Künstliche Intelligenz für datengestützte Innovation · White Paper Künstliche Intelligenz für...
14
White Paper Künstliche Intelligenz für datengestützte Innovation Warum die auf Machine Learning basierenden Innovationen in CLAIRE eine wesentlich effektivere Datennutzung ermöglichen
Transcript of Künstliche Intelligenz für datengestützte Innovation · White Paper Künstliche Intelligenz für...

White Paper
Künstliche Intelligenz für datengestützte InnovationWarum die auf Machine Learning basierenden Innovationen in CLAIRE eine wesentlich effektivere Datennutzung ermöglichen

Dieses Dokument enthält vertrauliche, unternehmenseigene und geheime Informationen („vertrauliche Informationen“) von Informatica und darf ohne vorherige schriftliche Genehmigung von Informatica weder kopiert, verteilt, vervielfältigt noch auf andere Weise reproduziert werden.
Es wurde alles unternommen, um die Genauigkeit und Vollständigkeit der in diesem Dokument enthaltenen Informationen sicherzustellen. Dennoch können Druckfehler oder technische Ungenauigkeiten nicht vollständig ausgeschlossen werden. Informatica übernimmt keine Verantwortung für Verluste, die aufgrund der in diesem Dokument enthaltenen Informationen entstehen können. Die hierin enthaltenen Informationen können sich ohne vorherige Ankündigung ändern.
Die Berücksichtigung der in diesem Dokument besprochenen Produktmerkmale in neuen Versionen oder Upgrades von Informatica Softwareprodukten sowie der Zeitpunkt der Veröffentlichung dieser Versionen oder Upgrades liegen im alleinigen Ermessen von Informatica.
Geschützt durch mindestens eines der folgenden US-Patente: 6032158, 5794246, 6014670, 6339775, 6044374, 6208990, 6208990, 6850947, 6895471 oder durch folgende angemeldete US-Patente: 09/644280, 10/966046, 10/727700.
Diese Ausgabe wurde im Mai 2017 veröffentlicht.

1
White Paper
Inhaltsverzeichnis
Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
Trends bei der Datenverwaltung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Was bedeutet das für IT-Experten? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Was bedeutet das für Führungskräfte? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Was ist Machine Learning? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Warum ist Machine Learning für die Datenverwaltung sinnvoll?. . . . . . . . . . . . . . . . 5
Die Grundlage für das Machine Learning bei der Datenverwaltung . . . . . . . . . . . . . 5
Informatica CLAIRE: Der „intelligente Kern“ der Intelligent Data Platform . . . . . . . . . 6
CLAIRE in der Praxis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Intelligente Datenähnlichkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Intelligent Domain Discovery mithilfe von Tags. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Intelligent Entity Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Intelligente Datenempfehlungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Intelligent Structure Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Intelligent Anomaly Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Schlussfolgerungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12

2
EinleitungWir befinden uns mitten in der digitalen Transformation. Unternehmen müssen sich entweder digital neu ausrichten oder damit rechnen, den Anschluss zu verlieren. Immer mehr Unternehmen setzen Initiativen zur digitalen Transformation um, um ihren Umsatz zu steigern und sich auf dem wettbewerbsintensiven Markt durchzusetzen. Diese Initiativen betreffen beispielsweise die Festigung der Beziehung zu Kunden, die Optimierung von Betriebsabläufen, das Angebot individueller Gesundheitsversorgung und die Vermeidung von Betrug.
Und der Erfolg dieser Initiativen hängt direkt von der zeitgerechten Bereitstellung hochwertiger Daten ab. Das Prinzip ist denkbar einfach: Erfolgreiche Strategien zur Digitalisierung beruhen auf Daten. Je besser Sie Ihre Daten verwalten, desto erfolgreicher ist Ihre Strategie zur Digitalisierung. Mit anderen Worten: Die Effizienz Ihrer Strategie zur Digitalisierung hängt von der Effizienz Ihrer Datenverwaltung ab.
Doch wenn Sie Ihre „Daten weiterhin so verwalten bis bisher“, werden Sie nicht viel erreichen. IT-Experten suchen nach Möglichkeiten, die Produktivität der Datenverwaltung zu erhöhen, damit allen Benutzern schnell hochwertige Daten zur Verfügung gestellt werden können.
Die CLAIRETM Engine von Informatica – oder Cloud-scale AI-powered Real-time Engine – nutzt künstliche Intelligenz (AI) und Machine Learning, um unternehmensweite Daten und Metadaten zu verarbeiten, so dass die Produktivität von Führungskräften und Benutzern im gesamten Unternehmen spürbar erhöht wird.

3
Trends bei der Datenverwaltung Es ist ein Umdenken hinsichtlich Daten und Datenarchitektur gefordert. Jahrzehntelang lag der Schwerpunkt auf Geschäftssystemen und -prozessen. Diese sind zwar immer noch wichtig, doch heutzutage geht es darum, Initiativen hochwertige und vollständige Daten zeitnah zur Verfügung zu stellen. Denn nur so können sich Unternehmen Wettbewerbsvorteile verschaffen. Doch da die meisten IT-Budgets nur geringfügig steigen, muss mit vorhandenen Ressourcen mehr erreicht werden.
Heutzutage sind bei der Verwaltung von Unternehmensdaten erhebliche Hürden zu meistern. Um das Potenzial von Daten voll ausschöpfen zu können, muss Ihre IT-Abteilung Folgendes leisten:
1. Mehr Daten:
• Datenmenge: 15,3 Zettabyte an globalem Datenverkehr aus dem Rechenzentrum.
• Komplexe und vielfältige Daten: Es gibt zahlreiche neue Datenquellen und Datentypen, sowohl extern als auch unternehmensintern.
• Datengeschwindigkeit: Aufgrund der Verbreitung des IoT (Internet of Things) mit 20 Milliarden vernetzten Geräten werden permanent Daten gestreamt.
2. Mehr Benutzer: Heutzutage verwenden 325 Mio. Business User Daten – Tendenz steigend. Jeder, vom Geschäftsanalysten über nichttechnische Benutzer bis zum Datenverwalter benötigt direkten und zeitnahen Zugriff auf Daten.
3. Mehr Integrationsmuster:
• Nutzung der Cloud: ERP-Suites werden immer häufiger in die Cloud verschoben.
• Analytics: Unternehmen nutzen immer öfter neue Technologien, wie Big Data, NoSQL und Predictive Analytics, um Data Warehouses zu ergänzen.
• Experimentieren: Benutzer benötigen unkomplizierten Zugriff auf Daten, um eine Hypothese schnell zu erstellen und zu testen sowie darauf aufzubauen, falls sie sich bestätigt. Bei der Erstellung einer Hypothese ist die Geschwindigkeit zunächst wichtiger als Präzision.

4
Was bedeutet das für IT-Experten?Aufgrund all dieser Entwicklungen und Trends ist die Datenverwaltung komplexer als je zuvor, da Unternehmen realisieren, dass die digitale Transformation nur mit hochwertigen Daten erfolgreich ist.
Dadurch bietet sich IT-Experten die Chance, ihr Unternehmen datenorientiert durch die digitale Transformation zu führen. Wie kann es IT-Experten jedoch ohne die Unterstützung eines kostspieligen Heers an Entwicklern gelingen, dem Unternehmen schneller zuverlässige Daten bereitzustellen?
Da IT-Budgets bestenfalls nur geringfügig erhöht werden, müssen drei Aspekte berücksichtigt werden:
• Erhöhung des Grads an Automatisierung und der Effizienz von Datenverwaltungsaufgaben und -projekten
• Erhöhung von Self-Service-Funktionen für Unternehmen
• Erhöhung der Zusammenarbeit, damit Teams auf geschäftlicher und technischer Seite optimal zusammenarbeiten
Was bedeutet das für Führungskräfte?Führungskräfte sind heutzutage in der Lage, innovative Initiativen durchzusetzen und Fragen zu stellen, die bislang aus wirtschaftlicher Sicht einfach nicht möglich waren. Doch die Qualität der Ergebnisse ihrer Initiativen zur Digitalisierung hängt von den zugrundeliegenden Daten ab.
Daher ist die Ausarbeitung eines Plans zur optimalen Nutzung von Daten von höchster Priorität.
Zudem ist es wichtig, dass Unternehmen intern über Datenverwaltungsexperten verfügen, da ihr Wissen die Grundlage für die Initiativen zur Digitalisierung bildet. Daten müssen als Asset verwaltet werden und allen Benutzern des Unternehmens zur Verfügung stehen. Zudem muss die Datenqualität dem jeweiligen Verwendungszweck entsprechen: hohe Qualität für wichtige Entscheidungen und Interaktionen und eine angemessene Qualität für schnelle Innovationen und Abläufe. Aus technologischer Sicht lassen sich die manuelle Programmierung und nicht integrierte Datenverwaltungstool nicht skalieren, um den Anforderungen des Unternehmens gerecht zu werden.

5
Was ist Machine Learning?Machine Learing ist eine Methode, bei der Programme permanent aus Inhalten lernen. Machine-Learning-Systeme erstellen auf Grundlage eingegebener Daten Vorhersagen oder treffen Entscheidungen. Diese Systeme lernen von Daten und können ihr Vorgehen selbst anpassen, um bessere Ergebnisse zu erzielen. Je mehr Daten ihnen zur Verfügung stehen, desto schneller lernen sie und desto genauer sind ihre Ergebnisse.
Warum ist Machine Learning für die Datenverwaltung sinnvoll?Die Schnelligkeit der Bereitstellung von Daten für wichtige Initiativen kann nur mit einem hohen Grad an Automatisierung erhöht werden. An dieser Stelle kommt das Machine Learning ins Spiel. Wenn unternehmensweit transparente Metadaten und Machine Learning genutzt werden, können Datenverwaltungstools dazu „angelernt werden“, intelligente Empfehlungen zu erstellen und Datenverwaltungsaufgaben zu automatisieren. Machine Learning ersetzt Datenanalysten und andere Benutzer nicht, sondern sorgt dafür, dass die Produktivität und Effizienz der an der Datenverwaltung beteiligten Mitarbeiter steigt.
Machine Learning dient darüber hinaus dazu, die Aufgaben zu automatisieren, die für Menschen aufwändig oder unmöglich zu leisten sind. Beispiele dafür sind:
1. Erkennung und Identifizierung
• Regeln zur Sicherstellung der Datenqualität, Business Entity Discovery
• Semantische Suche, Erkennung von Mustern und Klassifizierung von Daten
• Erkennung von Unregelmäßigkeiten sowie Meldung solcher Abweichungen
2. Prädiktive Abläufe
• Bursting, um Spitzenaufkommen bei Datenmengen zu bewältigen
• Priorisierung bei der Untersuchung betrieblicher Probleme
• „Selbstheilung“, um Änderungen an der Umgebung gerecht zu werden
3. Nächste logische Schritte und Empfehlungen
• Vorschläge zu Datensätzen, Umwandlungen und Regeln
• Automatisches Mapping, automatische Bereinigung und Standardisierung von Quellen zu Zielen
• Automatische Integration neuer Datenquellen
Die Grundlage für das Machine Learning bei der Datenverwaltung Für effektives Machine Learning müssen umfangreiche Datensätze zur Verfügung stehen, die in das System eingespeist werden. Die beste Datenquelle für die Datenverwaltung ist ein unternehmensweiter Datenkatalog. Die meisten Unternehmen haben Tausende von Datenbanken, Dateien, Anwendungen und Analytics-Systemen. Durch Erfassung der Metadaten dieser verschiedenen Daten-Repositories können Unternehmen einen umfangreichen Datenkatalog erstellen. Machine Learning in Kombination mit einem Datenkatalog mit unternehmensweit transparenten Metadaten bilden eine solide Datengrundlage, um die Produktivität der Datenverwaltung enorm zu steigern.
Dabei ist zu beachten, dass dieser Ansatz auch für SaaS-Anwendungen funktioniert, was bei der steigenden Nutzung der Cloud enorm wichtig ist. Aus SaaS-Anwendungen, wie Salesforce und Workday, werden Metadaten erfasst, die dann zum Unternehmenskatalog hinzugefügt werden.
6
Informatica CLAIRE: Der „intelligente Kern“ der Intelligent Data Platform Informatica hat folgende Lösung entwickelt, um die Produktivität der Datenverwaltung mithilfe von Machine Learning zu erhöhen:
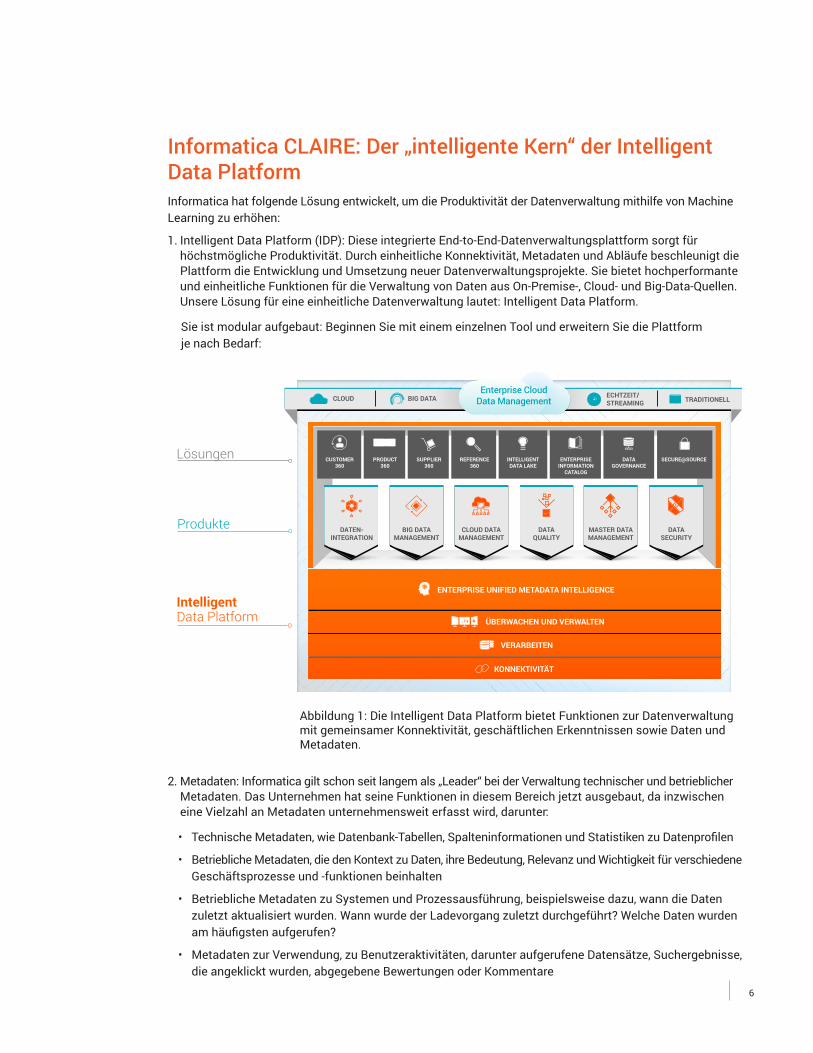
1. Intelligent Data Platform (IDP): Diese integrierte End-to-End-Datenverwaltungsplattform sorgt für höchstmögliche Produktivität. Durch einheitliche Konnektivität, Metadaten und Abläufe beschleunigt die Plattform die Entwicklung und Umsetzung neuer Datenverwaltungsprojekte. Sie bietet hochperformante und einheitliche Funktionen für die Verwaltung von Daten aus On-Premise-, Cloud- und Big-Data-Quellen. Unsere Lösung für eine einheitliche Datenverwaltung lautet: Intelligent Data Platform.
Sie ist modular aufgebaut: Beginnen Sie mit einem einzelnen Tool und erweitern Sie die Plattform je nach Bedarf:
2. Metadaten: Informatica gilt schon seit langem als „Leader“ bei der Verwaltung technischer und betrieblicher Metadaten. Das Unternehmen hat seine Funktionen in diesem Bereich jetzt ausgebaut, da inzwischen eine Vielzahl an Metadaten unternehmensweit erfasst wird, darunter:
• Technische Metadaten, wie Datenbank-Tabellen, Spalteninformationen und Statistiken zu Datenprofilen
• Betriebliche Metadaten, die den Kontext zu Daten, ihre Bedeutung, Relevanz und Wichtigkeit für verschiedene Geschäftsprozesse und -funktionen beinhalten
• Betriebliche Metadaten zu Systemen und Prozessausführung, beispielsweise dazu, wann die Daten zuletzt aktualisiert wurden. Wann wurde der Ladevorgang zuletzt durchgeführt? Welche Daten wurden am häufigsten aufgerufen?
• Metadaten zur Verwendung, zu Benutzeraktivitäten, darunter aufgerufene Datensätze, Suchergebnisse, die angeklickt wurden, abgegebene Bewertungen oder Kommentare
Lösungen
Produkte
IntelligentData Platform
CLOUD BIG DATA ECHTZEIT/STREAMING TRADITIONELL
ENTERPRISE UNIFIED METADATA INTELLIGENCE
ÜBERWACHEN UND VERWALTEN
VERARBEITEN
KONNEKTIVITÄT
DATEN-INTEGRATION
BIG DATA MANAGEMENT
CLOUD DATA MANAGEMENT
DATA QUALITY
MASTER DATA MANAGEMENT
DATA SECURITY
CUSTOMER 360
PRODUCT 360
SUPPLIER 360
REFERENCE 360
INTELLIGENT DATA LAKE
ENTERPRISE INFORMATION
CATALOG
DATA GOVERNANCE
SECURE@SOURCE
Enterprise Cloud Data Management
Abbildung 1: Die Intelligent Data Platform bietet Funktionen zur Datenverwaltung mit gemeinsamer Konnektivität, geschäftlichen Erkenntnissen sowie Daten und Metadaten.

7
Dieses breite Spektrum an Metadaten ist für das Machine Learning unerlässlich. Dank solcher Datensätze können Machine-Learning-Algorithmen „angelernt“ werden und passen sich an, um bessere Ergebnisse zu produzieren.
3. Intelligence: Informatica bietet mit CLAIRE eine Kombination aus Metadaten und künstlicher Intelligenz/Machine Learning.
Die von der Intelligent Data Platform erfassten Metadaten werden CLAIRE zur Verfügung gestellt, so dass die zugrundeliegenden Algorithmen mehr über die Datenlandschaft eines Unternehmens erfahren. Somit ist CLAIRE in der Lage, intelligente Empfehlungen zu erstellen, Entwicklung und Überwachung von Datenverwaltungsprojekten zu automatisieren und sich unternehmensinternen und externen Änderungen anzupassen. CLAIRE bildet die intelligente Grundlage für die Datenverwaltung mit der Intelligent Data Platform.
CLAIRE in der Praxis CLAIRE unterstützt Benutzer bei der Durchführung unterschiedlichster Aufgaben:
• Datenentwickler profitieren davon, dass sich viele Implementierungsaufgaben teilweise oder komplett automatisieren lassen.
• Datenanalysten können erforderliche Daten problemlos finden und vorbereiten.
• Business User können Daten, für die Data Governance und Compliance-Kontrollen vorgeschrieben sind, schneller finden.
• Datenwissenschaftler können Daten schneller verstehen und einschätzen.
• Datenverwalter können Daten unkompliziert grafisch darstellen.
• Experten für die Datensicherheit können die missbräuchliche Verwendung von Daten schneller erkennen, sensible Daten schützen und nachweisen, dass angemessene Sicherheitsvorkehrungen eingehalten werden.
• Administratoren und Betreiber profitieren von vorbeugender Wartung und optimalen Datenverwaltungs-prozessen.
Im Folgenden werden einige Beispielsituationen aufgeführt, in denen durch CLAIRE gewonnene Erkenntnisse heutzutage verwendet werden.
Intelligente DatenähnlichkeitCLAIRE verwendet auf Machine Learning basierende Methoden, wie Clustering, um unter Tausenden von Datenbanken und -sätzen ähnliche Daten zu finden. Die intelligente Datenähnlichkeit ist eine Funktion, die in vielerlei Hinsicht nützlich ist: zur Identifizierung von Daten, Erkennung von Duplikaten, Zusammenfassung verschiedener Datenfelder in Geschäftseinheiten, Erstellung von Tags für Datensätze und die Empfehlung von Datensätzen für Benutzer.
Bei der Datenähnlichkeit wird ermittelt, bis zu welchem Grad Daten in zwei Spalten übereinstimmen. Der Versuch, sämtliche Datensätze mit zwei Spalten in der Unternehmensumgebung miteinander zu vergleichen (beispielsweise über 100 Mio. Spalten hinweg) wäre gar nicht praktikabel. Bei der Datenähnlichkeit kommen auf Machine Learning basierende Methoden zum Einsatz, so dass ähnliche Spalten in einem Cluster zusammengefasst und mögliche Übereinstimmungen identifiziert werden.
Der Prozess umfasst mehrere Phasen. Zuerst einmal werden Spalten auf der Basis von Spaltenmerkmalen als Cluster zusammengefasst. Sich überschneidende Daten werden in jedem Cluster verarbeitet, um individuelle Werte zu ermitteln. Zu guter Letzt werden dann die vielversprechendsten Paare für die Überprüfung auf Datenähnlichkeit verwendet, unter Zuhilfenahme der Koeffizienten von Bray-Curtis und Jaccard.

8
Intelligent Domain Discovery mithilfe von TagsCLAIRE kann Datenfelder klassifizieren, indem jeder Spalte ein semantisches Label zugewiesen wird. Diese semantischen Label werden als Datendomänen bezeichnet.
Normalerweise werden semantische Label nach der Auswertung von Regeln angewendet, die auf regulären Ausdrücken, Referenztabellen oder einer anderen komplexen manuellen Programmierlogik beruhen. Doch die Definition und Pflege Tausender solcher Regeln ist sehr mühselig.
CLAIRE verwendet stattdessen Tags, um die Identifizierung und Kennzeichnung von Datenfeldern enorm zu vereinfachen. Für Spalten, die noch nicht klassifiziert worden sind, gibt der Benutzer einfache Tags an, die Aufschluss über den Spalteninhalt geben (z. B. „Forderungszahlungsdatum“). Das System lernt durch Assoziationen und versieht ähnliche Spalten mit demselben Tag. Die „Gesichtserkennung“ bei Daten entspricht dem Tagging von Menschen in Fotos auf Facebook, was dazu führt, dass dieselben Menschen in Millionen anderer Fotos getaggt werden.
Abbildung 3: Automatische Klassifizierung von Daten.
Auto infer domains for columns based on data patterns
Auto infer domains for columns based on data patterns
Relationships link all data assets associated with the domain
Relationships link all data assets associated with the domain
Firmen-nameE-MailVornamePost-
leitzahlTelefon-nummer
9
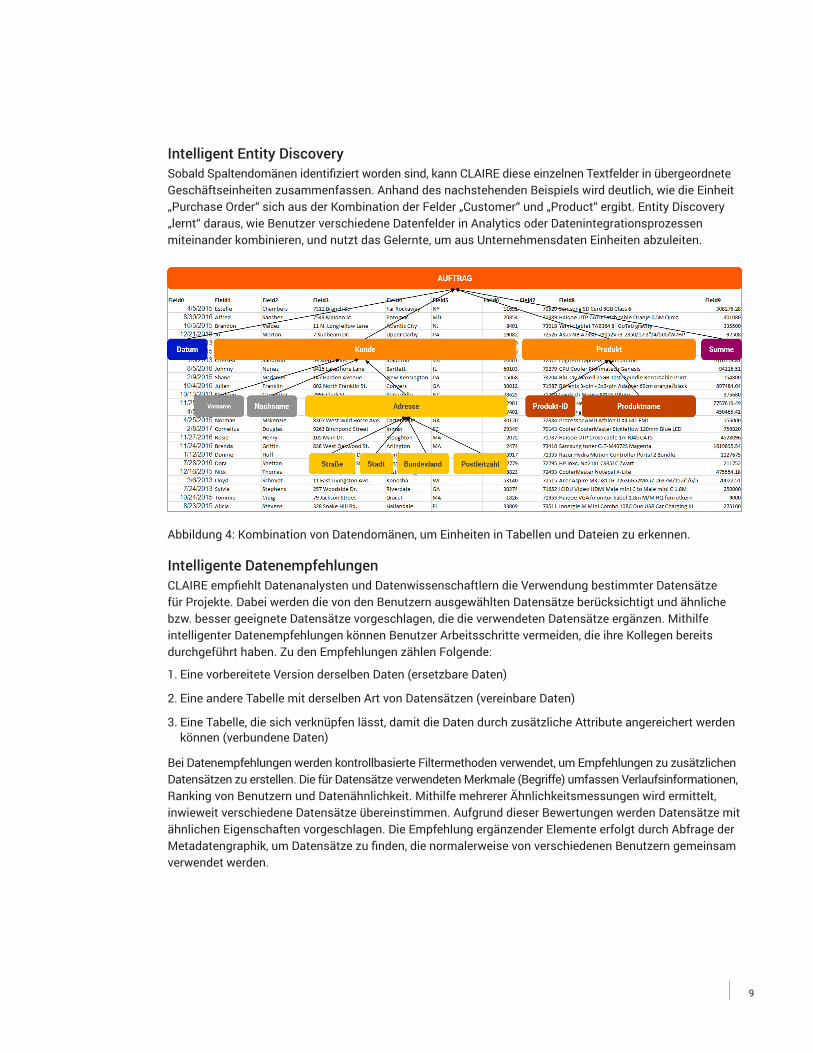
Intelligent Entity DiscoverySobald Spaltendomänen identifiziert worden sind, kann CLAIRE diese einzelnen Textfelder in übergeordnete Geschäftseinheiten zusammenfassen. Anhand des nachstehenden Beispiels wird deutlich, wie die Einheit „Purchase Order“ sich aus der Kombination der Felder „Customer“ und „Product“ ergibt. Entity Discovery „lernt“ daraus, wie Benutzer verschiedene Datenfelder in Analytics oder Datenintegrationsprozessen miteinander kombinieren, und nutzt das Gelernte, um aus Unternehmensdaten Einheiten abzuleiten.
Abbildung 4: Kombination von Datendomänen, um Einheiten in Tabellen und Dateien zu erkennen.
Intelligente Datenempfehlungen CLAIRE empfiehlt Datenanalysten und Datenwissenschaftlern die Verwendung bestimmter Datensätze für Projekte. Dabei werden die von den Benutzern ausgewählten Datensätze berücksichtigt und ähnliche bzw. besser geeignete Datensätze vorgeschlagen, die die verwendeten Datensätze ergänzen. Mithilfe intelligenter Datenempfehlungen können Benutzer Arbeitsschritte vermeiden, die ihre Kollegen bereits durchgeführt haben. Zu den Empfehlungen zählen Folgende:
1. Eine vorbereitete Version derselben Daten (ersetzbare Daten)
2. Eine andere Tabelle mit derselben Art von Datensätzen (vereinbare Daten)
3. Eine Tabelle, die sich verknüpfen lässt, damit die Daten durch zusätzliche Attribute angereichert werden können (verbundene Daten)
Bei Datenempfehlungen werden kontrollbasierte Filtermethoden verwendet, um Empfehlungen zu zusätz lichen Datensätzen zu erstellen. Die für Datensätze verwendeten Merkmale (Begriffe) umfassen Verlaufsinformationen, Ranking von Benutzern und Datenähnlichkeit. Mithilfe mehrerer Ähnlichkeitsmessungen wird ermittelt, inwieweit verschiedene Datensätze übereinstimmen. Aufgrund dieser Bewertungen werden Datensätze mit ähnlichen Eigenschaften vorgeschlagen. Die Empfehlung ergänzender Elemente erfolgt durch Abfrage der Metadatengraphik, um Datensätze zu finden, die normalerweise von verschiedenen Benutzern gemeinsam verwendet werden.

10
Intelligent Structure Discovery CLAIRE kann in ungeordneten Geräte- und Protokolldateien Strukturen erkennen, so dass sie verständlicher werden und einfacher verwendet werden können. Dank des inhaltsbasierten Ansatzes zum Parsing von Dateien passt sich CLAIRE häufigen Dateiänderungen an, ohne dass sich das auf die Dateiverarbeitung auswirkt.
Intelligent Structure Discovery basiert auf der Verwendung eines genetischen Algorithmus, um die Erkennung von Mustern in Dateien zu automatisieren. Bei diesem Ansatz wird das Konzept „Evolution“ verwendet, um die Ergebnisse zu verbessern. Jede Lösung umfasst verschiedene Eigenschaften, die sich ändern lassen, um zu testen, ob sie eine besser geeignete Lösung hervorbringen. Dabei wird die Struktur der Datei ohne Benutzereingriff definiert und ist nicht auf bestimmte branchenübliche Formate beschränkt. Die anfänglichen Strukturen der Datei lassen sich durch so genanntes Delimiter-based Parsing ableiten. Diese Strukturen werden dann anhand mehrerer Faktoren bewertet, beispielsweise Eingabe-Umfang und Anzahl abgeleiteter Domänen. Die Strukturen mit der besten Bewertung durchlaufen eine „Änderungphase“, bei der sie auf verschiedene Weise geändert werden. Dabei werden beispielsweise untergeordnete Strukturen kombiniert, um zu erfahren, ob sich die Bewertung dadurch verbessert. Der Prozess wird abgebrochen, wenn sich herausstellt, dass die Struktur für die Daten hinreichend geeignet ist.
Abbildung 5: Das intelligente Suchen nach einer Struktur in unstrukturierten Datendateien

11
Intelligent Anomaly DetectionCLAIRE nutzt statistische und Machine-Learning-Ansätze zur Erkennung von Datenanomalien und -ausreißern. Mithilfe der UBA-Funktion (User Behaviour Analytics) werden Verhaltensmuster von Benutzern erkannt, die riskant sein könnten und auf eine missbräuchliche Verwendung von Daten hinweisen können. Dank UBA können Identitätsdiebstahl, der Diebstahl von Anmeldedaten und Privilege-Escalation-Angriffe erkannt werden.
UBA nutzt unüberwachtes Machine Learning, um verschiedene Benutzeraktivitäten zu analysieren, u. a. die Anzahl an Datenspeichern, auf die der Benutzer zugreift, die Anzahl an Zugriffen sowie die Anzahl der davon betroffenen Datensätzen in verschiedenen Systemen. Der Umfang dieses Modells wird mittels der Hauptkomponentenanalyse eingeschränkt. Bei der unüberwachten hierarchischen Clusteranalyse wird mittels der BIRCH-Methode ermittelt, ob das Verhalten von Benutzern für einen bestimmten Zeitraum von der Norm abweicht. Um das abweichende Verhalten zu bewerten, werden auf Entfernung und Dichte basierende Ausreißerkennungsmethoden verwendet sowie statistische Grubbs-Tests, um nachzuweisen, dass es sich bei den Objekten, die durch die ersten beiden Methoden ermittelt wurden, tatsächlich um Ausreißer des Clustersystems handelt.
Im Folgenden werden einige Funktionen von CLAIRE vorgestellt, die in Kürze eingeführt werden:
Automatische Integration: Automatische Integration neuer Daten in die Prozesse zur Datenintegration. Identifizierung von Daten, Suche nach Integrationsmustern zur Verarbeitung ähnlicher Daten, automatische Umwandlung und Verschiebung von Daten mit Kenntnissen aus Millionen von vorhandenen Mappings und Benutzeraktionen.
Unterstützung bei der Entwicklung: Erstellung von Empfehlungen für Benutzer und Vorschläge für nächste logische Schritte während des Entwicklungsprozesses, darunter:
• Automatische Fertigstellung von Umwandlungen
• Empfehlungen für Templates
• Maskierungsvorschläge für sensible Daten
• Vorschläge zur Bereinigung und Standardisierung bei der Sicherstellung der Datenqualität
• Automatische Performance-Optimierung
Automatisches Mapping: Unternehmensweite Erkennung von Stammdateneinheiten und automatische Verknüpfung mit dem Stammdatenmodell unter Anwendung der erforderlichen Regeln für Umwandlungen und Sicherstellung der Datenqualität
Selbstheilung: Sinnvoller Umgang mit externen Systemproblemen, wie geringer Speicherplatz oder Rechenleistung. Beispielsweise durch Bereitstellung zusätzlicher Rechenleistung („Cloud Bursting“), um Spitzenaufkommen bei Datenmengen zu bewältigen.
Automatische Anpassung: Aktuelle Datenmengen und verfügbare Systemressourcen sagen Zeitpläne aufgrund historischer Informationen voraus bzw. passen sie an und nutzen Ressourcen optimal, um Performance-Kriterien zu erfüllen.
Automatischer Schutz: Automatische Erkennung sensibler Daten, die maskiert werden, bevor sie den sicheren Bereich verlassen.

Informatica GmbH, Ingersheimer Str. 10, 70499 Stuttgart Tel.: +49 (0) 711 139 84-0 Fax: +49 (0) 711 139 84-600 Tel: +1 800 653 3871 informatica.com linkedin.com/company/informatica twitter.com/Informatica© 2017 Informatica LLC. Alle Rechte vorbehalten. Informatica, das Logo von Informatica und CLAIRE™ sind Marken oder eingetragene Marken von Informatica LLC in den USA und in anderen Ländern. Die aktuelle Liste mit Marken von Informatica ist hier zu finden: https://www.informatica.com/trademarks.html. Alle weiterenFirmen- und Produktbezeichnungen können Handelsnamen oder Marken ihrer jeweiligen Eigentümer sein.
IN09_0517_3328
Schlussfolgerungen Datenorientierte Geschäftsstrategien beruhen heutzutage auf einer soliden Datengrundlage. Um sich auf dem wettbewerbsintensiven Markt durchzusetzen, benötigen Unternehmen umfassende Kenntnisse auf dem Gebiet der Datenverwaltung, um das Potenzial von Daten optimal nutzen zu können.
Doch mithilfe traditioneller Ansätze können die Herausforderungen bei der Datenverwaltung heutzutage nicht mehr gemeistert werden – ganz abgesehen von den Herausforderungen, die die Zukunft bringt. Eine Möglichkeit, um sicherzustellen, dass Ihre Daten bestmöglich genutzt werden, um Innovation zu fördern, besteht in der Verwendung einer End-to-End-Datenverwaltungsplattform, die Daten, Metadaten sowie Machine Learning/künstliche Intelligenz nutzt, um die Produktivität aller Benutzer zu erhöhen: durch die Bereitstellung von Self-Service-Funktionen für technische, betriebliche und Business User.
Kontaktieren Sie uns, um zu erfahren, wie Sie CLAIRE und die Intelligent Data Platform von Informatica nutzen können, um das Potenzial Ihrer Daten voll auszuschöpfen.
Informationen zu InformaticaDie digitale Transformation verändert unsere Welt. Als „Leader“ im Bereich Enterprise Cloud Data Management unterstützen wir Sie dabei, diese Trans-formation sinnvoll zu meistern. Wir ermöglichen es Ihnen, agiler zu werden, neue Wachstumsmöglichkeiten wahrzunehmen und die Innovation voranzutreiben. Wir laden Sie ein, das gesamte Angebot von Informatica zu erkunden – und das Potenzial der Daten zu nutzen und so Ihre nächste intelligente Innovation auf den Weg zu bringen. Nicht nur einmal, sondern immer wieder.