Neuronale Netze 03 - FB IKStlange/pdf/Neuronale Netze 1.pdf · FB Elektrotechnik Prof. Dr.-Ing....
59
FB Elektrotechnik 1 Prof. Dr.-Ing. Tatjana Lange Neuronale Netze Fachhochschule Merseburg Fachhochschule Merseburg Neuronale Netze Version 01 - Dezember 2002 Prof. Dr.-Ing. Tatjana Lange Fachhochschule Merseburg FB Elektrotechnik
Transcript of Neuronale Netze 03 - FB IKStlange/pdf/Neuronale Netze 1.pdf · FB Elektrotechnik Prof. Dr.-Ing....

FB Elektrotechnik
1Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Neuronale NetzeNeuronale Netze
Version 01 - Dezember 2002
Prof. Dr.-Ing. Tatjana LangeFachhochschule MerseburgFB Elektrotechnik

FB Elektrotechnik
2Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Literatur:Literatur:1. Rigoll, Gerhard: Neuronale Netze. Eine Einführung für Ingenieure, Informatiker und
Naturwissenschaftler. Expert-Verlag, 1994
Inhalt:Inhalt:
1. Einführung - Grundprinzipien neuronaler Netze
2. Aufbau und mathematische Beschreibung eines Neurons
3. Architekturen und mathematische Beschreibung neuronaler Netze
4. Varianten der Musterverarbeitung
5. Lernverfahren
6. Klassifikation bzw. Paradigmen neuronaler Netze
7. Faustregeln zur Auswahl der Paradigmen und der Netzkonfiguration
8. Klassische neuronale Netze - Perceptron, MLP, Adaline, Madaline
9. Die „Group Method of Data Handling (GMDH)“ - eine Verwandte der neuronalen
Netze ?

FB Elektrotechnik
3Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Was ist ein Neuron ?
NeuronalesNetz
Ein
gang
smus
ter
Aus
gang
smus
ter
Biologie: Nervenzelle, die Information verarbeitet
Technik, Informatik, Mathematik:mathematisches oder physikalischesModell, das Information verarbeitet
•Signale•Bitmuster•Zahlenwerte
•Signale•Bitmuster•Zahlenwerte
Informations-verarbeitung
1. Einführung - Grundprinzipien neuronaler Netze1. Einführung1. Einführung -- Grundprinzipien neuronaler NetzeGrundprinzipien neuronaler Netze

FB Elektrotechnik
4Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Beispiel fürEingangsmuster:
Beispiel fürEingangsmuster:
gesprochene Ziffern
• Null• Eins• Zwei• Drei• Vier• Fünf• Sechs• Sieben• Acht• Neun
mit sprecherindividuelleKlangfärbung
rechnergerechte Darstellung derZiffern0 0 0 00 0 0 10 0 1 00 0 1 10 1 0 00 1 0 10 1 1 00 1 1 11 0 0 01 0 0 1

FB Elektrotechnik
5Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Weitere Beispiele für Eingabe- und Ausgabemuster:
Eingabemuster Ausgabemuster
abgetastetes Sprachsignal
digitalisierte Handschrift
digitales Bild
Indizien eines Fehlers in einemtechnischen System
angekreuzter Fragebogen zurFeststellung vonKrankheitssymptomen
Binärcode für dengesprochenen Laut
Binärcode für diegeschriebenen Buchstaben
komprimiertes digitales Bild
Code der möglichen Ursache
Code der möglichenKrankheitsursache

FB Elektrotechnik
6Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
künstliches Neuron:
Modell=
dynamisches System
Das mathematische Modell beschreibt die Beziehungen zwischen denEingängen und Ausgängen des Neurons, wobei das Übertragungsverhaltendes Neurons insbesondere durch die Gewichte der Neuroneneingängebestimmt wird.
Das Neuronenmodell kann mit der Übertragungsfunktioneines dynamischen Systems verglichen werden:Vergleiche
Regelungstechnik:( ) ( )
( ) ....
....3
32
210
2210
+++++++==pbpbpbb
papaa
pN
pZpG
Hier bestimmen die Koeffizienten ai und bj das Übertragungsverhalten des Systems.
einfaches System bzw. Modell mitEingängen und einem Ausgang
x1x2
xn
y
= ∑
=
n
iii xwFy
1

FB Elektrotechnik
7Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Aus den Neuronen wird mehrstufiges Netz gebildet
Input Layer Output LayerHidden Layers
Ein
gang
smus
ter
Aus
gang
smus
ter

FB Elektrotechnik
8Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Beachte:Nicht alle Neuronen sind miteinander verbunden.Neuronen lassen sich in 3 Klassen aufteilen:
• Neuronen, die mit Eingangsmuster und anderen Neuronen verbunden sind.Diese Neuronen bilden das Input-Layer
• Neuronen, die das Ausgangsmuster ausgeben.Diese Neuronen bilden das Output-Layer
• Neuronen, die nur mit anderen Neuronen verbunden sind.Diese Neuronen bilden die Hidden Layers.Die Anzahl der Hidden Layers kann sehr groß sein.
Die Ein-/Ausgangsbeziehungen eines neuronalen Netzes sind sehrkomplex und im allgemeinen nichtlinear.Die Eins-/Ausgangsbeziehungen sind durch eine Vielzahl vonParametern bestimmt.

FB Elektrotechnik
9Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Typische Aufgabenstellung für neuronale Netze:
Gegeben:• Eingangsmuster• Ausgangsmuster
Gesucht:• Parameter des neuronalen Netzes, die das gewünschte Ein-
/Ausgangsverhalten realisieren („Übertragungsfunktion“)
Lösungsweg:Mit Hilfe von Beispielmusterpaaren (Eingangs-und Ausgangsmuster) undNutzung von Optimierungsverfahren die Parameter (Koeffizienten) derNeuronen so bestimmen, daß das Netz die gewünschtenÜbertragungseigenschaften annimmt (bzw. diesen möglichst nahe kommt).
Systemindentifikation !!!
Lern- oder Trainingsphase

FB Elektrotechnik
10Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Nach der Lernphasefolgt die Anwendungsphase:• Dem neuronalen Netz werden jetzt Eingangsmuster präsentiert, die in
der Lernphase nicht verwendet wurden. Es erzeugt darausAusgangsmuster.
Die in der Lernphase zu optimierendenParameter des neuronalen Netzes sind dieWichtungen wi (Gewichtskoeffizienten)der Verbindungen zwischen denNeuronen.
Merke:Typische Anwendungen neuronaler Netze bestehen aus 2 Phasen:1. der Lern- oder Trainingsphase2. der Anwendungsphase
Die Lernfähigkeit ist die wichtigste Eigenschaft neuronaler NetzDie Lernfähigkeit ist die wichtigste Eigenschaft neuronaler Netze !!!e !!!
= ∑
=
n
iii xwFy
1
x1
x2
xn
y
w1
w2
wn

FB Elektrotechnik
11Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Eigenschaften neuronaler Netze (1):
• LernfähigkeitBestimmung der optimalen Netzparameter (=Gewichte der Verbindungenin der Lern- bzw- Trainingsphase); dabei Bestimmung der wichtigsten,essentiellen Eigenschaften der Eingangsmuster (Beispiel:unterschiedliche Sprecher sagen das Wort „Eins“ - jedes Muster istunterschiedlich, aber es gibt in jedem Muster etwas Essentielles -dieEins)
• Adaptives VerhaltenEigenschaft einiger neuronaler Netze, die Parameter in derAnwendungsphase weiter anzupassen, also weiterzulernen.
• Fähigkeit zur Verarbeitung fehlerhafter und unvollständigerInformation
Bestimmung des richtigen Ausgangsmusters bei gestörtenEingangsmustern (oder unvollständigen Eingangsmustern als Sonderfalleines gestörten Musters)

FB Elektrotechnik
12Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Eigenschaften neuronaler Netze (2):
• Massive ParallelitätJedes Neuron kann als einzelnes, unabhängiges System betrachtetwerden. Die Simulationsprogramme der einzelnen Neuronen könnenparallel auf allen verfügbaren Prozessoren einesMultiprozessorsystems abgearbeitet werden.
• Hardware-ImplementierbarkeitRealisierung der Neutronen durch „maßgeschneiderte“ Chips
• FehlertoleranzAusfall eines Neurons führt nicht zum Totalausfall, nur zur meistunbedeutenden Verschlechterung des Übertragungsverhaltens desNetzes (Beispiel: die gesprochene „Eins“ wird nach wie vor in denmeisten Fällen richtig erkannt, die Fehlerwahrscheinlichkeit wirdallerdings etwas höher).

FB Elektrotechnik
13Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Beispiel für Sprachanalyse:
Fourier-Transformation
Fourier-Transformation
Fourier-Transformation
Fourier-Transformation
Fourier-Transformation
0
3
Null,Drei
1. Unterteilung der Sprachprobein Abschnitte
2. Fourier-Transformation derSprachabschnitte (schnelleFourier-Transformation -abgetastete Sprachsignalewerden auf Fourier-Koeffizienten abgebildet)
3. Fourier-Koeffizienten bildenEingangsmuster
12

FB Elektrotechnik
14Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Typische Einsatzgebiete neuronaler Netze:
• Vorhersage / Forecasting stationärer undnichtstationärer stochastischer Prozesse
• Mustererkennung
• Regelung
! Wetterprognose! Umweltprognosen! Prognose Wasserstände,
Wasserverschmutzung! Prognose von
Wirtschaftsprozessen
! Spracherkennung! Bilderkennung
! Informationssysteme! Robotik
! Automatisierungstechnik! Automotiv
FB Elektrotechnik
15Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
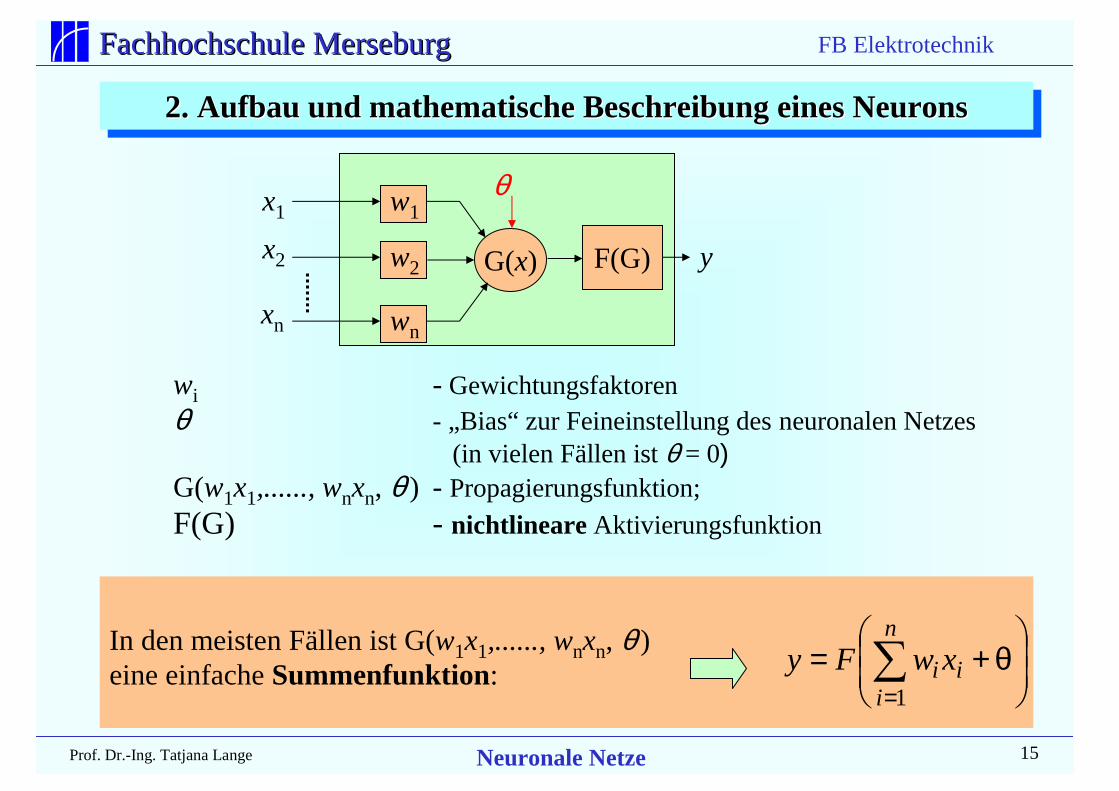
2. Aufbau und mathematische Beschreibung eines Neurons2. Aufbau und mathematische Beschreibung eines Neurons2. Aufbau und mathematische Beschreibung eines Neurons
θ+= ∑
=
n
iii xwFy
1
x1
x2
xn
y
w1
w2
wn
G(x) F(G)
wi - Gewichtungsfaktorenθ - „Bias“ zur Feineinstellung des neuronalen Netzes
(in vielen Fällen ist θ = 0)G(w1x1,......, wnxn, θ ) - Propagierungsfunktion;F(G) - nichtlineare Aktivierungsfunktion
In den meisten Fällen ist G(w1x1,......, wnxn, θ )eine einfache Summenfunktion:
θ

FB Elektrotechnik
16Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Eine wichtige Eigenschaft neuronaler Netze ist deren nichtlineares Verhalten,hervorgerufen durch die nichtlineare Aktivierungsfunktion F(G).
G
F(G)1
G
F(G)1
G
F(G)1
Typische Aktivierungsfunktionen:
Hard-Limiter: Schwellwert-Funktion: Sigmoid-Funktion:
≥<
=01
00)(
G
GGF
≥<≤
<=
aG
aGaG
G
GF
1
0
00
)( ( )aGeGF +−+
=1
1)(
binäre neuronale Netzeneuronale Netze mit
kontinuierlichenAusgangswerten

FB Elektrotechnik
17Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
θ+= ∑
=
n
iii xwFy
1
Mathematische Beschreibung eines Neuron:
Besser: Vektor-Schreibweise:
[ ][ ]Tn
Tn
www
xxx
θ=
=
,,.....,,
1,,.....,,
21
21
w
x
( )wx ⋅= TFy
Für ein Neuron mit Hard-Limiter gilt:
≥⋅<⋅=
01
00)(
wx
wxT
T
für
fürGF
Für ein Neuron mit Sigmoid-Funktion gilt:
( )aT
eGF
+⋅−+=
wx1
1)(

FB Elektrotechnik
18Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
3. Architekturen und mathematische Beschreibung neuronaler Netze3. Architekturen und mathematische Beschreibung neuronaler Netze3. Architekturen und mathematische Beschreibung neuronaler Netze
Man unterscheidet:• Feedforward-Netze• Feedback-Netze
Feedforward-Netze besitzen nur ineine Richtung weisendeVerbindungen - vom Input Layer überdie Hidden Layers hin zum OutputLayer bzw. „von unten nach oben“:
Typischerweise existieren immernur Verbindungen zwischenbenachbarten Schichten.
In den Neuronen des Input-Layerfindet keine Summenbildung undGewichtung statt (sinnlos).Sie repräsentieren nur dasEingangsmuster.
Typische Architektur einesFeedforward-Netzes
Ausgangsmuster
Eingangsmuster
Output Layer
Input Layer
Hidden Layers

FB Elektrotechnik
19Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Feedforward-Netze besitzen meist 3 aktive Neuronen-Schichten:• 2 Hidden Layers• 1 Output Layer
Typische Merkmale von Feedforward-Netzen sind:• kontinuierliche Ein-und Ausgangsgrößen• Sigmoid-Funktion als Aktivierungsfunktion• unterschiedliche Anzahl von Eingangsgrößen xi und Ausgangsgrößen yj
Hauptanwendungen von Feedforward-Netzen sind:• Mustererkennung• mathematische Modellierung statischer Systeme

FB Elektrotechnik
20Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Mathematische Beschreibung von Feedforward-Netzen:
Zur Erinnerung - allgemeine mathematische Beschreibung einesNeurons:
x1
x2
xn
y
w1
w2
wn
G(x) F(G)
θ
θ+= ∑
=
n
iii xwFy
1
( )wFy T ⋅= x
Eine Schicht eines neuronalen Netzes enthält viele Neuronen. Für das j-te Neuron gilt:
x1
x2
xn
y
w1j
w2j
wnj
G(x) F(G)
θj
θ+= ∑
=
n
ijiijj xwFy
1
( )jT
j wFy ⋅= x
Neuron j

FB Elektrotechnik
21Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Betrachten wir jetzt ein einfaches Feedforward-Netz mit 2 aktiven Schichten:
Ausgangsmuster
Eingangsmuster
Output Layer
Input Layer
Hidden Layer1. aktive Schicht mit 5 Neuronen
2. aktive Schicht mit 3 Neuronen
inaktive Eingangsschichtmit 4 Neuronen
z1 z2 z3
y1 y2 y4y3 y5
x2 x3x1 x4
x2 x3x1 x4

FB Elektrotechnik
22Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
w4jw1j
+
F(G)
w2j w3j
Neu
ron
j
yjDer Ausgang yj eines Neurons deruntersten aktiven Schicht (hierHidden Layer) wird beschrieben mit
( )jT
j Fy wx ⋅=
wobeiT
Njjjj www ],....,,[ 21=w
Diese Schicht hat jedoch M Ausgangsgrößen (hier M=5), also y1, y2, y3, y4, y5.In einer Matrix-Vektor-Darstellung ergibt sich für folgender Ausdruck zurBerechnung der der M Ausgangsgrößen der untersten aktiven Schicht:
(hier sei θ = 0)
[ ] [ ]( )MjT
M Fyyy wwwx ,....,,....,,.....,, 121 ⋅= (hier M = 5)
x2 x3x1 x4
x2 x3x1 x4und N - Anzahl der
Eingangsgrößen (hier N = 4)

FB Elektrotechnik
23Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
bzw. ( )Wxy ⋅= TT F
wobei
[ ]
==
NMNjN
Mj
Mj
www
www
......
...............
......
,....,,....,
1
1111
1 wwwW
die Gewichtsmatrix des betrachteten Layers des neuronalen Netzes ist.
Bezeichnen wir die Gewichtsmatrix des untersten bzw. 1. aktiven Layers mit W1 unddie des nächsten bzw. 2. aktiven Layers mit W2, so ergibt sich folgendemathematische Beschreibung des betrachteten neuronalen Netzes mit 2 aktiven Layer:
( ) ( )( )( )1
212
Wxy
WWxWyz
⋅=
⋅⋅=⋅=TT
TTT
F
FFFOutput Layer:
Hidden Layer:

FB Elektrotechnik
24Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
( )Wxy ⋅= TT FErläuterungen zur Beziehung
w41w11
+w21 w31
Neu
ron
1
y1
w42w12
+w22 w32
Neu
ron
2
y2
w43w13
+w23 w33
Neu
ron
3
y3
x1 x2 x4x3
4433332231133
4423322221122
4413312211111
xwxwxwxwy
xwxwxwxwy
xwxwxwxwy
⋅+⋅+⋅+⋅=⋅+⋅+⋅+⋅=⋅+⋅+⋅+⋅=
Dieses Netz kann durch einGleichungssystem beschrieben werden:
Betrachten wir dasnebenstehende Netz (in demdie Aktivierungsfunktion F(G)vernachlässigt wurde)
bzw. in Vektor-und Matrizen-schreibweise
⋅
=
4
3
2
1
43332313
42322212
41312111
3
2
1
x
x
x
x
wwww
wwww
wwww
y
y
y

FB Elektrotechnik
25Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Multiplikation von Matrizen:1. Anzahl der Spalten der Matrix A muß gleich Anzahl der Zeilen von Matrix B sein.2. Anzahl der Zeilen von Matrix C ist gleich Anzahl der Zeilen von Matrix A.3. Anzahl der Spalten von Matrix C ist gleich Anzahl der Spalten von Matrix B.
Wie berechnet man ein Element der Matrix C ?
cij= i-Zeilenvektor der Matrix A multipliziert mitj-ten Spaltenvektor der Matrix B
Matrix A:3 Zeilen4 Spalten
Matrix B:4 Zeilen2 Spalten
Matrix C:3 Zeilen2 Spalten
⋅
=
4241
3231
2221
1211
34333231
24232221
14131211
3331
2221
1211
bb
bb
bb
bb
aaaa
aaaa
aaaa
cc
cc
cc
Beispiel:422432232222122122 babababac +++=
Weitere Regeln:
( ) ( )( )
( ) TTT ABBA
ABBA
CABACBA
CBACBA
⋅=⋅
⋅≠⋅⋅+⋅=+⋅
⋅⋅=⋅⋅
!!!!!!!!!!!!
transponierte Matrizen
Zur Erinnerung - etwas Matrizenrechnung

FB Elektrotechnik
26Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Was ist eine transponierte Matrix ?
Das Transponieren einer Matrix
bedeutet Vertauschen der Indizes, also Tjiij aa = bzw.
=
342414
332313
322212
312111
aaa
aaa
aaa
aaa
TA
=
34333231
24232221
14131211
aaaa
aaaa
aaaa
A
Beim Transponieren geht ein Spaltenvektor in eineZeilenvektor über (und umgekehrt).
=
4
3
2
1
x
x
x
x
x
Beispiel:
[ ]4321 xxxxT =x
Spaltenvektor
Zeilenvektor
FB Elektrotechnik
27Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
⋅
=
4
3
2
1
43332313
42322212
41312111
3
2
1
x
x
x
x
wwww
wwww
wwww
y
y
y
xy ⋅
=
43332313
42322212
41312111
wwww
wwww
wwww
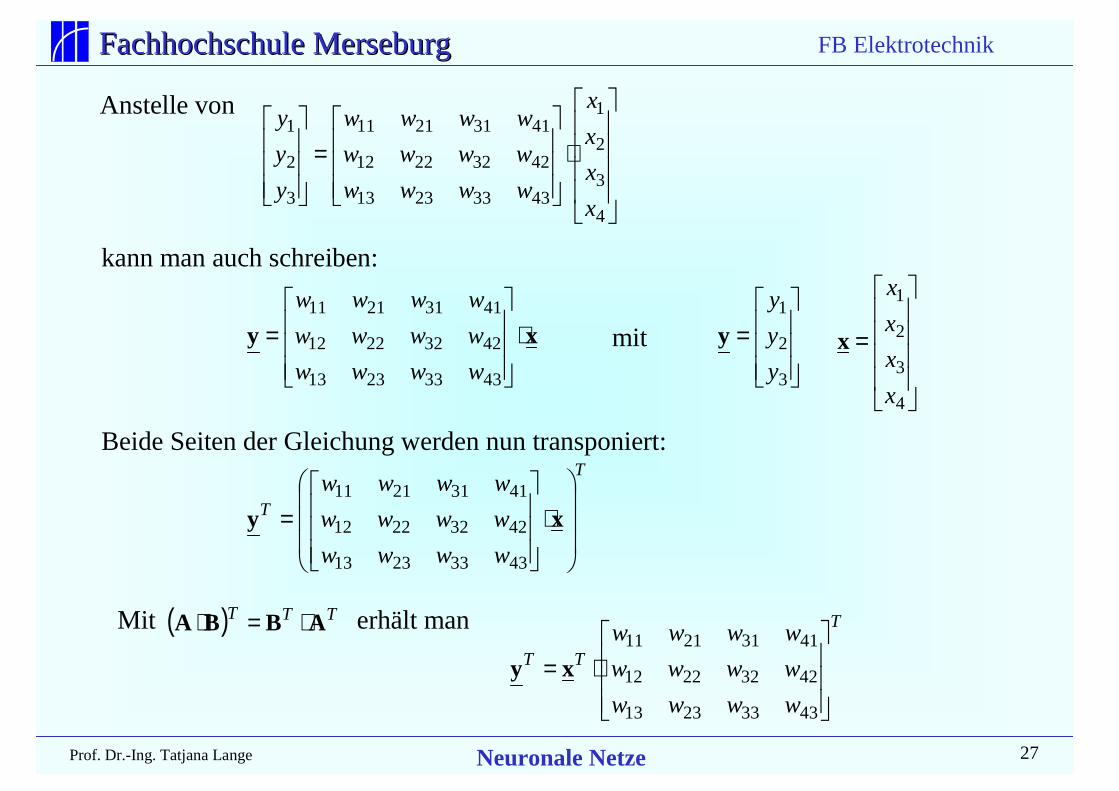
Anstelle von
kann man auch schreiben:
mit
=
4
3
2
1
x
x
x
x
x
=
3
2
1
y
y
y
y
T
T
wwww
wwww
wwww
⋅
= xy
43332313
42322212
41312111
( ) TTT ABBA ⋅=⋅ T
TT
wwww
wwww
wwww
⋅=
43332313
42322212
41312111
xy
Beide Seiten der Gleichung werden nun transponiert:
Mit erhält man

FB Elektrotechnik
28Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
T
wwww
wwww
wwww
www
www
www
www
=
=
43332313
42322212
41312111
434241
333231
232221
131211
W
und mit
kommt man zur Schreibweise
( )Wxy ⋅= TT F
Wxy ⋅= TT
bzw. bei Berücksichtigung der Aktivierungsfunktion F(G):
[ ] [ ]
⋅=
434241
333231
232221
131211
4321321 ,,,,,
www
www
www
www
xxxxyyy Beispiel

FB Elektrotechnik
29Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
1. Zeile
1.Sp
alte
3.Sp
alte
2.Sp
alte
[ ] [ ]
⋅=
434241
333231
232221
131211
4321321 ,,,,,
www
www
www
www
xxxxyyy
1.Sp
alte
3.Sp
alte
2.Sp
alte
Wenden wir nun auf yT=xTW die Multiplikationsregel für Matrizen an, soerhalten wir das ursprüngliche Gleichungssystem:
( ) ( )
( ) ( )
( ) ( )443333223113
133
442332222112
122
441331221111
111
derMatrixtorSpaltenvek.3derMatrixorZeilenvekt.1
derMatrixtorSpaltenvek.2derMatrixorZeilenvekt.1
derMatrixtorSpaltenvek.1derMatrixorZeilenvekt.1
xwxwxwxw
yy
xwxwxwxw
yy
xwxwxwxw
yy
⋅+⋅+⋅+⋅=⋅==
⋅+⋅+⋅+⋅=⋅==
⋅+⋅+⋅+⋅=⋅==
Wx
Wx
Wx

FB Elektrotechnik
30Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Feedback-Netze:
Feedback-Netze enthaltenneben den üblichenVorwärts-Verbindungen(von „unten nach oben“ -hier schwarze Linien) auchRückkopplungen innerhalbdes eigenen Layers (hierrote Linien) oder von einenhöheren Layer in tiefergelegene Layer (hier blaueLinien).
Die mathematischeBeschreibung erfolgtmittels rekursiverMethoden.
(Auf eine Behandlung dieser Methoden wird hier verzichtet.)

FB Elektrotechnik
31Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Feedbeack-Netze besitzen meist nur eine Neuronen-Schicht(aber nicht immer).
Typische Merkmale von Feedback-Netzen sind:• meist binäre Ein-und Ausgangsgrößen• Hard-Limiter als Aktivierungsfunktion• meist gleiche Anzahl von Eingangsgrößen xi und Ausgangsgrößen yj
(in Feedback-Netzen mit nur einer Neuronen-Schicht).
Hauptanwendungen von Feedback-Netzen sind:• Mustervervollständigung (Assoziativspeicher)

FB Elektrotechnik
32Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
4. Grundvarianten der Musterverarbeitung4. Grundvarianten der Musterverarbeitung4. Grundvarianten der Musterverarbeitung
Eines der wichtigsten Einsatzgebiete der neuronalen Netze ist dieMusterverarbeitung.
Man unterscheidet dabei 4 Grundvarianten:
1. Mustererkennung2. Musterzuordnng3. Mustevervollständigung4. Mustereinteilung

FB Elektrotechnik
33Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Ein bestimmtes Eingangsmuster (Vektor x) wird EINEM Element des Ausgangsvektorszugeordnet, d.h. es erfolgt eine Klassifikation bzw. Auswahl.In den Beispielen konnen die Eingangsmuster 10 unterschiedlichen Ziffern zugeordnetwerdenIm Beispiel 1 erkennt das neuronale Netz aus der Sprachprobe die Ziffer 0, im Beispiel 2die Ziffer 3.
[ ] [ ]TTxxxxx 0,0,0,0,0,0,0,0,0,1,,,, 54321 =→= yx
x1 x2 x3 x4 x5
neuronales Netz
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
x1 x2 x3 x4 x5
neuronales Netz
[ ] [ ]TTxxxxx 0,0,0,0,0,0,1,0,0,0,,,, 54321 =→= yx
Beispiel 1: Beispiel 2:
Mustererkennung (1)

FB Elektrotechnik
34Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Netzarchitektur:• vorzugsweise Feedforward-Netze
Training:• mit Hilfe aller möglichen Beispielpaare „Eingangsmuster ! Ausgangsmuster“ bzw.
Mustererkennung (2)
Anwendungen:• Spracherkennung (Sprachprobe ! binär kodiertes Wort bzw. Ziffer)• Bilderkennung (digitalisiertes Bild von Bauteilen ! Kode des Bauteils)• Diagnose (Symptome ! Krankheit)• Qualitätskontrolle (digitalisiertes Bild des Bauteils ! gut/schlecht-Entscheidung)
[ ] [ ]TTNxxx 0,....,0,1,....,, 002010 =→= yx
[ ] [ ]TTNxxx 0,....,1,0,....,, 112111 =→= yx
[ ] [ ]TTMNMMM xxx 1,....,0,0,....,, 21 =→= yx
FB Elektrotechnik
35Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
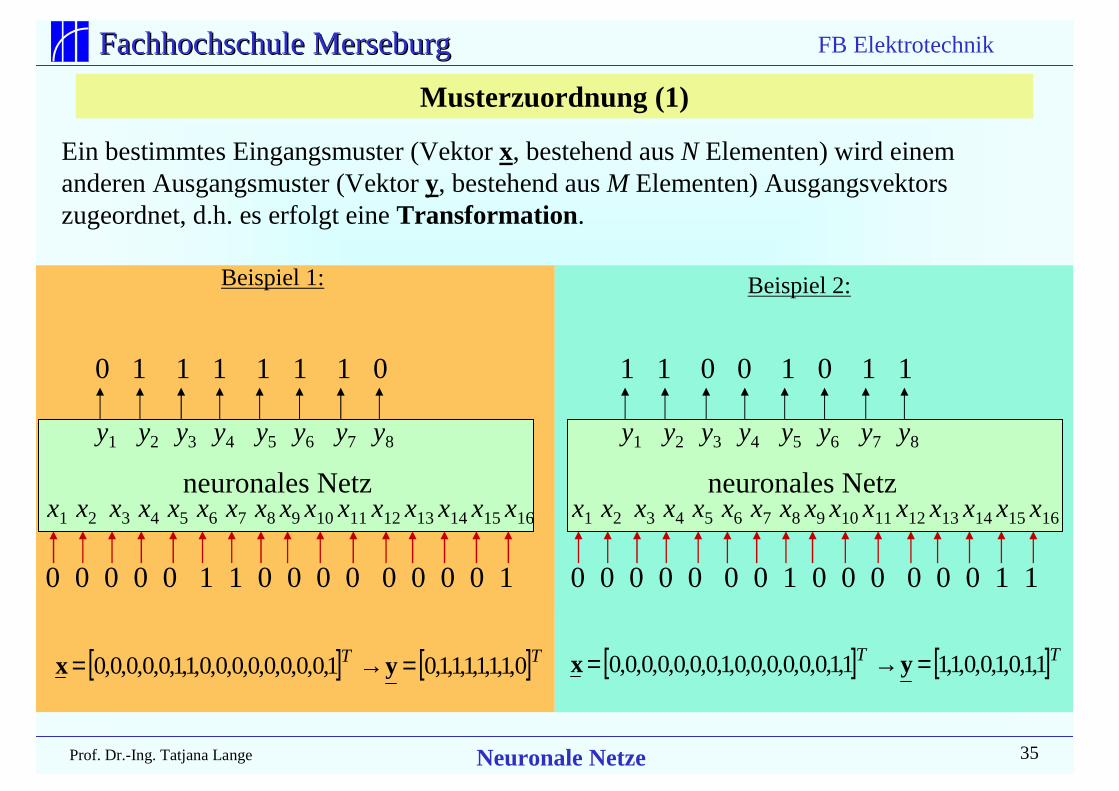
Ein bestimmtes Eingangsmuster (Vektor x, bestehend aus N Elementen) wird einemanderen Ausgangsmuster (Vektor y, bestehend aus M Elementen) Ausgangsvektorszugeordnet, d.h. es erfolgt eine Transformation.
[ ] [ ]TT 0,1,1,1,1,1,1,01,0,0,0,0,0,0,0,0,1,1,0,0,0,0,0 =→= yx
Beispiel 1: Beispiel 2:
Musterzuordnung (1)
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1
y1 y2 y3 y4 y5 y6 y7 y8
0 1 1 1 1 1 1 0
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1
y1 y2 y3 y4 y5 y6 y7 y8
1 1 0 0 1 0 1 1
[ ] [ ]TT 1,1,0,1,0,0,1,11,1,0,0,0,0,0,0,1,0,0,0,0,0,0,0 =→= yx

FB Elektrotechnik
36Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Netzarchitektur:• vorzugsweise Feedforward-Netze
Training:• mit Hilfe aller möglichen Beispielpaare „Eingangsmuster ! Ausgangsmuster“ bzw.
Anwendungen:• Sprachkomprimierung• Bildkomprimierung• Filterung verrauschter Signale• Signalprädiktion, d.h. Vorhersage der nächsten zu erwartenden Signalwerte• Regelung: Regelabweichung = Eingangsmuster ! Stellgröße = Ausgangsmuster
[ ] [ ]TMT
N yyyxxx 002010002010 ,....,,,....,, =→= yx
Musterzuordnung (2)
[ ] [ ]TMT
N yyyxxx 112111112111 ,....,,,....,, =→= yx
[ ] [ ]TLMLLLT
LNLLL yyyxxx ,....,,,....,, 2121 =→= yx
L - Anzahl der zumTrainingvorliegendenEingangsmuster
FB Elektrotechnik
37Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
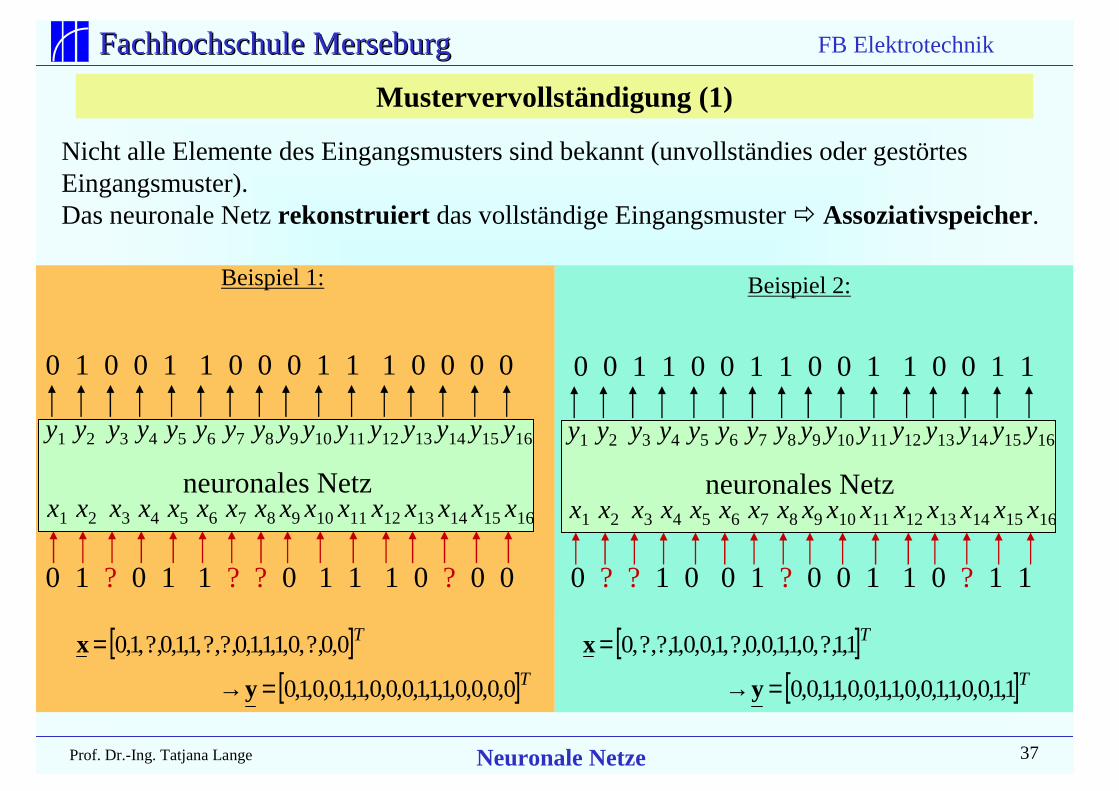
Mustervervollständigung (1)
Nicht alle Elemente des Eingangsmusters sind bekannt (unvollständies oder gestörtesEingangsmuster).Das neuronale Netz rekonstruiert das vollständige Eingangsmuster ! Assoziativspeicher.
[ ][ ]T
T
0,0,0,0,1,1,1,0,0,0,1,1,0,0,1,0
0,0?,,0,1,1,1,0?,?,,1,1,0?,,1,0
=→
=
y
x
Beispiel 1: Beispiel 2:
0 1 ? 0 1 1 ? ? 0 1 1 1 0 ? 0 0 0 ? ? 1 0 0 1 ? 0 0 1 1 0 ? 1 1
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
y1 y2 y3 y4 y5 y6 y7 y8 y9 y10 y11 y12 y13 y14 y15 y16
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
y1 y2 y3 y4 y5 y6 y7 y8 y9 y10 y11 y12 y13 y14 y15 y16
0 1 0 0 1 1 0 0 0 1 1 1 0 0 0 0 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1
[ ][ ]T
T
1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,0
1,1?,,0,1,1,0,0?,,1,0,0,1?,?,,0
=→
=
y
x

FB Elektrotechnik
38Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Netzarchitektur:• Feedback-Netze
Training:• nur mit Hilfe der vollständigen Eingangsmuster
[ ]T0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,00 =x
Mustervervollständigung (2)
[ ]T1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,11 =x
[ ]T1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,02 =x
[ ]T0,0,0,0,1,1,1,0,0,0,1,1,0,0,1,04 =x
[ ]T1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,03 =x
Das neuronale Netz speichert die vollständigen Muster.Das unvollständige Eingangsmuster wird auf das vollständige Muster abgebildet, demes am ähnlichsten ist (geringste Abweichung).Somit arbeitet das neuronale Netz wie ein Assoziativspeicher.
FB Elektrotechnik
39Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
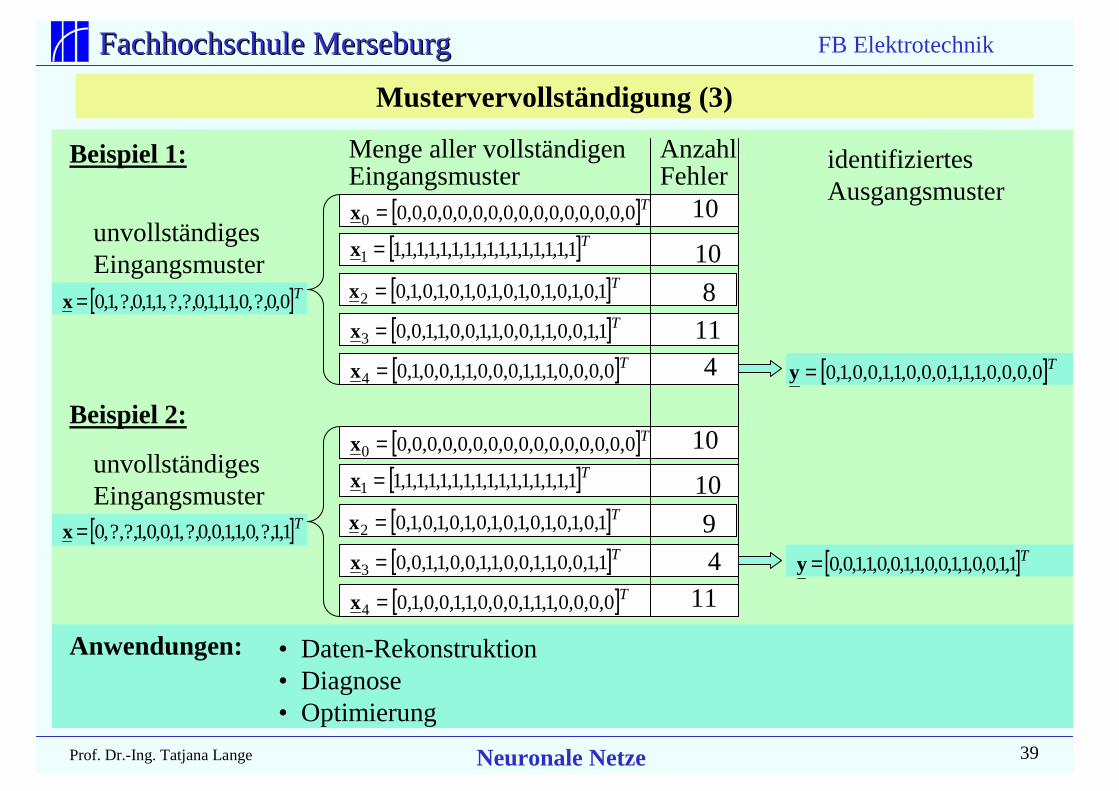
Anwendungen:
Mustervervollständigung (3)
Beispiel 1:
[ ]T0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,00 =x
[ ]T1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,11 =x
[ ]T1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,02 =x
[ ]T0,0,0,0,1,1,1,0,0,0,1,1,0,0,1,04 =x
[ ]T1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,03 =x[ ]T0,0?,,0,1,1,1,0?,?,,1,1,0?,,1,0=x
[ ]T0,0,0,0,1,1,1,0,0,0,1,1,0,0,1,0=y
unvollständigesEingangsmuster
Menge aller vollständigenEingangsmuster
AnzahlFehler
10
10
8
114
identifiziertesAusgangsmuster
Beispiel 2:[ ]T0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,00 =x
[ ]T1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,11 =x
[ ]T1,0,1,0,1,0,1,0,1,0,1,0,1,0,1,02 =x
[ ]T0,0,0,0,1,1,1,0,0,0,1,1,0,0,1,04 =x
[ ]T1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,03 =x
unvollständigesEingangsmuster
10
10
9
411
[ ]T1,1?,,0,1,1,0,0?,,1,0,0,1?,?,,0=x
[ ]T1,1,0,0,1,1,0,0,1,1,0,0,1,1,0,0=y
• Daten-Rekonstruktion• Diagnose• Optimierung

FB Elektrotechnik
40Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Ähnlich wie bei der Mustererkennung werden die Eingangsmuster klassifiziert und einemCluster mit bestimmten Merkmalen zugeordnet.Im Unterschied zur Mustererkennung sind gewöhnlich ALLE Elemente desAusgangsvektors ≠ 0. Die Klassifizierung erfolgt anhand des Maximums (oder Minimums)
[ ] [ ]TT 3,131,0,0,0,0,0,0,0,0,1,1,0,0,0,0,0 =→= yx
Beispiel 1: Beispiel 2:
Muster-Clusterisierung (1)
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1
y0
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16
neuronales Netz
0 1 1 1 1 0 0 1 0 1 1 1 0 0 1 1
[ ] [ ]TT 10,61,1,0,0,1,1,1,0,1,0,0,1,1,1,1,0 =→= yx
y1
13 3
y0 y1
6 10

FB Elektrotechnik
41Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Muster-Clusterisierung (2)
Netzarchitektur:• spezielle einschichtige Netze
Training:• erfolgt NUR mit Hilfe der Eingangsmuster.• Per selbstorganisation werden Clustermerkmale erkannt und wird die
Klassenzugehörigkeit zu einem Cluster ermittelt.
Anwendungen:• sehr breit gestreut, von
• Spracherkennung••• Robotik• Vorhersage• Optimierung
bis

FB Elektrotechnik
42Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
5. Lernverfahren5. Lernverfahren5. Lernverfahren
Prinzipieller Ablauf des Lernvorgangs in neuronalen Netzen
Die vielen Lernverfahren können in 2 große Gruppen geteilt werden:• supervised learning, bei dem die Regeln dem Lernfortschritt angepaßt werden
und die iterativ arbeiten• unsupervised learning, bei dem man nach einer fest vorgegebenen Regel
arbeitet und die Koeffizienten meist in einem Arbeitsschritt bestimmt.
Die Lernverfahren arbeiten meist nach folgendem Muster (Ausnahme -Selbstorganisation):
1. Man startet mit einem Netzwerk mit Anfangswerten für dieGewichtskoeffizienten wij (zufällig ausgewählte Anfangswerte oder auchAnfangswerte wij = 0).
2. Auf Basis der gegebenen Eingangsmuster (und ggf. Ausgangsmuster) undbestimmt man mit Hilfe bestimmter regeln die Gewichtskoeffizienten.
3. Es gibt eine Vielzahl von Regeln und folglich eine Vielzahl von Lernverfahren.

FB Elektrotechnik
43Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Unsupervised Learning
Das unsupervised learning ist ein sehr einfaches Verfahren, das folgendem Schemafolgt:
unbekanntes System
neuronales Netz
„Trainer“
Eingangsmuster Soll-Ausgangsmuster
Lernregel (Regel zurBerechnung derKoeffizienten)
Eine Überwachung des Lernprozesses findet nicht statt.
Hier soll nur eines der einfachsten Verfahren beispielhaft betrachtet werden - dieHebb‘sche Lernregel.

FB Elektrotechnik
44Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Hebb‘sche Lernregel:
w41w11
+
F(G)
w21 w31
Neu
ron
1
y1
w42w12
+
F(G)
w22 w32
Neu
ron
2
y2
w43w13
+
F(G)
w23 w33
Neu
ron
3
y3
x1 x2 x4x3
Die Hebb‘sche Lernregel gehtvon dem intuitiven Ansatzaus, daß die Änderung einesGewichtsfaktors proportionalzur Größe seinesEingangswertes und seinesAusgangswertes sein soll,also ∆wij = xiyj .
Dies gilt natürlich für alle Gewichtskoeffizienten, so daß man schreiben kann
[ ]321
4
3
2
1
434241
333231
232221
131211
,, yyy
x
x
x
x
www
www
www
www
⋅
=
=
∆∆∆
∆∆∆
∆∆∆
∆∆∆
∆W bzw. TyxW ⋅=∆
wobei ein Element der Matrix wiefolgt berechnet wird: jiij yxw ⋅=∆

FB Elektrotechnik
45Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Nach der Hebb‘schen Regel werden zunächst für jedes der vorhandenen Paare„Eingangsvektor ! Ausgangsvektor (x ! y)“ die Gewichtsfaktoren mit Hilfe derFormel
einzeln und getrennt berechnet und dann einfach summiert, also
KK jijijiij yxyxyxw ⋅++⋅+⋅= .....2211
( ) ∑=
⋅==K
kk
TkK
1
yxWW
Geht man nun davon aus, daß man K Musterpaare für den Lernvorgang hat und zuBeginn des Lernvorgangs alle wij = 0, so ergibt sich folgende einfache Formel für dieBestimmung der Gewichtsmatrix:
jiij yxw ⋅=∆

FB Elektrotechnik
46Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Beispiel:
x1 x2
+w11 w21
y1
+w12 w22
y2
+w14 w24
y4
+w13 w23
y3
Anzahl der Musterpaare = 4
Lerntabelle
x1 x2 y1 y2 y3 y4
-1 -1 1 0 0 0
+1 -1 0 1 0 0-1 +1 0 0 1 0+1 +1 0 0 0 1
k
1
234
( ) ( ) ( ) ( ) 10101011144332211 11111111
4
11111 −=⋅++⋅−+⋅++⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 10101011144332211 12121212
4
11221 −=⋅++⋅++⋅−+⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 10101110144332211 21212121
4
12112 +=⋅++⋅−+⋅++⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 10101110144332211 22222222
4
12222 −=⋅++⋅++⋅−+⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk

FB Elektrotechnik
47Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
( ) ( ) ( ) ( ) 10111010144332211 31313131
4
13113 −=⋅++⋅−+⋅++⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 10111010144332211 32323232
4
13223 +=⋅++⋅++⋅−+⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 11101010144332211 41414141
4
14114 +=⋅++⋅−+⋅++⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
( ) ( ) ( ) ( ) 11101010144332211 42424242
4
14224 +=⋅++⋅++⋅−+⋅−=⋅+⋅+⋅+⋅=⋅=∑
=yxyxyxyxyxw
kkk
Überprüfungdes Ergebnisses:
x1 x2
+-1 -1
y1
++1 -1
y2
++1 +1
y4
+-1 +1
y3
x1 x2
-1 -1 2 0 0 -2
+1 -1 0 2 -2 0-1 +1 0 -2 2 0+1 +1 -2 0 0 2
k
1
234
y 1=
-x1-
x 2
y 2=
+x 1
-x2
y 3=
-x1+
x 2y 4
=+
x 1+
x 2

FB Elektrotechnik
48Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
x1 x2
+-1 -1
y1
++1 -1
y2
++1 +1
y4
+-1 +1
y3
x1 x2
-1 -1 2 0 0 -2
+1 -1 0 2 -2 0-1 +1 0 -2 2 0+1 +1 -2 0 0 2
k
1
234
y 1*=
-x1-
x 2
y 2*=
+x 1
-x2
y 3*=
-x1+
x 2y 4
*=+
x 1+
x 2
θ θ θ θF(G) F(G)F(G)F(G)
Fügt man nun die Korrekturgrößeθ = −0,5 ein und nutzt den Hard-Limiter
≥−=<−=
=05,01
05,00)( *
*
j
j
yG
yGGF
G
F(G)1
so erhält man das gewünschte Netzverhalten:
y1 y2 y3 y4
1 0 0 0
0 1 0 00 0 1 00 0 0 1

FB Elektrotechnik
49Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Supervised Learning
Der Lernvorgang erfolgt hier iterativ, indem die Änderung der Gewichtskoeffizientendurch den Abstand zwischen Soll-Ausgangsmuster und Ist-Ausgangsmuster gesteuertwird:
unbekanntes System
neuronales Netz
„Trainer“
Eingangsmuster Soll-Ausgangsmuster
LernregelIst-Ausgangsmuster
Abweichung
Die bekannteste Regel für das supervised learning ist die Delta-Regel.

FB Elektrotechnik
50Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Delta-Regel:
Die Delta-Regel soll am Beispiel eines einfaches Netzes aus nur einem Neuronerläutert werden:
w1
w2
wN
x1
x2
xN
Σy
mittlererquadratischer
Fehler
ySoll-Ausgangswert
Ist-Ausgangswert (für die eingestellten Gewichtsfaktoren)
( )2
1
2 ˆˆ
⋅−=−=ε ∑
=
N
iii xwyyy
Meist verwendet man den mittleren quadratischen Fehler zur Bewertung derAbweichung des Ist-Ausgangswertes vom Soll-Ausgangswertes.

FB Elektrotechnik
51Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
( )2
1
2 ˆ2
1ˆ
2
1
⋅−=−=ε ∑
=
N
iii xwyyyAus dem Ausdruck
geht hervor, daß ε eine quadratische Funktion des Gewichtskoeffizienten wi ist undein Minimum besitzt, das offensichtlich dem optimalen Wert desGewichtskoeffizienten wi entspricht.:
Dieses Optimum findet man iterativ mitHilfe des Gradientenverfahrens. ε
wi
wi(s-1)wi(s) wiopt.
∆ε
∆wi
Je steiler die Tangente im Punkt ε(wi(s-1))ist, desto weiter befinden wir uns vomOptimum entfernt und um so größer ist derSchritt auf der wi -Achse zu wählen.
( ) ( )110lim
−=−=→∆ ∂ε∂=ε
∆
∆
swwiswwiwiiiii
ww
Die Steilheit der Tangente im Punkt wi(s-1)wird bestimmt durch den Wert der partiellenAbleitung in diesem Punkt:
He
rle
itu
ng

FB Elektrotechnik
52Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
)1(
)1()(−=∂
ε∂⋅β−−=swwi
ii
iiw
swsw
Befinden wir uns rechts vom Optimum, so hat die partielle Ableitung einen positivenWert, aber der Wert von wi muß verkleinert werden. Daraus ergibt sich die Regel
wobei β - ein Proportionalitätsfaktor ist, der die Schrittgröße bestimmt.
Dieser Algorithmus soll an einem einfachen Beispiel erläutert werden.
0
20
40
60
80
100
120
140
160
-5,5 -5 -4,5 -4 -3,5 -3 -2,5 -2 -1,5 -1 -0,5 0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5 5,5
1.
2.
w(1) w(2) w(0)
ε
w
Es sei 25w=ε
Dann istw
w10=
∂ε∂
Als zufälligen Startwertwählen wir w(0)=5.
Als Proportionalitätsfaktorwählen wir β = 0,15.
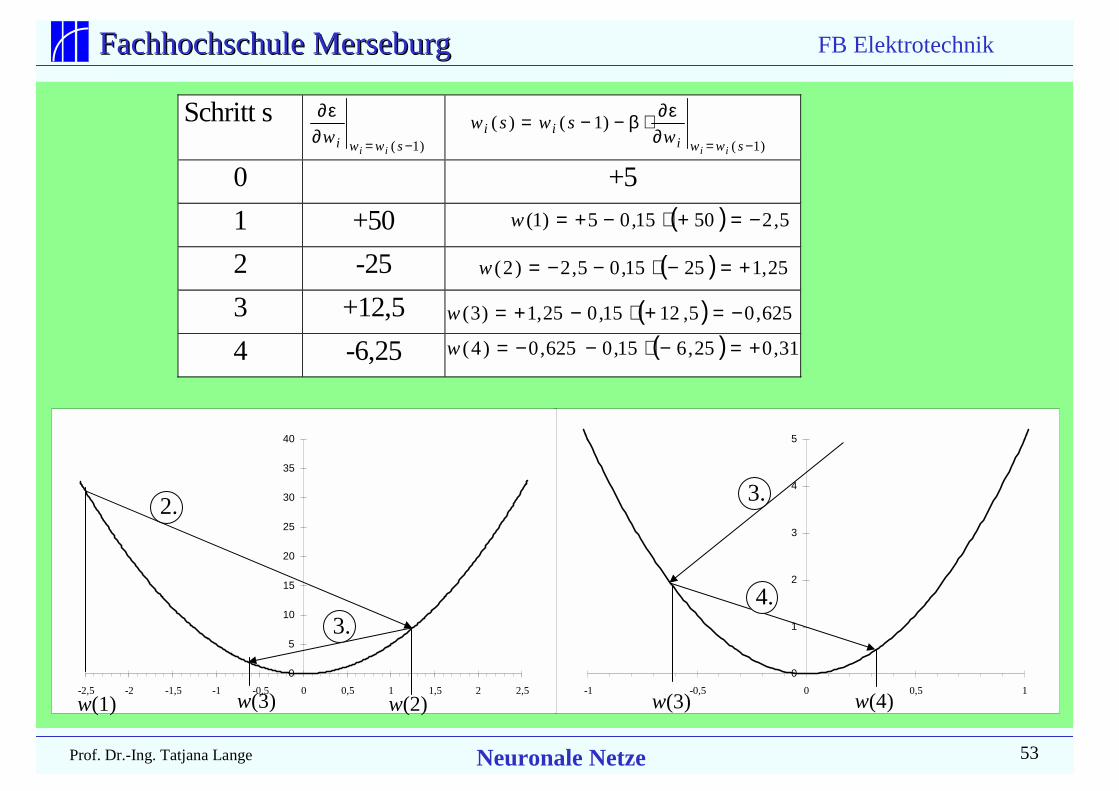
FB Elektrotechnik
53Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Schritt s
0 +5
1 +50
2 -25
3 +12,5
4 -6,25
)1(
)1()(−=∂
ε∂⋅β−−=swwi
ii
iiw
swsw)1( −=∂
ε∂
swwiii
w
( ) 5,25015,05)1( −=+⋅−+=w
( ) 25,12515,05,2)2( +=−⋅−−=w
( ) 625,05,1215,025,1)3( −=+⋅−+=w
( ) 31,025,615,0625,0)4( +=−⋅−−=w
0
1
2
3
4
5
-1 -0,5 0 0,5 1w(3) w(4)
3.
4.
0
5
10
15
20
25
30
35
40
-2,5 -2 -1,5 -1 -0,5 0 0,5 1 1,5 2 2,5
2.
3.
w(1) w(3) w(2)

FB Elektrotechnik
54Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
( ) iii xsyyswsw ⋅−−⋅β+−= )1(ˆ)1()(
wobeiwi(s-1) - der Wert des Gewichts-
koeffizienten wi ist, der beimvorhergehendenIterationsschritt ermittelt wurde;
y(s-1) - der mit wi(s-1) berechneteAusgangswert (Ist-Wert) ist;
β - ein (konstanter) Lernfaktor istDiese Formel gilt nur für EIN Eingangsmuster.
)1(
)1()(−=∂
ε∂⋅β−−=swwi
ii
iiw
swsw
( )
⋅+⋅−=
⋅−=−=ε ∑ ∑∑
= ==
N
i
N
iiiii
N
iii xwxwyyxwyyy
1
2
1
22
1
2 ˆ2ˆ2
1ˆ
2
1ˆ
2
1
Um zu einer für den Lernprozeß brauchbaren Formel zu kommen, müssen wirdie partielle Ableitung für die bekannte Abhängigkeit des mittleren quadratischenFehlers vom betrachteten Gewichtskoeffizienten wi ermitteln:
( )( )
( )( )( ) ii
sy
iiswwi
xsyyxxswyw
ii
⋅−−−=⋅
⋅−−−=
∂ε∂
−−=1ˆ1ˆ
114 34 21
da nur die Änderung eines bestimmtenKoeffizienten wi betrachtet wird unddamit die partielle Ableitung für alle
anderen Terme gleich Null ist
Damit erhält man aus
( ) ( ) iiiiiii
xxwyxwxyw
⋅⋅−−=⋅+⋅−=∂
ε∂ˆ2ˆ2
2
1 2
He
rle
itu
ng

FB Elektrotechnik
55Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Für K Eingansmuster gilt:
( )ki
K
kkkii xsyyswsw ⋅−−⋅β+−= ∑
=1
)1(ˆ)1()(
Die Iteration wird abgebrochen, wenn mit dem nächsten Schritt keine Verkleinerungdes mittleren quadratischen Fehlers mehr erreicht wird.
Die Delta-Regel funktioniert nur für einschichtige Neuronale Netze.Mehrschichtige neuronale Netze können nicht mit der Delta-Regel trainiert werden, dasie nicht festlegt, wie die Gewichte der Zwischenschichten optimiert werden können.
1985 wurde von Rumelhart eine Regel für mehrschichtige Feedforward-Netzeentwickelt, die noch heute am meisten angewandt wird - die Backpropagation-Regel.
Die Backpropagation-Regel wird im Zusammenhang mit den Multilayer-Perceptron(MLP) behandelt.
Ein Beispiel für die Anwendung der Delta-Regel wird im Zusammenhang mit demAdaline behandelt

FB Elektrotechnik
56Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
6. Klassifikation bzw. Paradigmen neuronaler Netze6. Klassifikation bzw. Paradigmen neuronaler Netze6. Klassifikation bzw. Paradigmen neuronaler Netze
Neuronale Netze unterscheiden sich1. in der Art und Weise des Lernens2. in ihrer Architektur3. in ihrer Eingangs-/Ausgangsrelation4. in der Art der Bestimmung der Musterklassen5. nach der Art der Eingangs- und Ausgangssignale6. nach der Art der Berechnung der Netzwerke
sogenannteParadigmenneuronalerNetze
1. Lernen(a) supervised(b) un-supervised
2. Architektur(a) feedforward - einschichtig(b) feedforward - mehrschichtig
(c) feedback - einschichtig(d) feedback - mehrschichtig
3. Eingangs-/Ausgangsrelation(a) Netze mit Musterzuordnung(b) Netze als Assoziativspeicher
4. Musterklassen(a) fest vorgegebene Anzahl
von Mustern mit typischenMerkmalen
(b) Musterbestimmung mittelsSelbstorganisation
5. Art der Signale(a) binär (digital)(b) kontinuiertlich (analog)
6. Art der Berechnung(a) determenistisch(b) probalistisch (mit
Methoder derWahrscheinlichkeits-theorie)
FB Elektrotechnik
57Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
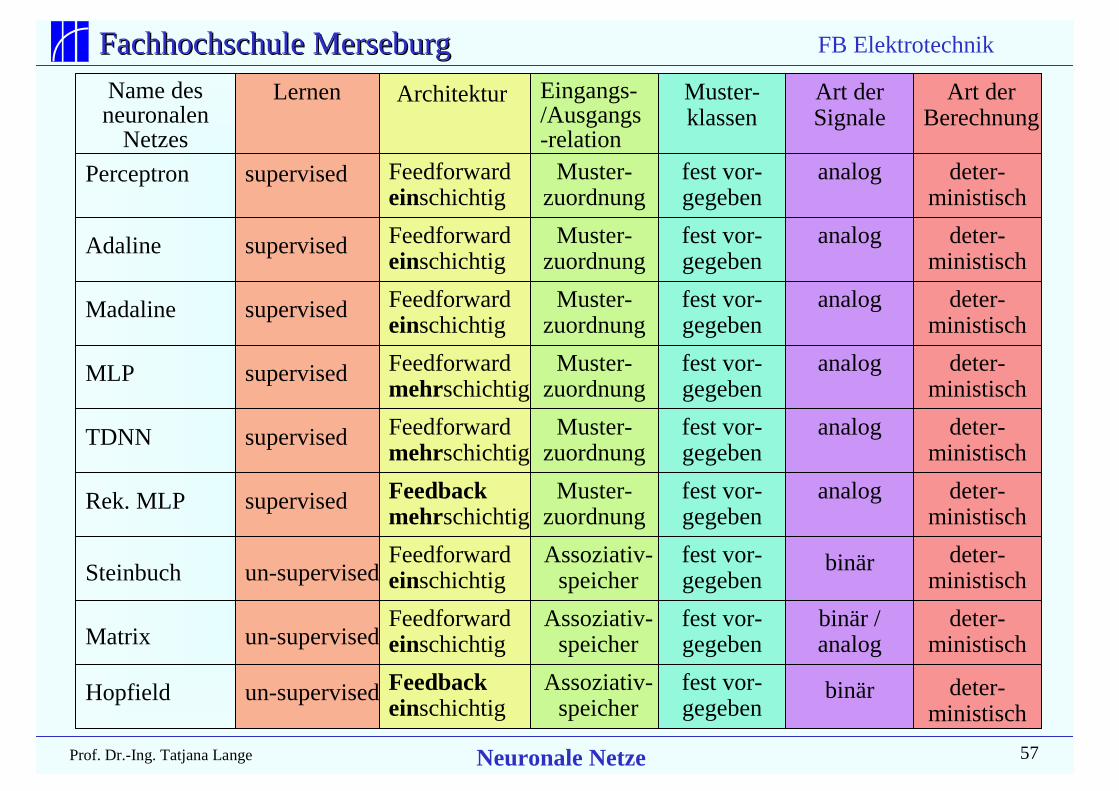
Fachhochschule MerseburgFachhochschule Merseburg
Lernen Architektur Eingangs-/Ausgangs-relation
Muster-klassen
Art derSignale
Art derBerechnung
supervisedPerceptron
Adaline
Madaline
MLP
TDNN
Rek. MLP
Steinbuch
Matrix
supervised
supervised
supervised
supervised
supervised
un-supervised
un-supervised
Feedforwardeinschichtig
Name desneuronalen
Netzes
Feedforwardeinschichtig
Feedforwardeinschichtig
Feedforwardmehrschichtig
Feedforwardmehrschichtig
Feedbackmehrschichtig
Feedforwardeinschichtig
Hopfield un-supervised
Feedforwardeinschichtig
Feedbackeinschichtig
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Assoziativ-speicher
Assoziativ-speicher
Assoziativ-speicher
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
analog
analog
binär /analog
analog
analog
analog
analog
binär
binär
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch

FB Elektrotechnik
58Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
Lernen Architektur Eingangs-/Ausgangs-relation
Muster-klassen
Art derSignale
Art derBerechnung
un-supervisedHaken
BAM
Hamming
BSB
ART
Counter
Kohonen
Boltzmann
un-supervised
un-supervised
un-supervised
un-supervised
un-supervised
un-supervised
supervised
Name desneuronalen
Netzes
probablistisch un-supervised
Muster-zuordnung /
Assoziativsp.
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Assoziativ-speicher
Assoziativ-speicher
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
Selbst-organisat.
fest vor-gegeben
fest vor-gegeben
fest vor-gegeben
analog
analog
binär
analog
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
deter-ministisch
proba-listisch
deter-ministisch
Feedbackmehrschichtig
Feedbackmehrschichtig
Feedbackmehrschichtig
Feedbackmehrschichtig
Feedbackmehrschichtig
Feedbackeinschichtig
Feedforwardmehrschichtig
Feedforwardeinschichtig
Feedforwardmehrschichtig
Muster-zuordnung
Muster-zuordnung
Muster-zuordnung
Selbst-organisat.
binär /analog
analog
binär
binär
binär
proba-listisch

FB Elektrotechnik
59Prof. Dr.-Ing. Tatjana Lange Neuronale Netze
Fachhochschule MerseburgFachhochschule Merseburg
7. Faustregeln zur Auswahl der Paradigmen und der Netzkonfiguration7. Faustregeln zur Auswahl der Paradigmen und der Netzkonfigurat7. Faustregeln zur Auswahl der Paradigmen und der Netzkonfigurationion
Auswahl des neuronalen Netzes:Das Multilayer Perceptron (MLP) ist fast immer einsetzbar. Ansonsten gilt:
• binäre Signale ! binäre Netze (einfacher zu trainieren), wie z.B. Steinbruch-Netze• keine Musterpaare vorhanden, sondern nur Eingangsmuster ! selbstorganisierende
Netze, z.B. ART-Netze (ART = Adaptive Resonance Theory)• Anzahl Trainingsdaten klein ! Assoziativnetze, z.B. Hopfield-Netze oder Hamming-
Netze• wahrscheinlichkeitstheoretisches Problem ? ! probalistische Netze, z.B. Probalistic
Neural nNetwork (PNN)
Netzdesign – Anzahl der Schichten und der Neuronen in den Schichten:Hier sind kaum Standard-Regeln verfügbar, meist muß man experimentieren.
Für MLP gelten folgende Empfehlungen:• 1 verdeckte Schicht und 1 Ausgabeschicht• Eingabevektor hat meist 20 – 200 Elemente• Ausgabevektor hat meist 2 – 100 Elemente• Anzahl der Neuronen in der verdeckten Schicht – 50 - 500