
Programmieren lernen mit Scratch® – So kreativ ist Informatik

fakultät für informatik informatik 12
technische universität dortmund
Rechnerarchitektur (RA)
Sommersemester 2015
Foliensatz 14: Speicherhierarchie: Scratchpad- und Flash-Speicher
Michael Engel Informatik 12 michael.engel@tu-.. http://ls12-www.cs.tu-dortmund.de/daes/ Tel.: 0231 755 6121
2015/05/26
- 2 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
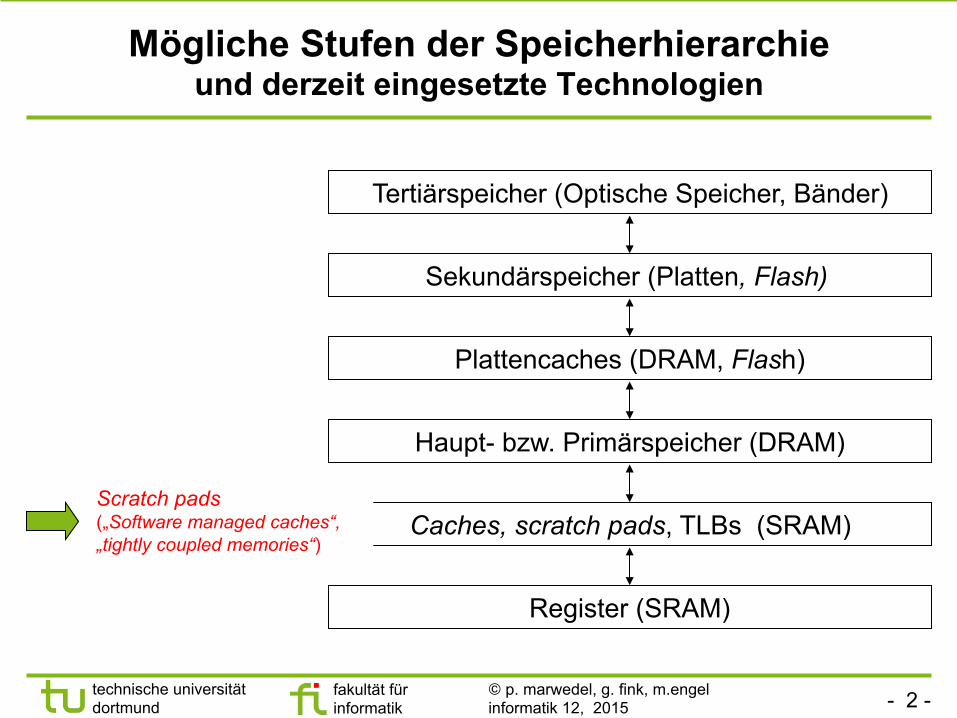
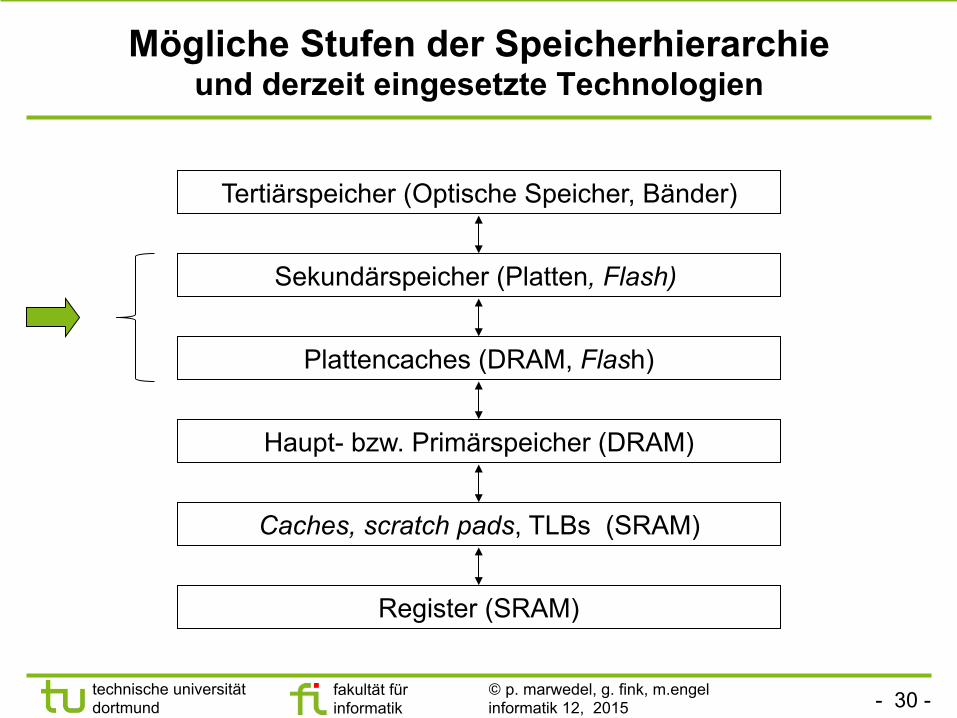
Mögliche Stufen der Speicherhierarchie und derzeit eingesetzte Technologien
Register (SRAM)
Caches, scratch pads, TLBs (SRAM)
Haupt- bzw. Primärspeicher (DRAM)
Plattencaches (DRAM, Flash)
Sekundärspeicher (Platten, Flash)
Tertiärspeicher (Optische Speicher, Bänder)
Scratch pads („Software managed caches“, „tightly coupled memories“)

- 3 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Scratch pad
Scratch pad? Scratch pad?
© G
. Mar
wed
el, 2
014
Scratch pad memory (SPM)! SPMs sind kleine, physikalisch separate Speicher, die in den Adressraum abgebildet werden
Adressraum
scratch pad memory
0
FFF..
- 4 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
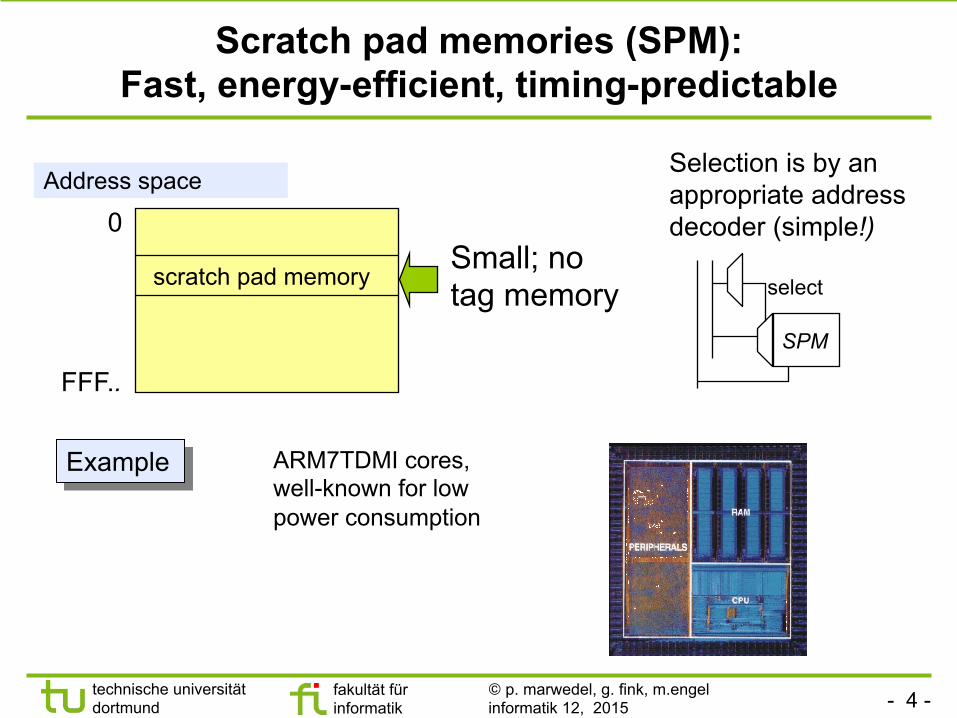
Scratch pad memories (SPM): Fast, energy-efficient, timing-predictable
Address space
scratch pad memory
0
FFF..
ARM7TDMI cores, well-known for low power consumption
Example
Small; no tag memory
Selection is by an appropriate address decoder (simple!)
SPM
select
- 5 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
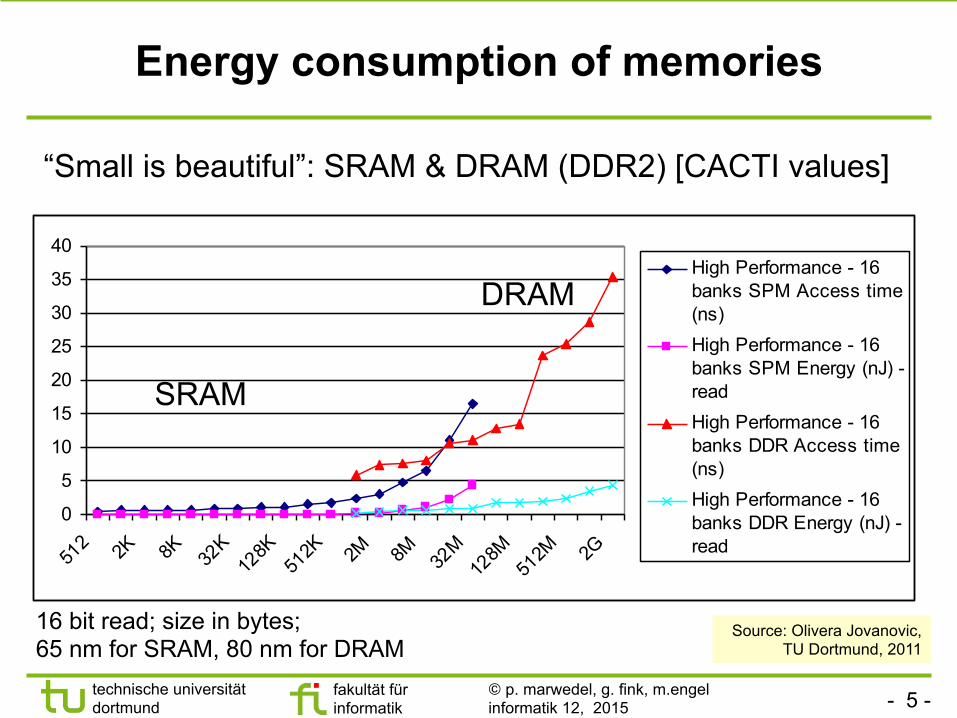
Energy consumption of memories
0
5
10
15
20
25
30
35
40
512 2K 8K 32
K12
8K51
2K 2M 8M 32M
128M
512M 2G
High Performance - 16banks SPM Access time(ns)High Performance - 16banks SPM Energy (nJ) -readHigh Performance - 16banks DDR Access time(ns)High Performance - 16banks DDR Energy (nJ) -read
Source: Olivera Jovanovic, TU Dortmund, 2011
SRAM
DRAM
“Small is beautiful”: SRAM & DRAM (DDR2) [CACTI values]
16 bit read; size in bytes; 65 nm for SRAM, 80 nm for DRAM

- 6 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Comparison of currents using measurements
E.g.: ATMEL board with ARM7TDMI and ext. SRAM
Current32 Bit-Load Instruction (Thumb)
48,2 50,9 44,4 53,1
116 77,2 82,21,16
0
50
100
150
200
Prog Main/ DataMain
Prog Main/ DataSPM
Prog SPM/ DataMain
Prog SPM/ Data SPM
mA
Core+SPM (mA) Main Memory Current (mA)
- 7 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
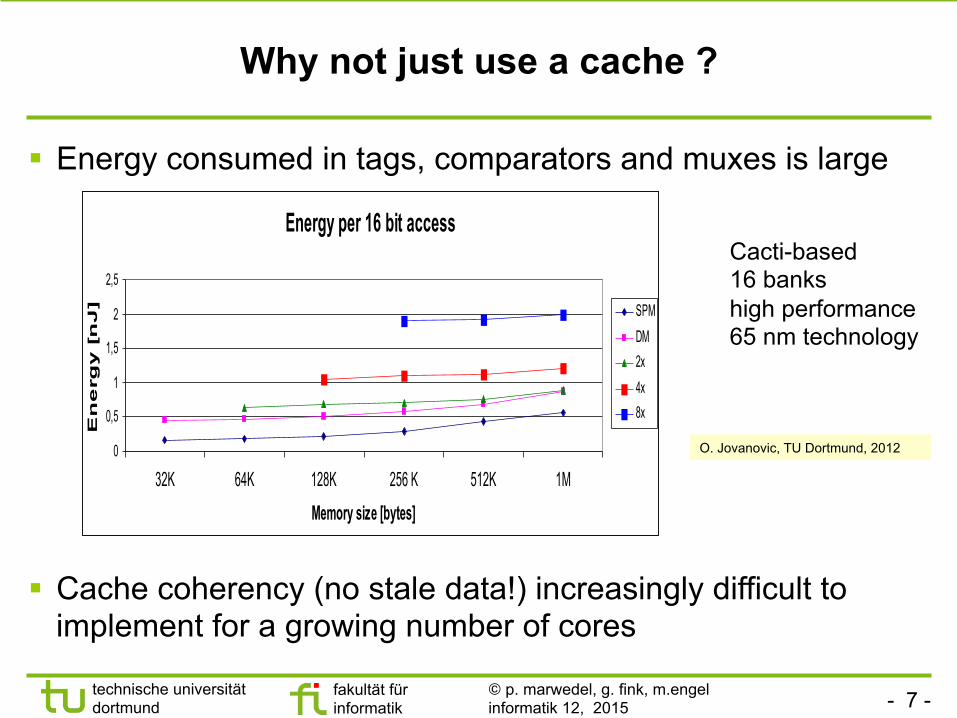
Why not just use a cache ?
§ Energy consumed in tags, comparators and muxes is large
O. Jovanovic, TU Dortmund, 2012
Cacti-based 16 banks high performance 65 nm technology
Energy per 16 bit access
0
0,5
1
1,5
2
2,5
32K 64K 128K 256 K 512K 1M
Memory size [bytes]
En
erg
y [
nJ
] SPMDM2x4x8x
§ Cache coherency (no stale data!) increasingly difficult to implement for a growing number of cores

- 8 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Predictability and scratch-pad memories
… In essence, we must reinvent computer science. Fortunately, we have quite a bit of knowledge and experience to draw upon. Architecture techniques such as software-managed caches promise to deliver much of the benefit of memory hierarchy without the timing unpredictability.
Edward Lee: Absolutely Positively on Time: What would it take?, IEEE Computer, 2005
… pre-run-time scheduling is often the only practical means of providing predictability in a complex system.
J. Xu, D. Parnas: On satisfying timing constraints in hard real-time systems, IEEE Trans. Soft. Engineering, 1993, p. 70–84
- 9 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
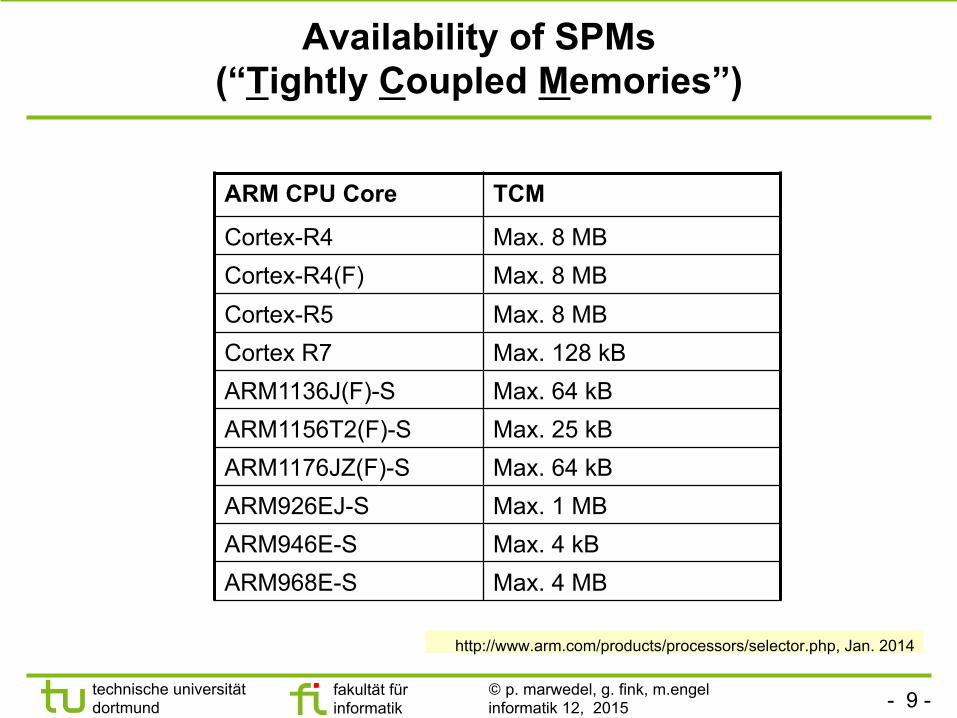
Availability of SPMs (“Tightly Coupled Memories”)
http://www.arm.com/products/processors/selector.php, Jan. 2014
ARM CPU Core TCM
Cortex-R4 Max. 8 MB Cortex-R4(F) Max. 8 MB Cortex-R5 Max. 8 MB Cortex R7 Max. 128 kB ARM1136J(F)-S Max. 64 kB ARM1156T2(F)-S Max. 25 kB ARM1176JZ(F)-S Max. 64 kB ARM926EJ-S Max. 1 MB ARM946E-S Max. 4 kB ARM968E-S Max. 4 MB
- 10 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
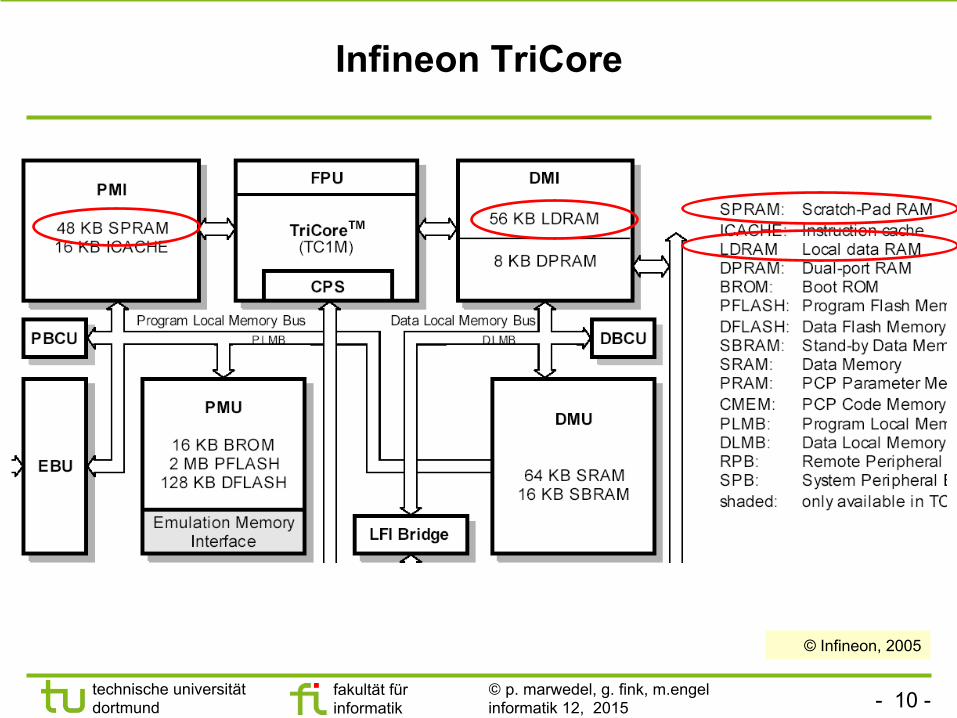
Infineon TriCore
© Infineon, 2005

- 11 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Many more SPMs
§ Early computers like IBM 360 model 25 and others § Cyrix 6x86: 256 Byte SPM § Sony PS1 and PS2 § M-core µcontr. (Freescale): 8-32 kB, on-chip, 1 cycle acc. § NVIDIA Fermi GPU § Merrimac supercomputer (U Stanford):
768 registers, 8 k x 64 bits SPM § Cyclops 64 (DoD, DoE, IBM):
80 processors per chip, each with a 32 kB SPM [Wikipedia]
§ Grape-DR (U. of Tokio), 256 x 72 bits local memory § Many digital signal processors § Processors with locked cache lines § PhysX
- 12 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
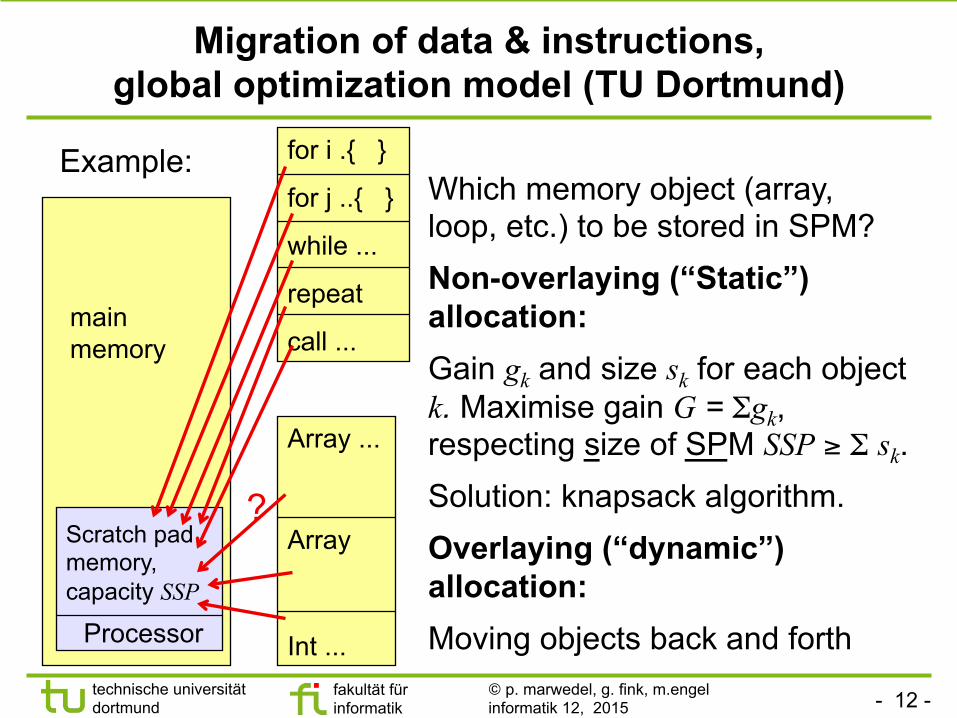
Migration of data & instructions, global optimization model (TU Dortmund)
Which memory object (array, loop, etc.) to be stored in SPM? Non-overlaying (“Static”) allocation: Gain gk and size sk for each object k. Maximise gain G = Σgk, respecting size of SPM SSP ≥ Σ sk. Solution: knapsack algorithm. Overlaying (“dynamic”) allocation: Moving objects back and forth Processor
Scratch pad memory, capacity SSP
main memory
?
for i .{ }
for j ..{ }
while ...
repeat
call ...
Array ...
Int ...
Array
Example:

- 13 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Pre-requisite: Integer linear programming models
Ingredients: § Cost function § Constraints
Involving linear expressions of integer variables from a set X
Def.: The problem of minimizing (1) subject to the constraints (2) is called an integer linear programming (ILP) problem.
If all xi are constrained to be either 0 or 1, the ILP problem said to be a 0/1 integer linear programming problem.
Cost function C = ∑i ai xi with ai ∈ℝ, xi∈ℕ (1)
Constraints: ∀j∈J: ∑i bi,j xi ≥ cj with bi,j, ci,j ∈ℝ (2)

- 14 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
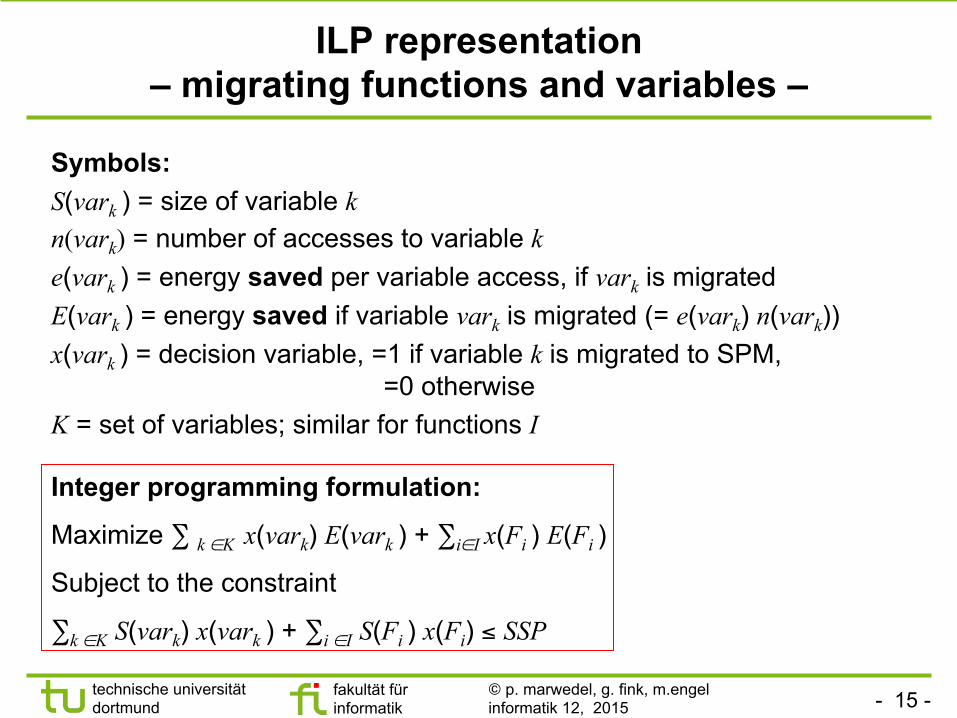
Pre-requisite: Example
321 465 xxxC ++=
}1,0{,,2
321
321
∈
≥++
xxxxxx
Optimal
C
- 15 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
ILP representation – migrating functions and variables –
Symbols: S(vark ) = size of variable k n(vark) = number of accesses to variable k e(vark ) = energy saved per variable access, if vark is migrated E(vark ) = energy saved if variable vark is migrated (= e(vark) n(vark)) x(vark ) = decision variable, =1 if variable k is migrated to SPM, =0 otherwise K = set of variables; similar for functions I
Integer programming formulation:
Maximize ∑ k ∈K x(vark) E(vark ) + ∑i∈I x(Fi ) E(Fi )
Subject to the constraint
∑k ∈K S(vark) x(vark ) + ∑i ∈I S(Fi ) x(Fi) ≤ SSP
- 16 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
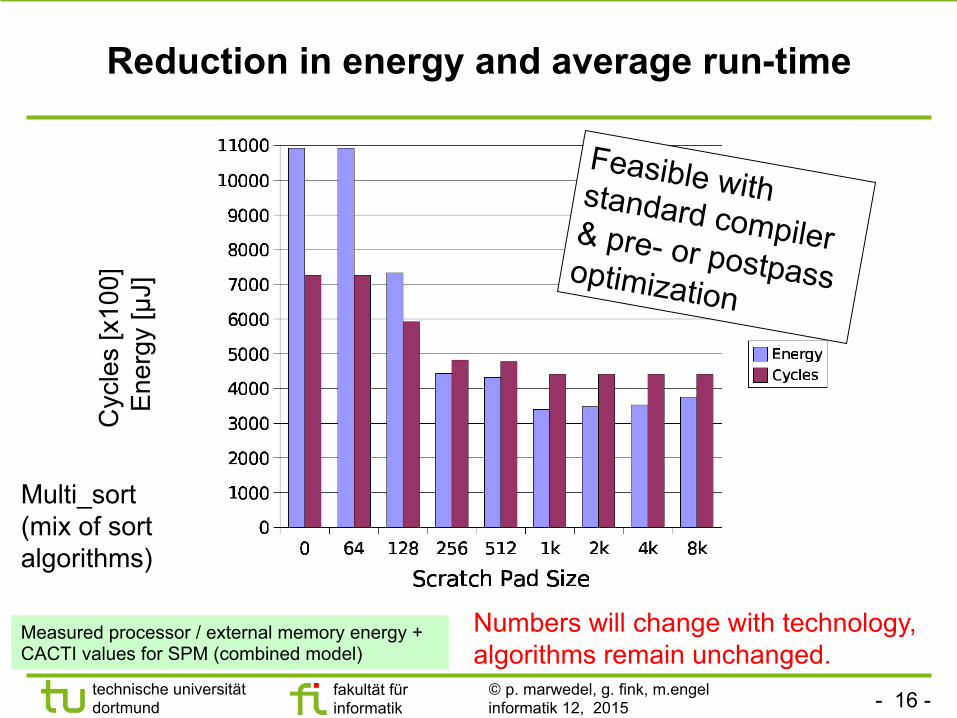
Reduction in energy and average run-time
Multi_sort (mix of sort algorithms)
Cyc
les
[x10
0]
Ene
rgy
[µJ]
Feasible with standard compiler & pre- or postpass optimization
Measured processor / external memory energy + CACTI values for SPM (combined model)
Numbers will change with technology, algorithms remain unchanged.

- 17 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Veröffentlichung mit recht vielen Zitaten
Peter Marwedel, Rajeshwari Banakar (Delhi, March 2013)
- 18 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
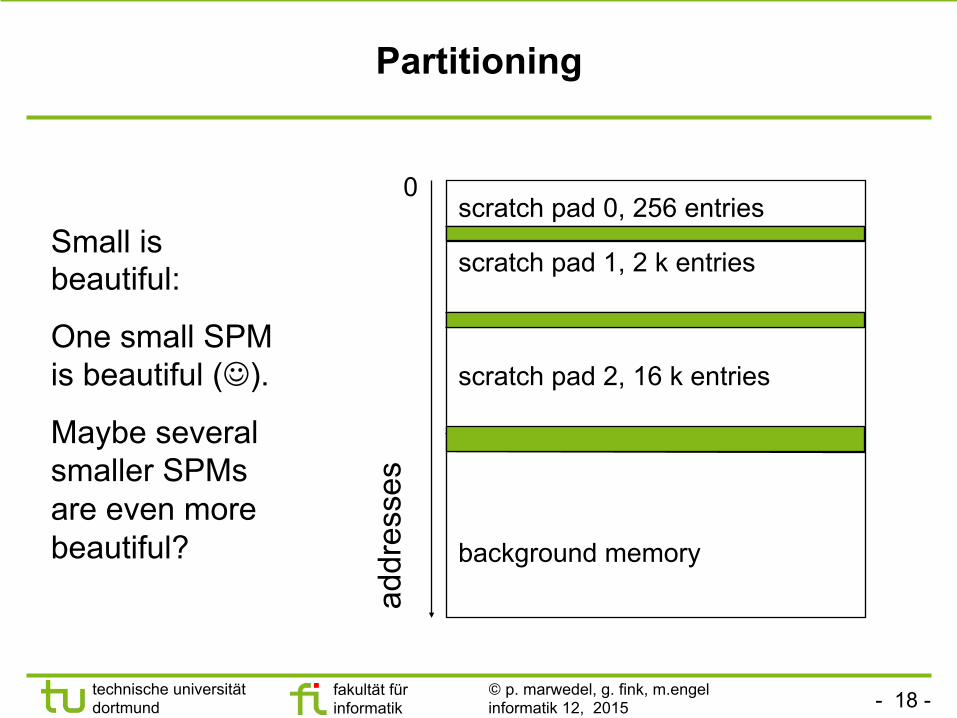
Partitioning
scratch pad 0, 256 entries
scratch pad 1, 2 k entries
scratch pad 2, 16 k entries
background memory
addr
esse
s
0
Small is beautiful:
One small SPM is beautiful (J).
Maybe several smaller SPMs are even more beautiful?
- 19 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
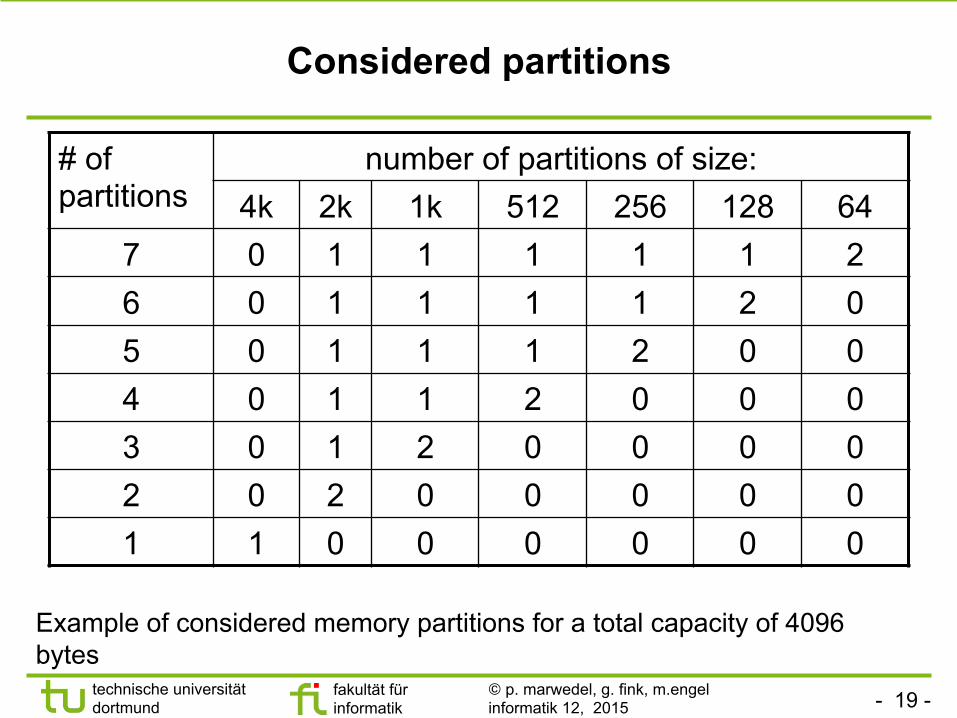
Considered partitions
# of partitions
number of partitions of size: 4k 2k 1k 512 256 128 64
7 0 1 1 1 1 1 2 6 0 1 1 1 1 2 0 5 0 1 1 1 2 0 0 4 0 1 1 2 0 0 0 3 0 1 2 0 0 0 0 2 0 2 0 0 0 0 0 1 1 0 0 0 0 0 0
Example of considered memory partitions for a total capacity of 4096 bytes
- 20 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
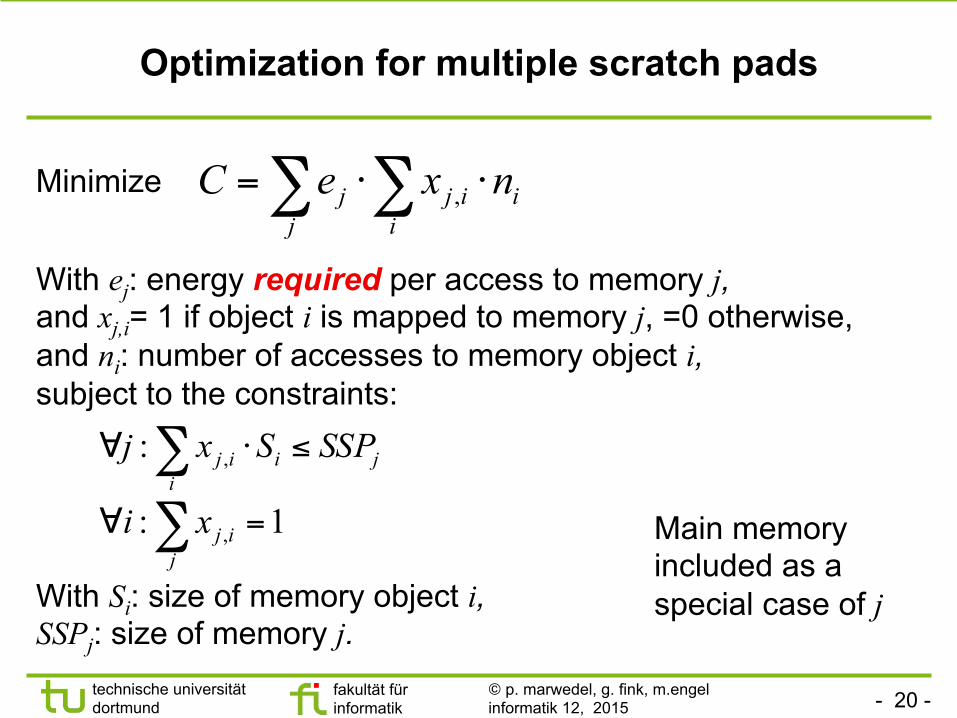
Optimization for multiple scratch pads
∑∑ ⋅⋅=i
iijj
j nxeC ,Minimize
With ej: energy required per access to memory j, and xj,i= 1 if object i is mapped to memory j, =0 otherwise, and ni: number of accesses to memory object i, subject to the constraints:
∑ ≤⋅∀i
jiij SSPSxj ,:
∑ =∀j
ijxi 1: ,
With Si: size of memory object i, SSPj: size of memory j.
Main memory included as a special case of j
- 21 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
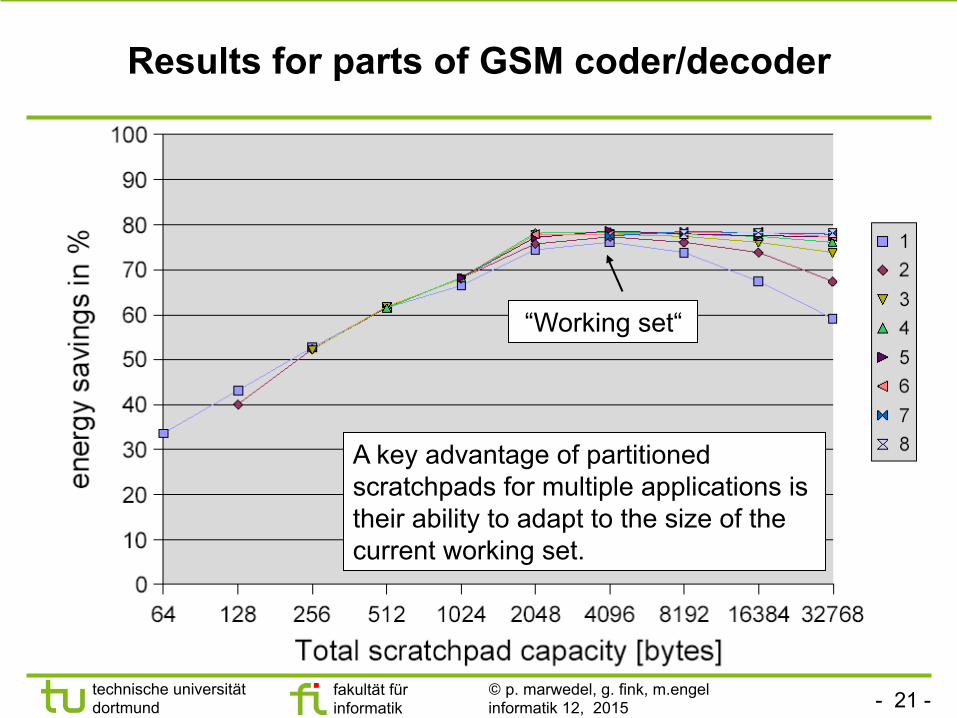
Results for parts of GSM coder/decoder
A key advantage of partitioned scratchpads for multiple applications is their ability to adapt to the size of the current working set.
“Working set“

- 22 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
How much better can we get?
where § P: fraction of memory references replaced by faster/more energy
efficient memory and
§ S: speed/energy improvement
Important not to have too many “untouchable” references (1-P), otherwise even S →∞ does not help
law) s(Amdahl’
SPP +−
=)1(
1timprovemen
SPP +−=− )1(nconsumptioy time/energrun d)(normalize new
- 23 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
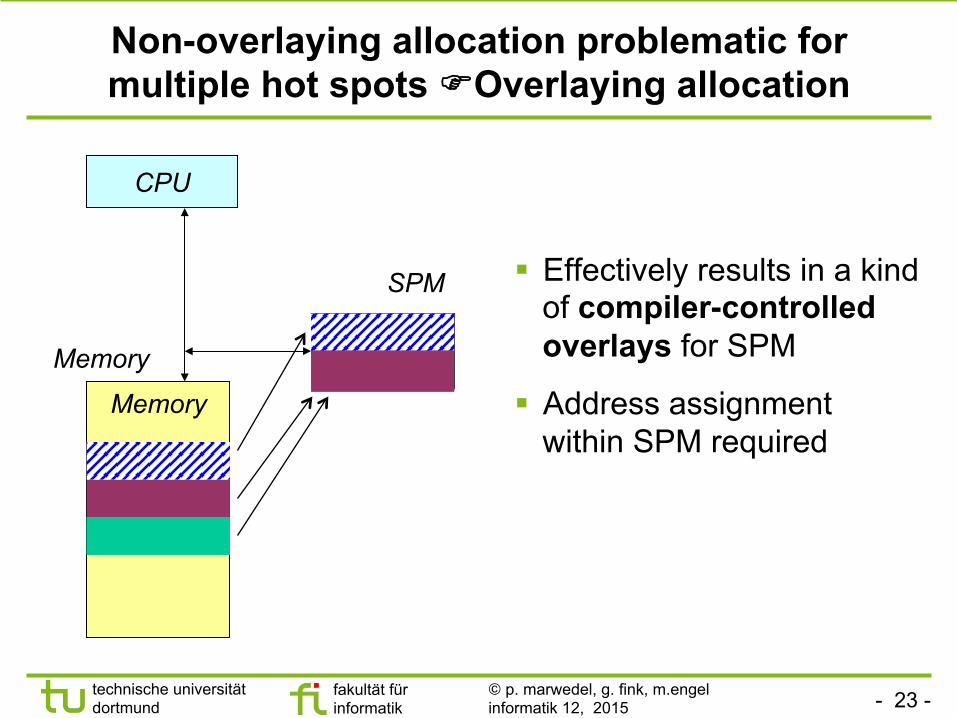
Non-overlaying allocation problematic for multiple hot spots FOverlaying allocation
§ Effectively results in a kind of compiler-controlled overlays for SPM
§ Address assignment within SPM required
CPU
Memory
Memory
SPM
- 24 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
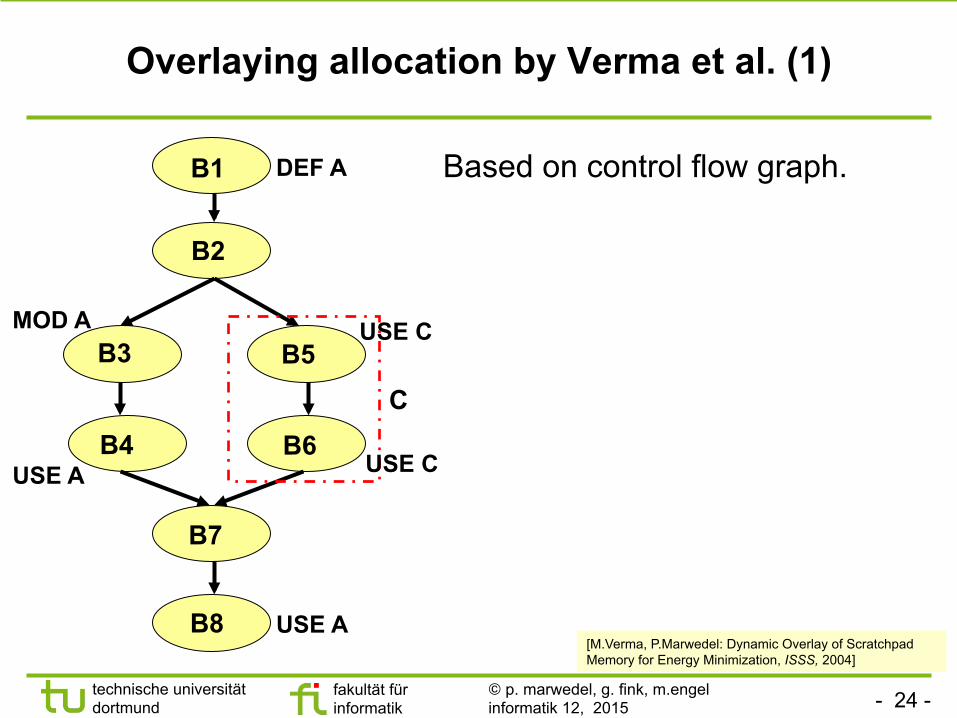
Overlaying allocation by Verma et al. (1)
C
DEF A
USE A
USE A
MOD A USE C
USE C
B1
B2
B3
B4
B5
B6
B7
B8
Based on control flow graph.
[M.Verma, P.Marwedel: Dynamic Overlay of Scratchpad Memory for Energy Minimization, ISSS, 2004]
- 25 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
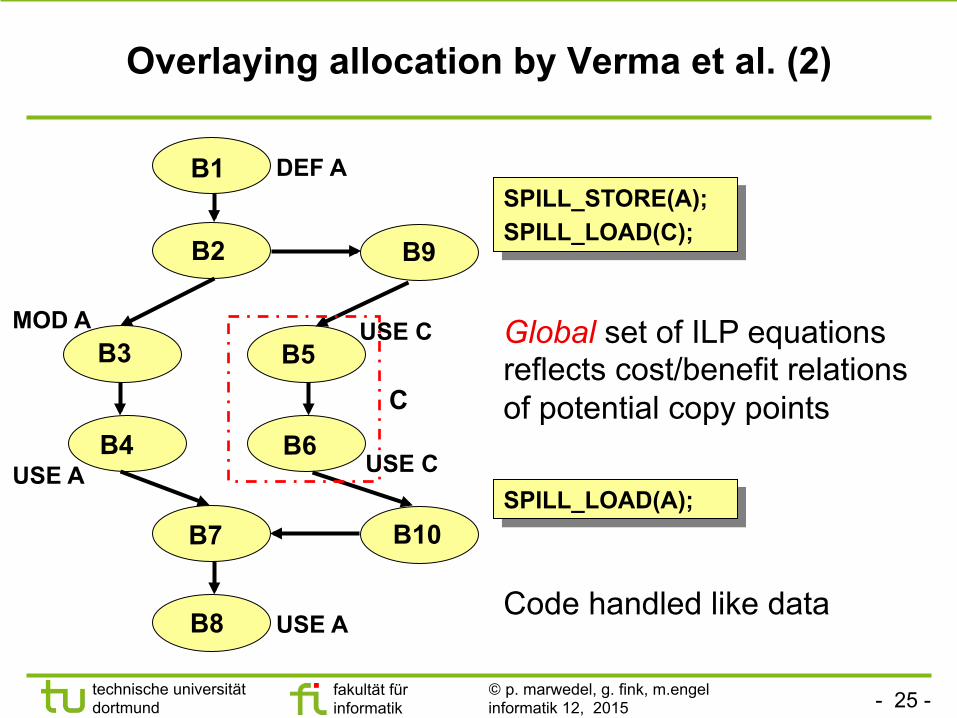
Overlaying allocation by Verma et al. (2)
SPILL_STORE(A); SPILL_LOAD(C);
SPILL_LOAD(A);
C
DEF A
USE A
USE A
MOD A USE C
USE C
B1
B2
B3
B4
B5
B6
B7
B8
B9
B10
Global set of ILP equations reflects cost/benefit relations of potential copy points
Code handled like data
- 26 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
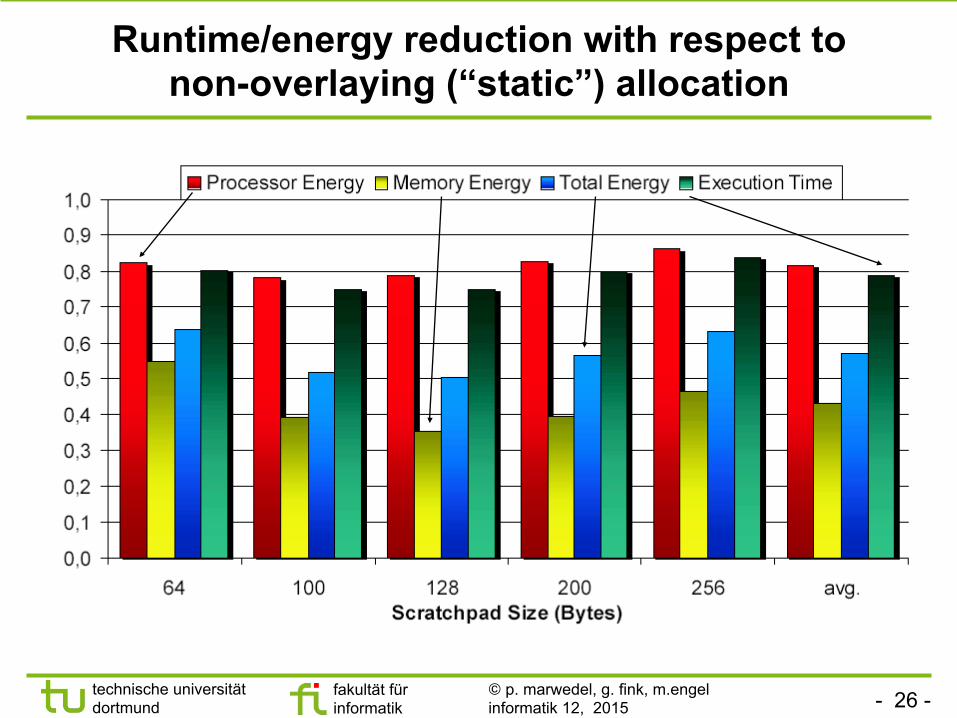
Runtime/energy reduction with respect to non-overlaying (“static”) allocation

- 27 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Less seriously …
F Some people got already completely rid of cache
© IE
EE
, 201
2

fakultät für informatik informatik 12
technische universität dortmund
Speicherhierarchie: Scratch Pad- und Flash-Speicher
- 29 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
[ITR
S 2
011]
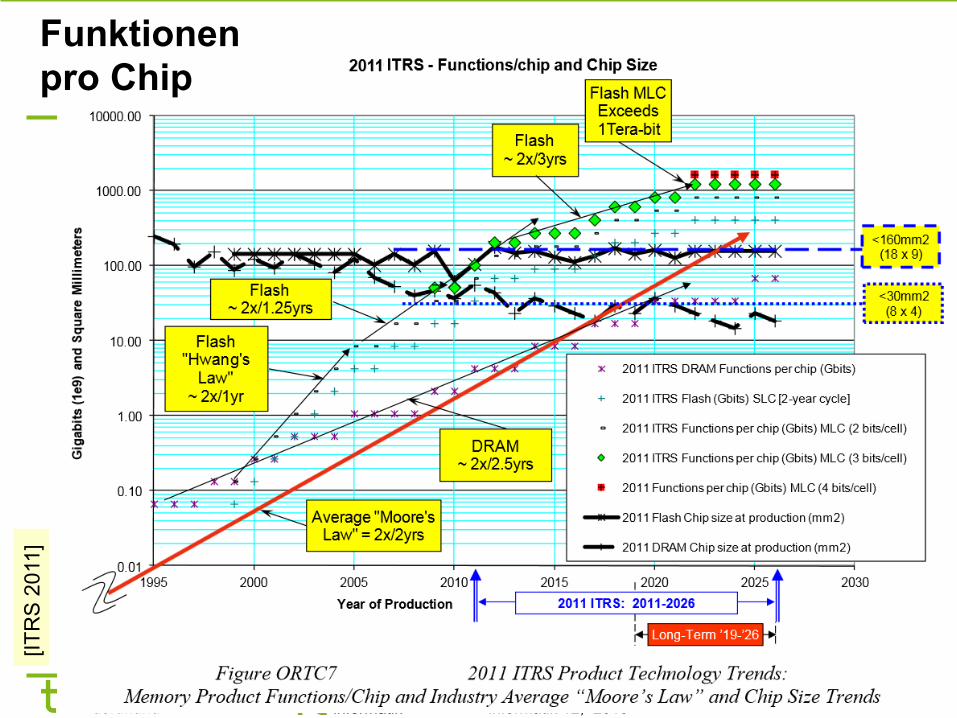
Funktionen pro Chip
- 30 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Mögliche Stufen der Speicherhierarchie und derzeit eingesetzte Technologien
Register (SRAM)
Caches, scratch pads, TLBs (SRAM)
Haupt- bzw. Primärspeicher (DRAM)
Plattencaches (DRAM, Flash)
Sekundärspeicher (Platten, Flash)
Tertiärspeicher (Optische Speicher, Bänder)
- 31 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
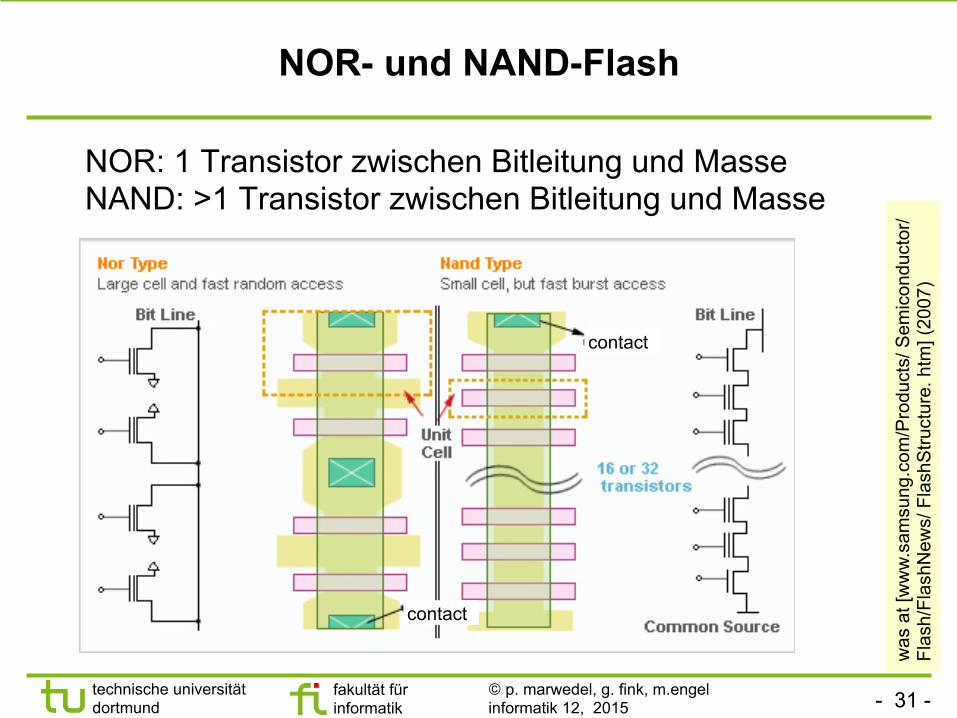
NOR- und NAND-Flash
NOR: 1 Transistor zwischen Bitleitung und Masse NAND: >1 Transistor zwischen Bitleitung und Masse
was
at [
ww
w.s
amsu
ng.c
om/P
rodu
cts/
Sem
icon
duct
or/
Flas
h/Fl
ashN
ews/
Fla
shS
truct
ure.
htm
] (20
07)
contact
contact
- 32 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
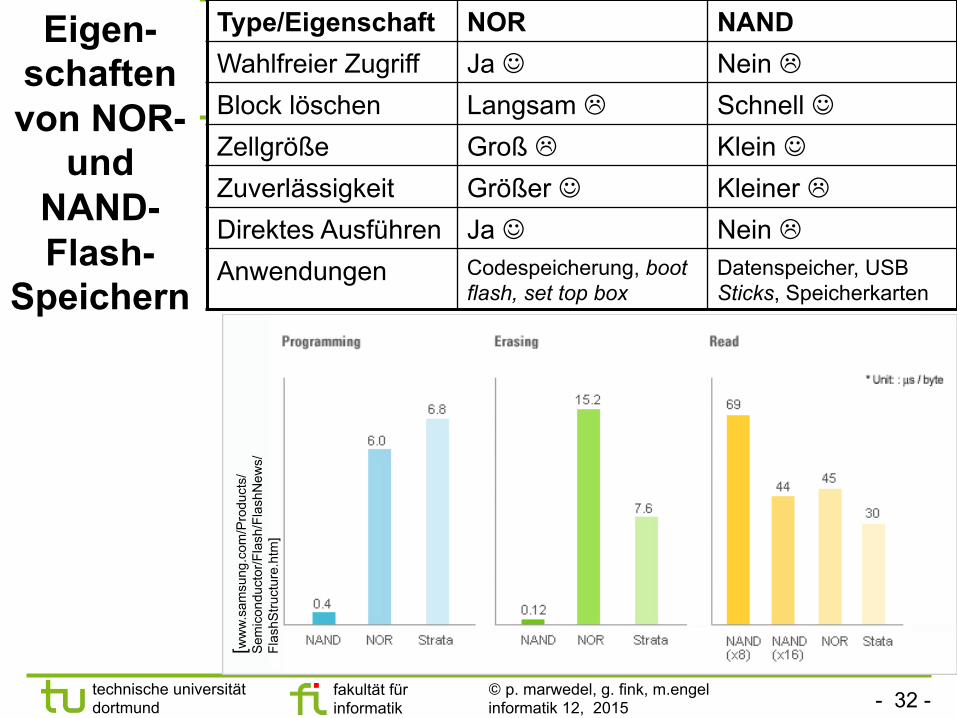
Eigen-schaften von NOR-
und NAND-Flash-
Speichern
Type/Eigenschaft NOR NAND Wahlfreier Zugriff Ja J Nein L Block löschen Langsam L Schnell J Zellgröße Groß L Klein J Zuverlässigkeit Größer J Kleiner L Direktes Ausführen Ja J Nein L Anwendungen Codespeicherung, boot
flash, set top box Datenspeicher, USB Sticks, Speicherkarten
[ww
w.s
amsu
ng.c
om/P
rodu
cts/
Sem
icon
duct
or/F
lash
/Fla
shN
ews/
Flas
hStru
ctur
e.ht
m]
- 33 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
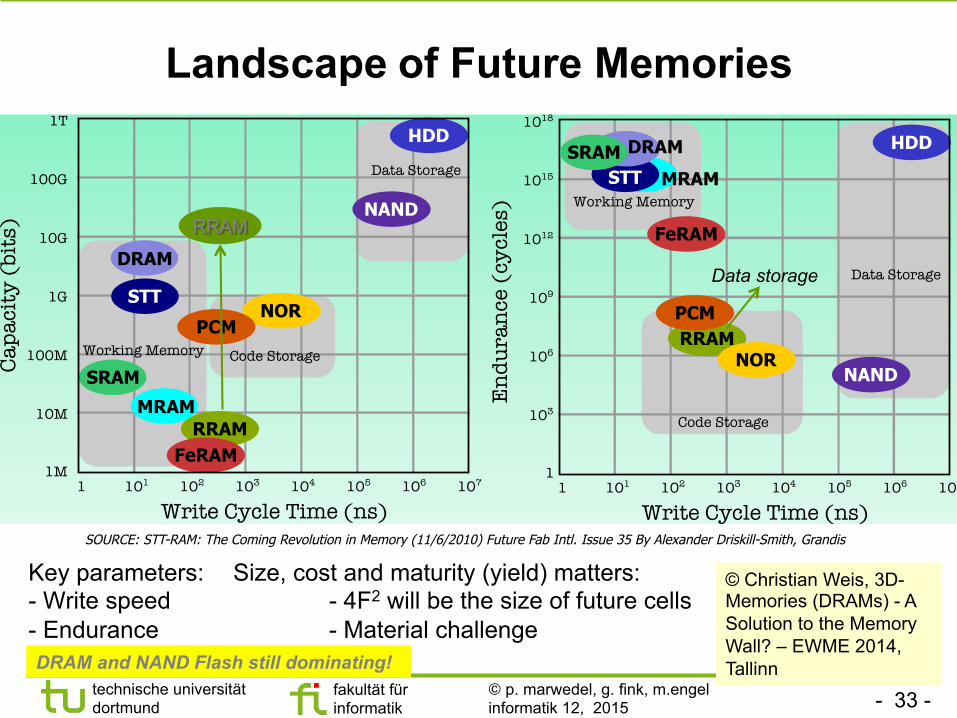
Landscape of Future Memories
Key parameters: Size, cost and maturity (yield) matters: - Write speed - 4F2 will be the size of future cells - Endurance - Material challenge
1 101 102 103 104 105 106 1071
103
106
109
1012
1015
1018HDD
NANDNOR
RRAMPCM
FeRAM
STT
DRAM
Code Storage
Data Storage
Working Memory
Write Cycle Time (ns)En
dura
nce
(cyc
les)
MRAM
1 101 102 103 104 105 106 1071M
10M
100M
1G
10G
100G
1T HDD
NAND
NOR
RRAM
PCM
FeRAM
STT
SRAM
DRAM
Code Storage
Data Storage
Working Memory
Write Cycle Time (ns)
Capa
city
(bits
)
MRAM
SRAM
SOURCE: STT-RAM: The Coming Revolution in Memory (11/6/2010) Future Fab Intl. Issue 35 By Alexander Driskill-Smith, Grandis
RRAM
Data storage
DRAM and NAND Flash still dominating!
© Christian Weis, 3D-Memories (DRAMs) - A Solution to the Memory Wall? – EWME 2014, Tallinn
- 34 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
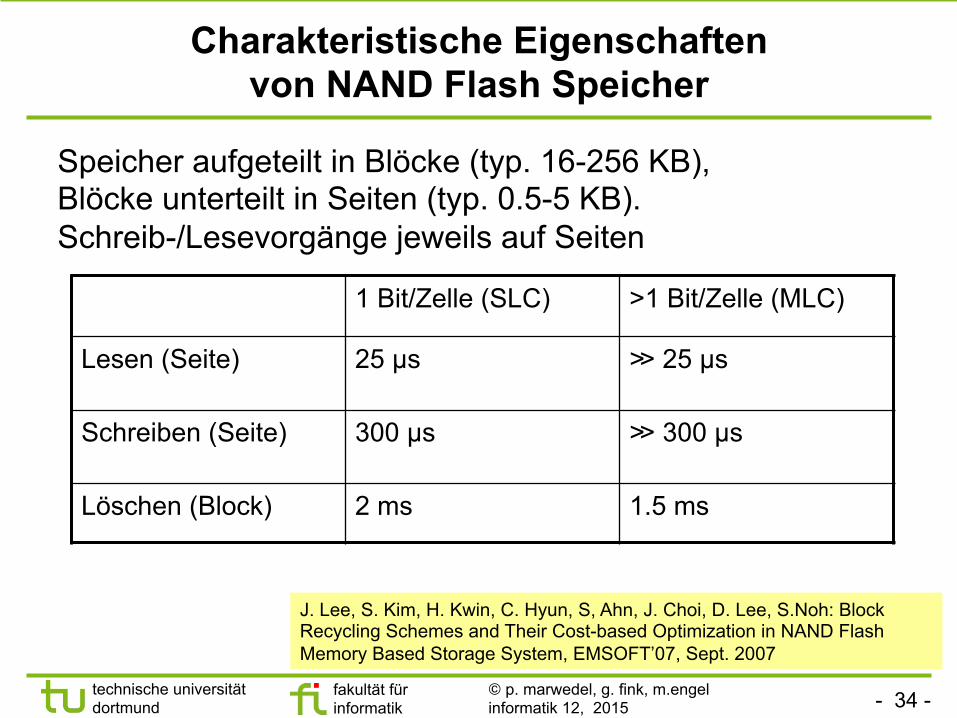
Charakteristische Eigenschaften von NAND Flash Speicher
Speicher aufgeteilt in Blöcke (typ. 16-256 KB), Blöcke unterteilt in Seiten (typ. 0.5-5 KB). Schreib-/Lesevorgänge jeweils auf Seiten
1 Bit/Zelle (SLC) >1 Bit/Zelle (MLC)
Lesen (Seite) 25 µs ≫ 25 µs
Schreiben (Seite) 300 µs ≫ 300 µs
Löschen (Block) 2 ms 1.5 ms
J. Lee, S. Kim, H. Kwin, C. Hyun, S, Ahn, J. Choi, D. Lee, S.Noh: Block Recycling Schemes and Their Cost-based Optimization in NAND Flash Memory Based Storage System, EMSOFT’07, Sept. 2007
- 35 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
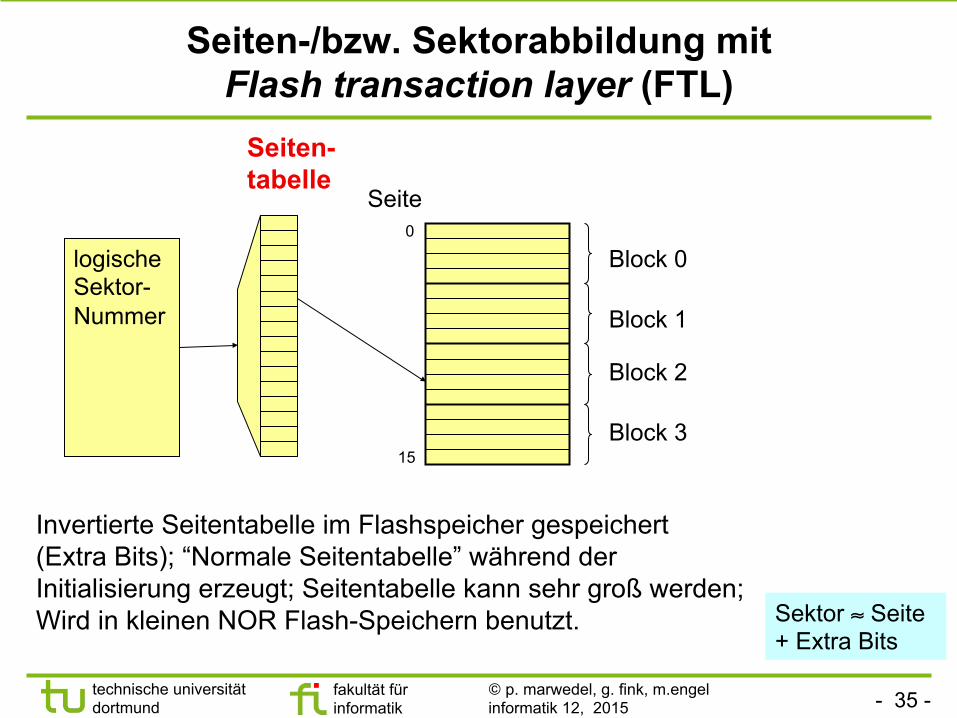
Seiten-/bzw. Sektorabbildung mit Flash transaction layer (FTL)
Invertierte Seitentabelle im Flashspeicher gespeichert (Extra Bits); “Normale Seitentabelle” während der Initialisierung erzeugt; Seitentabelle kann sehr groß werden; Wird in kleinen NOR Flash-Speichern benutzt.
Block 0
Block 1
Block 2
Block 3
logische Sektor- Nummer
Seiten-tabelle
15
0
Seite
Sektor ≈ Seite + Extra Bits
- 36 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
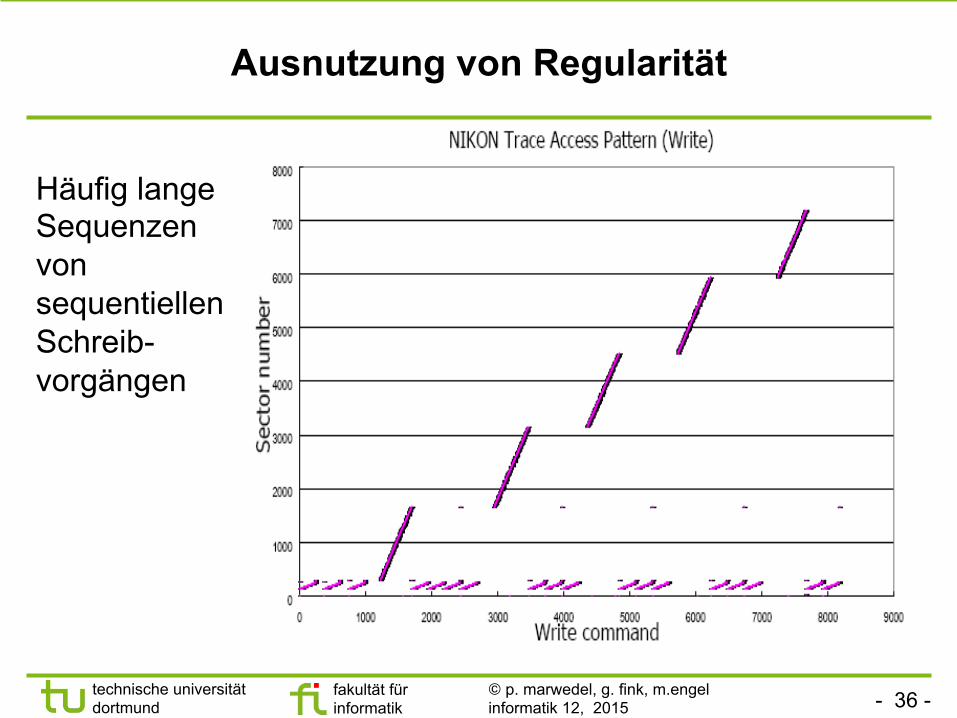
Ausnutzung von Regularität
Häufig lange Sequenzen von sequentiellen Schreib-vorgängen
- 37 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
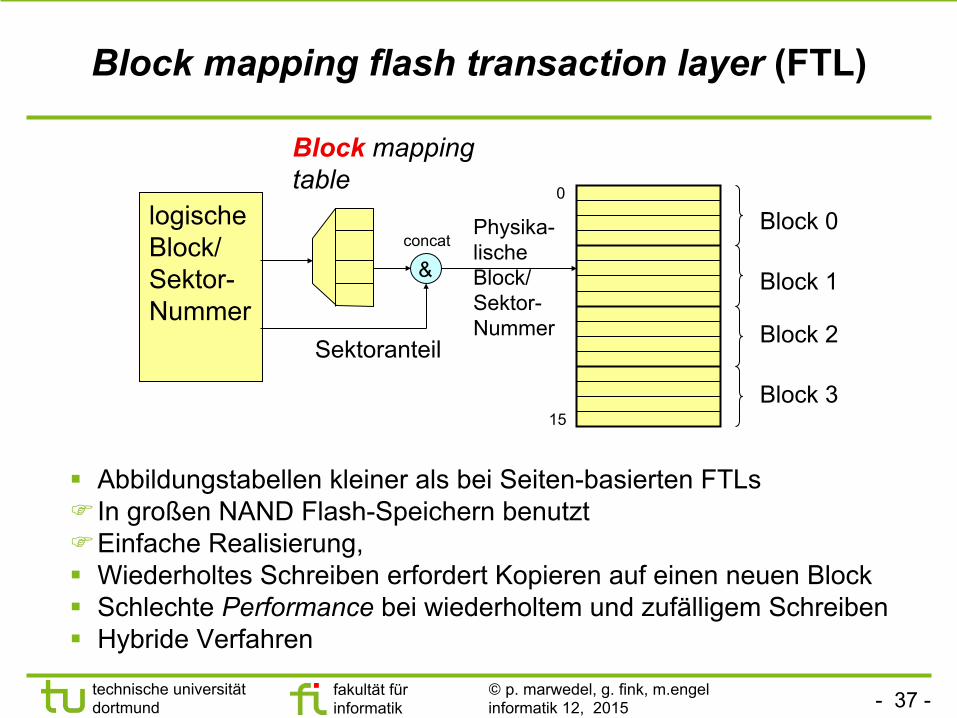
Block mapping flash transaction layer (FTL)
§ Abbildungstabellen kleiner als bei Seiten-basierten FTLs F In großen NAND Flash-Speichern benutzt F Einfache Realisierung, § Wiederholtes Schreiben erfordert Kopieren auf einen neuen Block § Schlechte Performance bei wiederholtem und zufälligem Schreiben § Hybride Verfahren
Block 0
Block 1
Block 2
Block 3
&
logische Block/ Sektor- Nummer
Block mapping table
Sektoranteil
Physika-lische Block/ Sektor- Nummer
concat
15
0

- 38 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Ausgleich der Abnutzung (wear levelling)
Beispiel (Lofgren et al., 2000, 2003): § Jede erase unit (Block) besitzt Löschzähler § 1 Block wird als Ersatz vorgehalten § Wenn ein häufig genutzter Block frei wird,
wird der Zähler gegen den des am wenigsten benutzten Blocks verglichen. Wenn der Unterschied groß ist:
• Inhalt wenig genutzten Blocks (≈ Konstanten) → Ersatz
• Inhalt häufig genutzten Blocks → am wenigsten genutzter Block
• Häufig genutzter Block wird zum Ersatzblock
Source: Gal, Toledo, ACM Computing Surveys, June 2005
Konst Ersatz Var
Var Konst Ersatz

- 39 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Flash als Hauptspeicher
Veröffentlichung von Wu und Zwaenepoel, 1994: § Verwendet MMU § RAM + Flash in den Adressbereich eingeblendet § Lesen von Flash liest einzelne Worte aus dem Flash § Schreiben kopiert Blöcke von Data ins RAM,
alle Aktualisierungen finden im RAM statt § Wenn das RAM voll ist, wird ein Block wieder ins Flash
kopiert § Flaschenhals: Schreibgeschwindigkeit
• Veröffentlichung basiert auf breitem Bus zwischen Flash und RAM für ausreichend schnelles Schreiben F Größere erase units, möglicherweise schnellere Alterung (wear out) M. Wu, W. Zwaenepoel: eNVy: A nonvolatile, main memory storage system. In
Proceedings of the 6th International Conference on Architectural Support for Programming Languages and Operating Systems. 1994, p. 86–97.

- 40 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Flash-spezifische Dateisysteme
§ Zwei Ebenen können ineffizient sein: • FTL bildet Magnetplatte nach • Standard-Dateisystem basiert auf Magnetplatten
Beispiel: Gelöschte Sektoren nicht markiert F nicht wieder verwendet
§ Log-strukturierte Dateisysteme fügen nur neue Informationen zu • Für Magnetplatten
- Schnelle Schreibvorgänge - Langsames Lesen (Kopfbewegungen für verteilte Daten)
• Ideal für Flash-basiertes Dateisystem: - Schreibvorgänge in leere Sektoren - Lesen nicht langsam, da keine Köpfe bewegt werden
F Spezifische log-basierte Flash-Dateisysteme - JFFS2 (NOR) - YAFFS (NAND)
Source: Gal, Toledo, ACM Computing Surveys, June 2005

- 41 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Flash-spezifische Betriebssystemoperationen
§ Laufwerk wird beim Löschen von Dateien mitgeteilt, dass es die davon betroffenen Blöcke als ungültig markieren kann
• Daten müssen nicht weiter vorgehalten werden • Information normalerweise nicht für Massenspeicher verfügbar
(Laufwerk kann nicht zwischen einem „wichtigen“ Block voller Null-Bytes und einem gelöschten Block unterscheiden)
§ Mit dem TRIM-Befehl (Teil des ATA-Standards) teilt das Betriebssystem der SSD mit, dass gelöschte oder anderweitig freigewordene Blöcke nicht mehr benutzt werden
§ Inhalte werden nicht mehr weiter mitgeschrieben, • Schreibzugriffe auf das Laufwerk werden beschleunigt • Abnutzungseffekte werden verringert
§ Von allen aktuellen Betriebssystemen unterstützt • Muss auch von SSD-Firmware unterstützt werden
- 42 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
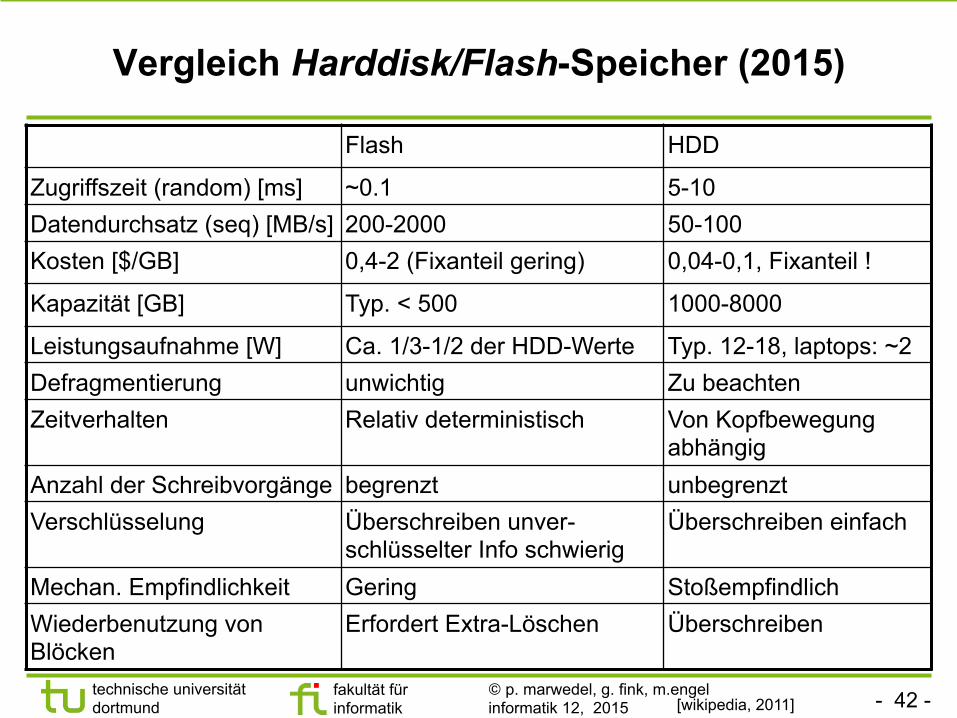
Vergleich Harddisk/Flash-Speicher (2015)
[wikipedia, 2011]
Flash HDD
Zugriffszeit (random) [ms] ~0.1 5-10 Datendurchsatz (seq) [MB/s] 200-2000 50-100 Kosten [$/GB] 0,4-2 (Fixanteil gering) 0,04-0,1, Fixanteil !
Kapazität [GB] Typ. < 500 1000-8000
Leistungsaufnahme [W] Ca. 1/3-1/2 der HDD-Werte Typ. 12-18, laptops: ~2 Defragmentierung unwichtig Zu beachten Zeitverhalten Relativ deterministisch Von Kopfbewegung
abhängig Anzahl der Schreibvorgänge begrenzt unbegrenzt Verschlüsselung Überschreiben unver-
schlüsselter Info schwierig Überschreiben einfach
Mechan. Empfindlichkeit Gering Stoßempfindlich Wiederbenutzung von Blöcken
Erfordert Extra-Löschen Überschreiben

- 43 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Re-writing algorithms for memory hierarchies
Analysis of algorithm complexity mostly using the RAM (random access machine; constant memory access times) model outdated F take memory hierarchies explicitly into account. Example: § Usually, divide-&-conquer algorithms are good. § “Cache”-oblivious algorithms (are good for any size
of the faster memory and any block size). Assuming • Optimal replacement (Belady’s algorithm) • 2 Memory levels considered (there can be more) • Full associativity • Automatic replacement
[Piyush Kumar: Cache Oblivious Algorithms, in: U. Meyer et al. (eds.): Algorithms for Memory Hierarchies, Lecture Notes in Computer Science, Volume 2625, 2003, pp. 193-212] [Naila Rahman: Algorithms for Hardware Caches and TLB, in: U. Meyer et al. (eds.): Algorithms for Memory Hierarchies, Lecture Notes in Computer Science, Volume 2625, 2003, pp. 171-192]
Unl
ikel
y to
be
ever
aut
omat
ic

- 44 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Zusammenfassung
Speicherhierarchie § Scratchpadspeicher SPM („Software managed caches“)
• Schnell, energieeffizient, timing predictable, • Populär wg. Aufwands für Cache-Kohärenz in Multiprozessor-Syst. • Statische, nicht-überlagernde Allokation (Knappsack, ILP) • Überlagernde, dynamische compile-time Allokation (ILP) • Run-time allocation (im Betriebssystem)
§ Flash-Speicher erfordern Anpassung an Eigenheiten • Ausgleich der Abnutzung • In der Regel Abbildung logische→reale Blockadressen (FTL/MMU) • Nur eingeschränkt als Hauptspeicher geeignet • Als Sekundärspeicher am besten mit speziellem Dateisystem!
§ Große Datenmengen F „Sekundärspeicher“ sind für die Performance die entscheidenden Komponenten
- 45 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
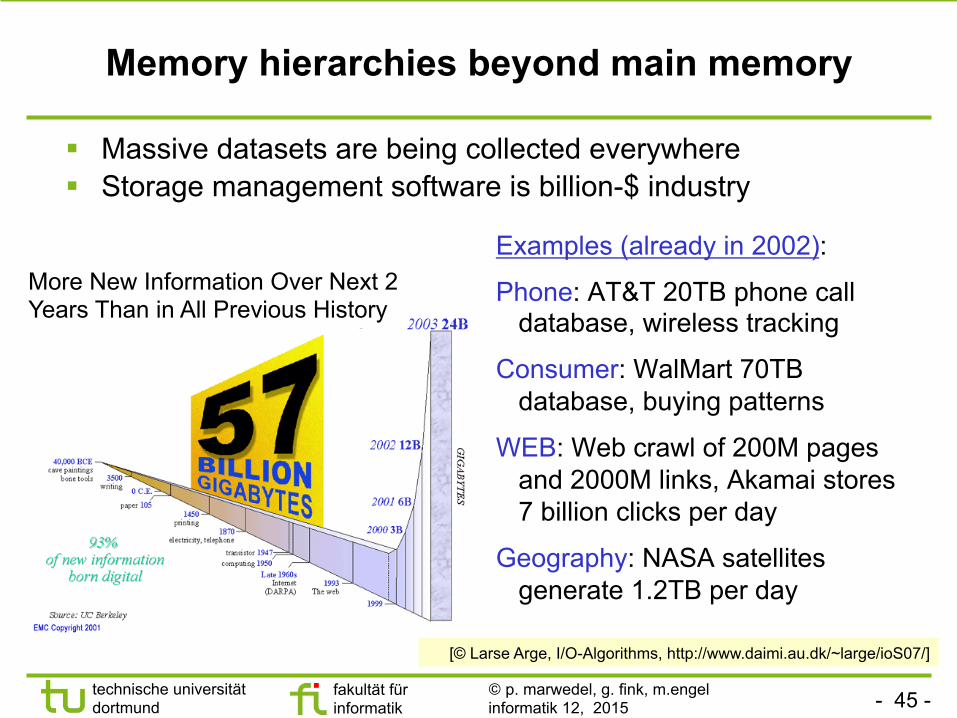
Memory hierarchies beyond main memory
§ Massive datasets are being collected everywhere § Storage management software is billion-$ industry
Examples (already in 2002):
Phone: AT&T 20TB phone call database, wireless tracking
Consumer: WalMart 70TB database, buying patterns
WEB: Web crawl of 200M pages and 2000M links, Akamai stores 7 billion clicks per day
Geography: NASA satellites generate 1.2TB per day
[© Larse Arge, I/O-Algorithms, http://www.daimi.au.dk/~large/ioS07/]
More New Information Over Next 2 Years Than in All Previous History

- 46 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Scalability Problems: Block Access Matters
§ Example: Reading an array from disk • Array size N = 10 elements • Disk block size B = 2 elements • Main memory size M = 4 elements (2 blocks)
1 2 10 9 5 6 3 4 8 7 1 5 2 6 3 8 9 4 7 10
Algorithm 2: N/B=5 I/Os Algorithm 1: N=10 I/Os
§ Difference between N and N/B large since block size is large
• Example: N = 256 x 106, B = 8000 , 1ms disk access time
⇒ N I/Os take 256 x 103 sec = 4266 min = 71 hr ⇒ N/B I/Os take 256/8 sec = 32 sec
[© Larse Arge, I/O-Algorithms, http://www.daimi.au.dk/~large/ioS07/]
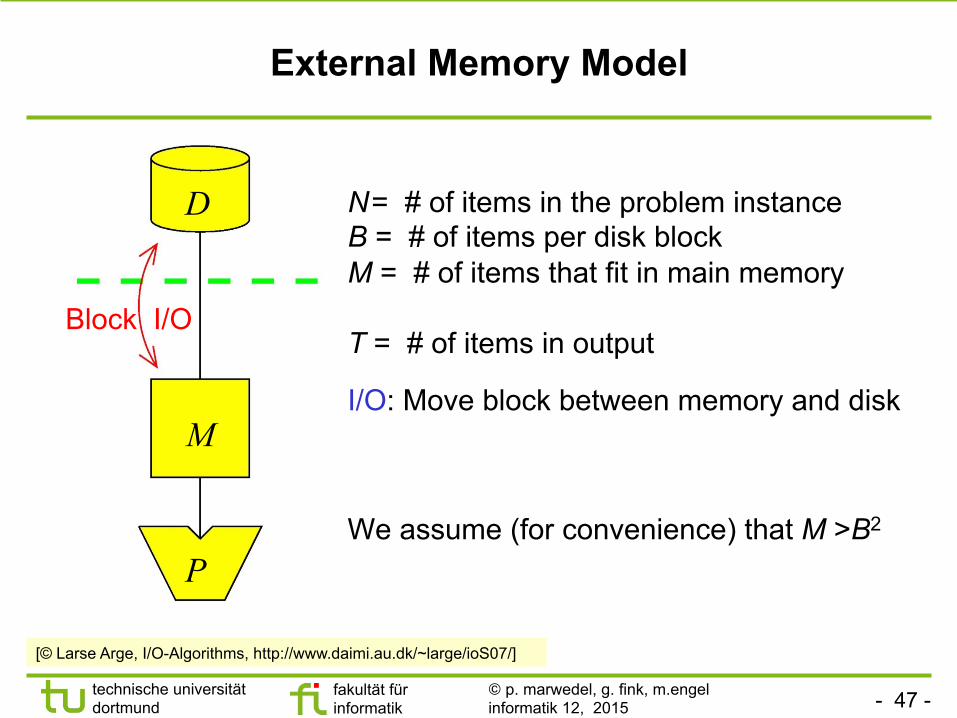
- 47 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
N = # of items in the problem instance B = # of items per disk block M = # of items that fit in main memory T = # of items in output
I/O: Move block between memory and disk
We assume (for convenience) that M >B2
D
P
M
Block I/O
External Memory Model
[© Larse Arge, I/O-Algorithms, http://www.daimi.au.dk/~large/ioS07/]
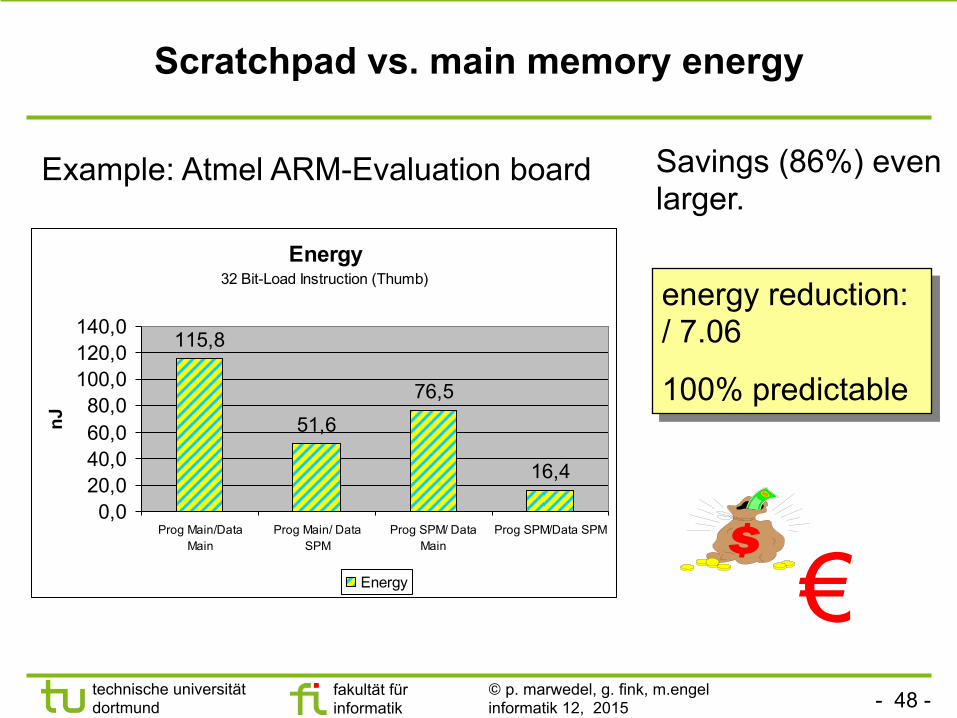
- 48 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Scratchpad vs. main memory energy
Energy32 Bit-Load Instruction (Thumb)
115,8
51,676,5
16,4
0,020,040,060,080,0
100,0120,0140,0
Prog Main/DataMain
Prog Main/ DataSPM
Prog SPM/ DataMain
Prog SPM/Data SPM
nJ
Energy
Example: Atmel ARM-Evaluation board Savings (86%) even larger.
energy reduction: / 7.06
100% predictable
€
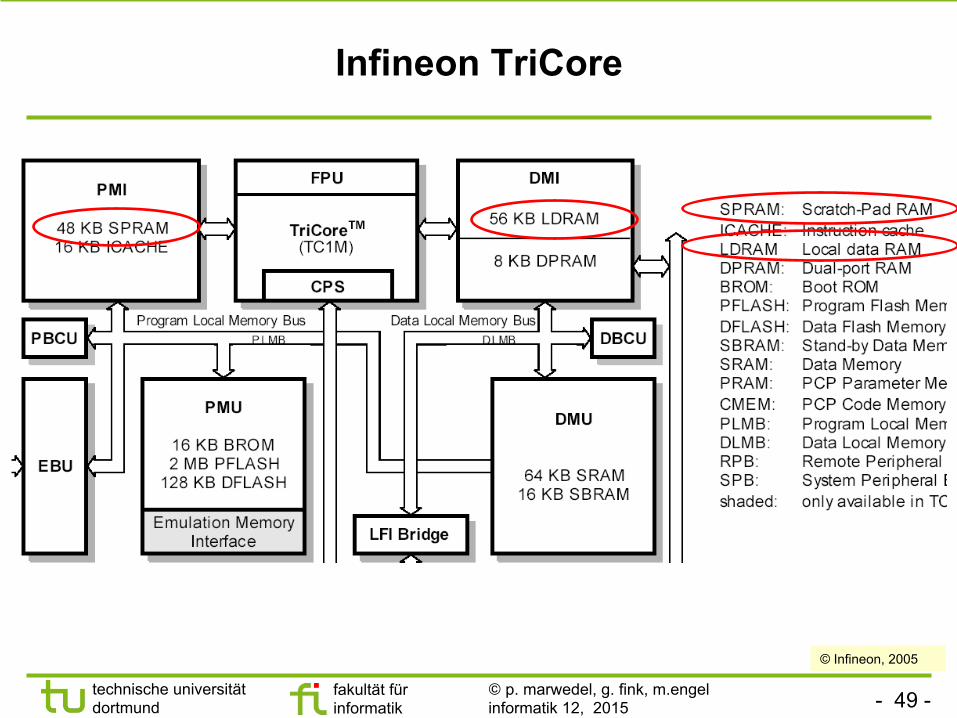
- 49 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Infineon TriCore
© Infineon, 2005
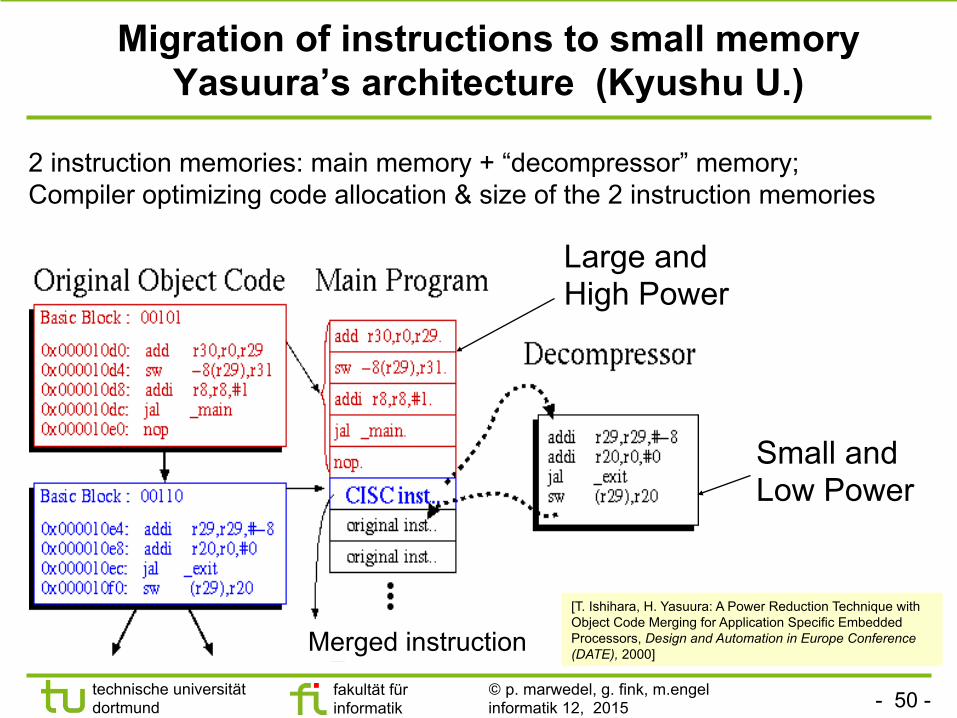
- 50 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
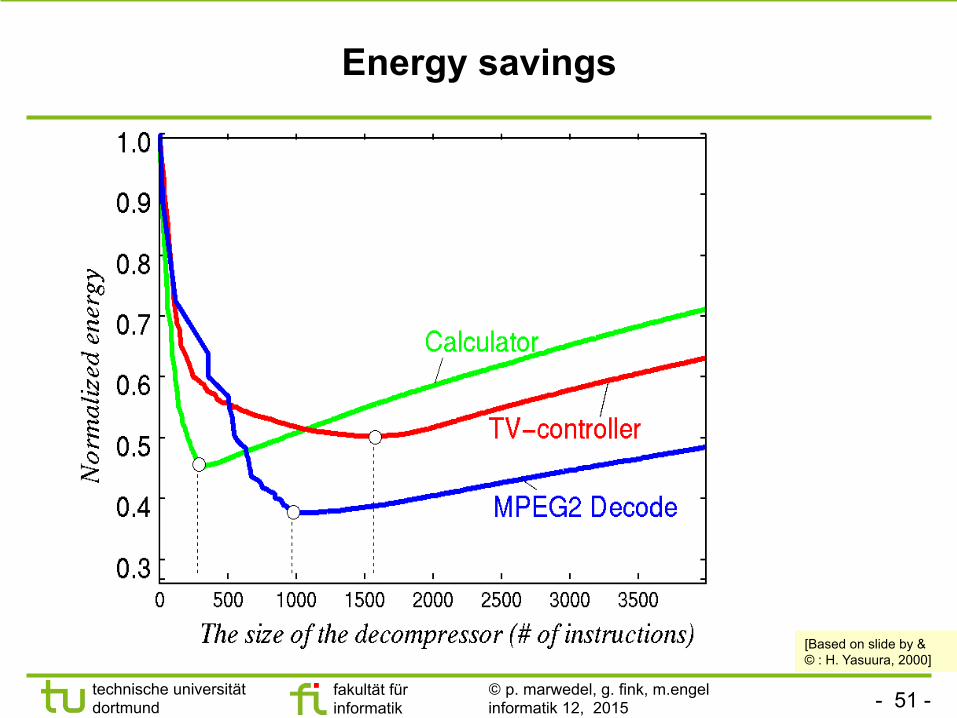
Migration of instructions to small memory Yasuura’s architecture (Kyushu U.)
e
2 instruction memories: main memory + “decompressor” memory; Compiler optimizing code allocation & size of the 2 instruction memories
Merged instruction
Small and Low Power
Large and High Power
[T. Ishihara, H. Yasuura: A Power Reduction Technique with Object Code Merging for Application Specific Embedded Processors, Design and Automation in Europe Conference (DATE), 2000]
- 51 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
[Based on slide by & © : H. Yasuura, 2000]
Energy savings

- 52 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
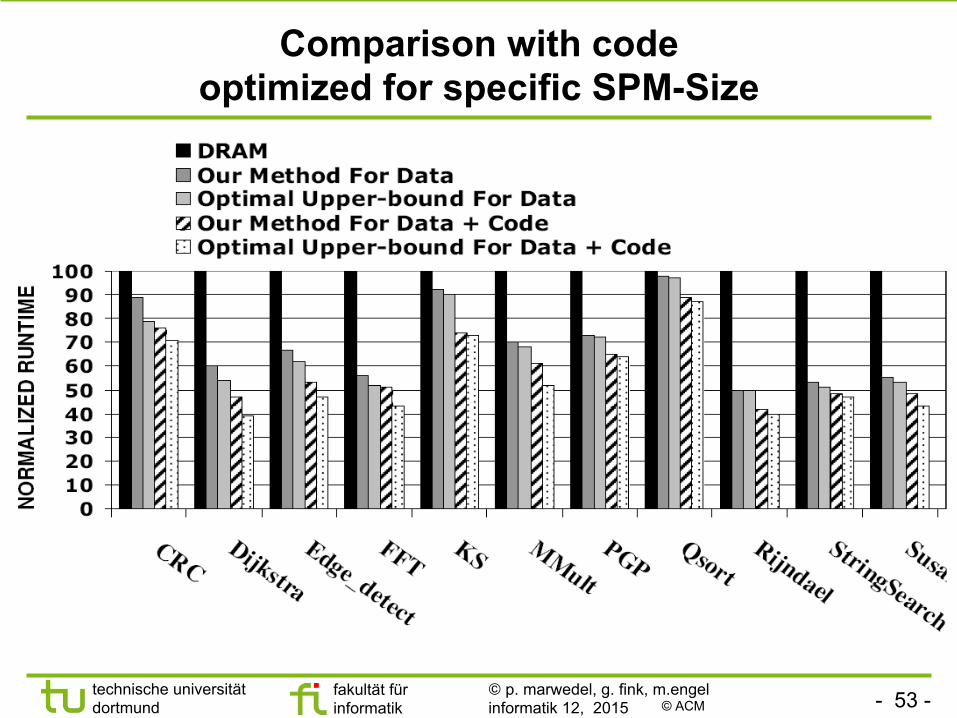
Considering SPM size at link time
§ Avoiding executables generated for a specific SPM size § Profiler stores variables sorted by their “frequency per
byte” (FPB) in executable § Compiler identifies access to variables with unknown
memory allocation by using global symbols. § After loading the program, a custom installer
• Reads SPM size of current architecture • Decides (using FPBs) which variables to put into SPM • Patches addresses of variables (incl. stack variables) • Tries to use SPM space not used on a calling path • Also moves code into SPM
[N. Nguyen, A. Dominguez, R. Barua: Memory Allocation for Embedded Systems with a Compile-Time-Unknown Scratch-Pad Size, Intern. conf. on Compilers, architectures and synthesis for embedded systems (CASES), 2005, p. 115-125]
- 53 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Comparison with code optimized for specific SPM-Size
© ACM
- 54 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
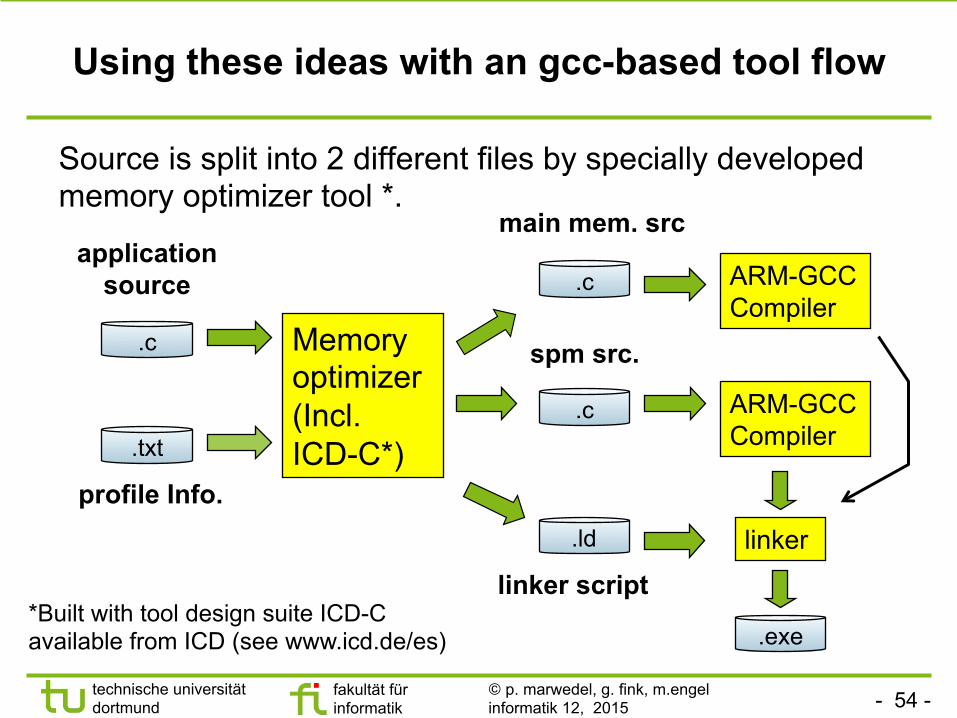
Using these ideas with an gcc-based tool flow
Source is split into 2 different files by specially developed memory optimizer tool *.
applicationsource
profile Info.
main mem. src
spm src.
linker script *Built with tool design suite ICD-C available from ICD (see www.icd.de/es) .exe
.ld linker
ARM-GCC Compiler
ARM-GCC Compiler
.c
.c
.c
.txt
Memory optimizer (Incl. ICD-C*)
- 55 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
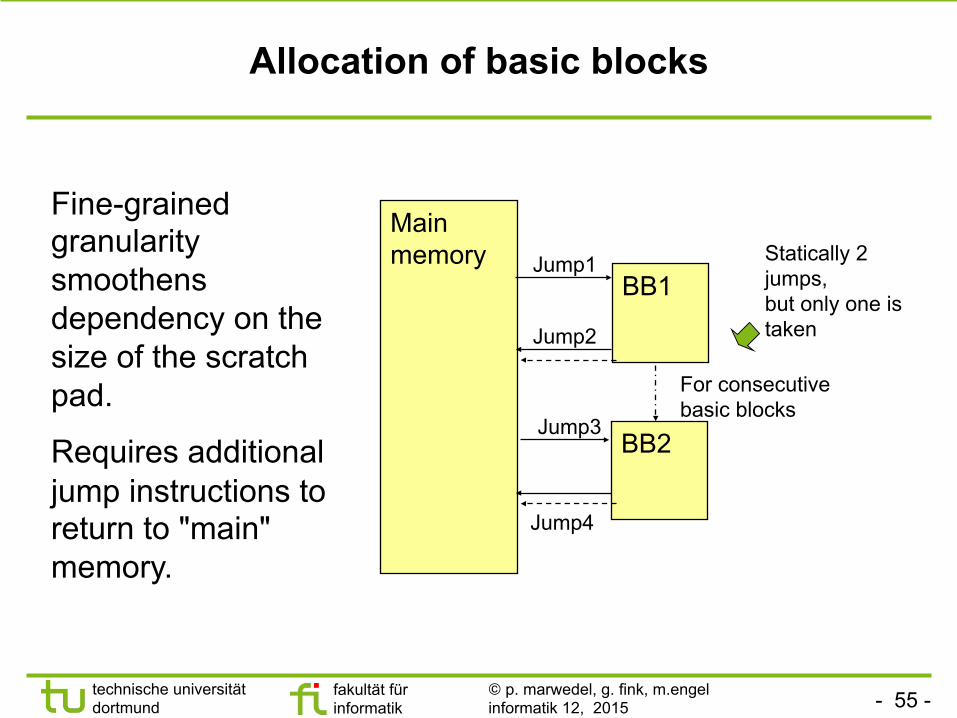
Allocation of basic blocks
Fine-grained granularity smoothens dependency on the size of the scratch pad.
Requires additional jump instructions to return to "main" memory.
Main memory
BB1
BB2
Jump1
Jump2
Jump4
Jump3
For consecutive basic blocks
Statically 2 jumps, but only one is taken
- 56 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Taking consecutive basic blocks into account
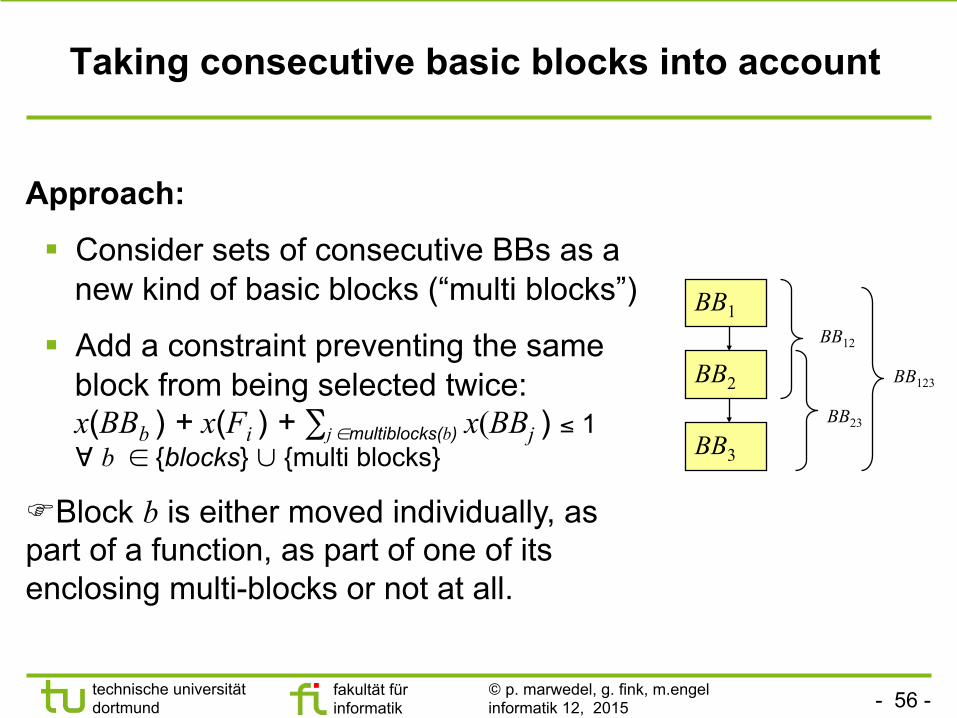
Approach:
§ Consider sets of consecutive BBs as a new kind of basic blocks (“multi blocks”)
§ Add a constraint preventing the same block from being selected twice: x(BBb ) + x(Fi ) + ∑j ∈multiblocks(b) x(BBj ) ≤ 1 ∀ b ∈ {blocks} ∪ {multi blocks}
FBlock b is either moved individually, as part of a function, as part of one of its enclosing multi-blocks or not at all.
BB1
BB3
BB2
BB12
BB23
BB123
- 57 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
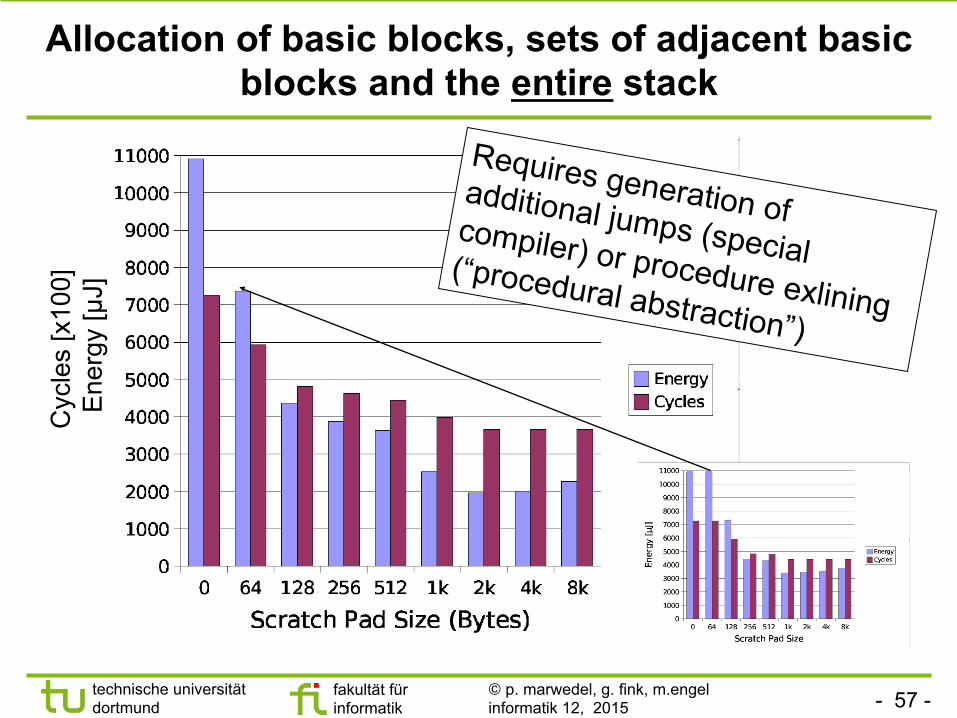
Allocation of basic blocks, sets of adjacent basic blocks and the entire stack
Requires generation of additional jumps (special compiler) or procedure exlining (“procedural abstraction”)
Cyc
les
[x10
0]
Ene
rgy
[µJ]
- 58 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
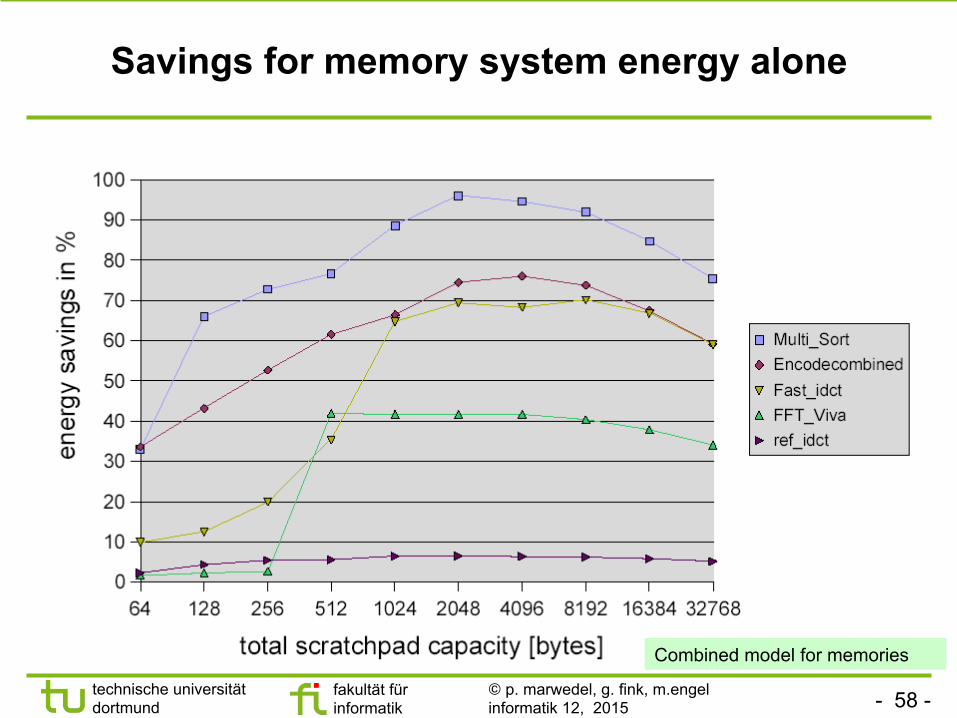
Savings for memory system energy alone
Combined model for memories
- 59 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
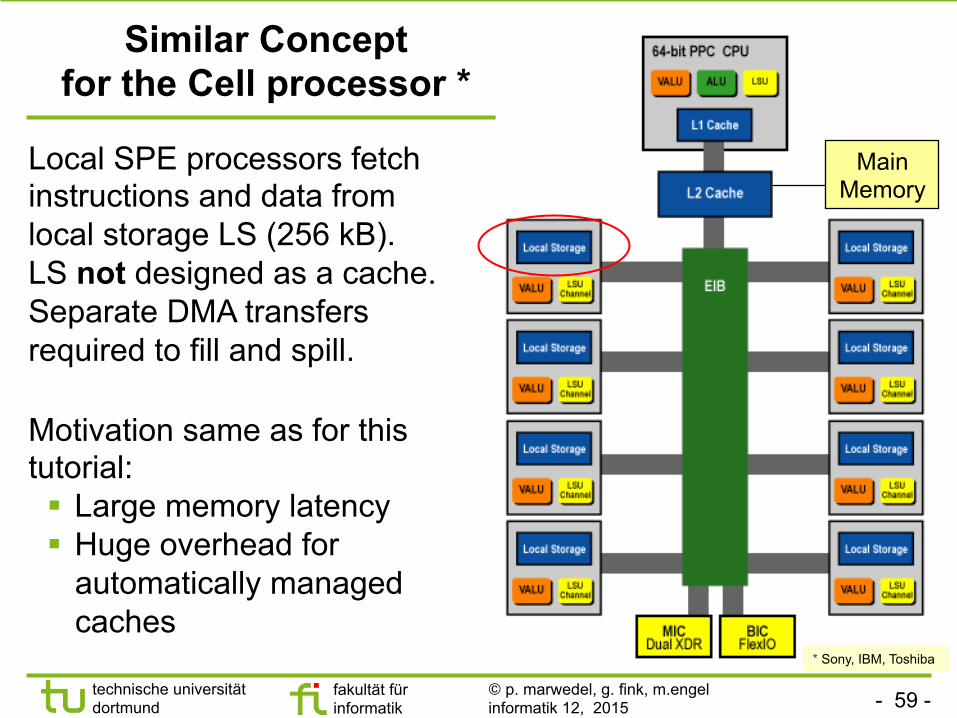
Similar Concept for the Cell processor *
Motivation same as for this tutorial: § Large memory latency § Huge overhead for
automatically managed caches
Local SPE processors fetch instructions and data from local storage LS (256 kB). LS not designed as a cache. Separate DMA transfers required to fill and spill.
* Sony, IBM, Toshiba
Main Memory
- 60 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
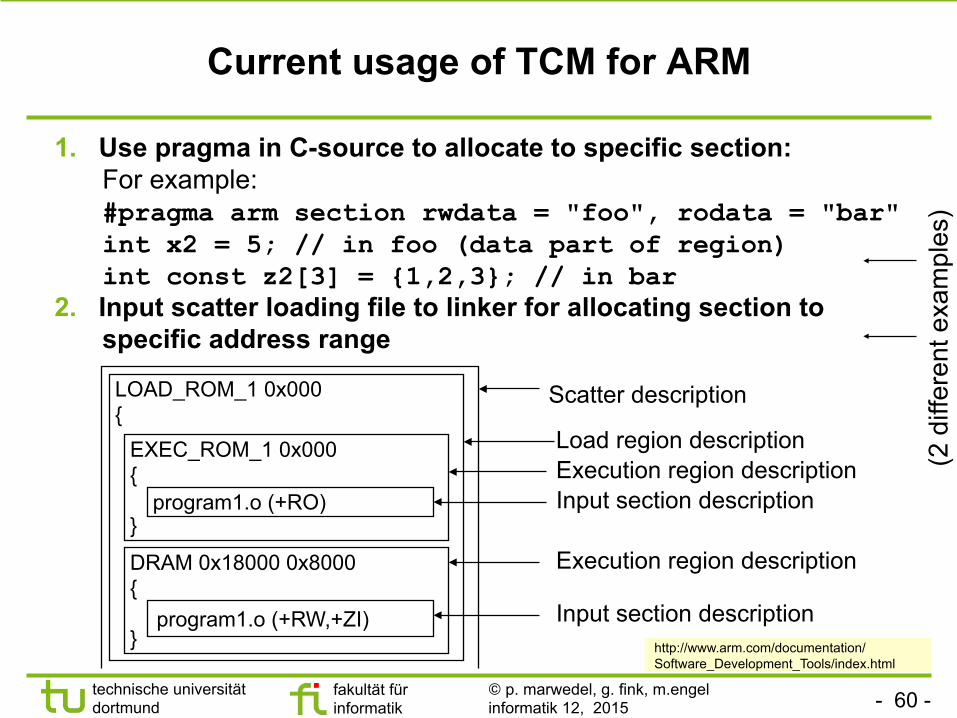
Current usage of TCM for ARM
1. Use pragma in C-source to allocate to specific section: For example: #pragma arm section rwdata = "foo", rodata = "bar" int x2 = 5; // in foo (data part of region) int const z2[3] = {1,2,3}; // in bar
2. Input scatter loading file to linker for allocating section to specific address range
http://www.arm.com/documentation/ Software_Development_Tools/index.html
(2 d
iffer
ent e
xam
ples
)
LOAD_ROM_1 0x000 {
EXEC_ROM_1 0x000 { }
program1.o (+RO)
program1.o (+RW,+ZI)
DRAM 0x18000 0x8000 { }
Scatter description
Load region description Execution region description
Input section description
Input section description
Execution region description
- 61 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
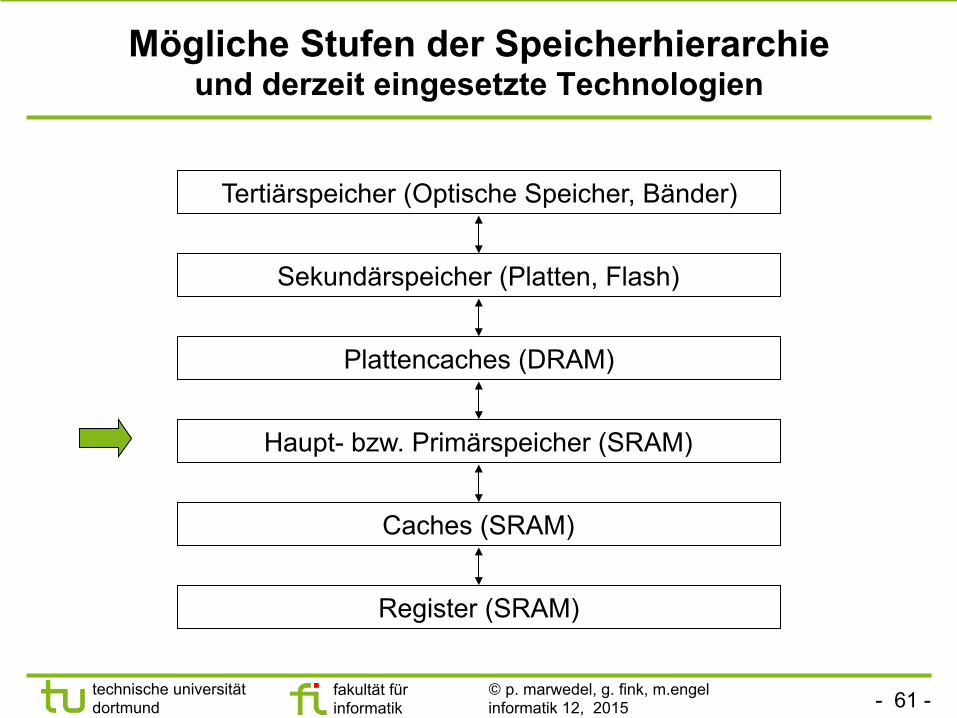
Mögliche Stufen der Speicherhierarchie und derzeit eingesetzte Technologien
Register (SRAM)
Caches (SRAM)
Haupt- bzw. Primärspeicher (SRAM)
Plattencaches (DRAM)
Sekundärspeicher (Platten, Flash)
Tertiärspeicher (Optische Speicher, Bänder)

- 62 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
Hautspeicherorganisation
Hauptspeicher ist weitere Ebene der Speicherhierarchie Für Leistung wichtig: Latenz und Bandbreite § Latenz relevant für Kosten eines Fehlzugriffs auf Cache § Bandbreite wichtig in Kombination mit ...
• großem L2-Cache ... • der große Cache-Blöcke verwendet.
F Große Transfereinheiten zwischen Cache und Hauptspeicher, kein wortweiser Zugriff! Verringerung der Latenz aufwendig Verbesserung der Bandbreite durch geeignete Organisation des Speichers (relativ leicht) möglich
- 63 - technische universität dortmund
fakultät für informatik
© p. marwedel, g. fink, m.engel informatik 12, 2015
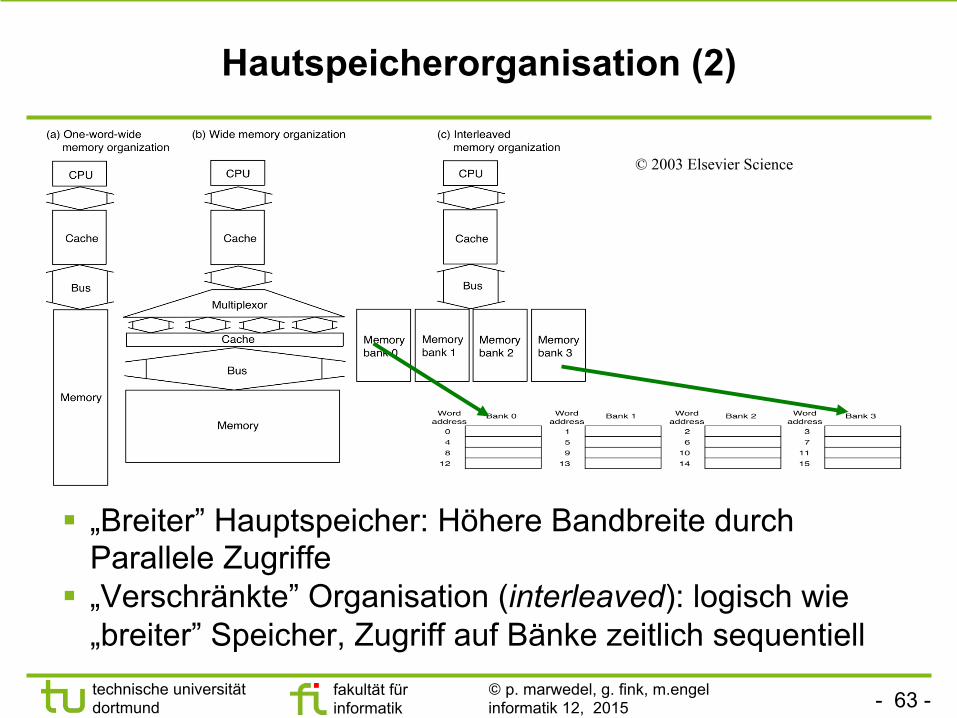
Hautspeicherorganisation (2)
§ „Breiter” Hauptspeicher: Höhere Bandbreite durch Parallele Zugriffe
§ „Verschränkte” Organisation (interleaved): logisch wie „breiter” Speicher, Zugriff auf Bänke zeitlich sequentiell
© 2003 Elsevier Science


















