Mathematik fur...
36
Mathematik f¨ ur Wirtschaftswissenschaftler Vorlesungsprogramm f¨ ur den 05. 06. 2007 (K. Steffen, Heinrich-Heine-Universit¨ at D¨ usseldorf, SS 2007) BEISPIELE (Anwendung der Kriterien zweiter Ordnung): (1) Wir betrachten die Funktionen von zwei Variablen f (x, y) = x 2 + y 2 - xy +2x - 2y g(x, y) = x 2 + y 2 - 3xy +2x - 2y h(x, y) = x 2 + y 2 - 2xy +2x - 2y Berechnung der kritischen Punkte: ∇f (x, y) = (2x - y +2, 2y - x - 2) = (0, 0) ⇐⇒ (x, y)=(- 2 3 , 2 3 ) , ∇g(x, y) = (2x - 3y +2, 2y - 3x - 2) = (0, 0) ⇐⇒ (x, y)=(- 2 5 , 2 5 ) , ∇h(x, y) = (2x - 2y +2, 2x - 2x - 2) = (0, 0) ⇐⇒ (x, y)=(x, x + 1) (x ∈ R). Die Hesse–Matrix ist f¨ ur alle drei Funktionen konstant auf R 2 , da es sich um Polynom- funktionen vom Grad 2 handelt, und zwar: ∂ 2 f ∂ (x, y) ≡ 2 -1 -1 2 , ∂ 2 g ∂ (x, y) ≡ 2 -3 -3 2 , ∂ 2 h ∂ (x, y) ≡ 2 -2 -2 2 . Die Hesse–Matrix von f ist positiv definit (nach dem Minorenkriterium, da die Dia- gonaleintr¨ age positiv sind und auch die Determinante den positiven Wert 3 hat), also liegt in dem kritischen Punkt (- 2 3 , 2 3 ) eine lokale strikte Minimumstelle vor. Tats¨ achlich ist dieser Punkt sogar die eindeutige Minimumstelle von f auf ganz R 2 , wie man an der Tatsache erkennt, dass f (x, y)= 1 2 x 2 + 1 2 y 2 + 1 2 (x - y) 2 +2x - 2y →∞ geht bei |(x, y)| → ∞, so dass f ein Minimum annimmt auf R 2 , was nur in dem einzigen kri- tischen Punkt passieren kann. Man bekommt also mit dem Ableitungskriterium erster Ordnung und der ¨ Uberlegung bzgl. der Existenz hier viel mehr Information als mit dem Kriterium zweiter Ordnung. (Oder schreibe die Funktion mit quadratischer Erg¨ anzung f (x, y)= 1 2 (x + 2 3 ) 2 + 1 2 (y - 2 3 ) 2 + 1 2 (x - y + 4 3 ) 2 - 4 3 , um das ganz ohne Differentialrech- nung zu sehen.) Die Hesse–Matrix von g ist indefinit, weil sie negative Determinante -5 < 0 hat (und weil die Determinante einer positiv oder negativ semidefiniten 2 ×2–Matrix ≥ 0 ist). Also liegt in dem einzigen kritischen Punkt keine lokale Extremstelle vor, sondern ein Sattelpunkt. Aus der Tatsache, dass g(x, x)= -x 2 beliebige negative Werte und g(x, -x)=4x 2 +4x beliebige positive Werte annimmt, kann man von vorneherein erkennen, dass der einzige kritische Punkt keine absolute Extremstelle auf R 2 sein kann. Das Kriterium zweiter Ordnung zeigt hier immerhin, dass es sich auch nicht um eine lokae Extremstelle handelt. Die Hesse–Matrix von h hat positive Diagonaleintr¨ age und Determinante = 0, ist also positiv semidefinit. Daraus kann man ¨ uber die Natur der kritischen Punkte (x, x + 1) gar nichts schließen. Quadratische Erg¨ anzung h(x, y)=(x - y + 1) 2 - 1 zeigt hier, dass alle kritischen Punkte tats¨ achlich absolute Minimumstellen sind, aber keine davon eine strikte lokale Minimumstelle, weil die absoluten Minimumstellen eine Gerade y = x + 1 bilden. 653
Transcript of Mathematik fur...

Mathematik fur Wirtschaftswissenschaftler
Vorlesungsprogramm fur den 05. 06. 2007
(K. Steffen, Heinrich-Heine-Universitat Dusseldorf, SS 2007)
BEISPIELE (Anwendung der Kriterien zweiter Ordnung):
(1) Wir betrachten die Funktionen von zwei Variablen
f(x, y) = x2 + y2 − xy + 2x− 2y
g(x, y) = x2 + y2 − 3xy + 2x− 2y
h(x, y) = x2 + y2 − 2xy + 2x− 2y
Berechnung der kritischen Punkte:
∇f(x, y) = (2x− y + 2, 2y − x− 2) = (0, 0) ⇐⇒ (x, y) = (−23, 2
3) ,
∇g(x, y) = (2x− 3y + 2, 2y − 3x− 2) = (0, 0) ⇐⇒ (x, y) = (−25, 2
5) ,
∇h(x, y) = (2x− 2y + 2, 2x− 2x− 2) = (0, 0) ⇐⇒ (x, y) = (x, x + 1) (x ∈ R).
Die Hesse–Matrix ist fur alle drei Funktionen konstant auf R2, da es sich um Polynom-funktionen vom Grad 2 handelt, und zwar:(
∂2f∂(x, y)
)≡(
2 −1−1 2
),
(∂2g
∂(x, y)
)≡(
2 −3−3 2
),
(∂2h
∂(x, y)
)≡(
2 −2−2 2
).
Die Hesse–Matrix von f ist positiv definit (nach dem Minorenkriterium, da die Dia-gonaleintrage positiv sind und auch die Determinante den positiven Wert 3 hat), alsoliegt in dem kritischen Punkt (−2
3, 2
3) eine lokale strikte Minimumstelle vor. Tatsachlich
ist dieser Punkt sogar die eindeutige Minimumstelle von f auf ganz R2, wie man ander Tatsache erkennt, dass f(x, y) = 1
2x2 + 1
2y2 + 1
2(x− y)2 + 2x − 2y → ∞ geht bei
|(x, y)|→∞, so dass f ein Minimum annimmt auf R2, was nur in dem einzigen kri-tischen Punkt passieren kann. Man bekommt also mit dem Ableitungskriterium ersterOrdnung und der Uberlegung bzgl. der Existenz hier viel mehr Information als mit demKriterium zweiter Ordnung. (Oder schreibe die Funktion mit quadratischer Erganzungf(x, y) = 1
2(x + 2
3)2 + 1
2(y− 2
3)2 + 1
2(x− y + 4
3)2 − 4
3, um das ganz ohne Differentialrech-
nung zu sehen.)
Die Hesse–Matrix von g ist indefinit, weil sie negative Determinante −5 < 0 hat (und weildie Determinante einer positiv oder negativ semidefiniten 2×2–Matrix ≥ 0 ist). Also liegtin dem einzigen kritischen Punkt keine lokale Extremstelle vor, sondern ein Sattelpunkt.Aus der Tatsache, dass g(x, x) = −x2 beliebige negative Werte und g(x,−x) = 4x2 + 4xbeliebige positive Werte annimmt, kann man von vorneherein erkennen, dass der einzigekritische Punkt keine absolute Extremstelle auf R2 sein kann. Das Kriterium zweiterOrdnung zeigt hier immerhin, dass es sich auch nicht um eine lokae Extremstelle handelt.
Die Hesse–Matrix von h hat positive Diagonaleintrage und Determinante = 0, ist alsopositiv semidefinit. Daraus kann man uber die Natur der kritischen Punkte (x, x + 1) garnichts schließen. Quadratische Erganzung h(x, y) = (x− y + 1)2 − 1 zeigt hier, dass allekritischen Punkte tatsachlich absolute Minimumstellen sind, aber keine davon eine striktelokale Minimumstelle, weil die absoluten Minimumstellen eine Gerade y = x + 1 bilden.
653

654 Mathematik fur Wirtschaftswissenschaftler
(2) Bei Funktionen f(x, y) von zwei Veranderlichen ist die Uberprufung der Definitheits-eigenschaften der Hesse–Matrix besonders einfach, wie wir in (1) schon gesehen haben:
Die Hesse–Matrix
(∂2f
∂(x, y)
)ist
positiv definit, genau wo∂2f∂x2 > 0 und
∂2f∂x2
∂2f∂y2 −
(∂2f∂x∂y
)2
> 0 ,
negativ definit, genau wo∂2f∂x2 < 0 und
∂2f∂x2
∂2f∂y2 −
(∂2f∂x∂y
)2
> 0 ,
positiv semidefinit, genau wo∂2f∂x2 ≥ 0,
∂2f∂y2 ≥ 0 und
∂2f∂x2
∂2f∂y2 −
(∂2f∂x∂y
)2
≥ 0 ,
negativ semidefinit, genau wo∂2f∂x2 ≤ 0,
∂2f∂y2 ≤ 0 und
∂2f∂x2
∂2f∂y2 −
(∂2f∂x∂y
)2
≥ 0 ,
indefinit, genau wo∂2f∂x2
∂2f∂y2 −
(∂2f∂x∂y
)2
< 0 .
Man beachte die Vorzeichenbedingungen an die Determinante: Sie ist, weil es sich hierum 2× 2–Matrizen handelt, auch bei einer negativ definiten Matrix positiv (!) und auchbei einer negativ semidefiniten Matrix nichtnegativ (!).
(3) Bei allgemeinen quadratischen Funktionen von n Variablen,
f(x) = 12x rAx + b rx + c = 1
2
n∑i,j=1
aijxixj +n∑
j=1
bjxj + c ,
ist die Hesse–Matrix konstant gleich der symmetrischen Koeffizientenmatrix A = (aij),(∂2f
∂xi∂xj(x)
)i,j=1...n
= (aij)i,j=1...n= A fur alle x ∈ Rn.
(Und wenn man A = (aij) nicht symmetrisch gewahlt hat, so ist die Hesse–Matrixkonstant gleich der Symmetrisierung 1
2(aij+ aji) .) Also kann die quadratische Funkti-
on hochstens dann Minimumstellen auf Rn haben, wenn die Koeffizientenmatrix (aij)positiv semidefinit ist. Außerdem sagt uns das hinreichende Kriterium zweiter Ordnungnoch, dass jeder kritische Punkt eine lokale strikte Minimumstelle ist, wenn die Matrix(aij) sogar positiv definit ist. (Aus der fruheren Diskussion der Extremstellen quadrati-scher Funktionen auf Rn in 5.5 wissen wir aber mehr: Im positiv definiten Fall gibt esgenau einen kritischen Punkt und der ist eindeutige absolute Minimumstelle von f aufRn.) Schließlich folgt aus dem Kriterium zweiter Ordnung noch, dass jeder kritische Punktvon f (sofern es welche gibt) ein Sattelpunkt sein muss, wenn (aij) indefinit ist.
BEMERKUNG und BEISPIEL: Es gibt auch Kriterien zweiter Ordnung furExtrema bei Nebenbedingungen (sowohl notwendige Kriterien als auch hinreichendeKriterien). Diese sind jedoch relativ kompliziert und nicht von großer praktischer Be-deutung. (Man findet sie z.B. bei Rommelfanger, Bd.2, §§ 7.3, 7.4.) Die hinreichendenKriterien liefern, wenn sie anwendbar sind, auch hier nur die Information, dass in ei-nem Extremstellenkandidaten x0 ein striktes lokales Extremum vorliegt im Vergleich mitden Funktionswerten an allen anderen den Nebenbedingungen genugenden Punkten einer(kleinen) Umgebung. Wenn man absolute Extrema bei Nebenbedingungen sucht, so istdiese Information praktisch wertlos, weil die Große der Umgebung nicht spezifiziert wird.

Kap. 5, Abschnitt 5.6 655
Warnung : Es ist nicht richtig, dass positive Definitheit der Hesse–Matrix(
∂2f∂x2 (x0)
)der Zielfunktion in einem Kandidaten x0 fur Extremstellen bei den Nebenbedingungeng1(x) = c1, . . . , gl(x) = cl, also an einer den Nebenbedingungen genugenden Stelle x0
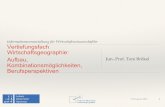
linearer Abhangigkeit der Gradienten ∇f(x0), ∇g1(x0), . . . ,∇gl(x0), schon die strikte lo-kale Minmalitat von x0 bei den Nebenbedingungen zur Folge hat. Dies zeigt das Bei-
spiel der Zielfunktion f(x, y) = 12(x2 + y2), bei
der Nebenbedingung g(x, y) = 2x2+y = 1, d.h.der (halbe quadrierte) Abstand zum Ursprungist auf der Parabel y = −2x2+1 zu optimieren.
Hier sind (x0, y0) = (0, 1) und (±√
38, 1
4) die
Stellen linearer Abhangigkeit von ∇f(x, y) =(x, y) und ∇g(x, y) = (4x, 1) auf der Parabel.Die Hesse–Matrix von f ist konstant gleich der2×2–Einheits–Matrix, also uberall positiv de-finit. Aber der Kandidat (0, 1) ist keine loka-le Minimumstelle von f auf der Parabel, son-dern vielmehr eine lokale strikte Maximumstel-le! (Die beiden anderen Kandidaten sind abso-lute Minimumstellen von f auf der Parabel.)
-x
6y
s(0, 1)
s(0, 0)
f ≡ 1
g ≡ 1
s s
Man sieht an diesem Beispiel, dass die Ableitungskriterien zweiter Ordnung bei Nebenbe-dingungen auch von zweiten Ableitungen der Funktionen gh abhangen mussen, welche dieNebenbedingungen definieren. Ein einfaches, aber selten anwendbares, hinreichendes Kri-terium zweiter Ordnung in diesem Sinne ist folgendes: Ist x0 ∈ Rn kritischer Punkt einerLagrange–Funktion L(x) = f(x)−λ1g1(x)− . . .−λlgl(x) mit gh(x0) = ch fur h = 1 . . . lund ist die Hesse–Matrix von L an der Stelle x0 positiv definit, so hat L eine lokalestrikte Minimumstelle in x0 relativ zu Rn, und dann ist offenbar erst recht x0 eine lokalestrikte Minimumstelle von f bei den Nebenbedingungen, weil ja λ1g1(x) + . . . + λlgl(x)konstant gleich λ1c1 + . . . + λlcl ist fur alle x, welche die Nebenbedingungen erfullen.Auch mit der Parametrisierungsmethode kann man Kriterien zweiter Ordnung erhalten:Wenn h : Rm ⊃ P → S ⊂ Rn mit h(ξ0) = x0 eine volle Umgebung S∩Uδ(x0) von x0 inS auf dem offenen Parameterbereich P in Rm bijektiv und stetig parametrisiert, so istx0 genau dann lokale (strikte) Minimum– bzw. Maximumstelle von f auf S ⊂ Rn, wennξ0 lokale (strikte) Minimum– bzw. Maximumstelle der Verkettung f ◦ h auf dem offenenParameterbereich P ⊂ Rm ist. Daher kann man die Kriterien zweiter Ordnung fur innereExtremstellen auf die Funktion f ◦h an der Stelle ξ0 anwenden und damit gegebenenfallsentscheiden, ob x0 = h(ξ0) lokale Extremstelle von f auf S ist oder nicht.
Die Hesse–Form bzw. die Hesse–Matrix einer reellen Funktion von mehreren Veranderli-chen stehen in engem Zusammenhang mit Konvexitat. Diese wird fur Funktionen f vonmehreren Variablen einfach dadurch erklart, dass f auf jeder Strecke im (konvexen) De-finitionsbereich eine konvexe Funktion einer einzigen Variablen ist. (Siehe 4.2 unf 4.6 fureine Diskussion konvexer Funktionen von einer Veranderlichen.)
Fur die folgende Definition erinnern wir daran, dass eine Teilmenge D von Rn konvexeMenge in Rn heißt, wenn mit je zwei Punkten x, x ∈ D auch ihre Verbindungsstrecke[x, x] = {(1−t)x + tx : 0 ≤ t ≤ 1} ganz in D enthalten ist.

656 Mathematik fur Wirtschaftswissenschaftler
DEFINITION: Eine skalare Funktion f : Rn ⊃ D → R heißt (streng) konvexeFunktion, wenn D eine konvexe Menge ist und wenn f auf jeder Strecke [x, x] ⊂ Dals Funktion von einer Variablen aufgefasst eine (streng) konvexe Funktion ist, wenn alsodie Konvexitatsungleichung gilt
f((1−t)x + tx) ≤ (1−t)f(x) + tf(x) fur alle x, x ∈ D, 0 ≤ t ≤ 1
(mit Gleichheit im streng konvexen Fall nur fur x = x oder t = 0 oder t = 1 ). DieFunktion f heißt (streng) konkave Funktion auf D, wenn ihr Negatives −f strengkonvex ist.
SATZ (uber konvexe Funktionen): Ist D ⊂ Rn offen und konvex und hat f : D → Rstetige partielle Ableitungen erster (bei (ii) und (ii’) ) bzw. zweiter (bei (iii) und (iii’) )Ordnung, so sind aquivalent:
(i) f ist konvexe Funktion auf D ;
(ii) f ist auf D nicht kleiner als seine affin linearen Approximationen, d.h.
f(x) ≥ f(x) + (x− x) r∇f(x) fur alle x, x ∈ D ;
(iii) die Hesse–Form bzw. die Hesse–Matrix ist uberall positiv semidefinit auf D, also
∂2uf(x) = u r(∂2f
∂x2 (x)
)u ≥ 0 fur alle x ∈ D, u ∈ Rn.
Außerdem folgen aus
(iii’) die Hesse–Matrix ist uberall positiv definit auf D, also
∂2uf(x) = u r(∂2f
∂x2 (x)
)u > 0 fur alle x ∈ D, 0 6= u ∈ Rn;
die zueinander aquivalenten Bedingungen:
(ii’) f ist auf D echt großer als seine affin linearen Approximationen, d.h.
f(x) > f(x) + (x− x) r∇f(x) fur alle x 6= x in D ;
(i’) f ist streng konvexe Funktion auf D .
Der Beweis ergibt sich aus dem entsprechenden Satz fur Funktionen ϕ(t) von einer reel-len Veranderlichen t in 4.6. Danach ist ϕ (streng) konvex, genaus wenn ϕ(t) ≥
(>)
ϕ(t0)+
(t − t0)ϕ′(t0) ist fur alle t 6= t0 im Definitionsintervall bzw. wenn ϕ′′(t) ≥ 0 ist fur alle
t (und dabei auf keinem Intervall positiver Lange Gleichheit eintritt). Das wendet manan auf ϕ(t) = f(x + tu) mit ϕ′(t) = u q∇f(x + tu) und ϕ′′(t) = ∂2
uf(x + tu) und erhaltsofort die Aussagen des obigen Satzes (mit der Wahl u = x− x bei (ii) und (ii’) ).
BEMERKUNGEN: (1) Die Bedeutung der Charakterisierung (ii) konvexer Funktio-nen f besteht darin, dass man bei Linearisierung um eine Stelle x das Vorzeichen desLinearisierungsfehlers f(x + v)− f(x)− v q∇f(x) ≥ 0 kennt; der Linearisierungsfeh-ler ist nie negativ, weil die Linearisierungen eben die Funktionswerte unterschatzen. Beikonkaven Funktionen uberschatzen die Linearisierungen dagegen stets die Funktionswerte.

Kap. 5, Abschnitt 5.6 657
Geometrisch bedeutet die Aussage (ii’), dass der Graph von streng konvexen Funktio-nen uber seinen Tangentialraumen verlauft — abgesehen vom jeweiligen Beruhrpunktnaturlich. Streng konkave Funktionen sind dagegen dadurch gekennzeichnet, dass ihrGraph unterhalb aller Tangentialraume liegt.
(2) Die Bedingung (iii’) der positiven Definitheit der Hesse–Matrix an allen Stellen des of-fenen und konvexen Definitionsbereichs, konnte man definite Konvexitat nennen. DieseBedingung ist starker als strenge Konvexitat, weil die Hesse-Matrix von streng konvexenFunktionen durchaus an einzelnen Stellen einen oder sogar alle Eigenwerte Null habenkann, wie z.B. f(x) = |x|4 = (x 2
1 +. . .+x 2n)2 im Ursprung x = 0. Eine konvexe Funktion f
ist genau dann streng konvex, wenn sie auf keiner Strecke positiver Lange im Definitions-bereich D affin linear ist, d.h. wenn fur kein 0 6= u ∈ R die zweite Richtungsableitung∂2
uf auf einer Strecke positiver Lange mit Richtung u verschwindet. Fur Konkavitat gel-ten analoge Aussagen; insbesondere ist definite Konkavitat, d.h. negative Definitheitder Hesse–Matrix an allen Stellen des offenen und konvexen Definitionsbereichs, eine et-was starkere Eigenschaft als strenge Konkavitat.
BEISPIELE: (1) Wir betrachten nochmal die Funktionen von zwei Variablen
f(x, y) = x2 + y2 − xy + 2x− 2y
g(x, y) = x2 + y2 − 3xy + 2x− 2y
h(x, y) = x2 + y2 − 2xy + 2x− 2y
Die Hesse–Matrizen haben wir in der letzten Beispielserie schon berechnet. Sie sind furalle drei Funktionen konstant auf R2, da es sich um Polynomfunktionen vom Grad 2handelt, und zwar:(
∂2f∂(x, y)
)≡(
2 −1−1 2
),
(∂2g
∂(x, y)
)≡(
2 −3−3 2
),
(∂2h
∂(x, y)
)≡(
2 −2−2 2
).
Die Hesse–Matrix von f ist positiv definit, also ist f streng konvexe Funktion auf R2
(sogar definit konvex). Die Hesse–Matrix von g ist indefinit, also ist g weder konvexnoch konkav auf irgendeiner offenen, konvexen Menge in R2. Die Hesse–Matrix von hschließlich ist positiv semidefinit und nicht Null, also ist h konvexe Funktion auf R3. DieRichtung u = 1√
2(1, 1) ist ein Eigenvektor der Hesse–Matrix von h zum Eigenwert Null
(an jeder Stelle, weil die Hesse–Matrix ja konstant ist). Daher ist ∂2uh ≡ 0 auf R2, d.h.
h ist auf jeder Geraden mit Richtung u affin linear (sogar konstant, weil auch ∂uh ≡ 0ist) und somit auf keiner offenen konvexen Menge eine streng konvexe Funktion.
(2) Bei allgemeinen quadratischen Funktionen von n Variablen,
f(x) = 12x rAx + b rx + c = 1
2
n∑i,j=1
aijxixj +n∑
j=1
bjxj + c ,
ist, wie schon gesehen, die Hesse–Matrix konstant gleich der symmetrischen Koeffizien-tenmatrix A = (aij). Daher ist eine solche Funktion genau dann konvex (bzw. konkav),wenn die Koeffizientenmatrix A positiv semidefinit ist (bzw. negativ semidefinit). HatA einen Eigenvektor u zum Eigenwert 0, so gilt 0 = u qAu = ∂2
uf(x) an allen Stellenx ∈ Rn, also ist dann f affin linear auf allen Geraden in Richtung u und deshalb aufkeiner offenen, konvexen Menge streng konvex oder streng konkav. Somit sind fur qua-dratische Funktionen f strenge Konvexitat und definite Konvexitat aquivalent, d.h. fist genau dann streng konvexe Funktion auf Rn, wenn die Koeffizientenmatrix A positivdefinit ist (und genau dann streng konkav, wenn A negativ definit ist).

658 Mathematik fur Wirtschaftswissenschaftler
(3) Wir untersuchen Potenzen der Euklidischen Normfunktion x (Abstand zum Ur-sprung)
|x|s =(x 2
1 + x 22 + . . . + x 2
n
)s/2
bezuglich Konvexitat /Konkavitat auf Rn bei Dimensionen n ≥ 2. Fur 0 6= x ∈ Rn ist∂|x|s∂xj
= s2(|x|2)s/2−12xj = sxj|x|s−2 und weitere Differentiation gibt
∂2|x|s∂xi∂xj
= s(s− 2)|x|s−4xixj fur i 6= j und∂2|x|s∂x2
j
= s(s− 2)|x|s−4x 2j + s|x|s−2 .
Fur u = (u1, . . . , un) ∈ Rn folgt
u r(∂2|x|2∂x2
)u =
n∑i,j=1
ui∂2|x|s∂xi∂xj
uj = s|x|s−2
n∑j=1
u 2j + s(s− 2)|x|s−4
n∑i,j=1
uixixjuj
= s|x|s−2|u|2+ s(s−2)|x|s−4
(n∑
j=1
ujxj
)2
= s|x|s−4[|x|2|u|2+ (s−2)(x ru)2
].
Das Ergebnis ist offenbar positiv fur alle x 6= 0 und u 6= 0, wenn s ≥ 2 ist, aber auchfur 1 < s < 2 wegen der Cauchy–Schwarz–Ungleichung |x q u| ≤ |x||u| (siehe 3.5 und5.2). Aus dem obigen Konvexitatssatz folgt damit, dass |x|s fur s > 1 streng konvex istauf jeder Geraden in Rn, die nicht durch den Ursprung geht. Auf Ursprungsgeraden Ruaber ist |x|s fur s > 1 ebenfalls streng konvex, weil d
dt|tu|s = d|t|s
dt|u| = s|t|s−1 sign(t)|u|
streng wachsend bzgl. t ∈ R ist, also ist |x|s fur s > 1 streng konvex auf ganz Rn. Furs = 1 zeigen dieselben Uberlegungen oder direkt die Dreiecksungleichung |(1−t)x+ tx| ≤(1−t)|x| + t|x| fur 0 ≤ t ≤ 1 noch Konvexitat der Normfunktion auf Rn; aber aufUrsprungsstrahlen R≥0u ist nun |tu| = t|u| linear, also ist die Konvexitat nicht mehrstreng. (Da in der Cauchy–Schwarz–Ungleichung Gleichheit |x qu| = |x||u| nur bei linearerAbhangigkeit von x und u eintritt, sind die Strecken auf Ursprungsgeraden auch dieeinzigen Strecken, auf denen die Normfunktion nicht streng konvex ist.) Fur 0 < s < 1schließlich ist die Hesse–Matrix an allen Stellen x 6= 0 indefinit; denn wahlt man u 6= 0
orthogonal zu x, also mit x qu = 0, so ist u q (∂2|x|s∂x2 )u = s|x|s−2|u|2 > 0, und fur u = x
ist andererseits u q (∂2|x|s∂x2 )u = s(s− 1)|x|s < 0. Dasselbe Resultat, nur mit umgekehrten
Vorzeichen, ergibt sich fur s < 0. Im Sonderfall s = 0 ist |x|s naturlich konstant gleich1 auf Rn (nach stetiger Erganzung auch im Nullpunkt) und damit konvex und konkav.
• Die Potenz |x|s der Euklidischen Normfunktion ist streng konvex auf Rn fur s > 1,
• konvex, aber nicht streng konvex, fur s = 1 und
• auf keiner offenen, konvexen Teilmenge von Rn konvex oder konkav fur 0 6= s < 1.
(4) Wir untersuchen eine Cobb–Douglas–Funktion
f(x) = c x s11 x s2
2 · . . . · xsnn (c, s1, s2, . . . , sn ∈ R>0)
bzgl. Konvexitat / Konkavitat auf Rn≥0. Notwendig fur Konvexitat bzw. Konkavitat ist,
dass f(x) als Funktion von jeder einzelnen Variablen xj konvex bzw. konkav ist. Daes sich hierbei um ein Vielfaches der Potenzfunktion x
sj
j handelt, ist also Konvexitatnur moglich, wenn alle Exponenten sj ≥ 1 sind und Konkavitat nur, wenn 0 < sj ≤ 1ist fur alle j. Eine starkere Einschrankung erhalten wir noch aus der Betrachtung der

Kap. 5, Abschnitt 5.6 659
Funktion auf Ursprungsstrahlen R>0u. Da f(tu) = tsf(u) ist mit der Exponentensummes = s1 + . . . + sn, muss sogar die Exponentensumme s ≤ 1 sein, wenn f konkav ist, weilR>0 3 t 7→ ts nur fur 0 < s ≤ 1 konkav ist. Betrachten wir f auf einer Strecke von einemRandpunkt x von Rn
≥0 etwa mit xi = 0 zu einem anderen Randpunkt x mit xj = 0,derart dass x und x keine gemeinsamen Nullkomponenten haben, so hat die Funktionf((1−t)x + tx) positive Werte fur 0 < t < 1 und Randwerte 0 fur t = 0 oder t = 1,also ist dies gewiss keine konvexe Funktion von t ∈ [0, 1]. Somit ist eine Cobb–Douglas–Funktion fur keine Wahl der Exponenten sj konvex auf Rn
≥0 (mit n ≥ 2).
Um f auf Konkavitat im Fall 0 < s ≤ 1 zu prufen, berechnen wir die Hesse–Matrix anStelle x ∈ Rn
>0:
∂f∂xj
(x) =sj
xjf(x) ,
∂2f∂xi∂xj
(x) =sisj
xixjf(x) fur i 6= j ,
∂2f∂x2
i
(x) =s2
j
x 2j
f(x)− sj
x 2j
f(x) .
Fur u ∈ Rn folgt:
u r(∂2f∂x2 (x)
)u = f(x)
n∑i,j=1
uiujsisj
xixj− f(x)
n∑j=1
sju2j
x 2j
= f(x)
( n∑j=1
sjuj
xj
) 2
−n∑
j=1
sju2j
x 2j
= f(x)[(s rv)2 − |v|2
],
wobei wir s = (√
s1, . . . ,√
sn) und v = (√
s1u1
x1, . . . ,
√sn
un
xn) gesetzt haben. Die Cauchy–
Schwarz–Ungleichung garantiert nun (s qv)2 ≤ |s|2|v|2 mit |s|2 = s1 + . . . + sn = s, und
weil v 6= 0 ist fur u 6= 0 folgt u q(∂2f∂x2 (x))u < 0 fur alle u 6= 0 im Fall 0 < s < 1, d.h. die
Hesse–Matrix ist dann negativ definit uberall auf Rn>0 und die Cobb–Douglas–Funktion
dort somit streng konkav. Im Fall s = 1 erhalten wir immer noch negative Semidefinitheit,jedoch u q(∂2f
∂x2 (x))u = 0, genau wenn s und v linear abhangig sind, was genau bei linearerAbhangigkeit von u und x eintritt. In diesem Fall s = 1 ist die Funktion f(tx) = tf(x)ja auch linear auf jedem Ursprungsstrahl. Im Fall s > 1 ist die Hesse–Matrix an allenStellen x ∈ Rn
>0 indefinit; denn bei der Wahl u = x ist u q (∂2f∂x2 (x))u = f(x)[s2 − s] > 0,
bei der Wahl 0 6= u ⊥ ( s1
x1, . . . , sn
xn) dagegen ist u q (∂2f
∂x2 (x))u = −f(x)|v|2 < 0. Wegender Stetigkeit von f auf Rn
≥0 ubertragt sich die (strenge) Konkavitat von Rn>0 auf den
Abschluss Rn≥0, und wir konnen als Ergebnis der Diskussion festhalten:
• Eine Cobb-Douglas–Funktion ist streng konkav auf Rn≥0, genau wenn die Exponen-
tensumme s = s1 + . . . + sn < 1 ist;
• im Fall s = 1 ist die Cobb–Douglas–Funktion noch konkav auf Rn≥0, jedoch nicht
streng konkav;
• im Fall s > 1 ist die Cobb–Douglas–Funktion auf keiner offenen, konvexen Mengein Rn
>0 konkav oder konvex.
Die Untersuchung konvexer Funktionen f auf innere Extremstellen ist besonders ein-fach: Jeder kritische Punkt x0 ist automatisch absolute Minimumstelle von f auf demkonvexen Definitionsbereich D ⊂ Rn. Das folgt unmittelbar aus der Tatsache, dass einekonvexe Funktion oberhalb ihrer Linearisierungen liegt, also aus der Ungleichung f(x) ≥f(x0)+(x−x0) q∇f(x0) zusammen mit ∇f(x0) = 0. (Die Ungleichung f(x) ≥ f(x0) gilt

660 Mathematik fur Wirtschaftswissenschaftler
auch noch, wenn x oder x0 ein Randpunkt von D ist; denn aus der Konvexitatsunglei-chung f((1−t)x0 + tx) − f(x0) ≤ t(f(x) − f(x0)) folgt durch Differentiation bei t = 0,wenn x0 kritischer Punkt ist, 0 = (x−x0) q∇f(x0) ≤ f(x)−f(x0).) Aus der Konvexitats-ungleichung f((1−t)x + tx) ≤ (1−t)f(x) + tf(x) ≤ (1−t)y + ty = y fur f(x) ≤ y undf(x) ≤ y folgt außerdem, dass jede Subniveaumenge {x ∈ D : f(x) ≤ y} eine konvexeTeilmenge von D ist. Das gilt insbesondere fur die Menge aller Minimumstellen von fauf D (wenn nichtleer). Fur y = minD f muss dabei immer Gleichheit eintreten, weil jakein Funktionswert kleiner als y sein kann. Im Falle strenger Konvexitat ist Gleichheitmit 0 < t < 1 aber nur moglich, wenn x = x ist, also kann es dann nur eine einzigeMinimumstelle geben. Wir halten diese Uberlegungen noch fest als
SATZ (uber Extremstellen konvexer Funktionen): Ist D eine konvexe Menge inRn und f : D → R eine konvexe [bzw. konkave] Funktion, so ist jeder kritische Punkt vonf in D absolute Minimumstelle [bzw. absolute Maximumstelle] von f auf D. Die Mengealler Minimumstellen [bzw. Maximumstellen] ist eine evtl. leere konvexe Teilmenge von Dund besteht im Falle strenger Konvexitat von f [bzw. strenger Konkavitat] aus hochstenseinem Punkt. Ist f nicht konstant, so kann f ein Maximum [bzw. ein Minimum] auf Dhochstens in einem Randpunkt annehmen.
Wir schließen diesen Abschnitt mit einer Diskussion der Taylor–Formel fur Funktionenvon mehreren Veranderlichen, welche die lineare Approximation von einmal differenzier-baren Funktionen durch ihr Differential verallgemeinert zu einer besseren polynomialenApproximation bei von hoherer Ordnung differenzierbaren Funktionen.
DISKUSSION (Taylor--Formel bei Funktionen von mehreren Veranderlichen):
1) Die Idee ist hier — wie bei Funktionen von einer Veranderlichen in 4.6 —, dass maneine Funktion f(x) von mehreren Veranderlichen nahe einer festen Stelle a ∈ Rn durcheine Polynomfunktion p(x) vom Grad ≤ l moglichst gut approximativ darstellen will,und zwar mit umso besserer Approximationsgute, je großer der erlaubte Grad l ist. Einegute Approximation kann dadurch beschrieben werden, dass die Ableitungen von f undp an der Stelle a bis zur Ordnung l ubereinstimmen, was anschaulich bedeutet, dass sichder Graph der Polynomfunktion dem Graphen der Funktion f bei der Stelle (a, f(a))entsprechend gut anschmiegt. Dazu stellen wir zunachst fest, wenn f an der Stelle apartielle Ableitungen bis zur Ordnung l besitzt:
• Es gibt genau eine Polynomfunktion p vom Grad ≤ l, deren partielle Ableitungenan der Stelle a mit denen von f bis zur Ordnung l ubereinstimmen.
Um das einzusehen, setzen wir an p(x) =∑
|α|≤l ca(x− a)α (Multiindexschreibweise, also
(x−a)α = (x1− a1)α1 · . . . ·(xn− an)αn und |α| = α1+ . . .+αn fur α = (α1, . . . , αn) ∈ Nn
0 ).Die Ableitungen der Monome (x− a)α haben wir bereits fruher berechnet. Insbesonderegilt:
∂|β|
∂xβ (x− a)α =
{α! = α1! · . . . · αn! fur β = α
0 an der Stelle x = a fur β 6= α,
letzteres weil die Ableitung den Faktor (xj − aj)αj−βj enthalt, wenn βj < αj ist, bzw.
weil die Ableitung uberall Null ist, wenn βj > αj. Man sieht nun, dass ∂|β|
∂xβ p(a) = ∂|β|
∂xβ f(a)fur alle partiellen Ableitungen mit Ordnung |β| ≤ l genau dann eintritt, wenn α!cα =∂|α|
∂xα f(a) gilt fur |α| ≤ l. Damit ist die Behauptung bewiesen und zugleich ein Formel furdas gesuchte Polynom gefunden:

Kap. 5, Abschnitt 5.6 661
2) Das l--te Taylorpolynom von f zur Stelle a ist
p(x) =∑|α|≤l
1α!
∂|α|f∂xα (a)(x− a)α
=∑
α1+...+αn≤l
1α1! · . . . · αn!
∂α1+...+αnf∂xα1
1 · · · ∂xαnn
(a) (x1− a1)α1 · . . . · (xn− an)αn .
Dies ist also das eindeutige Polynom vom Grad ≤ l, das an der Stelle a dieselben partiel-len Ableitungen bis zur Ordnung l hat wie die Funktion f . Das nullte Taylor–Polynom isteinfach die Konstante f(a) (fur α1 = . . . = αn = 0 ist der Summand im Taylor–Polynomals f(a) zu interpretieren), das erste ist die beste affin lineare Approximation zu f bei a,
f(a) +∂f∂x1
(a)(x1− a1) + . . . +∂f∂xn
(a)(xn− an) = f(a) + (x− a) r∇f(a)
und das zweite sieht so aus:
f(a) +∂f∂x1
(a)(x1− a1) + . . . +∂f∂xn
(a)(xn− an)
+ 12
∂2f∂x 2
1
(a)(x1− a1)2 + . . . + 1
2∂2f∂x 2
n
(a)(xn− an)2
+∂2f
∂x1∂x2(a)(x1− a1)(x2− a2) + . . . +
∂2f∂xn−1∂xn
(a)(xn−1− an−1)(xn− an)
= f(a) +n∑
j=1
∂f∂xj
(a)(xj− aj) + 12
n∑i,j=1
∂2f∂xi∂xj
(xi− ai)(xj− aj)
= f(a) + (x− a) r∇f(a) + 12(x− a) r(∂2f
∂x2 (a)
)(x− a) .
Die Formeln, welche den Gradienten bzw. die Hesse–Matrix enthalten, gelten dabei furskalare Funktionen f , die anderen auch fur Vektorfunktionen f = (f1, . . . , fm) (wobeidas Taylor–Polynom wie die partiellen Ableitungen komponentenweise gebildet wird). DasBildungsgesetz fur die Taylor–Polynome sollte nun klar sein. Mit dem totalen Differentiall–ter Ordnung dl
af(w1, . . . , wl) = ∂w1 · · · ∂wlf(a) kann man das l–te Taylor–Polynom
auch so schreiben:
f(a) + daf(x−a) + 12!d2
af(x−a, x−a) + . . . + 1l!dl
af(x−a, . . . , x−a) ,
wobei im k–ten Summanden k–mal der Vektor x− a in das mit 1k!
multiplizierte Diffe-rential k–ter Ordnung von f an der Stelle a einzusetzen ist, also die Richtungsableitungk–mal in Richtung des Vektors x− a gebildet wird,
dkaf(x−a, . . . , x−a) = (∂ k
x−af)(a) = dk
dtk t=0f(a + t(x− a)) .
Unterstellt ist dabei, dass f bei a stetige partielle Ableitungen bis zur Ordnung l hat.
3) Nutzlich wird das alles erst, wenn man den Fehler f(x) − p(x) bei Ersetzen von fdurch sein l-tes Taylor–Polynom zur Stelle a gut abbschatzen kann. Der Fehler sollte“von l–ter Ordnung klein” sein fur x nahe a. Um das quantitativ zu beschreiben, kannman wie in 4.6 vorgehen. Hier argumentieren wir etwas anders und betrachten wir fureinen festen Vektor v ∈ Rn die Funktion ϕ(t) = f(a + tv)− p(a + tv) von einer reellen

662 Mathematik fur Wirtschaftswissenschaftler
Variablen t. Bei t = 0 verschwinden dann alle Ableitungen von ϕ bis zur Ordnungl, so dass mit dem Hauptsatz der Differential– und Integralrechnung und wiederholterpartieller Integration folgt, wenn f auf der Strecke von a nach x = a + v (l+1)-maldifferenzierbar ist:
ϕ(1) = ϕ(1)− ϕ(0) =
∫ 1
0
ϕ′(t) dt =
∫ 1
0
ϕ′′(t) dt = . . . =
∫ 1
0
ϕ(l+1)(t)(1−t)l
l!dt .
(Die Randterme ϕ(k) (1−t)k
k!
t=1t=0 verschwinden fur k = 1 . . . l.) Weil p Grad ≤ l hat, ist hier
ϕ(l+1)(t) = ∂l+1v f(a + tv) und wegen ϕ(1) = f(a+v)− p(a+v) folgt die Taylor--Formel:
f(a + v)− p(a + v) =
∫ 1
0
(1− t)l
l!∂l+1
v f(a + tv) dt
bzw. f(x)− p(x) =
∫ 1
0
(1− t)l
l!dl+1
dtl+1f(a + t(x−a)) dt .
4) Diese Formel ist nun hervorragend geeignet zur Abschatzung des Fehlers f(x)− p(x),der auch das Restglied der Taylor–Entwicklung l–ter Ordnung zum Entwicklungspunkta genannt wird. Ist namlich C eine Konstante mit |dl+1
x f(u, . . . , u)| = |∂l+1u f(x)| ≤ C fur
alle Einheitsvektoren u und alle Punkte x aus einer Kugel Br(a) (eine solche endlicheKonstante gibt es, wenn die partiellen Ableitungen (l+1)–ter Ordnung stetig sind auf derabgeschlossenen Kugel Br(a) ), so gilt |∂l+1
v f(a + tv)| = |v|l+1|∂l+1v/|v|f(a + tv)| ≤ C|v|l+1
und daher|f(x)− p(x)| ≤ C
(l+1)!|x− a|l+1 fur |x− a| ≤ r ,
weil∫ 1
01l!(1−t)ldt = 1
(l+1)!ist. Der Fehler geht also bei x→ a schneller gegen Null als die
Potenz |x− a|l. Man sagt:
• Das l–te Taylor–Polynom von f zur Stelle a approximiert die Funktion f bei avon l–ter Ordnung.
5) Wir geben zwei Anwendungen der Taylor–Formel : Fur l = 1 bedeutet Approximationvon erster Ordnung, dass der Linearisierungsfehler f(x)− f(a)− (x−a) q∇f(a) schnellergegen Null geht als |x−a|, also die charakteristische Eigenschaft des Differentials (siehe5.3). Aber jetzt haben wir auch eine genaue Abschatzung des Linearisierungsfehlers:
|f(x)− f(a)− (x− a) r∇f(a)| ≤ C2|x− a|2 fur |x− a| ≤ r ,
wobei man als Konstante C das Supremum der Euklidischen Norm der Hesse–Matrix vonf (oder auch des großten Eigenwertbetrags dieser Matrix) auf der Strecke von a nach xnehmen kann. Fur l = 3 gilt analog∣∣∣∣f(x)− f(a)− (x−a) r∇f(a)− 1
2(x−a) r(∂2f
∂x2 (a))(x−a)
∣∣∣∣ ≤ C3!|x−a|3 fur |x−a| ≤ r ,
wenn C eine obere Schranke fur alle Richtungsableitungen dritter Ordnung |∂3uf(x)| mit
|u| = 1 an Stellen x ∈ Br(a) ist. Ist ∇f(a) = 0 und die Hesse–Matrix(
∂2f∂x2 (a)
)positiv definit mit kleinstem Eigenwert λ > 0, so folgt f(x) − f(a) ≥ 1
2λ|x− a|2 −
16C|x− a|3 = 1
2|x− a|2(λ − 1
3C|x− a|) > 0 fur 0 < |x− a| < 3λ/C. Damit erhalt man
nun eine untere Abschatzung fur den Radius strikter Minimalitat der lokalenisolierten Minimumstelle a :
f(x) > f(a) fur 0 < |x− a| < min(r, 3λ
C
)wenn ∂2
uf(a) ≥ λ > 0 und |∂3uf(x)| ≤ C fur |x− a| < r, |u| = 1 .

5.7 Auflosung von Gleichungen, implizite Funktionen
In diesem letzte Abschnitt geht es um allgemeine Systeme von m durch differenzierbare(im Allgemeinen nichtlineare) Funktionen gegebene Gleichungen fur n reelle Unbekannte
f1(x1, . . . , xn) = y1
f2(x1, . . . , xn) = y2...
fm(x1, . . . , xn) = ym
kurz F (x) = y .
Dafur gibt es keine so geschlossene und vollstandige Theorie, wie sie die Lineare Alge-bra fur lineare Gleichungssysteme zur Verfugung stellt. Jedoch lassen sich mit der Ideeder linearen Approximation gewisse Ergebnisse auf nichtlineare Gleichungssysteme uber-tragen — allerdings mit einer wesentlichen Einschrankung: Da eine gue Approximationdifferenzierbarer Funktionen durch lineare Abbildungen im Allgemeinen nur lokal, d.h.in der Nahe eines ins Auge gefassten festen Punktes, moglich ist, erhalt man auch nurlokale Aussagen uber die Losungen der nichtlinearen Gleichungssysteme, d.h. Aussagenuber ihre Losungen in der Nahe einer vorgegebenen fixierten Losung.
Wir betrachten zuerst den Fall eindeutiger Auflosbarkeit. Hat F (x) = y fur jedes y auseiner offenen Menge V in Rm genau eine Losung x in U ⊂ Rn, so ist die Umkehr-funktion F−1 : V → U ⊂ Rn erklart, indem man F−1(y) = x setzt fur y ∈ V . Neh-men wir an, dass F differenzierbar ist und dass auch die Losung F−1(y) differenzierbarvon der rechten Seite des Gleichungssystems abhangt, so erhalten wir durch Differentia-tion von F−1(F (x)) = x und F (F−1(y)) = y mit der Kettenregel die Beziehungen(
∂F−1
∂y(y)) (
∂F∂x
(x))
= In und(
∂F∂x
(x)) (
∂F−1
∂y(y))
= Im fur y = F (x), d.h. die Ablei-
tungsmatrix von F−1 an der Stelle y = F (x) ist die Inverse der Ableitungsmatrix vonF an der Stelle x. Das ist naturlich nur moglich, wenn beide Matrizen quadratischesFormat haben, d.h. wenn die Anzahl m der Gleichungen mit der Anzahl n der Unbe-kannten ubereinstimmt — und nur in diesem Fall konnen wir vernunftigerweise erwarten,dass das Gleichungssystem eindeutige Losungen hat. Der folgende Satz besagt, dass dieseErwartung zumindest lokal in der Nahe einer Stelle mit invertierbarer Ableitungsmatrixberechtigt ist.
SATZ (Umkehrsatz): Die Funktion F : Rn ⊃ D → Rn habe stetige partielle Ablei-tungen auf der offenen Menge D ⊂ Rn und die Ableitungsmatrix von F an der Stellex0 ∈ D sei invertierbar. Dann gibt es offene Mengen U, V in Rn mit x0 ∈ U ⊂ D undy0 = f(x0) ∈ V , derart dass F (U) = V ist und dass F (x) = y fur alle y ∈ V genaueine Losung x in U besitzt. Die somit durch F−1(y) = x definierte UmkehrabbildungF−1 : V → U ⊂ Rn hat dann stetige partielle Ableitungen bis zu derselben Ordnung wieF auf D und es gilt die Formel fur die Ableitung der Umkehrfunktion:(
∂F−1
∂y(y))
=(
∂F∂x
(x))−1
fur alle x ∈ U und y = F (x) ∈ V .
663

664 Mathematik fur Wirtschaftswissenschaftler
Der Beweis dieses Satzes beruht auf der Idee, dass die lineare Approximation L(x) =F (x0) +
(∂f∂x
(x0))(x − x0) zu F (x) bei x0 nach Voraussetzung eine Umkehrabbildung
L−1(y) = x0 +(
∂f∂x
(x0))−1
(y − y0) auf Rn hat. Da L(x) eine gute Approximation zuF (x) fur x nahe x0 ist, kann man sich denken, dass sich durch kleine Modifikationen derlinearen Umkehrabbildung L−1 bei y0 eine nahe y0 definierte differenzierbare Umkehr-abbildung zu F herstellen lasst. Die exakte mathematische Durchfuhrung ist aber rechtanspruchsvoll und wurde hier zu weit fuhren. Dass die Ableitungsmatrix von F−1 an derStelle y = F (x) dann die Inverse der Ableitungsmatrix von F an der Stelle x sein muss,haben wir vor dem Satz schon uberlegt.
DISKUSSION: 1) Der Umkehrsatz bedeutet, dass man ausgehend von einer Losungf(x0) = y0 mit invertierbarer Ableitungsmatrix von F in x0 bei Variationen der rechtenSeite der Losung ein Stuck weit eindeutig und in differenzierbarer Abhangigkeit von derrechten Seite folgen kann. Verandert man y0 zu y ∈ Rn nahe y0 (so nahe, dass y nochin der offenen Menge V um y0 liegt), so gehort dazu eine eindeutige Losung x nahe x0
(nahe in dem Sinne, dass x in der offenen Umgebung U zu x0 liegt). Die Formel fur dieAbleitung der Umkehrfunktion gibt auch eine lineare Naherung fur die eindeutigeLosung x = F−1(y), namlich
x ≈ x0 +(
∂F∂x
(x0))−1
(y − y0) ,
weil hier rechts ja die Linearisierung F−1(y0)+(
∂F−1
∂y(y0)
)(y− y0) der differenzierbaren
Umkehrfunktion um die Stelle y0 steht. Der Fehler bei dieser Naherung ist klein imVerhaltnis zur Große von |y − y0|, d.h. er strebt auch nach Division durch |y − y0| nochgegen Null bei y → y0.
2) Da die Kettenregel auch fur die Elastizitaten–Matrizen gilt, wenn die Variablen xund die Komponenten von y = F (x) alle positiv sind, haben wir analog:
• Die Elastizitaten–Matrix der differenzierbaren Umkehrfunktion F−1 an der Stelley = F (x) ist die Inverse der Elastizitaten–Matrix von F an der Stelle x .
Schreibt man yi = fi(x) fur die Komponentenfunktionen von F = (f1, . . . , fn) undxj = gj(y) fur die Komponenten der Umkehrfunktion F−1 = (g1, . . . , gn), so lasst sichdas in Formeln so ausdrucken:(
εxj ,yi(y))
=(εyi,xj
(x))−1
fur y = F (x) .
3) Der Umkehrsatz macht nur eine lokale Aussage, er sagt (leider) uberhaupt nichts ausuber die Große der moglicherweise winzig kleinen offenen Umgebungen U zu x0 und Vzu y0, derart dass F : U → V eine differenzierbare Umkehrabbildung F−1 : V → U hat.Die Ausfuhrung des Beweises zeigt immerhin, dass man z.B. U als offene Kugel Ur(x0)um x0 mit einem Radius r ≈ 1
2BCwahlen kann und dass V dann eine offene Kugel Us(y0)
mit Radius s ≈ 12Br
umfasst, wenn C eine obere Schranke fur die Normen der zweitenAbleitungen von F ist und B eine Schranke fur die Betrage der Eintrage in der inversen
Ableitungsmatrix(
∂F∂x
(x0))−1
. Man kann ubrigens eine beliebige der Umgebungen U, Vals offene Kugel wahlen, wenn man mochte, aber nicht U und V simultan, wenn F nichtzufallig Kugeln auf Kugeln abbildet; denn V = F (U) ist ja das Bild von U unter F undU = F−1(V ) das Bild von V unter F−1.

Kap. 5, Abschnitt 5.7 665
4) Bezuglich der Existenz einer globalen differenzierbaren Umkehrfunktion kann manfolgendes sagen:
• Ist F : Rn ⊃ D → Rn injektiv und stetig differenzierbar auf der offenen Menge Dmit uberall invertierbarer Ableitungsmatrix, so ist f(D) offen und es existiert eineglobale stetig differenzierbare Umkehrabbildung F−1 : Rn ⊃ F (D) → D ⊂ Rn.
Die Injektivitat von F besagt, dass verschiedene Punkte x 6= x in D auch verschie-dene Werte F (x) 6= F (x) in F (D) haben. Daher existiert die Umkehrabbildung F−1 :F (D) → D, die jedem y ∈ F (D) die eindeutige Losung x ∈ D zu F (x) = y zuordnet.Andererseits gibt uns der Umkehrsatz auf einer Umgebung V = F (U) eines beliebigenPunktes y0 = f(x0) mit x0 ∈ D eine lokale differenzierbare Umkehrfunktion mit Wertenin U ⊂ D, und diese muss auf V mit der globalen Umkehrabbildung F−1 ubereinstim-men (wegen der Eindeutigkeit der Losungen x ∈ D). Daher ist y0 innerer Punkt vonf(D) und F−1 nahe y0 stetig differenzierbar.
In der Mathematik werden verschiedene hinreichende Kriterien fur die Existenz einer glo-balen differenzierbaren Umkehrabbildung bewiesen. Eines, das auch fur die Wirtschafts-mathematik von Interesse ist, garantiert die Existenz einer globalen Umkehrabbildung zuF : Rn ⊃ D → Rn, wenn D offen und konvex ist und F eine sog. kleine Storung derIdentitat, d.h. es gibt 0 ≤ c < 1 mit∣∣∣u− (∂F
∂x(x))u∣∣∣ ≤ c < 1 fur alle Einheitsvektoren u ∈ Rn und alle x ∈ D .
Das ist z.B. erfullt, wenn sich die Ableitungsmatrix von F an jeder Stelle x ∈ D nur durcheine Matrix der Euklidischen Norm ≤ c < 1 von der n×n–Einheitsmatrix unterscheidet.
BEISPIELE: (1) F (x, y) = (f1(x, y), f2(x, y)) =(x4 − ey , 2y3 + ln 1+x2
2
)Die Ableitungsmatrix hat Determinante
det
(4x3 −ey
2x1 + x2 6y2
)= 24x3y2 + 2x
1+x2 ey = 2x
(12x2y2 +
ey
1+x2
).
Diese Determinante ist Null, genau wenn x = 0 ist. Nach dem Umkehrsatz ist alsoF lokal bei allen Stellen (x, y) ∈ R2 mit x 6= 0 differenzierbar umkehrbar (und dieUmkehrfunktion kann beliebig oft differenziert werden). Eine Losung zu
x4 − ey = 0
ln 1+x2
2+ 2y3 = 0
ist z.B. x = 1, y = 0. Der Umkehrsatz garantiert dann, dass es auch zu
x4 − ey = a
ln 1+x2
2+ 2y3 = b
fur alle rechten Seiten a, b von hinreichend kleinem Betrag genau eine Losung (x, y)nahe (1, 0) gibt, die zudem differenzierbar von (a, b) abhangt. Eine Naherung fur dieseLosung ist(
x
y
)≈(
1
0
)+(
∂F∂(x, y)
(1, 0))−1(
a
b
)=
(1
0
)+
(4 −1
1 0
)−1(a
b
)=
(b + 1
4b−a
).
Es ist aber im vorliegenden Fall (wohl) nicht moglich, die Losung durch explizite Auflosungdes Gleichungssystems als elementare Funktion der Variablen a, b darzustellen.

666 Mathematik fur Wirtschaftswissenschaftler
Der Umkehrsatz sagt ubrigens nicht, dass F (x, y) = (a, b) fur kleine Werte von |a| und|b| genau eine Losung in R2 hat, sondern eben nur, dass es genau eine Losung (x, y)nahe der Stelle (1, 0) gibt. Tatsachlich ist ja hier (−x, y) eine zweite Losung, die abernahe bei (−1, 0) liegt und nicht nahe bei (1, 0). An der Stelle (0, 0) ist die Ableitungs-matrix von F nicht invertierbar, der Umkehrsatz ist dort also nicht anwendbar. WegenF (−x, y) = F (x, y) kann hier auch auf keiner Umgebung von (0, 0) eine Umkehrfunk-tion existieren. (Allgemein kann man aus der Nichtinvertierbarkeit der Ableitungsmatrixan einer Stelle aber nur schließen, dass es dort lokal keine differenzierbare Umkehrabbil-dung geben kann. Eine nichtdifferenzierbare Umkehrabbildung ist durchaus moglich, wiedas Beispiel F (x, y) = (x3, y3) mit Ableitungsmatrix
(0 00 0
)im Nullpunkt und globaler
Umkehrfunktion F−1(a, b) = ((sign a) 3√|a|, (sign b) 3
√|b|) auf R2 zeigt.)
Global auf ganz R2 ist F sicher nicht umkehrbar; denn es gilt F (−x, y) = F (x, y), al-so hat F an den verschiedenen Stellen (x, y) und (−x, y) mit x > 0 denselben Wertund ist nicht injektiv auf R2. Man kann aber sehen, dass F auf der oberen HalbebeneR>0 × R injektiv ist; denn aus x4 − ey = a, 2y3 + ln 1+x2
2= b folgt y = ln(x4− a),
2(ln(x4− a))3 + ln 1+x2
2= b, und da links in der letzten Gleichung eine streng wachsende
Funktion von x2 (mit x4 > a) steht, kann es hochstens eine Losung x > 0 geben, die dannauch y eindeutig bestimmt. Da die Ableitungsmatrix uberall auf R>0×R invertierbar ist,gibt es somit eine globale differenzierbare Umkehrabbildung F−1 : F (R>0×R) → R>0×Rzu F auf der oberen Halbebene.
(2) Auf einem kontingentierten Markt werden die produzierten Mengen x1, . . . , xn von nGutern durch Quoten festgelegt und die Marktpreise durch Preisfunktionen p1(x1, . . . , xn),. . . , pn(x1, . . . , xn) bestimmt. Sind diese Preisfunktionen bekannt, so kann man die Aus-wirkungen einer Quotenanderung von x = (x1, . . . , xn) zu x = (x1, . . . , xn) mit Hilfe derPreisfunktionen exakt berechnen und naherungsweise durch die Zuwachsformel
p(x) = p(x) +(
∂p∂x
(x))(x−x) , pi(x) = pi(x) +
n∑j=1
∂pi
∂xj(x)(xj−xj)
beschreiben, wenn die Anderungen |xj −xj| klein sind. Stellt sich dagegen die Frage, wiedie Quotenanderung vorzunehmen ist, um eine gewunschte Anderung der Marktpreise vonp = (p1, . . . , pn) zu p = (p1, . . . , pn) zu erreichen, so ist das System der n Gleichungen
pi(x1, . . . , xn) = pi (1 ≤ i ≤ n)
nach den Unbekannten x1, . . . , xn aufzulosen. Es ist okonomisch keineswegs klar, dassdies moglich ist, dass man also durch entsprechende Quotenpolitik beliebige Marktpreisein einem gewissen Regime erreichen kann. Ist aber die Ableitungsmatrix
(∂p∂x
(x))
inver-tierbar, so garantiert der Umkehrsatz, dass zumindest fur Preisvektoren p nahe p genauein Quotenvektor x nahe x existiert, und naherungsweise erhalt man x durch
x ≈ x +(
∂p∂x
(x))−1
(p− p) .
Man beachte, dass man, um beispielsweise pi zu senken bei Konstanthalten aller anderenPreise ph, h 6= i, nicht einfach nur die Quote xi erhohen kann, sondern im allgemeinenalle Quoten xj verandern muss (außer wenn die Preise der anderen Produkte nicht vonden Angebotsmengen des i–ten Produkts abhangen).

Kap. 5, Abschnitt 5.7 667
Wir wenden uns nun folgender fur okonomische Anwendungen wichtigen Frage zu:
Wie muss man bei einer reellen Funktion f(x, y) von zwei Variablen den Wert vony korrigieren, um auf eine Anderung von x so zu reagieren, dass der Funktionswertinsgesamt nicht geandert wird?
(Die Funktion kann auch noch von weiteren Variablen abhangen, die man sich bei dieserFragestellung aber fixiert denkt.) Die okonomische Relevanz der Problemstellung ist klar.Man denke etwa an eine Produktionsfunktion, bei der ein Inputfaktor nicht unmittelbarbeeinflussbaren Anderungen unterliegt, wahrend ein anderer Produktionsfaktor zur Kom-pensation verandert werden kann, um das Produktionsniveau aufrecht zu erhalten. ZurBeantwortung der Frage mussen wir eigentlich, wenn etwa (x∗, y∗) die ursprunglichenWerte der Variablen sind und z = f(x∗, y∗) der Funktionswert, der sich nicht andern soll,fur den geanderten Wert x den zu bestimmenden Wert y aus der Gleichung f(x, y) = zberechnen. Unterstellt, es gibt zu jedem Wert von x (in einem gewissen Bereich um x∗)genau eines Losung y, so erhalten wir eine Funktion y = g(x), indem wir jedem x dieseLosung zuordnen. Man sagt, dass g die durch die Gleichung
f(x, g(x)) = z bzw. y = g(x) ⇐⇒ f(x, y) = z .
implizit definierte Funktion ist. Kann man die Gleichung durch Anwendung von Re-chenoperationen und elementaren Grundfunktionen nach y auflosen, so erhalt man eineexplizite Funktionsdarstellung fur g(x) als elementare Funktion von x. Dann liefertdiese Formel fur jede Anderung x−x∗ der ersten Variablen sofort die zugehorige Korrek-tur y− y∗ = g(x)− y∗ der zweiten Variablen, die notig ist, um das Funktionsniveau z zuerhalten. Bei nichtlinearen Gleichungen ist die explizite Auflosung nach einer Variablenoft nicht moglich. Doch kann man dann, wie wir sehen werden, mit Hilfe der Differential-rechnung fur kleine Anderungen x− x0 wenigstens naherungsweise eine kompensierendeAnderung y − y∗ angeben, derart dass |f(x, y)− z| von kleinerer Großenordnung ist als|x− x∗|. Fur praktische Zwecke ist das oft ausreichend.
Ist statt einer Gleichung fur zwei Variable ein System von m Gleichungen fur n > mUnbekannte gegeben,
f1(x1, . . . , xn) = y1
f2(x1, . . . , xn) = y2...
fm(x1, . . . , xn) = ym
,
so wird man erwarten, dass “im Normalfall” n−m Werte der Variablen xj frei als Para-meter gewahlt werden konnen und die Werte der restlichen m Variablen dann durch diem Gleichungen bestimmt sind. Wir wissen, dass das aber schon im Fall eines Systems vonm linearen Gleichungen nicht allgemein richtig ist, sondern nur, wenn die Gleichungenlinear unabhangig sind. Mit der Idee der linearen Approximation lasst sich dieser Sach-verhalt aus der Linearen Algebra auf Systeme nichtlinearer Gleichungen ubertragen, diedurch differenzierbare Funktionen f1, . . . , fm wie oben gegeben sind — allerdings nur lokalin der Nahe einer fixierten Ausgangslosung. Die Unabhangigkeit der nichtlinearen Glei-chungen wird dabei durch die Bedingung maximalen Rangs m fur die Ableitungsmatrixvon F = (f1, . . . , fm) in der Ausgangslosung formuliert, die ja die Koeffizientenmatrixdes approximierenden linearen Gleichungssystems ist. Durch Variablenvertauschung kannman dann immer erreichen, dass die aus den letzten m Spalten dieser Matrix gebildetem×m–Matrix invertierbar ist, und dies ist die Situation, die wir nun annehmen.

668 Mathematik fur Wirtschaftswissenschaftler
SATZ (uber implizite Funktionen): Die reellen Funktionen f1, . . . , fm seien aufeiner Umgebung von x∗ in Rn stetig partielll differenzierbar und die aus den letztenm < n Spalten der Ableitungsmatrix von F = (f1, . . . , fm) gebildete m×m–Untermatrix(
∂fi
∂xn−m+j
)1≤i,j≤m
sei an der Stelle x∗ invertierbar. Dann gibt es Umgebungen U zu x∗
in Rn und V zu y∗ = F (x∗) in Rm, sowie stetig partiell differenzierbare Funktioneng1(x1, . . . , xn−m; y), . . . , gm(x1, . . . , xn−m; y), die fur y ∈ V und (x1, . . . , xn−m) aus einerUmgebung von (x∗1, . . . , x
∗n−m) in Rn−m definiert sind und gj(x
∗1, . . . , x
∗n−m; y∗) = x∗n−m+j
erfullen, derart das das Gleichungssystem
f1(x1, . . . , xn) = y1
f2(x1, . . . , xn) = y2...
fm(x1, . . . , xn) = ym
bzw. F (x) = y
fur rechte Seiten y ∈ V als Losungen in U genau die Punkte x ∈ U besitzt mit
x1 , . . . , xn−m beliebig (als freie Parameter wahlbar),
xn−m+1 = g1(x1, . . . , xn−m; y)...
xn = gm(x1, . . . , xn−m; y)
(eindeutige Funktionen
der freien Parameter
und der rechten Seiten).
Der Beweis lasst sich mit dem Umkehrsatz fuhren, den man auf H(x) = (x′, F (x)) beider Stelle x∗ anwendet. Die Ableitungsmatrix von H an der Stelle x∗ ist invertierbar;denn sie hat Dreiecksblockgestalt
(In−m ∗0 A
), wobei A die nach Voraussetzung invertierbare
Untermatrix der Ableitungsmatrix von F ist. Nach dem Umkehrsatz ist H lokal bei x∗
differenzierbar umkehrbar. Die Umkehrabbildung hat die Form H−1(x′, y) = (x′, G(x′; y))und das Gleichungssystem F (x) = y ist fur x nahe x∗ aquivalent zu H(x) = (x′, y) bzw.x = H−1(x′, y) = (x′, G(x′; y)). Die Behauptung folgt daher mit den Komponentenfunk-tionen gj von G = (g1, . . . , gm).
DISKUSSION 1) Die entscheidende Voraussetzung des Satzes ist die Invertierbarkeitder Ableitungsuntermatrix, die aus den letzten m Spalten der Ableitungsmatrix vonF an der Stelle x∗ gebildet wird. Das lasst sich durch geeignete Nummerierung der Varia-blen x1, . . . , xn erreichen, wenn die Ableitungsmatrix
(∂F∂x
(x∗))
maximalen Rang hat; denndann sind m Spalten dieser Matrix linear unabhangig, und bei passender Nummerierungder Variablen eben die letzten m Spalten. Da der Zeilenrang gleich dem Spaltenrang ist,kann man die Bedingung maximalen Rangs an der Stelle x∗ so formulieren: Die Gradien-ten der Funktionen f1, . . . , fn im betrachteten Gleichungssystem sind linear unabhangigin x∗. Dies ist hier die adaquate Unabhangigkeitsbedingung fur die Gleichungen.
Der Satz besagt dann unter dieser Voraussetzung, dass man ausgehend von der LosungF (x∗) = y∗ die Losung zu F (x) = y in differenzierbarer Abhangigkeit von den Para-metern x1, . . . , xn−m und den rechten Seiten y1, . . . , ym ein Stuck weit verfolgen kann,d.h. dass die letzten m Komponenten der Losungen x als differenzierbare Funktionenxn−m+j = gj(x1, . . . , xn−m; y1, . . . , ym) darstellbar sind. Man sagt, dass diese Funktionenbzw. die Vektorfunktion G = (g1, . . . , gm) die durch das Gleichungssystem implizit defi-nierten Funktionen sind, bzw. dass das Gleichungssystem durch diese Funktionen lokaldifferenzierbar nach den letzten m Variablen aufgelost wird. (Naturlich kannman auch nach anderen m Variablen auflosen, wenn die Ableitungsuntermatrix aus denzugehorigen Spalten invertierbar ist; das ist nur eine Nummerierungsfrage.)

Kap. 5, Abschnitt 5.7 669
Ausgeschrieben lautet das Gleichungssystem, das die Funktionen gj implizit definiert:
f1(x′, g1(x
′; y), . . . , gm(x′; y)) = y1
f2(x′, g1(x
′; y), . . . , gm(x′; y)) = y2...
fm(x′, g1(x′; y), . . . , gm(x′; y)) = ym
( x′ = (x1, . . . , xn−m), y = (y1, . . . , ym) )
Oft ist man nicht an einer Variation der rechten Seiten des Gleichungssystems interessiert,sondern betrachtet die yi als Konstanten (die man dann auch subtraktiv auf die linke Seiteder Gleichungen schreiben kann, so dass die rechten Seiten alle = 0 sind). In diesem Fallunterdruckt man bei den Funktionen gj die Notation der Abhangigkeit von den rechtenSeiten und schreibt einfach gj(x1, . . . , xn−m) statt gj(x1, . . . , xn−m; y1, . . . , ym) mit denfixierten Werten yi = y∗i = fi(x
∗).
2) Im wichtigen Spezialfall einer einzigen Gleichung
f(x1, . . . , xn) = y
mit einer reellen stetig differenzierbaren Funktion f lautet die Voraussetzung des Satzesuber implizite Funktionen einfach
∂f∂xn
(x∗) 6= 0 .
Der Satz garantiert dann die Existenz einer Funktion g(x1, . . . , xn−1; y) mit stetigen par-tiellen Ableitungen, die fur (x1, . . . , xn−1) nahe (x∗1, . . . , x
∗n−1) und y nahe y∗ = f(x∗)
definiert ist und die Gleichung nahe x∗ nach xn auflost in dem Sinne, dass fur x =(x1, . . . , xn) aus einer Umgebung von x∗ gilt:
f(x1, . . . , xn−1, xn) = y ⇐⇒ xn = g(x1, . . . , xn−1; y) .
Das ist in diesem Spezialfall auch relativ einfach zu sehen: Ist etwa ∂f∂xn
(x∗) > 0, so ist∂f∂xn
≥ γ > 0 auf einem Wurfel [x∗1− δ, x∗1+ δ] × . . . × [x∗n− δ, x∗n+ δ], und f hangt dortstreng wachsend von der letzten Variablen ab, wobei fur ein ε > 0 alle Werte zwischenf(x∗)−ε und f(x∗)+ε durchlaufen werden, wenn xn zwischen x∗n−δ und x∗n+δ variiert(bei fixierten anderen Variablen). Daher ist fur maxn−1
i=1 |xi − x∗i | < δ und |y − y∗| < εnach dem Zwischenwertsatz klar, dass f(x′, xn) = y genau eine Losung xn ∈ ]x∗n−δ, x∗n+δ[hat. Durch g(x1, . . . , xn−1; y) := xn wird dann die auflosende Funktion definiert, und mitetwas mehr Arbeit kann man auch zeigen, dass g stetige partielle Ableitungen hat wie f .
Ist ∂f∂xn
(x∗) = 0, aber ∇f(x∗) 6= 0, also eine andere partielle Ableitung ∂f∂xj
(x∗) 6= 0, so
kann man die Gleichung nach der entsprechenden Variablen xj differenzierbar auflosenlokal bei x∗, indem man einfach die Variablen so umnummeriert, dass diese die letztewird.
3) Die Losungsmenge einer reellen Gleichung f(x) = y heißt, wie in 5.2 schon erklart,die Niveau–Menge der Funktion f zum Niveau y, bzw. in okonomischer Terminolo-gie die Isoquante oder Indifferente von f zum Niveau y (ersteres, weil f an allenStellen der Losungsmenge gleiche “Quantitat” hat, d.h. denselben Wert, letzteres weildie Funktion gegenuber Variationen des Arguments in der Losungsmenge “indifferent”ist, d.h. ihren Wert nicht andert). Bei reellen Funktionen f(x, y) von zwei Variablen,

670 Mathematik fur Wirtschaftswissenschaftler
sind die Niveaumengen normalerweise Kurven in der Ebene und werden deshalb auchNiveaukurven, Niveaulinien, Indifferenzlinien etc. genannt. Man kann sich hier ein Bildvom Funktionsverlauf machen, indem man einige Niveaulinien zeichnet und daran denjeweiligen Funktionswert (das Niveau) vermerkt, ganz wie die Hohenfunktion auf einerLandkarte durch Hohenlinien mit Hohenangabe dargestellt wird.
Der Satz uber implizite Funktionen besagt geometrisch, dass die Niveaumenge einer ste-tig differenzierbaren reellen Funktion f von n Variablen durch einen Punkt x∗ mit∂f∂xn
(x∗) 6= 0 lokal bei dieser Stelle als Graph einer stetig differenzierbaren reellen Funk-
tion U ′ 3 x′ = (x1, . . . , xn−1) 7→ g(x′) vonn − 1 Variablen dargestellt ist (mit g(x′) =g(x′; y∗) fur y∗ = f(x∗) ). Genauer ist esso, dass in einer Umgebung von x∗ (in derAbbildung gerahmt) auch die Niveaumengenzu Niveaus y nahe y∗ = f(x∗) durch Gra-phen stetig differenzierbarer reeller Funktio-nen x′ 7→ g(x′; y) von n−1 Variablen darge-stellt werden, die vom jeweiligen Niveau y alsParameter stetig differenzierbar abhangen. Indiesem Sinne gilt unter der Voraussetzung∂f∂xn
(x∗) 6= 0 :-x′
6xn
sx∗f≡ y
Graph(g)kf≡ y∗
DRn
] [U ′
• Die Niveaumenge von f : Rn ⊂ D → R durch x∗ ∈ D ist nahe x∗ eine differen-zierbare nirgends vertikale Flache der Dimension n−1 (Kurve, wenn n = 2 );
• und die Niveaumengen zu Niveaus y nahe y∗ = f(x∗) sind ebenfalls solche differen-zierbaren Flachen, die eine Umgebung von x∗ “blattern”, d.h. uberschneidungsfreiausfullen.
Das ist der geometrische Inhalt des Satzes uber implizite Funktionen. Ist ∂f∂xj
(x∗) 6= 0
fur einen Index j 6= n, so hat man im Prinzip dieselbe Situation aus einem anderenBlickwinkel: Die Niveaumengen konnen dann in manchen Punkten vertikal in Richtungder Achse Ren sein, d.h. eine Parallele dieser Achse als tangentiale Gerade haben, aberdie Geraden mit Richtung ej schneiden die Niveaumengen nahe x∗ transversal, so dasses sich in Richtung von ej gesehen (und nahe bei x∗) um Graphen differenzierbarerFunktionen handelt.
Fur stetig differenzierbare Vektorfunktionen F = (f1, . . . , fm) auf D ⊂ Rn gelten ana-loge Aussagen; allerdings spricht man hier meistens von den Fasern der Abbildung Fstatt von Niveaumengen. Die Fasern {x ∈ D : F (x) = y} sind lokal bei einer Stel-le x∗ ∈ D, bei der die Voraussetzung des Satzes uber implizite Funktionen erfullt ist,Graphen einer Rm–wertigen Funktion G(x′; y) = (g1(x
′; y), . . . , gm(x′; y)) von n−mVariablen x′ = (x1, . . . , xn−m), die auch differenzierbar abhangt von den Parameterny = (y1, . . . , ym), welche den jeweiligen Funktionswert von F bzw. die jeweiligen Niveausder Komponentenfunktionen f1, . . . , fm angeben. In diesem Sinne sind die Fasern von Fnahe x∗ differenzierbare Flachen der Dimension n−m (Kurven im Fall m = n−1) undeine Umgebung von x∗ ist durch solche differenzierbaren Flachen “geblattert”.
4) Wenn die Voraussetzung nicht erfullt ist, wenn also die aus den letzten Spalten derAbleitungsmatrix
(∂F∂x
(x∗))
gebildete quadratische m × m–Untermatrix A nicht inver-tierbar ist, so ist die Gleichung F (x) = y∗ im Allgemeinen nicht differenzierbar nach xn

Kap. 5, Abschnitt 5.7 671
bzw. nach den letzten m Variablen auflosbar. Das heißt: Es gibt x′ = (x1, . . . , xn−m)beliebig nahe bei x∗′ = (x∗1, . . . , x
∗n−m), derart dass F (x′, xn−m+1, . . . , xn) = y∗ keine
oder mehr als eine Losung (xn−m+1, . . . , xn) nahe bei (x∗n−m+1, . . . , x∗n) hat oder dass die
Losung nicht differenzierbar von den Parametern x1, . . . , xn−m abhangt. Wenn der Rangder Ableitungsmatrix von F im Punkt x∗ nicht maximal ist, so braucht die Niveaumen-ge durch x∗ keine differenzierbare (n−m)–dimensionale Flache zu sein, sondern sie kannz.B. Selbstschnitte oder Spitzen in x∗ haben oder auch zu einer Menge der Dimension< n−m degenerieren, im Extremfall sogar zu einem einzigen Punkt.
Und wenn die Gleichung F (x) = y∗ “zufallig” trotz der Nichtinvertierbarkeit der Ablei-tungsuntermatrix A doch differenzierbar nach den letzten m Variablen auflosbar ist nahex∗, so kann man jedenfalls der Losung nicht eindeutig in differenzierbarer Weise bei Varia-tionen der rechten Seite folgen. Genauer gesagt kann die Losung G(x∗′; y), wenn sie uber-haupt fur alle y nahe y∗ eindeutig existiert, nicht differenzierbar von y abhangen. Wenndas doch der Fall ware, so wurde man durch Differentiation von F (x∗′, G(x∗′; y)) = ynach y einen Widerspruch erhalten: Die Ableitungsmatrix der linken Seite bzgl. y an derStelle y∗ ware gemaß Kettenregel das Produkt der m × m–Matrix A mit der m × m–
Ableitungsmatrix(
∂G∂y
(x∗′; y∗))
von G bzgl. y, aber die Ableitungsmatrix der rechten
Seite ist die m × m–Einheitsmatrix Im, also musste A invertierbar sein entgegen derhier diskutierten Annahme, dass die Voraussetzung des Satzes uber implizite Funktionennicht erfullt ist.
BEISPIELE: (1) Fur die Funktion f(x, y) = x2+y2 von zwei Variablen ist ∇f(x, y) =(2x, 2y) 6= (0, 0) an allen Stellen (x, y) in R2
6=0. Die Niveaumengen in der Ebene sind au-ßerhalb des Ursprungs also glatte Kurven gemaß Satz uber implizite Funktionen. Hierkann man sie genau angeben: Die Niveaukurve zum Niveau z > 0 ist namlich die Kreisli-nie vom Radius
√z mit der Gleichung x2+ y2 = z. An allen Stellen (x∗, y∗) mit y∗ 6= 0
ist die Voraussetzung ∂f∂y
(x∗, y∗) 6= 0 fur differenzierbare Auflosbarkeit der Gleichung
x2+ y2 = z nach der Variablen y erfullt. Hier kann man die auflosende Funktion explizitbestimmen: Fur Niveaus z nahe z∗ = x2
∗ + y2∗ und x nahe bei x∗, so dass z − x2 noch
positiv ausfallt (beachte z∗ − x2∗ = y2
∗ > 0 ), ist die auflosende Funktion gegeben durchg(x; z) = (sign y∗)
√z − x2. Der Graph von x 7→ g(x; z) ist eine lokale Graphendarstellung
der Kreislinie vom Radius√
z um (0, 0) uber der horizontalen Achse. Das Vorzeichen beig haben wir so bestimmt, dass g(x∗, z∗) = y∗ ist, so dass die Losung y = g(x; z) nahebei y∗ liegt. Beachte, dass es noch eine zweite Losung y = −(sgn y∗)
√z − x2 gibt, die
aber nicht nahe bei y∗, sondern nahe bei −y∗ liegt. Das schließt der Satz uber impliziteFunktionen nicht aus: Er sagt hier nur, dass es fur x aus einer Umgebung von x∗ und zaus einer Umgebung von z∗ genau eine Losung y gibt, die nahe bei y∗ ist — weiter wegvon y∗ kann es durchaus noch weitere Losungen geben!
Nahe Punkten (x∗, 0) mit x2∗ = z∗ > 0 ist eine Graphendarstellung der Niveaukurven
nicht moglich, weil die Kreislinien mit vertikaler Tangente durch solche Punkte gehen. DieGleichung x2 + y2 = z hat dann fur x nahe x∗ und z nahe z∗ entweder keine Losung(wenn x2 > z ) oder genau eine (wenn x2 = z ) oder genau zwei Losungen y = ±
√z − x2
nahe 0 (wenn x2 < z ). Da aber ∂f∂x
(x∗, y) = 2x∗ 6= 0 ist, kann man nahe solchen Punkten— wie uberhaupt bei allen (x∗, y∗) mit x∗ 6= 0 — lokal differenzierbar nach x auflosendurch x = (sign x∗)
√z − y2. Die Kreislinien sind nahe (x∗, y∗) dann eben lokal als Gra-
phen uber der vertikalen Achse dargestellt.
Eine Sonderrolle spielt der Punkt (x∗, y∗) = (0, 0), in dem der Gradient verschwindet.Hier ist die Voraussetzung des Satzes uber implizite Funktionen weder fur differenzier-

672 Mathematik fur Wirtschaftswissenschaftler
bare Auflosung nach y noch nach x erfullt, und die Niveaumenge durch den Ursprungist auch keine differenzierbare Kurve, sondern zu einem Punkt {(0, 0)} degeneriert. Mankann der Losung zu x2 + y2 = z mit fixiertem Parameter x = 0 auch nicht in differen-zierbarer Abhangigkeit vom Niveau z folgen; denn fur z < 0 gibt es keine Losung undfur z > 0 zwei Losungszweige y = ±
√z, die beide bei z = 0 nicht differenzierbar sind.
(2) Auch fur die Funktion f(x, y) = x2−y2 verschwindet der Gradient nur im Ursprung.Die Niveaumengen sind also außerhalb des Ursprungs differenzierbare Kurven (zweiasti-ge nach rechts und links geoffnete Hyperbeln fur Niveaus > 0, zweiastige nach untenund oben geoffnete Hyperbeln fur Niveaus < 0). Die Niveaumenge x2 − y2 = 0 ist dieVereinigung der beiden Diagonalen y = ±x, die sich im Ursprung kreuzen. Dort ist dieNiveaumenge also nicht lokal eine differenzierbare Kurve, sondern hat eine “Singularitat”.Entsprechend ist die Auflosung der Gleichung x2 − y2 = 0 nach y in der Nahe des Ur-sprungs nicht durch eine, sondern nur durch zwei differenzierbare Funktionen y = x undy = −x zu beschreiben. So etwas kann nur passieren, wenn die Voraussetzung des Satzesuber implizite Funktionen (fur Auflosung nach irgendeiner Variablen) nicht erfullt sind.
Mit leichten Modifikationen kann man andere Arten von Singularitaten der Niveaumen-ge durch einen Punkt produzieren, in dem die Voraussetzung des Satzes uber impliziteFunktionen verletzt ist. Zum Beispiel hat g(x, y) = x4− y2 als Niveaumenge zum NiveauNull die Vereinigung von zwei Parabeln y = ±x2, die sich im Ursprung beruhren. DieNiveaumenge hat hier zwar eine Tangente im Nullpunkt, verzweigt sich aber und kannnicht lokal als Graph einer Funktion dargestellt werden. Und die auf R2 auch uberallstetig differenzierbare Funktion h(x, y) = |x|3/2 − y3 hat als Niveaumenge zum NiveauNull den Graphen der Funktion y =
√|x| , der die Vereinigung von zwei Halbparabeln in
der oberen Halbebene mit horizontaler Achse ist, die sich in einer gemeinsamen Spitze imUrsprung beruhren. Die Gleichung h(x, y) = 0 ist in diesem Fall zwar durch die Funktiony =
√|x| auflosbar, aber diese Funktion ist nicht differenzierbar in x = 0.
(3) Die Funktionen f(x, y) = x2− y, g(x, y) = (x2− y)2 und h(x, y) = (x2− y)3 habenim Wesentlichen dieselben Niveaumengen, namlich vertikal verschobene Normalparabelny = x2− z bei f bzw. y = x2− (sign z) 3
√|z| bei h und die Vereinigung zweier Parabeln
y = x2 ∓√
z zu Niveaus z > 0 bzw. die Normalparabel y = x2 zum Niveau z = 0bei g. Wegen ∂f
∂y(x, y) = −1 ist die Voraussetzung des Satzes uber implizite Funktionen
bei f an jeder Stelle erfullt; die Auflosung von f(x, y) = z nach y ist ja auch globaldifferenzierbar moglich mit y = x2 − z.
Fur g und h verschwindet dagegen der Gradient uberall auf der Normalparabel; im Null-punkt ist also die Voraussetzung des Satzes uber implizite Funktionen fur Auflosung nachy oder x definitiv nicht erfullt. Dennoch ist die differenzierbare Auflosung der Gleichun-gen g(x, y) = 0 und h(x, y) = 0 nach y hier “zufallig” moglich, namlich durch y = x2.Die Verletzung der Voraussetzungen des Satzes uber implizite Funktionen zeigt sich aber,wenn wir die rechte Seite variieren und die Losung zu g(x, y) = z bzw. h(x, y) = z bei-spielsweise fur den Parameter x = 0 als Funktion der rechten Seite z verfolgen wollen.Hier hat g(0, y) = z uberhaupt keine Losung fur z < 0 und zwei Losungszweige ±
√z fur
z > 0, die bei z = 0 nicht differenzierbar sind. Dagegen hat h(0, y) = z fur alle z die ein-deutige Losung y = −(sign z) 3
√|z|, aber die ist nicht differenzierbar bei z = 0 (Steigung
−∞). Die Beispiele g, h illustrieren Punkt 4) der vorangegangen Diskussion: Wenn dieVoraussetzung des Satzes uber implizite Funktionen in einem Punkt verletzt ist, so lasstsich diese Losung nicht lokal als eindeutige differenzierbare Funktion der rechten Seitendes Gleichungssystems (bei festgehaltenen Werten der Parametervariablen) verfolgen.

Kap. 5, Abschnitt 5.7 673
Nur in sehr einfachen Fallen wie in diesen Beispielen kann man eine nichtlineare Gleichungexplizit nach einer Variablen auflosen, oder gar eine System von m nichtlinearen Glei-chungen nach m der Variablen. Implizit definierte Funktionen sind eben im Allgemeinennicht durch eine explizite Formel als elementare Funktion darstellbar. Fur Anwendungenist es daher wichtig zu wissen, das man wenigstens die Ableitungen der impliziten Funk-tionen, also ihre linearen Approximationen, an den Stellen berechnen kann, die bekanntenLosungen der Gleichung bzw. des Gleichungssystems entsprechen. Es gilt namlich der
SATZ (Ableitungen implizit definierter Funktionen): Ist G(x′; y) ∈ Rm definiertund stetig partiell differenzierbar fur x′ = (x1, . . . , xn−m) aus einer offenen Menge inRn−m und y = (y1, . . . , ym) aus einer offenen Menge in Rm und ist das System
f1(x′; g1(x
′; y), . . . , gm(x′; y)) = y1...
fm(x′; g1(x′; y), . . . , gm(x′; y)) = ym
⇐⇒ F (x′; G(x′; y)) = y
erfullt mit der stetig partiell differenzierbaren Funktion F = (f1, . . . , fm) von n Varia-blen x = (x′; x′′) = (x1, . . . , xn−m; xn−m+1, . . . , xn), so gilt fur die Ableitungsmatrizen derFunktion G bzgl. der Variablen y und x′ :(
∂G∂y
(x′; y))
=(
∂F∂x′′
(x))−1
,(∂G∂x′
(x′; y))
= −(
∂F∂x′′
(x))−1 (∂F
∂x′(x))
,
wobei rechts x = (x′; G(x′; y)) einzusetzen ist.
Dabei ist(
∂F∂x′′
)die aus den letzten m Spalten der Ableitungsmatrix
(∂F∂x
)bestehende
m ×m–Untermatrix und(
∂F∂x′
)die aus den ersten n−m Spalten von
(∂F∂x
)bestehende
m × (n−m)–Untermatrix. Der Nutzen des Satzes besteht darin, dass man damit dieAbleitungen der implizit definierten Funktion G(x′; y) berechnen kann, wenn man dieAbleitungen der Funktion F = (f1, . . . , fm) an der Stelle x = (x′; G(x′; y)) kennt —ohne eine explizite Formel fur die Funktion G zu haben!
Der Beweis des Satzes ist eine Anwendung der Kettenregel 5.3. Die Ableitungsmatrix bzgl.
der Variablen y von F (x′; G(x′; y)) ist danach das Produkt(
∂F∂x′′
(x′; G(x′; y)))(
∂G∂y
(x′; y)).
Andererseits gilt F (x′; G(x′; y)) = y und die Ableitungsmatrix(
∂y∂y
)ist die m × m–
Einheitsmatrix Im. Daraus folgt(∂F∂x′′
(x′; G(x′; y))
)(∂G∂y
(x′; y)
)= Im
und damit die Invertierbarkeit der Matrix(
∂F∂x′′
(x′; G(x′; y)))
und die erste behauptete
Gleichung. (Das ist ubrigens genau die Matrix, deren Invertierbarkeit im Satz uber implizi-te Funktionen vorausgesetzt wird.) Die zweite Gleichung ergibt sich durch Differentiationvon F (x′; G(x′; y)) = y nach den Variablen x′. Rechts entsteht dabei die Nullmatrix unddie Berechnung der Ableitung links mit der Kettenregel ergibt daher(
∂F∂x′
(x′; G(x′; y))
)+
(∂F∂x′′
(x′; G(x′; y))
)(∂G∂x′
(x′; y)
)= 0 .
Multiplikation mit(
∂F∂x′′
(x′; G(x′; y)))−1
liefert dann die zweite behauptete Gleichung.
Sie gilt offenbar auch fur(
∂G∂x′
), wenn nur die Gultigkeit des Gleichungssystems fur ein
festes y vorausgesetzt und Invertierbarkeit von(
∂F∂x′′
)angenommen wird.

674 Mathematik fur Wirtschaftswissenschaftler
DISKUSSION: 1) Im Spezialfall einer einzigen Gleichung
f(x1, . . . , xn−1, g(x1, . . . , xn−1)) = y
mit ∂f∂xn
6= 0 lautet die Formel fur die partiellen Ableitungen der implizit definiertenFunktion g einfach
∂g∂xh
(x1, . . . , xn−1) = −∂f∂xh
(x1, . . . , xn−1, g(x1, . . . , xn−1))
∂f∂xn
(x1, . . . , xn−1, g(x1, . . . , xn−1))(h = 1 . . . n−1) ;
denn die Differentiation der Gleichung nach xh mit der Kettenregel gibt in diesem Fall
∂f∂xh
(x1, ... , xn−1, g(x1, ... , xn−1))+∂f∂xn
(x1, ... , xn−1, g(x1, ... , xn−1))∂g∂xh
(x1, ... , xn−1) = 0 .
Geometrisch interpretiert ist − ∂f∂xh
(x)/
∂f∂xn
(x) fur h = 1 . . . n−1 also die Steigung der
Isoquante von f im Punkt x in Richtung von eh , wenn der Nenner 6= 0 ist; denndie Isoquante ist ja dann lokal bei x der Graph der differenzierbaren Funktion g mitxn = g(x1, . . . , xn−1) und ∂g
∂xh(x1, . . . , xn−1) ist die Steigung dieses Graphen in Richtung
des kanonischen Basisvektors eh.
Wir haben hier die rechte Seite y der Gleichung fixiert und dementsprechend in derNotation die Abhangigkeit der auflosenden Funktion von y unterdruckt. Die Anderungder auflosenden Funktion bei Variation von y ergibt sich mit Differentiation der Gleichungf(x1, . . . , xn−1, g(x1, . . . , xn−1; y)) = y nach y zu
∂g∂y
(x1, . . . , xn−1; y) = 1∂f∂xn
(x1, . . . , xn−1, g(x1, . . . , xn−1; y)).
2) Anwendung in der Okonomie (und nicht nur dort): Wird bei einer reellen Funktionf(x, y) von zwei Veranderlichen die Variable x geandert zu x und soll das Niveau z =f(x, y) durch eine kompensierende Anderung von y zu y aufrecht erhalten werden — daswar ja die ursprungliche Problemstellung —, so ist y = g(x) der exakte geanderte y–Wert,wenn g die durch die Gleichung f(ξ, g(ξ)) = z implizit definierte Funktion mit g(x) = yist und x im Definitionsbereich von g liegt. Kennt man die Funktion g nicht explizit— und das wird meistens der Fall sein —, so kann man den Wert g(x) + g′(x)(x− x) =y + g′(x)(x− x) der Linearisierung von g um x als akzeptable Naherung fur y nehmen,wenn |x − x| klein ist. Ist ∂g
∂y(x, y) 6= 0, so sagt uns die Ableitungsformel fur implizite
Funktionen aus dem vorigen Satz bzw. aus 1) oben g′(x) = −∂f∂x
(x, y)/
∂f∂y
(x, y) , also
lautet die Naherungsformel fur die kompensierende Variablenanderung bei y :
y − y ≈ −∂f∂x
(x, y)
∂f∂y
(x, y)(x− x) .
Beachte, dass die unbekannte implizite Funktion g in dieser Naherungsformel nicht auf-tritt, sondern nur die gegebene Funktion f . Auf dieselbe Naherungsformel kommt manubrigens, wenn man f durch seine Linearisierung f(x, y)+ ∂f
∂x(x, y)(x−x)+ ∂f
∂y(x, y)(y−y)
um die Stelle (x, y) ersetzt und dann y zu gegebener Anderung x−x so bestimmt, dassdiese Linearisierung an der Stelle (x, y) denselben Wert f(x, y) = f(x, y) hat wie an derStelle (x, y).

Kap. 5, Abschnitt 5.7 675
3) Bei einer reellen Funktion f(x1, . . . , xn) von n ≥ 3 Veranderlichen lautet die ent-sprechende Naherungsformel fur die kompensierende Anderung der letzten Variablen zugegebenen (kleinen) Anderungen xh − xh, h = 1 . . . n−1, der ersten n−1 Variablen:
xn − x ≈ −n−1∑h=1
∂f∂xh
(x1, . . . , xn)
∂f∂xn
(x1, . . . , xn)(xh − xh) .
Vorausgesetzt ist dabei naturlich ∂f∂xn
(x) 6= 0; andernfalls ist es nicht moglich beliebige
kleine Anderungen der Variablen xh, 1 ≤ h < n, durch eine Anderung derselben kleinenGroßenordnung bei xn zu kompensieren. Bei Vektorfunktionen F (x) = (f1(x), . . . , fm(x))von n Variablen x = (x1, . . . , xn) kann man unter der Voraussetzung, dass die Un-termatrix der letzten m Spalten der Ableitungsmatrix von F invertierbar ist, kleineAnderungen xh − xh, h = 1 . . . n−m, bei den ersten n−m Variablen durch Ande-rungen xn−m+j − xn−m+j, j = 1 . . . m, bei den letzten m Variablen so kompensieren,dass die Niveaus yi (also die Werte) aller Komponentenfunktionen fi erhalten bleiben.Die exakten Werte fur diese Kompensation sind xn−m+j = gj(x1, . . . , xn−m) mit dendurch das Gleichungssystem fi(ξ, g1(ξ), . . . , gm(ξ)) = yi implizit definierten Funktionengj(ξ) = gj(ξ1, . . . , ξn−m), wobei gj(x1, . . . , xn−m) = xn−m+j. Ersetzt man diese Funktionendurch ihre Linearisierung um die Stelle (x1, . . . , xn−m), so erhalt man mit dem vorigen Satzfolgende Naherungsformel fur die kompensierenden Anderungen von xn−m+1, . . . , xn−m : xn−m+1 − xn−m+1
...xn − xn
≈(
∂fi
∂xn−m+j(x)
)−1
1≤i≤m1≤j≤m
(∂fi
∂xh(x)
)1≤i≤m
1≤h≤n−m
x1 − x1...
xn−m − xn−m
.
In der theoretischen Okonomie sind Argumentationen auf dem mathematischen Niveaudes letzten Satzes und der obigen Diskussion durchaus gangig. Das ist kein Wunder; dennin der Okonomie ist der Zusammenhang zwischen okonomischen Variablen haufig durchGleichungen gegeben und die Behandlung dieser Gleichungen durch Auszeichnung einigerVariablen als unabhangig (freie Parameter) und Bestimmung der anderen Variablen ausden Gleichungen fuhrt oft auf implizit definierte Funktionen, fur die keine explizite ele-mentare Formel zur Verfugung steht. Wir geben dafur nun einige konkrete
BEISPIELE (okonomische Anwendungen impliziter Funktionen):
(1) Gegeben sei eine Produktionsfunktion x(r1, . . . , rn), die den Output einer Produktion(in Mengeneinheiten) in Abhangigkeit vom Einsatz von Produktionsfaktoren r1, . . . , rn
(in jeweiligen Faktoreinheiten) angibt. Es wird nun bei Festhalten aller ubrigen Faktor-einsatze fur zwei Produktionsfaktoren rj und rk (j 6= k) das wechselseitige Substitutions-verhalten untersucht. Man fragt also, um wieviele Einheiten rk geandert werden muss,wenn der Faktoreinsatz rj um eine kleine Einheit erhoht wird und das ProduktionsniveauX = x(r1, . . . , rn) aufrecht erhalten werden soll. Im Fall ∂x
∂rk(r1, . . . , rn) 6= 0 garantiert der
Satz uber implizite Funktionen, dass man durch die Gleichung x(r1, . . . , rj, . . . , rk, . . . , rn)= X tatsachlich rk als differenzierbare Funktion von rj definieren kann (nahe den ur-sprunglichen Werten der Faktoreinsatze und bei c.p.–Bedingung, also konstant gehaltenemEinsatz aller anderen Produktionsfaktoren). Man schreibt dann rk(rj) fur diese Substi-tutionsfunktion, die fur jeden Wert des Faktors rj angibt, wie man den Faktoreinsatzrk einzurichten hat, damit das gegebene Produktionsniveau X eingehalten wird. (Beivollstandiger Angabe aller Abhangigkeiten musste die Substitutionsfunktion eigentlichrk(r1, . . . , rk−1, rk+1, . . . , rn; X) notiert werden.)

676 Mathematik fur Wirtschaftswissenschaftler
Fur die Substitutionsfunktion gilt also x(. . . , rj, . . . , rk(rj), . . .) = X und Differentiationnach xj mit der Kettenregel bzw. die Formel fur die Ableitung implizit definierter Funk-tionen gibt
drk
drj(rj) = −
∂x∂rj
(r1, . . . , rn)
∂x∂rk
(r1, . . . , rn).
• Die Grenzrate der Substitution des j–ten durch den k–ten Faktor ist der nega-tive Quotient der j–ten und k–ten Grenzproduktivitaten.
Die Okonomische Interpretation der Grenzrate der Substitution drk
drj(rj) ist die (approxi-
mative) Anderung, die bei rk vorzunehmen ist, wenn rj um eine (kleine) Einheit erhohtund das Produktionsniveau X eingehalten wird. Entsprechend geben die Grenzproduk-tivitaten (naherungsweise) an, um wieviele Einheiten der Produktions–Output gestei-gert wird, wenn man den jeweiligen Faktoreinsatz um eine (kleine) Einheit erhoht (beic.p.–Bedingung fur die anderen Faktoren). Da Produktionsfunktionen x(r1, . . . , rn) imallgemeinen streng wachsend von jeder einzelne Variablen abhangen, sind die Grenzpro-duktivitaten typischerweise positiv. Das Minuszeichen in der Formel fur die Grenzrate derSubstitution druckt daher aus, dass man bei Erhohung (bzw. Erniedrigung) des Faktor-einsatzes rj den Faktoreinsatz rk zu vermindern (bzw. zu steigern) hat, um das Produk-tionsniveau beizubehalten. Mit anderen Worten: Die Substitutionsfunktionen rk(rj) sindtypischerweise streng fallend (mit negativerAbleitung). Die geometrische Deutung derSubstitutionsfunktion ist, dass ihr Graph inder (rj, rk)–Ebene (die anderen konstantgehaltenen Faktoreinsatze werden in derNotation unterdruckt) die Isoquante derProduktionsfunktion zum Niveau X ist.Diese Isoquante ist also eine von links nachrechts fallende Kurve im positiven Qua-dranten, und der Bettrag ihrer negativeSteigung ist an jeder Stelle das Verhaltnisder entsprechenden Grenzproduktivitaten.
-rj
6rk
s 1︷ ︸︸ ︷}≈ ∂x
∂rj(r)
/∂x∂rk
(r)
Isoquante x(r) = X
��
rj
rk
(2) Ganz analoge Begriffsbildungen hat man in anderem okonomischem Zusammen-hang, z.B. bei einer Nutzenfunktion U(x1, . . . , xn), welche den Nutzen des Einsatzes vonx1, x2, . . . , xn Einheiten von n nutzenstiftenden Gutern beschreibt. Ist ∂U
∂xk(x1, . . . , xn) 6=
0, so kann man durch die Bedingung, dass der Nutzen U und die Einsatzmengen xi furj 6= i 6= k konstant gehalten werden, xk als implizit definierte Funktion von xj auffassen(fur Werte nahe der ursprunglichen Situation; k 6= j). Man erhalt dann fur die Grenzrateder Substitution des j–ten durch das k–te Gut:
dxk
dxj(xj) = −
∂U∂xj
(x1, . . . , xn)
∂U∂xk
(x1, . . . , xn),
also das Negative des Verhaltnisses des j–ten und k–ten Grenznutzens. Die Isoquantender (als Funktion der zwei Variablen xj, xk aufgefassten) Nutzenfunktion heißen hierIndifferenzlinien; die Indifferenzlinie zu einem gegebenen Nutzenniveau ist der Graph derzugehorigen Substitutionsfunktion xk(xj) . Diese Substitutionsfunktionen sind typischer-weise streng fallend, ihre negative Graphensteigung in einem Punkt (xj, xk(xj)) ist dieGrenzrate der Substitution an der jeweiligen Stelle xj .

Kap. 5, Abschnitt 5.7 677
(3) Haufig haben die Isoquanten / Indifferenzliien in Situationen wie oben nicht nur ne-gative Steigung (d.h. die Grenzrate der Substitution ist negativ), sondern sie, bzw. dieSubstitutionsfunktionen, sind auch degressiv fallend, d.h. der Absolutbetrag der negativenSteigung nimmt mit zunehmendem Wert der unabhangigen Variablen ab. Dieses Verhal-ten, also degressives Fallen der Substitutionsfunktion, bezeichnet man als abnehmendeGrenzrate der Substitution. Es bedeutet, dass man zur Kompensation der Erhohung derunabhangigen Variablen um eine Einheit, bei der substituierenden abhangigen Variablenumso weniger sparen kann, je großer der Wert der unabhangigen Variablen ist. Das ist ofteine okonomisch sinnvolle Annahme (Erhohung eines ohnehin schon sehr großen Faktor-einsatzes um eine Einheit bringt relativ wenig). Mathematisch lassen sich u.a. folgendehinreichende Kriterien fur abnehmende Grenzrate der Substituton fur eine gege-bene reelle (Produktions–, Nutzen–)Funktion f(x1, . . . , xn) aufstellen:
(i) f(x1, . . . , xn) ≥ 0 ist bezuglich jeder einzelnen Variablen xj konkav und wachsend,
also neoklassisch, und die gemischten partiellen Ableitungen zweiter Ordnung ∂2f∂xk∂xk
sind nichtnegativ;
(ii) oder f ist konkave Funktion von x = (x1, . . . , xn) (nicht nur konkav in jedereinzelnen Variablen) und wachsend bzgl. jeder einzelnen Variablen.
Das Kriterium (i) ergibt sich durch Differentiation der Gleichung fur die Grenzrate der
Substitution dxk
dxj(xj) = − ∂f
∂xj(xj, xk(xj))
/∂f∂xk
(xj, xk(xj)) nach xj (die anderen Variablen
xi mit j 6= i 6= k notieren wir nicht):
d2xk
dx 2j
=
(∂f∂xk
)−2 [− ∂f
∂xk
(∂2f∂x 2
j
+∂2f
∂xk∂xj
dxk
dxj
)+
(∂2f
∂xj∂xk+
∂2f∂x 2
k
dxk
dxj
)∂f∂xj
]=
(∂f∂xk
)−3[−(
∂f∂xk
)2∂2f∂x 2
j
+ 2∂f∂xk
∂f∂xj
∂2f∂xk∂xj
dxk
dxj−(
∂f∂xj
)2∂2f∂x 2
k
],
und wegen der Voraussetzungen ∂f∂xj
> 0, ∂f∂xk
> 0, ∂2f∂x 2
j< 0, ∂2f
∂x 2k
< 0, ∂2f∂xkxj
≥ 0 ist
der letzte Ausdruck positiv, die negative Grenzrate der Substitution also zunehmend unddie absolute Grenzrate abnehmend. (statt der Nichtnegativitat der gemischten zweiten
Ableitungen genugt hier sogar die Bedingung ∂2f∂xk∂xj
≥ −√
∂2f∂x 2
k
∂2f∂x 2
j.)
Zum Beweis des Kriteriums (ii) betrachten wir zwei Werte xj, xj und benutzen die Kon-kavitatsungleichung fur f , um fur 0 ≤ t ≤ 1 und das Niveau y, zu dem die Substituti-onsfunktion xk(xj) definiert ist, die Ungleichung
f((1−t)xj + txj , (1−t)xk(xj) + txk(xj))
≥ (1−t)f(xj, xk(xj)) + t f(xj, xk(xj)) = (1−t)y + ty = y
zu folgern. Andererseits ist f((1−t)xj + txj , xk((1−t)xj+ txj)) = y nach Definition derSubstitutionfunktion. Da f(. . .) nach Voraussetzung in der k–ten Variablen wachst, folgt
(1−t)xk(xj) + txk(xj) ≥ xk((1−t)xj + txj) ,
und das ist gerade die behauptete Konvexitat der Substitutionsfunktion. (Man hat beidiesem Argument die Konkavitat von f auf der Strecke von (xj, xk(xj)) nach (xj, xk(xj))im Definitionsbereich ausgenutzt, daher genugt die Konkavitat von f bzgl. jeder einzelnenVariablen hier nicht. Aber Konkavitat als Funktion der zwei Variablen (xj, xk) bei c.p.–Bedingung fur die restlichen Variablen genugt naturlich fur abnehmende Grenzrate derSubstitution von xj durch xk.)

678 Mathematik fur Wirtschaftswissenschaftler
(4) Betrachten wir konkret eine Produktionsfunktion vom Cobb–Douglas–Typ, die vonden Produktionsfaktoren Arbeit A > 0 und Kapital K > 0 abhangt:
x(A, K) = 0.5 A0.4K0.6.
Die Isoquante zum Produktionsniveau 4 ist gegeben durch
0.5 A0.4K0.6 = 4
was zum Beispiel nach K aufgelost werden kann:
K = 81/0.6A−0.4/0.6 = 85/3A−2/3 = 32 A−2/3.
Dies ist also die Substitutionsfunktion fur Substitution des Faktors Arbeit durch Kapital,und die Grenzrate dieser Substitution ist
dKdA
= −643
A−5/3.
Der Quotient der Grenzproduktivitaten von Arbeit und Kapital ist andererseits
∂x/∂A
∂x/∂K=
0.5 · 0.4 · A−0.6 ·K0.6
0.5 · A0.4 · 0.6 ·K−0,4= 2
3A−1K = 2
3· A−1 · 32 A−2/3 = 64
3A−5/3,
also das Negative der Grenzrate der Substitution — wie es ja auch nach der Ableitungs-formel fur implizit definierte Funktionen sein muss (siehe Punkt 1) der vorangegangenenDiskussion).
Hier ist |dKdA| = 64
3A−5/3 eine abnehmende Funktion von A, es gilt also das Gesetz der ab-
nehmenden Grenzrate der Substitution. Das hatte man aus dem Kriterium (i) in (3) obenauch von vorneherein sehen konnen, da x(A, K) in jeder der Variablen A, K wachsendund konkav ist mit positiver gemischter Ableitung ∂2x
∂A∂K. Bei A→∞ strebt dK
dA→ 0, was
bedeutet, dass bei Produktion mit schon sehr hohem Arbeitseinsatz eine Erhohung beimFaktor Arbeit praktisch keine Kapitaleinsparung mehr bringt (in diesem mathematischenModell des Produktionsvorgangs).
(5) Dieselbe Diskussion kann man offenbar fur beliebige Cobb–Douglas–Funktionen aufRn
>0
f(x1, . . . , xn) = c x s11 x s2
2 · . . . · x snn
mit Exponenten sj > 0 und Koeffizient c > 0 durchfuhren. Ist y = f(x1, . . . , xn) dasgegebene Niveau, so ergibt die Auflosung nach xk die explizite Substitutionsfunktion
xk =(
yc
)1/sk
x−s1/sk
1 · . . . · x−sk−1/sk
k−1 x−sk+1/sk
k+1 · . . . · x−sn/skn
als Funktion der Variablen xj, j 6= k, und des Niveaus y. Man sieht, dass xk Vielfacheseiner Potenzfunktion von xj mit negativem Exponenten ist, also sind die Isoquanten hierGraphen konvexer Funktionen und das Gesetz der abnehmenden Grenzrate der Substitu-tion ist erfullt. Das gilt fur beliebige positive Exponenten sj . Die Konkavitatseigenschaf-ten der Cobb–Douglas–Funktion f hangen dagegen von den Exponenten ab. Genau wenn0 < sj < 1 ist, hangt f(x1, . . . , xn) streng konkav von der Variablen xj ab, und genauwenn die Exponentensumme s = s1 + . . . + sn < 1 ist, hat man Konkavitat von f(x) alsFunktion der vektoriellen Variablen x ∈ Rn
≥0 (also Konkavitat auf jeder Strecke in Rn≥0;
das haben wir in 5.6 gezeigt).

Kap. 5, Abschnitt 5.7 679
Wie oft in der Okonomie, so ist es auch bei Substitutionsfunktionen sinnvoll, als ein vonEinheitenwahlen unabhangiges Maß der Anderung die Elastizitat zu betrachten.
DEFINITION: Ist xk(xj) eine implizit durch die Gleichung
f(x1, . . . , xj, . . . , xk(xj), . . . , xn) = y (bei konstanten xi fur j 6= i 6= k)
definierte “Substitutionsfunktion”, so heißt ihre Elastizitat die implizite Elastizitat vonxk bzgl. xj zur gegebenen Funktion f und dem Niveau y und wird notiert
µ(f ; y)xk,xj
(x) = µxk,xj(x) := εxk
(xj) =
xjdxk
dxj(xj)
xk(xj).
Diese implizite Elastizitat wird auch Elastizitat der Substitutionsfunktion oder Ela-stizitat der technischen Substitution genannt.
DISKUSSION: 1) Okonomische Bedeutung : Die implizite Elastizitat µxk,xj(x) gibt
an, um wieviel Prozent der Variablenwert xk (ungefahr) geandert werden muss, wennxj um 1% erhoht wird und das Niveau aufrecht erhalten werden soll. Wie immer imZusammenhang mit Elastizitaten wird hier naturlich angenommen, dass die Variablen xj
und xk nur positive Werte annehmen. Die Abhangigkeit der impliziten Elastizitat vonden anderen Variablen xi, j 6= i 6= k, wird oft nicht notiert, ebenso nicht die Abhangigkeitvom Niveau y und von der zu Grunde liegenden Funktion f , durch welche die Substitu-tionsfunktion implizit definiert ist.
(2) Drucken wir die Grenzrate der Substitution mit der Formel fur die Ableitung im-pliziter Funktionen durch partielle Ableitungen von f aus (vgl. (1) der vorangehendenBeispiele) und erweitern mit f(x), unterstellt dass f eine positive Funktion ist, so ergibtsich:
µxk,xj(x) = −
xj
f(x)∂f∂xj
(x)
xk
f(x)∂f∂xk
(x)= −εf,xj
(x)
εf,xk(x)
( xk = xk(xj) ).
• Die implizite Elastizitat von xk bzgl. xj ist das Negative des Quotienten der parti-ellen Elastizitaten von f bzgl. xj und xk .
Sind die partiellen Elastizitaten von f positiv, d.h. f(x1, . . . , xn) hangt wachsend vonjeder einzelnen Variablen ab, so sind also die impliziten Elastizitaten negativ, d.h. manmuss xk vermindern bei (geringer) Erhohung von xj , um das Niveau aufrecht zu erhalten.
(3) Weil die Substitutionsfunktionen xk(xj) durch die Bedingung konstanten Niveausf(x1, . . . , xj, . . . , xk(xj), . . . , xn) = y definiert sind, hangen sie nur von den Niveaumengenvon f ab.
• Die impliziten Elastizitaten µxk,xj(x) hangen nur von der Niveaumenge der definie-
renden Funktion f durch den Punkt x ab.
• Zwei Funktionen mit denselben Niveaumengen haben folglich auch gleiche impliziteElastizitaten an allen Stellen, wo diese definiert sind.

680 Mathematik fur Wirtschaftswissenschaftler
Ist ϕ eine streng monotone Funktion aus R, so haben f und die Verkettung ϕ◦f diesel-ben Niveaumengen (zum Niveau y bei f und zum Niveau ϕ(y) bei ϕ ◦ f ). Umgekehrtist z.B. auf einem konvexen Definitionsbereich jede stetige Funktion g mit denselben Ni-veaumengen wie die stetige reelle Funktion f von der Form g = ϕ ◦ f mit einer strengmonotonen stetigen Funktion ϕ auf R.
BEISPIEL: Wir berechnen die impliziten Elastizitaten einer Cobb–Douglas–Funktion
f(x1, . . . , xn) = c x s11 x s2
2 · . . . · x snn
auf Rn>0 mit Koeffizient c > 0 und Exponenten s1, . . . , sn ∈ R. Die partiellen Elasti-
zitaten sind εf,xj(x) =
xj
f(x)∂f∂xj
(x) = sj konstant, also gilt auch
µxk,xj(x) = −εf,xj
(x)
εf,xk(x)
= −sj
skkonstant.
• Die impliziten Elastizitaten µxk,xjeiner Cobb–Douglas–Funktion sind konstant gleich
dem Negativen Quotienten −sj/sk der entsprechenden Exponenten.
Der Wert der Elastizitat hangt also auch nicht ab von den Werten der anderen festge-haltenen Variablen xi und auch nicht vom Niveau y zu dem die impliziten Elastizitatendefiniert werden. Wir werden noch sehen, dass die Konstanz der impliziten Elastizitatendie Cobb–Douglas–Funktionen unter den homogenen Funktionen auf Rn
>0 kennzeichnet(“CD–Theorem”, s.u.).
Im Zusammenhang mit Substitutionsfunktionen gibt es noch eine andere in der Wirt-schaftsmathematik verwendete Elastizitat, die aber nicht das Anderungsverhalten derSubstitutionsfunktionen selbst beschreibt, sondern das ihrer Ableitung, also der Grenz-rate der Substitution. Es handelt sich dabei um eine Große zweiter Ableitungsordnung,welche die Degressivitat der Substitutionsfunktionen unabhangig von Einheiten misst.
DEFINITION und DISKUSSION; (1) Wir betrachten wieder eine Funktion rk(xj),die implizit definiert ist durch eine Gleichung f(x1, . . . , xj, . . . , xk(xj), . . . , xn) = y. Mitder Substitutionselastizitat oder Elastizitat der Substitution ist dann in der Wirt-schaftsmathematik (unglucklicherweise entgegen dem unmittelbaren Wortsinn) nicht dieElastizitat µxk,xj
dieser Substitutionsfunktion gemeint, sondern eine kompliziertere Großeσxk,xj
zweiter Ableitungsordnung, fur die in der Literatur mysteriose Formeln angegebenwerden wie z.B.
σxk,xj=
d(xk
xj)/
xk
xj
d(dxk
dxj)/
dxk
dxj
=
dxk
dxj
xk
xj
·d(xk
xj)
d(dxk
dxj)
oder
σxk,xj=
d(xk
xj)/
xk
xj
d(
∂f/∂xj
∂f/∂xk
)/∂f/∂xj
∂f/∂xk
.
Gemeint ist damit die relative Anderung des Quotienten xk/xj der ”Inputfaktoren”im Verhaltnis zur relativen Anderung der Grenzrate der Substitution dxk
dxj. Man fasst
also die Grenzrate der Substitution als unabhangige Variable auf und den Quotientenxk/xj als Funktion dieser Variablen; die Elastizitat dieser Funktion ist dann σxk,xj
. Siesollte also Elastizitat des Faktorverhaltnisses bzgl. der Substitutionsgrenzrateheißen. Die Substitutionselastizitat gibt (naherungsweise) die prozentuale Anderung desFaktorverhaltnisses xk/xj an, wenn der Punkt (xj, xk) auf der Isoquante mit der Glei-chung f(. . . , xj, . . . , xk, . . .) = y (bei c.p.–Bedingung) so verschoben wird, dass die abso-lute Steigung |dxk
dxj| der Isoquante um 1% zunimmt.

Kap. 5, Abschnitt 5.7 681
Hierbei wird angenommen, dass dxk
dxjwie ublich negativ ist; also ist |dxk
dxj| = ∂f
∂xj/ ∂f
∂xkdas
Verhaltnis der Grenzfunktionswerte bzgl. xj und xk. Da bei Erhohung der absolutenSteigung auch der Quotient xk/xj vergroßert wird, ist σxk,xj
dann positiv. (In der Lite-
ratur findet sich auch die Konvention, dass das umgekehrte Verhaltnis ∂f∂xk
/ ∂f∂xj
um 1%
zu erhohen ist; wegen 1.01 ≈ 1/0.99 lauft das auf eine Erniedrigung von |dxk
dxj| um 1%
hinaus, was zu einem negativen Vorzeichen der Substitutionselastizitat fuhrt.)
Es erscheint vielleicht abwegig, die direkt nicht beeinflussbare Grenzrate der Substitutionhier als unabhangige Variable zu betrachten. Einleuchtender ware es, das unmittelbar be-einflussbare Verhaltnis xk/xj der Inputfaktoren als unabhangige Variable zu nehmen unddie absolute Substitutionsgrenzrate |dxk
dxj| als Funktion davon aufzufassen. Aber das lauft
fast auf dasselbe hinaus, weil dies dann die Umkehrfunktion der oben betrachteten Funk-tion ist und ihre Elastizitat das Reziproke der oben definierten Substitutionselastizitat.
2) Um die Definition der Substitutionselastizitat in mathematisch akzeptabler Weise ab-zufassen, nehmen wir an, dass eine in der (xj, xk)–Ebene betrachtete Isoquantenlinie alsKurve (xj(t), xk(t)) mit einem reellen Parameter t parametrisiert ist (wobei alle xi mitj 6= i 6= k konstant gehalten werden). Dann ist der Faktorquotient xk(t)/xj(t) eine Funk-tion von t und die Substitutionsgrenzrate dxk
dxj(xj(t)) ebenfalls. Die Anderungen dieser
Funktionen ddt
xk(t)xj(t)
, ddt
(dxk
dxj(xj(t))
)als Funktionen des Parameters t sind dann zwar von
der Wahl Parametrisierung abhangig, nicht aber der Quotient dieser Anderungen; dennbei einem Wechsel der Parametrisierung durch eine Parametertransformation t 7→ τ(t)kurzt sich der bei Ableitung nach τ statt nach t entstehende Faktor dt
dτim Quotien-
ten heraus. Daher ist auch der Quotient der relativen Anderungen unabhangig von derParametrisierung und gibt die gewunschte Definition der Substitutionselastizitat:
σ(f ; y)xk,xj
(x) :=
ddt
(xk(t)xj(t)
)/xk(t)xj(t)
ddt
(dxk
dxj(xj(t))
)/dxk
dxj(xj(t))
(xj = xj(t), xk = xk(t),
f(. . . , xj(t), . . . , xk(t), . . .) = y,
xi konstant fur j 6= i 6= k.)
Vorausgesetzt ist dabei naturlich xj > 0, xk > 0, dxk
dxj6= 0 und d
dtdxk
dxj(xj(t)) 6= 0,
d.h. die Grenzrate der Substitution muss eine streng monotone Funktion des Parame-ters t mit nirgends verschwindender Ableitung sein. Nehmen wir t = xj als Parame-
ter, also die Graphenparametrisierung der Isoquante, so ergibt sich wegen ddxj
xk(xj)
xj=
1x 2
j
[xj
dxk
dxj(xj)− xk(xj)
]die Formel
σxk,xj(x) =
xj
(dxk
dxj(xj)
)2
− xkdxk
dxj(xj)
xjxkd2xk
dx 2j
(xj)( xk = xk(xj) ),
was mit x, y(x) stattxj, xk(xj) ganz kurz so geschrieben wird:
σy,x(x, y) =xy′2 − yy′
xyy′′( f(x, y) = const ).
(Dabei ist hier y die abhangige Variable, also die Substitutionsfunktion, und naturlichnicht das konstant gehaltene Produktionsniveau.) Voraussetzung ist neben xj > 0, xk > 0

682 Mathematik fur Wirtschaftswissenschaftler
dabei wieder, dass dxk
dxj6= 0 und d2xk
dx 2j6= 0 sind. Bei streng abnehmenden Substitu-
tionsfunktionen, die dem Gesetz der abnehmenden Grenzrate der Substitution d2xk
dx 2j
> 0
genugen, sind diese Voraussetzungen gegeben.
Man sieht an diesen Formeln fur die Substitutionselastizitat, dass es sich um eine Großezweiter Ableitungsordnung handelt; denn es gehen ja die zweiten Ableitungen der Substi-tutionsfunktion ein.
3) Der in 2) angegebene Ausdruck fur die Substitutionselastizitat ist zur Berechnung ge-eignet, wenn die Substitutionsfunktion xk(xj) explizit bekannt ist. Da diese Funktion aberimplizit durch f(. . . , xj, . . . , xk(xj), . . .) = y definiert ist, wird das normalerweise nichtder Fall sein. Deshalb brauchen wir noch eine Formel fur die Substitutionselastizitat, inder nur partielle Ableitungen der definierenden Funktion f auftreten. Diese lasst sichdurch Differentiation der Formel fur die Grenzrate der Substitution (Abbleitung implizitdefinierter Funktionen)
dxk
dxj(xj) = −
∂f∂xj
(xj, xk(xj))
∂f∂xk
(xj, xk(xj))
herleiten (wobei die festgehaltenen Variablen xi nicht notiert sind):
d2xk
dx 2j
= −∂f∂xk
(∂2f∂x 2
j+ ∂2f
∂xk∂xj
dxk
dxj
)− ∂f
∂xj
(∂2f
∂xj∂xk+ ∂2f
∂x 2k
dxk
dxj
)(
∂f∂xk
)2= −
(∂f∂xk
)2∂2f∂x 2
j− 2 ∂f
∂xk
∂f∂xj
∂2f∂xk∂xj
+(
∂f∂xj
)2∂2f∂x 2
k(∂f∂xk
)3 ,
wobei wir zuletzt die vorangegangene Formel fur dxk
dxjeingesetzt haben. Auszuwerten ist
der letzte Ausdruck naturlich an der Stelle x = (x1, . . . , xj, . . . , xk(xj), . . . , xn). Setzt man
die fur dxk
dxjund d2xk
dx 2j
gefundenen Ausdrucke nun in die Formel fur σxk,xj(x) in 3) ein, so
erhalten wir das gewunschte Resultat:
σ(f ; y)xk,xj
(x) =
− ∂f∂xk
[xj
(∂f∂xj
)2
− xk
(∂f∂xk
)2]
xjxk
[(∂f∂xk
)2∂2f∂x 2
j
− 2∂f∂xk
∂f∂xj
∂2f∂xk∂xj
+
(∂f∂xj
)2∂2f∂x 2
k
] ,
wobei xk = xk(xj) und in die partiellen Ableitungen von f sowie bei σxk,xj(x) naturlich
wieder die Stelle x = (x1, . . . , xj, . . . , xk(xj), . . . , xn) einzusetzen ist. Die Voraussetzungenfur die Definition der Substitutionselastizitat sind erfullt, wenn die partiellen Ableitungenerster Ordnung ∂f
∂xj, ∂f
∂xknicht Null sind (oft wird Positivitat vorausgesetzt) und wenn
der Nenner in dieser Formel nicht verschwindet.
5) Weil die Substitutionselastizitaten durch Ableitungen erster und zweiter Ordnungeiner Parametrisierung der Isoquantenkurve berechnet werden, gilt naturlich fur sie wiebei den impliziten Elastizitaten:
• Die Substitutionselastizitaten σ(f ; y)xk,xj(x) hangen nur von der Niveaumenge der defi-
nierenden Funktion f durch den Punkt x ab.

Kap. 5, Abschnitt 5.7 683
Man darf bezweifeln, dass Ausdrucke, welche die zweiten Ableitungen einer im Allge-meinen gar nicht genau bekannten okonomischen Funktion enthalten wie in den obigenFormeln fur die Substitutionselastizitaten, uberhaupt noch ein sinnvolles mathematischesModell okonomischer Abhangigkeiten ergeben konnen in dem Sinne, dass noch ein Bezugzu realen Gegebenheiten vorhanden ist. Aber die Substitutionselastizitat ist keine Erfin-dung der Mathematiker, sondern der theoretisch arbeitenden Okonomen!
BEISPIELE: (1) Fur eine Cobb–Douglas–Funktion auf Rn>0,
f(x1, . . . , xn) = c x s11 x s2
2 · . . . · x snn ,
mit Koeffizient c > 0 und Exponenten sj ∈ R hatten wir oben die Substitutionsfunktio-nen zum Niveau y explizit berechnet:
xk =(
yc
)1/sk
x−s1/sk
1 · . . . · x−sk−1/sk
k−1 x−sk+1/sk
k+1 · . . . · x−sn/skn .
Daraus ergibt sich
dxk
dxj= −sjxk(xj)
skxj, d2xk
dx 2j
= xk(xj)sj
sk
(1 +
sj
sk
)1x 2
j
und mit Einsetzen in die oben fur die Substitutionselastizitat hergeleitete Formel
σxk,xj(x) =
xj
(dxk
dxj(xj)
)2
− xkdxk
dxj(xj)
xjxkd2xk
dx 2j
(xj)=
x2k
xj
(sj
sk
)2
+x2
k
xj
sj
sk
x2k
xj
sj
sk
(1 +
sj
sk
) = 1
sofern sj 6= 0, sk 6= 0 und sj + sk 6= 0 (was z.B. erfullt ist, wenn alle Exponenten positivsind). Ist sj = 0 oder sk = 0 oder sj + sk = 0, so ist die Substitutionsfunktion xk(xj)nicht definiert oder sie hat zweite Ableitung Null, so dass die Substitutionselastizitat nichterklart ist.
• Die Substitutionselastizitat einer Cobb–Douglas–Funktion ist konstant 1.
(Durch Einfuhrung der absoluten Substitutionsgrenzrate R = |dxk
dxj| als unabhangige Va-
riable, also R =sj
sk
xk(R)xj(R)
, sehen wir ubrigens direkt, dass xk/xj als Funktion von R
aufgefasst die Elastizitat 1 hat. Das entspricht dem ursprunglichen Konzept der Substi-tutionselastizitat.)
(2) Es gibt noch andere Funktionen als die Cobb–Douglas–Funktionen, deren Substitu-tionselastizitat konstant 1 ist. Ein Beispiel ist
f(x, y) =r ln y + as ln x + b
(r, s ∈ R 6=0).
Hierfur gilt f(x, y) = z ⇐⇒ r ln y + a = z(s ln x + b) ⇐⇒ yrea = xzsecb ⇐⇒y = e(cb−a)/rxcs/r, und diese Funktion y(x) hat Substitutionselastizitat 1 bei Niveau
z 6= 0; denn fur R = y′(x) = csr
y(x)x
hat der Quotient y(x)x
= rcs
R als Funktion von Rkonstante Elastizitat 1 . Diese Funktion ist keine Cobb–Douglas–Funktion, weil sie z.B.nicht homogen ist. Tatsachlich sind die Cobb–Douglas–Funktionen die einzigen homoge-nen Funktionen mit konstanten Substitutionselastizitaten 1 (siehe das “CD–Theorem”unten).

684 Mathematik fur Wirtschaftswissenschaftler
(3) Unter einer CES--Funktion versteht man eine Funktion f(x1, . . . , xn), die fur alleVariablenpaare xj, xk und alle Niveaus die gleiche konstante Substitutionselastizitat hat(Constant Elasticity of Substitution). Dazu gehoren außer den Funktionen in (1) und (2)noch weitere Funktionstypen, z.B. auf Rn
>0 die sog. speziellen CES--Funktionen
fp(x1, . . . , xn) = b [a0 + a1xp1 + a2x
p2 + . . . + anx
pn]1/p
mit a0 ≥ 0, aj > 0 fur j = 1 . . . n, b > 0 und einem reellen Exponenten 0 6= p 6= 1. DieNiveaugleichung fp(x1, . . . , xn) = y ist hier aquivalent mit
a0 + a1xp1 + a2x
p2 + . . . + anx
pn =
(yb
)p
,
also lauten die Substitutionsfunktionen
xk(xj) =
[ypb−p − a0
ak− a1
akxp
1 − . . .− ak−1ak
xpk−1 −
ak+1ak
xpk+1 − . . .− an
akxp
n
]1/p
=[const− aj
akxp
j
]1/p
,
und mit der Substitutionsgrenzrate R = |dxk
dxj(xj)| = ∂fp
∂xj(x)/
∂fp
∂xk(x) =
ajxp−1j
akxk(xj)p−1 > 0
ergibt sich fur den Quotienten
xk(xj)xj
=
(aj
akR
) 1p−1
=
(akRaj
) 11−p
.
Als Funktion von R aufgefasst ist der Quotient xk/xj daher Vielfaches einer Potenz-funktion R1/(1−p) und hat somit Elastizitat 1
1−p. Also gilt:
• Die spezielle CES–Funktion mit Exponent p ∈ R 6=0, 6=1 hat konstante Substitutions-
elastizitat 11− p
.
Fur p = 1 ist f1(x) = a0 +a1x1 + . . .+anxn affin linear, die Niveaulinien in der (xj, xk)–
Ebene sind Geraden, also gilt d2xk
dx 2j
= 0 und die Substitutionselastizitaten sind nicht
definiert. Bei p→ 0 strebt a−1/pfp(x) fur a = a0 + a1 + . . . + an gegen das geometrischeMittel (1a0x a1
1 x a22 ·. . .·x an
n )1/a (siehe 1.5), daher sind die Cobb–Douglas–Funktionen in ei-nem gewissen Sinn der Grenzfall der speziellen CES–Funktionen bei Exponent p→ 0. Mankann zeigen (siehe das “CES–Theorem” unten), dass die vom Grad 1 homogenen posi-tiven CES–Funktionen auf Rn
>0 mit negativen Substitutionsgrenzraten genau die obenangegebenen speziellen CES–Funktionen mit Koeffizient a0 = 0 sind.
CES–Funktionen und deren Grenzfall, die Cobb–Douglas–Funktionen (CD–Funktionen),werden in der Okonomie vielfach als “Ansatzfunktionen” zur mathematischen Modellie-rung abhangiger okonomischer Großen verwendet (Produktionsfunktionen, Nutzenfunk-tionen,. . . ). Ein tieferer Grund hierfur ist, dass diese Funktionen durch gewisse einfacheHomogenitatseigenschaften und Elastizitatseigenschaften charakterisiert werden konnen,so dass naheliegende Annahmen uber die okonomischen Funktionen notwendigerweise aufCES– bzw. CD–Ansatze fuhren. Wir geben diese Charakterisierungen in den beiden fol-genden — die Vorlesung abschließenden — Satzen an und fuhren anschließend auch die

Kap. 5, Abschnitt 5.7 685
Beweise, weil diese selten und gelegentlich falsch prasentiert werden. Die Beweise sindaber recht anspruchsvoll und fur okonomische Anwendungen nicht wichtig; dafur genugtes, die Aussagen der Satze zur Kenntnis zu nehmen. Wir setzen voraus, dass die betrach-teten Funktionen f im Folgenden genugend oft differenzierbar sind.
SATZ (“CD--Theorem”, Charakterisierung der Cobb--Douglas--Funktionen):
Fur Funktionen f : Rn>0 → R>0 mit n ≥ 2 sind aquivalent:
(i) f ist eine Cobb–Douglas–Funktion, also von der Form
f(x1, . . . , xn) = c x s11 x s2
2 · . . . · x snn ( c > 0, sj ∈ R);
(ii) f(x1, . . . , xn) ist partiell homogen (vom Grad sj) in jeder Variablen xj ;
(iii) die partiellen Elastizitaten von f sind konstant (gleich sj );
(iv) (unter der Zusatzvoraussetzung ∂f∂xj
(x) 6= 0 fur alle x und j und im Fall n = 2
außerdem, dass f nicht homogen vom Grad 0 ist)
f ist homogen (vom Grad s1 + . . . + sn) mit konstanten impliziten Elastizitaten;
(v) (unter der weiteren Voraussetzung, dass alle Substitutionselastizitaten definiert sind)
f ist homogen und alle Substitutionselastizitaten sind konstant gleich 1 .
SATZ (“CES--Theorem”; Charakterisierung der Funktionen mit konstanterElastizitat der Substitution): Die vom Grad 1 homogenen positiven CES–Funktionenauf Rn
>0 n ≥ 2) mit negativer Grenzrate der Substitution und mit konstanter Substitu-tionselastizitat 6= 1 sind genau die speziellen CES–Funktionen
f(x1, . . . , xn) = b [a1xp1 + a2x
p2 + . . . + anx
pn]1/p
mit a1, . . . , an ∈ R>0 und Exponent p ∈ R 6=0, 6=1. Die entsprechenden vom Grad s 6= 0homogenen CES–Funktionen sind dann die Funktionen der Form f(x)s.
Beweis des CD–Theorems : (i) =⇒ (ii) – (v) ergibt sich durch Nachrechnen (fur (ii), (iii)sehr einfach, fur (iv), (v) schon fruher erledigt). (ii) =⇒ (i) ist einfach:
f(x1, x2, . . . , xn) = x s11 f(1, x2, . . . , xn) = x s1
1 x s22 f(1, 1, x3, . . . , xn) = . . . = cx s1
1 x s22 ·. . .·x sn
n
mit c = f(1, 1, . . . , 1). (iii)⇐⇒ (ii) wissen wir aus der Differentialrechnung einer Verander-lichen: Die Elastizitat einer Funktion von einer Variablen ist konstant, genau wenn es sichum ein Vielfaches einer Potenzfunktion handelt.
(iv) =⇒ (i): Wir bemerken zunachst, dass die Niveaulinien von f in jeder zur (xj, xk)–Ebene parallelen Ebene Graphen uber beiden Achsen sind, weil die partiellen Ableitungenvon f nach Voraussetzung keinen Vorzeichenwechsel haben, so dass f(x1, . . . , xn) von je-der Variablen streng monoton abhangt. Da nun die Substitutionsfunktion xn(x1) konstan-
te Elastizitat x1
xn(x1)dxn
dx1(x1) = t hat, ist xn(x1)x
−t1 konstant (nach x1 ableiten). Ist µ
(f ; y)xn,x1
konstant gleich t, so sind also alle Niveaulinien von f in Ebenen parallel zur (x1, xn)–Ebene durch Gleichungen der Form xnx
−t1 = c gegeben und mit (x1, x2, . . . , xn−1, xn)
liegt daher (1, x2, . . . , xn−1, xnx−t1 ) in derselben Niveaumenge von f . Das bedeutet nun
f(x1, x2, . . . , xn) = f(1, x2, . . . , xnx−t1 ), wobei t 6= 0 ist, weil ∂f
∂x16= 0 vorausgesetzt ist.

686 Mathematik fur Wirtschaftswissenschaftler
Dieselbe Argumentation auf die Substitutionsfunktion xn(x2) angewandt gibt die weitereGleichung f(x1, x2, x3, . . . , xn) = f(1, 1, x3, . . . , xnx
−t1 x−t′
2 ) mit einem weiteren Exponen-ten t′ ∈ R 6=0. So fortfahrend gelangen wir zu f(x1, . . . , xn) = f(1, . . . , 1, xnx
tn−1
n−1 · . . . · xt11 )
mit gewissen Exponenten tj ∈ R 6=0. Da f homogen von einem Grad s vorausgesetztist, also Ersetzung von allen xj durch rxj den Funktionswert um den Faktor rs andert,muss f(1, . . . , 1, ξ) in der letzten Variablen ξ homogen vom Grad s/(t1 + . . . + tn−1 + 1)sein. (Der Nenner kann hier nicht = 0 sein, weil sonst f vom Grad Null homogen ware.Das ist im Fall n = 2 nach Voraussetzung ausgeschlossen. Im Fall n ≥ 3 waren dieNiveaulinien Ursprungsstrahlen, die Exponenten t, t′, . . . oben also alle gleich 1 und da-her tj = −1 und t1 + . . . + tn−1 + 1 = −(n−1) + 1 = 2 − n 6= 0.) Damit erhalten wirletztlich f(x1, . . . , xn) = cxs1
1 · . . . · xsnn mit c = f(1, . . . , 1) und mit den Exponenten
sj = stj/(t1 + . . . + tn−1 + 1) fur 1 ≤ j < n und sn = s/(t1 + . . . + tn−1 + 1).
Dass man in (iv) im Fall der Dimension n = 2 die vom Grad 0 homogenen Funktionenausschließen muss, zeigt f(x1, x2) = ϕ(x1/x2) mit einer streng monotonen Funktion ϕohne Ableitungsnullstelle. Die Niveaulinien sind dann Ursprungsstrahlen, die implizitenElastizitaten also alle gleich 1, die partiellen Ableitungen von f verschwinden auch nit-gends auf R2
>0, aber wenn man ϕ nicht als Vielfaches einer Potenzfunktion wahlt, so istf keine Cobb–Douglas–Funktion.
(v) =⇒ (i): Wir betrachten eine Substitutionsfunktion xk(xj). Nach Voraussetzung lasstsich xk/xj als Funktion der Substitutionsrate R = |dxk
dxj| auffassen und hat als Funktion
von R die konstante Elastizitat 1 . Das bedeutetxk(xj(R))
xj(R)= ±βR = β dxk
dxjmit einer
Konstanten β 6= 0 (weil xj > 0 und xk > 0 ist). Es folgtxj
xk(xj)dxk
dxj(xj) = 1
β, also hat die
Substitutionsfunktion konstante Elastizitat 1β. Wie oben folgt daraus xk(xj) = a x
1/βj mit
einer weiteren Konstanten a > 0. Zu jeder Niveaulinie in der (xj, xk)–Ebene gibt es alsoKonstanten a > 0, α 6= 0, so dass sie durch die Gleichung xkx
−αj = a beschrieben ist. An-
ders als oben konnten hier die Konstanten a, α aber vom Niveau und von den (fixierten)Werten der anderen Variablen xi, j 6= i 6= k, abhangen. Die hauptsachliche Schwierigkeitdes Beweises ist zu zeigen, dass solche Abhangigkeit tatsachlich nicht besteht.
Um die Notation zu vereinfachen, fixieren wir jetzt x4, . . . , xn (ohne diese Variablen zu no-tieren) und das Niveau y, so dass die Konstanten a, α nur in Abhangigkeit von x1, x2, x3
untersucht werden. Auf der Niveauflache {(x1, x2, x3) ∈ R3>0 : f(x1, x2, x3) = y} gilt
nun x1x−α(x3)2 = a(x3) sowie x1x
−β(x2)3 = b(x2) und drittens noch x2x
−γ(x1)3 = c(x1). Es
folgt x1 = xα(x3)2 a(x3) = x
β(x2)3 b(x2) und α(x3) ln x2 + ln a(x3) = β(x2) ln x3 + ln b(x2).
Differenziert man nach nach x3 und dann nach x2 (wenn f dreimal stetig differen-zierbar ist, so lasst sich zeigen, dass dies moglich ist), so folgt α′(x3)
1x2
= β′(x2)1x3
bzw. x3α′(x3) = x2β
′(x2). Da man x2 und x3 unabhangig voneinander in der Ni-veauflache verandern kann (nach dem Satz uber implizite Funktionen wegen ∂f
∂x16= 0 ),
muss x3α′(x3) ≡ κ konstant sein und auch x2β
′(x2) ≡ κ, also gilt α(x3) = κ ln x3 + µ,β(x2) = κ ln x2 − ν mit gewissen Konstanten µ, ν. Einsetzen weiter oben gibt dannµ ln x2 + ln a(x3) = −ν ln x3 + ln b(x2) bzw. ln a(x3)− ν ln x3 = ln b(x2) + µ ln x2, so dasswieder folgt ln a(x3)− ν ln x3 ≡ ρ konstant und ln b(x2) + µ ln(x2) ≡ ρ. Insgesamt erhalt
man x1 = xα(x3)2 a(x3) = xκ ln x3+µ
2 eρ+ν ln x3 . Hier setzen wir x2 = xγ(x1)3 c(x1) ein und be-
kommen mit Logarithmieren:
ln x1 = γ(x1)κ(ln x3)2 + (κ ln c(x1) + µγ(x1) + ν) ln x3 + µ ln c(1) + ρ .
Diese Gleichung kann bei festem x1 und variierendem x3 (das geht in der Niveaumen-

Kap. 5, Abschnitt 5.7 687
ge, da man mit Anderung von x2 kompensieren kann) nur gelten, wenn die Koeffizien-ten vor (ln x3)
2 und vor ln x3 verschwinden. Insbesondere gilt also κ = 0 und damitx1 = xµ
2eρ+ν ln x3 = eρxµ2x
ν3. Resultat dieser Rechnungen ist also, dass α(x3) = µ von x3
unabhangig ist und dass auf der Niveauflache a(x3) = eρxν3 gilt mit konstanten ρ, ν.
Dies gilt nun analog aber auch fur x4, . . . , xn stattx3, also lautet die Gleichung der Ni-veaulinien in den Parallelen zur (x1, x2)–Ebene x1x
−µ2 = eσxν3
3 xν44 · . . . · xνn
n , wobei nunalle Exponenten nur noch vom Niveau y abhangen. Weil ein analoges Resultat auch furdie Niveaulinien in Parallelen zu anderen Koordinatenebenen gilt, folgt nun, dass die Ni-veaumenge von f zum Niveau y durch eine Gleichung x
t1(y)1 x
t2(y)2 · . . . · xtn(y)
n = eσ(y)
beschrieben wird. Dabei ist t1(y) + . . . + tn(y) 6= 0, sonst waren alle Ursprungsstrah-len Niveaulinien und die Substitutionelastizitaten nicht wie vorausgesetzt definiert. Ausdemselben Grund ist auch der Homogenitatsgrad s von f nicht Null. Dann aber nimmtf das Niveau y = 1 an, und mit t = t1(1) + . . . + tn(1), ϑ = σ(1), sj = stj(1)/t,
c = e−sϑ/t, r = eϑ/tx−s1/s1 · . . . · x−sn/s
n folgt wegen der Gultigkeit der Niveaugleichung(rx1)
t1(1) · . . . · (rxn)tn(1) = eσ(1) zum Niveau 1 fur (rx1, . . . , rxn) schließlich die Behaup-tung, mit der der Beweis des CD–Theorems beendet ist:
f(x1, . . . , xn) = r−sf(rx1, . . . , rxn) = r−s · 1 = c xs11 · . . . · xsn
n .
Wenn man in (iv) bzw. (v) die Homogenitat von f nicht voraussetzt, so zeigt der Beweis
immer noch, dass die Niveaumengen durch Gleichungen xt1(y) · . . . ·xtn(y)n = eσ(y) mit Expo-
nentensumme 6= 0 beschrieben sind, also durch lineare Gleichungen fur ln x1, . . . , ln xn .Weil f(x) fur x ∈ Rn
>0 definiert ist, also (ln x1, . . . , ln xn) beliebig in Rn variiert,und weil sich verschiedene Niveaumengen nicht schneiden, mussen die Koeffizienten-vektoren (t1(y), . . . , tn(y)) Vielfache λ(y)(s1, . . . , sn) desselben Vektors (s1, . . . , sn) mits1 + . . . + sn 6= 0 sein, so dass die Niveau–Gleichung auch x s1
1 · . . . · x snn = eσ(y)/λ(y)
geschrieben werden kann. Daher ist dann f(x) = ϕ(x s11 · . . . · x sn
n ) Verkettung der strengmonotonen Funktion ϕ mit ϕ−1(y) = eσ(y)/λ(y) und der CD–Funktion x s1
1 · . . . ·x snn . Um-
gekehrt hat jede solche Verkettung dieselben Niveaumengen wie die CD–Funktion, alsoauch konstante implizite Elastizitaten und Substitutionselastizitat konstant 1.
Beweis des CES–Theorems : Dass die speziellen CES–Funktionen zum Exponenten pkonstante Substitutionselastizitat 1
1−phaben fur p ∈ R 6=0, 6=1, haben wir schon fruher
vorgerechnet. Wir betrachten also nun f : Rn>0 → R>0 mit konstanter Substitutions-
elastizitat σ 6= 1. Bezuglich der Substitution von x1 durch x2 hat dann x2(x1(R))x1(R)
als
Funktion der Substitutionsgrenzrate R = |dx2
dx1(x1(R))| konstante Elastizitat σ, also gilt
x2(x1(R))x1(R)
= γRσ = γ|dx2
dx1(x1(R))|σ mit einer evtl. vom betrachteten Niveau y und von
x3, . . . , xn abhangigen Konstanten γ > 0. Wir erhalten damit eine Differentialgleichung
dx2
dx1(x1) = ±γ−1/σ
(x2(x1)
x1
)1/σ
, die mit Trennung der Variablen gelost werden kann (siehe
4.8):±x2(x1)
−1/σ dx2
dx1(x1) = γ−1/σx
−1/σ1 ⇐⇒ ±x2(x1)
1−1/σ = γ−1/σx1−1/σ1 + β
mit einer weiteren evtl. von y, x3, . . . , xn abhangigen Konstanten β. Kurzen wir p = 1− 1σ
ab und nutzen die (okonomisch sinnvolle) Voraussetzung negativer Substitutionsgrenzra-ten dx2
dx1< 0 aus, so ergibt sich als Gleichung der betrachteten Niveaulinie
x p1 + ax p
2 = α ,
wobei a > 0 und α > 0 evtl. von y, x3, . . . , xn abhangen, der Exponent p aber nicht(weil die Substitutionselastizitat nach Voraussetzung auf allen Niveaulinien dieselbe ist).

688 Mathematik fur Wirtschaftswissenschaftler
Eine solche Gleichung bekommt man nun aber auch fur alle Paare (xj, xk) mit j 6= k.Damit kann man zeigen, dass der Koeffizient a nur vom Niveau y abhangen kann. Dazufixieren wir etwa x4, . . . , xn und verwenden die Gleichungen
x p1 + a(x3)x
p2 = α(x3) , x p
1 + b(x2)xp3 = β(x3) , x p
2 + c(x1)xp3 = γ(x1) ,
die fur alle Punkte der Niveauflache {(x1, x2, x3) ∈ R3>0 : f(x1, x2, x3) = y} simultan
gelten. Aus den beiden ersten Gleichungen folgt a(x3)xp2 − α(x3) = b(x2)x
p3 − β(x2), und
mit Ableiten nach x2 und nach x3 ergibt sich a′(x3)xp−12 = b′(x2)x
p−13 , also x1−p
3 a′(x3) =x1−p
2 b′(x2). Da x2 und x3 unter Einhaltung des Niveaus unabhangig variiert werdenkonnen (wegen des Satzes uber implizite Funktionen und ∂f
∂x16= 0, was aus dx2
dx1< 0 folgt),
muss x1−p3 a′(x3) ≡ pκ konstant sein und auch x1−p
2 b′(x2) ≡ pκ, also a(x3) = κx p3 +µ und
b(x2) = κx p2 + ν. Einsetzen in die obigen Gleichungen gibt µx p
2 − α(x3) = νx p3 − β(x2),
woraus wiederum folgt, dass νx p3 + α(x3) ≡ ω konstant ist und auch µx p
2 + β(x2) ≡ ω.
Damit lautet die erste Gleichung fur die Niveauflache x p1 +(κx p
3 +µ)x p2 = ω−νx p
3 . Setzenwir hier x p
2 aus der dritten Gleichung ein, so folgt
x p1 + (κx p
3 + µ)(γ(x1)− c(x1)xp3 ) = ω − νx p
3 .
Diese quadratische Gleichung fur x p3 gilt nun bei festem x1 fur variables x3 (weil das
Niveau durch kompensierende Variation von x2 gehalten werden kann), und das ist of-fenbar nur bei κ = 0 moglich. Somit hangt a(x3) = µ allenfalls vom Niveau y ab und esgilt α(x3) = ω − νx p
3 . Dasselbe Argument auf x4, . . . , xn statt x3 angewandt zeigt, dassdie Niveaumengen von f insgesamt durch eine Gleichung
(∗) a1(y)x p1 + a2(y)x p
2 + . . . + an(y)x pn = α(y)
beschrieben werden mit allein vom Niveau y abhangigen Koeffizienten aj(y) > 0 undα(y) > 0. Ist nun f homogen von einem Grad s 6= 0 (der Homogenitatsgrad darf nichtNull sein, weil sonst Ursprungsstrahlen Niveaulinien waren und die Substitutionselasti-zitaten undefiniert), so setzen wir aj = aj(1), α = α(1), r = α1/p(a1x
p1 + . . . + anx
pn)−1/p,
so erfullt (rx1, . . . , rxn) die Gleichung zum Niveau 1, also folgt
f(x1, . . . , xn) = r−sf(rx1, . . . , rxn) = r−s · 1 = α−s/p (a1xp1 + . . . + anx
pn)s/p ,
d.h. f ist die s–te Potenz einer speziellen CES–Funktion zum Exponenten p.
Wenn keine Homogenitat von f vorausgesetzt ist, so zeigt der Beweis immer noch, dassdie Niveaumenge von f zum Niveau y durch eine Gleichung der Form (∗) mit evtl. vony abhangigen a1(y), . . . , an(y), α(y) ∈ R>0 gegeben ist. Umgekehrt hat jede Funktionmit solchen Niveaumengen konstante Substitutionselastizitat 1
1−p, weil jede ihrer Niveau-
mengen ja auch eine Niveaumenge einer speziellen CES–Funktion zum Exponenten p ist.Weil hier (x p
1 , . . . , x pn) nur Rn
>0 und nicht ganz Rn durchlauft, folgt aber nicht, dassalle Koeffizientenvektoren (a1(y), . . . , an(y)) Vielfache desselben Vektors sind, und des-halb muss f auch nicht Verkettung einer streng monotonen Funktion mit einer speziellen
CES–Funktion sein. Zum Beispiel hat f(x1, x2) = x p2 +√
x 2p2 + x p
1 die Niveaugleichungen
x p1 +2yx p
2 = y2, ist also CES–Funktion, aber nicht Verkettung einer monotonen Funktionmit einer speziellen CES–Funktion zum Exponenten p ∈ R 6=0, 6=1.
Damit beenden wir die Diskussion des CES–Theorems (und auch das Skript zu dieser Vorlesung).