Neuronale Netze in der modernen Spracherkennungdnt.kr.hsnr.de/ASR17/neuralnets_gref.pdf ·...
87
1/87 Einleitung und Motivation Grundlagen und Wiederholung Long short-term memory neural networks State-of-the-art ASR-Systeme Ausblick auf zuk¨ unftige Ans¨ atze Literatur Neuronale Netze in der modernen Spracherkennung Michael Gref 7. Februar 2018 Michael Gref Neuronale Netze in der modernen Spracherkennung
Transcript of Neuronale Netze in der modernen Spracherkennungdnt.kr.hsnr.de/ASR17/neuralnets_gref.pdf ·...

1/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Neuronale Netze in der modernenSpracherkennung
Michael Gref
7. Februar 2018
Michael Gref Neuronale Netze in der modernen Spracherkennung

2/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Agenda
Einleitung und Motivation
Grundlagen und Wiederholung
Long short-term memory neural networks
State-of-the-art ASR-Systeme
Ausblick auf zukunftige Ansatze
Michael Gref Neuronale Netze in der modernen Spracherkennung
3/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
EinleitungZielsetzung der Kurseinheit
Motivation I
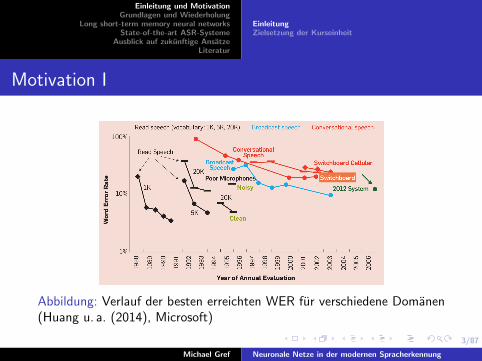
Abbildung: Verlauf der besten erreichten WER fur verschiedene Domanen(Huang u. a. (2014), Microsoft)
Michael Gref Neuronale Netze in der modernen Spracherkennung

4/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
EinleitungZielsetzung der Kurseinheit
Motivation II
Abbildung: Verlauf der besten erreichten WER fur die Switchboard-Taskim Verlaufe der Zeit (Quelle: Twitter, Oktober 2017, awnihannun)
Michael Gref Neuronale Netze in der modernen Spracherkennung

5/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
EinleitungZielsetzung der Kurseinheit
Motivation III
I Unter Einsatz komplexer Architekturen kunstlicher neuronalerNetze erreichen ASR-Systeme bei der Switchboard EnglishConversational Telephone Speech Recognition Task 2017erstmals Wortfehlerraten von ∼ 5.5%
I Kontroverse Diskussion, ob ASR-Systeme inzwischenmenschliche Wortfehlerraten erreichen!
I Bspw. IBM Watson (Saon u. a. (2017)),I vs. Microsoft AI and Research (Stolcke u. Droppo (2017))
I Gleichzeitig tun sich neue Herausforderungen auf. Bspw.erfreuen sich Sprachassistenten wie Alexa, Google Home oderSiri enormer Beliebtheit
Michael Gref Neuronale Netze in der modernen Spracherkennung
6/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
EinleitungZielsetzung der Kurseinheit
Motivation IV
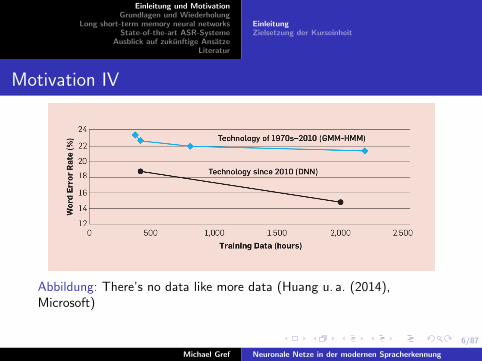
Abbildung: There’s no data like more data (Huang u. a. (2014),Microsoft)
Michael Gref Neuronale Netze in der modernen Spracherkennung

7/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
EinleitungZielsetzung der Kurseinheit
Das Ziel der Kurseinheit:
I Ein tieferes Verstandnis fur die Funktionsweise vonkunstlichen neuronalen Netzen die zur akustischenModellierung verwendet werden
I Insbesondere von sogenannten LSTMs und TDNNs
Michael Gref Neuronale Netze in der modernen Spracherkennung

8/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Grundlagen und Wiederholung
Michael Gref Neuronale Netze in der modernen Spracherkennung

9/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Kurze Wiederholung von:
I Aufbau und Funktionsweise einfacher kunstlicher neuronalerNetze (MLP)
I Notation als Funktionen und mit Strukturen der linearenAlgebra
I Training kunstlicher neuronaler Netze
I Einfache rekurrente Netze
Michael Gref Neuronale Netze in der modernen Spracherkennung

10/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Grundbaustein neuronaler Netze
Basis-Element jedes kunstlichen neuronalen Netzes ist das Neuron.Funktion, die eine endliche Folge oder einen Vektor reellerZahlenwerte auf eine reelle Zahl abbildet.
Michael Gref Neuronale Netze in der modernen Spracherkennung

11/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Schematischer Aufbau
wj,1
wj,2
wj,3
wj,D
x1
x2
x3
xD
wj,0
Σ h(⋅)zj
Abbildung: Schematischer Aufbau eines kunstlichen Neurons
Michael Gref Neuronale Netze in der modernen Spracherkennung

12/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Mathematische Beschreibung
In Anlehnung an (Bishop, 2006, S. 227) lasst sich das Verhalteneines einzelnen Neurons mit Index j ∈ N wie folgt modellieren:
zj : RD → R, x 7→ h
(D∑i=1
wj,i · xi + wj,0
)(1)
I x := (x1, ..., xD)T ∈ RD ein Eingangsvektor mit
I D ∈ N Eingangswerten und
I h eine (differenzierbare) Aktivierungsfunktion.
(Bezeichnung: Forward-Pass)
Michael Gref Neuronale Netze in der modernen Spracherkennung

13/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Anordnung von Neuronen zu Layern
I Neuronen innerhalb des neuronalen Netzes sind im einfachstenFall in sogenannten Dense-Layern angeordnet
I Alle Neuronen innerhalb eines Layers werden stets auf diegleichen Eingangsvektoren angewendet und haben stets diegleiche Aktivierungsfunktion.
I Die verwendeten Aktivierungsfunktionen sind je nachAnwendungsfall ublicherweise - jedoch nicht ausschließlich -die Identitatsfunktion (sog. lineare Aktivierung), dieSigmoidfunktion oder der Tangens-Hyperbolicus.
Michael Gref Neuronale Netze in der modernen Spracherkennung

14/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Mathematische Modellierung
Ein Layer mit Index l ∈ N der Große M ∈ N bestehend aus MNeuronen und kann als Funktion
RD → RM ,x 7→ z(l) (x) :=(z(l)1 (x) , ..., z
(l)M (x)
)T(2)
aufgefasst werden.Bezeichnung:
I Dense-Layer (in moderner Terminologie)
I oder Fully-Connected Layer
Michael Gref Neuronale Netze in der modernen Spracherkennung

15/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Kompakte Notation I
Das Verhalten des Layers lasst sich in Anlehnung an (Yu u. Deng,2015, S. 57) durch Matrix-Multiplikation kompakt schreiben als
z(l) (x) = h(l)(W(l) · x+w0
(l))
(3)
wobei h(l) die, auf einen Vektor elementweise angewendeteAktivierungsfunktion h(l) ist.
Michael Gref Neuronale Netze in der modernen Spracherkennung

16/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Kompakte Notation II
Es wirdw0
(l) := (w(l)1,0, ..., w
(l)M,0)
T (4)
als Bias-Vektor und
W(l) :=
w(l)1,1 · · · w
(l)1,i · · · w
(l)1,D
......
...
w(l)j,1 · · · w
(l)j,i · · · w
(l)j,D
......
...
w(l)M,1 · · · w
(l)M,i · · · w
(l)M,D
(5)
als Ubergangsmatrix des Layers definiert.
Michael Gref Neuronale Netze in der modernen Spracherkennung

17/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Anmerkung zur Notation
Wichtig: Sofern nicht anders angegeben, wird fur die
Ubersichtlichkeit im weiteren Verlauf bei Modellierung neuronalerNetze immer diese Notation verwendet.
Michael Gref Neuronale Netze in der modernen Spracherkennung

18/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Multi-Layer Perceptron I
Im Falle eines einfachen Feed-Forward-Netzes mit L ∈ Nhintereinander verbundenen Layern, lasst sich das Verhalten desgesamten neuronalen Netzes modellieren durch Komposition dereinzelnen Layer-Funktionen. Das heißt, dass der Ausgangswerteines neuronalen Netzes fur einen Eingangsvektor x durch
nnet (x) :=(z(L) ◦ · · · ◦ z(2) ◦ z(1) ◦ idRD
)(x) (6)
Michael Gref Neuronale Netze in der modernen Spracherkennung
19/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Multi-Layer Perceptron II
x0
x1
xD
z0
z1
zM
y1
yK
w(1)MD w
(2)KM
w(2)10
hidden units
inputs outputs
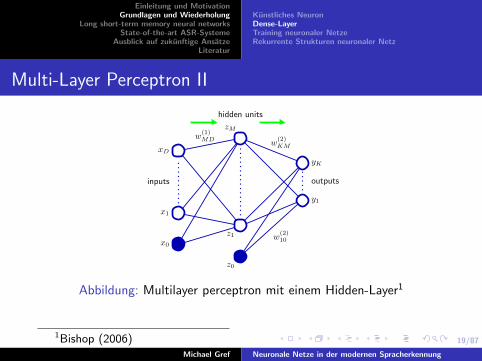
Abbildung: Multilayer perceptron mit einem Hidden-Layer1
1Bishop (2006)Michael Gref Neuronale Netze in der modernen Spracherkennung

20/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Training neuronaler Netze
Supervised-Learning:
I Trainingsdaten bestehen aus einer Menge Tupeln (x,y) mitx ∈ RD und einem Target-Vektor y ∈ RN .
I Ziel ist die Bestimmung der Gewichte aller Neuronen im Netz,so dass das Netz fur x eine
”beste“ Schatzung von y liefert.
(Was”beste“ bedeutet, wird durch eine Zielfunktion definiert)
Michael Gref Neuronale Netze in der modernen Spracherkennung

21/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Zielsetzung
Zielfunktion / Objective Function:
I Zu optimierende Funktion. Bei neuronalen Netzen der Fehlerzwischen Schatzung und Zielwert
I Verschiedene Varianten je nach Art der Aufgabenstellung.Bekannteste Beispiele:
I Fehlerquadrat, Betragsquadrat fur RegressionsaufgabenI Cross-Entropy fur Schatzung von Wahrscheinlichkeiten
Michael Gref Neuronale Netze in der modernen Spracherkennung

22/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Back-Propagation (Grundidee)
Ziel: Anpassung der Gewichtsmatrizen und Bias-Vektoren durch eininkrementelles Gradienten-Verfahren bspw. Stochastic GradientDescent (SGD).
I (Analytische) Differentiation der Zielfunktion nach denGewichten im neuronalen Netz
I Forward Pass: Berechnung der Schatzung des Netzes fur einTrainings-Tupel
I Berechnung des Fehlers mittels der Objective-Function
I Backward Pass: Aktualisierung der Gewichte (inAbhangigkeit ihres jeweiligen Beitrags)
Michael Gref Neuronale Netze in der modernen Spracherkennung

23/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Moglichkeiten zur Verbesserung des Trainings
I (Mini-)Batch-Training
I Shuffeling
I Adaptive Lernrate
I MomentumI Moderne Erweiterungen von SGD fur die Back-Propagation:2
I AdagradI AdadeltaI RMSpropI AdamI AdaMax
2Vergleich und Visualisierung: http://ruder.io/optimizing-gradient-descent/Michael Gref Neuronale Netze in der modernen Spracherkennung

24/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Einfache rekurrente Layer
I Elman network
ht = σh(Whxt +Uhht−1 + bh) (7)
yt = σy(Wyht + by) (8)
I Jordan network
ht = σh(Whxt +Uhyt−1 + bh) (9)
yt = σy(Wyht + by) (10)
Michael Gref Neuronale Netze in der modernen Spracherkennung

25/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Anmerkung zur Notation
I Man beachte: Die Addition der Ausgange zweier Dense-Layerohne Aktivierungsfunktion
f(x,h) = (W · x+ a1) + (U · h+ a2) (11)
kann durch”Aneinanderreihung“ der Vektoren mit nur einem
Dense-Layer realisiert werden:
f
([xh
]):=[W,U
] [xh
]+ (a1 + a2)︸ ︷︷ ︸
:=b
(12)
I Wir nutzenI in Formeln separate Gewichtsmatrizen fur jeden
Eingangsvektor (besseres Verstandnis).I in Skizzen Zusammenfassung zu einem Dense-Layer
(Ubersichtlichkeit).Michael Gref Neuronale Netze in der modernen Spracherkennung

26/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Aufbau einfacher rekurrenter Layer
Elman-RNN
Jordan-RNN
ht ytxth
T
y
Abbildung: Schematischer Aufbau einfacher rekurrenter Layer
Grune Boxen modellieren jeweils einen (vollverbundenen)Dense-Layer.
Michael Gref Neuronale Netze in der modernen Spracherkennung

27/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Back-Propagation Through Time I
Das Training rekurrenter Netze erfolgt mittels Back-PropagationThrough Time:
I Entfaltung der Ruckkopplung im Netz entlang der Zeit fur dieLange der jeweiligen Trainingssquenz
I Auf diese Struktur wird dann derBack-Propagation-Algortihmus angewendet
Michael Gref Neuronale Netze in der modernen Spracherkennung

28/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Back-Propagation Through Time II
Abbildung: Schematische Funktionsweise von BPTT3
Michael Gref Neuronale Netze in der modernen Spracherkennung

29/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Back-Propagation Through Time III
Abbildung: Schematische Darstellung von Verarbeitungsvarianten furSequenzen4
3Quelle: wikimedia.org4Quelle: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Michael Gref Neuronale Netze in der modernen Spracherkennung

30/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Problem: Rechenzeit
Zu beachten:
I Kann fur lange Training-Sequenzen sehr rechenintensivwerden! Vergleichbar mit sehr tiefen Feed-Forward-DNN
I Sequentielle Verarbeitungsschritte unvermeidbar.Parallelisierung nicht in dem Maße moglich, wie beiFeed-Forward-Netzen - insbesondere mit GPUs.
Michael Gref Neuronale Netze in der modernen Spracherkennung

31/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Kunstliches NeuronDense-LayerTraining neuronaler NetzeRekurrente Strukturen neuronaler Netz
Probleme rekurrenter Strukturen Anfang der 90er
nach Hochreiter u. Schmidhuber (1997):
I Bei klassischen rekurrenten Strukturen neigen Fehler-Signalebeim Training dazu im Verlauf der Zeit (bezogen auf eineTrainingssequenz) schnell gegen Null zu konvergiert oder zudivergieren
I Fuhrt zu oszillierenden Matrix-Gewichten oder gar zurDivergenz
I Zusammenhange bei langen Sequenzen konnen kaum gelerntwerden. Nur fur Kurzzeit-Gedachtnis (Short-Term Memory)geeignet (ublicherweise 5 bis 10 diskrete Zeitschritte)
Michael Gref Neuronale Netze in der modernen Spracherkennung

32/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Long short-term memory neural networks
Michael Gref Neuronale Netze in der modernen Spracherkennung

33/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) I
Modellierung eines LSTM-Layers nach (ursprunglicher) Idee vonHochreiter u. Schmidhuber (1997). Erweiterung des rekurrentenAnsatzes um:
I ein constant error carousel (CEC),
I ein multiplikatives Input-Gate, das Speichern von irrelevantenInformationen im CEC schutzen soll,
I ein multiplikatives Output-Gate, das die Ausgabe vonInformationen im CEC unterdrucken soll, die zum aktuellenZeitpunkt nicht relevant sind (aber spater relevant werdenkonnten)
Michael Gref Neuronale Netze in der modernen Spracherkennung

34/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) II
Die Grundidee in Formeln:
ot = σo(Wouo,t + bo) (13)
it = σi(Wiui,t + bi) (14)
ct = ct−1 + it · σc(Wcuc,t + bc) (15)
ht = ot · σh(ct) (16)
Mit der”Multiplikation von Vektoren“ ist die punktweise bzw.
elementweise Multiplikation der Eintrage gemeint.
Michael Gref Neuronale Netze in der modernen Spracherkennung

35/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) III
ht
T
ot
it
ctct-1
c~
i
o
×
+
×
σh
[CEC]
uc,t
ui,t
uo,t
Abbildung: Grundidee des ursprunglichen LSTM-Konzepts von 1997
Michael Gref Neuronale Netze in der modernen Spracherkennung

36/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) IV
I Durch das CEC soll bei der Back-Propagation der propagierteFehler entlang der Zeit konstant bleiben (Herleitung s. Paper)
I uo,t, ui,t und uc,t werden von Hochreiter nicht explizitdefiniert. Der Nutzer sollte selbst die passendeNetzwerk-Topologie festlegen
I Ublicherweise werden Eingangswerte (bzw. Ausgangswerte vonvorhergehenden Layern) xt und der gepufferte Ausgang desaktuellen Layers ht−1 als Eingangswerte fur die Gatesverwendet.
Michael Gref Neuronale Netze in der modernen Spracherkennung

37/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) V
Das heißt mit
uo,t := ui,t := uc,t :=
[xt
ht−1
](17)
erhalten wir fur das LSTM:
ot = σo(Woxt +Uoht−1 + bo) (18)
it = σi(Wixt +Uiht−1 + bi) (19)
ct = ct−1 + it · σc(Wcxt +Ucht−1 + bc) (20)
ht = ot · σh(ct) (21)
Michael Gref Neuronale Netze in der modernen Spracherkennung

38/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) VI
ht
T
ot
it
ctct-1
xt
ht-1
c~
i
o
×
+
×
σh
[CEC]
Abbildung: Bekannteste Variante des ursprunglichen LSTM-Konzepts
Michael Gref Neuronale Netze in der modernen Spracherkennung

39/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM nach Hochreiter u. Schmidhuber (1997) VII
I LSTMs konnten erstmals Informationen fur bis zu 1000diskrete Zeitschritte speichern
I Problem: Werte konnen zwar additiv ins CEC gespeichertwerden, uberlagern sich jedoch irgendwann
I Fur jede Berechnung muss der Speicher im LSTMzuruckgesetzt werden
Michael Gref Neuronale Netze in der modernen Spracherkennung

40/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
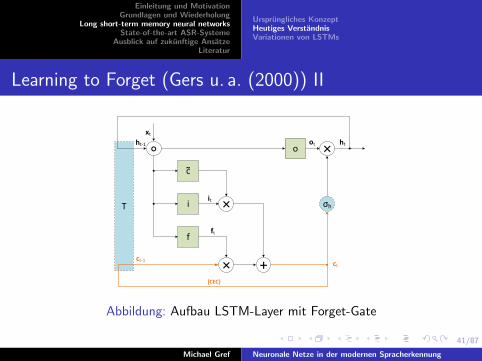
Learning to Forget (Gers u. a. (2000)) I
Erweiterung des Konzepts um ein multiplikatives Forget-Gate:
ot = σo(Woxt +Uoht−1 + bo) (22)
it = σi(Wixt +Uiht−1 + bi) (23)
ct = ft · ct−1 + it · σc(Wcxt +Ucht−1 + bc) (24)
ft = σf (Wfxt +Ufht−1 + bf ) (25)
ht = ot · σh(ct) (26)
Michael Gref Neuronale Netze in der modernen Spracherkennung
41/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Learning to Forget (Gers u. a. (2000)) II
ht
T
ot
it
ctct-1
xt
ht-1
c~
i
f
o
×
× +
×
σh
ft
[CEC]
Abbildung: Aufbau LSTM-Layer mit Forget-Gate
Michael Gref Neuronale Netze in der modernen Spracherkennung

42/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Zunachst einige Uberlegungen zur Komplexitat I
I Ein LSTM-Layer besteht im Prinzip aus 4 verschiedenenDense-Layern
I Wir definieren die Große des Input-Vektors
I = dim(xt) (27)
und die Große des Cell-Vektors
H = dim(ct) (28)
und erhalten die Anzahl der Parameter im LSTM-Layer:
4 · (I +H + 1) ·H (29)
Michael Gref Neuronale Netze in der modernen Spracherkennung

43/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Zunachst einige Uberlegungen zur Komplexitat II
I Bei H >> I skaliert die Anzahl der Gewichte quadratisch zurGroße des Ausgangs.
I Bspw. mit H = 2000 und I = 257 sind 18.064.000 Parameterzu trainieren
I Zum Vergleich Parameter eines Dense-Layer mit gleicherInput- und Output-Dimension:
(I + 1) ·H = 516.000 (30)
Michael Gref Neuronale Netze in der modernen Spracherkennung

44/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTM Variationen
I LSTMs mit Forget-Gates sind im Grunde das, was wirheutzutage mit LSTMs meinen
I CEC ermoglicht das Speichern von Informationen uber langeZeitraume (long) und das schnelle, dynamische Abrufen dieser(short-term memory)
I Es existieren weitere unterschiedliche LSTM-Variationen, diefur verschiedene Probleme beheben sollen.
I Variation sind beispielsweise durch die Wahl der Eingange derdrei Gates moglich oder durch Kombination mit Variation derVerarbeitungsreihenfolge.
I Nachfolgend drei Beispiele.
Michael Gref Neuronale Netze in der modernen Spracherkennung

45/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTMs lernen Zahlen I
I Die bisherige LSTM-Struktur kann zwar uber lange ZeitraumeInformationen speichern, jedoch nicht exakt Zahlen
I Beispiel zum Problemverstandnis:I Am Eingang liegt ein konstanter Wert anI Das LSTM soll alle t · 100 (mit t ∈ N ∪ {0}) Zeitschritte 1 am
Ausgang zeigen, ansonsten 0.I Was kann im LSTM passieren?
Michael Gref Neuronale Netze in der modernen Spracherkennung

46/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTMs lernen Zahlen II
Gedankenexperiment: Wir nehmen an das LSTM ist trainiert underfullt die Anforderung in hinreichendem Maße.
I Bei t = 0 hat das Netz den Ausgangswert 1
I Der Ausgangwert 1 wird bei t = 1 als Eingangswertverwendet. Informationen konnen uber die Gates in das CECgeschrieben werden.
I Idealerweise ist fur t ∈ {1, ..., 99} der Ausgang immer 0 (odersehr nah dran).
I Daraus folgt:[xt,ht−1]
T (31)
ist (nahezu) konstant fur 1 << t < 99
Michael Gref Neuronale Netze in der modernen Spracherkennung

47/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTMs lernen Zahlen III
I Cell-State bleibt nahezu unverandert, da Zugang zum CECnur uber Gates moglich ist
I Es existiert keine Moglichkeit im CEC uber lange Zeitraumehinweg zu zahlen, da nur Layer-Ausgang und Layer-EingangCEC beeinflussen.
I Widerspruch zur Annahme. ⇒ LSTM kann nicht ausreichendtrainiert werden.
Michael Gref Neuronale Netze in der modernen Spracherkennung

48/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTMs lernen Zahlen IV
Von Gers u. Schmidhuber (2000) eingefuhrte Peepholes erlaubtden Gates in das CEC zu blicken:
ot = σo(Woxt +Uoht−1 +Voct + bo) (32)
it = σi(Wixt +Uiht−1 +Vict−1 + bi) (33)
ct = ft · ct−1 + it · σc(Wcxt +Ucht−1 + bc) (34)
ft = σf (Wfxt +Ufht−1 +Vfct−1 + bf ) (35)
ht = ot · σh(ct) (36)
(Bzw. erlauben dem CEC den Zustand uber die Gates”aus sich
heraus“ zu beeinflussen)
Michael Gref Neuronale Netze in der modernen Spracherkennung

49/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
LSTMs lernen Zahlen V
ht
T
ot
it
ctct-1
xt
ht-1
c~
i
f
o
×
× +
×
σh
ft
[CEC]
Abbildung: Aufbau LSTM-Layer mit Peepholes
Michael Gref Neuronale Netze in der modernen Spracherkennung

50/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Verringerung der Komplexitat I
I Wie bereits gezeigt, konnen LSTMs sehr rechenintensivwerden und eine hohe Anzahl Parameter aufweisen.
I Mit Peepholes steigt die Zahl der Parameter weiter an:
4 · (I +H + 1) ·H + 3 ·H ·H (37)
I Fur das Beispiel mit H = 2000 und I = 257 steigt die Zahlder Parameter von 18.064.000 auf 30.064.000
I Projection-Layer nach Sak u. a. (2014) konnen da Abhilfeschaffen
Michael Gref Neuronale Netze in der modernen Spracherkennung

51/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Verringerung der Komplexitat II
ot = σo(Woxt +Uort−1 +Voct + bo) (38)
it = σi(Wixt +Uirt−1 +Vict−1 + bi) (39)
ct = ft · ct−1 + it · σc(Wcxt +Ucrt−1 + bc) (40)
ft = σf (Wfxt +Ufrt−1 +Vfct−1 + bf ) (41)
ht = ot · σh(ct) (42)
rt = Wrht (43)
Michael Gref Neuronale Netze in der modernen Spracherkennung

52/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Verringerung der Komplexitat III
ht
T
ot
it
ctct-1
xt
rt-1
c~
i
f
o
×
× +
×
σh
ft
[CEC]
rrt
Abbildung: Aufbau LSTM-Layer mit Peepholes und Projection-Layer
Michael Gref Neuronale Netze in der modernen Spracherkennung

53/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Verringerung der Komplexitat IV
I Projection-Layer entkoppeln Große des Ausgangs und desSpeichers
I Anzahl Parameter fur LSTM mit Peepholes undProjection-Layer:
4 · (I +R+ 1) ·H + 3 ·H ·H +H ·R (44)
I Hierbei wird dim(rt) =: R kleiner als H gewahlt.
Michael Gref Neuronale Netze in der modernen Spracherkennung

54/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Verringerung der Komplexitat V
Rechenbeispiel (Wieder mit H = 2000 und I = 257):
I Bspw. nach Cheng u. a. (2017) wird R = 14 ·H gewahlt.
I Zahl der Parameter sinkt von 30.064.000 auf 19.064.000.
I Nur 1.000.000 Parameter mehr als Standard-LSTM ohnePeepholes.
Michael Gref Neuronale Netze in der modernen Spracherkennung

55/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Bi-Direktionale rekurrente Layer I
I Bei der Spracherkennung liegt i.d.R. das Sprachsignal alsganzes Segment vor. Warum daher nur in die Vergangenheitoder (mittels Delay) hochstens ein Stuckchen in die Zukunftschauen?
I Bi-Direktionale rekurrente Layer ermoglichen den gesamtenzeitlichen Kontext in beide Zeit-Richtungen einzubeziehen.
I Voraussetzung: Endliche Lange von Eingangsvektoren!
Michael Gref Neuronale Netze in der modernen Spracherkennung

56/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Bi-Direktionale rekurrente Layer II
I Grundidee fur bi-direktionale rekurrente Netze wurde (u.A.) inSchuster u. Paliwal (1997) vorgestellt.
I Es werden pro Layer zwei (interne) Recurrent-Layer (bspw.LSTMs) verwendet. Einer fur die linken Werte der Zeitachsezum Zeitpunkt t, einer fur die rechten Werte.
I Funktionsweise zu normalen RNN bleibt im Grunde gleich.Lediglich die Reihenfolge der Berechnungen wird nun relevant.
Michael Gref Neuronale Netze in der modernen Spracherkennung

57/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Bi-Direktionale rekurrente Layer III
Abbildung: Schematischer Aufbau eines Bi-Direktionalen RNN5
Michael Gref Neuronale Netze in der modernen Spracherkennung

58/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Ursprungliches KonzeptHeutiges VerstandnisVariationen von LSTMs
Bi-Direktionale rekurrente Layer IV
Gegeben sei eine Training-Sequenz (z0, z1, ..., zT ) wobeizt := (xt, yt) das Tupel aus Eingangs- und Zielwerten ist.
I Forward-Pass:1. Berechnung der Ausgangswerte vom
I Forward-Recurrent-Layer fur die Folge (x0, ..., xT )I Backwards-Recurrent-Layer fur die Folge (xT , ..., x0)
und speichere die Werte zu jedem Zeitpunkt t ∈ (0, ..., T ).2. Fur jeden t ∈ (0, ..., T ):
Setze die gespeicherten Ausgangswert vom Forward-RNN undvom Backwards-RNN zusammen und gebe sie an denAusgangslayer weiter.
I Backward-Pass fur die Back-Propagation erfolgt analog.
5Schuster u. Paliwal (1997)Michael Gref Neuronale Netze in der modernen Spracherkennung

59/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
LSTMs als Komponenten in state-of-the-art ASR-Systemen
Michael Gref Neuronale Netze in der modernen Spracherkennung

60/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Renaissance von LSTMs I
Warum liefert ein 20 Jahre altes Verfahren erst heute, in denmodernsten ASR-Systemen herausragende Ergebnisse?
I Rechenleistung! Heutige Grafikkarten ermoglichen damalsUndenkbares:
I Deep-Learning. Training von Netzen mit mehrerenverketteten, großen LSTM-Layern sowie Kombinationenanderen komplexen Strukturen
I Verarbeitung enormer Datenmengen. Bspw. Googletrainiert ASR-Systeme mit (Grid-)LSTMs auf 18.000 StundenSprach-Daten (Li u. a. (2017)). Fur die Forschung mancheVerfahren sogar mit 125.000h (Soltau u. a. (2017))!
Michael Gref Neuronale Netze in der modernen Spracherkennung

61/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Renaissance von LSTMs II
I Open-Source! Kostenloser Zugang zu simpel verwendbarenDeep-Learning-Framesworks schafft eine hohe Reichweite. DiePopularitat des Themas bereichert im Gegenzug dieForschung und Open-Source-Entwicklung.
Michael Gref Neuronale Netze in der modernen Spracherkennung

62/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Alternative zu LSTMs
I Wie bei Deep-Learning ublich gilt: tiefe Netze (mit vielenSchichten) erreichen i.d.R. bessere Ergebnisse als breite flacheNetze
I Deep-Learning mit LSTMs ist auf Grund des Rechenaufwandsab einer gewissen Tiefe nicht mehr sinnvoll handhabbar
I Ein alternativer Ansatz zu rekurrenten Strukturen stammt von1989
Michael Gref Neuronale Netze in der modernen Spracherkennung

63/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Time-Delay Neural Networks
I Nicht-rekurrente Architektur eines neuronalen Netzes fur dieVerarbeitung zeitlicher Merkmalsfolgen
I Erstmal in Waibel u. a. (1989) zur Phonem-Erkennungvorgestellt
I Soll Informationen aus zeitlichen Kontext nutzen ohnezeitvariant zu sein
Michael Gref Neuronale Netze in der modernen Spracherkennung

64/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Time-Delay Neural Networks
Abbildung: TDNN-Architektur6
6Quelle: wikimedia.orgMichael Gref Neuronale Netze in der modernen Spracherkennung

65/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Time-Delay Neural Networks
Kann wie ein Spezialfall eines Convolutional-Neural-Networkaufgefasst werden:
I Lediglich Feed-Forward Operationen
I Hohe des Faltungskerns uber gesamte Anzahl der Merkmale⇒ 1-dimensionaler Output in diese Richtung
I Breite des Faltungskerns uber den gewahlten zeitlichenKontext (Delay: 3 im Beispiel)
I Ausgangsdimension (TDNN-Units) entspricht der Anzahl vonFaltungskernen in einem CNN
Michael Gref Neuronale Netze in der modernen Spracherkennung

66/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Time-Delay Neural Networks
TDNN ist, ahnlich wie LSTMs, in der Lage Informationen beivariablen zeitlichen Kontext zu erlernen
I Unteren Layer fuhren initiale Transformationen durch
I Oberen Layer lernen Informationen aus langerem zeitlichenKontext
I Langzeit-Speicherung limitiert durch gesamten resultierendenDelay aller Schichten
I Reduktion der Komplexitat durch sogenanntes sub-samplingmoglich (Peddinti u. a. (2015))
Michael Gref Neuronale Netze in der modernen Spracherkennung

67/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Das Kaldi-ASR-Toolkit I
I OpenSource Toolkit zum Training und Anwendung vonSpracherkennungssystem
I Erstmals vorgestellt in Povey u. a. (2011)
I Zusammenstellung zahlreicher Binaries und Skripte, u.a.:I Akustische Modellierung (mit HMM und DNN-Modellen)I Sprachmodellierung (klassisch und LSTM-Rescoring)I Decoding und Evaluation
Michael Gref Neuronale Netze in der modernen Spracherkennung
68/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Das Kaldi-ASR-Toolkit II
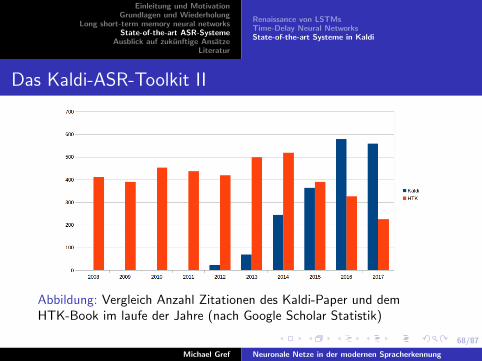
Abbildung: Vergleich Anzahl Zitationen des Kaldi-Paper und demHTK-Book im laufe der Jahre (nach Google Scholar Statistik)
Michael Gref Neuronale Netze in der modernen Spracherkennung

69/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Das Kaldi-ASR-Toolkit III
I Seit 2011 wurde das Kaldi-Paper laut Google Scholar 1869zitiert
I Das HTK-Book (in allen Version) bisher 6315 - seit 1993.
I Zitationen des HTK-Books seit 2015 rucklaufig.
I Kaldi ist aktuell das wahrscheinlich beliebteste ASR-Toolkit.
I In der aktuellsten Version sind verschiedenste Topologien undTrainingsalgorithmen fur ASR implementiert
Michael Gref Neuronale Netze in der modernen Spracherkennung

70/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Ubersicht Wortfehlerraten
Word-Error-Rate mit Kaldi auf eval2000 furSwitchboard-Trainingsdaten und Decoding mit FisherSprachmodell:
I TDNN: 11.6%
I 6 Layer mit 1024 Dim
I LSTM: 11.6%
I 3 Layer mit 1024 Cell-Dim, 256 Projection-Dim
I BiLSTM: 10.3%
Michael Gref Neuronale Netze in der modernen Spracherkennung

71/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
Wortfehlerraten bei Chain-Training
Sogenanntes Chain-Training nach Povey u. a. (2016):I TDNN: 9.8%
I 7 Layer mit 625 Dim
I LSTM: 10.5%I 3 Layer mit 1024 Cell-Dim, 256 Projection-Dim
I Gemischte Topologie: 8.8%I 3 × TDNN-Layer + 1 LSTM-LayerI + 2 × TDNN-Layer + 1 LSTM-LayerI + 2 × TDNN-Layer + 1 LSTM-Layer
Michael Gref Neuronale Netze in der modernen Spracherkennung

72/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Renaissance von LSTMsTime-Delay Neural NetworksState-of-the-art Systeme in Kaldi
TDNN-LSTM-Model
Abbildung: Aufbau Chain-TDNN-LSTM-Model (Cheng u. a. (2017))Michael Gref Neuronale Netze in der modernen Spracherkennung

73/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification I
Klassische HMM-DNN Ansatze:
I DNNs ersetzt die Schatzung derEmissionswahrscheinlichkeiten der Tied-States fur diebeobachteten Features
I Zeitliche Modellierung erfolgt weiterhin durch HMMs(Ubergangswahrscheinlichkeiten)
I Wozu braucht man noch HMMs, wenn LSTMs eigenstandigZahlen und Zeit modellieren konnen?
Michael Gref Neuronale Netze in der modernen Spracherkennung

74/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification II
I Bisher besprochene Art des Trainings minimiert ZielfunktionFrame-Weise (unabhangig von vorherigen und nachfolgendenOutput)
I Zielfunktion ungeeignet zum Training vonzusammenhangenden Zeitfolgen
I Graves u. a. (2006) stellen eine Zielfunktion vor, diestattdessen auf Klassifikation ganzer zusammenhangenderFolgen von Beobachtungen abzielt
Michael Gref Neuronale Netze in der modernen Spracherkennung

75/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification III
LSTM wird nicht mehr als Abbildung der Gestalt nnet : RD → RN
aufgefasst sondern als
nnet :(RD)T → (
RN)T
(45)
fur T ∈ N als Lange einer Sequenz.CTC erlaubt dem Netz das Wiederholen einer Klassifikation sowiedas Einfugen eines blank label ε. Beispiel: (X, ε, ε, Y, Y, Y, Z, Z, ε)ist ein gultiger Pfad (X,Y, Z). Kein Fehler wird zuruckpropagiert.
Michael Gref Neuronale Netze in der modernen Spracherkennung

76/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification IV
Abbildung: Framewise and CTC networks classifying a speech signal(Graves u. a. (2006))
Michael Gref Neuronale Netze in der modernen Spracherkennung

77/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification V
I CTC vereinfacht das Training und Decoding deutlich!
I Training von GMM-HMMs und Anwendung vonForced-Alignment entfallt.
I CTC funktioniert nicht nur auf Phonem-Ebene sondern auchfur Grapheme und Worte!
I Problem: Es scheint, dass deutlich mehr Trainingsdatennotwendig sind und die WER i.d.R. etwas hoher ist als beivergleichbaren DNN-HMM Ansatzen.
Michael Gref Neuronale Netze in der modernen Spracherkennung

78/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Connectionist Temporal Classification VI
CTC erlaubt neue Ansatze von LSTMs zur Spracherkennung!
I Google (Soltau u. a. (2017)) hat ein Akustik-zu-WortCTC-LSTM trainiert, das die Wahrscheinlichkeit ganzer Worteschatzt
I Phonem-Lexikon wird nicht mehr benotigt.
I Sprachmodell ist optional anwendbar.
I Ohne Sprachmodell denkbar einfachstes Decoding moglich.
I Erreicht ohne Sprach-Modell 12% WER bei einem Vokabularvon 82.473 ganzen Worten
I Mit 125.000 Stunden Youtube-gecrawlten Trainingsdaten
Michael Gref Neuronale Netze in der modernen Spracherkennung

79/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur I
[Bishop 2006] Bishop, Christopher M.: Pattern recognition andmachine learning. New York, NY : Springer, 2006 (Informationscience and statistics). – ISBN 978–0387–31073–2
[Cheng u. a. 2017] Cheng, Gaofeng ; Peddinti, Vijayaditya ;Povey, Daniel ; Manohar, Vimal ; Khudanpur, Sanjeev ;Yan, Yonghong: An Exploration of Dropout with LSTMs. In:Proc. Interspeech 2017, 2017, S. 1586–1590
Michael Gref Neuronale Netze in der modernen Spracherkennung

80/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur II
[Gers u. Schmidhuber 2000] Gers, F. A. ; Schmidhuber, J.:Recurrent nets that time and count. In: Proceedings of theIEEE-INNS-ENNS International Joint Conference on NeuralNetworks. IJCNN 2000. Neural Computing: New Challenges andPerspectives for the New Millennium Bd. 3, 2000. – ISSN1098–7576, S. 189–194 vol.3
[Gers u. a. 2000] Gers, F. A. ; Schmidhuber, J. ; Cummins, F.:Learning to Forget: Continual Prediction with LSTM. In: NeuralComputation 12 (2000), Oct, Nr. 10, S. 2451–2471. – ISSN0899–7667
Michael Gref Neuronale Netze in der modernen Spracherkennung

81/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur III
[Graves u. a. 2006] Graves, Alex ; Fernandez, Santiago ;Gomez, Faustino: Connectionist temporal classification:Labelling unsegmented sequence data with recurrent neuralnetworks. In: In Proceedings of the International Conference onMachine Learning, ICML 2006, 2006, S. 369–376
[Hochreiter u. Schmidhuber 1997] Hochreiter, Sepp ;Schmidhuber, Jurgen: Long Short-Term Memory. In: NeuralComputation 9 (1997), November, Nr. 8, S. 1735–1780. – ISSN0899–7667
[Huang u. a. 2014] Huang, Xuedong ; Baker, James ; Reddy,Raj: A Historical Perspective of Speech Recognition. 57 (2014),01, S. 94–103
Michael Gref Neuronale Netze in der modernen Spracherkennung

82/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur IV
[Li u. a. 2017] Li, Bo ; Sainath, Tara N. ; Narayanan, Arun ;Caroselli, Joe ; Bacchiani, Michiel ; Misra, Ananya ;Shafran, Izhak ; Sak, Hasim ; Pundak, Golan ; Chin, Kean; Sim, Khe C. ; Weiss, Ron J. ; Wilson, Kevin W. ; Variani,Ehsan ; Kim, Chanwoo ; Siohan, Olivier ; Weintraub,Mitchel ; McDermott, Erik ; Rose, Richard ; Shannon,Matt: Acoustic Modeling for Google Home. In: Proc.Interspeech 2017, 2017, S. 399–403
Michael Gref Neuronale Netze in der modernen Spracherkennung

83/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur V
[Peddinti u. a. 2015] Peddinti, Vijayaditya ; Povey, Daniel ;Khudanpur, Sanjeev: A time delay neural network architecturefor efficient modeling of long temporal contexts. In:INTERSPEECH 2015, 16th Annual Conference of theInternational Speech Communication Association, Dresden,Germany, September 6-10, 2015, 2015, S. 3214–3218
[Povey u. a. 2011] Povey, Daniel ; Ghoshal, Arnab ;Boulianne, Gilles ; Burget, Lukas ; Glembek, Ondrej ;Goel, Nagendra ; Hannemann, Mirko ; Motlicek, Petr ;Qian, Yanmin ; Schwarz, Petr ; Silovsky, Jan ; Stemmer,Georg ; Vesely, Karel: The Kaldi Speech Recognition Toolkit.
Michael Gref Neuronale Netze in der modernen Spracherkennung

84/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur VI
In: IEEE 2011 Workshop on Automatic Speech Recognition andUnderstanding (2011)
[Povey u. a. 2016] Povey, Daniel ; Peddinti, Vijayaditya ;Galvez, Daniel ; Ghahremani, Pegah ; Manohar, Vimal ;Na, Xingyu ; Wang, Yiming ; Khudanpur, Sanjeev: PurelySequence-Trained Neural Networks for ASR Based onLattice-Free MMI. In: Interspeech 2016, 2016, S. 2751–2755
[Sak u. a. 2014] Sak, Hasim ; Senior, Andrew W. ; Beaufays,Francoise: Long Short-Term Memory Based Recurrent NeuralNetwork Architectures for Large Vocabulary Speech Recognition.In: CoRR abs/1402.1128 (2014)
Michael Gref Neuronale Netze in der modernen Spracherkennung

85/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur VII
[Saon u. a. 2017] Saon, George ; Kurata, Gakuto ; Sercu, Tom; Audhkhasi, Kartik ; Thomas, Samuel ; Dimitriadis,Dimitrios ; Cui, Xiaodong ; Ramabhadran, Bhuvana ;Picheny, Michael ; Lim, Lynn-Li ; Roomi, Bergul ; Hall,Phil: English Conversational Telephone Speech Recognition byHumans and Machines. In: Proc. Interspeech 2017, 2017, S.132–136
[Schuster u. Paliwal 1997] Schuster, M. ; Paliwal, K. K.:Bidirectional recurrent neural networks. In: IEEE Transactionson Signal Processing 45 (1997), Nov, Nr. 11, S. 2673–2681. –ISSN 1053–587X
Michael Gref Neuronale Netze in der modernen Spracherkennung

86/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur VIII
[Soltau u. a. 2017] Soltau, Hagen ; Liao, Hank ; Sak, Hasim:Neural Speech Recognizer: Acoustic-to-Word LSTM Model forLarge Vocabulary Speech Recognition. In: Proc. Interspeech2017, 2017, S. 3707–3711
[Stolcke u. Droppo 2017] Stolcke, Andreas ; Droppo, Jasha:Comparing Human and Machine Errors in Conversational SpeechTranscription. In: Proc. Interspeech 2017, 2017, S. 137–141
Michael Gref Neuronale Netze in der modernen Spracherkennung

87/87
Einleitung und MotivationGrundlagen und Wiederholung
Long short-term memory neural networksState-of-the-art ASR-Systeme
Ausblick auf zukunftige AnsatzeLiteratur
Literatur IX
[Waibel u. a. 1989] Waibel, A. ; Hanazawa, T. ; Hinton, G. ;Shikano, K. ; Lang, K. J.: Phoneme recognition usingtime-delay neural networks. In: IEEE Transactions on Acoustics,Speech, and Signal Processing 37 (1989), Mar, Nr. 3, S.328–339. http://dx.doi.org/10.1109/29.21701. – DOI10.1109/29.21701. – ISSN 0096–3518
[Yu u. Deng 2015] Yu, Dong ; Deng, Li: Automatic speechrecognition: A deep learning approach. London : Springer, 2015(Signals and Communication Technology). – ISBN978–1–4471–5778–6
Michael Gref Neuronale Netze in der modernen Spracherkennung