
Grundlagen der Statistik, Klausurübungen, Erklärungen · Die Abbildung stammt von der...
21
1 Bettina Kietzmann 1D(neu) Februar 2013 Grundlagen der Statistik, Klausurübungen, Erklärungen 1. Aussagenlogik 2. Modalwert, Median, Mittelwert, Spannweite, Erwartungswert 3. Varianz, Standardabweichung 4. Absolute/relative Häufigkeit + Randverteilung/bedingte Wahrscheinlichkeit 5. Venn-Diagramme 6. Verteilungs-und Wahrscheinlichkeitsfunktion 7. Merkmalsklassifikation 8. Datenerhebung, Experiment und Stichprobenverfahren 9. Schätzen von Modellparametern (Punkt- und Intervallschätzung) 10. Kombinatorik- diskrete Verteilung (Binomialverteilung/-koeffizient, Bernoulli) 11. Konzentrationsmessung (Lorenzkurve, Gini-Koeffizient, Herfindahl-Index) 12. Zusammenhangsmessung/ Regressions- und Varianzanalyse 13. Testen, Gauß-Test; Fehler beim Testen, Gütefunktion Klausurhinweise 2012/2013 https://moodle.fernuni- hagen.de/file.php/30448/Klausurhinweise/Klausurhinweise-03-2013-BWiss.pdf Merksatz: ALLE bisherigen Klausuren RECHNEN RECHNEN RECHNEN!!!!Verstehen kommt dann…ich habe lange, zu lange den Fehler gemacht und erst verstehen wollen VOR dem Rechnen, das kann mir das „Bestehen“ jetzt kosten!!!!WEIL ich zu spät mit der Rechnerei begonnen habe …. 1. Aussagenlogik Hier ist es für die Lösung der Aufgaben notwendig, die Tabelle auszufüllen. Achtgeben muss man auf die Bedeutung der Zeichen ᴧ (UND) ν (ODER) und „nicht a“. Eine Konklusion ist korrekt, wenn mindestens eine der beiden Aussagen P1 oder P2 wahr sind, denn dann ist K (Ableitung der Prämissen, logischer Schluss) auch wahr. Gut verständlich- Übungssache. 2. Modalwert, Median, Mittelwert, Spannweite, Erwartungswert Beispiel eines Datensatzes aus POL/SOZ September 2011: 4,8 6,4 4,2 4,6 4,8 3,9 4,2 7,6 6,5 - Ich ordne prinzipiell erst einmal die Daten, also: 3,9 4,2 4,2 4,6 4,8 4,8 6,4 6,5 7,6
Transcript of Grundlagen der Statistik, Klausurübungen, Erklärungen · Die Abbildung stammt von der...

1 Bettina Kietzmann 1D(neu) Februar 2013
Grundlagen der Statistik, Klausurübungen, Erklärungen
1. Aussagenlogik
2. Modalwert, Median, Mittelwert, Spannweite, Erwartungswert
3. Varianz, Standardabweichung
4. Absolute/relative Häufigkeit + Randverteilung/bedingte Wahrscheinlichkeit
5. Venn-Diagramme
6. Verteilungs-und Wahrscheinlichkeitsfunktion
7. Merkmalsklassifikation
8. Datenerhebung, Experiment und Stichprobenverfahren
9. Schätzen von Modellparametern (Punkt- und Intervallschätzung)
10. Kombinatorik- diskrete Verteilung (Binomialverteilung/-koeffizient, Bernoulli)
11. Konzentrationsmessung (Lorenzkurve, Gini-Koeffizient, Herfindahl-Index)
12. Zusammenhangsmessung/ Regressions- und Varianzanalyse
13. Testen, Gauß-Test; Fehler beim Testen, Gütefunktion
Klausurhinweise 2012/2013 https://moodle.fernuni-
hagen.de/file.php/30448/Klausurhinweise/Klausurhinweise-03-2013-BWiss.pdf
Merksatz: ALLE bisherigen Klausuren RECHNEN RECHNEN RECHNEN!!!!Verstehen
kommt dann…ich habe lange, zu lange den Fehler gemacht und erst verstehen wollen VOR
dem Rechnen, das kann mir das „Bestehen“ jetzt kosten!!!!WEIL ich zu spät mit der
Rechnerei begonnen habe ….
1. Aussagenlogik
Hier ist es für die Lösung der Aufgaben notwendig, die Tabelle auszufüllen.
Achtgeben muss man auf die Bedeutung der Zeichen ᴧ (UND) ν (ODER) und „nicht
a“.
Eine Konklusion ist korrekt, wenn mindestens eine der beiden Aussagen P1 oder P2
wahr sind, denn dann ist K (Ableitung der Prämissen, logischer Schluss) auch wahr.
Gut verständlich- Übungssache.
2. Modalwert, Median, Mittelwert, Spannweite, Erwartungswert
Beispiel eines Datensatzes aus POL/SOZ September 2011:
4,8 6,4 4,2 4,6 4,8 3,9 4,2 7,6 6,5
- Ich ordne prinzipiell erst einmal die Daten, also:
3,9 4,2 4,2 4,6 4,8 4,8 6,4 6,5 7,6

2 Bettina Kietzmann 1D(neu) Februar 2013
Mittelwert (muss nicht geordnet sein!): dieser berechnet sich, wie ein
Notendurchschnitt. Ich summiere alle Daten und teile dann durch die Anzahl der
Daten. In diesem Falle 3,9+4,2+4,2+…Xn, dann Ergebnis geteilt durch 9. Lösung
Mittelwert= 47 ÷9= 5, 22222
Modalwert (muss nicht geordnet sein!): Fragen: „Welcher Wert tritt am häufigsten
auf?“ „Gibt es einen eindeutigen Modalwert?“ Antwort: In diesem Falle hat der
Datensatz keinen eindeutigen Modalwert sondern 2 Modalwerte, nämlich 4,2 und 4,8.
Median (Datensatz muss geordnet sein!): Nun gibt es 2 verschiedene Möglichkeiten:
1. Der Datensatz hat eine ungerade Zahl an Daten- hier zutreffend (9 Daten). Der
mittlere Wert des Datensatzes ist hier der Median, also der 5. Wert: 4,8
2. Der Datensatz hat eine gerade Zahl an Daten man berechnet in diesem Falle
alle Elemente n und dividiert durch 2. Dieser Wert und der darauffolgende werden
summiert und abermals dividiert durch 2. Das ist der Modalwert.
Beispiel: 3 5 7 1 5 9 2 8 = gerade ; 8÷2=4 die 4. Zahl im Datensatz ist 1, die
darauffolgende ist 5. Beide zusammen ergeben 6, dann 6÷2= 3 . Der Median
beträgt 3.
Spannweite (geordneter Datensatz!): Der letzte Wert wird mit dem ersten Wert
subtrahiert. Also hier: 7,6 -3,9 = 3,7 Die Gesamtlänge eines Boxplots ist die
Spannweite
Erwartungswert- Beispiel Würfel POL/SOZ März 2010. Ich werfe 10 mal und
bekomme die Werte 3 6 4 3 5 1 2 3 4 2 Der Erwartungswert berechnet sich
mit der Eintrittswahrscheinlichkeit
und der Summe aller k 1 2 3 4 5 6 also
(1+2+3+4+5+6)*
=
= 3,5 (=diskrete Verteilung)
Merke: Erwartungswerte werden verschieden berechnet je nachdem was gegeben ist.
Schaut in die Formelsammlung. Ganz wichtig ist der Umgang mit dieser!!!!
3. Varianz, Standardabweichung
Varianz= die durchschnittliche quadrierte Abweichung der Werte vom Mittelwert
- Halbiere ich alle Werte des Datensatzes geht die Varianz auf ein Viertel des
Ausgangswertes zurück.
S²=

3 Bettina Kietzmann 1D(neu) Februar 2013
Standardabweichung- Halbiere ich alle Werte des Datensatzes geht die
Standardabweichung auf die Hälfte des Ausgangswertes zurück. Wenn alle
Werte verdoppelt werden, vervierfacht sich s² und s verdoppelt sich.
Kleiner Zusatz: = 1 ; 0!=1 Formelsammlung S.10
4. Absolute/relative Häufigkeit + Randverteilung/bedingte Wahrscheinlichkeit
Je Aufgabe schreibe ich mir alle gegebenen Werte auf und skizziere mein Vorhaben.
Absolute Häufigkeit ist die Anzahl und die relative Häufigkeit zeigt genauer auf, in
welchen Verhältnissen die Anzahl vorliegt. Z.B. 500 Schüler 200 sind 18 Jahre alt.
Wie viel Prozent sind das? 200 ÷500 = 0,4 also 40%.
In den Aufgaben zur Randverteilung macht es Sinn ein Baumdiagramm ODER/UND
eine 4-Felder-Tafel zu erstellen. Zahlen trägt man ein und berechnet schrittweise die
relative Häufigkeit. Wichtig ist hier darauf zu achten, welche Grundgesamtheiten in
der Aufgabenstellung erfragt sind (es gibt auch oft Teilgesamtheiten (unabhängig von
der Grundgesamtheit), die eine relative Häufigkeit verlangen. Die kleinere Zahl wird
durch die Größere dividiert und man erhält die jeweiligen Prozente.
z.B. POL/SOZ März 2011 Aufgabe 7.
Gegeben: Gesamtbevölkerung 36 Mio.; Männer (auch Jungen) 49,5%; erwerbstätige
Männer 58 %; erwerbstätige Frauen 44,5%
Männer
Gesamtbevölkerung
36 Mio.
Frauen
nicht erwerbstätig 42%=7,4844Mio
Erwerbstätig 44,5%, also
18,18Mio*0,445=8,0901Mio
Erwerbstätig 58% also
17,82Mio*0,58 =10,3356Mio
Nicht erwerbstätig
55,5%=10,0899Mio 36Mio*0,505=18,18Mio
50,5%
36Mio *0,495=17,82Mio
49,5%

4 Bettina Kietzmann 1D(neu) Februar 2013
Bei der Berechnung muss darauf geachtet werden, dass die Anzahl der Männer und die
Anzahl der Frauen aus der Grundgesamt des Gesamtbevölkerung zu berechnen ist.
Möchten man allerdings die Anzahl der erwerbslosen Männer und Frauen berechnen,
muss man als Grundgesamtheit die Anzahl der Männer bzw. Frauen benutzen (nicht
die Gesamtbevölkerung!!!!).
5. Venn-Diagramme
Quelle: http://fos-mathe-trainer.de/tag/venn-diagramm/ 9.2.2013 11:32 Uhr
„Venn-Diagramme helfen in der Wahrscheinlichkeitsrechnung dabei, Zusammenhänge
zwischen zwei Ereignissen grafisch zu veranschaulichen. Die folgende Grafik zeigt alle
möglichen Ereignisse, die Ihr aus zwei Ereignissen A und B durch Vereinigen, Schneiden und
Bilden des Gegenereignisses bilden könnt. Rot markiert sind dabei die sich jeweils ergebenden
Teilmengen, also z. B. im zweiten Bild in der ersten Zeile . Unter jedem Bild steht,
wie man das Ereignis aus A und B erhält.“
„Das Formelsymbol steht für das “ausschließende Oder” (auch: “exklusives Oder”,
“XOR”) und bedeutet “entweder A oder B” — das dürft Ihr nicht mit “A oder B”
( ) verwechseln: Beim ausschließenden Oder gilt wenn x entweder
Element von A oder von B ist, nicht aber von beiden!
Die Abbildung stammt von der Wikipedia-Seite zu Venn-Diagrammen (Autor: Tilman
Piesk), ich habe die dort zu findenden Bildunterschriften auf Mengen/Ereignisse
angepasst.“
( Blau unterstrichene Mengen sind von mir eingefügt.--> für uns relevant)

5 Bettina Kietzmann 1D(neu) Februar 2013
Disjunkt sind beide Mengen, wenn sie kein gemeinsames Element haben!!
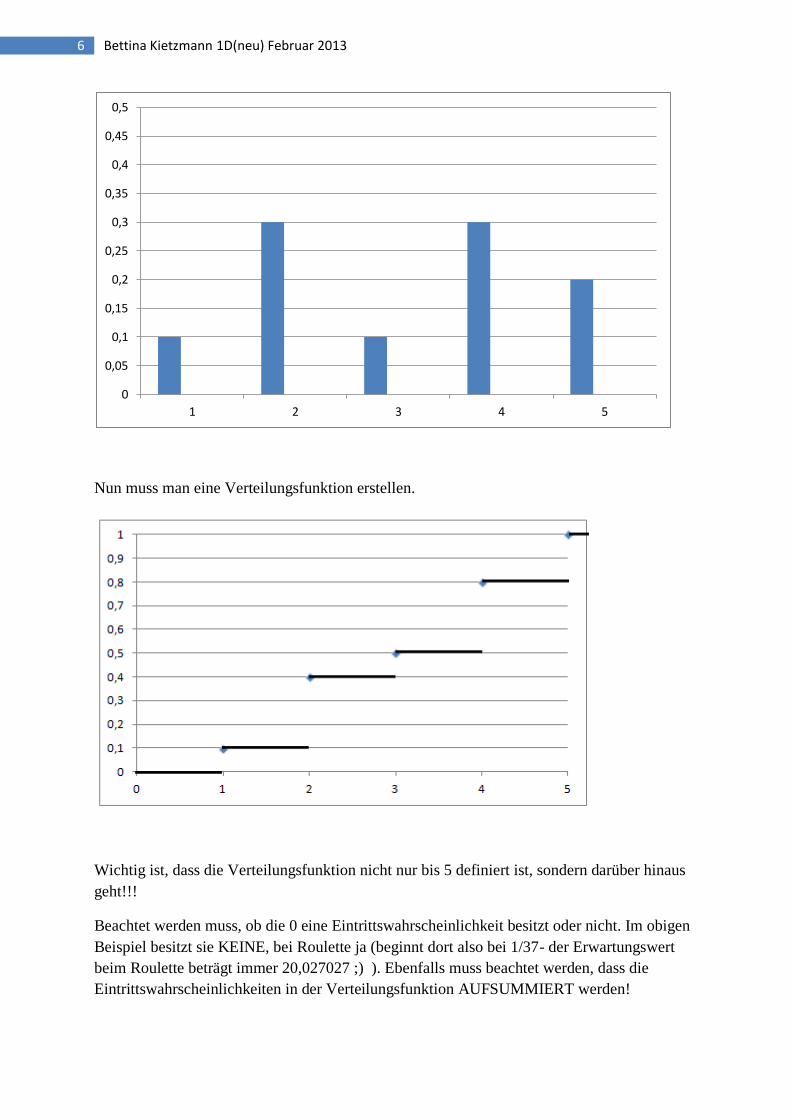
6. Verteilungs-und Wahrscheinlichkeitsfunktion
Beispiel POL/SOZ September 2010 Aufgabe 9:
Gegeben:
x-Achse: x
y-Achse: f(x)-Eintrittswahrscheinlichkeit
6 Bettina Kietzmann 1D(neu) Februar 2013
Nun muss man eine Verteilungsfunktion erstellen.
Wichtig ist, dass die Verteilungsfunktion nicht nur bis 5 definiert ist, sondern darüber hinaus
geht!!!
Beachtet werden muss, ob die 0 eine Eintrittswahrscheinlichkeit besitzt oder nicht. Im obigen
Beispiel besitzt sie KEINE, bei Roulette ja (beginnt dort also bei 1/37- der Erwartungswert
beim Roulette beträgt immer 20,027027 ;) ). Ebenfalls muss beachtet werden, dass die
Eintrittswahrscheinlichkeiten in der Verteilungsfunktion AUFSUMMIERT werden!
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0,5
1 2 3 4 5

7 Bettina Kietzmann 1D(neu) Februar 2013
Den Erwartungswert berechnet man durch Ablesen der Wahrscheinlichkeitsfunktion 1.
Abbildung und Aufsummierung, also 1*0,1+2*0,3+3*0,1+4*0,3+5*0,2= 3,2.
Die Verteilungsfunktion enthält die aufsummierten Eintrittswahrscheinlichkeiten, im Falle
x=3 nimmt die Verteilungsfunktion den Wert 0,5 an. Für alle Werte x von 2 ≤ x < 3 ergibt
sich der Wert 0,4.
Wird X transformiert wird zu Y= X+1, dann ist die Varianz von Y mit der von X identisch.
Der Erwartungswert E(x)= μ nimmt bei Transformation Y= X² = μ² an.
Beispiel Roulette: insgesamt 37 mögliche Ergebnisse.
Wie ist die Wahrscheinlichkeit bei einmaligen Spiel eine zweistellige Zahl zu erlangen?
Laplace
Uns interessieren die Zahlen, von 10-36, also 27 sind zweistellig.
Laplace=
=
= 0,7297
Wie ist die Wahrscheinlichkeit, in jedem der 2 Spiele eine 10 zu erhalten UND die Frage, ob
dies das Doppelte ist, von einem Spiel?
Habe 1/37 Wahrscheinlichkeit die 10 zu bekommen bei einmal Spielen
2. Spiel: wieder 1/37 Chance
1/37*1/37= 1/37²=
Ist das identisch mit der doppelten Wahrscheinlichkeit einmal eine 10 zu
werfen? 1/37=0,027027 dann: 0,027027*2= 0,054054 ist das gleiche, wie
2/37
die Wahrscheinlichkeit 2mal hintereinander die 10 zu werfen=
und das
vergleiche ich mit der doppelten Wahrscheinlichkeit einmal eine zu werfen,
also mit 2/37 0,00073 verglichen mit 0,054

8 Bettina Kietzmann 1D(neu) Februar 2013
7. Merkmalsklassifikation
- Die metrische Skala ist zu spezifizieren in Intervallskala und Verhältnisskala.
Letztere kann einen Sonderfall aufweisen: Absolutskala
- Nominal: Merkmalsausprägungen müssen nicht in eine Reihenfolge gebracht
werden
- Metrische Operationen sind NICHT für Ordinalskalen zulässig und
odinalskalierte Operationen (Rangfolge) sind NICHT zulässig für
nominalskalierte Operationen (keine Rangfolge) . Dagegen sind
ordinale Operationen auch für metrische zulässig. Metrische
Operationen können Differenzen in den Merkmalsausprägungen
aufweisen, wohingegen ordinalskalierte Operationen keine
Differenzen inne haben.
- Bsp nominal: „Bei einer Wahl gewählte Partei.“ Partei = Kategorie ohne
Rangordnung oder „Art der Heizung- Gas, Kohle etc.“ keine Rangordnung
Bildungsstand zum Beispiel ist mit Rangordnung (ohne Abschluss, HS, RS,
Gymnasium etc.), daher ORDINAL
- Stetiges Merkmal: z.B. Gewicht einer Person
- Diskretes Merkmal: Art der Heizung, Zählvariable, z.B. Anzahl der gemeldeten
EHEC-Fälle März 2011, Bildungsstand
- Metrisch= Entfernung zwischen Firma und zu Hause; Gewicht einer Person
- Nominal= Transportmittel von zu Hause bis zur Arbeit(PKW, Fahrrad)
- Quantitative Merkmale= metrisch
- Qualitative Merkmale= sowohl ordinal als auch nominal möglich
- Sowohl bei ordinal als auch bei nominal ist die Bildung von Differenzen NICHT
möglich
- Realdefinition: behaltet Aussage über Eigenschaften eines Gegenstandes oder
Sachverhaltes, also umfasst NICHT ALLE Eigenschaften des Definiendums). Die
Realdefinition kann falsch oder unvollständig sein.
- Nominaldefinition: der Gegenstand (Definiendum) wird durch anderen
Gegenstand (Definiens) erklärt, also ist eine Worterklärung mit gleicher
Begriffsbedeutung. Die Nominaldefinition kann NICHT falsch sein.
- Beide Definitionen sind NICHT NUR entweder richtig oder falsch
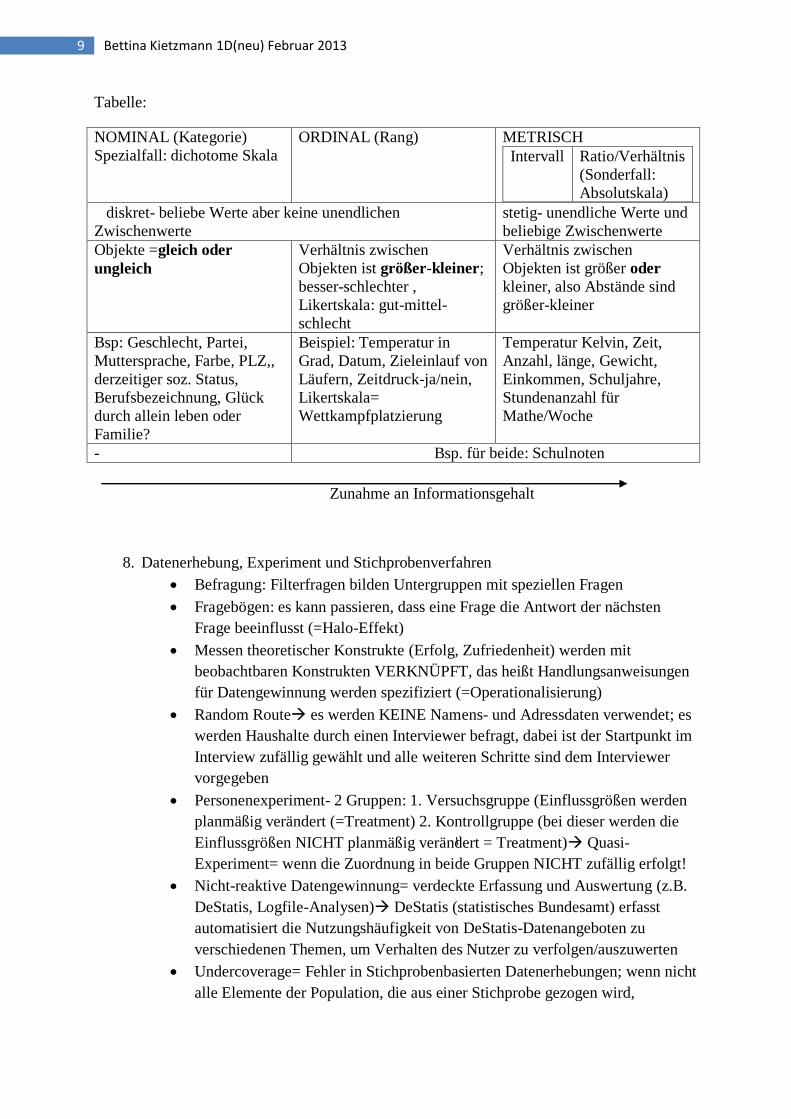
9 Bettina Kietzmann 1D(neu) Februar 2013
Tabelle:
NOMINAL (Kategorie)
Spezialfall: dichotome Skala
ORDINAL (Rang) METRISCH
Intervall Ratio/Verhältnis
(Sonderfall:
Absolutskala)
diskret- beliebe Werte aber keine unendlichen
Zwischenwerte
stetig- unendliche Werte und
beliebige Zwischenwerte
Objekte =gleich oder
ungleich
Verhältnis zwischen
Objekten ist größer-kleiner;
besser-schlechter ,
Likertskala: gut-mittel-
schlecht
Verhältnis zwischen
Objekten ist größer oder
kleiner, also Abstände sind
größer-kleiner
Bsp: Geschlecht, Partei,
Muttersprache, Farbe, PLZ,,
derzeitiger soz. Status,
Berufsbezeichnung, Glück
durch allein leben oder
Familie?
Beispiel: Temperatur in
Grad, Datum, Zieleinlauf von
Läufern, Zeitdruck-ja/nein,
Likertskala=
Wettkampfplatzierung
Temperatur Kelvin, Zeit,
Anzahl, länge, Gewicht,
Einkommen, Schuljahre,
Stundenanzahl für
Mathe/Woche
- Bsp. für beide: Schulnoten
Zunahme an Informationsgehalt
8. Datenerhebung, Experiment und Stichprobenverfahren
Befragung: Filterfragen bilden Untergruppen mit speziellen Fragen
Fragebögen: es kann passieren, dass eine Frage die Antwort der nächsten
Frage beeinflusst (=Halo-Effekt)
Messen theoretischer Konstrukte (Erfolg, Zufriedenheit) werden mit
beobachtbaren Konstrukten VERKNÜPFT, das heißt Handlungsanweisungen
für Datengewinnung werden spezifiziert (=Operationalisierung)
Random Route es werden KEINE Namens- und Adressdaten verwendet; es
werden Haushalte durch einen Interviewer befragt, dabei ist der Startpunkt im
Interview zufällig gewählt und alle weiteren Schritte sind dem Interviewer
vorgegeben
Personenexperiment- 2 Gruppen: 1. Versuchsgruppe (Einflussgrößen werden
planmäßig verändert (=Treatment) 2. Kontrollgruppe (bei dieser werden die
Einflussgrößen NICHT planmäßig verändert = Treatment) Quasi-
Experiment= wenn die Zuordnung in beide Gruppen NICHT zufällig erfolgt!
Nicht-reaktive Datengewinnung= verdeckte Erfassung und Auswertung (z.B.
DeStatis, Logfile-Analysen) DeStatis (statistisches Bundesamt) erfasst
automatisiert die Nutzungshäufigkeit von DeStatis-Datenangeboten zu
verschiedenen Themen, um Verhalten des Nutzer zu verfolgen/auszuwerten
Undercoverage= Fehler in Stichprobenbasierten Datenerhebungen; wenn nicht
alle Elemente der Population, die aus einer Stichprobe gezogen wird,

10 Bettina Kietzmann 1D(neu) Februar 2013
berücksichtigt werden, also Objekte gehören zur Grundgesamtheit, aber nicht
zur Auswahlgesamtheit
Overcoverage- Objekte gehören zur Auswahlgesamtheit, aber nicht zur
Grundgesamtheit; - Es werden Elemente ausgewählt, die nicht die
gewünschten Eigenschaften aufweisen
Wenn allgemeine Bevölkerungsumfrage durch freiwillige Befragung oder
offene Online-Befragung, können systematisch verzerrte Ergebnisse
aufkommen
Beispiel: Befragung von Schülern in Hauptschulen Deutschlands
Auswahleinheit= Hauptschulen in Dtl.; Erhebungseinheit= Schüler, die
befragt werden (stichprobenartig)
Gütekriterien für Messungen: OBJEKTIVITÄT, INTERSUBJEKTIVITÄT,
VALIDITÄT, RELIABILITÄT
Validität: „Wird wirklich DAS gemessen, was gemessen werden SOLL?“
Reliabilität: „Inwieweit liefert Messinstrument bei wiederholter Messung
gleiche Ergebnisse (Messwerte)?“
Aus der Reliabilität einer Messung folgt NICHT gleich deren Validität
Aus der Validität folgt stets auch die Reliabilität
Klumpenauswahl: 2 stufiger Auswahlprozess 1. Zufällig gewählte
Teilmenge der Grundgesamtheit 2. ALLE Elemente eines Klumpens
(Teilmenge)- nicht Untersuchungseinheiten!!!
Geschichtete Stichprobenauswahl - allgemein: Prozentsatz kann
grundsätzlich variieren
Geschichtete Stichprobenauswahl- proportional: hat festen Prozentsatz
(muss gleich sein) von Stichprobenelementen
Stichprobenauswahl mit proportionaler Schichtung 1. Grundgesamtheit
wird in Teilpopulationen zerlegt 2. Zufallsstichprobe aus dieser Teilpopulation
Quotenauswahlverfahren: 2stufiges Stichprobenverfahren zur Gewinnung
einer Stichprobe = zufallsgesteuert, d.h. 2. Stufe: systematische (kein Zufall)
Auswahl der Stichprobenelemente
Zusatz: dichotomisiert= 1. Aus vielen Variablen 2 machen (ordinal
nominal) 2. Z-Werte, Normierung
Binnendifferenzierung= z.B. methodische Maßnahmen für Verbesserung und
Gestaltung Unterricht; zusammengesetzt aus logischen Operatoren;
Operationalisierung samt innerer und äußerer Differenzierungen

11 Bettina Kietzmann 1D(neu) Februar 2013
9. Schätzen von Modellparametern (Punkt- und Intervallschätzung)
Die Stichprobenfunktion (bzw. Varianz s²) liefert eine VERZERRTE (nicht
übereinstimmende) Schätzung für die Varianz σ² man kann auch sagen,
dass man die Summe der quadratischen Abweichung bildet und mit n dividiert
= verzerrte Schätzung der Varianz
Stichprobenfunktion: X = 1. Stichprobenmittelwert 2. Stichprobenvarianz s²
Wenn der Erwartungswert anhand des Mittelwertes der
Stichprobenfunktion geschätzt wird ist dies UNVERZERRT (E( ) = μ FS
S.20) übereinstimmend)dann stimmt auch MSE (mittlere quadratische
Abweichung) mit Varianz überein (MSE=V(X)). Man kann auch sagen,
wenn man die Summe der MSE bildet und dann mit n dividiert, erhält man
eine verzerrte Schätzung für die Varianz.(unverzerrt= korrigierte Varianz
FS S.3)
Der Erwartungswert kann durch ein Konfidenzintervall geschätzt werden; die
Grenzen der Intervallschätzung sind ZUFALLSABÄNGIG
Bsp. Würfel: Mittelwert und Erwartungswert stimmen überein= unverzerrt,
ebenso stimmt auch der MSE mit Varianz überein.
Normalverteilung= Gaußglocke (Grafik Quelle: http://www.roulette-
portal.org/showwiki.php?title=Normalverteilung 10.2.2013 12:37 Uhr)
Korrigierte Varianz: Wenn man quadrierten Abweichungen aufsummiert und durch n-1 teilt,
ist dies eine unverzerrte Schätzung für die Varianz von X. Formelsammlung S.21

12 Bettina Kietzmann 1D(neu) Februar 2013
Konfidenzintervall (Grafik Quelle: http://eswf.uni-koeln.de/lehre/stathome/statcalc/v2202.htm
10.2.2013 12:40Uhr)
Je größer α, desto kleiner wird das Konfindenzintervall und umgekehrt.
Die Varianz vom Mittelwert geht, bei Verdopplung n, auf die Hälfte zurück.
(Nicht auf ein Viertel!) FS S.20 unten V( =
Bei Verdopplung n, nimmt Varianz um Faktor
und die Standardabweichung
um
=
ab.
10. Kombinatorik- diskrete Verteilung (Binomialverteilung/-koeffizient, Bernoulli)
Bernoulli-Experiment (-prozess): zufällig, 2 Versuchsausgänge
-der Erwartungswert berechnet sich durch n*p (p= Eintrittswahrscheinlichkeit)
Binomialverteilt= diskrete Wahrscheinlichkeitsverteilung; beschreibt die Anzahl/Folge
von gleichen, unabhängigen Versuchen (z.B. einer Münze), die je genau 2 mögliche
Ausgänge haben.
Bei einem Münzwurf ist X binomialverteilt mit n und p.
Varianz (X)- σ²= n*p(1-p)=
(NICHT
) ; q berechnet sich durch 1-p ; q und p sind
Eintrittswahrscheinlichkeiten.
Die Eintrittswahrscheinlichkeit p für z.B. Kopf kann man anhand Mittelwert X schätzen.
Varianz der Wahrscheinlichkeit (p und q)=
– bei fairen Münze:
; n= Anzahl der
Würfe.
Konfidenzintervall Erwartungswert μ
liegt „irgendwo im
Konfidenzitervall
ODER in α
α (auch:Fehler)
Symmetrisch-
Spiegel

13 Bettina Kietzmann 1D(neu) Februar 2013
Erwartungswert n*p für Binomialverteilung z.B. wenn man wissen möchte wie die
Wahrscheinlichkeit bei 9 mal werfen mit zwei Würfeln ist, dass ich eine 1 oder eine 2
habeman hat das Komplementärereignis A-Strich und A (2 mögliche Ausgänge)-davon
interessieren uns nur die ersten beiden Augenzahlen, also
=
=p und die Anzahl der Würfe
n=9E(X) =n*p wäre in diesem Falle 3.
Weiteres Beispiel September 2011 POL/SOZ Aufgabe 11 A:
Gegeben: faire Münze (Eintrittswahrscheinlichkeit p= 0,5) wird n= 8mal geworfen
X ist das Ereignis Zahl zu werfen.
Gesucht ist die Wahrscheinlichkeit mindestens 4 mal eine Zahl zu werfen.
Vorgehen: P (X ) – das heißt, ich berechne die Wahrscheinlichkeit für 4,5,6,7,8 dies
impliziert zu viele Rechenschritte, daher arbeitet man mit der
Komplementärwahrscheinlichkeit
P (X , also 1,2,3.
1. Schritt: Komplementärwahrscheinlichkeit berechnen über die Verteilungsfunktion
F(X)= binomialverteilt mit n=8; p=0,5 und k=3 (also über die Trägermenge k =0,1,2,3
mal eine Zahl zu werfen).
2. F(X)=
) * *
3. F(3)=
) * * = 0,3633 = die
Komplementärwahrscheinlichkeit
4. Nun ziehen wir die Komplementärwahrscheinlichkeit von 1 ab, also 1- 0,3633=
0,6367
= P (X
Kleiner Zusatz: Der Taschenrechner berechnet uns den Binomialkoeffizient
) - hier
die Formel:
) =
in den Taschenrechner gibt man
) folgendermaßen
ein: n Shift ÷ k
14 Bettina Kietzmann 1D(neu) Februar 2013
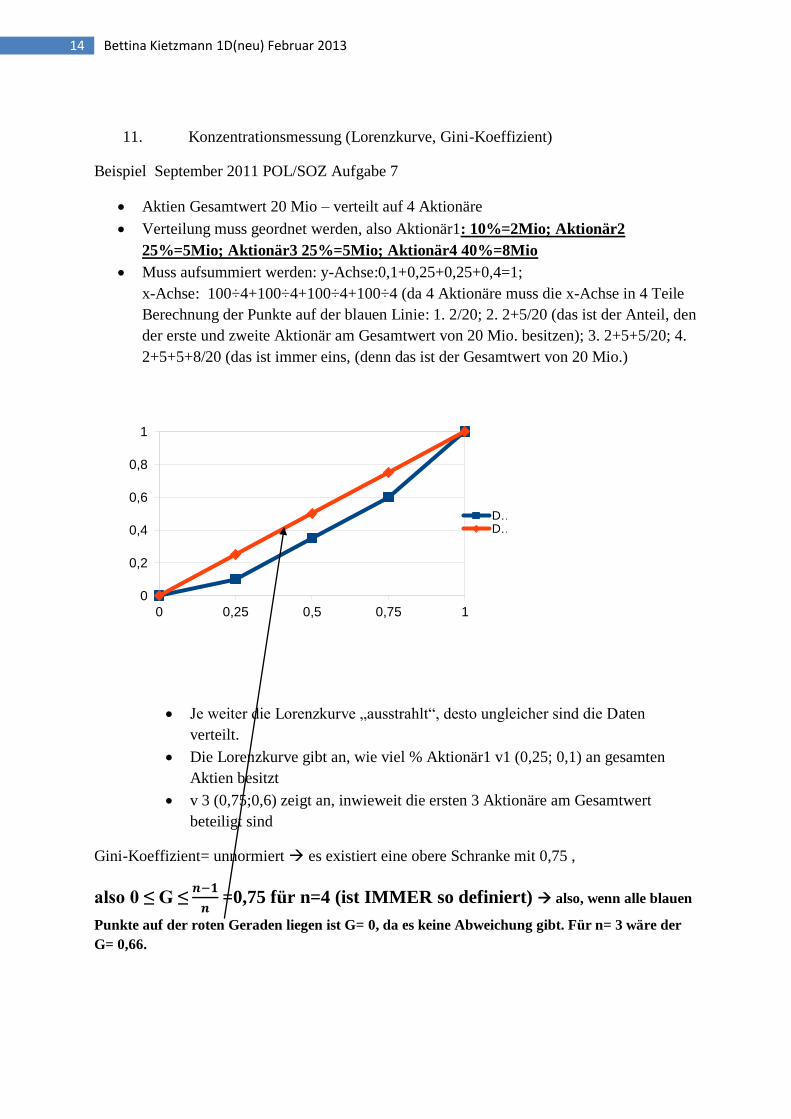
11. Konzentrationsmessung (Lorenzkurve, Gini-Koeffizient)
Beispiel September 2011 POL/SOZ Aufgabe 7
Aktien Gesamtwert 20 Mio – verteilt auf 4 Aktionäre
Verteilung muss geordnet werden, also Aktionär1: 10%=2Mio; Aktionär2
25%=5Mio; Aktionär3 25%=5Mio; Aktionär4 40%=8Mio
Muss aufsummiert werden: y-Achse:0,1+0,25+0,25+0,4=1;
x-Achse: 100÷4+100÷4+100÷4+100÷4 (da 4 Aktionäre muss die x-Achse in 4 Teile
Berechnung der Punkte auf der blauen Linie: 1. 2/20; 2. 2+5/20 (das ist der Anteil, den
der erste und zweite Aktionär am Gesamtwert von 20 Mio. besitzen); 3. 2+5+5/20; 4.
2+5+5+8/20 (das ist immer eins, (denn das ist der Gesamtwert von 20 Mio.)
Je weiter die Lorenzkurve „ausstrahlt“, desto ungleicher sind die Daten
verteilt.
Die Lorenzkurve gibt an, wie viel % Aktionär1 v1 (0,25; 0,1) an gesamten
Aktien besitzt
v 3 (0,75;0,6) zeigt an, inwieweit die ersten 3 Aktionäre am Gesamtwert
beteiligt sind
Gini-Koeffizient= unnormiert es existiert eine obere Schranke mit 0,75 ,
also 0 ≤ G ≤
=0,75 für n=4 (ist IMMER so definiert) also, wenn alle blauen
Punkte auf der roten Geraden liegen ist G= 0, da es keine Abweichung gibt. Für n= 3 wäre der
G= 0,66.
0
0,2
0,4
0,6
0,8
1
0 0,25 0,5 0,75 1
D… D…

15 Bettina Kietzmann 1D(neu) Februar 2013
Unterschied zwischen normiertem und unnormiertem Gini-Koeffizient:
Unnormiert G q =59 (1*2+2*5+3*5+4*8)
p =20 (2+5+5+8)
G=
G= 0,225
Normierter G* : G*=
* G (dafür benötigt man auch den unnormierten Gini-
Koeffizienten!)
G*=
* 0,225
G*= 0,3
Herfindahl- Index (Alternative zum Gini-Koeffizienten):
H es gilt:
H:=
) ² =
*
i= Laufvariable, nicht Multiplizieren!
(der Taschenrechner erkennt allerdings nicht, was X ist. Daher PER HAND aufsummieren!)
Beispiel für gegebene Werte:
H:=
* (2²+ 5²+ 5²+ 8²)= 0,295
Verdoppelt man xi, also in unserem Beispiel 2, 5, 5, 8, so verändern sich
beide Gini-Koeffizienten NICHT!
In der Klausur März 2011 POL/SOZ Aufgabe 11 Nummer C ist der SINN des
Gini-Koeffizienten erläutert: „Der Gini-Koeffizient liefert Aussagen des Typs
„x% der Merkmalsträger teilen sich y% der Merkmalssumme.“
16 Bettina Kietzmann 1D(neu) Februar 2013
12. Zusammenhangsmessung/ Regressions- und Varianzanalyse
Empirische Zusammenhänge sind durch Beobachtungen errechenbar; theoretische
Zusammenhangsmaße gelten für Zufallsvariablen.
Der Korrelationskoeffizient r (Brevais Pearson) misst die Stärke eines linearen
Zusammenhangs zwischen 2 Merkmalen X und Y und ist auf metrisch skalierte Daten
anwendbar.
Anforderungen an die Zusammenhangsmessung („Wie ist der Zusammenhang einer Zahl?
Beispiel: Je größer Einkommen, desto größer Konsum.“) die empirische Verteilung wird
durch den Korrelationskoeffizienten Bravais Pearsons beschrieben)
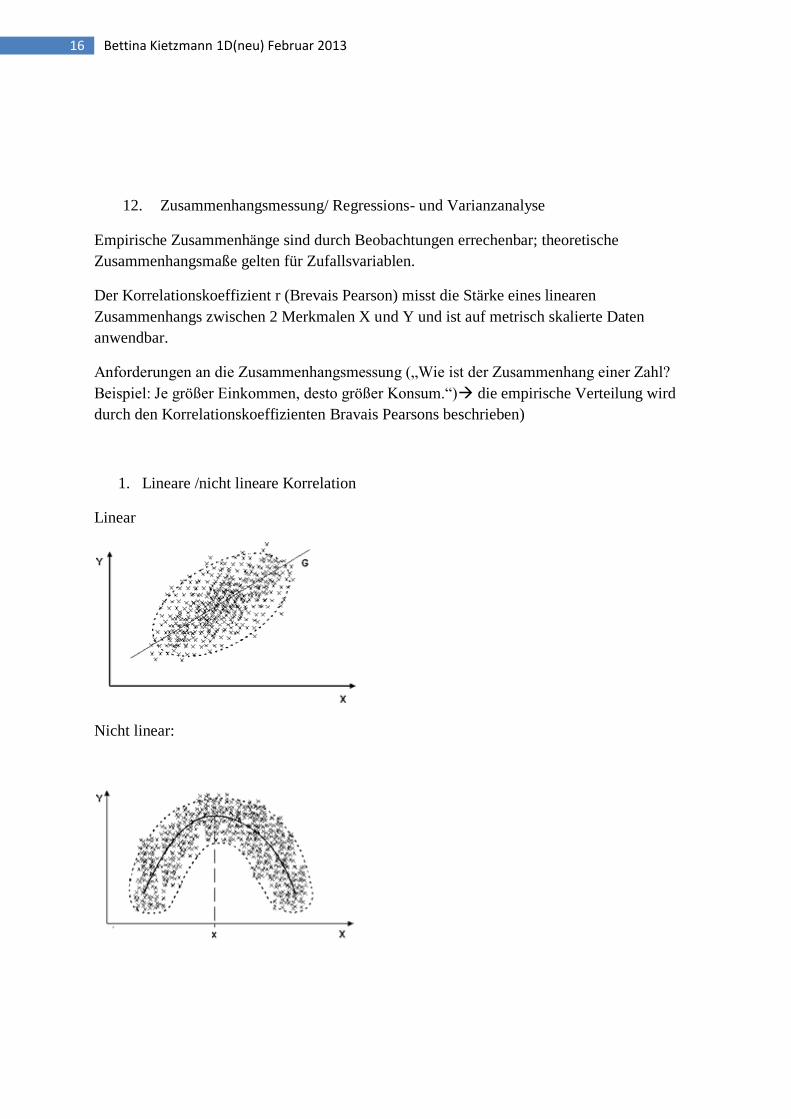
1. Lineare /nicht lineare Korrelation
Linear
Nicht linear:
17 Bettina Kietzmann 1D(neu) Februar 2013
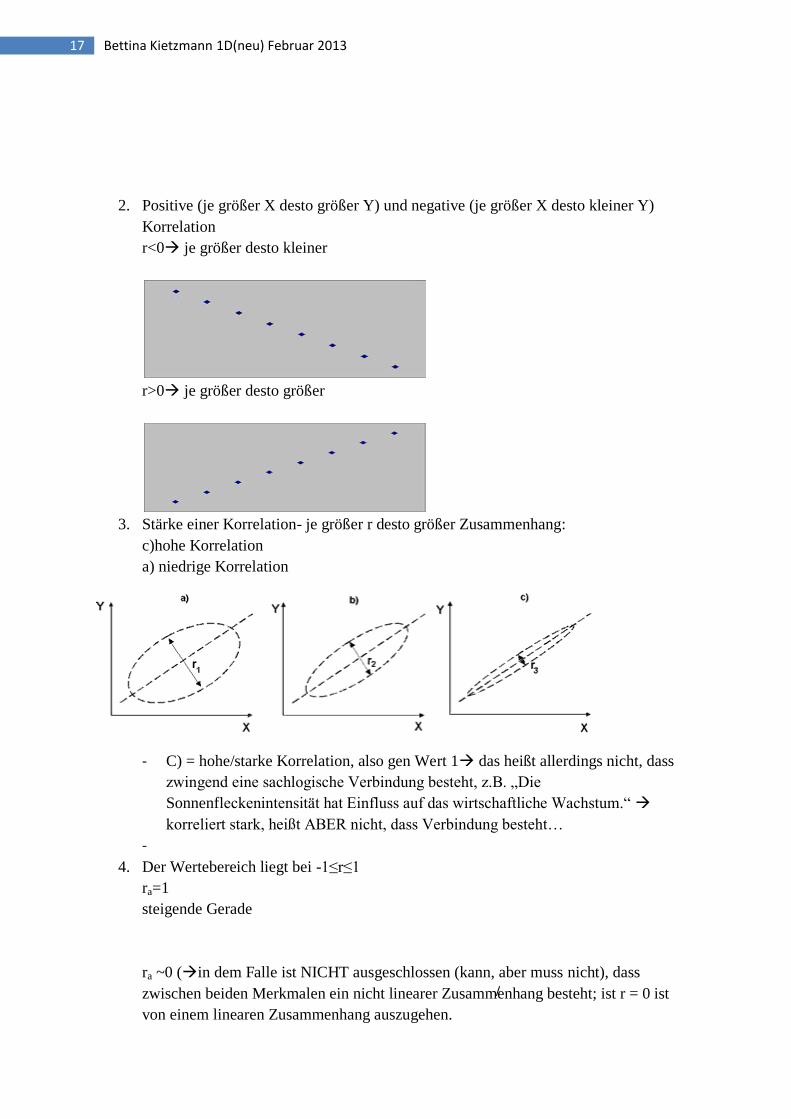
2. Positive (je größer X desto größer Y) und negative (je größer X desto kleiner Y)
Korrelation
r<0 je größer desto kleiner
r>0 je größer desto größer
3. Stärke einer Korrelation- je größer r desto größer Zusammenhang:
c)hohe Korrelation
a) niedrige Korrelation
- C) = hohe/starke Korrelation, also gen Wert 1 das heißt allerdings nicht, dass
zwingend eine sachlogische Verbindung besteht, z.B. „Die
Sonnenfleckenintensität hat Einfluss auf das wirtschaftliche Wachstum.“
korreliert stark, heißt ABER nicht, dass Verbindung besteht…
-
4. Der Wertebereich liegt bei -1≤r≤1
ra=1
steigende Gerade
ra ~0 (in dem Falle ist NICHT ausgeschlossen (kann, aber muss nicht), dass
zwischen beiden Merkmalen ein nicht linearer Zusammenhang besteht; ist r = 0 ist
von einem linearen Zusammenhang auszugehen.

18 Bettina Kietzmann 1D(neu) Februar 2013
ra=-1
fallende Gerade
Die Kovarianz ist NICHT das Zusammenhangsmaß, welches NUR Werte zwischen -1
und 1 annimmt denn das ist die NORMIERUNG der Kovarianz- diese liegt
zwischen -1 und 1.
Den Korrelationskoeffizienten berechnet man durch:
r:=
Kovarianz-cov:
sxy= Cov =
*
Beispiel Klausur September 2011 Aufgabe 14
Nummer A: Werte sind vorgegeben außer die Standardabweichung, allerdings muss
man nur noch die Wurzel aus der Varianz ziehen. Der Korrelationskoeffizient beträgt
demnach 0, 835. Nun kann man eine Aussage über diesen treffen: stark positive
Korrelation.
B: lineares Regressionsmodell
y i= β*x + αi + u i siehe Formelsammlung Seite 27
= eine Funktion für eine Gerade (Linearfunktion)
Manche kennen vielleicht aus der Schule: y=m*x+n
m= Anstieg = β
n= Schnittpunkt mit der Y-Achse= α
Und x ist x ;)
19 Bettina Kietzmann 1D(neu) Februar 2013
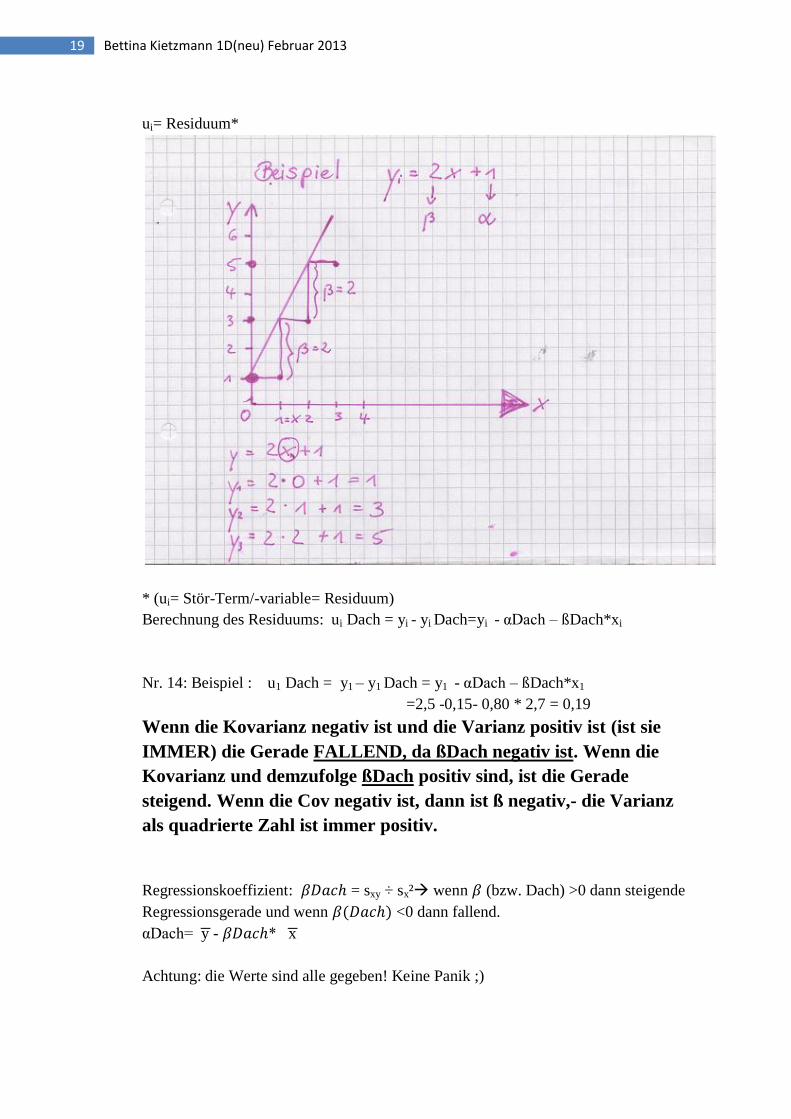
ui= Residuum*
* (ui= Stör-Term/-variable= Residuum)
Berechnung des Residuums: ui Dach = yi - yi Dach=yi - αDach – ßDach*xi
Nr. 14: Beispiel : u1 Dach = y1 – y1 Dach = y1 - αDach – ßDach*x1
=2,5 -0,15- 0,80 * 2,7 = 0,19
Wenn die Kovarianz negativ ist und die Varianz positiv ist (ist sie
IMMER) die Gerade FALLEND, da ßDach negativ ist. Wenn die
Kovarianz und demzufolge ßDach positiv sind, ist die Gerade
steigend. Wenn die Cov negativ ist, dann ist ß negativ,- die Varianz
als quadrierte Zahl ist immer positiv.
Regressionskoeffizient: = sxy ÷ sx² wenn (bzw. Dach) >0 dann steigende
Regressionsgerade und wenn <0 dann fallend.
αDach= y - * x
Achtung: die Werte sind alle gegeben! Keine Panik ;)

20 Bettina Kietzmann 1D(neu) Februar 2013
Für die Methode der kleinsten Quadrate braucht man αDach und ßDach Seite 27
Formelsammlung. Das sind alles nur geschätzte Werte, keine wahren Werte!
R²= Bestimmtheits- bzw. Gütemaß hat Definitionsbereich 0≤R²≤1 beurteilt, ob die
Regressionsgerade, die ich berechnet habe eine „gute“ oder „schlechte“ Anpassung an
den gegebenen Datensatz haben.
Fakt ist, dass versucht wird, die Abweichung der Regressionsgerade möglichst gering
zu halten- die Summe der quadrierten Residuen wird versucht gering zu halten. Bei
Null würden alle Daten des Datensatzes auf der Regressionsgeraden liegen und das ist
sehr selten der Fall.
Wenn R²=0 schließt nicht aus, dass zwischen X und Y ein nicht-linearer
Zusammenhang besteht.
R² (=Gütemaß)=r² (Korrelationskoeffizient ins Quadrat) Unterschied= dass r auch
negative Werte annehmen kann. 0≤R²≤1 und -1≤r≤1.
R²=
= s²yDach ÷ s²y = 1 – s²uDach ÷ s²y=
= r²
(Formelsammlung Seite 29)
Das Bestimmtheitsmaß bzw Gütemaß, z.B. 0,45 gibt an, dass 45% der
Gesamtvariation des Datensatzes durch das Regressionsmodell erklärt ist. Würde R²
beispielsweise 0,9 sein, dann bedeutet dies, dass 90% der Gesamtvariation des
Datensatzes durch das Regressionsmodell erklärt ist. Würde in einer Aufgabe stehen,
dass R² = 0,9 und dieser 65% der Gesamtvariation des Datensatzes durch das
Regressionsmodell erklärt, wäre dies FALSCH.
Beispiel März 2011 POL/SOZ Aufgabe 15 Nummer B.
R²=
= 0,1075
Lernsache bzw. Formelsammlung Seite 30: Die unabhängige Variable ist diskret und die
abhängige (Responsevariable) ist stetig.
13. Testen, Gauß-Test; Fehler beim Testen, Gütefunktion
Formelsammlung Seite 22.
Dazu findet ihr eine Grunderklärung meinerseits in einer weiteren Datei in diesem Artikel namens
Gauß-Test, mit sehr guter und vornehmlicher Hilfe dieses Linkes:
http://www.fernstudi.net/blogs/null-und-alternativhypothese-gauss-test
Numerische Aufgaben folgen in einer seperaten Datei.

21 Bettina Kietzmann 1D(neu) Februar 2013


















