
Kapitel: Kontextfreie Sprachen · Eine eindeutige Grammatik Wir definieren eine neue Grammatik G,...
78
Kapitel: Kontextfreie Sprachen Kontextfreie Sprachen 1 / 78
Transcript of Kapitel: Kontextfreie Sprachen · Eine eindeutige Grammatik Wir definieren eine neue Grammatik G,...

Kapitel:
Kontextfreie Sprachen
Kontextfreie Sprachen 1 / 78

Die Syntax von Programmiersprachen
Wie lässt sich die Syntax einer Programmiersprache definieren,so dass die nachfolgende Syntaxanalyse effizient durchführbar ist?
Wir definieren die Syntax durch eine Grammatik.
Beispiele:
Wie definiert man arithmetische Ausdrücke?Wenn V alle gültigen Variablennamen definiert, dann wird ein arithmetischerAusdruck A durch
A → A + A | A− A | A ∗ A | (A) | V
definiert.
Die Menge der gültigen Variablennamen lässt sich einfach durch eine reguläreGrammatik definieren, arithmetische Ausdrücke aber nicht.
Kontextfreie Sprachen 2 / 78

Kontextfreie Sprachen
Eine Grammatik G = (Σ,V ,S,P) mit Produktionen der Form
X → u mit X ∈ V und u ∈ (V ∪ Σ)∗
heißt kontextfrei.Eine Sprache L heißt kontextfrei, wenn es eine kontextfreie Grammatik G gibt, die Lerzeugt, d.h. wenn
L(G) = L.
Beachte:
Nur Variablen X dürfen ersetzt werden:
der Kontext von X spielt keine Rolle.
Kontextfreie Grammatiken sind mächtig, weil rekursive Definitionen ausgedrücktwerden können.
Die Produktionen A → A + A | A− A | A ∗ A | (A) | V stellen eine rekursiveDefinition arithmetischer Ausdrücke dar.
Kontextfreie Sprachen 3 / 78

Beispiele kontextfreier Sprachen
{anbn | n ∈ N} ist kontextfrei:I Wir arbeiten nur mit dem Startsymbol S undI den Produktionen S → aSb | ε.I Die erste Anwendung von S → aSb erzeugt das linkeste a und das
rechteste b.
Die Dyck-Sprache Dk aller Menge wohlgeformten Ausdrücke mit k Klammertypen(1, )1, . . . , (k , )k ist kontextfrei:
I Auch diesmal arbeiten wir nur mit dem Startsymbol S.I Die Produktionen: S → (1 S )1 | (2 S )2 | · · · | (k S )k | SS | ε.I Was modellieren Dyck-Sprachen?
F Die Klammerstruktur in arithmetischen oder Booleschen Ausdrücken,F die „Klammerstruktur“ von Codeblöcken
(z.B. geschweifte Klammern in C oder begin und end in Pascal),F die Syntax von HTML oder XML.
Kontextfreie Sprachen 4 / 78

Eine KFG für L := {w ∈ {0,1}+ : |w |0 = |w |1}
Wir arbeiten mit den drei Variablen S, Null, Eins und
den Produktionen
S → 0 Eins | 1 Null
Eins → 1 | 1 S | 0 Eins Eins
Null → 0 | 0 S | 1 Null Null
Idee:
Ein Wort w ∈ {0, 1}∗ ist genau dann aus Eins ableitbar, wenn w genau eine Einsmehr als Nullen hat.
w ist genau dann aus Null ableitbar, wenn w genau eine Null mehr als Einsenhat.
w ist genau dann S ableitbar, wenn w genau so viele Nullen wie Einsen hat.
Behauptung: L(G) = L.
Beweis: siehe Tafel!
Kontextfreie Sprachen 5 / 78

Ein Fragment von Pascal
Wir beschreiben einen (allerdings sehr kleinen) Ausschnitt von Pascal durch einekontextfreie Grammatik.
Wir benutzen das Alphabet Σ = {a, . . . ,z, ;, :=,begin,end,while,do} und
die Variablen S, statements, statement, assign-statement, while-statement,variable, boolean, expression.
variable, boolean und expression sind im Folgenden nicht weiter ausgeführt.
S → begin statements end
statements → statement | statement ; statements
statement → assign-statement | while-statement
assign-statement → variable := expression
while-statement → while boolean do statements
Kontextfreie Sprachen 6 / 78

Programmiersprachen und kontextfreie Sprachen
Lassen sich die syntaktisch korrekten Programme einer modernenProgrammiersprache durch eine kontextfreie Sprache definieren?
1. Antwort: Nein. In Pascal muss zum Beispiel sichergestellt werden, dass Anzahlund Typen der formalen und aktuellen Parameter übereinstimmen.
I Die Sprache {ww | w ∈ Σ∗} wird sich als nicht kontextfrei herausstellen.
2. Antwort: Im Wesentlichen ja, wenn man „Details“ wie Typ-Deklarationen undTyp-Überprüfungen ausklammert:
I Man beschreibt die Syntax durch eine kontextfreie Grammatik, die allesyntaktisch korrekten Programme erzeugt.
I Allerdings werden auch syntaktisch inkorrekte Progamme (z.B. aufgrund vonTyp-Inkonsistenzen) erzeugt.
I Die nicht-kontextfreien Syntax-Vorschriften können nach Erstellung desAbleitungsbaums überprüft werden.
Kontextfreie Sprachen 7 / 78

Die Backus-Naur NormalformDie Backus-Naur Normalform (BNF) wird zur Formalisierung der Syntax vonProgrammiersprachen genutzt.
Sie ist ein “Dialekt” der Kontextfreien Grammatiken.Produktionen der Form
X → aYb
(mit X ,Y ∈ V und a, b ∈ Σ) werden in BNF notiert als
<X> ::= a <Y> b
Beispiel: Eine Beschreibung der Syntax von Java in einer Variante der BNF aufhttp://docs.oracle.com/javase/specs/jls/se7/html/index.html
(zuletzt besucht am 23.05.2012)
Eine effiziente Syntaxanalyse ist möglich.
Frage: Was ist eine Syntaxanalyse?Antwort: Die Bestimmung einer Ableitung bzw. eines Ableitungsbaums.
Und was ist ein Ableitungsbaum?
Kontextfreie Sprachen 8 / 78

Ableitungsbäume undeindeutige Grammatiken
Ableitungsbäume 9 / 78

Ableitungsbäume
G = (Σ,V ,S,P) sei eine kontextfreie Grammatik.
Ein Baum B heißt Ableitungsbaum für das Wort w , falls Folgendes gilt:
w ist die links-nach-rechts Konkatenation der Blätter von B.
Die Wurzel von B ist mit S markiert.
Innere Knoten sind mit Variablen markiert.Blätter sind mit Buchstaben aus Σ oder dem Symbol ε markiert.
Für jeden Knoten v gilt:I Wenn v mit dem Symbol ε markiert ist, so ist v das einzige Kind seines
Elternknotens w , und w ist mit einer Variablen A markiert, so dass A→ εeine Produktion von G ist.
I Wenn v mit einer Variablen A markiert ist und die Kinder von v dieMarkierungen (von links nach rechts) v1, . . . , vs ∈ Σ ∪ V tragen, dann istA→ v1 · · · vs eine Produktion von G.
Ableitungsbäume 10 / 78
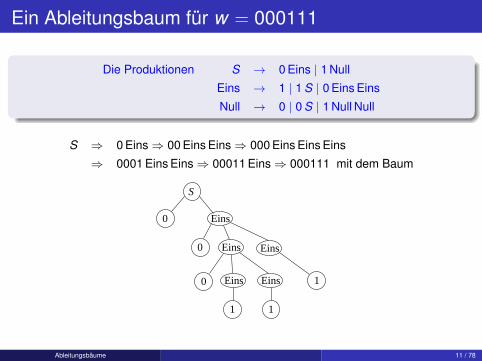
Ein Ableitungsbaum für w = 000111
Die Produktionen S → 0 Eins | 1 Null
Eins → 1 | 1 S | 0 Eins Eins
Null → 0 | 0 S | 1 Null Null
S ⇒ 0 Eins⇒ 00 Eins Eins⇒ 000 Eins Eins Eins
⇒ 0001 Eins Eins⇒ 00011 Eins⇒ 000111 mit dem Baum
0 Eins
0 Eins Eins
0 Eins Eins 1
S
1 1
Ableitungsbäume 11 / 78

Links- und Rechtsableitungen
Ein Ableitungsbaum „produziert“ Linksableitungen (ersetze jeweils die linkesteVariable) und Rechtsableitungen (ersetze rechteste Variable).
0 Eins
0 Eins Eins
0 Eins Eins 1
S
1 1
hat die Linksableitung
S ⇒ 0 Eins⇒ 00 Eins Eins⇒ 000 Eins Eins Eins
⇒ 0001 Eins Eins⇒ 00011 Eins⇒ 000111
und die Rechtsableitung
S ⇒ 0 Eins⇒ 00 Eins Eins⇒ 00 Eins 1
⇒ 000 Eins Eins 1⇒ 000 Eins 11⇒ 000111.
Ableitungsbäume 12 / 78

Eindeutigkeit und Mehrdeutigkeit
Angenommen, ein Programm hat unterschiedliche Ableitungsbäume B1,B2. Dann istdie Semantik des Programms unklar, wenn B1 und B2 unterschiedliche Bedeutungbesitzen!
Wir nennen eine Grammatik mehrdeutig, wenn ein Wort zwei oder mehrereAbleitungsbäume besitzt.
Eine Grammatik ist eindeutig, wenn jedes Wort höchstens einen Ableitungsbaumbesitzt.
Ein Sprache L ist eindeutig, wenn L = L(G) für eine eindeutige kontextfreieGrammatik G gilt. Ansonsten heißt L inhärent mehrdeutig.
Beispiel (hier ohne Beweis)
Die folgende kontextfreie Sprache ist inhärent mehrdeutig:
{ ajbk c` : j, k , ` ∈ N mit j = k oder k = ` }
(Ein Beweis findet sich in Kapitel 6.7 des Buchs von Ingo Wegener.)
Eindeutige Sprachen 13 / 78
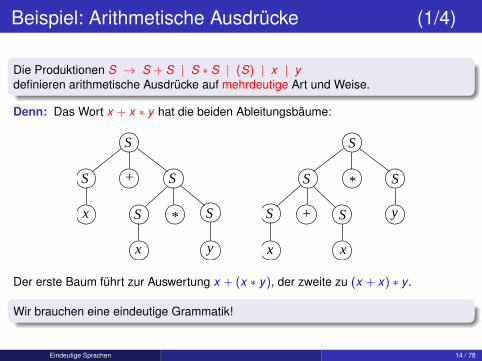
Beispiel: Arithmetische Ausdrücke (1/4)
Die Produktionen S → S + S | S ∗ S | (S) | x | ydefinieren arithmetische Ausdrücke auf mehrdeutige Art und Weise.
Denn: Das Wort x + x ∗ y hat die beiden Ableitungsbäume:
S
S S
S S
x
+
*x
y
*
S
S S
S S y
xx
+
Der erste Baum führt zur Auswertung x + (x ∗ y), der zweite zu (x + x) ∗ y .
Wir brauchen eine eindeutige Grammatik!
Eindeutige Sprachen 14 / 78

Beispiel: Arithmetische Ausdrücke (2/4)Eine eindeutige Grammatik
Wir definieren eine neue Grammatik G, die festlegt, dass die Multiplikation stärker“bindet” als die Addition.
Wir arbeiten mit dem Startsymbol S und den VariablenT (generiert Terme) und F (generiert Faktoren).
Die Produktionen von G haben die Form
S → S + T | T
T → T ∗ F | F
F → (S) | x | y .
Frage: Warum ist diese Grammatik eindeutig?
Eindeutige Sprachen 15 / 78

Beispiel: Arithmetische Ausdrücke (3/4)Nachweis der Eindeutigkeit: Induktionsanfang
Die Produktionen von G:
S → S + T | T
T → T ∗ F | F
F → (S) | x | y .
Wir führen einen Beweis über die Länge eines arithmetischen Ausdrucks A. D.h. wirzeigen für jedes n > 1 und jeden arithmetischen Ausdruck A der Länge n, dass Ahöchstens einen Ableitungsbaum besitzt.
Induktionsanfang: n = 1
Die Länge von A ist 1.
Dann ist A = x oder A = y .
Nur die Ableitung S ⇒ T ⇒ F ⇒ x bzw. S ⇒ T ⇒ F ⇒ y ist möglich.Insbesondere hat A genau einen Ableitungsbaum.
Eindeutige Sprachen 16 / 78

Beispiel: Arithmetische Ausdrücke (4/4)Nachweis der Eindeutigkeit: Induktionsschritt
Die Produktionen von G: S → S + T | T
T → T ∗ F | F
F → (S) | x | y .
Induktionsschritt: n→ n+1Wir müssen die folgenden 3 Fälle betrachten: A = A1 + A2, A = A1 ∗ A2, A = (A1),wobei A1 und A2 arithmetische Ausdrücke sind.Fall 1: A = A1 + A2. Dann gilt:Der Buchstabe + kann nur durch Anwenden der Produktion S → S + T eingeführtwerden.Also muss jeder Ableitungsbaum B von A mit der Produktion S → S + T beginnen(Warum?), und die mit S und T beschrifteten Kinder der Wurzel von B erzeugenarithmetische Ausdrücke A′1 und A′2, so dass A = A′1 + A′2.Wegen |A′1|, |A′2| < |A| sind gemäß Induktionsannahme ihre Ableitungsbäumeeindeutig. Also besitzt auch A höchstens einen Ableitungsbaum.
Fall 2: A = A1 ∗ A2 bzw. Fall 3: A = (A1): analog (Übung!).
Eindeutige Sprachen 17 / 78

Die Syntax von if-then-else
Die Syntax für geschachtelte If-Then-Else Anweisungen bei optionalerElse-Verzweigung:
S → anweisung | if bedingung then S |if bedingung then S else S
S ist eine Variable, anweisung und bedingung sind Buchstaben.
Und wie, bitte schön, ist
if bedingung then if bedingung then anweisung else anweisung
zu verstehen? Worauf bezieht sich das letzte else?
Diese Grammatik ist mehrdeutig.
Übungsaufgabe:Finde eine neue, eindeutige Grammatik, die dieselbe Sprache erzeugt!
Eindeutige Sprachen 18 / 78

Das Pumping Lemmafür kontextfreie Sprachen
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 19 / 78

Das Pumping Lemma für kontextfreie Sprachen
Das Pumping Lemma für Kontextfreie SprachenSei L eine kontextfreie Sprache.
Dann gibt es eine Pumpingkonstante n > 1, so dass
jedes Wort z ∈ L der Länge |z| > n
eine Zerlegung mit den folgenden Eigenschaften besitzt:I z = uvwxy , |vwx | 6 n, |vx | > 1 undI uv iwx iy ∈ L für jedes i > 0.
Beweis: Später, als direkte Folgerung aus Ogden’s Lemma.
Folgerung:
Wenn es für jede Pumpingkonstante n irgendein z ∈ L der Länge > n gibt, sodass Ab- oder Aufpumpen (i = 0 oder i > 2, für irgendein i) aus der Sprachehinausführt (d.h. uv iwx iy 6∈ L),
dann ist die Sprache NICHT kontextfrei.
Allerdings: Weder Pumpingkonstante noch Zerlegung sind bekannt.
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 20 / 78

Anwendung des Pumping Lemmas: Die Spielregeln
Wie kann man das Pumping Lemma nutzen, um zu zeigen, dass eine Sprache L nichtkontextfrei ist?
(1) Der “Gegner” wählt eine Pumpingkonstante n > 1.
(2) Wir wählen ein Wort z ∈ L mit |z| > n.
(3) Der Gegner zerlegt z in z = uvwxy , so dass gilt:|vwx | 6 n und |vx | > 1.
(4) Wir pumpen ab oder auf, d.h. wählen i = 0 oder i > 2.
(5) Wir haben gewonnen, wenn uv iwx iy 6∈ L; ansonsten hat der Gegner gewonnen.
Aus dem Pumping Lemma folgt:Wenn wir eine Gewinnstrategie in diesem Spiel haben, dann ist die Sprache L nichtkontextfrei.
Beachte: Der “Gegner” kontrolliert die Pumpingkonstante n vollständig unddie Zerlegung z = uvwxy teilweise, denn er muss |vwx | 6 n und |vx | > 1 garantieren.
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 21 / 78

Das Pumping Lemma: Ein Anwendungsbeispiel (1/2)
BeispielDie Sprache L := {ambmcm : m > 0} ist nicht kontextfrei.
Beweisidee:
(1) Der Gegner wählt die uns vorher nicht bekannte Pumpingkonstante n.
(2) Wir wählen z := anbncn.
(3) Der Gegner zerlegt z in z = uvwxy , so dass gilt:|vwx | 6 n und |vx | > 1.
(4) Wir sehen: Wegen |vwx | 6 n kann vwx nicht alle drei Buchstaben a, b, centhalten. Wegen |vx | > 1 ist vx ein nicht-leeres Wort, das höchstens 2verschiedene Buchstaben enthält. Wenn wir mit i := 2 aufpumpen, kann dasWort uv2wx2y nicht von allen drei Buchstaben a, b, c gleich viele enthalten.
(5) Also ist uv2wx2y 6∈ L. Wir haben also gewonnen.
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 22 / 78

Das Pumping Lemma: Ein Anwendungsbeispiel (2/2)
BeispielDie Sprache L := {ambmcm : m > 0} ist nicht kontextfrei.
Beweis: Angenommen, L ist doch kontextfrei.Gemäß Pumping Lemma gibt es dann eine Pumpingkonstante n > 1, so dass jedesWort z ∈ L mit |z| > n eine Zerlegung in z = uvwxy besitzt, so dass gilt:
(∗): |vwx | 6 n, |vx | > 1 und uv iwx iy ∈ L für alle i > 0.
Betrachte insbesondere das Wort z := anbncn. Es gilt: z ∈ L und |z| > n.Gemäß Pumping Lemma gibt es also eine Zerlegung z = uvwxy , so dass (∗) gilt.Wegen uvwxy = anbncn und |vwx | 6 n, kann vwx nicht alle drei Buchstaben a, b, centhalten.Wegen |vx | > 1, ist vx also ein nicht-leeres Wort, das höchstens zwei verschiedeneBuchstaben enthält.Aber dann kann das Wort uv2wx2y nicht von allen drei Buchstaben a, b, c gleich vieleenthalten. Somit ist uv2wx2y 6∈ L. WIDERSPRUCH!
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 23 / 78

Das Pumping Lemma: Noch ein Anwendungsbeispiel
BeispielDie Sprache L := {w#w : w ∈ {a, b}∗} ist nicht kontextfrei.
Beweisidee:
(1) Der Gegner wählt die uns vorher nicht bekannte Pumpingkonstante n.
(2) Wir wählen z := anbn#anbn.
(3) Der Gegner gibt uns eine Zerlegung z = uvwxy mit |vwx | 6 n und |vx | > 1.
(4) Wir pumpen mit i := 2 auf.Behauptung: uv2wx2y 6∈ L
Details: siehe Tafel
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 24 / 78

Grenzen des Pumping Lemmas
Es gibt Sprachen, die nicht kontextfrei sind, deren Nicht-Kontextfreiheit mit demPumping Lemma aber nicht nachgewiesen werden kann.
Beispiel: Die Sprache L := {ajbk c`dm : j = 0 oder k = ` = m}ist nicht kontextfrei, erfüllt aber die Aussage des Pumping Lemmas. D.h.:
Es gibt eine Pumpingkonstante n > 1 (nämlich n = 1), so dassI jedes Wort z ∈ L mit |z| > nI eine Zerlegung mit den folgenden Eigenschaften besitzt:
I z = uvwxy , |vwx | 6 n, |vx | > 1, undI uv iwx iy ∈ L für jedes i > 0.
Beweis:Die Nicht-Kontextfreiheit von L werden wir mit Ogden’s Lemma beweisen (später!).Rest: Siehe Tafel!
Das Pumping Lemma und Ogden’s Lemma Das Pumping Lemma 25 / 78

Ogden’s Lemma
Ogden’s LemmaSei L eine kontextfreie Sprache.
Dann gibt es eine Pumpingkonstante n > 1, so dass
jedes Wort z ∈ L und jede Markierung von mindestens n Positionen in z
eine Zerlegung mit folgenden Eigenschaften besitzt:I z = uvwxy , vwx enthält höchstens n markierte Positionen,
vx enthält mindestens eine markierte Position undI uv iwx iy ∈ L für jedes i > 0.
Beachte: Im Spiel gegen den Gegner hat unsere Kraft zugenommen:Wir wählen z ∈ L und markieren > n Positionen.Der Gegner kann immer noch die Zerlegung z = uvwxy wählen, muss abergewährleisten, dass
I vwx höchstens n markierte Positionen undI vx mindestens eine markierte Position besitzt!
Das Pumping Lemma folgt direkt aus Ogden’s Lemma, indem wir alle Buchstabenvon z markieren.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 26 / 78

Ogden’s Lemma: Ein Anwendungsbeispiel (1/2)
BeispielDie Sprache L := {ajbk c`dm : j = 0 oder k = ` = m} ist nicht kontextfrei.
Beweisidee:
(1) Der Gegner wählt die uns vorher nicht bekannte Pumpingkonstante n.
(2) Wir wählen z := a bncndn und markieren bncndn.
(3) Für die vom Gegner gewählte Zerlegung z = uvwxy gilt dann:
vwx besitzt kein b oder kein d ,denn vwx besitzt nur 6 n markierte Positionen.
Somit ist vx ein Wort, das kein b oder kein d , aber mindestens einen derBuchstaben b, c, d enthält (da vx mindestens eine markierte Position enthält).
(4) Wir pumpen mit i := 2 auf. Das dadurch entstehende Wort uv2wx2y besitzt zuwenige b’s oder zu wenige d ’s. Also ist uv2wx2y 6∈ L.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 27 / 78

Ogden’s Lemma: Ein Anwendungsbeispiel (2/2)
BeispielDie Sprache L := {ajbk c`dm : j = 0 oder k = ` = m} ist nicht kontextfrei.
Beweis: Angenommen, L ist doch kontextfrei.Gemäß Ogden’s Lemma gibt es dann eine Pumpingkonstante n > 1, so dass jedesWort z ∈ L und jede Markierung von mindestens n Positionen in z eine Zerlegung inz = uvwxy besitzt, so dass gilt:
(∗): vwx besitzt höchstens n markierte Positionen,vx besitzt mindestens eine markierte Position unduv iwx iy ∈ L für alle i > 0.
Betrachte insbesondere das Wort z := a bncndn und markiere die Positionen bncndn.Es gilt: z ∈ L, und es sind mindestens n Positionen von z markiert.Gemäß Ogden’s Lemma gibt es also eine Zerlegung z = uvwxy , so dass (∗) gilt.Wegen z = uvwxy = a bncndn besitzt vwx kein b oder kein d , da vwx nur höchstens nmarkierte Positionen enthält und wir die Positionen bncndn markiert haben.Somit ist vx ein Wort, das kein b oder kein d , aber mindestens einen der Buchstabenb, c, d enthält (da vx mindestens eine markierte Position enthält).Daher enthält das mit i = 2 aufgepumpte Wort uv2wx2y zu wenige b’s oder zu weniged ’s und liegt somit nicht in L. WIDERSPRUCH!
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 28 / 78

Vorarbeit zum Beweis von Ogden’s Lemma: Chomsky Normalform
Definition (Chomsky Normalform)Eine Grammatik G = (Σ,V ,S,P) ist in Chomsky-Normalform, wenn alle Produktionendie folgende Form haben:
A→ BC oder A→ a, mit A,B,C ∈ V und a ∈ Σ.
Satz (hier ohne Beweis):
Jede kontextfreie Sprache L mit ε 6∈ L wird durch eine Grammatik in ChomskyNormalform erzeugt.Es gibt einen Algorithmus, der bei Eingabe einer kontextfreien Grammatik G inquadratischer Zeit eine Grammatik G′ in Chomsky Normalform erzeugt mitL(G′) = L(G) \ {ε}.
Beispiel: Finde eine Grammatik in Chomsky Normalform für die Sprache
L = {anbn : n ∈ N>0}.
Antwort: S → AR | AB, A→ a, B → b, R → SB.Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 29 / 78

Ogden’s Lemma: Der Beweis (1/5)
Wir betrachten zuerst die „Rahmenbedingungen“:
Laut dem auf der vorhergehenden Folie zitierten Satz gibt es zur kontextfreienSprache L eine Grammatik G = (Σ,V ,S,P) in Chomsky Normalform mitL(G) = L \ {ε}.
Wir wählen n := 2|V |+1 als Pumpingkonstante (klar: n > 1).
Sei z ∈ L ein beliebiges Wort in L mit mindestens n markierten Positionen.
Wegen |z| > n > 1 ist z ∈ L \ {ε} = L(G).Somit gibt es einen Ableitungsbaum B für z bzgl. G.
Um eine Zerlegung z = uvwxy mit den gewünschten Eigenschaften zu finden,betrachten wir B genauer.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 30 / 78

Ogden’s Lemma: Der Beweis (2/5)Eigenschaften des Ableitungsbaums B für z:
B ist binär, da G in Chomsky-Normalform ist.Die Elternknoten von Blättern sind die einzigen Knoten vom Grad 1;alle anderen Knoten haben Grad 2.
B hat mindestens n = 2|V |+1 markierte Blätter, also Blätter, die einen markiertenBuchstaben speichern.
Notation:Ein Knoten v von B heißt Verzweigungsknoten, wenn v den Grad 2 hat und markierteBlätter sowohl im linken als auch im rechten Teilbaum besitzt.
Ein besonderer Weg in B:Sei W der in der Wurzel beginnende Weg zu einem Blatt, der in jedem Schritt dasKind mit den meisten markierten Blättern wählt.Es gilt: W besitzt mindestens |V |+ 1 Verzweigungsknoten.Denn: Unter der Wurzel sind > n markierte Blätter. Beim Durchlaufen einesVerzweigungsknotens wird die Anzahl der sich unterhalb des aktuellen Knotenbefindenden markierten Blätter höchstens halbiert; beim Durchlaufen eines anderenKnotens bleibt die Anzahl unverändert. Das Blatt am Ende des Weges besitzthöchstens einen markierten Knoten.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 31 / 78

Ogden’s Lemma: Der Beweis (3/5)
Wir wissen: W ist ein Weg in B von der Wurzel zu einem Blatt, der mindestens|V |+ 1 Verzweigungsknoten besitzt. Daher gilt:
Unter den letzten |V |+ 1 Verzweigungsknoten des Weges W muss eine Variable Azweimal vorkommen!
A
A
y
S
} } } }}
u v w x
Das unterste Vorkommen v2 von A nutzen wir zur Definition von w :w ist die Konkatenation der Blätter unterhalb von Knoten v2
Das darüber liegende Vorkommen v1 von A nutzen wir zur Definition von u, v , x , y :siehe Skizze.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 32 / 78

Ogden’s Lemma: Der Beweis (4/5)
A
A
y
S
} } } }}
u v w x
Da v1 ein Verzweigungsknoten ist, besitzt vx mindestens einen markiertenBuchstaben.
vwx besitzt höchstens 2|V |+1 = n markierte Buchstaben, denn
Wenn vwx mehr als n markierte Buchstaben besitzt, dann besitzt W (aufseinem Endstück) mehr als |V |+ 1 Verzweigungsknoten. (Warum?)
Wir haben somit eine Zerlegung z = uvwxy gefunden, so dass vwx höchstens nmarkierte Positionen und vx mindestens eine markierte Position enthält.
Frage: Können wir, wie gewünscht, auf- und abpumpen?
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 33 / 78
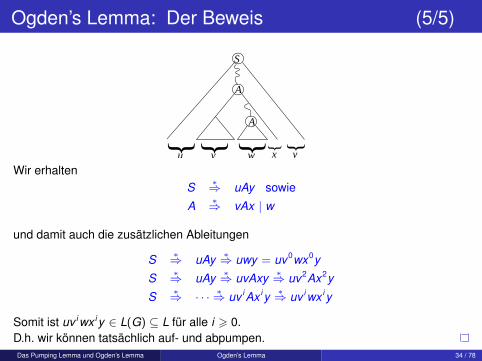
Ogden’s Lemma: Der Beweis (5/5)
A
A
y
S
} } } }}
u v w x
Wir erhaltenS ∗⇒ uAy sowie
A ∗⇒ vAx | w
und damit auch die zusätzlichen Ableitungen
S ∗⇒ uAy ∗⇒ uwy = uv0wx0y
S ∗⇒ uAy ∗⇒ uvAxy ∗⇒ uv2Ax2y
S ∗⇒ · · · ∗⇒ uv iAx iy ∗⇒ uv iwx iy
Somit ist uv iwx iy ∈ L(G) ⊆ L für alle i > 0.D.h. wir können tatsächlich auf- und abpumpen.
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 34 / 78

Anwendung und Grenzen von Ogden’s Lemma
I Wir können Ogden’s Lemma nutzen, um nachzuweisen, dass bestimmte Sprachennicht kontextfrei sind.
Beispiele dafür haben wir bereits kennen gelernt — sowohl in der Vorlesung alsauch in den Übungsaufgaben.
I Wir haben auch schon eine Sprache kennen gelernt, deren Nicht-Kontextfreiheitwir mit Ogden’s Lemma beweisen konnten, aber nicht mit dem Pumping Lemma.
I Aber auch Ogden’s Lemma hat seine Grenzen:
Es gibt Sprachen, die nicht kontextfrei sind, deren Nicht-Kontextfreiheit wir mitOgden’s Lemma aber nicht nachweisen können. (Details: Übung)
Das Pumping Lemma und Ogden’s Lemma Ogden’s Lemma 35 / 78

Abschlusseigenschaftenkontextfreier Sprachen
Abschlusseigenschaften 36 / 78

Abschlusseigenschaften
Satz:L, L1, L2 ⊆ Σ∗ seien kontextfreie Sprachen.Dann sind auch die folgenden Sprachen kontextfrei:
(a) L1 ∪ L2.
(b) L1 · L2.
(c) L∗.
(d) LR := {wR : w ∈ L} (Rückwärtslesen von L).
(e) h(L), wobei h : Σ∗ → Γ∗ ein Homomorphismus ist.
(f) L ∩ R, wobei R ⊆ Σ∗ eine reguläre Sprache ist.
Beweis: Übung!(a)–(e) folgen leicht durch Umbau der gegebenen KFGs für L, L1, L2.
Zum Beweis von (f) benutzt man am besten die Charakterisierung von KFGs durchnichtdeterministische Kellerautomaten, die im nächsten Abschnitt behandelt wird.
Abschlusseigenschaften 37 / 78

Nicht-AbschlusseigenschaftenBeobachtung:(a) Die Klasse der kontextfreien Sprachen ist nicht abgeschlossen unter
Durchschnittsbildung, d.h.
Es gibt kontextfreie Sprachen L1, L2, so dass L1 ∩ L2 nicht kontextfrei ist.
Beispiel: L1 := {anbnck : k , n ∈ N} und L2 := {ak bncn : k , n ∈ N} sind beidekontextfrei, aber L1 ∩ L2 = {anbncn : n ∈ N} ist es nicht.
Aber laut dem Satz auf der vorherigen Folie ist immerhin der Durchschnitt jederkontextfreien Sprache mit einer regulären Sprache wieder kontextfrei.
(b) Die Klasse der kontextfreien Sprachen ist nicht abgeschlossen unterKomplementbildung, d.h.
Es gibt eine kontextfreie Sprache L, deren Komplement L nicht kontextfrei ist.
Beweis: Wenn die kontextfreien Sprachen unter Komplementbildungabgeschlossen wären, dann auch unter Durchschnitten, denn
L1 ∩ L2 = L1 ∪ L2.
Abschlusseigenschaften 38 / 78

Wer ist kontextfrei und wer nicht?
I {anbn | n ∈ N} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I {anbmcn+m | n,m ∈ N} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I {anbnck | k , n ∈ N} ∪ {ak bncn | k , n ∈ N} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I {anbnck | k , n ∈ N} ∩ {ak bncn | k , n ∈ N} = {anbncn | n ∈ N } . . . . . . . . . . . (Nein!)
I {anbmck | n = m = k gilt nicht } . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I {w ∈ {a, b}∗ | w = wR} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Übung!)
I {w ∈ {a, b}∗ | w 6= wR} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Übung!)
I {u#v | u, v ∈ {a, b}∗, u = v} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Nein!)
I {u#v | u, v ∈ {a, b}∗, u 6= v} . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I Die Menge aller arithmetischen Ausdrücke. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (Ja!)
I Die Menge aller syntaktisch korrekten Java Programme.. . . . . . . . . . (Nein, aber fast)
Abschlusseigenschaften 39 / 78

Kellerautomaten
Kellerautomaten 40 / 78

Vorarbeit: Die Greibach Normalform
Definition (Greibach Normalform)Eine Grammatik G = (Σ,V ,S,P) in Greibach Normalform, wenn alle Produktionen diefolgende Form haben:
A→ aα mit A ∈ V , a ∈ Σ, α ∈ V ∗.
In Produktionen von Grammatiken in Greibach Normalform wird also jede Variableersetzt durch einen Buchstaben, gefolgt evtl. von weiteren Variablen.
Satz (hier ohne Beweis):
Jede kontextfreie Sprache L mit ε 6∈ L wird durch eine Grammatik in GreibachNormalform erzeugt.Es gibt einen Algorithmus, der bei Eingabe einer kontextfreien Grammatik G inkubischer Zeit eine Grammatik G′ in Greibach Normalform erzeugt mitL(G′) = L(G) \ {ε}.
(Ein Beweis findet sich in Kapitel 7.1 des Buchs von Ingo Wegener.)
Kellerautomaten Die Greibach Normalform 41 / 78

Ein Maschinenmodell für kontextfreie Sprachen
Aus der Perspektive einer Grammatik in Greibach Normalform:
I Die Ableitung S → aX1 · · ·Xk erzeugt den ersten Buchstaben.I Die Variablen X1, . . . ,Xk sind zu ersetzen, beginnend mit X1.I Wenn der Ersetzungsprozess für X1 abgeschlossen ist,
dann ist X2 dran. Danach X3 usw.
Aus der Perspektive eines Maschinenmodells:
I Lese den ersten Buchstaben a.I Die Variablen X1, . . . ,Xk müssen abgespeichert werden.
Aber mit welcher Datenstruktur?I Das sollte ein Keller sein! (engl: stack oder pushdown storage)
Kellerautomaten Die Greibach Normalform 42 / 78

Nichtdeterministische Kellerautomaten (PDAs, Pushdown Automata)
Ein PDA A = (Q,Σ, Γ, q0,Z0, δ) besteht aus
I einer endlichen Zustandsmenge Q,I einem endlichen Eingabealphabet Σ,I einem endlichen Kelleralphabet Γ,I einem Anfangszustand q0 ∈ Q,I dem anfängliche Kellerinhalt Z0 ∈ Γ, sowieI dem Programm
δ : Q ×(
Σ ∪ {ε})× Γ → P (Q × Γ∗) .
Wie arbeitet ein PDA?Das Eingabewort wird von links nach rechts gelesen.
Eine Konfiguration (q, u, γ) von A besteht aus dem aktuellen Zustand q ∈ Q, demnoch nicht gelesenen Teil u ∈ Σ∗ des Eingabeworts und dem Kellerinhalt γ ∈ Γ∗.
Startkonfiguration bei Eingabe w ∈ Σ∗: (q0,w ,Z0).Kellerautomaten Nichtdeterministische Kellerautomaten 43 / 78

Wie arbeitet ein PDA A?
Die aktuelle Konfiguration sei (q, a1 · · · am, γ1 · · · γr ), d.h.: Der akutelle Zustand ist q;auf dem Eingabeband wird das Symbol a1 gelesen; auf dem Keller das Symbol γ1.
Wenn (q′, δ1 · · · δs) ∈ δ(q, a1, γ1),dann kann A in den Zustand q′ gehen, den Kopf auf dem Eingabeband eineStelle nach rechts bewegen und im Keller das oberste Symbol γ1 durch das Wortδ1 · · · δs ersetzen. D.h.:
(q′, a2 · · · am, δ1 · · · δsγ2 · · · γr )
ist eine zulässige Nachfolgekonfiguration.
ε-Übergänge:Wenn (q′, δ1 · · · δs) ∈ δ(q, ε, γ1), dann kann A in den Zustand q′ gehen, aufdem Eingabeband den Kopf stehen lassen und im Keller das oberste Symbol γ1
durch das Wort δ1 · · · δs ersetzen. D.h.:
(q′, a1 · · · am, δ1 · · · δsγ2 · · · γr )
ist eine zulässige Nachfolgekonfiguration.
Kellerautomaten Nichtdeterministische Kellerautomaten 44 / 78

Wann akzeptiert ein PDA A?
Eine Berechnung von A bei Eingabe w ∈ Σ∗ ist eine Folge K = (k0, k1, . . . , kt ) vonKonfigurationen, so dass k0 = (q0,w ,Z0) die Startkonfiguration von A bei Eingabe wist, und für alle i > 0 gilt: ki+1 ist eine zulässige Nachfolgekonfiguration von ki .
kt = (q, u, γ) ist eine Endkonfiguration, wenn es keine zulässigeNachfolgekonfiguration gibt (u.a. ist dies der Fall, wenn γ = ε, d.h. der Keller leer ist).
Eine Berechnung K = (k0, k1, . . . , kt ) ist akzeptierend, falls kt = (q, ε, ε) ist (d.h. dasEingabewort wurde komplett gelesen und der Keller ist leer).
Akzeptanz durch leeren Keller: Eine Eingabe w wird akzeptiert, wenn es eineBerechnung gibt, die mit leerem Keller endet.
Die von einem PDA A akzeptierte Sprache istL(A) := { w ∈ Σ∗ : es gibt eine akzeptierende Berechnung von A bei Eingabe w }.
Kellerautomaten Nichtdeterministische Kellerautomaten 45 / 78

Ein Beispiel
Ein PDA A = (Q,Σ, Γ, q0,Z0, δ), der die Sprache
L = {w ·wR : w ∈ {a, b}∗}
akzeptiert:
Wir arbeiten mit den Zuständen push (=: q0), pop und fail.
Der Automat legt zuerst die Eingabe im Zustand push auf dem Keller ab,
rät die Mitte des Worts und wechselt in den Zustand pop.
Jetzt wird der Keller abgebaut: Wechsle in den Zustand fail, wennEingabebuchstabe und Stackinhalt nicht übereinstimmen.
Akzeptiere mit leerem Keller.
Details: siehe Tafel.
Kellerautomaten Nichtdeterministische Kellerautomaten 46 / 78

Variante: Akzeptanz durch ZuständeStatt Akzeptanz durch leeren Keller sind auch andere Varianten denkbar, z.B.:
Akzeptanz durch Zustände:Der PDA hat als zusätzliche Komponente eine Menge F ⊆ Q.Eine Eingabe w wird akzeptiert, wenn es eine Berechnung gibt, die das kompletteEingabewort verarbeitet und in einem Zustand q ∈ F endet.
Ein Beispiel: Ein PDA mit akzeptierenden Zuständen für die SpracheL := {u#v : u, v ∈ {a, b}∗, u 6= v }:
Der Automat rät eine Position i im ersten Teil der Eingabe,merkt sich den Buchstaben an dieser Position in seinem Zustandund benutzt den Keller, um sich an die Position zu erinnern (der Keller enthält einWort der Länge i).Dann wird verglichen, ob sich die erste und zweite Hälfte der Eingabe an derPosition i unterscheiden.Wenn ja, gehe in einen akzeptierenden Zustand und gehe auf dem Eingabebandnoch ganz nach rechts.
Die beiden Varianten Akzeptanz durch leeren Keller und Akzeptanz durchZustände sind äquivalent.
Kellerautomaten Nichtdeterministische Kellerautomaten 47 / 78

Akzeptanz durch Zustände =⇒ Akzeptanz durch leeren Keller
Der PDA A akzeptiere mit Zuständen.Dann gibt es einen PDA B, der mit leerem Keller akzeptiert, so dass L(B) = L(A).
Die Konstruktion von B:
B übernimmt das Programm von A.
Wenn ein Zustand in F erreicht wird, dann darf B nichtdeterministisch seinenKeller leeren.
Vorsicht: Wenn A am Ende seiner Berechnung “zufälligerweise” einen leerenKeller produziert, dann würde B akzeptieren.
Lösung: Am Anfang ersetze das Kellersymbol Z0 durch Z0Z ′0, wobei Z ′0 ein neuesSymbol im Kelleralphabet ist.
Kellerautomaten Nichtdeterministische Kellerautomaten 48 / 78

Akzeptanz durch leeren Keller =⇒ Akzeptanz durch Zustände
Der PDA B akzeptiere mit leerem Keller.Dann gibt es einen PDA A, der mit Zuständen akzeptiert, so dass L(A) = L(B).
Die Konstruktion von A:
Wir möchten, dass A bei leerem Keller noch in einen akzeptierenden Zustandwechseln kann.
Am Anfang ersetze Z0 über einen ε-Übergang durch Z0Z ′0, wobei Z ′0 ein neuesKellersymbol ist.
Wenn das Kellersymbol Z ′0 wieder erreicht wird, dann springe in einen neuen,akzeptierenden Zustand.
Kellerautomaten Nichtdeterministische Kellerautomaten 49 / 78

Kontextfreie Sprachen werden von PDAs akzeptiert
Sei G = (Σ,V ,S,P) eine kontextfreie Grammatik.Dann gibt es einen PDA A mit L(A) = L(G).
Der PDA A arbeitet mit nur einem Zustand q0,besitzt das Kelleralphabet Γ := Σ ∪ Vund hat anfangs das Startsymbol Z0 := S im Keller.
Wenn A das Symbol a ∈ Σ sowohl auf dem Eingabeband als auch auf dem Kellerliest, dann darf A dieses Kellersymbol löschen und den Kopf auf demEingabeband um eine Position nach rechts verschieben. D.h.:
(q0, ε) ∈ δ(q0, a, a), für alle a ∈ Σ
Wenn A das Symbol X ∈ V auf dem Keller liest und wenn X → α eine Produktionvon G ist (mit α ∈ (Σ ∪ V )∗), dann darf A einen ε-Übergang nutzen, um die aufdem Keller zuoberst liegende Variable X durch das Wort α zu ersetzen. D.h.:
(q0, α) ∈ δ(q0, ε,X ), für alle X ∈ V , (X → α) ∈ P.
Behauptung: Dieser PDA A akzeptiert genau die Sprache L = L(G).
Beweis: Übung!Kellerautomaten KFG 2 PDA 50 / 78

Sind Kellerautomaten zu mächtig?
Die Sprache L werde von einem PDA A akzeptiert (mit leerem Keller).Ziel: Konstruiere eine kontextfreie Grammatik G, so dass L(G) = L(A).
Sei A = (Q,Σ, Γ, q0,Z0, δ) der gegebene PDA.I Angenommen, A ist im Zustand p1, hat w1 · · ·wk gelesen, und der
Kellerinhalt ist X1 · · ·Xm.
1. Idee:Entwerfe die Grammatik G so, dass die Ableitung S ∗⇒ w1 · · ·wk p1 X1 · · ·Xm
möglich ist.I p1 ist die zu ersetzende Variable.I Problem: Der PDA A arbeitet aber in Abhängigkeit von p1 und X1.
So kann das nicht funktionieren:Wir bekommen so keine kontextfreie Grammatik!
Kellerautomaten Die Tripelkonstruktion 51 / 78

Wie sollen wir die Menge V der Variablen wählen?
2. Idee:
Wir fassen das Paar [p1,X1] als Variable auf!
Können wirS ∗⇒ w1 · · ·wk [p1,X1] [p2,X2] · · · [pm,Xm]
erreichen?
- Was ist p1? Der aktuelle Zustand!
- Was ist p2? Der geratene aktuelle Zustand, wenn X2 an die Spitze des Kellersgelangt.
Aber wie verifizieren wir, dass p2 auch der richtige Zustand ist?
3. Idee:
“Erinnere dich an den geratenen Zustand” — die Tripelkonstruktion.
Kellerautomaten Die Tripelkonstruktion 52 / 78

Die Tripelkonstruktion (1/4)
Wir entwerfen die Grammatik so, dass
S ∗⇒ w1 · · ·wk [p1,X1, p2] [p2,X2, p3] · · · [pm,Xm, pm+1]
ableitbar ist.
Die Absicht von Tripel [pi ,Xi , pi+1] ist, dass
pi der aktuelle Zustand ist, wenn Xi an die Spitze des Kellers gelangt und
dass pi+1 der aktuelle Zustand wird, wenn das direkt unter Xi liegende Symbol andie Spitze des Kellers gelangt.
Wie können wir diese Absicht in die Tat umsetzen?
Unsere Grammatik G(Σ,V ,S,P) hat die folgende Form:Σ ist das Eingabealphabet des PDA A.V besteht dem Startsymbol S und zusätzlich allen Tripeln [q,X , p] mit q, p ∈ Q, X ∈ Γ.
Kellerautomaten Die Tripelkonstruktion 53 / 78

Die Tripelkonstruktion (2/4)
P besteht aus folgenden Produktionen:
S → [q0,Z0, p], für jedes p ∈ Q.
Wir raten, dass p der Schlusszustand einer akzeptierenden Berechnung ist.
Für jeden Befehl (p1,X1 · · ·Xr ) ∈ δ(p, a,X )(mit p1 ∈ Q, a ∈ Σ ∪ {ε} , X1, . . . ,Xr ∈ Γ für r > 1) undfür alle Zustände p2, . . . , pr+1 ∈ Q füge als Produktionen hinzu:
[p,X , pr+1] → a [p1,X1, p2] [p2,X2, p3] · · · [pr ,Xr , pr+1].
Wir raten also, dass A beim Offenlegen des Kellersymbols Xi in den Zustand pi
gelangt.
Und wie wird hier gewährleistet, dass wir die richtigen Zustände p2, . . . , pr+1 geratenhaben?
Kellerautomaten Die Tripelkonstruktion 54 / 78

Die Tripelkonstruktion (3/4)
Für jeden Befehl (p1,X1 · · ·Xr ) ∈ δ(p, a,X )und alle p2, . . . , pr+1 ∈ Q füge die Produktion[p,X , pr+1] → a [p1,X1, p2] [p2,X2, p3] · · · [pr ,Xr , pr+1] hinzu.
Direkt nachdem A diesen Befehl ausgeführt hat, liegt ganz oben auf dem Keller dasSymbol X1.
Wenn im nächsten Schritt X1 durch ein nicht-leeres Wort ersetzt wird, dann wirddie Verifikation vertagt: Der für die Offenlegung von X2 geratene Zustand p2 wirdfestgehalten.
Wenn X1 durch das leere Wort ersetzt wird, dann müssen wir verifizieren:
Für jeden Befehl (q, ε) ∈ δ(p, a,X ) nimm
[p,X , q]→ a
als neue Produktion in P auf.
Kellerautomaten Die Tripelkonstruktion 55 / 78

Die Tripelkonstruktion (4/4)
P besteht also aus den ProduktionenI S → [q0,Z0, p], für jedes p ∈ Q,I [p,X , pr+1] → a [p1,X1, p2] [p2,X2, p3] · · · [pr ,Xr , pr+1],
für jeden Befehl (p1,X1 · · ·Xr ) ∈ δ(p, a,X ) von A undfür alle Zustände p2, . . . , pr+1 ∈ Q
I [p,X , q]→ a, für jeden Befehl (q, ε) ∈ δ(p, a,X ).
Behauptung:Für alle p, q ∈ Q, X ∈ Γ und w ∈ Σ∗ gilt:
[p,X , q]∗⇒G w ⇐⇒ (p,w ,X ) `∗A (q, ε, ε).
k `∗A k ′ bedeutet hier, dass es eine Berechnung von A gibt, die in endlich vielenSchritten von Konfiguration k zu Konfiguration k ′ gelangt.
Beweis: (Details: Übung)“=⇒”: Per Induktion nach der Länge von Ableitungen.“=⇒”: Per Induktion nach der Länge von Berechnungen.
Kellerautomaten Die Tripelkonstruktion 56 / 78

Zusammenfassung
Insgesamt haben wir also folgende Äquivalenz von KFGs und PDAs bewiesen:
Satz:Sei Σ ein endliches Alphabet. Eine Sprache L ⊆ Σ∗ ist genau dann kontextfrei, wennsie von einem nichtdeterministischen Kellerautomaten akzeptiert wird.
Kellerautomaten Die Tripelkonstruktion 57 / 78

Deterministisch kontextfreie Sprachen
Kellerautomaten Deterministisch kontextfreie Sprachen 58 / 78

Deterministisch kontextfreie SprachenZiel: Schränke die Definition von PDAs so ein, dass sie deterministisch sind, d.h. dasses bei jedem Schritt der Verarbeitung eines Eingabeworts w ∈ Σ∗ nur höchstens einemögliche Nachfolgekonfiguration gibt.
Definition: Ein deterministischer Kellerautomat (kurz: DPDA) istein PDA A = (Q,Σ, Γ, q0,Z0, δ,F ), der mit Zuständen akzeptiert, und für dessenProgramm δ gilt:
für alle q ∈ Q, a ∈ Σ und X ∈ Γ ist |δ(q, a,X )|+ |δ(q, ε,X )| 6 1.
Beachte: Ein DPDA kann stets höchstens eine Anweisung ausführen.
Frage: Warum erlauben wir hier ε-Übergänge?
Weil das unser Modell stärker macht. Beispielsweise wird die Sprache
{anbm$an : n,m ∈ N} ∪ {anbm#bm : n,m ∈ N}
von einem DPDA mit ε-Übergängen akzeptiert, aber nicht von einem “Echtzeit-DPDA”,der keine ε-Übergänge nutzt. (Details: Übung)
Frage: Warum akzeptieren wir hier mit Zuständen und nicht mit leerem Keller?
Kellerautomaten Deterministisch kontextfreie Sprachen 59 / 78

Akzeptanzmodus
Ein “DPDA”, der mit leerem Keller akzeptiert, kann stets durch einen DPDAsimuliert werden, der mit Zuständen akzeptiert. (Warum?)
Die Sprache L = {0, 01} lässt sich mit Zuständen akzeptieren (klar: sogar durcheinen DFA, der den Keller gar nicht nutzt), aber nicht durch einen “DPDA” mitAkzeptanzmodus “leerer Keller”, denn:
− Schreibt der Automat beim Eingabezeichen 0 ein Zeichen auf den Keller, sowird das Eingabewort 0 nicht akzeptiert: Fehler.
− Schreibt der Automat im Anfangszustand beim Eingabezeichen 0 nichts aufden Keller, so ist der Keller jetzt leer. Nachfolgende Buchstaben können jetztnicht mehr verarbeitet werden! Fehler.
Bei der Definition von DPDAs haben wir den stärkeren Modus „Akzeptanz durchZustände“ gewählt. Damit ist insbesondere auch gewährleistet, dass jedereguläre Sprache von einem DPDA akzeptiert wird.
DefinitionEine Sprache ist deterministisch kontextfrei, wenn sie von einem DPDA akzeptiert wird.
Kellerautomaten Deterministisch kontextfreie Sprachen 60 / 78

Beispiele deterministisch kontextfreier Sprachen
L = {anbn | n ∈ N>0}:
Idee:Lege zuerst alle a’s auf den Keller. Für jedes b nimm ein a vom Keller runter.
Details:L wird von dem DPDA A = (Q,Σ, Γ, q0,Z0, δ,F ) akzeptiert mit Q = {q0, q1, q2},Σ = {a, b}, Γ = {a, b,Z0}, F = {q2} und
δ(q0, a,Z0) = {(q0, aZ0)}, δ(q0, a, a) = {(q0, aa)},δ(q0, b, a) = {(q1, ε)}, δ(q1, b, a) = {(q1, ε)},δ(q1, ε,Z0) = {(q2, ε)}.
Die Sprache aller wohlgeformten Klammerausdrücke:
Idee:I Lege jede öffnende Klammer auf den KellerI und für jede schließende Klammer entferne eine Klammer vom Keller.
Details: Übung.
Kellerautomaten Deterministisch kontextfreie Sprachen 61 / 78

Abschlusseigenschaften deterministisch kontextfreier Sprachen
Satz:L, L1, L2 ⊆ Σ∗ seien deterministisch kontextfreie Sprachen.Dann sind auch die folgenden Sprachen deterministisch kontextfrei:
(a) L := Σ∗ \ L(Abschluss unter Komplementbildung)
(b) L ∩ R, wobei R ⊆ Σ∗ eine reguläre Sprache ist.(Abschluss unter Durchschnitt mit regulären Sprachen)
(c) h−1(L), wobei h : Γ∗ → Σ∗ ein Homomorphismus ist.(Abschluss unter inversen Homomorphismen)
Beweisidee:
(a) Sei A ein DPDA, der L akzeptiert. Für L bauen wir einen DPDA B, der einEingabewort genau dann verwirft, wenn A nach dem Lesen des letztenBuchstabens und vor dem Lesen des nächsten Buchstabens akzeptiert.Vorsicht: ε-Übergänge von A machen das ganze recht kompliziert.Details finden sich in Kapitel 8 des Buchs von Wegener.
(b) und (c): Gleicher Beweis wie bei kontextfreien Sprachen (Übung!)
Kellerautomaten Abschlusseigenschaften 62 / 78

Nicht-Abschlusseigenschaften
Beobachtung:
(a) Die Klasse der deterministisch kontextfreien Sprachen istnicht abgeschlossen unter Durchschnittbildung, d.h.
Es gibt deterministisch kontextfreie Sprachen L1, L2, so dass L1 ∩ L2
nicht deterministisch kontextfrei ist.
Beispiel: L1 := {anbnck : k , n ∈ N} und L2 := {ak bncn : k , n ∈ N} sind beidedeterministisch kontextfrei, aber L1 ∩ L2 = {anbncn : n ∈ N} ist nicht kontextfrei,also auch nicht deterministisch kontextfrei.
(b) Die Klasse der deterministisch kontextfreien Sprachen istnicht abgeschlossen unter Vereinigung, d.h.
Es gibt deterministisch kontextfreie Sprachen L1, L2, so dass L1 ∪ L2
nicht deterministisch kontextfrei ist.
Beweis: Übung!
Kellerautomaten Abschlusseigenschaften 63 / 78

Weitere Nicht-Abschlusseigenschaften
Beobachtung:
Die Klasse der deterministisch kontextfreien Sprachen istnicht abgeschlossen unter
(a) Konkatenation, d.h. es gibt deterministisch kontextfreie Sprachen L1, L2, so dassdie Sprache L1·L2 nicht deterministisch kontextfrei ist.
(b) Kleene-Stern, d.h. es gibt eine deterministisch kontextfreie Sprache L, so dass dieSprache L∗ nicht deterministisch kontextfrei ist.
(c) Rückwärtslesen, d.h. es gibt eine deterministisch kontextfreie Sprache L, so dassdie Sprache LR nicht deterministisch kontextfrei ist.
(d) Homomorphismen, d.h. es gibt eine deterministisch kontextfreie Sprache L undeinen Homomorphismus h, so dass h(L) nicht deterministisch kontextfrei ist.
Beweis: Übung!
Kellerautomaten Abschlusseigenschaften 64 / 78

Was weiss man noch über deterministisch kontextfreie Sprachen?
I Jede reguläre Sprache ist deterministisch kontextfrei.I Jede endliche Sprache ist regulär.I Jede deterministisch kontextfreie Sprache ist eindeutig. (Warum?)
I Das Wortproblem für deterministisch kontextfreie Sprachen L ⊆ Σ∗
Eingabe: Ein Wort w ∈ Σ∗.
Frage: Ist w ∈ L ?
kann in Linearzeit gelöst werden.
Begründung:Sei A ein DPDA, der L akzeptiert. Bei Eingabe von w lasse A laufen.Wenn A keine ε-Übergänge nutzt, dann macht A höchstens |w | Schritte.Auch für den Fall, dass A ε-Übergänge nutzt, kann man zeigen, dass O(|w |)Schitte ausreichen, um zu entscheiden, ob w akzeptiert wird oder ob der DPDA ineiner Endlosschleife gefangen ist. (Details: Übung.)
Kellerautomaten Eigenschaften det. kf. Sprachen 65 / 78

Einige Beispiele (1/2)
L := { anbmck | n,m, k ∈ N, n = m = k gilt nicht } ist kontextfrei, abernicht deterministisch kontextfrei.Kontextfrei: Haben wir bereits gesehen.Nicht deterministisch kontextfrei:
Intuitiver Grund:Ein DPDA weiss nicht, ob er a′s mit b’s oder a’s mit c’s vergleichen soll.Formaler Grund:I Das Komplement der Sprache, geschnitten mit L(a∗b∗c∗), ist{anbncn : n ∈ N}, also nicht kontextfrei.
I Aber die Klasse der deterministisch kontextfreien Sprachen istabgeschlossen unter Komplemenbildung und Schnitt mit regulärenSprachen.
Man kann sogar zeigen, dass die Sprache L inhärent mehrdeutig ist.
L = {w ·wR | w ∈ {a, b}∗} ist eindeutig, aber nicht deterministisch kontextfrei.Eindeutig: Wir können leicht eine eindeutige KFG angeben, die L erzeugt.Nicht deterministisch kontextfrei:
Intuitiver Grund: Ein DPDA kann die Mitte eines Worts nicht raten.Formaler Grund: siehe Buch von Hopcroft und Ullman
Kellerautomaten Eigenschaften det. kf. Sprachen 66 / 78

Einige Beispiele (2/2)
{anbmck | n,m, k ∈ N, n 6= m} ist deterministisch kontextfrei.
{anbmck | n,m, k ∈ N, n 6= k} ∪ {anbmck | n,m, k ∈ N, m 6= k} ist kontextfrei,aber nicht deterministisch kontextfrei.Die Sprache ist sogar inhärent mehrdeutig.
Lk = {0, 1}∗{1}{0, 1}k ist regulär.
{u#v | u, v ∈ {a, b}∗, u = v} ist nicht kontextfrei.
{u#v | u, v ∈ {a, b}∗, u 6= v} ist kontextfrei,aber nicht deterministisch kontextfrei.
Kellerautomaten Eigenschaften det. kf. Sprachen 67 / 78

Das Wortproblemfür kontextfreie Sprachen
Das Wortproblem 68 / 78

Das Wortproblem für kontextfreie Sprachen (1/2)
Die Klasse der kontextfreien Sprachen bildet die Grundlage für die Syntaxspezifikationmoderner Programmiersprachen.
Um zu überprüfen, ob ein eingegebener Programmtext ein syntaktisch korrektesProgramm der jeweiligen Programmiersprache ist, muss ein Compiler das folgendeProblem lösen:
Sei G = (Σ,V ,S,P) eine kontextfreie Grammatik, die die Grundform syntaktischkorrekter Programme unserer Programmiersprache beschreibt.
Das Wortproblem für G = (Σ,V ,S,P)
Eingabe: Ein Wort w ∈ Σ∗
Frage: Ist w ∈ L(G)?
Wenn wir zusätzlich noch einen Ableitungsbaum für w konstruieren, haben wir eineerfolgreiche Syntaxanalyse durchgeführt.
Natürlich wollen wir das Wortproblem möglichst schnell lösen.
Das Wortproblem Das Wortproblem 69 / 78

Das Wortproblem für kontextfreie Sprachen (2/2)
Wir wissen bereits, dass wir das Wortproblem für deterministisch kontextfreieSprachen in Linearzeit lösen können.
In einer Veranstaltung zum Thema “Compilerbau” können Sie lernen, dass DPDAsdurch bestimmte kontextfreie Grammatiken charakterisiert werden, so genannteLR(k)-Grammatiken.
Aber wie schwer ist das Wortproblem für allgemeine kontextfreie Grammatiken?
Es reicht, KFGs in Chomsky Normalform zu betrachten (d.h. alle Produktionen habendie Form A→ BC oder A→ a für A,B,C ∈ V und a ∈ Σ), denn wir wissen bereits,dass jede KFG G in quadratischer Zeit in eine KFG G′ in Chomsky Normalform mitL(G′) = L(G) \ {ε} umgeformt werden kann.
Das Wortproblem Das Wortproblem 70 / 78

Eine Lösung des Wortproblems für kontextfreie Sprachen
Der Satz von Cocke, Younger und KasamiSei G = (Σ,V ,S,P) eine kontextfreie Grammatik in Chomsky-Normalform.Dann kann in Zeit
O(|P| · |w |3
)entschieden werden, ob w ∈ L(G).
Beweis:
Die Eingabe sei w = w1 · · ·wn ∈ Σn (mit n > 1).
Wir benutzen die Methode der dynamischen Programmierung.
Für alle i, j mit 1 6 i 6 j 6 n bestimmen wir die Mengen
Vi,j :={
A ∈ V : A ∗⇒ wi · · ·wj}.
Klar: w ∈ L(G) ⇐⇒ S ∈ V1,n.
Das Wortproblem Die CYK Konstruktion 71 / 78

Eine Lösung der Teilprobleme (1/2)
Ziel: Bestimme Vi,j :={
A ∈ V : A ∗⇒ wi · · ·wj}.
Die Bestimmung der Mengen Vi,i (für alle i mit 1 6 i 6 n) ist leicht, dennG ist in Chomsky Normalform,d.h. alle Produktionen sind von der Form A→ BC oder A→ a. Somit ist
Vi,i ={
A ∈ V : A ∗⇒ wi}
={
A ∈ V : (A→ wi ) ∈ P}.
Beachte:Die Bestimmung der Mengen Vi,j wird umso komplizierter je größer j − i .
Wir bestimmen daher nach und nach für alle s = 0, 1, 2 . . . , n−1 nur diejenigenMengen Vi,j , für die j−i = s ist.
Für s = 0 wissen wir bereits, dass Vi,i = {A ∈ V : (A→ wi ) ∈ P} ist.
Um von s−1 nach s zu gelangen, nehmen wir an, dass die Mengen Vi,j mitj−i < s bereits alle bekannt sind. Dann sieht Vi,j für j−i = s wie folgt aus:
Das Wortproblem Die CYK Konstruktion 72 / 78

Eine Lösung der Teilprobleme (2/2)
Ziel: Bestimme Vi,j :={
A ∈ V : A ∗⇒ wi · · ·wj}.
Wir nehmen an, dass s > 1 ist und dass alle Mengen Vi,j mit j−i < s bereitsbekannt sind.Nun wollen wir die Mengen Vi,j für j−i = s bestimmen.Variable A gehört genau dann zu Vi,j , wenn
A ∗⇒ wi · · ·wj ,
d.h. wenn es eine Produktion (A→ BC) ∈ P und ein k mit i 6 k < j gibt, so dass
B ∗⇒ wi · · ·wk und C ∗⇒ wk+1 · · ·wj , d.h.
B ∈ Vi,k und C ∈ Vk+1,j .
Somit ist
Vi,j =
{A ∈ V :
es gibt (A → BC) ∈ P und k mit i 6 k < j ,so dass B ∈ Vi,k und C ∈ Vk+1,j
}Für jedes feste i, j können wir Vi,j in Zeit O(|P| · n) bestimmen.
Das Wortproblem Die CYK Konstruktion 73 / 78

Der CYK-AlgorithmusEingabe: Eine KFG G = (Σ,V ,S,P) in Chomsky Normalform
und ein Wort w = w1 · · ·wn ∈ Σn (für n > 1).Frage: Ist w ∈ L(G)?
Algorithmus:
(1) Für alle i = 1, . . . , n bestimme Vi,i := {A ∈ V : (A→ wi ) ∈ P}(2) Für alle s = 1, . . . , n−1 tue Folgendes:
(3) Für alle i, j mit 1 6 i < j 6 n und j−i = s bestimme
Vi,j :=
{A ∈ V :
es gibt (A → BC) ∈ P und k mit i 6 k < j ,so dass B ∈ Vi,k und C ∈ Vk+1,j
}.
(4) Falls S ∈ V1,n ist, so gib “ja” aus; sonst gib “nein” aus.
Dieser Algorithmus löst das Wortproblem! Laufzeit:I für (1): O(n · |P|) SchritteI jedes einzelne Vi,j in (3) benötigt O(|P| · n) Schritte;
insgesamt werden O(n2) dieser Vi,j bestimmt.I Somit ist die Gesamtlaufzeit O(|P| · n3).
Das Wortproblem Die CYK Konstruktion 74 / 78

Ein Beispiel
Sei G die KFG in Chomsky Normalform mit den folgenden Produktionen:
S → AB D → bA → CD | CF E → cB → c | EB F → ADC → a
Frage: Gehört w := aaabbbcc zu L(G)?
Die vom CYK-Algorithmus berechneten Mengen Vi,j können wir wir folgt als Tabelleaufschreiben:
— siehe Tafel (bzw. Kapitel 1.3.4 im Buch von Schöning) —
Das Wortproblem Die CYK Konstruktion 75 / 78

Syntaxanalyse
Der CYK-Algorithmus löst das Wortproblem.
Aber können wir damit auch einen Ableitungsbaum bestimmen?
JA! Dazu müssen wir im CYK-Algorithmus beim Einfügen eines A in die Menge Vi,j
zusätzlich speichern, warum es eingefügt wurde — d.h. wir merken uns die Produktion(A→ BC) ∈ P und die Zahl k mit i 6 k < j so dass B ∈ Vi,k und C ∈ Vk+1,j .
Wenn S ∈ V1,n ist, können wir anhand dieser gespeicherten Informationen direkt einenAbleitungsbaum für w erzeugen.
Das Wortproblem Die CYK Konstruktion 76 / 78

Zusammenfassung: Die wichtigsten Konzepte (1/2)
Kontextfreie Grammatiken definieren die Syntax moderner Programmiersprachen.
I Die Konstruktion eines Ableitungsbaums ist das wesentliche Ziel derSyntaxanalyse.
I Der CYK-Algorithmus erlaubt eine effiziente Lösung des Wortproblems wieauch eine schnelle Bestimmung eines Ableitungsbaums in Zeit O(|P| · n3).
Wir haben eindeutige Grammatiken und Sprachen definiert.I Eindeutige Grammatiken definieren eine eindeutige Semantik.I Es gibt inhärent mehrdeutige kontextfreie Sprachen wie etwa{ak blcm : k = l = m gilt nicht }.
Wir haben die deterministisch kontextfreien Sprachen kennen gelernt.I Für diese kann das Wortproblem sogar in Linearzeit gelöst werden.I Jede deterministisch kontextfreie Sprache ist eindeutig.I Aber es gibt Sprachen, die eindeutig, aber nicht deterministisch kontextfrei
sind. Beispiel: {w ·wR : w ∈ {a, b}∗}
Zusammenfassung 77 / 78

Zusammenfassung: Die wichtigsten Resultate (2/2)
Mit dem Pumping Lemma oder mit Ogden’s Lemma oder denAbschlusseigenschaften der Klasse der kontextfreien Sprachen können wirnachweisen, dass (manche) Sprachen NICHT kontextfrei sind.
Kontextfreie Grammatiken und nichtdeterministische Kellerautomaten definierendieselbe Sprachenklasse.
I Kellerautomaten haben uns erlaubt, deterministisch kontextfreie Spracheneinzuführen.
I Deterministisch kontextfreie Sprachen sind eindeutig.I Ihr Wortproblem kann in Linearzeit gelöst werden.
Da man die Syntax von Programmiersprachen durch deterministischkontextfreie Sprachen definiert, ist die Compilierung super-schnell.
Normalformen:I Die Chomsky Normalform war wesentlich für die Lösung des Wortproblems
(und praktisch für den Beweis von Ogden’s Lemma).I Die Greibach Normalform hat geholfen, das Konzept der Kellerautomaten
herzuleiten. (Mit ihrer Hilfe kann man auch die Äquivalenz von ndet. PDAsund “Echtzeit-PDAs”, d.h. ndet. PDAs ohne ε-Übergänge, nachweisen.)
Zusammenfassung 78 / 78


















