Inklusive SUSY-Suche mit statistischen Methodenthesis/data/iekp-ka2008-14.pdf · Prinzip der...
134
♣ Universit¨ at Karlsruhe (TH) IEKP-KA/2008-14 Inklusive SUSY-Suche mit statistischen Methoden Daniel A. Stricker-Shaver Diplomarbeit Fakult ¨ at f ¨ ur Physik, Universit ¨ at Karlsruhe Referent: Prof. Dr. W. de Boer Institut f¨ ur Experimentelle Kernphysik Korreferent: Prof. Dr. G. Quast Institut f¨ ur Experimentelle Kernphysik 19. Mai 2008
Transcript of Inklusive SUSY-Suche mit statistischen Methodenthesis/data/iekp-ka2008-14.pdf · Prinzip der...

ppppppppppppp Universitat Karlsruhe (TH)
IEKP-KA/2008-14
Inklusive SUSY-Suchemit statistischen Methoden
Daniel A. Stricker-Shaver
Diplomarbeit
Fakultat fur Physik,Universitat Karlsruhe
Referent: Prof. Dr. W. de BoerInstitut fur Experimentelle Kernphysik
Korreferent: Prof. Dr. G. QuastInstitut fur Experimentelle Kernphysik
19. Mai 2008


i

Einleitung ii
ii
Inhaltsverzeichnis
1 Einleitung ............................................................................................ 1
2 Das Standardmodell (SM) ................................................................. 3 2.1 Grundlagen – Das Prinzip der Eichtransformation ....................... 3 2.2 Felder und Teilchen....................................................................... 4 2.3 Eichgruppen und Eichtranformationen ......................................... 5
2.3.1 Eichgruppe der elektroschwachen Wechselwirkung ........... 5 2.3.2 Eichgruppe der starken Wechselwirkung ............................ 5
2.4 Higgs-Mechanismus...................................................................... 5 2.4.1 Das Problem der Massenerzeugung..................................... 5 2.4.2 Der Mechanismus ................................................................ 6 2.4.3 Massen der Eichbosonen und Fermionen ............................ 6
2.5 Das Higgs-Boson .......................................................................... 7 2.5.1 Die Produktionsmechanismen des Higgs-Bosons ............... 7 2.5.2 Zerfallskanäle ...................................................................... 8 2.5.3 Suchen nach dem Higgs-Boson ........................................... 8
3 Erweiterung des Standardmodells: Supersymmetrie ................... 11 3.1 Das grundlegende Prinzip der Supersymmetrie .......................... 12 3.2 MSSM (Minimales Supersymmetrisches Standard-Modell) ...... 12 3.3 Massenspektren von SUSY-Teilchen ......................................... 14 3.4 Higgs-Sektor im MSSM.............................................................. 15 3.5 GUT-Theorien→ constraint MSSM .......................................... 17
4 LHC und CMS.................................................................................. 19 4.1 Der Proton-Proton-Speicherring LHC ........................................ 19 4.2 Das CMS-Experiment ................................................................. 22
4.2.1 Elektromagnetisches Kalorimeter...................................... 23 4.2.2 Hadronisches Kalorimeter ................................................. 23 4.2.3 Myonsystem....................................................................... 23 4.2.4 Spurdetektor....................................................................... 23 4.2.5 Triggersystem .................................................................... 24 4.2.6 Zusätzliche Eigenschaften ................................................. 24
5 Statistische Methoden ...................................................................... 25 5.1 Grundlagen: einzelne Variable.................................................... 25
5.1.1 Erwartungswert und Standardabweichung ........................ 25 5.1.2 Von der Binomial- über die Poisson- zur Gleichverteilung25 5.1.3 Momente ............................................................................ 27 5.1.4 verschiedener Verteilungen ............................................... 27
5.2 Grundlagen: mehrere Variablen.................................................. 27

Einleitung iii
iii
5.2.1 Verteilungsfunktion und Schnitte im n-dim. Raum........... 27 5.2.2 μ , Varianz und Momente im n-dimensionalen Raum ...... 28
5.3 Kovarianzmatrix und Korrelationen............................................ 28 5.3.1 Definition der Kovarianzmatrix......................................... 28 5.3.2 Korrelationen ..................................................................... 29
5.4 Viele Funktionen eines Satzes von Zufallszahlen....................... 30 5.4.1 Koordinatentransformation (allgemein) ............................ 30 5.4.2 Koordinatentransformation (PCA) .................................... 31 5.4.3 Koordinatentransformation (Wurzel der Kovarianzmatrix)32
5.5 2χ -Test........................................................................................ 32
5.6 H-Matrix...................................................................................... 35 5.7 Maximum-Likelihood-Methode.................................................. 35
5.7.1 Projektiver Likelihood-Schätzer ........................................ 36 5.7.2 Mehrdimensionaler Likelihood Schätzer und PDERS ...... 37
5.8 Optimierung und Anpassung (Fitting) ........................................ 37 5.8.1 Simuliertes Abkühlen ........................................................ 38 5.8.2 Minuit-Minimierung .......................................................... 38 5.8.3 Monte-Carlo-Stichprobe .................................................... 38 5.8.4 Genetischer Algorithmus ................................................... 39
5.9 Gewichtete Entscheidungsbäume................................................ 40 5.10 Nächste-Nachbarn-Klassifikation ............................................... 43 5.11 Fishersche Diskriminanzfunktion ............................................... 43 5.12 Support-Vector-Machine (SVM) oder Stützvektormaschine...... 44 5.13 Vorausschauendes Lernen durch Regel-Ensembles (RuleFit) .... 45 5.14 Rechtwinklige Schnitt-Optimierung ........................................... 46 5.15 FDA (Function Discriminant Analysis) ...................................... 47 5.16 Künstliches Neuronales Netzwerk (KNN).................................. 47 5.17 Kolmogorow-Smirnow-Test ....................................................... 50
6 Werkzeuge......................................................................................... 51 6.1 CMSSW ...................................................................................... 51
6.1.1 Konfigurationsdatei und sonstige Veränderungen............. 51 6.2 Grid.............................................................................................. 51 6.3 TMVA ......................................................................................... 52 6.4 Neurobayes®............................................................................... 53
7 Analyse .............................................................................................. 55 7.1 Daten durch CMSSW und Grid .................................................. 55 7.2 Die Benutzung von TMVA ......................................................... 57
7.2.1 Overtraining (Übertrainieren von Klassifikatoren)............ 58

Einleitung iv
iv
7.2.2 Hilfsmittel für die Klassifikatoren ..................................... 59 7.3 Testen der Klassifikatoren........................................................... 60
7.3.1 Rechtwinklige Schnitte ...................................................... 62 7.3.2 Likelihood-Klassifikator.................................................... 63 7.3.3 PDERS und der K-NN-Algorithmus ................................. 66 7.3.4 Fisher-Klassifikator und H-Matrix-Klassifikator .............. 68 7.3.5 FDA ................................................................................... 69 7.3.6 Neuronales Netz................................................................. 70 7.3.7 SVM................................................................................... 72 7.3.8 Entscheidungsbäume ......................................................... 74 7.3.9 RuleFit ............................................................................... 75 7.3.10 Vielversprechende Klassifikatoren für die Analyse .......... 76 7.3.11 Ranking der Variablen durch Klassifikatoren ................... 77
7.4 Training der ausgewählten Klassifikatoren................................. 78 7.4.1 Vorauswahl ........................................................................ 78 7.4.2 Das Training für W+Jets.................................................... 80 7.4.3 Das Training für Z+Jets ..................................................... 90 7.4.4 Das Training für tt -Jets.................................................... 97
8 Zusammenfassung.......................................................................... 105
Quellen ................................................................................................. 107
Verwendete Methodenabkürzungen .................................................... iii
Anhang ..................................................................................................... v

Einleitung 1
1 Einleitung Voraussichtlich im Herbst 2008 wird am CERN bei Genf der Teilchenbeschleuniger LHC fertig gestellt. Mit diesem Hadronen-Beschleuniger wird es möglich sein, den Aufbau der Materie mit Energien von bisher nicht erreichten Größenordnungen zu untersuchen. Entlang der Strahlrohre dieses Beschleunigers entstehen zurzeit verschiedenste Experimente. Mit dem CMS-Experiment soll unter anderem das theoretisch durch das Standardmodell der Teilchenphysik vorausgesagte aber bisher nicht experimentell nachgewiesene Higgsboson gefunden werden. Im Standardmodell der Elementarteilchenphysik werden die Elementarteilchen und deren Wechselwirkung beschrieben. Die von dieser Quantenfeldtheorie beschriebenen Grundkräfte der Physik sind die schwache, die starke und die elektromagnetische Wechselwirkung. 1964 ist es Glashow, Salam und Weinberg gelungen die elektro-magnetische und schwache Wechselwirkung zur elektroschwachen Kraft zur vereinen. Die grand unification theories (GUT) gehen noch einen Schritt weiter. Sie fassen schwache und starke Wechselwirkung als verschiedene Zweige einer einheitlichen Wechselwirkung auf. Die Wechselwirkung wird durch Eichbosonen vermittelt. Die Stärke dieser Wechsel-wirkung wird durch die Kopplungskonstanten beschrieben. Es wird erwartet, dass die bei niedrigen Energien auftretende Symmetriebrechung bei sehr hohen Energien aufgehoben wird und die verschiedenen Kopplungskonstanten gleich groß werden. Ein viel versprechender Ansatz mit dem unter anderem diese Vereinigung der Kop-plungskonstanten erklärt werden kann, ist die Supersymmetrie (SUSY) und speziell die minimale supersymmetrische Erweiterung des Standardmodells (MSSM). Mit der mSUGRA-Theorie1 können die mehr als 100 freien Parameter der MSSM auf fünf Parameter reduziert werden. Nach Messergebnissen aus der Astronomie bestehen mehr als 90 Prozent des Universums aus unsichtbarer, nicht-baryonischer Materie, so genannter dunkler Materie und dunkler Energie. Die Teilchen dieser dunklen Materie, die so genannten WIMPs2 sind stabil, massiv und unterliegen nur der schwachen Wechselwirkung und der Gravitation. Die Theorie der Supersymmetrie beschreibt ein Teilchen, das leichteste Neutralino 0
1χ bzw. das leichteste supersymmetrische Teilchen (LSP), das dieselben Eigenschaften aufweist. Anhand der Daten der Satelliten-Experimente WMAP und EGRET werden die Eigenschaften der WIMPs weiter analysiert. Die Ergebnisse beschränken die Parameter der mSUGRA-Theorie auf Bereiche, in denen die Eigenschaften von LSPs und WIMPs übereinstimmen. Die in dieser Diplomarbeit analysierten statistischen Methoden werden anhand von simulierten supersymmetrischen Ereignissen, die diesem Parameterbereich entsprechen, überprüft. Die Arbeit geht im Folgenden zuerst auf das Standardmodell der Teilchenphysik und dessen supersymmetrischen Erweiterung ein, beschäftigt sich im weiteren Verlauf mit dem Large Hadron Collider und geht näher auf das CMS3-Experiment ein. Desweiteren werden verschiedene statistische Methoden vorgestellt und erläutert. In der Analyse werden die verschiedenen statistischen Methoden
1 minimal super gravity 2 weakly interacting massive particle 3 compact muon solinoid

Einleitung 2
verglichen und deren Eignung anhand simulierter Signal- und Untergrunddaten überprüft.

Das Standardmodell (SM) 3
2 Das Standardmodell (SM) Durch das Standardmodell der Teilchenphysik werden die grundlegenden Bausteine der Materie und deren Wechselwirkungen untereinander beschrieben. Diese Wechsel-wirkungen oder auch Elementarkräfte sind die starke, die schwache und die elektro-magnetische Wechselwirkung. Die vierte Wechselwirkung, die Gravitation, wird durch die allgemeine Relativitätstheorie beschrieben. Sie ist aber im Vergleich zu den anderen drei Kräften vernachlässigbar klein, da wir uns in zu kleinen Skalen bewegen. Vielleicht ist es irgendwann möglich alle vier Kräfte in einer Kraft zu vereinigen.
2.1 Grundlagen – Das Prinzip der Eichtransformation Die Lagrangedichte
beschreibt ein fermionisches Feld f der Masse m . Über die Variation der Wirkung findet man, analog zur klassischen Kontinuumsmechanik, zu den Euler-Lagrange-Bewegungsgleichungen (ELG). Die ELG ergeben für ein solches fermionisches Feld eines einzelnen Teilchens die bekannte Dirac-Gleichung
Mit dieser Gleichung wird die Bewegung eines Teilchens beschrieben, allerdings noch ohne Einfluss jeglicher Kraft. Um einen Wechselwirkungsterm hinzuzufügen, kann das Fermionfeld einer Eichtransformation unterzogen werden. Ist eine Eichtransformation lokal, d.h. abhängig vom Ort des Teilchens, werden die zusätzlich auftauchenden Terme in der Lagrangedichte als die Felder der Wechselwirkung interpretiert. Das einfachste Beispiel einer Eichtransformation ist jedoch eine globale Eichtransformation, beispielsweise die Multiplikation des Fermionfeldes mit einem konstanten Faktor:
Das Fermionfeld ändert sich dann zu
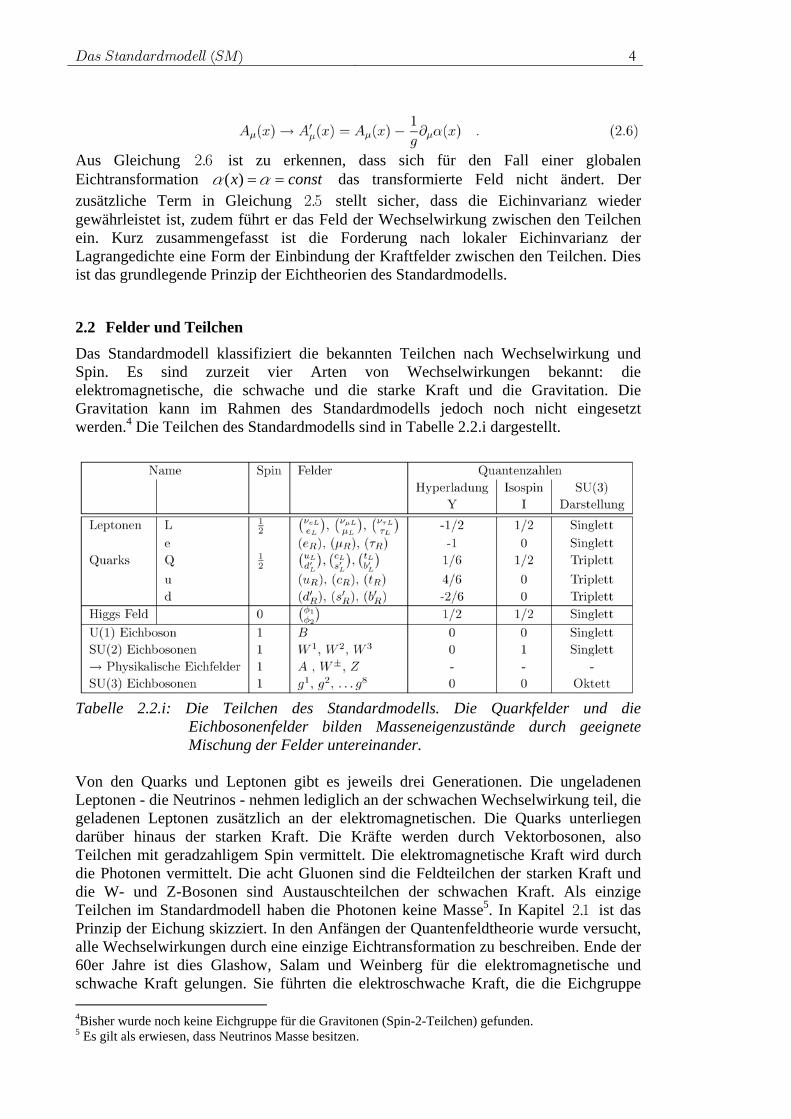
Die Lagrangedichte wird dabei nicht verändert. Ist jedoch die Transformation U von der Koordinate x des Fermionfeldes abhängig, entstehen durch die Ableitung zusätzliche Terme, die die ursprüngliche Lagrangedichte verändern. Um diese Veränderung auszugleichen, wird die Ableitung in Gleichung .2 1 durch eine so genannte kovariante Ableitung ersetzt:
Für das in der kovarianten Ableitung neu eingeführte Feld μA wird außerdem das Transformationsverhalten unter der ( )U 1 -Transformation aus ( . )2 3 neu festgelegt.
Das Standardmodell (SM) 4
Aus Gleichung .2 6 ist zu erkennen, dass sich für den Fall einer globalen Eichtransformation constx == αα )( das transformierte Feld nicht ändert. Der zusätzliche Term in Gleichung .2 5 stellt sicher, dass die Eichinvarianz wieder gewährleistet ist, zudem führt er das Feld der Wechselwirkung zwischen den Teilchen ein. Kurz zusammengefasst ist die Forderung nach lokaler Eichinvarianz der Lagrangedichte eine Form der Einbindung der Kraftfelder zwischen den Teilchen. Dies ist das grundlegende Prinzip der Eichtheorien des Standardmodells.
2.2 Felder und Teilchen Das Standardmodell klassifiziert die bekannten Teilchen nach Wechselwirkung und Spin. Es sind zurzeit vier Arten von Wechselwirkungen bekannt: die elektromagnetische, die schwache und die starke Kraft und die Gravitation. Die Gravitation kann im Rahmen des Standardmodells jedoch noch nicht eingesetzt werden.4 Die Teilchen des Standardmodells sind in Tabelle 2.2.i dargestellt.
Tabelle 2.2.i: Die Teilchen des Standardmodells. Die Quarkfelder und die
Eichbosonenfelder bilden Masseneigenzustände durch geeignete Mischung der Felder untereinander.
Von den Quarks und Leptonen gibt es jeweils drei Generationen. Die ungeladenen Leptonen - die Neutrinos - nehmen lediglich an der schwachen Wechselwirkung teil, die geladenen Leptonen zusätzlich an der elektromagnetischen. Die Quarks unterliegen darüber hinaus der starken Kraft. Die Kräfte werden durch Vektorbosonen, also Teilchen mit geradzahligem Spin vermittelt. Die elektromagnetische Kraft wird durch die Photonen vermittelt. Die acht Gluonen sind die Feldteilchen der starken Kraft und die W- und Z-Bosonen sind Austauschteilchen der schwachen Kraft. Als einzige Teilchen im Standardmodell haben die Photonen keine Masse5. In Kapitel .2 1 ist das Prinzip der Eichung skizziert. In den Anfängen der Quantenfeldtheorie wurde versucht, alle Wechselwirkungen durch eine einzige Eichtransformation zu beschreiben. Ende der 60er Jahre ist dies Glashow, Salam und Weinberg für die elektromagnetische und schwache Kraft gelungen. Sie führten die elektroschwache Kraft, die die Eichgruppe 4Bisher wurde noch keine Eichgruppe für die Gravitonen (Spin-2-Teilchen) gefunden. 5 Es gilt als erwiesen, dass Neutrinos Masse besitzen.

Das Standardmodell (SM) 5
L YSU( ) U( )2 ⊗ 1 als Grundlage einer lokalen, nicht-abelschen Quantenfeldtheorie hat, ein. Später wurde die starke Wechselwirkung (Quantenchromodynamik) durch die Eichgruppe CSU( )3 beschrieben, was zur C L YSU( ) SU( ) U( )3 ⊗ 2 ⊗ 1 -Eichgruppe des Standardmodells führte.
2.3 Eichgruppen und Eichtranformationen Wie in Abschnitt .2 1 erläutert, ist die Existenz von Kraftfeldern Folge einer lokalen Eichinvarianz der Lagrangedichte. Auf diese Weise werden die Kraftfelder in die Lagrangedichte einbezogen.
2.3.1 Eichgruppe der elektroschwachen Wechselwirkung Für die elektroschwache Kraft bedeutet lokale Eichinvarianz unter einer
L YSU( ) U( )2 ⊗ 1 -Transformation die Existenz von vier Feldern, B , ,W , W1 2 3 . Diese Felder sind ohne physikalische Bedeutung. Erst durch eine geeignete Mischung dieser Felder werden diese mit den in Experimenten beobachteten Teilchen, Z , W± und γ verknüpft, wobei die Stärke der Mischung durch den schwachen Mischungswinkel
Wθ bestimmt wird:
Es wird nun angenommen, dass unterhalb einer bestimmten Energie – die experimentell auf ca. 246 GeV festgelegt wird – die gemeinsame Symmetrie gebrochen wird und sich die jeweiligen Anteile der Eichgruppe LSU( )2 und YU( )1 trennen, welche prinzipiell unabhängig voneinander beobachtet werden könnten. Oberhalb dieser Skala sind beide Wechselwirkungen gleich stark und man spricht nur noch von der elektroschwachen Kraft.
2.3.2 Eichgruppe der starken Wechselwirkung
Die Eichgruppe CSU( )3 wirkt lediglich auf Quarks, alle anderen Teilchen des Standardmodells werden von einer lokalen Eichtransformation unter dieser Gruppe nicht berührt6. Die Dimension N = 3 dieser Untergruppe bewirkt, dass es N²−1 = 8 Generatoren für diese Transformation gibt, die als Gluonfelder interpretiert werden. Sie haben als Quantenzahl der starken Wechselwirkung die Farbladung.
2.4 Higgs-Mechanismus
2.4.1 Das Problem der Massenerzeugung Massenterme lassen sich leicht in die Lagrangedichte eines Dirac-Fermionfeldes einfügen: Ä , m| (x)|2φ = −0 5⋅ φ . So ein Massenterm ist eichinvariant. Ein Problem
6 Sie bilden Singuletts bezüglich einer solchen Transformation.

Das Standardmodell (SM) 6
entsteht jedoch bei den Massentermen der Eichbosonen. Durch die Transformation des Vektorfeldes entsprechend Gleichung .2 6 ergibt sich durch die Ableitung ein zusätzlicher Term, zu dem es kein Äquivalent gibt. Dieser Term ist unter einer lokalen Eichtransformation wie der L YSU( ) U( )2 ⊗ 1 oder der CSU( )3 nicht eichinvariant. Ein Problem ergibt sich dadurch, dass mit dieser Lagrangedichte keine Relation zu einem physikalischen Feld hergestellt werden kann. Der Higgs-Mechanismus löst dieses Problem auf besondere Art.
2.4.2 Der Mechanismus Das Higgs-Feld wird über die Higgs-Lagrangedichte in die Theorie eingeführt. Diese lässt sich wie folgt schreiben:
wobei das Higgs-Potential wie folgt gewählt wird7:
Sind die Parameter nun so gewählt, dass 2μ < 0 und λ > 0, liegt das nichttriviale Minimum des Potentials nun auf einer Fläche mit
Wird anstelle des trivialen Grundzustandes (| (x)| )2φ ≡ 0 der neue Grundzustand (| (x)| )2 2φ ≡ υ gewählt, also das Higgs-Feld in diesen Minimumzustand transformiert, ergibt sich eine neue Lagrangedichte. Diese enthält dann Terme wie:
und
Diese Terme stellen den Massenanteil der entwickelten -und lokal eichinvarianten- Lagrangedichte dar. Der Higgs-Mechanismus liefert automatisch die Massen des Higgs-Bosons, der W - und der Z -Bosonen. Der Parameter v kann aus Messungen an den W - und Z - Bosonen bestimmt werden, sein Wert liegt bei GeV /c²υ ≈ 246 . Der Parameter λ jedoch bleibt unbekannt und damit auch die Higgsmasse selbst. Eine obere Grenze lässt sich allerdings aus Unitaritätsbedingungen für die W W -Streuung zu etwa
H hm m TeV /c²= <1 ableiten, elektroschwache Präzisionsmessungen senken das obere Limit mit einer Sicherheit von 95% auf hm GeV /c²< 285 .
2.4.3 Massen der Eichbosonen und Fermionen Die Terme aus Gleichung .2 13 lassen sich direkt als Massenterme der Form Ä / m| (x)|²φ = −1 2 φ interpretieren, und man erhält daraus in führender Ordnung Störungstheorie die Massen für die W - und Z -
7Manche Notationen verwenden ein 2λ .

Das Standardmodell (SM) 7
Bosonen zu W Z W W Wm g/ , m g/ cos m /cos= υ 2 = υ 2 θ = θ . Der Higgs-Mechanismus hat den Nachteil, dass die Massen der Fermionen nicht natürlich in die entsprechenden Lagrangeterme eingebunden werden. Stattdessen müssen die Fermionfelder manuell an das Higgs-Feld gekoppelt werden um einen eichinvarianten Massenterm in der Lagrangedichte zu erhalten. Diese Kopplung wird Yukawa-Kopplung genannt. Die Kopplung des Higgs-Feldes an die Fermionen ist proportional zur Masse der Fermionen. Für jeden Typ der Fermionen gibt es eine Yukawa-Kopplung, die in keinerlei Beziehung zueinander stehen und prinzipiell frei wählbar ist. Darüber hinaus mischen sich die einzelnen Quarkfamilien untereinander über die CKM8-Mischungsmatrix. Dadurch entstehen vier neue Parameter.
2.5 Das Higgs-Boson
2.5.1 Die Produktionsmechanismen des Higgs-Bosons Es wird davon ausgegangen, dass das Higgs-Boson am Large Hadron Collider (LHC) auf unterschiedliche Weisen erzeugt werden kann. Feynmangraphen der Produktionskanäle sind in Abbildung 2.5.1.i gezeigt. Der dominante Produktions-mechanismus ist die Gluon-Fusion, sie ist von der Higgs-Masse weitgehend unabhängig. Der Gluon-Fusion folgt die Vektor-Boson-Fusion (VBF). Etwa zwei Größenordungen niedriger liegen die Wirkungsquerschnitte für die Produktion mit einem assoziierten Eichboson, beziehungsweise die Produktion mit einem assoziierten tt -Paar. In Abbildung 2.5.1.ii werden die Produktions-wirkungsquerschnitte in Abhängigkeit von der Higss-Boson-Masse dargestellt.
Abbildung 2.5.1.i:Higgs-Boson Produktionsmechanismen am LHC. Die Produktions-
kanäle sind nach fallendem Wirkungsquerschnitt angeordnet.
8 Cabbibo-Kobayashi-Maskawa
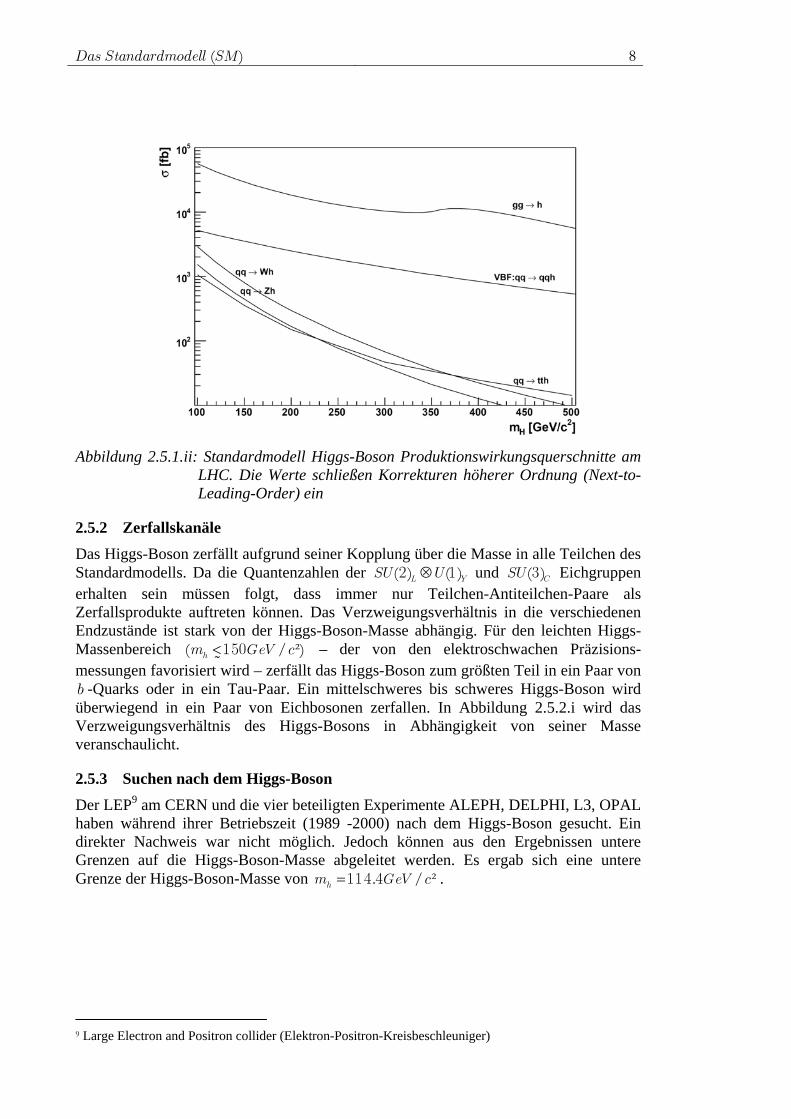
Das Standardmodell (SM) 8
Abbildung 2.5.1.ii: Standardmodell Higgs-Boson Produktionswirkungsquerschnitte am
LHC. Die Werte schließen Korrekturen höherer Ordnung (Next-to-Leading-Order) ein
2.5.2 Zerfallskanäle Das Higgs-Boson zerfällt aufgrund seiner Kopplung über die Masse in alle Teilchen des Standardmodells. Da die Quantenzahlen der L YSU( ) U( )2 ⊗ 1 und CSU( )3 Eichgruppen erhalten sein müssen folgt, dass immer nur Teilchen-Antiteilchen-Paare als Zerfallsprodukte auftreten können. Das Verzweigungsverhältnis in die verschiedenen Endzustände ist stark von der Higgs-Boson-Masse abhängig. Für den leichten Higgs-Massenbereich h(m GeV /c²)<150 – der von den elektroschwachen Präzisions-messungen favorisiert wird – zerfällt das Higgs-Boson zum größten Teil in ein Paar von b -Quarks oder in ein Tau-Paar. Ein mittelschweres bis schweres Higgs-Boson wird überwiegend in ein Paar von Eichbosonen zerfallen. In Abbildung 2.5.2.i wird das Verzweigungsverhältnis des Higgs-Bosons in Abhängigkeit von seiner Masse veranschaulicht.
2.5.3 Suchen nach dem Higgs-Boson Der LEP9 am CERN und die vier beteiligten Experimente ALEPH, DELPHI, L3, OPAL haben während ihrer Betriebszeit (1989 -2000) nach dem Higgs-Boson gesucht. Ein direkter Nachweis war nicht möglich. Jedoch können aus den Ergebnissen untere Grenzen auf die Higgs-Boson-Masse abgeleitet werden. Es ergab sich eine untere Grenze der Higgs-Boson-Masse von hm . GeV /c²=114 4 .
9 Large Electron and Positron collider (Elektron-Positron-Kreisbeschleuniger)
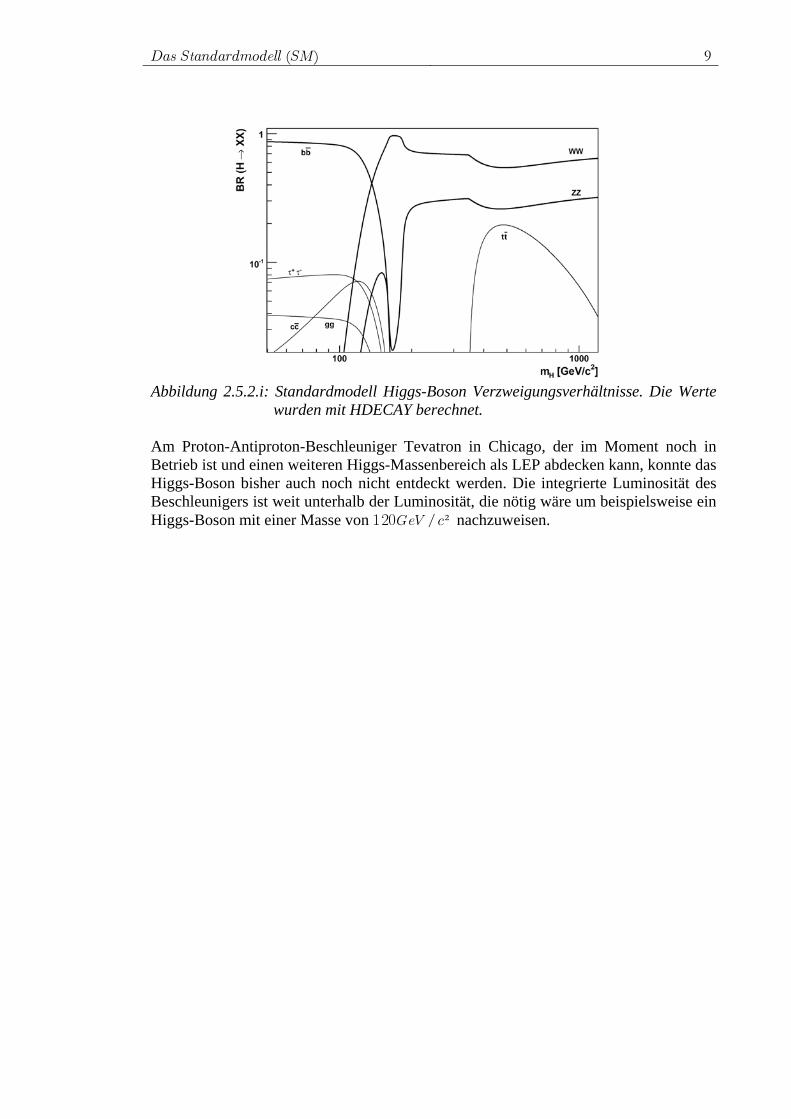
Das Standardmodell (SM) 9
Abbildung 2.5.2.i: Standardmodell Higgs-Boson Verzweigungsverhältnisse. Die Werte
wurden mit HDECAY berechnet. Am Proton-Antiproton-Beschleuniger Tevatron in Chicago, der im Moment noch in Betrieb ist und einen weiteren Higgs-Massenbereich als LEP abdecken kann, konnte das Higgs-Boson bisher auch noch nicht entdeckt werden. Die integrierte Luminosität des Beschleunigers ist weit unterhalb der Luminosität, die nötig wäre um beispielsweise ein Higgs-Boson mit einer Masse von GeV /c²120 nachzuweisen.

Das Standardmodell (SM) 10
Erweiterung des Standardmodells: 11
3 Erweiterung des Standardmodells: Supersymmetrie
Die SUperSYmmetrie ist eine der momentan am meisten untersuchten Erweiterungen des Standardmodells. Sie umgeht elegant viele der Unzulänglichkeiten des Standard-modells: • Hierarchie-Problem und Feinabstimmung: Es ist eine extrem genaue Abstimmung
der Higgsmasse notwendig, damit das Standardmodell eine gültige Theorie für den Energiebereich bis zur Planck-Masse PM GeV /c²19= 10 sein kann. Um Divergenzen in Schleifenkorrekturen der Higgs-Propagatoren zu vermeiden, ist eine Genauigkeit von h Pm / −16Λ =10 zwingend.
• Kopplungskonstanten: An der Planck-Skala wird eine Theorie erwartet, die die
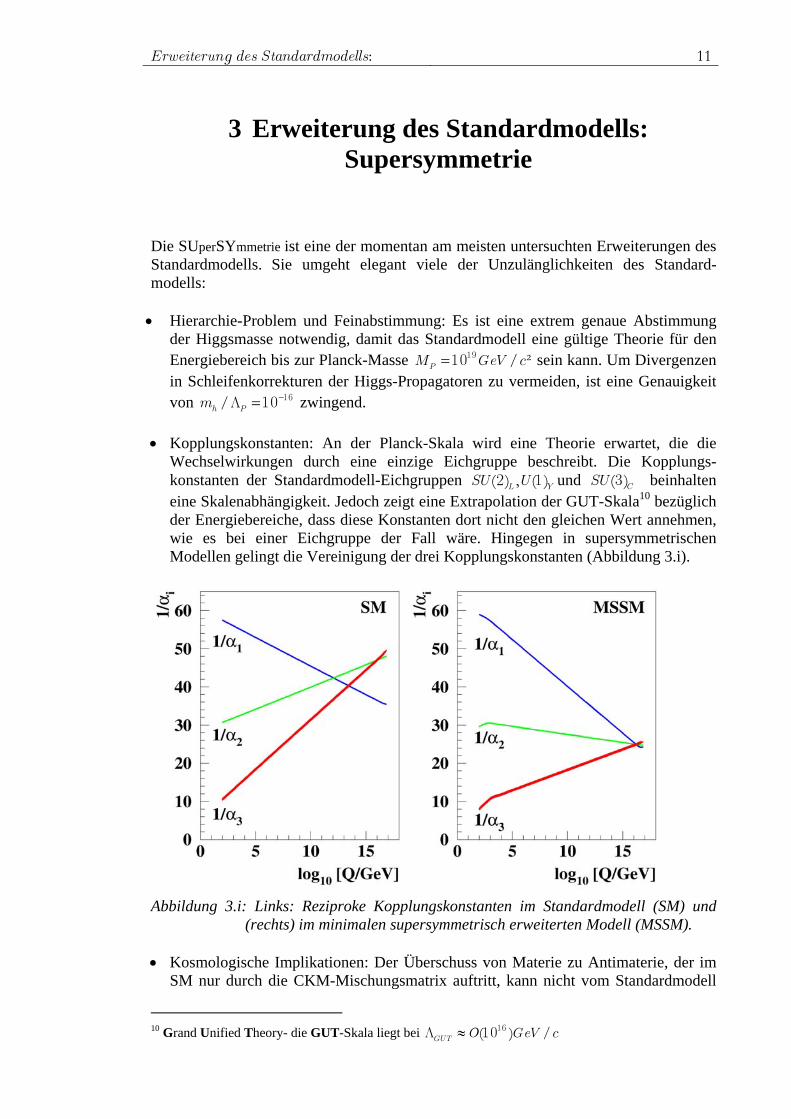
Wechselwirkungen durch eine einzige Eichgruppe beschreibt. Die Kopplungs-konstanten der Standardmodell-Eichgruppen L YSU( ) , U( )2 1 und CSU( )3 beinhalten eine Skalenabhängigkeit. Jedoch zeigt eine Extrapolation der GUT-Skala10 bezüglich der Energiebereiche, dass diese Konstanten dort nicht den gleichen Wert annehmen, wie es bei einer Eichgruppe der Fall wäre. Hingegen in supersymmetrischen Modellen gelingt die Vereinigung der drei Kopplungskonstanten (Abbildung 3.i).
Abbildung 3.i: Links: Reziproke Kopplungskonstanten im Standardmodell (SM) und
(rechts) im minimalen supersymmetrisch erweiterten Modell (MSSM). • Kosmologische Implikationen: Der Überschuss von Materie zu Antimaterie, der im
SM nur durch die CKM-Mischungsmatrix auftritt, kann nicht vom Standardmodell
10 Grand Unified Theory- die GUT-Skala liegt bei GUT O( )GeV / c16Λ ≈ 10

Erweiterung des Standardmodells: 12
erklärt werden. Ebenso wird die kalte dunkle Materie nicht berücksichtigt: aus Rotationsgeschwindigkeiten von Galaxien und Präzisionsmessungen der kosmischen Untergrundstrahlung des WMAP-Experiments ergibt sich eine Abschätzung für dunkle Energie und dunkle Materie zu 95% der Gesamtmasse des Universums. Was bedeutet, dass der Anteil der beobachtbaren Materie, welche das SM erklären kann, bei nur 5% liegt. Das Massenspektrum mancher supersymmetrischer Modelle lässt es zu, das leichteste supersymmetrische Teilchen (LSP)11
(in den meisten Fällen ist dies das Neutralino 0
1χ ) als Kandidat für die kalte dunkle Materie zu interpretieren.
3.1 Das grundlegende Prinzip der Supersymmetrie Zur Auslöschung der Divergenzen, die für das Hierarchieproblem verantwortlich sind, wird jedem Fermion ein bosonischer Partner zugeordnet und analog jedem Boson ein fermionischer, indem für jedes Feld mittels eines supersymmetrischen Operators ein korrespondierendes Feld komplementärer Statistik erzeugt wird: Q |Fermion ⟩ = |Boson ⟩ ,Q |Boson ⟩ = |Fermion ⟩ . In den Beiträgen aus den Schleifen heben sich so die quadratischen Divergenzen auf Grund der verschiedenen Vorzeichen der Bosonen und Fermionen exakt auf. Die Partnerteilchen der Fermionen werden Sleptonen, bzw. Squarks genannt, die Partnerteilchen der Bosonen erhalten das Suffix "ino" zum ursprünglichen bosonischen Namen. Zunächst stimmen die Quantenzahlen sowie die Massen, bis auf die Spinquantenzahl überein. Der Vorteil der Addition von zusätzlichen supersymmetrischen Partnerteilchen ist deren Beeinflussung der Kopplungskonstanten
iα in Bezug auf ihre Skalenabhängigkeit. In supersymmetrischen Modellen kommt es zur Vereinigung der Konstanten iα an der GUT-Skala. Da supersymmetrische Partnerteilchen bei exakter Symmetrie die gleichen Massen besitzen wie ihre Partner im Standardmodell, diese bisher aber noch nicht entdeckt wurden, muss diese Symmetrie gebrochen sein. Die Massen der SUSY-Teilchen müssen höher liegen, da sie durch bisherige Experimente nicht nachgewiesen werden konnten. Dies ergibt sich, falls auch SUSY eine spontan gebrochene Symmetrie ist. Theoretische Argumente zeigen, die Brechungsskala SUSYΛ darf nicht wesentlich größer sein als die elektroschwache Skala selbst, ansonsten kommt es ebenfalls zu einem Problem durch eine Feinabstimmung der Massen. Zugang zur Frage, auf welche Weise Supersymmetrie gebrochen wird, bekommt man auf zwei Arten: Entweder man fügt phänomenologisch jeden einzelnen Brechungsterm in die SUSY-Lagrangedichte ein oder man bindet fundamentale Brechungsmechanismen an der GUT-Skala in die Theorie ein, die SUSY bereits an dieser Stelle brechen. Der bisher populärste Ansatz eines solchen Brechungs-mechanismus ist die Gravitation. Jene Modelle, die die Gravitation für den Ursprung des SUSY-Brechungsmechanismus halten, tragen den Namen SUGRA [24], bzw. mSugra, das weitere Bedingungen an die Art der SUSY-Brechung stellt. Weitere Hochenergiemodelle sind AMSB und GMSB. Da das LSP in diesen Modellen nicht zwingend das Neutralino ist, wird auf diese Modelle in der vorliegenden Arbeit nicht weiter eingegangen.
3.2 MSSM (Minimales Supersymmetrisches Standard-Modell) Unter gewissen Annahmen [25] kann die allgemeine SUSY Lagrangedichte
MSSM SUSY SoftÄ Ä Ä= + konstruiert werden. Für den MSSM Lagrangian bleiben insgesamt 105 freie Parameter übrig. Bei weiteren Annahmen für das SUSY-Modell kann die
11 Lightest Supersummetric Particle

Erweiterung des Standardmodells: 13
Anzahl dieser freien Parameter durch die Erhaltung der R -Parität weiter reduziert werden. Bei der R -Parität handelt es sich um eine zusätzliche Quantenzahl, die von der Baryonenzahl B, der Leptonenzahl L und der Spinquantenzahl s wie folgt abhängt
R nimmt die Werte 1 für SM-Teilchen und -1 für SUSY-Partner an und bleibt in allen Erzeugungs- und Vernichtungsprozessen erhalten. Dass SUSY-Teilchen nur paarweise produziert werden können und das leichteste der supersymmetrischen Teilchen LSP stabil ist, ist die Bedeutung von R . Häufiger Kandidat für die kalte und dunkle Materie, in diesen Modellen, ist das LSP.
Tabelle 3.2.i: Die pMSSM Parameter. Die Liste repräsentiert den reduzierten
Parametersatz unter den im Abschnitt3.2.2 aufgelisteten Bedingungen. • Kein Mischen zwischen den Generationen. Man nimmt an, es gäbe keine Analogie
zur CKM-Mischungsmatrix des Standardmodells, sodass sich Squarks und Sleptonen zwischen den Generation nicht mischen.
• Keine neue Quelle der CP-verletzenden MSSMÄ -Terme. Dies führt zu reellen Werten
aller SUSY-Brechungsparameter. • Keine FCNC-Ströme12. Hierfür müssen die Massenmatrizen in führender Ordnung
der ersten zwei Sfermiongenerationen sowie die der trilinearen Kopplungsparameter diagonal sein.
Als Bezeichnung für dieses Modell findet sich in der Literatur auch pMSSM13. Aufgelistet sind die verbleibenden 24 Parameter sowie ihre Bedeutung in Tabelle 3.2.i.
12 Flavour Changing Neutral Current 13 phenomenological MSSM

Erweiterung des Standardmodells: 14
3.3 Massenspektren von SUSY-Teilchen Die SUSY-Partnerteilchen der SM-Teilchen bilden keine reinen Masseneigenzustände, sondern mischen untereinander. Aus reinen Flavoureigenzuständen der Eichgruppe
L YSU( ) U( )2 ⊗ 1 ergeben sich dann, durch Kombination über die jeweiligen Massen-matrizen, die physikalischen Masseneigenzustände. Sfermionen: Die drei Massenmatrizen für die Sfermionen der dritten Generation sind:
mit W Ws sin ² .2 = θ Die Massenmatrizen der ersten zwei Generationen sind äquivalent, doch werden, da diese proportional zu den Standardmodellfermionmassen zu denen der jeweiligen Generation sind, die nichtdiagonalen Elemente vernachlässigt. Analog zum Standardmodell setzen sich die Sneutrinos nur aus linkshändigen Feldern zusammen:
Gauginos: Die Masseneigenzustände der Charginos und Neutralinos bilden sich aus den reinen Flavoureigenzuständen der Winos W± , Higgsinos ,H1 2 , H± , und der Binos B . So
mischen die Winos W± und geladenen Higgsinos H± zu den Charginos. Und wie folgt verknüpft die Massenmatrix beiden Zustände:
Die Massen der zwei Charginos liefern die Eigenwerte der Mischungsmatrix. Neutralinos: Die Neutralinos entsprechen Masseneigenzustände der neutralen Teilchen B, W , H H3 0 0
1 2 und werden für diese Basis durch die Massenmatrix Y verknüpft:

Erweiterung des Standardmodells: 15
mit den Abkürzungen c cosβ = β und W Wc cos= θ . Die Massen der Neutralinos ergeben dann die Eigenwerte der Mischungsmatrix. Für den Grenzfall großer Massen
iZm m0χ
werden die Neutralinos durch die reinen Masseneigenzustände
und die Massen |M |1 , |M |2 , | |μ , Z|m |beschrieben. Da Neutralinos ebenso wie das Z-Boson Majorana-Teilchen sind, bilden sie ihre eigenen Antiteilchen. Gluino: In der niedrigsten Ordnung ergibt der Gluino-Massenparameter direkt die Gluinomasse:
In SUSY- Szenarien, in denen Gravitation und Eichbosonen die Symmetriebrechung vermitteln, ist das Gluino für gewöhnlich erheblich schwerer als die leichten Charginos und Neutralinos.
3.4 Higgs-Sektor im MSSM Im MSSM besteht der Higgs-Sektor aus zwei Dubletts
mit den Vakuumerwartungswerten (0; 1υ ); ( 2υ ; 0). Das gesamte Higgs-Potential ist gegeben durch
mit H im | |² m2 21 = μ + und den Kopplungskonstanten g,g′ Die Massenparameter
H Am , m , m1 2 12 sind mit den Parametern Am und tanβ über
verknüpft. Durch die Parameter Am und tanβ wird der gesamte Higgs-Sektor in niedrigster Ordnung vollständig beschrieben. In supersymmetrischen Modellen finden spontane Symmetriebrechungen des Higgs-Feldes statt. Masse der Higgs-Bosonen: Durch einen Mischungswinkel α werden, analog zu den Massen der Sfermionen die Masseneigenzustände der Higgs-Bosonen mit den Flavoureigenzuständen verknüpft:

Erweiterung des Standardmodells: 16
Ein zusätzliches physikalisches Higgs-Boson A ergibt sich durch die Verwendung von zwei Dubletts. Im Gegensatz zu h und H ist A ungerade unter CP-Transformationen. Auf Born-Niveau schreiben sich die Higgs-Boson-Massen14 als:
Darüber hinaus entstehen zwei weitere geladene Higgs-Bosonen H± mit den Massen
H W Am m m2 2± = + . Aus Gleichung .3 22 ist ersichtlich, dass h Zm m≤ gelten muss.
Insbesondere durch Schleifenbeiträge der top-Quarks und stop-Quarks wird, bei Korrekturen höherer Ordnung, die Higgsmasse stark angehoben. Es ist nun nicht mehr möglich den Higgs-Sektor allein durch Am und tanβ zu beschreiben. Die wichtigsten Parameter, die in die Next-to-Leading-Order Korrektur eingehen, sind: • SUSYM : die allgemeine SUSY-Brechungsskala (O(1TeV )). • μ :der Higgsino-Mischungsparameter. • M2 : der SU(2) Gaugino- (Wino-) Massenparameter. Gewöhnlich wird der U(1)-
Gaugino- (Bino-) Massenparameter über die GUT-Relation
Wtan1 2 25 1
Μ = θ Μ ≈ Μ3 2
berechnet.
• gm : die Gluino-Masse. Zerfallskanäle des supersymmetrischen Higgs-Bosons Es eröffnen sich neue Möglichkeiten der Higgs-Boson-Zerfälle durch das Vorhandensein von supersymmetrischen Teilchen. Zur Diskussion sollen im Folgenden nur die Zerfälle des leichtesten Higgs-Bosons h stehen. Zerfälle in Sfermionen Zerfälle der Art i jh ff→ sind auf Grund der experimentellen unteren Grenzen von LEP und Tevatron für die Massen von Sfermionen kinematisch weitestgehend ausgeschlossen[25]. Zerfälle in Charginos und Neutralinos Auf Born-Niveau ist die partielle Zerfallsbreite des leichten Higgs-Bosons in Charginos und Neutralinos gegeben durch[25]
14 Konventionell wird Am als einer Eingangsparameter des Modells betrachtet

Erweiterung des Standardmodells: 17
mit iε = ±1 , dem Vorzeichen des i-ten Eigenwertes der Neutralinomischungsmatrix Y , und ijhλ , der üblichen Zweikörperphasenraumfunktion definiert durch:
Die Kopplungen LR
ijhg werden im Folgenden explizit nur für die Neutralinos gegeben:
Die Neutralinomischungsmatrix Y aus Gleichung .3 13 wird durch die Matrix Z diagonalisiert, in voller Länge ist sie in [2] gegeben. Die Einträge Z Z11 12− stellen den Gaugino-Anteil der Kopplung, Z Z13 14− den Higgsino-Anteil der Kopplung dar. Die Kopplung des Higgs-Boson verschwindet an das Neutralino, für den Fall, dass das Neutralino i
0χ ein reiner Gaugino- oder Higgsino-Zustand ist. Für die Charginos gilt allgemein die gleiche Aussage. Ebenso kann die Higgskopplung an die Gauginos zufällig verschwinden für bestimmte Kombinationen von tanβ und α . Das Higgs-Boson koppelt demnach nur an Gaugino-Higgsino-Mischungen.
3.5 GUT-Theorien→ constraint MSSM
Annahmen über CP-Verletzung und flavourverändernde neutrale Ströme reduzieren den Parameterraum des allgemeinen MSSM enorm, wie in Abschnitt . .3 2 2 gezeigt. Fordert man das MSSM als Teil einer GUT-Theorie ist, sind weitere Vereinfachungen der SUSY Modelle möglich. So ist es natürlich anzunehmen, dass bei der GUT-Skala nicht nur die Kopplungskonstanten den gleichen Wert annehmen, sondern auch die Massen könnten auf diese Weise aus einer universellen Masse hervorgehen. Das so genannte constraint MSSM (cMSSM) führt folgende Bedingungen ein: • Universelle Gaugino-Masse: /m M M M1 2 1 2 3= = = . • Universelle Sfermion-Masse: m2
0 und Massenmatrizen diagonal. Die Vereinigung der Massen durch den Higgs-Sektor und die Vereinigung der Kopplungskonstanten ist ebenfalls möglich: • Universelle skalare Masse H Hm m m2 2 2
0 1 2= = • Universelle trilineare Kopplungen: t b u eA A A A A A0 τ= = = = = . mSugra Ein Modell, das alle diese Bedingungen beinhaltet ist mSugra. Die Gravitation bewirkt die Brechung der Supersymmetrie, die auf der GUT-Skala als eine lokale Symmetrie in die L Y CSU( ) U( ) SU( )2 ⊗ 1 ⊗ 3 Eichgruppe eingebunden ist. Hiermit bietet mSugra eine Möglichkeit, die Gravitation als letzte der vier bekannten Kräfte in das Modell zu integrieren. In mSugra vereinigen sich Kopplungskonstanten, Massen und trilineare Kopplungen an der GUT-Skala, womit der Parametersatz von 105 unabhängigen auf 4 kontinuierliche Parameter /(m , m , A , tan )1 2 0 0 β und ein Vorzeichen ( )μ = ±1 reduziert wird. Auf Grund des überschaubaren Parameterbereiches bildet mSugra daher für viele Physikstudien das Grundlagenmodell.

Erweiterung des Standardmodells: 18

LHC und CMS 19
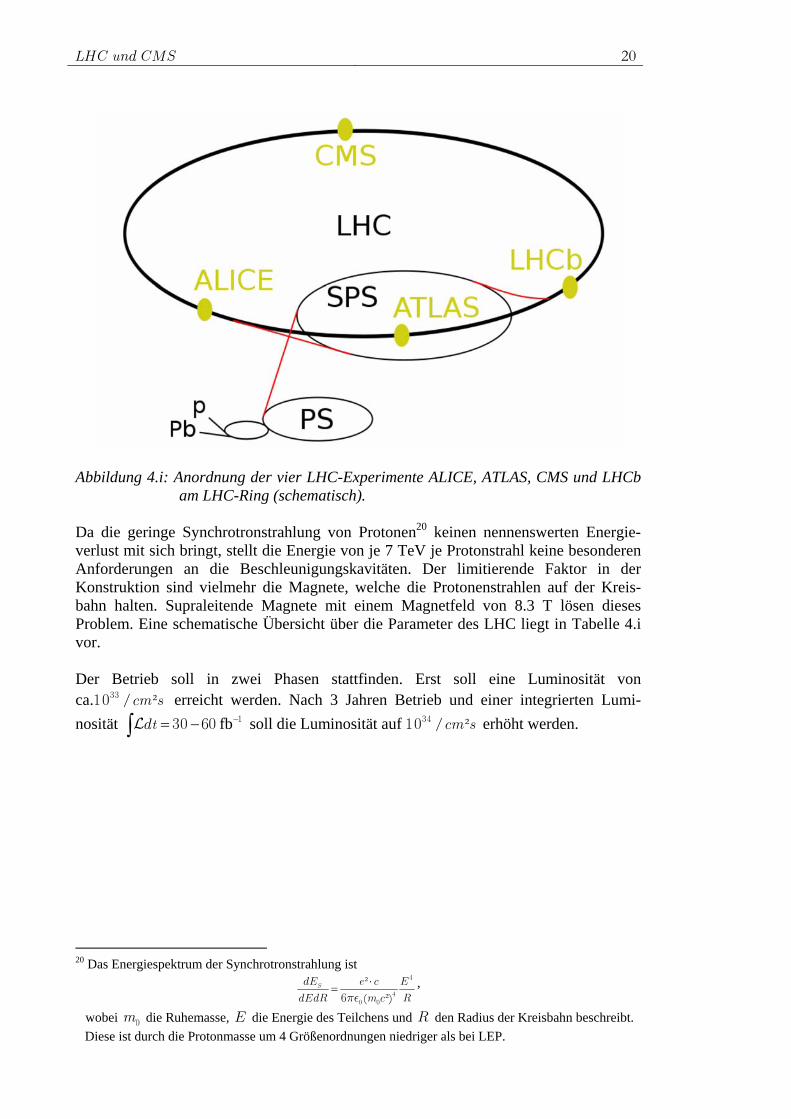
4 LHC und CMS In den vorhandenen Tunnel des LEP15-Speicherrings wird am europäischen Forschungszentrum CERN16 in Genf (Schweiz) der Large Hadron Collider (LHC) in installiert. Protonen- und Schwerionenkollisionen sollen dort untersucht werden. Geplant sind insgesamt vier Wechselwirkungspunkte. Abbildung 4.i zeigt eine schematische Übersicht der Experimente und des Ringbeschleunigers. Für den Proton-Proton-Betrieb existieren die Multifunktionsdetektoren ATLAS17 und CMS18. Während ALICE19 für Kollisionen von schweren Ionen ausgelegt ist und Aufschluss über das Verhalten von Kernbausteinen bei sehr hohen Dichten und Temperaturen geben (Untersuchungen zum Quark-Gluon-Plasma) soll, wird mit dem Experiment LHCb speziell b-Physik, sowie die Phänomenologie der CP-Verletzung untersucht. Die Fertigstellung des LHC-Beschleunigers ist für Mai 2008 geplant, der Beginn der Experimente ist zurzeit für Juni 2008 vorgesehen. Da sich aber alles bei CMS in den letzten Jahren immer wieder verzögert hat, obwohl man Zeiträume vorgegeben hatte, ist Herbst 2008 wohl wahrscheinlicher. Die Eigenschaften des LHC-Beschleunigers im Proton-Proton-Betrieb und der Aufbau des CMS-Detektors sollen im Folgenden beschrieben werden.
4.1 Der Proton-Proton-Speicherring LHC Etwa 10 km von Genf entfernt liegt der Proton-Proton-Speicherring LHC in einer Tiefe von 100 m. Die Tiefe ist für die Messung jedoch ohne Belang. Ab dieser Tiefe beginnt einfach erst der stabile Fels. Geplant ist für den Speicherring eine Schwerpunktsenergie von 14 TeV und eine Luminosität von / cm²s3410 . Die Luminosität L ist definiert als
wobei pN die Anzahl der Protonen pro Paket („Bunch“) ist, BN die Anzahl der Protonenbunche, c die Lichtgeschwindigkeit, eff x yA = 4πσ σ die effektive Querschnitts-fläche der Bunche (mit x,yσ als Strahlbreite) und U der Ringumfang.
15 Large Electron-Positron Collider 16 frz.: Conseil Europeen pour la Recherche Nucleaire 17 A Toroidal LHC ApparatuS 18 Compact Muon Solenoid 19 A Large Ion Collider Experiment
LHC und CMS 20
Abbildung 4.i: Anordnung der vier LHC-Experimente ALICE, ATLAS, CMS und LHCb am LHC-Ring (schematisch).
Da die geringe Synchrotronstrahlung von Protonen20 keinen nennenswerten Energie-verlust mit sich bringt, stellt die Energie von je 7 TeV je Protonstrahl keine besonderen Anforderungen an die Beschleunigungskavitäten. Der limitierende Faktor in der Konstruktion sind vielmehr die Magnete, welche die Protonenstrahlen auf der Kreis-bahn halten. Supraleitende Magnete mit einem Magnetfeld von 8.3 T lösen dieses Problem. Eine schematische Übersicht über die Parameter des LHC liegt in Tabelle 4.i vor. Der Betrieb soll in zwei Phasen stattfinden. Erst soll eine Luminosität von ca. / cm²s3310 erreicht werden. Nach 3 Jahren Betrieb und einer integrierten Lumi-nosität fbÄdt −1= 30−60∫ soll die Luminosität auf / cm²s3410 erhöht werden.
20 Das Energiespektrum der Synchrotronstrahlung ist
SdE e² c EdEdR (m c²) R
4
40 0
⋅=6πε
,
wobei m0 die Ruhemasse, E die Energie des Teilchens und R den Radius der Kreisbahn beschreibt. Diese ist durch die Protonmasse um 4 Größenordnungen niedriger als bei LEP.
LHC und CMS 21
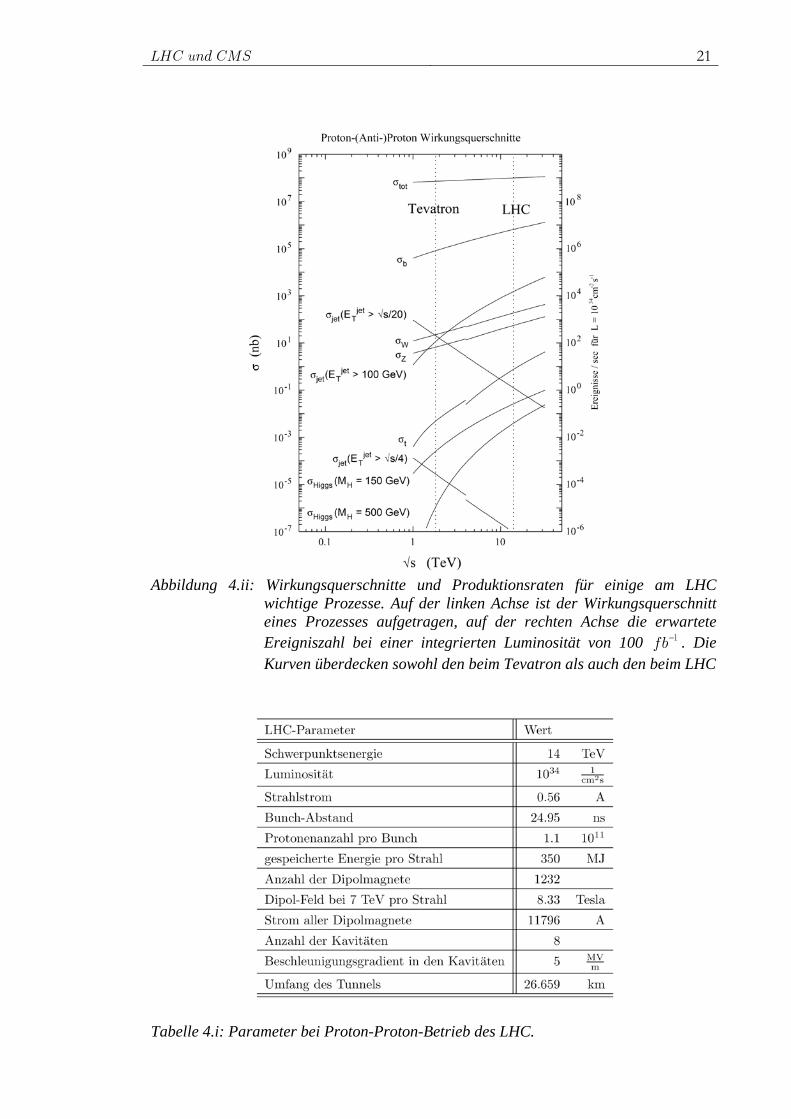
Abbildung 4.ii: Wirkungsquerschnitte und Produktionsraten für einige am LHC
wichtige Prozesse. Auf der linken Achse ist der Wirkungsquerschnitt eines Prozesses aufgetragen, auf der rechten Achse die erwartete Ereigniszahl bei einer integrierten Luminosität von 100 fb−1 . Die Kurven überdecken sowohl den beim Tevatron als auch den beim LHC
Tabelle 4.i: Parameter bei Proton-Proton-Betrieb des LHC.

LHC und CMS 22
4.2 Das CMS-Experiment
Der CMS-Detektor ist ein Teilchendetektor. Um möglichst alle zu erwartenden Phänomene messen zu können, ergibt sich folgende Konstruktion des Detektors: • Kalorimetrie: Eine gute Energieauflösung und Raumwinkelabdeckung für
Elektronen und Photonen, ergänzt durch eine präzise und hermetische Messung hadronischer Schauer und fehlender transversaler Energie.
• Myonsystem: Die Möglichkeit, Myonimpulse mit Hilfe des Myonsystems auch bei hohen Luminositäten gut messen zu können.
• Spurrekonstruktion: Präzise Impulsmessung und Identifikation von Leptonen. Weiterhin Möglichkeit der Bestimmung der primären Vertexposition und eventueller Sekundärvertizes, die insbesondere bei der Rekonstruktion von Tau-Leptonen und b-Quarks von Bedeutung sind.
• Trigger: Flexibles und schnelles Triggersystem zur Selektion der physikalisch interessanten Ereignisse.
Das Gesamtgewicht des CMS-Detektors liegt bei ca. 12,5 Kilotonnen, was der doppelten Masse von ATLAS entspricht, obwohl ATLAS das achtfache Volumen besitzt. Im Zentrum des zylinderförmigen Detektors, mit einer Länge von 21m und einem Durchmesser von 15m, treffen Protonenpaare, die entlang der Strahlachse zum Wechselwirkungspunkt des Detektors gelangen, mit einer Schwerpunktsenergie von 14TeV aufeinander. Die Detektorkomponenten sind kreisförmig um die Strahlachse angeordnet. In Abbildung 4.2.i ist ein Querschnitt des Detektors zu sehen.
Abbildung 4.2.i: Der CMS-Detektor und die einzelnen Detektorkomponenten. Als Erste der Komponenten ist der Siliziumspurdetektor um die Strahlachse angeordnet. Hinter dieser Schicht erstrecken sich das elektromagnetische Kalorimeter (ECAL) und das hadronische Kalorimeter (HCAL). Dann folgt die 4-Tesla-Magnetspule. Sie umschließt den Detektor. Die äußerste Detektorkomponente besteht aus Myonen-kammern.

LHC und CMS 23
4.2.1 Elektromagnetisches Kalorimeter Die meisten elektroschwachen Zerfallsprozesse enthalten Elektronen bzw. Photonen im Endzustand. Eine gute Identifikation und präzise Messung ist über ein hochauflösendes elektromagnetisches Kalorimeter möglich. Das elektromagnetische Kalorimeter (ECAL) ist aus 75 848 PbWO4 −Kristallen aufgebaut. Sie werden aufgrund ihrer exzellenten Energieauflösung, ihrer hohen Dichte (8,3 g/cm³ ) und der geringen Strahlungslänge benutzt. Somit lässt sich das Kalorimeter sehr kompakt gestalten und innerhalb der Magnetspule in die Detektorstruktur einfügen. Elektromagnetisch wechselwirkende Teilchen lösen in den Kristallen elektro-magnetische Schauer aus. Die Intensität des entstehenden Fluoreszenzlicht dieser Schauer wird als Indikator für die Energie der Teilchen benutzt.
4.2.2 Hadronisches Kalorimeter Der Fragmentierungs- und Hadronisationsprozess erzeugt viele einzelne Hadronen, die zusammen als Jets auftreten. Weil die Hadronen im Detektor über die starke Wechselwirkung ihre Energie deponieren, ist ihre Schauerlänge um ein Vielfaches größer als die der Elektronen/Photonen. Deshalb reicht das elektromagnetische Kalorimeter alleine nicht aus um die Hadronen messen zu können. Ein zusätzliches Kalorimeter mit vielfach größerer Wechselwirkungslänge für Hadronen schließt sich deshalb dem elektromagnetischen Kalorimeter an. Beim hadronische Kalorimeter wechseln passive und aktive Lagen einander ab. Er besteht abwechselnd aus Szintillatormaterial und Kupferabsorberschichten. Durch Wechselwirkung der Hadronen mit den Kupferkernen bilden sich hadronische Schauer aus. Über die in den Szintillatorschichten freigesetzten Photonen lässt sich die Energie der Hadronen bestimmen.
4.2.3 Myonsystem
Reine und zuverlässige Indikatoren interessanter physikalischer Prozesse können hochenergetische Myonen sein. Hinter dem hadronischen Kalorimeter existiert deshalb ein Myonsystem, um diese zu detektieren. Die Struktur besteht abwechselnd aus Myonkammern und Eisenplatten. Die Eisenplatten werden zur Abschirmung und zur Rückführung des Magnetsfeldes benötigt, das in dem Bereich der Myonkammern noch eine Stärke von 2T aufweist. Die Kammern sind aus gasgefüllten Teilchendetektoren aufgebaut. Das Myonsystem besteht aus drei verschiedenen Komponenten: den Driftröhren (DTs21), den Endkappenkathodenstreifenkammern (CSCs22) (beide dienen zur Identifizierung der Myonen und zur Bestimmung deren Ladung und Impuls) und den RPCs23. Alle drei sind zur Bestimmung und der Messung der zugehörigen Ereignisse gedacht, wobei die RPCs eine sehr exakte Auflösung haben. Daher werden sie unter anderem auch zum Triggern in den Endkappen benötigt.
4.2.4 Spurdetektor Ein Spurdetektor, der konzentrisch um die Strahlachse geordnet ist, ermöglicht die Rekonstruktion der durch das Magnetfeld gekrümmten Flugbahn der Teilchen und dann deren Impulsmessung. Mit Hilfe des Spurdetektors ist es außerdem möglich, rekon-struierte Spuren den Energiedepositionen im Kalorimeter oder Spursegmenten in den
21 barrel drift tube chamber 22 end cap cathode strip chamber 23 resistive plate chamber

LHC und CMS 24
Myonkammern zuzuordnen und somit aus dem Verhältnis E / p die Identität des Teilchens zu bestimmen. Der Siliziumdetektor ist aus Pixel- und Streifendetektoren auf-gebaut. • Der Pixeldetektor: Er bildet die am dichtesten zum Strahlrohr angeordnete Kom-
ponente und besteht aus insgesamt drei Lagen, die jeweils konzentrisch um das Strahlrohr angeordnet sind. Die Größe eines Pixels beträgt m²150⋅150μ . Die Pixel tragen zu einer hohen Ortsauflösung innerhalb einer Lage bei und erlauben eine Auflösung der Spurbestimmung von 15 mμ .
• Der Streifendetektor : Die Streifendetektoren unterteilen sich in einen inneren, aus vier Lagen aufgebauten, und einen äußeren, aus sechs Lagen bestehenden Ring und verbessern die Spurrekonstruktion der den Detektor durchquerenden Teilchen. Im Vergleich zu den Pixeldetektoren, die dreidimensionale Daten liefern, erlaubt die Struktur der Streifendetektoren nur eine zweidimensionale Datennahme.
4.2.5 Triggersystem
Die Zeit zwischen den Kollisionen zweier aufeinander folgender Teilchenpakete ("Bunchcrossing“) beträgt für den LHC ns≈ 25 . Diese Ereignisrate von 40 MHz ist zu groß, um jede Kollision individuell auslesen und speichern zu können. Andererseits sind die Wirkungsquerschnitte physikalisch interessanter Prozesse sehr klein, so dass nicht in jeder Kollision interessante Ereignisse zu erwarten sind. Man benötigt daher ein System, welches seltene und viel versprechende Ereignisse selektiert. Dieses Verfahren wird im Triggersystem realisiert.
4.2.6 Zusätzliche Eigenschaften Viele physikalische Prozesse haben im Endzustand Neutrinos oder eventuell neue Teilchen, die ohne Wechselwirkung den Detektor durchdringen und nicht nachgewiesen werden können. Dies beeinflusst die transversale Impulsbilanz des Ereignisses. Fehlende transversale Energie ist die Folge. Um möglichst alle wechselwirkenden Teilchen einer Kollision in die transversale Impulsbilanz summieren zu können, sollte der Detektor fast hermetisch sein.

Statistische Methoden 25
5 Statistische Methoden Experimente sind immer mit einer Unsicherheit verbunden, d.h. sie sind nicht völlig vorhersagbar. Zum einen gibt es eine Unsicherheit im Messprozess selbst, die zu Fehlmessungen führen kann. Außerdem gibt es den statistischen Charakter von physikalischen Prozessen. Mit Hilfe von statistischen Methoden kann man ihn für sich nutzbar machen, sofern man genug Ereignisse hat. Im Folgenden wird ein kurzer Überblick über die Statistik gegeben und es werden verschiedene statistische Methoden vorgestellt.
5.1 Grundlagen: einzelne Variable
5.1.1 Erwartungswert und Standardabweichung
Der Erwartungswert μ ist der Mittelwert, der sich nach mehrmaligem Wiederholen eines Experiments ergibt. Eine Funktion g(x) mit x als Zufallsvariable und Wahrscheinlichkeitsdichte f(x) hat den Erwartungswert:
(x) g(x)f(x)dx+∞
−∞μ = ∫ ( . )5 1
Entsprechend gilt für den Erwartungswert eines Zufallexperiments:
n
i ii
E(X) x P(X x )=1
= μ = =∑ ( .5 2 )
X ist eine diskrete Zufallsvariable und kann alle Werte von ix annehmen, i steht für das i -te Ereignis, n für Anzahl der Ereignisse. P ist die Wahrscheinlichkeit. Falls alle Ereignisse die gleiche Wahrscheinlichkeit aufweisen, gilt:
n
ii
xn =1
1μ = ∑ ( .5 3)
Die Standardabweichung σ gibt einen Bereich an, in dem das zu erwartende Ereignis mit hoher Wahrscheinlichkeit um den Erwartungswert liegt:
n
ii
(x )n
2
=1
1σ = −μ∑ ( .5 4 )
5.1.2 Von der Binomial- über die Poisson- zur Gleichverteilung Binomial-Verteilungen (Bernoulli-Verteilungen) treten auf, wenn man die betrachteten Ereignisse in zwei Klassen aufteilt mit den Wahrscheinlichkeiten p und ( p)1− . Die Wahrscheinlichkeit, dass bei n Ereignissen genau k mal das Ereignis mit der Wahrscheinlichkeit p eintrifft, ist:
k n knP(k) p ( p)
k−⎛ ⎞
= ⋅ ⋅ 1−⎜ ⎟⎝ ⎠
( .5 5 )
Es gilt für (p )npσ = −1 und für npμ = . Die natürliche Erweiterung der Binominal-Verteilung ist die Multinominal-Verteilung. Hier betrachten wir statt 2, l Klassen mit l verschiedenen Wahrscheinlichkeiten jp .
Statistische Methoden 26
Dann ist die Wahrscheinlichkeit P bei n Ereignissen, wobei das Ereignis mit der Wahrscheinlichkeit p1 , k1 -mal eintritt, das Ereignis mit der Wahrscheinlichkeit p2 , k2 -mal eintritt usw.
jkl
jl
j j
pP(k , , k ) n !
k !1=1
= ∏… wobei l
jj
k n=1
=∑ ( .5 6 )
Der Grenzfall einer Binomialverteilung mit einer sehr großen Zahl von möglichen Ereignissen, die aber jeweils eine sehr kleine Wahrscheinlichkeit haben, führt zu der Poisson-Verteilung:
k
P(k) ek!
−λμ= ⋅ ( .5 7 )
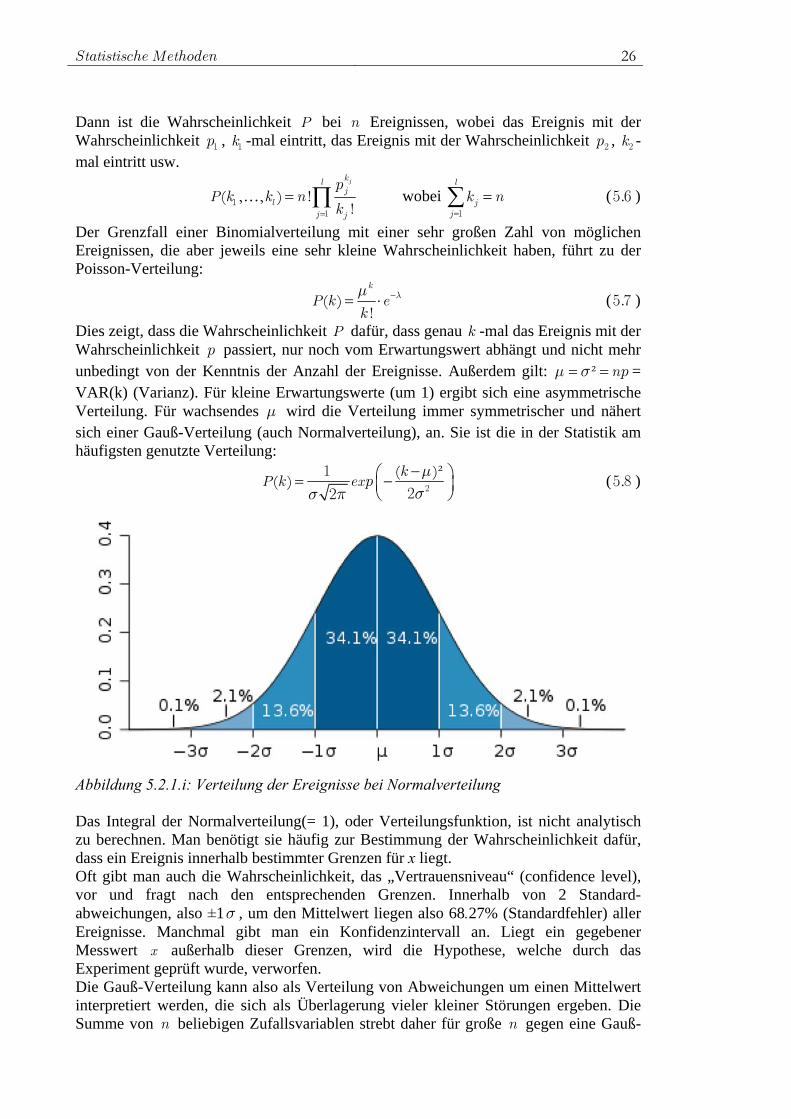
Dies zeigt, dass die Wahrscheinlichkeit P dafür, dass genau k -mal das Ereignis mit der Wahrscheinlichkeit p passiert, nur noch vom Erwartungswert abhängt und nicht mehr unbedingt von der Kenntnis der Anzahl der Ereignisse. Außerdem gilt: ² npμ = σ = = VAR(k) (Varianz). Für kleine Erwartungswerte (um 1) ergibt sich eine asymmetrische Verteilung. Für wachsendes μ wird die Verteilung immer symmetrischer und nähert sich einer Gauß-Verteilung (auch Normalverteilung), an. Sie ist die in der Statistik am häufigsten genutzte Verteilung:
(k )²P(k) exp 2
1 −μ⎛ ⎞= −⎜ ⎟2σσ 2π ⎝ ⎠ ( .5 8 )
Abbildung 5.2.1.i: Verteilung der Ereignisse bei Normalverteilung Das Integral der Normalverteilung(= 1), oder Verteilungsfunktion, ist nicht analytisch zu berechnen. Man benötigt sie häufig zur Bestimmung der Wahrscheinlichkeit dafür, dass ein Ereignis innerhalb bestimmter Grenzen für x liegt. Oft gibt man auch die Wahrscheinlichkeit, das „Vertrauensniveau“ (confidence level), vor und fragt nach den entsprechenden Grenzen. Innerhalb von 2 Standard-abweichungen, also ±1σ , um den Mittelwert liegen also 68.27% (Standardfehler) aller Ereignisse. Manchmal gibt man ein Konfidenzintervall an. Liegt ein gegebener Messwert x außerhalb dieser Grenzen, wird die Hypothese, welche durch das Experiment geprüft wurde, verworfen. Die Gauß-Verteilung kann also als Verteilung von Abweichungen um einen Mittelwert interpretiert werden, die sich als Überlagerung vieler kleiner Störungen ergeben. Die Summe von n beliebigen Zufallsvariablen strebt daher für große n gegen eine Gauß-

Statistische Methoden 27
Verteilung und ihre jeweiligen Erwartungswerte können addiert werden, um den neuen zu erhalten. Dies gilt auch für die Varianz (zentraler Grenzwertsatz).
5.1.3 Momente
Die Momente einer Verteilung sind durch die Erwartungswerte von x und (x )−μ gegeben: n
nu E(x )′ = n -tes algebraisches Moment ( .5 9) n
nu E((x ) )= −μ n -tes zentrales Moment ( .5 10 ) Daraus folgt: u1′= μ und u2 = σ ².24
5.1.4 verschiedener Verteilungen
Tabelle 5.1.4.i:Die wichtigsten Verteilungen im Überblick
5.2 Grundlagen: mehrere Variablen
5.2.1 Verteilungsfunktion und Schnitte im n-dim. Raum
Werden n Zufallsvariablen nx , , x1 … betrachtet, die in einem n -Tupel T
nx (x , , x )1= … ( .5 11) zusammenfasst werden, ergibt dies mit der Wahrscheinlichkeitsdichte f(x ) aus dem Integral über den n -dimensionalen Raum Ω die Verteilungsfunktion25
n
nx x
F(x ) ... dx dx ...dx1=−∞ =−∞
+∞ +∞
1 2= =1∫ ∫ ( .5 12 )
Die Randverteilung einer Variablen ix ist die Projektion der Wahrscheinlichkeit auf die i -te Koordinate, das heißt man betrachtet die Verteilung von ix gemittelt über alle anderen Variablen. Zum Beispiel ist die Randverteilung von x1 :
nh (x ) dx dx ... dx f(x )+∞ +∞ +∞
1 1 2 3−∞ −∞ −∞
= ∫ ∫ ∫ ( .5 13 )
24 Man kann auch die Wahrscheinlichkeitsdichte nach Momenten entwickeln. 25 analog zum 1-dimensionalen Fall

Statistische Methoden 28
Sollen die Wahrscheinlichkeitsdichten unter der Bedingung betrachtet werden, dass eine der Variablen einen bestimmten Wert hat, zum Beispiel x x1 5= , erhält man
nn
f(x x , x , ...x )f(x , x , ...x |x x )
h (x x )1 5 2
2 3 1 51 1 5
== =
= ( .5 14 )
Das ist eine Umnormierung der Wahrscheinlichkeitsdichte auf eine eindimensionale Hyperfläche, die durch (x x )1 5= festgelegt ist. In der Praxis wird meistens ein endliches Intervall L R[x , x ] vorgegeben und die Wahrscheinlichkeitsdichte für nx , x , ..., x2 3 muss auf diesen beschränkten n–dimensionalen Unterraum umnormiert werden.
R
L
R
L
x
nxn L R x
x
f(x x , x , ...x )dxf(x , x , ...x |x x x )
h (x x )dx
1 5 2 1
2 3 1
1 1 5 1
=< < =
=
∫∫
( .5 15 )
Diese Einschränkungen von Variablenbereichen ist bei multi-dimensionalen Datensätzen ein Standardverfahren zur Bereinigung der Daten von Untergrund und zur Untersuchung von Abhängigkeiten der Variablen untereinander. Häufig wird versucht Signale, die auf einem Untergrund sitzen, dadurch statistisch signifikanter zu machen, dass Bereiche, die einen relativ hohen Untergrundbeitrag liefern, weg geschnitten werden (Selektionsschnitte).
5.2.2 μ , Varianz und Momente im n-dimensionalen Raum
Der Erwartungswert μ oder E und die Varianz V von einer Funktion g(x ) und die Momente sind analog zum 1-dim. Fall definiert: nE(g(x )) g(x ) g(x )f(x )dx dx ...dx1 2
Ω
= ⟨ ⟩ = ∫ ( .5 16 )
nV(g(x )) E((g(x ) E(g(x ))² g(x ) (g(x ) g(x ) )²f(x )dx dx ...dx1 2Ω
= − = ⟨ ⟩ = − < >∫ ( .5 17 )
wobei f(x )wieder die Wahrscheinlichkeitsdichte ist. Das Moment um den Ursprung ist n
n
l l ll l ... l nu (x ) E(x x ... x )1 2
1 2 1 2′ = ⋅ ⋅ ⋅ ( .5 18 ) und das zentrale Moment ( )n
n
l l ll l ... l n nu (x ) E (x ) (x ) ... (x )1 2
1 2 1 1 2 2= −μ ⋅ −μ ⋅ ⋅ −μ ( .5 19 ) wobei iμ der Mittelwert oder Erwartungswert von ix ist: i i nx f(x )dx dx ...dx1 2
Ω
μ = ∫ ( .5 20 )
5.3 Kovarianzmatrix und Korrelationen
5.3.1 Definition der Kovarianzmatrix
Die Momente nl l ... lu
1 2( .5 19 ) mit il und jl ; kl = 0 für k i, k j≠ ≠ oder
i kl ; l= 2 = 0 für i j= und k i≠ werden in einer so genannten Kovarianzmatrix ijV zusammengefasst.
ij jiV V= für i j= ergibt sich die Varianz von ix : ii i i i i iV E((x )²) E(x ) (E(x ))2 2 2= −μ = − = σ ( .5 21)

Statistische Methoden 29
Für die nichtdiagonalen Elemente, i j≠ , ergeben sich die Kovarianzen: ij i j i i j j i j i jV cov(x , x ) E((x )(x )) E(x x ) E(x )E(x )= = −μ −μ = − ( .5 22 )
5.3.2 Korrelationen
Wenn die Zufallsgrößen ix unabhängig sind, kann die Wahrscheinlichkeitsdichte von x als Produkt der Wahrscheinlichkeitsdichten der einzelnen ix geschrieben werden: n nf(x ) f (x ) f (x ) ... f (x )1 1 2 2= ⋅ ⋅ ⋅ ( .5 23 ) Im allgemeinen Fall hat die Kovarianzmatrix unabhängiger Variablen Diagonalgestalt, da Kovarianzen stets 0 sind. Das ist allerdings nicht umkehrbar. Denn zum Beispiel können die Breiten der Verteilungen in Abhängigkeit von den anderen Variablen variieren. (Abbildung 5.3.2.i.d)
Abbildung 5.3.2.i: Stärke der Korrelation von 2 Variablen x1 und x2
a)ρ= 0, b)ρ<0, c)ρ ≈1, d)ρ= 0 Wenn die Kovarianzen nicht verschwinden, werden die entsprechenden Variablen korreliert genannt. Das Maß für den Grad der Korrelation ist der Korrelationskoeffizient:
ij i ji j
i jii ij
V cov(x , x )(x , x )
V Vρ = =
σ ⋅σ wobei i j(x , x )−1≤ ρ ≤ +1 ( .5 24 )
Je mehr der Korrelationskoeffizient von Null abweicht, umso besser kann aus der Kenntnis einer Variablen die andere vorhergesagt werden (Abbildung:5.3.2.i).

Statistische Methoden 30
(positiv korreliert)
unabhängig (nicht korreliert) (negativ korreliert)
i j i j
i j i j
i j i j
(x , x ) x x
(x , x ) x , x
(x , x ) x x
ρ → +1⇒ →
ρ → 0⇒
ρ → −1⇒ →−
( .5 25 )
5.4 Viele Funktionen eines Satzes von Zufallszahlen Sobald im LHC Kollisionen stattfinden werden, entstehen bei diesen Zusammenstößen zweier Teilchen (Events) neue Teilchen. Sie werden verschiedene Eigenschaften (Variablen) haben und einer solchen Kollision kann eine Funktion ig (x ) zugeordnet werden. Da mehr als nur ein Zusammenprall betrachtet wird, sollte dementsprechend auch einen Satz von Funktionen g(x ) gewählt werden. ix sind Variablen, die man für sinnvoll erachtet (zum Beispiel TEΣ , MET…). Im Folgenden wird wieder zur Theorie zurückgekehrt.
5.4.1 Koordinatentransformation (allgemein)
Es wird der allgemeine Fall, dass m Funktionen mg (g , ..., g )1= von den gleichen n Zufallszahlen n(x , ..., x )1 abhängen, betrachtet:
n
g (x )
g(x )g (x )
1⎛ ⎞⎜ ⎟= ⎜ ⎟⎜ ⎟⎝ ⎠
( .5 26 )
Oft ist eine Koordinatentransformation der Zufallsvariablen vorteilhaft: die transformierten Variablen sind im Allgemeinen eine Funktion aller ursprünglichen Variablen. Die Erwartungswerte der Funktionen jg und deren Varianzen ergeben sich für jede Funktion einzeln. Neu kommt jetzt allerdings hinzu, dass die Funktionen untereinander korreliert sein können und damit nicht-verschwindende Kovarianzen haben. Jede der Funktionen ( k , ..., m=1 ) in einer Umgebung um den Mittelwert iμ linearisiert.
n
kk k i i x
i i
Ögg (x ) g ( ) (x ) ...
Öx =μ=1
= μ + −μ +∑ ( .5 27 )
mit kki x
i
ÖgS
Öx =μ= erhält man aus ( .5 27 ):
g(x ) g( ) S(x )= μ + ( .5 28 ) und x μ sind Spaltenvektoren und S die Jacobische Funktionalmatrix.
Weil der zweite Term der Linearisierung bei der Erwartungswertbildung wegfällt26, sind die Erwartungswerte und Varianzen der Funktionen g(x ) daher: E(g(x )) g( )= μ ( .5 29 )
26 wegen i iE(x )−μ = 0

Statistische Methoden 31
kl k k l l
k li i j j
i j i j
Tk lij
i j i j
ki lj iji j
Tkl
V (g(x )) E(g (x ) E(g (x ))(g (x ) E(g (x )))Ög Ög
E((x )(x ))Öx Öx
Ög ÖgV (x) S
Öx Öx
S S V (x )
V (g(x )) S V (x ) S
= − −
= −μ −μ
= ⋅
= ⋅ ⋅
⇒ = ⋅ ⋅ ⋅
∑ ∑
∑ ∑
∑ ∑
( .5 30 )
Die Matrix S kann beispielsweise darüber bestimmt werden, dass die Transformation x y→ die Kovarianzmatrix V(y) diagonal gemacht wird, die neuen Variablen iy also nicht korreliert sind. Solch eine Transformation wirkt sich folgendermaßen auf die Wahrscheinlichkeits-dichte aus: aus n n n n(x , ..., x ) (y , ..., y ), f(x , ..., x ) h(y , ..., y )1 1 1 1→ → ( .5 31)
folgt nn n
n
Ö(x , ..., x )f(x )dx ...dx h(y)dy ...dy h(y) f(x(y ))
Ö(y , ..., y )1
1 11
= ⇒ = ( .5 32 )
wobei n
n
Ö(x , ..., x )Ö(y , ..., y )
1
1
die Jacobi-Determinante ist. Variablentransformationen wird unter
anderem auch deshalb durchgeführt, um einfachere Wahrscheinlichkeitsdichten zu erhalten.
5.4.2 Koordinatentransformation (PCA) Die Hauptkomponentenanalyse (Principal Component Analysis, PCA) ist aus der multivarianten Statistik bekannt. Sie dient dazu, umfangreiche Datensätze zu strukturieren, zu vereinfachen und zu veranschaulichen, indem eine Mehrzahl statistischer Variablen durch eine geringere Zahl möglichst aussagekräftiger Linearkombinationen (die "Hauptkomponenten") genähert wird. Ein Datensatz hat typischerweise die Struktur einer Matrix: an n Messungen wurden jeweils p Merkmale gemessen. Ein solcher Datensatz kann als Menge von n Punkten im p-dimensionalen Raum veranschaulicht werden. Ziel der Hauptkomponentenanalyse ist es, diese Datenpunkte so auf einen q-dimensionalen Unterraum qR (q<p) zu projizieren, dass dabei möglichst wenig Information verloren geht.
Es wird also eine Hauptachsentransformation durchgeführt: man minimiert die Korrelation mehrdimensionaler Merkmale durch Überführung in einen Vektorraum mit neuer Basis. Die Hauptkomponentenanalyse ist damit problemabhängig, weil für jeden Datensatz eine eigene Transformationsmatrix berechnet werden muss.
Die Varianz von Daten ist ein Maß für ihren Informationsgehalt. Die Daten liegen als Punktwolke in einem n-dimensionalen kartesischen Koordinatensystem vor. Es wird nun ein neues Koordinatensystem in die Punktwolke gelegt und dieses neue Koordinatensystem wird rotiert: Die erste Achse soll so durch die Punktwolke gelegt werden, dass die Varianz der Daten in dieser Richtung maximal wird. Die zweite Achse steht auf der ersten Achse senkrecht. In ihrer Richtung ist die Varianz am zweitgrößten usw. Für die n-dimensionalen Daten gibt es also grundsätzlich n Achsen, die

Statistische Methoden 32
aufeinander senkrecht stehen, sie sind orthogonal. Die Gesamtvarianz der Daten ist die Summe der einzelnen Achsenvarianzen. Wird nun durch die ersten p (p < n) Achsen der größte Prozentsatz der Gesamtvarianz abgedeckt, erscheinen die Faktoren, die durch die neuen Achsen repräsentiert werden, ausreichend für den Informationsgehalt der Daten.
Häufig können die Faktoren inhaltlich nicht mehr interpretiert werden. In der Statistik wird davon gesprochen, dass ihnen keine verständliche Hypothese zugeschrieben werden kann.
5.4.3 Koordinatentransformation (Wurzel der Kovarianzmatrix) Lineare Korrelationen, die aus den Trainingsdaten erhalten wurden, können durch Berechnung der Quadratwurzel der Kovarianzmatrix genutzt werden. Die Quadrat-Wurzel aus einer Matrix C ist die Matrix C′ , die mit sich selbst multipliziert C ergibt. Im allgemeinen berechnet man die Wurzel der Matrix durch die Diagonalisierung (symmetrisch) der Kovarianzmatrix. Die lineare Dekorrelation der Input-Variablen wird dann aus der Multiplikation der ursprünglichen Variablen durch die Inverse der Quadratwurzel-Matrix gebildet (Kapitel 5.4.1). Die Transformationen sind unter-schiedlich für Signal- und Untergrund-Ereignissse, weil ihre Korrelationsmuster in der Regel verschieden sind. Die Dekorrelation ist nur für linear korrelierte und Gauß-verteilte Variablen vollständig. In der Realität ist dies nicht oft der Fall, so dass manch-mal nur wenig zusätzliche Informationen durch die Dekorrelation sichtbar werden. Für stark nichtlineare Probleme kann das Training noch schlechtere Ergebnisse erzielen, falls lineare Dekorrelation erzwungen wird. Nichtlineare Klassifikatoren ohne vorherige Variablendekorrelation sollten in solchen Fällen benutzt werden.
5.5 2χ -Test
Soll überprüft werden ob eine Probe, die normalverteilt sein muß, eher anzunehmen oder zu verwerfen ist, dann kann dies mit dem 2χ -Tests geschehen. Es werden nun Stichproben n(x ...x )1 vom Umfang n aus einer Normalverteilung f(x) betrachtet. Mit der 2χ -Funktion:
n
i
i
(x )²²
2
=1
−μχ =
σ∑ ( .5 33)
ergibt sich dann f ( 2χ ) durch Einsetzen in die Normalverteilung, wobei mit wachsendem n die Dichte der 2χ -Verteilung immer mehr in die Normalverteilung übergeht (Abbildung 5.5.i).
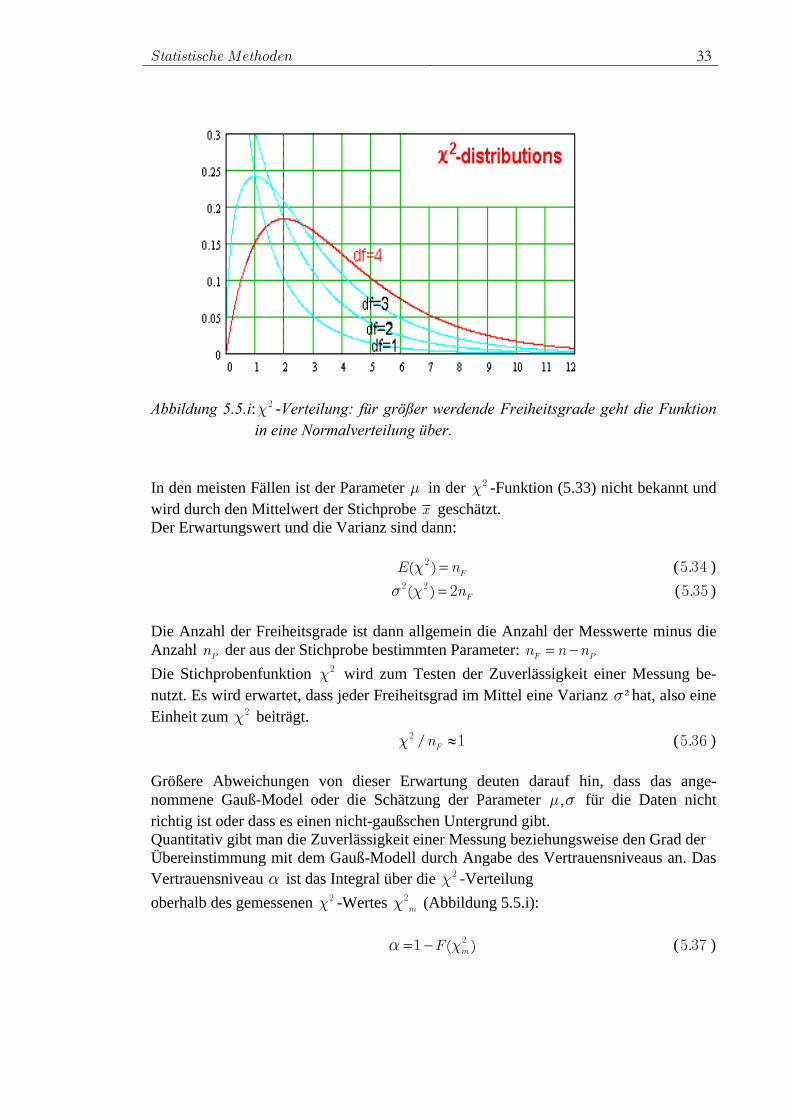
Statistische Methoden 33
Abbildung 5.5.i: 2χ -Verteilung: für größer werdende Freiheitsgrade geht die Funktion
in eine Normalverteilung über. In den meisten Fällen ist der Parameter μ in der 2χ -Funktion (5.33) nicht bekannt und wird durch den Mittelwert der Stichprobe x geschätzt. Der Erwartungswert und die Varianz sind dann: FE( ) n2χ = ( .5 34 ) F( ) n2 2σ χ = 2 ( .5 35 ) Die Anzahl der Freiheitsgrade ist dann allgemein die Anzahl der Messwerte minus die Anzahl Pn der aus der Stichprobe bestimmten Parameter: F Pn n n= − Die Stichprobenfunktion 2χ wird zum Testen der Zuverlässigkeit einer Messung be-nutzt. Es wird erwartet, dass jeder Freiheitsgrad im Mittel eine Varianz ²σ hat, also eine Einheit zum 2χ beiträgt. F/ n2χ ≈1 ( .5 36 ) Größere Abweichungen von dieser Erwartung deuten darauf hin, dass das ange-nommene Gauß-Model oder die Schätzung der Parameter ,μ σ für die Daten nicht richtig ist oder dass es einen nicht-gaußschen Untergrund gibt. Quantitativ gibt man die Zuverlässigkeit einer Messung beziehungsweise den Grad der Übereinstimmung mit dem Gauß-Modell durch Angabe des Vertrauensniveaus an. Das Vertrauensniveau α ist das Integral über die 2χ -Verteilung oberhalb des gemessenen 2χ -Wertes m
2χ (Abbildung 5.5.i): mF( )2α =1− χ ( .5 37 )
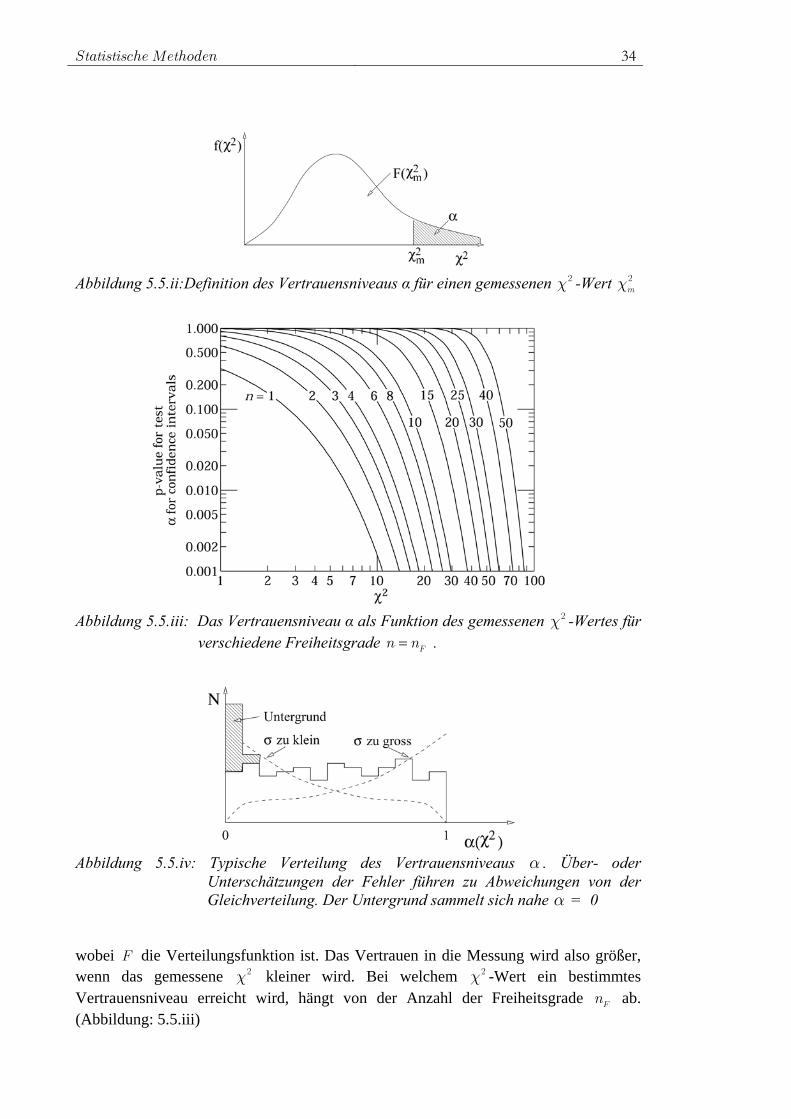
Statistische Methoden 34
Abbildung 5.5.ii:Definition des Vertrauensniveaus α für einen gemessenen 2χ -Wert m
2χ
Abbildung 5.5.iii: Das Vertrauensniveau α als Funktion des gemessenen 2χ -Wertes für
verschiedene Freiheitsgrade Fn n= .
Abbildung 5.5.iv: Typische Verteilung des Vertrauensniveaus α . Über- oder
Unterschätzungen der Fehler führen zu Abweichungen von der Gleichverteilung. Der Untergrund sammelt sich nahe α = 0
wobei F die Verteilungsfunktion ist. Das Vertrauen in die Messung wird also größer, wenn das gemessene 2χ kleiner wird. Bei welchem 2χ -Wert ein bestimmtes Vertrauensniveau erreicht wird, hängt von der Anzahl der Freiheitsgrade Fn ab. (Abbildung: 5.5.iii)

Statistische Methoden 35
Die Wahrscheinlichkeitsdichte von mF( )2χ und damit auch von mF( )2α =1− χ ist gleich-verteilt zwischen 0 und 1. Die Stichprobenfunktionen mF( )2χ und α sind dabei als Zufallsvariable zu betrachten. Wenn sehr viele Messungen gemacht werden, die einen
2χ -Tests erfüllen sollen, kann die gemessene α -Verteilung graphisch dargestellt werden. (Abbildung: 5.5.iv). Abweichungen von einer Gleichverteilung haben zumeist folgende Ursachen: • das Gauß-Modell ist falsch • die Standardabweichungen iσ sind zu groß (→ Verschiebung zu großen α ) • die Standardabweichungen iσ sind zu klein (→ Verschiebung zu kleinen α ) • es gibt nicht-gaußschen Untergrund Der Untergrund häuft sich bei kleinen Werten von α und kann mit einem Schnitt auf α entfernt werden. Beispiel: Bei Teilchenreaktionen werden oft die Impulse und Richtungen der beobachteten Teilchen mit gewissen Fehlern gemessen. Zusammen mit einer Hypothese für die Massen kann man Impuls- und Energieerhaltung mit einem 2χ -Test überprüfen. Ereignisse, bei denen wenigstens ein Teilchen dem Nachweis entgangen ist, werden sich bei einem kleinen Vertrauensniveau α ansammeln. Es treten grundsätzlich alle Werte von α gleich häufig auf. Es ist also nicht von vornherein ein Wert von α nahe 1 besser als einer nahe 0. Selektionsschnitte auf α sollten deshalb ausschließlich durch das Untergrundverhalten bestimmt sein.
5.6 H-Matrix Das ursprüngliche H-Matrix-Konzept geht zurück auf die Arbeiten von Fisher und Mahalanobis im Rahmen der Gauß-Klassifikatoren. Es unterscheidet zwischen einer Klasse (Signal) eines Merkmals-Vektors und einer anderen Klasse(Untergrund). Bei den korrelierten Elementen des Vektors wird davon ausgegangen, dass sie Gauß-verteilt sind. Die Inverse der Kovarianzmatrix ist die H-Matrix. Eine multivariante 2χ -Schätzfunktion (siehe Kapitel 5.5) wird gebildet, die die Unterschiede der mittleren Werte der Vektorelemente der beiden Klassen für die Zwecke der Diskriminierung nutzt. Der H-Matrix-Klassifikator, wie er in TMVA27 umgesetzt wurde, ist gleich oder weniger leistungsstark als die Fisher Diskriminanzanalyse (siehe Kapitel 5.10) und wurde nur der Vollständigkeit halber implementiert.
5.7 Maximum-Likelihood-Methode
Mit dem 2χ -Test kann quantitativ bestimmt werden, ob die Elemente einer Stichprobe Normalverteilungen mit angenommenen oder geschätzten Parametern i i,μ σ folgen. Durch Minimierung von 2χ als Funktion der Parameter kann eine optimale Schätzung der Parameter erreicht werden. Das ist die so genannte „Methode der kleinsten Quadrate“. Sie entspricht der Maximum-Likelihood-Methode für den Spezialfall, dass
27 An dieser Stelle sollte das Wissen aus Kapitel 6.3 gegeben sein, um dem weiteren Verlauf der Arbeit
folgen zu können

Statistische Methoden 36
die Stichproben aus Normalverteilungen stammen. Die Maximum-Likelihood-Methode (ML-Methode) ist eine allgemeine Methode zur Bestimmung von Parametern aus Stichproben für beliebige Wahrscheinlichkeitsverteilungen. Nun wird wieder die gleiche Stichprobe wie in Kapitel 5.5 gewählt, wobei jedes ix im Allgemeinen für einen ganzen Satz von Variablen stehen kann. Jetzt soll die Wahrscheinlichkeit für das Auftreten dieser Stichprobe berechnet werden unter der Annahme, dass die ix einer Wahrscheinlichkeitsdichte f(x| )θ folgen, die durch einen Satz von Parametern n, ...,1θ = θ θ bestimmt ist. Wenn die Messungen zufällig sind, ist diese Wahrscheinlichkeit das Produkt der Wahrscheinlichkeiten für das Auftreten jedes einzelnen Elementes der Stichprobe:
n
n ii
L(x , ..., x | ) f(x | )1=1
θ = θ∏ ( .5 38 )
Diese Stichprobenfunktion heißt Likelihood-Funktion. Das ML-Prinzip lässt sich nun wie folgt beschreiben: Es wird aus allen möglichen Parametersätzen θ denjenigen Satz θ als Schätzung gewählt, für den gilt: n n
ˆL(x , ..., x | ) L(x , ..., x | )1 1θ ≥ θ ∀θ ( .5 39) Das heißt, es muss das Maximum von L in Bezug auf die Parameter gefunden werden. Da L als Produkt von Wahrscheinlichkeiten sehr kleine Zahlenwerte haben kann, wird oft die so genannte Log-Likelihood-Funktion, also der Logarithmus der Likelihood-Funktion benutzt. Maximierungsbedingungen lauten dann:
und n
i ijii i i j ˆ
ÖL Ö ÖLˆ ˆl ogf(x | ) U ( )Ö Ö Ö=1 θ=θ
= θ = 0 ⇒ θ = θθ θ θθ∑ negativ definit ( .5 40 )
Die Matrix U ist negativ definit, wenn alle Eigenwerte kleiner 0 sind. Falls Gleichung 5.40 auf ein lineares Gleichungssystem führt, kann die Lösung durch Matrixinversion berechnet werden. Im Allgemeinen sind die Gleichungen nicht-linear und es muss eine numerische, meistens iterative Methode zur Lösung gefunden werden. Schwieriger ist die Beurteilung der Fehler einer Schätzung. Das Problem tritt dann auf, wenn die Likelihood-Funktion als Wahrscheinlichkeitsdichte der Parameter interpretiert und entsprechend benutzt wird. Zur Fehlerabschätzung wird eigentlich der Verlauf der gesamten Likelihood-Funktion benötigt. Die Likelihood-Funktion ist in Abhängigkeit von den Parametern nicht normiert. Um richtig normieren zu können, sollte zum einen der mögliche Bereich der Parameter genau bekannt sein und zum anderen sollte bekannt sein, ob alle Parameter gleich wahrscheinlich sind.
5.7.1 Projektiver Likelihood-Schätzer Die Methode der Maximum-Likelihood besteht aus einer Modellbildung von Wahrscheinlichkeitsdichtefunktionen (probability density functions, PDF), die die Input-Variablen für Signal und Untergrund reproduziert. Durch Multiplikation der Signalwahrscheinlichkeitsdichten aller Input-Variablen und deren Normalisierung durch die Summe der Signal- und Untergrund-Likelihoods kann für ein bestimmtes Ereignis die Wahrscheinlichkeit (Likelihood) für die Art des Signals bestimmt werden. Zu bemerken ist, dass die Korrelationen zwischen den Variablen dabei ignoriert werden. Das Likelihood-Verhältnis für das Event i ist definiert durch
SÄ( i )
S B
Ä (i)y
Ä (i) Ä (i)=
+ ( .5 41)

Statistische Methoden 37
wobei
varn
S( B ) S( B ),k kk
Ä (i) p (x (i))=1
=∏ ( .5 42 )
und wobei S( B ),kp die Signal- (Untergrund-) PDF für die k -te Inputvariable kx ist. Die PDFs werden folgendermaßen normiert:
S( B ),k k kp (x )dx , k+∞
−∞
=1 ∀∫ ( .5 43)
Abgesehen von Modellungenauigkeiten (z.B., dass Korrelationen zwischen Input-Variablen nicht durch Dekorrelationsverfahren entfernt wurden oder ein falsches Wahrscheinlichkeitsdichte-Modell), bietet das Verhältnis Ä( i )y eine optimale Signal-Untergrund-Trennung für die gegebene Reihe von Input-Variablen. Da die parametrische Form der PDF-Dateien im Allgemeinen nicht bekannt ist, werden die PDF-Formen empirisch an die Trainingsdaten angenähert. Dies geschieht durch nicht-parametrische Funktionen, die individuell für jede Variable ausgewählt werden können. Diese Funktionen sind entweder Polynome verschiedenen Grades, in Histogramme gefittet oder nicht eingekastete (unbinned) Kern-Dichte-Schätzer (kernel density estimators, KDE).
5.7.2 Mehrdimensionaler Likelihood Schätzer und PDERS Dies ist eine Verallgemeinerung des projektiven Likelihood-Klassifikators des Kapitels 5.7.2, für varn Dimensionen, wobei varn die Anzahl der genutzten Input-Variablen ist. Wenn die mehrdimensionale PDF für Signal und Untergrund bekannt ist, würde der Klassifikator alle Informationen nutzen, die in den Input-Variablen enthalten sind und somit optimal arbeiten. In der Praxis sind jedoch riesige Trainings-Proben notwendig, um ausreichende Informationen über den mehrdimensionalen Raum zu erhalten. Aufgrund der Korrelationen zwischen den Input-Variablen kann nur ein Unterraum des vollen Phasenraums genutzt werden. Kern-Schätzer-Methoden können verwendet werden um annähernd die Form der PDF für finite Trainingsstatistiken zu approximieren. Eine einfache Wahrscheinlichkeitsdichteschätzfunktion wird als PDE-Bereich-Suche oder PDERS (PDE range search) bezeichnet. Die PDE für ein bestimmtes Test-Ereignis (Diskriminanzanalyse) wird bestimmt, indem die (normierte) Anzahl der Signal- und Untergrund- (Trainings-) Events, die in der „Nähe“ der Test-Events liegen, gezählt werden. Die Einstufung der Test-Events erfolgt gemäß der Anzahl der nächstliegenden Trainingsevents. Das varn -dimensionale Volumen, welches die „Nähe“ umschließt, kann vom Benutzer definiert werden. Eine Suchmethode basierend auf binären Bäumen dient der Reduzierung der Rechenzeit bei TMVA. Zur Steigerung der Empfindlichkeit innerhalb des Volumens, werden Kern-Funktionen verwendet, um die Verweis-Events nach ihrer Entfernung vom Test-Event zu gewichten. PDERS ist eine Variante des k-nächste-Nachbarn-Klassifikators aus Kapitel 5.10.
5.8 Optimierung und Anpassung (Fitting) Mehrere Klassifikatoren (insbesondere Schnitt-Optimierung (Kapitel 5.11) und FDA (Kapitel 5.12)) erfordern ein Allzweck-Parameter-Fitting zur Optimierung des Wertes eines Schätzers. So kann beispielsweise eine Schätzfunktion die Summe der Abweichungen der Klassifikator-Ausgänge von „1“ für Signal Ereignissen und „0“ für

Statistische Methoden 38
Untergrund-Events liefern. Die Parameter werden so angepasst, dass diese Summe so klein wie möglich ist. Da die verschiedenen Probleme nach individuellen Lösungen verlangen, hat TMVA eine Fitter-Basisklasse, die von den Klassifikatoren genutzt wird. Dadurch kann der Nutzer entscheiden, welchen Fitter er als geeignet sieht und ihn konfigurieren. Derzeit sind vier Fitter in TMVA eingebunden: Monte-Carlo-Probenahme, Minuit-Minimierung, ein genetischer Algorithmus und das simulierte Abkühlen.
5.8.1 Simuliertes Abkühlen
Die simulierte Abkühlung (simulated annealing) ist ein heuristisches Opti-mierungsverfahren. Es wird zum Auffinden einer angenäherten Lösung von Problemen eingesetzt, die durch ihre hohe Komplexität das Ausprobieren aller Möglichkeiten und einfache mathematische Verfahren ausschließen. Die Idee ist die Nachbildung eines Abkühlungsprozesses. Nach Erhitzen eines Metalls sorgt die langsame Abkühlung dafür, dass die Moleküle genügend Zeit haben, sich zu ordnen und Kristalle zu bilden. Dadurch wird ein energiearmer Zustand, nahe an der besten Lösung erreicht. Übertragen auf das Optimierungsverfahren entspricht die Temperatur einer Wahrscheinlichkeit, mit der sich ein Zwischenergebnis der Optimierung auch verschlechtern darf. Der Metropolisalgorithmus ist die Grundlage der simulierten Abkühlung. Dieses Verfahren kann ein lokales Optimum wieder verlassen und ein besseres finden.
5.8.2 Minuit-Minimierung Minuit ist konzipiert, um den minimalen Wert einer Multi-Parameter-Schätzfunktion zu finden und die Form der Funktion rund um das Minimum zu analysieren (Fehler-Analyse). Die wichtigste Anwendung dieses TMVA-Fitters ist Minimierung, wobei die Form des Minimums in den meisten Fällen unerheblich ist. Die Verwendung von Minuit ist daher nicht notwendigerweise die effizienteste Lösung. Es ist aber ein sehr robustes Werkzeug. Minuit sucht die Lösung entlang des stärksten Gefälles (MIGRAD) des Schätzers, bis ein stationärer Punkt oder eine Kante gefunden wird. Es versucht nicht, die Suche auf ein globales Minimum zu erweitern, sondern ist zufrieden mit den lokalen Minima, solange sie nicht während der lokalen Analyse des Schätzers ein kleineres Minimum in der Umgebung gefunden wird. Insbesondere die Verwendung von MINOS kann eine verbesserte Analyse hervorbringen, da es Fehler entdecken wird wie zum Beispiel eine Konvergenz in einem lokalen Minimum. In diesem Fall wird die MIGRAD-Minimierung erneut aufgerufen. In Fällen, in denen es mehrere lokale und oder globale Lösungen gibt, sind andere Fitter vorzuziehen, die speziell bei dieser Art von Problemen greifen.
5.8.3 Monte-Carlo-Stichprobe Die einfachste, aber auch ineffiziente fitting-Methode ist es, die Fit-Parameter zufällig abzutasten und diejenigen auszuwählen, die den Schätzer optimieren. Es wird für die Stichprobe Gleichverteilungen oder Gaußverteilungen innerhalb der Parametergrenzen verwendet. Für Fitting-Probleme mit wenigen lokalen Minima von denen eines ein globales Minimum ist, kann die Effizienz erhöht werden, indem dem Parameter „Sigma“ ein

Statistische Methoden 39
positiver Wert zugewiesen wird. Die neu generierten Parameter sind dann nicht mehr unabhängig von den Parametern der vorangegangenen Proben. Der Zufallsgenerator wird zufällige Werte abhängig von der Gauß-Wahrscheinlichkeitsdichte ausgeben mit dem Mittelwert von dem derzeit bekannten besten Wert für den jeweiligen Parameter und die Breite in Einheiten der Intervallgröße, die von der Option Sigma vorgegeben ist. Punkte, die aus dem Parameter-Intervall erstellt werden, werden zurück in das Intervall abgebildet.
5.8.4 Genetischer Algorithmus Der Genetische Algorithmus (GA) ist ein Algorithmus, der die bestmögliche Lösung für ein nichtanalytisches Problem finden soll. Das Problem ist aus einer Gruppe (Population) aufgebaut, die aus abstrakten Lösungskandidaten (Genome) möglicher Lösungen (Individuen) besteht. Die in der biologischen Entwicklung gefundenen Prozesse werden hier ähnlich angewendet. Die Individuen der Population sollten sich in Richtung einer optimalen Lösung des Problems entwickeln. Prozesse, die üblicherweise in die evolutionären Algorithmen einzuordnen sind - so wie der Genetische Algorithmus - sind Vererbung, Mutation und „sexuelle Rekombination“. Außer den Genomen muss eine Fitness-Funktion definiert werden. Sie ist für die AAuusswweerrttuunngg der Güte eines Individuums gedacht und ist problemabhängig. Sie gibt entweder einen repräsentierenden Wert für die Güte des Individuums aus oder vergleicht zwei Individuen und zeigt, welches von ihnen besser funktioniert. Der Genetische Algorithmus läuft folgendermaßen ab: • Initialisierung: Eine startende Population oder Bevölkerung wird geschaffen. IIhhrree
Größe hängt vom zu lösenden Problem ab. Jedes zu der Bevölkerung gehörende Individuum wird durch das zufällige Setzen der Parameter (Variable) bei den Genomen geschaffen und auf diese Weise der Startpunkt in der Lösungsdomäne des Anfangsproblems erzeugt.
• AAuusswweerrttuunngg:: Jedes Individuum wird bei der Benutzung der Fitness-Funktion bewertet.
• Auswahl (Selektion): Individuen werden behalten oder auf Grund ihrer Fitness abgelehnt. Mehrere Auswahlverfahren nacheinander sind möglich. Das einfachste Verfahren ist, einfach den schlechtesten Bruchteil von der Bevölkerung zu trennen.
• Rekombination: Die überlebenden Individuen werden kopiert, verändert und gekreuzt, bis die Anfangsbevölkerungsgröße wieder erreicht ist.
• Beendigung: Die Auswahl und Nachbildungsschritte werden bis zu einem erreichen eines Maximums der Fitness-Funktion eine Individuums wiederholt, oder die maximale Zyklenzahl wird erreicht. Das beste Individuum wird ausgewählt und für die Lösung des Problems gehalten.
Normalerweise gibt es die Möglichkeit, die Rekombination während des Prozesses zu variieren, wenn sich die Bevölkerung nicht vielversprechend entwickelt.

Statistische Methoden 40
5.9 Gewichtete Entscheidungsbäume Ein Entscheidungsbaum ist ein binärer Baum strukturierter Klassifikatoren, wie in Abbildung 5.9.i skizziert.
Abbildung 5.9.i: Schematisierter AAuuffbbaauu eines Entscheidungsbaums. Startend vom
Stamm aus, wird eine Folge von binären Spagaten aufgerufen, welche die Entscheidungsvariable ix nutzt. Jede Spaltung benutzt die Variable, die an diesem Knoten vorgibt, die beste Trennung zwischen Signal und Untergrund zu schneiden. Die gleiche Variable kann damit an verschiedenen Knoten benutzt werden, während andere überhaupt nicht benutzt werden. Die Endpunkte des Baumes werden etikettiert: S für Signal und B für Untergrund.
Wiederholte links/richtig (ja/nein) Entscheidungen werden auf eine einzelne Variable so lange angewandt, bis ein Haltekriterium greift. So wird der Phasenraum in zwei Regionen geteilt, in Signal und Untergrund. Das Gewichten von einem Entscheidungsbaum (BDT)28 repräsentiert eine Erweiterung eines einzelnen Entscheidungsbaumes. Viele Entscheidungsbäume (einen Wald) erhält man, indem man von der gleichen Trainingsprobe die Ereignisse neu gewichtet. Sie werden verbunden um einen Klassifikator zu finden, der aus (gewichteten) MMaajjoorriittäättsseennttsscchheeiidduunnggeenn der individuellen Entscheidungsbäume besteht. Gewichtung stabilisiert die Antwort der Entscheidungsbäume in Bezug auf Fluktuationen in der Ausbildungsprobe. Entscheidungs-Bäume sind wohlbekannte Klassifikatoren (Classifier), die un-komplizierte Interpretationen erlauben, die sich durch eine einfache, zweidimensionale Baumstruktur vorstellt werden kann. So gesehen, sind rechtwinkelige Schnitte ähnlich. Aber während eine aus den Schnitten herrührende Analyse in der Lage ist nur einen Hyperraum als Region vom Phasenraum auszuwählen, ist der BDT in der Lage die Raumphase in einer Mehrzahl von Hyperräumen zu spalten, von welchen jeder entweder als signalähnlich oder als untergrundähnlich zu identifizieren ist. Der Weg am Baum entlang zum jeweiligen Knotenpunkt stellt eine getrennte Schnittreihenfolge dar, welche, je nach Art des Knotenpunkts, Signal oder Untergrund auswählt.
28 Boosted Decision Trees

Statistische Methoden 41
Ein Mangel von Entscheidungsbäumen bedeutet Unbeständigkeit hinsichtlich statistischer Schwankungen aus dem Sample, aus dem die Baumstruktur stammt. Zum Beispiel, wenn zwei Eingangsvariablen ähnliche Spaltungsstärke zeigen, kann eine Schwankung im Test verursachen, dass innerhalb der Baumwachstumsphase sich eine Variable abspaltet, während die andere Variable ohne Schwankungen ausgewählt werden könnte. In solchen Fällen ändert sich die ganze Baumstruktur unterhalb dieses Knotenpunktes. Dieses Problem wird durch die Errichtung eines „Walds“ überwunden und durch die Klassifizierung von jedem Ereignis nach Mehrzahl innerhalb der einzelnen Bäume des Waldes. Alle Bäume im Wald kommen aus demselben Testbeispiel. Alle werden nacheinander aufgrund ihres Testergebnisses einem so genannten Gewichten (Boosting) unterworfen, einer Prozedur, nach welcher ihre Gewichtung innerhalb des Samples verändert wird. Das Boosting erhöht die statistische Beständigkeit des Classifiers und verbessert typischerweise die einzelne Effizienz in Vergleich zum einfachen Entscheidungsbaum. Es sollte dennoch nicht der Interpretation des Entscheidungsbaums bedingungslos vertraut werden. Während es bei einer begrenzten Zahl von Bäumen möglich ist das Testresultat zu interpretieren, ist dies für Hunderte von Bäumen im Wald praktisch nicht durchführbar. Trotzdem kann die Hauptstruktur einer Unterscheidung verstanden werden, indem man eine begrenzte Zahl von einzelnen Bäume beobachtet. Gewichten: Das Gewichten ist nicht durch die Anzahl der Bäume begrenzt. Der gleiche Classifier wird nacheinander neu gewichtetet, indem er immer neue Ereignisse zum Training bekommt. Der Gesamt-Classifier ist dann aus der Kombination aller individuellen Classifier zu gewinnen. Ein guter TMVA-boosting-Algorithmus, AdaBoost (adaptive boost) genannt, ordnet, wenn das Event während des Testens von einem Baum falsch klassifiziert wurde, dem Event ein höheres Eventgewicht innerhalb des nachfolgenden Baumes zu. Während die ersten Bäume mit den ursprünglichen Eventgewichten getestet werden, wird jeder nachfolgende Baum durch Verwendung eines modifizierten Ereignis-Samples trainiert, in welchem das Gewicht des vorausgehenden falsch klassifizierten Events mit einem gemeinsamen Boost-Gewicht-Faktor α multipliziert wird. Das boost-Gewicht ist von dem Falschklassifizierungswert err des vorausgehenden Baumes abgeleitet:
errerr
1−α = ( .5 44 )
Das gesamte Eventsample wird dann wieder normiert, so dass die Gesamtzahl der Events (die Summe der Gewichte) in einem Baum konstant bleibt. Mit dem Ergebnis aus dem individuellen Baum h(x) (wobei x das Tupel der Inputvariabeln ist) werden dem Signal und Untergrund mit h(x) = +1 bzw. -1 zugwiesen. Die resultierende Eventklassifizierung BDTy (x) für einen Gewichtungsklassifikator ist: ,BDT i i
i Wald
y (x) ln( )h (x)∈
= α∑ ( .5 45 )
Wobei die Summe für alle Bäume im Wald steht. Kleine bzw. große Werte für BDTy (x) bedeuten Untergrund- bzw. Signal-ähnliche Events. Gleichung ( .5 45 ) ist das Standard-Boosting. Sie kann variiert werden. Die andere Boosting-Methode, die im TMVA verwendet wird, ist eine Re-Sampling-Methode, manchmal auch „bagging“ genannt. Das Re-Sampling wird durch die

Statistische Methoden 42
Ersetzung bewerkstelligt, das heißt, es ist erlaubt das gleiche Event durch zufällige Selektion aus dem elterlichen Sample mehrmals heraus zu picken. Dies ist äquivalent mit der Betrachtung, dass die Trainings-Samples, die Repräsentanten der Verteilung der Dichte der elterlichen Event-Ensembles-Dichte sind. Nimmt man ein Event aus dieser Gruppe, ist es wahrscheinlicher, dass man ein Event aus der Region des Phasenraums erhält, das einen großen Querschnitt aufweist, sowie das Monte-Carlo-Sample, das mehr Events in dieser Region hat. Wird ein ausgewähltes Event im original-Sample beibehalten, bleibt das elterliche Sample unverändert, so dass die zufällig heraus gepickten Samples die gleichen elterlichen Eigenschaften aufweisen würden, obwohl sie statistisch schwanken. Werden mehrere Entscheidungsbäume mit verschiedenen Re-Sampling-Daten trainiert und mit Wald-Ergebnissen innerhalb eines normalen Classifiers nur für das Boosting kombiniert, werden sie stabiler bezüglich ihrer statistischen Schwankungen im Trainings- Sample. Technisch wird das ReSampling durch Anlegen von zufälliger Gewichten auf jedes Event des elterlichen Samples durchgeführt. Das Training eines Entscheidungsbaumes: Das Training eines Entscheidungsbaums ist eine Prozedur, die durch die Spaltungseigenschaften jedes Knotenpunktes definiert wird. Es beginnt bei dem Stamm, bei dem ein anfängliches Spaltungs-Kriterium für das komplette Trainings-Sample entschieden wird. Die gespaltenen Daten werden dann beim nächsten Knotenpunkt anhand bestimmter Kriterien erneut getrennt. Diese Prozedur wiederholt sich bis der ganze Baum bebaut wurde. Auf jedem Knotenpunkt ist die Spaltung durch das Finden der jeweiligen Variablen und des entsprechenden Schnittwertes, die die beste Trennung zwischen Signal oder Untergrund darstellen, definiert. Das Knotenpunkttrennen hört auf, sobald eine minimale Zahl von Ereignissen erreicht wurde, die von der BDT-Einstellung vorgegeben wurden. Die Endpunkte sind als Signal oder Untergrund klassifiziert. Eine Mehrheit von Trennungskriterien kann konfiguriert werden, um die Leistung einer Variablen sowie die Erforderlichkeit eines bestimmten Schnitts zu berechnen. Da ein Schnitt, der hauptsächlich Untergrund auswählt, gleich wertvoll ist wie ein Schnitt, der Signal auswählt, sind die Kriterien symmetrisch hinsichtlich der Ereignis-Klassen. Alle Trennungskriterien erlangen ihr Maximum dort, wo sich die Samples völlig mischen, wie zum Beispiel bei der Wahrscheinlichkeit p ,= 0 5 und fallen dort auf Null wo ein Sample aus nur einer Ereignisklasse besteht. Tests zeigen keine erheblichen Effizienzunterschiede zwischen den folgenden Trennungskriterien: • p( p)1− • p( p) ln( p)− 1− ⋅ 1− • max(p, p)1− 1− • S / S B+ Dabei ist das Trennungskriterium immer ein Schnitt auf einer einzigen Variablen. Die Variable und der Schnittwert werden so ausgewählt, dass das Wachstum im Trennungsindex zwischen den elterlicher Knotenpunkten und der Summe der Zeiger zweier abgeleitender Tochterknotenpunkte optimiert wird, gewichtet durch ihren relativen Anteil von Ereignissen. Grundsätzlich könnte die Spaltung unaufhörlich fortgesetzt werden bis jeder Knotenpunkt nur Signal- oder Untergrund-Ereignisse enthält. Solch ein Entscheidungsbaum kann das Resultat von Übertraining (Overtraining) sein. Um Overtraining zu vermeiden, muss ein Entscheidungsbaum also gestutzt werden.

Statistische Methoden 43
5.10 Nächste-Nachbarn-Klassifikation
Die KNN (k-nächste-Nachbarn-Algorithmus)29 ist eine parameterfreie Methode zur Schätzung von Wahrscheinlichkeitsdichtefunktionen. Es ist ein Klassifikations-verfahren, bei dem eine Klassenzuordnung unter Beachtung seiner k nächsten Nachbarn durchgeführt wird. Der Teil des Lernens besteht aus einfachem Abspeichern der Trainingsbeispiele. Die Klassifikation eines Objekts nx∈ erfolgt im einfachsten Fall durch Mehrheitsentscheidung. An der Mehrheitsentscheidung beteiligen sich die k nächsten bereits klassifizierten Objekte von x . Dabei sind viele Abstandsmaße denkbar (euklidischer Abstand in TMVA). x wird der Klasse zugewiesen, die die größte Anzahl der Objekte dieser k Nachbarn besitzt. Für ein klein gewähltes k besteht die Gefahr, dass Rauschen in den Trainingsdaten die Klassifikationsergebnisse verschlechtert. Wird k zu groß gewählt, besteht die Gefahr, Punkte mit großem Abstand zu x in die Klassifikationsentscheidung mit einzubeziehen. Diese Gefahr ist besonders groß, wenn die Trainingsdaten nicht gleichverteilt vorliegen oder nur wenige Beispiele vorhanden sind. Bei nicht gleichmäßig verteilten Trainingsdaten kann eine gewichtete Ab-standsfunktion verwendet werden, die näheren Punkten ein höheres Gewicht zuweist als weiter entfernten. Ein Problem ist auch der Rechenaufwand des Algorithmus bei hochdimensionalen Räumen und vielen Trainingsdaten.
5.11 Fishersche Diskriminanzfunktion
Die Fishersche Diskriminanzfunktion ist eine Funktion, die das Fishersche Kriterium realisiert. Dieses wurde 1936 von R. A. Fisher entwickelt und beschreibt eine Metrik, die die Güte der Trennbarkeit zweier Klassen in einem Raum misst. Das Berechnen der optimal trennenden Hyperebene ist in zwei Dimensionen noch relativ einfach, wird allerdings in mehreren Dimensionen schnell komplexer. Daher bedient sich Fisher eines Tricks, der zunächst die Dimension reduziert und danach die Diskriminanzfunktion berechnet. Dazu werden die Daten auf eine einzige Dimension projiziert, wobei die Projektionsrichtung w von entscheidender Bedeutung ist.
Mit dem Fisherschen Kriterium kann bereits die optimale Projektionsrichtung, genauer gesagt, der Normalenvektor der optimal trennenden Hyperebene, bestimmt werden:
( S ) (S ) T ( B ) ( B ) Tw
x S x B
S (x m )(x m ) (x m )(x m )∈ ∈
= − − + − −∑ ∑ ( .5 46 )
wS ist die Intravarianz und zeigt die Varianz innerhalb der Klassen, ( i )m der Mittelwert
der Klassen B (Untergrund) und S (Signal), weiter ist S S T B B T
BS (m m)(m m) (m m)(m m)= − − + − − ( .5 47 ) die Intervarianz, also die Varianz zwischen den Klassen, m der Mittelwert im Raum. Die geeignetste Projektionsrichtung ist dann offensichtlich diejenige, welche die Intra-varianz der einzelnen Klassen minimiert, während die Intervarianz zwischen den Klas-sen maximiert wird.
29 engl: k-Nearest-Neighbor-Algorithmus

Statistische Methoden 44
Es muss dann nur noch für jedes Objekt getestet werden, auf welcher Seite der Hyperebene es liegt. Dazu wird das jeweilige Objekt zunächst auf die optimale Projektionsrichtung projiziert. Danach wird der Abstand zum Ursprung gegen einen vorher bestimmten Schwellwert w0 getestet. Die Fisher'sche Diskriminanzfunktion ist dann wie folgt:
Tf(x) w x w0= − ( .5 48 )
Einem neuen Objekt y wird nun je nach Ergebnis von f(y) entweder Signal oder Untergrund zugewiesen. Bei f(y) = 0 ist anwendungsabhängig zu entscheiden, ob y überhaupt einer der beiden Klassen zuzuordnen ist.
5.12 Support-Vector-Machine (SVM) oder Stützvektormaschine In den frühen Sechzigern ist eine lineare Support-Vector-Methode, für die Errichtung von trennbaren Hyperflächen für Muster-Wiedererkennungs-Probleme, entwickelt worden. Es hat 30 Jahre gedauert bis diese Methode auf nichtlineare Tren-nungsfunktionen und für die Einschätzung von Echtwertfunktionen (Regression) ange-wendet wurde. Es gehört im Augenblick zum generellen Ziel, einen Algorithmus zu finden, um Klassifikations- und Regressionsaufgaben durchzuführen, welche mit neuro-nalen Netzwerken und Wahrscheinlichkeitsdichte-Schätzern konkurrieren. Typische Anwendungen von SVM sind Textkategorisierungen, Zeichen(wieder)erkennung, Bioinformatik und Gesichtserkennung. Die Ausgangsbasis für den Bau einer Support-Vector-Machine ist eine Menge von Trainingsobjekten. Für sie muss jeweils bekannt sein, welcher Klasse sie zugehören. Jedes dieser Objekte wird durch einen bestimmten Vektor in einem Vektorraum repräsentiert. Die Aufgabe der Support-Vector-Machine ist es nun, in diesen Raum eine mehrdimensionale Hyperebene zu finden, die die Trainingsobjekte in zwei Klassen aufteilt. Der Abstand der Vektoren, die der Hyperebene am nächsten liegen, wird dabei maximiert. Dieser dadurch gebildete, breite, leere Rand soll später dafür sorgen, dass auch die Objekte, die nicht genau den Trainingsobjekten entsprechen, möglichst zuverlässig klassifiziert werden können. Beim Einsetzen der Hyperebene ist es nicht notwendig, alle Trainingsvektoren zu beachten. Die Vektoren, welche weiter von der Hyperebene entfernt liegen und dadurch gewissermaßen hinter einer Front anderer Vektoren versteckt sind, beeinflussen die Lage und die Position der Trennebene nicht. Denn die Hyperebene ist nur von den ihr am nächsten liegenden Vektoren abhängig, weil nur diese benötigt werden, um die Ebene mathematisch exakt zu beschreiben. Diese nächstliegenden Vektoren werden nach ihrer Funktion Stützvektoren (support vectors) genannt und geben den Support-Vector-Machines ihren Namen.
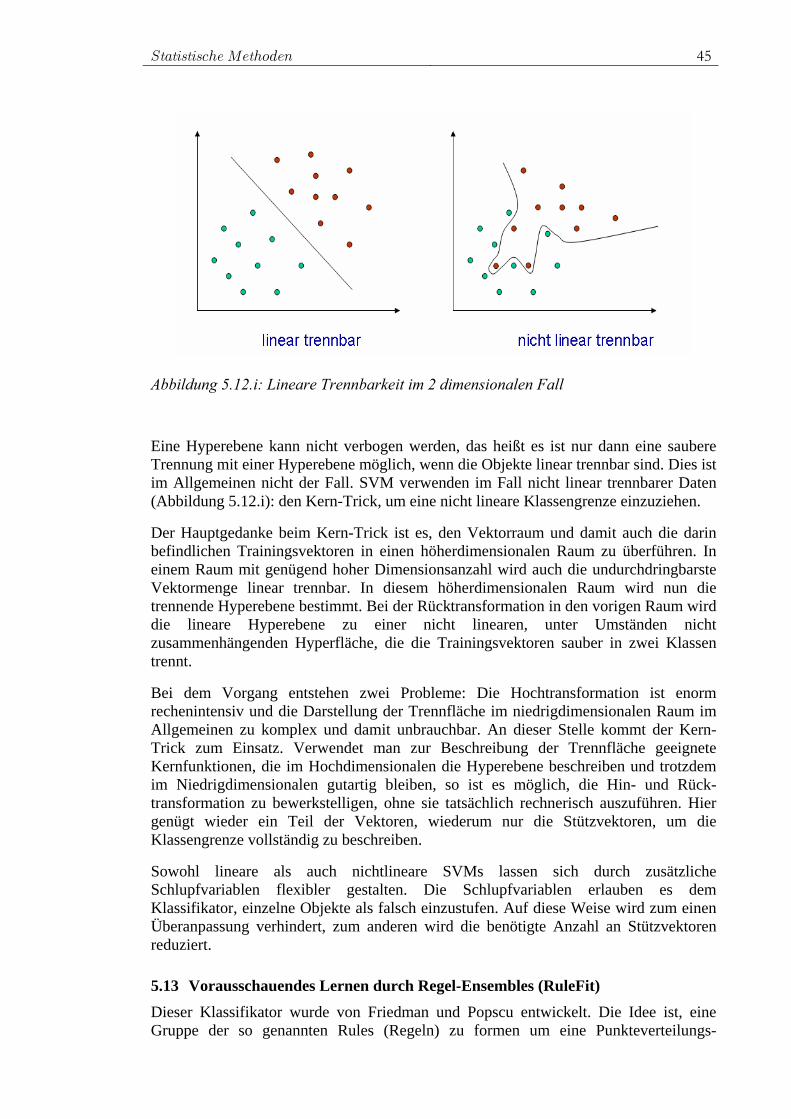
Statistische Methoden 45
Abbildung 5.12.i: Lineare Trennbarkeit im 2 dimensionalen Fall Eine Hyperebene kann nicht verbogen werden, das heißt es ist nur dann eine saubere Trennung mit einer Hyperebene möglich, wenn die Objekte linear trennbar sind. Dies ist im Allgemeinen nicht der Fall. SVM verwenden im Fall nicht linear trennbarer Daten (Abbildung 5.12.i): den Kern-Trick, um eine nicht lineare Klassengrenze einzuziehen.
Der Hauptgedanke beim Kern-Trick ist es, den Vektorraum und damit auch die darin befindlichen Trainingsvektoren in einen höherdimensionalen Raum zu überführen. In einem Raum mit genügend hoher Dimensionsanzahl wird auch die undurchdringbarste Vektormenge linear trennbar. In diesem höherdimensionalen Raum wird nun die trennende Hyperebene bestimmt. Bei der Rücktransformation in den vorigen Raum wird die lineare Hyperebene zu einer nicht linearen, unter Umständen nicht zusammenhängenden Hyperfläche, die die Trainingsvektoren sauber in zwei Klassen trennt.
Bei dem Vorgang entstehen zwei Probleme: Die Hochtransformation ist enorm rechenintensiv und die Darstellung der Trennfläche im niedrigdimensionalen Raum im Allgemeinen zu komplex und damit unbrauchbar. An dieser Stelle kommt der Kern-Trick zum Einsatz. Verwendet man zur Beschreibung der Trennfläche geeignete Kernfunktionen, die im Hochdimensionalen die Hyperebene beschreiben und trotzdem im Niedrigdimensionalen gutartig bleiben, so ist es möglich, die Hin- und Rück-transformation zu bewerkstelligen, ohne sie tatsächlich rechnerisch auszuführen. Hier genügt wieder ein Teil der Vektoren, wiederum nur die Stützvektoren, um die Klassengrenze vollständig zu beschreiben.
Sowohl lineare als auch nichtlineare SVMs lassen sich durch zusätzliche Schlupfvariablen flexibler gestalten. Die Schlupfvariablen erlauben es dem Klassifikator, einzelne Objekte als falsch einzustufen. Auf diese Weise wird zum einen Überanpassung verhindert, zum anderen wird die benötigte Anzahl an Stützvektoren reduziert.
5.13 Vorausschauendes Lernen durch Regel-Ensembles (RuleFit) Dieser Klassifikator wurde von Friedman und Popscu entwickelt. Die Idee ist, eine Gruppe der so genannten Rules (Regeln) zu formen um eine Punkteverteilungs-

Statistische Methoden 46
Funktion mit hoher Effizienz zu erzeugen. Jede Rule ir wird durch eine bestimmte Anzahl an Schnitten definiert. Wie zum Beispiel:
r (x) I(x . ) I(x . ),r (x) ...1 2 3
2
= <12 5 ⋅ > 37 0=
( .5 49)
Wobei ix für die Eingabe-Variable steht, und I(...) die Wahrheit des Arguments bestimmt. Eine Regel (Rule) auf ein bestimmtes Event angewandt, ist nur dann nicht Null wenn alle seiner Schnitte erfüllt sind, in diesem Fall wird 1 ausgegeben. Der einfachste Weg um eine Gruppe von Regeln zu formen, ist es sie aus einem Entscheidungsbaum herauszunehmen (Kapitel 5.9.). Jeder Knoten in einem Baum (außer dem Stamm) führt zu einer Sequenz von Schnitten, die erforderlich sind, um die Knoten vom Stamm aus zu erreichen, und kann als Regel (Rule) betrachtet werden. Auf diese Weise sind für den Baum in Abbildung 5.9.i eine Gesamtzahl von 8 Regeln (Rules) herauszunehmen. Linearkombinationen der Regeln in der Gruppe werden mit Koeffizienten (Rule Weights) gebildet, indem ein festgelegter Minimierungsprozess anwendet wird [26]. Die daraus resultierende Linearkombination aller Regeln ist als eine Score-Funktion definiert, welche den RuleFit-Ausgabewert RFy (x) liefert. In manchen Fällen ist ein sehr langes Regelensemble erforderlich, um eine bewertungsfähige Unterscheidung zwischen Signal und Untergrund zu erzeugen. Eine besonders schwierige Situation entsteht, wenn die wahre (aber unbekannte) Scoring-Funktion durch eine lineare Kombination der Inputvariablen beschrieben wird. In solchen Fällen, würde zum Beispiel eine Fischer-Diskriminante eine gute Leistung erbringen. Um das Regel-Optimierungsziel zu vereinfachen, wird eine lineare Kombination der Inputvariablen in TMVA zu dem Modell dazugegeben. Der Minimierungsprozess wird dann die passenden Koeffizienten für die Regeln und die linearen Gleichungen ausgeben.
5.14 Rechtwinklige Schnitt-Optimierung
Der einfachste und am häufigsten benutzte Klassifikator für die Auswahl der Signalereignisse aus einer gemischten Stichprobe von Signal und Untergrund ist die Anwendung eines Ensembles von rechteckigen Schnitten in unterschiedlichen Variablen. Im Gegensatz zu allen anderen Klassifikatoren liefern Schnitte als Klassifikatoren eine binäre Antwort (Signal oder Untergrund). Die Optimierung der Teilstücke von TMVA maximiert die Untergrund-Ablehnung bei einer bestimmten Signal-Effizienz und scannt das gesamte Spektrum der letzteren Menge. Bei bestimmten Analyse-Optimierungen, für die zum Beispiel die Signal-Signifikanz maximiert wird, ist es notwendig, dass die erwarteten Signal- und Untergrund-Ergebnisse bekannt sind, bevor man die Cuts anwendet. Für eine Mehrzweck-Diskriminierung ist dies nicht der Fall und wird deshalb von TMVA nicht benutzt. Das Übergehen des Schnitt-Ensembles zu einer maximalen Signifikanz entspricht einem bestimmten Arbeitspunkt in der Effizienzkurve, und kann damit leicht abgeleitet werden, nachdem der Cut (Schnitt)-Optimierungs-Scan abgeschlossen wurde. TMVA geschnittene Optimierung erfolgt mit der Verwendung von multivariaten Parameter-Fittern. Dies ist gegeben durch Klasse FitterBase. Jede Fitter-Implementierung (Kapitel 5.8) kann verwendet werden, wobei jedoch wegen des nicht eindeutigen Lösungsraums nur Monte-Carlo-Probenahme,

Statistische Methoden 47
simuliertes Abkühlen und der genetischen Algorithmus befriedigende Ergebnisse zeigen. Verwendung von Minuit zeigten oft nicht zufrieden stellende Ergebnisse.
5.15 FDA (Function Discriminant Analysis) Das gemeinsame Ziel aller Diskriminatoren ist die Bestimmung einer optimalen Trennung von Funktion im multivariaten Raum vertreten durch die Input-Variablen. Die Fisher-Diskriminante löst dieses analytisch für den linearen Fall, während die künstlichen neuronalen Netze, SVM oder gewichtete Entscheidungsbäume nichtlineare Annäherungen bieten mit - im Prinzip - beliebiger Genauigkeit, wenn genug Trainings-Statistiken verfügbar sind und die gewählte Struktur flexibel genug ist. Die Funktion-Diskriminanzanalyse (FDA) bietet eine Zwischenlösung für das Lösen relativ einfacher Probleme und teilweise nichtlinearer Probleme. Man wählt eine gewünschte Funktion mit einstellbaren Parametern und passt diese auf den Signal- (Untergrund)-Funktionswert so nahe wie möglich an 1 (0) an. Der Vorteil gegenüber den stärkeren und automatisch nichtlinearen Diskriminatoren ist die Einfachheit und Transparenz des Diskriminierungausdrucks. Ein Nachteil ist, dass die FDA unterperformed wird für Probleme mit komplizierten, phasenraumabhängigen, nichtlinearen Korrelationen.
5.16 Künstliches Neuronales Netzwerk (KNN) Die Neuroinformatik hat seit den 80er Jahre einen Aufschwung erfahren. Der Grund dafür ist sicherlich die Leistungssteigerung bei den Computern. Denn damit wurden Simulationen von komplexeren Gehirnmodellen und künstlichen neuronalen Netzen erst möglich. Es gibt Probleme, welche sich nicht in einen Algorithmus fassen lassen. Dafür kann unter anderem auf KNN zurückgegriffen werden. Ein KNN oder ANN (Artificial Neural Network) ist ganz allgemein jede simulierte Sammlung von miteinander verbundenen Neuronen, wobei jedes Neuron eine bestimmte Reaktion auf einen bestimmten Satz von Eingangssignalen zeigt. Durch die Eingabe eines externes Signal an einige so genannte (Input-) Neuronen wird das Netzwerk in einen definierten Zustand gebracht, der aus der Reaktion von einem oder mehreren (Output-) Neuronen gemessen werden kann. Mit anderen Worten ist ein neuronales Netz eine Zuordnung von einem Raum (der Input-Variablen nx , ..., x1 ) auf einen, im Falle eines Signal-versus-Untergrund-Diskriminierungsproblems, eindimen-sionalen Raum der Output Variable y . Die Zuordnung ist nichtlinear, wenn zumindest ein Neuron über eine nichtlineare Reaktion auf ihren Input wiedergibt. Drei TMVA-neuronales-Netz-Implementierungen stehen dem Benutzer zur Verfügung. Die erste wurde mit einem Fortran-Code entwickelt, an der Université Blaise Pascal von Clermont-Ferrand, der zweite ist die Umsetzung des ANN, die mit ROOT. Das Dritte ist ein neu entwickeltes neuronales Netz (MLP). Es ist schneller und flexibler als die beiden anderen und ist das empfohlene neuronale Netzwerk für die Verwendung mit TMVA. Alle drei neuronale Netze sind Feed-Forward-Multilayer-Perzeptrons. In Feed-Forward-Netzwerken sind die Neuronen geschichtet angeordnet. Die Verbindungen sind als streng nur in eine Richtung, jeweils zur nächst höheren Schicht, von der Eingabeschicht bis zur Ausgabeschicht laufend (ohne Rückkopplung) zu verstehen. Sehr oft, in unseren Fällen immer, ist jedes Neuron einer Schicht mit allen Neuronen einer nachfolgenden Schicht verknüpft (vollverknüpft). Das Verhalten eines künstlichen neuronalen Netzes wird durch die Gliederung der Neuronen, die Gewichte der Neuronen-Verbindungen untereinander und durch die Reaktion der Neuronen auf die Eingabe, welche durch die Neuron-Antwort-Funktion ρ beschrieben wird, ausgedrückt.

Statistische Methoden 48
Im Prinzip kann ein neuronales Netz mit n Neuronen n² Richtungs-Verbindungen haben. Die Komplexität kann durch die Organisation der Neuronen in Schichten und der zuvor genannten Verbindungen reduziert werden (Abbildung 5.16.i). Diese Art der neuronalen Netze wird als Multilayer-Perzeptron bezeichnet. Alle neuronalen Netz-Implementierungen in TMVA sind von diesem Typ (auch Neurobayes®). Die erste Schicht eines Multilayer-Perzeptrons ist die Input-Schicht. Die Letzte ist die Ausgabe-Schicht. Alle anderen Schichten, sind verborgene Schichten. Für ein Einstufungsproblem mit n Input-Variablen und 2 Ausgabe Klassen, besteht die Input-Schicht aus n Neuronen, welche die Eingabewerte nx , ..., x1 besitzen und einem Neuron in der Ausgabeschicht, welche die Ausgabe-Variable enthält, also die Schätzfunktion
ANNy . Jede direkte Verbindung zwischen dem Ausgang (Output) von einem Neuron und der Eingabe (Input) eines anderen hat ein zugehöriges Gewicht. Der Wert des Neuronenoutputs wird mit dem Gewicht multipliziert und als Eingabewert für das nächste Neuron verwenden.
Abbildung 5.16.i: Multilayer Perzeptron mit einer versteckten Schicht
Abbildung 5.16.ii:Einzelnes Neuron j in Schicht l mit n Input Verbindungen. Die
eintreffenden Verbindungen führen ein Gewichtung ( l )ijw −1 mit sich.
Die Neuron-Antwort-Funktion ρ überführt den Neuron-Eingang ni , ..., i1 auf den Neuron-Output (Abbildung 5.16.ii). Es kann oft eine Trennung in eine n →

Statistische Methoden 49
Synapsenfunktion κ und eine → Neuronaktivierungsfunktion α vorgenommen werden, so dass ρ = α κ ist. Die Funktionen α und κ kann die folgenden Formen annehmen:
Summe
Summe der Quadrate
Summe des Beträge
n( l ) ( l ) ( l )
j i iji
n( l ) ( l ) ( l ) ( l ) ( l ) ( l ) ( l )
n j nj j i iji
n( l ) ( l ) ( l )
j i iji
w y w
: (y , ..., y |w , ..., w ) w (y w )²
w |y w |
0=1
1 0 0=1
0=1
⎧+⎪
⎪⎪
κ → +⎨⎪⎪
+⎪⎩
∑
∑
∑
( .5 50 )
Linear
Sigmoid
Tanh
Radial
.kx
x x
x .x
x²/
x
e: x
e ee ee
−
−
−
− 2
⎧⎪ 1⎪1+⎪α → ⎨ −⎪⎪ +⎪⎩
( .5 51 )
Die Zahl der verborgenen Schichten in einem Netzwerk und die Zahl der Neuronen in diesen Schichten sind konfigurierbar über die Option HiddenLayers (nur in TMVA). Beim Aufbau eines Netzes sollte man folgendes berücksichtigen. Das Theorem von Weierstrass, welches besagt das für ein Multilayer-Perzeptron eine einzige verborgene Schicht ausreichend ist, um annähernd ein gutes Ergebnis zu erhalten, da ein beliebig große Zahl von Neuronen in der versteckten Schicht sein kann. Wenn die verfügbare Rechenleistung und die Größe der Stichprobenausbildungsdaten reichen, kann man damit eine Erhöhung der Zahl der Neuronen in der versteckten Schicht versuchen, bis die optimale Leistung erreicht ist. Es ist möglich, die gleiche Performance zu erreichen wie mit einem Netzwerk mit mehr als einer versteckten Schicht und einer potenziell viel kleineren Gesamtzahl von versteckten Neuronen. Dies würde zu kürzeren Ausbildungszeiten und einem robusteren Netzwerk führen. Der am häufigsten verwendete Algorithmus zur Anpassung der Gewichtsoptimierung ist die Einstufungsleistung eines neuronalen Netzes, die so genannte Zurück-Vermehrung (back propagation). Sie gehört zur Familie der überwachten Lernmethoden, wo die gewünschte Leistung für jedes Eingangsereignis bekannt ist. Zurückvermehrung wird von allen neuronalen Netzen in TMVA angewendet. Die Ausgabe eines Netzes (hier der Einfachheit halber, eine einzige versteckte Schicht mit einer Tanh-Aktivierungsfunktion und Aktivierung einer linearen Funktion in der Output-Schicht) ist gegeben durch
varh h nn n
( ) ( ) ( ) ( )ANN j j i ij j
j j i
y y w tanh x w w2 2 1 21 1
=1 =1 =1
⎛ ⎞= = ⋅⎜ ⎟
⎝ ⎠∑ ∑ ∑ ( .5 52 )
wobei varn und hn die Anzahl der Input-Variablen und der versteckten Schicht ist. ( )
ijw 1 ist die Gewichtung zwischen dem Inputschichtneuron i und dem Versteckteschichtneuron. j . ( )
jw 21 ist die Gewichtung zwischen dem Versteckteschichtneuron j und dem
Outputneuron. Es wurde hier außerdem die Summe als Synapsenfunktion κ verwendet. Während des Lernprozesses des Netzes wird mit N Trainingsereignissen gearbeitet x
vara n a(x , ..., x )1= , a , ..., N=1 . Für jedes Trainingsereignis a wird der neuronale

Statistische Methoden 50
Netzwerkoutput ANNy berechnet und mit dem gewünschten Ausgangswert ay ,∈ 1 0 (1 für Signal-Events und 0 für Untergrund-Events) belegt. Eine Fehlerfunktion E , welche die Netzantwort mit der gewünschten Antwort vergleicht, ist definiert durch
x x w x | wN N
N a a ANN,a aa a
ˆE( , ..., | ) E ( ) (y y )²1=1 =1
1= = −
2∑ ∑ ( .5 53 )
w bezeichnet das Ensemble der einstellbaren Gewichte im Netzwerk. Die Menge der Gewichte, die die Fehlerfunktion minimiert, kann mit der Methode des steilsten Abstiegs (oder Gefälles) gefunden werden, vorausgesetzt, dass die Neuron-antwortfunktion differenzierbar ist im Hinblick auf die Input-Gewichte. Ausgehend von einem zufälligen Satz von Gewichten w( )ρ werden die Gewichte aktualisiert, indem sie einen kleinen Weg im w-Raum in die Richtung wE−∇ zurücklegen. ww w( ) ( ) Eρ+1 ρ= − η∇ ( .5 54 ) wobei η eine positive Zahl ist und die Lernrate darstellt. Die Gewichte, die mit der Output-Ebene zusammenhängen werden aktualisiert, indem
N N
( ) ( )aj ANN,a a j,a( )
a aj
ÖE ˆw (y y ) yÖw
2 21 2
=1 =11
Δ = −η = −η −∑ ∑ ( .5 55 )
und die Gewichte im Zusammenhang mit den verborgenen Schichten werden folgendermaßen aktualisiert:
N N
( ) ( ) ( ) ( )aij ANN,a a j,a j,a j j,a( )
a aij
ÖE ˆw (y y ) y ( y )Öw xÖw
1 2 2 211
=1 =1
Δ = −η = −η − 1−∑ ∑ ( .5 56 )
Diese Art der Ausbildung des Netzwerks wird als „Bulk“-Lernen bezeichnet, da die Summe der Fehler aller Trainingsevents zur Aktualisierung der Gewichte dient. Eine Alternative ist das so genannte Online-Lernen, wobei die Aktualisierung der Gewichte nach jedem Event erfolgt. Dieses Gewicht-Update ist auch aus Gleichung ( .5 55 ) und ( .5 56 ) durch das Entfernen des Summenterms erhältlich. In diesem Fall ist es wichtig, eine gut durchmischte Trainingsstichprobe zu haben. Online-Lernen ist die übliche Lernmethode in TMVA.
5.17 Kolmogorow-Smirnow-Test
Der Kolmogorow-Smirnow-Test (KS-Test), der nach A. N. Kolmogorow und W. I. Smirnow benannt wurde, ist ein statistischer Test, der die Gleichheit zweier Wahrscheinlichkeitsverteilungen überprüft. Er ist in TMVA enthalten um das Training auf Übertrainieren zu überprüfen. Dies kann ein Vergleich von der Verteilung zweier Stichproben sein oder ein Test dafür, ob eine Stichprobe einer vorher angenommenen Wahrscheinlichkeitsverteilung folgt. Der KS-Test ist, im Gegensaz zum ²χ -Test, auch für kleine Stichproben nutzbar. Er ist ein nicht-parametrischer Test und daher sehr stabil und unanfällig. Ein weiterer Vorteil besteht darin, dass die zu untersuchende Zufallsvariable keiner Normalverteilung folgen muss.

Werkzeuge 51
6 Werkzeuge
6.1 CMSSW CMSSW ist der Versuch, alle Datenanalyseschritte in einem Programm zu vereinen. Die Software ist immer noch im Aufbau, so dass annähert monatlich eine neuere Versionen erscheint. In dieser Arbeit wurde die Version 1_6_11 für die Analyse genutzt. CMSSW ist ein modulbasiertes Software System und wurde mit der objektorientierten Programmiersprache C++ geschrieben. Die implementierten Module für die Simulation und die Analyse können in eine Konfigurationsdatei eingestellt werden. Die Daten der Simulation werden im HepMC-Format gespeichert. Schnittstellen für Generator- und Detektor-Simulation sind auch implementiert. Daher ist es sehr einfach zu entscheiden ob eine Analyse auf Generator-Niveau durchführt wird oder eine Detektor-Simulation benutzt wird.
6.1.1 Konfigurationsdatei und sonstige Veränderungen Für diese Arbeit wurden Daten genutzt, die über das GRID zugänglich sind (siehe Kapitel 6.2). In der Konfigurationsdatei wurden sämtliche Filter angeschaltet. Zum Beispiel, dass jedes Event MET(Missing Transverse Energy) besitzt oder dass über jedes entstandene Teilchen ein vollständiger Satz von Informationen erhältlich ist. Dadurch gehen natürlich viele Ereignisse verloren. An dieser Stelle wurden noch keine Trigger genutzt, sondern zuvor alle Events zugelassen, die die zum Teil oben erwähnten Filter passiert haben. Für die Diplomarbeit wurde SusyAnalyzer (Version 01-02-00) verwendet und darin ein für diese Arbeit geschriebenes Programm implementiert, indem eigene Variablen festgelegt wurden. Außerdem wurde hier eine sehr schwache Vorauswahl getroffen, ab wann ein Event übernommen werden soll. Eine detaillierte Beschreibung kann Kapitel 7 entnommen werden.
6.2 Grid Bei dem Konzept des Grid-Computing handelt es sich um eine Infrastruktur, die eine integrierte, gemeinschaftliche Verwendung von meist geographisch getrennt liegenden, autonomen Ressourcen erlaubt. Der Begriff Grid hat seinen Ursprung im Vergleich dieser Technologie mit dem Stromnetz (Power Grid). Der zentrale Verwaltungsknoten, an den die so genannten virtuellen Jobs geschickt und wieder abgeholt werden, steht am DESY in Hamburg. Das Grid sollte so genutzt werden, dass man seine Jobs an die Cluster schickt, an denen die riesigen Datenmengen liegen, die man für seine Analyse benutzten möchte. Vor Ort wird dann eine Rechenumgebung geschaffen, gerechnet und das Ergebnis zurückgeschickt. Im Rahmen dieser Arbeit wurde ein Skript geschrieben welches einen gewünschten Job abschickt und zurückholt. Dabei wird eine CMSSW- sowie eine SusyAnalyzer-Version auf einen lokalen PC installiert und von dort aus das Programm auf die dort liegenden Daten (in meinem Fall rekonstruierte Daten) angewendet. Dabei entstehen ROOT-Dateien in denen nun die selbst definierten Variablen enthalten sind, die dann für die

Werkzeuge 52
eigentliche Analyse verwendet werden (sobald sie lokal vorliegen). Das heißt, dass die komplette Analyse der statistischen Methoden in dieser Diplomarbeit an einem Rechner durchgeführt wurde. Es ist keine zufrieden stellende Lösung, dass man erst seine eigenen Variablen selbst festlegen muss, um sie nutzbar zu machen. In der Zukunft wird man die Dateien, die im Grid vorliegen direkt für eine Analyse nutzbar machen müssen.
6.3 TMVA Das Toolkit for Multivariate Analysis (TMVA) bietet eine ROOT-integrierte Umgebung für die parallele Verarbeitung und Auswertung von hoch entwickelten multivariaten Einstufungsverfahren. TMVA ist speziell für die Bedürfnisse der High-Energy-Physics (HEP)-Anwendungen konzipiert worden. Es ist auf der Homepage [28] frei erhältlich und erst teilweise in CMSSW eingebunden. Das Paket umfasst: - Rechtwinklige Schnitt-Optimierung - Projizierende Likelihood-Schätzung - Multidim. Likelihood-Schätzung (PDE,k-NN) - Lineare und nichtlineare Diskriminanzanalyse (H-Matrix, Fisher, FDA) - Künstliche Neuronale Netzwerke (Neurobayes® Plugin und drei weitere) - SVM - Gewichtete Entscheidungsbäume - RuleFit Das Softwarepaket besteht aus objektorientierten Implementierungen in C + + / ROOT. Für jedes dieser Diskriminierungstechniken gibt es Hilfswerkzeuge wie Parameter-Fitting und Transformationen. Es bietet Training, Prüfung und Leistungsbewertungs-Algorithmen und Visualisierungsskripte. Beschreibungen aller TMVA-Klassifikatoren und einige deren Einstellmöglichkeiten sind in Kapitel5, Kapitel 7.3 und in [28] zu finden. Ihre Ausbildung und Prüfung erfolgt durch den Einsatz von Daten, die in Form von ROOT-Trees oder Text-Dateien geliefert werden, in denen jedes Ereignis ein individuelles Gewicht erhalten kann. Das ist wichtig, wenn zum Beispiel mehr Signaldaten als Untergrunddaten vorhanden sind. Vorauswahl-Anforderungen und Transformationen können auf diese Daten angewandt werden. TMVA unterstützt die Verwendung von Variablen-Kombinationen und Formeln. Es arbeitet in einem transparenten Manufaktur(factory)-Modus um einen unvor-eingenommenen Performance-Vergleich zwischen den Klassifikatoren zu garantieren. Alle Klassifikatoren sehen die gleichen Trainings und Prüfdaten. Eine Factory-Klasse organisiert die Interaktion zwischen dem Benutzer und der Analyse-TMVA-Schritte. Sie führt Voranalyse und Vorverarbeitung der Trainigsdaten zur Bewertung der grundlegenden Eigenschaften der Diskriminierungsvariablen, welche dann als Input für die Klassifikatoren dient, durch. Die lineare Korrelations-Koeffizienten der Input-Variablen werden berechnet und angezeigt und eine vorläufige Rangliste abgeleitet (später ersetzt durch Klassifikator-spezifische Variable Rankings). Die Variablen können linear transformiert (individuell für jeden Klassifikator) und dadurch auf einen Nicht-Korrelation-variablen Raum projiziert werden. Um die Signal-Effizienz- und Untergrund-Ablehnung-Performance der Klassifikatoren zu vergleichen, gibt der Analyse-Job tabellarische Ergebnisse für einige Benchmark-Werte. Außerdem bietet es noch anderen Kriterien, wie eine Messung der Trennung und die maximale Signal-Signifikanz. Die Glatte Effizienz im Vergleich zu den Untergrund-Ablehnungs-Kurven ist in einer ROOT-Ausgabe-Datei, zusammen mit anderen grafischen Auswertungen

Werkzeuge 53
zugänglich. Diese Ergebnisse können mit ROOT-Makros über eine grafische Benutzeroberfläche dargestellt werden. TMVA läuft als ein ROOT-Skript oder als eigenständige ausführbare Datei. Es wurde ein ROOT-Skript in der aktuellsten Version 3_9_2, bei der im Rahmen dieser Arbeit auch mitgewirkt wurde, verwendet, da es bis zuletzt nicht möglich war das Neurobayes®-Plugin in TMVA als ausführbare Datei zu integrieren, was vermutlich auf Fehler der Neurobayes® Bibliothek zurückzuführen ist. Auf diese Bibliothek bestand allerdings kein Zugriff. Eine ausführbare Datei wäre von erheblichem Vorteil, weil dann nicht immer erst eine ROOT-Umgebung geschaffen werden müsste um TMVA anzuwenden und dadurch auch das GRID genutzt werden könnte. Jeder Klassifikator, der trainiert wurde, schreibt seine Ergebnisse in eine (Gewicht-) Datei, die in der Standard-Konfiguration ein lesbares Text-Format besitzt. Eine Reader-Klasse wird zur Verfügung gestellt, die die Gewicht-Dateien liest und interpretieren kann. Alle Klassifikatoren laufen mit Standard-Konfigurationen, die natürlich für seine Problemstellungen richtig eingestellt werden sollten, um das möglichst beste Ergebnis zu erhalten. Individuelle Optimierung und Anpassung der Klassifikatoren erfolgt über Konfigurations-Strings.
6.4 Neurobayes® Die Techniken und Algorithmen von Kapitel 5.16 und 5.4.1 werden in dem Software-Paket Neurobayes®, welches als Plugin in TMVA eingefügt wurde, benutzt. Die genaue Benutzung ist in [29] zu finden. Neurobayes® wurde ursprünglich von Michael Feindt und anderen Mitgliedern des Instituts für Experimentelle Kernphysik der Universität Karlsruhe (TH) umgesetzt. Der große Bereich der Anwendung über die Teilchenphysik hinaus veranlasste sie das Unternehmen Phi-T30zu gründen. Seit 2002 ist Neurobayes® weiter entwickelt und angewandt worden.
30 Physics Information Technologies GmbH Karlsruhe

Werkzeuge 54

Analyse 55
7 Analyse Dieser Teil der Arbeit beschäftigt sich hauptsächlich damit, wie die verschiedenen statistischen Methoden (vergleiche Kapitel 5) für die Suche nach supersymmetrischen Ereignissen sich zunutze gemacht werden können und welche, wann und wie am besten eingesetzt werden sollten. Im Folgenden wird zunächst darauf eingegangen mit welchen Daten gearbeitet wurde. Anschließend werden die Tests der statistischen Methoden vor dem Training erläutert. Dann wird das eigentliche Training besprochen und schließlich werden die Ergebnisse diskutiert.
7.1 Daten durch CMSSW und Grid In dieser Diplomarbeit wurden SUSY-Teilchen des LM9-Punktes als Signal genutzt. Der LM9-Punkt wird durch die mSUGRA Parameter folgendermaßen beschrieben:
/
m GeVm GeV
tanAsign( )
0
1 2
0
= 1450=175
β = 50= 0
μ = +1
Für den Untergrund wurden tt -, W+Jets- und Z+Jets-Ereignisse gewählt. Diese Daten kommen aus der so genannten CSA07 Produktion. Es handelt sich dabei um Daten-Ressourcen im Grid, welche mit den Generatoren Alpgen (Untergrund) und Softsusy+Pythia (Signal) produziert wurden. Es wurden große Mengen von Daten produziert, über die frei verfügt werden kann. Die Lage der Daten ist über das Internet [30] erhältlich: Als Untergrund wurde der CSA07Allevents-Chowder Datensatz gewählt (Tabelle 7.1.i), der aus ca. 5 Millionen Z+Jets-, 21,5 Millionen W+Jets- und 2 Millionen tt -Events aufgebaut ist. Für die Z+Jets-und W+Jets-Events entspricht dies ca. fb−11 und für die tt -Events ca. 2 fb−1 . Dabei wird ein Fehler zu Gunsten der Analyse gemacht. Wie in Tabelle 7.1.i gezeigt, sind sowohl bei Z+Jets als auch W+Jets, bei 0 Jets weniger als fb−11 vorhanden. Da aber vor dem Training auf der Anzahl der Jets geschnitten wird,
fällt es nicht ins Gewicht. Bei den LM9-Events handelt es sich um ca. 3,6 fb−1 .

Analyse 56
Events cs*br[pb] Int Lum[1/fb]/Z0jet 3251851 4400 0,74/Z1jet 944726 935 1,01/Z1jet 36135 30 1,2/Z2jet 289278 271 1,07/Z2jet 35285 28 1,26/Z3jet 73182 68 1,08/Z3jet 24316 13 1,87/Z4jet 33083 14 2,36/Z4jet 6616 4,3 1,54/Z5jet 12136 8,8 1,38/Z5jet 5966 4,9 1,22/W0jet 8796412 45000 0,195/W1jet 9088026 9200 0,99/W1jet 247013 250 0,99/W2jet 2380315 2500 0,95/W2jet 287472 225 1,28/W3jet 352855 590 0,6/W3jet 117608 100 1,18/W4jet 125849 125 1,01/W4jet 39719 40 0,99/W5jet 62238 85 0,73/W5jet 43865 40 1,1/tt0j 1456646 619 2,35/tt1j 361835 176 2,06/tt2j 81215 34 2,39/tt3j 14036 6 2,34/tt4j 5352 1,5 3,57
Tabelle 7.1.i: CSA07Allevents-Chowder Datensatz Zusammensetzung Um die Daten nutzen zu können, mussten zuerst an das Problem angepasste Variablen gebildet werden. So wurden beispielsweise die Winkel zwischen zwei Jets berechnet. Diese angepassten Daten wurden dann in eine ROOT-Datei geschrieben, die für die Analyse verwendet wurde. Pro Event wurden 218 Variable definiert, die je zur Hälfte aus Generatordaten und rekonstruierten Daten bestehen. Die rekonstruierten Daten wurden für die spätere Analyse benutzt. Die Variablen, die in das Training gelangt sind, werden in Kapitel 7.3 et seq. vorgestellt. Damit keine Fehler bei der späteren Analyse auftreten (Tabelle 7.1.ii) wurden in der Konfigurationsdatei alle Filter eingeschaltet. Der Hemisphären-Filter (also von welchem der 2 Urteilchen das aktuelle Teilchen kommt) wurde deaktiviert. Durch Auslassen der Prüfung, ob nur Events mit einem lesbaren Eintrag in der Hemisphären-Variable übernommen werden, sollten nach der Speicherung mehr Daten zur Verfügung stehen. Dadurch ist die Nutzung dieser Variable, um Fehler zu vermeiden, aus-geschlossen. Eine Nachträgliche Prüfung ergab, zumindest für Jets, keine Fehler in der besagten Variablen und konnte daher für die Analyse in Betracht gezogen werden. Außerdem wurden alle Trigger ausgeschaltet. Im Nachhinein wurde der L1-Trigger mit den entsprechenden Cuts [27] mit Hilfe eines root-Makros auf den gesamten Datensatz angewendet (Tabelle 7.2.i).

Analyse 57
PSet RejectEventParams = bool rej_NoTriggerData = false bool rej_NoL1fired = false bool rej_NoHLTfired = false bool rej_MissingRecoData = true bool rej_MissingTrackData = true bool rej_MissingCaloTowers = true bool rej_Empty = true bool rej_NoPrimary = true bool rej_BadHardJet = true bool rej_CleanEmpty = true bool rej_FinalEmpty = true bool rej_BadNoisy = true bool rej_BadMET= true bool rej_BadHemis = false
Tabelle 7.1.ii:Gefilterte Events in der cfg-Datei von CMSSW Zusätzlich musste noch getestet werden, ob es sich bei den Jets um Elektronen handelt (Doublecounting) und falls ja, wurden diese Jets aus den Samples entfernt. Dafür war ein Skript erforderlich, das auf alle Daten angewendet werden musste. Mit diesem Skript wurden die Winkel und Impuls von Jets und Elektronen verglichen. Ein Durchlauf der Daten nahm fünf Tage Rechenzeit in Anspruch. Es musste oft über alle Daten gelaufen werden, weil sich immer wieder Verbesserungen ergaben. Zum Beispiel sollte die Trennung der Suppe in Z+Jets-, W+Jets- und tt -Events anfangs nicht erfolgen, welche sich im Nachhinein als nicht trivial herausstellte. Das Signal wurde Event für Event zufällig in zwei Samples geteilt, zum Testen des Trainings und das Training selbst.
Org.Anzahl
Events
nach den Filtern und fehlerhaften ROOT-Dateien %
nach L1-Trigger % 1/fb faktor
ttbar 1919084 1566882 0,82 1558992 0,81 2,00 1,61 wjets 21541372 10187381 0,47 7982447 0,37 1,00 5,55 zjets 4712574 2640789 0,56 2193676 0,47 1,00 4,68 bkg_tot 28173030 14397705 0,51 1,2E+07 0,42 - lm9_sft 108357 78911 0,73 71886 0,66 3,60 1,00 Tabelle 7.2.i:Verbleibende Daten für die Analyse und die Faktoren für die spätere
Analyse: Von den Hintergrunddaten bleiben ca. 42% und vom Signal ca. 66% nach Durchlaufen der Filter und Trigger für die Analyse übrig.
Die resultierenden Faktoren sorgen für eine gleichwertige Verwendung der rekonstruierten Daten in der späteren Analyse.
7.2 Die Benutzung von TMVA Eine typisches TMVA-Analyse besteht aus zwei unabhängigen Phasen: Zum einen aus der Phase des Trainings, in der die multivarianten Klassifikatoren geschult, getestet und bewertet werden und zum anderen aus der Applikations-Phase, bei der die ausgewählten Klassifikatoren zur Einstufung konkreter Problemdaten auf die sie vorher trainiert wurden angewendet werden.

Analyse 58
In der Trainingsphase wird die Kommunikation des Anwenders mit den Datensätzen und den Klassifikatoren über das so genannte „Factory“-Objekt geregelt, welches am Anfang des Programms geschaffen wird. Die TMVA-Factory bietet Funktionen, um die Trainings- und Test-Datensätze festzulegen, die unterschiedlichen Input-Variablen zu registrieren und die Menge der multivariaten Klassifikatoren (auch Neurobayes®) zu nutzen. Die Daten wurden in Form von zwei ROOT-Dateien (Signal und Untergrund) eingelesen. Solange die Variablen in jeder Datei den gleichen Namen tragen, können beliebig viele ROOT-Dateien (Chain), beispielsweise für das Signal, eingelesen werden. Das Einlesen von txt-Dateien ist natürlich auch möglich. Während des Trainings wurden die Daten immer zu 90% für das Training und 10% zur Überprüfung eines Übertrainings genutzt. Dies führte zu den besten Ergebnissen. Es gibt verschiedene Möglichkeiten, sich aus dem Sample die Daten für das Training auszuwählen. Die Random-Funktion stellte sich als am geeignetsten heraus. Zusätzlich mussten die Trainingsdaten noch mit Gewichtsfaktoren multipliziert werden, um für Chancengleichheit von Signal- und Untergrund-Events zu sorgen (Tabelle 7.2.i). Es besteht die Möglichkeit zur Normierung der Input-Variablen vor der Verwendung in einem Klassifikator. Normierung ist sinnvoll, wenn der Variablenoutput oder die Koeffizienten von Variablen verglichen werden. Dies ist der Fall für Fisher, FDA und neuronale Netze. Folgenden Klassifikatoren unterstützen die Normierung nicht: PDERS, k-NN, BDT und RuleFit. Nach der Konfiguration führt die Factory das Training, die Prüfung und die Bewertung der gebuchten Klassifikatoren aus. Die Factory klassifiziert den Datensatz und führt eine vorläufige Beurteilung der Inputsignalvariablen durch, die von den Klassifikatoren genutzt werden. Zum Beispiel sind dies die Berechnung der linearen Korrelations-koeffizienten und die Einstufung der Variablen nach ihrer Trennungsstärke. Klassi-fikator-Ergebnis ("Gewicht")-Dateien werden nach der Trainingsphase erstellt. Die in Frage kommenden Klassifikatoren werden im folgenden Kapitel behandelt. Außerdem wird auf deren, im Rahmen dieser Arbeit erschlossene, geeignetste Konfiguration eingegangen. Die Anwendung der Ergebnisse des Trainings auf einen Datensatz einer unbekannten Probenzusammensetzung wird durch das Objekt „Reader“ veranschaulicht. Während der Initialisierung registriert der Benutzer die Input-Variablen zusammen mit ihren lokalen Speicher-Adressen, und bucht die Klassifikatoren, die sich während der Trainingsphase am besten geeignet haben. Als Buchungs-Argument wird der Name der Gewicht-Datei angegeben. Die Gewicht-Datei enthält nach dem Training für jeden der Klassifikatoren eine vollständige und konsistente Konfiguration. Während der Event-Schleife werden die Input-Variablen für jedes Ereignis aktualisiert und das ausgewählte Klassifikator-Ergebnis berechnet.
7.2.1 Overtraining (Übertrainieren von Klassifikatoren) Overtraining tritt auf, wenn ein maschinelles Lernproblem zu wenige Freiheitsgrade besitzt, weil zu viele Parameter des Klassifikators an zu wenige Datenpunkte angepasst wurden. Die Empfindlichkeit auf Overtraining hängt vom Klassifikator ab. Eine Fisher-Diskriminanzanalyse kann kaum übertrainiert werden, während ohne entsprechende Gegenmaßnahmen BDTs aufgrund ihrer großen Anzahl von Knoten in der Regel Overtraining erfahren. Overtraining führt zu einer scheinbaren Erhöhung der Einstufung der Leistung, wenn die Messung über die Trainings-Probe läuft und zu einem realen Rückgang bei der Performance führt, falls die Messung an einer unabhängigen Probe durchgeführt wird. Eine effiziente Art und Weise um Overtraining zu messen ist daher

Analyse 59
ein Vergleich der Ergebnisse der Einstufung zwischen Trainings- und Testproben. Eine solche Prüfung erfolgt durch TMVA. Es gibt verschiedene Klassifikator-spezifische Lösungen um Overtraining zu verhindern. Zum Beispiel können Likelihood-Distributionen geglättet werden, bevor ihre Form interpoliert wird. Ebenso können Kern-Dichte-Schätzer, vor der PDF-Bildung, jedes Trainingsevent verzerren. Neuronale Netze können kontinuierlich auf die Konvergenz des Fehlers der Schätzfunktion zwischen Trainings- und Prüfungs-Samples überwacht werden. Das Training wird beendet, wenn die Probe ihr Minimum erreicht hat. Die Anzahl der Knoten im gewichteten Entscheidungsbäumen kann reduziert werden durch die Beseitigung unbedeutender Äste (tree pruning „Baum-Beschneidung“), usw.
7.2.2 Hilfsmittel für die Klassifikatoren Die optimale Klassifikator-Verwendung, für eine spezifische Analyse hängt stark vom Problem ab und es gibt keine allgemeinen Empfehlungen. Zur Erleichterung der Wahl berechnet TMVA eine Reihe von Benchmark-Mengen, die die Beurteilung der Leistung der Klassifikatoren auf eine unabhängige Probe erleichtern soll. Dabei handelt es sich um: • Die Signal-Effizienz bei drei Vertretern der Untergrund-Effizienz (die Effizienz ist
gleich 1−Ablehnung), wird aus einem Schnitt auf dem Klassifikator-Output gewonnen. Dabei ist auch der Bereich der Untergrund-Ablehnung gegenüber der Signal-Effizienz-Funktion gegeben(Beispiele: Abbildungen 7.4.2.iv und 7.4.2.vi ).
• Die Trennung (Separation) S²⟨ ⟩ eines Klassifikators y , sie ist definiert durch das
Integral
S B
S B
ˆ ˆ(y (y) y (y))²S² dy,
ˆ ˆ(y (y) y (y))1 −
⟨ ⟩ =2 +∫ (7.1)
wobei Sy (y) und By (y) die Signal-und Untergrund-PDFs von y sind. Die Trennung ist identisch Null für gleiche Signal- und Untergrund-Formen, und sie ist 1 für Formen ohne Überschneidung. (Beispiel: Abbildung 7.4.2.vi)
• Die Diskriminierungs-Signifikanz eines Klassifikators wird durch die Differenz zwischen den Klassifikatormittelwerten für Signal und Untergrund geteilt durch das Quadrat der Summe ihrer quadratischen Mittelwerte definiert. (Beispiel: Abbildung 7.4.2.vi)
• Klassifikations-Wahrscheinlichkeit (probability): Die Techniken zur Schätzung der
Formen der PDFs werden beim Likelihood-Klassifikator eingesetzt und können für jede Methode individuell angepasst werden. Die Wahrscheinlichkeit für das Ereignis i ein Signal zu sein ergibt sich aus
S SS
S S S B
ˆf y (i)P (i) ,
ˆ ˆf y (i) ( f ) y (i)⋅
=⋅ + 1− ⋅
(7.2)
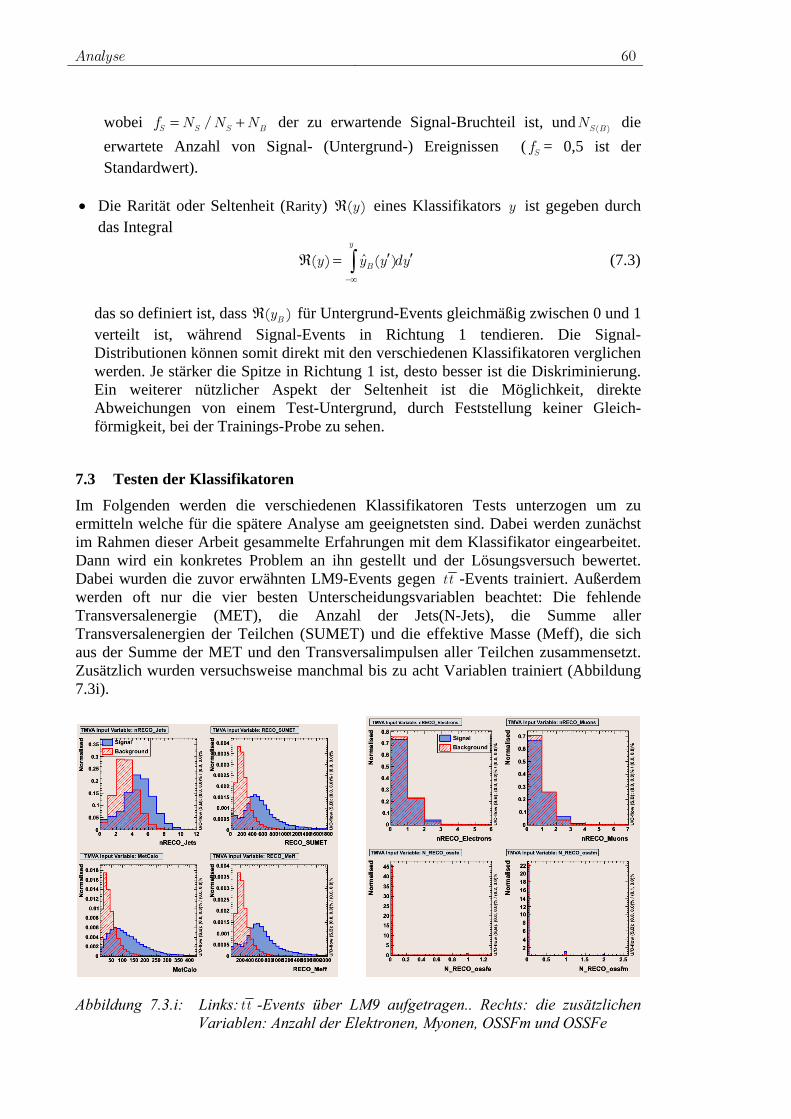
Analyse 60
wobei S S S Bf N / N N= + der zu erwartende Signal-Bruchteil ist, und S( B )N die erwartete Anzahl von Signal- (Untergrund-) Ereignissen ( Sf = 0,5 ist der Standardwert).
• Die Rarität oder Seltenheit (Rarity) (y)ℜ eines Klassifikators y ist gegeben durch das Integral
y
Bˆ(y) y (y )dy−∞
′ ′ℜ = ∫ (7.3)
das so definiert ist, dass B(y )ℜ für Untergrund-Events gleichmäßig zwischen 0 und 1 verteilt ist, während Signal-Events in Richtung 1 tendieren. Die Signal-Distributionen können somit direkt mit den verschiedenen Klassifikatoren verglichen werden. Je stärker die Spitze in Richtung 1 ist, desto besser ist die Diskriminierung. Ein weiterer nützlicher Aspekt der Seltenheit ist die Möglichkeit, direkte Abweichungen von einem Test-Untergrund, durch Feststellung keiner Gleich-förmigkeit, bei der Trainings-Probe zu sehen.
7.3 Testen der Klassifikatoren Im Folgenden werden die verschiedenen Klassifikatoren Tests unterzogen um zu ermitteln welche für die spätere Analyse am geeignetsten sind. Dabei werden zunächst im Rahmen dieser Arbeit gesammelte Erfahrungen mit dem Klassifikator eingearbeitet. Dann wird ein konkretes Problem an ihn gestellt und der Lösungsversuch bewertet. Dabei wurden die zuvor erwähnten LM9-Events gegen tt -Events trainiert. Außerdem werden oft nur die vier besten Unterscheidungsvariablen beachtet: Die fehlende Transversalenergie (MET), die Anzahl der Jets(N-Jets), die Summe aller Transversalenergien der Teilchen (SUMET) und die effektive Masse (Meff), die sich aus der Summe der MET und den Transversalimpulsen aller Teilchen zusammensetzt. Zusätzlich wurden versuchsweise manchmal bis zu acht Variablen trainiert (Abbildung 7.3i).
Abbildung 7.3.i: Links: tt -Events über LM9 aufgetragen.. Rechts: die zusätzlichen
Variablen: Anzahl der Elektronen, Myonen, OSSFm und OSSFe
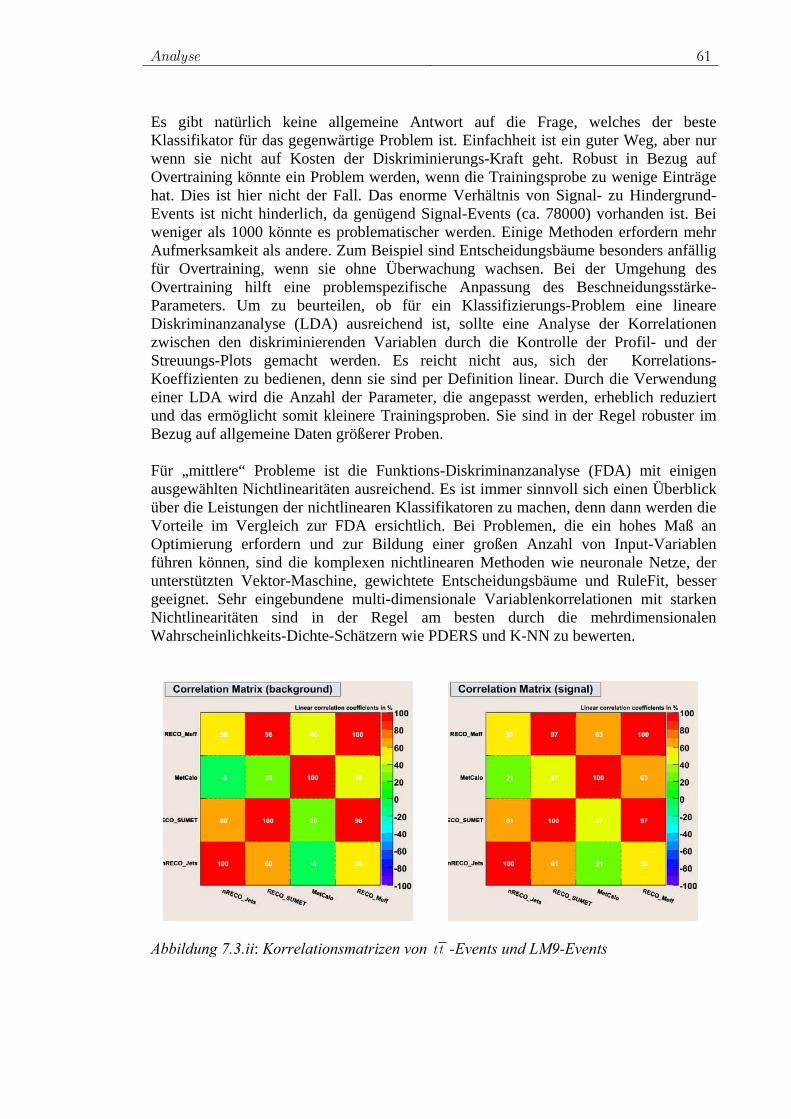
Analyse 61
Es gibt natürlich keine allgemeine Antwort auf die Frage, welches der beste Klassifikator für das gegenwärtige Problem ist. Einfachheit ist ein guter Weg, aber nur wenn sie nicht auf Kosten der Diskriminierungs-Kraft geht. Robust in Bezug auf Overtraining könnte ein Problem werden, wenn die Trainingsprobe zu wenige Einträge hat. Dies ist hier nicht der Fall. Das enorme Verhältnis von Signal- zu Hindergrund- Events ist nicht hinderlich, da genügend Signal-Events (ca. 78000) vorhanden ist. Bei weniger als 1000 könnte es problematischer werden. Einige Methoden erfordern mehr Aufmerksamkeit als andere. Zum Beispiel sind Entscheidungsbäume besonders anfällig für Overtraining, wenn sie ohne Überwachung wachsen. Bei der Umgehung des Overtraining hilft eine problemspezifische Anpassung des Beschneidungsstärke-Parameters. Um zu beurteilen, ob für ein Klassifizierungs-Problem eine lineare Diskriminanzanalyse (LDA) ausreichend ist, sollte eine Analyse der Korrelationen zwischen den diskriminierenden Variablen durch die Kontrolle der Profil- und der Streuungs-Plots gemacht werden. Es reicht nicht aus, sich der Korrelations-Koeffizienten zu bedienen, denn sie sind per Definition linear. Durch die Verwendung einer LDA wird die Anzahl der Parameter, die angepasst werden, erheblich reduziert und das ermöglicht somit kleinere Trainingsproben. Sie sind in der Regel robuster im Bezug auf allgemeine Daten größerer Proben. Für „mittlere“ Probleme ist die Funktions-Diskriminanzanalyse (FDA) mit einigen ausgewählten Nichtlinearitäten ausreichend. Es ist immer sinnvoll sich einen Überblick über die Leistungen der nichtlinearen Klassifikatoren zu machen, denn dann werden die Vorteile im Vergleich zur FDA ersichtlich. Bei Problemen, die ein hohes Maß an Optimierung erfordern und zur Bildung einer großen Anzahl von Input-Variablen führen können, sind die komplexen nichtlinearen Methoden wie neuronale Netze, der unterstützten Vektor-Maschine, gewichtete Entscheidungsbäume und RuleFit, besser geeignet. Sehr eingebundene multi-dimensionale Variablenkorrelationen mit starken Nichtlinearitäten sind in der Regel am besten durch die mehrdimensionalen Wahrscheinlichkeits-Dichte-Schätzern wie PDERS und K-NN zu bewerten.
Abbildung 7.3.ii: Korrelationsmatrizen von tt -Events und LM9-Events
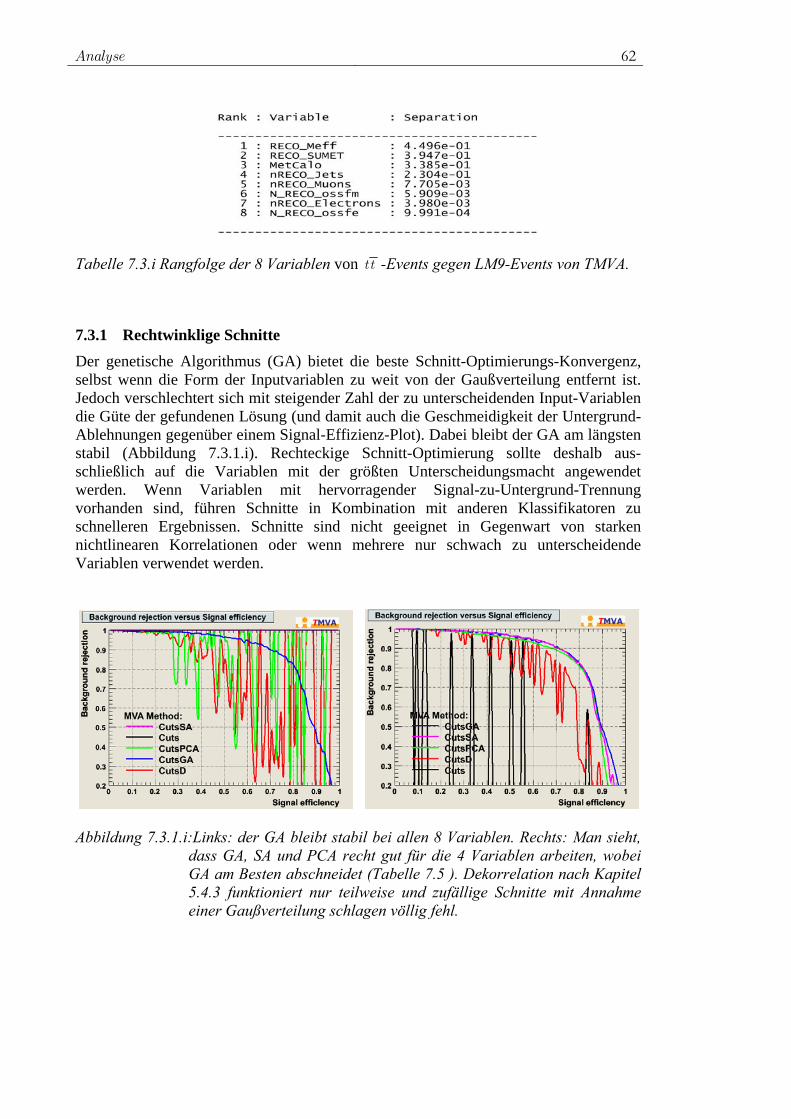
Analyse 62
Tabelle 7.3.i Rangfolge der 8 Variablen von tt -Events gegen LM9-Events von TMVA.
7.3.1 Rechtwinklige Schnitte Der genetische Algorithmus (GA) bietet die beste Schnitt-Optimierungs-Konvergenz, selbst wenn die Form der Inputvariablen zu weit von der Gaußverteilung entfernt ist. Jedoch verschlechtert sich mit steigender Zahl der zu unterscheidenden Input-Variablen die Güte der gefundenen Lösung (und damit auch die Geschmeidigkeit der Untergrund-Ablehnungen gegenüber einem Signal-Effizienz-Plot). Dabei bleibt der GA am längsten stabil (Abbildung 7.3.1.i). Rechteckige Schnitt-Optimierung sollte deshalb aus-schließlich auf die Variablen mit der größten Unterscheidungsmacht angewendet werden. Wenn Variablen mit hervorragender Signal-zu-Untergrund-Trennung vorhanden sind, führen Schnitte in Kombination mit anderen Klassifikatoren zu schnelleren Ergebnissen. Schnitte sind nicht geeignet in Gegenwart von starken nichtlinearen Korrelationen oder wenn mehrere nur schwach zu unterscheidende Variablen verwendet werden.
Abbildung 7.3.1.i:Links: der GA bleibt stabil bei allen 8 Variablen. Rechts: Man sieht,
dass GA, SA und PCA recht gut für die 4 Variablen arbeiten, wobei GA am Besten abschneidet (Tabelle 7.5 ). Dekorrelation nach Kapitel 5.4.3 funktioniert nur teilweise und zufällige Schnitte mit Annahme einer Gaußverteilung schlagen völlig fehl.

Analyse 63
Tabelle 7.3.1.ii:Oben: Bewertungsergebnisse nach der besten Signal-Effizienz und Trennung geordnet. Unten: Test-Effizienz im Vergleich zur Trainings-Effizienz (genaue Erklärung in Abbildung 7.4.2.vi)
Zusammenfassend kann gesagt werden, dass Schnitte für Vorcuts sehr gut geeignet sind, da sie am besten mit wenigen, aber dafür aussagekräftigen Variablen arbeiten. Außerdem ist eine große Anzahl an Events kein Problem, da der Klassifikator schnell arbeitet. Das Training (6000 Signale gegen 1,5 Mill. Untergrundereignisse) aller dieser getesteten Klassifikatoren hat mit dekorrelieren und testen der Güte, zusammen etwa 10 Stunden Rechenzeit in Anspruch genommen. Wenn Daten nicht oder kaum korrelieren, kann Dekorrelation sogar zu schlechteren Ergebnissen führen. Für alle anderen Fälle sind GA und SA gute Lösungsansätze, wobei GA selbst bei Erhöhung der Anzahl der Inputvariablen noch arbeitet. Jedoch ist davon im Allgemeinen abzuraten, wie auch im Rahmen dieser Arbeit gemachten Tests gezeigt, da sich die Güte der gefundenen Lösungen verschlechtert und sogar eher nachteilig im Vergleich zu wenigen, trennungsstarken Variablen entwickelt.
7.3.2 Likelihood-Klassifikator
Sowohl das Training als auch die Anwendung des Likelihood-Klassifikators sind sehr schnelle Vorgänge, die deshalb für große Datenmengen geeignet sind. Die Leistung des Klassifikators stützt sich auf die Genauigkeit des Wahrscheinlichkeitsmodells. Weil hohe Genauigkeit bei der PDF-Schätzung zwingend erforderlich ist, wird eine ausreichende Statistik benötigt um den Verlauf der Distributionen zu kennen. Die Vernachlässigung der Korrelationen zwischen Input-Variablen führt häufig zu einer Verringerung der Diskriminierungsleistung. Bei linearen Gauß-Korrelationen können diese „weg“-gedreht werden (Kapitel 5.4 und Abbildung 7.3.2.ii), Diese ideale Situation ist selten gegeben. Positive Korrelationen führen zu 2 Spitzen bei Äy ,→0 1 . Korrelationen können reduziert werden, indem die Datensamples kategorisiert und ein unabhängiger Wahrscheinlichkeitsklassifikator für jede Event-Kategorie erstellt wird. Diese Kategorien könnten geometrische Regionen im Detektor, kinematische Eigenschaften, usw. sein. Trotz realistischer Anwendungen mit einer großen Anzahl von Input-Variablen gibt es oft irreduzible Korrelationen, so dass der projektive Likelihood-Ansatz, wie der hier diskutierte, unterdurchschnittlich
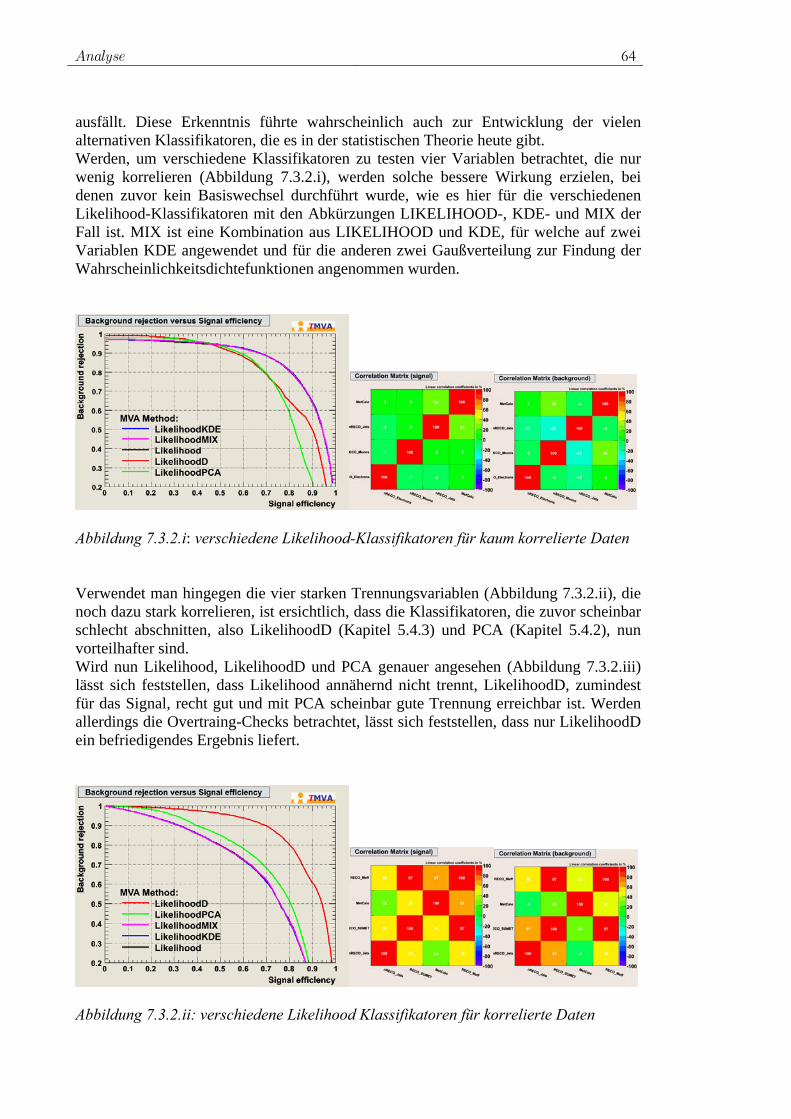
Analyse 64
ausfällt. Diese Erkenntnis führte wahrscheinlich auch zur Entwicklung der vielen alternativen Klassifikatoren, die es in der statistischen Theorie heute gibt. Werden, um verschiedene Klassifikatoren zu testen vier Variablen betrachtet, die nur wenig korrelieren (Abbildung 7.3.2.i), werden solche bessere Wirkung erzielen, bei denen zuvor kein Basiswechsel durchführt wurde, wie es hier für die verschiedenen Likelihood-Klassifikatoren mit den Abkürzungen LIKELIHOOD-, KDE- und MIX der Fall ist. MIX ist eine Kombination aus LIKELIHOOD und KDE, für welche auf zwei Variablen KDE angewendet und für die anderen zwei Gaußverteilung zur Findung der Wahrscheinlichkeitsdichtefunktionen angenommen wurden.
Abbildung 7.3.2.i: verschiedene Likelihood-Klassifikatoren für kaum korrelierte Daten Verwendet man hingegen die vier starken Trennungsvariablen (Abbildung 7.3.2.ii), die noch dazu stark korrelieren, ist ersichtlich, dass die Klassifikatoren, die zuvor scheinbar schlecht abschnitten, also LikelihoodD (Kapitel 5.4.3) und PCA (Kapitel 5.4.2), nun vorteilhafter sind. Wird nun Likelihood, LikelihoodD und PCA genauer angesehen (Abbildung 7.3.2.iii) lässt sich feststellen, dass Likelihood annähernd nicht trennt, LikelihoodD, zumindest für das Signal, recht gut und mit PCA scheinbar gute Trennung erreichbar ist. Werden allerdings die Overtraing-Checks betrachtet, lässt sich feststellen, dass nur LikelihoodD ein befriedigendes Ergebnis liefert.
Abbildung 7.3.2.ii: verschiedene Likelihood Klassifikatoren für korrelierte Daten
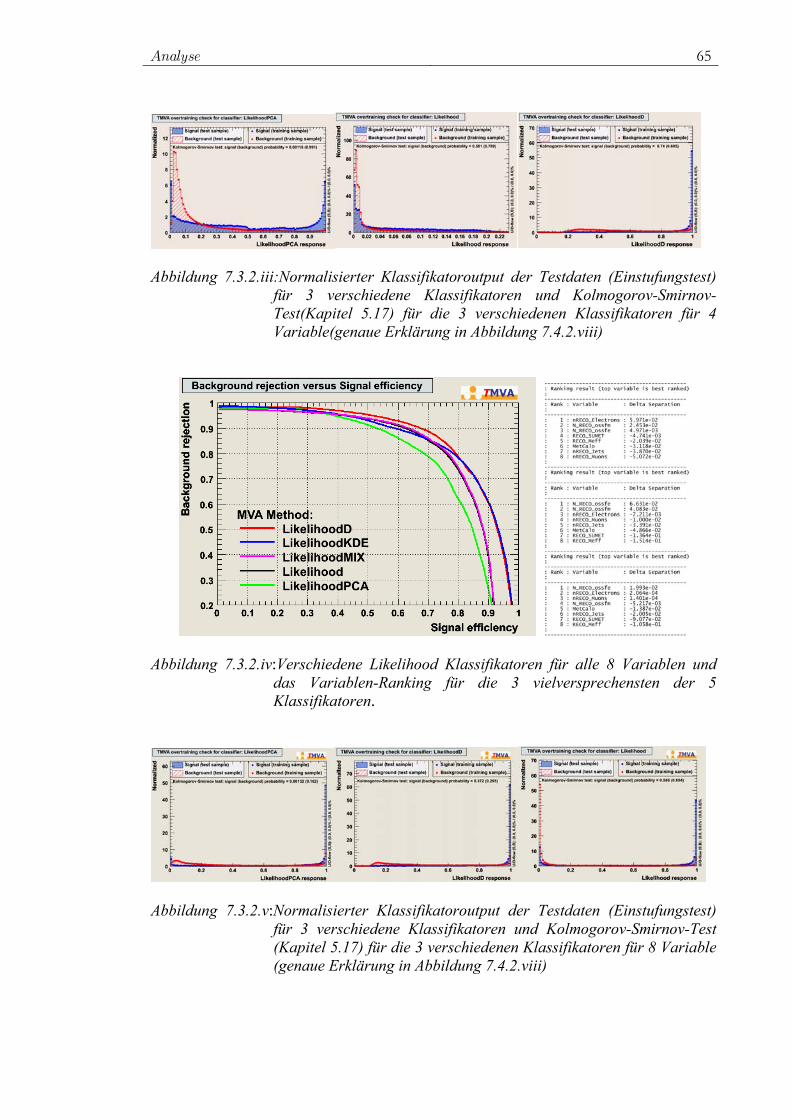
Analyse 65
Abbildung 7.3.2.iii:Normalisierter Klassifikatoroutput der Testdaten (Einstufungstest)
für 3 verschiedene Klassifikatoren und Kolmogorov-Smirnov-Test(Kapitel 5.17) für die 3 verschiedenen Klassifikatoren für 4 Variable(genaue Erklärung in Abbildung 7.4.2.viii)
Abbildung 7.3.2.iv:Verschiedene Likelihood Klassifikatoren für alle 8 Variablen und
das Variablen-Ranking für die 3 vielversprechensten der 5 Klassifikatoren.
Abbildung 7.3.2.v:Normalisierter Klassifikatoroutput der Testdaten (Einstufungstest)
für 3 verschiedene Klassifikatoren und Kolmogorov-Smirnov-Test (Kapitel 5.17) für die 3 verschiedenen Klassifikatoren für 8 Variable (genaue Erklärung in Abbildung 7.4.2.viii)
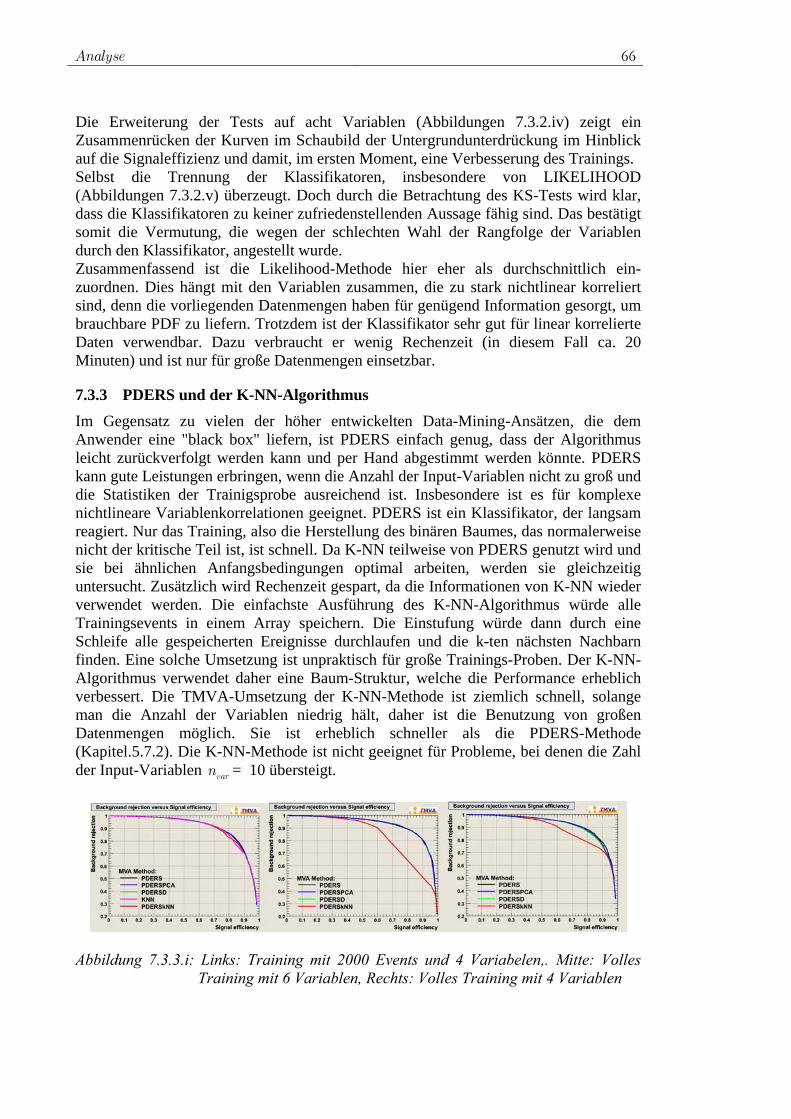
Analyse 66
Die Erweiterung der Tests auf acht Variablen (Abbildungen 7.3.2.iv) zeigt ein Zusammenrücken der Kurven im Schaubild der Untergrundunterdrückung im Hinblick auf die Signaleffizienz und damit, im ersten Moment, eine Verbesserung des Trainings. Selbst die Trennung der Klassifikatoren, insbesondere von LIKELIHOOD (Abbildungen 7.3.2.v) überzeugt. Doch durch die Betrachtung des KS-Tests wird klar, dass die Klassifikatoren zu keiner zufriedenstellenden Aussage fähig sind. Das bestätigt somit die Vermutung, die wegen der schlechten Wahl der Rangfolge der Variablen durch den Klassifikator, angestellt wurde. Zusammenfassend ist die Likelihood-Methode hier eher als durchschnittlich ein-zuordnen. Dies hängt mit den Variablen zusammen, die zu stark nichtlinear korreliert sind, denn die vorliegenden Datenmengen haben für genügend Information gesorgt, um brauchbare PDF zu liefern. Trotzdem ist der Klassifikator sehr gut für linear korrelierte Daten verwendbar. Dazu verbraucht er wenig Rechenzeit (in diesem Fall ca. 20 Minuten) und ist nur für große Datenmengen einsetzbar.
7.3.3 PDERS und der K-NN-Algorithmus
Im Gegensatz zu vielen der höher entwickelten Data-Mining-Ansätzen, die dem Anwender eine "black box" liefern, ist PDERS einfach genug, dass der Algorithmus leicht zurückverfolgt werden kann und per Hand abgestimmt werden könnte. PDERS kann gute Leistungen erbringen, wenn die Anzahl der Input-Variablen nicht zu groß und die Statistiken der Trainigsprobe ausreichend ist. Insbesondere ist es für komplexe nichtlineare Variablenkorrelationen geeignet. PDERS ist ein Klassifikator, der langsam reagiert. Nur das Training, also die Herstellung des binären Baumes, das normalerweise nicht der kritische Teil ist, ist schnell. Da K-NN teilweise von PDERS genutzt wird und sie bei ähnlichen Anfangsbedingungen optimal arbeiten, werden sie gleichzeitig untersucht. Zusätzlich wird Rechenzeit gespart, da die Informationen von K-NN wieder verwendet werden. Die einfachste Ausführung des K-NN-Algorithmus würde alle Trainingsevents in einem Array speichern. Die Einstufung würde dann durch eine Schleife alle gespeicherten Ereignisse durchlaufen und die k-ten nächsten Nachbarn finden. Eine solche Umsetzung ist unpraktisch für große Trainings-Proben. Der K-NN-Algorithmus verwendet daher eine Baum-Struktur, welche die Performance erheblich verbessert. Die TMVA-Umsetzung der K-NN-Methode ist ziemlich schnell, solange man die Anzahl der Variablen niedrig hält, daher ist die Benutzung von großen Datenmengen möglich. Sie ist erheblich schneller als die PDERS-Methode (Kapitel.5.7.2). Die K-NN-Methode ist nicht geeignet für Probleme, bei denen die Zahl der Input-Variablen varn = 10 übersteigt.
Abbildung 7.3.3.i: Links: Training mit 2000 Events und 4 Variabelen,. Mitte: Volles
Training mit 6 Variablen, Rechts: Volles Training mit 4 Variablen
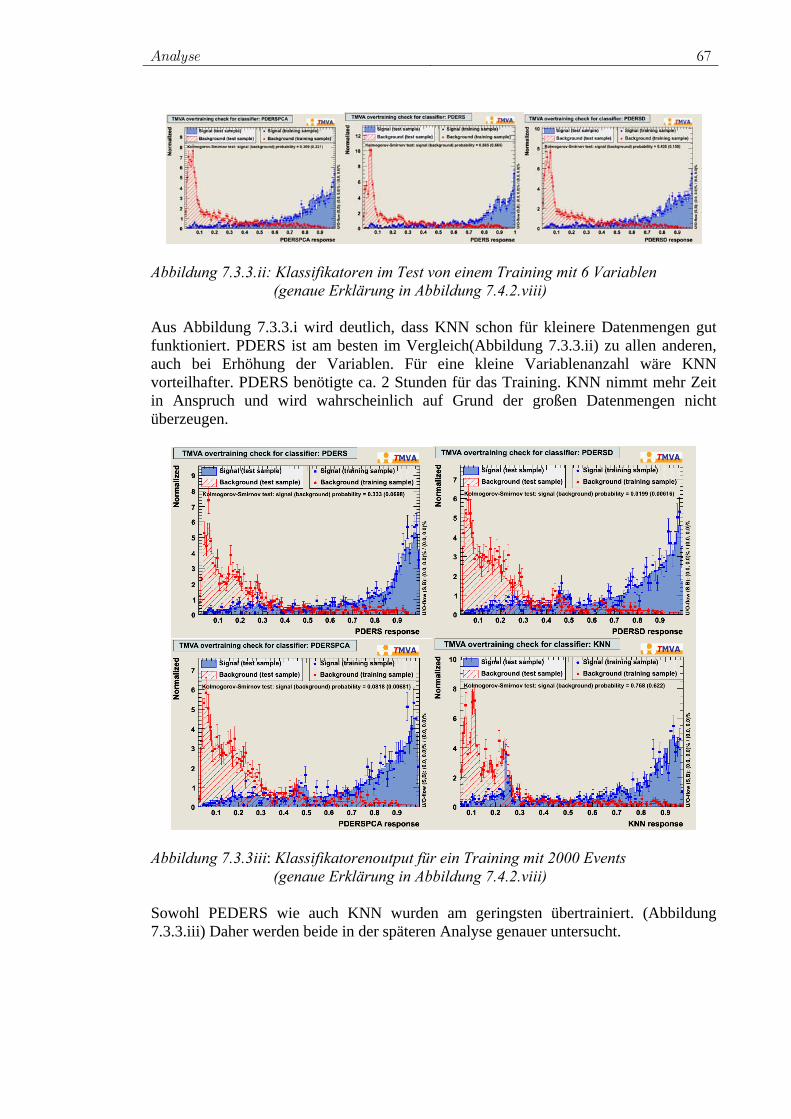
Analyse 67
Abbildung 7.3.3.ii: Klassifikatoren im Test von einem Training mit 6 Variablen (genaue Erklärung in Abbildung 7.4.2.viii) Aus Abbildung 7.3.3.i wird deutlich, dass KNN schon für kleinere Datenmengen gut funktioniert. PDERS ist am besten im Vergleich(Abbildung 7.3.3.ii) zu allen anderen, auch bei Erhöhung der Variablen. Für eine kleine Variablenanzahl wäre KNN vorteilhafter. PDERS benötigte ca. 2 Stunden für das Training. KNN nimmt mehr Zeit in Anspruch und wird wahrscheinlich auf Grund der großen Datenmengen nicht überzeugen.
Abbildung 7.3.3iii: Klassifikatorenoutput für ein Training mit 2000 Events (genaue Erklärung in Abbildung 7.4.2.viii) Sowohl PEDERS wie auch KNN wurden am geringsten übertrainiert. (Abbildung 7.3.3.iii) Daher werden beide in der späteren Analyse genauer untersucht.
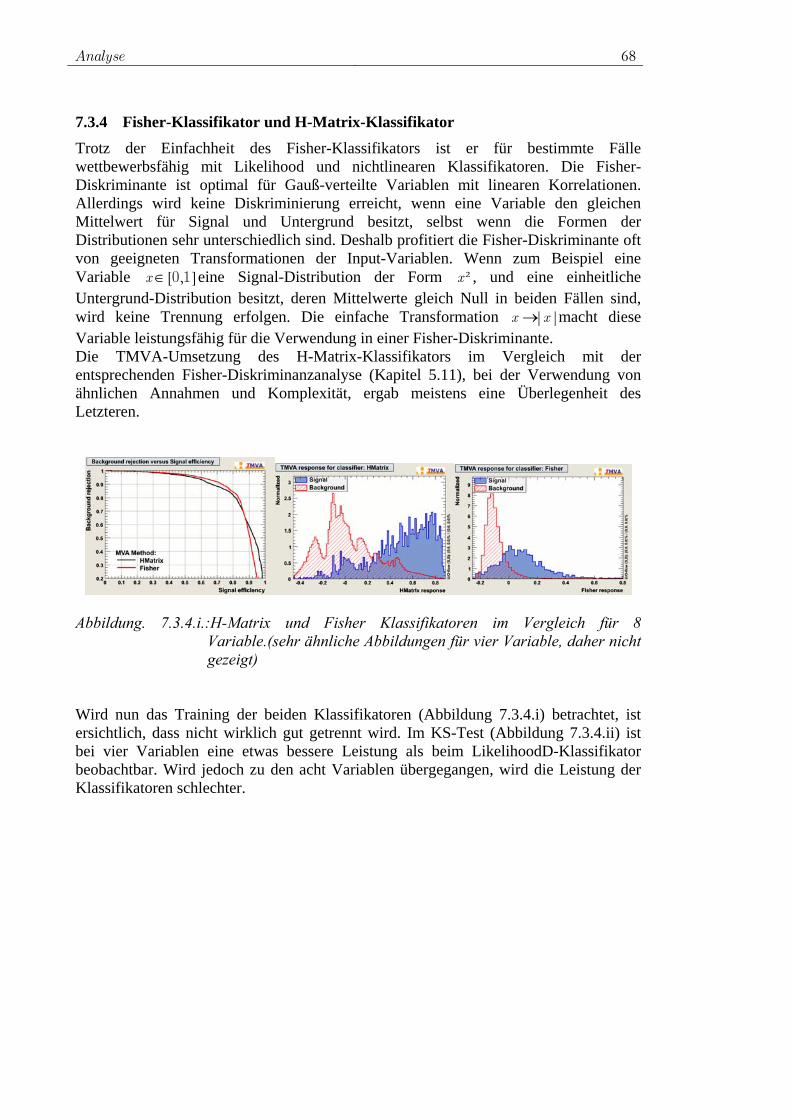
Analyse 68
7.3.4 Fisher-Klassifikator und H-Matrix-Klassifikator Trotz der Einfachheit des Fisher-Klassifikators ist er für bestimmte Fälle wettbewerbsfähig mit Likelihood und nichtlinearen Klassifikatoren. Die Fisher-Diskriminante ist optimal für Gauß-verteilte Variablen mit linearen Korrelationen. Allerdings wird keine Diskriminierung erreicht, wenn eine Variable den gleichen Mittelwert für Signal und Untergrund besitzt, selbst wenn die Formen der Distributionen sehr unterschiedlich sind. Deshalb profitiert die Fisher-Diskriminante oft von geeigneten Transformationen der Input-Variablen. Wenn zum Beispiel eine Variable x [ , ]∈ 0 1 eine Signal-Distribution der Form x² , und eine einheitliche Untergrund-Distribution besitzt, deren Mittelwerte gleich Null in beiden Fällen sind, wird keine Trennung erfolgen. Die einfache Transformation x |x|→ macht diese Variable leistungsfähig für die Verwendung in einer Fisher-Diskriminante. Die TMVA-Umsetzung des H-Matrix-Klassifikators im Vergleich mit der entsprechenden Fisher-Diskriminanzanalyse (Kapitel 5.11), bei der Verwendung von ähnlichen Annahmen und Komplexität, ergab meistens eine Überlegenheit des Letzteren.
Abbildung. 7.3.4.i.:H-Matrix und Fisher Klassifikatoren im Vergleich für 8
Variable.(sehr ähnliche Abbildungen für vier Variable, daher nicht gezeigt)
Wird nun das Training der beiden Klassifikatoren (Abbildung 7.3.4.i) betrachtet, ist ersichtlich, dass nicht wirklich gut getrennt wird. Im KS-Test (Abbildung 7.3.4.ii) ist bei vier Variablen eine etwas bessere Leistung als beim LikelihoodD-Klassifikator beobachtbar. Wird jedoch zu den acht Variablen übergegangen, wird die Leistung der Klassifikatoren schlechter.
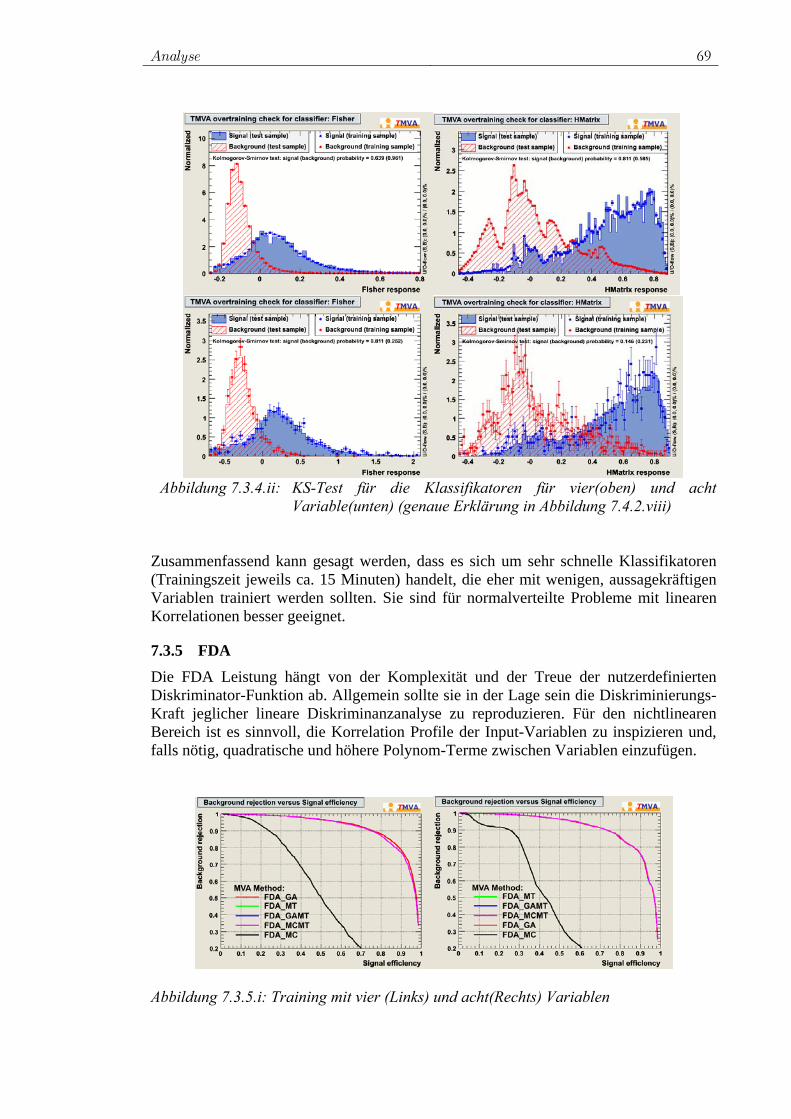
Analyse 69
Abbildung 7.3.4.ii: KS-Test für die Klassifikatoren für vier(oben) und acht
Variable(unten) (genaue Erklärung in Abbildung 7.4.2.viii) Zusammenfassend kann gesagt werden, dass es sich um sehr schnelle Klassifikatoren (Trainingszeit jeweils ca. 15 Minuten) handelt, die eher mit wenigen, aussagekräftigen Variablen trainiert werden sollten. Sie sind für normalverteilte Probleme mit linearen Korrelationen besser geeignet.
7.3.5 FDA Die FDA Leistung hängt von der Komplexität und der Treue der nutzerdefinierten Diskriminator-Funktion ab. Allgemein sollte sie in der Lage sein die Diskriminierungs-Kraft jeglicher lineare Diskriminanzanalyse zu reproduzieren. Für den nichtlinearen Bereich ist es sinnvoll, die Korrelation Profile der Input-Variablen zu inspizieren und, falls nötig, quadratische und höhere Polynom-Terme zwischen Variablen einzufügen.
Abbildung 7.3.5.i: Training mit vier (Links) und acht(Rechts) Variablen
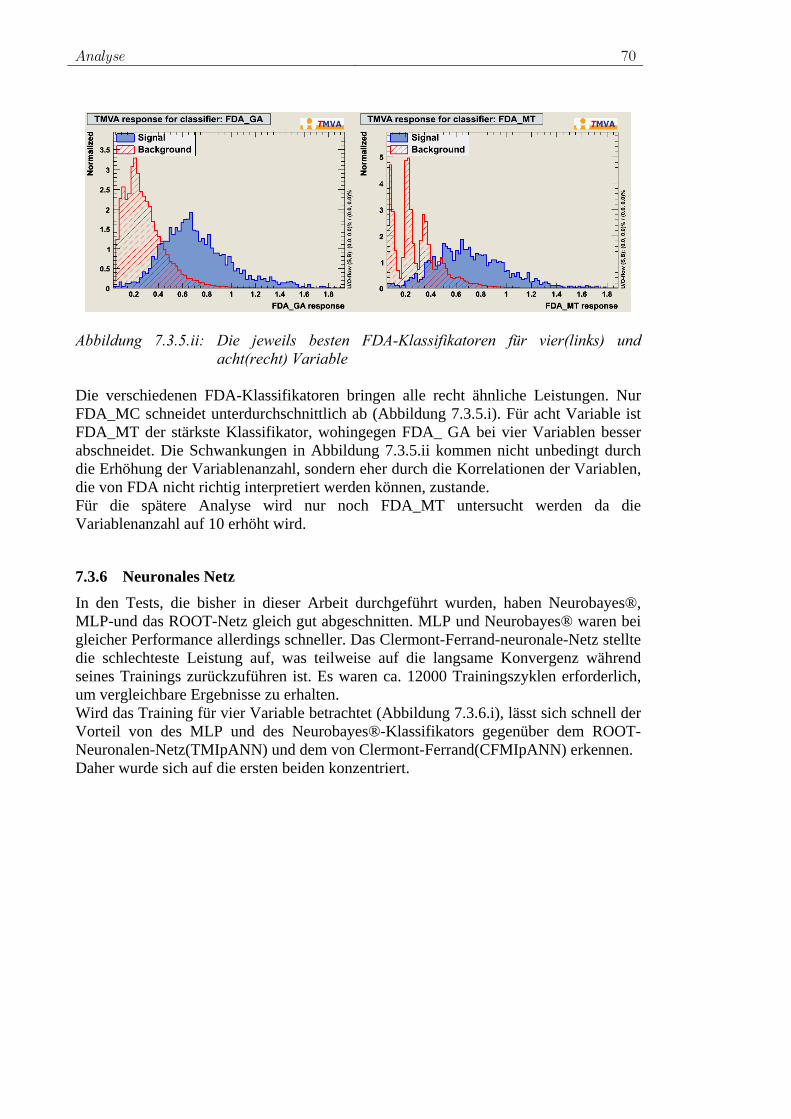
Analyse 70
Abbildung 7.3.5.ii: Die jeweils besten FDA-Klassifikatoren für vier(links) und
acht(recht) Variable Die verschiedenen FDA-Klassifikatoren bringen alle recht ähnliche Leistungen. Nur FDA_MC schneidet unterdurchschnittlich ab (Abbildung 7.3.5.i). Für acht Variable ist FDA_MT der stärkste Klassifikator, wohingegen FDA_ GA bei vier Variablen besser abschneidet. Die Schwankungen in Abbildung 7.3.5.ii kommen nicht unbedingt durch die Erhöhung der Variablenanzahl, sondern eher durch die Korrelationen der Variablen, die von FDA nicht richtig interpretiert werden können, zustande. Für die spätere Analyse wird nur noch FDA_MT untersucht werden da die Variablenanzahl auf 10 erhöht wird.
7.3.6 Neuronales Netz In den Tests, die bisher in dieser Arbeit durchgeführt wurden, haben Neurobayes®, MLP-und das ROOT-Netz gleich gut abgeschnitten. MLP und Neurobayes® waren bei gleicher Performance allerdings schneller. Das Clermont-Ferrand-neuronale-Netz stellte die schlechteste Leistung auf, was teilweise auf die langsame Konvergenz während seines Trainings zurückzuführen ist. Es waren ca. 12000 Trainingszyklen erforderlich, um vergleichbare Ergebnisse zu erhalten. Wird das Training für vier Variable betrachtet (Abbildung 7.3.6.i), lässt sich schnell der Vorteil von des MLP und des Neurobayes®-Klassifikators gegenüber dem ROOT-Neuronalen-Netz(TMIpANN) und dem von Clermont-Ferrand(CFMIpANN) erkennen. Daher wurde sich auf die ersten beiden konzentriert.
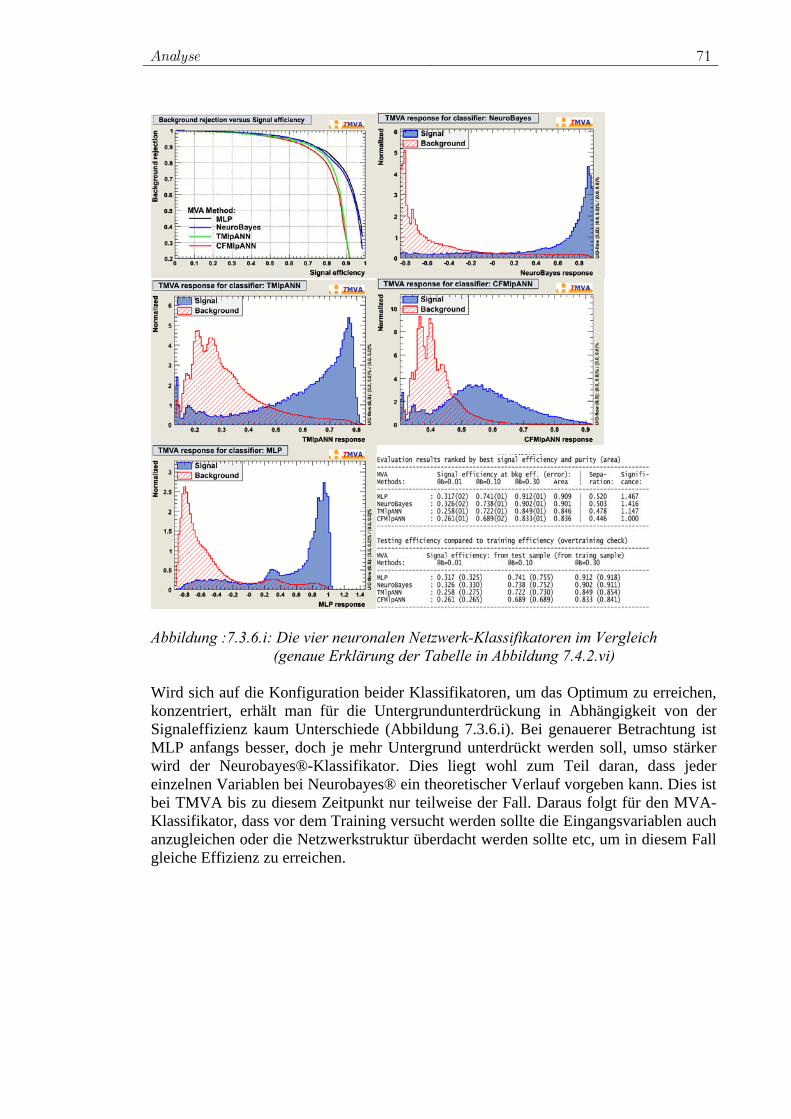
Analyse 71
Abbildung :7.3.6.i: Die vier neuronalen Netzwerk-Klassifikatoren im Vergleich (genaue Erklärung der Tabelle in Abbildung 7.4.2.vi) Wird sich auf die Konfiguration beider Klassifikatoren, um das Optimum zu erreichen, konzentriert, erhält man für die Untergrundunterdrückung in Abhängigkeit von der Signaleffizienz kaum Unterschiede (Abbildung 7.3.6.i). Bei genauerer Betrachtung ist MLP anfangs besser, doch je mehr Untergrund unterdrückt werden soll, umso stärker wird der Neurobayes®-Klassifikator. Dies liegt wohl zum Teil daran, dass jeder einzelnen Variablen bei Neurobayes® ein theoretischer Verlauf vorgeben kann. Dies ist bei TMVA bis zu diesem Zeitpunkt nur teilweise der Fall. Daraus folgt für den MVA-Klassifikator, dass vor dem Training versucht werden sollte die Eingangsvariablen auch anzugleichen oder die Netzwerkstruktur überdacht werden sollte etc, um in diesem Fall gleiche Effizienz zu erreichen.
Analyse 72
Abbildung 7.3.6.i: MLP von TMVA und Neurobayes® im Vergleich für 8 Variable für
den Fall von LM9-(Signal) und tt -Events(Untergrund) (genaue Erklärung der Tabelle in Abbildung 7.4.2.vi) Abschließend kann gesagt werden, dass nur zwei der vier neuronalen Netzwerke zu gebrauchen sind. Für welches man sich entscheidet, hängt von der Problemstellung ab. Beide sind sehr schnell trainiert, wobei für Standardeinstellungen(Default) MLP(42 Minuten) etwas mehr Rechenzeit benötigte wie Neurobayes®(32 Minuten). Dies kann aber immer durch Veränderung des Netzwerkaufbaus, also der Anzahl der Schichten und Neuronen pro Schicht, oder zum Beispiel durch Optimierung des Abbruch-kriteriums, bei gleicher Effizienz gesenkt, werden.
7.3.7 SVM
Der TMVA-SVM-Algorithmus arbeitet mit linearen, Polynom-, Gauß- und sigmoid Kern-Funktionen. Mit ausreichender Trainingsstatistik, führt der Gauß-Kern zu jeder annähernd richtigen Trennungs-Funktion im Input-Raum. Es ist von entscheidender Bedeutung für die Leistung des SVM, die Kern-Parameter zu bestimmen (die Breite im Falle eines Gauß-Kerns). Die optimale Abstimmung ist spezifisch für das Problem und hängt hier stark vom den richtigen Benutzereinstellungen ab. Die Erhöhung der Minimierungs-Toleranz hilft bei der Beschleunigung der Ausbildung. SVM ist ein nichtlinearer Allzweck-Klassifizierung-Algorithmus mit einer Leistung vergleichbar mit einem neuronalen Netzwerk (Kapitel 5.16) oder mit einer mehrdimensionalen Likelihood-Schätzfunktion (Kapitel 5.7.2).
Analyse 73
Abbildung 7.3.7.i: verschiedene SVM- Klassifikatoren für 4 (links) und 8(recht)
Variable SVM_Gauss ist bei wenigen Variablen die bessere Wahl als Klassifikator und SVM_Poly scheint besser bei Erhöhungs der Variablenanzahl.(Abbildung 3.3.7.i)
Abbildung 7.3.7.ii: verschiedene SVM-Klassifikatoren für 8 Variable (genaue Erklärung in Abbildung 7.4.2.viii) SVM_Poly ist wie gesagt auf den ersten Blick der beste Klassifikator. Wird nun der KS-Test (Abbildung 3.3.7.ii) betrachtet, wird deutlich das der SVM_Lin am geeignetsten ist. In der Abbildung(7.3.7.iii) kann man gut nachzuvollziehen, das SVM_Lin auch bei gleicher Anzahl der Input-Daten stabil arbeiten kann. Daher wird für die späteren Analysen SVM_Lin verwendet werden.
Abbildung 7.3.7.iii: Training mit 8 Variablen, 2000 Signal- und 10000 Untergrund-Ereignisse
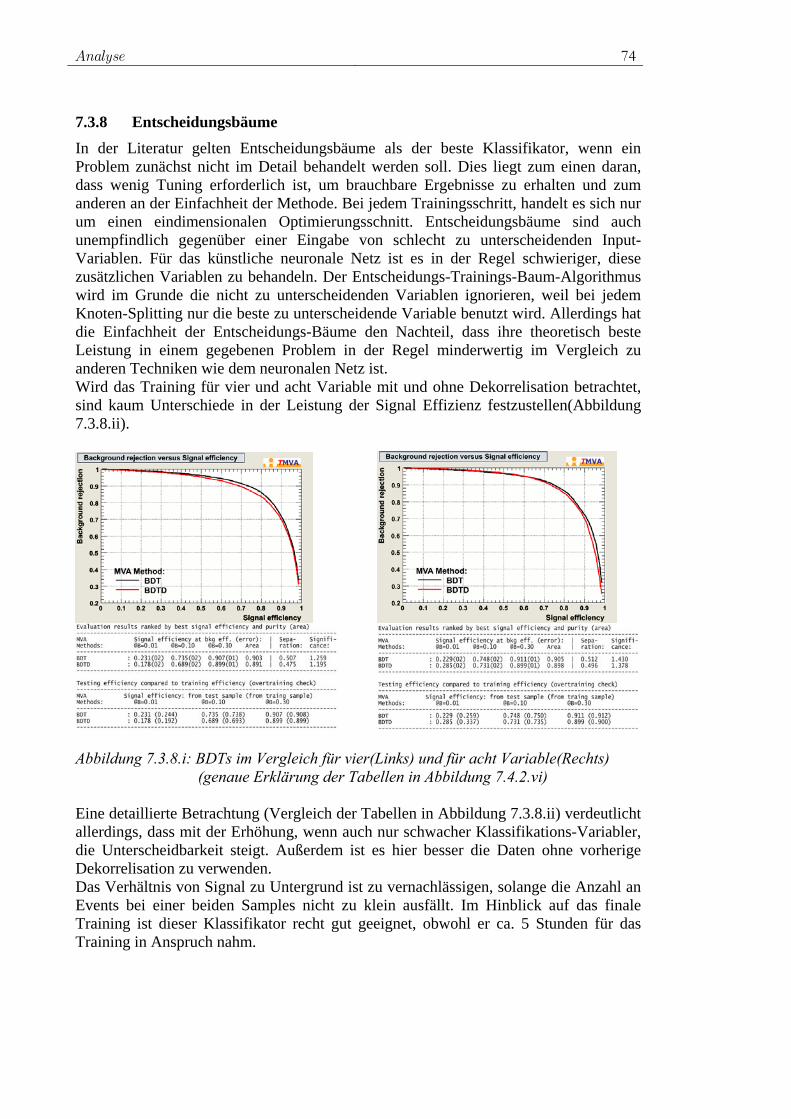
Analyse 74
7.3.8 Entscheidungsbäume In der Literatur gelten Entscheidungsbäume als der beste Klassifikator, wenn ein Problem zunächst nicht im Detail behandelt werden soll. Dies liegt zum einen daran, dass wenig Tuning erforderlich ist, um brauchbare Ergebnisse zu erhalten und zum anderen an der Einfachheit der Methode. Bei jedem Trainingsschritt, handelt es sich nur um einen eindimensionalen Optimierungsschnitt. Entscheidungsbäume sind auch unempfindlich gegenüber einer Eingabe von schlecht zu unterscheidenden Input-Variablen. Für das künstliche neuronale Netz ist es in der Regel schwieriger, diese zusätzlichen Variablen zu behandeln. Der Entscheidungs-Trainings-Baum-Algorithmus wird im Grunde die nicht zu unterscheidenden Variablen ignorieren, weil bei jedem Knoten-Splitting nur die beste zu unterscheidende Variable benutzt wird. Allerdings hat die Einfachheit der Entscheidungs-Bäume den Nachteil, dass ihre theoretisch beste Leistung in einem gegebenen Problem in der Regel minderwertig im Vergleich zu anderen Techniken wie dem neuronalen Netz ist. Wird das Training für vier und acht Variable mit und ohne Dekorrelisation betrachtet, sind kaum Unterschiede in der Leistung der Signal Effizienz festzustellen(Abbildung 7.3.8.ii).
Abbildung 7.3.8.i: BDTs im Vergleich für vier(Links) und für acht Variable(Rechts) (genaue Erklärung der Tabellen in Abbildung 7.4.2.vi) Eine detaillierte Betrachtung (Vergleich der Tabellen in Abbildung 7.3.8.ii) verdeutlicht allerdings, dass mit der Erhöhung, wenn auch nur schwacher Klassifikations-Variabler, die Unterscheidbarkeit steigt. Außerdem ist es hier besser die Daten ohne vorherige Dekorrelisation zu verwenden. Das Verhältnis von Signal zu Untergrund ist zu vernachlässigen, solange die Anzahl an Events bei einer beiden Samples nicht zu klein ausfällt. Im Hinblick auf das finale Training ist dieser Klassifikator recht gut geeignet, obwohl er ca. 5 Stunden für das Training in Anspruch nahm.
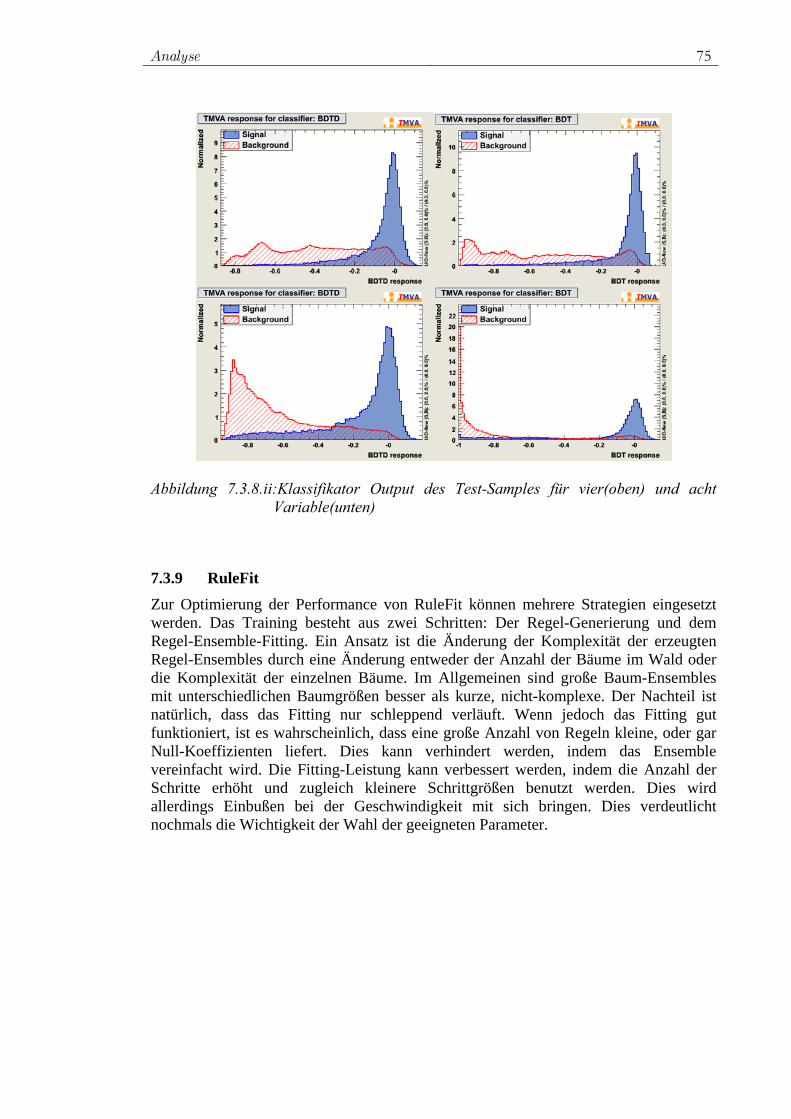
Analyse 75
Abbildung 7.3.8.ii:Klassifikator Output des Test-Samples für vier(oben) und acht
Variable(unten)
7.3.9 RuleFit
Zur Optimierung der Performance von RuleFit können mehrere Strategien eingesetzt werden. Das Training besteht aus zwei Schritten: Der Regel-Generierung und dem Regel-Ensemble-Fitting. Ein Ansatz ist die Änderung der Komplexität der erzeugten Regel-Ensembles durch eine Änderung entweder der Anzahl der Bäume im Wald oder die Komplexität der einzelnen Bäume. Im Allgemeinen sind große Baum-Ensembles mit unterschiedlichen Baumgrößen besser als kurze, nicht-komplexe. Der Nachteil ist natürlich, dass das Fitting nur schleppend verläuft. Wenn jedoch das Fitting gut funktioniert, ist es wahrscheinlich, dass eine große Anzahl von Regeln kleine, oder gar Null-Koeffizienten liefert. Dies kann verhindert werden, indem das Ensemble vereinfacht wird. Die Fitting-Leistung kann verbessert werden, indem die Anzahl der Schritte erhöht und zugleich kleinere Schrittgrößen benutzt werden. Dies wird allerdings Einbußen bei der Geschwindigkeit mit sich bringen. Dies verdeutlicht nochmals die Wichtigkeit der Wahl der geeigneten Parameter.
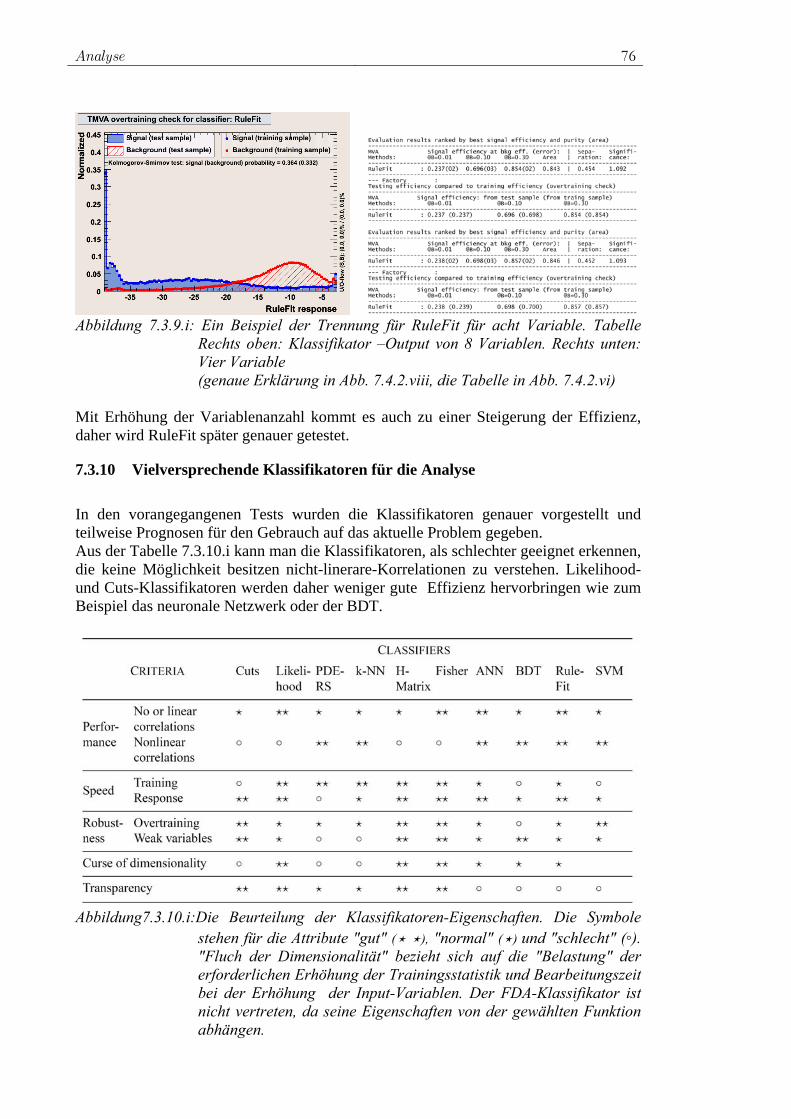
Analyse 76
Abbildung 7.3.9.i: Ein Beispiel der Trennung für RuleFit für acht Variable. Tabelle
Rechts oben: Klassifikator –Output von 8 Variablen. Rechts unten: Vier Variable
(genaue Erklärung in Abb. 7.4.2.viii, die Tabelle in Abb. 7.4.2.vi) Mit Erhöhung der Variablenanzahl kommt es auch zu einer Steigerung der Effizienz, daher wird RuleFit später genauer getestet.
7.3.10 Vielversprechende Klassifikatoren für die Analyse In den vorangegangenen Tests wurden die Klassifikatoren genauer vorgestellt und teilweise Prognosen für den Gebrauch auf das aktuelle Problem gegeben. Aus der Tabelle 7.3.10.i kann man die Klassifikatoren, als schlechter geeignet erkennen, die keine Möglichkeit besitzen nicht-linerare-Korrelationen zu verstehen. Likelihood- und Cuts-Klassifikatoren werden daher weniger gute Effizienz hervorbringen wie zum Beispiel das neuronale Netzwerk oder der BDT.
Abbildung7.3.10.i:Die Beurteilung der Klassifikatoren-Eigenschaften. Die Symbole
stehen für die Attribute "gut" (⋆ ⋆), "normal" (⋆) und "schlecht" (). "Fluch der Dimensionalität" bezieht sich auf die "Belastung" der erforderlichen Erhöhung der Trainingsstatistik und Bearbeitungszeit bei der Erhöhung der Input-Variablen. Der FDA-Klassifikator ist nicht vertreten, da seine Eigenschaften von der gewählten Funktion abhängen.

Analyse 77
7.3.11 Ranking der Variablen durch Klassifikatoren
TMVA liefert bereits ein Ranking welche die Variablen beurteilt und ordnet. Sie hängt von der Separation von Signal zu Hintergrund (7.1) ab, ohne dabei auf die Kor-relationen zu achten. Das Ranking der Variablen für die Klassifikatoren ist nur teilweise von TMVA gegeben und für Likelihood, MLP, BDT, RuleFit und Neurobayes® erhältlich und folgendermaßen definiert:
• MLP Das MLP-neuronale Netz besitzt ein Variable Ranking basierend auf der Summe der Gewichtequadrate der Verbindungen die in den Variablen-Input-Neuronen entspringen. Die Wichtigkeit (eng.: importance) iI der Input-Variable i ist gegeben durch:
hn
( )i i ij var
j
I x (w ) , i , ..., n2 1 2
=1
= =1∑ (7.4)
wobei ix der Sample-Mittelwert der Input-Variablen i ist.
• BDT
Gebildet wird die Rangfolge der Variablen beim BDT durch die Häufigkeit deren Auftretens beim Trennen der einzelnen Baumknoten, durch die Gewichtung jeder Trennung mit der quadrierten Unterscheidungsstärke, die erreicht wurde und durch die Anzahl der Ereignisse in jedem Knoten. Dies kann sowohl für einen einzelnen Entscheidungsbaum als auch für einen Wald benutzt werden.
Neurobayes®
Um bei Neurobayes® eine Rangfolge der Variablen zu erzeugen wird für jede Variable ein Training durchgeführt das diese Variable nicht benutzt. Dadurch wird für jede Variable ein Verlust in der totalen Korrelation bestimmt. Die Variable mit dem geringsten Informationsverlust wird weggelassen und die ganze Prozedur für die restlichen Variablen wiederholt. Zwei Variable, die stark korrelieren und gute Trennungseigenschaften besitzen werden daher in der Rangfolge weit auseinander liegen.
• RuleFit Da die Eingangsvariablen normalisiert sind, folgt die Rangfolge der Variablen aus den Koeffizienten des Modells. Jeder Regel Rm(m , ..., M )=1 wird eine Wichtigkeit zugeordnet durch
m m m mI a s ( , s ),= 1 0− (7.5)

Analyse 78
mit der Unterstützng (eng. Support) ms der Regel, die durch folgende Definition gegeben ist.
( )N
m m nn
s r xN =1
1= ∑ (7.6)
Die Unterstützung ist die durchschnittliche Antwort für eine gegebene Regel. Eine große Unterstützung bedeutet, dass viele Ereignisse das Schnittkriterium bestehen. Demzufolge können solche Schnitte keine große Unterscheidungs-stärke besitzen. Andererseits werden bei Regeln mit kleiner Unterstützung nur wenige Ereignisse akzeptiert. Die Definition der Wichtigkeit (7.5) unterdrückt also Regeln mit großer oder mit kleiner Unterstützung Für die linearen Terme lautet die Definition der Wichtigkeit i i iI b ,= σ (7.7) so dass Variablen kleiner Variation eine kleine Wichtigkeit zugewiesen wird. Dann wird die Unterscheidungsstärke definiert durch
i m
mi i
m x r m
IJ I ,
q∈
= + ∑ (7.8)
mit der Summe über alle Regeln, der Variablen ix und der Anzahl mq der Variablen, die von der Regel mr benutzt werden. Dadurch wird die Wichtigkeit unter den Variablen in Regeln mit mehr als einer Variablen gleich aufgeteilt.
• Likelihood Die Rangfolge der Variablen wird beim Likelihood-Klassifikator durch das Auftragen der Signal-und der Hintergrund-Events für jede Variable ermittelt. Je mehr Fläche sich überschneidet desto unwichtiger ist die Variable in diesem Fall. Die Wichtigkeit der Variable hängt hier also nur von der Unterscheidungsstärke ab.
7.4 Training der ausgewählten Klassifikatoren
7.4.1 Vorauswahl
Im Folgenden wird versucht die Klassifikatoren der vorigen Kapitel vorteilhaft einzusetzen und die Vorgehensweise bis zu Beginn des Trainings geschildert. Zuvor werden die anderen 16 Variablen vorgestellt: RECO_Jet_hemi[0-2] entspricht der Hemisphäre für die ersten 3 Jets abhängig von deren Indizes, RECO_Jet_pt[0-2] dem Transveralimpuls ,RECO_Jet_eta[0-2] dem Winkel Eta , RECO_Jet_phi[0-2] dem Winkel Phi, RECO_Delta_RECO_Jet1_MET dem Winkel zwischen dem ersten Jet und MET. Analog wurden die anderen Winkel mit RECO_Delta_RECO_Jet1_RECO_Jet2, RECO_Delta_RECO_Jet2_MET, RECO_Delta_RECO_Jet1_RECO_Jet3, RECO_Delta_RECO_Jet2_RECO_Jet3, RECO_Delta_RECO_Jet3_MET bezeichnet.

Analyse 79
Bevor die Klassifikatoren angewendet wurden, wurde ein Schnitt bei einer Anzahl von drei Jets getätigt. Dadurch ergaben sich die nun möglichen neuen Variablen für das Training, da nun jede dieser Variable einen Eintrag haben muss. Dabei gehen 25% des Signals verloren. Es wurden keine Schnitte bei der Anzahl der Elektronen oder Myonen durchgeführt, da sie zu einem noch höheren Verlust an Signal führen würden (Tabelle 7.4.1.ii). Dadurch wurde eine Auswahl von 26 Variablen für das Training ermöglicht.
Tabelle 7.4.1.i:Die Rangfolge der zu Auswahl stehenden Variablen, abhängig von ihrer
Unterscheidungsstärke für Signal von Hindergrund von links nach rechts: tt +Jets, W+Jets und Z+Jets -Events
An dieser Stelle muss betont werden, dass Neurobayes® aus der ganzen Spanne der zur Verfügung stehenden Variablen hätte wählen können, weil dort die Möglichkeit besteht Einträge als „unwichtig“ zu deklarieren. Dazu müssen die root-Files abgeändert werden, so dass wirklich jeder Variablen-Eintrag einen sinnvollen Wert besitzt, auch wenn sie eigentlich keinen erhalten hätten. Es wird dann zum Beispiel der Wert -999 eingetragen. Da aber nach einem Vergleich aller statistischen Methoden gesucht ist, wird diese Option dafür zunächst nicht benutzt. Bei dem darauf folgendem Vergleich von MLP und Neurobayes® wird diese Technik zum Einsatz kommen. Der nächste Schnitt erfolgte durch einen genetischen Algorithmus, deren Fitness-Funktion nach möglichst guten Schnitten im zweidimensionalen Raum von RECO_SUMET31 und MetCalo32sucht und diese ausgibt. Da der Untergrund für tt -Events am schwersten zu entfernen ist, wird der gewünschte Schnitt dafür durchgeführt. Der GA lieferte die Werte: RECO_SUMET >= 435 und MetCalo >= 95. Der resultierende Untergrund der W+Jets .- und Z+Jets Events wurde dementsprechend mitgeschnitten und führte zu folgendem Ergebnis:
original l1-cuts GA-Schnitt ttbar 1566882 1558992 28486 W+Jets 10187381 7982447 5696 Z+Jets 2640789 2193676 1055 lm9_sft 78911 71886 28255
Für das weitere Training werden die ersten 10 Variablen aus der Tabelle 7.4.1.i(links) genommen, da für manche Klassifikatoren damit die Grenzzahl erreicht ist und dadurch zufrieden stellende Ergebnisse erwartet werden können.
31 Summe der transversalen Energien aller drei benutzen Teilchen 32 Fehlende transversale Energie aus dem Kalorimeter

Analyse 80
Tabelle 7.4.1.ii: Signal(LM9-Events) und Untergrund Effizienz für Schnitte durch die
Anzahl der Jets, Elektronen und Myonen (Bedeutung des Ausdrucks von links unten: nach Schneiden bei 0 Jets, 1 Myon und 1 Elektron sind für tt +Jets noch ca. die Hälfte der Events vorhanden )
Nach den Vorcuts werden nun in den folgenden drei Absätzen die jeweiligen Ergebnisse der Klassifikatoren für die Hintergünde W+Jets, Z+Jets und tt +Jets gezeigt.
7.4.2 Das Training für W+Jets Im den folgenden Plots sind die Korrelationsmatrizen für W+Jets- und LM9 -Events gezeigt. Zur Veranschaulichung ihrer Unterscheidbarkeit sind die zehn gewählten Variablen von Signal- und Untergrundereignissen übereinander aufgetragen. Dann folgt das Trainingsergebnis in Form eines Graphen in dem die Untergrundunterdrückung über gegebener Signaleffizienz aufgetragen ist. Zur Erinnerung soll noch mal das Verhältnis von Signal und Untergrund Ereignissen erwähnt werden: ca. 5500 Untergrund- und 28000 Signal-Events.
Abbildung 7.4.2.i: Korrelationsmatritzen von W+Jets –und LM9-Events (mit 10
Variablen, mit GA-Cuts)
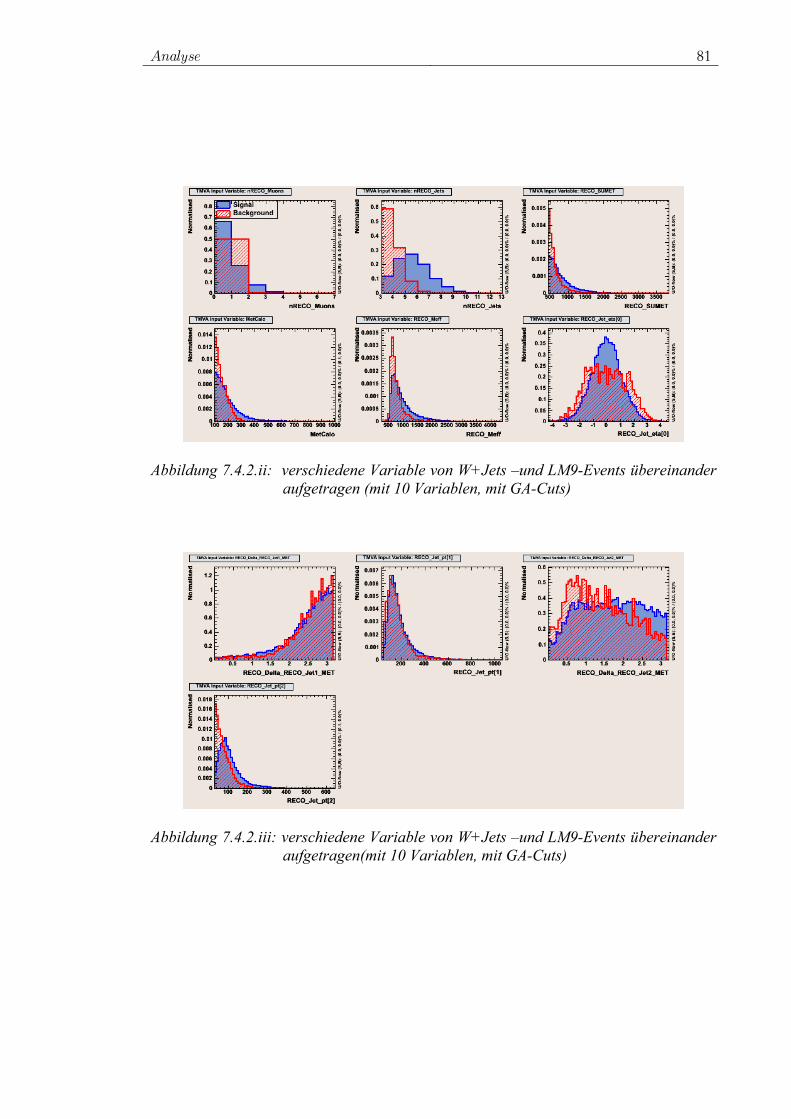
Analyse 81
Abbildung 7.4.2.ii: verschiedene Variable von W+Jets –und LM9-Events übereinander aufgetragen (mit 10 Variablen, mit GA-Cuts)
Abbildung 7.4.2.iii: verschiedene Variable von W+Jets –und LM9-Events übereinander aufgetragen(mit 10 Variablen, mit GA-Cuts)
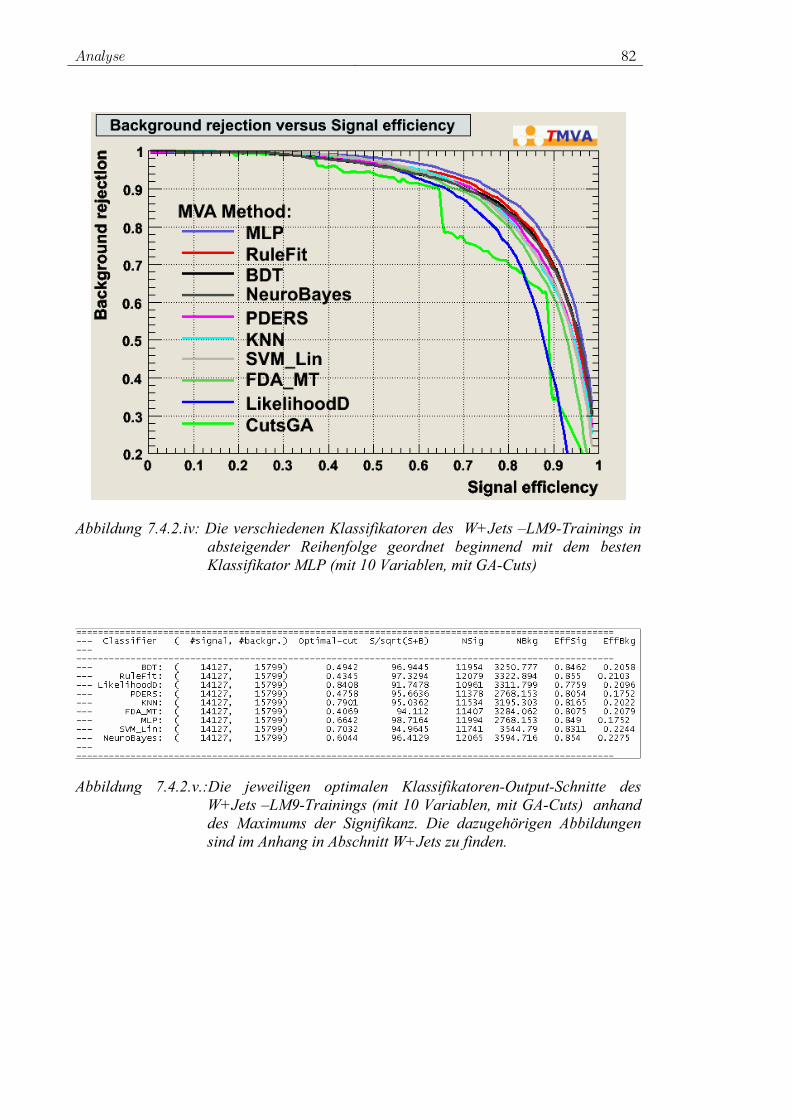
Analyse 82
Abbildung 7.4.2.iv: Die verschiedenen Klassifikatoren des W+Jets –LM9-Trainings in
absteigender Reihenfolge geordnet beginnend mit dem besten Klassifikator MLP (mit 10 Variablen, mit GA-Cuts)
Abbildung 7.4.2.v.:Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
W+Jets –LM9-Trainings (mit 10 Variablen, mit GA-Cuts) anhand des Maximums der Signifikanz. Die dazugehörigen Abbildungen sind im Anhang in Abschnitt W+Jets zu finden.
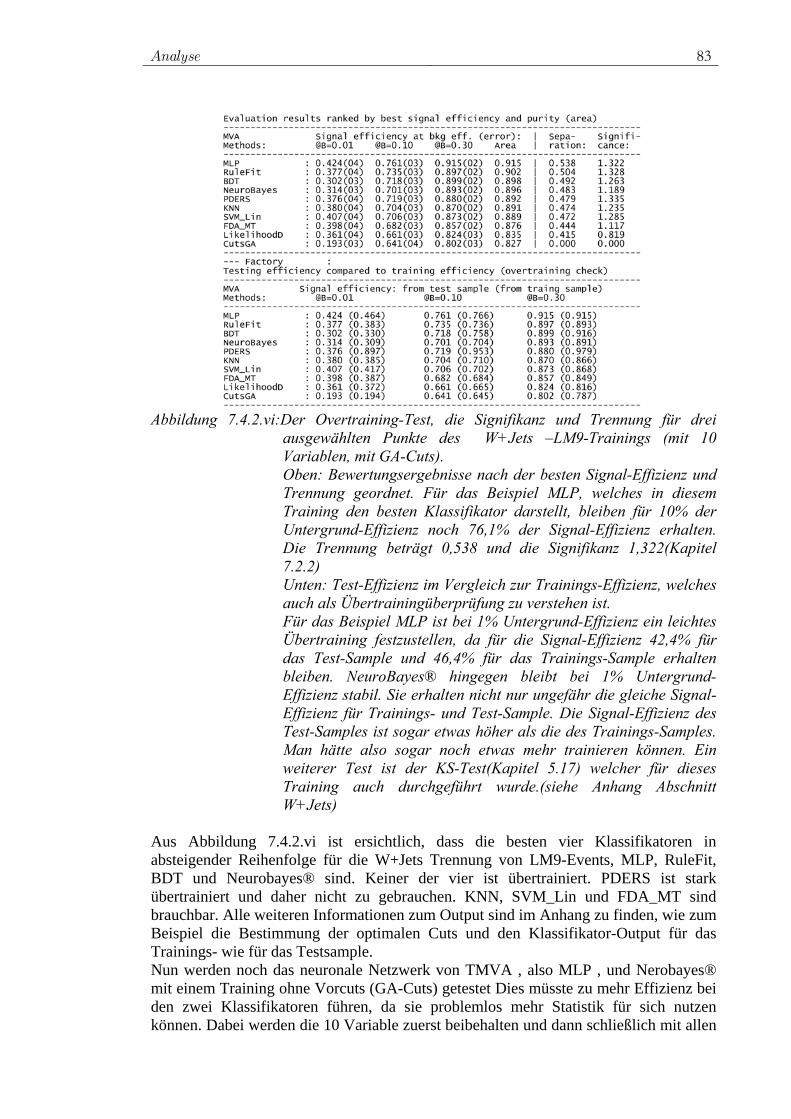
Analyse 83
Abbildung 7.4.2.vi:Der Overtraining-Test, die Signifikanz und Trennung für drei
ausgewählten Punkte des W+Jets –LM9-Trainings (mit 10 Variablen, mit GA-Cuts). Oben: Bewertungsergebnisse nach der besten Signal-Effizienz und Trennung geordnet. Für das Beispiel MLP, welches in diesem Training den besten Klassifikator darstellt, bleiben für 10% der Untergrund-Effizienz noch 76,1% der Signal-Effizienz erhalten. Die Trennung beträgt 0,538 und die Signifikanz 1,322(Kapitel 7.2.2) Unten: Test-Effizienz im Vergleich zur Trainings-Effizienz, welches auch als Übertrainingüberprüfung zu verstehen ist. Für das Beispiel MLP ist bei 1% Untergrund-Effizienz ein leichtes Übertraining festzustellen, da für die Signal-Effizienz 42,4% für das Test-Sample und 46,4% für das Trainings-Sample erhalten bleiben. NeuroBayes® hingegen bleibt bei 1% Untergrund-Effizienz stabil. Sie erhalten nicht nur ungefähr die gleiche Signal-Effizienz für Trainings- und Test-Sample. Die Signal-Effizienz des Test-Samples ist sogar etwas höher als die des Trainings-Samples. Man hätte also sogar noch etwas mehr trainieren können. Ein weiterer Test ist der KS-Test(Kapitel 5.17) welcher für dieses Training auch durchgeführt wurde.(siehe Anhang Abschnitt W+Jets)
Aus Abbildung 7.4.2.vi ist ersichtlich, dass die besten vier Klassifikatoren in absteigender Reihenfolge für die W+Jets Trennung von LM9-Events, MLP, RuleFit, BDT und Neurobayes® sind. Keiner der vier ist übertrainiert. PDERS ist stark übertrainiert und daher nicht zu gebrauchen. KNN, SVM_Lin und FDA_MT sind brauchbar. Alle weiteren Informationen zum Output sind im Anhang zu finden, wie zum Beispiel die Bestimmung der optimalen Cuts und den Klassifikator-Output für das Trainings- wie für das Testsample. Nun werden noch das neuronale Netzwerk von TMVA , also MLP , und Nerobayes® mit einem Training ohne Vorcuts (GA-Cuts) getestet Dies müsste zu mehr Effizienz bei den zwei Klassifikatoren führen, da sie problemlos mehr Statistik für sich nutzen können. Dabei werden die 10 Variable zuerst beibehalten und dann schließlich mit allen
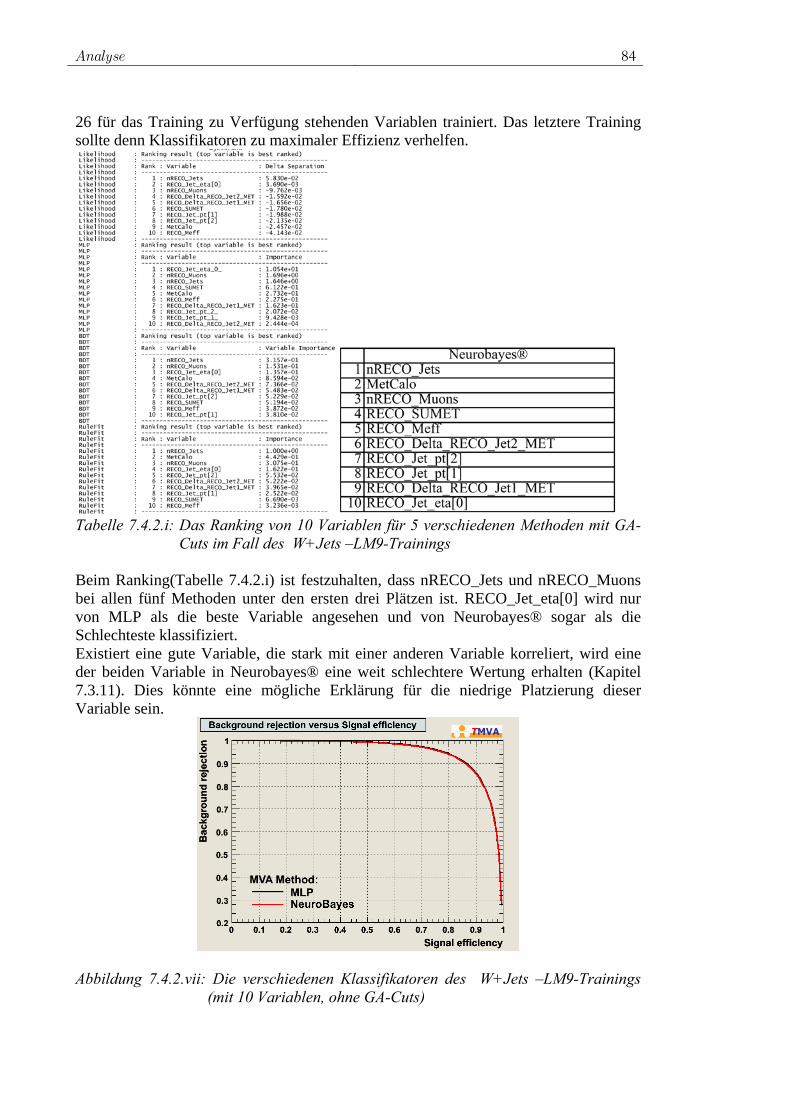
Analyse 84
26 für das Training zu Verfügung stehenden Variablen trainiert. Das letztere Training sollte denn Klassifikatoren zu maximaler Effizienz verhelfen.
Tabelle 7.4.2.i: Das Ranking von 10 Variablen für 5 verschiedenen Methoden mit GA-
Cuts im Fall des W+Jets –LM9-Trainings Beim Ranking(Tabelle 7.4.2.i) ist festzuhalten, dass nRECO_Jets und nRECO_Muons bei allen fünf Methoden unter den ersten drei Plätzen ist. RECO_Jet_eta[0] wird nur von MLP als die beste Variable angesehen und von Neurobayes® sogar als die Schlechteste klassifiziert. Existiert eine gute Variable, die stark mit einer anderen Variable korreliert, wird eine der beiden Variable in Neurobayes® eine weit schlechtere Wertung erhalten (Kapitel 7.3.11). Dies könnte eine mögliche Erklärung für die niedrige Platzierung dieser Variable sein.
Abbildung 7.4.2.vii: Die verschiedenen Klassifikatoren des W+Jets –LM9-Trainings
(mit 10 Variablen, ohne GA-Cuts)
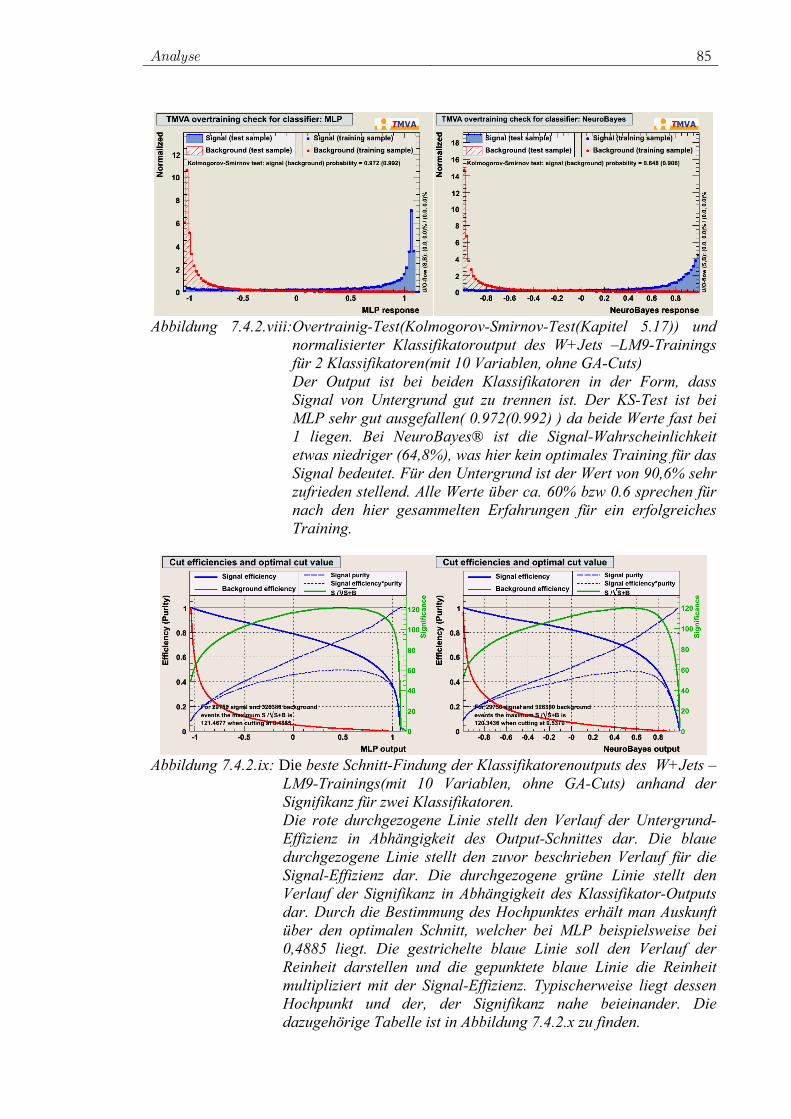
Analyse 85
Abbildung 7.4.2.viii:Overtrainig-Test(Kolmogorov-Smirnov-Test(Kapitel 5.17)) und
normalisierter Klassifikatoroutput des W+Jets –LM9-Trainings für 2 Klassifikatoren(mit 10 Variablen, ohne GA-Cuts) Der Output ist bei beiden Klassifikatoren in der Form, dass Signal von Untergrund gut zu trennen ist. Der KS-Test ist bei MLP sehr gut ausgefallen( 0.972(0.992) ) da beide Werte fast bei 1 liegen. Bei NeuroBayes® ist die Signal-Wahrscheinlichkeit etwas niedriger (64,8%), was hier kein optimales Training für das Signal bedeutet. Für den Untergrund ist der Wert von 90,6% sehr zufrieden stellend. Alle Werte über ca. 60% bzw 0.6 sprechen für nach den hier gesammelten Erfahrungen für ein erfolgreiches Training.
Abbildung 7.4.2.ix: Die beste Schnitt-Findung der Klassifikatorenoutputs des W+Jets –
LM9-Trainings(mit 10 Variablen, ohne GA-Cuts) anhand der Signifikanz für zwei Klassifikatoren. Die rote durchgezogene Linie stellt den Verlauf der Untergrund-Effizienz in Abhängigkeit des Output-Schnittes dar. Die blaue durchgezogene Linie stellt den zuvor beschrieben Verlauf für die Signal-Effizienz dar. Die durchgezogene grüne Linie stellt den Verlauf der Signifikanz in Abhängigkeit des Klassifikator-Outputs dar. Durch die Bestimmung des Hochpunktes erhält man Auskunft über den optimalen Schnitt, welcher bei MLP beispielsweise bei 0,4885 liegt. Die gestrichelte blaue Linie soll den Verlauf der Reinheit darstellen und die gepunktete blaue Linie die Reinheit multipliziert mit der Signal-Effizienz. Typischerweise liegt dessen Hochpunkt und der, der Signifikanz nahe beieinander. Die dazugehörige Tabelle ist in Abbildung 7.4.2.x zu finden.

Analyse 86
Abbildung 7.4.2.x: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
W+Jets –LM9-Trainings(mit 10 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.2.xi: Overtraining-Test und die Signifikanz und Trennung für drei
ausgewählten Punkte des W+Jets –LM9-Trainings (mit 10 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi) MLP ist stärker beim Separieren der Daten und Neurobayes® etwas besser bei der Signifikanz. (Abbildung7.4.2.xi) Insgesamt ist MLP weiterhin leicht im Vorteil, wenn die GA-Cuts nicht mehr genutzt werden (Abbildung7.4.2.x)
Tabelle 7.4.2.ii: Das Ranking von 10 Variablen für 2 verschiedenen Methoden ohne
GA-Cuts im Fall des W+Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.2.ii) ist wieder RECO_Jet_eta_0 auf Platz 1 bei MLP. Erstaunlicherweise ist MetCalo als schlechteste Variable eingestuft worden.
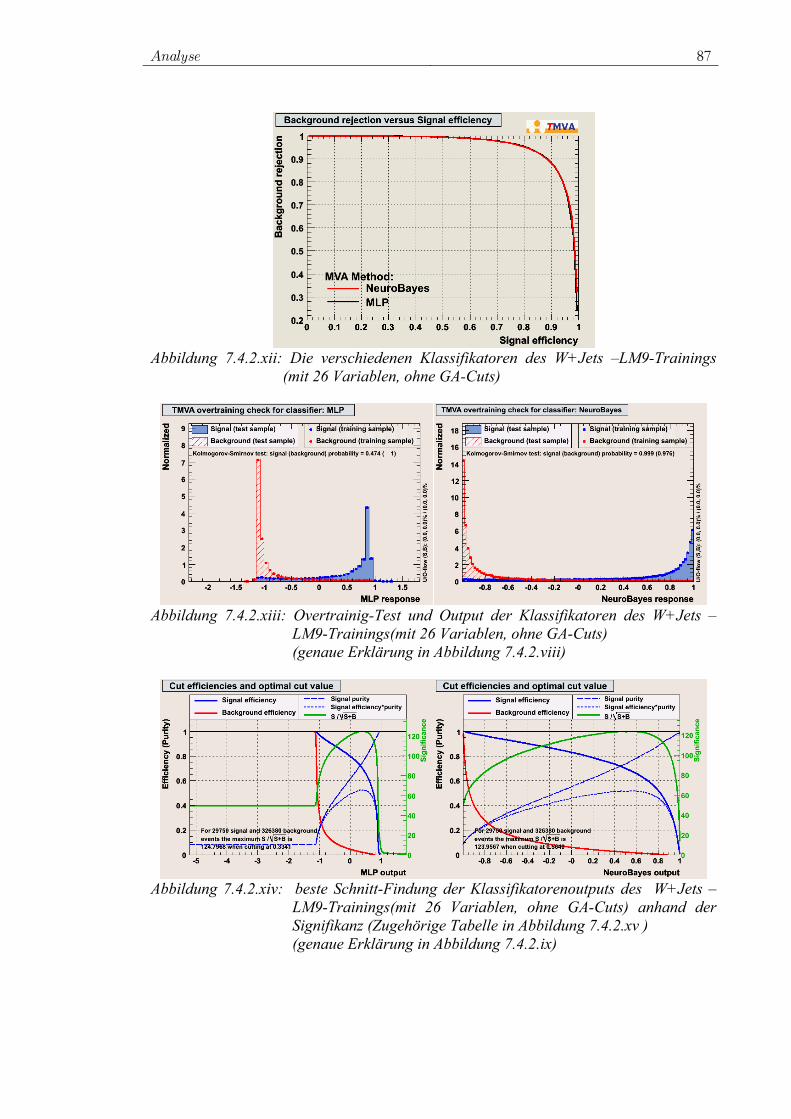
Analyse 87
Abbildung 7.4.2.xii: Die verschiedenen Klassifikatoren des W+Jets –LM9-Trainings
(mit 26 Variablen, ohne GA-Cuts)
Abbildung 7.4.2.xiii: Overtrainig-Test und Output der Klassifikatoren des W+Jets –
LM9-Trainings(mit 26 Variablen, ohne GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.viii)
Abbildung 7.4.2.xiv: beste Schnitt-Findung der Klassifikatorenoutputs des W+Jets –
LM9-Trainings(mit 26 Variablen, ohne GA-Cuts) anhand der Signifikanz (Zugehörige Tabelle in Abbildung 7.4.2.xv )
(genaue Erklärung in Abbildung 7.4.2.ix)

Analyse 88
Abbildung 7.4.2.xv.: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
W+Jets –LM9-Trainings(mit 26 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.2.xvi.:Overtraining-Test und die Signifikanz und Trennung für drei
ausgewählten Punkte des W+Jets –LM9-Trainings(mit 26 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi) Bei völliger Freiheit der Klassifikatoren, also ohne jegliche Cuts, gibt es für Neuronale Netzwerke die besten Resultate. Neurobayes® und MLP sind nun gleich auf. Wobei Neurobayes® diesmal einen Hauch besser ist als zuvor MLP. (Abbildung 7.4.2.xvi). An dieser Stelle sollte erwähnt werden, dass Neurobayes® einen sehr kleinen Vorteil hat. Es besitzt die Möglichkeit Variablen-Einträge nicht zu beachten. Wie zum Beispiel für die Variable „Winkel zwischen dem ersten und dem zweiten Jet“, die auch einen Wert erhalten muss wenn nur ein Jet entsteht. MLP auch diesen Vorteil zu verschaffen ist nicht unlösbar. Es müsste eine neue Variable einführen werden, die den Wert „1“ für Winkelentstehung und „0“ für zuwenig Jets trägt. Damit würde MLP die gleichen Informationen erhalten wie Neurobayes®. Aus zeitlichen Gründen wurde darauf verzichtet MLP diese 27., 28. und 29.Variable anzutrainieren. Der Vorteil von Neurobayes® in diesem Fall ist nur sehr gering. Eine schnelle Prüfung bestätigt diese Entscheidung, anhand der Wertung der Variablen durch beide Programme. Durch die Zahl der Jets, den Plots der drei in Frage kommenden Variablen (siehe Anhang) und dem Ranking (Tabelle 7.4.2.iii) wird dies ersichtlich.

Analyse 89
Tabelle 7.4.2.iii: Das Ranking von 26 Variablen für 2 verschiedenen Methoden ohne
GA-Cuts im Fall des W+Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.2.iii) wird MetCalo von MLP als eher schlecht eingestuft und von Neurobayes® als sehr gut. Es ist interessant zu wissen, dass die Rangfolge bei beiden neuronalen Netzwerken stark von der Variablen-Eingabereihenfolge abhängt. Dies hat zur folge, dass zwei neuronale Netzwerke, mit sehr unterschiedlichen Gewichtungen unter den Neuronen ein Problem annähernd gleich gut lösen können. Diese Gewichtungen führen dementsprechend auch zu unterschiedlichen Rangfolgen. Da die Variablen-Ranglisten außerdem noch auf so unterschiedliche Weise gebildet werden (Kapitel 7.3.11), waren Unterschiede zu erwarten. Beispielsweise war ab-zusehen, dass die Winkel η der drei Jets bei Neurobayes® sicher nicht dicht beieinander liegen werden, da sie stark korrelieren und beim MLP-Ranking sehr dicht im oberen Bereich beieinander platziert sind.
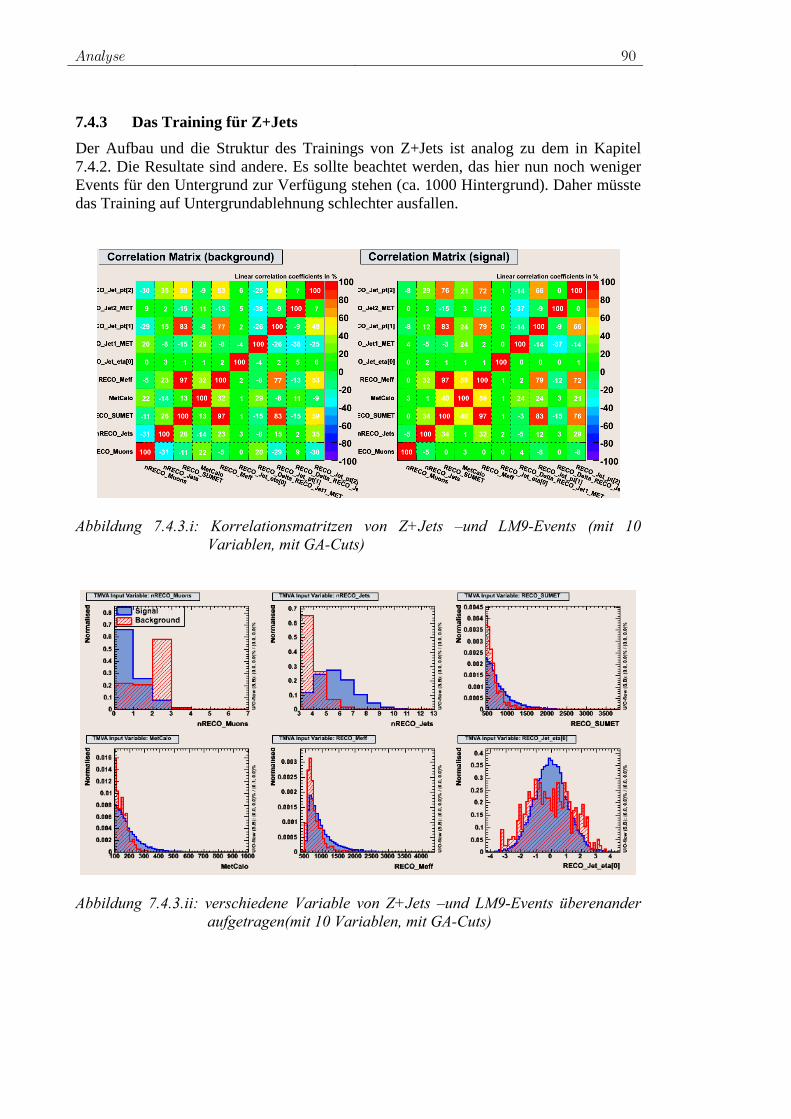
Analyse 90
7.4.3 Das Training für Z+Jets Der Aufbau und die Struktur des Trainings von Z+Jets ist analog zu dem in Kapitel 7.4.2. Die Resultate sind andere. Es sollte beachtet werden, das hier nun noch weniger Events für den Untergrund zur Verfügung stehen (ca. 1000 Hintergrund). Daher müsste das Training auf Untergrundablehnung schlechter ausfallen.
Abbildung 7.4.3.i: Korrelationsmatritzen von Z+Jets –und LM9-Events (mit 10
Variablen, mit GA-Cuts)
Abbildung 7.4.3.ii: verschiedene Variable von Z+Jets –und LM9-Events überenander
aufgetragen(mit 10 Variablen, mit GA-Cuts)
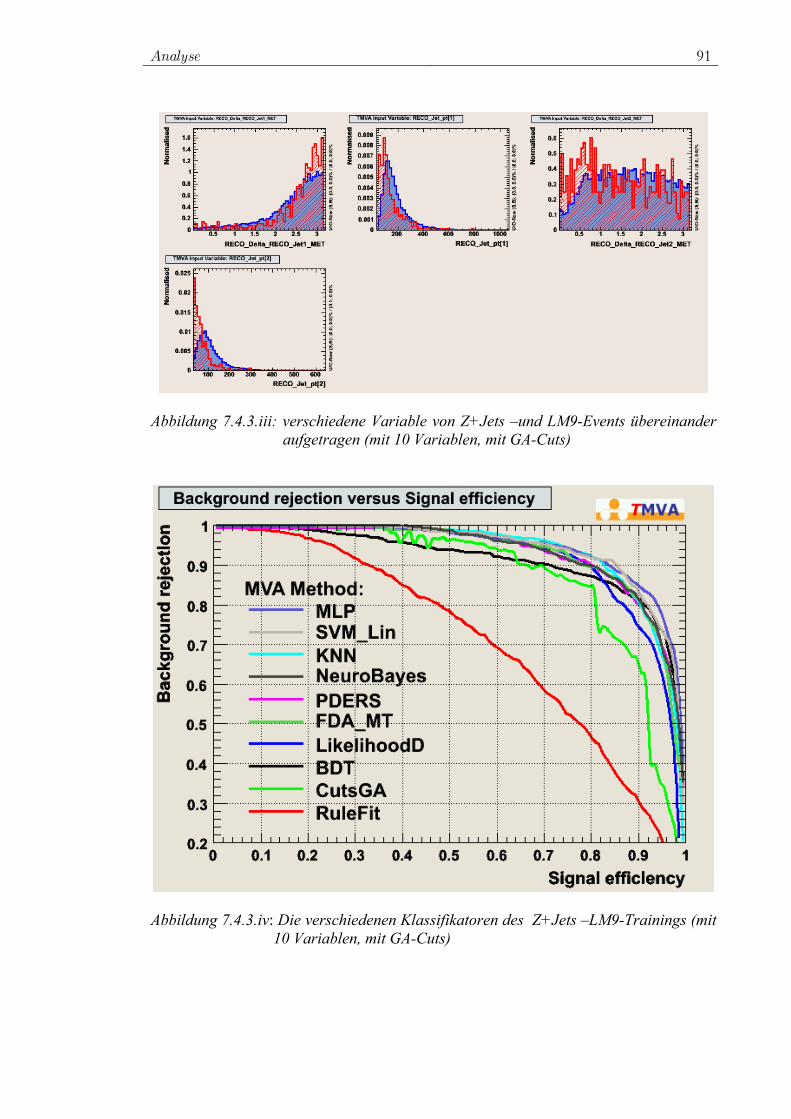
Analyse 91
Abbildung 7.4.3.iii: verschiedene Variable von Z+Jets –und LM9-Events übereinander
aufgetragen (mit 10 Variablen, mit GA-Cuts)
Abbildung 7.4.3.iv: Die verschiedenen Klassifikatoren des Z+Jets –LM9-Trainings (mit
10 Variablen, mit GA-Cuts)
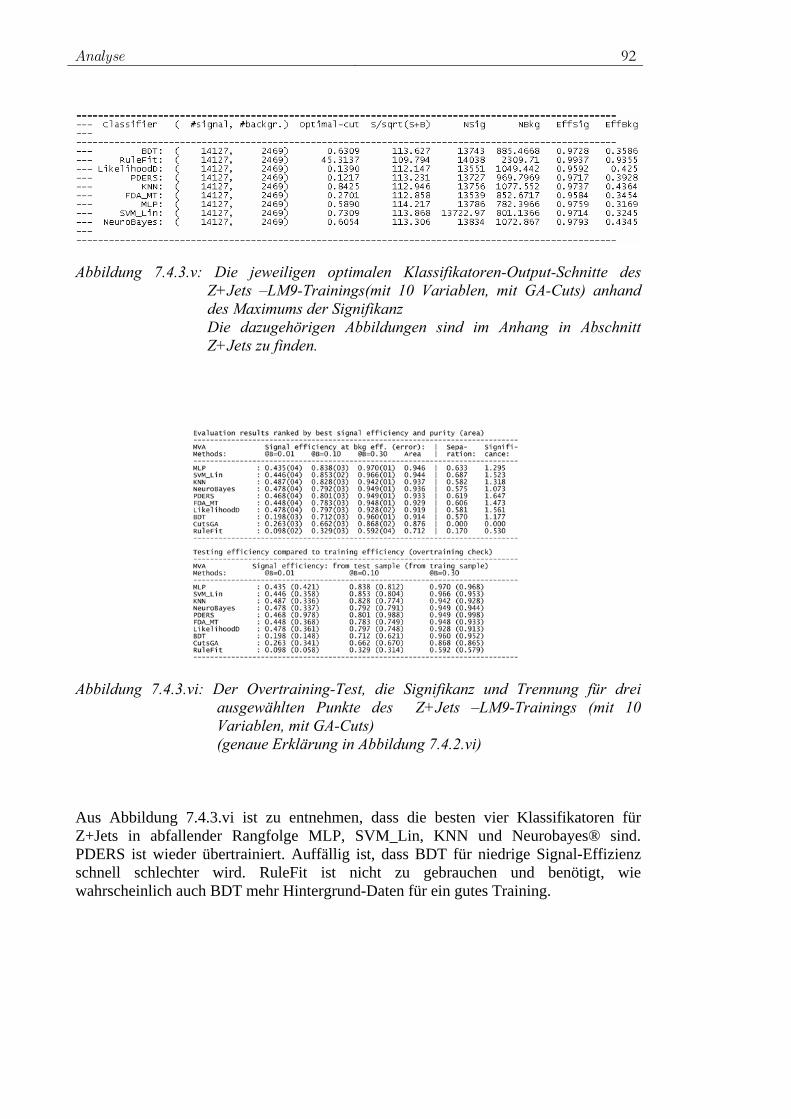
Analyse 92
Abbildung 7.4.3.v: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
Z+Jets –LM9-Trainings(mit 10 Variablen, mit GA-Cuts) anhand des Maximums der Signifikanz
Die dazugehörigen Abbildungen sind im Anhang in Abschnitt Z+Jets zu finden.
Abbildung 7.4.3.vi: Der Overtraining-Test, die Signifikanz und Trennung für drei
ausgewählten Punkte des Z+Jets –LM9-Trainings (mit 10 Variablen, mit GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi) Aus Abbildung 7.4.3.vi ist zu entnehmen, dass die besten vier Klassifikatoren für Z+Jets in abfallender Rangfolge MLP, SVM_Lin, KNN und Neurobayes® sind. PDERS ist wieder übertrainiert. Auffällig ist, dass BDT für niedrige Signal-Effizienz schnell schlechter wird. RuleFit ist nicht zu gebrauchen und benötigt, wie wahrscheinlich auch BDT mehr Hintergrund-Daten für ein gutes Training.
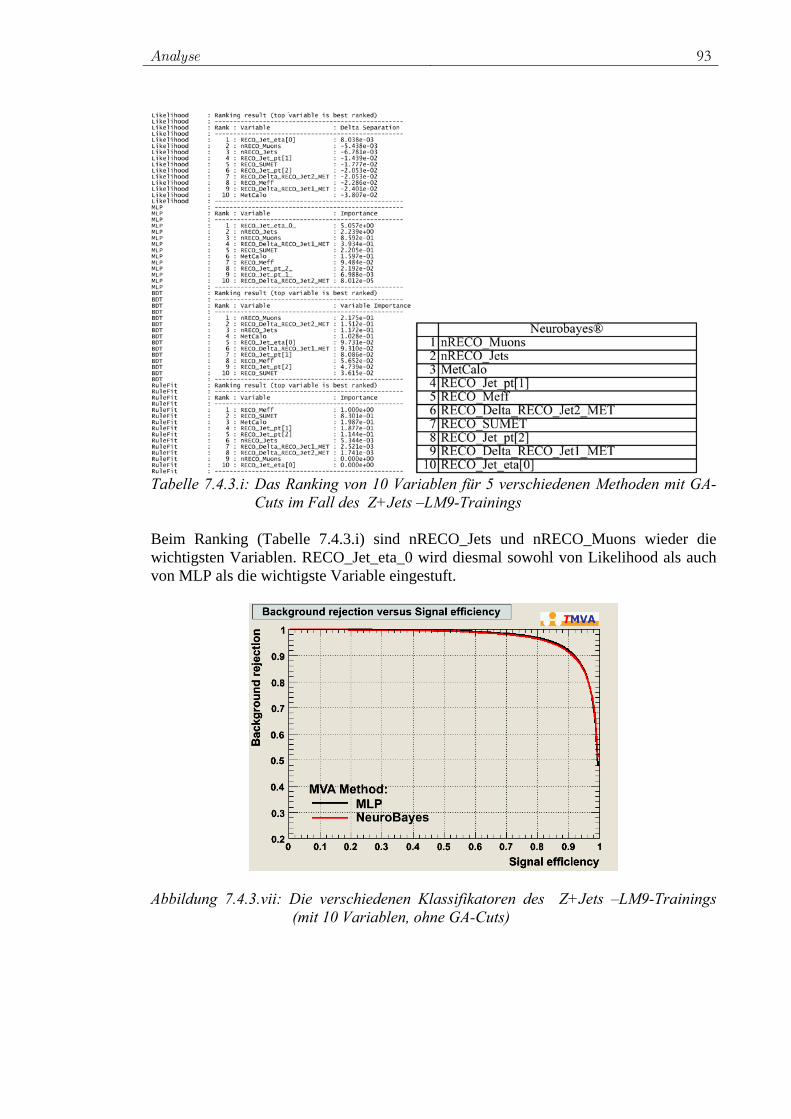
Analyse 93
Tabelle 7.4.3.i: Das Ranking von 10 Variablen für 5 verschiedenen Methoden mit GA-
Cuts im Fall des Z+Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.3.i) sind nRECO_Jets und nRECO_Muons wieder die wichtigsten Variablen. RECO_Jet_eta_0 wird diesmal sowohl von Likelihood als auch von MLP als die wichtigste Variable eingestuft.
Abbildung 7.4.3.vii: Die verschiedenen Klassifikatoren des Z+Jets –LM9-Trainings
(mit 10 Variablen, ohne GA-Cuts)
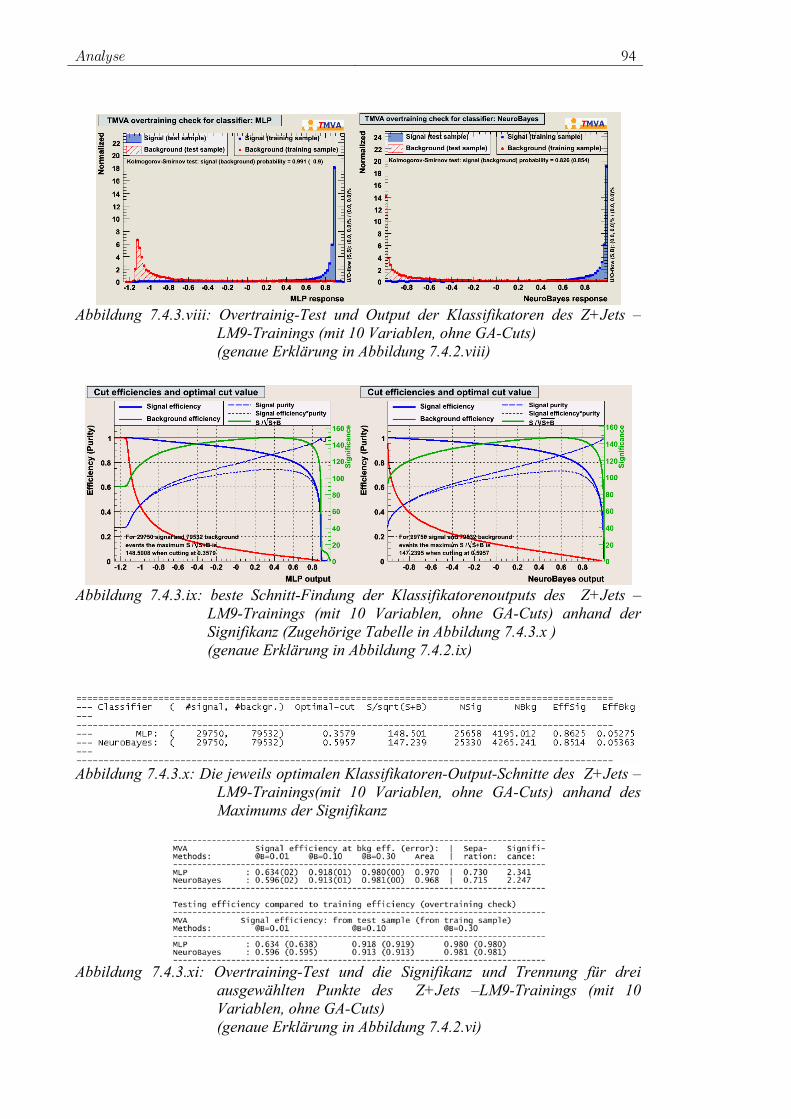
Analyse 94
Abbildung 7.4.3.viii: Overtrainig-Test und Output der Klassifikatoren des Z+Jets –
LM9-Trainings (mit 10 Variablen, ohne GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.viii)
Abbildung 7.4.3.ix: beste Schnitt-Findung der Klassifikatorenoutputs des Z+Jets –
LM9-Trainings (mit 10 Variablen, ohne GA-Cuts) anhand der Signifikanz (Zugehörige Tabelle in Abbildung 7.4.3.x )
(genaue Erklärung in Abbildung 7.4.2.ix)
Abbildung 7.4.3.x: Die jeweils optimalen Klassifikatoren-Output-Schnitte des Z+Jets –
LM9-Trainings(mit 10 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.3.xi: Overtraining-Test und die Signifikanz und Trennung für drei
ausgewählten Punkte des Z+Jets –LM9-Trainings (mit 10 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi)
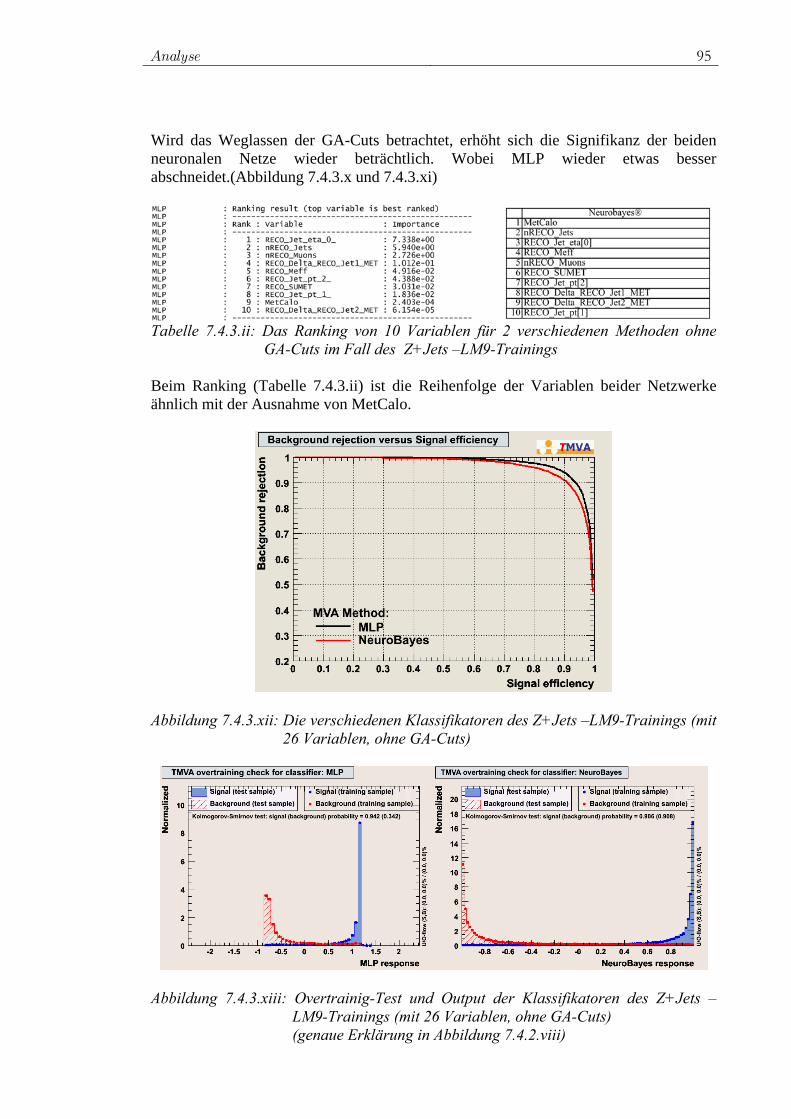
Analyse 95
Wird das Weglassen der GA-Cuts betrachtet, erhöht sich die Signifikanz der beiden neuronalen Netze wieder beträchtlich. Wobei MLP wieder etwas besser abschneidet.(Abbildung 7.4.3.x und 7.4.3.xi)
Tabelle 7.4.3.ii: Das Ranking von 10 Variablen für 2 verschiedenen Methoden ohne
GA-Cuts im Fall des Z+Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.3.ii) ist die Reihenfolge der Variablen beider Netzwerke ähnlich mit der Ausnahme von MetCalo.
Abbildung 7.4.3.xii: Die verschiedenen Klassifikatoren des Z+Jets –LM9-Trainings (mit 26 Variablen, ohne GA-Cuts)
Abbildung 7.4.3.xiii: Overtrainig-Test und Output der Klassifikatoren des Z+Jets –LM9-Trainings (mit 26 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.viii)
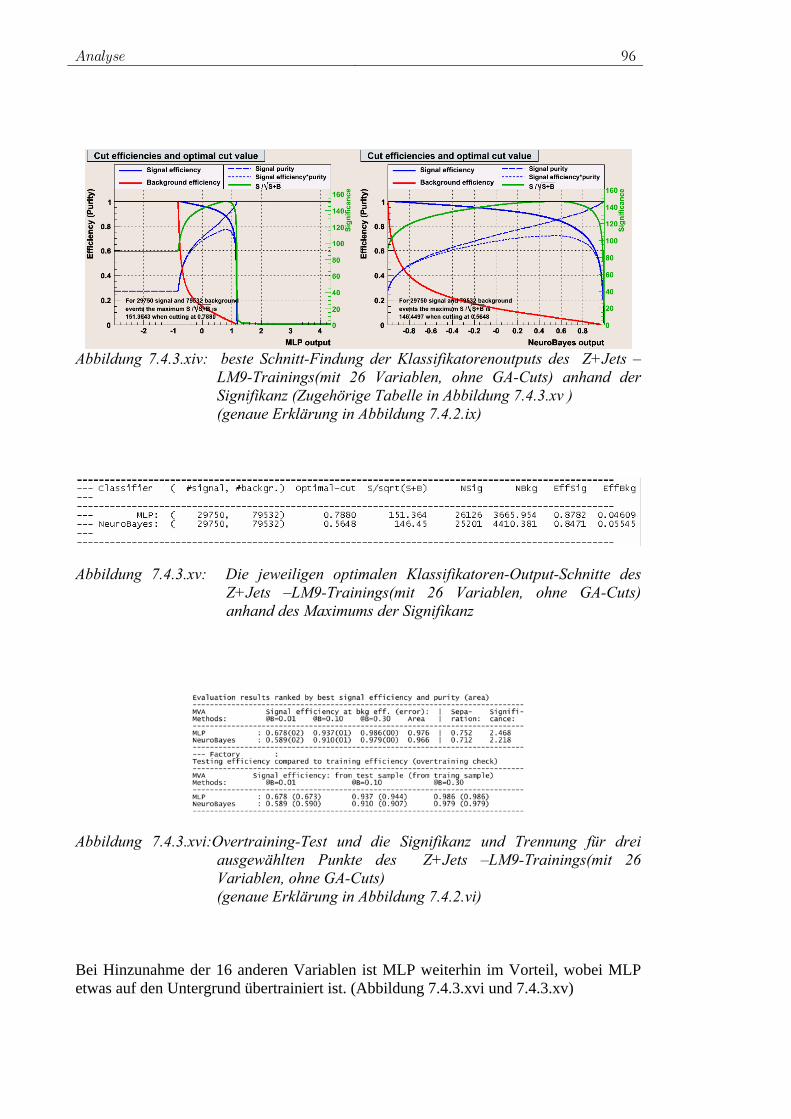
Analyse 96
Abbildung 7.4.3.xiv: beste Schnitt-Findung der Klassifikatorenoutputs des Z+Jets –
LM9-Trainings(mit 26 Variablen, ohne GA-Cuts) anhand der Signifikanz (Zugehörige Tabelle in Abbildung 7.4.3.xv )
(genaue Erklärung in Abbildung 7.4.2.ix)
Abbildung 7.4.3.xv: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
Z+Jets –LM9-Trainings(mit 26 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.3.xvi:Overtraining-Test und die Signifikanz und Trennung für drei
ausgewählten Punkte des Z+Jets –LM9-Trainings(mit 26 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi) Bei Hinzunahme der 16 anderen Variablen ist MLP weiterhin im Vorteil, wobei MLP etwas auf den Untergrund übertrainiert ist. (Abbildung 7.4.3.xvi und 7.4.3.xv)

Analyse 97
Tabelle 7.4.3.iii: Das Ranking von 26 Variablen für 2 verschiedenen Methoden ohne GA-
Cuts im Fall des Z+Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.3.iii) sind wieder die Winkel η der ersten 3 Jets im Fall von MLP sehr wichtig und MetCalo eher unwichtig. Neurobayes® hingegen gibt MetCalo die höchste Priorität und hällt nur den ersten Jetwinkel η für wichtig. Mögliche Gründe für die Ranking-Unterschiede wurden in den Diskussionen der vorigen Rankingtabellen bereits genannt.
7.4.4 Das Training für tt -Jets
Wieder wird in diesem Kapitel die Struktur der beiden vorherigen Kapitel beibehalten. Diesmal wurde zuvor darauf geachtet, dass die Anzahl der Signal-Events der der Hintergrund-Events ungefähr entspricht (jeweils ca.28000 Events)
Abbildung 7.4.4.i: Korrelationsmatritzen von tt +Jets –und LM9-Events (mit 10 Variablen, mit GA-Cuts)
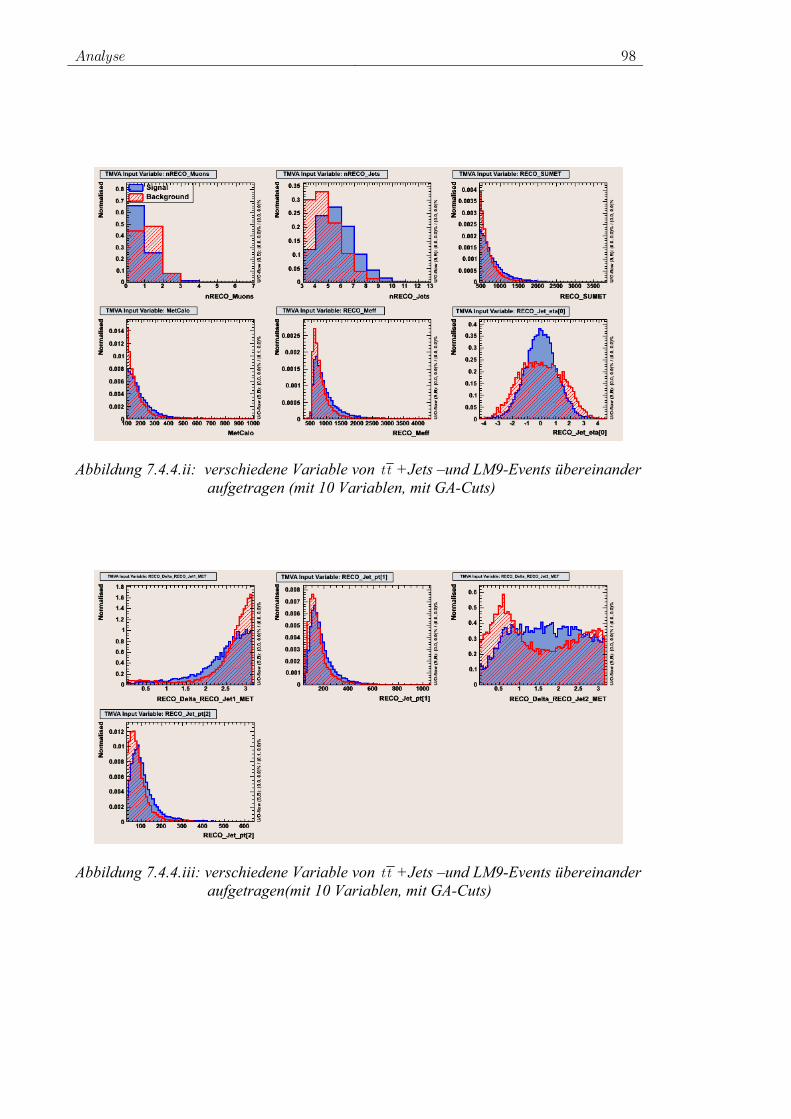
Analyse 98
Abbildung 7.4.4.ii: verschiedene Variable von tt +Jets –und LM9-Events übereinander
aufgetragen (mit 10 Variablen, mit GA-Cuts)
Abbildung 7.4.4.iii: verschiedene Variable von tt +Jets –und LM9-Events übereinander aufgetragen(mit 10 Variablen, mit GA-Cuts)
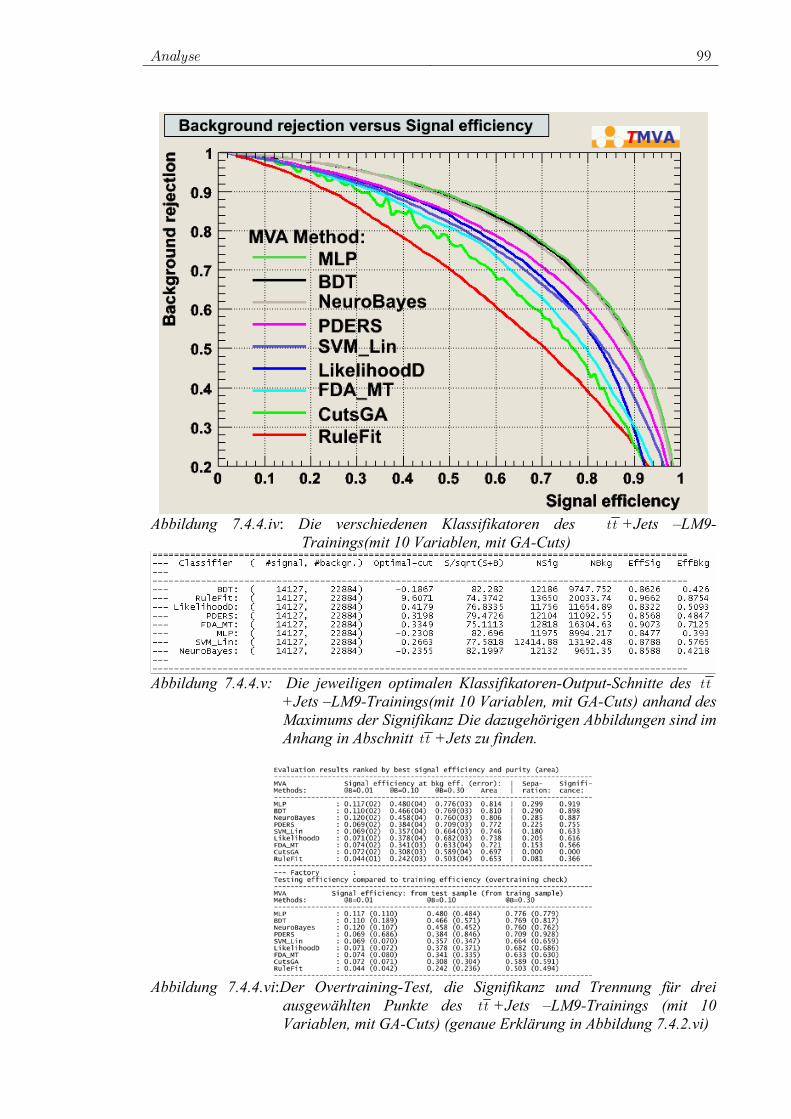
Analyse 99
Abbildung 7.4.4.iv: Die verschiedenen Klassifikatoren des tt +Jets –LM9-
Trainings(mit 10 Variablen, mit GA-Cuts)
Abbildung 7.4.4.v: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des tt
+Jets –LM9-Trainings(mit 10 Variablen, mit GA-Cuts) anhand des Maximums der Signifikanz Die dazugehörigen Abbildungen sind im Anhang in Abschnitt tt +Jets zu finden.
Abbildung 7.4.4.vi:Der Overtraining-Test, die Signifikanz und Trennung für drei
ausgewählten Punkte des tt +Jets –LM9-Trainings (mit 10 Variablen, mit GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.vi)

Analyse 100
In Abbildung 7.4.4.vi ist diesmal der KNN-Klassifikator nicht aufgeführt, da er nicht zu trainieren war, was mit der Anzahl der Variablen verbunden ist, die in Kombination von zu vielen Ereignissen zu einem Absturz des Programms führt. Das Verhindern des Absturzes hat bis jetzt immer zu deutlichen Effizienzeinbußungen geführt. Diesmal sind die besten vier Klassifikatoren MLP, BDT Neurobayes® und PDERS, wobei das zuletzt genannte eindeutig übertraininert ist, was der Tabelle oder dem Anhang entnommen werden kann. Wie zu erwarten waren, bis auf RuleFit, die restlichen Methoden stabil. Da es eine ähnliche Vorgehensweise aufweist wie BDT und BDT sehr gut mit den beiden neuronalen Netzen mithalten kann, war RuleFit ein überraschender Verlierer dieser Analyse.
Tabelle 7.4.4.i: Das Ranking von 10 Variablen für 5 verschiedenen Methoden mit GA-
Cuts im Fall des tt +Jets –LM9-Trainings Beim Ranking (Tabelle 7.4.4.i) wird nur nRECO_Jets eindeutig als eine der wichtigsten Variablen aufgeführt. nRECO_Muons und RECO_Delta_RECO_Jet1_MET haben auch ihren festen Platz. RuleFit ist hierbei zu vernachlässigen, da schlechte Ergebnisse mit dessen Training erzielt wurden.
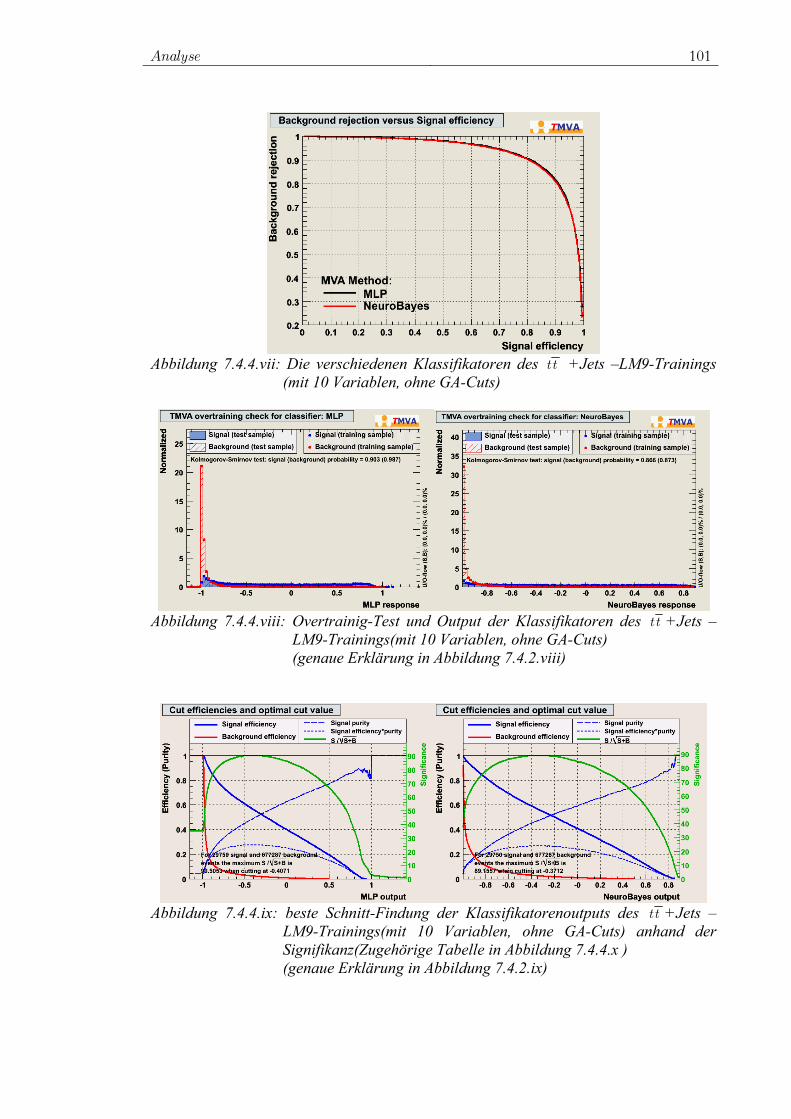
Analyse 101
Abbildung 7.4.4.vii: Die verschiedenen Klassifikatoren des tt +Jets –LM9-Trainings
(mit 10 Variablen, ohne GA-Cuts)
Abbildung 7.4.4.viii: Overtrainig-Test und Output der Klassifikatoren des tt +Jets –
LM9-Trainings(mit 10 Variablen, ohne GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.viii)
Abbildung 7.4.4.ix: beste Schnitt-Findung der Klassifikatorenoutputs des tt +Jets –
LM9-Trainings(mit 10 Variablen, ohne GA-Cuts) anhand der Signifikanz(Zugehörige Tabelle in Abbildung 7.4.4.x )
(genaue Erklärung in Abbildung 7.4.2.ix)
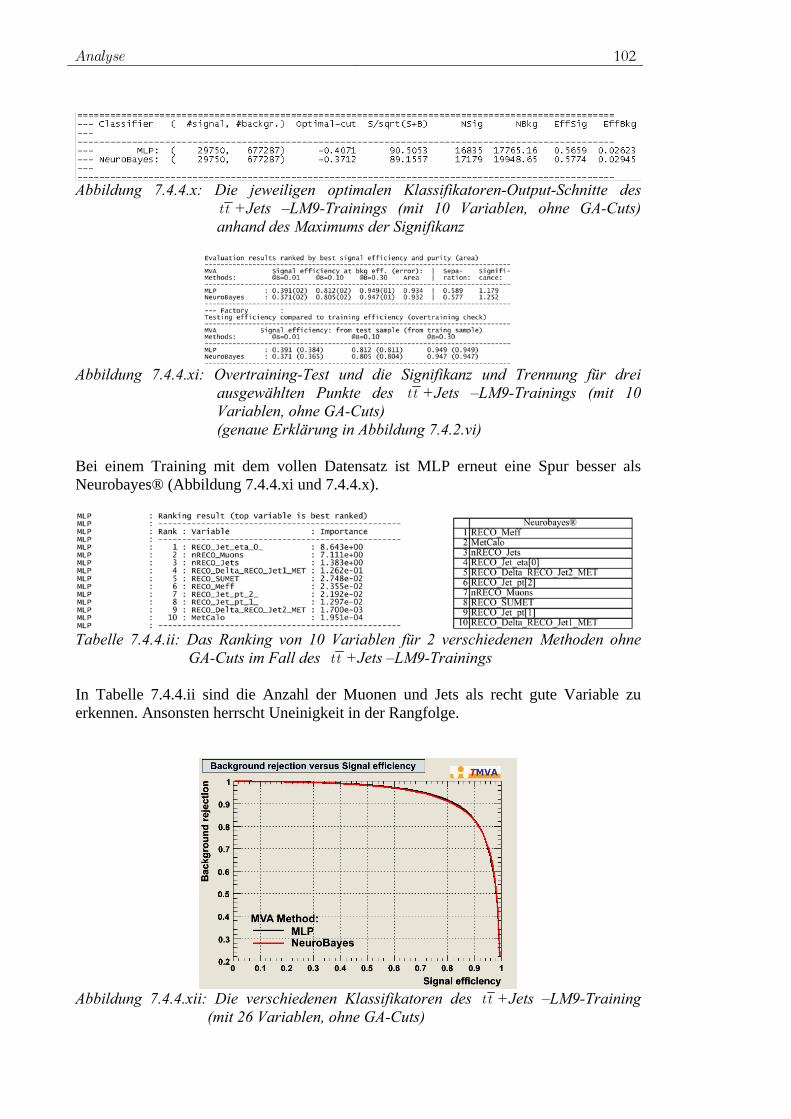
Analyse 102
Abbildung 7.4.4.x: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
tt +Jets –LM9-Trainings (mit 10 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.4.xi: Overtraining-Test und die Signifikanz und Trennung für drei
ausgewählten Punkte des tt +Jets –LM9-Trainings (mit 10 Variablen, ohne GA-Cuts)
(genaue Erklärung in Abbildung 7.4.2.vi) Bei einem Training mit dem vollen Datensatz ist MLP erneut eine Spur besser als Neurobayes® (Abbildung 7.4.4.xi und 7.4.4.x).
Tabelle 7.4.4.ii: Das Ranking von 10 Variablen für 2 verschiedenen Methoden ohne
GA-Cuts im Fall des tt +Jets –LM9-Trainings In Tabelle 7.4.4.ii sind die Anzahl der Muonen und Jets als recht gute Variable zu erkennen. Ansonsten herrscht Uneinigkeit in der Rangfolge.
Abbildung 7.4.4.xii: Die verschiedenen Klassifikatoren des tt +Jets –LM9-Training
(mit 26 Variablen, ohne GA-Cuts)
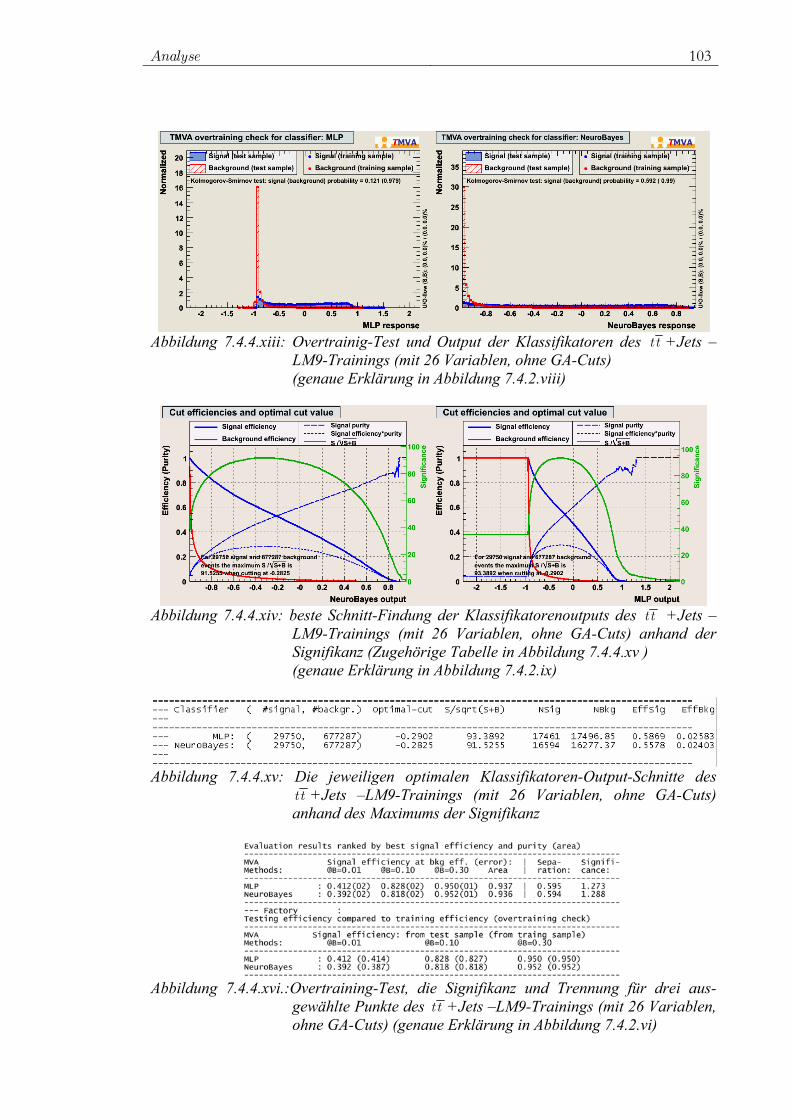
Analyse 103
Abbildung 7.4.4.xiii: Overtrainig-Test und Output der Klassifikatoren des tt +Jets –
LM9-Trainings (mit 26 Variablen, ohne GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.viii)
Abbildung 7.4.4.xiv: beste Schnitt-Findung der Klassifikatorenoutputs des tt +Jets –
LM9-Trainings (mit 26 Variablen, ohne GA-Cuts) anhand der Signifikanz (Zugehörige Tabelle in Abbildung 7.4.4.xv )
(genaue Erklärung in Abbildung 7.4.2.ix)
Abbildung 7.4.4.xv: Die jeweiligen optimalen Klassifikatoren-Output-Schnitte des
tt +Jets –LM9-Trainings (mit 26 Variablen, ohne GA-Cuts) anhand des Maximums der Signifikanz
Abbildung 7.4.4.xvi.:Overtraining-Test, die Signifikanz und Trennung für drei aus-
gewählte Punkte des tt +Jets –LM9-Trainings (mit 26 Variablen, ohne GA-Cuts) (genaue Erklärung in Abbildung 7.4.2.vi)

Analyse 104
Erneut ist MLP, wenn auch nur ein wenig, besser als Neurobayes®, was diesmal auf das erneute Übertrainieren des Untergrundes zurückzuführen ist (Abbildung 7.4.4.xvi).
Tabelle 7.4.4.iii: Das Ranking von 26 Variablen für 2 verschiedenen Methoden ohne
GA-Cuts im Fall des tt +Jets –LM9-Trainings In Tabelle 7.4.4.iii ist auffällig, dass MLP alle Winkel für relativ weit oben in der Wichtigkeit einstuft und die Anzahl der OSSFe in der Rangfolge noch vor der Anzahl der Myonen im Fall des Neurobayes®-Rankings ist.

Zusammenfassung 107
8 Zusammenfassung Diese Arbeit untersucht die Eignung verschiedener statistischer Methoden bei der Suche nach supersymmetrischen Prozessen im Rahmen des CMS-Experiments. Dabei wird der Parameterraum auf den CMS mSUGRA-Punkt LM9 festgelegt. Die durch das Programm TMVA nutzbar gemachten statistischen Methoden werden hierfür verwendet. Außerdem wurde noch ein weiteres Programm Neurobayes®, ein künstliches neuronales Netzwerk, in TMVA integriert und getestet. Durch die Anzahl der Events der Untergrunddatensätze sind Rückschlüsse auf des Verhalten bezüglich des Verhältnisses Signal zu Untergrund-Events ersichtlich. Das Verhältnis tt -Events zu LM9-Events ist daher zu Beginn der Analyse durch geschickte Schnitte mit dem GA auf 1 gebracht worden. Das Verhältnis der Anzahl an W+Jets-Events zu LM9-Events entspricht 5 und das von Z+Jets-Events zu LM9-Events ist gleich 20. Es wird ersichtlich dass BDT dann gut einsetzbar ist, wenn sich die zum Training gegebene Anzahl an Events für Signal und Untergrund nicht zu stark unterscheiden. Verdeutlicht wird dies dadurch, dass BDT zu den drei besten Klassi-fikatoren im tt +Jets-Training als auch im W+Jets-Training zählt, während es im Z+Jets-Training schlecht abschneidet, da hier das Verhältnis von Signal- zu Hinter-grund-Events zu groß ist. Damit gehört BDT zusammen mit den neuronalen Netzwerken zu den besten Klassifikatoren einer Analyse mit ähnlichen Problem-stellungen. Nur sollte das Übertrainieren nicht aus den Augen verloren werden, wobei es erheblich durch die Einführung des Gewichtens (Boost) reduziert wurde (Kapitel 5.9). Neurobayes® bleibt, nach allen Traningsprozessen, als einziger Klassifikator nicht übertrainiert. Damit ist er der stabilste Klassifikator, der selbst mit wenig Information von Inputdaten nicht zum Übertrainieren neigt. Das MLP ist ein wirklich mächtiger Klassifikator, wenn man es beherrscht. Es ist immer der beste Klassifikator gewesen, gemessen an seiner Signifikanz. Wenn ein Übertraining festgestellt wurde sollte er neu konfiguriert werden, indem zum Beispiel die Anzahl der Knoten oder versteckten Schichten geändert wird. Grundsätzlich hilft, immer auf Kosten der Effizienz, das Training früher enden zu lassen. Neurobayes® besitzt nicht die Möglichkeit die Anzahl der versteckten Schichten zu ändern, zumindest nicht in der für uns zugänglichen Version. Dies muss kein Nachteil sein (Kapitel 5.16), da durch die Erhöhung der Anzahl von Neuronen, jedes andere neuronale Netz nachgeahmt werden kann. Wer sich, bis jetzt, wenig mit neuronalen Netzen befasst hat, wird mit Neurobayes® schnell, gute Lösungen für komplexe Problemstellungen erhalten, da die Fehler die typischerweise beim Trainieren von neuronalen Netzwerken auftreten durch entsprechende Kontrollen im Code reduziert werden. Es wird für Experten zu ähnlichen Leistungen führen wie der für den freien Gebrauch verfügbaren MLP-Klassifikator von TMVA. SVM ist ein robuster Klassifikator in Bezug auf Übertrainieren. Er hat im Fall von Z+Jets überzeugt obwohl nur so wenige Hintergrund-Events vorhanden waren. Außerdem war er beim tt +Jets-Training unter den besten vier Klassifikatoren, da der PEDERS-Klassifikator auf Grund des Übertrainings ausgelassen werden kann. Es sollte nicht der Fehler gemacht werden ihn mit einer zu hohen Menge an Daten zu trainieren. Die Zugabe von weiteren Variablen oder das Weglassen der Anfangs getätigten Schnitte, würde zu einem massiven Rückgang der Effizienz führen (Kapitel 5.12).

Zusammenfassung 108
PDERS ist kein schlechter Klassifikator. Er ist für diese Problemstellung nicht zu gebrauchen, da er zu anfällig für „schlechte“ Variablen ist. Mit großen Trainings-mengen hat er keine Probleme. Es steigert sogar noch seine Effizienz, weil dadurch genauere PDFs (Kapitel 7.5.1) gebildet werden können. Auch die Zunahme von Variablen ist solange nicht von Belangen bis nicht mehr genügend Trainingsdaten für die Bildung der hochdimensionalen PDFs zur Verfügung stehen und die Form der Variablen „schön“ bleibt (Kapitel 5.7.2). Bei nicht ausreichenden Trainigsdaten kann man mit Hilfe von KNN(Kapitel 5.10) die PDF-Bildung umgehen, wobei diese Methode noch Empfindlicher auf „schlechte“ Variablen, zum Beispiel Variablen deren Verteilung der Form einer Delta-Distribution entsprechen, reagiert. Daher sind KNN und PDERS nur zweckmäßig geeignet, wenn man sich strikt an diese Einschränkungen hält. Der FDA-Klassifikator ist nicht zu vernachlässigen. Er schließt die Lücke zwischen den linearen wie dem Likelihood-Klassifikator und den sehr leistungsstarken neuronalen Netzwerken, für welche die Art der Korrelation der Variablen untereinander keine Rolle spielt. Daher ist die Effizienz noch gut für diese Analyse. Bei Erhöhung der Variablen sollte man auf ihn verzichten. Der Likelihood-Klassifikator gehört zu den besten Klassifikatoren solange, die Variablen linear korrelieren und ist in solchen Fällen sogar der Effizienteste. Abgesehen von der Fisher-Diskriminante und dem H-Matrix Klassifikator, die besonders gut auf Gauß-verteilte Probleme anwendbar sind, gibt es keine Konkurrenten. Er gehört bei dieser Analyse zu den Klassifikatoren, die mittelmäßig abschneiden, da er beispielsweise die nichtlinearen Korrelationen nicht beachtet. Er ist stabil und innerhalb von 10 Minuten über einen Datensatz von 10 Millionen Events gelaufen und damit gut zum Testen zu gebrauchen. Bei jedem Training sollte er mittrainiert werden. Es kann sich anhand von ihm gut orientieren werden, ob ein Klassifikator für ein Training geeignet ist, falls er eine bessere Effizienz aufweist. Von RuleFit wurde mehr erwartet, da das Verfahren eine ähnliche Struktur wie BDT aufweist und zu Anfang gut beim W+Jets-Training abschnitt. Es ist unzuverlässig und das Suchen nach den richtigen Parametereinstellungen ist zu zeitintensiv. Es rückt in der Bewertung auf den letzten Platz, da es auch in der Effizienz zweimal allen anderen unterliegt. Zusammenfassend sind Neuronale Netzwerke und gewichtete Entscheidungsbäume die besten Lösungsansätze für die in dieser Arbeit beschriebene Vorgehensweise der Suche nach supersymmetrischen Teilchen. Sie sind in zwei Belangen den meisten anderen statistischen Methoden überlegen: Zum einen sind ihre Diskriminierungssignifikanzen und Separationen (Kapitel 7.2.2) in Bezug auf die Testdatensätze sehr überzeugend, zum anderen führten Veränderungen der Konfigurationsdateien beider Methoden schnell zu brauchbaren Ergebnissen.

Quellen 107
Quellen
1 ALEPH-Homepage, http://aleph.web.cern.ch/aleph 2 M. M. El Kheishen, A. A. Shaflik and A. A. Aboshousha, Analytic formulas
for the neutralino masses and the neutralino mixing matrix Phys. Rev. D45, 4345 - 4348 (1992)
3 L3-Homepage, http://l3.web.cern.ch/l3 4 O.J.P. Eboli and D. Zeppenfeld, Observing an invisible Higgs bosonPhys.
Lett. B495 (2000) 147.-154 5 R.Barlow, Statistics : a guide to the use of statistical methods in the physical
sciences 6 W. de Boer and C. Sander, Global Electroweak Fits and Gauge Coupling
Unification, Phys.Lett. B585 (2004) 276-286 7 http://cmsdoc.cern.ch/cms/outreach/html/ 8 W. de Boer, C. Sander,V. Zhukov, A. V. Gladyshev and D. I. Kazakov,
EGRET Excess of Diffuse Galactic Gamma Rays Interpreted as a Signal of Dark Matter Annihilation, Phys. Rev. Lett. 95, 209001 (2005)
9 Povh, Rith, Scholz, Zetsche, Teilchen und Kerne (7.Auflage) 10 D. Griffiths, Introduction to Elementary Particles 11 K. Belotsky, D. Fargion, M. Khlopov, R. Konoplich und K. Shibaev,
Invisible Higgs Boson Decay into Massive Neutrinos of 4th Generation, Phys.Rev. D68 (2003) 054027
12 Upper Limits on a Stochastic Background of Gravitational Waves, Phys. Rev. Lett. 95, 221101 (2005)
13 OPAL-Homepage, http://opal.web.cern.ch/Opal 14 G. Abbiendi, Search for the Standard Model Higgs Boson at LEP, Phys. Lett.
B565 (2003), 61-75 15 TEVATRON-Homepage http://www-bdnew.fnal.gov/tevatron 16 J.Lehn und h. Wegmann, Einführung in die Statistik(5.Auflage) 17 N.Arkani-Hamed, S.Dimopoulos und G.Dvali, The Hierarchy Problem and
New Dimensions at a MillimetersPhys, Lett. B429 (1998) 263-272 18 M. Dine, A.E. Nelson, Y. ShirmanDynamical, Supersymmetry Breaking
Simplified, Phys.Rev. D51 (1995) 1362-1370 19 Grafiken für CMS und LHC http://en.wikipedia.org/wiki/ 20 S.Brandt, Datenanalyse : mit statistischen Methoden u.
Computerprogrammen (2. Auflage) 21 G.F. Giudice, M.A. Luty, H. Murayama and R. Rattazi, Gaugino Mass
without Singlets, JHEP 9812 (1998) 027 22 G. Belanger, F. Boudjema, A. Cottrant, R.M. Godbole, A.Semenov, The
MSSM invisible Higgs in the light of dark matter and g-2, Phys.Lett. B519 (2001) 93-102
23 The Super-Kamiokande Collaboration, Evidence for oscillation of atmospheric neutrinos, Phys.Rev.Lett. 81 (1998) 1562-1567
24 L. Alvarez-Gaume, J. Polchinski und M. Wise, Minimal Low-Energy Supergravity, Nucl. Phys. B221 495 (1983).
25 A. Djouadi, The Anatomy of Electro-Weak Symmetry Breaking. I+II 26 http://www-stat.stanford.edu/~jhf/ftp/RuleFit.pdf 27 L1-Trigger Daten:
https://twiki.cern.ch/twiki/bin/view/CMS/L1ExtraFromMCTruth122 28 TMVA-Homepage: http://tmva.sourceforge.net/

Quellen 108
29 <phi-t> The Neurobayes® Users`s Guide (Version April, 26th 2004) 30 https://cmsweb.cern.ch/dbs_discovery

Abkürzungen iii
Verwendete Methodenabkürzungen GA Genetischer Algorithmus (Kapitel 5.8.4) Cuts Rechtwinklige Schnitt-Optimierung (Kapitel 5.14) CutsPCA Cuts mit Koordinatentransformation (PCA) (Kapitel 5.4.2) CutsGA Cuts mit GA CutsD Cuts mit Dekorrelation (Kapitel 5.4.3) LikelihoodKDE Likelihood mit Kern-Dichte-Schätzer (KDE) (Kapitel 5.7.1) Likelihood Projektiver Likelihood-Schätzer (Kapitel 5.7.1) LikelihoodMIX Mischung aus Likelihood und LikelihoodKDE LikelihoodD Likelihood mit Dekorrelation (Kapitel 5.4.3) LikelihoodPCA Likelihood mit PCA (Kapitel 5.4.2) PEDERS Mehrdimensionaler Liklihood Schätzer (Kapitel 5.7.2) PEDERSPCA PEDERS mit PCA (Kapitel 5.4.2) PEDERSD PEDERS mit Dekorrelation (Kapitel 5.4.3) KNN Nächste-Nachbarn-Klassifikation (Kapitel 5.10) PEDERSKNN PEDERS mit KNN Fisher-Klassifikator (Kapitel 5.11) H-Matrix-Klassifikator (Kapitel 5.6) FDA_GA Funktion-Diskriminanzanalyse (FDA) (Kapitel 5.15) mit GA FDA_MT FDA mit Minuit-Minimierung (Kapitel 5.8.2) FDA_GAMT FDA mit GA und MT FDA_MC Monte-Carlo-Stichprobe(Kapitel 5.8.3) FDA_MCMT FDA mit MC und MT MLP Multilayer-Perzeptron(Kapitel 5.16) NeuroBayes (Kapitel 6.4 und 5.16) TMIpANN ROOT-Neuronalen-Netz(Kapitel 5.16) CFMIpANN Clermont-Ferrand(Kapitel 5.16) SVM_Gauss SVM (Kapitel 5.12) mit Gauss als Kernfunktion SVM_Lin SVM(Kapitel 5.12 mit Linear als Kernfunktion SVM_Poly SVM(Kapitel 5.12) mit Polynomial als Kernfunktion BDT Gewichtete Entscheidungsbäume(Kapitel 5.9) BDTD BDT mit Dekorrelation (Kapitel 5.4.3) RuleFit Vorrausschauendes Lernen mit Regel-Ensembles(Kapitel 5.13)

Abkürzungen iv
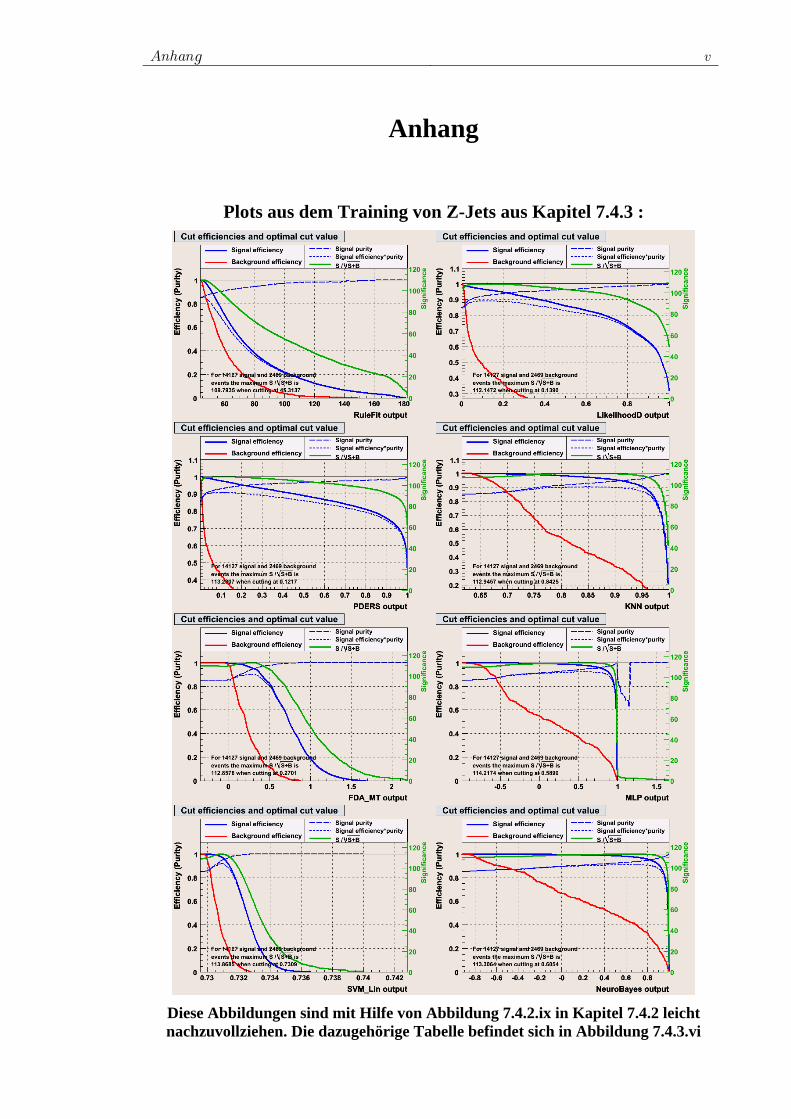
Anhang v
Anhang
Plots aus dem Training von Z-Jets aus Kapitel 7.4.3 :
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.ix in Kapitel 7.4.2 leicht nachzuvollziehen. Die dazugehörige Tabelle befindet sich in Abbildung 7.4.3.vi
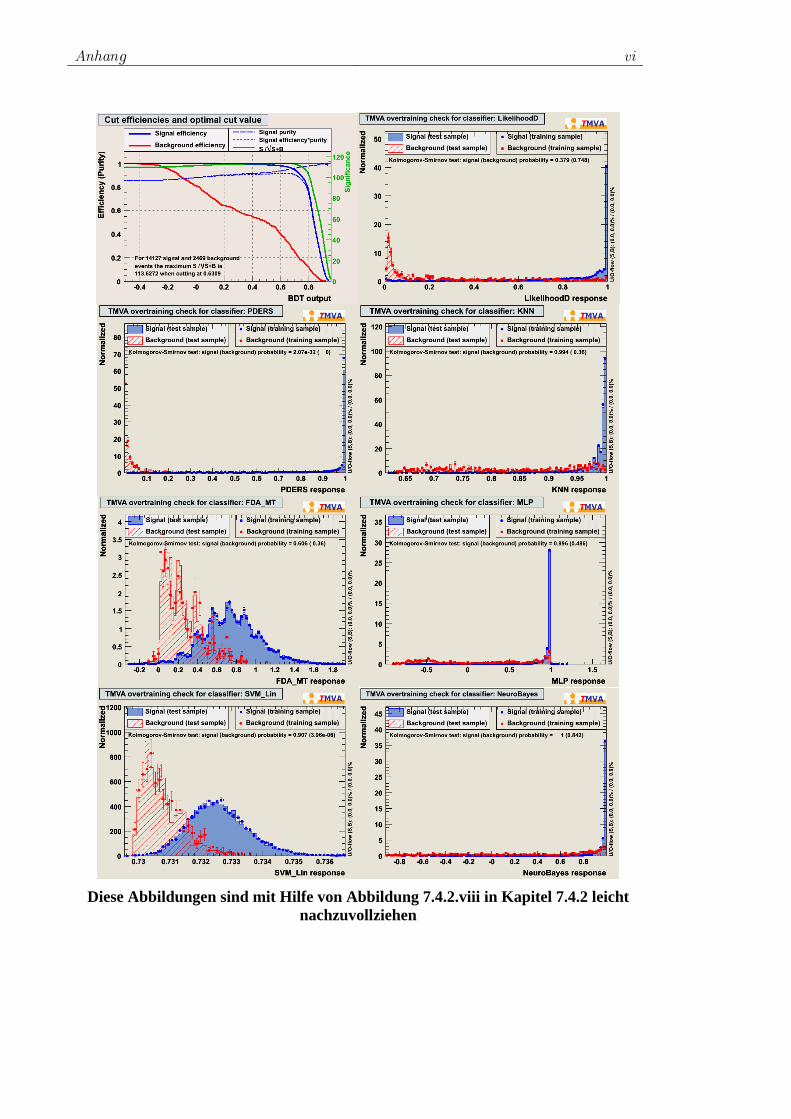
Anhang vi
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.viii in Kapitel 7.4.2 leicht
nachzuvollziehen
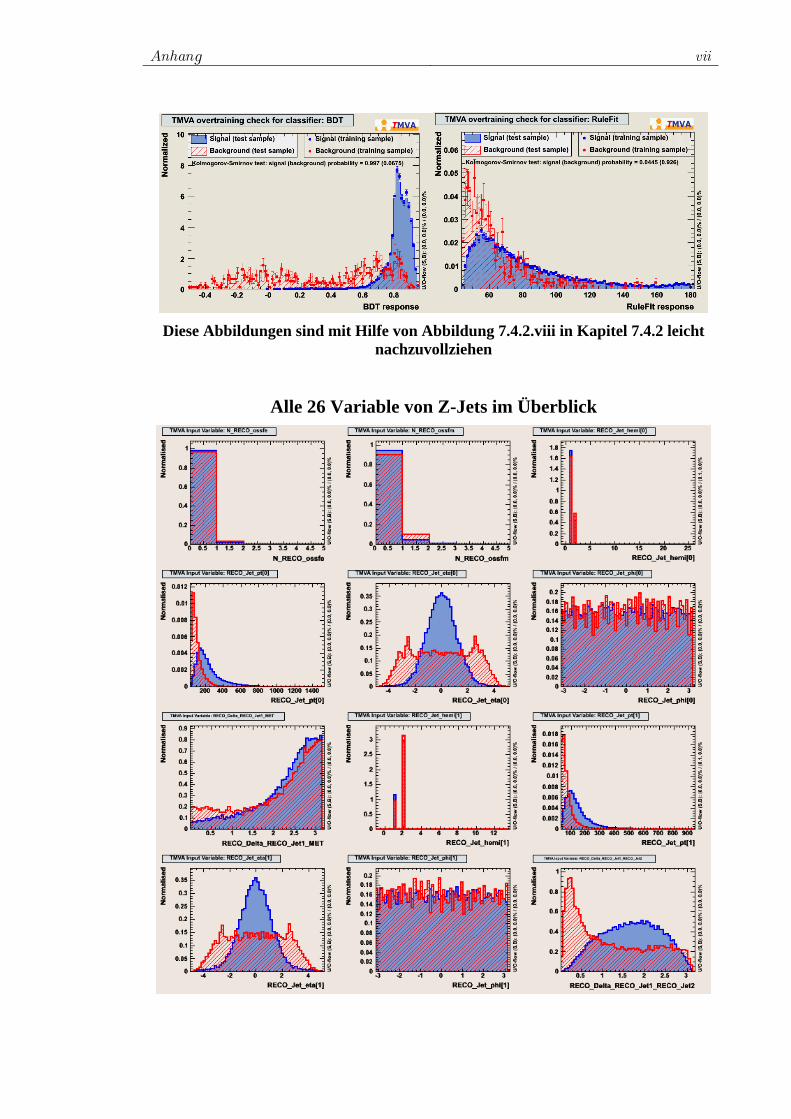
Anhang vii
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.viii in Kapitel 7.4.2 leicht
nachzuvollziehen
Alle 26 Variable von Z-Jets im Überblick
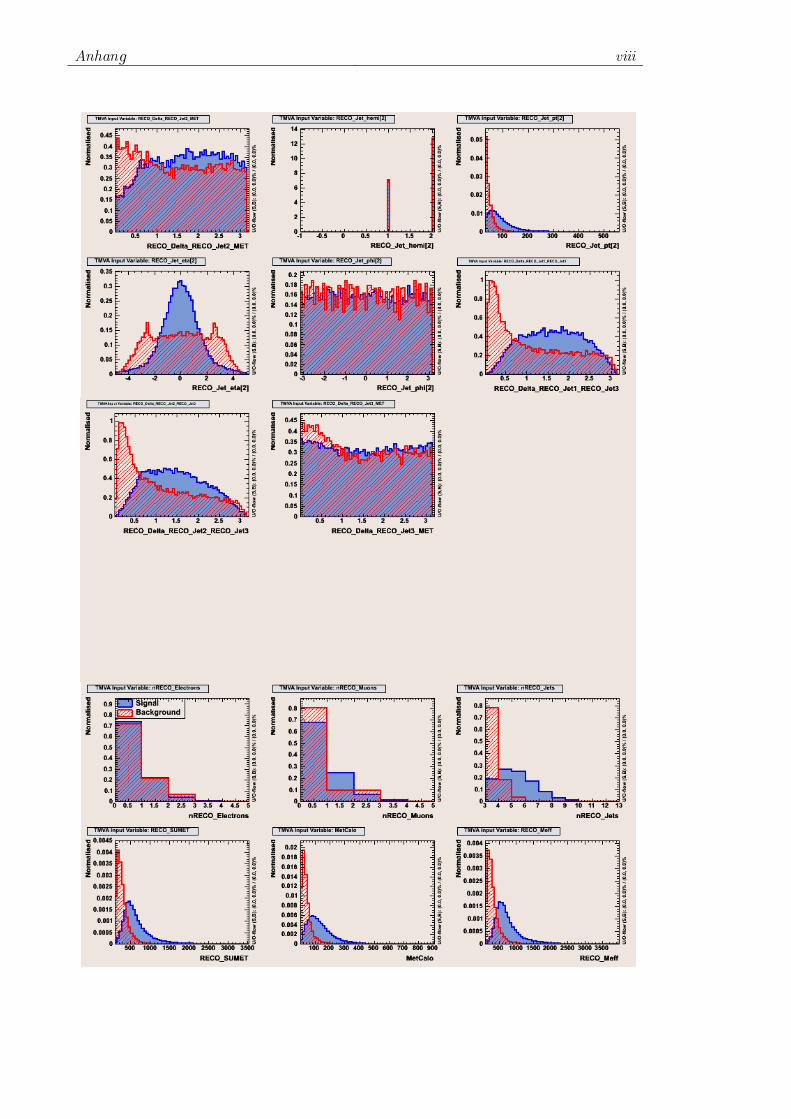
Anhang viii
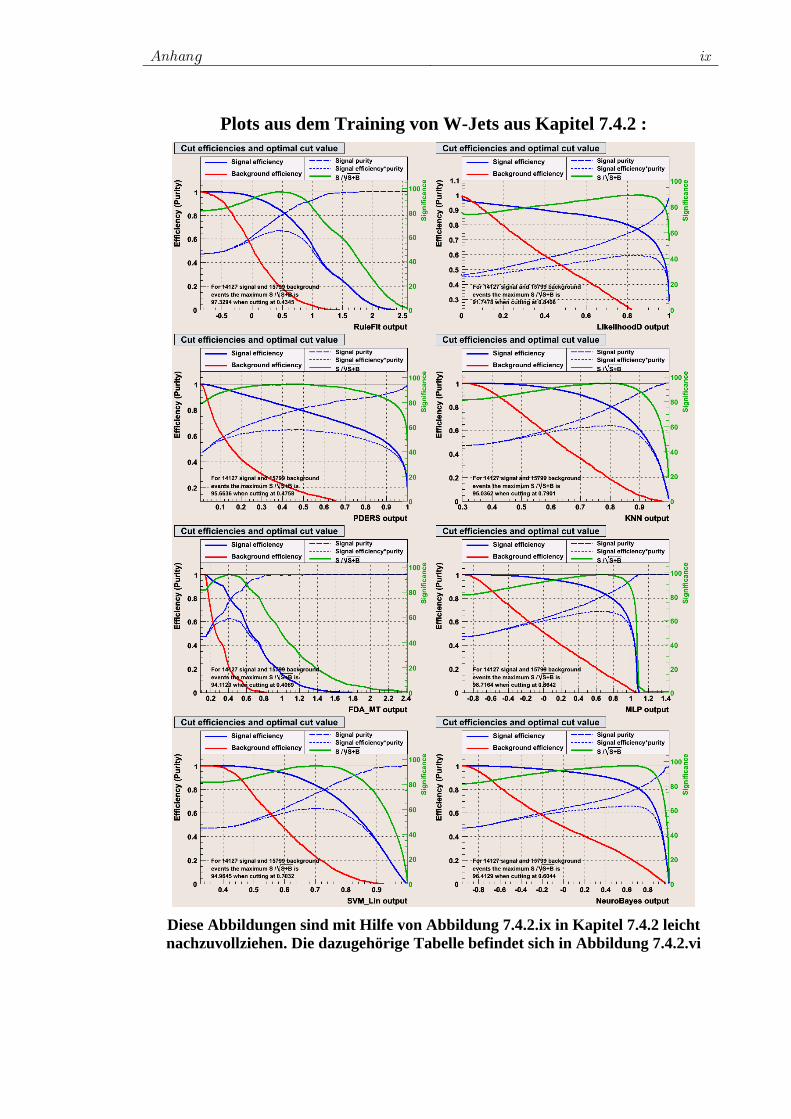
Anhang ix
Plots aus dem Training von W-Jets aus Kapitel 7.4.2 :
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.ix in Kapitel 7.4.2 leicht nachzuvollziehen. Die dazugehörige Tabelle befindet sich in Abbildung 7.4.2.vi
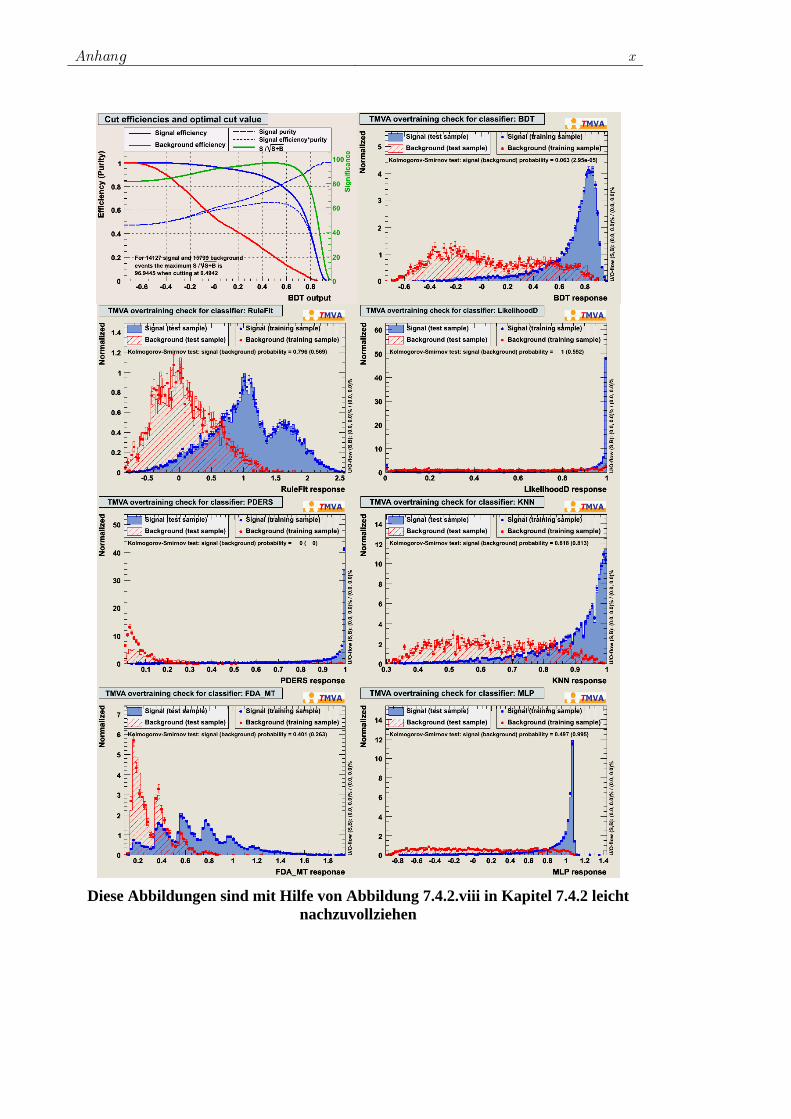
Anhang x
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.viii in Kapitel 7.4.2 leicht
nachzuvollziehen
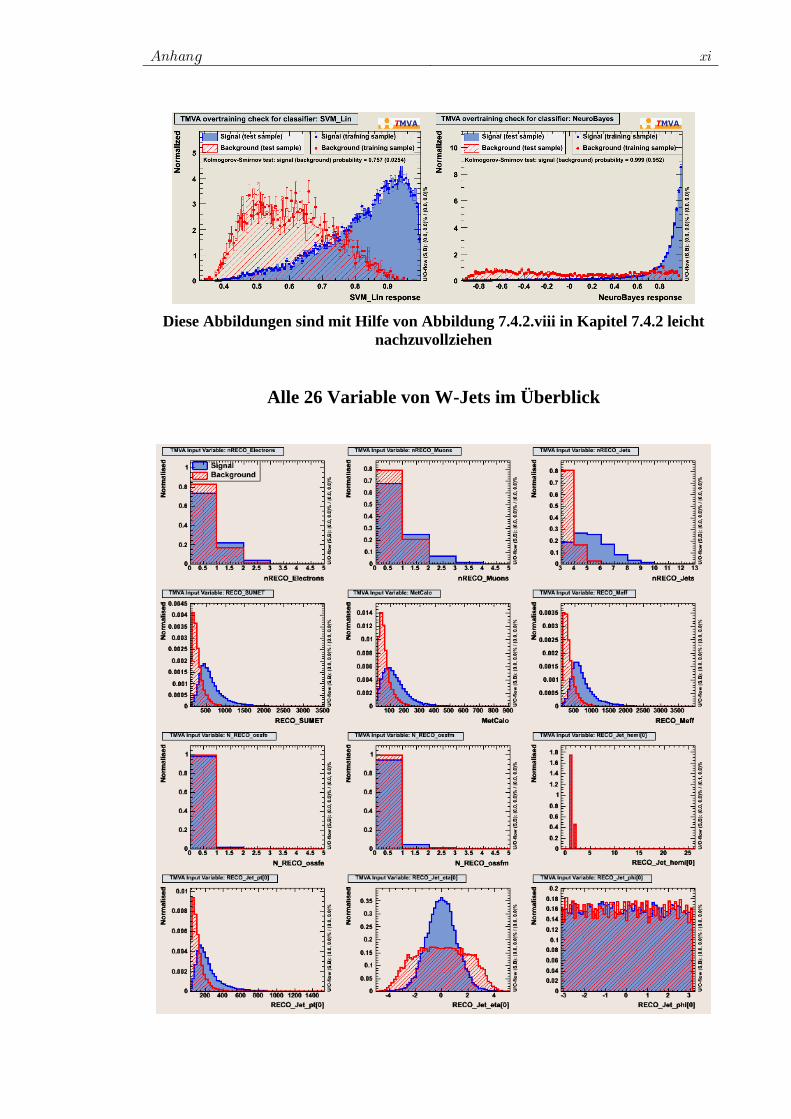
Anhang xi
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.viii in Kapitel 7.4.2 leicht
nachzuvollziehen
Alle 26 Variable von W-Jets im Überblick
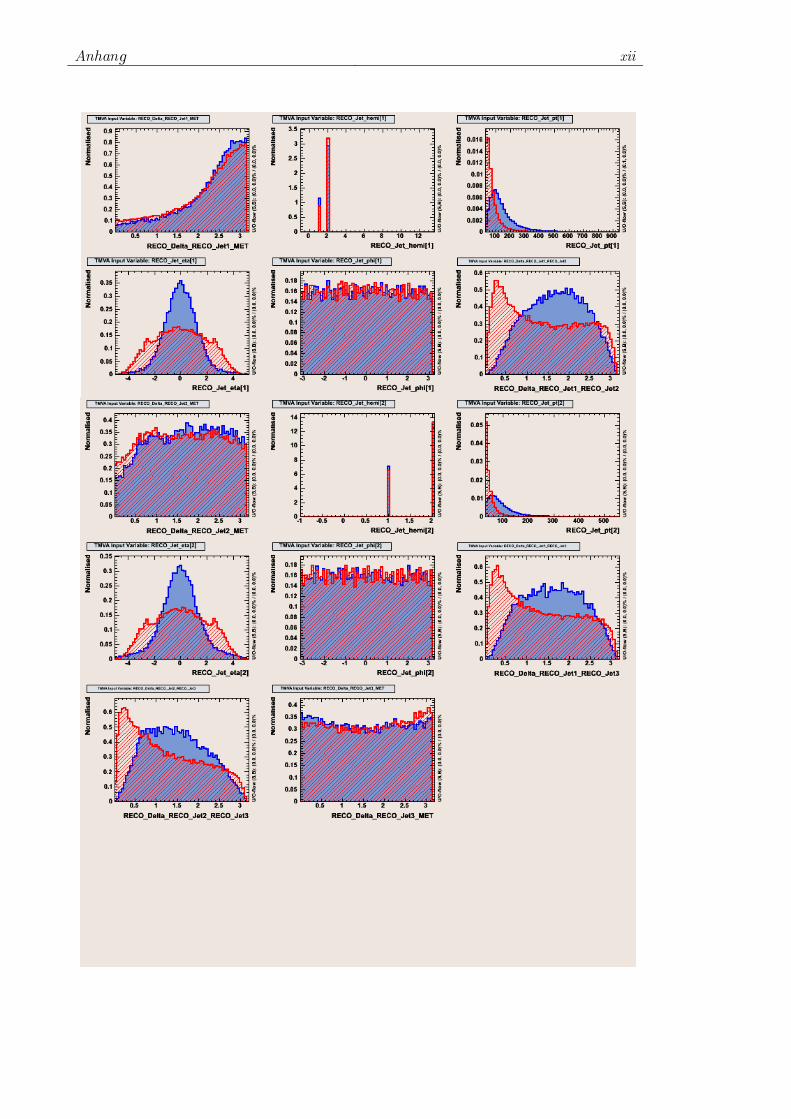
Anhang xii
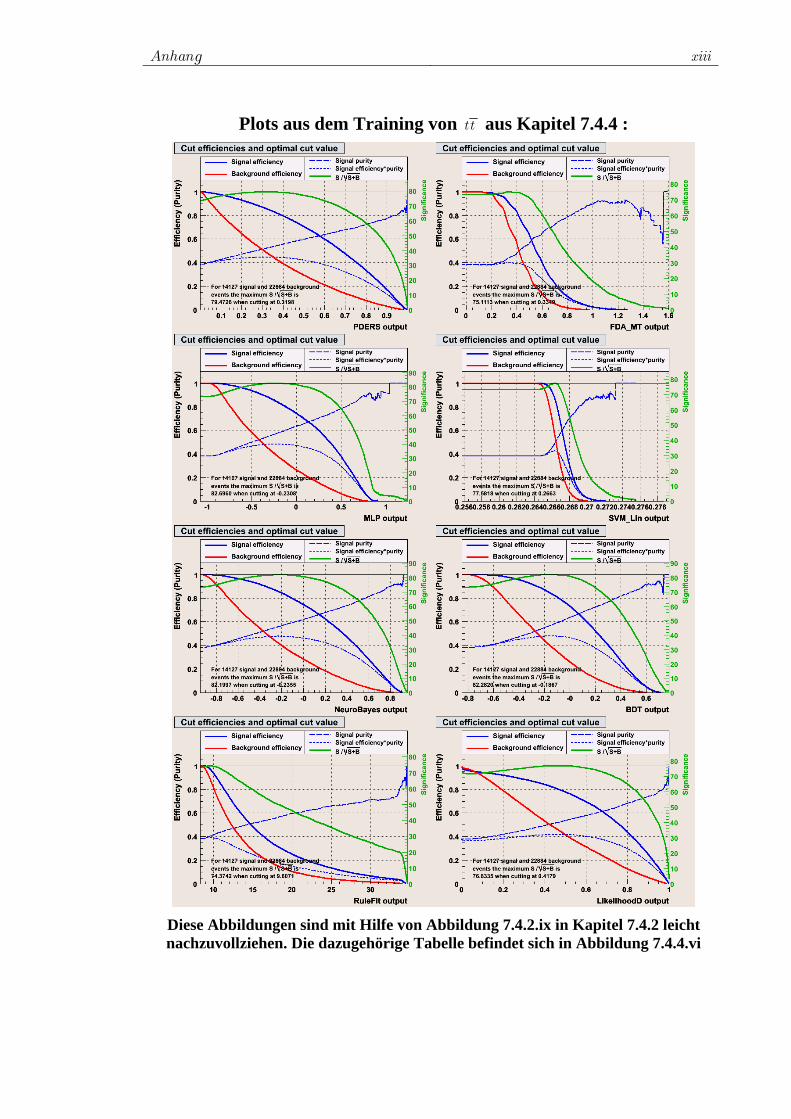
Anhang xiii
Plots aus dem Training von tt aus Kapitel 7.4.4 :
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.ix in Kapitel 7.4.2 leicht nachzuvollziehen. Die dazugehörige Tabelle befindet sich in Abbildung 7.4.4.vi
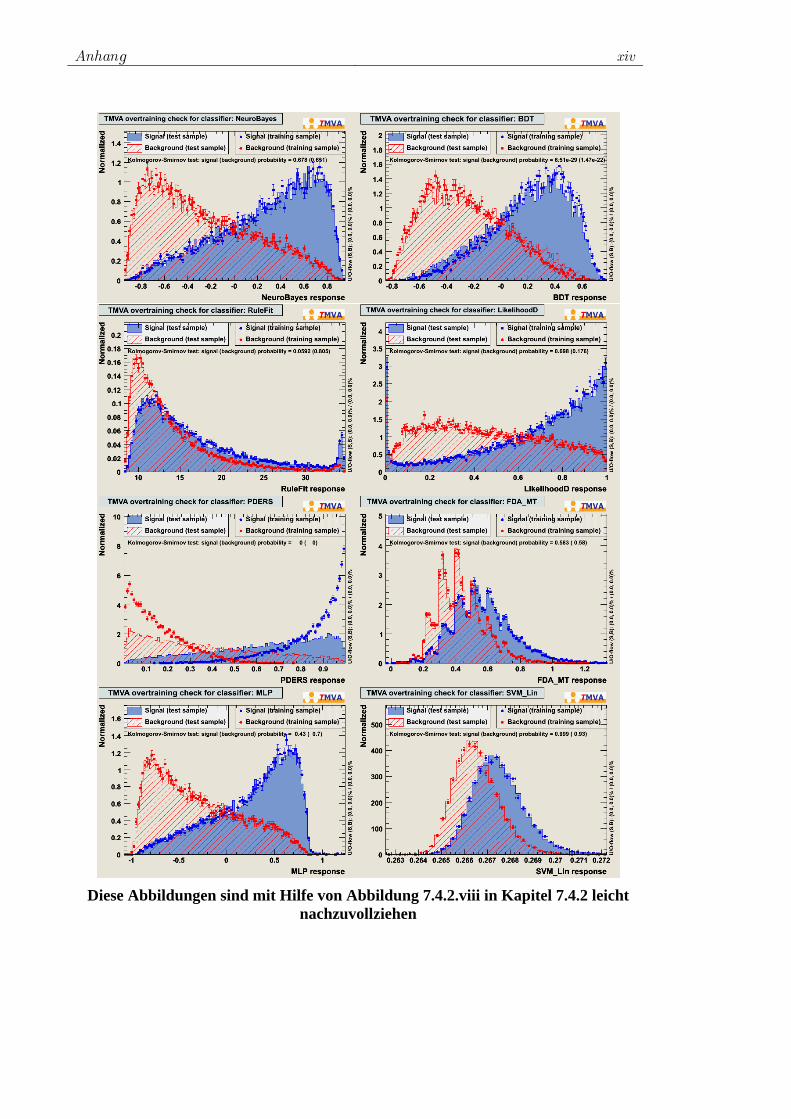
Anhang xiv
Diese Abbildungen sind mit Hilfe von Abbildung 7.4.2.viii in Kapitel 7.4.2 leicht
nachzuvollziehen
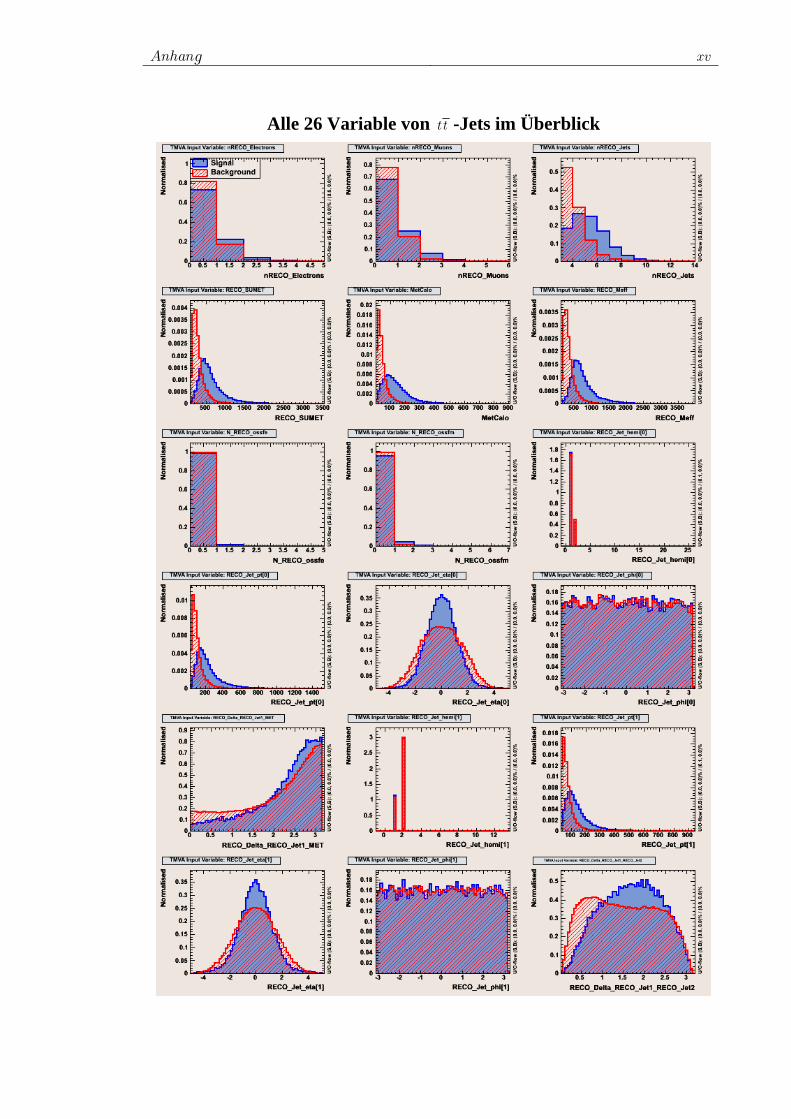
Anhang xv
Alle 26 Variable von tt -Jets im Überblick
Anhang xvi

Anhang xvii
Liste aller Variablen nRECO_Particles = Anzahl der Teilchen des Events RECO_SUMET = Summe der Transveralenrgien von Elektronen, Myonen und Jets nRECO_Electrons = Anzahl der Elektronen RECO_Electrons_pt = Transversalimpuls des iten Elektrons RECO_Electrons_e = Energie des iten Elektrons RECO_Electrons_parton = jtes MC Teilchen des iten Elektrons RECO_Electrons_hemi = Hemisphäre des iten Elektrons RECO_Electrons_px = Impuls des iten Elektrons in x-Richtung RECO_Electrons_py = Impuls des iten Elektrons in y-Richtung RECO_Electrons_pz = Impuls des iten Elektrons in z-Richtung RECO_Electrons_ptc = ites Teilchen des Events RECO_Electrons_eta = der Winkel eta des iten Elektrons RECO_Electrons_phi = der Winkel phi des iten Elektrons RECO_Electrons_Sg = die Ladung des iten Elektrons RECO_Electrons_ET = transversale Enertgie des iten Elektrons nRECO_Muons = Anzahl der Myonen RECO_Muons_pt = Transversalimpuls des iten Myons RECO_Muons_e = Energie des iten Myons RECO_Muons_parton = jtes MC Teilchen des iten Myons RECO_Muons_hemi = Hemisphäre des iten Myons RECO_Muons_px = Impuls des iten Myons in x-Richtung RECO_Muons_py = Impuls des iten Myons in y-Richtung RECO_Muons_pz = Impuls des iten Myons in z-Richtung RECO_Muons_ptc = ites Teilchen des Events RECO_Muons_eta = der Winkel eta des iten Myons RECO_Muons_phi = der Winkel phi des iten Myons RECO_Muons_Sg = die Ladung des iten Myons RECO_Muons_ET = transversale Enertgie des iten Myons nRECO_Jet = Anzahl der Jets RECO_Jet_pt = Transversalimpuls des iten Jets RECO_Jet_e = Energie des iten Jets RECO_Jet_parton = jtes MC Teilchen des iten Jets RECO_Jet_hemi = Hemisphäre des iten Jets RECO_Jet_px = Impuls des iten Jets in x-Richtung RECO_Jet_py = Impuls des iten Jets in y-Richtung RECO_Jet_pz = Impuls des iten Jets in z-Richtung RECO_Jet_ptc = ites Teilchen des Events RECO_Jet_eta = der Winkel eta des iten Jets RECO_Jet_phi = der Winkel phi des iten Jets RECO_Jet_Sg = die Ladung des iten Jets RECO_Jet_ET = transversale Enertgie des iten Jets RECO_Meff = MET + Transversalimpulse aller Teilchen N_RECO_ossfe = Anzahl er "opposite sign same flavor"-Elektonen N_RECO_ossfm = Anzahl er "opposite sign same flavor"-Myonen m_RECO_ossfe = invariante Masse des iten ossfe m_RECO_ossfm = invariante Masse des iten ossfm px_RECO_ossfe = Impuls in x-Richtung des ossfe py_RECO_ossfe = Impuls in y-Richtung des ossfe pz_RECO_ossfe = Impuls in z-Richtung des ossfe px_RECO_ossfm = Impuls in x-Richtung des ossfm py_RECO_ossfm = Impuls in y-Richtung des ossfm pz_RECO_ossfm = Impuls in z-Richtung des ossfm RECO_ossf_min_e = Anzahl der Elektronen mit Ladung -1 des Events RECO_ossf_plu_e = Anzahl der Positronen mit Ladung +1 des Events RECO_ossf_min_m = Anzahl der Myonen mit Ladung -1 des Events RECO_ossf_plu_m = Anzahl der Myonen mit Ladung +1 des Events posi_RECO_ossf_min_e = Zugehöriges Elektron mit Ladung -1 des ossfe posi_RECO_ossf_min_m = Zugehöriges Elektron mit Ladung +1 des ossfe posi_RECO_ossf_plu_e = Zugehöriges Myon mit Ladung -1 des ossfe posi_RECO_ossf_plu_m = Zugehöriges Myon mit Ladung +1 des ossfe eta_RECO_ossfe = der Winkel eta des ossfe eta_RECO_ossfm = der Winkel eta des ossfm phi_RECO_ossfm = der Winkel phi des ossfm phi_RECO_ossfe = der Winkel phi des ossfe RECO_Delta_RECO_Jet1_RECO_Jet2 = der Winkel zwischen Jet1 und Jet2 RECO_Delta_RECO_Jet1_RECO_Jet3 = der Winkel zwischen Jet1 und Jet3 RECO_Delta_RECO_Jet1_RECO_Jet4 = der Winkel zwischen Jet1 und Jet4 RECO_Delta_RECO_Jet2_RECO_Jet3 = der Winkel zwischen Jet2 und Jet3 RECO_Delta_RECO_Jet2_RECO_Jet4 = der Winkel zwischen Jet2 und Jet4 RECO_Delta_RECO_Jet3_RECO_Jet4 = der Winkel zwischen Jet3 und Jet4 RECO_Delta_RECO_ossfe1_RECO_Jet1 = der Winkel zwischen ossfe1 und Jet1 RECO_Delta_RECO_ossfe2_RECO_Jet1 = der Winkel zwischen ossfe2 und Jet1 RECO_Delta_RECO_ossfe3_RECO_Jet1 = der Winkel zwischen ossfe3 und Jet1

Anhang xviii
RECO_Delta_RECO_ossfm1_RECO_Jet1 = der Winkel zwischen ossfm1 und Jet1 RECO_Delta_RECO_ossfm2_RECO_Jet1 = der Winkel zwischen ossfm2 und Jet1 RECO_Delta_RECO_ossfm3_RECO_Jet1 = der Winkel zwischen ossfm3 und Jet1 RECO_Delta_RECO_ossfe1_RECO_Jet2 = der Winkel zwischen ossfe1 und Jet2 RECO_Delta_RECO_ossfe2_RECO_Jet2 = der Winkel zwischen ossfe2 und Jet2 RECO_Delta_RECO_ossfe3_RECO_Jet2 = der Winkel zwischen ossfe3 und Jet2 RECO_Delta_RECO_ossfm1_RECO_Jet2 = der Winkel zwischen ossfm1 und Jet2 RECO_Delta_RECO_ossfm2_RECO_Jet2 = der Winkel zwischen ossfm2 und Jet2 RECO_Delta_RECO_ossfm3_RECO_Jet2 = der Winkel zwischen ossfm3 und Jet2 RECO_Delta_RECO_ossfe1_RECO_Jet3 = der Winkel zwischen ossfe1 und Jet3 RECO_Delta_RECO_ossfe2_RECO_Jet3 = der Winkel zwischen ossfe2 und Jet3 RECO_Delta_RECO_ossfe3_RECO_Jet3 = der Winkel zwischen ossfe3 und Jet3 RECO_Delta_RECO_ossfm1_RECO_Jet3 = der Winkel zwischen ossfm1 und Jet3 RECO_Delta_RECO_ossfm2_RECO_Jet3 = der Winkel zwischen ossfm2 und Jet3 RECO_Delta_RECO_ossfm3_RECO_Jet3 = der Winkel zwischen ossfm3 und Jet3 RECO_Delta_RECO_ossfe1_RECO_Jet4 = der Winkel zwischen ossfe1 und Jet4 RECO_Delta_RECO_ossfe2_RECO_Jet4 = der Winkel zwischen ossfe2 und Jet4 RECO_Delta_RECO_ossfe3_RECO_Jet4 = der Winkel zwischen ossfe3 und Jet4 RECO_Delta_RECO_ossfm1_RECO_Jet4 = der Winkel zwischen ossfm1 und Jet4 RECO_Delta_RECO_ossfm2_RECO_Jet4 = der Winkel zwischen ossfm2 und Jet4 RECO_Delta_RECO_ossfm3_RECO_Jet4 = der Winkel zwischen ossfm3 und Jet4 RECO_Delta_RECO_Jet1_MET = der Winkel zwischen Jet1 und MET RECO_Delta_RECO_Jet2_MET = der Winkel zwischen Jet2 und MET RECO_Delta_RECO_Jet3_MET = der Winkel zwischen Jet3 und MET RECO_Delta_RECO_Jet4_MET = der Winkel zwischen Jet4 und MET RECO_Delta_RECO_ossfe1_MET = der Winkel zwischen ossfe1 und MET RECO_Delta_RECO_ossfe2_MET = der Winkel zwischen ossfe2 und MET RECO_Delta_RECO_ossfe3_MET = der Winkel zwischen ossfe3 und MET RECO_Delta_RECO_ossfm1_MET = der Winkel zwischen ossfm1 und MET RECO_Delta_RECO_ossfm2_MET = der Winkel zwischen ossfm2 und MET RECO_Delta_RECO_ossfm3_MET = der Winkel zwischen ossfm3 und MET MetMC = MET(missing transversal Energie) MetMCx = MET(missing transversal Energie) in x-Richtung MetMCy = MET(missing transversal Energie) in y-Richtung MetCalo = MET(missing transversal Energie) des Kalorimeters MetCalox = MET(missing transversal Energie) des Kalorimeters in x-Richtung MetCaloy = MET(missing transversal Energie) des Kalorimeters in y-Richtung nMC_Particles = Anzahl der Teilchen des Events MC_Particles_hemi = Hemisphäre des iten Teilchens MC_Particles_typ = MC Identifizierungsnummer des iten Teilchens MC_Particles_mo = Mutterteilchen des iten Teilchens MC_Particles_sta = Status des iten Teilchens MC_SUMET = Summe der Transveralenrgien von Elektronen, Myonen und Jets nMC_Electrons = Anzahl der Elektronen MC_Electrons_pt = Transversalimpuls des iten Elektrons MC_Electrons_e = Energie des iten Elektrons MC_Electrons_parton = jtes MC Teilchen des iten Elektrons MC_Electrons_hemi = Hemisphäre des iten Elektrons MC_Electrons_px = Impuls des iten Elektrons in x-Richtung MC_Electrons_py = Impuls des iten Elektrons in y-Richtung MC_Electrons_pz = Impuls des iten Elektrons in z-Richtung MC_Electrons_ptc = ites Teilchen des Events MC_Electrons_eta = der Winkel eta des iten Elektrons MC_Electrons_phi = der Winkel phi des iten Elektrons MC_Electrons_Sg = die Ladung des iten Elektrons MC_Electrons_ET = transversale Enertgie des iten Elektrons nMC_Muons = Anzahl der Myonen MC_Muons_pt = Transversalimpuls des iten Myons MC_Muons_e = Energie des iten Myons MC_Muons_parton = jtes MC Teilchen des iten Myons MC_Muons_hemi = Hemisphäre des iten Myons MC_Muons_px = Impuls des iten Myons in x-Richtung MC_Muons_py = Impuls des iten Myons in y-Richtung MC_Muons_pz = Impuls des iten Myons in z-Richtung MC_Muons_ptc = ites Teilchen des Events MC_Muons_eta = der Winkel eta des iten Myons MC_Muons_phi = der Winkel phi des iten Myons MC_Muons_Sg = die Ladung des iten Myons MC_Muons_ET = transversale Enertgie des iten Myons nMC_Jet = Anzahl der Jets MC_Jet_pt = Transversalimpuls des iten Jets MC_Jet_e = Energie des iten Jets MC_Jet_parton = jtes MC Teilchen des iten Jets MC_Jet_hemi = Hemisphäre des iten Jets MC_Jet_px = Impuls des iten Jets in x-Richtung MC_Jet_py = Impuls des iten Jets in y-Richtung

Anhang xix
MC_Jet_pz = Impuls des iten Jets in z-Richtung MC_Jet_ptc = ites Teilchen des Events MC_Jet_eta = der Winkel eta des iten Jets MC_Jet_phi = der Winkel phi des iten Jets MC_Jet_Sg = die Ladung des iten Jets MC_Jet_ET = transversale Enertgie des iten Jets MC_Meff = MET + Transversalimpulse aller Teilchen N_MC_ossfe = Anzahl er "opposite sign same flavor"-Elektonen N_MC_ossfm = Anzahl er "opposite sign same flavor"-Myonen m_MC_ossfe = invariante Masse des iten ossfe m_MC_ossfm = invariante Masse des iten ossfm px_MC_ossfe = Impuls in x-Richtung des ossfe py_MC_ossfe = Impuls in y-Richtung des ossfe pz_MC_ossfe = Impuls in z-Richtung des ossfe px_MC_ossfm = Impuls in x-Richtung des ossfm py_MC_ossfm = Impuls in y-Richtung des ossfm pz_MC_ossfm = Impuls in z-Richtung des ossfm MC_ossf_min_e = Anzahl der Elektronen mit Ladung -1 des Events MC_ossf_plu_e = Anzahl der Positronen mit Ladung +1 des Events MC_ossf_min_m = Anzahl der Myonen mit Ladung -1 des Events MC_ossf_plu_m = Anzahl der Myonen mit Ladung +1 des Events posi_MC_ossf_min_e = Zugehöriges Elektron mit Ladung -1 des ossfe posi_MC_ossf_min_m = Zugehöriges Elektron mit Ladung +1 des ossfe posi_MC_ossf_plu_e = Zugehöriges Myon mit Ladung -1 des ossfe posi_MC_ossf_plu_m = Zugehöriges Myon mit Ladung +1 des ossfe eta_MC_ossfe = der Winkel eta des ossfe eta_MC_ossfm = der Winkel eta des ossfm phi_MC_ossfm = der Winkel phi des ossfm phi_MC_ossfe = der Winkel phi des ossfe MC_Delta_MC_Jet1_MC_Jet2 = der Winkel zwischen Jet1 und Jet2 MC_Delta_MC_Jet1_MC_Jet3 = der Winkel zwischen Jet1 und Jet3 MC_Delta_MC_Jet1_MC_Jet4 = der Winkel zwischen Jet1 und Jet4 MC_Delta_MC_Jet2_MC_Jet3 = der Winkel zwischen Jet2 und Jet3 MC_Delta_MC_Jet2_MC_Jet4 = der Winkel zwischen Jet2 und Jet4 MC_Delta_MC_Jet3_MC_Jet4 = der Winkel zwischen Jet3 und Jet4 MC_Delta_MC_ossfe1_MC_Jet1 = der Winkel zwischen ossfe1 und Jet1 MC_Delta_MC_ossfe2_MC_Jet1 = der Winkel zwischen ossfe2 und Jet1 MC_Delta_MC_ossfe3_MC_Jet1 = der Winkel zwischen ossfe3 und Jet1 MC_Delta_MC_ossfm1_MC_Jet1 = der Winkel zwischen ossfm1 und Jet1 MC_Delta_MC_ossfm2_MC_Jet1 = der Winkel zwischen ossfm2 und Jet1 MC_Delta_MC_ossfm3_MC_Jet1 = der Winkel zwischen ossfm3 und Jet1 MC_Delta_MC_ossfe1_MC_Jet2 = der Winkel zwischen ossfe1 und Jet2 MC_Delta_MC_ossfe2_MC_Jet2 = der Winkel zwischen ossfe2 und Jet2 MC_Delta_MC_ossfe3_MC_Jet2 = der Winkel zwischen ossfe3 und Jet2 MC_Delta_MC_ossfm1_MC_Jet2 = der Winkel zwischen ossfm1 und Jet2 MC_Delta_MC_ossfm2_MC_Jet2 = der Winkel zwischen ossfm2 und Jet2 MC_Delta_MC_ossfm3_MC_Jet2 = der Winkel zwischen ossfm3 und Jet2 MC_Delta_MC_ossfe1_MC_Jet3 = der Winkel zwischen ossfe1 und Jet3 MC_Delta_MC_ossfe2_MC_Jet3 = der Winkel zwischen ossfe2 und Jet3 MC_Delta_MC_ossfe3_MC_Jet3 = der Winkel zwischen ossfe3 und Jet3 MC_Delta_MC_ossfm1_MC_Jet3 = der Winkel zwischen ossfm1 und Jet3 MC_Delta_MC_ossfm2_MC_Jet3 = der Winkel zwischen ossfm2 und Jet3 MC_Delta_MC_ossfm3_MC_Jet3 = der Winkel zwischen ossfm3 und Jet3 MC_Delta_MC_ossfe1_MC_Jet4 = der Winkel zwischen ossfe1 und Jet4 MC_Delta_MC_ossfe2_MC_Jet4 = der Winkel zwischen ossfe2 und Jet4 MC_Delta_MC_ossfe3_MC_Jet4 = der Winkel zwischen ossfe3 und Jet4 MC_Delta_MC_ossfm1_MC_Jet4 = der Winkel zwischen ossfm1 und Jet4 MC_Delta_MC_ossfm2_MC_Jet4 = der Winkel zwischen ossfm2 und Jet4 MC_Delta_MC_ossfm3_MC_Jet4 = der Winkel zwischen ossfm3 und Jet4 MC_Delta_MC_Jet1_MET = der Winkel zwischen Jet1 und MET MC_Delta_MC_Jet2_MET = der Winkel zwischen Jet2 und MET MC_Delta_MC_Jet3_MET = der Winkel zwischen Jet3 und MET MC_Delta_MC_Jet4_MET = der Winkel zwischen Jet4 und MET MC_Delta_MC_ossfe1_MET = der Winkel zwischen ossfe1 und MET MC_Delta_MC_ossfe2_MET = der Winkel zwischen ossfe2 und MET MC_Delta_MC_ossfe3_MET = der Winkel zwischen ossfe3 und MET MC_Delta_MC_ossfm1_MET = der Winkel zwischen ossfm1 und MET MC_Delta_MC_ossfm2_MET = der Winkel zwischen ossfm2 und MET MC_Delta_MC_ossfm3_MET = der Winkel zwischen ossfm3 und MET

Anhang xx

Erklärung
Ich versichere, dass ich meine Diplomarbeit ohne Hilfe Dritter und ohne Benutzung anderer als der angegebenen Quellen und Hilfsmittel angefertigt und die den benutzten Quellen wörtlich oder inhaltlich entnommenen Stellen als solche kenntlich gemacht habe.
Daniel A. Stricker-Shaver

Danksagung
An dieser Stelle möchte ich mich bei allen bedanken, die zum Gelingen dieser Arbeit beigetragen haben. Ganz besonderer Dank gilt dabei:
• Prof. Dr. Wim de Boer für die interessante Aufgabenstellung und die kompetente Betreuung während der Diplomarbeit
• Prof. Dr. Günter Quast für die Übernahme des Korreferats • Dr. Valery Zhukov für die Betreuung dieser Arbeit • Martin Niegel und Daniel Däuwel für interessante Diskussionen, viele Tipps und
die nette Unterstützung
• Der gesamten CMS-Arbeitsgruppe für die hilfreichen Ratschläge und ein gutes Arbeitsklima
• Dem TMVA-Team, insbesondere Andreas Höcker für die Hilfestellung bei
vielen Fragen
• Den Mitarbeitern der Arbeitsgruppe von Prof. Dr. Feindt für die Unterstützung rund um Neurobayes
• Allen Mitarbeitern des EKP für die angenehme Atmosphäre
• Meinen Eltern für ihre Unterstützung
• Allen, die diese Arbeit Korrektur gelesen haben