
Markovketten Monte-Carlo Methodenstochastik.math.uni-goettingen.de/~drudolf/lect/2.pdf ·...
104
Markovketten Monte-Carlo Methoden Dr. Daniel Rudolf 24. September 2015 Dieses Vorlesungsskript basiert auf der Lehrveranstaltung Markovketten Monte-Carlo Methoden, gehalten im Sommersemester 2015 an der Friedrich-Schiller-Universität Jena. Ich bedanke mich herzlich bei Stephan Wolf, der die Bilder erstellte und den Hauptteil des Textsatzes übernahm. Inhaltsverzeichnis 1 Motivation 2 2 Bedingter Erwartungswert und bedingte Verteilung 9 2.1 Bedingter Erwartungswert .................................. 9 2.2 Bedingte Verteilung ..................................... 13 2.3 Bedingte Verteilungsdichten ................................. 15 3 Markovketten 18 3.1 Definitionen und erste Eigenschaften ............................ 18 3.2 Grundlegende Algorithmen ................................. 31 3.2.1 Metropolis-Hastings Algorithmus ....................... 33 3.2.2 Hit-and-run-Algorithmus .............................. 37 3.2.3 Gibbs sampler .................................... 40 3.2.4 Slice sampling .................................... 42 3.3 Markovoperator ........................................ 45 3.4 Klassische Konvergenzeigenschaften von Markovketten ................. 49 4 Markovketten Monte-Carlo Methoden 55 4.1 Fehlerabschätzungen ..................................... 56 4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen ........... 68 4.2.1 Doeblin-Bedingung .................................. 68 4.2.2 Leitfähigkeit und Cheeger-Ungleichung ...................... 70 4.3 Anwendungen und Beispiele ................................. 80 4.3.1 Integration über konvexe Mengen .......................... 80 4.3.2 Integration bezüglich nichtnormierter Dichtefunktion ............... 86 Literatur 103 Index 104 1
Transcript of Markovketten Monte-Carlo Methodenstochastik.math.uni-goettingen.de/~drudolf/lect/2.pdf ·...

Markovketten Monte-Carlo Methoden
Dr. Daniel Rudolf
24. September 2015
Dieses Vorlesungsskript basiert auf der Lehrveranstaltung Markovketten Monte-Carlo Methoden,gehalten im Sommersemester 2015 an der Friedrich-Schiller-Universität Jena. Ich bedanke michherzlich bei Stephan Wolf, der die Bilder erstellte und den Hauptteil des Textsatzes übernahm.
Inhaltsverzeichnis1 Motivation 2
2 Bedingter Erwartungswert und bedingte Verteilung 92.1 Bedingter Erwartungswert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2 Bedingte Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3 Bedingte Verteilungsdichten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Markovketten 183.1 Definitionen und erste Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2 Grundlegende Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.1 Metropolis-Hastings Algorithmus . . . . . . . . . . . . . . . . . . . . . . . 333.2.2 Hit-and-run-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2.3 Gibbs sampler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.2.4 Slice sampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3 Markovoperator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.4 Klassische Konvergenzeigenschaften von Markovketten . . . . . . . . . . . . . . . . . 49
4 Markovketten Monte-Carlo Methoden 554.1 Fehlerabschätzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen . . . . . . . . . . . 68
4.2.1 Doeblin-Bedingung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 684.2.2 Leitfähigkeit und Cheeger-Ungleichung . . . . . . . . . . . . . . . . . . . . . . 70
4.3 Anwendungen und Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.3.1 Integration über konvexe Mengen . . . . . . . . . . . . . . . . . . . . . . . . . . 804.3.2 Integration bezüglich nichtnormierter Dichtefunktion . . . . . . . . . . . . . . . 86
Literatur 103
Index 104
1

1 Motivation
• (Ω,F ,P) Wraum
• Sei G ⊂ Rd beschränkt, d ∈ N, λd d-dimensionales Lebesguemaß und 0 < λ(G)∗<∞
(∗, da G beschränkt)
• B(G) sei die σ-Algebra der Borelmengen (bzgl. Euklidischer Metrik)
• (G,B(G)) messbarer Raum
• f : G→ R messbar mit∫G|f(x)|dx <∞
Ziel: BerechneS(f) = 1
λd(G)
∫G
f(x)dx
(S = Solution-Operator) für f ∈ F(G), wobei
F(G) = g : G→ R : ∫G |g(x)|dx <∞ + weitere Eigenschaften.
Bemerkung 1.1S(f) ist der Erwartungswert (EW) von f bezüglich der Gleichverteilung in G.
Gegebene Informationen / Annahmen:
(i) Wir besitzen eine „black box“ (auch Orakel genannt), die uns Funktionswerte von f liefert, d.h.für jedes x ∈ G können wir nach f(x) fragen.
(ii) Wir nehmen an, dass wir einen Zufallszahlengenerator bezüglich der Gleichverteilung in G besit-zen, d.h. wir haben eine Folge von unabhängig identisch verteilten (iid, bzw. uiv) Zufallsvariablen(ZVen) (Xi)i∈N, wobei
Xi : (Ω,F ,P)→ (G,B(G))
mitPXi(A) = λd(A)
λd(G) , A ∈ B(G).
Und wir können für n ∈ N nach einer Realisierung xi = Xi(ω), i = 1, . . . , n fragen (ω ∈ Ω fest)und erhalten eine Antwort.
Bemerkung 1.2Die zweite Annahme wird meist durch die Transformation von Zufallsvariablen mit „einfachen“ Ver-teilungen sichergestellt.
Beispiel
(i) G = [0, 1]d. Sei x1, . . . , xd ∈ [0, 1] eine Folge von Realisierungen von iid ZVen, die in [0, 1]gleichverteilt sind. Dann ist x = (x1, . . . , xd) ∈ [0, 1]d eine Realisierung der Gleichverteilung inG.
(ii) G = Bd := x ∈ Rd : |x| := (∑di=1 x
2i )1/2 ≤ 1. Wir benötigen folgende Notation:
• Sd−1 = x ∈ Rd : |x| = 1 = ∂Bd die Einheitssphäre (Rand der Einheitskugel)
• σ Oberflächenmaß auf Sd−1
2

• d-dimensionale Polarkoordinaten-Transformationsformel: f : Rd → R sei integrierbar.Dann gilt ∫
Rd
f(x)dx =x=θr
∞∫0
∫Sd−1
f(θr)rd−1σ(dθ)dr.
(siehe [5, Satz 8 in Kapitel 14])
Lemma 1.3Sei X : (Ω,F ,P)→ (Rd,B(Rd)) eine ZV mit rotationsinvarianter Lebesguedichte h : Rd → R, d.h.
∀x, y ∈ Rd : |x| = |y| =⇒ h(x) = h(y).
Desweiteren sei U : (Ω,F ,P)→ ([0, 1],B([0, 1])) eine gleichverteilte ZV in [0, 1], unabhängig von X.Dann gilt P(|X| = 0) = 0 und
(i) P( X|X| ∈ A) = σ(A)
σ(Sd−1) , für A ∈ B(Sd−1) (Gleichverteilung auf der Einheitssphäre).
(ii) P(U1/d X|X| ∈ A) = λd(A)
λd(Bd) , für A ∈ B(Bd) (Gleichverteilung in der Einheitskugel).
Notation: X ∈ A = ω ∈ Ω : X(ω) ∈ A
Beweis: Es gilt P(|X| = 0) = P(X ∈ 0) = 0, da 0 eine Nullmenge bezüglich des Lebesguemaßesist. Im Folgenden beweisen wir die Aussagen (i) und (ii).
(i)
P(X/|X| ∈ A) = E[1X/|X|∈A]
=∫Rd
1A(x/|x|)h(x)dx
=∞∫
0
∫Sd−1
1A(θ)h(θr)rd−1σ(dθ)dr
=∫
Sd−1
1A(θ)σ(dθ) ·∞∫
0
h(θr)rd−1dr (θ ∈ Sd−1 bel. wg. Rotat.inv.)
= σ(A)∞∫
0
h(θr)rd−1dr.
Sei für den Moment A = Sd−1. Dann gilt
1 = σ(Sd−1)∞∫
0
h(θr)rd−1dr.
Dies führt für beliebiges A ∈ B(Sd−1) zu
P(X/|X| ∈ A) = σ(A)σ(Sd−1) .
3

(ii) Es gilt
P(U1/dX/|X| ∈ A) = E[1U1/dX/|X|∈A]
=1∫
0
∫Sd−1
1A(u1/dθ) σ(dθ)σ(Sd−1)︸ ︷︷ ︸
=g(u1/d)
du
=1∫
0
g(u1/d)du =1∫
0
dtd−1g(t)dt
= d
σ(Sd−1)
1∫0
∫Sd−1
1A(tθ)σ(dθ)td−1dt
= d
σ(Sd−1)
∞∫0
∫Sd−1
1A(tθ)σ(dθ)td−1dt
= d
σ(Sd−1)
∫Rd
1A(x)dx = λd(A) · d
σ(Sd−1)
= λd(A)λd(Bd)
,
da λd(Bd) = σ(Sd−1)d .
(Zur Erinnerung: λd(Bd) = πd/2
Γ(d/2+1) , σ(Sd−1) = d πd/2
Γ(d/2+1) , siehe [5, Kapitel 7, unter (7.4)].)
Algorithmus zur Realisierung gleichverteilter ZV in Bd:
(i) Sei x = (x1, . . . , xd) ∈ Rd, wobei die Folge der xi eine Realisierung von iid Standardnormal-verteilten ZVen ist (ZV hat Dichte g(s) = 1√
2π e−s2/2). Da die Normalverteilung im Rd ein
Produktmaß ist, ist x eine Realisierung der d-dimensionalen Standardnormalverteilung. Dieseist rotationsinvariant (ZV hat die Dichte g(x) = 1
(2π)d/2 e−|x|2/2).
(ii) y = x/|x|, d.h. y ist Realisierung der Gleichverteilung in Sd−1.
(iii) Sei u ∈ [0, 1] eine Realisierung der Gleichverteilung in [0, 1], dann ist z = u1/dy eine Realisierungder Gleichverteilung in Bd.
Bemerkung 1.4Sei a ∈ Rd, r > 0 und B(a, r) = x ∈ Rd : |x−a| ≤ r. B(a, r) ist die Kugel mit Radius r um a. Dannist a+ ru1/d x
|x| (mit u aus (iii) und x aus (i)) eine Realisierung einer gleichverteilten ZV in B(a, r).
Zusammenfassend können wir sagen, dass die zweite Annahme für „gute“ Mengen G ⊂ Rd erfüllt ist.
Klassische Monte-Carlo Methode Sei (Ω,F ,P) Wahrscheinlichkeitsraum und X1, . . . , Xn iid-Folge von ZVen mit
Xi : (Ω,F ,P)→ (G,B(G))
4

undPXi(A) = P(Xi ∈ A) = λd(A)
λd(G) , A ∈ B(G).
Dann ist
Sn(f) = 1n
n∑i=1
f(Xi)
die klassische Monte-Carlo Methode zur Approximation von
S(f) = 1λd(G)
∫G
f(x)dx.
Satz 1.5 (Starkes Gesetz der großen Zahlen)Sei f : G→ R mit ‖f‖1 =
∫G|f(x)| dx
λd(G) <∞. Dann gilt
P( limn→∞
Sn(f) = S(f)) = 1.
Beweis: Siehe [4, Thm. 8.3.5].
Dies zeigt, dass die klassische Monte-Carlo Methode wohldefiniert ist. Die Approximation stellt einen„konsistenten“ Schätzer dar.
Fragen:
(i) Fehlerbegriff?
(ii) Fehlerabschätzung?
Sei An(f) irgendeine Methode/Formel zur Approximation von S(f), die n ZVen (nicht notwendiger-weise iid) und n Funktionswerte von f benutzt. Dann betrachten wir folgenden Fehler:
Definition 1.6Der Fehler von An(f) für f : G→ R mit ‖f‖1 <∞ ist durch
e(An, f) := (E|An(f)− S(f)|2)1/2
gegeben (E bezüglich der Verteilung von ZV An(f)).
Bemerkung 1.7
(i) e(An, f)2 ist der mittlere quadratische Fehler (mean square error, MSE).
(ii) Es gilte(An, f)2 = Var(An(f)) + Bias(An(f)),
wobei
Var(An(f)) = E|An(f)− EAn(f)|2,Bias(An(f)) = |EAn(f)− S(f)|2.
Die klassische Monte-Carlo Methode Sn(f) hat wegen Bias(Sn(f)) = 0 die Eigenschaft der Erwar-tungstreue, d.h. E(Sn(f)) = S(f) und es gilt e(Sn, f) = Var(Sn(f))1/2.
5

Satz 1.8 (Klassische Monte-Carlo Methode, Fehlerabschätzung)
Sei f : G→ R mit ‖f‖2 :=(∫
G|f(x)|2 dx
λd(G)
)1/2<∞. Dann gilt
e(Sn, f) =(E|Sn(f)− S(f)|2
)1/2 = (VarSn(f))1/2 ≤ ‖f‖2√n.
Beweis (siehe [17, Abschnitt 3.2.2]):
Da X1, . . . , Xn iid ist, ist auch f(X1), . . . , f(Xn) iid. Dann gilt
e(Sn, f)2 = Var
1n
n∑j=1
f(Xj)
= 1n2
n∑i=1
Var(f(Xi)) Formel von Bienayme, siehe [4, Thm. 8.1.2]
= 1n2
n∑i=1‖f − S(f)‖22
= 1n‖f − S(f)‖22 ≤
‖f‖22n
.
Wobei die letzte Ungleichung wegen Folgendem gilt:
‖f − S(f)‖22 =∫G
|f(x)− S(f)|2 dxλd(G)
=∫G
(f(x)2 − 2f(x)S(f) + S(f)2) dx
λd(G)
= ‖f‖22 − S(f)2 ≤ ‖f‖22.
Jetzt: Modifizierte Informationen
1) Funktionsauswertungen von f
2’) G ⊂ Rd ist durch ein Orakel, ein „Membership“-Orakel, gegeben, d.h. für x ∈ Rd können wir nach
1G(x) =
1 x ∈ G0 x /∈ G
fragen und erhalten eine Antwort.
Regularitätsannahme an G: Sei r ≥ 1 und Bd ⊆ G ⊆ rBd, wobei rBd = x ∈ Rd : |x| ≤ r undBd = 1Bd.
Bemerkung 1.9D.h. G ist nicht beliebig groß und nicht beliebig klein. Um die klassische Monte-Carlo Methodeanzuwenden müssen wir einen Zufallszahlengenerator konstruieren, der unter 2’) die Gleichverteilungerzeugt.
6

Erster Ansatz: Verwerfungsmethode
i) Erzeuge z ∈ rBd gleichverteilt (siehe Bemerkung 1.4).
ii) Falls z ∈ G, dann akzeptiere z, d.h. gebe z aus, ansonsten gehe zu i).
• Was ist die Akzeptanzwahrscheinlichkeit in ii)?
• Was ist die erwartete Anzahl von Orakelaufrufen von 1G?
Im schlechtesten Fall ist G = Bd. Dann ist die Akzeptanzwahrscheinlichkeit:
λd(Bd)λd(rBd)
= r−d,
da λd(rBd) = rdλd(Bd). Die erwartete Anzahl von Aufrufen von 1G ist rd.
Für große Dimensionen d ist r−d exponentiell klein und rd exponentiell groß. =⇒Ansatz schlägt fehl.Vielleicht ist Schritt i) zu schlecht?
Sei nun r =√d und G = Bd Zweiter Ansatz: Ersetze i) durch i’):
i’) Erzeuge x ∈ [−1, 1]d gleichverteilt.
D.h. i’) ausführen und dann zu ii), falls x verworfen wurde, gehe wieder zu i’).
Skizze:
Bd rBd
[−1, 1]d
[−1, 1]d ist die kleinste Box, die Bd enthält. Die Akzeptanzwahrscheinlichkeit ist
λd(Bd)2d , was sich asymptotisch wie
√2eπ
(eπ
d+ 1
)(d+1)/2verhält.
Dies ist exponentiell klein in d. Die erwartete Anzahl von Aufrufen von 1G ist 2dλd(Bd) . Das ist expo-
nentiell groß in d. =⇒Der Ansatz schlägt fehl.
Neue Idee: Markovketten Monte-Carlo Methoden
Mittels einer Folge von nicht notwendigerweise unabhängigen ZVen, einer Markovkette,
X1, X2, . . . , Xn+n0
wollen wir die Gleichverteilung in G approximieren, d.h.
P(Xn0 ∈ A) −→n0→∞
λd(A)λd(G) , A ∈ B(G). (1)
Dann berechne für f : G→ R
Sn,n0(f) = 1n
n∑j=1
f(Xj+n0)
7

als Approximation von S(f) = 1λd(G)
∫Gf(x)dx.
Wir stellen uns nun u.a. folgende Fragen:
1) Konvergenz in (1) quantifizierbar, d.h. Abschätzung zw. dem „Abstand“ der Verteilungen?
2) Ist dieser Algorithmus / diese Methode Sn,n0 konsistent? (Starkes Gesetz der großen Zahlen)
3) Fehlerabschätzung?
4) Information ausreichend? Bzw. welche Information wird benötigt?
8

2 Bedingter Erwartungswert und bedingte Verteilung
Dieser Abschnitt basiert im Wesentlichen auf [4, Kap. 10], siehe auch [1].
2.1 Bedingter Erwartungswert
Seien (Ω,F ,P) Wraum, X : (Ω,F ,P)→ (R,B(R)), X ∈ L1, d.h.∫
Ω |X|dP <∞.
Sei B ∈ F fest und P(B) > 0.
Zur Erinnerung: Für A ∈ F ist
P(A | B) = P(A ∩B)P(B) .
Es gilt
P(A | B) =∫Ω
1A∩B(ω)dP(ω)P(B) ,
d.h.dP(· | B)
dP (ω) = 1B(ω)P(B) .
Dann ist der elementare bedingte EW (bedingt auf B) gegeben durch
E[X | B] =∫Ω
X(ω)dP(ω | B) =∫Ω
X(ω)P(B) · 1B(ω)dP(ω) = E[1BX]
P(B) .
Verallgemeinerung: Erwarungswert unter der Bedingung E , wobei E ⊆ F σ-Algebra.
Intuitiv: Der Erwartungswert von X unter E sollte die „beste Vorhersage“ von X sein, wenn unsdie Information E zur Verfügung steht (EW als „Vorhersage“, zusätzliche Information sollte diesenpräzisieren).
Definition 2.1 (Bedingter Erwartungswert unter E)Eine ZV Z : (Ω,F ,P)→ (R,B(R)) heißt Version des bedingten EW von X unter E , falls
I) Z ist E-messbar (d.h. ∀A ∈ B(R) : Z−1(A) ∈ E),
II) ∀A ∈ E :∫AZdP =
∫AXdP.
Notation: E[X | E ] = Z
Satz 2.2 (Existenz und Eindeutigkeit P-f.s., [4, Thm. 10.1.1])Für beliebige X ∈ L1 (d.h.
∫Ω |X|dP < ∞) und E ⊆ F σ-Algebra existiert eine Version des
bedingten EW unter E und alle Versionen Z1, Z2 erfüllen Z1 = Z2 P-f.s.
Beispiel 2.3B ∈ F , 0 < P(B) < 1, E := ∅, B,Bc,Ω die von B erzeugte σ-Algebra,
Z(ω) := 1B(ω)E[X | B] + 1Bc(ω)E[X | Bc].
Wir zeigen, dass E[X | E ] = Z P-f.s.
9

2.1 Bedingter Erwartungswert
I) Z ist E-messbar: Sei A ∈ B(R),
Z−1(A) =
Ω E[X | B],E[X | Bc] ∈ A∅ E[X | B],E[X | Bc] /∈ AB E[X | B] ∈ A,E[X | Bc] /∈ ABc E[X | B] /∈ A,E[X | Bc] ∈ A
.
II) ∀A ∈ E :∫AZdP =
∫AXdP: A = ∅X, BX, BcX, ΩX.
Spezialfall: Sei Y : (Ω,F ,P)→ (G,G) ZV, (G,G) messbarer Raum und sei
Y −1(G) = Y −1(B)|B ∈ G.
Desweiteren sei σ(Y ) die kleinste σ-Algebra bezüglich der Y messbar ist, d.h.
σ(Y ) := σ(Y −1(G)).
Es gilt
1) Y −1(G) ⊆ F σ-Algebra,
2) σ(Y ) = Y −1(G).
Verallgemeinerung: Seien Yi : (Ω,F ,P) → (G,G) für i = 1, . . . , r ZVen. Es sei σ(Y1, . . . , Yr) diekleinste σ-Algebra bezüglich der Y1, . . . , Yr messbar, d.h.
σ(Y1, . . . , Yr) := σ(Y −1i (A)|A ∈ G, i = 1, . . . , r).
Definition 2.4E[X | Y ] := E[X | σ(Y )] und E[X | Y1, . . . , Yr] = E[X | σ(Y1, . . . , Yr)].
Satz 2.5 (Faktorisierungslemma, siehe [4, Thm. 4.2.8])Sei Z : (Ω,F ,P) → (R,B(R)) eine σ(Y )-messbare ZV. Dann ex. eine messbare Abbildung F :(G,G)→ (R,B(R)), s.d. Z = F (Y ).
(Ω,F ,P) (G,G)
(R,B(R))
Y
Z ∃F : Z = F (Y )
Folgerung 2.6Es existiert eine Abbildung F : (G,G) → (R,B(R)), s.d. E[X | Y ] = F (Y ) P-f.s. und wenn F1, F2solche Funktionen sind, dann folgt F1(Y ) = F2(Y ) P-f.s..
Definition 2.7Die Zahl F (y) heißt bedingter Erwartungswert von X unter der Bedingung Y = y, y ∈ G.
Notation: E[X | Y = y] := F (y), E[X | Y = ·] = F (·).
Vergleich der Definitionen
10

2.1 Bedingter Erwartungswert
Z : (Ω,F ,P)→ (R,B(R)) F : (G,G)→ (R,B(R))Z = E[X | E ], E ⊆ F σ-Algebra F (y) = E[X | Y = y]
Zusammenhang: F (Y ) = Z und E = σ(Y ).
Satz 2.8Gegeben sei eine messbare Abbildung F : (G,G)→ (R,B(R)). Dann gilt
F (y) = E[X | Y = y] PY -f.s. (y ∈ G)
genau dann, wenn∀B ∈ G :
∫B
F (y)PY (dy) =∫
Y −1(B)
XdP.
Beweis: Zunächst sei bemerkt, dass F (Y ) : (Ω,F ,P)→ (R,B(R)) σ(Y )-messbar ist. Dies gilt, weil
∀A ∈ B(R) : (F (Y ))−1(A) = Y −1(F−1(A)︸ ︷︷ ︸∈G
) ∈ σ(Y ).
Weiter gilt
F (y) = E[X | Y = y] PY -f.s. ⇐⇒ F (Y ) = E[X | Y ] P-f.s.
⇐⇒
I) F (Y ) σ(Y )−messbarII) ∀A ∈ σ(Y )
∫AF (Y )dP =
∫AXdP
A=Y −1(B), B∈G⇐⇒∫
Y −1(B)
XdP =∫
Y −1(B)
F (Y )dP =∫B
F (y)dPY (y) (Transf.-Satz)
Eigenschaften des bedingten EW:
E1 E = ∅,Ω =⇒E[X | E ] = E[X]
Beweis: klar
E2 Sei X E-messbar =⇒E[X | E ] = X P-f.s.
Beweis: Z = X erfüllt I) und II).
E3 E1 ⊆ E2 ⊆ F σ-Algebren =⇒E[X | E2] ∈ L1 und E[E[X | E2] | E1] = E[X | E1] P-f.s.
Beweis: Sei Z = E[X | E1]. Wir prüfen I) und II).
Zu I: Z ist E1 messbar: klar, da Z = E[X | E1].
Zu II: ∀A ∈ E1 gilt∫A
ZdP =∫A
E[X | E1] II=∫A
XdP E1⊆E2, A∈E2,II=∫A
E[X | E2]dP.
=⇒Z ist bedingter EW von E[X | E2] unter E1.
11

2.1 Bedingter Erwartungswert
E4 X ∈ L1, Y E-messbar, XY ∈ L1 =⇒E[XY | E ] = Y · E[X | E ] P-f.s.
Beweis (Idee):
Zu I: Klar, da Y · E[X | E ] als Komposition von E-messbaren Funktionen wieder E-messbar.
Zu II: (Standardbeweistechnik „Algebraische Induktion“)
• Zeige Behauptung für Y = 1A, A ∈ F .
• Zeige Behauptung für Y einf. Funktion.
• Zeige Behauptung für Y pos. Funktion.
• Zeige Behauptung für Y allg. Funktion.
E5 E[X | E ] ∈ L1 und E[E[X | E ]] = E[X]
Beweis: Sei E1 = ∅,Ω, E2 = E . Dann gilt
E[E[X | E ]] E1= E[E[X | E2] | E1] E3= E[X | E1] E1= E[X].
E6 Sei Y : (Ω,F ,P) → (G,G) ZV und U : (Ω,F ,P) → (E, E) ZV. Weiter sei Y (stochastisch)unabhängig von U und F : (G× E,G ⊗ E)→ (R,B(R)) messbar, mit
∫Ω |F (Y,U)|dP <∞. Dann
giltE[F (Y,U) | Y ](ω) =
∫Ω
F (Y (ω), U(ω))dP(ω) P-f.s.
Anders ausgedrückt: E[F (Y, U) | Y = y] = E[F (y, U)], y ∈ G.
Beweis (Idee):
Setze Z(ω) =∫
Ω F (Y (ω), U(ω))dP(ω) und prüfe I) und II).
Zu I: Z ist σ(Y )-messbar, wegen F (Y (ω), U(ω)) ist σ(Y )⊗σ(U)-messbar und dem Satz von Fubini(siehe [9, Satz 14.16]).
Zu II: Sei A ∈ σ(Y ), d.h. A = Y −1(B), B ∈ G. Wir erhalten∫A
ZdP =∫Ω
1A(ω)Z(ω) dP(ω) =∫Ω
1B(Y (ω))Z(ω) dP(ω)
=∫Ω
∫Ω
1B(Y (ω)) · F (Y (ω), U(ω)) dP(ω)dP(ω)
= E[1B(Y ) · F (Y, U)] (Unabhängigkeit von Y,U)
=∫Ω
1B(Y (ω))F (Y (ω), U(ω)) dP(ω)
=∫Ω
1A(ω)F (Y (ω), U(ω)) dP(ω)
=∫A
F (Y,U) dP.
12

2.2 Bedingte Verteilung
2.2 Bedingte Verteilung
Sei (Ω,F ,P) Wraum, E ⊆ F σ-Algebra. Es gilt: 1A ∈ L1 ∀A ∈ F , d.h. E[1A | E ] ist definiert.
Definition 2.9P(A | E)(ω) := E[1A | E ](ω) heißt Version der bedingten Wahrscheinlichkeit von A unter derBedingung E .
Satz 2.10 (siehe [4, Abschnitt 10.2])
1) P(Ω | E) = 1 P-f.s.
2) ∀A ∈ F : P(A | E) ≥ 0 P-f.s.
3) ∀An ∈ F paarweise disjunkt gilt P (⋃∞n=1An | E) =
∑∞n=1 P(An | E) P-f.s.
Bemerkung 2.11Die Ausnahmemengen für die Gültigkeit von 2) und 3) sind abhängig von A bzw. An. Insbesondereist P(A | E)(ω) im Allgemeinen kein Wmaß für alle ω ∈ Ω, auch nicht P-f.s..
Definition 2.12 (reguläre bedingte Wahrscheinlichkeit)Eine reguläre Version der bedingten Wahrscheinlichkeit von P unter E ist eine Funktion P E :Ω×F → [0, 1], s.d.
(i) ∀A ∈ F : P E(·, A) E-messbar,
(ii) ∀ω ∈ Ω : P E(ω, ·) Wmaß auf (Ω,F),
(iii) ∀A ∈ F : P E(·, A) = P(A | E) P-f.s.
(Aus (i) und (iii) folgt, dass P E eine Version der bedingten Wkt. von A unter E ist.)
Sei Y : (Ω,F ,P)→ (G,G) Zufallsvariable. Betrachte Ereignisse A = Y ∈ A, A ∈ G.
Definition 2.13 (reguläre bedingte Verteilung von Y unter E)Eine reguläre Version der bedingten Verteilung von Y unter der Bedingung E ist eine FunktionPY |E : Ω× G → [0, 1], s.d.
(i) ∀A ∈ G : PY |E(· | A) E-messbar,
(ii) ∀ω ∈ Ω : PY |E(ω, ·) Wmaß auf (G,G),
(iii) ∀A ∈ G : PY |E(·, A) = P(Y ∈ A | E) P-f.s.
(Aus (i) und (iii) folgt, dass PY |E eine Version der bedingten Wkt. von Y ∈ A unter E ist.)
Im Folgenden betrachten wir nur noch reguläre Versionen von bedingten Verteilungen. Es folgt: Zu-sammenhang zwischen regulären, bedingten Verteilungen und dem bedingten Erwartungswert.
Satz 2.14 (siehe [4, Thm 10.2.5])Seien (Ω,F ,P) Wraum, E ⊆ F σ-Algebra, Y : (Ω,F ,P) → (G,G) ZV und PY |E ist eine reguläreVersion der bedingten Verteilung von Y unter E . Dann gilt für alle messbaren Funktionen g :
13

2.2 Bedingte Verteilung
(G,G)→ (R,B(R)) mit∫G|g(y)|PY (dy) <∞, dass g integrierbar bezüglich PY |E(ω, ·) ist, d.h.∫
G
|g(y)|PY |E(ω,dy) <∞
für P-fast alle ω ∈ Ω, und
E[g(Y ) | E ](·) =∫G
g(y)PY |E(·,dy), P-f.s..
(D.h.∫Gg(y)PY |E(·,dy) ist eine Version des bedingten EW von g(Y ) unter E .)
Frage: Existieren reguläre Versionen der bedingten Verteilung? Eindeutigkeit?
Satz 2.15 (siehe [4, Thm 10.2.2])Seien (Ω,F ,P) Wraum, E ⊆ F σ-Algebra, G metrischer, vollständiger, separablera Raum, B(G)die σ-Algebra der Borelmengen, und Y : (Ω,F ,P)→ (G,B(G)) ZV. Dann existiert eine reguläreVersion der bedingten Verteilung von Y unter E und diese ist P-f.s. eindeutig.
aEin topologischer Raum heißt separabel, wenn es eine höchstens abzählbare Teilmenge gibt, die in diesem Raumdicht liegt.
Für uns ist der folgende Spezialfall am wichtigsten:
X : (Ω,F ,P)→ (H,H),
wobei (H,H) messbarer Raum und E = σ(X).
Definition 2.16 (reguläre bedingte Verteilung von Y unter X)Seien X : (Ω,F ,P)→ (H,H), Y : (Ω,F ,P)→ (G,G) ZVen. Dann heißt
PY |X : H × G → [0, 1]
eine reguläre Version der bedingten Verteilung von Y unter X, falls
(i) ∀A ∈ G : PY |X(·, A) H-messbar,
(ii) ∀x ∈ H : PY |X(x, ·) Wmaß auf (G,G),
(iii) ∀A ∈ G : PY |X(·, A) = P(Y ∈ A | X = ·) PX -f.s..
Satz 2.17 (teilweise Folgerung von Satz 2.14)Sei PY |X eine reguläre Version der bedingten Verteilung von Y unterX. Dann gilt für alle messbarenFunktionen g : (G,G) → (R,B(R)) mit
∫G|g(x)|PY (dy) < ∞, dass g integrierbar bzgl. PY |X(x, ·)
ist undE[g(Y ) | X = x] =
∫G
g(y)PY |X(x,dy) (2)
für PX -fast alle x ∈ H.
Desweiteren gilt für alle messbaren Funktionen
g : (H ×G,H⊗ G)→ (R,B(R))
14

2.3 Bedingte Verteilungsdichten
mit E|g(X,Y )| <∞, dass
(i) g(x, ·) integrierbar bzgl. PY |X(x, ·) für PX -fast alle x ∈ H,
(ii) E[g(X,Y )]] =∫H
∫Gg(x, y)PY |X(x,dy)PX(dx),
(iii) E[g(X,Y ) | X = x] =∫Gg(x, y)PY |X(x, dy) für PX -fast alle x ∈ H.
Beweis (Idee, bzw. Referenzen):
• (2) ist Folgerung aus Satz 2.14.
• (iii) folgt aus [8, Thm 5.4], siehe auch [1].
• (ii) folgt aus (iii) und
E[g(X,Y )] = E[E[g(X,Y ) | X]]
= E
∫G
g(X(·), y)PX|Y (X(·),dy)
=∫H
∫G
g(x, y)PX|Y (x,dy)PX(dx) (Transformationssatz)
• (i) folgt aus (ii)
Bei der Anwendung von Satz 2.17 ist meist (H,H) = (G,G), d.h. X,Y : (Ω,F ,P)→ (G,G) ZVen.
2.3 Bedingte Verteilungsdichten
Sei (Ω,F ,P) Wraum, r ∈ N und Z : (Ω,F ,P) → (Rr,B(Rr)) ein zufälliger Vektor, d.h. Z =(Z1, . . . , Zr) mit Zufallsvariablen Zi : (Ω,F ,P)→ (R,B(R)) für i = 1, . . . , r.
Definition 2.18 (Verteilungsdichte)Eine messbare Funktion fZ : Rr → [0,∞) heißt Verteilungsdichte (VD) von Z bzgl. (dem Lebes-guemaß) λr, falls
P(Z ∈ A) =∫A
fZ(z)λr(dz), A ∈ B(Rr).
Seien s, d ∈ N undY : (Ω,F ,P)→ (Rs,B(Rs))
X : (Ω,F ,P)→ (Rd,B(Rd))
mit Y = (Y1, . . . , Ys), X = (X1, . . . , Xd) und Xi, Yj : (Ω,F ,P)→ (R,B(R)) ZVen für i = 1, . . . , d undj = 1, . . . , s, d.h. X und Y zufällige Vektoren.
Satz 2.19Sei f(Y,X) : Rs × Rd → [0,∞) eine VD von (Y,X) bezüglich λs+d. Dann gilt
15

2.3 Bedingte Verteilungsdichten
(i)fY (y) =
∫Rd
f(Y,X)(y, x)λd(dx), y ∈ Rs
ist VD von Y bzgl. λs und
fX(x) =∫Rs
f(Y,X)(y, x)λs(dy), x ∈ Rd
ist VD von X bzgl. λd.
(ii) Eine reguläre Version der bedingten Verteilung PX|Y von X unter Y ist gegeben durch
PX|Y (y,A) =∫A
fX|Y=y(x)λd(dx)
für y ∈ Rs, A ∈ B(Rd) mit
fX|Y=y(x) =f(Y,X)(y,x)fY (y) fY (y) > 0
fX(x) fY (y) = 0, x ∈ Rd.
Definition 2.20fX|Y=y heißt bedingte Dichte von X unter Y = y.
Beweis: Wir beweisen die Aussagen von (i) und (ii) separat:
(i) fY : Rs → [0,∞), fX : Rd → [0,∞) sind messbar. Dies folgt aus der Messbarkeit von f(Y,X)und dem Satz von Fubini (siehe [9, Satz 14.16]). Für A ∈ B(Rs) gilt
P(Y ∈ A) = P((Y,X) ∈ A× Rd) =∫A
∫Rd
f(Y,X)(y, x)λd(dx)
︸ ︷︷ ︸=fY (y)
λs(dy).
Also fY VD von Y .
Analog zeigt man mit dem Satz von Fubini für B ∈ B(Rd), dass
P(X ∈ B) =∫B
fX(x)λd(dx).
(ii) Ansatz:PX|Y (y,B) :=
∫B
fX|Y=y(x)λd(dx), y ∈ Rs, B ∈ B(Rd)
Zu zeigen: PX|Y ist reguläre Version der bedingten Verteilung von X unter Y . D.h. prüfe (i)-(iii)aus Def. 2.13.
(i) PX|Y (·, B) ist B(Rs)-messbar: Dies gilt, da fX|Y=y(x) in (y, x) eine B(Rs ×Rd) messbareFunktion ist (als Komposition messbarer Funktionen). Nun folgt (i) mit Fubini-Argument.
(ii) PX|Y (y, ·) Wmaß:
16

2.3 Bedingte Verteilungsdichten
a) Sicher ist PX|Y (y, ·) Maß, wegen Eigenschaften des Integrals.
b) PX|Y (y,Rd) =
∫Rdf(Y,X)(y,x)λd(dx)
fY (y) fY (y) 6= 0∫Rd fX(x)λd(dx) fY (y) = 0
= 1
(da fX VD und Def. von fY ).
(iii) Zu zeigen: ∀B ∈ B(Rd) : PX|Y (·, B) = P(X ∈ B | Y = ·) PY -f.s. Idee: Wende Satz 2.8an. Sei dazu A ∈ B(Rs). Es gilt∫
A
PX|Y (y,B)PY (dy) =∫A
∫B
fX|Y=y(x)λd(dx)PY (dy)
=∫A
∫B
fX|Y=y(x)λd(dx) · fY (y)λs(dy)
=∫
A∩fY 6=0
∫B
f(Y,X)(y, x)fY (y) λd(dx)fY (y)λs(dy)
=∫
(A∩fY 6=0)×B
f(Y,X)(y, x)λs+d(d(y, x)) (Fubini)
= P((Y,X) ∈ (A ∩ fY 6= 0)×B)= P((Y,X) ∈ A×B) (da P((Y,X) ∈ fY = 0 ×B) = 0)
=∫
Y ∈A
1X∈BdP
=⇒Mit Satz 2.8 folgt (iii).
17

3 Markovketten
3.1 Definitionen und erste Eigenschaften
Seien (Ω,F ,P) ein Wahrscheinlichkeitsraum und (G,G) ein messbarer Raum. (G ist eigentlich immermetrischer, separabler, vollständiger Raum und G = B(G). Zum Beispiel G ⊆ Rd und B(G) bezüglichder euklidischen Metrik.)
Definition 3.1 (Übergangskern, Markovkern)Die Funktion K : G× G → [0, 1] heißt Markovkern oder Übergangskern, falls
(i) ∀x ∈ G ist K(x, ·) Wmaß auf (G,G),
(ii) ∀A ∈ G ist K(·, A) eine G-messbare Abbildung.
Interpretation: Sei x1 ∈ G. Dann können wir eine Folge x1, . . . , xn ∈ G, n ∈ N, erzeugen, indem füri ≥ 2, i ∈ N, xi bezüglich der Verteilung K(xi−1, ·) gewählt wird. K beschreibt in diesem Sinne denÜbergang zwischen xi−1 und xi.
Definition 3.2 (Markovkette, Startverteilung)Eine Folge von Zufallsvariablen (Xn)n∈N mit
Xi : (Ω,F ,P)→ (G,G)
für i ∈ N heißt Markovkette mit Übergangskern K, falls für alle n ∈ N und A ∈ G gilt:
(i) P(Xn+1 ∈ A | X1, . . . , Xn) = P(Xn+1 ∈ A|Xn) P-f.s.,
(ii) P(Xn+1 ∈ A | Xn = x) = K(x,A) PXn -f.s. in x ∈ G.
[Anders formuliert: P(Xn+1 ∈ A | Xn) = K(Xn, A) P-f.s.]
Die Verteilung ν(A) = P(X1 ∈ A), für A ∈ G, heißt Startverteilung.
Bemerkung 3.3
a) Die Gleichheit (i) wird Markoveigenschaft (ME) genannt. Intuitiv: Die Verteilung der Zu-kunft (also von Xn+1) hängt nur von der Gegenwart (Xn) ab und nicht von der Vergangenheit(X1, . . . , Xn−1).
b) Die Gleichheit in (ii) besagt, dass PXn+1|Xn(x,A) = K(x,A), n ∈ N, eine reguläre Version derbedingten Verteilung von Xn+1 unter Xn ist, und zwar für alle n ∈ N.
c) Eine Folge von Zufallsvariablen (Xn)n∈N, die (i) und (ii) erfüllt, heißt auch homogene Markov-kette (da in (ii) K unabhängig von n).
d) Die Indexmenge in (Xn)n∈N sind die natürlichen Zahlen. Solche Markovketten werden auch zeit-lich diskret genannt (zeitlich stetig (Indexmenge z.B. R, [0, 1]) heißt Markovprozess).
Frage: Nun sei K ein Übergangskern und ν ein Wahrscheinlichkeitsmaß auf (G,G). Wie können wireine Markovkette (Xn)n∈N mit Übergangskern K und Startverteilung ν bekommen?
Definition 3.4 (Update-Funktion)Sei (E, E , µ) Wraum. Dann heißt eine messbare Abbildung Φ : G × E → G Update-Funktion vonK, falls
P(Φ(x, U) ∈ A) = K(x,A), ∀x ∈ G,A ∈ G,
18

3.1 Definitionen und erste Eigenschaften
wobei U : (Ω,F ,P)→ (E, E) eine Zufallsvariable mit Verteilung µ ist (PU = µ).
Nun sei (Un)n∈N eine iid-Folge von Zufallsvariablen mit Ui : (Ω,F ,P) → (E, E) und PUi = µ, i ∈ N.Φ sei eine Update-Funktion von K. Desweiteren sei die ZV X1 : (Ω,F ,P) → (G,G) mit PX1 = ν,unabhängig von (Un)n∈N. Dann ist (Xn)n∈N gegeben durch
Xn = Φ(Xn−1, Un), n ≥ 2
eine Markovkette mit Übergangskern K und Startverteilung ν.
Beweis (Begründung):
Die Verteilung von X1 ist ν nach Definition. Zu (ii):
P(Xn ∈ A|Xn−1 = x) = P(Φ(Xn−1, Un) ∈ A|Xn−1 = x)= E(1A(Φ(Xn−1, Un))|Xn−1 = x)E6= E[1A(Φ(x, Un))] (Xn−1, Un unabh., Abschn. 2.1)= K(x,A) (Φ Update-Funktion).
Zu (i): Intuitiv klar. Man argumentiert ähnlich, wie im Beweis von (ii).
Frage: Wann existiert eine Update-Funktion von K?
Satz 3.5Sei G = R und G = B(R). Für jeden Übergangskern K auf (G,G) existiert eine Update-Funktion
Φ : G× [0, 1]→ G
mitP(Φ(x, U) ∈ A) = K(x,A), ∀x ∈ G,A ∈ B(G),
wobei U : (Ω,F ,P)→ ([0, 1],B([0, 1])) Zufallsvariable und PU ist die Gleichverteilung in [0, 1].
Beweis: Seien x, y ∈ R. Setze F (x, y) := K(x, (−∞, y]) (mit x parametrisierte Verteilungsfunktion).Eigenschaften von F :
1) F (x, y) = limh→0+ F (x, y + h) (rechtsseitig stetig)
2) ∀y < z gilt F (x, y) ≤ F (x, z) (Monotonie)
Nun sei Φ : G× [0, 1]→ G gegeben durch
Φ(x, u) = infy ∈ R : F (x, y) ≥ u (verallg. Inverse von F (x, ·))
gegeben. Es giltΦ(x, u) ≤ y ⇐⇒ F (x, y) ≥ u. (3)
„⇐“ X
„⇒“ z > y =⇒Φ(x, u) < z =⇒F (x, z) ≥ u und
F (x, y) = limh→0+
F (x, y + h)︸ ︷︷ ︸≥u
≥ u.
19

3.1 Definitionen und erste Eigenschaften
Zur Messbarkeit von Φ: Es genügt zu zeigen, dass Φ−1((−∞, r]) ∈ B(R)⊗B([0, 1]) für alle r ∈ R gilt.Dazu sei g : R × [0, 1] → R gegeben durch g(x, u) := F (x, r) − u. Diese Abbildung ist messbar, alsKomposition messbarer Abbildungen (F (·, r) messbar). Wir erhalten
Φ−1((−∞, r]) = (x, u) ∈ R× [0, 1] : Φ(x, u) ≤ r(3)= (x, u) ∈ R× [0, 1] : F (x, r) ≥ u= (x, u) ∈ R× [0, 1] : g(x, u) ≥ 0= g−1([0,∞)) ∈ B(R)⊗ B([0, 1]) (g messbar)
Nun zeigen wir, dass P(Φ(x, U) ≤ r) = K(x, (−∞, r]) für alle r ∈ R gilt, d.h. die Verteilungsfunktionvon Φ(x, U) und K(x, (−∞, r]) stimmen überein. Damit folgt P(Φ(x, U) ∈ A) = K(x,A), siehe dazu[4, Thm. 9.1.1 und Thm. 3.26] („Korrespondenzsatz“). Wir haben
P(Φ(x, U) ≤ r) (3)= P(F (x, r) ≥ U) = F (x, r) = K(x, (−∞, r]).
Bemerkung 3.6Wir haben uns auf den Fall G = R beschränkt. Für G ⊆ Rd oder allgemeine metrische, separable, voll-ständige Räume gilt das Ergebnis analog. Man argumentiert dann zusätzlich mit einem „Messraum-Isomorphismus“, siehe [9, S. 186, Def. 8.53 ff.].
Nun kommen wir zu Beispielen von Übergangskernen.
Beispiel 3.7Sei stets G ⊆ Rd, A ∈ B(G), x ∈ G.
0.) Sei
K(x,A) := 1A(x) =
0 x /∈ A1 x ∈ A
,
(beschreibt den Übergang, s.d. man immer in x verbleibt).
Update-Funktion: Φ(x, u) = x (für eine beliebige Menge E und alle u ∈ E).
1.) Sei π Wmaß auf (G,G) = (G,B(G)). Wir nehmen an, dass wir einen Zufallszahlengenerator fürdie Verteilung π zur Hand haben. Nun sei K(x,A) = π(A).
(D.h. eine Folge von iid ZVen mit Verteilung π bilden eine Markovkette.)
Update-Funktion: Φ(x, u) = u, wobei u eine Realisierung einer π-verteilten ZV U : (Ω,F ,P) →(G,G) darstellt.
2.) Jede Konvexkombination zweier Übergangskerne ist wieder ein Übergangskern. D.h. für alle λ ∈[0, 1] ist
K(x,A) = λK1(x,A) + (1− λ)K2(x,A)
ein Übergangskern für Übergangskerne K1 und K2.
Update-Funktion: Sei Φ1 eine Update-Fkt von K1 und Φ2 eine solche für K2, wobei Φ1,Φ2 :G × E → G. Sei u ∈ E und r ∈ [0, 1] zufällig gewählt, d.h. u ist eine Realisierung einer ZV mit
20

3.1 Definitionen und erste Eigenschaften
Verteilung µ (siehe Def. 3.4) und unabhängig davon sei r eine Realisierung der Gleichverteilungin [0, 1]. Wir definieren
Φ(x, (u, r)) = 1[0,λ)(r)Φ1(x, u) + 1[λ,1](r)Φ2(x, u).
Algorithmus
Input: x ∈ G, Φ1, Φ2Output: y ∈ G
a) Wähle r ∈ [0, 1] gleichverteilt und unabhängig von u bezüglich µ.
b) Falls λ ≤ r, setze y := Φ2(x, u), sonst y := Φ1(x, u).
3.) Sei δ > 0 und B(x, δ) = y ∈ Rd : |x − y| ≤ δ. Dann ist der Übergangskern des δ ball walkgegeben durch
Wδ(x,A) = λd(A ∩B(x, δ))λd(B(0, δ)) + 1A(x) ·
(1− λd(G ∩B(x, δ))
λd(B(0, δ))
).
Skizze: 1. Fall: B(x1, δ) ⊆ G, 2. Fall: B(x2, δ) ∩Gc 6= ∅.
G
x1
δ
x2
δ
Sei U : (Ω,F ,P)→ (Bd,B(Bd)) (wobei Bd = B(0, 1)) gleichverteilte ZV in Bd.
Update-Funktion: u sei Realisierung von U (Lemma 1.3 ff.)
Φ(x, u) =x+ δu x+ δu ∈ Gx x+ δu /∈ G
.
4.) Sei R ∈ Rd×d eine symmetrische, positiv definite Matrix und v ∈ Rd.
Dann ist die d-dimensionale Normalverteilung mit Erwartungswertvektor v und KovarianzmatrixR gegeben durch
N (v,R)(A) :=∫A
1(2π)d/2|R|d/2
exp(−1
2 〈z − v,R−1(z − v)〉
)dz, A ∈ B(Rd),
wobei |R| = detR und 〈·, ·〉 das euklidische Skalarprodukt bezeichnet.
Sei nun ein sogenannter „Gaußian random walk“ Kern auf G = Rd gegeben durch
N(x,A) = N (x, s2R)(A),
wobei s > 0 ein zusätzlicher Parameter ist.
(Auch etwas wie N(x,A) = N (√
1− s2x, s2R)(A) ist denkbar.)
21

3.1 Definitionen und erste Eigenschaften
Update-Funktion: Sei U : (Ω,F ,P) → (Rd,B(Rd)) standardnormalverteilte ZV, d.h. mit Ver-teilung N (0, Id). (Diese kann aus d eindimensionalen standardnormalverteilten ZVen konstruiertwerden.) Sei u ∈ Rd eine Realisierung von U . Dann ist
Φ(x, u) = x+ sR1/2u
eine Update-Funktion von N (Transformationssatz der Normalverteilung).
Es gibt auch unendlich-dimensionale Hilberträume, die mit Gaußmaßen ausgestattet werdenkönnen. In diesem Fall ist ein Übergangskern der Form N (oder N) auch denkbar.
5.) „Hit-and-run“ Übergangskern. Sei G ⊆ Rd beschränkt, Sd−1 Einheitssphäre und θ ∈ Sd−1, x ∈ G.Wir definieren
L(x, θ) = s ∈ R : x+ sθ ∈ G ⊆ R.
(D.h. L(x, θ) ist die Menge der Parameter s, in der die Gerade x + sθ, mit Stützvektor x undRichtungsvektor θ, das Gebiet G schneidet.)
Dann ist der Übergangskern vom „hit-and-run“-Algorithmus gegeben durch
H(x,A) = 1σ(Sd−1)
∫Sd−1
Hθ(x,A)dσ(θ)
mitHθ(x,A) =
∫L(x,θ)
1A(x+ sθ) dsλ1(L(x, θ)) .
Skizze:
G
x
x+ θ
x+ sθ
x+ sθ für s ∈ L(x, θ)
Update-Funktion als Algorithmus:
Input: x ∈ G
Output: y ∈ G
a) Wähle θ ∈ Sd−1 gleichverteilt (siehe Lemma 1.3).
b) Wähle s ∈ L(x, θ) gleichverteilt und setze y = x+ sθ.
6.) „Random scan Gibbs sampler“
Sei G ⊆ Rd beschränkt und e1, . . . , ed ⊆ Rd sei die Euklidische Einheitsbasis, d.h.
ei = (0, . . . , 0, 1↑
i-te Stelle
, 0, . . . , 0).
Dann ist
R(x,A) = 1d
d∑i=1
Hei(x,A)
22

3.1 Definitionen und erste Eigenschaften
ein Übergangskern, wobei die in 5.) eingeführte Notation benutzt wird.
Update-Funktion als Algorithmus:
Input: x ∈ G
Output: y ∈ G
a) Wähle i ∈ 1, . . . , d bezüglich der Gleichverteilung.
b) Wähle s ∈ L(x, ei) gleichverteilt und setze y = x+ sei.
Bemerkung (zu 5.) und 6.))Die Gleichverteilung in L(x, θ) für θ ∈ Sd−1 zu erzeugen, ist im Allgemeinen nicht einfach. Für konvexeMengen G ⊆ Rd ist es unter Verwendung von Auswertungen von 1G („Membership-Orakel“) mittelseiner eindimensionalen Verwerfungsmethode „vernünftig“ implementierbar.
An den Beispielen haben wir unter anderem gesehen, wie man aus Übergangskernen neue Über-gangskerne konstruiert. Beispielsweise ist die Konvexkombination von Übergangskernen wieder einÜbergangskern. Das ist soetwas wie die „Summe“ von Übergangskernen.
Frage: Was ist mit dem Produkt?
Im Folgenden seien K,K1,K2 Übergangskerne auf (G,G).
Definition 3.8 (Produkt von Übergangskernen)Sei x ∈ G, B ∈ G. Dann ist
K1K2(x,B) =∫G
K2(y,B)K1(x,dy)
das Produkt von K1 und K2.
Eigenschaften
E1 K1K2 ist wieder ein Übergangskern.
(Die Wmaß-Eigenschaft folgt aus K2 und Eigenschaften des Integrals. Zur Messbarkeit siehe [9,Satz 14.20])
E2 SetzeK0(x,A) := 1A(x)
und
Kn(x,A) :=∫G
Kn−1(y,A)K(x,dy) =∫G
K(y,A)Kn−1(x, dy).
E3 Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Dann gilt für allex ∈ G, A ∈ G und n, k ∈ N, dass
P(Xk+n ∈ A | Xk = x) = Kn(x,A) PXk -f.s..
D.h. Kn ist eine reguläre Version der bedingten Verteilung von Xk+n unter Xk.
23

3.1 Definitionen und erste Eigenschaften
Beweis: Induktion über n ∈ N. Für n = 1, siehe Definition einer Markovkette. X Sei nun n ≥ 1.Es gilt
P(Xk+n+1 ∈ A | Xk) = E[1Xk+n+1∈A | Xk]= E[E[1Xk+n+1∈A | X1, . . . , Xk+n] | Xk] (E3 in 2.1)= E[P[Xk+n+1 ∈ A | X1, . . . , Xk+n] | Xk]= E[P[Xk+n+1 ∈ A | Xk+n]︸ ︷︷ ︸
K(Xk+n,A)
| Xk] (Markoveigenschaft).
Mit dem Faktorisierungslemma folgt
P(Xk+n+1 ∈ A | Xk = x) = E[K(Xk+n, A) | Xk = x].
Nun betrachten wir
E[K(Xk+n, A) | Xk = x] Satz 2.17=∫G
K(y,A)PXk+n|Xk(x, dy).
Nach Induktionsvoraussetzung ist PXk+n|Xk = Kn und wir erhalten
E[K(Xk+n, A) | Xk = x] =∫G
K(y,A)Kn(x, dy) = Kn+1(x,A).
E4 Für alle m ∈ N gilt
P(Xm+1 ∈ A) =∫G
Km(y,A)ν(dy).
Beweis: Es gilt
P(Xm+1 ∈ A) = E[1Xm+1∈A]= E[E[1Xm+1∈A | X1]] (E5 in Abschnitt 2.1)= E[P(Xm+1 ∈ A | X1)]= E[Km(X1, A)] (E3 in Abschnitt 2.1)
=∫G
Km(y,A)PX1(dy)
=∫G
Km(y,A)ν(dy).
E5 Für jedes bezüglich Km(x, ·) integrierbare f : G→ R gilt
E[f(Xm+1) | X1 = x] =∫G
f(y)Km(x, dy).
24

3.1 Definitionen und erste Eigenschaften
Beweis: Wir haben
E[f(Xm+1) | X1 = x] Satz 2.17=∫G
f(y)PXm+1|X1(x,dy) E3=∫G
f(y)Km(x, dy).
E6 Für alle A,B ∈ G giltP(X1 ∈ A,X2 ∈ B) =
∫A
K(x,B)ν(dx).
Beweis: Es gilt
P(X1 ∈ A,X2 ∈ B) = E[1X1∈A,X2∈B]
=∫G
∫G
1A×B(x, y)PX2|X1(x, dy)PX1(dx) (Satz 2.17 (iii))
=∫A
K(x,B)ν(dx) (E3).
Bemerkung 3.9Sei A ∈
⊗ni=1 G = Gn, n ∈ N. Dann ist
P((X1, . . . , Xn) ∈ A)
ein Wahrscheinlichkeitsmaß auf (Gn,Gn) mit
P(X1 ∈ A1, . . . , Xn ∈ An) =∫A1
. . .
∫An
K(xn−1,dxn) . . .K(x1,dx2)ν(dx1).
Für einen Übergangskern K und ein Wmaß ν auf (G,G) benutzen wir im Folgenden für alle m ∈ Ndie Notation
νPm(A) :=∫G
Km(x,A)ν(dx).
(Dies ist das Produkt von Km und ν, nach Definition 3.8.) Wegen E4 (oder auch Def. 3.8) ist νPmwieder ein Wmaß auf (G,G).
Lemma 3.10Sei f : G→ R integrierbar bezüglich νPm. Dann gilt∫
G
f(y)νPm(dy) =∫G
∫G
f(y)Km(x, dy)ν(dx).
Beweis (Standardbeweistechnik der Integrationstheorie, Algebraische Induktion):
1. Schritt: f = 1A, für A ∈ G:
Es giltνPm(A) =
∫G
Km(x,A)ν(dx) =∫G
∫G
1A(y)K(x, dy)ν(dx).X
25

3.1 Definitionen und erste Eigenschaften
2. Schritt: f =∑ni=1 ci1Ai , für n ∈ N, ci ≥ 0, Ai ∈ G (also f nichtnegative, einfache Funktion):
Die Behauptung gilt, wegen der Linearität des Integrals und dem 1. Schritt.
3. Schritt: f ≥ 0 messbar: Dann existiert Folge (fn) von einfachen Funktionen mit fn ↑ f , d.h.fn ≤ fn+1 punktweise und limn→∞ fn = f .
Nun gilt die Behauptung unter Anwendung des Satzen von der monotonen Konvergenz(Satz von Beppo Levi1, siehe [4, Thm. 4.3.2]) und dem 2. Schritt.
Es gilt∫G
f(x)νPm(dx) := limn→∞
∫G
fn(x)νPm(dx) (Def. aus Integrationstheorie)
= limn→∞
∫G
∫G
fn(y)Km(x,dy)ν(dx) (2. Schritt)
=∫G
∫G
f(y)Km(x, dy)ν(dx) (2-mal Satz von Beppo Levi).
4. Schritt: f integrierbar bezüglich νPm: Dann f = f+ − f−, wobei f+(x) = maxf(x), 0 undf−(x) = max−f(x), 0.
Die Behauptung gilt mit dem 3. Schritt und der Linearität des Integrals. D.h.∫G
f(x)νPm(dx) =∫G
f+(x)νPm(dx)−∫G
f−(x)νPm(dx)
=∫G
∫G
f+(y)Km(x,dy)ν(dx)−∫G
∫G
f−(y)Km(x, dy)ν(dx)
=∫G
∫G
f(y)Km(x, dy)ν(dx).
Bemerkung 3.11Lemma 3.10 rechtfertigt die Notation∫
G
Km(x, dy)ν(dx) = νPm(dy).
Definition 3.12 (stationäre Verteilung)Sei π ein Wmaß auf (G,G). Dann heißt π stationäre Verteilung (von Übergangskern K), falls
π(A) =∫G
K(x,A)π(dx), A ∈ G.
1gn ≥ 0 monoton wachsende Folge messbarer Funktionen. Dann gilt∫limn→∞
gn(x)ν(dx) = limn→∞
∫gn(x)ν(dx).
26

3.1 Definitionen und erste Eigenschaften
(D.h. π(A) = πP (A) für alle A ∈ G, also π = πP .)
Interpretation: Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung π. Des-weiteren sei π eine stationäre Verteilung von K. Dann gilt
P(X1 ∈ A) = π(A) stationär= πP (A) E4= P(X2 ∈ A).
D.h. falls eine Markovkette eine stationäre Verteilung als Startverteilung besitzt, bleibt die Verteilungder Xi, für i ∈ N, gleich.
Folgerung 3.13Sei f : G→ R integrierbar bezüglich einer stationären Verteilung π von K. Dann gilt für alle m ∈ N∫
G
f(y)π(dy) =∫G
∫G
f(y)Km(x, dy)π(dx).
Bemerkung 3.14Folgerung 3.13 rechtfertigt die Notation
π(dy) =∫G
Km(x, dy)π(dx)
für alle m ∈ N, falls π eine stationäre Verteilung von K ist.
Beispiel 3.15Seien K1 und K2 Übergangskerne mit stationärer Verteilung π. Dann gilt
a) π ist eine stationäre Verteilung bezüglich λK1 + (1− λ)K2 für alle λ ∈ [0, 1],
b) π ist eine stationäre Verteilung von K1K2 und K2K1 (man benutzt Folgerung 3.13).
Definition 3.16 (Reversibilität)Sei π eine Verteilung auf (G,G). Dann heißt der Übergangskern K reversibel bezüglich π, falls∫
A
K(x,B)π(dx) =∫B
K(x,A)π(dx), ∀A,B ∈ G.
Interpretation: Sei (Xn)n∈N MK mit Übergangskern K und Startverteilung π. K sei reversibelbezüglich π. Dann gilt
P(X1 ∈ A,X2 ∈ B) E6=∫A
K(x,B)π(dx) rev.=∫B
K(x,A)π(dx) E6= P(X1 ∈ B,X2 ∈ A).
(Dies ist eine „gewisse“ Symmetrie in A und B.)
Lemma 3.17
(i) Ist K reversibel bezüglich π, dann ist π eine stationäre Verteilung von K.
(ii) Gilt für alle A,B ∈ G mit A ∩B = ∅∫A
K(x,B)π(dx) =∫B
K(x,A)π(dx),
27

3.1 Definitionen und erste Eigenschaften
folgt bereits, dass K reversibel bezüglich π ist.
(iii) Seien K reversibel bezüglich π, F : G×G→ R und m ∈ N. Dann gilt∫G
∫G
F (x, y)Km(x, dy)π(dx) =∫G
∫G
F (y, x)Km(x, dy)π(dx), (4)
falls eines der beiden Integrale existiert.
Beweis:
(i) Wir habenπP (A) =
∫G
K(x,A)π(dx) rev=∫A
K(x,G)︸ ︷︷ ︸=1
π(dx) = π(A).
(ii) Seien A,B ∈ G. Dann folgt∫A
K(x,B)π(dx) =∫
A\B
K(x,B)π(dx) +∫
A∩B
K(x,B)π(dx)
=∫B
K(x,A \B)π(dx) +∫
A∩B
(K(x,B \A) +K(x,A ∩B))π(dx)
=∫B
K(x,A \B)π(dx) +∫
B\A
K(x,A ∩B)π(dx) +∫
A∩B
K(x,A ∩B)π(dx)
=∫B
K(x,A \B)π(dx) +∫B
K(x,A ∩B)π(dx)
=∫B
K(x,A)π(dx).
(iii) Wir beschränken uns auf den Fall m = 1. Für m ∈ N folgt die Aussage per Induktion. Wirwenden wieder die Standardbeweistechnik der Integrationstheorie und einen „kleinen Trick“an.
0. Schritt Seien A,B ∈ G, F (x, y) = 1A(x) · 1B(y) = 1A×B(x, y). Dann gilt (4) wegen derReversibilität, d.h. ∫
A
K(x,B)π(dx) =∫B
K(x,A)π(dx).
1. Schritt Sei A ∈ G ⊗ G = σ(G × G). Ziel: Zeige, dass (4) für F (x, y) = 1A
(x, y) gilt. Wirbenutzen folgenden Satz.
Satz 3.18 (Dynkin-System-Theorem)Seien Ω 6= ∅ und C,D ∈ P(Ω) = 2Ω. Weiterhin gelte
a) A,B ∈ C =⇒A ∩B ∈ C
(D.h. C ist ein π-System),
28

3.1 Definitionen und erste Eigenschaften
b) 1) Ω ∈ D
2) A ∈ D =⇒Ac ∈ D
3) An ∈ D paarweise disjunkt =⇒⋃∞n=1An ∈ D
(D.h. D ist ein Dynkin-System.),
c) C ⊆ D.
Dann folgt: σ(C) ⊆ D.
Wir setzen C = G × G = A×B : A,B ∈ G und
D =
A ∈ σ(C) :∫G
∫G
1A(x, y)K(x,dy)π(dx) =∫G
∫G
1A(y, x)K(x, dy)π(dx)
.
Bedingung c) aus Satz 3.18 gilt wegen dem 0. Schritt. Weiterhin kann man zeigen,dass C ein π-System und D ein Dynkin-System ist. Dann folgt σ(C) = D und (4) istfür F (x, y) = 1
A(x, y) erfüllt.
C ist ein π-System: A,B ∈ C =⇒A = A1×A2 und B = B1×B2 für A1, A2, B1, B2 ∈ G.Also
A ∩B = (A1 ∩B1︸ ︷︷ ︸∈G
)× (A2 ×B2︸ ︷︷ ︸∈G
) ∈ C.
D ist ein Dynkin-System:
1) G×G ∈ D, da 1 = 1.
2) Sei A ∈ D. Nutze 1Ac = 1− 1A. Es folgt Ac ∈ D.
3) Seien An ∈ D paarweise disjunkt. Benutze 1⋃∞n=1
An=∑∞n=1 1An (da disjunkt)
und Satz von Lebesgue zum Vertauschen von Limes und Integral. Es folgt⋃∞n=1An ∈
D.
2. Schritt Für positive, einfache Funktionen F nutze man Schritt 1.
3. Schritt Sei F ≥ 0 messbar. Es existieren Fn ↑ F , einfache Funktionen mit Fn ≥ 0. Dann giltmit Satz von B. Levi und 2. Schritt die Behauptung.
4. Schritt F messbar und integrierbar. Zerlege F = F+−F− und Schritt 3 liefert die gewünschteAussage.
Bemerkung 3.19Lemma 3.17 (iii) rechtfertigt die Notation
K(x, dy)π(dx) = K(y,dx)π(dy),
für K reversibel bezüglich π.
Beispiel 3.20Sei G ⊆ Rd, G = B(Rd), A ∈ G, x ∈ G.
29

3.1 Definitionen und erste Eigenschaften
0.) Sei K(x,A) = 1A(x). Dann ist K reversibel bezüglich jedem Wmaß ν auf (G,G): Es gilt∫A
K(x,B)ν(dx) = ν(A ∩B) =∫B
K(x,A)ν(dx).
Insbesondere ist jedes ν eine stationäre Verteilung von K.
1.) Sei π ein Wmaß auf (G,G) und K(x,A) = π(A). Dann ist K reversibel bezüglich π: Es gilt∫A
K(x,B)π(dx) = π(A)π(B) =∫B
K(x,A)π(dx).
2.) Seien K1 und K2 reversibel bezüglich π. Dann gilt
λK1 + (1− λ)K2
ist reversibel bezüglich π (Beweis leicht). Im Allgemeinen sind aber K1K2 und K2K1 nicht wiederreversibel bezüglich π. Reversibilität gilt jedoch, falls K1K2 = K2K1 (sogar gdw., dazu vielleichtspäter mehr).
Beweis: Für A,B ∈ G erhalten wir∫A
K1K2(x,B)π(dx) =∫A
∫G
K2(y,B)K1(x, dy)π(dx)
=∫G
∫G
1A(x)K2(y,B)K1(x, dy)π(dx)
=∫G
∫G
1A(y)K2(x,B)K1(x, dy)π(dx) (Lemma 3.17 (iii))
=∫G
K2(x,B)K1(x,A)π(dx)
... zurück argumentieren
=∫B
K2K1(x,A)π(dx).
3.) „δ-ball-walk“. Sei δ > 0 und G ⊆ Rd beschränkt. Zur Erinnerung:
Wδ(x,A) = λd(A ∩B(x, δ))λd(B(0, δ)) + 1A(x)
(1− λd(G ∩B(x, δ))
λd(B(0, δ))
)G
x1
x2
x3
30

3.2 Grundlegende Algorithmen
Ansatz: Raten (bzw. Intuition) liefert einen Kandidaten für π: Die stationäre Verteilung π istgegeben durch die Gleichverteilung
Beweis: Um dies zu beweisen, prüfen wir Reversibilität bezüglich dieser. Seien dazu C,D ∈ B(G)und C ∩D = ∅. Dann gilt∫
C
Wδ(x,D)dx =∫C
λd(D ∩B(x, δ))λd(B(0, δ)) dx
= 1λd(B(0, δ))
∫C
∫D
1B(x,δ)(y)dydx
= 1λd(B(0, δ))
∫C
∫D
1B(y,δ)(x)dydx (da 1B(x,δ)(y) = 1B(y,δ)(x))
=∫D
Wδ(x,C)dx (Fubini).
Mit Lemma 3.17 (ii) erhalten wir, dass der δ-ball-walk reversibel bezüglich der Gleichverteilungist.
3.2 Grundlegende Algorithmen
Sei stets G ⊆ Rd, G = B(G) und ρ : G→ (0,∞) eine nichtnormierte Dichtefunktion, d.h.
0 <∫G
ρ(x)dx <∞.
(Es gilt nicht notwendigerweise∫Gρ(x)dx = 1.)
Mittels der nichtnormierten Dichtefunktion kann man ein Wmaß πρ mittels
πρ(A) =∫Aρ(x)dx∫
Gρ(y)dy
, A ∈ G
definieren.
Ziel: Konstruktion von Übergangskernen, die reversibel bezüglich πρ sind, oder zumindest πρ alsstationäre Verteilung besitzen.
Fragen:
1) Warum soll πρ eine stationäre Verteilung sein?
Intuitiv: Falls πρ eine stationäre Verteilung von Übergangskern K ist, dann gilt πρ = πρP . Dasheißt πρ ist eine Art „Fixpunkt“ der linearen Abbildung ν 7→ νP (ν Wmaß). Die Idee ist dann, einiteratives Verfahren zu starten, um den Fixpunkt zu approximieren. Falls P gewisse Eigenschaftenerfüllt (Kontraktionseigenschaft, wie beim Banachschen Fixpunktsatz gefordert) sollte νPn, fürn groß genug, „nahe“ an πρ liegen.
2) Warum gerade diese Form πρ?
31

3.2 Grundlegende Algorithmen
a) Sei G beschränkt und ρ(x) = 1G(x). Dann ist πρ die Gleichverteilung in G. Dies umfasst dasSzenario aus Abschnitt 1.
b) statistische Physik: Boltzmannverteilung,
µβ(A) = 1Zβ
∫A
e−βH(x)dx,
wobei β die inverse Temperatur, H die Hamiltonfunktion und Zβ die Normierungskonstanteist.
c) Bayesscher Ansatz in der Statistik:
Gegeben sind Beobachtungen / Daten / Messwerte b ∈ Rs, s ∈ N. Diese werden modelliert, alsRealisierungen von einem zufälligen Vektor
B : (Ω,F ,P)→ (Rs,B(Rs)), B = (B1, . . . , Bs), Bi zufällige Größen.
In der klassischen Statistik ist B ein zufälliger Vektor mit Verteilungsdichte
f : Rs × Rd → (0,∞), (b, x) 7→ f(b, x)
wobei x ∈ Rd als fester Parameter angenommen wird. Die VD heißt auch Likelihoodfunktion.Zum Beispiel: Wir machen den Ansatz Bi iid N (m, v2) (1-dimensional) normalverteilt, d.h.
f(b1, . . . , bs,m, v2︸ ︷︷ ︸=x
) = 1(2πv2)s/2
s∏i=1
e−(bi−m)2
2v2 .
Nun bestimmt die Maximum-Likelihood-Methode der klassischen Statistik den Parametervektorx, sodass f(b, x) maximal wird. Intuitiv hat die Realisierung b die höchste Wahrscheinlichkeit.
Bei dem Bayesschen Ansatz werden B und der Parameter X, hier gegeben durch
X : (Ω,F ,P)→ (Rd,B(Rd)),
als zufällige Vektoren mit gemeinsamer Verteilungsdichte
p(x) · f(b, x) x ∈ Rd, b ∈ Rs
angesehen. Dabei ist p : Rd → [0,∞) die W-dichte der sogenannten Priorverteilung von X undf(·, x) die bedingte Dichte von B unter X = x.
Nun ist die Posteriorverteilung von X unter B = b durch die bedingte Dichte (siehe Satz 2.16)
πX|B=b(x) = p(x) · f(b, x)∫Rd p(y)f(b, y)dy
gegeben und von Interesse.
In Kurzschreibweise (wobei ∝ für „proportional“ steht):
posterior ∝ prior × likelihood
32

3.2 Grundlegende Algorithmen
Frage: Warum „Bayes“?
In der Situation
fX|B=b bedingte Dichte von X unter der Bedingung b,fB|X=x bedingte Dichte von B unter der Bedingung x,
fX Dichte von X,fB Dichte von B,
besagt der Satz von Bayes:
fX|B=b(x) =Satz 2.16
fX(x) · fB|X=x(b)fB(b)
(Elementare Form: P(A | B) = P(A)P(B|A)P(B) .)
3.2.1 Metropolis-Hastings Algorithmus
Der Algorithmus wurde von Metropolis et al. in [14] vorgestellt und später von Hastings in [7]verallgemeinert.
Spezialfall: „Unabhängiger Metropolis sampler“
Annahmen:
• G beschränkt
• Q sei die Gleichverteilung in G, d.h.
Q(A) = λd(A)λd(G) , A ∈ B(G).
Wir erläutern einen Übergangsmechanismus von xi zu xi+1 (x1, x2, . . . ∈ G).
Algorithmus: Input: xi (aktueller Zustand) und Q (Vorschlagskern)Output: xi+1 (nächster Zustand)
1) Wähle voneinander unabhängig y bezüglich Q und u gleichverteilt in [0, 1].
2) Setze Akzeptanzwahrscheinlichkeit
α(xi, y) := min
1, ρ(y)ρ(xi)
.
Falls u ≥ α(xi, y) setze xi+1 := xi, sonst setze xi+1 := y.
3) Ausgabe xi+1.
Skizze:
33

3.2 Grundlegende Algorithmen
ρ
a byx1
α = 1
=
x2
x3
α = 1
x4x5
α = 3/4
G = [a, b], Folge der Realisierung x1 x2 x3 x4 x5Zustand in G y1 y2 y3 y3 y4
.
Warnung: Wir weisen auf den Unterschied zur Verwerfungsmethode zur Konstruktion von Zufalls-zahlengeneratoren hin (siehe Kapitel 1, Motivation). Bei dieser Verwerfungsmethode werden so langeZustände erzeugt, bis einer akzeptiert wird, und letztlich werden nur akzeptierte Zustände ausge-geben. Beim Metropolis-Hastings Algorithmus wird der akzeptierte oder der aktuelle Zustandzurückgegeben.
Zum allgemeinen Verfahren:
Sei q : G×G→ [0,∞) und für alle x ∈ G sei q(x, ·) integrierbar (bzgl. dem Lebesguemaß) mit∫G
q(x, y)dy ≤ 1.
Dann ist
Q(x,A) =∫A
q(x, y)dy + 1A(x)
1−∫G
q(x, y)dy
ein Übergangskern in (G,B(G)).
(In der Literatur wird q auch als Übergangsdichte bezeichnet.)
Wir nennen Q Vorschlagskern.
Frage: Wie können/müssen wir Q modifizieren, sodass ein Übergangskern heraus kommt, der rever-sibel bezüglich πρ ist? Wir wollen also eine messbare Funktion kρ : G×G→ [0,∞) mit∫
G
kρ(x, y)dy ≤ 1
angeben, sodass
Kρ(x,A) =∫A
kρ(x, y)dy + 1A(x)
1−∫G
kρ(x, y)dy
ein bezüglich πρ reversibler Übergangskern ist.
34

3.2 Grundlegende Algorithmen
Lemma 3.21Ein Übergangskern der Form Kρ ist genau dann reversibel bezüglich πρ, wenn
kρ(x, y)ρ(x) = kρ(y, x)ρ(y) f.ü. bzgl. Lebesguemaß.
Beweis: Seien A,B ∈ B(G) beliebig und c =∫Gρ(x)dx. Nun gilt:∫
A
Kρ(x,B)πρ(dx) =∫B
Kρ(x,A)πρ(dx)
⇐⇒∫A
∫B
kρ(x, y)ρ(x)dyc
dx+∫
A∩B
1−∫G
kρ(x, y)dy
ρ(x)dxc
=∫B
∫A
kρ(x, y)ρ(x)dyc
dx+∫
A∩B
1−∫G
kρ(x, y)dy
ρ(x)dxc
⇐⇒∫A
∫B
kρ(x, y)ρ(x)dydx =∫B
∫A
kρ(x, y)ρ(x)dydx
⇐⇒∫A
∫B
kρ(x, y)ρ(x)dydx =∫A
∫B
kρ(y, x)ρ(y)dydx (Fubini)
⇐⇒∫A
∫B
(kρ(x, y)ρ(x)− kρ(y, x)ρ(y)) dydx = 0
„⇐“ Trivial.
„⇒“ Sei f(x, y) = kρ(x, y)ρ(x)− kρ(y, x)ρ(y). Dann gilt für alle A,B ∈ B(G)∫A
∫B
f(x, y)d(x, y) = 0.
Mit dem Satz 3.18 folgt dann für A ∈ B(G×G), dass∫A
f(x, y)d(x, y) = 0.
Sei nun A = (x, y) ∈ G×G : f(x, y) ≥ 0 = f ≥ 0 ∈ B(G×G). Es gilt
0 =∫f≥0
fdλ =∫
G×G
f+dλ.
Und da f+ ≥ 0 folgt f+ = 0 λ-f.ü. Analog zeigt man f− = 0 λ-f.ü.
Dies impliziert f = f+− f− = 0 λ-f.ü. Also kρ(x, y)ρ(x) = kρ(y, x)ρ(y) λ-f.ü. und die Behauptung istbewiesen.
35

3.2 Grundlegende Algorithmen
Das heißt, falls für alle x, y ∈ G gilt, dass q(x, y)ρ(x) = q(y, x)ρ(y), wären wir bereits fertig. Dannwürden wir nämlich kρ = q setzen.
Wie sollen wir kρ wählen, s.d. Kρ reversibel bezüglich πρ ist? Wir können o.B.d.A. annehmen, dassx, y ∈ G exisitieren, mit
q(x, y)ρ(x) > q(y, x)ρ(y), (5)denn sonst läge bereits Reversibilität vor.
(Intuitiv: Übergang von x zu y tritt zu häufig auf und Übergang von y zu x zu selten.)
Wir modifizieren die linke Seite von (5): Wir multiplizieren diese mit einer Akzeptanzwahrscheinlich-keit 0 ≤ α(x, y) < 1, s.d. wir Gleichheit erhalten, d.h.
α(x, y)q(x, y)ρ(x) = q(y, x)ρ(y) = α(y, x)q(y, x)ρ(y), (6)
mit α(y, x) = 1. Wir setzen nunkρ(x, y) := α(x, y)q(x, y)
und erhalten Reversibilität, da
kρ(x, y)ρ(x) = α(x, y)q(x, y)ρ(x) = q(y, x)ρ(y) = α(y, x)q(y, x)ρ(y) = kρ(y, x)ρ(y).
Wie sieht jetzt α(x, y) aus? Aus der ersten Gleichheit in (6) folgt
α(x, y) = q(y, x)ρ(y)q(x, y)ρ(x) < 1 und α(y, x) = 1.
Zusammen ergibt das für alle x, y ∈ G
α(x, y) :=
min
1, q(y,x)ρ(y)q(x,y)ρ(x)
q(x, y)ρ(x) 6= 0
1 sonst.
Der Übergangskern ist dann
Kρ(x,A) =∫A
α(x, y)q(x, y)dy + 1A(x)
1−∫G
α(x, y)q(x, y)dy
=∫A
α(x, y)Q(x, dy) + 1A(x)
1−∫G
α(x, y)Q(x, dy)
,
denn Q(x, dy) = q(x, y)dy + 1dy(x)(1−∫Gq(x, z)dz) und Einsetzen in rechte Seite liefert∫
A
α(x, y)q(x, y)dy +∫G
1A(y)
1−∫G
q(x, z)dz
α(x, y)︸ ︷︷ ︸=1
1dy(x)
+ 1A(x)
1−∫G
α(x, y)q(x, y)dy −∫G
1−∫G
q(x, z)dz
α(x, y)︸ ︷︷ ︸=1
1dy(x)
=∫A
α(x, y)q(x, y)dy +
1A(x)
1−∫G
q(x, z)dz
+ 1A(x)
1−∫G
α(x, y)q(x, y)dy
−
1A(x)
1−∫G
q(x, z)dz
.36

3.2 Grundlegende Algorithmen
Im Prinzip folgt aus der vorherigen Betrachtung (der Wahl von α(·, ·)) folgendes Lemma.
Lemma 3.22Der Übergangskern Kρ, mit kρ = α(x, y)q(x, y), ist reversibel bezüglich πρ.
Beweis: Da kρ(x, y)ρ(x) = kρ(y, x)ρ(y) und unter Verwendung von Lemma 3.21.
Metropolis-Hastings-Algorithmus: Übergangskern von xi zu xi+1:
Eingabe: xi (aktueller Zustand)Q (Vorschlagskern)
Ausgabe: xi+1 (nächster Zustand)
1) Wähle unabhängig voneinander y mit Verteilung Q(xi, ·) und u ∈ [0, 1] gleichverteilt.
2) Berechne α(x, y) = min
1, q(y,xi)ρ(y)q(xi,y)ρ(xi)
.
Falls u ≥ α(xi, y), setze xi+1 = xi, sonst setze xi+1 = y.
3) Ausgabe xi+1.
Bemerkung 3.23
a) Falls q(x, y) = q(y, x), für alle x, y ∈ G, so heißt Kρ Metropolis-Algorithmus oder Metropolis-Kern.
b) Falls q(x, y) = η(y), für alle x, y ∈ G und eine Funktion η : G→ (0,∞), so heißt Kρ unabhängigerMetropolis-Algorithmus (siehe Spezialfall am Anfang dieses Abschnittes).
c) Für den Metropolis-Hastings-Algorithmus benötigt man (bezüglich ρ) eigentlich nur Quotien-ten ρ(x)
ρ(y) . Insbesondere spielt die Normierungskonstante keine Rolle. Funktionsauswertungen von ρ(bis auf einen konstanten Vorfaktor) reichen vollkommen aus.
Bemerkung 3.24In der Herleitung und Darstellung von Kρ taucht α : G×G→ [0, 1] auf. Um das Ziel „Kρ reversibelbezüglich πρ“ zu erreichen, kann man α auch durch andere Funktionen, bzw. Akzeptanzwahrschein-lichkeiten α : G×G→ [0, 1] ersetzen. Zum Beispiel falls q(x, y) = q(y, x), für alle x, y ∈ G, führt dieWahl
α(x, y) = ρ(y)ρ(x) + ρ(y)
auch zum Ziel. Der daraus resultierende Übergangsschritt, bzw. Übergangskern, wird Barkers Al-gorithmus genannt, siehe Barker [3].
Es gilt allerdings α(x, y) ≤ α(x, y), für alle x, y ∈ G.
3.2.2 Hit-and-run-Algorithmus
Seien G ⊆ Rd, G = B(G), ρ gegeben wie zu Beginn von Abschnitt 3 und
πρ(A) =∫Aρ(x)dx∫
Gρ(x)dx
.
(Für ρ(x) = 1G(x) siehe fünftes Beispiel in Bsp 3.7)
37

3.2 Grundlegende Algorithmen
Idee: Übergang von x zu y durch hit-and-run-Schritt.
G
x
x+ θ
x+ sθ
ρ|x+sθ∈G:s∈R
Übergangskern ist
Hρ(x,A) = 1σ(Sd−1)
∫Sd−1
Hθ,ρ(x,A)dσ(θ),
wobei
Hθ,ρ(x,A) =∫∞−∞ 1A(x+ sθ)ρ(x+ sθ)ds
`ρ(x, θ),
mit
`ρ(x, θ) =∞∫−∞
1G(x+ sθ)ρ(x+ sθ)ds.
Wir schreiben auch kurz Hθ für Hθ,ρ und ` für `ρ.
Bemerkung 3.25Hθ(x, ·) ist die Verteilung, die durch ρ eingeschränkt auf x+ sθ ∈ G : s ∈ R gegeben ist.
Hit-and-run-Algorithmus: Übergang von xi zu xi+1 durch hit-and-run-Algorithmus:
Input: xi (aktueller Zustand)Output: xi+1 (nächster Zustand)
1) Wähle θ ∈ Sd−1 gleichverteilt.
2) Wähle xi+1 bezüglich Hθ(xi, ·).
Bemerkung 3.26Schritt 2) ist unter Umständen nicht einfach zu implementieren. Idee für G beschränkt und konvex:
• Bestimme Schnittpunkte von Gerade mit G (falls G konvex erhalte ich 2 Punkte), z.B. mitBisektionsverfahren.
• Bestimme globales Maximum ρmax von ρ, eingeschränkt auf dem Segment x+sθ ∈ G : s ∈ R.
• Verwerfungsmethode auf 1-dimensionales Problem anwenden. Die auf dem Rechteck gleichver-teilten Punkte werden unterhalb des Graphen von ρ akzeptiert und darüber verworfen. Wirhaben die Hoffnung, dass hier die Akzeptanzwahrscheinlichkeit nicht zu klein ist.
Skizze:
38

3.2 Grundlegende Algorithmen
ρmax
ρ|x+sθ∈G:s∈R
Es ist nicht mehr so klar, welche Informationen wir von ρ für den Algorithmus benötigen. ReichenFunktionswerte von ρ aus? Unter weiteren Voraussetzungen kann man dies bejahen, z.B. G konvex,beschränkt und ρ log-konkav (d.h. log ρ konkav auf G).
Frage: Ist Hρ reversibel bezüglich πρ?
Lemma 3.27
(i) ∀θ ∈ Sd−1 ist Hθ reversibel bezüglich πρ.
(ii) Hρ ist reversibel bezüglich πρ.
Beweis:
(i) Sei c :=∫Gρ(x)dx, A,B ∈ B(G). Dann gilt
∫A
Hθ(x,B)πρ(dx) =∫Rd
∞∫−∞
1A(x)1B(x+ sθ)ρ(x+ sθ)c · `(x, θ) ρ(x)dsdx
=∞∫−∞
∫Rd
1A(y − sθ)1B(y)ρ(y)ρ(y − sθ)c · `(y − sθ, θ) dyds
=∫B
∞∫−∞
1A(y − sθ)ρ(y − sθ)`(y, θ) dsπρ(dy),
denn `(y − sθ, θ) = `(y, θ), wegen
`(y, θ) =∞∫−∞
1G(y + tθ)ρ(y + tθ)dt =∞∫−∞
1G(y + (t− s)θ)ρ(y + (t− s)θ)dt = `(y − sθ, θ).
Mit −s = t folgt
∫A
Hθ(x,B)πρ(dx) =∫B
∞∫−∞
1A(y + tθ)ρ(y + tθ)`(y, θ) dtπρ(dy)
=∫B
Hθ(y,A)ρ(dy).
39

3.2 Grundlegende Algorithmen
(ii) Seien A,B ∈ B(G) beliebig. Dann gilt∫A
Hρ(x,B)πρ(dx) =∫A
∫Sd−1
Hθ(x,B) σ(dθ)σ(Sd−1)πρ(dx)
= 1σ(Sd−1)
∫Sd−1
∫A
Hθ(x,B)πρ(dx)
︸ ︷︷ ︸∫BHθ(x,A)πρ(dx)
σ(dθ)
... zurückargumentieren
=∫B
Hρ(x,A)πρ(dx).
3.2.3 Gibbs sampler
Wir unterscheiden 2 verschiedene Algorithmen, die unter dem Begriff „Gibbs sampler“ zusammenge-fasst werden.
a) Random scan Gibbs sampler
Dieser ist konzeptionell sehr ähnlich zum hit-and-run Algorithmus.
Skizze: d = 2, G ⊆ R2 beschränkt
e1
e2
0
x x+ e1 y
Übergangskern
Rρ(x,A) = 1d
d∑i=1
Hei(x,A),
wobei e1, . . . , ed Euklidische Einheitsbasis im Rd ist, d.h.
ei = (0, . . . , 0, 1↑
i-te Stelle
, 0, . . . , 0),
und Hei(x,A) wie beim hit-and-run.
40

3.2 Grundlegende Algorithmen
Lemma 3.28Rρ ist reversibel bezüglich πρ.
Beweis: Analog zu Lemma 3.27 (ii).
b) Deterministic scan Gibbs sampler
Dρ(x,A) = He1He2 . . . Hed(x,A),
das Produkt von Übergangskernen. Skizze: d = 2, Übergang von x zu y:
x x+ e1
y
Lemma 3.29 (a) Dρ ist im Allgemeinen nicht reversibel bezüglich πρ.
(b) πρ ist eine stationäre Verteilung von Dρ.
Beweis:
(a) Konstruktion von nicht reversiblem Beispiel. Sei G = [0, 2]× [0, 2] \ [1, 2]× [1, 2] und ρ = 1G,d.h. d = 2 und πρ die Gleichverteilung auf G. Setze A1 = [0, 1]× [1, 2] und A2 = [1, 2]× [0, 1].
A1
A2 G
0 1 2
1
2
Wir haben ∫A1
He1He2(x,A2) dxλ2(G) 6=
∫A2
He1He2(x,A1) dxλ2(G) ,
denn für alle x ∈ A1 gilt He1He2(x,A2) = 0 und für alle x ∈ A2 gilt He1He2(x,A1) = 14 .
=⇒ Im Allgemeinen ist Dρ nicht reversibel bezüglich πρ.
(b) Aus Lemma 3.27 (i) wissen wir, dass Hej für j = 1, . . . , d reversibel bezüglich πρ ist. Insbe-sondere ist πρ eine stationäre Verteilung von Hej (siehe Lemma 3.17 (i)). Deshalb gilt
πρD(A) = πρHe1︸ ︷︷ ︸πρ
He2 . . . Hed(A) = πρHe2 . . . Hed(A) = . . . = πρ(A).
41

3.2 Grundlegende Algorithmen
Bemerkung 3.30Die „Kosten“ von einem Schritt bezüglich Dρ sind so hoch wie von d Schritten mit Rρ. Ein Vorteildes „deterministic scan Gibbs sampler“ ist, dass er Produktstrukturen ausnutzen kann. Zum Beispiel:G = [0, 1]d und ρ = 1G. Bei diesem Beispiel erzeugt ein Schritt von Dρ genau die richtige Verteilung.
3.2.4 Slice sampling
In diesem Abschnitt stellen wir den „simple slice sampler“ und eine Verallgemeinerung, den „hybridenSlice sampler“ vor.
Zur Erinnerung: G ⊆ Rd, ρ : G → (0,∞) mit 0 <∫Gρ(x)dx < ∞. Und zusätzlich sei ‖ρ‖∞ =
supx∈G |ρ(x)| < ∞. Dies ist nicht unbedingt nötig, schließt aber im Wesentlichen nur uninteressanteBeispiele aus.
Für t ∈ [0, ‖ρ‖∞] sei
G(t) = x ∈ G : ρ(x) ≥ t
die Levelmenge von ρ bezüglich t. Es sei bemerkt, dass aus
∞∫0
λd(G(t))dt =∞∫
0
∫G
1G(t)(x)dxdt =∞∫
0
∫G
1[0,ρ(x)](t)dxdt =∫G
ρ(x) <∞
folgt, dass λd(G(t)) <∞ für fast alle t ∈ [0, ‖ρ‖∞] bezüglich dem Lebesguemaß. Für t = 0 gilt diesnicht unbedingt, aber 0 ist Nullmenge.
a) Simple slice sampler
Idee/Skizze: Übergang von x zu y mit einem Schritt vom simple slice sampler: d = 1
ρt
x y
ρ(x)
G(t)
Skizze für d = 2:
42

3.2 Grundlegende Algorithmen
t
x
ρ(x)
y
G(t)
Übergangskern: Dazu sei
Ut(A) = λd(A ∩G(t))λ(G(t)) , A ∈ B(G),
die Gleichverteilung auf G(t). Das heißt (Ut)t>0 eine Folge von Übergangskernen/Verteilungen.Dann ist
U(x,A) = 1ρ(x)
ρ(x)∫0
Ut(A)dt
der Übergangskern vom simple slice sampler.
Algorithmus:
Eingabe: xi (aktueller Zustand)Ausgabe: xi+1 (nächster Zustand)
1) Wähle t ∈ [0, ρ(xi)] bezüglich Gleichverteilung.
2) Wähle xi+1 gleichverteilt in G(t).
Lemma 3.31U ist reversibel bezüglich πρ.
43

3.2 Grundlegende Algorithmen
Beweis: Seien A,B ∈ B(G) beliebig und c =∫Gρ(x)dx. Dann gilt
∫B
U(x,A)ρ(x)dxc
=∫B
ρ(x)∫0
Ut(A)dtdxc
=∞∫
0
∫B
1[0,ρ(x)](t)︸ ︷︷ ︸1G(t)(x)
Ut(A)dxdtc
=∞∫
0
Ut(A)Ut(B)λd(G(t))dtc
... zurück argumentieren
=∫A
U(x,B)πρ(dx).
Bemerkung 3.32Schritt 2) des Algorithmus ist problematisch, da das Erzeugen/ die Simulation der Gleichverteilungin einer d-dimensionalen Menge (zum Beispiel der Levelmenge G(t)) im Allgemeinen nicht invernünftiger Zeit realisierbar ist.
Diese Bemerkung stellt die Hauptmotivation für die folgende Verallgemeinerung, bzw. Modifikati-on, dar.
b) Hybride slice sampler
Sei (Qt)t>0 eine Folge von Übergangskernen, wobei Qt ein Übergangskern auf G(t) ⊆ Rd definiert.Wir setzen Qt auf (G,B(G)) wie folgt für x ∈ G,A ∈ B(G) fort:
Qt(x,A) :=
0 x /∈ G(t)Qt(x,A ∩G(t)) x ∈ G(t)
.
Allerdings schreiben wir für Qt einfach Qt.
Die Idee ist 2) im Algorithmus vom simple slice sampler durch einen Schritt mittels Qt zu ersetzen.Als Übergangskern ergibt sich für den hybriden slice sampler (basierend auf Qt)
Q(x,A) = 1ρ(x)
ρ(x)∫0
Qt(x,A)dt, x ∈ G,A ∈ B(G).
Frage: Unter welchen Voraussetzungen an Qt ist der Übergangskern Q reversibel bezüglich πρ?
Zur Vereinfachung der Notation definieren wir die Dichtefunktion
w(s) = λd(G(s))∫∞0 λd(G(t))dt
, s ∈ [0,∞),
auf ([0,∞),B([0,∞))).
44

3.3 Markovoperator
Lemma 3.33 (siehe auch [10])Q ist genau dann reversibel bezüglich πρ, wenn
∞∫0
∫B
Qt(x,A)Ut(dx)w(t)dt =∞∫
0
∫A
Qt(x,B)Ut(dx)w(t)dt
für alle A,B ∈ B(G).
Insbesondere: Falls Qt reversibel bezüglich Ut ist (für fast alle t bezüglich w), dann ist Q rever-sibel bezüglich πρ.
Wir bemerken: Die Gleichung aus Lemma 3.33, welche die Reversibilität bezüglich πρ charakte-risiert, kann als Reversibilitätsbedingung von Qt bezüglich Ut in Erwartung interpretiert werden,da
Ew(Q(x, dy)U(dx)) = Ew(Q(y,dx)U(dy)), ∀x, y ∈ G.
Beweis (des Lemmas):
Wir wissen bereits, dass c :=∫Gρ(x)dx =
∫∞0 λd(G(t))dt (siehe Anfang dieses Abschnittes). Seien
A,B ∈ B(G) beliebig. Wir erhalten∫B
Q(x,A)πρ(dx) =∫B
ρ(x)∫0
Qt(x,A)dtdxc
=∫B
∞∫0
1G(t)(x)︸ ︷︷ ︸=1[0,ρ(x)](t)
Qt(x,A)dtdxc
=∞∫
0
∫B
Qt(x,A) dxλd(G(t))
λd(G(t))c︸ ︷︷ ︸
=w(t)
dt
=∞∫
0
∫B
Qt(x,A)Ut(dx)w(t)dt.
Analog gilt ∫A
Q(x,B)πρ(dx) =∞∫
0
∫A
Qt(x,B)Ut(dx)w(t)dt.
Damit folgt die Behauptung.
3.3 Markovoperator
Sei (G,G) ein messbarer Raum und π Wmaß auf (G,G). Für p ∈ [1,∞) sei
Lp =
f : G→ R messbar : ‖f‖p :=(∫G
|f(x)|pπ(dx))1/p
<∞
45

3.3 Markovoperator
und für p =∞ sei
L∞ = f : G→ R messbar : ‖f‖∞ := ess supx∈G |f(x)| <∞.2
Die Funktionenräume Lp sind gegeben durch den Raum der Äquivalenzklassen [f ] =: f der π-f.ü.gleichen Funktionen mit Repräsentanten der Norm ‖f‖p <∞. Lp ist ein Banachraum für p ∈ [1,∞],d.h. ein normierter, vollständiger Raum.
Wichtige Ungleichungen:
• Jensensche Ungleichung
Sei f ∈ L1 und ϕ : [0,∞)→ R konvex, d.h.
∀λ ∈ [0, 1] ∀x, y ∈ [0,∞) : ϕ(λx+ (1− λ)y) ≤ λϕ(x) + (1− λ)ϕ(y).
Dann gilt
ϕ
∫G
|f |dπ
≤ ∫G
ϕ(|f |)dπ.
• Höldersche Ungleichung
Seien p, q ∈ [1,∞] mit 1p + 1
q = 1 und f ∈ Lp, g ∈ Lq. Dann gilt f · g ∈ L1 und
‖f · g‖1 ≤ ‖f‖p‖g‖q.
Für den Beweis der Jensenschen Ungleichung siehe [9, Satz 7.9] und für den Beweis der HölderschenUngleichung siehe [9, Satz 7.16].
Folgerung 3.34Sei p ≤ q und p, q ∈ [1,∞]. Dann gilt ‖f‖p ≤ ‖f‖q und damit Lq ⊆ Lp.
Beweis: Wir haben
‖f‖p =
∫G
|f |pdπ
1/p·q/q
≤
∫G
|f |p·q/pdπ
1/q
= ‖f‖q.
Nun sei K Übergangskern auf (G,G) und π eine stationäre Verteilung von K.
Definition 3.35 (Markovoperator)Sei f ∈ Lp. Dann ist der Markovoperator P gegeben durch
P f(x) =∫G
f(y)K(x, dy).
2Zur Erinnerung:ess supx∈G |f(x)| = inf
N∈Gπ(N)=0
supG\N
|f(x)|.
46

3.3 Markovoperator
Interpretation: Sei (Xn)n∈N Markovkette mit Übergangskern K. Dann gilt
E[f(X2) | X1 = x] E5 aus 3.1=∫G
f(y)K(x, dy).
Eigenschaften:
E0 P ist ein linearer Operator.
E1 Ist f(x) = 1 für alle x ∈ G, folgt P f(x) = f(x) = 1.
(Gilt auch allgemeiner für konstante Funktionen.)
E2 f ∈ L1 =⇒P(|f |)(x) =∫G|f(y)|K(x, dy) ist π-f.s. überall endlich.
Beweis: Nach Folgerung 3.13 ist∫G
∫G
|f(y)|K(x, dy)π(dx) =∫G
|f(y)|π(dy) <∞.
Wegen der Positivität des Integranden folgt die Behauptung.
E3 P : Lp → Lp und ‖P ‖Lp→Lp = 1 für p ∈ [1,∞].
Beweis: Sei f ∈ Lp. Es gilt
‖P f‖pp =∫G
|P f(x)|pπ(dx)
=∫G
∣∣∣∣ ∫G
f(y)K(x, dy)∣∣∣∣pπ(dx)
≤∫G
∫G
|f(y)|pK(x, dy)π(dx) (E2 und Jensen, da p ≥ 1)
= ‖f‖pp (Folg. 3.13)
Also haben wir ‖P f‖p ≤ ‖f‖p und ‖P 1‖p = 1. ‖P ‖Lp→Lp ist gegeben durch
‖P ‖Lp→Lp := sup‖f‖p≤1
‖P f‖p.
Also
1 ≤ ‖P ‖Lp→Lp ≤ 1
und somit ‖P ‖Lp→Lp = 1.
E4 f ∈ Lp =⇒Pm f(x) =∫Gf(y)Km(x,dy), für m ∈ N.
47

3.3 Markovoperator
Beweis: Induktion über m ∈ N. m = 1 X nach Definition. Weiterhin gilt
Pm+1 f(x) = P(Pm f)(x)
= P
∫G
f(z)Km(·,dz)
(x)
=∫G
∫G
f(z)Km(y,dz)K(x, dy)
=∫G
f(z)KKm(x, dz) (Lemma 3.10 mit ν = K)
=∫G
f(z)Km+1(x,dz).
E5 K reversibel bezüglich π ⇐⇒ P selbstadjungiert auf L2.
Bemerkung 3.36L2 ist ein Hilbertraum mit Skalarprodukt
〈f, g〉 :=∫G
f · g dπ, f, g ∈ L2
und P heißt selbstadjungiert, falls 〈P f, g〉 = 〈f,P g〉.
Beweis (von E5):
„⇐“ klar, da für A,B ∈ G gilt∫A
K(x,B)π(dx) = 〈1A,P1B〉 = 〈P1A,1B〉 =∫B
K(x,A)π(dx).
„⇒“ Es gilt für beliebige f, g ∈ L2
〈P f, g〉 =∫G
∫G
f(y)g(x)K(x,dy)π(dx)
=∫G
∫G
f(x)g(y)K(x,dy)π(dx) (Lemma 3.17 (iii))
= 〈f,P g〉.
Zur Erinnerung: Sei µ Wmaß auf (G,G). Dann ist
µPm(A) :=∫G
Km(x,A)µ(dx), A ∈ G
auch ein Wmaß auf (G,G) (siehe E4 in Abschnitt 3.1).
48

3.4 Klassische Konvergenzeigenschaften von Markovketten
Bemerkung 3.37Diese „Art von Operation“ lässt sich auch auf signierte Maße µ anwenden, d.h. auf σ-additive Funktio-nen µ : G → R mit µ(∅) = 0. Man kann dann auch zeigen, dass µ 7→ µP einen linearen, beschränktenOperator auf den signierten Maßen mit dµ
dπ ∈ Lp induziert (dµdπ verallgemeinerte Dichte von µ und π).
Lemma 3.38Sei µ ein Wmaß (G,G) mit dµ
dπ ∈ L2 (d.h. µ besitzt eine Dichte bezüglich π und ∀A ∈ G giltµ(A) =
∫A
dµdπdπ, sowie dµ
dπ ≥ 0).
Sei K reversibel bezüglich π. Dann gilt
d(µPm)dπ = Pm
(dµdπ
)π-f.s.
Beweis: Wir zeigen
µPm(A) =∫A
Pm(
dµdπ
)dπ, A ∈ G.
Dann gilt mit dem Satz von Radon-Nycodim, siehe [9, Korollar 7.34], dass d Pmdπ = Pm
(dµdπ
)π-f.s.
Wir haben
µPm(A) =∫G
Km(x,A)µ(dx)
=∫G
∫G
1A(y)Km(x, dy)dµdπ (x)π(dx)
=∫G
∫G
1A(x)dµdπ (y)Km(x,dy)π(dx) (Lemma 3.17 (iii))
=∫A
Pm(
dµdπ
)(x)π(dx).
3.4 Klassische Konvergenzeigenschaften von Markovketten
Sei (Xn)n∈N eine Markovkette (auf messbaren Raum (G,G)) mit Übergangskern K und Startver-teilung ν. Desweiteren sei K reversibel bezüglich π.
Frage: Wann gilt P(Xn ∈ A)︸ ︷︷ ︸=ν Pn−1(A)
n→∞−→ π(A), für beliebiges A ∈ G?
Definition 3.39Der totale Variationsabstand von 2 Wmaßen µ, ν auf (G,G) ist gegeben durch
‖µ− ν‖tv = supA∈G|ν(A)− µ(A)|.
(m(µ, ν) = ‖µ− ν‖tv ist in der Tat eine Metrik auf der Menge der Wmaße.)
49

3.4 Klassische Konvergenzeigenschaften von Markovketten
Lemma 3.40Seien µ, ν Wmaße auf (G,G). Wir nehmen an, dass die Dichtefunktionen dµ
dπ (Dichte von µ bezüglichπ) und dν
dπ (Dichte von ν bezüglich π) existieren. Dann gilt
‖µ− ν‖tv = 12 sup‖f‖∞≤1
∣∣∣∣ ∫G
f(x)(µ(dx)− ν(dx))∣∣∣∣ = 1
2
∥∥∥∥dνdπ −
dµdπ
∥∥∥∥1.
Beweis: Wir zeigen zunächst ‖µ− ν‖tv = 12 sup‖f‖∞≤1
∣∣∫Gf(x)(µ(dx)− ν(dx))
∣∣. Es gilt‖µ− ν‖tv = sup
B∈G|µ(B)− ν(B)|
= supB∈G
∣∣∣∣∣∣∫B
(dµdπ (x)− dν
dπ (x))π(dx)
∣∣∣∣∣∣= supB∈G
∣∣∣∣∣∣∫G
1B(x)(
dµdπ (x)− dν
dπ (x))π(dx)
∣∣∣∣∣∣︸ ︷︷ ︸(∗)
.
Für welches B wird (∗) am größten? Antwort: Der Integrand dµdπ−
dνdπ sollte immer positiv oder negativ
sein. D.h. fürA :=
x ∈ G : dµ
dπ (x) ≥ dνdπ (x)
oder Ac wird obiges Integral betragsmäßig am größten und
‖µ− ν‖tv = maxµ(A)− ν(A), ν(Ac)− µ(Ac) = µ(A)− ν(A).
Andererseits ist aber
12 sup‖f‖∞≤1
∣∣∣∣∣∣∫G
f(x)(ν(dx)− µ(dx)
∣∣∣∣∣∣ = 12 sup‖f‖∞≤1
∣∣∣∣∣∣∫G
f(x)(
dνdπ (x)− dµ
dπ (x))π(dx)
∣∣∣∣∣∣︸ ︷︷ ︸(?)
.
Für welche Funktion f wird (?) am größten? Antwort: Mit obiger Menge A für
g(x) :=−1 x ∈ A1 x ∈ Ac
.
Wir erhalten
12 sup‖f‖∞≤1
∣∣∣∣∣∣∫G
f(dν − dµ)
∣∣∣∣∣∣ = 12
∣∣∣∣∣∣∫G
g(x)(
dνdπ (x)− dµ
dπ (x))π(dx)
∣∣∣∣∣∣= 1
2 |ν(A)− µ(A)− ν(Ac) + µ(Ac)|
= |ν(A)− µ(A)| = µ(A)− ν(A).
50

3.4 Klassische Konvergenzeigenschaften von Markovketten
Damit haben wir die erste Gleichheit und eigentlich auch die zweite aufgrund der Wahl von A. Wirbieten aber auch eine alternative Argumentation an:
Wir zeigen nun sup‖f‖∞≤1 |∫Gf(x)(µ(dx)− ν(dx))| =
∥∥∥ dνdπ −
dµdπ
∥∥∥1. Es gilt
sup‖f‖∞≤1
∣∣∣∣∣∣∫G
f
(dνdπ −
dµdπ
)dπ
∣∣∣∣∣∣ ≤ sup‖f‖∞≤1
‖f‖∞∥∥∥∥dν
dπ −dµdπ
∥∥∥∥1.
Weiterhin gilt ∥∥∥∥dνdπ −
dµdπ
∥∥∥∥1
=∫G
∣∣∣∣dνdπ (x)− dµdπ (x)
∣∣∣∣π(dx)
=
∣∣∣∣∣∣∫G
g(x)(
dνdπ (x)− dµ
dπ (x))π(dx)
∣∣∣∣∣∣≤ sup‖f‖∞≤1
∣∣∣∣∣∣∫G
f
(dνdπ −
dµdπ
)dπ
∣∣∣∣∣∣ .
Nun fragen wir nach einer Abschätzung von ‖ν Pn−π‖tv (K reversibel bezüglich π, ν Startverteilung).Es gilt
2 ‖ν Pn−π‖tv =∥∥∥∥d(ν Pn)
dπ − 1∥∥∥∥
1(Lemma 3.40)
=∥∥∥∥Pn
(dνdπ
)− 1∥∥∥∥
1(Lemma 3.38)
=∥∥∥∥(Pn−S)
(dνdπ − 1
)∥∥∥∥1,
wobei S, wie üblich, der Solution Operator ist (S(f) =∫Gfdπ, S( dν
dπ − 1) = 0, P 1 = 1.) Damiterhalten wir folgenden Satz.
Satz 3.41Sei ν ein Wmaß und K reversibel bezüglich π. Weiter sei dν
dπ ∈ L1 und für f ∈ L1 sei S(f) =∫Gfdπ.
Dann gilt
(i) ‖ν Pn−π‖tv ≤12 ‖P
n−S‖L1→L1
∥∥ dνdπ − 1
∥∥1︸ ︷︷ ︸
≤2
,
(ii) ‖ν Pn−π‖tv ≤12 ‖P
n−S‖L2→L2
∥∥ dνdπ − 1
∥∥2, falls
dνdπ ∈ L2.
Beweis: Siehe Vorbetrachtung für Formel (i). Um (ii) zu zeigen wende Folgerung 3.34 an.
Bemerkung 3.42Falls ν = π, dann gilt ‖ν Pn−π‖tv = 0, da πPn = π.
In den Abschätzungen (i) und (ii) kommt∥∥ dν
dπ − 1∥∥
1 bzw.∥∥ dν
dπ − 1∥∥
2 vor. Diese Größen sind für ν = πebenfalls Null. D.h. falls die Markovkette bezüglich einer stationären Verteilung startet, dann sind dieAbschätzungen scharf, also erhalten wir Gleichheit.
51

3.4 Klassische Konvergenzeigenschaften von Markovketten
Sei nunL0
2 = f ∈ L2 : S(f) = 0.Dies ist ein abgeschlossener Unterraum von L2 und somit wieder ein Hilbertraum (gleiches Skalarpro-dukt und Norm in L2.) Desweiteren erhalten wir
L2 = L02 ⊕ (L0
2)⊥,
mit(L0
2)⊥ = f ∈ L2 : f ≡ c, c ∈ R,das orthogonale Komplement von L0
2, da für f ∈ L2 gilt
f = f − S(f)︸ ︷︷ ︸∈L0
2
+ S(f)︸︷︷︸∈(L0
2)⊥
.
Lemma 3.43Sei π eine stationäre Verteilung von K, n ∈ N. Dann gilt P : L0
2 → L02 und
‖Pn‖L02→L0
2= ‖Pn−S‖L2→L2
.
Beweis: Wir zeigen P : L02 → L0
2. Sei g ∈ L02. Zu zeigen: S(P g) = 0. Dies gilt wegen∫
G
∫G
g(y)K(x, dy)π(dx) Folg. 3.13=∫G
gdπ = S(g) = 0.
Nun zu den Operatornormen: Zunächst bemerken wir
Pn(S(f)) =∫G
S(f)Kn(x, dy) = S(f), (7)
‖f − S(f)‖22 = ‖f‖22 − (S(f))2 ≤ ‖f‖22 =⇒ ‖f − S(f)‖2 ≤ 1, falls ‖f‖2 ≤ 1. (8)
Damit erhalten wir
‖Pn−S‖L2→L2 = sup‖f‖2≤1
‖(Pn−S)f‖2
(7)= sup‖f‖2≤1
‖Pn(f − S(f))‖2
(8)≤ sup‖g‖2≤1g∈L0
2
‖Pn g‖2
= ‖Pn ‖L02→L0
2.
Andererseits
‖Pn ‖L02→L0
2= sup‖g‖2≤1g∈L0
2
‖Pn g − S(g)︸︷︷︸=0
‖ ≤ sup‖f‖2≤1
‖Pn f − S(f)‖2 = ‖Pn−S‖L2→L2 .
Damit folgt die Behauptung.
Diese Vorbetrachtungen motivieren folgende Konvergenzbegriffe:
52

3.4 Klassische Konvergenzeigenschaften von Markovketten
Definition 3.44 (L1-exponentielle Konvergenz)Sei α ∈ [0, 1), M ∈ (0,∞). Dann heißt der Übergangskern K L1-exponentiell konvergent mit(α,M), falls
‖Pn−S‖L1→L1 ≤ αnM, ∀n ∈ N.
Eine Markovkette mit Übergangskern K heißt L1-exponentiell konvergent, falls α und M existieren,s.d. K L1-exponentiell konvergent mit (α,M) ist.
Definition 3.45 (absolute Spektrallücke)Ein Übergangskern K und der dazugehörige Markovoperator P haben eine (absolute) Spektrallücke(1− β), falls
β = ‖P ‖L02→L0
2< 1.
Bemerkung 3.46
a) Falls P eine (absolute) Spektrallücke (1 − β) besitzt, folgt mittels der zwei vorherigen Resultate(Lemma 3.43 und Satz 3.41)
‖ν Pn−π‖tv ≤ βn
∥∥∥∥dνdπ − 1
∥∥∥∥2.
b) Der Name Spektrallücke kommt von folgender Interpretation: Mit σ(P | L2) bezeichnen wir dasSpektrum von P : L2 → L2. Wir wissen, dass P 1 = 1, d.h. 1 ∈ σ(P | L2) ist ein Eigenwert und(L0
2)⊥ der dazugehörige Eigenraum. Desweiteren gilt
‖P ‖L02→L0
2= sup|λ| : λ ∈ σ(P | L0
2),
siehe dazu [21, Korollar VII.1.2].
Da σ(P | L2) = σ(P | L02)∪1 wissen wir, dass 1 ein isolierter Punkt im Spektrum von P ist, falls
β = ‖P ‖L02→L0
2< 1. D.h. es existiert eine Lücke zur 1, die mit Spektrallücke bezeichnet wird.
Satz 3.47Seien α ∈ [0, 1) und M ∈ (0,∞). Sei Übergangskern K reversibel bezüglich π. Dann gilt
‖Pn−S‖L1→L1 ≤ αnM =⇒ ‖P ‖L02→L0
2≤ α
Beweis (Idee. Details in [18, Prop. 3.24]):
Es gilt wegen der Dualität von L1 und L∞ (wegen Reversibilität ist der duale Operator von P wiederP) die Äquivalenz
‖Pn−S‖L1→L1 ≤ αnM ⇐⇒ ‖Pn−S‖L∞→L∞ ≤ αnM.
Der Satz von Riesz-Thorin liefert
‖Pn−S‖L2→L2 ≤ αnM. (9)
(siehe Bennet, Sharpley „Interpolation of operators“ Kap. 4, Corollary 1.8)
Weiter gilt Pn−S = (P−S)n, n ∈ N. Dies zeigen wir per Induktion. n = 1 X.
Für n ≥ 1 gilt dann
(P−S)n+1 = (P−S)(P−S)n = (P−S)(Pn−S) = Pn+1−PS − S Pn +S2.
53

3.4 Klassische Konvergenzeigenschaften von Markovketten
Wegen
P(S(f)) = S(f),S(S(f)) = S(f) und
S(Pn(f)) =∫G
Pn f(x)π(dx) =∫G
∫G
f(y)Kn(x, dy)π(dx) = S(f)
gilt Pn−S = (P−S)n für alle n ∈ N. Nun folgt die Behauptung mit der Spektralradiusformel
‖P ‖L02→L0
2= ‖P−S‖L2→L2 (Lemma 3.43)
= limn→∞
‖(P−S)n‖1/nL2→L2(P − S selbstadj., siehe [21, VI.1.7])
(9)≤ lim
n→∞(αnM)1/n = α.
Wir führen einen weiteren Konvergenzbegriff ein.
Definition 3.48 (gleichmäßig ergodisch)Seien α ∈ [0, 1) undM ∈ (0,∞). Dann heißt der Übergangskern gleichmäßig ergodisch mit (α,M),falls π-f.ü.
‖Kn(x, ·)− π‖tv ≤ αnM, n ∈ N
gilt.
Eine Markovkette heißt gleichmäßig ergodisch, falls Konstanten α und M existieren, sodass der da-zugehörige Übergangskern K gleichmäßig ergodisch mit (α,M) ist.
Unter der Annahme der Reversibilität bezüglich π haben wir folgende Beziehungen zwischen denverschiedenen Konvergenzbegriffen:
β = ‖P ‖L02→L0
2≤ α
(L2 - Spektrallücke ≥ 1− α)
‖Pn−S‖Lp→Lp ≤
22/p−1α2n(p−1)/p p ∈ (1, 2)2(p−2)/pα2n/p p ∈ [2,∞)
‖Kn(x, ·)− π‖tv ≤ αnM(glm. erg. mit (α,M))
‖Pn−S‖L∞→L∞ ≤ 2Mαn
‖Pn−S‖L1→L1 ≤ 2Mαn
(L1-exp. konv. mit (α, 2M))
Satz 3.47
54

4 Markovketten Monte-Carlo Methoden
Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Sei K reversibel bezüglichπ.
Ziel: Approximation vonS(f) =
∫G
f(y)π(dy),
für integrierbare Funktionen f .
Approximationsschema: Markovketten Monte-Carlo Methode (MCMC)
Sn,n0(f) = 1n
n∑j=1
f(Xj+n0),
mit n, n0 ∈ N (n0 wird burn-in genannt).
Zunächst wollen wir das „starke Gesetz der großen Zahlen“ für Sn,n0 formulieren und damit zeigen,dass Sn,n0 wohldefiniert ist.
Satz 4.1 (Starkes Gesetz der großen Zahlen für MCMC)Sei K π-irreduzibel, d.h.
∀A ∈ G ∀x ∈ G ∃n ∈ N : π(A) > 0 =⇒ Kn(x,A) > 0.
Dann gilt für alle f ∈ L1
Px(
limn→∞
Sn,n0(f) = S(f))
= 1,
für π-fast alle x ∈ G. Hier zeigt x in Px an, dass die Startverteilung ν = δx (deterministischer Startin x ∈ G).
Bemerkung 4.2
(i) Einen Beweis dieses Satzes findet man in [15, Thm. 17.17]. Einen einfacheren Zugang bietet dieArbeit [2] von Asmussen u. Glynn „Harris-Recurrence and MCMC: A simplified approach“.
(ii) Die Bedingung der π-Irreduzibilität besagt, dass man jede Menge A ∈ G von jedem x ∈ G inendlich vielen Schritten mit der Markovkette erreichen kann, falls π(A) > 0 ist. Im Sinne vonlokalen „random walks“ (z.B. ball walk) ist dies eine Zusammenhangsbedingung an G.
Skizze: δ-ball walk
Abstand > δ
δ - ball walk nichtπ-irreduzibel
55

4.1 Fehlerabschätzungen
wahrscheinlich„schlechte Kon-vergenz“, ist aberπ-irreduzibel
Wir sind allerdings an expliziten Abschätzungen des Fehlers von Sn,n0 interessiert.
4.1 Fehlerabschätzungen
Wir betrachten den Fehlerbegriff aus Definition 1.6 für Sn,n0 . Zur Erinnerung:
eν(Sn,n0 , f) =(Eν,K |Sn,n0(f)− S(f)|2
)1/2.
Hier zeigt ν,K in Eν,K an, dass in Sn,n0 eine Markovkette mit Übergangskern K und Startverteilungν vorliegt.
Folgendes Lemma wird bei der Fehlerananlyse hilfreich sein.
Lemma 4.3Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν, sowie i, j ∈ N mitj ≥ i.
(a) Dann giltEν,K [f(Xi)f(Xj)] =
∫G
Pj−1(f · Pi−j f)dν(x).
(b) Insbesondere giltEπ,K [f(Xi)f(Xj)] = 〈f,Pi−j f〉.
Beweis: (b) folgt aus (a), der Stationarität (siehe Folgerung 3.13) und∫G
Pj−1(f Pi−j f)dν Lemma 3.10=∫G
f(x) Pi−j f(x)ν Pj−1(dx).
Es verbleibt also (a) zu zeigen. Es gilt
Eν,K [f(Xi)f(Xj)] =∫G
∫G
f(x)f(y) PXi|Xj (x, dy)PXj (dx) (Satz 2.16 (ii))
=∫G
∫G
f(x)f(y)Ki−j(x, dy)
︸ ︷︷ ︸f(x) Pi−j f(x)
ν Pj−1(dx) (E3,E4 aus Abschnitt 3.1)
=∫G
Pj−1(f Pi−j f)dν (Lemma 3.10).
56

4.1 Fehlerabschätzungen
Frage: Wie verhält sich der Fehler, falls die Startverteilung eine stationäre Verteilung ist?
Satz 4.4Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung π. Desweiteren sei π einestationäre Verteilung von K und β = ‖P ‖L0
2→L02< 1. Dann gilt für f ∈ L2
eπ(Sn,n0 , f) ≤√
1 + β√n√
1− β‖f‖2.
Lemma 4.5Sei α ∈ [0, 1). Dann gilt
1 + 2n∑j=1
αj ≤ 1 + α
1− α ≤2
1− α.
Beweis: Mittels der geometrischen Reihe erhalten wir
1 + 2n∑j=1
αj ≤ 1 + 2(
11− α − 1
)= 1 + α
1− α.
Beweis (von Satz 4.4):
Sei g(x) = f(x)− S(f). Dann gilt
eπ(Sn,n0 , f)2 = Eπ,K |Sn,n0(f)− S(f)|2
= Eπ,K
∣∣∣∣∣∣ 1nn∑j=1
g(Xj+n0)
∣∣∣∣∣∣2
= 1n2
n∑j=1
Eπ,K [g(Xj+n0)2] + 2n2
n−1∑j=1
n∑k=j+1
E[g(Xj+n0)g(Xk+n0)]
= 1n2
n∑j=1‖g‖22 + 2
n2
n−1∑j=1
n∑k=j+1
〈g,Pk−j g〉 (Lemma 4.3 (b))
≤ 1n‖g‖22 + 2
n2
n−1∑j=1
n−j∑l=1‖g‖2‖Pl g‖2 (Hölderungl. und Indexverschiebung)
≤ 1n‖g‖22
1 + 2n
n−1∑j=1
n∑l=1
βl
≤ 1n‖g‖22
(1 + 2
n∑l=1
βl
)
≤ 1 + β
1− β1n‖g‖22 (Lemma 4.5).
Da ‖g‖22 = ‖f‖22 − (S(f))2 ≤ ‖f‖22, gilt die Behauptung.
57

4.1 Fehlerabschätzungen
Bemerkung 4.6
0.) n0 können wir Null setzen.
1.) Sei K(x,A) = π(A) für alle x ∈ G und für alle A ∈ G (siehe Beispiel 3.7.1)). Dann betrachten wirdie klassische Monte-Carlo Methode (Erzeuge Xi iid bezüglich π). Es gilt
P f(x) =∫G
f(y)π(dy) = S(f)
und daraus folgt
β := ‖P ‖L02→L0
2
Lemma 3.43= ‖P−S‖L2→L2 = 0.
Wir erhalten
eπ(Sn,n0 , f)2 ≤ 1n‖f‖22
wie in Satz 1.8 (Fehlerabschätzung der klassischen Monte-Carlo Methode).
Frage: Wie verhält sich der Fehler eν(Sn,n0 , f) in Abhängigkeit von der Startverteilung?
Idee: Zerlege den Fehler eν(Sn,n0 , f) in geeigneter Form. Beispielsweise: Zerlegung in Bias
|E[Sn,n0(f)]− S(f)|
und Varianz
E|Sn,n0(f)− E[Sn,n0(f)]|2.
Den Bias kann man gut abschätzen, die Varianz macht aber Probleme.
Wir wollen Satz 4.4 benutzen und schlagen folgende Zerlegung vor:
eν(Sn,n0 , f)2 = eπ(Sn,n0 , f)2 + REST.
Das heißt
REST = eν(Sn,n0 , f)2 − eπ(Sn,n0 , f)2.
Diesen REST wollen wir nun abschätzen.Lemma 4.7Sei f ∈ L2. Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν mit dν
dπ ∈L∞. Dann gilt
eν(Sn,n0 , f)2 − eπ(Sn,n0 , f)2 = 1n2
n∑j=1
Lj+n0−1(g2) + 2n2
n−1∑j=1
n∑k=j+1
Lj+n0−1(gPk−j g),
wobei g = f − S(f) und Li(h) = 〈(Pi−S)h, dνdπ − 1〉 für h ∈ L1.
58

4.1 Fehlerabschätzungen
Beweis: Wir haben
eν(Sn,n0 , f)2 = Eν,K
∣∣∣∣∣∣ 1nn∑j=1
g(Xj+n0)
∣∣∣∣∣∣2
= 1n2
n∑j=1
Eν,K [g(Xj+n0)2] + 2n2
n−1∑j=1
n∑k=j+1
Eν,K [g(Xj+n0)g(Xk+n0)]
= 1n2
n∑j=1
∫G
Pj+n0−1(g2)dν + 2n2
n−1∑j=1
n∑k=j+1
∫G
Pj+n0−1(gP k−jg)dν,
wobei die letzte Gleichheit aus Lemma 4.3 (a) folgt. Für h ∈ L1 und i ∈ N betrachten wir∫G
Pi h(x)ν(dx)−∫G
Pi h(x)π(dx)
=∫G
Pi h(x) dνdπ (x)π(dx)−
∫G
Pi h(x)π(dx)
=∫G
Pi h(x)(
dνdπ (x)− 1
)π(dx)
=〈(Pi−S)h, dνdπ − 1〉 (da 〈S(h), dν
dπ − 1〉 = 0)
Nun setzen wir einmal h = g2 ∈ L1 (wegen g ∈ L2) und einmal h = gPk−j g.
Lemma 4.8Sei h ∈ L1, dν
dπ ∈ L∞ und K sei L1-exponentiell konvergent bezüglich (α,M), für ein α ∈ [0, 1) undM ∈ (0,∞). Dann gilt mit i ∈ N, dass
Li(h) ≤ |〈(Pi−S)h, dνdπ − 1〉| ≤ αnM‖h‖1‖ dν
dπ − 1‖∞.
Beweis: Die rechte Ungleichung folgt mit der Hölder-Ungleichung.
Wir haben jetzt alles beisammen um Fehlerabschätzungen für allgemeine Startverteilungen zu formu-lieren und zu beweisen.
Satz 4.9 (Fehlerabschätzung)Sei f ∈ L2. Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Sei Kreversibel bezüglich π und L1-exponentiell konvergent bezüglich (α,M) mit einem α ∈ [0, 1) undM ∈ (0,∞).
Weiterhin sei dνdπ ∈ L∞. Dann gilt
|eν(Sn,n0 , f)2 − eπ(Sn,n0 , f)2| ≤ 1 + α
n2(1− α)2M‖dνdπ − 1‖∞αn0‖f‖22.
59

4.1 Fehlerabschätzungen
Insbesondere gilt β ≤ α (siehe Satz 3.47), d.h. es existiert eine Spektrallücke und somit
eν(Sn,n0 , f)Satz 4.4≤ (1 + β)1/2
√n(1− β)1/2 ‖f‖2 + (1 + α)1/2
n(1− α)
√M‖ dν
dπ − 1‖∞αn0‖f‖2.
Beweis: Sei g(x) = f(x)− S(f). Dann gilt
|eν(Sn,n0 , f)2 − eπ(Sn,n0 , f)2|
≤ 1n2
n∑j=1
Lj+n0−1(g2) + 2n2
n−1∑j=1
n∑k=j+1
Lj+n0−1(gPk−j g) (Lemma 4.7)
≤ 1n2
n∑j=1
αj+n0−1M
∥∥∥∥dνdπ − 1
∥∥∥∥∞‖g‖22 + 2
n2
n−1∑j=1
n∑k=j+1
αj+n0−1M
∥∥∥∥dνdπ − 1
∥∥∥∥∥∥∥gPk−j g∥∥∥
1,
wobei die letzte Ungleichung mit Lemma 4.8 folgt.
Es gilt‖gPk−j g‖1 ≤ ‖g‖2‖Pk−j g‖2 ≤ ‖g‖22‖Pk−j ‖L0
2→L02
Satz 3.47≤ ‖g‖22αk−j .
Wir erhalten mit ε0 = αn0M∥∥ dν
dπ − 1∥∥∞ somit
|eν(Sn,n0 , f)2 − eπ(Sn,n0 , f)2|
≤ 1n2
n∑j=1
ε0αj−1‖g‖22 + 2
n2
n−1∑j=1
n∑k=j+1
ε0‖g‖22αk−1
= ε0‖g‖22n2
n∑j=1
αj−1 + 2n−1∑j=1
n∑k=j+1
αk−1
≤ ‖g‖
22ε0
n2
n∑j=1
αj−1 + 2n−1∑j=1
n∑l=1
αj−1+l
≤ ‖g‖
22ε0
n21
1− α
(1 + 2
n∑l=1
αl
)
≤ ‖g‖22ε0
n21 + α
(1− α)2 (Lemma 4.5.)
Und wegen ‖g‖2 ≤ ‖f‖2 gilt die Behauptung.
Bemerkung 4.10
1) Der burn-in von n0 Schritten ist sinnvoll um den Einfluss der Startverteilung zu verringern (odergar zu eleminieren). Für n hinreichend groß verhält sich eν(Sn,n0 , f) wie eπ(Sn,n0 , f).
2) Falls ν = π erhalten wir die Abschätzung aus Satz 4.4. Intuitiv: Je besser die Startverteilung („νnah an π“), umso näher ist eν(Sn,n0 , f) an eπ(Sn,n0 , f).
3) Falls K(x,A) = π(A), dann gilt mit α = 0 und M = 1 die L1-exponentielle Konvergenz. Wirerhalten
0 ≤ βSatz 3.47≤ α ≤ 0.
60

4.1 Fehlerabschätzungen
D.h. β = 0 und
eν(Sn,n0 , f) ≤ ‖f‖2√n
für n0 ≥ 1 (die rechte Seite der Ungleichung ist unabhängig von ν). Damit ist Satz 4.9 eineVerallgemeinerung der Fehlerabschätzung der klassischen Monte-Carlo Methode.
4) „Kritik“: Die Voraussetzung, dass K L1-exponentiell konvergent ist, ist restriktiv.
Frage: Gibt es eine ähnliche Abschätzung für Markovketten deren Übergangskern/Markovoperator„nur“ eine Spektrallücke besitzt?
Wir geben folgendes Ergebnis ohne Beweis an.
Satz 4.11 (siehe [18, Thm 3.41])Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Sei π eine stationäreVerteilung von K und β = ‖P ‖L0
2→L02< 1. Dann gilt für f ∈ L4 und dν
dπ ∈ L2
eν(Sn,n0 , f) ≤√
1 + β√n√
1− β‖f‖4 +
√128√βn0‖ dν
dπ − 1‖2n(1− β) ‖f‖4.
Bemerkung 4.12
a) Bemerkung 4.10 lässt sich sinngemäß auch für Satz 4.11 formulieren.
b) Für f ∈ Lp mit p > 2 gilt: Falls β < 1 und∥∥ dν
dπ∥∥p/(p−2)
< ∞ folgt eine Fehlerabschätzung vonSn,n0 , die für p→ 2 gegen unendlich strebt.
Frage: Wie sollte man n0 wählen?
Die Fehlerabschätzungen aus Satz 4.9 und Satz 4.11 von eν(Sn,n0 , f)2 haben im Wesentlichen für‖f‖p ≤ 1 (wobei p ∈ 2, 4) mit α = β die Form
e(n, n0) := 2n(1− β) + 2Cνβn0
n2(1− β)2 ,
mit einer Konstante Cν , die von M und/oder von∥∥ dν
dπ − 1∥∥pabhängt. Desweiteren sei N = n + n0
fest vorgegeben (N entspricht den verfügbaren Gesamtressourcen).
Ziel: Minimiere e(n, n0) unter der Nebenbedingung N = n+ n0.
Das ist äquivalent zum Bestimmen einer Minimalstelle von e(N − n0, n0). Es gilt folgendes Ergebnis(siehe [18, Lemma 2.26]):
Für alle η > 0 und N , sowie Cν groß genug, haben wir eine Minimalstelle nopt von e(N − n0, n0) mit
nopt ∈[
logCνlog β−1 , (1 + η) logCν
log β−1
].
Da log β−1 = (1− β) +∑∞j=2
(1−β)jj , gilt für β ∈ (0, 1]
log β−1 ≥ 1− β
61

4.1 Fehlerabschätzungen
und für β nahe bei 1 ist
n0 =⌈
logCν1− β
⌉eine gute Wahl für n0.
Man kann sich auch andere Fehlerbegriffe anschauen. Insbesondere sind Konfidenzabschätzungen vonSn,n0 von Interesse. Ziel ist, für gegebenen Fehlerparameter ε ∈ (0, 1) und Konfidenzparameter δ ∈(0, 1) eine Abschätzung der Form
Pν,K(|Sn,n0(f)− S(f)| ≥ ε) ≤ δ. (K)
Man erhält leicht folgenden Zusammenhang zum mittleren quadratischen Fehler.
Satz 4.13Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Dann gilt für ε ∈ (0, 1)
Pν,K(|Sn,n0(f)− S(f)| ≥ ε) ≤ eν(Sn,n0 , f)2
ε2 .
Falls K reversibel bezüglich π und L1-exponentiell konvergent mit (α,M), sowie f ∈ L2 unddνdπ ∈ L∞ erhalten wir für
n0 ≥log(M‖ dν
dπ − 1‖∞)logα−1
undn ≥ 4‖f‖22
1− α ε−2δ−1,
dass (K) erfüllt ist.
Folgendes Lemma ist hilfreich.
Lemma 4.14 (Markov Ungleichung)Sei h : R → [0,∞) monoton wachsend und Z Zufallsvariable mit Z : (Ω,F ,P) → (R,B(R)). Danngilt
h(c)P(Z ≥ c) ≤ E[h(Z)],
für c ∈ R.
Beweis: Es gilt
h(c)P(Z ≥ c) =∫Ω
h(c)1Z≥c(ω)dP(ω)
≤∫Ω
h(Z)1Z≥c(ω)dP(ω) (Monotonie von h)
≤ E[h(Z)].
Beweis (von Satz 4.13):
62

4.1 Fehlerabschätzungen
Wende Lemma 4.14 mit Z = |Sn,n0(f)− S(f)| und
h(z) =z2 z ≥ 00 sonst
an. Die Abschäztungen von n und n0 für L1-exponentiell konvergente Markovketten folgen aus Satz4.9.
Für f ∈ L∞ und die klassische Monte-Carlo Methode erhält man unter Verwendung der Hoeff-ding-Ungleichung (siehe [17, Abschnitt 3.4] oder Abschnitt 8.2 in „A probabilistic theory of patternrecognition“ Devoyre et al.) ein „besseres“ Resultat.
Satz 4.15Sei f ∈ L∞. Sei (Xn)n∈N eine iid-Folge von Zufallsvariablen mit PXn = π, für n ∈ N. Dann gilt
P(|Sn,0(f)− S(f)| ≥ ε) ≤ 2e−nε2
2‖f‖2∞ .
D.h. für n ≥ 2‖f‖2∞ log(2δ−1)ε−2 erhält man (K).
Bemerkung 4.16Satz 4.15 impliziert ein „besseres“ Resultat als Satz 4.13, da in der unteren Schranke an n, um (K)zu garantieren, ein log δ−1 statt δ−1 auftaucht.
Frage: Gilt eine ähnliche Abschätzung für allgemeine Sn,n0 , falls f ∈ L∞.
Satz 4.17 (Glynn und Ormoneit, siehe [6])Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Für ein α ∈ [0, 1) undM ∈ (0,∞). Sei
‖Pn−S‖L∞→L∞ ≤ αnM, n ∈ N ∪ 0
erfüllt. Für f ∈ L∞ gilt dann
Pν,K(|Sn,0(f)− S(f)| ≥ ε) ≤ 2 exp(−
(1− α)2(nε− 2M1−α‖f‖∞)2
2nM2‖f‖2∞
)
≤ 2 exp(− (1− α)εM‖f‖∞
(nε(1− α)2M‖f‖∞
− 2))
.
D.h. fürn ≥ 2 M2
(1− α)2 ‖f‖2∞ε−2 log(2δ−1) + 4‖f‖∞M
1− α ε−1
ist (K) erfüllt.
Folgendes Lemma ist hilfreich, um Satz 4.17 zu beweisen.
Lemma 4.18 (Lemma 8.1 Devoyre et al.)Sei Z Zufallsvariable, d.h. Z : (Ω,F ,P) → (R,B(R)) und EZ = 0, sowie a ≤ Z ≤ b, für a, b ∈ R.Dann gilt für c > 0
EecZ ≤ ec2(b−a)2
8 .
63

4.1 Fehlerabschätzungen
Beweis: Die Funktion ψ(z) = ecz ist konvex, d.h. insbesondere ∀λ ∈ [0, 1] gilt
e(λa+(1−λ)b)c ≤ λeac + (1− λ)ebc.
Die Wahl von λ = b−zb−a für z ∈ [a, b] liefert
ecz ≤ b− zb− a
eac + z − ab− a
ebc.
Wegen EZ = 0 gilt
EecZ ≤ b
b− aeac − a
b− aebc.
Sei p = − ab−a . Dann erhalten wir
EecZ ≤ (1− p)eac + pebc
= (1− p+ pe(b−a)c)eac
= (1− p+ pe(b−a)c)e−pc(b−a)
= eΦ(u),
mit u = c(b− a) undΦ(u) = −pu+ log(1− p+ peu).
Wir erhalten Φ(0) = Φ′(0) = 0 und
Φ′′(u) = e−u(1− p)p(p+ (1− p)e−u)2 ≤
14 ,
da rs(r+s)2 ≤ 1
4 für alle r, s ≥ 0 gilt.
Mit dem Satz von Taylor gilt: ∃ξ ∈ [0, u], s.d.
Φ(u) = Φ(0) + Φ′(0)u+ Φ′′(ξ)u2 .
Daraus folgt
Φ(u) ≤ u2
8 = c2(b− a)2
8und damit ist die Behauptung bewiesen.
Beweis (von Satz 4.17):
Sei g(x) = f(x)− S(x) und h(x) =∑∞k=0 Pk g(x).
1. Schritt: (Eigenschaften von h)
Lemma 4.19Es gilt ‖h‖∞ ≤ M‖f‖∞
1−α und für M ≥ 2 auch
‖h‖∞ ≤ 2‖f‖∞(
logM/2logα−1 + 1 + 1
1− α
).
64

4.1 Fehlerabschätzungen
Beweis (von Lemma 4.19):
Wir erhalten wegen ‖Pk −S‖L∞→L∞ ≤Mαk folgendes:
‖h‖∞ ≤∞∑k=0‖Pk g‖∞ =
∞∑k=0‖(Pk −S)f‖∞ ≤
∞∑k=0‖f‖∞‖Pk −S‖L∞→L∞ ≤
‖f‖∞M1− α .
Für M ≥ 2 ist es besser ‖P k − S‖L∞→L∞ ≤ min2, αkM zu benutzen.
Für k =⌈
logM/2logα−1
⌉gilt αkM ≤ 2. Damit erhalten wir
‖h‖∞ ≤∞∑k=0‖Pk −S‖L∞→L∞‖f‖∞
= ‖f‖∞
k−1∑k=0‖Pk −S‖L∞→L∞ +
∞∑k=k
‖Pk −S‖L∞→L∞
= ‖f‖∞
2k +∞∑k=k
αkM
≤ ‖f‖∞
(2 logM/2
logα−1 + 2 + αkM︸ ︷︷ ︸≤2
∞∑k=0
αk︸ ︷︷ ︸≤(1−α)−1
)
Nun ist nach dem Satz von Lebesgue („Integral und Limes vertauschbar“)
Ph(x) =∞∑k=0
Pk+1 g(x) =∞∑k=1
Pk g(x)
= g(x)− g(x) +∞∑k=1
Pk g(x) = h(x)− g(x).
Also g(x) = h(x)− Ph(x).
2. Schritt: (Eigenschaften von n · Sn,0(f)− n · S(f))
65

4.1 Fehlerabschätzungen
Es gilt
n · Sn,0(f)− n · S(f)
=n∑j=1
g(Xj)
=n∑j=1
h(Xj)− Ph(Xj) (nach Schritt 1)
= h(X1) +n∑j=2
(h(Xj)− Ph(Xj−1))− Ph(Xn) + h(Xn+1)− h(Xn+1)
= h(X1)− h(Xn+1) +n+1∑j=2
h(Xj)− Ph(Xj−1).
Sei D(Xi−1, Xi) = h(Xi)− Ph(Xi−1). Nun gilt
n · Sn,0(f)− n · S(f) ≤ 2‖h‖∞ +n+1∑j=2
D(Xj−1, Xj). (10)
Und für i = 2, . . . , n+ 1 haben wir
E[D(Xi−1, Xi) | X1, . . . , Xi−1] = E[D(Xi−1, Xi) | Xi−1]= E[h(Xi) | Xi−1]− Ph(Xi−1) = 0,
sowie
|D(Xi−1, Xi)| ≤ 2‖h‖∞.
Somit sind die Voraussetzungen von Lemma 4.18 für Z = D(Xi−1, Xi) erfüllt und wirerhalten
E[exp(cD(Xi−1, Xi)) | X1, . . . , Xi−1] ≤ ec2 ‖h‖2
∞8 , (11)
für c > 0.
3. Schritt: (Abschätzung von P(Sn,0(f)− S(f) ≥ ε))
Es gilt
P(Sn,0(f)− S(f) ≥ ε) = P(nc(Sn,0(f)− S(f)) ≥ ncε)
≤ E[ε(nc[Sn,0(f)− S(f)])]encε
(Lemma 4.14 für h(z) = ez),
66

4.1 Fehlerabschätzungen
für c > 0. Wir betrachten
E[ε(nc[Sn,0(f)− S(f)])]
≤ E
[exp
(c
n+1∑i=2
D(Xi−1, Xi))]
(mit (10))
= exp(2c‖h‖∞)E[E
[exp
(c
n+1∑i=2
D(Xi−1, Xi))| X1, . . . , Xn
]](E5, Abs. 2.1)
= exp(2c‖h‖∞)E[
exp(c
n∑i=2
D(Xi−1, Xi))· E[exp(cD(Xn, Xn+1)) | X1, . . . , Xn]︸ ︷︷ ︸
≤exp(c2‖h‖2∞/2), wg. (11)
]
≤ exp(2c‖h‖∞ + c2‖h‖2∞/2) · E[
exp(c
n∑i=2
D(Xi−1, Xi))]
.
Den letzten Abschätzungsschritt können wir iterativ durchführen und bekommen
E[exp(nc[Sn,0(f)− S(f)])] ≤ exp(2c‖h‖∞ + nc2‖h‖2∞/2).
Damit erhalten wir für beliebiges c > 0
P(Sn,0(f)− S(f) ≥ ε) ≤ exp(−ncε+ 2c‖h‖∞ + nc2‖h‖2∞/2).
Wir minimieren den Exponenten
Φ(c) = −ncε+ 2c‖h‖∞ + nc2‖h‖2∞/2
und erhalten die Minimalstelle
cmin = nε− 2‖h‖∞n‖h‖2∞
.
Einsetzen und Umformen liefert
P(Sn,0(f)− S(f) ≥ ε) ≤ exp(− (nε− 2‖h‖∞)2
2n‖h‖2∞
). (12)
4. Schritt: (Abschätzung von P(|Sn,0(f)− S(f)| ≥ ε))
Wir verwenden die Ungleichung (12) für f und −f . Es gilt
P(|Sn,0(f)− S(f)| ≥ ε) = P(Sn,0(f)− S(f) ≥ ε oder − Sn,0(f) + S(f) ≥ ε)≤ P(Sn,0(f)− S(f) ≥ ε) + P(Sn,0(−f)− S(−f) ≥ ε)
≤ 2 exp(− (nε− 2‖h‖∞)2
2n‖h‖2∞
).
Da Ψ(v) = − (nε−2v)2
2nv2 monoton wachsend ist, folgt mit ‖h‖∞ ≤ M1−α‖f‖∞ (Lemma 4.19) die
erste Ungleichung der Behauptung. Die zweite Ungleichung folgt aus Ψ(v) ≤ − εv (nε2v − 2).
Bemerkung 4.20
67

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
a) Die Abschätzung von Satz 4.17 gilt für beliebige Startverteilungen, aber sie erlaubt keine Feinein-stellung durch den burn-in.
b) Die Konvergenzbedingung‖Pn−S‖L∞→L∞ ≤ αnM
ist für reversible Übergangskerne zur L1-exponentiellen Konvergenz äquivalent (Übersicht EndeAbschnitt 3.4).
c) Die untere Schranke für n (aus Satz 4.17) um (K) zu garantieren hängt von log δ−1 anstatt vonδ−1 ab. Die Abhängigkeit von M ist im Vergleich zu Satz 4.13 „schlechter“. Diese kann verbessertwerden, indem man die Ungleichung
‖h‖∞ ≤ 2‖f‖∞(
1 + 11− α + logM/2
logα−1
)aus Lemma 4.19, statt ‖h‖∞ ≤ ‖f‖∞ M
1−α benutzt.
Als nächstes formulieren wir ein Ergebnis (ohne Beweis) für Markovketten mit L2-Spektrallücke.
Satz 4.21 (Miasojedow, siehe [16])Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung ν. Sei π eine stationäreVerteilung von K, f ∈ L∞, dν
dπ ∈ L2 und β := ‖P ‖L02→L0
2< 1. Dann gilt
Pν,K(|Sn,0(f)− S(f)| ≥ ε) ≤ 2∥∥∥∥dν
dπ
∥∥∥∥2
exp(−1− β
1 + β
ε2
2‖f‖2∞· n).
D.h. fürn ≥ 1 + β
1− β 4‖f‖2∞ε−2 log(
2∥∥∥∥dν
dπ
∥∥∥∥2δ−1)
ist (K) erfüllt.
Bemerkung 4.22In Satz 4.21 ist wieder eine Integrabilitätsbedingung der Dichtefunktion dν
dπ von nöten. Allerdings kannhier auch ein „burn-in“ zur Feineinstellung benutzt werden. Man betrachte dazu ν Pn0 , die Verteilungvon Xn0+1, als Startverteilung. Falls der Übergangskern reversibel bezüglich π ist, gilt dann∥∥∥∥d(ν Pn0)
dπ
∥∥∥∥2≤ 1 +
∥∥∥∥d(ν Pn0)dπ − 1
∥∥∥∥2
= 1 +∥∥∥∥Pn0
(dνdπ − 1
)∥∥∥∥2
(Lemma 3.38)
≤ 1 + βn0
∥∥∥∥dνdπ − 1
∥∥∥∥2
(S( dνdπ − 1) = 0, d.h. dν
dπ − 1 ∈ L02).
Es ist schwierig explizite Konvergenzabschätzungen von Markovketten zu bekommen. Im folgendenlernen wir 2 mögliche Techniken dafür kennen.
4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
4.2.1 Doeblin-Bedingung
Sei K ein Übergangskern und π eine stationäre Verteilung auf (G,G).
68

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Satz 4.23Wir nehmen an, dass ein c > 0 existiert, s.d.
∀x ∈ G ∀A ∈ G : K(x,A) ≥ c · π(A). (D)
Dann gilt‖Pn−S‖L1→L1 ≤ 2(1− c)n.
Bemerkung 4.24Die Bedingung, die in (D) formuliert ist, wird Doeblin-Bedingung genannt. Offensichtlich ist auchc ≤ 1.
Wir benötigen folgendes Lemma.
Lemma 4.25Seien µ, ν Wahrscheinlichkeitsmaße auf (G,G) und für c > 0 gelte
µ(A) ≥ c · ν(A), ∀A ∈ G.
Dann exisitert die Dichtefunktion dνdµ und es gilt
0 ≤ dνdµ ≤
1c
µ− f.s.
Beweis (des Lemmas):
Aus dem Satz von Radon-Nikodym (siehe [9, Korollar 7.34]) folgt, dass eine Dichtefunktion dνdµ ≥ 0
existiert. Wir zeigen dνdµ ≤
1c µ-f.s. Sei dazu A = dν
dµ >1c. Angenommen µ(A) > 0, dann gilt
ν(A) =∫A
dνdµdµ > 1
cµ(A) ≥ ν(A).
Also µ(A) = 0 und es folgt die Behauptung.
Beweis (des Satzes 4.23):
Aus Lemma 4.25 folgt, dass ∀x ∈ G eine Dichtefunktion dπdK(x,·) mit
dπdK(x, ·) ≤
1c
K(x, ·)− f.s.
existiert.
69

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Sei g ∈ L1 und S(g) = 0. Dann gilt
|P g(x)| =∣∣∣∣ ∫G
g(y)K(x, dy)∣∣∣∣
=∣∣∣∣ ∫G
g(y)K(x, dy)− c∫G
g(y) dπdK(x, ·) (y)K(x, dy)
︸ ︷︷ ︸=0 da S(g)=0
∣∣∣∣
=∣∣∣∣ ∫G
g(y)(
1− c dπdK(x, ·) (y)
)︸ ︷︷ ︸
≥0 nach Vor.
K(x, dy)∣∣∣∣
≤∫G
|g(y)|(
1− c dπdK(x, ·) (y)
)K(x, dy)
=∫G
|g(y)|K(x,dy)− c∫G
|g(y)|π(dy).
Also folgt‖P g‖ =
∫G
|P g(x)|π(dx)π stat.≤ ‖g‖1 − c‖g‖1 = (1− c)‖g‖1.
Da S(Pn g) = 0, falls S(g) = 0 (weil π stationäre Verteilung ist), können wir die letzte Ungleichungiterativ anwenden. D.h.
‖Pn g‖1 ≤ (1− c)‖Pn−1 g‖1 ≤ . . . ≤ (1− c)n‖g‖1.
Schließlich folgt
‖Pn−S‖L1→L1 = sup‖f‖1≤1
‖(Pn−S)f‖1
= sup‖f‖1≤1
‖Pn(f − S(f))‖1
≤ sup‖f‖1≤1
(1− c)n ‖f − S(f)‖1︸ ︷︷ ︸≤‖f‖1+|S(f)|≤2‖f‖1
≤ 2(1− c)n.
4.2.2 Leitfähigkeit und Cheeger-Ungleichung
Sei K Übergangskern der reversibel bezüglich π ist. Desweiteren nehmen wir an, dass der Markovope-rator P (von K) positiv semidefinit ist, d.h.
∀f ∈ L2 : 〈P f, f〉 ≥ 0.
Wir nutzen folgende Darstellung von ‖P ‖L02→L0
2:
70

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Lemma 4.26Sei K reversibel bezüglich π und P positiv semidefinit. Dann gilt
‖P ‖L02→L0
2= supg∈L2g 6=0
〈P g, g〉〈g, g〉
.
Beweis: Diese Aussage folgt, da für selbstadjungierte, lineare Operatoren T : H → H (H Hilbert-raum)
‖T‖H→H = supf∈Hf 6=0
〈Tf, f〉〈f, f〉
(13)
gilt. Dies ist ein Standardresultat aus der Funktionalanalysis, siehe beispielsweise [21, Satz V.5.7]. Wirsetzen H = L0
2 und somit folgt die Behauptung wegen der Reversibilität, (13) und 〈P g, g〉 ≥ 0.
Nun kommen wir zu dem Begriff der Leitfähigkeit / conductance.
Definition 4.27 (Leitfähigkeit)Sei K reversibel bezüglich π. Dann heißt
ϕ = infπ(A)∈(0, 12 ]
∫AK(x,Ac)π(dx)
π(A) = infπ(A)∈(0, 12 ]
〈1A,P1Ac〉π(A)
Leitfähigkeit von K. Wir schreiben auch manchmal ϕ(K), statt ϕ.
In der Literatur findet der englische Begriff „conductance“ (= Leitfähigkeit) Anwendung.
Bemerkung (Interpretation)Sei (Xn)n∈N eine Markovkette mit Übergangskern K und Startverteilung π. Dann ist für π(A) > 0:∫
AK(x,Ac)π(dx)
π(A) = P(X2 ∈ Ac | X1 ∈ A)
(da PX1 = π).
Es gibt in der Literatur verschiedene Versionen der Leitfähigkeit. Manche sind äquivalent zu obigerDefinition. Insbesondere unterschiedet sich der Nenner im Quotienten in ϕ und die Bedingung imInfimum.
Wir benötigen folgendes Lemma:
Lemma 4.28Sei (G,G, π) ein Wahrscheinlichkeitsraum und h : G → [0,∞) eine Mengenfunktion mit h(A) =h(Ac), für alle A ∈ G. Dann gilt
infπ(A)∈(0,1/2]
h(A) = infπ(A)∈(0,1)
h(A).
71

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Beweis: Es gilt
infπ(A)∈(0,1)
h(A) = infh(A) : π(A) ∈ (0, 1/2] ∪ [1/2, 1)
= min infh(A) : π(A) ∈ (0, 1/2], infh(A) : π(A) ∈ [1/2, 1)= min infh(A) : π(A) ∈ (0, 1/2], infh(A) : π(Ac) ∈ (0, 1/2]= min infh(A) : π(A) ∈ (0, 1/2], infh(Ac) : π(A) ∈ (0, 1/2]= infπ(A)∈(0,1/2]
h(A) (da h(A) = h(Ac)).
Folgerung 4.29Es gilt
ϕ = infπ(A)∈(0,1)
〈1A,P1Ac〉minπ(A), π(Ac) .
Beweis: Wir haben
ϕ = infπ(A)∈(0, 1
2 ]
〈1A,P1Ac〉π(A)
π(A)=minπ(A),π(Ac)= infπ(A)∈(0, 1
2 ]
〈1A,P1Ac〉minπ(A), π(Ac) .
Da K reversibel bezüglich π ist, folgt die Selbstadjungiertheit von P (siehe E5 aus Abschnitt 3.3). Für
h(A) = 〈1A,P1Ac〉minπ(A), π(Ac)
erhalten wir damit h(A) = h(Ac).
Somit gilt die Behauptung mit Lemma 4.29.
Nun kommen wir zum Hauptergebnis dieses Abschnittes. Es folgt die Beziehung zwischen Leitfähigkeitund der Spektrallücke 1− β = 1− ‖P ‖L0
2→L02.
Satz 4.30 (Cheeger-Ungleichung)Sei K reversibel bezüglich π und der dazugehörige Markovoperator P sei positiv semidefinit. Danngilt
ϕ2
2 ≤ 1− ‖P ‖L02→L0
2≤ 2ϕ.
Bemerkung 4.31Die Ungleichung kann man im Allgemeinen nicht (wesentlich) verbessern. Siehe dazu [11].
Lemma 4.32Sei g ∈ L2 und π(g2 > 0) ≤ 1
2 . Dann gilt∫G
∫G
(g(x)− g(y))2K(x, dy)π(dx) ≥ ϕ2‖g‖22.
Bemerkung 4.33Sei (Xn)n∈N Markovkette mit Übergangskern K und Startverteilung π (K reversibel bezüglich π).
72

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Dann giltEπ,K |g(X1)− g(X2)|2 =
∫G
∫G
(g(x)− g(y))2K(x,dy)π(dx).
Beweis (von Lemma 4.32):
O.B.d.A. sei g 6= 0, d.h. ‖g‖2 6= 0. Es gilt nach 3. binomischer Formel und Hölder-Ungleichung(p = q = 2) (∫
G
∫G
|g(x)2 − g(y)2|K(x,dy)π(dx))2
≤∫G
∫G
(g(x)− g(y))2K(x, dy)π(dx) ·∫G
∫G
(g(x) + g(y))2︸ ︷︷ ︸≤2g(x)2+2g(y)2
K(x, dy)π(dx).
Nebenbetrachtung: Es gilt
2∫G
∫G
(g(x) + g(y))2K(x, dy)π(dx) = 2‖g‖22 + 2〈P g2, 1〉 = 4‖g‖22.
Damit folgt∫G
∫G
(g(x)− g(y))2K(x, dy)π(dx) ≥ 1‖g‖22
(∫G
∫G
|g(x)2 − g(y)2|K(x,dy)π(dx))2. (W)
Nun sei A(t) = x ∈ G : g(x)2 > t die Levelmenge von g2 (für t1 ≤ t2 gilt A(t2) ⊆ A(t1)). Damiterhalten wir für x, y ∈ G
(g(x)2 − g(y)2)1A(g(y)2)(x) =( g(x)2∫
0
dt−g(y)2∫0
dt)1A(g(y)2)(x)
=( ∞∫
0
(1[0,g(x)2)(t)− 1[0,g(y)2](t))dt)1A(g(y)2)(x)
=( ∞∫
0
1[g(y)2,g(x)2)(t)dt)1A(g(y)2)(x)
=∞∫
0
1A(t)(x)1A(t)c(y)dt,
denn es gilt
1[g(y)2,g(x)2)(t) =
1 g(y)2 ≤ t, g(x)2 > t
0 sonst= 1A(t)(x) · 1A(t)c(y).
Wir betrachten nun den Faktor ∫G
∫G
|g(x)2 − g(y)2|K(x,dy)π(dx)
73

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
aus (W). Es gilt∫G
∫G
|g(x)2 − g(y)2|K(x,dy)π(dx)
= 2∫G
∫G
(g(x)2 − g(y)2)1A(g(y)2)(x)K(x,dy)π(dx) (Betrag symm. + Reversibilität)
= 2∫G
∫G
∞∫0
1A(t)(x)1A(t)c(y)dtK(x, dy)π(dx)
= 2∞∫
0
∫G
∫G
1A(t)(x)1A(t)c(y)K(x,dy)π(dx)dt (Fubini)
= 2∞∫
0
〈1A(t),P1A(t)c〉dt
= 2t∗∫
0
〈1A(t),P1A(t)c〉π(A(t)) π(A(t))dt,
wobei t∗ := supt : π(A(t)) > 0. Wegen π(A(t)) ≤ π(A(0)) = π(g2 > 0) ≤ 12 gilt folgende
Abschätzung:
∫G
∫G
|g(x)2 − g(y)2|K(x, dy)π(dx) ≥ 2ϕt∗∫
0
π(A(t))dt
= 2ϕ∞∫
0
∫G
1A(t)(x)π(dx)dt
= 2ϕ∫G
g(x)2π(dx)
= 2ϕ‖g‖22.
Dies setzen wir in (W) ein und erhalten
∫G
∫G
(g(x)− g(y))2K(x,dy)π(dx) ≥ 2ϕ2‖g‖424‖g‖22
= ϕ2‖g‖22.
Damit ist das Lemma bewiesen.
Beweis (von Satz 4.30):
1. Teil: Wir beweisen zunächstϕ2
2 ≤ 1− ‖P ‖L02→L0
2.
74

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Es gilt
ϕ2
2 ≤ 1− ‖P ‖L02→L0
2
⇐⇒ supf 6=0f∈L0
2
〈P f, f〉〈f, f〉
≤ 1− ϕ2
2
⇐⇒ ∀f ∈ L02 : 〈P f, f〉 ≤
(1− ϕ2
2
)〈f, f〉
⇐⇒ ∀f ∈ L02 : 2〈(I − P)f, f〉 ≥ ‖f‖22ϕ2.
Wobei I der Identitätsoperator (mit If = f) ist.
Sei f ∈ L02 und r (ein) Median von f bezüglich π, d.h.
π(f > r) ≤ 12 und π(f < r) ≤ 1
2 .
Wir setzen für alle x ∈ G
f+(x) := maxf(x)− r, 0,
f−(x) := minf(x)− r, 0,
es gilt f+ ≥ 0 und f−(x) ≤ 0.
Wir erhalten
π(f2+ > 0) = π(f > r) ≤ 1
2 ,
π(f2− > 0) = π(f < r) ≤ 1
2 ,
da r ein Median ist.
Somit gilt wegen Lemma 4.32
∫G
∫G
(f+(x)− f+(y))2K(x,dy)π(dy) ≥ ϕ2‖f+‖22 (14)
und ∫G
∫G
(f−(x)− f−(y))2K(x, dy)π(dy) ≥ ϕ2‖f−‖22. (15)
75

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Nun betrachten wir
2〈(I − P)f, f〉 =∫G
∫G
(f(x)− f(y))2K(x, dy)π(dx) (binom. Formel)
=∫G
∫G
[ f(x)− r︸ ︷︷ ︸=f+(x)+f−(x)
−( f(y)− r︸ ︷︷ ︸=f+(y)+f−(y)
)]2K(x, dy)π(dx)
=∫G
∫G
[(f+(x)− f+(y)) + (f−(x)− f−(y))]2K(x, dy)π(dx)
≥∫G
∫G
(f+(x)− f+(y))2K(x,dy)π(dx)
+∫G
∫G
(f−(x)− f−(y))2K(x,dy)π(dx)
(wegen 2(f+(x)− f+(y))(f−(x)− f−(y)) ≥ 0)≥ ϕ2[‖f+‖22 + ‖f−‖22] (mit (14) und (15)).
Also
2〈(I − P)f, f〉 ≥ ϕ2[‖f+‖22 + ‖f−‖22]
= ϕ
∫f>r
(f(x)− r)2π(dx) +∫
f<r
(f(x)− r)π(dx)
= ϕ2
∫G
(f(x)− r)2π(dx)
= ϕ2(‖f‖22 − 2S(f)︸︷︷︸=0
r + r2)
= ϕ2(‖f‖22 + r2)≥ ϕ2‖f‖22.
2. Teil: Nun beweisen wir1− ‖P ‖L0
2→L02≤ 2ϕ.
Es reicht zu zeigen (Lemma 4.26)
1− 2ϕ ≤ supf∈L0
2f 6=0
〈P f, f〉〈f, f〉
.
Idee: Wähle eine einfache Funktion f ∈ L02, f 6= 0 und berechne 〈P f,f〉〈f,f〉 . Damit erhalten wir
eine untere Abschätzung von ‖P ‖L02→L0
2. Es gilt mit f = 1A − π(A) und π(A) ∈ (0, 1
2 ]
supf∈L0
2f 6=0
〈P f, f〉〈f, f〉
≥ 〈P(1A − π(A)),1A − π(A)〉〈1A − π(A),1(A)− π(A)〉 .
76

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Dabei ist
〈1A − π(A),1(A)− π(A)〉 = π(A)− 2π(A)2 + π(A) = π(A)π(Ac).
Das heißt
supf∈L0
2f 6=0
〈P f, f〉〈f, f〉
≥ 〈P1A,1A〉 − 2〈P1A, π(A)〉+ π(A)2
π(A)π(Ac)
= 〈P1A,1A〉 − π(A)2
π(A)π(Ac)
= π(A)− 〈P1Ac ,1A〉 − π(A)2
π(A)π(Ac) (1A = 1− 1Ac)
= 1− 〈P1Ac ,1A〉π(A)π(Ac)
≥ 1− 2 〈P1Ac ,1A〉π(A) (π(Ac) ≥ 1/2).
Wir nehmen das Supremum über alle A mit π(A) ∈ (0, 12 ] über die rechte Seite und erhalten
supf∈L0
2f 6=0
〈P f, f〉〈f, f〉
≥ 1− 2 infπ(A)∈(0,1/2]
〈P1Ac ,1A〉π(A) = 1− 2ϕ.
Somit ist der Satz bewiesen.
Bemerkung 4.34Ist die Annahme, dass P positiv semidefinit ist, sehr restriktiv?
Falls K reversibel bezüglich π und der dazugehörige Markovoperator P nicht positiv semidefinit ist(oder man kann die positive Semidefinitheit für P nicht zeigen), dann kann man sich den Übergangs-kern
K(x,A) = 12(1A(x) +K(x,A)), x ∈ G,A ∈ G
anschauen. K wird „lazy version“ vonK genannt. Der Übergangskern K ist wieder reversibel bezüglichπ und induziert zusätzlich einen positiv semidefiniten Operator P. Letzteres gilt wegen
〈Pf, f〉 =∫G
12
(f(x) +
∫G
f(y)K(x, dy))f(x)π(dx)
= 12‖f‖
22 + 〈P f, f〉2
≥ 0 (wg. |〈P f, f〉| ≤ ‖P f‖2‖f‖2 ≤ ‖f‖22).
Folgendes Lemma ist später hilfreich.
Lemma 4.35Sei K reversibel bezüglich π und K(x,A) = 1
2 (1A(x)+K(x,A)) ist die „lazy version“ von K. Dann
77

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
giltϕ(K) = 1
2ϕ(K).
Beweis: Wir wissen bereits aus Bem. 4.31, dass K wieder reversibel bezüglich π ist. Es gilt
ϕ(K) = infπ(A)∈(0,1/2]
〈1A, P1Ac〉π(A)
= infπ(A)∈(0,1/2]
12
=0︷ ︸︸ ︷〈1Ac ,1A〉+〈P1Ac ,1A〉
π(A) = 12ϕ(K)
Folgendes Resultat gibt eine hinreichende Bedingung für eine untere Schranke von ϕ.
Satz 4.36Sei K reversibel bezüglich π und κ > 0. Für beliebiges A ∈ G seien
T1(A, κ) := x ∈ A : K(x,Ac) < κ,
T2(A, κ) := y ∈ Ac : K(y,A) < κ,
T3(A, κ) := G \ (T1(A, κ) ∪ T2(A, κ)).
Für ein γ > 0 gelte für alle A ∈ G
π(T3(A, κ)) ≥ 2γminπ(T1(A, κ), π(T2(A), κ)).
Dann folgtϕ ≥ κ
2 min1, γ.
Skizze:
G
A Ac
T3(A, κ)T1(A, κ) T2(A, κ)
T1(A, κ) „Übergang von T1(A, κ) zu Ac nicht so häufig.“T2(A, κ) „Übergang von T2(A, κ) zu A nicht so häufig.“T3(A, κ) „Übergang von A nach Ac und zurück häufig.“
Intuitiv: Die Leitfähigkeit ist „groß“, falls Übergang von A zu Ac (bezüglich K) sehr häufig, für alleA ∈ G. Die Menge T3(A, κ) sollte im Vergleich zu T1(A, κ) und T2(A, κ) ein großes Maß haben.
78

4.2 Hinreichende Bedingungen für explizite Konvergenzabschätzungen
Beweis: Zur Vereinfachung der Notationen sei Ti := Ti(A, κ), i = 1, 2, 3. Wir machen eine Fallunter-scheidung.
1. Fall: π(T1) < 12π(A)
Wir erhalten ∫A
K(x,Ac)π(dx) ≥∫
A\T1
K(x,Ac)π(dx)
≥ κ · π(A \ T1) = κ(π(A)− π(T1))
≥ κ
2π(A) (nach Fallunterscheidung)
≥ κ
2 minπ(A), π(Ac).
2. Fall: π(T2) < 12π(Ac)
Wir erhalten ∫A
K(x,Ac)π(dx) =∫Ac
K(x,A)π(dx) (Reversibilität)
≥∫
Ac\T2
K(x,A)π(dx)
≥ κπ(Ac \ T2) = κ(π(Ac)− π(T2))
≥ κ
2π(Ac) (nach Fallunterscheidung)
≥ κ
2 minπ(A), π(Ac).
3. Fall: π(T1) ≥ π(A)2 und π(T2) ≥ π(Ac)
2
Wir erhalten∫A
K(x,Ac)π(dx) = 12
(∫A
K(x,Ac)π(dx) +∫Ac
K(x,A)π(dx))
(Rev.)
≥ 12
( ∫A∩T3
K(x,Ac)π(dx) +∫
Ac∩T3
K(x,A)π(dx))
≥ 12(π(A ∩ T3) + π(Ac ∩ T3)) = κ
2π(T3)
≥ κγminπ(T1), π(T2)
≥ κγ
2 minπ(A), π(Ac).
Durch Zusammenfügen der Fälle und unter Verwendung von Folgerung 4.30 erhalten wir dieBehauptung.
79

4.3 Anwendungen und Beispiele
4.3 Anwendungen und Beispiele
4.3.1 Integration über konvexe Mengen
Wir betrachten die Fragestellung aus Abschnitt 1.
Sei r ≥ 1, d ∈ N undK := G ⊆ Rd : G konvex, Bd ⊆ G ⊆ rBd.
Sei πG die Gleichverteilung in G ∈ K und Lp = Lp(πG), für p ∈ [1,∞]. Wir definieren
FK,p := (f,G) : G ∈ K, f ∈ Lp, ‖f‖p ≤ 1.
Ziel: BerechneS(f,G) =
∫Gf(x)dxλd(G)
für beliebige (f,G) ∈ FK,p.
Der hit-and-run Algorithmus auf G scheint zur Approximation von πG geeignet zu sein (siehe Beispiel3.7.5 und oder Abschnitt 3.2.2).
Der Übergangskern ist gegeben durch
H(x,A) = 1σ(Sd−1)
∫Sd−1
∫L(x,θ) 1A(x+ sθ)dsλ1(L(x, θ)) σ(dθ),
mitL(x, θ) = s ∈ R : x+ sθ ∈ G.
Gegebene Informationen:
1) Für beliebiges x erhalten wir von einem Orakel den Funktionswert f(x) auf Anfrage.
2) Ein weiteres Orakel kann für jede Gerade L(x, θ) = x + sθ : s ∈ R, mit x ∈ rBd und θ ∈ Sd−1,die Gleichverteilung in L(x, θ) ∩G simulieren.
(Diese Annahme passt zur Diskussion in Bemerkung 3.26.)
MCMC Methode: Sei G ∈ K, (Xn)n∈N Markovkette mit Übergangskern H (auf G) und Startver-teilung πBd (Gleichverteilung in Bd). Berechne
Sn,n0(f,G) = 1n
n∑j=1
f(Xj+n0).
Für die Anwendung der Fehlerabschätzungen, stellen sich für beliebiges G ∈ K folgende Fragen:
• Ist H L1-exponentiell konvergent mit (α,M)? Gibt es explizite Konstanten α und M?
• Explizite Abschätzungen der Spektrallücke? Oder explizite Abschätzung der Leitfähigkeit?
• Ist H (als Markovoperator) positiv semidefinit in L2?
Im Folgenden bezeichnen wir mit H auch den Markovoperator vom hit-and-run Algorithmus. Ausdem Kontext ist immer klar, ob wir Übergangskern oder Operator meinen.
80

4.3 Anwendungen und Beispiele
Lemma 4.37Für beliebige G ⊆ Rd gilt
H(x,A) ≥ 2σ(Sd−1)
λd(G)diam(G)dπG(A), (16)
wobei x ∈ G,A ∈ B(G) und diam(G) = supx,y∈G |x− y|.
Außerdem giltλd(Bd)(2r)d ≤ inf
G∈K
λd(G)diam(G)d ≤
(2r)λd−1(Bd−1)(2r)d . (17)
D.h. für alle G ∈ K giltH(x,A) ≥
σ(Sd−1)=dλd(Bd)
2d(2r)dπG(A)
und‖Hn − S‖L1→L1 ≤
Satz 4.232(
1− 2d(2r)d
)n.
Beweis: Die erste Ungleichung in (17) ist sofort klar, da man Zähler und Nenner getrennt abschätzenkann. Für die zweite Ungleichung konstruieren wir eine Menge G ∈ K, die die Ungleichung erfüllt.Dazu betrachten wir die folgende Skizze in der Dimension d = 3:
rG
Bd
rBd
Bd−1
Nun gilt offenbar λd(G) ≤ (2r)λd−1(Bd−1) und diam(G) = 2r. Dieses Argument funktioniert analogfür beliebiges d, womit sich die zweite Ungleichung in (17) ergibt.
Es genügt nun (16) zu zeigen, denn der Rest folgt daraus.
81

4.3 Anwendungen und Beispiele
Für x ∈ G und A ∈ B(G) haben wir
H(x,A) = 1σ(Sd−1)
∫Sd−1
∞∫−∞
1A(x+ sθ)λ1(L(x, θ))dsdσ(θ)
= 1σ(Sd−1)
( ∫Sd−1
0∫−∞
1A(x+ sθ)λ1(L(x, θ))dsdσ(θ) +
∫Sd−1
∞∫0
1A(x+ sθ)λ1(L(x, θ))dsdσ(θ)
)
= 1σ(Sd−1)
( ∫Sd−1
∞∫0
1A(x− sθ)λ1(L(x, θ))dsdσ(θ) +
∫Sd−1
∞∫0
1A(x+ sθ)λ1(L(x, θ))dsdσ(θ)
),
wobei wir die letzte Umformung durch Substitution t = −s im ersten Summanden erhalten. MitPolarkoordinatentransformation∫
Rd
f(y)dy =y=rθ
y=|y| y|y|
∫Sd−1
∞∫0
f(rθ)rd−1drσ(dθ)
erhalten wir weiterhin
H(x,A) = 1σ(Sd−1)
(∫Rd
1A(x− y)λ1(L(x, y/|y|))|y|d−1 dy +
∫Rd
1A(x+ y)λ1(L(x, y/|y|))|y|d−1 dy
).
Wir substituieren im ersten Integral x− y = z, d.h. y = x− z, und im zweiten Integral x+ y = z, d.h.y = z − x. Also
H(x,A) = 1σ(Sd−1)
(∫Rd
1A(z)λ1(L(x, x−z|x−z| ))|x− z|d−1 dz +
∫Rd
1A(z)λ1(L(x, z−x|z−x| ))|z − x|d−1 dz
).
Wegen λ1(L(x, θ)) = λ1(L(x,−θ)) folgt schließlich
H(x,A) = 2σ(Sd−1)
∫Rd
1A(z)λ1(L(x, x−z|x−z| ))|x− z|d−1 dz
≥ 2σ(Sd−1)
λd(G)diam(G)dπG(A) (wegen λ1(L(x, θ)) ≤ diam(G)).
Aus dem Lemma folgt, dass wir eigentlich jede Fehlerabschätzung für die MCMC Methode anwendenkönnen, da H L1-exponentiell konvergent bezüglich (α,M) mit α = 1− 2
d(2r)d und M = 2. Allerdingstaucht letztlich dann in jeder Abschätzung die Größe 1−α = 2
d(2r)d im Nenner auf. D.h. Lemma 3.27impliziert Fehlerabschätzungen, die in der Dimension d exponentiell „schlecht“ sind. Im Wesentlichenwie bei der Konstruktion von Zufallszahlengeneratoren für πG, siehe Abschnitt 1.
Folgendes Ergebnis ist hilfreich um Satz 4.36 anwenden zu können.
82
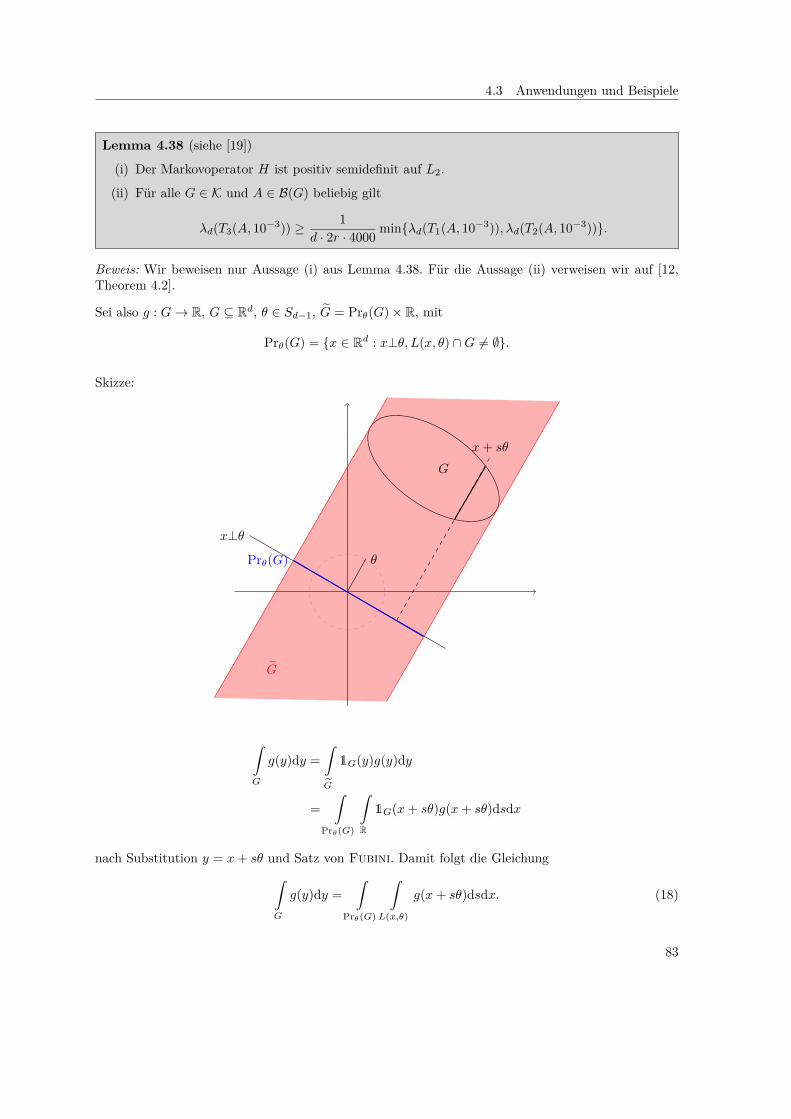
4.3 Anwendungen und Beispiele
Lemma 4.38 (siehe [19])
(i) Der Markovoperator H ist positiv semidefinit auf L2.
(ii) Für alle G ∈ K und A ∈ B(G) beliebig gilt
λd(T3(A, 10−3)) ≥ 1d · 2r · 4000 minλd(T1(A, 10−3)), λd(T2(A, 10−3)).
Beweis: Wir beweisen nur Aussage (i) aus Lemma 4.38. Für die Aussage (ii) verweisen wir auf [12,Theorem 4.2].
Sei also g : G→ R, G ⊆ Rd, θ ∈ Sd−1, G = Prθ(G)× R, mit
Prθ(G) = x ∈ Rd : x⊥θ, L(x, θ) ∩G 6= ∅.
Skizze:
G
θ
G
x⊥θ
Prθ(G)
x+ sθ
∫G
g(y)dy =∫G
1G(y)g(y)dy
=∫
Prθ(G)
∫R
1G(x+ sθ)g(x+ sθ)dsdx
nach Substitution y = x+ sθ und Satz von Fubini. Damit folgt die Gleichung∫G
g(y)dy =∫
Prθ(G)
∫L(x,θ)
g(x+ sθ)dsdx. (18)
83

4.3 Anwendungen und Beispiele
Für f ∈ L2 bekommt man nun
〈f,Hf〉 =∫G
∫G
f(y)f(z)H(y,dz) dyλd(G)
= 1λd(G)σ(Sd−1)
∫G
∫Sd−1
∫L(y,θ)
f(y + tθ)λ1(L(y, θ))dr · f(y)
︸ ︷︷ ︸=:gθ(y)
dσ(θ)dy
= 1λd(G)σ(Sd−1)
∫Sd−1
∫G
gθ(y)dydσ(θ)
= 1λd(G)σ(Sd−1)
∫Prθ(G)
∫L(x,θ)
gθ(x+ sθ)ds
︸ ︷︷ ︸Ziel: ≥0
dxdσ(θ).
Wir betrachten ∫L(x,θ)
∫L(x+sθ,θ)
f(x+ (r + s)θ)λ1(L(x+ sθ, θ))drf(x+ sθ)ds
?= 1λ1(L(x, θ))
∫L(x,θ)
∫L(x+sθ,θ)
f(x+ (r + s)θ)drf(x+ sθ)ds
= 1λ1(L(x, θ))
∫L(x,θ)
f(x+ sθ)∫
L(x+rθ)
drds (mit r + s = r)
≥ 1λ1(L(x, θ))
∫L(x,θ)
f(x+ sθ)ds
2
≥ 0.
Wir begründen ?: Wir wollen λ(L(x+ sθ, θ)) = λ1(L(x, θ)) zeigen. Dies gilt wegen
L(x+ sθ, θ) = r ∈ R : x+ (r + s)θ ∈ G+ s
= r + s ∈ R : x+ (r + s)θ ∈ G= t ∈ R : x+ tθ ∈ G= L(x, θ).
Damit folgt die Behauptung 〈Hf, f〉 ≥ 0.
Nun sind wir in der Lage die Fehlerabschätzung vom mittleren quadratischen Fehler aus Satz 4.11anzuwenden.Satz 4.39Sei G ∈ K beliebig und (Xn)n∈N eine Markovkette mit Übergangskern H (auf (G,B(G))) undStartverteilung πBd (Gleichverteilung in Bd). Mit
n0 = d3r2 log r · 2, 56 · 1014
84

4.3 Anwendungen und Beispiele
erhalten wirsup
(f,G)∈FK,4eπBd (Sn,n0 , (f,G)) ≤ 3, 2 · 107dr√
n+ 5, 8 · 1015d2r2
n.
Beweis:
1. Schritt: (Untere Schranke für Spektrallücke)
Wegen Lemma 3.39 (i) wissen wir, dass H positiv semidefinit ist. D.h. wir können dieCheeger-Ungleichung (Satz 4.31) anwenden und erhalten mit β = ‖H‖L0
2→L02, dass
1− β ≥ ϕ2
2gilt.
Aus Satz 4.36 und Lemma 3.38 (ii) folgt
ϕ ≥κ=10−3
12000 min1, (dr · 16000)−1 = 1
dr · 32 · 106
Somit gilt
1− β ≥ d−2r−2
5, 12 · 10−14 .
2. Schritt: (Startverteilung)
Es giltπBd(A) =
∫A
1Bd(x)λd(Bd)
λd(G)πG(dx)
und wir habendπBddπG
(x) = 1Bd(x)λd(G)λd(Bd)
.
Daraus folgt ∥∥∥∥dπBddπG
− 1∥∥∥∥2
2=∫G
∣∣∣∣1Bd(x)λd(Bd)
λd(G)− 1∣∣∣∣2 dxλd(G)
= λd(G)λd(Bd)
− 1 (binom. Formel)
≤ rd − 1 (G ⊆ rBd)≤ rd
3. Schritt: (Fehlerabschätzung)
Bestimme n0:
log∥∥∥dπBd
dπG − 1∥∥∥
21− β ≤ d
2 log rd2r2 · 5, 12 · 1014
= 2, 56 · 1014d3r2 log r=: n0.
85

4.3 Anwendungen und Beispiele
Dann gilt unter Verwendung vom 1. Schritt und Satz 4.11
sup(f,G)∈FK,4
eπBd (Sn,n0(G, f)) ≤√
2√n(1− β)1/2 +
√128
n(1− β) .
Damit folgt die Behauptung.
Bemerkung 4.40
(a) Bemerkenswert ist, dass die Fehlerabschätzung polynomiell von d abhängt.
(b) Die vorkommenden Konstanten sind sehr groß. D.h. aus praktischer Sicht ist die Fehlerabschät-zung wahrscheinlich nicht brauchbar. Für kleine d und r ist es unter Umständen besser die ausLemma 4.37 resultierende Fehlerabschätzung zu benutzen.
(c) Man könnte auch Satz 4.21 anwenden und damit für f ∈ L∞ Aussage über Konfidenzabschätzun-gen treffen.
4.3.2 Integration bezüglich nichtnormierter Dichtefunktion
Sei G ⊂ Rd beschränkt und fest. Sei ρ : G→ (0,∞) integrierbar bezüglich dem Lebesguemaß und
πρ(A) :=∫Aρ(x)dx∫
Gρ(x)dx
, A ∈ B(G).
Für c ≥ 1 definieren wir die Menge
Rc = ρ : G→ (0,∞) | ∀x ∈ G : 1 ≤ ρ(x) ≤ c.
Lemma 4.41
(a) Für alle ρ ∈ Rc giltsup ρinf ρ = supx∈G ρ(x)
infx∈G ρ(x) ≤ c.
(b) Sei ρ : G→ (0,∞) und sup ρinf ρ ≤ c. Dann folgt
c · ρ(x)‖ρ‖∞
∈ Rc.
Beweis: Teil (a) ist klar und Teil (b) folgt aussup ρc≤ ρ(x) ≤ sup ρ = ‖ρ‖∞.
Wir betrachtenFRc,2 = (f, ρ) : ρ ∈ Rc, f ∈ L2(πρ), ‖f‖2 ≤ 1.
Ziel: BerechneS(f, ρ) =
∫Gf(x)ρ(x)dx∫Gρ(x)dx
=∫G
f(x)πρ(dx)
86

4.3 Anwendungen und Beispiele
für ein beliebiges Paar (f, ρ) ∈ FRc,2.
Wir betrachten hier den/einen „unabhängigen Metropolis sampler“ (siehe Spezialfall in Abschnitt3.2.1). Dabei bezeichnen wir mit µG die Gleichverteilung in G. Der Vorschlagskern ist gegeben durch
Q(x,A) = µG(A) := λd(A)λd(G) , A ∈ B(G)
und der Metropoliskern mit Vorschlag µG und ρ ∈ Rc hat die Form
Mρ(x,A) =∫A
min
1, ρ(y)ρ(x)
dy
λd(G) + 1A(x)
1−∫G
min
1, ρ(y)ρ(x)
dy
λd(G)
.
Mit Mρ bezeichnen wir den Übergangskern und den zugehörigen Markovoperator.
Gegebene / benötigte Informationen:
1) Wir haben ein Orakel welches uns Funktionswerte von f liefert und ein Orakel welches Funktions-werte von ρ liefert.
2) Wir haben einen Zufallszahlengenerator für die Gleichverteilung in G („G hat eine recht einfacheStruktur.“).
MCMC Methode
Sei (f, ρ) ∈ FRc,2 und (Xn)n∈N eine Markovkette mit Übergangskern Mρ und Startverteilung µG.Berechne
Sn,n0(f, ρ) = 1n
n∑j=1
f(Xj+n0)
als Approximation von S(f, ρ).
Lemma 4.42Für alle ρ ∈ Rc, x ∈ G und A ∈ B(G) gilt
Mρ(x,A) ≥ c−1πρ(A).
Das heißt unter Verwendung von Satz 4.23 folgt
‖Mnρ − S‖L1→L1 ≤ 2(1− c−1)n.
Beweis: Wir haben
Mρ(x,A) ≥∫A
min
1, ρ(y)ρ(x)
dy
λd(G)
=∫A
minρ(y)−1, ρ(x)−1∫Gρ(z)dzλd(G) πρ(dy)
=∫A
min
∫G
ρ(z)ρ(y)dz,
∫G
ρ(z)ρ(x)dz
πρ(dy)λd(G)
≥ c−1πρ(A) (wegen ρ(z)ρ(y) ≥
inf ρsup ρ ≥ c
−1).
87

4.3 Anwendungen und Beispiele
Wir können nun die Fehlerabschätzung aus Satz 4.9 für L1-exponentiell konvergente Übergangskerneanwenden.Satz 4.43Für ρ ∈ Rc sei (Xn)n∈N eine Markovkette mit Übergangskern Mρ und Startverteilung µG. Mit
n0 = c log(2c)
erhalten wirsup
(f,ρ)∈FRc,2e(Sn,n0 , (f, ρ)) ≤
√2c√n
+ 2cn.
Beweis:
1. Schritt: (Konvergenzeigenschaft)
Aus Lemma 4.42 und wegen der Reversibilität folgt, dass Mρ L1-exponentiell konvergentmit (1− c−1, 2) und
β := ‖Mρ‖L02→L0
2≤ 1− c−1.
2. Schritt: (Startverteilung)
Es gilt
µG(A) =∫A
ρ(x)∫Gρ(y)dy
∫Gρ(y)dyρ(x)
dxλd(G) =
∫A
∫Gρ(y)dy
ρ(x)λd(G)πρ(dx)
und somitdµGdπρ
(x) =∫Gρ(y)dy
ρ(x)λd(G) .
Wir erhalten ∥∥∥∥dµGdπρ
− 1∥∥∥∥∞
≤a,b≥0
|a−b|≤maxa,b
max
1,∥∥∥∥dµG
dπρ
∥∥∥∥∞
≤ c.
3. Schritt: (Fehlerabschätzung bzw. Wahl von n0)
log(M∥∥∥dµG
dπρ − 1∥∥∥∞
)1− α ≤
M=21−α=c−1
c · log(2c) =: n0
und wir erhalten mit Satz 4.9 die Behauptung.
Bemerkung 4.44Prinzipiell ist für ρ ∈ Rc die Konstruktion von Zufallszahlengeneratoren möglich. Die Akzeptanz-wahrscheinlichkeit einer einfachen Verwerfungsmethode zur Simulation von πρ liegt mindestens beic−1.
88

4.3 Anwendungen und Beispiele
Die obige Fehlerabschätzung ist unabhängig von d, solange c unabhängig von der Dimension ist. Diesist unter Umständen nicht der Fall. Zum Beispiel mit α ≥ 0 und
ρ(x) = exp(−α|x|2).
Für G = Rd wäre dies die nichtnormierte Dichte von N (0,√
2α−1).
Falls nun G = Bd, dann ist exp(α) · ρ ∈ Rexp(α), da
supx∈Bd ρ(x)infx∈Bd ρ(x) ≤
1e−α
= eα
und wegen Lemma 4.41.
Und falls G = [−1, 1]d, so ist exp(αd) · ρ ∈ Rexp(αd), da
supx∈[−1,1]d ρ(x)infx∈[−1,1]d ρ(x) ≤
1e−αd
= eαd.
Das heißt, abhängig von G, kann c exponentiell von d abhängen. Die Abhängigkeit von α ist in beidenFällen exponentiell.
Wir hätten gerne eine Fehlerabschätzung, die nur von log c abhängt. Für die Klasse FRc,2 ist diesleider nicht möglich.
Wir formulieren folgendes Ergebnis ohne Beweis.
Satz 4.45 (folgt aus [13, Theorem 1])Für jeden randomisierten Algorithmus Sn (Zufallsvariable Sn), der n Funktionswerte von f und ρbenutzen darf, gilt
sup(f,ρ)∈FRc,2
e(Sn, (f, ρ)) = sup(f,ρ)∈FRc,2
(E|Sn(f, ρ)− S(f, ρ)|2
)2≥√
26 ·
√c
2n 2n ≥ c− 13c
c+2n−1 2n < c− 1.
Die Klasse FRc,2 ist einfach zu groß! Wir betrachten daher eine kleinere Klasse von Dichtefunktionen.Wir beginnen dafür mit der Definition und Eigenschaften von log-konkaven Funktionen auf Rd.
Definition 4.46Eine Funktion f : Rd → [0,∞) heißt log-konkav, falls
f(x) = exp(−ϕ(x)), x ∈ Rd
für eine konvexe Funktion ϕ : Rd → (−∞,∞] gilt (e−∞ = 0).
Weiterhin sei für f : Rd → [0,∞)
supp f = x ∈ Rd : f(x) > 0
der Support von f , auch Träger genannt, und für t ≥ 0 sei
Lt(f) = x ∈ Rd : f(x) ≥ t
die Levelmenge von f zu Level t.
89

4.3 Anwendungen und Beispiele
Beispiel 4.47
1) Sei G ⊆ Rd konvex und λd(G) ∈ (0,∞), dann ist die Dichte der Gleichverteilung in G
ρ(x) = 1G(x)λd(G)
log-konkav.
Dies gilt, da
ρ(x) = exp(−ϕ(x)− λd(G)) für ϕ(x) =
0 x ∈ G∞ x /∈ G
gilt.
2) Die Funktion ρ(x) = exp(−α|x|2), mit α > 0 ist log-konkav. Diese Funktion ist die nichtnormierteDichtefunktion von N (0,
√2α−1Id). Allgemein gilt, dass die Dichte von N (µ,R) mit µ ∈ Rd und
Kovarianzmatrix R (symmetrisch, positiv definit) log-konkav ist.
Eigenschaften log-konkaver Funktionen
Sei ρ : Rd → [0,∞).
E1: Folgende Aussagen sind äquivalent
(a) ρ ist log-konkav,
(b) ∀x, y ∈ Rd ∀λ ∈ [0, 1] : ρ(λx+ (1− λ)y) ≥ ρ(x)λ ρ(y)1−λ,
(c) supp ρ ist konvex und log ρ ist konkav auf supp ρ.
Beweis:
(a)=⇒ (b) ρ log-konkav =⇒∃ϕ : Rd → (−∞,∞] konvex mit ρ(x) = exp(−ϕ(x)). Wegen ϕkonvex, folgt
∀x, y ∈ Rd ∀λ ∈ [0, 1] : −ϕ(λx+ (1− λ)y) ≥ −λϕ(x)− (1− λ)ϕ(y).
Damit folgt
∀x, y ∈ Rd ∀λ ∈ [0, 1] : e−ϕ(λx+(1−λ)y) ≥ e−λϕ(x)e−(1−λ)ϕ(y).
Die Definition von ϕ liefert schließlich die Behauptung
∀x, y ∈ Rd ∀λ ∈ [0, 1] : ρ(λx+ (1− λ)y) ≥ ρ(x)λ ρ(y)(1−λ).
(b)=⇒ (c) supp ρ ist konvex, da ∀x, y ∈ supp ρ ∀λ ∈ [0, 1] gilt
ρ(λx+ (1− λ)y)(b)≥ ρ(x)λρ(y)1−λ >
x,y∈supp ρ0.
D.h. reicht es genügt nun zu zeigen, dass log ρ konkav auf supp ρ. Seien x, y ∈ supp ρ undλ ∈ [0, 1] beliebig. Dann haben wir
ρ(λx+ (1− λ)y︸ ︷︷ ︸∈supp ρ
)(b)≥ ρ(x)λρ(y)1−λ
⇐⇒ log ρ(λx+ (1− λ)y) ≥ λ log ρ(x) + (1− λ) log ρ(y).
Also ist log ρ konkav auf supp ρ.
90

4.3 Anwendungen und Beispiele
(c)=⇒ (a) Da log ρ konkav auf supp ρ, ist − log ρ konvex auf supp ρ und wir haben
ρ(x) = exp(−ϕ(x))
mit
ϕ(x) =− log ρ(x) x ∈ supp ρ∞ sonst
.
E2: Falls ρ auf supp ρ konkav und supp ρ konvex, dann ist ρ log-konkav.
Beweis: Wegen E1 g.z.z., dass log ρ konkav auf supp ρ. Wir haben für x, y ∈ supp ρ, λ ∈ [0, 1]
logρ(λx+ (1− λ)y) ≥ logλρ(x) + (1− λ)ρ(y) ≥ λ log ρ(x) + (1− λ) log ρ(y).
E3: Sind ρ1, ρ2 log-konkav, dann auch ρ1ρ2 und minρ1, ρ2 log-konkav.
E4: ρ log-konkav =⇒∀t ∈ (0,∞) ist Lt(ρ) konvex.
Beweis: Seien x, y ∈ Lt(ρ), λ ∈ [0, 1]. Dann ist
ρ(λx+ (1− λ)y)E1 (b)≥ ρ(x)λρ(y)1−λ ≥ tλt1−λ = t.
Bemerkung 4.48Funktionen deren Levelmengen konvex sind, werden auch quasi-konvex gennant.
quasi-konvex
nicht quasi-konvex
In der Literatur wird manchmal der Begriff „unimodal“ für quasi-konvex verwendet. „Unimodal“ kannaber auch heißen, dass eine Funktion nur einen „Mode = Modus“ hat, d.h. die Maximalstellen bildeneine konvexe Menge.
Folgendes Resultat über log-konkave Funktionen ist sehr wichtig.
91

4.3 Anwendungen und Beispiele
Lemma 4.49 (Isoperimetrische Ungleichung)Sei ρ log-konkav mit beschränktem „support“, d.h.
D := diam(supp ρ) = supx,y∈supp ρ
|x− y| <∞.
Es sei T1, T2, T3 eine paarweise disjunkte Zerlegung von supp ρ. Dann gilt
πρ(T3) ≥ 2
Dinfx∈T1y∈T2
|x− y| ·minπρ(T1), π
ρ(T2).
Beweis: Einen Beweis dieser Behauptung und weitere Ungleichungen dieser Art finden sich in [20].
Wir wollen nun eine Klasse von Dichtefunktionen mit zusätzlicher Struktur einführen.
Für α ≥ 0 sei nun ρ ∈ Lα, falls ρ : G→ (0,∞), G ⊆ Rd, G konvex und
a) Es existiert eine log-konkave Funktion ρ mit supp ρ = G und ρ = ρ auf G.
b) Für alle x, y ∈ G gilt | log ρ(x)− log ρ(y)| ≤ α|x− y|.
Wir können sagen, dass Lα log-konkave, log-Lipschitz-stetige, nichtnormierte Dichtefunktionen ent-hält.
Nun betrachten wirFLα,4 = (f, ρ) : ρ ∈ Lα, f ∈ L4(πρ), ‖f‖4 ≤ 1.
Ziel: Für geeignete Mengen G berechne
S(f, ρ) =∫Gf(x)ρ(x)dx∫Gρ(x)dx
=∫G
f(x)πρ(dx), (f, ρ) ∈ FLα,4.
Gegebene Informationen:
1) Funktionsauswertungen von f
2) Funktionsauswertungen von ρ
3) Zufallszahlengenerator zur Simulation der Gleichverteilung in G.
Als Markovkette schauen wir uns einen Metropolis-Algorithmus mit „ball-walk“ als Vorschlagskernan. Für δ > 0 ist der Übergangskern des „δ-ball-walk“ gegeben durch
Wδ(x,A) = λd(A ∩B(x, δ))λd(B(0, δ)) + 1A(x)
(1− λd(G ∩B(x, δ))
λd(B(0, δ))
),
für A ∈ B(G) und x ∈ G. Und der Metropoliskern mit Vorschlag Wδ sowie ρ ∈ Lα hat die Form
Mρ,δ(x,A) =∫A
min1, ρ(y)ρ(x)Wδ(x, dy) + 1A(x)
1−∫G
min1, ρ(y)ρ(x)Wδ(x,dy)
.
Sei Mρ,δ(x,A) = 12 (Mρ,δ(x,A) + 1A(x)) die „lazy version“ von Mρ,δ. Wir betrachten Mρ,δ um sicher-
zustellen, dass der Markovoperator positiv semidefinit ist, siehe Abschnitt 4.2.2.
92

4.3 Anwendungen und Beispiele
Notation: Wir bezeichnen mit Mρ,δ, bzw. Mρ,δ, Markovoperator und Markovkern.
MCMC Methode: Sei (f, ρ) ∈ FLα,4 und (Xn)n∈N eine Markovkette mit Übergangskern Mρ,δ undStartverteilung µG (Gleichverteilung in G). Berechne
Sn,n0(f, ρ) = 1n
n∑j=1
f(Xj+n0)
als Approximation von S(f, ρ).
Wir benötigen einige Eigenschaften des „δ-ball-walk“. Zunächst definieren wir für einen allgemeinenÜbergangskern K die local conductance
`K(x) = K(x,G \ x).
Interpretation: Sei r > 0 und Ar := x ∈ G : `K(x) < r und π(Ar) ∈ (0, 1/2], sowie K reversibelbezüglich π. Dann gilt
ϕ = infπ(A)∈(0,1/2)
∫AK(x,Ac)π(dx)
π(A)
≤∫Ar
K(x,Acr)π(dx)π(Ar)
≤∫Ar
K(x,G \ x)︸ ︷︷ ︸<r
π(dx)π(Ar)
< r.
D.h., intuitiv, falls r sehr klein und Ar genügend groß (π(Ar) ∈ (0, 1/2]) haben wir kleines ϕ. Für Wδ
und Mρ,δ zeigen wir die Umkehrung.
Ziel: Falls `Wδ(x) ≥ ` > 0, bzw. `Mρ,δ
(x) ≥ ` > 0 für alle x ∈ G und ` „groß genug“, dann ist auchϕ(Wδ) bzw. ϕ(Mρ,δ) „groß“.
Für Wδ erhalten wir`Wδ
(x) = λd(G ∩B(x, δ))λd(B(0, δ))
Skizze:
x1 x2
x3G
`Wδ(x1) = 1/4
`Wδ(x2) = 1/2
`Wδ(x3) = 1
93

4.3 Anwendungen und Beispiele
Im Folgenden benutzen wir öfter die Ungleichung
λd−1(Bd−1)λd(Bd)
≤√d+ 1
2π . (BR)
Für einen Beweis siehe [13]. (BR) folgt im Wesentlichen aus
Γ(z + 1/2)Γ(z) ≤
√z,
mit der Gammafunktion Γ(z) =∫∞
0 tz−1e−tdt.
Lemma 4.50Für δ ≤ 1√
d+1 , G = Bd und beliebiges x ∈ Bd gilt `Wδ(x) ≥ 0, 3.
Beweis: Es ist klar, dass `Wδ(x) für x ∈ ∂Bd = Sd−1 am kleinsten ist. Es sei H die Tangentialhyper-
ebene am Punkt x bezüglich Bd. Dann halbiert diese B(x, δ).
x B(x, δ)
H
Grundfläche von Z(h)
Z(h)
h
Bd
Desweiteren sei Z(h) der d-dimensionale Zylinder, der die (d − 1)-dimensionale Kugel um x mitRadius δ als Grundfläche besitzt. Die Höhe h des Zylinders ergibt sich aus dem Abstand von H undder Hyperebene, die durch Bd∩∂B(x, δ) bestimmt wird. Diese Höhe h kann man mit Hilfe des Satzesvon Thales und einer Verhältnisungleichung genau berechnen.
94

4.3 Anwendungen und Beispiele
A B
C
δh
2
δ
h
∆ABC liegt auf Halbkreis über AB, also liegt nach Satz des Thales bei C ein rechter Winkel. Damitfolgt mit Strahlensatz h
δ = δ2 , also h = δ2
2 .
Nach obiger Konstruktion können wir `Wδ(x) wie folgt abschätzen
`Wδ(x) = λd(B(x, δ) ∩Bd)
λd(B(0, δ)) ≥ 12 −
λd(Z(h))λd(B(0, δ)) .
Da λd(Z(h)) = h · λd−1(δBd−1) = δ2
2 δd−1λd−1(Bd−1) erhalten wir
`Wδ(x) ≥ 1
2 −hδd−1λd−1(Bd−1)
δdλd(B2)
= 12
(1− δ λd−1(Bd−1)
λd(Bd)
)≥ 1
2
(1− δ
√d− 1√
2π
)(mit (BR)).
Für δ ≤ 1/√d+1 bekommen wir
`Wδ(x) ≥ 1
2 (1− 1/√
2π) ≥ 0, 3
und damit ist der Beweis abgeschlossen.
Wir benötigen 2 weitere technische Lemmas über Wδ.
Lemma 4.51Sei δ > 0 und t ∈ (0, 1). Falls x, y ∈ Rd mit
|x− y| ≤ tδ√
2π√d+ 1
,
dann istλd(B(x, δ) ∩B(y, δ)) ≥ (1− t)λd(B(0, δ)).
95
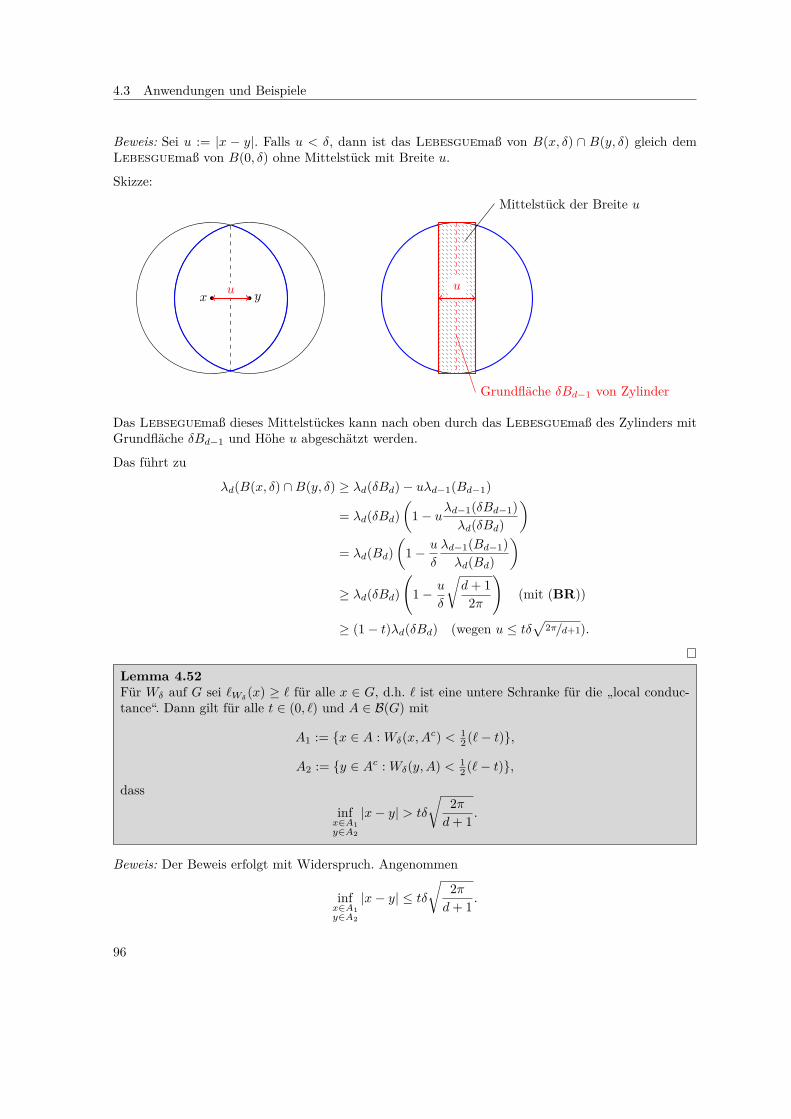
4.3 Anwendungen und Beispiele
Beweis: Sei u := |x − y|. Falls u < δ, dann ist das Lebesguemaß von B(x, δ) ∩ B(y, δ) gleich demLebesguemaß von B(0, δ) ohne Mittelstück mit Breite u.
Skizze:
x yu u
Mittelstück der Breite u
Grundfläche δBd−1 von Zylinder
Das Lebseguemaß dieses Mittelstückes kann nach oben durch das Lebesguemaß des Zylinders mitGrundfläche δBd−1 und Höhe u abgeschätzt werden.
Das führt zu
λd(B(x, δ) ∩B(y, δ) ≥ λd(δBd)− uλd−1(Bd−1)
= λd(δBd)(
1− uλd−1(δBd−1)λd(δBd)
)= λd(Bd)
(1− u
δ
λd−1(Bd−1)λd(Bd)
)≥ λd(δBd)
(1− u
δ
√d+ 1
2π
)(mit (BR))
≥ (1− t)λd(δBd) (wegen u ≤ tδ√
2π/d+1).
Lemma 4.52Für Wδ auf G sei `Wδ
(x) ≥ ` für alle x ∈ G, d.h. ` ist eine untere Schranke für die „local conduc-tance“. Dann gilt für alle t ∈ (0, `) und A ∈ B(G) mit
A1 := x ∈ A : Wδ(x,Ac) < 12 (`− t),
A2 := y ∈ Ac : Wδ(y,A) < 12 (`− t),
dassinfx∈A1y∈A2
|x− y| > tδ
√2πd+ 1 .
Beweis: Der Beweis erfolgt mit Widerspruch. Angenommen
infx∈A1y∈A2
|x− y| ≤ tδ√
2πd+ 1 .
96

4.3 Anwendungen und Beispiele
Dann folgt
λd(B(x, δ) ∩B(y, δ) ∩G)= λd ((B(x, δ) ∩G) \ (B(x, δ) \B(y, δ))) (wegen A ∩B ∩ C = (A ∩B) \ (A \ C))≥ λd(B(x, δ) ∩G)− λd(B(x, δ) \B(y, δ))= λd(B(x, δ) ∩G)− λd(B(x, δ) \ [B(x, δ) ∩B(y, δ)])= λd(B(x, δ) ∩G)− λd(δBd)− λd(B(x, δ) ∩B(y, δ)).
Wegen obiger Annahme können wir Lemma 4.51 anwenden. Damit und mit
`Wδ= λd(Bx,δ ∩G)
λd(B(0, δ)) ≥ `
folgtλd(B(x, δ) ∩B(y, δ) ∩G) ≥ `λd(δBd)− λd(δBd) + (1− t)λd(δBd). (19)
Nun giltB(x, δ) ∩B(y, δ) ∩G ⊆ (B(x, δ) ∩G ∩Ac) ∪ (B(y, δ) ∩G ∩A).
Wegen der Monotonie des Lebesguemaßes folgt
λd(B(x, δ) ∩B(y, δ) ∩G) ≤ λd((B(x, δ) ∩G ∩Ac) ∪ (B(y, δ) ∩G ∩A))≤ λd(B(x, δ) ∩G ∩Ac) + λd(B(y, δ) ∩G ∩A).
Aus (19) und vorheriger Ungleichung folgt
λd(B(x, δ) ∩G ∩Ac) + λd(B(y, δ) ∩G ∩A) ≥ (`− t)λd(B(0, δ)).
Mit Wδ ausgedrückt ergibt dies
Wδ(x,Ac) +Wδ(y,A) ≥ `− t.
Dies ist ein Widerspruch zu x ∈ A1 und y ∈ A2.
Folgerung 4.53Für Wδ auf G ⊆ Rd sei `Wδ
(x) ≥ ` für alle x ∈ G. Desweiteren sei G konvex und beschränkt mitD := diam(G). Dann gilt für d ≥ 6 und δ < D
ϕ(Wδ) ≥`2
8δ
D
√2πd+ 1 .
Insbesondere ist für G = Bd
ϕ(Wd) ≥9√π√
2 · 8001
d+ 1 .
Beweis: Mit Lemma 4.52 erhalten wir für t ∈ (0, `) und A ∈ B(G) mit
A1 := x ∈ A : Wδ(x,Ac) < 12 (`− t),
A2 := y ∈ Ac : Wδ(y,A) < 12 (`− t),
dassinfx∈A1y∈A2
|x− y| > tδ
√2πd+ 1 .
97

4.3 Anwendungen und Beispiele
Da G konvex ist, folgt 1G(x)λd(G) ist log-konkav. Aus Lemma 4.49 folgt mit A3 = G \ (A1 ∪A2)
µG(A3) ≥ 2Dtδ
√2πd+ 1 minµG(A1), µG(A2).
Da Wδ reversibel bezüglich µG erhalten wir mit Satz 4.36
ϕ(Wδ) ≥`− t
2 min
1, tδD
√2πd+ 1
≥ `− t2
tδ
D
√2πd+ 1 (wegen d ≥ 6, δ ≤ D, t ∈ (0, `) und ` ≤ 1)
= `2
8δ
D
√2πd+ 1 (wegen t(`− t) maximal für tmax = /2).
Der letzte Teil folgt mit Lemma 4.35.
Wir können dieses Ergebnis verallgemeinern.
Satz 4.54Sei ρ ∈ Lα, `Wδ
≥ ` für alle x ∈ G und D := diam(G) <∞. Dann gilt
ϕ(Mρ,δ) ≥`e−αδ
8 min
1,√π
2`δ
D√d+ 1
.
Beweis:
1. Schritt: (Mρ,δ(x,A) ≥ e−αδWδ(x,A))
Für ρ ∈ Lα gilt mit y ∈ B(x, δ), x ∈ G und der log-Lipschitz-Bedingung, dass
min
1, ρ(y)ρ(x)
= min
1, elog ρ(y)−log ρ(x)
≥ e−α|x−y| ≥ e−αδ.
Damit erhalten wir
Mρ,δ(x,A) ≥∫A
min
1, ρ(y)ρ(x)
Wδ(x, dy)
=∫A
1B(x,δ)(y) min
1, ρ(y)ρ(x)
Wδ(x, dy)
≥ e−αδ∫A
1B(x,δ)(y)Wδ(x, dy)
= e−αδWδ(x,A).
2. Schritt: (Verallgemeinerung von Lemma 4.52)
Für A ∈ B(G) sei
T1 :=x ∈ A : Mρ,δ(x,Ac) < e−αδ
`
4
,
98

4.3 Anwendungen und Beispiele
T2 :=y ∈ Ac : Mρ,δ(y,A) < e−αδ
`
4
.
Wir zeigen T1 ⊆ A1 und T2 ⊆ A2 mit A1, A2 aus Lemma 4.52 und t = /2.
Es gilt für x ∈ T1, dass
Wδ(x,A) ≤1. Schritt
eαδMρ,δ(x,Ac) <x∈T1
`
4
und somit x ∈ A1. Analog zeigt man T2 ⊆ A2. Damit erhalten wir
infx∈T1y∈T2
|x− y| ≥ infx∈A1y∈A2
|x− y|Lemma 4.52
>`
2δ√
2πd+ 1 .
3. Schritt: (Anwendung isoperimetrischer Ungleichung, Lemma 4.49)
Es sei T3 := G \ (T1 ∪ T2) und da ρ log-konkav, folgt mit Lemma 4.49 und dem 2. Schritt,dass
πρ(T3) ≥ 2D
`
2δ√
2πd+ 1 minπρ(T1), πρ(T2).
4. Schritt: (Anwendung von Satz 4.36)
Da Mρ,δ reversibel bezüglich πρ und mit den Schritten 1 bis 3 erhalten wir unter Verwen-dung von Satz 4.36
ϕ(Mρ,δ) ≥`
8e−αδ min
1, `2
δ
D
√2πd+ 1
und die Behauptung des Satzes ist bewiesen.
Folgerung 4.55Es sei ρ ∈ Lα mit G = Bd und δ ≤ (d+ 1)−1/2. Dann gilt
ϕ(Mρ,δ) ≥√π
29δe−αδ
1600 ·√d+ 1
.
Um ϕ(Mρ,δ) zu maximieren, setzen wir
δ∗ := min
1√d+ 1
,1α
und erhalten
ϕ(Mρ,δ) ≥√π
29e−1
16001√d+ 1
min
1√d+ 1
,1α
.
Beweis: Die Aussagen sind direkte Folgerungen aus Satz 4.54 und Lemma 4.50.
Nun haben wir alles Beisammen um eine Fehlerabschätzung für die MCMC Methode basierend aufMρ,δ („lazy version“ von Mρ,δ) zu formulieren und zu beweisen.
99

4.3 Anwendungen und Beispiele
Satz 4.56Für G = Bd, ρ ∈ Lα und δ∗ = min(d+ 1)−1/2, α−1 sei (Xn)n∈N eine Markovkette mit Übergangs-kern Mρ,δ∗ und Startverteilung µBd . Mit
n0 := 1189362 α(d+ 1) maxd+ 1, α2
erhalten wir
sup(f,ρ)∈FLα,4
eµBd (Sn,n0 , (f, ρ)) ≤ 1543√n
√d+ 1 max
√d+ 1, α+ 13456095
n(d+ 1) maxd+ 1, α2.
Beweis:
1. Schritt (Konvergenzeigenschaft)
Mit Lemma 4.35, Folgerung 4.40 und der Wahl von δ∗ erhalten wir
ϕ(Mρ,δ∗) = ϕ(Mρ,δ∗)2 ≥
√π
29
3200 e1√d+ 1
·min
1√d+ 1
,1α
.
Mit der Cheeger-Ungleichung (Satz 4.31) erhalten wir dann
1− ‖Mρ,δ‖L02→L0
2≥ 1
2π
281
32002 e2︸ ︷︷ ︸≈0,841·10−6
1d+ 1 min
1
d+ 1 ,1α2
.
2. Schritt (Startverteilung)
Es gilt
µBd(A) =∫A
ρ(A)∫Bdρ(y)dy
·∫Bdρ(y)dyρ(x)
dxλd(Bd)
=∫A
∫Bd
ρ(y)dy 1ρ(x)λd(Bd)
πρ(dx)
und somit
dµBddπρ
(x) = 1ρ(x) ·
∫Bd
ρ(y) dyλd(Bd)
.
100

4.3 Anwendungen und Beispiele
Mit c :=∫Bdρ(y)dy folgt∥∥∥∥dµBd
dπρ− 1∥∥∥∥2
2=∫Bd
∣∣∣∣ c
λd(Bd)ρ(x)−1 − 1
∣∣∣∣2 ρ(x)c
dx︸ ︷︷ ︸πρ(dx)
=∫Bd
(c2
λd(Bd)21
ρ(x)
2− 2 c
λd(Bd)ρ(x) + 1)ρ(x)c
dx
=∫Bd
c
λd(Bd)2ρ(x)dx− 1
≤∫Bd
∫Bd
ρ(y)ρ(x)
dxλd(Bd)
dyλd(Bd)
(c einsetzen)
(?)≤ e2α,
wobei (?) wegen
ρ(y)ρ(x) = exp(log(ρ(y))− log(ρ(x))) ≤ eα|x−y| ≤
x,y∈Bde2α
gilt.
Das heißt ∥∥∥∥dµBddπρ
− 1∥∥∥∥
2≤ eα.
3. Schritt (Fehlerabschätzung, Anwendung von Satz 4.11)
Bestimme n0: Es gilt
log(‖ dνdπρ − 1‖)
1− β1. und 2. Schritt
≤ α(d+ 1) maxd+ 1, α2 · 1189362.
Dann gilt unter Verwendung vom 1. Schritt und Satz 4.11 die Fehlerabschätzung.
101

LITERATUR
Literatur
[1] G. Alsmeyer. Wahrscheinlichkeitstheorie (Vorlesungsskript). http://www.math.uni-muenster.de/statistik/lehre/SS13/WT/Skript/WT-Buch_8.pdf, 2013. [Online; Zugriff am 31.07.2015].
[2] S. Asmussen and P. Glynn. A new proof of convergence of MCMC via the ergodic theorem.Statist. Probab. Lett., 81:1482–1485, 2011.
[3] A. Barker. Monte Carlo calculations of the radial distribution functions for a proton-electronplasma. Aust. J. Phys., 18:119–133, 1965.
[4] R. Dudley. Real analysis and probability, volume 74 of Cambridge Studies in Advanced Mathe-matics. Cambridge University Press, Cambridge, 2002. Revised reprint of the 1989 original.
[5] O. Forster. Analysis 3: Maß- und Integrationstheorie, Integralsätze im Rn und Anwendungen.Wiesbaden: Springer Spektrum, 7th revised ed. edition, 2012.
[6] P. Glynn and D. Ormoneit. Hoeffding’s inequality for uniformly ergodic Markov chains. Statist.Probab. Lett., 56(2):143–146, 2002.
[7] W. Hastings. Monte Carlo sampling methods using Markov chains and their applications. Bio-metrika, 57(1):97–109, 1970.
[8] O. Kallenberg. Foundations of Modern Probability. Probability and its Applications. Springer-Verlag, New York, Second edition, 2002.
[9] A. Klenke. Wahrscheinlichkeitstheorie. Springer, 2006. in German.
[10] K. Łatuszyński and D. Rudolf. Convergence of hybrid slice sampling via spectral gap.http://arxiv.org/abs/1409.2709, 2014.
[11] G. Lawler and A. Sokal. Bounds on the L2 spectrum for Markov chains and Markov processes:a generalization of Cheeger’s inequality. Trans. Amer. Math. Soc., 309(2):557–580, 1988.
[12] L. Lovász and S. Vempala. Hit-and-run from a corner. SIAM J. Comput., 35(4):985–1005, 2006.
[13] P. Mathé and E. Novak. Simple Monte Carlo and the Metropolis algorithm. J. Complexity,23(4-6):673–696, 2007.
[14] N. Metropolis, A. Rosenbluth, M. Rosenbluth, A. Teller, and E. Teller. Equation of state calcu-lations by fast computing machines. Journal of Chemical Physics, 21(6):1087–1092, 1953.
[15] S. Meyn and R. Tweedie. Markov chains and stochastic stability. Cambridge University Press,second edition, 2009.
[16] B. Miasojedow. Hoeffding’s inequalities for geometrically ergodic markov chains on general statespace. Preprint, Available at http://arxiv.org/abs/1201.2265, 2012.
[17] T. Müller-Gronbach, E. Novak, and K. Ritter. Monte Carlo-Algorithmen. Springer, 2012. inGerman.
[18] D. Rudolf. Explicit error bounds for Markov chain Monte Carlo. Dissertationes Math., 485:93pp., 2012.
[19] D. Rudolf and M. Ullrich. Positivity of hit-and-run and related algorithms. Electron. Commun.Probab., 18:1–8, 2013.
102

LITERATUR
[20] S. Vempala. Geometric random walks: A survey. Combinatorial and computational geometry,52:573–612, 2005.
[21] D. Werner. Funktionalanalysis. Springer Verlag, 2005.
103

INDEX
IndexL1-exponentielle Konvergenz, 53δ ball walk, 21π-irreduzibel, 55log-konkav, 89Übergangsdichte, 34Übergangskern, 18Gibbs sampler
Deterministic scan Gibbs sampler, 41Random scan Gibbs sampler, 40
bedingte Dichte, 16bedingter Erwartungswert, 10burn-in, 55
Doeblin, 69
Fehler, 5
Gibbs sampler, 40gleichmäßig ergodisch, 54
homogene Markovkette, 18
Leitfähigkeit, 71Levelmenge, 42local conductance, 93
Markoveigenschaft, 18Markovkern, 18Markovkette, 7, 18Markovoperator, 46
Markovprozess, 18
quasi-konvex, 91
reguläre Version, 13reguläre Version der bedingten Verteilung, 13,
14Reversibilität, 27
Slice sampling, 42Hybride slice sampler, 44Simple slice sampler, 42
Spektrallücke, 53Startverteilung, 18stationäre Verteilung, 26Support, 89
totaler Variationsabstand, 49Träger, 89
Update-Funktion, 18
Version der bedingten Wahrscheinlichkeit, 13Version des bedingten Erwartungswertes, 9Verteilungsdichte, 15Vorschlagskern, 34
zeitlich diskret, 18zeitlich stetig, 18zufällige Vektoren, 15
104


















