus
Probleme mit unbekannten Worterner | bestellt | ein | bier | im | n | epo | m | u | k
Tagging-Ansatze r b e s t e l l t e i n b i e r i m g a s t h a u s
1 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0
Es gibt keine allgemeingultige Definition von “Wort”(vgl. computer screen vs. Computerbildschirm)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 16 / 172

Linguistische Annotation
Fur die linguistische Forschung und die Sprachverarbeitung werdenKorpora linguistisch annotiert
Tokenisierung
morphologische Analyse der Worter (→ nachstes Thema)
Wortart-Annotation
Lemmatisierung
syntaktische Annotation (Parsing)
Erkennung von Namen
...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 17 / 172

Morphologie
Morphologie untersucht die Struktur von Wortern
Zerlegung in Morpheme: Formel-ab-leit-ung-enMorpheme sind die kleinsten bedeutungstragenden Einheiten
weitergehende Analyse:
Basislemma leiten/VPrafigierung ab/PART leiten/VNominalisierung ab/PART leiten/V ung/NNKomposition Formel/NN ab/PART leiten/V ung/NNFlexion Formel/NN ab/PART leiten/V ung/NN en/Pl
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 18 / 172

Morphologische Prozesse
Flexion
Flexionsmorpheme markieren syntaktische Eigenschaftenrechn-est 2. Sg. Prasensge-rechn-et Partizip Perfektrechn-en Infinitiv, 1. Pl. Prasens, 3. Pl. Prasens
Die Flexionsmorpheme werden an den Wortstamm angefugt
Flexion von Verben: Konjugation
Flexion von Nomen, Adjektiven: Deklination
Deutsch ist eine fusionale Sprache, d.h. ein Morphem reprasentiertmehrere syntaktische Merkmale → “-est” - 2. Sg. Prasens
Deutsch zeigt außerdem Synkretismus, d.h. eine Form hat mehrereAnalysen → rechnen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 19 / 172

Morphologische Prozesse
Flexion
Flexionsmorpheme markieren syntaktische Eigenschaftenrechn-est 2. Sg. Prasensge-rechn-et Partizip Perfektrechn-en Infinitiv, 1. Pl. Prasens, 3. Pl. Prasens
Die Flexionsmorpheme werden an den Wortstamm angefugt
Flexion von Verben: Konjugation
Flexion von Nomen, Adjektiven: Deklination
Deutsch ist eine fusionale Sprache, d.h. ein Morphem reprasentiertmehrere syntaktische Merkmale → “-est” - 2. Sg. Prasens
Deutsch zeigt außerdem Synkretismus, d.h. eine Form hat mehrereAnalysen → rechnen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 19 / 172

Morphologische Prozesse
Turkisch hat eine sehr komplexe Flexion (agglutinierende Sprache)
pisirdiler - they caused it to be cooked
pis to cook (Stamm)ir Kausativdi Vergangenheitler Plural
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 20 / 172

Morphologische Prozesse
Derivation
Ableitung neuer Wortformen mit anderer Wortart oder Bedeutung ausvorhandenen Wortformen
setzen → ubersetzen → ubersetzbar → unubersetzbar → Unubersetzbarkeit
uber- Verbprafix
-bar leitet ein Adjektiv aus einem Verb ab
un- negierendes Adjektivprafix
keit leitet ein Nomen aus einem Adjektiv ab
Derivationsmorpheme konnen auch leer sein: wohnen → das Wohnen(Konversion)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 21 / 172

Neoklassische Wortbildung
existiert parallel zur normalen deutschen Wortbildung
in vielen europaischen Sprachen
Grund: Latein war lange die Sprache der Wissenschaft. Lateinische(und griechische) Fachbegriffe wurden ins Deutsche ubernommen undangepasst
Deutsch Englisch Franzosisch
Norm norm normenormal normal normalNormalitat normality normaliteabnormal abnormal anormal
Wie konnte das Wort Inaktivitat gebildet worden sein?
Inaktivitat → inaktiv → aktiv → akt(ion)/ag(ieren)
analoges deutsches Wort mit ganz anderen Morphemen:
Untatigkeit → untatig → tatig → Tat/tunHelmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 22 / 172

Neoklassische Wortbildung
existiert parallel zur normalen deutschen Wortbildung
in vielen europaischen Sprachen
Grund: Latein war lange die Sprache der Wissenschaft. Lateinische(und griechische) Fachbegriffe wurden ins Deutsche ubernommen undangepasst
Deutsch Englisch Franzosisch
Norm norm normenormal normal normalNormalitat normality normaliteabnormal abnormal anormal
Wie konnte das Wort Inaktivitat gebildet worden sein?
Inaktivitat → inaktiv → aktiv → akt(ion)/ag(ieren)
analoges deutsches Wort mit ganz anderen Morphemen:
Untatigkeit → untatig → tatig → Tat/tunHelmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 22 / 172

Neoklassische Wortbildung
existiert parallel zur normalen deutschen Wortbildung
in vielen europaischen Sprachen
Grund: Latein war lange die Sprache der Wissenschaft. Lateinische(und griechische) Fachbegriffe wurden ins Deutsche ubernommen undangepasst
Deutsch Englisch Franzosisch
Norm norm normenormal normal normalNormalitat normality normaliteabnormal abnormal anormal
Wie konnte das Wort Inaktivitat gebildet worden sein?
Inaktivitat → inaktiv → aktiv → akt(ion)/ag(ieren)
analoges deutsches Wort mit ganz anderen Morphemen:
Untatigkeit → untatig → tatig → Tat/tunHelmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 22 / 172

Neoklassische Wortbildung
existiert parallel zur normalen deutschen Wortbildung
in vielen europaischen Sprachen
Grund: Latein war lange die Sprache der Wissenschaft. Lateinische(und griechische) Fachbegriffe wurden ins Deutsche ubernommen undangepasst
Deutsch Englisch Franzosisch
Norm norm normenormal normal normalNormalitat normality normaliteabnormal abnormal anormal
Wie konnte das Wort Inaktivitat gebildet worden sein?
Inaktivitat → inaktiv → aktiv → akt(ion)/ag(ieren)
analoges deutsches Wort mit ganz anderen Morphemen:
Untatigkeit → untatig → tatig → Tat/tunHelmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 22 / 172

Morphologische Prozesse
Komposition
Bildung einer neuen Wortform aus zwei vorhandenenDonau-dampf-schiff-fahrt-s-Kapitan
Das ’-s-’ ist ein Fugenmorphem
Deutsch ist fur seine komplexen Komposita bekannt
Typen deutscher WortstammeI Derivationsstamm (oft mit Umlautung)
bauer-lich
I Kompositionsstamme:
Bauers-frau, Bauern-krieg, Bauer-berufBaumes-wipfel, Baume-fallen, baum-lang
Wie werden diese Stamme gebildet?
I Einige Derivationsendungen kombinieren mit Kompositionsstammen:taten-los, zahlen-maßig, damen-haft (vs. dam-lich)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 23 / 172

Morphologische Prozesse
Komposition
Bildung einer neuen Wortform aus zwei vorhandenenDonau-dampf-schiff-fahrt-s-Kapitan
Das ’-s-’ ist ein Fugenmorphem
Deutsch ist fur seine komplexen Komposita bekannt
Typen deutscher WortstammeI Derivationsstamm (oft mit Umlautung)
bauer-lich
I Kompositionsstamme:
Bauers-frau, Bauern-krieg, Bauer-berufBaumes-wipfel, Baume-fallen, baum-lang
Wie werden diese Stamme gebildet?
I Einige Derivationsendungen kombinieren mit Kompositionsstammen:taten-los, zahlen-maßig, damen-haft (vs. dam-lich)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 23 / 172

Morphologische Prozesse
Klitisierung
Ein Klitik ist ein Wort, das mit einem benachbarten Wort verschmolzen(und dabei eventuell reduziert) wurde.
I’ve I have (engl.)C’est Ce est (franz.)fermarla fermar la (ital.)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 24 / 172

Morphologische Prozesse
nicht-konkatenative Morphologie
Hier werden Morpheme nicht einfach aneinandergereiht
Beispiel: Root-and-Pattern-Morphologie (semitische Sprachen)I Wurzel lmd (lernen, Hebraisch)I plus das Muster CaCaC (fur Aktiv)I ergibt das Wort lamad
I Fur die drei C’s werden die drei Konsonanten eingesetzt
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 25 / 172

Mehr zu Morphologie
Affixe schließen Prafixe, Suffixe, Infixe und Zirkumfixe ein.I ge-...-t in getaucht ist ein Zirkumfix (Partizip Perfekt)I In abgetaucht stellt ge- ein Infix dar.
Einige morphologische Prozesse sind nicht mehr produktiv(d.h. sie werden nicht mehr zur Bildung neuer Worter benutzt)
I -sam in “einsam”, “kleidsam”, “arbeitsam”I -sal in “Trubsal”, “Labsal”, “Muhsal”
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 26 / 172

Flexionsklassen
Flektierende Worter kann man in Flexionsklassen einteilen
Lateinische a-Deklination: casa, casae, casae, casam, casa, ...Lateinische o-Deklination: avus, avi, avo, avum, avo, ...Lateinische u-Deklination: portus, portus, portui, portum, ...
Alle Worter einer Flexionsklasse werden nach demselben Schemaflektiert.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 27 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172

Tiwa-Morphologie
temiban I wentamiban you wenttemiwe I am goingmimiay he was goingtewanban I cametewanhi I will come
Bedeutung des Prafixes ’te-’? IBedeutung des Prafixes ’a-’? youBedeutung des Prafixes ’mi-’? heBedeutung des Suffixes ’-ban’? pastBedeutung des Suffixes ’-we? present progr.Bedeutung des Suffixes ’-ay? past progr.Bedeutung des Suffixes ’-hi? future
Wie sagt man in Tiwa: “he went” mimiban
regularer Ausdruck fur die Flexion: (te|a|mi) (mi|wan) (ban|we|ay|hi)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 28 / 172
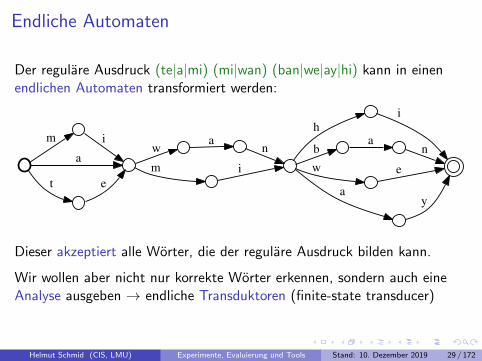
Endliche Automaten
Der regulare Ausdruck (te|a|mi) (mi|wan) (ban|we|ay|hi) kann in einenendlichen Automaten transformiert werden:
m
a
t
iw
m
e
a
i
n
h
b
w
a
i
a
e
y
n
Dieser akzeptiert alle Worter, die der regulare Ausdruck bilden kann.
Wir wollen aber nicht nur korrekte Worter erkennen, sondern auch eineAnalyse ausgeben → endliche Transduktoren (finite-state transducer)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 29 / 172
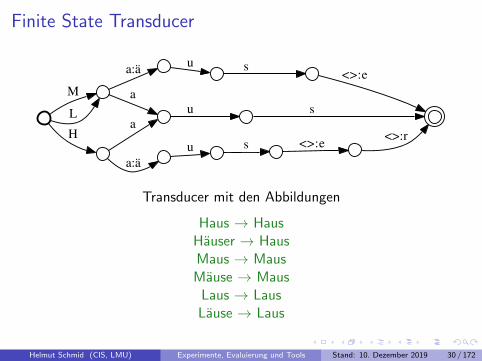
Finite State Transducer
M
L
H
a:ä
a
a
a:ä
u
u
s<>:e
s
u s <>:e<>:r
Transducer mit den Abbildungen
Haus → HausHauser → HausMaus → MausMause → Maus
Laus → LausLause → Laus
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 30 / 172

Finite State Transducer
endlicher Automat mit Symbolpaaren an den Ubergangen.
definiert eine Abbildung zwischen zwei regularen Sprachen(regulare Relation)
in beide Richtungen (Analyse, Generierung) anwendbar
Standardmethode zur Implementierung morphologischerAnalysewerkzeuge
FSTs konnen durch erweiterte regulare Ausdrucke definiert werden
(M:M|L:L) a:a u:u s:s <>:e bildet Mause/Lause auf Maus/Laus ab
<> ist das leere Symbol
→ Aufgabe 2→ FST-Programmiersprache
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 31 / 172

SFST-Werkzeuge
Programmiersprache fur FSTs
Compiler, der die Programme in Transducer ubersetzt
Programme zur Anwendung von FSTs (Interpreter)
Beispiel:
> echo ’Maus | Laus | (M:M|L:L) a:a u:u s:s <>:e’ > test.fst
> fst-compiler-utf8 test.fst test.a
> fst-mor test.a
analyze> Maus
Maus
analyze> Mause
Maus
analyze> # Leerzeile schaltet auf Generierung um
generate> Maus
Maus
Mause
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 32 / 172

Die SFST-Programmiersprache
Regulare Ausdrucke
a:b b wird als a analysiert
a Abkurzung fur a:a
Konkatenation a b:B c
Kleene’s Operator a*
Plus Operator b+
Optionalitat <>:e ?
Klammern (ab)*
Leerzeichen werden ignoriert.
Werden die Zeichen :+*?()[ ] und Leerzeichen als solche benotigt,mussen sie mit einem \ gequotet werden.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 33 / 172

Die SFST-Programmiersprache
weitere Operatoren
Disjunktion a:a | a:b | c
[a-c]:[A-C] kurz fur a:A | b:B | c:C
[a-c] kurz fur [a-c]:[a-c]
{abc}:{AB} kurz fur a:A b:B c:<>
Konjunktion [ab]*abba[ab]* & [ab]*baab[ab]*
Negation [ab]*abba[ab]* & ![ab]*baab[ab]*(aquivalent zu [ab]*abba[ab]* - [ab]*baab[ab]*)
Kommentare werden mit % eingeleitet und enden am Zeilenende.
Variablen beginnen und enden mit $ (bspw. $var$) und speichern einenregularen Ausdruck (Transducer).
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 34 / 172

Kompositionsoperator
$T1$ || $T2$
T1 und T2 werden (in Generierungsrichtung) hintereinanderausgefuhrt.
Die Ausgabe von T1 bildet die Eingabe von T2
Der Compiler erzeugt einen Transducer, der dieselbe Abbildung ineinem Schritt ausfuhrt.
Beispiel: [a-z]:[A-Z]* || [A-Z]:[a-z]*
Was macht dieser Transducer?
Der Transducer ist identisch zu [a-z]*
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 35 / 172

Kompositionsoperator
$T1$ || $T2$
T1 und T2 werden (in Generierungsrichtung) hintereinanderausgefuhrt.
Die Ausgabe von T1 bildet die Eingabe von T2
Der Compiler erzeugt einen Transducer, der dieselbe Abbildung ineinem Schritt ausfuhrt.
Beispiel: [a-z]:[A-Z]* || [A-Z]:[a-z]*
Was macht dieser Transducer?
Der Transducer ist identisch zu [a-z]*
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 35 / 172

Das Alphabet
Der Befehl ALPHABET = [a-z]:[A-Z] [a-z]:[a-z] definiert einAlphabet.
Auf der rechten Seite kann ein beliebiger Transducerausdruck stehen.
Das Alphabet umfasst alle Symbolpaare, die an Ubergangen desTransducers auftauchen.
Das Wildcardsymbol “.” steht fur die Disjunktion aller Symbolpaare imAlphabet.
“a:.” steht fur die Disjunktion aller Symbolpaare im Alphabet mit “a” aufder linken Seite.
Was macht der Transducer “.*” bei obiger Definition des Alphabetes?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 36 / 172

Das Alphabet
Der Befehl ALPHABET = [a-z]:[A-Z] [a-z]:[a-z] definiert einAlphabet.
Auf der rechten Seite kann ein beliebiger Transducerausdruck stehen.
Das Alphabet umfasst alle Symbolpaare, die an Ubergangen desTransducers auftauchen.
Das Wildcardsymbol “.” steht fur die Disjunktion aller Symbolpaare imAlphabet.
“a:.” steht fur die Disjunktion aller Symbolpaare im Alphabet mit “a” aufder linken Seite.
Was macht der Transducer “.*” bei obiger Definition des Alphabetes?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 36 / 172

SFST-Programme
Programmstruktur
Ein SFST-Programm besteht aus einer Folge von Variablen-Definitionen,Alphabet-Definitionen und anderen Befehlen gefolgt von einem einzigenErgebnisausdruck, dessen Wert nach der Kompilierung in der Ausgabedateigespeichert wird.
Es werden aus einfacheren Transducern (regularen Ausdrucken) immerkomplexere Transducer aufgebaut, bis der gewunschte Ergebnis-Transducerfertiggestellt ist.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 37 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172

SFST-Beispiele
ALPHABET = [a-zA-Z]
[a-zA-Z]:[A-Za-z]+
Welche “Analyse” wird ausgegeben fur “LaTeX”?
[ab]* - .*ba.*
Welche Strings akzeptiert dieser Automat?
.* {ll}:{LL}? .*
“Analyse” von “Hallo”?“Analyse” von “HaLLo”?
{Hallo}:{<>Hallo}
“Analyse” von “Hallo”?
{Hallo}:{<>Hallo} & Hallo
Ausgabe fur “Hallo”?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 38 / 172
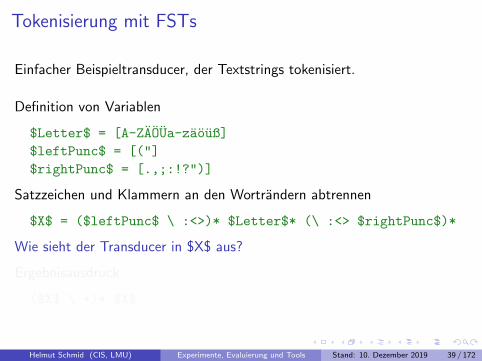
Tokenisierung mit FSTs
Einfacher Beispieltransducer, der Textstrings tokenisiert.
Definition von Variablen
$Letter$ = [A-ZAOUa-zaouß]
$leftPunc$ = [("]
$rightPunc$ = [.,;:!?")]
Satzzeichen und Klammern an den Wortrandern abtrennen
$X$ = ($leftPunc$ \ :<>)* $Letter$* (\ :<> $rightPunc$)*
Wie sieht der Transducer in $X$ aus?
Ergebnisausdruck
($X$ \ +)* $X$
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 39 / 172

Tokenisierung mit FSTs
Einfacher Beispieltransducer, der Textstrings tokenisiert.
Definition von Variablen
$Letter$ = [A-ZAOUa-zaouß]
$leftPunc$ = [("]
$rightPunc$ = [.,;:!?")]
Satzzeichen und Klammern an den Wortrandern abtrennen
$X$ = ($leftPunc$ \ :<>)* $Letter$* (\ :<> $rightPunc$)*
Wie sieht der Transducer in $X$ aus?
Ergebnisausdruck
($X$ \ +)* $X$
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 39 / 172

Tokenisierung mit FSTs
Anwendung des Transducers
> fst-compiler-utf8 tokenize.fst tokenize.a
> fst-mor tokenize.a
analyze> Er kam, sah, und siegte.
Er kam , sah , und siegte .
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 40 / 172

Erkennung von Abkurzungen
Definition von Variablen
...
$all$ = $Letter$ $leftPunc$ $rightPunc$ [\ ]
Satzzeichen und Klammern an den Wortrandern abtrennen$X$ = ($leftPunc$ \ :<>)* $Letter$* (\ :<> $rightPunc$)*
$X$ = ($X$ \ +)* $X$
Abkurzungen wieder zusammenfugen
ALPHABET = $all$
$R$ = (<>:\ ) _-> ((Fr|Hr|Prof|Dr|etc|usw) __ \.)
$R$ || $X$
analyze> "Heureka!", sagte Hr. Muller.
" Heureka ! " , sagte Hr. Muller .
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 41 / 172

Ersetzungsregeln
(b:B) ^-> (a __ c) Ersetze b zwischen a und c durch B an derOberflache
(b:B) _-> (A __ C) Ersetze B zwischen A und C durch b in derAnalyse
Bei leerem Kontext wird immer ersetzt:
(b:B) ^-> () (b:B) _-> ()
allgemeine Syntax: Ersetzung ^-> (linker Kontext __ rechter Kontext)
Ersetzung ist ein beliebiger Transducer
linker/rechter Kontext muss ein Automat sein (d.h. darf kein ’:’ enthalten)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 42 / 172

Weitere Operatoren
Der Operator ^$A$ macht die Analysesymbole im Transducer $A$identisch zu den Oberflachensymbolen (also ^a:b = b:b)
Der Operator _$A$ macht die Oberflachensymbole identisch zu denAnalysesymbolen (also _a:b = a:a)
Der Operator ^_$A$ vertauscht die Oberflachen- und Analysesymbole(also ^_{ab}:{AB} = {AB}:{ab})
Der Operator "Datei" liest den Inhalt von “Datei” und bildet einenTransducer durch Disjunktion der eingelesenen Zeilen. In der eingelesenenDatei werden nur die Symbole < > : \ als Operatoren interpretiert.
Der Operator "<Datei>" liest einen bereits kompilierten Transducer aus“Datei”.
Zeichenketten der Form <...> werden als atomare Symbole behandelt wieeinzelne Buchstaben.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 43 / 172
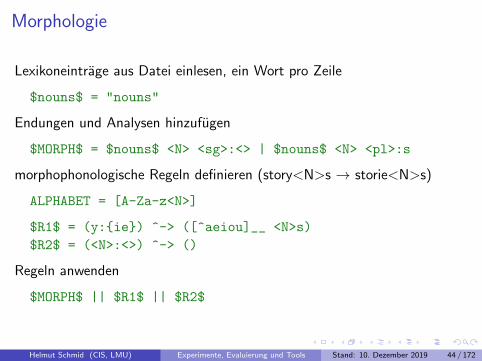
Morphologie
Lexikoneintrage aus Datei einlesen, ein Wort pro Zeile
$nouns$ = "nouns"
Endungen und Analysen hinzufugen
$MORPH$ = $nouns$ <N> <sg>:<> | $nouns$ <N> <pl>:s
morphophonologische Regeln definieren (story<N>s → storie<N>s)
ALPHABET = [A-Za-z<N>]
$R1$ = (y:{ie}) ^-> ([^aeiou]__ <N>s)
$R2$ = (<N>:<>) ^-> ()
Regeln anwenden
$MORPH$ || $R1$ || $R2$
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 44 / 172

Ausfuhren der Morphologie
> fst-compiler-utf8 morph.fst morph.a
> fst-mor morph.a
analyze> lobbies
lobby<N><pl>
analyze> stores
store<N><pl>
analyze> houses
house<N><pl>
analyze>
generate> house<N><pl>
houses
generate> house<N><sg>
house
generate> q
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 45 / 172

Einlesen von Lexikondateien
$nouns$ = "nouns"
$verbs$ = "verbs"
$present-verbs$ = "present-verbs"
$past-verbs$ = "past-verbs"
$part-verbs$ = "part-verbs"
$adjectives$ = "adjectives"
$gradable-adjectives$ = "gradable-adjectives"
$MORPH$ = $nouns$ <N> (<sg>:<> | <pl>:s)
...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 46 / 172

Anfugen der Analysen und Flexionsendungen
...
$MORPH$ = $MORPH$ |\
$verbs$ <V> {<inf>}:{} |\
$verbs$ <V> {<pres><n3s>}:{} |\
$verbs$ <V> {<pres><3s>}:{s} |\
$verbs$ <V> {<gerund>}:{ing} |\
$verbs$ <V> {<past>}:{ed} |\
$verbs$ <V> {<part>}:{ed} |\
$present-verbs$ <V> {<inf>}:{} |\
$present-verbs$ <V> {<pres><n3s>}:{} |\
$present-verbs$ <V> {<pres><3s>}:{s} |\
$present-verbs$ <V> {<gerund>}:{ing} |\
$past-verbs$ <V> {<past>}:{} |\
$part-verbs$ <V> {<part>}:{}
$MORPH$ = $MORPH$ |\
$adjectives$ <ADJ> {<pos>}:{} |\
$gradable-adjectives$ <ADJ> {<pos>}:{} |\
$gradable-adjectives$ <ADJ> {<comp>}:{er} |\
$gradable-adjectives$ <ADJ> {<sup>}:{est}
...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 47 / 172

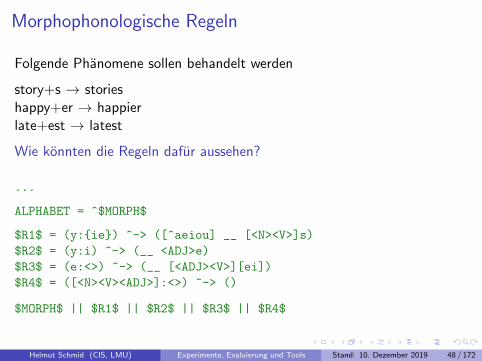
Morphophonologische Regeln
Folgende Phanomene sollen behandelt werden
story+s → storieshappy+er → happierlate+est → latest
Wie konnten die Regeln dafur aussehen?
...
ALPHABET = ^$MORPH$
$R1$ = (y:{ie}) ^-> ([^aeiou] __ [<N><V>]s)
$R2$ = (y:i) ^-> (__ <ADJ>e)
$R3$ = (e:<>) ^-> (__ [<ADJ><V>][ei])
$R4$ = ([<N><V><ADJ>]:<>) ^-> ()
$MORPH$ || $R1$ || $R2$ || $R3$ || $R4$
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 48 / 172
Morphophonologische Regeln
Folgende Phanomene sollen behandelt werden
story+s → storieshappy+er → happierlate+est → latest
Wie konnten die Regeln dafur aussehen?
...
ALPHABET = ^$MORPH$
$R1$ = (y:{ie}) ^-> ([^aeiou] __ [<N><V>]s)
$R2$ = (y:i) ^-> (__ <ADJ>e)
$R3$ = (e:<>) ^-> (__ [<ADJ><V>][ei])
$R4$ = ([<N><V><ADJ>]:<>) ^-> ()
$MORPH$ || $R1$ || $R2$ || $R3$ || $R4$
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 48 / 172

Morphophonologische Regeln
Bei der Bildung des englischen Komparativs oder Superlativs wird der letzteKonsonant des Adjektivs verdoppelt, wenn
das Adjektiv nur eine Silbe umfasst und
auf Konsonant-Vokal-Konsonant endet und
der letzte Konsonant nicht “y” oder “w” ist
big bigger biggestfat fatter fattestthin thinner thinnestgrey greyer greyestslow slower slowestplain plainer plainest
Wie konnte eine Regel dafur aussehen?
({g}:{gg}|{t}:{tt}|{n}:{nn}) ^-> ($cons$ $vowel$ __ <ADJ>er)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 49 / 172

Morphophonologische Regeln
Bei der Bildung des englischen Komparativs oder Superlativs wird der letzteKonsonant des Adjektivs verdoppelt, wenn
das Adjektiv nur eine Silbe umfasst und
auf Konsonant-Vokal-Konsonant endet und
der letzte Konsonant nicht “y” oder “w” ist
big bigger biggestfat fatter fattestthin thinner thinnestgrey greyer greyestslow slower slowestplain plainer plainest
Wie konnte eine Regel dafur aussehen?
({g}:{gg}|{t}:{tt}|{n}:{nn}) ^-> ($cons$ $vowel$ __ <ADJ>er)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 49 / 172

Kopier-Operationen
({g}:{gg}|{t}:{tt}|{n}:{nn})
Diese Ausdruck zum Kopieren eines Buchstabens wird sehr lang, wenn eralle Konsonanten umfassen soll. Die Losung sind Kopiervariablen.
Variablen fur Symbolmengen:
#vowel# = aeiou
#cons# = bcdfghjklmnpqrstvx
$vowel$ = [#vowel#]
$cons$ = [#cons#]
Kopiervariable:
#=c# = #cons#
{[#=c#]}:{[#=c#][#=c#]} ^-> ($cons$ $vowel$ __ <ADJ>er)#}
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 50 / 172

Entwicklung einer Morphologie
Vorgehensweise
zu behandelnde Phanomene festlegenI Flexion, Derivation, Komposition?I welche Wortarten?I unregelmaßig gebildete Formen?I welche morphophonologische Regeln?I weitere Phanomene wie Klitika?
Stammlexika anlegen
Lexika einlesen
ggf. Derivationsendungen hinzufugen
ggf. Kompositums-Erstglieder hinzufugen
Flexionsendungen hinzufugen
morphophonologische Regeln anwenden
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 51 / 172
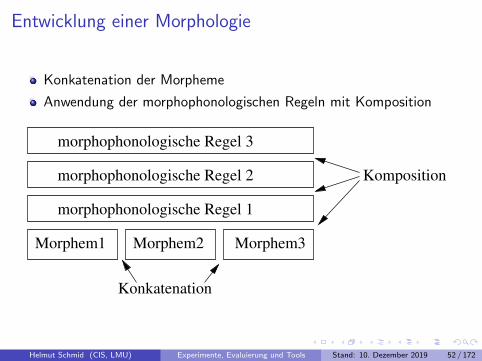
Entwicklung einer Morphologie
Konkatenation der Morpheme
Anwendung der morphophonologischen Regeln mit Komposition
morphophonologische Regel 2
morphophonologische Regel 1
morphophonologische Regel 3
Morphem1 Morphem2 Morphem3
Konkatenation
Komposition
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 52 / 172

Debugging
Testworter ausprobieren
Zwischenergebnisse im Programm ausgeben mit dem Befehl$var$ >> "tmp.a"
Dann den ausgegebenen Transducer untersuchen mit> fst-generate tmp.a
> fst-generate -l tmp.a nur die Strings der Analyseebene> fst-generate -u tmp.a nur die Strings der OberflachenebeneMit grep die interessanten String herausfiltern
Bei Fehlersuche die Lexika auf genau die relevanten Eintragereduzieren⇒ schnellere Kompilierung, einfachere Fehlersuche
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 53 / 172

Beispiel
> cat test.fst
{Hut}:{Hute}
> fst-compiler-utf8 test.fst test.a
test.fst: 2
> fst-print test.a
0 1 H H
1 2 u u
2 3 t t
3 4 <> e
4
> fst-generate test.a
Hu:ut<>:e
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 54 / 172

Aufgabe bis morgen
SFST-Tutorial auf der Kursseite durcharbeiten
Gedanken zur neuen Ubungsaufgabe machen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 55 / 172

Textklassifikation
Wozu dient Textklassifikation?
im Folgenden einige Beispiele
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 56 / 172

Spam-Erkennung
Wie kann man Spam von normaler Mail unterscheiden?
Subject: Great news!From: [email protected]: undisclosed-recipients;Congratulations!You have been selected to be the winner of XXX. Click on the followinglink to login for more information about the exciting price.http://www.123contact.com/contact-form-1234.htmlRegards,
XYZ
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 57 / 172

Spam-Erkennung
Wie kann man Spam von normaler Mail unterscheiden?
Subject: Great news!From: [email protected]: undisclosed-recipients;Congratulations!You have been selected to be the winner of XXX. Click on the followinglink to login for more information about the exciting price.http://www.123contact.com/contact-form-1234.htmlRegards,XYZ
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 58 / 172

Geschlecht eines Autors
Vorhersage des Geschlechteseines Autors
S. Argamon et. al.Gender, Genre, Writing Style inFormal Written Texts
Korpus mit 604 Dokumentenaus dem British NationalCorpus
typische GeschlechtsunterschiedeI Manner: viele Artikel (a, the, that, these) und Quantoren (one, two,
more, some)I Frauen: viele Pronomen (I, you, she, her, myself, yourself)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 59 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Filmbewertungen
Wurde der Film positiv oder negativ rezensiert?
1 Dieser Film ist großartig! ,2 Das ist der langweiligste Film, den ich je gesehen habe. /3 Die Leistung der Schauspieler ist nicht uberzeugend. /4 Der Film ist nicht schlecht. ,?
5 Wenn Sie ein absoluter Fan von Till Schweiger sind, gefallt Ihnendieser Film vielleicht. /
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 60 / 172

Textklassifikationsmethoden
handgeschriebene RegelnI Regeln auf Basis der Worter und anderer Merkmale (z.B. Listen
bekannter Spam-Adressen)I Gute Genauigkeit, aber hoher AufwandI Regeln mussen aufwendig angepasst werden, wenn sich die Daten
andern (z.B. weil Spammer gelernt haben, die Regeln auszutricksen)
maschinelles LernenI Der Computer lernt die Klassifikation selbst aus Beispielen, deren
Klasse bekannt istI ideal, wenn solche Beispiele bereits vorhanden sindI Eine Methode fur die Textklassifikation ist → Naıve Bayes
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 61 / 172

Textklassifikationsmethoden
handgeschriebene RegelnI Regeln auf Basis der Worter und anderer Merkmale (z.B. Listen
bekannter Spam-Adressen)I Gute Genauigkeit, aber hoher AufwandI Regeln mussen aufwendig angepasst werden, wenn sich die Daten
andern (z.B. weil Spammer gelernt haben, die Regeln auszutricksen)
maschinelles LernenI Der Computer lernt die Klassifikation selbst aus Beispielen, deren
Klasse bekannt istI ideal, wenn solche Beispiele bereits vorhanden sindI Eine Methode fur die Textklassifikation ist → Naıve Bayes
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 61 / 172

Textklassifikation mit Naıve Bayes
Grundidee:
Worter, die haufig in Texten einer bestimmten Klasse auftauchen,sind ein Indiz fur diese Klasse.
Jedes Wort wird einzeln betrachtet.
Die Reihenfolge der Worter spielt keine Rolle⇒ “Bag of Words”-Modell
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 62 / 172

Textklassifikation mit Naıve BayesWir wollen die wahrscheinlichste Klasse c des Dokumentes d bestimmen:
c = arg maxc
p(c |d)
Die bed. Wk. p(c|d) kann nicht direkt geschatzt werden (zu viele Parameter)
Wir wandeln den Ausdruck um (gemaß der Def. von bed. Wken)
c = arg maxc
p(c , d)
p(d)
Die positive Konstante p(d) hat keinen Einfluß auf das Ergebnis derMaximierung.
c = arg maxc
p(c , d)
Das gemeinsame Modell von c und d konnen wir umschreiben zu:
c = arg maxc
p(c) p(d |c)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 63 / 172

Parameterschatzung
c = arg maxc
p(c) p(d |c)
p(c) kann nach folgender Formel aus den Klassenhaufigkeiten f (c)geschatzt werden:
p(c) =f (c)∑c ′ f (c ′)
Aber wie bekommt man p(d |c)?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 64 / 172

Naıve Bayes
d besteht aus der Folge der Worter w1, ...,wn
Wir nehmen an, dass die Reihenfolge der Worter egal ist, und dass dieWorter statistisch voneinander unabhangig sind, wenn c bekannt ist, alsop(w ,w ′|c) = p(w |c)p(w ′|c)
Somit gilt:p(d |c) = p(w1, ...,wn|c) =
n∏i=1
p(wi |c)
Zusammengefasst ergibt sich das Naıve Bayes-Modell:
c = arg maxc
p(c)n∏
i=1
p(wi |c)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 65 / 172

Naıve Bayes
modellierter Prozess:
zufallige Wahl eines Dokumenttyps (Spam, Ham)
WiederholeI zufallige Wahl eines Wortes gegeben die DokumentklasseI bis ein Endetoken gewahlt wurde
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 66 / 172

Parameterschatzung
Die Wortwahrscheinlichkeiten konnen mit relativen Haufigkeiten geschatztwerden
p(w |c) =f (w , c)∑w ′ f (w ′, c)
Wenn ein Wort nicht in Dokumenten der Klasse c aufgetaucht ist, wirdp(w |c) = 0 und damit auch der ganze Ausdruck des Naıve Bayes-Modelles.
→ Beispiel
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 67 / 172
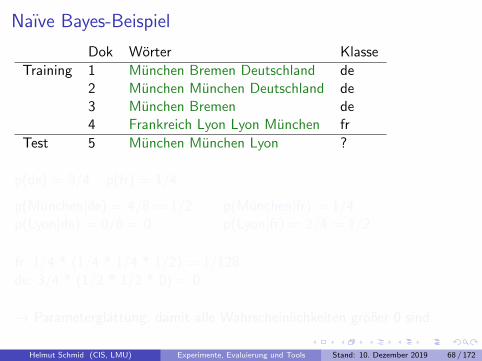
Naıve Bayes-Beispiel
Dok Worter Klasse
Training 1 Munchen Bremen Deutschland de2 Munchen Munchen Deutschland de3 Munchen Bremen de4 Frankreich Lyon Lyon Munchen fr
Test 5 Munchen Munchen Lyon ?
p(de) = 3/4 p(fr) = 1/4
p(Munchen|de) = 4/8 = 1/2p(Lyon|de) = 0/8 = 0
p(Munchen|fr) = 1/4p(Lyon|fr) = 2/4 = 1/2
fr: 1/4 * (1/4 * 1/4 * 1/2) = 1/128de: 3/4 * (1/2 * 1/2 * 0) = 0
→ Parameterglattung, damit alle Wahrscheinlichkeiten großer 0 sind.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 68 / 172

Naıve Bayes-Beispiel
Dok Worter Klasse
Training 1 Munchen Bremen Deutschland de2 Munchen Munchen Deutschland de3 Munchen Bremen de4 Frankreich Lyon Lyon Munchen fr
Test 5 Munchen Munchen Lyon ?
p(de) = 3/4 p(fr) = 1/4
p(Munchen|de) = 4/8 = 1/2p(Lyon|de) = 0/8 = 0
p(Munchen|fr) = 1/4p(Lyon|fr) = 2/4 = 1/2
fr: 1/4 * (1/4 * 1/4 * 1/2) = 1/128de: 3/4 * (1/2 * 1/2 * 0) = 0
→ Parameterglattung, damit alle Wahrscheinlichkeiten großer 0 sind.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 68 / 172

Naıve Bayes-Beispiel
Dok Worter Klasse
Training 1 Munchen Bremen Deutschland de2 Munchen Munchen Deutschland de3 Munchen Bremen de4 Frankreich Lyon Lyon Munchen fr
Test 5 Munchen Munchen Lyon ?
p(de) = 3/4 p(fr) = 1/4
p(Munchen|de) = 4/8 = 1/2p(Lyon|de) = 0/8 = 0
p(Munchen|fr) = 1/4p(Lyon|fr) = 2/4 = 1/2
fr: 1/4 * (1/4 * 1/4 * 1/2) = 1/128de: 3/4 * (1/2 * 1/2 * 0) = 0
→ Parameterglattung, damit alle Wahrscheinlichkeiten großer 0 sind.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 68 / 172

Naıve Bayes-Beispiel
Dok Worter Klasse
Training 1 Munchen Bremen Deutschland de2 Munchen Munchen Deutschland de3 Munchen Bremen de4 Frankreich Lyon Lyon Munchen fr
Test 5 Munchen Munchen Lyon ?
p(de) = 3/4 p(fr) = 1/4
p(Munchen|de) = 4/8 = 1/2p(Lyon|de) = 0/8 = 0
p(Munchen|fr) = 1/4p(Lyon|fr) = 2/4 = 1/2
fr: 1/4 * (1/4 * 1/4 * 1/2) = 1/128de: 3/4 * (1/2 * 1/2 * 0) = 0
→ Parameterglattung, damit alle Wahrscheinlichkeiten großer 0 sind.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 68 / 172

Backoff-GlattungWir berechnen relative Haufigkeiten, wobei von den positiven Haufigkeitenein kleiner Betrag δ (Discount) abgezogen wird:
r(w |c) =f (w , c)− δ∑w ′ f (w ′, c)
(Nullhaufigkeiten bleiben unverandert.)
Durch das Discounting wird Wahrscheinlichkeitsmasse frei, die uber alleWorter proportional zu einer Backoff-Verteilung p(w) verteilt wird:
p(w |c) = r(w |c) + α(c)p(w)
Der Backoff-Faktor α(c) wird so definiert, dass∑
w p(w |c) = 1:
α(c) = 1−∑w ′
r(w ′|c)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 69 / 172

Discount
Nach Kneser/Essen/Ney kann der Discount folgendermaßen definiertwerden:
δ =N1
N1 + 2N2
N1 ist die Zahl der Paare (w,c) mit f (w , c) = 1N2 ist die Zahl der Paare (w,c) mit f (w , c) = 2
Wie wird die Backoff-Wahrscheinlichkeitsverteilung p(w) definiert?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 70 / 172

Backoff-Verteilung
Als Backoff-Verteilung nehmen wir die Apriori-Wahrscheinlichkeiten derWorter
p(w) =f (w)∑w ′ f (w ′)
mit f (w) =∑
c f (w , c)
→ Aufgabe 3
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 71 / 172

Nachteile von Naıve Bayes
Worter sind nicht immer statistisch unabhangigI Beispiel: Wenn ein Text das Wort Francisco enthalt, enthalt er meist
auch das Wort San. Daher
p(San Francisco|c) 6= p(San|c) p(Francisco|c)
sondern eher
p(San Francisco|c) ≈ p(Francisco|c)
Es ist schwierig, beliebige weitere Merkmale in das Modell zuintegrieren z.B.
I WortprafixeI ob ein Wort in einem Sentiment-Lexikon enthalten istI an welcher Position im Artikel sich ein Wort befindet
→ Diskriminative Modelle vermeiden diese Probleme
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 72 / 172

Nachteile von Naıve Bayes
Worter sind nicht immer statistisch unabhangigI Beispiel: Wenn ein Text das Wort Francisco enthalt, enthalt er meist
auch das Wort San. Daher
p(San Francisco|c) 6= p(San|c) p(Francisco|c)
sondern eher
p(San Francisco|c) ≈ p(Francisco|c)
Es ist schwierig, beliebige weitere Merkmale in das Modell zuintegrieren z.B.
I WortprafixeI ob ein Wort in einem Sentiment-Lexikon enthalten istI an welcher Position im Artikel sich ein Wort befindet
→ Diskriminative Modelle vermeiden diese Probleme
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 72 / 172

Diskriminative Modelle
Generative Modelle (wie Naıve Bayes) definieren eine gemeinsameWahrscheinlichkeit von Klasse c und Dokument d:
p(c , d)
Diskriminative Modelle definieren eine bedingte Wahrscheinlichkeit vonKlasse c gegeben Dokument d:
p(c |d)
Beispiele von diskriminativen Modellen
Maximum-Entropy-Modelle
Conditional Random Fields
Oberbegriff: → log-lineare Modelle
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 73 / 172

Diskriminative Modelle
Generative Modelle (wie Naıve Bayes) definieren eine gemeinsameWahrscheinlichkeit von Klasse c und Dokument d:
p(c , d)
Diskriminative Modelle definieren eine bedingte Wahrscheinlichkeit vonKlasse c gegeben Dokument d:
p(c |d)
Beispiele von diskriminativen Modellen
Maximum-Entropy-Modelle
Conditional Random Fields
Oberbegriff: → log-lineare Modelle
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 73 / 172

Log-lineare Modelle
1
3
2,5
7
* 2,5 = 2,5
* 5,1 = 15,3
Text Merkmale Gewichte Summe Wk
28,95
* −1,7 = 11,9
* −0,3 = −0,75
0,92
Grundidee:
Manuell erstellte Merkmalsfunktionen extrahieren relevanteInformation aus dem Dokument.
Jeder Merkmalswert wird mit einem Gewicht multipliziert, dasausdruckt, ob das Merkmal auf eine bestimmte Klasse hindeutet.
Die gewichteten Merkmalswerte werden aufsummiert und inWahrscheinlichkeiten transformiert.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 74 / 172

Merkmale
Log-lineare Modelle definieren eine Menge von Merkmalsfunktionenf1(c , d), ..., fM(c , d)
binare Merkmale
f1(c , d) =
{1 falls Textlange ∈ [20, ..., 40) und c = negativ0 sonst
numerische Merkmale
f2(c , d) =
{n falls ,,toll” n-mal auftaucht und c = positiv0 falls c 6= positiv
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 75 / 172

Merkmale
Beispieltext:
Das ist ein spannender Film aber die Handlung des Filmes ist sehrklischeehaft.
extrahierte Merkmale (nach Stoppwortentfernung und Lemmatisierung)
Klasse: positiv
positiv, spannend 1positiv, Film 2positiv, Handlung 1positiv, klischeehaft 1
Klasse: negativ
negativ, spannend 1negativ, Film 2negativ, Handlung 1negativ, klischeehaft 1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 76 / 172

Gewichte
Jedem Merkmal fi (c, d) wird ein Gewicht θi zugeordnet
θi > 0: das Merkmal fi (c , d) deutet auf die Klasse c hin
θi < 0: das Merkmal fi (c , d) deutet auf eine andere Klasse als c hin
Die Gewichte sind bel. reelle Zahlen und entsprechen in ihrer Funktion den
logarithmierten Wahrscheinlichkeiten eines Naıve-Bayes-Modelles. Sie werden aber nicht
aus Haufigkeiten geschatzt, sondern anders gelernt.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 77 / 172

Lineare Klassifikatoren
Die Merkmale fi (c , d) und Gewichte θi werden multipliziert undaufsummiert:
score(c , d) =∑i
θi fi (c , d)
Die Werte konnen direkt zur Klassifikation verwendet werden (linearerKlassifikator)
c = arg maxc
score(c , d)
Wir wollen aber eine Wahrscheinlichkeitsverteilung definieren(also nicht-negative Werte, die zu 1 summieren)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 78 / 172

Log-Lineare Modelle
Die “Scores” sind beliebige reelle Zahlen.
Exponentiation liefert nicht-negative Werte:
escore(c,d) = e∑
i θi fi (c,d)
Normalisierung liefert Werte, die zu 1 summieren:
p(c |d) =1
Ze∑
i θi fi (c,d) mit Z =∑c ′
e∑
i θi fi (c′,d)
Ein solches Modell heißt log-lineares Modell.
Vektorschreibweise: p(c |d) = 1Z e
θ·f(c,d)
Die Gewichte werden durch Training auf Dokumenten mit bekannter Klassegelernt.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 79 / 172

Log-Lineare Modelle: Training
Ziel des Trainings: Die Modell-Wahrscheinlichkeit derTrainingsdaten soll moglichst groß werden.
Da die Summe der Wahrscheinlichkeiten konstant ist, mussen dieWahrscheinlichkeiten der nicht beobachteten Daten moglichst klein werden
Die Wahrscheinlichkeiten konnen nie 0 werden, da ex immer positiv ist.
→ Parameterglattung nicht notig
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 80 / 172

Log-Lineare Modelle: Training
Trainingsdaten: D = {(c1, d1), (c2, d2), ..., (cN , dN)}
Wir wollen den Gewichtsvektor θ finden, der die bedingteWahrscheinlichkeit (Likelihood) der korrekten Klassen maximiert:
θ = arg maxθ
∏(c,d)∈D
pθ(c |d)
Wir schreiben hier pθ(c|d), um zu verdeutlichen, dass die Wahrscheinlichkeit von den
Parametern θ abhangt. Man kann auch schreiben p(c|d , θ).
Statt der Wahrscheinlichkeit der Daten maximiert man meist derenLogarithmus (Log-Likelihood):
LLθ(D) =∑
(c,d)∈D
log pθ(c |d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 81 / 172

Log-Lineare Modelle: Training
Trainingsdaten: D = {(c1, d1), (c2, d2), ..., (cN , dN)}
Wir wollen den Gewichtsvektor θ finden, der die bedingteWahrscheinlichkeit (Likelihood) der korrekten Klassen maximiert:
θ = arg maxθ
∏(c,d)∈D
pθ(c |d)
Wir schreiben hier pθ(c|d), um zu verdeutlichen, dass die Wahrscheinlichkeit von den
Parametern θ abhangt. Man kann auch schreiben p(c|d , θ).
Statt der Wahrscheinlichkeit der Daten maximiert man meist derenLogarithmus (Log-Likelihood):
LLθ(D) =∑
(c,d)∈D
log pθ(c |d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 81 / 172

Log-Likelihood
Umformung des Ausdruckes:
LLθ(D) =∑
(c,d)∈D
log pθ(c |d)
=∑
(c,d)∈D
log
(1
Zθ(d)e∑m
i=1 θi fi (c,d)
)
=∑
(c,d)∈D
(log
1
Zθ(d)+ log e
∑mi=1 θi fi (c,d)
)
=∑
(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d)
Um das Maximum der Log-Likelihood in Abhangigkeit von den Parametern θj zufinden, setzen wir die partiellen Ableitungen nach θj gleich 0.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 82 / 172

Log-Likelihood
Umformung des Ausdruckes:
LLθ(D) =∑
(c,d)∈D
log pθ(c |d)
=∑
(c,d)∈D
log
(1
Zθ(d)e∑m
i=1 θi fi (c,d)
)
=∑
(c,d)∈D
(log
1
Zθ(d)+ log e
∑mi=1 θi fi (c,d)
)
=∑
(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d)
Um das Maximum der Log-Likelihood in Abhangigkeit von den Parametern θj zufinden, setzen wir die partiellen Ableitungen nach θj gleich 0.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 82 / 172

Log-Likelihood
Umformung des Ausdruckes:
LLθ(D) =∑
(c,d)∈D
log pθ(c |d)
=∑
(c,d)∈D
log
(1
Zθ(d)e∑m
i=1 θi fi (c,d)
)
=∑
(c,d)∈D
(log
1
Zθ(d)+ log e
∑mi=1 θi fi (c,d)
)
=∑
(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d)
Um das Maximum der Log-Likelihood in Abhangigkeit von den Parametern θj zufinden, setzen wir die partiellen Ableitungen nach θj gleich 0.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 82 / 172

Ableitung der Log-Likelihood nach θj
∂
∂θj
∑(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d) = 0
Ableitung des linken Ausdrucks:
∂
∂θj
m∑i=1
θi fi (c , d) = fj(c , d)
Ableitung des rechten Ausdrucks:
∂
∂θjlog Zθ(d) =
∂
∂θjlog
∑c′
e∑m
i=1 θi fi (c′,d)
=1∑
c′ e∑m
i=1 θi fi (c′,d)
(∑c′
e∑m
i=1 θi fi (c′,d)fj(c
′, d)
)=
∑c′
pθ(c ′|d) fj(c′, d)
= Epθ(c′|d) fj(c′, d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 83 / 172

Ableitung der Log-Likelihood nach θj
∂
∂θj
∑(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d) = 0
Ableitung des linken Ausdrucks:
∂
∂θj
m∑i=1
θi fi (c , d) = fj(c , d)
Ableitung des rechten Ausdrucks:
∂
∂θjlog Zθ(d) =
∂
∂θjlog
∑c′
e∑m
i=1 θi fi (c′,d)
=1∑
c′ e∑m
i=1 θi fi (c′,d)
(∑c′
e∑m
i=1 θi fi (c′,d)fj(c
′, d)
)=
∑c′
pθ(c ′|d) fj(c′, d)
= Epθ(c′|d) fj(c′, d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 83 / 172

Ableitung der Log-Likelihood nach θj
∂
∂θj
∑(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d) = 0
Ableitung des linken Ausdrucks:
∂
∂θj
m∑i=1
θi fi (c , d) = fj(c , d)
Ableitung des rechten Ausdrucks:
∂
∂θjlog Zθ(d) =
∂
∂θjlog
∑c′
e∑m
i=1 θi fi (c′,d)
=1∑
c′ e∑m
i=1 θi fi (c′,d)
(∑c′
e∑m
i=1 θi fi (c′,d)fj(c
′, d)
)=
∑c′
pθ(c ′|d) fj(c′, d)
= Epθ(c′|d) fj(c′, d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 83 / 172

Ableitung der Log-Likelihood nach θj
∂
∂θj
∑(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d) = 0
Ableitung des linken Ausdrucks:
∂
∂θj
m∑i=1
θi fi (c , d) = fj(c , d)
Ableitung des rechten Ausdrucks:
∂
∂θjlog Zθ(d) =
∂
∂θjlog
∑c′
e∑m
i=1 θi fi (c′,d)
=1∑
c′ e∑m
i=1 θi fi (c′,d)
(∑c′
e∑m
i=1 θi fi (c′,d)fj(c
′, d)
)=
∑c′
pθ(c ′|d) fj(c′, d)
= Epθ(c′|d) fj(c′, d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 83 / 172

Ableitung der Log-Likelihood nach θj
∂
∂θj
∑(c,d)∈D
m∑i=1
θi fi (c , d)−∑
(c,d)∈D
log Zθ(d) = 0
Ableitung des linken Ausdrucks:
∂
∂θj
m∑i=1
θi fi (c , d) = fj(c , d)
Ableitung des rechten Ausdrucks:
∂
∂θjlog Zθ(d) =
∂
∂θjlog
∑c′
e∑m
i=1 θi fi (c′,d)
=1∑
c′ e∑m
i=1 θi fi (c′,d)
(∑c′
e∑m
i=1 θi fi (c′,d)fj(c
′, d)
)=
∑c′
pθ(c ′|d) fj(c′, d)
= Epθ(c′|d) fj(c′, d)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 83 / 172

Log-Lineare Modelle
Zusammensetzen der Teilergebnisse:
∂LLθ(D)
∂θj=
∑(c,d)∈D
fj(c , d)−∑
(c,d)∈D
Epθ(c ′|d)fj(c′, d) = 0
∑(c,d)∈D
fj(c, d) =∑
(c,d)∈D
Epθ(c ′|d)fj(c′, d)
⇒ Die erwartete Haufigkeit jedes Merkmales muss gleich der beobachtetenHaufigkeit werden.
⇒ Die partielle Ableitung ist gleich der Differenz der beiden Haufigkeiten.
⇒ Der Gradient ∇LLθ(D) fasst alle partiellen Ableitungen zu einem Vektorzusammen.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 84 / 172

Training mit Gradientenanstieg
Um die Likelihood zu erhohen, mussen wir dieParameter in Richtung steigender Likelihoodverandern (Gradientenanstieg).
Algorithmus
initialize θfor N iterations do
θ ← θ + η∇LLθ(D)
aus Wikipedia
Die Lernrate η bestimmt, wie groß die einzelnen Schritte sind.
Wenn eine Funktion minimiert werden muss, spricht man von Gradientenabstieg.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 85 / 172

Varianten von Gradientenanstieg
(Batch-)GradientenanstiegI berechnet die Ableitung fur alle Daten zusammenI Anpassung der Gewichte nachdem alle Daten verarbeitet wurdenI konvergiert langsam
Stochastischer GradientenanstiegI berechnet die Ableitung einzeln fur jeden DatensatzI passt die Gewichte nach jedem Datensatz anI lernt schneller, aber konvergiert nicht
Minibatch-GradientenanstiegI berechnet die Ableitung fur eine bestimmte Zahl von DatensatzenI passt die Gewichte nach der Verarbeitung jedes solchen Minibatches anI Eigenschaften zwischen Batch GD und SGD je nach Minibatchgroße
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 86 / 172

Overfitting
Bei begrenzten Trainingsdaten besteht die Gefahr des Overfitting.
Beipiel: (falschlich als negativ klassifizierte Filmbewertung in Trainingsdaten)
Dieser Film ist unglaublich spannend. Die Hauptfigur Hugh Glass wird vonLeonardo DiCaprio gespielt.
Wenn das Wort Glass nur in dieser Rezension auftaucht, dann wird dasGewicht des Merkmals (Glass, negativ) im Training so lange erhoht, bis dieRezension als negativ klassifiziert wird.
Das Problem taucht nicht nur bei Annotationsfehlern in den Trainingsdaten auf,sondern auch dann, wenn die vorhandenen Merkmale nicht alle notwendigenInformationen reprasentieren.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 87 / 172

Regularisierung
Gegenmaßnahme:
Ziel-Funktion so modifizieren, dass große Gewichte ,,bestraft” werden:
LLθ(D)− µ
2
∑i
θ2i (L2-Regularisierung)
LLθ(D)− µ∑i
|θi | (L1-Regularisierung)
⇒ Große Gewichte sind nur erlaubt, wenn sie eine große Verbesserung derLikelihood bewirken.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 88 / 172

Regularisierung
neuer Trainingsalgorithmus
initialize θfor N iterations do
δ ←{µθ falls L2-Regularisierungµsign(θ) falls L1-Regularisierung
θ ← θ + η(∇LLθ(D)− δ)
weitere Regularisierungsmethode (kombinierbar)
Early Stopping: Optimale Zahl von Trainingsiterationen mit Heldout-Datenbestimmen
→ Aufgabe 4
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 89 / 172

Andere Lernalgorithmen
Neben Gradientenanstieg gibt es weitere Trainingsverfahren
generalized iterative scaling (nicht mehr oft genutzt)
conjugate gradient
L-BFGS (limited memory Broyden-Fletcher–Goldfarb-Shannon)(Batchverfahren, schnell konvergierend, erfordert viel Speicherplatz)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 90 / 172

Taggen mit log-linearen Modellen
Log-lineare Modelle konnen auch zum Wortart-Taggen verwendet werden.
Es gibt 2 Moglichkeiten, einen Wort-Tagger zu implementieren:
Jedes Tag wird unabhangig von allen anderen Tags zugewiesen
Pierre Vinken will join the board
PN PN MD VB DT NN
Problem: inkonsistente Ausgaben
Beispiel: Das ist die/Nom beste/Nom Losung/Akk ./$.
Alle Worter werden gemeinsam desambiguiert (analog HMMs)Dabei hangt jedes Tag vom vorherigen Tag ab.
Pierre Vinken will join the board
PN PN MD VB DT NN
→ (Linear Chain) Conditional Random Field
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 91 / 172

Conditional Random Field
Fur jede Wortposition wird eine Menge von Merkmalen extrahiert
1 lexikalische Merkmale (ohne Nachbartag-Information)Wort+Tag, Wortsuffix+Tag, Wort”shape”+Tag, voriges Wort+Tag,
nachstes Wort+Wort+Tag, Wort+Tag im Lexikon
2 Kontext-Merkmale (mit Nachbartag-Information)voriges Tag+Tag, letzte2Tags+Tag, voriges Tag+Wort+Tag
Die Merkmale fk werden mit Gewichten θk multipliziert und uber allePositionen aufsummiert.
p(tn1 |wn1 ) =
1
Z (wn1 )
e∑n+1
i=1
∑k θk fk (t ii−m,w
n1 ,i)
m: Zahl der Vorgangertags, von denen das nachste Tag abhangt
i iteriert bis n + 1, weil ein Satzende-Tag 〈s〉 hinzugefugt wird.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 92 / 172

Conditional Random Fields
Pierre Vinken will join the board
PN PN MD VB DT NN
Jedes Tag darf abhangen von
beliebigen Wortern (einfaches log-lineares Modell)
zusatzlich vom letzten Tag (LC-CRF 1. Ordnung)
zusatzlich vom vorletzten Tag (LC-CRF 2. Ordnung)
wichtig: Bei einem LC-CRF sind Algorithmen der dynamischenProgrammierung anwendbar (Viterbi, Forward-Backward)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 93 / 172

Conditional Random FieldsBezug zu Hidden-Markow-Modellen
tn1 = arg maxtn1
p(tn1 |wn1 ) = arg max
tn1
1
Z (wn1 )
e∑n+1
i=1
∑k θk fk (t ii−m,w
n1 ,i)
= arg maxtn1
e∑n+1
i=1
∑k θk fk (t ii−m,w
n1 ,i) Normalisierungskonstante ignorieren
= arg maxtn1
n+1∏i=1
e∑
k θk fk (t ii−m,wn1 ,i)
= arg maxtn1
n+1∏i=1
e∑
k θLk f
Lk (ti ,w
n1 ,i)︸ ︷︷ ︸
lexikalische Merkmale
e∑
k θCk f
Ck (t ii−m,w
n1 ,i)︸ ︷︷ ︸
Kontextmerkmale
Formel ahnelt der HMM-Formel
Taggen mit dem Viterbi-Algorithmus (analog HMMs)∏i e
∑k ... kann durch
∑i
∑k ... ersetzt werden (log. Darstellung)
→ Aufgabe 5Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 94 / 172

Viterbi-Algorithmus (Bigramm-Tagger)
berechnet die beste Tagfolge (hier mit logarithmierten Viterbiwahrsch.)
lokaler Score: s(t ′, t,wn1 , i) :=
∑k θk fk(t ′, t,wn
1 , i)
1. Initialisierung: δt(0) =
{0 falls t = 〈s〉−inf sonst
2. Berechnung: δt(k) = maxt′
δt′(k − 1) + s(t ′, t,wn1 , i)
ψt(k) = arg maxt′
δt′(k − 1) + s(t ′, t,wn1 , i)
3. Ausgabe tn+1 = 〈s〉tk−1 = ψtk (k)
t und t′ sind Tags, k ist eine Wortposition, δt(k) ein Viterbiwert und ψt(k) das beste
Vorgangertag.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 95 / 172

Training von Conditional Random Fields
Fur das Training mit Gradientenanstieg werden die erwartetenMerkmalshaufigkeiten benotigt.
I Wie bei den HMMs werden diese mit demForward-Backward-Algorithmus berechnet.
I Hier wird er aber fur uberwachtes Training eingesetzt.
Die erwarteten Haufigkeiten werden von den beobachtetenHaufigkeiten in den Trainingsdaten subtrahiert, um den Gradienten zuerhalten.
Der Gradient wird mit der Lernrate multipliziert und zumGewichtsvektor addiert. (Gradientenabstieg)
Diese Schritte werden N-mal wiederholt.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 96 / 172

Training von Conditional Random Fields
p(tn1 |wn1 ) =
1
Z (wn1 )
n+1∏i=1
e∑
k θk fk (t ii−m,wn1 ,i)
Zur Berechnung der erwarteten Merkmalshaufigkeiten eines lex. Merkmalsmuss berechnet werden:∑
Wk. aller Tagfolgen mit Tag t an Position i∑Wk. aller Tagfolgen insgesamt
Die Normalisierungskonstanten Z (wn1 ) konnen im Zahler und Nenner
aus der Summe ausgeklammert und gekurzt werden.
Die Summe im Zahler wird als Produkt von Forward- undBackward-Wahrscheinlichkeiten berechnet.
Die Summe im Nenner (ohne Normalisierungskonstante) ist gleichdem Wert der Forward-Funktion fur das Satzende-Tag.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 97 / 172

Conditional Random Fields
z(t ′, t,wn1 , i) := es(t′,t,wn
1 ,i) = e∑
k θk fk (t′,t,wn1 ,i)
Training mit Forward-Backward-Algorithmus (Modell 1. Ordnung)
α<s>(0) = 1
αt(i) =∑t′
αt′(i − 1) z(t ′, t,wn1 , i)
β<s>(n + 1) = 1
βt(i − 1) =∑t′
βt′(i) z(t, t ′,wn1 , i)
γt(i) =αt(i) βt(i)
α<s>(n + 1)
γtt′(i) =αt(i − 1) z(t, t ′,wn
1 , i) βt′(i)
α<s>(n + 1)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 98 / 172

LC-CRFs
Hauptaufgabe bei der Entwicklung von LC-CRFs
gute Merkmale finden
→ “Feature Engineering”, linguistische Intuition hilfreich
optimale Kombination der Merkmale bestimmen
weniger wichtig bei gut funktionierender Regularisierung
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 99 / 172

Evaluierung
Die Evaluierung eines Wortart-Taggers erfordert ein manuell
annotiertes Testkorpus, das nicht Teil der Trainingsdaten war.
1 Training des Taggers auf den Trainingsdaten
2 Taggen der Wortfolge des Testkorpus mit dem Tagger
3 Vergleich der Taggerausgabe mit den Tags im Korpus
4 Genauigkeit = #korrekte Tags / #Worter
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 100 / 172

Signifikanztest
Beim Vergleich eines verbesserten Taggers mit einem existierenden ist eswichtig zu wissen, ob die Verbesserung der Genauigkeit signifikant ist.
⇒ Statistischer Test
Angenommen
Bei 100 Wortern lag genau einer der Tagger richtig
Bei 60 dieser Worter lag der neue Tagger richtig
Bei 40 dieser Worter lag der alte Tagger richtig
Nullhypothese: Der neue Tagger ist nicht besser als der alte Tagger
Dies ist ein einseitiger Binomialtest. Wir berechnen:
b(≥ 60, 100, 0.5) ≈ 0.03
⇒ Der Unterschied ist signifikant (< 0.05).
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 101 / 172

Optimierung der Metaparameter
datenTestdatenTrainingsdaten
Entwicklungs
Der CRF-Tagger hat eine Reihe von Metaparametern (Liste derMerkmale, Lernrate, Regularisierung, Zahl der Trainingsiterationen), diebeliebig gewahlt werden konnen.
Um gute Werte auszuwahlen, kann die Genauigkeit des Taggers fur dieeinzelnen Parameterwerte auf Testdaten evaluiert werden, die aber nichtmit den Testdaten fur die eigentliche Evaluierung identisch sein durfen.
Solche Daten fur die Parameter-Optimierung nennt manEntwicklungsdaten (Developmentdaten).
In der Regel braucht man fur Experimente in der ComputerlinguistikTrainingsdaten, Developmentdaten und Testdaten.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 102 / 172

Lernen von Reprasentationen
Eine gute Menge von Merkmalen zu finden ist sehr zeitaufwendig.
Die gefundene Menge ist selten optimal.
Die Arbeit muss neu gemacht werden,wenn sich die Aufgabe andert.
Konnte man die Merkmale automatisch lernen?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 103 / 172
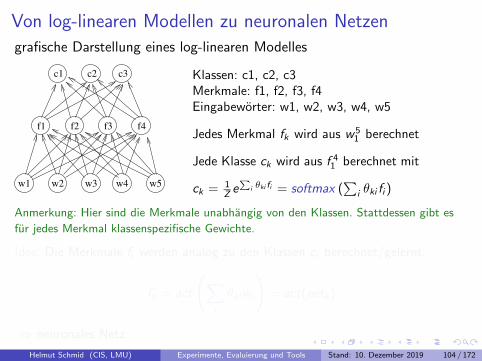
Von log-linearen Modellen zu neuronalen Netzen
grafische Darstellung eines log-linearen Modelles
c1 c2 c3
f1 f2 f3 f4
w2 w3 w4 w5w1
Klassen: c1, c2, c3Merkmale: f1, f2, f3, f4Eingabeworter: w1, w2, w3, w4, w5
Jedes Merkmal fk wird aus w51 berechnet
Jede Klasse ck wird aus f 41 berechnet mit
ck = 1Z e
∑i θki fi = softmax (
∑i θki fi )
Anmerkung: Hier sind die Merkmale unabhangig von den Klassen. Stattdessen gibt es
fur jedes Merkmal klassenspezifische Gewichte.
Idee: Die Merkmale fi werden analog zu den Klassen ci berechnet/gelernt:
fk = act
(∑i
θkiwi
)= act(netk)
⇒ neuronales Netz
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 104 / 172
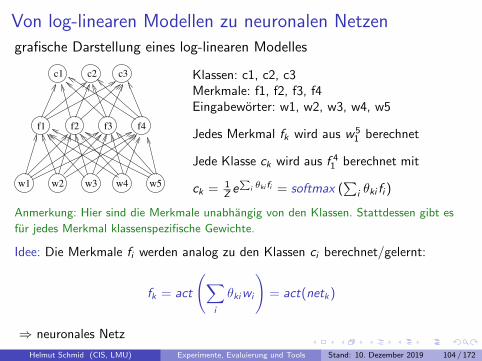
Von log-linearen Modellen zu neuronalen Netzen
grafische Darstellung eines log-linearen Modelles
c1 c2 c3
f1 f2 f3 f4
w2 w3 w4 w5w1
Klassen: c1, c2, c3Merkmale: f1, f2, f3, f4Eingabeworter: w1, w2, w3, w4, w5
Jedes Merkmal fk wird aus w51 berechnet
Jede Klasse ck wird aus f 41 berechnet mit
ck = 1Z e
∑i θki fi = softmax (
∑i θki fi )
Anmerkung: Hier sind die Merkmale unabhangig von den Klassen. Stattdessen gibt es
fur jedes Merkmal klassenspezifische Gewichte.
Idee: Die Merkmale fi werden analog zu den Klassen ci berechnet/gelernt:
fk = act
(∑i
θkiwi
)= act(netk)
⇒ neuronales Netz
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 104 / 172

Embeddings
fk = act
(∑i
θkiwi
)
Die Eingabe wi muss eine numerische Reprasentation des Wortes sein.
Moglichkeiten
1 binarer Vektor (1-hot-Reprasentation)I Beispiel: whot
i = (0 0 0 0 0 0 0 0 1 0 0 0 0 0)I Dimension = Vokabulargroße⇒ Alle Worter sind sich gleich ahnlich/unahnlich
2 reeller Vektor (verteilte Reprasentation, distributed representation)I Beispiel: wdist
i = (3.275, -7.295, 0.174, 5.7332)I Vektorlange beliebig wahlbarI Ziel: Ahnliche Worter durch ahnliche Vektoren reprasentieren
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 105 / 172

Embeddings
fk = act
(∑i
θkiwi
)
Die Eingabe wi muss eine numerische Reprasentation des Wortes sein.
Moglichkeiten
1 binarer Vektor (1-hot-Reprasentation)I Beispiel: whot
i = (0 0 0 0 0 0 0 0 1 0 0 0 0 0)I Dimension = Vokabulargroße⇒ Alle Worter sind sich gleich ahnlich/unahnlich
2 reeller Vektor (verteilte Reprasentation, distributed representation)I Beispiel: wdist
i = (3.275, -7.295, 0.174, 5.7332)I Vektorlange beliebig wahlbarI Ziel: Ahnliche Worter durch ahnliche Vektoren reprasentieren
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 105 / 172

Embeddings
fk = act
(∑i
θkiwi
)
Die Eingabe wi muss eine numerische Reprasentation des Wortes sein.
Moglichkeiten
1 binarer Vektor (1-hot-Reprasentation)I Beispiel: whot
i = (0 0 0 0 0 0 0 0 1 0 0 0 0 0)I Dimension = Vokabulargroße⇒ Alle Worter sind sich gleich ahnlich/unahnlich
2 reeller Vektor (verteilte Reprasentation, distributed representation)I Beispiel: wdist
i = (3.275, -7.295, 0.174, 5.7332)I Vektorlange beliebig wahlbarI Ziel: Ahnliche Worter durch ahnliche Vektoren reprasentieren
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 105 / 172

Embeddings
Wir konnen die 1-hot-Reprasentation in einem neuronalen Netz auf dieverteilte Reprasentation (Embedding) abbilden:
w2 w3 w4 w5w1 1−hot
Embedding
Da nur ein 1-hot-Neuron den Wert 1 und alle anderen den Wert 0 haben,ist die verteilte Reprasentation identisch zu den Gewichten des aktivenNeurons. (Die Aktivierungsfunktion ist hier die Identitat act(x) = x)
Die Embeddings werden dann ebenfalls im Training gelernt.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 106 / 172
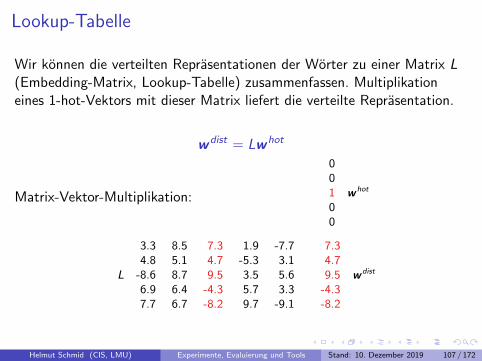
Lookup-Tabelle
Wir konnen die verteilten Reprasentationen der Worter zu einer Matrix L(Embedding-Matrix, Lookup-Tabelle) zusammenfassen. Multiplikationeines 1-hot-Vektors mit dieser Matrix liefert die verteilte Reprasentation.
wdist = Lwhot
Matrix-Vektor-Multiplikation:
00100
w hot
L
3.3 8.5 7.3 1.9 -7.74.8 5.1 4.7 -5.3 3.1
-8.6 8.7 9.5 3.5 5.66.9 6.4 -4.3 5.7 3.37.7 6.7 -8.2 9.7 -9.1
7.34.79.5
-4.3-8.2
w dist
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 107 / 172

Aktivierungsfunktionen
Neuron: fk = act
(∑i
θkiwi
)= act(netk)
In der Ausgabeebene eines neuronalen Netzes wird (wie bei log-linearenModellen) oft die Softmax-Aktivierungsfunktion verwendet.
ck = softmax(netk) =1
Zenetk mit Z =
∑k ′
enetk′
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 108 / 172

Spezialfall: 2 Klassen
SoftMax: ck =1
Zenetk mit netk =
∑i
θki fi = θTk f = θk · f
Im Falle von zwei Klassen c1 und c2 ergibt sich:
c1 =eθ1·f
eθ1·f + eθ2·fe−θ1·f
e−θ1·f
=1
1 + e−(θ1−θ2)·f
Nach einer Umparametrisierung erhalten wir die Sigmoid-Funktion
c1 =1
1 + e−θfmit θ = θ1 − θ2
c2 = 1− c1
⇒ Bei 2-Klassen-Problemen genugt ein Neuron.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 109 / 172
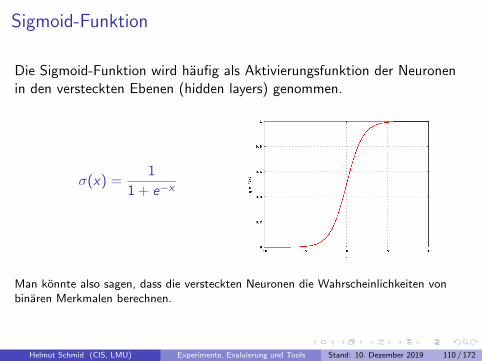
Sigmoid-Funktion
Die Sigmoid-Funktion wird haufig als Aktivierungsfunktion der Neuronenin den versteckten Ebenen (hidden layers) genommen.
σ(x) =1
1 + e−x
Man konnte also sagen, dass die versteckten Neuronen die Wahrscheinlichkeiten vonbinaren Merkmalen berechnen.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 110 / 172
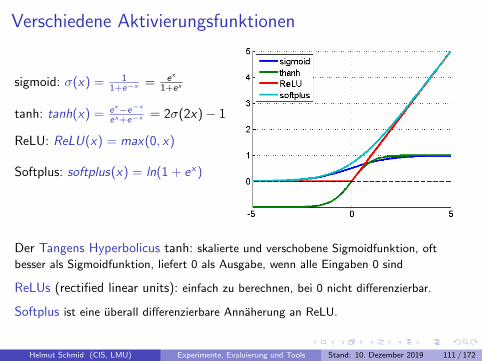
Verschiedene Aktivierungsfunktionen
sigmoid: σ(x) = 11+e−x = ex
1+ex
tanh: tanh(x) = ex−e−x
ex+e−x = 2σ(2x)− 1
ReLU: ReLU(x) = max(0, x)
Softplus: softplus(x) = ln(1 + ex)
Der Tangens Hyperbolicus tanh: skalierte und verschobene Sigmoidfunktion, oft
besser als Sigmoidfunktion, liefert 0 als Ausgabe, wenn alle Eingaben 0 sind
ReLUs (rectified linear units): einfach zu berechnen, bei 0 nicht differenzierbar.
Softplus ist eine uberall differenzierbare Annaherung an ReLU.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 111 / 172
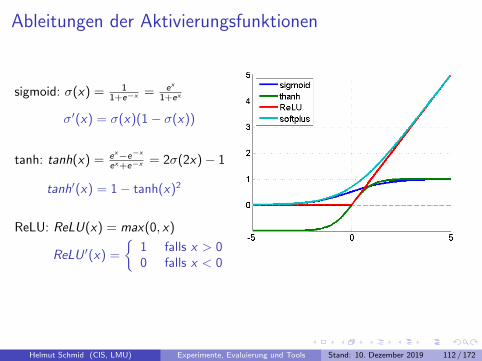
Ableitungen der Aktivierungsfunktionen
sigmoid: σ(x) = 11+e−x = ex
1+ex
σ′(x) = σ(x)(1− σ(x))
tanh: tanh(x) = ex−e−x
ex+e−x = 2σ(2x)− 1
tanh′(x) = 1− tanh(x)2
ReLU: ReLU(x) = max(0, x)
ReLU ′(x) =
{1 falls x > 00 falls x < 0
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 112 / 172

Warum ist die Aktivierungsfunktion wichtig?
Ohne (bzw. mit linearer) Aktivierungsfunktion gilt:
Jede Ebene eines neuronalen Netzes fuhrt eine lineare Transformationder Eingabe durch (= Multiplikation mit einer Matrix).
Eine Folge von linearen Transformationen kann immer durch eineeinzige lineare Transformation ersetzt werden.
⇒ Jedes mehrstufige neuronale Netz mit linearer Aktivierungsfunktionkann durch ein aquivalentes einstufiges Netz ersetzt werden.
⇒ Mehrstufige Netze machen also nur Sinn, wenn nicht-lineareAktivierungsfunktionen verwendet werden.Ausnahme: Embedding-Schicht mit gekoppelten Parametern
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 113 / 172

Neuronale Netze
Die Aktivierung ak eines Neurons ist gleich der Summeder gewichteten Eingaben ei moduliert durch eine Akti-vierungsfunktion act.
ak = act(∑i
wikei + bk)
Der zusatzliche Biasterm bk ermoglicht, dass bei einem Null-
vektor als Eingabe die Ausgabe nicht-null ist.
Vektorschreibweise ak = act(wk
Te + bk)
Matrixschreibweise a = act (W e + b)
wobei act elementweise angewendet wird:
act([z1, z2, z3]) = [act(z1), act(z2), act(z3)]
trainierbare Parameter: W ,b
f
Ausgabe
Summe
Eingaben
Aktivierungs−
funktion
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 114 / 172

Zielfunktionen
Die verwendeten Ausgabefunktionen und Zielfunktionen hangen von derAufgabe ab.
Regression: Ein Ausgabeneuron, welches einen Zahl liefertBeispiel: Vorhersage der Restlebenszeit eines Patienten in Abhangigkeit von
verschiedenen Faktoren wie Alter, Blutdruck, Rauch- und Essgewohnheiten,
Sportaktivitaten etc.
Aktivierungsfunktion der Ausgabeneuronen: act(x) = x (Identitat)Kostenfunktion: (y − o)2 quadrierter Abstand zwischen gewunschterAusgabe y und tatsachlicher Ausgabe o
Klassifikation: n mogliche disjunkte Ausgabeklassen reprasentiertdurch je ein AusgabeneuronBeispiel: Diagnose der Krankheit eines Patienten in Abhangigkeit von
Symptomen
Aktivierungsfunktion der Ausgabeneuronen: softmaxKostenfunktion: log(yTo) (Loglikelihood, Crossentropie)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 115 / 172

Zielfunktionen
Die verwendeten Ausgabefunktionen und Zielfunktionen hangen von derAufgabe ab.
Regression: Ein Ausgabeneuron, welches einen Zahl liefertBeispiel: Vorhersage der Restlebenszeit eines Patienten in Abhangigkeit von
verschiedenen Faktoren wie Alter, Blutdruck, Rauch- und Essgewohnheiten,
Sportaktivitaten etc.
Aktivierungsfunktion der Ausgabeneuronen: act(x) = x (Identitat)Kostenfunktion: (y − o)2 quadrierter Abstand zwischen gewunschterAusgabe y und tatsachlicher Ausgabe o
Klassifikation: n mogliche disjunkte Ausgabeklassen reprasentiertdurch je ein AusgabeneuronBeispiel: Diagnose der Krankheit eines Patienten in Abhangigkeit von
Symptomen
Aktivierungsfunktion der Ausgabeneuronen: softmaxKostenfunktion: log(yTo) (Loglikelihood, Crossentropie)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 115 / 172
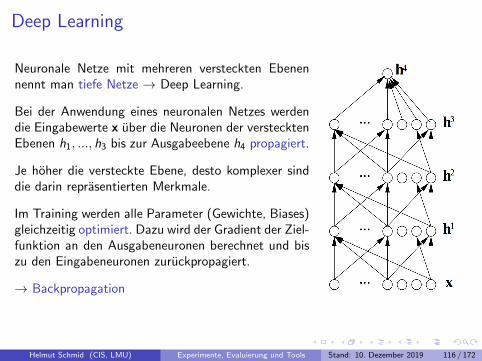
Deep Learning
Neuronale Netze mit mehreren versteckten Ebenennennt man tiefe Netze → Deep Learning.
Bei der Anwendung eines neuronalen Netzes werdendie Eingabewerte x uber die Neuronen der verstecktenEbenen h1, ..., h3 bis zur Ausgabeebene h4 propagiert.
Je hoher die versteckte Ebene, desto komplexer sinddie darin reprasentierten Merkmale.
Im Training werden alle Parameter (Gewichte, Biases)gleichzeitig optimiert. Dazu wird der Gradient der Ziel-funktion an den Ausgabeneuronen berechnet und biszu den Eingabeneuronen zuruckpropagiert.
→ Backpropagation
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 116 / 172

Neuronale Netze (Deep Learning)
Neuronale Netze (NN) sind keine neue Erfindung.Warum werden sie erst jetzt in großem Stil in derComputerlinguistik verwendet?
Schnellere Hardware erlaubt das Training großer NN
NN passen ideal zu aktuellen Hardware-Trends (Parallelisierung)
Die Grundoperation eines neuronalen Netzes ist die Multiplikation zweier großer
Matrizen → ideale Aufgabe fur GPUs (Grafikkarten)
NN profitieren von den großen Datenmengen, die verfugbar werden
Neue Netzarchitekturen (LSTMs, Highway Networks, Residual Networks)und Initialisierungsmethoden (Glorot-Initialisierung) ermoglichen dasTraining von tiefen und rekurrenten Netzen.
Neuronale Netze sind ideal fur einige scheinbar einfache Aufgaben, die MaschinenProbleme bereiten:
gehen, Objekte erkennen, gesprochene Sprache verstehen, radfahren usw.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 117 / 172
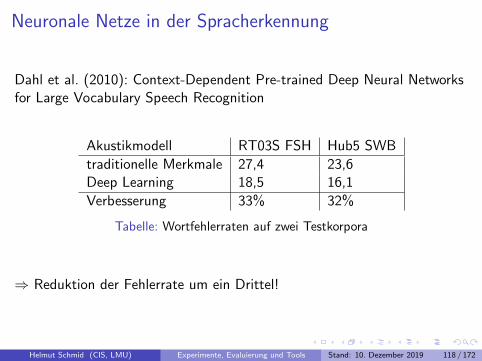
Neuronale Netze in der Spracherkennung
Dahl et al. (2010): Context-Dependent Pre-trained Deep Neural Networksfor Large Vocabulary Speech Recognition
Akustikmodell RT03S FSH Hub5 SWB
traditionelle Merkmale 27,4 23,6Deep Learning 18,5 16,1
Verbesserung 33% 32%
Tabelle: Wortfehlerraten auf zwei Testkorpora
⇒ Reduktion der Fehlerrate um ein Drittel!
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 118 / 172

Neuronale Netze in der Bilderkennung
Krizhevsky et al. (2012): ImageNet Classification with Deep ConvolutionalNeural Networks
Ebene 3: Gesichter
Ebene 2: Augen, Nasen, Munder
Ebene 1: einfache Kanten und Flachen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 119 / 172
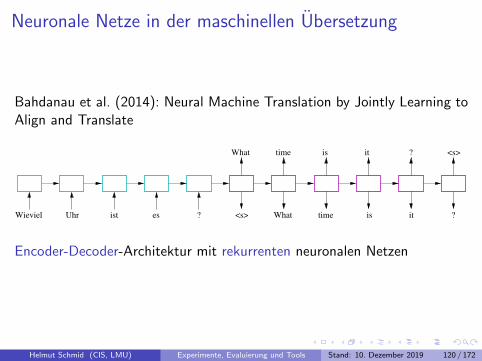
Neuronale Netze in der maschinellen Ubersetzung
Bahdanau et al. (2014): Neural Machine Translation by Jointly Learning toAlign and Translate
Uhr ist es ? <s> What time is it ?
<s>
Wieviel
What time is it ?
Encoder-Decoder-Architektur mit rekurrenten neuronalen Netzen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 120 / 172

Arbeitsweise eines neuronalen Netzes
Forward-Schritt: Die Aktivierung der Eingabeneuronen wird uber dieNeuronen der versteckten Ebenen zu den Neuronen der Ausgabeebenepropagiert.
Backward-Schritt: Im Training wird anschließend der Gradient einerzu optimierenden Zielfunktion an den Ausgabeneuronen berechnetund zu den Eingabeneuronen zuruckpropagiert.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 121 / 172

Forward-PropagationEin neuronales Netz mit Eingabevektor x , verstecktem Vektor h und skalaremAusgabewert o kann wie folgt definiert werden:
neth(x) = Whxx + bh
h(x) = tanh(neth)
= tanh(Whxx + bh)
neto(x) = Wohh + bo
= Woh tanh(Whxx + bh) + bo
o(x) = softmax(neto)
= softmax(Woh tanh(Whxx + bh) + bo)
o2
o1
o3
o4
h2 h3 h4h1
x1
x2
x3
x4
Who
xhW
Das Training maximiert die Log-Likelihood der Daten
LL(x , y) = log(yTo)
= log(yT softmax(Woh tanh(Whxx + bh) + bo))
y reprasentiert die gewunschte Ausgabe als 1-hot-Vektor
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 122 / 172

Backward-Propagation
Fur die Parameteroptimierung mussen die Ableitungen des Ausdruckes
LL(x , y) = log(yT softmax(Woh tanh(Whxx + bh) + bo))
bzgl.der Parameter Whx , bh, Woh und bo berechnet werden.
Am besten benutzt man dazu automatische Differentiation (z.B. in PyTorch).
anschließend Anpassung der Parameter θ mit Gradientenanstieg:
θt+1 = θt + η∇LLθt
Das Training mit Gradientenanstieg ist oft langsam.
Es gibt verschiedene Techniken, um es zu beschleunigen. →
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 123 / 172

Backward-Propagation
Fur die Parameteroptimierung mussen die Ableitungen des Ausdruckes
LL(x , y) = log(yT softmax(Woh tanh(Whxx + bh) + bo))
bzgl.der Parameter Whx , bh, Woh und bo berechnet werden.
Am besten benutzt man dazu automatische Differentiation (z.B. in PyTorch).
anschließend Anpassung der Parameter θ mit Gradientenanstieg:
θt+1 = θt + η∇LLθt
Das Training mit Gradientenanstieg ist oft langsam.
Es gibt verschiedene Techniken, um es zu beschleunigen. →
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 123 / 172

Backward-Propagation
Fur die Parameteroptimierung mussen die Ableitungen des Ausdruckes
LL(x , y) = log(yT softmax(Woh tanh(Whxx + bh) + bo))
bzgl.der Parameter Whx , bh, Woh und bo berechnet werden.
Am besten benutzt man dazu automatische Differentiation (z.B. in PyTorch).
anschließend Anpassung der Parameter θ mit Gradientenanstieg:
θt+1 = θt + η∇LLθt
Das Training mit Gradientenanstieg ist oft langsam.
Es gibt verschiedene Techniken, um es zu beschleunigen. →
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 123 / 172

Beschleunigung des Trainings
Momentum-Term
v t+1 = µv t + η∇LLθt mit 0 < µ < 1
θt+1 = θt + v t+1
Verbesserung: Nesterov’s Accelerated Gradient:
v t+1 = µv t + η∂LL(θt + µv t)
θt+1 = θt + v t+1
Da man sowieso im nachsten Schritt µvt zu θt addieren wird, ist es besser gleich
mit θt + µvt zu evaluieren.
Lernratenoptimierung:I Lernrate kleiner werden lassen, z.B. ηt = ηmax
11+δt
I gewichtspezifische Lernraten: Adagrad, RMSProp, Adadelta, Adam
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 124 / 172

Beschleunigung des Trainings
Momentum-Term
v t+1 = µv t + η∇LLθt mit 0 < µ < 1
θt+1 = θt + v t+1
Verbesserung: Nesterov’s Accelerated Gradient:
v t+1 = µv t + η∂LL(θt + µv t)
θt+1 = θt + v t+1
Da man sowieso im nachsten Schritt µvt zu θt addieren wird, ist es besser gleich
mit θt + µvt zu evaluieren.
Lernratenoptimierung:I Lernrate kleiner werden lassen, z.B. ηt = ηmax
11+δt
I gewichtspezifische Lernraten: Adagrad, RMSProp, Adadelta, Adam
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 124 / 172

Beschleunigung des Trainings
Momentum-Term
v t+1 = µv t + η∇LLθt mit 0 < µ < 1
θt+1 = θt + v t+1
Verbesserung: Nesterov’s Accelerated Gradient:
v t+1 = µv t + η∂LL(θt + µv t)
θt+1 = θt + v t+1
Da man sowieso im nachsten Schritt µvt zu θt addieren wird, ist es besser gleich
mit θt + µvt zu evaluieren.
Lernratenoptimierung:I Lernrate kleiner werden lassen, z.B. ηt = ηmax
11+δt
I gewichtspezifische Lernraten: Adagrad, RMSProp, Adadelta, Adam
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 124 / 172

Vor- und Nachteile von NN
+ kein Feature Engineering notwendig
+ gute Ergebnisse ohne lange Entwicklungszeiten
+ geringer Speicherplatzbedarf
− Blackbox: schwer zu analysieren, wie ein Ergebnis zustandekam
− Training ist sehr rechenintensivLosung: Parallelisierung auf Mehrprozessorsystemen (vor allem GPUs)
− Es gibt sehr viel Metaparameter, an denen man herumschrauben kannArchitektur, Zahl der Neuronen/Ebenen, Aktivierungsfunktion, Initialisierung,
Lernrate usw.
In der maschinellen Sprachverarbeitung sind neuronale Netze dabei,andere Lernverfahren in vielen Bereichen zu verdrangen.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 125 / 172
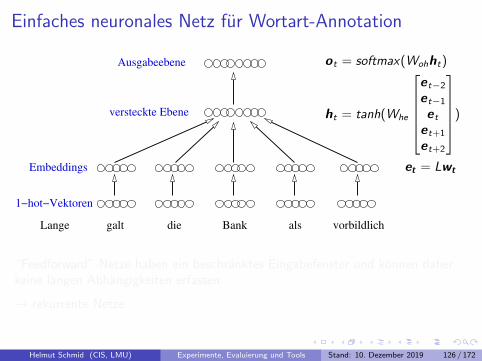
Einfaches neuronales Netz fur Wortart-Annotation
Lange galt vorbildlichBank alsdie
Ausgabeebene
versteckte Ebene
Embeddings
1−hot−Vektoren
ot = softmax(Wohht)
ht = tanh(Whe
et−2
et−1
et
et+1
et+2
)
et = Lwt
“Feedforward”-Netze haben ein beschranktes Eingabefenster und konnen daherkeine langen Abhangigkeiten erfassen.
→ rekurrente Netze
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 126 / 172
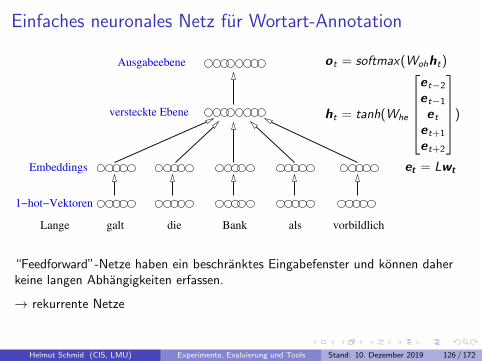
Einfaches neuronales Netz fur Wortart-Annotation
Lange galt vorbildlichBank alsdie
Ausgabeebene
versteckte Ebene
Embeddings
1−hot−Vektoren
ot = softmax(Wohht)
ht = tanh(Whe
et−2
et−1
et
et+1
et+2
)
et = Lwt
“Feedforward”-Netze haben ein beschranktes Eingabefenster und konnen daherkeine langen Abhangigkeiten erfassen.
→ rekurrente Netze
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 126 / 172
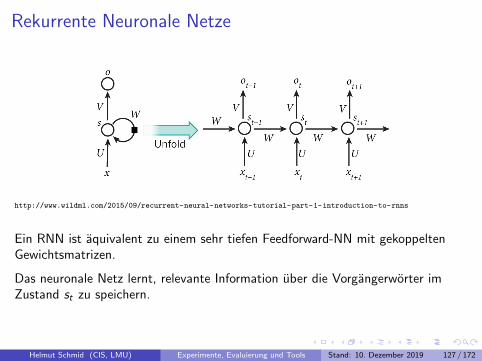
Rekurrente Neuronale Netze
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns
Ein RNN ist aquivalent zu einem sehr tiefen Feedforward-NN mit gekoppeltenGewichtsmatrizen.
Das neuronale Netz lernt, relevante Information uber die Vorgangerworter imZustand st zu speichern.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 127 / 172
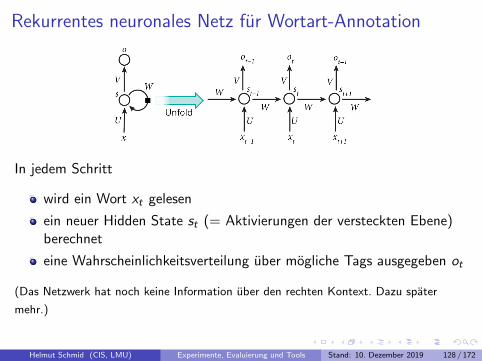
Rekurrentes neuronales Netz fur Wortart-Annotation
In jedem Schritt
wird ein Wort xt gelesen
ein neuer Hidden State st (= Aktivierungen der versteckten Ebene)berechnet
eine Wahrscheinlichkeitsverteilung uber mogliche Tags ausgegeben ot
(Das Netzwerk hat noch keine Information uber den rechten Kontext. Dazu spater
mehr.)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 128 / 172

Backpropagation Through Time (BPTT)
Zum Trainieren wird das rekurrente Netz zu einem Feedforward-Netzaufgefaltet
Der Gradient wird von den Ausgabeneuronen ot zu den verstecktenNeuronen st und von dort weiter zu den Eingabeneuronen xt und denvorherigen versteckten Neuronen st−1 propagiert (Backpropagation throughtime)
An den versteckten Neuronen werden zwei Gradienten addiert.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 129 / 172
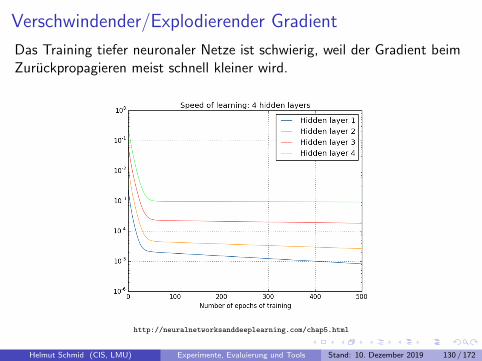
Verschwindender/Explodierender Gradient
Das Training tiefer neuronaler Netze ist schwierig, weil der Gradient beimZuruckpropagieren meist schnell kleiner wird.
http://neuralnetworksanddeeplearning.com/chap5.html
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 130 / 172

Verschwindender/Explodierender Gradient
Warum wird der Gradient exponentiell kleiner mit der Zahl der Ebenen?
Betrachten wir ein neuronales Netz mit 5 Ebenen und einem Neuron pro Ebene
http://neuralnetworksanddeeplearning.com/chap5.html
wi ist ein Gewicht, bi ein Bias, C die Kostenfunktion, ai die Aktivierung eines Neurons
und zi die gewichtete Eingabe eines Neurons
Der Gradient wird in jeder Ebene mit dem Ausdruck wi × σ′(zi ) multipliziert.
Wie groß ist dieser Ausdruck?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 131 / 172
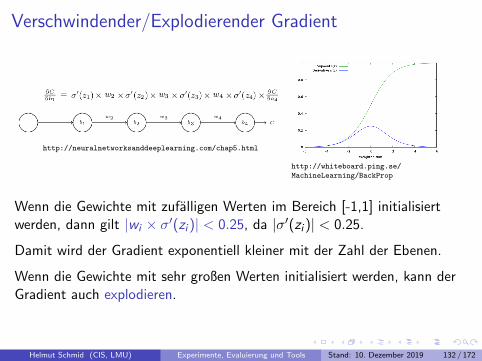
Verschwindender/Explodierender Gradient
http://neuralnetworksanddeeplearning.com/chap5.html
http://whiteboard.ping.se/
MachineLearning/BackProp
Wenn die Gewichte mit zufalligen Werten im Bereich [-1,1] initialisiertwerden, dann gilt |wi × σ′(zi )| < 0.25, da |σ′(zi )| < 0.25.
Damit wird der Gradient exponentiell kleiner mit der Zahl der Ebenen.
Wenn die Gewichte mit sehr großen Werten initialisiert werden, kann derGradient auch explodieren.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 132 / 172

Long Short Term Memory
entwickelt von Sepp Hochreiter und Jurgen Schmidhuber (TUM)
lost das Problem der instabilen Gradienten fur rekurrente Netze
Eine Speicherzelle (cell) bewahrt den Wert des letzten Zeitschritts
Der Gradient wird beim Zuruckpropagieren nicht mehr mit Gewichtenmultipliziert und bleibt uber viele Zeitschritte erhalten
cell1
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 133 / 172
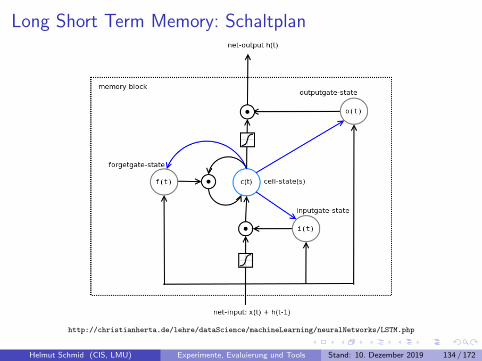
Long Short Term Memory: Schaltplan
http://christianherta.de/lehre/dataScience/machineLearning/neuralNetworks/LSTM.php
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 134 / 172

Long Short Term Memory
Berechnung eines LSTMs (ohne Peephole-Verbindungen)
zt = tanh(Wzxt + Rzht−1 + bz) (input activation)
it = σ(Wixt + Riht−1 + bi ) (input gate)
ft = σ(Wf xt + Rf ht−1 + bf ) (forget gate)
ot = σ(Wxxt + Roht−1 + bo) (output gate)
ct = ft � ct−1 + it � zt (cell)
ht = ot � tanh(ct) (output activation)
mit a� b = (a1b1, a2b2, ..., anbn)
Die LSTM-Zellen ersetzen einfache normale Neuronen in rekurrenten Netzen.
Man schreibt kurz:z = LSTM(x)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 135 / 172

Long Short Term Memory
Vorteile
lost das Problem mit instabilen Gradienten
exzellente Ergebnisse in vielen Einsatzbereichen
Nachteile
deutlich komplexer als ein normales Neuron
hoherer Rechenzeitbedarf
Alternative
Gated recurrent Units (GRU) (Cho et al.)
etwas einfacher (nur 2 Gates)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 136 / 172

Gated Recurrent Units
http://image.slidesharecdn.com/2016-clipping-lstm-gru-urnn2851-160727133046/95/
2016-clipping-lstm-gru-urnn-12-638.jpg
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 137 / 172
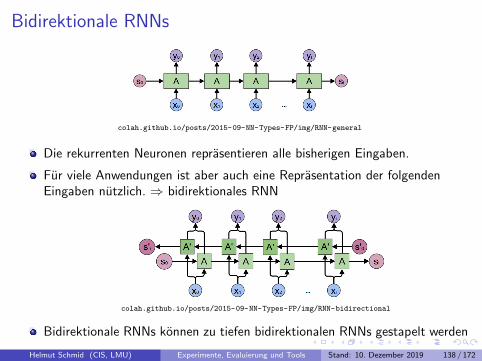
Bidirektionale RNNs
colah.github.io/posts/2015-09-NN-Types-FP/img/RNN-general
Die rekurrenten Neuronen reprasentieren alle bisherigen Eingaben.
Fur viele Anwendungen ist aber auch eine Reprasentation der folgendenEingaben nutzlich. ⇒ bidirektionales RNN
colah.github.io/posts/2015-09-NN-Types-FP/img/RNN-bidirectional
Bidirektionale RNNs konnen zu tiefen bidirektionalen RNNs gestapelt werden
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 138 / 172
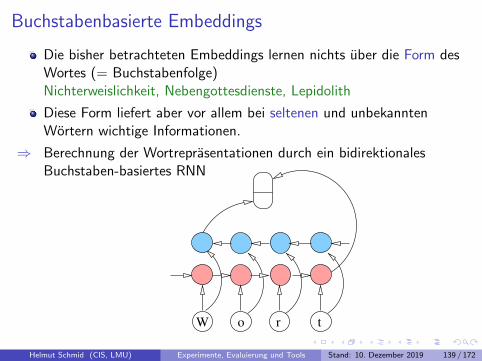
Buchstabenbasierte Embeddings
Die bisher betrachteten Embeddings lernen nichts uber die Form desWortes (= Buchstabenfolge)Nichterweislichkeit, Nebengottesdienste, Lepidolith
Diese Form liefert aber vor allem bei seltenen und unbekanntenWortern wichtige Informationen.
⇒ Berechnung der Wortreprasentationen durch ein bidirektionalesBuchstaben-basiertes RNN
o tW r
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 139 / 172

Programmierung von neuronalen Netzen
Verbreitete Frameworks
Theano + Python (Universitat Montreal)
Tensorflow + Python (Google)
Keras (nutzt Theano oder Tensorflow als Backend)
Torch + Lua (IDIAP)
PyTorch + Python (Facebook)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 140 / 172

Programmierung von neuronalen Netzen
PyTorch
Python-Bibliothek fur neuronale Netze und andere komplexemathematische Funktionen
Syntax ahnelt Numpy
automatisches Differenzieren von Funktionen (→ NN-Training)
GPU-Unterstutzung
Vorteile gegenuber Theano/Tensorflow/KerasI PyTorch-Befehle werden sofort ausgefuhrt
(ohne erst einen Berechnungsgraphen erstellen zu mussen)I normale ProgrammierungI einfaches Debugging
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 141 / 172

Numpy
Python-Bibliothek fur numerische Aufgaben
Datentypen: Skalare, Vektoren, Matrizen und Tensoren
viele Operatoren (z.B. Matrizenprodukte)
effiziente C-Implementierungen der Operatoren
Numpy+SciPy+Matplotlib kann MATLAB ersetzen
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 142 / 172
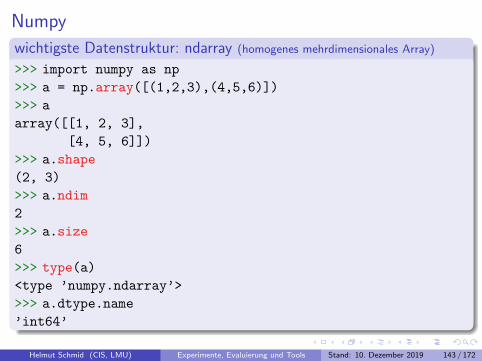
Numpy
wichtigste Datenstruktur: ndarray (homogenes mehrdimensionales Array)
>>> import numpy as np
>>> a = np.array([(1,2,3),(4,5,6)])
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> a.shape
(2, 3)
>>> a.ndim
2
>>> a.size
6
>>> type(a)
<type ’numpy.ndarray’>
>>> a.dtype.name
’int64’
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 143 / 172
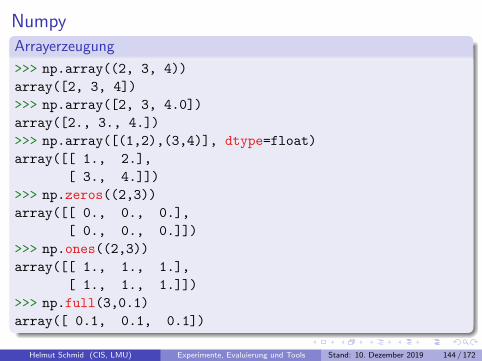
NumpyArrayerzeugung
>>> np.array((2, 3, 4))
array([2, 3, 4])
>>> np.array([2, 3, 4.0])
array([2., 3., 4.])
>>> np.array([(1,2),(3,4)], dtype=float)
array([[ 1., 2.],
[ 3., 4.]])
>>> np.zeros((2,3))
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> np.ones((2,3))
array([[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> np.full(3,0.1)
array([ 0.1, 0.1, 0.1])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 144 / 172

Numpy
Zahlenfolgen
>>> np.arange(3)
array([0, 1, 2])
>>> np.arange(3.0)
array([0., 1., 2.])
>>> np.arange(3,0,-1)
array([3, 2, 1])
>>> np.arange(3,0,-.9)
array([ 3., 2.1, 1.2, 0.3])
>>> np.arange(6).reshape(2,3)
array([[0, 1, 2],
[3, 4, 5]])
>>> np.linspace(0,2,9)
array([ 0., 0.25, 0.5, 0.75, 1., 1.25, 1.5, 1.75, 2. ])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 145 / 172

Numpy
Arrayerzeugung (Cont’d)
>>> a = np.arange(6).reshape(2,3)
>>> a
array([[0, 1, 2],
[3, 4, 5]])
>>> b = np.ones_like(a, dtype=float)
>>> b
array([[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> np.identity(3)
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 146 / 172

Numpy
Arithmetische Operationen
>>> a = np.array([20,30,40,50])
>>> b = np.arange( 4 )
>>> b-2
array([20, 29, 38, 47])
>>> a*b
array([ 0, 30, 80, 150])
>>> b**2
array([0, 1, 4, 9])
>>> 10 * np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a<35
array([ True, True, False, False], dtype=bool)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 147 / 172

Numpy
Matrix-Operationen>>> a
array([20, 30, 40, 50])
>>> b
array([0, 1, 2, 3])
>>> a.dot(b)
260
>>> M = np.arange(8).reshape(2,4)
>>> M
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> M.dot(a)
array([260, 820])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 148 / 172

Numpy
Matrix-Operationen
>>> a.dot(M)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: objects are not aligned
>>> M.transpose() // = M.T
array([[0, 4],
[1, 5],
[2, 6],
[3, 7]])
>>> a.dot(M.transpose())
array([260, 820])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 149 / 172
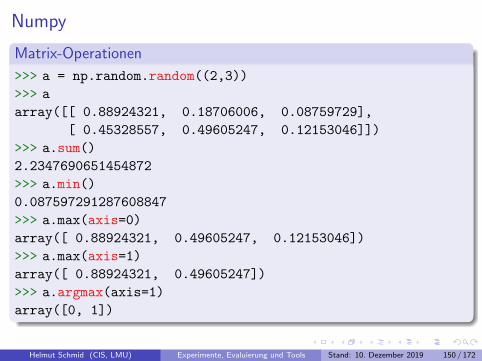
Numpy
Matrix-Operationen
>>> a = np.random.random((2,3))
>>> a
array([[ 0.88924321, 0.18706006, 0.08759729],
[ 0.45328557, 0.49605247, 0.12153046]])
>>> a.sum()
2.2347690651454872
>>> a.min()
0.087597291287608847
>>> a.max(axis=0)
array([ 0.88924321, 0.49605247, 0.12153046])
>>> a.max(axis=1)
array([ 0.88924321, 0.49605247])
>>> a.argmax(axis=1)
array([0, 1])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 150 / 172

Numpy
Broadcasting
>>> x1
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.]])
>>> x2
array([ 0., 1., 2.])
>>> x1+x2
array([[ 0., 2., 4.],
[ 3., 5., 7.],
[ 6., 8., 10.]])
>>> np.add(x1, x2)
array([[ 0., 2., 4.],
[ 3., 5., 7.],
[ 6., 8., 10.]])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 151 / 172

Numpy
Slicing
>>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[0:6:2]
array([ 0, 8, 64])
>>> a[:6:2]=-1
>>> a
array([ -1, 1, -1, 27, -1, 125, 216, 343, 512, 729])
>>> a[::-1]
array([729, 512, 343, 216, 125, -1, 27, -1, 1, -1])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 152 / 172

NumpyMultidimensional Slicing
>>> def f(x,y):
... return 10*x+y
>>> b = np.fromfunction(f,(5,4),dtype=int)
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1]
array([ 1, 11, 21, 31, 41])
>>> b[:, 1]
array([ 1, 11, 21, 31, 41])
>>> b[1:3, 2:0:-1]
array([[12, 11],
[22, 21]])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 153 / 172

Numpy
Advanced Indexing
>>> a = numpy.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a[[(0,1),(1,2)]]
array([1, 6])
>>> a[[0,2]]
array([[ 0, 1, 2, 3],
[ 8, 9, 10, 11]])
>>> a[a>5]
array([ 6, 7, 8, 9, 10, 11])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 154 / 172
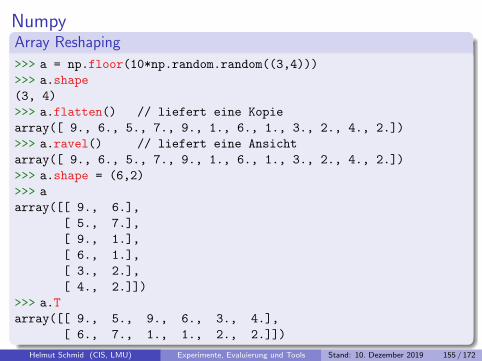
NumpyArray Reshaping
>>> a = np.floor(10*np.random.random((3,4)))
>>> a.shape
(3, 4)
>>> a.flatten() // liefert eine Kopie
array([ 9., 6., 5., 7., 9., 1., 6., 1., 3., 2., 4., 2.])
>>> a.ravel() // liefert eine Ansicht
array([ 9., 6., 5., 7., 9., 1., 6., 1., 3., 2., 4., 2.])
>>> a.shape = (6,2)
>>> a
array([[ 9., 6.],
[ 5., 7.],
[ 9., 1.],
[ 6., 1.],
[ 3., 2.],
[ 4., 2.]])
>>> a.T
array([[ 9., 5., 9., 6., 3., 4.],
[ 6., 7., 1., 1., 2., 2.]])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 155 / 172

Numpy
Views
>>> a = np.arange(12)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> b = a.view()
>>> b
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> b.resize((3,4)) // wie reshape aber "in-place"
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 156 / 172

PyTorch
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 157 / 172

PyTorch-Beispiel
import functools, operator, torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input channel, 6 output channels, 5x5 convolution kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 158 / 172

PyTorch-Beispiel (Forts.)
class Net(nn.Module):
...
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
num_flat_features = self.prod(x.size()[1:])
x = x.view(-1, num_flat_features)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def prod(self, x): # Python has no prod function:
return functools.reduce(operator.mul, x, 1)
...
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 159 / 172

PyTorch-Beispiel (Forts.)
...
net = Net() # build the network
criterion = nn.MSELoss() # definition of the loss function
optimizer = optim.SGD(net.parameters(), lr=0.01) # optimizer
input = Variable(torch.randn(1, 1, 32, 32)) # some random input
output = net(input) # calls the forward method
target = Variable(torch.arange(1, 11)) # a dummy target, for example
target = target.view(1, -1) # add a batch dimension
net.zero_grad() # do not accumulate gradients
loss = criterion(output, target)
loss.backward() # backpropagation
optimizer.step() # weight update
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 160 / 172

Batchverarbeitung
Die vordefinierten PyTorch-NN-Module erwarten eine Folge vonTrainingsbeispielen (Minibatch) als Eingabe.
Die Minibatch-Verarbeitung lastet die GPU besser aus.
Wenn auf Satzen trainiert wird, mussen alle Satze dieselbe Langehaben, damit sie zu einer Matrix zusammengefasst werden konnen.
Kurzere Satze mussen daher mit Dummysymbolen aufgefullt werden(Padding)
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 161 / 172

Konstituentenparsing mit neuronalen Netzen
Grundlage: Gaddy et al. (Link auf Kursseite)
Strategie:
Fur jede mogliche Konstituente (i , k , l) mit Startposition i ,Endposition k und Kategorie l wird eine Bewertung s(i , k , l)berechnet.
Die Bewertung eines Parsebaumes T ist die Summe der Bewertungenaller enthaltenen Konstituenten:
s(T ) =∑
(i ,k,l)∈T
s(i , k, l)
Der Parser sucht den am besten bewerteten Parse:
T = arg maxT
s(T )
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 162 / 172

Konstituentenparsing mit neuronalen Netzen
Zu klarende Fragen
Wie werden mogliche Konstituenten reprasentiert?
Wie werden die Konstituenten-Kategorien bewertet?
Wie werden Worter reprasentiert?
Wie wird der beste Parse berechnet?
Wie wird der Parser trainiert?
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 163 / 172
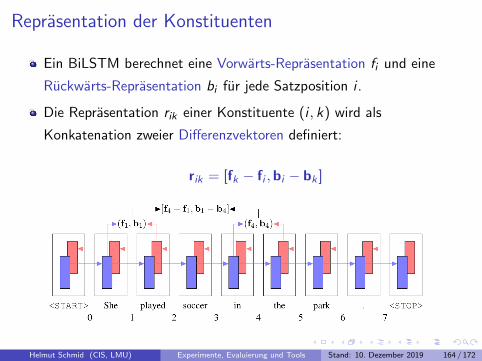
Reprasentation der Konstituenten
Ein BiLSTM berechnet eine Vorwarts-Reprasentation fi und eine
Ruckwarts-Reprasentation bi fur jede Satzposition i .
Die Reprasentation rik einer Konstituente (i , k) wird als
Konkatenation zweier Differenzvektoren definiert:
rik = [fk − fi ,bi − bk ]
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 164 / 172

Bewertung der Konstituenten-Kategorien
Die Bewertungen der Kategorien werden durch ein neuronales Netz mit
einer Hidden Layer aus der Konstituenten-Reprasentation berechnet:
s(i , k , l) = [W2g(W1rik + z1) + z2]l
g ist hier die Aktivierungsfunktion, z.B. ReLU.
Die Ausgabeebene enthalt fur jede Konstituenten-Kategorie ein Neuron und
verwendet keine Aktivierungsfunktion.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 165 / 172

Reprasentation der Worter
Moglichkeit 1: Wort-Embeddings
Nachteil: schlechte Reprasentationen fur seltene/unbekannte Worter
Moglichkeit 2: buchstabenbasierte Reprasentation berechnet mit
BiLSTM
Endzustande des Vorwarts- und Ruckwarts-LSTMs werden konkateniert.
Die beiden Reprasentationen konnen auch kombiniert werden
(durch Addition oder Konkatenation)
⇒ Gaddy et al. zeigen aber, dass buchstabenbasierte Reprasentationen
ausreichen.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 166 / 172

Parsing
verwendet den CKY-Algorithmus
Kettenregeln der Form VP → V werden durch Verwendung komplexer
Kategorien VP-V eliminiert.
Nicht-binare Konstituenten wie VP → V NP PP werden geparst,
indem zunachst V und NP zu einer Hilfskonstituente der Kategorie ∅zusammengefasst werden, wobei s(i , k , ∅) = 0.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 167 / 172

Parsing
Berechnung der Bewertungen von Konstituenten der Lange 1
sbest(i , i + 1) = maxl
s(i , i + 1, l)
= Bewertung der besten Kategorie l
Berechnung der Bewertungen von Konstituenten der Lange k − i > 1
sbest(i , k) = maxl
s(i , k , l) + maxi<j<k
[sbest(i , j) + sbest(j , k)]
Wichtig: Die beste Kategorie l und die beste binare Zerlegung der
Konstituente konnen unabhangig voneinander berechnet werden.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 168 / 172

Parsing
Der Parser berechnet bottom-up alle Bewertungen s(i , k).
Er merkt sich dabei fur jede (mogliche) Konstituente die beste
Kategorie und die beste binare Zerlegung.
Schließlich wird der beste Parsebaum top-down extrahiert.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 169 / 172

Pseudocode
for l in 1...n-1 do # Fur alle Konstituentenlangenfor i in 0...n-l do # Fur alle Startpositionen
k = i+l # Endpositionfor sym in Kategorie-Inventar do
compute score[i , k, sym] # Bewertung der Kategorie sym berechnenlabel [i , k] = arg maxsym score[i , k, sym] # Beste Kategorievscore[i , k] = score[i , k, label [i , k]] # Beste Bewertungif l > 1 then
split[i , k] = arg maxi<j<k vscore[i , j ] + vscore[j , k] # Beste Zerlegungvscore[i , k] = vscore[i , k] + vscore[i , split[i , k]] + vscore[split[i , k], k]
output(0, n) # Parsebaum ausgeben
def output(i,k)print “(“, label[i,k] # Spezialfall der Kettenregeln hier nicht behandeltif k == i+1 then
print word[i]else
output(i, split[i,k]); output(split[i,k], k) # Rekursionprint “)“
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 170 / 172

Parser-Training
Der Original-Parser verwendet Margin-basiertes Training mit derHinge-Lossfunktion
max (0,maxT [s(T ) + ∆(T ,T ∗)]− s(T ∗))
Hier ist ∆(T ,T ∗) die Zahl der falsch gelabelten moglichen Konstituenten.
Das Loss wird 0, wenn die Bewertung s(T ∗) des korrekten Parsebaumes T ∗ um
∆(T ,T ∗) großer ist als die Bewertung jedes anderen Parsebaumes T .
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 171 / 172

Parser-Training
Stattdessen kann man auch einfach die Summe der logarithmiertenWahrscheinlichkeiten der korrekten Labels fur alle moglichenKonstituenten (i,k) maximieren:
n−1∑i=0
n∑k=i+1
log pi ,k,label[i ,k]
label[i , k] ist gleich der ID der korrekten Kategorie, falls wi , ...,wk−1 eine Konstituenteist, und andernfalls gleich der ID von ∅.
pi,k,l = [softmax(scorei.k)]l ist die Wahrscheinlichkeit der Kategorie mit der ID l fur die
Wortfolge wi , ...,wk−1.
Helmut Schmid (CIS, LMU) Experimente, Evaluierung und Tools Stand: 10. Dezember 2019 172 / 172