
Skript zur Vorlesung - Willkommen an der Universität ...bm0061/skr_wiwi2007.article.pdf ·...
190
Beata Strycharz-Szemberg Skript zur Vorlesung Mathematik f ¨ ur Wirtschaftswissenschaftler UNIVERSIT ¨ AT DUI SBURG ESSEN Essen 2007
Transcript of Skript zur Vorlesung - Willkommen an der Universität ...bm0061/skr_wiwi2007.article.pdf ·...

Beata Strycharz-Szemberg
Skript zur Vorlesung
Mathematik fur Wirtschaftswissenschaftler
UNIVERSITAT
D U I S B U R GE S S E N
Essen 2007

Inhaltsverzeichnis
I Grundlagen 5
1 Logik 5
2 Mengenlehre 6
3 Zahlenmengen 10
3.1 Naturliche Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 Ganze Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.3 Rationale Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.4 Reelle Zahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.5 Die Menge Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.6 Summen- und Produktzeichen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 Abbildungen 17
II Lineare Algebra 21
5 Der Rn als Vektorraum 21
5.1 Unterraume . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5.2 Linear unabhangige Vektoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.3 Basis und Dimension endlich-dimensionaler Vektorraume . . . . . . . . . . . . . . . . . . 30
5.4 Lineare Abbildungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
6 Matrizen und Operationen zwischen Matrizen 35
6.1 Matrizenaddition und Skalarmultiplikation . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.2 Multiplikation von Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6.3 Zusammenhang von linearen Abbildungen und Matrizen . . . . . . . . . . . . . . . . . . 48

INHALTSVERZEICHNIS 2
7 Homogene und inhomogene lineare Gleichungssysteme 50
7.1 Graphische Losung eines linearen Gleichungssystems . . . . . . . . . . . . . . . . . . . . 52
7.2 Lineare Gleichungssysteme und lineare Abbildungen . . . . . . . . . . . . . . . . . . . . . 55
7.3 Losungsmenge eines linearen Gleichungssystems . . . . . . . . . . . . . . . . . . . . . . . 56
7.4 Gauß–Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
7.5 Losbarkeit linearer Gleichungssysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7.6 Berechnung von inversen Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
7.7 Lineare Gleichungssysteme und Vektoren . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
8 Determinanten und Cramersche Regel 73
8.1 Berechnung von Determinanten großerer Ordnung . . . . . . . . . . . . . . . . . . . . . . 78
8.1.1 Laplace–Entwicklung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
8.1.2 Eliminationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
8.2 Determinanten und Vektoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
8.3 Determinanten und inverse Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
8.4 Lineare Gleichungssysteme und Cramersche Regel . . . . . . . . . . . . . . . . . . . . . . 83
III Analysis 85
9 Intervalle und Umgebungen 85
9.1 Betrag und Signum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
9.2 Intervalle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
10 Folgen und Reihen 88
10.1 Der Folgebegriff und Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
10.2 Konvergenz von reellen Zahlenfolgen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
10.2.1 Cauchy–Konvergenzkriterium . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
10.2.2 Konvergenz beschrankter und monotoner Folgen . . . . . . . . . . . . . . . . . . . 93
10.3 Berechnung von Grenzwerten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
10.3.1 Ungleichungen und konvergente Folgen . . . . . . . . . . . . . . . . . . . . . . . . 95
10.3.2 Konvergenz von rekursiv definierten Folgen . . . . . . . . . . . . . . . . . . . . . . 97
10.4 Begriff der Reihe, Beispiele und Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . 98
10.5 Konvergenzkriterien fur Zahlenreihen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102

INHALTSVERZEICHNIS 3
11 Funktionen einer reellen Veranderlichen 105
11.1 Der Funktionsbegriff und Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
11.2 Rechnen mit Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
11.3 Erste Eigenschaften reeller Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
11.3.1 Nullstellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
11.3.2 Symmetrie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
11.3.3 Periodizitat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
11.3.4 Monotonie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
11.4 Grenzwerte von Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
11.5 Stetigkeit von Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
11.6 Eigenschaften stetiger Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
11.7 Monotone Funktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
11.7.1 Die Exponentialfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
11.7.2 Die Logarithmusfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
11.7.3 Allgemeine Exponential- und Logarithmusfunktionen . . . . . . . . . . . . . . . . 126
12 Differentialrechnung fur Funktionen einer reellen Variablen 128
12.1 Der Ableitungsbegriff . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
12.2 Ableitungsregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
12.3 Hohere Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
12.4 Ableitungen und Grenzwerte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
12.5 Extremwerte und Monotonie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
12.5.1 Der Mittelwertsatz der Differentialrechnung . . . . . . . . . . . . . . . . . . . . . 141
12.5.2 Ableitungen und Monotonieverhalten . . . . . . . . . . . . . . . . . . . . . . . . . 142
12.6 Krummung und zweite Ableitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
12.7 Kurvendiskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
13 Funktionen von mehreren Variablen 149
13.1 Norm, Umgebung, offene und abgeschlossene Teilmengen des Rn . . . . . . . . . . . . . . 151
13.2 Folgen im Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
13.3 Stetige Funktionen in Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154

LITERATUR 4
14 Differentialrechnung fur Funktionen in mehreren Variablen 155
14.1 Richtungsableitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
14.2 Partielle Ableitungen hoherer Ordnung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
14.3 Extremwerte von Funktionen in mehreren Variablen . . . . . . . . . . . . . . . . . . . . . 162
14.3.1 Positiv (Negativ) definite Matrizen . . . . . . . . . . . . . . . . . . . . . . . . . . 165
14.3.2 Hinreichende Bedingungen fur Extrema . . . . . . . . . . . . . . . . . . . . . . . . 168
14.4 Extremwerte mit Nebenbedingungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
14.4.1 Variablensubstitution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
14.4.2 Lagrange–Multiplikatorenregel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
15 Integralrechnung 177
15.1 Das Riemann-Integral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
15.2 Stammfunktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
15.3 Integrationsregeln . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
15.4 Uneigentliche Integrale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
15.4.1 Der unbeschrankte Integrationsbereich . . . . . . . . . . . . . . . . . . . . . . . . 186
15.4.2 Der unbeschrankte Integrand . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
Literatur
[1] Tietze, J.: Einfuhrung in die angewandte Wirtschaftsmathematik (Ubungsbuch)
[2] Dorsam, P.: Mathematik anschaulich dargestellt fur Studierende der Wirtschaftswissenschaften(Ubungsbuch)
[3] Rommelfanger, H.: Mathematik fur Wirtschaftswissenschaftler (Ubungsbuch)
[4] Gal, Th. et all: Mathematik fur Wirtschaftswissenschaftler

5
Teil I
Grundlagen
1 Logik
Seien A, B, . . . Aussagen, wie z. B.”die Sonne scheint” oder
”3 ist großer als 5”, die entweder wahr
oder falsch sind (zweiwertige Logik), und seien A(x), B(x), . . . Aussagenformen, d. h. Aussagen, indenen eine oder mehrere Variablen auftreten und die erst dann wahr oder falsch werden, wenn fur dieVariablen Elemente aus einer sinnvollen Menge eingesetzt werden.
Beispiele 1.1.
• Essen ist eine Stadt in NRW (w)
•√
2 ist eine rationale Zahl (f)
• 32 − 2 · 3 + 1 > 0 (w)
• Der Graph einer quadratischen Funktion ist eine Gerade (f)
• Winkelsumme im Dreieck ist 180◦ (w)
• x ist eine Primzahl
• x | 27 (x ist ein Teiler von 27)
• x2 + y2 = 4
Wir werden als Abkurzungen einige Symbole benutzen:
• Negation, Verneinung:¬A, ∼ A —
”nicht A”.
• Konjunktion, Verbindung:A ∧ B —
”sowohl A als auch B”,
”A und B”.
• Disjunktion:A ∨ B —
”A oder B ist wahr, oder beide sind wahr”.
• Implikation, Folgerung:A⇒ B —
”aus A folgt B”,
”wenn A, dann auch B”,
”B ist notwendig fur A”,
”A ist hinreichend fur B”;
A – Voraussetzung oder Pramisse,B – Behauptung oder Konklusion.

2 MENGENLEHRE 6
• Aquivalenz, Gleichwertigkeit:A⇔ B —
”A gilt genau dann, wenn B gilt”,
”A und B sind gleichwertig”,
”A ist aquivalent mit B”,
”aus A folgt B und umgekehrt”,
”A ist notwendig und hinreichend fur B und umgekehrt”.
• Quantoren:Sei G eine gegebene Grundmenge derart, dass A(x) zu einer Aussage wird, wenn man fur x einElement von G einsetzt.∀x∈GA(x) —
”A(x) fur alle x aus der Menge G ”
”fur alle x aus der Menge G ist A(x) wahr”.
∃x∈GA(x) —”A(x) fur mindestens ein x aus der Menge G ”,
”es existiert mindestens ein x aus G, so dass A(x) wahr ist”.
Wir werden auch die folgende Symbole benutzen:∀ ! —
”fur fast alle . . . ”
∃ ! —”es existiert genau ein . . . ”
2 Mengenlehre
Mengen werden charakterisiert entweder durch Aufzahlen ihrer Elemente in geschweiften Klammern (dieReihenfolge der Aufzahlung ist ohne Bedeutung), z. B.:
M := {He, Ne, Ar, Kr, Xe, Rn} ,
oder durch Angabe einer charakteristischen Eigenschaft, z. B.:
M := {a : a ist ein Edelgas} ,
oder durch graphische Darstellung, z. B.:
M
HeNe
Ar
KrXe
Rn
Der Definitionsdoppelpunkt”:=” ist folgendermassen zu verstehen:
”definitionsgemaß gleich”,
”bedeu-
tet”,”soll sein”.

2 MENGENLEHRE 7
Wir werden die folgenden Bezeichnungen benutzen:
• A, B, M , X, Y , . . . — Mengen, große lateinische Buchstaben;
• a, b, m, x, y, . . . — Elemente, kleine lateinische Buchstaben;
• a ∈ A — a ist ein Element der Menge A;
• a 6∈ A — a ist kein Element der Menge A;
• Ø — die leere Menge; die Menge, die kein Element besitzt.
Fur Mengen verwenden wir die folgenden Beziehungen und Verknupfungen:
Definition 2.1. Seien A und B Mengen.
a) A ist Teilmenge von B genau dann, wenn aus a ∈ A stets a ∈ B folgt:
A ⊆ B ⇐⇒ (a ∈ A ⇒ a ∈ B) .
Die Menge B heißt in diesem Fall auch Obermenge von A.
b) A und B sind gleich genau dann, wenn A ⊆ B und B ⊆ A:
A = B ⇐⇒ (a ∈ A ⇔ a ∈ B) .
c) A heißt echte Teilmenge von B genau dann, wenn A ⊆ B und A 6= B:
A ⊂ B ⇐⇒ (a ∈ A ⇒ a ∈ B) ∧ (∃ a ∈ B : a 6∈ A) .
Die leere Menge Teilmenge jeder Menge ist: ∀A−Menge Ø ⊆ A.
Beispiel 2.2.
❶ {2, 4, 6, 8} ⊆ {1, 2, 3, 4, 5, 6, 7, 8, 9}{2, 4, 6, 8} ⊆ {8, 6, 4, 2}
❷ {2, 4, 6, 8} = {8, 6, 4, 2, 2, 4, 6, 8}
❸ {2, 4, 6, 8} ⊂ {1, 2, 3, 4, 5, 6, 7, 8, 9}¬(
{2, 4, 6, 8} ⊂ {8, 6, 4, 2})
2 MENGENLEHRE 8
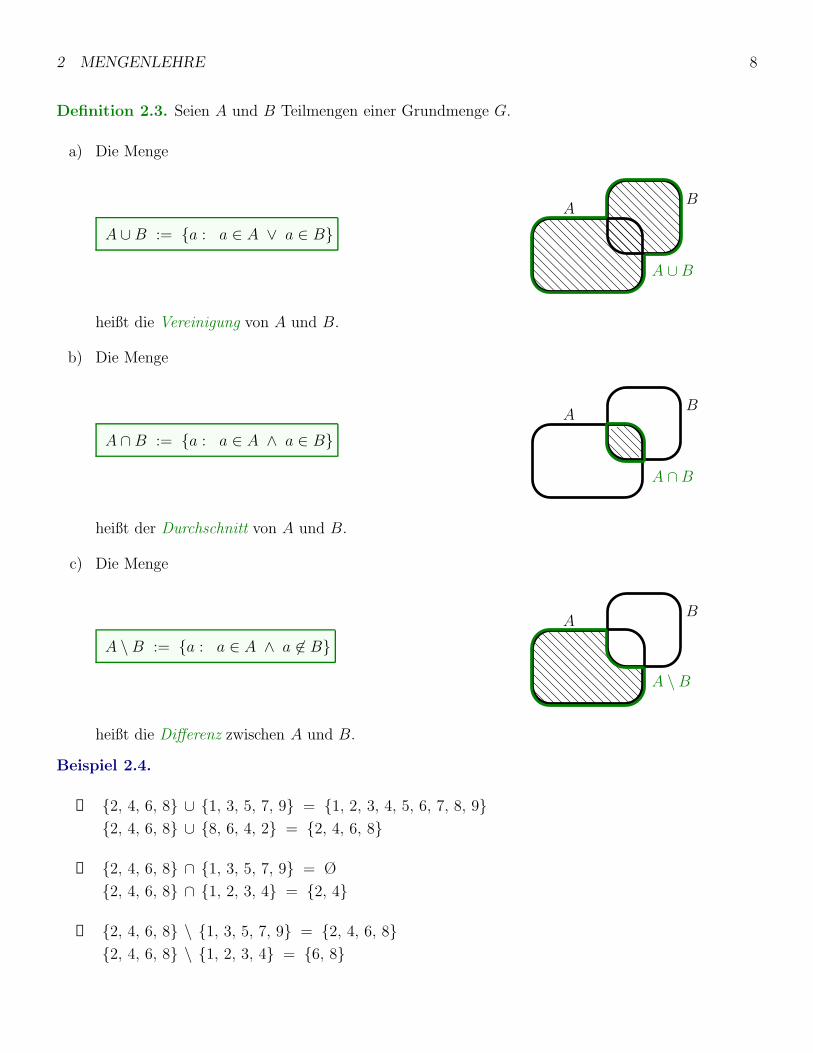
Definition 2.3. Seien A und B Teilmengen einer Grundmenge G.
a) Die Menge
A ∪ B := {a : a ∈ A ∨ a ∈ B}A
B
A ∪B
heißt die Vereinigung von A und B.
b) Die Menge
A ∩ B := {a : a ∈ A ∧ a ∈ B}A
B
A ∩B
heißt der Durchschnitt von A und B.
c) Die Menge
A \B := {a : a ∈ A ∧ a 6∈ B}A
B
A \B
heißt die Differenz zwischen A und B.
Beispiel 2.4.
❶ {2, 4, 6, 8} ∪ {1, 3, 5, 7, 9} = {1, 2, 3, 4, 5, 6, 7, 8, 9}{2, 4, 6, 8} ∪ {8, 6, 4, 2} = {2, 4, 6, 8}
❷ {2, 4, 6, 8} ∩ {1, 3, 5, 7, 9} = Ø
{2, 4, 6, 8} ∩ {1, 2, 3, 4} = {2, 4}
❸ {2, 4, 6, 8} \ {1, 3, 5, 7, 9} = {2, 4, 6, 8}{2, 4, 6, 8} \ {1, 2, 3, 4} = {6, 8}

2 MENGENLEHRE 9
Die Verknupfung verschiedener Mengenoperationen kann nicht willkurlich geschehen; sie ist vielmehrdurch strenge Gesetzmaßigkeiten geregelt. Wir listen die wichtigsten dieser Gesetze hier auf.
Eigenschaften 2.5. Seien A, B und C Teilmengen einer Grundmenge G. Dann gelten:
• Kommutativgesetze:
A ∪ B = B ∪A und A ∩B = B ∩ A;
• Assoziativgesetze:
(A ∪ B) ∪ C = A ∪ (B ∪ C) =: A ∪ B ∪ C,(A ∩ B) ∩ C = A ∩ (B ∩ C) =: A ∩ B ∩ C;
• Distributivgesetze:
A ∪ (B ∩ C) = (A ∪ B) ∩ (A ∪ C),
A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C);
• Idempotenzgesetze:
A ∪ A = A und A ∩A = A;
• Neutrale Elemente:
A ∩G = A und A ∪Ø = A;
• Dominante Elemente:
A ∩Ø = Ø und A ∪G = G.
Von Bedeutung wird im Folgenden noch der Begriff des Produktes von Mengen sein:
Definition 2.6. Fur zwei Mengen A und B heißt die Menge
A×B := {(a, b) : a ∈ A ∧ b ∈ B}
kartesisches Produkt von A und B. Das Paar (a, b) heißt geordnetes Paar.

3 ZAHLENMENGEN 10
Beispiel 2.7.
❶ Das Produkt der Mengen A = {1, 3, 5} und B = {0, 2} ist die Menge
A×B = {(1, 0) , (1, 2) , (3, 0) , (3, 2) , (5, 0) , (5, 2)} .
❷ Fur jede Menge A giltA×Ø = Ø und Ø×A = Ø.
3 Zahlenmengen
3.1 Naturliche Zahlen
Die Menge der naturlichen Zahlen werden wir mit
N := {1, 2, 3, . . .}
bezeichnen. Praktisch, und haufig verwendet, ist die Bezeichnung
N0 := {0, 1, 2, 3, . . .}.
Die Grundoperationen: Addition”+” und Multiplikation
”·” sind in der Menge der naturlichen Zah-
len N uneingeschrankt durchfuhrbar. Summe und Produkt zweier naturlicher Zahlen sind wieder einenaturliche Zahl. Das heißt, die Menge N ist unter den beiden algebraischen Operationen
”+” und
”·”
abgeschlossen.
Bemerkung 3.1.
Die Gleichungenx + 5 = 3 und 5 · x = 3
sind in der Menge der naturlichen Zahlen nicht losbar (d. h. es existiert keine naturliche Zahl x, diediese Gleichungen erfullt). Andersgesagt: die Umkehrungen der Addition und der Multiplikation, d. h.die Subtraktion und die Division, sind nur manchmal in N durchfurbar:
3 − 5 6∈ N und3
56∈ N.

3 ZAHLENMENGEN 11
3.2 Ganze Zahlen
Die Menge der ganzen Zahlen bezeichnen wir mit
Z := {. . . , −3, −2, −1, 0, 1, 2, 3, . . .}.
Die Elemente von {. . . , −3, −2, −1} heißen negative ganze Zahlen und die Elemente von {1, 2, 3, . . .}positive ganze Zahlen. Es gilt N ⊂ Z.
Bemerkung 3.2.
Zu je zwei ganzen Zahlen a und b existiert genau eine ganze Zahl x, so dass a+x = b; kurz geschrieben:
∀ a, b ∈ Z ∃ ! x ∈ Z : x+ a = b, (x := b− a)
d. h. die Subtraktion ist in der Menge der ganzen Zahlen uneingeschrankt durchfuhrbar.
3.3 Rationale Zahlen
Die Menge der rationalen Zahlen wird mit
Q :=
{p
q: p, q ∈ Z ∧ q 6= 0
}
= Menge der periodischen Dezimalbruche.
bezeichnet. Es gilt Z ⊂ Q, da die Zahl p ∈ Z mit dem Bruch p
1∈ Q identifiziert werden kann.
Bemerkung 3.3.
Zu je zwei rationalen Zahlen a 6= 0 und b existiert genau eine rationale Zahl x, so dass a · x = b; kurzgeschrieben:
∀ a ∈ Z \ {0}, b ∈ Z ∃ ! x ∈ Q : a · x = b,
(
x :=b
a
)
.
In Q sind jetzt die vier Grundoperationen Addition, Multiplikation, Subtraktion und Division (außerdurch 0!) unbeschrankt ausfuhrbar, d. h. die Menge der rationalen Zahlen ist bzgl. dieser Operationenabgeschlossen.
3 ZAHLENMENGEN 12
3.4 Reelle Zahlen
Rationale Zahlen kann man mit Punkten einer geraden Linie, der Zahlengerade, identifizieren. Aberdann wird man feststellen, dass diese Gerade kein Kontinuum ist. Es gibt Lucken in der
”rationalen”
Zahlengerade:
√20 1
Es gibt nichtrationale Zahlen, z. B.√
2 oder 0,1 01 001 0001 00001 . . . – nichtperiodischer Dezimalbruch.
Bekannte irrationale Zahlen:√
2 = 1,41421356 . . . – die Lange der Diagonale in einem Quadrat der Seitenlange 1,
π = 3,141592654 . . . – die Kreiszahl,
e = 2,71828182 . . . – die Eulersche Zahl.
Die Menge der reellen Zahlen R erhalt man aus Q durch die Forderung der Vollstandigkeit: Wirwollen, dass die Zahlengerade luckenlos (ein Kontinuum) ist, wie uns die Anschauung lehrt.Diese anschauliche Erklarung der Menge R stellt naturlich keine exakte Definition dar.
Wir werden uns R als Menge der Dezimalbruche vorstellen
R := Menge der Dezimalbruche
Es gilt Q ⊂ R, und auch in R sind die vier Grundoperationen naturlich unbeschrankt ausfuhrbar.
Zwei reelle Zahlen x, y ∈ R kann man
addieren: x+ y ∈ R
multiplizieren: x · y ∈ R,
dabei gelten die aus der Schule bekannten Regeln:

3 ZAHLENMENGEN 13
Eigenschaften und Regeln 3.4. Es seien x, y, z ∈ R.
• Assoziativitat der Addition:
(x+ y) + z = x + (y + z)
• Existenz der Null – des neutralen Elementes bzgl. der Addition:
∀x ∈ R : x + 0 = x = 0 + x
• Existenz des Negativen (−x):
∀x ∈ R ∃! (−x) ∈ R : x + (−x) = 0 = (−x) + x
• Kommutativitat der Addition:
x + y = y + x
• Assoziativitat der Multiplikation:
(x · y) · z = x · (y · z)
• Existenz der Eins – des neutralen Elementes bzgl. der Multiplikation:
∀x ∈ R : x · 1 = x = 1 · x
• Existenz des Inversen 1x:
∀x ∈ R \ {0} ∃! 1x∈ R : x ·
(1
x
)
= 1 =
(1
x
)
· x
• Kommutativitat der Multiplikation:
x · y = y · x

3 ZAHLENMENGEN 14
• Distributivitat:
x · (y + z) = x · y + x · z
Aus den obigen Rechenregeln konnen jetzt die zahlreichen Rechengesetze der Arithmetik abgeleitetwerden, die zum Großteil zum Schulstoff gehoren. Besonders erwahnt werden soll, dass R nullteilerfreiist.
• x · y = x · z ∧ x 6= 0 =⇒ y = z (Kurzungsregel);
• x · y = 0 ⇐⇒ x = 0 ∨ y = 0.
Beispiel 3.5.☞ In der Vorlesung!
Die Menge der reellen Zahlen R ist geordnet, d. h. es gilt
Trichotomiegesetz: Fur je zwei Zahlen x, y ∈ R gilt genau eine der folgenden drei Beziehungen:
x < y oder x = y oder y < x.
Manchmal ist es sinnvoll, den Gleichheitsfall anzuschließen und anstelle von”<” die schwachere Ord-
nungsrelationx ≤ y :⇐⇒ x < y oder x = y
zu betrachten.
Wir listen jetzt wichtige Rechenregeln fur Ungleichungen auf.
Rechenregeln 3.6. Es seien x, x′, y, y′, z ∈ R.
• Transitivitat:
x < y und y < z =⇒ x < z
• Monotonie der Addition:
x < y =⇒ x+ a < y + a fur alle a ∈ R
x < y und x′ < y′ =⇒ x+ x′ < y + y′

3 ZAHLENMENGEN 15
• Monotonie der Multiplikation:
x < y =⇒ a · x < a · y fur alle a > 0
x < y =⇒ a · x > a · y fur alle a < 0
0 ≤ x < y und 0 ≤ x′ < y′ =⇒ 0 ≤ x · x′ < y · y′
•
0 < x < y =⇒ 1
y<
1
x
•
x < y =⇒ x < λx+ (1− λ)y < y fur alle λ ∈ R mit 0 < λ < 1
3.5 Die Menge Rn
Definition 3.7. Fur n ∈ N ist Rn die Menge der geordneten n-Tupel mit Komponenten aus R:
Rn := {x = (x1, x2, . . . , xn) : xi ∈ R, i ∈ {1, . . . , n}} .
In der linearen Algebra bezeichnet man x ∈ Rn auch als Vektor. Dabei schreibt man x als”Spaltenvek-
tor”
x =
x1
x2...xn
= (x1, x2, . . . , xn)t.
In der Analysis werden die Elemente vom Rn als Punkte bezeichnet und, damit die Formeln nicht zulang werden, als
”Zeilenvektoren” geschrieben, also x = (x1, x2, . . . , xn). Fur n = 2 bzw. n = 3 kann
man sich die Elemente vom Rn auch als Punkte in der Ebene R×R (s. Def. 2.6) bzw. im Raum R×R×R
vorstellen. Außerdem ist naturlich R1 = R.

3 ZAHLENMENGEN 16
3.6 Summen- und Produktzeichen
Fur die Summe bzw. fur das Produkt von mehreren Zahlen am, am+1, am+2, . . . , an, m,n ∈ N, m ≤ n
werden folgende Bezeichnungen benutzt:
n∑
i=m
ai := am + am+1 + am+2 + · · · + an,
n∏
i=m
ai := am · am+1 · am+2 · . . . · an.
Rechenregeln 3.8.
• Zerlegen einer Summe: Ist l eine ganze Zahl zwischen m und n, so ist
n∑
i=m
ai =l∑
i=m
ai +n∑
i=l+1
ai.
• Assoziativitat:
n∑
i=m
(ai + bi) =n∑
i=m
ai +n∑
i=m
bi.
• Distributivitat:
n∑
i=m
(c · ai) = c ·n∑
i=m
ai.
• Indexverschiebung: Man kann ein beliebiges Symbol (ausgenommen n) als Summationsindex ver-wenden
n∑
i=m
aij:=i−m
=
n−m∑
j=0
aj+m.
Die untere Summationsgrenze ist oft die Zahl 0 oder 1.

4 ABBILDUNGEN 17
• Doppelsummen: Summanden konnen manchmal zwei Indizes haben, etwa ai,j = 1i+j
. Eine Summe
n,m∑
i,j=1
ai,j
heißt Doppelsumme. Man rechnet sie aus, indem man zuerst uber einen Index addiert und dannuber den anderen:
n,m∑
i,j=1
ai,j :=
n∑
i=1
(m∑
j=1
ai,j
)
=
m∑
j=1
(n∑
i=1
ai,j
)
.
Beispiele 3.9.☞ In der Vorlesung!
Fur Produkte gelten ganz ahnliche Regeln.
Beispiel 3.10. Als ein wichtiges Beispiel nennen wir hier n–Fakultat:
n! :=
n∏
i=1
i = 1 · 2 · 3 · . . . · (n− 1) · n,
fur alle n ∈ N. Vereinbarungsgemass setzt man
0! := 1.
☞ Ein weiteres Beispiel wird in der Vorlesung angegeben!
4 Abbildungen
Das wichtigste Hilfsmittel zur Untersuchung von Mengenstrukturen sind Abbildungen von einer MengeX in eine zweite Menge Y . Wir werden spater ausfuhrlicher auf diesen Begriff eingehen und beschrankenuns hier nur auf die Erlauterung der Grundtatsachen.
Definition 4.1. Seien X und Y Mengen. Eine Zuordnungsvorschrift f , die jedem Element x ∈ X genauein Element y ∈ Y zuordnet, heißt eine Abbildung von X nach Y .
Schreibweise:
f : X → Y, bzw. f :
{X −→ Y
x 7−→ y.

4 ABBILDUNGEN 18
a) Das Element x heißt Urbild von y bezuglich f .
b) Die Menge X heißt Vormenge, Definitionsmenge (Definitionsbereich) oder Urbildmenge der Ab-bildung f .
c) Die Menge Y nennt man (potentielle) Nachmenge von f .
d) Das Element y heißt das Bild von x unter f und wird mit dem Symbol f(x) bezeichnet.
e) Die Menge f(X) = {f(x) : x ∈ X} ⊆ Y bezeichnet man als Bild von f , Bildmenge oderWertebereich.
f) Die Menge Γf = {(x, y) ∈ X × Y : y = f(x)} heißt Graph von f .
Beispiel 4.2.Eine Abbildung f : {1, 2, 3} → {a, b, c}:
X
1
23
Y
a
bc
Keine Abbildung:
X
1
23
Y
a
bc
Definition 4.3. Gegeben seien Mengen X und Y und eine Abbildung f : X → Y .
a) Das Bild von M ⊆ X unter f ist
f(M) := {y ∈ Y : ∃x∈M mit f(x) = y} ⊆ Y.
b) Das Urbild von N ⊆ Y bezuglich f ist
f−1(N) := {x ∈ X : f(x) ∈ N} ⊆ X.
Ist N = {y} fur y ∈ Y , so ist
f−1(y) := f−1({y}) = {x ∈ X : f(x) = y}.

4 ABBILDUNGEN 19
Beispiel 4.4. Wir betrachten die Abbildung aus dem Beispiel 4.2. Dann
❶ f ({3}) = {a}, f ({1, 2}) = {a, b}, f ({1, 2, 3}) = {a, b}
❷ f−1 ({a}) = {2, 3}, f−1 ({b}) = {1}, f−1 ({c}) = Ø
☞ Weitere Beispiele werden in der Vorlesung angegeben!
Definition 4.5. Gegeben seien Mengen X und Y . Eine Abbildung f : X → Y heißt
a) surjektiv (oder Abbildung auf), falls
• f−1(y) fur jedes y ∈ Y aus mindestens einem Element besteht, d. h.:
• ∀y∈Y ∃x∈X f(x) = y, d. h.:
• f(X) = Y .
b) injektiv (oder eineindeutige Abbildung), falls
• f−1(y) fur jedes y ∈ Y aus hochstens einem Element besteht, d. h.:
• ∀x1,x2∈X f(x1) = f(x2) =⇒ x1 = x2, d. h.:
• ∀x1,x2∈X x1 6= x2 =⇒ f(x1) 6= f(x2).
c) bijektiv (oder eineindeutige Abbildung auf), falls f injektiv und surjektiv ist, d. h.:
• f−1(y) fur jedes y ∈ Y aus genau einem Element besteht, d. h.:
• ∀y∈Y ∃!x∈X f(x) = y.
d) Ist f bijektiv, so definiert man die Umkehrabbildung f−1 : Y → X durch:
f−1(y) = x ⇐⇒ f(x) = y.
Beispiel 4.6. Die Abbildung aus dem Beispiel 4.2 ist weder surjektiv (f−1 ({c}) = Ø) noch injektiv(f−1 ({a}) = {2, 3}).☞ Weitere Beispiele werden in der Vorlesung angegeben!
Definition 4.7. Seien X, Y , Z Mengen, und seien f : X → Y und g : Y → Z Abbildungen. Dannheißt die Abbildung
g ◦ f :
{X → Z
x 7−→ g (f(x))
die Verknupfung von f mit g.

4 ABBILDUNGEN 20
X
x
Y
y
Z
z
f g
g ◦ f
Beispiel 4.8.☞ In der Vorlesung!

21
Teil II
Lineare Algebra
5 Der Rn als Vektorraum
Beispiel 5.1. Die Unternehmen U1 und U2 produzieren die gleichen Guter G1, G2, G3 und G4.
Das Unternehmen U1 produziert pro Tag 9 Einheiten G1, 5 Einheiten G2, 7 Einheiten G3 und 2 EinheitenG4, das Unternehmen U2 produziert pro Tag 3 Einheiten G1, 5 Einheiten G2, 8 Einheiten G3 und 7Einheiten G4.
Die Tagesproduktion der beiden Unternehmen kann durch ihren Produktionsvektoren PU1 und PU2
beschrieben werden, wobei i-te Komponente eines Produktionsvektors die Produktion des Gutes Gi proTag angeben soll:
PU1 =
9572
und PU2 =
3587
.
Die Tagesproduktion der beiden Unternehmen zusammen kann durch den Vektor:
PU1+U2 =
9 + 35 + 57 + 82 + 7
=
1210159
beschrieben werden. Weiter werden die Produktionsmengen von U1 bzw. U2 pro Woche durch diefolgenden Vektoren dargestellt:
PWU1
=
7 · 97 · 57 · 77 · 2
=
63354914
bzw.
PWU2
=
7 · 37 · 57 · 87 · 7
=
21355649
.

5 DER RN ALS VEKTORRAUM 22
Motiviert durch dieses Beispiel stellen wir jetzt folgende Definition dar, die die Addition zweierVektoren des Rn und die Multiplikation eines Vektors mit einer Zahl (Skalar) betrifft.
Definition 5.2. Es seien
a =
a1
a2...an
und b =
b1b2...bn
zwei Vektoren des Rn, und es sei λ eine reelle Zahl.
a) Die Vektoraddition ist erklart durch:
a + b =
a1
a2...an
+
b1b2...bn
:=
a1 + b1a2 + b2
...an + bn
.
b) Die Skalarmultiplikation ist erklart durch:
λ · a = λ ·
a1
a2...an
:=
λ · a1
λ · a2...
λ · an
.
Bemerkung. Vektoraddition und Skalarmultiplikation wirken komponentenweise. Man kann also nurVektoren mit der gleichen Anzahl von Eintragen addieren, und das Ergebnis ist ein Vektor mit genausovielen Komponenten.Das Ergebnis der Multiplikation eines Vektors des Rn mit einer reellen Zahl ist auch ein Vektor des Rn.
Da Vektoraddition und Skalarmultiplikation komponentenweise auf das Rechnen mit reellen Zahlenzuruckgefuhrt werden konnen, ubertragen sich die Rechengesetze 3.4 auf Rn.
Satz 5.3. Seien λ, µ ∈ R und a, b, c ∈ Rn, dann gelten die folgende Gesetze:
• Assoziativitat der Addition:
(a+ b) + c = a+ (b+ c)

5 DER RN ALS VEKTORRAUM 23
• Existenz des neutralen Elements der Addition (der Nullvektor):
0 + a = a = a + 0
• Existenz des inversen Elements zu a bzgl. der Addition:
a+ (−1) · a = 0 = (−1) · a+ a
• Kommutativitat der Addition:
a+ b = b+ a
• Assoziativitat der Skalarmultiplikation:
(λ · µ) · a = λ · (µ · a)
• Distributivitat:
(λ+ µ) · a = λ · a+ µ · aλ · (a+ b) = λ · a + λ · b
• Existenz des neutralen Elements der Skalarmultiplikation (die Zahl 1):
1 · a = a.
Wir benutzen hier die folgende Notation:
0 :=
00...0
fur den Nullvektor.
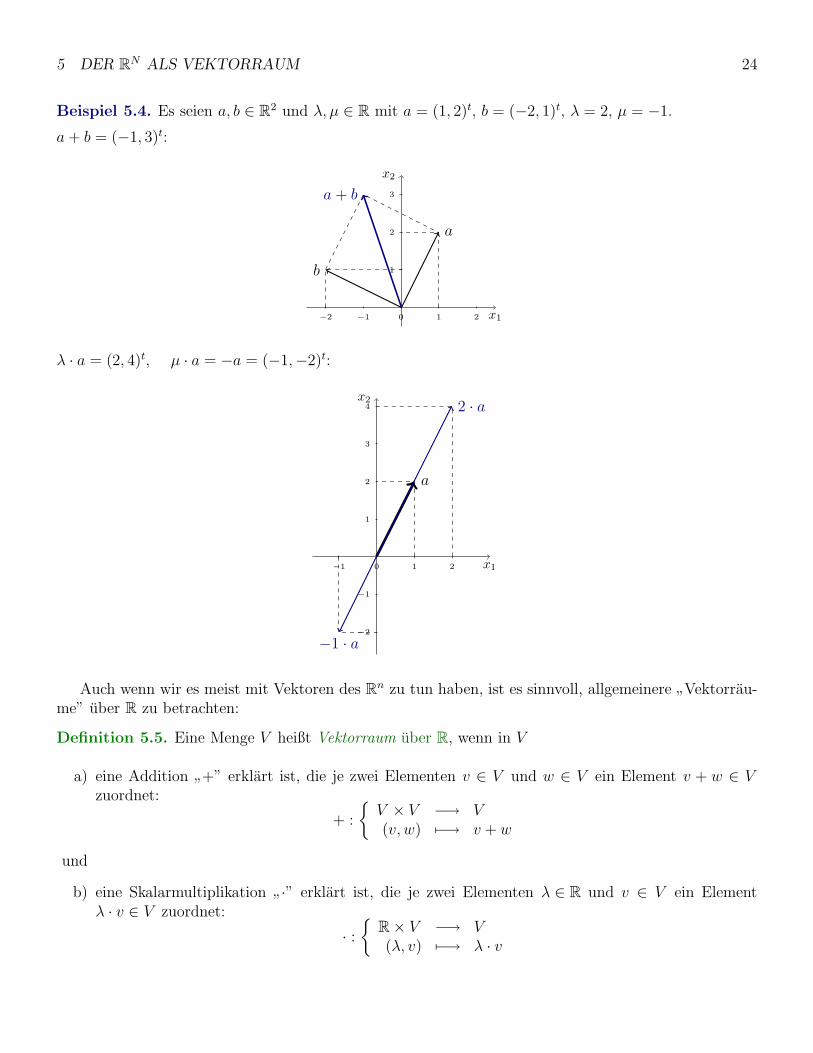
Geometrische Interpretation fur n = 2 (und n = 3):
Vektoren a werden durch Pfeile−→0a im kartesischen Koordinatensystem dargestellt. Die Vektoraddition
kann dann mit Hilfe einer”Paralellogrammregel” durchgefuhrt werden, und die Skalarmultiplikation
entspricht einer”Streckung” des Vektors a um den Faktor λ.
5 DER RN ALS VEKTORRAUM 24
Beispiel 5.4. Es seien a, b ∈ R2 und λ, µ ∈ R mit a = (1, 2)t, b = (−2, 1)t, λ = 2, µ = −1.
a + b = (−1, 3)t:
x1
x2
−2 −1 0 1 2
1
2
3
a
b
a + b
λ · a = (2, 4)t, µ · a = −a = (−1,−2)t:
x1
x2
−1 0 1 2
−2
−1
1
2
3
4
a
2 · a
−1 · a
Auch wenn wir es meist mit Vektoren des Rn zu tun haben, ist es sinnvoll, allgemeinere”Vektorrau-
me” uber R zu betrachten:
Definition 5.5. Eine Menge V heißt Vektorraum uber R, wenn in V
a) eine Addition”+” erklart ist, die je zwei Elementen v ∈ V und w ∈ V ein Element v + w ∈ V
zuordnet:
+ :
{V × V −→ V
(v, w) 7−→ v + w
und
b) eine Skalarmultiplikation”·” erklart ist, die je zwei Elementen λ ∈ R und v ∈ V ein Element
λ · v ∈ V zuordnet:
· :{
R× V −→ V
(λ, v) 7−→ λ · v

5 DER RN ALS VEKTORRAUM 25
so dass gilt:
• Assoziativgesetz fur die Addition:
∀ v,w,u∈V : (v + w) + u = v + (w + u)
• Existenz des neutralen Elements der Addition (das Nullelement des Vektorraumes):
∃! 0∈V ∀ v∈V : v + 0 = v = 0 + v
• Existenz des inversen Elements zu v bzgl. der Addition:
∀ v∈V ∃ v∈V : v + v = 0 = v + v
• Kommutativgesetz der Addition:
∀ v,w∈V : v + w = w + v ∈ V
• Assoziativgesetz der Skalarmultiplikation:
∀ v∈V ∀ λ,µ∈R : (λ · µ) · v = λ · (µ · v)
• Distributivgesetze:
∀ v,w∈V ∀ λ,µ∈R :
{
(λ+ µ) · v = λ · v + µ · vλ · (v + w) = λ · v + λ · w
• Existenz des neutralen Elements der Skalarmultiplikation (die Zahl 1):
∀ v∈V : 1 · v = v
Die Elemente von V bezeichnet man als Vektoren und die Elemente von R als Skalare.

5 DER RN ALS VEKTORRAUM 26
Beispiele 5.6. fur Vektorraume.
❶ Man kann nun leicht nachprufen (s. Satz 5.3), dass der Rn fur alle n ∈ N mit der oben definiertenAddition und Multiplikation (Def. 5.2) ein Vektorraum ist, den man auch Euklidischen Vektorraumnennt.
❷ Der”kleinste” Vektorraum V ist der, der nur ein Element (die Null) enthalt. Man schreibt V = {0}
und nennt V den Nullraum.
❸ Sei X eine nichtleere Menge und sei A(X,R) die Menge aller Abbildungen von X nach R:
A(X,R) := {f : X → R – eine Abbildung} .
Fur alle f, g ∈ A(X,R) (d. h. f, g : X → R) und λ ∈ R definieren wirdie Vektoraddition:
f + g ∈ A(X,R) mit (f + g)(x) := f(x) + g(x)
und die Skalarmultiplikation:
λ · f ∈ A(X,R) mit (λ · f)(x) := λ · f(x).
A(X,R) ist der sogenannte Funktionenraum uber R.
5.1 Unterraume
Definition 5.7. Sei V ein Vektorraum. Eine Teilmenge Ø 6= U ⊆ V heißt Unterraum (Teilraum) von Vgenau dann, wenn sie bezuglich der Vektoraddition und der Skalarmultiplikation abgeschlossen ist, d. h.
a) aus u1 ∈ U und u2 ∈ U folgt u1 + u2 ∈ U :
(u1 ∈ U ∧ u2 ∈ U) ⇒ u1 + u2 ∈ U
b) aus u ∈ U und λ ∈ R folgt λ · u ∈ U :
(u ∈ U ∧ λ ∈ R) ⇒ λ · u ∈ U
Der Unterraum U ist selbst ein Vektorraum, wobei die Addition und Multiplikation dieselben sindwie die in V .
Aus b) folgt, dass jeder Unterraum den Nullvektor enthalt (0 · u = 0).

5 DER RN ALS VEKTORRAUM 27
Beispiel 5.8. Fur jeden Vektorraum V sind U = V und U = {0} die trivialen Unterraume.
Beispiel 5.9. Sei V = R3. Dann sind die folgenden Mengen Unterraume von V :
❶ U ={(0, x2, 0)t : x2 ∈ R
},
❷ U ={(x1, x2, 0)t : x1, x2 ∈ R
},
❸ U = {u ∈ R3 : u = λ1 · v1 + λ2 · v2, λ1, λ2 ∈ R}, wobei die Vektoren v1, v2 ∈ R3 vorgegebensind.
☞ Dies wird in der Vorlesung berechnet.
5.2 Linear unabhangige Vektoren
Definition 5.10. Es seien V ein Vektorraum und v1, v2, . . . , vn ∈ V , n ∈ N, feste Vektoren. EineSumme
n∑
i=1
λi · vi := λ1 · v1 + λ2 · v2 + · · ·+ λn · vn ∈ V ,
mit λi ∈ R, i = 1, . . . , n, nennt man eine Linearkombination der Vektoren vi, i = 1, . . . , n.Die Skalare λi ∈ R, i = 1, . . . , n, heißen Koeffizienten der Linearkombination.
Beispiel 5.11. Es sei V = R3 gesetzt, und es seien v1 = (3, 1, 2)t und v2 = (2, 2, 4)t.
Aus
2 · v1 + 1 · v2 = 2 ·
312
+ 1 ·
224
=
624
+
224
=
848
folgt, dass der Vektor v := (8, 4, 8)t eine Linearkombination der Vektoren v1, v2 mit Koeffizienten 2, 1ist.
☞ In der Vorlesung berechnen wir noch eine Linearkombination der Vektoren v1, v2 mitKoeffizienten 1, -1.
Definition 5.12. Es seien V ein Vektorraum und v1, v2, . . . , vn ∈ V , n ∈ N, feste Vektoren. Die Mengealler Vektoren v ∈ V , die als Linearkombination der Vektoren v1, v2, . . . , vn dargestellt werden konnen,heißt lineare Hulle von {v1, v2, . . . , vn} und wird mit Span{v1, v2, . . . , vn} bezeichnet, d. h.
Span{v1, v2, . . . , vn} :=
{
v ∈ V : v =
n∑
i=1
λi · vi, λi ∈ R, i = 1, . . . , n
}
.
Man sagt: Span{v1, v2, . . . , vn} wird von Vektoren {v1, v2, . . . , vn} aufgespannt oder erzeugt.

5 DER RN ALS VEKTORRAUM 28
Satz 5.13. Es seien V ein Vektorraum und v1, v2, . . . , vn ∈ V , n ∈ N, feste Vektoren.
a) Span{v1, v2, . . . , vn} ist ein Unterraum von V .
b) Span{v1, v2, . . . , vn} ist der”kleinste” Unterraum von V , der alle Vektoren v1, v2, . . . , vn enthalt,
d. h. es gibt keinen nichttrivialen Unterraum von Span{v1, v2, . . . , vn}, in dem die Vektorenv1, v2, . . . , vn enthalten sind.
Beispiel 5.14. Es sei V = R3.
❶ Wir setzen v1 = e1 := (1, 0, 0)t und v2 = e2 := (0, 1, 0)t. Dann erzeugen die Einheitsvektoren e1, e2die lineare Hulle
Span{e1, e2} = {v ∈ R3 : v = λ1 · e1 + λ2 · e2, λ1, λ2 ∈ R} =
=
v ∈ R3 : v = λ1 ·
100
+ λ2 ·
010
, λ1, λ2 ∈ R
=
=
v ∈ R3 : v =
λ1
λ2
0
, λ1, λ2 ∈ R
.
❷ Jetzt setzen wir v1 := (1, 2, 0)t und v2 := (2, 4, 0)t. Dann ist
Span{v1, v2} = {v ∈ R3 : v = λ1 · v1 + λ2 · v2, λ1, λ2 ∈ R} =
=
v ∈ R3 : v = λ1 ·
120
+ λ2 ·
240
, λ1, λ2 ∈ R
.
Aber v2 = 2v1, also kann man v als v = (λ1 + 2λ2) · v1 schreiben, d. h.
Span{v1, v2} =
v ∈ R3 : v = λ ·
120
, λ ∈ R
= Span{v1}.
Analog v1 = 12v2, und weiter v =
(12· λ1 + λ2
)· v2, d. h.
Span{v1, v2} =
v ∈ R3 : v = λ ·
240
, λ ∈ R
= Span{v2}.
In diesem Beispiel wird nur einer der beiden Vektoren v1, v2 benotigt, um denselben Unterraumvon R2 zu erzeugen.
Bemerkung 5.15. Es sei 0 6= v ∈ R3 ein fester Vektor. Dann ist Span{v} eine Gerade in R3 durch 0.Ferner sei Vektor w ∈ V \ Span{v} fixiert. Dann ist Span{v, w} eine Ebene in R3 durch 0 (betrachtenSie auch die Bilder im Beispiel 5.4).

5 DER RN ALS VEKTORRAUM 29
Definition und Satz 5.16. Sei V ein Vektorraum.
a) Die Vektoren {v1, v2, . . . , vn} ⊆ V heißen linear unabhangig genau dann, wenn
n∑
i=1
λi · vi = 0 =⇒ λi = 0 fur alle i = 1, . . . , n.
Das heißt, es existiert nur die triviale Darstellung des Nullvektors. Damit sind die Vektoren{v1, v2, . . . , vn} linear unabhangig, falls
• keiner der Vektoren aus {v1, v2, . . . , vn} als Linearkombination der anderen Vektoren aus{v1, v2, . . . , vn} geschrieben werden kann;
• jeder Vektor v ∈ Span{v1, v2, . . . , vn} genau eine Linearkombination aus den Vektoren{v1, v2, . . . , vn} besitzt.
b) Ist hingegenn∑
i=1
λi · vi = 0 fur Zahlen λ1, . . . , λn mit mindestens einem λj 6= 0, j ∈ {1, . . . , n},so heißen die Vektoren {v1, v2, . . . , vn} linear abhangig. Das heißt, es existiert eine nichttrivialeDarstellung des Nullvektors.In diesem Fall sagt man auch: vj ist linear abhangig von {v1, . . . , vj−1, vj+1, . . . , vn}.Damit sind die Vektoren {v1, v2, . . . , vn} linear abhangig, falls
• mindestens einer der Vektoren aus {v1, v2, . . . , vn} als Linearkombination der anderen Vek-toren aus {v1, v2, . . . , vn} geschrieben werden kann;
• es einen Vektor v ∈ Span{v1, v2, . . . , vn} gibt, der mindestens zwei verschiedene Linearkom-binationen aus den Vektoren {v1, v2, . . . , vn} besitzt.
Beispiel 5.17. In Beispiel 5.14 b) ist der Vektor v1 := (1, 2, 0)t linear abhangig vom Vektor v2 :=(2, 4, 0)t, denn es gilt
v1 =1
2· v2.
Umgekehrt ist auch v2 linear abhangig von v1, denn
v2 = 2 · v1.
Eine nichttriviale Darstellung des Nullvektors ist z. B.
0 = −2 · v1 + v2.
Beispiel 5.18. Im Vektorraum V = R4 sind die Vektoren v1 = (6, 2, 3, 4)t, v2 = (0, 5,−3, 1)t, v3 =(0, 0, 7,−2)t linear unabhangig.
Um diese Behauptung zu zeigen, uberprufen wir, dass die Gleichung
λ1 · v1 + λ2 · v2 + λ3 · v3 = 0 mit λ1, λ2, λ3 ∈ R,

5 DER RN ALS VEKTORRAUM 30
genau fur λ1 = λ2 = λ3 = 0 erfullt ist.
Wir setzen in die obige Gleichung die Vektoren v1, v2, v3 ein:
λ1 ·
6234
+ λ2 ·
05−3
1
+ λ3 ·
007−2
=
0000
und benutzen die Definition 5.2 fur die Vektoraddition und Skalarmultiplikation:
6 · λ1
2 · λ1 + 5 · λ2
3 · λ1 − 3 · λ2 + 7 · λ3
4 · λ1 + λ2 − 2 · λ3
=
0000
.
Zwei Vektoren sind gleich, wenn entsprechende Komponenten gleich sind, also folgt
6 · λ1 = 0 =⇒ λ1 = 0
2 · λ1 + 5 · λ2 = 0 =⇒ λ2 = 0
3 · λ1 − 3 · λ2 + 7 · λ3 = 0 =⇒ λ3 = 0
4 · λ1 + λ2 − 2 · λ3 = 0
und die Behauptung ist gezeigt.
Bemerkung 5.19. In V = Rn reduziert sich Nachprufen der linearen Unabhangigkeit eines Vektor-systems v1, v2, . . . , vm ∈ Rn auf das Losen eines homogenen linearen Gleichungssystems mitn Gleichungen und m Unbekannten.Die Losungsmethoden von solchen Gleichungssystemen werden in den nachsten Abschnitten erlautert(s. Abschnitte 7.7 und 8.2).
5.3 Basis und Dimension endlich-dimensionaler Vektorraume
Definition 5.20. Es sei V ein Vektorraum.
a) Der Vektorraum V heißt endlich-dimensional, falls es ein Vektorsystem{v1, v2, . . . , vn} ⊆ V gibt, das V erzeugt, d. h.
V = Span{v1, v2, . . . , vn}.
Andernfalls heißt V unendlich-dimensional.
b) Sind zusatzlich die Vektoren v1, v2, . . . , vn linear unabhangig, so nennt man das System{v1, v2, . . . , vn} Basis von V .

5 DER RN ALS VEKTORRAUM 31
c) Die maximale Anzahl von Vektoren in einer Basis {v1, v2, . . . , vn} von V heißt Dimension von Vund wird mit
dimV := n
bezeichnet. Insbesondere definiert man fur den Nullraum: dim{0} := 0.
Bemerkung 5.21.
a) Eine Basis eines Vektorraumes V ist nicht eindeutig bestimmt. Man kann jedoch zeigen, dass alleBasen eines endlich-dimensionalen Vektorraumes V dieselbe Anzahl von Vektoren haben, d. h.die Dimension ist eindeutig festgelegt. Jedes Vektorsystem mit mehr als n := dimV Vektoren istlinear abhangig.
b) Ist {v1, v2, . . . , vn} eine Basis von V , so laßt sich also jeder Vektor v ∈ V auf genau eine Weiseals Linearkombination der Elemente aus {v1, v2, . . . , vn} darstellen, d. h.
∃!(λ1,...,λn)∈Rn : v =
n∑
i=1
λi · vi.
Die eindeutig bestimmte Skalare λ1, . . . , λn ∈ R heißen Koordinaten von v bezuglich der Basis{v1, v2, . . . , vn}.
c) Es sei U ⊆ V ein Unterraum von V . Dann ist
• dim(U) ≤ dim(V )
• dim(U) = dim(V ) =⇒ U = V .
Beispiel 5.22. Es sei V = R2. Die Einheitsvektoren e1 =
(10
)
und e2 =
(01
)
bilden eine Basis des
R2, d. h. dim R2 = 2. Denn
❶ R2 ist von den Vektoren e1, e2 erzeugt, da jeder Vektor (a1, a2)t ∈ R2 sich als Linearkombination
von {e1, e2} darstellen laßt, und zwar als
(a1
a2
)
= a1 ·(
10
)
+ a2 ·(
01
)
.
❷ Die Vektoren e1, e2 sind linear unabhangig, da
0 = λ1 · e1 + λ2 · e2 =
(λ1
0
)
+
(0λ2
)
=
(λ1
λ2
)
genau dann, wenn λ1 = λ2 = 0.

5 DER RN ALS VEKTORRAUM 32
Ebenso rechnet man nach, dass dim Rn = n fur n ∈ N. Dazu betrachtet man wieder die Standardbasis(die kanonische Basis):
Beispiel 5.23. Die Standardbasis des Rn ist:
e1 =
10...0
, e2 =
01...0
, . . . , en =
00...1
.
Man nennt ej auch den j-ten Einheitsvektor des Rn.
Mit dieser Schreibweise ist
λ1...λn
=
n∑
i=1
λi · ei,
und die Skalare λ1, . . . , λn ∈ R sind eindeutig bestimmt. Die Koordinaten eines Vektors des Rn
bezuglich der kanonischen Basis stimmen also mit den Komponenten des Vektors uberein.
5.4 Lineare Abbildungen
Definition 5.24. Seien V und W zwei Vektorraume. Eine Abbildung ϕ : V → W heißt linear, wennfur alle v1, v2, v ∈ V und λ ∈ R gilt:
a)
ϕ (v1 + v2) = ϕ (v1) + ϕ (v2),
b)
ϕ(λ · v) = λ · ϕ(v).
Beispiel 5.25. Es sei V ein Vektorraum, und es sei α ∈ R eine feste Zahl. Dann ist
ϕ :
{V −→ V
v 7−→ α · v
eine lineare Abbildung.☞ Erklarung in der Vorlesung!
Speziallfalle: fur α = 0 die triviale Abbildung ϕ(v) = 0 fur alle v ∈ V ,
fur α = 1 die identische Abbildung oder Identitat ϕ(v) = v fur alle v ∈ V .

5 DER RN ALS VEKTORRAUM 33
Bemerkungen 5.26.
a) Setzt man in der Definition 5.24 b) λ = 0, so ergibt sich sofort, dass
ϕ(0) = 0,
d. h. bei einer linearen Abbildung wird der Nullvektor des Definitionsvektorraumes auf den Null-vektor des Bildvektorraumes abgebildet.
b) Die beiden Gleichungen in der Definition 5.24 lassen sich zusammenfassen zu
ϕ (λ1 · v1 + λ2 · v2) = λ1 · ϕ (v1) + λ2 · ϕ (v2)
fur alle v1, v2 ∈ V und λ1, λ2 ∈ R.
c) Weiter, gilt fur alle n ∈ N:
ϕ
(n∑
i=1
λi · vi
)
=n∑
i=1
λi · ϕ (vi) ,
wobei v1, . . . , vn ∈ V und λ1, . . . , λn ∈ R. [.5ex] Insbesondere bedeutet das, dass eine lineareAbbildung ϕ durch die Angabe von ϕ (v1) , . . . , ϕ (vn) eindeutig bestimmt ist, falls {v1, . . . , vn}eine Basis von V ist.
Satz 5.27. Seien V , W und U Vektorraume, und ϕ, ϕ1, ϕ2 : V →W und ψ : W → U lineare Abbildun-gen, sowie λ1, λ2 ∈ R. Dann sind die folgenden Abbildungen
a) λ1 · ϕ1 + λ2 · ϕ2 : V → W mit
(λ1ϕ1 + λ2ϕ2) (v) := λ1ϕ1(v) + λ2ϕ2(v) fur alle v ∈ V,
(siehe Bsp. 5.6);
b) ψ ◦ ϕ : V → U , (siehe Def. 4.1);
c) ϕ−1 : W → V , falls ϕ bijektiv ist, (siehe Def. 4.1)
auch linear.
Definition 5.28. Es seien V und W Vektorraume, und es ei ϕ : V →W eine lineare Abbildung.
a) Die Menge aller Vektoren v ∈ V , die auf den Nullvektor (von W ) abgebildet werden

5 DER RN ALS VEKTORRAUM 34
Kernϕ := {v ∈ V : ϕ(v) = 0},
wird der Kern von ϕ genannt.
b) Die Menge
Bildϕ := ϕ(V ) = {w ∈ W : ∃v∈V w = ϕ(v)}
nennt man das Bild von ϕ.
Beispiel 5.29. Es sei V = W = R3 und eine Abbildung ϕ : R3 → R3 mit
ϕ
x1
x2
x3
:=
x1
x2
0
,
die Projektion von R3 auf R2.
❶ Die Abbildung ϕ ist linear.☞ Erklarung in der Vorlesung!
❷ Der Kern von ϕ ist
Kernϕ :={x = (x1, x2, x3)
t ∈ R3 : ϕ (x) = 0}
=
=
x = (x1, x2, x3)
t ∈ R3 :
x1
x2
0
=
000
=
={x = (x1, x2, x3)
t ∈ R3 : x1 = x2 = 0}
=
={(0, 0, x3)
t : x3 ∈ R}.
❸ Das Bild von ϕ ist
Bildϕ :={x = (x1, x2, x3)
t ∈ R3 : x3 = 0}
={(x1, x2, 0)t : x1, x2 ∈ R
}
Satz 5.30. Es seien V und W Vektorraume, und es ei ϕ : V →W eine lineare Abbildung. Es gilt:
a) Kernϕ ist ein Unterraum von V .
b) Bildϕ ist ein Unterraum von W .
c) dimV = dim (Bildϕ) + dim (Kernϕ).
d) ϕ ist injektiv (siehe Def. 4.1) genau dann, wenn Kernϕ = {0} ist.
e) ϕ ist bijektiv (siehe Def. 4.1) genau dann, wenn ϕ injektiv ist und dimV = dimW .
f) ϕ ist bijektiv genau dann, wenn ϕ surjektiv ist und dimV = dimW .

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 35
6 Matrizen und Operationen zwischen Matrizen
Beispiel 6.1. Ein Betrieb montiert aus Einzelteilen T1, . . . , T5 Baugruppen B1, . . . , B4 und fertigt ausden Baugruppen Enderzeugnisse E1, E2, E3. Die beiden folgenden Tabellen (sogenannte Verbrauchs-oder Input-Output-Tabellen) zeigen, wieviel Einzelteile fur die Montage einer Baugruppe und wievielBaugruppen fur die Fertigung eines Endprodukts benotigt werden:
B1 B2 B3 B4
T1 2 1 3 4T2 2 0 5 3T3 6 3 4 2T4 3 4 0 1T5 1 1 1 9
E1 E2 E3
B1 3 6 2B2 4 1 6B3 0 4 5B4 8 0 0
Der Betrieb soll 400 Stuck von Endprodukt E1, 500 Stuck von Endprodukt E2 und 300 Stuck vonEndprodukt E3 liefern. Man kann diese Menge im Produktionsvektor p = (400, 500, 300)t zusammen-fassen.
Der Gesamtbedarf an einzelnen Baugruppen kann man mit dem folgenden Bedarfsvektor beschreiben:
b =
b1b2b3b4
=
3 · 400 + 6 · 500 + 2 · 300
4 · 400 + 1 · 500 + 6 · 300
0 · 400 + 4 · 500 + 5 · 300
8 · 400 + 0 · 500 + 0 · 300
=
4 800
3 900
3 500
3 200
.
Die Zahl bj , j = 1, 2, 3, 4, bedeutet hier die Anzahl der Einheiten der Baugruppe Bj , die fur denvorgegebenen Produktionsvektor benotigt werden.
Der Gesamtbedarf an Einzelteilen wird dann durch den Bedarfsvektort = (t1, t2, t3, t4, t5)
t angegeben:
t =
t1t2t3t4t5
=
2 · 4 800 + 1 · 3 900 + 3 · 3 500 + 4 · 3 200
2 · 4 800 + 0 · 3 900 + 5 · 3 500 + 3 · 3 200
6 · 4 800 + 3 · 3 900 + 4 · 3 500 + 2 · 3 200
3 · 4 800 + 4 · 3 900 + 0 · 3 500 + 1 · 3 200
1 · 4 800 + 1 · 3 900 + 1 · 3 500 + 9 · 3 200
=
36 80036 70060 90033 20041 000
.
Die Zahl ti, i = 1, 2, 3, 4, 5, bedeutet hier die Anzahl der Einheiten des Einzelteils Ti, die fur denvorgegebenen Produktionsvektor benotigt werden.
Eine Tabelle, die direkt angibt, wieviel Einzelteile der Art Ti, i = 1, 2, 3, 4, 5, in eine Einheit des

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 36
Enderzeugnisses Ej, j = 1, 2, 3, eingehen, ist durch folgende Operationen zu bekommen:
E1 E2 E3
T1 2 · 3 + 1 · 4 + 3 · 0 + 4 · 8 2 · 6 + 1 · 1 + 3 · 4 + 4 · 0 2 · 2 + 1 · 6 + 3 · 5 + 4 · 0T2 2 · 3 + 0 · 4 + 5 · 0 + 3 · 8 2 · 6 + 0 · 1 + 5 · 4 + 3 · 0 2 · 2 + 0 · 6 + 5 · 5 + 3 · 0T3 6 · 3 + 3 · 4 + 4 · 0 + 2 · 8 6 · 6 + 3 · 1 + 4 · 4 + 2 · 0 6 · 2 + 3 · 6 + 4 · 5 + 2 · 0T4 3 · 3 + 4 · 4 + 0 · 0 + 1 · 8 3 · 6 + 4 · 1 + 0 · 4 + 1 · 0 3 · 2 + 4 · 6 + 0 · 5 + 1 · 0T5 1 · 3 + 1 · 4 + 1 · 0 + 9 · 8 1 · 6 + 1 · 1 + 1 · 4 + 9 · 0 1 · 2 + 1 · 6 + 1 · 5 + 9 · 0
Nach Rechnungen:E1 E2 E3
T1 42 25 25T2 30 32 29T3 46 55 50T4 33 22 30T5 79 11 13
Am Ende dieses Abschnitts kehren wir zu diesem Beispiel zuruck.
Definition 6.2. Seien m,n ∈ N. Ein geordnetes rechteckiges Zahlenschema
A :=
a1,1 a1,2 · · · a1,j · · · a1,n
a2,1 a2,2 · · · a2,j · · · a2,n
......
......
ai,1 ai,2 · · · ai,j · · · ai,n
......
......
am,1 am,2 · · · am,j · · · am,n
bestehend aus m Zeilen und n Spalten und m · n Zahlen ai,j ∈ R, wobei i = 1, . . . , m und j = 1, . . . , n,wird eine (m× n)–Matrix (lies:
”m Kreuz n Matrix”) genannt.
Die Zahlen ai,j werden als Elemente oder Glieder der Matrix A bezeichnet.
Matrix A schreibt man oft in der Form
A = (ai,j)i=1,...,mj=1,...,n
oder kurz A = (ai,j) .
Die Position der Elemente ai,j in der Matrix ergibt sich dabei durch die Vereinbarung, dass der ersteIndex (hier: i) der Zeilenindex und der zweite Index (hier: j) der Spaltenindex ist, d. h. das Element ai,j
gehort zur i-ten Zeile und zur j-ten Spalte, man sagt auch: ai,j steht an der Position (i, j).

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 37
Definition 6.3. Zwei (m × n)–Matrizen A = (ai,j) und B = (bi,j) heißen gleich, wenn ihre Elementeauf allen Positionen ubereinstimmen:
A = B ⇐⇒ ai,j = bi,j
fur alle i = 1, . . . , m und alle j = 1, . . . , n.
Bemerkung. Notwendigerweise ist Gleichheit nur fur gleichdimensionierte Matrizen (die gleich vieleZeilen und Spalten haben) definiert!
Definition 6.4. Spezielle Matrizen:Sei n,m, i, j ∈ N.
a) Eine (m× 1)–Matrix (mit nur einer Spalte) ist ein Spaltenvektor:
a1,1
a2,1...
am,1
=
a1
a2...am
.
Speziell kann man dann eine (m×n)–Matrix als Zusammenfassung von n Spaltenvektoren auffas-sen.
b) Eine (1× n)–Matrix (mit nur einer Zeile) ist ein Zeilenvektor:
(a1,1 a1,2 . . . a1,n) = (a1, a2, . . . , an) .
Speziell kann man dann eine (m×n)–Matrix als Zusammenfassung vonm Zeilenvektoren auffassen.
c) Eine (n×n)–Matrix heißt quadratisch. Die ubereinstimmende Anzahl von Zeilen und Spalten wirdOrdnung der (quadratischen) Matrix genannt.Ist A = (ai,j) eine quadratische (n × n)–Matrix, so bilden die Positionen der Elemente ai,j miti = j (d. h. mit gleichen Spalten- und Zeilenindex) die Hauptdiagonale:
a1,1 a1,2 . . . a1,n−1 a1,n
a2,1 a2,2 . . . a2,n−1 a2,n
......
. . ....
...an−1,1 an−1,2 . . . an−1,n−1 an−1,n
an,1 an,2 . . . an,n−1 an,n
.
Entsprechend bilden die Positionen der Elemente ai,j mit i+j = n+1, d. h. an,1, a(n−1),2, . . . , a1,n,die Nebendiagonale.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 38
i. Eine quadratische Matrix, in der nur die Elemente auf der Hauptdiagonale ungleich Null sind,heißt Diagonalmatrix:
a1,1 0 . . . 0
0 a2,2. . . 0
.... . .
. . . 00 . . . 0 an,n
.
• Eine Diagonalmatrix, in der die Hauptdiagonalelemente gleich Eins sind, heißt (n× n)–Einheitsmatrix und wird mit En bezeichnet:
En :=
1 0 . . . 0
0 1. . . 0
.... . .
. . . 00 . . . 0 1
.
ii. Eine quadratische Matrix, die auf einer Seite der Hauptdiagonalen nur Nullen enthalt, heißtDreiecksmatrix.
• Befinden sich die Nullen unterhalb der Hauptdiagonalen, so spricht man von einer oberenDreiecksmatrix:
a1,1 a1,2 . . . a1,n
0 a2,2 . . . a2,n
.... . .
. . ....
0 . . . 0 an,n
,
• Befinden sich dagegen die Nullen oberhalb der Hauptdiagonalen, so spricht man voneiner unteren Dreiecksmatrix:
a1,1 0 . . . 0a2,1 a2,2 . . . 0...
.... . .
...an,1 an,2 . . . an,n
.
d) Eine (m× n)–Matrix, die nur Nullen enthalt, heißt (m× n)–Nullmatrix.
Beispiele 6.5. ☞ In der Vorlesung.
Definition 6.6.
a) Sei A = (ai,j)i=1,...,mj=1,...,n
eine (m× n)-Matrix. Die (n×m)-Matrix
At := (aj,i)j=1,...,ni=1,...,m
,

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 39
die man erhalt, indem man die Zeilen und Spalten von A miteinander vertauscht, wird als die zuA transponierte Matrix bezeichnet, d. h.:
At =
a1,1 a2,1 · · · am,1
a1,2 a2,2 · · · am,2...
......
a1,n a2,n · · · am,n
.
b) Eine Matrix A heißt symmetrisch, wenn
A = At
gilt.
Insbesondere konnen nur quadratische Matrizen symmetrisch sein.
Beispiele 6.7. ☞ In der Vorlesung.
Man kann zeigen, dass die maximale Anzahl linear unabhangiger Zeilenvektoren einer Matrix mitder maximalen Anzahl linear unabhangiger Spaltenvektoren dieser Matrix ubereinstimmt.
Diese Tatsache erlaubt uns, die folgende Definition vorzunehmen:
Definition 6.8. Es sei A eine (m× n)–Matrix. Als Rang der Matrix A bezeichnet man die maximaleAnzahl linear unabhangiger Zeilenvektoren (bzw. Spaltenvektoren) von A und notiert ihn mit rang (A).
Insbesondere ist
rang (A) ≤ min{m,n}.
Beispiele 6.9.
❶ Betrachten wir jetzt die (2× 3)–Matrix A mit
A =
(1 2 02 4 0
)
.
Aus der Definition 6.8 folgt, dass
rang (A) ≤ min{2, 3} = 2.
Aber nach Beispiel 5.17 sind die Zeilenvektoren (1, 2, 0) und (2, 4, 0) linear abhangig, und es giltdaher
rang (A) = 1.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 40
❷ Betrachten wir die (4× 3)–Matrix B mit
B =
6 0 02 5 03 −3 74 1 −2
.
Aus der Definition 6.8 folgt wieder, dass
rang (B) ≤ min{4, 3} = 3.
Aber nach Beispiel 5.18 die Spaltenvektoren (6, 2, 3, 4)t, (0, 5,−3, 1)t, (0, 0, 7,−2)t linear un-abhangig, und es gilt daher
rang (B) = 3.
Definition 6.10. Eine quadratische (n× n)–Matrix A heißt regular (oder nichtsingular), wenn
rang (A) = n.
Quadratische Matrizen, die nicht regular sind, heißen singular.
Singulare Matrizen besitzen linear abhangige Spalten- und Zeilenvektoren, und ihr Rang ist echtkleiner als ihre Ordnung.
Beispiel 6.11. ☞ In der Vorlesung.
6.1 Matrizenaddition und Skalarmultiplikation
Die nachfolgenden Matrizenoperationen sind direkte Verallgemeinerungen der Rechenoperationen, diefur Vektoren des Rn eingefuhrt wurden (siehe Def. 5.2).
Definition 6.12. Es seien
A = (ai,j)i=1,...,mj=1,...,n
und B = (bi,j)i=1,...,mj=1,...,n
zwei (m× n)–Matrizen, m,n ∈ N, und es sei λ eine reelle Zahl.
a) Addition von Matrizen: Die Summe von A und B ist die (m× n)–Matrix
A+B := (ai,j + bi,j)i=1,...,mj=1,...,n
,
d. h. die Elemente, die an derselben Stelle stehen, werden addiert.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 41
b) Multiplikation einer Matrix mit einem Skalar: Das Produkt von A mit λ ist die (m× n)-Matrix
λ · A := (λ · ai,j)i=1,...,mj=1,...,n
,
d. h. jedes Element ai,j der Matrix A wird mit dem Skalar λ multipliziert.
Bemerkung 6.13.
• Wie bei Vektoren werden hier Addition und Skalarmultiplikation komponentenweise durchgefuhrt.Man kann also nur gleichdimensionierte Matrizen addieren.
• Die beiden algebraische Operationen haben wieder die Eigenschaften aus der Definition 5.5 einesVektorraums, d. h. die Menge aller (m× n)–Matrizen (fur festgelegte naturliche Zahlen m und n)bildet mit der Matrixaddition und der Skalarmultiplikation einen Vektorraum uber R.
Insbesondere gelten die folgende Rechenregeln:
Assoziativgesetz fur die Addition:
A + (B + C) = (A+B) + C
Kommutativgesetz fur die Addition:
A + B = B + A
Assoziativgesetz fur die Skalarmultiplikation:
λ · (µ · A) = (λ · µ) · A
Distributivgesetze:
λ · (A+B) = λ · A + λ · B(λ+ µ) · A = λ · A + µ · A
Beispiele 6.14. Es seien A und B zwei (3× 4)–Matrizen mit
A =
1 0 −2 3−4 1 5 −2
0 −1 2 3
und B =
−1 0 1 12 −1 1 32 1 1 −1
,
und es sei λ = 2. Dann ist

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 42
❶ die Summe von A und B gleich
A +B =
1 + (−1) 0 + 0 −2 + 1 3 + 1−4 + 2 1 + (−1) 5 + 1 −2 + 3
0 + 2 −1 + 1 2 + 1 3 + (−1)
=
=
0 0 −1 4−2 0 6 1
2 0 3 2
.
❷ das Produkt von A mit λ gleich
2 · A =
2 · 1 2 · 0 2 · (−2) 2 · 32 · (−4) 2 · 1 2 · 5 2 · (−2)
2 · 0 2 · (−1) 2 · 2 2 · 3
=
=
2 0 −4 6−8 2 10 −4
0 −2 4 6
.
6.2 Multiplikation von Matrizen
Schwieriger als Addition und Skalarmultiplikation ist die nachste Operation: Matrizenmultiplikation:
Definition 6.15. Multiplikation von Matrizen
Sei A = (ai,j)i=1,...,mj=1,...,n
eine (m× n)-Matrix und B = (bj,k)j=1,...,nk=1,...,r
eine (n× r)-Matrix.
Das Produkt der Matrix A mit der Matrix B ist die (m× r)-Matrix C
A · B = C = (ci,k)i=1,...,mk=1,...,r
,
mit den Koeffizienten ci,k, i = 1, . . . , m, k = 1, . . . , r, die nach folgender Vorschrift zu bilden sind:
ci,k := ai,1 · b1,k + ai,2 · b2,k + · · · + ai,n · bn,k =
n∑
j=1
ai,j · bj,k,
d. h. der Koeffizient ci,k entsteht, wenn man die Elemente der i-ten Zeile der Matrix A mit den entspre-chenden Elementen der k-ten Spalte der Matrix B multipliziert und zusammen addiert.
Bemerkung. Zwei Matrizen konnen gemaß dieser Definition nur dann miteinander multipliziert werden,wenn die erste Matrix genauso viele Spalten hat wie die zweite Matrix Zeilen.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 43
Die Berechnung der Produktmatrix lasst sich ubersichtlich mit der sogennanten FALKschen Anord-nung durchfuhren:
b1,1 . . . b1,k . . . b1,r
b2,1 . . . b2,k . . . b2,r
B =...
......
bn,1 . . . bn,k . . . bn,r
a1,1 a1,2 . . . a1,n |...
...... ↓
A = ai,1 ai,2 . . . ai,n − → ci,k = A · B...
......
am,1 am,2 . . . am,n
Beispiel 6.16. Es seien A eine (3× 2)–Matrix und B eine (2× 4)–Matrix mit
A =
2 −10 11 −4
und B =
(1 1 2 04 3 −1 −2
)
.
Dann ist das Produkt A · B eine (3× 4)–Matrix C = (ci,k) i=1,2,3k=1,2,3,4
mit
c1,1 = 2 · 1 + (−1) · 4 = − 2c1,2 = 2 · 1 + (−1) · 3 = − 1c1,3 = 2 · 2 + (−1) · (−1) = 5c1,4 = 2 · 0 + (−1) · (−2) = 2c2,1 = 0 · 1 + 1 · 4 = 4c2,2 = 0 · 1 + 1 · 3 = 3c2,3 = 0 · 2 + 1 · (−1) = − 1c2,4 = 0 · 0 + 1 · (−2) = − 2c3,1 = 1 · 1 + (−4) · 4 = − 15c3,2 = 1 · 1 + (−4) · 3 = − 11c3,3 = 1 · 2 + (−4) · (−1) = 6c3,4 = 1 · 0 + (−4) · (−2) = 8.
FALKsche Anordnung:
1 1 2 0
B = 4 3 − 1 −2
2 − 1 − 2 − 1 5 2
A = 0 1 4 3 −1 −2 = A ·B1 −4 −15 −11 6 8
Das Produkt B ·A ist dagegen nicht definiert, da die Anzahl der Spalten der (2× 4)–Matrix B vonder Anzahl der Zeilen der (3× 2)–Matrix A verschieden ist.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 44
Doch selbst wenn fur zwei Matrizen A und B sowohl das Produkt A ·B als auch das Produkt B ·Adefiniert ist, gilt im allgemeinen B · A 6= A · B, d. h. die Matrizenmultiplikation ist nicht kommutativ.
Beispiel 6.17. Es seien A eine (2× 3)–Matrix und B eine (3× 2)–Matrix mit
A =
(1 2 32 4 6
)
und B =
1 41 1−1 −2
.
Das Produkt der Matrix A mit der Matrix B ist eine (2× 2)–Matrix A · B:
1 4
B = 1 1
−1 −2
A = 1 2 3 0 0 = A · B2 4 6 0 0
wogegen das Produkt B · A eine (3× 3)-Matrix ergibt
A = 1 2 3
2 4 6
1 4 9 18 27
B = 1 1 3 6 9 = B · A−1 −2 − 5 − 10 − 15
Selbst wenn die beide Produkte definiert sind und die gleiche Matrixform haben (fur quadratischeMatrizen A und B), stimmen sie im allgemeinen nicht uberein, wie im nachsten Beispiel zu sehen ist.
Beispiel 6.18. Das Produkt
(1 −10 2
)
·(
1 12 −2
)
=
(−1 3
4 −4
)
ist nicht identisch mit dem Produkt
(1 12 −2
)
·(
1 −10 2
)
=
(1 12 −6
)
.
Im Beispiel 6.17 ist das Produkt A · B gleich der Nullmatrix, obwohl alle Elemente der Matrizen A
und B von Null verschieden sind. Also laßt sich die Aussage (s. Seite 14)
a · b = 0 ⇐⇒ a = 0 oder b = 0,
die fur das Produkt reeller Zahlen allgemein gultig ist, nicht auf das Matrizenprodukt ubertragen.
Auch die Kurzungsregel ist nicht ohne weiteres auf das Matrizenprodukt ubertragbar, wie das nachsteBeispiel zeigt.
Beispiel 6.19. ☞ In der Vorlesung.

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 45
Fur die Matrizenmultiplikation gelten die folgenden Rechenregeln, sofern die Multiplikationendefiniert sind:
Satz 6.20.
a) Assoziativgesetz fur die Multiplikation:
(A · B) · C = A · (B · C)
b) Distributivgesetze:
A · (B + C) = A · B + A · C(A+B) · C = A · C + B · C
Ein Kommutativgesetz A · B = B · A gilt im allgemeinen nicht, wie obige Beispiele lehren.
Ist A eine (m× n)–Matrix, dann
A · En = A und Em · A = A,
wobei En die (n× n)– und Em die (m×m)–Einheitsmatrizen sind.
Satz 6.21. In der Menge aller quadratischen (n× n)–Matrizen gibt es ein neutrales Element bezuglichder Multiplikation. Dieses neutrale Element ist
En :=
1 0 . . . 0
0 1. . . 0
.... . .
. . . 00 . . . 0 1
die (n× n)–Einheitsmatrix, d. h. es gilt:
A · En = A = En · A
fur alle (n× n)–Matrizen A.
Definition 6.22. Sei A eine quadratische (n×n)–Matrix. Eine (n×n)–Matrix, die mit A−1 bezeichnetwird, mit der Eigenschaft
A ·A−1 = En = A−1 · A
heißt die zu A Inverse (Matrix).

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 46
Bemerkung 6.23.
a) Nicht zu allen quadratischen Matrizen gibt es i. A. Inverse. Man kann z. B. zeigen, dass es zur(2× 2)–Matrix
A :=
(1 00 0
)
keine (2× 2)–Matrix A−1 gibt mit
A ·A−1 = E2 =
(1 00 1
)
.
☞ In der Vorlesung!
b) Andererseits gibt es quadratische Matrizen, die eine Inverse haben, z. B. die (2× 2)–Matrix
A :=
(2 10 −1
)
.
Erklarung: Fur die (2× 2)–Matrix A−1 mit
A−1 :=
(12
12
0 −1
)
gilt:A · A−1 = E2 = A−1 · A.
☞ In der Vorlesung!
Satz 6.24. Jede regulare Matrix (s. Def. 6.10) besitzt eine eindeutig bestimmte Inverse.
Es stellt sich also die Frage nach einem einfachen Algorithmus zur Berechnung von A−1. Diese Fragewerden wir spater beantworten (s. Abschnitt 7.6).
Wir kehren jetzt zum Beispiel 6.1 zuruck:
Beispiel 6.25. Die beiden Verbrauchs–Tabellen kann man als Matrizen betrachten:
MT→B :=
2 1 3 42 0 5 36 3 4 23 4 0 11 1 1 9
und MB→E :=
3 6 24 1 60 4 58 0 0
Der Bedarfsvektor der einzelnen Baugruppen kann dann als Produkt der Matrix MB→E mit demProduktionsvektor p berechnet werden:
b =
b1b2b3b4
= MB→E · p =
3 6 24 1 60 4 58 0 0
·
400500300
=
4 8003 9003 5003 200
.
6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 47
Der Bedarfsvektor der Einzelteilen kann weiter als Produkt der Matrix MT→B mit dem Bedarfsvektorder Baugruppen b berechnet werden:
t =
t1t2t3t4t5
= MT→B · b =
2 1 3 42 0 5 36 3 4 23 4 0 11 1 1 9
·
4 8003 9003 5003 200
=
36 80036 70060 90033 20041 000
.
Weil t = MT→B · b und b = MB→E · p, ist t = (MT→B ·MB→E) · p. Folglich kann man eine Tabelle,die direkt angibt, wieviele Einzelteile der Art Ti, i = 1, 2, 3, 4, 5, in eine Einheit des EnderzeugnissesEj , j = 1, 2, 3, eingehen, auch als eine Matrix MT→E betrachten, die gleich dem Produkt der MatrizenMT→B und MB→E ist:
MT→E = MT→B ·MB→E =
2 1 3 42 0 5 36 3 4 23 4 0 11 1 1 9
·
3 6 24 1 60 4 58 0 0
=
42 25 2530 32 2946 55 5033 22 3079 11 13
.
Und noch ein Motivationsbeispiel:
Beispiel 6.26.
Fluge einer Fluglinie sind in einem Diagrammdargestellt:
1Dublin
2Krakow
4
Munchen
3Essen
5Napoli
Man kann diese Fluge auch in Form einer Matrixdarstellen:
Ziel
1 2 3 4 5
A =
0 0 1 1 11 0 1 0 00 0 0 0 10 1 0 0 00 0 0 1 0
1
2
3
4
5
Start
❶ Berechnen wir die Matrix A2 := A · A.
A2 =
0 1 0 1 10 0 1 1 20 0 0 1 01 0 1 0 00 1 0 0 0

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 48
• Was bedeutet 1 in der zweiten Reihe und der dritten Spalte?
• Was bedeutet 2 in der zweiten Reihe und der funften Spalte?
• Wie kann man Elemente von A2, die nicht an der Diagonale liegen, interpretieren?
❷ Berechnen Sie die Matrix A + A2 + A3. Geben Sie die Interpretation dieser Matrix an.
6.3 Zusammenhang von linearen Abbildungen und Matrizen
Die Addition und Multiplikation von Matrizen kann man auch mit Hilfe von linearen Abbildungeninterpretieren.
Jeder (m× n)–Matrix A wird eine lineare Abbildung ϕA : Rn → Rm mit
ϕA(v) := A · v =
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
...am,1 am,2 · · · am,n
·
v1
v2...vn
=
n∑
j=1
a1,j · vj
...n∑
j=1
am,j · vj
zugeordnet, wobei v = (v1, v2, . . . , vn)t.
Umgekehrt entspricht jeder linearen Abbildung ϕ : Rn → Rm eine Matrix Aϕ derart, dass sich dieZuordnungsvorschrift durch das obigen Produkt ausdrucken lasst.
Dazu betrachten wir in Rn die kanonische Basis {e1, e2, . . . , en} und schreiben einen beliebigenVektor v = (v1, v2, . . . , vn)t ∈ Rn als (eindeutige) Linearkombination von Basisvektoren (s. Bsp. 5.23):
v =
v1
v2...vn
=
n∑
j=1
vj · ej.
Die lineare Abbildung ϕ : Rn → Rm ist dann durch die Angabe von {ϕ (e1), ϕ (e2), . . ., ϕ (en)} eindeutigbestimmt (s. Bem. 5.26):
ϕ(v) = ϕ
(n∑
j=1
vj · ej
)
=n∑
j=1
vj · ϕ (ej) . (6.1)
Die Vektoren ϕ (ej) ∈ Rm lassen sich durch die Basisvektoren {e1, e2, . . . , em} der kanonischen Basisvom Rm ausdrucken:
ϕ (ej) =m∑
i=1
ai,j · ei =
a1,j
a2,j
...am,j
, j = 1, . . . , n. (6.2)

6 MATRIZEN UND OPERATIONEN ZWISCHEN MATRIZEN 49
Man kann also der linearen Abbildung ϕ die Matrix Aϕ = (ai,j)i=1,...,mj=1,...,n
zuordnen, so dass die Koordinaten
des Vektors ϕ (ej) bzgl. der kanonischen Basis in Rm die Elemente der j-ten Spalte der Matrix Aϕ sind.
Aus den Gleichungen 6.1 und 6.2 ergibt sich
ϕ(v) =n∑
j=1
vj ·(
m∑
i=1
ai,j ei
)
=m∑
i=1
(n∑
j=1
vj ai,j
)
ei =
=
n∑
j=1
a1,j · vj
...n∑
j=1
am,j · vj
=
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
...am,1 am,2 · · · am,n
·
v1
v2...vn
= Aϕ · v,
(6.3)
d. h. man bekommt die Koordinaten des Vektors ϕ(v) ∈ Rm bzgl. der kanonischen Basis, indem mandie Matrix Aϕ mit dem Spaltenvektor (v1, . . . , vn)t multipliziert.
Die einer linearen Abbildung zugehorige Matrix wird auch Abbildungsmatrix genannt.
Beispiel 6.27. Gegeben sei die lineare Abbildung
ϕ :
R5 −→ R3
x1
x2
x3
x4
x5
7−→
x1 − 2x5 + x3
x2 + 4x4 − x3
x4 − x1
.
Zu bestimmen ist die zugehorige (3× 5)–Abbildungsmatrix Aϕ bezuglich der kanonischen Basen imR5 und R3.
Wir berechnen die Bilder der Einheitsvektoren {e1, e2, e3, e4, e5} aus der kanonischen Basis des R5
unter der Abbildung ϕ:
ϕ (e1) =
10−1
, ϕ (e2) =
010
, ϕ (e3) =
1−1
0
, ϕ (e4) =
041
, ϕ (e5) =
−200
.
Weil die Koordinaten eines Vektors des R3 bezuglich der kanonischen Basis mit den Komponenten desVektors ubereinstimmen, ergibt sich
Aϕ :=(
ϕ (e1) , ϕ (e2) , ϕ (e3) , ϕ (e4) , ϕ (e5))
=
1 0 1 0 −20 1 −1 4 0−1 0 0 1 0
.
Man kann jetzt uberprufen, dass das Bild ϕ(x) eines Vektors x ∈ R5 unter ϕ gleich dem Produkt Aϕ ·xist (☞ Ubung!).

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 50
Bemerkungen 6.28.
• Das obige Ergebnis kann man fur lineare Abbildungen von beliebigen Vektorraumen verallgemei-nern:Sei V ein n–dimensionaler Vektorraum mit Basis {v1, v2, . . . , vn} und W ein m–dimensionalerVektorraum mit Basis {w1, w2, . . . , wm}. Dann entspricht jeder linearen Abbildung ϕ : V → W
bezuglich dieser Basen genau eine (m × n)–Matrix, so dass A = (ai,j) in der j–ten Spalte dieKoeffizienten der Darstellung von ϕ (vj) als Linearkombination von w1, w2, . . . , wm enthalt.Insbesondere gilt fur v = λ1 · v1 + · · ·+ λn · vn ∈ V :
ϕ(v) = µ1 · w1 + · · · + µm · wm
mit
µ1...µm
= A ·
λ1...λn
.
• Eine lineare Abbildung ist erst nach Wahl der Basen des Definitionsvektorraumes und des Bild-vektorraumes eindeutig durch eine Matrix bestimmt.
• Die Addition und Multiplikation von Matrizen entspricht unter dieser Zuordnung gerade der Ad-dition und der Verknupfung linearer Abbildungen.
• Das Bild einer linearen Abbildung ϕ wird von den Spaltenvektoren der zugehorigen Abbildungs-matrix A erzeugt, deshalb
rang (A) = dim (Bild (ϕ)) .
7 Homogene und inhomogene lineare Gleichungssysteme
Beispiel 7.1. Ein Nahrungsmittel enthalt verschiedene Schadstoffe S1, S2, S3, S4, S5, die als Bestand-teile handelsublicher Pflanzenschutz- und Konservierungsmittel Ml,Mr,Mv,Mg,Me in das Endproduktgeraten sind. Der Einsatz dieser Chemikalien bei Produnktion und Vertrieb ist in der Tabelle
Landwirt : Ml
Rohproduktlager : Mr
Veredelungsbetrieb : Mv
Grossist : Mg
Einzelhandler : Me

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 51
aufgelistet. In der zweiten Tabelle ist die Zusammensetzung der verschiedenen Chemikalien nach Anteilender Schadstoffe S1, S2, S3, S4, S5 aufgeschlusselt:
S1 S2 S3 S4 S5
Ml 0,2 0,5 − 0,3 −Mr 0,1 0,6 0,3 − −Mv 0,1 0,2 0,2 0,3 0,2Mg − − 0,1 0,4 0,5Me − 0,1 0,3 0,3 0,3
Eine Probe des fertigen Nahrungsmittels beim Einzelhandler ergab die folgende Analyse
S1 S2 S3 S4 S5
0,75 2,25 0,65 1,6 0,75
Wir wollen fesstellen, mit welchen Mengen die einzelnen Stationen an der Schadstoffbelastung des Fer-tigproduktes beteiligt sind.
Wir fuhren die folgenden Bezeichnungen ein:
x1 – die Menge der Chemikalie Ml,
x2 – die Menge der Chemikalie Mr,
x3 – die Menge der Chemikalie Mv,
x4 – die Menge der Chemikalie Mg,
x5 – die Menge der Chemikalie Me.
Zu losen ist dann das folgende System von funf Gleichungen mit funf Unbekannten x1, x2, x3, x4, x5:
0,2 · x1 + 0,1 · x2 + 0,1 · x3 + 0 · x4 + 0 · x5 = 0,75,
0,5 · x1 + 0,6 · x2 + 0,2 · x3 + 0 · x4 + 0,1 · x5 = 2,25,
0 · x1 + 0,3 · x2 + 0,2 · x3 + 0,1 · x4 + 0,3 · x5 = 0,65,
0,3 · x1 + 0 · x2 + 0,3 · x3 + 0,4 · x4 + 0,3 · x5 = 1,6,
0 · x1 + 0 · x2 + 0,2 · x3 + 0,5 · x4 + 0,3 · x5 = 0,75.
Definition 7.2. Seien die reellen Zahlen bi und ai,j fur i = 1, . . . , m und j = 1, . . . , n vorgegeben.
Ein lineares Gleichungssystem besteht aus m Gleichungen
a1,1 x1 + a1,2 x2 + · · · + a1,n xn = b1
a2,1 x1 + a2,2 x2 + · · · + a2,n xn = b2
......
......
am,1 x1 + am,2 x2 + · · · + am,n xn = bm
mit n Unbekannten x1, . . . , xn, wobei m,n ∈ N.
Die Elemente ai,j heißen die Koeffizienten, und die Elemente bi rechte Seiten des linearen Gleichungssy-stems.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 52
Die Aufgabe ist, n reelle Zahlen zu finden, die, wenn man sie fur x1, . . . , xn einsetzt, alle Gleichungenlosen.
Drei Hauptprobleme treten im Zusammenhang mit der Losung von linearen Gleichungssystemen auf:
❶ Existenz der Losung:
Wann existieren Losungstupel (x1, x2, . . . , xn)?
❷ Eindeutigkeit der Losung:
Sind Losungstupel eindeutig bestimmt?
❸ Losungsverfahren:
Wie konnen Losungstupel algorithmisch bestimmt werden?
Die Beantwortung dieser Fragen gestaltet sich in einigen Spezialfallen sehr elementar, siehe z. B. dasBeispiel 5.18.
7.1 Graphische Losung eines linearen Gleichungssystems
Andere einfache Spezialfalle linearer Gleichungssysteme lassen sich graphisch losen. Dies gilt vor allemfur den Fall n = 2, da sich die Losungsmenge jeder Gleichung in einem solchen System als Gerade ineinem zweidimensionalem Koordinatensystem darstellen lasst.
Beispiel 7.3.
Das Gleichungssystem
x1 + x2 = 3
3x1 − x2 = 1
hat die eindeutige Losung
(x∗1, x∗2) = (1, 2),
da die beiden Geraden genau einen Schnitt-punkt haben.
1 2 3 4 5
1
2
3
4
5
x1
x2
3x1 − x2 = 1
x1 + x2 = 3
(1, 2)

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 53
Das Gleichungssystem
x1 + x2 = 3
3x1 + 3x2 = 9
hat unendlich viele Losungen, da die bei-den Geraden zusammenfallen.
1 2 3 4 5
1
2
3
4
x1
x2
x1 + x2 = 3 ≡ 3x1 + 3x2 = 9
Das Gleichungssystem
x1 + x2 = 3x1 + x2 = 5
hat keine Losung, da die parallelen Geradenkeinen gemeinsamen Punkt haben.
1 2 3 4 5
1
2
3
4
5
x1
x2
x1 + x2 = 5
x1 + x2 = 3
Auch fur drei Variablen x1, x2 und x3 laßt sich ein lineares Gleichungssystem geometrisch interpretie-ren. Die Losung jeder Gleichung a1x1 + a2x2 + a3x3 = b (mit (a1, a2, a3) 6= 0) bildet eine Ebene in einemdreidimensionalen Koordinatensystem, und je nach Lage der Ebenen zueinander gibt es einen eindeuti-gen gemeinsamen Schnittpunkt, unendlich viele gemeinsame Schnittpunkte oder keinen Schnittpunkt.
Fur drei Gleichungen und damit drei Ebenen konnen u. a. die folgenden Falle auftreten:
Fall 1:
Die drei Ebenen haben genau einen gemeinsamenSchnittpunkt, also besteht die Losungsmenge nur auseinem Punkt – eindeutige Losung.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 54
Fall 2a:
Die drei Ebenen haben genau eine Schnittgerade ge-meinsam, also besteht die Losungsmenge aus einerGerade – Losung mit einem Freiheitsgrad.
Fall 2b:
Alle Ebenen fallen zusammen, also besteht die Losungsmenge aus einer Ebene – Losung mit zwei Frei-heitsgraden.
Fall 3a:
Die drei Ebenen haben keinen gemeinsamen Schnitt-punkt – keine Losung.
Fall 3b:
Die drei parallen Ebenen haben keinen gemeinsamenSchnittpunkt – keine Losung.
Die Beobachtung, dass ein lineares Gleichungssystem entweder eine eindeutige Losung oder unendlichviele Losungen oder keine Losung hat, laßt sich auch auf Systeme mit mehreren Variablen ubertragen.Da aber die menschliche Vorstellungswelt auf den dreidimensionalen Raum beschrankt ist, ist einegeometrische Veranschaulichung der Losungsmengen nicht mehr moglich.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 55
Wir werden uns daher demnachst mit einem rechnerischen Verfahren zu Losung von linearen Glei-chungssystemen befassen. Es wird sich dabei herausstellen, dass das Verfahren neben den Losungengleichzeitig Informationen uber die Losbarkeit des Gleichungssystems liefert.
7.2 Zusammenhang von linearen Gleichungssystemen und linearen Abbil-dungen
Fasst man im linearen Gleichungssystem aus 7.2 die Koeffizienten ai,j, (i = 1, . . . , m, j = 1, . . . , n), zueiner (m× n)–Matrix A, die Unbekannten xj zu einem Vektor x ∈ Rn und die rechte Seiten bi zu einemVektor b ∈ Rm zusammen:
A = (ai,j)i=1,...,mj=1,...,n
, x =
x1...xn
und b =
b1...bm
,
so ist dieses lineare Gleichungssystem gleichbedeutend mit der Vektorgleichung
A · x = b.
Dabei heißt A die Koeffizientenmatrix, b die rechte Seite und x der Unbekanntenvektor.
Ausfuhrlich geschrieben:
A · x =
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
...am,1 am,2 · · · am,n
·
x1
x2...xn
=
=
a1,1 x1 + a1,2 x2 + · · · + a1,n xn
a2,1 x1 + a2,2 x2 + · · · + a2,n xn
......
...
am,1 x1 + am,2 x2 + · · · + am,n xn
=
b1b2...bm
= b.
Wegen dieser Aquivalenz wird oft die Vektorgleichung A · x = b selbst ein lineares Gleichungssystemgenannt.
Fur eine gegebene (m× n)–Koeffizientenmatrix A und gegebenen Vektor b ∈ Rm hat die GleichnugA · x = b
stetshochstensgenau
eine Losung x ∈ X, falls ϕA
surjektiv
injektiv
bijektiv
ist,

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 56
wobei ϕA : Rn → Rm die durch A definierte lineare Abbildung ist.
Die Frage nach den Losungen des linearen Gleichungssystems ist dann aquivalent mit der Bestimmungdes Urbilds ϕ−1
A (b).
7.3 Losungsmenge eines linearen Gleichungssystems
Definition 7.4. Gegeben seien eine (m × n)–Matrix A und ein Vektor b ∈ Rm. Wir betrachten einlineares Gleichungssystem der Form A · x = b.
a) Das Gleichungssystem heißt homogen, wenn b = 0 der Nullvektor in Rm ist, andernfalls (also furb 6= 0) heißt es inhomogen.
Man nennt
A · x = 0
das zum linearen Gleichungssystem A · x = b gehorige homogene lineare Gleichungssystem.
b) Die Losungsmenge des linearen Gleichungssystems bezeichnet man mit
L(A, b) :=
x =
x1...xn
∈ Rn : A · x = b
.
c) Der Nullraum von A ist definiert als die Losungsmenge des homogenen Gleichungssystems:
N (A) := L(A,0) =
x =
x1...xn
∈ Rn : A · x = 0
.
Bemerkungen 7.5.
• Der Nullraum von A ist gleich dem Kern der durch A definierten linearen Abbildung ϕA : Rn → Rm
N (A) = KernϕA,
insbesondere ist N (A) ein Unterraum des Rn.
• Jedes homogene lineare Gleichungssystem hat eine Losung x = 0 ∈ Rn, da A · 0 = 0 fur alle(m× n)–Matrizen A.Insbesondere: 0 ∈ N (A).

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 57
• Jedes lineare Gleichungssystem A · x = b mit regularer Koeffizientenmatrix A hat die eindeutigeLosung x := A−1 · b (s. Def 6.10 und Satz 6.24).
Satz 7.6. Gegeben seien eine (m × n)–Matrix A und ein Vektor b ∈ Rm. Die Losungsmenge eineslinearen Gleichungssystems der Form A · x = b ist gegeben als
L(A, b) = x0 + N (A) := {x ∈ Rn : x = x0 + y mit y ∈ N (A)} ,
wobei x0 eine spezielle Losung des inhomogenen linearen Gleichungssystems ist (falls eine solche uber-haupt existiert).
Die Losungsmenge von A · x = b besteht also, falls sie nicht leer ist, aus”einer speziellen Losung”,
zu der man alle Losungen des dazugehorigen homogenen Gleichungssystems addiert.
Fur L(A, b) kann man damit drei Falle unterscheiden (siehe auch: Beispiel 7.3):
❶ L(A, b) besteht aus genau einem Vektor (N (A) = {0}).Dann sagt man, das lineare Gleichungssystem ist eindeutig losbar.
❷ L(A, b) besteht aus unendlich vielen Vektoren.Das ist genau dann der Fall, wenn es eine Losung x0 von A · x = b gibt, und wenn N (A) 6= {0}ist.
❸ L(A, b) ist die leere Menge.Dann ist das Gleichungssystem unlosbar.
Ein lineares Gleichungssystem kann nicht genau 2, 3, . . . , k verschiedene Losungen haben. Man kannzeigen, dass aus der Existenz von nur zwei Losungen die Existenz von beliebig vielen verschiedenenLosungen folgt.
In einigen Spezialfallen, wenn alle Elemente ai,j der Koeffizientenmatrix mit i > j gleich Null sind,kann man die Losungsmenge eines linearen Gleichungssystems sehr elementar bestimmen. Diese Fallewerden wir an Beispielen erklaren.
Fall 1: Alle Elemente aj,j, j = 1, . . . , n, in der (m × n)–Koeffizientenmatrix, m ≥ n, sind von Nullverschieden.Dann ist das Gleichungssystem eindeutig losbar und die Losung x = (x1, . . . , xn)t lasst sich, beginnendmit xn, durch Ruckwartseinsetzen verhaltnissmaßig leicht ermitteln:
xn =bn
an,n
,
xj =1
aj,j
(
bj −n∑
k=j+1
aj,kxk
)
, fur alle j = n− 1, n− 2, . . . , 1.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 58
Beispiel 7.7. Betrachten wir das folgende lineare Gleichungssystem mit 5 Gleichungen und 4 Unbe-kannten:
2 −1 −2 10 3 −1 10 0 1 10 0 0 10 0 0 0
·
x1
x2
x3
x4
=
0−8
620
.
Aus der vorletzten Zeile folgt x4 = 2. Setzt man das in die dritte Zeile ein, so bekommt man x3 = 4.Analog kann man x2 = −2 aus der zweiten Zeile und x1 = 2 aus der ersten Zeile ausrechnen.
Die Losungsmenge ist L(A, b) ={(2,−2, 4, 2)t
}.
Fall 2: Nicht alle Koeffizienten aj,j sind von Null verschieden, die entsprechenden Unbekannten xj sindfrei wahlbar. Dann besteht die Losungsmenge aus unendlich vielen Losungen.
Beispiel 7.8. Betrachten wir das folgende lineare Gleichungssystem mit 3 Gleichungen und 4 Unbe-kannten:
2 1 −1 −30 1 −1 10 0 0 0
·
x1
x2
x3
x4
=
310
.
Die Unbekannten x3 = C1 und x4 = C2 konnen mit beliebigen Werten C1, C2 ∈ R belegt werden.Werden die Ausdrucke mit x3 = C1 und x4 = C2 auf die rechte Seite gebracht, so entsteht ein linearesGleichungssystem aus Fall 1:
2 10 10 0
·(x1
x2
)
=
3 + C1 + 3C2
1 + C1 − C2
0
mit der Losung
x1
x2
x3
x4
=
1 + 2C2
1 + C1 − C2
C1
C2
=
1100
+ C1
0110
+ C2
2−1
01
Fall 3: In der Koeffizientenmatrix gibt es eine Zeile, die nur aus Nullen besteht, aber die ensprechenderechte Seite ist von Null verschieden. Dann ist die Losungsmenge leer und das Gleichungssystem istunlosbar.
Beispiel 7.9. Betrachten wir das folgende lineare Gleichungssystem mit 4 Gleichungen und 4 Unbe-kannten:
2 −1 −2 10 3 −1 10 0 1 10 0 0 0
·
x1
x2
x3
x4
=
0−8
61
.
Die vierte Gleichung 0 · x1 + 0 · x2 + 0 · x3 + 0 · x4 = 1 ist offensichtlich durch keine Wahl von x1, x2,x3, x4 erfullbar.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 59
Gelingt es, ein beliebiges lineares Gleichungssystem ohne Anderung der Losungsmenge (aquivalenteUmformung) in die obige
”Stufenform” zu bringen, so gewinnt man die Losung (oder zeigt man die
Unlosbarkeit) gemaß den oben angegebenen Schritten.
7.4 Gauß–Algorithmus
Gegeben seien eine (m×n)–Matrix A und ein Vektor b ∈ Rm. Im folgenden soll ein Verfahren zur Losungdes linearen Gleichungssystems A · x = b angegeben werden, wobei x = (x1, . . . , xn)t ∈ Rn.
Die Grundidee des Losungsverfahrens ist, das gegebene Gleichungssystem A · x = b derart in ein
”einfaches” Gleichungssystem A∗ ·x = b∗ umzuformen, dass L(A∗, b∗) = L(A, b) (bis auf Umnumerierung
der Variablen) ist und die Losung von A∗ ·x = b∗ unmittelbar ablesbar ist (oder gleich zu sehen ist, dassdas Gleichungssystem unlosbar ist).
Dazu benotigen wir den Begriff einer elementaren Umformung (Gauß–Schritt):
Definition 7.10. Die folgenden drei Operationen heißen elementare Zeilenumformungen eines linearenGleichungssystems:
❶ Vertauschen zweier Zeilen: Zj ↔ Zk;
❷ Multiplikation einer Zeile mit einer reellen Zahl ungleich Null: c · Zj;
❸ Addition eines Vielfachen einer Zeile zu einer anderen: Zj + c · Zk.
Satz 7.11. Die Losungsmenge L(A, b) eines linearen Gleichungssystems A · x = b andert sich nicht,wenn man elementare Zeilenumformungen anwendet.
Die zum linearen Gleichungssystem gehorige erweiterte Matrix
Betrachten wir das lineare Gleichungssystem A · x = b. Fugt man den Vektor b zur Matrix A als letzteSpalte hinzu, dann bekommt man eine (m× (n + 1))–Matrix. Diese Matrix bezeichnet man mit
(A, b) :=
a1,1 a1,2 · · · a1,n b1a2,1 a2,2 · · · a2,n b2...
......
...am,1 am,2 · · · am,n bm
,
und man nennt sie die zum linearen Gleichungssystem gehorige erweiterte Matrix, weil in ihr alle fur einlineares Gleichungssystem notwendige Information enthalten ist.
Bemerkung 7.12. Die elementare Zeilenumformungen (s. Def. 7.10) eines linearen GleichungssystemsA · x = b entsprechen der Zeilenumformungen der zum linearen Gleichungssystem gehorigen erweitertenMatrix (A, b).
☞ Erklarung in der Vorlesung!

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 60
Bemerkung. Zusatzlich kann man zwei Spalten vertauschen, aber dann muss man beachten, dass dieseiner Vertauschung der entsprechenden Variablen entspricht.
Definition 7.13. Es sei B = (bi,j)i=1,...,mj=1,...,n
eine (m × n)–Matrix. Die Matrix B heißt ausgeraumt, wenn
sie fur ein 0 ≤ k ≤ min{m,n} die Form
1 0 0 · · · 0 b∗1,k · · · b∗1,n
0 1 0 · · · 0 b∗2,k · · · b∗2,n
0 0 1 · · · 0 b∗3,k · · · b∗3,n
......
.... . .
......
...
0 0 0 · · · 1 b∗k−1,k · · · b∗k−1,n
0 0 0 · · · 0 0 · · · 0...
......
......
...0 0 0 · · · 0 0 · · · 0
hat, also wenn gilt:
• bi,i = 1 fur i = 1, . . . , k − 1.
• bi,j = 0 fur i > j.
• bi,j = 0 fur i < j und j < k.
• bi,j = 0 fur i > k − 1.
In abgekurzter Schreibweise ware B also von der Form
(Ek−1 ∗
0 0
)
,
wobei Ek−1 eine Einheitsmatrix der Ordnung k − 1 ist, ∗ fur eine ((k − 1)× (n− k + 1))–Matrix steht,und die beiden 0 fur ((m− k+ 1)× (k− 1)) bzw. ((m− k+ 1)× (n− k+ 1))–Nullmatrizen stehen, d. h.alle Eintrage in diesen Matrizen sind Null.
Das Verfahren:
Um das gegebene Gleichungssystem A · x = b zu losen, geht man nun folgendermaßen vor:
Zunachst fugt man den Vektor b zur Matrix A als letzte Spalte hinzu und bekommt die zu diesemGleichungssystem gehorige erweiterte Matrix (A, b).
Auf diese Matrix (A, b) wendet man die folgenden Umformungsschritte an, bis man anstelle von A
eine ausgeraumte Matrix erhalt.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 61
Teil 1: Nehmen wir an, dass wir nach k − 1 Schritten, k ≥ 1, eine Matrix (A(k−1), b(k−1)) erhaltenhaben, fur die die ersten k−1 Diagonalelemente nicht Null sind, und fur die in den ersten k−1 Spaltenunterhalb der Diagonalen nur Nullen stehen.
(A(k−1), b(k−1)
)=
a(k−1)1,1 a
(k−1)1,2 · · · a
(k−1)1,k−1 a
(k−1)1,k · · · a
(k−1)1,n b
(k−1)1
0 a(k−1)2,2 · · · a
(k−1)2,k−1 a
(k−1)2,k · · · a
(k−1)2,n b
(k−1)2
......
......
......
0 0 · · · a(k−1)k−1,k−1 a
(k−1)k−1,k · · · a
(k−1)k−1,n b
(k−1)k−1
0 0 · · · 0 a(k−1)k,k · · · a
(k−1)k,n b
(k−1)k
0 0 · · · 0 a(k−1)k+1,k · · · a
(k−1)k+1,n b
(k−1)k+1
......
......
......
0 0 · · · 0 a(k−1)m,k · · · a
(k−1)m,n b
(k−1)m
Ist a(k−1)k,k 6= 0, wird im k–ten Schritt in der Matrix (A(k−1), b(k−1)) jeweils ein geeignetes Vielfaches
der k-ten Zeile von den nachfolgenden Zeilen subtrahiert, so dass in diesen Zeilen die Koeffizienten, diein der k-ten Spalte stehen, Null werden.In dem Falle setzen wir:
a(k)i,j =
a(k−1)i,j fur i = 1, . . . , k und j = 1, . . . , n
a(k−1)i,j −
a(k−1)i,k
a(k−1)k,k
· a(k−1)k,j fur i = k + 1, . . . , m und j = 1, . . . , n
und
b(k)i =
b(k−1)i fur i ≤ k − 1
b(k−1)i −
a(k−1)i,k
a(k−1)k,k
· b(k−1)k fur i > k − 1.
Falls a(k−1)k,k = 0, ist der k–te Schritt, wie er oben beschrieben ist, nicht durchfuhrbar. Folgende drei
Falle konnen dabei auftreten:
• Es existiert ein p > k mit a(k−1)p,k 6= 0. Dann vertauscht man die k–te und die p–te Zeile und kann
das Verfahren fortsetzen.
• Es existiert ein q > k mit a(k−1)k,q 6= 0. Dann vertauscht man die k–te und die q–te Spalte der
Matrix und setzt das Verfahren fort. Dabei muss man beachten, dass diese Spaltenvertauschungeiner Vertauschung der Variablen xk und xq entspricht, die man am Ende des Verfahrens wiederruckgangig machen muss.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 62
• Es gilt keiner der beiden oberen Falle, aber es gibt ein p > k und q > k mit a(k−1)p,q 6= 0. Dann
vertauscht man in (A(k−1), b(k−1)) zunachst die k–te und die p–te Zeile und anschließend die k–teund die q–te Spalte und setzt das Verfahren fort. Die Spaltenvertauschung muss am Ende desVerfahrens wieder ruckgangig gemacht werden.
Tritt keiner der drei Falle ein, ist der erste Teil des Verfahrens nach k − 1 Schritten beendet, undman hat folgende Matrix:
(A(k−1), b(k−1)
)=
a(k−1)1,1 a
(k−1)1,2 · · · a
(k−1)1,k−1 a
(k−1)1,k · · · a
(k−1)1,n b
(k−1)1
0 a(k−1)2,2 · · · a
(k−1)2,k−1 a
(k−1)2,k · · · a
(k−1)2,n b
(k−1)2
......
......
......
0 0 · · · a(k−1)k−1,k−1 a
(k−1)k−1,k · · · a
(k−1)k−1,n b
(k−1)k−1
0 0 · · · 0 0 · · · 0 b(k−1)k
......
......
......
0 0 · · · 0 0 · · · 0 b(k−1)m
Falls b(k−1)j 6= 0 fur ein j > k− 1, kann man das Verfahren beendet. Das gegebene Gleichungssystem
hat keine Losung, d. h. L(A, b) = Ø.
Teil 2: Wenn dies nicht der Fall ist, wendet man den zweiten Teil des Verfahrens an, der folgendermaßenlautet:
• Man multipliziert zunachst fur i = 1, . . . , k − 1 die i-te Zeile von(A(k−1), b(k−1)
)mit 1
a(k−1)i,i
und
erzeugt somit Einsen auf der Hauptdiagonalen.
• Uber diesen Einsen sollen nun noch Nullen erzeugt werden. Dies erreicht man, indem man zuerstvon der (k − 2)–Zeile ein geeignetes Vielfaches der (k − 1)–Zeile subtrahiert, so dass der (k − 1)–Koeffizient der (k − 2)–Zeile Null wird. In der so erhaltenen Matrix subtrahiert man darauf vonder (k − 3)–Zeile jeweils eine geeignete Linearkombination der (k − 1)– und (k − 2)–Zeile, so dassin der (k − 3)–Zeile oberhalb der Hauptdiagonale Nullen stehen, usw.
Man erhalt schließlich eine Matrix
(A∗, b∗) =
1 0 0 · · · 0 a∗1,k · · · a∗1,n b∗1
0 1 0 · · · 0 a∗2,k · · · a∗2,n b∗2
0 0 1 · · · 0 a∗3,k · · · a∗3,n b∗3...
......
. . ....
......
...
0 0 0 · · · 1 a∗k−1,k · · · a∗k−1,n b∗k−1
0 0 0 · · · 0 0 · · · 0 0...
......
......
......
0 0 0 · · · 0 0 · · · 0 0
,

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 63
wobei die Matrix A∗ ausgeraumt ist.
Die Losungsmenge des Gleichungssystems A∗ · x = b∗ lautet:
L (A∗, b∗) =
{
b+
n−k+1∑
j=1
λj · vj : λj ∈ R fur j = 1, . . . , n− k + 1
}
,
wobei b, vj ∈ Rn sind, mit
b :=
b∗1...
b∗k−1
0...0
und vj :=
a∗1,k−1+j...
a∗k−1,k−1+j
0...0
−10...0
.
← (k − 1 + j)–te Stelle
Dabei sind die Komponenten von diesen Vektoren mit Indizes großer als k−1 gleich Null mit Ausnahmeder (k − 1 + j)–ten Stelle in vj , wo die
”−1” steht.
Man definiere
T =
a∗1,k · · · a∗1,n...
...a∗k−1,k · · · a∗k−1,n
.
Die Vektoren vj erhalt man also, indem man unter den j–ten Spaltenvektor der((k − 1)× (n− k + 1))–Matrix T noch das negative des j–ten Einheitsvektors des Rn−k+1 schreibt.
In der abgekurzten Schreibweise von Blockmatrizen kann man sich das auch so merken: Man nimmtdie Matrix T und schreibt darunter −En−k+1. Die Vektoren vj sind dann gerade die Spaltenvektoren derMatrix (
T
−En−k+1
)
.
Es gilt der folgende
Satz 7.14. Die Vektoren v1, . . . , vn−k+1 sind linear unabhangig und spannen den Losungsraum vonA∗ · x = 0 auf:
N (A∗) = L (A∗, 0) =
{n−k+1∑
j=1
λj · vj : λj ∈ Rn fur j = 1, . . . , n− (k − 1)
}
,

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 64
d. h. {v1, . . . , vn−k+1} ist Basis des Nullraums von A∗.
Bemerkung 7.15.
• Da der Vektor b eine spezielle Losung von A∗ · x = b∗ ist, sieht man wieder, dass L(A∗, b∗) ge-schrieben werden kann als
”eine spezielle Losung plus alle Losungen des dazugehorigen homogenen
linearen Gleichungssystems”.
• Um nun schließlich L(A, b) zu bestimmen, muß man noch beachten, dass beim Ausraumen von Aeventuell Spaltenvertauschungen vorgenommen worden sind.Eine Vertauschung der p–ten mit der q–ten Spalte entsprach einer Vertauschung der Variablen xp
und xq im linearen Gleichungssystem.
Satz 7.16. Wenn beim Ausraumen von A keine Spaltenvertauschungen gemacht worden sind, ist
L(A, b) = L(A∗, b∗).
Wenn Spaltenvertauschungen gemacht worden sind, erhalt man L(A, b) aus L(A∗, b∗), indem man dieVertauschungen ruckgangig macht, also die Komponenten der Vektoren von L(A∗, b∗) entsprechend denvorher gemachten Vertauschungen zuruckvertauscht (in der umgekehrten Reihenfolge!).
Beispiel 7.17. Gegeben sei das lineare Gleichungssystem
x1 + 2 · x2 + 3 · x3 + 4 · x4 = 07 · x1 + 14 · x2 + 20 · x3 + 27 · x4 = 05 · x1 + 10 · x2 + 16 · x3 + 19 · x4 = −23 · x1 + 5 · x2 + 6 · x3 + 13 · x4 = 5
Man muss also die folgende erweiterte Matrix
(A, b) =
1 2 3 4 07 14 20 27 05 10 16 19 −23 5 6 13 5
in die ausgeraumte Form umformen:
1 2 3 4 07 14 20 27 05 10 16 19 −23 5 6 13 5
−−−−−99K
Z2−7·Z1Z3−5·Z1Z4−3·Z1
1 2 3 4 00 0 −1 −1 00 0 1 −1 −20 −1 −3 1 5
−−−−−99K
Z2 ↔Z4
1 2 3 4 00 −1 −3 1 50 0 1 −1 −20 0 −1 −1 0
−−−−−99K
−1·Z2
1 2 3 4 00 1 3 −1 −50 0 1 −1 −20 0 −1 −1 0
−−−−−99K
Z4+Z3

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 65
1 2 3 4 00 1 3 −1 −50 0 1 −1 −20 0 0 −2 −2
−−−−−99K
− 12·Z4
1 2 3 4 00 1 3 −1 −50 0 1 −1 −20 0 0 1 1
−−−−−99K
Z1−4·Z4
Z2+Z4
Z3+Z4
1 2 3 0 −40 1 3 0 −40 0 1 0 −10 0 0 1 1
−−−−−99K
Z1−3·Z3
Z2−3·Z3
1 2 0 0 −10 1 0 0 −10 0 1 0 −10 0 0 1 1
−−−−−99K
Z1−2·Z2
1 0 0 0 10 1 0 0 −10 0 1 0 −10 0 0 1 1
= (A∗, b∗) .
Daraus folgt, dass
b =
1−1−1
1
und v =
0000
,
d. h. der Nullraum N (A) = N (A∗) = {0} und das obige Gleichungsystem hat eine eindeutige Losung:
L(A, b) = L (A∗, b∗) ={
b}
=
1−1−1
1
.
Beispiel 7.18. Gegeben sei das lineare Gleichungssystem
x1 + x2 = 1x1 + x2 + x3 = 4
x2 + x3 + x4 = −3x3 + x4 + x5 = 2
Man muss also die folgende, erweiterte Matrix
(A, b) =
1 1 0 0 0 11 1 1 0 0 40 1 1 1 0 −30 0 1 1 1 2
umformen:
1 1 0 0 0 11 1 1 0 0 40 1 1 1 0 −30 0 1 1 1 2
−−−−−99K
Z2−Z1
1 1 0 0 0 10 0 1 0 0 30 1 1 1 0 −30 0 1 1 1 2
−−−−−99K
Z2 ↔Z3

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 66
1 1 0 0 0 10 1 1 1 0 −30 0 1 0 0 30 0 1 1 1 2
−−−−−99K
Z4−Z3
1 1 0 0 0 10 1 1 1 0 −30 0 1 0 0 30 0 0 1 1 −1
−−−−−99K
Z2−(Z3+Z4)
1 1 0 0 0 10 1 0 0 −1 −50 0 1 0 0 30 0 0 1 1 −1
−−−−−99K
Z1−Z2
1 0 0 0 1 60 1 0 0 −1 −50 0 1 0 0 30 0 0 1 1 −1
= (A∗, b∗)
Daraus folgt, dass
b =
6−5
3−1
0
und v1 =
1−1
01−1
,
d. h. der Nullraum N (A) = N (A∗) = Span{v1} und
L(A, b) = L (A∗, b∗) = b + N (A∗) = b + Span{v1}.Ausfuhrlich geschrieben: das obige Gleichungsystem hat unendlich viele Losungen mit einem Freiheits-grad:
L(A, b) ={
b+ λ1 · v1 : λ1 ∈ R
}
=
6−5
3−1
0
+ λ1 ·
1−1
01−1
: λ1 ∈ R
.
Beispiel 7.19. Gegeben sei das lineare Gleichungssystem
−x2 − 2 · x3 + 3 · x4 = 1−x1 + x2 − 2 · x3 + 2 · x4 = 4
−2 · x1 + 3 · x2 − 2 · x3 + x4 = 7x1 − 2 · x2 + x4 = −3
2 · x2 + 4 · x2 − 6 · x4 = −2
man muss also die folgende erweiterte Matrix
(A, b) =
0 −1 −2 3 1−1 1 −2 2 4−2 3 −2 1 7
1 −2 0 1 −30 2 4 −6 −2
umformen:
0 −1 −2 3 1−1 1 −2 2 4−2 3 −2 1 7
1 −2 0 1 −30 2 4 −6 −2
−−−−−99K
Z1 ↔Z4
1 −2 0 1 −3−1 1 −2 2 4−2 3 −2 1 7
0 −1 −2 3 10 2 4 −6 −2
−−−−−99K
Z2+Z1
Z3+2·Z1

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 67
1 −2 0 1 −30 −1 −2 3 10 −1 −2 3 10 −1 −2 3 10 2 4 −6 −2
−−−−−99K
−1·Z2
1 −2 0 1 −30 1 2 −3 −10 −1 −2 3 10 −1 −2 3 10 2 4 −6 −2
−−−−−99K
Z3+Z2
Z4+Z2
Z5−2·Z2
1 −2 0 1 −30 1 2 −3 −10 0 0 0 00 0 0 0 00 0 0 0 0
−−−−−99K
Z1+2·Z2
1 0 4 −5 −50 1 2 −3 −10 0 0 0 00 0 0 0 00 0 0 0 0
= (A∗, b∗).
Daraus folgt, dass
b =
−5−1
00
und v1 =
42−1
0
und v2 =
−5−3
0−1
d. h. der Nullraum N (A) = N (A∗) = Span{v1, v2} und das obige Gleichungsystem hat unendlich vieleLosungen mit zwei Freiheitsgraden:
L(A, b) = L (A∗, b∗) = b + Span{v1, v2} ={
b+ λ1 · v1 + λ2 · v2 : λ1, λ2 ∈ R
}
=
−5−1
00
+ λ1 ·
42−1
0
+ λ2 ·
−5−3
0−1
: λ1, λ2 ∈ R
.
Beispiel 7.20. Gegeben sei das lineare Gleichungssystem
x1 − 3 · x2 − 2 · x3 = 3x1 + 2 · x2 + 3 · x3 = −1
2 · x1 − x2 + x3 = −2
Man muss also die folgende erweiterte Matrix
(A, b) =
1 −3 −2 31 2 3 −12 −1 1 −2
umformen:
1 −3 −2 31 2 3 −12 −1 1 −2
−−−−−99K
Z2−Z1
Z3−2·Z1
1 −3 −2 30 5 5 −40 5 5 −8
−−−−−99K
Z3−Z2
1 −3 −2 30 5 5 −40 0 0 −4
= (A∗, b∗)

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 68
Die letzte Gleichung in dem Gleichungssystem A∗·x = b∗ ist offensichtlich durch keine Wahl von x1, x2, x3
erfullbar. Daraus folgt, dass auch das Gleichungssystem A · x = b keine Losung hat, d. h.
L(A, b) = L (A∗, b∗) = Ø.
Beispiel 7.21. Gegeben sei das lineare Gleichungssystem
−x2 + x3 + 2 · x4 = 37 · x1 − 5 · x2 − 2 · x3 − 4 · x4 = 8−3 · x1 + 2 · x2 + x3 + 2 · x4 = −3
2 · x1 − x2 − x3 − 2 · x4 = 1−x1 + x3 + 4 · x4 = 1
man muss also die folgende erweiterte Matrix
(A, b) =
0 −1 1 2 37 −5 −2 −4 8−3 2 1 2 −3
2 −1 −1 −2 1−1 0 1 4 1
umformen:
0 −1 1 2 37 −5 −2 −4 8−3 2 1 2 −3
2 −1 −1 −2 1−1 0 1 4 1
−−−−−99K
Z1 ↔Z5
−1 0 1 4 17 −5 −2 −4 8−3 2 1 2 −3
2 −1 −1 −2 10 −1 1 2 3
−−−−−99K
−1·Z1
1 0 −1 −4 −17 −5 −2 −4 8−3 2 1 2 −3
2 −1 −1 −2 10 −1 1 2 3
−−−−−99K
Z2−7·Z1
Z3+3·Z1
Z4−2·Z1
1 0 −1 −4 −10 −5 5 24 150 2 −2 −10 −60 −1 1 6 30 −1 1 2 3
−−−−−99K
Z2 ↔Z5
1 0 −1 −4 −10 −1 1 2 30 2 −2 −10 −60 −1 1 6 30 −5 5 24 15
−−−−−99K
−1·Z2
1 0 −1 −4 −10 1 −1 −2 −30 2 −2 −10 −60 −1 1 6 30 −5 5 24 15
−−−−−99K
Z3−2·Z2
Z4+Z2
Z5+5·Z2
x3↓
x4↓
1 0 −1 −4 −10 1 −1 −2 −30 0 0 −6 00 0 0 4 00 0 0 14 0
−−−−−99K
S3 ↔S4
x4↓
x3↓
1 0 −4 −1 −10 1 −2 −1 −30 0 −6 0 00 0 4 0 00 0 14 0 0
−−−−−99K
− 16Z3

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 69
1 0 −4 −1 −10 1 −2 −1 −30 0 1 0 00 0 4 0 00 0 14 0 0
Z1+4·Z3
Z2+2·Z3−−−−−99K
Z4−4·Z3
Z5−14·Z3
1 0 0 −1 −10 1 0 −1 −30 0 1 0 00 0 0 0 00 0 0 0 0
= (A∗, b∗).
Daraus folgt, dass
b =
−1−3
00
und v =
−1−1
0−1
d. h. die Losungsmenge der Gleichung A∗ · x = b∗ ist gleich
L (A∗, b∗) ={
b+ λ · v : λ ∈ R
}
.
Da eine Vertauschung der dritten mit der vierten Spalte gemacht worden ist, erhalt man L(A, b) ausL(A∗, b∗), indem man die Vertauschung ruckgangig macht, also die dritte mit der vierten Komponenteder Vektoren von L(A∗, b∗) zuruckvertauscht:
L (A, b) =
−1−3
00
+ λ ·
−1−1−1
0
: λ ∈ R
.
7.5 Losbarkeit linearer Gleichungssysteme
Das beschriebene Losungsverfahren fur lineare Gleichungssysteme liefert neben den Losungen auch Aus-sagen uber die Losbarkeit, d. h. es beantwortet die Frage, ob das Gleichungssystem eine eindeutigeLosung, unendlich viele Losungen oder keine Losungen besitzt.
Ein wichtiger Begriff bei der Formulierung der Losbarkeitskriterien ist der Rang einer Matrix(s. Def. 6.8). Man kann beweisen, dass elementare Zeilenumformungen (s. Def. 7.10) (bzw. analogeSpaltenumformungen) den Rang einer Matrix unverandert lassen.Deswegen kann man mit Gaußschem Algorithmus den Rang jeder Matrix bestimmen, indem man sieauf eine einfache Gestalt bringt, aus der der Rang unmittelbar abgelesen werden kann.
Dazu wendet man die obigen Schritte auf die gegebene (m×n)–Matrix A selbst an (ohne die Matrixmit b zu erweitern). Ist dann A(k−1) die Matrix, bei der das Verfahren abbricht, oder A die ausgeraumteMatrix, so ist
rang (A) = rang(A(k−1)
)= rang
(
A)
= m−# Nullzeilen = k − 1,
wobei das Symbol #”die Anzahl von” bedeutet.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 70
Satz 7.22. Sei A eine (m × n)–Matrix und sei b ∈ Rm.[.5ex] Ein lineares Gleichungssystem der FormA · x = b ist genau dann losbar, falls
rang (A) = rang (A, b),
wobei (A, b) die um die rechte Seite b erweiterte Koeffizientenmatrix A ist. [.5ex] Das losbare lineareGleichungssystem A · x = b ist genau dann
• eindeutig losbar, falls
rang (A) = n,
• mehrdeutig losbar, falls
rang (A) < n.
In diesem Fall gilt esdimN (A) = n − rang (A).
Beispiele 7.23.
❶ Im Beispiel 7.17 giltrang (A) = rang (A, b) = 4 = n.
Das Gleichungssystem ist eindeutig losbar.
❷ Im Beispiel 7.18 gilt
rang (A) = rang (A, b) = 4 < 5 = n =⇒ dimN (A) = 5− 4 = 1.
Das Gleichungssystem hat unendlich viele Losungen mit einem Freiheitsgrad.
❸ Im Beispiel 7.19 gilt
rang (A) = rang (A, b) = 2 < 4 = n =⇒ dimN (A) = 4− 2 = 2.
Das Gleichungssystem hat unendlich viele Losungen mit zwei Freiheitsgraden.
❹ Im Beispiel 7.20 giltrang (A) = 2 6= 3 = rang (A, b).
Das Gleichungssystem ist unlosbar.
❺ Im Beispiel 7.21 gilt
rang (A) = rang (A, b) = 3 < n = 4 =⇒ dimN (A) = 4− 3 = 1.
Das Gleichungssystem hat unendlich viele Losungen mit einem Freiheitsgrad.

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 71
7.6 Berechnung von inversen Matrizen
Mit dem Gauß–Algorithmus kann man jetzt leicht uberprufen, ob eine gegebene (n×n)–Matrix A regularist, d. h. ob ihr Rang gleich n ist (s. Def. 6.10). Nach Satz 6.24 hat jede regulare Matrix eine Inverse(s. Def. 6.22), die man auch mit dem Gauß–Algorithmus bestimmen kann.
Fur eine gegebene (n× n)–Matrix A wird also eine Matrix X gesucht, so dass gilt:
A ·X = En,
wobei En eine Einheitsmatrix der Ordnung n ist, d. h. ausfuhrlich geschrieben:
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
. . ....
an,1 an,2 · · · an,n
·
x1,1 x1,2 · · · x1,n
x2,1 x2,2 · · · x2,n
......
. . ....
xn,1 xn,2 · · · xn,n
=
1 0 · · · 00 1 · · · 0...
.... . .
...0 0 · · · 1
q q · · · q
X�,1 X
�,2 · · · X�,n
q q · · · q
e1 e2 · · · en
Die Matrizengleichung A · X = En ist also aquivalent zum folgenden System, das aus n linearenGleichungssystemen besteht:
A ·X�,1 = e1,
......
...A ·X
�,n = en,
wobei man mit X�,j den j-ten Spaltenvektor der Matrix X und mit ej den j-ten Einheitsvektor des Rn,
j = 1, . . . , n, bezeichnet.
Jedes von diesen n linearen Gleichungssystemen konnen wir losen, indem wir den Gauß–Algorithmusauf die erweiterte Matrix (A, ej) anwenden, j = 1, . . . , n, d. h. die Matrix (A, ej) auf ausgeraumte Formbringen und dann die Losung ablesen bzw. feststellen, dass keine Losung existiert.
Da alle diese lineare Gleichnugssysteme dieselbe Koeffizientenmatrix haben, konnen wir sie gleich-zeitig losen, indem wir A um alle n rechten Seiten e1, . . . , en erweitern und die Matrix
(A, e1, . . . , en) = (A,En)
ausraumen. Dabei sind nur die elementare Zeilenumformungen erlaubt (siehe Def. 7.10).
Erhalt man eine Matrix (En, X), so gilt A−1 = X, sonst ist A singular und A−1 existiert nicht.
Beispiel 7.24. Wir bestimmen die Inverse der Matrix
A =
1 2 10 −1 11 0 −1
,

7 HOMOGENE UND INHOMOGENE LINEARE GLEICHUNGSSYSTEME 72
indem wir die folgende erweiterte Matrix
(A,En) =
1 2 1 1 0 00 −1 1 0 1 01 0 −1 0 0 1
umformen:
1 2 1 1 0 00 −1 1 0 1 01 0 −1 0 0 1
−−−−−99K
Z3−Z1
1 2 1 1 0 00 −1 1 0 1 00 −2 −2 −1 0 1
−−−−−99K
−1·Z2
1 2 1 1 0 00 1 −1 0 −1 00 −2 −2 −1 0 1
−−−−−99K
Z3+2·Z2
1 2 1 1 0 00 1 −1 0 −1 00 0 −4 −1 −2 1
−−−−−99K
− 14·Z3
1 2 1 1 0 00 1 −1 0 −1 0
0 0 1 14
12−1
4
−−−−−99K
Z1−Z3Z2+Z3
1 2 0 34−1
214
0 1 0 14−1
2−1
4
0 0 1 14
12−1
4
−−−−−99K
Z1−2·Z2
1 0 0 14
12
34
0 1 0 14−1
2−1
4
0 0 1 14
12−1
4
.
Die Matrix A ist also regular und ihre Inverse ist gleich
A−1 =
14
12
34
14−1
2−1
4
14
12−1
4
=
1
4·
1 2 31 −2 −11 2 −1
.
Satz 7.25. Fur jede regulare Matrix A hat das lineare Gleichungssystem A · x = b die eindeutigbestimmte Losung
x = A−1 · b.
Dieses Ergebnis ist wegen des Aufwands zur Berechnung von A−1 nur dann von praktischer Bedeu-tung, wenn das lineare Gleichungssystem A ·x = b fur mehrere rechte Seiten b = bk, k = 1, . . . , K, gelostwerden soll.
Beispiel 7.26. ☞ In der Vorlesung!
7.7 Lineare Gleichungssysteme und Vektoren
Wir haben uns schon in Kapitel 5 uberlegt, dass man die lineare Abhangigkeit bzw. Unabhangigkeit vonVektoren in einem Vektorraum uberprufen kann, indem man ein geeignetes homogenes lineares Gleich-ungssystem aufstellt (s. Bsp. 5.18 und Bemerkung 5.19). Dieses Verfahren wollen wir nun formalisieren.

8 DETERMINANTEN UND CRAMERSCHE REGEL 73
Direkt aus der Definition der linearen Unabhangigkeit (s. Def. 5.16) folgt der nachste Satz:
Satz 7.27. Sei {a1, . . . , an} ⊆ Rm eine gegebene Menge von (Spalten–) Vektoren.Die Vektoren {a1, . . . , an} sind linear unabhangig genau dann, wenn das homogene Gleichnugssystem
A · x = 0
die eindeutige Losung x = 0 hat, was (nach dem Satz 7.22) aquivalent mit der Bedingung
rang (A) = n
ist. Dabei ist A = (a1, . . . , an) die (m× n)–Matrix, deren j–te Spalte der Vektor aj ist, j = 1, . . . , n.
Folgerung 7.28. Im Vektorraum Rm sind n > m Vektoren stets linear abhangig.
Aus dem obigen Satz folgt, dass man zum Testen der linearen Unabhangigkeit einer Menge vonVektoren in Rm wieder den Gauß–Algorithmus anwenden kann.
Beispiel 7.29. ☞ In der Vorlesung!
Ganz analog kann man auch ein anderes Problem losen:
Satz 7.30. Sei {a1, . . . , an} ⊆ Rm eine gegebene Menge von (Spalten–) Vektoren.Fur ein Vektor v ∈ Rm gilt auch v ∈ Span{a1, . . . , an} genau dann, wenn das inhomogene Gleichungs-system
A · x = v
losbar ist, wobei A = (a1, . . . , an) die (m× n)–Matrix, deren j–te Spalte der Vektor aj ist, j = 1, . . . , n.
Benutzt man zum Uberprufen der Losbarkeit des linearen Gleichungssystems den Gauß–Algorithmus,dann erfahrt man gleichzeitig, ob die Vektoren {a1, . . . , an} linear unabhangig oder linear abhangig sind.
Beispiel 7.31. ☞ In der Vorlesung!
8 Determinanten und Cramersche Regel
Betrachte das lineare Gleichungssystem A · x = b mit einer (2× 2)–Matrix A und b ∈ R2:
{a1,1 · x1 + a1,2 · x2 = b1a2,1 · x1 + a2,2 · x2 = b2.
Multipliziert man die erste Gleichung mit a2,2, die zweite Gleichung mit (−a1,2) und addiert die beideGleichungen zusammen, so erhalt man
(a1,1 · a2,2 − a1,2 · a2,1) · x1 = a2,2 · b1 − a1,2 · b2.

8 DETERMINANTEN UND CRAMERSCHE REGEL 74
Ob das System eindeutig losbar ist, richtet sich also nach der Zahl
a1,1 · a2,2 − a1,2 · a2,1.
Ist a1,1 · a2,2 − a1,2 · a2,1 6= 0, so ist x1 und auch x2 eindeutig bestimmt und gleich
x1 =a2,2 · b1 − a1,2 · b2a1,1 · a2,2 − a1,2 · a2,1
und x2 =a1,1 · b2 − a2,1 · b1a1,1 · a2,2 − a1,2 · a2,1
.
Die Frage ist, ob man so ein Ergebnis fur beliebig große Koeffizientenmatrizen bekommen kann.Diese Frage wird im Abschnitt 8.4 beantwortet.
Definition 8.1. Sei n ∈ N. Die Elemente der Menge
Sn := {σ : {1, . . . , n} → {1, . . . , n} : σ ist bijektiv }
heißen Permutationen (Vertauschungen) der Elemente 1 . . . , n:
Man beweist leicht, dass die Anzahl der Elemente von Sn gleich n! (s. Def. 3.10) ist.
Beispiel 8.2. Fur n = 3 gibt es genau 3! = 1 · 2 · 3 = 6 Permutationen:
(1 2 31 2 3
)
,
(1 2 32 1 3
)
,
(1 2 33 1 2
)
,
(1 2 31 3 2
)
,
(1 2 32 3 1
)
,
(1 2 33 2 1
)
.
Bemerkung 8.3. Seien σ, τ ∈ Sn. Dann ist auch die Verkettung σ ◦ τ ein Element von Sn.
Definition 8.4. Eine Permutation σ ∈ Sn, wobei n ≥ 2, heißt Transposition, wenn gilt:
Es existieren zwei Elemente i, j ∈ {1, . . . , n} mit i 6= j und σ(i) = j, σ(j) = i und mit σ(k) = k fur allek ∈ {1, . . . , n}\{i, j}.
Eine Transposition vertauscht also genau zwei Elemente von {1, . . . , n} miteinander und lasst dieanderen fest.
Satz 8.5. Sei n ≥ 2 und σ ∈ Sn, dann existieren Transpositionen π1, . . . , πτ ∈ Sn, so dass σ =πτ ◦ πτ−1 ◦ · · · ◦ π1 ist.
Man kann also jedes Element σ ∈ Sn als Hintereinanderausfuhrung von Transpositionen darstellen.Diese Darstellung ist zwar nicht eindeutig, aber die Anzahl der Transpositionen (hier τ genannt), dieman benotigt, um σ darzustellen, ist entweder immer gerade oder immer ungerade. Dabei ist fur σ = id
der Wert von τ gleich Null.

8 DETERMINANTEN UND CRAMERSCHE REGEL 75
Definition 8.6. Sei n ≥ 2, σ ∈ Sn, und seien π1, . . . , πτ ∈ Sn Transpositionen mit σ = πτ ◦ · · · ◦ π1.Dann nennt man
sign (σ) := (−1)τ
das Signum (Vorzeichen) von σ.
Man beachte, dass diese Definition nur aufgrund des vorherigen Satzes moglich ist.
Beispiel 8.7. Betrachten wir die Permutationen aus Beispiel 8.2. Dann
sign
(1 2 31 2 3
)
= (−1)0 = 1
sign
(1 2 32 1 3
)
= (−1)1 = −1
sign
(1 2 33 1 2
)
= (−1)2 = 1, da
(1 2 33 1 2
)
=
(1 2 33 2 1
)
◦(
1 2 32 1 3
)
sign
(1 2 31 3 2
)
= (−1)1 = −1
sign
(1 2 32 3 1
)
= (−1)2 = 1, da
(1 2 32 3 1
)
=
(1 2 33 2 1
)
◦(
1 2 31 3 2
)
sign
(1 2 33 2 1
)
= (−1)1 = −1.
Definition 8.8. Sei A = (ai,j)i=1,...,nj=1,...,n
eine (n× n)–Matrix mit
A =
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
. . ....
an,1 an,2 · · · an,n
.
Dann nennt man die reelle Zahl
det(A) = |A| :=∑
σ∈Sn
(
sign(σ) ·n∏
i=1
ai,σ(i)
)
=
=∑
σ∈Sn
(sign(σ) · a1,σ(1) · a2,σ(2) · . . . · an,σ(n)
)
die Determinante (der Ordnung n) von A.

8 DETERMINANTEN UND CRAMERSCHE REGEL 76
Bemerkung. Determinanten fur allgemeine nichtquadratische (m × n)–Matrizen, m 6= n, sind nichterklart!
Folgerung 8.9. Sei A eine (2× 2)–Matrix mit
A =
(a1,1 a1,2
a2,1 a2,2
)
.
In diesem Fall ist n = 2 und S2 hat zwei Elemente, namlich die Transposition σ:
σ(1) = 2 und σ(2) = 1,
mit sign(σ) = −1, und die Identitatsabbildung τ :
τ(1) = 1 und τ(2) = 2,
mit sign(τ) = 1.
Daher istdet(A) = sign(σ) · a1,σ(1) · a2,σ(2) + sign(τ) · a1,τ(1) · a2,τ(2) =
= −1 · a1,2 · a2,1 + 1 · a1,1 · a2,2 =
= a1,1 · a2,2 − a2,1 · a1,2,
d. h. das Produkt der Glieder auf einem Pfeil von links oben nach rechts unten hat ein positives Vor-zeichen, das Produkt der Glieder auf einem Pfeil von links unten nach rechts oben hat ein negativesVorzeichen:
det(A) =
∣∣∣∣∣
a1,1 a1,2
ցւa2,1 a2,2
∣∣∣∣∣.
− +
Beispiel 8.10.
❶ Sei A eine (2× 2)–Matrix mit
A =
(1 23 4
)
.
Dann
det(A) =
∣∣∣∣
1 23 4
∣∣∣∣
= 1 · 4− 2 · 3 = −2.
❷ ☞ In der Vorlesung!
Folgerung 8.11. Sei A eine (3× 3)–Matrix mit
A =
a1,1 a1,2 a1,3
a2,1 a2,2 a2,3
a3,1 a3,2 a3,3
.

8 DETERMINANTEN UND CRAMERSCHE REGEL 77
In diesem Fall ist n = 3 und S3 hat sechs Elemente, die in Beispiel 8.2 aufgelistet worden sind und derenVorzeichen in Beispiel 8.7 berechnet worden sind. Genauso wie in Folgerung 8.9 kann man dann zeigen,dass
det(A) = a1,1 · a2,2 · a3,3 + a1,2 · a2,3 · a3,1 + a1,3 · a2,1 · a3,2 +
− a1,2 · a2,1 · a3,3 − a1,3 · a2,2 · a3,1 − a1,1 · a2,3 · a3,2.
Die Determinante einer (3 × 3)–Matrix kann man mit Hilfe der leicht zu merkenden Regel vonSarrus ausrechnen, die anhand der folgenden Zeichnung angegeben wird:
detA =
∣∣∣∣∣∣∣∣
a1,1 a1,2 a1,3 | a1,1 a1,2ց ցւ ցւ ւ
a2,1 a2,2 a2,3 | a2,1 a2,2
ւ ցւ ցւ ցa3,1 a3,2 a3,3 | a3,1 a3,2
− − − + + +
Man erweitert die Matrix A, indem man die ersten beiden Spalten noch einmal rechts neben dieMatrix schreibt. Die erweiterte Matrix hat drei
”Diagonalen”, die von links oben nach rechts unten
gehen, und drei”Diagonalen”, die von rechts oben nach links unten gehen. Um det(A) zu berechnen,
addiert man nun die Produkte der Elemente der erstgenannten drei Diagonalen, und davon subtrahiertman die drei Produkte der Elemente der letztgenannten drei Diagonalen.
Beispiel 8.12. Sei A eine (3× 3) Matrix mit
A =
2 −3 11 3 −1−2 5 4
.
Dann
det(A) =
∣∣∣∣∣∣
2 −3 11 3 −1−2 5 4
∣∣∣∣∣∣
2 −31 3−2 5
=
= 2 · 3 · 4 + (−3) · (−1) · (−2) + 1 · 1 · 5− 1 · 3 · (−2)− 2 · (−1) · 5− (−3) · 1 · 4 =
= 24 + (−6) + 5− (−6)− (−10)− (−12) = 51.
Fur Determinanten der Ordnung n ≥ 4 gibt es keine der Regel von Sarrus ensprechende Berech-nungsvorschrift! Im nachsten Abschnitt werden zwei Methoden angegeben, eine Determinante hohererOrdnung auszurechnen.
Satz 8.13. Rechenregeln fur Determinanten: Es sei A eine (n× n)–Matrix.
• Ist At die zu A transponierte Matrix (s. Def. 6.6), so gilt
det(A) = det (At).
Damit gelten alle”Zeilenregeln” analog als
”Spaltenregeln”.

8 DETERMINANTEN UND CRAMERSCHE REGEL 78
• Entsteht die Matrix A∗ aus A dadurch, dass eine Zeile bzw. eine Spalte mit einer reellen Zahl λmultipliziert wird, so gilt:
det (A∗) = λ · det(A).
• Entsteht die Matrix A∗ aus A dadurch, dass zwei Zeilen bzw. zwei Spalten miteinander vertauschtwerden, so gilt
det (A∗) = − det(A).
• Entsteht die Matrix A∗ aus A dadurch, dass zu einer Zeile bzw. einer Spalte ein Vielfaches eineranderen Zeile (bzw. Spalte) addiert wird, so gilt
det (A∗) = det(A).
• Zwei Determinanten, welche sich nur in einer Zeile bzw. nur in einer Spalte unterscheiden, kannman addieren, indem man diese beiden Zeilen bzw. Spalten gliedweise addiert.
• Besteht eine Zeile bzw. eine Spalte der Matrix A aus lauter Nullen, so gilt det(A) = 0.
• Stimmen zwei Zeilen bzw. zwei Spalten der Matrix A uberein, so gilt det(A) = 0.
• Sei B eine (n× n)-Matrix, dann ist
det(A · B) = det(A) · det(B).
• Ist A eine Dreiecksmatrix, dann ist die Determinante gleich dem Produkt der Elemente in derHauptdiagonalen. Insbesondere
det (En) = 1.
8.1 Berechnung von Determinanten großerer Ordnung
8.1.1 Laplace–Entwicklung
Die erste Methode zur Berechnung von Determinanten hoherer Ordnung ist die sogenannte Laplace–Entwicklung, die diese schrittweise in Determinanten niedrigerer Ordnung uberfuhrt.

8 DETERMINANTEN UND CRAMERSCHE REGEL 79
Definition 8.14. Es sei
A Ai,j =
a1,1 a1,2 · · · a1,j−1 a1,j a1,j+1 · · · a1,n
a2,1 a2,2 · · · a2,j−1 a2,j a2,j+1 · · · a2,n
......
......
......
ai−1,1 ai−1,2 · · · ai−1,j−1 ai−1,j ai−1,j+1 · · · ai−1,n
ai,1 ai,2 · · · ai,j−1 ai,j ai,j+1 · · · ai,n
ai+1,1 ai+1,2 · · · ai+1,j−1 ai+1,j ai+1,j+1 · · · ai+1,n
......
......
......
an,1 an,2 · · · an,j−1 an,j an,j+1 · · · an,n
eine (n × n)-Matrix, und Ai,j sei die sogenannte (i, j)–Untermatrix (Streichungsmatrix), d. h. die((n− 1)× (n− 1))–Matrix, die man erhalt, wenn man in A die i–te Zeile und die j–te Spalte streicht:
Ai,j :=
a1,1 a1,2 · · · a1,j−1 a1,j+1 · · · a1,n
a2,1 a2,2 · · · a2,j−1 a2,j+1 · · · a2,n
......
......
ai−1,1 ai−1,2 · · · ai−1,j−1 ai−1,j+1 · · · ai−1,n
ai+1,1 ai+1,2 · · · ai+1,j−1 ai+1,j+1 · · · ai+1,n
......
......
an,1 an,2 · · · an,j−1 an,j+1 · · · an,n
.
Satz 8.15. Sei A eine (n× n)–Matrix. Dann gilt:
a) Entwicklung nach der j–ten Spalte:
det(A) =
n∑
i=1
(−1)i+j · ai,j · det(Ai,j) mit j ∈ {1, . . . , n}.
b) Entwicklung nach der i–ten Zeile:
det(A) =
n∑
j=1
(−1)i+j · ai,j · det(Ai,j) mit i ∈ {1, . . . , n}.
Mit dem Laplace–Entwicklungssatz kann jetzt die n–reihige Determinante det(A) berechnet werden:
• Man versehe die Matrix A mit einem”Vorzeichenschachbrett”:
⊕ a1,1 ⊖ a1,2 ⊕ a1,3 · · ·⊖ a2,1 ⊕ a2,2 ⊖ a2,3 · · ·⊕ a3,1 ⊖ a3,2 ⊕ a3,3 · · ·
......
.... . .

8 DETERMINANTEN UND CRAMERSCHE REGEL 80
• Man suche diejenige Zeile oder Spalte mit den meisten Nullen, weil man dann fur jedes ai,j, dasNull ist, det(Ai,j) nicht auszurechnen braucht, denn das Produkt (−1)i+j · ai,j · det(Ai,j) ist dannnaturlich auch Null.
• Man entwickle nach dem Entwicklungssatz nach dieser Zeile oder Spalte.
• Man wiederhole diesen Prozess fur alle Determinanten der Matrizen Ai,j, bis man (3×3)–Matrizenerhalt, deren Determinanten dann unter Verwendung der Regel von Sarrus ausgewertet werdenkonnen.
Man sieht gleich, dass diese Vorgehensweise sehr aufwendig sein kann, besonders wenn die Ordnungder Matrix n≫ 4 ist und wenn die Matrix nur wenig Nullen enthalt.
Beispiel 8.16. Sei A eine (4× 4)–Matrix mit
A =
0 2 5 14 0 − 3 20 1 − 2 00 3 0 2
.
Um det(A) zu bestimmen, bietet es sich an, nach der ersten Spalte zu entwickeln. Man erhalt dann:
det(A) = (−1)1+1 · 0 · det(A1,1) + (−1)2+1 · 4 · det(A2,1) +
+ (−1)3+1 · 0 · det(A3,1) + (−1)4+1 · 0 · det(A2,1) =
= (−1)2+1 · 4 · det(A2,1)
wobei A2,1 eine (3× 3)–Matrix ist mit
A2,1 =
2 5 11 −2 03 0 2
.
Nach der Regel von Sarrus ist det (A2,1) = −8 + 6− 10 = −12, also det(A) = 48.
8.1.2 Eliminationsverfahren
Die zweite Methode basiert auf den Eigenschaften von Determinanten (s. Satz 8.13). Die Berechnungder Determinante einer großeren (n× n)–Matrix A fur n > 3 wird dadurch wesentlich vereinfacht.
Man kann die Matrix A (ohne die Spalte b) genau wie beim ersten Teil des Gauß-Verfahrens imAbschnitt 7.4 in eine Matrix A∗ (Dreiecksmatrix) umformen, deren Determinante leicht zu berechnenist, und von der man dann auf die Determinante der ursprunglichen Matrix A schließen kann. Dabeisind die folgenden beiden Operationen erlaubt:
• Ersetzen einer Zeile (bzw. Spalte) durch die Summe aus dieser Zeile (bzw. Spalte) und dem λ–fachen einer anderen Zeile (bzw. Spalte). Diese Umformung andert die Wert der Determinantenicht.

8 DETERMINANTEN UND CRAMERSCHE REGEL 81
• Zeilen- bzw. Spaltenvertauschungen (die Anzahl sei z bzw. s). Diese Umformung andert lediglichdas Vorzeichen der Determinante.
Ist
A∗ =
a∗1,1 a∗1,2 · · · a∗1,n
0 a∗2,2 · · · a∗2,n
......
. . ....
0 0 · · · a∗n,n
,
danndet (A∗) = a∗1,1 · a∗2,2 · . . . · a∗n,n
unddet(A) = (−1)z+s · det (A∗) = (−1)z+s · a∗1,1 · a∗2,2 · . . . · a∗n,n.
Beispiel 8.17. Sei A eine (4× 4)–Matrix mit
A =
1 3 4 70 1 3 51 2 −2 12 5 1 0
.
det(A) =
∣∣∣∣∣∣∣∣
1 3 4 70 1 3 51 2 −2 12 5 1 0
∣∣∣∣∣∣∣∣
=Z3−Z1
Z4−2·Z1
∣∣∣∣∣∣∣∣
1 3 4 70 1 3 50 −1 −6 −60 −1 −7 −14
∣∣∣∣∣∣∣∣
=Z3+Z2
Z4+Z2
∣∣∣∣∣∣∣∣
1 3 4 70 1 3 50 0 −3 −10 0 −4 −9
∣∣∣∣∣∣∣∣
=S3↔S4
= −
∣∣∣∣∣∣∣∣
1 3 7 40 1 5 30 0 −1 −30 0 −9 −4
∣∣∣∣∣∣∣∣
=Z4−9·Z3
−
∣∣∣∣∣∣∣∣
1 3 7 40 1 5 30 0 −1 −30 0 0 23
∣∣∣∣∣∣∣∣
= −1 · 1 · (−1) · 23 = 23.
Man beachte: Bei der Berechnung von Determinanten ist es oft vorteilhaft, ein gemischtes Verfahrenanzuwenden!
Beispiel 8.18. Berechnen Sie die Determinante der (5× 5)–Matrix A mit
detA =
∣∣∣∣∣∣∣∣∣∣
a b c d 1a b c 1 d
a b 1 c d
a 1 b c d
1 a b c d
∣∣∣∣∣∣∣∣∣∣

8 DETERMINANTEN UND CRAMERSCHE REGEL 82
8.2 Determinanten und Vektoren
Satz 8.19. Es sei A eine (n× n)–Matrix. Dann gilt
rang (A) = n ⇐⇒ det(A) 6= 0.
Die lineare Unabhangigkeit einer Menge von Vektoren {a1, . . . , an} ⊆ Rn kann man also uberprufen,indem man Determinante der Matrix A = (a1, . . . , an), deren j–te Spalte der Vektor aj ist, berechnet.Ist die Determinante gleich Null, dann sind die Vektoren {a1, . . . , an} linear abhangig, sonst sind sielinear unabangig.
Beispiel 8.20. ☞ In der Vorlesung!
8.3 Determinanten und inverse Matrizen
Aus Satz 8.19 folgt direkt, dass jede (n × n)–Matrix A mit det(A) 6= 0 regular ist (s. Def. 6.10) unddamit eine Inverse hat (s. Satz 6.24 und Def. 6.22).
Insbesondere ist
det(A−1) =1
det(A),
weil1 = det (En) = det
(A · A−1
)= det(A) · det
(A−1
).
Die Inverse A−1 lasst sich mit Hilfe von Determinanten berechnen. Dazu benotigen wir noch eineDefinition:
Definition 8.21. Es sei A eine (n× n)–Matrix. Die (n× n)–Matrix Aad := (ai,j)i=1,...,nj=1,...,n
mit
ai,j = (−1)i+j · det (Aj,i)
nennt man die zu A adjungierte Matrix. Das heißt
Aad =
(−1)1+1 · det (A1,1) (−1)1+2 · det (A2,1) · · · (−1)1+n · det (An,1)
(−1)2+1 · det (A1,2) (−1)2+2 · det (A2,2) · · · (−1)2+n · det (An,2)
......
. . ....
(−1)n+1 · det (A1,n) (−1)n+2 · det (A2,n) · · · (−1)n+n · det (An,n)
.
Mit Aj,i bezeichnen wir dabei die (j, i)–Untermatrix von A (s. Def. 8.14).

8 DETERMINANTEN UND CRAMERSCHE REGEL 83
Satz 8.22. Es sei A eine (n× n)–Matrix mit det(A) 6= 0. Dann A ist invertierbar, und es gilt:
A−1 =1
det(A)·Aad.
Beispiel 8.23. Gegeben sei die Matrix
A =
1 2 10 −1 11 0 −1
Zuerst bestimmen wir die Determinante von A:
det(A) =
∣∣∣∣∣∣
1 2 10 −1 11 0 −1
∣∣∣∣∣∣
= 1 + 2 + 0 + 1− 0− 0 = 4
und dann alle ihre Unterdeterminanten:
A1,1 =
∣∣∣∣
−1 10 −1
∣∣∣∣= 1, A1,2 =
∣∣∣∣
0 11 −1
∣∣∣∣= − 1, A1,3 =
∣∣∣∣
0 −11 0
∣∣∣∣= 1,
A2,1 =
∣∣∣∣
2 10 −1
∣∣∣∣= − 2, A2,2 =
∣∣∣∣
1 11 −1
∣∣∣∣= − 2, A2,3 =
∣∣∣∣
1 21 0
∣∣∣∣= − 2,
A3,1 =
∣∣∣∣
2 1−1 1
∣∣∣∣= 3, A3,2 =
∣∣∣∣
1 10 1
∣∣∣∣= 1, A3,3 =
∣∣∣∣
1 20 −1
∣∣∣∣= − 1.
Mit der Regel 8.22 erhalt man die Inverse
A−1 =1
4
1 2 31 −2 −11 2 −1
.
Das gleiche Ergebnis hatten wir im Beispiel 7.24 durch die Anwendung von elementaren Umformungenbekommen.
Wegen des hohen Rechenaufwandes ist die obige Methode kaum geeignet fur die Berechnung derInversen einer regularen Matrix von Ordnung großer als 3. Es ist effektiver, die Inverse einer Matrixmittels der Methode, die im Abschnitt 7.6 beschrieben wurde, zu bestimmen.
8.4 Lineare Gleichungssysteme und Cramersche Regel
Fur eine (n × n)–Koeffizientenmatrix ist das lineare Gleichungssystem A · x = b genau dann fur jederechte Seite b ∈ Rn eindeutig losbar, wenn rang (A) = n ist (s. Satz 7.22), und dies ist nach dem Satz 8.19genau dann der Fall, wenn det(A) 6= 0 ist. Die Losung ist dann in der Form x = A−1 · b darstellbar(s. Satz 7.25), und aus dem Laplaceschen Entwicklungsatz folgt:

8 DETERMINANTEN UND CRAMERSCHE REGEL 84
Satz 8.24. Cramersche Regel: Es sei A eine (n× n)–Matrix. Das lineare Gleichungssystem A · x = b
ist genau dann fur jede rechte Seite b ∈ Rn eindeutig losbar, wenn gilt:
det(A) 6= 0.
Die eindeutig bestimmte Losungsvektor (x1, x2, . . . , xn)t ∈ Rn ist dann in der folgenden Form darstellbar:
xj =det(A(j)(b)
)
det(A), fur j = 1, . . . , n,
dabei entsteht die Matrix A(j)(b) aus der Matrix A, indem ihr j–ter Spaltenvektor durch den Vektor bersetzt wird:
A = (A�,1, . . . , A�,j−1,A�,j, A�,j+1, . . . , A�,n) −→ (A
�,1, . . . , A�,j−1, b, A�,j+1, . . . , A�,n) =: A(j)(b).
Bemerkung. Die Cramersche Regel gilt ausschliesslich fur regulare quadratische Matrizen!
Beispiel 8.25. ☞ In der Vorlesung!
Die Cramersche Regel ist im allgemeinen wegen des viel zu hohen Rechenaufwandes in der Praxis un-durchfuhrbar. Der Gaußsche Algorithmus ist ein effektiveres Verfahren, das auch bei nichtquadratischenMatrizen angewendet werden kann.
Zusammenfassung. Es sei A eine (n× n)–Matrix. Dann gilt:
a) A ist singular ⇐⇒ rang (A) < n
⇐⇒ det(A) = 0
⇐⇒ die Zeilenvektoren von A sind linear abhangig
⇐⇒ die Spaltenvektoren von A sind linear abhangig.
b) A ist regular ⇐⇒ rang (A) = n
⇐⇒ det(A) 6= 0
⇐⇒ die Zeilenvektoren von A sind linear unabhangig
⇐⇒ die Spaltenvektoren von A sind linear unabhangig
⇐⇒ A hat eine Inverse A−1
⇐⇒ A · x = b hat fur jedes b ∈ Rn genau eine Losung
⇐⇒ die Abbildung ϕA : Rn → Rn ist bijektiv.

85
Teil III
Analysis
Im Abschnitt 3.4 haben wir die Menge R der reellen Zahlen dargestellt und die Rechenregeln, die fur dieAddition und Multiplikation gelten (s. Satz 3.4), besprochen. Wir haben auch gesagt, dass die Mengeder reellen Zahlen geordnet ist, und haben die Rechenregeln fur Ungleichungen (s. Satz 3.6) aufgelistet.
9 Intervalle und Umgebungen
9.1 Betrag und Signum
Definition 9.1. Fur jede Zahl x ∈ R heißt die nichtnegative Zahl
|x| :=
x falls x > 0,0 falls x = 0,−x falls x < 0
der Absolutbetrag von x.
Beispiel 9.2.
|0| = 0, |4| = 4,
∣∣∣∣−1
2
∣∣∣∣=
1
2, |x− 1| =
{x− 1, wenn x ≥ 1
−(x− 1), wenn x < 1.
Eigenschaften 9.3. Fur alle x, y ∈ R gilt:
•
|x| ≥ 0 und(
|x| = 0 ⇐⇒ x = 0)
•
| − x| = |x|

9 INTERVALLE UND UMGEBUNGEN 86
•
|x · y| = |x| · |y|
•∣∣∣∣
x
y
∣∣∣∣
=|x||y| , falls y 6= 0
• Dreiecksungleichung:
|x+ y| ≤ |x| + |y|
• Minus – Dreiecksungleichung:
∣∣|x| − |y|
∣∣ ≤ |x+ y|
Bemerkung 9.4. Der Betrag |x| einer reellen Zahl x ∈ R hat auf der Zahlengeraden die geometrischeBedeutung des Abstandes oder der Distanz zum Nullpunkt.Allgemeiner ist
|x− y| fur alle x, y ∈ R
der Abstand der Zahlen x und y.
Definition 9.5. Fur reelle Zahlen x ∈ R heißt
sgn x :=
1, falls x > 0,0, falls x = 0,−1, falls x < 0
das Signum von x.Man beachte: |x| = sgn x · x.
9.2 Intervalle
Spezielle Mengen reeller Zahlen sind Intervalle:
Definition 9.6. Fur a, b ∈ R mit a < b definiert man:
offenes Intervall: (a, b) := {x ∈ R : a < x < b}
xa b

9 INTERVALLE UND UMGEBUNGEN 87
abgeschlossenes Intervall: [a, b] := {x ∈ R : a ≤ x ≤ b}
xa b
(nach links) halboffenes Intervall: (a, b] := {x ∈ R : a < x ≤ b}
xa b
(nach rechts) halboffenes Intervall: [a, b) := {x ∈ R : a ≤ x < b}
xa b
Bemerkung 9.7.
• Offene Intervalle haben weder ein kleinstes noch ein grosstes Element.
• Die Zahl b− a ist die Lange der Intervalle [a, b], [a, b), (a, b], (a, b).
• Jedes Intervall mit endlicher Lange heißt beschrankt.Zur Bezeichnung unbeschrankter Intervallen benutzt man ±∞:
[a,∞) := {x ∈ R : x ≥ a}, (a,∞) := {x ∈ R : x > a},(−∞, b] := {x ∈ R : x ≤ b}, (−∞, b) := {x ∈ R : x < b},
wobei a, b ∈ R. Ferner(−∞,∞) := R.
Bemerkung 9.8. Wir werden als Teilmengen D von R nur Intervalle oder die endliche disjunkte Ver-einigung
D = ≺ a1, b1 ≻ ∪ ≺ a2, b2 ≻ ∪ . . . ∪ ≺ aℓ, bℓ ≻, ℓ ∈ N,
von Intervallen betrachten. Dabei steht das erste Symbol ≺ fur”( ” oder
”[ ”, und das zweite Symbol
≻ fur”) ” oder
”] ”, z. B.: D = [a1, b1) ∪ (a2, b2] ∪ (a3, b3).
Es ist dabei−∞ ≤ a1 < b1 ≤ a2 < b2 ≤ · · · ≤ aℓ < bℓ ≤ ∞.
Definition 9.9. Sei D wie in Bemerkung 9.8.
Das Innere D◦ von D istD◦ = (a1, b1) ∪ (a2, b2) ∪ . . . ∪ (aℓ, bℓ)
und der Abschluß D von D ist
D = [a1, b1] ∪ [a2, b2] ∪ . . . ∪ [aℓ, bℓ] .
Die Menge D heißt offen, falls D◦ = D ist.
Die Menge D heißt abgeschlossen, falls D = D ist.
Die Punkte in D −D◦ nennt man Randpunkte.

10 FOLGEN UND REIHEN 88
Definition 9.10. Sei ε > 0 und a ∈ R. Dann definiert man die ε–Umgebung von a als
Uε(a) := {x ∈ R : |x− a| < ε} = (a− ε, a+ ε).
xa− ε a+ εa
Jede Menge U , fur die es ein ε > 0 gibt, so dass Uε(a) ⊂ U , wird Umgebung von a genannt.
10 Folgen und Reihen
10.1 Der Folgebegriff und Beispiele
Definition 10.1. Eine Abbildung der naturlichen Zahlen in die reellen Zahlen
{N −→ R
n 7−→ an
heißt eine reelle Zahlenfolge, oder einfach Folge.
Schreibweise:(an) , (an)n∈N
, (an)n≥1 , (a1, a2, a3, . . .) .
• an, n ∈ N, nennt man n-tes Folgenglied der Folge (an).
• Das erste Folgenglied einer Folge heißt Anfangsglied.
Gelegentlich beginnt man mit dem Folgenindex nicht bei 1, sondern bei 0: (an)n≥0, oder bei eineranderen naturlichen Zahl k: (an)n≥k. Der Folgenindex n kann auch anders bezeichnet werden, z. B. mitm, k, l, . . ..
Eine Folge (an)n∈N= (a1, a2, a3, . . .) muss man von der Menge {an : n ∈ N} = {a1, a2, a3, . . .}
unterscheiden. Das sieht man am besten bei der konstanten Folge, definiert durch an := a ∈ R fur allen ∈ N. Die Folge (an)n∈N
= (a, a, a, . . .) ist unendlich lang, wahrend die Menge {an : n ∈ N} = {a} nurdas eine Element a enthalt.Bei einer Folge ist weiterhin die Reihenfolge ihrer Folgenglieder wesentlich, bei einer Menge kommt esauf die Reihenfolge, in der man die Elemente angibt, nicht an.
Es gibt verschiedene Arten, eine Folge zu definieren. Die wichtigsten erlautern wir an Beispielen.
Beispiele 10.2.
• Die Glieder einer Folge sind explizit uber eine Funktionsgleichung (Bildungsgesetz) berechenbar,z. B.:

10 FOLGEN UND REIHEN 89
❶ Die konstante Folge: an = a fur alle n ∈ N, also
(an)n∈N= (a, a, a, . . .).
❷ Die harmonische Folge: an = 1n
fur alle n ∈ N, also
(an)n∈N=
(
1,1
2,
1
3,
1
4, . . .
)
.
❸ Die geometrische Folge: an = qn fur alle n ∈ N0, also
(an)n∈N0=(1, q, q2, q3, q4, . . .
).
❹ Die alternierende Folge: an = (−1)n fur alle n ∈ N, also
(an)n∈N= (−1, 1, −1, 1, . . .) .
❺ Die alternierende harmonische Folge: an = (−1)n
nfur alle n ∈ N, also
(an)n∈N=
(
−1,1
2, −1
3,
1
4, . . .
)
.
❻ Die Folge an =(1 + 1
n
)nfur alle n ∈ N, also
(
2,9
4,
64
27,
625
256, . . .
)
.
• Eine Folge kann auch rekursiv bestimmt sein, d. h. man muss alle Folgenglieder bis an−1 kennen,um an mittels einer Rekursionsformel zu berechnen, z. B.:
❼ Die Fibonacci–Folge (0, 1, 1, 2, 3, 5, 8, . . .) ist durch
a0 = 0, a1 = 1, an = an−1 + an−2 fur n ≥ 2
gegeben.
❽ Die Folge(2, 3
2, 17
12, 577
408, . . .
)ist durch
a0 = 2, an =1
2
(
an−1 +2
an−1
)
fur n ≥ 1
gegeben.
• Manchmal kann eine Folge nicht durch Formeln erfasst werden, z. B. wenn sich die Glieder durchMessungen oder Beobachtungen ergeben. In diesem Fall muss man die einzelnen Folgengliederaufzahlen. Aus offensichtlichen Grunden werden wir solche Folgen nicht betrachten.

10 FOLGEN UND REIHEN 90
Definition 10.3. Eine Folge (an)n∈Nheißt
a) monoton wachsend (bzw. streng monoton wachsend), falls
an ≤ an+1, (bzw. an < an+1)
fur alle n ∈ N;
b) monoton fallend (bzw. streng monoton fallend), falls
an ≥ an+1, (bzw. an > an+1)
fur alle n ∈ N;
c) monoton (bzw. streng monoton), wenn sie entweder monoton wachsend oder monoton fallend (bzw.entweder streng monoton wachsend oder streng monoton fallend) ist;
d) nach oben beschrankt, falls es ein S ∈ R gibt mit
an ≤ S
fur alle n ∈ N, die Zahl S nennt man dann eine obere Schranke;
e) nach unten beschrankt, falls es ein s ∈ R gibt mit
an ≥ s
fur alle n ∈ N, die Zahl s nennt man dann eine untere Schranke;
f) beschrankt, falls sie nach oben und nach unten beschrankt ist.
Beispiele 10.4. ☞ In der Vorlesung!
10.2 Konvergenz von reellen Zahlenfolgen
Jetzt kommen wir zum ersten, ganz zentralen Begriff der Analysis, namlich der Konvergenz. Er istgenauso wichtig wie spater die Begriffe Ableitung und Integral.
Definition 10.5. Konvergenz von Folgen: Eine Folge (an)n∈Nheißt konvergent gegen den Grenzwert
a ∈ R, wenn es zu jedem ε > 0 eine Zahl nε ∈ N gibt mit
|an − a| < ε fur alle n > nε.
Kurz:∀ ε > 0 ∃nε ∈ N ∀n > nε : |an − a| < ε.
In diesem Fall schreibt man
a = limn→∞
an oder ann→∞−→ a oder an → a fur n→∞.

10 FOLGEN UND REIHEN 91
Diese Definition von Grenzwert bedeutet:
• die Folge (an) approximiert die Zahl a, d. h. fur fast alle Folgenglieder an ist der Abstand |an−a|kleiner als jede vorgegebene Zahl ε;
• in jeder ε-Umgebung von a (s. Def. 9.10) liegen fast alle Folgenglieder an;
• das Konvergenzverhalten einer Folge (an) wird nicht beeinflusst, wenn man endlich viele Folgen-glieder am Anfang der Folge abandert, hinzufugt oder weglasst.Insbesondere, ist lim
n→∞an = a, so ist auch lim
n→∞an+k = a fur k ∈ N.
Unter dem Ausdruck”fast alle” versteht man: alle bis auf endlich viele (namlich diejenigen an mit
n ≤ nε).
Bezeichnung: Eine Folge mit Grenzwert 0 wird auch als Nullfolge bezeichnet.
Beispiele 10.6.
❶ Betrachten wir die harmonische Folge (an)n∈Nmit an = 1
nfur alle n ∈ N, also
(an)n∈N=
(
1,1
2,
1
3,
1
4,
1
5, . . .
)
.
Beh.: limn→∞
an = 0.
Beweis: Sei ε > 0 beliebig gewahlt. Dann folgt fur alle n > nε :=[
1ε
]+ 1
∣∣∣∣
1
n− 0
∣∣∣∣
=1
n<
1
nε
<11ε
= ε
wobei[
1ε
]die großte naturliche Zahl ≤ 1
εist (d. h.
[1ε
]+ 1 > 1
ε).
❷ Es sei (an)n∈Neine Folge mit an := n
n+1fur alle n ∈ N, also
(an)n∈N=
(1
2,
2
3,
3
4,
4
5, . . .
)
.
Beh.: limn→∞
an = 1.
Beweis: Sei ε > 0 beliebig gewahlt. Dann folgt fur alle n > nε :=[
1ε
]
|an − 1| =
∣∣∣∣
n
n+ 1− 1
∣∣∣∣
=1
n + 1<
1
nε + 1<
11ε
= ε.
Satz 10.7. Der Grenzwert einer konvergenten Folge ist eindeutig bestimmt.

10 FOLGEN UND REIHEN 92
Definition 10.8.
a) Eine Folge (an), die nicht konvergiert, heißt divergent.
b) Man sagt, dass eine Folge (an) (bestimmt) divergent gegen ∞ ist und schreibt
limn→∞
an = ∞
genau dann, wenn es zu jeder Zahl M ∈ R eine Zahl nM ∈ N gibt mit
an > M fur alle n > nM .
c) Man sagt, dass eine Folge (an) (bestimmt) divergent gegen −∞ ist und schreibt
limn→∞
an = −∞
genau dann, wenn es zu jeder Zahl m ∈ R eine Zahl nm ∈ N gibt mit
an < m fur alle n > nm.
Beispiele 10.9.
❶ Es sei (an)n∈Ndie alternierende Folge mit an := (−1)n fur alle n ∈ N, d. h.
(an)n∈N= (−1, 1, −1, 1, −1, . . .) .
Beh.: Die Folge (an)n∈Nist divergent.
Beweis: Nehmen wir an, dass (an)n∈Ngegen a ∈ R konvergiert. Sei ε = 1
2, dann gibt es ein
n 12∈ N, so dass |an − a| < 1
2fur alle n > n 1
2. Daraus folgt, dass
|an+1 − an| ≤ |an+1 − a| + |an − a| <1
2+
1
2= 1.
Das ist ein Widerspruch, weil |an+1 − an| = |(−1)n+1 − (−1)n| = 2.
❷ Es sei (an)n∈Neine Folge mit an = 2n fur alle n ∈ N, d. h.
(an)n∈N= (2, 4, 8, 16, 32, 64, . . .) .
Beh.: limn→∞
an =∞.
Beweis: Sei M ∈ R beliebig gewahlt. Dann folgt fur alle n > nM := [log2M ] + 1
an = 2n > 2nM > 2log2 M = M.
Wir wollen jetzt Methoden zum Nachweis der Konvergenz fur eine Folge darstellen, fur die dieexplizite Kenntnis des Grenzwerts nicht notig ist.

10 FOLGEN UND REIHEN 93
10.2.1 Cauchy–Konvergenzkriterium
Die nachste Definition wird fur die Formulierung des ersten Kriteriums benotigt.
Definition 10.10. Eine Folge (an)n∈Nheißt Cauchy-Folge, wenn gilt: Zu jedem ε > 0 gibt es ein nε ∈ N
mit|an − am| < ε fur alle n,m ≥ nε.
Kurz:∀ ε > 0 ∃nε ∈ N ∀n,m > nε : |an − am| < ε.
Die Formulierung in dieser Definition ist wortlich dieselbe, wie in der Definition der Konvergenz, nurist der Abstand |an − a| des Folgengliedes an vom Grenzwert a durch den Abstand |an − am| zweierFolgenglieder voneinander ersetzt.
Satz 10.11. Jede konvergente Folge (an) ist eine Cauchy-Folge, und jede Cauchy-Folge (an) reellerZahlen besitzt einen Grenzwert a ∈ R.
Beispiel 10.12. ☞ In der Vorlesung!
10.2.2 Konvergenz beschrankter und monotoner Folgen
Satz 10.13. Jede konvergente Folge (an) ist beschrankt.
Die umgekehrte Aussage ist nicht wahr. Ein Gegenbeispiel liefert die alternierende Folge (an) mitan = (−1)n. Sie ist beschrankt, etwa durch |an| < 2, aber konvergiert nicht. Fur beschrankte Folgen gibtes eine Konvergenzaussage in stark abgeschwachter Form, die aber nicht in den Umfang dieser Vorlesunggehort.
Satz 10.14.
a) Jede monoton wachsende und nach oben beschrankte Folge ist konvergent.
b) Jede monoton fallende und nach unten beschrankte Folge ist konvergent.
Bemerkung 10.15. Mit Satz 10.14 kann man beweisen, dass die Folge (an)n∈Nmit
an :=
(
1 +1
n
)n
fur alle n ∈ N,
konvergent ist; den Grenzwert bezeichnet man mit e (Eulersche Zahl):
e := limn→∞
(
1 +1
n
)n
.

10 FOLGEN UND REIHEN 94
10.3 Berechnung von Grenzwerten
Im vorhergehenden Abschnitt haben wir uns mit den Begriffen, Definitionen und theoretischen Konver-genzuntersuchungen beschaftigt, hier kommt es uns jetzt mehr auf das Rechnen an.
Satz 10.16. Rechenregeln fur Grenzwerte:Es seien (an)n∈N
und (bn)n∈Nkonvergente Folgen mit lim
n→∞an = a ∈ R und lim
n→∞bn = b ∈ R.
Dann gilt:
a) Die Summen- bzw. Differenzenfolge (an ± bn)n∈Nkonvergiert mit
limn→∞
(an ± bn) = a± b.
b) Die Produktfolge (an · bn)n∈Nkonvergiert mit
limn→∞
(an · bn) = a · b,
insbesondere
limn→∞
(a · bn) = a · limn→∞
bn.
c) Die Quotientenfolge(
an
bn
)
n≥n0
konvergiert mit
limn→∞
an
bn=
a
b,
falls b = limn→∞
bn 6= 0 ist.
Bemerkung 10.17. Die obigen Aussagen gelten manchmal auch, wenn man∞ und −∞ als Grenzwertevon (an)n∈N
und (bn)n∈Nzulasst.
Fur a ∈ R gelten dabei folgende Regeln:
∞+ a = a + ∞ = ∞,∞ + ∞ = ∞,−∞ + (−∞) = −∞,∞ · a = a · ∞ = ∞ fur a > 0,
∞ · a = a · ∞ = −∞ fur a < 0,
∞ ·∞ = (−∞) · (−∞) = ∞,∞ · (−∞) = (−∞) · ∞ = −∞,a
∞ =a
−∞ = 0.

10 FOLGEN UND REIHEN 95
Die Ausdrucke
[0 · ∞], [∞−∞],[∞∞]
,
[0
0
]
sind nicht bestimmt!
Beispiel 10.18.❶
limn→∞
n3 + 2n2 + 3n+ 4
n3= lim
n→∞
(
1 +2
n+
3
n2+
4
n3
)
=
= limn→∞
1 + limn→∞
2
n+ lim
n→∞
3
n2+ lim
n→∞
4
n3=
= 1 + 2 · limn→∞
1
n+ 3 · lim
n→∞
1
n2+ 4 · lim
n→∞
1
n3=
= 1 + 2 · 0 + 3 · limn→∞
1
n· lim
n→∞
1
n+ 4 · lim
n→∞
1
n· lim
n→∞
1
n· lim
n→∞
1
n=
= 1 + 0 + 3 · 0 · 0 + 4 · 0 · 0 · 0 = 1
❷
limn→∞
n3 − 2n2 + 4
4n2 + 3n− 5= lim
n→∞
n− 2 + 4n2
4 + 3n− 5
n2
=lim
n→∞
(n− 2 + 4
n2
)
limn→∞
(4 + 3
n− 5
n2
) =
=lim
n→∞n− 2 + 0
4 + 0− 0= +∞
10.3.1 Ungleichungen und konvergente Folgen
Satz 10.19. Die Folgen (an) und (bn) seien konvergent. Gilt
an ≤ bn
fur alle n > n0, n0 ∈ N, dann gilt auch
limn→∞
an ≤ limn→∞
bn.
Die entsprechende Aussage fur das strikte”<”–Zeichen gilt nicht! Ein Gegenbeispiel liefern die
konstante Folge (an) mit an = 0 und die harmonische Folge (bn) mit bn = 1n. Dann ist an < bn fur alle
n ∈ N, aberlim
n→∞an = 0 = lim
n→∞bn
und nicht limn→∞
an < limn→∞
bn.

10 FOLGEN UND REIHEN 96
Zur Berechnung von Grenzwerten ist das folgende Einschließungskriterium mitunter nutzlich.
Satz 10.20. Einschließungskriterium oder Sandwichsatz:
Seien (an)n∈N, (bn)n∈N
und (cn)n∈Nreelle Zahlenfolgen mit
bn ≤ an ≤ cn fur alle n ∈ N.
Ist limn→∞
bn = a = limn→∞
cn, so konvergiert (an)n∈Nebenfalls gegen a.
Beispiele 10.21.
❶ Sei (an)n≥2 die Folge mit an = nn2−1
fur n ≥ 2.
Beh.: limn→∞
an = 0.
Beweis: Wir betrachten die Folge (bn)n≥2 mit bn = 1n+1
, dann
limn→∞
bn = limn→∞
1
n + 1= 0.
Weiter gilt fur alle n ≥ 2:
bn =1
n+ 1=
1
n+ 1· n− 1
n− 1=
n− 1
n2 − 1<
n
n2 − 1= an.
Fur die Folge (cn)n≥2 mit cn = 1n−1
fur n ≥ 2, und
limn→∞
cn = limn→∞
1
n− 1= 0
gilt:
cn =1
n− 1=
1
n− 1· n + 1
n + 1=
n+ 1
n2 − 1>
n
n2 − 1= an.
Somit gilt mit dem Sandwichsatz
limn→∞
n
n2 − 1= 0.
❷ Sei (an)n∈Ndie Folge mit an = (−1)n
nfur n ∈ N.
Beh.: limn→∞
an = 0.
Beweis: Fur alle n ∈ N gilt−1
n≤ (−1)n
n≤ 1
n.
Weil limn→∞
1n
= 0 = limn→∞
−1n
, dann auch
limn→∞
(−1)n
n= 0.

10 FOLGEN UND REIHEN 97
10.3.2 Konvergenz von rekursiv definierten Folgen
Beispiel 10.22. Sei (an)n∈Nrekursiv definiert durch
a0 = 2 und an+1 =1
2
(
an +2
an
)
.
Beh.: limn→∞
an =√
2.
Beweis: Aus der Rekursionsformel folgt, dass an > 0 fur alle n ∈ N. Also ist die Folge (an)n∈Nnach
unten beschrankt, z. B. durch 0.
Wir wollen zeigen, dass die Folge (an)n∈Nauch monoton fallend ist. Dafur benotigen wir als Hilfsmittel
eine bessere untere Schranke.
Wir haben die folgenden gleichwertigen Ungleichungen:
an+1 ≥√
2Rekursionsformel⇐⇒ 1
2
(
an +2
an
)
≥√
2
⇐⇒ an +2
an
≥ 2√
2
an>0⇐⇒ a2n + 2 ≥ 2
√2 · an
⇐⇒ a2n − 2
√2 · an + 2 ≥ 0
⇐⇒(
an −√
2)2
≥ 0.
Also an+1 ≥√
2, da die letzte Ungleichung immer gilt.
Nun betrachten wir den Quotienten
an+1
an
=1
2
(
1 +2
a2n
)
≤ 1
2
(
1 +2
2
)
=1
2· 2 = 1.
Aus an ≥√
2 fur n ≥ 1 folgt 1a2
n≤ 1
2, also
an+1
an
≤ 1
2
(
1 +2
2
)
=1
2· 2 = 1.
Die Folgenglieder sind positiv, also folgt aus der Ungleichung an+1
an≤ 1, dass an+1 ≤ an fur n ≥ 1.
Nach Satz 10.14 ist die Folge (an)n≥1 konvergent, d. h. es existiert eine Zahl g, so dass limn→∞
an = g.
Mit der Rekursionsformel und Rechenregeln fur Grenzwerte 10.16 gilt also
g = limn→∞
an+1 = limn→∞
1
2
(
an +2
an
)
=1
2
(
g +2
g
)
.

10 FOLGEN UND REIHEN 98
Wir werden jetzt die erhaltene Gleichung bezuglich g losen:
g =1
2
(
g +2
g
)
⇐⇒ 2g = g +2
g⇐⇒ g =
2
g⇐⇒
⇐⇒ g2 = 2 ⇐⇒ g =√
2,
da g positiv sein muss.
Wir haben also gezeigt, dass die durch obige Rekursionsformel gegebene Folge (an)n≥1 konvergent
gegen√
2 ist.
10.4 Begriff der Reihe, Beispiele und Eigenschaften
Definition 10.23. Es sei (an)n∈Neine Folge reeller Zahlen.
a) Die Folge (Sn)n∈Nmit
Sn :=
n∑
i=1
ai = a1 + a2 + a3 + · · · + an
heißt die aus (an)n∈Ngebildete unendliche Reihe.
Schreibweise: ∞∑
n=1
an,∑
n≥1
an,∑
n∈N
an,∑
an
Die wohldefinierte endliche Summe reeller Zahlen Sn, n ∈ N, nennt man die n-te Partialsumme(Teilsumme).
b) Die Reihe∞∑
n=1
an heißt konvergent gegen S ∈ R, wenn die Folge der Partialsummen (Sn)n∈Nkon-
vergiert mit limn→∞
Sn = S.
Schreibweise:
S =∞∑
n=1
an.
Analoge Definitionen gelten auch fur Reihen∞∑
n=k
an mit festen k ∈ Z (siehe auch die Bemerkung nach
der Definition 10.1).
Keinesfalls ist∞∑
n=1
an als eine”Summe von unendlich vielen Summanden” aufzufassen, weil das nur
zu Verwirrung fuhrt (s. das nachste Beispiel).

10 FOLGEN UND REIHEN 99
Beispiele 10.24.
❶ Es sei ai = qi mit i ∈ N0 und q ∈ R. Dann heißt die Folge (Sn)n∈N0mit
Sn =
n∑
i=0
qi = 1 + q + q2 + · · · + qn
die geometrische Reihe.
Die Partialsummen der geometrischen Reihe sind
Sn =
n∑
i=0
qi =
1− qn+1
1− q fur q 6= 1;
n + 1 fur q = 1.
Daraus folgt, dass die geometrische Reihe fur |q| < 1 konvergiert und
∞∑
n=0
qn =1
1− q .
Fur |q| ≥ 1 ist die geometrische Reihe∞∑
n=0
qn divergent.
❷ Die harmonische Reihe∞∑
n=1
1n
konvergiert nicht (divergiert).
Die Folge der Partialsummen (Sn)n∈Nmit
Sn =
n∑
i=1
1
i= 1 +
1
2+
1
3+ · · · + 1
n
ist offensichtlich monoton wachsend. Wir zeigen, dass diese Folge nicht nach oben beschrankt ist,dann ist sie nicht konvergent. Dazu betrachten wir die folgenden Partialsummen:
S1 = 1,
S2 = 1 +1
2,
S4 = 1 +1
2+
(1
3+
1
4
)
︸ ︷︷ ︸
> 12
> 1 +1
2+
1
2,
S8 = 1 +1
2+
(1
3+
1
4
)
︸ ︷︷ ︸
> 12
+
(1
5+
1
6+
1
7+
1
8
)
︸ ︷︷ ︸
> 12
>
> 1 +1
2+
1
2+
1
2,

10 FOLGEN UND REIHEN 100
Allgemein erhalt man:
S2k ≥ 1 +k
2, k = 1, 2, 3, . . .
Daraus folgt, dass (Sn)n∈Nunbeschrankt wachst und die harmonische Reihe
∞∑
n=1
1n
nicht konvergiert.
❸ Die Reihe∞∑
n=1
1n2 konvergiert.
Die Folge der Partialsummen (Sn)n∈Nmit
Sn =n∑
i=1
1
i2= 1 +
1
22+
1
32+ · · · + 1
n2
ist monoton wachsend.
Außerdem ist fur alle n ∈ N
Sn = 1 +1
2 · 2 +1
3 · 3 + · · · + 1
n · n =
< 1 +1
1 · 2 +1
2 · 3 + · · · + 1
(n− 1) · n =
= 1 +
(1
1− 1
2
)
+
(1
2− 1
3
)
+ · · · +(
1
n− 1− 1
n
)
=
= 1 + 1 − 1
n< 2.
Somit ist die Folge der Partialsummen (Sn)n∈Nbeschrankt und nach dem Satz 10.14 auch konver-
gent. Nach Definition ist die Reihe∞∑
n=1
1n2 konvergent. Man kann sogar zeigen, dass
∞∑
n=1
1n2 = π2
6.
❹ Die Reihe∞∑
n=0
(−1)n divergiert.
Die Folge der Partialsummen (Sn)n∈Nmit
Sn = 1− 1 + 1− 1 + · · ·+ (−1)n
︸ ︷︷ ︸
n+1 Glieder
=
{1 fur gerades n0 fur ungerades n
ist divergent (vgl. Bsp. 10.9 a).
Reihen sind spezielle Folgen, namlich Folgen von Partialsummen. Umgekehrt sind Folgen spezielleReihen, weil man jede Folge (an)n∈N
als Teleskopsumme
an = a1 −n∑
i=2
(ai−1 − ai)

10 FOLGEN UND REIHEN 101
darstellen kann. Es ist also nur eine Frage der Schreibweise, ob man unendliche Reihen oder unendlicheFolgen benutzt.
Da die Konvergenz von Reihen durch die Konvergenz der Partialsummen definiert ist, ergibt sichaus den Rechenregeln fur konvergente Folgen (s. Satz 10.16) ohne weiteres der folgende Satz:
Satz 10.25. Sind∞∑
n=1
an und∞∑
n=1
bn konvergente Reihen, und sind α, β ∈ R beliebig, so konvergiert auch
die Reihe∞∑
n=1
(α · an + β · bn) und es ist
∞∑
n=1
(α · an + β · bn) = α ·∞∑
n=1
an + β ·∞∑
n=1
bn.
Von grosser theoretischer, aber geringer praktischer Bedeutung ist die Umformulierung der Konver-genz von Cauchy–Folgen in der Sprache der Reihen:Die Partialsummen Sn der Reihe
∑
i∈N
ai bilden eine Cauchy-Folge (s. Def. 10.10), wenn zu jedem ε > 0
ein nε ∈ N existiert mit |Sm − Sn| < ε fur alle m,n > nε. Falls m > n, ist
Sm − Sn =m∑
i=1
ai −n∑
i=1
ai =m∑
i=n+1
ai.
Aus Satz 10.11 folgt daher unmittelbar
Satz 10.26. Cauchy-Konvergenzkriterium fur Reihen:
Die Reihe∞∑
n=1
an konvergiert genau dann, wenn es zu jedem ε > 0 ein nε ∈ N existiert mit
∣∣∣∣∣
m∑
i=n+1
ai
∣∣∣∣∣< ε
fur alle m > n > nε.Kurz:
∀ ε > 0 ∃ nε ∈ N ∀ m > n > nε :
∣∣∣∣∣
m∑
i=n+1
ai
∣∣∣∣∣< ε.
Folgerung 10.27. Notwendige Konvergenzbedingung:
Bei einer konvergenten Reihe∞∑
n=1
an bildet die Gliederfolge (an)n∈Neine Nullfolge, d. h. lim
n→∞an = 0.
Die Bedingung limn→∞
an = 0 ist keinesfalls hinreichend fur die Konvergenz der Reihe∞∑
n=1
an, siehe
das Beispiel 10.24 b).
Weiß man von einer Reihe∞∑
n=1
an nur, dass limn→∞
an = 0, so kann man uber ihr Konvergenzverhalten
noch nichts Bestimmtes sagen. Hat man jedoch festgestellt, dass (an)n∈Nkeine Nullfolge ist, so muss die
Reihe notwendig divergieren, siehe das Beispiel 10.24 d).

10 FOLGEN UND REIHEN 102
Satz 10.28. Eine Reihe∑
n∈N
an mit an ≥ 0 fur alle n ∈ N konvergiert genau dann, wenn die Folge der
Partialsummen beschrankt ist.
Beispiel 10.29. ☞ In der Vorlesung und siehe das Beispiel 10.24 b), c).
Bemerkung 10.30. Fur jedes feste k ∈ N haben∞∑
n=1
an und∞∑
n=k
an dasselbe Konvergenzverhalten
(aber nicht denselben Summenwert). Das heißt, durch Weglassen endlich vieler Reihenglieder wird dasKonvergenzverhalten einer Reihe nicht verandert.
10.5 Konvergenzkriterien fur Zahlenreihen
Wir fangen mit einem Konvergenzkriterium an, welches von Gottfried Wilhelm Leibniz (1646–1716)bewiesen wurde.
Satz 10.31. Leibniz–Kriterium:Die alternierende Reihe ∑
(−1)n an
mit an ≥ 0 ist konvergent, falls (an) eine monoton fallende Nullfolge ist.
Fur viele Untersuchungen ist es sinnvoll, zu einer Reihe∑an die Reihe der Absolutbetrage der
Reihenglieder∑ |an| zu betrachten:
Definition 10.32. Ist die Reihe∑ |an| konvergent, so nennt man die Reihe
∑an absolut konvergent.
Bemerkung. Aus der Konvergenz einer Reihe∑an folgt im Allgemeinen nicht ihre absolute Konver-
genz.Eine konvergente, aber nicht absolut konvergente Reihe nennt man bedingt konvergent.
Beispiel 10.33. Die Reihe∑
n∈N
(−1)n
nist nach Satz 10.31 konvergent, aber
∑
n∈N
∣∣∣∣
(−1)n
n
∣∣∣∣
=∑
n∈N
1
n
ist divergent (s. Beispiel 10.24 b)).
Allerdings gilt die Umkehrung, d. h.:
Satz 10.34. Jede absolut konvergente Reihe ist auch konvergent.
Definition 10.35. Seien∑an und
∑bn zwei Reihen reeller Zahlen.
a) Die Reihe∑bn heißt eine Majorante der Reihe
∑an, wenn
|an| ≤ bn
fur fast alle n.

10 FOLGEN UND REIHEN 103
b) Die Reihe∑an heißt eine Minorante der Reihe
∑bn, wenn
0 ≤ an ≤ bn
fur fast alle n.
Satz 10.36. Vergleichskriterien fur die Konvergenz unendlicher Reihen:
a) Majorantenkriterium:
Besitzt∑an eine konvergente Majorante, so ist
∑an absolut konvergent.
b) Minorantenkriterium:
Besitzt∑bn eine divergente Minorante, so ist
∑bn divergent.
Besonders leicht anzuwenden ist das
Satz 10.37. Grenzwertkriterium:
Sind∑an und
∑bn zwei Reihen mit positiven Gliedern und
0 < limn→∞
an
bn< +∞,
so haben die beiden Reihen dasselbe Konvergenzverhalten.
Beispiele 10.38.
❶ Die Reihe∞∑
n=1
3n2−2n4+5n
ist konvergent.
Beweis: Die Reihe∞∑
n=1
1n2 ist konvergent (s. Beispiel 10.24 c)) und
limn→∞
3n2−2n4+5n
1n2
= limn→∞
(3n2 − 2) · n2
n4 + 5n= lim
n→∞
3n4 − 2n2
n4 + 5n= lim
n→∞
3 + 2n2
1 + 5n3
= 3.
Nach dem Grenzwertkriterium ist die Reihe∞∑
n=1
3n2−2n4+5n
konvergent.
❷ Die Reihe∞∑
n=1
2n+53n2−2n
ist divergent.
Beweis: Die Reihe∞∑
n=1
1n
ist divergent (s. Beispiel 10.24 b)) und
limn→∞
2n+53n2−2n
1n
= limn→∞
(2n+ 5) · n3n2 − 2n
= limn→∞
2n2 + 5n
3n2 − 2n= lim
n→∞
2 + 5n
3− 2n
=2
3.
Nach dem Grenzwertkriterium ist die Reihe∞∑
n=1
2n+53n2−2n
divergent.

10 FOLGEN UND REIHEN 104
Wir haben im Beispiel 10.24 gesehen, dass die geometrische Reihe∞∑
n=0
qn genau dann konvergiert,
wenn |q| < 1 gilt. Man kann diese Reihe nun in Satz 10.36 als Vergleichsreihe benutzen, um weitereKriterien fur die absolute Konvergenz von Reihen herzuleiten. Das erste Kriterium tragt den Namen derbeiden franzosischen Mathematiker A. Cauchy und J. Hadamard (1865–1963).
Satz 10.39. Wurzelkriterium von Cauchy–Hadamard:
Es sei∑an eine Reihe mit
limn→∞
n√
|an| = q.
Ist
• q < 1, dann ist die Reihe∑an absolut konvergent;
• q > 1, dann ist die Reihe∑an divergent.
Im Falle q = 1 ist eine zusatzliche Untersuchung erforderlich: die Reihe kann konvergent, sie kann aberauch divergent sein.
Beispiel 10.40. Die Reihe∞∑
n=1
(2n+53n−1
)2nist konvergent, da
limn→∞
n
√(
2n+ 5
3n− 1
)2n
= limn→∞
[(2n+ 5
3n− 1
)2n] 1
n
= limn→∞
(2n+ 5
3n− 1
)2n· 1n
=
= limn→∞
(2n+ 5
3n− 1
)2
=4
9< 1.
Das nachste Kriterium stammt von dem franzosichen Mathematiker Jean Baptiste Le Rond D’Alembert(1717–1783).
Satz 10.41. Quotientenkriterium von D’Alembert:Es sei
∑an eine Reihe mit
limn→∞
∣∣∣∣
an+1
an
∣∣∣∣
= q.
Ist
• q < 1, dann ist die Reihe∑an absolut konvergent;
• q > 1, dann ist die Reihe∑an divergent.
Im Falle q = 1 ist eine zusatzliche Untersuchung erforderlich: die Reihe kann konvergent, sie kann aber
auch divergent sein (berechne limn→∞
∣∣∣an+1
an
∣∣∣ fur die Reihen aus dem Beispiel 10.24 b) und c)).

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 105
Beispiel 10.42.
❶ Die Reihe∞∑
n=1
n3
2n ist konvergent, da
limn→∞
∣∣∣∣
an+1
an
∣∣∣∣
= limn→∞
(n+1)3
2n+1
n3
2n
= limn→∞
(n + 1)3 · 2n
2n+1 · n3= lim
n→∞
1
2·(
1 +1
n
)3
=1
2< 1.
❷ Die Reihe∞∑
n=1
n!3n ist divergent, da
limn→∞
∣∣∣∣
an+1
an
∣∣∣∣
= limn→∞
(n+1)!3n+1
n!3n
= limn→∞
n + 1
3= ∞ > 1.
Bemerkung.
• Im Falle limn→∞
n√
|an| = 1 = limn→∞
∣∣∣an+1
an
∣∣∣ versagen sowohl Wurzel- als auch Quotientenkriterium. Man
kann jedoch zeigen: Versagt das Quotientenkriterium nicht, so auch nicht das Wurzelkriterium. DieUmkehrung ist im allgemeinen falsch, denn das Wurzelkriterium ist starker.
• Fur Reihen der Form∑
n∈N
1nα versagen sowohl Wurzel- als auch Quotientenkriterium. Aber ihr
Konvergenzverhalten ist bekannt:
Die Reihe∑
n∈N
1
nαist
{divergent fur α ≤ 1;
konvergent fur α > 1.
Daher sollte man stets versuchen, diese Reihe als Vergleichsreihe heranzuziehen, wenn beide Kri-terien bei einer Reihe
∑an auf den unentscheidbaren Fall fuhren.
11 Funktionen einer reellen Veranderlichen
11.1 Der Funktionsbegriff und Beispiele
Definition 11.1. Sei D eine Teilemenge von R. Eine Abbildung f : D → R wird eine reelle Funktiongenannt (s. Def. 4.1).Wir schreiben
f :
{D −→ R
x 7−→ y = f(x).

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 106
Die Menge D = Df heißt Definitionsbereich von f .Die Menge
Wf := f(D) = {y = f(x) ∈ R : x ∈ D} ⊆ R
heißt Wertebereich von f .Die Menge
Γf :={(x, y) ∈ R2 : x ∈ D ∧ y = f(x)
}
heißt der Graph von f .
Bemerkungen 11.2.
• Die Angabe des Definitionsbereichs ist Bestandteil der Definition einer Funktion, nicht nur die
”Abbildungsvorschrift”.
Wenn der Definitionsbereich einer Funktion nicht ausdrucklich angegeben ist, so wahlt man ubli-cherweise den großtmoglichen Definitionsbereich; oder man beschrankt sich in Anwendungen auf
”sinnvolle” Definitionsbereiche, z. B. Zeit t ≥ 0.
• Um eine bessere Vorstellung uber eine Funktion f : D → R zu erhalten, macht man am besten eineSkizze des Graphen Γf . Dazu berechnet man fur einige x ∈ D den Funktionswert f(x) und zeichnetdie Zahlenpaare (x, f(x)) in ein zweidimensionales Koordinatensystem ein. Anschließend verbindetman die Punkte. Besser gelingt eine solche Skizze, wenn man zunachst eine Kurvendiskussiondurchfuhrt, wie spater erlautert wird.
Definition 11.3. Eine Funktion f : R→ R von der Form
f(x) = a0 + a1 · x + a2 · x2 + . . . + an · xn =
n∑
i=0
aixi mit ai ∈ R
nennt man ein Polynom. Das Polynom hat den Grad n, wenn an 6= 0 ist.
Beispiele 11.4.
❶ Konstante Funktionen sind Polynome vom Grad 0.Es sei a ∈ R. Man definiere
f :
{R −→ R
x 7−→ a.
Definitionsbereich: Df = R;
Wertebereich: Wf = {a};Γf : eine zur x-Achse parallele Gerade:
1 2 3−1−2−3
1
2
x
y
y = aa
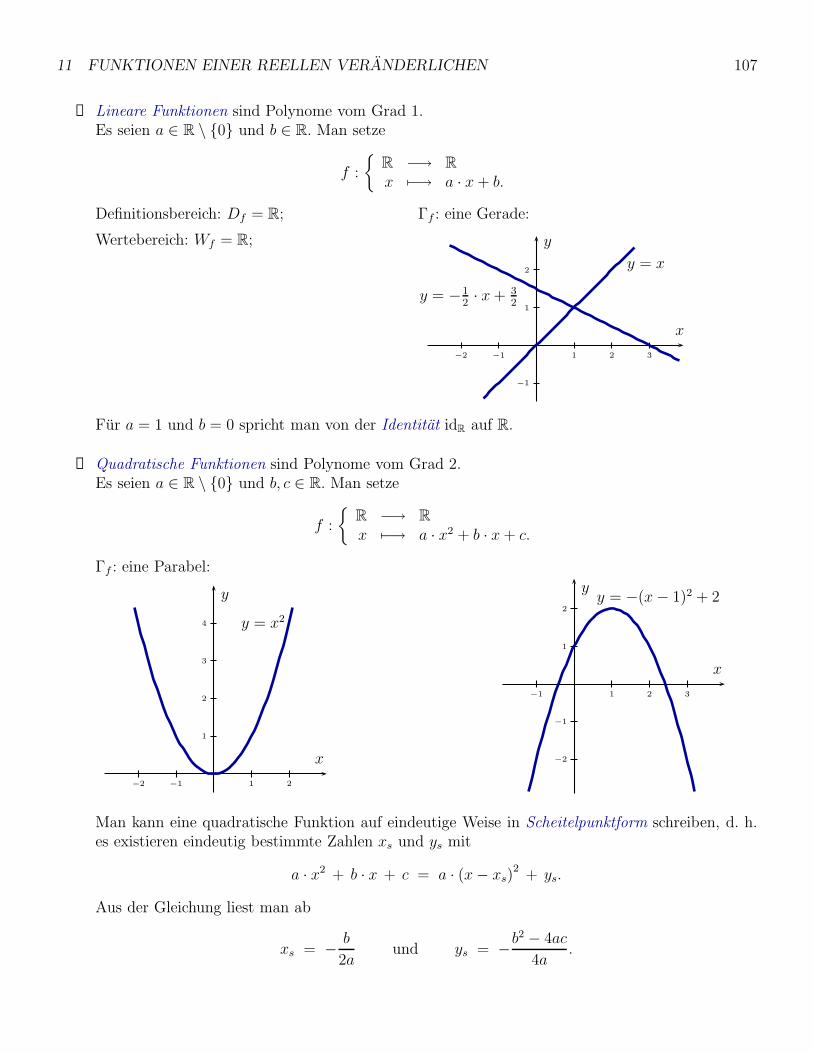
11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 107
❷ Lineare Funktionen sind Polynome vom Grad 1.Es seien a ∈ R \ {0} und b ∈ R. Man setze
f :
{R −→ R
x 7−→ a · x+ b.
Definitionsbereich: Df = R;
Wertebereich: Wf = R;
Γf : eine Gerade:
1 2 3−1−2
1
2
−1
x
y
y = −12· x+ 3
2
y = x
Fur a = 1 und b = 0 spricht man von der Identitat idR auf R.
❸ Quadratische Funktionen sind Polynome vom Grad 2.Es seien a ∈ R \ {0} und b, c ∈ R. Man setze
f :
{R −→ R
x 7−→ a · x2 + b · x+ c.
Γf : eine Parabel:
1 2−1−2
1
2
3
4
x
y
y = x2
1 2 3−1
1
2
−1
−2
x
yy = −(x− 1)2 + 2
Man kann eine quadratische Funktion auf eindeutige Weise in Scheitelpunktform schreiben, d. h.es existieren eindeutig bestimmte Zahlen xs und ys mit
a · x2 + b · x + c = a · (x− xs)2 + ys.
Aus der Gleichung liest man ab
xs = − b
2aund ys = −b
2 − 4ac
4a.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 108
Der Punkt (xs, ys) ∈ Γf heißt Scheitelpunkt der Parabel.
Definitionsbereich: Df = R;
Wertebereich: Wf =
{
y ∈ R : y ≥ − b2−4ac4a
}
falls a > 0,{
y ∈ R : y ≤ − b2−4ac4a
}
falls a < 0.
Definition 11.5. Es seien f und g zwei Polynome. Eine Funktion
r :
Dr −→ R
x 7−→ f(x)
g(x).
nennt man eine rationale Funktion.[1ex] Der Definitionsbereich ist Dr = {x ∈ R : g(x) 6= 0}.
Beispiel 11.6. Sei
r :
R \ {0} −→ R
x 7−→ 1
x.
Definitionsbereich: Df = R \ {0}
Wertebereich: Wf = R \ {0}
Γf : eine Hyperbel
1 2 3 4−1−2−3−4
1
2
3
4
−1
−2
−3
−4
x
y
y = 1x
Definition 11.7. Sei n ≥ 2. Die Funktion
f :
{[0,∞) −→ [0,∞)
x 7−→ x1n = n√x
nennt man Wurzelfunktion. Dabei bezeichnet n√x die Zahl q mit qn = x.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 109
Beispiel 11.8. Sei n = 2 und
f :
{
[0,∞) −→ [0,∞)
x 7−→ x12 =√x
Definitionsbereich: Df = [0,∞)
Wertebereich: Wf = [0,∞)
Γf :
1 2 3 4−1
1
2
x
y y =√x
Wir geben jetzt weitere Beispiele von reellen Funktionen an:
Beispiele 11.9. Alle unten dargestellte Funktionen sind fur alle reelle Zahlen definiert.
❶ Der Absolutbetrag
f :
{R −→ R
x 7−→ |x|,
wobei die Zahl |x| in Def. 9.1 definiert ist.
Wertebereich: Wf = [0,∞). 1 2−1−2
1
2
x
y
❷ Die Vorzeichenfunktion
f :
{R −→ R
x 7−→ sgn(x),
wobei die Zahl sgn(x) in Def. 9.5 definiert ist.
Wertebereich: Wf = {−1, 0, 1}
1 2−1−2
1
−1
x
y
❸ Die Heavysidesche Sprungfunktion
f :
R −→ R
x 7−→{
0 falls x < 01 falls x ≥ 0.
Wertebereich: Wf = {0, 1}1 2−1−2
1
x
y

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 110
❹ Die (untere) Gauß-Klammer
f :
{R −→ R
x 7−→ [x],
wobei [x] := m ∈ Z, so dass x ∈ [m,m+ 1).
Wertebereich: Wf = Z.1 2 3−1−2
1
2
−1
−2
x
y
❺ Die Sagezahnfunktion
f :
{R −→ R
x 7−→ x− [x],
Wertebereich: Wf = [0, 1).
1 2 3−1−2
1
2
x
y
❻ Die Dirichlet–Funktion
f :
R −→ R
x 7−→{
0 falls x ∈ Q
1 falls x ∈ R \Q.
Wertebereich: Wf = {0, 1}.
❼ Eine Folge (an)n∈Nist auch eine Funktion
f :
{
N −→ R
n 7−→ an
mit Definitionsbereich N.
11.2 Rechnen mit Funktionen
Nachdem wir jetzt einige typische Beispiele von Funktionen dargestellt haben, stellen wir die wichtigstenRechenoperationen zusammen, die man auf Funktionen anwenden kann.
Die algebraischen Rechenoperationen fur reelle Zahlen vererben sich auf Funktionen, indem mandiese Rechenoperationen auf die Funktionswerte anwendet.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 111
Definition 11.10. Es seien f : Df → R und g : Dg → R zwei reelle Funktionen.
a) Das Skalarprodukt von f mit der Zahl λ ∈ R ist die Funktion
λ · f :
{Df −→ R
x 7−→ λ · f(x) (Multiplikation in R) ,
b) Die Summe bzw. die Differenz von f und g ist die Funktion
f ± g :
{Df ∩Dg −→ R
x 7−→ f(x)± g(x) (Addition in R) ,
c) Das Produkt von f und g ist die Funktion
f · g :
{Df ∩Dg −→ R
x 7−→ f(x) · g(x) (Multiplikation in R) ,
d) Der Quotient von f und g ist die Funktion
f
g:
(Df ∩Dg) \ {g(x) = 0} −→ R
x 7−→ f(x)
g(x)(Division in R) ,
Man kann auch zwei Funktionen hintereinanderschalten (s. Def. 4.7) und eine zusammengesetzteFunktion bekommen.
Definition 11.11. Es seien f : Df → R und g : Dg → R zwei reelle Funktionen. Die Verknupfung(Komposition, Hintereinanderausfuhrung) von f und g ist die Funktion
f ◦ g :
{
{x ∈ Dg : g(x) ∈ Df} −→ R
x 7−→ f (g(x)) ,
Beispiel 11.12. ☞ In der Vorlesung!
11.3 Erste Eigenschaften reeller Funktionen
Es wird empfohlen, sich an dieser Stelle nochmals die wichtigen Begriffe der Surjektivitat, Injektivitat,Bijektivitat und Umkehrabbildung fur f : X −→ Y aus Definition 4.5 in Erinnerung zu rufen.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 112
11.3.1 Nullstellen
Definition 11.13. Es sei f : Df → R eine reelle Funktion. Eine Zahl x0 ∈ Df heißt Nullstelle von f ,wenn
f (x0) = 0
gilt. Man sagt auch: f besitzt an der Stelle x0 eine Nullstelle.
Eine Zahl x0 ∈ Df ist genau dann Nullstelle von f , wenn der Graph Γf die x-Achse im Punkt (x0, 0)schneidet.
Satz 11.14. Ein Polynom vom Grad n hat hochstens n Nullstellen. Diese sind fur große n meist nurdurch Naherungsverfahren bestimmbar.
Beispiele 11.15.
❶ Eine lineare Funktion f : R → R mit x 7→ ax + b, a 6= 0, besitzt genau eine Nullstelle, namlichx0 = − b
a.
❷ Eine quadratische Funktion f : R→ R mit x 7→ ax2 + bx+ c, a 6= 0, besitzt
keine reelle Nullstelle ⇐⇒ ∆ < 0,
genau eine Nullstelle: x0 = − b2a
⇐⇒ ∆ = 0,
genau zwei Nullstellen: x1 = −b−√
∆2a
und x2 = −b+√
∆2a
⇐⇒ ∆ > 0,
wobei ∆ := b2 − 4ac Diskriminante heißt.
❸ Die Sagezahnfunktion (s. Bsp. 11.9 e)) besitzt unendlich viele Nullstellen x0 ∈ Z.
11.3.2 Symmetrie
Definition 11.16.
a) Eine reelle Funktion f : Df → R heißt gerade, wenn fur alle x ∈ Df gilt:
− x ∈ Df und f(−x) = f(x).
b) Eine reelle Funktion f : Df → R heißt ungerade, wenn fur alle x ∈ Df gilt:
− x ∈ Df und f(−x) = −f(x).
Bemerkung 11.17.
• Eine Funktion f : Df → R ist genau dann gerade, wenn ihr Graph Γf spiegelsymmetrisch bezuglichder y-Achse ist.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 113
• Eine Funktion f : Df → R ist genau dann ungerade, wenn ihr Graph Γf drehsymmetrisch bezuglichdes Ursprungs ist.
Beispiele 11.18.
❶ Gerade Funktionen: • konstante Funktionen,• quadratische Funktionen der Form f(x) = ax2 + c, a 6= 0,• der Absolutbetrag,• die Funktion f(x) = 1
|x| ,
• die Kosinusfunktion.
❷ Ungerade Funktionen: • lineare Funktionen der Form f(x) = ax, a 6= 0,• die rationale Funktion f(x) = 1
x,
• die Vorzeichenfunktion,• die Funktion f(x) = x3,• die Sinusfunktion.
11.3.3 Periodizitat
Definition 11.19. Es sei f : Df → R eine reelle Funktion. Eine Zahl p ∈ R \ {0} heißt Periode von f ,wenn fur alle x ∈ Df gilt:
x± p ∈ Df und f(x± p) = f(x).
Die Funktion f heißt periodisch, wenn sie eine Periode besitzt. Die kleinste positive Periode einer peri-odischen, nicht konstanten Funktion wird primitive Periode genannt.
Beispiele 11.20.
❶ Die Sinus- und Kosinusfunktion sind periodisch mit primitiver Periode 2π.
❷ Die Tangens- und Kotangensfunktion sind periodisch mit primitiver Periode π.
❸ Die Sagezahnfunktion ist periodisch mit primitiver Periode 1.
11.3.4 Monotonie
Definition 11.21. Sei f : Df → R eine reelle Funktion, und sei I ⊂ Df ein Intervall. Die Funktion f
heißt
a) monoton wachsend (steigend) in I, wenn fur alle x1, x2 ∈ I gilt:
x1 ≤ x2 =⇒ f (x1) ≤ f (x2) .
b) streng monoton wachsend (steigend) in I, wenn fur alle x1, x2 ∈ I gilt:
x1 < x2 =⇒ f (x1) < f (x2) .

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 114
c) monoton fallend in I, wenn fur alle x1, x2 ∈ I gilt:
x1 ≤ x2 =⇒ f (x1) ≥ f (x2) .
d) streng monoton fallend in I, wenn fur alle x1, x2 ∈ I gilt:
x1 < x2 =⇒ f (x1) > f (x2) .
Bemerkung 11.22. Jede streng monoton wachsende/fallende Funktion f : Df → Wf ist nach Defini-tion auch umkehrbar.
Beispiele 11.23.
❶ Jede konstante Funktion ist sowohl monoton wachsend als auch monoton fallend in R, aber wederstreng monoton wachsend noch streng monoton fallend.
❷ Eine lineare Funktion f : R → R, x 7→ ax + b, a 6= 0, ist genau dann streng monoton wachsendbzw. streng monoton fallend, wenn a > 0 bzw. a < 0 gilt.
❸ Eine quadratische Funktion f : R → R, x 7→ ax2 + bx + c, a > 0, ist streng monoton fallend in(−∞,− b
2a
)und streng monoton wachsend in
(− b
2a,∞).
❹ Die Funktion f : R→ R, x 7→ x3 ist streng monoton wachsend.
❺ Die Funktion f : R \ {0} → R, x 7→ 1x
ist streng monoton fallend in (−∞, 0) und in (0,∞).
❻ Die Funktion f : [0,∞)→ [0,∞), x 7→ √x ist streng monoton wachsend.
❼ Die untere Gaußklammer ist monoton wachsend, aber nicht streng monoton wachsend.
❽ Die Sagezahnfunktion ist streng monoton wachsend in jedem Intervall [m,m+ 1) mit m ∈ Z.
11.4 Grenzwerte von Funktionen
Definition 11.24. Es seien f : Df → R eine reelle Funktion und x0 ∈ Df eine reelle Zahl. Dann heißtg ∈ R ∪ {∞,−∞}
a) Grenzwert von f an der Stelle x0, wenn
• es ein δ > 0 mit Uδ (x0) \ {x0} ⊂ Df gibt und
• fur jede Folge (xn)n∈N⊂ Df \ {x0} mit lim
n→∞xn = x0 gilt:
limn→∞
f (xn) = g.
Schreibweise: g = limx→x0
f(x) oder f(x)→ g fur x→ x0.
Sprechweise:”Limes von f(x) fur x gegen x0 ist gleich g” oder
”f(x) konvergiert fur x → x0
gegen g”.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 115
b) rechtsseitiger Grenzwert von f an der Stelle x0, wenn
• es ein δ > 0 mit (x0, x0 + δ) ⊂ Df gibt und
• fur jede Folge (xn)n∈N⊂ Df mit xn > x0 fur alle n ∈ N und lim
n→∞xn = x0 gilt:
limn→∞
f (xn) = g.
Schreibweise: g = limx→x+
0
f(x) oder g = limx→x0x>x0
f(x).
c) linksseitiger Grenzwert von f an der Stelle x0, wenn
• es ein δ > 0 mit (x0 − δ, x0) ⊂ Df gibt und
• fur jede Folge (xn)n∈N⊂ Df mit xn < x0 fur alle n ∈ N und lim
n→∞xn = x0 gilt:
limn→∞
f (xn) = g.
Schreibweise: g = limx→x−0
f(x) oder g = limx→x0x<x0
f(x).
Ist g = ±∞, dann sprechen wir von einem uneigentlichen Grenzwert.
Falls Df nach oben bzw. unten nicht beschrankt ist, d. h. wenn in der Beschreibung von Df in 9.8bℓ =∞ bzw. a1 = −∞ ist, kann man die Definitionen auf x0 =∞ bzw. x0 = −∞ ausdehnen:
d) g = limx→∞
f(x), wenn
• es ein R ∈ R mit (R,∞) ⊂ Df gibt und
• fur jede Folge (xn)n∈N⊂ Df mit lim
n→∞xn =∞ gilt:
limn→∞
f (xn) = g.
e) g = limx→−∞
f(x), wenn
• es ein R ∈ R mit (−∞, R) ⊂ Df gibt und
• fur jede Folge (xn)n∈N⊂ Df mit lim
n→∞xn = −∞ gilt:
limn→∞
f (xn) = g.
In den getroffenen Definitionen wird der Funktionswert f (x0) nicht benotigt. Deshalb kommt esnicht darauf an, ob x0 zum Definitionsbereich Df gehort oder nicht.
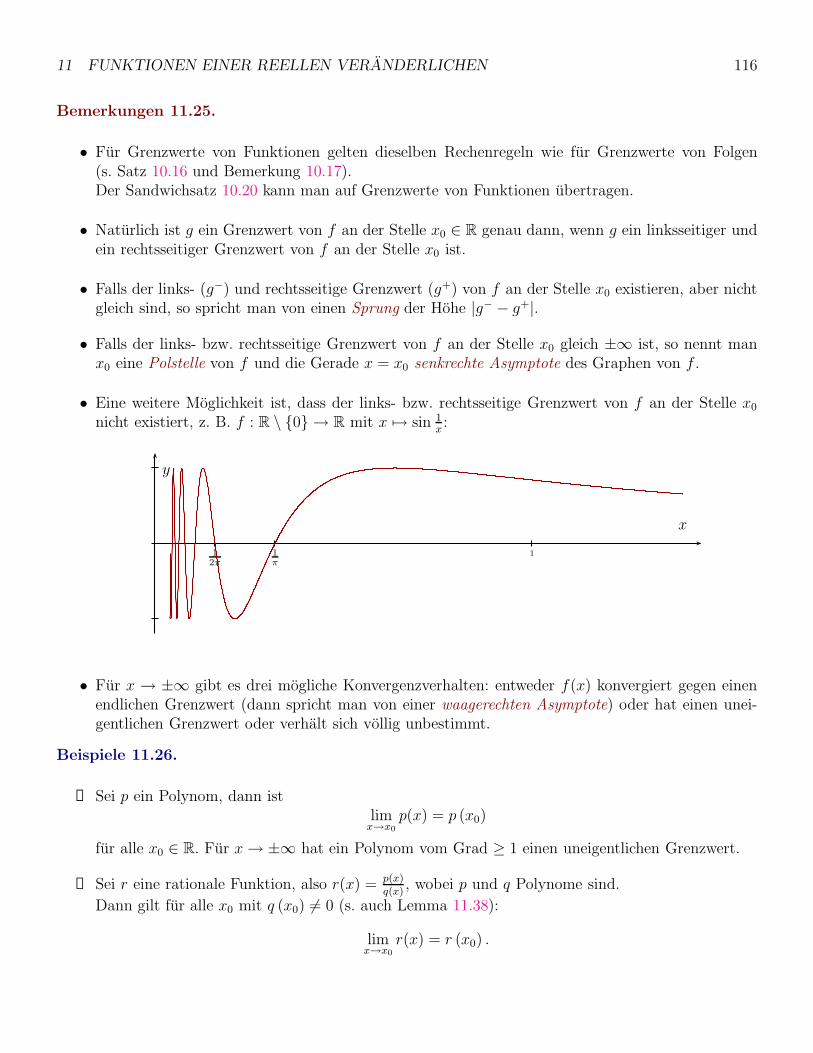
11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 116
Bemerkungen 11.25.
• Fur Grenzwerte von Funktionen gelten dieselben Rechenregeln wie fur Grenzwerte von Folgen(s. Satz 10.16 und Bemerkung 10.17).Der Sandwichsatz 10.20 kann man auf Grenzwerte von Funktionen ubertragen.
• Naturlich ist g ein Grenzwert von f an der Stelle x0 ∈ R genau dann, wenn g ein linksseitiger undein rechtsseitiger Grenzwert von f an der Stelle x0 ist.
• Falls der links- (g−) und rechtsseitige Grenzwert (g+) von f an der Stelle x0 existieren, aber nichtgleich sind, so spricht man von einen Sprung der Hohe |g− − g+|.
• Falls der links- bzw. rechtsseitige Grenzwert von f an der Stelle x0 gleich ±∞ ist, so nennt manx0 eine Polstelle von f und die Gerade x = x0 senkrechte Asymptote des Graphen von f .
• Eine weitere Moglichkeit ist, dass der links- bzw. rechtsseitige Grenzwert von f an der Stelle x0
nicht existiert, z. B. f : R \ {0} → R mit x 7→ sin 1x:
1
π
1
2π
1
1
1
x
y
• Fur x → ±∞ gibt es drei mogliche Konvergenzverhalten: entweder f(x) konvergiert gegen einenendlichen Grenzwert (dann spricht man von einer waagerechten Asymptote) oder hat einen unei-gentlichen Grenzwert oder verhalt sich vollig unbestimmt.
Beispiele 11.26.
❶ Sei p ein Polynom, dann istlim
x→x0
p(x) = p (x0)
fur alle x0 ∈ R. Fur x→ ±∞ hat ein Polynom vom Grad ≥ 1 einen uneigentlichen Grenzwert.
❷ Sei r eine rationale Funktion, also r(x) = p(x)q(x)
, wobei p und q Polynome sind.
Dann gilt fur alle x0 mit q (x0) 6= 0 (s. auch Lemma 11.38):
limx→x0
r(x) = r (x0) .

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 117
❸ Es sei f : R \ {0} → R mit x 7→ 1x
(vgl. Bild im Bsp. 11.6).
Es gilt dann z. B.: limx→1
f(x) = 1.
Außerdemlim
x→0+f(x) =∞ und lim
x→0−f(x) = −∞.
Die Funktion f hat also keinen Grenzwert an der Stelle 0 und die Gerade x = 0 ist eine senkrechteAsymptote des Graphen von f . Wir sprechen von einer Polstelle mit Vorzeichenwechsel.Weiter gilt:
limx→∞
f(x) = 0 und limx→−∞
f(x) = 0,
daher ist die Gerade y = 0 waagerechte Asymptote des Graphen von f(x) = 1x
fur x→ ±∞.
❹ Die Vorzeichenfunktion (s. Bsp. 11.9 b)) hat an der Stelle x0 = 0 einen Sprung der Hohe 2, da
limx→0+
sgn(x) = 1 und limx→0−
sgn(x) = −1.
❺ Die Heavysidesche Sprungfunktion (s. Bsp. 11.9 c)) hat an der Stelle x0 = 0 einen Sprung derHohe 1, da
limx→0+
f(x) = 1 und limx→0−
f(x) = 0.
❻ Fur die untere Gaußklammer (s. Bsp. 11.9 d)) ist limx→x0
[x] = [x0] fur x0 6∈ Z, aber fur jedes m ∈ Z
hat sie einen Sprung:lim
x→m+[x] = m und lim
x→m−[x] = m− 1.
Die Existenz eines Funktionenlimes kann auch in der folgenden Form formuliert werden, die keineFolgen benutzt
Satz 11.27. Die Funktion f : Df → R hat an der Stelle x0 ∈ R den Grenzwert g ∈ R genau dann,wenn gilt:Zu jeder Zahl ε > 0 gibt es eine Zahl δε > 0 mit Uδε
(x0) \ {x0} ⊆ Df , so dass
|f(x)− g| < ε fur alle x ∈ Uδε(x0) \ {x0}.
Satz 11.27 gilt mit entsprechender Modifikation auch fur einseitige Grenzwerte.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 118
11.5 Stetigkeit von Funktionen
Definition 11.28. Es sei f : Df → R eine reelle Funktion.
a) Die Funktion f heißt stetig in x0 ∈ Df , wenn der Grenzwert von f in x0 existiert und
limx→x0
f(x) = f (x0)
b) Die Funktion f heißt rechtsseitig stetig in x0 ∈ Df , wenn der rechtsseitige Grenzwert von f in x0
existiert und
limx→x+
0
f(x) = f (x0) .
c) Die Funktion f heißt linksseitig stetig in x0 ∈ Df , wenn der linksseitige Grenzwert von f in x0
existiert und
limx→x−0
f(x) = f (x0) .
d) Die Funktion f heißt stetig auf Df , wenn f in jedem Punkt x0 ∈ D◦f stetig und in jedem
x0 ∈ Df \D◦f links- bzw. rechtsseitig stetig ist.
Bemerkungen.
• Die obige Definition kann man komprimiert so schreiben:Eine Funktion f : Df → R ist stetig, wenn fur jede Folge (xn)n∈N
⊂ Df gilt:
f(
limn→∞
xn
)
= limn→∞
f (xn) .
In dieser Form ist das eine Vertauschungsregel: man kann Grenzubergang und Funktionsvorschriftbei stetigen Funktionen vertauschen.
• Anders als bei der Definition von Funktionengrenzwerten muss der Punkt x0 bei Stetigkeits-betrachtungen zum Definitionsbereich Df gehoren. Das heißt, es muss ein Funktionswert f (x0)existieren.
• Anschaulich bedeutet Stetigkeit in x0, dass man den Graphen von f durch den Punkt (x0, f (x0))durchzeichnen kann, ohne abzusetzen. Diese Vorstellung darf aber nicht als Definition der Stetigkeitbetrachtet werden.Zum Beispiel ist die Funktion f(x) = sin 1
xauf dem Intervall (0,∞) stetig, ihr Graph ist jedoch in
der Nahe von Null nicht zeichenbar (s. Bem. 11.25 e)).

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 119
Eine andere, gelaufige Definition von Stetigkeit ist die sogenannte”ε−δ–Definition” (vgl. Satz 11.27).
Satz 11.29. Die reelle Funktion f : Df → R ist an der Stelle x0 ∈ Df genau dann stetig, wenn folgendesgilt:Zu jeder Zahl ε > 0 gibt es eine Zahl δε > 0 mit Uδε
(x0) ⊆ Df , so dass
|f(x)− f (x0) | < ε fur alle x ∈ Uδε(x0) .
Analoge Formulierungen gelten fur die rechts- bzw. linksseitige Stetigkeit in x0.Beachte: Die Zahl δε hangt i. a. auch vom Punkt x0 ab.
Beispiele 11.30. (S. Bsp. 11.26)
❶ Polynome, rationale Funktionen und Wurzelfunktionen sind in jedem Punkt ihres Definitionsbe-reiches stetig.
❷ Der Absolutbetrag ist stetig in jedem Punkt in R.
❸ Die Heavysidesche Sprungfunktion ist an der Stelle x0 = 0 rechtsseitig, aber nicht linksseitig stetig.In allen anderen Punkten ist sie stetig.
❹ Die Vorzeichenfunktion ist an der Stelle x0 = 0 weder links- noch rechtsseitig stetig. In allenanderen Punkten ist sie stetig.
❺ Die untere Gaußklammer ist in jedem Punkt x0 ∈ R \ Z stetig. An einer Stelle x0 ∈ Z ist sierechtsseitig, aber nicht linksseitig stetig.
❻ Die Dirichlet-Funktion ist nirgendwo stetig.
Der folgende Satz ergibt sich unmittelbar aus den Rechenregeln fur Grenzwerte bzw. der Definitionvon Stetigkeit.
Satz 11.31. Stetigkeit und algebraische Rechenoperationen: Es seien f : Df → R und g :Dg → R stetige Funktionen und λ ∈ R. Dann sind die Funktionen
λ · f, f ± g, f · g, f
gund f ◦ g
ebenfalls in ihrem jeweiligen Definitionsbereich stetig (s. Def. 11.10).
Beispiel 11.32. Die Funktion f : R→ R mit x 7→ 3
√∣∣∣sin
(5√
|x|)∣∣∣ ist stetig auf R.
Funktionen, die an einzelnen Stellen x0 ∈ R nicht definiert sind, lassen sich unter bestimmtenUmstanden dort stetig fortsetzen:
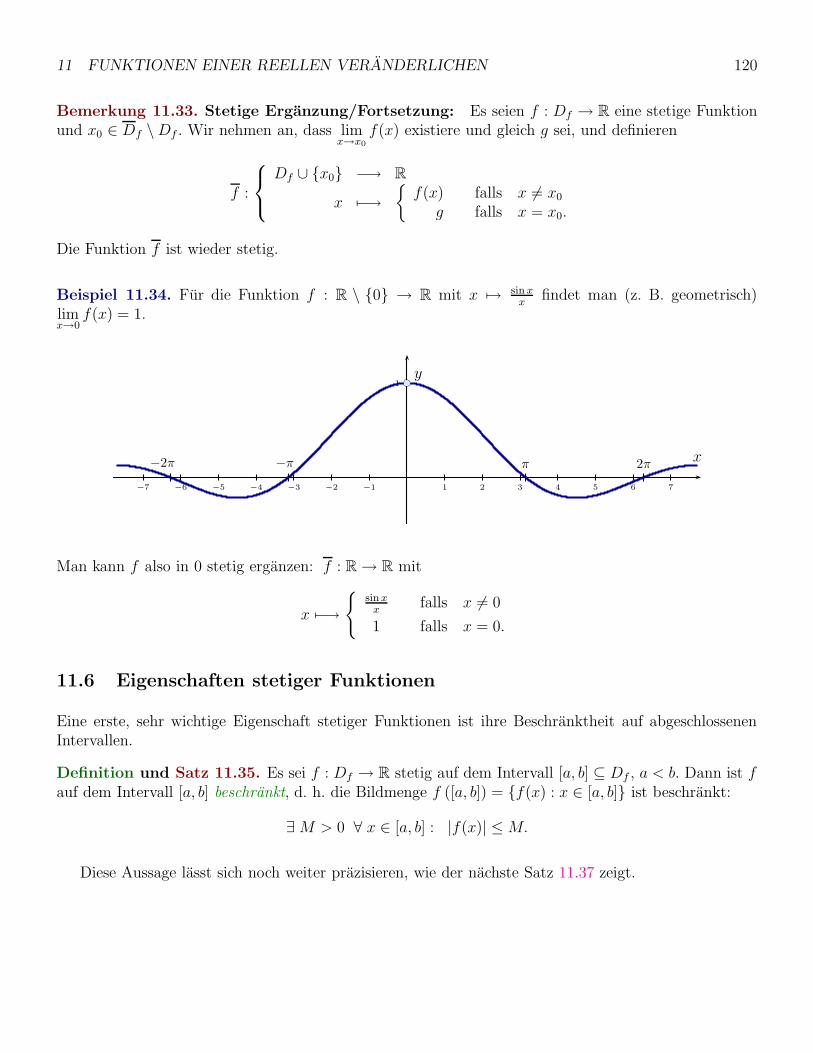
11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 120
Bemerkung 11.33. Stetige Erganzung/Fortsetzung: Es seien f : Df → R eine stetige Funktionund x0 ∈ Df \Df . Wir nehmen an, dass lim
x→x0
f(x) existiere und gleich g sei, und definieren
f :
Df ∪ {x0} −→ R
x 7−→{f(x) falls x 6= x0
g falls x = x0.
Die Funktion f ist wieder stetig.
Beispiel 11.34. Fur die Funktion f : R \ {0} → R mit x 7→ sin xx
findet man (z. B. geometrisch)limx→0
f(x) = 1.
π−π 2π−2π
1 2 3 4 5 6 7−1−2−3−4−5−6−7
1
x
y
Man kann f also in 0 stetig erganzen: f : R→ R mit
x 7−→{
sinxx
falls x 6= 0
1 falls x = 0.
11.6 Eigenschaften stetiger Funktionen
Eine erste, sehr wichtige Eigenschaft stetiger Funktionen ist ihre Beschranktheit auf abgeschlossenenIntervallen.
Definition und Satz 11.35. Es sei f : Df → R stetig auf dem Intervall [a, b] ⊆ Df , a < b. Dann ist fauf dem Intervall [a, b] beschrankt, d. h. die Bildmenge f ([a, b]) = {f(x) : x ∈ [a, b]} ist beschrankt:
∃M > 0 ∀ x ∈ [a, b] : |f(x)| ≤M.
Diese Aussage lasst sich noch weiter prazisieren, wie der nachste Satz 11.37 zeigt.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 121
Definition 11.36. Es sei f : Df → R eine reelle Funktion. Die Funktion f hat im Punkt x0 ∈ Df
a) ein globales (absolutes) Maximum, wenn f (x0) das maximale Element der WertemengeWf := f (Df ) von f ist, d. h.
f (x0) = max {f(x) : x ∈ Df} ⇐⇒ f (x0) ≥ f(x) fur alle x ∈ Df .
b) ein globales (absolutes) Minimum, wenn f (x0) das minimale Element der WertemengeWf := f (Df ) von f ist, d. h.
f (x0) = min {f(x) : x ∈ Df} ⇐⇒ f (x0) ≤ f(x) fur alle x ∈ Df .
Man sagt auch, die Funktion f nimmt an der Stelle x0 ihr Maximum bzw. Minimum an.Der Oberbegriff fur Maximum und Minimum einer Funktion ist Extremum.Der Punkt x0 ∈ Df wird oft Maximal- bzw. Minimalstelle und der Funktionswert f (x0) Maximal- bzw.Minimalwert genannt.
Satz 11.37. Extremalsatz:Es sei f : Df → R stetig auf dem Intervall [a, b] ⊆ Df , a < b. Dann nimmt f auf [a, b] sein globalesMinimum und sein globales Maximum an, d. h.:Es gibt zwei Punkte xm, xM ∈ [a, b] mit
f (xm) ≤ f(x) ≤ f (xM )
fur alle x ∈ [a, b].
Bemerkungen.
• Die Extremalstellen xm, xM ∈ [a, b] mussen nicht eindeutig festgelegt sein. In Satz 11.37 wird nurdie Existenz mindestens eines solchen Paares behauptet.Z. B. nimmt die Funktion cos x im Intervall [−nπ, nπ], n ∈ N, ihr Minimum in den Punktenxj
m := (2j + 1)π und ihr Maximum in den Punkten xjM := 2jπ, j ∈ Z, an.
• Die Aussage von Satz 11.37 ist fur (halb)offene Intervalle falsch. Man betrachte z. B. f : (0, 1]→ R
mit x 7→ 1x.
Und jetzt besprechen wir weitere Eigenschaften stetiger Funktionen.
Lemma 11.38. Die Funktion f : Df → R sei stetig, und x0 ∈ Df sei ein Punkt mit f (x0) > 0. Danngibt es eine δ–Umgebung Uδ (x0) von x0, auf der auch f(x) > 0 gilt.
Genauso gilt f(x) < 0 in einer Umgebung von x0, wenn f (x0) < 0 ist, und beides zusammen ergibtf(x) 6= 0 in einer Umgebung von x0, wenn f (x0) 6= 0 ist.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 122
Eine Folgerung aus Lemma 11.38 ist der fundamentale
Satz 11.39. Nullstellensatz von Bolzano:Es sei f : Df → R stetig auf dem Intervall [a, b] ⊂ Df , a < b, mit f(a) · f(b) < 0 (d. h. entwederf(a) < 0 < f(b) oder f(a) > 0 > f(b)).
Dann besitzt f mindestens eine Nullstelle in (a, b), d. h.: es gibt einen Punkt x0 ∈ (a, b), so dassf (x0) = 0.
Bemerkung. Fur unstetige Funktionen ist Satz 11.39 i. a. falsch.
Z. B. es sei f(x) := h(x)− 12, x ∈ [−1, 1], wobei h die Heavysidesche Sprungfunktion ist. Die Bedingung
f(−1) · f(1) < 0 ist zwar erfullt, aber f hat im Intervall (−1, 1) keine Nullstellen.
Folgerung 11.40.
• Jedes Polynom ungeraden Grades p : R→ R mit
p(x) =2N+1∑
n=0
anxn, N ∈ N, und a2N+1 6= 0
(z. B. p(x) = x3 + x2 + x+ 1) hat mindestens eine Nullstelle in R.
• Besitzt die Gleichungx = 2 sin x mit x > 0
eine Losung? Wir definierenf(x) := x− 2 sin x, x > 0.
Die Funktion f ist stetig, und es ist f(
π2
)= π
2−2 < 0 und f(π) = π > 0. Nach dem Nullstellensatz
hat f mindestens eine Nullstelle im Intervall[
π2, π]. Folglich besitzt die obige Gleichung im Intervall
[π2, π]
mindestens eine Losung.
Satz 11.39 wollen wir im Folgenden noch verallgemeinern:
Satz 11.41. Zwischenwertsatz von Bolzano:Es sei f : Df → R stetig auf dem Intervall [a, b] ⊆ Df ,a < b, und es seien xm eine Minimalstelle undxM eine Maximalstelle von f auf [a, b]. [1ex] Dann nimmt f jeden Wert aus [f (xm) , f (xM)] mindestenseinmal an, d. h.:
Zu jeder Zahl y ∈ [f (xm) , f (xM)] existiert eine Zahl x ∈ [a, b] mit f (x) = y.
Aus diesem Satz folgt, dass der Wertebereich einer auf einem Intervall stetigen Funktion auch einIntervall Wf = [f (xm) , f (xM )] ist.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 123
11.7 Monotone Funktionen
Satz 11.42. Es sei f : [a, b] → R eine stetige und streng monoton wachsende bzw. fallende Funktion.Dann ist Wf := f ([a, b]) ein Intervall ([f(a), f(b)] bzw. [f(b), f(a)]), die Funktion f : [a, b] → f ([a, b])ist bijektiv und die Umkehrfunktion f−1 : f ([a, b])→ [a, b] ist ebenfalls stetig und im gleichen Sinne wief streng monoton.
Beispiel 11.43. Die Potenzfunktionen f : [0,∞) → [0,∞) mit f(x) = xn, n ∈ N sind stetig, strengmonoton wachsend und bilden das Intervall [0, k] mit k ∈ N auf das Intervall [0, kn] ab. Nach demSatz 11.42 gibt es eine stetige und monoton wachsende Umkehrfunktion, die man n-te Wurzelfunktion,notiert als n
√x oder x
1n , nennt.
Lasst man k ∈ N laufen und bildet die Vereinigung [0,∞) aller Intervalle [0, k], so ist die Vereinigungder Bildvereinigung auch wieder die reelle Halbachse [0,∞). Deswegen sind die Funktionen n
√x auf der
gesamten Halbachse definiert und stetig.
11.7.1 Die Exponentialfunktion
In Bemerkung 10.15 wurde die Eulersche Zahl als
e := limn→∞
(
1 +1
n
)n
definiert. Die Eulersche Zahl ist irrational: e = 2,718 281 828 459 . . ..Mit Hilfe des binomischen Satzes kann man auch zeigen, dass e =
∑
n≥0
1n!
(mit dem Quotientenkriterium
kann man zeigen, dass diese Reihe konvergent ist).
Ganzzahlige Potenzen einer reellen Zahl (also auch der Eulerschen Zahl) genugen dem Gesetz
em+n = em · en.
Ist es moglich, die Potenz ex fur reelle Exponenten so zu definieren, dass das Potenzgesetz ex+y = ex · ey
fur beliebige x, y ∈ R erhalten bleibt?
Satz 11.44. Es existiert eine stetige und streng monoton wachsende Funktion, die Exponentialfunktion
exp :
R −→ R
x 7−→∞∑
n=0
xn
n!= 1 + x +
x2
2!+x3
3!+ · · ·
mit folgenden Eigenschaften:
• exp(0) = 1,
• exp(1) = e,
• exp(x+ y) = exp(x) · exp(y) fur alle x ∈ R,

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 124
• exp(−x) =1
exp(x)fur alle x ∈ R,
• exp(x) > 0 fur alle x ∈ R,
• exp(n) = en fur alle n ∈ N und sogar exp(r) = er fur alle r ∈ Q,
• limx→+∞
exp x = +∞, limx→−∞
exp x = 0,
limx→+∞
exp x
xn=∞, lim
x→+∞xn · exp(−x) = 0 fur alle n ∈ N.
Wenn x ∈ R \ Q, existiert eine Folge (xn)n∈N⊂ Q mit lim
n→∞xn = x. Wegen der Stetigkeit der
Exponentialfunktion istexp(x) = lim
n→∞exp (xn) = lim
n→∞exn.
Also ist es sinnvoll, exp(x) auch fur x ∈ R \Q mit ex zu bezeichnen.
11.7.2 Die Logarithmusfunktion
Die Exponentialfunktion exp : R → R ist stetig und streng monoton wachsend. Nach Satz 11.42 bildetsie die reelle Achse R bijektiv auf die reelle Halbachse (0,∞) ab, d. h. Wexp = (0,∞), und hat einestetige und streng monoton wachsende Umkehrfunktion.
Definition 11.45. Die Umkehrfunktion der Exponentialfunktion nennt man naturlichen Logarithmus:
ln :
{(0,∞) −→ R
x 7−→ ln x.
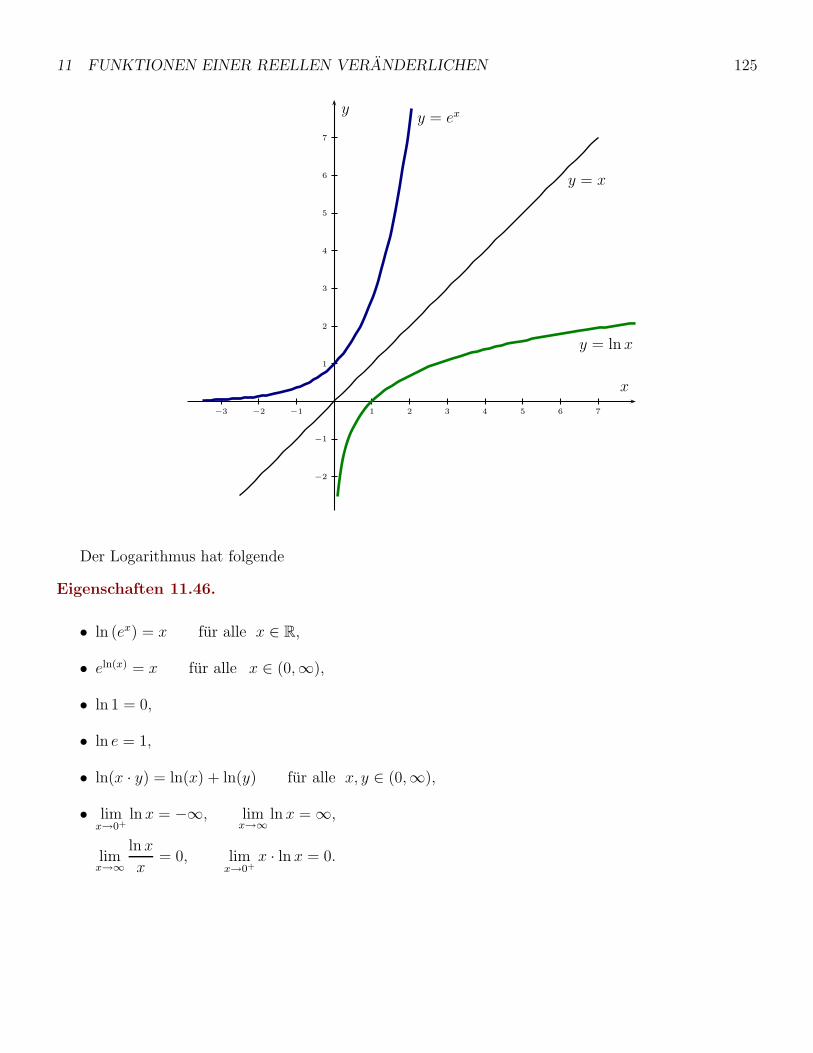
11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 125
1 2 3 4 5 6 7−1−2−3
1
2
3
4
5
6
7
−1
−2
x
yy = ex
y = ln x
y = x
Der Logarithmus hat folgende
Eigenschaften 11.46.
• ln (ex) = x fur alle x ∈ R,
• eln(x) = x fur alle x ∈ (0,∞),
• ln 1 = 0,
• ln e = 1,
• ln(x · y) = ln(x) + ln(y) fur alle x, y ∈ (0,∞),
• limx→0+
ln x = −∞, limx→∞
ln x =∞,
limx→∞
ln x
x= 0, lim
x→0+x · ln x = 0.

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 126
11.7.3 Allgemeine Exponential- und Logarithmusfunktionen
Wir haben die Exponentialfunktion und den Logarithmus auf die Zahl e als Basis, die sogenanntenaturliche Basis bezogen. Der Ubergang von der Basis e zu einer beliebigen anderen positiven Zahla > 0 laßt sich leicht vollziehen. Wir gehen aus von der Eigenschaft aus dem vorangehenden Satz:
eln(a) = a fur jede reelle Zahl a > 0.
Nun definieren wir die Exponentialfunktion ax zur Basis a > 0 durch den Ausdruck
ax := ex·ln(a) = exp (x · ln a) .
eln(a) = a fur jede reelle Zahl a > 0.
Insbesondere ist
• a0 = e0·ln(a) = 1,
• a1 = e1·ln a = a,
• ax+y = ax · ay fur alle x ∈ R,
• (a · b)x = ax · bx fur alle x ∈ R und b > 0,
• a−x = e−x·lna =1
ex·lna=
1
axfur alle x ∈ R,
• ax > 0 fur alle x ∈ R.
1 2 3−1−2−3
1
2
3
4
5
6
7
x
y10x ex 2x
(12
)x
1x

11 FUNKTIONEN EINER REELLEN VERANDERLICHEN 127
Bemerkungen.
• Fur alle x ∈ R gilt 1x = 1.
• Das Monotonieverhalten der Funktion ax sowie ihr Verhalten im Unendlichen hangt davon ab, oba < 1 oder a > 1 ist.
• Fur naturliche Zahlen n ∈ N haben wir an auf zwei Weisen definiert:
an := a · . . . · a︸ ︷︷ ︸
n−mal
oder an := exp (n · ln a) .
Beide Definitionen stimmen aber uberein. Das zeigt man genauso wie fur den Spezialfall a = e.
Die allgemeine Logarithmusfunktion loga zur Basis a > 0 und a 6= 1 ist definiert durch
loga x :=ln x
ln a.
Damit wirdaloga x = eloga x·lna = e
ln xlna
·ln a = eln x = x.
Die Funktion loga x ist also die Umkehrfunktion zu ax.
1 2 3 4 5 6 7 8
1
2
3
−1
−2
−3
x
y
log10 x
ln x
log2 x
log 12x
Viele bekannte Funktionen konnen durch Reihen definiert werden.
Beispiele 11.47.
❶
sin x =∑
n≥0
(−1)n x2n+1
(2n+ 1)!,
❷
cos x =∑
n≥0
(−1)n x2n
(2n)!.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 128
12 Differentialrechnung fur Funktionen einer reellen Variab-
len
12.1 Der Ableitungsbegriff
Definition 12.1. Gegeben seien eine reelle Funktion
f :
{Df −→ R
x 7−→ f(x)
und x0 ∈ D◦f .
a) Die Funktion f heißt differenzierbar in einem Punkt x0 ∈ D◦f genau dann, wenn der Grenzwert
limh→0
f (x0 + h)− f (x0)
h,
(h 6= 0 und x0 + h ∈ Df), in R existiert.In diesem Fall nennt man diesen Grenzwert Differentialquotient oder Ableitung von f im Punktx0 und bezeichnet ihn mit f ′ (x0).Der Ausdruck
∆f,x0(h) :=f(x0 + h)− f(x0)
h
heißt Differenzen–Quotient von f zwischen x0 und x0 + h.
b) Die Funktion f heißt differenzierbar auf ihrem Definitionsbereich Df genau dann, wenn Df offenist und wenn f in jedem Punkt von Df differenzierbar ist.In diesem Fall heißt die Funktion
f ′ :
{Df −→ R
x 7−→ f ′(x)
die (erste) Ableitung von f in Df .
Bemerkung 12.2. Der Differenzen-Quotient gibt die durchschnittliche Anderungsrate von f zwischenden Punkten (x0, f (x0)) und (x0 + h, f (x0 + h)) an.
Dieser Differenzen-Quotient hat einegeometrische Bedeutung:
Er ist die Steigung der Geraden durchdie beiden Punkten (x0, f (x0)) und(x0 + h, f (x0 + h)) auf dem Funktions-graphen. Diese Gerade ist eine Sekantedes Funktionsgraphen.
x
y
x0 x0 + h
(x0, f (x0))
(x0 + h, f (x0 + h))
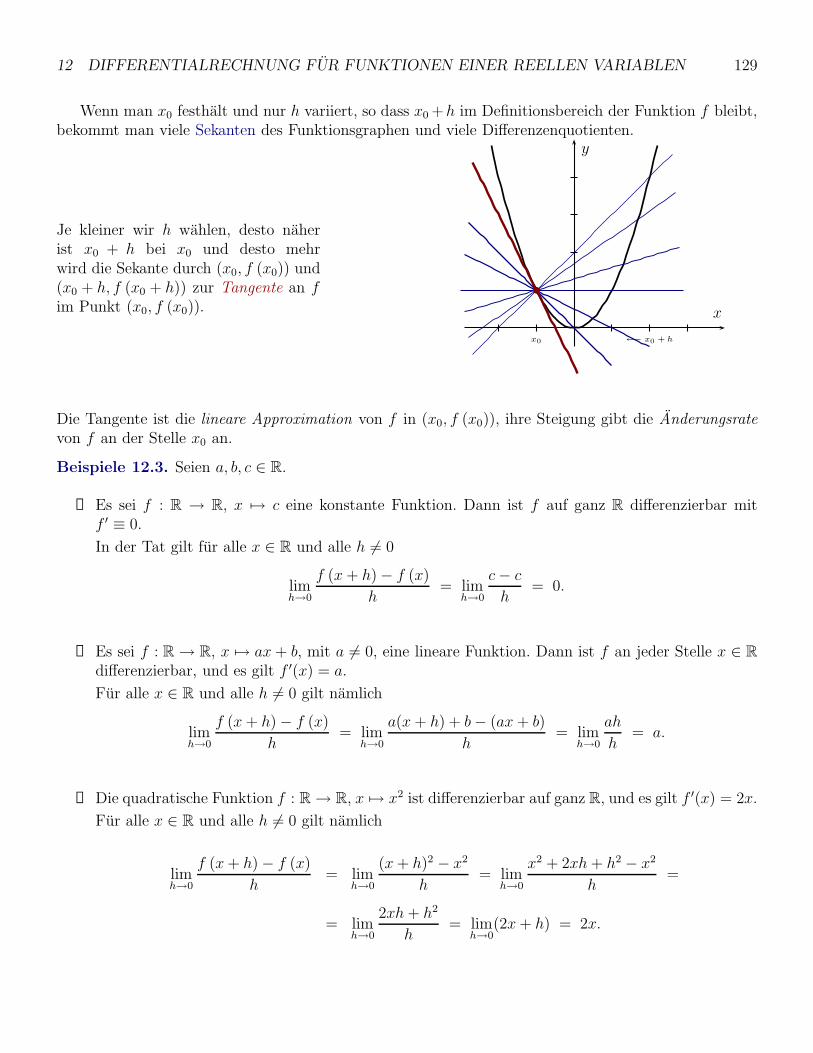
12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 129
Wenn man x0 festhalt und nur h variiert, so dass x0 +h im Definitionsbereich der Funktion f bleibt,bekommt man viele Sekanten des Funktionsgraphen und viele Differenzenquotienten.
Je kleiner wir h wahlen, desto naherist x0 + h bei x0 und desto mehrwird die Sekante durch (x0, f (x0)) und(x0 + h, f (x0 + h)) zur Tangente an f
im Punkt (x0, f (x0)). x
y
x0 ←− x0 + h
Die Tangente ist die lineare Approximation von f in (x0, f (x0)), ihre Steigung gibt die Anderungsratevon f an der Stelle x0 an.
Beispiele 12.3. Seien a, b, c ∈ R.
❶ Es sei f : R → R, x 7→ c eine konstante Funktion. Dann ist f auf ganz R differenzierbar mitf ′ ≡ 0.
In der Tat gilt fur alle x ∈ R und alle h 6= 0
limh→0
f (x+ h)− f (x)
h= lim
h→0
c− ch
= 0.
❷ Es sei f : R→ R, x 7→ ax+ b, mit a 6= 0, eine lineare Funktion. Dann ist f an jeder Stelle x ∈ R
differenzierbar, und es gilt f ′(x) = a.
Fur alle x ∈ R und alle h 6= 0 gilt namlich
limh→0
f (x+ h)− f (x)
h= lim
h→0
a(x+ h) + b− (ax+ b)
h= lim
h→0
ah
h= a.
❸ Die quadratische Funktion f : R→ R, x 7→ x2 ist differenzierbar auf ganz R, und es gilt f ′(x) = 2x.
Fur alle x ∈ R und alle h 6= 0 gilt namlich
limh→0
f (x+ h)− f (x)
h= lim
h→0
(x+ h)2 − x2
h= lim
h→0
x2 + 2xh+ h2 − x2
h=
= limh→0
2xh+ h2
h= lim
h→0(2x+ h) = 2x.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 130
❹ Wir betrachten die rationale Funktion f : R\{0} → R, x 7→ 1x. Diese Funktion ist uberall in ihrem
Definitionsbereich differenzierbar, und die Ableitung ist f ′ : R \ {0} → R, x 7→ − 1x2 .
Fur x, h ∈ R \ {0} gilt
limh→0
f (x+ h)− f (x)
h= lim
h→0
1x+h− 1
x
h= lim
h→0
1
h·(
1
x+ h− 1
x
)
=
= limh→0
1
h· x− (x+ h)
x(x+ h)= − lim
h→0
1
x2 + xh= − 1
x2.
❺ Die Wurzelfunktion f : [0,∞) → R ist auf (0,∞) differenzierbar, und die Ableitung istf ′ : (0,∞)→ R, x 7→ 1
2√
x.
Fur alle x ∈ (0,∞) und alle h 6= 0 gilt namlich
limh→0
f (x+ h)− f (x)
h= lim
h→0
√x+ h−√xx+ h− x =
= limh→0
√x+ h−√x
(√x+ h+
√x)·(√
x+ h−√x) =
= limh→0
1√x+ h +
√x
=1
2√x.
❻ Der Absolutbetrag f : R→ R, x 7→ |x| ist an der Stelle 0 nicht differenzierbar. In jedem anderenPunkt ist der Betrag differenzierbar. Die Ableitung ist die Funktion
f ′ :
R \ {0} −→ R
x 7−→ sgn (x) =
{
1 falls x > 0,−1 falls x < 0.
Fur x = 0 und h ∈ R \ {0} gilt
|0 + h| − |0|h
=|h|h
=
{
1 falls h > 0,−1 falls h < 0
d. h.
limh→0+
|h|h
= 1 und limh→0−
|h|h
= −1.
Folglich existiert der Grenzwert limh→0
|0 + h| − |0|h
nicht.
Satz 12.4. Die Funktion f : Df → R sei in x0 ∈ Df differenzierbar. Dann ist sie in x0 stetig.
Die Umkehrung dieses Satzes gilt nicht: eine stetige Funktion braucht nicht differenzierbar zu sein.Das Standardbeispiel dafur ist die Betragsfunktion (s. Bsp. 12.3 f).

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 131
12.2 Ableitungsregeln
An den vorangegangenen Beispielen 12.3 haben wir gesehen, dass die Berechnung der Ableitung unterVerwendung der Definition 12.1 ein recht muhsamer Prozess ist. Nur in den einfachsten Fallen kannman die entsprechende Grenzwerte elementar berechnen. Wir werden deshalb in diesem Abschnitt eineReihe von Ableitungsregeln bereitstellen, mit deren Hilfe in der Praxis die kompliziertere Funktionendifferenziert werden konnen.
Satz 12.5. Seien f : Df → R und g : Dg → R zwei reelle Funktionen, und x0 ∈ Df ∩Dg sei ein Punkt,in dem sowohl f als auch g differenzierbar sind. Dann gilt:
a) Faktorregel:Fur jede reelle Zahl λ ist λ · f in x0 differenzierbar, und es gilt
(λ · f)′ (x0) = λ · (f ′ (x0)) .
b) Summenregel:Die Summe f + g ist in x0 differenzierbar, und es gilt
(f + g)′ (x0) = f ′ (x0) + g′ (x0) .
c) Produktregel:Das Produkt f · g ist in x0 differenzierbar, und es gilt
(f · g)′ (x0) = f ′ (x0) · g (x0) + f (x0) · g′ (x0) .
d) Quotientenregel:Ist g (x0) 6= 0, so ist der Quotient f
gin x0 differenzierbar, und es gilt
(f
g
)′(x0) =
f ′ (x0) · g (x0)− f (x0) · g′ (x0)
(g (x0))2 .
Behandeln wir einige Beispiele:
Beispiele 12.6.
❶ Fur n ∈ N ist die Funktion f : R → R, x 7→ xn auf ganz R differenzierbar mit Ableitungf ′(x) = nxn−1.
Fur n = 1 und n = 2 siehe Beispiel 12.3 b), c).

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 132
Nehmen wir an, dass fur n = k die Ableitung f ′(x) = kxk−1 ist.Sei jetzt n = k + 1, dann
f ′(x) =(xk+1
)′=(xk · x
)′ Produktregel=
(xk)′ · x + xk · (x)′ =
= kxk−1 · x + xk · 1 = (k + 1) · xk.
❷ Es sei p : R→ R, x 7→n∑
i=0
aixi ein Polynom mit an 6= 0.
Mit der Faktorregel und der Summenregel folgt, dass p uberall differenzierbar ist mit Ableitung
p′ : R→ R, x 7→n∑
i=1
iaixi−1.
❸ Es sei f : R \ {0} → R, x 7→ 1xn mit n ∈ N eine rationale Funktion.
Nach der Quotientenregel ist f in jedem Punkt x 6= 0 differenzierbar mit
f ′(x) = − n · xn−1
x2n= −n 1
xn+1.
Satz 12.7. Die Exponentialfunktion ist auf ganz R differenzierbar, und es gilt:
exp′(x) = exp(x), bzw. (ex)′ = ex,
fur alle x ∈ R.
Satz 12.8. Kettenregel:Es seien f : Df → R und g : Dg → R zwei reellen Funktionen, und x0 ∈ Df◦g. Sind g in x0 und f ing (x0) differenzierbar, so ist die zusammengesetzte Funktion f ◦ g in x0 differenzierbar mit
(f ◦ g)′ (x0) = f ′ (g (x0)) · g′ (x0) .
In der Praxis wird man eine gegebene Funktion h erst in der Form f ◦ g schreiben mussen, um dieKettenregel anwenden zu konnen.
Beispiele 12.9.
❶ Wir betrachten die Funktion h : R→ R, x 7→ (x3 − 2x2 + 4x− 3)2. Wir schreiben sie in der Form
f ◦ g, wobei g(x) = x3 − 2x2 + 4x − 3 und f(y) = y2. Die Funktionen g und f , als Polynome,sind differenzierbar mit Ableitungen g′(x) = 3x2− 4x+ 4 und f ′(y) = 2y. Daraus folgt, dass (mity = g(x))
h′(x) = (f ◦ g)′(x) = f ′ (g(x)) · g′(x) = 2g(x) · (3x2 − 4x+ 4) =
= 2 (x3 − 2x2 + 4x− 3) · (3x2 − 4x+ 4) =
= 6x5 − 20x4 + 48x3 − 50x2 + 56x− 24.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 133
❷ Wir betrachten jetzt die Funktion h : R → R, x 7→ ex2, die man als Verkettung der Funktion
g(x) = x2 und der Funktion f(y) = ey schreiben kann. Folglich
h′(x) = (f ◦ g)′(x) = f ′ (g(x)) · g′(x) = eg(x) · 2x = ex2 · 2x.
❸ ☞ In der Vorlesung!
Satz 12.10. Ableitung der Umkehrfunktion:Es seien f : Df → R eine stetige und streng monotone Funktion und f−1 : Wf → R ihre Umkehr-funktion. Ist die Funktion f im Punkt x0 ∈ Df differenzierbar mit Ableitung f ′ (x0) 6= 0, dann ist dieUmkehrfunktion f−1 in y0 := f (x0) differenzierbar mit
(f−1)′
(y0) =1
f ′ (x0)=
1
(f ′ ◦ f−1) (y0).
Beispiele 12.11.
❶ Die Exponentialfunktion exp ist auf ganz R differenzierbar, und ihre Ableitung exp ist immergroßer Null. Daher ist die Umkehrfunktion ln : (0,∞)→ R uberall differenzierbar, und es gilt
ln′(x) =1
(exp ◦ ln)(x)=
1
x.
Analog kann man die Ableitung der allgemeinen Logarithmusfunktionen x 7→ loga x, a ∈ (0, 1) ∪(1,∞), (s. Abschnitt 11.7.3) berechnen.
❷ Sei n ∈ N \ {0}. Die Funktion f : R → R, x 7→ xn ist auf ganz R differenzierbar, und Ableitungist f ′(x) = nxn−1 6= 0 fur x 6= 0. Ihre Umkehrfunktion f−1 : [0,∞) → R, x 7→ n
√x ist daher auf
(0,∞) differenzierbar, und
(f−1)′
(x) =1
(f ′ ◦ f−1) (x)=
1
f ′ ( n√x)
=1
n ( n√x)
n−1 =1
nx1− 1n
=1
nx
1n−1.
Fur n = 2 erhalt man wieder (s. Bsp. 12.3 e) die Ableitung der quadratischen Wurzelfunktion
(√x)′
=1
2x
12−1 =
1
2√x.
❸ ☞ In der Vorlesung!

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 134
Fassen wir alle Ableitungen, die wir berechnet haben, noch einmal ubersichtlich zusammen:
Tabelle von Ableitungen einiger wichtiger Funktionen:
f f ′
x 7→ a, a ∈ R x 7→ 0
xr, r ∈ R \ {0} rxr−1
ex ex
ax, a ∈ R, a > 0 ax · ln a
ln x, x > 0 1x
loga x, a ∈ (0, 1) ∪ (1,∞), x > 0 1x ln a
sin x cosx
cosx − sin x
tan x, x 6= π2
+ kπ, k ∈ Z 1cos2 x
cot x, x 6= kπ, k ∈ Z −1sin2 x
12.3 Hohere Ableitungen
Ist die Funktion f : Df → R in Df differenzierbar, so wird durch
Df ∋ x 7−→ f ′(x) ∈ R
eine neue Funktion f ′, die Ableitung von f , definiert.Wenn f ′ an der Stelle x0 ∈ Df differenzierbar ist, lasst sich die zweite Ableitung
f ′′ (x0) := (f ′)′(x0)
bilden. Existiert diese fur jedes x0 ∈ Df , so ist auch f ′′ : Df → R eine Funktion. Auf diese Weise kannman auch dritte und hohere Ableitungen definieren.
Definition 12.12. Sei f : Df → R eine reelle Funktion und sei n ∈ N.
a) Die Funktion f heißt (n+ 1)-mal an der Stelle x ∈ Df differenzierbar, wenn
• f in einer Umgebung von x n-mal differenzierbar ist und
• f (n) in x differenzierbar ist.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 135
Wir setzenf (n+1) (x) :=
(f (n)
)′(x) .
Existiert diese fur alle x ∈ Df , so definieren wir die (n + 1)-te Ableitung von f als die Funktion
f (n+1) :
{Df −→ R,
x 7−→ f (n+1)(x).
b) Die Funktion f heißt stetig differenzierbar in Df genau dann, wenn die Funktion f differenzierbarist und die Ableitung f ′ stetig in Df ist.
c) Die Funktion f heißt n-mal (stetig) differenzierbar in Df genau dann, wenn die n-te Ableitungvon f existiert und stetig ist.
Beispiele 12.13.
❶ Die konstante Funktion ist beliebig oft differenzierbar, und alle Ableitungen sind identisch Null.
❷ In Bsp. 12.3 haben wir gezeigt, dass die lineare Funktion f : R → R, x 7→ ax + b differenzierbarist mit Ableitung f ′(x) = a. Wegen a) ist f beliebig oft differenzierbar und f (n) ≡ 0 fur n ≥ 2.
❸ Genauso kann man zeigen, dass quadratische Funktionen beliebig oft differenzierbar sind und ihreAbleitungen ab Ordnung 3 identisch verschwinden.Allgemein, ist f : R → R ein Polynom vom Grad n, so ist f beliebig oft differenzierbar undf (n+1) ≡ 0.
❹ In Bsp. 12.3 haben wir auch gezeigt, dass die Funktion f : R \ {0} → R, x 7→ 1x
differenzierbar istmit Ableitung f ′(x) = − 1
x2 .Mit der Quotientenregel erhalt man, dass f beliebig oft differenzierbar ist und alle Ableitungennicht trivial sind.
Bemerkung: Im Allgemeinen folgt aus der Differenzierbarkeit einer Funktion f : Df → R nicht, dassdie Ableitung f ′ : Df → R wieder differenzierbar und/oder stetig ist.
Fur k ∈ N0 betrachten wir die Funktion fk : R −→ R mit
fk(x) =
{
xk · sin 1x
falls x 6= 0
0 falls x = 0.
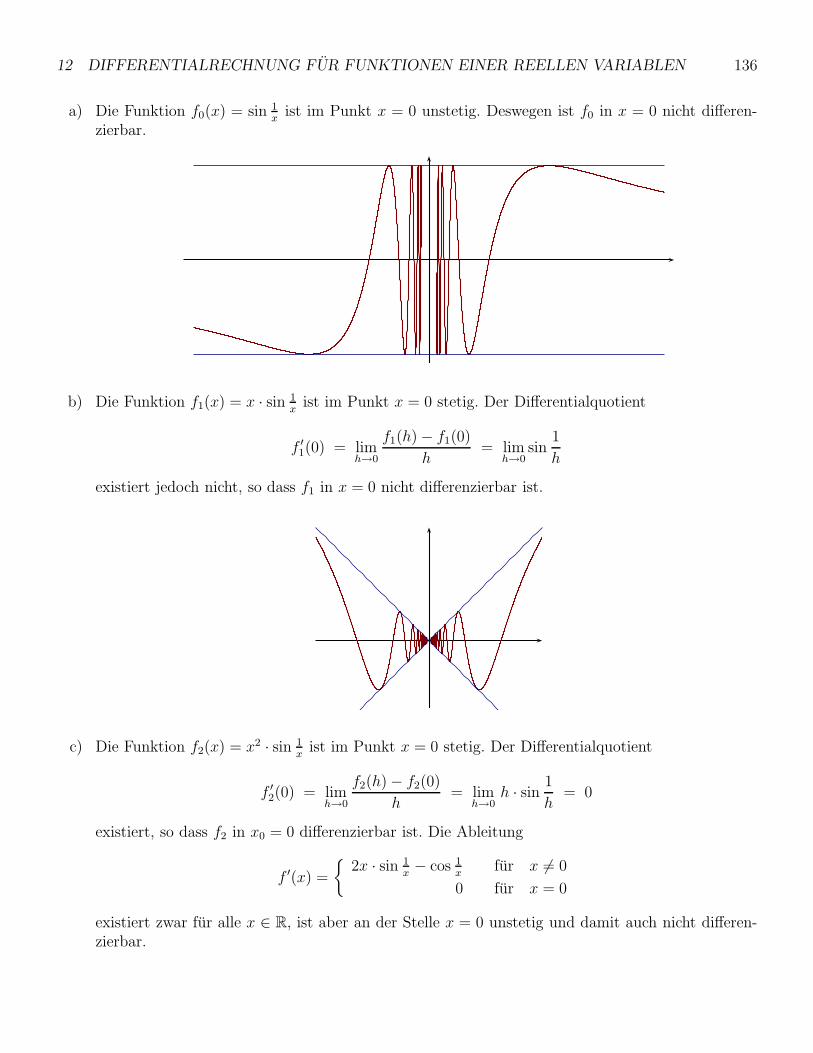
12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 136
a) Die Funktion f0(x) = sin 1x
ist im Punkt x = 0 unstetig. Deswegen ist f0 in x = 0 nicht differen-zierbar.
b) Die Funktion f1(x) = x · sin 1x
ist im Punkt x = 0 stetig. Der Differentialquotient
f ′1(0) = lim
h→0
f1(h)− f1(0)
h= lim
h→0sin
1
h
existiert jedoch nicht, so dass f1 in x = 0 nicht differenzierbar ist.
c) Die Funktion f2(x) = x2 · sin 1x
ist im Punkt x = 0 stetig. Der Differentialquotient
f ′2(0) = lim
h→0
f2(h)− f2(0)
h= lim
h→0h · sin 1
h= 0
existiert, so dass f2 in x0 = 0 differenzierbar ist. Die Ableitung
f ′(x) =
{2x · sin 1
x− cos 1
xfur x 6= 0
0 fur x = 0
existiert zwar fur alle x ∈ R, ist aber an der Stelle x = 0 unstetig und damit auch nicht differen-zierbar.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 137
12.4 Ableitungen und Grenzwerte
Im Abschnitt 11.4 haben wir schon erwahnt, dass bei der Berechnung von Grenzwerten u. a. die Quoti-entenregel
limx→x0
f(x)
g(x)=
limx→x0
f(x)
limx→x0
g(x)
hilfreich ist. Aber diese Regel kann man nicht benutzen, falls beide Funktionen f und g fur x → x0
gleichzeitig gegen 0 bzw. gegen ±∞ streben. In diesen Fallen erhalt man formal einen unbestimmtenAusdruck
[00
]bzw.
[∞∞].
Genauso kann man nicht die Produktregel
limx→x0
f(x) · g(x) = limx→x0
f(x) · limx→x0
g(x)
benutzen, wenn eine Funktion gegen 0 und die andere gegen ±∞ strebt.Aber auch Grenzwerte wie lim
x→x0
f(x)g(x), wenn z. B. fur x→ x0 beide Funktionen f und g gegen 0 oder
f gegen 1 und g gegen ±∞ streben, sind interessant.
Man hat allgemein die folgenden Typen von unbestimmten Ausdrucken vorliegen:
[0
0
]
,[∞∞]
, [0 · ∞] , [∞−∞] ,[00], [1∞] ,
[∞0].
Mit Hilfe des unten dargestellten Satzes ist in den beiden ersten Fallen eine einfache Losung desProblems moglich. Die anderen Falle lassen sich auf diese zuruckfuhren.
Satz 12.14. Die Regel von de l’Hospital:Es seien f, g : D → R zwei in einer Umgebung (a, b) \ {x0} von x0 ∈ D differenzierbare Funktionengegeben mit g′(x) 6= 0 fur alle x ∈ (a, b) \ {x0}. Weiter gelte einer der beiden Falle:
limx→x0
f(x) = 0 und limx→x0
g(x) = 0

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 138
oderlim
x→x0
f(x) = ±∞ und limx→x0
g(x) = ±∞.
Wenn der (eigentliche oder uneigentliche) Grenzwert limx→x0
f ′(x)g′(x)
existiert, dann existiert auch der Grenz-
wert limx→x0
f(x)g(x)
, und es gilt:
limx→x0
f(x)
g(x)= lim
x→x0
f ′(x)
g′(x).
Im Satz 12.14 sind auch x0 = a oder x0 = b (einseitige Grenzwerte) zugelassen, ebenso x0 = a = −∞bzw. x0 = b = +∞ (wenn D nach unten bzw. nach oben unbeschrankt ist).
Beispiele 12.15.
❶ Wir wollen den Grenzwert
limx→0
sin x
x.
berechnen. Dazu wahlen wir f, g : R → R mit f(x) = sin x und g(x) = x. Weil die Funktionen f
und g stetig sind, gilt
limx→0
f(x) = f(0) = sin(0) = 0 und limx→0
g(x) = g(0) = 0.
Die Funktionen f und g sind auch differenzierbar mit f ′(x) = cos x und g′(x) = 1 6= 0. Folglich istder Satz von de l’Hospital anwendbar und
limx→0
sin x
x= lim
x→0
cosx
1= 1.
❷ Jetzt wollen wir
limx→0
ex − 1
x
berechnen. Dazu wahlen wir f(x) = ex − 1 und g(x) = x. Es gilt also
limx→0
f(x) = f(0) = e0 − 1 = 0 und limx→0
g(x) = limx→0
x = 0.
Die Funktionen f und g sind differenzierbar mit f ′(x) = ex und g′(x) = 1 6= 0.Es folgt
limx→0
ex − 1
x= lim
x→0
ex
1= e0 = 1.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 139
❸ Manchmal muss man eine gegebene Funktion erst als Quotienten schreiben, damit man den Satzvon de l’Hospital anwenden kann.
Es ist der Grenzwert
limx→0+
xn ln(x) = limx→0+
ln(x)
x−n
fur n ∈ N zu berechnen. Leitet man jetzt Zahler und Nenner getrennt ab, so folgt:
limx→0+
ln(x)
x−n= lim
x→0
1x
−nx−n−1= lim
x→0−1
nxn = 0.
❹ Es kann auch vorkommen, dass man den Satz von de l’Hospital mehrmals hintereinander anwendenmuss (sofern die erforderlichen Voraussetzungen erfullt sind):
limx→∞
xn
exp(x)= lim
x→∞
nxn−1
exp(x)= lim
x→∞
n(n− 1)xn−2
exp(x)= . . . = lim
x→∞
n!
exp(x)= 0.
❺ Etwas schwieriger ist schon
limx→0
(1 + x)1x = lim
x→0e(
1x·ln(1+x)).
Mit dem Satz von de l’Hospital sehen wir
limx→0
ln(1 + x)
x= lim
x→0
11+x
1= 1,
und weil die Exponentialfunktion stetig ist, ist
limx→0
e(1x·ln(1+x)) = e1 = e.
Aus diesem Resultat folgt naturlich auch (fur x = 1n) die Formel
limn→∞
(
1 +1
n
)n
= e,
die wir schon in Bemerkung 10.15 gesehen haben.
12.5 Extremwerte und Monotonie
Nach dem Extremalsatz 11.37 besitzt eine stetige reelle Funktion f auf einem beschrankten, abgeschlos-senen Interval [a, b] immer ein (globales) Maximum f (xM) = max{f(x) : x ∈ [a, b]} und ein (globales)Minimum f (xm) = min{f(x) : x ∈ [a, b]} (fur Definition von globalen Extremwerten s. Def. 11.36).Naturlich ist hiermit nichts daruber ausgesagt, wie man die Extremalstellen finden kann und wie derGraph Γf zwischen diesen beiden Punkten verlauft. Die Funktion braucht insbesondere nicht monotonzu sein.
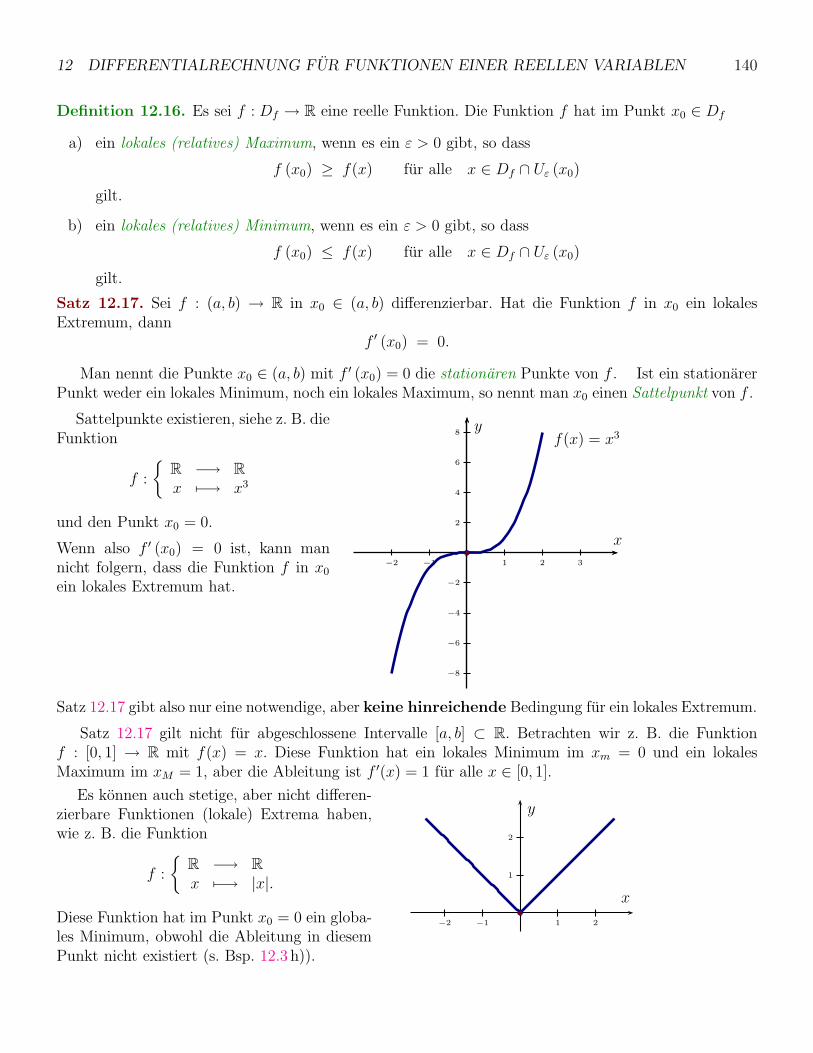
12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 140
Definition 12.16. Es sei f : Df → R eine reelle Funktion. Die Funktion f hat im Punkt x0 ∈ Df
a) ein lokales (relatives) Maximum, wenn es ein ε > 0 gibt, so dass
f (x0) ≥ f(x) fur alle x ∈ Df ∩ Uε (x0)
gilt.
b) ein lokales (relatives) Minimum, wenn es ein ε > 0 gibt, so dass
f (x0) ≤ f(x) fur alle x ∈ Df ∩ Uε (x0)
gilt.
Satz 12.17. Sei f : (a, b) → R in x0 ∈ (a, b) differenzierbar. Hat die Funktion f in x0 ein lokalesExtremum, dann
f ′ (x0) = 0.
Man nennt die Punkte x0 ∈ (a, b) mit f ′ (x0) = 0 die stationaren Punkte von f . Ist ein stationarerPunkt weder ein lokales Minimum, noch ein lokales Maximum, so nennt man x0 einen Sattelpunkt von f .
Sattelpunkte existieren, siehe z. B. dieFunktion
f :
{R −→ R
x 7−→ x3
und den Punkt x0 = 0.
Wenn also f ′ (x0) = 0 ist, kann mannicht folgern, dass die Funktion f in x0
ein lokales Extremum hat.
1 2 3−1−2
2
4
6
8
−2
−4
−6
−8
x
yf(x) = x3
Satz 12.17 gibt also nur eine notwendige, aber keine hinreichende Bedingung fur ein lokales Extremum.
Satz 12.17 gilt nicht fur abgeschlossene Intervalle [a, b] ⊂ R. Betrachten wir z. B. die Funktionf : [0, 1] → R mit f(x) = x. Diese Funktion hat ein lokales Minimum im xm = 0 und ein lokalesMaximum im xM = 1, aber die Ableitung ist f ′(x) = 1 fur alle x ∈ [0, 1].
Es konnen auch stetige, aber nicht differen-zierbare Funktionen (lokale) Extrema haben,wie z. B. die Funktion
f :
{R −→ R
x 7−→ |x|.
Diese Funktion hat im Punkt x0 = 0 ein globa-les Minimum, obwohl die Ableitung in diesemPunkt nicht existiert (s. Bsp. 12.3 h)).
1 2−1−2
1
2
x
y

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 141
Bemerkung. Zur Bestimmung aller Extremwerte einer Funktion f : [a, b]→ R mussen also
• alle Punkte mit f ′ (x0) = 0, x0 ∈ (a, b), und
• die Randpunkte x0 = a und x0 = b, und
• die Punkte, in denen die Funktion nicht differenzierbar ist,
auf das Vorliegen eines Extremums untersucht werden.
max min max sp
Dazu kann zum Beispiel das Monotonieverhalten von f in einer Umgebung von Kandidaten x0 ∈ [a, b]untersucht werden. Wir werden darauf im nachsten Abschnitt zuruckkommen.
12.5.1 Der Mittelwertsatz der Differentialrechnung
Es gibt drei Versionen des Mittelwertsatzes. Die einfachste Version davon ist der folgende Satz, eineFolgerung aus Satz 12.17, der notwendigen Bedingung fur Extremwerte.
Satz 12.18. Satz von Rolle:Sei f : [a, b] → R eine stetige und auf dem offenen Intervall (a, b) differenzierbare Funktion. Wennf(a) = f(b) gilt, dann gibt es mindestens ein x0 ∈ (a, b) mit
f ′ (x0) = 0.f(a) = f(b)
a b

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 142
Satz 12.19. I Mittelwertsatz der Differentialrechnung:Fur jede stetige Funktion f : [a, b]→ R, die auf dem offenen Intervall (a, b) differenzierbar ist, existiertein x0 ∈ (a, b) mit
f ′ (x0) =f(b)− f(a)
b− a .
a b
Der Satz von Rolle ist der Spezialfall f(a) = f(b) des Mittelwertsatzes.
Der Mittelwertsatz besitzt noch eine Verallgemeinerung.
Satz 12.20. II Mittelwertsatz der Differentialrechnung:Seien f, g : [a, b]→ R zwei stetige und auf dem offenen Intervall (a, b) differenzierbare Funktionen. Istg′ (x) 6= 0 fur alle x ∈ (a, b), dann ist g(a) 6= g(b) und existiert ein x0 ∈ (a, b) mit
f ′ (x0)
g′ (x0)=
f(b)− f(a)
g(b)− g(a) .
Der erste Mittelwertsatz ist der Spezialfall g(x) = x dieses Satzes.
12.5.2 Ableitungen und Monotonieverhalten
Der Mittelwertsatz selbst ist ziemlich theoretisch, aber seine Anwendungen sind sehr wichtig.
Folgerung 12.21. Es sei f : [a, b] → R eine stetige Funktion, die auf (a, b) differenzierbar ist. Ist ihreAbleitung f ′ durch zwei Konstanten m,M ∈ R beschrankt:
m ≤ f ′(x) ≤ M fur alle x ∈ (a, b),
dann gilt:m · (x2 − x1) ≤ f (x2)− f (x1) ≤ M · (x2 − x1)
fur alle Punkte x1, x2 ∈ [a, b] mit x1 ≤ x2.
Folgerung 12.22. Es sei f : [a, b]→ R eine stetige Funktion, die auf (a, b) differenzierbar ist.
a) Ist f ′(x) = 0 fur alle x ∈ (a, b), dann ist f konstant.
c) Ist f ′(x) ≥ 0 fur alle x ∈ (a, b), dann ist f monoton wachsend auf [a, b].
d) Ist f ′(x) > 0 fur alle x ∈ (a, b), dann ist f streng monoton wachsend auf [a, b].

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 143
e) Ist f ′(x) ≤ 0 fur alle x ∈ (a, b), dann ist f monoton fallend auf [a, b].
f) Ist f ′(x) < 0 fur alle x ∈ (a, b), dann ist f streng monoton fallend auf [a, b].
Satz 12.23. Hinreichende Bedingungen fur Extrema:Es sei f : (a, b)→ R eine differenzierbare Funktion, und x0 ∈ (a, b) sei ein Punkt mit f ′ (x0) = 0.
a) Gibt es ein ε > 0, so dass
• f ′(x) < 0 fur alle x ∈ (x0 − ε, x0) und f ′(x) > 0 fur alle x ∈ (x0, x0 + ε), dann hat dieFunktion f in x0 ein lokales Minimum.
• f ′(x) > 0 fur alle x ∈ (x0 − ε, x0) und f ′(x) < 0 fur alle x ∈ (x0, x0 + ε), dann hat dieFunktion f in x0 ein lokales Maximum.
b) Die Funktion f sei in x0 zweimal differenzierbar.
• Ist f ′′ (x0) > 0, dann hat die Funktion f in x0 ein lokales Minimum.
• Ist f ′′ (x0) < 0, dann hat die Funktion f in x0 ein lokales Maximum.
Beispiele 12.24.
❶ Die Funktion f(x) = xn ist fur ungerades n strikt monoton steigend und hat in Null ein Sattel-punkt.Falls n gerade ist, ist f auf dem Intervall (−∞, 0) strikt monoton fallend und auf dem Intervall(0,∞) strikt monoton steigend, und f hat ein Minimum in 0.
❷ Die Funktionen exp und ln sind streng monoton wachsend auf ihrem gesamten Definitionsbereich.Da der Definitionsbereich offen ist, konnen keine Randmaxima oder Minima existieren, und beideFunktionen haben somit keine Extremwerte.
Folgerung 12.25. Es seien f, g : [a, b]→ R zwei stetige und auf (a, b) differenzierabare Funktionen mitf ′(x) = g′(x) fur alle x ∈ (a, b).Dann existiert ein C ∈ R, so dass f(x) = g(x) + C fur alle x ∈ [a, b].
Folgerung 12.26. Eindeutigkeit der Exponentialfunktion:Es sei f : [a, b]→ R eine stetige Funktion, die auf (a, b) differenzierbar ist mit f ′ ≡ f . Dann gilt
f(x) = C · exp(x) fur x ∈ (a, b),
wobei C ∈ R eine Konstante ist.
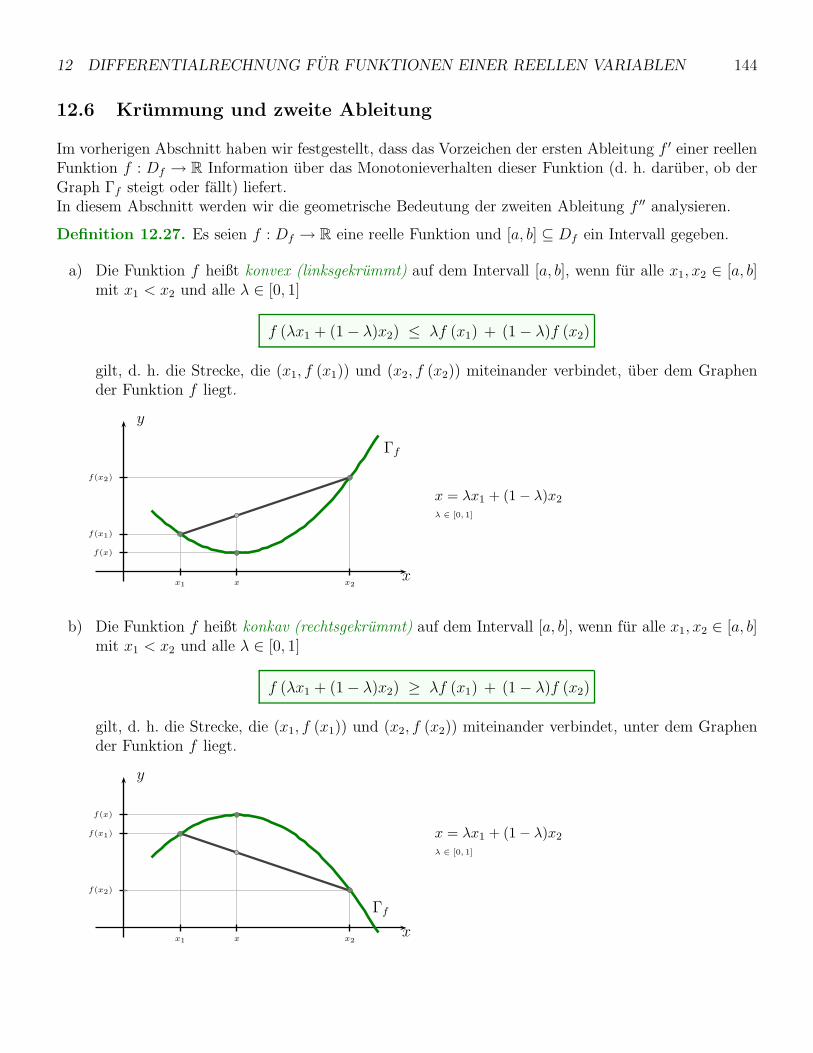
12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 144
12.6 Krummung und zweite Ableitung
Im vorherigen Abschnitt haben wir festgestellt, dass das Vorzeichen der ersten Ableitung f ′ einer reellenFunktion f : Df → R Information uber das Monotonieverhalten dieser Funktion (d. h. daruber, ob derGraph Γf steigt oder fallt) liefert.In diesem Abschnitt werden wir die geometrische Bedeutung der zweiten Ableitung f ′′ analysieren.
Definition 12.27. Es seien f : Df → R eine reelle Funktion und [a, b] ⊆ Df ein Intervall gegeben.
a) Die Funktion f heißt konvex (linksgekrummt) auf dem Intervall [a, b], wenn fur alle x1, x2 ∈ [a, b]mit x1 < x2 und alle λ ∈ [0, 1]
f (λx1 + (1− λ)x2) ≤ λf (x1) + (1− λ)f (x2)
gilt, d. h. die Strecke, die (x1, f (x1)) und (x2, f (x2)) miteinander verbindet, uber dem Graphender Funktion f liegt.
x
y
x1 x x2
f(x1)
f(x)
f(x2)
Γf
x = λx1 + (1− λ)x2
λ ∈ [0, 1]
b) Die Funktion f heißt konkav (rechtsgekrummt) auf dem Intervall [a, b], wenn fur alle x1, x2 ∈ [a, b]mit x1 < x2 und alle λ ∈ [0, 1]
f (λx1 + (1− λ)x2) ≥ λf (x1) + (1− λ)f (x2)
gilt, d. h. die Strecke, die (x1, f (x1)) und (x2, f (x2)) miteinander verbindet, unter dem Graphender Funktion f liegt.
x
y
x1 x x2
f(x2)
f(x)
f(x1)
Γf
x = λx1 + (1− λ)x2
λ ∈ [0, 1]

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 145
c) Ein Punkt x0 ∈ (a, b) heißt Wendepunkt, wenn es ein ε > 0 gibt mit einer der beiden folgendenEigenschaften:
• f ist auf (x0 − ε, x0] konvex und auf [x0, x0 + ε) konkav;
• f ist auf (x0 − ε, x0] konkav und auf [x0, x0 + ε) konvex.
x
y
Γf
x0
Die Ausdrucke”rechtsgekrummt” bzw.
”linksgekrummt” beschreiben die Gestalt des Graphen Γf .
Bemerkung. Eine reelle Funktion f : [a, b]→ R ist genau dann konvex, wenn die Funktion −f konkavist. Diese Behauptung folgt direkt aus der Definition 12.27 durch Multiplikation mit −1.
Satz 12.28. Es sei f : [a, b]→ R eine stetige und auf dem offenen Intervall (a, b) zweimal differenzierbareFunktion. Dann ist
a) f genau dann konkav auf (a, b), wenn f ′′(x) ≤ 0 fur alle x ∈ (a, b);
b) f genau dann konvex auf (a, b), wenn f ′′(x) ≥ 0 fur alle x ∈ (a, b).
Beispiele 12.29.
❶ Die Funktionen f : (0,∞)→ R mit f(x) = ln(x) und g : R→ R mit g(x) = −x2 sind konkav.
❷ Die Funktionen f : R→ R mit f(x) = exp(x) und g : R→ R mit g(x) = x2 sind konvex.
❸ Es sei die Funktion f : R→ R mit f(x) = xn gegeben. Ihre zweite Ableitung f ′′(x) = n(n−1)xn−2
ist uberall positiv fur gerades n, und daher ist f konvex auf R. Falls n ungerade ist, ist f ′′ negativfur x < 0 und positiv fur x > 0. Daher ist f auf dem Intervall (−∞, 0] konkav, auf dem Intervall[0,∞) konvex und hat in x0 = 0 einen Wendepunkt.
☞ Ein weiteres Beispiel wird in der Vorlesung berechnet.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 146
Der Zusammenhang der Krummung mit Extremwerten wird im folgenden Satz gegeben:
Satz 12.30. Es sei f : (a, b) → R eine differenzierbare Funktion, und x0 ∈ (a, b) sei ein Punkt mitf ′ (x0) = 0.
a) Ist die Funktion f konvex auf (a, b) (z. B. wenn f ′′ existiert und f ′′(x) ≥ 0 ist), dann hat f in x0
ein globales Minimum.
b) Ist die Funktion f konkav auf (a, b) (z. B. wenn f ′′ existiert und f ′′(x) ≤ 0 ist), dann hat f in x0
ein globales Maximum.
Beispiel 12.31. ☞ In der Vorlesung!
12.7 Kurvendiskussion
Nehmen wir an, dass eine Funktion f durch eine Gleichung vorgegeben ist.Ziel der Kurvendiskussion ist es, wichtige Eigenschaften der Funktion wie Symmetrie, Periodizitat, Ex-tremstellen, Krummungsverhalten usw. herauszufinden und anhand der gewonnenen Erkenntnisse ihrenGraphen zu skizzieren, um so eine bessere Anschauung fur das Verhalten der Funktion zu haben.Es wird empfohlen, bei der Kurvendiskussion systematisch vorzugehen, etwa nach den folgenden Punk-ten:
• Bestimmung des maximalen Definitionsbereiches Df von f .
• Soweit erkennbar: Symmetrie, Periodizitat.
• Bestimmung des Verhaltens von f am Rande des Definitionsbereiches, d. h. Berechnung vonlimx→a
f(x) fur a ∈ Df \Df und/oder fur a = ±∞.
• Bestimmung der Nullstellen von f und der Intervalle, auf denen f positive bzw. negative Funkti-onswerte annimmt.
• Berechnung der Ableitungen, i. A. f ′ und f ′′, und ihrer Definitionsbereiche.
• Bestimmung des Monotonieverhaltens.
• Bestimmung lokaler und globaler Extremwerte von f .
• Bestimmung des Krummungsverhalten.
• Bestimmung der Wendepunkte von f .
• Bestimmung des Wertebereiches.
• Skizze des Funktionsgraphen.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 147
Beispiel 12.32. Es sei
f(x) =|x− 1|x2
=
−x+ 1
x2fur x < 1
x− 1
x2fur x ≥ 1
gegeben.
❶ Die Funktion ist ausserhalb der Nullstellen des Nenners definiert, i. e. Df = R \ {0}.
❷ Wir berechnen die Grenzwerte
limx→−∞
|x− 1|x2
= limx→−∞
−x+ 1
x2= 0 und lim
x→∞
|x− 1|x2
= limx→−∞
x− 1
x2= 0,
daher ist die Gerade y = 0 die waagerechte Asymptote des Graphen von f fur x→ ±∞.Weiter berechnen wir die Grenzwerte
limx→0−
|x− 1|x2
=∞ und limx→0+
|x− 1|x2
=∞,
daher hat f an der Stelle x = 0 einen Pol, und die Gerade x = 0 ist die senkrechte Asymptote desGraphen von f .
❸ Die einzige Nullstelle der Funktion f ist x = 1, sonst nimmt f nur positive Funktionswerte an.
❹ Die erste Ableitung der Funktion ist gleich
f ′(x) =
x− 2
x3fur x ∈ (−∞, 0) ∪ (0, 1)
−x+ 2
x3fur x ∈ (1,∞).
Die einzige Nullstelle der ersten Ableitung ist x = 2, f ′(x) > 0 fur x ∈ (−∞, 0)∪ (1, 2), f ′(x) < 0fur x ∈ (0, 1) ∪ (2,∞). Daher ist die Funktion f in den Intervallen (−∞, 0) und (1, 2) strengmonoton wachsend und in den Intervallen (0, 1) und (2,∞) streng monoton fallend. Folglich liegtin x = 1 ein lokales Minimum und in x = 2 ein lokales Maximum vor.
❺ Die zweite Ableitung der Funktion ist gleich
f ′′(x) =
2(−x+ 3)
x4fur x ∈ (−∞, 0) ∪ (0, 1)
2(x− 3)
x4fur x ∈ (1,∞).
Die einzige Nullstelle der zweiten Ableitung ist x = 3, f ′′(x) > 0 fur x ∈ (−∞, 0)∪ (0, 1)∪ (3,∞),f ′′(x) < 0 fur x ∈ (1, 3). Daher ist die Funktion f in den Intervallen (−∞, 0), (0, 1), (3,∞) konvexund im Intervall (1, 3) konkav. Folglich sind die Punkte x = 1 und x = 3 die Wendepunkte desFunktionsgraphen.

12 DIFFERENTIALRECHNUNG FUR FUNKTIONEN EINER REELLEN VARIABLEN 148
❻ Aus den bisherigen Berechnungen folgt, dass der Wertebereich der Funktion f gleich Wf = [0,∞)ist.
❼ Um den Graphen der Funktion zu skizzieren, ist es oft gunstig, die gewonnenen Erkenntnisse ineiner Tabelle zusammenzufassen:
x (−∞, 0) 0 (0, 1) 1 (1, 2) 2 (2, 3) 3 (3,∞)
f ′(x) + × − × + 0 − −f ′′(x) + × + × − − 0 +
f(x) 0 ∞|∞ 0minWP
14
max
29
WP0
MinWP
1
4ց
Max
2
9ր
WP1 2 3 4 5 6 7−1−2−3−4−5−6
0.5
1.0
1.5
x
y
f(x) =|x− 1|x2

13 FUNKTIONEN VON MEHREREN VARIABLEN 149
13 Funktionen von mehreren Variablen
Der allgemeine Funktionsbegriff wurde bereits in Definition 4.1 eingefuhrt, und zwar als Abbildung f
von einer Menge X in eine Menge Y , notiert als f : X → Y .
In diesem Abschnitt werden uns mit dem Fall X ⊆ Rn, n > 1, und Y ⊆ R befassen, d. h. wir werdenskalarwertige Funktionen mehrerer Variablen (Veranderlicher) untersuchen.
Definition 13.1. Sei Df eine Teilemenge von Rn. Eine Abbildung
f :
{Df −→ R
(x1, . . . , xn) 7−→ y = f (x1, . . . , xn)
wird eine reellwertige Funktion von n (unabhangigen) Variablen genannt.
Die Menge Df heißt Definitionsbereich von f .Die Menge
Wf := f (Df) = {y = f (x1, . . . , xn) ∈ R : (x1, . . . , xn) ∈ Df}heißt Wertebereich von f .
Bemerkung.
• Wenn nur wenige unabhangige Variable auftreten, dann werden wir auch f(x, y) bzw. f(x, y, z)schreiben.
• Man beachte, dass zur Beschreibung einer Funktion die Angabe des Definitionsbereiches und derVorschrift benotigt wird.
Fur eine Funktion f : R2 → R von zwei Variablen ist eine graphische Darstellung moglich:Der Graph
Γf :={(x1, x2, y) ∈ R3 : y = f (x1, x2) ∧ (x1, x2) ∈ Df
}
ist eine Teilmenge des dreidimensionalen Raumes R3 (eine Flache in R3) und somit unserer Anschauungzuganglich.
Beispiele 13.2.
❶ Die Funktionf (x1, x2) := x2
1 + x22,
hat Definitionsbereich Df = R2 und Wertebereich Wf = [0,∞).
Der Graph von f ist ein sogenanntes Rotationsparaboloid:

13 FUNKTIONEN VON MEHREREN VARIABLEN 150
❷ Die Funktion
f (x1, x2) :=√
x21 + x2
2,
hat Definitionsbereich Df = R2 und Wertebereich Wf = [0,∞).
Der Graph von f ist ein sogenannter Kegel:
❸ Die Funktion
f (x1, x2) :=√
1− x21 − x2
2,
hat Definitionsbereich Df = {(x1, x2) ∈ R2 : x21 + x2
2 ≤ 1} und Wertebereich Wf = [0, 1].
Der Graph von f ist die Oberflache einer Halbkugel vom Radius 1 mit dem Mittelpunkt (0, 0, 0):
❹ Die Funktionf (x1, x2) := x1 · x2,
hat Definitionsbereich Df = R2 und Wertebereich Wf = R.
Der Graph von f ist ein sogenanntes hyperbolisches Paraboloid:

13 FUNKTIONEN VON MEHREREN VARIABLEN 151
Eine weitere Darstellungsmoglichkeit einer Funktion in zwei Variablen eroffnet sich, wenn ihr Graphmit Ebenen y = const geschnitten wird. Die entstehenden Schnittlinien werden orthogonal auf die(x1, x2)–Ebene projiziert und man erhalt eine Niveaulinien–Darstellung der Funktion.
Unter eine Niveaulinie (Hohenlinie, Aquipotentiallinie) von f : R2 → R zum Niveau h ∈ R verstehtman die Menge aller Punkte aus dem Definitionsbereich von f mit demselben Funktionswert h:
{(x1, x2) ∈ Df : f (x1, x2) = h} .
Zum Beispiel sind in den ersten drei Fallen die Niveaulinien Kreislinien und im letzten Fall Hyperbeln.
Funktionen f : Rn → R mit n > 3 sind der Anschauung nicht mehr unmittelbar zuganglich, ihrGraph ist eine Teilmenge des Rn+1.
Bevor wir mit der Differentialrechnung fur Funktionen mehrerer Veranderlicher anfangen konnen,brauchen wir zunachst einige mathematische Grundlagen, die insbesondere Begriffe wie Konvergenz,Beschranktheit usw. auf den Rn verallgemeinern.
13.1 Norm, Umgebung, offene und abgeschlossene Teilmengen des Rn
Es wird empfohlen, sich an dieser Stelle nochmals die im Abschnitt 9 definierte Begriffe in Erinnerungzu rufen.
Definition 13.3. Die (Euklidische) Norm auf Rn ist definiert durch
‖x‖ :=√
x21 + · · ·+ x2
n
mit x = (x1, . . . , xn) ∈ Rn.
Die Norm hat folgenden Eigenschaften (vgl. Definition 9.1 des Betrags und seine Eigenschaften 9.3):
Eigenschaften 13.4. Fur alle x ∈ Rn und λ ∈ R gilt:
•
‖x‖ ≥ 0 und(
‖x‖ = 0 ⇐⇒ x = 0)
•
‖λ · x‖ = |λ| · ‖y‖
• Dreiecksungleichung:
‖x+ y‖ ≤ ‖x‖ + ‖y‖

13 FUNKTIONEN VON MEHREREN VARIABLEN 152
Bemerkung. Die Norm ‖x‖ eines Punktes x ∈ Rn hat im n-dimensionalen Koordinatensystem diegeometrische Bedeutung des Abstandes oder der Distanz zum Ursprung.Allgemeiner ist
‖x− y‖ fur alle x, y ∈ Rn
der Abstand der Punkte x und y.
Definition 13.5. Seien ε > 0 und a ∈ Rn. Dann definiert man die ε–Umgebung von a (s. auch Def. 9.10)als
Uε(a) := {x ∈ Rn : ‖a− x‖ < ε} .
x1
x2
a
ε
Jede Menge U ⊆ Rn, fur die es ein ε > 0 gibt, so dass Uε(a) ⊂ U , wird Umgebung von a genannt.
Definition 13.6. Es sei M eine Teilmenge von Rn.
a) Ein Punkt a ∈ Rn heißt ein Randpunkt von M , wenn in jeder Umgebung von a sowohl ein Punktvon M als auch ein Punkt von Rn \M liegt.
x1
x2
M a
Die Menge aller Randpunkte von M bezeichnen wir mit ∂M und nennen sie den Rand von M .
b) Die MengeM◦ := M \ ∂M
wird das Innere von M genannt.

13 FUNKTIONEN VON MEHREREN VARIABLEN 153
c) Die MengeM := M ∪ ∂M
wird der Abschluss von M genannt.
Definition 13.7. Es sei M eine Teilmenge von Rn.
a) Die Menge M heißt offen, wenn M = M◦.
b) Die Menge M heißt abgeschlossen, wenn M = M .
Eine Menge M ⊆ Rn ist genau dann abgeschlossen, wenn Rn \M offen ist.
Definition 13.8. Es sei M eine Teilmenge vom Rn.
a) Die Menge M heißt beschrankt, wenn fur ein R ∈ R und fur alle x in M die Norm ‖x‖ ≤ R ist.
b) Die Menge M heißt kompakt, wenn M abgeschlossen und beschrankt ist.
13.2 Folgen im Rn
Viele Begriffe der Analysis wie Stetigkeit, Differenzierbarkeit etc. sind verbunden mit dem Begriff derKonvergenz von Folgen. Dies hatten wir fur Funktionen einer reellen Variablen gesehen.Deswegen werden wir jetzt die Definition von Folgen aus Abschnitt 10 auf den Fall Rn verallgemeinern.
Wie angekundigt, schreiben wir die Punkte x im Rn als Zeilenvektoren x = (x1, . . . , xn). Dies zwingtuns, in Folgen die Indizes nach oben zu setzen.
Definition 13.9. Eine Abbildung der naturlichen Zahlen in die Menge Rn
{N −→ Rn
ν 7−→ x(ν) =(
x(ν)1 , . . . , x
(ν)n
)
heißt eine Folge im Rn.
Schreibweise:(x(ν)),
(x(ν))
ν∈N,
(x(ν))
ν≥1.
Ist nun(x(ν))
ν∈Neine Folge im Rn, so ist jedes Folgenglied x(ν) ∈ Rn ein Vektor mit Elementen
x(ν) =(
x(ν)1 , . . . , x
(ν)n
)
. Man erhalt also aus der Folge(x(ν))
ν∈Ngenau n reellen Zahlenfolgen
(
x(ν)i
)
ν∈N
,
i = 1, . . . , n, mit Folgengliedern x(ν)i ∈ R.

13 FUNKTIONEN VON MEHREREN VARIABLEN 154
Definition 13.10. Es sei(x(ν))
ν∈Neine Folge im Rn, und es sei a = (a1, . . . , an) ∈ Rn.
Die Folge(x(ν))
ν∈Nheißt konvergent gegen den Grenzwert a genau dann, wenn ai = lim
ν→∞x
(ν)i fur alle
i = 1, . . . , n.
In diesem Fall schreibt man
a = limν→∞
x(ν) oder x(ν) ν→∞−→ a oder x(ν) −→ a fur ν →∞.
Der Grenzwert einer konvergenten Folge ist eindeutig bestimmt.
Die Rechenregeln fur Grenzwerte der Zahlenfolgen aus dem Satz 10.16 ubertragen sich offensichtlichauf Grenzwerte der Folgen im Rn.
Beispiel 13.11. ☞ In der Vorlesung!
13.3 Stetige Funktionen in Rn
Nun verallgemeinern wir noch die zentralen Begriffe aus Abschnitten 11.4 und 11.5.
Definition 13.12. Es seien f : Df → R eine Funktion mit Df ⊆ Rn und x(0) ∈ Df .
a) Man sagt g ∈ R ∪ {∞,−∞} ist Grenzwert von f an der Stelle x(0) und schreibt
limx→x(0)
f(x) = g
genau dann, wenn
• es ein δ > 0 mit Uδ
(x(0))\ {x(0)} ⊆ Df gibt und
• fur jede Folge(x(ν))
ν∈N⊆ Df \
{x(0)}
mit limν→∞
x(ν) = x(0) gilt:
limν→∞
f(x(ν))
= g.
b) Die Funktion f heißt stetig in x(0) ∈ D◦f , wenn der Grenzwert von f in x(0) existiert und
limx→x(0)
f(x) = f(x(0)).
c) Die Funktion f heißt stetig, wenn f in jedem Punkt x(0) ∈ D◦f stetig ist.
Bemerkung. Ergeben sich fur verschiedene Folgen(x(ν))
ν∈N⊆ Df mit lim
ν→∞x(ν) = x(0) verschiedene
Grenzwerte limν→∞
f(x(ν)), so ist f sicher unstetig in x(0) ∈ D◦
f .

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 155
Satz 13.13. Summe, Differenz, Produkt, Quotient und die Verkettung von stetigen Funktionen inmehreren Variablen sind stetig, wobei naturlich dieselben Einschrankungen gelten wie im Falle derFunktionen in einer Variable (s. Satz 11.31).
Beispiel 13.14. ☞ In der Vorlesung!
Man kann auch den Extremalsatz 11.37 aus Abschnitt 11.6 verallgemeinern.
Satz 13.15. Es sei f : Df → R eine stetige Funktion mit Df ⊆ Rn. Ist die Teilmenge K ⊆ Df
kompakt, dann nimmt die Funktion f auf K ihr globales Minimum und Maximum an, d. h.:Es gibt zwei Punkte x(m), x(M) ∈ K mit
f(x(m)
)≤ f(x) ≤ f
(x(M)
),
fur alle x ∈ K.
14 Differentialrechnung fur Funktionen in mehreren Varia-
blen
Im Abschnitt 12.1 haben wir die Ableitung einer reellen Funktion f : R ⊇ Df → R im Punkt x0 ∈ D◦f
als den Grenzwert
f ′ (x0) := limh→0
f (x0 + h)− f (x0)
h
definiert. Eine direkte Ubertragung dieser Definition auf den Rn ist nicht moglich. Ware h eine Zahl,dann ware die Summe x0 + h eines Vektors mit einer Zahl nicht definiert. Ware dagegen h ∈ Rn, dannware die Division f(x0+h)−f(x0)
heiner Zahl durch einen Vektor nicht definiert.
Wir haben aber gesagt, dass die Ableitung das Wachstumverhalten einer Funktion (bzw. ihres Gra-phen) beschreibt. Der Graph einer Funktion von n Variablen ist eine Teilmenge des Rn+1 und dasWachstumverhalten hangt von der Richtung ab, in die man sich bewegt. Deswegen wird die Ableitungrichtungsweise definiert: in Richtung der x1–Achse, der x2–Achse, . . ., der xn–Achse. Dabei werden alleanderen Variablen als konstant angenommen.
Definition 14.1. Gegeben seien eine Funktion
f :
{Rn ⊇ Df −→ R
x = (x1, . . . , xn) 7−→ f (x1, . . . , xn) .
und x(0) =(
x(0)1 , . . . , x
(0)n
)
∈ D◦f .
a) Die Funktion f heißt im Punkt x(0) partiell nach der j-ten Koordinatenrichtung (bzw. nach xj),j = 1, . . . , n, differenzierbar genau dann, wenn die Funktion einer Variablen
fj (xj) := f(
x(0)1 , . . . , x
(0)j−1, xj , x
(0)j+1, . . . , x
(0)n
)
in x(0)j differenzierbar ist.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 156
In diesem Fall heißt die Ableitung
f ′j
(
x(0)j
)
= limh→0
f(
x(0)1 , . . . , x
(0)j−1, x
(0)j + h, x
(0)j+1, . . . , x
(0)n
)
− f(
x(0)1 , . . . , x
(0)n
)
h
die partielle Ableitung von f nach xj im Punkt x(0) und wird mit
∂f
∂xj
(x(0))
= fxj
(x(0))
:= f ′j
(
x(0)j
)
bezeichnet.
b) Die Funktion f heißt auf ihrem Definitionsbereich Df partiell nach xj, j = 1, . . . , n, differenzierbargenau dann, wenn Df offen ist und wenn f in jedem Punkt von Df partiell differenzierbar nachxj ist. In diesem Fall heißt die Funktion
∂f
∂xj
= fxj:
{
Df −→ R
x = (x1, . . . , xn) 7−→ ∂f
∂xj(x1, . . . , xn) = fxj
(x1, . . . , xn)
die partielle Ableitung von f nach xj in Df .
c) Die Funktion f heißt partiell differenzierbar auf Df genau dann, wenn f partiell differenzierbarnach allen xj , fur j = 1, . . . , n, ist.
d) Ist die Funktion f partiell differenzierbar in x(0), so heißt der Vektor
∇f(x(0))
:=
(∂f
∂x1
(x(0)), . . . ,
∂f
∂xn
(x(0)))
der Gradient von f im Punkt x(0) (man liest ∇ als”Nabla”).
Lasst man x(0) in Df varieren, so bekommt man eine Abbildung (ein Vektorfeld)
∇f : Df ∋ x −→ ∇f (x) ∈ Rn.
e) Die Funktion f heißt stetig differenzierbar genau dann, wenn f partiell differenzierbar ist und wennalle partiellen Ableitungen existieren und stetig sind.
Man erhalt also also die partielle Ableitung nach einer Variablen, indem man die gewohnliche Ab-leitung nach dieser Variablen bildet und dabei die anderen Variablen als Konstanten betrachtet.
Die Faktor-, Summen-, Produkt- und Quotientenregeln fur die gewohnlichen Ableitungen(s. Satz 12.5) gelten deswegen auch fur partiellen Ableitungen.
Beispiel 14.2. Gegeben sei f : R3 → R mit
f (x1, x2, x3) = x1 · x22 + x1 · x2 · x3 − x2
2 · x23.
Um die partiellen Ableitungen ∂f
∂xjfur j = 1, 2, 3 zu berechnen, betrachtet man xi fur i 6= j als konstante
Zahlen und leitet f dann wie gewohnt ab (d. h. nur nach xj). Damit erhalt man
∂f
∂x1
= x22 + x2 · x3,
∂f
∂x2
= x1 · 2x2 + x1 · x3 − 2x2 · x23,
∂f
∂x3
= x1 · x2 − x22 · 2x3.
☞ Weitere Beispiele werden in der Vorlesung berechnet.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 157
Man beachte, dass aus der Existenz von allen partiellen Ableitungen im Punkt x(0) im Allgemeinennicht die Stetigkeit an der Stelle x(0) folgt (vgl. Satz 12.4 fur Funktionen f : R → R!). Sogar wenndie partiellen Ableitungen im gesamten Definitionsbereich von f existieren, braucht die Funktion imallgemeinen nicht stetig zu sein.
Beispiel 14.3.
❶ Es sei f : R2 → R mitf(x, y) := sgn (x) · sgn (y)
gegeben.
Dann ∂f
∂x(0, 0) = lim
h→0
f(0+h,0)−f(0,0)h
= 0,
∂f
∂x(1, 0) = lim
h→0
f(1+h,0)−f(1,0)h
= 0,
∂f
∂x(0, 1) = lim
h→0
f(0+h,1)−f(0,1)h
= limh→0
sgn (h)·sgn (1)h
– existiert nicht,
∂f
∂y(0, 0) = lim
h→0
f(0,0+h)−f(0,0)h
= 0,
∂f
∂y(1, 0) = lim
h→0
f(1,0+h)−f(1,0)h
= limh→0
sgn (1)·sgn (h)h
– existiert nicht,
∂f
∂y(0, 1) = lim
h→0
f(0,1+h)−f(0,1)h
= 0.
Man beachte: Die Funktion f hat partielle Ableitungen im Punkt (0, 0), ist aber in diesem Punktnicht stetig.
❷ Es sei f : R2 → R mit
f(x, y) :=
{xy
x2+y2 fur (x, y) 6= (0, 0),
0 fur (x, y) = (0, 0)
gegeben.
Dann∂f
∂x(0, 0) = lim
h→0
f(0+h,0)−f(0,0)h
= limh→0
h·0h2+02
−0
h= 0,
∂f
∂y(0, 0) = lim
h→0
f(0,0+h)−f(0,0)h
= limh→0
0·h02+h2 −0
h= 0,
und fur (x, y) 6= (0, 0):
∂f
∂x(x, y) =
(xy
x2+y2
)′QR=
y·(x2+y2)−2x·xy
(x2+y2)2=
y(y2−x2)(x2+y2)2
,
∂f
∂y(x, y) =
(xy
x2+y2
)′QR=
x·(x2+y2)−2y·xy
(x2+y2)2=
x(x2−y2)(x2+y2)2
.
Die partiellen Ableitungen von f existieren in jedem Punkt, die Funktion f ist aber nicht stetigim Punkt (0, 0), wegen
(1
n,1
n
)
→ (0, 0), aber f
(1
n,1
n
)
=1n· 1
n1n2 + 1
n2
=1n2
2n2
=1
26→ f(0, 0).

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 158
Satz 14.4. Sei Df ⊆ Rn eine offene Menge. Ist eine Funktion f : Df → R von n Variablen stetigdifferenzierbar, so ist f auch stetig.
Die Kettenregel fur Funktionen von einer Variable gibt uns eine Formel zur Berechnung der Ableitungvon einer verketteten Funktion. Fur die Verkettungen von Funktionen von mehreren Variablen gelteneigene Versionen der Kettenregel, in denen gewohnliche und partielle Ableitungen auftreten.
Satz 14.5. Kettenregel (Spezialfall)Sei Df ⊆ Rn eine offene Menge und (a, b) ⊂ R ein offenes Intervall.Ist f : Df → R eine stetig differenzierbare Funktion und sind ϕj : (a, b) → R, j = 1, . . . , n, stetigdifferenzierbare Funktionen, so dass (ϕ1(t), . . . , ϕn(t)) ∈ Df fur alle t ∈ (a, b), dann ist die verketteteFunktion
F := f ◦ (ϕ1, . . . , ϕn) : (a, b)→ R mit F (t) = f (ϕ1(t), . . . , ϕn(t))
differenzierbar und es gilt
F ′(t) =n∑
j=1
∂f
∂xj
(ϕ1(t), . . . , ϕn(t)) · ϕ′j(t).
Beispiel 14.6. Es seien f : R3 → R mit
f (x1, x2, x3) := x1 · ex2·x23
undϕ1(t) : (0,∞) ∋ t→ ln t ∈ R, ϕ2(t) : R ∋ t→ t2 ∈ R, ϕ3(t) : R ∋ t→ et ∈ R
gegeben.
Wir berechnen die partiellen Ableitungen von f :
∂f
∂x1= ex2·x2
3 ,
∂f
∂x2= x1 · ex2·x2
3 · x23 = x1 · x2
3 · ex2·x23,
∂f
∂x3= x1 · ex2·x2
3 · x2 · 2x3 = 2x1 · x2 · x3 · ex2·x23.
und die gewohnlichen Ableitungen von ϕ1, ϕ2 und ϕ3
ϕ′1(t) =
1
t, ϕ′
2 = 2t und ϕ′3 = et.
Nach der Kettenregel ist die Ableitung von F := f ◦ (ϕ1, . . . , ϕn) gleich
F ′(t) = ∂f
∂x1(ln t, t2, et) · ϕ′
1(t) + ∂f
∂x2(ln t, t2, et) · ϕ′
2(t) + ∂f
∂x3(ln t, t2, et) · ϕ′
3(t) =
= et2·(et)2
· 1t
+ ln t · (et)2 · et2·(et)
2
· 2t + 2 ln t · t2 · et · et2·(et)2
=
= 1tet2·e2t
+ 2t ln t · e2t+t2·e2t
+ 2t2 ln t · e2t+t2·e2t
.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 159
14.1 Richtungsableitung
Die partielle Ableitungen beschreiben das Wachstumsverhalten einer Funktion entlang von Parallelenzu den Koordinatenachsen. Wir wollen nun auch Richtungen betrachten, die nicht achsenparallel sind.
Definition 14.7. Es seien Df ⊆ Rn eine offene Menge und r ∈ Rn ein Vektor gegeben. Ist f : Df → R
eine stetig differenzierbare Funktion, dann heißt die Ableitung der Funktion
F (t) := f(x+ tr) = f (x1 + tr1, . . . , xn + trn)
nach t in t = 0 die Richtungsableitung von f an der Stelle x in Richtung r.
Schreibweise:∂f
∂r(x) := F ′(0).
Nach der Kettenregel ist dies
∂f
∂r(x) =
n∑
j=1
∂f
∂xj
(x) · rj.
Mit Hilfe des Skalarprodukts kann man auch schreiben: ∂f
∂r(x) = 〈∇f(x), r〉.
Beispiel 14.8. Ist r := ei = (0, . . . , 0,
i↓
1, 0, . . . , 0) der i-te Einheitsvektor in Rn, so gilt offensichtlich:
∂f
∂ei
(x) =∂f
∂xi
(x),
da F (t) = f (x1, . . . , xi−1, xi + t, xi+1, . . . , xn) (vgl. Def. 14.1).
Beispiel 14.9. Es seien f : R2 → R mit f (x, y) = 6 − 3x2 − y2 und r =(
1√2,− 1√
2
)
gegeben. Zu
berechnen ist die Richtungsableitung von f an der Stelle (1, 2).Zuerst berechnen wir die partiellen Ableitungen von f :
∂f
∂x(x, y) = −6x und
∂f
∂y(x, y) = −2y.
Folglich
∂f
∂r(1, 2) =
∂f
∂x(1, 2) · 1√
2+∂f
∂y(1, 2) · −1√
2= −6 · 1√
2+ (−4) · −1√
2= −
√2.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 160
14.2 Partielle Ableitungen hoherer Ordnung
Die partiellen Ableitungen einer Funktion von n unabhangigen Variablen sind im Allgemeinen wiederFunktionen von n Variablen, und sie konnen somit wiederum partielle Ableitungen besitzen. Man wirdalso zum Begriff der zweiten (und hoheren) partiellen Ableitung einer Funktion gefuhrt.
Definition 14.10. Es seien Df ⊆ Rn eine offene Menge und f : Df → R eine stetig differenzierbareFunktion in n Variablen.
Sind alle partiellen Ableitungen ∂f
∂xi: Df → R selbst wieder stetig differenzierbar, so heißen ihre partiellen
Ableitungen
∂(
∂f
∂xi
)
∂xj
, fur i, j ∈ {1, . . . , n},
die partiellen Ableitungen zweiter Ordnung von f , und f heißt zweimal stetig differenzierbar.
In diesem Fall schreibt man:
∂2f
∂xj∂xi
= fxjxi:=
∂(
∂f
∂xi
)
∂xj
, fur i, j ∈ {1, . . . , n},
∂2f
∂x2i
= fxixi:=
∂(
∂f
∂xi
)
∂xi
, fur i ∈ {1, . . . , n}
Entsprechend definiert man rekursiv, dass eine Funktion f : Df → R k-mal stetig differenzierbar ist,wenn alle (k − 1)-ten partiellen Ableitungen stetig differenzierbar sind.Fur die partiellen Ableitungen k-ter Ordnung von f schreibt man:
∂kf
∂xi1 . . . ∂xik
= fxi1...xik
:=∂
∂xi1
(∂k−1f
∂xi2 . . . ∂xik
)
fur k ≥ 2 und i1, . . . , ik ∈ {1, . . . , n}.Beispiel 14.11. Es sei eine Funktion
f :
{Df = {(x, y) ∈ R2 : y > 0} −→ R
(x, y) 7−→ 2x3 + x2 · y − 4x · y2 − ex + ln(y)
von zwei Variablen gegeben.
Partielle Ableitungen 1. Ordnung:∂f
∂x(x, y) = fx(x, y) = 6x2 + 2x · y − 4y2 − ex,
∂f
∂y(x, y) = fy(x, y) = x2 − 8x · y + 1
y.
Partielle Ableitungen 2. Ordnung:
∂2f
∂x2 = fxx = 12x + 2y − ex,
∂2f
∂y∂x= fyx = 2x − 8y,
∂2f
∂x∂y= fxy = 2x − 8y,
∂2f
∂y2 = fyy = −8x − 1y2 .

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 161
Die Gleichheit der gemischten partiellen Ableitungen ∂2f
∂x∂y= ∂2f
∂y∂xist keinesfalls zufallig. Es gilt
namlich allgemein:
Satz 14.12. Satz von Schwarz:Es seien Df ⊆ Rn eine offene Menge und f : Df → R eine zweimal stetig differenzierbare Funktion.Dann gilt fur alle i, j = 1, . . . , n:
∂2f
∂xi∂xj
=∂2f
∂xj∂xi
,
d. h. bei den partiellen Ableitungen zweiter Ordnung ist die Reihenfolge der Differenziationen vertausch-bar.
Bemerkung. Der Satz von Schwarz lasst sich entsprechend fur k-mal stetig differenzierbare Funktionenverallgemeinern.
Beispiel 14.13. Es sei f : R2 → R mit
f(x, y) :=
{x2·y
x2+y2 fur (x, y) 6= (0, 0),
0 fur (x, y) = (0, 0)
gegeben.
Wie in Beispiel 14.3 b) zeigt man
∂f
∂x(0, 0) = 0 und
∂f
∂y(0, 0) = 0,
und fur (x, y) 6= (0, 0):
∂f
∂x(x, y) =
2x · y3
(x2 + y2)2 und∂f
∂y(x, y) =
x2 (x2 − y2)
(x2 + y2)2 .
Die partiellen Ableitungen von f existieren also in jedem Punkt, aber sie sind nicht stetig im Punkt(0, 0), wegen z. B.
(1
n,1
n
)
→ (0, 0), aber∂f
∂x
(1
n,1
n
)
=2 1
n· 1
n3
(1n2 + 1
n2
)2 =2n4
4n4
=1
26→ 0 =
∂f
∂x(0, 0).
Jetzt wollen wir mit Hilfe des Differenzenquotienten die zweiten partiellen Ableitungen im Punkt(0, 0) bestimmen:
∂2f
∂x∂y(0, 0) = lim
h→0
∂f
∂x(0, h)− ∂f
∂x(0, 0)
h= lim
h→0
0
h= 0,
∂2f
∂y∂x(0, 0) = lim
h→0
∂f
∂y(h, 0)− ∂f
∂y(0, 0)
h= lim
h→0
1
h= ±∞.
Daraus folgt, dass die partielle Ableitung ∂2f
∂y∂x(0, 0) uberhaupt nicht existiert.
Die Schwarzsche Vertauschungsregel gilt hier nicht, da die Voraussetzungen von Satz 14.12 nichterfullt sind.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 162
14.3 Extremwerte von Funktionen in mehreren Variablen
Definition 14.14. Es seien Df ⊆ Rn eine offene Menge und f : Df → R eine Funktion. Die Funktionf hat im Punkt x(0) ∈ Df
a) ein globales Maximum (bzw. globales Minimum), wenn fur alle x ∈ Df gilt:
f(x(0))≥ f(x),
(bzw. f
(x(0))≤ f(x)
).
b) ein lokales Maximum (bzw. lokales Minimum), wenn es eine Umgebung Uε
(x(0))⊂ Df von x(0)
gibt, so dass gilt:f(x(0))≥ f(x),
(bzw. f
(x(0))≤ f(x)
)
fur alle x ∈ Uε
(x(0)).
Der Punkt x(0) ∈ Df wird oft (globale/lokale) Maximal- bzw. Minimalstelle von f auf Df und derFunktionswert f
(x(0))
Maximal- bzw. Minimalwert genannt. Jede Maximalstelle oder Minimalstelle vonf heißt auch (globale/lokale) Extremalstelle.
Es ist offensichtlich, dass jede globale Extremalstelle auch eine lokale Extremalstelle ist.
Das Problem
minx∈Df
f(x)
wird auch als ein unrestringiertes Optimierungsproblem bezeichnet. Die Funktion f wird Zielfunktiongenannt.
Satz 14.15. Notwendige Bedingung fur ein Extremum:Es sei Df ⊆ Rn eine offene Menge, und die Funktion f : Df → R sei in einem Punkt x(0) von Df partielldifferenzierbar. Liegt in x(0) ein lokales Extremum von f vor, so ist
∇f(x(0))
= (0, . . . , 0),
d. h. ∂f
∂xi
(x(0))
= 0 fur alle i = 1, . . . , n.
Beispiel 14.16. Betrachten wir die drei Funktionen aus Beispiel 13.2.
❶ Die Funktion f : R2 → R mitf (x1, x2) := x2
1 + x22.
Die partiellen Ableitungen von f sind gleich
∂f
∂x1(x1, x2) = 2x1 und
∂f
∂x2(x1, x2) = 2x2.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 163
Daraus folgt, dass ∂f
∂x1(x1, x2) = 0 fur x1 = 0 und ∂f
∂x2(x1, x2) = 0 fur x2 = 0. Folglich
∇f (x1, x2) = 0 ⇐⇒ (x1, x2) = (0, 0).
Das heißt, ein lokales Extremum kann hochstens im Punkt x(0) = (0, 0) vorliegen.
Die Funktion f hat in der Tat ein Minimum in x(0) = (0, 0) (s. Abbildung in Beispiel 13.2 a)).
❷ Es sei f : R2 → R mit
f (x1, x2) =√
x21 + x2
2.
Die partiellen Ableitungen von f sind gleich
∂f
∂x1
(x1, x2) =x1
√
x21 + x2
2
und∂f
∂x2
(x1, x2) =x2
√
x21 + x2
2
.
Daraus folgt, dass f im Punkt (0, 0) ∈ Df nicht partiell differenzierbar ist.
Ferner, da ∂f
∂x1(x1, x2) = 0 nur fur x1 = 0 und ∂f
∂x2(x1, x2) = 0 nur fur x2 = 0, existiert kein Punkt
(x1, x2) mit ∇f (x1, x2) = 0.
Die Funktion f hat aber ein Minimum im Punkt x(0) = (0, 0), weil f(0, 0) = 0 und f (x1, x2) ≥ 0fur alle (x1, x2) ∈ R2 (s. auch Abbildung in Beispiel 13.2 b)).
❸ Die Funktion f : R2 → R mitf (x1, x2) := x1 · x2.
Die partiellen Ableitungen von f sind gleich
∂f
∂x1(x1, x2) = x2 und
∂f
∂x2(x1, x2) = x1.
Daraus folgt, dass ∂f
∂x1(x1, x2) = 0 fur x2 = 0 und ∂f
∂x2(x1, x2) = 0 fur x1 = 0. Folglich
∇f (x1, x2) = 0 ⇐⇒ (x1, x2) = (0, 0).
Das heißt, ein lokales Extremum kann hochstens im Punkt x(0) = (0, 0) vorliegen.
Dies ist aber offensichtlich nicht der Fall (s. Abbildung in Beispiel 13.2 d)).
Bemerkung.
• Die Bedingung ∇f(x(0))
= (0, . . . , 0) ist also eine notwendige Bedingung fur das Vorliegeneines Extremums, jedoch keine hinreichende Bedingung.
• Aus Satz 14.15 folgt, dass ein lokales Extremum nur in den Punkten vorliegen kann, in denen diepartiellen Ableitungen existieren und gleich Null sind oder in denen eine der partiellen Ableitungennicht existiert.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 164
Ein Punkt x(0) ∈ Df mit ∇f(x(0))
= (0, . . . , 0), oder in dem eine von der partiellen Ableitungennicht existiert, heißt auch stationarer (kritischer) Punkt von f .Einen stationaren Punkt, der weder ein lokales Minimum noch ein lokales Maximum ist, nennt maneinen Sattelpunkt.
Nehmen wir an, dass ein Punkt x(0) ein stationarer Punkt einer Funktion f ist. Wie kann man dannuberprufen, ob f im x(0) ein Extremum hat und von welchem Typ?
Beispiele 14.17.
❶ Es sei f : R2 → R mitf(x, y) = 3 − x2 + 2x − y2 − 4y
gegeben. Man bestimme die stationaren Punkte und Extremalstellen von f .
Die Funktion f ist uberall partial differenzierbar, d. h. lokale Extrema liegen in den Punkten (x, y)mit ∇f(x, y) = (0, 0) vor. Die partiellen Ableitungen von f sind gleich
∂f
∂x(x, y) = −2x + 2 und
∂f
∂y(x, y) = −2y − 4.
Daraus folgt, dass ∂f
∂x(x, y) = 0 fur x = 1 und ∂f
∂y(x, y) = 0 fur y = −2. Folglich
∇f(x, y) = 0 ⇐⇒ (x, y) = (1,−2)
und (1,−2) ist der einzige stationare Punkt von f .
Mit quadratischer Erganzung kann man die Funktionsgleichung von f in eine Form bringen, ander gleich zu sehen ist, ob im stationaren Punkt ein lokales Extremum vorliegt. Namlich
f(x, y) = 3 − x2 + 2x − y2 − 4y =
= 3 − (x2 − 2x+ 1) − (y2 + 4y + 4) + 1 + 4 =
= 8 − (x− 1)2 − (y + 2)2.
Da (x − 1)2 ≥ 0 und (y + 2)2 ≥ 0 fur alle x, y ∈ R, ist es jetzt offensichtlich, dass (1,−2) einelokale (sogar globale) Maximalstelle von f ist, und dass f(1,−2) = 8.
❷ Es sei f : R2 → R mitf(x, y) = y2 − x2
gegeben. Man zeige, dass der Punkt (0, 0) ein stationarer Punkt von f ist, aber keine Extremalstelle.
In diesem Fall sind die partielle Ableitungen von f gleich
∂f
∂x(x, y) = −2x und
∂f
∂y(x, y) = 2y,
d. h. (0, 0) ist der einzige stationare Punkt von f .
Jedoch ist (0, 0) keine Extremalstelle von f , da f(x, 0) = −x2 < 0 fur alle x 6= 0 und f(0, y) =y2 > 0 fur alle y 6= 0, sondern ein Sattelpunkt (entlang der x-Achse hat f ein Maximum undentlang der y-Achse ein Minimum).
Die Tricks, die wir im obigen Beispiel angewandt haben, sind nicht befriedigend. Unser Ziel ist, einehinreichende Bedingung fur das Vorliegen eines Extremwertes zu formulieren.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 165
14.3.1 Positiv (Negativ) definite Matrizen
Dazu benotigen wir zunachst einige allgemeine Definitionen fur symmetrische (n × n)–Matrizen(s. Def. 6.6 b)).Da wir dies in der Analysis anwenden wollen, betrachten wir die Punkte des Rn jetzt als Zeilenvektoren.Ist x ein Zeilenvektor, so ist, mit der Bezeichnung aus Def. 6.6 a) xt ein Spaltenvektor. Wir schreibenalso in diesem Abschnitt
x = (x1, . . . , xn) ∈ Rn und xt =
x1...xn
.
Definition 14.18. Es sei A eine symmetrische (n× n)–Matrix. Dann heißt die Matrix A
a) positiv definit (A > 0), wenn gilt
x ·A · xt > 0 fur alle x ∈ Rn \ {0}.
b) positiv semidefinit (A ≥ 0), wenn gilt
x ·A · xt ≥ 0 fur alle x ∈ Rn.
c) negativ definit (A < 0), wenn gilt
x ·A · xt < 0 fur alle x ∈ Rn \ {0}.
d) negativ semidefinit (A ≤ 0), wenn gilt
x ·A · xt ≤ 0 fur alle x ∈ Rn.
e) indefinit, wenn A weder positiv noch negativ semidefinit ist, d. h. falls es x, y ∈ Rn gibt, so dassx · A · xt < 0 und y ·A · yt > 0.
Beispiel 14.19. Es sei En die (n× n)–Einheitsmatrix, dann
x ·En · xt = (x1, . . . , xn) ·
1 0 · · · 00 1 · · · 0...
.... . .
...0 0 · · · 1
·
x1...xn
=
n∑
i=1
x2i .
Daraus folgt, dass fur alle x ∈ Rn gilt:
x · En · xt ≥ 0 und x ·En · xt = 0 ⇐⇒ x = 0.
Diese Eigenschaft besagt, dass die Matrix En positiv definit ist.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 166
Bemerkung. Das Produkt
x · En · yt =
n∑
i=1
xi · yi,
heißt Skalarprodukt der Vektoren x und y und wird mit dem Symbol 〈x, y〉 bezeichnet.Man beachte, dass fur die in Def. 13.3 eingefuhrte Norm ‖x‖ =
√
〈x, x〉 gilt.
Beispiel 14.20.
❶ Sei
A =
(2 00 2
)
eine (2× 2)–Matrix, und sei x = (x1, x2) ∈ R2.
Damit ist
x · A · xt = (x1, x2) ·(
2 00 2
)
·(
x1
x2
)
= (x1, x2) ·(
2x1
2x2
)
= 2x21 + 2x2
2.
Daraus folgt, dass fur alle x ∈ Rn gilt:
x · A · xt ≥ 0 und x · A · xt = 0 ⇐⇒ x = 0,
d. h. die Matrix A ist positiv definit.
❷ Sei
B =
(0 11 0
)
eine (2× 2)–Matrix, und sei x = (x1, x2) ∈ R2.
Damit ist
x · B · xt = (x1, x2) ·(
0 11 0
)
·(
x1
x2
)
= (x1, x2) ·(
x2
x1
)
= 2x1 · x2.
Fur x = (1,−1) ist x · B · xt = −2 < 0 und fur x = (1, 1) ist x · B · xt = 2 > 0.Daraus folgt, dass die Matrix B indefinit ist.
Definition 14.21. Es sei A = (ai,j) eine (n × n)–Matrix und S = {i1, . . . , ik} ⊂ {1, . . . , n}. Dannbezeichnet
AS,S =(aiν ,iµ
)
µ=1,...,kν=1,...,k
die (k × k)–Matrix, die man erhalt indem man alle Zeilen und Spalten streicht, deren Index nicht in Sist. Man nennt det(AS,S) eine (symmetrische) Minore von A.
Besonders wichtig sind die k-ten, k = 1, . . . , n, Hauptminoren oder Hauptdeterminanten. Dies sinddie det(AS,S) fur die Indexmengen S = {1}, S = {1, 2}, S = {1, 2, 3}, . . ., S = {1, 2, . . . , n}.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 167
Satz 14.22. Es sei A eine symmetrische (n× n)–Matrix.
a) Die Matrix A ist positiv definit genau dann, wenn
detAS,S = det
a1,1 · · · a1,k
.... . .
...ak,1 · · · ak,k
> 0
ist, fur k = 1, . . . , n und S = {1, . . . , k}.Mit anderen Worten: alle Hauptminoren mussen positiv sein.
b) Die Matrix A ist negativ definit genau dann, wenn
(−1)k · detAS,S = (−1)k · det
a1,1 · · · a1,k
.... . .
...ak,1 · · · ak,k
> 0
ist, fur k = 1, . . . , n und S = {1, . . . , k}.Mit anderen Worten: die Hauptminoren sind nicht gleich 0 und das Vorzeichen der k-ten Haupt-minore ist (−1)k.
Fur”semidefinit” muss man alle S ⊂ {1, . . . , n} nachprufen:
Satz 14.23. Es sei A eine symmetrische Matrix.
a) Die Matrix A ist positiv semidefinit genau dann, wenn
detAS,S ≥ 0
ist, fur alle S ⊆ {1, . . . , n}.
b) Die Matrix A ist negativ semidefinit genau dann, wenn
(−1)#S · detAS,S ≥ 0
ist, fur alle S ⊆ {1, . . . , n}.
Bemerkung 14.24.
a) Die Matrix A =
(a11 a12
a12 a22
)
ist positiv definit, falls gilt
a11 > 0 und det(A) = a11 · a22 − a212 > 0.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 168
b) Die Matrix A =
(a11 a12
a12 a22
)
ist negativ definit, falls gilt
a11 < 0 und det(A) = a11 · a22 − a212 > 0.
Beispiel 14.25.
❶ Sei
A =
(2 00 2
)
eine (2× 2)–Matrix. Dann sind ihre Hauptminoren
a1,1 = 2 > 0 und det(A) = 4 > 0
und A ist positiv definit (vgl. Bsp. 14.20 a)).
❷ Sei
A =
1 0 10 0 01 0 0
eine (3× 3)–Matrix. Dann sind ihre Hauptminoren
a11 = 1 > 0, det
(
1 00 0
)
= 0 und det(A) = 0.
Trotzdem ist A indefinit, da z. B. Minor
det
(a11 a13
a31 a33
)
= det
(
1 11 0
)
= −1.
Man kann das auch ohne Satz 14.23 sehen:Fur x = (−1, 0, 1) ist x · A · xt = −1, aber fur y = (1, 0, 0) ist y · A · yt = 1.
14.3.2 Hinreichende Bedingungen fur Extrema
Um eine hinreichende Bedingung fur das Vorliegen eines Extremwertes zu erhalten, betrachten wir diepartiellen Ableitungen zweiter Ordnung und benutzen den Begriff der Definitheit.
Definition 14.26. Sei Df ⊆ Rn eine offene Menge und sei f : Df → R eine zweimal stetig differenzier-bare Funktion. Dann heißt die symmetrische (n× n)–Matrix
Hf
(x(0))
=
∂2f
∂x21
(x(0))
∂2f
∂x1∂x2
(x(0))· · · ∂2f
∂x1∂xn
(x(0))
∂2f
∂x2∂x1
(x(0))
∂2f
∂x22
(x(0))· · · ∂2f
∂x2∂xn
(x(0))
......
. . ....
∂2f
∂xn∂x1
(x(0))
∂2f
∂xn∂x2
(x(0))· · · ∂2f
∂xn∂xn
(x(0))
die Hesse–Matrix von f im Punkt x(0) ∈ Df .

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 169
Bemerkung. Die Hesse–Matrix ist nach Satz 14.12 von Schwarz unter den gegebenen Voraussetzungentatsachlich symmetrisch.
Der nachste Satz 14.27 entspricht Satz 12.23 b) fur Funktionen einer Variable.
Satz 14.27. Hinreichende Bedingungen fur Extrema:Es seien Df ⊆ Rn eine offene Menge und x(0) ∈ Df ein Punkt. Ist f : Df → R eine zweimal stetigdifferenzierbare Funktion in einer Umgebung von x(0) mit ∇f
(x(0))
= (0, . . . , 0), so
a) hat f in x(0) ein lokales Minimum, falls Hf
(x(0))
positiv definit ist,
b) hat f in x(0) ein lokales Maximum, falls Hf
(x(0))
negativ definit ist,
c) hat f in x(0) einen Sattelpunkt, falls Hf
(x(0))
indefinit ist.
Beispiel 14.28.
❶ Betrachten wir die Funktion f : R2 → R mit
f (x1, x2) := x21 + x2
2
aus Bsp. 14.16 a). Wir haben festgestellt, dass sie im Punkt (0, 0) ein Minimum hat. Die Hesse–Matrix von f ist tatsachlich positiv definit (s. Bsp. 14.20 a)).
❷ Betrachten wir noch die Funktion f : R2 → R mit
f (x1, x2) := x1 · x2
aus Bsp. 14.16 c). Wir haben festgestellt, dass sie im stationaren Punkt (0, 0) kein Extremum hat.Der im Punkt (0, 0) vorhandene Sattelpunkt zeichnet sich auch durch eine indefinite(s. Bsp. 14.20 b)) Hesse–Matrix aus.
Bemerkung.
• Ist die Hesse–Matrix nur positiv semidefinit, so handelt es sich bei dem stationaren Punkt entwederum ein lokales Minimum oder aber um einen Sattelpunkt.
• Ist die Hesse–Matrix nur negativ semidefinit, so handelt es sich bei dem stationaren Punkt entwederum ein lokales Maximum oder aber um einen Sattelpunkt.
Eine Charakterisierung ist dann mit Hilfe hoherer Ableitungen moglich, was kompliziert ist, und des-wegen wird davon abgeraten. In der Regel kann man durch eine Analyse der Umgebung des stationarenPunktes auf direktem Wege eine Aussage uber seinen Charakter treffen.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 170
Berechnungsschema fur Extremalstellen und Sattelpunkte einer zweimal stetig differenzierbarenFunktion f in zwei Variablen x und y (s. Bemerkung 14.24):
• Berechnung der partiellen Ableitungen ∂f
∂xund ∂f
∂y.
• Bestimmung aller stationaren Punkte, also aller Punkte(x(0), y(0)
)mit
∂f
∂x
(x(0), y(0)
)= 0 und
∂f
∂y
(x(0), y(0)
)= 0.
• Berechnung der Hesse-Matrix
Hf =
(∂2f
∂x2∂2f
∂x∂y
∂2f
∂y∂x
∂2f
∂y2
)
.
• Man definiere
D := detHf =∂2f
∂x2· ∂
2f
∂y2−(∂2f
∂x∂y
)2
.
Bestimmung des Vorzeichens von D(x(0), y(0)
)und ∂2f
∂x2
(x(0), y(0)
)fur alle stationaren Punkte
(x(0), y(0)
).
• Dann gilt:
∗ Ist D(x(0), y(0)
)< 0, so hat f einen Sattelpunkt an der Stelle
(x(0), y(0)
).
∗ Ist D(x(0), y(0)
)= 0, so ist keine Entscheidung moglich.
∗ Ist D(x(0), y(0)
)> 0, so hat f ein lokales Extremum an der Stelle
(x(0), y(0)
)und zwar
⋆ ein lokales Minimum, falls ∂2f
∂x2
(x(0), y(0)
)> 0,
⋆ ein lokales Maximum, falls ∂2f
∂x2
(x(0), y(0)
)< 0.
Wegen der Bedingung D(x(0), y(0)
)> 0 kann ∂2f
∂x2
(x(0), y(0)
)nicht Null sein.
Beispiel 14.29. Es sei f : R2 → R mit
f(x, y) = x3 − 12x · y + 6y2
gegeben. Man bestimme die stationaren Punkte und Extremalstellen von f .
❶ Die partiellen Ableitungen von f sind gleich
∂f
∂x(x, y) = 3x2 − 12y und
∂f
∂y(x, y) = −12x+ 12y.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 171
❷ Wir losen
∇f (x, y) = (0, 0) ⇐⇒{
3x2 − 12y = 0,−12x + 12y = 0
und bekommen zwei stationare Punkte
(x0, y0
)= (0, 0) und
(x0, y0
)= (4, 4).
❸ Die Hesse–Matrix ist gleich
Hf(x, y) =
(6x −12−12 12
)
.
❹ Folglich D(x, y) = detHf(x, y) = 72x− 144.
∗ D(0, 0) = 72 · 0− 144 < 0, somit hat f in (0, 0) einen Sattelpunkt,
∗ D(4, 4) = 72 · 4− 144 = 288− 144 > 0, somit hat f in (4, 4) ein lokales Extremum, und zwar
ein lokales Minimum, weil ∂2f
∂x2 (4, 4) = 6 · 4 = 24 > 0.
Der nachste Satz entspricht Satz 12.30 fur Funktionen einer Variablen.
Satz 14.30. Es seien Df ⊆ Rn eine offene Menge und f : Df → R eine zweimal stetig differenzierbareFunktion. Ist x(0) ∈ Df ein Punkt mit ∇f
(x(0))
= (0, . . . , 0), so hat f in x(0)
a) ein globales Minimum, falls die Hesse–Matrix Hf(x) fur jedes x ∈ Df positiv semidefinit ist,
b) ein globales Maximum, falls die Hesse–Matrix Hf (x) fur jedes x ∈ Df negativ semidefinit ist.
Beispiel 14.31. Es seien f : R2 → R und g : R2 → R mit
f(x, y) = x4 + y4 und g(x, y) = x3 + y3
gegeben.
❶ Die partielle Ableitungen von f und g:
∂f
∂x(x, y) = 4x3 und
∂f
∂y(x, y) = 4y3
∂g
∂x(x, y) = 3x2 und
∂g
∂y(x, y) = 3y2.
❷ Der Punkt (0, 0) ist der stationare Punkt von beiden Funktionen.
❸ Die Hesse–Matrizen von f und g:
Hf(x, y) =
(12x2 0
0 12y2
)
und Hg(x, y) =
(6x 00 6y
)
.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 172
❹ Folglich Df(x, y) = detHf(x, y) = 144x2y2 und Dg(x, y) = detHg(x, y) = 36xy.
❺ Der Satz 14.27 gibt keine Aussage, weil Df (0, 0) = 0 und Dg(0, 0) = 0.
❻ Die Hesse–Matrix Hf (x, y) ist positiv semidefinit fur alle (x, y) ∈ R2, weil
∂2f
∂x2(x, y) = 12x2 ≥ 0 und Df(x, y) = 144x2y2 ≥ 0
fur alle (x, y) ∈ R2. Nach dem Satz 14.30 hat die Funktion f ein globales Minimum auf der Stelle(0, 0).
Die Funktion g hat kein Extremum im (0, 0), da g(0, 0) = 0 und g in jeder Umgebung von (0, 0)negative und positive Funktionswerte annimmt.
14.4 Extremwerte mit Nebenbedingungen
In den Wirtschaftswissenschaften treten oft Optimierungsprobleme auf, bei denen eine Funktion f unterBeachtung von zusatzlichen Nebenbedingungen (Restriktionen) zu minimieren bzw. zu maximieren ist.Durch die Nebenbedingungen wird der zugelassene Definitionsbereich auf eine (meistens abgeschlossene)Teilmenge eingeschrankt.
Definition 14.32. Es seien Df ⊆ Rn eine offene Menge und f, g1, . . . , gm : Df → R Funktionen mitm ≤ n.Die Funktion f hat im Punkt x(0) ∈ Df ein lokales Minimum (bzw. lokales Maximum) unter denNebenbedingungen (in Gleichungsform) g1(x) = 0, . . ., gm(x) = 0, wenn
x(0) ∈ N := {x ∈ Df : g1 (x) = . . . = gm (x) = 0} ,und wenn es eine Umgebung Uε
(x(0))⊂ Df gibt, so dass fur alle x ∈ Uε
(x(0))∩ N gilt:
f(x(0))≤ f(x),
(bzw. f
(x(0))≥ f(x)
).
Das Problem
minx∈Df
f(x), bzw. maxx∈Df
f(x)
unter den Nebenbedingungen
g1(x) = 0, . . . , gm(x) = 0
wird als ein restringiertes Optimierungsproblem bezeichnet. Die Funktion f heißt die Zielfunktion unddie Menge N aller Vektoren x ∈ Rn, die alle Nebenbedingungen erfullen, nennt man Restriktionsmenge.
Das im vorherigen Abschnitt diskutierte Verfahren zur Bestimmung der Extremwerte kann hiernicht kritiklos auf das soeben formulierte restringierte Optimierungsproblem ubertragen werden, da dieRestriktionsmenge im allgemeinen nicht offen ist, so dass die Regeln der Differentation meistens nichtanwendbar sind.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 173
14.4.1 Variablensubstitution
Bei einfachen Problemen kann man versuchen, mit Hilfe der Nebenbedingungen eine oder mehrereVariablen in der Funktionsgleichung durch die ubrigen Variablen zu ersetzen.
Beispiel 14.33. Es sei f : R2 → R mit
f(x, y) := x2 + 4y3
gegeben. Man bestimme die globalen Extrema von f unter der Nebenbedingung x2 + 2y2 = 1.
Man lost die Nebenbedingung x2 + 2y2 = 1 nach x2 auf: x2 = 1 − 2y2 und substituiert damit in derZielfunktion f . Nun ist die Funktion einer Variable
f(y) := 4y3 − 2y2 + 1 mit y ∈[
− 1√2,
1√2
]
auf Extremalwerte zu untersuchen.
Die Ableitung von f ist
f ′(y) = 12y2 − 4y =⇒ f ′(y) = 0 ⇐⇒ y = 0 oder y =1
3.
Es gilt
f ′′(y) = 24y − 4 =⇒ f ′′(0) = −4 und f ′′(
1
3
)
= 4.
In y = 0 liegt also das einzige lokale Maximum und in y = 13
das einzige lokale Minimum der Funktion
f im Intervall(
− 1√2, 1√
2
)
vor.
Durch Vergleich der Funktionswerte an den gefundenen Extremalstellen
f(0) = 1 und f
(1
3
)
=25
27
mit den Funktionswerten in den Randpunkten des Definitionsintervalls
f
(
− 1√2
)
= −√
2 und f
(1√2
)
=√
2
erhalt man, dass die Funktion f im Punkt y = − 1√2
ihr globales Minimum und im Punkt y = 1√2
ihr
globales Maximum auf dem Intervall[
− 1√2, 1√
2
]
annimmt.
Folglich: Der Punkt(
0,− 1√2
)
ist die globale Minimalstelle von f mit f(
0,− 1√2
)
= −√
2 und der Punkt(
0, 1√2
)
ist die globale Maximalstelle mit f(
0, 1√2
)
=√
2 unter der gegebenen Nebenbedingung.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 174
14.4.2 Lagrange–Multiplikatorenregel
Satz 14.34. Es seien Df ⊆ Rn eine offene Menge, f, g1, . . . , gm : Df → R, m ≤ n, stetig dif-ferenzierbare Funktionen, und f besitze in x(0) ein lokales Extremum unter den Nebenbedingungeng1(x) = 0, . . ., gm(x) = 0.
Hat die Matrix(
∂gi
∂xj
(x(0)))
i=1...mj=1...n
den Rang m, so gibt es eindeutig bestimmte reelle Zahlen λ1, . . . , λm
(Lagrange–Multiplikatoren) mit
∂f
∂x1
(x(0))
...∂f
∂xn
(x(0))
+ λ1 ·
∂g1
∂x1
(x(0))
...∂g1
∂xn
(x(0))
+ . . . + λm ·
∂gm
∂x1
(x(0))
...∂gm
∂xn
(x(0))
= 0.
Bemerkung.
• Der Satz 14.34 vermittelt lediglich ein notwendiges Kriterium fur das Auffinden eines lokalenExtremum unter den gegebenen Nebenbedingungen.Hinreichende Bedingungen wie im Fall des unrestringierten Optimierungsproblems (ohne Neben-bedingungen) sollen hier nicht formuliert werden.
• Ist die Restriktionsmenge N kompakt, also beschrankt und abgeschlossen, so mussen bei einerstetigen Funktion f : Rn → R Maximum und Minimum notwendig auf N angenommen werden(s. Satz 13.15). Also ist in diesem Fall die Existenz von Extremstellen (und somit die Losbarkeitdes restringierten Optimierungsproblems) gewahrleistet.
Berechnungsschema: Um die Stellen lokaler Extrema von f unter den Nebenbedingungeng1(x) = 0, . . ., gm(x) = 0 zu bestimmen, betrachtet man die Funktion
F (x, λ1, . . . , λm) := f(x) + λ1 · g1(x) + · · · + λm · gm(x)
und geht wie folgt vor:
• Man bildet alle partiellen Ableitungen der Funktion F nach x1, . . . , xn, λ1, . . . , λm und setzt siegleich Null. So erhalt man die Gleichungen
∂F
∂xi
(x) =∂f
∂xi
(x) + λ1 ·∂g1
∂xi
(x) + · · · + λm ·∂gm
∂xi
(x) = 0 fur i = 1, . . . , n,
∂F
∂λj
(x) = gj(x) = 0 fur j = 1, . . . , m.
• Nun lost man das erhaltene Gleichungssystem.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 175
• Ist x(0)1 , . . . , x
(0)n , λ1, . . . , λm eine der gefundenen Losungen, so steht der Punkt
x(0) =(
x(0)1 , . . . , x
(0)n
)
∈ Rn gemaß Multiplikatorenregel im Verdacht, Stelle eines lokalen Extre-
mums von f unter den Nebenbedingungen g1(x) = 0, . . ., gm(x) = 0 mit Lagrange-Multiplikatoren(λ1, . . . , λm) zu sein.
• Ob in einem solchen Punkte x(0) aber tatsachlich ein Minimum oder Maximum von f vorliegt,kann nur durch zusatzliche Uberlegungen festgestellt werden.
Beispiel 14.35. Bestimme die globalen Extrema der Funktion
f(x, y) = e−x2−y2
unter den Nebenbedingungen 2x2 + y2 = 1.
Hier ist also n = 2 und m = 1, und die Funktion F ist gegeben durch
F (x, y, λ) := e−x2−y2
+ λ ·(2x2 + y2 − 1
).
Die partiellen Ableitungen von F sind:
∂F∂x
(x, y, λ) = − 2x · e−x2−y2+ λ · 4x,
∂F∂y
(x, y, λ) = − 2y · e−x2−y2+ λ · 2y,
∂F∂λ
(x, y, λ) = 2x2 + y2 − 1.
Die gemeinsamen Nullstellen von den partiellen Ableitungen sind:
(0, 1, −e−1
),
(0, −1, −e−1
),
(1√2, 0, −1
2e−
12
)
,
(
− 1√2, 0, −1
2e−
12
)
.
Die moglichen Extremalstellen sind
(0, 1), (0, −1),
(1√2, 0
)
,
(
− 1√2, 0
)
.
Da die Restriktionsmenge kompakt ist, nimmt f nach Satz 13.15 ihr Maximum und Minimum auf
dieser Menge an. Der kleinste bzw. großte der Werte f (0, 1), f (0, −1), f(
1√2, 0)
, f(
− 1√2, 0)
ist dann
das Minimum bzw. das Maximum von f . Durch Einsetzen findet man
f (0, 1) = f (0, −1) < f
(1√2, 0
)
= f
(
− 1√2, 0
)
,
d. h. die Funktion f hat in (0, 1) und (0, −1) ein globales Minimum und in(
1√2, 0)
und(
− 1√2, 0)
ein
globales Maximum unter den Nebenbedingungen 2x2 + y2 = 1.

14 DIFFERENTIALRECHNUNG FUR FUNKTIONEN IN MEHREREN VARIABLEN 176
Beispiel 14.36. Bestimme die Extremalwerte der Funktion
f(x, y) := 3x2 + 2y2 − 4y + 1
auf der Kreisscheibe x2 + y2 ≤ 16.
Nach Satz 13.15 nimmt die Funktion f auf dem Kreis ihr Maximum und Minimum an, und siekonnen sich entweder auf dem Rand x2 + y2 = 16 oder im Inneren x2 + y2 < 16 befinden.
Zuerst benutzen wir die Lagrange–Multiplikatorenregel, um die moglichen Extremalstellen von f aufder Kreislinie zu bestimmen. Die partiellen Ableitungen von
F (x, y, λ) := 3x2 + 2y2 − 4y + 1 + λ ·(x2 + y2 − 16
)
setzt man gleich Null und erhalt das Gleichungssystem
∂F∂x
(x, y, λ) = 6x + λ · 2x = 0,
∂F∂y
(x, y, λ) = 4y − 4 + λ · 2y = 0,
∂F∂λ
(x, y, λ) = x2 + y2 − 16 = 0.
Die moglichen Extremalstellen von f auf dem Rand sind also
(0, 4), (0, −4),(√
12, −2)
,(
−√
12, −2)
.
Nun kehren wir zum Inneren des Kreises zuruck und berechnen die partiellen Ableitungen von f :
∂f
∂x= 6x und
∂f
∂y= 4y − 4.
Folglich ∇f(x, y) = (0, 0) im Punkt (0, 1).
Durch Vergleich der Funktionswerte an allen gefundenen Stellen
f(0, 4) = 17, f(0,−4) = 49, f(√
12,−2)
= f(
−√
12,−2)
= 53, f(0, 1) = −1
erhalt man, dass der Maximalwert von f auf dem Kreis 53 und der Minimalwert −1 ist.
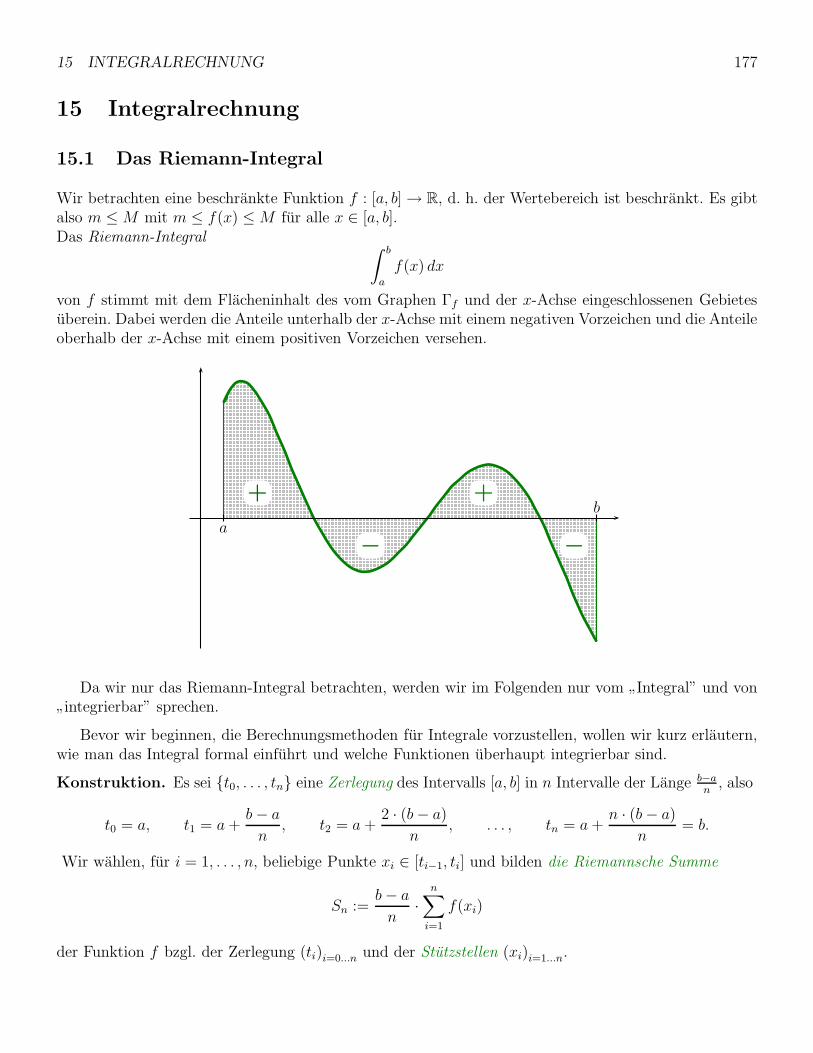
15 INTEGRALRECHNUNG 177
15 Integralrechnung
15.1 Das Riemann-Integral
Wir betrachten eine beschrankte Funktion f : [a, b]→ R, d. h. der Wertebereich ist beschrankt. Es gibtalso m ≤M mit m ≤ f(x) ≤M fur alle x ∈ [a, b].Das Riemann-Integral
∫ b
a
f(x) dx
von f stimmt mit dem Flacheninhalt des vom Graphen Γf und der x-Achse eingeschlossenen Gebietesuberein. Dabei werden die Anteile unterhalb der x-Achse mit einem negativen Vorzeichen und die Anteileoberhalb der x-Achse mit einem positiven Vorzeichen versehen.
a
b+
−
+
−
Da wir nur das Riemann-Integral betrachten, werden wir im Folgenden nur vom”Integral” und von
”integrierbar” sprechen.
Bevor wir beginnen, die Berechnungsmethoden fur Integrale vorzustellen, wollen wir kurz erlautern,wie man das Integral formal einfuhrt und welche Funktionen uberhaupt integrierbar sind.
Konstruktion. Es sei {t0, . . . , tn} eine Zerlegung des Intervalls [a, b] in n Intervalle der Lange b−an
, also
t0 = a, t1 = a+b− an
, t2 = a+2 · (b− a)
n, . . . , tn = a+
n · (b− a)n
= b.
Wir wahlen, fur i = 1, . . . , n, beliebige Punkte xi ∈ [ti−1, ti] und bilden die Riemannsche Summe
Sn :=b− an·
n∑
i=1
f(xi)
der Funktion f bzgl. der Zerlegung (ti)i=0...n und der Stutzstellen (xi)i=1...n.

15 INTEGRALRECHNUNG 178
x1 x2 x3 x4 x5 x6t0 = a t1 t2 t3 t4 t5 t6 = b
Definition 15.1. Die Funktion f : [a, b] → R heißt (Riemann-) integrierbar, wenn fur alle moglichenAuswahlen von Punkten xi der Grenzwert lim
n→∞Sn existiert, und wenn der Wert lim
n→∞Sn unabhangig von
den gewahlten Punkten ist.
Man definiert in diesem Fall das (Riemann-) Integral von f als∫ b
a
f(x) dx := limn→∞
Sn.
Manchmal nennt man∫ b
af(x) dx auch das bestimmte Integral von f uber [a, b].
Das Symbol∫
ist das Integralzeichen, die Zahlen a und b nennt man untere bzw. obere Grenze derIntegration und die Funktion f , die im Integral erscheint, den Integranden.
Das Integral∫ b
af(x) dx ist eine Zahl, die nur von f , a und b abhangig ist. Die Variable x, die im
Integral steht, kann durch jede andere Variable ersetzt werden, d. h.:∫ b
a
f(x) dx =
∫ b
a
f(t) dt =
∫ b
a
f(u) du.
Selbst fur einfache Funktionen ist es schwierig, mit Definition 15.1 die”Integrierbarkeit” nachzu-
weisen. Jedoch erlaubt Definition 15.1 numerische Berechnungen fur Funktionen, deren Integrierbarkeitbekannt ist, z. B. durch den folgenden Satz 15.2.
Satz 15.2. Es sei f : [a, b] → R beschrankt und an hochstens endlich vielen Stellen unstetig. Dann istf integrierbar.
Beispiel 15.3. Die Dirichlet–Funktion f : [0, 1]→ R mit
x 7−→{
1 fur x ∈ Q ∩ [0, 1],0 sonst
ist nicht integrierbar.

15 INTEGRALRECHNUNG 179
Definition 15.4. Es sei f : [a, b]→ R eine integrierbare Funktion. Man definiert∫ a
a
f(x) dx := 0
und ∫ a
b
f(x) dx := −∫ b
a
f(x) dx.
Satz 15.5. Eigenschaften des Integrals:Es seien f, g : [a, b]→ R zwei Funktionen.
a) Es sei c ∈ (a, b). Dann ist f genau dann integrierbar, wenn f : [a, c] → R und f : [c, b] → R
integrierbar sind, und es gilt
∫ c
a
f(x) dx =
∫ b
a
f(x) dx +
∫ c
b
f(x) dx.
b) Faktorregel:Es sei f integrierbar und es sei λ ∈ R. Dann ist die Funktion λ · f integrierbar mit
∫ b
a
(λ · f) (x) dx = λ ·∫ b
a
f(x) dx.
c) Summenregel:Es seien f und g integrierbar. Dann ist auch die Funktion f + g integrierbar mit
∫ b
a
(f + g) (x) dx =
∫ b
a
f(x) dx +
∫ b
a
g(x) dx.
d) Monotonie:Es seien f und g integrierbar mit f ≤ g. Dann gilt
∫ b
a
f(x) dx ≤∫ b
a
g(x) dx.
e) Rechteckregel:Es sei c eine beliebige Zahl. Dann gilt
∫ b
a
c dx = c · (b− a).
Satz 15.6. Mittelwertsatz der Integralrechnung:Es sei f : [a, b]→ R eine stetige Funktion. Dann gibt es eine Zahl ξ ∈ [a, b], so dass
∫ b
a
f(x) dx = f(ξ) · (b− a).
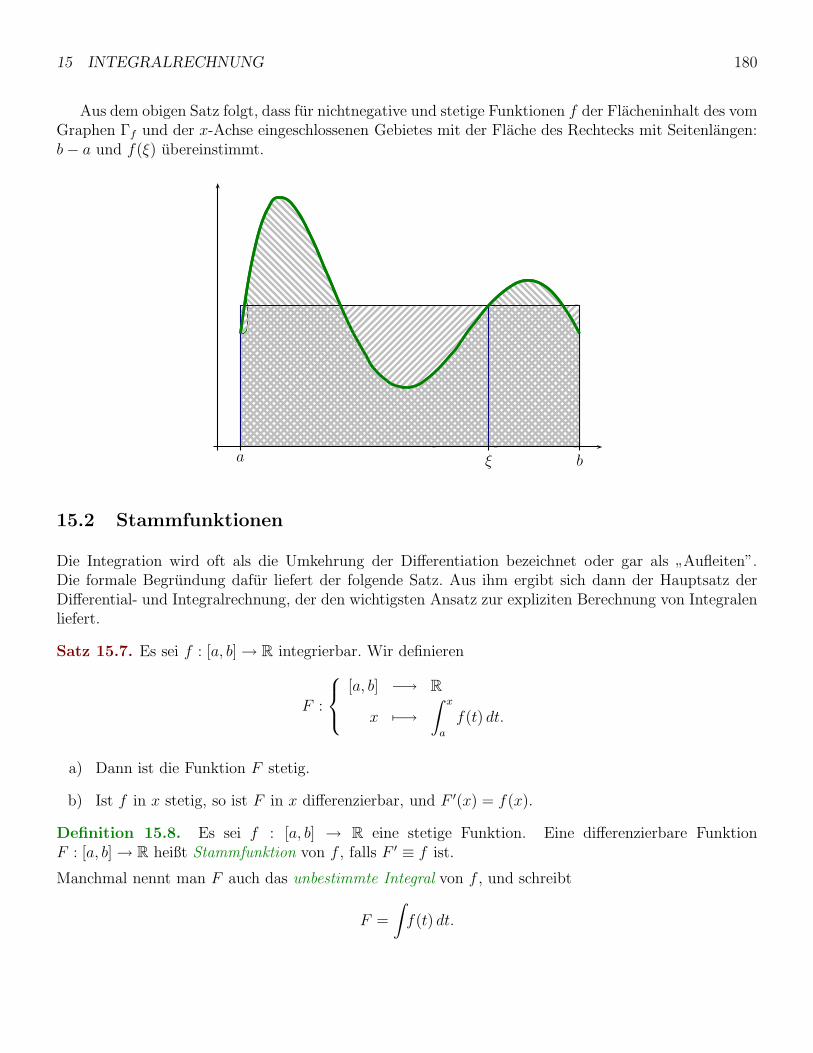
15 INTEGRALRECHNUNG 180
Aus dem obigen Satz folgt, dass fur nichtnegative und stetige Funktionen f der Flacheninhalt des vomGraphen Γf und der x-Achse eingeschlossenen Gebietes mit der Flache des Rechtecks mit Seitenlangen:b− a und f(ξ) ubereinstimmt.
ξa b
15.2 Stammfunktionen
Die Integration wird oft als die Umkehrung der Differentiation bezeichnet oder gar als”Aufleiten”.
Die formale Begrundung dafur liefert der folgende Satz. Aus ihm ergibt sich dann der Hauptsatz derDifferential- und Integralrechnung, der den wichtigsten Ansatz zur expliziten Berechnung von Integralenliefert.
Satz 15.7. Es sei f : [a, b]→ R integrierbar. Wir definieren
F :
[a, b] −→ R
x 7−→∫ x
a
f(t) dt.
a) Dann ist die Funktion F stetig.
b) Ist f in x stetig, so ist F in x differenzierbar, und F ′(x) = f(x).
Definition 15.8. Es sei f : [a, b] → R eine stetige Funktion. Eine differenzierbare FunktionF : [a, b]→ R heißt Stammfunktion von f , falls F ′ ≡ f ist.
Manchmal nennt man F auch das unbestimmte Integral von f , und schreibt
F =
∫
f(t) dt.

15 INTEGRALRECHNUNG 181
Nach dem letzten Satz besitzt jede stetige Funktion auf einem offenen Intervall eine Stammfunktion.Die Stammfunktion ist jedoch nicht eindeutig bestimmt.Es gilt: Ist F eine Stammfunktion von f und c ∈ R eine Konstante, dann ist auch F + c eine Stamm-funktion von f .Und umgekehrt: Sind F und G Stammfunktionen von f , dann gibt es eine Konstante c ∈ R mitG = F + c. In der Tat gilt ja: (F −G)′ = F ′ −G′ = f − f ≡ 0. Als Folgerung des Mittelwertsatzes derDifferentialrechnung schliessen wir daraus, dass F −G eine konstante Funktion ist.
Die gerade geschilderte Mehrdeutigkeit muss man bei der Schreibweise∫f(t) dt = F im Hinterkopf
behalten. Manchmal schreibt man auch etwas korrekter∫f(t) dt = F + c.
Bemerkung. Es seien f, g : [a, b]→ R zwei Funktionen mit Stammfunktionen F und G, und sei λ ∈ R.Dann ist λ · F eine Stammfunktion von λ · f , und F +G eine Stammfunktion von f + g.
Satz 15.9. Hauptsatz der Differential- und Integralrechnung:Es seien f : [a, b]→ R eine integrierbare Funktion und F eine Stammfunktion von f . Dann ist
∫ b
a
f(x)dx = F (b) − F (a) =: F (x)∣∣∣
b
a.
Tabelle von Stammfunktionen einiger wichtiger Funktionen:
f F
x 7→ a, a ∈ R x 7→ a · x+ c
xr, r ∈ R \ {−1} xr+1
r+1+ c
1x
ln |x|+ c
ex ex + c
ax, a ∈ R, a > 0 1ln a· ax + c
sin x − cos x+ c
cosx sin x+ c
wobei c ∈ R eine beliebige Zahl ist.
Beispiele 15.10.
❶ Wir berechnen ∫ 2
0
x2 dx.

15 INTEGRALRECHNUNG 182
Eine Stammfunktion fur x2 ist 13· x3. Nach dem Hauptsatz der Differential- und Integralrechnung
gilt somit∫ 2
0
x2 dx =1
3· x3
∣∣∣∣
2
0
=1
3· 23 − 1
3· 03 =
8
3.
❷ Gesucht ist das Integral∫ 2
1
(x4 − 3x2 + 4x− 2
)dx.
Eine Stammfunktion fur den Integranden ist
F (x) =1
5x5 − 3 · 1
3x3 + 4 · 1
2x2 − 2x.
Demnach gilt∫ 2
1
(x4 − 3x2 + 4x− 2
)dx =
[1
5x5 − x3 + 2x2 − 2x
]∣∣∣∣
2
1
=
=
(1
5· 32− 8 + 8− 4
)
−(
1
5− 1 + 2− 2
)
=
=12
5−(
−4
5
)
=16
5.
Bemerkung. In der Differentialrechnung kann man fur jede differenzierbare Funktion ihre Ableitungangeben.Hingegen gibt es in der Integralrechnung Funktionen, die eine Stammfunktion besitzen, doch kann mandiese durch keine elementare Funktionen, wie z. B. ln, exp, sin, und deren Verkettungen beschreiben.Dies trifft z. B. auf die folgeneden unbestimmten Integrale zu, die nicht mehr auf elementare Funktionenzuruckgefuhrt werden konnen:
∫ex
xdx,
∫sin
xdx,
∫
eλx2
dx fur λ 6= 0.
15.3 Integrationsregeln
Die nun folgenden Integrationsregeln sind Konsequenzen des Hauptsatzes der Differential- und Integral-rechnung und der bereits bekannten Differentationsregeln.
Aus der Produktregel der Differentialrechnung (f · g)′ = f ′ · g + f · g′ folgt:
Satz 15.11. Partielle Integration:Es seien I ein offenes Intervall und f, g : I → R zwei stetig differenzierbare Funktionen. Dann gilt fura, b ∈ I
∫ b
a
f(x) · g′(x) dx = f(x) · g(x)∣∣∣
b
a−∫ b
a
f ′(x) · g(x) dx.

15 INTEGRALRECHNUNG 183
Fur das unbestimmte Integral lautet die Regel:
∫
f(x) · g′(x) dx = f(x) · g(x) −∫
f ′(x) · g(x) dx.
Die partielle Integration erfordert die richtige Intuition bzw. eine gewisse Erfahrung, um zum Zielzu kommen. Beim Integral ∫
x · exp(x) dx
haben wir z. B. zwei Moglichkeiten.
❶ Wir wahlenf(x) = x =⇒ f ′(x) = 1,
g′(x) = exp(x) =⇒ g(x) = exp(x).
Es folgt ∫
x︸︷︷︸
f
· exp(x)︸ ︷︷ ︸
g′
dx = x︸︷︷︸
f
· exp(x)︸ ︷︷ ︸
g
−∫
1︸︷︷︸
f ′
· exp(x)︸ ︷︷ ︸
g
dx =
= x · exp(x) − exp(x) = (x− 1) · exp(x).
❷ Diesmal wahlen wir
f(x) = exp(x) =⇒ f ′(x) = exp(x),
g′(x) = x =⇒ g(x) = 12x2.
Also ∫
x︸︷︷︸
g′
· exp(x)︸ ︷︷ ︸
f
dx =1
2x2
︸︷︷︸
g
· exp(x)︸ ︷︷ ︸
f
−∫
1
2x2
︸︷︷︸
g
· exp(x)︸ ︷︷ ︸
f ′
dx.
Diese Vorgehensweise war wenig hilfreich, da wir nun ein komplizierteres Integral zu berechnenhaben.
Beispiel 15.12. Wir berechnen, fur a, b > 0, das Integral∫ b
a
ln(x) dx.
Wir wahlenf(x) = ln(x) =⇒ f ′(x) = 1
x
g′(x) = 1 =⇒ g(x) = x.
Partielle Integration ergibt∫ b
a
ln(x) dx =
∫ b
a
ln(x) · 1 dx = x · ln(x)∣∣∣
b
a−∫ b
a
x · 1xdx =
= x · ln(x)∣∣∣
b
a− x
∣∣∣
b
a= x · (ln(x)− 1)
∣∣∣
b
a= b (ln(b)− 1)− a (ln(a)− 1) .
Insbesondere ist x · (ln(x)− 1) eine Stammfunktion des naturlichen Logarithmus.

15 INTEGRALRECHNUNG 184
Bemerkung. Die partielle Integration ist besonders geeignet fur Integrale der Form∫
p(x) · eax dx,
∫
p(x) · ln x dx,∫
p(x) · sin(ax) dx,
∫
p(x) · cos(ax) dx,
wobei p ein Polynom ist.
Aus der Kettenregel der Differentialrechnung (F (ϕ(x)))′ = F ′ (ϕ(x)) · ϕ′(x) folgt:
Satz 15.13. Integration durch Substitution:Es seien I und J offene Intervalle, f : I → R eine stetige Funktion und ϕ : J → R eine stetigdifferenzierbare (d. h. ϕ′ ist ebenfalls stetig) und umkehrbare Funktion mit ϕ(J) ⊂ I. Dann gilt fura, b ∈ J :
∫ b
a
f (ϕ(x)) · ϕ′(x) dx =
∫ ϕ(b)
ϕ(a)
f(y) dy.
Man kann die Substitutionsregel sowohl von links nach rechts als auch von rechts nach links lesen.Wenn man sie von links nach rechts liest, versucht man den Integranden in der Form f (ϕ(x)) ·ϕ′(x) zuschreiben. Wenn f dann eine Funktion ist, die man integrieren kann, z. B. weil man eine Stammfunktionkennt, dann hat man das Integral gelost.Liest man die Regel von rechts nach links, dann startet man mit einem Ausdruck der Form
∫ b
af(y) dy
und fuhrt eine Variablensubstitution y = ϕ(x) aus. Mit der Merkregel
dy
dx= ϕ′(x) also dy = ϕ′(x) dx
ersetzt man dy durch ϕ′(x) dx. Schließlich muss man die Integrationsgrenzen a und b durch a′ und b′
mit ϕ(a′) = a und ϕ(b′) = b ersetzen. Man sollte dabei ϕ naturlich so wahlen, dass das neue Integraleinfacher wird.Das nachste Beispiel erlautert diese beide Vorgehensweisen.
Beispiele 15.14.
❶ Wir wollen das Integral∫ 1
0
x4
(x5 + 1)3 dx
berechnen.
Wir sehen, dass 5x4 die Ableitung der Funktion x5 +1 ist. Es ist also hilfreich, das zu bestimmendeIntegral nach der Faktorregel in eine etwas andere Form zu schreiben:
∫ 1
0
x4
(x5 + 1)3 dx =1
5
∫ 1
0
5x4
(x5 + 1)3 dx.
Es sei also
y = ϕ(x) := x5 + 1 =⇒ dy = 5x4 dx und f(y) =1
y3.

15 INTEGRALRECHNUNG 185
Man muss noch die Integrationsgrenzen entsprechend transformieren:
x = 0 =⇒ y = 1 und x = 1 =⇒ y = 2.
Nach der Substitutionsregel gilt nun∫ 1
0
x4
(x5 + 1)3 dx =1
5
∫ 1
0
1
(x5 + 1)3
︸ ︷︷ ︸1
y3
· 5x4 dx︸ ︷︷ ︸
dy
=1
5
∫ 2
1
1
y3dy =
=1
5
(
−1
2· 1
y2
) ∣∣∣∣
2
1
=1
5·(
−1
8
)
− 1
5·(
−1
2
)
=3
40.
❷ Zu berechnen ist das unbestimmte Integral∫
dx3√x2 +
√x.
Wir setzen jetzt x = t6 an. Dann giltdx = 6t5 dt.
Ferner wird aus3√x2 +
√x =
3√t12 +
√t6 = t4 + t3.
Nach der Substitutionsregel gilt nun∫
dx3√x2 +
√x
=
∫6t5
t4 + t3dt = 6
∫t2
t+ 1dt = 6
∫t2 − 1 + 1
t+ 1dt =
= 6
∫ (t2 − 1
t+ 1+
1
t+ 1
)
dt = 6
∫
(t− 1) dt+ 6
∫1
t+ 1dt =
= 6
(1
2t2 − t
)
+ 6 ln |t+ 1|+ C =
= 6
(1
23√x− 6√x+ ln
∣∣ 6√x+ 1
∣∣
)
+ C,
wobei C eine Integrationskonstante ist.
❸ ☞ Weitere Beispiele in der Vorlesung.
15.4 Uneigentliche Integrale
Bisher wurden nur solche Integrale betrachtet, deren Integrationsintervall abgeschlossen und beschranktwar. Auch die Funktionen, welche integriert wurden, waren immer beschrankt.Jetzt werden wir Falle betrachten, bei denen entweder der Integrand oder der Integrationsbereich un-beschrankt ist, und diese unter dem Begriff des uneigentlichen Integrals zusammenfassen. UneigentlicheIntegrale kann man als Grenzwerte von gewohnlichen Integralen auffassen. Wir gehen nun die verschie-denen Falle durch.

15 INTEGRALRECHNUNG 186
15.4.1 Der unbeschrankte Integrationsbereich
Der unbeschrankte Integrationsbereich bedeutet, dass mindestens eine Integrationsgrenze unendlich ist.
Definition 15.15.
a) Es sei f : [a,∞) → R eine Funktion, die uber jedem Interval [a, b], b ∈ (a,∞), integrierbar ist.Existiert der Grenzwert
limb→∞
∫ b
a
f(x) dx
als reelle Zahl, so sagt man, dass das uneigentliche Integral∞∫
a
f(x) dx konvergent ist, und definiert
∫ ∞
a
f(x) dx := limb→∞
∫ b
a
f(x) dx.
Andernfalls nennt man das uneigentliche Integral∞∫
a
f(x) dx divergent und ordnet diesem keine
Wert zu.
b) Es sei f : (−∞, b]→ R eine Funktion, die uber jedem Interval [a, b], a ∈ (−∞, b), integrierbar ist.Existiert der Grenzwert
lima→−∞
∫ b
a
f(x) dx
als reelle Zahl, so sagt man, dass das uneigentliche Integralb∫
−∞f(x) dx konvergent ist, und definiert
∫ b
−∞f(x) dx := lim
a→−∞
∫ b
a
f(x) dx.
Andernfalls nennt man das uneigentliche Integralb∫
−∞f(x) dx divergent und ordnet diesem keine
Wert zu.
Beispiele 15.16. Es sei b > 1.
❶ Dann gilt∫ b
1
1
x2dx =
1
−2 + 1· x−2+1
∣∣∣∣
b
1
= −1
x
∣∣∣∣
b
1
= −1
b+ 1 = 1− 1
b.
Es gilt limb→∞
1b
= 0, so dass das uneigentliche Integral∞∫
1
1x2 dx konvergiert mit
∞∫
1
1
x2dx := lim
b→∞
(
1− 1
b
)
= 1.

15 INTEGRALRECHNUNG 187
❷ Dagegenb∫
1
1
xdx = ln x
∣∣∣
b
1= ln b − ln 1 = ln b.
Wegen limb→∞
ln b =∞ ist das uneigentliche Integral∞∫
1
1xdx divergent.
15.4.2 Der unbeschrankte Integrand
Der unbeschrankte Integrand bedeutet, dass der Integrand an einer Integrationsgrenze nicht definiertist.
Definition 15.17.
a) Es sei f : [a, b)→ R eine in der Nahe von b unbeschrankte Funktion, die uber jedem Teilintervall[a, b− ε] mit 0 < ε < b− a integrierbar ist. Existiert der Grenzwert
limε→0
∫ b−ε
a
f(x) dx
als reelle Zahl, so sagt man, dass das uneigentliche Integralb∫
a
f(x) dx konvergent ist, und definiert
∫ b
a
f(x) dx := limε→0
∫ b−ε
a
f(x) dx
Andernfalls nennt man das uneigentliche Integralb∫
a
f(x) dx divergent und ordnet diesem keine
Wert zu.
b) Es sei f : (a, b]→ R eine in der Nahe von a unbeschrankte Funktion, die uber jedem Teilintervall[a + ε, b] mit 0 < ε < b− a integrierbar ist. Existiert der Grenzwert
limε→0
∫ b
a+ε
f(x) dx
als reelle Zahl, so sagt man, dass das uneigentliche Integralb∫
a
f(x) dx konvergent ist, und definiert
∫ b
a
f(x) dx := limε→0
∫ b
a+ε
f(x) dx

15 INTEGRALRECHNUNG 188
Andernfalls nennt man das uneigentliche Integralb∫
a
f(x) dx divergent und ordnet diesem keine
Wert zu.
Beispiele 15.18. Es sei ε > 0.
❶ Man betrachte die Funktion f : (0, 1] ∋ x 7→ 1√x∈ R. Dann gilt
∫ 1
ε
1√xdx = 2
√x∣∣∣
1
ε= 2√
1 − 2√ε = 2 − 2
√ε
undlimε→0
(2− 2
√ε)
= 2.
Folglich konvergiert das uneigentliche Integral1∫
0
1√xdx mit
1∫
0
1√xdx := 2.
❷ Man betrachte die Funktion f : (0, 1] ∋ x 7→ 1x∈ R. Dann gilt
∫ 1
ε
1
xdx = ln x
∣∣∣
1
ε= ln 1 − 2 ln ε = − ln ε.
Aber limε→0
(− ln ε) =∞, daher ist das uneigentliche Integral1∫
0
1xdx divergent.
Integrale konnen auf mehr als eine Weise uneigentlich sein. Z. B. ist der Integrand in∞∫
0
1x2 dx un-
beschrankt in der Nahe von Null, und das Integrationsintervall ist auch unbeschrankt. In diesem Fall
sagt man, dass das uneigentliche Integral konvergiert, wenn fur ein c > 0 beide Integralec∫
0
1x2 dx und
∞∫
c
1x2 dx konvergieren. Man kann beweisen: Falls beide Integrale fur ein c ∈ (0,+∞) konvergieren, dann
konvergieren sie fur alle c ∈ (0,+∞). Um die Divergenz des uneigentlichen Integrals∞∫
0
1x2 dx zu zeigen,
reicht es daher, ein c > 0 zu finden, fur das entwederc∫
0
1x2 dx oder
∞∫
c
1x2 dx divergent ist.

15 INTEGRALRECHNUNG 189
Beispiel 15.19. Wir werden zeigen, dass das uneigentliche Integral
∞∫
0
1
x2dx
divergent ist.
Sei c = 1 und ε > 0. Dann gilt:
1∫
ε
1
x2dx = − 1
x
∣∣∣∣
1
ε
=1
ε− 1
ε→0−→ ∞,
daher ist1∫
0
1x2 dx divergent und damit auch
∞∫
0
1x2 dx.


















