
Separate Morphologiebehandlung als Methode zur ... · Hiermit erkl are ich, dass ich die...
57
Universit¨ at Stuttgart Institut f¨ ur Maschinelle Sprachverarbeitung Azenbergstraße 12, 70174 Stuttgart Separate Morphologiebehandlung als Methode zur Verbesserung statistischer maschineller ¨ Ubersetzung Marion Weller Studienarbeit Nr. 84 11.02.09 - 11.05.09 Betreuer: Dr. Alexander Fraser Dr. Aoife Cahill Pr¨ ufer: Prof. Dr. Hinrich Sch¨ utze
Transcript of Separate Morphologiebehandlung als Methode zur ... · Hiermit erkl are ich, dass ich die...

Universitat StuttgartInstitut fur Maschinelle Sprachverarbeitung
Azenbergstraße 12, 70174 Stuttgart
Separate Morphologiebehandlungals Methode zur Verbesserung
statistischer maschineller Ubersetzung
Marion Weller
Studienarbeit Nr. 84
11.02.09 - 11.05.09
Betreuer:Dr. Alexander Fraser
Dr. Aoife Cahill
Prufer:Prof. Dr. Hinrich Schutze


Hiermit erklare ich, dass ich die vorliegende Arbeit selbstandig verfassthabe und dabei keine andere als die angegebene Literatur verwendet habe.Alle Zitate und sinngemaßen Entlehnungen sind als solche unter genauerAngabe der Quelle gekennzeichnet.


Inhaltsverzeichnis
1 Einleitung 11.1 Ahnliche Arbeiten auf diesem Gebiet . . . . . . . . . . . . . . 21.2 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Reprasentation der fur die Ubersetzung benutzten Trai-ningsdaten . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2 Berechnung der flektierten Formen . . . . . . . . . . . 51.3 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Begriffserklarungen 82.1 n-Gramm-Modelle . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Hidden-Markov-Modelle und Viterbi-Algorithmus . . . . . . . 92.3 SRI Language Modeling Toolkit . . . . . . . . . . . . . . . . . 11
2.3.1 Demonstration an Beispieldaten . . . . . . . . . . . . 112.4 SMOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Baseline 133.1 Durchfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Wortstamme und Map-Eintrage mit SMOR . . . . . . . . . . 15
3.2.1 Behandlung falscher Wortformen . . . . . . . . . . . . 163.3 Auswertung der Baseline . . . . . . . . . . . . . . . . . . . . . 16
4 Training und Generierung mit POS-Tags 184.1 Tagbasierte Methode ohne Einbindung zusatzlicher Informa-
tionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.1.1 Vorbereitung des Trainingskorpus und der Map . . . . 184.1.2 Generierung . . . . . . . . . . . . . . . . . . . . . . . . 214.1.3 Erste Ergebnisse . . . . . . . . . . . . . . . . . . . . . 21
4.2 Einbinden von Informationen aus Quell- und Zielsprache . . . 224.2.1 In der Zielsprache enthaltene Informationen . . . . . . 224.2.2 Numerusinformation bei Nomen . . . . . . . . . . . . 23
4.3 Trennung der annotierten Merkmale in unabhangige Einheiten 244.3.1 Aufbau der Trainingskorpora und Maps . . . . . . . . 24
5 Ergebnisse und Auswertung 265.1 Vergleich der verschiedenen Versionen . . . . . . . . . . . . . 26
5.1.1 Entfernen falscher Wortformen mit einer Wortliste . . 275.2 Einfluss der Trainingskorpusgroße und der Ordnung des Sprach-
modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28

5.3 Detaillierte Analyse der generierten Formen . . . . . . . . . . 295.3.1 Relativpronomen . . . . . . . . . . . . . . . . . . . . . 315.3.2 Kasus . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6 Modifikation der Berechnung des Kasusmerkmals 346.1 Behandlung von Genitiven . . . . . . . . . . . . . . . . . . . . 35
6.1.1 Erkennen von Genitiven im englischen Text . . . . . . 356.1.2 Auswertung . . . . . . . . . . . . . . . . . . . . . . . . 36
6.2 Kasusinformationen aus Verben . . . . . . . . . . . . . . . . . 38
7 Experiment: Anwendung des Verfahrens auf maschinell uber-setzten Text 397.1 Durchfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
7.1.1 Vergleich der unbearbeiteten Trainingsdaten mit demauf Wortstamme reduzierten Trainingskorpus . . . . . 40
7.2 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427.2.1 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . 43
8 Zusammenfassung und Ausblick 45
Literatur 47
A Tagliste 50
B Manuell entfernte Wortformen 50
C Prapositionen mit Genitiv 51

1 Einleitung
Die statistische Ubersetzung von Sprachen mit unterschiedlich morpholo-gischer Reichhaltigkeit stellt eine Herausforderung dar: Ausdrucke, die ineiner morphologiereichen Sprache durch Variation in Kasus, Genus, Nume-rus, Verbaspekt, usw. unterschiedliche Formen annehmen konnen, werdenin einer Sprache, deren Morphologie nur schwach ausgepragt ist, wenigerdifferenziert dargestellt. Die in der einen Sprache mit morphologischen Mit-teln ausgedruckten Informationen werden in der anderen Sprache entwederstark vereinfacht oder auf vollkommen andere Weise wiedergegeben. Sprachenmit schwach ausgepragter Morphologie haben zum Beispiel oft einen wenigflexiblen Satzbau, bei der die Subjekt- und Objektpositionen weitgehendvorgegeben sind.
Dies hat zur Folge, dass bei der Ubersetzung von einer morphologiearmenin eine morphologiereiche Sprache die Worte der Quellsprache nicht diebenotigten Informationen enthalten, um mit einem statistischen Verfahrendie entsprechend komplexeren Worter der Zielsprache auswahlen zu konnen.Durch die Reichhaltigkeit der Zielsprache kommen weiterhin viele Ober-flachenformen eines Wortstammes auch in einem sehr großen Trainingstextuberhaupt nicht vor. Dies ist ein Problem, das beide Ubersetzungsrichtungenbetrifft: Bei einer Ubersetzung in die morphologiereiche Sprache wird es da-durch in vielen Fallen unmoglich, die richtige Form fur einen neuen Kontextin einem ubersetzten Satz zu finden. In umgekehrter Richtung kann ein Wort,welches in den Trainingsdaten nicht enthalten ist, nicht ubersetzt werden.Durch Vereinfachen des Trainingstextes soll eine allgemeine Verbesserungder Ubersetzungsqualitat herbeigefuhrt werden.
In der vorliegenden Arbeit soll untersucht werden, in welchem Maße esmoglich ist, eine Ubersetzung in vereinfachtes, d.h. um morphologische Merk-male reduziertes Deutsch durchzufuhren, um dann in einem zweiten Schrittdie fehlende Morphologie zu berechnen und flektierte Formen zu generieren.Als Quellsprache wird hierbei in einigen Experimenten Englisch benutzt, derAnsatz soll von der Auswahl der Quellsprache jedoch weitgehend unabhangigsein. Die Morphologiegenerierung wird an Referenzsatzen durchgefuhrt, umzu gewahrleisten, dass andere Aspekte die Analyse nicht beeinflussen. Als Bei-spiel hierfur ware unter anderem die fehlerhafte Satzstellung von maschinellubersetzten Satzen zu nennen.
Ziel der Arbeit ist es, Phrasen zu generieren, die den Agreementsbe-dingungen des Deutschen genugen. Es wird gezeigt, dass die Berechnungmorphologischer Werte mit einem auf POS-Tags und morphologische Beschrei-bung reduzierten Trainingstext einen rein wortbasierten Ansatz ubertrifft.
1

Mit einem Trainingstext, der nicht ausschließlich aus POS-Tags besteht,sondern Verben und Prapositionen als Informationstrager fur das MerkmalKasus enthalt, sowie mit Vorgabe des Merkmals Numerus bei Nomen wirddas beste Ergebnis erzielt.
1.1 Ahnliche Arbeiten auf diesem Gebiet
Diese Arbeit ist weitgehend an [Minkov et al., 2007] angelehnt. Die Autorenbetrachten die Ubersetzung vom Englischen ins Russische und Arabische, ihrAnsatz ist im Prinzip jedoch unabhangig von der Wahl der Sprachpaare. BeideZielsprachen weisen eine Vielzahl morphologischer Merkmale auf, die durcheine Kombination von Prafixen und Suffixen ausgedruckt werden. Weiterhingibt es verschiedene Arten von Agreement; ein russisches Verb zum Beispielmuss in Genus, Numerus und Person mit dem Subjekt ubereinstimmen undfur die Flexion arabischer Verben ist es zusatzlich in einigen Fallen relevant,ob das Subjekt menschlich ist oder nicht.
Fur jedes Oberflachenwort eines mit einem MU-System erhaltenen Satzesstehen drei Mengen zur Verfugung: Die Menge der moglichen Stamme einesWortes, die Menge der flektierten Formen derjenigen Stamme, die eine Ober-flachenform besitzen kann, sowie die Menge der morphologischen Analysendes Wortes. Weiterhin ist das Wortalignment zur Quellsprache bekannt,ebenso syntaktische Analysen beider Sprachen. Die Wahrscheinlichkeit einerSequenz flektierter Formen wird mithilfe eines Markov-Modells aufgrundder vorhergehenden flektierten Formen bestimmt. Zusatzlich zu flektiertenFormen wird auch eine morphologische Analyse bestimmt. Dies ermoglicht es,das Agreement in einem Merkmal aus den schon berechneten Werten diesesMerkmals in vorhergehenden Positionen abzuleiten. Die benutzten morpho-logischen Merkmale werden in zwei Kategorien eingeteilt: monolinguale undbilinguale Merkmale. Fur die monolingualen Informationen eines Wortes wirdder Stamm eines Wortes betrachtet, die Stamme der beiden umgebendenWorter und die morphologische Analyse der beiden vorhergehenden Worter,sowie der Stamm des Elternknotens. Die bilingualen Merkmale eines Wortesumfassen die mit ihm alignierten Worte in der Quellsprache sowie deren un-mittelbare Nachbarworter. Bestimmte Strukturen in der Quellsprache konnenAufschluss uber morphologische Merkmale geben. Aus dem Vorhandenseineiner Praposition im Englischen beispielsweise kann die Notwendigkeit einesprapositionalen Prafixes im Arabischen abgeleitet werden. Die Autoren be-nutzen gultige, d.h.manuell erstellte Ubersetzungen fur ihre Experimente underreichen eine Genauigkeit von 91,5% (englisch-russisch), beziehungsweise73,3% (englisch-arabisch). In [Toutanova et al., 2008] wird das Verfahren
2

erfolgreich in ein MU-System integriert.Eine fruhere Arbeit von [Toutanova and Suzuki, 2006] beschaftigt sich
mit der Generierung von kasusmarkierenden Partikeln im Japanischen beiUbersetzung aus dem Englischen. Japanische Partikel haben im Allgemeinenkeine entsprechenden Ubersetzungen. Ein Klassifizierer bestimmt zunachst,ob eine Phrase einen Partikel benotigt und wahlt dann gegebenenfalls einenaus einer vorgegebenen Menge aus. Die Abhangigkeit verschiedener Partikeluntereinander muss dabei berucksichtigt werden.
[Fraser, 2009] betrachtet morphosyntaktische Aspekte bei beiden Uberset-zungsrichtungen Deutsch-Englisch. Um die unterschiedlichen Wortstellungenvon deutschen und englischen Satzen anzugleichen, wird die Satzstellung imdeutschen Trainingstext wie auch in den Testsatzen der englischen Wortstel-lung angepasst. Der deutsche Trainingstext wird außerdem stark vereinfacht:Durch das Eliminieren von Suffixen werden morphologische Merkmale, die furdie Ubersetzung nicht wichtig sind, entfernt und so die Anzahl der Wortfor-men reduziert. Weiterhin werden Komposita in ihre Komponenten aufgeteilt.Englische Satze werden zuerst in dieses vereinfachte Deutsch ubersetzt, umsie in einem zweiten Schritt in flektiertes Deutsch zu ubersetzen. Dabeimussen zuerst die geteilten Komposita wiederhergestellt und danach Fle-xionssuffixe bestimmt werden. Mit einem parallelen Trainingskorpus ausflektiertem und vereinfachten Deutsch wird die Ubersetzung in flektiertesDeutsch durchgefuhrt.
[Popovic and Ney, 2004] untersuchen die Ubersetzung ins Englische ausden Sprachen Spanisch, Katalanisch und Serbisch durch Reduktion vonWortformen auf Stammformen. Offene Wortklassen im Serbischen weiseneine Vielzahl von Suffixen auf, deren Bedeutung nicht zur Ubersetzung insEnglische beitragt. Sie konnen daher entfernt werden. Im Gegensatz dazuenthalten die Endungen spanischer und katalanischer Verben Informationenuber Person und Zeit, welche fur die Ubersetzung von Bedeutung sind. Eineflektierte Verbform wird daher durch ihren Stamm sowie eine Sequenz vonTags mit morphologischen Angaben ersetzt. Dadurch wird nicht nur dieAnzahl der flektierten Formen reduziert, auch Ubersetzungsfehler, die durchden haufigen Verzicht der Subjektperson im Spanischen, bzw. Katalanischenentstehen, konnen verringert werden. Fur die Ubersetzung aus allen dreiSprachen kann eine deutliche Verbesserung festgestellt werden.
Ein ahnliches Vorgehen beschreiben auch [El-Kahlout and Oflazer, 2006]in ihrer Arbeit uber die Ubersetzung vom Englischen ins Turkische. DaTurkisch eine agglutinierende Sprache ist, konnen sehr viele Wortformengebildet werden. Insbesondere Verben und Nomen konnen Hunderte flektierteund abgeleitete Formen haben. Die Autoren reduzieren komplexe Wortformen
3

Trainings-korpus
EN
Trainings-korpus
DEvereinfacht:
Reduktion aufWortstämme
und POS-Tags
TextEN
TextDE
(vereinf.)Übersetzung
TextDE
POS-Tags TextDE
TrainingskorpusDE
Pos-Tags mitMorphologie
Berechnen einer Merk-malskombination für
jedes Tag Generierung flektierter
Formen
Simulation der Morphologie-ergänzung mit Referenzsätzen
TextPOS-Tags
Abbildung 1: Ubersetzung aus dem Englischen mit aligniertem Parallelkorpusin vereinfachtes Deutsch und anschließende Morphologieerganzung. Fur dasUbertragen der Problemstellung auf Referenzsatze wird das aus der Ausgabeeines MU-Systems ableitbare Format aus POS-Tags angenommen.
auf ihren Stamm und eine Sequenz aus Symbolen, die die zugrunde liegendenmorphologischen Prozesse beschreibt. Ziel ist eine drastische Reduktion derOberflachenformen und das Erkennen von Relationen zwischen Morphemenund Funktionswortern in Quell- und Zielsprache. Die von einem statistischenMU-System produzierte Ausgabe besteht aus Wortstammen, gefolgt voneiner Sequenz aus Morphomen. Mithilfe morphologischer Regeln wird dieseAusgabe in eine Abfolge gultiger Worter uberfuhrt.
1.2 Aufbau der Arbeit
Im Anschluss an die Einleitung werden die verwendeten Werkzeuge sowiezugrunde liegende Modelle und Algorithmen vorgestellt. Darauf folgt dieModellierung einer Baseline. Die Berechnung der morphologischen Features,sowie die Generierung der flektierten Formen, bilden den Hauptteil derArbeit. Diese Berechnungen werden an korrekten Satzen durchgefuhrt; am
4

Ende der Arbeit soll das Verfahren auch auf maschinell ubersetzte, d.h.ungrammatische Satze angewandt werden.
Abbildung 1 gibt einen Uberblick uber das Gesamtkonzept dieser Arbeitund wie die vorgestellten Schritte darin einzuordnen sind. Grundlegende Ideehierbei ist es, zunachst eine Ubersetzung in eine vereinfachte Reprasentationder Zielsprache anzufertigen. Ausgehend von dieser Reprasentation wird eineBeschreibung der Worter des Zielsatzes berechnet: Dazu wird die Ausgabe desMU-Systems in eine Darstellung aus POS-Tags uberfuhrt. Die aus POS-Tagsbestehenden Trainingsdaten bilden die Grundlage fur die Berechnung einerMerkmalskombination fur jedes Tag des Satzes. Mit den Merkmalen und demWortstamm als Eingabe fur ein Generierungswerkzeug werden schließlichdie flektierten Wortformen gebildet. Fur die Morphologieerganzung mitReferenzsatzen wird das Format aus POS-Tags angenommen, eine detaillierteBeschreibung folgt in Abschnitt 1.2.2.
1.2.1 Reprasentation der fur die Ubersetzung benutzten Trai-ningsdaten
Die Vereinfachung des Trainingstextes besteht darin, jede Oberflachenformdurch ihren Wortstamm, ihre Wortart und in einigen Fallen durch eineSequenz aus einigen morphologischen Informationen zu ersetzen. Die Mengeder enthaltenen Informationen ist von der Wortart abhangig; ein Nomenzum Beispiel hat - bis auf wenige Ausnahmen - ein eindeutiges Geschlecht.Daher kann das Merkmal Genus als ein Teil des Stammes aufgefasst werden.Bei Artikeln, Adjektiven, usw. kann dieses Merkmal jedoch beliebige andereWerte annehmen; entscheidend dafur ist der Kontext, in dem das Wortauftritt. Der Wert wird daher bei diesen Wortern nicht angegeben, sondernerst im zweiten Schritt berechnet. Ahnliches gilt fur den Numerus einesNomens: er wird durch den Numerus des jeweiligen Nomens der Quellsprachebestimmt und muss somit in der Ausgabe der Ubersetzung enthalten sein.
1.2.2 Berechnung der flektierten Formen
Nominal- und Prapositionalphrasen im Deutschen stimmen in Numerus, Ka-sus und Genus miteinander uberein. Weiterhin bestimmt ein Artikelwort dieArt der Flexion (starke oder schwache Flexion). Ebenso stimmt das Subjektim Numerus mit dem finiten Verb uberein. Außerdem gibt es verschiedeneFormen weiterer Abhangigkeiten, wie zum Beispiel die zwischen Relativpro-nomen und dem Nomen, auf das es sich bezieht. Sie werden ebenfalls imVerlauf der Arbeit angesprochen. All diesen Forderungen ist gemein, dass
5

Referenzsatz
Sequenz aus POS-Tags
Sequenz aus Wortstämmen
dass eine neue Entscheidung
KOUS ART-indef ADJ NN-fem-sg
dass ein neu EntscheidungPOS-Tags mit morpholog. BeschreibungKOUS ART-indef-fem-sg ADJ-fem-sg NN-fem-sg
Trainingskorpus: POS-Tags + Morphologie
ART-def-masc-pl ADJ-masc-pl NN-masc-plART-indef-fem-sg ADV ADJ-fem-sg NN-fem-sg
Wortstämme + morphologische Beschreibungdass ein-fem-sg neu-fem-sg Entscheidung-fem-sg
Satz mit flektierten Formendass eine neue Entscheidung
Generierung der flektierten Formenmit SMOR
1
2
3 4
5
6
Abbildung 2: Ubersicht uber die Generierung der Werte fur Genus undNumerus an Referenzsatzen. Die dargestellten Schritte entsprechen den TeilenBerechnen von Merkmalskombinationen und Generierung von Wortformenaus Abbildung 1.
sie im Allgemeinen nicht von dem tatsachlichen Wort abhangen, sondernvon den morphologischen Eigenschaften der Worter in ihrer Umgebung. Dasbedeutet zum Beispiel, dass ein Adjektiv, das nach einem Artikel und voreinem Nomen steht, hochstwahrscheinlich die gleichen Werte fur Genus, Ka-sus, Numerus und Art der Flexion besitzt, wie die beiden Worter, die esumgeben - unabhangig vom tatsachlichen Wortlaut dieser Phrase. DiesenUmstand kann man dazu nutzen, die fehlende Morphologie zu berechnen.
Abbildung 2 zeigt den Ablauf der einzelnen Schritte. Zunachst wirdjedes Wort des Satzes durch sein POS-Tag und seinen Wortstamm ersetzt(Schritte 1−3). Die Folge aus POS-Tags bildet die Eingabe fur den nachstenSchritt, in dem fur jedes Tag eine Kombination aus den in den Trainingsdatenenthaltenen Merkmalen mittels eines Sprachmodells berechnet wird. Box 4zeigt das Ergebnis fur Numerus und Genus. Die Wahrscheinlichkeit einerMerkmalskombination eines Wortes wird durch die Merkmalskombinationen
6

der vorausgehenden Worter bedingt. Durch die Vorgabe einzelner Werte anbestimmten Stellen im Satz kann die Auswahl beeinflusst und Teile einerMerkmalskombination erzwungen werden. In Box 2 in Abbildung 2 sindbeide Werte beim Nomen vorgegeben und werden auf das Adjektiv und denArtikel ubertragen. Unterschiedliche Durchfuhrungen dieser Grundidee sowieVariationen in der Gestaltung des Trainingstextes bilden die Grundlage derim Verlauf der Arbeit beschriebenen Experimente.
Die ermittelte Merkmalskombination und der Wortstamm werden zueiner vollstandigen Beschreibung des Wortes zusammengefugt (Box 5). Siebildet die Eingabe fur das Generierungswerkzeug SMOR (siehe Kapitel 2.4),mit dem schließlich die flektierte Formen generiert werden (Box 6).
Die ermittelte morphologische Beschreibung einer Wortform ist un-abhangig von dem tatsachlichen Vorkommen dieser Wortform im ursprungli-chen, unbearbeiteten Trainingstext. Daher ist es moglich, auch solche Wortfor-men zu generieren, die im Trainigskorpus nicht vorkommen. Das Ubersetzenin ungesehene Wortformen ist bei statistischer Ubersetzung ublicherweisenicht moglich ([Koehn et al., 2003]). [Koehn and Hoang, 2007] beschreibenjedoch einen Ansatz, bei dem jedes Wort durch einen Vektor aus Eigenschaf-ten wie Wortart, Lemma und morphologische Analyse reprasentiert wird.Dies ermoglicht eine getrennte Ubersetzung von Wortlemma und Morphologieund die anschließende Generierung einer Oberflachenform.
1.3 Beispiele
Die im Folgenden aufgefuhrten Satze wurden aus dem Englischen ubersetzt.Im deutschen Teil des Paralleltextes1 wurde lediglich eine Angleichung deralten an die neue Rechtschreibung durchgefuhrt. Beispiele (1) und (2) zeigenFalle, in denen Agreementsbedingungen verletzt sind. Es ist kein Kontextdenkbar, in dem die Sequenz dieser schwerwiegenden Vorfall vorkommenkonnte. Moglich ware z.B. entweder dieser schwerwiegende Vorfall (Sg) oderdiese schwerwiegenden Vorfalle (Pl), nicht aber eine Kombination aus beidem.Ahnliches gilt fur den Ausschnitt Definition dieser Mehrwert in (2).
(1) Ich kann Ihnen mitteilen , dass Frau Fontaine - das wurde mir mitgeteilt ,und ich mochte mich den im Namen des Prasidiums - dieser schwerwiegendenVorfall zutiefst bedauert
(2) Diese Bereiche ausgewahlt werden durch die Anwendung der Kriterien zurDefinition dieser Mehrwert bei der Schaffung von Ranglisten und Ausgren-zung .
11502301 Satze aus Europarl, Alignment mit GIZA++, Standard Moses System
7

(3) In einem anderen Fall , die ich mit eigenen Augen gesehen , ...
(4) ... , wenn die europaischen Institutionen und das Europaische Parlamentdas peruanische Volk helfen ,
(3) zeigt ein Beispiel mit einem falschen Relativpronomen, wahrend in (4)die einzelnen Phrasen zwar wohlgeformt sind, aber die Objekt-NP das pe-ruanische Volk den falschen Kasus hat. Die Probleme in (1)-(3) sollen durchden beschriebenen Ansatz gelost werden. Fur (4) kann mit dem vorgestelltenAnsatz keine ausreichende Losung gefunden werden, da es sich nicht um einrein morphologisches, sondern auch um ein syntaktisches Problem handelt.
Auffallig bei diesen Satzen ist insbesondere die fehlerhafte Satzstellungund das Fehlen von Verben. Da fur die Berechnung der morphologischenFeatures der Satzbau eine wesentliche Rolle spielt, wurde die Berechnung anReferenzsatzen simuliert. Das bedeutet, dass nicht die tatsachliche Ausgabeeines MU-Systems benutzt wurde, sondern korrekte, von einem menschlichenUbersetzer erstellte Satze. Indem fur jedes Wort dieser Satze der Stammund das POS-Tag ermittelt wird, wird das erwartete Format des maschinellubersetzten Textes konstruiert. So soll sichergestellt werden, dass die Feh-leranalyse der Morphologieerganzung nicht durch andere Faktoren verzerrtwird.
2 Begriffserklarungen
Im folgenden Kapitel wird ein Uberblick uber Sprachmodelle, Hidden-Markov-Modelle und den Viterbi-Algorithmus, sowie die fur die Experimente benutzteSoftware gegeben. Außerdem wird SMOR vorgestellt, ein Werkzeug, mit demWortformen generiert und morphologisch analysiert werden konnen.
2.1 n-Gramm-Modelle
Ein Sprachmodell beschreibt die Wahrscheinlichkeit fur eine Wortfolge aufGrundlage der im Trainingskorpus beobachteten Haufigkeiten der Worter,bzw. Wortsequenzen. Bei einem Trigramm-Modell wird die Wahrscheinlichkeiteines Wortes w i durch die beiden vorhergehenden Worter w i−1 und w i−2
bedingt, fur einen Satz der Lange l ergibt sich die folgende Wahrscheinlichkeit:
p(w1 ...w l ) =∏
i=1lp(w i |w i−2 w i−1 )
Die Wahrscheinlichkeit p(wi |wi−2wi−1 ) wird als Quotient aus der Anzahlder Trigramme w i−2 w i−1 w i und der Anzahl aller beobachteten Trigrammew i−2 w i−1 wk berechnet. Man nennt dies einen Maximum-Likelihood-Schatzer;
8

mit ihm erhalt man die Parameter des Modells, mit dem die Wahrscheinlich-keit der Trainingsdaten am hochsten ist.
Die Wahrscheinlichkeit eines Satzes, der eine Wortkombination enthalt,die im Trainingstext nicht beobachtet werden konnte, wird auf 0 geschatzt. Da-her mussen Pseudo-Wahrscheinlichkeiten fur nicht vorkommende n-Grammegeschatzt werden. In den in den folgenden Kapiteln beschriebenen Experimen-ten wurde das Glattungsverfahren nach Kneser-Ney [Kneser and Ney, 1995]benutzt, das eine Erweiterung der Methode des absolute Discounting ist. Beimabsolute Discounting wird ein fester Betrag von allen positiven Haufigkeitenabgezogen und auf gleichmaßig auf nicht auftretende Ereignisse verteilt. Beider Kneser-Ney-Glattung wird die Summe der abgezogenen Betrage nichtgleichmaßig verteilt, sondern gemaß der Anzahl der Worter, auf die es folgt.So wird erreicht, dass ein Wort, welches zwar haufig, aber nur in wenigenKontexten auftritt, eine vergleichsweise geringe Wahrscheinlichkeit in ei-nem nichtbeobachteten Kontext erhalt (vgl. [Manning and Schutze, 1999],[Chen and Goodman, 1998], [Nugues, 2006]).
2.2 Hidden-Markov-Modelle und Viterbi-Algorithmus
Eine Markovkette ist eine Sequenz {X 1 ,X 2 , ...,X T}, wobei X t eine Zu-fallsvariable zur Zeit t ist. In linguistischen Anwendungen ist t als Positioneines Wortes in einem Satz der Lange T zu verstehen. X nimmt Werte ausder endlichen Zustandsmenge {q1 , ..., qN } an. Eine Markov-Kette hat diefolgenden Eigenschaften:
• Jeder Zustand hangt von einer festen Anzahl vorheriger Zustande ab(Gedachtnislosigkeit). In einer Markovkette erster Ordnung ist dies einZustand:P(X t = q j |X 1 , ...,X t−1 ) = P(X t = q j |X t−1 )
• Eine Markov-Kette kann als Ubergangsmatrix A beschrieben werden:a ij = P(X t = q j |X t−1 = q i ) mit 1 ≤ i , j ≤ N, aij ≥ 0 ,
∑i=1
N a ij = 1
• Die Wahrscheinlichkeit des Startzustandes betragt πi = P(X 1 = q i)mit
∑i=1
Nπi = 1
Markov-Ketten beschreiben zufallige Zustandsubergange in einem probabilis-tischen Automaten. Die Abfolge der Zustande entspricht dabei der Wortfolgein einem Satz der Lange T. Die Ubergangsmatrix einer Markov-Kette ersterOrdnung entspricht den Wahrscheinlichkeiten einer Bigramm-Modellierung.
Wahrend bei einer Markov-Kette die Zustande sichtbar sind, ist dies beieinem Hidden Markov Model nicht der Fall. Zu jedem Zeitpunkt t werden
9

jedoch, gemaß einer vom aktuellen Zustand abhangigen Wahrscheinlichkeits-verteilung, Ausgabesymbole erzeugt, die Ruckschlusse auf die Zustandsse-quenz zulassen. Die formale Definition eines Hidden-Markov-Modells ist dereiner Markov-Kette ahnlich; sie wird um einen zweiten Zufallsprozeß erganzt,namlich die Eigenschaft, Symbole auszugeben:
• Eine endliche Zustandsmenge S = {q1 , q2 , ..., qN }
• Ein endliches Ausgabealphabet V = {v1 , v2 , ..., vM }
• Die beobachtete Sequenz O = {o1 , o2 , ..., oT} mit oi ∈ V
• Die Ubergangsmatrix A = {a ij }
• B = {bj (vk )} beschreibt die Wahrscheinlichkeit, das Symbol vk inZustand q j auszugeben
• Die Wahrscheinlichkeiten der Startzustande Π = {πi}
Hidden-Markov-Modelle werden oft fur Part-of-Speech-Tagging eingesetzt;dabei entspricht die Zustandsmenge S dem Tagset, wahrend die beobachteteSequenz, die Worter, aus dem Vokabular V stammen. Fur eine beobachtbareWortfolge O wird eine Zustandsabfolge berechnet. Dies deckt sich mit demin den anschließenden Kapiteln beschriebenen Problem, morphologischeInformationen an Wortstamme oder POS-Tags zu annotieren.
Fur Hidden-Markov-Modelle gibt es drei grundlegende Problemstellungen.Zum einen ist dies, die Wahrscheinlichkeit fur eine beobachtete Sequenz zuberechnen. Die zweite Problemstellung ist das Lernen der Parameter einesHidden-Markov-Modells, die die beobachtete Sequenz am besten erklaren.Das dritte Problem ist die Frage nach der wahrscheinlichsten Zustandssequenzfur eine gegebene Ausgabesequenz und ein gegebenes Modell λ. Sie kann mitdem Viterbi-Algorithmus gelost werden (vgl. [Manning and Schutze, 1999],[Nugues, 2006]).
Die Große δj (t) = max s1 ...st−1 P(s1 ...s t−1 , s t = q j , o1 ...ot−1 |λ) beschreibtdie maximale Wahrscheinlichkeit fur die ersten t Beobachtungen unter derBedingung, dass der Pfad zum Zeitpunkt t in Zustand q j endet. Eine Va-riable Ψ j (t) speichert den letzten Zustand dieser Folge vor dem Zustandq j . Im ersten der drei Schritte des Viterbi-Algorithmus werden die Werteinitialisiert.
δj (1 ) = πj mit 1 ≤ j ≤ N
Im Induktionsschritt von t nach t+1 wird erneut das Maximum ermitteltund der Pfad in die Speichervariable Ψ aufgenommen.
10

δj (t + 1 ) = max 1≤i≤N δi(t)a ij bj (ot+1 ) mit 1 ≤ j ≤ N
Ψ j (t + 1 ) = arg max1≤i≤N δi(t)a ij bj (ot+1 ) mit 1 ≤ j ≤ N
Schließlich muss die optimale Zustandsabfolge gefunden werden. Dies ge-schieht durch Backtracking.
P(s∗) = max 1≤i≤N δi(T )
s∗T = arg max1≤i≤N δi(T )
s∗T−1 = Ψ s∗T (T ), s∗T−2 = Ψ s∗T−1 (T − 1 ), ...
2.3 SRI Language Modeling Toolkit
Das SRI Language Modeling Toolkit (SRILM) [Stolcke, 2002] ist eine freiverfugbare Sammlung von Programmen fur statistische Sprachverarbeitung.Das Erstellen von n-gramm-Modellen ermoglicht die Funktion ngram-count.
Fur das Anbringen von Tags mit morphologischen Informationen anWortstamme oder POS-Tags eignet sich die Funktion disambig. Sie ubersetzteine Folge von Token aus einem Vokabular V1 in eine Folge von Token auseinem Vokabular V2. Die Tokenfolge aus V1 entspricht dabei der beobach-teten Sequenz O = {o1 , o2 , ...} und V2 der Zustandsmenge S eines HiddenMarkov Modells. Die resultierende Folge aus V2 ist die wahrscheinlichsteZustandssequenz des Hidden Markov Models fur die beobachtete Folge ausV1. disambig benotigt als Eingabeparameter das mit ngram-count berechneteSprachmodell, die Ordnung n, einen Text aus Token aus V1 und ein Lexikon,das angibt, auf welche Token der Menge V2 ein Token aus V1 abgebildetwird. Dieses Lexikon wird im Folgenden Map genannt, es kann neben derAufzahlung der Token aus V2 auch ihre Vorkommenshaufigkeiten enthalten.
2.3.1 Demonstration an Beispieldaten
Mit dem Beispiel in Tabelle 1 soll die Berechnung eines Wertes fur NN indem Satz der NN schwimmt mit uberschaubaren Trainingsdaten verdeutlichtwerden. NN dient als Platzhalter fur das Lemma Fisch und kann kanndie zwei Werte {Fisch, Fische} annehmen. Beide Formen kommen in denTrainingssatzen in verschiedenen Kontexten vor. Die beiden anderen Worterin dem Eingabesatz sind hier vorgegeben.
Die Funktion ngram-count fugt jedem Satz ein Anfangs- und ein Endsym-bol an. disambig ermittelt den wahrscheinlichsten Pfad durch die Zustands-menge V2, welche der ’rechten Seite’ der Map entspricht.
11
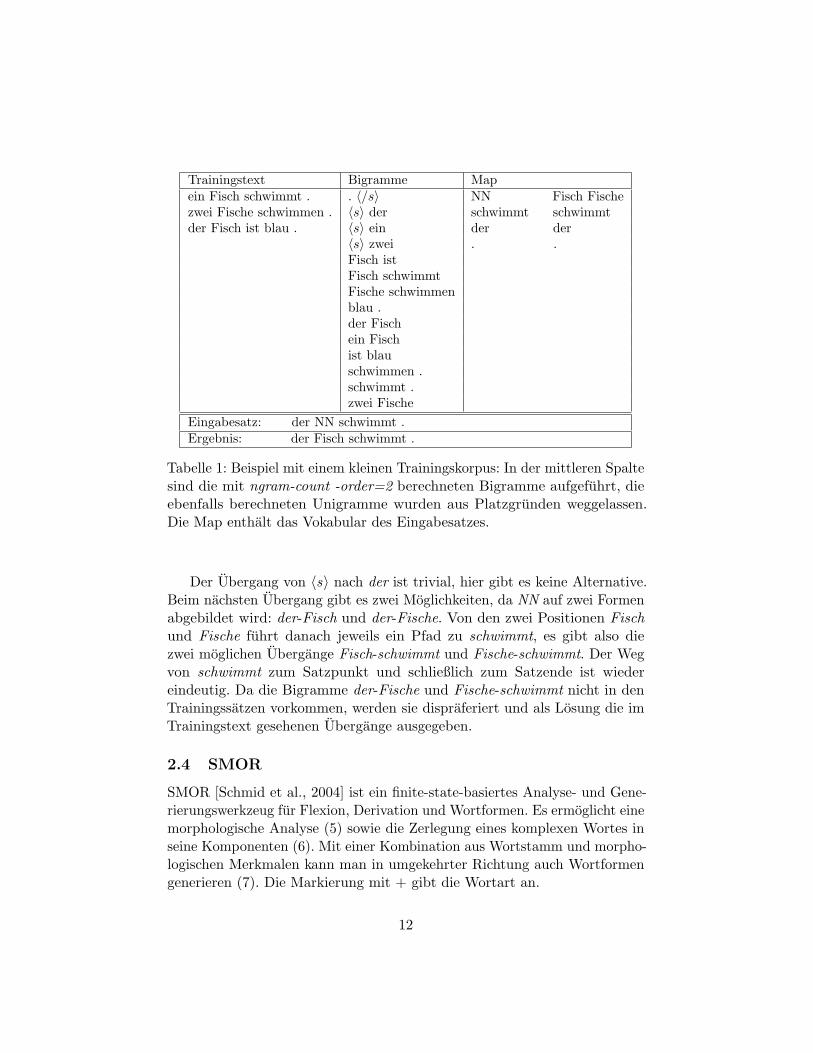
Trainingstext Bigramme Mapein Fisch schwimmt . . 〈/s〉 NN Fisch Fischezwei Fische schwimmen . 〈s〉 der schwimmt schwimmtder Fisch ist blau . 〈s〉 ein der der
〈s〉 zwei . .Fisch istFisch schwimmtFische schwimmenblau .der Fischein Fischist blauschwimmen .schwimmt .zwei Fische
Eingabesatz: der NN schwimmt .Ergebnis: der Fisch schwimmt .
Tabelle 1: Beispiel mit einem kleinen Trainingskorpus: In der mittleren Spaltesind die mit ngram-count -order=2 berechneten Bigramme aufgefuhrt, dieebenfalls berechneten Unigramme wurden aus Platzgrunden weggelassen.Die Map enthalt das Vokabular des Eingabesatzes.
Der Ubergang von 〈s〉 nach der ist trivial, hier gibt es keine Alternative.Beim nachsten Ubergang gibt es zwei Moglichkeiten, da NN auf zwei Formenabgebildet wird: der-Fisch und der-Fische. Von den zwei Positionen Fischund Fische fuhrt danach jeweils ein Pfad zu schwimmt, es gibt also diezwei moglichen Ubergange Fisch-schwimmt und Fische-schwimmt. Der Wegvon schwimmt zum Satzpunkt und schließlich zum Satzende ist wiedereindeutig. Da die Bigramme der-Fische und Fische-schwimmt nicht in denTrainingssatzen vorkommen, werden sie dispraferiert und als Losung die imTrainingstext gesehenen Ubergange ausgegeben.
2.4 SMOR
SMOR [Schmid et al., 2004] ist ein finite-state-basiertes Analyse- und Gene-rierungswerkzeug fur Flexion, Derivation und Wortformen. Es ermoglicht einemorphologische Analyse (5) sowie die Zerlegung eines komplexen Wortes inseine Komponenten (6). Mit einer Kombination aus Wortstamm und morpho-logischen Merkmalen kann man in umgekehrter Richtung auch Wortformengenerieren (7). Die Markierung mit + gibt die Wortart an.
12

(5) analyze : KindernKind<+NN><Neut><Dat><Pl>
(6) analyze : reibungslosemreiben<V>ung<NN><SUFF>los<SUFF><+ADJ><Pos><Neut><Dat><Sg><St>reiben<V>ung<NN><SUFF>los<SUFF><+ADJ><Pos><Masc><Dat><Sg><St>
(7) generate : Unterschied<+NN><Masc><Nom><Sg>Unterschied
Fur die Generierung von Nomen, Adjektiven, Pronomen und Artikelworternmussen der Wortstamm und eine Sequenz mit den Werten von Genus, Kasusund Numerus bekannt sein. In Fallen, wo ein Unterschied zwischen denjeweiligen Formen besteht, muss auch angegeben werden, ob stark (<St>)oder schwach (<Wk>) flektiert werden soll. Dies ist der Fall bei (8, 9), nichtaber bei (5) oder (7).
(8) analyze : AngestellterAngestellte<+NN><Masc><Nom><Sg><St>
Ein Angestellter kauft eine Zeitung.
(9) analyze : AngestellteAngestellte<+NN><Masc><Nom><Sg><Wk>
Der Angestellte kauft eine Zeitung.
Es gibt einen weiteren Wert NoGend, der dann benutzt wird, wenn eineForm fur Fem, Masc und Neut gleich ist, beispielsweise beim Artikelwortdie-Nom-Pl.
3 Baseline
Als untere Grenze fur das Funktionieren der Morphologieerganzung wirdmit der in 2.3.1 beschriebenen Methode die Realisierung von Wortstammenaus einer gegebenen Menge von flektierten Formen berechnet. Das bedeutet,dass in der Map fur einen Wortstamm jeweils alle Formen angegeben werden,die mit diesem Stamm gebildet werden konnen. Morphologische Merkmalewerden hier noch nicht explizit berucksichtigt: Es wird die in einem gegebenKontext wahrscheinlichste Form eines Stammes aus der Menge aller moglichenflektierten Formen ausgewahlt, nicht jedoch eine Form, die einer bestimmtenmorphologischen Beschreibung genugt.
Der Versuch soll zeigen, welche Qualitat mit einer rein statistischenMethode und ohne das Einbringen von linguististischem Wissen erreichtwerden kann, sowie Aufschluss daruber geben, welche Fehler und Problemehaufig auftreten.
13

3.1 Durchfuhrung
Die in den Testsatzen vorkommenden Nomen, Adjektive, Artikel, Possessiv-und Relativpronomen sowie Portemanteau-Prapositionen werden durch ihrenStamm ersetzt, (10) und (11). Der Stamm wird durch eine Analyse derWorter mit SMOR (siehe folgender Abschnitt) gewonnen. Er beinhaltet keineAngaben uber Numerus, Genus, Kasus und starke oder schwache Flexion. Furjeden dieser Stamme wird anschließend eine Liste generiert, die alle moglichenRealisierungen dieses Stammes enthalt. Alle ubrigen Worter werden auf sichselbst abgebildet (12). Die Menge dieser Eintrage ist die fur die Berechnungmit disambig benotigte Map. Variationen in Groß- und Kleinschreibungwerden durch die Reduktion auf den Stamm ausgeglichen, indem ein Wortunabhangig davon, ob es groß- oder kleingeschrieben wird, jeweils die gleicheAnalyse und damit den gleichen Mapeintrag erhalt. Dabei passiert es, dassein im Testsatz großgeschriebenes Wort durch ein kleingeschriebenes Wortersetzt wird.
(10) Es gibt Milliardensubventionen fur Wenige, die mit ihrenWindradern die Landschaft verschandeln.
(11) Es gibt Milliarde<NN>Subvention<+NN> fur<+PREPART>wenige<+INDEF><Pro> , die<+ART><Def> .mit ihre<+POSS>Wind<NN>Rad<+NN> die<+ART><Def> Landschaft<+NN> verschandeln .
(12) Milliarde<NN>Subvention<+NN> MilliardensubventionMilliardensubventionen
fur<+PREPART> fur furswenige<+INDEF><Pro> wenige wenigem wenigen weniger wenigesdie<+ART><Def> das dem den der des dieihre<+POSS> ihre ihrem ihren ihrer ihres ihrWind<NN>Rad<+NN> Windrad Windrader Windrads Windrades
WindradernLandschaft<+NN> Landschaft LandschaftenEs Esgibt gibt, ,mit mitverschandeln verschandeln. .
Aus dem Beispiel wird ersichtlich, dass keine tiefgehende Analyse stattfindet,sondern allein die Wortformen betrachtet werden. Das bedeutet zum Beispiel,dass das Relativpronomen in (10) nicht als solches dargestellt wird, sondernals definiter Artikel, der die gleiche Oberflachenform besitzt.
14

Fur alle Stamme, fur die in der Map mehrere flektierte Formen angegebensind, soll mit disambig jeweils diejenige ausgewahlt werden, die zusammen mitden restlichen Formen die wahrscheinlichste Wortfolge bildet. Jene Eintragein der Map, die nur eine flektierte Form haben, konnen als vorgegebenbetrachtet werden.
Die Berechnung mit einem Trigramm-Modell liefert fur den Satz (11) dasErgebnis (13).
(13) Es gibt Milliardensubventionen fur wenige , diemit ihrem Windrad die Landschaft verschandeln .
3.2 Wortstamme und Map-Eintrage mit SMOR
Da viele Worter des Deutschen eine ambige Oberflachenform haben konnen[Evert, 2004], erhalt man oft mehrere Analysen fur ein Wort (14). Da in denTestsatzen und in der Map Kasus, Genus und Numerus jedoch nicht benotigtwerden, konnen sie entfernt werden. So erhalt man in den meisten Falleneinen eindeutigen Stamm (15).
(14) analyze : LandschaftLandschaft<+NN><Fem><Dat><Sg>Landschaft<+NN><Fem><Acc><Sg>Landschaft<+NN><Fem><Gen><Sg>Landschaft<+NN><Fem><Nom><Sg>
(15) Landschaft<+NN>
Fur die Generierung der flektierten Formen werden fur jeden Wortstammalle Permutationen aus den Merkmalen Nom, Acc, Dat, Gen, Fem, Masc,Neut, NoGend, Sg, Pl und St, Wk, ∅ gebildet. Auf diese Weise erhalt manalle moglichen Formen eines Stammes und muss nicht berucksichtigen, obfur ein Wort z.B. das Merkmal St, Wk oder ∅ angegeben werden muss, oderob ein Wort uberhaupt eine Pluralform besitzt. Ungultige Sequenzen fuhrenzu keiner Generierung, bei mehrfach generierten Formen wird nur eine in dieMap aufgenommen.
Die Mapeintrage der Artikel, Pronomen und Prapositionen sind manuellerstellt. Verschiedene Analysen von beispielsweise der, die, das usw. alsArtikelwort oder Reflexivpronomen werden durch einen gemeinsamen Stammdargestellt. Da hier nur Oberflachenformen und keine Wortarten betrachtetwerden, ist die interne Reprasentation eines Stammes unwichtig.
15

3.2.1 Behandlung falscher Wortformen
Da SMOR nicht nur eine morphologische Analyse durchfuhrt, sondern auchden Wortstamm selbst untersucht, kann es vorkommen, dass fur eine Wort-form mehrere Wortstamme vorgeschlagen werden. Das ist dann problematisch,wenn einige dieser Analysen zu fehlerhaften Generierungen fuhren (16). Inumgekehrter Richtung ist es moglich, dass ausgehend von dem (korrekten)Wortstamm eines Kompositums mehrere Formen generiert werden, von denenunter Umstanden aber nur eine - Abfallprodukt in (17) - richtig ist.
(16) analyze> Burgerinnenburgen<V>Rinne<+NN><Fem><Nom><Pl>Burge<NN>Rinne<+NN><Fem><Nom><Pl>Burger<NN>in<SUFF><+NN><Fem><Nom><Pl>
generate> Burge<NN>Rinne<+NN><Fem><Nom><Sg>Burgenrinne Burgerinne
(17) generate> Abfall<NN>Produkt<+NN><Neut><Nom><Sg>Abfalleprodukt Abfallesprodukt Abfallprodukt Abfallsprodukt
Um die Menge der Falle wie in (16) moglichst gering zu halten, wurdeneinfache Analysen vorgezogen und Analysen, die eine Kombination ausmehreren Nomen, bzw, Verben vorschlagen, nach Moglichkeit verworfen.
Um fehlerhafte Generierungen wie in (17) zu entfernen, wurde mit Hilfedes Tree-Taggers [Schmid, 1994] das Lemma des Wortes ermittelt und mit dengenerierten Formen verglichen. Auf diese Weise konnen Formen mit falschemFugen-S herausgefiltert werden; Falle mit falscher Umlautung werden damitjedoch nicht zuverlassig erkannt. Es ist aber anzunehmen, dass eine falschgenerierte Wortform, die zusammen mit richtigen Wortformen zur Auswahlsteht, nur mit einer sehr geringen Wahrscheinlichkeit ausgewahlt wird, dasie im Trainingskorpus entweder gar nicht oder nur in bedeutend geringererZahl als die gultigen Wortformen vorkommt.
3.3 Auswertung der Baseline
In der Auszahlung berucksichtigt werden nur die Wortformen, die tatsachlichvon dem System vorhergesagt werden. Verben, Adverben, Konjunktionenusw. werden in der Auszahlung also nicht berucksichtigt. Eine Wortform giltdann als richtig, wenn sie mit dem entsprechenden Wort im Referenztextubereinstimmt. Dieser Ansatz berucksichtigt nicht die Tatsache, dass in eini-gen Fallen auch mehrere Formen richtig sein konnen, z.B. Entwicklung der
16

privaten Versicherungssysteme vs. Entwicklung des privaten Versicherungs-systems oder dass eine Wortform zwei mogliche Realisierungen haben kann,wie zum Beispiel Programms oder Programmes. Der Vergleich vorhergesagterWortformen mit der entsprechenden Wortform im Referenztext wird auch inden folgenden Versuchen als Auswertungsmethode eingesetzt.
Mit dem Trainingskorpus (10.193.376 Satze Zeitungstext) wurde ein Uni-gramm-Modell und ein Trigramm-Modell berechnet. Das Testset umfasst2000 Satze, 100 Satze wurden zusatzlich detaillierter untersucht. Bei derUnigramm-basierten Version stimmen 58,98% der ermittelten Wortformen,werden Trigramme benutzt, so sind 77,65% der ermittelten Wortformenkorrekt. Reduziert man die Trainingsdaten auf 1.222.918 Satze, was derGroße des spater benutzten Trainingskorpus entspricht, sinkt die Anzahlder mit Trigrammen berechneten richtigen Formen auf 74,56%, die Zahl derunigrammbasierten Methode andert sich fast nicht (58,62%). Diese Ergebnisselassen sich dadurch erklaren, dass viele Wortformen des Deutschen ambigsind; Worter mit der Endung -ung variieren beispielsweise nur im Numerus,nicht aber im Kasus (siehe auch Beispiel 14).
Kriterien sind neben der Anzahl richtiger Formen auch die Wohlgeformt-heit einzelner Phrasen und deren Ubereinstimmung in Kasus und Numerusmit dem Verb, sowie die Frage, ob Adjektive flektiert sind oder nicht, d.h.ob sie adverbial, pradikativ oder attributiv benutzt werden.
Bei der Durchfuhrung mit Trigrammen sind in 100 Satzen 74% der NPenwohlgeformt (18), im Gegesatz zu (19). Aber nur 57% der NPen stehen ineinem Kasus, der in Kombination mit dem vorkommendenVerb passend ist.
(18) zu Beginn dieser Sitzungsperiode
(19) eine vollstandiger Initiativbericht
Auffallig ist die hohe Anzahl von Genitiv-NPen, die haufig auch am Satzan-fang vorkommen (20). Die Anzahl der korrekten PPen betragt 67%; hierbeiist neben der Frage, ob die Praposition mit dem Artikel fusioniert, auchproblematisch, dass auf einige Prapositionen unterschiedliche Kasus folgenkonnen (21).
76% der Adjektive, die pradikativ oder adverbial benutzt werden unddaher unflektiert bleiben, werden korrekt gebildet. Satz (22) zeigt ein Beispielfur einen solchen Fehler.
(20) <s> der Verordnung ist im Grundsatz positiv zu bewerten, ...
(21) ... dass sich diese Verordnung sowohl auf allen Politikbereichenals auch auf alle Institutionen ... erstreckt.
(22) ... sein Wissen ist abhangigen von ...
17

4 Training und Generierung mit POS-Tags
Die Schwachen der Unigramm-basierten Baseline sind offensichtlich: JedesLemma wird durch die im Trainingskorpus am haufigsten beobacheteteRealisierung ersetzt; so ist zum Beispiel der die einzige in den Ergebnissatzenvorkommende Artikelform. Auch wenn durch das Benutzen von Trigrammenim Vergleich zu Unigrammen eine Verbesserung von knapp 19% erzieltwerden kann, sind jedoch auch hier Grenzen gesetzt, da es unmoglich ist, aufdiese Weise zusatzlich linguistisches Wissen oder in den Quellsprachsatzenenthaltene Informationen zu benutzen. Vor allem ist jedoch wunschenswert,dass Nominal- und Prapositionalphrasen wohlgeformt sind.
Die Wohlgeformtheit von Phrasen hangt nicht von ihrem Wortlaut ab,sondern von der Ubereinstimmung ihrer morphologischen Merkmale. Daherbestehen die Trainingsdaten im Folgenden aus POS-Tags mit Werten furKasus, Numerus, Genus und starker/schwacher Flexion. Die Eingabesatze ent-halten nur POS-Tags, ihre morpholgische Beschreibung soll ermittelt werden,um dann mit dem Wortstamm und den berechneten Werten eine flektierteForm zu generieren. Das Benutzen derart reduzierter Trainingsdaten bietetnicht nur die Moglichkeit, mehr Informationen zu benutzen und linguistischesWissen einzusetzen. Es ergibt sich auch eine gewisse Unabhangigkeit imVergleich mit einem aus normalem Text bestehenden Trainingskorpus, dajede Form eines Stammes gebildet werden kann und das System nicht auf dieFormen beschrankt ist, die tatsachlich in den Trainingsdaten vorkommen.
Es ist wichtig, sich daran zu erinnern, dass das Eingabeformat derTestsatze von korrekten Satzen abgeleitet wird, nicht von der Ausgabe einesstatistischen MU-Systems. Bei der Ubersetzung in vereinfachtes Deutsch(siehe Abbildung 1) ist die Wortart jedoch enthalten und die Ausgabe desMU-Systems kann in das Eingabeformat aus POS-Tags konvertiert werden.
4.1 Tagbasierte Methode ohne Einbindung zusatzlicher In-formationen
Die folgenden Abschnitte verdeutlichen die Idee des Arbeitens mit POS-Tagsund zeigen ihre Vorteile, aber auch die Notwendigkeit, Informationen ausder Zielsprache zu benutzen.
4.1.1 Vorbereitung des Trainingskorpus und der Map
Der Trainingstext wurde mit BitPar [Schmid, 2004] geparst und die POS-Tags extrahiert. Diese enthalten im Fall von Adjektiven, Nomen und Pro-
18

nomen auch Informationen uber Numerus und Kasus. Einige Tags wurdenleicht vereinfacht indem verschiedene Typen eines Tags einer Kategorie, z.B.NN-NK, NN-HD, NN-CJ, usw. zu jeweils einem Tag (NN) zusammenge-fasst wurden. Eine Liste der benutzen Tags ist in Abschnitt A des Anhangsaufgefuhrt.
Das notwendige Merkmal Genus war in der Ausgabe des Parsers nichtenthalten und wurde nachtraglich annotiert. Die Analyse mit SMOR liefertdas Genus eines Nomens fast immer eindeutig, nicht jedoch bei Artikeln undAdjektiven. Daher wird das Genus von jedem Nomen in einer NP oder PPbestimmt und an die Tags jedes dafur in Frage kommenden Tokens angefugt,wobei eingebettete Phrasen beachtet werden mussen. Auf die gleiche Artwurden Informationen uber starke und schwache Flexion erganzt. Dies hangtin den meisten Fallen von der Art des Artikels (definit oder indefinit) ab. Aufdefinite Artikel, Demonstrativpronomen und einige indefinite Artikel (z.B.jeder, alle) folgt immer schwache Flektion; sie werden daher entsprechendmarkiert. Tabelle 2 verdeutlicht den Vorgang an einem Beispiel. Bei jedemArtikelwort, auf das nicht eindeutig schwache Flexion folgt, wird gemischteFlexion angenommen und die jeweiligen Worter entsprechend markiert. Diesbedeutet, dass bei bestimmten Kombinationen aus Kasus, Genus und Nu-merus stark, bzw. schwach flektiert wird und in einigen Fallen die Formenzusammenfallen. Gemischte Flexion kommt u.a. nach unbestimmtem Artikel,einigen indefiniten Artikeln (kein) sowie Possessivpronomen. Stark flektiertwerden artikellose Phrasen oder Worter nach relativ selten auftretenden,unveranderlichen Artikeln wie derlei. Starke Flexion und gemischte Flexionwerden zu einem Merkmal zusammengefasst. Die endgultige Auswahl wirderst zum Zeitpunkt der Generierung getroffen, wenn alle anderen Wertebekannt sind.
Satz das auf der Straße parkende neue FahrzeugParser ART APPR ART NN ADJA ADJA NN Tag
Nom Dat Dat Dat Nom Nom KasusSg Sg Sg Sg Sg Sg Num
Erganzung Neut Fem Fem Fem Neut Neut GenusWk Wk Wk Wk Wk Wk Flexion
Tabelle 2: Erganzung der Merkmale Genus und starke/schwache Flexion inden Trainingsdaten
(23) zeigt ein Beispiel fur einen Satz aus dem Trainingstext, (24) das For-mat der Testsatze. Die Originalversion der Testsatze dient als Referenz, ausder die Stamme der zu generierenden Worter gewonnen und die Wortformen
19

ubernommen werden, fur die keine morphologischen Merkmale berechnetwerden sollen. In der Map (25) werden nicht nur die einzelnen Vorkommender Tags, sondern auch ihre Haufigkeit im Trainingskorpus gespeichert. Wiein der Baseline wird fur Worter, fur die keine morphologischen Merkmaleberechnet werden sollen, keine Alternative angegeben.
Ein Sternchen anstelle eines Merkmals bedeutet, dass entweder der Parserkeine Angabe zu Kasus oder Numerus gemacht hat, oder mit SMOR keinErgebnis fur das Merkmal Genus einer Wortform gefunden werden konnte.In spateren Versuchen werden Eintrage, die ein oder mehrere Sternchenenthalten, aus der Map entfernt. In den Eingabesatzen werden als NN getaggteToken, die von SMOR nicht erkannt wurden, mit dem Tag NE als Eigennamedargestellt und in weiteren Auszahlungen nicht weiter berucksichtigt2.
(23) ART-Nom.Sg.Neut.Wk NN-Nom.Sg.Neut.Wk VVFIN APPRDas Militar blockierte vor
PIS-NK-Dat ART-Acc.Sg.Masc.<> NN-Acc.Sg.Masc.<>kurzem einen Zug
(24) ART NN VVFIN ART NN PTKVZ $.Das Parlament nimmt die Entschließung an .
(25) NN NN-Acc.Sg.Neut.Wk [6656] NN-Acc.Pl.Neut.Wk [2261]NN-Acc.Sg.Neut.<> [9085] NN-Dat.Pl.Neut.Wk [3697]NN-Nom.Sg.Masc.Wk [10539] NN-Dat.Pl.Masc.<> [8846]NN-Acc.Sg.Masc.<> [12313] ...
VVFIN VVFIN [123633]PTKVZ PTKVZ [7878]
Mit einem Trigramm-Modell und der Map soll nun fur die entsprechendenTags die beste Kombination aus den fur die Generierung notwendigen Infor-mationen berechnet werden. Fur den Satz (24) erhalt man die Tagsequenzin (26) als Ergebnis.
(26) ART-Nom.Sg.Neut.Wk NN-Nom.Sg.Neut.Wk VVFIN(das) (Parlament) (nimmt)
ART-Acc.Sg.Fem.Wk NN-Acc.Sg.Fem.Wk PTKVZ $.(die) (Entschließung) (an) .
2In 100 Satzen war dies bei 16 Wortern der Fall; davon waren 10 Eigennamen, 4Abkurzungen und die 2 Komposita Sacharowpreises und Kapitaladaquanzvorschriften
20

4.1.2 Generierung
Der fur die Generierung notwendige Stamm in SMOR-Format wird gemaßder in 3.2 erfolgten Beschreibung ermittelt. Zusammen mit der berechnetenMerkmalskombination konnen nun die Formen generiert werden.
(27) entschließen<V>ung<SUFF><+NN> + NN-Acc.Sg.Fem.Wk
generate : entschließen<V>ung<SUFF><+NN><Fem><Acc><Sg>Entschließung
(28) generate : entschließen<V>ung<SUFF><+NN><Fem><Acc><Sg><Wk>no result for entschließen<V>ung<SUFF><+NN><Fem><Acc><Sg><Wk>
Das Beispiel in (27) verdeutlicht, wie aus dem Stamm und den ermitteltenWerten eine Eingabe fur SMOR gebildet werden kann, mit der die Generierungerfolgt. Die ermittelten Werte konnen in der Regel einfach ubernommenwerden. Eine Ausnahme bildet die Art der Flexion: Auch in den eigentlicheindeutigen Fallen mit dem Wert Wk, wo im Gegensatz zur gemischtenFlexion immer schwache Flexion erwartet wird, muss auch die Moglichkeitberucksichtigt werden, dass dieser Wert leer bleiben muss, wie in Beispiel(27). Dies ist nur dann der Fall, wenn es keine unterschiedlichen Formen gibt.Es werden immer beide Moglichkeiten probiert, aber nur eine davon fuhrt zueiner erfolgreichen Generierung (28). Wurde nicht das Merkmal Wk vergeben,so wird zuerst gemischte Flexion angenommen. In diesem Fall werden dieKombinationen Sg/Nom/Masc, Sg/Nom/Neut und Sg/Acc/Neut stark unddie verbleibenden schwach flektiert. Eine Generierung ohne Angabe ist hiernaturlich auch moglich. Konnte noch keine Form generiert werden, wird eineGenerierung mit einer noch nicht benutzten Kombination probiert. Da imTrainingstext der von SMOR benutzte Wert NoGend nicht vorkommt, wirdzusatzlich bei jeder Kombination der Wert fur Genus durch NoGend ersetztund mit beiden Varianten generiert.
4.1.3 Erste Ergebnisse
Die mit dem tagbasierten Verfahren erhaltenen Sequenzen fur Nominal-bzw. Prapositionalphrasen sind wohlgeformt, da im Trainingskorpus vorkom-mende Tag-Folgen mit einheitlichen Merkmalen auf die in den Testsatzenvorkommenden Phrasen ubertragen werden. Das Benutzen von Tags bietetauch eine Losung fur die Unterscheidung von pradikativ, attributiv oderadverbial gebrauchten Adjektiven, da der Parser verschiedene Tags fur at-tributive (ADJA), pradikative (ADJD) oder adverbiale (ADJD) Adjektive
21

verwendet; das Gleiche gilt fur die Unterscheidung von Adjektiven und Ad-verben. Ebenso konnen nun Artikelworter und Relativpronomen voneinanderunterschieden werden. Dies ist interessant, weil Relativpronomen einige Merk-male des Nomens, auf das sie referieren, ubernehmen. Die Generierung vonRelativpronomen wird in Abschnitt 5.3.1 ausfuhrlicher behandelt.
Ein nicht-wohlgeformter Satz (Baseline) wie in (29) sollte durch die tagba-sierte Methode, zumindest in Fallen von einfachen Phrasen, also weitgehendausgeschlossen sein; (30) zeigt das wohlgeformte Ergebnis der tagbasiertenMethode. Die Formen fur den Artikel und das Adjektiv konnen generiertwerden, nicht jedoch die Form des Nomens. Wahrend die Merkmale Numerus,Kasus und Flexion vom Kontext abhangen und beliebige Werte annehmenkonnen, ist das Merkmal Genus eine Eigenschaft des Wortstammes unddaher nicht frei wahlbar. Im Beispiel wurde der Wert Fem vergeben, richtigware Neut. Um auszuschließen, dass die Werte bestimmter Merkmale zufalliggewahlt werden, mussen die Werte dieser Merkmale vorgegeben werden.
(29) einen gefahrlichem Abfallprodukte
(30) ART-Acc.Sg.Fem.<> ADJA-Pos.Acc.Sg.Fem.<> NN-Acc.Sg.Fem.<>
4.2 Einbinden von Informationen aus Quell- und Zielsprache
Gibt man die Werte fur Merkmale an ausgewahlten Stellen in den Ein-gabesatzen vor, so kann man die Berechnung dahingehend beeinflussen,eine (wohlgeformte) Tagsequenz zuruckzugeben, die die vorgegebenen Wertebeinhaltet.
4.2.1 In der Zielsprache enthaltene Informationen
Das Merkmal Genus eines Nomens ist Teil des Wortstammes und wird andas Tag des Nomens im Eingabesatz angefugt, indem das ursprunglicheTag NN durch eines der Tags NNfem, NNmasc oder NNneut ersetzt wird.Außerdem ist ein wertefreies Tag NN* notwendig, um Falle, in denen eskeine ausreichende Analyse gab, abdecken zu konnen. Entsprechend mussenauch die Eintrage in der Map verandert werden. Statt eines Eintrages furNN gibt es nun jeweils einen fur jedes der neuen Tags. Finite Verben werdenmit ihrem Numerus markiert. Da Artikel die Art der Flexion bestimmen,werden sie entsprechend mit Wk fur schwache und <> fur gemischte Flexiongekennzeichnet.
Die in Prapositionen enthalte Kasusinformation wird genutzt, indemPrapositionen nicht durch ein Tag dargestellt werden, sondern ihre Formbehalten. So kann der Umstand, dass auf viele Prapositionen jeweils nur ein
22

Kasus folgt, in das Sprachmodell aufgenommen werden. In der Map werdensie jeweils auf sich selbst abgebildet. Ein ahnlicher Ansatz ware auch furVerben denkbar, problematisch ist allerdings die Tatsache, dass Subjekt undObjekt verschiedene Positionen im Satz einnehmen konnen, wahrend derAufbau einer Prapositionalphrase einem festen Muster folgt. Außerdem bildenPrapositionen im Gegensatz zu Verben eine geschlossene Wortklasse underhohen somit die Menge der Tags im Trainingstext nur in einem geringenMaße. Zudem kann man davon ausgehen, dass jede Praposition, die in einemEingabesatz vorkommt, auch im Tainingstext vertreten ist.
(31) und (32) zeigen die Eingabe und das Ergebnis eines Satzes, das mitder in 4.1.1 beschriebenen Methode berechnet wurde. Es ist offensichtlich, dassmit Fem fur das Wort Parlament keine erfolgreiche Generierung durchgefuhrtwerden kann, wahrend mit dem neuen Eingabeformat (33) der richtige Wertschon vorgegeben ist.
(31) ART NN VVFIN ART ADJA PTKVZ $.das Parlament nimmt die neue Entschließung an .
(32) ART-Nom.Sg.Fem.Wk NN-Nom.Sg.Fem.Wk VVFIN ART-Acc.Sg.Fem.Wk(Das) (Parlament) (nimmt) (die)
ADJA-Acc.Sg.Fem.Wk NN-Acc.Sg.Fem.Wk PTKVZ $.(neue) (Entschließung) (an) .
(33) ARTwk NNneut VVFINsg ARTwk ADJA NNfem PTKVZ $.Das Parlament nimmt die neue Entschließung an .
4.2.2 Numerusinformation bei Nomen
Der Numerus des Subjekts ist indirekt durch den Numerus des finiten Verbsvorgegeben, fur alle weiteren Nomen konnen ohne Vorgabe beliebige Wertegewahlt werden.. Dies fuhrt zum Einen zu ungrammatischen Satzen wie esist 12 Uhren. Zum Anderen geht in einer realen Anwendung die Parallelitatzwischen Quell- und Zielsprache verloren. Die beiden Satze ich muss mitdem Minister sprechen und ich muss mit den Ministern sprechen sind zwarbeide grammatisch, aber nur einer gibt die Aussage des Quellsatzes wieder.Haben Nomen in der Quellsprache jeweils eine eigene Oberflachenform furSingular und Plural, dann ist anzunehmen, dass sie auch jweils auf eineunterschiedliche Form in der Zielsprache ubersetzt werden. Diese Annahmeist jedoch nicht selbstverstandlich: In vielen nicht-europaischen Sprachen,zum Beispiel Chinesisch, existieren oft keine eigene Formen fur den Plural.
23

In der Regel wird ein Plural nur dann angegeben, wenn der Numerus ausdem Kontext nicht direkt ersichtlich ist oder die genaue Anzahl bekannt seinsoll. Dies kann unter Anderem durch die syntaktische Struktur, Suffixe oderZahlworte geschehen, die wiederum von der Art des Nomens abhangen.
Im Folgenden wird der Numerus von Nomen und Personalpronomenals gegeben betrachtet; dies ist mit der in einigen Experimenten benutztenQuellsprache Englisch vereinbar. Ausnahmen wie furniture-sg und Mobel-plwurden allerdings nicht behandelt, ebensowenig Formen wie sheep, die keineeigene Pluralform haben.
4.3 Trennung der annotierten Merkmale in unabhangige Ein-heiten
Bisher wurden die vier Merkmale zusammen berechnet; bis auf eine Ausnahmesind sie jedoch voneinander unabhangig und die Berechnung kann deshalbauch getrennt erfolgen. Die Trennung der Merkmale besteht darin, viervoneinander unabhangige Systeme zu erzeugen, von denen jedes nur einMerkmal berechnet. Diese Teilergebnisse werden am Schluss zusammengefugt,so dass die Generierung der Wortformen wie schon beschrieben durchgefuhrtwerden kann.
Die einzige Abhangigkeit besteht zwischen dem Merkmalspaar Kasus undNumerus: Die Subjekt-NP stimmt im Numerus mit dem finiten Verb uberein.Das Erkennen dieses Zusammenhangs ist uberflussig, wenn der der Numerusvon Nomen und Personalpronomen jeweils vorgegeben ist. Die Abhangigkeitvon Kasus und Numerus besteht in keiner anderen Konstellation (Objekt-NP,Prapositionalphrasen, usw.). Die gemeinsame Darstellung der Merkmalefuhrt solche falschen Abhangigkeiten aber in einem gewissen Maße ein undbeeintrachtigt somit die Qualitat der Berechnungen. Das Aufspalten in vierSysteme garantiert eine unabhangige Berechnung jedes Merkmals und damitauch eine besserer Ausnutzung der vier Trainingstexte.
4.3.1 Aufbau der Trainingskorpora und Maps
Jedes der Modelle hat einen eigenen Trainingskorpus und eine eigene Map.Am Beispiel des Merkmals Genus soll deren Aussehen beschrieben werden.
Beispiel (34) zeigt einen Auschnitt aus dem Trainingskorpus. Alle inFrage kommenden Tags enthalten nur das Merkmal Genus, die restlichenTags bleiben wie in den vorhergehenden Varianten leer.
(34) KOUS APPRART-Neut NNneut-Neut ADV ART-Fem NNfem-FemART-Neut NNneut-Neut KON NNneut-Neut VVINF VAFINsg $,
24

(35) NNfem NN-Fem [2558669]NNmasc NN-Masc [1738035]NNneut NN-Neut [1010786]NN* NN*-* [1221974]ADJA-Pos ADJA-Pos.Neut [319276] ADJA-Pos.Masc [379674]
ADJA-Pos.Fem [789595]ART ART-Masc [907335] ART-Fem [1615990]
ART-Neut [589072]
(36) ART ART-Masc [...] ART-Fem [...]ART-Neut [...] ART-* [...]
Beispiel (35) zeigt einige Eintrage in der Map: Bei Nomen besteht nun keineAuswahl mehr, es muss der vorgegebene Wert angenommen werden. BeiArtikeln, Adjektiven, usw. muss weiterhin eine Entscheidung zwischen denWerten Fem, Masc und Neut getroffen werden. Eintrage mit unbekanntenWerten (*) wie in (36) werden entfernt. Die Auswahl eines solchen Werteskann nicht zu einer erfolgreichen Generierung fuhren und soll deshalb aus-geschlossen werden. Trotzdem ist das Tag NN* notwendig. Es wird danngebraucht, wenn fur ein Nomen im Eingabesatz kein Wert ermittelt werdenkonnte.
Fur den in (37, 38) gezeigten Eingabesatz sollen die Werte fur die beidenArtikel und das Adjektiv gefunden werden; das Ergebnis fur Genus steht in(39).
Auf die gleiche Art werden fur die drei restlichen Eingabesatze weitereErgebnissequenzen erzeugt, die jeweils Informationen zu Kasus, Numerusund Art der Flexion enthalten (40-42) und zu einem einzigen Satz mit allenInformationen zusammengefugt (43).
(37) Die Erweiterung ist ein historisches Vorhaben .
(38) ART NNfem VAFINsg ART ADJA-Pos NNneut $.
(39) ART-Fem NN-Fem VAFINsg ART-Neut ADJA-Pos.Neut NN-Neut $.
(40) ART NN VAFINsg ART ADJA-Pos NN $.ART-Nom NN-Nom VAFINsg ART-Nom ADJA-Pos.Nom NN-Nom $.Kasus
(41) ARTwk NN VAFINsg ART<> ADJA-Pos NN $.ARTwk NNwk VAFINsg ART<> ADJA-Pos.<> NN-<> $.starke/schwache Flexion
(42) ART NN-Sg VAFINsg ART ADJA-Pos NN-Sg $.ART-Sg NN-Sg VAFINsg ART-Sg ADJA-Pos.Sg NN-Sg $.Numerus
(43) ART-Nom.Sg.Fem.wk NN-Nom.Sg.Fem.wk VAFINsg ART-Nom.Sg.Neut.<>ADJA-Pos.Nom.Sg.Neut.<> NN-Nom.Sg.Neut.<> $.
25

Fur die vollstandig beschriebenen Formen in Satz (43) konnen die flektiertenFormen generiert werden.
5 Ergebnisse und Auswertung
In diesem Kapitel werden die Ergebnisse der bisher vorgestellten Versionenverglichen und der Einfluss der Große des Trainingskorpus untersucht. EineFehleranalyse fur die verschiedenen Wortarten zeigt, welche Probleme mitdem System gelost werden konnen und welche Schwierigkeiten noch bleiben.
5.1 Vergleich der verschiedenen Versionen
Version keine Korrektur BeschreibungKorrektur mit einer
Wortliste vorgegebene MerkmaleBaseline 58,62 % − lemmabasiert (Unigramm, K1)Baseline 77,65 % − lemmabasiert (Trigramm, K1)Baseline 58,98 % − lemmabasiert (Unigramm, K2)Baseline 74,56 % − lemmabasiert (Trigramm, K2)V0 74,36 % 77,35 % zusammen Genus FlexionV1 72,89 % 77,03 % getrennt Genus FlexionV2 82,03 % 87,19 % getrennt Genus Flexion Numerus
Tabelle 3: Zahl der korrekt bestimmten Formen in den vorgestellten Varianten.Bewertet wurden jeweils 2000 Satze. Das Trainingskorpus der tagbasiertenVersionen wurde aus 1.222.918 geparsten Satzen (Europarl) gewonnen. DieBerechnungen erfolgten mit einem Trigramm-Modell. Die Zahlen fur dieBaseline stammen aus Abschnitt 3.3. (K1: volle Große des Zeitungskorpus,K2: Reduktion auf die Große des Korpus der tagbasierten Version.) EineErlauterung zur Korrektur mit einer Wortliste folgt in Abschnitt 5.1.1.
Wie bei der Auswertung der Baseline gilt eine Wortform als richtig,wenn sie mit dem entsprechenden Wort im Referenzsatz ubereinstimmt.Daher ist es moglich, dass einige eigentlich richtige Formen verloren gehen,wenn das Wort im Referenztext ungewohnlich geschrieben wurde, wie z.B.ArbeitnehmerInnen, oder wenn ein Wort auf zwei Arten realisiert werden kann.Dies kann bei Formen im Genitiv der Fall sein (Programms vs. Programmes),oder bei einigen Formen im Dativ (Tod vs. zu Tode kommen).
Das Ergebnis von V0 ohne Korrektur liegt nahe an dem der Baselinemit der gleichen Trainingskorpusgroße. Hier ist zwar die Wohlgeformtheit
26

einzelner Phrasen gegeben, aber der Numerus, der bis auf die Subjekts-NP inkeinerlei Abhangigkeit mit anderen, im Trainingstext enthaltenen Merkmalensteht, wird willkurlich ausgewahlt. Dies fuhrt oftmals zu schlichtweg falschenErgebnissen (z.B. es ist 12 Uhren), zu ungultigen Wertekombinationen, dienicht zu einer erfolgreichen Generierung mit SMOR fuhren, (z.B. Verkehr-pl)oder zu Phrasen, die zwar grammatisch sind, aber nicht mit dem Referenzsatzubereinstimmen.
Die lemmabasierte Version modelliert haufig vorkommende Muster wievor allem oder auf jeden Fall besser als die tagbasierte Version. Da dortnur die Tagfolge auf PIAT NNmasc bekannt ist und auf die Prapositionauf sowohl Dativ als auch Akkusativ folgen konnen, konnen die Formen aufjeden Fall, auf jedem Fall, auf jede Falle und auf auf jeden Fallen gebildetwerden. Dies ist jedoch ein Problem, das auch in den verbesserten Varianten- zumindest teilsweise - bestehen bleibt.
Die Darstellung der benutzen Merkmale ist in den vier getrennten Syste-men von V1 weniger komplex und schopft die Trainingsdaten besser aus, weilunerwunschte Abhangigkeiten die Berechnungen nicht mehr beeintrachtigen.Trotzdem schneidet V1 schlechter ab als V0, weil die einzige tatsachlicheAbhangigkeit verloren geht. In der Darstellung von V0 wird erwartet, dassnur eine Phrase, die im Numerus mit dem finiten Verb ubereinstimmt, denWert Nominativ erhalten kann, bzw. eine Phrase mit dem Wert Nominativden Numerus mit dem finiten Verb teilen muss. Obwohl diese Einschatzungnur fur Falle realistisch ist, in denen diese NP nahe beim Verb steht, gibt esdoch einen merklichen Unterschied, vor allem bei Satzen mit der typischenAbfolge Subjekt Verb Objekt.
In der getrennten Darstellung von V2 ist zusatzlich der Numerus derNomen bekannt. Dadurch wird das Ableiten des Numerus aus dem Kasusuberflussig und die durch zufallige Numerusauswahl entstandenen Fehler inV0 fallen großtenteils weg.
5.1.1 Entfernen falscher Wortformen mit einer Wortliste
In einigen Fallen generiert SMOR mehrere Varianten einer Wortform (sie-he Beispiel 17), von denen einige falsch sind. Bisher bestand die einzigeMaßnahme zum Verhindern fehlerhafter Wortformen darin, eine moglichstgute Analyse als Wortstamm auszuwahlen (siehe Abschnitt 3.2.1). Dochauch mit korrekten Wortstammen werden mehrere Formen generiert. Dies isthauptsachlich bei Komposita der Fall, deren Komponenten auf verschiedeneArten miteinander verbunden werden konnen: mit/ohne Fugen-S, mit/ohnePluralendung, usw. (z.B. Klimataanderung) .
27

Berechnet SMOR mehrere Wortformen, wird mit Hilfe einer Wortlistediejenige Form ausgewahlt, deren Vorkommenshaufigkeit in den fur die Er-stellung der Wortliste benutzten Daten am großten ist. Eine solche Listestellt eine sehr gute Annaherung an eine manuelle Korrektur dar. Die großeMehrzahl der falsch generierten Wortformen sind relativ gangige Kompo-sita wie Klimaanderung, die in einem ausreichend großen Textkorpus zumgroßten Teil vorkommen. Problematisch sind ungewohnliche Komposita wieDoppelhullentanker, deren Vorkommen auch in einem sehr großen Korpuseher unwahrscheinlich ist. Deshalb bringt eine Vergroßerung der fur dieBerechnung der Wortliste benutzten Textmenge ab einer bestimmten Großenur noch unwesentliche Verbesserungen.
Bei der Baseline wurde die Methode schon indirekt angewandt, da nurFormen ausgewahlt werden konnten, die auch im Trainingskorpus vorkamen.
Eine Liste zum Herausfiltern falscher Wortformen wurde aus den Trai-ningsdaten3 und weiteren 1,9 GB Zeitungstext gewonnen. Sie hat 5.293.480Eintrage, die jeweils aus einem Wort und der Anzahl der Vorkommen diesesWortes in den Korpora bestehen. Die mit ihr erreichten Verbesserungen sindin Tabelle 3 aufgefuhrt. Auch in allen weiteren Versuchen werden falscheFormen mit dieser Liste herausgefiltert.
Fur 100 Satze aus dem Testset wurden falsche Formen mit einer manuellerstellten Liste4 entfernt. Damit wurde das gleiche Ergebnis erzielt wie mitder aus Textkorpora gewonnenen Wortformliste.
5.2 Einfluss der Trainingskorpusgroße und der Ordnung desSprachmodells
Die verschiedenen Methoden wurden mit unterschiedlich großen Trainings-korpora getestet (Tabelle 4). Version V0, bei der alle Informationen aufeinmal berechnet werden ist starker von der Große anhangig, da es deutlichmehr Kombinationsmoglichkeiten fur die Tags gibt als bei den Versionen V1und V2. Trotzdem werden aufgrund des begrenzten Vokabulars auch miteinem kleineren Trainingskorpus noch gute Ergebnisse erzielt. Ein zusatzli-cher Grund ist, dass nur fur 17 Tags eine echte Voraussage getroffen wird,wahrend alle anderen Tags wie VVFIN, KON fest sind. Am wenigsten wirdV2 durch die Reduktion der Trainingsdaten beeintrachtigt.
Nicht nur die Große des Trainingskorpus, auch die Ordnung des vondisambig benutzten Sprachmodells (Tabelle 5) tragt zur Qualitat der Er-
310.193.376 Satze Zeitungstext, 1.222.918 Satze aus Europarl4in Teil B des Anhangs
28

Trainingskorpusgroße V0 V1 V2K = 1222918 Satze 77,35 % 77,03 % 87,19 %
110 K 76,51 % 76,5 % 86,87 %1
100 K 74,5 % 75,21 % 86,11 %1
1000 K 70,83 % 72,94 % 84,81 %
Tabelle 4: Ergebnisse mit unterschiedlichen Trainingskorpusgroßen. Fehler-hafte Wortformen wurden mit der in 5.1.1 beschriebenen Wortliste entfernt.Es wurden jeweils Trigramm-Modelle und der gleiche Trainingstext wie inTabelle 3 benutzt
Ordnung n 1 2 3 4 5 6Ergebnis 63,22 % 85,76 % 87,19 % 87,95 % 87,82 % 87,45 %
Tabelle 5: Ergebnisse fur V2 mit Sprachmodellen der Ordnung n = 1..6
gebnisse bei. Die mit Unigrammen erreichte Zahl liegt etwas hoher als dasErgebnis der mit Unigrammen berechneten Baseline. Das bedeutet, dass eineKombination aus den jeweils am haufigsten auftretenden Merkmalen einebessere Schatzung ist, als die haufigste Kombination aus allen Merkmalen,d.h. die Tag-Wert-Sequenz, die am haufigsten vorkommt. Die Werte furn = 3 .. 6 liegen sehr nahe beieinander; das beste Ergebnis erhalt man mitn = 4, danach sinken die Werte wieder leicht ab. Fur diese Ordnungenmussten mehr Trainingsdaten gegeben sein.
5.3 Detaillierte Analyse der generierten Formen
Tabelle 6 gibt eine Ubersicht uber alle Tags, fur die eine Morphologievorhersa-ge getroffen wurde. Angegeben ist jeweils die Anzahl der Tags mit der Mengeder korrekt ermittelten Formen, sowie einige Beispiele fur die jeweiligenWortarten. Im ersten Drittel der Tabelle sind neben normalen Nomen auchattributive Adjektive und Pronomen aufgefuhrt (Endung -AT). Eine Sequenzaus dieser Kategorie hat ublicherweise die gleichen Eigenschaften. AuchRelativpronomen (PRELS) teilen sich Eigenschaften mit dem Nomen, aufdas sie verweisen. Im zweiten Abschnitt von Tabelle 6 stehen substituierendePronomen. Sie kommen nicht als Teil einer Phrase vor, sondern ersetzendiese, wie etwa in Dies ist ein Beispiel. Der letzte Abschnitt enthalt alleverbleibenden Kategorien. Viele Nomen konnen nur zwei Oberflachenformenannehmen; dies erklart den Umstand, dass der Anteil der korrekten Nomen
29
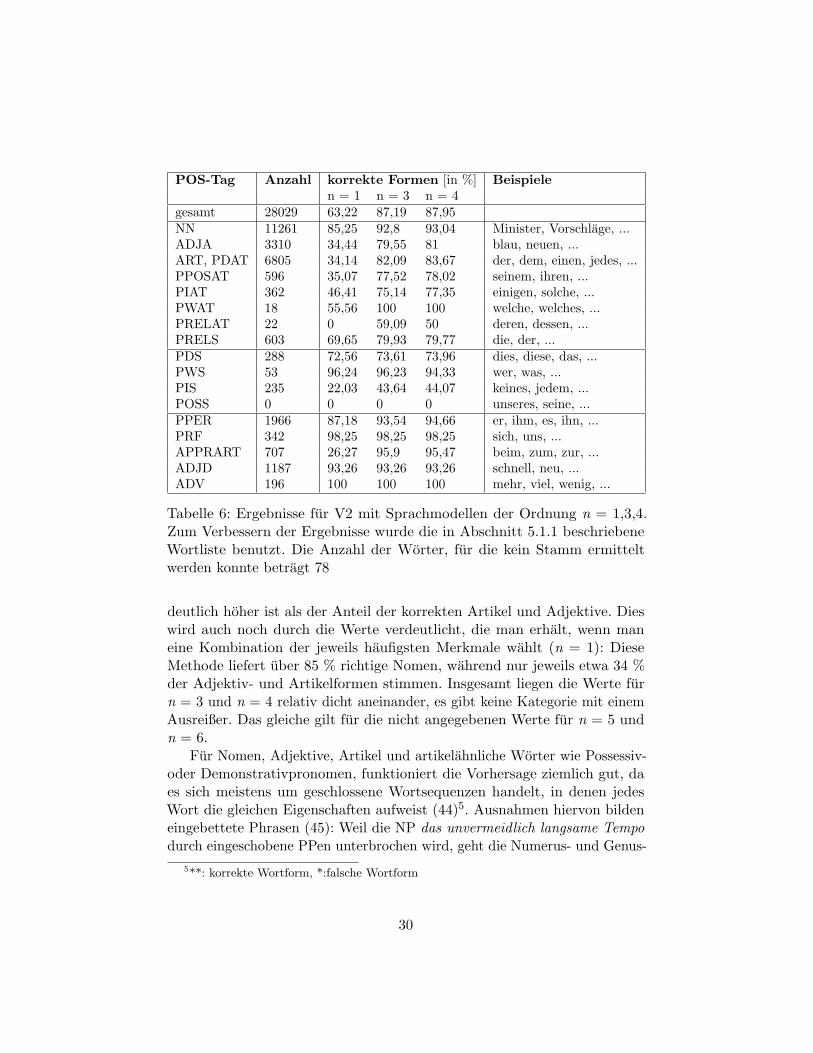
POS-Tag Anzahl korrekte Formen [in %] Beispielen = 1 n = 3 n = 4
gesamt 28029 63,22 87,19 87,95NN 11261 85,25 92,8 93,04 Minister, Vorschlage, ...ADJA 3310 34,44 79,55 81 blau, neuen, ...ART, PDAT 6805 34,14 82,09 83,67 der, dem, einen, jedes, ...PPOSAT 596 35,07 77,52 78,02 seinem, ihren, ...PIAT 362 46,41 75,14 77,35 einigen, solche, ...PWAT 18 55,56 100 100 welche, welches, ...PRELAT 22 0 59,09 50 deren, dessen, ...PRELS 603 69,65 79,93 79,77 die, der, ...PDS 288 72,56 73,61 73,96 dies, diese, das, ...PWS 53 96,24 96,23 94,33 wer, was, ...PIS 235 22,03 43,64 44,07 keines, jedem, ...POSS 0 0 0 0 unseres, seine, ...PPER 1966 87,18 93,54 94,66 er, ihm, es, ihn, ...PRF 342 98,25 98,25 98,25 sich, uns, ...APPRART 707 26,27 95,9 95,47 beim, zum, zur, ...ADJD 1187 93,26 93,26 93,26 schnell, neu, ...ADV 196 100 100 100 mehr, viel, wenig, ...
Tabelle 6: Ergebnisse fur V2 mit Sprachmodellen der Ordnung n = 1,3,4.Zum Verbessern der Ergebnisse wurde die in Abschnitt 5.1.1 beschriebeneWortliste benutzt. Die Anzahl der Worter, fur die kein Stamm ermitteltwerden konnte betragt 78
deutlich hoher ist als der Anteil der korrekten Artikel und Adjektive. Dieswird auch noch durch die Werte verdeutlicht, die man erhalt, wenn maneine Kombination der jeweils haufigsten Merkmale wahlt (n = 1): DieseMethode liefert uber 85 % richtige Nomen, wahrend nur jeweils etwa 34 %der Adjektiv- und Artikelformen stimmen. Insgesamt liegen die Werte furn = 3 und n = 4 relativ dicht aneinander, es gibt keine Kategorie mit einemAusreißer. Das gleiche gilt fur die nicht angegebenen Werte fur n = 5 undn = 6.
Fur Nomen, Adjektive, Artikel und artikelahnliche Worter wie Possessiv-oder Demonstrativpronomen, funktioniert die Vorhersage ziemlich gut, daes sich meistens um geschlossene Wortsequenzen handelt, in denen jedesWort die gleichen Eigenschaften aufweist (44)5. Ausnahmen hiervon bildeneingebettete Phrasen (45): Weil die NP das unvermeidlich langsame Tempodurch eingeschobene PPen unterbrochen wird, geht die Numerus- und Genus-
5**: korrekte Wortform, *:falsche Wortform
30

Information des Kopfnomes verloren und fuhrt zu einer falschen Artikelwahl.
(44) trotz **der allseits **anerkannten **konstruktiven **Haltung**der **zypriotischen **Regierung aufgrund **der **unverandert**ablehnenden **Einstellung **der **turkischen **Seite
(45) und hinzu kommt *die bei **der **Beschlussfassung auf**Gemeinschaftsebene **unvermeidlich *langsamen **Tempo
Bei Adverben und adverbial gebrauchten Adjektiven (ADJD) muss keineVorhersage getroffen werden, sie mussen lediglich als unveranderlich erkanntwerden. In der in Kapitel 3 beschriebenen lemmabasierten Baseline wurdendiese Formen jedoch haufig falsch gewahlt, da sie auch in flektierter Formin den Trainingsdaten vorkommen. Bei Personalpronomen (PPER) bestehtdie Schwierigkeit hauptsachlich darin, zwischen Akkusativ und Dativ zuunterscheiden.
Auf viele Prapositionen kann jeweils nur ein Kasus folgen, die Berech-nung der Werte fur APPRART stellt daher keine großen Schwierigkeitendar: Genus und Numerus ist durch das Kopfnomen der Phrase gegeben,die Kasusinformation kann fur die Praposition aus dem Trigramm-Modellabgeleitet werden. Auf einige Prapositionen konnen jedoch mehrere Kasusfolgen. Dies wurde schon in Kapitel 3 beobachtet und kann auch mit demtagbasierten Ansatz nicht gelost werden.
5.3.1 Relativpronomen
Bei Relativpronomen hat es sich gezeigt, dass es besser ist, die von disambigberechneten Werte fur Genus und Numerus zu verwerfen und dafur dieWerte von dem am nachsten links stehenden Nomen einzusetzen6. Mit dieserZusatzregel werden 79,93 % der Relativpronomen richtig berechnet (sieheTabelle 6). Behalt man die von disambig berechneten Werte bei, sind es nur69,49 %. Dieses Verfahren funktioniert im Allgemeinen gut, (46) und (47),jedoch keinesfalls immer (48).
(46) **die **Vorschlage , **die **im ... **Bericht gemacht wurden
(47) **Hilfe sollte auf **der **Stufe eingesetzt werden ,auf **der **Probleme entstehen
(48) hat ... **einen **Rahmen fur **die **sozialpolitische**Agenda gesetzt , von *der **ich meine , dass , ...
6Falle wie der Plan des Ministers, PRELS ... sind besonders problematisch, da sich dasRelativpronomen auf das erste (Plan) oder das zweite Nomen (Minister) beziehen kann. Indiesem Versuch wurde angenommen, dass das Relativpronomen auf das erste, d.h. nicht imGenitiv stehende Nomen referiert. Diese Annahme ist jedoch zu stark verallgemeinernd.
31

Der Kasus eines Relativpronomens kann mit der hier verwendeten Methodenur sehr unzuverlassig berechnet werden; da die Rolle des Relativpronomensvom Verb abhangt, musste das Verb nahe am Relativpronomen stehen undzudem Informationen uber seinen Subkategorisierungsrahmen bekannt sein.
(49) **die **Aufnahme von ... in *der **Gruppe von **Landern , *die*der *Europaischen **Investitionsbank **Darlehen gewahren darf
(50) die Gruppe , die der europaischen Bank Darlehen gewahren darfdie Gruppe , der die europaische Bank Darlehen gewahren darf
In Beispiel (49) ware zusatzlich eine tiefergehende Analyse notwendig; tatsach-lich ist der Nebensatz in (49) grammatikalisch nicht falsch, er druckt jedochnicht das aus, was der Verfasser des Textes beabsichtigte. Moglich sind diebeiden Versionen in (50), wobei die erste, und auch das Ergebnis in (49),dem fur deutsche Satze ublichen Schema folgt, dass das Subjekt vor Verbund Objekt steht.
Ahnliche Schwierigkeiten treten bei der Generierung von substituierendenPronomen (PDS, PIS, POSS) auf. Fur sie sind in den Trainingsdaten nichtimmer aller notwendigen Merkmale vorhanden. Sie kommen jedoch haufigin Konstellationen wie (51, 52) vor, daher wurden, wenn nicht alle Werteberechnet werden konnten, Num = Sg und Gen = Neut|NoGend gesetzt.
(51) **das ist **konsequente **Umsetzung **des *Gender-Mainstream-ing-Konzeptes .
(52) **was **die **Kontrolle ... voraussetzt .
5.3.2 Kasus
Tabelle 7 zeigt die Verteilung der Kasus in den Testsatzen. In der erstenSpalte stehen die vom Parser ermittelten Werte, in der zweiten Spalte die mit
geparst disambig DifferenzAkk 3410 3557 + 147Dat 3316 3125 − 191Nom 2986 2688 − 298Gen 1776 1900 + 124
Tabelle 7: Kasus der Nomen in 2000 Testsatzen, Berechnung mit V2, n=3.Die Zahlen in den beiden Spalten addieren sich nicht zu einem gleichen Wertauf, da Worter ohne oder mit ungenugender morphologischen Analyse imVerlauf der Berechnung nicht berucksichtigt wurden (siehe die Reihen * undNE in Tabelle 8)
32
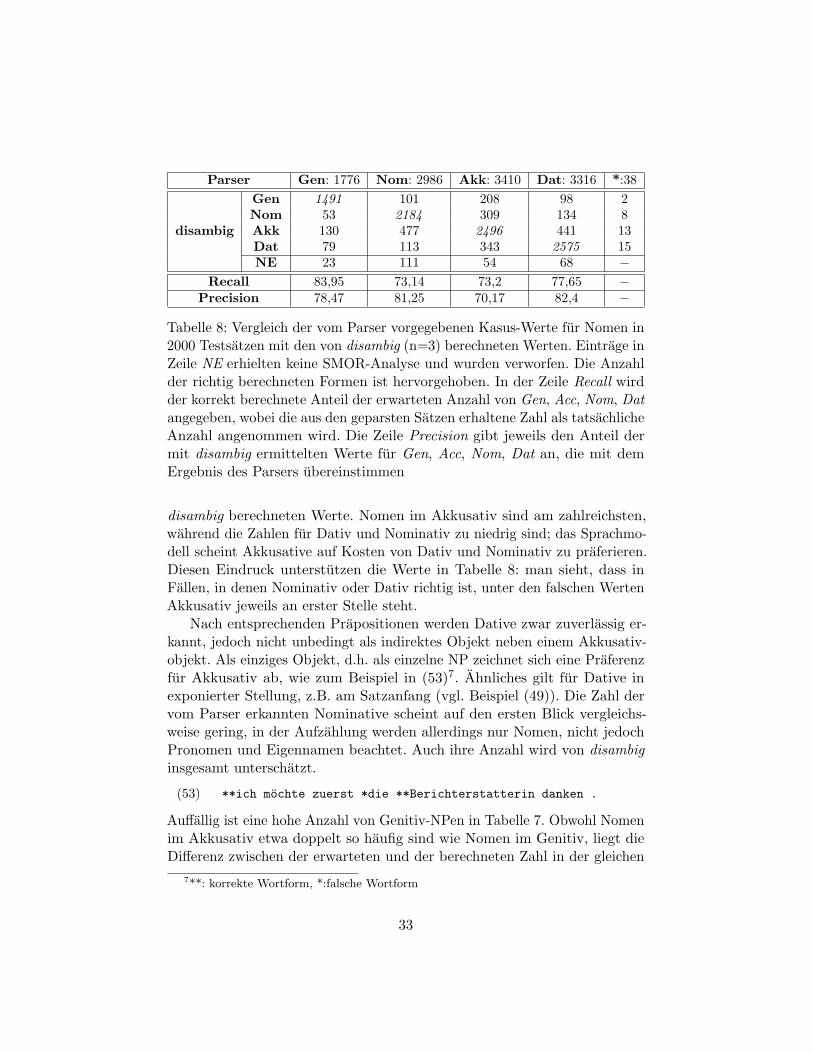
Parser Gen: 1776 Nom: 2986 Akk: 3410 Dat: 3316 *:38
disambig
Gen 1491 101 208 98 2Nom 53 2184 309 134 8Akk 130 477 2496 441 13Dat 79 113 343 2575 15NE 23 111 54 68 −
Recall 83,95 73,14 73,2 77,65 −Precision 78,47 81,25 70,17 82,4 −
Tabelle 8: Vergleich der vom Parser vorgegebenen Kasus-Werte fur Nomen in2000 Testsatzen mit den von disambig (n=3) berechneten Werten. Eintrage inZeile NE erhielten keine SMOR-Analyse und wurden verworfen. Die Anzahlder richtig berechneten Formen ist hervorgehoben. In der Zeile Recall wirdder korrekt berechnete Anteil der erwarteten Anzahl von Gen, Acc, Nom, Datangegeben, wobei die aus den geparsten Satzen erhaltene Zahl als tatsachlicheAnzahl angenommen wird. Die Zeile Precision gibt jeweils den Anteil dermit disambig ermittelten Werte fur Gen, Acc, Nom, Dat an, die mit demErgebnis des Parsers ubereinstimmen
disambig berechneten Werte. Nomen im Akkusativ sind am zahlreichsten,wahrend die Zahlen fur Dativ und Nominativ zu niedrig sind; das Sprachmo-dell scheint Akkusative auf Kosten von Dativ und Nominativ zu praferieren.Diesen Eindruck unterstutzen die Werte in Tabelle 8: man sieht, dass inFallen, in denen Nominativ oder Dativ richtig ist, unter den falschen WertenAkkusativ jeweils an erster Stelle steht.
Nach entsprechenden Prapositionen werden Dative zwar zuverlassig er-kannt, jedoch nicht unbedingt als indirektes Objekt neben einem Akkusativ-objekt. Als einziges Objekt, d.h. als einzelne NP zeichnet sich eine Praferenzfur Akkusativ ab, wie zum Beispiel in (53)7. Ahnliches gilt fur Dative inexponierter Stellung, z.B. am Satzanfang (vgl. Beispiel (49)). Die Zahl dervom Parser erkannten Nominative scheint auf den ersten Blick vergleichs-weise gering, in der Aufzahlung werden allerdings nur Nomen, nicht jedochPronomen und Eigennamen beachtet. Auch ihre Anzahl wird von disambiginsgesamt unterschatzt.
(53) **ich mochte zuerst *die **Berichterstatterin danken .
Auffallig ist eine hohe Anzahl von Genitiv-NPen in Tabelle 7. Obwohl Nomenim Akkusativ etwa doppelt so haufig sind wie Nomen im Genitiv, liegt dieDifferenz zwischen der erwarteten und der berechneten Zahl in der gleichen
7**: korrekte Wortform, *:falsche Wortform
33

Großenordnung. Tabelle 8 zeigt, dass der Wert Genitiv haufig dann vergebenwird, wenn Akkusativ richtig ware, die restlichen uberzahligen Genitiveverteilen sich zu etwa gleichen Teilen auf Nominativ und Dativ. Dass Genitiv-NPen haufig anstelle eines direkten oder indirekten Objektes nach einer NPgebildet werden, illustrieren die Beispiele (54),(55) und (56).
(54) Vietnam hat seit **diesem **Zeitpunkt *einer **Außenpolitik**der **offenen **Turen betrieben , durch **die **das **Land*des *Platzes einnimmt , ...
(55) so wie **dies ja auch bei **einem **Grundungsmitglied *des*Falls war ,
(56) Bereits **der *Heiliger Benedikt zwang **seine **Monche , zu**jedem **Mahl *eines *Viertels **Wein zu trinken , um ...
Da nur sehr wenige Verben ein regulares Genitivobjekt forden (wie zumBeispiel jdn seines Amtes entheben), ist die haufig auftretende Konstruktioneiner modifizierenden Genitiv-NP nach einem Nomen neben Prapositionen,die einen Genitiv verlangen, praktisch die einzige Situation, in der ein Genitivstehen kann. Damit kommen fast alle Genitive in nur zwei Kontexten vorund sollten somit gut zu berechnen sein. Zwar werden 83,96% der vorhandenGenitive als solche erkannt, aber der Anteil der richtig erkannten Genitivevon allen gefundenen Genitiven fallt mit 78,47 % geringer aus. Umgekehrtverhalt sich der Dativ: Es werden zwar nur 77,65 % aller Dative richtigerkannt, aber die die Genauigkeit liegt mit 82,4 % am hochsten. Dass Dativerelativ zuverlassig erkannt werden, kann auf die Menge der Prapositionenzuruckzufuhren sein, die eindeutig einen Dativ verlangen. Dass auf einigePrapositionen aber auch Akkusativ folgen kann, tragt, ebenso wie die Wahlvon direktem oder indirektem Objekt, zu Fehlern bei der Entscheidungzwischen Akkusativ und Dativ bei.
6 Modifikation der Berechnung des Kasusmerkmals
Kasus ist das Merkmal, auf das bisher am wenigsten Einfluss genommenwurde. Bei Nomen sind sowohl Genus als auch Numerus vorgegeben unddie Werte fur Flexion werden zum Zeitpunkt der Generierung noch einmalangepasst. Die nachsten Abschnitte beschreiben zwei Versuche in denendie Auswahl des Kasus-Wertes verbessert werden soll. Die Idee der erstenMoglichkeit ist, die Anzahl der Genitive zu reduzieren, im zweiten Versuchwerden Verben in das Sprachmodell integriert und die in ihnen enthaltenenKasusinformationen genutzt.
34

6.1 Behandlung von Genitiven
Die Auswahl des Kasus kann, ebenso wie durch die Vorgabe von Numerusund Genus, beeinflusst werden. Um die Auswahl des Wertes Genitiv zukontrollieren, musste man also alle Nomen, die im Genitiv stehen sollen,zuverlassig erkennen und als solche markieren konnen. Da Numerus undGenus ebenfalls festgelegt sind, musste bei ihnen nur noch bestimmt werden,ob stark oder schwach flektiert werden soll. Fur alle ubrigen Nomen stehendann nur noch Nominativ, Dativ und Akkusativ zur Verfugung.
Im Folgenden soll in einem Versuch mit Englisch als angenommenerQuellsprache versucht werden, Genitive in der Quellsprache zu erkennenund auf die Tagsequenz des deutschen Eingabesatzes zu ubertragen. Da imEnglischen Plural ein distinktives Merkmal ist, kann die Modellierung V2benutzt werden. Außerdem werden Genitivkonstruktionen im Englischen nichtdurch die Satzstellung, sondern durch benachbarte Artikelworter dargestelltund konnen ohne syntaktische Analyse erkannt werden. Auch fur diesemVersuch wurden Referensatze benutzt. Um eine Ubersetzung zu simulieren,wurden Wort-Alignments mit GIZA++ [Och and Ney, 2003]8 zwischen demenglischen und deutschen Teil des Testsets erstellt.
6.1.1 Erkennen von Genitiven im englischen Text
Genitive kommen ublicherweise in den Konstruktionen NN of (the,a,..) NNsowie NN’s NN vor. Diese Strukturen konnen mit einem regularen Ausdruck,der auch Abweichungen wie z.B. andere oder keine Artikel oder Adjektivevor dem zweiten Nomen zulasst, gefunden werden. Uber das Wort-Alignmentsoll das entsprechende deutsche Wort gefunden und als Genitiv markiertwerden.
Die englischen Satze werden auf Vorkommen des Musters NN1 of ART?(ADV|ADJ)* NN2 untersucht und deren Ubersetzungen anschließend inden deutschen Satzen gesucht. Ist das auf diese Art erhaltene Fragmentdes deutschen Satzes wohlgeformt, was bedeutet, dass es dem Muster NN1(ART|POSS|...)? (ADJ|ADV)* NN2 entspricht, so kann angenommen wer-den, dass NN2 im Genitiv steht und ensprechend markiert werden (sieheAbbildung 3). In allen anderen Fallen wird angenommen, dass es sich nichtum einen Genitiv handelt. Dies ist zum Beispiel der Fall, wenn die englischeStruktur auf genau ein Kompositum abbildet, wie etwa point of depar-ture → Ausgangspunkt, oder wenn die Ubersetzung eine Prapositionalphrase
8mit ’grow-diag-final-and heuristic’, [Koehn et al., 2003]
35

Nach
dem
erfreulichen
Ausgang
der
Wahlen
in
Serbien
Following
the
happy
outcome
of
the
elections
in
Serbia
Angesichts
der
doppelten
Herausforderung
In
the
face
of
the
twofold
challenge
Abbildung 3: Beispiele fur Wort-Alignment
mit von ist, zum Beispiel der Ausgang von den serbischen Wahlen. In vielenFallen entspricht die deutsche Ubersetzung auch keinem bestimmten Muster.
Weitherhin ist es moglich, dass die englische Struktur einem Fragmenteiner PP im deutschen Satz entspricht. Wenn die Praposition dieser PP einenGenitiv verlangt, wird das Nomen ebenfalls entsprechend markiert (sieheAbbildung 3). Eine Liste dieser Prapositionen findet sich im Anhang in TeilC. Die Struktur NN’s NN wird zumeist nicht durch eine Genitivkonstruktionubersetzt.
6.1.2 Auswertung
Dieses Verfahren unterschatzt Nomen im Genitiv sehr stark: Wahrend fur1776 Nomen im Testset der Wert Genitiv erwartet wird, werden mit derbeschriebenen Methode nur 341 Genitivkandidaten ausgegeben, von denen253 im Vergleich mit dem geparsten Text als Genitive bestatigt werdenkonnen.
Diese Unterschatzung liegt zum Teil an nicht strukturisomorpher Uber-setzung (57), aber auch an fehlerhaftem Wortalignment. Dabei darf mannicht vergessen, dass das Wortalignment zwischen korrekten englischen unddeutschen Satzen erstellt worden ist. Bei einer statistischen Ubersetzung istmit noch schlechteren Ergebnissen zu rechnen.
(57) Cyprus has close links with ...Dank der engen Beziehungen Zyperns zu ...
36

Um die Auswahl des Kasus bei der Berechnung der morphologischen Merk-male beeinflussen zu konnen, werden die auf diese Art gefundenen Nomenin den Eingabesatzen9 markiert (58), der Eintrag fur Nomen in der Map(59) muss daraufhin ebenfalls verandert werden: Ein als Genitiv markiertesNomen muss den Wert Gen annehmen, fur alle anderen Nomen stehen dieWerte Nom, Acc und Dat zur Verfugung. Alle ubrigen Eintrage in der Mapbleiben unverandert. Die Berechnung der Werte fur Numerus, Flexion undGenus wird von V2 ubernommen.
(58) angesichts ART ADJA-Pos NNgangesichts der doppelten Herausforderung
(59) NNg NN-Gen [938076]NN NN-Nom [1651292] NN-Dat [1915662] NN-Acc [1973887]
Da das Verfahren die Anzahl der Genitive stark unterschatzt, liegt die Anzahlder richtig berechenten Worter nur bei 81,13%. Das ist deutlich schlechterals das vorherige Ergebnis von V2 (87,19%, in Tabelle 3). Sind dagegen alleGenitiv-Nomen bekannt, so steigt die Anzahl der richtig berechneten Worterauf 89,24%, was den ursprunglichen Wert von V2 ubersteigt. Diese obereGrenze erhalt man, wenn man die vom Parser vorgegeben Genitive einsetztund fur die restlichen Nomen nur noch die Werte Nominativ, Akkusativ undDativ zur Verfugung stellt.
Um die Zahl der Genitive zu erhohen, mussen zusatzlich zu den bisherals Genitiv erkannten Wortern weitere zugelassen werden. Dazu werden zweiErgebnissets berechnet, die miteinander abgeglichen werden. Das erste Ergeb-nisset wird wie in (58) und (59) beschrieben berechnet. Die dort gefundenenGenitive gelten als sicher. Das zweite Ergebnisset wird nach der ursprungli-chen Methode von V2 berechnet. Alle mit Genitiv gekennzeichneten Nomen,die nach einer genitivauslosenden Praposition kommen, werden ebenfalls als’echte’ Genitive betrachtet und in das erste Ergebnisset eingetragen. Auf dieseWeise erhohte sich die Anzahl der Genitivkandidaten auf 393, von denensich 291 als echte Genitive erweisen. Im Vergleich zu der vorher gefundenenAnzahl steigt zwar der Recall, aber der Anteil der tatsachlichen Genitiveunter den Kandidaten sinkt von 74,19 % auf 74,04 %. Der durch die Beispiele(58) und (59) illustrierte Berechnungsschritt wurde erneut durchgefuhrt. DieAnzahl der korrekt ermittelten Wortformen liegt mit 82,29% immernochunter dem Ergebnis von V2.
Diese Ergebnisse zeigen, dass es schwierig ist, das Genitivmerkmal nuraus der Quellsprache herzuleiten. Es muss mehr Aufwand betrieben werden,um es in der Zielsprache zuverlassig erkennen zu konnen.
9Methode V2 mit Trigrammen
37

6.2 Kasusinformationen aus Verben
Ahnlich wie aus Prapositionen kann man auch aus Verben den Kasus derumgebenden NPen ableiten. Das ist in diesem Fall jedoch schwieriger, dasich Subjekt und direktes, bzw. indirektes Objekt auf verschiedene Arten umdas Verb anordnen lassen, wahrend der Aufbau einer Prapositionalphrasefest ist. Außerdem bilden Verben eine offenen Wortklasse; wenn man sie alsoin die Berechnungen miteinbezieht, verliert man in einem gewissen Maße dieVorteile, die sich aus einem auf Tags und eine vergleichsweise geringe MengePrapositionen reduzierten Trainingskorpus ergeben.
Grundlage fur diesen Versuch bildet die Modellierung von V2. Die ge-trennte Reprasentation der vier Merkmale erlaubt es, nur die Daten zuverandern, die das Merkmal Kasus betreffen. In dem Trainingtext, auf demdie Kasus-Werte berechnet werden, werden alle Verbtags (VVFIN, VVINF,VVPP, usw) durch ihren Wortstamm ersetzt. Verben, die ohne Analysebleiben, behalten ihr ursprungliches Tag. Die gleiche Modifikation erfahrendie Testatze, mit dem Zusatz, dass Verben, die nicht in den Trainingsdatenvorkommen, ebenfalls durch ihr POS-Tag dargestellt werden. Auf diese Artkonnen unbekannte Verben ebenfalls im Trainingskorpus ’gesehen’ werden.Beispiel (60) zeigt einen Satz aus dem neuen Trainingstext, Beispiel (61)einen Eingabesatz. Das Ergebnis der Berechnung von (61) steht in (62).
(60) PIAT-Nom NN-Nom wollen<+V> ART-Dat NN-Dat bei<VPART>treten<+V>alle Kandidaten wollen der Wahrungsunion beitreten
(61) PPER danken<+V> PPER , KOUS PPER PPOSAT NN ADV ADJDauf<VPART>nehmen<+V> haben<+V> ,ich danke Ihnen , dass Sie meine Rede so wohlwollend aufgenommen haben,
(62) PPER-Nom danken<+V> PPER-Dat $, KOUS PPER-Nom PPOSAT-AccNN-Acc ADV ADJD auf<VPART>nehmen<+V> haben<+V> ,
Insgesamt kann gegenuber V2 eine leichte Verbesserung festgestellt werden(Tabelle 9). Auch nahert sich die Anzahl der Werte an die vom Parser vorge-gebene Anzahl an, was bedeutet, dass im Vergleich zu V2 mehr Nominativeund Dative und dafur weniger Genitive und Akkusative berechnet werden.Fur die Merkmale Akkusativ, Dativ und Nominativ wurde jeweils eine hohere
Ordnung n 2 3 4V2 85,76 % 87,19 % 87,95 %V2 mit Verben 86,44 % 87.77 % 88,45 %
Tabelle 9: Vergleich der Ergebnisse von V2 und der neu vorgestellten Methode.
38
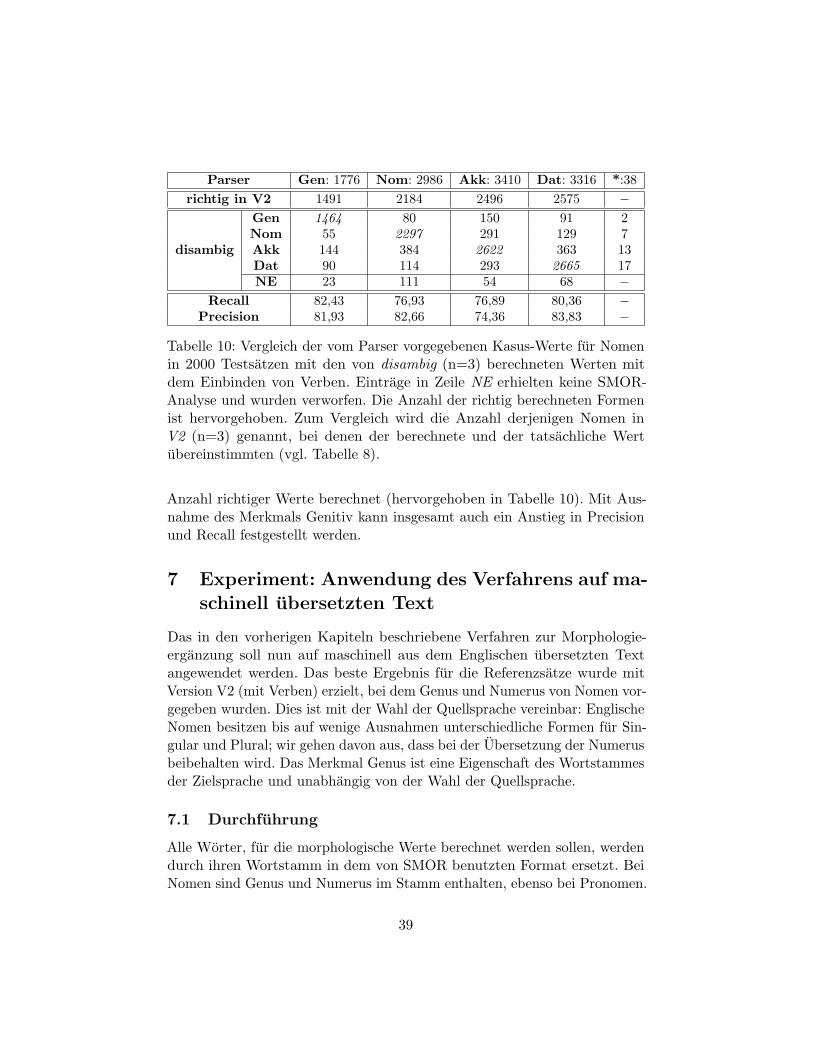
Parser Gen: 1776 Nom: 2986 Akk: 3410 Dat: 3316 *:38richtig in V2 1491 2184 2496 2575 −
disambig
Gen 1464 80 150 91 2Nom 55 2297 291 129 7Akk 144 384 2622 363 13Dat 90 114 293 2665 17NE 23 111 54 68 −
Recall 82,43 76,93 76,89 80,36 −Precision 81,93 82,66 74,36 83,83 −
Tabelle 10: Vergleich der vom Parser vorgegebenen Kasus-Werte fur Nomenin 2000 Testsatzen mit den von disambig (n=3) berechneten Werten mitdem Einbinden von Verben. Eintrage in Zeile NE erhielten keine SMOR-Analyse und wurden verworfen. Die Anzahl der richtig berechneten Formenist hervorgehoben. Zum Vergleich wird die Anzahl derjenigen Nomen inV2 (n=3) genannt, bei denen der berechnete und der tatsachliche Wertubereinstimmten (vgl. Tabelle 8).
Anzahl richtiger Werte berechnet (hervorgehoben in Tabelle 10). Mit Aus-nahme des Merkmals Genitiv kann insgesamt auch ein Anstieg in Precisionund Recall festgestellt werden.
7 Experiment: Anwendung des Verfahrens auf ma-schinell ubersetzten Text
Das in den vorherigen Kapiteln beschriebene Verfahren zur Morphologie-erganzung soll nun auf maschinell aus dem Englischen ubersetzten Textangewendet werden. Das beste Ergebnis fur die Referenzsatze wurde mitVersion V2 (mit Verben) erzielt, bei dem Genus und Numerus von Nomen vor-gegeben wurden. Dies ist mit der Wahl der Quellsprache vereinbar: EnglischeNomen besitzen bis auf wenige Ausnahmen unterschiedliche Formen fur Sin-gular und Plural; wir gehen davon aus, dass bei der Ubersetzung der Numerusbeibehalten wird. Das Merkmal Genus ist eine Eigenschaft des Wortstammesder Zielsprache und unabhangig von der Wahl der Quellsprache.
7.1 Durchfuhrung
Alle Worter, fur die morphologische Werte berechnet werden sollen, werdendurch ihren Wortstamm in dem von SMOR benutzten Format ersetzt. BeiNomen sind Genus und Numerus im Stamm enthalten, ebenso bei Pronomen.
39

Fur sie mussen nur noch die Werte fur Kasus und gegebenenfalls Flexionberechnet werden. Die Beispiele (63) und (64) zeigen Ausschnitte aus demTrainigskorpus.
(63) und<KON> die<+ART><Def><PDS> sage<VVFIN><Sg>sie<+PPRO><Pers><1><Sg><NoGend> mit<APPR> alle<+INDEF><Pro>Nachdruck<+NN><Masc><Sg>und das sage ich mit allem Nachdruck
(64) dafur<PROAV> gelten<VVFIN><Pl> die<+ART><Def>besonder<+ADJ><Pos> Bestimmung<+NN><Fem><Pl> die<+ART><Def>Vertrag<+NN><Masc><Sg> von<APPR> Maastricht<NE> .dafur gelten die besonderen Bestimmungen des Vertrags von Maastricht .
Finite Verben behalten ihre flektierte Form, bekommen aber zusatzlichein POS-Tag und eine Angabe mit ihrem Numerus. Um Mehrdeutigkeitenbeim Numerus von Nomen aufzulosen und infinite Verben von Verben inder 3. Person Plural unterscheiden zu konnen, wurde der Trainingstextmit BitPar geparst. Substituierende Pronomen (PDS, PIS, PWS) werdenextra gekennzeichnet. Sie haben zwar die gleichen Oberflachenformen wieattributive Artikel, kommen aber in vollkommen anderen Kontexten vor,(siehe Beispiel 63). Alle restlichen Worter (Konjunktionen, Eigennamen, usw.)ubernehmen die vom Parser bestimmte Wortart. Die Wortart ist wichtig furdie Konvertierung in das Format fur die Berechnung der morphologischenWerte. Worter, die nicht ubersetzt wurden, sind als Eigennamen markiert.
Tabelle 11 verdeutlicht an einem Beispiel den Ablauf der Schritte, die furdie Bearbeitung eines Satzes notwendig sind. Dort wird deutlich, wie aus derAusgabe des MU-Systems die Tagfolge gewonnen wird, die V2 als Eingabedient.
7.1.1 Vergleich der unbearbeiteten Trainingsdaten mit dem aufWortstamme reduzierten Trainingskorpus
Tabelle 12 zeigt einen Vergleich der vollstandig flektierten Daten mit dem aufWortstamme vereinfachten Trainingskorpus. Die ersten drei Zeilenblocke derTabelle zeigen, wie verschiedene Realisierungen eines Lemmas auf den vonSMOR gebrauchten Wortstamm abgebildet werden. Dabei wird in einigenFallen die Wortart unterschieden. Dies wird im Eintrag des Lemmas jededeutlich, dessen Formen auch substituierende Pronomen sein konnen. DieseUnterscheidung ist fur den weiteren Berechnungsvorgang von Bedeutung,da Worter der beiden Wortarten jeweils sehr unterschiedliche Eigenschaftenhaben. Nomen werden in Singular- und Pluralvorkommen aufgeteilt, insbe-sondere werden auch unterschiedliche Schreibweisen ausgeglichen. Auf den
40
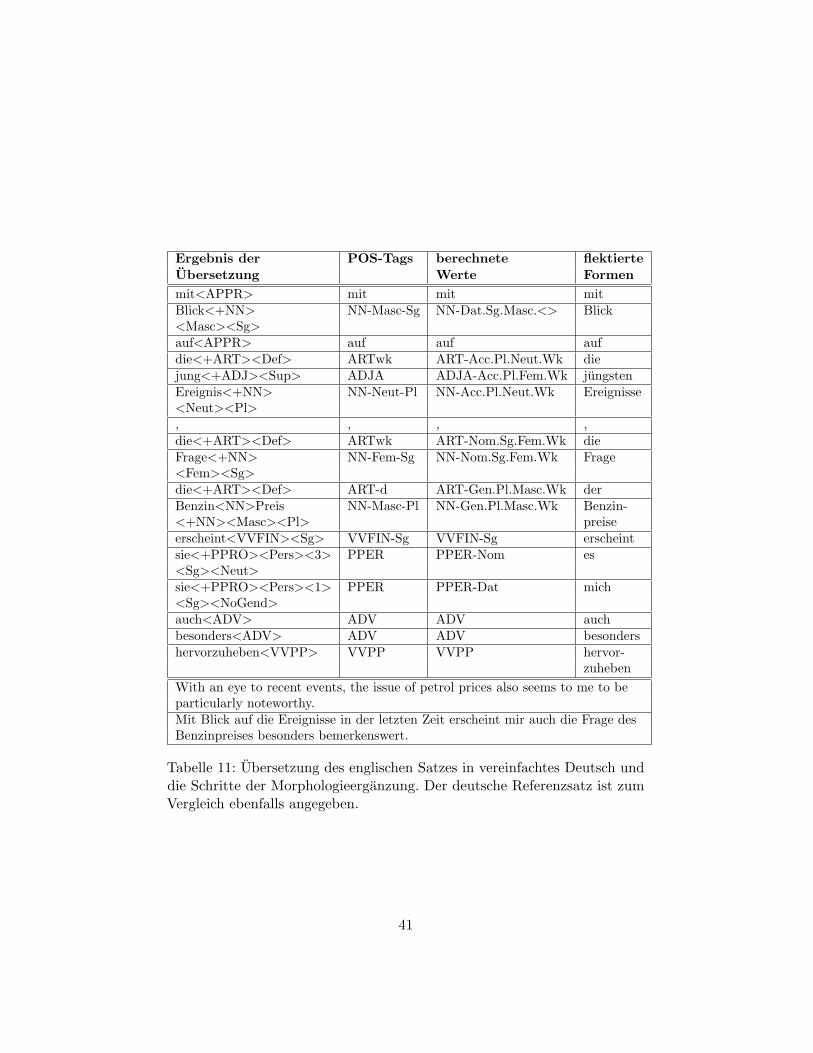
Ergebnis der POS-Tags berechnete flektierteUbersetzung Werte Formenmit<APPR> mit mit mitBlick<+NN> NN-Masc-Sg NN-Dat.Sg.Masc.<> Blick<Masc><Sg>auf<APPR> auf auf aufdie<+ART><Def> ARTwk ART-Acc.Pl.Neut.Wk diejung<+ADJ><Sup> ADJA ADJA-Acc.Pl.Fem.Wk jungstenEreignis<+NN> NN-Neut-Pl NN-Acc.Pl.Neut.Wk Ereignisse<Neut><Pl>, , , ,die<+ART><Def> ARTwk ART-Nom.Sg.Fem.Wk dieFrage<+NN> NN-Fem-Sg NN-Nom.Sg.Fem.Wk Frage<Fem><Sg>die<+ART><Def> ART-d ART-Gen.Pl.Masc.Wk derBenzin<NN>Preis NN-Masc-Pl NN-Gen.Pl.Masc.Wk Benzin-<+NN><Masc><Pl> preiseerscheint<VVFIN><Sg> VVFIN-Sg VVFIN-Sg erscheintsie<+PPRO><Pers><3> PPER PPER-Nom es<Sg><Neut>sie<+PPRO><Pers><1> PPER PPER-Dat mich<Sg><NoGend>auch<ADV> ADV ADV auchbesonders<ADV> ADV ADV besondershervorzuheben<VVPP> VVPP VVPP hervor-
zuhebenWith an eye to recent events, the issue of petrol prices also seems to me to beparticularly noteworthy.Mit Blick auf die Ereignisse in der letzten Zeit erscheint mir auch die Frage desBenzinpreises besonders bemerkenswert.
Tabelle 11: Ubersetzung des englischen Satzes in vereinfachtes Deutsch unddie Schritte der Morphologieerganzung. Der deutsche Referenzsatz ist zumVergleich ebenfalls angegeben.
41
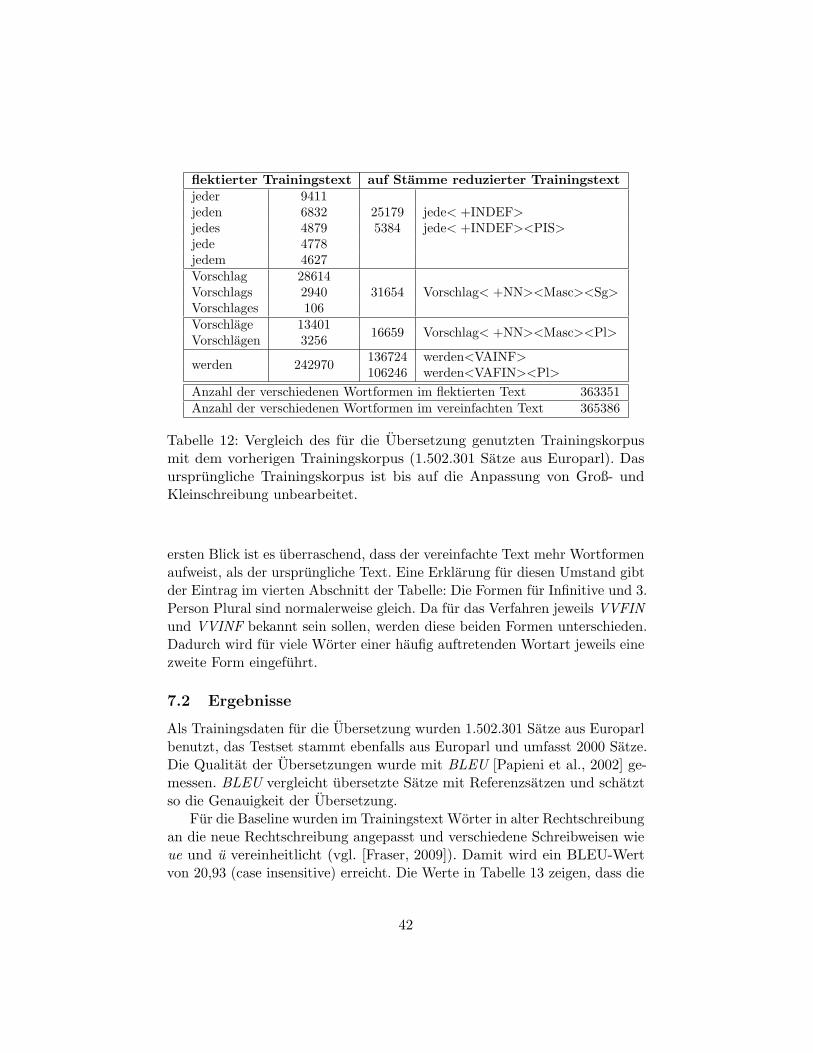
flektierter Trainingstext auf Stamme reduzierter Trainingstextjeder 9411jeden 6832 25179 jede< +INDEF>jedes 4879 5384 jede< +INDEF><PIS>jede 4778jedem 4627Vorschlag 28614Vorschlags 2940 31654 Vorschlag< +NN><Masc><Sg>Vorschlages 106Vorschlage 13401 16659 Vorschlag< +NN><Masc><Pl>Vorschlagen 3256
werden 242970 136724 werden<VAINF>106246 werden<VAFIN><Pl>
Anzahl der verschiedenen Wortformen im flektierten Text 363351Anzahl der verschiedenen Wortformen im vereinfachten Text 365386
Tabelle 12: Vergleich des fur die Ubersetzung genutzten Trainingskorpusmit dem vorherigen Trainingskorpus (1.502.301 Satze aus Europarl). Dasursprungliche Trainingskorpus ist bis auf die Anpassung von Groß- undKleinschreibung unbearbeitet.
ersten Blick ist es uberraschend, dass der vereinfachte Text mehr Wortformenaufweist, als der ursprungliche Text. Eine Erklarung fur diesen Umstand gibtder Eintrag im vierten Abschnitt der Tabelle: Die Formen fur Infinitive und 3.Person Plural sind normalerweise gleich. Da fur das Verfahren jeweils VVFINund VVINF bekannt sein sollen, werden diese beiden Formen unterschieden.Dadurch wird fur viele Worter einer haufig auftretenden Wortart jeweils einezweite Form eingefuhrt.
7.2 Ergebnisse
Als Trainingsdaten fur die Ubersetzung wurden 1.502.301 Satze aus Europarlbenutzt, das Testset stammt ebenfalls aus Europarl und umfasst 2000 Satze.Die Qualitat der Ubersetzungen wurde mit BLEU [Papieni et al., 2002] ge-messen. BLEU vergleicht ubersetzte Satze mit Referenzsatzen und schatztso die Genauigkeit der Ubersetzung.
Fur die Baseline wurden im Trainingstext Worter in alter Rechtschreibungan die neue Rechtschreibung angepasst und verschiedene Schreibweisen wieue und u vereinheitlicht (vgl. [Fraser, 2009]). Damit wird ein BLEU-Wertvon 20,93 (case insensitive) erreicht. Die Werte in Tabelle 13 zeigen, dass die
42

Ordnung n 2 3 4 5V2 19,16 19,40 19,41 19,18V2 mit Verben 19,28 19,52 19,60 19,42
Tabelle 13: BLEU-Werte (case-insensitive) fur die ubersetzten Satze nach derMorphologieerganzung. Die Verfahren V2 und die Erweiterung von V2 umVerben wurden unter gleichen Bedingungen wie in den vorher beschriebenenVersuchen auf die Satze angewandt.
Unterschiede zwischen den unterschiedlichen Varianten in dieser Anwendungdenen in der Anwendung auf Referenzsatzen ungefahr entsprechen. Das besteErgebnis von 19,6 wird mit n=4 und der um Verben erweiterten Versionerreicht. Dass auch dieser Wert unter der Baseline von 20,93 liegt, liegt zueinem großen Teil an der unzureichenden Qualitat der Ubersetzung unddem daraus resultierenden Fehlen von Verben und der falschen Satzstellung.Beispiel (65) zeigt einen Satz, dessen Struktur keine sinnvolle Berechnungmorphologischer Features erlaubt.
Durch die verschiedenen Arbeitschritte - Analyse, Berechnen, Generie-ren - kommen zusatzlich Verarbeitungsfehler dazu, die unter Umstandenweitergegeben werden und Fehler in einem großeren Kontext auslosen. EinBeispiel hierfur ist die Vorgabe von falschen Werten des Merkmals Genusbei Nomen. Obwohl die Analyse Mangel-masc in einem Text wie Europarlnaheliegender ist als Mangel-fem, wurde fur einige Formen des Lemmas Man-gel im Trainingstext fur die Ubersetzung die Analyse Mangel-fem eingesetzt.Dies fuhrt dazu, dass die flektierten Formen in einer NP/PP mit diesemLemma falsch sind, wie der Satz in (66) illustriert. Ein weiterer Aspekt, dersich aus der schlechten Analysewahl dieses Wortes ergibt, ist, dass andereRealisierungen dieses Lemmas, die keine zweite Analyse zulassen, die passen-de und damit eine andere Analyse erhalten und somit Formen eines Lemmasunterschiedliche Stamme haben. Beispiel (67) zeigt einen Satz, in dem Man-gel korrekt als maskulines Wort erkannt und verarbeitet wurde. Um solcheFehler zu vermeiden, ware es sinnvoll, solche Analysen im Trainingskorpuszu korrigieren und auch Werte fur Genus bei bestimmten Abkurzungen wieEU oder NATO vorzugeben (vgl. Beispiel 69)).
7.2.1 Beispiele
Die folgenden Beispielsatze sind der Ausgabe des besten Systems entnommen;mit * markierte Formen wurden vom System generiert.
43

(65) *wir sind *uns *allen *die *gleiche wollen , und *wir mussen sehr klar sagen ,*die hier *im *Parlament .Wir wollen alle das Gleiche , und das mussen wir auch an dieser Stellesagen .We all want the same thing and we have to say this very clearly here inParliament.
(66) *eines *der *Probleme , *die *das *Parlament hat *sich in *den *letzten*Jahren ist *eine *Mangel an *einheitlichen *Informationen uber *die*Kontrolle *der *Institutionen .In den vergangenen Jahren stand das Parlament vor dem Problem, dasszu wenige genormte Informationen zur Finanzkontrolle aus den Organenkamen.One of the problems Parliament has faced in recent years is a lack ofstandardised information on financial control from the institutions.
(67) aber *ich habe *vielen *Einwande gegen *die *Schaffung von *Praze-denzfallen *rechtlicher *Mangel und *der *sozialen *Probleme , *die standigungelost .Noch weitaus mehr Einwande habe ich jedoch dagegen , juristische Schwach-en und Prazedenzwirkungen dazu zu nutzen , ein gesellschaftliches Problemauf Dauer ungelost zu lassen .But I have many more objections to tackling legal weaknesses and settingprecedents in ways that leave social problems permanently unsolved.
(68) *die *europaische *Lebensmittelbehorde wird auch *klare und *zugangliche*Informationen uber *Fragen *im *Zusammenhang mit *seinem *Mandat .Die europaische Lebensmittelbehorde soll außerdem klare und verstandlicheInformationen uber die in ihr Aufgabengebiet fallenden Fragen liefern .The European Food Agency will also provide clear and accessible informationon issues arising out of its mandate.
(69) *ich unterstutze *die *Forderung *des *Ausschusses fur *die *Rechte *der*Frauen in *diesem *Bericht fur *eine *umfassende *Studie *der *Frauenin *dem EU und in *den *Beitrittslandern als *Ausgangspunkt fur *die*weitere *Arbeit .Ich mochte die in diesem Bericht enthaltene Bitte des Ausschusses furdie Rechte der Frau um eine umfassende Studie zur Lage der Frau in derEuropaischen Union und in den beitrittswilligen Landern als Ausgangspunktfur die kunftige Arbeit unterstutzen .I would support the request of the Committee on Women’s Rights in thisreport for a major study of women in the EU and in the candidate countriesas a starting point for future work.
Zusammenfassend kann man jedoch trotzdem sagen, dass die Berechnungmorphologischer Features und die Generierung flektierter Formen auch aufdie Ausgabe eines MU-Systems ubertragen werden konnen. Das zentraleKriterium - die Wohlgeformtheit einzelner Phrasen - wird auch hier in vielen
44

Fallen erfullt. Dies verdeutlichen die Satze in den Beispielen (68, 69), diejeweils eine relativ grammatische Satzstruktur aufweisen und fur die bis aufdie Ausnahme dem EU richtige Formen generiert werden konnten.
8 Zusammenfassung und Ausblick
Die Ergebnisse in Kapitel 5 haben gezeigt, dass es moglich ist, die Wertemorphologischer Merkmale anhand von POS-Tags an korrekten Satzen zuberechnen und die vollstandige Form in einem weiteren Schritt zu generieren.Das beste System (V2, n = 4) ubertrifft mit 87,95% richtigen Formen dieTrigramm-basierte Baseline (77,65% richtige Formen). Die Erweiterung derTrainingsdaten um Verben bringt eine zusatzliche Verbesserung auf 88,45 %,wahrend der Versuch, Genitive vorzugeben, nicht erfolgreich war.
Zusammenfassend kann man sagen, dass das Verfahren auf lokaler Ebe-ne, das heißt, innerhalb einzelner Nominal- bzw. Prapositionalphrasen, gutfunktioniert. Das Zusammenspiel dieser einzelnen, wohlgeformten Kompo-nenten, zum Beispiel die Vergabe der Rollen als Subjekt, Akkusativ- oderDativobjekt, ist jedoch nicht ausgereift.
Die Struktur des Quellsatzes wurde bisher nicht benutzt, durch eine(syntaktische) Analyse kann man jedoch weitere Informationen wie zum Bei-spiel uber die Verteilung der Objekte und des Subjekts gewinnen, und dieseErkenntnis auf die Ubersetzung ubertragen. Auf der Seite der Zielsprachewurde man davon profitieren, mehr Informationen uber die Struktur der vonVerben geforderten Objekte einzubeziehen. Ebenso ware eine Verbesserungder Modellierung von Teilproblemen, wie die Behandlung von Relativprono-men oder von verschachtelten Phrasenstrukturen, hilfreich. Diesen Problemenist gemein, dass unter anderem vorher ermittelte Werte wieder aufgegriffenwerden mussen.
Ein klarer Vorteil von wortbasierter Verarbeitung ist, dass haufig auftre-tende Wortfolgen sehr gut wiedergegeben werden. Dieser Vorteil geht in dertag-basierten Verarbeitung, die eher auf die Verbesserung von Wortformenzielt, die im Trainingskorpus selten oder sogar gar nicht vorkommen, kom-plett verloren. Es ware interessant, eine Erweiterung zu betrachten, in derbesonders haufig auftretende Wortfolgen berucksichtigt werden. Da einigesolcher Konstruktionen eine Praposition beinhalten, auf die entweder Akku-sativ oder Dativ folgen kann, kann man sich vorstellen, diese Informationim Trainingstext fur die Ubersetzung nicht uberall zu entfernen, sondern insolchen Fallen beizubehalten, und ahnlich wie beim Merkmal Numerus einenWert wahrend des Ubersetzungsvorgangs bestimmen zu lassen.
45

Das Ubersetzen mit reduziertem Trainingstext mag zwar einen positivenEinfluss auf die allgemeine Qualitat der Ubersetzung haben; dieser Effekt wirddurch den dadurch zusatzlich notwendigen Schritt jedoch wieder zunichtegemacht. Das Einfuhren einer zusatzliche Behandlung vom Komposita wie in[Fraser, 2009] wurde diesen Effekt jedoch positiv verstarken, weil auf dieseArt sehr viele komplexe Formen vereinfacht werden.
Da andere Probleme, wie fehlerhafte Satzstellung und das Fehlen oder dop-pelte Auftreten von (Auxiliar-)Verben nicht beeinflusst werden und weiterhinauftreten, kann die Berechnung und Generierung der flektierten Formen nurin einem geringeren Maß als an den Referenzsatzen funktionieren. Weil dieMethode sehr stark von der Gesamtqualitat der Satzstruktur abhangt, wurdesie am meisten von einer Verbesserung der allgemeinen Ubersetzungsqualitatprofitieren.
46

Literatur
[Chen and Goodman, 1998] Chen, S. F. and Goodman, J. (1998). An em-pirical study of smoothing techniques for language modeling. HarvardUniversity, Cambridge, Massachusetts.
[El-Kahlout and Oflazer, 2006] El-Kahlout, I. D. and Oflazer, K. (2006).Initial explorations in english to turkish statistical machine translation.In Proceedings of the Workshop on Statistical Machine Translation, pages7–14, New York, USA.
[Evert, 2004] Evert, S. (2004). The statistical analysis of morphosyntacticdistributions. In Proceedings of the Fourth International Conference onLanguage Resources and Evaluation (LREC), pages 1539–1542, Lisbon,Portugal.
[Fraser, 2009] Fraser, A. (2009). Experiments in morphosyntactic processingfor translation to and from german. In Proceedings of the 4th EACLWorkshop on Statistical Machine Translation, pages 115–119, Athens,Greece.
[Kneser and Ney, 1995] Kneser, R. and Ney, H. (1995). Improved backing-offfor m-gram language modeling. In Proceedings of the IEEE InternationalConference on Acoustics, Speech and Signal Processing, volume 1, pages181–184.
[Koehn and Hoang, 2007] Koehn, P. and Hoang, H. (2007). Factored transla-tion models. In Proceedings of the Joint Conference on Empirical Methodsin Natural Language Processing and Computational Natural LanguageLearning, pages 868–876, Prague, Czech Republic.
[Koehn et al., 2003] Koehn, P., Och, F. J., and Marcu, D. (2003). Statisticalphrase-based translation. In Proceedings of the Joint Conference on HumanLanguage Technologies and the Annual Meeting of the North AmericanChapter of the Association of Computational Linguistics, pages 127–133,Edmonton, Canada.
[Manning and Schutze, 1999] Manning, C. D. and Schutze, H. (1999). Foun-dations of Statistical Natural Language Processing. MIT Press, Cambridge,MA.
[Minkov et al., 2007] Minkov, E., Toutanova, K., and Suzuki, H. (2007).Generating complex morphology for machine translation. In Proceedings of
47

the 45th Annual Meeting of the Association of Computational Linguistics,pages 128–135, Prague, Czech Republic.
[Nugues, 2006] Nugues, P. M. (2006). An Introduction to Language Proces-sing with Perl and Prolog. Springer Verlag, Berlin/Heidelberg, Deutsch-land.
[Och and Ney, 2003] Och, F. J. and Ney, H. (2003). A systematic compari-son of various statistical alignment models. Computational Linguistics,29(1):19–51.
[Papieni et al., 2002] Papieni, K., Ward, T., Roukos, S., and Zhu, W.-J.(2002). Bleu : a method for automatic evaluation of machine translati-on. In Proceedings of the 40th Annual Meeting of the Association forComputational Linguistics, pages 311–318.
[Popovic and Ney, 2004] Popovic, M. and Ney, H. (2004). Towards the use ofword stems and suffixes for statistical machine translation. In LREC2004,pages 1585–1588, Lisbon, Portugal.
[Schmid, 1994] Schmid, H. (1994). Probabilistic part-of-speech tagging usingdecision trees. In Proceedings of International Conference on New Methodsin Language Processing, pages 44–49, Manchester, UK.
[Schmid, 2004] Schmid, H. (2004). Efficient parsing of highly ambiguouscontext-free grammars with bit vectors. In Proceedings of the 20th Inter-national Conference on Computational Linguistics, Genf, Switzerland.
[Schmid et al., 2004] Schmid, H., Fitschen, A., and Heid, U. (2004). SMOR:a German computational morphology covering derivation, composition,and inflection. In Proceedings of the Fourth International Conference onLanguage Resources and Evaluation (LREC), pages 1263–1266, Lissabon,Portugal.
[Stolcke, 2002] Stolcke, A. (2002). SRILM - an extensible language modelingtoolkit. In Intl. Conf. Spoken Language Processing, Denver, Colorado.www.speech.sri.com/projects/srilm.
[Toutanova and Suzuki, 2006] Toutanova, K. and Suzuki, H. (2006). Gene-rating case markers in machine translationlearning to predict case markersin japanese. In Proceedings of the 21st International Conference on Com-putational Linguistics, pages 1049–1056, Sydney.
48

[Toutanova et al., 2008] Toutanova, K., Suzuki, H., and Ruopp, A. (2008).Applying morphology generation models to machine translation. In Pro-ceedings of the 46th Annual Meeting of the Association for ComputationalLinguistics: Human Language Technologies.
49

A Tagliste
ADJA-Comp, ADJA-NK, ADJA-Pos, ADJA-Sup, ADJD, ADV, APPO, APPRART,APZR-AC, ART, CARD, FM, ITJ-DM, ITJ-MO, ITJ-TOP, ITJ-UC, KOKOM,KON, KOUI, KOUS, NE, NNE-NK, NN, ORD, PDS, PIAT, PIS, PPER, PPOSAT,PPOSS, PRELAT, PRELS, PRF, PROAV, PTKA-MO, PTKANT, PTKA-PM,PTKNEG, PTKVZ, PTKZU-PM, PWAT, PWAV, PWS, TRUNC, VAFIN, VAINF,VAPP, VMFIN, VMINF, VMPP, VVFIN, VVIMP, VVINF, VVIZU, VVPP, XY
B Manuell entfernte Wortformen
Abfallesprodukt Abfalleswirtschaft Abfallsprodukt Abfallswirtschaft AbfalleproduktAbfallewirtschaft Absichrung Aktionenplanen anderm andern andre andrem andrenandrer andres Berichteerstatter Berichteerstatterin Berichteerstattern Berichteer-statters Berichteerstatter Berichteerstatterin Berichteerstattern BerichteerstattersBerichterstatter Berichterstatterin Berichterstattern Berichterstatters BerichtesBerichteserstatterin Berichteserstattern Berichteserstatters Berichteserstatterin Be-richteserstattern Berichteserstatters Berichtserstatter Berichtserstatterin Berichtser-stattern Berichtserstatters Berichtserstatter Berichtserstatterin BerichtserstatternBerichtserstatters Bunderepublik Bundestaat Burgenrinnen Bundrepublik Bundsre-publik Bundsstaat Bundstaat Chancegleichheit Dienstleistungenverkehres Dienst-leistungenverkehrs Dienstleistungsverkehres Eigenkapitalienunterlegung Eigenka-pitalsunterlegung Eigenmittelsrichtlinie Energieenautonomie EnergienautonomieEntwickelung Friedenprozess Friedeprozess Gelderding Geldesding Geldsding gemein-schaftenweiten gemeinschaftenweiter Gesetzeentwurf Gesetzesentwurf Gesundheiten-versorgung Gesundheitenversorgungssystem Gesundheitenwesen HandlungenfreiheitHausesarbeit Haushaltegehilfin Haushaltegehilfinnen Haushaltekontrolle Haushal-tesgehilfin Haushaltesgehilfinnen Haushalteskontrolle Haushaltgehilfin Haushaltge-hilfinnen Haushaltkontrolle Hauserarbeit Industrienbereiche Informationenpflichtinhaltelose inhaltelosen inhalteslose inhalteslosen inhaltlose inhaltlosen Interesse-gruppe Interessesgruppe Kerneenergie Kernsenergie Klimaandrung KlimaandrungenKlimasanderung Klimasanderungen Klimasandrung Klimasandrungen Klimataande-rung Klimataanderungen Klimataandrung Klimataandrungen Kommissarin Kre-diteinstituten Krediterisiken Kreditesinstituten Kreditesrisiken KreditsinstitutenKreditsrisiken Landeswirte Landswirte Lebensmittelskonzerne letztern letztre letz-tren letztrer letztres Landerwirte Milliardesubventionen Mitburgerinne MitburgrinneMitburgrinnen Mitgliederstaaten Mitgliedesstaaten Mitgliedsstaaten Mittelmeere-raum Mittelmeeresraum Mittelmeersraum Andrung Andrungen AndrungsantrageAndrungsvorschlage Parlamentes Politikenbereiche Projektes Protokolles RatesRechtsstaats Redzeit Reglung Reglungen Reihefolge Rindeswahnsinn RindswahnsinnRindwahnsinn Risikengehalt Risikosgehalt Sackesgasse Sacksgasse SchutzesniveausSackegasse Sicherheitenpolitik Sicherheitenpolitiken Sitzungenperioden Staaten-wesens Staateswesens Staatwesens Stellewert steuernahnlichen steuernahnlichersteuersahnlichen steuersahnlicher Subsidiaritatengrundsatzes Tagesitzung Tagsit-
50

zung Tagssitzung tapfern tapfre tapfren Umsetzeung Umweltenziele VerbessrungenVerbittrung Verfasserin Verordenung Versicherungensysteme Versicherungensyste-mes Versicherungensystems Versicherungssystemes Weiterentwickelung Wettbewerb-bedingungen Wettbewerbebedingungen Wettbewerbesbedingungen WinderadernWindesradern Windsradern Wirtschaftenprozesses Wirtschaftenwachstumes Wirt-schaftenwachstums Wirtschaftswachstumes Wissengesellschaft WTO-VerhandelungWTO-Verhandelungen Zeitenpunkt Zielesstellungen Zielestellungen Zielsstellungen
C Prapositionen mit Genitiv
abseits abzuglich angesichts anhand anlasslich anstatt anstelle aufgrund aufseitenausschließlich außerhalb betreffs bezuglich dank diesseits eingedenk einschließlichexklusive halber hinsichtlich infolge inklusive inmitten innerhalb jenseits kraft langslaut mangels mithilfe mittels oberhalb seitens statt trotz seitlich unfern ungeachtetunterhalb unweit vonseiten wahrend wegen zugunsten zulasten zuseiten zuzuglichzwecks(aus: www.canoo.net)
51


















