
Johannes Hain - Universität Würzburg: Startseite · Verteilungsanalyse metrischer Daten...
31
Verteilungsanalyse Johannes Hain Lehrstuhl f¨ ur Mathematik VIII – Statistik 1 / 31
Transcript of Johannes Hain - Universität Würzburg: Startseite · Verteilungsanalyse metrischer Daten...

Verteilungsanalyse
Johannes Hain
Lehrstuhl fur Mathematik VIII – Statistik
1 / 31

Datentypen
Als Sammeln von Daten bezeichnet man in der Statistik dasAufzeichnen von Fakten. Erhobene Daten klassifziert man inunterschiedliche Skalenniveaus:
kategoriale (= nominal skalierte) Daten: GrobstesSkalenniveau; klassifiziert Daten nur in verschiedeneKategorien ohne Ordnung.Beispiele: Farben, Stadte, Automarken
Metrische Daten sind Messungen, die durch Zahlen sinnvollinterpretiert werden konnen. Man unterscheidet hierbei nochdie beiden folgenden Skalenniveaus:
ordinalskalierte Daten: Daten liegt interne Ordnungzugrunde, sodass Bildung einer Reihenfolge moglich ist.Beispiele: Schulnoten, Schulabschlusseintervallskalierte Daten: Daten besitzen luckenlosenWertebereich, Abstande zwischen den einzelnen Daten sindvon Bedeutung und interpretierbar.Beispiele: Korpergroße, Temperatur
2 / 31

Verteilungsanalyse metrischer Daten
Die Verteilung von kategorialen Daten veranschaulicht man sichz.B. mit Hilfe von Balkendiagrammen. Dies ist bei metrischenDaten wegen des stetigen Wertebereichs (meist) nicht moglich. DieVerteilung wird in diesem Fall mit einem Histogramm dargestellt:
Größe der Frau140 145 150 155 160 165 170 175
0.00
0.02
0.04
0.06
3 / 31

Verteilungsanalyse metrischer Daten
Erstellung eines Histogramms in R
hist(mannfrau$große.frau, freq = F, breaks = 20,
xlab = "Große der Frau", ylab = "", main = "")
Mit dem Argument breaks verandert man die Bandbreite derBalken und somit auch die Gestalt des Histogramms. Je hoher dieZahl im Argument, desto kleiner wird die Bandbreite.
Das Arguemnt freq = F bewirkt, dass sich die Flacheninhalte derBalken zum Wert 1 aufsummieren.
4 / 31
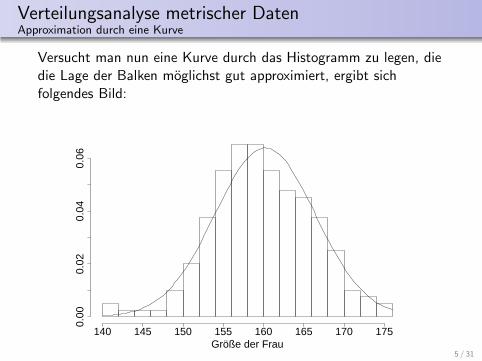
Verteilungsanalyse metrischer DatenApproximation durch eine Kurve
Versucht man nun eine Kurve durch das Histogramm zu legen, diedie Lage der Balken moglichst gut approximiert, ergibt sichfolgendes Bild:
Größe der Frau140 145 150 155 160 165 170 175
0.00
0.02
0.04
0.06
5 / 31

Verteilungsanalyse metrischer DatenApproximation durch eine Kurve
Erstellung eines Histogramms in R
# Histogramm der Große der Frau
hist(mannfrau$große.frau, freq = F, breaks = 20,
xlab = "Große der Frau", ylab = "", main = "")
# Einzeichnen der Kurve
x <- seq(140, 180, 0.01)
curve(dnorm(x, mean = mean(mannfrau$große.frau),
sd = sd(mannfrau$große.frau)), add = T)
Mit dem Argument add = T wird die Kurve zu dem bereitserstellten Histogramm hinzugefugt.
Mit dem Argument lwd kann in der Funktion curve() zusatzlichdie Dicke der gezeichneten Linie verandert werden.
6 / 31

Verteilungsanalyse metrischer DatenDichtefunktion
Die eingezeichnete Approximationskurve ist die sogenannte Dichteder Normalverteilung (daher auch die Funktion dnorm()). Wirverallgemeinern
Definition: Dichte
Die Dichte einer Verteilung fX ist eine Funktion, mit der sich dieWahrscheinlichkeit berechnen lasst, dass eine Zufallsvariable vomstetigen Typ in ein gewisses Intervall fallt.
Ubersetzung ins Mathematische:
Eine Funktion fX heißt Dichte einer Zufallsvariable X , falls gilt
P(a < X < b) =
∫
b
a
fX (t) dt.
7 / 31

Verteilungsanalyse metrischer DatenDichtefunktion der Normalverteilung
Die Dichtefunktion der Normalverteilung lautet:
fµ,σ(x) =1√2µσ
· exp(
−(x − µ)2
2σ2
)
, x ∈ R.
Beispiel: Fur µ = 0 und σ = 1 ergibt sich dieStandardnormalverteilung, N(0, 1):
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Dichte der Standardnormalverteilung N(0,1)
8 / 31

Kenngroßen der Normalverteilung
Die Normalverteilung wird charakterisiert durch zwei wichtigeKenngroßen: den Erwartungswert und die Varianz.
Interpretation des Erwartungswertes
Der Erwartungswert einer Zufallsvariablen, E (X ), beschreibtdenjenigen Wert, den man bei sehr haufiger Wiederholung von X
im Mittel beobachten wird. (Dies bezeichnet man auch als dasGesetz der großen Zahlen.)
Definition der Varianz
Die Varianz σ2 einer Zufallsvariablen definiert sich als die mittlerequadratische Abweichung vom Erwartungswert, d.h.
σ2 := Var(X ) := E(
(X − E (X ))2)
.
Die Standardabweichung σ ist definiert durch: σ :=√
Var(X ).
9 / 31

Kenngroßen von Zufallsvariablen
Den Erwartunswert nennt man auch Lageparameter derVerteilung:
−4 −2 0 2 4 6 8
0.0
0.1
0.2
0.3
0.4
Gleiche Varianz, verschiedene Erwartungswerte
10 / 31

Kenngroßen von Zufallsvariablen
Die Varianz nennt man auch Streuungsparameter einerVerteilung:
−4 −2 0 2 4 6 8
0.0
0.1
0.2
0.3
0.4
Gleiche Erwartungswerte, verschiedene Varianzen
11 / 31

Empirische Kenngroßen
Dilemma in der Statistik
Die Kenngroßen Erwartungswert und Varianz einer Zufallsvariablensind von zentraler Bedeutung, aber unbekannt!
Man behilft sich durch die Berechnung von Schatzern basierendauf der Stichprobe X1, . . . ,Xn. Die Schatzer hangen von derzufalligen Stichprobe ab, sind also selbst wiederum zufallig sind.Man unterliegt beim Schatzen einer theoretischen Kenngroße alsostets einer gewissen Unsicherheit.
Hinweis auf das R-Handbuch
Naheres zu den Schatzverfahren von Erwartungswert und Varianzerfahrt man im Handbuch in Kapitel 6. In Kapitel 8 wird außerdemnoch auf das Problem von Aufreißern in Daten und robustenSchatzern eingegangen.
12 / 31

Verteilungsanalyse metrischer DatenAndere Wahrscheinlichkeitsverteilungen
Es existieren in der Statistik aber noch viele andereWahrscheinlichkeitsverteilungen, z.B.
die Poissonverteilung: fλ(x) = e−λ λx
x!
→ Anzahl der Selbstmorde pro Tag, Anzahl der Storfalle in einemKernkraftwerk, usw.
die Exponentialverteilung: fλ(x) = λe−λx
→ Zeit zwischen zwei Meteoriteneinschlagen, Lebensdauer vonelektronischen Bauelementen, usw.
die Lognormalverteilung:
fµ,σ(x) =1
√
2πσxexp
(
− (log(x)−µ)2
2σ2
)
→ Aktienkurse, Brutto-/Nettoeinkommen einer Bevolkerung,usw.
13 / 31

Verteilungsanalyse metrischer DatenNormalverteilung
Uns interessiert aber hauptsachlich die Normalverteilung. Genauergesagt, betrachten wir fur unsere Zwecke die folgende Frage:
Fragestellung bei der Verteilungsananlyse
Konnen die vorliegenden metrischen Daten (ungefahr) durch eineNormalverteilung angenahert werden oder nicht?
→ Wie kann man diese Frage untersuchen?
14 / 31

Verteilungsanalyse: Allgemeine Situation
Um eine Aussage zu erhalten, ob die vorliegende Stichprobe durcheine Normalverteilung approximiert werden kann, konnen sowohlgrafische Hilfsmittel als auch Hypothesentests durchgefuhrtwerden. Man sollte aber stets beide Moglichkeiten betrachten!
Die wichtigsten grafischen Hilfsmittel zur Verteilungsanalyse sind:
Histogramm
Boxplot
Es existieren noch weitere grafische Hilfsmittel wie beispielsweiseQ-Q-Diagramme oder Stamm-Blatt-Diagramme. Die beidenoben genannten Darstellungen der Daten sind aber diegebrauchlichsten, weshalb auf die Einfuhrung weitererDarstellungen verzichtet wird. Fur Q-Q-Diagramme werfe maneinen Blick in das Handbuch.
15 / 31
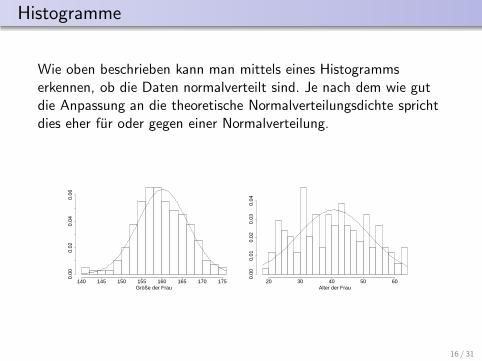
Histogramme
Wie oben beschrieben kann man mittels eines Histogrammserkennen, ob die Daten normalverteilt sind. Je nach dem wie gutdie Anpassung an die theoretische Normalverteilungsdichte sprichtdies eher fur oder gegen einer Normalverteilung.
Größe der Frau140 145 150 155 160 165 170 175
0.00
0.02
0.04
0.06
Alter der Frau20 30 40 50 60
0.00
0.01
0.02
0.03
0.04
16 / 31

Boxplots
Ein weiteres wichtiges grafisches Hilfsmittel zur Beschreibung einesDatensatzes ist der Box-Whisker-Plot, kurz Boxplot.
Konstruktion eines Boxplots
Ein Boxplot basiert auf dem Interquartilabstand (IQR), der genaudie Werte in der
”Box“ umfasst. Der Balken in der Mitte der Box
ist der Median. Die Whisker beschreiben die Lage der Daten in denAußenbereichen und enden an den Stellen ±1.5 · IQR . Alle Werteunter- und uberhalb davon werden als Ausreißer gekennzeichnet.
=⇒ Der Vorteil des Boxplots besteht darin, dass man nicht nuruber die Lokation der Daten, sondern auch uber die Streuungder Daten (=Dispersion) auf einen Blick informiert wird.
=⇒ Sind die Daten beispielsweise nicht symmetrisch, konnen dieWhisker unterschiedlich lang sein, sowie der Median nicht inder Mitte der Box liegen.
17 / 31

Boxplots
Beispiel fur einen Boxplot:
jung alt140
150
160
170
Größe der Frau
18 / 31
Boxplots
Erstellung eines Boxplots in R
# Boxplot ohne Gruppierung
boxplot(mannfrau$große.frau,
main = "Große der Frau ")
# Boxplot mit Gruppierung
plot(mannfrau$alter.f.codiert, mannfrau$große.frau,
main = "Große der Frau ")
Bei Verwendung der Funktion plot() wird automatisch einBoxplot erstellt, wenn das erste Argument eine Variable vom Typfactor ist und das zweite Argument eine Variable vom Typ numeric
ist.
Alternativ kann man die gruppierten Boxplots auch mit demfolgenden Befehl erstellen:
boxplot(mannfrau$große.frau~mannfrau$alter.f.codiert)
19 / 31

Normalverteilungstests
Neben den grafischen Hilfsmittel gibt es auch inferenzstatistischeMoglichkeiten, Aussagen daruber zu machen, ob die Daten einerNormalverteilung folgen.
In R ist der Standardtest hierfur der Shapiro-Wilk-Test. Um zuverstehen wie ein statistischer Test durchgefuhrt wird und wie manein Testergebnis korrekt interpretiert, behandeln wir zunachst dieGrundlagen von statistischen Hypothesentests.
20 / 31

Induktive Statistik
Neben der deskriptiven und der explorativen Statistik, ist das drittegroße Teilgebiet der Statistik die induktive Statistik (auchschließende Statistik genannt).
Gegenstand der induktiven Statistik
Es wird versucht mit Hilfe einer Stichprobe auf Eigenschaften derGrundgesamtheit zu schließen. Diese Grundgesamtheit ist imAllgemeinen sehr viel großer als der Umfang der Stichprobe.
Die Methoden der induktiven Statistik bezeichnet man auch auchals Testverfahren. Dabei wird eine zu uberprufende Hypothese,auch Nullhypothese (oder H0) aufgestellt, die mit einem Test aufKorrektheit uberpruft wird.
Merke:Nullhypothesen sind Prazisierungen der zu untersuchendenFragestellung.
21 / 31

HypothesentestenBeispiele fur Nullhypothesen
Beispiele fur Nullhypothesen:
H0 : Die Zufallsvariable X ist nach irgendeiner NormalverteilungN(µ, σ2)-verteilt, wobei µ und σ2 beliebig seien.
H1 : Die Zufallsvariable X ist nicht normalverteilt.
H0 : Manner und Frauen haben einen gleich hohen IQ-Wert.
H1 : Der IQ-Wert von Mannern und Frauen ist nicht gleich.
H0 : In der Firma XY verdienen Frauen genauso viel oder mehr alsManner.
H1 : In der Firma XY verdienen Frauen weniger als Manner.
22 / 31

Hypothesentesten
Fassen wir zusammen:
Zu einer aufgestellten Nullhypothese H0 wird auch immer eineinhaltlich komplementare Alternativhypothese H1 formuliert.
Die Nullhypothese H0 stellt dann die Basis dar, von der ausentschieden wird, ob die Alternativhypothese H1 akzeptiertwerden kann oder nicht.
=⇒ Die eigentlich zu prufende Hypothese muss also in dieAlternativhypothese H1 gesteckt werden!!
Achtung: Warum ist die Formulierung von
H0 : Wohlhabende Kinder und sozial schwache Kinderunterschieden sich nicht in ihren Lesefahigkeiten.
H1 : Wohlhabende Kinder konnen besser lesen als sozial schwacheKinder.
statistisch nicht korrekt?23 / 31

HypothesentestenTeststatistik
Grundlegende Idee zur Uberprufung von H0
Anhand einer gegebenen Stichprobe X1, . . . ,Xn von unabhangigund identisch verteilten Zufallsvariablen wird ein konkreter Wert,die sog. Teststatistik T = T (X1, . . . ,Xn) berechnet. Anhand vonT und seiner Verteilung wird dann eine Entscheidung getroffen.
Beispiele fur Teststatistiken werden wir bei der Besprechung derTestverfahren viele kennen lernen.
Die popularste Methode zur Hypothesenbeurteilung basierend aufeiner Teststatistik T ist die Betrachtung des p-Wertes.
24 / 31

HypothesentestenDer p-Wert
Der p-Wert
Der p-Wert ist die Wahrscheinlichkeit dafur, dass man unter derNullhypothese H0 das tatsachlich beobachtete Resultat oder sogarein noch extremeres erhalt.
=⇒ Je unwahrscheinlicher also die Gultigkeit von H0, desto kleinerwird der p-Wert. Wenn eine gewisse Wahrscheinlichkeitsgrenzeunterschritten wird, ist H0 also so unwahrscheinlich, dass mansich fur die Gultigkeit der Alternativhypothese H1 entscheidet.
→ Die popularste Grenze fur die Wahrscheinlichkeit betragt 0.05,d.h. ab einem p-Wert von kleiner oder gleich 0.05 wird H0
abgelehnt.
=⇒ Der p-Wert ist sozusagen also ein Maß fur dieGlaubwurdigkeit der Nullhypothese.
25 / 31

HypothesentestenKorrekte Interpretation des Testergebnisses
Ein Signifikanztest gestattet nur eine der beiden folgendenEntscheidungen:
Ablehung von H0 = Annahme von H1
oder
Nicht-Ablehnung von H0 6= Annahme von H0
Dies bedeutet also:
=⇒ Die Nicht-Ablehnung von H0 darf keinesfalls als ein Nachweisder statistischen Richtigkeit der Nullhypothesefehlinterpertiert werden.
=⇒ Streng genommen bedeutet eine Nicht-Ablehnung von H0 alsoeine Stimmenthaltung, d.h. das Stichprobenergebnis ist mit
der Nullhypohthese vereinbar.
26 / 31

HypothesentestenFehler bei der Testentscheidung
Bei einer Entscheidung basierend auf einem Signifikanztest hatman niemals absolute Sicherheit – egal wie man sich entscheidet esbesteht also immer die Gefahr eine Fehlentscheidung zu treffen:
H0 ist wahr H0 ist nicht wahr
Entscheidung fur H0 kein Fehler Fehler 2. Art (β)
Entscheidung fur H1 Fehler 1. Art (α) kein Fehler
Bei einem Signifikanztest kann man leider immer nur denFehler 1. Art kontrollieren. Dieser ist stehts ≤ 0.05.
Der Fehler 2. Art hingegen kann unter Umstanden relativ großwerden.
→ Dies ist die Begrundung fur das Vorgehen auf Folie 23, dassdie eigentlich zu prufende Hypothese als H1 formuliert werdenmuss.
27 / 31

Ruckkehr zum eigentlichen Problem
Nachdem die Grundzuge der Testtheorie behandelt wurden, konnenwir nun zum Test auf Normalverteilung zuruckkehren. In R ist derStandardtest hierfur der Shapiro-Wilk-Test. Die Nullhypothesebei diesem Test lautet:
H0 : Die Stichprobe ist normalverteilt
Man beachte hierbei, dass man in diesem Fall daran interessiert istH0 nicht zu verwerfen – im Idealfall der p-Wert also großer als 0.05sein sollte!
28 / 31

Normalverteilungstests
Durchfuhrung des Shapiro-Wilk-Tests in R:
# Shapiro-Wilk-Test fur alle Daten mit dem Alter des
Manns
shapiro.test(mannfrau$alter.frau)
# Shapiro-Wilk-Test fur die Große getrennt nach
Altersgruppen
tapply(mannfrau$große.frau, mannfrau$alter.f.codiert,
shapiro.test)
29 / 31

Zusammenfassung
Man hat nun also zwei Moglichkeiten die Verteilungseigenschaftender Daten zu uberprufen:
grafisch: Boxplots, Histogramme, Q-Q-Plots, . . .
inferenzstatistisch: Shapiro-Wilk-Test, . . .
Dabei ist aber immer zu beachten:
Grundregel bei der Verteilungsanalyse
Man betrachtet aber nie nur eine der beiden Moglichkeiten,sondern immer beide zusammen!
Manchmal verrat eine der beiden Moglichkeiten namlich mehr uberdie Eigenschaften der Daten als die andere . . .
30 / 31

HypothesentestenVoraussetzungen von Testverfahren
Zu jedem Testverfahren, dass spater besprochen und durchgefuhrtwird gibt es gewisse Voraussetzungen an die Daten, die erfullt seinmussen um die Aussagekraft des Testverfahrens sicher zu stellen(z.B. muss die Normalverteilungsannahme erfullt sein).
Man beachte stets
Aussagen in der Statistik sind hochstens so sicher wie dieVoraussetzungen dieser Aussagen.
=⇒ Sind die Voraussetzugen eines Testverfahrens nicht oder nurteilweise erfullt, so muss dies in einer entsprechendenvorsichtigen Interpretation des Resultates berucksichtigtwerden!
=⇒ Im Zweifelsfall ist es besser auf statistische Tests zu verzichtenund sich mit einer einfachen Beschreibung der Daten anhandtabellarischer und grafischer Darstellungen zu begnugen!
31 / 31


















