
NUMERISCHE MATHEMATIK II Sommersemester 2010num.math.uni-goettingen.de/lube/NM2-2010.pdf ·...
152
NUMERISCHE MATHEMATIK II Sommersemester 2010 G. Lube Georg-August-Universit¨ at G¨ ottingen, NAM 2. Juli 2010
Transcript of NUMERISCHE MATHEMATIK II Sommersemester 2010num.math.uni-goettingen.de/lube/NM2-2010.pdf ·...

NUMERISCHE MATHEMATIK II
Sommersemester 2010
G. Lube
Georg-August-Universitat Gottingen, NAM
2. Juli 2010

2

Einleitung
Die Vorlesung Numerische Mathematik II setzt den Einfuhrungskurs uber Numerische Mathe-matik I aus dem Wintersemester fort. Dabei werden numerische Verfahren zur approximativenLosung der folgenden Grundaufgaben behandelt und analysiert:
• Teil I: Numerische Losung gewohnlicher Differentialgleichungen
– Anfangswertaufgaben bei gewohnlichen Differentialgleichungen (Kapitel 1-5)
– Zweipunkt-Randwertprobleme (Kapitel 6-8)
• Teil II: Numerische Lineare Algebra
– Lineare Gleichungssysteme großer Dimension (Kapitel 9)
– Eigenwertaufgaben (Kapitel 10-12)
• Teil III: Lineare Optimierung (Kapitel 13-15)
Die Vorlesung wendet sich an Studierende der Mathematik, Physik und Angewandten Informatiksowie an Lehramtskandidaten mit dem Fach Mathematik ab dem vierten Semester. Vorausge-setzt werden die Vorlesungen Differential- und Integralrechnung I und II, Lineare Algebra I undNumerische Mathematik I.
Zur aktiven und grundlichen Aneigung des Vorlesungsstoffes ist die Teilnahme an den Ubungensehr zweckmaßig. Im Wintersemester 2010/11 wird sich voraussichtlich ein Seminar zur Nu-merischen Mathematik mit Themen anschließen, die an potentielle Graduierungsarbeiten her-anfuhren.
In den Ubungen werden wir (aufbauend auf den guten Erfahrungen im Wintersemester) mit demSoftware-Paket MATLAB arbeiten. Dieses System hat sich in den letzten Jahren internationalals wichtiges Arbeitsinstrument in Lehre und Forschung bewahrt. Es ist somit auch potentiellein Arbeitsinstrument fur nachfolgende Graduierungsarbeiten.
In den Ubungen werden wieder in großerem Umfang Programmieraufgaben gestellt. Dazu sindProgrammierkenntnisse in C nutzlich.
3

4

Inhaltsverzeichnis
I Numerische Losung gewohnlicher Differentialgleichungen 7
1 Anfangswertaufgaben 9
1.1 Explizite Differentialgleichungen 1. Ordnung . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Lokale Existenzaussagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3 Existenz globaler Losungen. Regularitat. Evolution . . . . . . . . . . . . . . . . . . . . . . 15
1.4 Stabilitat der Losung von AWP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Einschritt-Verfahren 21
2.1 Definition und Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2 Konsistenz von Einschritt-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3 Konvergenz von Einschritt-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3 Explizite Runge-Kutta Verfahren 27
3.1 Idee von Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Ordnungsbedingungen nach Butcher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3 Konvergenz expliziter Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . 34
4 Adaptive Gittersteuerung 37
4.1 Adaptiver Basisalgorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Lokale Fehlerschatzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.3 Eingebettete Runge-Kutta-Verfahren. Fehlberg-Trick . . . . . . . . . . . . . . . . . . . . . 40
5 Implizite Verfahren fur steife AWP 45
5.1 Eignung expliziter Verfahren fur steife AWP . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Implizite Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.3 Implementation impliziter RK-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.4 Konstruktion impliziter RK-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.5 Stabilitat impliziter Runge-Kutta-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.6 Eingebettete Runge-Kutta-Verfahren in Matlab . . . . . . . . . . . . . . . . . . . . . . . 55
6 Randwertaufgaben 57
6.1 Einfuhrendes Beispiel. Definitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.2 Losbarkeit des 1. RWP im symmetrischen Fall . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.3 Losbarkeit des 1. RWP im nichtsymmetrischen Fall . . . . . . . . . . . . . . . . . . . . . . 60
6.4 Exkurs: Klassische Losungen elliptischer RWP . . . . . . . . . . . . . . . . . . . . . . . . . 62
7 Finite-Differenzen-Verfahren 65
7.1 Definition der klassischen FDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
7.2 Losung des diskreten Problems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
7.3 Stabilitats- und Konvergenzanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.4 Exkurs: Finite-Differenzen-Methode fur Poisson-Problem . . . . . . . . . . . . . . . . . . . 72
5

6 INHALTSVERZEICHNIS
8 Ritz-Galerkin-Verfahren fur RWP 778.1 Variationsgleichungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 778.2 Verallgemeinerte Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 798.3 Ritz-Galerkin Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 808.4 Finite-Elemente-Methode fur Zweipunkt-RWP . . . . . . . . . . . . . . . . . . . . . . . . 83
II Numerische Lineare Algebra 87
9 Krylov-Unterraum-Methoden 899.1 Krylov-Unterraume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 899.2 Arnoldi-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 919.3 FOM-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 939.4 GMRES-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 949.5 Vorkonditionierung von Krylov-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
10 Eigenwertprobleme 10110.1 Einfuhrende Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10110.2 Algebraische Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10210.3 Spezialfall hermitescher Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10410.4 Lokalisierung von Eigenwerten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
11 Verfahren der Vektoriteration 10911.1 Potenzmethode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10911.2 Inverse Iteration mit shift-Strategie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11111.3 Rayleigh-Quotienten-Iteration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
12 QR-Verfahren fur allgemeine EWP 11512.1 Basisalgorithmus des QR-Verfahrens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11512.2 Konvergenz des einfachen QR-Verfahrens . . . . . . . . . . . . . . . . . . . . . . . . . . . 11712.3 Nachteile des Basisverfahrens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11912.4 Reduktionsschritt auf Hessenberg-Form . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12012.5 QR-Zerlegung mit Givens-Rotationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12212.6 Konvergenzbeschleunigung durch shift-Strategie . . . . . . . . . . . . . . . . . . . . . . . . 124
III Lineare Optimierung 127
13 Grundlagen der Optimierung 12913.1 Definitionen. Vorbemerkungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12913.2 Optimalitatsbedingungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13013.3 Lagrange-Formalismus fur lineare Gleichungsrestriktionen . . . . . . . . . . . . . . . . . . 13113.4 KKT-Bedingungen fur lineare Ungleichungsbedingungen . . . . . . . . . . . . . . . . . . . 13313.5 Farkas-Lemma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
14 Lineare Optimierung 13714.1 Einfuhrende Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13714.2 Existenz von Losungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13814.3 Dualitat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
15 Simplex-Verfahren 14315.1 Ecken und Basislosungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14315.2 Entwicklung des Simplex-Verfahrens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14515.3 Analyse eines Simplex-Schritts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14715.4 Bemerkungen zur Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14815.5 Bestimmung einer Basislosung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149

Teil I
Numerische Losung gewohnlicherDifferentialgleichungen
7


Kapitel 1
Anfangswertaufgaben
Die Theorie der gewohnlichen Differentialgleichungen ist eines der wesentlichen und am bestenverstandenen Instrumente der Mathematik. Sie untersucht Entwicklungsprozesse (Evolutions-prozesse), die deterministisch, endlichdimensional sowie differenzierbar sind.
Wir betrachten zunachst Anfangswertprobleme (AWP) fur i.a. gekoppelte Systeme gewohnlicherDifferentialgleichungen zu gegebenen Anfangswerten und deren numerischer Losung mit Ein-schrittverfahren. Zunachst stellen wir im Kapitel 1 Grundbegriffe sowie Aussagen zur Losbarkeitvon AWP zusammen. In Kapitel 2 gehen wir auf die Grundlagen von Einschritt-Verfahren ein.Kapitel 3 ist der Konstruktion von expliziten Runge-Kutta Verfahren gewidmet. In Kapitel 4betrachten wir fur diese Verfahren Adaptionsmethoden. Schließlich behandeln wir in Kapitel 5implizite Runge-Kutta Verfahren fur sogenannte steife AWP.
Der Losung von Randwertaufgaben fur gewohnliche Differentialgleichungen widmen wir uns inden restlichen Kapiteln von Teil I.
1.1 Explizite Differentialgleichungen 1. Ordnung
Definition 1.1. Auf dem Gebiet I × G ⊆ R × Rn sei f ∈ C(I × G; R) eine gegebene stetige
Funktion. Dann heißt x(t) = (x1(t), ..., xn(t))T ∈ C1(I; Rn)) klassische Losung der explizitengewohnlichen Differentialgleichung 1. Ordnung
x′(t) = f(t;x(t)). (1.1)
bzw.x′
i(t) = fi(t;x1(t), ..., xn(t)), i = 1, ..., n, (1.2)
falls (t, x(t)) ∈ I × G und x′(t) = f(t, x(t)) fur alle t ∈ I.
Im skalaren Fall n = 1 entspricht die Aufgabe (1.1) der Bestimmung von Kurven x = x(t), derenSteigung in jedem Kurvenpunkt durch das vorgegebene Richtungsfeld f(t;x(t)) bestimmt ist.
Im allgemeinen vektorwertigen Fall n ≥ 1 bezeichnen wir die unabhangige Variable t als Zeit so-wie den Vektor x ∈ G ⊂ R
n als Zustandsvektor. Die Menge I×G heißt erweiterter Zustands- odererweiterter Phasenraum. Der Graph (t, x(t)) einer Losung des Systems (1.1) wird als Phasen-kurve (bzw. Trajektorie oder Orbit) im erweiterten Phasenraum unter dem Fluß f interpretiert.Oft ist auch die Projektion der Phasenkurven in den Phasenraum G ⊂ R
n von Interesse.
Die Losung des Systems (1.1) ist im allgemeinen Fall nicht eindeutig bestimmt. Bei konkretenAnwendungen interessiert man sich in der Regel auch nicht fur die Gesamtheit der Losungen,
9

10 KAPITEL 1. ANFANGSWERTAUFGABEN
sondern fur eine spezielle Losung bei Vorgabe einer Zusatzbedingung. Bei einem Anfangswert-problem (AWP) sucht man eine Losung von (1.1), die den Anfangsbedingungen
xi(t0) = x0i , i = 1, ..., n; t0 ∈ (a, b) (1.3)
genugt. In kompakter Form erhalt man das AWP
x′ = f(t, x(t)), x(t0) = x0 := (x01, ..., x
0n)T . (1.4)
Die Losung von (1.4) fuhrt somit auf die Auswahl einer speziellen Losungstrajektorie, die durchden Punkt (t0, x
0) fuhrt.
Bemerkung 1.2. Die Vorgabe von Anfangsbedingungen ist nicht die einzige Moglichkeit zurAuswahl einer speziellen Losung von (1.1). Oft ist die Ermittlung periodischer Losungen vonpraktischem Interesse. Wir konnen jedoch hier nicht auf diesen Punkt eingehen. 2
Wir wollen einige wichtige Spezialfalle besprechen.
(i) Nichtautonome und autonome Systeme:
Hangt die gegebene Funktion f nicht explizit von t ab, d.h. f = f(x), so heißt (1.1) autonomesoder dynamisches System. Anderenfalls nennt man (1.1) nichtautonom. Bei autonomen Syste-men mit I = R ist mit einer Losung x(·) auch jede Funktion x(· − t∗) fur alle t∗ ∈ R Losung desSystems. Die Losung x = x(t), t ∈ R eines AWP fur ein autonomes System stellt die Parame-terdarstellung einer Trajektorie durch den Punkt x0 dar. Ohne Beschrankung der Allgemeinheitist t0 = 0.
Man kann jedes nichtautonome AWP (1.4) mittels x(t) = (t, x(t)T )T in die autonome Formbringen:
x′(t) = g(x) := (1, f(t;x)T )T , x(t0) = (t0, x(t0)T )T .
(ii) Gleichungen und Systeme hoherer Ordnung:
Es besteht ein enger Zusammenhang zwischen einem System 1. Ordnung und einer Differential-gleichung n−ter Ordnung
x(n) :=dnx
dtn= F (t;x, x′, ..., x(n−1)). (1.5)
Mit den Festsetzungen x1 := x, x2 := x′, ...., xn := x(n−1) erhalt man das aquivalente System1. Ordnung
x′i = xi+1, i = 1, ..., n − 1; x′
n = F (t;x1, ..., xn). (1.6)
Man kann diesen Sachverhalt sinngemaß auf explizite Systeme gewohnlicher Differentialgleichun-gen
x(m)(t) = F (t;x(t), ..., x(m−1)(t))
der Ordnung m mit x = (x1, ..., xn)T und F = (F1, ..., Fn)T ubertragen. Man erhalt dann einexplizites System von n · m gewohnlichen Differentialgleichungen 1. Ordnung.
(iii) Systeme linearer Differentialgleichungen:
Die praktische Behandlung der im allgemeinen Fall nichtlinearen Aufgabe (1.1) erfordert in derRegel eine geeignete Linearisierung. Oft bemuht man sich schon in der Modellierung prakti-scher Vorgange um die Aufstellung von Systemen linearer Differentialgleichungen, d.h. mit derspeziellen Gestalt
x′(t) = f(t, x) := A(t)x + g(t), (1.7)

1.1. EXPLIZITE DIFFERENTIALGLEICHUNGEN 1. ORDNUNG 11
wobei g ∈ C(I; Rn) eine stetige Funktion und A = (aij)ni,j=1 ∈ C(I; Rn×n) eine Matrix mit ste-
tigen Eintragen aij : I → R sind. Lineare Aufgaben haben besonders markante Eigenschaften,auf die wir in den Ubungen eingehen.
Zur Illustration bringen wir zwei einfache Beispiele:
Beispiel 1.3. Bewegung eines MassepunktesDie Bewegung eines Massepunktes m zur Zeit t am Ort x wird beschrieben durch die Differen-tialgleichung 2. Ordnung
mx′′(t) = g(t;x).
Die Funktion g beschreibt dabei die Wirkung außerer Krafte. So gilt fur die Schwingungeneiner einseitig eingespannten Feder fur die rucktreibende Federkraft g(t;x) = −kx mit derFederkonstanten k. Zur eindeutigen Beschreibung der Bewegung werden ferner der Anfangspunktx0 = x(t0) und die Anfangsgeschwindigkeit x′
0 = x′(t0) vorgegeben. Das aquivalente System
x′1(t) = x2(t), x′
2(t) = −kx1(t)
x1(t0) = x0, x2(t0) = x′0
ist linear und autonom. Die periodische Losung x(t) = x1(t) = x0 cos(√
kmt) + x′
0 sin(√
km t) ist
zusammen mit der Ableitung x′(t) = x2(t) in Abbildung 1.1 dargestellt. 2
Loesung und Ableitung
–1.5
–1
–0.5
0
0.5
1
1.5
1 2 3 4 5 6
Phasenkurve
–1.5
–1
–0.5
0
0.5
1
1.5
–0.8 –0.6 –0.4 –0.2 0.2 0.4 0.6 0.8
Abbildung 1.1: Federschwingung: Losung und Ableitung sowie Phasenkurve
Beispiel 1.4. Volterra-Lottka ZyklusWir betrachten ein stark vereinfachtes okologisches System, bei dem die erste Art der zweiten alsNahrung dient. Die Populationen der ersten bzw. zweiten Art zur Zeit t werden mit x1(t) bzw.x2(t) bezeichnet. Die Wachstumsrate der Population ergibt sich als Differenz von Geburts- undSterberate. Fur die erste Population sei genugend Nahrung vorhanden, so daß die Geburtsrateals konstant angesehen werden kann. Mit geeigneten Konstanten α, β > 0 gilt dann
x′1
x1= α − βx2.
Bei Annahme einer konstanten Sterberate fur die zweite Art erhalt man mit geeigneten Kon-stanten γ, δ > 0
x′2
x2= γx1 − δ.

12 KAPITEL 1. ANFANGSWERTAUFGABEN
Somit wird das sogenannte Rauber-Beute Verhaltnis durch ein System 1. Ordnung aus zweinichtlinearen Gleichungen beschrieben:
x′1 = αx1 − βx1x2, x′
2 = γx1x2 − δx1.
Abbildung 1.2 zeigt, daß sich eine periodische Losung (Volterra-Lottka Zyklus) einstellt. 2
Volterra-Lotks-Zyklus
100
200
300
400
0 2 4 6 8 10
Periodische Phasenkurve
100
200
300
400
Raeuber
50 100 150 200 250 300Beute
Abbildung 1.2: Losungstrajektorien und Phasenkurve des Rauber-Beute-Zyklus
1.2 Lokale Existenzaussagen
Grundlage des fundamentalen Existenz- und Eindeutigkeitssatzes von Picard-Lindelof ist derFixpunktsatz von Banach fur das Fixpunktproblem
Finde x ∈ M ⊆ X : x = T (x). (1.8)
Ferner untersuchen wir zur Naherungslosung von (1.8) das Verfahren der sukzessiven Approxi-mation:
Finde xn+1 ∈ M ⊆ X : xn+1 = T (xn), n ∈ N0; x0 ∈ M. (1.9)
Theorem 1.5. (Fixpunktsatz von Banach)
Seien (X, ‖ · ‖) vollstandiger, normierter Raum und M ⊆ X eine abgeschlossene, nichtleereMenge. Der Operator T sei selbstabbildend, d.h.
T : M ⊆ X → M, (1.10)
und kontraktiv, d.h. es gilt die gleichmaßige Lipschitz-Bedingung
∃κ ∈ [0, 1) : ‖T (x) − T (y)‖ ≤ κ‖x − y‖, ∀x, y ∈ M. (1.11)
Dann besitzen die Probleme (1.8) bzw. (1.9) jeweils eine und nur eine Losung x bzw. xn in M .Ferner konvergiert die durch (1.9) erzeugte Folge (xn)n gegen x und es gilt die Fehlerabschatzung
‖xn − x‖ ≤ κn
1 − κ‖x0 − x1‖ → 0, n → ∞. (1.12)
Ferner betrachten wir das parameterabhangige Fixpunktproblem:
Finde xλ ∈ M ⊆ X : xλ = Tλ(xλ). λ ∈ Λ (1.13)

1.2. LOKALE EXISTENZAUSSAGEN 13
Satz 1.6. Sei Λ metrischer Raum. Ferner erfulle Tλ fur alle λ, λ0 ∈ Λ die Voraussetzungen vonTheorem 1.5 mit einer von λ unabhangigen Konstanten κ und es gelte
limλ→λ0
Tλ(x) = Tλ0(x), ∀x ∈ M. (1.14)
Dann besitzt das Problem (1.13) fur alle λ ∈ Λ eine und nur eine Losung xλ ∈ M . Ferner gilt
limλ→λ0
xλ = xλ0 .
Beweis: (i) Existenz: Die Existenzaussage folgt nach Theorem 1.5 zunachst fur festes λ ∈ Λ.
(ii) Stetigkeit: Nach Dreiecksungleichung und (1.11) folgt
‖xλ − xλ0‖ = ‖Tλ(xλ) − Tλ0(xλ0)‖≤ ‖Tλ(xλ) − Tλ(xλ0)‖ + ‖Tλ(xλ0) − Tλ0(xλ0)‖,≤ κ‖xλ − xλ0‖ + ‖Tλ(xλ0) − Tλ0(xλ0)‖,
d.h. mit (1.14)
‖xλ − xλ0‖ ≤ 1
1 − κ‖Tλ(xλ0) − Tλ0(xλ0)‖ → 0, λ → λ0. 2
Wir betrachten auf dem Definitionsgebiet I ×G von f in einer Umgebung von t0 ∈ I das AWP
x′(t) = f(t;x(t)), x(t0) = x0, (1.15)
mit x(t) = (x1(t), ..., xn(t))T , f = (f1, ..., fn)T sowie x0 = (x01, ..., x
0n)T ∈ R
n. Der entscheidendeKunstgriff ist die Wahl der folgenden parameterabhangigen Fixpunktform
x(t) = x0 +
∫ t
t0
f(τ, x(τ)) dτ ≡ Tx0(x(t)) (1.16)
bei fixiertem Anfangspunkt t0. Der Anfangswert x0 wird als Parameter angesehen. Weiter wahlenwir mit Ic = [t0 − c, t0 + c] mit c > 0 den Banach-Raum
X := C0(Ic; Rn), ‖x‖ := ‖x‖∞ := max
t∈Ic
maxi=1,...,n
|xi(t)|
und die Menge M := x ∈ X : ‖x − x0‖∞ ≤ R ⊂ G mit R > 0. Wir vermerken nur, daß dieMaximum-Norm ‖ · ‖∞ durch eine andere Vektor-Norm ersetzt werden kann.
Man untersucht also die Losbarkeit des AWP im Raum stetiger vektorwertiger Funktionen. Mitden Voraussetzungen des folgenden Resultates sind das AWP (1.15) und (1.16) aquivalent.
Theorem 1.7. (Picard-Lindelof)
Auf dem Streifengebiet QR := (t, x) ∈ R × Rn : |t − t0| ≤ a, ‖x − x0‖∞ ≤ R ⊂ I × G gelte
mit festen Werten K,L ∈ [0,∞), a, c ∈ (0,∞), daß
(i) f ∈ C0(QR; Rn), |fi(t, x)| ≤ K auf QR
(ii) |fi(t, x) − fi(t, x)| ≤ L‖x − x‖∞ auf QR
(iii) 0 < c < a, cK < R, cL < 1 (d.h. c hinreichend klein) .

14 KAPITEL 1. ANFANGSWERTAUFGABEN
Dann existiert genau eine Losung von (1.15) mit x(·) ∈ M ⊂ C0(Ic; Rn). Sie hangt in der
Norm von X stetig von den Anfangswerten x0 ab und liegt sogar im Raum C1(Ic; Rn). Ferner
konvergiert das Verfahren der sukzessiven Approximation
x(0)(t) = x0; x(n+1)(t) = x0 +
∫ t
t0
f(τ, x(n)(τ)) dτ, t ∈ Ic, n ∈ N0
gegen die Losung von (1.15) mitlim
n→∞‖x − x(n)‖ = 0.
Beweis: Wir wenden zunachst Theorem 1.5 mit Tx0 = T fur festen Anfangswert x0 an:
(i) Selbstabbildung (1.10): Die Aussage T : M → M folgt aus
‖T (x) − x0‖ = ‖∫ t
t0
f(τ, x(τ)) dτ‖∞ = maxt∈Ic
maxi=1,...,n
|∫ t
t0
fi(τ, x(τ)) dτ | ≤ cK < R.
(ii) Kontraktivitat (1.11): Dies ergibt sich mit κ := cL < 1 aus
‖T (x1) − T (x2)‖ = ‖∫ t
t0
[f(τ, x1(τ)) − f(τ, x2(τ))] dτ‖∞
= maxt∈Ic
maxi=1,...,n
|∫ t
t0
[fi(τ, x1(τ)) − fi(τ, x2(τ))] dτ |
≤ cL‖x1 − x2‖∞ ≡ κ‖x1 − x2‖.
Theorem 1.5 sichert Existenz und Eindeutigkeit der Losung des AWP sowie die Konvergenzaus-sage fur das Verfahren der sukzessiven Approximation im Raum X = C0(Ic; R
n).
(iii) Regularitat der Losung: Die stetige Differenzierbarkeit xi ∈ C1(Ic) folgt wegen der Stetig-keit des Integranden f in der Operatordefinition von T und wegen x ∈ C0(Ic; R
n).
(iv) Stetige Abhangigkeit: Wir wenden Satz 1.6 mit Λ = Rn an. Sei x0n eine Folge in R
n mitx0n → x0. Wegen
‖Tx0n(x) − Tx0(x)‖ = ‖x0n − x0‖∞ → 0, n → ∞, ∀x ∈ M
sind dann die Voraussetzungen von Satz 1.6 (evt. bei Abanderung der Konstanten a,R und c)erfullt. Daraus folgt die Aussage. 2
Bemerkung 1.8. Seien die Voraussetzungen (i) und (iii) des Satzes von Picard-Lindelof mitAusnahme der Forderung der Lipschitz-Stetigkeit (ii) von f (und damit ohne die Beschrankungder Konstante c bezuglich der Lipschitz-Konstante L) erfullt. Dann gibt es mindestens eineLosung x(·) ∈ C1([t0 − c, t0 + c]; Rn) des AWP (1.15). Dies ist die Aussage des Satzes vonPeano.
Ohne die Voraussetzung der Lipschitz-Stetigkeit gilt im allgemeinen Fall die Eindeutigkeit derLosung des AWP (1.15) nicht mehr. Wir betrachten das AWP
x′ = f(x) :=√
|x|, x(0) = 0.
Offenbar ist die Funktion f nicht Lipschitz-stetig im Punkt x = 0. Man pruft sofort nachdurch Einsetzen, daß sowohl x1(t) ≡ 0 als auch die Trajektorie mit x2(t) = t2/4, t ≥ 0 undx2(t) = 0, t ≤ 0 Losung des AWP sind. Die Losung ist also nicht eindeutig bestimmt. 2

1.3. EXISTENZ GLOBALER LOSUNGEN. REGULARITAT. EVOLUTION 15
Bemerkung 1.9. Das Resultat des Satzes von Peano zeigt, daß das AWP (1.15) eigentlich sehrgutartig gestellt ist: Stetigkeit der Daten impliziert die Losbarkeit. Bei der Analyse numerischerVerfahren werden wir jedoch im Verlauf der Vorlesung stets Voraussetzungen benotigen, die weituber die der Stetigkeit von f hinausgehen. Auch wird (implizit) immer die Eindeutigkeit derLosung angenommen. Daher hat der Satz von Peano wegen der moglichen Nichteindeutigkeitder Losung im Rahmen dieser Vorlesung keine weitere Bedeutung. 2
Von praktischer Bedeutung ist folgendes Kriterium fur gleichmaßige Lipschitz-Stetigkeit von f ,das sich aus dem Mittelwertsatz ergibt.
Lemma 1.10. Gelte auf dem Streifengebiet QR (vgl. Thm. 1.7) neben der Stetigkeitsforderungf ∈ C0(QR, Rn) auch die Stetigkeit der partiellen Ableitungen, d.h. fur die Eintrage der Jacobi-Matrix gilt ∂fi
∂xj∈ C0(QR, Rn), i, j = 1, ..., n. Dann sind die Funktionen fi (fur t fest) gleichmaßig
Lipschitz-stetig bezuglich x mit
|fi(t, x) − fi(t, x)| ≤ Li‖x − x‖∞, Li(t) = sup‖x−x0‖∞≤R
n∑
j=1
∣∣∣∣
∂fi
∂xj(t, x)
∣∣∣∣. (1.17)
1.3 Existenz globaler Losungen. Regularitat. Evolution
Der Satz von Picard-Lindelof ist in der angegebenen Form zunachst nur ein lokaler Existenz-satz, da das Intervall I = [t0 − c, t0 + c] ggf. hinreichend klein ist. Von Bedeutung ist oft dieFortsetzbarkeit der Losung auf großere Zeitintervalle. Im allgemeinen Fall ist die Losung nichtauf die gesamte reelle Zeitachse R fortsetzbar, wie folgendes Beispiel zeigt.
Beispiel 1.11. Das AWPx′ = x2, x(0) = 1
hat nach dem Satz von Picard-Lindelof eine eindeutige Losung. Sie hat fur −∞ < t < 1 dieGestalt x(t) = 1
1−t . Die Losung ist jedoch nicht bis t+ = 1 und fur t ≥ 1 fortsetzbar.
Interessant ist, daß diese Tatsache sogar schon fur uberlineares Wachstum der rechten Seitebezuglich x, d.h. bei f(x) = |x|α mit α > 1 gilt. Das Beispiel zeigt, daß ein uberlineares Wachs-tum der rechten Seiten eines AWP die Gefahr des ”blow up” in sich tragt. 2
Einen globalen Existenzsatz (bzw. fur die Fortsetzbarkeit der Losung fur alle Zeiten) erhalt manmit einer scheinbar geringfugigen Modifikation des Beweises von Theorem 1.7.
Satz 1.12. (Fortsetzbarkeit der Losung)
Die Voraussetzungen (i), (ii) von Theorem 1.7 seien fur beliebiges R > 0 und eine von Runabhangige Lipschitz-Konstante L erfullt. Ferner entfalle die Einschrankung (iii) an die Kon-stante c. Dann existiert eine und nur eine Losung des AWP (1.15) in C0([t0 − a, t0 + a]; Rn),d.h. die Losung ist fortsetzbar auf das Intervall [t0 − a, t0 + a]. Der Fall a → ∞ ist zugelassen.
Beweis: Wir setzen Ia := [t0 − a, t0 + a] und wahlen den Raum M = X = C0(Ia; Rn) mit der
modifizierten Norm‖|x‖| := max
t∈Ia
maxi=1,...,n
(
|xi(t)| e−L|t−t0|)
. (1.18)
Sei o.B.d.A. t0 = 0. Die Norm ‖| · ‖| ist zur im Theorem 1.7 verwendeten Norm ‖ · ‖∞ aquivalentwegen
e−La‖x‖∞ ≤ ‖|x‖| ≤ ‖x‖∞,
d.h. (X, ‖| · ‖|) ist ebenfalls Banach–Raum.

16 KAPITEL 1. ANFANGSWERTAUFGABEN
Die Selbstabbildung T (X) = X ist trivial. Die Kontraktivitat von T auf X ersieht man aus
‖|T (x1) − T (x2)‖| = maxt∈[−a,a]
maxi=1,...,n
∣∣∣∣
∫ t
0[fi(τ, x1(τ)) − fi(τ, x2(τ))] dτ e−L|t|
∣∣∣∣
≤ maxt∈[−a,a]
∫ t
0L ‖x1(τ) − x2(τ)‖∞︸ ︷︷ ︸
≤eL|τ |‖|x1−x2‖|
dτ e−L|t|
≤ maxt∈[−a,a]
(∫ t
0L eL(|τ |−|t|) dτ
)
︸ ︷︷ ︸
≤ 1−e−La
‖|x1 − x2‖|.
Der Fixpunktsatz von Banach ergibt dann die Behauptung. 2
Beispiel 1.13. (Fortsetzbarkeit der Losung linearer AWP)
Das lineare AWP
x′ = A(t)x + g(t), x(t0) = x0, t ∈ R (1.19)
mit Funktionen g ∈ C(R; Rn) und A = (aij)ni,j=1 ∈ C(R; Rn×n) besitzt bei beliebigen gegebenem
Anfangswerten x(t0) = x0 eine eindeutige Losung, die sich bis t± = ±∞ fortsetzen laßt. Speziellfolgt die Aussage der Lipschitz-Stetigkeit wegen f(t, x)−f(t, x) = A(t)(x− x), sofern A in einerMatrixnorm gleichmaßig beschrankt ist. 2
Bemerkung 1.14. Die Aussage von Satz 1.12 gilt auch noch fur (nichtlineare) Aufgaben
x′ = f(t;x), ‖f(t;x)‖∞ ≤ α(t)‖x‖∞ + β(t), α(·), β(·) ∈ C(R+), (1.20)
d.h. bei maximal linearem Wachstum bezuglich der Losung, vgl. [1], Satz 7.8. Beispiel 1.11 stelltklar, daß die Fortsetzbarkeit fur alle Zeiten i.a. nicht fur nichtlineare AWP mit uberlinearemWachstum von f bezuglich ‖x‖ gelten kann.
Allgemeiner laßt sich die Losung des AWP (1.15) bis zum Rand des Definitionsgebietes I × Gder Daten im erweiterten Phasenraum R × R
n fortsetzen. Man vgl. hierzu [1], Satz II. 7.6) 2
Neben der stetigen Abhangigkeit der Losung von den Daten interessiert oft die Regularitat derLosung des AWP (1.15), d.h. ob sie hinreichend oft differenzierbar bezuglich der unabhangigenVariablen t und eventuell bezuglich der Anfangswerte ist. Von der Regularitat werden wir spaterbei der Analyse numerischer Losungsverfahren standig Gebrauch machen. Ohne Beweis (vgl. z.B.[2], Kap. 4.3) zitieren wir folgendes Resultat.
Satz 1.15. Neben den Voraussetzungen des Satzes von Picard-Lindelof sei f ∈ Cr(I×G; Rn)mit r ∈ N. Dann gehort die Losung zur Klasse x(·) ∈ Cr(Ic; R
n). Ferner ist sie r-fach stetigdifferenzierbar nach den Anfangswerten t0 und x0.
Wir vermerken, daß die Regularitat der Losung auch bezuglich weiterer Parameter in der rechtenSeite f = f(t, λ, x) gilt bei hinreichender Regularitat von f bezuglich λ (vgl. [2], Kap. 4.3).
Nachfolgend nehmen wir an, daß f : I × G → Rn die Voraussetzungen des Satzes von Picard-
Lindelof erfullt. Damit existiert fur jedes (t0, x0) ∈ I × G lokal, d.h. fur hinreichend kleines
|t − t0|, eine eindeutige Losung x = x(t) des AWP (1.15). Dann wird durch
Φt,t0x0 := x(t)

1.4. STABILITAT DER LOSUNG VON AWP 17
eine zweiparametrige Familie von Abbildungen von Rn nach R
n, die sogenannte Evolution derDifferentialgleichung x′ = f(t;x), wohldefiniert. Sie bildet den Wert einer beliebigen Losungs-trajektorie zur Zeit t = t0 auf den Wert der Trajektorie zur Zeit t ab.
Lemma 1.16. Die Evolution Φ von x′ = f(t;x) hat fur alle (t, x) ∈ I × G und hinreichendkleine |t1 − t|, |t2 − t| die Eigenschaften
Φt,tx = x (1.21)
d
dτΦt+τ,tx|τ=0 = f(t;x) (1.22)
Φt2,tx = Φt2,t1Φt1,tx. (1.23)
Durch diese Bedingungen ist die Evolution eindeutig bestimmt.
Beweis: Die Eigenschaften (1.21), (1.22) folgen unmittelbar aus der Definition von Φ. ZumNachweis von (1.23) betrachten wir das AWP
y′(τ) = f(τ, y(τ)), y(t1) = Φt1,tx
mit der Losung y(τ) = Φτ,tx. Damit folgt Φt2,t1Φt1,tx = y(t2) = Φt2,tx.
Zum Nachweis der Eindeutigkeit sei Ψ eine weitere Evolution, die (1.21)-(1.23) genugt. Wirsetzen x(t) := Ψt,t0x0. Wegen (1.23) und (1.22) gilt dann
x′(t) =d
dτΨt+τ,t0x0|τ=0 =
d
dτΨt+τ,tΨt,t0x0|τ=0 = f(t; Ψt,t0x0) = f(t;x(t)).
Ferner impliziert (1.21) auch x(t0) = Φt0,t0x0 = x0. damit ist Ψ = Φ. 2
Fur autonome Systeme hangt die Evolution Φτ+t0,t0 nicht vom Anfangszeitpunkt t0 ab. ZurVereinfachung setzen wir daher
Φτx0 := Φτ,0x0. (1.24)
1.4 Stabilitat der Losung von AWP
Die Losung des AWPx′(t) = f(t;x(t)), x(t0) = x0 (1.25)
hangt nach dem Satz von Picard-Lindelof stetig vom Anfangswert ab. Oft mochte man diesenZusammenhang quantifizieren. Beschrankt man sich o.B.d.A. auf Auswirkungen von Storungender Anfangsbedingung auf die ”Zukunft”, d.h. fur t ≥ t0, kann die Forderung der Lipschitz-Stetigkeit an f abgeschwacht werden.
Definition 1.17. Seien 〈·, ·〉 ein Skalarprodukt auf Rn und ‖·‖ die durch ‖x‖2 := 〈x, x〉 induzierte
Norm. Ferner sei l : [t0,∞] → R eine stuckweise stetige Funktion. Dann genugt die Funktion feiner einseitigen Lipschitz-Bedingung, falls
〈f(t;x) − f(t; x), x − x〉 ≤ l(t)‖x − x‖2, ∀t ≥ t0, ∀x, x ∈ Rn. (1.26)
l(·) heißt einseitige Lipschitz-Konstante von f .
Bemerkung 1.18. Die einseitige Lipschitz-Stetigkeit schwacht die Lipschitz-Stetigkeit ab:
〈f(t;x) − f(t; x), x − x〉 ≤ ‖f(t;x) − f(t; x)‖ ‖x − x‖ ≤ L‖x − x‖2.

18 KAPITEL 1. ANFANGSWERTAUFGABEN
Die Konstante l(·) kann negativ sein, wie das Beispiel f(t;x) = −x mit l(t) = −1 zeigt. 2
Bemerkung 1.19. Der Begriff der einseitigen Lipschitz-Stetigkeit erlaubt sogar eine Verfeine-rung des Satzes von Picard-Lindelof. Nach [17], Satz 5.1.2 hat das autonome AWP x′ =f(x), x(t0) = x0 genau eine Losung x(·) ∈ C1([t0,∞); Rn), falls f = f(x) einer einseitigenLipschitz-Bedingung mit l(t) ≡ l0 ∈ R genugt. 2
Es gilt folgende Abschatzung.
Satz 1.20. Sei l(t) die einseitige Lipschitz-Konstante der Funktion f : [t0,∞)×G → Rn. Dann
gilt fur die Evolution Φ von x′ = f(t;x) mit der Norm ‖ · ‖ := 〈·, ·〉 12 die Abschatzung
‖Φt,t0x0 − Φt,t0 x0‖ ≤ exp
(∫ t
t0
l(s) ds
)
‖x0 − x0‖, ∀x0, x0 ∈ G, t0 ≤ t. (1.27)
Beweis: Mit x(t) = Φt,t0x0 und x(t) = Φt,t0 x0 ist die Funktion
φ(t) := ‖x(t) − x(t)‖2 = 〈x(t) − x(t), x(t) − x(t)〉
stetig differenzierbar mit
φ′(t) = 2〈x′(t) − x′(t), x(t) − x(t)〉 = 2〈f(t, x(t)) − f(t, x(t)), x(t) − x(t)〉.
Die einseitige Lipschitz-Stetigkeit impliziert
φ′(t) ≤ 2l(t)‖x(t) − x(t)‖2 = 2l(t)φ(t).
Mit η(t) := exp (−2∫ tt0
l(s) ds) erhalt man
(φη)′ = φ′η + φη′ = φ′η − 2l(t)φη = η[φ′ − 2l(t)φ
]≤ 0, ∀t ≥ t0.
Somit ist φη monoton fallend, d.h. φ(t)η(t) ≤ φ(t0)η(t0) fur alle t ≥ t0. Wegen η > 0 folgt (1.27)wegen
φ(t) ≤ φ(t0)η(t0)
η(t)= φ(t0) exp
(
2
∫ t
t0
l(s) ds
)
. 2
Abschatzung (1.27) zeigt, daß die Losungstrajektorien mit (beliebig dicht) benachbarten An-fangswerten im Fall l(t) > 0 eventuell exponentiell schnell auseinander driften. Eine derartigesVerhalten spiegelt sich bereits in der Normwahl im Beweis von Satz 1.12 wider. Insbesonderekonnen dann Anfangsstorungen exponentiell anwachsen.
Ein exponentielles Anwachsen von Storungen fur t → ∞ ist jedoch nicht zwingend. Eine beson-dere Rolle spielen dissipative Systeme, die bei irreversiblen Prozessen in der MathematischenPhysik auftreten.
Definition 1.21. Das System x′ = f(t;x) mit einseitiger Lipschitz-Konstante l(t) ≤ 0 heißtdissipativ bezuglich der Norm ‖ · ‖.Insbesondere gilt die Abschatzung
‖Φt,t0x0 − Φt,t0 x0‖ ≤ ‖x0 − x0‖, ∀x0, x0 ∈ G, t0 ≤ t. (1.28)
Man sagt auch, die Losungen verhalten sich nichtexpansiv.

1.4. STABILITAT DER LOSUNG VON AWP 19
Definition 1.22. Das AWP (1.25) wird als steif auf dem Intervall [t0, T ] bezeichnet, wenn gilt
∫ T
t0
l(s) ds ≪∫ T
t0
L(s) ds. (1.29)
Beispiel 1.23. Betrachtet wird das autonome System
x′(t) = Ax(t), x(t0) = x0,
bei dem die konstante Matrix A ∈ Cn×n diagonalisierbar ist. Es existiert also eine nichtsingulare
Matrix P mitP−1AP = Λ := diag(λ1, . . . , λn)
und den Eigenwerten λ1, . . . , λn der Matrix A. Durch die Transformation x = Py erhalt manaus dem Ausgangssystem zunachst Py′ = APy und damit das System
y′ = Λy, y(t0) = y0 := P−1x0.
Da Λ = diag(λ1, ..., λn) Diagonalgestalt hat, zerfallt das ursprunglich gekoppelte System in nskalare Differentialgleichungen mit der Losung
y(t) = eΛty0 :=(
y01e
λ1t, ..., y0neλnt
)T.
Die Losung des AWP zum Ausgangssystem lautet damit
x(t) = PeΛtP−1x0, eΛt := diag(eλ1t, ..., eλnt).
Komponenten der Losung zu einem Eigenwert mit positiven Realteil, wachsen in der Tat expo-nentiell schnell fur t > t0. Falls alle Eigenwerte negativen Realteil haben, so ist die Losung furt > t0 dissipativ. (Ubungsaufgabe) Wie wir in Kapitel 5 sehen werden, dient diese Situation alsTestfall fur die Stabilitat von Diskretisierungsverfahren fur AWP.
Beispiel 1.24. Das Anfangs-Randwertproblem der Warmeleitungsgleichung
∂u
∂t=
∂2u
∂x2, t ≥ 0, x ∈ (0, 1); u(t, 0) = u(t, 1) = 0, t > 0, u(0, x) = u0(x)
wird mittels Differenzen-Verfahren in den Punkten xi = ih, h = 1n+1 , i = 0, . . . , n + 1 semidis-
kretisiert, d.h. man approximiert ui(t) ≈ u(t, xi), setzt u0(t) = un+1(t) = 0 und approximiert
∂2u
∂x2(t, xi) ≈
1
h2(ui+1(t) − 2ui(t) + ui−1(t)), i = 1, . . . , n.
Man kann sich uberlegen, dass das resultierende Differentialgleichungssystem stets einer einsei-tigen Lipschitz-Bedingung genugt, dissipativ und steif ist. (Ubungsaufgabe)

20 KAPITEL 1. ANFANGSWERTAUFGABEN

Kapitel 2
Einschritt-Verfahren
Die Losung vonx′(t) = f(t;x(t)), x(t0) = x0, t ∈ [t0, T ] (2.1)
ist i.a. (selbst bei skalaren Aufgaben mit n = 1) nicht in geschlossener Form angebbar. Oft istauch die Funktion f nur durch Meßwerte gegeben. Bei Anwendungen auf zeitabhangige partielleDifferentialgleichungen ist die Dimension n des Losungsvektors x(·) sehr groß.
Bei der numerischen Behandlung von AWP ermittelt man die Losung naherungsweise an diskre-ten Punkten. Ausgangspunkt ist die zum AWP aquivalente Fixpunktgleichung (1.16). Grundlagefur die Konstruktion numerischer Verfahren ist die Anwendung geeigneter Integrationsformelnin dieser Fixpunktgleichung. Wir fuhren hier die Klasse der Einschritt-Verfahren (ESV) ein undbehandeln die Grundaussagen der Konvergenztheorie. Fur das AWP (2.1) seien die Vorausset-zungen des Satzes von Picard-Lindelof (vgl. Kap. 1) erfullt.
2.1 Definition und Beispiele
Gesucht werden auf dem Intervall [t0, T ] Naherungswerte an den gesuchten Losungsvektor x(·)des AWP (2.1) auf dem (nicht notwendig aquidistanten) Gitter
∆ := t0, t1, . . . , tN, t0 < t1 < . . . tN = T.
Dabei heißen die Großen τj := tj+1 − tj Schrittweiten. Als Feinheit des Gitters bezeichnen wir
τ∆ := maxj=0,...,N−1
τj.
Gesucht wird eine Gitterfunktionx∆ : ∆ → R
n,
die die Losung x(·) von (2.1) auf dem Gitter moglichst gut approximiert.
Bei Einschritt-Verfahren ermittelt man x∆ durch eine Zweiterm-Rekursion, d.h. bei der Be-rechnung von x∆(tj+1) benutzt man nur den (bereits bekannten) Wert x∆(tj). Bei Mehrschritt-Verfahren verwendet man allgemeiner eine Mehrterm-Rekursion, d.h. in die Berechnung vonx∆(tj+1) gehen die Werte x∆(tj), . . . , x∆(tj−m) mit m ∈ N0 ein. Wir beschranken uns jedoch imRahmen dieser Vorlesung auf Einschritt-Verfahren, d.h. den Fall m = 0.
Bei der Festlegung eines Einschritt-Verfahrens ersetzt man die Evolution Φ der Differentialglei-chung durch eine diskrete Evolution Ψ, d.h. man approximiert
x(tj+1) = Φtj+1,tjx(tj), x(t0) = x0
21

22 KAPITEL 2. EINSCHRITT-VERFAHREN
durchx∆(tj+1) := Ψtj+1,tjx∆(tj), x∆(t0) := x0. (2.2)
Ausgehend von
x(t + τ) = x(t) +
∫ t+τ
tf(s;x(s)) ds (2.3)
verschafft man sich einfache Beispiele von ESV durch geeignete Integrationsformeln.
Beispiel 2.1. Die Anwendung der linken Eckpunktregel∫ t+τt f(s;x(s)) ds ≈ τf(t;x(t)) fuhrt
auf das explizite Euler-Verfahren
x∆(tj+1) = Ψtj+1,tjEEV x∆(tj) := x∆(tj) + τjf(tj;x∆(tj)). (2.4)
Vorteilhaft ist, daß x∆(tj+1) explizit bestimmt wird, d.h. ohne Losung eines i.a. nichtlinearenGleichungssystems. Das Verfahren benutzt in den Naherungspunkten (tj, x∆(tj)) den Anstieg desdurch (2.1) definierten Richtungsfeldes zur Ermittlung des folgenden Naherungsvektors x∆(tj+1).Wegen der anschaulichen geometrischen Konstruktion heißt es im skalaren Fall n = 1 auchPolygonzug-Verfahren.
Wir erwahnen an dieser Stelle bereits, daß bei Wahl der rechten Eckpunktregel
∫ t+τ
tf(s;x(s)) ds ≈ τf(t + τ ;x(t + τ))
das implizite Euler-Verfahren
x∆(tj+1) = Ψtj+1,tjIEV x∆(tj) := x∆(tj) + τjf(tj+1;x∆(tj+1)) (2.5)
entsteht, bei dem in jedem Zeitschritt (!) ein (i.a. Fall) nichtlineares Gleichungssytem fur denVektor x∆(tj+1) zu losen ist. Wir gehen auf implizite Verfahren dann in Kapitel 5 ein. 2
Beispiel 2.2. Wahlt man zur Integralauswertung in (2.3) die Trapezregel
∫ t+τ
tf(s;x(s)) ds ≈ τ
f(t;x) + f(t + τ ;x(t + τ))
2,
so erhalt man das verbesserte Euler- bzw. Euler-Heun Verfahren
x∆(tj+1) = Ψtj+1,tjEHV x∆(tj) := x∆(tj) +
τj
2[f(tj;x∆(tj) + f(tj+1;x∆(tj+1)] . (2.6)
Dies ist ein implizites Verfahren, da in jedem Zeitschritt der Vektor x∆(tj+1) aus einem i.a.nichtlinearen System ermittelt werden muß. Ein einfaches Naherungsverfahren beschreibt
Lemma 2.3. Die Funktion f(t, ·) in (2.1) sei Lipschitz-stetig bezuglich x mit Lipschitz-KonstanteL. Dann laßt sich das Gleichungssystem (2.6) durch sukzessive Approximation
x(m+1)∆ (tj+1) := x∆(tj) +
τj
2
[
f(tj;x∆(tj)) + f(tj+1;x(m)∆ (tj+1))
]
, m ∈ N0 (2.7)
losen, sofern Lτj/2 < 1.
Zum Nachweis untersucht man g(x) := x∆(tj)+τj
2 [f(tj;x∆(tj)) + f(tj+1;x)] auf Kontraktivitat:
‖g(x) − g(x)‖ =τj
2‖f(tj+1;x) − f(tj+1; x)‖ ≤ τjL
2‖x − x‖.

2.2. KONSISTENZ VON EINSCHRITT-VERFAHREN 23
Die Erfahrung und die mathematische Analyse zeigen, daß in vielen Fallen ein Iterationsschrittin (2.7) ausreichend ist. Man erhalt dann mit dem Startwert (Pradiktor)
x∆(tj+1) := x∆(tj) + τjf(tj;x∆(tj)) (2.8)
aus dem expliziten Euler-Verfahren uber den Korrektor-Schritt
x∆(tj+1) = Ψtj+1,tjPKV x∆(tj) := x∆(tj) +
τj
2[f(tj;x∆(tj)) + f(tj+1; x∆(tj+1))] (2.9)
die Pradiktor-Korrektor Variante des Verfahrens von Euler-Heun.
Beispiel 2.4. Wir vergleichen die Qualitat der bisher eingefuhrten Verfahren anhand des ska-laren AWP
x′ = f(t;x) := x − t2 + 1, 0 ≤ t ≤ 2, x(0) = 0.5.
Tabelle 2.1 zeigt fur die (grobe) Schrittweite τ = 0.2 Ergebnisse und Fehler fur das (explizite)Euler-Verfahren bzw. die Pradiktor-Korrektor Variante. Die Pradiktor-Korrektor Variante ist
Tabelle 2.1: Vergleich von explizitem Euler- und Pradiktor-Korrektor-Verfahren in Beispiel 2.4
ti x(ti) xEEV∆ (ti) |xEEV
∆ (ti) − x(ti)| xPKV∆ (ti) |xPKV
∆ (ti) − x(ti)|0.0 0.5000000 0.5000000 0.0000000 0.5000000 0.00000000.2 0.8000000 0.8292986 0.0292986 0.8032986 0.00329860.4 1.2140877 1.1520000 0.0620877 1.2069200 0.00716770.6 1.6489406 1.5504000 0.0985406 1.6372424 0.01169820.8 2.1272295 1.9884800 0.1387495 2.1102357 0.01699381.0 2.6408591 2.4581760 0.1826831 2.6176876 0.02317151.2 3.1799415 2.9498112 0.2301303 3.1495789 0.03036271.4 3.7324000 3.4517734 0.2806266 3.6936862 0.03871381.6 4.2834838 3.9501281 0.3333557 4.2350972 0.04838661.8 4.8151763 4.4281538 0.3870225 4.7556185 0.05955772.0 5.3054720 4.8657845 0.4396874 5.2330546 0.0724173
dem expliziten Euler-Verfahren aus Genauigkeitsgrunden uberlegen. Die hohere Genauigkeiterfordert jedoch, daß sich pro Zeitschritt die Zahl von Funktionsauswertungen erhoht. 2
In den Ubungen werden Matlab-Funktionen fur die hier angegebenen einfachen Verfahrenbenutzt. In den folgenden Abschnitten fuhren wir eine Konvergenzanalyse von ESV durch. InKapitel 3 zeigen wir dann, wie man systematisch Verfahren hoherer Genauigkeit konstruiert.
2.2 Konsistenz von Einschritt-Verfahren
Wir erinnern an die Bedingungen (1.21)-(1.23) an die Evolution Φ der Differentialgleichungx′ = f(t;x). Moglichst viele dieser Bedingungen sollen an die diskrete Evolution Ψ ”vererbt”werden. Da man nicht auf Ψ = Φ hoffen kann, sollen mindestens die ersten beiden Eigenschaften,d.h. (1.21)-(1.22), erhalten bleiben. Nachfolgend betrachten wir das Gebiet D ⊂ R × R
n.
Definition 2.5. Eine diskrete Evolution Ψ heißt konsistent zur Gleichung x′ = f(t;x), falls fur

24 KAPITEL 2. EINSCHRITT-VERFAHREN
alle (t0, x0) ∈ D gilt
Ψt0,t0x0 = x0 (2.10)
d
dτΨt0+τ,t0x0|τ=0 = f(t0;x
0). (2.11)
Ein ESV heißt konsistent, falls es jeder hinreichend glatten Funktion f eine konsistente diskreteEvolution Ψ[f ] zuordnet.
Wir suchen aquivalente Konsistenzkriterien. Hierbei sei ‖ · ‖ eine beliebige Norm auf Rn.
Lemma 2.6. Die diskrete Evolution Ψt0+τ,t0x0 sei fur alle (t0, x0) ∈ D und hinreichend kleines
τ differenzierbar. Dann sind folgende Aussagen zur Konsistenz von Ψ aquivalent:
(i) Es gibt eine bezuglich τ stetige Verfahrensfunktion φ = φ(t0, x0, τ) mit den Eigenschaften
Ψt0+τ,t0x0 = x0 + τφ(t0, x0, τ) (2.12)
φ(t0, x0, 0) = f(t0;x
0). (2.13)
(ii) Es gilt
limτ→0
1
τ‖Ψt0+τ,t0x0 − Φt0+τ,t0x0‖ = 0. (2.14)
Beweis:
1. Sei Ψ konsistent. Wir setzen φ(t0, x0, τ) := 1
τ (Ψt0+τ,t0x0 − x0), so daß (2.12) erfullt ist.Wegen (2.11) ist dann aber auch (2.13) erfullt, d.h. Aussage (i) ist gultig.
2. Sei Eigenschaft (i) erfullt, d.h. fur eine Verfahrensfunktion φ gelten (2.12), (2.13). Wegen(1.22), der Stetigkeit von φ bezuglich τ und (2.13) haben wir
limτ→0
1
τ‖Ψt0+τ,t0x0 − Φt0+τ,t0x0‖ = lim
τ→0
∥∥∥∥
Ψt0+τ,t0x0 − x0
τ− Φt0+τ,t0x0 − x0
τ
∥∥∥∥
= ‖φ(t0, x0, 0) − f(t0, x
0)‖ = 0,
d.h. Aussage (ii) ist gultig.
3. Sei nun (ii) erfullt. Die Eigenschaften (1.21), (1.22) der exakten Evolution Φ ergeben
Φt0+τ,t0x0 = x0 + τf(t0;x0) + o(τ), τ → 0.
Wegen der Differenzierbarkeit von Ψ nach τ gilt andererseits
Ψt0+τ,t0x0 = Ψt0,t0x0 + τd
dτΨt0+τ,t0x0|τ=0 + o(τ), τ → 0.
Ein Koeffizientenvergleich liefert mit (2.14) gerade (2.10), (2.11), d.h. Ψ ist konsistent. 2
Zur Untersuchung der Genauigkeit von ESV nutzen wir Begriffe, die die lokale Approximationder Differentialgleichung durch das ESV beschreiben.
Definition 2.7. Eine diskrete Evolution Ψ fur eine gegebene Differentialgleichung x′ = f(t;x)mit f : D → R
n hat die Konsistenzordnung p > 0, falls es fur jedes kompakte Teilgebiet D ⊂ Deine Konstante C > 0 gibt, so daß fur alle (t, x) ∈ D und alle hinreichend kleinen τ ≥ 0 gilt
1
τ‖Ψt+τ,tx − Φt+τ,tx‖ ≤ Cτp. (2.15)

2.3. KONVERGENZ VON EINSCHRITT-VERFAHREN 25
Ein ESV hat die Konsistenzordnung p > 0, falls fur alle f ∈ C∞(D; Rn) die zugeordnete diskreteEvolution Ψ = Ψ[f ] die Konsistenzordnung p hat.
Wir werden im Kapitel 3 sehen, wie man die Konsistenzordnung bestimmter ESV in systemati-scher Weise ermittelt. Hier untersuchen wir exemplarisch das explizite Euler-Verfahren.
Korollar 2.8. Das explizite Euler-Verfahren hat fur f ∈ C1(D; Rn) die Konsistenzordnung 1.
Beweis: Wegen der Kompaktheit von D ⊂ D ist dist(D, ∂D) > 0. Somit gibt es ein weitereskompaktes Teilgebiet D mit D ⊂ D ⊂ D und dist(D, ∂D) > 0 sowie dist(D, ∂D) > 0. Fernergibt es eine Zahl τ > 0, so daß (t + τ,Φt+τ,tx) ∈ D fur alle (t, x) ∈ D und 0 ≤ τ ≤ τ .
Wir berechnen fur (t, x) ∈ D die Taylor-Reihe von τ 7→ Φt+τ,tx bei τ = 0. Es gilt
d
dτΦt+τ,tx = f(t + τ ; Φt+τ,tx),
d2
dτ2Φt+τ,tx = ft(t + τ ; Φt+τ,tx) + fx(t + τ ; Φt+τ,tx)f(t + τ ; Φt+τ,tx)
mit ft := ∂f∂t und der Jacobi-Matrix fx ∈ R
n×n von f bezuglich x = (x1, . . . , xn)T . Die Taylor-Entwicklung mit Restglied in Integraldarstellung lautet dann
Φt+τ,tx = x + τf(t;x) + τ2
∫ 1
0(1 − s)(ft + fxf)(t + s; Φt+sτ,tx) ds.
Somit finden wir
‖Ψt+τ,tEEV x − Φt+τ,tx‖ ≤ τ2 sup
(s,z)∈D
‖ft(s; z) + fx(s; z)f(s; z)‖.
Wegen der Kompaktheit von D und der Stetigkeit des Normausdrucks in der letzten Zeile istdas dort zu bildende Supremum endlich. 2
2.3 Konvergenz von Einschritt-Verfahren
Wir haben bislang nur den lokalen Fehler eines ESV betrachtet, der in einem einzelnen Schrittdes Verfahrens bei Berechnung von x∆ gemacht wird. Naturlich mochte man eine Abschatzungdes globalen Fehlers ‖x∆(t) − x(t)‖ fur beliebige Gitterpunkte t ∈ ∆ gewinnen.
Definition 2.9. Ein Einschritt-Verfahren heißt auf dem Gitter ∆ konvergent, falls gilt
limτ→0
maxt∈∆
‖x∆(t) − x(t)‖ = 0.
Fur Konvergenzuntersuchungen benotigen wir neben einer (gleichmaßigen) Konsistenzbedingungnoch eine Stabilitatsbedingung an die diskrete Evolution Ψ, die die Verstarkung von lokalenFehlern im Verlauf der Rechnung kontrolliert. Der folgende Satz ist ein Beispiel fur das in derNumerischen Mathematik oft zu findende Beweisschema
Konsistenz + Stabilitat =⇒ Konvergenz .
Satz 2.10. Die diskrete Evolution Ψ sei in einer Umgebung U der Trajektorie (t, x(t)) : t ∈[t0, T ] definiert und erfulle die folgenden Bedingungen:

26 KAPITEL 2. EINSCHRITT-VERFAHREN
1. Stabilitatsbedingung: Es gibt Konstanten LΨ ≥ 0 und τ0 > 0, so daß
‖Ψt+τ,tx − Ψt+τ,tx‖ ≤ eLΨτ‖x − x‖, ∀(t, x, ), (t, x) ∈ U , ∀τ ∈ [0, τ0]. (2.16)
2. Konsistenzbedingung: Fur τ ∈ [0, τ0] gibt es eine Funktion err(τ) mit limτ→0 err(τ) = 0,so daß
1
τ‖Φt+τ,tx(t) − Ψt+τ,tx‖ ≤ err(τ), ∀t ∈ [t0, T ]. (2.17)
Dann gibt es eine Zahl τ1 > 0, so daß fur jedes Gitter ∆ auf dem Intervall [t0, T ] mit Feinheitτ∆ ≤ τ1 die Gitterfunktion x∆ nach (2.2) wohldefiniert ist. Fur alle t ∈ ∆ gilt fur den Fehler
‖x∆(t) − x(t)‖ ≤ r(τ∆) :=
err(τ∆)eLΨ(t−t0)−1LΨ
, LΨ > 0,
err(τ∆)(t − t0), LΨ = 0.(2.18)
Beweis: Wir wahlen τ1 so klein, daß fur alle t ∈ [t0, T ] und alle x1 ∈ Rn mit ‖x1 −x(t)‖ ≤ r(τ1)
gilt, daß (t, x1) ∈ U . Wir zeigen durch Induktion nach j, daß die Abschatzung (2.18) fur alletj ∈ ∆ erfullt ist. Speziell ist dann x∆(tj) fur alle tj ∈ ∆ wohldefiniert.
Aussage (2.18) ist fur j = 0 wegen x∆(t0) = x0 = x(t0) richtig. Sei dann (2.18) fur t = tj mitj < N erfullt. Fur den Fall LΨ > 0 gilt zunachst
‖x∆(tj+1) − x(tj+1)‖ = ‖Ψtj+1,tjx∆(tj) − Φtj+1,tjx(tj)‖≤ ‖Ψtj+1,tjx∆(tj) − Ψtj+1,tjx(tj)‖ + ‖Ψtj+1,tjx(tj) − Φtj+1,tjx(tj)‖≤ eLΨ(tj+1−tj)‖x∆(tj) − x(tj)‖ + err(τ∆)(tj+1 − tj)
≤ err(τ∆)
LΨ
(
eLΨ(tj+1−tj)(eLΨ(tj−t0) − 1) + LΨ(tj+1 − tj))
≤ err(τ∆)eLΨ(tj+1−t0) − 1
LΨ.
Hierbei wurde die Ungleichung ea ≥ 1 + a mit a := LΨ(tj+1 − tj) benutzt. Die Regel vonl’Hospital ergibt die Aussage auch fur LΨ → 0. 2
Wir wollen jetzt die Konvergenzgeschwindigkeit von ESV genauer charakterisieren.
Definition 2.11. Ein Einschritt-Verfahren hat die Konvergenzordnung p > 0, falls fur jedeLosung x : [t0, T ] → R
n des AWP (2.1) mit rechter Seite f ∈ C∞(D; Rn) der globale Fehler derNaherungslosung x∆ auf einem Gitter ∆ mit hinreichend kleiner Feinheit τ∆ der Abschatzung
maxt∈∆
‖x∆(t) − x(t)‖ ≤ CKτp∆ (2.19)
mit vom Gitter unabhangiger Konstante CK genugt.
Satz 2.12. Ein Einschritt-Verfahren der Konsistenzordnung p, das die Stabilitatsbedingung(2.16) erfullt, hat die Konvergenzordnung p.
Beweis: Die Konsistenzbedingung (2.17) ist mit err(τ) = Cτp erfullt. Dann folgt die Behaup-tung aus (2.18) mit CK = C
LΨ(eLΨ(T−t0) − 1) fur LΨ > 0 und CK = C(T − t0) bei LΨ = 0. 2
Beispiel 2.13. Das explizite Euler-Verfahren hat die Konsistenzordnung 1, vgl. Korollar 2.8.Ferner gilt fur bezuglich x Lipschitz-stetige Funktionen f , daß
‖Ψt+τ,tEEV x − Ψt+τ,t
EEV x‖ ≤ ‖x − x‖ + τ‖f(t;x) − f(t; x)‖≤ (1 + τL)‖x − x‖≤ eτL‖x − x‖.
Damit ist auch die Stabilitatsbedingung (2.16) erfullt. Satz 2.12 ergibt die Behauptung. 2

Kapitel 3
Explizite Runge-Kutta Verfahren
Im vorliegenden Kapitel wollen wir zur numerischen Losung des AWP
x′(t) = f(t;x(t)), x(t0) = x0 (3.1)
die expliziten Runge-Kutta-Verfahren als wichtigste Klasse von Einschritt-Verfahren (ESV)fur nichtsteife AWP untersuchen. Nach Behandlung der Konstruktion und Grundaussagen zurKonvergenztheorie dieser Verfahren wollen wir dann in Kapitel 4 sehen, wie sich die Konvergenzdieser Verfahren steuern und beschleunigen laßt. Mehrschrittverfahren werden im Rahmen dieserVorlesung nicht besprochen, da sie sich weniger gut fur adaptive Verfahren eignen.
3.1 Idee von Runge-Kutta-Verfahren
Die Konstruktion von ESV hoherer Ordnung erfordert nach dem Konvergenzsatz 2.12 die Be-stimmung diskreter Evolutionen Ψ mit gewunschter Konsistenzordnung. Dazu ist eine Taylor-Entwicklung der exakten Evolution Φ erforderlich
Φt+τ,tx = x + τf(t;x) +1
2τ2(ft(t;x) + fx(t;x)f(t;x)) + 0(τ3).
Man erhalt gerade das explizite Euler-Verfahren mit
Ψt+τ,tx = x + τf(t;x)
bei Berucksichtigung der Entwicklung 1. Ordnung von Φ. Verwendet man die Entwicklung 2.Ordnung, so gelangt man zu einem ESV der Konsistenz- und Konvergenzordnung 2:
Ψt+τ,tx = x + τf(t;x) +1
2τ2(ft(t;x) + fx(t;x)f(t;x)).
Die Verallgemeinerung dieser Methodik der Taylor-Verfahren fur beliebig hohe Ordnung hatden wesentlichen Nachteil, daß in der Regel die vollstandige Jacobi-Matrix fx ∈ R
n×n auszu-werten ist. Nachfolgend wollen wir eine wesentlich effizientere und leichter zu implementierendeMoglichkeit betrachten.
Wir hatten in Kapitel 2 das explizite Euler-Verfahren durch die Auswertung der Integraldar-stellung
Ψt+τ,tx = x +
∫ t+τ
tf(t + s; Φt+s,tx) ds
27

28 KAPITEL 3. EXPLIZITE RUNGE-KUTTA VERFAHREN
durch die linke Eckpunkt-Regel∫ t+τ
tf(t + s; Φt+s,tx) ds = τf(t;x) + 0(τ2)
motiviert. Die Mittelpunkt-Regel∫ t+τ
tf(t + s; Φt+s,tx) ds = τf(t +
τ
2;Φt+τ/2,tx) + 0(τ3)
sollte ein Verfahren hoherer Ordnung ergeben. Leider ist aber der Wert von Φt+τ/2,tx nichtbekannt. Daher versucht man, diesen Ausdruck durch das explizite Euler-Verfahren
Φt+τ/2,tx = x +1
2τf(t;x) + 0(τ2)
auszuwerten. Dies fuhrt auf das von Runge eingefuhrte Verfahren mit der diskreten Evolution
Ψt+τ,tx = x + τf(
t +τ
2;x +
τ
2f(t;x)
)
.
Im Unterschied zum oben vorgestellten Taylor-Verfahren 2. Ordnung ist hier nur eine ver-schachtelte zweifache Auswertung von f erforderlich. Das sieht man noch deutlicher in derfolgenden Darstellung des Runge-Verfahrens:
k1 = f(t;x)
k2 = f(
t +τ
2;x +
τ
2k1
)
Ψt+τ,tx = x + τk2.
Diese Idee geschachtelter Auswertungen von f wird bei den expliziten Runge-Kutta-Verfahren(RK-Verfahren) verallgemeinert durch folgende systematische Konstruktion: Mit reellen Zahlencj , aij und bj ermittelt man die Naherungen
Ψt+τ,tx := x + τ
s∑
j=1
bjkj . (3.2)
uber die rekursiv durch Funktionsauswertung zu berechnenden Großen (Stufen)
k1 = f(t;x)
k2 = f(t + c2τ ;x + a21k1τ)
k3 = f(t + c3τ ;x + a31k1τ + a32k2τ)
......
ks = f
t + csτ ;x + τs−1∑
j=1
asjkj
.
In ubersichtlicher Weise hat man das folgende Butcher-Koeffizientenschema:
c2 a21
c3 a31 a32
· · · ·cs as1 as2 · as,s−1
b1 b2 · bs−1 bs
bzw.c A
bT

3.1. IDEE VON RUNGE-KUTTA-VERFAHREN 29
mit
A =
0 . . . 0a21 0
a31 a32 0...
......
. . .. . .
as1 as2 . . . as,s−1 0
, b =
b1...bs
, c =
c1...cs
.
Bei den expliziten Runge-Kutta-Verfahren gilt also aij = 0, j ≥ i. Die Stufenzahl s desVerfahrens beschreibt die Tiefe der Schachtelung und damit die erforderliche Anzahl von f -Auswertungen. In dieses Schema ordnen sich folgende Verfahren ein:
1. Explizites Euler-Verfahren:0 0
1
2. Runge-Verfahren (Explizite Mittelpunkt-Regel):
0 01/2 1/2 0
0 1
3. ”Klassisches” Runge-Kutta-Verfahren der Ordnung 4:
0 01/2 1/2 01/2 0 1/2 01 0 0 1 0
1/6 1/3 1/3 1/6
bzw.
k1 = f(t;x),
k2 = f(t +τ
2;x +
τ
2k1),
k3 = f(t +τ
2;x +
τ
2k2),
k4 = f (t + τ ;x + τk3) ,
Ψt+τ,tx := x +τ
6(k1 + 2k2 + 2k3 + k4)
Die expliziten RK-Verfahren sind mit gegebenen Daten (A, b, c) und fur (t, x) ∈ D bei hinrei-chend kleiner Schrittweite τ wohldefiniert. Ferner hat man folgende Aussagen zur Konsistenz.
Lemma 3.1. Das s−stufige explizite RK-Verfahren (3.2) mit (A, b, c) ist konsistent fur alleFunktionen f ∈ C(D, Rn) genau dann, wenn
s∑
j=1
bj = 1. (3.3)
Das Verfahren hat fur beliebige f ∈ C∞(D, Rn) hochstens die Konsistenzordnung p ≤ s.

30 KAPITEL 3. EXPLIZITE RUNGE-KUTTA VERFAHREN
Beweis: (i) Wir benutzen die zur Konsistenz aquivalenten Bedingungen aus Lemma 2.6 (i). Esgilt
Ψt+τ,tx = x + τφ(t, x, τ), φ(t, x, τ) :=
s∑
j=1
bjkj(t, x, τ).
Wegen kj(t, x, 0) = f(t;x) ist dann φ(t, x, 0) = f(t;x) genau dann, wenn (3.3) gilt.
(ii) Fur das spezielle AWP x′(t) = x(t), x(0) = 1 gilt offenbar Φτ,0 1 = eτ , daher folgt
Φτ,0 1 =
p∑
j=0
1
j!τ j + 0(τp+1), τ → 0.
Per Induktion uber j = 1, . . . , s folgt unmittelbar, daß die Stufe kj(0, 1, ·) ein Polynom vonmaximalen Grad j − 1 ist. Damit ist Ψ·,0 1 ein Polynom vom maximalen Grad s. Folglich kanndie Konsistenzaussage
|Ψτ,0 1 − Φτ,0 1| = 0(τp+1), τ → 0
hochstens fur p ≤ s gelten. 2
3.2 Ordnungsbedingungen nach Butcher
Die Daten (A, b, c) des expliziten RK-Verfahrens, d.h. Koeffizienten bj , aij und cj , sind so zuwahlen, daß die gewunschte Konsistenzordnung erreicht wird. Wir wollen uns die Arbeit etwaserleichtern, indem wir die Aquivalenz des AWP (3.1) zu einem (erweiterten) autonomen AWPausnutzen. Es gilt
(Φt+τ,txt + τ
)
= Φt+τ,t
(xt
)
.
Diese Eigenschaft der Evolution Φ des autonomen Systems soll auf die diskrete Evolution ”ver-erbt” werden, d.h.
(Ψt+τ,txt + τ
)
= Ψt+τ,t
(xt
)
.
Man bezeichnet Verfahren als invariant gegen Autonomisierung, falls das gleiche numerische Er-gebnis bei Anwendung auf die gegebene Differentialgleichung bzw. auf das erweiterte autonomeSystem entsteht.
Lemma 3.2. Ein explizites RK-Verfahren ist invariant gegenuber Autonomisierung genau dann,wenn es konsistent ist und
ci =
s−1∑
j=1
aij, i = 1, . . . , s.
Beweis: Die Stufen von Ψ seien Ki =
(ki
li
)
. Dann gilt
ki = f(t + τ
s−1∑
j=1
aij lj ;x + τ
s−1∑
j=1
aij kj), li = 1, i = 1, . . . , s
sowie
Ψt+τ,t
(xt
)
=
(
x + τ∑s−1
j=1 bj kj
t + τ∑s−1
j=1 bj
)

3.2. ORDNUNGSBEDINGUNGEN NACH BUTCHER 31
Die erste Komponente stimmt genau dann mit Ψt+τ,tx uberein fur alle f , wenn
ki = ki = f(t + ciτ ;x + τ
s−1∑
j=1
aijkj), i = 1, . . . , s.
Dies ist genau fur ci =∑s−1
j=1 aij erfullt. Bezuglich der zweiten Komponente hat man Uberein-
stimmung mit t + τ genau fur∑s−1
j=1 bj = 1. Das war nach Lemma 3.1 gerade die zur Konsistenzaquivalente Bedingung. 2
Wir werden fur gegen Autonomisierung invariante RK-Verfahren kurz die Notation (A, b) be-nutzen. Die weiteren Betrachtungen beziehen sich dann auf das autonome AWP
x′ = f(x), x(0) = x0 (3.4)
fur f ∈ C(D0; Rn) mit offener Menge D0 ⊂ R
n. Man schreibt verkurzt Ψτx := Ψt+τ,tx.
Wir leiten jetzt Bedingungen an die Koeffizienten (A, b) eines gegen Autonomisierung invariantenRK-Verfahrens ab, die die Konsistenzordnung p sichern, d.h.
1
τ‖Ψτx − Φτx‖ = 0(τp), τ → 0.
Dazu fuhren wir Taylor-Entwicklungen von τ 7→ Φτx und τ 7→ Ψτx durch und gleichen danndie Koeffizienten bis zur gewunschten Ordnung ab.
Sei f : D0 ⊂ Rn → R
n hinreichend glatt. Wir erinnern an die Richtungsableitung
(Dhf)(x) := limǫ→0
1
ǫ(f(x + ǫh) − f(x)) =
n∑
j=1
hj∂f
∂xj(x)
sowie fur die Richtungen h1, . . . , hp ∈ Rn an die symmetrische, p-lineare Abbildung f (p) : R
n ×R
np → Rn mit
f (p)[x](h1, . . . , hp) := (Dh1Dh2 · · ·Dhpf)(x) =
n∑
i1=1
· · ·n∑
ip=1
h1i1 · · ·h
pip
∂f (p)
∂xi1 · · · ∂xip
(x).
Dann gilt die Taylor-Formel
f(x + h) =
p∑
k=0
1
k!f (k)[x](h, . . . , h) + 0(‖h‖p+1), ‖h‖ → 0.
Taylor-Entwicklung der exakten Evolution Φτ : Es gilt
Φτx = Φ0x + τd
dτΦτx|τ=0 + 0(τ2) = x + τf(x) + 0(τ2).
Einsetzen in die Differentialgleichung (3.4) und Taylor-Entwicklung ergeben
d
dτΦτx = f(Φτx) = f(x + τf(x) + 0(τ2))
= f(x) + f ′[x](τf(x) + 0(τ2)) + 0(‖τf(x)‖2)
= f(x) + τf ′[x](f(x)) + 0(τ2).

32 KAPITEL 3. EXPLIZITE RUNGE-KUTTA VERFAHREN
Integration ergibt die Taylor-Entwicklung 3. Ordnung von Φτx mit
Φτx = x + τf(x) +τ2
2f ′[x](f(x)) + 0(τ3).
Erneutes Einsetzen in (3.4) und Taylor-Entwicklung fuhrt (bei Weglassung der Argumente (x),[x]) auf
d
dτΦτx = f(Φτx)
= f(x + τf +τ2
2f ′(f) + 0(τ3))
= f + f ′(τf +τ2
2f ′(f)) +
1
2f ′′(τf, τf) + 0(τ3)
= f + τf ′(f) + τ2
(1
2f ′(f ′(f)) +
1
2f ′′(f, f)
)
+ 0(τ3).
Erneute Integration ergibt die Taylor-Entwicklung 4. Ordnung
Φτx = x + τf +τ2
2f ′(f) + τ3
(1
6f ′(f ′(f)) +
1
6f ′′(f, f)
)
+ 0(τ4). (3.5)
Taylor-Entwicklung der diskreten Evolution Ψτ : Die Stufen der diskreten Evolution Ψτxsind erklart durch
ki = f
x + τ
s−1∑
j=1
aijkj
, i = 1, . . . , s. (3.6)
Wegen der Stetigkeit von f ist ki = 0(1), τ → 0. Einsetzen in (3.6) und Taylor-Entwicklungergibt
ki = f(x + 0(τ)) = f + 0(τ).
Erneutes Einsetzen in (3.6) liefert
ki = f
x + τ
s−1∑
j=1
aijf + 0(τ2)
= f + τ
s−1∑
j=1
aij
︸ ︷︷ ︸
=ci
f ′(f) + 0(τ2).
Wiederholung der letzeren Prozedur fuhrt auf
ki = f
x + τcif + τ2s−1∑
j=1
aijcjf′(f) + 0(τ3)
= f + τcif′(f) + τ2
s−1∑
j=1
aijcjf′(f ′(f)) +
1
2τ2c2
i f′′(f, f) + 0(τ3).
Nach Einsetzen in die diskrete Evolution folgt
Ψτx = x + τ
s∑
i=1
biki

3.2. ORDNUNGSBEDINGUNGEN NACH BUTCHER 33
= x + τ
(s∑
i=1
bif
)
+ τ2
(s∑
i=1
bicif′(f)
)
(3.7)
+τ3
1
2
s∑
i=1
bic2i f
′′(f, f) +∑
i,j
biaijcjf′(f ′(f))
+ 0(τ4).
Koeffizientenvergleich: Wir vergleichen nun in den Taylor-Entwicklungen (3.6) und (3.7)die Koeffzienten und erhalten die sogenannten Ordnungsbedingungen an ein RK-Verfahren biszur Ordnung 3. Die Prozedur kann sinngemaß fur Entwicklungen hoherer Ordnung ausgefuhrtwerden. (Naturlich kann man die Rechnung einem Computeralgebra-System uberlassen, vgl.Ubungsaufgabe !).
Der folgende Satz faßt die Ordnungsbedingungen fur die Ordnungen p = 1, 2, 3, 4 zusammen.
Satz 3.3. Ein gegenuber Autonomisierung invariantes Runge-Kutta Verfahren (A, b) hat furjede Differentialgleichung x′ = f(x) mit f ∈ Cp(D) die Konsistenzordnung
• p = 1, falls∑
i
bi = 1, (3.8)
• p = 2, falls zusatzlich∑
i
bici =1
2, (3.9)
• p = 3, falls zusatzlich
∑
i
bic2i =
1
3, (3.10)
∑
i,j
biaijcj =1
6, (3.11)
• p = 4, falls zusatzlich
∑
i
bic3i =
1
4, (3.12)
∑
i,j
biciaijcj =1
8, (3.13)
∑
i,j
biaijc2j =
1
12, (3.14)
∑
i,j,k
biaijajkck =1
24. (3.15)
Bemerkung 3.4. Interessant ist der Zusammenhang zur numerischen Integration aus demKurs ”Numerische Mathematik I”, denn die Integralberechnung ist ein Spezialfall der Losungvon AWP. Das AWP x′(t) = f(t), x(0) = 0 mit f ∈ C([0, 1]; R) hat die Losung x(t) =
∫ t0 f(s) ds.
Ein RK-Verfahren (A, b, c) fuhrt auf die Quadraturformel
∫ 1
0f(s) ds = x(1) ≈
s∑
j=1
bjkj =
s∑
j=1
bjf(cj).

34 KAPITEL 3. EXPLIZITE RUNGE-KUTTA VERFAHREN
Die Ordnungsbedingungen (3.8), (3.9), (3.10) und (3.12) aus dem Satz 3.3 entstehen alternativdurch die Forderung, daß diese Formel mit Gewichten bj und Stutzstellen cj exakt fur die Mo-nome ti, i = 0, . . . , 3 ist. 2
Die Ordnungsbedingungen aus Satz 3.3 entsprechen uberbestimmten nichtlinearen Gleichungs-systemen fur die Daten (A, b, c) des RK-Verfahrens. Wir diskutieren einige Spezialfalle.
s=1: Der einzige Freiheitsgrad ist aus (3.8) festgelegt auf b1 = 1. Dies entspricht dem explizitenEuler-Verfahren, das somit das einzige einstufige, explizite und gegen Autonomisierunginvariante RK-Verfahren 1. Ordnung.
s=2: Fur die Freiheitsgrade b1, b2 und a21 = c2 hat man nur die Gleichungen (3.8), (3.9). EineLosung hat man mit der expliziten Mittelpunkt-Regel, jedoch auch die explizite Trapez-Regel ist moglich:
0 01 1 0
12
12
.
s=4: Fur die 10 Unbekannten b1, . . . , b4, a21, a31, a32, a41, a42, a43 hat man 8 Gleichungen. NachBemerkung 3.4 sind (3.8), (3.9), (3.10) und (3.12) genau dann erfullt, wenn Polynomeaus Π3 exakt integriert werden. Wir betrachten exemplarisch die Simpson-Regel. Da vierStutzstellen erforderlich sind, wahlen wir (aus Symmetriegrunden) die mittlere Stutzstelledoppelt und erhalten
cT = (0,1
2,1
2, 1), bT = (
1
6,1
3,1
3,1
6).
Man rechnet aus den verbleibenden Bedingungen aus Satz 3.3 fur p = 4 leicht nach, daßdurch a21 = a32 = 1
2 , a31 = a41 = a42 = 0, a43 = 1 eine Losung gegeben ist. Dies entsprichtgerade dem ”klassischen” RK-Verfahren 4. Ordnung.
Bei steigender Ordnung p steigt die Zahl der Ordnungsbedingungen rasant und erschwert daherderen Losung. So hat man fur p = 10 bereits 1205 und fur p = 20 sogar 20.247.374 Bedingungen.
3.3 Konvergenz expliziter Runge-Kutta-Verfahren
Wir haben gerade gesehen, wie man systematisch explizite RK-Verfahren der Konsistenzordnungp konstruieren kann. Fur den Konvergenzsatz 2.10 ist noch die Stabilitatsbedingung offen.
Satz 3.5. Fur die Funktion f ∈ C(D0, Rn) der autonomen Gleichung (3.4) gelte die globale
Lipschitz-Bedingung
‖f(x) − f(x)‖ ≤ L‖x − x‖, ∀x, x ∈ D0. (3.16)
Dann genugt die diskrete Evolution eines gegen Autonomisierung invarianten RK-Verfahrensder Stabilitatsbedingung (2.16) aus Satz 2.10 mit LΨ = γL. Dabei ist γ = γ(A, b) ≥ 0.
Im Spezialfall p = s ≤ 4 mit bi, aij ≥ 0 fur alle Indizes i, j gilt γ = 1.
Korollar 3.6. Unter der Voraussetzung (3.16) hat ein gegen Autonomisierung invariantes RK-Verfahren der Konsistenzordnung p auch die Konvergenzordnung p.

3.3. KONVERGENZ EXPLIZITER RUNGE-KUTTA-VERFAHREN 35
Beweis von Satz 3.5. Fur i = 1, . . . , s gilt zunachst unter Beachtung von (3.16)
‖ki(x, τ) − ki(x, τ)‖ = ‖f(x + τ∑
j
aijkj(x, τ)) − f(x + τ∑
j
aijkj(x, τ))‖
≤ L
‖x − x‖ + τ∑
j
|aij | ‖kj(x, τ) − kj(x, τ)‖
.
Wiederholtes Einsetzen dieser Ungleichung in die rechte Seite ergibt
‖ki(x, τ) − ki(x, τ)‖ = L
1 + τL∑
j
|aij |
‖x − x‖ + (τL)2∑
j,l
|aij ||ajl|‖kl(x, τ) − kl(x, τ)‖
≤ L
1 + τL∑
j
|aij | + (τL)2∑
j,l
|aij ||ajl|
‖x − x‖
+(τL)3∑
j,l,m
|aij ||ajl||alm| ‖km(x, τ) − km(x, τ)‖
≤ . . .
Zur Abkurzung verwenden wir
(b+)i := |bi|, (A+)ij := |aij |, eT = (1, . . . , 1).
Im Schritt q hat man somit
‖ki(x, τ) − ki(x, τ)‖ ≤ L(1 + τL(A+e)i + . . . + (τL)q(Aq
+e)i)‖x − x‖
+(τL)q+1∑
j
(Aq+1+ )ij‖kj(x, τ) − kj(x, τ)‖.
Wegen aij = 0 fur j ≥ i ist offenbar As+ = 0, damit
‖ki(x, τ) − ki(x, τ)‖ ≤ L‖x − x‖(1 + τL(A+e)i + . . . + (τL)s−1(As−1
+ e)i).
sowie
‖Ψτx − Ψτ x‖ ≤ ‖x − x‖ + τ∑
i
|bi| ‖ki(x, τ) − ki(x, τ)‖
≤
1 +
s∑
j=1
(τL)jbT+(Aj−1
+ e)
‖x − x‖
≤∞∑
j=0
(γτL)j
j!‖x − x‖ = eγτL‖x − x‖
mit
γ := maxj=1,...,s
(
j! bT+(Aj−1
+ e)) 1
j.
Im Spezialfall p = s ≤ 4 mit bi, aij ≥ 0 hat man b+ = b und A+ = A. Aus den Ordnungsbedin-gungen (3.8), (3.9), (3.11) und (3.15) findet man j! bT (Aj−1e) = 1 fur j = 1, . . . , s und damitγ = 1. 2
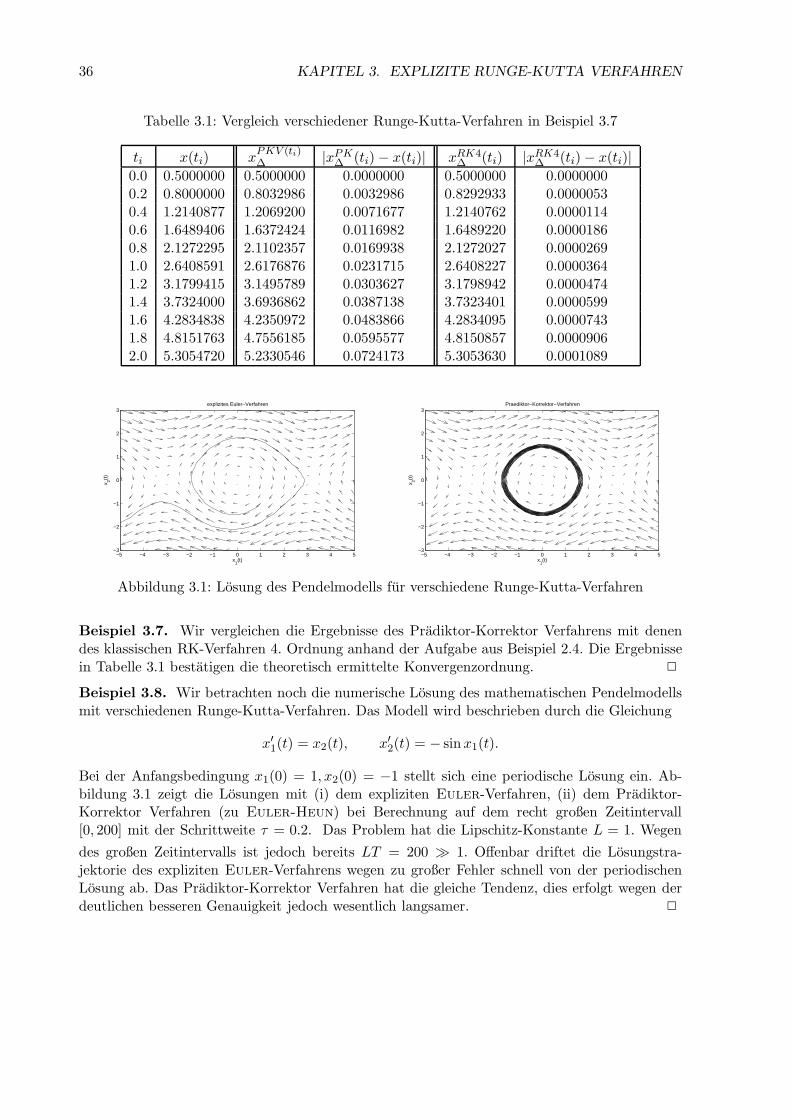
36 KAPITEL 3. EXPLIZITE RUNGE-KUTTA VERFAHREN
Tabelle 3.1: Vergleich verschiedener Runge-Kutta-Verfahren in Beispiel 3.7
ti x(ti) xPKV (ti)∆ |xPK
∆ (ti) − x(ti)| xRK4∆ (ti) |xRK4
∆ (ti) − x(ti)|0.0 0.5000000 0.5000000 0.0000000 0.5000000 0.00000000.2 0.8000000 0.8032986 0.0032986 0.8292933 0.00000530.4 1.2140877 1.2069200 0.0071677 1.2140762 0.00001140.6 1.6489406 1.6372424 0.0116982 1.6489220 0.00001860.8 2.1272295 2.1102357 0.0169938 2.1272027 0.00002691.0 2.6408591 2.6176876 0.0231715 2.6408227 0.00003641.2 3.1799415 3.1495789 0.0303627 3.1798942 0.00004741.4 3.7324000 3.6936862 0.0387138 3.7323401 0.00005991.6 4.2834838 4.2350972 0.0483866 4.2834095 0.00007431.8 4.8151763 4.7556185 0.0595577 4.8150857 0.00009062.0 5.3054720 5.2330546 0.0724173 5.3053630 0.0001089
−5 −4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
x1(t)
x 2(t)
explizites Euler−Verfahren
−5 −4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
x1(t)
x 2(t)
Praediktor−Korrektor−Verfahren
Abbildung 3.1: Losung des Pendelmodells fur verschiedene Runge-Kutta-Verfahren
Beispiel 3.7. Wir vergleichen die Ergebnisse des Pradiktor-Korrektor Verfahrens mit denendes klassischen RK-Verfahren 4. Ordnung anhand der Aufgabe aus Beispiel 2.4. Die Ergebnissein Tabelle 3.1 bestatigen die theoretisch ermittelte Konvergenzordnung. 2
Beispiel 3.8. Wir betrachten noch die numerische Losung des mathematischen Pendelmodellsmit verschiedenen Runge-Kutta-Verfahren. Das Modell wird beschrieben durch die Gleichung
x′1(t) = x2(t), x′
2(t) = − sinx1(t).
Bei der Anfangsbedingung x1(0) = 1, x2(0) = −1 stellt sich eine periodische Losung ein. Ab-bildung 3.1 zeigt die Losungen mit (i) dem expliziten Euler-Verfahren, (ii) dem Pradiktor-Korrektor Verfahren (zu Euler-Heun) bei Berechnung auf dem recht großen Zeitintervall[0, 200] mit der Schrittweite τ = 0.2. Das Problem hat die Lipschitz-Konstante L = 1. Wegen
des großen Zeitintervalls ist jedoch bereits LT = 200 ≫ 1. Offenbar driftet die Losungstra-jektorie des expliziten Euler-Verfahrens wegen zu großer Fehler schnell von der periodischenLosung ab. Das Pradiktor-Korrektor Verfahren hat die gleiche Tendenz, dies erfolgt wegen derdeutlichen besseren Genauigkeit jedoch wesentlich langsamer. 2

Kapitel 4
Adaptive Gittersteuerung
Der Aufwand eines expliziten Runge-Kutta-Verfahrens zur Losung des AWP
x′(t) = f(t;x(t)), t ∈ [t0, T ]; x(t0) = x0 (4.1)
hangt wesentlich von der Zahl erforderlicher Funktionsauswertungen ab. Die Effizienz des Ver-fahrens wird ferner signifikant durch Steuerung der Schrittweite τ im Losungsprozeß beeinflußt.In Intervallen mit starker Losungsanderung muß man zur Erzielung eines kleinen lokalen Diskre-tisierungsfehlers kleine Werte τ wahlen, in Intervallen mit geringer Anderung der Losung kannman zur Reduktion der Rechenzeit zu großeren Werten τ ubergehen.
Ziel ist eine automatische Schrittweitensteuerung fur (nichtsteife) AWP. Eine solche Steuerungbasiert auf einer Schatzung des lokalen Diskretisierungsfehlers. Man hofft, daß dabei auch derglobale Diskretisierungsfehler nicht zu stark wachst.
4.1 Adaptiver Basisalgorithmus
Die Losung x∆ zu einem AWP sei bis zum Zeitpunkt t = tj ermittelt. Nun soll der nachsteGitterpunkt tj+1 geeignet bestimmt werden. Der globale Diskretisierungsfehler
e∆(tj+1) := x∆(tj+1) − x(tj+1)
wird durch
e∆(tj+1) =(Ψtj+1,tjx∆(tj) − Φtj+1,tjx∆(tj)
)
︸ ︷︷ ︸
=:ǫj+1
+(Φtj+1,tjx∆(tj) − Φtj+1,tjx(tj)
)
︸ ︷︷ ︸
=:pj+1
(4.2)
zerlegt in den lokalen Diskretisierungsfehler (Konsistenzfehler) ǫj+1 und den Propagationsfehler(Fortpflanzungsfehler) pj+1.
Wir hatten zwar in der Konvergenztheorie fur Einschritt-Verfahren gesehen, daß der globaleDiskretisierungsfehler durch den lokalen beschrankt ist. Man kennt jedoch in der Regel nichtdie Abschatzungskonstanten. So kann man pj+1 nur durch Neustart der Rechnung beeinflussen.Theoretisch kann man den lokalen Anteil bei vorgegebener Toleranz TOL beschranken durchdie Forderung
‖ǫj+1‖ ≤ TOL. (4.3)
Aber leider kann man auch fur ǫj+1 nur auf einen lokalen Fehlerschatzer [ǫj+1] ≈ ǫj+1 hoffen,d.h. wir ersetzen (4.3) durch
‖[ǫj+1]‖ ≤ TOL. (4.4)
37

38 KAPITEL 4. ADAPTIVE GITTERSTEUERUNG
Ist (4.4) nicht erfullt, bestimmt man eine neue Schrittweite τ∗j , mit der der Schritt wiederholt
wird. Diese wird so gewahlt, daß
‖[ǫj+1]‖ ≈ TOL, (4.5)
d.h. die vorgegebene Toleranz soll weder deutlich unterschritten bzw. uberschritten werden. Manspricht auch von Effizienz bzw. Verlaßlichkeit des Fehlerschatzers. Ist die Forderung (4.4) erfullt,wird die Berechnung akzeptiert und im nachsten Schritt die Schrittweite τ∗
j verwendet.
Fur die Berechnung einer ”optimierten” Schrittweite τ∗j nimmt man an, daß der lokale Schatzer
eine asymptotische Darstellung der Form
‖[ǫj+1]‖ ≈ d(tj)τp+1j + 0(τp+2
j ) ≈ d(tj)τp+1j , τ → 0 (4.6)
mit einer in der Regel nicht bekannten Konstanten d(tj) besitzt.
Bemerkung 4.1. Bei hinreichend glatter Funktion f und diskreter Evolution Ψ kann mantatsachlich eine asymptotische Entwicklung des Konsistenzfehlers ǫj+1 angeben und von dieserauf eine analoge Entwicklung fur den Diskretisierungsfehler schließen, siehe [8]. 2
Sinngemaß gilt
TOL ≈ ‖[ǫ∗j+1]‖ ≈ d(tj) (τ∗j )p+1.
Nach Division durch (4.6) kurzt sich der (unbekannte) Faktor d(tj) heraus, man erhalt
TOL
‖[ǫj+1]‖≈(
τ∗j
τj
)p+1
.
Auflosung nach τ∗j ergibt unter Einfuhrung eines Sicherheitsfaktors ρ < 1 auf
τ∗j = ρ
(TOL
‖[ǫj+1]‖
) 1p+1
τj. (4.7)
Da ‖[ǫj+1]‖ klein werden kann, fuhrt man Beschrankungen τ∗j ≤ qτj mit vorgegebenem Faktor
q > 1 und/oder τ∗j ≤ τmax mit vorgegebener maximaler Schrittweite τmax ein. Ferner soll sicher
im (j + 1)-ten Schritt noch tj+1 + τ∗j+1 ≤ T gelten.
Adaptiver Basisalgorithmus fur AWP (4.1)
Initialisierung: Diskrete Evolution Ψ der Ordnung p, lokaler Fehlerschatzer,Toleranz TOL, Startschrittweite τ0 ∈ (0, T − t0],Hochschaltfaktor q > 1, Sicherheitsfaktor ρ ∈ (0, 1), maximale Schrittweite τmax
j := 0∆ := t0;x∆(t0) := x0;while (tj < T ) do
t := tj + τj;
x := Ψt,tjx∆(tj);
Berechne Fehlerschatzer ‖[ǫ]‖;
τ := min
(
qτj, τmax, ρτj
(TOL‖[ǫj+1]‖
) 1p+1
)
;

4.2. LOKALE FEHLERSCHATZUNG 39
if (‖[ǫj+1]‖ > TOL) // Schritt wird nicht akzeptiert
τj := min(τ, T − tj);
else // Schritt wird akzeptiert
tj+1 := t;
∆ := ∆ ∪ tj+1;x∆(tj+1) := x;
τj+1 := min(τ, T − tj1);
j := j + 1;
end
end
4.2 Lokale Fehlerschatzung
Zur Schatzung des lokalen Diskretisierungsfehlers rechnet man oft mit zwei verschiedenen Diskre-tisierungen, d.h. mit zwei diskreten Evolutionen Ψ und Ψ. Fur die lokalen Diskretisierungsfehlergilt dann
ǫ = Ψt+τ,tx − Φt+τ,tx, ǫ = Ψt+τ,tx − Φt+τ,tx.
O.B.d.A. sei Ψ die genauere Evaluation mit
θ :=‖ǫ‖‖ǫ‖ < 1. (4.8)
Als Schatzung fur ǫ wahlen wir
[ǫ] := Ψt+τ,tx − Ψt+τ,tx.
Wegen [ǫ] = ǫ − ǫ ist‖[ǫ] − ǫ‖ = ‖ǫ‖ = θ‖ǫ‖.
Nach Dreiecksungleichung folgt
‖[ǫ]‖ − ‖ǫ‖ ≤ θ‖ǫ‖, −‖[ǫ]‖ + ‖ǫ‖ ≤ θ‖ǫ‖
und daraus(1 − θ)‖ǫ‖ ≤ ‖[ǫ]‖ ≤ (1 + θ)‖ǫ‖.
Daher wird der Fehler im Fall von (4.8) weder stark uber- noch unterschatzt. Ist die Diskreti-sierung mit Ψ von hoherer Ordnung als Ψ, gilt sogar limτ→0 θ = 0. Dann ist der Fehlerschatzerasymptotisch exakt, d.h.
limτ→0
‖[ǫ]‖ = ‖ǫ‖.
Rechnet man nun mit der genaueren Approximation Ψt+τ,tx an Ψt+τ,tx weiter, wird die Tole-ranzbedingung bei θ ≤ 1
2 sogar ubererfullt, denn
‖ǫ‖ = θ‖ǫ‖ ≤ θ
1 − θ‖[ǫ]‖ ≤ ‖[ǫ]‖ ≈ TOL.
Bei dieser in der Praxis oft genutzten Vorgehensweise gibt man damit eigentlich das Konzept derFehlerschatzung auf, denn man optimiert das Gitter fur das ungenauere Verfahren Ψ. Man hofft,daß es dann auch in der Regel ein gutes Gitter fur das genauere Verfahren Ψ ist. Im folgendenAbschnitt besprechen wir diese Idee genauer fur eingebettete Runge-Kutta-Verfahren.

40 KAPITEL 4. ADAPTIVE GITTERSTEUERUNG
4.3 Eingebettete Runge-Kutta-Verfahren. Fehlberg-Trick
Wir bezeichnen mit RKp(q) ein adaptives RK-Verfahren, bei dem mit einer Evolution der Ord-nung p weitergerechnet und eine Evolution der Ordnung q zur Fehlerschatzung bzw. Gitter-steuerung genutzt wird. Zur Reduktion der Funktionsauswertungen von f betrachtet man Paarediskreter Evolutionen Ψ,Ψ, die zu RK-Verfahren (A, b) bzw. (A, b) mit der gleichen MatrixA gehoren. Man spricht auch von eingebetteten RK-Verfahren und kennzeichnet sie durch daserweiterte Butcher-Schema
c A
bT
bT
Beispiel 4.2. Wir suchen exemplarisch ein eingebettetes RK-Verfahren RK4(3), bei dem diegenauere Evolution Ψ durch das ”klassische” RK-Verfahren 4. Ordnung gegeben ist, d.h.
A =
0 0 0 012 0 0 00 1
2 0 00 0 1 0
, b =
16131316
.
Satz 3.3 liefert im Fall s = 3 die folgenden Ordnungsbedingungen fur den Vektor b = (b1, b2, b3, b4)T :
b1 + b2 + b3 + b4 = 11
2b2 +
1
2b3 + b4 =
1
21
4b2 +
1
4b3 + b4 =
1
31
4b3 +
1
2b4 =
1
6.
Als eindeutige Losung erhalt man b = (16 , 1
3 , 13 , 1
6)T , also b = b und damit Ψ = Ψ. Man findet
also auf diesem Weg kein passendes eingebettetes RK-Verfahren. Ein von Ψ abweichendes RK-Verfahren Ψ der Ordnung 3 mit den Stufen ki, i = 1, 2, 3, 4 von Ψ erfordert somit paradoxerweiseweitere Stufen von Ψ.
Einen Kompromiss bietet die Idee von Fehlberg, als zusatzliche Stufe die ohnehin zu berech-nende erste Stufe des folgenden Zeitschritts zu wahlen. Allgemein lauten bei einem s-stufigenRK-Verfahren (A, b) die Stufe ks und die Stufe k∗
1 des nachsten Schrittes
ks = f(t + csτ ;x + τs−1∑
j=1
asjkj),
k∗1 = f(t + τ ;x + τ
s∑
j=1
bjkj).
Aus der Forderung ks = k∗1 findet man die Bedingungen
cs = 1, bs = 0; asj = bj , j = 1, . . . , s − 1. (4.9)

4.3. EINGEBETTETE RUNGE-KUTTA-VERFAHREN. FEHLBERG-TRICK 41
Im Fall p = 4, q = 3 fuhrt der Fehlberg-Trick wegen (4.9) also auf den funf-stufigen Ansatz
012
12
12 0 1
21 0 0 11 1
613
13
16
16
13
13
16
b1 b2 b3 b4 b5
.
Satz 3.3 ergibt im Fall s = 3 die Ordnungsbedingungen
b1 + b2 + b3 + b4 + b5 = 11
2b2 +
1
2b3 + b4 + b5 =
1
21
4b2 +
1
4b3 + b4 + b5 =
1
31
4b3 +
1
2b4 +
1
2b5 =
1
6.
Man kann offenbar in diesem System die Rolle von b4 und b5 vertauschen. Daher ist mit bT =(16 , 1
3 , 13 , 1
6 , 0) auch bT = (16 , 1
3 , 13 , 0, 1
6) eine Losung. Der zu diesem vier-stufigen Verfahren vomTyp RK4(3) gehorige Fehlerschatzer ist
[ǫ] = Ψt+τ,tx − Ψt+τ,tx =1
6τ(k4 − k∗
1). 2
Beispiel 4.3. Dem Matlab-Solver ode23 liegt ein eingebettetes RK-Verfahren vom Typ RK3(2)zugrunde mit
012
12
34 0 3
41 2
913
49
29
13
49 0
724
14
13
18
2
Beispiel 4.4. Von Dormand und Prince stammt ein unter verschiedenen Aspekten optimierteseingebettetes Verfahren vom Typ RK5(4). Es ist im Matlab-Solver ode45 implementiert undist heute das Standardverfahren vom Typ RK5(4). 2
Beispiel 4.5. Der Lorenz-Attraktor wird durch das parameterbehaftete autonome System
x′1(t) = f1(x) := −σx1 + σx2
x′2(t) = f2(x) := rx1 − x2 − x1x3
x′3(t) = f3(x) := x1x2 − bx3
beschrieben. Er beschreibt sehr grob vereinfacht ein Problem aus der Metereologie. Fur be-stimmte Parameterwerte (σ, r, b) zeigte das System einen ”chaotischen” Losungsverlauf. Mankann beweisen, daß alle Losungen fur t → ∞ in einer hinreichend großen Umgebung des Null-punktes verbleiben. Die Grenzmenge fur t → ∞ , der sogenannte Attraktor, hat aber einekomplizierte Gestalt. Die Abbildung 4.1 (i) zeigt eine Losungstraktorie fur die Parameterwerte

42 KAPITEL 4. ADAPTIVE GITTERSTEUERUNG
−20
−10
0
10
20
−30
−20
−10
0
10
20
300
10
20
30
40
50
y1(t)y
2(t)
y 3(t)
Abbildung 4.1: Losung des Lorenz-Modells mit expliziten Runge-Kutta Verfahren
σ = 10, r = 28, b = 8/3. Hinsichtlich der nichttrivialen Untersuchung dieses beruhmt geworde-nen Beispiels konsultiere man etwa [15].
Naturlich erwartet man Schwierigkeiten bei der numerischen Losung dieses Systems. Fur denhier betrachteten Parameterfall (σ, r, b) = (10, 28, 8/3) ist die Lipschitz-Konstante der rechtenSeite nicht mehr sehr klein. Auf dem recht großen Intervall 0 ≤ t ≤ 30 wird LT ≫ 1. Abbildung4.1 zeigt die Losung fur die Anfangsbedingung x(0) = (0, 1; 0.1; 0.05) bei aquidistanter Schritt-weite τ = 3/100.
Offenbar muß man Verfahren hoherer Ordnung oder sogar implizite Methoden mit Schrittwei-tensteuerung verwenden. Abbildung 4.2 zeigt die Verlaufe der berechneten Normen ‖x(t)‖ furden Bereich von 0 ≤ t ≤ 30. Eine genauere Ansicht zeigt, daß sich die Kurvenverlaufe insbeson-dere fur t ≥ 15 signifikant unterscheiden.
Zur Losung wurden die folgenden in Matlab verfugbaren Losungsverfahren benutzt:
• Die Methoden ode23 und ode45 sind explizite Runge-Kutta Verfahren nach Bogacki/Shampine bzw. Dormand/ Price mit Extrapolation und Schrittweitensteuerung. Insbeson-dere ist ode45 ein sechs-stufiges RKV.
• Die beiden anderen Methoden ode23tb und ode23s sind spezielle implizite Runge-Kutta-Verfahren. Auf derartige Methoden gehen wir in Kapitel 5 ein.
Hinsichtlich einer genaueren Ubersicht zu den in Matlab verfugbaren Verfahren wird auf denUbersichtsartikel [14] und die dort angegebene Literatur verwiesen. 2
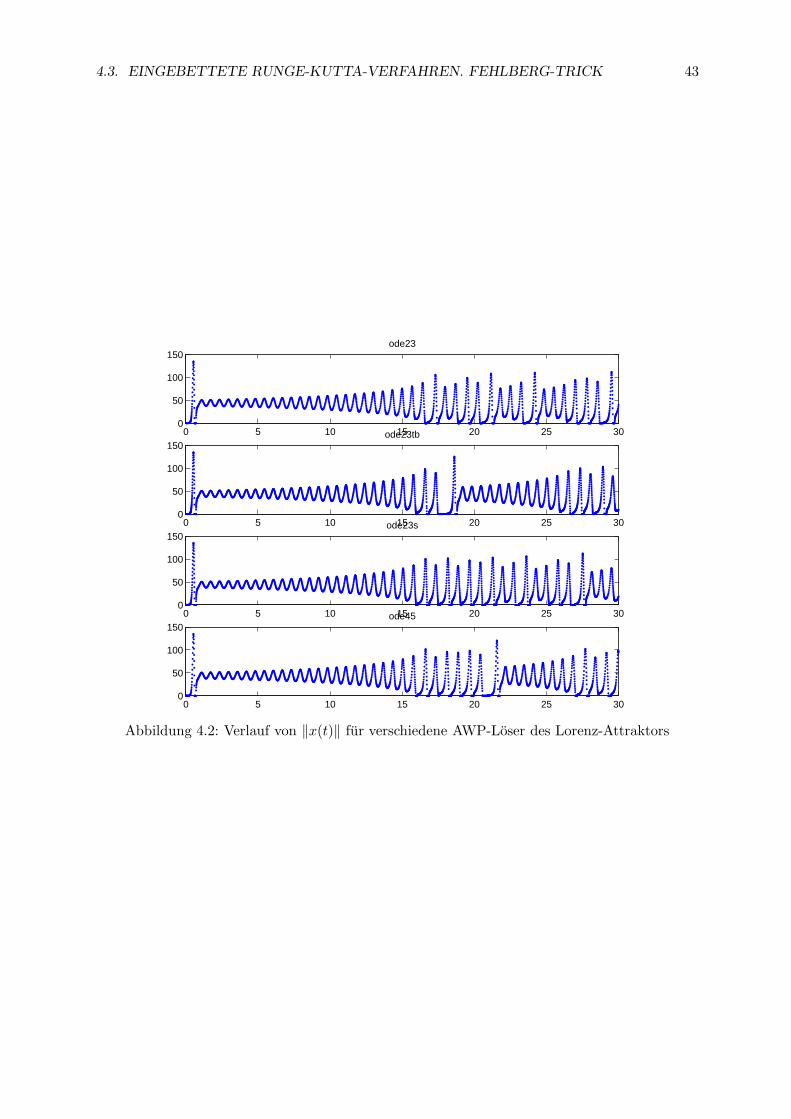
4.3. EINGEBETTETE RUNGE-KUTTA-VERFAHREN. FEHLBERG-TRICK 43
0 5 10 15 20 25 300
50
100
150ode23
0 5 10 15 20 25 300
50
100
150ode23s
0 5 10 15 20 25 300
50
100
150ode45
0 5 10 15 20 25 300
50
100
150ode23tb
Abbildung 4.2: Verlauf von ‖x(t)‖ fur verschiedene AWP-Loser des Lorenz-Attraktors

44 KAPITEL 4. ADAPTIVE GITTERSTEUERUNG

Kapitel 5
Implizite Verfahren fur steife AWP
Zunachst zeigen wir, daß explizite Einschrittverfahren (ESV) i.a. nicht fur steife AWP geeignetsind. Die Konvergenztheorie aus Kapitel 2 ist nur fur unvertretbar kleine Schrittweiten anwend-bar. Daher werden implizite Runge-Kutta-Verfahren als wichtigste Klasse von ESV eingefuhrt,die wesentlich gunstigere Stabilitatseigenschaften haben.
5.1 Eignung expliziter Verfahren fur steife AWP
Wir betrachten das skalare Testproblem
x′(t) = λx(t), Re(λ) < 0, x(0) = 1 (5.1)
mit λ ∈ R− := z ∈ C : Im(z) = 0, Re(z) < 0. Das AWP hat die exponentiell abklingende
Losung x(t) = eλt. Untersucht werden soll die Eignung expliziter Runge-Kutta-Verfahren furdieses Problem.
Beispiel 5.1. Zur Losung von Aufgabe (5.1) verwenden wir das explizite Euler-Verfahren
x∆(tj+1) = x∆(tj) + λτx∆(tj) = (1 + λτ)x∆(tj) = ... = (1 + λτ)j+1x0.
Nur bei Schrittweitenbeschrankung τ < 2/|λ| erhalt man im Fall λ < 0 eine monoton abneh-mende Folge (x∆(tj))j . Lost man etwa (5.1) fur λ = −100 auf dem Intervall [0, 5], so brauchteman wenigstens eine Schrittweite τ < 0.02 bzw. mehr als 250 Integrationsschritte, obwohl dieLosung x(t) sehr schnell auf Null abklingt.
Das implizite Euler-Schema
x∆(tj+1) = x∆(tj) + λτx∆(tj+1)
erzeugt fur beliebige Schrittweiten τ > 0 eine monoton abnehmende diskrete Losungsfolge mit
x∆(tj+1) =1
1 − λτx∆(tj) = ... =
1
(1 − λτ)j+1x0.
Fur λ = −100 und die sehr grobe Schrittweite τ = 1 erhalt man die folgenden Losungen
j 0 1 2 3 4 5
x∆(tj) 1 9.90-3 9.80-5 9.71–7 9.61-9 9.57-11x(tj) 1 < 10−45 0 0 0 0
45

46 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
Explizite RK-Verfahren bereiten generell bei Anwendung auf das Testproblem (5.1) Probleme.
Lemma 5.2. Sei Ψτλ die Evolution eines konsistenten expliziten RK-Verfahrens fur die Aufgabe
(5.1). Fur festes τ > 0 giltlim
|λ|→∞|Ψτ
λ1| = ∞.
Beweis: Analog zum Beweis von Lemma 3.1 erhalt man, daß Ψτλ1 = p(λτ) mit einem Polynom
p vom Grad ≤ s ist. Wegen der vorausgesetzten Konsistenz hat p mindestens den Grad 1, vgl.auch Beweis von Lemma 2.6. Daher folgt lim|z|→∞ |p(z)| = ∞. 2
Somit sind explizite ESV fur die Losung steifer AWP i.a. ungeeignet. Daher betrachten wirnachfolgend implizite RK-Verfahren als interessanteste Klasse impliziter ESV. 2
Nach Satz 1.20 erfullt die Losung des AWP
x′(t) = f(t;x(t)), x(t0) = x0. (5.2)
bei Gultigkeit einer einseitigen Lipschitz-Bedingung (1.26) an f folgende Stabilitatsbedingung:
‖Φt,t0x0 − Φt,t0x0‖ ≤ exp
(∫ t
t0
l(s) ds
)
‖x0 − x0‖, t ≥ t0. (5.3)
Fur das Testproblem (5.1) ist l(s) = Re(λ); fur die Lipschitz-Konstante jedoch gilt L = |λ|.Fur explizite RK-Verfahren hatten wir in Satz 3.5 gezeigt, daß dessen diskrete Evolution Ψ dieStabilitatseigenschaft (5.3) lediglich mit dem Faktor LΨ = γL ”erbt”. Ferner gilt die Fehler-abschatzung
‖x∆(t) − x(t)‖ ≤ CeLΨ|t−t0| − 1
LΨτp, t ∈ ∆, (5.4)
vgl. Satze 2.10, 2.12. Kritisch ist, daß die Konvergenzordnung p im steifen Fall LΨ|T − t0| ≫l|T−t0| auf dem Intervall [t0, T ] durch den exponentiellen Vorfaktor unbrauchbar wird. Naturlichist (5.4) eine ”worst case”-Abschatzung. Daher mochte man bei Abschatzungen fur steife AWPmoglichst nur mit der einseitigen Lipschitz-Konstanten arbeiten.
5.2 Implizite Runge-Kutta-Verfahren
Nach Beispiel 5.1 ist das implizite viel besser als das explizite Euler-Verfahren zur Losung desfur Re(λ) ≪ |λ| steifen AWP (5.1) geeignet. Neben der Stabilitat eines Verfahrens (vgl. dazuAbschnitt 5.5) ist aber auch dessen Ordnung wesentlich. Zur Illustration zeigt Abbildung 5.1 dieLosungen zum Pendel-Problem (vgl. Bsp. 3.8) bzw. zum Lorenz-Attraktor (vgl. Bsp. 4.5) mitdem impliziten Euler-Verfahren. Die Losung strebt jeweils inkorrekt auf einen Fixpunkt zu,das Verfahren ist ”zu dissipativ”. Wir suchen daher implizite RK-Verfahren hoherer Ordnung.
Definition 5.3. Ein s−stufiges (implizites) RK-Verfahren ist gegeben durch die Vorschrift
x∆(t + τ) := Ψt+τ,tx∆(t) := x∆(t) + τ
s∑
j=1
bjkj(t, x∆(t), τ), t ∈ ∆ (5.5)
ki(t, x, τ) := f
t + ciτ, x + τs∑
j=1
aijkj(t, x, τ)
, i = 1, ..., s. (5.6)
Die Werte ci bzw. ki heißen Knoten bzw. Steigungen.
Das entsprechende Butcher-Schema lautet:

5.3. IMPLEMENTATION IMPLIZITER RK-VERFAHREN 47
−5 −4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
x1(t)
x 2(t)
implizites Euler−Verfahren
(i) Losungsverlauf fur mathematisches Pendel
0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
x1(t)
x 2(t)
implizites Euler−Verfahren
(ii) Losungsverlauf fur Lorenz-Attraktor
Abbildung 5.1: Dissipatives Verhalten des impliziten Euler-Verfahrens
c A
bT bzw.
c1 a11 a12 · · · a1,s−1 a1s
c2 a21 a22 · · · a2,s−1 a2s...
......
......
...cs as1 as2 · · · as,s−1 as,s
b1 b2 · · · bs−1 bs
Definition 5.4. (i) Fur aij = 0, i ≤ j erhalt man die expliziten RK-Verfahren (vgl. Kap. 3).
(ii) Fur aij = 0, i < j erhalt man die diagonal-impliziten RK-Verfahren (DIRK). Gilt sogarγ = aii, i = 1, . . . , s, so spricht man von einfach diagonal-impliziten RK-Verfahren (SDIRK;engl. singly diagonally implicit RK method)
(iii) Existiert ein Index j > i mit aij 6= 0, so spricht man von voll-impliziten RK-Verfahren.
5.3 Implementation impliziter RK-Verfahren
In jedem Zeitschrit sind die Steigungen ki durch Losung des Gleichungssystems (5.6)
ki(t, x, τ) = f(
t + ciτ, x + τs∑
j=1
aijkj(t, x, τ))
, i = 1, ..., s
zu ermitteln. Bei expliziten Verfahren ermittelt man die ki rekursiv. Leider ist dies bei echtimpliziten RK-Verfahren nicht moglich. Der Versuch mit der einfachen Fixpunktiteration
k(m+1)i (t, x, τ) = f
(
t + ciτ, x + τ
s∑
j=1
aijk(m)j (t, x, τ)
)
, i = 1, ..., s; m ∈ N0
fuhrt aber zu Schrittweitenbeschrankungen (vgl. Lemma 2.3 fur modifiziertes Euler-Verfahren).Fur steife AWP ist das eine inakzeptable Einschrankung. Man muß also ”intelligentere” Losungs-verfahren, z.B. das Newton- bzw. Newton-artige Verfahren, benutzen. Beim DIRK-Verfahrenzerfallt speziell die Losung des s · n-dimensionalen Gleichungssystems in die sukzessive Berech-nung von s Gleichungssystemen der Dimension n. Bei den SDIRK-Verfahren ist sogar nur einmaldie Matrix I − τγ ∂f
∂x mit der Jacobi-Matrix ∂f∂x zu invertieren.
Zur Vermeidung von Rundungsfehlern (insbesondere im steifen Fall) formen wir das System(5.6) um: Ist x(s) := Φs,t0x0 die durch (t0, x
0) verlaufende Losungstrajektorie, so sind die Stufenki des RK-Verfahrens Approximationen ki ≈ x′(t+ ciτ). Man kann dann auch Approximationen

48 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
zi ≈ x(t + ciτ) − x(t) als Zwischenstufen benutzen.
Lemma 5.5. Betrachtet wird ein RK-Verfahren mit den Daten (A, b, c).
(i) Sind k1, . . . , ks Losung von (5.6), so ist zi := τ∑s
j=1 aijkj , i = 1, . . . , s Losung des Systems
zi = τ
s∑
j=1
aijf(t + cjτ ;x + zj), i = 1, . . . , s. (5.7)
(ii) Sind z1, . . . , zs Losung von (5.7), so ist ki := f(t + ciτ ;x + zi), i = 1, . . . , s Losung von(5.6). Fur die diskrete Evolution des RK-Verfahrens gilt
Ψt+τ,tx = x + τs∑
i=1
bif(t + ciτ ;x + zi). (5.8)
(iii) Bei invertierbarer Matrix A = (aij) ∈ Rs×s des RK-Verfahrens kann man die diskrete
Evolution ohne zusatzliche Auswertung von f ermitteln aus
Ψt+τ,tx = x +s∑
i=1
wizi, (w1, . . . , ws)T := (AT )−1b. (5.9)
Beweis: (i) Es gilt nach Definition und (5.6)
zi = τ
s∑
j=1
aijkj = τ
s∑
j=1
aijf
(
t + cjτ ;x + τ
s∑
l=1
ajlkl
)
= τ
s∑
j=1
aijf(t + cjτ ;x + zj).
(ii) Nach Definition und (5.7) ist wegen
ki = f(t + ciτ ;x + zi) = f
t + ciτ ;x + τ
s∑
j=1
aij f(t + cjτ ;x + zj)
= f
t + ciτ ;x + τs∑
j=1
aijkj
(5.6) erfullt. Die Erfullung von (5.8) ergibt sich unter Anwendung der Definitionen.
(iii) (5.7) ergibt
x +
s∑
i=1
wizi = x + τ
s∑
j=1
s∑
i=1
aijwi f(t + cjτ ;x + zj).
Wegen∑s
i=1 aijwi = (AT w)j = bj ergibt sich mit (5.8) schließlich die Aussage (5.9). 2
Im steifen Fall konnen die Werte von f und der ki betragsmaßig groß sein und die Formel (5.7)ist dann weniger anfallig als (5.6) gegen Rundungsfehler. Vorteil der Formulierung (5.7),(5.9)fur implizite RK-Verfahren mit invertierbarer Matrix A ist gegenuber (5.7),(5.8), daß keinezusatzlichen Auswertungen von f notwendig sind.
Wir wollen nun das modifizierte System (5.7) mittels Newton-Verfahren losen. Mit der Notation
Z :=
z1...zs
∈ R
sn, X :=
x...x
∈ R
sn, F (τ,X + Z) :=
f(t + c1τ ;x + z1)...
f(t + csτ ;x + zs)
(5.10)

5.3. IMPLEMENTATION IMPLIZITER RK-VERFAHREN 49
sowie
A ⊗ In :=
a11In... a1sIn
......
as1In · · · assIn
∈ Rsn×sn
und der Einheitsmatrix In ∈ Rn×n konnen wir das System (5.7) kompakt schreiben als
G(Z) := Z − τ(A ⊗ In)F (τ,X + Z) = 0.
Mit dem Startwert Z(0) := 0 lautet dann ein Schritt des Newton-Verfahrens fur m ∈ N0:
(Isn − τ(A ⊗ In)(DXF )(τ,X + Z(m)))∆Z(m) = −G(Z(m))
Z(m+1) = Z(m) + ∆Z(m).
Mit der VereinfachungDXF (τ,X + Z) ≈ DXF (0,X + Z)
und J := Dxf(t;x) hat man
(A ⊗ In)((DXF )(0,X + Z(m)) = (A ⊗ In)(In ⊗ J) = A ⊗ J
und damit das vereinfachte Newton-Verfahren
(Isn − τA ⊗ J)∆Z(m) = −Z(m) + τ(A ⊗ In)F (τ,X + Z(m)).
Pro Iterationszyklus in jedem Runge-Kutta-Schritt hat man die Jacobi-Matrix J nur einmalauszuwerten und nur eine LU -Zerlegung von Isn − τA ⊗ J zu berechnen. Vergleichsweise hatman beim exakten Newton-Verfahren in jedem Newton-Schritt (!) s Jacobi-Matrizen von fzu berechnen und jeweils eine weitere Matrix aus R
sn×sn zu invertieren.
Dieser enormen Rechenvereinfachung beim vereinfachten Newton-Verfahren steht naturlich derVerlust der quadratischen Konvergenzordnung des exakten Newton-Verfahrens entgegen. Wirwissen aber bereits aus dem Kurs Numerische Mathematik I, daß das vereinfachte Verfahrenwenigstens linear konvergiert.
Als Abbruchkriterium der (vereinfachten) Newton-Iteration hatte man bei vorgegebener Tole-ranz TOL der Schrittweitensteuerung gerne
‖Z − Z(m)‖ ≤ κ TOL, κ ≪ 1
mit einem Sicherheitsfaktor κ, der ublicherweise aus dem Intervall [10−4, 10−2] gewahlt wird.Naturlich muß man eine geeignete Approximation hieran wahlen, da die Losung Z nicht bekanntist. Eine derartige Wahl findet man im folgenden Verfahren.

50 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
Implementierung eines impliziten RK-Verfahrens mit Schrittweitensteuerung:
Initialisierung: (t, x0) ∈ R × Rn Anfangspunkt;
(f(t;x) rechte Seite der Differentialgleichung;F und X definiert wie in (5.10);τ > 0 Schrittweite;TOL > 0 Toleranz fur Fehlerschatzer, 0 < κ ≪ 1;
J := Dxf(t;x);Berechne LU -Zerlegung von B := Isn − τA ⊗ J ;Lose B∆Z(1) = −τ(A ⊗ In)F (τ,X) mittels LU -Zerlegung von B;Z(1) := ∆Z(1);m := 1;do
Lose B∆Z(m) = −Z(m) + τ(A ⊗ In)F (τ,X + Z(m)) mittels LU -Zerlegung von B;
Z(m+1) := Z(m) + ∆Z(m);
qm := ‖∆Z(m)‖‖∆Z(m−1)‖ ; // Schatzung des Kontraktionsfaktors
if qm ≥ 1
Newton-Verfahren divergiert ! Wiederhole RK-Schritt mit Schrittweite 12τ ;
end
m := m + 1;
until qm
1−qm‖∆Z(m)‖ ≤ κ TOL
Fur DIRK vereinfacht sich der Algorithmus weiter, da er mit geringen Modifikationen s-fachhintereinander fur jede Stufe benutzt werden kann.
5.4 Konstruktion impliziter RK-Verfahren
In Abschnitt 5.1 hatten wir bereits das sehr stabile einstufige implizite Euler-Verfahren mitdem Butcher-Schema
1 1
1
betrachtet. Leider hat es nur die Konsistenzordnung p = 1. Das ebenfalls einstufige impliziteMittelpunkt-Verfahren
x∆(tj+1) = x∆(tj) + τf
(
tj +τ
2;x∆(tj) + x∆(tj+1)
2
)
.
mit dem Butcher-Schema12
12
1
hat, wie wir noch sehen werden, sogar die Konsistenzordnung p = 2.
Wir wollen jetzt systematisch implizite RK-Verfahren hoherer Ordnung konstruieren. Dies er-fordert die Festlegung der bis zu s2 + 2s Parameter bi, ci, aij mit i, j = 1, ..., s. Bei Kollokations-Verfahren approximiert man die Losung des AWP (5.2) durch ein vektorwertiges Polynomw ∈ (Πs)
n, das die Anfangsbedingung
w(t0) = x0 (5.11)

5.4. KONSTRUKTION IMPLIZITER RK-VERFAHREN 51
und die Differentialgleichung an s vorgegebenen Kollokationspunkten t0+ciτ, i = 1, . . . , s erfullt,d.h.
w′(t0 + ciτ) = f(t0 + ciτ ;w(t0 + ciτ)), i = 1, . . . , s. (5.12)
Das folgende Resultat zeigt, daß durch Kollokation implizite RK-Verfahren erzeugt werden.Insbesondere wird dabei die Zahl der unbekannten Parameter auf s reduziert.
Lemma 5.6. Fur die Parameter 0 ≤ c1 < · · · < cs ≤ 1 sei das System (5.11), (5.12) eindeutiglosbar. Dann wird durch die diskrete Evolution
Ψt0+τ,t0x0 := w(t0 + τ). (5.13)
ein implizites RK-Verfahren definiert.
Beweis: Sei L1, . . . , Ls die Lagrange-Basis bezuglich der Punkte c1, . . . , cs mit Li ∈ Πs undLi(cj) = δij , i, j = 1, . . . , s. Wegen w′ ∈ (Πs−1)
n kann man w′ in der Lagrange-Basis darstellen
w′(t0 + θτ) =s∑
j=1
kjLj(θ), kj := w′(t0 + cjτ), j = 1, . . . , s.
Dann ergibt die Anfangsbedingung (5.11) nach Integration
w(t0 + θτ) = x0 + τ
s∑
j=1
kj
∫ θ
0Lj(σ) dσ.
Mit dem Ansatz
aij :=
∫ ci
0Lj(θ) dθ, i, j = 1, . . . , s (5.14)
kann man die Kollokations-Bedingungen (5.12) aquivalent schreiben als
ki = f(t0 + ciτ ;x0 + τs∑
j=1
aijkj), i = 1, . . . , s.
Mit
bi :=
∫ 1
0Li(θ) dθ, i = 1, . . . , s (5.15)
folgt fur (5.13)
Ψt0+τ,t0x0 = x0 + τ
s∑
i=1
biki.
Somit kann jedes Kollokations-Verfahren als implizites RK-Verfahren mit den durch (5.14),(5.15) definierten Koeffizienten aij, bi dargestellt werden. 2
Man kann ohne Beweisanderung zeigen, daß sich die fur explizite RK-Verfahren bewiesenen Be-dingungen fur Konsistenz und Invarianz gegen Autonomisierung (Lemmata 3.1 und 3.2) sowieSatz 3.3 uber die Butcher-Bedingungen sinngemaß auf implizite RK-Verfahren ubertragen.Das folgende Resultat zeigt, daß Kollokations-Verfahren bereits einige dieser Bedingungen im-plizieren.

52 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
Lemma 5.7. Fur die Koeffizienten eines durch Kollokation definierten impliziten RK-Verfahrensgilt (mit 00 = 1)
s∑
j=1
ck−1j bj =
1
k, k = 1, ..., s (5.16)
s∑
j=1
ck−1j aij =
1
kcki , i, k = 1, ..., s. (5.17)
Insbesondere sind diese Verfahren konsistent und invariant gegen Autonomisierung.
Beweis: Wir schreiben die Monome θk−1, k = 1, . . . , s in der Lagrange-Basis als
θk−1 =s∑
j=1
ck−1j Lj(θ).
Dann gilt
s∑
j=1
bjck−1j =
∫ 1
0
s∑
j=1
ck−1j Lj(θ) dθ =
∫ 1
0θk−1 dθ =
1
k,
s∑
j=1
ck−1j aij =
∫ ci
0
s∑
j=1
Lj(θ)ck−1j dθ =
∫ ci
0θk−1 dθ =
1
kcki .
Die Konsistenz- und Invarianzaussage ergeben sich fur k = 1, vgl. Lemmata 3.1 und 3.2. 2
Das folgende etwas tieferliegende Resultat gibt einen Hinweis auf die Wahl der Parameterc1, . . . , cs.
Lemma 5.8. Fur gegebene Parameter c1, . . . , cs sei die Quadraturformel
∫ 1
0g(t) dt ≈
s∑
i=1
big(ci)
exakt fur alle Polynome in Πp−1 mit p ≥ s. Dann hat das zu c1, . . . , cs gehorige, durch Kolloka-tion gewonnene implizite RK-Verfahren die Konsistenzordnung p.
Beweis: vgl. [4], Abschnitt 6.3.1. 2
Wir wollen jetzt Beispiele fur durch Kollokation erzeugte implizite RK-Verfahren angeben.
Beispiel 5.9. (Gauß-Verfahren mit p = 2s)
Aus Satz 14.4. aus dem Kurs Numerische Mathematik I wissen wir, daß Quadraturformeln zu sStutzstellen maximal die Ordnung p = 2s haben. Zur Erzielung der maximal moglichen Konsi-stenzordnung p = 2s muß man die Knoten ci des Verfahrens geeignet wahlen. Seien die Werteci gerade die paarweise verschiedenen Nullstellen des verschobenen Legendre-Polynoms
Ps(t) := Ps(2t − 1) :=1
s!
ds
dts[ts(t − 1)s] .
Man erhalt dann die Gauß-Verfahren mit p = 2s mit den Parametern bi und aij nach Lemma5.7, vgl. die Falle s = 1 bzw. s = 2 in Abb. 5.2. Fur s = 1 ist dies gerade die implizite Mittel-punktregel.

5.5. STABILITAT IMPLIZITER RUNGE-KUTTA-VERFAHREN 53
12
12
1
,
3−√
36
14
3−2√
312
3+√
36
3+2√
312
14
12
12
.
Abbildung 5.2: Gauß-Verfahren der Ordnung 2 und 4
−5 −4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
x1(t)
x 2(t)
implizites RK−Verfahren
(i) Losungsverlauf fur mathematisches Pendel
−20 −15 −10 −5 0 5 10 15 20−30
−20
−10
0
10
20
30
x1(t)
x 2(t)
implizites RK−Verfahren
(ii) Losungsverlauf fur Lorenz-Attraktor
Abbildung 5.3: Losungen mit dem Gauß-Verfahren mit s = 2 nach Beispiel 5.12
Wir wollen den Effekt der hoheren Ordnung eines impliziten RK-Verfahrens vergleichen mitden Ergebnissen zum impliziten Euler-Verfahren (vgl. Abb. 5.1 in Abschnitt 5.1). Abbildung5.3 zeigt die Losungen zum Pendel-Problem (vgl. Beispiel 3.8) bzw. zum Lorenz-Attraktor (vgl.Beispiel 4.5) mit dem Gauß-Verfahren mit s = 2. In beiden Fallen ist der Genauigkeitsgewinngegenuber dem impliziten Euler-Verfahren signifikant. Tatsachlich gilt folgendes Ergebnis:
Lemma 5.10. Ein s-stufiges Gauß-Verfahren hat die (maximal mogliche) Konsistenzordnungp = 2s.
Beweis: vgl. Strehmel/Weiner [17], Satz 6.1.3. 2
Bemerkung 5.11. Man kann zeigen, daß Gauß-Verfahren zwar optimale Konvergenzordnunghaben, jedoch sind die Stabilitatseigenschaften nicht vollstandig befriedigend. Durch Absen-kung der Konsistenzforderung kommt man zu Verfahren mit besseren Stabilitatseigenschaften.RK-Verfahren mit Konsistenzordnung p = 2s− 1 werden als Radau-Verfahren bezeichnet. Ver-fahren der Ordnung p = 2s− 2 nennt man Lobatto-Verfahren. Details uber Konstruktion undEigenschaften findet man in [17], Abschnitt 6.1.3. 2
5.5 Stabilitat impliziter Runge-Kutta-Verfahren
Wir betrachten noch kurz Stabilitatseigenschaften impliziter RK-Verfahren. Ausgangspunkt ver-schiedener Stabilitatsbegriffe ist das skalare Testproblem
x′(t) = λx(t), Re(λ) ≤ 0 (5.18)
mit der Losung x(t + τ) = eτλx(t) mit den folgende Eigenschaften:
(i) |x(t + τ)| ≤ |x(t)|, ∀ τ > 0; (ii) limτRe(λ)→−∞
x(t + τ) = 0. (5.19)

54 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
Dann heißen RK-Verfahren, fur die (i) bzw. (i), (ii) ”vererbt” werden, A-stabil bzw. L-stabil.
Erfahrungsgemaß reicht bei linearen steifen AWP bzw. bei nichtlinearen Systemen der Formx′ = f(t;x) := Ax + g(t, x) mit moderater Lipschitz-Konstante von g bezuglich x ein Verfahrenmit A-Stabilitat aus. Fur allgemeinere nichtlineare Probleme ist im sehr steifen Fall auch derA-Stabilitatsbegriff zu schwach. Wir beschranken uns hier auf den wichtigen Fall dissipativerAWP, die zum Beispiel bei ortlicher Semidiskretisierung bestimmter zeitabhangiger partiellerDifferentialgleichungen entstehen.
Wir erinnern an die Notation aus Abschnitt 1.4: Das System x′ = f(t, x) heißt dissipativbezuglich der Norm ‖ · ‖ , falls fur beliebige Losungen x(·), x(·) gilt
‖x(t2) − x(t2)‖ ≤ ‖x(t1) − x(t1)‖, ∀t1, t2 : t0 ≤ t1 ≤ t2 < ∞. (5.20)
Man sagt auch, die Losungen verhalten sich nicht-expansiv.
Definition 5.12. Ein Einschritt-Verfahren heißt B-stabil, falls die diskrete Evolution Ψ = Ψ[f ]auf der Klasse der dissipativen Systeme nicht-expansiv ist, d.h. falls
‖Ψt+τ,tx − Ψt+τ,tx‖ ≤ ‖x − x‖
fur alle (t, x), (t, x) ∈ D und alle zulassigen τ ≥ 0.
Durch Anwendung der Definition auf die skalare Testgleichung (5.18) ersieht man sofort, daßB-Stabilitat eines Verfahrens auch dessen A-Stabilitat impliziert. Ferner ist bei dissipativen Dif-ferentialgleichungen die Stabilitatsbedingung (2.16) aus dem Konvergenzsatz 2.10 mit LΨ = 0erfullt. Insbesondere entfallt dann der bei expliziten RK-Verfahren auftretende exponentielleVorfaktor 1
LΨ(eLΨ(t−t0) − 1) in der Fehlerabschatzung.
In der Klasse der impliziten RK-Verfahren (5.5) gibt es B-stabile Verfahren beliebig hoher Ord-nung. Wir beschranken uns auf folgende Aussage.
Lemma 5.13. Die Gauß-Verfahren sind B-stabil.
Beweis: Seien (t, x), (t, x) ∈ D sowie w(t + θ) = Ψt+θ,tx bzw. w(t + θ) = Ψt+θ,tx dieKollokations-Polynome des s-stufigen Gauß-Verfahrens. Mit χ(s) := ‖w(s) − w(s)‖2
2 fur s ∈ R
erhalten wir an den Kollokationspunkten ti := t + ciτ , daß
χ′(ti) = 2[[(w(ti) − w(ti)]T · [f(ti;w(ti)) − f(ti; w(ti))] ≤ 0.
Nun ist χ′ ∈ Π2s−1, d.h. dieses Polynom wird durch die Gauß- Quadratur-Formel exakt inte-griert. Damit erhalten wir die Behauptung wegen
‖Ψt+τ,tx − Ψt+τ,tx‖22 = χ(t + τ) = χ(t) +
∫ t+τ
tχ′(θ) dθ
= χ(t) + τ
s∑
j=1
bjχ′(tj)
≤ χ(t) = ‖x − x‖22,
da die Quadratur-Gewichte bj positiv sind, vgl. Lemma 14.5 in ”Numerische Mathematik I”. 2
Bemerkung 5.14. Die Aussage von Lemma 5.13 kann auf bestimmte Radau- bzw. Lobatto-Verfahren ubertragen werden. 2

5.6. EINGEBETTETE RUNGE-KUTTA-VERFAHREN IN MATLAB 55
Leider ist der Begriff der B-Stabilitat allein noch nicht ausreichend zur Charakterisierung geeig-neter RK-Verfahren fur steife, dissipative AWP. Es kann das Phanomen der Ordnungsreduktionauftreten.
Beispiel 5.15. Das Prothero-Robinson Modell
x′(t) = λ[x(t) − g(t)] + g′(t), x(0) = x0
mit λ < 0 und glatter Funktion g verallgemeinert das Testproblem (5.1) mit g ≡ 0. In derLosung
x(t) = eλt[x0 − g(0)] + g(t)
fallt der exponentielle Anteil im Fall g(0) = x0 weg. Das Gauß-Verfahren mit s = 1 hat denKonsistenzfehler ∣
∣∣∣
λτ
4(2 − λτ)τg′′(tn)
∣∣∣∣.
Fur große Werte von |λ| reduziert sich die Ordnung des Verfahrens von 2 auf 1. 2
Fur steife, dissipative Systeme muß man die Begriffe Konsistenz und Konvergenz verscharfen.
Definition 5.16. Ein RK-Verfahren hat die B-Konsistenzordnung p , wenn auf der Klasse derAWP x′ = f(t;x) mit einseitiger Lipschitz-Bedingung die in die Konsistenzdefinition einge-hende Konstante (vgl. Definition 2.7) nur von der einseitigen Lipschitz-Konstanten l(·) und derGlattheit der Losung, jedoch nicht von der Lipschitz-Konstanten L der Funktion f abhangt.
Sinngemaß definiert man den Begriff der B-Konvergenz. Aus B-Stabilitat und B-Konsistenzfolgt dann die B-Konvergenz des Verfahrens. Hinsichtlich genauerer Untersuchunge kann hierjedoch nur auf die Spezialliteratur verwiesen werden, etwa [9], Kap. IV.15.
Beim impliziten Euler-Verfahren stimmen die ”klassische” und B-Konvergenzordnung 1 uberein.Hingegen haben s-stufige Gauß-Verfahren s ≥ 2 im Gegensatz zur ”klassischen” Konsistenz-und Konvergenzordnung 2s nur die B-Konvergenzordnung s. Fur das Verfahren mit s = 1aus Beispiel 5.15 tritt zwar ggf. eine Reduktion der Konsistenzordnung auf, jedoch hat es dieB-Konvergenzordnung 2.
5.6 Eingebettete Runge-Kutta-Verfahren in Matlab
Man kann die in Kapitel 4 dargelegte Methode der Schrittweitensteuerung mittels eingebetteterRK-Verfahren auf implizite Verfahren erweitern. Wir gehen abschließend noch kurz auf diagonal-implizite eingebettete RK-Verfahren vom Typ RK3(2) ein, die in der ode-Suite von Matlabimplementiert sind. Wir hatten die beiden Verfahren ode23s und ode23tb bereits erfolgreich inBeispiel 4.5 zum Lorenz-Attraktor als typischem steifem Anfangswertproblem benutzt.
Eine genauere Information zum Verfahren ode23s, das insbesondere fur steife AWP konstru-iert wurde, findet man in dem Ubersichtsartikel zur Matlab-ode-Suite von Shampine undReichelt [14] bzw. im Lehrbuch von Hanke-Bourgeois [10], Kap. 80. Als Kontrollverfahrenwird ein Verfahren dritter Ordnung mittels Fehlberg-Trick verwendet. Ferner ist ode23s L-stabil, falls in jedem Zeitschritt die exakte Jacobi-Matrix J = Dxf benutzt wrd.
Im Verfahren ode23t wird mit der durch bT = (14 , 1
2 , 14)T definierten diskreten Evolution wei-
tergerechnet. Sie entspricht der Anwendung von zwei Schritten der impliziten Mittelpunkt-regel und hat die Konsistenzordnung p = 2. Die durch bT = (1
6 , 23 , 1
6)T definierte diskreteEvolution hat die Ordnung p = 3, jedoch schlechtere Stabilitateigenschaften. Sie wird daher

56 KAPITEL 5. IMPLIZITE VERFAHREN FUR STEIFE AWP
0 0 0 012
14
14 0
1 14
12
14
14
12
14
16
23
16
,
0 0 0 0
2 −√
2 2−√
22
2−√
22 0
1√
24
√2
42−
√2
2√2
4
√2
42−
√2
213 −
√2
1213 +
√2
42−
√2
6
.
Abbildung 5.4: Eingebettete RK-Verfahren ode23t und ode23tb in Matlab
nur zur Fehlerschatzung verwendet. Die Anwendung der Vektoren bT = (√
24 ,
√2
4 , 2−√
22 )T und
bT = (13 −
√2
12 , 13 +
√2
4 , 2−√
26 )T finden beim Verfahren ode23tb analog Verwendung. Beide Ver-
fahren basieren wieder auf dem Trick von Fehlberg und sind effektiv zweistufig.

Kapitel 6
Randwertaufgaben
Wir setzen in den folgenden drei Kapiteln die Einfuhrung in die numerische Behandlung gewohn-licher Differentialgleichungen mit Randwertaufgaben 2. Ordnung fort. Dabei sucht man dieLosung einer Differentialgleichung zweiter Ordnung. Deren eindeutige Festlegung erfolgt durchRandbedingungen, d.h. Bedingungen an die Losung am Randes des betrachteten Losungsinter-valls.
6.1 Einfuhrendes Beispiel. Definitionen
Beispiel 6.1. Wir betrachten einen isothermen Stromungsreaktor mit kontinuierlicher Zufuhrbzw. Abfuhr der Reaktionsmasse bzw. des Reaktionsproduktes. Die Konzentrationsverteilungc(x1, x2, x3, t) im Reaktor ergibt sich aus der Stoffbilanzgleichung
∂c
∂t= −
3∑
i=1
∂
∂xi(wic) +
3∑
i=1
∂
∂xi(D
∂c
∂xi) + r(c).
Dabei sind w = (wi)i das Geschwindigkeitsfeld der Stromung im Reaktor, D der Diffusionsko-effizient und r(c) der Reaktionsterm. Zur Vereinfachung nehmen wir einen stationaren Reaktor-betrieb, d.h. ∂c
∂t = 0, konstante Diffusionskonstante D und ein konstantes Geschwindigkeitsfeldw = (w, 0, 0) an. Ferner sollen Anderungen der Konzentration c nur in axialer Richtung x desrotationssymmetrischen Reaktors betrachtet werden. Dann vereinfacht sich die Stoffbilanzglei-chung zur gewohnlichen Differentialgleichung 2. Ordnung
−Dd2c
dx2+ w
dc
dx+ r(c) = 0, 0 < x < L.
Durch Entdimensionierung mittels ξ := xL , u := c
c0mit der Anfangskonzentration c0 erhalten wir
mit der Peclet-Zahl P := wLD
− 1
P
d2u
dξ2+
du
dξ+ R(u) = 0, 0 < ξ < 1.
Die Losung kann vereinfachend durch die Randbedingungen
u(0) − 1
P
du(0)
dξ= 1,
du(1)
dξ= 0
festgelegt werden. 2
57

58 KAPITEL 6. RANDWERTAUFGABEN
Wir geben nachfolgend eine Klassifikation gewohnlicher Differentialgleichungen 2. Ordnung
F (x, u(x), u′(x), u′′(x)) = 0. (6.1)
Definition 6.2. Eine Differentialgleichung 2. Ordnung heißt quasilinear, falls
F (x, u, u′, u′′) := −u′′ + B(x, u)u′ + C(x, u) = 0,
semilinear, falls
F (x, u, u′, u′′) := −u′′ + b(x)u′ + C(x, u) = 0,
bzw. linear, falls
F (x, u, u′, u′′) := −u′′ + b(x)u′ + c(x)u − f(x) = 0.
Offenbar ist die im Beispiel 6.1 betrachtete Gleichung semilinear.
Die Randbedingungen sind im allgemeinen Fall
Gi(a, b, u(a), u(b), u′(a), u′(b)) = 0, i = 1, 2
nichtlinear und gekoppelt. In Anwendungen ist es oft ausreichend, Randbedingungen in linearerund entkoppelter Form zu betrachten. Dies vereinfacht auch die Untersuchung entsprechenderRandwertprobleme (RWP) erheblich.
Definition 6.3. Lineare und entkoppelte Randbedingungen der Form
u(a) = α, u(b) = β (6.2)
u′(a) = α, u′(b) = β (6.3)
c1u(a) + u′(a) = α, c2u(b) + u′(b) = β (6.4)
heißen Randbedingungen 1. Art (oder vom Dirichlet-Typ), 2. Art (oder vom Neumann-Typ)bzw. 3. Art (oder vom Robin-Typ).
Man spricht von gemischten Randbedingungen, wenn auf x = a und x = b unterschiedlicheTypen von Randbedingungen gestellt werden. Dies trifft in Beispiel 6.1 zu.
Bei den weiteren Betrachtungen werden wir in der Regel vereinfachend lineare RWP 1. Art, d.h.
(Lu)(x) := −u′′(x) + b(x)u′(x) + c(x)u(x) = f(x), a < x < b (6.5)
u(a) = α, u(b) = β (6.6)
betrachten. Mittels
u(x) = v(x) + αx − b
a − b+ β
x − a
b − a
kann man die Untersuchung auf den Fall homogener Randbedingungen, d.h. α = β = 0 zuruckfuhren.Uber x = (b − a)ξ transformiert man das RWP auch oft auf das Einheitsintervall, d.h.
(Lu)(x) := −u′′(x) + b(x)u′(x) + c(x)u(x) = f(x), 0 < x < 1 (6.7)
u(0) = u(1) = 0. (6.8)

6.2. LOSBARKEIT DES 1. RWP IM SYMMETRISCHEN FALL 59
6.2 Losbarkeit des 1. RWP im symmetrischen Fall
Nachfolgendes Beispiel zeigt, daß RWP 2. Ordnung nicht in jedem Fall losbar oder eindeutiglosbar sind.
Beispiel 6.4. Die allgemeine Losung der Schwingungsgleichung
−u′′(x) − u(x) = 0, 0 < x < b
hat die Form u(x) = c1 cos x+c2 sin x. Die beiden Konstanten sind so zu bestimmen, daß jeweilsdie folgenden Randbedingungen u(0) = α, u(b) = β erfullt werden. Daraus ergibt sich daslineare System
cos(0)c1 + sin(0)c2 = α, cos(b)c1 + sin(b)c2 = β.
Die Matrix A dieses Systems hat die Determinante det(A) = sin b. Aus der Losungstheorielinearer Gleichungssysteme folgt, daß das System bei sin b 6= 0 eine eindeutige Losung sowie beisin b = 0 in Abhangigkeit von b, α und β entweder keine oder unendlich viele Losungen hat. 2
Wir betrachten noch einen Spezialfall, in dem die Losung in Integralform angebbar ist. Diemehrdimensionale Verallgemeinerung ist das fur Anwendungen wichtige Poisson-Problem.
Lemma 6.5. Die Funktion
u(x) =
∫ 1
0G(x, t)f(t)dt, x ∈ [0, 1]
mit der Greenschen Funktion (vgl. dazu Ubungsaufgabe)
G(x, t) :=
t(1 − x), 0 ≤ t ≤ x ≤ 1x(1 − t), 0 ≤ x ≤ t ≤ 1
lost das 1. RWP der Poisson-Gleichung
−u′′(x) = f(x), x ∈ (0, 1); u(0) = u(1) = 0.
Zur Klarung der Losbarkeit des RWP (6.7), (6.8) betrachten wir hier zunachst den allgemeinensymmetrischen Fall mit b(x) ≡ 0. Hier gilt der
Satz 6.6. Gelte c, f ∈ C[0, 1] sowie b(x) ≡ 0, c(x) ≥ 0 in [0, 1]. Dann existiert eine und nureine Losung u ∈ C2[0, 1] des RWP (6.7), (6.8).
Beweis: (i) Eindeutigkeit: Wir nehmen an, u1, u2 sind Losungen des RWP (6.7), (6.8). Danngenugt u := u1 − u2 dem homogenen RWP
−u′′ + cu = 0, 0 < x < 1; u(0) = u(1) = 0.
Multiplikation der Differentialgleichung mit u, Integration uber [0, 1] und partielle Integrationdes Integralterms mit u′′u fuhrt unter Beachtung der Randbedingungen auf
0 =
∫ 1
0(−u′′ + cu)udx =
∫ 1
0(u′)2 + cu2dx.
Wegen c ≥ 0 und u ∈ C[0, 1] folgt daraus u(x) ≡ 0 in [0, 1] und damit die Eindeutigkeit derLosung von (6.7), (6.8).

60 KAPITEL 6. RANDWERTAUFGABEN
(ii) Existenz: Die allgemeine Losung des RWP (6.7), (6.8) hat die Gestalt
u(x) = α1u1(x) + α2u2(x) + u(x).
Dabei bilden u1, u2 ein Fundamentalsystem aus zwei linear unabhangigen Losungen der homoge-nen Differentialgleichung (d.h. mit f(x) ≡ 0.) u ist eine (beliebige) Losung der Gleichung (6.7).Die Aussage laßt sich mit Hilfe des Satzes von Picard-Lindelof zeigen, der im Zusammenhangmit der Losbarkeit von Anfangswertproblemen behandelt wurde (vgl. Ubungsaufgabe dazu).Zur Erfullung der Randbedingungen entsteht das lineare Gleichungssystem
u1(0)α1 + u2(0)α2 = −u(0)
u1(1)α1 + u2(1)α2 = −u(1)
fur die Koeffizienten α1 und α2. Dieses System ist eindeutig losbar. Sind namlich αi, i = 1, 2Losung des zugehorigen homogenen Systems, ware u = α1u1 + α2u2 Losung des entsprechendenhomogenen RWP und damit u ≡ 0 nach Teil (i). Wegen der linearen Unabhangigkeit von u1, u2
impliziert dies α1 = α2 = 0. 2
Bemerkung 6.7. Die Existenz- und Eindeutigkeitsaussage von Satz 6.6 laßt sich unter Verwen-dung Greenscher Funktionen ausdehnen auch auf den semilinearen Fall
−u′′(x) = g(x, u(x)), x ∈ (0, 1), u(0) = u(1) = 0.
6.3 Losbarkeit des 1. RWP im nichtsymmetrischen Fall
Wir betrachten nun das (eventuell nichtsymmetrische) RWP
(Lu)(x) := −u′′(x) + b(x)u′(x) + c(x)u(x) = f(x), 0 < x < 1 (6.9)
u(0) = α, u(1) = β. (6.10)
Zunachst gelingt eine Transformation auf den symmetrischen Fall mittels
u(x) = v(x) exp
1
2
∫ x
0b(t)dt
.
Nach kurzer Rechnung erhalt man fur v das RWP
(Lv)(x) := −v′′(x) + c(x)v(x) = f(x), 0 < x < 1; v(0) = α, v(1) = β
mit
c(x) := c(x) +1
4b2(x) − 1
2b′(x), f(x) := f(x) exp
−1
2
∫ x
0b(t)dt
.
Unter der Voraussetzung c(x) ≥ 0, x ∈ [0, 1] erhalt man sofort nach Satz 6.6 Existenz undEindeutigkeit der Losung des RWP (6.9),(6.10), sofern etwa b ∈ C1[0, 1] gilt.
Allgemeiner gilt der folgende Satz.
Satz 6.8. (i) Hat das (6.9),(6.10) zugeordnete homogene RWP (d.h. f(x) ≡ 0, α = β = 0) nurdie triviale Losung, so hat das RWP (6.9),(6.10), eine und nur eine Losung in
X := v ∈ C2[0, 1] : v(0) = α, v(1) = β.

6.3. LOSBARKEIT DES 1. RWP IM NICHTSYMMETRISCHEN FALL 61
(ii) Ist c(x) ≥ 0, so hat das (6.9),(6.10) zugeordnete homogene RWP nur die triviale Losung.(Nach Aussage von Teil (i) des Satzes 6.8. ergibt sich daraus auch eine Existenzaussage fur dasRWP (6.9),(6.10).)
Wir beweisen hier nur das Resultat (ii) mittels des wichtigen Maximum-Minimum Prinzips.
Lemma 6.9. Gelte b, c ∈ C[0, 1) sowie c(x) ≥ 0. Dann gelten fur u ∈ C[0, 1] ∩ C2(0, 1) dieAussagen:
(i) (Lu)(x) ≤ 0 in (0, 1) =⇒ u(x) ≤ max0;u(0), u(1)
(ii) (Lu)(x) ≥ 0 in (0, 1) =⇒ u(x) ≥ min0;u(0), u(1).Beweis: (1) Fur den Differentialoperator Lu := −u′′ + bu′, d.h. c ≡ 0, beweisen wir zuerst dieAussagen
(i’) (Lu)(x) ≤ 0 in (0, 1) =⇒ u(x) ≤ maxu(0), u(1)
(ii’) (Lu)(x) ≥ 0 in (0, 1) =⇒ u(x) ≥ minu(0), u(1).Wir beschranken uns beim Nachweis auf (i’).
(i′1) Sei (Lu)(x) < 0 in (0, 1). Wir nehmen an, daß u ein Maximum in x0 ∈ (0, 1) annimmt.Wegen u′(x0) = 0 folgt
(Lu)(x0) = −u′′(x0) < 0
im Widerspruch zur Bedingung u′′(x0) < 0 fur ein Maximum.
(i′2) Sei nun (Lu)(x) ≤ 0 in (0, 1). Fur die Hilfsfunktion v(x) := δ exp (λx) mit δ > 0 gilt
(Lv)(x) = λ(b − λ)δeλx < 0
fur geeignetes λ. Wegen L(u + v)(x) < 0 ergibt (i′1)
(u + v)(x) ≤ max(u + v)(0), (u + v)(1).
Im Grenzfall δ → 0 folgt die gesuchte Aussage.
(2) Sei jetzt c(x) ≥ 0 in (0, 1) Die Punktmenge
G+ := x ∈ (0, 1) : u(x) > 0
ist wegen u ∈ C[0, 1] offen. Ferner ist
(Lu)(x) ≤ −c(x)u(x) ≤ 0 auf G+.
Anwendung von (1) auf jeder Zusammenhangskomponente Gi von G+ zeigt
u(x) ≤ maxx∈∂Gi
u(x), ∀x ∈ G+.
Dabei ist ∂Gi der Rand von Gi. Nach Definition von G+ impliziert das die gewunschte Aussage
u(x) ≤ max0;u(0), u(1).
(3) Die Minimumaussage (ii) wird analog bewiesen. 2
Als Folgerung beweisen wir folgendes Resultat uber die Stabilitat der Losung bezuglich der Pro-blemdaten f, α, β.

62 KAPITEL 6. RANDWERTAUFGABEN
Satz 6.10. Seien b, c ∈ C[0, 1] und c(x) ≥ 0. Fur Losungen u ∈ C2(0, 1) ∩ C[0, 1] des RWP
Lu(x) = f(x), x ∈ (0, 1); u(0) = α, u(1) = β
gilt‖u‖C[0,1] ≤ C‖f‖C[0,1] + max u(0), u(1).
Beweis: Fur die Hilfsfunktion
v(x) := A − Beλx, A,B > 0
mit hinreichend großer Konstante λ > 0 gilt
Lv(x) = −Beλxc(x) + b(x)λ − λ2 + c(x)A
≥ Beλxλ2 − λb(x) − c(x) ≥ B.
Mit B := ‖f‖C[0,1] folgern wir daraus
L(v ± u)(x) ≥ B ± f(x) ≥ B − ‖f‖C[0,1] = 0.
Ferner gilt fur die Randwerte x = 0 und x = 1
(v ± u)(x) = A − Beλx ± u(x) ≥ A − Beλ − max u(0), u(1) = 0,
sofern A := max u(0), u(1) + Beλ. Wegen L(v ± u) ≥ 0 in (0, 1) und v ± u ≥ 0 fur dieRandpunkte x = 0 und x = 1 erhalten wir nach dem Lemma 6.9
(v ± u)(x) ≥ 0, x ∈ (0, 1),
d.h.
|u(x)| ≤ v(x) ≤ A − B
≤ max u(0), u(1) + B(eλ − 1)
≤ max u(0), u(1) + (eλ − 1)‖f‖C[0,1].
Das ist die Behauptung. 2
Beweis von Satz 6.8 (ii): Die Aussage des Satzes 6.10 impliziert nun die Eindeutigkeit derLosung, d.h. die Aussage von Satz 6.8 (ii). 2
6.4 Exkurs: Klassische Losungen elliptischer RWP
Man kann viele Aussagen fur Zweipunkt-RWP ubertragen auf lineare elliptische Differentialglei-chungen 2. Ordnung
(Lu)(x) := −n∑
i=1
∂2u
∂x2i
(x) +
n∑
j=1
bj(x)∂u
∂xj(x) + c(x)u(x) = f(x), x ∈ Ω (6.11)
bei gegebenen Funktionen bj , c, f : Ω → R, j = 1, ..., n in einem beschrankten Gebiet Ω ⊂ Rn.
Einfachster und zugleich wichtiger Spezialfall von (6.11) ist die Poisson-Gleichung
−n∑
i=1
∂2u
∂x2i
(x) = f(x), x ∈ Ω. (6.12)

6.4. EXKURS: KLASSISCHE LOSUNGEN ELLIPTISCHER RWP 63
Bei gegebener Funktion g : ∂Ω → R betrachten wir das Dirichletsche RWP
(Lu)(x) = f(x), x ∈ Ω; u(x) = g(x), x ∈ ∂Ω. (6.13)
Fur die nachfolgenden Ausfuhrungen benotigen wir den Begriff Holder-Stetigkeit. Seien 0 ≤ s ≤ 1und m ∈ N0. Dann istr Holder-Raum Cm;s(Ω) die Menge der Funktionen aus Cm(Ω) mit
‖u‖Cm;s(Ω) := ‖u‖Cm(Ω) +∑
|α|=m
supx,y∈ Ω
x 6=y
|Dαu(x) − Dαu(y)||x − y|s < ∞. (6.14)
Man sagt, dass der Gebietsrand ∂Ω zur Klasse Cm,s gehort, falls eine endliche offene Uberdeckungdes Randes lokal mittels Funktionen aus der Klasse Cm,s beschrieben werden kann.
Definition 6.11. Fur ein beschranktes Gebiet Ω ⊂ Rn der Klasse C2;s mit s ∈ (0, 1] und
hinreichend glatte Daten gemaß
bj, c, f ∈ C0;s(Ω), i, j = 1, ..., n; ∃g ∈ C2;s(Ω) : g|∂Ω = g (6.15)
heißt u ∈ C2;s(Ω) klassische Losung des Dirichletschen Randwertproblems (6.13) genau dann,wenn die Gleichungen (6.13) punktweise auf Ω bzw. ∂Ω erfullt sind.
Es kann gezeigt werden, daß der (gegenuber Definition 6.11) abgeschwachte klassische Losungs-begriff u ∈ C2(Ω) ∩ C(Ω) nicht fur eine geeignete Losbarkeitstheorie fur das Randwertproblem(6.13) ausreichend ist. Von Schauder stammt eine entsprechende Existenztheorie in Holder-Raumen C2;s(Ω) mit s ∈ (0, 1). Insbesondere gilt folgender Alternativsatz, den wir bereits furden eindimensionalen Fall in Kapitel 1 besprochen hatten.
Satz 6.12. Unter den Voraussetzungen der Definition 6.11 gilt fur die Losbarkeit des Randwert-problems (6.13) die folgende Fredholm-Alternative: Es gilt genau einer der Falle (i) oder (ii).
(i) Das homogene RWP
(Lu)(x) = 0 in Ω; u(x) = 0 auf ∂Ω
hat nur die triviale Losung. Dann besitzt das inhomogene RWP
(Lu)(x) = f(x) in Ω; u(x) = g(x) auf ∂Ω
eine und nur eine klassische Losung u ∈ C2;s(Ω) fur beliebige Daten f und g gemaß (6.15).
(ii) Das homogene Problem hat nichttriviale Losungen, die einen endlichdimensionalen Teilraumvon C2;s(Ω) bilden.
Wir suchen nun (wie bereits im eindimensionalen Fall in Abschnitt 6.3) nach hinreichenden Be-dingungen fur die Eindeutigkeit der Losung des Randwertproblems (6.13) oder alternativ dafur,daß das entsprechende homogene Problem nur die triviale Losung besitzt. Dazu kann man denfolgenden Vergleichssatz benutzen, der aus dem Maximum-Prinzip folgt.
Satz 6.13. Sei Ω ⊂ Rn ein beschranktes Gebiet mit mindestens Lipschitz-stetigem Rand. Der
Differentialoperator L aus (6.13) sei gleichmaßig elliptisch, ferner sei c(x) ≥ 0. Fur zwei Funk-tionen U, V ∈ C2(Ω) ∩ C(Ω) gelte
(LU)(x) ≤ (LV )(x) ∀x ∈ Ω
U(x) ≤ V (x) ∀x ∈ ∂Ω.

64 KAPITEL 6. RANDWERTAUFGABEN
Dann folgt U(x) ≤ V (x) fur alle Punkte x ∈ Ω.
Beweis: Folgerung aus nachstehendem Maximum-Minimum Prinzip.
Fur die Daten des Operators L seien die Voraussetzungen von Satz 6.14 erfullt. Fur die Funktionu ∈ C2(Ω) ∩ C(Ω) gelten dann folgende Aussagen:
(i) Aus (Lu)(x) ≤ 0 folgt u(x) ≤ max0;maxx∈∂Ω u(x).(ii) Aus (Lu)(x) ≥ 0 folgt u(x) ≥ min0;minx∈∂Ω u(x).(Beweis: vgl. Ubungsaufgabe - erfolgt analog zum eindimensionalen Fall) 2
Als Folgerung ergibt sich die gesuchte Existenzaussage.
Folgerung 6.14. Unter den Voraussetzungen der Definition 6.11 und des Satzes 6.13 gibt eseine und nur eine klassische Losung des RWP (6.13).

Kapitel 7
Finite-Differenzen-Verfahren
Im vorliegenden Kapitel besprechen wir das klassische Finite Differenzen Verfahren (FDM)zur Losung von Zweipunkt-Randwertaufgaben. Bei der Finite-Differenzen Methode ersetzt manAbleitungen in der Differentialgleichung durch Differenzenquotienten. Dies fuhrt dann zu einemlinearen Gleichungssystem fur Naherungswerte u∆ an die gesuchten Werte u der Losung invorgegebenen Knotenpunkten.
7.1 Definition der klassischen FDM
Ausgangspunkt ist das lineare Randwertproblem (RWP)
−u′′(x) + b(x)u′(x) + c(x)u(x) = f(x), 0 < x < 1 (7.1)
u(0) = u(1) = 0. (7.2)
Wir betrachten vereinfachend eine aquidistante Zerlegung ∆ := xi = ih, i = 0, ..., n + 1 mitder Schrittweite h = 1
n+1 , n ∈ N. Zur Approximation der ersten Ableitung u′(xi) betrachten wirdrei Varianten, die auf dem sogenannten Dreipunktestern xi−1, xi, xi+1 basieren.
• Vorwartsdifferenzen-Quotient: D+u(xi) := u(xi+1)−u(xi)h
• Ruckwartsdifferenzen-Quotient: D−u(xi) :=u(xi)−u(xi−1)
h
• Zentraler Differenzen-Quotient: D0u(xi) := u(xi+1)−u(xi−1)2h
Zur Approximation von u′′(xi) nutzen wir den zentralen Differenzenquotienten 2. Ordnung
D+D−u(xi) :=u(xi+1) − 2u(xi) + u(xi−1)
h2.
Fur die Naherungswerte u∆(xi) an die gesuchten Losungswerte u(xi) in den Knotenpunkten xi
erhalten wir bei Approximation der ersten und zweiten Ableitungen in der Differentialgleichung(7.1) durch die zentralen Differenzenquotienten 1. bzw. 2. Ordnung das System
−u∆(xi+1) − 2u∆(xi) + u∆(xi−1)
h2+ b(xi)
u∆(xi+1) − u∆(xi−1)
2h+ c(xi)u∆(xi) = f(xi)
Mit der Notation
ui := u∆(xi); bi := b(xi), ci := c(xi), fi := f(xi)
65

66 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
erhalten wir das System von Differenzengleichungen
1
h2
[
−(
1 +bih
2
)
ui−1 +(2 + cih
2)ui −
(
1 − bih
2
)
ui+1
]
= fi, i = 1, ..., n. (7.3)
Hinzu kommen wegen der Randbedingungen (7.2) die Forderungen
u0 = un+1 = 0. (7.4)
Mit den Bezeichnungen
A :=1
h2tridiag
−(
1 +bih
2
)
; (2 + cih2);−
(
1 − bih
2
)
und U = (u1, ..., un)T , F = (f1, ..., fn)T ergibt sich aus (7.3), (7.4) das lineare Gleichungssystem
AU = F. (7.5)
Bemerkung 7.1. Im Fall inhomogener Randbedingungen 1. Art u(0) = α, u(1) = β setzt man
u0 = α, un+1 = β und bringt die entsprechenden Matrixeintrage 1h2
(
1 + b1h2
)
α fur i = 1 und
1h2
(1 − bnh
2
)β fur i = n auf die rechte Seite.
Die Diskretisierung von Randbedingungen 2. und 3. Art behandeln wir in den Ubungen. 2
Von Interesse sind nun folgende Fragen:
• Losbarkeit des diskreten Problems (7.5)
• Konvergenz der Losung von (7.5) fur h → 0 gegen die Losung des Zweipunkt-RWP(7.1),(7.2).
7.2 Losung des diskreten Problems
Eine hinreichende Losbarkeitsbedingung fur das diskrete Problem (7.5) gibt
Satz 7.2. Fur das Problem (7.1),(7.2) gelte
ci = c(xi) ≥ 0,
∣∣∣∣
bih
2
∣∣∣∣≤ 1, i = 1, ..., n. (7.6)
Dann hat das zugehorige klassische Finite-Differenzen Schema (7.3),(7.4) bzw. (7.5) eine undnur eine Losung U = (u1, ...., un)T .
Bemerkung 7.3. Fur bi 6= 0 ergibt Bedingung (7.6) eine Schrittweitenbeschrankung h ≤ h0.Wir kommen auf dieses Problem in Abschnitt 7.3 zuruck. 2
Beweis von Satz 7.2: Die Matrix A ist unter Voraussetzung (7.6) schwach diagonal-dominant,denn:
|aii| := |2 + cih2| ≥
∑
j 6=i
|aij | :=
∣∣∣∣1 +
bih
2
∣∣∣∣+
∣∣∣∣1 − bih
2
∣∣∣∣= 2, i = 1, . . . , n.
Ferner ist A irreduzibel. Dies impliziert die Invertierbarkeit von A und damit die eindeutigeLosbarkeit des Systems (7.5). 2
Unter den Voraussetzungen von Satz 7.2 ist das diskrete Problem durch die einfachsten itera-tiven Verfahren (wie Gesamt- und Einzelschritt Verfahren, SOR) losbar. Ein derartiger Zugang

7.2. LOSUNG DES DISKRETEN PROBLEMS 67
ist auch beim allgemeineren Problem von Randwertaufgaben bei partiellen Differentialgleichun-gen fur die dort entstehenden sehr großen und schwachbesetzten linearen Gleichungssystemeerforderlich. Aufgrund der sehr speziellen Tridiagonalstruktur der Matrix A erweist sich aberhier die direkte Losung mittels LU−Zerlegung als wesentlich efffizienter. Wir betrachten dazuallgemeiner Tridiagonalmatrizen
A = tridiag (bi, ai, ci) ∈ Rn×n, b1 = cn = 0.
Fur die LU−Zerlegung setzen wir an
A = LU, L = tridiag(bi;αi; 0) ∈ Rn×n, U = tridiag(0; 1; γi) ∈ R
n×n.
Ausmultiplizieren auf der Hauptdiagonalen ergibt die Beziehungen
a1 = α1; ai = αi + biγi−1, i = 2, ..., n,
auf der oberen Nebendiagonalen entsteht
ci = γiαi, i = 1, ..., n − 1.
Dies ermoglicht eine rekursive Berechnung der Großen αi und γi uber
α1 = a1; γi−1 =ci−1
αi−1, αi = ai − biγi−1, i = 2, ..., n.
Die Realisierbarkeit dieses Verfahrens ist bei αi 6= 0, i = 1, ..., n gesichert (siehe unten).
Wir erhalten damit den folgenden Thomas-Algorithmus:
1. LU−Zerlegung von A, d.h. Bestimmung von αi, γi
2. Lose das gestaffelte System Lz = F durch Vorwartseinsetzenz1 = f1
α1, zi = 1
αi(fi − bizi−1), i = 2, ..., n
3. Lose das gestaffelte System Uu = z durch Ruckwartseinsetzenun = zn, ui = zi − γiui+1, i = n − 1, ..., 1.
Eine hinreichende Losbarkeitsbedingung liefert das
Lemma 7.4. Fur die Matrix A = tridiag (bi, ai, ci) ∈ Rn×n gelte
|a1| > |c1| > 0; |an| > |cn| > 0;
|ai| ≥ |bi| + |ci| > 0, bici 6= 0, i = 2, ..., n − 1. (7.7)
Dann ist die Matrix A nichtsingular und fur die Koeffizienten der LU−Zerlegung gilt
|γi| < 1, i = 1, ..., n − 1; αi 6= 0, i = 1, ..., n.
Beweis: vgl. Kurs Numerische Mathematik I , Lemma 2.18 2
Bemerkung 7.5. Fur den Thomas-Algorithmus benotigt man 0(n) wesentliche Operationen,d.h. der Rechenaufwand ist asymptotisch fur n → ∞ optimal. 2

68 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
7.3 Stabilitats- und Konvergenzanalyse
Wir fuhren hier die fur die Fehleranalyse des Verfahrens wesentlichen Begriffe ein. Sie sind soallgemein gehalten, daß sich die Analyse auf allgemeinere Diskretisierungsverfahren fur Rand-wertaufgaben ubertragen laßt.
Seien ∆ := x1, ..., xn die inneren Knotenpunkte im Intervall (0, 1) und γ := ∆\∆ = x0, xn+1die Randpunkte. Rhv bezeichne die Einschrankung von v ∈ C[0, 1] auf ∆ und L den Differen-tialoperator des Randwertproblems. u bzw. U sind die Losung des Randwertproblems bzw. desdiskreten Problems. Dann gilt fur den Diskretisierungsfehler Rhu − U
A(Rhu − U) = ARhu − AU = ARhu − F = ARhu − RhLu.
Der letzte Term wird auch als Defekt bezeichnet.
Zur Fehlerabschatzung sind nun sowohl eine Abschatzung des Defekts nach oben (Konsistenz-analyse) als auch eine Abschatzung des links stehenden Terms nach unten (Stabilitatsanalyse) ineiner geeigneten Norm erforderlich. Bei unseren Untersuchungen verwenden wir die Maximum-Norm
‖V ‖∞,∆ := maxi=1,...,n
|vi| fur V = (v1, ..., vn)T .
Dies fuhrt auf die
Definition 7.6. (i) Eine FDM heißt konsistent in der Maximum–Norm , falls
limh→0
‖ARhu − RhLu‖∞,∆ = 0.
(ii) Die FDM hat die Konsistenzordnung p, falls mit einer von h unabhangigen KonstantenCK > 0 gilt
‖ARhu − RhLu‖∞,∆ ≤ CKhp.
Der Konsistenzbegriff beschreibt, wie gut der Differentialoperator durch das Differenzenverfah-ren approximiert wird.
Definition 7.7. Eine FDM heißt stabil in der Maximum-Norm, falls fur den Vektor W aus
AW = F in ∆, W = 0 in γ
die Existenz einer von h unabhangigen Konstanten CS folgt mit
‖W‖∞,∆ = ‖A−1F‖∞,∆ ≤ CS‖F‖∞,∆.
Definition 7.8. (i) Eine FDM heißt konvergent in der Maximum-Norm , falls
limh→0
‖Rhu − U‖∞,∆ = 0.
(ii) Die FDM hat die Konvergenzordnung p, falls mit einer von h unabhangigen KonstantenM > 0 gilt
‖Rhu − U‖∞,∆ ≤ Mhp.
Wir beginnen mit der Analyse des Konsistenzfehlers:Die Abschatzung des Konsistenzfehlers der klassischen FDM (7.3),(7.4) fur das Zweipunkt-RWP(7.1),(7.2) erfolgt mittels des Taylorschen Satzes. Zunachst betrachten wir die Genauigkeit der

7.3. STABILITATS- UND KONVERGENZANALYSE 69
Approximation der auftretenden Ableitungen durch zentrale Differenzenquotienten.
Lemma 7.9. Es gilt
(i) (D0u)(x) = u′(x) + h2R, |R| ≤ 1
6‖u(3)‖C[0,1], falls u ∈ C3[0, 1]
bzw.
(ii) (D+D−u)(x) = u′′(x) + h2R, |R| ≤ 1
12‖u(4)‖C[0,1], falls u ∈ C4[0, 1].
Beweis: Aus der Taylor-Entwicklung an der Stelle x folgt
u(x ± h) = u(x) ± hu′(x) + h2 u′′(x)
2± h3R±
3
u(x ± h) = u(x) ± hu′(x) + h2 u′′(x)
2± h3 u(3)(x)
6+ h4R±
4
mit
R±3 =
1
h3
∫ x±h
x
[u′′(t) − u′′(x)
](x ± h − t)dt
R±4 =
1
h4
∫ x±h
x
[
u(3)(t) − u(3)(x)] (x ± h − t)2
2dt.
Dann ergibt sich die Aussage (i) aus
(D0u)(x) =u(x + h) − u(x − h)
2h= u′(x) + h2
(R+
3 − R−3
)
und einer Abschatzung der Restglied–Differenz. Aussage (ii) beweist man analog. 2
Damit finden wir
Lemma 7.10. Unter der Voraussetzung u ∈ C4[0, 1] an die Losung des RWP (7.1),(7.2) hatdie FDM (7.3),(7.4) die Konsistenzordnung 2.
Beweis: Aus (7.3),(7.4) bzw. (7.1),(7.2) haben wir unter Beachtung der eingefuhrten Bezeich-nungen
(ARhu − RhLu)(xi) =(−D+D−u(xi) + biD
0u(xi) + ciu(xi))
−(−u′′(xi) + biu
′(xi) + ciu(xi)).
Lemma 7.9 ergibt daraus
|(ARhu − RhLu)(x)| ≤ 1
12h2‖u(4)‖C[0,1] +
1
6h2‖b‖C[0,1]‖u(3)‖C[0,1], x ∈ ∆.
Maximumbildung uber alle Gitterpunkte xi liefert die Behauptung. 2
Bemerkung 7.11. Die Voraussetzung an die Losung u des RWP ist in der Regel nicht reali-stisch. Eine sorgfaltige Abschatzung zeigt
‖ARhu − RhLu‖∞,∆ ≤
Chα, u ∈ C2;α[0, 1]Ch1+α, u ∈ C3;α[0, 1]

70 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
mit 0 ≤ α ≤ 1 und den Holder–Raumen
Ck;α[0, 1] :=
v ∈ Ck[0, 1] : supx,y∈0,1);x 6=y
|v(k)(x) − v(k)(y)|‖x − y‖α
< ∞
. 2
Wir kommen nun zur Stabilitatsanalyse der klassischen FDM: Die oben angegebene Stabilitats-definition ist aquivalent zu
‖A−1‖∞ ≤ CS mit ‖B‖∞ := maxi=1,...,n
n∑
j=1
|bij| .
Bei den weiteren Untersuchungen nutzen wir die Halbordnungsrelation x ≥ 0 fur Vektoren x,falls komponentenweise gilt xi ≥ 0. Entsprechend gilt x ≥ y, falls x − y ≥ 0. Ferner schreibenwir fur Matrizen A ≥ 0, falls komponentenweise gilt aij ≥ 0.
Definition 7.12. Eine Matrix A heißt inversmonoton, falls aus der HalbordnungsrelationAx ≤ Ay auch x ≤ y folgt.
Zur Inversmonotonie von A ist die Existenz von A−1 mit A−1 ≥ 0 aquivalent.
Lemma 7.13. Unter den Voraussetzungen von Satz 7.2 ist A inversmonoton, d.h. A−1 ≥ 0.
Beweis: Wir betrachten die iterative Losung des linearen Gleichungssystems Az = r mitdem Gesamtschritt- oder Jacobi-Verfahren. Aus der Zerlegung A = D + AL + AR mit derDiagonalmatrix D und den strikten unteren bzw. oberen Dreiecksmatrizen AL und AR ergibtsich die Iteration
zm+1 = −D−1(AL + AR)zm + D−1r, m = 0, 1, .... (7.8)
Das Jacobi-Verfahren konvergiert unter den Voraussetzungen des Satzes 7.2, denn die Matrix Aist sowohl schwach diagonaldominant als auch irreduzibel. Man vergleiche hierzu die Ergebnissevon Kapitel 5 aus dem Kurs Numerische Mathematik I.
Fur die Spalten der inversen Matrix A−1 = (a1, ..., an) gilt Aai = ei, i = 1, ..., n mit denkartesischen Einheitsvektoren ei. Damit entsteht ai als Grenzelement der Iteration (7.8) mitr = ei und dem Startvektor z0 = 0.
Nach den Voraussetzungen von Satz 7.2 sind die Elemente von D−1 und −D−1(AL + AR)nichtnegativ. Daraus folgt die Aussage A−1 ≥ 0. 2
Nun besteht das Ziel darin, die Stabilitatskonstante CS abzuschatzen. Wir nutzen dazu das
Lemma 7.14. (M-Kriterium)Sei A ∈ R
n×n L−Matrix, d.h. gelte aij ≤ 0, i 6= j. Dann ist A inversmonoton genau dann, wennein (majorisierender) Vektor e > 0 existiert mit Ae > 0. Ferner gilt dann die Abschatzung
‖A−1‖∞ ≤ ‖e‖mink(Ae)k
.
Beweis: (i) Sei A inversmonoton. Dann wahle man e = A−1 (1, . . . , 1)T .
(ii) Ubungsaufgabe ! 2
Die gesuchte Abschatzung der Stabilitatskonstanten CS gelingt nun bei geeigneter Wahl einesmajorisierenden Vektors e zur Matrix A gemaß Lemma 7.14.
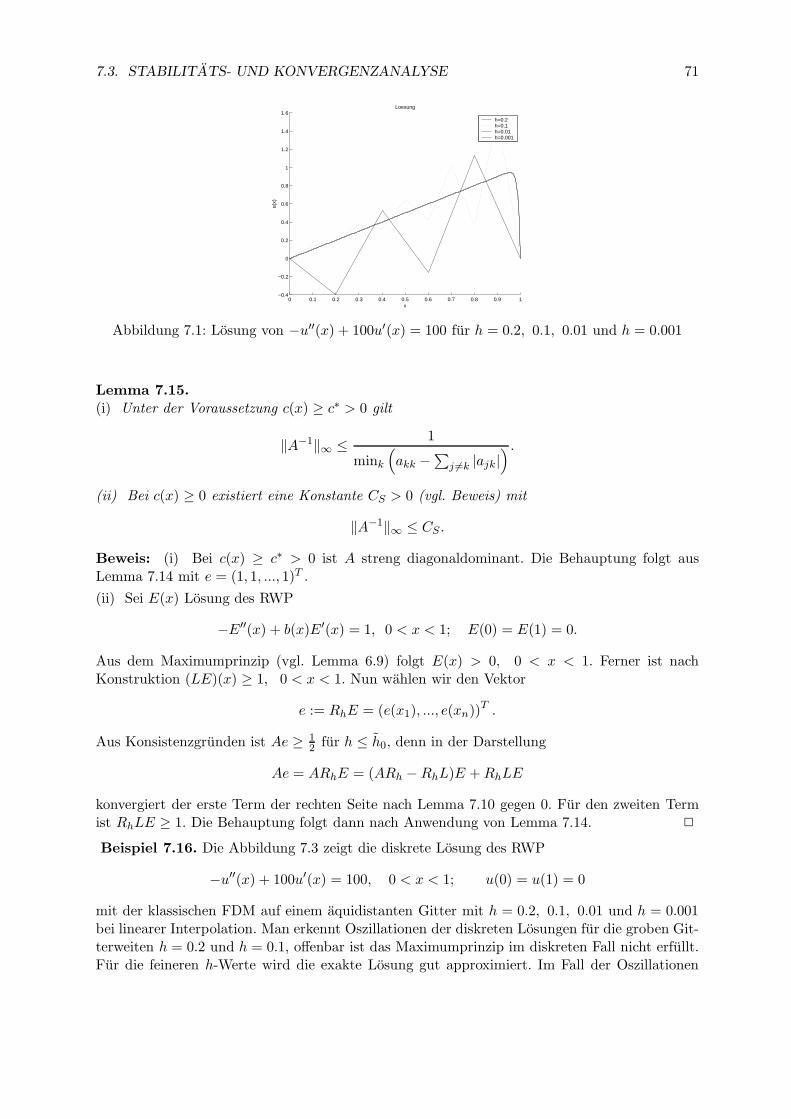
7.3. STABILITATS- UND KONVERGENZANALYSE 71
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6Loesung
x
u(x)
h=0.2 h=0.1 h=0.01 h=0.001
Abbildung 7.1: Losung von −u′′(x) + 100u′(x) = 100 fur h = 0.2, 0.1, 0.01 und h = 0.001
Lemma 7.15.(i) Unter der Voraussetzung c(x) ≥ c∗ > 0 gilt
‖A−1‖∞ ≤ 1
mink
(
akk −∑
j 6=k |ajk|) .
(ii) Bei c(x) ≥ 0 existiert eine Konstante CS > 0 (vgl. Beweis) mit
‖A−1‖∞ ≤ CS .
Beweis: (i) Bei c(x) ≥ c∗ > 0 ist A streng diagonaldominant. Die Behauptung folgt ausLemma 7.14 mit e = (1, 1, ..., 1)T .
(ii) Sei E(x) Losung des RWP
−E′′(x) + b(x)E′(x) = 1, 0 < x < 1; E(0) = E(1) = 0.
Aus dem Maximumprinzip (vgl. Lemma 6.9) folgt E(x) > 0, 0 < x < 1. Ferner ist nachKonstruktion (LE)(x) ≥ 1, 0 < x < 1. Nun wahlen wir den Vektor
e := RhE = (e(x1), ..., e(xn))T .
Aus Konsistenzgrunden ist Ae ≥ 12 fur h ≤ h0, denn in der Darstellung
Ae = ARhE = (ARh − RhL)E + RhLE
konvergiert der erste Term der rechten Seite nach Lemma 7.10 gegen 0. Fur den zweiten Termist RhLE ≥ 1. Die Behauptung folgt dann nach Anwendung von Lemma 7.14. 2
Beispiel 7.16. Die Abbildung 7.3 zeigt die diskrete Losung des RWP
−u′′(x) + 100u′(x) = 100, 0 < x < 1; u(0) = u(1) = 0
mit der klassischen FDM auf einem aquidistanten Gitter mit h = 0.2, 0.1, 0.01 und h = 0.001bei linearer Interpolation. Man erkennt Oszillationen der diskreten Losungen fur die groben Git-terweiten h = 0.2 und h = 0.1, offenbar ist das Maximumprinzip im diskreten Fall nicht erfullt.Fur die feineren h-Werte wird die exakte Losung gut approximiert. Im Fall der Oszillationen

72 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.05
0.1
0.15
0.2
0.25Loesung
x
u(x)
h=0.2 h=0.1 h=0.01 h=0.001
Abbildung 7.2: FDM-Losung zu Beispiel 7.18 bei h = 12 , 1
10 , 1100 , 1
1000
ist die Bedingung 12h|bi| ≤ 1 aus Satz 7.2 nicht erfullt; insofern ist diese Bedingung scharf (vgl.
auch Ubungsaufgabe, Blatt 7). 2
Wir kombinieren die Ergebnisse zum folgenden Konvergenzsatz.
Satz 7.17. Unter den Voraussetzungen von Satz 7.2 liege die Losung u des RWP (7.1),(7.2) inC4[0, 1]. Ferner sei eventuell h hinreichend klein. Dann gilt fur den Diskretisierungsfehler derklassischen FDM (7.3),(7.4)
‖Rhu − U‖∞,∆ = maxi
|u(xi) − ui| ≤ Mh2,
d.h. das Verfahren hat die Konvergenzordnung 2.
Beweis: Nach Konstruktion ist Rhu − U = 0 auf γh. Nach Lemma 7.10 ist ferner
‖ARhu − RhLu‖∞,∆ ≤ CKh2.
Mittels Lemma 7.15 folgt
C−1S ‖Rhu − U‖∞,∆ ≤ ‖ARhu − RhLu‖∞,∆ ≤ CKh2
und damit die Konvergenzaussage mit M = CSCK . 2
Beispiel 7.18. Die Abbildung 7.2 zeigt die diskrete Losung des RWP
−u′′(x) + sin(πx)u(x) = 2 + sin(πx)x(1 − x), 0 < x < 1; u(0) = u(1) = 0
mittels klassischer FDM auf einem aquidistanten Gitter mit den Schrittweiten h = 0.2, 0.1, 0.01und h = 0.0001. Die Knotenwerte wurden linear interpoliert. Man erkennt die Konvergenz derdiskreten Losung fur h → 0.
7.4 Exkurs: Finite-Differenzen-Methode fur Poisson-Problem
Wir wollen nun die numerische Losung von Zweipunkt-RWP im eindimensionalen Fall aufmehrdimensionale Probleme erweitern. Vereinfachend betrachten wir auf dem EinheitsquadratΩ = (0, 1) × (0, 1) das Dirichletsche RWP der Poisson-Gleichung, d.h.
−(∆u)(x1, x2) := −(
∂2u
∂x21
+∂2u
∂x22
)
= f(x1, x2), (x1, x2) ∈ Ω (7.9)
u(x1, x2) = g(x1, x2), (x1, x2) ∈ ∂Ω. (7.10)

7.4. EXKURS: FINITE-DIFFERENZEN-METHODE FUR POISSON-PROBLEM 73
Zur Definition des klassischen Differenzen-Verfahrens (FDM) definieren wir mit der (vereinfa-chend) aquidistanten Schrittweite h = 1
N , N ∈ N die Menge der Gitterpunkte
Zh := (x1, x2) : x1 = z1h, x2 = z2h, z1, z2 ganz.
Die Menge der inneren Gitterpunkte sei ωh := Zh∩Ω, die Menge der Randgitterpunkte entspre-chend γh := Zh ∩ ∂Ω.
Wir approximieren die zweiten partiellen Ableitungen in x1− bzw. x2-Richtung wie im eindi-mensionalen Fall durch den zentralen Differenzenquotienten 2. Ordnung, d.h.
(∆hu)(x1, x2) :=1
h2(u(x1 + h, x2) − 2u(x1, x2) + u(x1 − h, x2)
+ u(x1, x2 + h) − 2u(x1, x2) + u(x1, x2 − h)) . (7.11)
Man spricht auch von einem sogenannten Funfpunkte-Stern. Bezeichne wie im eindimensionalenFall Rhv die Einschrankung einer Funktion v : Ω → R auf das Gitter ωh∪γh. Ferner sei der VektorU = (Ui)
Mi=1 die durch die FDM erzeugte Naherung an die Werte Rhu der gesuchten stetigen
Losung auf dem Gitter. Dann lautet das dem 1. RWP der Poisson-Gleichung zugeordnete lineareGleichungssystem
−∆hU = Rhf in ωh (7.12)
U = Rhg in γh. (7.13)
Im Fall Dirichletscher Randbedingungen kann man die Randwerte U = Rhg eliminieren. Diekonkrete Gestalt des linearen Gleichungssystems hangt dann von der Numerierung der Gitter-punkte in ωh ab. Der einfachste Fall entsteht bei lexikographischer Anordnung gemaß
(h, h), (2h, h), ..., (1 − h, h)(h, 2h), (2h, 2h), ..., (1 − h, 2h)
...,...,
...,...,
(h, 1 − h), (2h, 1 − h), ..., (1 − h, 1 − h)
und Numerierung der Unbekannten in den Gitterpunkten auf ωh gemaß
U1, ..., UN−1, UN , ..., U2N−2, U2N−1...., U3N−3, ..., U(N−1)(N−1) .
Mit der Tridagonal-Matrix
T = tridiag (−1, 4, −1) ∈ R(N−1)×(N−1)
und der Einheitsmatrix I ∈ R(N−1)×(N−1) hat die entstehende Systemmatrix die Blocktridiagonal-
Gestalt
A =1
h2tridiag(−I, T, −I) ∈ R
(N−1)2×(N−1)2 . (7.14)
Man charakterisiert Differenzenverfahren auf regelmaßigen Gittern oft durch Differenzenster-ne bezuglich eines Gitterpunktes (x1, x2). Im allgemeinen Fall entsteht als Approximation desDifferentialoperators bei geeigneten Großen cij das Schema
∑
i,j
cijU(x1 + ih, x2 + jh).

74 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
Fur den Fall |i|, |j| ≤ 1 spricht man von kompakten Differenzen-Sternen. Der allgemeinste Fallist dabei dann ein Neunpunkte-Stern. Der oben genannte Funfpunkte-Stern ist ein Spezialfall.
Man kann die FDM auf allgemeineren Gebieten als dem hier betrachteten Einheitsquadrat er-zeugen. Man uberzieht den R
2 erneut mit dem Gitter Zh und verfahrt in inneren GitterpunktenZh ∩ Ω wie oben beschrieben. Die Approximation in den randnahen Gitterpunkten erfordertjedoch eine gesonderte Behandlung.
Wir analysieren nun exemplarisch die gerade eingefuhrte klassische FDM fur das 1. RWP desPoisson-Problems (7.9),(7.10) auf dem Einheitsquadrat. Dabei benutzen wir die zuvor eingefuhr-ten Grundbegriffe Konsistenz, Stabilitat und Konvergenz wieder bezuglich der Maximum-Norm.
Lemma 7.19. Die klassische Losung des Problems (7.9),(7.10) liege in C4(Ω). Dann gilt furden Konsistenzfehler der klassischen FDM (7.12),(7.13)
‖ARhu − RhLu‖∞,ωh≤ 1
6h2‖u‖C4(Ω). (7.15)
Beweis: vgl. Ubungsaufgabe 2
Lemma 7.20. Die klassische FDM (7.12),(7.13) fur das Problem (7.9),(7.10) ist bezuglich derMaximum-Norm stabil. Es gilt
‖A−1‖∞ ≤ CS =1
8. (7.16)
Beweis: Wir betrachten (ohne Beschrankung der Allgemeinheit) die bei lexikographischerAnordnung der inneren Gitterpunkte entstehende Matrix A aus (7.14). A = (aij) ist eineL0−Matrix, denn es gilt aii > 0 sowie aij < 0 fur i 6= j. Ferner pruft man sofort nach, daßdie Matrix schwach diagonaldominant und irreduzibel ist. Damit ist A M−Matrix, daher kanndas M−Kriterium angewendet werden.
Wir nehmen vereinfachend an, daß der Punkt (12 , 1
2) zum Gitter ωh gehort. Fur das Polynome∗(x1, x2) := x1(1−x1)+x2(1−x2) gilt offenbar sowohl e∗ > 0 als auch −∆e∗ = 4. Fur e := Rhe∗
gilt −∆he = 4, da quadratische Polynome durch den Funfpunkte-Stern exakt diskretisiert wer-den. Wegen ‖e‖∞,ωh
≤ 12 folgt nach dem M−Kriterium die gesuchte Aussage. 2
Beide Lemmata ergeben dann die gewunschte Konvergenzaussage
Satz 7.21. Die klassische FDM (7.12),(7.13) fur das Problem (7.9),(7.10) ist unter der Regu-laritatsvoraussetzung u ∈ C4(Ω) bezuglich der Maximum-Norm konvergent. Es gilt
‖Rhu − U‖∞,ωh≤ 1
48h2‖u‖C4(Ω). (7.17)
Zur Illustration dieser Untersuchungen betrachten wir die folgenden Beispiele. Die Rechnungenwurden dazu mit einem in MATLAB erstellten Finite-Differenzen-Programm durchgefuhrt.
Beispiel 7.22. Wir betrachten das Problem (7.9)- (7.10) mit f(x1, x2) = 4 sin 2πx1 sin πx2 undg(x1, x2) = 0. Die Losung u(x1, x2) = sin 2πx1 sin πx2 entspricht damit gerade einer Eigenfunk-tion des Laplace-Operators mit homogenen Dirichlet-Bedingungen. Die Abbildung 7.3 zeigt dieLosung und den Fehler des Finite-Differenzen-Schemas bei grober aquidistanter Schrittweiteh = 0.1. Ferner wird der Fehler in der Maximum-Norm in zwei Diagrammen dokumentiert. Inder halblogarithmischen Darstellung erkennt man sehr gut die in Satz 7.21 ermittelte quadrati-sche Konvergenzordnung. 2
Beispiel 7.23. Wir ermitteln die Losung von Problem (7.9) - (7.10) mit g(x1, x2) = 0 und der
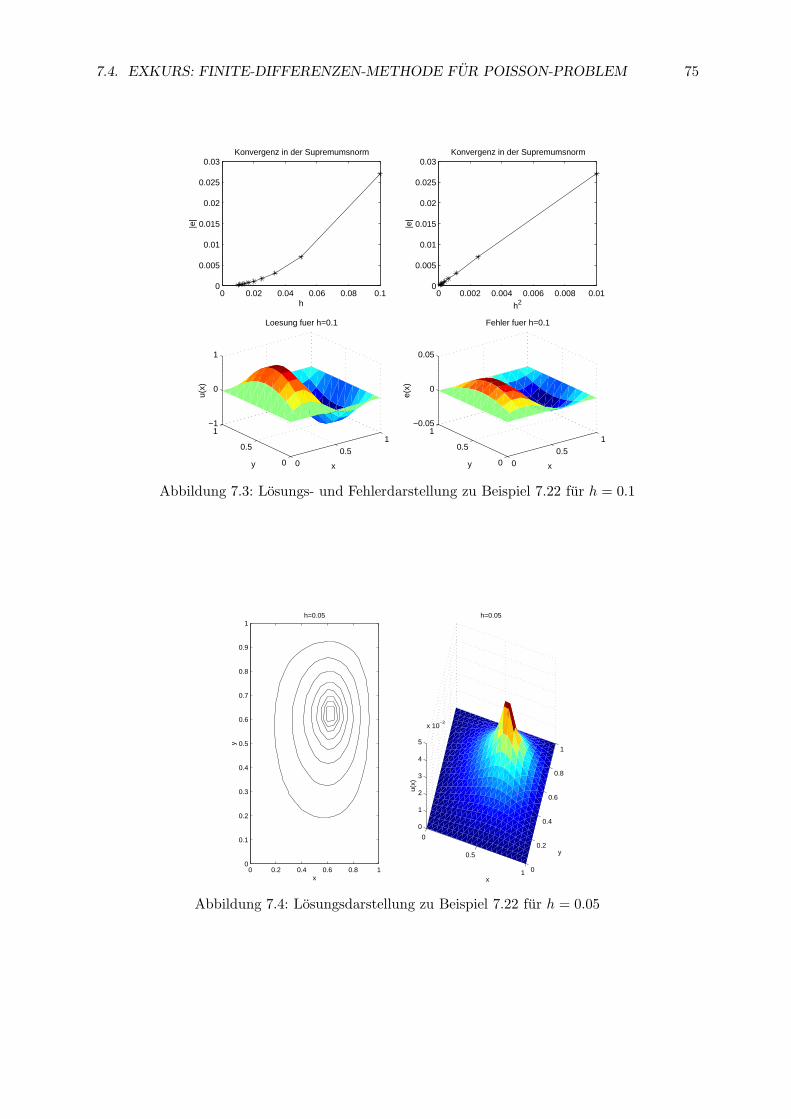
7.4. EXKURS: FINITE-DIFFERENZEN-METHODE FUR POISSON-PROBLEM 75
0 0.02 0.04 0.06 0.08 0.10
0.005
0.01
0.015
0.02
0.025
0.03Konvergenz in der Supremumsnorm
h
|e|
0 0.002 0.004 0.006 0.008 0.010
0.005
0.01
0.015
0.02
0.025
0.03Konvergenz in der Supremumsnorm
h2
|e|
00.5
1
0
0.5
1−0.05
0
0.05
x
Fehler fuer h=0.1
y
e(x)
00.5
1
0
0.5
1−1
0
1
x
Loesung fuer h=0.1
y
u(x)
Abbildung 7.3: Losungs- und Fehlerdarstellung zu Beispiel 7.22 fur h = 0.1
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1h=0.05
x
y
0
0.5
1 0
0.2
0.4
0.6
0.8
1
0
1
2
3
4
5
x 10−3
y
h=0.05
x
u(x)
Abbildung 7.4: Losungsdarstellung zu Beispiel 7.22 fur h = 0.05

76 KAPITEL 7. FINITE-DIFFERENZEN-VERFAHREN
unstetigen Quellfunktion f mit f(x1, x2) = 1 in Ω0 := [0.6, 0.65] × [0.6, 0.65] und f(x1, x2) = 0in Ω \ Ω0.
Die FDM-Losung mit der aquidistanten Schrittweite h = 0.05 ist in Abbildung 7.4 zu sehen.Trotz der relativ groben Diskretisierung wird die korrekte Losung qualitativ richtig widergespie-gelt. Man kann die Losung u als Temperatur interpretieren. Insbesondere erkennt man die Rolledes Laplace-Operators, der die im Teilgebiet Ω0 vorgegebene (unstetige) Warmequelle diffusivverteilt. 2

Kapitel 8
Ritz-Galerkin-Verfahren fur RWP
Im vorliegenden Kapitel schwachen wir den bisher verwendeten ”klassischen” Losungsbegrifffur Zweipunkt-Randwertaufgaben ab. Dies erlaubt zugleich einen naturlichen Zugang zu derFinite-Elemente Methode (FEM) und vereinfacht die Konvergenzanalyse.
8.1 Variationsgleichungen
Betrachtet wird die Zweipunkt-Randwertaufgabe
−u′′(x) + b(x)u′(x) + c(x)u(x) = f(x), 0 < x < 1 (8.1)
u(0) = u(1) = 0. (8.2)
Zunachst streben wir eine Abschwachung des klassischen Losungsbegriffs, d.h. von u ∈ C2(0, 1)∩C[0, 1], an. Sei etwa b = c ≡ 0 sowie f 6∈ C(0, 1). Dann liegt die Losung nicht in C2(0, 1).
Multiplikation von Gleichung (8.1) mit einer beliebigen Testfunktion
v ∈ X := w ∈ C1(0, 1) ∩ C[0, 1] : w(0) = w(1) = 0 (8.3)
und Integration uber (0, 1) ergibt
∫ 1
0
(−u′′ + bu′ + cu
)v dx =
∫ 1
0fv dx.
Partielle Integration des Terms −∫ 10 u′′v dx liefert unter Beachtung der Randwerte v(0) =
v(1) = 0∫ 1
0u′v′ dx +
∫ 1
0
(bu′ + cu
)v dx =
∫ 1
0fv dx ∀v ∈ X. (8.4)
Klassische Losungen u ∈ C2(0, 1)∩C[0, 1] von (8.1),(8.2) losen offenbar auch (8.4). Ebenso sind(bei hinreichend glatten Daten) nach Ruckwartsausfuhrung der vorgenommenen Umformungenklassische Losungen von (8.4) auch Losungen von (8.1),(8.2). Offenbar reicht aber z.B. schon dieForderung u ∈ X fur die Losungen von (8.4) aus. Daher bezeichnet man die Aufgabe
Finde u ∈ X, so daß a(u, v) = f(v), ∀v ∈ X (8.5)
77

78 KAPITEL 8. RITZ-GALERKIN-VERFAHREN FUR RWP
mit
a(u, v) :=
∫ 1
0u′v′ dx +
∫ 1
0
(bu′ + cu
)v dx (8.6)
f(v) :=
∫ 1
0fv dx (8.7)
auch als verallgemeinerte Aufgabenstellung zu (8.1),(8.2) bzw. als zugehorige Variationsglei-chung.
Wir vertiefen diesen Gedanken im Abschnitt 8.2 weiter. Zuvor betrachten wir noch den Zu-sammenhang mit Variationsproblemen. Seien vereinfachend b(x) ≡ 0 und c(x) ≥ 0. Mit demFunktional
J(u) :=1
2a(u, u) − f(u) (8.8)
=1
2
∫ 1
0(u′)2 + cu2 dx −
∫ 1
0fu dx, u ∈ X
betrachten wir das Variationsproblem
Finde u ∈ X, so daß J(u) ≤ J(v), ∀v ∈ X. (8.9)
Dann gilt
Lemma 8.1. Notwendige Losbarkeitsbedingung fur das Variationsproblem (8.9) ist im Fallb(x) ≡ 0, c(x) ≥ 0 die Variationsgleichung (8.5).
Beweis: Wir setzen fur festes u, v ∈ X und t ∈ R
Φ(t) := J(u + tv).
Notwendige Minimumbedingung fur die reellwertige Funktion Φ ist wegen
J(u + tv) =1
2
∫ 1
0(u′ + tv′)2 + c(u + tv)2 dx −
∫ 1
0f(u + tv) dx
dann
Φ′(0) =1
2
∫ 1
02(u′ + tv′)v′ + 2c(u + tv)v dx |t=0 −
∫ 1
0fv dx
= a(u, v) − f(v) = 0. 2
Bemerkung 8.2. Man kann zeigen, daß unter gewissen Glattheitsforderungen an die Daten(z.B. c, f ∈ C[0, 1]) eine Losung u ∈ X der Variationsgleichung (8.5) auch Minimum von (8.9)ist. 2
Variationsprobleme treten sehr oft in Naturwissenschaften und Technik als bekannte Grundprin-zipien (z.B. Prinzip der minimalen Energie usw.) auf und bilden einen wesentlichen Zugang zurmathematischen Modellierung realer Vorgange.
Es sei hervorgehoben, daß die Variationsgleichung (8.5) als verallgemeinerte Aufgabenstellungzu (8.1)-(8.2) auch im allgemeinen Fall sinnvoll bleibt, wenn nicht b(x) ≡ 0 gilt.

8.2. VERALLGEMEINERTE ABLEITUNGEN 79
8.2 Verallgemeinerte Ableitungen
Wir untersuchen jetzt Eigenschaften des Raumes X (vgl. (8.3)) in Verbindung mit der Sobolev-Norm
‖u‖H1 :=
∫ 1
0
[u′(x)
]2dx +
∫ 1
0[u(x)]2 dx
1/2
. (8.10)
Der Raum X ; ‖ · ‖H1 ist offenbar normierter Raum, jedoch nicht vollstandiger Raum (vgl.Ubungsaufgabe), d.h. kein Banach-Raum.
Die Norm (8.10) ist auch noch fur meßbare Funktionen u, u′ sinnvoll, die quadratisch uber (0, 1)im Lebesgue-Sinne integrierbar sind, d.h. fur Funktionen im Lebesgue-Raum
L2(0, 1) := v : (0, 1) → R meßbar :
∫ 1
0[v(x)]2 dx < ∞. (8.11)
Im Hinblick auf die Naherungslosung von Zweipunkt-Randwertaufgaben mittels FEM ist eineweitere Abschwachung des klassischen Losungsbegriffs sinnvoll. Wir wollen den entsprechendenGedankengang hier nur skizzieren:
Zunachst benotigen wir einige Begriffe. Es bezeichnet clV (A) den Abschluß der Teilmenge A vonV in der Topologie des Raumes V. Dann heißt
supp v := clRx ∈ (0, 1) : v(x) 6= 0
Trager von v ∈ C[0, 1]. Sei
C∞0 (0, 1) := v ∈ C∞(0, 1) : supp v ⊂ (0, 1),
d.h. Elemente dieser Menge verschwinden von beliebiger Ordnung bei x = 0 und x = 1. Fernersei
L1loc(0, 1) := v : (0, 1) → R meßbar :
∫
A|v(x)| dx < ∞ ∀A ⊂⊂ (0, 1)).
A ⊂⊂ B bedeutet dabei, daß A abgeschlossen ist und A ⊂ B gilt.
Partielle Integration ergibt fur u ∈ C1[0, 1] und beliebige Testfunktionen v ∈ C∞0 (0, 1)
∫ 1
0u′v dx = −
∫ 1
0uv′ dx. (8.12)
Nach der Holder’schen Ungleichung
∣∣∣∣
∫ 1
0uv′ dx
∣∣∣∣=
∣∣∣∣
∫
supp vuv′ dx
∣∣∣∣≤ ‖v′‖C[0,1]
∫
supp v|u| dx
bzw. ∣∣∣∣
∫ 1
0u′v dx
∣∣∣∣=
∣∣∣∣
∫
supp vu′v dx
∣∣∣∣≤ ‖v‖C[0,1]
∫
supp v|u′| dx
ergeben die Integrale in (8.12) noch Sinn fur u, u′ ∈ L1loc(0, 1).
Definition 8.3 w ∈ L1loc(0, 1) heißt verallgemeinerte erste Ableitung von u ∈ L1
loc(0, 1), falls
∫ 1
0wv dx = −
∫ 1
0uv′ dx, ∀v ∈ C∞
0 (0, 1)

80 KAPITEL 8. RITZ-GALERKIN-VERFAHREN FUR RWP
gilt. Man schreibt w = u′.
Wir erklaren nun
Definition 8.4. Die Menge
H1(0, 1) := v ∈ L2(0, 1) : ∃v′ ∈ L2(0, 1)
heißt Sobolev-Raum der Funktionen mit verallgemeinerten und quadratisch auf (0, 1) inte-grierbaren Ableitungen. Ferner ist
H10 (0, 1) := clH1(0,1)C
∞0 (0, 1).
Bemerkung 8.5. Man kann zeigen, daß auch gilt
H1(0, 1) := clH1(0,1)C∞(0, 1). 2
Ohne Beweis zitieren wir
Satz 8.6. Die Raume H1(0, 1); ‖ · ‖H1(0,1) und H10 (0, 1); ‖ · ‖H1(0,1) sind Hilbert-Raume
mit dem Skalarprodukt
(u, v)H1 :=
∫ 1
0uv dx +
∫ 1
0u′v′ dx.
Offenbar ist X := H10 (0, 1) der geeignete Funktionenraum, um eine verallgemeinerte Aufgaben-
stellung zu (8.1)-(8.2) bzw. zu (8.5)-(8.7) zu formulieren:
Finde u ∈ H10 (0, 1) : a(u, v) = f(v) ∀v ∈ H1
0 (0, 1). (8.13)
Vertiefende Kenntnisse uber die hier zum Teil nur heuristisch eingefuhrten Inhalte, insbesonderezur Existenz verallgemeinerter Losungen (Satz von Lax-Milgram) kann man in einer Vorlesunguber partielle Differentialgleichungen oder uber Lineare Funktionalanalysis erwerben.
8.3 Ritz-Galerkin Verfahren
Im vorliegenden Kapitel fuhren wir Naherungsverfahren zur approximativen Losung von Varia-tionsgleichungen ein. Die Darstellung ist dabei zunachst moglichst allgemein gehalten. Erst imabschließenden Teil betrachten wir speziell eine Finite-Elemente-Methode (FEM) fur Zweipunkt-Randwertaufgaben.
Ausgangspunkt ist die Variationsgleichung
Finde u ∈ X : a(u, v) = f(v) ∀v ∈ X (8.14)
im Hilbert-Raum X. Dabei verwenden wir die im Kapitel vorne eingefuhrten Bezeichnungenund Voraussetzungen an die Bilinearform a(·, ·) sowie die Linearform f(·).Gesucht ist nun eine Naherung un an die Losung u von (8.14) im endlich-dimensionalen TeilraumXn ⊂ X mit dim Xn = n < ∞. Offenbar ist dann Xn; ‖ · ‖X Banach-Raum.
Definition 8.7. Die Aufgabe
Finde un ∈ Xn : a(un, v) = f(v) ∀v ∈ Xn (8.15)
heißt Ritz-Galerkin-Verfahren zur Variationsgleichung (8.14).

8.3. RITZ-GALERKIN VERFAHREN 81
Wir zeigen nun, daß das Ritz-Galerkin-Verfahren stets einem linearen Gleichungssystem ent-spricht. Sei φin
i=1 Basis von Xn. Es bezeichne P : Rn → Xn ⊂ X die durch
Pv =n∑
i=1
viφi, v = (v1, ..., vn)T
erklarte Abbildung. Offensichtlich ist P ein Isomorphismus zwischen Rn und Xn. Unter Beach-
tung der Basisdarstellung in Xn = spanφ1, ..., φn erhalt man das
Lemma 8.8. Das Ritz-Galerkin-Verfahren (8.15) ist aquivalent zu dem System der Glei-chungen
Finde un ∈ Xn : a(un, φi) = f(φi) i = 1, ..., n (8.16)
Mit den Bezeichnungen
u = (u1, ..., un)T ∈ Rn, un := Pu;
A = (aij) ∈ Rn×n, aij := a(φj , φi)
f = (f1, ..., fn)T ∈ Rn, fi := f(φi)
formulieren wir
Satz 8.9. Das Ritz-Galerkin-Verfahren (8.15) ist aquivalent zu dem linearen Gleichungssy-stem
Au = f. (8.17)
Beweis: Nach Lemma 8.8 sind (8.15) und (8.16) aquivalent. Die Behauptung folgt nun mitun = Pu =
∑nj=1 ujφj aus
a(un, φi) =n∑
j=1
uja(φj , φi) =n∑
j=1
aijuj = f(φi) = fi, i = 1, ..., n 2
Bemerkungen 8.10. (i) Mit dem Skalarprodukt
〈u, v〉 :=n∑
i=1
uivi
im Rn sowie u = Pu, v = Pv gilt
a(u, v) = 〈Au, v〉, f(v) = 〈f, v〉.
(ii) Das lineare Gleichungssystem (8.17) besitzt genau dann eine eindeutig bestimmte Losungun ∈ Xn, wenn die Matrix A nicht singular ist. 2
Folgende Aufgaben sind nun zu losen:
• Konstruktion geeigneter Unterraume Xn
• Generierung und Losung des linearen Gleichungssytems
• Fehlerabschatzung.

82 KAPITEL 8. RITZ-GALERKIN-VERFAHREN FUR RWP
Nachfolgend geben wir hinreichende Losbarkeitsbedingungen fur das Ritz-Galerkin-Verfahrensowie eine a-priori Abschatzung der Losung an.
Satz 8.11. Seien Xn ⊂ X, dim Xn = n < ∞ und X Hilbert-Raum. Ferner sei a(·, ·) :X × X → R X−elliptische, stetige Bilinearform, d.h. gelte
∃γ > 0 : a(v, v) ≥ γ‖v‖2X ∀v ∈ X (8.18)
sowie∃M > 0 : |a(u, v)| ≤ M‖u‖X‖v‖X ∀u, v ∈ X, (8.19)
und f : X → R sei linear und stetig, d.h.
∃K > 0 : |f(v)| ≤ K‖v‖X ∀v ∈ X. (8.20)
Dann gilt(i) Die Matrix A = (a(φj , φi)) ∈ R
n×n ist nicht singular. (Daraus folgt die eindeutige Losbarkeitvon (8.17).)(ii) Fur die Losung un ∈ Xn des Ritz-Galerkin-Verfahrens gilt die a-priori Abschatzung
‖un‖X ≤ K
γ. (8.21)
Beweis: (i) Mit u 6= 0 folgt Pu 6= 0 sowie wegen der X−Elliptizitat von a(·, ·) die Aussage
< Au, u >= a(Pu,Pu) ≥ γ‖Pu‖2X > 0,
d.h. Au 6= 0.
(ii) Wegen (8.19) und (8.20) gilt
γ‖Pu‖2X ≤ a(Pu,Pu) = f(Pu) ≤ K‖Pu‖X ,
also (8.21). 2
Eine Abschatzung zwischen den Losungen u ∈ X der Variationsgleichung (8.14) und un ∈ Xn
des Ritz-Galerkin-Verfahrens (8.15) liefert der
Satz 8.12. Seien Xn ⊂ X, dim Xn = n < ∞, X Hilbert-Raum und a(·, ·) : X × X → R
X−elliptische, stetige Bilinearform, d.h. gelte (8.18) und (8.19).Dann folgt
‖u − un‖X ≤ M
γinf
v∈Xn
‖u − v‖X . (8.22)
Beweis: Aus (8.14) und (8.15) folgern wir zunachst die sogenannte Fehlergleichung
a(u − un, w) = a(u,w) − a(un, w) = 0 ∀w ∈ Xn. (8.23)
Man nennt (8.23) auch Galerkin-Orthogonalitat. Unter Beachtung von (8.14),(8.15) und (8.19)ergibt sich
γ‖u − un‖2X ≤ a(u − un, u − un) = a(u − un, u − w)
≤ M‖u − un‖X‖u − w‖X , ∀w ∈ Xn.
Daraus folgt durch Bildung des Infimums in Xn die Behauptung (8.22). 2

8.4. FINITE-ELEMENTE-METHODE FUR ZWEIPUNKT-RWP 83
Mit dem Satz 8.12 ist die Fehlerabschatzung auf eine Abschatzung des Interpolationsfehlerszuruckgefuhrt. Auf Details dieser Interpolationstheorie in Sobolev-Raumen konnen wir hiernicht eingehen. Es gilt zumindest
Lemma 8.13. SeienX1 ⊂ ... ⊂ Xn−1 ⊂ Xn ⊂ ... ⊂ X
sowie X = ∪∞n=1Xn. Dann ist
limn→∞
infw∈Xn
‖u − w‖X = 0. (8.24)
Beweis: Folgerung aus Dichtheit von ∪∞n=1Xn in X. 2
8.4 Finite-Elemente-Methode fur Zweipunkt-RWP
Wir betrachten jetzt speziell die zum Zweipunkt-RWP
−u′′(x) = f(x), x ∈ (0, 1); u(0) = u(1) = 0 (8.25)
gehorige Variationsgleichung
Finde u ∈ X = H10 (0, 1) : a(u, v) = f(v) ∀v ∈ X (8.26)
mit
a(u, v) :=
∫ 1
0u′(x)v′(x) dx, f(v) :=
∫ 1
0f(x)v(x) dx. (8.27)
Man kann einfach zeigen (uber die Friedrichs-Ungleichung im Beweis von Lemma 8.15), daßdurch die Halbnorm
‖v‖X := (a(v, v))12 =
(∫ 1
0u′(x)v′(x) dx
) 12
sogar eine Norm auf dem Raum X = H10 (0, 1) erklart wird. Hierbei sind die (verallgemeinerten)
homogenen Randbedingungen wesentlich. Dann ist die Bilinearform a offenbar X-elliptisch mitder Konstanten γ = 1 und stetig mit der Konstanten M = 1. Beide Konstanten sind optimal.
Wir konstruieren nun passende Unterraume Xn ⊂ X. Unter Zerlegung des Intervalls
[0, 1] = ∪n+1i=1 Mi, Mi := [xi−1, xi]
mit der Gitterweite hi := xi − xi−1 betrachten wir den endlich-dimensionalen Raum
Xn := v ∈ C[0, 1] : v(0) = v(1) = 0, v|Mi∈ Π1(Mi), i = 1, ..., n + 1. (8.28)
Mittels stuckweise linearer Lagrange’scher Basisfunktionen (finite Elemente)
φi(x) :=
x−xi−1
xi−xi−1, x ∈ Mi
xi+1−xxi+1−xi
, x ∈ Mi+1
0, sonst
, i = 1, . . . , n
ergibt sichXn = spanφ1(x), ...., φn(x) ⊂ X. (8.29)

84 KAPITEL 8. RITZ-GALERKIN-VERFAHREN FUR RWP
Man beachte hierbei, daß die Funktionen aus Xn per Konstruktion die homogenen Dirichlet-Randbedingungen erfullen.
Lemma 8.14. Jede Funktion vn ∈ Xn ist durch die Knotenwerte vi = v(xi) eindeutig festgelegtund besitzt die Darstellung
vn =n∑
j=1
vjφj(x).
Beweis: Ubungsaufgabe.
Wir kommen nun zur Generierung des linearen Gleichungssystems: Wegen supp(φi) = (xi−1, xi+1)ist
aij =
∫ 1
0φ′
jφ′i dx = 0, |i − j| ≥ 2.
Fur die Nichtnullelemente der Matrix A erhalten wir nach kurzer Rechnung
ai,i−1 =−1
xi − xi−1, ai,i =
1
xi − xi−1+
1
xi+1 − xi, ai,i+1 =
−1
xi+1 − xi,
d.h.
A = tridiag
− 1
hi;
1
hi+
1
hi+1; − 1
hi+1
. (8.30)
Fur die rechte Seite des Gleichungssystems folgt
fi =
∫ 1
0fφi dx =
∫ xi
xi−1
fφi dx +
∫ xi+1
xi
fφi dx. (8.31)
Die Koeffizienten aij sind in diesem Spezialfall exakt integrierbar. Im allgemeinen Fall interpo-liert man die Daten durch Splines und/oder integriert mit passenden Quadraturformeln. Dadurchentsteht dann in der Regel ein kleiner Konsistenzfehler.
Die bei der klassischen Finite-Differenzen Methode entstehende Matrix A fur Problem (8.25)stimmt mit der bei stuckweise linearen finiten Elementen entstehenden Matrix A im aquidistan-ten Fall h = hi, i = 1, ..., n + 1 bis auf den Skalierungsfaktor 1
h uberein. Unterschiede entstehenjedoch ggf. bei der rechten Seite. Zur Losung des linearen Gleichungssystems fur die FEM konnendamit der Thomas-Algorithmus oder Standard-Iterationsverfahren herangezogen werden.
Es verbleibt die Ableitung einer Fehlerabschatzung. Zuvor beweisen wir Interpolationsabschatzun-gen im Finite-Elemente-Raum Xn.
Lemma 8.15. Unter der Voraussetzung u′′ ∈ L2(a, b) gilt
infw∈Xn
‖u − w‖L2(a,b) ≤ (b − a)2‖u′′‖L2(a,b). (8.32)
sowieinf
w∈Xn
‖(u − w)′‖L2(a,b) ≤ (b − a)‖u′′‖L2(a,b). (8.33)
Beweis: Fur ζ ∈ C1[a, b] mit ζ(a) = 0 gilt ζ(x) =∫ xa ζ ′(t)dt. Mit Ungleichung von Cauchy-
Schwarz folgt|ζ(x)|2 ≤ (b − a)‖ζ ′‖2
L2(a,b), x ∈ [a, b].
Durch Integration uber (a, b) folgt die sogenannte Friedrichs-Ungleichung
‖ζ‖L2(a,b) ≤ (b − a)‖ζ ′‖L2(a,b).

8.4. FINITE-ELEMENTE-METHODE FUR ZWEIPUNKT-RWP 85
Sei zunachst u ∈ C2[a, b], Πhu die lineare Lagrange-Interpolierende sowie Ru := u−Πhu. We-gen der Interpolationsbedingungen ist (Ru)(a) = (Ru)(b) = 0. Dann ergibt partielle Integration
∫ b
a[u′ − (Πhu)′]2dx =
∫ b
au′′(Πhu − u)dx.
Die Ungleichung von Cauchy-Schwarz sowie die Friedrichs-Ungleichung fur ζ := Ru liefern dann
‖(Ru)′‖2L2(a,b) ≤ ‖u′′‖L2(a,b)‖Ru‖L2(a,b) ≤ (b − a)‖u′′‖L2(a,b)‖(Ru)′‖L2(a,b),
also ‖(Ru)′‖2L2(a,b) ≤ (b − a)‖u′′‖L2(a,b). Erneute Anwendung der Friedrichs-Ungleichung ergibt
‖Ru‖2L2(a,b) ≤ (b − a)2‖u′′‖L2(a,b).
Damit sind die gesuchten Aussagen fur u ∈ C2[a, b] bewiesen. Sie gelten auch noch fur u′ ∈H1(a, b) mit u′′ ∈ L2(a, b), da der Raum C1(a, b) dicht in H1(a, b) ist. 2
Damit konnen wir unter Benutzung von Satz 8.12 folgende Konvergenzaussage zeigen.
Satz 8.16. Fur die Losung u ∈ H10 (0, 1) gelte u′′ ∈ L2(0, 1). Dann gilt fur den Approximati-
onsfehler der FEM mit stuckweise linearer Lagrange-Basis
‖(u − un)′‖L2(0,1) ≤ h‖u′′‖L2(0,1).
Beweis: Nach Satz 8.12 gilt die Abschatzung
‖u − un‖H10 (0,1) := ‖(u − un)′‖L2(0,1) ≤ inf
w∈Xn
‖(u − w)′)‖L2(0,1),
denn fur die Elliptizitatskonstante und Beschranktheitskonstante gilt γ = M = 1. Dann liefertLemma 8.15 die Behauptung, indem man die Aussage uber die Approximation fur jedes derTeilintervalle (a, b) := Mi, i = 1, . . . , n anwendet und aufsummiert. 2
Mit einem Dualitatsargument nach Aubin/ Nitsche kann man eine bessere Fehlerabschatzungin der L2-Norm ableiten.
Satz 8.17. Unter den Voraussetzungen von Satz 8.16 gilt
‖u − un‖L2(0,1) ≤ Ch2‖u′′‖L2(0,1).
Beweis: Sei zn ∈ H10 (0, 1) verallgemeinerte Losung des Problems
a(v, zn) = (v, u − un)L2(0,1) ∀v ∈ H10 (0, 1).
Mit v = u − un folgta(u − un, zn) = ‖u − un‖2
L2(0,1). (8.34)
Wegen a(v, u) = a(v, un) = f(v) fur alle v ∈ Xn und der Symmetrie von a gilt
a(v, u − un) = a(u − un, v) = 0 ∀v ∈ Xn. (8.35)
Sei nun zn ∈ Xn Ritz-Galerkin Losung zu zn. Wir setzen in (8.35) v = zn und ziehen dies von(8.34) ab. Dann gilt wegen der Beschranktheit von a
‖u − un‖2L2(0,1) = a(u − un, zn − zn) ≤ ‖(u − un)′‖L2(0,1)‖(zn − zn)′‖L2(0,1).

86 KAPITEL 8. RITZ-GALERKIN-VERFAHREN FUR RWP
Satz 8.16 ergibt‖u − un‖2
L2(0,1) ≤ Kh2‖u′′‖L2(0,1)‖(zn)′′‖L2(0,1).
Aus der Differentialgleichung −(zn)′′ = u−un ersieht man sofort ‖(zn)′′‖L2(0,1) ≤ ‖u−un‖L2(0,1)
und damit die gesuchte Aussage. 2
Bemerkung 8.18. Zur Gewinnung der optimalen Fehlerabschatzung im Raum X bzw. inL2(0, 1) muß man zusatzlich die Existenz der verallgemeinerten zweiten Ableitung u′′ ∈ L2(0, 1)fordern. Man vergleiche jedoch die hier verwendeten Regularitatsannahmen an die Losung desRWP mit denen, die fur die Konvergenzanalyse bei der klassischen Finite-Differenzen-Methodein Kapitel 7 gestellt wurden. 2
Die Darlegungen in diesem Abschnitt konnen in mehrfacher Hinsicht verallgemeinert werden:
• Zunachst kann die Methode auf den Fall des RWP (8.1),(8.2) sowie fur gemischte Rand-bedingungen erweitert werden. Die Voraussetzungen der Existenz- und Konvergenzsatzegelten zum Beispiel beim 1. RWP unter der Voraussetzung c(x) − 1
2b′(x) ≥ 0.
• Bei der Generierung des entsprechenden linearen Gleichungssystems muß man bei variablenDaten b, c, f aber numerisch integrieren.
• Schließlich kann man allgemeiner global stetige und stuckweise polynomiale Basisfunktio-nen hoheren Grades verwenden.

Teil II
Numerische Lineare Algebra
87


Kapitel 9
Krylov-Unterraum-Methoden
In Teil II der Vorlesung wollen wir die Kenntnisse zur Numerischen Linearen Algebra aus demKurs Numerische Mathematik I erweitern. Zunachst befassen wir uns im vorliegenden Kapitelmit Krylov-Unterraum-Methoden. Dies sind spezielle iterative Losungsmethoden fur lineareGleichungssysteme
Au = b (9.1)
mit regularer Koeffizientenmatrix A. Bei dieser Verfahrensklasse ist vor allem die effiziente Be-rechenbarkeit gewisser Matrix-Vektorprodukte (z.B. Au) wesentlich.
Ihren Ursprung haben diese Methoden im Verfahren der konjugierten Gradienten (CG-Verfahren)von Hestenes und Stiefel (1952) fur den Spezialfall symmetrischer und positiv definiter Ma-trizen. Es gibt inzwischen zahlreiche Verallgemeinerungen auf Gleichungssysteme mit nichtsym-metrischer und/oder indefiniter Matrix A. Einen guten Uberblick findet man in den Lehrbuchernvon A. Greenbaum [7] oder von Y. Saad [19].
9.1 Krylov-Unterraume
Iterationsverfahren vom Krylov-Typ basieren auf der Konstruktion von Teilraumen des Rn,
die der Matrix A angepaßt sind.
Definition 9.1. Fur eine gegebene Matrix A ∈ Rn×n und einen Vektor v ∈ R
n \ 0 wird einKrylov-Unterraum definiert durch
Kk(A, v) := spanv,Av, . . . , Ak−1v = p(A)v : p ∈ Pk−1. (9.2)
Sind keine Mißverstandnisse moglich, schreiben wir auch Kk := Kk(A, v).
Sei u0 eine Naherung an die Losung des Gleichungssystems (9.1). Dann gilt fur das Start-Residuum bzw. den -Defekt
r0 := b − Au0
in der Regel r0 6= 0, anderenfalls ware u0 bereits Losung. Bei einem Krylov-Verfahren suchtman eine geeignete Naherungslosung uk im affinen Teilraum u0 + Kk(A, r0) durch bestimmteZusatzforderungen: Entweder soll der Defekt
rk := b − Auk, k ∈ N
zu Kk(A, r0) bzw. einem anderen geeigneten Krylov-Unterraum orthogonal sein (Galerkin-Bedingung) oder man minimiert rk in einer passenden Norm auf Kk(A, r0) bw. einem an-deren geeigneten Krylov-Unterraum. Dann erhoht man k oder startet das Verfahren mit
89

90 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
u0 := uk, r0 := b − Au0 neu (Restart). Man hofft, daß man bereits fur k ≪ n eine guteNaherung erhalt.
Wir definieren implizit im nachsten Lemma die Dimension eines Krylov-Unterraumes. Sei dazu
deg(v) := minl : ∃p ∈ Pl \ 0 mit p(A)v = 0. (9.3)
Wir erinnern an den Satz von Caley/Hamilton: Sei p(λ) := det(A−λI) das charakteristischePolynom der Matrix A ∈ R
n×n. Dann gilt p(A) = 0. Insbesondere folgt dann fur beliebigeVektoren v ∈ R
n, daß deg(v) ≤ n.
Lemma 9.2. Gegeben seien die Matrix A ∈ Rn×n und der Vektor v ∈ R
n \ 0. Weiter seim := deg(v). Dann gelten folgende Aussagen:
(i) Es gilt A(Km) ⊂ Km, d.h. der Krylov-Unterraum Km ist invariant unter A. Ferner giltKk = Km fur alle k ≥ m.
(ii) Es gilt dim (Kk) = k genau fur m ≥ k.
(iii) Es gilt dim (Kk) = min(k,m).
Beweis: (i) Fur u ∈ Km gilt per Konstruktion u =∑m−1
i=0 αiAiv. Ferner findet man Konstanten
β0, . . . , βm, die nicht alle gleichzeitig verschwinden, so daß
m∑
i=0
βiAiv = 0.
Wegen deg(v) = m ist βm 6= 0. Daraus folgt nach Nullerganzung wegen
Au =
m∑
i=1
αi−1Aiv − αm−1
βm
m∑
i=0
βiAiv
= −αm−1
βmβ0v +
m−1∑
i=1
(
αi−1 −αm−1
βmβi
)
Aiv ∈ Km,
daß A(Km) ⊂ Km. Fur k ≥ m folgt Km ⊂ Kk.
Seien nun k > m und u ∈ Kk. Dann gilt u =∑k−1
i=0 αiAiv. Außerdem findet man Konstanten
β0, . . . , βm mit βm 6= 0 undm∑
i=0
βiAiv = 0.
Nullerganzung ergibt
u =k−1∑
i=0
αiAiv − αk−1
βmAk−m−1
(m∑
i=0
βiAiv
)
=k−1∑
i=0
αiAiv − αk−1
βm
m∑
i=0
βiAi+k−m−1v ∈ Kk−1.
Dieser Schluß kann bis zur Aussage u ∈ Km fortgefuhrt werden. Damit ist Teil (i) bewiesen.

9.2. ARNOLDI-VERFAHREN 91
(ii) Die Vektoren v,Av, . . . , Ak−1v bilden genau dann eine Basis von Kk, wenn fur jede Mengeγ0, . . . , γk−1 nicht gleichzeitig verschwindender Zahlen die Aussage
k−1∑
i=0
γiAiv 6= 0
folgt. Dies entspricht aber gerade der Bedingung, daß genau das Nullpolynom p in Pk−1 derBedingung p(A)v = 0 genugt. Dies ist aquivalent zu m = deg(v) ≥ k.
(iii) Aussage (ii) impliziert
dim (Kk) = k = min(k,m), m ≥ k.
Im Fall m < k liefert Teil (i) die Aussage Kk = Km, somit ist dim (Kk) = dim (Km) = m. Damitist der Satz bewiesen. 2
9.2 Arnoldi-Verfahren
Jetzt konstruieren wir ein Orthonormalsystem (ONS) fur den Krylov-Unterraum
Kk := spanv,Av, . . . , Ak−1v,wobei wir k ≪ n annehmen wollen. Wir betrachten das folgende modifizierte Gram-Schmidt-Verfahren. Es heißt in der aktuellen Literatur auch
Arnoldi-Verfahren bzw. Modifiziertes Gram-Schmidt-Verfahren
(1) Eingabegroßen: A ∈ Rn×n, v ∈ R
n \ 0 sowie k ∈ N.
(2) Berechne q1 := v/‖v‖2.
(3) Fur j = 1, . . . , k:
– w := Aqj
– Fur i = 1, . . . , j:
∗ hij := qTi w
∗ w := w − hijqi.
– hj+1,j := ‖w‖2
– Falls hj+1,j = 0, dann: STOP.
– qj+1 := w/hj+1,j .
(4) Ausgabegroßen: Ohne vorherigen Abbruch erhalt man die Matrizen
Qk := ( q1 · · · qk ) ∈ Rn×k, (9.4)
und
Hk :=
h11 h12 · · · · · · h1k
h21 h22. . . h2k
. . .. . .
. . ....
. . .. . . hk−1,k
hk,k−1 hk,k
hk+1,k
∈ R(k+1)×k. (9.5)

92 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
Mit Hk ∈ Rk×k bezeichnen wir die Hessenberg-Matrix, die aus Hk durch Streichen der
letzten Zeile entsteht. Ferner ermittelt man auch den Vektor qk+1 ∈ Rn. Damit ist auch
die Matrix Qk+1 := ( Qk qk+1 ) wohldefiniert.
Die Eigenschaften der im Verfahren erzeugten Matrizen fassen wir zusammen im
Lemma 9.3. Das oben beschriebene Arnoldi-Verfahren breche nicht vorzeitig ab. Dann geltenfolgende Aussagen:
(i) Die Spalten q1, . . . , qk von Qk bilden eine Orthonormalbasis von Kk.
(ii) Es gilt AQk = Qk+1Hk sowie QTk AQk = Hk.
Beweis: (i) Mittels vollstandiger Induktion nach j beweisen wir, daß q1, . . . , qj mit j =1, . . . k + 1 ein ONS bildet. Der Induktionsanfang fur j = 1 ist wegen q1 := v/‖v‖2 offenbarerfullt.
Sei q1, . . . , qj ein ONS. Per Konstruktion ist ‖qj+1‖2 = 1. Zu zeigen ist noch qTl qj+1 = 0 fur
l = 1, . . . j. Dazu notieren wir die Berechnungsvorschrift fur qj+1 wie folgt:
• w(0) := Aqj .
• Fur i = 1, . . . , j: w(i) := w(i−1) − qTi w(i−1)qi.
• qj+1 := w(j)/‖w(j)‖2.
Hieraus folgt fur l = 1, . . . , j mit der Induktionsvoraussetzung qTl qj = δlj , daß
qTl w(j) = qT
l w(j−1) − qTj w(j−1)qT
l qj = qTl w(j−1) − qT
j w(j−1)δlj.
Damit ist qTl w(j) = 0 fur l = j, ferner gilt qT
l w(j) = qTl w(j−1) fur l < j.
Nun schließen wir analog weiter wegen
qTl w(j−1) = qT
l w(j−2) − qTj−1w
(j−2)qTl qj−1 = qT
l w(j−2) − qTj−1w
(j−2)δl,j−1.
Diese Prozedur kann weitergefuhrt werden. Man erhalt, daß w(j) und damit qj+1 orthogonal zuq1, . . . , qj ist. Daher ist q1, . . . , qj+1 ein ONS.
Wir zeigen, daß Kk = spanq1, . . . , qk. Hierzu wird durch vollstandige Induktion nach j bewie-sen, daß mit geeignetem Polynom pj−1 ∈ Pj−1 gilt qj = pj−1(A)v. Der Induktionsanfang furj = 1 folgt wegen q1 = v/‖v‖2 mit p0(t) := 1/‖v‖2.
Fur den Induktionsschritt sehen wir mit der Festsetzung des Polynoms pj ∈ Pj mittels
pj(t) :=1
‖w‖2
(
tpj−1(t) −j∑
i=1
hijpi−1(t)
)
daß
qj+1 =w
‖w‖2=
1
‖w‖2
(
Aqj −j∑
i=1
hijqi
)
=1
‖w‖2
(
Apj−1(A)v −j∑
i=1
hijpi−1(A)v
)
= pj(A)v.

9.3. FOM-VERFAHREN 93
Hieraus folgt spanq1, . . . , qk ⊂ Kk. Per Konstruktion ist q1, . . . , qk ONS von Kk.
(ii) Wir notieren zuerst
AQkej = Aqj =
j+1∑
i=1
hijqi = Qk+1Hkej , j = 1, . . . , k.
Damit ist AQk = Qk+1Hk, folglich auch QTk AQk = QT
k Qk+1Hk. Es bleibt zu zeigen, daßQT
k Qk+1Hk = Hk ist. Dies folgt aber wegen
QTk Qk+1Hk = QT
k ( Qk qk+1 )
(Hk
hk+1,keTk
)
= ( I 0 )
(Hk
hk+1,keTk
)
= Hk.
Daraus ergibt sich die noch fehlende Aussage QTk AQk = Hk. 2
Notwendige und hinreichende Abbruchbedingungen beim Arnoldi-Verfahren gibt
Lemma 9.4. Das Arnoldi-Verfahren bricht im Schritt j genau dann ab, wenn deg(v) = j.Dann ist Kj ein unter A invarianter Unterraum.
Beweis: Gelte deg(v) = j. Nach Lemma 9.2 hat man dim(Kj) = j, das Arnoldi-Verfahrenkann also nicht vor dem Schritt j abgebrochen sein. Es bricht jedoch zwingend im Schrit j ab.Sonst konnte der normierte und zu q1, . . . , qj orthogonale Vektor qj+1 ermittelt werden. Dannware im Widerspruch zu Aussage (iii) von Lemma 9.2 dim (Kj+1) = j + 1.
Wir nehmen nun an, daß das Arnoldi-Verfahren im Schritt j abbricht. Nach Definition desGrades ware dann deg(v) ≤ j. Tatsachlich ist deg(v) = j, denn sonst ware der Algorithmusschon in einem fruheren Schritt abgebrochen. 2
9.3 FOM-Verfahren
Zur Naherungslosung des linearen Systems Au = b mit regularer Matrix A ∈ Rn×n und b ∈ R
n
wird zu einer Startlosung u0 ∈ Rn der Defekt r0 := b−Au0 berechnet. Der zugehorige Krylov-
Unterraum istKk := Kk(A, r0) = spanr0, Ar0, . . . , A
k−1r0.Das hier darzustellende FOM-Verfahren bestimmt eine Naherung uk ∈ u0 + Kk so, daß
b − Auk ⊥ Kk.
Es basiert auf dem folgenden technischen Resultat.
Lemma 9.5. Sei dim (Kk) = k. Mit dem Arnoldi-Verfahren seien die Matrix Qk = (q1 · · · qk) ∈R
n×k und die obere Hessenberg-Matrix Hk ∈ Rk×k mit
QTk Qk = I, Kk = spanq1, . . . , qk, QT
k AQk = Hk
ermittelt worden, insbesondere ist q1 = r0/‖r0‖2. Ferner sei Hk nichtsingular. Dann gelten furden Vektor
uk := u0 + QkH−1k (‖r0‖2e1) (9.6)
die Aussagen uk ∈ u0 + Kk und b − Auk ⊥ Kk.
Beweis: Die Spalten von Qk bilden nach Lemma 9.3 (i) eine Basis des Krylov-UnterraumsKk. Daher ist uk ∈ u0 + Kk.

94 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
Da q1, . . . , qk Basis von Kk ist, gilt b − Auk ⊥ Kk genau bei QTk (b − Auk) = 0. Die letztere
Beziehung gilt wegen
QTk (b − Auk) = QT
k r0 − QTk AQkH
−1k
︸ ︷︷ ︸
=I
(‖r0‖2e1) = QTk r0 − ‖r0‖2e1
= QTk (r0 − ‖r0‖2Qke1) = QT
k (r0 − ‖r0‖2q1) = 0.
Daraus folgt die Behauptung. 2
Auf Basis des Arnoldi-Verfahrens erhalt man folgendes Verfahren zur Losung von (9.1):
”Full Orthogonalization Method” (FOM) Arnoldi-Verfahren
(1) Berechne fur die Startlosung u0 den Defekt r0 := b−Au0 sowie q1 := r0/‖r0‖2. InitialisiereHk = (hij)1≤i,j≤k := 0.
(2) Fur j = 1, . . . , k:
– w := Aqj
– Fur i = 1, . . . , j:
∗ hij := qTi w
∗ w := w − hijqi.
– hj+1,j := ‖w‖2
– Falls hj+1,j = 0, dann: Setze k := j und gehe zu Schritt (3).
– qj+1 := w/hj+1,j .
(3) Setze Qk := ( q1 · · · qk ) ∈ Rn×k, Hk := (hij)1≤i,j≤k und berechne
uk := u0 + QkH−1k (‖r0‖2e1).
Das im Vergleich zum Ausgangsproblems (9.1) niedrigdimensionale System
Hky = ‖r0‖2e1, (9.7)
kann mittels Givens-Rotationen (vgl. folgender Abschnitt) oder auch einem direkten Eliminati-onsverfahren effizient realisiert werden. Der wesentliche Aufwand des Verfahrens liegt im Schritt(2) beim Arnoldi-Verfahren in der Berechnung der Matrix-Vektorprodukte Aqj.
9.4 GMRES-Verfahren
Wir behandeln nun eine alternative Methode zur Losung des Problems (9.1). Wir benutzen dieBezeichnungen und den Ansatz aus dem vorhergehenden Abschnitt. Im Unterschied zur FOMwird jetzt die neue Losung uk ∈ u0 + Kk durch den Minimierungsansatz
Minimiere ‖b − Au‖2, u ∈ u0 + Kk. (9.8)
Mittels der Orthonormalbasis q1, · · · , qk von Kk bzw. der Matrix Qk = ( q1 · · · qk ) erhaltman die aquivalente Aufgabe
Minimiere J(y) := ‖b − A(u0 + Qky)‖2 = ‖r0 − AQky‖2, y ∈ Rk. (9.9)

9.4. GMRES-VERFAHREN 95
Nach Lemma 9.3 gilt AQk = Qk+1Hk mit der aus dem Arnoldi-Verfahren bestimmten MatrixHk ∈ R
(k+1)×k. Fur den ersten Spaltenvektor von Qk bzw. Qk+1 gilt q1 = r0/‖r0‖2, damit gilt
r0 − AQky = Qk+1
(
‖r0‖2e1 − Hky)
.
Die Spalten der Matrix Qk+1 sind jedoch orthonormiert, somit ist das folgende lineare Aus-gleichsproblem zu losen:
Minimiere J(y) :=∥∥∥‖r0‖2e1 − Hky
∥∥∥
2, y ∈ R
k. (9.10)
Fur die unreduzierte obere Hessenberg-Matrix Hk ist hj+1,j 6= 0 bei j = 1, . . . k, somit hat Hk
den Rang k. Dies impliziert die eindeutige Losbarkeit des Ausgleichsproblems.
Damit ergibt sich das folgende Verfahren.
”Generalized Minimum Residual Method” (GMRES):
(1) Berechne fur die Startlosung u0 den Defekt r0 := b − Au0 sowie q1 := r0/‖r0‖2.Initialisiere
Hk = (hij) 1≤i≤k+11≤j≤k
:= 0.
(2) Fur j = 1, . . . , k:
– w := Aqj
– Fur i = 1, . . . , j:
∗ hij := qTi w
∗ w := w − hijqi.
– hj+1,j := ‖w‖2
– Falls hj+1,j = 0, dann: Setze k := j und gehe zu Schritt (3).
– qj+1 := w/hj+1,j .
(3) Bestimme die Losung yk des linearen Ausgleichsproblems
Minimiere J(y) :=∥∥∥‖r0‖2e1 − Hky
∥∥∥
2, y ∈ R
k.
Setze anschließend uk := u0 + Qkyk mit Qk := (q1 · · · qk).
Der Hauptaufwand des Verfahrens liegt wieder im Arnoldi-Prozeß in der Berechnung derMatrix-Vektorprodukte in Schritt (2). Zur effizienten Losung des linearen Ausgleichsproblemsmit der niedrigdimensionalen Hessenberg-Matrix Hk bietet sich die QR-Zerlegung mittelsGivens-Rotationen an:
Dabei multipliziert man die Matrix ( Hk ‖r0‖2e1 ) ∈ R(k+1)×(k+1) sukzessive mit den Rotations-
matrizen Gj,j+1, die sich von der Einheitsmatrix lediglich in den Positionen (j, j), (j, j + 1), (j +1, j), (j + 1, j + 1) unterscheiden, in denen sie die Werte
(cj sj
−sj cj
)
, j = 1, . . . , k (9.11)

96 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
annehmen mit cj = cos φ, sj = sin φ. Durch Wahl des Winkels φ wird erreicht, daß in der jeweilsaktuellen Matrix das an der Position (j +1, j) stehende Element fur j = 1, · · · , k annuliert wird.Somit erhalt man nach k Schritten die Matrix
( Rk gk ) := Fk( Hk ‖r0‖2e1 ), Fk := Gk,k+1 · · ·G12.
Offenbar sind die Rotationsmatrizen und damit auch Fk orthogonal. (Hinsichtlich einer genaue-ren Darstellung zur Givens-Rotation sei auf Abschnitt 12.5 verwiesen.)
Wir bezeichnen jetzt mit Rk ∈ Rk×k die aus Rk ∈ R
(k+1)×k durch Streichen der letzten (Null-)Zeile entstehende Matrix. Analog erhalt man aus gk = (γi)
k+1i=1 ∈ R
k+1 den Vektor gk ∈ Rk durch
Weglassen der letzten Komponente.
Da Hk den Rang k hat, ist Rk regular. Dann ist die Losung des linearen Ausgleichsproblemsgegeben durch
yk = R−1k gk.
Wegen der Dreiecksstruktur von Rk benotigt man hier nur eine Ruckwartselimination. Fernerist
b − Auk = Qk+1
(
‖r0‖2e1 − Hkyk
)
= Qk+1FTk (gk − Rkyk) = Qk+1F
Tk (γk+1ek+1)
und aufgrund der Orthonormierung der Spalten von Qj+1 sowie der Orthogonalitat von Fk ergibtsich
‖b − Auk‖2 = |γk+1|.Man kann den Vektor gk = (γi)1≤i≤k+1 sehr einfach wie folgt berechnen: Wegen
gk = Fk(‖r0‖2e1) = Gk,k+1 · · ·G12(‖r0‖2e1)
mit den Givens-Rotationen aus (9.11) erhalt man γ1, . . . , γk+1 aus
• γ1 := ‖r0‖2.
• Fur j = 1, . . . , k :(
γj
γj+1
)
:=
(cj sj
−sj cj
)(γj
0
)
.
Insbesondere ist γj+1 = −sjγj. Daraus ergibt sich ein Abbruchkriterium fur das GMRES-Verfahren.
Lemma 9.6. Bei regularer Matrix A ∈ Rn×n bricht das GMRES-Verfahren im j−ten Schritt
wegen hj+1,j = 0 genau dann ab, wenn uj bereits Losung des zu losenden GleichungssytemsAu = b ist.
Beweis: Wir nehmen an, daß hj+1,j = 0 ist. Im Verfahren wird dann k := j gesetzt. Da daszu annulierende Element bereits verschwindet, ist die letzte Givens-Rotation die Identitat, d.h.sk = 0 und damit γk+1 = 0. Also ist Auk = b. Die Umkehrung wird analog gezeigt. 2
Wir wollen uns nun mit Konvergenzeigenschaften des GMRES-Verfahrens fur wachsende Dimen-sion der Krylov-Unterraume Kk(A, r0) befassen. Theoretisch wurde man bei exakter Arithmetikspatestens fur k = n die exakte Losung des Systems b − Au = 0 erhalten. Da der Rechen- undSpeicheraufwand des Verfahrens mit k wachst, hofft man auf Konvergenz des Residuums untereine bestimmte Toleranz fur k ≪ n. Eine praktisch wichtige Variante besteht in der Restart-Version GMRES(m). Dabei beschankt man beim Aufbau der Arnoldi-Basis deren Dimensionauf m ∈ N mit m ≪ n. Nach Berechnung der Losungsfolge (uk) fur k ≤ m setzt man dann

9.4. GMRES-VERFAHREN 97
u0 := um und startet den GMRES-Prozess neu.
Wir wollen jetzt das Konvergenzverhalten der Restart-Version GMRES(m) untersuchen. Sei uLosung des Gleichungssystems. Per Konstruktion ist dann
Minimiere ‖b − Au‖2 = ‖A(u − u)‖2, u ∈ u0 + Kk, (9.12)
also ‖b − Auk‖2 ≤ ‖b − Au0‖2. Die Defektfolge ist also zumindest nach oben beschrankt. Furpositiv definite, aber nicht notwendig symmetrische Matrizen A gilt sogar
Satz 9.7. Sei A ∈ Rn×n strikt positiv definit, d.h. vT Av ≥ α‖v‖2
2 fur beliebige v ∈ Rn \0. Fur
die Naherungslosung uk des GMRES(m)-Verfahrens mit Restart-Lange m und Startwert u0 gilt
‖b − Auk‖2 ≤(
1 − α2
σ2
)k/2
‖b − Au0‖2, k ∈ N. (9.13)
Dabei ist σ := ‖A‖2. Insbesondere konvergiert das Verfahren fur k → ∞ gegen die Losung desSystems Au = b.
Beweis: Fur beliebiges ω ∈ R und v ∈ Rn gilt
‖(I − ωA)v‖22 = ‖v‖2
2 − 2ωvT Av + ω2‖Av‖22 ≤ (1 − 2ωα + ω2‖A‖2
2)‖v‖22.
Fur ω = ω0 := α‖A‖2
2folgt
‖(I − ω0A)v‖ ≤ q‖v‖2, q :=
(
1 − α2
‖A‖22
) 12
.
Fur 1 ≤ k ≤ m stimmen die Naherung uk des GMRES(m)-Verfahrens und die des GMRES-Verfahrens uberein. Wegen der Minimaleigenschaft der GMRES-Iterierten kann man das zu-gehorige Residuum vergleichen mit dem Residuum von
uk = u0 + ω0
k−1∑
j=0
(I − ω0A)jr0 ∈ u0 + Kk(A, r0).
Wegen
b − Auk = r0 − ω0Ak−1∑
j=0
(I − ω0A)jr0
= r0 −k−1∑
j=0
(I − ω0A)jr0 +k−1∑
j=0
(I − ω0A)j+1r0
= r0 − r0 + (I − ω0A)kr0 = (I − ω0A)kr0
folgt
‖b − Auk‖2 ≤ ‖b − Auk‖2 = ‖(I − ω0A)kr0‖2 ≤ qk‖r0‖2.
Nach dem ersten Restart, d.h. fur m < k ≤ 2m gilt entsprechend
‖b − Auk‖2 ≤ qk−m‖b − Aum‖2 ≤ qk−mqm‖r0‖2.

98 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
Analog gilt diese Abschatzung fur alle k ∈ N. Die Konvergenz des Verfahrens fur k → ∞ gegendie Losung von Au = b ergibt sich wegen u − uk = A−1b − uk = A−1(b − Auk) aus
‖u − uk‖2 ≤ qk‖A−1‖2‖r0‖2, k ∈ N. 2
Bemerkung 9.8. (i) Die Konvergenzaussage von Satz 9.7 ist wenig hilfreich, wenn α ≪ σ :=‖A‖2 gilt. In vielen Fallen kann man jedoch die Situation durch geeignete Vorkonditionierung(vgl. folgender Abschnitt) erheblich verbessern.
(ii) Die Aussage von Satz 9.7 kann verallgemeinert werden auf den Fall diagonalisierbarerMatrizen A, d.h. man findet eine Matrix X ∈ R
n×n mit A = XΛX−1 und Λ := diag(λ1, . . . , λn).Dabei sind λ1, . . . , λn die Eigenwerte von A. 2
9.5 Vorkonditionierung von Krylov-Verfahren
Bemerkung 9.8 zeigt, daß die Konvergenz des GMRES-Verfahrens wesentlich vom Spektrum, d.h.den Eigenwerten der Matrix A, abhangt. Bei der Diskretisierung von Randwertaufgaben folgtfur die aus der Diskretisierung resultierenden Matrizen mit der Verfeinerung des Gitters, daßlimh→0
α2
σ2 = 0. Das GMRES-Verfahren konvergiert dann in der bisherigen Version zunehmendschlechter.
Ein Ausweg aus dieser Situation ergibt sich durch geeignete Vorkonditionierung des Problemsmit einer regularen Matrix M ∈ R
n×n. Bei der Linksvorkonditionierung betrachtet man das zumAusgangssystem (9.1) aquivalente Problem
M−1Au = M−1b. (9.14)
Dabei soll M so gewahlt werden, daß einerseits M−1A ≈ I und damit die Kondition des geander-ten Systems gunstiger als die von A ist. Andererseits soll (9.14) ”leicht(er)” losbar sein als dasAusgangsproblem.
Bei der Rechtsvorkonditionierung gelangt man uber die Transformation u = M−1x zum SystemAM−1x = b. Man konstruiert M so, daß moglichst AM−1 ≈ I gilt. Man kann die Links- undRechtvorkonditionierung auch kombinieren durch u = M−1
2 x und M−11 AM−1
2 x = M−11 b.
Wir besprechen exemplarisch die Vorkonditionierung des GMRES-Verfahrens. Dabei spezifizie-ren wir die Vorkonditionierungsmatrizen noch nicht.
Algorithmus: GMRES-Verfahren mit Linksvorkonditionierung
(1) Berechne fur die Startlosung u0 den vorkonditionierten Defekt z0 := M−1(b − Au0) sowieq1 := z0/‖z0‖2. Initialisiere
Hk = (hij) 1≤i≤k+11≤j≤k
:= 0.
(2) Fur j = 1, · · · , k:
– w := M−1Aqj
– Fur i = 1, · · · , j:∗ hij := qT
i w
∗ w := w − hijqi.
– hj+1,j := ‖w‖2

9.5. VORKONDITIONIERUNG VON KRYLOV-VERFAHREN 99
– Falls hj+1,j = 0, dann: Setze k := j und gehe zu Schritt (3).
– qj+1 := w/hj+1,j .
(3) Bestimme die Losung yk des linearen Ausgleichsproblems
Minimiere J(y) :=∥∥∥‖z0‖2e1 − Hky
∥∥∥
2, y ∈ R
k.
Setze anschließend uk := u0 + Qkyk mit Qk := ( q1 · · · qk ).
Hier wird eine Orthonormalbasis zum modifizierten Krylov-Raum Kk(M−1A, z0) bestimmt.
Man beachte, daß dabei der Defekt vorkonditioniert wird. Man hat jedoch nicht unmittelbar Zu-griff auf den nicht vorkonditionierten Defekt. Dies gilt jedoch auch fur den jetzt zu betrachtendenFall der Rechtsvorkonditionierung, bei dem zunachst eine Orthonormalbasis fur Kk(AM−1, r0)bestimmt wird.
Algorithmus: GMRES-Verfahren mit Rechtsvorkonditionierung
(1) Berechne fur die Startlosung u0 den Defekt r0 := b−Au0 sowie q1 := r0/‖r0‖2. Initialisiere
Hk = (hij) 1≤i≤k+11≤j≤k
:= 0.
(2) Fur j = 1, · · · , k:
– w := AM−1qj
– Fur i = 1, · · · , j:∗ hij := qT
i w
∗ w := w − hijqi.
– hj+1,j := ‖w‖2
– Falls hj+1,j = 0, dann: Setze k := j und gehe zu Schritt (3).
– qj+1 := w/hj+1,j .
(3) Bestimme die Losung yk des linearen Ausgleichsproblems
Minimiere J(y) :=∥∥∥‖r0‖2e1 − Hky
∥∥∥
2, y ∈ R
k.
Setze anschließend uk := u0 + M−1Qkyk mit Qk := ( q1 · · · qk ).
Der wesentliche Unterschied zwischen beiden Varianten der Vorkonditionierung soll im folgendenLemma verdeutlicht werden.
Lemma 9.9. Die Naherungslosung uk ergibt sich im Fall des von links vorkonditioniertenGMRES als Losung von
Minimiere ‖M−1(b − Au)‖2, u ∈ u0 + Kk(M−1A, z0).
im Fall des von rechts vorkonditionierten GMRES als Losung von
Minimiere ‖b − Au‖2, u ∈ u0 + M−1Kk(AM−1, r0),

100 KAPITEL 9. KRYLOV-UNTERRAUM-METHODEN
mit r0 := b − Ax0 und z0 := M−1r0. In beiden Varianten haben die (nicht zwingend gleichen)Losungen uk die Gestalt
uk = u0 + sk−1(M−1A)z0 = u0 + M−1sk−1(AM−1)r0, sk−1 ∈ Pk−1.
Beweis: Die Aussage zur Linksvorkonditionierung folgt, da uk bei Anwendung von GMRES aufdas System M−1Au = M−1b gebildet wird. Speziell findet man ein Polynom sk−1 ∈ Pk−1 mit
uk = u0 + sk−1(M−1A)z0 = u0 + sk−1(M
−1A)M−1r0 = u0 + M−1sk−1(AM−1)r0.
Hierbei benutzt man die durch vollstandige Induktion beweisbare Aussage
(M−1A)jM−1 = M−1(AM−1)j , j = 0, · · · k − 1.
Im Fall der Rechtsvorkonditionierung ist uk = M−1xk, wobei xk Losung der Minimierungsauf-gabe
Minimiere ‖b − AM−1x‖2, x ∈ x0 + Kk(AM−1, r0)
mit u0 = M−1x0 und r0 := b−Au0 ist. Die gesuchte Aussage erhalt man mittels Transformationu = M−1x. 2
Zur Vorkonditionierung kommen zum Beispiel folgende Verfahren in Frage:
• Basis-Iterationsverfahren wie Gesamt- bzw. Einzelschrittverfahren bzw. dazugehorige Re-laxationsverfahren (vgl. Kurs Numerische Mathematik I),
• unvollstandige LU−Zerlegungen.
In der Regel erhalt man dadurch eine deutliche Beschleunigung gegenuber nichtvorkonditionier-ten Krylov-Methoden. Mitunter erreicht man auch erst dadurch Konvergenz der Iteration.

Kapitel 10
Eigenwertprobleme
In den nachfolgenden Kapiteln behandeln wir Eigenwertprobleme (EWP) quadratischer Matri-zen. Diesem Problem begenet man oft in der Physik oder in Ingenieurwissenschaften (z.B. bei derBerechnung von Schwingungsvorgangen), aber auch in der Satistik im Kontext von Varianzana-lysen. Im Kurs Numerische Mathematik I traten EWP be der Bestimmung der Konditionszahlvon Matrizen auf. Dabei bauen wir auf Kenntnissenden in den Kursen AGLA und NumerischeMathematik I auf.
10.1 Einfuhrende Beispiele
Definition 10.1. Eine Zahl λ ∈ C heißt Eigenwert einer Matrix A ∈ Cn×n, wenn es ein
Element x ∈ Cn mit x 6= 0 und der Eigenschaft
Ax = λx (10.1)
gibt. x heißt Eigenvektor (oder Eigenelement) zum Eigenwert λ. Der Nullraum
N(A − λI) := x ∈ Cn : Ax = λx (10.2)
wird als Eigenraum, seine Dimension als Vielfachheit des Eigenwertes bezeichnet.
Zur Motivation betrachten wir zwei einfache Beispiele.
Beispiel 10.2. Schwingungen einer SaiteDie Wellengleichung
∂2u
∂x2=
1
c2
∂2u
∂t2
mit den Randbedingungen
u(0, t) = u(1, t) = 0, t ≥ 0
beschreibt die vertikale Auslenkung u = u(x, t) (d.h. die Schwingungen) einer eingespanntenSaite. c ist dabei die Schallgeschwindigkeit in der Saite. Mit dem zeitharmonischen Ansatz
u(x, t) = U(x)eiωt
ergibt sich die Eigenwertgleichung
−U ′′(x) = λU(x), λ :=ω2
c2, 0 < x < 1 (10.3)
101

102 KAPITEL 10. EIGENWERTPROBLEME
mit den Nebenbedingungen
U(0) = U(1) = 0. (10.4)
Mit den Festsetzungen X = C[0, 1], U = v ∈ C2[0, 1] : v(0) = v(1) = 0 und A : U → Xmit A : v 7→ −v′′ erhalten wir ein Eigenwertproblem fur den linearen Operator A auf demunendlich-dimensionalen Raum X. In diesem Fall kann man das EWP relativ elementar losen.
Eine Diskretisierung des Eigenwertproblems (10.3), (10.4) in den Gitterpunkten
xi = ih, i = 0, ..., n + 1, h =1
n + 1
und mit Approximation des Operators d2
dx2 durch den zentralen Differenzenquotienten 2. Ordnung
v′′(xi) ≈1
h2v(xi+1) − 2v(xi) + v(xi−1)
fuhrt mit der Bezeichnung vi = v(xi) auf das System von Differenzengleichungen
−vi−1 + 2vi − vi+1 = h2λvi, i = 1, ..., n
mit v0 = vn+1 = 0 fur die Naherungen vi an die Funktionswerte U(xi). In Matrixschreibweiseerhalt man mit
Ah :=1
h2tridiag(−1, 2,−1), u = (v1, ..., vn)∗
das lineare Matrix-EWP Ahu = λu. 2
Beispiel 10.3. Losung linearer GleichungwsystemeAuch bei der iterativen Losung linearer Gleichungssysteme
Au = b
mit regularer Matrix A ∈ CN×N stoßt man auf EWP. Wir schreiben das Problem in der folgenden
aquivalenten Form
Bu = (B − A)u + b
mit einer zu spezifizierenden regularen Matrix B. Zur iterativen Berechnung der Losung be-trachten wir das Verfahren
Buk+1 = (B − A)uk + b
mit geeignetem Startvektor u0 ∈ CN . Notwendig und hinreichend fur die Konvergenz des Ver-
fahrens ist, daß der Spektralradius, also der betragsmaßig großte Eigenwert der IterationsmatrixB−1(B − A) kleiner als 1 ist.
10.2 Algebraische Grundlagen
Wir stellen einige elementare Grundlagen der Eigenwert-Theorie zusammen, die uns spater nutz-lich sein werden.
Lemma 10.4. Fur eine Matrix A = (aik ∈ Cn×n gelten folgende Aussagen:
(i) Die Matrix hat mindestens einen und hochstens n Eigenwerte.
(ii) Eigenvektoren zu verschiedenen Eigenwerten sind linear unabhangig.

10.2. ALGEBRAISCHE GRUNDLAGEN 103
(iii) Die Eigenwerte der Matrix A und der adjungierten Matrix A∗ = (a∗ik) mit a∗ik = aki sindzueinander konjugiert komplex.
Beweis: (i): Folgerung aus dem Fundamentalsatz der Algebra fur das charakteristische Poly-nom det (A − λI).
(ii): Wir fuhren den Induktionsbeweis nach der Anzahl m der Eigenvektoren. Offenbar ist dieBehauptung richtig fur m = 1. Unter der Annahme der linearen Unabhangigkeit der Eigenvek-toren zu m paarweise verschiedenen Eigenwerten sei
Axi = λxi, i = 1, ...,m + 1, mit λi 6= λj , i 6= j.
Uber den Ansatzm+1∑
i=1
αixi = 0
folgtm+1∑
i=1
αiλixi = 0
nach Multiplikation mit A. Subtraktion der beiden letzten Gleichungen liefert
m∑
i=1
αi(λi − λm+1)xi = 0.
Per Annahme ist αi(λi − λm+1) = 0, damit αi = 0, i = 1, ...,m. Folglich ist auch αm+1 = 0.
(iii): Die Aussage
(Ax, y) = (x,A∗y), ∀x, y ∈ Cm
folgt aus
(Ax, y) =m∑
i=1
(Ax)iyi =m∑
i=1
m∑
k=1
aikxkyi
=m∑
k=1
m∑
i=1
xka∗kiyi =
m∑
k=1
xkA∗yk = (x,A∗y).
Die Behauptung (iii) folgt wegen det (λI − A) = det (λI − A∗). 2
Eine naive Idee ware die Bestimmung der Egenwerte von A durch Ermittlung der Nullstellen descharakteristischen Polynoms det (λI − A). Dies ware ohnhin nur fur kleine Werte von n sinnvoll.Aber selbst hierbei ist zu beachten, daß die Nullstellenbestimmung von Polynomen schlechtkonditioniert und daher sehr anfallig gegenuber Rundungsfehlern ist.
Im allgemeinen Fall benutzt man zur Berechnung von Eigenwerten iterative Naherungsverfahren,die wir in den folgenden Kapiteln behandeln. Eine Grundidee besteht in der Konstruktion einerFolge von Matrizen (Qn) mit
Q−1n AQn → D, n → ∞,
wobei die Eigenwerte von D leicht bestimmbar sind. Dabei nutzt man folgendes Resultat.
Lemma 10.5. Die Eigenwerte einer Matrix A andern sich bei einer AhnlichkeitstransformationQ−1AQ mit einer regularen Matrix Q nicht.

104 KAPITEL 10. EIGENWERTPROBLEME
Beweis: Unter Nutzung des Multiplikationssatzes fur Determinanten ergibt sich aus
det(λI − A) = det(λI − A)det(Q−1Q) = det[Q−1(λI − A)Q] = det(λI − Q−1AQ) (10.5)
bereits die Gleichheit der Eigenwerte von A und Q−1AQ. 2
Wir erinnern an den Begriff der unitaren oder orthogonalen Matrix Q mit QQ∗ = Q∗Q = I,d.h. Q∗ = Q−1.
Lemma 10.6. (Satz von Schur)Zu jeder Matrix A existiert eine unitare Matrix Q so, daß R := Q∗AQ obere Dreiecksmatrix ist.Die Darstellung A = QRQ∗ heisst Schur--Zerlegung von A.
Beweis: Sei λ Eigenwert einer Matrix An := A ∈ Cn×n mit dem (o.B.d.A. orthonormierten)
Eigenvektor u, d.h. (u, u) = 1. Man kann nun u (zum Beispiel unter Nutzung des Orthogonali-sierungsverfahrens von Gram-Schmidt) zu einer orthonormalen Basis u, v2, ..., vn des RaumesC
n erweitern. Offenbar ist die Matrix
U := (u v2 ... vn)
unitar. Unter Beachtung von (u, vi) = 0, i = 2, ..., n finden wir
U∗AnU = U∗(λu Anv2 ... Anvn) =
(λ ∗0 An−1
)
mit einer Matrix An−1 ∈ C(n−1)×(n−1). Nun verfahrt man induktiv. 2
Ene wichtige Folgerung aus dem Lemma von Schur ist, daß man die Eigenwerte der Matrix Aauf der Diagonale der oberen Dreiecksmatrix R findet.
10.3 Spezialfall hermitescher Matrizen
Wir betrachten nun den wichtigen Fall hermitescher Matrizen, d.h. A = A∗. Der folgende Satzbeschreibt gerade die Hauptachsentransformation hermitescher Matrizen.
Lemma 10.7. Fur hermitesche Matrizen A ergibt sich
R := Q∗AQ = D := diag(λ1, ..., λn). (10.6)
Die Spalten der Matrix Q = (u1 ... un) sind die Eigenvektoren von A. Sie bilden ein Orthonor-malsystem des C
n. Ferner sind die Eigenwerte von A samtlich reell.
Beweis: Unter Benutzung von Lemma 10.6 gilt
R∗ = (Q∗AQ)∗ = Q∗A∗Q∗∗ = Q∗AQ = R.
Also ist R Diagonalmatrix. Die Darstellung (10.6) folgt aus dem Beweis von Lemma 10.6.
Aus Q∗AQ = D ergibt sich AQ = QD, d.h. fur die Spalten in Q gilt Aui = λiui, i = 1, ..., n.Die Vektoren ui sind somit die Eigenvektoren von A und formieren ein Orthonormalsystem desC
n. Wegenλi = (Aui, ui) = (ui, Aui) = (Aui, ui)
sind alle Eigenwerte von A reell. 2
Jetzt geben wir Charakterisierungen der Eigenwerte hermitescher Matrizen.

10.3. SPEZIALFALL HERMITESCHER MATRIZEN 105
Satz 10.8. (Satz von Rayleigh)Sei A hermitesche Matrix mit den Eigenwerten λ1 ≥ λ2 ≥ ... ≥ λn und den zugehorigen ortho-normalen Eigenvektoren x1, x2, ..., xn. Mit den Unterraumen V1 := C
n sowie
Vk := x ∈ Cn : (x, xi) = 0, i = 1, ..., k − 1, k = 2, ..., n (10.7)
gilt die Darstellung
λk = maxx ∈ Vk
‖x‖2 = 1
(Ax, x), k = 1, ..., n. (10.8)
Beweis: Sei x ∈ Vk mit ‖x‖2 = 1. Dann haben wir
x =
n∑
i=k
(x, xi)xi mit
n∑
i=k
|(x, xi)|2 = 1.
Daraus ergeben sich
Ax =n∑
i=k
λi(x, xi)xi
sowie
(Ax, x) =n∑
i=k
λi|(x, xi)|2 ≤ λk
n∑
i=k
|(x, xi)|2 = λk.
Daraus folgern wir nun
supx ∈ Vk
‖x‖2 = 1
(Ax, x) ≤ λk.
Die Behauptung folgt dann mit (Axk, xk) = λk sowie xk ∈ Vk. 2
Satz 10.8 erlaubt untere Abschatzungen fur den kleinsten Eigenwert. Schranken fur die weiterenEigenwerte erfordern Kenntnis der Eigenvektoren. Abhilfe schafft
Satz 10.9. (Minimum-Maximum Prinzip von Courant)Sei A hermitesche Matrix mit den Eigenwerten λ1 ≥ λ2 ≥ ... ≥ λn. Dann gilt die Darstellung
λk = minUk⊂Mk
maxx ∈ Uk
‖x‖2 = 1
(Ax, x), k = 1, ..., n, (10.9)
wobei Mk die Menge aller Unterraume Uk von Cn der Dimension n + 1 − k ist.
Beweis: Zunachst ist festzustellen, dass wegen der Stetigkeit der Abbildung x 7→ (Ax, x) dasin (10.9) auftretende Maximum tatsachlich existiert.
Seien x1, ..., xn die nach Lemma 10.7 orthonormalen Eigenvektoren zu den Eigenwerten λ1 ≥λ2 ≥ ... ≥ λn. Es wird nun gezeigt, daß zu einem Unterraum Uk stets ein Element x ∈ Uk
existiert mit
(x, xi) = 0, i = k + 1, ..., n.
Sei φ1, ..., φn+1−k eine Basis von Uk. Mit der Basisdarstellung
x =
n+1−k∑
j=1
ajφj (10.10)

106 KAPITEL 10. EIGENWERTPROBLEME
sind die n + 1− k Koeffizienten a1, ..., an+1−k aus dem nichttrivial losbaren linearen Gleichungs-system
n+1−k∑
j=1
aj(φj , xi) = 0, i = k + 1, ..., n
mit n−k Gleichungen zu bestimmen. O.B.d.A. ist fur x aus (10.10) ‖x‖2 = 1. Mit der Darstellung
x =
k∑
j=1
(x, xj)xj
folgern wir
(Ax, x) =
k∑
j=1
λj |(x, xj)|2 ≥ λk
k∑
j=1
|(x, xj)|2 = λk.
Daraus folgtmaxx ∈ Uk
‖x‖2 = 1
(Ax, x) ≥ λk.
Andererseits besteht nach Satz 10.8 fur Uk := x ∈ Cn : (x, xi) = 0, i = 1, ..., k − 1 die
Gleichheitmaxx ∈ Uk
‖x‖2 = 1
(Ax, x) = λk. 2
10.4 Lokalisierung von Eigenwerten
Wir zeigen nachfolgend einige Abschatzungen uber die Lage von Eigenwerten aus den Matrixda-ten. Derartige Angaben sind u.a. von Interesse, um geeignete Startwerte fur Iterationsverfahrenzur Bestimmung der Eigenwerte zu finden.
Lemma 10.10. Seien A und B hermitesche Matrizen mit den Eigenwerten
λ1(A) ≥ λ2(A) ≥ ... ≥ λn(A) und λ1(B) ≥ λ2(B) ≥ ... ≥ λn(B).
Dann gilt in jeder Norm die Abschatzung
|λk(A) − λk(B)| ≤ ‖A − B‖, k = 1, ..., n. (10.11)
Beweis: Die Cauchy-Schwarzsche Ungleichung zeigt
((A − B)x, x) ≤ ‖(A − B)x‖2‖x‖2 ≤ ‖A − B‖2‖x‖22,
daher(Ax, x) ≤ (Bx, x) + ‖A − B‖2‖x‖2
2.
Mit den Bezeichungen von Satz 10.9 bilden wir nacheinander fur k = 1, . . . , n das Supremumuber x ∈ Uk zuerst auf der rechten und dann auf der linken Seite der Ungleichung. Dann bildenwir das Infimum uber Uk ⊂ Mk auf der linken und dann auf der rechten Seite. Satz 10.9 ergibtdann
λk(A) ≤ λk(B) + ‖A − B‖2, k = 1, ..., n
und nach Vertauschung von A und B
λk(B) ≤ λk(A) + ‖A − B‖2, k = 1, ..., n

10.4. LOKALISIERUNG VON EIGENWERTEN 107
somit|λk(A) − λk(B)| ≤ ‖A − B‖2, k = 1, ..., n.
Die Behauptung des Lemmas folgt aus der Abschatzung fur den Spektralradius ρ
‖A − B‖2 = ρ(A − B) ≤ ‖A − B‖.
In der letzten Abschatzungskette haben wir die Satze 4.23 und 4.24 aus dem Kurs NumerischeMathematik I benutzt. 2
Folgerung 10.11. Fur die Eigenwerte λ1 ≥ λ2 ≥ ... ≥ λn einer hermiteschen Matrix A = (aik)gilt
|λj − a,jj|2 ≤
∑
i, k
i 6= k
|aik|2, j = 1, ..., n. (10.12)
Dabei ist a,11, ..., a
,nn eine geeignete Permutation der Hauptdiagonalelemente a11, ..., ann von A
derart, daß a,11 ≥ a,
22 ≥ ... ≥ a,nn.
Beweis: Man wendet Lemma 10.10 mit B = diag(a,ii) und der Norm ‖ · ‖2 an. 2
Im Fall allgemeiner Matrizen gilt der folgende Lokalisierungssatz fur Eigenwerte.
Satz 10.12. (Satz von Gerschgorin)Seien A = (aik) ∈ C
n×n sowie
Ki :=
λ ∈ C : |λ − aii| ≤n∑
k = 1k 6= i
|aik|
, i = 1, ..., n (10.13)
und
K∗i :=
λ ∈ C : |λ − aii| ≤n∑
k = 1k 6= i
|aki|
, i = 1, ..., n. (10.14)
Dann erhalt man fur alle Eigenwerte λ von A die Abschatzung
λ ∈(
n⋃
i=1
Ki
)
∩(
n⋃
i=1
K∗i
)
. (10.15)
Beweis: Sei Ax = λx und ‖x‖∞ = 1. Wahlt man einen Index i mit |xi| = ‖x‖∞ = 1, so giltwegen
n∑
k=1
aikxk = λxi
die Aussage
|λ − aii| = |(λ − aii)xi| =
∣∣∣∣∣∣∣∣
n∑
k = 1k 6= i
aikxk
∣∣∣∣∣∣∣∣
≤n∑
k = 1k 6= i
|aik|.
Daraus ergibt sich
λ ∈n⋃
i=1
Ki.

108 KAPITEL 10. EIGENWERTPROBLEME
Da A∗ nach Lemma 10.4 die konjugiert komplexen Eigenwerte der Matrix A hat, gilt auch
λ ∈n⋃
i=1
K∗i . 2
Bemerkung 10.13. Die hier angegebenen Lokalisierungsresultate konnen auch benutzt werden,um bei den nachfolgend zu beschreibeneden iterativen Losungsverfahren fur Eigenwerte in jedemSchritt eine a posteriori Fehlerschrake zu erhalten. Man kann dann jeweils entscheiden, ob dieerzielte Genauigkeit ausreicht oder weitere Iterationsschritte erforderlich sind. 2

Kapitel 11
Verfahren der Vektoriteration
Wir betrachten in den beiden folgenden Kapiteln numerische Losungsverfahren fur allgemeine(nichtsymmetrische) Eigenwertprobleme. Dabei konzentrieren wir uns vor allem auf diagonali-sierbare (oder diagonalahnliche) Matrizen, d.h. es gibt eine regulare Matrix X ∈ C
n×n, so daßX−1AX Diagonalmatrix ist. Nach Lemma 10.7 trifft dies naturlich auf hermitesche Matrizenals Spezialfall zu. Wir gehen zunachst im Kapitel 11 auf Methoden der Vektoriteration ein.Dann betrachten wir in Kapitel 12 das heute im Fall allgemeiner quadratischer Matrizen wohlwichtigste numerische Verfahren zur Eigenwertberechnung von Matrizen, das QR-Verfahren.
11.1 Potenzmethode
Die Potenzmethode nach von Mises (1929) erlaubt die iterative Berechnung des betragsmaßiggroßten Eigenwertes, der als kritischer Parameter in Anwendungen oftmals zuerst interessiert.
Wir betrachten eine diagonalisierbare Matrix A nehmen an, daß ein Eigenwert die anderenbetragsmaßig dominiert, d.h.
|λ1| > |λ2| ≥ · · · ≥ |λn|. (11.1)
Die zugehorigen Eigenvektoren x1, ..., xn bilden eine Basis des Cn. (Fur hermitesche Matrizen
folgt dies aus Lemma 10.7. Im Fall diagonalisierbarer Matrizen sei dies zur Ubung empfohlen.)
Bei beliebigem Startvektor v(0) ∈ Cn iteriert man
v(k) := Akv(0), k ∈ N, d.h. v(k) := Av(k−1). (11.2)
Aus Stabilitatsgrunden baut man bei der Implementierung jedoch eine Orthonormierung ein.
Vektoriteration nach von MISES
Initialisierung: A ∈ Cn×n, Startvektor v(0) =
∑ni=1 αixi ∈ C
n mit α1 6= 0;k = 0;repeat
y(k+1) := Av(k);
v(k+1) := y(k+1)/‖y(k+1)‖2;
k := k + 1;until stop
Ergebnis: v(k) ist Naherung eines Eigenvektors zum Eigenwert λ1 und ‖y(k)‖2 ≈ |λ1|.Die von Mises-Iteration setzt naturlich nicht die Diagonalisierbarkeit von A voraus. Unter dieser
109

110 KAPITEL 11. VERFAHREN DER VEKTORITERATION
Voraussetzung kann man aber den folgenden Konvergenzsatz beweisen.
Satz 11.1. Sei A ∈ Cn×n eine diagonalisierbare Matrix mit Eigenwerten gemaß (11.1). Ferner
gelte in der Basisdarstellung des Startvektors v(0) =∑n
i=1 αixi, daß α1 6= 0. Dann ergibt sichfur die Potenzmethode die Konvergenzaussage
dist(v(k), spanx1) := minβ∈C
‖v(k) − βx1‖2 ≤ M
∣∣∣∣
λ2
λ1
∣∣∣∣
k
. (11.3)
Ferner gilt
|‖y(k)‖2 − |λ1|| ≤ M
∣∣∣∣
λ2
λ1
∣∣∣∣
k
. (11.4)
Beweis: Nach Iterationsvorschrift und Voraussetzung an den Startvektor gilt induktiv
Av(0) =n∑
i=1
αiAxi =n∑
i=1
αiλixi,
A2v(0) =
n∑
i=1
αiλiAxi =
n∑
i=1
αiλ2i xi
......
Akv(0) =n∑
i=1
αiλki Axi = α1λ
k1
[
x1 +n∑
i=2
αi
α1
(λi
λ1
)k
xi
]
,
ferner
v(k) = Akv(0)/‖Akv(0)‖2 ∈ spanAkv(0), ‖v(k)‖2 = 1, k = 1, 2, . . . .
Sei sign(λ) := λ/|λ| fur λ ∈ C \ 0. Dann folgt (11.3) aus
minβ∈C
‖v(k) − βx1‖2 = minβ∈C
∥∥∥∥∥
Akv(0)
‖Akv(0)‖2− βx1
∥∥∥∥∥
2
= minβ∈C
∥∥∥∥∥∥∥
sign(α1λk1)
x1 +∑n
i=2αi
α1
(λi
λ1
)kxi
‖x1 +∑n
i=2αi
α1
(λi
λ1
)kxi‖2
− βx1
∥∥∥∥∥∥∥
2
≤ 1
‖x1 +∑n
i=2αi
α1
(λi
λ1
)kxi‖2
n∑
i=2
∣∣∣∣
αi
α1
∣∣∣∣
( |λi||λ1|
)k
‖xi‖2
≤ M
∣∣∣∣
λ2
λ1
∣∣∣∣
k
.
Hinsichtlich des Beweises fur die Ausage (11.4) wird verwiesen auf [10], Satz 25.1. 2
Satz 11.1 zeigt, daß die Folge v(k) der ”Richtung nach gegen x1 konvergiert”. Der Skalierungs-faktor λk
1 ist a-priori unbekannt. Dies ist unwesentlich, da der Eigenvektor x1 nur bis auf einemultiplikative Konstante bestimmt ist. Wesentlich ist lediglich die Richtung des Eigenvektors.
Die Konvergenz des Verfahrens hangt naturlich vom Kontraktionsfaktor q := |λ2|/|λ1| ab. Dasfolgende einfache Beispiel zeigt, daß die praktische Konvergenz des Verfahrens nicht befriedigt.

11.2. INVERSE ITERATION MIT SHIFT-STRATEGIE 111
Beispiel 11.2. Die Matrix
A =
−4 14 0−5 13 0−1 0 2
hat die Eigenwerte λ1 = 6, λ2 = 3 und λ3 = 2. Die Voraussetzungen von Satz 11.1 sind erfullt mitdem Startvektor v(0) = (1, 1, 1)T . Tabelle 11.1 zeigt die lineare Konvergenz der mit der Methode
Tabelle 11.1: Konvergenz der Potenzmethode fur Beispiel 11.2
k v(k)1 v
(k)2 v
(k)3 λk
0 1.0 1.000000 1.0000001 1.0 0.800000 0.100000 10.000002 1.0 0.750000 -0.111000 7.2000003 1.0 0.730769 -0.188034 6.5000004 1.0 0.722200 -0.220850 6.2307695 1.0 0.718182 -0.235915 6.1110006 1.0 0.716216 -0.243095 6.054546...
......
......
10 1.0 0.714405 -0.249579 6.00335211 1.0 0.714346 -0.249790 6.00167512 1.0 0.714316 -0.249895 6.000837
erzeugten Folge (v(k)) zur Naherung des dominierenden Eigenwertes λ1 = 6. Wir werden in denfolgenden Abschnitten sehen, dass sich diese unbefriedigende Konvergenzgeschwindigkeit durchgeeignete Modifikation des Basisverfahrens deutlich verbessern lasst. 2
Bemerkung 11.3. Die Bedingung α1 6= 0, d.h. v(0) 6∈ spanx2, ..., xn, stellt sich im allgemeinenFall durch Rundungsfehler ein. 2
11.2 Inverse Iteration mit shift-Strategie
Die Potenzmethode erlaubt nur die Berechnung des betragsmaßig großten Eigenwertes und einesdazugehorigen Eigenvektors. Durch eine scheinbar einfache Modifikation kann man auch dieanderen Eigenwerte und Eigenvektoren ermitteln:
• Bei der inversen Iteration ersetzt man die regulare Matrix A durch A−1. Da A−1 die Eigen-werte λ−1
i , i = 1, . . . , n mit den gleichen Eigenvektoren hat, konvergiert dieses Verfahrengegen den dominanten Eigenwert λ−1
n von A−1.
• Sei σ eine Naherung an einen Eigenwert λj von A und selbst aber kein Eigenwert. Dannverwendet man die inverse Iteration mit shift oder gebrochene Iteration nach Wielandt.(A − σI)−1 hat die Eigenwerte (λi − σ)−1, i = 1, . . . , n. Die Iteration approximiert danneinen Eigenvektor zu dem Eigenwert λj von A, der am nachsten zu σ liegt.
Inverse Iteration mit shift nach WIELANDT
Initialisierung: Naherung σ ∈ C an Eigenwert λj von A ∈ Cn×n, Startvektor v(0) ∈ C
n;
k = 0;repeat

112 KAPITEL 11. VERFAHREN DER VEKTORITERATION
y(k+1) := (A − σI)−1v(k);
v(k+1) := y(k+1)/‖y(k+1)‖2;
k := k + 1;until stop
Ergebnis: v(k) ist Naherung eines Eigenvektors zum Eigenwert λj.
Im Unterschied zur Potenzmethode ist hier zur Berechnung von y(k+1), d.h. in jedem Iterations-schritt, ein lineares Gleichungssystem mit der Matrix A − σI zu losen. Dies ist naturlich teurerals die Matrix-Vektor-Multiplikationen bei der Potenzmethode. Wir wollen jedoch motivieren,warum die inverse Iteration potentiell sehr gute Konvergenzeigenschaften hat.
Ausgehend von der Basisdarstellung des Startvektors erhalt man analog zum Beweis von Satz11.1 die Aussagen v(k) ∈ span(A − σI)−kv(0) und
(A − σI)−kv(0) =
n∑
i=1
αi
(λi − σ)kxi. (11.5)
Falls der Parameter σ sehr viel naher beim Eigenwert λj als bei den restlichen Eigenwertenλi, i 6= j liegt, erhalt man
1
|λi − σ| ≪1
|λj − σ| , i 6= j. (11.6)
Aus der Darstellung (11.5) ersieht man, daß der j−te Summand die ubrigen Terme der rechtsstehenden Summe stark dominiert. Dies bedeutet, daß v(k) eine gute Naherung fur den zumEigenwert λj gehorenden Eigenvektor ist. Die Konvergenzgeschwindigkeit des Verfahrens wirddann bestimmt durch den Kontraktionsfaktor
q := maxi6=j
|λj − σ||λi − σ| ≪ 1.
Die Idee des shift-Verfahrens durch Wahl eines geeigneten Parameters σ werden wir auch beimQR-Verfahren im nachsten Kapitel aufgreifen.
11.3 Rayleigh-Quotienten-Iteration
Man kann bei der Potenzmethode bzw. der inversen (gebrochenen) Iteration eine deutliche Ver-besserung der Konvergenzgeschwindigkeit fur den gesuchten Eigenwert λj erreichen, wenn manihn durch die Naherungsfolge auf Basis des sogenannten Rayleigh-Quotienten ermittelt, d.h.
RA(v) :=(Av, v)
(v, v).
Seien nachfolgend λ1, . . . , λn die Eigenwerte von A sowie x1, . . . , xn ein zugehoriges Orthonor-malsystem von Eigenvektoren. Das Rayleigh-Quotienten Verfahren basiert im Fall hermitescherMatrizen auf den folgenden Beobachtungen:
• Die Funktion f : R → R mit f(λ) := 12‖Ax − λx‖2
2 nimmt bei gegebenem x 6= 0 ihreindeutiges Minimum auf R in RA(x) an, denn
f(λ) =λ2
2‖x‖2
2 − λx∗Ax +1
2‖Ax‖2
2
nimmt das (eindeutige) Minimum an bei λ = RA(x). Ist also v 6= 0 eine brauchbare Nahe-rung fur einen Eigenvektor von A, so ist RA(v) eine gute Naherung fur einen zugehorigenEigenwert.

11.3. RAYLEIGH-QUOTIENTEN-ITERATION 113
• Sei λ eine gute Naherung fur einen Eigenwert von A, jedoch selbst kein Eigenwert. Fernersei v ∈ C
n mit ‖v‖2 = 1 eine Naherung fur einen zugehorigen Eigenvektor. Dann ergibtsich mit
v+ :=(A − λI)−1v
‖(A − λI)−1v‖2(11.7)
in der Regel eine verbesserte Approximation fur einen normierten Eigenvektor.
Sei genauer λ eine wesentliche bessere Naherung fur den Eigenwert λj als fur die restlichenEigenwerte. Ferner sei v =
∑ni=1 αixi. Dann ist
v+ :=(A − λI)−1v
‖(A − λI)−1v‖2=
∑
iαi
λi−λxi
[∑
iα2
i
(λi−λ)2]12
=sign(λj − λ)αjxj +
∑
i6=j αiλj−λ|λi−λ|xi
[
α2j +
∑
i6=j α2i
[λj−λλi−λ
]2]1
2
(11.8)
wegen |λj − λ| ≪ |λi − λ|, i 6= j eine i.a. bessere Naherung fur den Eigenvektor xj als v.
Darauf basiert das Rayleigh-Quotienten Verfahren, bei dem zu einer aktuellen Naherung fureinen Eigenvektor zunachst der zugehorige Rayleigh-Quotient berechnet und danach mit diesenDaten ein Schritt der inversen Iteration ausgefuhrt wird.
Rayleigh-Quotienten-Verfahren
Initialisierung: Matrix A ∈ Cn×n, Startvektor v(0) ∈ C
n mit ‖v0‖2 = 1.;
k = 0;repeat
ρk := RA(vk);
if A − ρkI singular
v(k+1) mit (A − ρkI)v(k+1) = 0, ‖v(k+1)‖2 = 1, stop;
else
y(k+1) := (A − ρkI)−1v(k);
v(k+1) := y(k+1)/‖y(k+1)‖2;
k := k + 1;
until stop
Ergebnis: v(k) ist Naherung eines Eigenvektors A. ρk ist Naherung an zugehorigen Eigenwert.
In jedem Iterationsschritt ist also wie bei der inversen Iteration ein lineares Gleichungssystem
(A − ρkI)y(k+1) = v(k) (11.9)
zu losen. Im Unterschied zur inversen Iteration ist jedoch in jedem Iterationsschritt die Koeffi-zientenmatrix zu modifizieren.
Die hervorragenden Eigenschaften des Verfahrens im Fall hermitescher Matrizen beschreibt derfolgende lokale Konvergenzsatz.

114 KAPITEL 11. VERFAHREN DER VEKTORITERATION
Satz 11.4. Durch das Rayleigh-Quotienten Verfahren fur die hermitesche Matrix A ∈ Cn×n
werde die Folge (v(k), ρk) erzeugt, wobei v(k) gegen einen durch ‖z‖2 = 1 normierten Eigen-vektor z von A mit Eigenwert λ konvergiere. Dann konvergieren die Folge v(k) kubisch gegenz und die Folge ρk quadratisch gegen λ. Genauer gibt es Konstanten C1, C2 > 0 mit
‖v(k+1) − z‖2 ≤ C1‖v(k) − z‖32, |ρk − λ| ≤ C2‖vk − z‖2
2.
Beweis: Der Beweis ist technisch hinreichend kompliziert. Wir verweisen hierzu auf [12], S. 70ff. Eine Beweisskizze findet man bei [10], Satz 25.4. 2
Bemerkung 11.5. Man kann naturlich auch bei der Potenzmethode oder der Wielandt-Iteration eine verbesserte Naherung an den jeweiligen Eigenwert durch Benutzung des Rayleigh-Quotienten erreichen. Fur hermitesche Matrizen kann im Fall der Potenzmethode folgende ge-genuber (11.4) verbesserte Konvergenzaussage bewiesen werden
|λ1 − ρk| ≤ M
∣∣∣∣
λ2
λ1
∣∣∣∣
2k
.
Einen Beweis findet man in [10], Korollar 25.3. 2

Kapitel 12
QR-Verfahren fur allgemeine EWP
Wir behandeln nun das derzeit wohl wichtigste numerische Verfahren zur Eigenwertberechnungvon Matrizen, das QR-Verfahren. Wir entwickeln zunachst die Idee des Verfahrens und beweisendie Konvergenz im einfachsten Fall. Hier betrachten wir den Fall diagonalisierbarer Matrizen.Dann gehen wir auf Fragen der effizienten Implementierung und Konvergenzbeschleunigung ein.Die Darstellung folgt teilweise der bei [10], Kap. 26-27.
12.1 Basisalgorithmus des QR-Verfahrens
Die QR-Zerlegung ist uns bereits aus dem Kurs Numerische Mathematik I, Kap. 3 bekannt.Beim QR-Verfahren erzeugt man auf der Basis von QR-Zerlegungen eine Folge von Ahnlichkeits-Transformationen der Matrix A. Diese konvergiert unter bestimmten Voraussetzungen gegen eineobere Dreiecksmatrix, auf deren Diagonale die Eigenwerte von A stehen.
QR-Verfahren (Basisalgorithmus)
Initialisierung: A ∈ Cn×n gegebene Matrix
m = 0;A0 := A;repeat
Am = QmRm; // QR-Zerlegung
Am+1 := RmQm;
m := m + 1;
until stop
Ausgabe: Mit Qm := Q0Q1 · · ·Qm−1 ist A = QmAmQ∗m, wobei QmAmQ∗
m i.a. Fall gegen eineSchur-Zerlegung von A konvergiert.
Das folgende Lemma zeigt, daß hierbei tatsachlich eine Folge von Ahnlichkeitstransformationenentsteht.
Lemma 12.1. Fur den Basisalgorithmus des QR-Verfahrens gilt fur m ∈ N:
Am = Q∗m−1Am−1Qm−1 (12.1)
Am = Q∗mAQm, (12.2)
Am = QmRm mit Rm := Rm−1 · · ·R0. (12.3)
115

116 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
Beweis: (i) Aussage (12.1) folgt aus
Am = Rm−1Qm−1 = Q∗m−1Qm−1Rm−1Qm−1 = Q∗
m−1Am−1Qm−1.
(ii) Aussage (12.2) ergibt sich aus (12.1) nach Induktion uber m.
(iii) Erneute Induktion uber m liefert mittels (12.2)
Am+1 = AAm = QmAmQ∗mQmRm = QmQmRmRm = Qm+1Rm+1. 2
Wir werden den aufwendigen Nachweis, dass die Folge (Am)m gegen eine obere Dreiecksmatrixkonvergiert, erst im folgenden Abschnitt bringen. Wir wollen aber bereits hier diese Konvergenzunter Bezug auf Verfahren der Vektoriteration motivieren.
Ein Spaltenvergleich in (12.3) zeigt
Ame1 = QmRme1 = Qmr(m)11 e1 = r
(m)11 q
(m)1 .
Dabei sind r(m)11 = (Rm)11 sowie q
(m)1 der erste Spaltenvektor von Qm. Bis auf Normierung
stimmen also die Vektoren q(m)1 mit denen uberein, die bei Anwendung der Vektoriteration mit
Startwert x0 = e1 entstehen. Nach Satz 11.1 konvergiert die Folge (q(m)1 ) i.a. Fall gegen einen
Eigenvektor zum betragsmaßig großten Eigenwert λ1. (Dieser Satz gilt auch ohne die bei derPotenzmethode vorgenommene Orthonormierung.) Unter Benutzung von (12.2) gilt damit furhinreichend große Zahlen m
Ame1 = Q∗mAQme1 = Q∗
mAq(m)1 ≈ λ1Q
∗mq
(m)1 = λ1e1,
d.h. es gilt
Am ≈
λ1 ∗ · · · ∗0 ∗ ∗...
......
0 ∗ · · · ∗
.
Wenn A regular ist, so entsteht fur die letzte Spalte q(m)n von Qm unter Benutzung von (12.3)
die Relation
q(m)∗n = e∗nQ
∗m = e∗nQ
−1m = e∗nRmA−m = r(m)
nn e∗nA−m.
Daher ist q(m)n das Ergebnis von m Schritten der inversen Iteration zur Berechnung des be-
tragsmaßig kleinsten Eigenwertes von A∗. Letzterer ist konjugiert-komplex zum betragsmaßigkleinsten Eigenwert λn von A. Nach Satz 11.1 erhalten wir somit
e∗nAm = e∗nQ∗mAQm = q(m)
n AQm = (A∗q(m)n )∗Qm ≈ λnq
(m)∗n Qm = λne∗n.
Da die letzte Zeile von Am somit approximativ ein Vielfaches von e∗n ist, erhalten wir zusammenmit der oberen Darstellung
Am ≈
λ1 ∗ · · · ∗0 ∗ ∗...
......
0 ∗ · · · ∗0 0 · · · λn
.

12.2. KONVERGENZ DES EINFACHEN QR-VERFAHRENS 117
12.2 Konvergenz des einfachen QR-Verfahrens
Wir zeigen nun die Konvergenz des einfachen QR-Verfahrens fur den Fall, daß alle Eigenwertepaarweise verschiedenen Betrag haben. Dabei nutzen wir die Eindeutigkeit der QR-Zerlegung.
Lemma 12.2. Seien A = Q1R1 = Q2R2 zwei QR-Zerlegungen einer regularen Matrix A ∈Cn×n. Dann existiert eine unitare Diagonalmatrix S mit Q1 = Q2S
∗ und R1 = SR2.
Beweis: Wegen der Regularitat von A und damit von R2 folgt Q∗1Q2 = R1R
−12 . Daher muß
die obere Dreiecksmatrix S := R1R−12 unitar sein. Wegen der Orthogonalitat der Spalten einer
unitaren Matrix ist S Diagonalmatrix. Damit ist der Beweis vollstandig. 2
Satz 12.3. Sei A ∈ Cn×n diagonalisierbar mit Eigenwerten
|λ1| > |λ2| > ... > |λn| > 0. (12.4)
Sei Λ := diag(λ1, . . . , λn) die Eigenwert-Matrix und X := (x1, . . . , xn) die zugehorige Eigenvektor-Matrix, d.h. es ist A = XΛX−1. Ferner existiere eine LU -Zerlegung X−1 = LU . Dann konver-gieren die Matrizen Am des Basis-Verfahrens des QR-Verfahrens gegen eine obere Dreiecksma-trix. Die Diagonaleintrage (Am)ii konvergieren mindestens linear gegen die Eigenwerte λi.
Beweis: (i) QR-Zerlegung von Am: Wegen der existierenden Zerlegung X−1 = LU folgt
Am = (XΛX−1)m = XΛmX−1 = XΛmLU = (XΛmLΛ−m)︸ ︷︷ ︸
=:Xm
ΛmU.
Sei nun Xm = PmUm eine QR-Zerlegung von Xm. Wegen der Regularitat von Xm ist auch dieobere Dreiecksmatrix Um regular. Neben (12.3) finden wir somit eine weitere QR-Zerlegung
Am = Pm(UmΛmU).
Nach Lemma 12.2 gibt es dann eine unitare Diagonalmatrix Sm mit
Qm = PmS∗m, Rm = SmUmΛmU. (12.5)
(ii) Asymptotik der Matrizen Xm: Die Diagonaleintrage der Matrix L = (lij) sind gleich 1und die Eintrage λi der Diagonalmatrix Λ sind der Große nach geordnet. Dann gelten mitq := maxi=2,...,n |λi|/|λi−1| ∈ (0, 1) die Aussagen
(ΛmLΛ−m)ij = λmi lijλ
−mj =
0, falls i < j1, falls i = j
0(qm), falls i > j
sowie
Xm = XΛmLΛ−m = X + Em, ‖Em‖2 = 0(qm), m → ∞. (12.6)
(iii) Darstellung von Am: Wegen der Definition von Qm und Rm sowie wegen (12.5) haben wir
Qm = Q−1m Qm+1 = SmP−1
m Pm+1S∗m+1
und
Rm = Rm+1R−1m = Sm+1Um+1Λ
m+1UU−1Λ−mU−1m S∗
m = Sm+1Um+1ΛU−1m S∗
m.

118 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
Daraus folgt
Am = QmRm = SmP−1m Pm+1S
∗m+1Sm+1Um+1ΛU−1
m S∗m
= SmUmU−1m P−1
m Pm+1Um+1ΛU−1m S∗
m
= SmUmX−1m Xm+1ΛU−1
m S∗m. (12.7)
(iv) Konvergenz der Matrizen Am: Wegen (12.6) ist
X−1m Xm+1 = (X + Em)−1(X + Em+1) = I + Fm, ‖Fm‖2 = 0(qm).
Dann liefert (12.7)
Am = SmUmΛU−1m S∗
m + SmUmFmΛU−1m S∗
m.
Wegen Xm = PmUm und der Unitaritat der Matrizen Pm und Sm ist
‖Um‖2 = ‖P ∗mXm‖2 = ‖Xm‖2, ‖U−1
m ‖2 = ‖X−1m ‖2.
Fur den zweiten Summanden in der letzten Formel fur Am ergibt sich dann
‖SmUmFmΛU−1m S∗
m‖2 ≤ ‖Xm‖2‖X−1m ‖2 |λ1| ‖Fm‖2 = 0(qm), m → ∞ (12.8)
und damit die asymptotische Darstellung
Am ∼ SmUmΛU−1m S∗
m, m → ∞.
Dabei ist die rechte Seite als Produkt oberer Dreieckmatrizen selbst obere Dreiecksmatrix. Dannerhalten wir
diag(Am) ∼ Smdiag(Um)Λ diag(Um)−1S∗m = Λ, m → ∞.
Wegen (12.8) erhalten wir fur den Fehler
‖Am − SmUmΛU−1m S∗
m‖2 = ‖SmUmFmΛU−1m S∗
m‖2
lineare Konvergenz gegen Null. 2
Die Voraussetzung der Existenz einer LU-Zerlegung von X−1 verallgemeinert die Voraussetzungaus Satz 11.1 fur die Potenzmethode, daß der Startvektor nicht eine Linearkombination derubrigen Eigenvektoren ist. Diesen Sachverhalt beschreibt das folgende Lemma.
Lemma 12.4. Fur die Matrix X−1 existiert genau dann eine LU-Zerlegung, wenn
spane1, . . . , ek ∩ spanxk+1, . . . , xn = 0, k = 1, . . . , n − 1. (12.9)
Beweis: Fur k ∈ 1, . . . , n − 1 gehort der Vektor x ∈ Cn genau dann zu der Menge auf der
linken Seite von (12.9), d.h. es gilt fur Koeffizienten αj , βj ∈ C
x =
k∑
j=1
αjej =
n∑
j=k+1
βjxj ,
falls
X−1x =k∑
j=1
αjX−1ej =
n∑
j=k+1
βjej .

12.3. NACHTEILE DES BASISVERFAHRENS 119
Einen derartigen Vektor x 6= 0 findet man genau dann, wenn die k-te Hauptabschnittsdetermi-nante von X−1 nicht verschwindet. Die Behauptung folgt somit, da eine Matrix genau dann eineLU-Zerlegung besitzt, wenn alle Hauptabschnittsdeterminanten nicht verschwinden. 2
Bemerkungen 12.5. (i) Die technische Voraussetzung (12.9) ist nicht erforderlich. Man erhaltdann unter der Voraussetzung (12.4) noch Konvergenz des QR-Verfahrens, jedoch sind die Eigen-werte auf der Hauptdiagonale nicht mehr notwendig betragsmaßig der Große nach angeordnet.
(ii) Im Falle von Eigenwerten gleichen Betrages konvergiert die Folge (Am) gegen eine obereBlockmatrix. Dabei entspricht die Große der Blocke gerade der Anzahl der Eigenwerte gleichenBetrages. Hinsichtlich einer genaueren Darstellung dieses allgemeineren Falles verweisen wir auf[13], Kap. 6.4. 2
12.3 Nachteile des Basisverfahrens
Wir wollen zunachst diskutieren, daß die Basisvariante des QR-Verfahrens aus Abschnitt 12.1nicht effizient ist. Folgendes Beispiel zeigt, daß die Konvergenz selbst bei kleiner Dimension nunzureichend ist.
Beispiel 12.6. Fur die Matrix
A = A1 :=
2 −1 0−1 2 −1
0 −1 2
∈ R3×3
lauten die Eigenwerte mit einer Genauigkeit von 10−5:
λ1 = 3.414214, λ2 = 2.000000, λ3 = 0.5857864.
Das einfache QR-Verfahren liefert die Iterierten
A2 =
2.8000 −0.7483 −0.0000−0.7483 2.3429 0.6389−0.0000 0.6389 0.8571
A3 =
3.1429 −0.5594 0.0000−0.5594 2.2484 −0.1878
0.0000 −0.1878 0.6087
A4 =
3.3084 −0.3722 −0.0000−0.3722 2.1039 0.0522−0.0000 0.0522 0.5876
A5 =
3.3761 −0.2292 0.0000−0.2292 2.0380 −0.0149
0.0000 −0.0149 0.5859
A6 =
3.4009 −0.1367 −0.0000−0.1367 2.0133 0.0043−0.0000 0.0043 0.5858
A7 =
3.4096 −0.0805 0.0000−0.0805 2.0046 −0.0013
0.0000 −0.0013 0.5858
. 2

120 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
Neben dieser unbefriedigenden Konvergenzaussage erfordert jeder (!) Schritt des QR-Basisalgorithmusbei vollbesetzter Matrix A ∈ C
n×n bis zu O(n3) wesentliche Rechenoperationen. Naturlich redu-ziert sich diese Zahl (bei geschickter Implementierung) stark, wenn die Matrix A schwachbesetztist, d.h. sehr viele Nullelemente hat. Speziell sind alle iterierten Matrizen von Tridiagonalmatri-zen selbst wieder Tridiagonalmatrizen. Ebenso bleibt die Form von Hessenberg-Matrizen, d.h.bei Matrizen A = (aik) mit
aik = 0, 1 ≤ k ≤ i − 2, i = 3, ..., n,
bei der QR-Zerlegung erhalten.
Man erhalt eine erhebliche Senkung des Rechenaufwandes und eine Konvergenzbeschleunigungmit dem shift QR-Verfahren, das folgenden Aufbau hat:
• In einem Reduktionsschritt fuhrt man die gegebene Matrix A ∈ Cn×n in eine orthogonal
ahnliche obere Hessenberg-Matrix A0 uber.
• Fur m = 0, 1, . . .:
– Bestimme einen shift-Parameter σm ∈ R.
– Bestimme den orthogonalen Anteil Qm ∈ Cn×n einer QR-Zerlegung Am − σmI =
QmRm und berechne Am+1 := Q∗mAmQm.
12.4 Reduktionsschritt auf Hessenberg-Form
Der Reduktionsschritt auf eine orthogonal ahnliche Hessenberg-Matrix A0 erfolgt mit Hilfevon n − 2 Ahnlichkeitstransformationen mit Householder-Matrizen. Man konstruiert geeigneteHouseholder-Matrizen P1, . . . , Pn−2 und transformiert A schrittweise
A 7→ A0 = P ∗AP, P := P1 · · ·Pn−2.
Bei dieser abwechselnden Links- und Rechtstransformation mit Householder-Matrizen verschwin-den nacheinander die Eintrage unter der ersten unteren Nebendiagonalen. Bei den Rechtsmul-tiplikationen wird diese Struktur nicht zerstort, wie man an dem folgenden Schema fur n = 5sieht. Dabei stehen • bzw. ∗ fur Elemente, die im aktuellen Schritt unverandert bzw. verandertwerden.
A =
• • • • •• • • • •• • • • •• • • • •• • • • •
→P1·
• • • • •* ∗ ∗ ∗ ∗
∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗
→·P1
• ∗ ∗ ∗ ∗• ∗ ∗ ∗ ∗
∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗
→P2·
• • • • •• • • • •
∗ ∗ ∗ ∗∗ ∗ ∗∗ ∗ ∗
→·P2
• • ∗ ∗ ∗• • ∗ ∗ ∗
• ∗ ∗ ∗∗ ∗ ∗∗ ∗ ∗
→P3·
• • • • •• • • • •
• • • •∗ ∗ ∗
∗ ∗
→·P3
• • • ∗ ∗• • • ∗ ∗
• • ∗ ∗• ∗ ∗
∗ ∗
Wir erinnern an folgende Eigenschaft von Householder-Matrizen, die fur v ∈ Cn \ 0 definiert
sind durch Pv = I − 2v∗vvv∗. Nachfolgend wird folgende Aussage wesentlich benutzt.

12.4. REDUKTIONSSCHRITT AUF HESSENBERG-FORM 121
Lemma 12.7. Fur u ∈ Cn \ 0 sei v := 1
‖u‖2(u + u1‖u‖2
|u1| e1) fur u1 6= 0 bzw. v := u‖u‖2
+ e1 furu1 = 0. Dann gilt
Pvu = −sign(u1)‖u‖2e1, sign(u1) :=
u1|u1| , u1 6= 0
1, u1 = 0.
Wir benutzen jetzt zur Konstruktion des Reduktionsschrittes ein Induktionsargument: Seienbereits k − 1 Householder-Matrizen P1, . . . , Pk−1 bestimmt mit
Pk−1 · · ·P1AP1 · · ·Pk−1 =
(Hk Bk
0 ak Ck
)
(12.10)
mit einer Hessenberg-Matrix Hk ∈ Ck×k, den Matrizen Bk ∈ C
k×(n−k), Ck ∈ C(n−k)×(n−k) und
dem Vektor ak ∈ Cn−k. Man wahlt nun Pk gemaß
Pk =
(Ik 0
0 Pk
)
mit der Einheitsmatrix Ik ∈ Rk×k und einer Householder-Matrix Pk, fur die Pkak ein Vielfaches
des ersten Einheitsvektors im Cn−k ergibt. Nach Lemma 12.7 ist das gewahrleistet, wenn ak 6= 0.
Sonst setzt man Pk = In−k. Dann erhalten wir
Pk · · ·P1AP1 · · ·Pk =
(Ik 0
0 Pk
)(Hk Bk
0 ak Ck
)(Ik 0
0 Pk
)
=
(Hk BkPk
0 Pkak PkCkPk
)
.
Dies ist gerade eine Zerlegung der Form (12.10) fur k. Daher liefert der folgende Algorithmusdie Transformation einer Matrix in n − 2 Schritten auf Hessenberg-Form.
Reduktion auf Hessenberg-Gestalt
Initialisierung: A = (aij) ∈ Cn×n.
for k = 1, . . . , n − 2 do
γk :=√∑n
j=k+1 |ajk|2;
if γk = 0;
Pk = In;
else
uk := (ak+1,k + sign(ak+1,k)γk, ak+2,k, . . . , an,k)∗;
βk := 1γk(γk+|ak+1,k|)
Pk := In−k − βkuku∗k;
Pk := diag (Ik, Pk);
A := PkAPk;
end

122 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
end
Ergebnis: Die Matrix A wird in n−2 Schritten mit der orthogonal ahnlichen oberen Hessenberg-Matrix P ∗AP mit P := P1 · · ·Pn−2 uberschrieben.
Wie beim QR-Verfahren (vgl. Kurs Numerische Mathematik I, Kap. 3) vermeidet man teureMatrix-Matrix-Multiplikationen der Hessenberg-Matrix P = I +βvv∗ mit einer Matrix B durchgeschickte Klammerung
PB = B + βv(v∗B), BP = B + (Bv)(βv∗).
Die Ermittlung von PkCkPk erfordert etwa 2(n − k)2 wesentliche Operationen. Die Berechnungvon BkPk benotigt etwa 2k(n − k) wesentliche Operationen. Die Komplexitat des Reduktions-schritts besteht damit aus
n−2∑
k=1
[2(n − k)2 + 2k(n − k)
]≈
n∑
m=1
(2m2 + 2mn) ≈ 2
3n3 + n3 =
5
3n3
wesentlichen Rechenoperationen.
Bemerkung 12.8. Im Fall hermitescher Matrizen entsteht im Reduktionsschritt sogar eineTridiagonalmatrix, denn eine hermitesche Hessenberg-Matrix ist tridiagonal. 2
12.5 QR-Zerlegung mit Givens-Rotationen
Fur die QR-Zerlegung der erhaltenen Hessenberg-Matrix benutzt man jetzt Givens-Rotationenanstelle von Householder-Matrizen. Dabei heißt eine Matrix aus C
n×n der Form
G(j, k; c, s) =
1. . .
1
c s1
. . .
1−s c
1. . .
1
Givens-Rotation, falls |c|2 + |s|2 = 1. In der Darstellung stehen die Eintrage c, s in der j-tenZeile und −s, c in der k-ten Zeile.
Offenbar sind Givens-Rotationen unitar, denn
(c s−s c
)(c −ss c
)
=
(|c|2 + |s|2 0
0 |c|2 + |s|2)
.
Im wichtigsten Fall c, s ∈ R gibt es einen Winkel θ ∈ [0, 2π) mit c = cos θ und s = sin θ. Die
Matrix
(c s−s c
)
beschreibt eine Drehung in der Ebene R2 um den Winkel θ.

12.5. QR-ZERLEGUNG MIT GIVENS-ROTATIONEN 123
Bei einer Linksmultiplikation GA einer Matrix A ∈ Cn×n bewirkt die Givens-Rotation G =
G(j, k; c, s), daß die j-te bzw. k-te Zeile a∗j bzw. a∗k von A durch ca∗j +sa∗k bzw. −sa∗j +ca∗k ersetztwird. Man kann nun zu gegebenen Indizes j, k, l mit j 6= k und gegebener Matrix A ∈ C
n×n eineGivens-Rotation G = G(j, k; c, s) finden, daß (GA)kl = 0 wird. Dies entspricht der Losung von
−sajl + cakl = 0, |c|2 + |s|2 = 1.
Eine Losung ist(
cs
)
= giv rot(ajl, akl) :=1
√
|ajl|2 + |akl|2(
ajl
akl
)
.
Zur overflow-Vermeidung verwendet man die dazu aquivalenten Formeln
c =ajl/|ajl|√
1 + |t|2, s =
t√
1 + |t|2, t =
akl
|ajl|, falls |ajl| ≥ |akl|,
c =t
√
1 + |t|2, s =
akl/|akl|√
1 + |t|2, t =
ajl
|akl|, falls |ajl| < |akl|,
Fur eine QR-Zerlegung der Hessenberg-Matrix A(0) := A ∈ Cn×n benutzen wir
A(k) := G(k, k + 1; ck, sk)A(k−1), (ck, sk)
T = giv rot(A(k−1)kk , A
(k−1)k+1,k); k = 1, . . . , n − 1.
Fur n = 4 verlauft dies schematisch wie folgt:
A =
• • • •• • • •
• • •• •
→k=1
∗ ∗ ∗ ∗∗ ∗ ∗• • •
• •
→k=2
• • • •∗ ∗ ∗
∗ ∗• •
→k=3
• • • •• • •
∗ ∗∗
= R.
Dabei kennzeichnet ∗ Elemente, die in einem Schritt verandert werden, und • die sonstigen (i.a.Fall) von Null verschiedenen Elemente.
In algorithmischer Form ist folgendes auszufuhren:
QR-Zerlegung einer Hessenberg-Matrix mit Givens-Rotationen
Initialisierung: Hessenberg-Matrix A = (ajk) ∈ Cn×n;
for k = 1, . . . , n − 1 do
(ck, sk)T := giv rot(akk, ak+1,k);
for l = k, . . . , n do(
akl
ak+1,l
)
:=
(ck sk
−sk ck
)(akl
ak+1,l
)
;
end
end
Ergebnis: A wird mit der oberen Dreiecksmatrix R = G(n − 1, n; cn−1, sn−1) · · ·G(1, 2; c1 , s1)Auberschrieben.
Die Anzahl von Multiplikationen fur diesen Algoritmus ist etwa
n−1∑
k=1
4(n − k + 1) =n∑
k=2
4k ≈ 2n2

124 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
und damit um den Faktor 13n kleiner als bei einer QR-Zerlegung mit Householder-Matrizen.
Bemerkung 12.9. Im Fall einer hermiteschen Matrix entstand im Reduktionsschritt einehermitesche Tridiagonalmatrix. Bei der Givens-Rotation kommt man dann sogar mit O(n) ele-mentaren Operationen statt ca. O(n2) aus. 2
12.6 Konvergenzbeschleunigung durch shift-Strategie
Wir hatten bereits bei der inversen Iteration gesehen, daß die Konvergenz des Verfahrens erheb-lich mittels einer shift-Strategie beschleunigt werden kann. Man nutzt aus, daß die Eigenvektorenvon A mit denen von A − σI, σ ∈ C ubereinstimmen und die Eigenwerte von A − σI geradeλj −σ, j = 1, . . . , n sind. Daher kann das QR-Verfahren auch auf die Matrix mit shift angewen-det werden. Ferner modifiziert man den shift-Parameter eventuell in jedem Schritt. Dann giltfolgende Verallgemeinerung von Lemma 12.1. Das Resultat zeigt wieder, daß im modifiziertenAlgorithmus tatsachlich eine Folge von Ahnlichkeitstransformationen entsteht.
Lemma 12.10. Seien A = A0 ∈ Cn×n eine gegebene Matrix und σ0, σ1, . . . ∈ C gegebene shift-
Parameter. Sind die Matrizen Am, Qm, Rm fur m ∈ N0 gegeben durch
Am − σmI = QmRm (QR-Zerlegung) (12.11)
Am+1 = RmQm + σmI, (12.12)
so gelten die Aussagen (12.1)-(12.2) aus Lemma 12.1 mit Qm := Q0 · · ·Qm−1 und Rm :=Rm−1 · · ·R0 sowie
m∏
k=0
(A − σkI) = Qm+1Rm+1. (12.13)
Beweis: Aussage (12.1) ergibt sich wegen (12.11)-(12.12) aus
Am+1 = RmQm + σmI = Q∗m(QmRm + σmI)Qm = Q∗
mAmQm.
Aussage (12.2) folgt hieraus durch Induktion.
Wir zeigen noch (12.13) durch Induktion uber m. Fur m = 0 ist (12.13) mit (12.11) identisch.Wenn (12.13) fur m− 1 ∈ N0 gilt, so ergibt sich aus der Voraussetzung sowie (12.11) und (12.2)schließlich
Qm+1Rm+1 = QmQmRmRm = Qm(Am − σmI)Rm
= QmQ∗mAQmRm − σmQmRm
= (A − σmI)QmRm =m∏
k=0
(A − σk)I. 2
Nun wollen wir uberlegen, wie man die shift-Parameter σm geeignet wahlt. Nach Abschnitt 11.2folgt, daß die Basisversion des QR-Verfahrens der Wielandt-Iteration fur den betragsmaßigkleinsten Eigenwert von A entspricht. Wir wollen dabei den shift-Parameter so bestimmen, daßdie Wielandt-Iteration durch die wesentlich schneller konvergierende Rayleigh-Quotienten-Methode ersetzt wird. In Abschnitt 12.1 hatten wir gezeigt, daß en eine Naherung eines Ei-genvektors zum kleinsten Eigenwert λn von A∗
m ist. Der zugehorige Rayleigh-Quotient istσm = e∗nAmen = (Am)nn. Man darf daher schnelle Konvergenz von (Am)nn gegen λn erwarten,wenn man σm = (Am)nn setzt.

12.6. KONVERGENZBESCHLEUNIGUNG DURCH SHIFT-STRATEGIE 125
Noch gunstiger ist in der Regel, wenn man den rechten unteren 2 × 2-Block von Am = (a(m)ik ),
d.h.
A2×2m =
(
a(m)n−1,n−1 a
(m)n−1,n
a(m)n,n−1 a
(m)n,n
)
,
zur Bestimmung des shift-Parameters benutzt. Man wahlt σm als den Eigenwert von A2×2m , der
am nachsten bei a(m)n,n liegt. Dann konvergiert a
(m)n,n in der Regel sehr schnell gegen einen Eigenwert
von A und a(m)n,n−1 konvergiert gegen 0, d.h.
Am →
∗ · · · · ∗ ∗. . .
......
. . .. . .
......
0 ∗ ∗ ∗0 · · · · · · 0 λn
=
∗Bm
...∗
0 · · · 0 λn
.
Erfahrungsgemaß reichen zwei Iterationen aus, damit der Wert |a(m)n,n−1| hinreichend klein wird.
Man kann dann im weiteren Verlauf mit der kleineren Hessenberg-Matrix Bm ∈ C(n−1)×(n−1)
weiter rechnen. Es findet also eine systematische Ordnungsreduktion statt. Daraus ergibt sichfolgender Algorithmus.
QR-Verfahren mit shifts
Initialisierung: Matrix A ∈ Cn×n;
TOL > 0 Toleranzwert;
Reduziere A mit Householder-Transformationen auf Hessenberg-Gestalt A := U∗AU ;for j = n, n − 1, . . . , 2 do
while |aj,j−1| > TOL(|ajj | + |aj−1,j−1|) do
Wahle σ als Eigenwert von
(aj−1,j−1 aj−1,j
aj,j−1 ajj
)
, der am nachsten zu ajj liegt;
Berechne QR-Zerlegung QR = A − σI mit Givens-Rotationen;
Setze A := RQ + σI;
end
end
Ergebnis: A wird mit einer unitar aquivalenten oberen Dreiecksmatrix uberschrieben.
Bei der Implementierung sind folgende Punkte zu beachten:
• Man berechnet die unitare Matrix
Q∗ = G(n − 1, n; cn−1, sn−1) · · ·G(1, 2; c1, s1)
aus Effizienzgrunden nicht explizit. Es reicht aus, die Koeffizienten cj , sj der Givens-Rotationen zu speichern. Zur Berechnung von RQ werden Givens-Rotationen von rechtsan R multipliziert. Analog zur Multiplikation von Givens-Rotationen von links realisiertman dies durch Bildung von Linearkombinationen von Spalten von R.

126 KAPITEL 12. QR-VERFAHREN FUR ALLGEMEINE EWP
• Fur j < n ist die rechte untere Teilmatrix von R vom Format (n − j + 1) × (n − j + 1)bereits obere Dreiecksmatrix. Daher sind nur j−1 Givens-Rotationen fur die QR-Zerlegungerforderlich.
• Falls A reelle Matrix mit lediglich reellen Eigenwerten ist, kann die beschriebene Versiondes QR-Verfahrens bei Wahl von reellen shift-Parametern in reeller Arithmetik ausgefuhrtwerden. Hat A Paare konjugiert-komplexer Eigenwerte, sind die shift-Parameter komplexzu wahlen, um Konvergenz gegen eine obere Dreiecksmatrix zu gewahrleisten. Durch einensogenannten QR-Doppelschritt kann man jedoch auch dann die komplexe Arithmetik um-gehen. Im Grenzprozeß erhalt man (wie bei der reellen Jordan-Zerlegung) eine reelle Matrixmit 2× 2-Blocken auf der Diagonalen, deren Eigenwerte den gesuchten Paaren konjugiert-komplexer Eigenwerte von A entsprechen.

Teil III
Lineare Optimierung
127


Kapitel 13
Grundlagen der Optimierung
In der endlich-dimensionalen (kontinuierlichen) Optimierung sucht man das Infimum einer Ziel-funktion f : M → R auf einer Menge der zulassigen Punkte M ⊂ R
n, d.h.
Finde infx∈M
f(x). (13.1)
Im Fall der Existenz sucht man einen Punkt x∗ ∈ M mit f(x∗) = infx∈M f(x). Die Menge Mwird in der Regel durch Restriktionen in Gleichungs- und Ungleichungsform charakterisiert.
Wir werden uns in den folgenden Kapiteln 14 und 15 vorwiegend mit linearen Optimierungs-problemen befassen. Hierbei sind sowohl die Zielfunktion als auch die Restriktionen linear. Imvorliegenden Kapitel darf die Zielfunktion noch nichtlinear sein.
13.1 Definitionen. Vorbemerkungen
Wir wollen zunachst die Beschreibung der Nebenbedingungen formalisieren. Seien G bzw. Udisjunkte, endliche Indexmengen sowie ci : R
n → R mit i ∈ G ∪ U Funktionen. Dann sei dieMenge der Nebenbedingungen (Restriktionen) gegeben durch
M := x ∈ Rn : ci(x) = 0, i ∈ G; ci(x) ≥ 0, i ∈ U. (13.2)
Jede Nebenbedingung kann o.B.d.A. so formuliert werden, daß auf der rechten Seite der Bedin-gung 0 steht und bei Ungleichungsrestriktionen das ≥-Zeichen steht.
Ferner kann man das Maximierungsproblem supx∈M f(x) auf ein Minimierungsproblem (12.1)umformen wegen
supx∈M
f(x) = − infx∈M
[−f(x)].
Im Fall M = Rn, d.h. bei G∪U = ∅ nennt man (13.1) unrestringiertes Optimierungsproblem. Wir
behandeln in Teil III dieser Vorlesung lediglich (das in der Regel kompliziertere) restringierteOptimierungsproblem fur affin-lineare Funktionen ci, i ∈ G ∪ U und lineare Zielfunktionen f .
Nimmt eine Funktion f : M → R auf einer Menge M ∈ Rn ihr Infimum auf M an, d.h. es gibt
ein x∗ ∈ M mit f(x∗) = minx∈M f(x), so schreiben wir infx∈M f(x) = minx∈M f(x).
Das Minimum muß nicht zwingend existieren, wie die Funktion f(x) = 1x in Verbindung mit
der Menge M = [1,∞) zeigt. Ferner kann das Infimum auch −∞ sein. Dazu betrachte man dieFunktion f(x) = −x mit der Menge M = [1,∞).
Definition 13.1. Fur M ⊂ Rn und f : M → R heißt ein Punkt x ∈ M
129

130 KAPITEL 13. GRUNDLAGEN DER OPTIMIERUNG
• lokales Minimum von f in M , wenn es eine Umgebung U(x) ⊂ M mit f(x) ≤ f(y) furalle y ∈ U(x) gibt,
• striktes lokales Minimum von f in M , wenn sogar f(x) < f(y) fur alle y ∈ U(x)\x gilt,
• globales Minimum von f in M , falls f(x) ≤ f(y) fur alle y ∈ M .
Fur eine in x ∈ M differenzierbare Funktion f mit ∇f(x) = 0 heißt x stationarer Punkt von f .
13.2 Optimalitatsbedingungen
Wir erinnern an die Landau-Symbolik: Fur normierte Raume X,Y sei U ⊂ X und x0 ∈ U . FurFunktionen f : U \ x0 → Y und g : U \ x0 → (0,∞) schreibt man
f(x) = o(g(x)), x → x0, falls limx→x0
‖f(x)‖Y
g(x)= 0,
f(x) = O(g(x)), x → x0, falls lim supx→x0
‖f(x)‖Y
g(x)< ∞.
Wir wollen nun allgemeine Optimalitatsbedingungen herleiten.
Satz 13.2. (Notwendige Optimalitatsbedingungen 1. Ordnung)Seien M ⊂ Rn eine offene Menge und f : M → R eine differenzierbare Funktion. Ist x ∈ Mlokales Minimum von f , so gilt ∇f(x) = 0.
Beweis: Sei p := −∇f(x) 6= 0. Wegen der Offenheit von M gibt es eine Zahl r > 0, so daßx + ǫp ∈ M fur alle |ǫ| < r. Die Differenzierbarkeit von f impliziert die Taylor-Entwicklung
f(x + ǫp) = f(x) + ǫpT∇f(x) + o(ǫ) = f(x) − ǫ‖∇f(x)‖22 + o(ǫ), ǫ → 0.
Damit gilt f(x + ǫp) < f(x) fur hinreichend kleine Werte ǫ > 0. Dies ergibt einen Widerspruchzur Voraussetzung eines Minimums im Punkt x. 2
Fur eine zweimal differenzierbare Funktionen f definieren wir die Hesse-Matrix
(Hf)(x) :=
(∂2f
∂xi∂xj(x)
)
i,j=1,...,n
.
Wegen der Vertauschbarkeit der Differentiationsreihenfolge ist (Hf)(x) symmetrisch.
Satz 13.3. (Optimalitatsbedingungen 2. Ordnung)Seien M ⊂ R
n eine offene Menge und f ∈ C2(M). Ferner sei x ∈ M stationarer Punkt von f .Dann gelten folgende Aussagen:
(i) Hinreichende Bedingung: Ist (Hf)(x) positiv definit, d.h. yT (Hf)(x)y > 0 fur alle y ∈R
n \ 0, so ist x lokales Minimum von f .
(ii) Notwendige Bedingung: Ist x lokales Minimum von f , so ist (Hf)(x) positiv semi-definit,d.h. yT (Hf)(x)y ≥ 0 fur alle y ∈ R
n.
Beweis: Fur f ∈ C2(M) gilt die Taylor-Entwicklung
f(x + h) = f(x) + hT∇f(x) +1
2hT (Hf)(x)h + r(h), r(h) = o(‖h‖2), h → 0.

13.3. LAGRANGE-FORMALISMUS FUR LINEARE GLEICHUNGSRESTRIKTIONEN 131
Wegen ∇f(x) = 0 ist dann
f(x + h) − f(x) =1
2hT (Hf)(x)h + r(h). (13.3)
Wegen der Symmetrie der Hesse-Matrix gibt es nach dem Satz uber die Hauptachsentrans-formation (vgl. Lemma 10.7) eine orthogonale Matrix U ∈ R
n×n und eine DiagonalmatrixD = diag(d1, . . . , dn) mit
(Hf)(x) = UDUT .
(i) Sei zunachst (Hf)(x) positiv definit: Mit dem j-ten Einheitsvektor ej gilt
dj = eTj Dej = eT
j UT UDUT Uej = (Uej)T (Hf)(x)(Uej) > 0.
Dann gilt κ := mind1, . . . , dn > 0. Mit beliebigem h ∈ Rn und g := UT h ergibt die Orthogo-
nalitat von U , daß
hT (Hf)(x)h = gT Dg =
n∑
i=1
g2i di ≥ κ
n∑
i=1
g2i = κ‖g‖2
2 = κ‖h‖22.
Wegen der letzten Ungleichung und (13.3) findet man eine Zahl ǫ > 0, so daß f(x+h)−f(x) > 0fur alle ‖h‖ < ǫ und h 6= 0. Damit hat f in x ein lokales Minimum.
(ii) Sei x lokales Minimum von f : Fur h ∈ Rn folgt aus (13.3) wegen r(ǫh) = o(ǫ2) die Aussage
1
2hT (Hf)(x)h = lim
ǫ→0
1
2ǫ2(ǫh)T (Hf)(x)(ǫh)
= limǫ→0
1
ǫ2[f(x + ǫh) − f(x) − r(ǫh)]
= limǫ→0
1
ǫ2[f(x + ǫh) − f(x)].
Da f in x ein lokales Minimum hat, gilt offenbar f(x + ǫh) − f(x) > 0 bei hinreichend kleinenWerten ǫ. Dann ist aber 1
2hT (Hf)(x)h ≥ 0, d.h. (Hf)(x) positiv semidefinit. 2
13.3 Lagrange-Formalismus fur lineare Gleichungsrestriktionen
Wir behandeln von jetzt ab Optimierungsprobleme mit (affin)-linearen Nebenbedingungen
Minimiere f(x) auf M := x ∈ Rn : AGx = bG, AUx ≥ bU (13.4)
mit AG ∈ RmG×n, AU ∈ R
mU×n, bG ∈ RmG , bU ∈ R
mU mit mG,mU ∈ N0. Dabei wird furVektoren x, y ∈ R
k die Relation x ≤ y komponentenweise verstanden.
Als Standardform der Restriktionen bezeichnet man fur x ∈ Rn und A ∈ R
m×n, b ∈ Rm fur
m ∈ N0, n ∈ N die Darstellung:Ax = b, x ≥ 0. (13.5)
Jedes Problem der Form (13.4) kann auf Standardform gebracht werden:
• Man fuhrt Schlupfvariable z ∈ RmU ein und ersetzt die Restriktionen AUx ≥ b durch
AUx − z = bU , z ≥ 0.

132 KAPITEL 13. GRUNDLAGEN DER OPTIMIERUNG
• Eine Vorzeichenbeschrankung der Variablen erhalt man durch
x+ := maxx, 0, x− := max−x, 0.
Dann gilt x = x+ − x−, x+, x− ≥ 0 sowie AG/U := AG/Ux+ − AG/Ux−.
Man erhalt dann die Restriktionen in der Form
(AG −AG 0AU −AU −I
)
x+
x−
z
=
(bG
bU
)
,
x+
x−
z
≥ 0.
Lemma 13.4: Seien M0 ⊂ Rn ein Untervektorraum, m0 ∈ R
n sowie M := m0 + M0. Fernerseien f : R
n → R differenzierbar und x∗ ein lokales Minimum von f auf M . Dann gilt
∇f(x∗) ∈ M⊥0 := v ∈ R
n : vT w = 0 ∀w ∈ M0.
Beweis: Sei ∇f(x∗) 6∈ M⊥0 . Dann gibt es ein Element p ∈ M0 mit pT∇f(x∗) 6= 0. Die skalare
Funktion φ : R → M mit φ(t) := f(x∗ + tp) ist wohldefiniert mit φ′(0) = pT∇f(x∗) 6= 0. Somithat φ in t = 0 kein lokales Minimum im Widerspruch zur Voraussetzung uber die Existenz eineslokalen Minimums von f in x∗. 2
Folgerung 13.5. Unter den Voraussetzungen von Lemma 13.4 sei
M := x ∈ Rn : aT
j x = bj , j = 1, . . . ,m
mit linear unabhangigen Vektoren a1, . . . , am ∈ Rn und b1, . . . , bm ∈ R. Dann existieren eindeutig
Zahlen λ1, . . . , λm ∈ R mit
∇f(x∗) =
m∑
i=1
λiai. (13.6)
Beweis: Man benutzt Lemma 13.4 mit
M0 := x ∈ Rn : aT
j x = 0, j = 1, . . . ,m, M⊥0 = spana1, . . . , am. 2
Die Zahl λj wird als Lagrange-Multiplikator zur Nebenbedingung aTj x = bj bezeichnet. Die-
ser Parameter ist ein Maß fur die Sensitivitat des Minimums gegenuber der Verletzung derzugehorigen Restriktion. Als Beispiel betrachten wir die gestorten Nebenbedingungen
aT1 x = b1 + ǫ; aT
j x = bj , j = 2, . . . ,m
mit dem kleinen Parameter ǫ > 0. Fur hinreichend kleines ǫ sei x∗(ǫ) eine nach ǫ differenzierbareLosung des gestorten Optimierungsproblems. Dann gilt
aTj
d
dǫx∗(ǫ) = δ1j
sowie
d
dǫf(x∗(ǫ))|ǫ=0 = ∇f(x∗(0))T
d
dǫx∗|ǫ=0 =
m∑
j=1
λjaTj
d
dǫx∗|ǫ=0 =
m∑
j=1
λjδ1j = λ1.
Somit zeigt λ1 an, wie stark sich das Minimum von f andert, wenn man b1 in der ersten Re-striktion stort.

13.4. KKT-BEDINGUNGEN FUR LINEARE UNGLEICHUNGSBEDINGUNGEN 133
Definition 13.6. Als Lagrange-Funktion L : Rn × R
m → R fur das Optimierungsproblem
Minimiere f(x) unter den Restriktionen aTj x = bj, j = 1, . . . ,m
bezeichnet man
L(x, λ) := f(x) −m∑
j=1
λj(aTj x − bj). (13.7)
Mittels Lemma 13.4 und Folgerung 13.5 ergeben sich die Optimalitatsbedingungen erster Ord-nung fur die Lagrange-Funktion wie folgt.
Folgerung 13.7. Unter den Voraussetzungen von Lemma 13.4 und Folgerung 13.5 existiert eineindeutig bestimmter Vektor λ∗ ∈ R
m mit
∇xL(x∗, λ∗) = 0, (13.8)
∇λL(x∗, λ∗) = 0, (13.9)
d.h. (x∗, λ∗) ist stationarer Punkt von L bzw. ∇L(x∗, λ∗) = 0.
Beweis: (13.8) ist aquivalent zu (13.6). Wegen ∂L∂λj
= −(aTj x − bj) ist (13.9) aquivalent zu
x∗ ∈ M . 2.
Durch Einfuhrung der Lagrange-Multiplikatoren wird gegenuber dem ursprunglichen Opti-mierungsproblem einerseits die Dimension des Problems von n auf n + m reelle Variable erhoht.Andererseits entledigt man sich der Nebenbedingungen auf der (n−m)-dimensionalen Mannig-faltigkeit M durch Ubergang zu einem Gleichungssystem. Man kann dann zum Beispiel direktmit dem Newton-Verfahren arbeiten.
13.4 KKT-Bedingungen fur lineare Ungleichungsbedingungen
Wir suchen jetzt nach Optimalitatsbedingungen, falls zusatzlich zur Situation im vorgehendenAbschnitt auch lineare Ungleichungsrestriktionen vorliegen. Wir starten mit einem Beispiel.
Beispiel 13.8. Fur eine differenzierbare Funktion f : R → R sowie a, b ∈ R mit a 6= 0 wirddas skalare Problem
Minimiere f(x) auf M := x ∈ R : ax ≥ b.
betrachtet. Sei x∗ ∈ M lokales Minimum von f in M , so existiert (Begrundung ?) ein Lagrange-Multiplikator s∗ ≥ 0 mit
f ′(x∗) = as∗, s∗(ax∗ − b) = 0.
Im Fall ax∗ − b > 0 liegt x∗ im Inneren von M . Nach Satz 13.2 gilt f ′(x∗) = 0. Dann sind diebeiden Gleichungen mit s∗ = 0 erfullt.
Bei ax∗−b = 0 liegt x∗ auf dem Rand von M . Die Optimalitatsbedingung von x∗ impliziert danneine Vorzeichenbeschrankung an f ′(x∗), die durch die erste Bedingung charakterisiert wird. 2
Wir kommen nun sofort zur Verallgemeinerung dieses Resultates fur Optimierungsprobleme mitlinearen Nebenbedingungen
Minimiere f(x) auf M := x ∈ Rn : AGx = bG, AUx ≥ bU (13.10)
mit den Bezeichnungen aus Abschnitt 13.3.

134 KAPITEL 13. GRUNDLAGEN DER OPTIMIERUNG
Satz 13.9. (KKT-Bedingungen)Sei f : R
n → R differenzierbar. Ist x∗ ∈ M lokales Minimum des Optimierungsproblems (13.10),so gibt es Lagrange-Multiplikatoren λ∗ ∈ R
mG und s∗ ∈ RmU+ , die die folgenden Karush-
Kuhn-Tucker-Bedingungen (KKT-Bedingungen) erfullen:
∇f(x∗) = ATGλ∗ + AT
Us∗ (13.11)
(AUx∗ − bU )T s∗ = 0. (13.12)
Beweis: vgl. nachster Abschnitt. 2
Mit der Lagrange-Funktion
L(x, λ, s) := f(x) − (AGx − bG)T λ − (AUx − bU )T s
kann man (13.11) analog zu Folgerung 13.7 einfach notieren als
∇xL(x∗, λ∗, s∗) = 0.
Mit AU = (a1 · · · amU)T und bU = (b1 · · · bmU
)T lauten die Ungleichungsrestriktionen in (13.10)
aTi x − bi ≥ 0, i = 1, . . . ,mU .
Fur jeden zulassigen Vektor x ∈ M wird die Indexmenge U := 1, . . . ,mU disjunkt zerlegtgemaß U = A(x) ∪ I(x) mit i ∈ A(x), falls aT
i x − bi = 0. Ungleichungen mit Index i ∈ A(x)bzw. i ∈ I(x) = U \ A(x) heißen aktive Restriktion in x bzw. inaktive Restriktion in x.
Die sogenannte Komplementaritatsbedingung (13.12) kann mit s∗ = (s1, . . . , smU)T notiert wer-
den als ∑
i∈U(aT
i x∗ − bi)si = 0.
Die Lagrange-Multiplikatoren der inaktiven Ungleichungen verschwinden notwendig, da alleSummanden nichtnegativ sind. Die Umkehrung gilt auch, d.h.
(13.12) ⇐⇒ si = 0, ∀i ∈ I(x∗). (13.13)
13.5 Farkas-Lemma
Zum Beweis der KKT-Bedingungen benotigen wir das Farkas-Lemma.
Definition 13.10. Eine Teilmenge K ⊂ Rn heißt Kegel, falls aus x ∈ K auch λx ∈ K fur alle
λ > 0 folgt.
Lemma 13.11. Fur a1, . . . , am ∈ Rm ist durch
cone a1, . . . , am :=
m∑
i=1
λiai : λ1, . . . , λm ≥ 0
(13.14)
ein konvexer, abgeschlossener Kegel gegeben.
Beweis: Per Definition ist K := cone a1, . . . , am ein Kegel. Die Konvexitat folgt ebenfallsaus der Definition.
Zum Nachweis der Abgeschlossenheit fuhren wir eine Induktion uber m durch. Der Induktions-anfang fur m = 1 ist offenbar erfullt. Induktionsannahme sei nun, daß jeder von weniger als m

13.5. FARKAS-LEMMA 135
Vektoren erzeugte Kegel abgeschlossen ist. Sei (x(k))k∈N eine Folge im Kegel K, die gegen einenPunkt x∗ ∈ R
n konvergiert. Zu zeigen ist die Aussage x∗ ∈ K.
Wegen der Definition von K in (13.14) gibt es Zahlen λ(k)i ≥ 0 mit x(k) =
∑mi=1 λ
(k)i ai fur k ∈ N.
Der Unterraum V := spana1, . . . , am ist abgeschlossen. Die Folge (x(k))k∈N liegt in V , somitist auch x∗ ∈ V . Somit findet man Zahlen α1, . . . , αm ∈ R mit x∗ =
∑mi=1 αiai.
Der Beweis ware erledigt bei αi ≥ 0, i = 1, . . . ,m. Wir nehmen daher an, daß es wenigstenseinen Index i ∈ 1, . . . ,m mit αi < 0 gibt. Wir konstruieren nun eine Vektorfolge
z(k) := x(k) + γk(x∗ − x(k)), γk ∈ [0, 1],
so daß in
z(k) =
m∑
i=1
r(k)i ai, r
(k)i = λ
(k)i + γk(αi − λ
(k)i )
alle Zahlen r(k)i nichtnegativ sind und es fur jedes k ∈ N wenigstens einen Index ik mit r
(k)ik
= 0gibt. Fur
γk := min
λ(k)i
λ(k)i − αi
: i ∈ 1, . . . ,m mit αi < 0
.
ist γk ∈ [0, 1], ferner ist
r(k)i = λ
(k)i + γk(αi − λ
(k)i ) ≥ 0, i = 1, . . . ,m.
Fur wenigstens einen Index i = ik gilt Gleichheit.
Nach Konstruktion ist z(k) ∈ K und wegen γk ∈ [0, 1] gilt
‖z(k) − x∗‖2 = (1 − γk)‖x(k) − x∗‖2 → 0, k → ∞,
d.h. es folgt auch z(k) → x∗, k → ∞.
Die Indexfolge (ik)k∈N hat wenigstens einen Haufungpunkt i∗ ∈ 1, . . . ,m , d.h. man findet
eine Teilfolge (ik(l))l∈N mit ik(l) = i∗ fur alle l ∈ N. Dann ist r(k(l))i∗
= 0 fur alle l ∈ N und daher
z(k(l)) ∈ K∗ := cone ai : i 6= i∗. Wegen der Induktionsvoraussetzung ergibt sich, daß x∗ alsGrenzwert der Folge (zk(l))l∈N zur Menge K∗ gehort. Wegen der Inklusion K∗ ⊂ K folgt dieAbgeschlossenheit von K. 2
Lemma 13.12. (Lemma von Farkas)Bei gegebenen Vektoren a1, . . . , am ∈ R
n und g ∈ Rn sind die folgende Aussagen aquivalent:
(i) g ∈ K := cone a1, . . . , am.
(ii) Fur alle d ∈ Rn mit aT
j d ≥ 0 fur j = 1, . . . ,m gilt dT g ≥ 0.
Beweis: ”(i) ⇒ (ii)”: Sei g =∑m
i=1 λiai mit λi ≥ 0. Ferner sei d ∈ Rn mit dT ai ≥ 0 fur
i = 1, . . . ,m. Dann folgt
dT g =
m∑
i=1
λidT ai ≥ 0.
”(ii) ⇒ (i)”: Wir fuhren den Beweis indirekt. Sei also (i) nicht richtig, d.h. g 6∈ K . Die Funktionl(h) := ‖h − g‖2 wachst fur ‖h‖2 → ∞ nach unendlich. Da ferner K abgeschlossen ist, gibt esein globales Minimum g0 ∈ K von l in K. Wegen g 6∈ K ist
d := g0 − g 6= 0.

136 KAPITEL 13. GRUNDLAGEN DER OPTIMIERUNG
Wegen der Kegeleigenschaft von K ist tg0 ∈ K fur t ≥ 0. Somit ist 12‖tg0 − g‖2
2 minimal furt = 1 und es folgt
0 =1
2
d
dt‖tg0 − g‖2
2|t=1 = (g0 − g)T g0 = dT g0. (13.15)
Fur einen weiteren Vektor h ∈ K gilt wegen der Konvexitat von K und der Minimalitatseigen-schaft von g0, daß
‖g0 + t(h − g0) − g‖22 ≥ ‖g0 − g‖2
2, t ≥ 0.
Dies impliziert2tdT (h − g0) + t2‖h − g0‖2
2 ≥ 0
bzw. nach Division durch 2t und Grenzubergang fur t → +0 und Beachtung von (13.15), daß
0 ≤ dT (h − g0) = dT h, ∀h ∈ K.
Speziell fur h = aj , j = 1, . . . ,m ist aTj d ≥ 0 und damit erneut mit (13.15)
dT g = dT (g0 − d) = dT g0 − dT d = −‖d‖22 < 0.
Daher kann Aussage (ii) nicht gelten. Nach dem Prinzip des indirekten Beweises folgt dann (i)aus (ii). 2
Wir konnen nun schließlich den Satz uber die KKT-Bedingungen beweisen.
Beweis von Satz 13.9. Wegen
aTi x = bi ⇐⇒ aT
i x − bi ≥ 0, −aTi x + bi ≥ 0
konnen wir nachfolgend lediglich mit Ungleichungsrestriktionen arbeiten.
Wir fuhren den Beweis indirekt. Sei dazu x∗ lokales Minimum von f in
M := x ∈ Rn : aT
i x ≥ bi, i = 1, . . . ,mU
und es gabe kein s∗ = (si) ∈ RmU+ , das die KKT-Bedingungen erfullt. Fur alle Vektoren s∗ ∈
RmU+ , die (13.12) erfullen, kann dann (13.11) nicht gelten, d.h. ∇f(x∗) 6= AT
Us∗. Die Aussage(13.13) impliziert dann si = 0 fur i ∈ I(x∗) und daher
∇f(x∗) 6∈ cone ai : i ∈ A(x∗).
Nach dem Farkas-Lemma findet man dann einen Vektor d ∈ Rn mit aT
i d ≥ 0 fur alle i ∈ A(x∗)und
dT∇f(x∗) < 0. (13.16)
Sei φ(t) := f(x∗ + td), t ≥ 0. Wegen φ′(0) = dT∇f(x∗) < 0 liegt im Nullpunkt kein Minimumvon φ im Bereich [0,∞). Wir wollen zeigen, daß es eine Zahl t0 > 0 gibt mit x∗ + td ∈ Mfur t ∈ [0, t0]. Dann hatten wir einen Widerspruch erzeugt zur Annahme, daß x∗ ein lokalesMinimum von f in M ist,
Fur i ∈ A(x∗) istaT
i (x∗ + td) = aTi x∗ + taT
i d ≥ aTi x∗ = bi, ∀t ≥ 0,
d.h. x∗ + td erfullt alle in x∗ aktiven Restriktionen fur alle t ≥ 0. Sei dann i ∈ I(x∗), d.h.aT
i x∗ − bi > 0. Dann gibt es ein ti > 0 mit
aTi (x∗ + td) − bi ≥ 0, t ∈ [0, ti].
Mit t0 := minti : i ∈ I(x∗) > 0 ist x∗ + td ∈ M fur t ∈ [0, t0]. Der Beweis ist damit gefuhrt. 2

Kapitel 14
Lineare Optimierung
Im vorliegenden und folgenden Kapitel betrachten wir das lineare Optimierungsproblem (LOP)
Minimiere f(x) := cT x auf M := x ∈ Rn : AGx = bG, AUx ≥ bU (14.1)
mit c ∈ Rn, AG ∈ R
mG×n, AU ∈ RmU×n, bG ∈ R
mG, bU ∈ RmU und mG,mU ∈ N0.
14.1 Einfuhrende Beispiele
Beispiel 14.1. (Produktionsplanung)
Es sind n verschiedene Produkte aus m verschiedenen Ausgangsstoffen herzustellen. Sollen xj
Einheiten des j−ten Produktes hergestellt werden, so kann der Produktionsplan durch den Vektorx = (x1, . . . , xn)T charakterisiert werden. Zur Beschreibung des Problems fuhren wir folgendeGroßen ein:
cj – Nettogewinn bei Herstellung einer Einheit des j−ten Produktesaij – Einheiten des i−ten Ausgangsstoffes zur Herstellung einer Einheit
des j−ten Produktesbi – Einheiten des i−ten Ausgangsstoffes als Ressource.
Die Erzielung eines moglichst großen Nettogewinns wird durch die Maximierung der linearenZielfunktion
f(x) := cT x =
n∑
i=1
cixi
charakterisiert. Ein zulassiger Produktionsplan x = (x1, . . . , xn)T liegt vor, wenn die Vorzei-chenbedingungen
xj ≥ 0, i = 1, . . . , n
und Nebenbedingungenn∑
j=1
aijxj ≤ bi, i = 1, . . . ,m
erfullt sind. Mit der Matrix A = (aij) ergibt sich fur den zulassigen Bereich
M := x ∈ Rn : Ax ≤ b, x ≥ 0.
Das den gesuchten Produktionsplan beschreibende lineare Optimierungsproblem lautet dann:
Bestimme x = (x1, . . . , xn)T ∈ M, so daß f(x) ≥ f(z), ∀z ∈ M. 2
137

138 KAPITEL 14. LINEARE OPTIMIERUNG
Wir wollen noch ein weiteres Beispiel zur Produktionsplanung besprechen, bei dem jedoch Ziel-funktion und Nebenbedingungen in etwas anderer Form vorkommen.
Beispiel 14.2. (Diatplan)
Ein Diatplan soll aus n verschiedenen Nahrungsmitteln, die ihrerseits aus m Grundsubstanzenbestehen, zusammengestellt werden. Dabei enthalt eine Einheit des j−ten Nahrungsmittels aij
Einheiten der i−ten Grundsubstanz. Der Diatplan verlangt, daß von der i−ten Grundsubstanzmindestens bi Einheiten enthalten sind. Ferner koste eine Einheit des j−ten Nahrungsmittels cj
Geldeinheiten.
Ein Diatplan kann nun durch den Vektor x = (x1, . . . , xn)T charakterisiert werden, wobei xj dieZahl der im Plan enthaltenen Einheiten des j−ten Nahrungsmittels ist. Die Kosten des Diatpla-nes beschreibt die lineare Funktion f(x) := cT x, die nachfolgend minimiert werden soll.
Wir erhalten in diesem Fall Nebenbedingungen der Form
n∑
j=1
aijxj ≥ bi, i = 1, . . . ,m
sowie als Vorzeichenbedingungen xj ≥ 0, j = 1, . . . , n. Der zulassige Bereich wird unter Benut-zung der Matrix A = (aij) beschrieben durch die Menge
M := x ∈ Rn : Ax ≥ b, x ≥ 0.
Das den gesuchten Diatplan charakterisierende lineare Optimierungsproblem ist dann
Bestimme x = (x1, . . . , xn)T ∈ M, so daß f(x) ≤ f(z), ∀z ∈ M. 2
14.2 Existenz von Losungen
Wir wenden zunachst den Satz 13.9 uber die KKT-Bedingungen auf das Problem (14.1) an.
Satz 14.3. Fur das lineare Optimierungsproblem (14.1) sind in einem zulassigen Punkt x∗ ∈ Mfolgende Aussagen aquivalent:
(i) Der Punkt x∗ ist globales Minimum von f in M .
(ii) Es existieren die Lagrange-Multiplikatoren λ∗ ∈ RmG und s∗ ∈ RmU
+ mit
ATGλ∗ + AT
Us∗ = c (14.2)
(AUx∗ − bU )T s∗ = 0. (14.3)
In diesem Fall gilt
cT x∗ = bTGλ∗ + bT
Us∗. (14.4)
Ferner ist x ∈ M genau dann ein globales Minimum von f in M , wenn
(AUx − bU )T s∗ = 0. (14.5)
Beweis: ”(i) ⇒ (ii)”: Wegen ∇f(x) = c fur alle x ∈ Rn ergibt sich dieser Schluß gerade aus
Satz 13.9 uber die KKT-Bedingungen.

14.2. EXISTENZ VON LOSUNGEN 139
”(ii) ⇒ (i)”: Seien nun die Bedingungen (14.2)-(14.3) erfullt. Wegen dieser Bedingungen sowiemit AGx∗ = bG folgt die Aussage (14.4), denn
cT x∗ = (ATGλ∗ + AT
Us∗)T x∗ = bT
Gλ∗ + bTUs∗.
Fur einen beliebigen zulassigen Punkt x ∈ M gilt AGx = bG und AUx − bU ≥ 0. Wegen s∗ ≥ 0und (14.4) erhalten wir
cT x = (ATGλ∗ + AT
Us∗)T x = bT
Gλ∗ + (AUx)T s∗ ≥ bTGλ∗ + bT
Us∗ = cT x∗,
d.h. x∗ ist globales Minimum von f in M . Die letzte Formelzeile zeigt ferner, daß der Punkt xgenau dann globales Minimum von f in M ist, wenn (14.5) gilt. 2
Im Gegensatz zu allgemeinen Optimierungsproblemen kann man fur lineare Optimierungspro-bleme zeigen, daß das Minimierungsproblem immer eine Losung besitzt, sofern das Infimum vonf auf M nur endlich ist. Im Beweis spielt wieder das Lemma von Farkas eine zentrale Rolle.
Satz 14.4. Fur das lineare Optimierungsproblem (14.1) sei infx∈M cT x ∈ R. Dann gibt es einenPunkt x∗ ∈ M mit
cT x∗ = infx∈M
cT x.
Beweis: Wir gehen o.B.d.A. von der Standardform M = x ∈ Rn : Ax = b, x ≥ 0 aus. Nach
Voraussetzung ist f∗ := infx∈M cT x endlich. Der Beweis wird indirekt gefuhrt.
Wir nehmen an, daß kein Punkt x ≥ 0 existiert mit cT x = f∗ und Ax = b. Mit der Festsetzung
g :=
(f∗
−b
)
, ai := (ci,−a1i, . . . ,−ami)T , i = 1, . . . , n
ist die Annahme aquivalent zu g 6∈ conea1, . . . , an. Nach dem Lemma von Farkas findet mandann einen Punkt dT = (α, λ)T ∈ R × R
m mit
0 > dT g = αf∗ − λT b (14.6)
sowie
0 ≤ aTi d = αci −
m∑
j=1
ajiλj , i = 1, . . . , n.
Die letzte Bedingung kann man kurz notieren als
0 ≤ αc − AT λ. (14.7)
Per Voraussetzung ist infx∈M cT x 6= ∞, d.h. M 6= ∅, und es existiert wenigstens ein Punktx ∈ M . Linksmultiplikation in (14.7) mit xT liefert mit (14.6)
αxT c ≥ xT AT λ = bT λ > αf∗.
Wegen der Annahme cT x > f∗ ergibt dies α > 0. Dann konnen wir (14.6) und (14.7) jeweilsdurch α divieren und erhalten
f∗ < λTb, AT λ ≤ c; λ :=
1
αλ.
Mit einer Minimalfolge (xk) in M , d.h. mit limk→∞ cT xk = infx∈M cT x, erhalten wir nun einenWiderspruch, denn
f∗ = limk→∞
xTk c ≥ lim
k→∞xT
k AT λ = bT λ > f∗.
Damit ergibt sich nach dem Prinzip des indirekten Beweises die gewunschte Aussage. 2

140 KAPITEL 14. LINEARE OPTIMIERUNG
14.3 Dualitat
Betrachtet wird jetzt ein lineares Optimierungsproblem in Standardform
Minimiere cT x auf M := x ∈ Rn : Ax = b, x ≥ 0 (14.8)
mit c ∈ Rn, A ∈ R
m×n, b ∈ Rm.
Definition 14.5. Als zum (primalen) Problem (14.8) zugeordnetes duales Problem bezeichnetman die Aufgabe
Maximiere bT λ auf N := λ ∈ Rm : AT λ ≤ c. (14.9)
Es gilt zunachst folgender Zusammenhang zwischen dualem und primalem Problem.
Lemma 14.6. Die Lagrange-Multiplikatoren λ des primalen Problems sind die optimalenLosungen des dualen Problems. Die Lagrange-Multiplikatoren x des dualen Problems sind dieoptimalen Losungen des primalen Problems.
Beweis: Wir schreiben das duale Problem (14.9) als
Minimiere − bT λ auf N := λ ∈ Rm : − AT λ ≥ −c.
Nach Satz 14.3 ist λ∗ ∈ Rm genau dann Losung des dualen Problems, wenn es Lagrange-
Multiplikatoren x ∈ Rn gibt mit
Ax = b, (14.10)
(c − AT λ)T x = 0, (14.11)
AT λ ≤ c, (14.12)
x ≥ 0. (14.13)
Hier sind (14.10)-(14.11) gerade die KKT-Bedingungen (14.2)-(14.3). Ferner sind (14.12) dieNebenbedingung und (14.3) die Vorzeichenbedingung x ∈ R
n+ an die Lagrange-Multipikatoren.
Mittels Transformation
s = c − AT λ (14.14)
findet man das aquivalente System
Ax = b, (14.15)
sT x = 0, (14.16)
s ≥ 0, (14.17)
x ≥ 0. (14.18)
Hierbei sind (14.14) und (14.16) die KKT-Bedingungen (14.2)-(14.3) des primalen Problems.(14.15) und (14.18) sind die Nebenbedingungen sowie (14.17) die Vorzeichenbedingung an dieLagrange-Multiplikatoren. 2
Weiterhin gilt folgendes Resultat:
Lemma 14.7. Das zum dualen Problem duale Problem ist aquivalent zum primalen Problem.

14.3. DUALITAT 141
Beweis: Man transformiert das duale Problem mit den Schlupfvariablen s = c − AT λ ≥ 0 undder Zerlegung λ = λ+ − λ− mit λ+, λ− ≥ 0 auf Standardform:
Minimiere
−bb0
T
λ+
λ−s
mit (AT − AT I)
λ+
λ−s
= c,
λ+
λ−s
≥ 0.
Per Definition ist das hierzu duale Problem gerade
Maximiere cT z mit
A−A
I
z ≤
−bb0
.
Die beiden Ungleichungen Az ≤ −b und −Az ≤ b sind aquivalent zu Az = b. Damit erhaltenwir das aquivalente Problem
Maximiere cT z mit Az = b, z ≤ 0.
Mit z = −x erhalten wir hieraus das primale Problem (14.8). 2
Wir konnen nun den zentralen Satz dieses Abschnitts, den Dualitatssatz, behandeln.
Satz 14.8. Fur das primale Problem (14.8) und das duale Problem (14.9) sei M 6= ∅ oderN 6= ∅. Dann gilt
infx∈M
cT x = supλ∈N
bT λ. (14.19)
Ferner gelten folgende Aquivalenzen:
(i) M = ∅ ⇐⇒ supλ∈N
bT λ = ∞, (ii) N = ∅ ⇐⇒ infx∈M
cT x = −∞,
Beweis: Fur x ∈ M und λ ∈ N gilt
0 ≤ xT (c − AT λ) = cT x − bT λ
und damit bT λ ≤ cT x sowie
supλ∈N
bT λ ≤ infx∈M
cT x. (14.20)
(i) Fall infx∈M cT x = −∞: Es muß N = ∅ sein, sonst entsteht ein Widerspruch zu (14.20).
(ii) Fall infx∈M cT x ∈ R: Nach dem Existenzsatz 14.4 gibt es eine Losung x∗ ∈ M mit cT x∗ =infx∈M cT x. Nach Satz 14.3 findet man die Vektoren λ∗ ∈ R
m und s∗ ∈ Rn+ mit
AT λ∗ + s∗ = c, cT x∗ = bT λ∗.
Wegen AT λ∗ ≤ c ist λ∗ ∈ N . Man erhalt somit (14.19).
(iii) Fall infx∈M cT x = ∞: Dann ist M = ∅. Wir nehmen an, daß supλ∈N bT λ < ∞. Wegen derAnnahme M 6= ∅ und/oder N 6= ∅ gilt supλ∈N bT λ > −∞. Nach dem Existenzsatz 14.4 findetman λ∗ ∈ N mit bT λ∗ = supλ∈N bT λ. und nach Satz 14.3 einen Lagrange-Multiplikator x∗ ≥ 0mit −Ax∗ = −b. Damit ist x∗ ∈ M im Widerspruch zur Annahme M = ∅. 2
Anhand des Produktionsplanes aus Beispiel 14.1 kann man eine anschauliche okonomische In-terpretation des Dualitatssatzes geben.

142 KAPITEL 14. LINEARE OPTIMIERUNG
Beispiel 14.9. Wir bringen das Problem des Produktionsplans
Maximiere cT x mit Ax ≤ b, x ≥ 0 (14.21)
auf Standardform
Minimiere (−c 0)
(xy
)
mit
(xy
)
≥ 0, (A I)
(xy
)
≥ b.
Das hierzu duale Problem ist
Maximiere bT λ mit AT λ ≤ −c, λ ≤ 0
bzw. mit der Transformation µ = −λ
Minimiere bT µ mit AT µ ≥ c, µ ≥ 0. (14.22)
Wir interpretieren das Problem (14.22) okonomisch wie folgt:
Ein Konkurrent will von einem Betrieb bi Einheiten des i−ten Ausgangsstoffes kaufen oder mie-ten. Dafur bietet er µi Geldeinheiten pro Einheit. Somit waren seine Gesamtkosten bT µ, die ernaturlich minimieren will. Der Betrieb kann aus okonomischen Grunden auf das Konkurrenz-angebot nur eingehen, wenn fur jedes Produkt j die Summe der Preise fur die zur Herstellungerforderlichen Ausgangsstoffe
∑mi=1 aijµi mindestens so groß ist wie der Reingewinn cj , der bei
Eigenproduktion erzielt werden konnte. Damit erhalten wir die Nebenbedingung AT µ ≥ c. Willder Konkurrent alle Ausgangsstoffe kaufen, d.h. fur b = b, hat er gerade das duale Problem(14.22) zu losen.
Der Dualitatssatz hat nun folgende Bedeutung: Seien x ein zulassiger Produktionsplan und µein akzeptables Konkurrenzangebot, so gilt wegen (14.19)
cT x ≤ bT µ.
Geht der Betrieb also auf das Angebot ein, so macht er wenigstens so viel Gewinn, als wenn erselbst produzieren wurde. Er muß nicht einmal einen optimalen Produktionsplan suchen.
Ist x∗ ein optimaler Produktionsplan und µ∗ ein fur den Konkurrenten optimales Angebot, sogilt
cT x∗ = bT µ∗.
Man nennt die Zahlen (µ∗)i auch Schattenpreise. Nach dem Satz 13.9 uber die KKT-Bedingungenhat man die Komplementaritatsbedingungen
(Ax∗ − b)µ∗ = 0, (AT µ∗ − c)x∗ = 0.
Wird also die Kapazitatsschranke bi fur den i−ten Ausgangsstoff nicht ausgenutzt, so wird derKonkurrent in einem optimalen Angebot nichts fur diesen Ausgangsstoff bezahlen, d.h. µi = 0.Wird das j−te Produkt produziert, ist damit (x∗)j > 0, d.h. es muß bei dem optimalen Angebotdie Restriktion
m∑
i=1
aijµi ≥ cj
mit Gleichheit erfullt sein. 2

Kapitel 15
Simplex-Verfahren
Im abschließenden Kapitel betrachten wir mit dem Simplex-Verfahren das klassische Verfahrenzur numerischen Losung des linearen Optimierungsproblems (LOP)
Minimiere f(x) := cT x auf M := x ∈ Rn : AGx = bG, AUx ≥ bU (15.1)
mit c ∈ Rn, AG ∈ R
mG×n, AU ∈ RmU×n, bG ∈ R
mG, bU ∈ RmU und mG,mU ∈ N0.
Auf die Klasse der Innere-Punkte-Methoden konnen wir aus Zeitgrunden im Rahmen dieserEinfuhrung leider nicht eingehen.
15.1 Ecken und Basislosungen
Definition 15.1. Als abgeschlossenen Halbraum bezeichnet man Teilmengen des Rn der Form
x ∈ Rn : aT x ≥ b, a ∈ R
n \ 0, b ∈ R.
Ein Polyeder ist die Schnittmenge endlich vieler abgeschlossener Halbraume. Ein beschranktesPolyeder heißt Polytop.
Ein Punkt eines Polyeders P heißt Ecke. falls er sich nicht als Konvexkombination von zweianderen Punkten des Polyeders darstellen laßt, d.h.
x = (1 − t)y + tz, t ∈ [0, 1], y, z ∈ P =⇒ x = y = z.
Wir gehen von einem linearen Optimierungsproblem in Standardform aus und konnen damitden zulassigen Bereich
M = x ∈ Rn : x ≥ 0, Ax = b (15.2)
mit A ∈ Rm×n, n ≥ m und b ∈ R
m als spezielles Polyeder betrachten. O.B.d.A. ist
rang (A) = m, (15.3)
denn sonst streicht man ggf. einige (redundante) Zeilen von A und b. Fur Polyeder (15.2) mitBedingung (15.3) gibt es eine schone algebraische Charakterisierung von Ecken. Zuvor benotigenwir aber einige Begriffe, fur die wir eine Matlab-Notation benutzen.
Definition 15.2. Seien m,n, r ∈ N sowie I = i1, . . . , ir ⊂ 1, 2, . . . , n mit i1 < i2 < · · · < ir.Fur einen Vektor x ∈ R
n und eine Matrix A ∈ Rm×n definiert man
xI := (xi1 , . . . , xir)T ∈ R
r, A[:,I] :=
a1,i1 · · · a1,ir...
...am,i1 · · · am,ir
∈ R
m×r.
143

144 KAPITEL 15. SIMPLEX-VERFAHREN
Fur die zulassige Menge M aus (15.2) mit Bedingung (15.3) heißt ein Punkt x ∈ M Basislosungmit Basisindizes B = b1, . . . , bm ⊂ 1, . . . , n, falls
(i) xi = 0, i 6∈ B; (ii) A[:,B] regular. (15.4)
Eine Basislosung x ∈ M heißt nicht-entartet, falls xB > 0. Anderenfalls heißt x entartet.
Die gesuchte algebraische Charakterisierung gibt das folgende Lemma.
Lemma 15.3. Ein Punkt x ∈ M ist genau dann Ecke von M , wenn x Basislosung ist.
Beweis: (i) Fur die Basislosung x zur Basis B sei o.B.d.A. B = 1, . . . ,m. Sei nun x =(1 − t)y + tz mit y, z ∈ M und t ∈ [0, 1]. Wegen xi = 0, i = m + 1, . . . , n folgt fur diese Indizesauch yi = zi = 0. Dann ist Ax = Ay = Az = b und damit A[:,B]xB = A[:,B]yB = A[:,B]zB.Wegen (15.4)(ii) folgt xB = yB = zB, damit x = y = z. Nach Definition ist x dann Ecke von M .
(ii) Sei nun x Ecke von M . Wir setzen I := i : xi > 0 und J := j : xj = 0. Wir nehmenan, daß die Spalten der Matrix A[:,I] linear abhangig sind. Dann muß ein Vektor zI ∈ R
r \ 0mit A[:,I]zI = 0 existieren. Durch die Komplettierung zJ = 0 erhalten wir einen Vektor z ∈ R
n
und definieren
x(δ) := x + δz, δ ∈ R. (15.5)
Es gilt Ax(δ) = Ax + δAz = b. Wegen xI > 0 ist x(δ)I > 0 fur hinreichend kleines |δ|. Dannfindet man eine Zahl δ > 0 mit x(δ), x(−δ) ∈ M und x = 1
2x(δ) + 12x(−δ). Das ist aber ein
Widerspruch zur Annahme, daß x Ecke von M ist. Daher sind die Spalten von A[: .I] linearunabhangig. Aufgrund der Annahme rang(A) = m kann man die Indexmenge I zu einer MengeB mit m Elementen erganzen, so daß Bedingung (15.4) (ii) gilt. 2
Satz 15.4. Sei M gegeben durch (15.2)-(15.3) sowie sei c ∈ Rn. Dann gelten folgende Aussagen:
(i) M besitzt mindestens eine und hochstens endlich viele Basislosungen.
(ii) Existiert ein globales Minimum von f(x) = cT x in M , so gibt es auch ein globales Mini-mum, das Ecke von M ist.
Beweis: zu (i): Es kann nur endlich viele Basislosungen in M geben, da maximal
(nm
)
Teil-
mengen der Indexmenge 1, . . . , n existieren. Somit ist noch die Existenz mindestens einerBasislosung zu zeigen. Dazu sei x ∈ M ein Vektor, der unter allen Vektoren in M eine Mini-malzahl nichtverschwindender Komponenten besitzt. Diese Zahl sei p. Ferner benutzen wir diebereits eingefuhrten Bezeichnungen I := i : xi > 0 und J := j : xj = 0.Wir nehmen an, daß die Spalten der Matrix A[:,I] linear abhangig sind. Weiterhin benutzenwir die Vektoren z und x(δ) aus dem Beweis von Lemma 15.3. Fur hinreichend kleines |δ| giltx(δ)I > 0, sowie x(δ)J = 0 und Ax(δ) = b fur alle δ ∈ R. Wegen z 6= 0 findet man ein be-tragsmaßig kleinstes δ ∈ R, so daß x(δ)I ≥ 0 gilt und wenigstens eine Komponente von x(δ)Iverschwindet. Dann ist x(δ) ∈ M und x(δ) hat hochstens p−1 nichtverschwindende Komponen-ten. Das steht aber im Widerspruch zur Festsetzung von p. Daher sind die Spalten von A[:,I]linear unabhangig. Weiterhin kann man die Indexmenge I zu einer m-elementigen Menge Berganzen, so daß die Matrix A[:,B] regular ist. Dann ist x Basislosung zur Basis B.
zu (ii): Sei x ∈ M globales Minimum der Zielfunktion f in M mit einer Minimalzahl p nichtver-schwindender Komponenten. Wir nehmen dann an, daß die Matrix A[:,I] nicht vollen Spalten-rang hat. Definiert man nun x und x(δ) wie im Beweisteil (ii) zu Lemma 15.3, gilt x(δ) ∈ M fur

15.2. ENTWICKLUNG DES SIMPLEX-VERFAHRENS 145
hinreichend kleines |δ|. Ferner ist fur diese Werte auch cT (x+δz) ≥ cT x, da x globales Minimumist. Folglich muß cT z = 0 sein. Wie in Teil (i) des Beweises gibt es ein δ 6= 0, so daß x(δ) ∈ Mund cT x(δ) = cT x gilt und daß x(δ) hochstens p− 1 nichtverschwindende Komponenten besitzt.Dies steht wieder im Widerspruch zur Festlegung von p. Die Spalten von A[:,I] sind somit linearunabhangig. Man kann I zu einer m−elementigen Indexmenge B erganzen, so daß A[:,B] regularist. Somit ist x Basislosung. 2
15.2 Entwicklung des Simplex-Verfahrens
Ausgangspunkt ist ein lineares Optimierungsproblem in der Standardform
Minimiere f(x) := cT x auf M := x ∈ Rn : Ax = b, x ≥ 0 (15.6)
mit der Bedingung rang(A) = m ≤ n. Ist ferner M 6= ∅ und die Zielfunktion auf M nach untenbeschrankt, so muß nach den Satzen 14.4 und 15.4 eine der (endlich vielen) Ecken des PolyedersM eine Losung von (15.6) sein. Da die Anzahl der Ecken jedoch sehr groß sein kann, verbietetsich eine unsystematische Durchmusterung aller Ecken.
Beim Simplex-Verfahren gelangt man in jedem Schritt von einer Ecke x von M zu einer benach-barten Ecke durch Austausch eines Index der entsprechenden Basis B(x). Dabei soll sich derWert der Zielfunktion nicht vergroßern und moglichst immer verringern.
Bei der Entscheidung, einen Index der aktuellen Basis B zu wahlen, machen wir Gebrauch vonden KKT-Bedingungen. Nach Satz 14.3 ist ein optimales Losungstripel (x∗, λ∗, s∗) ∈ R
n ×Rm×
Rn eindeutig bestimmt durch die folgenden Bedingungen:
Ax∗ = b, (15.7)
x∗ ≥ 0 (15.8)
AT λ∗ + s∗ = c, (15.9)
s∗ ≥ 0, (15.10)
xT∗ s∗ = 0. (15.11)
Sei bereits die Basis B einer beliebigen Basislosung x von M bekannt. Sei N := 1, . . . , n \ B.Dann ist x wegen (15.7) gegeben durch
xN = 0, xB = A[:,B]−1b. (15.12)
Wegen der Annahme x ∈ M ist auch Bedingung (15.8) erfullt.
Wir wollen nun die Lagrange-Multiplikatoren s und λ aus den restlichen KKT-Bedingungenbestimmen. Wegen (15.11) setzen wir
sB = 0.
Damit folgt aus (15.9)
A[:,B]T λ = cB, A[:,N ]T λ + sN = cN .
Wegen der Regularitat von A[:,B] finden wir
λ = A[:,B]−T cB, (15.13)
sN = cN − A[:,N ]T λ. (15.14)

146 KAPITEL 15. SIMPLEX-VERFAHREN
Bis auf (15.10) sind damit alle KKT-Bedingungen erfullt. Andererseits ist nach Satz 14.3 eineoptimale Losung ermittelt und man kann abbrechen, wenn (15.10) erfullt ist.
Im allgemeinen Fall ist sB = 0, nicht jedoch sN = 0. Man wird daher einen Index q ∈ Nmit sq < 0 als neuen Index in die Basis B aufnehmen. Ferner ist zu uberlegen, welcher Indexhierfur aus der Basis B zu entfernen ist. Man fordert fur die neue Basislosung x+, daß fur alleIndizes j von N \ q weiter xj = 0 bleibt. Der Fall x+
q > 0 ist zugelassen. Weiterhin soll geltenAx+ = b = Ax, d.h.
A[:,B]x+B + A[:, q]x+
q = A[:,B]xB.
Dies ergibtx+B = xB − A[:,B]−1A[:, q]x+
q .
Wir definieren w ∈ Rn durch
wB := A[:,B]−1A[:, q]; wq := −1, wN\q := 0.
Spater wird gezeigt, daß sich f in Richtung w verringert, d.h. w ist eine Abstiegsrichtung.
Man wahlt jetzt
x+q := min
xi
wi: i ∈ B, wi > 0
.
Dies bedeutet geometrisch gerade, daß man sich vom Punkt x soweit auf der durch die Richtungw bestimmten Kante bewegt, bis man zum nachsten Eckpunkt gelangt. Im Fall w ≤ 0 kann manx+
q beliebig groß wahlen. Es wird noch gezeigt, daß die Zielfunktion in diesem Fall nicht nachunten beschrankt ist. Der Algorithmus soll dann mit einer entsprechenden Meldung abbrechen.
Wir beschreiben jetzt einen Schritt des Simplex-Verfahrens.
Schritt des Simplex-Verfahrens
Initialisierung: Vektor c ∈ Rn der Zielfunktion cT x;
Zulassigkeitsbereich M = x ∈ Rn : x ≥ 0, Ax = b;
Basis B ⊂ 1, . . . , n einer Basislosung von M ;
B := A[:,B];N := 1, . . . , n \ B;Berechne Basislosung x ∈ R
n mit xB := B−1b und xN := 0;λ := B−T cB;sN := cN − A[:,N ]T λ;
if sN ≥ 0
STOP: x ist Losung des Minimierungsproblems.
Bestimme ein q ∈ N mit sq = minsi : i ∈ N;Berechne wB := B−1A[:, q];if wB ≤ 0
STOP: Zielfunktion ist in M nicht nach unten beschrankt.
x+ = 0;Setze x+
q := min xi
wi: i ∈ B, wi > 0 und bestimme p ∈ B mit x+
q =xp
wp;
x+B := xB − wBx+
q ;B+ := (B ∪ q) \ p;Ergebnis: Falls der Algorithmus nicht vorzeitig abbricht, ist x+ Basislosung zur Basis B+. Esgilt cT x+ ≤ cT x.

15.3. ANALYSE EINES SIMPLEX-SCHRITTS 147
15.3 Analyse eines Simplex-Schritts
Satz 15.5. Es wird angenommen, daß der Simplex-Schritt nicht mit einer optimalen Losungabbricht wegen sN ≥ 0. Dann gelten folgende Aussagen:
(i) Sei wB 6≤ 0. Ist A[:, p] die k−te Spalte von B und fugt man die neue Spalte A[:, q] an dergleichen Stelle in die Matrix B, so ist die Matrix
B+ := B + (A[:, q] − A[:, p])eTk
regular und die inverse Matrix erfullt die update-Formel
B−1+ =
(
I − (wB − ek)eTk
wp
)
B−1. (15.15)
(ii) Ist wB 6≤ 0, so ist x+ Basislosung zur Basis B+.
(iii) Falls wB ≤ 0, so gilt infx∈M cT x = −∞, anderenfalls ist
cT x+ ≤ cT x. (15.16)
Ist x nicht entartet, so gilt sogar cT x+ < cT x.
Beweis: zu (i): Mit v := A[:, q] − A[:, p] gilt
B+ = B + veTk , B−1v = wB − ek.
Hierzu sei daran erinnert, daß A[:, p] die p−te Spalte von A, aber die k-te Spalte von B = A[:,B]ist.
Aus den Nebenrechnungen
(
I − B−1veTk
1 + eTk B−1v
)
B−1(B + veTk ) =
(
I − B−1veTk
1 + eTk B−1v
)
(I + B−1veTk )
= I + B−1veTk
(
1 +−1 − eT
k B−1v
1 + eTk B−1v
)
= I
sowie1 + eT
k B−1v = 1 + eTk (B−1A[:, q] − B−1A[:, p]) = 1 + eT
k (wB − ek) = wp > 0
ergibt sich (15.15).
zu (ii): Zunachst erhalt man
Ax+ = Bx+B + A[:, q]x+
q
= BxB − BwBx+q + A[:, q]x+
q (15.17)
= b − A[:, q]x+q + A[:, q]x+
q = b
Bei der Herleitung des Simplex-Schrittes im vorhergehenden Abschnit hatten wir gesehen, daßwegen w 6≤ 0 fur die angegebene Wahl von x+
q die Aussage x+ ≥ 0 folgt. Somit ist x+B ∈ M .
Ferner ist x+i = 0 fur i 6∈ B+∪q und x+
p = xp−wpx+q = xp−wp
xp
wp= 0. Wegen der Regularitat
von B+ nach (i) ist x+ dann Basislosung zur Basis B+.

148 KAPITEL 15. SIMPLEX-VERFAHREN
zu (iii): Aufgrund der Voraussetzung sN 6≥ 0 ist sq ≤ 0. Wir betrachten zuerst den Fall w 6≤ 0,fur den gilt
cT x+ = cTBx+
B + cqx+q
= cTBxB − x+
q cTBB−1A[:, q] + cqx
+q
= cTBxB + x+
q (cq − λT A[:, q])
= cT x + x+q sq. (15.18)
Wegen x+q ≥ 0 und sq < 0 erhalten wir (15.16).
Falls x nicht-entartet ist, gilt xq =xp
wp> 0 und damit cT x+ < cT x.
Im Fall wB ≤ 0 hat man bei beliebiger Wahl von x+q > 0 und x+
B := xB − wx+q sowie x+
i := 0bei i ∈ N \ q, daß Ax+ = b wie in (15.17) sowie x+ ≥ 0. Damit ist x+ ∈ M . Wegen (15.18)ist somit die Zielfunktion cT x auf M nicht nach unten beschrankt. 2
15.4 Bemerkungen zur Implementierung
Sei eine geeignete Basislosung zum Start des Simplex-Verfahrens bekannt, vgl. folgender Ab-schnitt. Man fuhrt dann solange Simplex-Schritte aus, bis eines der Abbruchkriterien erfulltist. Beim neuen Simplex-Schritt wird dabei jeweils als Basis B die im vorhergehenden Schrittberechnete Basis B+ verwendet.
Wenn alle Basislosungen des Problems nicht entarten, so hat man in jedem Schritt eine tatsachli-che Reduktion der Zielfunktion. Dann kann eine Basislosung bzw. Ecke von M nicht mehrfach”besucht” werden. Nach Satz 15.4 gibt es nur endlich viele Basislosungen von M . Da wenigstenseine Ecke davon Losung des Minimierungsproblems ist, muß der Algorithmus nach endlich vielenSchritten abbrechen.
Falls nun eine Basislosung x zur Basis B entartet, kann der Fall B+ 6= B mit x+ = x eintreten.Hier muß man am besten durch geeignete Modifikation des Verfahrens eine Reduktion der Ziel-funktion erzwingen. Gelangt man jedoch zu einer bereits zuvor berechneten Basis zuruck, wirdman in einem Zyklus immer wieder zu dieser Basis zuruckkehren. Derartige Zyklen treten in derPraxis sehr selten auf. Man findet aber in der Literatur konstruierte Beispiele.
Durch Zusatzregeln, sogenannnte Anti-Zyklen-Regeln, bei der Auswahl der Indizes q und p kannman Zyklen vermeiden. Eine einfache Variante ist, daß q als kleinster Index mit sq < 0 und pals kleinster Index mit x+
q =xp
wpgewahlt wird.
Insgesamt gilt folgender Sachverhalt:
Folgerung 15.6. Seien alle Ecken von M nicht-entartet. Dann bricht das Simplex-Verfahrennach endlich vielen Schritten mit einem globalen Minimum oder der Mitteilung infx∈M cT x =−∞ ab. Die gleiche Aussage gilt auch bei entarteten Ecken, wenn durch eine Anti-Zyklen-Regelbei der Auswahl der Indizes q und p gesichert wird, daß dieselbe Basis B nicht zweimal auftau-chen kann.
Wir schließen diesen Abschnitt mit Bemerkungen uber den Aufwand des Verfahrens. Der Haupt-aufwand besteht in der Berechnung von λ = B−T cB und von wB = B−1A[:, q]. Statt der Berech-nung einer LU -Zerlegung von B in jedem Schritt empfiehlt es sich, einmal die Inverse von Bauszuwerten und dann eine Aktualisierung mittels Formel (15.15) vorzunehmen. Mit der Klam-merung
B−1+ = B−1 − wB − ek
wp(eT
k B−1)

15.5. BESTIMMUNG EINER BASISLOSUNG 149
wird dabei der Rechenaufwand gegenuber (15.15) mit O(m3) Operationen auf O(m2) wesentlicheOperationen reduziert. Eine andere Variante besteht in der Berechnung einer LU -Zerlegung vonB, die standig aktualisiert wird. Diese Moglichkeit weist bessere Stabilitatseigenschaften auf.
Im ungunstigsten Fall steigt der Aufwand exponentiell mit der Zahl der Unbekannten. Von Kleeund Minty wurde 1972 tatsachlich ein derartiges Beispiel konstruiert. Praktisch konvergiert dasSimplex-Verfahren jedoch in der Regel erheblich schneller.
15.5 Bestimmung einer Basislosung
Bislang blieb offen, wie man eine zulassige Basislosung zum Start des Simplex-Verfahrens erhalt.Der einfachste Fall liegt vor, wenn das Ausgangsproblem die Form
Minimiere cT x unter den Nebenbedingungen Ax ≤ b, x ≥ 0 (15.19)
mit b ≥ 0 hat. Durch Uberfuhrung auf Standardform
Minimiere
(c0
)T (xs
)
unter den Nebenbedingungen Ax + s = b, x ≥ 0, s ≥ 0
findet man sofort die Basislosung x = 0, s = b.
Ein wichtiges Beispiel fur den angegebenen Fall hat man mit der Produktionsplanung, vgl.Beispiel 14.1. Ein anderer Fall liegt beim dualen Problem (14.9) eines allgemeinen Minimie-rungsproblems der Form (14.8) vor, nachdem man die Zerlegung λ = λ+ − λ− mit λ+, λ− ≥ 0wahlt, falls der Kostenvektor des primalen Problems (14.12) c ≥ 0 erfullt.
Im allgemeinen Fall ermittelt man eine zulassige Basislosung mittels eines Hilfsproblems
Minimiere cT x + MeT z unter den Nebenbedingungen Ax + z = b, x ≥ 0, z ≥ 0 (15.20)
mit e := (1, . . . , 1)T ∈ Rm und einer Zahl M > 0. Dabei wird benutzt, daß man bei Gleichungs-restriktionen (ggf. nach Multiplikation mit dem Faktor −1) o.B.d.A. eine nicht-negative rechteSeite annehmen kann. Es ist jedoch keine Rangbedingung an A gefordert.
Satz 15.7. Vorausgesetzt wird, daß im LOP (15.6) b ≥ 0 gilt. Dann gelten fur das Hilfsproblem(15.20) folgende Aussagen:
(i) Das Hilfsproblem (15.20) hat die Basislosung
(x∗z∗
)
=
(0b
)
zur Basis B = n + 1, . . . , n + m.
(ii) Ist
(x∗z∗
)
eine Losung von (15.20) mit z∗ = 0, so ist x∗ eine Losung von (15.2).
(iii) Hat das Problem (15.6) eine Losung, so gibt es eine Konstante M∗ > 0, so daß fur M > M∗
gilt: Das Hilfsproblem (15.20) ist losbar. Fur jede Losung
(x∗z∗
)
von (15.20) ist z∗ = 0.
Beweis: zu (i): Die Basislosung
(0b
)
ist zulassig wegen b ≥ 0. Die zur Basis gehorige Teilmatrix
ist gerade die Einheitsmatrix. Wegen x∗ = 0 liegt eine Basislosung vor.

150 KAPITEL 15. SIMPLEX-VERFAHREN
zu (ii): Aufgrund der Voraussetzungen ist x∗ zulassige Basislosung des LOP (15.6). Sei x ein
beliebiger zulassiger Vektor von (15.6). Dann ist
(x0
)
zulassiger Punkt von (15.20). Aufgrund
der Optimalitat von
(x∗0
)
haben wir
cT x∗ = cT x∗ + MeT z∗ ≤ cT x + MeT 0 = cT x,
d.h. x∗ ist Losung von (15.7).
zu (iii): Die dualen Probleme sind zum LOP in Standardform (15.7):
Maximiere bT λ auf N := λ ∈ Rm : AT λ ≤ c (15.21)
sowie zum Hilfsproblem (15.20):
Maximiere bT λ unter der Nebenbedingung
(AT
Im
)
λ ≤(
cMe
)
bzw.
Maximiere bT λ auf NM := λ ∈ Rm : AT λ ≤ c, λi ≤ M, i = 1, . . . ,m. (15.22)
Eine Losung x von (15.7) existiert nach Voraussetzung. Die entsprechenden Lagrange-Multipli-katoren λ sind Losung des dualen Problems (15.21). Mit M∗ := ‖λ‖∞ hat man λ ∈ NM furM ≥ M∗. Wegen NM ⊂ N ergibt sich
supλ∈NM
bT λ ≤ supλ∈N
bT λ = bT λ, falls M ≥ M∗.
Daher ist λ auch Losung von (15.22) fur M ≥ M∗.
Die primale Aufgabe (15.20) hat ebenso eine Losung
(xz
)
mit dem Lagrange-Multiplikator
λ. Nach Formel (14.5) aus Satz 14.3 ist ein zulassiger Punkt
(x∗z∗
)
genau dann Losung des
Hilfsproblems (15.20), wenn die Komplementaritatsbedingungen[(
cMe
)
−(
AT
Im
)
λ
]
i
·(
x∗z∗
)
i
= 0, i = 1, . . . , n + m
erfullt sind. Wegen M > M∗ findet man aus dem unteren Block, daß z∗ = 0. 2
Bei einem konkreten Beispiel stellt man zunachst die Form mit b ≥ 0 her. Dann startet mandas Simplex-Verfahren fur das Hilfsproblem (15.20) mit einer beliebigen Zahl M > 0, z.B. mitM = 103, mit dem in Satz 15.7 (i) angegebenen Startvektor.
• Ergibt das Verfahren eine Losung
(x∗z∗
)
mit z∗ = 0, so hat man nach Satz 15.7 (ii) eine
Losung x∗ des Ausgangsproblems gefunden.
• Anderenfalls vergroßert man die Zahl M , etwa durch Multiplikation mit dem Faktor 10,und wendet erneut das Simplex-Verfahren an. Gestartet werden kann mit der Losung desletzten Hilfsproblems. Besitzt das Problem (15.2) eine Losung, so erhalt man mit dieser
Vorgehensweise nach endlich vielen Schritten eine Losung von (15.20) mit
(x∗0
)
.
Bemerkung 15.8. Man kann zeigen, daß die Zielfunktion im Hilfsproblem (15.20) genau dannnach unten unbeschrankt ist, wenn dies auch auf (15.2) zutrifft. 2

Literaturverzeichnis
[1] H. Amann: Gewohnliche Differentialgleichungen, de Gruyter Lehrbuch 1983
[2] V.I. Arnold: Gewohnliche Differentialgleichungen, Deutscher Verlag der Wissenschaften,Berlin 1979
[3] J.C. Butcher: Implicit Runge-Kutta processes, Math. Comp. 18 (1964), 50-64 .
[4] P. Deuflhard, F. Bornemann: Numerische Mathematik II, de Gruyter Lehrbuch, Berlin -New York 1994
[5] O. Forster: Analysis 2, Differentialrechnung im Rn. Gewohnliche Differentialgleichungen,Vieweg Braunschweig 1984
[6] G. Fulford, P. Forrester, A. Jones: Modelling with Differential and Difference Equations,Austral. Math. Soc. Lect. Series 10, Cambridge. Univ. Press 1997
[7] A. Greenbaum: Iterative Methods for Solving Linear Systems, SIAM 1997.
[8] E. Hairer, C. Lubich: Asymptotic expansions of the global error of fixed-stepsize methods,Numer. Math. 45 (1984), 345-360
[9] E. Hairer, G. Wanner: Solving Ordinary Differential Equations II. Stiff and Differential-Algebraic Problems, Springer-Verlag 1991
[10] M. Hanke-Bourgeois: Grundlagen der Numerischen Mathematik und des WissenschaftlichenRechnens, Teubner-Verlag 2006
[11] R. Kreß: Numerical Analysis, Graduate Texts in Mathematics 181, Springer 1998
[12] B.N. Parlett: The symmetric eigenvalue problem, Prentice-Hall, Englewood Cliffs 1980.
[13] H.R. Schwarz Numerische Mathematik, B.G. Teubner, Stuttgart 1993
[14] L.F. Shampine, M.W. Reichelt: The MATLAB ODE Suite, SIAM J. Sc. Comput. 18 (1997)1, 1-22
[15] C. Sparrow: The Lorenz Equations: Bifurcations, Chaos, and Strange Attractors, Springer,New York, 1982
[16] J. Stoer, R. Bulirsch: Numerische Mathematik 2., Springer 1990
[17] K. Strehmel, R. Weiner: Numerik gewohnlicher Differentialgleichungen, Teubner Stu-dienbucher Mathematik, Stuttgart 1995
151

152 LITERATURVERZEICHNIS
[18] W. Walther: Gewohnliche Differentialgleichungen, Springer-Verlag, Berlin, Heidelberg, NewYork 1985
[19] Y. Saad: Iterative Methods for Sparse Linear Systems, PWS Publ. Comp. 2003


















![Numerische Verfahren zur L˜osung parabolischer partieller ... · Runge-Kutta-Chebyshev-Formeln basiert und 1980 von Sommeijer und Ver- wer vorgestellt wurde [15]. 1997 wurde dann](https://static.fdokument.com/doc/165x107/5d56d62d88c99300778b94bf/numerische-verfahren-zur-losung-parabolischer-partieller-runge-kutta-chebyshev-formeln.jpg)