
Multi-Class SVM Learning (de)
22
PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN VOLKER GERDES & SVEN ESMARK Zusammenfassung. Der nachfolgende Text umfaßt die L¨ osung des letzten Aufgabenblatts des Mustererkennungspraktikums. Die Aufgaben drehen sich um Support-Vektor-Maschinen: sie umfassen ihre Implementierung, die optimale Parameterwahl und Klassifika- tionsstrategien von mehr als zwei Datenklassen. Vorangestellt wird eine Zusammenfassung der Theorie der Support-Vektor-Maschinen. Date : 30. August 2002. 1
Transcript of Multi-Class SVM Learning (de)

PRAKTIKUMSBERICHT ZUSUPPORT-VEKTOR-MASCHINEN
VOLKER GERDES & SVEN ESMARK
Zusammenfassung. Der nachfolgende Text umfaßt die Losungdes letzten Aufgabenblatts des Mustererkennungspraktikums. DieAufgaben drehen sich um Support-Vektor-Maschinen: sie umfassenihre Implementierung, die optimale Parameterwahl und Klassifika-tionsstrategien von mehr als zwei Datenklassen. Vorangestellt wirdeine Zusammenfassung der Theorie der Support-Vektor-Maschinen.
Date: 30. August 2002.1

2 VOLKER GERDES & SVEN ESMARK
1. Grundzuge der SupportVektorMaschinen
1.1. Ubersicht. SVM sind eine Moglichkeit des verteilungsfreien Ler-nens in der Mustererkennung.
Dazu werden Trainingsdaten (y1, z1), ..., (yl, zl), zi ∈ Rn, yi ∈ {−1, 1}
in einen hoherdimensionalen Merkmalsraum (y1, x1), ..., (yl, xl), xi ∈ H,(etwa H = R
N , N � n), xi = ϕ(zi) abgebildet und dort versuchsweiselinear separiert, wobei probiert wird, einen großtmoglichen Abstandder Datenpunkte zu der Trennebene zu erzielen. Dieser Ansatz erlaubtes, wie spater noch genauer erlautert wird, den Generalisierungsfehlerrelativ gering zu halten.
1.2. Linear separierbarer Fall. Wenn die Daten linear separierbarsind, dann ist die optimale Hyperebene (w0, b0), die den großten Ab-stand zu allen Trainingspunkten xi in Abhangigkeit von den Nebenbe-dingungen
(1.1) yi[(xi · w) + b] ≥ 1, i = 1...l
hat, bestimmt durch das Minimum der quadratischen Form
(1.2) Q(w) = (w · w).
Wendet man auf dieses Optimierungsproblem die Lagrangemethode an,so erhalt man die Lagrangefunktion
(1.3) L(w, b, α) =1
2‖w‖2 −
l∑
i=1
αi(yi · ((xi · w) + b) − 1)
mit den Lagrangemultiplikatoren αi ≥ 0. Dabei wird L bezuglich derPrimarvariablen w und b maximiert und bezuglich der dualen Variablenαi minimiert. Am gesuchten Sattelpunkt verschwinden also die Ablei-tungen:
(1.4)∂
∂bL(w, b, α) = 0,
∂
∂wL(w, b, α) = 0.
Daraus ergibt sich
(1.5)
l∑
i=1
αiyi = 0, sowie w =
l∑
i=0
αiyixi.
Der Losungsvektor ist also eine Linearkombination der Trainingsvek-toren xi, deren Langrangemultiplikator αi > 0 ist und dieser Fall trittnach den komplementaren Karush-Kuhn-Tucker Bedingungen (KKT)
(1.6) αi[yi · ((xi · w) + b) − 1)] = 0, i = 1, ..., l

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 3
immer dann ein, wenn xi den freibleibenden Grenzstreifen beruhrt, derdie Losungsebene umgibt (im folgenden Grenze genannt). Nur dieseTrainingsdaten sind losungsrelevant und werden Supportvektoren ge-nannt. Setzt man (1.5) in L ein, dann verschwinden die Primarvariablenund man erhalt das duale Wolf-Optimierungsproblem: finde αi, die
(1.7) W (α) =l∑
i=1
αi −1
2
l∑
i,j=1
αiαjyiyj(xi · xj)
maximieren, wobei
(1.8) αi ≥ 0, i = 1, ..., l, undl∑
i=1
αiyi = 0
die Nebenbedingungen sind. Die Klassifikatorfunktion kann nun folgen-dermaßen formuliert werden:
(1.9) f(x) = sgn
(
l∑
i=1
yiαi(x · xi) + b
)
,
wobei b durch (1.6) bestimmt wird.
1.3. Nicht linear separierbarer Fall. Wenn die Daten nicht linearseparierbar sind, dann weicht man die Nebenbedingungen (1.1) etwasauf, indem einzelne Trainingsdaten falsch klassifiziert werden durfen,dann aber zu einem erhohten Kostenfunktional beitragen: minimiere
(1.10) Φ(ξ) = Cl∑
i=1
θ(ξi) + (w · w)
mit den Nebenbedingungen
(1.11) yi[(xi · w) + b] ≥ 1 − ξi, i = 1...l, ξi ≥ 0,
wobei C ”genugend großund
(1.12) θ(ξ) =
{
0 wenn ξ = 01 wenn ξ = 1
gewahlt wird. Da dieses Problem NP-vollstandig ist, optimiert manstattdessen folgende Approximation: minimiere
(1.13) Φ(ξ) = C
l∑
i=1
ξσi + (w · w)

4 VOLKER GERDES & SVEN ESMARK
unter denselben Nebenbedingungen mit kleinem σ ≥ 0. Aus analyti-schen Gesichtspunkten wird meistens σ = 1 gewahlt. Das duale Wolf-problem lautet dann: maximiere
(1.14) W (α) =l∑
i=1
αi −1
2
l∑
i,j=1
αiαjyiyj(xi · xj),
wobei
(1.15) 0 ≤ αi ≤ C, i = 1, ..., l, undl∑
i=1
αiyi = 0
zu erfullen sind.Ersetzt man in (1.14) die xi durch die abgebildeten Daten des Ur-
sprungsraums ϕ(zi), so erhalt man
(1.16) W (α) =l∑
i=1
αi −1
2
l∑
i,j=1
αiαjyiyj(ϕ(zi) · ϕ(zj)).
Man kann nun in (1.16) ϕ(zi) ·ϕ(zj) durch eine Funktion K(zi, zj) sub-stituieren, solange es einen Hilbertraum H und eine Funktionϕ : R
n → H gibt, so daß K mit ϕ und dem inneren Produkt vonH kommutiert: K(zi, zj) = ϕ(zi) · ϕ(zj). Das Problem lautet dann:maximiere
(1.17) W (α) =
l∑
i=1
αi −1
2
l∑
i,j=1
αiαjyiyjK(zi, zj)
zu denselben Nebenbedingungen wie unter (1.15).Das Mercer-Theorem gibt eine notwendige und hinreichende Be-
dingung an, wann zu einer vorgegebene Funktion K(u, v) ein Hilber-traum gefunden werden kann, in dem K(u, v) inneres Produkt ist:notwendig und hinreichend dafur, daß eine stetige und symmetrischeFunktion K(u, v) aus L2(C) eine Darstellung der Form K(u, v) =∑∞
m=1 amzm(u)zm(v) mit Koeffizienten am ≥ 0 hat, ist
(1.18)
∫ ∫
K(u, v)g(u)g(v) du dv ≥ 0
fur alle g ∈ L2(C). Diese Bedingung wird zum Beispiel von den haufigverwendeten Kernen
K(zi, zj) = [(zi · zj) + 1]d,(1.19)
K(zi, zj) = tanh(κ(zi · zj) + θ) oder(1.20)
K(zi, zj) = exp(−‖zi − zj‖2/(2σ2))(1.21)

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 5
erfullt, in (1.20) allerdings nur von einigen Parameterwerten von κ undθ.
Der Kern (1.19) beschreibt das Skalarprodukt in dem Merkmals-raum, der sich aus allen Monomen des Merkmalsdatums zi1 · zi2 · · · zis
bis zum Grad d, also s ≤ d, zusammensetzt.Trainieren SVM mit dem Kern (1.20), so sind sie aquivalent zu 2-
schichtigen Neuronalen Netzen mit variabler Anzahl der Neuronen inder ersten Schicht und variablen Gewichten aller Verbundvektoren.
Werden SVM mit dem Kern (1.21) bestuckt, so optimieren sie imGegensatz zu klassischen RBF-Netzen auch die Anzahl der Zentren,sowie die Zentren selbst.
Die allgemeine Klassifikatorfunktion fur Kerne lautet nun:
(1.22) f(z) = sgn
(
l∑
i=1
yiαiK(z, zi) + b
)
,
1.4. SVM-Algorithmen. Der SVM Ansatz fuhrt also zu der Auf-gabe, folgendes quadratisches Optimierungsproblem losen zu mussen:finde den l-dimensionalen Losungsvektor α, der
(1.23)1
2αT Qα − eT α
minimiert und dabei die Nebenbedingungen 0 ≤ αi ≤ C sowie yTα = 0einhalt (vergl. auch (1.14) und (1.15)). Dabei bezeichne
(1.24) qi,j = K(zi, zj)yiyj.
Zur Losung dieses Problems existieren verschiedene Verfahren, die al-lerdings eine explizite Anpassung an die Problemstellung erfordern,denn z.B. muß auf eine Zerlegung der Matrix Q ∈ l × l aus Speicher-platzgrunden bereits bei Problemstellungen mittlerer Große verzichtetwerden. Aus demselben Grund verbieten sich fur solche Falle auch jeneAlgorithmen, die permanent die Gesamtmatrix Q im Speicher haltenmussen, um jederzeit auf beliebige Eintrage qi,j zugreifen zu konnen,anstatt sie auszugsweise in Blocken zu benutzen.
Auch aus Grunden der Laufzeit nutzt man vielmehr die Tatsache,daß in den meisten SVM-Losungen ein Großteil der αi = 0 ist. Dennwurde man den Gradienten von (1.23) auf herkommliche Art bestim-men, mußte man l2 + O(l) Multiplikationen durchfuhren; wenn α hin-gegen s Nulleintrage hat, reduziert sich auch der Rechenaufwand aufls+o(l) Multiplikationen und man braucht nur den Zugriff auf s Spal-ten von Q. In vielen Fallen ist auch das noch zu viel und Vapnik schlug1979 ein Verfahren namens Chunking vor, bei dem die Problemstellungin kleine Unterprobleme aufgeteilt wird:

6 VOLKER GERDES & SVEN ESMARK
Vapnik-Algorithmus(1) Trainiere auf einigen der Trainingsvektoren.(2) Teste den Rest.(3) Wenn Testfehler auftreten, nimm die falsch klassifi-
zierten Trainingsvektoren zum Trainieren mit hinzuund wiederhole den Vorgang.
Dieser Algorithmus konvergiert zwar, allerdings nicht unbedingt ge-gen die Losung des allgemeinen QP Problems. Der sogenanntePlatt-Algorithmus, auch Sequential Minimal Optimization (SMO) ge-nannt, fuhrt den Vapnik-Ansatz am konsequentesten durch: er opti-miert in jedem Schritt immer nur zwei Lagrangeparameter. Der Vorteildabei ist, das dieser update-Schritt analytisch gelost werden kann undnicht numerisch-iterativ durchgefuhrt werden muß. Zusatzlich werdenzwei Heuristiken eingesetzt, die bestimmen, welche beiden Lagrange-parameter optimiert werden sollen.
Die außere Schleife des SMO Algorithmus bestimmt den ersten Para-meter: sie lauft zunachst uber alle Trainingsvektoren und verifiziert dieGultigkeit der KKT-Bedingungen. Sobald eine Verletzung der KKTauftritt, kann dieser Lagrangeparameter zur Optimierung herangezo-gen werden. Sein Partner wird in der inneren Schleife ausgesucht undso bestimmt, daß der erzielbare Optimierungsgewinn moglichst großausfallt.
Im Vergleich zu herkommlichen Projected Conjugated Gradient Chun-king (PCG Chunking) Verfahren, deren Speicherbenutzung zwischenlinearer und kubischer Abhangigkeit von den Trainingsdaten liegen,bedarf der SMO Algorithmus nur maximal quadratisch skalierendenSpeicheraufwandes.
Der Rechenaufwand des SMO wird vom Rechenaufwand fur dasLosen von SVMs begrenzt und SMO arbeitet am schnellsten bei li-nearen SVMs mit dunnbesetzten Trainingsdaten.
1.5. Fehlerabschatzung. Um den Generalisierungsfehler des Klassi-fikators abzuschatzen, konnte man versucht sein, den Ansatz derStructural Risk Minimization (SRM) zu verwenden. Dieser besagt: wennHi eine aufsteigende Folge von Hypothesenklassen mit VC-DimensionVC(Hi) = hi und µ irgendeine Datenverteilung auf S = X × {−1, 1}ist, dann kann man den Generalisierungsfehler von f ∈ Hi mit Wahr-scheinlichkeit 1 − δ abschatzen durch
(1.25) 2Ex(f) +1
l
(
8 log
(
2l
δ
)
+ 4hi log
(
2el
hi
))
,

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 7
wenn die l Trainingsdaten unabhangig nach µ gezogen wurden undh ≤ l erfullt ist. Ex(f) ist Fehler auf den Trainingsdaten.
Wurde man im hochdimensionalen Merkmalsraum mit allen affi-nen Ebenen arbeiten, ware diese Abschatzung bereits fur den Poly-nomialkern vom Grad 3 bei einer einfachen Zeichenerkennungsaufgabevon 16 × 16-großen Grauwertbildern unbrauchbar, da die Dimensiondes Raums und damit die VC Dimension der affinen Ebenen in derGroßenordnung 1 × 106 liegt.
SVM hingegen beschranken ihren Suchraum auf alle sogenanntenkanonischen Hyperebenen der Form |(xi · w) + b| ≥ 1, i = 1...l und mi-nimieren den Ebenenvektor w, maximieren also den Rand. Die Mengedieser kanonischen Hyperebenen hat bei beschranktem Ebenenvektor|w| ≤ A eine wesentlich kleinere VC-Dimension h, und zwar gilt:
(1.26) h ≤ min([R2A2], N) + 1,
wobei R den Umkreiskugelradius der Trainingsdaten angibt und N dieDimension des Merkmalsraums ist.
Definiert man nun HA als Menge aller kanonischen Hyperebenen mit|w| ≤ A, dann betreiben SVM - so konnte man glauben - SRM undliefern die Losung mit dem kleinsten Generalisierungsfehler.
Allerdings begeht man bei dieser Analyse einen Fehler: beim Be-weis der SRM wird vollige Unkenntnis der Trainingsdaten verlangt,zur Festsetzung der Struktur der obigen Hi benotigt man jedoch diesesa priori-Wissen.
Eine Modifikation des Ansatzes der SRM, die sogenanntedatenabhangige SRM, umgeht diese Art der Probleme und erlaubt es,die Hierarchie der Klassifikatoren nach Durchsicht der Daten aufzustel-len.
Dazu wird zunachst das Konzept der VC-Dimension erweitert: Sei Feine Menge reellwertiger Funktionen. Eine Punktmenge X wirdγ−shattered durch F genannt, wenn es reelle Zahlen rx, x ∈ X gibt,so daß fur alle Binarvektoren b, die von X indiziert werden, es eineFunktion fb ∈ F gibt mit:
(1.27) fb(x) =
{
≥ rx + γ wenn bx = 1≤ rx − γ ansonsten
Die fat-shattering Dimension fatF der Menge F ist eine Funktion derpositiven rellen Zahlen in die ganzen Zahlen, die γ den Umfang dergroßten γ−geshattereten Teilmenge von X zuordnet. Mit diesem Kon-zept laßt sich folgende Abschatzung beweisen:

8 VOLKER GERDES & SVEN ESMARK
Sei F eine Menge reellwertiger Funktionen. Wenn ein Klassifikatorsgn(f) ∈ sgn(F ) einen Rand der Große γ auf l unabhangig gezoge-nen Trainingsdaten x hat, dann ist mit Wahrscheinlichkeit 1 − δ derGeneralisierungsfehler nicht großer als
(1.28)2
l
(
h log2
(
8el
h
)
log2(32l) + log2
(
8l
δ
))
,
wobei h = fatF (γ/16). Weiterhin gilt mit Wahrscheinlichkeit 1− δ, daßjeder Klassifikator sgn(f) ∈ sgn(F ) einen Generalisierungsfehler kleinerals
(1.29) b/l +
√
2
l(h log(34el/h)log2(578l) + log(4/δ))
hat, wobei b die Anzahl der Trainingsdaten darstellt, deren Rand klei-ner als γ ist.
Unabdingbar fur die Fehlerabschatzung der Klassifikatoren ist nunwieder eine Abschatzung der fat shattering Dimension der Klassifikato-renmenge: bezeichne R wieder den Umkreiskugelradius der Trainings-daten und sei F die Klassifikatorenmenge, dann ist
(1.30) fatF (γ) ≤
(
R
γ
)2
.
Zusammenfassend ergibt dies folgende Abschatzung: Es gibt eine Kon-stante c, so daß fur alle Trainingsdatenverteilungen µ der Generalisie-rungsfehler eines Klassifikators, der einen Rand großer als γ besitzt,mit Wahrscheinlichkeit 1 − δ kleiner ist als
(1.31)c
l
(
R2
γ2log2 l + log(1/δ)
)
ist. Fur beliebige Klassifikatoren ist der Generalisierungsfehler kleinerals
(1.32) b/l +
√
c
l
(
R2
γ2log2 l + log(1/δ)
)
.

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 9
2. SVMs und Mehrklassenprobleme
Eine Support Vektor Maschine ermoglicht die binare Klassifikationder Daten durch eine Hyperebene im Merkmalsraum. Es existiert kei-ne naturliche Erweiterung des Konzeptes fur die Diskriminierung vonmehr als 2 Klassen.
Typischerweise werden deshalb zum Aufbau eines Multi-Klassen Klas-sifikators (K ≥ 2) einzelne binare Klassifikatoren zur Entscheidungs-findung kombiniert.
Im Rahmen des Praktikums sollen drei alternative Strategien evalu-iert werden:
2.1. Einer gegen alle. Es werden K einzelne SVMs trainiert, die je-weils zwischen der ihnen zugeordneten Klasse k und den restlichenDaten (der Klassen i 6= k) unterscheiden.
Zur Klassifikation eines unbekannten Datenpunktes z wird fur jedeeinzelne der K SVMs entweder der euklidische Abstand zur Hyperebe-ne im Merkmalsraum oder alternativ die nicht durch ‖w‖1 normierteGroße
(2.1) dk(z) = wk · ϕ(z) =
l∑
i=1
αi,kyi,kK (z, zi) + bk,
ausgewertet.2 Der Datenpunkt z wird dann derjenigen Klasse zugespro-chen, bei der der Abstand zwischen z und Hyperebene am großten istbzw. alternativ der Klasse f(z) = arg max
k(dk(z)) zugewiesen
Sowohl die Leistung der normierten als auch der unnormierten Ver-sion soll untersucht werden.
2.2. Binare Entscheidungsbaume. Bei einem binaren Entscheidungs-baum ist jedem Blatt des Baumes eindeutig eine der K Klassen zuge-ordnet. Innere Knoten lernen die Entscheidung zwischen den durchihre beiden Teilaste definierten Klassenmengen.3
Zur Klassifikation eines Datenpunktes z wird nun der Entscheidungs-baum von der Wurzel bis zu einem Blatt durchlaufen, wobei an jedemzu passierenden Knoten eine fur die Diskriminierung der beiden Klas-senmengen trainierte SVM ausgewertet wird.
1Entgegen anders lautender Behauptungen ist ‖w‖ =√
〈w, w〉 =√
∑l
i=1α2
i · K (zi, zi)2Dies entspricht dem Abstand zur Entscheidungsgrenze gemessen als Vielfaches
des Margins3D.h. alle an dem jeweiligen Ast hangenden Blatter (=Klassen)

10 VOLKER GERDES & SVEN ESMARK
Bei der Festlegung einer gunstigen Partitionierung (bzw. Klassen-zuordnung der Blatter) sollte berucksichtigt werden, dass wahrend derKlassifikation hoher liegende Blatter haufiger besucht werden und keinespateren Korrekturen einer Entscheidung moglich sind.
Somit liegt es nahe, die gesuchte Partitionierung durch ein greedy-Verfahren zu bestimmen: Ausgehend von der Wurzel wird die Mengeder (verbleibenden) Klassen an jedem Knoten so in 2 Teile partitioniert,dass die bestmogliche SVM-Trennbarkeit gewahrleistet wird.
Da jedoch aufgrund des hohen Trainingsaufwandes der SVMs die di-rekte Validierung aller moglichen Partitionierungen ausscheidet4, sollein an das Fischerkriterium angelehtes Gutekriterium verwendet wer-den, um die Trennbarkeit im Merkmalsraum abzuschatzen: Der Sepera-bilitatsindex s12 vergleicht den mittleren Abstand der Punkte zwischen
den verschiedenen Klassenmengen mit dem mittlerem Abstand inner-
halb der beiden Klassenmengen uber das durch den Kern K gegebeneSkalarprodukt im Merkmalsraum:
Seien ZS und ZT die Menge der Datenvektoren der KlassenmengenS bzw. T , und
dS,T = 1|ZS ||ZT |
∑
zi∈ZS
∑
zj∈ZTK (zi − zj, zi − zj)
der mittlere Abstand der Datenmengen, so ist der Seperabilitatsindex
definiert als sS,T =dS,T
dS,S ·dT,T.5
2.3. Fehlertolerante Ausgabecodes (Hammingcodes). Fehlerto-lerante Ausgabecodes gehoren zur allgemeinen Klasse der verteilten
Ausgabecodes. Dabei wird jede Klasse durch eine eindeutige Binarsequenzb = 〈b1, . . . , bn〉 aus n Bits codiert. Fur jedes dieser Bits wird ein Klas-sifikator fi trainiert, der die Klassen mit bi = 0 von den Klassen mitbi = 1 trennt. Zur Klassifikation eines unbekannten Datenpunktes zwird durch Auswertung der n Klassifikatoren der zugehorige Binarcodeb(z) = 〈f1(z), . . . , fn(z))〉 generiert und mit Hilfe eines Distanzmaßesdie Klasse durch den ahnlichsten Binarcode bestimmt.
In der Anwendung haben die Bits haufig eine semantische Bedeutung
und jedes Bit entscheidet uber das Vorhandensein bzw. nicht Vorhan-densein eines vom Designer des Klassifikators ausgewahlten Merkmals.Auswahlkriterien sind z.B. leichte Erkennbarkeit und gute Diskriminie-rung zwischen den Klassen.
Eine alternative Herangehensweise sind die Fehlertoleranten Ausga-
becodes. Die 2 Designkriterien sind:
4Alleine fur die Wurzel mußten(
10
5
)
SVMs ausgewertet werden5Bei Tests hat sich allerdings herausgestellt, dass der unnormierte Abstand dS,T
starker mit dem Trainingsfehler der SVM korreliert ist als sS,T . Siehe Abschnitt 4.

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 11
Fehlertoleranter Ausgabecode fur K = 10f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 f11 f12 f13 f14 f15
Klasse 0 1 1 0 0 0 0 1 0 1 0 0 1 1 0 1Klasse 1 0 0 1 1 1 1 0 1 0 1 1 0 0 1 0Klasse 2 1 0 0 1 0 0 0 1 1 1 1 0 1 0 1Klasse 3 0 0 1 1 0 1 1 1 0 0 0 0 1 0 1Klasse 4 1 1 1 0 1 0 1 1 0 0 1 0 0 0 1Klasse 5 0 1 0 0 1 1 0 1 1 1 0 0 0 0 1Klasse 6 1 0 1 1 1 0 0 0 0 1 0 1 0 0 1Klasse 7 0 0 0 1 1 1 1 0 1 0 1 1 0 0 1Klasse 8 1 1 0 1 0 1 1 0 0 1 0 0 0 1 1Klasse 9 0 1 1 1 0 0 0 0 1 0 1 0 0 1 1
Der verwendete 15 Bit Code fur K = 10 Klassen mit einerHammingdistanz von 7 Bit aus [TGD95].
(1) (Zeilenabstand6) Die Klassencodes sollten sich in vielen Bitsunterscheiden, um so die Gefahr der Verwechslung zu minimie-ren. Maximiert wird also die minimale Bitdistanz zwischen denCodewortern, der sogenannte Hammingabstand.7
(2) (Spaltenabstand) Der Klassifikator fi (und die zugehorige Klas-senaufteilung) sollte unkorreliert zu den Klassifikatoren der an-deren Bitpositionen fj 6=i sein, um Bitfolgefehler zu vermeiden.Dies kann durch die Maximierung des Hammingabstandes zwi-schen den Spalten bzw. deren Komplement erreicht werden.8
Freiheit besteht noch in der Zuweisung der Codeworter zu den einzel-nen Klassen, die die zu diskriminierenden Klassenmengen der einzelnenBits beeinflusst.
Fur das Praktikum wird die Hammingdistanz zur Bestimmung desahnlichsten Klassencodes auf der binaren Ausgabe der SVMs vorge-schlagen. [TGD95] hingegen fassen die Ausgabe des Klassifikators alsWahrscheinlichkeit auf, und berechnen die L1 Distanz zwischen Wahr-scheinlichkeitsvektor b(z) und Klassencode.
6vgl. Matrixnotation in Tabelle 2.37Bei einer Hammingdistanz von d Bits lassen sich Storungen von bis zu b d−1
2c
Bits korrigieren und d − 1 Bits erkennen8Ein binarer Klassifikator lernt implizit auch die inverse Abbildung. Abzuglich
der nutzlosen konstanten Abbildung verbleiben so 2K−1−1 potentielle Spalten, ausdenen eine Untermenge U mit |U | = n und maximaler Hammingdistanz gesuchtwird. Optimierungsstrategien fur verschiedene (K, n) finden sich in [TGD95]

12 VOLKER GERDES & SVEN ESMARK
3. Datensatze und Merkmalsraume
3.1. Chair-Datensatz [BSB+96]. Der Datensatz enthalt 16× 16 Bil-der gerenderter 3D Stuhlmodelle (Siehe Abbildung 1). K = 25 verschie-dene Modelle stehen zur Auswahl, je nach Trainingsdatensatz wurdenpro Modell 25, 89, 100 oder 400 verschiedene Blickwinkel berechnet.Der Testdatensatz besteht aus 100 zufalligen Blickwinkeln.
Neben dem eigentlichen Grauwertbild werden zu jeder Ansicht Kan-tenbilder 4 verschiedener Orientierungen geliefert, sodass sich darausein maximal nutzbarer Datenraum von 1280 Dimensionen mit 614 Bei-spielpunkten pro Klasse ergibt.
Abbildung 1. CHAIR Beispiele: Zwei Stuhle (Bild &4 Kantenoperatoren) aus 6 verschiedenen Blickwinkeln
@todo:Noch nichts getestet. Ergebnisse in [BSB+96]
3.2. MNIST-Datensatz [LR]. Der MNIST Datensatz enthalt 28 ×28 Bilder handgeschriebener Ziffern aus 2 verschiedenen NIST Ur-sprungsdatensatzen (Siehe Figur 3.2). Die Bilder wurden aus den NIST-Binarbildern durch Normalisierung auf 20×20 Pixel und Schwerpunkt-Zentrierung in dem 28×28 Fenster generiert. 60000 Trainingsdaten und1000 Testdaten stehen zur Verfugung.
3.3. Trainingsgrundlage. Als Trainingsvektoren der SVMs dienendie nicht vorverarbeiteten Grauwert-Bildmatrizen der beiden Datensatze.Dies stellt hohe Anforderungen an die Generalisierungsfahigkeit desKlassifikators, bei 1280 bzw. 768 dimensionalen Datenraumen leideraber auch an die Rechenleistung wahrend der Lernphase, so dass im

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 13
Abbildung 2. MNIST Beispiele: Ersten 25 Ziffern des Datensatzes
Rahmen des Praktikums nur ein Bruchteil der Daten zum Trainingverwendet werden konnte.
Damit konnen auch leider keine Strategien zur Steigerung der Klas-sifikationsleistung mittels Erzeugung weiterer virtueller Trainingsdaten(wie das Einbeziehen leichter Verschiebungen bzw. anderer Verzerrun-gen) verfolgt werden, so dass davon auszugehen ist, dass die prakti-sche Klassifikationsleistung weit hinter der theoretisch trainierbarenLeistung liegen wird.
4. Theorie: Modellwahl / Parameterwahl
Zum Trainieren der Support-Vektor-Maschinen stehen unterschied-liche Kerne zur Wahl, wir beschranken uns auf die in (1.19), (1.21)und (1.20) vorgestellten Funktionen. Um den Einfluß der Parameterzu bestimmen, beschrankten wir uns auf ein einzelnes Trainingsszena-rio (”7 gegen Rest”, 500 Trainingsdaten, 1000 Testdaten) und wahltenverschiedene Einstellungen fur den Bestrafungsfaktor fur Grenzverlet-zungen und variierten die Parameter der Kerne.
Die Klassifikationsleistung nimmt bei Polynomialkernen deutlich mitansteigendem C zu, das konnte auf einen zu geringen Trainingsda-tenumfang zuruckzufuhren sein, aus Zeitkomplexitatsgrunden war eingroßerer Trainingsumfang jedoch nicht moglich.
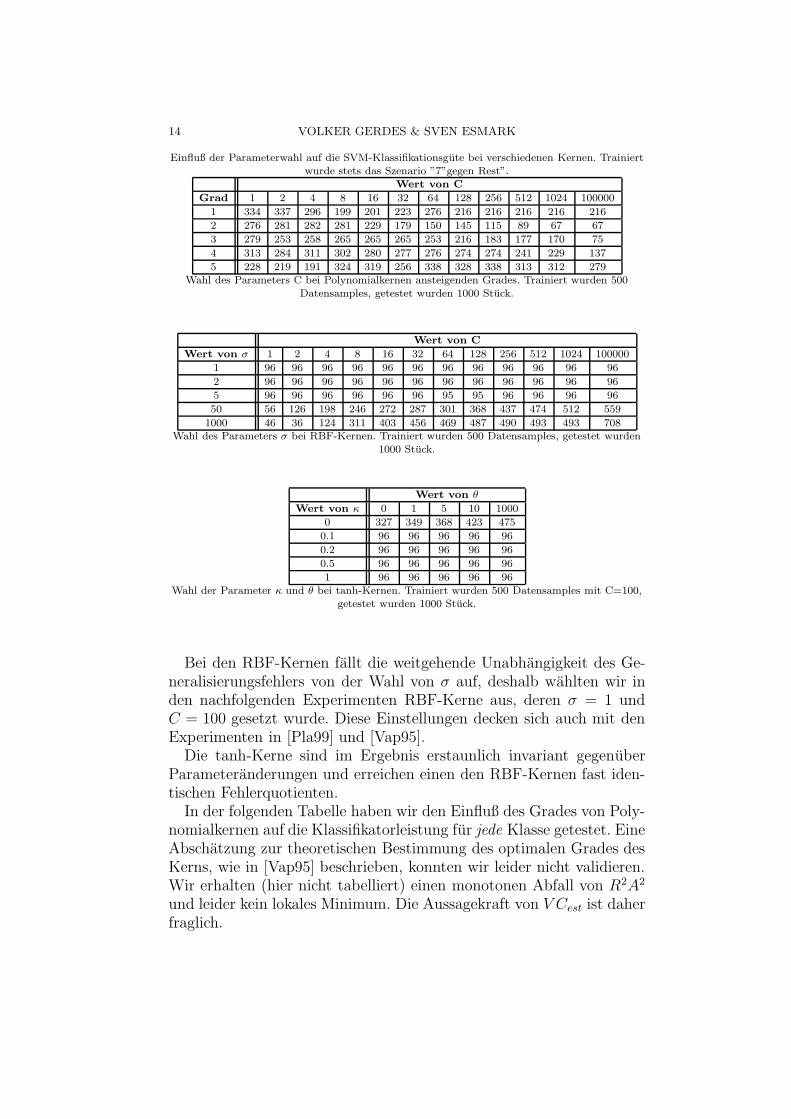
14 VOLKER GERDES & SVEN ESMARK
Einfluß der Parameterwahl auf die SVM-Klassifikationsgute bei verschiedenen Kernen. Trainiertwurde stets das Szenario ”7”gegen Rest”.
Wert von C
Grad 1 2 4 8 16 32 64 128 256 512 1024 100000
1 334 337 296 199 201 223 276 216 216 216 216 216
2 276 281 282 281 229 179 150 145 115 89 67 67
3 279 253 258 265 265 265 253 216 183 177 170 75
4 313 284 311 302 280 277 276 274 274 241 229 137
5 228 219 191 324 319 256 338 328 338 313 312 279Wahl des Parameters C bei Polynomialkernen ansteigenden Grades. Trainiert wurden 500
Datensamples, getestet wurden 1000 Stuck.
Wert von C
Wert von σ 1 2 4 8 16 32 64 128 256 512 1024 100000
1 96 96 96 96 96 96 96 96 96 96 96 96
2 96 96 96 96 96 96 96 96 96 96 96 96
5 96 96 96 96 96 96 95 95 96 96 96 96
50 56 126 198 246 272 287 301 368 437 474 512 559
1000 46 36 124 311 403 456 469 487 490 493 493 708Wahl des Parameters σ bei RBF-Kernen. Trainiert wurden 500 Datensamples, getestet wurden
1000 Stuck.
Wert von θ
Wert von κ 0 1 5 10 1000
0 327 349 368 423 475
0.1 96 96 96 96 96
0.2 96 96 96 96 96
0.5 96 96 96 96 96
1 96 96 96 96 96Wahl der Parameter κ und θ bei tanh-Kernen. Trainiert wurden 500 Datensamples mit C=100,
getestet wurden 1000 Stuck.
Bei den RBF-Kernen fallt die weitgehende Unabhangigkeit des Ge-neralisierungsfehlers von der Wahl von σ auf, deshalb wahlten wir inden nachfolgenden Experimenten RBF-Kerne aus, deren σ = 1 undC = 100 gesetzt wurde. Diese Einstellungen decken sich auch mit denExperimenten in [Pla99] und [Vap95].
Die tanh-Kerne sind im Ergebnis erstaunlich invariant gegenuberParameteranderungen und erreichen einen den RBF-Kernen fast iden-tischen Fehlerquotienten.
In der folgenden Tabelle haben wir den Einfluß des Grades von Poly-nomialkernen auf die Klassifikatorleistung fur jede Klasse getestet. EineAbschatzung zur theoretischen Bestimmung des optimalen Grades desKerns, wie in [Vap95] beschrieben, konnten wir leider nicht validieren.Wir erhalten (hier nicht tabelliert) einen monotonen Abfall von R2A2
und leider kein lokales Minimum. Die Aussagekraft von V Cest ist daherfraglich.
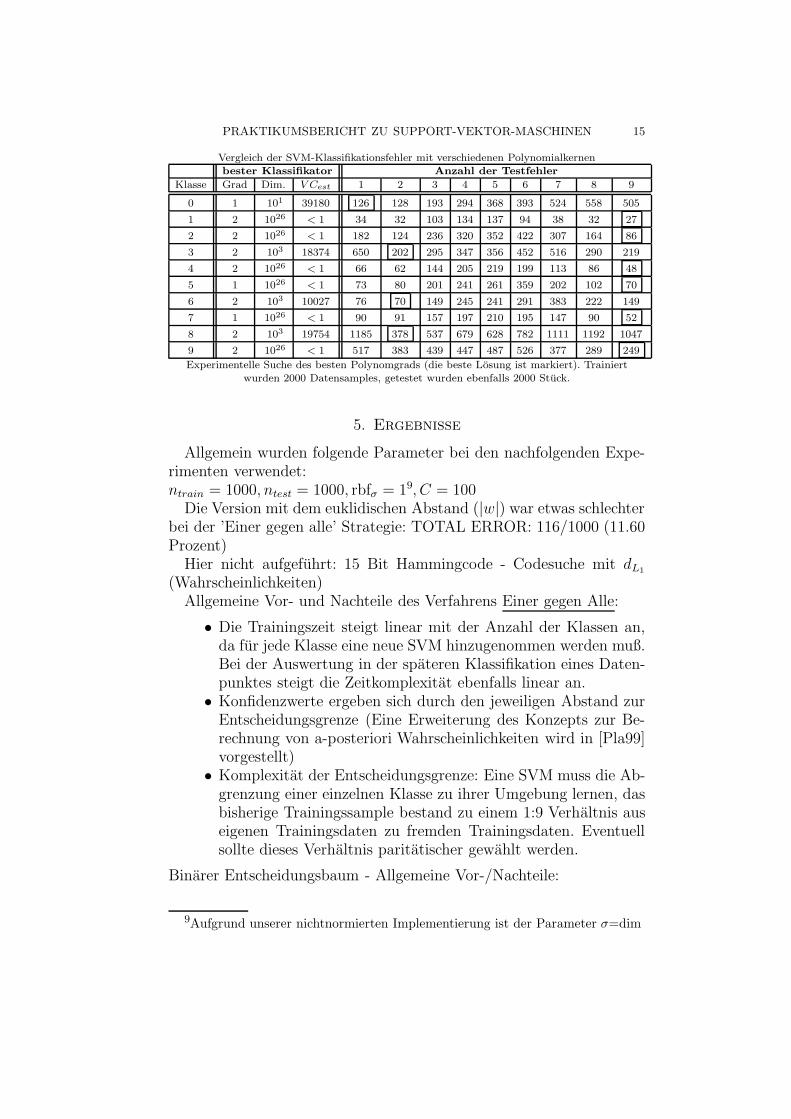
PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 15
Vergleich der SVM-Klassifikationsfehler mit verschiedenen Polynomialkernenbester Klassifikator Anzahl der Testfehler
Klasse Grad Dim. V Cest 1 2 3 4 5 6 7 8 9
0 1 101 39180 126 128 193 294 368 393 524 558 505
1 2 1026 < 1 34 32 103 134 137 94 38 32 27
2 2 1026 < 1 182 124 236 320 352 422 307 164 86
3 2 103 18374 650 202 295 347 356 452 516 290 219
4 2 1026 < 1 66 62 144 205 219 199 113 86 48
5 1 1026 < 1 73 80 201 241 261 359 202 102 70
6 2 103 10027 76 70 149 245 241 291 383 222 149
7 1 1026 < 1 90 91 157 197 210 195 147 90 52
8 2 103 19754 1185 378 537 679 628 782 1111 1192 1047
9 2 1026 < 1 517 383 439 447 487 526 377 289 249
Experimentelle Suche des besten Polynomgrads (die beste Losung ist markiert). Trainiertwurden 2000 Datensamples, getestet wurden ebenfalls 2000 Stuck.
5. Ergebnisse
Allgemein wurden folgende Parameter bei den nachfolgenden Expe-rimenten verwendet:ntrain = 1000, ntest = 1000, rbfσ = 19, C = 100
Die Version mit dem euklidischen Abstand (|w|) war etwas schlechterbei der ’Einer gegen alle’ Strategie: TOTAL ERROR: 116/1000 (11.60Prozent)
Hier nicht aufgefuhrt: 15 Bit Hammingcode - Codesuche mit dL1
(Wahrscheinlichkeiten)Allgemeine Vor- und Nachteile des Verfahrens Einer gegen Alle:
• Die Trainingszeit steigt linear mit der Anzahl der Klassen an,da fur jede Klasse eine neue SVM hinzugenommen werden muß.Bei der Auswertung in der spateren Klassifikation eines Daten-punktes steigt die Zeitkomplexitat ebenfalls linear an.
• Konfidenzwerte ergeben sich durch den jeweiligen Abstand zurEntscheidungsgrenze (Eine Erweiterung des Konzepts zur Be-rechnung von a-posteriori Wahrscheinlichkeiten wird in [Pla99]vorgestellt)
• Komplexitat der Entscheidungsgrenze: Eine SVM muss die Ab-grenzung einer einzelnen Klasse zu ihrer Umgebung lernen, dasbisherige Trainingssample bestand zu einem 1:9 Verhaltnis auseigenen Trainingsdaten zu fremden Trainingsdaten. Eventuellsollte dieses Verhaltnis paritatischer gewahlt werden.
Binarer Entscheidungsbaum - Allgemeine Vor-/Nachteile:
9Aufgrund unserer nichtnormierten Implementierung ist der Parameter σ=dim

16 VOLKER GERDES & SVEN ESMARK
Max−Abstand Klassifizierung (normiert) "rbf" Kernel, 1000 n
Training, 1000 n
Test
vs. 95 SV (9.5%) − sep 0.618 − 0.0% train 1.0% test
vs. 99 SV (9.9%) − sep 0.627 − 0.0% train 1.4% test
vs. 164 SV (16.4%) − sep 0.546 − 0.0% train 3.5% test
vs. 149 SV (14.9%) − sep 0.564 − 0.0% train 3.5% test
vs. 142 SV (14.2%) − sep 0.559 − 0.0% train 2.7% test
vs. 193 SV (19.3%) − sep 0.525 − 0.0% train 2.6% test
vs. 118 SV (11.8%) − sep 0.583 − 0.0% train 1.2% test
vs. 124 SV (12.4%) − sep 0.574 − 0.0% train 1.8% test
vs. 160 SV (16.0%) − sep 0.548 − 0.0% train 4.7% test
vs. 196 SV (19.6%) − sep 0.546 − 0.0% train 3.3% test
Abbildung 3. Einer gegen alle: Gewinner durch relati-ven Abstand - TOTAL ERROR: 113/1000 (11.30 Pro-zent)
• Bei diesem Konzept ergibt sich lediglich eine LogarithmischeEntscheidungstiefe log(K) fur die Klassifikation10
• Weiterhin mussen bei einem ausgeglichenen Binarbaum ≥ K−1Binarklassifikatoren trainiert werden11 und somit hat die Lern-zeitkomplexitat wieder eine lineare Komponente
• Fehlentscheidungen konnen im Entscheidungsprozeß zur Auf-teilung des Baums spater nicht mehr korrigiert werden
10Im Rahmen des Praktikums sollen nur ausgeglichene Entscheidungsbaumeberucksichtigt werden
11Entgegen anders lautender Behauptungen (K · (K − 1)/2) ;-)

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 17
Hamming−Abstand Klassifizierung "rbf" Kernel, 1000 n
Training, 1000 n
Test
vs. 324 SV (32.4%) − sep 0.533 − 0.0% train 8.5% test
vs. 343 SV (34.3%) − sep 0.520 − 0.0% train 7.7% test
vs. 372 SV (37.2%) − sep 0.518 − 0.0% train 8.7% test
vs. 297 SV (29.7%) − sep 0.530 − 0.0% train 7.4% test
vs. 397 SV (39.7%) − sep 0.522 − 0.0% train 8.8% test
vs. 324 SV (32.4%) − sep 0.534 − 0.0% train 7.6% test
vs. 455 SV (45.5%) − sep 0.519 − 0.0% train 13.4% test
vs. 363 SV (36.3%) − sep 0.520 − 0.0% train 11.0% test
vs. 384 SV (38.4%) − sep 0.519 − 0.0% train 12.3% test
vs. 300 SV (30.0%) − sep 0.533 − 0.0% train 7.9% test
vs. 303 SV (30.3%) − sep 0.536 − 0.0% train 6.4% test
vs. 305 SV (30.5%) − sep 0.531 − 0.0% train 6.2% test
vs. 269 SV (26.9%) − sep 0.543 − 0.0% train 7.8% test
vs. 299 SV (29.9%) − sep 0.538 − 0.0% train 8.2% test
vs. 99 SV (9.9%) − sep 0.627 − 0.0% train 1.4% test
Abbildung 4. 15 Bit Hammingcode: CodesuchedHamming - TOTAL ERROR: 120/1000 (12.00 Prozent)
• Komplexitat der Entscheidungsgrenze: Komplexe Klassenparti-tionierung an der Wurzel, geringer werdende Komplexitat bishin zu einer-gegen-einer Entscheidungen fur die Blatter
Allgemeine Vor-/Nachteile: Fehlertolerante Ausgabecodes
• Es liegt eine steuerbare Komplexitat ≥ K der Anzahl zu lernen-den Binarklassifikatoren und spateren Klassifikationsentschei-dung durch Anzahl der Bits des CRC-Codes vor
• Eine Erkennung und Korrektur von Fehlentscheidungen erfolgtgemaß der Theorie der CRC-Codes
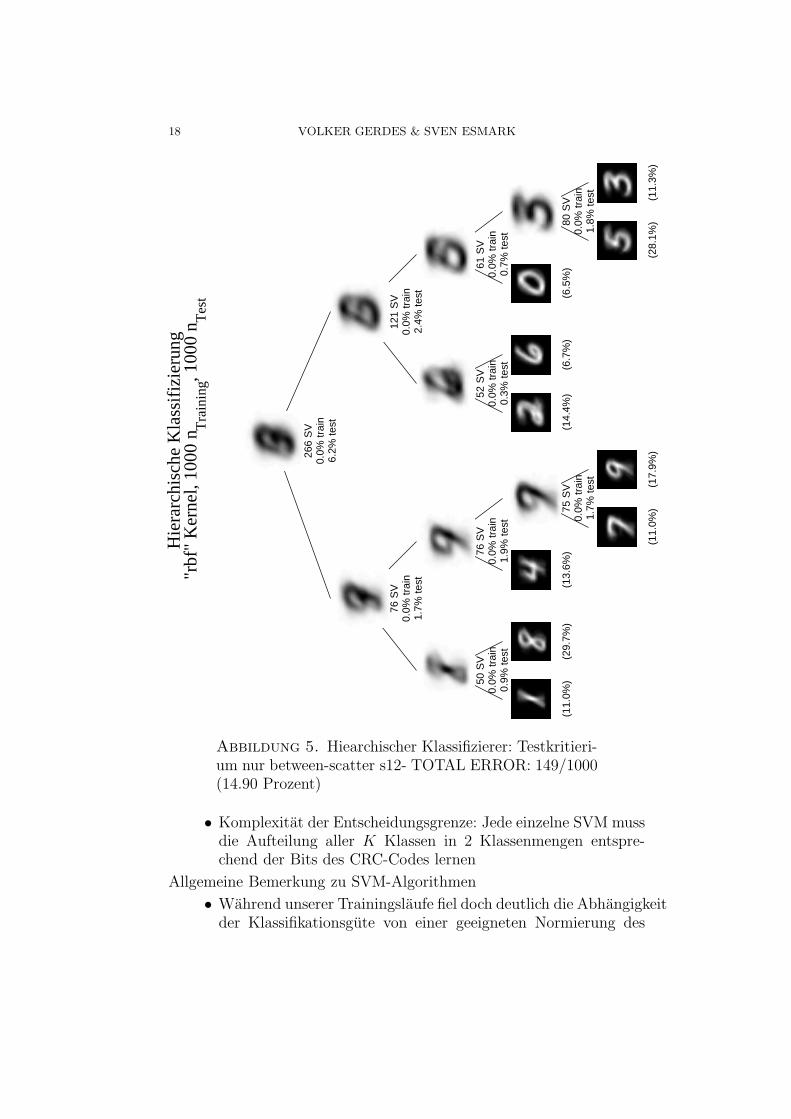
18 VOLKER GERDES & SVEN ESMARK
Hie
rarc
hisc
he K
lass
ifiz
ieru
ng "
rbf"
Ker
nel,
1000
nT
rain
ing, 1
000
n Tes
t
(11.
3%)
(28.
1%)
(17.
9%)
(11.
0%)
80 S
V0.
0% tr
ain
1.8%
test
(6.5
%)
(6.7
%)
(14.
4%)
75 S
V0.
0% tr
ain
1.7%
test
(13.
6%)
(29.
7%)
(11.
0%)
61 S
V0.
0% tr
ain
0.7%
test
52 S
V0.
0% tr
ain
0.3%
test
76 S
V0.
0% tr
ain
1.9%
test
50 S
V0.
0% tr
ain
0.9%
test
121
SV
0.0%
trai
n2.
4% te
st
76 S
V0.
0% tr
ain
1.7%
test
266
SV
0.0%
trai
n6.
2% te
st
Abbildung 5. Hiearchischer Klassifizierer: Testkritieri-um nur between-scatter s12- TOTAL ERROR: 149/1000(14.90 Prozent)
• Komplexitat der Entscheidungsgrenze: Jede einzelne SVM mussdie Aufteilung aller K Klassen in 2 Klassenmengen entspre-chend der Bits des CRC-Codes lernen
Allgemeine Bemerkung zu SVM-Algorithmen
• Wahrend unserer Trainingslaufe fiel doch deutlich die Abhangigkeitder Klassifikationsgute von einer geeigneten Normierung des
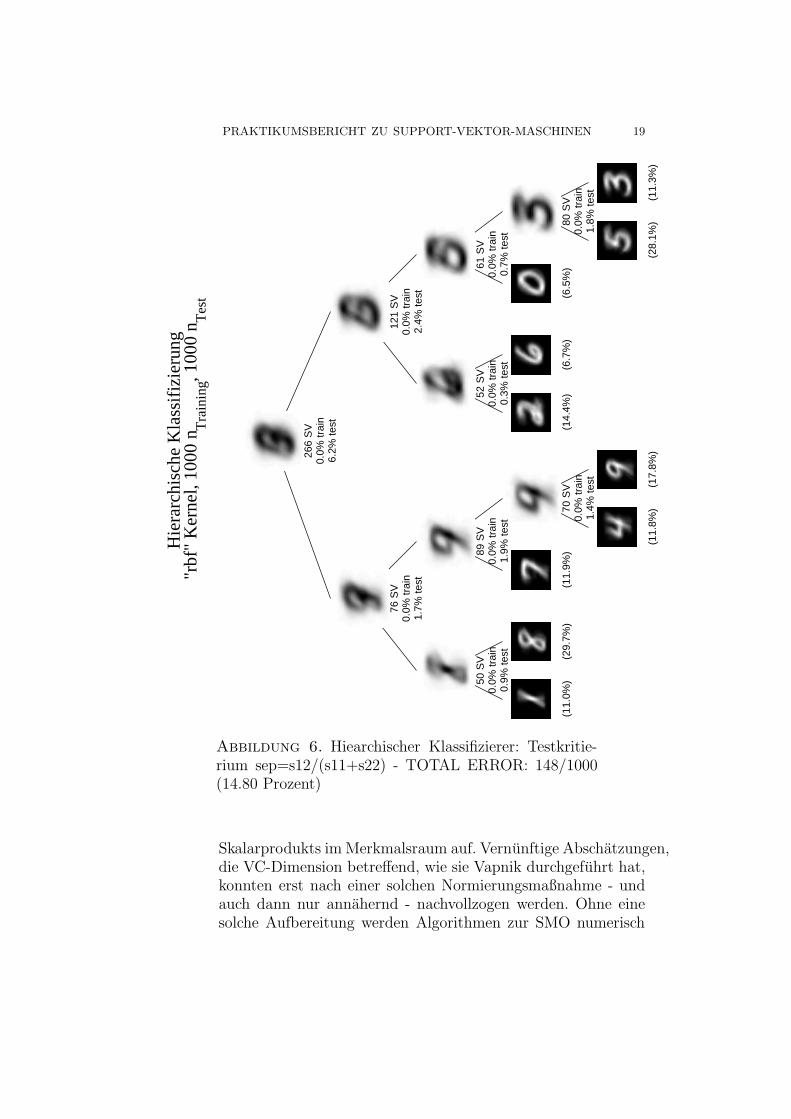
PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 19
Hie
rarc
hisc
he K
lass
ifiz
ieru
ng "
rbf"
Ker
nel,
1000
nT
rain
ing, 1
000
n Tes
t
(11.
3%)
(28.
1%)
(17.
8%)
(11.
8%)
80 S
V0.
0% tr
ain
1.8%
test
(6.5
%)
(6.7
%)
(14.
4%)
70 S
V0.
0% tr
ain
1.4%
test
(11.
9%)
(29.
7%)
(11.
0%)
61 S
V0.
0% tr
ain
0.7%
test
52 S
V0.
0% tr
ain
0.3%
test
89 S
V0.
0% tr
ain
1.9%
test
50 S
V0.
0% tr
ain
0.9%
test
121
SV
0.0%
trai
n2.
4% te
st
76 S
V0.
0% tr
ain
1.7%
test
266
SV
0.0%
trai
n6.
2% te
st
Abbildung 6. Hiearchischer Klassifizierer: Testkritie-rium sep=s12/(s11+s22) - TOTAL ERROR: 148/1000(14.80 Prozent)
Skalarprodukts im Merkmalsraum auf. Vernunftige Abschatzungen,die VC-Dimension betreffend, wie sie Vapnik durchgefuhrt hat,konnten erst nach einer solchen Normierungsmaßnahme - undauch dann nur annahernd - nachvollzogen werden. Ohne einesolche Aufbereitung werden Algorithmen zur SMO numerisch

20 VOLKER GERDES & SVEN ESMARK
instabil und liefern fur verschiedene Parameterwerte der Kerneabsurde Ergebnisse
Anhang A. Kurzdokumentation der MATLAB/MEXFunktionen
Die MATLAB Syntax der SVM Funktionen orientiert sich an der desPaketes von S. R. Gunn Paketes. [Gun]
Beim Training der SVM stutzt sich die Gunn Implementierung aufdie Losung eines quadratischen Programms (qp) durch die MATLABOptiermierungstoolbox.
Die hier gewahlte Implementierung benutzt das Konzept der MAT-LAB MEX Funktionen, ein Mechanismus zur Ausfuhrung von nativenC++ oder Fortran Programmen aus der MATLAB Umgebung.Durch Verwendung des C++ Platt-Algorithmus kann somit beim Trai-ning der SVM auf das MATLAB Optimierungspaket verzichtet werden.
A.0.1. svc 7−→ svcmex. Trainiert die Support-Vektor-Maschine mit-tels Platt-Optimierung.Aufruf :[nSV alpha bias |w|] = svcmex(X, Y, kerName, C, kerParam)
Parameter :X : TrainingsdatenY : TrainingslabelC : Bestrafungsfaktor fur GrenzverletzungkerName : Name des Kerns K(u, v). Zulassige Werte
sind: (Siehe Diskussion in Abschnitt ??)
linear : u′vpoly : (u′v)d
poly1 : [(u · v) + 1]d
rbf : exp(− |u − v| /σ)sigmoid : tanh(κ(u · v) − θ)
Ruckgabewerte:nSV : Anzahl der Supportvektorenalpha : Lagrange Faktorenbias : Bias der Hyperebene‖w‖ : Lange des Hyperebenen Normalenvektors
A.0.2. svcoutput 7−→ svcoutputmex. Funktion zur Klassifizierungneuer Testdaten durch eine trainierte Support-Vektor-MaschineAufruf :tstY = svcoutput(trnX, trnY, tstX, ker, alpha, bias, actfunc, params)

PRAKTIKUMSBERICHT ZU SUPPORT-VEKTOR-MASCHINEN 21
Parameter :trnX : Merkmalsvektoren der TrainingsdatentrnY : Klassenlabel der Trainingsdaten ∈ {−1, 1}tstX : Testdatenker : verwendeter Kernel der SVMalpha : gelernte Lagrange Multiplier der SVMbias : gelernter Bias der SVMactfunc : Aktivierungsfunktion fur zu liefernde Antwort.
0 (linear) Entfernung der Daten als Vielfa-ches des Margins (w · ϕ(z))
1 (soft) auf [−1 : 1] abgeschnittene Werte(Gunn default)
2 (hard) eine binare Antwort uber die sign-Funktion
Ruckgabewerte:
tstY : Antwort der SVM auf Testdaten tstX nach actfunc
A.0.3. scattermex. Hilfsfunktion zur Berechnung der mittleren Da-tenstreuung im Merkmalsraum.Aufruf :
scatter = scattermex(kerName, kerParams, X1 [,X2])
Parameter :kerName : Name des Kerns (scalar product in target space)kerParams : kernel parametersX1 : datapoints of class 1X2 : datapoints of class 2 (optional)
Ruckgabewert :scatter : WITHIN-class scatter if ONE class is given
: BETWEEN-class scatter if TWO classes are given
A.0.4. knn 7−→ knnmex. k-Nearest-Neigbour KlassifikatorAufruf :
[tstY distance] = knnmex(trnX, trnY, tstX, k=1, distnorm=L2)
Parameter :trnX : Merkmalsvektoren der TrainingsdatentrnY : Klassenlabel der TrainingsdatentstX : Testdatenk : k-Nachbarn berucksichtigen
Ruckgabewerte:tstY : Antwort des Klassifikators auf Testdaten tstXdistance : Distanzen zu nachstem Nachbarn

22 VOLKER GERDES & SVEN ESMARK
Literatur
[BSB+96] Volker Blanz, Bernhard Scholkopf, Heinrich H. Bulthoff, Chris Burges,Vladimir Vapnik, and Thomas Vetter. Comparison of view-based objectrecognition algorithms using realistic 3d models. In ICANN, pages 251–256, 1996.
[Gun] S. R. Gunn. Matlab support vector machines toolbox.[LR] Yann LeCun (AT+T Labs-Research). The mnist database of handwrit-
ten digits. www.research.att.com/???, ???[Pla99] John C. Platt. Probabilistic outputs for support vector machines and
comparison to regularized likelihood methods. In Bernhard ScholkopfDale Schuurmans Alexander J. Smola, Peter Bartlett, editor, Advances
in Large Margin Classifiers. MIT Press, 1999.[TGD95] Ghulum Bakiri Thomas G. Dietterich. Solving multiclass learning pro-
blems via error-correction output codes. Journal of Artificial Intelligence
Research 2, pages 263–286, 1995.[Vap95] Vladimir N. Vapnik. The Nature of Statistical Learning Theory. AT+T
Labs Research, Red Bank, NJ, 1995.
E-mail address : [email protected], [email protected]


















