
Prof. Dr. T. Felderhoff Skript zur Vorlesung€¦ · Kapitel 1 Einleitung 1.1 Motivation f ur die...
30
Fachhochschule Dortmund Mikroprozessortechnik Prof. Dr. T. Felderhoff Skript zur Vorlesung
Transcript of Prof. Dr. T. Felderhoff Skript zur Vorlesung€¦ · Kapitel 1 Einleitung 1.1 Motivation f ur die...

Fachhochschule Dortmund
Mikroprozessortechnik
Prof. Dr. T. Felderhoff
Skript zur Vorlesung

Inhaltsverzeichnis
1 Einleitung 31.1 Motivation fur die Lehrinhalte . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Inhalte der Vorlesung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Verzahnung mit anderen Lehrinhalten . . . . . . . . . . . . . . . . . . . . . 31.4 Modulprufung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Klassifikation und Grundlagen von Mikroprozessoren 42.1 Anwendungsfelder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Architektur und Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Bestimmung der Rechenleistung . . . . . . . . . . . . . . . . . . . . . . . . 52.4 Echtzeitfahigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.5 Interrupt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Zahlenformate 83.1 Zahlenumwandlung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Zweierkomplement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.3 Wertebereich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.4 Addition und Subtraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.5 Multiplikation und Division . . . . . . . . . . . . . . . . . . . . . . . . . . 133.6 Berechnungen im Gleitkommazahlenformat . . . . . . . . . . . . . . . . . . 14
3.6.1 Multiplikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.6.2 Addition und Subtraktion . . . . . . . . . . . . . . . . . . . . . . . 15
3.7 Zahlenbereichserweiterung, Quantisierungund Sattigung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Digitaler Signalprozessor DSP56xxx 184.1 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.2 Register- und
Akkumulatorzahlenformate . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.3 Ausgewahlte Assembler-Befehle . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3.1 Direkte Adressierung . . . . . . . . . . . . . . . . . . . . . . . . . . 194.3.2 Indirekte Adressierung . . . . . . . . . . . . . . . . . . . . . . . . . 204.3.3 Logik-Befehle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.3.4 Arithmetik-Befehle . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.3.5 Sonstige Befehle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.4 Parallelitat und Pipelining . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.5 Applikationsbeispiel FIR-Filter . . . . . . . . . . . . . . . . . . . . . . . . 23
1

2
5 Digitale Signalprozessoren von Texas Instruments 245.1 Entwicklung digitaler Signalprozessoren . . . . . . . . . . . . . . . . . . . . 245.2 Idee der gemeinsamen Prozessor-Familie . . . . . . . . . . . . . . . . . . . 245.3 Architektur der C6xxx-Familie . . . . . . . . . . . . . . . . . . . . . . . . . 255.4 Verwendetes Gleitkommazahlenformat . . . . . . . . . . . . . . . . . . . . 26
6 Field Programmable Gate Array (FPGA) 276.1 FPGA vs µC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276.2 Entscheidung zwischen FPGA und ASIC . . . . . . . . . . . . . . . . . . . 276.3 Weltweit fuhrende FPGA-Hersteller . . . . . . . . . . . . . . . . . . . . . . 286.4 Anwendungsgebiete fur FPGAs . . . . . . . . . . . . . . . . . . . . . . . . 286.5 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 286.6 Leitungsmerkmale einiger Xilinx-FPGAs . . . . . . . . . . . . . . . . . . . 29

Kapitel 1
Einleitung
1.1 Motivation fur die Lehrinhalte
TEXT
1.2 Inhalte der Vorlesung
TEXT
1.3 Verzahnung mit anderen Lehrinhalten
• Zahlenformate
• Quantisierung
• Quantisierungsfehler
1.4 Modulprufung
• 4 Aufgaben mit jeweils 15 Punkten
• Zahlenformate
• Freescale-Prozessor
• Texas Instrument
• FPGA
3

Kapitel 2
Klassifikation und Grundlagen vonMikroprozessoren
Mikroprozessor
Mikrocontroller (µC)
Festkommaformatxxxxxxxx,8...16 (32) Bit
Digitaler Signalprozessor (DSP)
Fest- und Gleitkommaformat16...24 / 32...64 Bit
DSCDigital Signal Controller
2.1 Anwendungsfelder
Komplexität(Rechenaufwand)
fA
Abtastfrequenz
Radar
DVB
Audio
Video
Signalverarbeitung
Finanzwesen
Wetter
Abbildung 2.1: Anwendungsfelder
4

KAPITEL 2. KLASSIFIKATION UNDGRUNDLAGENVONMIKROPROZESSOREN5
2.2 Architektur und Komponenten
Takt CPUCentral Processing Unit
Adressbus
Datenbus
Speicher
(a) von Neumann Architektur
Takt CPUCentral Processing Unit
Adressbus 1
Datenbus 1
Speicher1
Adressbus 2
Datenbus 2
Speicher2
(b) Harvard Architektur
2.3 Bestimmung der Rechenleistung
FP Prozessortaktfrequenz ist Indiz fur Leistungsumfang
TP =1
FP
Prozessortaktperiode
Befehle an den Prozessor starten immer mit einer TaktflankeBefehle dauern mind. eine Prozessortaktperiode TP ggf. auch das Mehrfache dieser Pro-zessortaktperiode, also n · TP
Beispiel: Filter besteht aus:
h(kT)x(kT) y(kT)
500 Additionen a jeweils 1 · TP
350 Multiplikationen a jeweils 2 · TP
800 Speicherzugriffe a jeweils 3 · TP
Wie lange dauert die Verarbeitung?∆t = 500 · 1TP + 350 · 2TP + 800 · 3TP = 3600TP
T T
3600 TP
3600 TP
t
3600TP < T → in Echtzeit verarbeitet

KAPITEL 2. KLASSIFIKATION UNDGRUNDLAGENVONMIKROPROZESSOREN6
2.4 Echtzeitfahigkeit
Berechnungen”kosten “eine gewisse Rechenzeit
T T T
Δt Δt Δt
t(k-1)T kT (k+1)T
TP
TP << T1
TP
>>1
TFP >> F
Rechenzeit ∆t = N · TP
N = Anzahl an Prozessortakten
Gilt ∆t < T , dann ist die Berechnung auf jeden Fall abgeschlossen bevor der nachsteAbtastwert zur weiteren Verarbeitung zur Verfugung steht.Wurden wir gegen ∆t < T verstoßen, dann konnten innerhalb einer Berechnung mind.zwei Abtastwerte gebildet werden, von denen nur der letzte dann verarbeitet wird. Soware dann keine Verarbeitung in Echtzeit gegeben.
2.5 Interrupt
T
Δt Δt Δt
t
TP
T T T T T T T
Gefahr, dass diese Abtastwerte verloren gehen
Losung: Interrupt-Flags konnen auf anstehende (neue) Abtastwerte hinweisen.⇒ hat der Prozessor eine
”Interrupt Service Routine “,
• dann wird das aktuelle Programm unterbrochen
• die aktuelle Verarbeitungsposition und die Registerwerte gespeichert
• (neuer) Abtastwert wird geholt und gespeichert
• Wiederherstellen der Registerwerte
• Fortsetzung der Verarbeitung ab gesicherter Position

KAPITEL 2. KLASSIFIKATION UNDGRUNDLAGENVONMIKROPROZESSOREN7
T
Δ Δt + 2ISR
Δ Δt + 3ISR Δt
t
TP
T T T T T T TT TΔ
ISRΔ
ISR
Verarbeitung ist jetzt abgeschlossen nach ∆t+ n ·∆ISR, wobei n so gewahlt wird, dassdie maximal vorkommenden Unterbrechungen beschrieben werden (worst case).Ist z.B. ∆t+n ·∆ISR < k ·T , wobei k die Anzahl von Abtastwerten in einem Datenblockbeschreibt, dann ist die Realisierung echtzeitfahig.

Kapitel 3
Zahlenformate
2
ZK
Festkommazahlenformat Gleitkommazahlenformat
z.B xxxxxxxx,|2
ZKxxxxxxxx,|
ZKx,xxxxxxx|
z.B. m,mmm|ZK
eeee|•2
Mantisse Exponentenoder gemäß IEEE754 Standard(-1)
s eeeeeeee| -128•2 •(1+o,fff...f| )2
3.1 Zahlenumwandlung
10010001, |2 = 1 · 27 + 0 · 26 + 0 · 25 + 1 · 24 + 0 · 23 + 0 · 22 + 0 · 21 + 1 · 20
= 128 + 16 + 1
= 145
10010001, |ZK = −128 + 16 + 1
= −111xxxxxxxx, |2 x, xxxxxxx|2z.B. 00101100, |2 z.B. 0, 0101100|2= 1 · 25 + 1 · 23 + 1 · 22 = 1 · 2−2 + 1 · 2−4 + 1 · 2−5
= 32 + 8 + 4 =1
4+
1
16+
1
32
= 44 =11
32
=11
32· 27 = (1 · 25 + 1 · 23 + 1 · 22) · 2−7
=11
32· 128 = 0, 34375
= 44
8

KAPITEL 3. ZAHLENFORMATE 9
Von Dezimal auf Dual
sukzessives Dividieren:44,= ?44 : 2teilen, auf Divisionsrest uberprufen
44:2 = 22 Rest 022:2 = 11 Rest 011:2 = 5 Rest 15:2 = 2 Rest 12:2 = 1 Rest 01:2 = 0 Rest 1
Die Reste von unten nach oben ergeben die Dualzahl 101100
44,= 00101100,
sukzessives Multiplizieren:
0, 34375 =?0, 34375cdot2multiplizieren, auf ≥ 1uberprufen
0,34375 · 2 = 0,6875 + 00,6875 · 2 = 0,375 + 10,375 · 2 = 0,75 + 00,75 · 2 = 0,5 + 10,5 · 2 = 0,0 + 10,0 · 2 = 0 + 0
Die Ubertrage von oben nach unten ergeben die Dualzahl 010110
0, 34375 = 0, 0101100
Daraus folgt: 44, 34375 = 00101100, 0101100|2
Vorkommastellen : sukzessives Dividieren durch 2Nachkommastellen: sukzessives Multiplizieren mit 2

KAPITEL 3. ZAHLENFORMATE 10
3.2 Zweierkomplement
x x x x x x x x, |ZK x, x x x x x x x |ZK
-2 2 2 2 2 2 2 27 6 5 4 3 2 1 0
-2 2 2 2 2 2 2 20 -1 -2 -3 -4 -5 -6 -7
0 0 1 0 1 1 0 0, |ZK 0, 0 1 0 1 1 0 0 |ZK
Addiert
0 0 1 0 1 1 0 0, 0 1 0 1 1 0 0 | = 44,343752
Umwandlung ins Zweierkomplement:Da das MSB nicht gesetzt ist, bleibt die Berechnung gleich
0 0 1 0 1 1 0 0, 0 1 0 1 1 0 0 |ZK

KAPITEL 3. ZAHLENFORMATE 11
Negative Zahl ins Zweierkomplement umwandeln:
2 Methoden
Methode 1:-44,34375 = 0 0 1 0 1 1 0 0,0 1 0 1 1 0 0 |ZK der positiven Zahl
Von hinten bis zurersten 1 abschreiben
Dann alle vorderen Bitsinvertieren
= 1 1 0 1 0 0 1 1,1 0 1 0 1 0 0 |ZK der negativen Zahl
Methode 2:-44,34375 = 0 0 1 0 1 1 0 0,0 1 0 1 1 0 0 |ZK der positiven Zahl
Jedes Bit invertieren 1 1 0 1 0 0 1 1,1 0 1 0 0 1 1 |Einerkomplement
+ 1 rechnen 0 0 0 0 0 0 0 0,0 0 0 0 0 0 1 |Zweierkomplement+
1 1 0 1 0 0 1 1,1 0 1 0 1 0 0 |ZK der negativen Zahl
1 1
MSB negativ gewichtet!

KAPITEL 3. ZAHLENFORMATE 12
3.3 Wertebereich
x x x x x x x x, |2
2 2 2 2 2 2 2 27 6 5 4 3 2 1 0
kleinste Zahl 0 0 0 0 0 0 0 0 |2
1 1 1 1 1 1 1 1 |2
0 0 0 0 0 0 0 1 |2
größte Zahl
kleinste pos.Zahl
größte neg. Zahl -
x x x x x x x x, |2
-2 2 2 2 2 2 2 27 6 5 4 3 2 1 0
1 0 0 0 0 0 0 0 |ZK
0 1 1 1 1 1 1 1 |ZK
0 0 0 0 0 0 0 1 |ZK
1 1 1 1 1 1 1 1 |ZK
3.4 Addition und Subtraktion
Addition I: 0 0 0 1 1 1, |ZK
0 1 0 1 1 0, |ZK
0 1 1 1 0 1 |ZK
Addition II: 0 1 1 1 0 0, |ZK
+
+ 0 1 0 1 1 0, |ZK
1 1
1 1
1 1 0 0 1 0 |ZK
Die Summe zweier positiverZahlen kann nicht negativ sein!
Das Ergebnis ist außerhalb des darstellbaren Wertebereichs.

KAPITEL 3. ZAHLENFORMATE 13
sinvoll: Wertebereich erweitern
Addition II: 0 0 1 1 1 0 0, |ZK
+ 0 0 1 0 1 1 0, |ZK
1 1
0 1 1 0 0 1 0 |ZK
MSB wird kopiert
Adition III: 1 1 0 0 1 0 0 |ZK
1 1 0 1 1 1 0 |ZK+
1 0 1 0 0 1 0 |ZK
1 1 1
Subtraktion: A−B = A+ (−B)
3.5 Multiplikation und Division
0 0 1,0 1 1 0 1 | • 0 1 0,1 1 0 0 0 |ZK ZK
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
1 1 1 1
0 0 1 1,1 1 0 1 1 1 1 0 0 0
Addiert
Akku-Register: |x x x x x x , x x x x x x x x x x ZK
0 0 0 0 1 1 , 1 1 0 1 1 1 1 0 0 0

KAPITEL 3. ZAHLENFORMATE 14
1 1 0,1 0 0 1 1 | • 0 1 0,1 1 0 0 0 |ZK ZK
1 1 0,1 0 0 1 1
1 1 0,1 0 0 1 1
1 1 0,1 0 0 1 1
...1 1 1 1
...1 1 1 1
...1 1 1 1
11 11 11 11 1 1 1 1 1 1
1 1 1 1 1 0 0,0 0 1 0 0 0 1 0 0 0 |ZK
Akku-Register: x x x x x x , x x x x x x x x x x |ZK
1 1 1 1 0 0 , 0 0 1 0 0 0 1 0 0 0
0 0 1,0 1 1 0 1 | • ... 1 1 1 1 1 1 0 1,0 1 0 0 0 |ZK ZK
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 10 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
0 0 1,0 1 1 0 1
1 1 1 1 1 1 0 0,0 0 1 0 0 0 1 0 0 0
||| ||| ||| ||| ||| ||| ||| 11 11 1 1 1
Akkuformat
Division:Y
X= A⇔ Y = A ·X
= numerischer Ansatz, der bitweise die Bits im Akkuformat uberpruft (Zeitaufwandig)
Zuruck zur Multiplikation:Der Akkumulator, in den exakt das Ergebnis der Multiplikation zweier Register zu schrei-ben ist, muss mind. so viele Vorkammbits spendieren wie die Summe der Vorkommabitsder beiden Faktoren (Register) ergibt UND er muss mind. so viele Nachkommabits spen-dieren, wie die Summe der Nachkommabits der beiden Faktoren (Register) ergibt.
3.6 Berechnungen im Gleitkommazahlenformat
Z = M · 2EM : m,mmmmm · · · |ZK MantisseE : · · · eeeeee, |ZK Exponent

KAPITEL 3. ZAHLENFORMATE 15
3.6.1 Multiplikation
M · 2E = Z = Z1 · Z2 = M1 · 2E1 ·M2 · 2E2
= M1 ·M2 · 2E1 · 2E2
= M1 ·M2 · 2E1+E2
⇒M = M1 ·M2
E = E1 + E2
3.6.2 Addition und Subtraktion
M · 2E = Z = Z1 · Z2 = M1 · 2E1 ·M2 · 2E2
= (M1 · 2E1−E2 +M2) · 2E2 , wenn E2 ≥ E1
= (M1 +M2 · 2E2−E1) · 2E1 , wenn E1 ≥ E2
Achtung: Prozessoren verwenden oftmals IEEE-754 Standard, siehe Kapitel 5
3.7 Zahlenbereichserweiterung, Quantisierung
und Sattigung
A: a a a a a , a a a a a |ZK
X: x x x , x x x |ZK
X A
X: x x x , x x x x x |ZK
A: a a a a a a , a a a a a a a a a a |ZK
Bsp: A X:← 1 1 0 , 1 0 0 1 1 |ZK
1 1 1 1 1 0 , 1 0 0 1 1 0 0 0 0 0 |ZKA:
Wdh.des MSB
Auffüllenmit Nullen

KAPITEL 3. ZAHLENFORMATE 16
001
010
011
000
111
110
101
100
schneidenBetrag schneiden
runden
xQ
x
Qx(kT) x (kT)Q
außerhalb des Wertebereichs unseres Quantisierers wird der kleinste darstellbare Wertangenommen, wenn wir den Wertebereich nach unten unterschreiten bzw. wird der großtedarstellbare Wert angenommen, wenn wir den Wertebereich nach oben uberschreiten.Dieses Verfahren nennt man Sattigung.

KAPITEL 3. ZAHLENFORMATE 17
Beispiel:
A: 0 0 0 0 1 , 0 1 1 1 0 |ZK
schneiden X: 0 0 1 , 0 1 1 |ZK
runden X: 0 0 1 , 1 0 0 |ZK
betragschneiden X: 0 0 1 , 0 1 1 |ZK
aufrunden (plus 1 LSB)= 001,011 + 000,001 |ZK
A: 1 1 1 0 0 , 0 1 0 0 1 |ZK
schneiden X: 1 0 0 , 0 1 0 |ZK
runden X: 1 0 0 , 0 1 0 |ZK
betragschneiden X: 1 0 0 , 0 1 1 |ZK
„abrunden“
= 100,010 + 000,001 |ZK
A: 1 0 1 0 1 , 0 1 0 1 0 |ZK
X: 1 0 0 , 0 0 0 |ZK
außerhalb des Wertebereichsdes Registerformats Sättigung
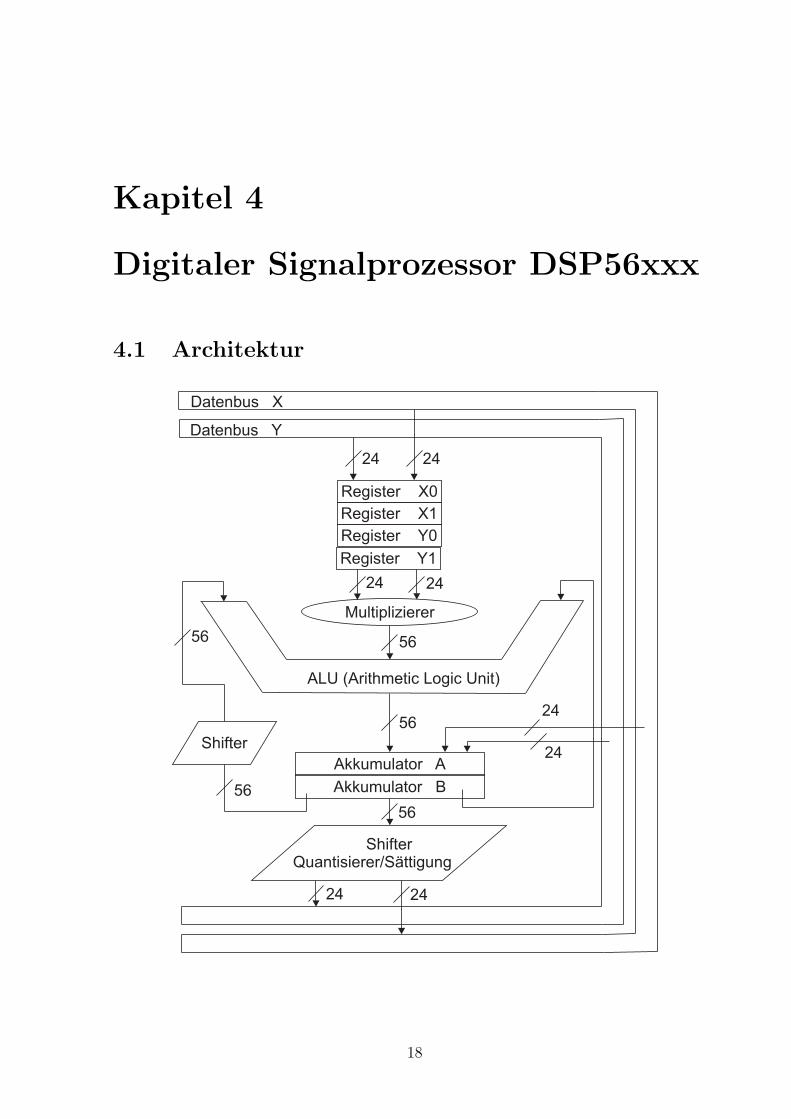
Kapitel 4
Digitaler Signalprozessor DSP56xxx
4.1 Architektur
Register X0
Register X1
Register Y0
Register Y1
Multiplizierer
24 24
ALU (Arithmetic Logic Unit)
56
Akkumulator A
Akkumulator B
56
ShifterQuantisierer/Sättigung
56
Datenbus X
Datenbus Y
24 24
24
24
24 24
Shifter
56
56
18

KAPITEL 4. DIGITALER SIGNALPROZESSOR DSP56XXX 19
4.2 Register- und
Akkumulatorzahlenformate
Register x,xxxxxxxxxxxxxxxxxxxxxxxxaaaaaaaaa,aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
ZK
ZKAkkumulator
A2 A1 A0
Kennbits
4.3 Ausgewahlte Assembler-Befehle
4.3.1 Direkte Adressierung
Adresse X-Speicher
#108
#109
#10A
#10B
#10C
#10D
(Register)-Datenwortbreite
MOVE X: (#10A), B„Lesen aus Speicher“
MOVE A, X: (#10D)„Speichern im Speicher“
MOVE X : (#10A), B ⇒”Lesen aus Speicher“
MOVE A,X : (#10D) ⇒”Speichern im Speicher“
Wir sind fur die Belegung der Speicherplatze verantwortlich.

KAPITEL 4. DIGITALER SIGNALPROZESSOR DSP56XXX 20
4.3.2 Indirekte Adressierung
Adresse X-Speicher
#108
#109
#10A
#10B
#10C
#10D
(Register)-Datenwortbreite
MOVE #10A, R0
MOVE X: (R0) , B
R0
MOVE #10A,R0
MOVE X : (R0), B
zu Ri gibt es jeweils ein Ni und ein Mi
Ni bezeichnet das Inkrement/ DekrementMi beschreibt als ”
Modulo-Register “, dass mit Mi+1 Speicherstellen zu einem Ringspei-cher zusammengefasst werden.
MOVE X : (R0+), B 1. Auslesen der Bitfolge des X-Speichersauf die der Zeiger R0 zeigt2. R0← R0 +N0(Zeigerposition um N0 inkrementiert
MOVE A1, X(−R0) 1. R0← R0−N0(Zeigerposition zuerst um N0 dekrementieren)2. Speichern der Bitfolge A1 im X-Speicheran der Position auf die (der neue Wert von)R0 zeigt
auch moglich ist MOVE X : (R0+), B A1, Y : (R4−)

KAPITEL 4. DIGITALER SIGNALPROZESSOR DSP56XXX 21
4.3.3 Logik-Befehle
NOT A = A1← A1A47A46...A25A24 ← A47 A46...A25 A24
LSL A = C ← A47
A47A46...A25 ← A46A45...A24
A24 ← 0
ROL A = A24 ← C
LSR A = C ← A24
A24A25...A46 ← A25A26...A47
A47 ← 0
ROR A = A47 ← C
AND A,B = B1← A1 ∧B1
OR B , A = A1← B1 ∨ A1
4.3.4 Arithmetik-Befehle
NEG A A← −A
ASL A A← 2 · A
ASR A A← A
2
CLR A A← 0
ABS A A← |A|
ADD A, B B ← A+B
SUB A, B B ← B − A (oder B + A|ZK)
ADD L A, B B ← B + 2 · ASUB L A, B B ← B − 2 · A
ADD R B, A A← A+B
2
SUB R B, A A← A− B
2
MPY X0, X1, B B ← X0 ·X1MAC XO, Y 0, A A← A+X0 · Y 0MAC R X0, Y 0, A A← [A+X0 · Y 0]

KAPITEL 4. DIGITALER SIGNALPROZESSOR DSP56XXX 22
4.3.5 Sonstige Befehle
REP < Zahlenwert > = Wiederholung der nachfolgenden ProgrammzeileZahlenwert +1 - mal
4.4 Parallelitat und Pipelining
Parallelitat: zeitgleiche Ausfuhrung von Operationen
• zeitgleicher SpeicherzugriffMOVE X : (R0), AMOVE Y : (R4), B
• Rechenoperation und SpeicherzugriffADD A, B X : (R0), X0
• Rechenoperation und SpeicherzugriffMAC X0, Y 0, A X : (R0), Y 0 Y : (R4), Y 1
Pipelining: effektive Ausnutzung der Parallelitat derart, dass wahrend einer Rechen-operation bereits die Speicherzugriffe erfolgen, die fur die nachfolgende Rechenoperationerforderlich sind. Als Konsequenz ergibt sich optimal, dass mit einer Rechenoperation nieauf einen noch zu erfolgenden Speicherzugriff gewartet werden muss.

KAPITEL 4. DIGITALER SIGNALPROZESSOR DSP56XXX 23
4.5 Applikationsbeispiel FIR-Filter
T T T
+ + +
T T T
+ + +
T T
+ +
T T
+ +
α0 α1α2 α3
x(kT) x(kT-T) x(kT-2T) x(kT-3T)
αN-2αN-1 αN
x(kT-(N-1)T) x(kT-NT)
y(kT)
+
y(kT ) = α0x(kT ) + α1x(kT − T ) + α2x(kT − 2T ) + ...+ αNx(kT −NT )
α1
α2
α3
...
...
αN-2
x(kT-T)
x(kT-2T)
...
...
...
x(kT-NT)
R0 R4
X-Speicher Y-Speicher
α0
αN-1
αN
x(kT)
x(kT-3T)
...
R0 auf Startadresse N0 = 1 M0 = N RingspeicherR4 auf Startadresse im Y -Speicher N4 = 1 M4 = N
loopMOVE RX, BMOVE B, Y: (R4)MOVE X: (R0)+ , X0 Y: (R4)+ , X1MPY X0 , X1 , A X: (R0)+ , X0 Y: (R4)+ , X1REP #(N−2)MAC X0 , X1 , A X: (R0)+ , X0 Y: (R4)+ , X1MAC X0 , X1 , A Y: (R4)− , Y0MOVE A, TXJMP loop

Kapitel 5
Digitale Signalprozessoren von TexasInstruments
5.1 Entwicklung digitaler Signalprozessoren
Zeit1983
C1xC2x
C3x
C4x C5x
C2xxx
C5xxx
C6xxx
Festkomma-Prozessoren
Gleitkomma-Prozessoren
Kombination aus Fest- und Gleitkomma Prozessoren
Leistungsfähigkeit
5.2 Idee der gemeinsamen Prozessor-Familie
• Fest- und Gleitkomma-ZahlenformatBasis 32-Bit Datenbus
• leichtere Entwicklung
• besserer Ubergang von Gleit- zu Festkomma moglich
24
KAPITEL 5. DIGITALE SIGNALPROZESSOREN VON TEXAS INSTRUMENTS 25
•”Kundenbindung “
• schnellere, uberzeugendere Produktentwicklung
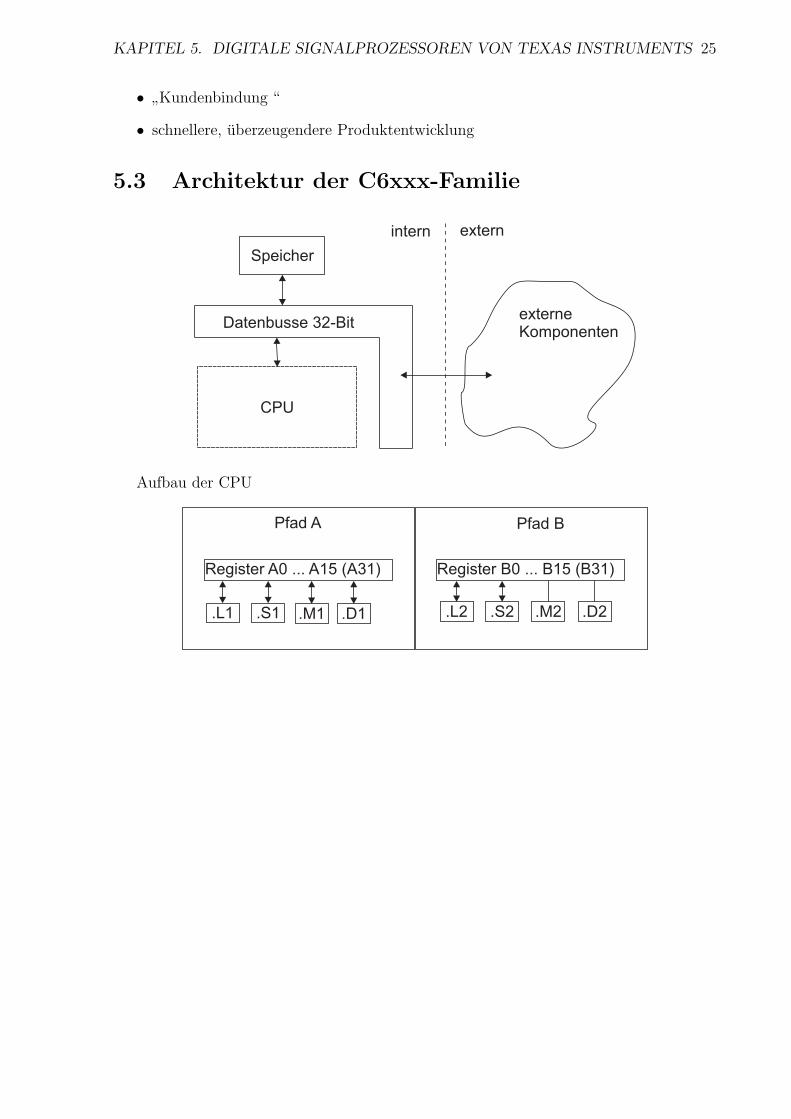
5.3 Architektur der C6xxx-Familie
Speicher
Datenbusse 32-Bit
CPU
intern extern
externeKomponenten
Aufbau der CPU
Pfad A
Register A0 ... A15 (A31)
.L1 .S1 .M1 .D1
Register B0 ... B15 (B31)
.S2 .M2 .D2.L2
Pfad B

KAPITEL 5. DIGITALE SIGNALPROZESSOREN VON TEXAS INSTRUMENTS 26
• Li: arithmetisch/logische Operation
• SI: arithmetisch/logische Operation + Bitmanipulation
• Mi: Multiplikation
• Di: Datenaustausch/ Adressierung
MPY .M1 A0, A1, A2 A2 ← A0 · A1∥ ADD .L1 A5, A10, A3 A3 ← A5 + A10∥ ADD .S1x A4, B4, A14 A14 ← A4 + B4
im Festkommaformat: MPYH, MPYLH, MPYHLweil 16 Bits · 16 Bits zu 32 Losungsbits multipliziert werden.
5.4 Verwendetes Gleitkommazahlenformat
IEEE-754 Standard
”single“
s e fe e eeee e ff f f f f f f f f f f f f f f f f f f f f
1 8 23
”double“(Bild ist krumm ;) )
s e fe e eeee e ff f f f f f f f f f f f f f f f f f f ffe e e ...
1 11 52
Beispiel:
100, 25 = 00001100100, 010000...|2⇒ 00001, 10010001000...|2 · 26
= (−1)0 · 2133−127 · (1 + 0, 10010001000...|2)⇒ 01000010110010001000000000000000

Kapitel 6
Field Programmable Gate Array(FPGA)
6.1 FPGA vs µC
Mikrocontroller
General PurposMikroprozessoren
Digitaler Signalprozessor
Prozessor/ Applikationsspezifischer Befehlssatz
FPGA - frei programmierbare Hardware
SoC (System on a Chip)
ASIC (Application Specific Intefrated Circuit
Ste
ige
run
gd
er
Fle
xib
ilitä
t
Ste
igeru
ng d
er E
ffizie
nz fü
rA
nw
endung
ein
e
6.2 Entscheidung zwischen FPGA und ASIC
Kosten
EntwicklungskostenAlgorithmus, Programmierung
Absicherung derUmsetzung, Maskenentwicklungskosten
ASIC
FPGA
Stückzahl
27

KAPITEL 6. FIELD PROGRAMMABLE GATE ARRAY (FPGA) 28
6.3 Weltweit fuhrende FPGA-Hersteller
• Xilinx (ca. 50%)
• Altera (ca. 30%)
• Lattice (ca. 15%)
• ...
6.4 Anwendungsgebiete fur FPGAs
• grundsatzlich nicht anders als bei Mikroprozessoren
• an Schnittstellen, Datenbussen, Konvertierung von Daten
• zunehmend mehr Signalverarbeitungsaufgaben, zum Teil durch FPGAs mit DSI-Kern (klassische DSP Architektur in FPGA integriert) effektiv umsetzbar
6.5 Architektur
CLBConfigurable
LogicBlock
CLB
IO IO IO IO IO IO IOIO IO IO IO IO
IO
IO
IO
IO
IO
IO
IO
Konkrete Nutzung der Verschaltungselemente und die Konfiguration der CLBs erfolgtmit Softwaretool.

KAPITEL 6. FIELD PROGRAMMABLE GATE ARRAY (FPGA) 29
LUTCarry
&Control
D
> Q
D
> Q
LUTCarry
&Control
D
> Q
D
> Q
Eingänge
Eingänge
Ausgänge
LUT: Look Up TableD-Flip Flops zur Speicherung von Bitinformationen uber einen Takt.
• Datenworte fur Signale (z.B. 16 Bits) setzen sich aus (16) einzelnen Bits zusammen.Bei FPGAs werden diese einzelnen Bits betrachtet.
• Dies hat zur Konsequenz, dass wir auf FPGAs beliebige Datenwerte bilden konnen,d.h. eine beliebige Anzahl von Bits kombinieren konnen. Das gilt sowohl fur Festkomma-als auch fur Gleitkommaformate.
6.6 Leitungsmerkmale einiger Xilinx-FPGAs
FPGA Anzahl CLBsSpartan 3A ca. 25.000 zusatzlich DSP-FunktionalitatSpartan 3E ca. 33.000Spartan 3 ca. 75.000Virtex 4-LX bis zu 200.000Virtex 4-SX bis zu 55.000 zusatzlich DSP-FunktionalitatVitex 4-FX bis zu 140.000 zusatzlich 1-2 Power PC (-Einheiten)Virtex 5 bis zu 330.000


















