
Kurs 01212 Lineare Optimierung - fernuni-hagen.de · Das Werk ist urheberrechtlich gesch utzt. Die...
52
Lineare Optimierung Prof. Dr. Winfried Hochstättler Kurs 01212 LESEPROBE
Transcript of Kurs 01212 Lineare Optimierung - fernuni-hagen.de · Das Werk ist urheberrechtlich gesch utzt. Die...

Lineare Optimierung
Prof. Dr. Winfried Hochstättler
Kurs 01212
LESEPROBE

Das Werk ist urheberrechtlich geschutzt. Die dadurch begrundeten Rechte, insbesondere das Recht der Vervielfaltigung
und Verbreitung sowie der Ubersetzung und des Nachdrucks bleiben, auch bei nur auszugsweiser Verwertung, vorbe-
halten. Kein Teil des Werkes darf in irgendeiner Form (Druck, Fotokopie, Mikrofilm oder ein anderes Verfahren) ohne
schriftliche Genehmigung der FernUniversitat reproduziert oder unter Verwendung elektronischer Systeme verarbeitet,
vervielfaltigt oder verbreitet werden.

Inhaltsverzeichnis
Einfuhrung vii
Notation xi
Index xiv
1 Lineare Optimierung - Aufgabenstellung und Modellbildung 11.1 Erste Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Ein Diatproblem . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 Gier ist nicht immer gut . . . . . . . . . . . . . . . . . . . 41.1.3 Ein Mischungsproblem . . . . . . . . . . . . . . . . . . . . 7
1.2 Die allgemeine lineare Optimierungsaufgabe . . . . . . . . . . . . 101.2.1 Techniken zur aquivalenten Umformung . . . . . . . . . . . 12
1.3 Losen lassen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.3.1 Das Diatproblem . . . . . . . . . . . . . . . . . . . . . . . 181.3.2 Von Nudeln zu Kartoffeln . . . . . . . . . . . . . . . . . . 21
1.4 Die graphische Methode . . . . . . . . . . . . . . . . . . . . . . . 231.5 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 27
2 Hullen und Kombinationen 352.1 Affine Unterraume des Kn . . . . . . . . . . . . . . . . . . . . . . 352.2 Konvexe Kegel im Kn . . . . . . . . . . . . . . . . . . . . . . . . 382.3 Konvexe Mengen im Kn . . . . . . . . . . . . . . . . . . . . . . . 422.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . 462.5 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 49
3 Dualitat 533.1 Eine andere Sicht auf das Diatproblem . . . . . . . . . . . . . . . . 543.2 Farkas’ Lemma . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
iii

iv Inhaltsverzeichnis
3.3 Der Dualitatssatz der Linearen Programmierung . . . . . . . . . . . 633.4 Dualisieren von Linearen Programmen . . . . . . . . . . . . . . . . 683.5 Der Satz vom komplementaren Schlupf . . . . . . . . . . . . . . . 693.6 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 71
4 Polyeder 774.1 Zweiklassengesellschaft? . . . . . . . . . . . . . . . . . . . . . . . 774.2 Seitenflachen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 784.3 Facetten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.4 Ecken und Kanten . . . . . . . . . . . . . . . . . . . . . . . . . . . 844.5 Zum Beispiel das Permutahedron . . . . . . . . . . . . . . . . . . . 874.6 Der Seitenflachenverband . . . . . . . . . . . . . . . . . . . . . . . 924.7 Kegel und die ”dichte Version“ von Farkas’ Lemma . . . . . . . . . 944.8 Der Satz von Weyl . . . . . . . . . . . . . . . . . . . . . . . . . . 984.9 Der Polarisierungstrick fur Kegel und der Satz von Minkowski . . . 994.10 Polaritat und verbandstheoretische Dualitat . . . . . . . . . . . . . 1014.11 Der Fundamentalsatz der Polyedertheorie . . . . . . . . . . . . . . 1054.12 Polaritat von Polytopen . . . . . . . . . . . . . . . . . . . . . . . . 1114.13 Fourier-Motzkin Elimination . . . . . . . . . . . . . . . . . . . . . 1134.14 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 117
5 Das Simplexverfahren 1275.1 Das 1-Skelett eines Polytops . . . . . . . . . . . . . . . . . . . . . 1275.2 Die geometrische Idee des Simplexalgorithmus . . . . . . . . . . . 1315.3 Wiederholung Gauß-Jordan-Algorithmus . . . . . . . . . . . . . . 1415.4 Tableauform des Simplexalgorithmus . . . . . . . . . . . . . . . . 1425.5 Pivotwahl, Entartung, Endlichkeit . . . . . . . . . . . . . . . . . . 1455.6 Bemerkungen zur Numerik . . . . . . . . . . . . . . . . . . . . . . 1515.7 Die Zweiphasenmethode . . . . . . . . . . . . . . . . . . . . . . . 1525.8 Die Big-M -Methode . . . . . . . . . . . . . . . . . . . . . . . . . 1575.9 Der revidierte Simplexalgorithmus . . . . . . . . . . . . . . . . . . 1625.10 Postoptimierung und Sensitivitatsanalyse . . . . . . . . . . . . . . 1655.11 Duale Simplexschritte . . . . . . . . . . . . . . . . . . . . . . . . . 1675.12 Obere Schranken . . . . . . . . . . . . . . . . . . . . . . . . . . . 1695.13 The Name of the Game . . . . . . . . . . . . . . . . . . . . . . . . 1735.14 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 175

Inhaltsverzeichnis v
6 Zur Komplexitat des Simplexalgorithmus 1896.1 Streng polynomiale Algorithmen und ein fraktionaler Rucksack . . 1896.2 Personaleinsatzplanung . . . . . . . . . . . . . . . . . . . . . . . . 1936.3 Klee-Minty Cubes . . . . . . . . . . . . . . . . . . . . . . . . . . . 2016.4 Die mittlere Laufzeit des Simplexalgorithmus . . . . . . . . . . . . 2096.5 Dantzig-Wolfe Dekomposition . . . . . . . . . . . . . . . . . . . . 2176.6 Anhang: Die Landau-Symbole . . . . . . . . . . . . . . . . . . . . 2246.7 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 229
7 Die Ellipsoidmethode 2357.1 Reduktionen bei algorithmischen Problemen . . . . . . . . . . . . . 2357.2 Zur Kodierungslange der Losungen von Linearen Programmen . . . 2407.3 Zulassigkeitstest und Optimierung . . . . . . . . . . . . . . . . . . 246
7.3.1 Ausnutzung der Dualitat . . . . . . . . . . . . . . . . . . . 2477.3.2 Binare Suche . . . . . . . . . . . . . . . . . . . . . . . . . 248
7.4 Die geometrische Idee der Ellipsoidmethode . . . . . . . . . . . . . 2487.5 Die Ellipsoidmethode in der Linearen Programmierung . . . . . . . 2537.6 Wie lost man das Problem mit der exakten Arithmetik? . . . . . . . 2597.7 Optimieren und Separieren . . . . . . . . . . . . . . . . . . . . . . 2607.8 Ein mathematischer Sputnik . . . . . . . . . . . . . . . . . . . . . 2637.9 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 265
8 Innere-Punkt-Methoden 2718.1 Das Karmarkar-Verfahren . . . . . . . . . . . . . . . . . . . . . . . 272
8.1.1 Die projektive Transformation des Einheitssimplex . . . . . 2738.1.2 Die geometrische Idee des Karmarkar-Verfahrens . . . . . . 2758.1.3 Zur Korrektheit und Laufzeitanalyse . . . . . . . . . . . . . 2768.1.4 Die Karmarkar-Normalform . . . . . . . . . . . . . . . . . 284
8.2 Ein pfadverfolgender Algorithmus . . . . . . . . . . . . . . . . . . 2858.2.1 Geometrische Ideen . . . . . . . . . . . . . . . . . . . . . 2858.2.2 Einige Vorbereitungen . . . . . . . . . . . . . . . . . . . . 2878.2.3 Das schiefsymmetrisch selbstduale Modell . . . . . . . . . 2898.2.4 Der zentrale Pfad und die optimale Partition . . . . . . . . . 2918.2.5 Finden der optimalen Partition . . . . . . . . . . . . . . . . 2988.2.6 Finden einer exakten Losung . . . . . . . . . . . . . . . . . 3018.2.7 Ein generisches Innere-Punkt-Verfahren . . . . . . . . . . . 303
8.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308

vi Inhaltsverzeichnis
8.4 Losungsvorschlage zu den Ubungen . . . . . . . . . . . . . . . . . 309
Literaturverzeichnis 319

Kapitel 6
Zur Komplexitat desSimplexalgorithmus
Der Simplexalgorithmus hat sich seit seiner Entdeckung als in der Praxis effizientesVerfahren etabliert. Aus Sicht der Theorie hat man dafur keine wirklich befriedi-gende Erklarung. Wir werden in diesem Kapitel einen ersten, einfacheren Komple-xitatsbegriff kennen lernen und den Simplexalgorithmus aus dieser Warte betrach-ten.
6.1 Streng polynomiale Algorithmen und ein fraktio-naler Rucksack
Wenn wir die Gute eines Algorithmus beurteilen wollen, so werden wir auch einemguten Verfahren zugestehen, dass es an großeren Aufgaben langer rechnet. Dafurmussen wir aber zunachst die Große einer Aufgabe definieren. Außerdem solltenwir zumindest eine ungefahre Definition eines Algorithmus geben.
Unter einem ”Algorithmus fur ein Problem“ (oder fur eine Problemklasse) ver-stehen wir eine Folge von wohldefinierten Regeln bzw. Befehlen, die in einer end-lichen Anzahl von Elementarschritten aus jeder spezifischen Eingabe, einer Instanzdes Problems, eine spezifische Ausgabe erzeugt. Wir forden also:
i) Ein Algorithmus muss sich in einem Text endlicher Lange beschreiben lassen.
ii) Die Abfolge der Schritte ist in jeder Berechnung eindeutig.
iii) Jeder Elementarschritt lasst sich mechanisch und effizient ausfuhren.
189

190 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
iv) Der Algorithmus stoppt bei jeder Eingabe nach endlich vielen Schritten.
Ein wichtiges Qualitatskriterium eines Algorithmus ist die jeweilige Anzahl derbis zur Terminierung des Algorithmus auszufuhrenden Elementarschritte. Was einElementarschritt ist, hangt vom jeweiligen Maschinenmodell ab. Wir wollen hiernicht auf Details eingehen, sondern auf einschlagige Kurse und Bucher der Kom-plexitatstheorie, etwa [8, 17, 2] verweisen. Sie konnen sich unter einem Elemen-tarschritt etwa einen Maschinenbefehl vorstellen. Wir unterscheiden hier zwischenMaschinen, die alle elementaren Rechenoperationen in einem Schritt durchfuhrenkonnen oder – realistischer – solchen, bei denen die Anzahl der Elementarschritte,z.B. fur die Multiplikation zweier beliebig großer ganzer Zahlen, auch von derenGroße abhangig ist. Die Anzahl der ausgefuhrten Elementarschritte wird in beidenFallen als Laufzeit des Algorithmus bezeichnet.
Werden die Instanzen großer, so wird man dem Algorithmus auch eine langereLaufzeit zugestehen. Deswegen betrachten wir die Laufzeit eines Algorithmus inAbhangigkeit der Lange der Eingabedaten. Dabei gehen wir davon aus, dass dieDaten in einem sinnvollen Format gespeichert sind. Im Falle einer ganzen Zahl zwahlt man als Kodierungslange ublicherweise 1+dlog2(1+ |z|)e . Damit kann mandas Vorzeichen und den Betrag in der Binardarstellung von z speichern.
6.1.1 Beispiel. Wenn wir etwa die Zahl −314 binar kodieren wollen und vereinba-ren, dass das erste Zeichen als Vorzeichen interpretiert wird, wobei 1 fur negativesund 0 fur ein positives Vorzeichen steht, so wird −314 =−(256+32+16+8+2)durch die Zeichenkette 1100111010 kodiert, diese besteht aus
1+ dlog2(315)e= 1+ d8.2992e= 10
Zeichen.
Wir bezeichnen mit 〈w〉 die Kodierungslange einer Instanz w . Diese Definiti-on der Kodierungslange wird uns in den folgenden Kapiteln des Kurses begleiten,wenn wir Verfahren kennen lernen werden, die lineare Programme beweisbar effizi-ent losen. In diesem Kapitel werden wir aber den Simplexalgorithmus im Hinblickauf die Anzahl I(w) der Daten in einer Eingabe untersuchen, wobei wir die Langeder Kodierung einzelner Zahlen ignorieren.
6.1.2 Aufgabe. Sei maxc>x | Ax = b,x≥ 0 eine Instanz w des linearen Optimie-rungsproblems. Bestimmen Sie grob 〈w〉 und I(w) . Nehmen Sie der Einfachheithalber an, dass alle Eingangsdaten ganzzahlig sind.

6.1. Streng polynomiale Algorithmen und ein fraktionaler Rucksack 191
Losung siehe Losung 6.7.1.Ist M ein Algorithmus und w die Eingabe, so bezeichnen wir mit timeM(w)
die Zahl der Elementarschritte, die M bei Eingabe von w bis zur Terminierungbenotigt.
Betrachten wir Maschinenmodelle, bei denen die Multiplikation zweier ganzerZahlen nicht in einem Elementarschritt moglich ist, so bezeichnen wir mit
tM(n) = max timeM(w) | 〈w〉= n
die Komplexitat oder auch Worst-Case-Komplexitat des Algorithmus.Analog definieren wir fur Maschinen, bei denen elementare Rechenoperationen
Elementarschritte sind
tsM(n) = max timeM(w) | I(w) = n.
Die genauen Funktionswerte tM(n) bzw. tsM(n) fur jedes n zu bestimmen,
wird in den seltensten Fallen moglich sein. Die exakten Zahlen sind auch nicht sowesentlich. Interessanter ist das asymptotische Verhalten. Dafur haben Sie eventuellim informatischen Nebenfach die ”Big-Oh“-Notation kennengelernt. Sollte diesnicht der Fall sein, konnen Sie sie im Anhang dieser Einheit in Abschnitt 6.6nachschlagen.
Als sinnvolles Maß fur die Effizienz von Algorithmen haben sich polynomialeSchranken fur die Laufzeiten erwiesen. Ist tM(n) = O(nk) fur ein k ∈ N , so ist dieLaufzeit durch ein Polynom in der Kodierungslange beschrankt. Man spricht vonPolynomialzeit, und der Algorithmus heißt polynomial.
Ist tsM(n) = O(nk) fur ein k ∈ N , so sagen wir, der Algorithmus ist streng
polynomial.
6.1.3 Aufgabe. Zeigen Sie: Kann man die elementaren Rechenoperationen auf ei-nem Maschinenmodell in Polynomialzeit ausfuhren und bleibt die Kodierungslangealler Zahlen bei Zwischenrechnungen polynomial beschrankt, so liefert ein strengpolynomialer Algorithmus einen polynomialen Algorithmus.
Losung siehe Losung 6.7.2.Als Beispiel betrachten wir das fraktionale Rucksackproblem:
6.1.4 Beispiel. Seien c1, . . .cn, a1, . . . ,an, b ∈ R+ . Wir betrachten das lineare Pro-gramm
max
n
∑i=1
cixi |n
∑i=1
aixi ≤ b,0≤ xi ≤ 1
.

192 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Verlangt man von den Variablen, dass sie nur die Werte 0 und 1 annehmen durfen,so haben wir hier das klassische RUCKSACK PROBLEM (engl. KNAPSACK PRO-BLEM). Dabei interpretiert man b als die Kapazitat eines Rucksacks, ci als denNutzen des Gegenstandes i und ai als das Volumen oder Gewicht dieses Gegen-standes. Man mochte nun so Gegenstande in den Rucksack packen, dass die Kapa-zitatsrestriktion beachtet wird, und der Nutzen maximiert wird.
Ausgehend von einem leeren Rucksack losen wir das Problem mit der upperbound technique aus Abschnitt 5.12. Als ”Pivotregel“ wollen wir dabei vereinbaren,dass wir als Pivotspalte die Nichtbasisvariable nehmen, bei der der Quotient ci
aiam
großten ist, also mit dem großten Nutzen pro Kapazitatseinheit. Wir nehmen imFolgenden an, dass die Indizes so geordnet sind, dass
ci
ai≥ ci+1
ai+1fur 1≤ i≤ n−1.
Wenden wir mit dieser Regel die upper bound technique an, so werden, so lange
∑i0−1i=1 aixi < b ist, nacheinander die Variablen x1, . . . ,xi0−1 von der unteren auf die
obere Schranke gesetzt. Die Basis und die reduzierten Kosten andern sich nicht,bleiben also auf c . Sobald ∑
i0i=1 aixi ≥ b ist, nehmen wir i0 in die Basis auf. Die
reduzierten Kosten andern sich uberall zu
ci−aici0ai0
.
Auf Grund der Annahme an die Sortierung der Indizes ist dieser Ausdruck nun nichtnegativ fur alle Indizes i < i0 . Bei diesen Indizes nehmen die Nichtbasisvariablenden Wert der oberen Schranke an. Ferner ist der Wert nicht positiv fur alle Indizesi > i0 , bei denen die Variablen auf Null stehen. Also ist das Optimalitatskriteriumder upper bound technique erfullt.
Da die Auswahl jedes einzelnen Pivotelements naiv in O(n) – oder durch Ord-nen die gesamte Pivotwahl mit einem Gesamtaufwand von O(n logn) erledigt wer-den kann1, und die Kosten eines Pivotschritts O(nm) betragen, hat dieses Vorgeheneine Laufzeit
tsM(nm) = O(mn2 +n logn),
denn nach Aufgabe 6.1.2 ist die Datenmenge I(w) eines linearen Programms geradeI(w) = O(nm) . Also ist der Algorithmus streng polynomial.
1Fur Sortieralgorithmen und deren Komplexitat verweisen wir auf [13]

6.2. Personaleinsatzplanung 193
Bleibt hingegen die Ganzzahligkeitsforderung bestehen, so ist das ProblemN P -vollstandig. Somit ist es vermutlich nicht in Polynomialzeit losbar. Wir wer-den im nachsten Kapitel etwas detaillierter uber den Begriff der N P -Vollstandig-keit sprechen. Fur eine exakte Exposition mussen wir aber wieder auf [8, 17, 2]verweisen.
6.2 Personaleinsatzplanung
Wir wollen hier noch ein weiteres Problem der kombinatorischen Optimierung, dasgewichtete bipartite Matching, vorstellen, zu dem man einen streng polynomialenAlgorithmus kennt, der als Simplexpivotalgorithmus aufgefasst werden kann. Furdas allgemeine lineare Optimierungsproblem kennt man einen solchen Algorithmusbis heute, August 2016, noch nicht.
6.2.1 Beispiel. Sie sind in der Personaleinsatzplanung eines Beratungsunterneh-mens tatig. Da ihre Berater immer zum Kunden geschickt werden, haben sie keineeigenen Buros, sondern fahren von Ihrer eigenen Wohnung zum Kunden. Sie habenn Berater, die Sie bei n Kunden einsetzen wollen, je ein Berater bei einem Kunden.Beim Einsatz von Berater i beim Kunden j entstehen Reisekosten der Hohe ci j≥ 0.Ziel ist es, die Berater so einzusetzen, dass die Reisekosten minimiert werden.
Wir modellieren dies als lineares Programm. Die Variable xi j soll angeben, obBerater i beim Kunden j eingesetzt wird. Dass Berater i genau einmal eingesetztwird, ergibt die Gleichung
n
∑j=1
xi j = 1.
Dass Kunde j nur einen Berater erhalt, ergibt
n
∑i=1
xi j = 1.
Die Variablen xi j sollen 0 oder 1 sein. In der linearen Optimierung konnen wir nurfordern, dass 0 ≤ xi j ≤ 1. In diesem Falle reicht das aber, wie wir gleich zeigenwerden. Zunachst einmal geben wir noch als Zielfunktion
minn
∑i=1
n
∑j=1
ci jxi j.
an.

194 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
6.2.2 Definition. Eine Matrix A∈Km×n heißt total unimodular, wenn alle Unterde-terminanten (Determinanten quadratischer Untermatrizen) einen Wert in 0,1,−1haben.
6.2.3 Proposition. Sei A total unimodular und b ∈ Zm . Ist x∗ eine Ecke von
P = x ∈Kn | Ax≤ b,
so ist x∗ ∈ Zn ganzzahlig.
Beweis. Da x∗ Ecke ist, ist nach Satz 4.4.2 rg(Aeq(x∗).) = n . Wir konnen alsoI ⊆ eq(x∗) so wahlen, dass AI. eine regulare Matrix ist und x∗ = A−1
I. bI . DerVektor x∗ ist somit Losung des linearen Gleichungssystems AI.x∗ = bI . Nach derCramerschen Regel erhalten wir fur i = 1, . . . ,n
x∗i =det(Ai)
det(AI.),
wobei die Matrix Ai aus der Matrix AI. entsteht, indem die i-te Spalte durch bersetzt wird. Da alle Eintrage einer Matrix selber (1×1)-Unterdeterminanten sind,hat AI. nur Eintrage 0, 1 und −1. Nach Voraussetzung ist b ∈ Zm und damit sindauch alle Ai ganzzahlige Matrizen. Die Determinante einer ganzzahligen Matrix istaber auch ganzzahlig. Dies liest man etwa sofort an der Leibnizformel ab. Also istdet(Ai) ∈ Z . Nach Voraussetzung ist A unimodular. Da AI. regular ist, schließenwir det(AI.) ∈ 1,−1 . Also ist x∗ ∈ Zn . 2
Um zu zeigen, dass die Matrix unseres Problems total unimodular ist, zeigenwir allgemeiner:
6.2.4 Proposition. Sei A ∈Km×n eine total unimodulare Matrix. Dann gilt:
i) Jede Matrix, die man erhalt, wenn man Zeilen oder Spalten von A mit −1multipliziert, ist total unimodular.
ii) Auch die Matrix(A
In
)ist total unimodular.
iii) Sei B ∈ Km×n eine Matrix, die in jeder Spalte hochstens zwei Nichtnull-eintrage hat. Diese Nichtnulleintrage von B seien 1 oder −1 . Ferner habe Bin keiner Spalte zwei gleiche Nichtnulleintrage. Dann ist B total unimodular.
Beweis.
i) Dies folgt sofort aus der Multilinearitat der Determinante.

6.2. Personaleinsatzplanung 195
ii) Sei A eine quadratische (k× k )-Untermatrix von(A
In
). Wir zeigen die Be-
hauptung per Induktion uber k . Da A und In Matrizen mit Eintragen aus0,1,−1 sind, ist fur k = 1 die Behauptung richtig. Sei also k > 1. Ist Aquadratische Untermatrix von A , so gilt die Behauptung, da A total unimo-dular ist. Andernfalls gibt es eine Zeile, die hochstens einen Nichtnulleintraghat und dieser ist dann gleich 1. Ist die Zeile Null, so gilt dies offensichtlichauch fur die Determinante. Andernfalls sei Ai j = 1 der einzige Nichtnullein-trag dieser Zeile. Dann ist
det(A) = (−1)i+ j det(Ai j),
wobei Ai j die ((k−1)× (k−1))-Untermatrix von A ist, die durch Streichender i-ten Zeile und j -ten Spalte entsteht. Die Behauptung folgt dann aus derInduktionsvoraussetzung.
iii) Auch hier fuhren wir Induktion uber die Große k der quadratischen Unterma-trizen und zeigen, dass deren Determinanten jeweils 0, 1 oder −1 sind. DieMatrix B hat nur Eintrage 0, 1 und −1. Damit sind alle (1×1)-Unterdeter-minanten von diesen Werten und die Induktion ist verankert. Sei also A eine(k× k)-Untermatrix. Wir unterscheiden drei Falle:
(a) Gibt es eine Spalte, in der nur Nullen stehen, so ist det(A) = 0.
(b) Gibt es keine Nullspalte, aber eine Spalte mit genau einem Nichtnullein-trag etwa Ai j , so entwickeln wir nach dieser Spalte und erhalten
det(A) = (−1)i+ j−1Ai j det(Ai j),
Da Ai j auch eine Untermatrix von B ist, hat sie nach Induktionsvoraus-setzung die Determinate 0, 1 oder −1. Wegen Ai j ∈ 1,−1 gilt diesauch fur A . Nach dem Induktionsprinzip folgt also die Behauptung.
(c) Im letzten Fall haben wir in jeder Spalte genau eine 1 und eine −1.Dann ist aber die Summe der Zeilen der Nullvektor, also hat die Matrixnicht vollen Rang und det(A) = 0.
2
Das Polyeder zu unserer Optimierungsaufgabe wird beschrieben durch Ax = 1,0≤ x≤ 1. Multiplizieren wir dabei in der Matrix A die Zeilen der Kunden mit −1,erhalten wir nach Proposition 6.2.4 iii) eine total unimodulare Matrix, denn jedeVariable taucht je genau einmal in einer Kundenzeile und in einer Beraterzeile auf.

196 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Mit A ist nach Proposition 6.2.4 i) auch( A−A
)total unimodular und schließlich nach
Proposition 6.2.4 ii) die Matrix, die den zulassigen Bereich unseres Problems inUngleichungsform beschreibt. Also sind nach Proposition 6.2.3 alle Ecken unsereslinearen Programms ganzzahlig.
Wir wollen unser Problem mit so etwas wie dem dualen Simplexalgorithmuslosen, da wir fur das duale Problem sofort eine zulassige Losung haben. Notierenwir unser primales Programm einmal explizit, so lautet es:
min∑ni=1 ∑
nj=1 ci jxi j
unter ∑ni=1 xi j = 1 fur alle 1≤ j ≤ n
∑nj=1 xi j = 1 fur alle 1≤ i≤ n
xi j ≥ 0.
Das duale Problem lautet dann
max ∑ni=1 ui +∑
nj=1 v j
unter ui + v j ≤ ci j ∀1≤ i, j ≤ n.(6.1)
Bei unserer Interpretation der folgenden Prozedur als Spezialfall des Simplexal-gorithmus haben wir eigentlich das Problem, dass
i) die Variablen nicht vorzeichenbeschrankt sind und
ii) der zulassige Bereich nicht spitz ist.
Addiert man namlich eine (nicht notwendig positive) Konstante zu allen Beraternund zieht die gleiche Konstante von allen Kunden ab, so erhalt diese Operationdie Zulassigkeit. Also ist der Linearitatsraum des dualen Problems nicht trivial undsomit das zugehorige Polyeder nicht spitz.
Man konnte dies dadurch auflosen, dass man die Variablen aufspaltet. Daswurde aber das folgende Verfahren unnotig verkomplizieren.
Wir konstruieren im Folgenden zulassige Losungen fur das duale Problem unddazu komplementare, nicht notwendig zulassige Losungen des primalen Problems.Sind wir auch primal zulassig, so haben wir nach dem Satz vom komplementarenSchlupf eine Optimallosung gefunden. Wie gesagt, in der Darstellung hier ignorie-ren wir die Tatsache, dass die duale Losung keine Ecklosung ist. Wie wir sehenwerden, ist die primale Losung eine Ecke.
Um komplementare Losungen zu finden, betrachten wir den bipartiten Graphender dichten Kanten.

6.2. Personaleinsatzplanung 197
6.2.5 Definition. Sei G = (W,E) ein Graph. Dann heißt G bipartit , wenn es einePartition W =U∪V der Knotenmenge gibt, so dass
∀e ∈ E : e∩U 6= /0 6= e∩V,
also alle Kanten je einen Endknoten in jeder Menge haben.Sei (u,v) zulassig fur (6.1). Initial setzen wir dafur (u,v)= (0,0) . Diese Losung
ist zulassig, da nach Voraussetzung ci j ≥ 0 ist. Sei U die Menge der Beraterund V die Menge der Kunden. Diese Mengen sind disjunkt. Dies sollten Sie imHinterkopf behalten, auch wenn wir im Folgenden dennoch fur beide Mengen dieZahlen von 1, . . . ,n verwenden, um nicht unnotig die Notation zu verkomplizieren.Wir definieren dann den bipartiten Graphen Guv der dichten Kanten vermoge
W =U ∪V und(i, j ∈ E ⇐⇒ ui + v j = ci j
).
Nun suchen wir im Graph der dichten Kanten nach einer moglichst großenZuordnung von Beratern zu Kunden. Dies machen wir wie folgt:
• Ausgehend von einer initialen Zuordnung von Beratern zu Kunden versuchenwir, diese zu verbessern.
• Entweder finden wir dabei eine Zuordnung, die mehr Berater-Kunde-Paareenthalt, wobei jeder Berater und jeder Kunde, die vorher zugewiesen waren,weiter zugewiesen bleiben, oder
• wir konnen die Dualvariablen so modifizieren, dass wir eine neue Kante inden Graph der dichten Kanten aufnehmen, die uns den Suchraum vergroßernlasst.
Ausgehend von einem nicht zugeordneten Berater bauen wir dafur einen gerich-teten Suchbaum T , einen Wurzelbaum, auf. Zur Klarung, was ein Wurzelbaum ist,machen wir noch ein paar kleine Definitionen.
6.2.6 Definition. Sei G = (V,E) ein Graph. Ein Zyklus in G ist eine (geschlossene)Folge von Knoten und Kanten v0e1v1e1v2 . . .vk−1ekvk , wobei ei = vi−1,vi fur1≤ i≤ k und v0 = vk . Ein zyklenfreier Graph heißt Wald, ein zusammenhangenderWald heißt Baum.
Ein gerichteter Graph oder auch Digraph ist eine binare Relation. Ein Wur-zelbaum ist ein Digraph, dessen zu Grunde liegender Graph (wir ”vergessen“ dieRichtungen der Kanten) ein Baum ist, bei dem es einen ausgezeichneten Knoten,die Wurzel, gibt und alle Kanten so gerichtet sind, dass man von der Wurzel alleKnoten auf gerichteten Wegen erreichen kann.

198 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Sei also nun eine Zuordnung von Beratern zu Kunden j gegeben und i0 einnicht zugeordneter Berater. Wir nehmen dann alle Knoten j mit i0, j ∈ Gu,v inunseren Suchbaum T auf, orientieren die Kanten von i0 nach j und markiereni0 als abgearbeitet. Gibt es unter den so erreichten j einen Kunden, der noch nichteinem Berater zugeordnet ist, so konnen wir die Zuordnung vergroßern. Andernfallsnehmen wir die zugeordneten Berater in T auf, wobei die Kanten vom Kunden zumBerater orientiert werden. So lange wir nun noch einen nicht abgearbeiteten Beraterin T haben, untersuchen wir, ob wir von ihm aus neue Kunden in T aufnehmenkonnen. Finden wir dabei einen Kunden j0 , der noch keinen Berater hat, so bestehtder Weg von i0 nach j0 in T abwechselnd aus Kanten, die nicht einer Zuordnungentsprechen und Kanten, die einer Zuordnung entsprechen. Lassen wir die Kantenauf dem Weg die Rollen wechseln, erhalten wir eine Zuordnung, bei der zusatzlichi0 nicht mehr untatig ist und j0 beraten wird. Andernfalls nehmen wir die Beraterder neu gefundenen Knoten wie eben in T auf.
Endet die Suche, ohne dass wir die Zuordnung vergroßern konnten, so sind alleKunden in T mit einem Berater versorgt. Da auch i0 in T ist, enthalt T einenBerater mehr, als er Kunden enthalt. Erhohen wir nun die u-Variablen der Beraterin T und erniedrigen die v-Variablen der Kunden in T , so bleiben alle Kantenvon T im Graph der dichten Kanten erhalten, und wir verbessern die Zielfunktion.Genauer andern wir den Wert aller dieser Dualvariablen um
minci j−ui− v j | i ∈ T, j 6∈ T> 0.
Wird dieses Minimum in der Kante i, j angenommen, so gehort diese zum Graphder dichten Kanten bzgl. der aufdatierten Dualvariablen und wir konnen die Suchefortsetzen.
Das Verfahren endet, wenn alle Berater mit Kunden versorgt sind. Dies liefertuns eine Losung des Ausgangsproblems. Da alle Variablen xi j auf 0 oder 1 stehen,ist das eine Ecklosung, denn sie kann nicht echte Konvexkombination von Punktendes zulassigen Bereichs sein.
• Wir wollen nun grob die Komplexitat dieses Verfahrens abschatzen. Ist weine Instanz des Problems, so ist I(w) = n2 + n = O(n2) , da die Daten ausden paarweisen Entfernungen zwischen Beratern und Kunden bestehen.
• Die Menge der eingesetzten Berater konnen wir hochstens n mal vergroßern.
• Beim Hinzufugen einer Kante zum Suchbaum wachst die Anzahl der Knotenim Suchbaum. Das kann hochstens 2n−1 mal passieren.

6.2. Personaleinsatzplanung 199
• Das Bestimmen von minci j−ui− v j | i ∈ T, j 6∈ T> 0 kann naiv in O(n2)
erledigt werden.
• Also haben wir fur I(w) = n2 eine Gesamtlaufzeit von O(n4) = O((n2)2) .
Unser primal-duales Verfahren ist also streng polynomial mit quadratischerLaufzeit.
Und nun noch ein Rechenbeispiel im Beispiel. Wir betrachten ein Problem mit5 Beratern und 5 Kunden. Die Einsatzkosten finden wir in der folgenden Matrixwieder, wobei die Zeilen den Beratern und die Spalten den Kunden zugeordnetsind. Die Dualvariablen tragen wir links neben den Zeilen bzw. uber den Spaltenab. Da alle Daten nicht-negativ sind, konnen wir zu Beginn alle Dualvariablen aufNull setzen.
0 0 0 0 0
0 1 2 3 4 50 6 7 8 7 20 1 3 4 4 50 3 6 2 8 70 4 1 3 5 4
Die Dualvariablen sind genau dann zulassig, wenn die Summen aus Zeilen- und
Spaltenvariable stets kleiner oder gleich dem Eintrag in der Matrix sind. DichteKanten erhalten wir, wo Gleichheit herrscht. Zu Anfang ist also der Graph derdichten Kanten leer und die Suche, welche beim ersten Berater startet, endet auchdirekt wieder. Folglich erhohen wir die Variable des ersten Beraters auf 1 undordnen ihn dem ersten Kunden zu. Im nachsten Schritt setzen wir die Dualvariabledes zweiten Beraters auf 2 und ordnen ihn dem funften Kunden zu. Im dritten Schritterhohen wir die Dualvariable des dritten Beraters auf 1, konnen aber den Beraternicht dem ersten Kunden zuordnen, da dieser bereits vom ersten Berater versorgtwird.
Wir haben also nun folgende Situation:
0 0 0 0 0
1 1 2 3 4 52 6 7 8 7 21 1 3 4 4 50 3 6 2 8 70 4 1 3 5 4

200 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Wenn wir ausgehend vom dritten Berater suchen, haben wir Berater 1 und 3,sowie Kunden 1 in T . Also erhohen wir die Variablen von Berater 1 und 3 underniedrigen die von Kunde 1. Da c12 = 2 ist, konnen wir nur um 1 erhohen, ohneZulassigkeit zu verlieren.
−1 0 0 0 0
2 1 2 3 4 52 6 7 8 7 22 1 3 4 4 50 3 6 2 8 70 4 1 3 5 4
Wir ordnen nun Berater 1 Kunden 2 und Berater 3 Kunden 1 zu. Im nachstenSchritt erhohen wir die Dualvariable von Berater 4 auf zwei und ordnen ihn demdritten Kunden zu. Dann setzen wir die Dualvariable von Berater 5 auf 1. Allerdingsist Kunde 2 schon versorgt. Also konstruieren wir wieder unseren Baum T .
−1 0 0 0 0
2 1 2 3 4 52 6 7 8 7 22 1 3 4 4 52 3 6 2 8 71 4 1 3 5 4
Dieser enthalt die Berater 1,3 und 5 und die Kunden 2 und 1. Wegen c13 = 3erhohen wir wieder nur um 1.
−2 −1 0 0 0
3 1 2 3 4 52 6 7 8 7 23 1 3 4 4 52 3 6 2 8 72 4 1 3 5 4
Durch die neue Kante gelangen auch Berater 4 und Kunde 3 in den Baum.Wegen c14 = c34 = 4 andern wir die Dualvariablen wieder nur um 1.

6.3. Klee-Minty Cubes 201
−3 −2 −1 0 0
4 1 2 3 4 52 6 7 8 7 24 1 3 4 4 53 3 6 2 8 73 4 1 3 5 4
Nun bleibt Berater 5 dem Kunden 2 zugeordnet, Berater 1 berat nun Kunde 4,
Berater 3 Kunde 1. Berater 2 ist weiter fur Kunde 5 und Berater 4 weiterhin furKunde 3 zustandig. Die Gesamtkosten sind mit 10 minimal.
6.2.7 Aufgabe. Betrachten Sie den etwa aus dem Kurs ”Lineare Algebra“ bekannteneuklidischen Algorithmus zur Bestimmung des großten gemeinsamen Teilers zweiernaturlicher Zahlen.
Zeigen Sie: Der euklidische Algorithmus ist ein polynomiales, aber kein strengpolynomiales Verfahren.
Losung siehe Losung 6.7.3.
6.3 Klee-Minty Cubes
Wir hatten im letzten Abschnitt angedeutet, dass kein streng polynomiales Verfah-ren fur das Problem der linearen Optimierung bekannt ist. Da andererseits ein ein-zelner Pivotschritt in beiden Modellen nur polynomial viel Rechenzeit benotigt,wurde eine Pivotregel fur den Simplexalgorithmus, die einen polynomialen Algo-rithmus liefert, schon eine streng polynomiale Variante des Simplexalgorithmus lie-fern. Leider ist keine polynomiale Pivotregel bekannt. Im Gegenteil. Erst kurzlichsind zu einigen Regeln, deren ”Scheitern“ man vorher noch nicht explizit beweisenkonnte, Klassen von linearen Programmen gefunden worden, die zeigen, dass dieRegeln nicht polynomial sind. Wir werden auf die jungere Literatur am Ende diesesAbschnitts noch einmal hinweisen.
Zunachst wollen wir explizit ein klassisches Beispiel angeben, bei dem derSimplexalgorithmus unter Verwendung der Dantzigschen Regel exponentiell vieleIterationen benotigt. Die Darstellung orientiert sich dabei an [21].
Die zu Grunde liegende Idee ist die Folgende. Der Hyperwurfel
Hn := x ∈ Rn | 0≤ xi ≤ 1

202 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
ist durch nur n Ungleichungen und n Vorzeichenrestriktionen gegeben. Die Input-große ist also I(w) = n2 . Hn hat aber 2n Ecken, namlich alle Vektoren in 0,1n .Wenn wir nun den Simplexalgorithmus durch eine geeignete Verzerrung dieses Po-lyeders dazu bringen konnen, bei Vorgehen mit der Dantzigschen Regel alle Eckendes so verzerrten Hyperwurfels zu durchlaufen, dann zeigt dies, dass das Verfahrenexponentielle Laufzeit in der Anzahl der Variablen hat. Dies kann nicht polynomialin der Inputdatengroße sein.
Die folgende Klasse linearer Programme (LPn) fur n∈N leistet das Gewunsch-te, wie wir nun zeigen werden.
(LPn)
max 2n−1x1 + 2n−2x2 + . . . + 2xn−1 + xn
unter x1 ≤ 54x1 + x2 ≤ 258x1 + 4x2 + x3 ≤ 125
......
......
2nx1 + 2n−1x2 + . . . + 4xn−1 + xn ≤ 5n
x ≥ 0
Zunachst einmal wollen wir nachweisen, dass es sich hierbei tatsachlich umeinen verzerrten Hyperwurfel handelt.
Wir beobachten:
6.3.1 Proposition. Sei x zulassig fur (LPn) . Dann gilt fur alle i = 1, . . . ,n:
i) Ist xi = 0 , so ist die i-te Ungleichung strikt.
ii) Ist die i-te Ungleichung nicht strikt, so ist xi > 0 .
Beweis.
i) Die Behauptung ist offensichtlich richtig fur i = 1. Ist i > 1, so liefert die(i−1)-te Ungleichung
2i−1x1 +2i−2x2 + . . .+4xi−2 + xi−1 ≤ 5i−1.

6.3. Klee-Minty Cubes 203
Hieraus erhalten wir
2ix1 +2i−1x2 + . . .+4xi−1 + xixi=0= 2(2i−1x1 + . . .+4xi−2 + xi−1)+2xi−1
xi−1≤5i−1
≤ 2(2i−1x1 + . . .+4xi−2 + xi−1︸ ︷︷ ︸≤5i−1
)+2 ·5i−1
≤ 4 ·5i−1 < 5i.
Also ist die i-te Ungleichung strikt.
ii) Da nach Voraussetzung xi ≥ 0 ist, handelt es sich bei ii) um die Kontrapositi-on von i).
2
Nach Proposition 6.3.1 hat (LPn) also keine entarteten Ecken und jede Eckebesteht aus einem komplementaren Satz von Ungleichungs- und Vorzeichenrestrik-tionen. Dass alle diese komplementaren Paare auch eine Ecke liefern, besagt derfolgende Satz:
6.3.2 Satz. Der zulassige Bereich von (LPn) hat 2n Ecken. Und zwar erhalt man furjede Teilmenge S ⊆ 1, . . . ,n eine Ecke, wenn man xi = 0 fur alle i ∈ S setzt undGleichheit der Ungleichungsnebenbedingungen in allen ubrigen Indizes fordert.
Beweis. Dass wir keine weiteren Ecken erhalten, folgt aus Proposition 6.3.1. AufGrund der unteren Dreiecksgestalt der Restriktionsmatrix fuhren alle diese Wahlender Nichtnegativitats- und Ungleichungsrestriktionen zu regularen Gleichheitsma-trizen, liefern also Basen. Offensichtlich sind zugehorigen Ecken paarweise ver-schieden. Wir mussen also nur noch nachrechnen, dass sie zulassig sind. Somitmussen wir fur die zugehorigen Ecklosungen nachweisen, dass die von Null ver-schiedenen Koordinaten nicht negativ sind, und dass die nicht mit Gleichheit erfull-ten Ungleichungen nicht verletzt werden. Dies zeigen wir mittels vollstandiger In-duktion uber den Index i .
Fur i = 1 ist entweder x1 = 0 oder x1 = 5. In beiden Fallen sind die Behaup-tungen erfullt.
Sei also i > 1. Falls xi = 0 ist, so haben wir eben berechnet, dass
2ix1 +2i−1x2 + . . .+4xi−1 + xixi=0= 2(2i−1x1 + . . .+4xi−2 + xi−1︸ ︷︷ ︸
IV≤5i−1
)
≤ 4 ·5i−1 < 5i.

204 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Also ist die i-te Ungleichung strikt erfullt. Ebenso hatten wir gefunden, dass
2ix1 +2i−1x2 + . . .+4xi−1 + xi = 5i
nach Induktionsvoraussetzung die Ungleichung
xi ≥ 5i−4 ·5i−1 > 0
impliziert. 2
6.3.3 Korollar. i) Sei I eine Teilmenge der Ungleichungen und J+n eine Teil-menge der Vorzeichenrestriktionen, wobei wir ”xi ≥ 0“ mit dem Index i+ nversehen haben. Dann ist
face(I∪ (J+n)) 6= /0 ⇐⇒ I∩ J = /0.
ii) Der Seitenflachenverband des zulassigen Bereichs ist isomorph zum Seiten-flachenverband von Hn .
Beweis. Als Ubung. 2
6.3.4 Aufgabe. Beweisen Sie Korollar 6.3.3.
Losung siehe Losung 6.7.4.Bevor wir den induktiven Aufbau von (LPn) nutzen, um nachzuweisen, dass
der Simplexalgorithmus mit Dantzigscher Pivotregel, ausgehend von der Startecke(0, . . . ,0)> , tatsachlich alle Ecken durchlauft, geben wir zunachst einmal an, wo dasOptimum angenommen wird.
6.3.5 Proposition. Das eindeutige Optimum von (LPn) wird in (0, . . . ,0,5n)> an-genommen.
Beweis. LPn ist vom Typ
maxc>x | Ax≤ b,x≥ 0.
Als duales Problem erhalten wir also nach Losung 3.6.5 v)
miny>b | y>A≥ c>, y≥ 0.
Ausfuhrlich haben wir also:

6.3. Klee-Minty Cubes 205
min 5y1 + 25y2 + . . . + 5n−1yn−1 + 5nyn
unter y1 + 4y2 + 8y3 + . . . + 2nyn ≥ 2n−1
y2 + 4y3 + . . . + 2n−1yn ≥ 2n−2
y3 + . . . + 2n−2yn ≥ 2n−3
. . . .... . . ...
yn−1 + 4yn ≥ 2yn ≥ 1
y1, . . . ,yn ≥ 0.
Die Belegung yn = 1,yi = 0 fur i = 0, . . . ,n−1 ist zulassig fur das duale Optimie-rungsproblem mit Zielfunktionswert 5n . Da das primale Optimierungsproblem mitder angegebenen Losung den gleichen Zielfunktionswert annimmt, mussen beidenach dem Dualitatssatz Optimallosungen sein.
Ist andererseits x∗ eine Optimallosung der primalen Aufgabenstellung, so habenwir wegen der Zielfunktion und der letzten Restriktion
2n−1x∗1 +2n−2x∗2 + . . .+2x∗n−1 + x∗n = 5n
2nx∗1 +2n−1x∗2 + . . .+4x∗n−1 + x∗n ≤ 5n
und somit
2n−1x∗1 +2n−2x∗2 + . . .+2x∗n−1 ≤ 0.
Da alle Variablen nicht-negativ sind, folgt hieraus x∗1 = . . . = x∗n−1 = 0 und somitx∗n = 5n , also auch die Eindeutigkeit der Losung.
2
Nach diesen Vorbereitungen zeigen wir:
6.3.6 Satz. Der Simplex-Algorithmus mit der Dantzigschen Pivotregel benotigt fur(LPn) 2n−1 Pivotsschritte.
Beweis.Die Behauptung ist offensichlich aquivalent dazu, dass wir bei diesem Verfahren
2n Tableaus durchlaufen. Dies zeigen wir mittels vollstandiger Induktion uber n .Genauer zeigen wir:

206 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
i) (LPn) durchlauft bei Anwendung der Dantzigschen Gradienten-regel 2n Tableaus.
ii) In jedem der Tableaus sind die reduzierten Kosten ganzzahlig.
iii) Die Nicht-Null-Eintrage in den reduzierten Kosten sind paarweiseverschieden.
Fur n = 1 ist dies trivial, da wir in einem Schritt von 0 auf 5 wechseln und diereduzierten Kosten von (1,0) auf (0,−1) wechseln. Sei n > 1. Nach Induktions-annahme haben das erste und das 2n−1 -te Tableau von LPn−1 folgende Gestalt
c 1 0 0 0A 0 In−2 0 b
2c 1 0 1 5n−1
Tableau 1
−c 0 0 −1 −5n−1
A 0 In−2 0 b2c 1 0 1 5n−1
Tableau 2n−1
Dabei haben wir die (n− 1)-ste Variable und die (n− 1)-ste Nebenbedingungmit ihrer Schlupfvariablen abgespalten.
Betrachten wir nun zunachst das Starttableau fur das Problem (LPn) .
2c 2 1 0 0 0 0A 0 0 In−2 0 0 b
2c 1 0 0 1 0 5n−1
4c 4 1 0 0 1 5n
Tableau 1
Streichen wir aus Tableau 1 die Spalten der n-ten Variable und der n-tenSchlupfvariable sowie die n-te Gleichungszeile, so erhalten wir das Startableau vonLPn−1 , bei dem die Zeile der reduzierten Kosten mit zwei durchmultipliziert wur-de. Nach Induktionsvoraussetzung sind aber die reduzierten Kosten von (LPn−1)
wahrend des Durchlaufs des Algorithmus zu jeder Zeit ganzzahlig. Also sind siehier stets Vielfache von zwei. Insbesondere wird die Spalte der n-ten Variable nachder Dantzigschen Pivotregel nicht zur Pivotspalte, solange wir wie in LPn−1 , alsoauch nicht auf einem Element der letzten Zeile, pivotieren. Dies ist aber dadurchsicher gestellt, dass nach Satz 6.3.2 die n-te Schlupfvariable die Basis nur dannverlassen darf, wenn die n-te Variable in die Basis aufgenommen wird. Also durch-laufen wir alle Schritte von (LPn−1) , bis dieses Unterproblem optimal ist. NachInduktionsvoraussetzung geschieht das im 2n−1 -sten Tableau, das also wie folgtaussieht:

6.3. Klee-Minty Cubes 207
−2c 0 1 0 −2 0 −2 ·5n−1
A 0 0 In−2 0 0 b2c 1 0 0 1 0 5n−1
−4c 0 1 0 −4 1 5n−1
Tableau 2n−1
Als einzige Spalte mit positiven reduzierten Kosten bleibt nur die Spalte dern-ten Variablen und wir erhalten als nachstes Tableau:
2c 0 0 0 2 −1 −3 ·5n−1
A 0 0 In−2 0 0 b2c 1 0 0 1 0 5n−1
−4c 0 1 0 −4 1 5n−1
Tableau 2n−1 +1
Auch dieses sieht wieder aus wie ein erweitertes erstes Tableau fur LPn−1 , nurdass zusatzlich die Spalten der (n−1)-ten Variablen und der (n−1)-sten Schlupf-variablen vertauscht sind. Dies andert jedoch nichts an der Pivotwahl, die diese Ver-tauschung nachvollziehen muss, da die Nichtnulleintrage in den reduzierten Kostenpaarweise verschieden sind und deswegen die Spalte mit großtem Eintrag stets ein-deutig ist. Folglich mussen wir wiederum 2n−1 Iterationen machen, um bei Tableau2n zu landen.
−2c −2 0 0 0 −1 −5n
A 0 0 In−2 0 0 b2c 1 0 0 1 0 5n−1
4c 4 1 0 0 1 5n
Tableau 2n
Dieses ist optimal, wurde aber erst nach 2n−1 Schritten erreicht. 2
Wir haben somit bewiesen:
6.3.7 Satz. Der Simplexalgorithmus unter Verwendung der Dantzigschen Pivotregelist kein streng polynomialer Algorithmus und also auch kein polynomialer Algorith-mus.
Beweis. Die Inputdatengroße ist I(LPn) = O(n2) bzw. 〈LPn〉 = O(n3) , da diegroßte vorkommende Zahl 5n unter Verwendung von hochstens 3n Bits kodiertwerden kann.

208 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Also ist, unabhangig von den Kosten der Rechenoperationen, in beiden Model-len schon die Anzahl der Pivotschritte exponentiell in der Anzahl der Variablen. 2
6.3.8 Bemerkung. Dieses Beispiel wurde fur verschiedene Pivotregeln modifiziert.So laßt sich zeigen, dass z.B. auch Bland’s Rule, die großter-Fortschritt-Regelund die steilster-Anstieg-Regel keine polynomialen Pivotregeln sind. Ersteres wirddurch leichte Modifikation der Argumente fur die Dantzigsche Pivotregel im Prin-zip mit dem gleichen Beispiel erreicht. Fur die anderen beiden Regeln sehen dieBeispiele anders aus.
Bis vor kurzem gab es einige wenige Pivotregeln, bei denen keine Beispiele be-kannt waren, die zeigten, dass diese nicht zu polynomialen Algorithmen fuhrten.Die beiden prominentesten dabei sind Zadehs Least-Entered-Rule und Cunning-hams Round-Robin-Rule:
Least-Entered-Rule: Wahle als Pivotspalte diejenige, die bisher am wenigstenhaufig in die Basis aufgenommen worden ist. Die Zeilenauswahlregel ist nichtgenau spezifiziert.
Round-Robin-Rule: Fixiere eine Ordnung der Variablen. Wahle als Pivotspaltediejenige, deren Variable am langsten nicht angefasst worden ist. Wahle alsPivotzeile diejenige, deren basisverlassende Variable am langsten in der Basiswar.
Oliver Friedmann hat in seiner Dissertation [7] unter anderem fur diese Regelngezeigt, dass sie mehr als polynomial viele Pivotschritte benotigen konnen. Dafurhat er 2012 den Tucker Prize der Mathematical Optimization Society erhalten.
6.3.9 Aufgabe. Zeigen Sie: Der Simplexalgorithmus unter Verwendung von BlandsRule ist kein Polynomialzeitalgorithmus.
Losung siehe Losung 6.7.5.Zu folgender Vermutung von W.M. Hirsch wurde erst 2010 ein Gegenbeispiel
gefunden [19]. Wie Sie sehen, hat es auch in diesem prominenten Fall 2 Jahre biszur Veroffentlichung der Arbeit gedauert.
Hirsch-Vermutung 1957, falsifiziert 2010 von Santos: Sei P ein d -dimensiona-les Polytop mit k Facetten und seien v,w Ecken von P . Dann gibt es im1-Skelett von P einen Pfad von v nach w der Lange hochstens k−d .

6.4. Die mittlere Laufzeit des Simplexalgorithmus 209
Der Durchmesser des 1-Skeletts konnte trotz der Gegenbeispiele von Santosnoch immer linearen Durchmesser haben, oder Durchmesser polynomial in m undn . Konnte man solche kurzen Pfade effizient durch lokale Auswahl an jeder Eckebestimmen, so hatte man eine polynomiale Pivotregel gefunden.
Andererseits wurde eine untere Schranke, die beweist, dass der Durchmessereiner Klasse von Polytopen nicht polynomial beschrankt ist, zeigen, dass der Sim-plexalgorithmus mit keiner Pivotregel ein polynomiales Verfahren werden kann.
6.4 Die mittlere Laufzeit des Simplexalgorithmus
In diesem Abschnitt werden wir ein Resultat vorstellen, das beweist, dass, beiVerwendung der so genannten Schatteneckenregel und unter gewissen Annahmenan die Verteilung der linearen Optimierungsprobleme, die erwartete Anzahl anIterationen des Simplexverfahrens im Gegensatz zum worst-case sogar linear ist.Dieses Resultat, mit dem eine Beobachtung, die man in der Praxis heuristischschon gemacht hatte, theoretisch untermauert zu werden schien, wurde 1982 vonBorgwardt erzielt. Wir geben hier ein verbessertes Resultat von Haimovich wieder.In der Darstellung orientieren wir uns auch hier an [21].
Wir betrachten hier zunachst lineare Optimierungsaufgaben in der Formmaxc>x unter Ax ≤ b ∈ Rm und werden danach weitere Resultate fur den allge-meinen Fall nur zitieren.
Zunachst einmal wollen wir die Schatteneckenregel vorstellen. Diese wird lokalin der jeweiligen Ecke x0 von P(A,b) definiert. Dafur wahlen wir zunachst einenzufalligen Vektor c ∈ P(Aeq(x0).,0)
∆ .
6.4.1 Proposition. x0 ist Optimallosung des linearen Programms max c>x unterAx≤ b genau dann, wenn c ∈ P(Aeq(x0).,0)
∆ .
Beweis. Nach Lemma 4.9.3 ist
P(Aeq(x0).,0)∆ = Cone(A>eq(x0).
).
Ist also c ∈ P(Aeq(x0).,0)∆ , so gibt es ein u0 ≥ 0 mit u>0 A = c , welches komple-
mentar zu x0 bzgl. Ax≤ b ist. Das duale Problem zu max c>x unter Ax≤ b lautetaber
min u>b unter u>A = c und u≥ 0.
Also ist u0 zulassig fur das duale Problem und komplementar zu x0 . Die Behaup-tung folgt damit aus dem Satz vom komplementaren Schlupf 3.5.1.

210 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Ist x0 umgekehrt Optimallosung des linearen Programms
max c>x unter Ax≤ b,
so gibt es nach dem Satz vom komplementaren Schlupf ein u , welches zulassig furdas duale Problem und komplementar zu x0 ist. Also ist c ∈ P(Aeq(x0).,0)
∆ . 2
Das lineare Funktional c>x nennen wir Kozielfunktion.Die Idee ist nun, das Polyeder auf die von c und c aufgespannte Ebene zu
projizieren, die verbessernde Nachbarecke in dieser Projektion zu bestimmen unddann eine Nachbarecke von x0 im Ausgangspolyeder zu suchen, die auf diese Eckeprojeziert wurde. Daraufhin wird dann die Kozielfunktion so an die neue Eckeangepasst, dass Ziel- und Kozielfunktion weiterhin die gleiche Ebene aufspannenund die neue Ecke optimal bzgl. der Kozielfunktion ist.
Die Schatteneckenregel von Karl Heinz Borgwardt lautet dann:
Schatteneckenregel: In der zulassigen Ecke xk , die (λc+ c)>x fur ein λ ≥ 0,aber nicht c>x uber P maximiert, wahle einen Nachbarn xk+1 von xk , der(λ ′c+ c)>x fur ein λ ′ > λ maximiert oder bestimme eine Extremale µy mitEcke xk und (λ ′c+ c)>y > 0 fur ein λ ′ > λ .
Den Simplexalgorithmus unter Verwendung der Schatteneckenregel wollen wirab nun als Schatteneckenalgorithmus bezeichnen. Ausgehend von x0 und λ = 0ist dies eine zulassige Pivotregel. Sie ist auch leicht zu implementieren. BeimUbergang von λ zu λ ′ wird zu einem Zeitpunkt die gesamte Kante von xk undxk+1 optimal sein. Die reduzierten Kosten von λc+ c lassen sich durch Additionvon einem Vielfachen der reduzierten Kosten von c aufdatieren. Also wahlen wirein µ so, dass das Optimalitatskriterium fur xk erhalten bleibt, aber zusatzlich diereduzierten Kosten fur ein Nichtbasiselement j Null werden. Dieses pivotieren wirin die Basis und erhalten so xk+1 und setzen λ ′ = λ +µ , wobei wir in Gedanken inder Kozielfunktion das λ ′ noch einen Ticken großer machen. Fur das Rechnen istdas aber eher unbequem.
Bevor wir ein Beispiel durchrechnen, wollen wir aber zunachst das theoretischeResultat herleiten. Wir hatten angekundigt, dass wir dafur gewisse Annahmen an dieWahrscheinlichkeitsverteilung der linearen Optimierungsprobleme machen. UnsereGrundmenge besteht dabei fur feste Parameter m,n ∈ N aus allen Quadrupeln(A,b,c, c) mit A ∈Km×n,b ∈Km,c, c ∈Kn . Die Annahmen sehen zunachst einmalrecht harmlos und plausibel aus:

6.4. Die mittlere Laufzeit des Simplexalgorithmus 211
i) Fur feste Kozielfunktion andert die Invertierung eines Ungleichheitszeichens(genauer die Multiplikation einer Zeile mit −1) in Ax ≤ b , falls die Losunguber dem modifizierten System weiterhin endlich ist, die Wahrscheinlichkeitvon A,b,c, c nicht.
ii) Fur feste Kozielfunktion andert die Ersetzung von c durch −c , falls dieLosung uber dem modifizierten System weiterhin endlich ist, die Wahrschein-lichkeit von A,b,c, c nicht.
iii) Die Wahl von A,b,c, c , so dass es n linear abhangige Spalten in (c, c,A>)oder n+1 linear abhangige Zeilen in (A,b) gibt, hat Wahrscheinlichkeit 0.
Insbesondere sind also fast alle LPs nicht-entartet, d.h. sie haben keine einzigeentartete Ecke. Eine uniforme Verteilung hat gewiss diese Eigenschaften, aber nichtnur uniforme Verteilungen.
Man kann die praktische Bedeutung dieser Annahmen in Frage stellen, wennman realisiert, dass eigentlich alle in der Praxis vorkommenden Probleme mittelseiner Modellierungssoftware generiert werden, sehr strukturiert und damit in derRegel hochgradig entartet sind. Dies ist allerdings vor allem die personliche Sichtdes Autors. Doch kommen wir zuruck zum Thema:
6.4.2 Proposition. Sei xkxk+1 eine Kante, die vom Schatteneckenalgorithmusdurchlaufen wird. Nach Konstruktion gilt:
c>xk+1 > c>xk und c>xk+1 < c>xk, (6.2)
Beweis. Weil xk+1 optimal bzgl. der Zielfunktion (λ ′c+ c) ist, gilt
(λ ′c+ c)>(xk+1− xk)> 0. (6.3)
Weil xk optimal bzgl. der Zielfunktion (λc+ c) ist, gilt
(−λc− c)>(xk+1− xk)> 0. (6.4)
Addieren wir (6.3) und (6.4), so erhalten wir
(λ ′−λ )c>(xk+1− xk)> 0 (6.5)
und damit die erste Behauptung.Multiplizieren wir (6.3) mit λ ≥ 0 und (6.4) mit λ ′ > 0 und addieren die so
abgeleiteten Ungleichungen, so erhalten wir
(λ −λ′︸ ︷︷ ︸
<0
)c>(xk+1− xk)> 0 (6.6)
und damit den zweiten Teil der Behauptung. 2

212 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
6.4.3 Proposition. Findet man eine extremale Richtung y, so ist das Problemunbeschrankt.
Beweis. Nach Annahme haben wir
(λ ′c+ c)>y > 0. (6.7)
Weil y keine Extremale in xk war, schließen wir (λc+ c)y≤ 0 und somit
(−λc− c)>y≥ 0. (6.8)
Addition dieser beiden Ungleichungen ergibt
(λ ′−λ︸ ︷︷ ︸>0
)c>y > 0. (6.9)
und damit ist y auch eine extremale Richtung fur das Ausgangsproblem. 2
Wir nehmen nun einen zufalligen Datensatz A,b,c, c her. Nach der Annahmean die Verteilung sind die Spalten von A und b in allgemeiner Lage, ebenso dieZeilen von A,c und c . Wir betrachten nun die Hyperebenen, die den zulassigenBereich begrenzen und definieren. Das zugehorige Hyperebenenarrangement defi-niert eine Zerlegung des Kn in Polyeder. Wir erhalten jedes dieser Polyeder ausden Daten, wenn wir eine Teilmenge der ≤-Restriktionen mit −1 multiplizieren.In Abbildung 6.1 haben wir die Situation im Zweidimensionalen skizziert.
Abbildung 6.1: Ein Linienarrangement zu einem Polytop
Das Linienarrangement dort soll von dem schraffierten Sechseck induziert wor-den sein. Wir zahlen 10 beschrankte Zellen (Polytope) und 12 unbeschrankte Po-lyeder. Dies ist kein Zufall. Denn in einem affinen Hyperebenenarrangement H

6.4. Die mittlere Laufzeit des Simplexalgorithmus 213
mit n ≥ 1 Hyperebenen in allgemeiner Lage im Kd ist die Anzahl Lb(H ) derbeschrankten volldimensionalen Zellen gegeben durch
Lb(H ) =
(n−1
d
)(6.10)
und die Anzahl L(H ) der volldimensionalen Zellen durch
L(H ) =d
∑i=0
(ni
). (6.11)
6.4.4 Aufgabe. Beweisen Sie (6.10) und (6.11).
Losung siehe Losung 6.7.6.
Wir betrachten im Folgenden nur noch die endlich vielen linearen Optimie-rungsprobleme, die aus den so durch A,b und Multiplikation der Ungleichungenmit −1 gegebenen Polyedern sowie den Zielfunktionen c und −c definiert sind.Nach Annahme an die Verteilung sind diese Probleme alle gleichwahrscheinlich.
Nun sind wir gewappnet, das folgende Resultat zu beweisen:
6.4.5 Satz (Haimovich 1983). Die Klasse der LP maxAx≤b c>x kann mit dem Sim-plexalgorithmus unter Verwendung der Schatteneckenregel unter jeder Wahrschein-lichkeitsverteilung, die die oben gemachten Annahmen erfullt, mit hochstens n
2 Ite-rationen im Durchschnitt gelost werden.
Beweis. Wegen der Annahmen an die Wahrscheinlichkeitsverteilung konnen wirohne Einschrankung davon ausgehen, dass die Daten in allgemeiner Lage sind. Sei-en z1, . . . ,zt die Basislosungen von Ax≤ b , also alle Ecken des Hyperebenenarran-gements, da wir auch unzulassige Basislosungen mitzahlen. Wegen der allgemeinenLage ist t =
(mn
).
Sei nun zunachst L die Klasse der beschrankten LPs, die man aus maxAx≤b c>xdurch Muliplikation einer, eventuell leeren, Teilmenge der Ungleichungen und/oderder Zielfunktion mit −1 erhalt. Dann ist |L | = 2t , denn jede Ecke ist Opti-mallosung fur genau jeweils ein LP mit Zielfunktion c und eines mit Zielfunktion−c . Diese geometrisch sofort einsichtige Tatsache kann man, wie folgt algebraischbeweisen:
Ist zi eine solche Ecke, so ist rg(Aeq(zi).) = n , also ist c Linearkombination derZeilen von Aeq(zi). . Wegen der allgemeinen Lage der Daten ist die Linearkombina-tion eindeutig und alle Zeilen treten mit nicht verschwindenden Koeffizienten λ j
auf. Mit den Argumenten aus dem Beweis von Proposition 6.4.1 erhalten wir ein

214 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
lineares Programm, zu dem zi mit Zielfunktion c Optimallosung ist, indem wir dieUngleichungen in eq(zi) zu den λ j , die mit negativem Vorzeichen auftreten, mit−1 multiplizieren. Genauso ist zi Optimallosung des Problems mit Zielfunktion−c , wenn wir die Ungleichungen, bei denen die λ j positiv sind, mit −1 multipli-zieren. Weitere Programme in unserer Klasse kann es auf Grund der Eindeutigkeitder Linearkombination und Proposition 6.4.1 nicht geben.
Es sollte Sie nicht irritieren, dass sich die Anzahl der beschrankten linearenProgramme nicht mit der Anzahl der beschrankten Zellen aus (6.10) deckt. Dasliegt daran, dass ein lineares Programm auch dann beschrankt sein kann, wenn esder zulassige Bereich nicht ist.
Wir wollen nun die Kanten untersuchen. Hier interessiert uns vor allem die Fra-gestellung, wie oft eine feste Kante von einem der betrachteten linearen Program-me vom Simplexalgorithmus unter Verwendung der Schatteneckenregel durchlau-fen wird. Die Kanten und Extremalen erhalten wir wegen der allgemeinen Lage,indem wir in n−1 der Ungleichungen Gleichheit fordern. Globaler betrachten wirdie
( mn−1
)1-dimensionalen affinen Unterraume des Kn , die man aus dem System
(A,b) durch Gleichsetzen von n−1 Ungleichungen erhalten kann. Jeder dieser af-finen Unterraume enthalt m−n+1 der zi , also m−n Kanten und zwei Extremalen.
Sind zi und z j benachbarte Ecken auf einer solchen affinen Geraden, so behaup-ten wir:
Die Strecke ziz j wird von hochstens einem LP aus L durchlaufen.
Ist namlich maxAx≤b c>x ein solches Programm, so gibt es wegen Propositi-on 6.4.2 ein λ > 0, so dass
ziz j = x ∈ Rn | Ax≤ b,(c+λ c)>x = (c+λ c)>zi
und es gilt (c+ λ c)>x ≤ (c+ λ c)>zi fur alle x ∈ P(A, b) . Wegen der allgemei-nen Lage sind alle bis auf n− 1 Ungleichungen im Inneren von ziz j strikt, alsofestgelegt. Da das Programm auf der Strecke ziz j optimal, also konstant, ist, undrg(Aeq(ziz j).) = n− 1 ist, muss c+λc Linearkombination der Zeilen von Aeq(ziz j).
sein. Also liefern uns, analog zum Fall der Ecken, die Koeffizienten der Darstellungvon c+λ c als Linearkombination der Zeilen von Aeq(ziz j). mittels Proposition 6.4.1die Richtung der Ungleichung auf eq(ziz j). Diese Kante wird folglich in hochstenseinem Programm aus L durchlaufen. Beachte, c+λc ist zwar hier nicht mehr inallgemeiner Lage, aber wegen der allgemeinen Lage von c und c darf keiner der

6.4. Die mittlere Laufzeit des Simplexalgorithmus 215
n− 1 Koeffizienten in der Linearkombination, die diesen Vektor in den Zeilen derKantengleichungen darstellt, verschwinden.
Analog wird jede Extremale von hochstens einem Programm in L betreten.Von den zwei Extremalen einer dieser affinen Geraden entfallt eine wegen c>y > 0,denn wie im Beweis von Proposition 6.4.3 schließen wir zunachst (λ ′−λ )c>y < 0und somit gilt wegen λ ′ > λ fur einen gefundenen Strahl c>y < 0.
Fassen wir die Resultate zusammen. Wir betrachten alle linearen Programmedie durch die Daten A,b,c definiert werden. Das sind mehr als |L | = 2
(mn
), die
Anzahl der beschrankten linearen Programme. Jede der (m− n)( m
n−1
)Kanten des
Hyperebenenarrangements wird fur hochstens ein lineares Programm bei Verwen-dung des Schatteneckenalgorithmus durchlaufen. Das gleiche gilt fur
( mn−1
)Extre-
malen. Also ist die durchschnittliche Anzahl an Iterationen eines LP in L nachoben beschrankt durch
(m−n+1)( m
n−1
)|L |
=
(m−n+1)m!(m−n+1)!(n−1)!
2 m!n!(m−n)!
=m!n!(m−n)!
2(m−n)!(n−1)!m!
=n2.
2
Wie versprochen geben wir nun noch Resultate fur weitere Klassen von LPsohne Beweis an.
6.4.6 Satz (Haimovich 1983). Sei A ∈Rm×n,b ∈Rm,c ∈Rn . Dann gelten folgendeobere Schranken fur Erwartungswerte an die Anzahl der Iterationen fur das Sim-plexverfahren mit der Schatteneckenregel, jeweils mit den obigen Verteilungsannah-men
i)(
2n+
2m+1
)−1
fur die Problemklasse maxc>x | Ax≤ b, x≥ 0 ,
ii)(
2n+
2m−n+1
)−1
fur die Problemklasse maxc>x | Ax≤ b ,
iii)(
2n−m
+2
m+1
)−1
fur die Problemklasse maxc>x | Ax = b, x≥ 0 .

216 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Beweis. siehe Mordecai Haimovich, “The Simplex Algorithm Is Very Good!: Onthe Expected Number of Pivot Steps and Related Properties of Random Linear Pro-grams” (February 1996). Discussion Paper 99, Center for Rationality and InteractiveDecision Theory, The Hebrew University of Jerusalem. 2
6.4.7 Bemerkung. Goldfarb [9] gab 1983 ein Beispiel an, dass Borgwardts Schat-teneckenalgorithmus auch keine polynomiale Pivotregel liefert.
6.4.8 Beispiel. Wir losen das folgende lineare Programm mit dem Schatteneckenal-gorithmus. Maximiere
−2ξ1 +ξ2 +ξ3
unter der Bedingungξ1 − ξ2 + ξ3 ≤ 2−ξ1 + ξ2 + ξ3 ≤ 2
ξ1,ξ2,ξ3 ≥ 0.
Als Startecke sei (0,0,0)> gegeben und als Kozielfunktion
minξ1 +ξ2 +ξ3.
Das ergibt dann das Startableau
−2 1 1 0 0 0−1 −1 −1 0 0 0
1 −1 1 1 0 2−1 1 1 0 1 2.
Wir addieren nun vorsichtig ein Vielfaches der eigentlichen Zielfunktion zur Ko-zielfunktion, bis ein Eintrag der reduzierten Kosten Null wird.
Bei der Anwendung der Schatteneckenregel tritt Entartung in der Wahl desneuen Basiselementes auf, die Daten sind auch offensichtlich nicht in allgemeinerLage. Wir entscheiden uns fur die zweite Spalte. Das nachste Tableau ist dann, daλ = 1 ist
−1 0 0 0 −1 −2−3 0 0 0 0 0
0 0 2 1 1 4−1 1 1 0 1 2
und die Ecke ist nun auch optimal bzgl. der Ausgangszielfunktion. Also ist(0,2,0)> eine Optimallosung und der Optimalwert 2.

6.5. Dantzig-Wolfe Dekomposition 217
6.4.9 Bemerkung. Zu Beginn dieses Jahrtausends haben Spielmann und Teng [22]eine weitere Analysevariante der Komplexitat des Simplexalgorithmus vorgestellt,die ein Mittelding zwischen worst-case-Komplexitat und mittlerer Laufzeit bildensoll. Dabei werden die linearen Programme und lokal perturbiert und die Laufzeituber die Umgebungen gemittelt und dann das Supremum aller dieser Werte ge-bildet. Dieses Modell teilt mit dem oben ausgefuhrten das Problem, dass entarteteProgramme im Wesentlichen nicht berucksichtigt werden.
6.5 Dantzig-Wolfe Dekomposition
Zum Abschluss dieses Kapitels wollen wir noch eine Dekompositionstechnik vor-stellen. Oftmals hat man es mit linearen Optimierungsproblemen zu tun, bei denenein Teilproblem gutartig ist. Eventuell kennt man fur dieses sogar einen streng po-lynomialen Algorithmus.
Wir wollen hier Lineare Programme betrachten, bei denen ein Teil der Restrik-tionsmatrix eine einfache Struktur hat, also von dem Typ
max c>xunter
(AD
)x =
(bd
)x ≥ 0.
Zusatzlich nehmen wir an, dass das Polyeder P= x∈Rn+ |Dx= d beschrankt
ist, und die Menge seiner Ecken bekannt ist oder zumindest leicht zu bestimmen ist,etwa weil das Teilproblem streng polynomial losbar ist. Wir bezeichnen die Eckendieses Teilproblems mit v1, . . . ,vt . Dann konnen wir das Programm umschreibenzu:
max ∑ti=1 λic>vi
(T) unter ∑ti=1 λiAvi = b
∑ti=1 λi = 1
λ ≥ 0.
Da ublicherweise die Anzahl der Ecken des Unterproblems zu groß ist, als dassman dieses Programm explizit losen konnte, werden wir versuchen, die ”richtigen“Ecken dafur auszuwahlen. Beachte, dass in obigem Problem die Spalten der Restrik-tionsmatrix das Aussehen
(Avi1
)haben und die λi die Variablen sind. Eine Basis ist
also gegeben durch m+1 Ecken vi . Schreiben wir die ((m+1)× t)-Matrix, derenSpalten die
(Avi1
)sind als A , und den analogen Kostenvektor als c ∈Rt , nennen die

218 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Basis B und betrachten wir unser Optimalitatskriterium, so lautet dieses
c>− c>B A−1.B A≤ 0.
Den Teil c>B A−1.B der reduzierten Kosten kennen wir auch als Dualvariablen zu den
Restriktionen des Programms, wir konnen sie mit der Basis als bekannt annehmen.Eine dieser Dualvariablen gehort zu der Restriktion ∑
ti=1 λi = 1, nennen wir diese
α und die ubrigen w , so konnen wir (w>,α) = c>B A−1.B als bekannt annehmen. Das
Optimalitatskriterium konnen wir dann uberprufen, indem wir
tmaxi=1
c>vi− (w>,α)
(Avi
1
)bestimmen, wobei α eine, von Subproblem zu Subproblem variierende Konstanteist. Hierfur haben wir also das lineare Teilproblem
max c>x−w>Axunter Dx = d
x ≥ 0
zu losen. Dies ist auf Grund der angenommenen einfachen Struktur des Teilpro-blems leicht und wir konnen durch einen Schritt des revidierten Simplexverfahrenseine Spalte mit positiven reduzierten Kosten neu in die Basis aufnehmen. Da dasSubproblem und somit auch das gesamte Problem beschrankt ist, konnen wir einbasisverlassendes Element bestimmen und iterieren so lange, bis die Losung desTeilproblems beweist, dass die aktuelle Basis optimal fur das Gesamtproblem ist.Wir fassen zusammen:
Schematische Skizze des Dekompositionsverfahrens nach Dantzig-Wolfe:
Eingabedaten: A ∈ Rm×n mit vollem Zeilenrang, Y ∈ Rn×k , ein Polytop X =
Conv(Y ) , b ∈ Rm,b≥ 0, A.B =(AY
1
)als zulassige Basis, c ∈ Rn .
Berechne die Dualvariablen (w>,α) und vk ∈ argmaxx∈X c>x−w>Ax.
Solange c>vk−w>Avk > α :
Zeilenwahl: Bestimme basisverlassendes Element v j als Argument von
min
(
A−1.B(b
1
))r(
A−1.B(Avk
1
))r
|(
A−1.B
(Avk
1
))r> 0
.

6.5. Dantzig-Wolfe Dekomposition 219
Basiswechsel: Nehme vk in die Basis auf und entferne v j .
Spaltenwahl: Berechne die Dualvariablen (w>,α) und
vk ∈ argmaxx∈X
c>x−w>Ax.
6.5.1 Bemerkung. i) Unter Berucksichtigung der Transformation des Teilpro-blems handelt es sich um eine direkte Implementierung des revidierten Sim-plexalgorithmus fur das Problem (T ) , bei der die Berechnung der reduzier-ten Kosten ausgelagert wurde. Unter der Annahme, dass kein Zykeln auftritt(oder durch Maßnahmen wie Zykelerkennung und Perturbation oder ande-re Methoden verhindert wird), folgt sofort Endlichkeit und Korrektheit desAlgorithmus.
ii) Man nennt diese Methode auch “Column Generation”, da in jedem Schritt dieSpalte der Matrix fur die neue Basisvariable erst erzeugt werden muss.
iii) Bei der Losung des Teilproblems andern sich jeweils nur die Dualvariablendes Masterproblems und damit die Kostenfunktion. Dies ermoglicht bei man-chen Teilproblemen einen ”Warmstart“.
iv) Es ist nicht unbedingt notig, in jedem Schritt das Teilproblem bis zur Opti-malitat zu losen, da es genugt, eine Variable mit positiven reduzierten Kostenzu bestimmen.
Vor einem numerischen Beispiel wollen wir noch eine obere Schranke fur dieBerechnungen bestimmen. Auf Grund der Vielzahl an Variablen kann es sein, dassdie Bestimmung einer Optimallosung des Problems zu aufwandig erscheint undman stattdessen mit einer gewissen garantierten Qualitat der Losung zufriedenist. Da das Verfahren stets zulassige Losungen produziert, die also somit eineuntere Schranke fur die Optimallosung sind, ware das also der Fall, wenn derUnterschied zwischen unterer und oberer Schranke (absolut oder relativ) einengewissen Schwellwert unterschreitet.
6.5.2 Proposition. Sei w die Menge der Dualvariablen zu einer Basis B desProblems und k Index einer Optimallosung des zugehorigen Teilproblems. Dannist
maxAx=bx∈X
c>x≤ cBA−1.B
(b1
)+ c>vk−w>Avk−α.

220 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Beweis.
c>vk−w>Avk−αvk opt.≥ c>x−w>Ax−α
⇐⇒ c>x ≤ w>Ax−w>Avk + c>vk
⇐⇒ c>x ≤ w>b−w>Avk + c>vk
⇐⇒ c>x(w,α)=cBA−1
.B≤ cBA−1
.B
(b1
)−α−w>Avk + c>vk.
2
Da cBA−1.B(b
1
)der Zielfunktionswert der aktuellen Losung ist und c>vk−w>Avk
bis auf α der Zielfunktionswert des Teilproblems ist, kann man den Unterschiedzwischen oberer und unterer Schranke leicht berechnen, bzw. kommt dieser in denBerechnungen sowieso vor.
6.5.3 Beispiel. Wir betrachten das Problem
max 2x1 + x2 + x3 − x4
unter x1 + x3 ≤ 2x1 + x2 + 2x4 ≤ 3x1 ≤ 2x1 + 2x2 ≤ 5
− x3 + x4 ≤ 22x3 + x4 ≤ 6
x ≥ 0
Die letzten vier Restriktionen haben eine einfache Struktur, da die dritte und vierteRestriktion nur x1 und x2 und die funfte und sechste Restriktion nur x3 und x4
betreffen. Wir setzen also
X :=
x ∈ R4
∣∣∣∣∣∣∣∣∣∣∣∣
x1 ≤ 2x1 + 2x2 ≤ 5
− x3 + x4 ≤ 22x3 + x4 ≤ 6
x ≥ 0.
Dann ist X das Kartesische Produkt der beiden zweidimensionalen Polygone inAbbildung 6.2. Also ist X ein vierdimensionales Polytop mit 16 Ecken v1, . . . ,v16 .
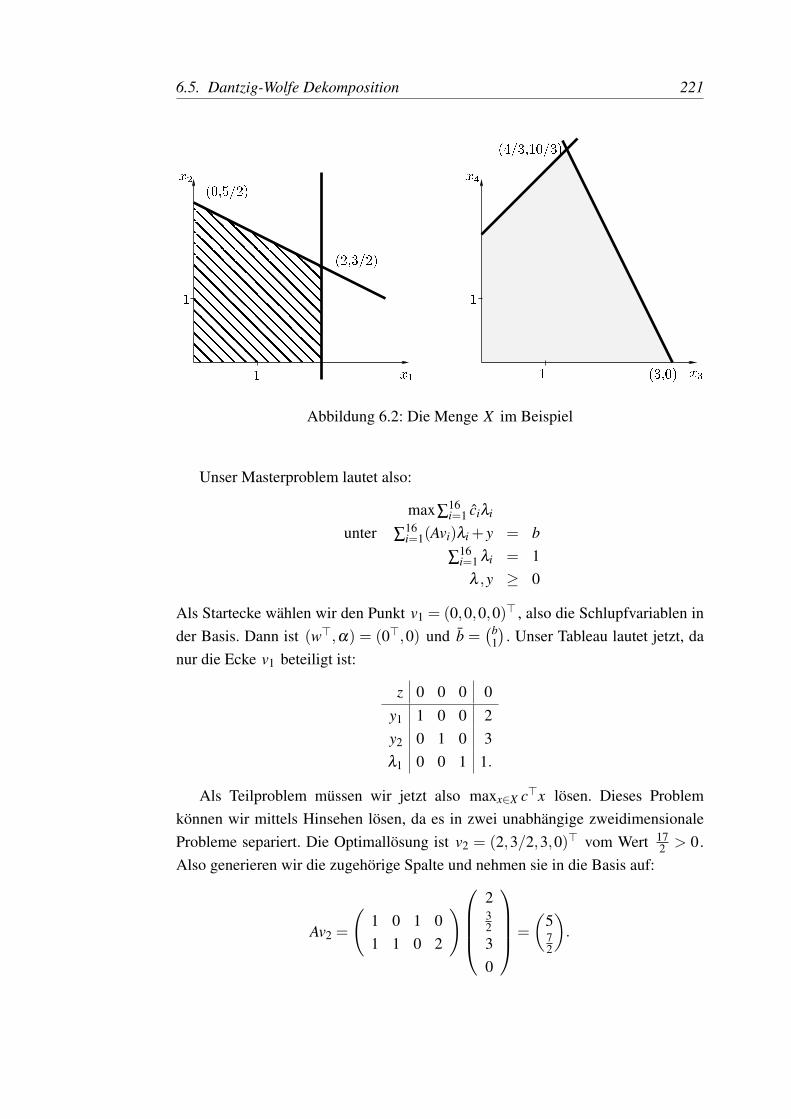
6.5. Dantzig-Wolfe Dekomposition 221
Abbildung 6.2: Die Menge X im Beispiel
Unser Masterproblem lautet also:
max∑16i=1 ciλi
unter ∑16i=1(Avi)λi + y = b
∑16i=1 λi = 1
λ ,y ≥ 0
Als Startecke wahlen wir den Punkt v1 = (0,0,0,0)> , also die Schlupfvariablen inder Basis. Dann ist (w>,α) = (0>,0) und b =
(b1
). Unser Tableau lautet jetzt, da
nur die Ecke v1 beteiligt ist:
z 0 0 0 0y1 1 0 0 2y2 0 1 0 3λ1 0 0 1 1.
Als Teilproblem mussen wir jetzt also maxx∈X c>x losen. Dieses Problemkonnen wir mittels Hinsehen losen, da es in zwei unabhangige zweidimensionaleProbleme separiert. Die Optimallosung ist v2 = (2,3/2,3,0)> vom Wert 17
2 > 0.Also generieren wir die zugehorige Spalte und nehmen sie in die Basis auf:
Av2 =
(1 0 1 01 1 0 2
)23230
=
(572
).

222 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Somit ist, da A.B die Einheitsmatrix ist, unsere neue Spalte (172 ,5,
72 ,1)
> .
z 0 0 0 0 172
y1 1 0 0 2 5y2 0 1 0 3 7
2λ1 0 0 1 1 1
Wir lesen als obere Schranke 172 −0 = 8.5 ab. Der Minimalquotiententest identifi-
ziert 5 als Pivotelement und wir erhalten als neues Tableau:
z −1710 0 0 −17
5
λ215 0 0 2
5y2 − 7
10 1 0 85
λ1 −15 0 1 3
5
Dies gehort zu der Losung 35(0,0,0,0)
>+ 25(2,
32 ,3,0)
> = 15(4,3,6,0)
> mit Ziel-funktionswert 17
5 = 3.4. Wir haben (w1,w2,α) = (1710 ,0,0) .
Also berechnen wir als Zielfunktion fur das Teilproblem
(2,1,1,−1)− (1710
,0)
(1 0 1 01 1 0 2
)= (
310
,1,− 710
,−1).
Als Losung unseres Teilproblems lesen wir aus Abbildung 6.2 v3 = (0, 52 ,0,0)
>
mit Zielfunktionswert 52 ab und berechnen
Av3 =
(052
).
Wir berechnen
A−1.B
(Av3
1
)=
15 0 0
− 710 1 0−1
5 0 1
0
521
=
0521
.
Somit ist unsere neue Spalte (52 ,0,
52 ,1)
> .
z −1710 0 0 −17
552
λ215 0 0 2
5 0y2 − 7
10 1 0 85
52
λ1 −15 0 1 3
5 1
Wir lesen als obere Schranke ab 52 +
175 = 5.9 ab und nach dem Pivot erhalten
wir:

6.5. Dantzig-Wolfe Dekomposition 223
z −65 0 −5
2 −4910
λ215 0 0 2
5y2 −1
5 1 −52
110
λ3 −15 0 1 3
5 .
Hierzu gehort die Losung
25(2,
32,3,0)>+
35(0,
52,0,0)> = (
45,2110
,65,0)>
mit Zielfunktionswert 4910 = 4.9. Wir berechnen die Zielfunktion des Teilproblems
(2,1,1,−1)− (65,0)
(1 0 1 01 1 0 2
)= (
45,1,−1
5,−1)
und lesen als Optimallosung v4 = (2, 32 ,0,0)
> ab. Da α = 52 ist, haben wir immer
noch positive reduzierte Kosten, namlich 85 +
32 −
52 = 3
5 . Wir berechnen
Av4 =
(1 0 1 01 1 0 2
)23200
=
(272
)
und
A−1.B
(Av4
1
)=
15 0 0−1
5 1 −52
−15 0 1
2
721
=
253535
.
Somit ist unsere neue Spalte (35 ,
25 ,
35 ,
35)> .
z −65 0 −5
2 −4910
35
λ215 0 0 2
525
y2 −15 1 −5
2110
35
λ3 −15 0 1 3
535 .
Wir lesen als obere Schranke ab 35 +
4910 = 11
2 = 5.5. Man beachte, dass diereduzierten Kosten der generierten Spalte stets die Differenz zwischen aktuellembesten Zielfunktionswert und oberer Schranke darstellen. Nach dem Pivot erhaltenwir.
z −1 −1 0 −5λ2
13 −2
353
13
λ4 −13
53 −25
616
λ3 0 −1 72
12

224 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Abbildung 6.3: Obere und untere Schranke
Hierzu gehort die Losung
13(2,
32,3,0)>+
12(0,
52,0,0)>+
16(2,
32,0,0)> = (1,2,1,0)>
mit Zielfunktionswert 5 und wir lesen ab (w>,α) = (1,1,0) . Wir berechnen dieZielfunktion des Teilproblems
(2,1,1,−1)− (1,1)
(1 0 1 01 1 0 2
)= (0,0,0,−3)
und lesen als Losung des Teilproblems v5 = (0,0,0,0)> ab. Da α = 0 ist, habenwir Optimalitat in der Ecke (1,2,1,0)> erreicht. In Abbildung 6.3 haben wir dieEntwicklung von Zielfunktion und oberer Schranke aus Proposition 6.5.2 geplottet.
6.5.4 Bemerkung. i) Eine zulassige Startlosung kann man, ahnlich wie beimgewohnlichen Simplex, mittels Zweiphasen- oder Big-M -Methode bestim-men.
ii) Im Falle eines unbeschrankten Bereiches X muss man das Verfahren somodifizieren, dass Punkte in X = Conv(V )+Cone(E) generiert werden.
6.6 Anhang: Die Landau-Symbole
Bei der Abschatzung von Laufzeiten von Algorithmen oder bei der Messung vonKonvergenzgeschwindigkeiten benutzt man ublicherweise die Landau-Symbole.

6.6. Anhang: Die Landau-Symbole 225
Damit kann man auf bequeme Weise Aussagen uber das asymptotische Verhaltenreeller Folgen machen, wobei wir z.B. ganzzahlige Folgen als Spezialfalle reellerFolgen betrachten.
Wir werden hier etwas ausfuhrlicher auf die Abschatzung nach oben, die alsBig-Oh-Notation bekannt ist, eingehen und die anderen Symbole am Schluß nurdefinieren.
6.6.1 Definition. Seien f ,g : N→ R Abbildungen. Dann schreiben wir
f = O(g)
oderf (n) = O(g(n)),
wenn es eine Konstante C und einen Startpunkt n1 ∈N gibt, so dass fur alle n ∈N ,n≥ n1 , gilt | f (n)| ≤Cg(n) .
Vorsicht! Die ”Big-Oh“-Notation liefert nur eine Abschatzung nach oben, nichtnach unten. Zum Beispiel ist n = O(n5) . Insbesondere ist das hier benutzte Gleich-heitszeichen nicht kommutativ. Diese Schreibweise ist aber allgemein ublich unddeswegen verwenden wir sie ebenso.
Folgende Zusammenhange sind nutzlich bei Abschatzungen (z. B. auch vonLaufzeiten von Algorithmen).
6.6.2 Proposition. Seien C,a,α,β > 0 feste reelle, positive Zahlen unabhangig vonn. Dann gilt
i) α ≤ β ⇒ nα = O(nβ ) ,
ii) a > 1⇒ nC = O(an) ,
iii) α > 0⇒ (lnn)C = O(nα) .
Beweis.
i) Wir haben zu zeigen, dass nα ≤Cnβ zumindest ab einem gewissen n0 gilt.Da aber nβ = nα nβ−α︸ ︷︷ ︸
≥1
haben wir sogar stets nα ≤ nβ mit der Konstanten
C = 1.
ii) Wir betrachten die Folge
an :=(
nn−1
)C
.

226 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Nach den Grenzwertsatzen und wegen der Stetigkeit der Exponentialfunktionist limn→∞ an = 1. Da a > 1 ist, gibt es fur ε = a−1 ein n1 ∈ N , so dass furalle n≥ n1 gilt |an−1|< ε = a−1, also insbesondere
∀n≥ n1 : an = an−1+1≤ |an−1|+1 < a−1+1 = a.
Nun setzen wir
C1 :=nC
1an1
und zeigennC ≤C1an (6.12)
mittels vollstandiger Induktion fur n≥ n1 . Zu Anfang haben wir
nC1 =C1an1.
Sei also n > n1 . Dann ist unter Ausnutzung der Induktionsvoraussetzung undwegen an ≤ a
nC =
(n
n−1
)C
(n−1)C = an(n−1)CIV≤ anC1an−1
an≤a≤ aC1an−1 =C1an.
Also gilt (6.12) fur n≥ n1 , also per definitionem nC = O(an) .
iii) Wir setzen a := eα . Dann ist a > 1 und wir wahlen n1 und C1 wie eben. Fer-ner wahlen wir n2 mit ln(n2)≥ n1 . Indem wir die Monotonie und Stetigkeitdes Logarithmus ausnutzen, erhalten wir fur n≥ n2 nach b)
(lnn)C ≤ C1alnn
⇐⇒ (lnn)C ≤ C1(elna)lnn =C1(elnn)lna =C1nlna
⇐⇒ (lnn)C ≤ C1nα .
2
Wir merken uns, dass Logarithmen langsamer wachsen als Wurzel- und Poly-nomfunktionen und diese wiederum langsamer als Exponentialfunktionen.
6.6.3 Beispiel. Wenn man eine Formelsammlung zur Hand hat, schlagt man nach(und beweist mittels vollstandiger Induktion), dass
n
∑i=1
i3 =n2(n+1)2
4. (6.13)

6.6. Anhang: Die Landau-Symbole 227
Hat man keine Formelsammlung zur Hand, ist die Herleitung dieser Formel rechtmuhselig. Darum schatzen wir ab: Zunachst ist ∑
ni=1 i3 ≤ ∑
ni=1 n3 = n4 . Außerdem
ist ∑ni=1 i3≥∑
ni=b n
2 c(n
2
)3≥ n4
16 . Also verhalt sich die Summe ”bis auf einen konstan-
ten Faktor“ wie n4 .
Im Falle des Beispiels ist n4 nicht nur eine obere, sondern auch eine untereSchranke. Auch dafur gibt es Symbole wie z. B.
f (n) = o(g(n)) :⇔ limn→∞f (n)g(n) = 0, also wachst f echt langsamer als g ,
f (n) = Ω(g(n)) :⇔ g(n) = O( f (n)) , g(n) ist eine untere Schranke fur f (n) furgroße n ,
f (n) = Θ(g(n)) :⇔ f (n) = O(g(n)) und f (n) = Ω(g(n)) , also verhalten sich fund g ”bis auf einen konstanten Faktor“ asymptotisch gleich, genauer gibt esc1,c2 > 0 und n0 ∈ N mit
∀n≥ n0 : c1g(n)≤ f (n)≤ c2g(n).
f (n)∼ g(n) :⇔ limn→∞f (n)g(n) = 1, wie eben, aber ”exakt“ mit Faktor 1.

228 Kapitel 6. Zur Komplexitat des Simplexalgorithmus

6.7. Losungsvorschlage zu den Ubungen 229
6.7 Losungsvorschlage zu den Ubungen
6.7.1 Losung (zu Aufgabe 6.1.2).Eingangsgroßen sind fur uns A ∈ Zm×n,b ∈ Zm,c ∈ Zn . Das sind mn + m + nZahlen. Also ist
I(w) = mn+m+n = O(nm).
Fur die andere Maßgroße setzen wir zunachst
C = max|Ai j|, |c j|, |bi| | 1≤ i≤ m,1≤ j ≤ n
+1.
Dann ist
〈w〉 =m
∑i=1
n
∑j=1
(1+ dlog2(|Ai j|+1)e)+m
∑i=1
(1+ dlog2(|bi|+1))
+n
∑j=1
(1+ dlog2(|c j|+1)e)
= O(log2(C+1)mn).
6.7.2 Losung (zu Aufgabe 6.1.3).Sei C der Betrag der großten in den Berechnungen auf w vorkommenden Zahl plus1. Dann ist
〈w〉= O(log2(C)I(w)).
Sei nk ein Polynom, das asymptotisch eine obere Schranke fur die Anzahl derelementaren Rechenoperationen des streng polynomialen Algorithmus liefert, alsomit
tsM(n) = O(nk).
Sei nl ein Polynom, das asymptotisch eine obere Schranke fur die Rechenzeit derelementaren Rechenoperationen liefert. Dann ist
tM(n) = tM(< w >)
≤ tM((1+ dlog2(C)e)I(w))= O((1+ dlog2(C)e)klI(w)k)
= O(nk+kl).
ein Polynom, das die Laufzeit des Algorithmus begrenzt.

230 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
Man beachte, dass in dieser Schreibweise der O-Notation die Gleichheit nichtkommutativ ist. So ist etwa O(nk) = O(nk+1) , aber O(nk+1) 6= O(nk) . Manche Au-toren ersetzen daher das Gleichheitssymbol durch ein Element oder Inklusionssym-bol, da es sich auf der rechten Seite streng genommen um eine Funktionenklassehandelt. Wir verwenden hier die ublichere, aber unsauberere Schreibweise.
6.7.3 Losung (zu Aufgabe 6.2.7).Wir zeigen zunachst, dass der euklidische Algorithmus zur Bestimmung des
großten gemeinsamen Teilers zweier Zahlen a1,a2 ∈ N nach hochstens
2dmaxlog2(a1), log2(a2)e+1
Iterationen terminiert.Seien dazu a1,a2 ∈ N gegeben, auch alle weiteren ai,qi seien stets positive
naturliche Zahlen. O.E. sei a1 > a2 , andernfalls fuhrt die erste Iteration des eukli-dischen Algorithmus eine Vertauschung der Elemente durch oder der Algorithmusterminiert, da a1 = a2 ist.
Seien im Folgenden dann fur 1≤ i≤ k−1 die Zahlen 0 < ai+2 < ai+1 definiertdurch ai = qiai+1 + ai+2 und ak = qkak+1 . Dann ist bekanntlich ak+1 der großtegemeinsame Teiler von a1 und a2 . Wir behaupten nun
∀i = 1, . . . ,k−1 : ai+2 <12
ai.
Wenn wir zusatzlich ak+2 := 0 setzen, haben wir namlich
ai = qiai+1 +ai+2
= qi(qi+1ai+2 +ai+3)+ai+2
= (qiqi+1 +1)ai+2 +qi+1ai+3
> 2ai+2.
Die großte vorkommende Zahl halbiert sich also alle zwei Iterationen. Wenn wir al-so 2dlog2(a1)e Iterationen benotigen wurden, ware die großte vorkommende posi-tive naturliche Zahl, die wir dann betrachten kleiner als 1. Aus diesem Widerspruchschließen wir, dass k < 2dlog2(a1)e ist. Nehmen wir noch die eine Iteration zureventuellen Vertauschung der Startziffern hinzu, erhalten wir die Behauptung.
Nun zur Behauptung, dass der euklidische Algorithmus kein streng polynomia-ler Algorithmus ist. Da die Eingabe stets aus 2 Zahlen besteht, ist dies gleichbedeu-tend damit, dass die Anzahl der Iterationen des Algorithmus nicht beschrankt ist.Dafur betrachten wir die Folge der Fibonaccizahlen definiert durch
F0 = 0 F1 = 1 Fn = Fn−1 +Fn−2 fur n≥ 2

6.7. Losungsvorschlage zu den Ubungen 231
und zeigen mittels vollstandiger Induktion uber n≥ 1:
Bei Eingabe von Fn+2 und Fn+1 benotigt der euklidische Algorithmusn Iterationen.
Fur n = 1 haben wir F3 = 2 und F2 = 1 und der Algorithmus terminiert nach derersten Iteration:
Sei also n > 1. Dann berechnet der euklidische Algorithmus in der erstenIteration
Fn+2 = 1 ·Fn+1 +Fn
und fahrt mit Fn+1 und Fn fort. Dafur benotigt er nach Induktionsvoraussetzungn−1 weitere Schritte, woraus die Behauptung mit dem Induktionsprinzip folgt.
6.7.4 Losung (zu Aufgabe 6.3.4).
i) Da der zulassige Bereich von (LPn) offensichtlich beschrankt ist, ist der Li-nearitatsraum leer und insbesondere hat jede Seitenflache eine Ecke. Hierausfolgt, dass die Gleichheitsmenge einer Seitenflache aus einer Teilmenge derUngleichungen und Vorzeichenrestriktionen bestehen muss, deren Indizesdisjunkt sind. Somit ist die Bedingung notwendig.
Betrachten wir umgekehrt eine Partition der Indizes in Ungleichungen undVorzeichenrestriktionen, so ist dies nach Satz 6.3.2 die Gleichheitsmengeeiner Ecke v . Da die Ecke v Dimension Null hat und das Polyeder Dimensionn hat, muss jede der k -elementige Teilmenge der Gleichheitsmenge eine(n− k)-dimensionale Seitenflache definieren. Also ist die Bedingung auchhinreichend.
ii) Nach dem vorherigen Teil entsprechen die Seitenflachen des zulassigen Be-reichs von (LPn) bijektiv, den Vektoren in 1,0,∗ , wobei 1 in der i-tenKoordinate bedeutet, dass die i-te Ungleichung in der Gleichheitsmenge ist,0, dass die i-te Vorzeichenrestriktion in der Gleichheitsmenge ist und ∗ , dasskeine von beiden dazu gehort.
Der Verband auf diesen Vektoren, der durch die Relationen 0≤ ∗ und 1≤ ∗induziert wird, ist offensichtlich sowohl zum Seitenflachenverband des Klee-Minty-Cubes (LPn) als auch zu dem von Hn isomorph. Die Behauptung folgtalso aus der Transitivitat der Isomorphie.
6.7.5 Losung (zu Aufgabe 6.3.9).Wir betrachten ein Tableau zu (LPn), bei dem allerdings die Spalten so umsortiert

232 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
sind, dass Spalten zu echten Variablen und Schlupfvariablen alternieren. Dies andertoffensichtlich nichts an der Gultigkeit von 6.3.1, 6.3.2, 6.3.3 und 6.3.5.
Wir gehen nun vor wie im Beweis von Satz 6.3.6. Die Induktionsverankerungkonnen wir identisch ubernehmen. Zu untersuchen bleibt also der Induktionsschritt.
Beachten Sie, dass die Ordnung der Variablen nur fur die Pivotauswahl gilt.In der folgenden Darstellung behalten wir, außer im relevanten letzten Index, dieSortierung der Spalten zu echten und Schlupfvariablen aus Grunden der Ubersicht-lichkeit wie bei der Dantzigschen Gradientenregel bei.
Sei n > 1. Nach Induktionsannahme haben das erste und das 2n−1 -te Tableauvon LPn−1 folgende Gestalt
c 0 1 0 0A In−2 0 0 b
2c 0 1 1 5n−1
Tableau 1
−c 0 0 −1 −5n−1
A In−2 0 0 b2c 0 1 1 5n−1
Tableau 2n−1
Wieder betrachten wir Tableaus fur das Problem LPn .
2c 0 2 0 1 0 0A In−2 0 0 0 0 b
2c 0 1 1 0 0 5n−1
4c 0 4 0 1 1 5n
Tableau 1
−2c 0 0 −2 1 0 −2 ·5n−1
A In−2 0 0 0 0 b2c 0 1 1 0 0 5n−1
−4c 0 0 −4 1 1 5n−1
Tableau 2n−1
2c 0 0 2 0 −1 −3 ·5n−1
A In−2 0 0 0 0 b2c 0 1 1 0 0 5n−1
−4c 0 0 −4 1 1 5n−1
Tableau 2n−1 +1
−2c 0 0 −2 1 0 5n
A In−2 0 0 0 0 b2c 0 1 1 0 0 5n−1
−4c 0 0 −4 1 1 5n−1
Tableau 2n
Mit der gleichen Argumentation wie bei der Dantzigschen Regel schließen wir,dass die (2n− 1)-ste Spalte in den ersten 2n−1− 1 Schritten nicht zur Pivotspaltewird, also die letzte Zeile auch nicht zur Pivotzeile. Wiederum ist die Pivotwahlidentisch zu der Wahl fur LPn−1 und wir erreichen Tableau 2n−1 und Tableau2n−1 +1 als das darauf Folgende. Auch dieses sieht wieder aus wie ein erweiterteserstes Tableau fur LPn−1 , nur dass wieder zwei Spalten vertauscht sind. Dies andertjedoch nichts an der Pivotwahl, da das Element, was in die optimale Basis gehort,

6.7. Losungsvorschlage zu den Ubungen 233
den großten Index hat. Folglich mussen wir wiederum insgesamt 2n Iterationenvornehmen.
6.7.6 Losung (zu Aufgabe 6.4.4).Wir zeigen dies mittels doppelter vollstandiger Induktion uber d und n . Wir ver-ankern fur d = 1 und n beliebig. Die n Punkte auf der Gerade unterteilen diese inn−1 =
(n−11
)Strecken und zwei Halbstrahlen. Da(
n0
)+
(n1
)= 1+n =
(n−1
1
)+2,
ist die Behauptung auch fur den allgemeinen Fall verankert.Sei nun d > 1. Besteht unser Arrangement H nur aus einer Hyperebene, so ha-
ben wir nur zwei unbeschrankte Zellen, also(0
d
)= 0 beschrankte und
(10
)+(1
1
)= 2
volldimensionale Zellen. Sei also n > 1. Wir betrachten eine feste Hyperebene H .Da die Hyperebenen in allgemeiner Lage sind, also keinerlei Parallelitat auftritt,induziert der Schnitt von H mit den ubrigen Hyperebenen auf H ein (d − 1)-dimensionales Hyperebenarrangement. Nach Induktionsvoraussetzung gilt fur die-ses Arrangement H ′
Lb(H′) =
(n−2d−1
), L(H ′) =
d−1
∑i=0
(n−1
i
).
Außerdem betrachten wir das d -dimensionale Hyperebenenarrangement, H ′′ , dasentsteht, wenn wir H aus H entfernen. Dann gilt nach Induktionsvoraussetzung
Lb(H′′) =
(n−2
d
), L(H ′′) =
d
∑i=0
(n−1
i
).
Wenn wir nun H zu H wieder hinzufugen, entsteht fur jede beschrankte Zelleaus H ′ eine zusatzliche beschrankte Zelle. Durchschneidet H eine beschrankteZelle von H ′′ , so ist dies sofort klar. Durchschneidet sie aber eine unbeschrankteZelle, so muss, da die Schnittflache beschrankt ist, eine der beiden entstehendenZellen beschrankt sein. In beiden Fallen erzeugen wir also genau eine zusatzlichebeschrankte Zelle. Offensichtlich erzeugt jede volldimensionale Zelle in H ′ genaueine zusatzliche volldimensionale Zelle in H gegenuber H ′′ .
Also schließen wir
Lb(H ) = Lb(H′)+Lb(H
′′)
=
(n−2d−1
)+
(n−2
d
)=
(n−1
d
)

234 Kapitel 6. Zur Komplexitat des Simplexalgorithmus
und ebenso
L(H ) = L(H ′)+L(H ′′)
=d−1
∑i=0
(n−1
i
)+
d
∑i=0
(n−1
i
)= 1+
d
∑i=1
((n−1i−1
)+
(n−1
i
))=
(n0
)+
d
∑i=1
(ni
)=
d
∑i=0
(ni
).


















