
Nr. 10 Nr. 10 Dezember 2010 - hlrn.de fileDas MPP-System, die Hauptkomponente der Aus-schreibung,...
4
HLRN Informationen Vor sich haben Sie die zehnte Ausgabe der HLRN-In- formationen. Details zum Abonnement per E-Mail und zum Download sind auf der letzten Seite unter Redak- tionelles zu finden. Das HLRN-II-System Schwerpunkt der Aktivitäten im 2. Halbjahr 2010 war die Installation und Inbetriebnahme des SMP-Teils der Aus- baustufe 2, des Systems SGI Altix UltraViolet 1000 (UV). Mit der Inbetriebnahme dieses Systems am 9. Septem- ber ist die gesamte Beschaffungsmaßnahme HLRN-II abgeschlossen worden. Beschaffung und Inbetrieb- nahme erfolgten in insgesamt 3 Stufen, beginnend im Sommer 2008. In dieser Ausgabe der HLRN-Informa- tionen wird zum einen die UltraViolet näher beschrieben, zum anderen wird das heterogene Gesamtsystem mit seinen einzelnen Komponenten im Überblick dargestellt. Das SMP-System der Ausbaustufe 2, die SGI Altix UltraViolet 1000 Im August dieses Jahres wurden sowohl in Berlin als auch in Hannover die letzte Ausbaustufe des HLRN-II- Systems installiert, jeweils fünf Racks mit je 32 eng gepackten Compute-Blades, siehe Abbildung 1 (Rack 5 besitzt nur 24 Blades). Die Highlights sind: • Nur eine Linux-Instanz (SLES 11) pro Rack • 32 bzw. 24 Blades mit je 2 Prozessor-Sockets • Jeder Socket bestückt mit einem Intel Xeon Nehalem-EX Prozessor (X7560) mit acht Cores, Taktrate 2,266 GHz, 16 MByte Level-3-Cache und 32 GByte Hauptspeicher • Enge interne Kommunikation zwischen den Sock- ets eines Blades durch den Intel QuickPath Inter- connect • Enge interne Kommunikation zwischen den Blades eines Racks durch den SGI NumaLink5 Intercon- nect mit einer aggregierten Bandbreite von 50 GByte/s • 2 TByte direkt adressierbarer Hauptspeicher pro Rack Die UltraViolet wird, wie auch die übrigen Compute-Ein- heiten, ausschließlich im Batchbetrieb angeboten. Die kleinste Scheduling-Einheit ist ein Blade mit 16 Cores und 64 GByte Hauptspeicher. Rack-übergreifende Jobs sind nicht möglich. Da ein Blade für das Betriebssystem reserviert ist, kann die größte Anwendung über 31 Bla- des mit 496 Cores und 1.9 TByte Hauptspeicher verfü- gen. Die theoretische Rechenleistung liegt damit für eine Anwendung bei 4,6 TFlop/s. Der normale Betrieb sieht vor, dass Batchjobs von den Gateway-Knoten aus zu den UV-Systemen abgesetzt werden. Es besteht auch die Möglichkeit der interaktiven Nutzung der UltraViolet. Diese interaktive Nutzung ist aber in das Moab/Torque-Scheduling eingebunden. Vom Gateway-Knoten aus fordert der Benutzer die gewünschten Ressourcen an. Dazu dient der Parameter –I beim msub-Kommando. Nach Bereitstellen der ge- wünschten Ressourcen meldet sich das System mit einem Shellprompt, und der Anwender kann den Dialog beginnen. Zu beachten ist, dass auch hier vollständige Blades vergeben und entsprechend der Sitzungszeit abgerechnet werden. Die fünf Racks sind untereinander mit einem InfiniBand- Netzwerk verknüpft. Ebenfalls über InfiniBand besteht Zugriff zu den Dateisystemen $HOME, $WORK und $WORK2. Auf der Basis von Leistungsvergleichen realer Anwen- dungen wurde die Bewertung in der im HLRN verwen- deten Leistungseinheit NPL auch für die UltraViolet bestimmt: Die Belegung eines Blades über eine Stunde wird mit einer NPL berechnet. Damit wird der Beobach- tung Rechnung getragen, dass die Leistung eines ein- zelnen Cores der UltraViolet im Mittel über typische Anwendungen zwischen den Leistungen der ICE-1 und der ICE-2 liegt. Das hervorstechende Merkmal der UltraViolet ist der große direkt adressierbare Hauptspeicher (ca. 2 TByte) für einzelne Anwendungen. Auf diesem System können Anwendungen mit großen Speicheranforderungen zur Ausführung gebracht werden, ohne dass eine Zerlegung der Daten für einen einzelnen Prozess implementiert werden muss (OpenMP-Programmiermodell). Folgende Jobprofile können auf der UltraViolet bevorzugt ausge- führt werden: HLRN ▪ Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen URL: https://www.hlrn.de ▪ E-Mail: [email protected] 1 ■ Nr. 10 ■ Dezember 2010 ▪ Nr. 10 ▪ Dezember 2010 Abbildung 1: Drei Racks der UltraViolet mit je 32 Compute- Blades
Transcript of Nr. 10 Nr. 10 Dezember 2010 - hlrn.de fileDas MPP-System, die Hauptkomponente der Aus-schreibung,...

HLRN Informationen
Vor sich haben Sie die zehnte Ausgabe der HLRN-In-formationen. Details zum Abonnement per E-Mail und zum Download sind auf der letzten Seite unter Redak-tionelles zu finden.
Das HLRN-II-System
Schwerpunkt der Aktivitäten im 2. Halbjahr 2010 war die Installation und Inbetriebnahme des SMP-Teils der Aus-baustufe 2, des Systems SGI Altix UltraViolet 1000 (UV). Mit der Inbetriebnahme dieses Systems am 9. Septem-ber ist die gesamte Beschaffungsmaßnahme HLRN-II abgeschlossen worden. Beschaffung und Inbetrieb-nahme erfolgten in insgesamt 3 Stufen, beginnend im Sommer 2008. In dieser Ausgabe der HLRN-Informa-tionen wird zum einen die UltraViolet näher beschrieben, zum anderen wird das heterogene Gesamtsystem mit seinen einzelnen Komponenten im Überblick dargestellt.
Das SMP-System der Ausbaustufe 2, die SGI Altix UltraViolet 1000
Im August dieses Jahres wurden sowohl in Berlin als auch in Hannover die letzte Ausbaustufe des HLRN-II-Systems installiert, jeweils fünf Racks mit je 32 eng gepackten Compute-Blades, siehe Abbildung 1 (Rack 5 besitzt nur 24 Blades). Die Highlights sind:
• Nur eine Linux-Instanz (SLES 11) pro Rack• 32 bzw. 24 Blades mit je 2 Prozessor-Sockets• Jeder Socket bestückt mit einem Intel Xeon
Nehalem-EX Prozessor (X7560) mit acht Cores, Taktrate 2,266 GHz, 16 MByte Level-3-Cache und 32 GByte Hauptspeicher
• Enge interne Kommunikation zwischen den Sock-ets eines Blades durch den Intel QuickPath Inter-connect
• Enge interne Kommunikation zwischen den Blades eines Racks durch den SGI NumaLink5 Intercon-nect mit einer aggregierten Bandbreite von 50 GByte/s
• 2 TByte direkt adressierbarer Hauptspeicher pro Rack
Die UltraViolet wird, wie auch die übrigen Compute-Ein-heiten, ausschließlich im Batchbetrieb angeboten. Die kleinste Scheduling-Einheit ist ein Blade mit 16 Cores und 64 GByte Hauptspeicher. Rack-übergreifende Jobs sind nicht möglich. Da ein Blade für das Betriebssystem reserviert ist, kann die größte Anwendung über 31 Bla-des mit 496 Cores und 1.9 TByte Hauptspeicher verfü-gen. Die theoretische Rechenleistung liegt damit für eine Anwendung bei 4,6 TFlop/s.
Der normale Betrieb sieht vor, dass Batchjobs von den Gateway-Knoten aus zu den UV-Systemen abgesetzt werden. Es besteht auch die Möglichkeit der interaktiven Nutzung der UltraViolet. Diese interaktive Nutzung ist
aber in das Moab/Torque-Scheduling eingebunden. Vom Gateway-Knoten aus fordert der Benutzer die gewünschten Ressourcen an. Dazu dient der Parameter –I beim msub-Kommando. Nach Bereitstellen der ge-wünschten Ressourcen meldet sich das System mit einem Shellprompt, und der Anwender kann den Dialog beginnen. Zu beachten ist, dass auch hier vollständige Blades vergeben und entsprechend der Sitzungszeit abgerechnet werden.
Die fünf Racks sind untereinander mit einem InfiniBand-Netzwerk verknüpft. Ebenfalls über InfiniBand besteht Zugriff zu den Dateisystemen $HOME, $WORK und $WORK2.
Auf der Basis von Leistungsvergleichen realer Anwen-dungen wurde die Bewertung in der im HLRN verwen-deten Leistungseinheit NPL auch für die UltraViolet bestimmt: Die Belegung eines Blades über eine Stunde wird mit einer NPL berechnet. Damit wird der Beobach-tung Rechnung getragen, dass die Leistung eines ein-zelnen Cores der UltraViolet im Mittel über typische Anwendungen zwischen den Leistungen der ICE-1 und der ICE-2 liegt.
Das hervorstechende Merkmal der UltraViolet ist der große direkt adressierbare Hauptspeicher (ca. 2 TByte) für einzelne Anwendungen. Auf diesem System können Anwendungen mit großen Speicheranforderungen zur Ausführung gebracht werden, ohne dass eine Zerlegung der Daten für einen einzelnen Prozess implementiert werden muss (OpenMP-Programmiermodell). Folgende Jobprofile können auf der UltraViolet bevorzugt ausge-führt werden:
HLRN ▪ Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen
URL: https://www.hlrn.de ▪ E-Mail: [email protected] 1
■ Nr. 10 ■ Dezember 2010 ▪ Nr. 10 ▪ Dezember 2010
Abbildung 1: Drei Racks der UltraViolet mit je 32 Compute-Blades
• Anwendungen mit einem Hauptspeicherbedarf pro Prozess, der durch einen XE- oder ICE-Knoten nicht befriedigt werden kann
• Anwendungen, die rein thread-parallel (z.B. OpenMP) arbeiten und gut über 8 Threads hinaus skalieren, was auf einem XE- oder ICE-Knoten nicht ausgeschöpft werden kann
Wegen der mehrstufigen unterschiedlichen Zugriffsband-breiten des Hauptspeichers ist die konkrete Zuordnung von Daten zu physikalisch verteiltenen Rechenkernen für ein effektives Arbeiten solcher Programme unerläss-lich. Das NUMA-Prinzip (Non-Uniform Memory Access) ist bei diesem System in der Regel zu berücksichtigen. Unterstützung bei einer sinnvollen Verteilung der Daten im Speicher finden Sie in der vom HLRN bereitgestellten Dokumentation und durch direkten Kontakt mit Ihren HLRN-Fachberatern. Natürlich kann die UltraViolet auch im üblichen MPI-Programmiermodell genutzt werden.
Das Gesamtsystem HLRN-II in seinem Endausbau
Die europaweite Ausschreibung für das HLRN-II-System fand bereits im Jahr 2007 statt. In der Leistungsbe-schreibung zur Ausschreibung wurde dem Nutzerbedarf entsprechend u.a. gefordert, dass das verteilte Hochleis-tungsrechnersystem aus zwei gekoppelten, im Wesentli-chen identischen Komplexen an den beiden Standorten ZIB (Berlin) und RRZN (Hannover) gebildet wird. Jeder Komplex besteht aus dem Datenarchiv und dem Compu-te-System. Letzteres setzt sich aus einem MPP-System und einem SMP-System zusammen, die u.a. aus wirt-schaftlichen Gründen in mehreren Stufen geliefert wur-den.
Das MPP-System, die Hauptkomponente der Aus-schreibung, war als ein massiv paralleles Rechnersys-tem für hochskalierende Anwendungen beschrieben. Das SMP-System war charakterisiert zur Nutzung von Anwendungen, die einen großen Hauptspeicherbedarf pro Knoten haben. Das SMP-System sollte etwa 10% der Leistung des Gesamtsystems besitzen. Die Fa. SGI gewann im Jahr 2007 die Ausschreibung und lieferte, beginnend im Juli 2008, die verschiedenen Komponen-ten des HLRN-II entsprechend dieser Spezifikation. Das Compute-System des HLRN-II ist nunmehr komplett in Betrieb gegangen. Komponenten und Eigenschaften eines Komplexes sind in der nebenstehenden Tabelle aufgeführt. Anhand der dort zusammengestellten Daten kann sich der Anwender das für sein Problem effektivste Teilsystem aussuchen. Kriterien können sein:
• Größe des Hauptspeichers
• Leistung des Prozessors
• Leistung des Hauptspeichers
• Leistung des Kommunikationsnetzwerkes
• Reale Ausführungszeit
• Kosten der Anwendung (in NPL)
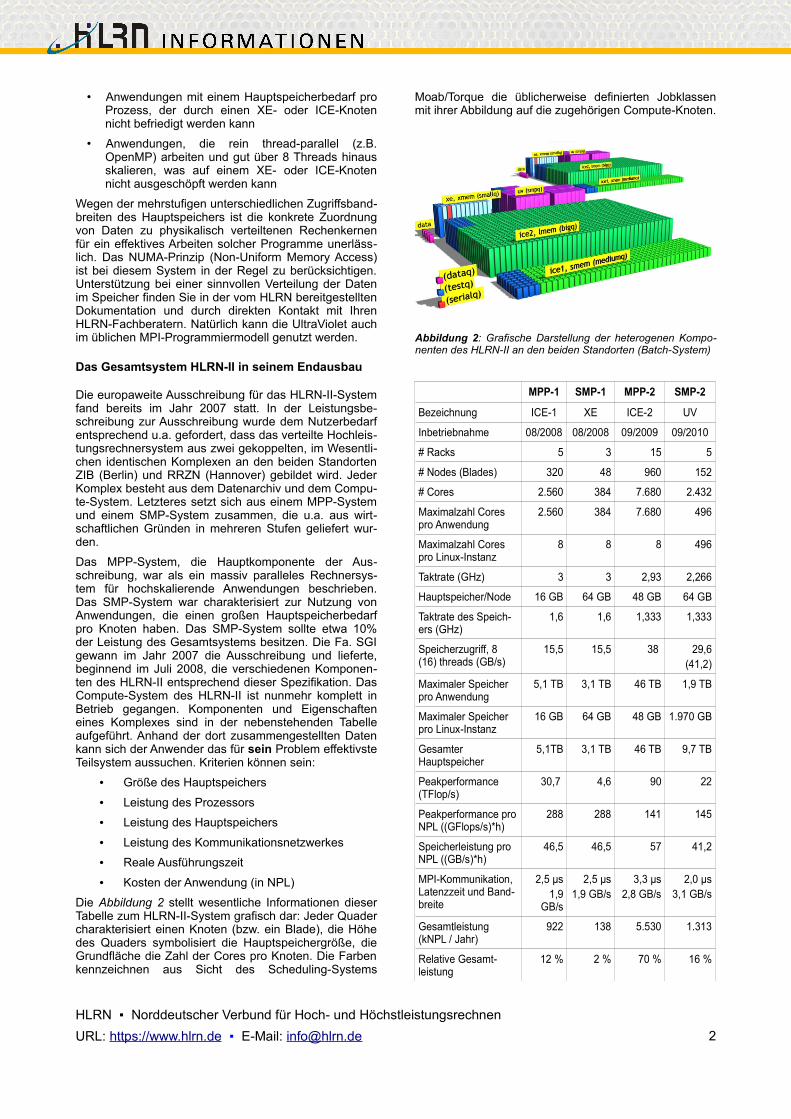
Die Abbildung 2 stellt wesentliche Informationen dieser Tabelle zum HLRN-II-System grafisch dar: Jeder Quader charakterisiert einen Knoten (bzw. ein Blade), die Höhe des Quaders symbolisiert die Hauptspeichergröße, die Grundfläche die Zahl der Cores pro Knoten. Die Farben kennzeichnen aus Sicht des Scheduling-Systems
Moab/Torque die üblicherweise definierten Jobklassen mit ihrer Abbildung auf die zugehörigen Compute-Knoten.
MPP-1 SMP-1 MPP-2 SMP-2
Bezeichnung ICE-1 XE ICE-2 UV
Inbetriebnahme 08/2008 08/2008 09/2009 09/2010
# Racks 5 3 15 5
# Nodes (Blades) 320 48 960 152
# Cores 2.560 384 7.680 2.432
Maximalzahl Cores pro Anwendung
2.560 384 7.680 496
Maximalzahl Cores pro Linux-Instanz
8 8 8 496
Taktrate (GHz) 3 3 2,93 2,266
Hauptspeicher/Node 16 GB 64 GB 48 GB 64 GB
Taktrate des Speich-ers (GHz)
1,6 1,6 1,333 1,333
Speicherzugriff, 8 (16) threads (GB/s)
15,5 15,5 38 29,6(41,2)
Maximaler Speicher pro Anwendung
5,1 TB 3,1 TB 46 TB 1,9 TB
Maximaler Speicher pro Linux-Instanz
16 GB 64 GB 48 GB 1.970 GB
Gesamter Hauptspeicher
5,1TB 3,1 TB 46 TB 9,7 TB
Peakperformance (TFlop/s)
30,7 4,6 90 22
Peakperformance pro NPL ((GFlops/s)*h)
288 288 141 145
Speicherleistung pro NPL ((GB/s)*h)
46,5 46,5 57 41,2
MPI-Kommunikation, Latenzzeit und Band-breite
2,5 µs1,9
GB/s
2,5 µs1,9 GB/s
3,3 µs2,8 GB/s
2,0 µs3,1 GB/s
Gesamtleistung (kNPL / Jahr)
922 138 5.530 1.313
Relative Gesamt-leistung
12 % 2 % 70 % 16 %
HLRN ▪ Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen
URL: https://www.hlrn.de ▪ E-Mail: [email protected] 2
Abbildung 2: Grafische Darstellung der heterogenen Kompo-nenten des HLRN-II an den beiden Standorten (Batch-System)

Projekte am HLRN
Auf den HLRN-Systemen werden Projekte aus vielen Forschungsgebieten bearbeitet. Hier stellen wir jeweils ein Projekt vor, das gerade bearbeitet wird oder abgeschlossen wurde. In dieser Ausgabe präsentieren wir ein Projekt aus der Theoretischen Physik.
Solving Two-time Quantum Kinetic Equations
K. Balzer, S. Bauch, T. Ott, and M. Bonitz
Institut für Theoretische Physik und Astrophysik, Christian-Albrechts-Universität zu Kiel
HLRN grant No. shp0006: ”First principle simulations of classical and quantum charged-particle systems''
Quantum many-particle systems in nonequilibrium are of rapidly increasing importance for many fields. Examples are atoms and molecules excited by (sub)femtosecond laser pulses. Such systems pose extreme challenges to the theory. The method of nonequilibrium Green func-tions (NEGFs) provides one of the most general frame-works to describe interacting quantum many-particle systems out of equilibrium and has attracted attention in many areas such as molecular quantum transport, high-energy plasmas, nuclear matter and astrophysics. Thereby, NEGFs obey multi-time quantum kinetic equa-tions [1] the direct numerical solution of which has become possible due to advances in computer techno-logy but is, so far, limited to a few classes of many-body approximations (MBAs). However, NEGFs contain a wealth of information and its concept can be applied to closed and open systems. They provide an approach to systems that are too large for solving the time-depend-ent Schrödinger equation, such as the homogeneous electron gas or solids. In addition, in contrast to time-de-pendent density functional theory (TDDFT) or density matrix methods based on the Bogoliubov-BornGreen-Kirkwood-Yvon hierarchy, in NEGF calculations, MBAs can be easily constructed to satisfy macroscopic conser-vation laws.
The primary goal of this project is to enable extended NEGF calculations for finite, spatially inhomogeneous systems like atoms or molecules containing only a lim-ited number of particles, and to test the quality of the applied MBAs by computing the correlated particle dynamics. The one-particle NEGF with a second-quant-ized particle field x , t is defined as a generalized density matrix [Eq. (1)]
G x+ , t+ ; x - , t -=−i/ ℏ⟨T Cx+ , t+† x - , t -⟩
with x += r+ , + denoting space and spin variables and
times t+ /- varying on the complex Keldysh-contour Cwhich links the system to a finite temperature
−1=k BT .
Further, T C ensures time-ordering. The time dependence is governed by the Kadanoff-Baym equation (KBE) which, in a very compact form, reads as [Eq. (2)]
±iℏ ∂
∂ t +/-−H t+ /-G< ,> , l , r t+ ; t -= I < ,> , l , r t+ ;t -
where symbols denote different times on the contour C , cf. Fig. 1, and space and spin variables are suppressed. Equation (2) in this form is exact, and the one-particle Hamiltonian H t+/- may contain arbitrary time-dependent
fields. Diagrammatic MBAs enter in the collisions integ-rals I t+ ; t - .
Approximations beyond mean-field (Hartree-Fock) level are indispensable to resolve correlations effects. How-ever, they lead to non-markovian behavior of the KBE, i.e., during time propagation, the collision integrals con-nect the current Green function to all NEGFs with pre-ceding time arguments, see the blue area and the red lines in Fig. 3. This memory kernel defines the cost of computation particularly for finite system applications, as, here, the relevance of the history does generally not decay fast with progressing time. As a consequence, all different components G< , G> , G l and Gr , although they are not completely independent, have to be recorded, and, for storage and processing, require non-standard computing facilities. Due to a favorable basis representa-tion of the NEGF [2] along with a recently developed dis-tributed memory scheme based on MPI to cleverly organize memory kernel integrations, see Ref. [3], we are now able to perform efficient simulations on the supercomputers at HLRN with communication loss as low as 10% and including typically up to 1024 pro-cesses.
Any basis representation of the NEGF transforms the KBE into an integro-differential matrix equation, which can be satisfactorily propagated with unitary transforma-tion algorithms. Pure lattice approaches are not advant-ageous. For our purposes, we combine finite elements with the discrete variable representation [2]. This, for a given MBA, has the additional benefit that summations over parts of Feynman diagrams are greatly simplified.
As an example, we, in Fig. 4, show NEGF results for the closed-shell molecule lithium hydride (LiH) modeled in one spatial dimensional by a four-electron Hamiltonian [3] which is barely treatable exactly by the time-depend-ent Schrödinger equation. In the second Born approxim-ation, electron-electron correlations affect the molecular ground state properties, such as binding energy, bond
HLRN ▪ Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen
URL: https://www.hlrn.de ▪ E-Mail: [email protected] 3
Figure 3: Two-time propagation of the NEGF at fixed temperat-ure
−1=k BT including initial correlations characterized by the
Matsubara Green function GM indicated by the green line. The red lines indicate the memory kernel extension relevant to propagate G< from point A to point B.

length and electron density (Fig. 2 (a)). These quantities are self-consistently obtained from the Matsubara Green function GM with being appropriately large. On the other hand, correlations have strong influence also on the dynamics in strong fields. Fig. 2 (b) and (c) show snapshots of the electronic LiH density⟨ ne ⟩ x , t =−i ℏTrG
<x , t ; x , t if the molecule is exposed to
a permanent laser field. Our calculations show, that, already at the simple level of the second Born approxim-ation, correlation effects are incorporated to a substantial level in time-dependent observables. This motivates to address further questions, such as: How well are mul-tiply-excited states - being absent in a Hartree-Fock the-ory - described within a two-time framework, or how large are correlation corrections to dipole spectra and how do they depend on the MBA used? Precise answers to these questions are necessary to understand the cor-related many-body dynamics and involve resources available at HLRN.
From the numerical point of view, the computational needs for solving the two-time KBE strongly vary with system size, affecting the extent of the basis, and scale for the most essential part, G< ,> , quadratically with simu-lation time where t is typically as small as t=0.01 a.u.. In contrast, the actual particle number is less crucial. As a long-term goal, inhomogeneous NEGF applications may become interesting as a complementary technique to TDDFT being superiorly predictive concerning exchange-correlation effects. Moreover, in an ab initio fashion, its generality promises approaches to many dif-ferent quantum systems out of equilibrium, including finite temperatures and coupling mechanisms, that do not conserve particle number. To reach this goal, how-ever, even more advanced computer power is required.
Bibliography
[1] M. Bonitz, Quantum Kinetic Theory, B.G. Teubner, Stuttgart/Leipzig (1998).
[2] K. Balzer, S. Bauch, and M. Bonitz, Efficient grid-based method in nonequilibrium Green's function calculations. Applic-ation to model atoms and molecules, Phys. Rev. A 81 (2010) 022510 [arXiv:0910.5458 [cond-mat.str-el]].
[3] K. Balzer, S. Bauch, and M. Bonitz, Time-dependent second-order Born calculations for model atoms and molecules in strong laser fields, Phys. Rev. A 82 (2010) 033427 [arXiv:1008.4621 [physics.atom-ph]].
Termine
Großprojekte: Antragstermin 28.01.2011
Nächster Termin für die Abgabe von Rechenzeit-Anträ-gen für Großprojekte ist der 28.01.2011, darauf fol-gender Termin ist der 28.04.2011.
Parallele Programmierung mit MPI und OpenMP
In Bremen (10.-14.01.2011, Kontakt BremHLR) und in Berlin (28.02.-04.03.2011, Kontakt ZIB) werden Work-shops zur parallelen Programmierung mit MPI und OpenMP durchgeführt.
Workshop Optimierung für Einzelprozessoren
An der Universität Bremen (Kontakt BremHLR) findet vom 28.-30. März 2011 ein Workshop zur Programmopti-mierung für Einzelprozessoren statt.
Einzelheiten zu den Workshops entnehmen Sie bitte den Ankündigungen in den HLRN News und auf der HLRN-Veranstaltungsseite.
Redaktionelles
Abonnement und Download
Wenn Sie die HLRN-Informationen per E-Mail abon-nieren wollen, senden Sie eine E-Mail an die Adresse [email protected] mit dem Wort subscribe im Text. Sie erhalten dann einmalig eine automatische Antwort mit Hinweisen, wie Sie Ihr Abonnenment bestäti-gen müsssen.
Wenn Sie die HLRN-Informationen per E-Mail abbestel-len wollen, senden Sie ebenfalls eine Mail an die Adresse [email protected] mit dem Wort unsubscribe im Text.
Diese Hinweise und alle Ausgaben der HLRN Informati o - nen sind auch auf dem Webserver des HLRN zu finden.
Redaktion
Wolfgang Baumann ([email protected])Claus-Peter Rückemann ([email protected])
Die nächste Ausgabe der HLRN Informationen erscheint im Juni 2011.
HLRN ▪ Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen
URL: https://www.hlrn.de ▪ E-Mail: [email protected] 4
Die Mitarbeiterinnen und Mitarbeiter des HLRN wünschen Ihnen Frohe Feiertage und einen guten Start in das Jahr 2011.
Figure 4: Electron density for lithium hydride in a laser field of intensity 2.0×1016 W/cm² and photon energy=35.5 eV (field is switched on at t=0 ): Time-depend-
ent Schrödinger equation [exact solution] (red dashed line), time-dependent Hartree-Fock (green dash-dotted line) and second Born approximation (blue solid line).


















