
Maschinelles Lernen und Data Mining - Universität Potsdam · Für jedes Dokument und jedes Wort...
43
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Michael Großhans Paul Prasse
Transcript of Maschinelles Lernen und Data Mining - Universität Potsdam · Für jedes Dokument und jedes Wort...

Universität Potsdam Institut für Informatik
Lehrstuhl Maschinelles Lernen
Latente Dirichlet-Allokation
Tobias Scheffer
Michael Großhans
Paul Prasse

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Themenmodellierung
Themenmodellierung (Topic modeling) liefert
Methoden, große elektronische Archive
automatisch zu organisieren, verstehen,
durchsuchen und zusammenzufassen
1. Versteckte Themenmuster finden, die in der
Dokumentensammlung reflektiert sind
2. Dokumente anhand der gefundenen Themen
annotieren
3. Annotationen verwenden, um Dokumente zu
organisieren und durchsuchen
2

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Themenmodellierung (Beispielsystem)
3

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Probabilistische Modellierung
1. Behandlung der Daten als Beobachtungen, die
aus einem generativen probabilistischen Prozess
mit versteckten Variablen entstehen
Bei Dokumenten reflektieren die versteckten
Variablen die thematische Struktur der
Textsammlung
2. Versteckte Struktur finden mit Posterior-Inferenz
Was sind die Themen, die diese Sammlung
beschreiben?
3. Neue Daten in das geschätzte Modell
„einsortieren“
Wie passt das neue Dokument in die
Themenstruktur? 4

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Generatives Modell für Texte:
Modelliert gemeinsame Wahrscheinlichkeit für
Beobachtungen, Label und versteckten Variablen.
Beschreibt Prozess wie Beobachtungen, Label und
versteckte Variablen erzeugt werden.
Beobachtungen sind Wörter der Dokumente.
Versteckte Variablen sind Themen für jedes
Dokument und die Zusammensetzung der Themen
an sich
5

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
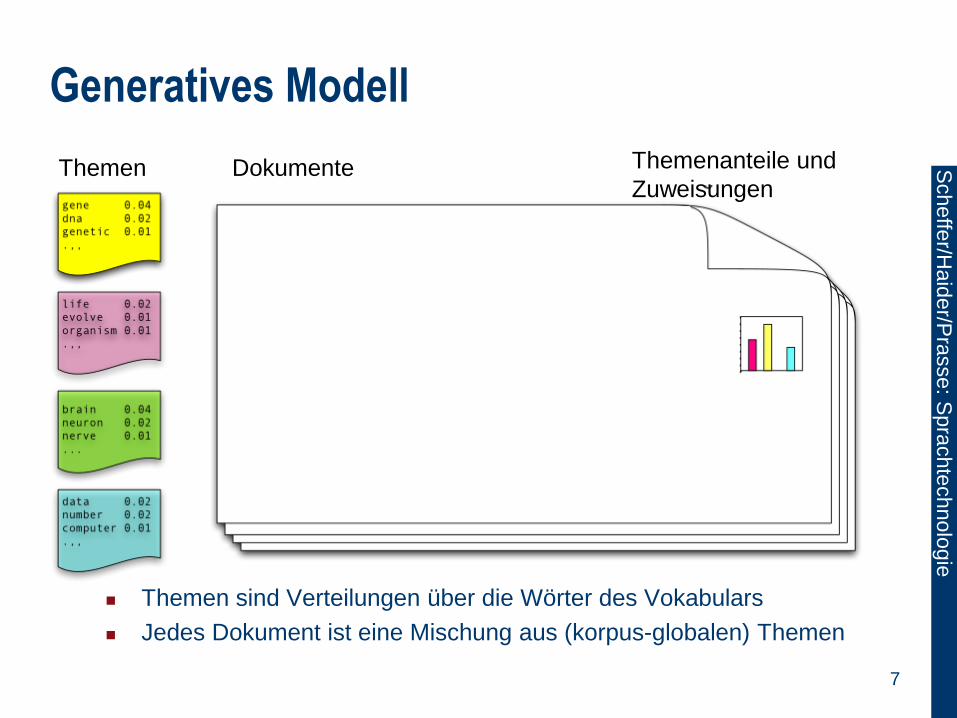
Generatives Modell
Themen sind Verteilungen über die Wörter des Vokabulars
6
Themen
Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Generatives Modell
Themen sind Verteilungen über die Wörter des Vokabulars
Jedes Dokument ist eine Mischung aus (korpus-globalen) Themen
7
Themen Dokumente Themenanteile und
Zuweisungen

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Generatives Modell
Themen sind Verteilungen über die Wörter des Vokabulars
Jedes Dokument ist eine Mischung aus (korpus-globalen) Themen
Jedes Wort ist aus einem der Themen gezogen 8
Themen Dokumente Themenanteile und
Zuweisungen

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Inferenzproblem
In Wirklichkeit sind nur die Wörter beobachtet
Das Ziel ist, die zugrundeliegende Themenstruktur zu inferieren
9
Themen Dokumente Themenanteile und
Zuweisungen

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Generatives Modell für Texte (als bag-of-words)
Jeder Text ist Mischung verschiedener Themen:
Für jedes Thema ist die Zusammensetzung (die
Worthäufigkeiten) eine versteckte Variablen.
Für jeden Text ist die Mischung über die Themen
eine versteckte Variable.
Wörter sind Beobachtungen des generativen
Modells:
Jeder Stelle des Dokuments ist ein Thema gemäß der
Themenmischung des Dokuments zugewiesen.
An jeder Stelle wird ein Wort erzeugt, gemäß der
Worthäufigkeiten des entsprechenden Themas
10

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
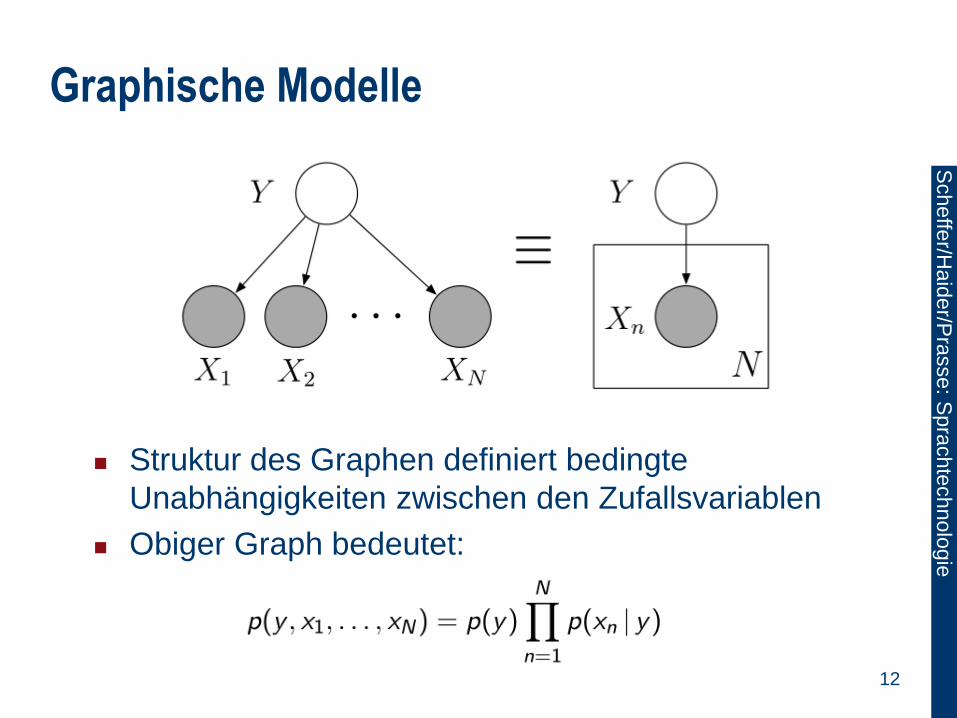
Graphische Modelle
Knoten sind Zufallsvariablen
Kanten beschreiben mögliche Abhängigkeiten
Beobachtete Variablen sind schattiert
Tafeln (plates) beschreiben replizierte Struktur
11
Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Graphische Modelle
12
Struktur des Graphen definiert bedingte
Unabhängigkeiten zwischen den Zufallsvariablen
Obiger Graph bedeutet:

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Im Folgenden seien:
K die Anzahl der Themen,
V die Größe des Vokabulars,
D die Anzahl der Dokumente und
Nd die Anzahl von Wörtern im d-ten Dokument.
13

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Für jedes Thema ist die Zusammensetzung (die
Worthäufigkeiten) eine versteckte Variablen:
Für jedes Thema ist eine V-dimensionale
Zufallsvariable
Alle besitzen die gleiche (Prior)-Verteilung
ist Hyperparameter der gemeinsamen Verteilung
(später mehr)
14
|kP
1, ,k K
k
k

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Für jeden Text ist die Mischung über die Themen
eine versteckte Variable:
Für jedes Dokument ist eine K-
dimensionale Zufallsvariable
Alle besitzen die gleiche Verteilung
ist Hyperparameter der gemeinsamen Verteilung
(später mehr)
15
|dP
1, ,d D
d
d

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Latente Dirichlet-Allokation
Jedes Wort wird aus einem der Themen erzeugt:
Für jedes Dokument und jedes Wort
ist eine 1-dimensionale Zufallsvariable.
legt das Thema an der Stelle n in Dokument d fest.
ist multinomialverteilt, wobei die
Einzelwahrscheinlichkeiten spezifiziert.
Für jedes Dokument und jedes Wort
ist eine 1-dimensionale Zufallsvariable.
legt das Wort an der Stelle n in Dokument d fest,
gegeben das Thema dieser Stelle.
ist multinomialverteilt, wobei
die Einzelwahrscheinlichkeiten spezifiziert.
16
1, ,d D
, 1, ,d nZ K
1, , dn N
,d nZ
, | Multd n d dZ d
, 1, ,d nW V
1, , dn N 1, ,d D
,d nW
,, ,| , Mult
d nd n d n ZW Z ,d nZ
Schreibweise für: entspricht der
Wahrscheinlichkeitsfunktion einer Multinomialverteilung
mit Parameter
, ,| ,d n d nP W Z
,d nZ
Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
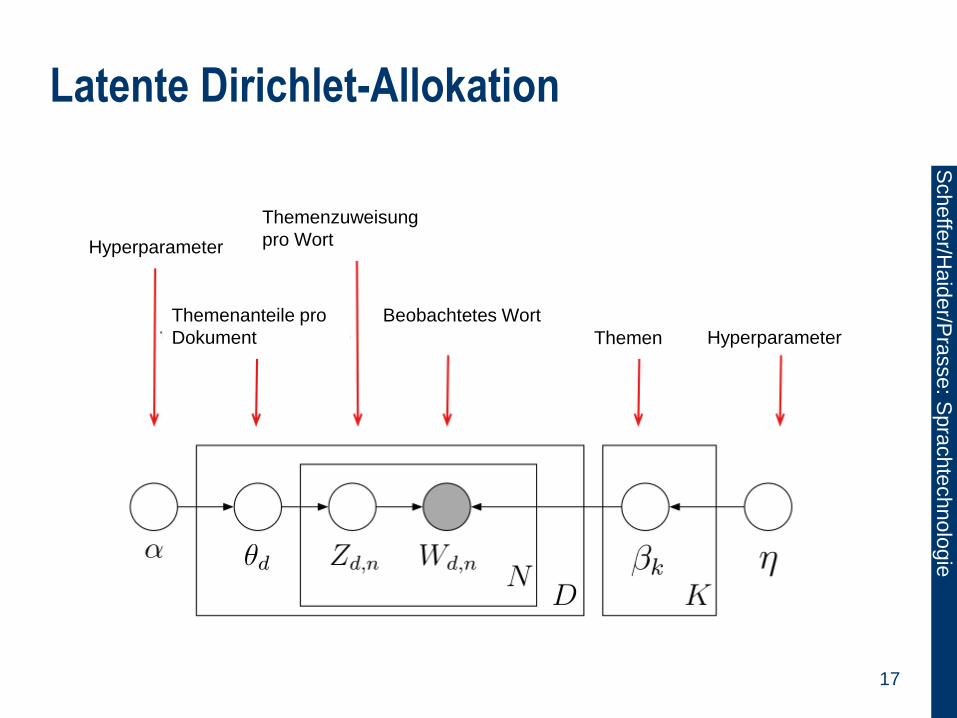
Latente Dirichlet-Allokation
17
Hyperparameter
Themenzuweisung
pro Wort
Themenanteile pro
Dokument
Beobachtetes Wort
Themen
Hyperparameter
Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
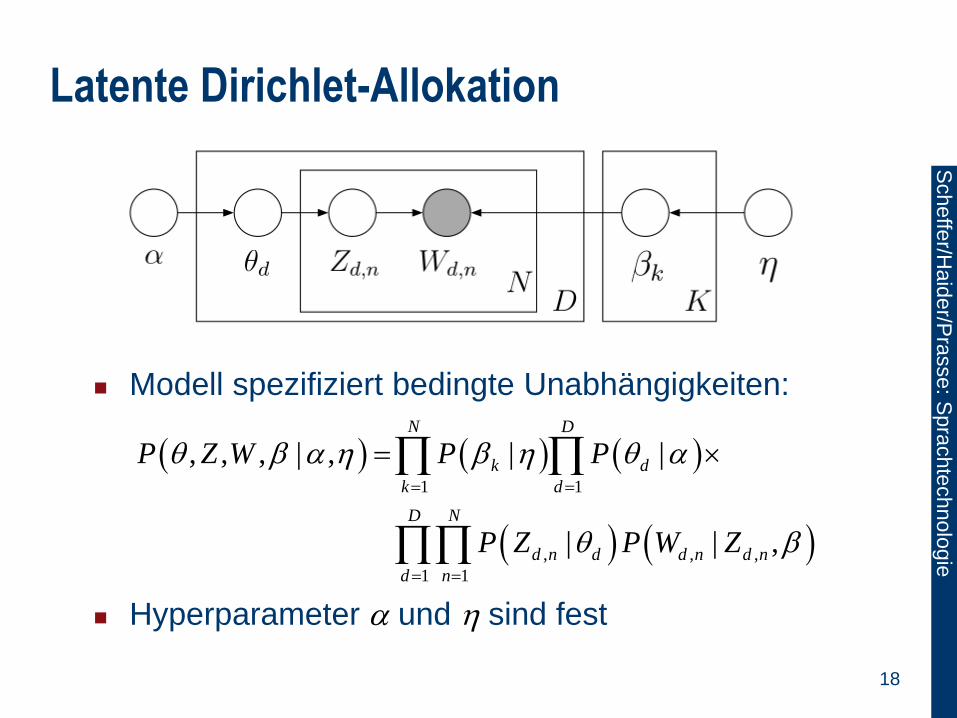
Latente Dirichlet-Allokation
18
Modell spezifiziert bedingte Unabhängigkeiten:
Hyperparameter und sind fest
1 1
, , ,
1 1
, , , | , | |
| | ,
N D
k d
k d
D N
d n d d n d n
d n
P Z W P P
P Z P W Z

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Modellierung der einzelnen Verteilungen:
ist multinomialverteilt.
ist multinomialverteilt.
Wie sollte man und wählen?
Konjugierte Verteilung zu Mutlinomialverteilung
1 1
, , ,
1 1
, , , | , | |
| | ,
N D
k d
k d
D N
d n d d n d n
d n
P Z W P P
P Z P W Z
Latente Dirichlet-Allokation
19
, | Multd n d dZ
,, ,| , Mult
d nd n d n ZW Z
| |k dP P

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
11
1
11
| , , i
DD
iiD iD
iii
P
Wiederholung: Dirichlet-Verteilung
Verteilung über Vektoren , mit:
Alle Einträge sind positiv,
Die Summe der Einträge ist .
Verallgemeinerung der Beta-Verteilung auf mehr
als 2 Dimensionen
Parametrisiert durch Vektor mit
Dichtefunktion:
20
Verallgemeinerte
Beta-Funktion
1, , D
0d
1
1D
d
d
1, , D 0d
Gamma-Funktion

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Wiederholung: Dirichlet-Verteilung
21
α = (2, 3, 4). α = (6, 2, 6).
α = (3, 7, 5). α = (6, 2, 2).
x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
x1
x2

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Wiederholung: Dirichlet-Verteilung
Je größer die Summe der Alphas, desto „spitzer“ ist
die Verteilung
Man erhält schwach variierende Vektoren
Je kleiner die Summe der Alphas, desto mehr
Wahrscheinlichkeitsmasse konzentriert sich auf die
Ränder und Ecken
Man erhält sparse Vektoren (meiste Komponenten 0)
22

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Wiederholung: Dirichlet-Verteilung
Dirichlet-Verteilung ist der konjugierte Prior der
Multinomialverteilung
Posterior hat selbe Form wie der Prior
Bei LDA: normalerweise austauschbarer
Dirichletprior
alle Komponenten des Parametervektors identisch
effektiv nur ein Parameter
23
Gamma-Funktion
1
1
|
DD
i
i
PD

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Modellierung der einzelnen Verteilungen:
ist multinomalverteilt.
ist multinomalverteilt.
ist Dirichlet-verteilt.
ist Dirichlet-verteilt.
Wichtig: <1, damit nur wenige Themen pro Dokument
vergeben werden
1 1
, , ,
1 1
, , , | , | |
| | ,
N D
k d
k d
D N
d n d d n d n
d n
P Z W P P
P Z P W Z
Latente Dirichlet-Allokation
24
, | Multd n d dZ
,, ,| , Mult
d nd n d n ZW Z
| Dirk
| Dird

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
LDA: Teilprobleme
Aus gegebener Dokumentensammlung, inferiere
Posterior-Verteilung von
Themenzuweisungen für jedes Wort zd,n
Themenanteile für jedes Dokument d
Verteilung über Vokabular für jedes Thema k
Benutze Erwartungswerte des Posteriors für
verschiedene Anwendungen
25

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
, , , | ,, , | , ,
, , , | ,Z
P Z WP Z W
P Z W d d
Posterior-Inferenz
Berechnung der Posterior-Verteilung zu schwierig:
Daher: Approximative Posterior-Inferenz
Mehrere Möglichkeiten:
Mean-field-variational-Methoden
Expectation propagation
Collapsed variational inference
Gibbs-Sampling
einfachstes Verfahren
26

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling
Echte Posteriorverteilung zu
schwierig
Gibbs-Sampling produziert I Samples aus der
echten Verteilung
Idee: Posterior für einzelne Zufallsvariablen ist
leicht zu berechnen, z.B.
nacheinander jede Zufallsvariable neu aus ihrem
Posterior gegeben alle anderen Variablen ziehen
27
1 1 1, , , , , , , , | , ,I I IZ Z P Z W

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling
Ein MCMC (Markov-Chain-Monte-Carlo) -
Algorithmus
Neuziehen von einzelnen Variablen entspricht
Zustandsübergang
Zustand = komplette Belegung von allen Variablen
Iteratives neu ziehen ist Random Walk auf dem
Zustandsgraphen
28

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling
Häufigkeiten des Besuchs von Zuständen
entspricht Verteilung über die Belegungen der
Zufallsvariablen
29

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling
Theorem: Wenn man sich lange genug auf dem
Zustandsgraphen bewegt, und die
Zustandsübergänge aus den Einzel-Posteriors
zieht, konvergieren die Besuchshäufigkeiten zur
Gesamt-Posterior-Verteilung.
Bemerkung: Der Startpunkt ist spielt keine Rolle.
30

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling
Um Samples
aus dem Gesamtposterior zu erhalten:
mit beliebigem Startwert beginnen, und samplen, bis
die Verteilung konvergiert
zwischen dem Entnehmen einzelner Samples viele
Sampleschritte durchführen, damit die Samples
voneinander unabhängig sind
31
1 1 1, , , , , , , , | , ,I I IZ Z P Z W

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Gibbs-Sampling: Algorithmus
Für i von 1 bis I
Für j von 1 bis 1000
Für alle Themen k:
• Ziehe
Für alle Dokumente d:
• Ziehe
• Für alle Wörter n in Dokument d:
– Ziehe
Gib Posterior-Sample aus.
32
z.B.

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Collapsed Gibbs-Sampling
Bei normalem Gibbs-Sampling: sehr viele
Iterationen notwendig
Verbesserung: nur Z samplen, und
rausintegrieren
Idee dahinter: kleinerer Zustandsgraph, da Zustand
nur noch aus Z besteht
Statt :
33
, , ,
, , ,
| , , ,
| , , , , , , | , , ,
d n d n d n
d n d n d n
z P z Z W
P z Z W P Z W d d
, , ,| , , , , ,d n d n d nz P z Z W

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Collapsed Gibbs-Sampling
34
, , ,
1 1 1 1
, , , | ,
| | | | ,N D D N
k d d n d d n d n
k d d n
P Z W
P P P Z P W Z
, ,
, , ,
, ,
, , , , , , ,
, , , , , , ,
, ,
, , , ,
| , , ,
, , | , , | ,
, , | ,
| , , , , , , | ,
| , , , , | , , ,
, | ,
| , ,
d n d n
d n d n d n
d n d n
d n d n d n d n d n d n d n
d n d n d n d n d n d n d n
d n d n
d n d n d n d
P z Z W
P z Z W P Z W
P z Z W
P w z Z W P z Z W
P w z Z W P z Z W
P Z W
P w z Z W
, , ,
, , , , , ,
, , | , , ,
| , , , | ,
n d n d n d n
d n d n d n d n d n d n
P z Z W
P w z Z W P z Z
Produktregel
Zähler
Produktregel
Produktregel
Letzten Faktor
ignorieren
Bedingte
Unabhängigkeit

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
, , , ,
, , ,
,
| , , ,
| , | ,
Dir | counts ,
counts ,
counts
z
z
d n d n d n d n
d n d n z z d n z
z w z z
P w w z z Z W
P w w z z P W d
z d
z w
z V
Collapsed Gibbs-Sampling
Erwartungswert
Dirichlet
35
1. Term („Likelihood“):
Zähler, wie oft Wort w Thema z zugewiesen ist (ohne wd,n)
Größe des Vokabulars
, , ,
1 1 1 1
, , , | ,
| | | | ,N D D N
k d d n d d n d n
k d d n
P Z W
P P P Z P W Z
Zähler, wie viele Wörter Thema z zugewiesen sind (ohne wd,n)
Randverteilung,
Produktregel,
Unabhängigkeit
Definitionen

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Collapsed Gibbs-Sampling
36
2. Term („Prior“):
Zähler, wie viele Wörter in d Thema z zugewiesen sind (ohne wd,n)
Anzahl der Wörter in d (ohne wd,n)
Anzahl der Themen
, , ,
1 1 1 1
, , , | ,
| | | | ,N D D N
k d d n d d n d n
k d d n
P Z W
P P P Z P W Z
Erwartungswert
Dirichlet
Randverteilung,
Produktregel,
Unabhängigkeit
Definitionen

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Collapsed Gibbs-Sampling
37
Effizient implementierbar
Man muss sich immer nur die 4 verschiedenen
Typen von Zählern merken
Bei Bedarf lassen sich zusätzlich Samples für und
generieren
Einfach aus Posterior oder
ziehen
Kleinerer Zustandsgraph schnelleres Einpendeln
auf richtige Verteilung
| ,zP W | ,dP Z

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Anwendung (Eingangsbeispiel)
38
|zE W |dE W
, |d nE z z W
Ähnlichkeit der Themen
(nächste Folie)

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Anwendung (Ähnlichkeit von Dokumenten)
Berechnung der Ähnlichkeit zweier Dokumente als
inneres Produkt der Themenverteilungen
39
Bayesian Model Averaging
Ersetzen des Integrals über die Posterior-Verteilung
durch Summe über Gibbs-Samples aus dem Posterior

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Erweiterung (Entwicklung von Themen über die Zeit)
40
Variablen verändern sich über Zeit t=1,…,
,z t

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Erweiterung (Zusammenhänge zwischen Themen)
41
Darstellung von:
den 5 häufigsten Wörtern pro Thema,
der Häufigkeit des Themas im Corkus (Schriftgröße)
Covarianz der Themen (Graph)

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Fragen?
42

Scheffe
r/Vanck: S
pra
chte
chnolo
gie
S
cheffe
r/Haid
er/P
rasse
: Spra
chte
chnolo
gie
Acknowledgements
Folien basieren teilweise auf Tutorial von David
Blei, Machine Learning Summer School 2009
43















![Vorlesung 5a Varianz und Kovarianz - math.uni-frankfurt.deismi/wakolbinger/teaching/EleSto17/... · Statt Var[X]schreiben wir auch VarX oder σ2 X oder (wenn klar ist, welche Zufallsvariable](https://static.fdokument.com/doc/165x107/5d55a09588c993f8298b4aae/vorlesung-5a-varianz-und-kovarianz-mathuni-ismiwakolbingerteachingelesto17.jpg)

