
14. Dez 2008Karl Eckmayr, BSI1 Erstanmeldung Mit der Eingabe der Adresse //.

G. Hirsch Version: pA11 Seite 1
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Nachstehend finden Sie eine Sammlung von Übungsaufgaben und Laborexperimenten, die im
Rahmen der Übungen und Praktika des Moduls Spracherkennung bearbeitet werden sollen. Die
Übungsaufgaben (als „Aufgaben“ bezeichnet) sollen auf dem „Papier“ bearbeitet und gelöst
werden, wobei Taschenrechner oder/und Matlab als Hilfsmittel eingesetzt werden können. Die
Laborexperimente (als „praktische Übung“ bezeichnet) sollen unter Verwendung von Matlab sowie
einer Sammlung graphischer Benutzerschnittstellen, die zur Durchführung von Praktika zur
Sprachsignalverarbeitung und zur Spracherkennung entwickelt und zusammengestellt wurden,
durchgeführt werden. Das Praktikum wird im Folgenden kurz vorgestellt.
Praktikum zur Sprachsignalverarbeitung
Im Labor „Digitale Nachrichtentechnik“ ist ein auf dem Betriebssystem Linux basierendes
Rechnernetzwerk vorhanden. Es steht eine Sammlung graphischer Oberflächen als „Praktikum zur
Sprachverarbeitung und Spracherkennung“ zur Verfügung, die unter Matlab programmiert wurden.
Sie arbeiten unter dem Benutzer „praktiku“. Matlab kann durch einfaches Klicken auf das
entsprechende Icon gestartet werden (Der Windows Doppelklick startet Matlab zweimal).
Das Praktikum wird durch Eingabe von praktikum_sp im Kommandofenster von Matlab gestartet.

G. Hirsch Version: pA11 Seite 2
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Geben Sie Ihre Gruppenbezeichnung (ASRx mit x=Ziffer) und Ihren Namen ein. Durch Eingabe
der Gruppenbezeichnung wird das zugehörige Arbeitsverzeichnis Ihrer Gruppe festgelegt. Der Pfad,
unter dem Sie ihr Arbeitsverzeichnis finden, lautet: /data/praktikum_dsv/ASRx
Zur Erzeugung von Signalen stehen die beiden Oberflächen „Mikrofon-Aufnahme“ und
„Signalgenerator“ zur Verfügung. Mit der Oberfläche „Mikrofon-Aufnahme“ können Sie eigene
Aufnahmen über Mikrofon erzeugen. Die Oberfläche „Signalgenerator“ dient zur Generierung von
Signalen mit einem gewünschten Verlauf (z.B. Sinus, Rechteck, Dreieck) oder bestimmten
Charakteristika (z.B. Rauschen).
Mit den in der linken Spalte aufgeführten Oberflächen kann ein Signal in verschiedener Form
analysiert werden. Die Oberflächen der mittleren Spalte eröffnen Möglichkeiten zur Verarbeitung
eines Signals. In der rechten Spalte finden sich graphische Benutzer-Schnittstellen zur direkten
Spracherkennung über Mikrofon als auch zur Durchführung von Simulationsexperimenten mit
Sprachdatensammlungen.
Bei den meisten Oberflächen besteht die Möglichkeit, Signale aus dem Aufnahme- oder
Generatorfenster unmittelbar zu übernehmen. Generell ist es nicht notwendig bzw. empfehlenswert,
beim Wechsel zwischen verschiedenen Oberflächen diese zu schließen, sondern nur zu
„minimieren“.
Praktische Übung 1
Das Ziel dieses Experiments ist die Bestimmung der charakteristischen Merkmale im zeitlichen
Signalverlauf verschiedener Laute.
Analyse von Vokalen
Nehmen Sie getrennt die von Ihnen gesprochenen Vokale „a“, „e“ und „o“ in der Oberfläche zur
Mikrofon Aufnahme bei Wahl einer Abtastfrequenz von 16000 Hz auf. Beachten Sie, dass die
Aufnahmen keine zu langen Pausen (länger als etwa 1 sec) vor und nach der eigentlichen Sprache
beinhalten. Sollten die Signalverläufe keine Aussteuerung im Amplitudenbereich von mindestens ±
0,5 besitzen, so können Sie durch Betätigen eines Schiebreglers die Signale entsprechend
verstärken. Speichern Sie die Signale im „WAV“ Format ab. Gehen Sie in die Oberfläche
„Zeitsignal“, mit der Signale im Zeitbereich analysiert werden können. Darin können Sie durch
Markieren eines bestimmten Bereichs einen kurzen Signalabschnitt auswählen, der im unteren
Fenster dargestellt wird und den sie sich auch separat anhören können.
Welches charakteristische Merkmal weisen die Signalverläufe der Vokale auf: ……………………..

G. Hirsch Version: pA11 Seite 3
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Bestimmen Sie bei jedem Vokal näherungsweise die Länge einer Periode (in ms) sowie die
zugehörige Grundfrequenz (in Hz):
Vokal „A“: tper = ….. ms f0 = ….. Hz
Vokal „E“: tper = ….. ms f0 = ….. Hz
Vokal „O“: tper = ….. ms f0 = ….. Hz
Sie können exemplarisch auch eine Darstellung auf dem Drucker ausgeben.
Nehmen Sie versuchsweise nochmals einen Vokal auf, wobei Sie im Fall einer männlichen Stimme
versuchen, eine „hohe“ weibliche Stimme zu imitieren, im Fall einer weiblichen Stimme versuchen,
eine „tiefe“ Stimme zu imitieren.
Welche Periodenlänge und Grundfrequenz ergibt sich in diesem Fall: tper = ….. ms f0 = ….. Hz
Analyse stimmloser Laute
Nehmen Sie das Wort „es“ auf, das im hinteren Teil den stimmlosen Zischlaut beinhaltet.
Extrahieren Sie in der Oberfläche zur Analyse des Zeitsignals den Abschnitt des Zischlauts.
Welches charakteristische Merkmal beinhaltet der Signalverlauf: ………………………………….
Sie können die Beobachtung dieses charakteristischen Verlaufs bei Aufnahme des Worts „Zeh“ im
vorderen Abschnitt des Signals, bei Aufnahme des Worts „Affe“ im mittleren Teil des Signals und
bei Aufnahme des Worts „Schaf“ am Anfang und am Ende des Signals feststellen.
Analyse von Plosiven
Nehmen Sie das Wort „Schuppen“ auf, das in der Mitte einen Plosivlaut beinhaltet.
Welches charakteristische Merkmal zeigt der Signalverlauf: ……….……………………………….
Bestimmen Sie näherungsweise die Länge der Pause: …… ms
Wiederholen Sie das Experiment mit den Wörtern „Leiter“ und „Scheck“.
Welche Längen weisen die Pausen auf?
Wort „Leiter“: ……. ms
Wort „Scheck“: ……. ms

G. Hirsch Version: pA11 Seite 4
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 2
Ein Cosinussignal )2cos()( tfts wird zur digitalen Verarbeitung des Signals mit einer
Abtastfrequenz von fa = 8 kHz abgetastet.
a) Bei welchen Zeitpunkten erfolgt die Abtastung des Signals im Zeitbereich 0 t 1 ms, wenn
die Abtastung bei t = 0 ms einsetzt.
b) Berechnen Sie die Abtastwerte eines Cosinussignals x1(t), das eine Frequenz von 1 kHz besitzt,
und eines Cosinussignals x2(t), das eine Frequenz von 2 kHz besitzt, im Zeitbereich 0 t 1
ms. Wie viele Abtastwerte beschreiben jeweils eine Periode des Signals? Skizzieren Sie die
Abtastwerte in den nachstehenden Diagrammen.
Skizzieren Sie in den nachstehenden Diagrammen die Fourier-Betragsspektren der abgetasteten
Cosinussignale in einer zweiseitigen spektralen Darstellung.
-1
+1
1 0,5
Zeit/ms
0
x2(nT)
0 2 4 6 8 10 12 -12 -10 -8 -6 -4 -2
f/kHz
|X1ab(f)|
-1
+1
1 0,5
Zeit/ms
0
x1(nT)

G. Hirsch Version: pA11 Seite 5
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
c) Bis zu welcher Frequenz können Sie bei einer Abtastung mit fa = 8 kHz Cosinussignale
fehlerfrei erfassen?
d) Bestimmen Sie die Abtastwerte eines Cosinussignals s3(t), das eine Frequenz von 4 kHz besitzt,
und eines Sinussignals s4(t), das ebenfalls eine Frequenz von 4 kHz besitzt. Kann ein Signal, das
eine Frequenzkomponente bei der halben Abtastfrequenz beinhaltet, fehlerfrei erfasst werden?
e) Bestimmen Sie die Abtastwerte eines Cosinussignals x5(t), das eine Frequenz von 7 kHz besitzt?
Vergleichen Sie die Werte mit den unter b) berechneten Werten. Skizzieren Sie das
Betragsspektrum des abgetasteten Signals im nachstehenden Diagramm.
Praktische Übung 2
1. Kontrollieren Sie Ihre Berechnungen in Aufgabe 2, in dem Sie die Abtastwerte in der
graphischen Oberfläche des „Signal-Generators“ bestimmen.
2. Generieren Sie einen 1 s langen Sinuston mit der Frequenz 2 kHz bei einer Abtastfrequenz von
16 kHz. Hören Sie sich den Ton an. Bei Verletzung des Abtasttheorems tritt der so genannte
Aliasing Effekt auf, bei dem Frequenzanteile oberhalb der halben Abtastfrequenz an der
halben Abtastfrequenz gespiegelt unterhalb wieder auftreten ( ff
ff aa
22).
Überlegen Sie, bei welcher höheren Frequenz (oberhalb der halben Abtastfrequenz) eines
Sinussignals sich ein digitales Signal ergibt, das nach der Rekonstruktion ebenfalls als 2 kHz
Ton hörbar wird: ……… kHz
3. Kontrollieren Sie Ihre Überlegung durch Generierung und Anhören des entsprechenden
Sinustons.
0 2 4 6 8 10 12 14 16 -16 -14 -12 -10 -8 -6 -4 -2
f/kHz
|X2ab(f)|
0 2 4 6 8 10 12 -12 -10 -8 -6 -4 -2
f/kHz
|X5ab(f)|

G. Hirsch Version: pA11 Seite 6
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 3
Es wird ein analoges Signal x(t) betrachtet, dessen Betragsspektrum im nachfolgenden Bild
dargestellt ist.
Das analoge Signal wird zu diskreten Zeitpunkten mit einer Frequenz von 8 kHz abgetastet.
Skizzieren Sie das Spektrum des abgetasteten Signals im Bereich von –16 kHz bis +16 kHz in der
nachstehenden, zweiseitigen spektralen Darstellung.
Skizzieren Sie im nachstehenden Diagramm das Spektrum des abgetasteten Signals im Bereich von
–16 kHz bis +16 kHz, wenn das analoge Signal mit einer Frequenz von 12 kHz abgetastet wird.
Aufgabe 4
Die Abtastwerte eines zeitdiskreten Signals s(n) werden quantisiert. Dazu wird der
Amplitudenbereich -1 s(n) 1 linear in 8 Intervalle unterteilt. Alle in einem Intervall auftretenden
Amplitudenwerte werden zur späteren Rekonstruktion des wiederum analogen Signals auf den Wert
in der Intervallmitte abgebildet.
a) Welche Breite besitzt ein Quantisierungsintervall? Geben Sie die Amplitudenwerte an den
Intervallgrenzen an. Skizzieren Sie die Quantisierungskennlinie im nachstehenden Diagramm.
0 1 2 3 4 5
0
1
f/kHz
|X(f)|
0 2 4 6 8 10 12 14 16 -16 -14 -12 -10 -8 -6 -4 -2
f/kHz
|Xab8(f)|
0 2 4 6 8 10 12 14 16 -16 -14 -12 -10 -8 -6 -4 -2
f/kHz
|Xab12(f)|

G. Hirsch Version: pA11 Seite 7
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
b) Geben Sie eine mathematische Beziehung an, mit der Sie aus dem Amplitudenwert s(n) den
quantisierten Wert )(ˆ ns bestimmen können.
Im folgenden Bild sind 4 Amplitudenwerte eines abgetasteten Signals dargestellt.
c) Bestimmen Sie die sich ergebenden Amplitudenwerte bei einer Quantisierung mit der zuvor
bestimmten Quantisierungskennlinie. Bestimmen Sie die Quantisierungsfehler.
d) Wie viele Bits werden zur Darstellung der 8 Quantisierungsniveaus in einem Digitalrechner
benötigt?
…
…
-0.7
-0.3
0.9
0.625
2 3 4
-0.25
-0.5
-0.75
x(n)
1.0
Index n
0.75
0.5
0.25
0 1
ns
ns

G. Hirsch Version: pA11 Seite 8
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
e) Welche Dualzahlen ergeben sich in einem Digitalrechner für die 4 zuvor betrachteten
Amplitudenwerte, wenn die Zuordnung der Dualzahlen zu den einzelnen Quantisierungsniveaus
mit Hilfe einer Darstellung im Zweierkomplement erfolgt?
f) In welchem Wertebereich können Quantisierungsfehler auftreten?
g) Geben Sie die Formel zur Berechnung des Signal/Rauschleistungsverhältnisses SNR an, wenn
die Quantisierung allgemein mit k Bits vorgenommen wird und man ein Signal annimmt, dessen
Amplituden gleichverteilt im gesamten Quantisierungsbereich auftreten.
h) Geben Sie SNR Werte für die in der nachstehenden Tabelle angegebene Bitanzahl an.
k/Bit 1 2 4 6 8 10
SNR/dB
Praktische Übung 4
Laden Sie in der graphischen Oberfläche zur „Quantisierung“ das Sprachsignal „bahn2_16k.wav“.
Bestimmen Sie das sich einstellende SNR bei einer Codierung mit k = 10, 8, 6, 4, 2, 1 Bit. Tragen
Sie die Werte in die nachstehende Tabelle ein. Hören Sie sich das quantisierte Signal und den
Quantisierungsfehler jeweils an.
k/Bit 1 2 4 6 8 10
SNR/dB
Erzeugen Sie in der graphischen Oberfläche des Signalgenerators ein 1s langes Dreieckssignal bei
einer Abtastfrequenz von 16 kHz, das eine Frequenz von 1 Hz besitzt. Analysieren Sie die
Auftrittswahrscheinlichkeiten der Amplitudenwerte dieses Signals mit Hilfe der graphischen
Oberfläche zur „Verteilungsdichte“. Skizzieren Sie im nachstehenden Diagramm den Verlauf der
Wahrscheinlichkeitsdichtefunktion mit Angabe von Werten auf x- und y-Achse.
Analysieren Sie parallel die Wahrscheinlichkeitsdichtefunktion des Sprachsignals
„bahn2_16k.wav“.
Laden Sie das zuvor erzeugte Dreieckssignal in der graphischen Oberfläche zur „Quantisierung“.
Amplitude s
Wahrscheinlichkeitsdichte p(s)

G. Hirsch Version: pA11 Seite 9
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Welches SNR ergibt sich bei einer Quantisierung mit 6 Bit: …… dB
Welches SNR ergibt sich bei einer Quantisierung mit 10 Bit: …… dB
Vergleichen Sie die SNR Werte mit den in der vorherigen Aufgabe berechneten Werten.
Vergleichen Sie die SNR Werte mit den bei Quantisierung des Sprachsignals bestimmten Werten.
Warum sind die SNR Werte bei Quantisierung des Sprachsignals mit der gleichen Bitanzahl kleiner
im Vergleich zum Dreieckssignal: …………………………………………………………………
Analysieren Sie die Auftrittswahrscheinlichkeiten der Amplitudenwerte des Musiksignals
„africa_16k.wav“ mit Hilfe der graphischen Oberfläche zur „Verteilungsdichte“. Skizzieren Sie im
nachstehenden Diagramm den Verlauf der Wahrscheinlichkeitsdichtefunktion mit Angabe von
Werten auf x- und y-Achse.
Aufgabe 5
Als einer der ersten Verarbeitungsschritte bei der Sprachanalyse eines Erkennungssystems wird
häufig eine so genannte Höhenanhebung (preemphasis) des Sprachsignals vorgenommen. Dabei
werden zu jedem Abtastzeitpunkt nT der aktuelle Abtastwert s(n) und der vorhergehende
Abtastwert s(n-1) gewichtet gemäß der nachstehenden Beziehung subtrahiert. Man bezeichnet diese
Darstellung auch als Differenzengleichung: TnsTnsTnx 197,0 bzw.
bei Vernachlässigung der Zeit T zwischen 2 Abtastwerten und alleiniger Verwendung des
Abtastindex 197,0 nsnsny
Im Folgenden werden dieser Verarbeitungsschritt und seine Auswirkungen auf das Signal s durch
eine Darstellung als Signalverarbeitungsblock mit einer Bestimmung der zugehörigen
Impulsantwort und der Übertragungsfunktion analysiert.
Amplitude s
Wahrscheinlichkeitsdichte p(s)

G. Hirsch Version: pA11 Seite 10
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
a) Bestimmen Sie die Werte der Impulsantwort h(n) eines Systems, das die Verarbeitung gemäß
der angegebenen Differenzengleichung beinhaltet. s(n) ist das Eingangssignal, y(n) das
Ausgangssignal des Systems.
(Hinweis: Bestimmen Sie dazu alle Werte y(n), die einen Wert ungleich Null annehmen, wenn
man als Eingangssignal s(n) einen Diracimpuls
00
01
nfür
nfürn
verwendet.
Skizzieren Sie die Werte der Impulsantwort h(n) im nachstehenden Diagramm.
b) Bestimmen Sie mit Hilfe der Faltung die Abtastwerte y(n) des Ausgangssignals für das im
nachstehenden Diagramm angegebene Eingangssignal s(n). Skizzieren Sie die Werte y(n) in
dem darunter liegenden Diagramm.
s(t), s(n)
S(f) H(f)
h(t), h(n) )()()(
)()()(
nhnsny
thtsty
)()()( fHfSfY
Lineares, zeitinvariantes System
im Zeit- und Frequenzbereich
-1
+1
-3 -2 -1 0 1 2 3 4 5
h(n)
Zeitindex n
-1
+1
-3 -2 -1 0 1 2 3 4 5 6 7 8
y(n)
Zeitindex n
+1
-3 -2 -1 0 1 2 3 4 5 6 7 8
s(n)
Zeitindex n

G. Hirsch Version: pA11 Seite 11
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Im Matlab steht zur Faltung die Funktion conv zur Verfügung. Kontrollieren Sie damit die zuvor
durchgeführte Bestimmung des Ausgangssignals y(n).
c) Erzeugen Sie in Matlab einen Vektor, der die Abtastwerte von 3 Perioden eines Sinussignals mit
der relativen Frequenz 8
1af
f beinhaltet. Verwenden Sie diesen Vektor als Eingangssignal
s(n) und falten Sie ihn mit der Impulsantwort h(n). Stellen Sie das Eingangssignal s(n) und das
Ausgangssignal y(n) in zwei übereinander angeordneten Teilgraphiken dar.
d) Bestimmen Sie die Fourier Transformierte der Differenzengleichung.
Hinweis: Verwenden Sie S(f) als Fourier Transformierte von s(n) und X(f) als Fourier
Transformierte von x(n). Der zeitliche Versatz eines Signals führt zu einem multiplikativen
Phasenterm im Spektrum: 020 )()(
tfiefStts
e) Leiten Sie daraus die mathematische Beschreibung der Übertragungsfunktion H(f) ab.
f) Berechnen Sie (z.B. mit Matlab) einige Betragswerte der Übertragungsfunktion |H(f)| im
Bereich 2
0 aff . Skizzieren Sie mit Hilfe dieser Werte den Verlauf des Betrags der
Übertragungsfunktion im nachstehenden Diagramm.
g) Handelt es sich bei dieser Filtercharakteristik um einen Tiefpass, einen Bandpass oder einen
Hochpass?

G. Hirsch Version: pA11 Seite 12
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 6
Das abgetastete Signal 8
32sin4
2cos2 nnnx soll mit Hilfe einer DFT spektral
analysiert werden.
a) Geben Sie zunächst die Frequenz der Cosinusschwingung sowie die Frequenz der
Sinusschwingung bei einer Abtastfrequenz von 1000 Hz an, in dem Sie x(n) auf die zugehörige
Beschreibung als analoges Signals x(t) zurückführen.
Im Folgenden sollen 16 aufeinander folgende Abtastwerte von x(n) mit 0 n 15 mit einer DFT
transformiert werden.
b) Erzeugen Sie mit Hilfe von Matlab einen Vektor n, der die Abtastindices beinhaltet. Bestimmen
Sie zunächst die Abtastwerte getrennt für den Cosinusanteil und für den Sinusanteil des Signals.
Stellen Sie die Abtastwerte jeweils mit der Funktion stem graphisch dar. Wie viele Perioden des
Cosinusanteils werden durch die 16 Abtastwerte beschrieben? Wie viele Perioden des
Sinusanteils werden durch die 16 Abtastwerte beschrieben?
c) Ausgehend von den im vorherigen Unterpunkt gewonnenen Erkenntnissen können Sie die
Vorüberlegung anstellen, für welche Indices k die DFT Komponenten X(k) einen Wert ungleich
Null annehmen?
d) Geben Sie die Summenformel zur Berechnung von 4Re X sowie die Summenformel zur
Berechnung von 6Im X an. Erzeugen Sie in Matlab einen Vektor, der die Abtastwerte x(n)
beinhaltet, in dem Sie die Abtastwerte des Cosinus- und des Sinusanteils additiv überlagern. Zur
Berechnung der beiden Summenformeln können Sie die Funktion sum verwenden. Tragen Sie
die Ergebnisse in den nachstehenden Diagrammen ein. Überprüfen Sie exemplarisch für einige
Werte von k, dass 40Re kfürkX und 60Im kfürkX ist.
3 9 11 13 15 Index k
0 1 2 3 5 7
Re{X(k)}

G. Hirsch Version: pA11 Seite 13
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Ergänzen Sie in den Diagrammen die zu den von Ihnen berechneten Werten gehörigen
Komponenten oberhalb der halben Abtastfrequenz. Welcher Index k entspricht der halben
Abtastfrequenz?
e) Für welche Werte von k sollte sich für X(k) ein Wert ungleich Null ergeben, wenn die
Transformation nur mit den 8 aufeinander folgenden Abtastwerten von x(n) mit 0 n 7,
entsprechend einem nur halb so langen Signalabschnitt im Vergleich zu den 16 Abtastwerten,
durchgeführt wird?
f) Für welche Werte von k sollte sich für X(k) ein Wert ungleich Null ergeben, wenn die
Transformation mit den 32 aufeinander folgenden Abtastwerten von x(n) mit 0 n 31,
entsprechend einem doppelt so langen Signalabschnitt im Vergleich zu den 16 Abtastwerten,
durchgeführt wird?
e) Berechnen Sie die Energie des Signalabschnitts mit 16 Abtastwerten im Zeitbereich. Berechnen
Sie die Energie im Frequenzbereich.
Aufgabe 7
Eine Periode eines periodischen Signals, das mit einer Frequenz von 2000 Hz abgetastet wurde,
besteht aus N=16 Abtastwerten. Die 16 Abtastwerte werden zur Spektralanalyse mit Hilfe einer
DFT (Diskreten Fourier Transformation) transformiert.
a) Welche zeitliche Länge (in ms) besitzt der aus 16 Abtastwerten bestehende Signalabschnitt?
Welcher Grundfrequenz entspricht diese zeitliche Dauer?
b) In welchem spektralen Abstand Δf werden die Linien des Spektrums bei Anwendung der DFT
bestimmt? Für welche diskreten Frequenzen fk mit k=0,1,…,N/2-1 lassen sich mit der DFT die
Spektralanteile des Signals berechnen?
Als Ergebnis der DFT ergibt sich, dass alle Werte des Imaginärteils gleich Null sind. Für die Werte
des Realteils werden für die DFT Indices von k=0 bis k=7 die in der folgenden Darstellung
skizzierten Werte bestimmt.
3 9 11 13 15 Index k
0 1 2 3 5 7
Im{X(k)}

G. Hirsch Version: pA11 Seite 14
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
c) Besteht das analoge Signale
aus Cosinusanteilen oder
aus Sinusanteilen oder
aus Cosinus- und Sinusanteilen? Begründen Sie Ihre Antwort.
d) Beschreiben Sie das analoge Signal x(t) in mathematischer Form mit Angabe der Frequenzwerte.
Hinweis: Für die Amplituden der Cosinus- oder Sinusanteile (wie zuvor bestimmt) können Sie
die nachstehend angegebenen Werte annehmen:
k 0 1 2 3 4 5 6 7
Amplitude 0 1 0 -1/3 0 1/5 0 -1/7
Praktische Übung 7
Erzeugen Sie in der graphischen Oberfläche des Signalgenerators die 16 Abtastwerte einer Periode
des in der vorherigen Aufgabe unter 7d) bestimmten analogen Signals, in dem Sie die
entsprechenden Cosinus- bzw. Sinusschwingungen aufaddieren. Speichern Sie diese Abtastwerte in
einem File ab.
Schreiben Sie in Matlab ein kurzes Skript, um die Abtastwerte aus dem File zu lesen, eine DFT zu
berechnen und das Ergebnis graphisch darzustellen. Zum Lesen können Sie Funktion wavread und
zur Berechnung der DFT die Funktion fft verwenden. Erzeugen Sie mit Hilfe der Funktionen
subplot und stem eine dreigeteilte Graphik, in der im obersten Fenster die Abtastwerte des Signals,
im mittleren Fenster der Realteil des DFT Spektrums und im unteren Fenster der Imaginärteil des
DFT Spektrums dargestellt wird. Mit der graphischen Darstellung sollte sich das in der vorherigen
Aufgabe angegebene DFT Spektrum verifizieren lassen.
Erzeugen Sie einen Vektor, der 32 Abtastwerte und damit 2 Perioden des periodischen Signals
beinhaltet. Berechnen Sie die DFT der 32 Abtastwerte und stellen Sie das Ergebnis wiederum
graphisch dar. Bei welchen Indices k treten in diesem Fall die von Null verschiedenen
Komponenten auf?
-A/3
3
5
7 Index k
0 1
Re{S(k)} A

G. Hirsch Version: pA11 Seite 15
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Praktische Übung 8
Das Ziel dieses Experiments ist
die Bestimmung des Energieverlaufs von Sprachsignalen und
die Frequenzanalyse eines Sprachsignals und die Darstellung als Spektrogramm.
Analyse von Energieverläufen
Nehmen Sie mit der Oberfläche zur „Aufnahme“ von Signalen ein Wort bei einer Abtastfrequenz
von 16 kHz auf, in dem stimmlose Laute am Anfang und am Ende und ein Vokal in der Mitte
enthalten sind, z.B. „Schaf“. Gehen Sie in die Oberfläche, mit der Sie die „Energiekontur“ des
aufgenommenen Signals bestimmen können. Wählen Sie die Breite eines Analysefensters zu 20 ms
und die Verschiebung aufeinander folgender Analysefenster zu 10 ms. Drucken Sie das Ergebnis
aus.
Markieren Sie im Signalverlauf und in der Energiekontur in etwa die zeitlichen Bereiche der
einzelnen Laute.
Bei welchem Laut nimmt der Verlauf der Kurzzeit-Energie seine größten Werte an: ………
Speichern Sie das aufgenommene Signal in der „Aufnahme“ Oberfläche ab. Laden Sie das Signal in
der Oberfläche des Signalgenerators. Addieren Sie zu dem Signal ein gaußverteiltes Rauschen, das
einen um 5 dB geringeren Pegel als das Sprachsignal besitzt.
Analysieren Sie in der Oberfläche zur Darstellung des Energieverlaufs das verrauschte Signal.
Drucken Sie das Ergebnis aus. Markieren Sie wieder die zeitlichen Bereiche der einzelnen Laute.
Lassen sich der Beginn und das Ende des Worts mit Hilfe des Verlaufs der Kurzzeit-Energie exakt
bestimmen?
Beginn des Worts: ……………. Ende des Worts: ……………
Spektralanalyse (= Analyse der Frequenzzusammensetzung) kurzer Signalabschnitte
Im Praktikum steht zur Spektralanalyse die Oberfläche „FFT Analyse“ zur Verfügung. Laden Sie
die von Ihnen gesprochenen Vokale. Wählen Sie die Länge der FFT (=Breite des Analysefensters)
zu 512.
Welcher zeitlichen Dauer (in ms) entspricht diese Länge, wenn das Signal mit 16 kHz abgetastet
wurde: …… ms
Verschieben Sie das Analysefenster in den Bereich des periodischen Signalverlaufs eines Vokals.
Welche zeitliche Länge (in ms) besitzt eine Periode näherungsweise: ….. ms
Bei welchen Frequenzen (in Hz) dürfte das Signal nur Spektralkomponenten ungleich Null besitzen,
wenn man einen idealen periodischen Verlauf mit der ermittelten Periodenlänge annimmt:
………………………………………………………………….. Hz

G. Hirsch Version: pA11 Seite 16
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Vergleichen Sie die in der Oberfläche die logarithmierten Leistungsdichtespektren, die sich bei
Einsatz eines Rechteckfensters im Vergleich zum Einsatz eines Hamming- (oder Hanning-)
Fensters ergeben. Drucken Sie das Ergebnis aus.
Analysieren Sie ebenfalls den Signalabschnitt eines stimmlosen Lauts.
Betrachtung von Spektrogrammen
Zur Spracherkennung analysiert man kurze (ca. 20 bis 30 ms lange) aufeinander folgende
Abschnitte des Sprachsignals. Dabei wird von den im zeitlichen Abstand von etwa 10 ms
aufeinander folgenden Abschnitten das Spektrum mit einer DFT bestimmt. Das Ergebnis einer
solchen Kurzzeit-Spektralanalyse kann man sich als sogenanntes „Spektrogramm“ in einer
graphischen Oberfläche zur „Spektralen Analyse“ anschauen. Dabei kann man die aufeinander
folgenden Spektren in einer dreidimensionalen Darstellung oder in einer zweidimensionalen
Darstellung über Zeit und Frequenz darstellen. In der zweidimensionalen Darstellung wird die
Amplitude der Frequenzkomponenten farblich codiert. Mit der Farbe „blau“ werden kleine
Amplituden und mit der Farbe „rot“ die großen Amplituden dargestellt. Die Abbildung der
dazwischen liegenden Amplituden erfolgt mit Hilfe des Farbspektrums.
Nehmen Sie das Wort „eins“ bei einer Abtastfrequenz von 16 kHz auf.
In der Oberfläche zur Betrachtung des „Zeitsignals“ können Sie durch Markieren von
Signalabschnitten und das Anhören der Abschnitte ungefähr feststellen, in welchem zeitlichen
Bereich die Laute „ai“, „n“ und „s“ auftreten. Diese Kenntnis können Sie für die Analyse des
Signals im Frequenzbereich nutzen.
Betrachten Sie dazu das zugehörige Spektrogramm bei einer Analyse von 32 ms langen
Abschnitten, einer Verschiebung des Analysefensters um 10 ms sowie einer FFT-Länge von 512.
In welchem ungefähren Frequenzbereich besitzt der stimmhafte Laut „ai“ seine größten
Amplituden: …………………………. Hz
In welchem ungefähren Frequenzbereich besitzt der nasale Laut „n“ seine größten Amplituden:
…………………………. Hz
In welchem ungefähren Frequenzbereich besitzt der stimmlose Laut „s“ seine größten Amplituden:
…………………………. Hz
Nehmen Sie nacheinander die Wörter „zwei“ und „drei“ auf und betrachten Sie die zugehörigen
Spektrogramme.
In welchem Abschnitt des Worts unterscheiden sich die Spektrogramme: ………………………..
Es sollte sichtbar werden, dass die Spektrogramme von „zwei“ und „drei“ sehr ähnlich aussehen.
Dies macht bereits die Problematik einer möglichen Verwechslung dieser beiden Wörter deutlich.

G. Hirsch Version: pA11 Seite 17
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 9
In einem Spracherkennungssystem werden die aus der Analyse mit einer MEL Filterbank
resultierenden Cepstral-Koeffizienten als akustische Parameter extrahiert. Der Zusammenhang
zwischen der Pseudoeinheit MEL und der Frequenz wird beschrieben durch:
)700
1(log2595)( 10
ffMel
Das Sprachsignal wird mit 8 kHz abgetastet. Die MEL Filterbank deckt den Bereich von 200 bis 4
kHz ab und besteht aus 20 Teilbändern. Die Filter werden so festgelegt, dass sie sich ohne
Überlappung aneinander reihen. Die Eckfrequenzen der Filter resultieren aus einer linearen
Unterteilung des entsprechenden MEL Bereichs in 20 Bänder.
a) Welchem MEL Wert entspricht der Frequenzwert bei 200 Hz und welchem MEL Wert der bei
4000 Hz?
b) Welche Breite in MEL nehmen die auf der MEL Skala gleichbreiten Teilfilter an?
c) Bestimmen Sie die MEL Werte, die die Grenzen des 1., 10. und 20. Teilfilters festlegen.
d) Welche zugehörigen Frequenzwerte legen die Eckfrequenzen der drei Teilfilter fest?
e) Welche FFT Indices liegen in dem durch die 3 Teilfilter jeweils beschriebenen Frequenzbereich,
wenn eine FFT der Länge 256 verwendet wird?
Mit Hilfe einer DCT werden aus den Teilbandenergien der MEL Filterbank die 11 Cepstral-
Koeffizienten C0 bis C10 alle 10 ms bestimmt. Neben den Cepstral-Koeffizienten wird auch die
Kurzzeitenergie logE alle 10 ms bestimmt. Ein Merkmalsvektor setzt sich aus den 10 Cepstral-
Koeffizienten C1 bis C10 und dem Energiewert logE sowie den zugehörigen Delta und Delta-Delta
Koeffizienten zusammen.
f) Wie groß muss der Speicherbereich (in Byte) sein, der zum Abspeichern aller
Merkmalsvektoren einer Sekunde Sprache benötigt wird, wenn jede Komponente des
Merkmalsvektors mit einem Byte abgespeichert werden kann?
Praktische Übung 10
Das Ziel dieser Übung ist die Programmierung einer Funktion zur Extraktion akustischer Merkmale
aus den Abtastwerten eines Sprachsignals.

G. Hirsch Version: pA11 Seite 18
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Anforderungen
Die Funktion erhält als Eingangswerte die Abtastwerte eines Sprachsignals, die in einer Variablen
als Spaltenvektor enthalten sind. Es wird vorausgesetzt, dass es sich um Signale handelt, die mit
einer Frequenz von 8 kHz abgetastet wurden. In der Funktion sollen verschiedene akustische
Parameter für Signalabschnitte mit einer Länge von 25 ms und in einem zeitlichen Abstand von 10
ms bestimmt werden. Konkret sollen die logarithmierte Kurzzeitenergie logE und die 12 Mel-
Cepstral-Koeffizienten C1 bis C12 für jeden Signalabschnitt berechnet werden.
In der Funktion soll
eine Präemphase (Höhenanhebung) des kompletten Signals mit einem FIR Filter 1. Ordnung
sowie
eine abschnittsweise Bestimmung der Energie und der Cepstralkoeffizienten vorgenommen
werden.
Die Kurzzeitenergie soll aus den Abtastwerten eines Sprachabschnitts berechnet werden. Zur
Bestimmung der Cepstralkoeffizienten werden
die Abtastwerte eines Signalabschnitts mit einem Hamming- oder Hanningfenster gewichtet,
mit einer DFT in den Spektralbereich transformiert,
die Betragswerte des komplexen DFT Spektrums bestimmt,
die DFT Betragswerte gemäß einer Mel Filterbank in 24 Bändern zusammengefasst,
der Logarithmus der Mel Spektralwerte berechnet und
die logarithmierten Mel Spektralwerte mit einer DCT in den Cepstralbereich transformiert
werden.
Die Funktion gibt als Ausgangswert eine Matrix zurück, in der in jeder Zeile die akustischen
Parameter eines Signalabschnitts enthalten sind. Die Zeilenindices entsprechen der zeitlichen
Aufeinanderfolge der Signalabschnitte. Speichern Sie den Wert für die Kurzzeitenergie in der
letzten Spalte jeder Zeile.
Erstellen Sie ein Struktogramm, in dem die zuvor aufgeführten Verarbeitungsschritte nur als Blöcke
aufgeführt werden. Es soll deutlich werden, wie Sie die abschnittsweise Analyse realisieren werden.
Details
Die Filterkoeffizienten zur Präemphase können Sie als b = [1 -0.95]; definieren. Die
Filterung selbst kann mit Hilfe der Funktion filter(b, 1., eingangssignal); ausgeführt
werden.

G. Hirsch Version: pA11 Seite 19
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Zur Energieberechnung können Sie die Funktion sum verwenden.
Zur Definition der Fensterfunktion stehen die Funktionen hamming bzw. hanning zur
Verfügung.
Die DFT kann mit der Funktion fft ausgeführt werden.
Die Funktion abs kann zur Betragsbildung verwendet werden.
Die Zusammenfassung in den Mel Bändern kann gegebenenfalls als Unterfunktion realisiert
werden. Erstellen Sie auch dazu zunächst ein Struktogramm.
Die DCT
1205.024
coslog24
1
imitkmeli
kmelSCkmel
kmel
meli
kann als Matrizenmultiplikation realisiert werden, wobei die Werte des Cosinusterms in einer
Matrix mit i und kmel als Zeilen- und Spaltenindices im Vorhinein bestimmt werden können.
Aufgabe 11
In einem Spracherkennungssystem sollen neben den akustischen Parametern, die aus der Analyse
kurzer Signalabschnitte gewonnen werden, auch die zeitlichen Ableitungen der Parameterverläufe,
die so genannten Delta-Koeffizienten, verwendet werden.
In der nachstehenden Tabelle sind auszugsweise die Werte des akustischen Merkmals rx5 für
eine Reihe aufeinander folgender Sprachabschnitte in Abhängigkeit des Segmentindex r gegeben,
die bei der Analyse eines Sprachsignals bestimmt wurden.
r … 10 11 12 13 14 …
rx5 … -1.83 -1.54 -0.78 0.03 0.24 …
a) Berechnen Sie den Wert 125x des Delta-Koeffizienten, wobei die Berechnung der Delta
Koeffizienten gemäß
2
1
2
2
12
j
jjnormmit
norm
jrxjrxj
rx
erfolgen soll.

G. Hirsch Version: pA11 Seite 20
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Die gleiche sprachliche Äußerung wurde in einer anderen akustischen Umgebung aufgezeichnet.
Bei der Analyse dieses Signals wurden die nachstehenden Werte für das akustische Merkmal rx5
bestimmt, wobei es sich um den gleichen zeitlichen Abschnitt der Äußerung handelt:
r … 10 11 12 13 14 …
rx5 … -1.34 -0.98 -0.32 0.49 0.76 …
b) Berechnen Sie den Wert 125x des Delta-Koeffizienten.
c) Berechnen Sie den Betrag der Differenz von 1212 55 ab xx sowie von 1212 55 ab xx
aus den in den Unterpunkten a) und b) gegebenen bzw. bestimmten Werten. Welcher akustische
Parameter zeigt die größere Abhängigkeit von der akustischen Umgebung?
Aufgabe 12
Bei einem einfachen, sprecherabhängigen Erkennungssystem werden in der Trainingsphase für drei
zu erkennende Wörter <1>, <2> und <3> die nachstehend tabellarisch dargestellten
Vektorsequenzen {XX}refx als Referenzmuster bestimmt. Jeder Vektor beinhaltet dabei nur zwei
akustische Merkmale x1 und x2.
Zur Bestimmung eines Maßes der Unähnlichkeit zweier Vektorsequenzen wird der Algorithmus,
der als „Dynamic Time Warping“ (DTW) bezeichnet wird, eingesetzt. Bei einem Einsatz des
Erkennungssystems wurde die nachstehend angegebene Vektorsequenz {XX}u bei der
Merkmalsextraktion einer sprachlichen Eingabe bestimmt.
{XX}ref1
{XX}ref2
{XX}ref3
{XX}u
t1=1,2,…
x1
x2
1,2
0,2
1,9
0,8
0,5
0,8
2,2
2,4
1,4
0,4
2,8
1,2
3,6
1,7
0,7
2,2
3,2
1,8
0,6
2,7
2,8
2,2
4,8
0,9
2,2
1,3
4,7
4,8
1,6
1,1
3,8
2,2
5,6
3,5
2,4
0,7
0,8
0,4
2,4
1,2
1,8
2,8
0,7
1,8
1,5
0,7
3,2
1,5
4,5
2,3
0,6
0,7
t2=1,2,…
Vektorindices

G. Hirsch Version: pA11 Seite 21
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Bestimmen Sie mit Hilfe des DTW Algorithmus das Maß der Unähnlichkeit der Vektorsequenz
{XX}u zu jeder der drei Referenzsequenzen {XX}ref.
Hinweis: Zur Bestimmung der Unähnlichkeit zweier Vektoren X1 und X2 wird der Euklidische
Abstand
2
1
2212,1
i
ii xxXXd
verwendet. Die aufakkumulierte Unähnlichkeit D(t1, t2)
aller bis zum Vektorindex t1 des zu erkennenden Sprachsignals und bis zum Vektorindex t2 des
Referenzmusters aufgetretenen Vektoren wird schrittweise mit Hilfe der nachstehend aufgeführten
mathematischen Beziehung bestimmt:
12,1,12,11,2,112,12,1 ttDttDttDMINtXreftXudttD
Tragen Sie in die nachstehende Tabelle die Werte D(t1, t2) ein, die sich für das Referenzmuster mit
der geringsten Unähnlichkeit ergeben haben. Skizzieren Sie darin den Pfad, der die Zuordnung der
Vektoren der Sequenz {XX}u zu den Vektoren der Sequenz {XX}refbest verdeutlicht gemäß der
Fähigkeit des DTW Algorithmus, eine nicht lineare Zeitanpassung zwischen zwei Vektorsequenzen
zu ermöglichen.
Aufgabe 13
Zur Spracherkennung werden zwei akustische Merkmale rx1 und rx2 für kurze zeitliche
Abschnitte des Sprachsignals bestimmt, wobei r zur Indizierung der einzelnen Abschnitte dient.
t1
t2
1uX
2uX
…
1refX
2refX
…

G. Hirsch Version: pA11 Seite 22
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Zum initialen Training eines Referenzmusters für ein Wort wird das Wort dreimal geäußert. Die
Folgen der Merkmalsvektoren, die bei der Analyse der 3 Äußerungen bestimmt wurden, sind im
nachstehenden Bild dargestellt. Das Referenzmuster wird als Folge von 3 Zuständen mit
Übergangswahrscheinlichkeiten zwischen den Zuständen modelliert. Jeder Zustand beinhaltet eine
multivariate Normalverteilungsdichtefunktion, mit der das Auftreten der beiden akustischen
Merkmale in den zugehörigen Signalabschnitten in statistischer Form beschrieben wird.
Jede der 3 Äußerungen wird in 3 Abschnitte unterteilt. Die Segmentierung wird aufgrund der in der
Folge von Merkmalsvektoren enthaltenen spektralen Änderung vorgenommen.
a) Berechnen Sie für die von den 3 Zuständen ausgehenden Übergänge die
Übergangswahrscheinlichkeiten.
b) Berechnen Sie für den Zustand S2 den Vektor, der die Mittelwerte der beiden akustischen
Merkmale beinhaltet. Berechnen Sie die Werte der Kovarianzmatrix.
Praktische Übung 13
Schreiben Sie in Matlab ein Skript, um die multivariate Normalverteilungsdichtefunktion, deren
Mittelwerte und Kovarianzwerte in Aufgabe 13b) bestimmt wurden, graphisch zu visualisieren.
0,74
3,45
0,98
3,03
2,14
2,23
1,53
2,49
1,49
2,54
1,45
2,59
1,34
2,78
x1
x2
x1
x2
x1
x2
x1
x2
x1
x2
x1
x2
0,85
1,98
1,23
2,39
2,02
1,74
1,82
3,56
1,55
3,34
1,50
2,58
1,45
2,52
x1
x2
x1
x2
x1
x2
x1
x2
0,68
3,02
1,76
1,88
1,52
2,48
1,48
2,52
1,44
2,67
1,13
2,97
x1
x2
x1
x2
x1
x2
x1
x2
x1
x2
x1
x2
S3
2,36
1,78
Segmentindex r
S2 S1 Send

G. Hirsch Version: pA11 Seite 23
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
mXmX
M
T
eSXp
1
2
1
2
2
1
Zu Bestimmung der Determinante steht die Funktion det und zur Berechnung der
Exponentialfunktion die Funktion exp zur Verfügung.
Berechnen Sie für alle Kombinationen der Werte 40 1 x und 40 2 x bei einer Schrittweite
von 0,1 für x1 und x2 die Werte der Verteilungsdichtefunktion. Speichern Sie diese Werte in einer
Matrix ab. Zur dreidimensionalen Darstellung der in der Matrix enthaltenen Werte steht die
Funktion mesh zur Verfügung.
Setzen Sie die Werte in der Kovarianzmatrix, die nicht auf der Hauptdiagonalen sind, gleich Null.
Berechnen und visualisieren Sie wiederum die Werte der Verteilungsdichtefunktion.
Aufgabe 14
Das Ziel dieser Aufgabe ist die Berechnung der „Forward-Backward“ Wahrscheinlichkeiten, die die
„Soft“information zur „weichen“ Zuordnung jedes Merkmalsvektors zu einem der Zustände eines
HMMs beinhalten.
Zur Spracherkennung wird eine Merkmalsextraktion eingesetzt, bei der zwei akustische Merkmale
rx1 und rx2 für kurze zeitliche Abschnitte des Sprachsignals bestimmt werden. Der Index r
dient zur Indizierung der zeitlich aufeinander folgenden Abschnitte. Die beiden Merkmale werden
als statistisch voneinander unabhängig angenommen. Die in der nachstehenden Tabelle aufgeführte
Folge von 4 Merkmalsvektoren wird neben einer Vielzahl anderer Vektorfolgen zur Bestimmung
der Parameter eines HMMs verwendet.
Zeitindex r 1 2 3 4
Merkmal x1 1,23 1,37 1,95 2,72
Merkmal x2 2,45 2,34 1,87 0,87
Nachstehend ist die Struktur des HMMs dargestellt, das aus drei Zuständen besteht. In einer ersten
Trainingsphase wurden die angegebenen Übergangswahrscheinlichkeiten, Mittelwerte und
Varianzen der beiden Merkmalswerte bestimmt.
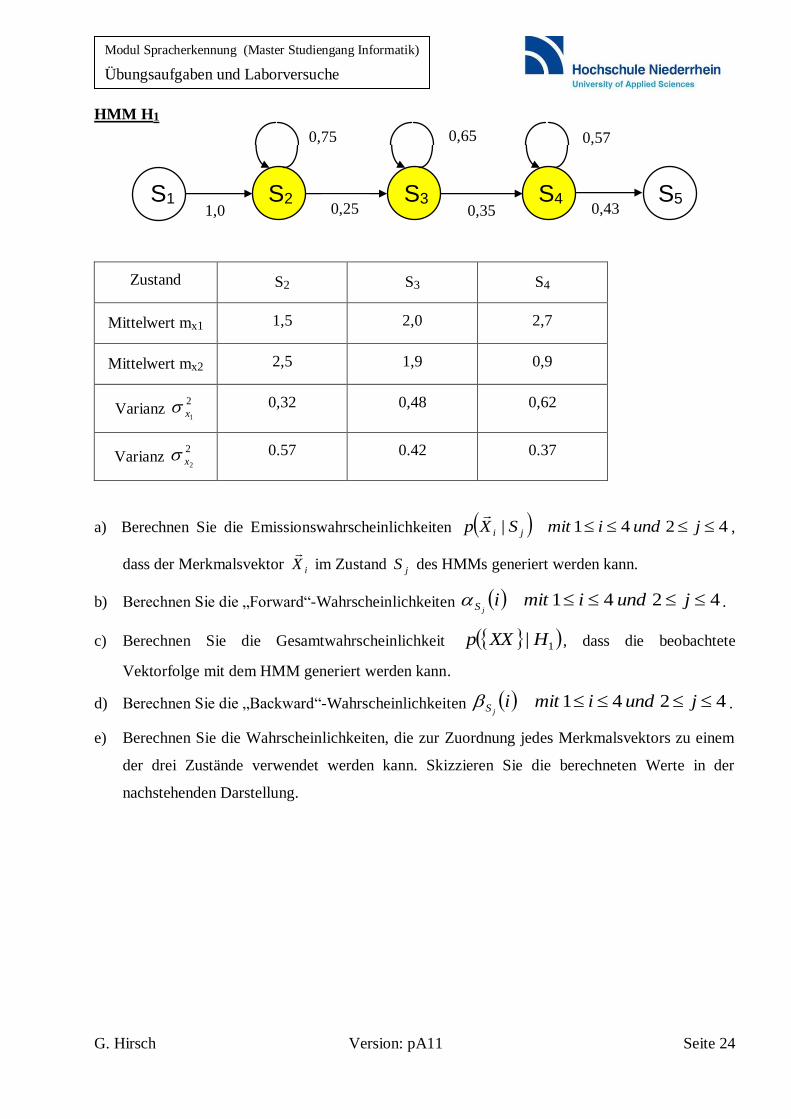
G. Hirsch Version: pA11 Seite 24
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
HMM H1
Zustand S2 S3 S4
Mittelwert mx1 1,5 2,0 2,7
Mittelwert mx2 2,5 1,9 0,9
Varianz 2
1x 0,32 0,48 0,62
Varianz 2
2x 0.57 0.42 0.37
a) Berechnen Sie die Emissionswahrscheinlichkeiten 4241| jundimitSXp ji
,
dass der Merkmalsvektor iX
im Zustand jS des HMMs generiert werden kann.
b) Berechnen Sie die „Forward“-Wahrscheinlichkeiten 4241 jundimitijS .
c) Berechnen Sie die Gesamtwahrscheinlichkeit 1| HXXp , dass die beobachtete
Vektorfolge mit dem HMM generiert werden kann.
d) Berechnen Sie die „Backward“-Wahrscheinlichkeiten 4241 jundimitijS .
e) Berechnen Sie die Wahrscheinlichkeiten, die zur Zuordnung jedes Merkmalsvektors zu einem
der drei Zustände verwendet werden kann. Skizzieren Sie die berechneten Werte in der
nachstehenden Darstellung.
S4 S3 S2 S5 S1 1,0
0,75
0,25
0,65
0,35
0,57
0,43

G. Hirsch Version: pA11 Seite 25
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 15
Zur Spracherkennung werden zwei akustische Merkmale rx1 und rx2 für kurze zeitliche
Abschnitte des Sprachsignals bestimmt, wobei r zur Indizierung der zeitlich aufeinander folgenden
Abschnitte dient. Die beiden Merkmale können als statistisch voneinander unabhängig
angenommen werden. Zur Erkennung eines isoliert gesprochenen Worts wurde nach einer
Wortgrenzendetektion die in der nachstehenden Tabelle aufgeführte Folge von 4 Merkmalsvektoren
ermittelt:
Zeitindex r 1 2 3 4
Merkmal x1 1,23 1,37 1,95 2,72
Merkmal x2 2,45 2,34 1,87 0,87

G. Hirsch Version: pA11 Seite 26
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Zur Erkennung der Wörter „ja“ und „nein“ stehen zwei HMMs zur Verfügung, deren Parameter aus
vielen Äußerungen einer großen Sprachdatenbasis zuvor bestimmt wurden. Die Struktur und die
Parameter der HMMs sind nachstehend gegeben:
HMM H1 des Worts „ja“
Zustand S2 S3 S4
Mittelwert mx1 1,5 2,0 2,7
Mittelwert mx2 2,5 1,9 0,9
Varianz 2
1x 0,32 0,48 0,62
Varianz 2
2x 0.57 0.42 0.37
HMM H2 des Worts „nein“
Zustand S2 S3 S4
Mittelwert mx1 2,1 1,7 1,2
Mittelwert mx2 1,1 1,8 2,0
Varianz 2
1x 0,51 0,42 0,35
Varianz 2
2x 0,37 0,45 0,52
S4 S3 S2 Send Sini 1,0
0,75
0,25
0,65
0,35
0,57
0,43
0,1
0,65
0,1
0,55 0,57
S4 S3 S2 Send Sini 1,0 0,25 0,35 0,43

G. Hirsch Version: pA11 Seite 27
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
a) Berechnen Sie die Wahrscheinlichkeiten 33 | SXp
, dass der 3. Merkmalsvektor (r=3)
jeweils im Zustand S3 eines der HMMs generiert wird.
b) Skizzieren Sie in den beiden anhängenden Diagrammen die möglichen Zustandsfolgen, aus
denen die 4 Merkmalsvektoren generiert werden können.
c) Berechnen Sie für jedes der HMMs den Logarithmus der Wahrscheinlichkeit
iHXXp | , die sich aus der Betrachtung der Zustandsfolge bestimmt, die mit größter
Wahrscheinlichkeit die Folge von Merkmalsvektoren generiert. Zur näherungsweisen Bestimmung
der Zustandsfolge mit der größten Wahrscheinlichkeit wird der Viterbi Algorithmus verwendet.
d) Bestimmen und skizzieren Sie in den nachstehenden Diagrammen die Zustandsfolge, die zu
den unter c) berechneten Wahrscheinlichkeiten geführt hat. Dies kann durch Rückwärtsverfolgung
des Pfades, ausgehend vom Endzustand, unter Einbeziehung der mit Hilfe des Viterbi Algorithmus
getroffenen Entscheidungen erfolgen.
HMM H1 „ja“
S2
S3
S4
Sini
Send
2X
1X
3X
4X
Send

G. Hirsch Version: pA11 Seite 28
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
HMM H2 „nein“
Einführung der neuronalen Netze
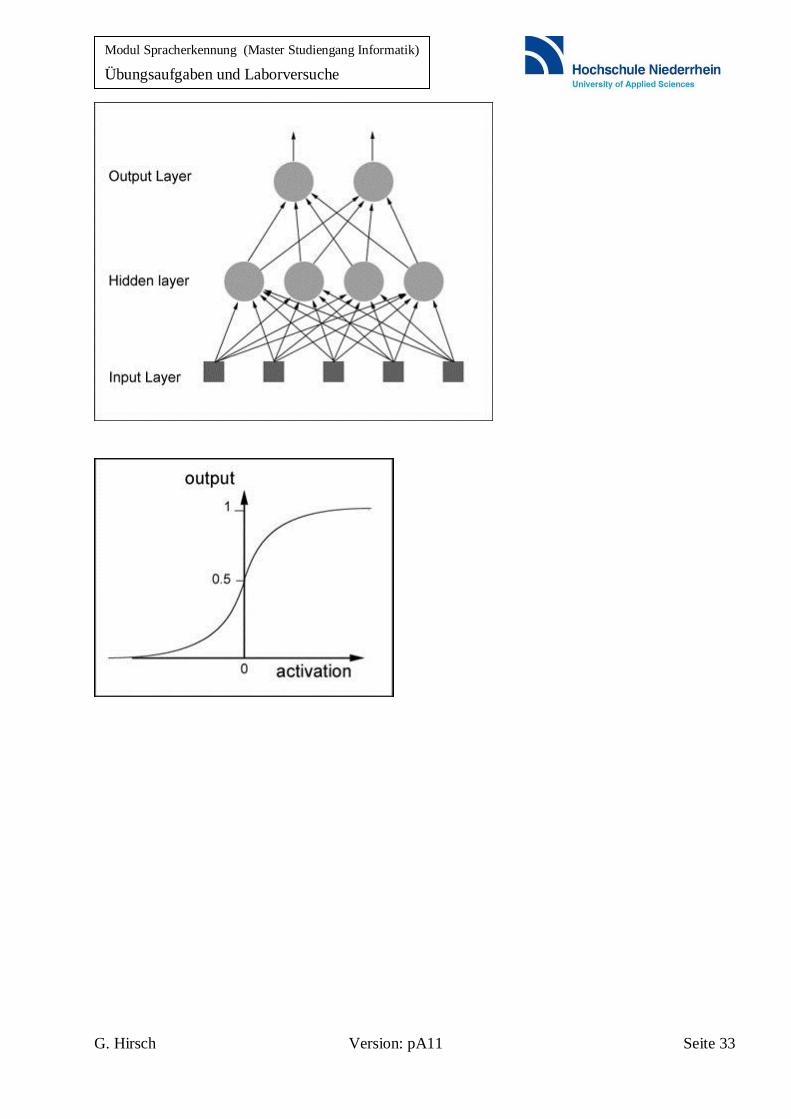
Die Kernkomponente eines neuronalen Netzes ist ein künstliches Neuron, wie es im nachstehenden
Bild dargestellt ist. Die Eingangswerte x1 bis xn stehen dabei für die Aktivitäten anderer Neuronen,
mit denen das betrachtete Neuron in Verbindung steht.
Die Merkmalswerte x1 bis xn am Eingang des Neurons werden dabei mit den Gewichtungsfaktoren
w1j bis wnj multipliziert und anschließend addiert:
n
i
iijj xwnet
1
Mit dem Index j wird dieses Neuron als Komponente eines in der Regel aus vielen Neuronen
bestehenden Netzes gekennzeichnet. Zur Begrenzung der Werte netj auf einen gewünschten
Wertebereich, z.B. 0<netj<1, wird eine Aktivierungsfunktion angewendet. Eine einfache
Aktivierungsfunktion könnte beispielsweise eine binäre Schwellwertfunktion sein, die so definiert
ist: sonst
netfüro
jjj
0
1 , wobei j einen zu definierenden Schwellwert darstellt.
S2
S3
S4
Sini
Send
2X
1X
3X
4X
Send

G. Hirsch Version: pA11 Seite 29
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Um bei einem aus mehreren Neuronen bestehenden Netz die gleiche Aktivierungsfunktion mit dem
gleichen Schwellwert benutzen zu können, z.B. 0j , kann man die Eingangswerte um einen
weiteren konstanten Wert, den so genannten Bias, erweitern. Der Bias, der in der Regel den Wert 1
annimmt, wird auch mit einem individuellen Gewichtsfaktor multipliziert, wobei dieser
Gewichtsfaktor den individuellen Schwellwert des betrachteten Knotens repräsentiert. Ein
Eingangsvektor des Netzes definiert sich damit zu: 121 nxxxX
Mehrere Neuronen kann man zu einem Neuronalen Netz verknüpfen. Ein einfaches Beispiel dazu
ist im nachfolgenden Bild dargestellt, in dem 2 Merkmalswerte x1 und x2 als Eingangswerte zweier
Neuronen dienen.
Am Ausgang des neuronalen Netzes findet man die beiden Ausgangswerte o1 und o2. Die sechs
Gewichtsfaktoren kann man in einer Matrix zusammenfassen, mit der der Eingangsvektor
121 xxX
zur Berechnung der Werte netj multipliziert wird: wXnet
x1
xn
x2 oj
Neuron …
x1
2 o2
1 o1
x2

G. Hirsch Version: pA11 Seite 30
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 15
Es wird das neuronale Netz betrachtet, dass durch die Gewichtsmatrix
32
32
11
w und die
Aktivierungsfunktion sonst
netfüro
jj
0
0
1
definiert ist.
a) Geben Sie beiden Ungleichungen an, für die die Ausgangswerte o1 und o2 jeweils den Wert 1
annehmen. Formen Sie die Ungleichungen so um, dass Sie eine Darstellung in der
Form 1212 . xfxbzwxfx erhalten. Markieren Sie in der durch die beiden Variablen x1
und x2 aufgespannten Merkmalsebene jeweils die Bereiche, in denen o1 bzw. o2 den Wert 1
annehmen.
b) Überprüfen Sie die unter a) gewonnenen Erkenntnisse, in dem Sie die Ausgangswerte für die 3
Vektoren 1211 X
, 1222 X
und 1063 X
berechnen.
c) Markieren Sie in der durch die beiden Variablen x1 und x2 aufgespannten Merkmalsebene die
Bereiche, in denen die Vektoren zweier Klassen liegen müssen, damit man sie mit dem
neuronalen Netz eindeutig zuordnen kann.
Im Folgenden wird das Netz um einen weiteren Knoten erweitert, wie man es der nachfolgenden
Darstellung entnehmen kann. Der Knoten 3 stellt dabei einen weiteren Layer dar. Die Bezeichnung
als Knoten 3 ist unüblich, eigentlich handelt es sich um den ersten (und in dem Fall einzigen)
Knoten des zusätzlichen Layers ℓ2.
Der Ausgangswert o3 berechnet sich durch Ergänzung der beiden Eingangswerte o1 und o2 um den
Bias 1 und der Multiplikation mit der Matrix (= Vektor)
1
6,0
6,0
2w
d) Geben Sie die Ungleichung in der Form 1212 . ofobzwofo an, die den Wertebereich
definiert, in dem o3 den Wert 1 annimmt. Markieren Sie in der durch die beiden Variablen o1 und
o2 aufgespannten Merkmalsebene den Bereich, in dem o3 den Wert 1 annimmt. Welchen Wert
müssen o1 und o2 annehmen, damit o3 den Wert 1 annimmt? Markieren Sie in der durch die
beiden Variablen x1 und x2 aufgespannten Merkmalsebene den Bereich, in dem o3 den Wert 1
annimmt.
o3 x1
2 o2
1 o1
x2
3

G. Hirsch Version: pA11 Seite 31
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Praktische Übung 16
Schreiben Sie eine Funktion o=nn_layer(X, w) in Matlab, um die Ausgangswerte eines Layers eines
neuronalen Netzes als Elemente des Vektors o zu berechnen. Eingangswerte der Funktion sind der
Vektor X mit den Eingangswerten für diesen Layer sowie die Matrix w mit den Gewichten des
neuronalen Netzes. Als Aktivierungsfunktion verwenden Sie die Sigmoid Funktion jnetj
eo
1
1
Schreiben Sie eine Funktion o=neural_net(X, W) in Matlab, um die Ausgangswerte eines
mehrlagigen neuronalen Netzes als Elemente des Vektors o zu berechnen. Eingangswerte der
Funktion sind der Vektor X mit den Eingangswerten des neuronalen Netzes sowie ein Vektor W,
der cell Elemente beinhaltet. Die Anzahl der cell Elemente entspricht der Anzahl der Layer des
Netzes. Das Element W{k} beinhaltet die Matrix der Gewichte des k-ten Layers.
Zur Überprüfung der Funktionalität der von Ihnen programmierten Funktionen wird eine
Aufgabenstellung betrachtet, bei der die Klassifikation von 6 verschiedenen Vokalen an Hand von
DFT Spektren, die jeweils 440 Werte beinhalten, vorgenommen werden soll. Es wurden die
Gewichte neuronaler Netze trainiert, die 6 Ausgangswerte erzeugen. Die Ausgangswerte sollten den
Wert 1 für den der Vokalklasse zugeordneten Knoten und ansonsten den Wert 0 annehmen. Die
DFT Spektren und die Gewichte verschiedener Netze wurden in dem matlabspezifischen Datenfile
neural_net_test2.mat zusammen abgespeichert. Nach dem Laden des Files neural_net_test2.mat
werden die Variablen
specs, die eine Matrix mit einem DFT Spektrum in jeder Zeile beinhaltet,
groups, die einen Vektor mit Ziffern (1 bis 6) zur Zuordnung der DFT Spektren zu einer
Klasse beinhaltet,
W_two_layer_50_6, die zwei cell Elemente mit den Gewichten eines zweilagigen Netzes
beinhaltet,
W_three_layer_50_20_6, die drei cell Elemente mit den Gewichten eines dreilagigen Netzes
beinhaltet,
angelegt.
Schreiben Sie ein Skript oder eine Funktion, um alle DFT Spektren mit einem Netz zu klassifizieren
und am Ende eine Fehlerrate zu bestimmen. Bestimmen Sie die Fehlerraten für die beiden
Netzvarianten.
W_two_layer_50_6 W_three_layer_50_20_6
Fehlerrate/%

G. Hirsch Version: pA11 Seite 32
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
G. Hirsch Version: pA11 Seite 33
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche

G. Hirsch Version: pA11 Seite 34
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Aufgabe 5 (erweitert , schon eingefügt)
Als einer der ersten Verarbeitungsschritte bei der Sprachanalyse eines Erkennungssystems wird
häufig eine so genannte Höhenanhebung (preemphasis) des Sprachsignals vorgenommen. Dabei
werden zu jedem Abtastzeitpunkt nT der aktuelle Abtastwert s(n) und der vorhergehende
Abtastwert s(n-1) gewichtet gemäß der nachstehenden Beziehung subtrahiert. Man bezeichnet diese
Darstellung auch als Differenzengleichung: TnsTnsTnx 197,0 bzw.
bei Vernachlässigung der Zeit T zwischen 2 Abtastwerten und alleiniger Verwendung des
Abtastindex 197,0 nsnsny
Im Folgenden werden dieser Verarbeitungsschritt und seine Auswirkungen auf das Signal s durch
eine Darstellung als Signalverarbeitungsblock mit einer Bestimmung der zugehörigen
Impulsantwort und der Übertragungsfunktion analysiert.
a) Bestimmen Sie die Werte der Impulsantwort h(n) eines Systems, das die Verarbeitung gemäß
der angegebenen Differenzengleichung beinhaltet. s(n) ist das Eingangssignal, y(n) das
Ausgangssignal des Systems.
(Hinweis: Bestimmen Sie dazu alle Werte y(n), die einen Wert ungleich Null annehmen, wenn
man als Eingangssignal s(n) einen Diracimpuls
00
01
nfür
nfürn
verwendet.
Skizzieren Sie die Werte der Impulsantwort h(n) im nachstehenden Diagramm.
s(t), s(n)
S(f) H(f)
h(t), h(n) )()()(
)()()(
nhnsny
thtsty
)()()( fHfSfY
Lineares, zeitinvariantes System
im Zeit- und Frequenzbereich
-1
+1
-3 -2 -1 0 1 2 3 4 5
h(n)
Zeitindex n

G. Hirsch Version: pA11 Seite 35
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
b) Bestimmen Sie mit Hilfe der Faltung die Abtastwerte y(n) des Ausgangssignals für das im
nachstehenden Diagramm angegebene Eingangssignal s(n). Skizzieren Sie die Werte y(n) in
dem darunter liegenden Diagramm.
Im Matlab steht zur Faltung die Funktion conv zur Verfügung. Kontrollieren Sie damit die zuvor
durchgeführte Bestimmung des Ausgangssignals y(n).
c) Erzeugen Sie in Matlab einen Vektor, der die Abtastwerte von 3 Perioden eines Sinussignals mit
der relativen Frequenz 8
1af
f beinhaltet. Verwenden Sie diesen Vektor als Eingangssignal
s(n) und falten Sie ihn mit der Impulsantwort h(n). Stellen Sie das Eingangssignal s(n) und das
Ausgangssignal y(n) in zwei übereinander angeordneten Teilgraphiken dar.
d) Bestimmen Sie die Fourier Transformierte der Differenzengleichung.
Hinweis: Verwenden Sie S(f) als Fourier Transformierte von s(n) und X(f) als Fourier
Transformierte von x(n). Der zeitliche Versatz eines Signals führt zu einem multiplikativen
Phasenterm im Spektrum: 020 )()(
tfiefStts
e) Leiten Sie daraus die mathematische Beschreibung der Übertragungsfunktion H(f) ab.
g) Berechnen Sie (z.B. mit Matlab) einige Betragswerte der Übertragungsfunktion |H(f)| im
Bereich 2
0 aff . Skizzieren Sie mit Hilfe dieser Werte den Verlauf des Betrags der
Übertragungsfunktion im nachstehenden Diagramm.
-1
+1
-3 -2 -1 0 1 2 3 4 5 6 7 8
y(n)
Zeitindex n
+1
-3 -2 -1 0 1 2 3 4 5 6 7 8
s(n)
Zeitindex n

G. Hirsch Version: pA11 Seite 36
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
g) Handelt es sich bei dieser Filtercharakteristik um einen Tiefpass, einen Bandpass oder einen
Hochpass?
Praktische Übung 15
Das Ziel dieses vollständigen Erkennungsexperiments ist
die Extraktion der akustischen Merkmale für eine Liste sprachlicher Äußerungen,
das Training von HMMs mit Hilfe von HTK,
die Durchführung von Erkennungsexperimenten sowie
eine vergleichende Analyse der Erkennungsraten bei Verwendung der eigenen
Merkmalsextraktion im Vergleich zu einer von ETSI standardisierten Merkmalsextraktion
Extraktion der akustischen Merkmale einer Liste von Sprachfiles
Die von Ihnen geschriebene Matlab Funktion, mit der aus einem Sprachsignal die relevanten
akustischen Merkmale (Energie- und cepstrale Koeffizienten) extrahiert werden können, soll zur
Analyse einer ganzen Liste von Sprachfiles verwendet werden. Dazu steht Ihnen eine Matlab
Funktion zur Verfügung: anal_liste(’list of wave files’, ’destination directory’);
Diese benötigt zwei Argumente. Das erste ist ein String, der den Namen eines Listenfiles beinhaltet.
In Ihrem Arbeitsverzeichnis sollte ein Listenfile mit der Bezeichnung „digits_80.waves“ vorhanden
sein. Darin sind 80 Sprachfiles aufgelistet, die aus der Aufnahme isoliert gesprochener deutscher

G. Hirsch Version: pA11 Seite 37
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Ziffern hervorgegangen sind. Das zweite Argument ist der Namen eines Verzeichnisses (als string),
das Sie zuvor z.B. als Unterverzeichnis Ihres Arbeitsverzeichnisses anlegen sollten. Darin werden
die Folgen von Merkmalsvektoren, die mit Ihrer Funktion erzeugt werden, als separate Files für
jedes Sprachfile in einem HTK spezifischen Format abgespeichert.
In der Funktion anal_liste muss der Aufruf Ihrer Analysefunktion erfolgen. Suchen Sie den Aufruf
der Funktion „anal_etsi1“. Dort finden Sie einen Kommentar zum Ersetzen des Aufrufs der
Funktion „anal_etsi1“ durch Ihre Funktion.
Beim Aufruf der Funktion anal_liste sollten Sie für jedes analysierte Sprachfile eine Ausgabe im
Kommandofenster erhalten. Abschließend sollten im „destination directory“ 80 Files erzeugt
worden sein. Diese 80 Muster (=pattern) Files mit der Dateierweiterung „.pat“ können im
Folgenden für ein Training von Hidden-Markov Modellen (HMMs) mit den Programmen von HTK
verwendet werden.
Training von HMMs mit HInit
Zum Bestimmung der Parameter von HMMs steht im Praktikum eine graphische Oberfläche
„HMM Training“ zur Verfügung. Es stehen mehrere Trainingsmodi zur Verfügung. Wählen Sie den
Modus des initialen Trainings (processing mode = Training HInit) unter Verwendung des HTK
Programms HInit.
Zum Training werden Folgen mit Merkmalsvektoren (abgespeichert im HTK Format) benötigt, die
aus der Analyse einer Vielzahl sprachlicher Äußerungen erzeugt wurden. Dabei können Sie
zunächst die 80 Files verwenden, die Sie mit der von Ihnen geschriebenen Funktion zur Extraktion
akustischer Merkmale erzeugt haben. In der Trainingsoberfläche können Sie unten links das
Verzeichnis angeben, in dem Sie die Files abgespeichert haben. Die 80 Files sind aus der Analyse
von Sprachfiles entstanden, in denen die 10 deutschen Ziffern („null“ bis „neun“) von 8
verschiedenen männlichen Sprechern gesprochen wurden.
Als Listenfile, das die zu trainierenden Wörter, also die 10 Ziffern, im Textformat beinhaltet,
können Sie das File „digit.labels“ angeben, das in Ihrem Arbeitsverzeichnis vorhanden sein sollte.
Als Master-label File können Sie das File „aachen.mlf“ auswählen, das ebenfalls in Ihrem
Arbeitsverzeichnis vorhanden sein sollte, oder Sie können alternativ den Namen
„/data/aachen_srt/label“ des Verzeichnisses, in dem für jedes Sprachfile ein sogenanntes Label file
existiert, angeben. Das Master Labelfile bzw. die Label files beinhalten die Information, was in dem
jeweiligen Sprachfile (und wann es) gesprochen wurde. Des Weiteren wird noch ein

G. Hirsch Version: pA11 Seite 38
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Konfigurationsfile benötigt, wobei in Ihrem Arbeitsverzeichnis ein File „config“ vorhanden sein
sollte.
Zur Definition der HMM Struktur jedes Wortmodells sowie des Pausemodells stehen die beiden
Files „proto_word_12mfcc_e“ und „proto_silence_12mfcc_e“ zur Verfügung.
Aus wie vielen „echten“ Zuständen bestehen bei Verwendung dieser Files die HMMs?
Wortmodell: ………. Pausemodell: ……….
Abschließend müssen Sie noch ein Verzeichnis als „destination path“ anlegen und in der
Oberfläche angeben, in dem die aus dem Training resultierenden HMM Files abgespeichert werden
sollen.
Wenn Sie alle benötigten Eingaben bzw. Einstellungen vorgenommen haben, können Sie durch
Betätigen des „Start“ Feldes das Training starten. Dabei wird das Programm HInit des HTK
Toolkits im Hintergrund gestartet. Der Startknopf erhält eine rote Farbe. In dem schmalen
Ausgabefenster neben dem Startknopf sollte angezeigt werden, welches Wort gerade trainiert wird.
Nach Beendigung des Trainings wird der Startknopf wieder grün dargestellt, und es erscheint die
Ausgabe „finished“ im Textfenster.
Im Ergebnisverzeichnis sollten nun die Files mit den HMM Parametern vorhanden sein. Da diese
Files die Parameter im Textformat beinhalten, können Sie sich diese unmittelbar anschauen.
Erkennung der zum Training verwendeten Files
Zur eigentlichen Spracherkennung steht im Praktikum die Oberfläche mit der Bezeichnung
„Analyse & Erkennung“ zur Verfügung. Diese Oberfläche erlaubt verschiedene Arbeitsmodi.
Wählen Sie den Modus zur „Erkennung“.
Es wird ein Listenfile benötigt, in dem im Textformat alle zu erkennenden Merkmalsfiles
aufgelistet werden. Dies kann z.B. in einer Linux Konsole durch
ls -1 <complete path>/*.pat > <name of list file>
erzeugt werden. Der Name dieses Listenfiles ist in der Oberfläche zur Festlegung der zu
bearbeitenden Merkmalsfiles anzugeben.
Des Weiteren kann in gleicher Weise ein Listfile generiert werden, in dem die Namen aller
erzeugten HMM-Files enthalten sind. Der Name dieses Listenfiles ist in der Oberfläche zur
Festlegung der zur Erkennung zu verwendenden HMMs anzugeben.
Als Syntaxfile, mit dem definiert werden kann, welche der HMMs und in welcher Reihenfolge die
Modelle erkannt werden können, sollten Sie das File „digits10.syn“ auswählen. Damit wird die
Erkennung einer einzelnen der 10 Ziffern erlaubt.

G. Hirsch Version: pA11 Seite 39
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Abschließend müssen Sie noch ein Ergebnisverzeichnis anlegen und dieses in der Oberfläche zum
Abspeichern der Ergebnisse festlegen. Darin wird für jedes Merkmalsfile ein bis auf die File-
Endung gleichnamiges Textfile erzeugt, in dem wie bei einem Labelfile das Erkennungsergebnis
abgespeichert wird.
Wenn Sie alle benötigten Eingaben bzw. Einstellungen vorgenommen haben, können Sie durch
Betätigen des „Start“ Feldes die Erkennung starten, die als Matlab Funktion ausgeführt wird. Der
Startknopf wird dann rot. Im benachbarten Textfenster werden die Namen der aktuell bearbeiteten
Files angezeigt. Nach Beendigung der Erkennung wird der Startknopf wieder grün. Die
Erkennungsergebnisse können den Ergebnisfiles in Textform entnommen werden.
Zur Auswertung kann das Shell-Skript eval_results verwendet werden, das in Ihrem
Arbeitsverzeichnis vorhanden sein sollte. Durch Aufruf von
./eval_results <name of result directory>
in Ihrem Arbeitsverzeichnis in einer Linux Konsole wird eine Textausgabe in der Konsole erzeugt,
bei der die Erkennungsraten sowie eine Verwechslungsmatrix ausgegeben werden.
Wie hoch ist die erzielte Erkennungsrate: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..
Sie können das gesamte Experiment von der Extraktion der akustischen Merkmale bis hin zur
Erkennung für eine größere Anzahl von Sprachfiles wiederholen. Dazu sollten Sie das Listenfile
„digits_single.waves“ verwenden, das die Namen von 1258 Sprachfiles beinhaltet. Analysieren Sie
diese Sprachfiles zunächst mit der Funktion anal_liste.
Dann können Sie ein Erkennungsexperiment unter Verwendung der HMMs, die Sie aus den 80
sprachlichen Äußerungen erzeugt hatten, durchführen.
Welche Erkennungsrate stellt sich dabei ein: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..
Anschließend können Sie ein erneutes Training unter Verwendung der 1258 Files durchführen.
Welche Erkennungsrate stellt sich bei Verwendung dieser HMMs ein: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..
Verwendung der ETSI Merkmalsextraktion
Alternativ zur Verwendung Ihrer Merkmalsextraktion können Sie auch eine von ETSI
standardisierte Merkmalsextraktion einsetzen. Dazu können in der Oberfläche zur „Analyse &

G. Hirsch Version: pA11 Seite 40
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Erkennung“ im Arbeitsmodus „Analyse“ die 80 Sprachfiles unter Auswahl des „ETSI-1“
Verfahrens mit einer Bestimmung der akustischen Merkmale „MFCC_E“ analysiert und in einem
separaten Verzeichnis abgespeichert werden.
Es kann wie zuvor ein Training mit HInit durchgeführt werden. Anschließend können Sie das
Erkennungsexperiment mit den zugehörigen Merkmalsfiles und den zugehörigen HMM files
wiederholen.
Wie hoch ist die erzielte Erkennungsrate: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..
Da nur eine geringe Zahl von Fehlern auftreten sollte, wird im Weiteren eine größere Anzahl
einzeln gesprochener Ziffern zur Erkennung herangezogen. Dazu steht ein Listenfile
„digits_single.waves“ zur Verfügung. Analysieren Sie diese Files in der Oberfläche zur „Analyse &
Erkennung“ im Arbeitsmodus „Analyse“. Bestimmen Sie wiederum im Arbeitsmodus „Analyse“
die akustischen Merkmale „MFCC_E“. Nach Beendigung der Analyse können Sie die Erkennung
der Files mit den Folgen von Merkmalsvektoren in der gleichen Oberfläche im Arbeitsmodus
„Erkennung“ starten. Dazu müssen Sie sich wieder ein Listenfile aller Merkmalsfiles erzeugen.
Wie viele gesprochene Ziffern werden zur Erkennung benutzt: ………
Wie hoch ist die erzielte Erkennungsrate: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..
Bei der erzielten (vermutlich niedrigen) Erkennungsrate ist zu berücksichtigen, dass die HMMs nur
aus den Äußerungen 8 männlicher Sprecher bestimmt wurden, zur Erkennung aber auch die
Sprachproben weiblicher Sprecher herangezogen wurden.
Daher soll als nächster Schritt ein Training mit HInit unter Verwendung aller analysierter
Sprachproben durchgeführt werden. Verwenden Sie die gleichen Prototyp-HMMs wie bei dem
Training mit der geringen Anzahl von Sprachproben. Nehmen Sie nach dem Training wieder eine
Erkennung aller Merkmalsfiles unter Verwendung der neuen HMMs vor.
Wie hoch ist die erzielte Erkennungsrate: ……….. %
Wie viele Ziffern werden nicht erkannt: ……..

G. Hirsch Version: pA11 Seite 41
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Google Spracherkennung
Die Firma Google benutzt für einige ihrer Anwendungen (z.B. Browser, Maps, …) als eine
Eingabemöglichkeit ein „zentral“ auf einem oder mehreren ihrer Servern implementiertes eigenes
Spracherkennungssystem. Der Zugang und die Eingabemöglichkeiten zur Benutzung dieses
Erkennungssystems wurden von Google selbst bisher nicht oder nur in geringem Umfang
dokumentiert. Daher findet man nur Informationen von Benutzern dieses Erkennungssystems, die
verschiedene Optionen auf Grund ihrer eigenen Erfahrungswerte beschreiben.
Prinzipiell funktioniert die Erkennung in der Weise, dass die Abtastwerte des zu erkennenden
Sprachsegments in einem File gespeichert werden und dieses File bei dem Aufruf des Erkenners zu
einem der Google Server transferiert wird. Der Aufruf und Filetransfer kann mit Hilfe des
Unix/Linux Tools namens wget erfolgen.
Der Aufruf von wget in einer Linux Konsole könnte beispielsweise so aussehen:
wget -q -U "Mozilla/5.0" --post-file <FILENAME> --header="Content-Type: audio/x-flac;
rate=8000" -O - "https://www.google.com/speech-api/v2/recognize?output=json&lang=de-
DE&key=<KEY>"

G. Hirsch Version: pA11 Seite 42
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
An Stelle des Platzhalters <FILENAME> ist der Filename, evtl. mit Pfadangabe, des zu
erkennenden Sprachfiles einzugeben. Benutzt wird eine Version v2 dieses von Google als „Speech-
API“ bezeichneten Erkenners. Bei der vorhergehenden Version v1 gab es keinerlei Restriktionen,
was den prinzipiellen Zugriff als auch die Anzahl der Zugriffe angeht. Die Version v1 ist aber nicht
mehr verfügbar. Die Benutzung der Version v2 erfordert eine Registrierung bei Google
(https://accounts.google.com/ServiceLogin), im Zuge dessen ein Account für den registrierten
Benutzer angelegt wird. Nach erfolgter Registrierung kann man über den angelegten account einen
<KEY> zur Benutzung der Speech-API erhalten (https://console.developers.google.com/). Des
Weiteren wurde die Benutzung des Google Erkenners auf 50 Zugriffe pro Tag beschränkt. Für
einige Tests im Rahmen der Veranstaltung steht ein KEY zur Verfügung. Sollten Sie allerdings eine
intensivere private Nutzung anstreben, so sollten Sie einen eigenen account anlegen und einen
persönlichen KEY erzeugen.
Nachstehend werden die Argumente und die möglichen Eingabewerte (so weit bekannt) erläutert:
Das File mit den Abtastwerten des Sprachsignals kann ein File im WAV Format sein, bei
dem die Abtastwerte als 16 Bit Werte abgespeichert wurden. Das Header Argument ist dann
wie folgt zu definieren: --header="Content-Type: audio/l16; rate=8000
Die Zahlenangabe hinter rate= definiert die Abtastfrequenz. Getestet wurde die
Unterstützung der beiden Abtastfrequenzen 8000 und 16000 Hz.
Alternativ kann ein File im FLAC (free lossless audio codec) Format verwendet werden.
Wie der Name es schon aussagt, handelt es sich dabei um eine verlustfrei codierte Variante
des Sprachsignals, die in dem FLAC File enthalten ist. Die Filegröße und damit die zu
transferierende Datenmenge kann dabei auf eine bis zu halb so hohe Byteanzahl im
Vergleich zum WAV File reduziert werden. Die Angabe von audio/l16 im Header
Argument ist dabei durch audio/x-flac zu ersetzen. Zur Codierung im FLAC Format ist in
den meisten Linux Distributionen das frei verfügbare Tool flac enthalten. Alternativ kann
beispielsweise auch das Tool mit dem Namen sox eingesetzt werden, mit dem eine
Konvertierung zwischen einer Vielzahl von Audioformaten möglich ist.
Mit dem URL kann auch die Sprache des Erkennungssystems festgelegt werden. Der Aufruf
mit &lang=de-DE definiert eine Spracheingabe im Deutschen. Durch den Austausch von
de-DE können Eingaben in anderen Sprachen festgelegt werden, z.B. definiert das Kürzel
en-US eine Eingabe in amerikanischem Englisch.
Mit der Angabe ?output=json im URL wird die Rückgabe des Erkennungsergebnisses im
Textformat JSON (JavaScript Object Notation) definiert.

G. Hirsch Version: pA11 Seite 43
Modul Spracherkennung (Master Studiengang Informatik)
Übungsaufgaben und Laborversuche
Bei der Version v1 des Erkenners bestand noch die Möglichkeit mit der Angabe von
&maxresults=5 im URL die Anzahl der besterkannten Wortfolgen (im Beispiel 5)
festzulegen. Dann werden neben der best erkannten Wortfolge auch das zweitbeste, das
drittbeste, u.s.w. Erkennungsergebnis zurückgegeben.
Für den Aufruf des Erkenners aus Matlab heraus steht eine Funktion
[res_str, conf, err] = google_recog_v2(signal, fs, KEY)
zur Verfügung. signal ist dabei ein Vektor mit den Abtastwerten des zu erkennenden Sprachsignals,
fs definiert die Abtastfrequenz. KEY beinhaltet die Sequenz von Zeichen als Schlüssel zur
Benutzung des Erkenners. Wird kein KEY an die Funktion übergeben, so benutzt die Funktion den
zu Testzwecken zur Verfügung stehenden KEY. res_str ist ein Vektor mit cell Elementen.
res_str{1} beinhaltet die mit höchster Wahrscheinlichkeit erkannte Wortfolge, res_str{2} die
zweitbeste, u.s.w.
conf beinhaltet vermutlich einen Zahlenwert zwischen 0 und 1, der ein Maß für die
Vertrauenswürdigkeit des besten Erkennungsergebnisses darstellt. err stellt ein Flag dar, das den
Wert 1 annimmt, wenn der Aufruf oder die Kommunikation mit dem Google Erkenner nicht
möglich ist und somit auch kein Erkennungsergebnis zur Verfügung steht.


















