Key Value Stores - Abteilung Datenbanken Leipzig · CouchDB - Einführung „Apache CouchDB is a...
62
1 Key Value Stores (CouchDB, BigTable, Hadoop, Dynamo, Cassandra)
Transcript of Key Value Stores - Abteilung Datenbanken Leipzig · CouchDB - Einführung „Apache CouchDB is a...

1
Key Value Stores(CouchDB, BigTable, Hadoop, Dynamo, Cassandra)

2
Neue Herausforderungen● große Datenmengen in Unternehmen
● Twitter, youtube, facebook, … (social media)
● Daten als Ware bzw. Rohstoff → x TB / Tag
● Relationales Modell bietet/benötigt:
● viel Normalisierung ● viele hierarchische Informationen ● viele Tabellen
● SQL Server sind komplex, formell, mächtig→ Unnötig für simple Datenhaltung
● Write Once – Read Many

3
SQL● mächtige Anfragesprache zur Analyse und
Extraktion großer Datenmengen aus relationalen Tabellen (festes Schema)
● Outer- und Inner Joins, Unions, Komplexe Berechnungen, Groups, Erweiterungen...
● erlaubt hoch dynamische Queries
● Transaktionsbasierter Zugriff
● Integritätsbedingungen → Konsistenz OLTP + OLAP

4
NoSQL
● Community von Entwicklern alternativer, nicht-relationaler Datenbanken
● behandeln nicht nur Key Value Stores sondern auch z.B. BerkleyDB, O2, GemStone, Statice
(objekt-relationale, NF2, etc.)
● Nicht gegen SQL generell sondern gegen die generelle Nutzung für (unpassende) Zwecke
N SQL✮

5
Key Value Stores
● Datenbank für Values indexiert über Key → f(K) = V● meist B*-Baum Index ● versuchen effizienter für (Web-) Applikationen mit
vielen aber einfachen Daten zu sein● brauchen keine beliebig komplexen Queries● speichern schemalose Daten● fokussieren auf Skalierbarkeit,
Distribution/Synchronisation, Fehlertoleranz ● Value kann (oft) beliebiger Datentyp sein
(auch Arrays, Dokumente, Objekte, Bytes, ...)

6
CAP Theorem
● Eric Brewer● Die Schnittmenge aller 3 (Mitte) ist leer!
Consistency(Konsistenz)
Availability(Verfügbarkeit)
Partitioning(Partitionierbarkeit) Key Value Stores
Eventual Consistency= letztendliche Konsistenz(aber nicht sofort)
RDBMSErzwungene Konsistenz
PaxosEinigungsprotokoll
http://www.julianbrowne.com/article/viewer/brewers-cap-theorem

7
Key-Value mit ruby + pstorerequire "pstore"
store = PStore.new("data-file.pstore")
store.transaction do
store[:mytext] = "Lorem ipsum dolor sit amet..."
store[:obj_heirarchy] = {
"nice" => ["ruby", "nosql"],"irgh" => ["php", "mysql"]
}
end
my_var = store[:mytext]Quelle letzte 6 Seiten
Mark Seeger: Key Value Stores – a practical overview

8
Fahrplan
● Einführung● BigTable (Google, proprietär)● HBase (Apache)● CouchDB (Apache 2 Lizenz)● Dynamo (Amazon, proprietär)● Cassandra (facebook, zuerst proprietär -
jetzt Apache 2.0 Lizenz)● Zusammenfassung

9
Viele Andere – nicht behandelt
● Tokyo Cabinet (mixi.jp - ein japanischer facebook Klon, LGPL)
● Redis (BSD-Lizenz)● memcacheDB (BSD-Lizenz)● MongoDB (AGPL Lizenz)● voldemort (LinkedIn, Apache 2.0 Lizenz, Klon
von Amazons Dynamo)
...

10
BigTable

11
Google Requirements
● asynchrone Prozesse updaten kontinuierlich● hohe read/write Raten (Millionen ops/sec)● Scans über die gesamten Daten bzw. Teile● Joins (mit MapReduce)● Datenveränderungen im Zeitverlauf analysieren

12
Google BigTable
● hohe Performanz, hohe Verfügbarkeit● komprimierte Datenhaltung● proprietär, nicht öffentlich zugänglich● schnell und extrem gut skalierend
● Petabyte HDD-Daten● Terabyte in-memory Daten● tausende Server (zu Clustern zusammengefasst)
● load balance Selbstmanagement

13
Datenmodell● kein voll relationales Modell
● a sparse distributed multidimensional sorted map● (row:string, column:string, time:int64) → string● Form der Datenhaltung ist Teil des Schemas● versioniert

14
Nutzung I
quasi überall bei Google
YouTube
"My Search History"

15
Nutzung II
● BigTable bezeichnet nicht nur das konkrete System, das von Google entwickelt wurde, sondern auch das dahinter stehende Konzept
● Da BigTable nur indirekt über die Google App Engine zugänglich ist, gibt es Open-Source Implementierungen, die genau dieses Konzept umsetzen. Zum Beispiel:● Cassandra● HBase● Hypertable Auführliches Paper:
Bigtable: A Distributed Storage System for Structured Datahttp://labs.google.com/papers/bigtable-osdi06.pdf
16
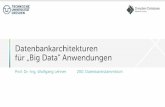
HBase● Datenbank von Hadoop, nutzt das „Ecosystem“● Open-Source Implementierung von BigTable● Ziel: Milliarden Rows, X Tausend Columns,
X tausend Versionen● Java● skaliert● verteilt● RESTful● Thrift
(RPC)
Realität: <100Realität: x Mio.
http://wiki.apache.org/hadoop/Hbase

17
Datenmodell – Column Families● konzeptuell
● Intern (vom User festgelegt im Schema!)
Row Key Time Stamp
Column "contents:"
Column "anchor:"
Column "mime:"
"com.cnn.www" t9 "<html>abc..." "anchor:cnnsi.com"
"CNN"
t8 "<html>def..." "anchor:my.look.ca"
"CNN.com"
t6 "<html>ghi..." "text/html"
Row Key Time Stamp
Column "contents:"
"com.cnn.www" t9 "<html>abc..."
t8 "<html>def..."
t6 "<html>ghi..."
Row Key Time Stamp
Column "anchor:"
"com.cnn.www" t9 "anchor:cnnsi.com"
t8 "anchor:my.look.ca"
...

18
Beispiel
${HBASE_HOME}/bin/start-hbase.sh
${HBASE_HOME}/bin/hbase shell
hbase> create "mylittletable", "mylittlecolumnfamily"
hbase> describe "mylittletable"
hbase> put "mylittletable", "x"
hbase> get "mylittletable", "x"
hbase> # get "mylittletable", "x", {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> scan "mylittletable"

19
Regions (Row Ranges)● konzeptuell: Table = Liste von Tupeln (Row)
sortiert nach Row Key aufsteigend, Column Name aufsteigend und Timestamp absteigend
● physisch/intern, Table geteilt in Row Ranges genannt Regions. Jeder Row Range enthält Rows vom start-key (inklusive) bis end-key ( )∉
● zu große Regions werden gesplited● Regions können sequentiell mit Iterator
(Scanner) durchlaufen werden

20
Architecture Design I
RegionServer● Write Requests (schreibt zuerst write-ahead log Cache/Buffer)
● Read Requests (ließt zuerst write-ahead log; sonst StoreFiles)
● Cache Flushes (wenn Cache zu groß: flush nach StoreFiles)
● Compactions ● letzte x StoreFiles werden zusammengefasst und komprimiert● selten: alle StoreFiles werden zusammengefasst – I/O intensiv
● Region Splits● parent → { child1[start, mitte], child2[mitte, ende] }● setze parent offline, registriere childs in Meta Table ohne
RegionServer● informiere Master → weist RegionServer zu● komprimiere childs, setze online, parent → Garbage Collector

21
Architecture Design II● Multiple Client – Multiple Server
● Cluster = 1 Master, n RegionServer, n Clients
● Master ist erster Anlaufpunkt bei Suche (daher light weight)● verteilt Regions auf RegionServer● verwaltet das Schema● reagiert auf Crashes von RegionServern● erste Region ist die ROOT Region/Table
diese verweist auf alle Regions der META Table
● META Table enthält Infos über alle Regions. Jeweils:● Start- und End-Row-Keys, ● ob die Region online oder offline ist● die Adresse des RegionServer, der die Region hält

22
Architecture Design III● jede Column Family in einer Region wird von einem Store verwaltet
● jeder Store kann aus einer oder mehreren StoreFiles (ein Hadoop HDFS file type) bestehen
● HDFS sorgt für● Distribution (Verteiltheit) der physischen Speicherung
● Skalierbarkeit
● Replikation (3fach, Rack-Awareness, re-balancing
Client
● fragt Master nach ROOT Region (cacht möglichst)
● scannt ROOT Region nach Ort der META Region
● scannt META Region nach RegionServer für gesuchte Region
● kontaktiert RegionServer und scannt gesuchte Region

23
ROOT

24
Einschränkungen HBase● keine SQL Datenbank:
● nicht relational● keine Joins● keine hochentwickelte Query Engine● keine Datentypen für Columns● keine eingebaute Warehouse-Funktionalität (dafür Hive)● keine Transaktionen
(„atomic per row“ geht - weiteres ist in Entwicklung)● keine „secondary“ Indexes (dafür MapReduce)
→ kein 1:1 Ersatz für RDBS
● nicht fertig (Version: 0.20.2 << 1) noch API-Changes aber großteils stable

25

26
CouchDB - Einführung
„Apache CouchDB is a documentoriented database that can be queried and indexed in a MapReduce fashion using JavaScript. CouchDB also offers incremental replication with bidirectional conflict detection and resolution.“
„Dokumente“ sind JSON Objekte● Folge von Name/Wert Paaren● beliebig genestete Struktur● Datentypen: JavaScript Primitive (string, int, float, array, ...)● kann binary file „attachments“ enthalten● Version ist Metainformation jedes Dokuments

27
JSON Beispiel{
“_id”: "2DA92AAA628CB4156134F36927CF4876",
“_rev”: “75AA3DA9”,
“type”: “contact”,
“firstname”: “Smith”,
“lastname’: “John”,
“picture”: “http://example.com/john.jpg”,
“current_cart”: [
{“aid”: 45456,
“amount”: 2
}, {
“aid”: 66345, “amount”: “1”
}],
....
}
Reservierte Attribute
Binary Data? Auch möglich
http://json.org/
28
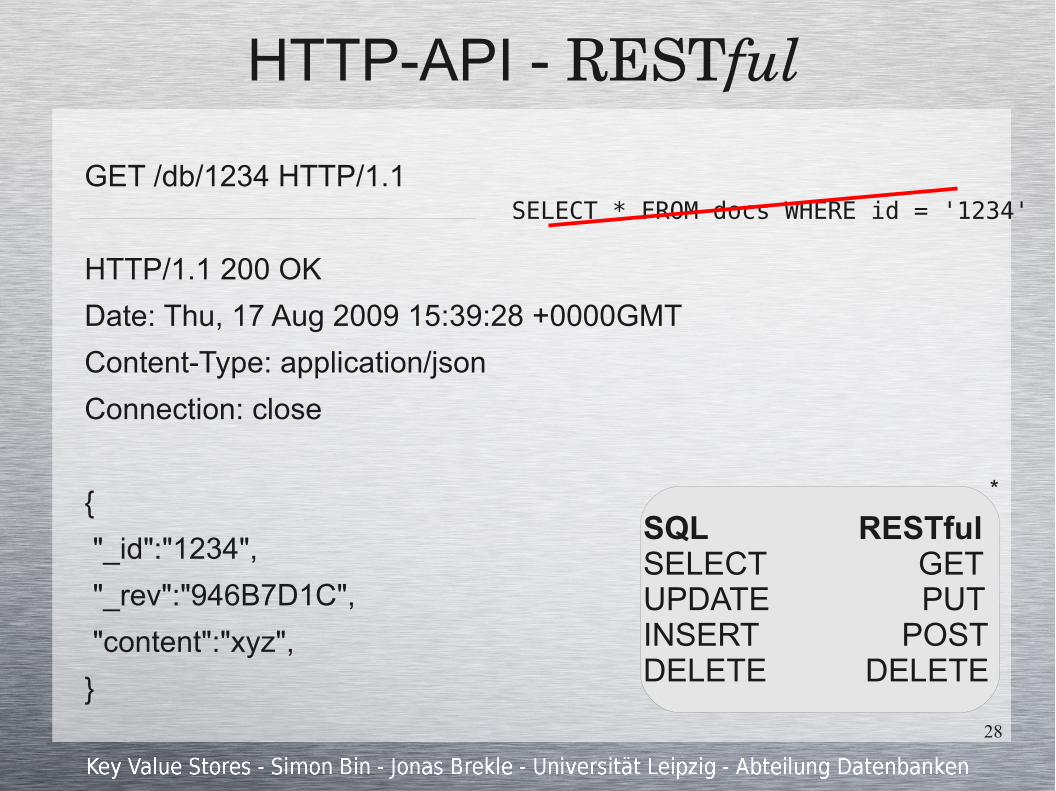
HTTP-API - RESTful
GET /db/1234 HTTP/1.1
HTTP/1.1 200 OK
Date: Thu, 17 Aug 2009 15:39:28 +0000GMT
Content-Type: application/json
Connection: close
{
"_id":"1234",
"_rev":"946B7D1C",
"content":"xyz",
}
SELECT * FROM docs WHERE id = '1234'
SQL RESTfulSELECT GETUPDATE PUTINSERT POST DELETE DELETE
*

29
Synchronisationskonflikte
● sind „gewöhnlich“ - keine Ausnahme● Konflikte entstehen und werden nicht vom
System aufgelöst. ● eine gewinnende Revision wird deterministisch
gewählt● Die verlierende Rev. bleibt aber erhalten● Dokumente werden markiert („_conflicts“: true)● Auflösung ist der Anwendung überlassen
(bzw. dem User)

30
Konsistenz
● innerhalb eines Nodes:
Multiversion concurrency control
→ Versionierung
→ No locking
→ optimistic commits
→ Übertragung der Rev.-Nr. vom Lesen
(siehe SVN)

31
Zusammenfassung couchDB● einfach● für „kleine“ Anwendungen
● Websites (bbc.co.uk, meebo, ...)● Desktop-Syncing (desktopcouch, UbuntuOne), ● Handys („offline by default“)
● „build of the web“● HTTP, JSON, JavaScript
● Konfliktlösung und Replikation ist der Anwendung überlassen
Quelle: http://books.couchdb.org/

32
Amazon Dynamo
Designziele
● Performanz● Zuverlässigkeit● Effizienz● hohe Skalierbarkeit
Quelle SOSP07: DeCandia et al.: Dynamo: amazon’s highly available key-value store. In: SOSP ’07: Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles, Seiten 205–220, New York 2007

33
Anforderung Amazon
Ungestörtes Benutzererlebnis, auch unter:
● Ausfall von Platten● Zusammenbruch der Routen● Zerstörung des Data Centers durch Tornados
→ es fällt immer irgendwas aus

34
Was ist Dynamo?
● Datenbank (Key-Value-Store) für kleine Datenmengen
● Technologie● Interface● Replikation● Versionierung● Ausfälle

35
Einsatz von Dynamo bei Amazon
Quelle: SOSP07

36
Dynamo Technologie (1)
Partitionierung / Replizierung:● Konsistentes Hashing
● Schlüssel-Hash-Wert steuert die Verteilung
Konsistenz:● Objekt-Versionierung
● pro Knoten eigene Versionsnummer
● Quorum● Mindestanzahl Knoten mit erfolgreicher Operation

37
Dynamo Technologie (2)
Ausfallerkennung & Teilnehmerprotokoll:● Gossip
● Benachrichtigung über (permanentes) Eintreten und Austreten von Knoten
● periodische Verbreitung der Information über alle vorhandenen Knoten
● zufälliger Knoten wird sekündlich kontaktiert● nicht praktikabel bei 10-tausenden Knoten

38
Dynamo – Vorteile der TechnologienProblem Technologie Vorteil
Partitionierung Konsistentes Hashing Schrittweise Skalierbarkeit
Hohe Verfügbarkeit bei Schreibzugriffen
Vektoruhren mit Abgleich während Leseoperationen
Trennung von Versionierung und Aktualisierungsort
Behandlung nicht-dauerhafter Ausfälle
Sloppy Quorum und Hinted Handoff
Hohe Verfügbarkeit und Garantie der
Dauerhaftigkeit wenn Replikationsknoten
nicht erreichbar sind.Wiederherstellung nach dauerhaften
Ausfällen
Anti-entropy mit Merkle-Bäumen
Synchronisierung abweichender
Replikationsknoten im Hintergrund
Mitglieder und Ausfallerkennung
Gossip-basiertes Mitgliederprotokoll und
Ausfallerkennung.
Vermeidung zentraler Datenbanken und
Knoten mit speziellen Aufgaben.Quelle: SOSP07

39
Einschränkungen von Dynamo
● nur ein Primärschlüssel zum Zugriff auf Daten● in vielen Fällen ausreichend
● nicht voll ACID● Teilnehmerprotokoll skaliert nicht endlos
● Einführung von mehreren Schichten / DHT denkbar
● für große Daten nicht optimiert● Auswahl anderer Technologien je nach Anforderung

40
Dynamo – ACID?
● ACID ↔ schlechte Verfügbarkeit
Dynamo kann ACID nicht erfüllen:● schwache Konsistenz● keine Isolationsgarantie● keine Transaktionen

41
Dynamo Interface
● get( key )
Objekt mit Schlüssel „key“ aus dem Speicher abrufen
● put( key , object )¹
Objekt „objekt“ unter dem Schlüssel „key“ abspeichern/aktualisieren
¹ intern wird noch ein context mitgegeben

42
Dynamo Datentypen
● key : byte[]● object : byte[]
● keinerlei Datentypen!● Entscheidung liegt bei der Anwendungssoftware
● Ablegen des Schlüssels unter dessen MD5-Hash

43
Partitionierung
● Jeder Knoten besitzt eine zufällige ID („token“)
→ bestimmt Zuständigkeit für einen Schlüssel-(MD5-)Bereich
● Vorteil: Wegfall von Knoten betrifft nur dessen „Nachbarn“
● Virtuelle Knoten: ein physischer Knoten hat mehrere token

44
Replikation (1)
Quelle: SOSP07

45
Replikation (2)
● Replizieren der Daten zu den Nachfolgeknoten● jeder Knoten hat durch den Hash festgelegte
Nachfolgeknoten● die Daten werden an die jeweils N nachfolgenden
Knoten (Hash-Wert + n) repliziert– N vorher festgelegt, kann je nach Anwendung optimiert
werden

46
Versionierung
Quelle:SOSP07
● Versionierung der Daten● Daten können durch
Schreibvorgänge auf unterschiedlichen Knoten inkonsistent werden
● Verwendung von Vektorzeit ermöglicht jederzeit Erkennung
● System sucht die aktuellste(n) Versionen
● Ggf. durch Software

47
Ausfälle (1)
● Quorum● um gegen temporäre Ausfälle geschützt zu sein,
werden Schreib- und Leseoperationen akzeptiert, wenn mindestens W bzw. R Knoten die Operation erfolgreich ausführen– W und R konfigurierbar und erlauben Anpassung an die
Anforderungen der Software
● Hinted Handoff● Wenn Knoten nicht erreichbar sind, übernehmen
weiter hinter liegende Knoten die Schreiboperation an deren Stelle (später wird zurücksynchronisiert)

48
Ausfälle (2)
● Merkle-Bäume● Synchronisation zwischen Replikationen● Merkle-Baum: Blätter enthalten Hash-Wert der
Daten („object“), Knoten die Hash-Werte ihrer Unterknoten
→ schnelle Überprüfung von Teilbäumen

49
Ausfallerkennung und MP
● Gossip● Permanentes Hinzufügen und Entfernen von Knoten
benötigt expliziten Befehl● Teilnehmerliste wird sekündlich an zufällige Knoten
übermittelt, so stellt sich irgendwann ein konsistenter Zustand ein
● Spezielle Keim-Knoten („Seeds“) sind in der Konfigurationsdatei eingetragen und werden bevorzugt befragt
● Ausfall von Nachbarknoten wird lokal von jeweiligem Knoten erkannt (Antwortzeit zu lange)

50
Apache Cassandra
Designziele
● große Datenmengen● hohe Verfügbarkeit● keine starke Konsistenz● „BigTable auf Dynamo-Infrastruktur“?● Einsatz in Facebook
Quelle: Lakshman & Malik: Cassandra – A Decentralized Structured Storage System. In: LADIS 2009: The 3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware, New York, 2009

51
Anforderungen Facebook
● riesiges soziales Netzwerk, >250 Mio. Nutzer● siehe Vorlesung/Seminar MANET/P2P
● ähnlich Amazon: Datenzentren mit tausenden Komponenten
● Ursprung des Problems: Funktion „Inbox Search“● Nutzer des sozialen Netzwerks wollen ihren
Posteingang durchsuchen● MySQL zu langsam!

52
Idee
● Dynamos Vektorzeit hat Nachteile bei hohem Datendurchsatz¹
● BigTable benötigt verteiltes Dateisystem
● Lässt sich da was kombinieren?● Cassandra ist von den technologischen Ideen
hinter Dynamo und BigTable inspiriert (verwendet diese aber nicht direkt)
¹ siehe vorige Kapitel

53
Cassandras „BigTable“
● Wie schon bei HBase vorgestellt werden Tabellen verwendet● column families● super columns (Spalten in denen sich eine column
family befindet, also verschachtelte Spalten)
● key: string (ca. 16 bis 36 byte)● Spalten sortiert entweder nach Zeit oder nach
Name, nützlich für Posteingang (sortiert nach Zeit)

54
Cassandra Interface
● insert( table , key , column , value , ts , c )● fügt den Wert „value“ in der Spalte „column“ ein
– ts: Zeitstempel– c: Konsistenz-Anweisung
● get( table , key , column , c )● liest den Wert der entsprechenden Spalte
● remove( table , key , column , ts )● Entfernt einen Wert aus einer Spalte

55
Systemarchitektur (1)
● Partitionierung● Konsistentes Hashing, aber die Sortierung bleibt
erhalten (korrespondiert mit der Sortierung des Hashwerts)
● Zur besseren Lastverteilung ändern sich die zugeteilten Hashwerte von nicht ausgelasteten Knoten
● Replikation● kann auf Rack (Serverschrank) oder Datenzentrum
begrenzt werden

56
Systemarchitektur (2)
● Teilnehmerprotokoll● Gossip-Protokoll, auch für Systemnachrichten
● Ausfallerkennung● Basierend auf dem Empfang (bzw. Nicht-Empfang)
von Gossip-Nachrichten eines Knotens wird dessen Ausfallwahrscheinlichkeit von jedem Knoten selbst ermittelt
● Erste Implementierung dieser Art
● Eintreten eines neuen Knotens startet mit Kopieren der Daten eines anderen Knotens

57
Lese-/Schreiboperationen
● Leseoperationen● Weiterleiten der Anfrage an den/die Knoten mit den
Daten● aktuellste Ergebnisse zurückliefern● ggf. nicht aktuelle Knoten aktualisieren
● Schreiboperation● warten, bis ein Quorum an Knoten die
Schreiboperation bestätigt

58
Datenspeicher
● Speicherung auf Festplatte und im Hauptspeicher
● Daten werden binär auf die Platte geschrieben● Indizes für den Schlüssel und Startpositionen
der einzelnen Spalten● „Superindex“ sagt, in welchen Dateien ein
Schlüssel überhaupt vorkommt● Anfrage schaut erst im Speicher, dann auf der
Festplatte unter Zuhilfenahme der Indizes

59
Cassandra Datenverarbeitung
● Programmierbeispiel

60
KVS - lessons learned
● es skaliert... mit möglicher Inkonsistenz● CouchDB für kleine und mittlere Anwendungen● HBase für große Projekte, gute Community● Amazon Dynamo für große kommerzielle
Projekte mit kleinen Daten● Cassandra ist Konkurrent zu HBASE, teilweise
überlegen, P2P-Architektur, nicht so aktive Community

61
KVS - Datenauswertung
● CouchDB Map/Reduce auf 1 Knoten, repliziert● HBase Map/Reduce, alles verteilt● Dynamo nur Key/Value Zugriff, Amazon-intern● Cassandra ohne Datenauswertung, nur Zugriff
auf sortierte Spalten

62
Vielen Dank für Ihre Aufmerksamkeit!
Fragen?






![Key Value Stores - Dynamo und Cassandra · 3 Apache Cassandra 14 ... Für eine ausführlichere Einführung in das Thema sei außerdem auf [Bre10] verwiesen, der Allgemeines zum Thema](https://static.fdokument.com/doc/165x107/5b9f8eb609d3f2857a8b51d8/key-value-stores-dynamo-und-cassandra-3-apache-cassandra-14-fuer-eine.jpg)