
SQL aus der Praxis - doag.org · PDF fileWie werden diese Mengen in SQL dargestellt? Dazu gibt...
26
SQL aus der Praxis Neue Funktionen für Bäume und Beispiele für Analytic functions Autor: Helmut Skarka
Transcript of SQL aus der Praxis - doag.org · PDF fileWie werden diese Mengen in SQL dargestellt? Dazu gibt...

DOAG 2008 © pdv Technische Automation + Systeme GmbH, 2008 www.pdv-tas.de Seite 1
SQL aus der PraxisNeue Funktionen für Bäume und Beispiele für Analytic functions
Autor: Helmut Skarka

ÜBERBLICK
Im folgenden wird an 3 Beispielen aus der jüngeren Praxis dargestellt, wie
mit Hilfe von neuen und alten SQL-Funktionen effektive und einfache
Statements geschrieben werden können:
• Filter in Baumstrukturen durch Einsatz der seit 10g existierenden
Funktion connect_by_root
• die analytic functions row_number, rank und dense_rank, um Gruppen zu
markieren oder zu nummerieren
• die analytic functions lead und lag, um Informationen aus vor- resp.
nachgelagerten Datensätzen einer Query zu erhalten.
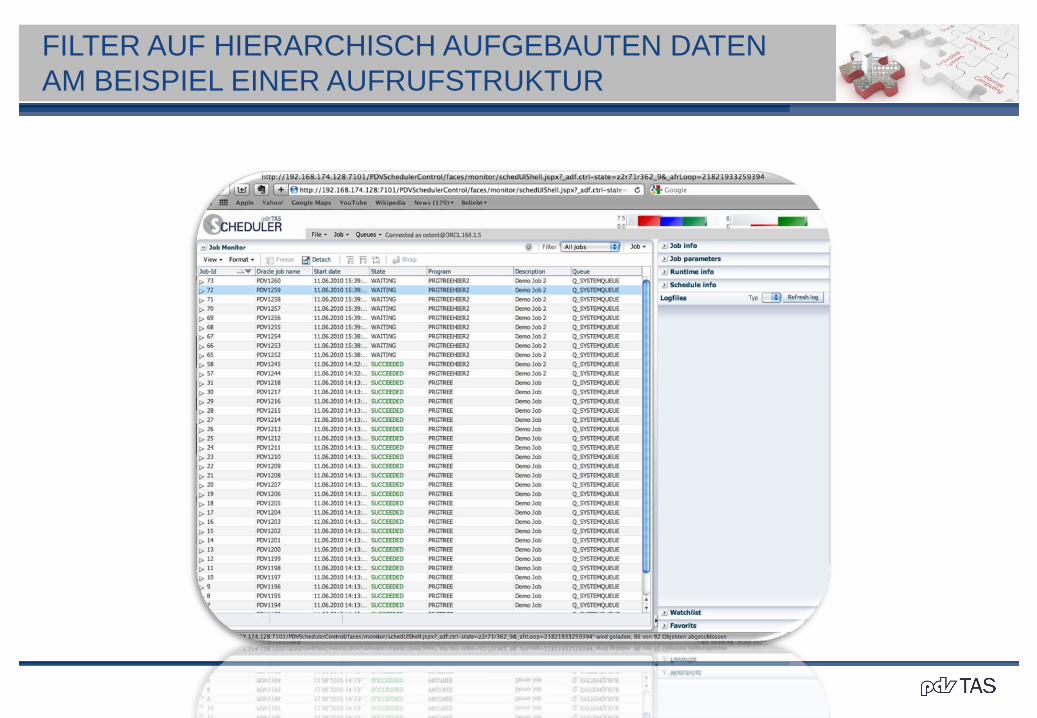
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR
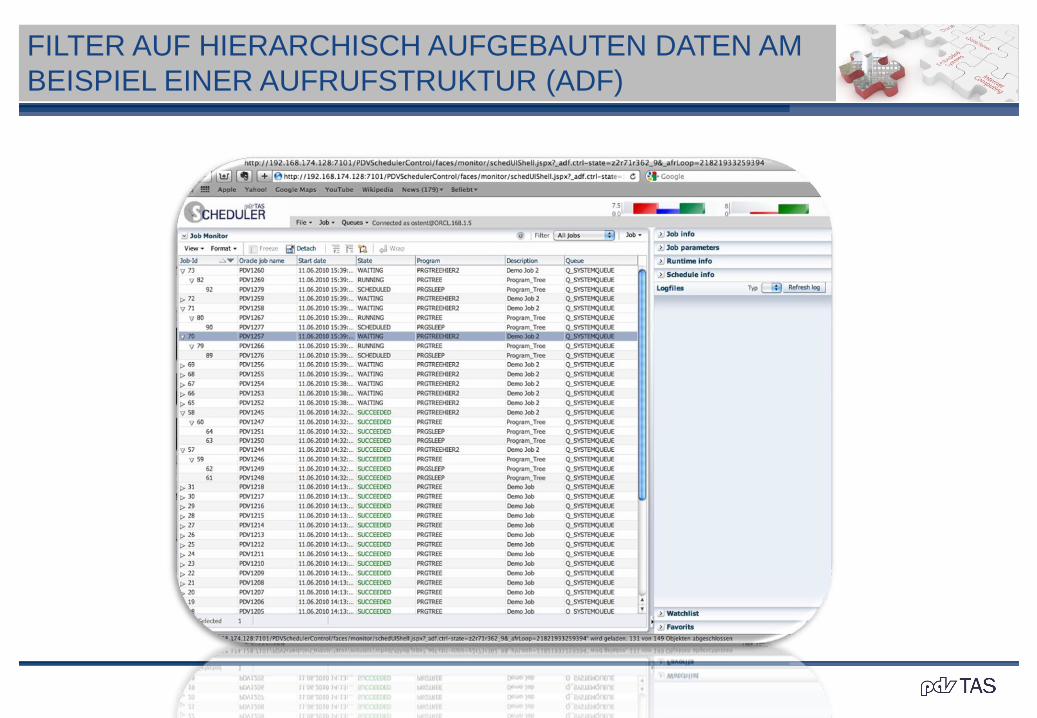
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN AM
BEISPIEL EINER AUFRUFSTRUKTUR (ADF)

In der Datenbank stellen wir die Daten als Tabelle my_tree dar.
CREATE TABLE MY_TREE
(
NAME VARCHAR2(30 BYTE) NOT NULL,
NAME_FROM VARCHAR2(30 BYTE),
DESCRIPTION VARCHAR2(1024 CHAR),
QUEUE VARCHAR2(100 BYTE),
STATE VARCHAR2(30 BYTE),
ATT1 VARCHAR2(100 BYTE), -- sonstige Attribute
ATT2 INTEGER,
ATT3 DATE)
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR

Für das Beispiel definieren wir die Menge
J als { name aus der Tabelle my_tree | name_from IS NULL}
J enthält genau alle Roots von my_tree.
Ein Filter auf J definiert eine Teilmenge von J, die sich aus Eigenschaften der Attribute in
my_tree ableitet.
Beispiel:e:
sei F1 = {j aus J| es gibt Sätze k in my_tree mit k.state=‘S2‘ und Root j}
F2 = { j aus J| es gibt Sätze k in my_tree mit k.queue=‘Q1‘ und Root j}
F3 = { j aus J| alle Sätze k mit Root j haben k.state=‘S5‘}
Also sind in F1 alle Roots mit mindestens einem Job mit Status S2 und in F2 alle Roots, von
denen mindestens ein Job in der Queue Q1 läuft. F3 ist ein eher untypischer Baumfilter.
Interessieren den Anwender alle Aufrufbäume mit Jobs mit beiden Eigenschaften,
dann ist das der Durchschnitt von F1 und F2.
Neben INTERSECT kann man auch MINUS und UNION benutzen.
Definiert man zuerst einfache Filter, kommt man durch Mengenoperationen zu komplexeren.
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR
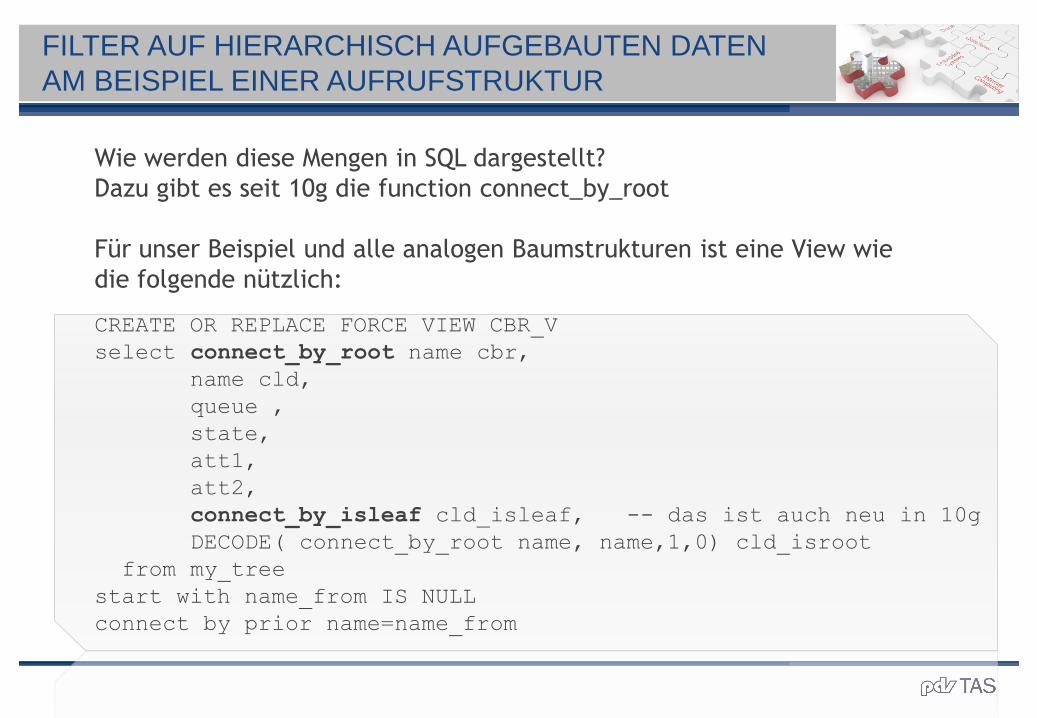
Wie werden diese Mengen in SQL dargestellt?
Dazu gibt es seit 10g die function connect_by_root
Für unser Beispiel und alle analogen Baumstrukturen ist eine View wie
die folgende nützlich:
CREATE OR REPLACE FORCE VIEW CBR_V
select connect_by_root name cbr,
name cld,
queue ,
state,
att1,
att2,
connect_by_isleaf cld_isleaf, -- das ist auch neu in 10g
DECODE( connect_by_root name, name,1,0) cld_isroot
from my_tree
start with name_from IS NULL
connect by prior name=name_from
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR

F1:
SELECT cbr
FROM cbr_v
WHERE cbr IN (
SELECT cbr FROM cbr_v
WHERE state = ‘S2’)
F2:
SELECT cbr
FROM cbr_v
WHERE cbr IN (
SELECT cbr FROM cbr_v
WHERE state = ‘Q1’)
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR
Die Mengen F1 und F2 ergeben sich aus folgenden SQL-Statements:
Diese Statements lassen sich leicht generieren und Operationen mit
INTERSECT oder MINUS sind dann trivial.
Kleine Aufgabe nebenbei: UNION liefert immer eine echte Menge, also keine doppelten Sätze;
letzteres kann man durch UNION ALL erzwingen.
Suchen Sie ein Beispiel, in dem Sie zwingend das UNION ALL benutzen müssen.
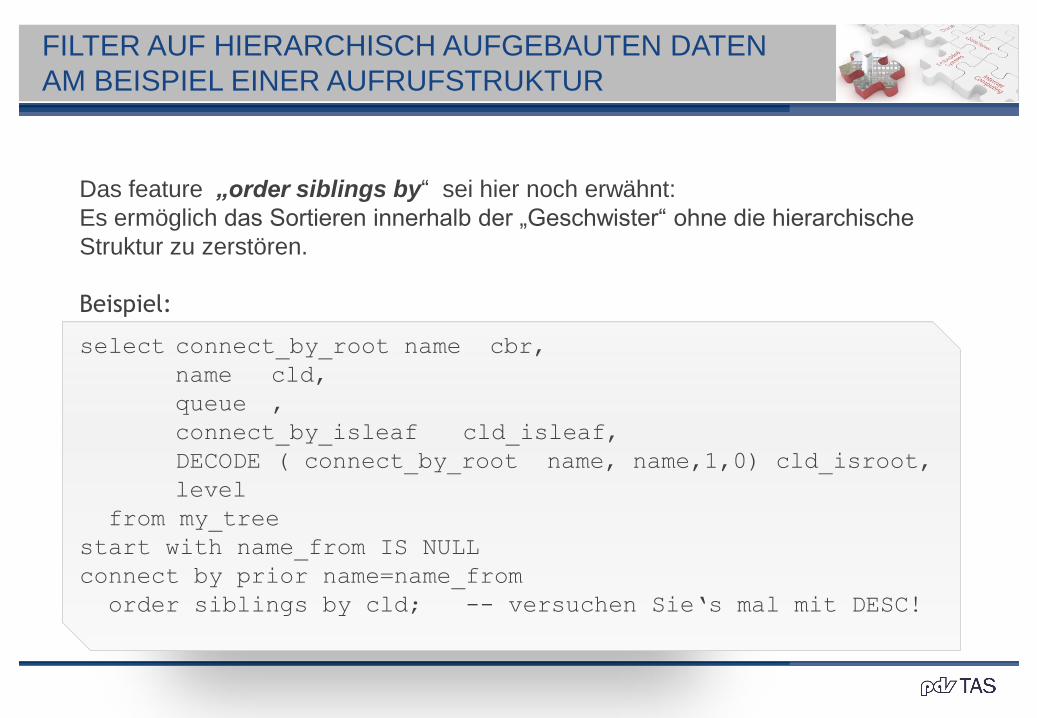
Das feature „order siblings by“ sei hier noch erwähnt:
Es ermöglich das Sortieren innerhalb der „Geschwister“ ohne die hierarchische
Struktur zu zerstören.
Beispiel:
select connect_by_root name cbr,
name cld,
queue ,
connect_by_isleaf cld_isleaf,
DECODE ( connect_by_root name, name,1,0) cld_isroot,
level
from my_tree
start with name_from IS NULL
connect by prior name=name_from
order siblings by cld; -- versuchen Sie‘s mal mit DESC!
FILTER AUF HIERARCHISCH AUFGEBAUTEN DATEN
AM BEISPIEL EINER AUFRUFSTRUKTUR

Window Funktionen (analytic functions)
1. Teil
row_number, rank, dense_rank

Kennen Sie noch die alten DIN A3 Drucker mit dem lindgrün-
weiß gestreiften Papier?
Breite Reports sind da sehr gut zu lesen; also wünscht der
Kunde einen vergleichbaren Ausdruck mit Report-Writer.
Eine Zeilennummerierung und dann MOD(zeilennummer,2)
wäre ein Lösungsansatz, scheitert aber, wenn die Daten
Gruppen bilden.
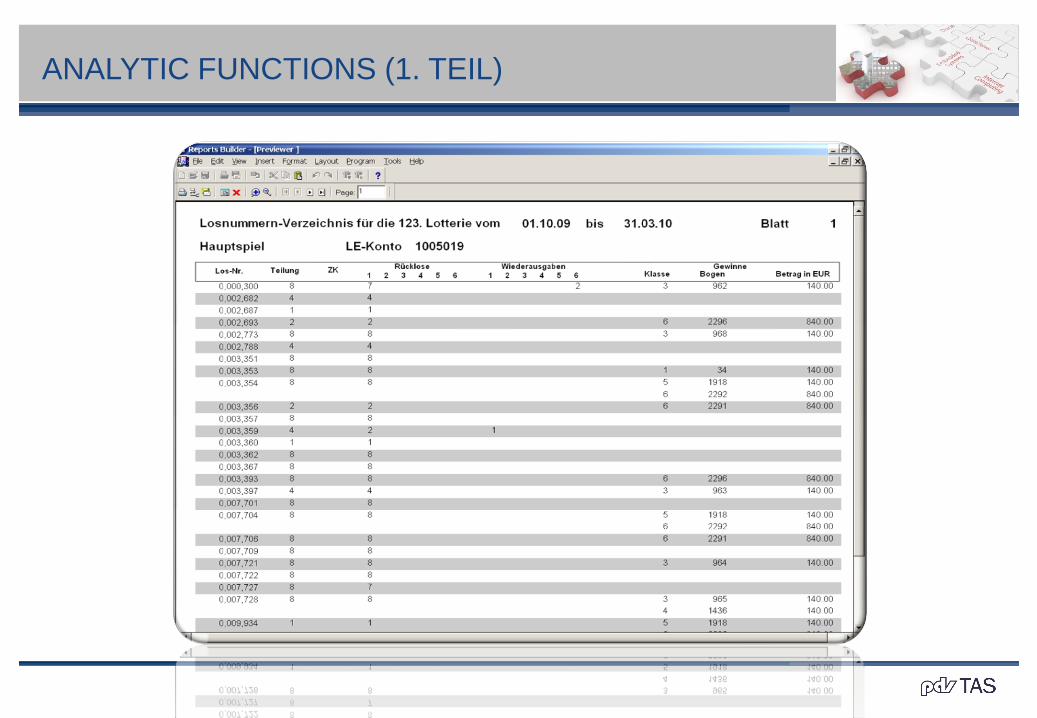
Der Bericht soll wie das folgende Bild aussehen.
ANALYTIC FUNCTIONS (1. TEIL)
ANALYTIC FUNCTIONS (1. TEIL)

ANALYTIC FUNCTIONS (1. TEIL)
Wie kann man ganz allgemein Datensätze innerhalb von Gruppen nummerieren oder
die Gruppen selbst nummerieren?
Das obige Beispiel zeigt Losnummern einer Lotterie und die auf das jeweilige Los
gefallenen Gewinne; da Lose mehrfach gewinnen können, bilden die einzelnen Lose
je eine Gruppe, die aus einem oder mehreren Elementen besteht.
Ziel ist, die Gruppen lückenlos und eindeutig zu nummerieren, so dass aufeinander
folgende Gruppen durch MOD(Gruppennummer, 2) unterscheidbar sind.
Das simple Datenmodell hierfür besteht aus den folgenden beiden Tabellen; auf
primary keys als Sequence-Ids wird hier verzichtet.
Die anfallenden Datenmengen sind beachtlich, so dass die Lösung eine gewisse
Performanz aufweisen muss.
Die analytische Funktion dense_rank wird das Gewünschte leisten.

CREATE TABLE LS_LOSE_T
(
LOTTERIE NUMBER (3) NOT NULL,
LOSNUMMER NUMBER (7) NOT NULL,
LE_KONTO NUMBER (7) NOT NULL
)
Pro Lotterie 3000000 Lose, 3 Lotterien sind eingelesen.
CREATE TABLE SIG.LS_GEWINNE_T
(
LOTTERIE NUMBER(3),
LOSNUMMER NUMBER(7),
GEWINNUMMER NUMBER(7) DEFAULT 0,
GEWINNKLASSE NUMBER(1) DEFAULT 1,
GEWINNZIEHUNG NUMBER(2) DEFAULT 1,
GEWINNBETRAG NUMBER(12,2) DEFAULT 0,
ABSCHNITT NUMBER(2),
BOGENNUMMER NUMBER(7) DEFAULT 0
ANALYTIC FUNCTIONS (1. TEIL) – DIE DATEN

Vorüberlegung:
Das Statement
Select count(*)
name, queue
from my_tree
group by name
ANALYTIC FUNCTIONS (1. TEIL)
liefert ORA-00979: Kein GROUP BY-Ausdruck.
Klar, bei Gruppen kann man keine Details anzeigen; aber umgekehrt geht das sehr wohl
und genau das leisten die Window-Funktionen, die Oracle analytic functions nennt.
Syntax:
Funktion(<optional arguments>) OVER (<analytic clause>)
Wichtig: die analytic functions werden erst nach WHERE und GROUP BY ausgeführt!

ANALYTIC FUNCTIONS (1. TEIL)
Im folgenden SQL-Statement sind als Demonstration auch die Funktionen
row_number() und rank() aufgeführt:
row_number() nummeriert innerhalb der Partition entsprechend dem order by
ohne mehrfach auftretende Losnummern zu berücksichtigen, wobei innerhalb
der Gruppe unvorhersehbar nummeriert wird. Für den Report unbrauchbar, da
bei Gruppen mit gerader Mitgliederzahl die MOD-2-Bedingung verletzt ist.
Rank() arbeitet wie die Medaillienvergabe bei Olympia, wenn z.B. zwei Athleten
den ersten Platz belegen: dann gibt es zweimal Gold, aber kein Silber; es wird
gezählt 1,1,3. Auch das können wir hier nicht brauchen; erst dense_rank() zählt
„richtig“: 1,1,2.
Das Bild nach den SQL zeigt eine Lösung in Reports.

ANALYTIC FUNCTIONS (1. TEIL)
SELECT row_number() OVER (PARTITION BY t1.le_konto ORDER BY t1.losnummer) rown,
rank() OVER (PARTITION BY t1.le_konto ORDER BY t1.losnummer) rn,
dense_rank() OVER (PARTITION BY t1.le_konto ORDER BY t1.losnummer) denrn,
DECODE(MOD(dense_rank() OVER
(PARTITION BY t1.le_kontoORDER BY t1.losnummer),2),
0,'grün','weiß') color,
t1.le_konto, t1.lotterie, t1.losnummer,
gewinnummer, gewinnklasse, bogennummer, gewinnbetrag
FROM ls_lose_t t1,
ls_gewinne_t t3
WHERE t1.lotterie = :p_lotterie
AND t1.lotterie = t3.lotterie (+)
AND t1.losnummer= t3.losnummer (+)
AND t1.le_konto IN ( :p_le_konto1, :p_le_konto2)
ORDER BY lotterie, le_konto, losnummer, gewinnklasse
Hier das SQL-Statement für unseren Report mit mehreren Funktionen:
ANALYTIC FUNCTIONS (1. TEIL)

WINDOW-FUNKTIONEN
(ANALYTIC FUNCTIONS)
2. TEIL
LAG() UND LEAD()

ANALYTIC FUNCTIONS (2. TEIL) - LAG() UND LEAD()
Aufgabe (ganz allgemein): Finde in einer Tabelle zusammenhängende Sätze
entsprechend einer vorgegebenen Einschränkung, Sortierung und Länge.
Beispiel:
Losserien in der obigen Tabelle ls_lose_t sortiert nach
Losnummern mit Mindestlänge gap_min, die zu einer
Lotterie und einem vorgegebenen le_konto gehören.
Dann Verschärfung der Bedingung: Nicht nur für eine Lotterie, sondern auch
für weitere nachfolgende mit der Bedingung: alles was in einer der Lotterien
eine Serie ist, muss es auch in den anderen Lotterien sein.

ANALYTIC FUNCTIONS (2. TEIL) - LAG() UND LEAD()
1. Lösung für eine Lotterie: prozedurales PL-SQL
(Ganz formlos)
Initialisieren
LOOP über Losbereich
Gehört Los zur LE (positiv-Ansatz)
dann zählen
sonst prüfen, ob Länge ausreicht …
Endebedingungen
2. Lösung für eine Lotterie: reines SQL
Selektieren alle Lose, die nicht zur LE gehören. Die Zwischenräume, die
lang genug sind, sind die gesuchten Serien.
Für die Bestimmung des Zwischenraums braucht man Informationen
über den Vorgängersatz; jetzt kommt lag() ins Spiel.b

SELECT :lotterie,
:le_konto,
vorher+1 losnummer_anfang,
losnummer-1 losnummer_ende,
losnummer-vorher-1 gap
FROM
( SELECT losnummer
lag(losnummer,1,:los_von-1) OVER(order by losnummer) vorher
-- liefert die Losnummer des vorherigen Satzes!!
-- lead würde die des nächsten Satzes liefern
FROM
(SELECT losnummer
FROM ls_lose_t
WHERE lotterie = :lotterie
AND le_konto <> :le_konto
AND losnummer >= :los_von
AND losnummer <= :los_bis
UNION
SELECT :los_bis+1 FROM dual)) -- wird gebraucht, um das Ende sauber
WHERE vorher IS NOT NULL -- zu erkennen
AND losnummer-vorher-1>=:gap_min
ANALYTIC FUNCTIONS (2. TEIL) - LAG() UND LEAD()

SELECT losnummer
FROM ls_lose_t
WHERE lotterie IN (:lotterie1,…, :lotterieN)
AND le_konto <> :le_konto
AND losnummer >= :los_von
AND losnummer <= :los_bis
Problem: über mehrere Lotterien
hier wird der prozedurale Ansatz problematisch
Lösung: Selektiere die auszuschliessenden Losnummern über alle
Lotterien hinweg.
Also sieht die innere View dann einfach wie folgt aus, der Rest bleibt gleich:
ANALYTIC FUNCTIONS (2. TEIL) - LAG() UND LEAD()

Eckdaten pdv TAS
Entwicklung von Individual-Software
Client & Server Computing / Datenbanken
Internet + Mobile Computing
Embedded Systems
Mitarbeiter / Umsatz
ca. 35 Mitarbeiter
ca. 4 Mio Umsatz

Leitmotiv

Kontakt


















