
Experimente für die Statistik-Grundausbildung · Die einfachsten Fragestellungen haben die...
47
Experimente für die Statistik-Grundausbildung File: expstatga.rev in: /home/wiwi/pwolf/projekte/experimente March 27, 2009 Inhalt 1 Einleitung 3 2 Experimente zu Maßzahlen 5 2.1 Effekt von Einzelwerten auf Median und Mittel ............ 5 3 Graphiken zur Beschreibung von Datensätzen 6 3.1 Reaktion des Histogramms auf Klassenanzahlen ............ 6 3.2 Gebrauch der empirischen Verteilungsfunktion ............. 7 3.3 Box-Cox-Transformation und Symmetrie ................ 8 4 Regression 9 4.1 Fitting by Eye ................................ 9 4.2 Geradeanpassungen bei nichtlinearen Zusammenhängen ....... 10 4.3 Ausreißerempfindlichkeit ......................... 11 4.4 Das Bestimmtheitsmaß von Punktewolken ............... 12 4.5 Ausreißer und Bestimmtheitsmaß ..................... 13 5 Wahrscheinlichkeiten 14 5.1 Relative Häufigkeiten beim Würfeln ................... 14 6 Experimente – aus WNT und andere 15 6.1 Erfolgsanzahlen bei Bernoulli-Experimenten .............. 15 6.2 Wahrscheinlichkeiten und Häufigkeiten bei der Binomialverteilung . 15 6.3 Realisationen in Schwankungsintervallen ................ 16 6.4 Schwankungen von Erfolgshäufigkeiten ................. 17 6.5 Die hypergeometrische und die Binomialverteilung .......... 18 6.6 Summen gleichverteilter Zufallsvariablen ................ 18 6.7 Von der geometrischen zur Exponentialverteilung ........... 19 6.8 Casino- und Würfel-Fragen ........................ 20 6.9 Poisson-Verteilung checken ........................ 21 6.10 Vergleich von Schätzfunktionen ...................... 22 6.11 Verteilung des Mittels aus der Exponentialverteilung ......... 23 6.12 Mittel und Median von Stichproben aus gemischten NV ....... 24 6.13 Schätzer bei wachsenden Stichprobenumfängen ............ 25 6.14 Variabilität des von ˆ λ bei der Poisson-Verteilung ............ 26 6.15 Unterschiedlichkeit geschätzter Modelle ................. 27 6.16 NV-Anpassung an Beta-Verteilungen ................... 28 6.17 Ausreißer-Einfluss bei der Modellschätzung .............. 29 6.18 Unterschiedlichkeit von Konfidenzintervallen ............. 29 1
Transcript of Experimente für die Statistik-Grundausbildung · Die einfachsten Fragestellungen haben die...

Experimente für die Statistik-Grundausbildung
File: expstatga.revin: /home/wiwi/pwolf/projekte/experimente
March 27, 2009
Inhalt
1 Einleitung 3
2 Experimente zu Maßzahlen 52.1 Effekt von Einzelwerten auf Median und Mittel . . . . . . . . . . . . 5
3 Graphiken zur Beschreibung von Datensätzen 63.1 Reaktion des Histogramms auf Klassenanzahlen . . . . . . . . . . . . 63.2 Gebrauch der empirischen Verteilungsfunktion . . . . . . . . . . . . . 73.3 Box-Cox-Transformation und Symmetrie . . . . . . . . . . . . . . . . 8
4 Regression 94.1 Fitting by Eye . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2 Geradeanpassungen bei nichtlinearen Zusammenhängen . . . . . . . 104.3 Ausreißerempfindlichkeit . . . . . . . . . . . . . . . . . . . . . . . . . 114.4 Das Bestimmtheitsmaß von Punktewolken . . . . . . . . . . . . . . . 124.5 Ausreißer und Bestimmtheitsmaß . . . . . . . . . . . . . . . . . . . . . 13
5 Wahrscheinlichkeiten 145.1 Relative Häufigkeiten beim Würfeln . . . . . . . . . . . . . . . . . . . 14
6 Experimente – aus WNT und andere 156.1 Erfolgsanzahlen bei Bernoulli-Experimenten . . . . . . . . . . . . . . 156.2 Wahrscheinlichkeiten und Häufigkeiten bei der Binomialverteilung . 156.3 Realisationen in Schwankungsintervallen . . . . . . . . . . . . . . . . 166.4 Schwankungen von Erfolgshäufigkeiten . . . . . . . . . . . . . . . . . 176.5 Die hypergeometrische und die Binomialverteilung . . . . . . . . . . 186.6 Summen gleichverteilter Zufallsvariablen . . . . . . . . . . . . . . . . 186.7 Von der geometrischen zur Exponentialverteilung . . . . . . . . . . . 196.8 Casino- und Würfel-Fragen . . . . . . . . . . . . . . . . . . . . . . . . 206.9 Poisson-Verteilung checken . . . . . . . . . . . . . . . . . . . . . . . . 216.10 Vergleich von Schätzfunktionen . . . . . . . . . . . . . . . . . . . . . . 226.11 Verteilung des Mittels aus der Exponentialverteilung . . . . . . . . . 236.12 Mittel und Median von Stichproben aus gemischten NV . . . . . . . 246.13 Schätzer bei wachsenden Stichprobenumfängen . . . . . . . . . . . . 256.14 Variabilität des von λ bei der Poisson-Verteilung . . . . . . . . . . . . 266.15 Unterschiedlichkeit geschätzter Modelle . . . . . . . . . . . . . . . . . 276.16 NV-Anpassung an Beta-Verteilungen . . . . . . . . . . . . . . . . . . . 286.17 Ausreißer-Einfluss bei der Modellschätzung . . . . . . . . . . . . . . 296.18 Unterschiedlichkeit von Konfidenzintervallen . . . . . . . . . . . . . 29
1

7 Implementationen 307.1 slider() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307.2 exp.median.mean() . . . . . . . . . . . . . . . . . . . . . . . . . . . 317.3 exp.hist() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337.4 exp.F.dach.lookup() . . . . . . . . . . . . . . . . . . . . . . . . . 337.5 exp.fbe.fit() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347.6 exp.boxcox() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357.7 exp.fit.poly() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357.8 exp.check.point.influence() . . . . . . . . . . . . . . . . . . . 367.9 exp.adjust.Rq() . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377.10 exp.Rq.outlier() . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377.11 exp.sample.dice() . . . . . . . . . . . . . . . . . . . . . . . . . . . 387.12 exp.g.dach() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 397.13 erfolge.bei.bernoulli.experimenten() . . . . . . . . . . . . 397.14 hyper.to.binom . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407.15 sum.zv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407.16 exp.nv.mischung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417.17 exp.ki.p . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417.18 exp.outlier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427.19 exp.nv.an.beta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437.20 exp.nv.est . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437.21 exp.exp.mittel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437.22 exp.est.fns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 447.23 g.dach.x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 447.24 exp.mere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 457.25 geo.to.exp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 457.26 p.est . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467.27 binomial.experiment . . . . . . . . . . . . . . . . . . . . . . . . . 467.28 binomial.zentrales.schwankungsintervall . . . . . . . . . 47
2

1 Einleitung
Wofür taugt eigentlich der Computer aus Sicht der Statistiskausbildung? Zweiklassische Verwendungen liegen auf der Hand:
1. Berechnungen. In der Datenanalyse werden unterschiedliche Maßzahlenberechnet, um Datensätze zu charakterisieren. Weiter werden Modelle ge-schätzt und Prognosen gerechnet, die letztendlich ebenfalls zu Zahlenwertenführen. Diese numerischen Ergebnisse bilden die Grundlage für die verbalenInterpretationen der Daten.
2. Graphiken. Durch die modernen Technologien gewinnen graphische Ergeb-nisse einen immer größeren Stellenwert. Mit diesen lassen sich ausdrucks-fähigere und vielschichtigere Beschreibungen von Datensätzen und Zusam-menhängen erstellen, so dass zum Beispiel auch viele Missinterpretationenvon Maßzahlen verhindert werden können.
Während ohne die Existenz von Computern reine Konzepte im Vordergrund ste-hen und zur Illustration nur einige Mickey-Maus-Beispielen ergänzt werden kön-nen, verlangt der computergewöhnte sofort, gefundene Konzepte, Ansätze undFormeln umzusetzen. Mit dem Rechner kann jeder Statistik tun und Ergebnisseselbst produzieren.
Gerade in der Statistik-Ausbildung gehen die Verwendungen aber noch weiter.Sehr gebräuchlich sind
1. zielgerichtete Visualisierung spezieller Eigenschaften von Datensätzen wieSymmetrie
2. Untersuchung von Maßzahlen in schwierigen Datensituationen, wie Aus-reißerempfindlichkeit
3. Vergleich komplizierter Verfahren, zum Beispiel zu Regressionsfragestellun-gen
4. Darstellung von theoretischen Konstrukten, wieVerteilungen (Dichten,Wahrscheinlichkeitsfunktionen, Verteilungsfunktionen)
5. Demonstration von Zusammenhängen, siehe Galton-Brett oder Demos zumzentralen Grenzwertsatz
6. Für viele Fragen können Simulationen auf Basis künstlicher Grundgesamt-heiten oder Stichproben große Dienste leisten.
Diese Möglichkeiten sind zunächst einmal Möglichkeiten des Lehrers, um im Un-terricht verschiedene Dinge zu zeigen und zu experimentieren. Deshalb stellt sichals zweite Frage:
Was kann der Lernende mit dem Rechner anfangen? Dieses ist eng verbun-den mit der Frage, welche Aufträge wir dem Studierenden im Unterricht oder alsHausaufgaben geben können. Die einfachsten Fragestellungen haben die Kompo-nenten
1. wiederhole vorgeführte Anweisungen
2. führe Berechnungen mit alternativen Datensätzen durch
3

3. überlege und probiere Anweisungen, um einen vorgegebenen Zweck zu er-füllen.
Damit kann der Lehrende wie der Lernende von reinen Berechnungen über Ex-perimente zur Klärung von Fragen bzgl. Daten und Verfahren bishin zu komplet-ten Datenanalysen verschiedenste Aktionen vom Computer als Werkzeug umset-zen lassen. Leider kommt sehr oft die Gegenfrage: Was sollen wir denn jetzt genaumachen? Der Lernende benötigt also immer wieder recht konkrete Vorgaben, waser an welcher Stelle des Gedankengangs (mit dem Rechner) machen soll. Ohnesolche Aufträge scheint nicht genügendes Problembewusstsein vorhanden zu sein.Entsprechend ist nach Aktionen mit dem Rechner oft zu beobachten, dass kaumErkenntnis aus dem Beobachteten gezogen wird. Auch an dieser Stelle muss derLernende unterstützt werden, indem das Sehen exemplarisch eingeübt wird. Bei-des kann gut im Rahmen von Experimenten fabriziert werden.
Experimente Wir wollen uns primär mit Experimenten auseinandersetzen undeine Sammlung für die Grundausbildung zusammenstellen. Ein Experiment inunserem Sinne besteht aus einer Fragestellung, einer Konstruktionsbeschreibungmit Bemerkungen zum Aufbau, zum Ablauf und was zu beobachten ist, derDurchführung sowie der Auswertung.
Der Rohling hat folgende Struktur:1
\experiment{% NAME:}{% Frage}{% Konstruktion}{% Durchf\"uhrung}<<* >>=--- Auftrag an den Rechner ---@\experimentend{% Ergebnisse und Auswertung}\paragraph{Anschlussfrage}
Wir wollen gleich ein Beispiel konstruieren.
1Für die Umsetzung dieser Struktur sind passende Makros eingerichtet worden.
4

2 Experimente zu Maßzahlen
2.1 Effekt von Einzelwerten auf Median und Mittel
Experiment zur Frage: Wie reagieren Mittel und Median auf die Veränderungeinzelner Werte? Oft ist die unterschiedliche Wirkung einzelner Elemente auf Mit-tel und Median unbekannt. Deshalb kann der Experimentator mit diesem Experi-ment seine Vorurteile überprüfen.Konstruktion: In diesem Experiment werden zu einem Datenvektor das Mittelund der Median berechnet. Die Einzelwerte, ein Boxplot der Daten und die bei-den Maßzahlen werden dem Experimentator angezeigt. Über Schieber kann erjeweils einen Wert auswählen und verändern. Dem Experiment kann ein Daten-vektor übergeben werden. Andernfalls wird ein Zufallsvektor als Datenmaterialverwendet.
Verändern Sie den kleinsten Wert der Daten und vergrößern Sie ihn Schritt fürSchritt, bis er zum größten geworden ist, und beobachten Sie, wie sich Mittel undBoxplot ändern. Wann ändert sich der Median, wann ändert er sich nicht?Durchführung:
1 〈* 1〉 ≡exp.median.mean(co2[1:7])
Auswertung: Wie man verfolgen kann, ändert sich der Mittelwert kontinuierlichmit der Verschiebung eines Datenpunktes. Er geht ja auch linear in die Formel zurBerechnung des Mittelwertes ein. Der Median verändert sich erst, wenn der ver-schobene Punkt die Mitte erreicht. Beim Boxplot ändern sich zunächst der linkeRand bzw. Extremwert, dann das erste Quartil und, nachdem die Mitte überschrit-ten ist, entsprechend das dritte Quartil, der rechte Whisker, der sich zum Schlussvon dem extremen Datenpunkt trennt.
−0.5 0.0 0.5 1.0 1.5
Effekt von Einzelwertenauf Median und Mittel
Mittel
Median
1 2 34 56 7 8 9101
Abb. 1: Beispiel Graphik und Steuerung für Median-Mittel-Experiment
Anschlussaufgabe. Erzeugen Sie Zufallsdaten und verschieben Sie das Maxi-mum soweit, bis Mittel und Median übereinstimmen. Wie würden Sie den Daten-satz mit Blick auf den Boxplot charakterisieren?
2 〈* 1〉+ ≡set.seed(13); exp.median.mean(rexp(10))
5

3 Graphiken zur Beschreibung von Datensätzen
3.1 Reaktion des Histogramms auf Klassenanzahlen
Experiment zur Frage: Wie reagiert das Histogramm auf unterschiedlicheKlasseneinteilungen? Sehr viele Klassen führen zu einer barcode-Graphik, ganzwenige sind zu grob, so dass die Struktur eines Datensatzes nicht deutlich wird.Darum sollte der Statistiker Erfahrungen mit verschiedene Klassenanzahlen sam-meln. Dieses erlaubt das vorliegende Experiment.Konstruktion: Zu einem Datensatz wird das Histogramm gezeichnet. Über Schie-ber können die Klassen des Histogramms verändert werden.
Bei welcher Klassenanzahl erscheint Ihnen das Histogramm am geeignetsten?Durchführung:
3 〈* 1〉+ ≡exp.hist()
Auswertung:
Effekt von Klassenanzahlauf Histogramm
x
−3 −2 −1 0 1 2
0.0
0.1
0.2
0.3
0.4
0.5
13 Klassen, n =260, seed =1
Abb. 2: Beispiel Graphik und Steuerung für Histogrammgrenzen-Experiment
Es ist schon erstaunlich, wie stark sich die Histogramme bei Variation der Klas-senanzahl verändern. Mit zunehmender Klassenanzahl wird die Abbildung im-mer unruhiger. Der Kompromiss zwischen Glattheit und Informationsgehalt istnicht einfach zu fällen. Er hängt auch davon ab, was mit dem Bild transportiertwerden soll. Besonders in den Randbereichen machen oft vergrößerte KlassenSinn. Auch können bei schiefen Verteilungen unterschiedlich breite Klassenvorteilhaft sein.
Anschlussaufgabe. Erzeugen Sie Zufallsdaten aus einer schiefen Verteilung unduntersuchen dort den Effekt.
4 〈* 1〉+ ≡set.seed(13); exp.hist(rexp(200))
6
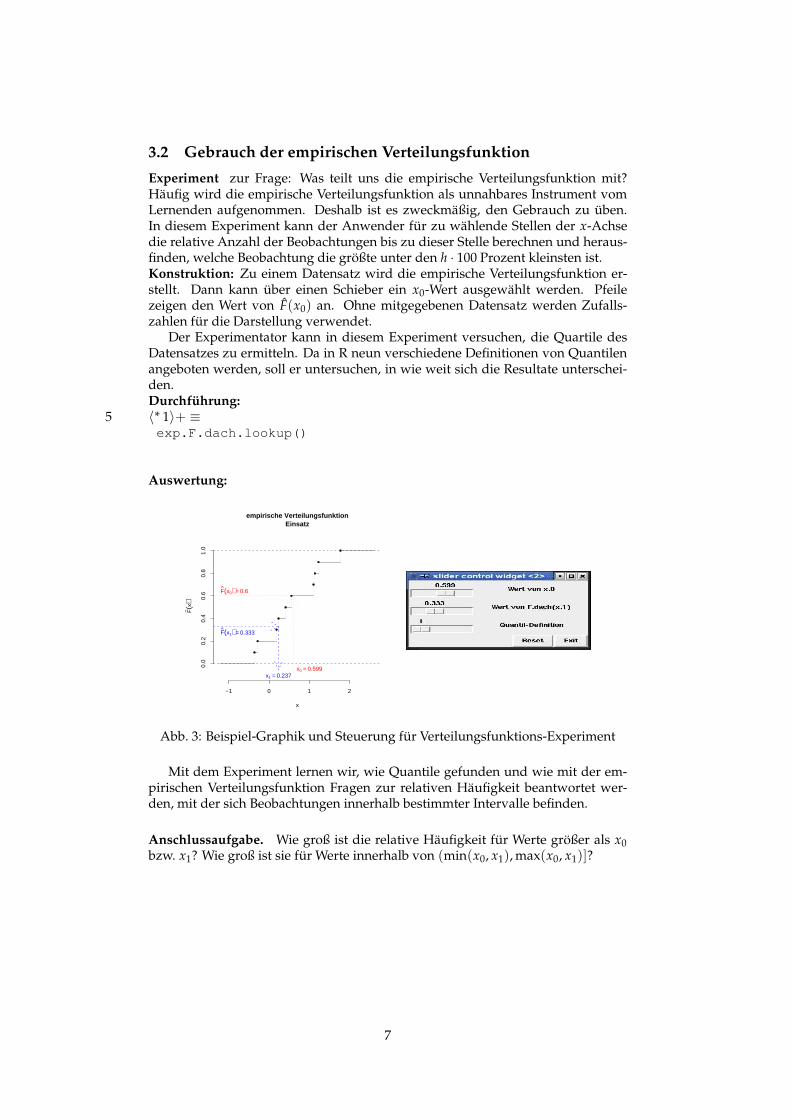
3.2 Gebrauch der empirischen Verteilungsfunktion
Experiment zur Frage: Was teilt uns die empirische Verteilungsfunktion mit?Häufig wird die empirische Verteilungsfunktion als unnahbares Instrument vomLernenden aufgenommen. Deshalb ist es zweckmäßig, den Gebrauch zu üben.In diesem Experiment kann der Anwender für zu wählende Stellen der x-Achsedie relative Anzahl der Beobachtungen bis zu dieser Stelle berechnen und heraus-finden, welche Beobachtung die größte unter den h · 100 Prozent kleinsten ist.Konstruktion: Zu einem Datensatz wird die empirische Verteilungsfunktion er-stellt. Dann kann über einen Schieber ein x0-Wert ausgewählt werden. Pfeilezeigen den Wert von F(x0) an. Ohne mitgegebenen Datensatz werden Zufalls-zahlen für die Darstellung verwendet.
Der Experimentator kann in diesem Experiment versuchen, die Quartile desDatensatzes zu ermitteln. Da in R neun verschiedene Definitionen von Quantilenangeboten werden, soll er untersuchen, in wie weit sich die Resultate unterschei-den.Durchführung:
5 〈* 1〉+ ≡exp.F.dach.lookup()
Auswertung:
−1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
x
F(x
)
x0 = 0.599
F(x0) = 0.6
x1 = 0.237
F(x1) = 0.333
empirische VerteilungsfunktionEinsatz
Abb. 3: Beispiel-Graphik und Steuerung für Verteilungsfunktions-Experiment
Mit dem Experiment lernen wir, wie Quantile gefunden und wie mit der em-pirischen Verteilungsfunktion Fragen zur relativen Häufigkeit beantwortet wer-den, mit der sich Beobachtungen innerhalb bestimmter Intervalle befinden.
Anschlussaufgabe. Wie groß ist die relative Häufigkeit für Werte größer als x0bzw. x1? Wie groß ist sie für Werte innerhalb von (min(x0, x1), max(x0, x1)]?
7
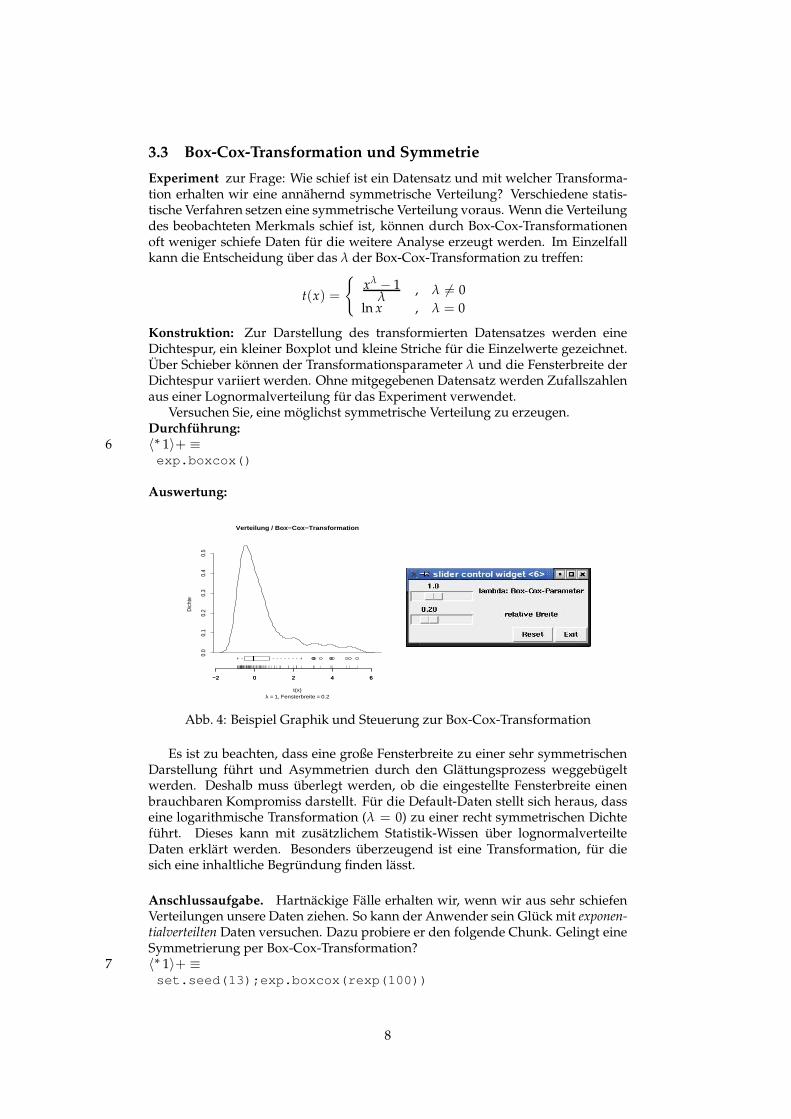
3.3 Box-Cox-Transformation und Symmetrie
Experiment zur Frage: Wie schief ist ein Datensatz und mit welcher Transforma-tion erhalten wir eine annähernd symmetrische Verteilung? Verschiedene statis-tische Verfahren setzen eine symmetrische Verteilung voraus. Wenn die Verteilungdes beobachteten Merkmals schief ist, können durch Box-Cox-Transformationenoft weniger schiefe Daten für die weitere Analyse erzeugt werden. Im Einzelfallkann die Entscheidung über das λ der Box-Cox-Transformation zu treffen:
t(x) =
{
xλ − 1λ
, λ 6= 0ln x , λ = 0
Konstruktion: Zur Darstellung des transformierten Datensatzes werden eineDichtespur, ein kleiner Boxplot und kleine Striche für die Einzelwerte gezeichnet.Über Schieber können der Transformationsparameter λ und die Fensterbreite derDichtespur variiert werden. Ohne mitgegebenen Datensatz werden Zufallszahlenaus einer Lognormalverteilung für das Experiment verwendet.
Versuchen Sie, eine möglichst symmetrische Verteilung zu erzeugen.Durchführung:
6 〈* 1〉+ ≡exp.boxcox()
Auswertung:
−2 0 2 4 6
0.0
0.1
0.2
0.3
0.4
0.5
t(x)
Dic
hte
Verteilung / Box−Cox−Transformation
λ = 1, Fensterbreite = 0.2
−2 0 2 4 6
Abb. 4: Beispiel Graphik und Steuerung zur Box-Cox-Transformation
Es ist zu beachten, dass eine große Fensterbreite zu einer sehr symmetrischenDarstellung führt und Asymmetrien durch den Glättungsprozess weggebügeltwerden. Deshalb muss überlegt werden, ob die eingestellte Fensterbreite einenbrauchbaren Kompromiss darstellt. Für die Default-Daten stellt sich heraus, dasseine logarithmische Transformation (λ = 0) zu einer recht symmetrischen Dichteführt. Dieses kann mit zusätzlichem Statistik-Wissen über lognormalverteilteDaten erklärt werden. Besonders überzeugend ist eine Transformation, für diesich eine inhaltliche Begründung finden lässt.
Anschlussaufgabe. Hartnäckige Fälle erhalten wir, wenn wir aus sehr schiefenVerteilungen unsere Daten ziehen. So kann der Anwender sein Glück mit exponen-tialverteilten Daten versuchen. Dazu probiere er den folgende Chunk. Gelingt eineSymmetrierung per Box-Cox-Transformation?
7 〈* 1〉+ ≡set.seed(13);exp.boxcox(rexp(100))
8
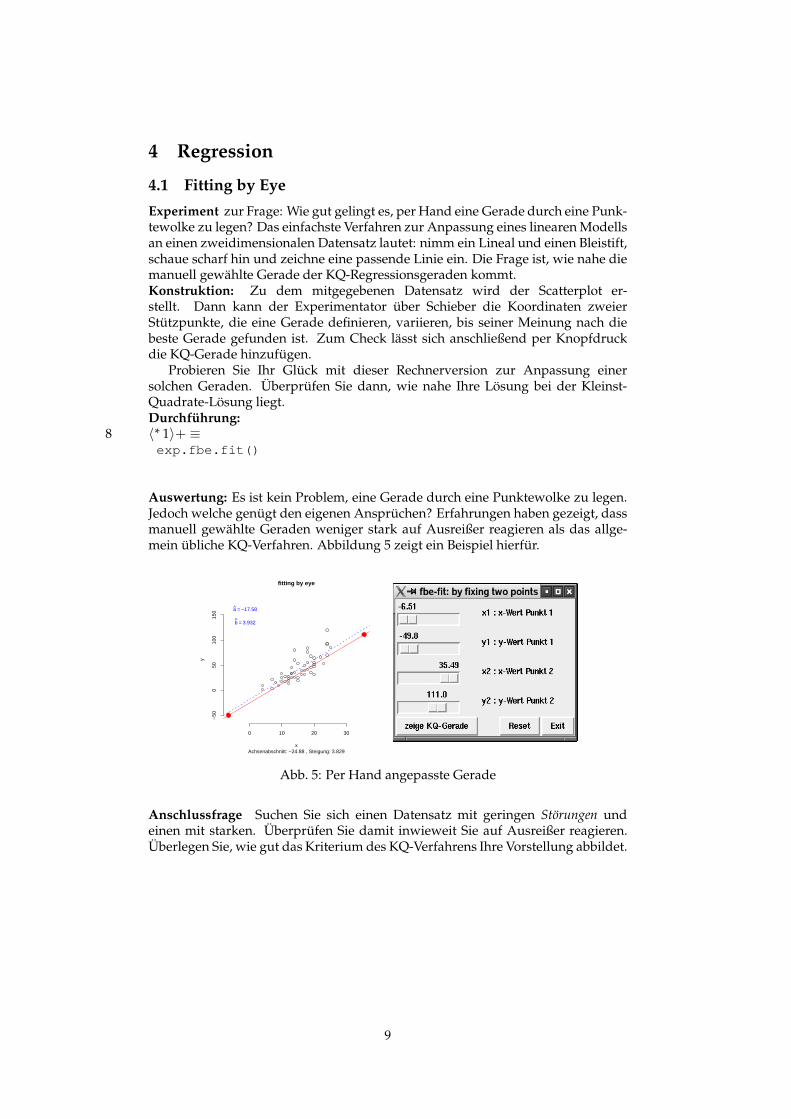
4 Regression
4.1 Fitting by Eye
Experiment zur Frage: Wie gut gelingt es, per Hand eine Gerade durch eine Punk-tewolke zu legen? Das einfachste Verfahren zur Anpassung eines linearen Modellsan einen zweidimensionalen Datensatz lautet: nimm ein Lineal und einen Bleistift,schaue scharf hin und zeichne eine passende Linie ein. Die Frage ist, wie nahe diemanuell gewählte Gerade der KQ-Regressionsgeraden kommt.Konstruktion: Zu dem mitgegebenen Datensatz wird der Scatterplot er-stellt. Dann kann der Experimentator über Schieber die Koordinaten zweierStützpunkte, die eine Gerade definieren, variieren, bis seiner Meinung nach diebeste Gerade gefunden ist. Zum Check lässt sich anschließend per Knopfdruckdie KQ-Gerade hinzufügen.
Probieren Sie Ihr Glück mit dieser Rechnerversion zur Anpassung einersolchen Geraden. Überprüfen Sie dann, wie nahe Ihre Lösung bei der Kleinst-Quadrate-Lösung liegt.Durchführung:
8 〈* 1〉+ ≡exp.fbe.fit()
Auswertung: Es ist kein Problem, eine Gerade durch eine Punktewolke zu legen.Jedoch welche genügt den eigenen Ansprüchen? Erfahrungen haben gezeigt, dassmanuell gewählte Geraden weniger stark auf Ausreißer reagieren als das allge-mein übliche KQ-Verfahren. Abbildung 5 zeigt ein Beispiel hierfür.
0 10 20 30
−50
050
100
150
fitting by eye
x
y
Achsenabschnitt: −24.88 , Steigung: 3.829
a = −17.58
b = 3.932
Abb. 5: Per Hand angepasste Gerade
Anschlussfrage Suchen Sie sich einen Datensatz mit geringen Störungen undeinen mit starken. Überprüfen Sie damit inwieweit Sie auf Ausreißer reagieren.Überlegen Sie, wie gut das Kriterium des KQ-Verfahrens Ihre Vorstellung abbildet.
9

4.2 Geradeanpassungen bei nichtlinearen Zusammenhängen
Experiment zur Frage: Welches Geradenmodell wählt das Kleinst-Quadrate-Kriterium im Falle nicht linearer Zusammenhängen aus? Viele Zusammenhängein unserer Welt sind zumindest in kleinen Intervallen approximitv linear. Dann istdie Anpassung einer Geraden angemessen. Doch was passiert, wenn der Zusam-menhang nicht linear ist?Konstruktion: In diesem Experiment betrachten wir zwei Variablen X und Y, fürdie gilt:
yi = a0 + a1 · x + a2 · x2 + a3 · x3 + ui
Zu diesem werden zufällig Beobachtungen generiert, geplottet und das KQ-Modell eingezeichnet. Veränderbar sind Koeffizienten ai und die Störungsvarianzσu, die Anzahl der Beobachtungen und der Polynomgrad des angepassten Mod-ells.
Stellen Sie fest, welche Größen auf die Schätzung einen Einfluss haben. Wiewirkt sich die Störungsvarianz aus? Wie gut sind die Schätzungen, wenn der Mo-dellpolynomgrad kleiner oder größer als der wahre ist?Durchführung:
9 〈* 1〉+ ≡exp.fit.poly()
Auswertung:
0 20 40 60 80 100
−60
000
0
x
y
a = ( 41400, −3040, 25.8 )
y = 20000x0 + 0x1 + −50x2 + 0.5x3 + u
0 20 40 60 80 100
−20
000
020
000
Residualplot
x
Abb. 6: Anpassung eines Polynoms an kubischen Zusammenhang
Die Methode der kleinsten Quadrate findet Kurven, die durch die Datenpunkteverlaufen. Bei einer geringen Störungsvarianz sind die Anpassungen sehr gut. Fürgrößere Polynomgrade als notwendig ergeben sich Koeffizienten, die vom Betrageher klein ausfallen. Ist der Polynomgrad des Modells zu klein, kann das Modellden wahren Verlauf nicht richtig rekonstruieren. Wir erhalten zum Beispiel zumBeispiel den in Abbildung 6 gezeigten Output. Rechts daneben ist das Steuerungs-fenster gezeigt.
Anschlussaufgabe. Wieso hat die Veränderung von a0 keine Auswirkung auf diegraphische Darstellung?
10

4.3 Ausreißerempfindlichkeit
Experiment zur Frage: Wie stark können einzelne Beobachtungen die Geraden-Schätzung stören? Jeder Datenpunkt geht in die Schätzformel der Modellparam-eter in gleicher Weise ein. Deshalb werden Ausreißer die Lage einer geschätztenModellgeraden beeinflussen. Mit diesem Experiment soll untersucht werden, wiestark sich ein einzelner Punkt auswirken kann.Konstruktion: Es werden eine geringe Anzahl Zufallspunkte gezogen und einScatterplot mit der Regressionsgeraden gezeichnet. Zusätzlich wird ein Residu-alplot erstellt. Der Anwender kann sich einen Punkt auswählen und dessen Ko-ordinaten verändern. Modellgerade und Residualplot werden dann unmittelbarangepasst. Wird kein Datensatz übergeben, wird ein zufälliger verwendet.
Wo muss der erste Punkt hin verschoben werden, damit sich eine Gerade mitder Steigung 0 ergibt? Zunächst sollte der Experimentator diese Frage aus einerVorstellung heraus beantworten und dann die Antwort am Rechner überprüfen.Durchführung:
10 〈* 1〉+ ≡exp.check.point.influence()
Auswertung:
−10 0 5 10 20
−10
−5
05
1015
2025
x
y
1
2
3
4
5
6
789
10
2
a.dach=5.5, b.dach=0.0026
0 5 10 15
−10
−5
05
Residualplot
x
resu
lt$re
sid
Abb. 7: Einfluss von Einzelwerten auf Regression
Wir sehen, dass ein einzelner Wert die Schätzung der Regressionsgeraden er-heblich stören kann. Manchmal werden – wie schon erlebt – fehlende Werte zurKennzeichnung durch eine seltsame Zahl wie 99999 ersetzt. Dieses kann fataleFolgen haben. Deshalb ist ein Blick auf Scatterplots und Residualplots unbedingtnotwendig.
Anschlussaufgabe. Es können sich natürlich auch zwei Ausreißer in den Datenbefinden. Welche Konsequenz haben zwei Ausreißer mit demselben x-Wert, diejedoch bzgl. der zweiten Variablen in entgegengesetzte Richtung ausreißen?
11
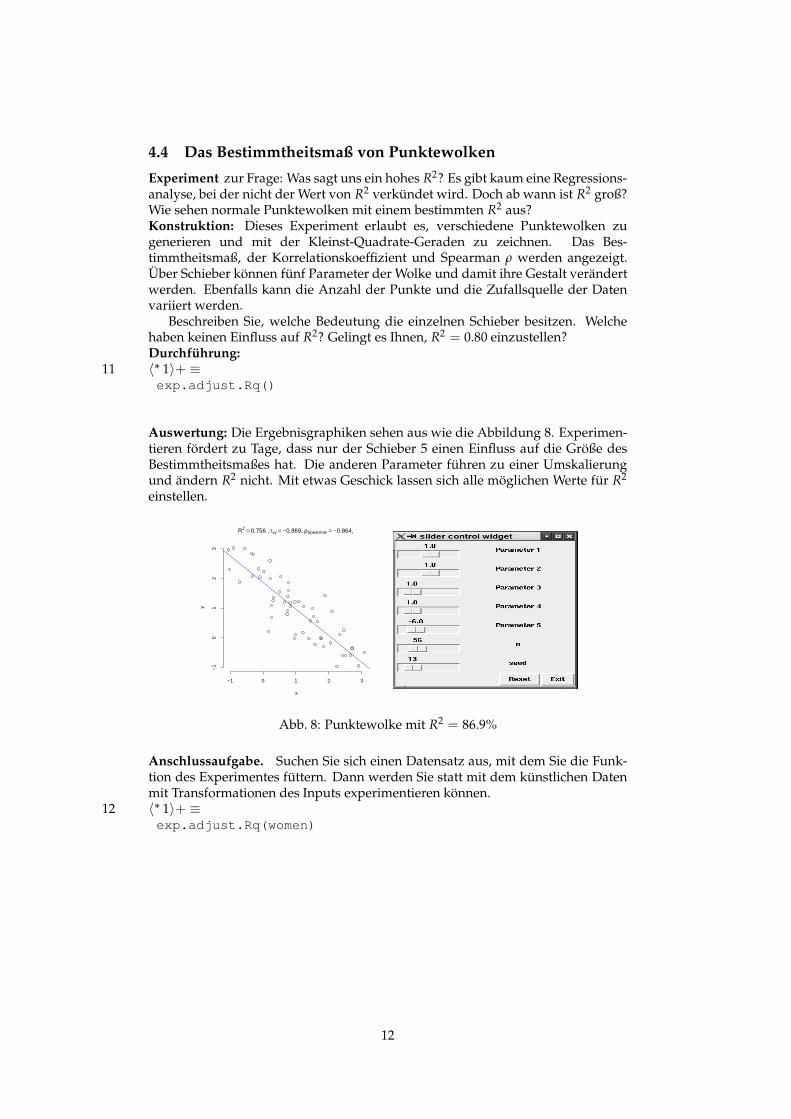
4.4 Das Bestimmtheitsmaß von Punktewolken
Experiment zur Frage: Was sagt uns ein hohes R2? Es gibt kaum eine Regressions-analyse, bei der nicht der Wert von R2 verkündet wird. Doch ab wann ist R2 groß?Wie sehen normale Punktewolken mit einem bestimmten R2 aus?Konstruktion: Dieses Experiment erlaubt es, verschiedene Punktewolken zugenerieren und mit der Kleinst-Quadrate-Geraden zu zeichnen. Das Bes-timmtheitsmaß, der Korrelationskoeffizient und Spearman ρ werden angezeigt.Über Schieber können fünf Parameter der Wolke und damit ihre Gestalt verändertwerden. Ebenfalls kann die Anzahl der Punkte und die Zufallsquelle der Datenvariiert werden.
Beschreiben Sie, welche Bedeutung die einzelnen Schieber besitzen. Welchehaben keinen Einfluss auf R2? Gelingt es Ihnen, R2 = 0.80 einzustellen?Durchführung:
11 〈* 1〉+ ≡exp.adjust.Rq()
Auswertung: Die Ergebnisgraphiken sehen aus wie die Abbildung 8. Experimen-tieren fördert zu Tage, dass nur der Schieber 5 einen Einfluss auf die Größe desBestimmtheitsmaßes hat. Die anderen Parameter führen zu einer Umskalierungund ändern R2 nicht. Mit etwas Geschick lassen sich alle möglichen Werte für R2
einstellen.
−1 0 1 2 3
−1
01
23
x
y
R2 = 0.756 , rxy = −0.869, ρSpearman = −0.864,
Abb. 8: Punktewolke mit R2 = 86.9%
Anschlussaufgabe. Suchen Sie sich einen Datensatz aus, mit dem Sie die Funk-tion des Experimentes füttern. Dann werden Sie statt mit dem künstlichen Datenmit Transformationen des Inputs experimentieren können.
12 〈* 1〉+ ≡exp.adjust.Rq(women)
12

4.5 Ausreißer und Bestimmtheitsmaß
Experiment zur Frage: Wie empfindlich reagiert R2 auf einzelne Werte? Wiedas arithmetische Mittel und die Regressionskoeffizienten ist R2 auch aus-reißerempfindlich. Fraglich ist jedoch, in welcher Bandbreite eine einzelneBeobachtung wirken kann.Konstruktion: Dieses Experiment zeigt dem Anwender eine Wolke unkorrelierterPunkte mit der QK-Regressionsgeraden. Ein einzelner Punkt kann durch den Ex-perimentator sowohl in seiner Entfernung und Richtung bezogen auf das Zentrumvariiert werden. Mit jeder Veränderung wird die Regressionsgerade neu gezeich-net und der Wert des Bestimmtheitsmaßes eingeblendet. Zur Information werdenaußerdem die Werte des Korrelationskoeffizienten, von Kendalls τ und Spearmansρ gezeigt.
Der Experimentator soll probieren, die Abhängigkeit von R2 von der Lage desAusreißers zu beschreiben. Suchen Sie verschiedene Positionen für den Ausreißer,der zu einem R2 von 80% führt.Durchführung:
13 〈* 1〉+ ≡exp.Rq.outlier()
Auswertung: Wie der Versuch zeigt, kann ein einzelner Punkt den Wert von R2 er-heblich stören. Für den Fall, dass mit Ausreißern gerechnet wird, ist es deshalb rat-sam auf Alternativen aus der Nichtparametrischen Statistik überzuwechseln undSpearmans ρ oder Kendalls τ zu berechnen.
−10 −5 0 5 10
−10
−5
05
10
x
y
R2 und Ausreißer
R2 = 0.0596, rxy = −0.244, τKendall = 0.602, ρSpearman = 0.724
Abb. 9: R2 bei einem Ausreißer
Abbildung 9 zeigt zum Beispiel eine Darstellung des R-Datensatzes cars , demein deutlich entfernt liegender Ausreißer hinzugefügt wurde.
Anschlussaufgabe. Suchen Sie sich einen Datensatz und überprüfen Sie, wieweit bei diesem ein Ausreißer entfernt liegen muss, damit er eine durchschlagendeWirkung auf das R2 ausübt. Probiere zum Beispiel:
14 〈* 1〉+ ≡exp.Rq.outlier(cars)
13

5 Wahrscheinlichkeiten
5.1 Relative Häufigkeiten beim Würfeln
Experiment zur Frage: Wie entwickeln sich die relativen Häufigkeiten beimWürfeln bzw. allgemeiner im Gleichmöglichkeitsmodell? In der Theorie ist dieWahrscheinlichkeit beim Würfeln eine 6 zu bekommen 1/6. An diesen Wertsoll sich die relative Häufigkeit annähern, wenn wir die Versuchsanzahl wachsenlassen. Stimmt das?Konstruktion: Wir untersuchen diese Frage experimentell, indem wir mit einemLaplace-Würfel mit n.gg Seitenflächen n Würfe durchführen. Das Würfelergeb-nis wird einerseits in Form eines Stabdiagramms dargestellt. Andererseits wirdder Entwicklungsprozess der relativen Häufigkeit eines ausgewählten Ereignisses– wie das einer 6 – durch eine Linie dargestellt. Veränderbar sind die Seitenan-zahlen des Würfels, die Anzahl der Wiederholungen, der Start des Zufallszah-len und die Auswahl des Ereignisses, für die die Entwicklung der relativen Häu-figkeiten gezeigt wird. Der Experimentator soll feststellen, welche Eigenschaftendie relativen Häufigkeiten besitzen. Dazu sollte er beispielsweise verschiedeneStartwerte des Zufallszahlengenerators ausprobieren.Durchführung:
15 〈* 1〉+ ≡exp.sample.dice()
Auswertung: Wir sehen an dem Experimentergebnis 10, dass sich die relativeHäufigkeit im groben mit wachsendem Stichprobenumfang immer mehr an dietheoretische Wahrscheinlichkeit annähert. Für eine sehr kleine Abweichung istmanchmal schon ein beträchtlicher Stichprobenumfang notwendig, in anderenFällen ist die Annäherung auch für kleine Stichproben sehr gut.
0.00
0.10
0.20
relative Häufigkeiten −− gesamt
h i
1 2 3 4 5 6
0 100 200 300 400 500
0.0
0.4
0.8
... für Augenzahl 6 bis Versuch no
6 −er Würfel , Versuche = 500, Zufallsstart = 1no
h i
Abb. 10: Approximation von Wahrscheinlichkeiten durch relative Häufigkeiten
Anschlussfrage Versuchen Sie durch Variation der Experimentparameter typi-sche und extreme Fälle zu erzeugen und zu beschreiben. Für diese Phänomenekann die Theorie Erklärungen liefern, an dieser Stelle soll jedoch der Leser nursensibilisiert und neugierig gemacht werden.
14

6 Experimente – aus WNT und andere
6.1 Erfolgsanzahlen bei Bernoulli-Experimenten
Experiment zur Untersuchungsfrage: Wie unterschiedlich kann die Anzahl derErfolge bei 50 Bernoulli-Experimenten ausfallen, wenn in der Grundgesamtheit 29von 50 Elementen ein Erfolgsergebnis liefern?
Modell: Stichprobenziehung wird durch 50 unabhängige Bernoulli-Experimente mit Erfolgswahrscheinlichkeit 29/50 modelliert.
Aufbau / Ablauf: Durch wiederholte Stichprobenziehungen erhalten wir ver-schiedene Realisationen der Zufallsvariablen S, der Erfolgsanzahl in einer Stich-probe. Die empirische Verteilung der Realisationen von S wird als Stabdiagrammdargestellt und das jeweilige Ergebnis unter dem Namen result abgelegt.
Durchführung: Zum interaktiven Experimentieren wird eine spezielle Funktionangeboten. Diese zeigt uns ein neues Fenster, mit dem wir Erfolgsprozentsatz inder Grundgesamtheit, Stichprobenumfang, Anzahl der Wiederholungen und dieStart des Zufallsgenerators setzen können.
16 〈* 1〉+ ≡erfolge.bei.bernoulli.experimenten()
Die Parameter lassen sich steuern mit einer Steuerungsfläche. Ergebnis: Wir erhal-ten beispielsweise:
0 10 20 30 40 50
0.00
0.05
0.10
0.15
Erfolgsprozentsatz in GG=58, n.stpr=50, WD=1000, Zufall=19
Erfolgsanzahl
rela
tive
Häau
figke
it
Abb. 11: Einfangen von p und Steuerung
Als Ergebnis erhalten wir:
Min. 1st Qu. Median Mean 3rd Qu. Max.18.00 27.00 29.00 29.05 31.00 39.00
Auswertung: Unter den idealisierten Bedingungen haben sich Realisationenzwischen 19 und 42 eingestellt. Am Stabdiagramm erkennen wir, dass sich beiden meisten künstlichen Untersuchungen Ergebnisse zwischen 24 und 34 Erfolgeeingestellt haben. Werte um 29 sind am häufigsten, Erfolgsanzahlen kleiner als 21oder größer als 37 kaum anzutreffen. Dennoch kommen bei den vielen Wiederhol-ungen auch einige sehr extreme Erfolgsanzahlen vor.
6.2 Wahrscheinlichkeiten und Häufigkeiten bei der Binomi-alverteilung
Experiment zur Frage Simulation und Modell.Nicht nur zur zusätzlichen Bestätigung der Modellierung, sondern auch zur
Ermittlung elementarer Wahrscheinlichkeiten bieten wir nun ein weiteres Rech-nerexperiment an.
15

Untersuchungsfrage: Wie unterscheiden sich die Wahrscheinlichkeiten der Bino-mialverteilung von simulierten Häufigkeiten?
Aufbau / Ablauf: Zur Abschätzung der Unter-schiede konstruieren wir für eine anzugebendeParameterkonstellation Wahrscheinlichkeits-und Verteilungsfunktion einer binomialverteil-ten Zufallsvariablen und stellen diese den em-pirischen, simulierten Pendants gegenüber. Füreine spezielle Stelle s0 können die Wahrschein-lichkeiten f (s0), F(s0), (1 − F(s0)) abgelesenwerden.
Durchführung17 〈* 1〉+ ≡
binomial.experiment()Abbildung 6.12: Steuerung:Binomialexperimentes
Mit den Einstellungen aus Abbildung 6.12 können wir beispielsweise den Output
von Abbildung 13 hervorrufen.
0 10 20 30 40 50
0.00
0.10
f(s),
f.dac
h(s) P(S=31)=0.0979
0 10 20 30 40 50
0.00.4
0.8
F(s),
F.da
ch(s)
o SimulationsergebnisP(S<=31)=0.7617P(S> 31)=0.2383
binom(p*100=58, n=50)Simulation: WD=200, Zufall=13
Abb. 13: Binomialverteilung mit Simulation
Interpretation. Wie man sieht, ist der Unterschied nicht sehr groß, die Model-lierung ist also gar nicht so schlecht.
6.3 Realisationen in Schwankungsintervallen
Experiment zur Auswirkungen verschiedener Parametersetzungen bei der Bino-mialverteilung.
Untersuchungsfrage: Mit diesem Experiment soll der Einfluss der Param-eter auf die Wahrscheinlichkeit einer Beobachtung, in ein k-faches zentralesSchwankungsintervall zu fallen, studieren werden.
Aufbau / Ablauf: Unter Berücksichtigung der beiden Parameter n und p derBinomialverteilung hängt die Wahrscheinlichkeit für eine Realisation im k-fachenzentralen Schwankungsintervall von den drei Parametern n, p und k ab. Haltenwir jeweils zwei Parameter fest, können wir die Trefferwahrscheinlichkeit in Ab-hängigkeit vom dritten Parameter graphisch darstellen. Auf diese Weise lassensich drei verschiedene Darstellungen konstruieren.
Durchführung:18 〈* 1〉+ ≡
binomial.zentrales.schwankungsintervall()
16
0.0 0.2 0.4 0.6 0.8 1.0
0.00.2
0.40.6
0.81.0
p
Pp
n=50, k=1, p variabel
0 20 40 60 80 100
0.00.2
0.40.6
0.81.0
nPn
p=0.5, k=1, n variabel
0.5 1.5 2.5 3.5
0.00.2
0.40.6
0.81.0
k
Pk
n=50, p=0.5, k variabel
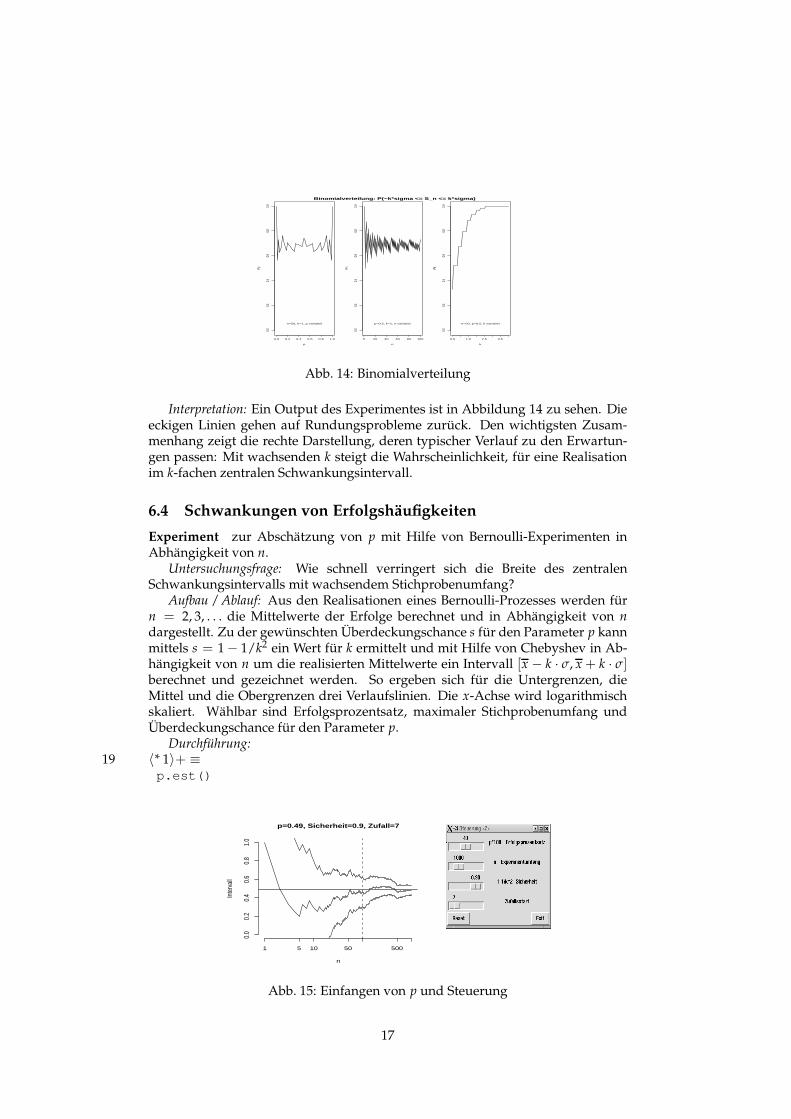
Binomialverteilung: P(−k*sigma <= S_n <= k*sigma)
Abb. 14: Binomialverteilung
Interpretation: Ein Output des Experimentes ist in Abbildung 14 zu sehen. Dieeckigen Linien gehen auf Rundungsprobleme zurück. Den wichtigsten Zusam-menhang zeigt die rechte Darstellung, deren typischer Verlauf zu den Erwartun-gen passen: Mit wachsenden k steigt die Wahrscheinlichkeit, für eine Realisationim k-fachen zentralen Schwankungsintervall.
6.4 Schwankungen von Erfolgshäufigkeiten
Experiment zur Abschätzung von p mit Hilfe von Bernoulli-Experimenten inAbhängigkeit von n.
Untersuchungsfrage: Wie schnell verringert sich die Breite des zentralenSchwankungsintervalls mit wachsendem Stichprobenumfang?
Aufbau / Ablauf: Aus den Realisationen eines Bernoulli-Prozesses werden fürn = 2, 3, . . . die Mittelwerte der Erfolge berechnet und in Abhängigkeit von ndargestellt. Zu der gewünschten Überdeckungschance s für den Parameter p kannmittels s = 1 − 1/k2 ein Wert für k ermittelt und mit Hilfe von Chebyshev in Ab-hängigkeit von n um die realisierten Mittelwerte ein Intervall [x − k · σ, x + k · σ]berechnet und gezeichnet werden. So ergeben sich für die Untergrenzen, dieMittel und die Obergrenzen drei Verlaufslinien. Die x-Achse wird logarithmischskaliert. Wählbar sind Erfolgsprozentsatz, maximaler Stichprobenumfang undÜberdeckungschance für den Parameter p.
Durchführung:19 〈* 1〉+ ≡
p.est()
1 5 10 50 500
0.0
0.2
0.4
0.6
0.8
1.0
n
Inte
rval
l
p=0.49, Sicherheit=0.9, Zufall=7
Abb. 15: Einfangen von p und Steuerung
17

Interpretation: Laut Formel geht der Stichprobenumfang mit dem Kehrwertseiner Wurzel in die Berechnung der Intervallgrenzen ein. Folglich muss fürdie Halbierung der Intervalllänge der Stichprobenumfang vervierfacht werden.Dieser Zusammenhang ist uns im
√n-Gesetz begegnet. Die Auswirkungen kön-
nen an Outputs, wie der in Abbildung 15 gezeigte, studiert werden.
6.5 Die hypergeometrische und die Binomialverteilung
Experiment zum Verteilungsvergleich. Dieses Experiment erlaubt das Studiumdes Unterschieds von hypergeometrischer und Binomialverteilung.
Untersuchungsfrage: Es wird argumentiert, dass sich die beiden Verteilungenfür bestimmte Parameterszenarien (m und n groß) kaum unterscheiden. Er-wartungswert und Varianz, genauer deren Formeln, stützen diese These. Die Dif-ferenz soll im Experiment gezeigt werden.
Aufbau / Ablauf: Wir berechnen die Wahrscheinlichkeitsfunktionen der hy-pergeometrischen Verteilung mit den Parametern (m, n, k) und der Binomi-alverteilung binom(nb, p) mit den Parametern nb = k und p = m/(m + n) undzeichnen diese sowie die Differenzen der Wahrscheinlichkeiten
Durchführung: Für eigene Studien kann das Experiment mit verschiedenen Pa-rameter wiederholt werden. Was passiert, wenn beispielsweise m, m/(m + n) oderm und n bei konstantem k wachsen?
20 〈* 1〉+ ≡hyper.to.binom()
0 2 4 6 8
0.00
0.15
0.30
hypergeometrisch: m=22,n=14,k=9
x
f.hyp
er
P(X= 2)=0.0084P(X<=2)=0.0091P(X> 2)=0.9909
0 2 4 6 8
0.00
0.15
0.30
binomial: n=9,p=0.6111
x
f.bin
om
0 2 4 6 8
−0.0
20.
01
Unterschiede
f.hyp
er −
f.bi
nom
Abb. 16: Binomial- und hypergeometrische Verteilung
Interpretation: Abbildung 16 umfasst als ein möglicher Ausdruck drei einzelnePlots. Der erste Plot zeigt die Wahrscheinlichkeitsfunktion der hyperge-ometrischen Verteilung, der zweite die Binomialverteilung und der dritte die Dif-ferenzen der Wahrscheinlichkeiten. Wir erkennen an den Beträgen der Differen-zen, dass schon bei der Konstellation (m = 22, n = 14, k = 9) die Abweichungenzwischen den beiden Verteilungen sehr klein sind. Nach der Auflistung wichtigerR-Idioms werden wir uns mit einer Approximation der Binomialverteilung durcheine weitere Verteilung, der Poisson-Verteilung befassen.
6.6 Summen gleichverteilter Zufallsvariablen
Experiment zum Studium der Auswirkung eines Summationsprozesses. Hierzuwerden wir in diesem Abschnitt ein Rechnerexperiment mit der Gleichverteilungdurchführen. Extreme Betrachtungen – wie Experimente mit der Gleichverteilung– helfen, ein Gefühl für Grenzsituationen zu entwickeln. Dann lässt sich überlegen,inwieweit reale Situationen durch diese Grenzen eingefangen werden.
18
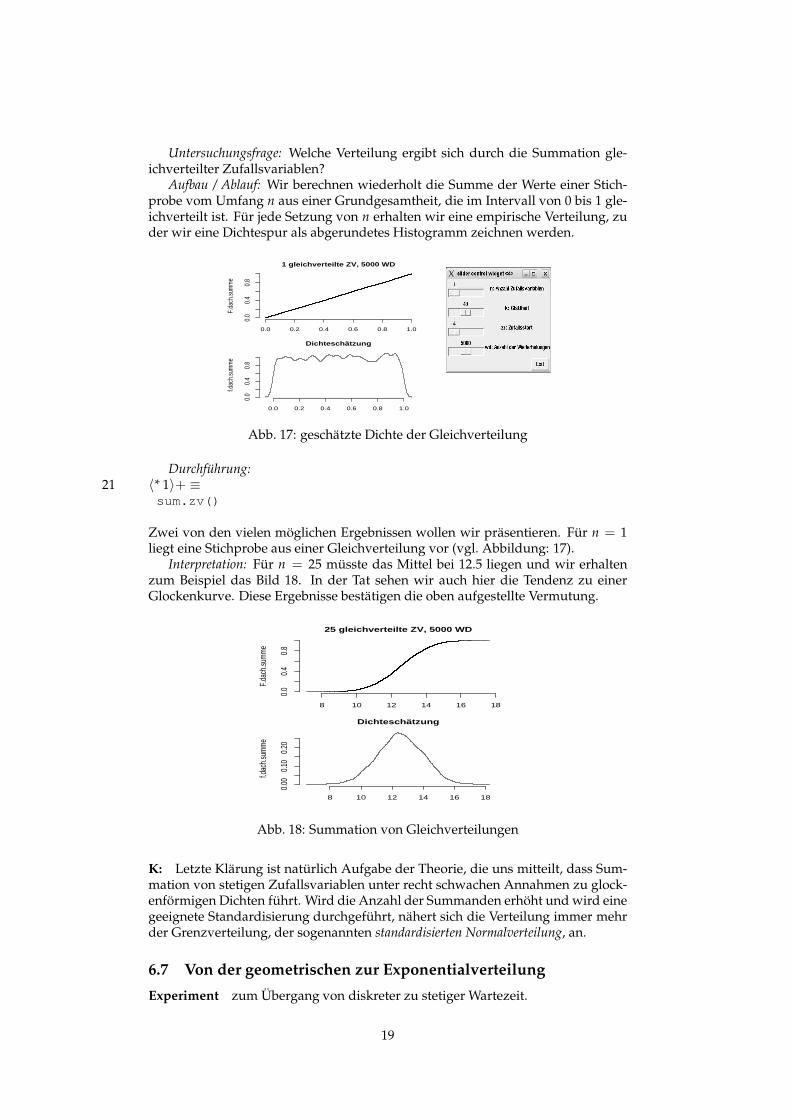
Untersuchungsfrage: Welche Verteilung ergibt sich durch die Summation gle-ichverteilter Zufallsvariablen?
Aufbau / Ablauf: Wir berechnen wiederholt die Summe der Werte einer Stich-probe vom Umfang n aus einer Grundgesamtheit, die im Intervall von 0 bis 1 gle-ichverteilt ist. Für jede Setzung von n erhalten wir eine empirische Verteilung, zuder wir eine Dichtespur als abgerundetes Histogramm zeichnen werden.
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
F.da
ch.s
umm
e
1 gleichverteilte ZV, 5000 WD
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
Dichteschätzung
f.dac
h.su
mm
e
Abb. 17: geschätzte Dichte der Gleichverteilung
Durchführung:21 〈* 1〉+ ≡
sum.zv()
Zwei von den vielen möglichen Ergebnissen wollen wir präsentieren. Für n = 1liegt eine Stichprobe aus einer Gleichverteilung vor (vgl. Abbildung: 17).
Interpretation: Für n = 25 müsste das Mittel bei 12.5 liegen und wir erhaltenzum Beispiel das Bild 18. In der Tat sehen wir auch hier die Tendenz zu einerGlockenkurve. Diese Ergebnisse bestätigen die oben aufgestellte Vermutung.
8 10 12 14 16 18
0.0
0.4
0.8
F.da
ch.su
mm
e
25 gleichverteilte ZV, 5000 WD
8 10 12 14 16 18
0.00
0.10
0.20
Dichteschätzung
f.dac
h.su
mm
e
Abb. 18: Summation von Gleichverteilungen
K: Letzte Klärung ist natürlich Aufgabe der Theorie, die uns mitteilt, dass Sum-mation von stetigen Zufallsvariablen unter recht schwachen Annahmen zu glock-enförmigen Dichten führt. Wird die Anzahl der Summanden erhöht und wird einegeeignete Standardisierung durchgeführt, nähert sich die Verteilung immer mehrder Grenzverteilung, der sogenannten standardisierten Normalverteilung, an.
6.7 Von der geometrischen zur Exponentialverteilung
Experiment zum Übergang von diskreter zu stetiger Wartezeit.
19
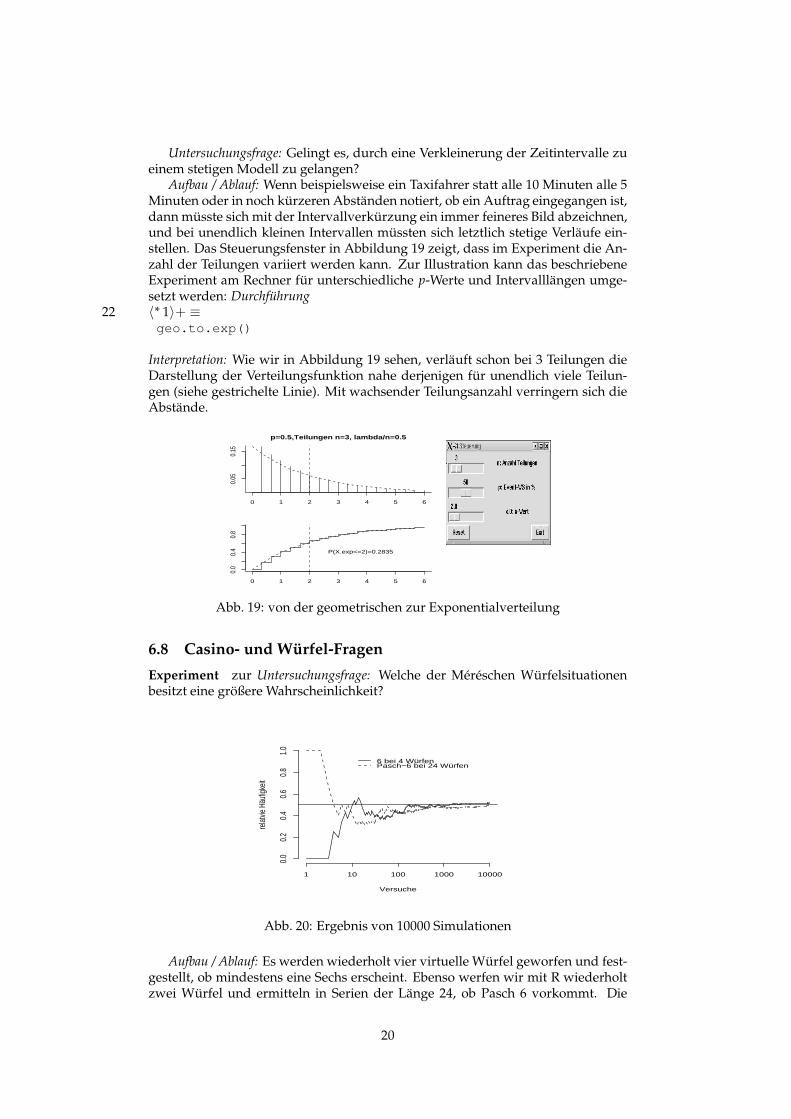
Untersuchungsfrage: Gelingt es, durch eine Verkleinerung der Zeitintervalle zueinem stetigen Modell zu gelangen?
Aufbau / Ablauf: Wenn beispielsweise ein Taxifahrer statt alle 10 Minuten alle 5Minuten oder in noch kürzeren Abständen notiert, ob ein Auftrag eingegangen ist,dann müsste sich mit der Intervallverkürzung ein immer feineres Bild abzeichnen,und bei unendlich kleinen Intervallen müssten sich letztlich stetige Verläufe ein-stellen. Das Steuerungsfenster in Abbildung 19 zeigt, dass im Experiment die An-zahl der Teilungen variiert werden kann. Zur Illustration kann das beschriebeneExperiment am Rechner für unterschiedliche p-Werte und Intervalllängen umge-setzt werden: Durchführung
22 〈* 1〉+ ≡geo.to.exp()
Interpretation: Wie wir in Abbildung 19 sehen, verläuft schon bei 3 Teilungen dieDarstellung der Verteilungsfunktion nahe derjenigen für unendlich viele Teilun-gen (siehe gestrichelte Linie). Mit wachsender Teilungsanzahl verringern sich dieAbstände.
0 1 2 3 4 5 6
0.05
0.15
p=0.5,Teilungen n=3, lambda/n=0.5
0 1 2 3 4 5 6
0.0
0.4
0.8
P(X.exp<=2)=0.2835
Abb. 19: von der geometrischen zur Exponentialverteilung
6.8 Casino- und Würfel-Fragen
Experiment zur Untersuchungsfrage: Welche der Méréschen Würfelsituationenbesitzt eine größere Wahrscheinlichkeit?
1 10 100 1000 10000
0.0
0.2
0.4
0.6
0.8
1.0
Versuche
relat
vie H
äufig
keit
6 bei 4 WürfenPasch−6 bei 24 Würfen
Abb. 20: Ergebnis von 10000 Simulationen
Aufbau / Ablauf: Es werden wiederholt vier virtuelle Würfel geworfen und fest-gestellt, ob mindestens eine Sechs erscheint. Ebenso werfen wir mit R wiederholtzwei Würfel und ermitteln in Serien der Länge 24, ob Pasch 6 vorkommt. Die
20

Entwicklung der relativen Häufigkeiten werden geplottet. Variierbar ist der Zu-fallsstart, wie auch die Anzahl der Einzelversuche.
Durchführung23 〈* 1〉+ ≡
exp.mere()
Abbildung 20 zeigt eine Ergebnisgraphik.Interpretation. Nach Abbildung 20 liegt die Wahrscheinlichkeit für eine Sechs
mit vier Würfeln knapp über 0.5, wogegen diejenige für Pasch 6 einem Wert etwasunter 0.5 zustrebt. Können wir dieses Ergebnis glauben? Sollte man besser nochmehr Versuche unternehmen?
Im Gegensatz zu Experimenten in einem richtigen Casino werden eigene Wür-felexperimente nicht zur Zahlungsunfähigkeit führen. Jedoch kann die Zeit zurDurchführung manueller Versuche viel besser für Rechnerexperimente und zumStudium dieses Kapitels genutzt werden. Hierdurch wird der Leser eine begrün-dete Antwort auf die Mérésche und andere Fragen bekommen.
6.9 Poisson-Verteilung checken
Experiment zum Check der Untersuchungsfrage , ob die Poisson-Verteilung alsModell passen könnte. Für die Poisson-Verteilung gilt:
g(x) =x · P(X = x)
P(X = x − 1)= λ x = 1, 2, . . .
Schätzen wir mittels relativer Häufigkeiten, können wir die Funktion g(·) mit
g(x) = x · Häufigkeit(x)
Häufigkeit(x − 1)
zeichen und interpretieren.Aufbau / Ablauf: Zur Klärung ziehen wir Stichproben aus künstlichen binomial-,
Poisson-, geometrischen und gleichverteilten Grundgesamtheiten und plottendann g(x). Wählbar sind: Stichprobenumfang, die Parameter der Verteilungensowie der Start für den Zufallszahlengenerator. Die Größe der Punkte soll die An-zahl der sie unterstützenden Punkte reflektieren.
Durchführung24 〈* 1〉+ ≡
exp.g.dach()
Abbildung 21 zeigt eine mögliche Ergebnisgraphik.
21

3 4 5 6 7 8 9 10
02
46
810
binom( 10 , 0.5 ), seed= 13 N= 100 , s^2/Mittel: 0.511
xg.
dach
(x)
1 2 3 4 5 6 7
01
23
45
67
pois( 2.5 ), seed= 13 N= 100 , s^2/Mittel: 0.962
x
g.da
ch(x
)
1 2 3 4 5 6 7
01
23
45
67
geom( 0.5 ), seed= 13 N= 100 , s^2/Mittel: 2.07
x
g.da
ch(x
)
3 4 5 6 7 8 9 10
02
46
812
unif( 1 10 ), seed= 13 N= 100 , s^2/Mittel: 1.13
xg.
dach
(x)
Abb. 21: Simulation von g(x) für verschiedene Verteilungen
Interpretation. Dieses Experimentes zeigt uns einen riesigen Stichprobeneffekt.Am Rechner lassen sich durch Variation des Startwertes sehr unterschiedlicheGraphiken erzeugen. Wir erkennen, dass selbst bei größeren Stichprobenum-fängen g(·) enorm vom Idealverlauf g(·) abweichen kann. Der Stichprobenef-fekt kann für bestimmte Verteilungen auch einzeln studiert werden. WiederholteAufrufe folgendes Chunks zeigen beispielsweise eine Umsetzung für eine Poisson-Verteilung mit λ = 0.8:
25 〈* 1〉+ ≡g.dach.x(rpois(50,.8),"test",ylim=c(0,2))
Wir müssen uns also davor hüten, vorschnell aufgrund einer plausiblen (eventuellausreißerempfindlichen) Maßzahl bzw. eines suggestiven Bildes eine Entschei-dung zu fällen. Solche Graphiken lassen sich jedoch zur Unterstützung einsetzen.Dieses Experiment verdeutlicht ebenfalls, dass ein naives Vorgehen, bei dem Vari-abilitäten unberücksichtigt bleiben, zu falschen Schlussfolgerungen führen kannund deshalb das Thema Schätzen seine Berechtigung besitzt.
6.10 Vergleich von Schätzfunktionen
Experiment zur Untersuchungsfrage: Wie geeignet sind die Schätzfunktionen2
θ1, θ2, θ3, θ4, θ5?
θ5(X1, . . . , Xn) = Median(X1, . . . , Xn)
θ4(X1, . . . , Xn) = X
θ3(X1, . . . , Xn) = 0.05 · X − 3.33
θ2(X1, . . . , Xn) = X1
θ1(X1, . . . , Xn) = 1
Aufbau / Ablauf: Wir ziehen wiederholt Stichproben aus einer Poisson-Verteilung und berechnen die Werte der Stichprobenfunktionen. Dann stellen wirdie Werte für die einzelnen Funktion als Boxplots dar.
Durchführung
2aus WNT(2006), p.200
22

26 〈* 1〉+ ≡exp.est.fns()
Abbildung 22 zeigt eine mögliche Ergebnisgraphik.
−5 0 5 10
θ1
θ2
θ3
θ4
θ5
n=20, wd=20, lambda=5, seed=7
Abb. 22: Boxplots von Realisationen der fünf Schätzfunktionen
Interpretation. θ1 liefert immer den Wert 1 und reagiert in keiner Weise aufdie Stichprobe. θ2 besitzt eine sehr große Variabilität, dafür erscheint die Lagebrauchbar. θ3 hat zwar eine geringe Variabilität, liegt aber völlig daneben. θ4 re-alisiert sich in der Umgebung der gesuchten Stelle, die Lage ist passend und dieVariabilität nicht sehr groß. θ5 besitzt die Eigenschaft, fast nur ganzzahlige Wertehervorzubringen, in der Realität werden jedoch Parameter von Poisson-verteiltenGrundgesamtheiten normalerweise nicht ganzzahlig sein. θ4 ist damit unter denfünf Vertretern offensichtlich am besten geeignet.
6.11 Verteilung des Mittels aus der Exponentialverteilung
Experiment zur Untersuchungsfrage: Wie schnell nähert sich das Mittel einerStichprobe aus einer exponentialverteilten Grundgesamtheit für wachsendenStichprobenumfang an die Normalverteilung an? Uns interessiert, ab welchemStichprobenumfang die Approximation brauchbar ist.
Aufbau / Ablauf: Wir ziehen wiederholt Stichproben aus Exp(1) und präsen-tieren einen QQ-Plot, in dem die Stichprobenmittel Quantilen der Standardnor-malverteilung gegenübergestellt werden.
Durchführung: Das Experiment ist schnell gebaut:27 〈* 1〉+ ≡
n<-10; wd<-1000; mittel<-numeric(wd)for(i in 1:wd) mittel[i]<-mean(rexp(n))qqnorm(mittel)
Mit der Funktion exp.exp.mittel() bieten wir diese Anweisungen in Formeines interaktiven Experimentes an, bei dem zusätzlich die empirische Verteilungs-funktion der Mittelwerte gezeigt wird.
28 〈* 1〉+ ≡exp.exp.mittel()
Interpretation: Für n=30 , wd =500 und seed=2 erhalten wir beispielsweise alsOutput die Abbildung 23, aus der wir sehen können, dass die Approximation derVerteilung des Stichprobenmittels für einen Stichprobenumfang von 30 schon er-staunlich gut ist.
23
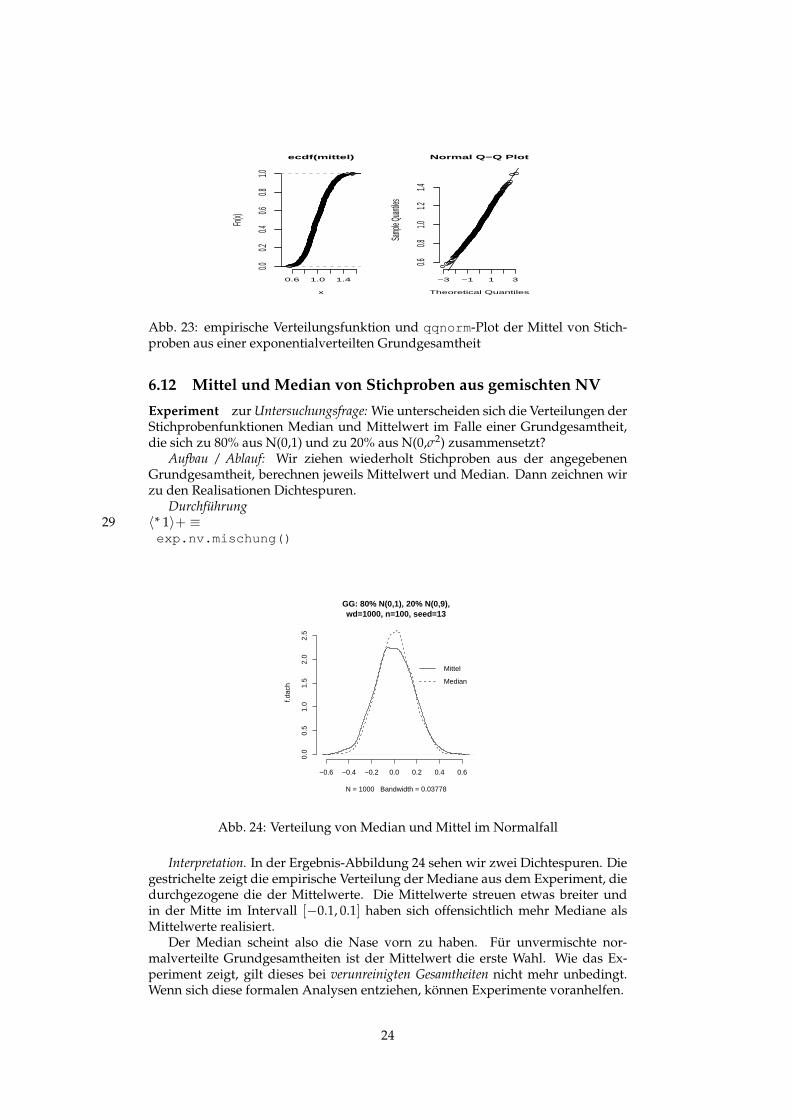
0.6 1.0 1.4
0.00.2
0.40.6
0.81.0
ecdf(mittel)
x
Fn(x)
−3 −1 1 3
0.60.8
1.01.2
1.4
Normal Q−Q Plot
Theoretical Quantiles
Samp
le Quan
tiles
Abb. 23: empirische Verteilungsfunktion und qqnorm -Plot der Mittel von Stich-proben aus einer exponentialverteilten Grundgesamtheit
6.12 Mittel und Median von Stichproben aus gemischten NV
Experiment zur Untersuchungsfrage: Wie unterscheiden sich die Verteilungen derStichprobenfunktionen Median und Mittelwert im Falle einer Grundgesamtheit,die sich zu 80% aus N(0,1) und zu 20% aus N(0,σ2) zusammensetzt?
Aufbau / Ablauf: Wir ziehen wiederholt Stichproben aus der angegebenenGrundgesamtheit, berechnen jeweils Mittelwert und Median. Dann zeichnen wirzu den Realisationen Dichtespuren.
Durchführung29 〈* 1〉+ ≡
exp.nv.mischung()
−0.6 −0.4 −0.2 0.0 0.2 0.4 0.6
0.0
0.5
1.0
1.5
2.0
2.5
N = 1000 Bandwidth = 0.03778
f.dac
h
Mittel
Median
GG: 80% N(0,1), 20% N(0,9),wd=1000, n=100, seed=13
Abb. 24: Verteilung von Median und Mittel im Normalfall
Interpretation. In der Ergebnis-Abbildung 24 sehen wir zwei Dichtespuren. Diegestrichelte zeigt die empirische Verteilung der Mediane aus dem Experiment, diedurchgezogene die der Mittelwerte. Die Mittelwerte streuen etwas breiter undin der Mitte im Intervall [−0.1, 0.1] haben sich offensichtlich mehr Mediane alsMittelwerte realisiert.
Der Median scheint also die Nase vorn zu haben. Für unvermischte nor-malverteilte Grundgesamtheiten ist der Mittelwert die erste Wahl. Wie das Ex-periment zeigt, gilt dieses bei verunreinigten Gesamtheiten nicht mehr unbedingt.Wenn sich diese formalen Analysen entziehen, können Experimente voranhelfen.
24

6.13 Schätzer bei wachsenden Stichprobenumfängen
Experiment zur Untersuchungsfrage: Wie verbessern sich die Schätzer der Param-eter einer Normalverteilung bei wachsendem Stichprobenumfang?
Aufbau / Ablauf:
1. ziehe eine Stichprobe vom Umfang n aus einer Standardnormalverteilung,
2. berechne für m = 2, . . . , n zu den Teilstichproben (x1, . . . , xm) die beidenSchätzer µm = µm(x1, . . . , xm) = xm und σ2
m = σ2m(x1, . . . , xm) = s2
m,
3. verbinde in einer Graphik die Punkte (µm, σ2m) mit m = 2, . . . , n,
4. markiere mit Hilfslinien den Ort der wahren Parameter.
Durchführung:30 〈* 1〉+ ≡
exp.nv.est()
Dieser Aufruf liefert Bilder wie z.B. Abbildung 25 bzw. 26
−1.0 −0.5 0.0 0.5 1.0
0.4
0.6
0.8
1.0
1.2
1.4
1.6
mue.dach
sigm
a.q.
dach
Stichprobenumfang bis 10
−1.0 −0.5 0.0 0.5 1.0
0.4
0.6
0.8
1.0
1.2
1.4
1.6
mue.dach
sigm
a.q.
dach
Stichprobenumfang bis 20
Abb. 25: Entwicklung bis 10 bzw. 20
−0.4 −0.2 0.0 0.2 0.4
0.8
0.9
1.0
1.1
1.2
mue.dach
sigm
a.q.
dach
Stichprobenumfang bis 100
−0.4 −0.2 0.0 0.2 0.4
0.8
0.9
1.0
1.1
1.2
mue.dach
sigm
a.q.
dach
Stichprobenumfang bis 1000
Abb. 26: Entwicklung bis 80 bzw. 500
Eigene Versuche lassen sich mit folgender Sparversion des Experimentes umset-zen, ...
31 〈* 1〉+ ≡n.max<-1000; set.seed(13)stpr<-rnorm(n.max,mean=0,sd=1)stpr.mean<-cumsum(stpr)/(1:n.max)plot(1:n.max,stpr.mean,type="l")
... die zum Beispiel für den Zufallszahlenstart 13 die Abbildung 27 hervorbringt.
25

0 200 400 600 800 1000
0.0
0.2
0.4
0.6
1:n.max
stpr
.mea
n
Abb. 27: Entwicklung des Stichprobenmittels bis 1000 Versuche
Interpretation. Mittelwerte nähern sich mit wachsendem Stichprobenumfangden Erwartungswerten und Stichprobenvarianzen der Varianz der Grundgesamt-heit immer mehr an. Diese Eigenschaft überträgt sich auf die Schätzer. DieGraphiken visualieren den Annäherungsprozess.
6.14 Variabilität des von λ bei der Poisson-Verteilung
Experiment zur Untersuchungsfrage: Welche Variabilität besitzt ein Schätzer?Mit diesem Experiment wollen wir die Variabilität der Schätzfunktion λ =λ(X1, . . . , Xn) = X zur Schätzung des Parameters λ der Poisson-Verteilung sicht-bar machen.
Aufbau / Ablauf:
1. ziehe wd Stichproben vom Umfang n aus einer Poisson-Verteilung mit Pa-rameter lambda ,
2. berechne für die einzelnen Stichproben (jx1, . . . , jxn) die Schätzwerte derSchätzfunktion: λj = λj(
jx1, . . . , jxn) = x j, j = 1, . . . , wd,
3. zeichne zu den Realisationen einen Boxplot ergänzt um einen Jitterplot.
Durchführung.32 〈* 1〉+ ≡
# Experimentparameter festlegenn <- 20; wd <- 100; lambda<-5; set.seed(13)# Stichproben als Spalten in X ablegenX <- matrix(rpois(n * wd, lambda),n,wd)# Schaetzer -- apply(X,2,mean) berechnet Spaltenmittel vo n Xlambda.dach<-apply(X,2,mean)# Graphik erstelleny.jitter<-2+10 * jitter(rep(0,wd))plot(lambda.dach,y.jitter,ylim=c(0.5,2.5),bty="n",y lab="",axes=F)boxplot(lambda.dach,horizontal=T,add=T)
26

lambda.dach
4.0 4.5 5.0 5.5 6.0
Abb. 28: empirische Verteilung von X gezogen aus Poisson(5)
Interpretation. Bei einem Stichprobenumfang von n=20 und bei wd=100Wiederholungen besitzen die Schätzwerte eine fast symmetrische Verteilung. Derwahre Parameterwert 5 stimmt nicht ganz mit dem Median der Stichprobenüberein. Alle Schätzwerte liegen zwischen 3.85 und 6.3, also recht weit aus einan-der.
6.15 Unterschiedlichkeit geschätzter Modelle
Experiment zur Untersuchungsfrage: Wie unterschiedlich fallen geschätzteModelle aus? Als Demonstrationsobjekt haben wir die Exponentialverteilung aus-gewählt.
Versuchsaufbau: Wir setzen folgende Schritte um:
1. ziehe wd Stichproben vom Umfang n aus einer Exponentialverteilung mitParameter lambda ,
2. berechne für die einzelnen Stichproben (jx1, . . . , jxn) die Schätzwerte derSchätzfunktion: λj = λj(
jx1, . . . , jxn) = 1/X j, j = 1, . . . , wd,
3. zeichne zu den Schätzern die Dichten und Verteilungsfunktionen.
Durchführung:33 〈* 1〉+ ≡
# Experimentparameter festlegenn <- 20; wd <- 30; lambda <- 1; set.seed(13)# Stichprobe ziehen, Berechnungen durchfuehrenlambda.dach<-numeric(wd)for(j in 1:wd){
stpr<-rexp(n, lambda)lambda.dach[j]<-1/mean(stpr)
}# Graphik erstellenx<-seq(0,5,length=100)plot(x,x,type="n",ylim=c(0,2),bty="n")for(j in 1:wd) lines(x,dexp(x,lambda.dach[j]))
27
0 1 2 3 4 5
0.0
0.5
1.0
1.5
2.0
x
x
Abb. 29: Variabilität von f (x) bei Exponentialverteilung für n=20 und wd=30Wiederholungen
Interpretation: Wie zu erwarten ist bei allen Dichten die Grundstruktur gleich.Die Werte der Dichten verlaufen an der Stelle 1 sehr dicht beieinander.
6.16 NV-Anpassung an Beta-Verteilungen
Experiment zur Untersuchungsfrage: Was passiert, wenn wir an eine Beta-Verteilung, die nur Realisationen zwischen 0 und 1 hervorbringen kann, eine Nor-malverteilung anpassen?
Versuchsaufbau: Wir definieren folgende Schritte:
1. wähle Parameter a und b einer Beta-Verteilung,
2. ziehe wd Stichproben vom Umfang n aus dieser Beta-Verteilung,
3. schätze Normalverteilungsparameter,
4. zeichne Dichte der Beta-Verteilung und die von angepassten Modelle.
Durchführung:34 〈* 1〉+ ≡
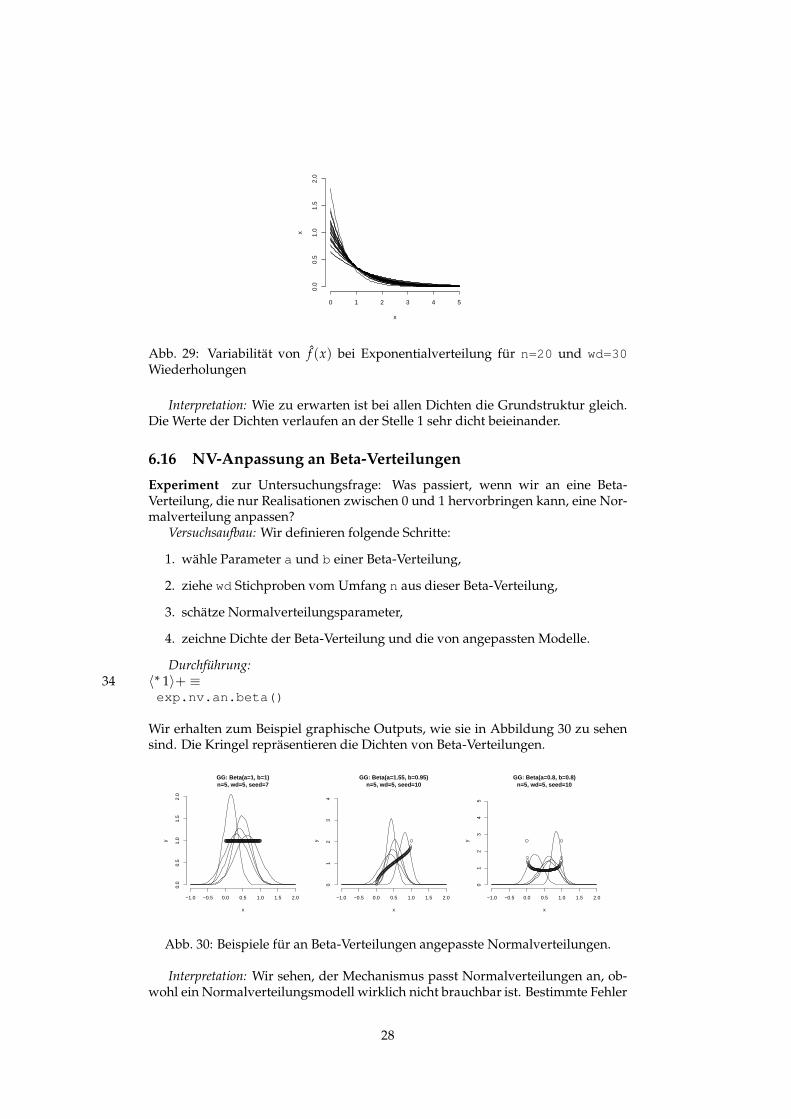
exp.nv.an.beta()
Wir erhalten zum Beispiel graphische Outputs, wie sie in Abbildung 30 zu sehensind. Die Kringel repräsentieren die Dichten von Beta-Verteilungen.
−1.0 −0.5 0.0 0.5 1.0 1.5 2.0
0.0
0.5
1.0
1.5
2.0
x
y
GG: Beta(a=1, b=1)n=5, wd=5, seed=7
−1.0 −0.5 0.0 0.5 1.0 1.5 2.0
01
23
4
x
y
GG: Beta(a=1.55, b=0.95)n=5, wd=5, seed=10
−1.0 −0.5 0.0 0.5 1.0 1.5 2.0
01
23
45
x
y
GG: Beta(a=0.8, b=0.8)n=5, wd=5, seed=10
Abb. 30: Beispiele für an Beta-Verteilungen angepasste Normalverteilungen.
Interpretation: Wir sehen, der Mechanismus passt Normalverteilungen an, ob-wohl ein Normalverteilungsmodell wirklich nicht brauchbar ist. Bestimmte Fehler
28

in der Modelltypwahl sind offensichtlich nicht reparabel. Es könnte eingewen-det werden, dass kein Mensch auf die Idee kommt, an Daten aus einer Beta(1,1)-Verteilung (also einer (0,1)-Gleichverteilung) ein Normalverteilungsmodell anzu-passen. Doch Statistiker haben schon Schlimmeres erlebt!
6.17 Ausreißer-Einfluss bei der Modellschätzung
Experiment zur Untersuchungsfrage: Wie beeinflussen Ausreißer in einer nor-malverteilten Grundgesamtheit das angepasste Normalverteilungsmodell?
Versuchsaufbau:
1. Aus einer Grundgesamtheit mit Elementen, die zu einem Anteil von (1 − p)aus N(0,1) und zu einem Anteil von p aus N(µAusreißer, σ2
Ausreißer) be-steht, ziehen wir wd Stichproben vom Umfang n.
2. Wir schätzen aufgrund jeder Stichprobe ein Normalverteilungsmodell und
3. zeichnen die Dichte der Grundgesamtheit sowie die angepassten Nor-malverteilungsdichten.
Durchführung:35 〈* 1〉+ ≡
exp.outlier()
Abbildung 31 zeigt eine Ergebnisgraphik.
−4 −2 0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
x
f.x
90% norm(0,1) und 10% norm(7,1)n=20, wd=10
Abb. 31: angepasste Normalverteilungsdichten an NV mit Ausreißern
Interpretation: Eine angepasste Normalverteilung kann nicht die Bimodalitätder Grundgesamtheit wiedergeben. Es ist eine leichte Verschiebung sowie eineviel zu große Variabilität zu erkennen. Auch hier können weitere Darstellungenwie ein QQ-Plot helfen, stark abweichende Werte (Ausreißer) zu entdecken, diedann ggf. entfernt werden können.
6.18 Unterschiedlichkeit von Konfidenzintervallen
Experiment zur Untersuchungsfrage: Welche Konfidenzintervalle für p ergebensich bei wiederholter Stichprobenziehung?
Aufbau / Ablauf: Wir ziehen wiederholt Stichproben, berechnen jeweils Konfi-denzintervalle und repräsentieren diese durch senkrechte Striche
Durchführung
29

36 〈* 1〉+ ≡exp.ki.p()
Versuche
real
isier
te K
Is
0.0
0.2
0.4
0.6
0.8
1.0
n=10, alpha=0.05, p=0.5, seed=1
Abb. 32: Realisationen von Konfidenzintervallen
Interpretation: Zum Beispiel erhalten wir die Abbildung 32. Wir sehen, dasseinige wenige Intervalle den Parameter nicht überdecken.
7 Implementationen
7.1 slider()37 〈start 37〉 ≡
par(bty="n")slider<-function (sl.functions, sl.names, sl.mins, sl.m axs, sl.deltas,
sl.defaults, but.functions, but.names, no, set.no.value ,obj.name, obj.value, reset.function, title, prompt = FALS E)
{ # Version 2009-03slider.env <- "1"rm("slider.env")if (!exists("slider.env"))
slider <- slider.env <<- new.env(parent = .GlobalEnv)if (!missing(no))
return(as.numeric(tclvalue(get(paste("slider", no, se p = ""),env = slider.env))))
if (!missing(set.no.value)) {try(eval(parse(text = paste("tclvalue(slider", set.no. value[1],
")<-", set.no.value[2], sep = "")), env = slider.env))return(set.no.value[2])
}if (!missing(obj.name)) {
if (!missing(obj.value))assign(obj.name, obj.value, env = slider.env)
else obj.value <- get(obj.name, env = slider.env)return(obj.value)
}if (missing(title))
title <- "slider control widget"if (missing(sl.names)) {
sl.defaults <- sl.names <- NULL}if (missing(sl.functions))
sl.functions <- function(...) {}
require(tcltk)nt <- tktoplevel()tkwm.title(nt, title)tkwm.geometry(nt, "+0+15")
30

assign("tktop.slider", nt, env = slider.env)"relax"for (i in seq(sl.names)) {
"relax"eval(parse(text = paste("assign(’slider", i, "’,tclVar( sl.defaults[i]),env=slider.env)",
sep = "")))}for (i in seq(sl.names)) {
tkpack(fr <- tkframe(nt))lab <- tklabel(fr, text = sl.names[i], width = "25")sc <- tkscale(fr, from = sl.mins[i], to = sl.maxs[i],
showvalue = TRUE, resolution = sl.deltas[i], orient = "hori z")tkpack(lab, sc, side = "right")assign("sc", sc, env = slider.env)eval(parse(text = paste("tkconfigure(sc,variable=slid er",
i, ")", sep = "")), env = slider.env)sl.fun <- if (length(sl.functions) > 1)
sl.functions[[i]]else sl.functionsif (!is.function(sl.fun))
sl.fun <- eval(parse(text = paste("function(...){",sl.fun, "}")))
if (prompt)tkconfigure(sc, command = sl.fun)
else tkbind(sc, "<ButtonRelease>", sl.fun)}assign("slider.values.old", sl.defaults, env = slider.e nv)tkpack(f.but <- tkframe(nt), fill = "x")tkpack(tkbutton(f.but, text = "Exit", command = function( ) tkdestroy(nt)),
side = "right")if (!missing(reset.function)) {
if (!is.function(reset.function))reset.function <- eval(parse(text = paste("function(... ){",
reset.function, "}")))tkpack(tkbutton(f.but, text = "Reset", command = function () {
for (i in seq(sl.names)) eval(parse(text = paste("tclvalu e(slider",i, ")<-", sl.defaults[i], sep = "")), env = slider.env)
reset.function()}), side = "right")
}if (missing(but.names))
but.names <- NULLfor (i in seq(but.names)) {
but.fun <- if (length(but.functions) > 1)but.functions[[i]]
else but.functionsif (!is.function(but.fun))
but.fun <- eval(parse(text = c("function(...){",but.fun, "}")))
tkpack(tkbutton(f.but, text = but.names[i], command = but .fun),side = "left")
}invisible(nt)
}
7.2 exp.median.mean()38 〈start 37〉+ ≡
exp.median.mean<-function(x){〈hole ggf. Funktion slider NA〉
if(missing(x)){set.seed(13); x<-runif(10)}slider(obj.name="i.alt",obj.value=1)slider(obj.name="x",obj.value=x)refresh.code<-function(...){# Experimentparameter
31

i<-slider(no=2); i.alt<-slider(obj.name="i.alt")if(i!=i.alt) slider(set.no.value=c(1,x[i]))wert<-slider(no=1); slider(obj.name="i.alt",obj.valu e=i)
# Umsetzungx<-slider(obj.name="x"); x[i]<-wertslider(obj.name="x",obj.value=x)
# Ergebnisdarstellungrx<-range(x); eps<-0.5 * diff(rx)xlim<-c(rx[1]-eps,rx[2]+eps)plot(x,rep(0,length(x)),bty="n", xlab="",ylab="", cex =2,
xlim=xlim, ylim=c(-2,2),yaxt="n",main="Effekt von Einzelwerten\nauf Median und Mittel")
m<-mean(x); segments(m, 1,m, 0.2)text(m, 1.25,"Mittel",cex=2)m<-median(x); segments(m,-1,m,-0.2)text(m,-1.25,"Median",cex=2)points(x[i],0,col="red",cex=2)text(x[-i],rep(.5,length(x)-1),as.character(seq(x)) [-i],cex=1)text(x[i],.5,as.character(i),col="red",cex=2)boxplot(x,axes=F,add=T,horizontal=T,
at=par()$usr[3]+diff(par()$usr[3:4]) * .05, # 0.017boxwex=0.1 * diff(par()$usr[3:4]),pch=8) # 0.02 *
}x<-sort(x); del<-1.5 * diff(range(x))bereich<-c(min(x)-del,max(x)+del)slider(refresh.code,c("Wert von x[i]","Auswahl von i"),
c(bereich[1],1),c(bereich[2],length(x)),c(del/100,1),c(x[1],1),prompt=TRUE )
refresh.code()"ok"
}
Zu jede Funktion müsste natürlich eine Help-Seite geben. Diese können so aussehen:39 〈help 39〉 ≡
\name{exp.median.mean}\alias{exp.median.mean}\title{ experiment to demonstrate differences of median an d mean }\description{
Outliers may have a great influence on the mean.On the other side the median will not react on the extremedata values. The experiment shows you the reaction of singlevariation of single data values.
}\usage{
exp.median.mean(x)}%- maybe also ’usage’ for other objects documented here.\arguments{
\item{x}{ a not too large data set for the experiment}}\details{
In the experiment the data values are represented by circlesand the locations of mean and median are shown. By a slideryou can choose a single point and you can move it to the rightand to the left. In doing so the positions of the median andthe mean will be corrected.
}\value{}\references{ }\author{ Peter Wolf }\note{}% \seealso{ ~~objects to See Also as \code{\link{help}}, ~~ ~ }\examples{##---- Should be DIRECTLY executable !! ----
32

##-- ==> Define data, use random,##-- or do help(data=index) for the standard data sets.exp.median.mean(c(1:5,20))
7.3 exp.hist()40 〈start 37〉+ ≡
exp.hist<-function(x){〈hole ggf. Funktion slider NA〉
refresh.code<-function(...){# Experimentparameter
n.breaks<-slider(no=1)+1if(nox) {
n<-slider(no=2); set.seed(seed<-slider(no=3))x<-rnorm(n)
}# Umsetzung
breaks<-seq(min(x),max(x),length=n.breaks)# Ergebnisdarstellung
hist(x,breaks=breaks,prob=T,ylab="",main="Effekt von Klassenanzahl\nauf Histogramm")
rug(x)if(nox) {
xx<-seq(-3,3,length=100); lines(xx,dnorm(xx))title(sub=paste(n.breaks-1," Klassen, n =",n,
", seed =",seed,sep=""))}
}if(missing(x)){
nox<-TRUEslider(refresh.code,
c("Klassenanzahl","Werteanzahl","Zufall"),c(1,10,1),c(200,500,100),c(1,10,1),c(9,100,1) )
}else{nox<-FALSEbreaks.default<-length(hist(x,plot=FALSE)$breaks)slider(refresh.code,c("Klassenanzahl"),
c(1),c(200),c(1),c(breaks.default) )}refresh.code()"ok"
}
7.4 exp.F.dach.lookup()41 〈start 37〉+ ≡
exp.F.dach.lookup<-function(x){〈hole ggf. Funktion slider NA〉
if(missing(x)){set.seed(13); x<-rnorm(10)}n<-length(x); x<-sort(x)refresh.code<-function(...){
x0<-slider(no=1); h1<-slider(no=2); qty<-slider(no=3)F.dach<-(0:n)/nF.x0<-F.dach[ 1+sum(x<=x0) ]x1<-quantile(x,h1,type=qty)plot(x,F.dach[-1],bty="n",pch=20,
ylab=expression(hat(F)(x)),xlim=bereich,ylim=c(-.1,1.1))
abline(h=0:1,lty=2)segments(c(bereich[1],x),(0:n)/n,c(x,bereich[2]),(0 :n)/n)segments(x,((1:n)-1)/n,x,(1:n)/n,lty=3)arrows(x0,-.05,x0,F.x0,col="red",lty=3)arrows(x0,F.x0,par()$usr[1],F.x0,col="red",lty=3)text(x0+del * .1,-0.05,bquote(x[0]==.(signif(x0,3))),
col="red",adj=0)
33

text(par()$usr[1]+del * .2,F.x0+0.05,adj=0,bquote(hat(F)(x[0])==.(signif(F.x0,3))),col="red")
arrows(x1,h1,x1,-.05,col="blue",lty=2)arrows(par()$usr[1],h1,x1,h1,col="blue",lty=2)text(x1,-0.11,bquote(x[1]==.(signif(x1,3))),col="bl ue")text(par()$usr[1]+del * .2,h1-0.05,adj=0,
bquote(hat(F)(x[1])==.(signif(h1,3))),col="blue")title("empirische Verteilungsfunktion\nEinsatz")
}del<-0.4 * diff(range(x)); bereich<-c(min(x)-del,max(x)+del)slider(refresh.code,
c("Wert von x.0","Wert von F.dach(x.1)","Quantil-Definition"),
c(bereich[1],0,1),c(bereich[2]-.9 * del,1,9),c(del/100,.001,1),c(mean(x),.5,1) )
refresh.code()"ok"
}
7.5 exp.fbe.fit()42 〈start 37〉+ ≡
exp.fbe.fit<-function(x,y){〈hole ggf. Funktion slider NA〉
if(missing(x)|| missing(x)) {x<-cars[,1];y<-cars[,2]}replot<-function(...){
x1<-slider(no=1); y1<-slider(no=2)x2<-slider(no=3); y2<-slider(no=4)b<-(y2-y1)/(x2-x1); a<-y1-b * x1xlim<-range(c(xlim,0)); ylim<-range(c(ylim,0))plot(x,y,bty="n",xlim=xlim,ylim=ylim,
main="fitting by eye")title(main=paste("\n\n\n y =",signif(a,4),
"+",signif(b,4)," * x"))abline(a,b,col="red")points(x1,y1,col="red",pch=16,cex=2)points(x2,y2,col="red",pch=16,cex=2)
}showls<-function(...){
res<-lsfit(x,y)$coefabline(res,lty=2,col="blue")h<-par()$usrif(res[2]>0){
text(h[1]+0.15 * diff(h[1:2]),h[4]-0.1 * diff(h[3:4]),bquote(hat(a)==.(signif(res[1],4))),col="blue")
text(h[1]+0.15 * diff(h[1:2]),h[4]-0.2 * diff(h[3:4]),bquote(hat(b)==.(signif(res[2],4))),col="blue")
}else{text(h[2]-0.15 * diff(h[1:2]),h[4]-0.1 * diff(h[3:4]),
bquote(hat(a)==.(signif(res[1],4))),col="blue")text(h[2]-0.15 * diff(h[1:2]),h[4]-0.2 * diff(h[3:4]),
bquote(hat(b)==.(signif(res[2],4))),col="blue")}
}xlim<-range(x); ylim<-range(y)dx<-diff(xlim);dy<-diff(ylim)xlim<-xlim+c(-.5,.5) * dxylim<-ylim+c(-.5,.5) * dyslider(replot,c("x1 : x-Wert Punkt 1","y1 : y-Wert Punkt 1" ,
"x2 : x-Wert Punkt 2","y2 : y-Wert Punkt 2"),c(xlim[1],ylim[1],xlim[1],ylim[1]),c(xlim[2],ylim[2],xlim[2],ylim[2]),0.001 * c(dx,dy,dx,dy),c(xlim[1],ylim[1],xlim[2],ylim[2]),
showls,"zeige KQ-Gerade",
34

title="fbe-fit: by fixing two points")replot()"ok"
}
7.6 exp.boxcox()43 〈start 37〉+ ≡
exp.boxcox<-function(x){〈hole ggf. Funktion slider NA〉
if(missing(x)){set.seed(13); x<-rlnorm(100)}if (any(x <= 0)) {
x <- x - min(x) + 1e-04 * diff(range(x))print("WARNUNG: x Werte wurden verschoben, da z.T. <=0!")
}jittervalues<-runif(length(x))refresh.fns<-function(...){# Parameter holen
lambda<-slider(no=1); rel.width<-slider(no=2)# Umsetzung
xx<-if(lambda!=0) (x^lambda-1)/lambda else log(x)h<-density(xx,width=rel.width * (max(xx)-min(xx)),n=200)par(mfrow=c(1,1))op<-par(mfrow=c(1,1)) # ,xaxs="i")ylim<-range(h$y); ydel<-diff(ylim); ylim<-ylim-c(.1 * ydel,0)plot(h$x, h$y, type="l",bty="n",xlab="t(x)",
ylab="Dichte",ylim=ylim)title("Verteilung / Box-Cox-Transformation")title(sub=bquote(list(lambda==.(lambda),
Fensterbreite==.(rel.width))))abline(h=0)xlim<-par()$usr[1:2]boxplot(xx,axes=F,add=T,horizontal=T,
at=-0.05 * ydel,boxwex=0.06 * diff(par()$usr[3:4]))rug(xx,side=1,ticksize=.02) # * diff(par()$usr[3:4]))axis(1)par(op)
}slider(refresh.fns,c("lambda: Box-Cox-Parameter",
"relative Breite"),c(-2,0.01),c(8,1),c(.1,.01),c(1,0 .2))refresh.fns()"ok"
}
7.7 exp.fit.poly()44 〈start 37〉+ ≡
exp.fit.poly<-function(){〈hole ggf. Funktion slider NA〉
replot<-function(...){# Einstellungen lesen
n<-slider(no=1); sigma.u<-slider(no=2); set.seed(13)p.coef<-c(slider(no=3),slider(no=4),slider(no=5),sl ider(no=6))pg<-slider(no=7)
# Daten erzeugenx<-runif(n,0,100); u<-rnorm(n,0,sigma.u)y<-p.coef[1]+p.coef[2] * x+p.coef[3] * x^2+p.coef[4] * x^3+uxy<-data.frame(x=x,y=y)
# Modell ermittelnformula<-paste(c("x","+I(x^2)","+I(x^3)","+I(x^4)", "+I(x^5)")
[1:pg],collapse="")
code<-paste("lm(y~",formula,",xy)")
35

result<-eval(parse(text=code))# Punkte zeichnen
par(mfrow=c(2,1))plot(xy,bty="n")
# Modelllinienewdata<-data.frame(x=seq(min(x),max(x),length=100) )newdata.fitted<-predict(result,newdata=newdata)lines(newdata$x,newdata.fitted,col="blue")
a.est<-paste(signif(result$coef,3),collapse=", ")a.est<-paste("(",a.est,")")title(sub=bquote(hat(a)==.(a.est)))title(bquote(y==.(p.coef[1]) * x^0+.(p.coef[2]) * x^1
+.(p.coef[3]) * x^2+.(p.coef[4]) * x^3+u))
# Residuenplot(x,result$resid,type="h",bty="n",main="Residual plot",ylab="")par(mfrow=c(1,1))
}slider(replot,c("n","sigma.U","a0","a1","a2","a3"," Modell-Polynomgrad"),
c(20,50,-20000,-1000,-100,-1,1),c(200,10000,20000,1000,100,1,5),c(10,50,1000,100,10,.1,1),c(20,50,20000,-14,-50,.5,1))
replot()"ok"
}
7.8 exp.check.point.influence()45 〈start 37〉+ ≡
exp.check.point.influence<-function(x,y,seed=13){〈hole ggf. Funktion slider NA〉
if(missing(x)) {n<-10; set.seed(seed)x<-runif(n,0,10); u<-rnorm(n,0,1)y<-2+x+u
}n<-length(x)delta.x<-diff(range(x)); delta.y<-diff(range(y))xmin<-min(x)-delta.x; ymin<-min(y)-delta.yxmax<-max(x)+delta.x; ymax<-max(y)+delta.yslider(obj.name="j",obj.value=1)slider(obj.name="x",obj.value=x)slider(obj.name="y",obj.value=y)replot<-function(...){
j.alt<-slider(obj.name="j"); j<-slider(no=1)x<-slider(obj.name="x"); y<-slider(obj.name="y")if(j.alt!=j){
slider(set.no.value=c(2,x[j]))slider(set.no.value=c(3,y[j]))slider(obj.name="j",obj.value=j)
}xneu<-slider(no=2); yneu<-slider(no=3)x[j]<-xneu; y[j]<-yneuslider(obj.name="x",obj.value=x)slider(obj.name="y",obj.value=y)result<-lsfit(x,y)par(mfrow=c(1,2))plot(x,y,bty="n",type="n",
xlim=c(xmin,xmax),ylim=c(ymin,ymax))abline(result,col="blue")text(x,y,as.character(1:n))text(x[j],y[j],as.character(j),col="red")title(paste( "a.dach=",signif(result$coef[1],2),
36

", b.dach=",signif(result$coef[2],2),sep=""))plot(x,result$resid,type="h",bty="n",main="Residual plot")points(x[j],result$resid[j],type="h",col="red")par(mfrow=c(1,1))
}slider(replot,c("Punkt?","neuer x-Wert?","neuer y-Wer t?"),
c(1, xmin,ymin),c(n, max(x)+delta.x,max(y)+delta.y),c(1, xmin,ymin),c(1,x[1], y[1]))
replot()"ok"
}
7.9 exp.adjust.Rq()46 〈start 37〉+ ≡
exp.adjust.Rq<-function(x,y){〈hole ggf. Funktion slider NA〉
nodata<-TRUEif(!missing(x)){
if(is.matrix(x)||is.data.frame(x)){y<-x[,2]; x<-x[,1]; nodata<-FALSE
} else {if(!missing(y)) nodata<-FALSE
}}replot<-function(...){
n<-slider(no=6); seed<-slider(no=7); set.seed(seed)mu1<-slider(no=1); mu2<-slider(no=2)sd1<-slider(no=3); sd2<-slider(no=4)sdxy<-slider(no=5)/10 * (sd1 * sd2)^0.5if(nodata){
x<-rnorm(n); y<-rnorm(n); xy<-cbind(x,y)} else {
xy<-cbind(x,y); xy<-xy[sample(1:length(xy[,1]),size= n,replace=T),]}xy<-xy% * %matrix(c(sd1,sdxy,sdxy,sd2),2,2)x<-xy[,1]+mu1; y<-xy[,2]+mu2plot(x,y,bty="n"); abline(lsfit(x,y),col="blue")title(bquote(list(
R^2==.(paste(signif(cor(x,y)^2,3),"")),r[xy]==.(signif(cor(x,y),3)),rho[Spearman]==.(signif(cor(x,y,method="spearman"), 3)),
)))}# ... 7.3, 100, 13 -> .90slider(replot,
c("Parameter 1","Parameter 2","Parameter 3","Parameter 4","Parameter 5","n","seed"),
c(-10,-10,0,0,-10,10,1),c(10,10,10,10,10,200,100),c(.1,.1,.1,.1,.1,1,1),c(1,1,1,1,0,50,13))
replot()"ok"
}
7.10 exp.Rq.outlier()47 〈start 37〉+ ≡
exp.Rq.outlier<-function(x,y){〈hole ggf. Funktion slider NA〉
nodata<-TRUEif(!missing(x)){
37

if(is.matrix(x)||is.data.frame(x)){y<-x[,2]; x<-x[,1]; nodata<-FALSE
} else {if(!missing(y)) nodata<-FALSE
}}
replot<-function(...){n<-20; a<-1; b<-1set.seed(13)if(nodata){
x<-runif(n-1,-1,1); y<-runif(n-1,-1,1)}else{
x<-(x-mean(x))/sd(x); y<-(y-mean(y))/sd(y)}distance<-slider(no=1); alpha<--(slider(no=2)-3) * 2* pi/12x<-c(distance * cos(alpha),x)y<-c(distance * sin(alpha),y)lim<-max(c(x,distance))xlim<-c(-lim,lim)plot(x,y, bty="n",xlim=xlim,ylim=xlim); abline(lsfit( x,y),col="blue")points(x[1],y[1],col="red",pch=20)title(bquote(paste(R^2," und Ausrei\337er")))title(sub=bquote(list(
R^2==.(signif(cor(x,y)^2,3)),r[xy]==.(signif(cor(x,y),3)),tau[Kendall]==.(signif(cor(x,y,method="kendall"),3) ),rho[Spearman]==.(signif(cor(x,y,method="spearman"), 3))
)))}slider(replot,c("Entfernung","Richtung"),
c(0,-6),c(50,18),c(.2,0.25),c(5,1.5))replot()"ok"
}
7.11 exp.sample.dice()48 〈start 37〉+ ≡
exp.sample.dice<-function(){〈hole ggf. Funktion slider NA〉
redo<-function(...){opar<-par(bty="n",mfrow=2:1)n.gg<-slider(no=1); n<-slider(no=2); seed<-slider(no= 4)welcher<-slider(no=3)if(n.gg<welcher){
welcher<-min(welcher,n.gg);slider(set.no.value=c(3, welcher))}
set.seed(seed); x<-sample(1:n.gg,size=n,replace=TRUE )table.x<-table(sort(c(x,1:n.gg)))-1; table.x<-table. x/sum(table.x)plot(table.x,ylab=bquote(h[i]),main="relative H\344u figkeiten -- gesamt")plot(1:n,type="n",ylim=0:1,
sub=bquote(list(.(paste(n.gg,"-er Würfel ")),Versuche ==.(n),Zufallsstart==.(seed))),
main=(paste("... für Augenzahl",welcher,"bis Versuch no ")),ylab=bquote(paste(h[i])), xlab="no")
# for(i in 1:n.gg)lines(1:n,cumsum(x==i)/(1:n),lty=2)abline(h=1/n.gg,col="blue")lines(1:n,cumsum(x==welcher)/(1:n),lty=1,col="red")par(opar)
}slider(redo,
c("-er W\334rfel","Versuche","Augenzahl","Zufallsstart"),
c(2,2,2,1),c(20,1000,20,1000),c(1,1,1,1),c(6,100,6, 1))
38

redo()"ok"
}
7.12 exp.g.dach()49 〈start 37〉+ ≡
exp.g.dach<-function(){refresh<-function(...){g.dach.plot<-function(stpr,typ){
mittel<-mean(stpr); s.q<-var(stpr); N<-length(stpr)x.max<-max(stpr);x.min<-min(stpr)freq<-table(factor(stpr,x.min:x.max))g.x<-((x.min+1):x.max) * freq[-1]/freq[-length(freq)]ok<-(!is.nan(g.x))& g.x<Infcex<-sqrt(freq[-1] * freq[-length(freq)])[ok]; cex<-cex/max(cex) * 5plot(((x.min+1):x.max)[ok],g.x[ok],cex=cex,ylab="g.dach(x)",xlab="x",ylim=c(0,max(g.x[ok])),main=paste(typ,"\nN=",N,", s^2/Mittel:",signif(s.q/m ittel,3)))
}par(mfrow=c(2,2))
N<-slider(no=1)n.binom<-slider(no=2); p.binom<-slider(no=3)lambda<-slider(no=4)p.geom<-slider(no=5)n.unif<-slider(no=6)seed<-slider(no=7); set.seed(seed)stpr<-rbinom(N,n.binom,p.binom)g.dach.plot(stpr,paste("binom(",n.binom,",",p.binom ,"), seed=",seed))stpr<-rpois(N,lambda)g.dach.plot(stpr,paste("pois(",lambda,"), seed=",see d))stpr<-rgeom(N,p.geom)g.dach.plot(stpr,paste("geom(",p.geom,"), seed=",see d))stpr<-ceiling(runif(N,1,n.unif))g.dach.plot(stpr,paste("unif( 1",n.unif,"), seed=",se ed))par(mfrow=c(1,1))
}slider(refresh,c("N","n.binom","p.binom","lambda"," p.geom","n.unif","zufall"),
c(20,4,.05,0.5,.05,3,1),c(2000,100,.95,20,.95,20,99 9),c(10,1,0.05,.01,.05,1,1),c(100,10,.5,2.5,.5,10,13))
refresh()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.13 erfolge.bei.bernoulli.experimenten()50 〈start 37〉+ ≡
erfolge.bei.bernoulli.experimenten<-function(){refresh.code<-function(...){# Modellierung
prozent.ok<-slider(no=1); f.ok<-prozent.ok/100; h.ok< -21000 * f.okgg<-c(rep(1,h.ok),rep(0,21000-h.ok))
# Experimentparametern.stpr<-slider(no=2); wd<-slider(no=3); set.seed(zz<- slider(no=4))
# Umsetzungresult<-unlist(lapply(1:wd,function(x) { stpr<-sample (gg,size=n.stpr); sum(stpr) }))
# Ergebnisdarstellungf.anz<-table(result)/wdplot(as.character(names(f.anz)),f.anz,
xlab="Erfolgsanzahl",ylab="relative H\344aufigkeit",xlim=c(0,n.stpr),ylim=c(0,1.5 * dbinom(round(n.stpr * .5),n.stpr,.5)),main=paste("H\344ufigkeiten verschiedener Erfolgsanza hlen\n","% Erfolge in GG=",
prozent.ok,", n.stpr=",n.stpr,", WD=",wd,", Zufall=",z z,sep=""),type="h")
39

print(summary(result))}slider(refresh.code,
c("GG: Erfolgsprozentsatz","Stichprobenumfang","Expe riment-Wiederholungen","Zufallsstart"),c(1,10,100,1),c(99,100,3000,30),c(1,5,200,1),c(58,5 0,500,13) )
refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.14 hyper.to.binom51 〈start 37〉+ ≡
hyper.to.binom<-function(){refresh.code<-function(...){# Vorbereitung
m<-slider(no=1); n<-slider(no=2); k<-slider(no=3); x.0 <-slider(no=4)if(k>(m+n)) k<-slider(set.no.value=c(3,m+n))
# Berechnungx<-0:k; f.hyper<-dhyper(x,m,n,k)p<-m/(m+n); f.binom<-dbinom(x,k,p)
# Plotif(is.nan(f.hyper[1])){
plot(1,type="n");text(1,1,"nicht definiert")}else{
par(mfrow=c(3,1))plot(x,f.hyper,type="h",bty="l",
main=paste("hypergeometrisch: m=",m,",n=",n,",k=",k, sep=""))abline(v=x.0, col="red", lty=2)ymax<-par()$usr[4]nice<-function(x)paste(floor(x),".",substring(round (10000 * (1+x)),
2,5),sep="")if(m>=n){pos<-4;xt<-0}else{pos<-2;xt<-k}
text(xt,ymax * 0.9,pos=pos,paste("P(X= ",x.0,")=",nice(dhyper(x.0,m,n,k)),sep=" "))text(xt,ymax * 0.8,pos=pos,paste("P(X<=",x.0,")=",nice(phyper(x.0,m,n,k)),sep= ""))text(xt,ymax * 0.7,pos=pos,paste("P(X> ",x.0,")=",nice(1-phyper(x.0,m,n,k)),sep =""))
plot(x,f.binom,type="h",bty="l",ylim=c(0,ymax),main=paste("binomial: n=",k,",p=",nice(p),sep=""))
plot(x,f.hyper-f.binom,type="h",bty="l",main="Unter schiede")abline(h=0)par(mfrow=c(1,1))
}}slider(refresh.code,
c("m weisse Kugeln","n schwarze Kugeln","k Stichprobenum fang","x.0 spezielle Stelle"),
c(1,1,1,1),c(99,99,99,99),c(1,1,1,1),c(10,10,10,5) )refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.15 sum.zv52 〈start 37〉+ ≡
sum.zv<-function(){refresh.code<-function(...){# Vorbereitung
n<-slider(no=1); k<-slider(no=2); zz<-slider(no=3); wd <-slider(no=4)# Berechnung
set.seed(zz); result<-apply(matrix(runif(n * wd),n,wd),2,sum)# Plot
40

par(mfrow=c(2,1))plot(sort(result),seq(result)/length(result),type=" s",
xlab="Summe",ylab="F.dach.summe")title(paste("Summation",n,"gleichverteilter ZV,",wd, "Wiederholungen"))ds<-density(result,width=0.02 * k* diff(range(result))/wd^0.3)plot(ds,type="l",main="Dichtesch\344tzung",ylab="f. dach.summe")par(mfrow=c(1,1))
}slider(refresh.code,
c("n: Anzahl Zufallsvariablen","k: Glattheit","zz: Zufallsstart","wd: Anzahl der Wiederholungen"),
c(1,1,1,100),c(50,99,999,10000),c(1,1,1,100),c(1,50 ,16,100) )refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.16 exp.nv.mischung53 〈start 37〉+ ≡
exp.nv.mischung<-function(){replot<-function(...){
proz<-slider(no=1)mu1<-slider(no=2); sig1<-slider(no=3)mu2<-slider(no=4); sig2<-slider(no=5)ziehe.stichprobe<-function(n){
c(rnorm(ceiling(n * proz),mu1,sig1),rnorm(ceiling(n * (1-proz)),mu2,sig2))
}# n<-100;wd<-1000;seed<-13; set.seed(seed)n<-slider(no=6);wd<-slider(no=7);seed<-slider(no=8) ; set.seed(seed)titel<-paste("GG:",
floor(proz * 100),"% N(",signif(mu1,3),",",signif(sig1,3),"),",floor((1-proz) * 100),"% N(",signif(mu2,3),",",signif(sig2,3),")")
result.mean<-result.median<-rep(0,wd)for(i in 1:wd){
stpr<-ziehe.stichprobe(n)result.mean[i]<-mean(stpr);result.median[i]<-median (stpr)
}xy1<-density(result.mean);xy2<-density(result.media n)ymax<-max(xy1$y,xy2$y)plot(xy1,type="l",main="",ylab="f.dach",ylim=c(0,ym ax))lines(xy2$x,xy2$y,lty=2)legend(par()$usr[1] * .9+par()$usr[2] * .1,6 * par()$usr[4]/7,
c("Mittelwert","Median"),lty=1:2,bty="n")title(paste("Verteilung von Stichprobenfunktionen\n",
titel,"\nwd=",wd,", n=",n,", seed=",seed,sep=""))}slider(replot,c("Prozentsatz von Typ 1","Mittel 1","Std -Abw 1",
"Mittel 2","Std-Abw 2","n","WD","Zufallsstart"),c(0.01,-1,0.2,-1,0.2,10,100,1),c(0.99,1,5,1,5,100,1000,50),c(0.01,.2,.2,.2,.2,10,100,1),c(0.20,0,1,0,0.3,100,500,13))
replot()cat("Plot erstellt\n"); NULL
}
7.17 exp.ki.p54 〈start 37〉+ ≡
exp.ki.p<-function(){redo<-function(...){
41

n<-slider(no=1); alpha<-slider(no=2); wd<-slider(no=3 )p<-slider(no=4); seed<-slider(no=5)set.seed(seed); u<-o<-numeric(wd)t.value<-qt(1-alpha/2,n-1)for(i in 1:wd){
p.dach<-mean(rbinom(n,1,p))sigma.dach<-sqrt(p.dach * (1-p.dach)/n)step<-t.value * sigma.dachu[i]<-p.dach-step; o[i]<-p.dach+step
}plot(u,type="n",ylim=0:1,bty="n",xlab="Versuche",
ylab="realisierte KIs",axes=F)axis(2)
title(paste("n=",n,", alpha=",alpha,", p=",p,", seed=",seed,sep=""))
segments(1:wd,u,1:wd,o)abline(h=p)
}slider(redo,c("n","alpha","wd","p","seed"),
c(5,.001,5,.01,1),c(500,.3,100,.99,100),c(1,.001,1,.01,1),c(10,.05,10,.5,1))
redo()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.18 exp.outlier55 〈start 37〉+ ≡
exp.outlier<-function(){redo<-function(...){
n<-slider(no=1); wd<-slider(no=2)anteil.outlier<-slider(no=3)/100lage.outlier<-slider(no=4); sd.outlier<-slider(no=5)set.seed(seed<-slider(no=6))n.normal<-ceiling(n * (1-anteil.outlier))stpr<-c(rnorm(wd * n.normal),
rnorm(wd * (n-n.normal), lage.outlier,sd.outlier))stpr<-matrix(stpr,n,wd,byrow=TRUE)stpr.mittel<-apply(stpr,2,mean)stpr.sd<-apply(stpr,2,sd)xmin<-min(-3.5,lage.outlier-3.5 * sd.outlier)xmax<-max(3.5,lage.outlier+3.5 * sd.outlier)ymax<-max(dnorm(0), dnorm(lage.outlier,lage.outlier, sd.outlier))
x<-seq(xmin,xmax,length=100)f.x<-dnorm(x) * (1-anteil.outlier)+
dnorm(x,lage.outlier,sd.outlier) * anteil.outlierplot(x,f.x,type="b",xlim=c(xmin,xmax), ylim=c(0,ymax ))
title(paste(100 * (1-anteil.outlier),"% norm(0,1) und ",100* anteil.outlier, "% norm(",
lage.outlier,",",sd.outlier,")\n","n=",n,", wd=",wd,"\n", sep=""))
for(i in 1:wd)curve(dnorm(x,stpr.mittel[i],stpr.sd[i] ),xmin,xmax,add=T)}slider(redo,c("n","wd","Prozent Ausreisser",
"Lage AusreiSSer","Std.-Abw. Ausreisser","seed"),c(10,2,0,-20,0.5,1),c(200,20,50,20,10,100),c(1,1,0,0,0.5,1),c(20,10,10,7,1,1)
)redo()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
42

7.19 exp.nv.an.beta56 〈start 37〉+ ≡
exp.nv.an.beta<-function(){redo<-function(...){
n<-slider(no=1); wd<-slider(no=2)a<-slider(no=3); b<-slider(no=4); set.seed(seed<-slid er(no=5))stpr<-matrix(rbeta(n * wd,a,b),n,wd)stpr.mittel<-apply(stpr,2,mean)stpr.sd<-apply(stpr,2,var)^0.5x<-seq(0.001,.999,length=100)y<-dbeta(x,a,b)plot(x,y,type="p",col="red",
xlim=c(-1,2),ylim=c(0,2 * max(y)))title(paste("GG: Beta(a=",a,", b=",b,")\nn=",n,", wd=" ,wd,", seed=",seed,sep=""))for(i in 1:wd)
curve(dnorm(x,stpr.mittel[i],stpr.sd[i]),-1,2,add=T )}slider(redo,c("n","wd","beta: Par.1","beta: Par.2","s eed"),
c(3,2,0.05,0.05,1),c(50,20,3,3,100),c(1,1,0.05,0.05,1),c(5,3,1,1,7)
)redo()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.20 exp.nv.est57 〈start 37〉+ ≡
exp.nv.est<-function(mue=0,sd=1){redo<-function(...){
n.max<-slider(no=1);zoom<-slider(no=2);set.seed(sli der(no=3))X <- rnorm(n.max, mue, sd)n.vec<-1:n.maxmue.dach<-(cumsum(X)/n.vec)[-1]sigma.q.dach<-(cumsum(X^2)/(n.vec-1))[-1]+
-mue.dach^2 * (n.vec/(n.vec-1))[-1]plot(mue.dach,sigma.q.dach,type="l",
xlim=c(mue-2 * sd/zoom,mue+2 * sd/zoom),ylim=c(sd-sd/zoom,sd+sd/zoom))
abline(v=mue,h=sd)title(paste("Stichprobenumfang bis",n.max))return(c(mean(X),var(X)))
}slider(redo,c("n.max","Zoom Faktor","seed"),
c(3,1,1),c(2000,20,1000),c(1,1,1),c(20,.3,1))redo()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.21 exp.exp.mittel58 〈start 37〉+ ≡
exp.exp.mittel<-function(){redo<-function(...){
n<-slider(no=1);wd<-slider(no=2);seed<-slider(no=3)set.seed(seed);mittel<-numeric(wd)for(i in 1:wd) mittel[i]<-mean(rexp(n))old<-par(mfrow=1:2)plot(ecdf(mittel),main=paste("Mittel aus exp(1),n=",n ,
", wd=",wd,"\necdf(mittel)",sep=""))
43

mx<-mean(mittel); sdx<-sd(mittel)x<-seq(mx-4 * sdx,mx+4 * sdx,length=100)F.x<-pnorm(x,mx,sdx)lines(x,F.x,col="red")qqnorm(mittel); qqline(mittel)par(old)
}slider(redo,c("Stichprobenumfang","Wiederholungen", "Zufall"),
c(2,2,2),c(50,1000,1000),c(1,1,1),c(10,100,2))redo()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.22 exp.est.fns59 〈start 37〉+ ≡
exp.est.fns<-function(){refresh<-function(...){
n<-slider(no=1)wd<-slider(no=2)lambda<-slider(no=3)set.seed(seed<-slider(no=4))result<-matrix(0,5,wd)for(i in 1:wd){
stpr<-rpois(n,lambda)theta1<-1theta2<-stpr[1]theta3<-0.05 * mean(stpr)-3.33theta4<-mean(stpr)theta5<-median(stpr)result[,i]<-c(theta1,theta2,theta3,theta4,theta5)
}boxplot(split(result,row(result)),horizontal=TRUE,names=c("theta=1","X_1","mean/20-3.33","mean","medi an"))title(paste("n=",n,"wd=",wd,"lambda=",lambda,"seed= ",seed))abline(h=lambda,lty=2)
}slider(refresh,c("n","Wiederholungen","lambda","see d"),
c(2,5,.2,1),c(1000,100,30,1000),c(1,10,.1,1),c(20,2 0,5,7))refresh()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.23 g.dach.x60 〈start 37〉+ ≡
g.dach.x<-function(data,main,...){data<-sort(data)freq.x<-table(factor(data,x<-min(data):max(data)))g.dach<-x[-1] * freq.x[-1]/freq.x[-length(freq.x)]cex<-sqrt(freq.x[-1] * freq.x[-length(freq.x)]); cex<-1+cex/max(cex) * 4plot(x[-1],g.dach,cex=cex,main=main,...)title(paste("\n\nMittel:",signif(mean(data),4),
"/ Stichprobenvarianz:",signif(var(data),4)))}
44

7.24 exp.mere61 〈start 37〉+ ≡
exp.mere<-function(){restart<-function(...){
set.seed(slider(no=2))versuche<-slider(no=1); n<-versuche * 4x<-matrix(sample(1:6,n,T),versuche,4)sechs.in.4<-apply(x==6,1,any)freq.6.in.4<-cumsum(sechs.in.4)/(1:versuche)n<-versuche * 48x<-matrix(sample(1:6,n,T),versuche,48)doppel.6.in.24<-apply(x==6,1,function(x)any(x[1:24] &x[25:48]))freq.doppel.6.in.24<-cumsum(doppel.6.in.24)/(1:vers uche)plot(freq.6.in.4,ylim=0:1,log="x",type="l",bty="n", # xlim=c(1,1000),
ylab="relatvie H\344ufigkeit",xlab="Versuche")lines(1:versuche,freq.doppel.6.in.24,lty=2,col=2)abline(h=0.5)legend(100,0.95,bty="n",lty=1:2,col=1:2,legend=c("6 bei 4 W\374rfen",
"Doppel-6 bei 24 W\374rfen mit 2 W\374rfeln"))title("Wahrscheinlichkeitsfrage von Chevalier de M\351r \351")
}slider(restart,c("Anzahl Versuche","Zufallsstart"),
c(100,1), c(10000,100), c(100,1), c(100,59))restart()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.25 geo.to.exp62 〈start 37〉+ ≡
geo.to.exp<-function(){refresh.code<-function(...){# Vorbereitung
n<-slider(no=1); p<-slider(no=2)/100; x.0<-slider(no= 3)# Berechnung
pn<-p/n; x<-1:(1/pn * 3);xn<-x/n; lambda<-pnf.geo<-dgeom(x-1,pn); f.exp<-dexp(x-1,lambda)F.geo<-pgeom(x-1,pn); F.exp<-pexp(x-1,lambda)if(x.0>max(xn)) x.0<-slider(set.no.value=c(3,ceiling (max(xn))))
# Plotpar(mfrow=c(2,1))plot(xn,f.geo,type="h",bty="l",xlim=c(0,max(xn)),
xlab="Untersuchungszeitpunkte",ylab="f.geo | f.exp",main=paste("Anzahl Versuche, p=",round(p,2),",\nTeilungen n=",n,", lambda/n=",round(lambda * n,2),sep=""))
lines(xn-xn[1],f.exp,lty=2); abline(v=x.0,col="red", lty=2)
plot(c(0,xn),c(0,F.geo),type="s",bty="l",xlab="Untersuchungszeitpunkte",ylab="F.geo | F.exp",xlim=c(0,max(xn)),ylim=0:1)
lines(xn-xn[1],F.exp,lty=2); abline(v=x.0,col="red", lty=2)xt<-0.7 * par()$usr[2]text(xt,0.4,pos=4,paste("P(X.exp<=",x.0,")=",
round(pexp(x.0,lambda),4),sep=""))par(mfrow=c(1,1))}slider(refresh.code,
c("n: Anzahl Teilungen","p: Event-WS in %",
"x.0: x-Wert"),c(1,1,.02),c(25,99,300),c(1,1,.2),c(1,50,2) )
refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
45

7.26 p.est63 〈start 37〉+ ≡
p.est<-function(){refresh.code<-function(...){# Vorbereitung
p<-slider(no=1)/100; n<-slider(no=2); kk<-slider(no=3 ); zz<-slider(no=4)set.seed(zz)x<-1:n; res<-rbinom(n,1,p)f.x<-cumsum(res)/xk<-1/(1-kk)^0.5delta<-k * 0.5/sqrt(1:n)ug<-f.x-delta; og<-f.x+delta
# plotplot(x,f.x,xlim=c(1,n),ylim=0:1,xlab="n",ylab="Inte rvall",type="l",log="x")title(paste("p mit Mittel einfangen\np=",p,", Sicherhei t=",kk,", Zufall=",zz,sep=""))abline(h=p,col="red")lines(x,ug); lines(x,og)
}slider(refresh.code,
c("p * 100 Erfolgsprozentsatz","n Experimentumfang","1-1/k^2 Sicherheit","Zufallsstart"),
c(1,1,0.01,1),c(99,5001,.99,999),c(1,50,0.01,1),c(5 0,2000,.9,7) )refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.27 binomial.experiment64 〈start 37〉+ ≡
binomial.experiment<-function(){refresh.code<-function(...){# Modellierung
prozent.ok<-slider(no=1); n<-slider(no=2); s0<-slider (no=3)p<-prozent.ok/100
# Experimentparameterwd<-slider(no=4); set.seed(zz<-slider(no=5))
# Umsetzungstpr<-sample(c(1,0), size=n * wd, prob=c(p, 1-p),replace=T)result.tab<-table(result<-apply(matrix(stpr,nrow=n) ,2,sum))/wds<-0:n;f.s<-dbinom(s,n,p);F.s<-pbinom(s,n,p)f.s0<-dbinom(s0,n,p);F.s0<-pbinom(s0,n,p); F.quer.s0 <-1-pbinom(s0,n,p)
# Ergebnisdarstellungpar(mfrow=c(2,1))plot(as.character(names(result.tab)),result.tab,
xlab="s",ylab="f(s), f.dach(s)", xlim=c(0,n),# ylim=c(0,2.0 * dbinom(round(n * .5),n,.5)),col="blue",lty=2,type="p")points(s,f.s,type="h")nice<-function(x)paste(floor(x),".",substring(round (10000 * (1+x)),2,5),sep="")x<-0; y<-0.90 * par()$usr[4]; if(p<0.5){ x<-n/2 }text(x,y,paste("P(S=",s0,")=",nice(f.s0),sep=""),po s=4)lines(c(s0,s0,0),c(0,f.s0,f.s0),lty=2,col="red")x<-as.character(names(result.tab));y<-cumsum(result .tab)
plot(x,y, xlab="s",ylab="F(s), F.dach(s)",xlim=c(0,n),ylim=c(0,1.1),col="blue",type="p",lty=2 )
points(c(0,s,n+1),c(0,F.s,1),type="s")text(n/2,1.05,"o Simulationsergebnis",col="blue")x<-0; y<-0.95; if(p<0.5){ x<-n/2; y<-0.15 }
46

text(x,y,paste("P(S<=",s0,")=",nice(F.s0),sep=""),p os=4)text(x,y-0.1,paste("P(S> ",s0,")=",nice(F.quer.s0),s ep=""),pos=4)lines(c(s0,s0,0),c(0,F.s0,F.s0),lty=2,col="red")
par(mfrow=c(1,1))title(paste("Binomialverteilung,",
"p * 100=", prozent.ok,", n=",n,"\nSimulation: WD=",wd,", Zu fall=",zz,sep=""))}slider(refresh.code,
c("p * 100 Erfolgsprozentsatz","n Experimentanzahl","s0 spezi elle Realisation","wd Simulationsanzahl","Zufallsstart"),
c(1,1,0,100,1),c(99,100,100,3000,30),c(1,1,1,100,1) ,c(50,10,5,50,13) )refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
7.28 binomial.zentrales.schwankungsintervall65 〈start 37〉+ ≡
binomial.zentrales.schwankungsintervall<-function() {refresh.code<-function(...){# Vorbereitung
pp<-slider(no=1)/100; nn<-slider(no=2); kk<-slider(no =3)par(mfrow=c(1,3))ZSI<-function(n,p,k){ EW<-n * p; sigma<-(EW * (1-p))^0.5
ug<-ceiling(EW-k * sigma); og<-floor(EW+k * sigma)pbinom(og,n,p)-pbinom(ug-1,n,p) }
# p freie Variablep<-seq(0,1,length=50)Pp<-unlist(sapply(p,function(pp) ZSI(nn,pp,kk)))plot(p,Pp,type="l",ylim=0:1)text(mean(p),0.05,paste("n=",nn,", k=",kk,", p variabe l",sep=""))
# n freie Variablen<-1:100Pn<-unlist(sapply(n,function(nn)ZSI(nn,pp,kk)))plot(n,Pn,type="l",ylim=0:1)
text(mean(n),0.05,paste("p=",pp,", k=",kk,", n variabe l",sep=""))# k freie Variable
k<-seq(0.5,4,length=50)Pk<-unlist(sapply(k,function(kk)ZSI(nn,pp,kk)))plot(k,Pk,type="l",ylim=0:1)
text(mean(k),0.05,paste("n=",nn,", p=",pp,", k variabe l",sep=""))par(mfrow=c(1,1)); title("Binomialverteilung: P(-k * sigma <= S_n <= k * sigma)")
}slider(refresh.code,
c("p * 100 Erfolgsprozentsatz","n Experimentanzahl","k Interv allbreite"),c(1,1,0.5),c(99,200,5),c(1,1,0.1),c(50,50,1) )
refresh.code()cat("Demo gestartet, siehe Steuerungsfenster\n"); NULL
}
47


















