NoSQL-Datenbanken · 2017-04-12 · Quelle: Stefan Edlich, Achim Friedland, Jens Hampe,Benjamin...
57
2-1 NoSQL-Datenbanken Kapitel 2: Key-Value Stores Dr. Anika Groß Sommersemester 2017 Universität Leipzig http://dbs.uni-leipzig.de
Transcript of NoSQL-Datenbanken · 2017-04-12 · Quelle: Stefan Edlich, Achim Friedland, Jens Hampe,Benjamin...

2-1
NoSQL-Datenbanken
Kapitel 2: Key-Value Stores
Dr. Anika Groß
Sommersemester 2017
Universität Leipzig
http://dbs.uni-leipzig.de

2-2
Inhaltsverzeichnis
• Key-Value Stores
– Einführung
– Amazon Dynamo
– Redis
– Object Storage Service: Microsoft Azure Storage

2-3
DB Ranking
• alle
Quelle: http://db-engines.com/en/ranking/
• Key-Value-Stores

2-4
Key-Value-Store
• Einfache, sehr flexible Form eines Datenbankmanagementsystems
• Datenstruktur: assoziative Arrays
– dictionary, map, hash, hash map, hash table …
– Kollektion von (ggf. komplexen) Objekten
• Einfache API
– put(key, value)
– get(key)
– remove(key)
• Häufiger Einsatz in verteilter Umgebung
• Beispiele: Amazon DynamoDB, Redis, Memcached,Riak …

2-5
Anwendungen
• z.B. Session-Daten, E-Commerce Warenkörbe
Eigenschaften:
• Große, unstrukturierte Datensätze
– hohe Performanz für große Objektanzahl erforderlich
• Einfaches Datenmodell und einfache Anfragen
– Zugriff + Speicherung via Schlüssel
– Keine Fremdschlüssel, seltene Joins
• Hohe Lese-/Schreibraten
– Einfache Indizierung nach Primärschlüssel
2-6
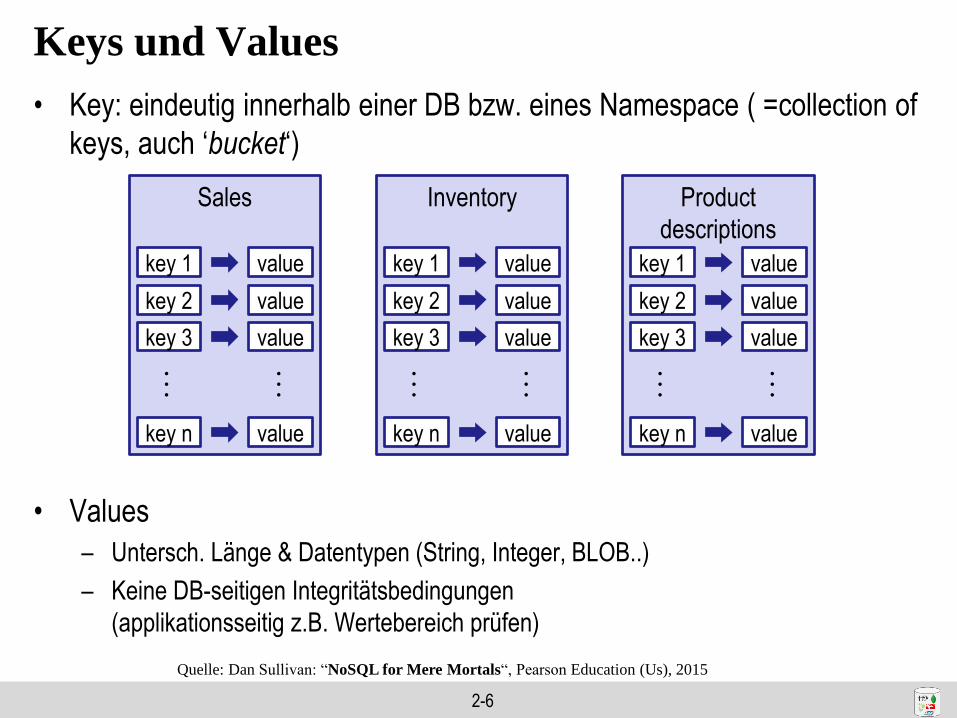
Keys und Values
• Key: eindeutig innerhalb einer DB bzw. eines Namespace ( =collection of
keys, auch ‘bucket‘)
• Values
– Untersch. Länge & Datentypen (String, Integer, BLOB..)
– Keine DB-seitigen Integritätsbedingungen
(applikationsseitig z.B. Wertebereich prüfen)
Sales
key 1 value
key 2 value
key 3 value
key n value
… …
Inventory
key 1 value
key 2 value
key 3 value
key n value
… …
Product
descriptions
key 1 value
key 2 value
key 3 value
key n value
… …
Quelle: Dan Sullivan: “NoSQL for Mere Mortals“, Pearson Education (Us), 2015

2-7
[1] Dan Sullivan: “NoSQL for Mere Mortals“, Pearson Education (Us), 2015
[2] Ilya Katsov: NoSQL Data Modeling Techniques. Highly Scalable Blog, 2012
https://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniqes/
Key Naming Convention
• Bezug zu relationaler Modellierung
– z.B. Konkatenation Tabellenname, Primärschlüssel, Spaltenname
• Composite keys
– Nutzung z.B. für Indexierung
und Aggregationen
ID (PK) name address
123
…
… …
Kunden
cust 123.address
[1]
[2]
Beispiel
Index

2-8
Amazon Dynamo: Übersicht
• Amazon S3 basiert auf Amazon Dynamo
• Verteilter, skalierbarer Key-Value-Speicher– v.a. für kleine Datensätze (z.B. 1 MB/Key), z.B. Warenkörbe
– (Software/API-gestützte Aufteilung größerer Daten)
• Eigenschaften– hochverfügbar
– geringe Latenz
• “Eventually consistent data store”– Schreibzugriffe sollen immer möglich sein
– Reduzierte Konsistenzzusicherungen zugunsten Verfügbarkeit
• Performance SLA (Service Level Agreement)– “response within 300ms for 99.9% of requests for peak client load of 500 requests
per second”
• P2P-artige Verteilung – keine Master-Knoten
– alle Knoten haben selbe FunktionalitätQuelle: [Dynamo]
2-9
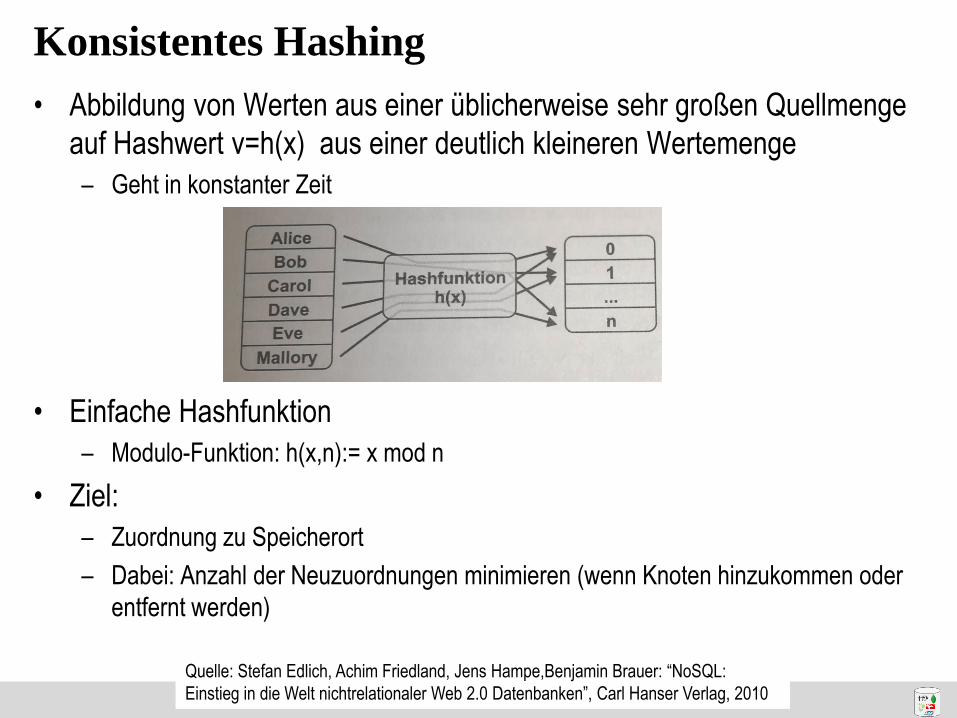
Konsistentes Hashing
• Abbildung von Werten aus einer üblicherweise sehr großen Quellmenge
auf Hashwert v=h(x) aus einer deutlich kleineren Wertemenge
– Geht in konstanter Zeit
• Einfache Hashfunktion
– Modulo-Funktion: h(x,n):= x mod n
• Ziel:
– Zuordnung zu Speicherort
– Dabei: Anzahl der Neuzuordnungen minimieren (wenn Knoten hinzukommen oder
entfernt werden)
Quelle: Stefan Edlich, Achim Friedland, Jens Hampe,Benjamin Brauer: “NoSQL:
Einstieg in die Welt nichtrelationaler Web 2.0 Datenbanken”, Carl Hanser Verlag, 2010

2-10
Amazon Dynamo: Partitionierung
• Knoten bilden logischen Ring
– Position entspricht zufälligem Punkt im Wertebereich einer Hashfunktion
• Zuordnung zwischen Daten und Knoten
– Bestimme Hash-Wert des Keys
– Speicherung auf den – im Uhrzeigersinn –
N Folgeknoten
– Bsp: Hash-Wert zwischen A und B
bei N=3: Knoten B, C und D
– Einfügen, Löschen, Verschieben von Knoten
performant, da nur Nachbarknoten betroffen
• Präferenzliste
– Liste der N Knoten, die zur Datenspeicherung für einen Key zuständig
– wird von jedem Knoten geführt
• Consistent-Hashing
– Geeignete Hash-Funktion für Daten-Lokalität und Lastverteilung
A
B
C
DE
F
G
Hash(key)
2-11
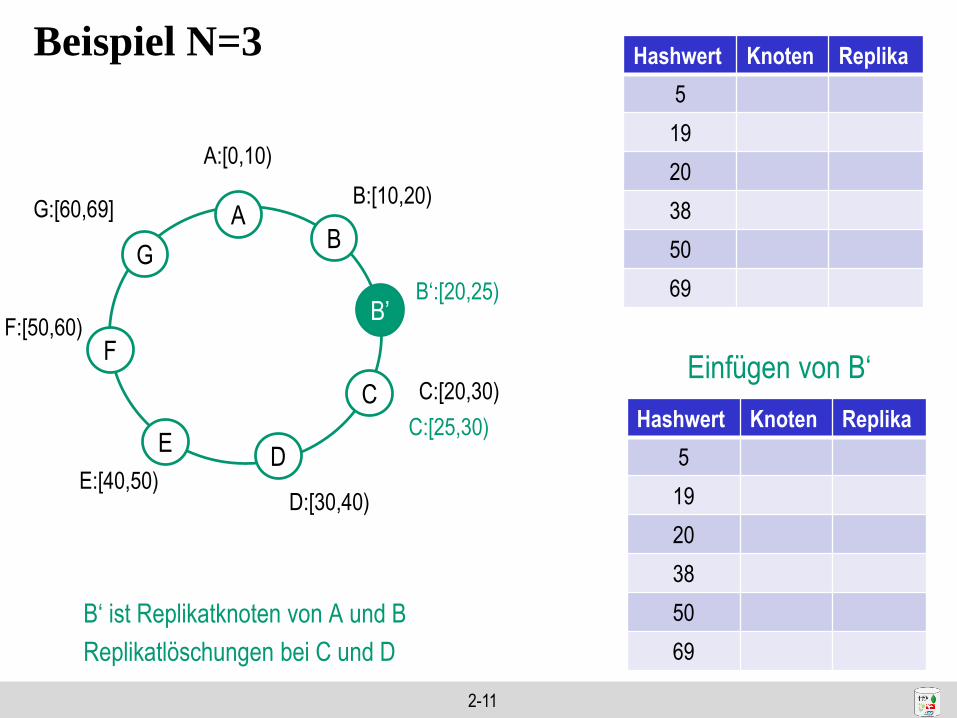
Beispiel N=3
A:[0,10)
AB
C
DE
F
G
B:[10,20)
D:[30,40)E:[40,50)
F:[50,60)
G:[60,69]
C:[20,30)
Hashwert Knoten Replika
5
19
20
38
50
69
Hashwert Knoten Replika
5
19
20
38
50
69
Einfügen von B‘
C:[25,30)
B‘:[20,25)B’
B‘ ist Replikatknoten von A und B
Replikatlöschungen bei C und D

2-12
Amazon Dynamo: Datenzugriff
• Key-Value-Store-Interface
– Primary-Key-Zugriff; keine komplexen Queries
– Anfrage kann an beliebigen Knoten des Ringes gesendet werden
– Weiterleitung an einen (meist ersten) Knoten der Präferenzliste dieses Keys
• Put (Key, Context, Object)
– Koordinator erstellt “Vector Clock” (Versionierung) auf Basis des Contexts
– Lokales Schreiben des Objektes inkl. Vektor Clock
– Replikation
• Write-Request an N-1 andere Knoten der Präferenzliste
• Erfolg, wenn (mindestens) W-1 Knoten antworten
• asynchrone Aktualisierung der Replikate W<N Konsistenzprobleme
• Get (Key)
– Read-Request an N Knoten der Präferenzliste
– Rückgabe von Responses von R Knoten Kann mehrere Versionen eines
Objektes zurückliefern: Liste von (Object, Context)-Paaren

2-13
Amazon Dynamo: Replikation
• Verwendung von Read/Write-Quoren
– R/W = minimale Anzahl der N Replikat-Knoten, die für erfolgreiche Read/Write
Operation übereinstimmen müssen
– Anwendung kann (N,R,W) an Bedürfnisse bzgl. Performanz, Verfügbarkeit und
Dauerhaftigkeit anpassen
• Aktuelle Version wird immer gelesen wenn R + W > N
– Strong consistency
– Kein Informationsverlust
– üblich z.B. (3,2,2)
– Ggf. nutzergesteuerte Konfliktbehandlung für abweichende Versionen nötig
2-14
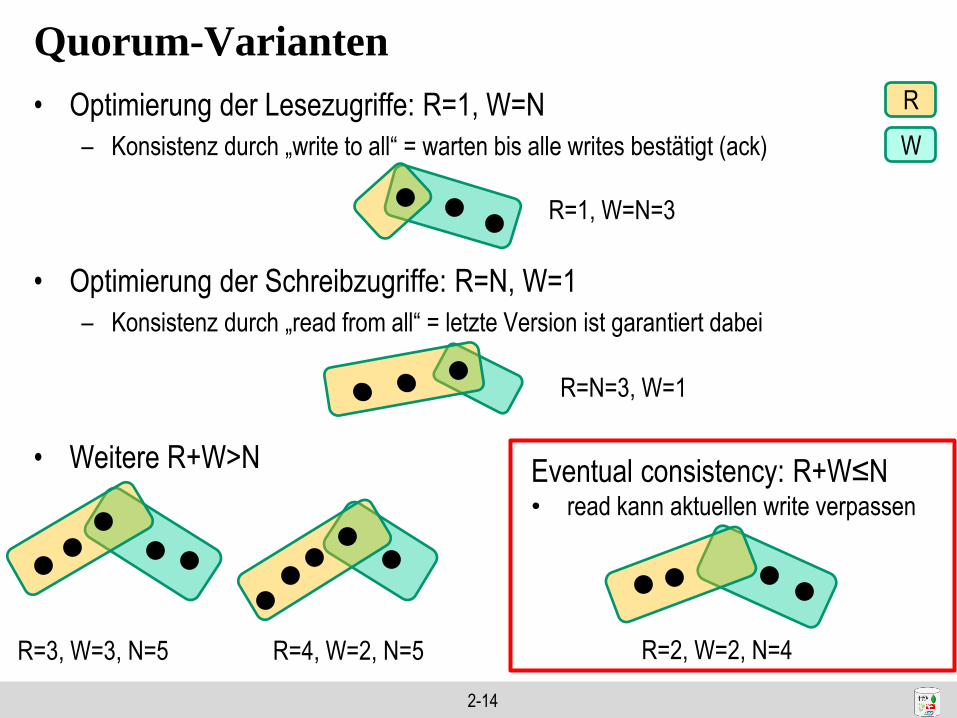
Quorum-Varianten
• Optimierung der Lesezugriffe: R=1, W=N
– Konsistenz durch „write to all“ = warten bis alle writes bestätigt (ack)
• Optimierung der Schreibzugriffe: R=N, W=1
– Konsistenz durch „read from all“ = letzte Version ist garantiert dabei
• Weitere R+W>N
R=N=3, W=1
R
W
R=1, W=N=3
R=3, W=3, N=5 R=4, W=2, N=5
Eventual consistency: R+W≤N • read kann aktuellen write verpassen
R=2, W=2, N=4

2-15
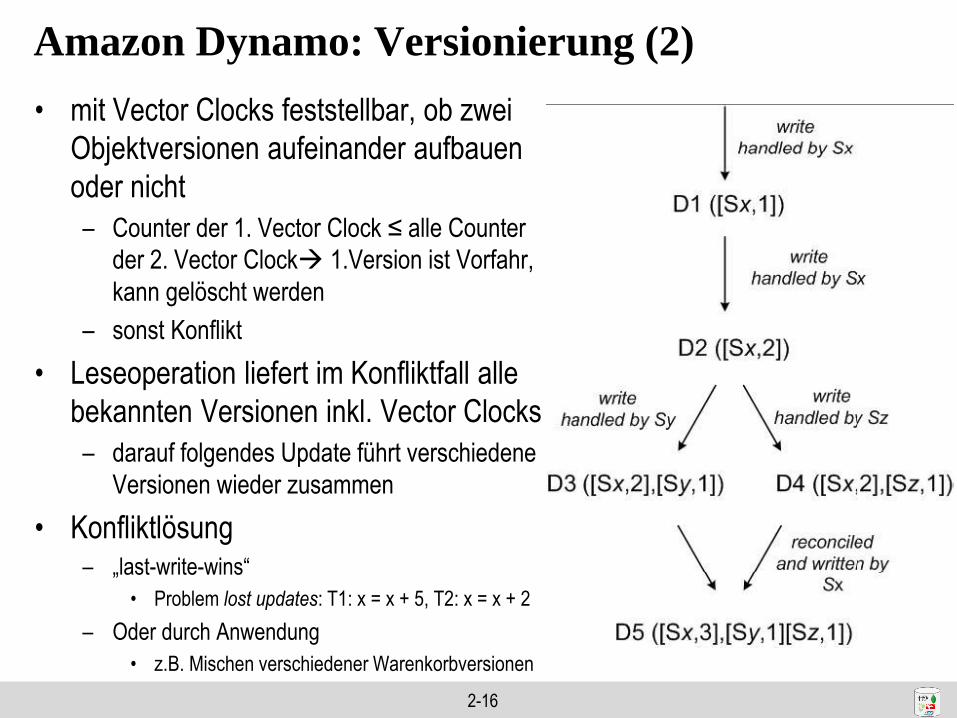
Amazon Dynamo: Versionierung
• Verwenden von “Vector Clocks” um Abhängigkeiten zwischen
verschiedenen Versionen eines Objektes darzustellen
– Versionsnummer/zähler pro Replikat-Knoten
z.B. D ([Sx, 1]) für Objekt D, Speicherknoten Sx, Version 1
– Vector Clock : Liste von (node,counter)-Paaren zur Anzeige welche
Objektversionen bekannt sind
• Beispiel zur Entwicklung von Objektversionen
Sx
Sy
Sz
2-16
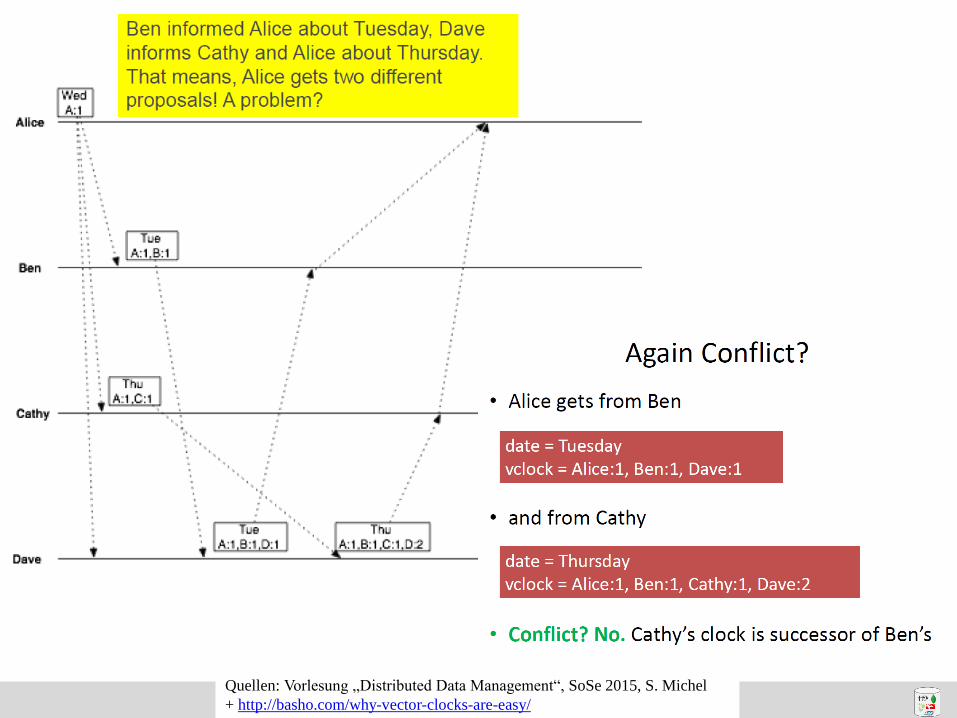
Amazon Dynamo: Versionierung (2)
• mit Vector Clocks feststellbar, ob zwei
Objektversionen aufeinander aufbauen
oder nicht
– Counter der 1. Vector Clock ≤ alle Counter
der 2. Vector Clock 1.Version ist Vorfahr,
kann gelöscht werden
– sonst Konflikt
• Leseoperation liefert im Konfliktfall alle
bekannten Versionen inkl. Vector Clocks
– darauf folgendes Update führt verschiedene
Versionen wieder zusammen
• Konfliktlösung– „last-write-wins“
• Problem lost updates: T1: x = x + 5, T2: x = x + 2
– Oder durch Anwendung
• z.B. Mischen verschiedener Warenkorbversionen

2-17
Beispiel Vector Clocks
• Quellen: Vorlesung Prof. Sebastian Michel „Distributed Data
Management“, SoSe 2015, TU Kaiserslautern
+ http://basho.com/why-vector-clocks-are-easy/

2-18Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-19Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-20Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-21Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-22Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-23Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/
2-24Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/

2-25Quellen: Vorlesung „Distributed Data Management“, SoSe 2015, S. Michel
+ http://basho.com/why-vector-clocks-are-easy/
2-26
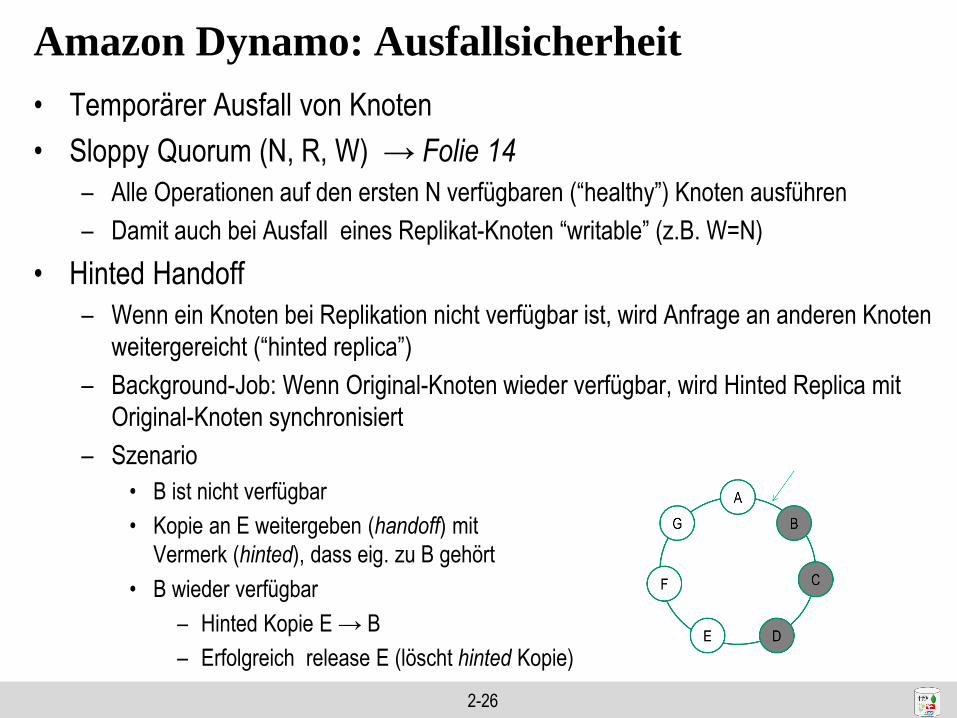
Amazon Dynamo: Ausfallsicherheit
• Temporärer Ausfall von Knoten
• Sloppy Quorum (N, R, W) → Folie 14
– Alle Operationen auf den ersten N verfügbaren (“healthy”) Knoten ausführen
– Damit auch bei Ausfall eines Replikat-Knoten “writable” (z.B. W=N)
• Hinted Handoff
– Wenn ein Knoten bei Replikation nicht verfügbar ist, wird Anfrage an anderen Knoten
weitergereicht (“hinted replica”)
– Background-Job: Wenn Original-Knoten wieder verfügbar, wird Hinted Replica mit
Original-Knoten synchronisiert
– Szenario
• B ist nicht verfügbar
• Kopie an E weitergeben (handoff) mit
Vermerk (hinted), dass eig. zu B gehört
• B wieder verfügbar
– Hinted Kopie E → B
– Erfolgreich release E (löscht hinted Kopie)

2-27
Amazon Dynamo: Synchronisation v. Replikaten
• Hash-Tree (Merkle Tree) für Key-Range
– Blätter sind Hash-Werte der values von keys
– Eltern-Knoten sind Hash-Werte der Kind-Knoten-Werte
• Vorteile
– Effiziente Überprüfung ob zwei
Replikate synchron sind: Wurzel-
Knoten haben gleichen Wert
– Effiziente Identifikation nicht-
synchroner Teile: Rekursive
Analyse der Teilbäume
• Nachteile
– Neuberechnung bei
Re-Partitionierung
(z.B. neue Knoten)
K1
V1
K2
V2
K3
V3
K4
V4
H(k1) H(k2) H(k4)H(k3)
H(H(k1), H(k2)) H(H(k3), H(k4))
H(H(H(k1), H(k2)), H(H(k3), H(k4)))
...
...
H(...)
...
2-28
Amazon Dynamo: Techniken (Übersicht)
• Weitere Techniken u.a.
– Gossip-artiges Protokoll für P2P-Organisation (neue Knoten, Ausfallerkennung, ...)
• (hinted handoff nur für temporären Ausfall)
Problem Technologie Vorteil
Partitionierung Consistent Hashing
Hochverfügbarkeit
von Schreibzugriffen
Vector Clocks mit
Konfliktbehandlung
bei Lesezugriffen
Temporärer Ausfall
von Knoten
Sloppy Quorum und
Hinted Handoff
Recovering Hash Tree
(Merkle Tree)

2-29
Dynamo Services / Implementierungen
• Amazon Dynamo DB
– http://aws.amazon.com/de/dynamodb/
– Vollständig verwalteter NoSQL-
Datenbankservice von AWS
• Key Value und Document Store
– Basiert auf Dynamo (weist aber Unterschiede auf)
• Synchrone Replikation über mehrere Datacenter
• Replikation über 3 Standorte einer AWS Region für Fehlertoleranz
– Schneller Zugriff, geringe Latenzen: ausschließlich SSDs
• Voldemort
– http://www.project-voldemort.com/voldemort/
– Open-Source Implementierung von Amazons Dynamo Key-Value Store

2-30
Redis
• REmote DIctionary Server
• Aktuelle stabile Version: Redis 3.0.5
• In C implementierte In-Memory-Datenbank
• Key-Value
– Neben Speicherung von Strings auch komplexere Datentypen
wie Listen, Mengen, Hashes
• Persistenz: Snapshotting oder Journal
• Replikation: Master / Slave
• Performanz
– Sehr schnell (in-memory), ohne Persistenz
– Keine Sperren
– Nicht per se distributed! einzelne Redis Instanz: single process, single-threaded
– Redis Cluster für data sharding
• Oft als Cache (statt als DB) genutzt
• Users: GitHub, Flickr, Twitter, Stack Overflow, …
Quelle: [Redis]

2-31
Redis Datenmodell
• Key
– Printable ASCII
• Value
– Strings
– Container: Hashes, Lists, Sets, Sorted Sets
user:1
Value: Hash
field value
user Alice
mail al@ice...
user:1:followers
Value: Set
http://blog.redsmin.com/post/85995135615/slides-introduction-to-redis
user:1:tweets
Value: List
0 1 2 3
Hi Alice
…
How
…
Are
you…
Today,
…
23 8 19 5 34
7 14 40
user:mostfollowed
Value: Sorted Set
field score
@bob 4233689
@eve 4438430
@dave 4908207
@carol 5197422
hmset myhash f1 v1 f2 v2
set mykey myvalue
rpush mylist v1 v2 v3sadd myset v1 v2 v3 zadd mysortset score v1

2-32
Persistenz
• In-Memory: Gefahr des Datenverlusts, z.B. bei Serverabsturz
1. RDB persistence
• = Snapshotting / “periodic dump” (.rdb files)
• Automatisiertes regelmäßiges Abspeichern der gesamten DB auf Disk
• Asynchrone Übertragung der Daten aus dem Hauptspeicher auf Disk semi-persistent
• Wann? save points nach X Sekunden oder Y Änderungen
• Auch für “Disaster Recovery”: z.b. RDB backup auf Amazon S3
2. AOF persistence
• = Protokolldatei/Log-Datei/Journal (“Append Only”)
• ACID konforme Konfiguration möglich
– 3 Settings: no fsync, fsync every second (default), fsync always
• Bei jedem write wird Änderung an Journal angehängt
(fast) vollständige Persistenz: Rekonstruktion nach Systemcrash möglich
• “Rewrite” des Journals möglich, um “unendliches Wachstum” des Journals zu verhindern
• oder Kombination RDB + AOF (bei Restart wird AOF genutzt, RDBs für backup)
• oder ohne Persistenz (disable RDB+AOF)
+ i/o Performanz,
schneller Restart
– Persistenz
+ Persistenz (in
Balance mit
Performance)
– i/o Performanz bei
fsync always,
langsamerer Restart

2-33
Redis Replikation
• Ziel: Ausfallsicherheit durch Redundanz
– keine Datenverteilung / partitioning (erst mit Redis Cluster!)
• Asynchrone Master-Slave Replikation
– Slaves: exakte Kopien von Master Server
– Slave senden periodisch ‘acknowledgement’, welche Daten verarbeitet wurden
• Gute Skalierbarkeit für reads (nicht für writes)
• Ein Master kann mehrere Slaves haben
• Slave kann Master oder anderer Slave sein
• Daten von jedem Redis Server können auf beliebige Anzahl Slaves
repliziert werden
• Slaves können sich untereinander verbinden (graph-like structure)
2-34
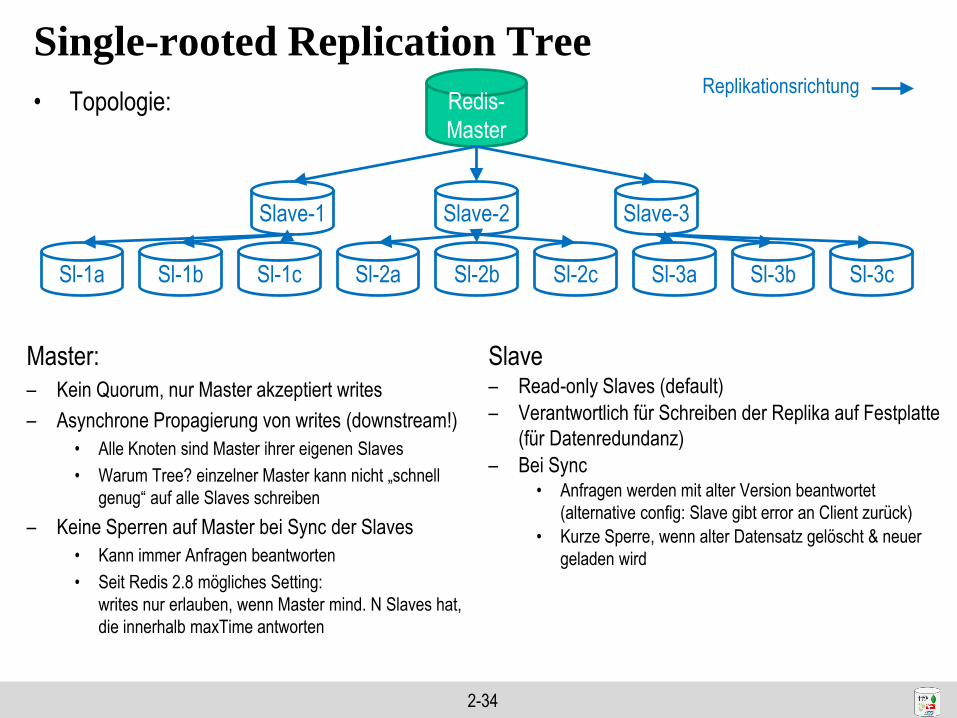
Single-rooted Replication Tree
• Topologie: Redis-
Master
Slave-1 Slave-2 Slave-3
Sl-1a Sl-1b Sl-1c Sl-2a Sl-2b Sl-2c Sl-3a Sl-3b Sl-3c
Replikationsrichtung
Master:
– Kein Quorum, nur Master akzeptiert writes
– Asynchrone Propagierung von writes (downstream!)
• Alle Knoten sind Master ihrer eigenen Slaves
• Warum Tree? einzelner Master kann nicht „schnell
genug“ auf alle Slaves schreiben
– Keine Sperren auf Master bei Sync der Slaves
• Kann immer Anfragen beantworten
• Seit Redis 2.8 mögliches Setting:
writes nur erlauben, wenn Master mind. N Slaves hat,
die innerhalb maxTime antworten
Slave– Read-only Slaves (default)
– Verantwortlich für Schreiben der Replika auf Festplatte
(für Datenredundanz)
– Bei Sync• Anfragen werden mit alter Version beantwortet
(alternative config: Slave gibt error an Client zurück)
• Kurze Sperre, wenn alter Datensatz gelöscht & neuer
geladen wird

2-35
Redis Replikation (2)
• Verringerte Schreiblast Master: Slave kann das Schreiben auf Festplatte übernehmen
– Auto Restart am Master vermeiden, falls “persistence off”, sonst Restart des Masters mit
leerer DB + Replikation der leeren DB an Slaves → überschreibt backup)
• Hinzufügen eines Slave
– Sendet SYNC command
– Master startet background saving und puffert alle neuen Schreiboperationen/Änderungen
– background saving vollständig: Master sendet Datei an Slave
– Slave speichert diese auf Disk + lädt sie in den Hauptspeicher
+ empfängt gepufferte Änderungen
• Netzwerkausfall/unterbrechung
– Automatische Neuverbindung der Slaves zum Master
– Bei konkurrierenden Anfragen → ein background saving → an alle Slaves
– Auch partielle statt vollständiger Resynchronisation
• Dafür in-Memory Backlog des Replikation-Stream auf Master (agree über replication offset zw.
Master und allen Slaves)
• „Diskless“ Replikation: keine Zwischenspeicherung auf Festplatte, Master sendet RDB
direkt an Slaves

2-36
Redis Transaktionen
• Gruppierung von mehreren Operationen in einer Transaktion möglich
• Reduktion der Anzahl der “Network Roundtrips”, auf die Client warten muss
• Dabei wird garantiert:
– Isolation: alle Operationen einer Transaktion werden serialisiert und
sequentiell ausgeführt
– Atomarität: alle oder keine der Operationen einer TA werden ausgeführt
• MULTI: Start einer Transaktion, alle folgenden Operationen in eine Queue
• EXEC: führt alle Operationen der Queue in einer TA aus
– Bei AOF wird sichergestellt, dass Redis TA als ein write verarbeitet
– Bei System Crash: möglich dass nur Teil der Änderungen geschrieben wird
• Mit Redis-Check-AOF Tool → Entfernen der partiellen TA möglich
• Verhindern von Lost Updates durch Optimistic Locking mit WATCH mykey
– Überwachen von Änderungen bzgl. key
– In Bsp.: anderer Client versucht val zwischen WATCH und EXECzu ändern → TA schlägt fehl
– Dann wird TA wiederholt (i.d. Hoffnung, dass es nicht wieder fehlschlägt)
WATCH mykeyval = GET mykeyval = val + 1 MULTISET mykey $valEXEC

2-37
Redis Cluster
• Ermöglicht Data Sharding
– Verteilung des Datensatzes über mehrere Knoten
– Alle Befehle der nicht-verteilten Version von Redis werden unterstützt
• Ziele:
1) Hohe Performanz + Skalierbarkeit bis zu 1000 Knoten
2) Akzeptable Konsistenz („small windows where
acknowledged writes can be lost“ [2])
3) Availability bei Netzwerkpartitionierung
• Cluster verfügbar, solange Mehrheit
der Master erreichbar + weitere Bedingungen
• Jeder Knoten hat 2 offene TCP Verbindungen
– Kommunikation mit Clients: z.B. 6379
– Node-to-Node Kommunikation:
Cluster Bus Port = „high port“ (+10000) 16379
Quellen: [1] http://redis.io/topics/cluster-tutorial, [2] http://redis.io/topics/cluster-spec,
Bild: http://redis.io/presentation/Redis_Cluster.pdf

2-38
Kommunikation zwischen Knoten
• Clients können alle Knoten anfragen und werden ggf. an anderen Knoten
umgeleitet (Clients können aber Map zwischen Keys und Knoten cachen)
• Gossip-Protokoll für Austausch von Informationen zwischen Cluster nodes
– Erkennen neuer Knoten; Sicherstellen, ob Knoten erreichbar
Quelle: http://redis.io/presentation/Redis_Cluster.pdf

2-39
Redis Cluster - Sharding
• Sharding: jeder key ist Teil eines Hash Slot
– Kein konsistentes Hashing
• Es gibt 16384 Hash Slots in Redis Cluster
• Hash Slot Zuordnung eines keys
– Berechnung: CRC16 key modulo 16384
• Jeder Knoten in Cluster ist für Teilmenge der Hash Slots verantwortlich
• Bsp. 3 Knoten
– Node A Hash Slots 0 - 5500
– Node B Hash Slots 5501 - 11000
– Node C Hash Slots 11001 – 16384
– Hinzufügen neuer Knoten D: Teil der Hashslots von A, B, C muss verschoben werden
(System kann dabei weiterlaufen)
• Mit Hash Tags kann erzwungen werden, dass keys im gleichen Slot landen
– Verwende {} in key → nur innerer Teil wird gehasht
– this{foo}key und another{foo}key landen im gleichen Hash Slot

2-40
Sharding und Redundanz
• Alle Knoten stehen in Verbindung und sind funktionell äquivalent
• Zwei Arten: Masters und Slaves (=exakte Kopien von Master Server)
Bild: http://redis.io/presentation/Redis_Cluster.pdf

2-41
Redis Cluster - Availability
• Verfügbarkeit nur für “majority partition“
– Mehrheit der Master muss erreichbar sein
– und mind. ein Slave pro nicht erreichbarem Master
– Cluster wieder verfügbar nach „node timeout“ + Zeit für Wahl eines Slaves zum
neuen Master (1-2 Sek.)
• Ausfälle einzelner Knoten können gehandelt werden, jedoch keine
größeren Netzwerkausfälle
• Szenario: N Master Knoten mit je 1 Slave
– Verfügbarkeit majority partition, wenn max. 1 Knoten wegfällt (2 ∙ 𝑁 − 1 Knoten)
– Ausfallwahrscheinlichkeit für Master ohne Replika: 1
2∙𝑁−1
– Bsp. 5 Master, je 1 Slave: 1
5∗2−1⇒ 11.11% Wahrscheinlichkeit, dass bei Ausfall
eines weiteren Knoten Netzwerk nicht mehr verfügbar
• Replica Migration Feature: Master ohne Replika → Migration von Replika auf diese
„orphaned master“ (bessere Verfügbarkeit in „Realworld Szenarien“)

2-42
• Asynchrone Replikation, „last failover wins“ (kein merge von Änderungen)– Letzter Master-Datensatz kann ggf. alle Replikas überschreiben
• Keine Strong Consistency
• Unter bestimmten Bedingungen können writes verloren gehen!!
1.) Aufgrund asynchroner Replikation– Client schreibt an Master B; Master B antwortet OK (=ack)
– Master B propagiert Änderung an Slaves B1, B2, B3 (wartet nicht auf ack!)
– Problem: Crash von B bevor write bei Slave, der als neuer Master gewählt wird
→ write verloren
2.) Aufgrund Netzwerkpartitionierung– Ein Client wird in „minor partition“ mit ≥1 Master isoliert
– Bsp: 3 Master A, B, C, 3 Slaves A1, B1, C1 + Client Z1• Falls Partitioning lange andauert, wird B1 zum neuen Master
in “major partition” gewählt → writes von Z1 an B in minor partition verloren
• B muss in „node timeout“, damit Z1 keine writes mehr an B schickt
• Synchrone Writes können mit WAIT Befehl erzwungen werden (aber sehr
negativer Einfluss auf Performanz)
Redis Cluster - Consistency
A
B1A1
Z1B
C
C1

2-43
Inhaltsverzeichnis
• Key-Value Stores
– Einführung
– Amazon Dynamo
– Redis
– Object Storage Service: Microsoft Azure Storage

2-44
Object Storage Services
• Dienste zum Speichern von Objekten (Binärdaten) in der Cloud
– Upload + Speicherung auf mehreren Knoten
• Einfache Strukturierung
– Buckets: einfache (flache) Container
– Objekte: beliebige Daten (z.B. Datei), beliebige Größe
– Authentifizierung, Zugriffsrechte
• Einfache API
– HTTP-Requests (REST-ful API): PUT, GET, DELETE
– Einfache Nutzung durch Anwendungen, z.B. DropBox (Online Backup & Sync Tool)
• Performanz
– Schnell, skalierbar, hochverfügbar
• Kosten
– “Pay as you go”: #Request , Datenmenge, Upload- und Download-Menge
• Beispiele: Microsoft Azure Storage, Amazon S3, Google Cloud Storage

2-45
Probleme
• Mehrere Nutzer können auf die gleichen Daten zugreifen
– YouTube-Videos, kollaborative Arbeit an Dokumenten, ...
• Problem 1: Konkurrierende Schreibzugriffe
– Conditional Updates: “IF AktuelleVersion=X THEN Update”
– Knoten-basierte Versionierung
• Kopien von Daten werden auf verschiedenen Knoten gespeichert
– Zuverlässigkeit
• Redundanz zum Schutz gegen Knoten-Ausfall
– Lese-Geschwindigkeit
• Mehrere Clients können verschiedene Kopien parallel lesen
• Ausnutzung von Lokalität
• Problem 2: Synchronisation der Replikate
– Strong Consistency: Nach Write lesen alle Clients sofort die aktuellen Daten
– Eventual Consistency: Nach Write lesen alle Clients letztendlich die aktuellen Daten
– Read-your-writes Consistency: EC + schreibender Client liest sofort aktuelle Daten

2-46
Azure Storage
• Ziele
– Hohe Verfügbarkeit mit strenger Konsistenz
• Datenzugang bei Ausfällen und Netzwerkpartitionierung
– Durability
• Replikation innerhalb und über mehrere Datacenter
• Geographische Replikation für Disaster Recovery
– Skalierbarkeit
• > Exabyte Bereich
• Automatische Lastbalancierung für hohe Zugriffsraten auf Daten (Peaks)
• Globaler, partitionierter Namespace:
http(s)://AccountName.<service>.core.windows.net/PartitionName/ObjectName
• Storage für Container (Blobs), Table (Entities), …
Quelle: [Azure]

2-47
Windows Azure Storage Stamps
VIP
Data
access
Partition Layer
Front-Ends
Stream Layer
Intra-stamp replication
VIP
Partition Layer
Front-Ends
Stream Layer
Intra-stamp replication
Inter-stamp
(Geo) replication
Quelle: http://www.sigops.org/sosp/sosp11/current/2011-Cascais/11-calder.pptx
Location
Service
Storage StampStorage Stamp
- Mehrere Locations in den 3
geographischen Regionen
(Nordamerika, Europa, Asien)
- Jede Location umfasst
mehrere Storage Stamps
Synchrone Replikation
Asynchrone
Replikation

2-48
Architektur
M
Extent Nodes (EN)
Paxos
Front End
LayerFE
Incoming Write Request
M
M
Partition
Server
Partition
Server
Partition
Server
Partition
Master
FE FE FE
Lock
Service
Ack
Partition
Layer
Stream
Layer
(Distributed
File System)
Quelle: http://www.sigops.org/sosp/sosp11/current/2011-Cascais/11-calder.pptx
FE
2-49
Quelle: http://www.sigops.org/sosp/sosp11/current/2011-Cascais/11-calder.pptx
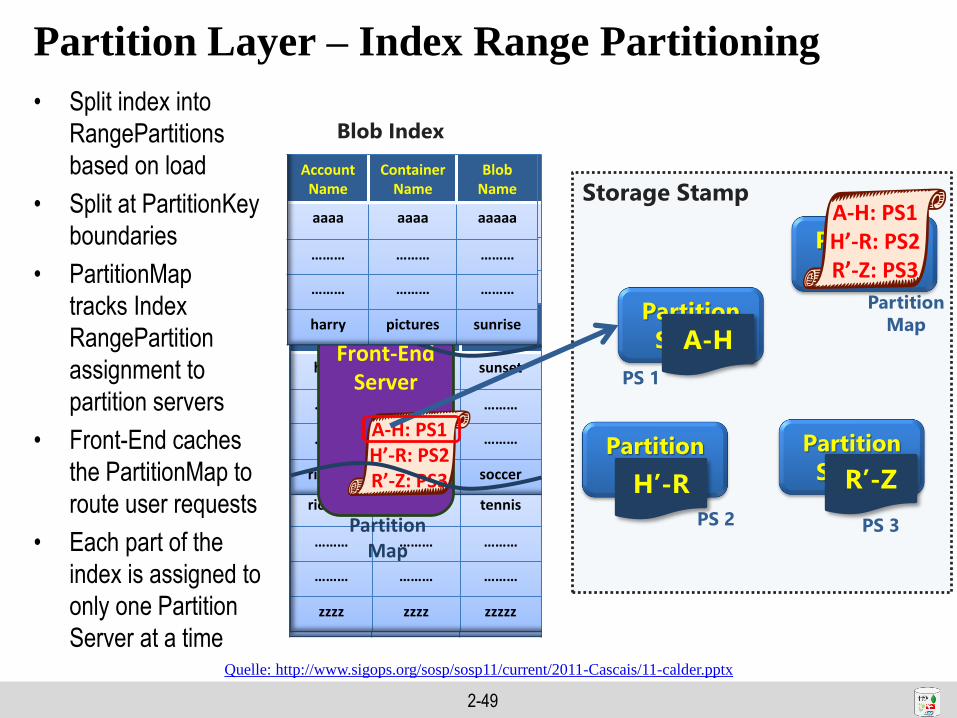
Partition Layer – Index Range Partitioning
• Split index into
RangePartitions
based on load
• Split at PartitionKey
boundaries
• PartitionMap
tracks Index
RangePartition
assignment to
partition servers
• Front-End caches
the PartitionMap to
route user requests
• Each part of the
index is assigned to
only one Partition
Server at a time
AccountName
ContainerName
BlobName
aaaa aaaa aaaaa
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
…….. …….. ……..
zzzz zzzz zzzzz
Storage Stamp
Partition
ServerPartition
ServerAccount
NameContainer
NameBlob
Name
richard videos tennis
……… ……… ………
……… ……… ………
zzzz zzzz zzzzz
AccountName
ContainerName
BlobName
harry pictures sunset
……… ……… ………
……… ……… ………
richard videos soccer
Partition
Server
Partition
Master
Front-EndServer
PS 2 PS 3
PS 1
A-H: PS1H’-R: PS2R’-Z: PS3
A-H: PS1H’-R: PS2R’-Z: PS3
PartitionMap
Blob Index
Partition
Map
AccountName
ContainerName
BlobName
aaaa aaaa aaaaa
……… ……… ………
……… ……… ………
harry pictures sunriseA-H
R’-ZH’-R

2-51
Azure Storage: Request Lifecycle
• Beispiel: PUT <account>.blob.core.windows.net
• DNS-Auflösung
– Ermittle IP-Adresse eines Front-End-Server der Geo-Location des Accounts
• Front-End-Server
– Authentifizierung, Autorisierung
– Partition Map: Object-Name Partition Server
• Partition Server
– GET: Falls Daten nicht im Memory-Cache Request an einen DFS-Server
– PUT: Request an primary DFS-Server
• DFS Server: Replikation
– Primary DFS Server + Replikation bei 2 Secondary Servern
Strong Consistency

2-52
Azure Storage: Ausfall-Behandlung
• Front-End-Server
– Entfernen von DNS-Liste
• Partition Server
– Partitionen werden von anderem Server verwaltet
– Anpassung der Partition Map des „zu Hilfe eilenden“ Front End Server
– Keine Verschiebung der Daten (nur Metadaten-Anpassung)
• DFS Server
– Nutzung eines neuen DFS Servers
– Erstellung eines neuen Replikats

2-53
Azure Storage: Conditional Updates
• Update-Request enthält Versionsnummer (ETag) der aus “Client-Sicht”
aktuellen Version
– Erfolg, wenn Client-Versionsnummer = Knoten-Versionsnummer; sonst Fehler
– bei Neuerstellung “Version=0”
• Verhindert unbeabsichtigtes Überschreiben
– Konsistenzwahrung wird auf Anwendung übertragen
• Beispiel
GET
UPD V7
V8OK
V7 GETV7
ERRORUPD V7
Zei
t

2-54
Azure Storage: Content Delivery Network
• Erweiterung um ein CDN sinnvoll für
– Daten mit hohen Lesezugriffen (in einem bestimmten Zeitraum)
– Daten mit geografisch stark verteilten Zugriffen
• Einführung von Edge locations
– “Server nahe am Client/Nutzer” performanter Zugriff
– Fungieren als Proxy-Server für Zugriffe auf Azure Storage
• Request Lifecycle
– Client fragt CDN-URL für Objekt an
– DNS routet an nächstgelegene Edge Location
– Wenn Datei im Cache Response
– Andernfalls Request an Azure Storage; Speicherung im Cache; Response
– Time-to-Live für Cache-Objekt
• Keine Strong-Consistency mehr
– Updates werden wegen Cache verzögert repliziert
2-55
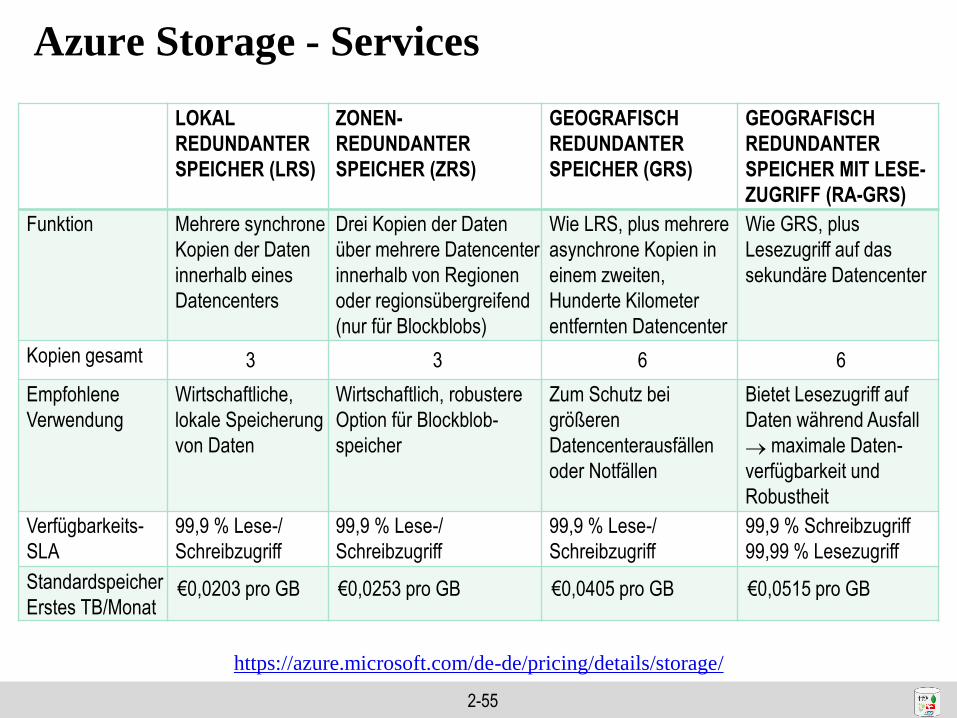
Azure Storage - Services
LOKAL
REDUNDANTER
SPEICHER (LRS)
ZONEN-
REDUNDANTER
SPEICHER (ZRS)
GEOGRAFISCH
REDUNDANTER
SPEICHER (GRS)
GEOGRAFISCH
REDUNDANTER
SPEICHER MIT LESE-
ZUGRIFF (RA-GRS)
Funktion Mehrere synchrone
Kopien der Daten
innerhalb eines
Datencenters
Drei Kopien der Daten
über mehrere Datencenter
innerhalb von Regionen
oder regionsübergreifend
(nur für Blockblobs)
Wie LRS, plus mehrere
asynchrone Kopien in
einem zweiten,
Hunderte Kilometer
entfernten Datencenter
Wie GRS, plus
Lesezugriff auf das
sekundäre Datencenter
Kopien gesamt 3 3 6 6
Empfohlene
Verwendung
Wirtschaftliche,
lokale Speicherung
von Daten
Wirtschaftlich, robustere
Option für Blockblob-
speicher
Zum Schutz bei
größeren
Datencenterausfällen
oder Notfällen
Bietet Lesezugriff auf
Daten während Ausfall
maximale Daten-
verfügbarkeit und
Robustheit
Verfügbarkeits-
SLA
99,9 % Lese-/
Schreibzugriff
99,9 % Lese-/
Schreibzugriff
99,9 % Lese-/
Schreibzugriff
99,9 % Schreibzugriff
99,99 % Lesezugriff
Standardspeicher
Erstes TB/Monat€0,0203 pro GB €0,0253 pro GB €0,0405 pro GB €0,0515 pro GB
https://azure.microsoft.com/de-de/pricing/details/storage/

2-56
Azure Redis Cache + Azure Storage
• Azure Redis Cache: Redis Cache hosted and managed by Microsoft
• Suche auf Primärindex sehr schnell
• Für andere Anfragen secondary index im Cache
https://azure.microsoft.com/de-de/documentation/videos/azure-redis-cache-102-application-patterns/
Redis Cache
Alice:001:234
Bob:002:765
Ted:001:923…
Azure Table Storage
001:234:Alice:1st road …
001:923:Ted:3rd avenue …
…
002:765:Bob:2nd street …
Azure Web Site
Alice 001:234 001:234

2-57
Vergleich
Amazon Dynamo Redis (Cluster) Azure Storage
Partitionierung Hash-Funktion Hash-Funktion Objekt-Name
Dynam. erweiterbar + + +
Routing P2P Hierarchisch Hierarchisch
Replikation Asynchron Asynchron Synchron
Konsistenz Eventual Consistency Strong Consistency
Behandlung
konkurrierender
Writes
Performanz
(Fokus)

2-58
Literatur
• [Dynamo]: DeCandia et al.: „Dynamo: Amazon’s Highly Available Key-
value Store“, SOSP’07
• [Redis]: http://redis.io/documentation
• [Azure]: Calder et al.: “Windows Azure Storage: A Highly Available Cloud
Storage Service with Strong Consistency”, SOSP’11