
Gabriele Kern-Isberner LS 1 { Information Engineering · (Statistik!) G. Kern-Isberner (TU...
232
Commonsense Reasoning Gabriele Kern-Isberner LS 1 – Information Engineering TU Dortmund Sommersemester 2016 G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 1 / 232
Transcript of Gabriele Kern-Isberner LS 1 { Information Engineering · (Statistik!) G. Kern-Isberner (TU...

Commonsense Reasoning
Gabriele Kern-IsbernerLS 1 – Information Engineering
TU DortmundSommersemester 2016
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 1 / 232

Commonsense Reasoning – Ubersicht
• Ubersicht, Organisatorisches und Einfuhrung
• Nichtklassisches Schlussfolgern
• Rangfunktionen – ein einfaches epistemisches Modell
• Probabilistische Folgerungsmodelle und -strategien
• Qualitative und Quantitative Wissensreprasentation
• Argumentation
• (Commonsense Reasoning in Multi-Agentensystemen)
• Schlussteil und Prufungsvorbereitung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 2 / 232

Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 3 / 232

Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 4 / 232

Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 5 / 232

Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.1 Einfuhrung und Ubersicht
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 6 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Qualitative und quantitative Information
Fur die Durchfuhrung semantisch sinnvoller Inferenzen sind extralogische,qualitative Information (gegeben z.B. durch Plausibilitatsrelationen oder-range) notwendig.
Default-Schlussfolgern fallt besonders leicht im Rahmen derOCF-Funktionen, bei denen man – wie in der Wahrscheinlichkeitstheorie –konditionieren konnte und die tatsachlich als qualitativeWahrscheinlichkeiten gedeutet werden konnen (s. spater).
• Was hat Wahrscheinlichkeitstheorie mit Commonsense Reasoning zutun?
• Gibt es generell quantitatives Commonsense Reasoning?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 7 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Eine lange Tradition . . .
• Die Idee, Wissen mit Sicherheitsgraden zu versehen, ist sehr alt – dieWahrscheinlichkeitstheorie ist die alteste Theorie der Unsicherheit.
• Es ist auch die alteste Theorie, in der uber Wissensdynamiknachgedacht wurde – Konditionalisierungen mittels bedingterWahrscheinlichkeiten machen Wissensanderungen unter Einbeziehungneuer Informationen moglich.
• Daruber hinaus ist die fundierte Reprasentation und Verarbeitungkonditionalen Wissens mittels bedingter Wahrscheinlichkeiten bisheute ein wichtiges Vorbild fur das Default-Schlussfolgern.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 8 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Wahrscheinlichkeit und Dynamik
Im Rahmen der Wahrscheinlichkeiten scheint also eine Flexibilisierung undDynamisierung von Wissen besonders leicht moglich.
Aufgrund des Zusammenhangs zwischen Wahrscheinlichkeit undInformation
Inf(A) = − logP (A)
kann man sogar von einer inharenten Dynamik von Wahrscheinlichkeitensprechen, da sie den Wert eines potentiellen Informationsflusses messen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 9 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Wahrscheinlichkeit als zentraler Ansatz
In der Wahrscheinlichkeitstheorie fließen also die fundamentalen Ideen(und Wunsche!) des Commonsense Reasonings zusammen:
• Nichtmonotonie
• meta-logische Informationen
• Konditionale
• Flexibilisierung, Dynamik
• Verbindung zum subjektiven Agenten-Wissen (Information!)
• Fur Informatiker: Verbindung zum objektiven Daten-Wissen(Statistik!)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 10 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Wahrscheinlichkeit und Struktur
Die flexible Darstellung von Wissen durch Wahrscheinlichkeiten hat auchNachteile – das Schlussfolgern mit Wahrscheinlichkeiten ist hochgradignichtmonoton; probabilistischer Logik fehlt die Eigenschaft derKompositionalitat bzw. Wahrheitsfunktionalitat.
Zur Strukturierung probabilistischen Wissens hat sich das Konzept derbedingten Unabhangigkeit bewahrt, zu seiner Organisation undVerarbeitung benutzt man gerne probabilistische Netzwerke.
Wichtig ist, eine Verbindung zwischen qualitativer/struktureller undquantitativer/numerischer Information zu schaffen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 11 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Ubersicht Kapitel 4
Kapitel 4 wird sich im Wesentlichen mit folgenden Themen beschaftigen:
• Folgern uber Abhangigkeiten und Unabhangigkeiten;
• probabilistische Informationsflusse und probabilistische Inferenzen;
• Inferenz auf der Basis optimaler Entropie.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 12 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Mehrwertige Aussagevariable 1/2
Anstelle von binaren (logischen) Aussagenvariablen werden wir hier in derRegel mehrwertige Aussagevariable betrachten, das sind Aussagevariablen,die mehr als nur zwei Werte annehmen konnen.
Aussagenvariablen werden mit großen Buchstaben bezeichnet, ihre Wertemit kleinen Buchstaben:
A = {a1, . . . , an}
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 13 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Mehrwertige Aussagevariable 2/2
Beispiel: Spielkartenfarbe ist eine mehrwertige Aussagevariable mit denAuspragungen
Herz, Karo, Kreuz, Pik ,
ebenso ist Spielkartenwert eine mehrwertige Aussagevariable mit denAuspragungen
1,2, . . . , 10, Bube, Dame, Konig, As.
Jede Spielkarte wird eindeutig durch diese beiden Variablen beschrieben,z.B.:
Herz As: Spielkartenfarbe = HerzSpielkartenwert = As ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 14 / 232

Probabilistische Folgerungsmodelle und -strategien Einfuhrung und Ubersicht
Literatur
Die Vorlesung orientiert sich in diesem Kapitel an einem Klassiker:
J. Pearl (Turing Award Winner 2012!).Probabilistic Reasoning in Intelligent Systems.Morgan Kaufmann, San Mateo, Ca., 1988.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 15 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 16 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.2 Wahrscheinlichkeitstheorie undCommonsense Reasoning
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 17 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Typische Probleme beim Commonsense Reasoning1/2
Die Probleme beim Commonsense Reasoning werden hauptsachlich durchzwei Faktoren verursacht:
• Mogliche Ausnahmen;
• Allgemeine Unsicherheit aufgrund von Umstanden, die wir nichtkennen.
Beides lasst sich im realen Leben nicht vermeiden!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 18 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Typische Probleme beim Commonsense Reasoning2/2
Losungsansatz: Man quantifiziert Unsicherheit, d.h. misst die Sicherheitvon Aussagen mit Sicherheitsgraden.
Allerdings – Sicherheitsgrade sind keine Wahrheitswerte:
• Wahrheitswerte sind Einschatzungen von sichtbaren Dingen;
• Sicherheitsgrade sind Einschatzungen von unsichtbaren Dingen.
Klassische, syntaxorientierte Formelauswertung funktioniert hervorragendfur die Verarbeitung sichtbarer Fakten, kann aber vollstandig versagen furdie Verarbeitung unsichtbarer Fakten.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 19 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Beispiel – Gift
G1 und G2 sind hochwirksame Gifte, ihre letale Wirkung bei Einnahmelasst sich (z.B.) mit den Sicherheitsgraden 0.95 und 0.99 quantifizieren:
G1 [0.95], G2 [0.99].
Agent A ist experimentierfreudig, er schluckt beides:
G1 ∧G2 [?] – was passiert?
• Fall 1: G1, G2 verstarken sich: G1 ∧G2 [0.999999].
• Fall 2: G1, G2 beeinflussen sich nicht in ihrer Wirkung: G1 ∧G2 [0.99].
• Fall 3: G1 ist Gegengift zu G2: G1 ∧G2 [0.001].
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 20 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Extensionalitat und Intensionalitat 1/2
Es gibt zwei Ansatze, Sicherheitsgrade zu verarbeiten:
• extensionaler oder syntaktischer Ansatz: Hier werden Sicherheitsgradeals verallgemeinerte Wahrheitswerte behandelt, und die Sicherheiteiner Formel ist eine Funktion der Wahrheitswerte ihrer Teilformeln(Wahrheitsfunktionalitat).
• intensionaler oder semantischer Ansatz: Hier wird die Unsicherheitmoglichen Welten zugeordnet und auch dort ausgewertet.
Vor- und Nachteile:
• Extensionale Ansatze sind maschinell gut berechenbar, abersemantisch unzureichend (liefern nur Approximation).
• Intensionale Ansatze sind semantisch perfekt, aber ihre maschinelleAbbildung ist schwierig.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 21 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Extensionalitat und Intensionalitat 2/2
Wichtig ist auch die unterschiedliche Behandlung von Regeln in beidenAnsatzen:
• Eine extensionale Regel A→ B[m] ist eine Lizenz, auf B mitSicherheit m zu schließen, wann immer man A beobachtet (lokalerKontext).
• Eine intensionale Regel A→ B[m] ist ein elastischer Constraint, umdie Modelle von AB in einer gewissen, von m abhangigen Weiseniedriger einzuschatzen als die von AB oder ¬A ∨B (globalerKontext).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 22 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Qualitative Anspruche des CommonsenseReasoning 1/2
Auch in numerischen Umgebungen lasst sich die Qualitat von plausiblenFolgerungen qualitativ beurteilen:
• Kontextsensitivitat: Folgerungen sollen den Kontext des Problemsberucksichtigen, der durch die verfugbare Information bestimmt wird.
• Relevanz: Es soll moglich sein, zwischen relevanten und irrelevantenFaktoren/Merkmalen zu unterscheiden.
• Bidirektionale Inferenzen: Korrekte Behandlung von abduktiven undinduktiven Inferenzen.Beispiel: Feuer verursacht Rauch (induktiv/Prognose), Rauch lasstauf Feuer schließen (abduktiv/Diagnose). ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 23 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Qualitative Anspruche des CommonsenseReasoning 2/2
Wichtiger Aspekt des Commonsense Reasoning: Moglichkeit, (transitive)Abhangigkeiten zu blockieren und Abhangigkeiten zu induzieren:
Blockieren von Abhangigkeiten – Beispiel:
Wenn der Sprinkler an ist, dann ist der Rasen nass. (induktiv)Wenn der Rasen nass ist, dann hat es geregnet. (abduktiv)
Wenn der Sprinkler an ist, dann hat es geregnet. ?!♣
Induzieren von Abhangigkeiten (explaining away) – Beispiel:
Einbrecher losen Alarm aus.Der Alarm ist ausgelost.
Einbrecher (abduktiv)
Erdbeben losen Alarm aus.Erdbeben
Alarm (induktiv)Alarm, Erdbeben
¬ Einbrecher
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 24 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Wahrscheinlichkeiten im Commonsense Reasoning
Man kann zeigen:
Die Wahrscheinlichkeitstheorie ist die einzige unsichereFolgerungsmethodik ist, die alle Anspruche des Commonsense
Reasoning erfullt.
R.T. CoxProbability, frequency and reasonable expectationAmerican Journal of Physics 14(1), p. 1-13, 1946
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 25 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Wahrscheinlichkeiten in der KI und im alltaglichenLeben
Einerseits – sehr alltaglich:
• “Da kommt eine große dunkle Wolke, es wird wahrscheinlich regnen.”
andererseits –
• “Wahrscheinlichkeiten sind epistemologisch unangemessen.”[McCarthy 1969]
• “Um mit Wahrscheinlichkeiten zu arbeiten, brauche ich jede MengeDaten.”
• “Menschen konnen nicht gut Wahrscheinlichkeiten verarbeiten, das istpsychologisch erwiesen.”
• “Statistiken lugen.” – “Ich mag keine Wahrscheinlichkeiten, die habeich noch nie verstanden.”
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 26 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Wahrscheinlichkeiten – effizient oder ineffizient?
Einerseits – als intensionales, semantisches Folgerungsinstrument istprobabilistisches Schlussfolgern sehr ressourcenintensiv.
Andererseits – in unsicheren Umgebungen hat man nur zwei “sichere”Alternativen:
• Man ignoriert Unsicherheit und wendet klassische Methoden an (mitz.T. katastrophalen Folgen!).
• Man versucht (so gut es geht), alle Moglichkeiten zu betrachten –Zeitverschwendung!
Wahrscheinlichkeiten bieten einen Ausweg aus diesem Dilemma:
Indem man wahrscheinliche Moglichkeiten berucksichtigt undunwahrscheinliche Moglichkeiten ausblendet, spart man wertvolle Zeit.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 27 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Ein einfuhrendes Beispiel 1/2
Alice und Bob spielen Karten:
♥A, ♥D, ♠A, ♠D.
Alice bekommt zwei Karten:
Alice : ∗1, ∗2
Einige (kombinatorische) a priori-Wahrscheinlichkeiten, die Bob berechnet:
P (♥A ∧ ♠A) = 1/6 P (♥A ∨ ♠A) = 5/6P (♥A) = 1/2 P (♠A) = 1/2
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 28 / 232

Probabilistische Folgerungsmodelle und -strategien Wahrscheinlichkeitstheorie und Commonsense Reasoning
Ein einfuhrendes Beispiel 2/2
Alice sagt nun: Ich habe ein As:
Alice : A ≡ ♥A ∨ ♠A.
Bob berechnet nun:
P (♥A ∧ ♠A|A) = 1/5 > 1/6.
Alice wird noch etwas genauer: Ich habe Pik As:
Alice : ♠A.
Bob: P (♥A ∧ ♠A|♠A) = 1/3 > 1/5.
Andererseits: Auch P (♥A ∧ ♠A|♥A) = 1/3, und Bob weiß schon bei A,dass Alice eines von beiden Assen haben muss.
Warum ist es dann entscheidend zu wissen, welches As Alice hat ?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 29 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 30 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.3 Grundideen probabilistischenSchlussfolgerns
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 31 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Probabilistik und plausibles Schlussfolgern 1/4
George Polya (1887-1985) machte sich in seinem 1954 erschienen BuchMathematics and plausible reasoning ernsthaft Gedanken um dasmenschliche Schlussfolgern; er stellte einige allgemeine Prinzipien fur dasplausible Schlussfolgern auf, darunter auch das folgende
Induktive Prinzip: Die Bestatigung einer Konsequenz macht eineHypothese glaubhafter.
Beispiel: Die Hypothese “Es regnete letzte Nacht.” wird glaubhafter, wennwir feststellen: “Das Gras ist nass.”
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 32 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Probabilistik und plausibles Schlussfolgern 2/4
Polya glaubte, dass die Wahrscheinlichkeitstheorie der ideale Rahmenware, in dem sich plausibles Schlussfolgern realisieren ließe, da die Axiomeder Wahrscheinlichkeitstheorie keine Fehlschlusse zulassen wurden.
Tatsachlich lasst sich das induktive Prinzip probabilistisch nachvollziehen:
Nehmen wir an, es gilt A⇒ B und wir stellen B fest; nachzuweisen ist,dass A plausibler geworden ist durch B, d.h. es sollte gelten
P (A|B) ≥ P (A), wenn P (A⇒ B) = 1;
das lasst sich aber mit dem Satz von Bayes leicht zeigen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 33 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Probabilistik und plausibles Schlussfolgern 3/4
Der Haken hierbei ist, dass diese Schlussfolgerung nicht nur alleine von Aund B abhangt, sondern auch vom Kontext bzw. von anderen moglichenEvidenzen (= Beobachtungen).
Sind die Variablen
A : Es regnete letzte Nacht.B : Mein Rasen ist nass.C : Der Rasen meines Nachbarn ist trocken.
gegeben, so sollte fur eine “vernunftige” Wahrscheinlichkeitsverteilung Pgelten:
P (A|B) > P (A), aber P (A|B,C) < P (A).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 34 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Probabilistik und plausibles Schlussfolgern 4/4
Plausibles Schlussfolgern ist also nichtmodular – es genugt nicht,Bedingungen lokal zu uberprufen, sondern man muss immer den Kontextrelevanter Bedingungen sehen.
Wir werden sehen, dass dieser Kontext nicht zuletzt durch die Fragebestimmt wird, durch die die Berechnung der Wahrscheinlichkeitenangestoßen wird.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 35 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 1/7
Drei Gefange A,B,C warten auf die Urteilsverkundung. Sie wissen, dass(genau) einer von ihnen zum Tode verurteilt und am nachsten Morgengehenkt wird. In der Nacht bittet A den Warter, ihm zu verraten, wer vonden anderen beiden nicht gehenkt wird; da er ja weiß, dass mindestenseiner von ihnen freigelassen wird, nutzt ihm die Information nichts, sodenkt er. Der Warter antwortet ihm, dass B freigelassen wird. Als A zuseinem Bett zuruckgeht, stutzt er: “Seltsam, bevor ich mit dem Wartergesprochen habe, waren meine Chancen, gehenkt zu werden, 1/3. Nun, daich weiß, dass B morgen freigelassen wird, sind nur noch C und ich ubrig,also hat sich fur mich die Chance, gehenkt zu werden, auf 1/2 erhoht. . . ?!”
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 36 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 2/7
Wir arbeiten zunachst mit den folgenden Variablen:
GA A wird schuldig gesprochen (G = guilty)IB B wird frei gesprochen (I = innocent)
Die Wahrscheinlichkeit, dass A schuldig gesprochen wird, wenn B alsunschuldig gilt, betragt (nach dem Satz von Bayes):
P (GA|IB) =P (IB|GA)P (GA)
P (IB)
=1 · 1
323
=1
2
Ist das jedoch die Situation, in der sich A befindet ?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 37 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 3/7
Eigentlich muss man doch folgende Variable betrachten:
I ′B Warter sagt, B wurde freigesprochen
Damit erhalt man als aktuelle Wahrscheinlichkeit
P (GA|I ′B) =P (I ′B|GA)P (GA)
P (I ′B)
=12 ·
13
12
=1
3
Dies ist die korrekte Wahrscheinlichkeit, da sie den Kontext der Fragebesser berucksichtigt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 38 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 4/7
Nehmen wir nun an, es sind nicht drei, sondern 1000 Gefangene, diebesorgt dem nachsten Morgen entgegensehen, an dem genau einer vonihnen hingerichtet wird. A ist einer dieser Gefangenen, seineWahrscheinlichkeit, hingerichtet zu werden, betragt a priori 1
1000 .
Nun findet A eine Liste L, auf der 998 Namen von Gefangenen aufgefuhrtsind, alle mit dem Vermerk unschuldig – sein Name ist nicht darunter!Steigt seine Wahrscheinlichkeit, hingerichtet zu werden, damit auf 1
2 statt1
1000?
Ja, offensichtlich!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 39 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 5/7
Was aber ware, wenn A nun unten auf der Liste den folgenden Zusatzfinden wurde:
Ausdruck der Namen von 998 unschuldigen rechtshandigenGefangenen
und A wusste, er ware der einzige Linkshander unter den Gefangenen?
In diesem Fall sollte sich die Wahrscheinlichkeit doch wieder bei 11000
einpendeln . . . oder ?.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 40 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 6/7
LRA A taucht auf der Liste der 998 unschuldigen rechtshandigenGefangenen auf
Gesucht ist die Wahrscheinlichkeit P (GA|¬LRA):
P (GA|¬LRA) = P (GA) = 0.001,
wegen des Satzes von Bayes.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 41 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Das Gefangenenparadoxon 7/7
Fur den rechtshandigen Gefangenen B, dessen Name auch nicht auf derListe auftaucht, gilt jedoch
P (GB|¬LRB) =P (¬LRB|GB) P (GB)
P (¬LRB)
=1 · P (GB)
1− P (LRB)
=0.001
0.002= 0.5
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 42 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Bedeutung des Kontextes
Fur die wahrscheinlichkeitstheoretische Beantwortung einer Frage ist alsoder Kontext von besonderer Bedeutung, wobei dieser durch die folgendenAspekte bestimmt wird:
• die Problemstellung und ihre Umgebung muss expliziert werden;
• die Fragestellung muss so genau wie moglich reprasentiert werden;
• man muss in der Regel einen Uberblick uber die moglichen Antwortenhaben.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 43 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Autonome Informations-Agenten
Es ist jedoch nicht immer moglich, den Ursprung gewonnener Informationso genau in Erfahrung zu bringen.
Stellen wir uns die Situation vor, wir wurden zur Klarung einerFragestellung eine Reihe autonomer Informations-Agenten aussenden, dieInformationen zu bestimmten Teilfragestellungen zusammentragen sollen.Die Agenten benutzen zur Informationsgewinnung private Prozeduren, wirwissen also nicht, auf welche Weise die Informationen gewonnen wurden.
Wenn wir annehmen, dass die Teilfragestellungen zueinander disjunkt sind– d.h. jeder der Agenten sammelt Informationen zu einem eigenenTeilbereich – und dass die Information aus einer Wahrscheinlichkeit zueiner Teilfragestellung besteht, so fuhrt uns das auf Jeffrey’s Regel.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 44 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Jeffrey’s Regel 1/4
Seien B1, . . . , Bn disjunkte Aussagen, uber die zunachstWahrscheinlichkeiten
P (B1), . . . , P (Bn)
bekannt sind; wir konnen annehmen, dass B1, . . . , Bn auch erschopfendsind, d.h. dass gilt
P (B1) + . . .+ P (Bn) = 1.
Wie verandert sich die gesamte Verteilung P , wenn nun neueInformationen uber die Wahrscheinlichkeiten der Bi bekannt werden?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 45 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Beispiel Kerzenlicht
Ein Agent untersucht ein Stuck Stoff bei schummeriger Beleuchtung; erschatzt die Farbe des Stoffes wie folgt ein:
P (grun) = 0.30, P (blau) = 0.30, P (lila) = 0.40;
er zundet nun eine Kerze an und revidiert nun seine Entscheidung:
P ∗(grun) = 0.70, P ∗(blau) = 0.25, P ∗(lila) = 0.05.
Im Prinzip ist P ∗ = P (·|e), wobei e die visuelle Wahrnehmung desAgenten bei Kerzenlicht reprasentiert, die sich jedoch in der Regel wederexplizit beschreiben lasst noch uberhaupt syntaktischer Bestandteil derProblemsprache ist.
Frage: Wie lasst sich dennoch P ∗ bestimmen?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 46 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Jeffrey’s Regel 2/4
Die Losung zu diesem Problem liefert eine Annahme, die man alsprobability kinematics bezeichnet – namlich, dass die neuenWahrscheinlichkeiten der Bi keine der unter Bi bedingtenWahrscheinlichkeiten andern sollte:
P ∗(A|Bi) = P (A|Bi)
Daraus ergibt sich sofort mit dem Satz von der totalen Wahrscheinlichkeit
P ∗(A) =
n∑i=1
P ∗(A|Bi)P ∗(Bi)
die Regel von Jeffrey:
P ∗(A) =
n∑i=1
P (A|Bi)P ∗(Bi).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 47 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Jeffrey’s und Bayes Regel
Jeffrey’s Regel verallgemeinert die Konditionalisierung nach Bayes:
Liegt namlich nur ein Ereignis B mit Wahrscheinlichkeit P ∗(B) = 1 vor,so ergibt Jeffrey’s Regel:
P ∗(A) = P (A|B)P ∗(B) = P (A|B),
d.h. die posteriori Wahrscheinlichkeit ist nichts anderes als die nach Bkonditionalisierte priori Wahrscheinlichkeit; umgekehrt erhalt man diebedingte Wahrscheinlichkeit als Spezialfall der Regel von Jeffrey, wenn dieneue Information sicher ist, also Wahrscheinlichkeit 1 besitzt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 48 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Jeffrey’s Regel 3/4
Die Anwendbarkeit von Jeffrey’s Regel hangt jedoch entscheidend von derAnwendbarkeit der probability kinematics-Annahme ab; wenn wir denAnsatz
P ∗ = P (·|e)
verwenden, konnen wir den folgenden Vergleich ziehen:
P ∗(A) =
n∑i=1
P (A|Bi)P ∗(Bi) (Satz von Jeffrey)
P (A|e) =
n∑i=1
P (A|Bi, e)P (Bi|e) (Satz v.d. totalen bed. W’keit).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 49 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Jeffrey’s Regel 4/4
Dieser Vergleich ist jedoch nur haltbar, wenn gilt
P (A|Bi) = P (A|Bi, e),
d.h. wenn A und e bedingt unabhangig unter Bi sind, d.h. e soll keinendirekten Einfluss auf A haben.
Dies ist eine wichtige Voraussetzung fur Jeffrey’s Regel!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 50 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Bedingte Unabhangigkeit 1/2
≈ Unabhangigkeit unter gewissen Umstanden
A,B,C (disjunkte) Mengen von mehrwertigen Aussagevariablen mitP (c) > 0 fur alle Vollkonjunktionen c uber C.
A und B heißen bedingt unabhangig gegeben C, in Zeichen
A |= P B | C,gdw. P (a|c ∧ b) = P (a|c).
Das ist aquivalent zu
P (a ∧ b|c) = P (a|c) · P (b|c).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 51 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Bedingte Unabhangigkeit 2/2
A,B,C mussen nicht unbedingt 6= ∅ sein:
• A = ∅ oder B = ∅: ∅ |= P B | C und A |= P ∅ | C gelten immer!
• C = ∅ → statistische Unabhangigkeit
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 52 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Beispiel Kerzenlicht (Forts.)
Nehmen wir an, dass die Chancen des Verkaufs des Stoffes (A)ausschließlich von seiner Farbe abhangen, und zwar wie folgt:
Prob(A|grun) = 0.40,
P rob(A|blau) = 0.40,
P rob(A|lila) = 0.80,
wobei Prob jede der beiden Wahrscheinlichkeiten P und P ∗ bezeichnet.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 53 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Beispiel Kerzenlicht (Forts.)
Wir konnen nun die Wahrscheinlichkeit, dass der Stoff am nachsten Tagverkauft werden kann, als priori- und als posteriori-Wahrscheinlichkeitberechnen:
P (A) = P (A|grun)P (grun) + P (A|blau)P (blau)
+P (A|lila)P (lila)
= 0.40 · 0.30 + 0.40 · 0.30 + 0.80 · 0.40= 0.56;
P ∗(A) = 0.40 · 0.70 + 0.40 · 0.25 + 0.80 · 0.05= 0.42
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 54 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Beispiel Kerzenlicht (Forts.)
Die probability kinematics-Annahme, die in diesem Beispiel uberpruftwerden muss, ist die folgende
P (A|Farbe, e) = P (A|Farbe).
Da wir annehmen, dass die Moglichkeit des Verkaufs ausschließlich von derFarbe abhangt, ist die Annahme gerechtfertigt, wir konnten also die Regelvon Jeffrey anwenden.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 55 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Modifiziertes Beispiel Kerzenlicht
Nehmen wir an, das Hauptinteresse des Betrachters gilt gar nicht demStoff, sondern der Kerze selbst – es sei bekannt, dass ein bestimmtesbilliges Wachs eine Flamme hervorbringt, deren Licht Lila-Tone verfalscht.
A Die Kerze ist aus dem billigen Wachs.
Die Voraussetzungen seien wie oben:
P (grun) = 0.30, P (blau) = 0.30, P (lila) = 0.40;P ∗(grun) = 0.70, P ∗(blau) = 0.25, P ∗(lila) = 0.05.
Kann man nun P ∗(A) mit Jeffrey’s Regel berechnen?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 56 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Modifiziertes Beispiel Kerzenlicht (Forts.)
In diesem Fall sind nun sicherlich vor dem Anzunden der Kerze (d.h. in P )A und Farbe voneinander unabhangig, d.h. es gilt
P (A|Bi) = P (A);
Die Anwendung von Jeffrey’s Regel ergibt dann
P ∗(A) =
3∑i=1
P (A)P ∗(Bi) = P (A),
d.h. das Anzunden der Kerze wurde keine neuen Erkenntnisse uber Abringen !
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 57 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Modifiziertes Beispiel Kerzenlicht (Forts.)
Die Ursache dieses kontraintuitiven Ergebnisses liegt darin, dass hier dieprobability kinematics-Annahme
P (A|Bi, e) = P (A|Bi)
nicht haltbar ist, da die Farben im Kerzenlicht (Bi ∧ e) Ruckschlusse aufdas Kerzenwachs erlauben, die Farben alleine (Bi) jedoch nicht.
Das Konzept der bedingten Unabhangigkeit ist also von entscheidenderBedeutung fur das Schlussfolgern mit Wahrscheinlichkeiten.
→ Probabilistische Netzwerke (Netzwerktopologie druckt bedingteUnabhangigkeiten aus)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 58 / 232

Probabilistische Folgerungsmodelle und -strategien Grundideen probabilistischen Schlussfolgerns
Markov- und Bayes-Netze – Ruckblick (DVEW)
Die bedingte Unabhangigkeit zwischen Variablen ist eine wichtigequalitative Information zur Strukturierung probabilistischer Information inNetzwerken:
• In (ungerichteten) Markov-Netzen zeigt die globaleMarkov-Eigenschaft bedingte Unabhangigkeiten an:
A |= G B | C impliziert A |= P B | C• In (gerichteten) Bayes-Netzen schirmen die Elternknoten die
Kindknoten gegen direkte Einflusse ab:
Ai |= P nd(Ai) | pa(Ai) fur alle i = 1, . . . , n
Zunachst einmal beschaftigen wir uns intensiver mit dem qualitativenPhanomen der bedingten Unabhangigkeit.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 59 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 60 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.4 Schlussfolgern uber Unabhangigkeiten
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 61 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Relevanz und Abhangigkeit 1/3
Einer der wichtigsten Aspekte des menschlichen Schlussfolgern ist die
Fahigkeit, relevante Informationen fur einen Kontext zu erken-nen und irrelevante Details auszublenden.
Relevanz 6= Abhangigkeit
Es ist wichtig, Relevanz und Abhangigkeit voneinander zu unterscheiden.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 62 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Relevanz und Abhangigkeit 2/3
• Relevanz impliziert immer AbhangigkeitBeispiel: Die Lesefahigkeit eines Kindes hangt von seiner Korpergroßeab. ♣
• Abhangigkeit impliziert aber nicht immer Relevanz, sondern hangtvon der verfugbaren Information ab.Beispiel: Ist das Lebensalter eines Kindes bekannt, so ist dieKorpergroße irrelevant fur seine Lesefahigkeit. ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 63 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Relevanz und Abhangigkeit 3/3
Relevanz von Informationen (informational relevance) zu erkennen ist einequalitative Eigenschaft des Commonsense Reasoning, die sich aberquantitativ abbilden lasst durch die probabilistische Eigenschaft derbedingten Unabhangigkeit:
P (A|K,B) = P (A|K) (K = Kontext)Im Kontext K liefert B keine zusatzliche Information fur A.
Beispiel: A = Lesefahigkeit, B = Korpergroße, K = Lebensalter. Dannist
P (A ∧B) 6= P (A) · P (B) A und B sind abhangig, aberP (A|B ∧K) = P (A|K) A und B sind
bedingt unabhangig im Kontext K.♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 64 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Markov-Netze – Ruckblick (DVEW)
Die bedingte Unabhangigkeit zwischen Variablen ist eine wichtigequalitative Information zur Strukturierung probabilistischer Information(z.B.) in Markov-Netzwerken.
Markov-Netze sind ungerichtete, minimale Unabhangigkeitsgraphen, d.h.
• es gilt die globale Markov-Eigenschaft
A |= G B | C impliziert A |= P B | C,d.h. fehlende Kanten zeigen bedingte Unabhangigkeiten an.
• Es gibt keine uberflussige Kanten, d.h. besteht zwischen zwei KnotenA,B eine Kante, so sind A,B nicht bedingt unabhangig im Kontextder restlichen Knoten.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 65 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
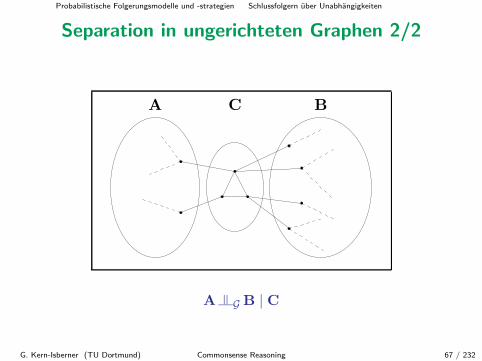
Separation in ungerichteten Graphen 1/2 (DVEW)
Sei G = GV ein ungerichteter Graph mit Knotenmenge V.
Separation in G:
• paarweise disjunkte Teilmengen A,B,C von V;
• C separiert A und B,
Schreibweise: A |= G B | C
gdw. jeder Weg zwischen einem Knoten in A und einem Knoten in Bmindestens einen Knoten von C enthalt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 66 / 232
Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Separation in ungerichteten Graphen 2/2
A C B
A |= G B | C
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 67 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Bedingte Unabhangigkeit und Separation 1/2
Graphen sind also wichtige qualitative Mittel, um
• allgemeine Abhangigkeiten → Zusammenhang im Graphen
und gleichzeitig
• bedingte Unabhangigkeiten → fehlende Kanten
auszudrucken.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 68 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Bedingte Unabhangigkeit und Separation 2/2
Aber: Graphische Separation und bedingte Unabhangigkeit sind ahnliche,aber keine aquivalenten Konzepte, d.h.A |= P B | C gdw. A |= G B | C ist (im Allgemeinen) nicht moglich, denn
• A |= G B | C impliziert A |= G B | (C ∪C′);
• es ist jedoch moglich, dass A |= P B | C gilt, nicht aberA |= P B | (C ∪C′).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 69 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Beispiel – (bedingte) Unabhangigkeit
G = {fem,mal} Geschlecht (fem = female, mal = male)M = {mar,mar} verheiratet (married)P = {preg, preg} schwanger (pregnant)
mal fem
mar preg 0.00 0.06
preg 0.20 0.14
mar preg 0.00 0.02
preg 0.30 0.28
Die Variablen Geschlecht und verheiratet sind statistisch unabhangig:gender |= P marriage | ∅ ,
aber sie sind bedingt abhangig gegeben Schwangerschaft:
nicht ( gender |= P marriage | pregnancy) !!!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 70 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Eigenschaften der bedingten Unabhangigkeit
Welche qualitativen Eigenschaften hat die bedingteUnabhangigkeit?
D.h. was lasst sich (logisch) uber die Relation A |= P B | C sagen?
Sicherlich gilt:
Wenn A |= P B | C, dann auch A |= P B | C fur jedes Paar von VariablenA ∈ A, B ∈ B.
Allerdings gilt hier nicht die Umkehrung – d.h. es gibt Beispiele mitVariablenmengen A,B,C so dass fur jedes Paar von VariablenA ∈ A, B ∈ B A und B bedingt unabhangig sind gegeben C, abertrotzdem gilt nicht A |= P B | C.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 71 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Formale Eigenschaften 1/3
Seien A,B,C,D disjunkte Teilmengen von V.
• Symmetrie: A |= B | C gdw. B |= A | CIm Kontext C soll gelten: Wenn A uns nichts Neues uber B sagt,dann sagt uns auch B nichts Neues uber A.
• Zerlegung: A |= (B ∪D) | C impliziert A |= B | C undA |= D | CIst die Gesamtinformation B ∪D (im Kontext C) irrelevant fur A, soist auch jede einzelne Information irrelevant fur A.
• Schwache Vereinigung:A |= (B ∪D) | C impliziert A |= B | (C ∪D)
Der Relevanz-Kontext C kann vergroßert werden um Information, dieschon als irrelevant eingestuft wurde.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 72 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Formale Eigenschaften 2/3
• Kontraktion:A |= B | C und A |= D | (C ∪B) impliziert A |= (B ∪D) | C
Schatzen wir D als irrelevant ein, nachdem wir irrelevante InformationB gelernt haben, dann muss D schon vorher irrelevant gewesen sein.
Schwache Vereinigung und Kontraktion besagen, dass irrelevanteInformationen nicht die Relevanzbeziehungen anderer Aussagenfureinander beeinflussen –
• relevante Aussagen bleiben relevant fureinander,
• irrelevante Aussagen bleiben irrelevant fureinander.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 73 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Formale Eigenschaften 3/3
• Schnitt: A |= B | (C ∪D) und A |= D | (C ∪B) impliziertA |= (B ∪D) | CIst jede der Informationen B,D im jeweils um die andere Informationvergroßerten Kontext C irrelevant fur A, so ist auch dieGesamtinformation B ∪D im Kontext C irrelevant fur A.
Proposition 1
Ist P eine Verteilung uber V, so erfullt · |= P · | · die EigenschaftenSymmetrie, Zerlegung, Schwache Vereinigung und Kontraktion. Ist Paußerdem noch strikt positiv (d.h. P (v) > 0 fur alle v), so erfullt · |= P · | ·auch Schnitt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 74 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Formale Eigenschaften – Anmerkungen
• Die Schreibweise A |= B | (C ∪D) besagt dasselbe wieA |= B | (C,D). Wichtig ist, dass C ∪D nicht etwa C ∨Dbedeutet, sondern hier werden die Variablenmengen vereinigt, uberdie dann Vollkonjunktionen bzw. Konfigurationen gebildet werden.
• Alle genannten Eigenschaften werden auch von graphischerSeparation erfullt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 75 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Disjunkte Variablenmengen?
Die beteiligten Variablenmengen mussen nicht unbedingt disjunkt sein. Furallgemeine Variablenmengen muss man noch die folgende Eigenschaftbeachten:
A |= B | B
Dann gilt (gemeinsam mit den restlichen Eigenschaften):
A |= B | C gdw. A−C |= B−C | C
Alle genannten Eigenschaften sind von den anderen unabhangig, d.h. keineder Eigenschaften ist uberflussig.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 76 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Strikte Positivitat bei Schnitt 1/2
Die Voraussetzung der strikten Positivitat von P ist fur den Nachweis derSchnitteigenschaft notwendig, wie das folgende Beispiel zeigt:
Beispiel “Ausflug”: A = {A},B = {B},C = ∅,D = {D}mit den folgenden Bedeutungen
A Wir machen einen Ausflug.B Das Wetter ist schon.D Es ist warm und sonnig.
A B D P (ω) A B D P (ω)
0 0 0 0.7 1 0 0 0.010 0 1 0 1 0 1 00 1 0 0 1 1 0 00 1 1 0.09 1 1 1 0.2
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 77 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Strikte Positivitat bei Schnitt 2/2
P (b|d)=P (b|d)=P (d|b)=P (d|b)=1,
P (b|d)=P (b|d)=P (d|b)=P (d|b)=0
Daher A |= P B | D und A |= P D | B; die Schnitteigenschaft wurde abernun implizieren: {A} |= P {B,D} | ∅; es gilt aber
P (abd) = 0.2, P (a)P (bd) = 0.21 · 0.29 = 0.0609
und daher P (abd) 6= P (a)P (bd).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 78 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Markov-Graphen
Ein Markov-Graph G zu einer Wahrscheinlichkeitsverteilung P ist einminimaler Unabhangigkeitsgraph bezgl. P , d.h., es gilt die globaleMarkov-Eigenschaft:
A |= G B | C impliziert A |= P B | C,
und G enthalt keine uberflussigen Kanten.
Es gelten die folgenden Resultate:
• Zu jeder positiven Wahrscheinlichkeitsverteilung P gibt es einen(eindeutig bestimmten) Markov-Graph G0 = 〈V, E0〉, so dass(A,B) /∈ E0 gdw. A |= P B | (V − {A,B}).
• Andererseits lasst sich zu jedem ungerichteten Graphen G eineVerteilung P angeben, so dass G ein Unabhangigkeitsgraph von P ist.P heißt dann Markov-Feld bezgl. G.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 79 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Verteilung → Markov-Graph:
Ausgehend von einem vollstandigen Graphen auf V entfernt man alleKanten (A,B), fur die A |= P B | (V − {A,B}) gilt.
Umgekehrt kann man naturlich auch von einem leeren Graphen startenund nur die Knoten verbinden, bei denen A |= P B | (V − {A,B}) fur dieentsprechenden Variablen falsch ist.
Theorem 1
Jede strikt positive Wahrscheinlichkeitsverteilung P besitzt einen eindeutigbestimmten Markov-Graphen G0 = 〈V, E0〉 mit
(A,B) /∈ E0 gdw. A |= P B | (V − {A,B})paarweise Markov-Eigenschaft
Auf die Voraussetzung der strikten Positivitat von P kann hier nichtverzichtet werden kann.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 80 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Markov-Graphen – Beispiel
Vier (binare) Variablen A1, A2, A3, A4 mit
P (a1a2a3a4) =
{0.5 wenn a1 = a2 = a3 = a4
0 sonst
Es gelten die folgenden bedingten Unabhangigkeiten:
Ai |= P Aj | {Ak, Al}
Der nach der obigen Idee konstruierte Graph besitzt also gar keine Kanten,besteht folglich aus vier isolierten Knoten. Dies ist jedoch keinUnabhangigkeitsgraph fur P , da die vier Variablen naturlich nichtunabhangig voneinander sind.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 81 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Markov-Decke und Markov-Rand 1/2
Als Markov-Decke (Markov blanket), bl(A), von A ∈ V wird jedeVariablenmenge B ⊆ V bezeichnet, fur die gilt:
A |= P [V − (B ∪ {A})] | B
Ein Markov-Rand (Markov boundary), br(A), von A ist eine minimaleMarkov-Decke von A.
Da trivialerweise A |= P ∅ | (V − {A}) gilt, ist die Existenz vonMarkov-Decken und damit auch von Markov-Randern gesichert.
Fur strikt positive Verteilungen besitzen Markov-Rander eine anschaulichegraphische Interpretation:
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 82 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Markov-Decke und Markov-Rand 2/2
Theorem 2
Ist P eine strikt positive Wahrscheinlichkeitsverteilung, so besitzt jedesElement A ∈ V einen eindeutig bestimmten Markov-Rand br(A), dergerade aus den Nachbarknoten nb(A) von A im Markov-Graphen G0
besteht; es gilt also
A |= P [V − (nb(A) ∪ {A})] | nb(A)lokale Markov-Eigenschaft
Es gilt die folgende Implikationskette:
global Markov⇒ lokal Markov⇒ paarweise Markov
Im Allgemeinen sind die drei Markov-Eigenschaften unterschiedlich, untergewissen Bedingungen (insbesondere fur alle strikt positiven Verteilungen)besteht jedoch Aquivalenz.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 83 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussfolgern uber Unabhangigkeiten
Wichtig: Potentialdarstellungen (→ DVEW)
Sei P eine gemeinsame Verteilung uber den Variablen in V;sei {Wi | 1 ≤ i ≤ p} eine Menge von Teilmengen von V mit⋃pi=1 Wi = V; seien
ψi : {wi | wi ist Vollkonjunktion uber Wi, 1 ≤ i ≤ p} → IR≥0
Funktionen, die jeder Vollkonjunktion von Variablen in Wi (1 ≤ i ≤ p)eine nicht-negative reelle Zahl zuordnen. Gilt nun
P (V) = K ·∏pi=1 ψi(Wi)
so heißt {W1, . . . ,Wp;ψi} eine Potentialdarstellung von P .
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 84 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 85 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.5 Propagation in baumartigen Netzen
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 86 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in probabilistischen Netzen – Ubersicht
Die Wissenspropagation in probabilistischen Netzen wird realisiert durchUpdate-Regeln, die Belief-Parameter mittels lokaler Kommunikationverandern, so dass sich im Netz ein Gleichgewichtszustand etabliert, derdie posteriori-Wahrscheinlichkeiten korrekt wiedergibt.
Wir werden Wissenspropagation in folgenden Typen probabilistischer Netzebetrachten:
• Ketten und
• Baume.
• (DAG → Bayes-Netze in DVEW)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 87 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Basis-Ideen
• Neue Information uber einen Knoten des Netzwerks soll entlang derKanten durch das ganze Netzwerk propagiert werden, so dass sichneue, passende Wahrscheinlichkeiten an den Knoten einstellen.
• Der Update-Prozess soll lokal erfolgen, d.h. jeder Knotenkommuniziert nur mit seinen Nachbarn, mit minimaler externerUberwachung.
• Jeder Knoten wird damit als autonomer, informationsverarbeitenderProzessor betrachtet.
• Strikte Trennung von Bereichs- und Kontrollwissen;
• Der Propagationsprozess verlauft prinzipiell regelbasiert, d.h. unterVerwendung bedingter Wahrscheinlichkeiten.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 88 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Vergleich mit MYCIN 1/2 (s. DVEW)
MYCIN war – wie gewunscht – regelbasiert, und dieInformationsverarbeitung wurde weitgehend entlang der Kanten einesRegelnetzwerkes durch die folgenden Propagationsregeln realisiert:
1 Konjunktion: CF [A ∧B] = min{CF [A],CF [B]}.2 Disjunktion: CF [A ∨B] = max{CF [A],CF [B]}.3 serielle Kombination:
CF [B, {A}] = CF (A→ B) ·max{0,CF [A]}.
4 parallele Kombination: Fur n > 1 ist
CF [B, {A1, . . . , An}] = f(CF [B, {A1, . . . , An−1}],CF [B, {An}]).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 89 / 232
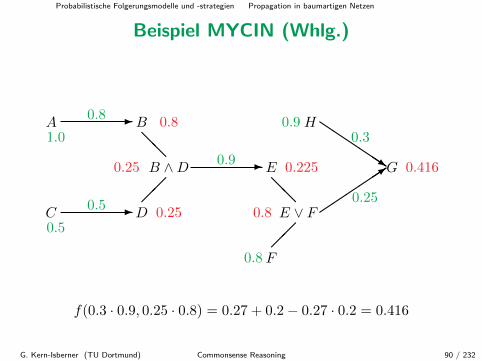
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel MYCIN (Whlg.)
0.5C
1.0A
-0.5
-0.8
D
B
��
@@B ∧D -0.9
E
@@
��
E ∨ F
F0.8
0.9 H
G
0.3
0.25������3
QQQQQQs
0.25
0.8
0.25 0.225
0.8
0.416
f(0.3 · 0.9, 0.25 · 0.8) = 0.27 + 0.2− 0.27 · 0.2 = 0.416
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 90 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Vergleich mit MYCIN 2/2
Allerdings waren die MYCIN-Regeln evidenzbasiert, d.h. von der Form
Beobachtung → Ursache,
wahrend die Regeln in probabilistischen (z.B. Bayesschen) Netzen meistenskausale Beziehungen der Form
Ursache → Wirkung
kodieren.
Außerdem gibt es zu MYCIN keine klare (probabilistische) Semantik, d.h.,die Bedeutung der Zahlen ist nicht klar.
Evidenz = neue Information im Sinne von: Beobachtung, Indiz, Beweisetc.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 91 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Probleme 1/5
Wie konnen/sollen Wahrscheinlichkeiten propagiert werden?
Im einfachsten Fall haben wir eine Regel der Form
A→ B,
bei der wir die (bedingten) Wahrscheinlichkeiten P (A) und P (B|A)kennen.
Daraus konnen wir jedoch nicht die Wahrscheinlichkeit von B ableiten, esgilt lediglich
P (B) ≥ P (AB) = P (A)P (B|A).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 92 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Probleme 2/5
Ist auch die Wahrscheinlichkeit P (B|A) bekannt, so erhalten wirwenigstens
P (B) = P (B|A)P (A) + P (B|A)P (A),
so dass sich P (B) nun berechnen lasst.
Was passiert jedoch, wenn neue Evidenz e bekannt wird und dieWahrscheinlichkeit P (B|e) berechnet werden soll?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 93 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Probleme 3/5
Die Gleichung
P (B|e) = P (B|A, e)P (A|e) + P (B|A, e)P (A|e)
zeigt, dass die gesuchte Wahrscheinlichkeit von einer Fulle andererWahrscheinlichkeiten abhangt, sich also nicht mehr direkt lokal berechnenlasst; sie kann sich zudem drastisch von der ursprunglichenWahrscheinlichkeit unterscheiden.
Damit wird die Information P (B|A) nutzlos – es mussen nicht nur dieKnotenwahrscheinlichkeiten, sondern auch die Kantenwahrscheinlichkeiten(d.h. bedingte Wahrscheinlichkeiten) angepasst werden, was der Idee derlokalen Propagation widerspricht.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 94 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Probleme 4/5
Ein anderes Problem ist das der ungerechtfertigten verstarkendenRuckkoppelung.
Beispiel 1: Nehmen wir an, Agent A verbreitet ein Gerucht, das erirgendwo aufgeschnappt hat. Nach einigen Tagen erzahlt ihm Agent Bdasselbe Gerucht. Die Frage, ob A nun seinen Glauben in die Richtigkeitdieses Geruchts verstarken soll, hangt entscheidend davon ab, ob B dasGerucht noch aus einer anderen Quelle (unter transitivem Abschluss!)gehort hat oder nicht, lasst sich also nicht lokal entscheiden. ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 95 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in prob. Netzen – Probleme 5/5
Beispiel 2: Feuer verursacht Rauch, Rauch lasst auf Feuer schließen –beide Evidenzen verstarken den Glauben in die jeweils andere. Einefestimplementierte, lokale positive Verstarkung kann dann dazu fuhren,dass am Ende sowohl Feuer als auch Rauch (unbegrundet) fast sichergeglaubt werden. ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 96 / 232
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
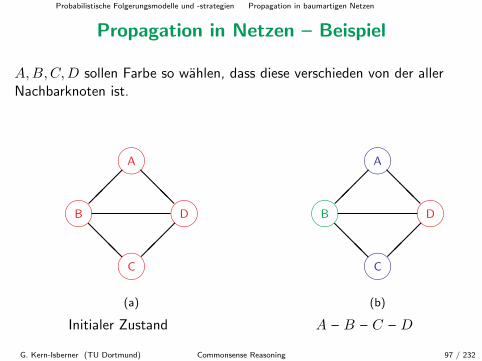
Propagation in Netzen – Beispiel
A,B,C,D sollen Farbe so wahlen, dass diese verschieden von der allerNachbarknoten ist.
����A����B ����D����C
���
@@@
@@@
���
(a)
Initialer Zustand
����A����B ����D����C
���
@@@
@@@
���
(b)
A – B – C – D
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 97 / 232
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
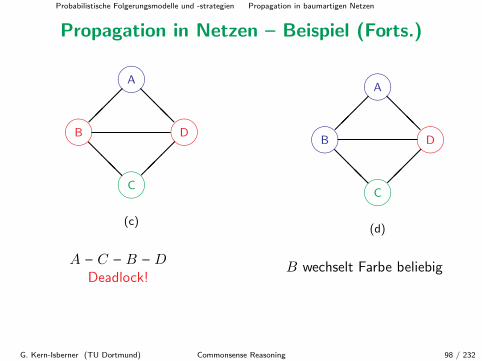
Propagation in Netzen – Beispiel (Forts.)
����A����B ����D����C
���
@@@
@@@
���
(c)
A – C – B – DDeadlock!
����A����B ����D����C
���
@@@
@@@
���
(d)
B wechselt Farbe beliebig
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 98 / 232
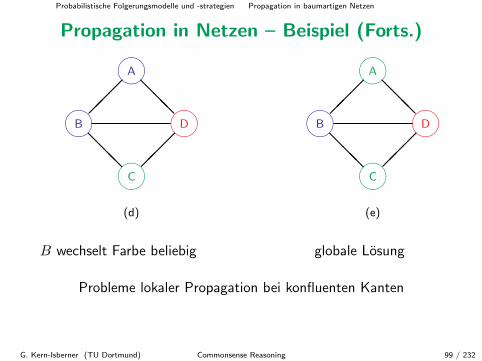
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in Netzen – Beispiel (Forts.)
����A����B ����D����C
���
@@@
@@@
���
(d)
B wechselt Farbe beliebig
����A����B ����D����C
���
@@@
@@@
���
(e)
globale Losung
Probleme lokaler Propagation bei konfluenten Kanten
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 99 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Kausale Baumnetze
In kausalen Baumnetzen hat jeder Knoten (6= Wurzelknoten) genau einenElternknoten, das Verursacherprinzip ist also klar geregelt.
Jeder Knoten reprasentiert eine mehrwertige Variable.
Notationen:
A,B, . . . ,X, Y, . . . Variablena, b, . . . , x, y, . . . Variablenwerte
a, b, . . . , x, y, . . . (beliebige, aber) fixe Variablenwerte,
fettgedruckte Buchstaben reprasentieren Mengen von Variablen bzw.Vollkonjunktionen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 100 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Kausale Baumnetze (Forts.)
Zu jeder (gerichteten) Kante
X → Y , X = {x1, . . . , xm}, Y = {y1, . . . , yn}
assoziieren wir eine Matrix M = M(Y |X) mit bedingtenWahrscheinlichkeiten:
M = M(Y |X) =
P (y1|x1) P (y2|x1) . . . P (yn|x1)P (y1|x2) P (y2|x2) . . . P (yn|x2)
......
...P (y1|xm) P (y2|xm) . . . P (yn|xm)
,also M(x,y) = P (y|x) = P (Y = y|X = x), mit Spaltenvektoren My|X undZeilenvektoren MY |x.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 101 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord
In einem Mordverfahren gibt es 3 Verdachtige, A,B,C, von denen genaueiner definitiv den Mord begangen hat. Auf der Mordwaffe gibt esFingerabdrucke. Wir benutzen folgende Variablen:
X Morder, x1 = A, x2 = B, x3 = C;(letzter Benutzer der Waffe)
Y Person, deren Fingerabdrucke auf der Waffe gefunden wurden,y1 = A, y2 = B, y3 = C;
Z Ergebnis des Labors (Typ des Fingerabdrucks)
Offensichtlich modelliert das folgende Bayessche Netz die korrektenAbhangigkeiten:
X −→ Y −→ Z.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 102 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Wir benotigen die folgenden bedingten Wahrscheinlichkeiten:
• eine 3× 3-Matrix M = M(Y |X) mit
My|x = P (y|x) =
{0.80 wenn x = y, x, y ∈ {A,B,C}0.10 wenn x 6= y x, y ∈ {A,B,C} ;
• sowie eine Matrix M(Z|Y ) mit Mz|y = P (z|y) und∑
zMz|y = 1 fury ∈ {A,B,C}; Mz|y reprasentiert dann die Wahrscheinlichkeit, mitder ein Fingerabdruck vom Verdachtigen y als Ergebnis vom Typ zerscheint.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 103 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Spezifische und virtuelle Evidenz
Wir unterscheiden zwischen spezifischer und virtueller Evidenz:
• Spezifische Evidenz bezieht sich auf die direkte Beobachtung vonVariablen im Netzwerk.
• Virtuelle Evidenz reprasentiert nicht weiter spezifizierteBeobachtungen, die sich auf Variablen außerhalb des Netzwerkesbeziehen, die sich also einer genaueren Spezifikation entziehen.
Virtuelle Evidenzen werden durch Dummy-Knoten mit nur einerAuspragung im Netzwerk dargestellt, die entsprechenden Kantenkonnen nur in einer Richtung benutzt werden.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 104 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Virtuelle Evidenz – Beispiel
Im Mord-Beispiel kann es weder moglich noch sinnvoll sein, alle moglichenFingerabdrucktypen z aufzufuhren.
In diesem Fall wurde man Z durch einen Dummy-Knoten reprasentieren,und die Kante Y → Z wurde die Wahrscheinlichkeit angeben, mit der derFingerabdruck eines der Verdachtigen zu dem Labor-Ergebnis z passt, alsobeispielsweise
P (z|Y ) = (0.80, 0.60, 0.50).
Beachten Sie: Die Wahrscheinlichkeiten mussen sich nicht zu 1aufsummieren, wichtig sind hier nur die Verhaltnisse derWahrscheinlichkeiten!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 105 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Evidenzen und Belief
Die Konjunktion aller Evidenzen (von spezifischen und virtuellenVariablen) wird durch e angegeben, wobei die Menge aller instantiiertenVariablen manchmal mit E angefuhrt wird.
Die fixen bedingten Wahrscheinlichkeiten an den Kanten werden weiterhinmit P bezeichnet, wahrend die dynamischen, subjektivenWahrscheinlichkeiten unter Informations- bzw. Evidenzeinfluss mit Pbelbezeichnet werden, also beispielsweise
Pbel(x) = P (x|e)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 106 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Einige Formalia
Die Wahrscheinlichkeiten, mit denen Werte einer Variablen X auftreten,konnen als Vektor angegeben werden:
P (X) = (P (xi))1≤i≤n,
wobei sich die Komponenten des Vektors zu 1 aufsummieren.
Diese Normierung ist fur die Semantik der Wahrscheinlichkeiten außerstwichtig, aber oft reicht es, diese Normierung nur einmal zum Schlussdurchzufuhren. Zu diesem Zweck benutzen wir α als normalisierendeKonstante, z.B.
α(1, 1, 3) = (0.2, 0.2, 0.6) fur α = 0.2.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 107 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Einige Formalia (Forts.)
Das Symbol β wird hier als beliebige Konstante benutzt, also z.B.
P (z|Y ) = (0.80, 0.60, 0.50) = β(0.40, 0.30, 0.25).
Durch den Gebrauch der Symbole α und β lassen sich viele Gleichungenvereinfachen, z.B.
Kβ(xi)i = β(xi)i
αβ(xi)i = α(xi)i
• bezeichnet Skalarprodukt bzw. Matrixprodukt, wahrend juxtaponierteVektoren komponentenweise multipliziert werden:
(1, 2, 3)(3, 2, 1) = (1 · 3, 2 · 2, 3 · 1) = (3, 4, 3)
(1, 2, 3) • (3, 2, 1) = 1 · 3 + 2 · 2 + 3 · 1 = 10.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 108 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Ein ganz einfacher Fall . . .
Der einfachste nicht-triviale Baum besteht aus zwei Knoten und einerKante:
X → Y
gemeinsam mit einer Matrix M(Y |X), die im Knoten Y abgespeichertwird.
Nehmen wir nun an, Y wird instanziiert und liefert Evidenz e : Y = y.
P (x) wird dann aktualisiert zu
Pbel(x) = P (x|e) =P (e|x)P (x)
P (e),
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 109 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Ein ganz einfacher Fall . . . (Forts.)
also Pbel(x) = αP (x)λ(x)
mit α = [P (e)]−1 und λ(x) = P (e|x) = P (y|x);
in Vektorschreibweise gilt dann einfach
Pbel(X) = αP (X)λ(X) mit λ(X) = My|X
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 110 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
. . . und eine Erweiterung
Verlangern wir die Kette etwas:
X → Y → Z
mit der Bayesschen Semantik, d.h. es gilt X |= P Z | Y , und nun werde Zinstanziiert: e : Z = z.
Dann ist zunachst
Pbel(Y ) = αP (Y )λ(Y ) mit λ(Y ) = P (e|Y ) = P (z|Y ) = Mz|Y .
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 111 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
. . . und eine Erweiterung (Forts.)
Es gilt weiterhinPbel(x) = αP (x)λ(x)
mit
λ(x) = P (e|x) =∑y
P (e|y, x)P (y|x)
=∑y
P (e|y)P (y|x) =∑y
P (y|x)λ(y)
alsoλ(X) = M(Y |X) • λ(Y )
Der λ-Vektor von X kann also berechnet werden aus dem λ-Vektor von Yund der Link-Matrix M(Y |X).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 112 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Ketten
Was passiert, wenn Information auch vom anderen Ende der Ketteeintrifft?
Wir betrachten die folgende Kette:
ei → T → U → X → Y → Z → ef
(ei = initiale Evidenz/Ursache, ef = finale Evidenz/Beobachtung)
Sei A ein Knoten, der zwischen ei und ef liegt; der Einfluss der Evidenzenwerde nun durch die folgenden beiden Vektoren kodiert:
λ(A) = P (ef |A) und π(A) = P (A|ei)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 113 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Ketten (Forts.)
Die aktualisierte Wahrscheinlichkeit von A unter beiden Evidenzen lasstsich dann wie folgt berechnen:
Pbel(A) = P (A|ei, ef )
= αP (ef |A, ei)P (A|ei)= αP (ef |A)P (A|ei)= αλ(A)π(A)
Wir haben oben gesehen, dass sich der λ-Vektor eines Knoten ausInformationen seines Kindknoten berechnen lasst; fur den π-Vektor giltAhnliches.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 114 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Ketten (Forts.)
Wir betrachten z.B. den Knoten X:
π(X) = P (X|ei)=
∑u
P (X|u, ei)P (u|ei)
=∑u
P (X|u)π(u)
= π(U) •M(X|U)
Der π-Vektor eines Knoten lasst sich also aus dem π-Vektor seinesElternknoten und der zugehorigen Link-Matrix berechnen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 115 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Ketten (Forts.)
Insgesamt ergibt sich also folgendes Bild fur die Propagation vonInformationen innerhalb der Kette:
λ-Vektor Nachricht Kind → Elternπ-Vektor Nachricht Eltern → Kind
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 116 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Unsere Evidenzen seien hier die folgenden:
ef : Z = z finale Evidenz: Fingerabdruck (Laborergebnis)ei initiale Evidenz: Motiv, Alibi, allg. Situation
π(x) = P (x|ei) W’keit(x ist (nach allg. Beweislage) der Morder)π(y) = P (y|ei) W’keit(y’s Fingerabdrucke sind auf der Waffe)λ(y) = P (ef |y) W’keit, dass die gefundenen Fingerabdrucke
von y sind
Wir setzen π(X) = (0.8, 0.1, 0.1) und nehmen an, dass noch keinLaborergebnis uber die Fingerabdrucke vorliegt, d.h. alle Komponentenaller λ-Vektoren sind 1.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 117 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Fur den π-Vektor von Y berechnet man dann:
π(Y ) = π(X) •M(Y |X)
= (0.8, 0.1, 0.1) •
0.8 0.1 0.10.1 0.8 0.10.1 0.1 0.8
= (0.66, 0.17, 0.17)
Nun trifft der Labor-Bericht ein:
λ(Y ) = β(0.8, 0.6, 0.5).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 118 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Wir aktualisieren P (Y ):
Pbel(Y ) = αλ(Y )π(Y )
= α(0.8, 0.6, 0.5)(0.66, 0.17, 0.17)
= (0.738, 0.143, 0.119)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 119 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
X aktualisiert zunachst mit Hilfe von λ(Y ) seinen λ-Vektor:
λ(X) = M(Y |X) • λ(Y )
= β
0.8 0.1 0.10.1 0.8 0.10.1 0.1 0.8
• 0.8
0.60.5
= β
0.750.610.54
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 120 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Damit ist
Pbel(X) = αλ(X)π(X)
= α(0.75, 0.61, 0.54)(0.8, 0.1, 0.1)
= α(0.6, 0.061, 0.054)
= (0.839, 0.085, 0.076)
Kandidat A ist mit der bei weitem großten Wahrscheinlichkeit der Morder.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 121 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Nehmen wir nun an, der Verdachtige A weise ein handfestes Alibi nach,das seine Taterwahrscheinlichkeit von 0.80 auf 0.28 drastisch reduziert;damit andert sich π(X) = P (X|ei) zu
π(X) = (0.28, 0.36, 0.36).
Diese Anderung gibt X an seinen Kindknoten Y weiter:
π(Y ) = π(X) •M(Y |X)
= (0.28, 0.36, 0.36) •
0.8 0.1 0.10.1 0.8 0.10.1 0.1 0.8
= (0.30, 0.35, 0.35)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 122 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Die aktualisierte Wahrscheinlichkeit jedes Knoten kann nun lokalberechnet werden:
Pbel(X) = απ(X)λ(X)
= α(0.28, 0.36, 0.36)(0.75, 0.61, 0.54)
= α(0.210, 0.220, 0.194)
= (0.337, 0.352, 0.311)
Pbel(Y ) = απ(Y )λ(Y )
= α(0.30, 0.35, 0.35)(0.8, 0.6, 0.5)
= α(0.240, 0.210, 0.175)
= (0.384, 0.336, 0.280)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 123 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Pbel(X) = (0.337, 0.352, 0.311) W’keit, dass A,B oder Cder Morder ist;
Pbel(Y ) = (0.384, 0.336, 0.280) W’keit, dass A’s, B’s oder C’sFingerabdrucke auf der Waffe sind.
B ist folglich mit der großten Wahrscheinlichkeit der Morder, obwohl sichauf der Waffe wahrscheinlich A’s Fingerabdrucke befinden. Allerdingsliegen die jeweiligen Wahrscheinlichkeiten bzgl. A und B sehr dichtbeieinander.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 124 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Lokale Propagation in Ketten 1/5
In einer Kette kommuniziert also jeder Knoten lokal mit seinen Nachbarn(jeweils ein Eltern- und Kindknoten) mittels der π- und λ-Nachrichten.
Die Unterteilung in zwei Typen von Nachrichten ermoglicht dieUnterscheidung zwischen kausalem und evidentiellem Einfluss, so dass jedeungerechtfertigte Verstarkung unterbunden wird.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 125 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Lokale Propagation in Ketten 2/5
Wir stellen uns jeden Knoten X als lokalen Prozessor mit einem Λ- undeinem Π-Register vor; dann kann das Verhalten des Prozessors X mitElternknoten U und Kindknoten Y wie folgt beschrieben werden:
Wenn (X → Y )M(Y |X) und Λ(Y ) = λ(Y ),
dann Λ(X) = M(Y |X) • λ(Y ),Wenn (U → X)M(X|U) und Π(U) = π(U),
dann Π(X) = π(U) •M(X|U),Wenn Λ(X) = λ(X) und Π(X) = π(X),
dann Pbel(X) = αλ(X)π(X).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 126 / 232
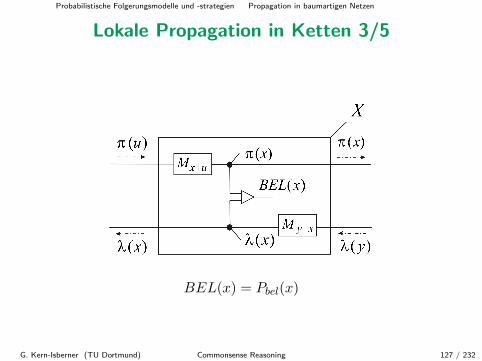
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Lokale Propagation in Ketten 3/5
BEL(x) = Pbel(x)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 127 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Lokale Propagation in Ketten 4/5
Bei diesem Modell speichert jeder Knoten die Link-Matrizen M(X|U) undM(Y |X) (von seinem Elternknoten U und zu seinem Kindknoten Y ) undberechnet daraus seine π- und λ-Nachrichten.
Eine effizientere Alternative ist hier das Modell, bei jedem Knoten nur eineMatrix (jede also nur einmal!) zu speichern, und zwar die, die zu seinerElternverbindung gehort.
Jeder Knoten erhalt dann die π-Nachricht seines Elternknoten und seineeigene λ-Nachricht und berechnet seine eigene π-Nachricht (die er an seinKind weiterleitet) und die λ-Nachricht seines Elternknoten (die er anseinen Elternknoten weiterleitet).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 128 / 232
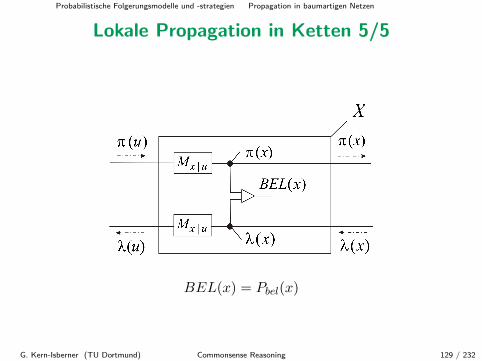
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Lokale Propagation in Ketten 5/5
BEL(x) = Pbel(x)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 129 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Ketten - Summary
• Die notwendige Anderung von Wahrscheinlichkeiten durchKonditionalisierung kann durch lokale Informationsflusse zwischenNachbarknoten realisiert werden.
• Das Problem der ungerechtfertigten Verstarkung wird durchIdentifikation und Trennung von evidentiellen und kausalen Einflussengelost.
• Es ist im Prinzip irrelevant, in welcher ReihenfolgeUpdate-Operationen ausgefuhrt werden – sie mussen nur solange undan allen Knoten ausgefuhrt werden, bis die Kette einenGleichgewichtszustand erreicht hat.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 130 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen
Wir wollen nun den Ansatz mit lokalen λ- und π-Nachrichten auf dieBehandlung von Informationspropagation in Baumen verallgemeinern.
Die Idee ist ahnlich, aber Folgendes ist zu beachten, denn jeder Knotenkann nun mehrere Kinder haben:
• Jeder Knoten muss die λ-Nachrichten seiner Kinder kombinieren bzw.fusionieren, um eine Gesamtsicht der aufsteigenden Information zubekommen.
• Jeder Knoten muss geeignete π-Nachrichten an alle seine Kinderverschicken.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 131 / 232
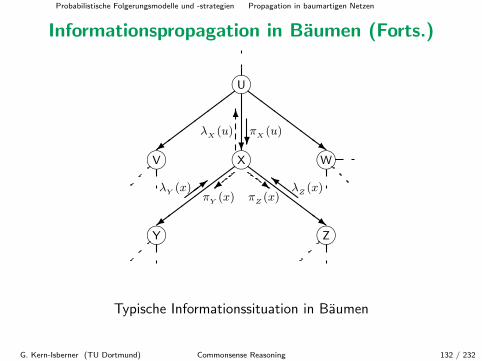
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
mU
mWmXmV
mZmY
���
���= ?
ZZZZZZ~
���
���=
ZZZZZZ~
6λX (u)
?πX (u)
��>λY (x) =πY (x) Z
Z} λZ (x)~
πZ (x)
Typische Informationssituation in Baumen
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 132 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Die Information, die auf einen (inneren) Knoten X in einem Baumeinwirkt, lasst sich aufsplitten in
• Information, die aus dem Teilbaum mit Wurzel X kommt, also imPrinzip uber die Kinder von X aufsteigt; diese Information bzw.Evidenz wird mit e+
X bezeichnet.
• Information, die aus dem Rest des Baumes kommt; diese Informationbzw. Evidenz wird mit e−X bezeichnet.
Fur einen Blattknoten / fur die Wurzel wird e+X / e−X als
Beobachtungswissen / Hintergrundwissen aufgefasst.
Mit eX = e−X , e+X wird die gesamte Information bezeichnet, die auf den
Knoten X einwirkt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 133 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Wegen der Unabhangigkeitsbedingungen in Bayesschen Netzen gelten diefolgenden Beziehungen:
• Ist U der Elternknoten von X, so gilt
P (X|U, e−X) = P (X|U)
• Ist V ein Geschwisterknoten von X (also mit gleichem ElternknotenU), so gilt
P (X,V |U) = P (X|U)P (V |U)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 134 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Die korrekte aktualisierte Wahrscheinlichkeit Pbel(X) berechnet sich wiefolgt:
Pbel(X) = P (X|e) = P (X|e−X , e+X)
= αP (e+X |e−X , X)P (X|e−X)
= αP (e+X |X)P (X|e−X)
Fur die Berechnung werden also die folgenden beiden Vektoren benotigt:
λ(X) = P (e+X |X) und π(X) = P (X|e−X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 135 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Ahnlich wie bei der Propagation in einfachen Ketten reprasentieren λ- undπ-Nachrichten folgende Typen von Information:
• π(X) stellt kausale oder pradiktive Information dar, die von denNicht-Nachkommen von X kommt und durch den Elternknoten vonX gebundelt wird;
• λ(X) stellt diagnostische oder retrospektivische Information dar, dievon den Nachkommen von X aufgenommen wird und durch dieKinder von X kanalisiert wird.
Pbel(X) = αλ(X)π(X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 136 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Schauen wir uns zunachst die diagnostische Information λ(X) an, wobeiwir (wie im Beispielbaum) annehmen, dass X die beiden Kinder Y und Zhat:
λ(X) = P (e+X |X)
= P (e+Y , e
+Z |X)
= P (e+Y |X)︸ ︷︷ ︸
λY (X)
P (e+Z |X)︸ ︷︷ ︸
λZ(X)
.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 137 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Also gilt fur die diagnostische Information, die am Knoten X ankommt
λ(X) = λY (X)λZ(X),
oder allgemeiner, fur alle Kinder Y1, . . . , Yk von X:
λ(X) =k∏i=1
λYi(X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 138 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Wir erweitern unser Mord-Beispiel auf der evidentiellen Seite, indem wirden Fingerabdruck-Befund eines zweiten, unabhangigen Labors zusatzlichberucksichtigen:
λZ1(Y ) = β(0.80, 0.60, 0.50)
λZ2(Y ) = β(0.30, 0.50, 0.90)
Insgesamt wurde Y also die λ-Information
λ(Y ) = β(0.80, 0.60, 0.50)(0.30, 0.50, 0.90) = β(0.24, 0.30, 0.45)
erhalten.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 139 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Kombinieren wir dies mit der letzten kausalen Informationπ(Y ) = (0.30, 0.35, 0.35), so erhalten wir die folgende aktualisierteWahrscheinlichkeit fur Y :
Pbel(Y ) = α(0.24, 0.30, 0.45)(0.30, 0.35, 0.35)
= α(0.072, 0.105, 0.1575)
= (0.215, 0.314, 0.471)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 140 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Was wurde passieren, wenn der Verdachtige B nun auf einmal gesteht,dass er als Letzter die Waffe in der Hand gehalten hat, dass also seineFingerabdrucke auf der Waffe zu finden sein mussten?
Wir behandeln dies als ein drittes Beweisstuck zur Frage derFingerabdrucke:
λZ3(Y ) = (0, 1, 0).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 141 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord (Forts.)
Insgesamt ergibt sich also fur die λ-Nachricht
λ(Y ) = β(0.80, 0.60, 0.50)(0.30, 0.50, 0.90)(0, 1, 0)
= β(0, 0.30, 0),
und fur die aktualisierte Wahrscheinlichkeit
Pbel(Y ) = α(0, 0.30, 0)(0.30, 0.35, 0.35)
= α(0, 0.105, 0)
= (0, 1, 0).
Die starke Information des Gestandnisses von B uberschreibt also dieschwacheren Informationen der Laborbefunde vollstandig.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 142 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Nachdem der λ-Vektor von X bestimmt worden ist, muss nun noch derπ-Vektor des Knoten X berechnet werden:
π(X) = P (X|e−X)
=∑u
P (X|e−X , u)P (u|e−X)
=∑u
P (X|u)P (u|e−X)︸ ︷︷ ︸πX(u)
,
also
π(X) =∑
u P (X|u)πX(u) = πX(U) •M(X|U)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 143 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Damit ergibt sich insgesamt die aktualisierte Wahrscheinlichkeit einesKnoten X mit Elternknoten U und Kindknoten Y1, . . . , Yn wie folgt:
Pbel(X) = α
k∏i=1
λYi(X)︸ ︷︷ ︸λ(X)
∑u
P (X|u)πX(u)︸ ︷︷ ︸π(X)
mit
λYi(X) = P (e+Yi|X)
πX(U) = P (U |e−X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 144 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Nachdem Knoten X seine eigene Wahrscheinlichkeit aktualisiert hat,mussen nun noch seine eigenen π- und λ-Nachrichten, die er an seineKinder bzw. seinen Elternknoten schickt, berechnet werden.
Fur die λ-Nachricht gilt:
λX(U) = P (e+X |U) =
∑x
P (e+X |U, x)P (x|U)
=∑x
P (e+X |x)P (x|U)
=∑x
λ(x)P (x|U)
= M(X|U) • λ(X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 145 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
An einen Kindknoten Y schickt X die folgenden Nachricht:
πY (X) = P (X|e−Y ) = P (X|e−X , e+Z )
= αP (e+Z |X, e
−X)P (X|e−X)
= αP (e+Z |X)P (X|e−X)
= αλZ(X)π(X);
Bei mehreren Kindknoten Yi gilt
πYi(X) = α∏j 6=i
λYj (X)π(X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 146 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
Ein Vergleich mit der Gleichung fur Pbel(X) liefert direkt
πY (X) = αPbel(X)
λY (X)
fur einen Kindknoten Y von X.
Anstatt also X fur jeden Knoten einen gesonderten λ-Wert berechnen zulassen, ist es effizienter, X an alle seine Kinder den aktualisierten WertPbel(X) schicken zu lassen und erst in den Kindknoten die notigenπY -Werte als Quotient von Pbel(X) und der eigenen λ-Nachricht an X zuberechnen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 147 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen – Summary 1/5
Wir fassen die einzelnen Aktivitaten der Informationspropagation, die eintypischer Knoten X mit k Kindknoten Y1, . . . , Yk und Elternknoten U zuleisten hat, zusammen:
Es mussen folgende Parameter in X zur Verfugung stehen:
• die kausale Information πX(U) = P (U |e−X) vom Elternknoten U ;
• die diagnostische Informationen λYi(X) = P (e+Yi|X) der Kindknoten
Y1, . . . , Yk;
• die Link-Matrix M(X|U).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 148 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen – Summary 2/5
Schritt 1: Belief updatingberechnet die aktualisierte Wahrscheinlichkeit von X:
Pbel(X) = αλ(X)π(X)
mit
• λ(X) =∏ki=1 λYi(X);
• π(X) = πX(U) •M(X|U) =∑
u P (X|u)πX(u).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 149 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen – Summary 3/5
Schritt 2: Bottom up-Propagationberechnet die λ-Nachricht fur den Elternknoten U :
λX(U) = M(X|U) • λ(X) =∑x
λ(x)P (x|U)
Schritt 3: Top down-Propagationberechnet die π-Nachrichten zu den Kindern:
πYi(X) = απ(X)∏j 6=i
λYj (X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 150 / 232
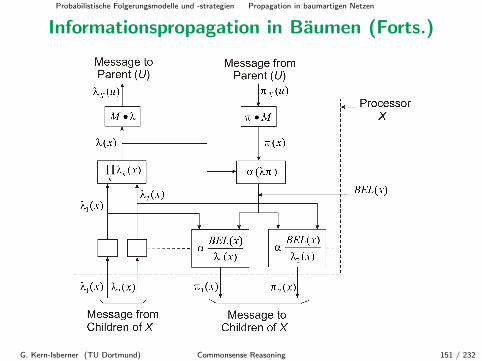
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen (Forts.)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 151 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen – Summary 4/5
Alle Parameter behalten die ursprungliche probabilistische Interpretation:
λX(U) = P (e+X |U)
πY (X) = P (X|e−Y )
Pbel(X) = P (X|e−X , e+X)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 152 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationspropagation in Baumen – Summary 5/5
Die Informationspropagation kann in beliebiger Reihenfolge durchgefuhrtwerden, bis sich ein Gleichgewichtszustand eingestellt hat; folgendeKnoten nehmen dabei besondere Rollen wahr:
• ein antizipatorischer Knoten ist ein Blatt, das noch nicht instanziiertwurde; hier ist Pbel = π und λ = (1, . . . , 1);
• ein Evidenzknoten ist ein instanziierter Blattknoten X = xj ; wirsetzen dann λ(X) = (0, . . . , 1, . . . , 0) (1 an j-ter Stelle);
• ein Dummy-Knoten reprasentiert virtuelle Evidenz fur einen(Eltern)Knoten X; wir setzen λDummy(X) = βP (Beobachtung |X);
• fur den Wurzelknoten entspricht π(root) der priori-Wahrscheinlichkeitder Wurzel-Variablen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 153 / 232
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationsflusse in Baumen 1/5
eee e
eee ee
,,
ll
��
@@
%%@@
(a)
eee e
eee ee
b b,,
ll
��
@@
%%@@
##
(b)
Data
Data
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 154 / 232
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationsflusse in Baumen 2/5
eee e
eee ee
b b,,
ll
��
@@
%%@@
##
(b)
Data
Data
eee e
eee ee
rb rbb b,,
ll
��
@@
%%@@
(c)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 155 / 232
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationsflusse in Baumen 3/5
eee e
eee ee
rb rbb b,,
ll
��
@@
%%@@
(c)
rb rb
rbrb
eee e
eee ee
,,
ll
��
@@
%%@@
(d)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 156 / 232
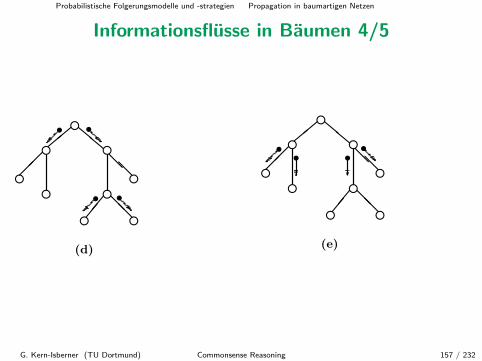
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationsflusse in Baumen 4/5
rb rb
rbrb
eee e
eee ee
,,
ll
��
@@
%%@@
(d)
rbrbrb rbee
e ee
ee ee
,,
ll
��
@@
%%@@
(e)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 157 / 232
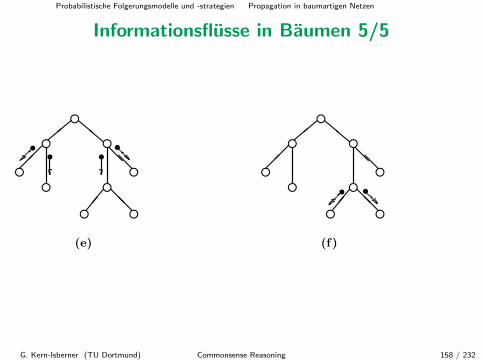
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Informationsflusse in Baumen 5/5
rbrbrb rbee
e ee
ee ee
,,
ll
��
@@
%%@@
(e)
rbrb
eee e
eee ee
,,
ll
��
@@
%%@@
(f)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 158 / 232
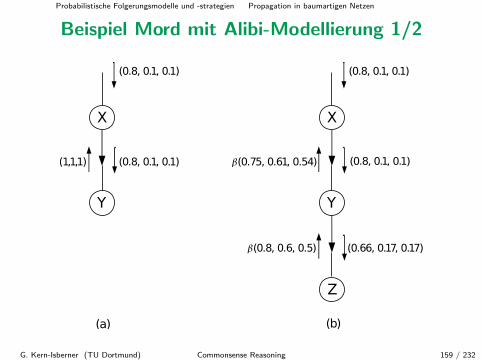
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord mit Alibi-Modellierung 1/2
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 159 / 232
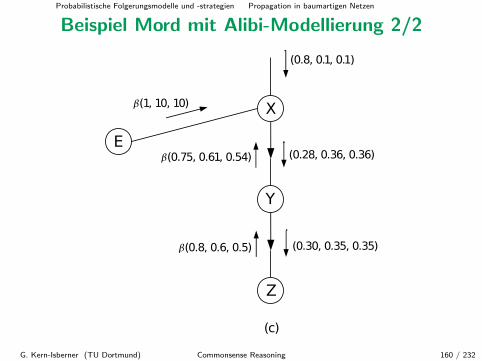
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Mord mit Alibi-Modellierung 2/2
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 160 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug
Wir betrachten die folgenden Variablen:
A = {a1, a2} Er/Sie betrugt ja / neinB = {b1, b2} Er/Sie geht mit einer anderen/einem anderen essen
ja / neinC = {c1, c2} Er/Sie wurde im Restaurant mit einer anderen/
einem anderen gesehen ja / neinD = {d1, d2} anderer Mann/andere Frau am Telefon ja / nein
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 161 / 232
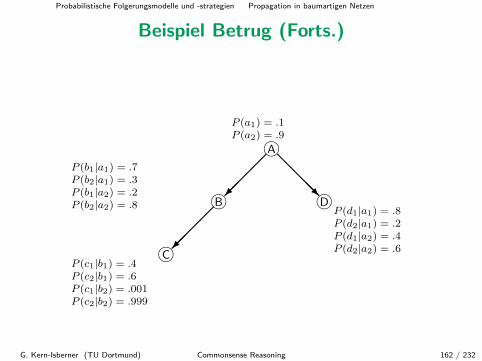
Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug (Forts.)
jAP (a1) = .1P (a2) = .9
jBP (b1|a1) = .7P (b2|a1) = .3P (b1|a2) = .2P (b2|a2) = .8
jDP (d1|a1) = .8P (d2|a1) = .2P (d1|a2) = .4P (d2|a2) = .6jC
P (c1|b1) = .4P (c2|b1) = .6P (c1|b2) = .001P (c2|b2) = .999
��
��
��
��
@@@@R
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 162 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug (Forts.)
jAπ(A)λ(A)
jBπ(B)λ(B) jD
π(D)λ(D)jC
π(C)λ(C)
����←πB
(A)
λB(A
)→
��
��←πC
(B)
λC(B
)→
@@@@R
πD (A
)→←λD (A
)
Alle priori π- und λ-Nachrichten
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 163 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug (Forts.)
jAπ(A) = (.1, .9)λ(A) = (1, 1)P (A) = (.1, .9)
jBπ(B) = (.25, .75)λ(B) = (1, 1)P (B) = (.25, .75) jD
π(D) = (.44, .56)λ(D) = (1, 1)P (D) = (.44, .56)jC
π(C) = (.10075, .89925)λ(C) = (1, 1)P (C) = (.10075, .89925)
����←
(.1,.9)
(1, 1
)→
��
��←(.25, .
75)
(1, 1
)→
@@@@R
(.1, .9)→←
(1, 1)
Startwerte: π(A) = P (A) = (0.1, 0.9), λ(C) = λ(D) = (1, 1)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 164 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug (Forts.)
jAπ(A) = (.1, .9)λ(A) = (.7, .2)P (A|b1) = (.28, .72)
jBπ(B) = (.25, .75)λ(B) = (1, 0)P (B|b1) = (1, 0) jD
π(D) = (.512, .488)λ(D) = (1, 1)P (D|b1) = (.512, .488)jC
π(C) = (.4, .6)λ(C) = (1, 1)P (C|b1) = (.4, .6)
����←
(.1,.9)
(.7,.2)→
��
��←
(1, 0
)
(1, 1
)→
@@@@R
(.28, .72)→
←(1, 1)
Er/Sie war mit einer/einem anderen essen . . .
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 165 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Beispiel Betrug (Forts.)
jAπ(A) = (.1, .9)λ(A) = (.14, .12)P (A|b1, d2) = (.1148, .8852)
jBπ(B) = (.2179, .7821)λ(B) = (1, 0)P (B|b1, d2) = (1, 0) jD
π(D) = (.512, .488)λ(D) = (0, 1)P (D|b1, d2) = (0, 1)jC
π(C) = (.4, .6)λ(C) = (1, 1)P (C|b1, d2) = (.4, .6)
����←(.03
6,0.96
4)
(.7,.2)→
��
��←
(1, 0
)
(1, 1
)→
@@@@R
(.28, .72)→
←(.2, .6)
. . . aber es gab keinen verdachtigen Anruf.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 166 / 232

Probabilistische Folgerungsmodelle und -strategien Propagation in baumartigen Netzen
Propagation in komplexeren Graphen
Der Propagationsmechanismus kann nicht nur benutzt werden, umWahrscheinlichkeiten zu aktualisieren, sondern auch, umWahrscheinlichkeiten von Knoten zu berechnen, wenn nur partielleInformationen uber Eingangsgroßen des Baumes bekannt sind.
Man kann ahnliche Propationsmechanismen auch fur Baume mit mehrerenWurzeln entwerfen.
Dies fuhrt auf das Problem der konfluenten Information und – nochallgemeiner – auf das Problem der Propagation in DAG’s, d.h. inbeliebigen Bayesschen Netzen (s. DVEW).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 167 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 168 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.6 Probabilistische Inferenz auf der Basisoptimaler Entropie
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 169 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistisches Wissen
Probabilistische Regeln als Wissensreprasentationsmittel sind gut, weilintuitiv und ausdrucksstark.
Wie schon ware das Leben, wenn man . . .
• . . . nur das (Regel)Wissen angeben konnte, das man selbst furrelevant halt?
• . . . sich nicht um den Aufbau des Netzes kummern musste?
• . . . somit Strukturanderungen in probabilistischen Netzen einfachdurch Hinzunahme oder Weglassen von Regeln vornehmen konnte?
• . . . uberhaupt eine Methodik hatte, die sich um alle lastigentechnischen Details kummern wurde, so dass man sich auf dieWissensmodellierung konzentrieren konnte?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 170 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Maximale Entropie (ME)
Unterschiedliche Aspekte der ME -Methodik:
• Einfuhrung, Uberblick und ME -System
• LEG-Netze
• Eigenschaften der ME -Inferenz
• ME -Prinzip und Commonsense Reasoning
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 171 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistische Logik
Syntax: L aussagenlogische Sprache (uber Σ)
Lprob = {A[x] | A ∈ L, x ∈ [0, 1]}(L | L)prob = {(B|A)[x] | A,B ∈ L, x ∈ [0, 1]}
Eine Verteilung P erfullt eine probabilistische Regel (B|A) [x],
P |= (B|A) [x] gdw. P (A) > 0 und P (B|A) = x
d.h. probabilistische Regeln werden durch bedingte Wahrscheinlichkeiteninterpretiert, und Wahrscheinlichkeitsverteilungen sind die Modelle (→Semantik) probabilistischer Regeln.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 172 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistische Regelbasen
Die Wissensbasis hat also die Form einer Regelmenge
R = {(B1|A1) [x1], . . . , (Bn|An) [xn]}
Im Allgemeinen wird es eine unubersehbar große Zahl von Verteilungengeben, die eine probabilistische Wissensbasis (≈ Menge vonprobabilistischen Constraints)
R = {(B1|A1) [x1], . . . , (Bn|An) [xn]}
erfullen – die durch R spezifizierte Information ist unvollstandig!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 173 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistische Konsequenz-Operation (DVEW)
In Analogie zur klassischen Logik wird die probabilistischeKonsequenz-Operation Cnprob : 2(L|L)prob → 2(L|L)prob definiert durch
Cnprob(R) = {φ ∈ (L | L)prob | P |= φ fur alle P ∈ Mod(R)}
Cnprob erfullt
• Inklusion/Reflexivitat: R ⊆ Cnprob(R);
• Schnitt: R ⊆ S ⊆ Cnprob(R) impliziert Cnprob(S) ⊆ Cnprob(R);
• Monotonie: R ⊆ S impliziert Cnprob(R) ⊆ Cnprob(S)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 174 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistische Auswahl-Inferenz? (DVEW)
• Probabilistisches Schließen auf der Basis aller Modelle (i.e.Verteilungen) ist daher meistens viel zu schwach!
• Gibt es besonders gute Modelle?
• Philosophie: Nimm diejenige Verteilung P ∗ zu nehmen, die nur dasWissen in R und seine probabilistischen Konsequenzen darstellt undsonst keine Information hinzufugt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 175 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Der MaxEnt-Ansatz (ME) 1/2
Gegeben: Probabilistische WissensbasisR = {(B1|A1) [x1], . . . , (Bn|An) [xn]};
Gesucht: Diejenige Verteilung P ∗, die nur das Wissenin R und seine probabilistischen Konsequenzen darstelltund sonst keine Information hinzufugt.
Prinzip der maximalen Entropie
Maximiere Unbestimmtheit (d.h. Entropie)
H(P ) = −∑ω
P (ω) log2 P (ω),
gegeben Information R = {(B1|A1) [x1], . . . , (Bn|An) [xn]}
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 176 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Der MaxEnt-Ansatz (ME) 2/2
Das Optimierungsproblem
(arg) maxP |=R
H(P ) = −∑ω
P (ω) log2 P (ω)
ist eindeutig losbar mit Losung P ∗ = ME (R).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 177 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Beispiel – Grippe 1/2 (DVEW)
Die Zusammenhange zwischen
G = Grippe, K = Kranksein und S = KopfSchmerzen
konnten in der folgenden Weise beschrieben sein:
R = {(k|g) [1], (s|g) [0.9], (k|s) [0.8]}
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 178 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Beispiel – Grippe 2/2 (DVEW)
R = {(k|g) [1], (s|g) [0.9], (k|s) [0.8]}
K G S P ∗ = ME (R)
0 0 0 0.18910 0 1 0.11850 1 0 00 1 1 01 0 0 0.18911 0 1 0.21251 1 0 0.02911 1 1 0.2617
P ∗(k|g) ≈ 0.57 P ∗(k|gs) ≈ 0.64
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 179 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Das ME-System SPIRIT (DVEW)
• Experte/Benutzer spezifiziert eine Menge probabilistischer Regeln(verfugbares Wissen, im Allgemeinen unvollstandig!)
• ein probabilistisches Netzwerk (sog. LEG-Netzwerk) wird automatischaufgebaut;
• Wahrscheinlichkeiten werden in informationstheoretisch-optimalerWeise (d.h. auf der Basis des ME-Prinzips) aufgebaut;
• LEG-Netzwerk (Cliquen zusammen mit lokalen Randverteilungen)wird als Wissensbasis zur Wissenspropagation und zur Beantwortungvon Anfragen genutzt.
http://www.fernuni-hagen.de/BWLOR/spirit/index.php
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 180 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Wissenspropagation in SPIRIT
• SPIRIT erzeugt aus der Menge R einen Hypergraphen; zu diesemZweck werden alle Variablen, die in einer Regel in R vorkommen,durch eine Hyperkante verbunden.
• Der entstandene Hypergraph wird dann durch einen Hyperbaum〈V, C〉 uberdeckt.
• Der zugehorige Verbindungsbaum mit der Knotenmenge C und derSeparatorenmenge S stellt schließlich die passende Struktur furReprasentation und Propagation dar; es gilt namlich
P ∗(ω) =
∏C∈C P
∗(C)∏S∈S P
∗(S)
Potentialdarstellung der ME -Verteilung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 181 / 232
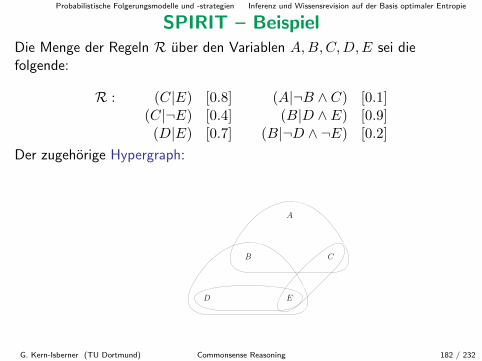
Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
SPIRIT – BeispielDie Menge der Regeln R uber den Variablen A,B,C,D,E sei diefolgende:
R : (C|E) [0.8] (A|¬B ∧ C) [0.1](C|¬E) [0.4] (B|D ∧ E) [0.9]
(D|E) [0.7] (B|¬D ∧ ¬E) [0.2]
Der zugehorige Hypergraph:
D
B
E
A
C
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 182 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke 1/4
LEG = Local Event Group
Sei V eine Menge von Aussagevariablen, und W1, . . . ,Wm eine Mengeuberdeckender Teilmengen von V, d.h. Wi ⊆ V, 1 ≤ i ≤ m, mit∪mi=1Wi = V. Sei Pi eine Wahrscheinlichkeitsverteilung auf Wi,1 ≤ i ≤ m.
(Wi, Pi)mi=1 heißt LEG-Netzwerk, wenn es eine Verteilung P auf V gibt
mitP (Wi) = Pi(Wi)
die Pi also alle Randverteilungen einer gemeinsamen Verteilung P sind.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 183 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke 2/4
Ist ein solches System (Wi, Pi)mi=1 von lokalen Verteilungen gegeben, so
stellt sich die Frage, ob es sich dabei um ein LEG-Netzwerk handelt, d.h.ob es eine gemeinsame Verteilung P auf V gibt, so dass sich alle Pi alsRandverteilung von P realisieren lassen.
Denn nur in diesem Fall hat man die Moglichkeit, die lokalen Verteilungenals globale Information zu nutzen!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 184 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke 3/4
Eine notwendige Bedingung fur ein LEG-Netzwerk ist sicherlich diefolgende Konsistenz-Bedingung:
Ist Wi ∩Wj 6= ∅, so ist Pi(Wi ∩Wj) = Pj(Wi ∩Wj).
D.h. auf den Schnitten stimmen alle Verteilungen uberein.
Allerdings – die Konsistenz-Bedingung ist nicht hinreichend! D.h. selbstwenn die Wahrscheinlichkeiten auf allen Schnitten ubereinstimmen, musses nicht zwangslaufig eine globale gemeinsame Verteilung geben!
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 185 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke – Beispiel 1/2
Sei V = {A,B,C},seien W1 = {A,B},W2 = {A,C},W3 = {B,C},
und seien die lokalen Verteilungen Pi wie folgt gegeben:
w1 P1(w1) w2 P2(w2) w3 P3(w3)
ab 0.6 ac 0.0 bc 0.1
ab 0.2 ac 0.8 bc 0.5
ab 0.0 ac 0.2 bc 0.1
ab 0.2 a c 0.0 bc 0.3
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 186 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke – Beispiel 2/2
Uberprufung der Konsistenz-Bedingung:
W1 ∩W2 = {A} : P1(a) = 0.8 = P2(a)
W1 ∩W3 = {B} : P1(b) = 0.6 = P3(b)
W2 ∩W3 = {C} : P2(c) = 0.2 = P3(c)
Angenommen, es gibt ein P mit P (Wi) = Pi(Wi); dann gilt:
0 = P2(ac) = P (abc) + P (abc), d.h. P (abc) = P (abc) = 0;
0 = P1(ab) = P (abc) + P (abc), d.h. P (abc) = P (abc) = 0;
also P (bc) = P (abc) + P (abc) = 0,
aber P (bc) = P3(bc) = 0.1 6= 0.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 187 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
LEG-Netzwerke 4/4
Eine hinreichende Bedingung fur ein LEG-Netzwerk ist gegeben, wenn die(Wi)i eine Art Baum bilden; in diesem Fall berechnet sich die gemeinsameVerteilung als Potentialdarstellung aus den lokalen Verteilungen.
Wir werden uns also nun mit Hypergraphen und Hyperbaumenbeschaftigen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 188 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Hypergraphen 1/4
V (endliche) Menge von KnotenE = {E1, . . . ,Em}, ∅ 6= Ei ⊆ V, 1 ≤ i ≤ m
(endliche) Menge nichtleerer Teilmengen von V mit
V =
m⋃i=1
Ei
Dann heißt H = 〈V, E〉 Hypergraph und die Elemente von E werden alsHyperkanten bezeichnet.
Ein Hypergraph heißt reduziert, wenn keine Hyperkante echt in eineranderen Hyperkante enthalten ist.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 189 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Beispiel Hypergraph
D
B
E
A
C
Wir betrachten den obigen Hypergraphen mit der KnotenmengeV = {A,B,C,D,E} mit den HyperkantenE = {{A,B,C}, {B,D,E}, {C,E}, {D,E}}. Dieser Hypergraph ist nichtreduziert, da die Hyperkante {D,E} in der Hyperkante {B,D,E}enthalten ist.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 190 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Hypergraphen 2/4
Der einem Hypergraphen H = 〈V, E〉 zugeordnete VerbindungsgraphJ(H) ist ein ungerichteter Graph mit den Hyperkanten E als Knoten. Zweisolche Knoten sind genau dann durch eine Kante verbunden, wenn derSchnitt der zugehorigen Hyperkanten nichtleer ist.
Die Schnitte der Hyperkanten werden wieder als Separatoren bezeichnetund an den Kanten notiert.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 191 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Hypergraphen 3/4
Ein Hypergraph H = 〈V, E〉 heißt Hyperbaum, wenn es eine (lineare)Anordnung E1,E2, . . . ,Em seiner Hyperkanten gibt, die die RIP1 besitzt:
Ei ∩ (E1 ∪ . . . ∪Ei−1) ⊆ Ej , j < i.
Bei der Uberprufung der Baumeigenschaft eines Hypergraphen H = 〈V, E〉kann man sich auf Anordnungen beschranken, die durch eine Variante dermaximum cardinality search entstanden sind.
1RIP = Running Intersection PropertyG. Kern-Isberner (TU Dortmund) Commonsense Reasoning 192 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Hypergraphen 4/4
Maximum Cardinality Search (MCS) fur Hypergraphen:
• Man ordnet einer beliebigen Hyperkante E ∈ E den Index 1 zu undnummeriert die Knoten in E in beliebiger, aufsteigender Reihenfolge.
• Als nachste Hyperkante wahlt man nun sukzessive jeweils einederjenigen Hyperkanten aus, die eine Maximalzahl bereitsnummerierter Knoten enthalt. Die noch nicht nummerierten Knotender neuen Hyperkante werden weiter in aufsteigender Reihenfolgenummeriert.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 193 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Testen auf Hyperbaum-Eigenschaft
Proposition
Ein Hypergraph H = 〈V, E〉 ist genau dann ein Hyperbaum, wennirgendeine MCS-Nummerierung der Hyperkanten von H die RIP besitzt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 194 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Beispiel Hypergraph (Forts.)
Wir wenden die maximum cardinality search auf unseren Hypergraphen anund erhalten (z.B.) die folgende Anordnung der Hyperkanten:
E1 = {A,B,C}, E2 = {B,D,E}, E3 = {D,E}, E4 = {C,E}
wobei die Knoten dem Alphabet entsprechend geordnet werden:A < B < C < D < E. Diese Ordnung besitzt nicht die RIP, da
E4 ∩ (E1 ∪E2 ∪E3) = {C,E}
in keiner der Hyperkanten E1,E2,E3 enthalten ist. Unser Hypergraph istalso kein Hyperbaum.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 195 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Schnittgraph
Der Schnittgraph eines Hypergraphen H = 〈V, E〉 ist der Graph
Hs = 〈V, Es〉
mit(v, w) ∈ Es gdw. ∃ E ∈ E mit v, w ∈ E
Zwei Knoten aus V werden im Schnittgraphen Hs also genau dann durcheine (normale) Kante verbunden, wenn es eine Hyperkante von H gibt, inder beide liegen.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 196 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Vom Hypergraph zum Hyperbaum 1/2
Aus einem beliebigen Hypergraphen H = 〈V, E〉 kann man durch eineFill-in-Technik einen uberdeckenden Hyperbaum H′ = 〈V, E ′〉 gewinnen,d.h. jede Hyperkante E ∈ E ist Teilmenge einer Hyperkante E′ ∈ E ′:
• Bilde den Schnittgraph Hs von H;
• die Knoten in V werden durch eine MCS (im Hypergraphen)aufsteigend geordnet;
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 197 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Vom Hypergraph zum Hyperbaum 2/2
• der Schnittgraph wird durch Einfugen von Kanten zu einemFill-in-Graphen aufgefullt wie folgt: Fur jeden Knoten vj verbindetman die Menge
{vi | (vi, vj) ∈ Es, i < j}
aller “kleineren” Nachbarn zu einem vollstandigen Graphen;
• bestimme die Cliquen C1, . . . ,Cq des Fill-in-Graphen von Hs;• dann ist H′ = 〈V, {C1, . . . ,Cq}〉 ein uberdeckender Hyperbaum zuH.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 198 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Beispiel Hypergraph (Forts.)
Wir setzen unser Beispiel fort und gehen von der alphabetischen Ordnungder Knoten A,B,C,D,E aus. Die kleineren Nachbarn der Knoten sind
Knoten kleinere Nachbarn
A −−B AC A,BD BE B,C,D
Um den Schnittgraphen zu vervollstandigen, muss also noch die Kante(C,D) eingefugt werden. Ein uberdeckender Hyperbaum zu H ist dannH′ = 〈V, {{A,B,C}, {B,C,D,E}}〉.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 199 / 232
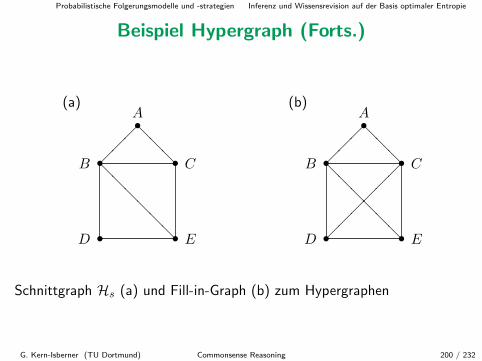
Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Beispiel Hypergraph (Forts.)
(a)
D s
B s
Es
CsAs
���@@@
@@@@@@
(b)
D s
B s
Es
CsAs
���@@@
@@@@@@
������
Schnittgraph Hs (a) und Fill-in-Graph (b) zum Hypergraphen
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 200 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Implementierung
Das qualitative (graphische) Gerust einer ME -Verteilung wird also mitHilfe ahnlicher Verfahren wie bei Bayes-Netzen aufgebaut.
Die probabilistische Informationspropagation ist vom Prinzip her auchahnlich – entlang der Hyperbaumstruktur und uber die Separatoren.
Allerdings wird die ME -Verteilung durch ein (in der Regel) approximativesVerfahren berechnet, bei dem Wahrscheinlichkeiten resultieren, die nichtmehr einfach nachvollziehbar sind (s. auch Grippe-Beispiel).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 201 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Verteilung – Beispiel
Nehmen wir an, unser Wissen besteht nur aus einer Regel:
R = {(B|A)[0.8]}
uber der Signatur Σ = {A,B};
wir berechnen – mit Hilfe von SPIRIT – die Verteilung ME (R) = P :
ω P (ω) ω P (ω)
AB 0.361 AB 0.274
AB 0.091 AB 0.274
Fur A,B ergeben sich die Wahrscheinlichkeiten:
P (A) = 0.452, P (B) = 0.636
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 202 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Inferenz
Praktisches Arbeiten mit der ME -Methodik ist also einfach moglich, aberdas Verfahren wirkt intransparent.
Logische und formale Ansatze ermoglichen einen klareren Blick auf dieME -Methodik.
Logisch gestattet die ME -Methodik eine probabilistische Auswahl-Inferenz:
CME(R) = {φ ∈ (L | L)prob | ME (R) |= φ}
d.h. aus einer probabilistischen Regelbasis werden alle (bedingten)probabilistischen Formeln abgeleitet, die in der zugehorigen ME -Verteilungerfullt sind.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 203 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Beispiel – Grippe (Forts.)
R = {(k|g) [1], (s|g) [0.9], (k|s) [0.8]}
K G S P ∗ = ME (R)
0 0 0 0.18910 0 1 0.11850 1 0 00 1 1 01 0 0 0.18911 0 1 0.21251 1 0 0.02911 1 1 0.2617
P ∗(k|g) ≈ 0.57, P ∗(k|gs) ≈ 0.64⇒
CME(R) 3 (k|g)[0.57], (k|gs)[0.64], (s|g) [0.9], (kgs)[0.2125], . . .
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 204 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Eigenschaften der ME-Inferenz
Der ME -Inferenzoperator CME erfullt die folgenden Eigenschaften:
• Inklusion/Reflexivitat: R ⊆ CME(R).
• Kumulativitat, d.h. Schnitt und vorsichtige Monotonie:
R ⊆ S ⊆ CME(R) impliziert CME(R) = CME(S)
• Supraklassizitat, d.h. es gilt: Cnprob(R) ⊆ CME(R)
• Loop: Sind R1, . . . ,Rm ⊆ (L | L)prob mit Ri+1 ⊆ CME(Ri),i modulo m, dann gilt
CME(Ri) = CME(Rj) fur alle i, j = 1, . . . ,m
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 205 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Verteilung unter der Lupe
Fur R = {(B1|A1) [x1], . . . , (Bn|An) [xn]} erhalten wir
ME (R)(ω) = α0
∏1≤i≤n
ω|=AiBi
α1−xii
∏1≤i≤n
ω|=AiBi
α−xii
mit αi =xi
1− xi
∑ω|=AiBi
∏j 6=i
ω|=AjBj
α1−xj
j
∏j 6=i
ω|=AjBj
α−xj
j
∑ω|=AiBi
∏j 6=i
ω|=AjBj
α1−xj
j
∏j 6=i
ω|=AjBj
α−xj
j
,
und αi
> 0 : xi ∈ (0, 1)=∞ : xi = 1= 0 : xi = 0
, 1 ≤ i ≤ n.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 206 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Ableitungsregeln
Wir wollen im Folgenden fur (wichtige) Spezialfalle ME -Inferenzen“berechnen” und Ableitungsregeln aufstellen; dabei benutzen wir diefolgende Notation
R : (B1|A1) [x1], . . . , (Bn|An) [xn]
(B∗1 |A∗1) [x∗1], . . . , (B∗m|A∗m) [x∗m]
genau dann, wenn
R = {(B1|A1) [x1], . . . , (Bn|An) [xn]}und ME (R) |= {(B∗1 |A∗1) [x∗1], . . . (B∗m|A∗m) [x∗m]}
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 207 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Ableitungsregeln (Forts.)
Mit Hilfe der obigen Formel lassen sich z.B. folgende Ableitungsregelnbeweisen:
Transitive Verkettung
R : (B|A)[x1], (C|B)[x2]
(C|A)[1
2(2x1x2 + 1− x1)]
Beispiel: A jung sein, B Single sein, C Kinder haben
R = {(B|A)[0.9], (C|B)[0.85]}.
Mit der Transitiven Verkettung errechnet man als ME -Folgerung
(C|A)[0.815] ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 208 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Transitive Verkettung – Beweis
R : (B|A)[x1], (C|B)[x2]
(C|A)[1
2(2x1x2 + 1− x1)]
Die ME-Verteilung P ∗ = ME (R),R = {(B|A)[x1], (C|B)[x2]}, kann wiefolgt berechnet werden:
ω P ∗ ω P ∗
ABC α0α1−x11 α1−x2
2 ABC α0α1−x22
ABC α0α1−x11 α−x22 ABC α0α
−x22
ABC α0α−x11 ABC α0
ABC α0α−x11 ABC α0
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 209 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Transitive Verkettung – Beweis (Forts.)
mit
α1 =x1
1− x1
2
α1−x22 + α−x22
=x1
1− x1αx22
2
α2 + 1
α2 =x2
1− x2
Damit berechnet man
P ∗(C|A) =P ∗(AC)
P ∗(A)
=P ∗(ABC) + P ∗(ABC)
P ∗(ABC) + P ∗(ABC) + P ∗(ABC) + P ∗(ABC)
=α1α
1−x22 + 1
α1α−x22 (α2 + 1) + 2
=1
2(2x1x2 + 1− x1)
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 210 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Ableitungsregeln (Forts.)
Vorsichtige Monotonie
R : (B|A)[x1], (C|A)[x2]
(C|AB)[x2]
Beispiel: A Student sein, B jung sein, C Single sein
R = {(B|A)[0.9], (C|A)[0.8]}
Mit der vorsichtigen Monotonie folgt dann
(C|AB)[0.8] ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 211 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME-Ableitungsregeln (Forts.)
Schnitt
R : (C|AB)[x1], (B|A)[x2]
(C|A)[1
2(2x1x2 + 1− x2)]
Beispiel: A Student sein, B jung sein, C Single sein
R = {(C|AB)[0.8], (B|A)[0.9]}
Mit der Schnittregel folgt dann
(C|A)[0.77] ♣
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 212 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
ME und Commonsense Reasoning
Was hat ME mit Commonsense Reasoning zu tun?
Jeff Paris:Common sense and maximum entropy.Synthese 117, 75-93, 1999, Kluwer Academic Publishers
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 213 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Symmetrie-Prinzip
Eines der grundlegendsten und einfachsten Prinzipien des CommonsenseReasoning ist das
Symmetrie-Prinzip
(Wesentlich) Ahnliche Probleme haben (im Wesentlichen) ahnlicheLosungen. (B. van Fraassen, 1989)
• Welche Ahnlichkeit ist hier gemeint?
• Was ist denn uberhaupt das Problem?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 214 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Intelligente Agenten in probabilistischer Umgebung
Nehmen wir an,
• der Agent kann sein (d.h. alles(!) relevante) Wissen in Form einerprobabilistischen Regelbasis ausdrucken, und
• er ist in der Lage, sein Wissen korrekt und optimal zu verarbeiten,
dann kann er zu jeder Anfrage φ eine passende Wahrscheinlichkeitproduzieren.
Wir wollen also den Agenten als einen Inferenzprozess N modellieren, derzu jeder Menge R von probabilistischen Regeln eineWahrscheinlichkeitsverteilung produziert.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 215 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistischer Inferenzprozess 1/2
Σ = {A1, . . . , An} Alphabet,d.h. Menge von (binaren) Aussagenvariablen
Form(Σ) Menge der Formeln uber ΣP(Σ) Menge aller Wahrscheinlichkeitsverteilungen
uber Σ, d.h.
P(Σ) = {(p1, . . . , p2n) | pi ≥ 0,2n∑i=1
pi = 1}
KB(Σ) Menge aller konsistenten probabilistischen Regelbasen uber Σ
Ist Σ1 ⊆ Σ2, so ist auch KB(Σ1) ⊆ KB(Σ2).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 216 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Probabilistischer Inferenzprozess 2/2
Definition 3 (Probabilistischer Inferenzprozess)
Ein probabilistischer Inferenzprozess NΣ ist eine Abbildung
NΣ : KB(Σ) → P(Σ),
R 7→ P,
die jeder konsistenten Regelbasis uber Σ eine Verteilung P uber Σzuordnet mit P |= R.
NΣ spezifiziert also einen induktiven Inferenzprozess.Welche CR-Prinzipien zeichnen einen “guten” Inferenzprozess aus?
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 217 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 1: Irrelevante Information
Irrelevante-Information-Prinzip
Information uber ganz andere Themenbereiche soll das Ergebnis desInferenzprozesses nicht beeinflussen.
Seien Σ1,Σ2 zwei disjunkte Signaturen, Σ1 ∩ Σ2 = ∅, und seienR1 ∈ KB(Σ1),R2 ∈ KB(Σ2). Fur alle φ ∈ Form(Σ1) soll dann gelten:
NΣ1(R1)(φ) = NΣ1∪Σ2(R1 ∪R2)(φ).
Das Ergebnis der Inferenz soll also nur vom relevanten Teil der Signaturabhangen. Wir schreiben daher im Folgenden haufig N statt NΣ.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 218 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 2: Semantische Aquivalenz
Aquivalenz-Prinzip
Haben zwei Wissensbasen exakt die gleiche (semantische) Bedeutung, sosoll auch exakt das Gleiche gefolgert werden.
Beschreiben R1,R2 ∈ KB(Σ) denselben Losungsraum in P(Σ), so sollgelten N(R1) = N(R2).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 219 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 3: Umbenennung
Umbenennungs-Prinzip
Eine isomorphe Umbennung der Variablen in der Wissensbasis soll keinenEffekt auf das Ergebnis der Inferenz haben.
Formalisierung: . . .
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 220 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 4: Kontext-Relativierung
Relativierungs-Prinzip
Information, die sich auf die Nichterfullung eines Kontextes bezieht, istirrelevant fur die kontextbezogene Inferenz.
Sei A ∈ Form(Σ), seien R1,R2 ∈ KB(Σ) die folgenden Wissensbasen:
R1 = {A[x], (Bi ∧A)[xi], (Cj ∧ ¬A)[yj ]}i,j ,R2 = {A[x], (Bi ∧A)[xi]}i.
Fur φ ∈ Form(Σ) soll dann gelten:
N(R1)(φ ∧A) = N(R2)(φ ∧A).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 221 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 5: Hartnackigkeit
Hartnackigkeits-Prinzip
Information, die das bestatigt, was der Agent bereits glaubt, soll dasErgebnis der Inferenz nicht beeinflussen.
Sind R1,R2 ∈ KB(Σ), und erfullt N(R1) bereits R2, so soll gelten:
N(R1) = N(R1 ∪R2).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 222 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 6: Schwache Unabhangigkeit
Schwaches Unabhangigkeits-Prinzip
Information uber eine echte Alternative soll das Ergebnis der Inferenz nichtbeeinflussen.
Sei Σ = {A,B,C}, und seien R1,R2 ∈ KB(Σ) die folgendenWissensbasen:
R1 = {A[x], B[y]},R2 = {A[x], B[y], C[z], AC[0]}.
Dann soll gelten N(R1)(A ∧B) = N(R2)(A ∧B).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 223 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
CR-Prinzip 7: Stetigkeit
Stetigkeits-Prinzip
Mikroskopisch kleine Anderungen in der Weltbeschreibung sollen keinemakroskopisch großen Anderungen in den Wahrscheinlichkeitenverursachen.
Fur jedes φ ∈ Form(Σ) hangt N(R)(φ) stetig von denWahrscheinlichkeiten des Faktenwissens in R ab.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 224 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Haupttheorem
Theorem 4
Jeder Inferenzprozess N , der alle CR-Prinzipien 1-7 erfullt, stimmt mit derME-Inferenz uberein.
Die ME -Methodik erlaubt also optimales Commonsense Reasoning improbabilistischen Bereich und wird durch die CR-Prinzipien 1-7 eindeutigbestimmt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 225 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Fazit ME-Methodik 1/2
ME -Rehabilitation
Das MaxEnt-Verfahren ist kein technisches Black-Box-Verfahrenohne Sinn und Logik!
• Die ME -Methodik ermoglicht induktive Inferenz in ihrer allgemeinstenForm: Komplexe Wissenszustande (Wahrscheinlichkeitsverteilungen)konnen aus Information in komplexer Form (Mengen probabilistischerKonditionale) erzeugt werden.
• ME -Inferenz erfullt zahlreiche der Eigenschaften, die man annichtmonotone Inferenzrelationen i.Allg. stellt, z.B. die Kumulativitatund Loop.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 226 / 232

Probabilistische Folgerungsmodelle und -strategien Inferenz und Wissensrevision auf der Basis optimaler Entropie
Fazit ME-Methodik 2/2
• Auch auf der Ebene der Wahrscheinlichkeiten lassen sich einige derInferenzregeln simulieren (z.B. Vorsichtige Monotonie, Schnitt).
• Die ME -Methodik lasst sich als optimale Umsetzung desCommonsense Reasoning in einer probabilistischen Umgebungauffassen.
• Fur die Wissensrevision gibt es einen ebenso hochwertigen “großenBruder”, das Prinzip der minimalen Relativ-Entropie.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 227 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussworte und Zusammenfassung
Ubersicht Kapitel 4 – Probabilistik
4.1 Einfuhrung und Ubersicht
4.2 Wahrscheinlichkeitstheorie und Commonsense Reasoning
4.3 Grundideen probabilistischen Schlussfolgerns
4.4 Schlussfolgern uber Unabhangigkeiten
4.5 Propagation in baumartigen Netzen
4.6 Probabilistische Inferenz auf der Basis optimaler Entropie
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 228 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussworte und Zusammenfassung
Kapitel 4
4. ProbabilistischeFolgerungsmodelle und -strategien
4.7 Schlussworte und Zusammenfassung
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 229 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussworte und Zusammenfassung
Zusammenfassung Kapitel 4
• Bedingte Wahrscheinlichkeiten (= Konditionale mitWahrscheinlichkeiten) sind die Reprasentanten generischen Wissensund wichtige Bausteine probabilistischer Netzwerke.
• Auch in gerichteten probabilistischen Netzwerken istWissenspropagation in beiden Richtungen moglich.
• In einfachen probabilistischen Netzwerken (Baumen) ist ein direkterInformationsfluss uber die Kanten moglich.
• In probabilistischen Netzwerken mit konfluenter Information (DAG)oder allgemeinen Abhangigkeiten (LEG-Netze) muss zunachst eineHyperbaum-Struktur aufgebaut werden; der Informationsfluss erfolgtzwischen benachbarten Hyperkanten uber deren Schnitte(Separatoren).
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 230 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussworte und Zusammenfassung
Zusammenfassung Kapitel 4 (Forts.)
• Das Problem unvollstandiger probabilistischer Informationen wird inBayes-Netzen durch klare Spezifikationsvorgaben und die Annahmebedingter Unabhangigkeiten gelost.
• Mit Hilfe der ME-Methodik kann aus einer Menge probabilistischerRegeln (unvollstandige Information!) ohne weitere Annahmen einevollstandige Verteilung aufgebaut werden. Bedingte Unabhangigkeitenentstehen hier aus dem Kontext heraus, werden aber nichtvorausgesetzt.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 231 / 232

Probabilistische Folgerungsmodelle und -strategien Schlussworte und Zusammenfassung
Zusammenfassung Kapitel 4 (Forts.)
• Bayessche Netze modellieren bedingte Unabhangigkeiten, wahrend dieME -Methodik sich auf die konsequente Ausnutzung bedingterAbhangigkeiten konzentriert.
• Die ME -Inferenz ist ein machtige Methode fur die probabilistischeWissensreprasentation mit hervorragenden Eigenschaften.
G. Kern-Isberner (TU Dortmund) Commonsense Reasoning 232 / 232


















