
Statistische Methoden -...
206
Statististische Methoden Statistische Methoden Kurt Hornik Kurt Hornik 2006
Transcript of Statistische Methoden -...

Statististische Methoden
Statistische Methoden
Kurt Hornik
Kurt Hornik 2006

Statististische Methoden
Statistik: Einfuhrung und Grundlegendes
Kurt Hornik 2006

Statististische Methoden
Was ist Statistik?
Das Wort Statistik hat zwei Bedeutungen:
• Eine wissenschaftliche Disziplin (englisch:”statistics“)
• Ergebnisse dieser wissenschaftlichen Betatigung (englisch:”statistic“; e.g.:
Verbraucherpreisstatistik)
Kurt Hornik 2006

Statististische Methoden
Arbeitsdefinition
Statistik beschaftigt sich mit dem Sammeln, der Prasentation und derAnalyse von Daten.
Sammeln: Wie komme ich zu der Information die ich benotige?
Prasentation: Wie kann ich Information kommunizieren?
Analyse: Welche Schlusse kann ich ziehen? Wie kann ich aufgrund von Stichpro-beninformation allgemeine Aussagen treffen?
Kurt Hornik 2006

Statististische Methoden
Beschreibende und schließende Statistik
Deskriptive (beschreibende) Statistik: Methoden, um Daten ubersichtlich undinformativ zu organisieren, zusammenzufassen und zu prasentieren.
Grafische und numerische Methoden.
Inferenzstatistik (schließende Statistik): Methode, wie man ausgehend vonStichprobendaten Schlussfolgerungen auf Charakteristika einer Population zie-hen kann.
Schatzen, Testen, Modellieren.
Kurt Hornik 2006

Statististische Methoden
Grundbegriffe
Beobachtungseinheiten: (Falle, Cases) Trager von Merkmalen die von Interessesind
Population: Gesamtmenge aller (relevanter) Beobachtungseinheiten
Merkmale: (Variablen) Charakteristika von Beobachtungseinheiten
Vollerhebung: wenn Daten von allen Elementen der Population gesammelt werden
Stichprobenerhebung: wenn eine Stichprobe (Teil der Population) gewahlt wirdund nur fur diese Daten gesammelt werden
Kurt Hornik 2006
Statististische Methoden
Datenerhebung
Das Sammeln von Daten impliziert immer eine Art von Messung, auch wenn es sichnur um simple Einteilung handelt.
Kriterien fur gute Messung:
Objektivitat: das zu ermittelnde Merkmal wird eindeutig festgestellt (hangt nichtvon der messenden Person ab)
Validitat: ein Messinstrument misst tatsachlich das was es messen soll
Reliabilitat: die Messung ist exakt in dem Sinn dass bei mehrmaliger Messung”im
wesentlichen“ dasselbe herauskommt
Kurt Hornik 2006

Statististische Methoden
Klassifikation von Merkmalen
Unterscheidung
Qualitativ: Ergebnis der Messung erfolgt durch Einteilung in Kategorien (”es gibt
nur das eine oder das andere“)
Quantitativ: Ergebnis kommt durch eine Art von Zahlen zustande (”es gibt mehr
oder weniger“)
Unterscheidung
Diskret: Messen (im Prinzip) nur mit ganzen Zahlen
Stetig: Messen (im Prinzip) mit reellen Zahlen
Kurt Hornik 2006

Statististische Methoden
Klassische Skalenniveaus
Nominalskala: man kann einzelne Kategorien zahlenmaßig nicht vergleichen(konnen beliebig angeordnet werden)
Ordinalskala: (Rangskala) Kategorien konnen in eine sinnvolle Reihenfolge ge-bracht werden, es gibt aber keine Quantisierung der Großenunterschiede
Intervallskala: Messungen auf einer Skala mit gleichgroßen Einheiten, man kannaber keine Verhaltnisse bilden weil kein absoluter Nullpunkt
Ratio(nal)skala: Wie Intervallskala mit absolutem Nullpunkt.
Absolutskala: Wie Ratioskala, aber in naturlichen Einheiten (Zahlungen, Wahr-scheinlichkeiten, . . . )
Kurt Hornik 2006

Statististische Methoden
In weiterer Folge . . .
Vereinfachte Klassifikation:
Kategoriale Merkmale: entstehen durch Zuordnung in Kategorien. (Im wesentli-chen: qualitativ; Nominal- oder Ordinalskala)
Metrische Merkmale: entstehen durch Zahlen oder Messen im engeren Sinn. (Imwesentlichen: quantitativ; Intervall-, Ratio- oder Absolutskala)
Kurt Hornik 2006

Statististische Methoden
Ein kategoriales Merkmal
Kurt Hornik 2006

Statististische Methoden
Kategoriale Merkmale
Entstehen durch Zuordnung in Kategorien (Klasseneinteilung, gegebenenfalls auchdurch Gruppierung metrischer Merkmale).
Beschreibungen beruhen auf den Haufigkeiten der Kategorien in den Daten:
Absolute Haufigkeiten: Anzahl der Beobachtungseinheiten in einer bestimmtenKategorie
Relative Haufigkeiten: (Anteilswerte) Absolute Haufigkeiten bezogen auf die Ge-samtanzahl der Beobachtungseinheiten
Prozent: relative Haufigkeit × 100.
Bei ordinalen Merkmalen konnen auch kumulative Haufigkeiten von Interesse sein.
Kurt Hornik 2006

Statististische Methoden
Datensatz: BBBClub
Der Bookbinder’s Book Club ist ein amerikanischer Bucherclub, der 20,000 Kundeneine Brochure fur das Buch
”The Art History of Florence“ zugesandt hat. Von
diesen haben 1,806 Kunden dieses Buch daraufhin gekauft. Der BBB Club hatverschiedene Merkmale dieser Kunden erhoben, um damit ein Prognosemodell furdie Kaufentscheidung zu entwickeln.
Einen Ausschnitt von 1,300 Beobachtungen ist verfugbar im Datensatz BBB-Club.rda (beziehungsweise BBBClub.csv) mit den folgenden Merkmalen:
Kurt Hornik 2006

Statististische Methoden
Datensatz: BBBClub Merkmale
CHOICE Hat der Kunde das Buch”The Art History of Florence“ gekauft?
GENDER Geschlecht.AMOUNT Gesamtsumme der Ausgaben beim BBB Club.FREQ Gesamtanzahl von Kaufen beim BBB Club.LAST Monate seit dem letzten Kauf.FIRST Monate seit dem ersten Kauf.CHILD Anzahl gekaufter Kinderbucher.YOUTH Anzahl gekaufter Jugendbucher.COOK Anzahl gekaufter Kochbucher.DIY Anzahl gekaufter Do-It-Yourself-Bucher.ART Anzahl gekaufter Kunstbucher.
Kurt Hornik 2006

Statististische Methoden
R: Daten einlesen
R> load("BBBClub.rda")R> dim(BBBClub)[1] 1300 11R> names(BBBClub)[1] "CHOICE" "GENDER" "AMOUNT" "FREQ" "LAST" "FIRST" "CHILD" "YOUTH"[9] "COOK" "DIY" "ART"
R> attach(BBBClub)
Kurt Hornik 2006
Statististische Methoden
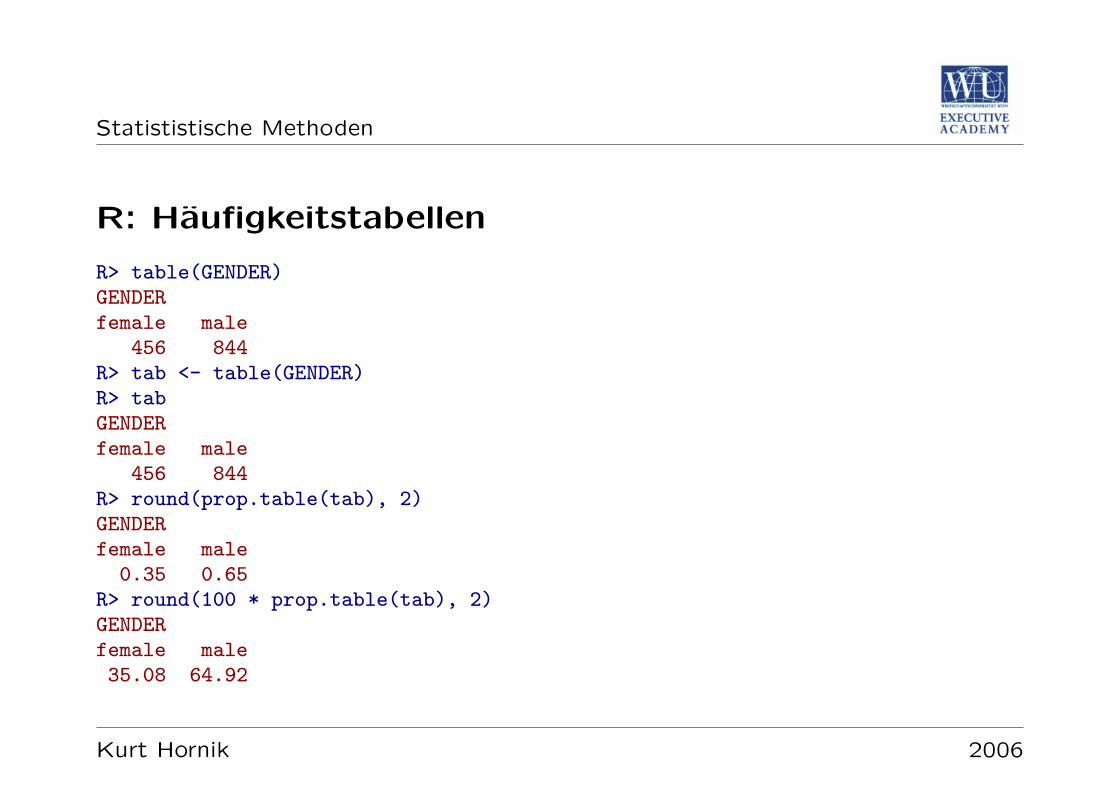
R: Haufigkeitstabellen
R> table(GENDER)GENDERfemale male
456 844R> tab <- table(GENDER)R> tabGENDERfemale male
456 844R> round(prop.table(tab), 2)GENDERfemale male
0.35 0.65R> round(100 * prop.table(tab), 2)GENDERfemale male35.08 64.92
Kurt Hornik 2006

Statististische Methoden
Grafische Beschreibung
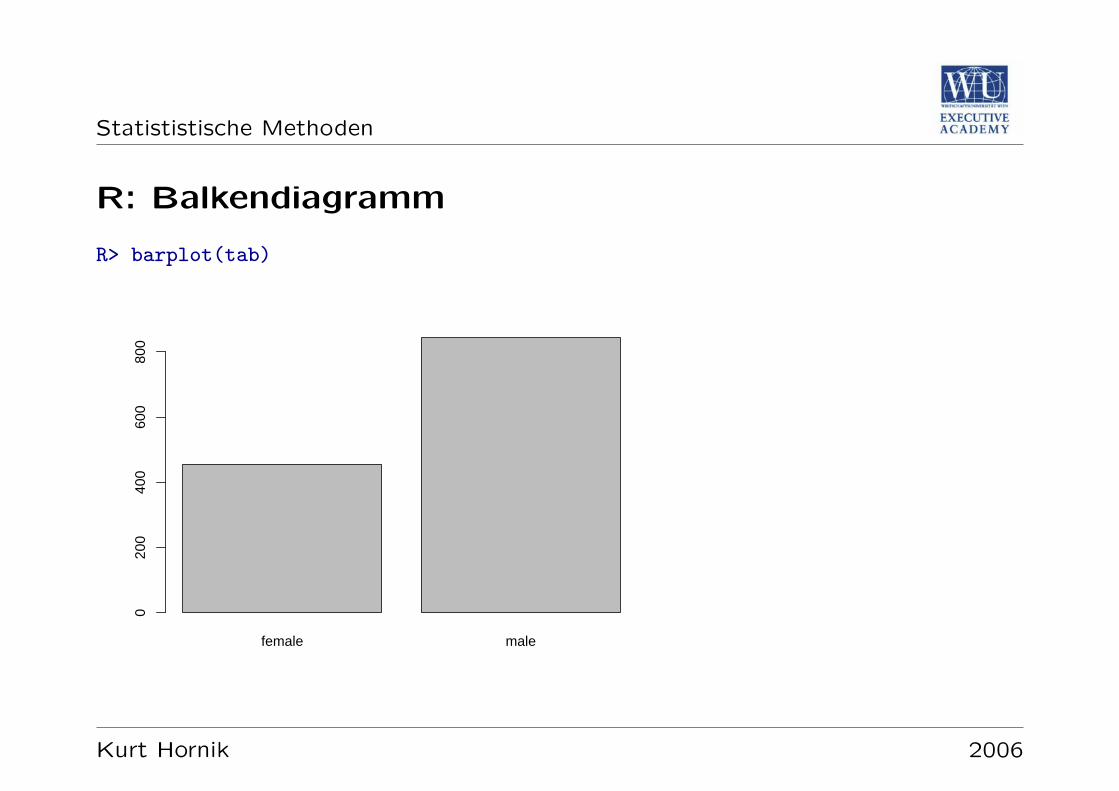
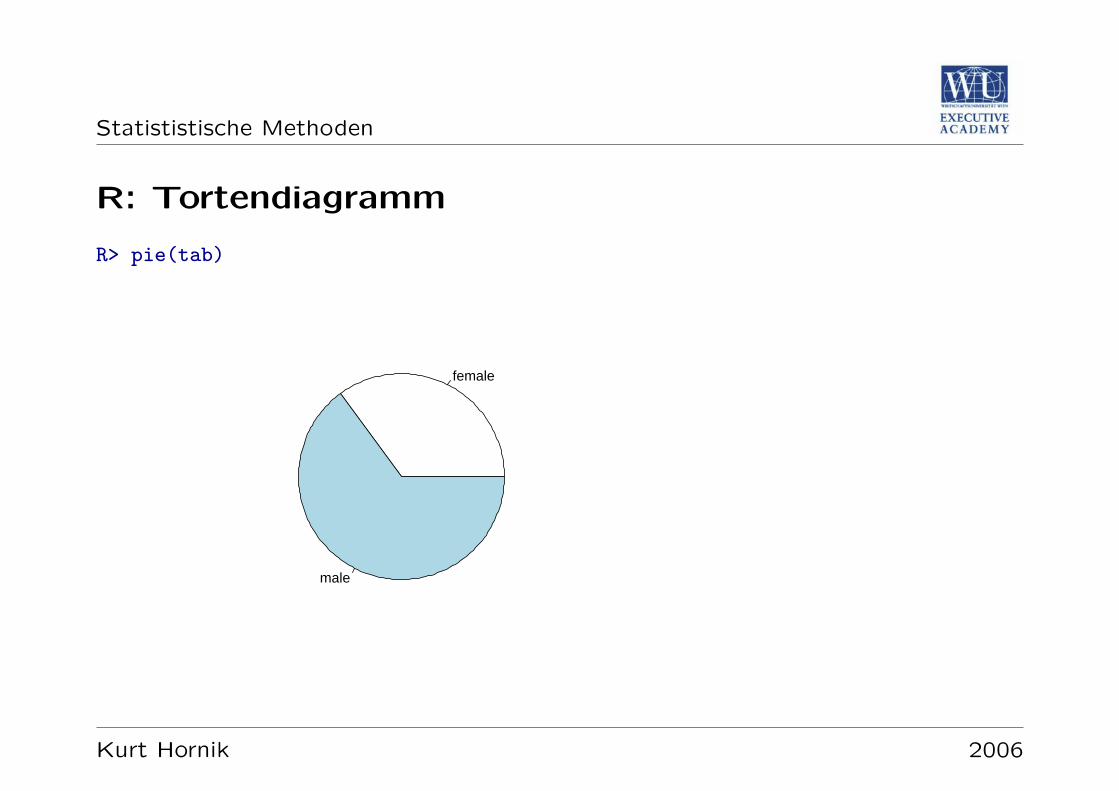
Balkendiagramme (Bar Charts); gegebenenfalls auch Tortendiagramme (Pie Charts;Kreisdiagramme)
Balkendiagramme: flachenproporzionale Darstellung von Haufigkeiten durchRechtecke konstanter Breite auf der selben Grundlinie (auch: langenpropo-zional via Hohe der Balken)
Tortendiagramme: flachenproporzionale Darstellung von Haufigkeiten durchKreissektoren (auch: langenpropozional via Bogenlange der Sektoren)
Balkendiagramme erlauben wesentlich besser, Haufigkeiten untereinander zu ver-gleich.
Tortendiagramme mussen annotiert werden, damit die tatsachlichen Werte derHaufigkeiten vermittelt werden konnen.
Kurt Hornik 2006
Statististische Methoden
R: Balkendiagramm
R> barplot(tab)
female male
020
040
060
080
0
Kurt Hornik 2006
Statististische Methoden
R: Tortendiagramm
R> pie(tab)
female
male
Kurt Hornik 2006

Statististische Methoden
Inferenz fur ein kategoriales Merkmal
Typische Fragestellungen:
• Kommen alle Kategorien gleich haufig vor?
• Entsprechen die Haufigkeiten in den Kategorien einer bestimmten Vorgabe?
• Entspricht die Haufigkeit (Anteilswert, Prozentsatz) in einer Kategorie einerbestimmten Vorgabe?
• In welchem Bereich kann man den Anteil einer Kategorie in der Grundgesamt-heit erwarten?
Kurt Hornik 2006

Statististische Methoden
Schatzung von Anteilswerten
Welche Schlusse uber die Lage des Anteilswertes p in der Population konnen wirauf Basis einer Stichprobe ziehen?
Naheliegende Idee: Schatzung von p durch den Anteilswert p in der Stichprobe(allgemeinere Prinzipien fur die Schatzung e.g. durch die Maximum Likelihood Me-thode: jenen Wert nehmen sodaß die beobachteten Daten
”am wahrscheinlichsten“
werden).
Aber wie gut sind diese Schatzungen? Brauchen Schwankungsbreiten I = [p−l, p+r],die unsere Einschatzung der Unsicherheit beim Schluss von der Stichprobe auf diePopulation zum Ausdruck bringt.
Der Anteilswert in der Grundgesamtheit soll mit”hinreichend hoher“ Sicherheit im
sogenannten Konfidenzintervall I liegen.
Kurt Hornik 2006

Statististische Methoden
Konfidenzintervalle: Methode
Dazu brauchen wir geeignete Modelle, um Unsicherheit quantifizieren zu konnen.Typischerweise Annahme:
Die Stichprobe ist durch”zufalliges“ Ziehen aus der Grundgesamtheit ent-
standen.
Dann kann man (annahernd) die Haufigkeit berechnen, dass fur zufallig gezogeneStichproben der wahre Anteilswert p in dem aus der Stichprobe berechneten Konfi-denzintervall liegt (sogenannte Uberdeckungswahrscheinlichkeit, Confidence Level).
Durch geeignete Wahl der Schwankungsbreiten kann das Confidence Level hinrei-chend groß (e.g., ≥ 95%) gemacht werden.
Kurt Hornik 2006

Statististische Methoden
Konfidenzintervalle: Interpretation
Beachte:
• Fur jede Stichprobe liegt der (unbekannte) wahre Anteilswert p im Konfidenz-intervall oder nicht (keine
”Fuzziness“).
• Die Unsicherheit besteht darin, welche dieser Stichproben (”gute oder schlech-
te“) gezogen wurden.
• Zufallig gezogene Stichproben sind mit zumindest der Uberdeckungswahr-scheinlichkeit
”gut“ (Interpretation durch Anwendung des frequentistischen
Wahrscheinlichkeitsbegriffes).
Kurt Hornik 2006

Statististische Methoden
Konfidenzintervalle: Eigenschaften
Konfidenzintervalle sind
• umso großer, je großer die Uberdeckungswahrscheinlichkeit ist
• umso kleiner, je großer der Stichprobenumfang n (Anzahl der Beobachtungs-einheiten in der Stichprobe) ist. In typischen Fallen ist die Lange proporzionalzu 1/
√n.
Kurt Hornik 2006

Statististische Methoden
Testen von Anteilswerten auf Gleichheit
Wie konnen wir auf Basis einer Stichprobe darauf schließen ob die Kategorien inder Grundgesamtheit gleich haufig sind oder nicht?
Grundidee: auf Basis der Stichprobe erhalten wir die beobachteten (absoluten)Haufigkeiten oi = npi. Sind alle k Kategorien in der Grundgesamtheit gleich haufig,so wurden wir dagegen (
”im Idealfall“) Haufigkeiten von
”in etwa“ ei = n/k erwar-
ten.
Je starker sich die oi von den ei unterscheiden, desto schlechter passen die Beob-achtungen zur Annahme der Gleichheit.
Allerdings ist dabei wieder unsere Unsicherheit beim Schluss von der Stichprobe aufdie Population zu quantifizieren.
Kurt Hornik 2006

Statististische Methoden
Testen a la Neyman-Pearson
Vergleich zweier Hypothese (Aussagen):
Nullhypothese (H0) (in unserem Fall: die Kategorien kommen gleich haufig vor)
Alternativhypothese (HA) (in unserem Fall: die Kategorien kommen nicht gleichhaufig vor).
Je schlechter die Daten zur Nullhypothese passen, desto eher sind wir geneigt, diesezugunsten der Alternativhypothese zu verwerfen.
Dabei wird die Wahrscheinlichkeit, die Nullhypothese falschlicherweise zu verwerfen(Fehler erster Art), kontrolliert (Signifikanzniveau α des Tests).
Beachte die fundamentale Asymmetrie zwischen H0 und HA!
Kurt Hornik 2006

Statististische Methoden
Testen mit p-Werten
Wir berechnen unter der Nullhypothese die Wahrscheinlichkeit, etwas zu beobachtenwas noch schlechter zur Nullhypothese passt als das was wir beobachtet haben:ergibt den sogenannten p-Wert.
Je kleiner der p-Wert ist, desto schlechter passen die Daten zur Nullhypothese.Diese wird daher verworfen, wenn der p-Wert hinreichend klein (kleiner als einvorgegebenes Signifikanzniveau, e.g. 5%) ist.
Beachte: der p-Wert hangt von der Stichprobe ab (keine Wahrscheinlichkeit aufBasis der Grundgesamtheit). Also Vorsicht bei der frequentistischen Interpretation!
Kurt Hornik 2006

Statististische Methoden
Testen von Anteilswerten auf Gleichheit
Auf Basis der allgemeinen Prinzipien brauchen wir ein Maß fur die Verschiedenheitvon beobachteten und erwarteten Haufigkeiten oi und ei. Ein solches ist die Funktion
X2 =k∑i=1
(oi − ei)2/ei
(sogenannter Chi-Quadrat Abstand); man konnte aber grundsatzlich auch andereVerschiedenheitsmaße verwenden. Unter der Nullhypothese besitzt X2 annaherndeine χ2-Verteilung mit k−1 Freiheitsgraden auf deren Basis daher die p-Werte diesessogenannten Chi-Quadrat-Tests auf Gleichverteilung berechnet werden konnen.
Kurt Hornik 2006

Statististische Methoden
Weitere Tests fur Anteilswerte
Testen von Anteilswerten auf eine bestimmte Vorgabe ist analog zum Test aufGleichheit (die ei sind dann npi mit den vorgegebenen pi).
Sind einfache Nullhypothesen uber einen einzelnen Anteilswert (pi = π) von Inter-esse, so sind mehrere Alternativhypothesen denkbar.
• pi 6= π (zweiseitiger Test: große Abweichungen von π in beide Richtungen sindsignifikant)
• pi < π oder pi > π (einseitiger Test: nur große Abweichungen von π in eineRichtung sind signifikant)
Moglichkeit in HA das zu stecken”was man wirklich wissen will“.
Kurt Hornik 2006

Statististische Methoden
R: Inferenz fur einen Anteilswert
(Approximative) p-Werte fur ein- und zweiseitige Hypothesentests und Konfidenz-intervalle fur Anteilswerte mit der Funktion binom.test (auch: prop.test).
R> x <- table(GENDER)["female"]R> xfemale
456R> n <- sum(table(GENDER))R> n[1] 1300R> x/n
female0.3507692
Kurt Hornik 2006

Statististische Methoden
R> binom.test(x, n, p = 1/3)Exact binomial test
data: x and nnumber of successes = 456, number of trials = 1300, p-value = 0.1856alternative hypothesis: true probability of success is not equal to 0.333333395 percent confidence interval:0.3248057 0.3774095
sample estimates:probability of success
0.3507692
Kurt Hornik 2006

Statististische Methoden
R> binom.test(x, n, p = 0.3, "less")Exact binomial test
data: x and nnumber of successes = 456, number of trials = 1300, p-value = 1alternative hypothesis: true probability of success is less than 0.395 percent confidence interval:0.0000000 0.3731595
sample estimates:probability of success
0.3507692
Kurt Hornik 2006

Statististische Methoden
R: Vergleich von Anteilswerten
Test aller Haufigkeiten auf Gleichheit oder bestimmte Vorgabe mit der Funktionchisq.test.
R> chisq.test(table(GENDER))Chi-squared test for given probabilities
data: table(GENDER)X-squared = 115.8031, df = 1, p-value < 2.2e-16
Kurt Hornik 2006

Statististische Methoden
Ein metrisches Merkmal
Kurt Hornik 2006

Statististische Methoden
Beschreibung
Bei metrischen (vor allem stetigen) Merkmalen gibt es im allgemeinen”zu vie-
le“ verschiedene Werte, als dass eine Beschreibung auf Basis der Haufigkeiten derbeobachteten Werte wirklich informativ ware.
• Bildung von Gruppen durch Einteilung in Intervalle und Beschreibung derHaufigkeiten dieser Gruppen
• Entwicklung geeigneter (weniger) Maßzahlen, die die Verteilung der Datenadaquat beschreiben
Kurt Hornik 2006

Statististische Methoden
Histogramme
Histogramme sind flachenpropozionale rechteck-basierte Darstellungen der Haufig-keiten metrischer Merkmale in bestimmten Intervallen.
Sind alle Intervalle gleich breit, so ist die Darstellung auch langenpropozional (zurHohe).
Beachte den fundamentalen Unterschied zu Balkendiagrammen: die Balken sindnicht voneinander getrennt; die x Achse entspricht den gemessenen Werten von xund legt daher die Lage der Balken fest.
Die Darstellung der Information hangt von der Wahl der Intervalle (im einfachstenFall: der Klassenbreite) ab.
Kurt Hornik 2006
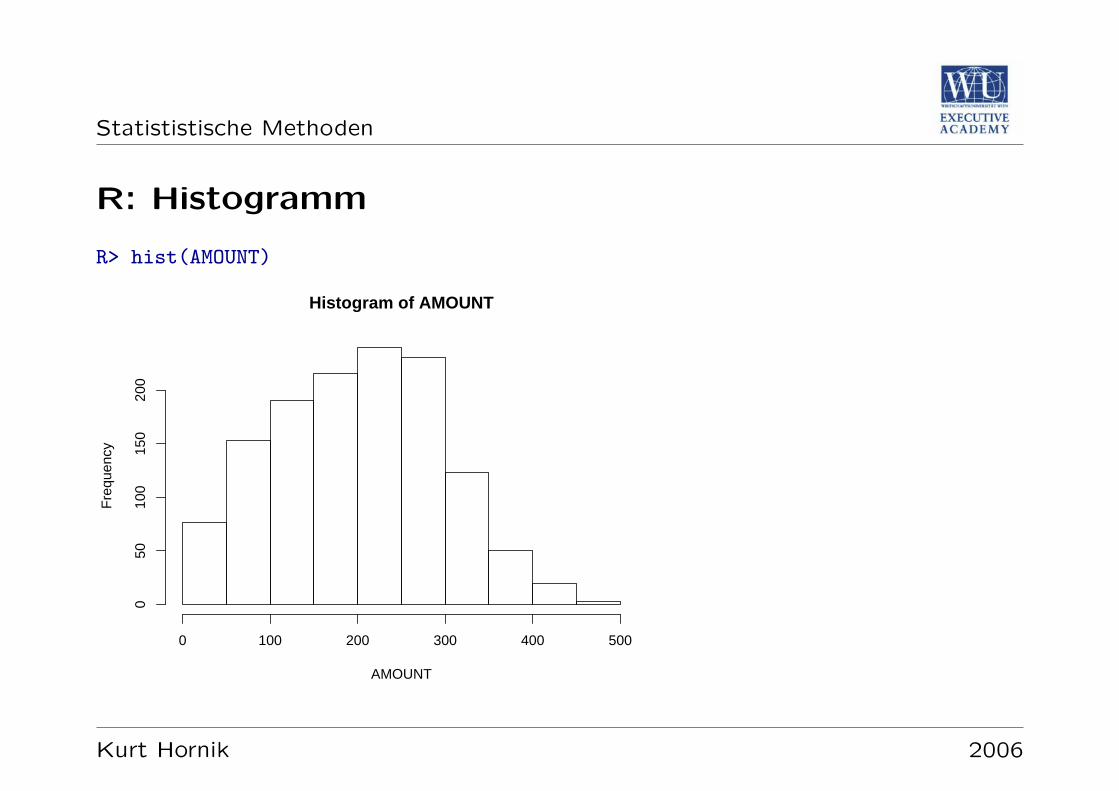
Statististische Methoden
R: Histogramm
R> hist(AMOUNT)
Histogram of AMOUNT
AMOUNT
Fre
quen
cy
0 100 200 300 400 500
050
100
150
200
Kurt Hornik 2006

Statististische Methoden
Histogramme
Bei aquidistanten Klassen werden in R standardmassig”Frequencies“, also absolute
Haufigkeiten aufgetragen. Bei Verwendung von”Densities“ (relative Haufigkeiten,
argument freq = FALSE) wird die Flache unter dem Histogramm 1.
Geglattete Dichteschatzer erhalt man mittels density; diese konnen mit plot einzelnoder mit lines zusammen mit dem Histogramm gezeichnet werden.
Kurt Hornik 2006
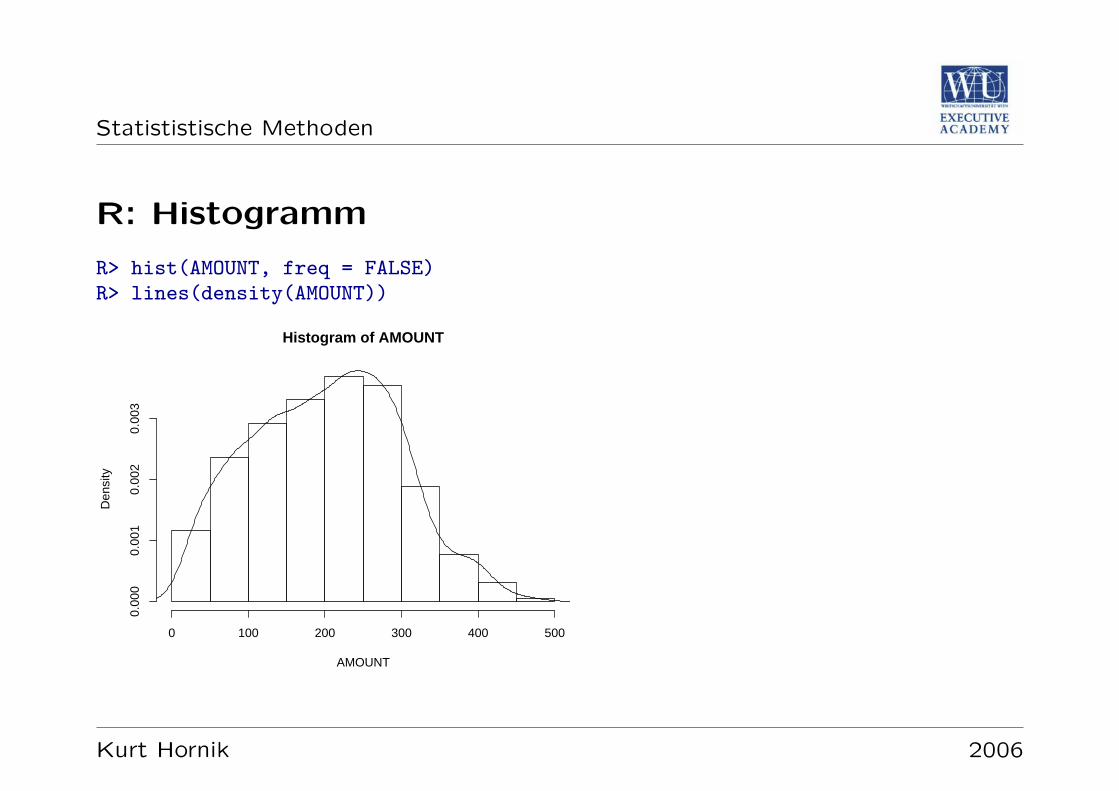
Statististische Methoden
R: Histogramm
R> hist(AMOUNT, freq = FALSE)R> lines(density(AMOUNT))
Histogram of AMOUNT
AMOUNT
Den
sity
0 100 200 300 400 500
0.00
00.
001
0.00
20.
003
Kurt Hornik 2006

Statististische Methoden
Lagemaße
Lagemaße beschreiben die Lage einer Verteilung.
Mittelwert: arithmetisches Mittel der Werte, x = (1/n)∑n
i=1 xi
Median: der”Wert in der Mitte“, sodass die Halfte der Daten kleiner (beziehungs-
weise: nicht großer) und die Halfte der Daten großer (beziehungsweise: nichtkleiner) als dieser Wert sind.
Modus: der Wert der am haufigsten vorkommt
Quantile: analog zum Median: Werte sodass 100p% der Daten links und 100(1−p)% der Daten rechts von diesen liegen. Vor allem: erstes (oder: unteres)Quartil (Q1, p = 0.25) und drittes Quartil (Q3, p = 0.75).
Kurt Hornik 2006

Statististische Methoden
R: Lagemaße
R> mean(AMOUNT)[1] 201.3692R> median(AMOUNT)[1] 204R> summary(AMOUNT)
Min. 1st Qu. Median Mean 3rd Qu. Max.15.0 127.0 204.0 201.4 273.0 474.0
Kurt Hornik 2006

Statististische Methoden
Wann sind Daten gut durch ein Lagemaß beschreibbar?
• Bei eingipfeligen symmetrischen Daten sind Mittelwert, Median und Modus imwesentlichen gleich, und
”typisch“ fur die Daten.
• Andernfalls (beispielsweise fur schiefe, U-formige, mehrgipfelige, oder gleich-verteilte Daten) reicht ein Lagemaß nicht aus, um die Verteilung gut zu be-schreiben.
Beachte: Modus auch fur Nominalskalen, Median auch fur Ordinalskalen sinnvoll.
Oft sind Daten”einfach“ auf annahernd eingipfelig symmetrische Form transfor-
mierbar (e.g., log fur monetare Großen).
Kurt Hornik 2006
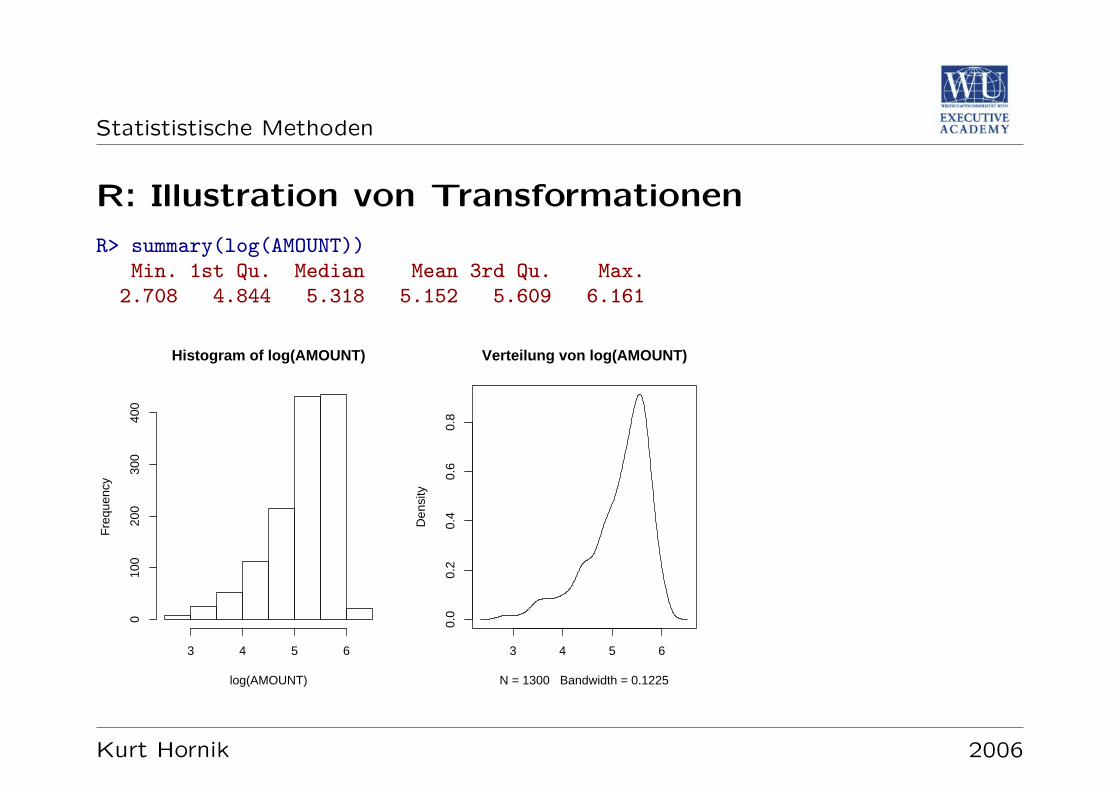
Statististische Methoden
R: Illustration von Transformationen
R> summary(log(AMOUNT))Min. 1st Qu. Median Mean 3rd Qu. Max.
2.708 4.844 5.318 5.152 5.609 6.161
Histogram of log(AMOUNT)
log(AMOUNT)
Fre
quen
cy
3 4 5 6
010
020
030
040
0
3 4 5 6
0.0
0.2
0.4
0.6
0.8
Verteilung von log(AMOUNT)
N = 1300 Bandwidth = 0.1225
Den
sity
Kurt Hornik 2006

Statististische Methoden
Streuungsmaße
Streuungsmaße geben an, wie sehr Daten (um ein Lagemaß) streuen, oder in wel-chen Bereichen die Daten liegen.
Mittlere absolute Abweichung: (1/N)∑
i |xi − x|, wobei N gleich n oder n− 1
Varianz: σ2 = (1/N)∑
i(xi − x)2 (mittlere quadratische Abweichung vom Mittel-wert)
Standardabweichung: σ, die Wurzel aus der Varianz
Interquartilsabstand: Q3−Q1, Lange des Intervalls in dem die mittleren 50% derDaten liegen
Spannweite: Differenz von großtem und kleinstem Wert
Sind nur bei eingipfeligen symmetrischen Verteilung gut interpretierbar.
Kurt Hornik 2006

Statististische Methoden
Boxplots
Oft ergibt sich eine brauchbare Beschreibung der Daten durch die”5-Punkt Zu-
sammenfassung“: Minimum, erstes Quartil, Median, drittes Quartil, Maximum (imwesentlichen; enthalt 5 Lagemaße und die Streuungsmaße Interquartilsabstand undSpannweite).
Diese Zusammenfassung kann durch Boxplots (Box-and-Whisker Plots) visualisiertwerden. Im einfachsten Fall: Schachtel zwischen erstem und drittem Quartil, Trenn-strich beim Median; Schnurrbarthaare zwischen Minimum und Q1 beziehungsweiseQ3 und Maximum.
Erweiterungen: Visualisierung von Ausreissern (Outliers) als solche Werte, die vonder Box mit den mittleren 50% weit weg sind (sogenannte inner und outer fences,standardmaßig je das 1.5-fache der Lange der Box nach rechts und links); Schnurr-barthaare nur bis zu den letzten Punkten innerhalb der inner fences.
Kurt Hornik 2006

Statististische Methoden
R: Boxplots
R> boxplot(AMOUNT)R> title(main = "Boxplot von AMOUNT")
010
020
030
040
0
Boxplot von AMOUNT
Kurt Hornik 2006

Statististische Methoden
Inferenz
Wichtige inferenzstatistische Fragen:
• Entspricht der Mittelwert einer bestimmten Vorgabe? (Beziehungsweise: ist einMittelwert anders/großer/kleiner als eine bestimmte Vorgabe?)
• In welchem Bereich kann man einen Mittelwert in der Grundgesamtheit erwar-ten?
Vorgangsweise analog zur Inferenz uber Anteilswerte: zunachst ist es naheliegend,den Mittelwert µ der Grundgesamtheit durch den Mittelwert x der Stichprobe zuschatzen.
Daraus ergeben sich (symmetrische) Konfidenzintervalle fur µ (allgemein: auf Ba-sis des zentralen Grenzverteilungssatzes; in Spezialfallen genauer [Normalverteilungmit bekannter beziehungsweise unbekannter Varianz: Standardnormalverteilung be-ziehungsweise t Verteilung])
Analog Tests von Hypothesen uber µ auf Basis von x.
Kurt Hornik 2006

Statististische Methoden
Inferenz mit R
(Approximative) p-Werte fur ein- und zweiseitige Hypothesentests und Konfidenz-intervalle fur Mittelwerte mit der Funktion t.test.
R> t.test(AMOUNT, mu = 200, alternative = "greater")One Sample t-test
data: AMOUNTt = 0.5217, df = 1299, p-value = 0.301alternative hypothesis: true mean is greater than 20095 percent confidence interval:197.0492 Inf
sample estimates:mean of x201.3692
Kurt Hornik 2006

Statististische Methoden
Zwei oder mehr Merkmale
Kurt Hornik 2006

Statististische Methoden
Mehrere Merkmale
Wir konnen zwei Fragenkomplexe unterscheiden:
• Fragen nach Gemeinsamkeiten und Unterschieden
• Fragen nach Zusammenhangen (Wenn/Dann Beziehungen)
Zusammenhange konnen entweder”ungerichtet“ sein oder eine naturliche Rich-
tung haben, sodass von einer Gruppe von Merkmalen (unabhangige oder erklaren-de Merkmale, Inputs) auf eine zweite Gruppe (abhangige oder erklarte, Out-puts/Targets) geschlossen wird (Predictive Modeling)
Achtung:”Abhangigkeit“ hier nicht im Sinne der Wahrscheinlichkeitsrechnung ge-
meint.
Im ersten Fall sind gemeinsame, im zweiten bedingte Verteilungen von Interesse.
Beachte: die Art der Datenerhebung hat Auswirkungen auf mogliche Schlusse dieaus den Daten gezogen werden konnen.
Kurt Hornik 2006

Statististische Methoden
Zwei (oder mehr) kategoriale Merkmale
Kurt Hornik 2006

Statististische Methoden
Beschreibung
Beschreibungen beruhen (wieder) auf den (gemeinsamen) Haufigkeiten der Kate-gorien in den Daten.
Fur zwei kategoriale Merkmale: nij Haufigkeit der Beochachtungseinheiten, fur diedas erste Merkmal in Kategorie i und das zweite in Kategorie j ist.
Ubersichtliche Anordnungsmoglichkeit in einem rechteckigen Schema mit i alsZeilen- und j als Spaltenindex:
n11 n12 · · · n1l
n21 n22 · · · n2l... ... ...nk1 nk2 · · · nkl
Kurt Hornik 2006

Statististische Methoden
Kontingenztafeln
Dabei entsprechen Zeilen dem (den Kategorien des) ersten Merkmal(s) und Spalten(den Kategorien des) zweiten Merkmal(s).
Solche Tabellen nennt man Kontingenztafeln (Kreuztabellen, Kreuzklassifikatio-nen):
Kontigenztafeln entstehen durch Aufteilen der Haufigkeiten eines Merk-mals nach den Kategorien eines zweiten Merkmals.
Die einzelnen Eintrage nij heissen Zellen der Kontingenztafel.
Durch Bildung von Zeilen- beziehungsweise Spaltensummen entstehe die Rander(Margins): diese beschreiben die (Rand-)Haufigkeiten von jeweils nur einem Merk-mal.
Kurt Hornik 2006

Statististische Methoden
Gemeinsame und bedingte Information
Die Haufigkeit nij ist die (absolute) Haufigkeit des gemeinsamen Auftretens vonKategorie i des ersten und Kategorie j des zweiten Merkmals. Konnten diese auchals relative Haufigkeiten (Anteilswerte, Prozent) bezogen auf die Gesamtanzahl vonBeobachtungen angeben. Entspricht der gemeinsamen Verteilung P (x = i, y = j).
Bezieht man diese Haufigkeiten auf die Randhaufigkeiten in den Zeilen beziehungs-weise Spalten (
”Zeilenprozent“ beziehungsweise
”Spalteprozent“), so gelangt man
zu entsprechender bedingter Information (”von den Beobachtungen in Gruppe i
bezuglich A sind x% in Gruppe j bezuglich B). Entspricht der bedingten VerteilungP (y = j|x = i).
Beachte: fur das Ruckrechnen auf die gemeinsame Information braucht man dieentsprechende (fehlende) Randinformation.
Kurt Hornik 2006

Statististische Methoden
R: Kontingenztafeln
R> table(GENDER, CHOICE)CHOICE
GENDER no yesfemale 273 183male 627 217
R> tab <- table(GENDER, CHOICE)R> round(100 * prop.table(tab, 1), 2)
CHOICEGENDER no yes
female 59.87 40.13male 74.29 25.71
Kurt Hornik 2006

Statististische Methoden
Grafische Beschreibung
Moderne Methoden:
Mosaikplots: flachenproporzionale Darstellung der gemeinsamen Haufigkeit durchgeeignet angeordnete Rechtecke (
”Tiles“). Zusatzliche Information kann e.g.
durch farbliche Annotation dargestellt werden.
Spineplots: Spezialfall von Mosaikplots fur den Fall eines ahangigen kategorialenMerkmals y (Verallgemeinerung der klassischen gestapelten Balkendiagrammefur kategoriales x). Visualisierung der bedingten Verteilung von y gegeben xnach der Randverteilung von x.
Kurt Hornik 2006
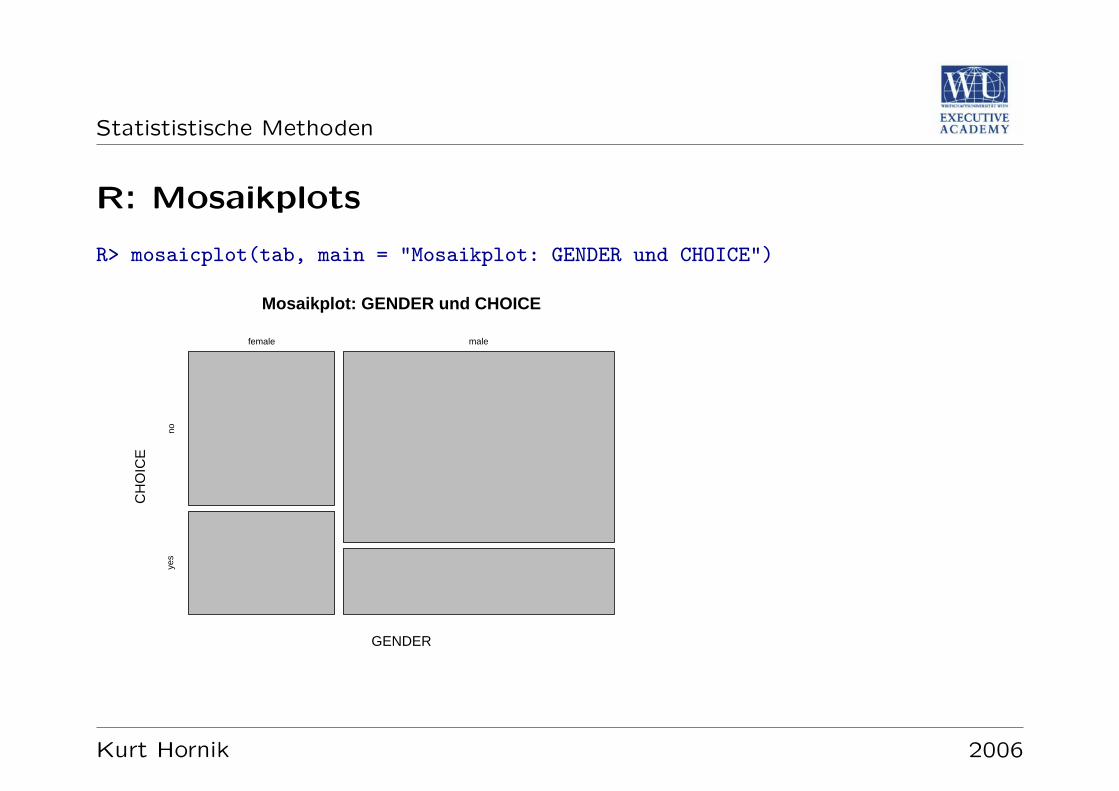
Statististische Methoden
R: Mosaikplots
R> mosaicplot(tab, main = "Mosaikplot: GENDER und CHOICE")
Mosaikplot: GENDER und CHOICE
GENDER
CH
OIC
E
female male
noye
s
Kurt Hornik 2006
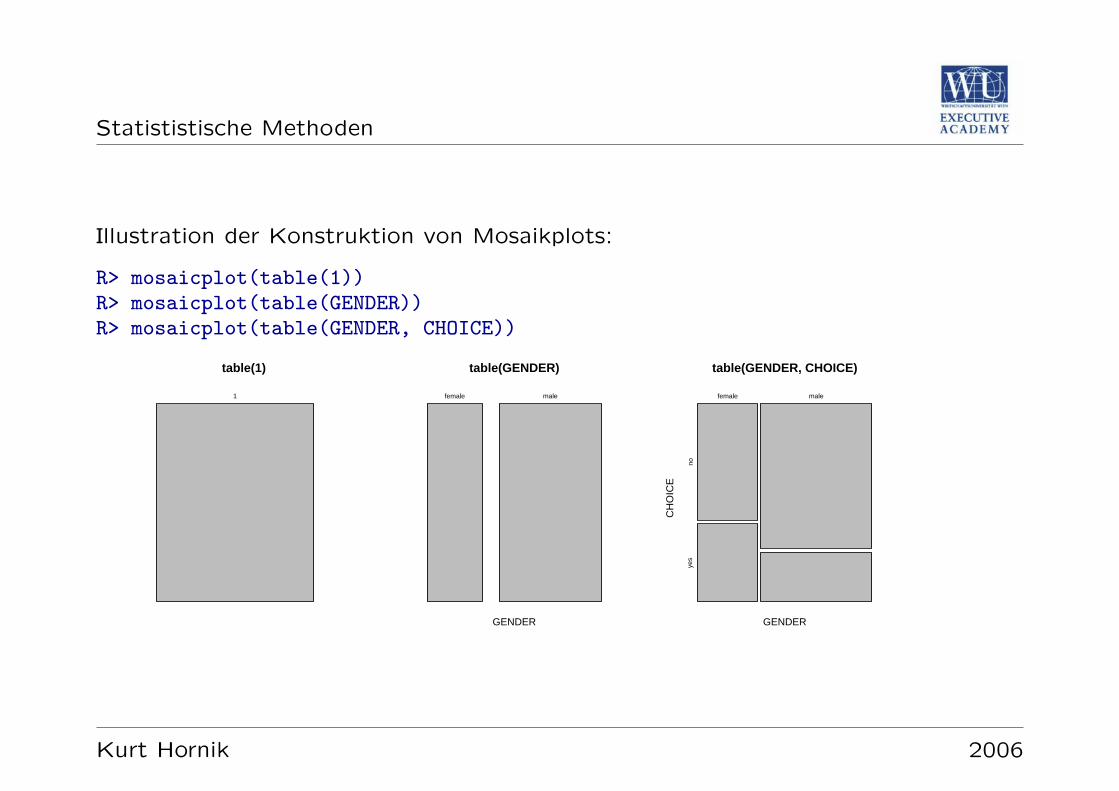
Statististische Methoden
Illustration der Konstruktion von Mosaikplots:
R> mosaicplot(table(1))R> mosaicplot(table(GENDER))R> mosaicplot(table(GENDER, CHOICE))
table(1)
1
table(GENDER)
GENDER
female male
table(GENDER, CHOICE)
GENDER
CH
OIC
E
female male
noye
s
Kurt Hornik 2006
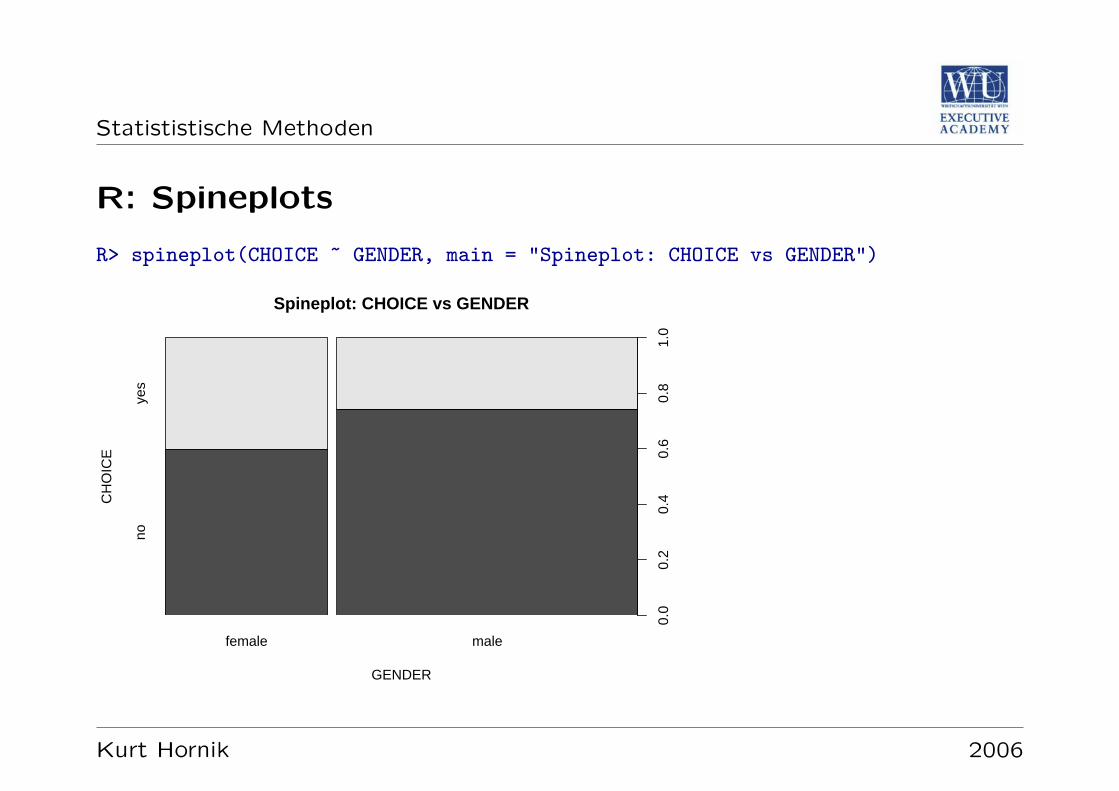
Statististische Methoden
R: Spineplots
R> spineplot(CHOICE ~ GENDER, main = "Spineplot: CHOICE vs GENDER")
Spineplot: CHOICE vs GENDER
GENDER
CH
OIC
E
female male
noye
s
0.0
0.2
0.4
0.6
0.8
1.0
Kurt Hornik 2006

Statististische Methoden
Mehr als zwei kategoriale Merkmale
Beschreibungen beruhen immer auf den gemeinsamen Haufigkeiten ni1,...,im der Kate-gorien der einzelnen Merkmale (sogenannte hoherdimensionale Kontingenztafeln).
Fur die tabellarische Darstellung gerne geeignete”Ausflachung“.
Fur die grafische Beschreibung: Mosaikplots und Verallgemeinerung (geeignete An-ordnung von flachenproporzionalen rechteck-basierten Plots bestimmter Haufigkei-ten in Abhangigkeit davon, welche bedingte Verteilung visualisiert werden soll).
Kurt Hornik 2006

Statististische Methoden
Tabellarische Beschreibung von 3 kategorialen Merkmalen durch”Ausflachung“ der
Kontingenztafel:
R> BOUGHT_ART <- (ART > 0)R> ftable(table(GENDER, BOUGHT_ART, CHOICE))
CHOICE no yesGENDER BOUGHT_ARTfemale FALSE 211 94
TRUE 62 89male FALSE 486 82
TRUE 141 135
Kurt Hornik 2006

Statististische Methoden
Tabellarische Beschreibung von 3 kategorialen Merkmalen durch Mosaikplots:
R> mosaicplot(table(GENDER, CHOICE, BOUGHT_ART), main = "")R> title(main = "Mosaikplot: GENDER, CHOICE und BOUGHT_ART")
GENDER
CH
OIC
E
female male
noye
s
FALSE TRUE FALSE TRUE
Mosaikplot: GENDER, CHOICE und BOUGHT_ART
Kurt Hornik 2006

Statististische Methoden
Inferenz fur zwei kategoriales Merkmale
Typische Fragestellungen:
• Unterscheiden sich die Haufigkeiten eines kategorialen Merkmals y zwischen denGruppen eines zweiten kategorialen Merkmals x? (Frage nach Zusammenhang,y ist das abhangige Merkmal.) ⇒ Homogenitatsproblem
• Sind zwei kategoriale Merkmale voneinander unabhangig? (Frage nach(Nicht-)Zusammenhang, es gibt keine abhangigen Merkmale.) ⇒ Unabhangig-keitsproblem
• Unterscheiden sich die Verteilungen zweier kategorialer Merkmale, die an denselben Beobachtungseinheiten erhoben wurden? ⇒ Symmetrieproblem (
”Mc-
Nemar Test“)
Kurt Hornik 2006

Statististische Methoden
Homogenitatsproblem
Wir greifen die Ideen des Vergleiches von Beobachtetem und unter der Nullhypo-these (hier: Homogenitat, i.e., kein Unterschied zwischen den Gruppen) auf.
• Beobachtet werden die gemeinsamen Haufigkeiten oij = nij.
• Erwarten wurden wir (unter H0), dass sich die gemeinsamen Haufigkeiten imVerhaltnis der Randhaufigkeiten aufteilen (oder: dass die bedingten Haufigkei-ten alle gleich sind):
eij = ni.n.j/n
wobei ni. und n.j die Randhaufigkeiten (Zeilen- und Spaltensummen) bezeich-nen.
Kurt Hornik 2006

Statististische Methoden
Homogenitatstests
Zur Messung der Verschiedenheit von beobachteten und erwarteten Haufigkeitenoij und eij konnen wir wieder den Chi-Quadrat Abstand
X2 =∑i,j
(oij − eij)2
eij
verwenden. Unter H0 besitzt X2 annahernd eine χ2-Verteilung mit (k − 1)(l − 1)Freiheitsgraden.
Besser (weil bedingtes Inferenzproblem) und moderner ist es einen Permutations-test durchzufuhren (alle moglichen Tabellen mit festen Randern betrachten;
”Fis-
her’s Exact Test“), gegebenfalls sogar mit anderer Teststatistik (”Mythos des Chi-
Quadrat-Homogenitatstests“).
Abweichungen von H0 konnen durch erweiterte Mosaikplots illustriert werden.
Kurt Hornik 2006

Statististische Methoden
Unabhangigkeitstests
Analog zum Fall der Homogenitat wurden wir unter der Nullhypothese der Un-abhangigkeit (von Zeilen und Spalten) erwarten dass
eij = ni.n,j/n
Konnen daher analog zum Homogenitatsproblem vorgehen. E.g., das selbe Verschie-denheitsmass und darauf basierend den sogenannten Chi-Quadrat Unabhangigkeit-stest verwenden.
Aber beachte den”grundlegenden“ Unterschied zwischen den beiden Inferenzpro-
blemen!
Kurt Hornik 2006

Statististische Methoden
R: Homogenitats- und Unabhangigkeitstests
R> table(GENDER, CHOICE)CHOICE
GENDER no yesfemale 273 183male 627 217
R> chisq.test(table(GENDER, CHOICE))Pearson’s Chi-squared test with Yates’ continuity correction
data: table(GENDER, CHOICE)X-squared = 28.2284, df = 1, p-value = 1.078e-07
Kurt Hornik 2006

Statististische Methoden
Zwei (oder mehr) metrische Merkmale
Kurt Hornik 2006

Statististische Methoden
Beschreibung
Die Beschreibung zweier metrischer Merkmale beruht auf der Tatsache dass dieseals Punkte (x, y) in einem rechtwinkeligen kartesischen Koordinatensystem (i.e., alsPunkte in der x-y Ebene) interpretiert werden konnen.
Grafische Beschreibung: einfach diese Punkte zeichnen (Streudiagramm, Scatter-plot).
Aber was kann man aus diesen”Rohdaten“ erkennen? Brauchen einfachere Metho-
den (Maßzahlen, geeignete Ersatzkurven durch die Daten).
Kurt Hornik 2006
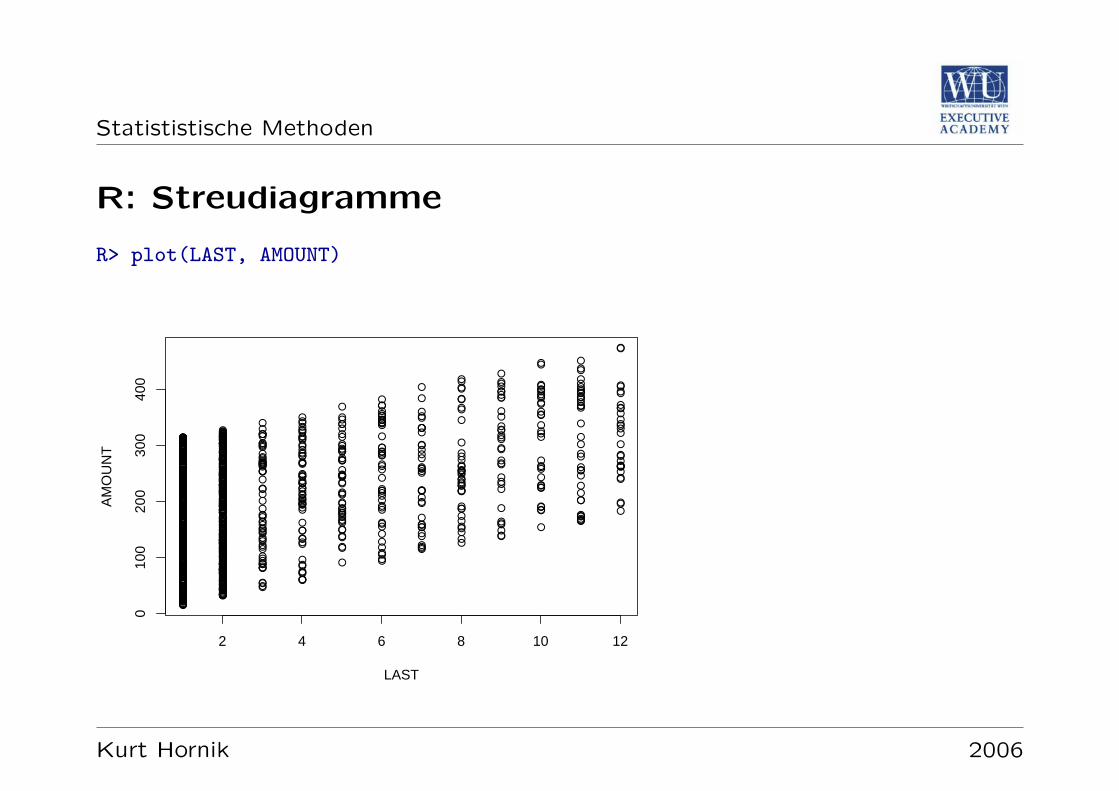
Statististische Methoden
R: Streudiagramme
R> plot(LAST, AMOUNT)
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
● ●●
●
●
● ●●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
● ●
●
●●
●●
●
●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
● ●
●
●
●
●
●●
● ●●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
● ●
●
●●●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
2 4 6 8 10 12
010
020
030
040
0
LAST
AM
OU
NT
Kurt Hornik 2006

Statististische Methoden
Assoziationsmaße
Assoziationsmaße messen die Starke des (ungerichteten) Zusammenhangs zwischenzwei Merkmalen.
Fur einfache je-desto Assoziationen Grundidee: Daten jeweils”in der Mitte“ (am
Mittelwert) teilen. Punkte (xi, yi) rechts oben (xi ≥ x, yi ≥ y) und links unten(xi ≤ x, yi ≤ y) stehen fur positiven (je mehr, desto mehr); die anderen Punktefur negativen (je mehr, desto weniger) Zusammenhang.
Kombination beispielsweise durch Mittel der Produkte der Differenzen von den Mit-telwerten, sogenannte Kovarianz: (1/N)
∑i(xi − x)(yi − y).
Kurt Hornik 2006

Statististische Methoden
Korrelationskoeffizient
Kovarianz ist skalenabhangig; Skalenunabhangigkeit durch Skalieren mit den Stan-dardabweichungen ergibt den (Pearson’schen) Korrelationskoeffizienten
ρ =Cov(x, y)√
Var(x)Var(y)=
∑i(xi − x)(yi − y)√∑
i(xi − x)2√∑
i(yi − y)2
Maß fur die lineare Abhangigkeit: ±1 genau dann wenn die Punkte entlang einerGeraden liegen.
Beachte: Punkte konnen exakt auf einer Kurve (e.g., Kreis) liegen, also perfektabhangig sein, und dennoch unkorreliert!
ρ ist nicht robust gegenuber Ausreissern.
Kurt Hornik 2006

Statististische Methoden
R: Assoziationsmaße
R> cor(LAST, AMOUNT)[1] 0.4521105
Kurt Hornik 2006

Statististische Methoden
Beschreibung von mehr als zwei metrischen Merkma-len
Kurz gesagt:”es ist alles sehr schwierig“.
Vielzahl von Visualisierungstechniken: 3-dimensionale Streudiagramme;”margi-
nal Views“ (e.g., Matrizen von 2-dimensionalen Scatterplots) und”conditional
Views“ (e.g., Co-Plots), geeignete Projektionen auf niedrigdimensionalere (e.g.,2-dimensionale) Raume (Hauptkomponentananalyse, Multidimensionale Skalierung,. . . ).
Fur den Fall weniger Beobachtungen multivariater Datensatze kann man Darstellun-gen wie Sterndiagramme (Star-Plots) oder (mittlerweile nur noch von historischemInteresse) Chernoff-Gesichter einsetzen.
Kurt Hornik 2006

Statististische Methoden
Datensatz: USArrests
Gibt fur die 50 US-amerikanischen Bundesstaaten und das Jahr 1973 die Rate derVerhaftungen pro 100,000 Bewohner fur Korperverletzung, Totschlag, und Verge-waltigung, sowie den prozentuellen Anteil der landlichen Bevolkerung an.
R> data("USArrests")R> summary(USArrests)
Murder Assault UrbanPop RapeMin. : 0.800 Min. : 45.0 Min. :32.00 Min. : 7.301st Qu.: 4.075 1st Qu.:109.0 1st Qu.:54.50 1st Qu.:15.07Median : 7.250 Median :159.0 Median :66.00 Median :20.10Mean : 7.788 Mean :170.8 Mean :65.54 Mean :21.233rd Qu.:11.250 3rd Qu.:249.0 3rd Qu.:77.75 3rd Qu.:26.18Max. :17.400 Max. :337.0 Max. :91.00 Max. :46.00
Kurt Hornik 2006

Statististische Methoden
R: Star-Plots
R> stars(USArrests, nrow = 5, ncol = 10)
AlabamaAlaska
ArizonaArkansas
CaliforniaColorado
ConnecticutDelaware
FloridaGeorgia
HawaiiIdaho
IllinoisIndiana
IowaKansas
KentuckyLouisiana
MaineMaryland
MassachusettsMichigan
MinnesotaMississippi
MissouriMontana
NebraskaNevada
New HampshireNew Jersey
New MexicoNew York
North CarolinaNorth Dakota
OhioOklahoma
OregonPennsylvania
Rhode IslandSouth Carolina
South DakotaTennessee
TexasUtah
VermontVirginia
WashingtonWest Virginia
WisconsinWyoming
Kurt Hornik 2006

Statististische Methoden
R: Chernoff-Gesichter
(Nicht im R Lieferumfang enthalten.)
R> source("faces.R")R> faces(USArrests, labels = state.abb, nrow = 4, ncol = 13)
Index
AL
Index
AK
Index
AZ
Index
AR
Index
CA
Index
CO
Index
CT
Index
DE
Index
FL
Index
GA
Index
HI
Index
ID
Index
IL
Index
IN
Index
IA
Index
KS
Index
KY
Index
LA
Index
ME
Index
MD
Index
MA
Index
MI
Index
MN
Index
MS
Index
MO
Index
MT
Index
NE
Index
NV
Index
NH
Index
NJ
Index
NM
Index
NY
Index
NC
Index
ND
Index
OH
Index
OK
Index
OR
Index
PA
Index
RI
Index
SC
Index
SD
Index
TN
Index
TX
Index
UT
Index
VT
Index
VA
Index
WA
Index
WV
Index
WI
Index
WY
Kurt Hornik 2006

Statististische Methoden
Ersatzkurven
Konnen wir die Daten durch einfache”Beziehungen“ beschreiben? Dazu denken
wir uns y als Funktion von x (i.e., y als abhangiges Merkmal).
Einfachste Funktion: Gerade. Wie konnen wir”moglichst gut“ eine Gerade durch
die Punkte legen? Idee e.g.: durchschnittlicher Abstand der Punkte von der Geradesoll moglichst klein werden. Aber nicht der (geometrische) Normalabstand—denny ist als Funktion von x gedacht, relevant sind die Abweichungen in y-Richtung!
Sei y = a+ bx die Gleichung der Gerade. Fur einen Punkt (xi, yi) ist yi = a+ bxi derentsprechende Punkt auf der Gerade (geschatztes yi) und ei = yi− yi der Fehler beider Schatzung (sogenanntes Residuum).
Kurt Hornik 2006

Statististische Methoden
Regressiongerade
Eine moglichst gute Gerade macht also die (eine geeignete Funktion der) Residuenmoglichst klein. Aber welche Funktion?
Lineares Ausgleichsproblem: minimiere die Summe der Fehlerquadrate
mina,b
n∑i=1
(yi − a− bxi)2
Diese Aufgabe lasst sich explizit losen: ergibt die Regressionskoeffizienten
b =Cov(x, y)
Var(x)= ρ
σy
σx, a = y − bx
Das Bestimmtheitsmaß R2 = (Var(y) − Var(e))/Var(y) (= ρ2) misst die Gute derBeschreibung der Punkte durch die Regressiongerade.
Kurt Hornik 2006

Statististische Methoden
Einfaches lineares Regressionmodell
Bis jetzt diente die Regressiongerade ausschließlich der Beschreibung der Daten.Aber wie konnen wir wissen ob e.g. der Anstieg der Gerade in der Grundgesamtheitvon Null verschieden ist?
Fuhrt auf einfaches lineares Regressionmodell:
y = α+ βx+ e, e normalverteilt mit Mittel 0 und Varianz σ2
(Falls nicht normalverteilt und viele Daten: p-Werte stimmen approximativ.)
In diesem Modell kann man nun die Nullhypothese β = 0 gegen die Alternativhypo-these β 6= 0 testen (
”t Tests“).
Kurt Hornik 2006

Statististische Methoden
Multiples lineares Regressionsmodell
Verallgemeinerung auf
y = α+ β1x1 + · · ·+ βkxk + e
Analog zum einfachen Modell: Regressionkoeffizienten als Losung des linearen Aus-gleichsproblems bestimmen; Hypothesentests dass einzelne βi von Null verschiedensind, beziehungsweise dass nicht alle gleich Null sind (
”F Test“).
Beachte: Asymmetrie zwischen Null- und Alternativhypothese; Ergebnis ob Regres-sionskoeffizienten signifikant von Null verschieden sind.
Kurt Hornik 2006

Statististische Methoden
Einfaches und multiples Regressionsmodell in R
Diese Regressionsmodelle konnen mit der Funktion lm”geschatzt“ (angepasst)
werden.
Im einfachsten Fall liefert dies die Regressionkoeffizienten.
Aus dem Ergebnis lassen sich aber auch e.g. die”fitted values“ yi und Residuen
ei und, mittels summary, eine Zusammenfassung mit einfacher Modelldiagnostik undHypothesentests bekommen.
Kurt Hornik 2006

Statististische Methoden
R: Einfaches lineares Regressionsmodell
R> lm(AMOUNT ~ LAST)Call:lm(formula = AMOUNT ~ LAST)
Coefficients:(Intercept) LAST
156.28 14.09
Kurt Hornik 2006

Statististische Methoden
R> summary(lm(AMOUNT ~ LAST))Call:lm(formula = AMOUNT ~ LAST)
Residuals:Min 1Q Median 3Q Max
-155.366 -68.563 5.328 70.644 149.847
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 156.2787 3.4031 45.92 <2e-16 ***LAST 14.0874 0.7714 18.26 <2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 84.44 on 1298 degrees of freedomMultiple R-Squared: 0.2044, Adjusted R-squared: 0.2038F-statistic: 333.5 on 1 and 1298 DF, p-value: < 2.2e-16
Kurt Hornik 2006
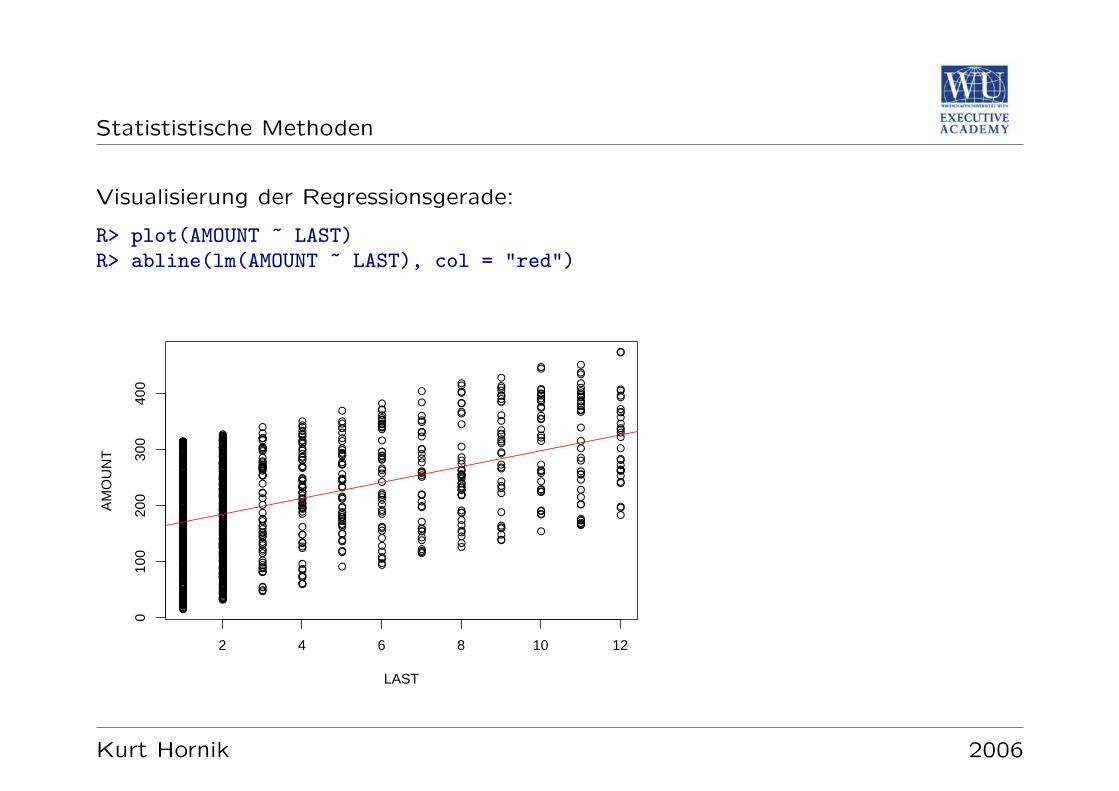
Statististische Methoden
Visualisierung der Regressionsgerade:
R> plot(AMOUNT ~ LAST)R> abline(lm(AMOUNT ~ LAST), col = "red")
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
● ●●
●
●
● ●●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
● ●
●
●●
●●
●
●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
● ●
●
●
●
●
●●
● ●●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
● ●
●
●●●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
2 4 6 8 10 12
010
020
030
040
0
LAST
AM
OU
NT
Kurt Hornik 2006
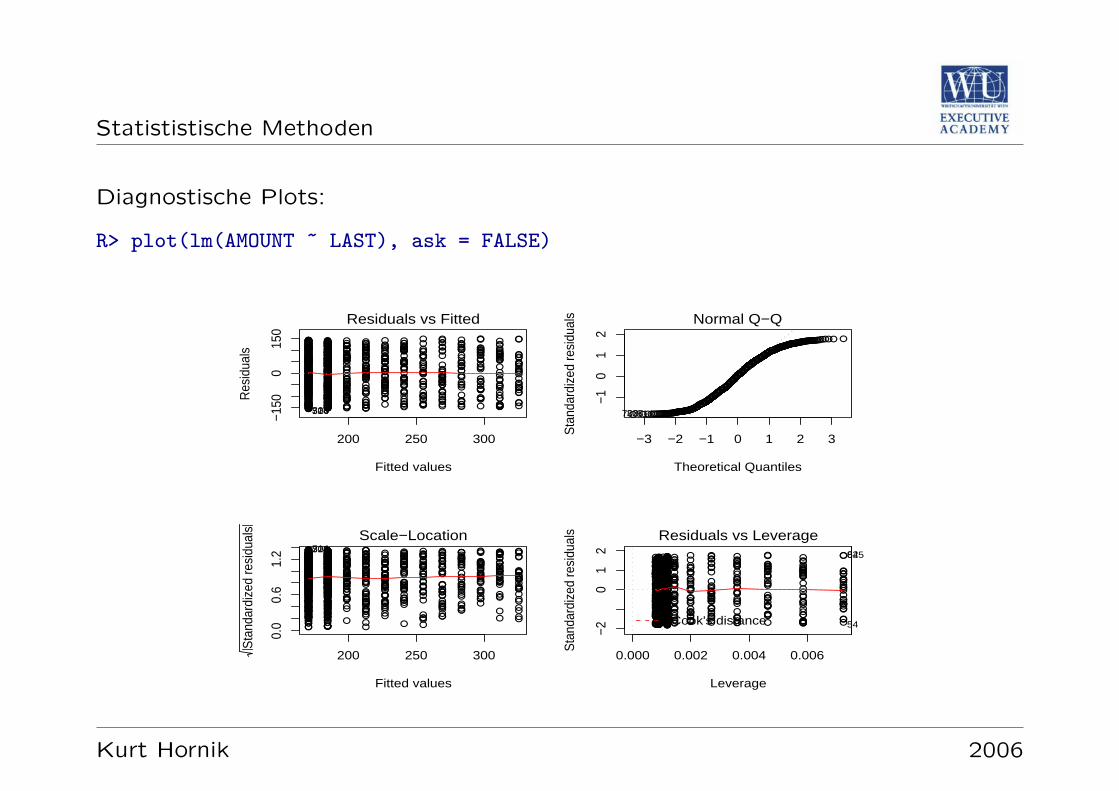
Statististische Methoden
Diagnostische Plots:
R> plot(lm(AMOUNT ~ LAST), ask = FALSE)
200 250 300
−150
015
0
Fitted values
Res
idua
ls
●
●●
●
●●
●
● ●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
● ●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●● ●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●●
●
●
●●
●
●●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●● ●
● ●
●● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
● ● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●● ● ●
●
●
●
●
●●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●●
●
●
●
●● ●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
● ●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●● ●
●
●
●
●
●●
●
●●
●
●●
●● ●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
● ●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●●
●
●
●
● ●
●●
●●
●
●
●●●
●●
●
●
●
●
●
●●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
● ●
●
●●
●
●
●●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
● ●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
● ●
●●
●●
●●
●
●
●
●● ●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
● ●
●●
●●
●
●●
●
●
●
●
●●●● ●● ●
●
●
●●
●
●
●
●●
●
●
●●●
●
● ●
●
●●
●
●
●
●●
●
●●●
●
●
●
●● ●●
● ●●
●
● ●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
● ●●
●●
●
●●●
●
●●
●
●●●●
●●
●
●
●
●
● ●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●●
● ●●
●
●
●●
●●●
● ●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
● ●
●●
● ●
●
●
●●
●
●
●
●●
●
●
●●
● ●●
● ●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●● ●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
● ●●●
●
●●●
●
●
●
●
●
●
●
●
●●
● ●
●
●
●●
●
●
● ●●
●●●
●●
●●
●
●●●
●
●
●
● ●●●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●● ●●
●●
●
●
●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
● ●
●
●●●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●●
●●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
● ●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
● ●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
Residuals vs Fitted
514700328
●
●●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●●
●
●
●●
●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
● ●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●●
●
●
●
●●
●●
●●
●
●
●●●
●●
●
●
●
●
●
●●
●●
●●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
● ●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●●
●●
●●
●
●
●
●●
●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●●●●●
●●
●
●
●●
●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●●
●
●●●
●
●
●
●●●●
●●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●●
●
●●
●●
●●
●
●● ●●
●●
●
●
●
●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●●
●●
●
●●
●●●
● ●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●●
●
●
●●
●●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●●●●
●
●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●●●
●●●
●●
●●
●
●●●
●
●
●
●●●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●●
●●
● ●
●
●
●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
● ●
●●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
−3 −2 −1 0 1 2 3
−10
12
Theoretical Quantiles
Sta
ndar
dize
d re
sidu
als Normal Q−Q
514700328
200 250 300
0.0
0.6
1.2
Fitted values
Sta
ndar
dize
d re
sidu
als
●
●●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
● ●
● ●
●● ●
●
●●●
●
●
●
●
●
●●
●●
●
●
●
●● ●
●●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●● ●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●●●
●●
● ●●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
● ●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
● ●●
●●
●
●
●
●●
●
●
●
●
●●
●
● ●
●
●●
●
●
●●
●
●●
●
●
●
●●
● ●
●
●
●
●
●
●
●
●●
●
●●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●
●
●
●
●
●●● ●
●●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
● ●
●●●●
●
●
●● ●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●● ●
●●
●
●●●
●● ●
●●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●● ●
●
●●
●
●
●
●
●●
●●
●
●●
●●
●
●
●●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●●
●● ●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
● ●
●●
●
●
●
●
●●
●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
● ●
●●
●●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●●● ●● ●
●●
●
●
●
●
●
●
● ● ●
●●
●
●● ●
●●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●●●
●●
●
●
●
●
● ●
●
●
● ●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●●
●●
●●
●
●●
●●
●
● ●
● ●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●●●
●●
●
●
●
● ●
●
●
● ●
●
●
●●
●
●
●
●●
●
●
●●
●●
●
● ●
●●
●
● ●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
● ●●●
●●●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●●
●
●
● ●●
●
●●
●●
●●
●
●●
●●
●
●
●●
●●
●
●●
● ●
●●●
●
●●
●
●
●
●●
●
● ●
●
●
●
●
●
●●●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●●●
●
●
●
●
● ●
●●
●●
●
●●●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
● ●●
●●●
●
●●●
●
●
●
●●
●
●
●●
●
●
●
●
●
Scale−Location514700328
0.000 0.002 0.004 0.006
−20
12
Leverage
Sta
ndar
dize
d re
sidu
als
●
●●
●
●●
●
● ●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
● ●
●●
●
●
● ●
●
●
●
●
●
● ●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●●
●
●
●
● ● ●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
● ●
● ●
●●
●
●
●●
●
● ●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●● ●
● ●
●● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
● ● ●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●●●●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●● ●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●●
●
● ●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●● ●
●
●
●
●
●●
●
●●
●
●●
●● ●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
● ●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
● ●
●
●
●●
●
● ●●
●
●
●●
●
●
●
●●
●●
●●
●
●
●●●
●●
●
●
●
●
●
●●
●●
●●
●●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
● ●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
● ●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
● ●
●●
●●
●●
●
●
●
●●●●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●●●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
● ●
●
●●
●●
●●
●●
●
●●
●
●
●
●
●● ●● ●● ●
●
●
●●
●
●
●
●●
●
●
●●●
●
●●
●
●●
●
●
●
● ●
●
●●●
●
●
●
●●● ●
● ●●
●
● ●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●● ●
●
●
●
● ●●
●●
●
●●●
●
●●
●
●●●●
●●
●
●
●
●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●
●
●
●
●
●●●
●
●
●
●
●●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●● ●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●● ●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●●●
●
●
●●
●●●
● ●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●
●●
●
●
●●●●
●
● ●
●●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●●●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
● ●●●
●
●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●●
●
●●●
●●●
●●
●●
●
● ●●
●
●
●
●● ●●
●
●●
●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●
● ●
●
●
●
●● ●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●● ●●●
●●
●
●
●
●
●
●
●●●
● ●●
●
●
●
●
●
●
●
●●
●
● ●●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●●
●●
●
●
●●
● ●●
●
●
●●
●
●
●
● ●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
● ●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●
Cook's distance
Residuals vs Leverage82645
54
Kurt Hornik 2006

Statististische Methoden
R: Multiples lineares Regressionsmodell
R> summary(lm(AMOUNT ~ LAST + FIRST))Call:lm(formula = AMOUNT ~ LAST + FIRST)
Residuals:Min 1Q Median 3Q Max
-156.159 -69.401 5.728 70.721 152.823
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 154.3886 4.0208 38.397 <2e-16 ***LAST 13.1389 1.3227 9.933 <2e-16 ***FIRST 0.2210 0.2504 0.883 0.378---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 84.44 on 1297 degrees of freedomMultiple R-Squared: 0.2049, Adjusted R-squared: 0.2037F-statistic: 167.1 on 2 and 1297 DF, p-value: < 2.2e-16
Kurt Hornik 2006

Statististische Methoden
Ein abhangiges metrisches Merkmal
Kurt Hornik 2006

Statististische Methoden
Grundlegendes
Falls ein unabhangiges metrisches Merkmal x: bereits behandelt.
Falls ein unabhangiges kategoriales Merkmal x: von zentralem Interesse ist hier derUnterschied in y zwischen den Kategorien (Gruppen) von x (also der Vergleich derbedingten Verteilungen).
Numerische Beschreibung: e.g., Vergleich von Maßzahlen zwischen den Gruppen
Grafische Beschreibung: e.g., nebeneinanderliegende Boxplots zum Vergleich vonLage und Streuung.
Kurt Hornik 2006

Statististische Methoden
R: Gruppenvergleiche
R> tapply(AMOUNT, GENDER, mean)female male
203.4912 200.2227R> tapply(AMOUNT, GENDER, median)female male199.5 205.5
R> tapply(AMOUNT, GENDER, summary)$female
Min. 1st Qu. Median Mean 3rd Qu. Max.17.0 132.0 199.5 203.5 273.2 473.0
$maleMin. 1st Qu. Median Mean 3rd Qu. Max.15.0 125.0 205.5 200.2 272.0 474.0
Kurt Hornik 2006

Statististische Methoden
R: Nebeneinanderliegende Boxplots
R> boxplot(AMOUNT ~ GENDER, main = "AMOUNT nach GENDER")R> boxplot(AMOUNT ~ BOUGHT_ART, main = "AMOUNT nach BOUGHT_ART")
female male
010
020
030
040
0
AMOUNT nach GENDER
●
FALSE TRUE
010
020
030
040
0
AMOUNT nach BOUGHT_ART
Kurt Hornik 2006

Statististische Methoden
Inferenz
Einfaches Modell fur Unterschiede in der Lage:
y = µ+ αi + e falls Beobachtung in Gruppe i
(”einfache Varianzanalyse“ unter Normalverteilungsannahmen).
Auch gerne geschrieben als: yij = µ+αi+ εij, wobei yij die j-te Beobachtung in deri-ten Gruppe ist.
Problem: in obiger Formulierung sind sind die Modellparameter”nicht identifizier-
bar“ (es gibt einen zu viel). Strategien:
• Kein globales µ.
• Ein α, e.g., α1, gleich 0 setzen; andere α sind dann relativ zu dieser”Baseline“
(”Treatment Contrasts“)
•∑
i αi = 0 (”Sum Contrasts“)
Kurt Hornik 2006

Statististische Methoden
Erweiterungen
Bei zwei unabhangigen kategorialen Merkmalen:
y = µ+ αi + βj + e
y = µ+ αi + βj + γij + e
(fur Beobachtungen in Gruppe i und j bezuglich des ersten beziehungsweise zweitenFaktors): sogenannte
”zweifache Varianzanalyse“ ohne beziehungsweise mit Wech-
selwirkungen.
Bei je einem unabhangigen kategorialen und metrischen Merkmal:
y = µ+ αi + βx+ e falls Beobachtung in Gruppe i
sogenannte”einfache Kovarianzanalyse“.
Kurt Hornik 2006

Statististische Methoden
Allgemeines lineares Regressionsmodell
Das Modell der einfachen Kovarianzanalyse konnen unter Einfuhrung der sogenann-ten
”Dummy Merkmale“ I1, . . . , Ik auch schreiben als
y = µ+ α1I1 + · · ·+ αkIk + βx+ e
wobei Ii genau dann eins ist, falls die Beobachtung in Gruppe i ist, und Null sonst(Indikator von Gruppe i).
Alle obigen Modelle (und viele mehr) konnen durch Einfuhrung geeigneter Dummiesgeschrieben werden als
y = µ+ α1I1 + · · ·+ αpIl + β1x1 + · · ·+ βqxq + e = β(x) + e
wobei β(x) der lineare Pradiktor von y auf Basis aller unabhangigen Merkmale x ist(linear in den Regressionskoeffizienten!).
Das ist das sogenannte allgemeine lineare Regressionmodell.
Kurt Hornik 2006

Statististische Methoden
Allgemeine lineare Regression in R
Das Anpassen von linearen Regressionsmodellen erfolgt mit
lm(MODELLFORMEL)
wobei die Formel von der Form y ~ RHS ist, Das abhangige Merkmal ist auf der linkenSeite, eine geeignete Kombination der unabhangigen Merkmale auf der rechten:
• + und - fur Inklusion beziehungsweise Exklusion von Termen;
• * fur die Interaktion.
(Wilkinson-Rogers Notation).
Kurt Hornik 2006

Statististische Methoden
Modellformeln
Der Aufbau des linearen Pradiktors auf Basis der Modellformel wird”automatisch“
erledigt (kein explizites Dummy Encoding erforderlich).
Sind e.g. x (”Kovariat“) metrisch und A, B kategorial (
”Faktoren“), so ist
y ~ g einfache Varianzanalysey ~ g - 1 einfache Varianzanalyse ohne
”grand mean“
y ~ g + h zweifache Varianzanalyse ohne Wechselwirkungy ~ g * h zweifache Varianzanalyse mit Wechselwirkungy ~ x + g einfache Kovarianzanalyse
Die Modellsprache bietet auch weitere Moglichkeiten fur den Aufbau des linearenModells.
Kurt Hornik 2006

Statististische Methoden
Weitere wichtige Funktionen
Mit summary bekommt man die ubliche Zusammenfassung mit Werten und p-Wertenfur die Modellparameter, und einfacher Modelldiagnostik.
Einfacher Modellvergleich (fur geschachtelte Modelle) via anova (”Analysis of Va-
riance“)
Einfache Modellselektion (”Stepwise Regression“) via step.
Kurt Hornik 2006

Statististische Methoden
Einfache Varianzanalyse:
R> summary(lm(AMOUNT ~ BOUGHT_ART))Call:lm(formula = AMOUNT ~ BOUGHT_ART)
Residuals:Min 1Q Median 3Q Max
-209.5644 -69.5644 0.9356 70.4356 286.3998
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 186.600 3.123 59.749 < 2e-16 ***BOUGHT_ARTTRUE 44.964 5.449 8.251 3.80e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 92.28 on 1298 degrees of freedomMultiple R-Squared: 0.04984, Adjusted R-squared: 0.04911F-statistic: 68.09 on 1 and 1298 DF, p-value: 3.804e-16
Kurt Hornik 2006

Statististische Methoden
Kovarianzanalyse:
R> summary(lm(AMOUNT ~ BOUGHT_ART + LAST))Call:lm(formula = AMOUNT ~ BOUGHT_ART + LAST)
Residuals:Min 1Q Median 3Q Max
-157.655 -67.422 4.244 71.159 154.982
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 155.3028 3.4651 44.819 <2e-16 ***BOUGHT_ARTTRUE 8.1141 5.4932 1.477 0.14LAST 13.5596 0.8498 15.956 <2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 84.4 on 1297 degrees of freedomMultiple R-Squared: 0.2057, Adjusted R-squared: 0.2045F-statistic: 168 on 2 and 1297 DF, p-value: < 2.2e-16
Kurt Hornik 2006
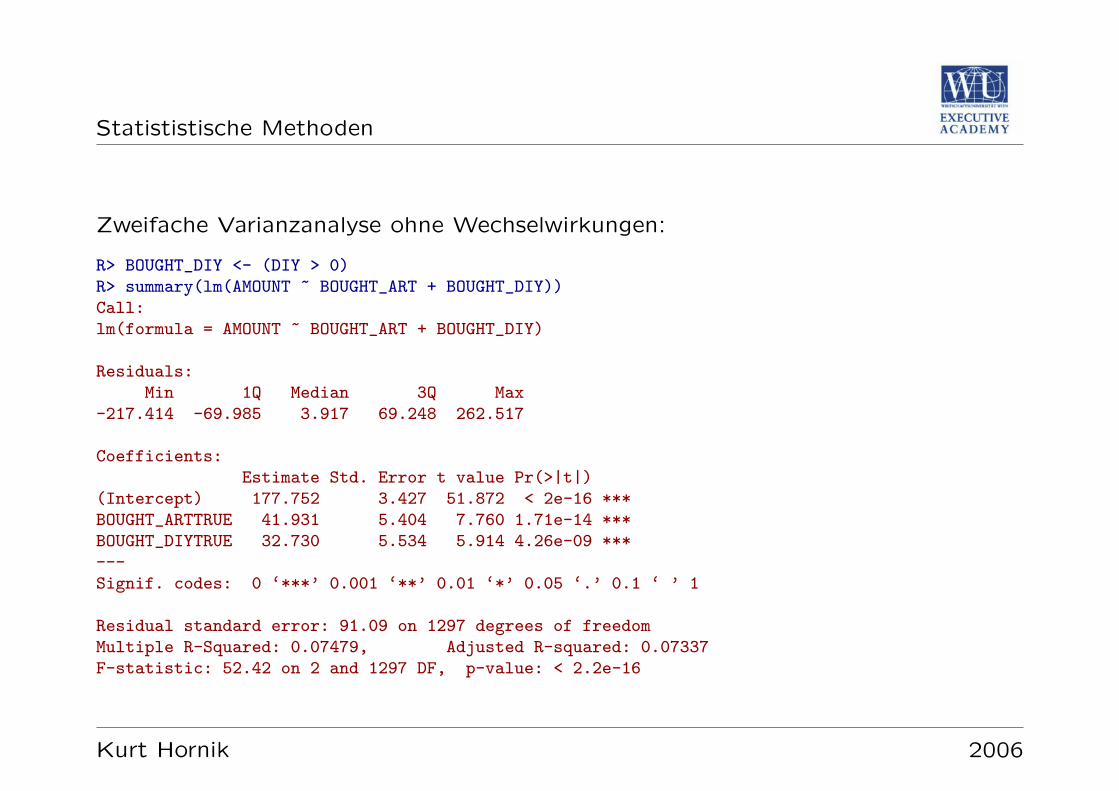
Statististische Methoden
Zweifache Varianzanalyse ohne Wechselwirkungen:
R> BOUGHT_DIY <- (DIY > 0)R> summary(lm(AMOUNT ~ BOUGHT_ART + BOUGHT_DIY))Call:lm(formula = AMOUNT ~ BOUGHT_ART + BOUGHT_DIY)
Residuals:Min 1Q Median 3Q Max
-217.414 -69.985 3.917 69.248 262.517
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 177.752 3.427 51.872 < 2e-16 ***BOUGHT_ARTTRUE 41.931 5.404 7.760 1.71e-14 ***BOUGHT_DIYTRUE 32.730 5.534 5.914 4.26e-09 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 91.09 on 1297 degrees of freedomMultiple R-Squared: 0.07479, Adjusted R-squared: 0.07337F-statistic: 52.42 on 2 and 1297 DF, p-value: < 2.2e-16
Kurt Hornik 2006
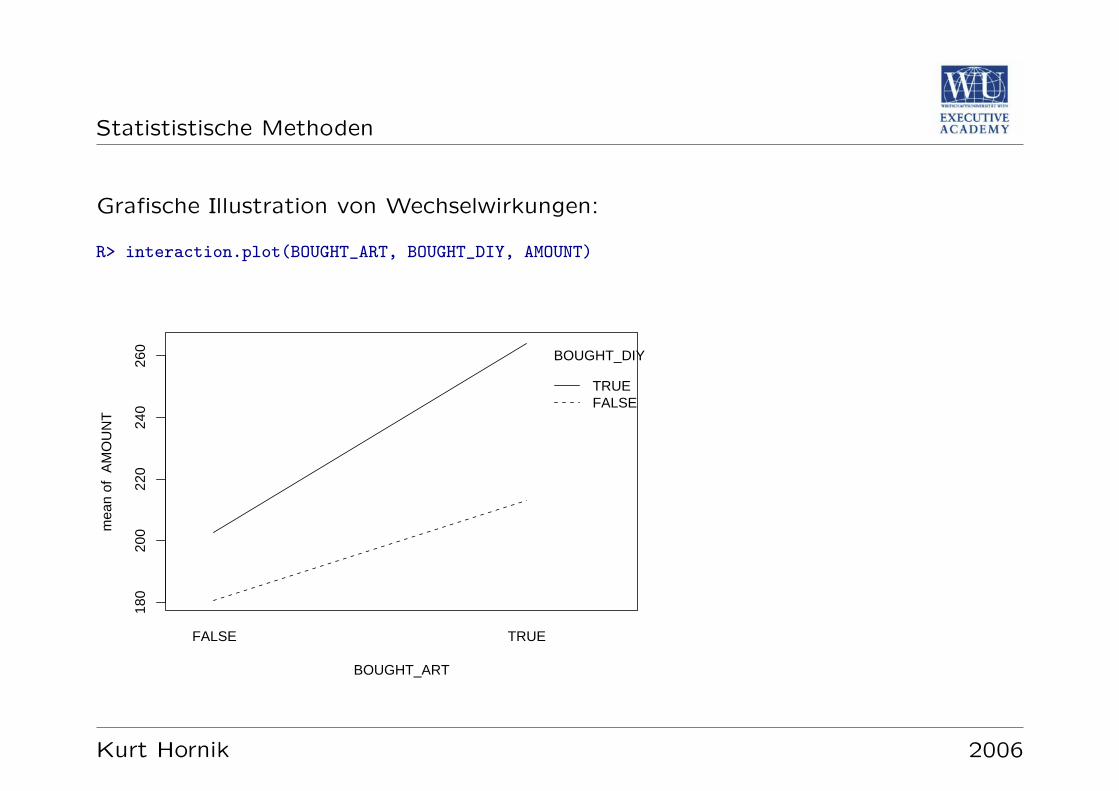
Statististische Methoden
Grafische Illustration von Wechselwirkungen:
R> interaction.plot(BOUGHT_ART, BOUGHT_DIY, AMOUNT)
180
200
220
240
260
BOUGHT_ART
mea
n of
AM
OU
NT
FALSE TRUE
BOUGHT_DIY
TRUEFALSE
Kurt Hornik 2006

Statististische Methoden
Zweifache Varianzanalyse mit Wechselwirkungen:
R> summary(lm(AMOUNT ~ BOUGHT_ART * BOUGHT_DIY))Call:lm(formula = AMOUNT ~ BOUGHT_ART * BOUGHT_DIY)
Residuals:Min 1Q Median 3Q Max
-229.15 -72.65 2.31 69.50 270.23
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 180.609 3.602 50.146 < 2e-16 ***BOUGHT_ARTTRUE 32.384 6.584 4.918 9.85e-07 ***BOUGHT_DIYTRUE 22.162 6.927 3.199 0.00141 **BOUGHT_ARTTRUE:BOUGHT_DIYTRUE 29.000 11.475 2.527 0.01161 *---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 90.9 on 1296 degrees of freedomMultiple R-Squared: 0.07933, Adjusted R-squared: 0.0772F-statistic: 37.22 on 3 and 1296 DF, p-value: < 2.2e-16
Kurt Hornik 2006

Statististische Methoden
R: Modellvergleich
R> lm1 <- lm(AMOUNT ~ 1)R> lm2 <- lm(AMOUNT ~ FIRST)R> lm3 <- lm(AMOUNT ~ FIRST + LAST)R> anova(lm1, lm2, lm3)Analysis of Variance Table
Model 1: AMOUNT ~ 1Model 2: AMOUNT ~ FIRSTModel 3: AMOUNT ~ FIRST + LAST
Res.Df RSS Df Sum of Sq F Pr(>F)1 1299 116319292 1298 9952353 1 1679576 235.535 < 2.2e-16 ***3 1297 9248760 1 703593 98.668 < 2.2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Kurt Hornik 2006

Statististische Methoden
Ein abhangiges kategoriales Merkmal
Kurt Hornik 2006

Statististische Methoden
Grundlegendes
Falls ein unabhangiges kategoriales Merkmal x: bereits behandelt.
Falls ein unabhangiges metrisches Merkmal x: von zentralem Interesse ist die be-dingte Verteilung von y gegeben x, also hier einfach: P (y|x).
Grafische Beschreibung am besten durch”Conditional Density“ (CD) Plots oder
Spinograms. Konzeptuell plotten CD Plots P (y|x) gegen x (auf Basis geglatte-ter Histogramme), dagegen Spinograms P (y|x) gegen die Randverteilung P (x) deserklarenden Markmals (analog zu Spineplots fur ein kategoriales erklarendes Merk-mal).
Kurt Hornik 2006
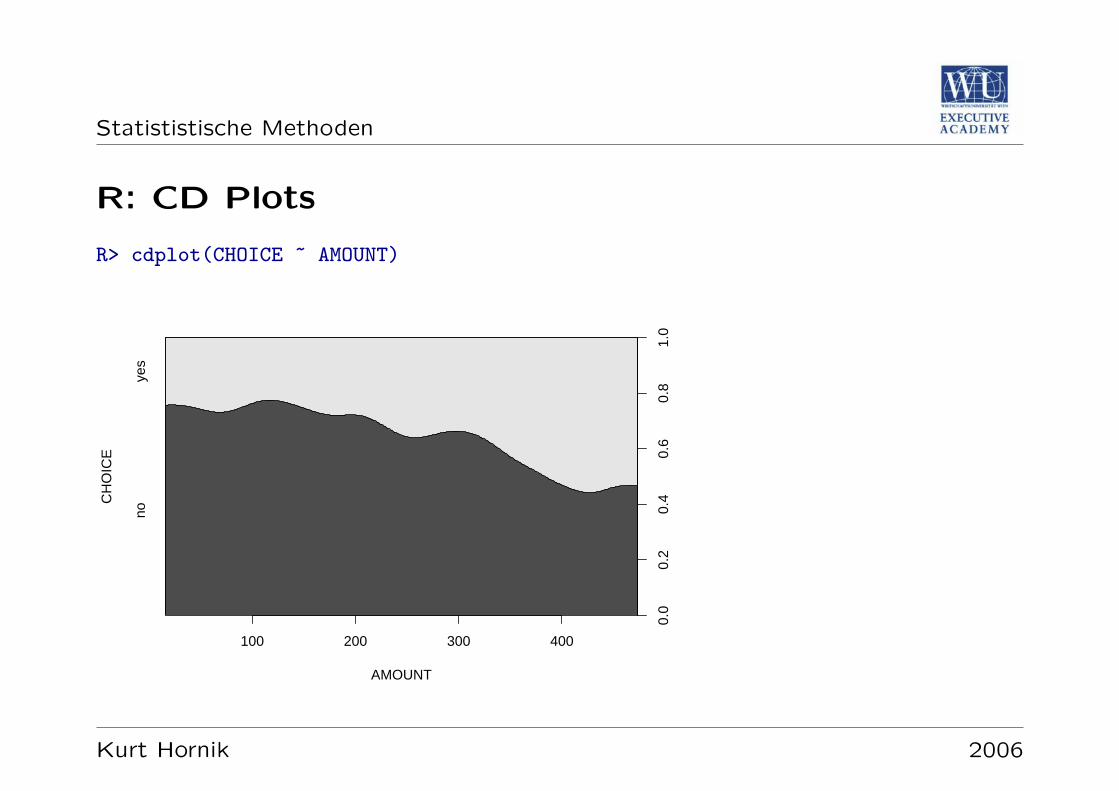
Statististische Methoden
R: CD Plots
R> cdplot(CHOICE ~ AMOUNT)
AMOUNT
CH
OIC
E
100 200 300 400
noye
s
0.0
0.2
0.4
0.6
0.8
1.0
Kurt Hornik 2006

Statististische Methoden
R: Spinograms
R> tab <- spineplot(CHOICE ~ AMOUNT, breaks = fivenum(AMOUNT))
R> tabCHOICE
AMOUNT no yes[15,127] 247 79(127,204] 240 87(204,273] 219 111(273,474] 194 123
Kurt Hornik 2006
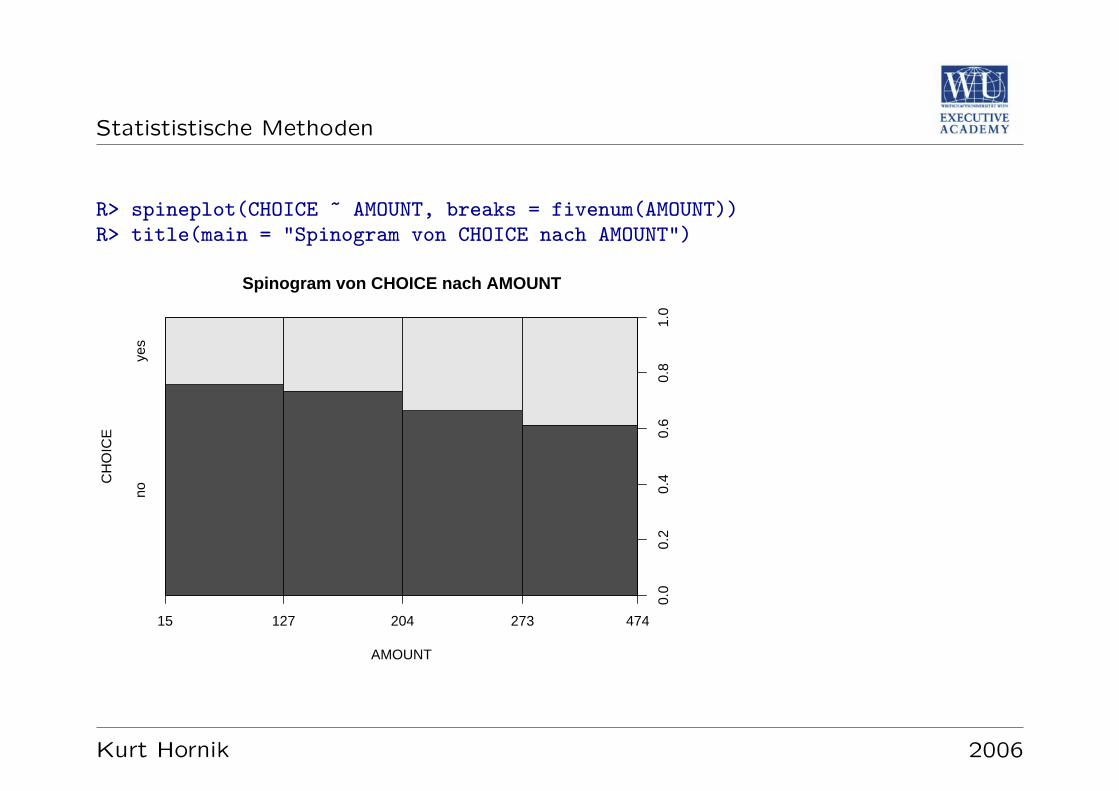
Statististische Methoden
R> spineplot(CHOICE ~ AMOUNT, breaks = fivenum(AMOUNT))R> title(main = "Spinogram von CHOICE nach AMOUNT")
AMOUNT
CH
OIC
E
15 127 204 273 474
noye
s
0.0
0.2
0.4
0.6
0.8
1.0
Spinogram von CHOICE nach AMOUNT
Kurt Hornik 2006

Statististische Methoden
R> tab <- spineplot(CHOICE ~ AMOUNT)
R> tabCHOICE
AMOUNT no yes[0,50] 57 19(50,100] 112 41(100,150] 146 44(150,200] 158 57(200,250] 164 76(250,300] 151 79(300,350] 77 46(350,400] 25 25(400,450] 9 11(450,500] 1 2
Kurt Hornik 2006
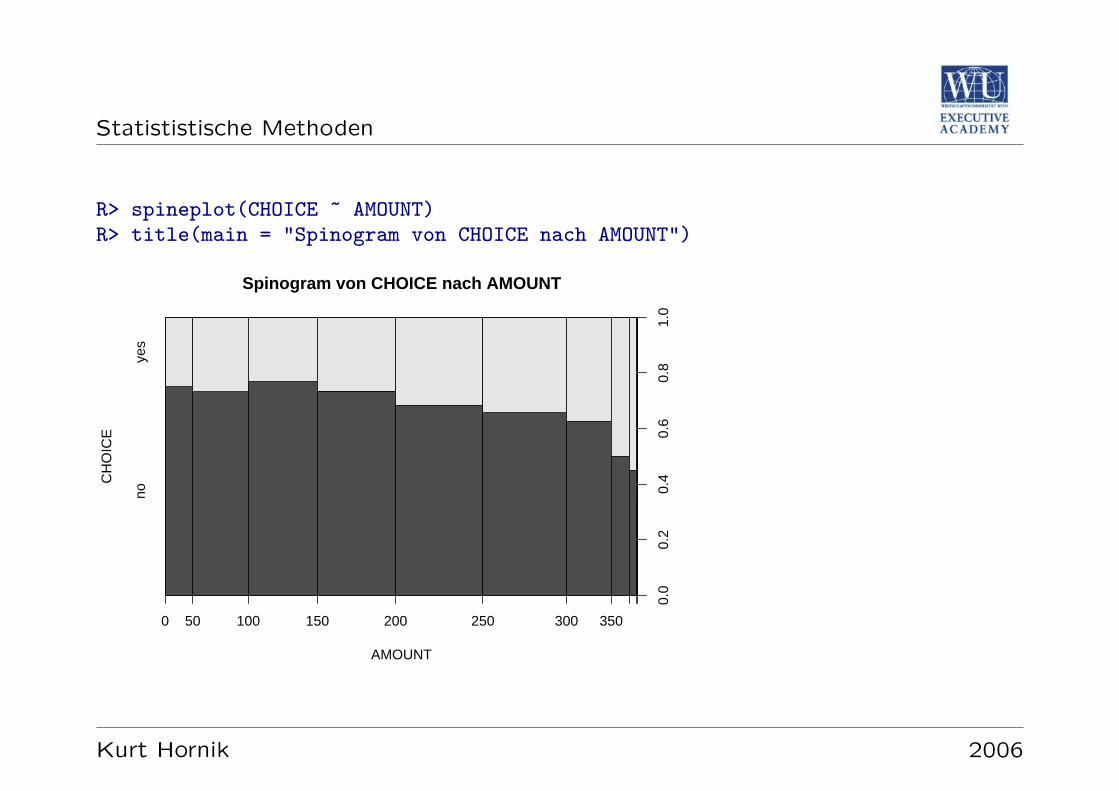
Statististische Methoden
R> spineplot(CHOICE ~ AMOUNT)R> title(main = "Spinogram von CHOICE nach AMOUNT")
AMOUNT
CH
OIC
E
0 50 100 150 200 250 300 350
noye
s
0.0
0.2
0.4
0.6
0.8
1.0
Spinogram von CHOICE nach AMOUNT
Kurt Hornik 2006

Statististische Methoden
Inferenz
Der Einfachheit halber sei y binar (also nur zwei mogliche Kategorien) und mit 0(falsch,
”Misserfolg“) und 1 (wahr,
”Erfolg“) kodiert.
Warum kann man nicht einfach ein lineares Modell fur y bauen?
• Falsche Struktur: denn y ist diskret und das Modell stetig
• Keine geeignete Verteilung fur die Fehler in einem solchen Modell
Frage: konnen wir geeignete”lineare Modelle“ fur die bedingte Verteilung von y
gegeben x bauen?
Kurt Hornik 2006

Statististische Methoden
Logistische Regression
Im einfachen logistischen Regressionsmodell:
P (y = 1|x) =1
1 + e−(β+β1x)
die bedingte Wahrscheinlichkeit ist also von der Form P (y = 1|x) = f(β0 + β1x),eine Funktion des linearen Pradiktors.
Durch Umformen der Gleichung p = 1/(1 + e−z) ergibt sich log(p/(1− p) = z, alsounter Definition der Funktion logit(p) = log(p/(1− p) die Beziehung:
logit(P (y = 1|x)) = β0 + β1x
(”lineares Modell“ fur den logit der bedingten Wahrscheinlichkeit).
Kurt Hornik 2006

Statististische Methoden
Allgemeines logistisches Regressionsmodell
Das einfach Modell kann in zwei Richtungen verallgemeinert werden:
• Statt der logit Funktion andere sogenannte Link Funktionen ` in der Beziehung`(P (y = 1|x)) = β0+β1x, grundsatzlich beliebige Transformationen von [0,1] in(−∞,∞), popular vor allem
”probit“ (Umkehrfunktion der Verteilungsfunktion
der Standardnormalverteilung) und”complimentary log-log“ `(p) = log(− log p)
(e.g., fur Uberlebenszeitmodelle)
• Aufnahme von mehr Pradiktoren (unabhangigen Merkmalen) in das Modell:analog zum Ubergang vom einfachen zum allgemeinen linearen Regressions-modell
Kurt Hornik 2006

Statististische Methoden
Verallgemeinerte lineare Modelle
Wir beachten, dass fur binare 0/1 kodierte Merkmale P (y = 1|x) gleich dem Mit-telwert µ(x) der bedingten Verteilung von y gegeben x ist.
Schreiben wir β(x) fur den linearen Pradiktor, so konnen wir das allgemeine logisti-sche Regressionsmodell auch schreiben als
`(µ(x)) = β(x)
Sogenannte”verallgemeinerte linearer Modelle“ (Generalized Linear Models) ver-
knupfen diese Gleichung mit geeigneten Annahmen uber die Verteilung von y (so-genannte Exponentialfamilien).
GLMs auch fur abhangige metrische Variable fur die das lineare Regressionsmodell(Normalverteilungsannahmen) nicht passt: e.g., Poisson und Gamma Familien.
Kurt Hornik 2006

Statististische Methoden
Modellselektion
Der Vergleich”geschachtelter“ Modelle ist einfacher.
Welchte Terme sollen im Modell inkludiert werden? Heuristiken:
Ruckwartselimination e.g., immer den Term mit dem großten”zu hohen“ p-Wert
eliminieren und mit den verbleibenden Termen das Modell neu bauen
Vorwartsselektion e.g., immer den Term mit dem kleinsten”hinreichend niedri-
gen“ p-Wert inkludieren und neu bauen
Stepwise Prozedur geeignete Kombination aus Vorwarts- und Ruckwartsschrit-ten.
Problem der Signifikanz von Interaktionstermen fur die entsprechende Randtermenicht signifikant sind: aus Interpretabilitatsgrunden hierarchische Modelle bevorzu-gen.
Kurt Hornik 2006

Statististische Methoden
Kollinearitat
Falls Pradiktoren linear abhangig oder hoch korreliert sind: (Multi-)Kollinearitat.
Erkennbar: paarweise Korrelationen; R2i bei linearer Regression von Pradiktor i auf
alle anderen Pradiktoren; Konditionszahl der”Design Matrix“.
Effekte:
• Parameter schlechter schatzbar: hohere Varianz, hohere (nicht signifikante)p-Werte
• Reduktion der Interpretabilitat
Abhilfe e.g. durch”Amputation“.
Kurt Hornik 2006

Statististische Methoden
Logistische Regression in R
Das Anpassen von logistischen Regressionsmodellen erfolgt mit
glm(MODELLFORMEL, family = "binomial")
(Binomialfamilie des verallgemeinerten linearen Modells).
Dabei werden die Modellparameter ublicherweise Maximum Likelihood mit Hilfedes
”Iterative Reweighted Least Squares“ Verfahrens geschatzt; die p-Werte kom-
men aus der Grenzverteilung (im Gegensatz zur sogenannten”exakten logistischen
Regression“).
Kurt Hornik 2006

Statististische Methoden
Weitere wichtige Funktionen
Mit summary bekommt man die ubliche Zusammenfassung mit Werten und p-Wertenfur die Modellparameter, und einfacher Modelldiagnostik.
Einfacher Modellvergleich (fur geschachtelte Modelle) via anova (”Analysis of De-
viance“, hier p-Werte nicht standardmaßig).
Einfache Modellselektion (”Stepwise Logistic Regression“) via step.
(Ganz analog zum allgemeinen linearen Modell.)
Wichtig: Interpretation des Vorzeichens der Regressionskoeffizienten! Falls positiv,steigt die bedingte Wahrscheinlichkeit.
Kurt Hornik 2006

Statististische Methoden
R: Logistische RegressionR> lrm1 <- glm(CHOICE ~ AMOUNT, family = "binomial")R> summary(lrm1)Call:glm(formula = CHOICE ~ AMOUNT, family = "binomial")
Deviance Residuals:Min 1Q Median 3Q Max
-1.1847 -0.8839 -0.7734 1.3967 1.8004
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.4532828 0.1499533 -9.692 < 2e-16 ***AMOUNT 0.0031088 0.0006477 4.800 1.59e-06 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1581.3 on 1298 degrees of freedomAIC: 1585.3
Number of Fisher Scoring iterations: 4
Kurt Hornik 2006

Statististische Methoden
Modellierte Kaufwahrscheinlichkeiten
R> predict(lrm1, data.frame(AMOUNT = 200), type = "response")[1] 0.3033211R> amounts <- seq(from = 100, to = 300, by = 20)R> p <- predict(lrm1, data.frame(AMOUNT = amounts), type = "response")R> names(p) <- amountsR> p
100 120 140 160 180 200 220 2400.2418786 0.2534620 0.2654059 0.2777033 0.2903453 0.3033211 0.3166181 0.3302217
260 280 3000.3441154 0.3582811 0.3726985
Kurt Hornik 2006
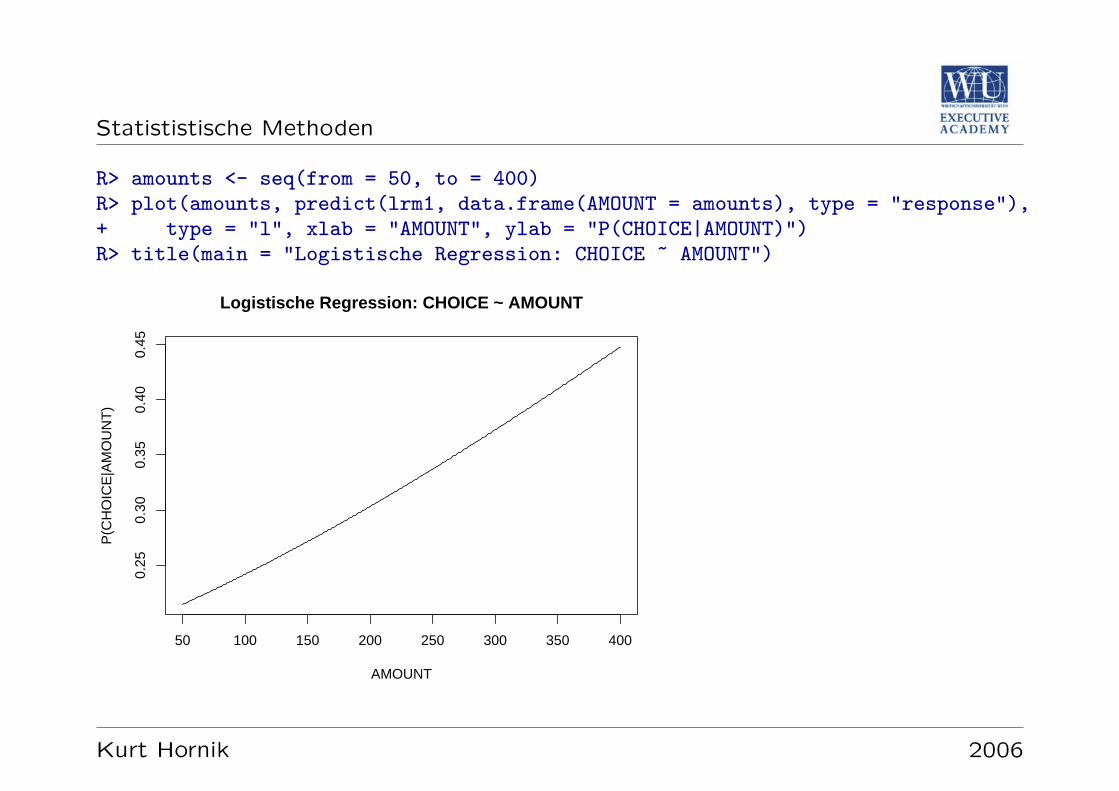
Statististische Methoden
R> amounts <- seq(from = 50, to = 400)R> plot(amounts, predict(lrm1, data.frame(AMOUNT = amounts), type = "response"),+ type = "l", xlab = "AMOUNT", ylab = "P(CHOICE|AMOUNT)")R> title(main = "Logistische Regression: CHOICE ~ AMOUNT")
50 100 150 200 250 300 350 400
0.25
0.30
0.35
0.40
0.45
AMOUNT
P(C
HO
ICE
|AM
OU
NT
)
Logistische Regression: CHOICE ~ AMOUNT
Kurt Hornik 2006
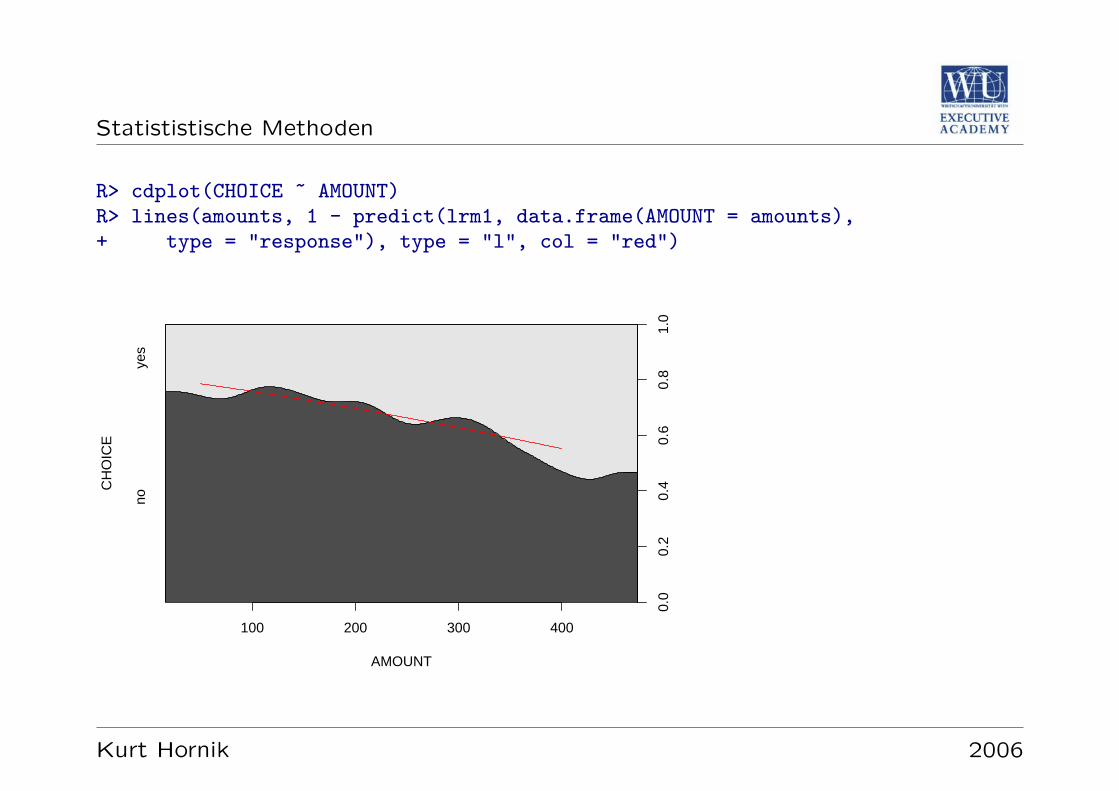
Statististische Methoden
R> cdplot(CHOICE ~ AMOUNT)R> lines(amounts, 1 - predict(lrm1, data.frame(AMOUNT = amounts),+ type = "response"), type = "l", col = "red")
AMOUNT
CH
OIC
E
100 200 300 400
noye
s
0.0
0.2
0.4
0.6
0.8
1.0
Kurt Hornik 2006

Statististische Methoden
R> lrm2 <- glm(CHOICE ~ GENDER, family = "binomial")R> summary(lrm2)Call:glm(formula = CHOICE ~ GENDER, family = "binomial")
Deviance Residuals:Min 1Q Median 3Q Max
-1.013 -0.771 -0.771 1.351 1.648
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.39999 0.09554 -4.187 2.83e-05 ***GENDERmale -0.66106 0.12382 -5.339 9.34e-08 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1576.4 on 1298 degrees of freedomAIC: 1580.4
Number of Fisher Scoring iterations: 4
Kurt Hornik 2006

Statististische Methoden
R: Modellbauen
Im folgenden bauen wir zunachst ein plausibles grosseres Modell mit den Erklarungs-merkmalen GENDER, AMOUNT, LAST, und BOUGHT ART.
Dann bauen wir ein grosses Modell in dem auch alle paarweisen Interaktionen dieserMerkmale enthalten sind, und verwenden die step Heuristik um dieses geeignet zuvereinfachen.
Schließlich vergleichen wir die so erhaltenen Modelle mittels anova.
Kurt Hornik 2006

Statististische Methoden
R> lrm3 <- glm(CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ART, family = binomial)R> summary(lrm3)Call:glm(formula = CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ART, family = binomial)
Deviance Residuals:Min 1Q Median 3Q Max
-1.5512 -0.8017 -0.5854 1.0033 2.0284
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.2389818 0.1751744 -7.073 1.52e-12 ***GENDERmale -0.7386038 0.1326381 -5.569 2.57e-08 ***AMOUNT 0.0016225 0.0007689 2.110 0.0349 *LAST -0.0014548 0.0244400 -0.060 0.9525BOUGHT_ARTTRUE 1.4521542 0.1436768 10.107 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1431.8 on 1295 degrees of freedomAIC: 1441.8
Number of Fisher Scoring iterations: 4
Kurt Hornik 2006
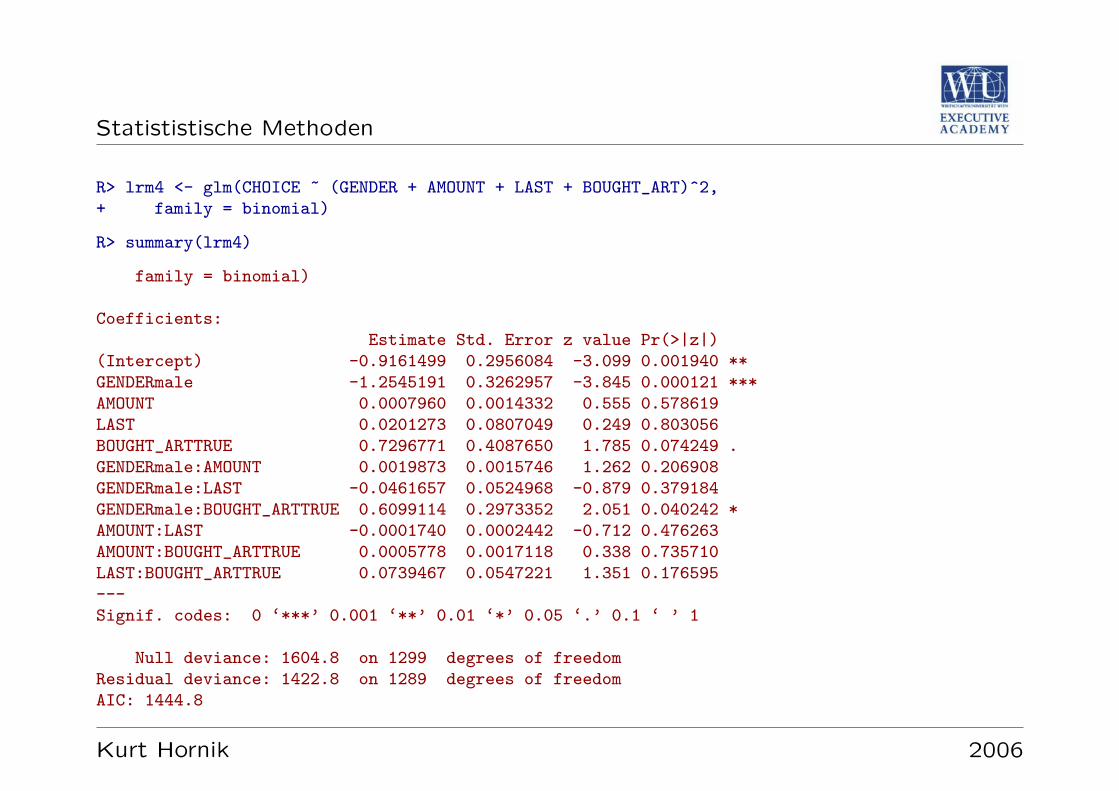
Statististische Methoden
R> lrm4 <- glm(CHOICE ~ (GENDER + AMOUNT + LAST + BOUGHT_ART)^2,+ family = binomial)
R> summary(lrm4)
family = binomial)
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.9161499 0.2956084 -3.099 0.001940 **GENDERmale -1.2545191 0.3262957 -3.845 0.000121 ***AMOUNT 0.0007960 0.0014332 0.555 0.578619LAST 0.0201273 0.0807049 0.249 0.803056BOUGHT_ARTTRUE 0.7296771 0.4087650 1.785 0.074249 .GENDERmale:AMOUNT 0.0019873 0.0015746 1.262 0.206908GENDERmale:LAST -0.0461657 0.0524968 -0.879 0.379184GENDERmale:BOUGHT_ARTTRUE 0.6099114 0.2973352 2.051 0.040242 *AMOUNT:LAST -0.0001740 0.0002442 -0.712 0.476263AMOUNT:BOUGHT_ARTTRUE 0.0005778 0.0017118 0.338 0.735710LAST:BOUGHT_ARTTRUE 0.0739467 0.0547221 1.351 0.176595---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1422.8 on 1289 degrees of freedomAIC: 1444.8
Kurt Hornik 2006

Statististische Methoden
R> lrm5 <- step(lrm4)
R> summary(lrm5)
Call:glm(formula = CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ART +
GENDER:BOUGHT_ART + LAST:BOUGHT_ART, family = binomial)
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.9866452 0.2012103 -4.904 9.41e-07 ***GENDERmale -0.9744561 0.1727279 -5.642 1.69e-08 ***AMOUNT 0.0015867 0.0007699 2.061 0.039316 *LAST -0.0531217 0.0424208 -1.252 0.210477BOUGHT_ARTTRUE 0.8835929 0.2637654 3.350 0.000808 ***GENDERmale:BOUGHT_ARTTRUE 0.5558719 0.2686883 2.069 0.038561 *LAST:BOUGHT_ARTTRUE 0.0744236 0.0492706 1.511 0.130914---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1425.2 on 1293 degrees of freedomAIC: 1439.2
Kurt Hornik 2006

Statististische Methoden
R> lrm6 <- glm(CHOICE ~ GENDER * BOUGHT_ART + AMOUNT, family = binomial)R> summary(lrm6)Call:glm(formula = CHOICE ~ GENDER * BOUGHT_ART + AMOUNT, family = binomial)
Deviance Residuals:Min 1Q Median 3Q Max
-1.4534 -0.8436 -0.5578 1.0760 2.0695
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.1103699 0.1838584 -6.039 1.55e-09 ***GENDERmale -0.9638114 0.1724316 -5.590 2.28e-08 ***BOUGHT_ARTTRUE 1.1157547 0.2083854 5.354 8.59e-08 ***AMOUNT 0.0015624 0.0006927 2.255 0.0241 *GENDERmale:BOUGHT_ARTTRUE 0.5509284 0.2681018 2.055 0.0399 *---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1604.8 on 1299 degrees of freedomResidual deviance: 1427.6 on 1295 degrees of freedomAIC: 1437.6
Number of Fisher Scoring iterations: 4
Kurt Hornik 2006
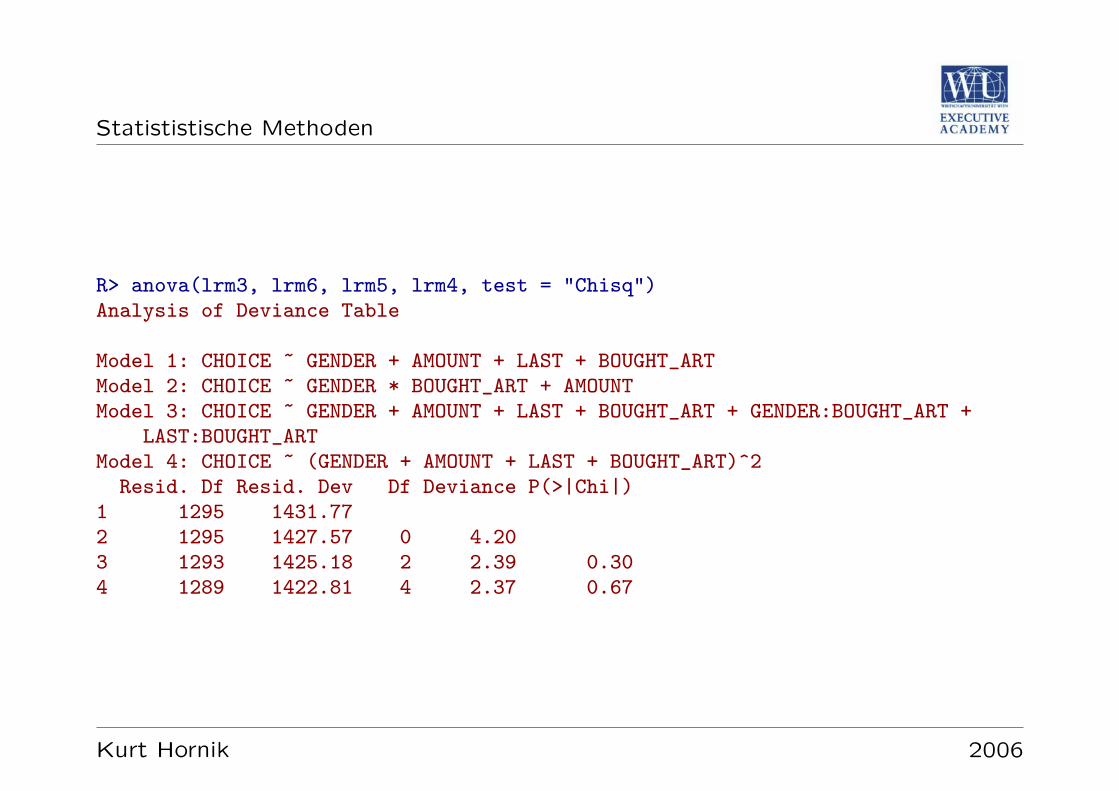
Statististische Methoden
R> anova(lrm3, lrm6, lrm5, lrm4, test = "Chisq")Analysis of Deviance Table
Model 1: CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ARTModel 2: CHOICE ~ GENDER * BOUGHT_ART + AMOUNTModel 3: CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ART + GENDER:BOUGHT_ART +
LAST:BOUGHT_ARTModel 4: CHOICE ~ (GENDER + AMOUNT + LAST + BOUGHT_ART)^2
Resid. Df Resid. Dev Df Deviance P(>|Chi|)1 1295 1431.772 1295 1427.57 0 4.203 1293 1425.18 2 2.39 0.304 1289 1422.81 4 2.37 0.67
Kurt Hornik 2006

Statististische Methoden
Clusteranalyse
Kurt Hornik 2006

Statististische Methoden
Clustering
Ziel: finde Gruppen in gegebenen Objekten x1, . . . , xn.
Fundamentales Konzept: Messung der Ahnlichkeit (Similarity) beziehungsweise Ver-schiedenheit (Dissimilarity, Distanz) zwischen Objekten.
Beispiele:
euklidisch Ublicher euklidischer (quadratischer) Abstand zwischen Vektoren (2-Norm);
Manhattan Absoluter Abstand zwischen Vektoren (1-Norm);
Jaccard Vektoren werden als Bits aufgefasst: von 0 verschiedene Elemente sind
”an“. Der Abstand ist der Anteil an Bits die in genau einem Vektor an sind
unter jenen die in mindestens einem Vektor an sind.
Kurt Hornik 2006

Statististische Methoden
Basistypologie von Verfahren der Clusteranalyse:
partitionierend Bildung von Gruppen (Partitionen)
hierarchisch Bildung von Hierarchien (agglomerativ und divisiv)
Dabei muß die Zugehorigkeit von Objekten zu Gruppen nicht notwendigerweise
”hart“ (ja oder nein) sein, sondern kann auch durch einen
”Membership Value“
quantifiziert werden: probabilistic, possibilistic und fuzzy Clustering.
Kurt Hornik 2006

Statististische Methoden
Partitionierung durch kombinatorische Verfahren
Eine naheliegende Idee fur die Zerlegung in Gruppen: maximiere die Ahnlichkeitinnerhalb der Gruppen, e.g. durch Minimierung der
”durchschnittlichen“ Verschie-
denheiten
1
2
k∑i=1
∑xα,xβ∈Gi
d(xα, xβ) → min!
Entspricht dual: maximiere die aggregierten Verschiedenheiten zwischen Gruppen.
Beachte: Verschiedenheiten innerhalb und zwischen Gruppen konnen auch andersgemessen werden.
Kurt Hornik 2006

Statististische Methoden
Die Minimierung von Zielfunktionen des obigen Typs fuhrt auf Probleme der kom-binatorischen Optimierung die
”sehr schwierig“ sind.
Die Anzahl aller moglichen Zuordnungen von n Objekten zu k Gruppen ist
1
k!
k∑i=1
(−1)k−i(ki
)in
Daher ist eine vollstandige Enumeration (explizites Durchsuchen aller moglichenPartitionen) fur die meisten Anwendungen
”computationally infeasible“.
Man verwendet daher”greedy“ Heuristiken, e.g.: schrittweise objektweise umgrup-
pieren bis keine Verbesserung mehr erzielt wird.
Kurt Hornik 2006

Statististische Methoden
Prototypenbasierte Partitionen
Prototypenbasierte Verfahren basieren auf folgender Grundidee: es wird ein”Code-
book“ von Prototypen (Medoiden, . . . ) ermittelt sodass
• Jedes Objekt in die Gruppe jenes Prototypen kommt dem es am nachsten ist;
• Die Prototypen so bestimmt werden dass die Summe der Abstande von Ob-jekten und ihren Prototypen minimiert wird.
Kurt Hornik 2006

Statististische Methoden
k-means
Falls der euklidischen Abstand zur Messung von Verschiedenheit verwendet wird(idealerweise: alle Merkmale metrisch), dann gilt:∑
xα,xβ∈G
d(xα, xβ) = 2|G|∑xα∈G
d(xα,m),
wobei m der Mittelwert der xα in G ist.
Fur eine gegebene Gruppierung ergeben sich also die Gruppenmittelwerte als Pro-totypen.
Dies motiviert den k-means Algorithmus.
Kurt Hornik 2006

Statististische Methoden
k-means Algorithmus
Wiederhole
1. Minimiere fur gegebene Gruppierung G1, . . . , Gk
k∑i=1
(∑xα∈Gi
d(xα,m)
)bezuglich m1, . . . ,mk.
2. Verandere G1, . . . , Gk so, dass jedes Objekt x in die Gruppe des ihm nachstenm kommt.
bis sich nichts mehr andert.
Kurt Hornik 2006

Statististische Methoden
k-medoids
Fur nicht-euklidische Verschiedenheiten (korrekt falls nicht alle Merkmale metrisch)funktioniert der
”Trick“ mit den Mittelwerten nicht.
Eine Idee ist naturlich das explizite Losen der Aufgabe∑xα∈Gi
d(xα,m) ⇒ min
(verallgemeinertes Medianproblem) was aber im allgemeinen sehr schwierig ist.
Eine substanzielle Vereinfachung ergibt sich wenn man fordert dass die PrototypenObjekte sein mussen. Man lost also einfach∑
xα∈Gi
d(xα, xβ) ⇒ minβ
(Medoidproblem).
Dies motiviert den k-medoids Algorithmus.
Kurt Hornik 2006

Statististische Methoden
k-medoids Algorithmus
Wiederhole
1. Finde fur jede Gruppe Gi jenes Objekt mi = xβ in Gi, das∑
xα∈Gid(xα, xβ)
minimiert.
2. Verandere G1, . . . , Gk so, dass jedes Objekt x in die Gruppe des ihm nachstenm kommt.
bis sich nichts mehr andert.
Kurt Hornik 2006

Statististische Methoden
Soft Clustering
Objekte konnen auch mehreren Gruppen zugeordnet werden.
uαi ”Membership“ von Objekt xα in Gruppe Gi.
Das bekannteste solche Verfahren ist der fuzzy c-means Algorithmus zur Losungder Optimierungsaufgabe ∑
α
∑i
uqαid(xα,mi) → min!,
wobei d euklidische Verschiedenheit ist und q > 1 die”fuzziness“ steuert.
Ahnlich fur probabilistische Ansatze (Mixture Modeling).
Kurt Hornik 2006

Statististische Methoden
Diskussion partitionierender Clusterverfahren
Die Anzahl k der verwendeten Gruppen ist ein”Hyperparameter“ der fur das Finden
”guter“ Zerlegungen ebenfalls zu optimieren ist.
Dabei stellt sich die Frage nach der Interpretabilitat der Ergebnisse, auch inAbhangigkeit von k. Eine Idee dazu ist die Erklarung anhand weiterer Merkmaledie fur die Gruppenbildung nicht in Betracht gezogen wurden.
Computationale Probleme und Reproduzierbarkeit.
Der Methodenpluralismus fuhrt dazu dass es jedenfalls eine Vielzahl moglicherLosungen gibt. Deren Aggregation in
”Consensus“ Partitionen kann stabilere und
interpretablere Ergebnisse liefern.
Kurt Hornik 2006

Statististische Methoden
R: Partitionierende Clusterverfahren
R> require("clue")Loading required package: clue[1] TRUER> require("cluster")Loading required package: cluster[1] TRUER> names(USArrests)[1] "Murder" "Assault" "UrbanPop" "Rape"
Kurt Hornik 2006

Statististische Methoden
k-means fur k = 3:
R> kmns <- kmeans(USArrests[-3], 3)
R> kmns
K-means clustering with 3 clusters of sizes 14, 16, 20
Cluster means:Murder Assault Rape
1 8.214286 173.2857 22.842862 11.812500 272.5625 28.375003 4.270000 87.5500 14.39000
Clustering vector:Alabama Alaska Arizona Arkansas California
2 2 2 1 2Colorado Connecticut Delaware Florida Georgia
1 3 2 2 1Hawaii Idaho Illinois Indiana Iowa
Within cluster sum of squares by cluster:[1] 7311.429 15964.425 15580.010
Available components:[1] "cluster" "centers" "withinss" "size"
Kurt Hornik 2006

Statististische Methoden
k-medoids fur k = 3:
R> kmed <- pam(USArrests[-3], 3)
R> kmed
Medoids:ID Murder Assault Rape
New York 32 11.1 254 26.1New Jersey 30 7.4 159 18.8South Dakota 41 3.8 86 12.8Clustering vector:
Alabama Alaska Arizona Arkansas California1 1 1 2 1
Colorado Connecticut Delaware Florida Georgia2 3 1 1 1
Hawaii Idaho Illinois Indiana Iowa3 3 1 3 3
Objective function:build swap
24.96821 24.96821
Available components:[1] "medoids" "id.med" "clustering" "objective" "isolation"[6] "clusinfo" "silinfo" "diss" "call" "data"
Kurt Hornik 2006

Statististische Methoden
Vergleich von k-means und k-medoids fur k = 3.
R> classes_kmns <- cl_class_ids(kmns)R> classes_kmed <- cl_class_ids(kmed)R> table(classes_kmns, classes_kmed)
classes_kmedclasses_kmns 1 2 3
1 1 13 02 16 0 03 0 0 20
(Praktisch ident.)
Kurt Hornik 2006

Statististische Methoden
Versuch der Interpretation der gefundenen Losung anhand des Anteils der landlichenBevolkerung:
R> boxplot(USArrests$Urban ~ classes_kmns)
1 2 3
3040
5060
7080
90
Kurt Hornik 2006

Statististische Methoden
Versuch der Interpretation der gefundenen Losung anhand der Lage der Bundes-staaten. Dazu Hilfscode:
R> require("maps")Loading required package: maps[1] TRUER> stateplot <- function(classes, colors = NULL, names = NULL) {+ nms_in_db <- map("state", namesonly = TRUE, plot = FALSE)+ nms_in_db <- sub(":.*", "", nms_in_db)+ nms <- if (is.null(names))+ names(classes)+ else names+ if (is.null(nms))+ stop("No state names available for classes.")+ if (is.null(colors))+ colors <- gray.colors(length(unique(classes)))+ nms <- tolower(nms)+ pos <- match(nms_in_db, nms)+ map("state", col = colors[classes[pos]], fill = TRUE)+ }
Kurt Hornik 2006
Statististische Methoden
R: Partitionierende ClusterverfahrenR> stateplot(classes_kmns)R> title(main = "Clusters Found by K-Means")
Clusters Found by K−Means
Kurt Hornik 2006
Statististische Methoden
R> stateplot(classes_kmns, rev(gray.colors(3)))R> title(main = "Clusters Found by K-Means")
Clusters Found by K−Means
Kurt Hornik 2006
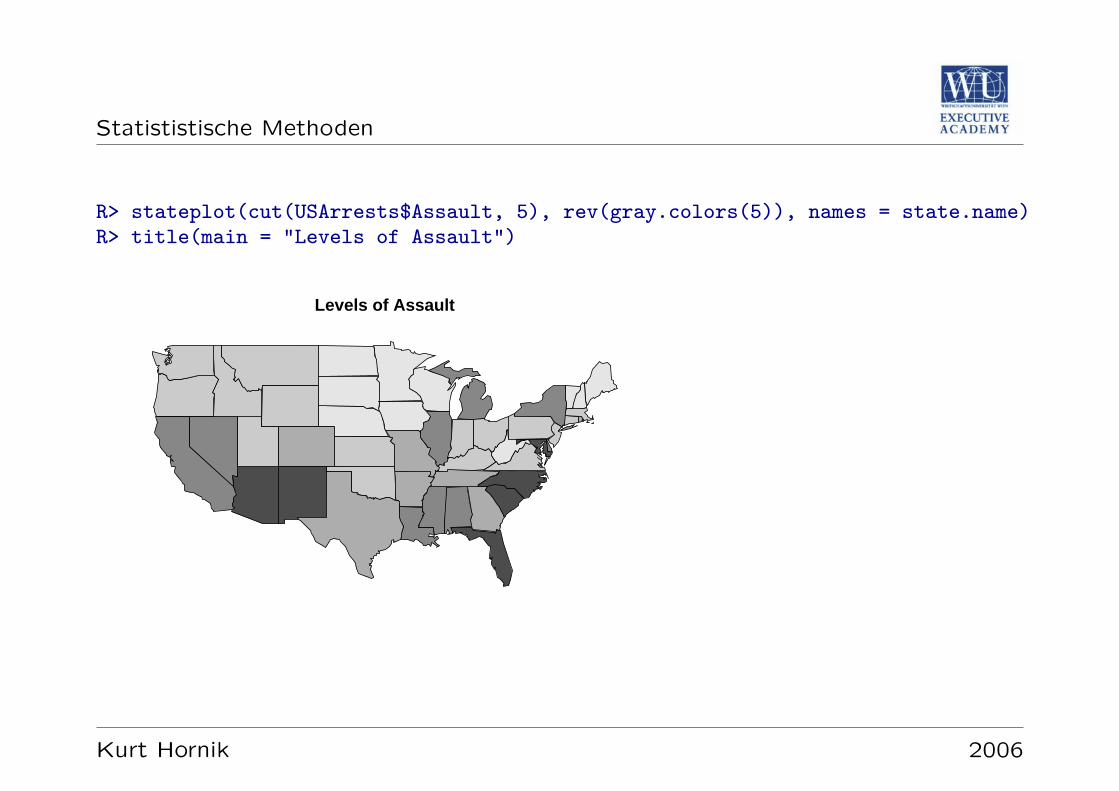
Statististische Methoden
R> stateplot(cut(USArrests$Assault, 5), rev(gray.colors(5)), names = state.name)R> title(main = "Levels of Assault")
Levels of Assault
Kurt Hornik 2006
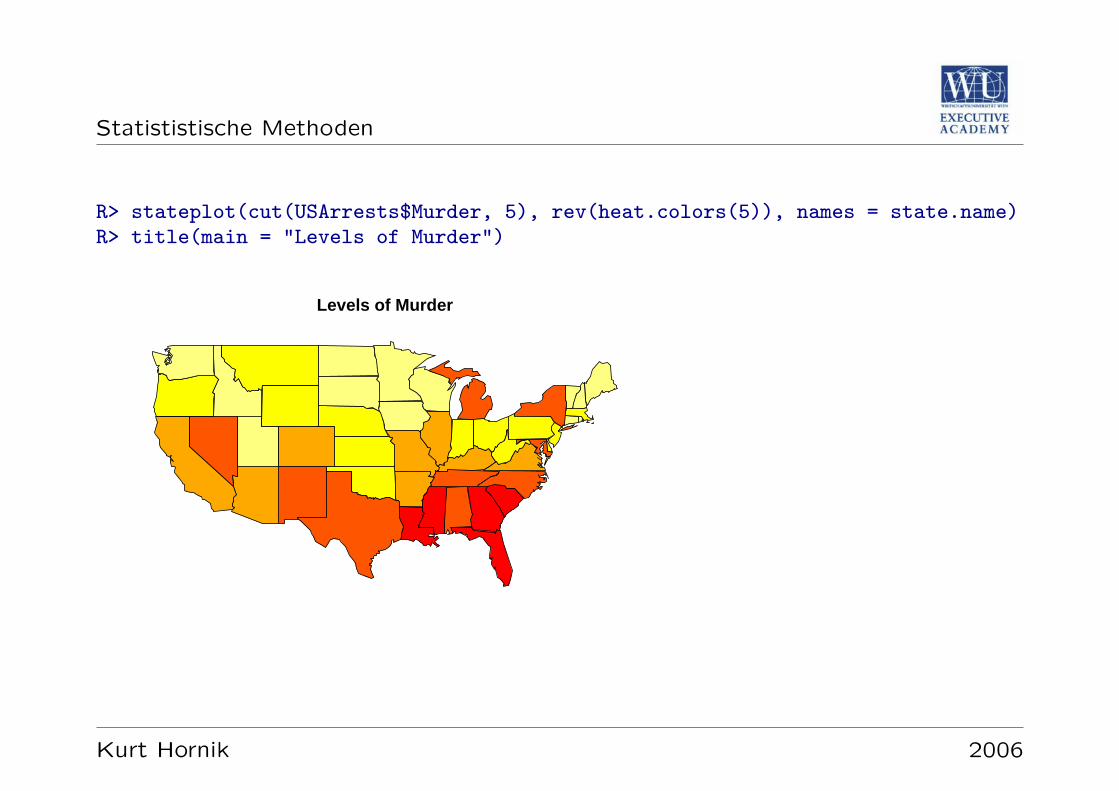
Statististische Methoden
R> stateplot(cut(USArrests$Murder, 5), rev(heat.colors(5)), names = state.name)R> title(main = "Levels of Murder")
Levels of Murder
Kurt Hornik 2006
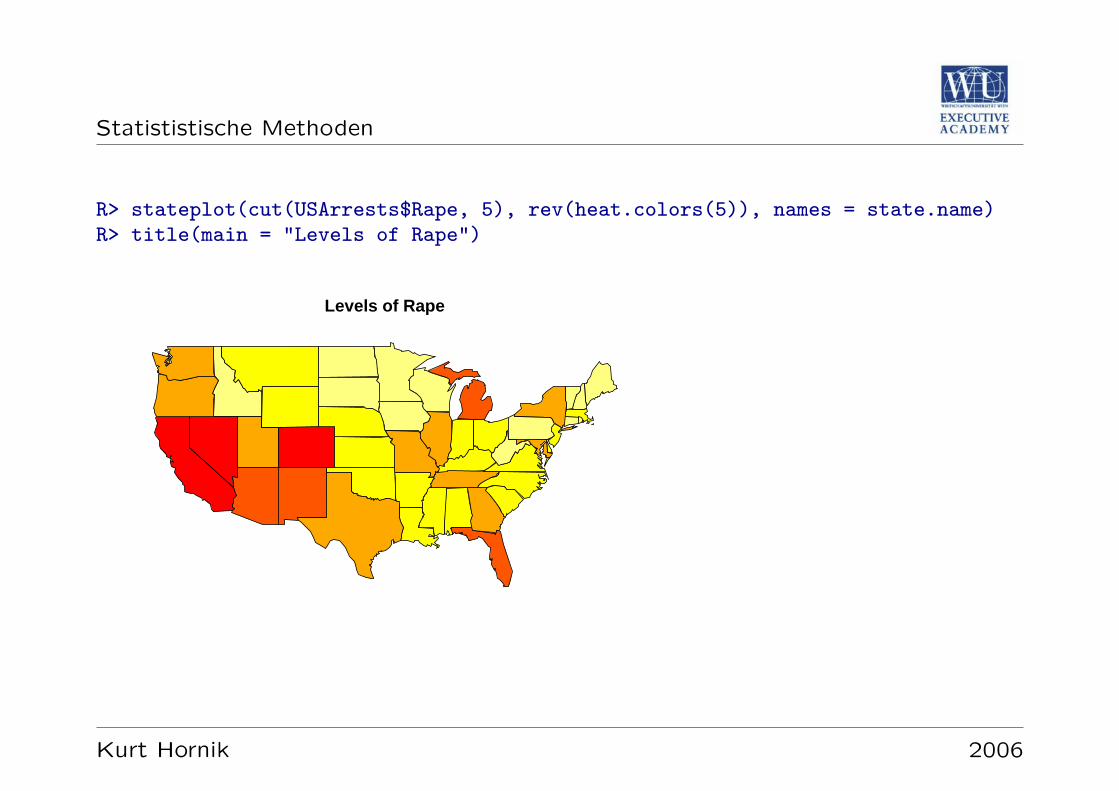
Statististische Methoden
R> stateplot(cut(USArrests$Rape, 5), rev(heat.colors(5)), names = state.name)R> title(main = "Levels of Rape")
Levels of Rape
Kurt Hornik 2006

Statististische Methoden
Agglomeratives hierarchisches Clustern
Idee: sukzessive die zwei”ahnlichsten“ Gruppen zu einer zusammenfassen; am An-
fang ist jedes Objekt seine eigene Gruppe, zuletzt sind alle Objekte in einer Gruppe.
Dazu muss man die Verschiedenheit von Gruppen von Objekten messen konnen.Gangige solche Verschiedenheitsmaße:
d(G,H) = min /mean/med/max{d(xα, xβ) : xα ∈ G, xβ ∈ H}(single, average, complete Linkage, . . . ).
Erzeugt Hierarchie von binaren Splits, die durch einen Baum (Dendrogramm) vi-sualisiert werden kann.
Kurt Hornik 2006

Statististische Methoden
R: Hierarchische Clusterverfahren
R> hc1 <- hclust(dist(USArrests[-3]))R> plot(hc1)R> rect.hclust(hc1, k = 3, border = "red")
Flo
rida
Nor
th C
arol
ina
Ariz
ona
Mar
ylan
dC
alifo
rnia
New
Mex
ico
Sou
th C
arol
ina
Ala
ska
Mic
higa
nN
evad
aA
laba
ma
Del
awar
eM
issi
ssip
piN
ew Y
ork
Illin
ois
Loui
sian
aM
inne
sota
Sou
th D
akot
aM
aine
Wes
t Virg
inia
Haw
aii
Wis
cons
inIo
wa
New
Ham
pshi
reN
orth
Dak
ota
Ver
mon
tC
olor
ado
Geo
rgia
Tex
asR
hode
Isla
ndM
isso
uri
Ark
ansa
sT
enne
ssee
Neb
rask
aC
onne
ctic
utK
entu
cky
Mon
tana
Pen
nsyl
vani
aId
aho
Indi
ana
Kan
sas
Ohi
oU
tah
Was
hing
ton
Mas
sach
uset
tsO
klah
oma
Ore
gon
Wyo
min
gN
ew J
erse
yV
irgin
ia
050
150
250
Cluster Dendrogram
hclust (*, "complete")dist(USArrests[−3])
Hei
ght
Kurt Hornik 2006

Statististische Methoden
Vergleich mit der k-means Losung:
R> classes_hc1 <- cutree(hc1, 3)R> table(classes_kmns, classes_hc1)
classes_hc1classes_kmns 1 2 3
1 0 14 02 16 0 03 0 10 10
Kurt Hornik 2006
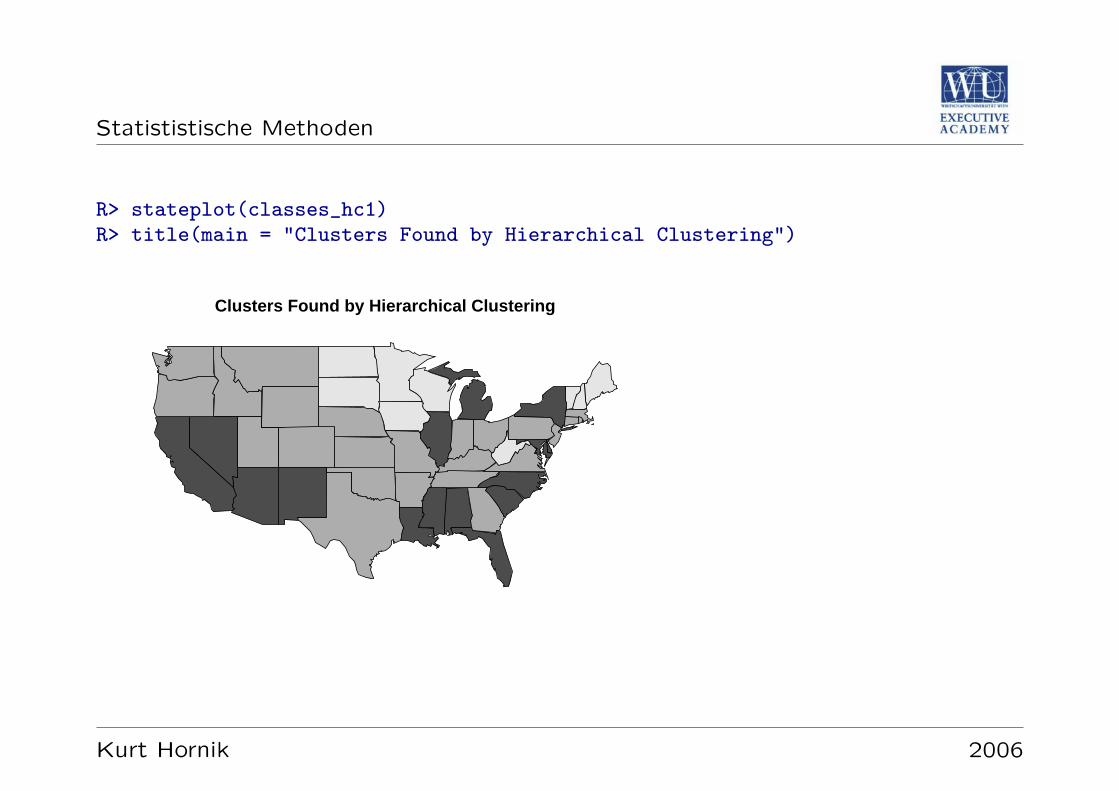
Statististische Methoden
R> stateplot(classes_hc1)R> title(main = "Clusters Found by Hierarchical Clustering")
Clusters Found by Hierarchical Clustering
Kurt Hornik 2006

Statististische Methoden
Effekt der Skalierung:
R> hc2 <- hclust(dist(scale(USArrests[-3])))R> plot(hc2)R> rect.hclust(hc2, k = 4, border = "red")
New
Ham
pshi
reW
isco
nsin
Iow
aV
erm
ont
Mai
neN
orth
Dak
ota
Haw
aii
Mas
sach
uset
tsN
ebra
ska
Kan
sas
Mon
tana
Pen
nsyl
vani
aW
est V
irgin
iaM
inne
sota
Idah
oC
onne
ctic
utS
outh
Dak
ota Uta
hO
rego
nW
ashi
ngto
nA
rkan
sas
Virg
inia
Wyo
min
gN
ew J
erse
yO
klah
oma
Ken
tuck
yIn
dian
aO
hio
Del
awar
eR
hode
Isla
ndIll
inoi
sN
ew Y
ork
Mis
sour
iT
enne
ssee
Tex
asC
olor
ado
Nev
ada
Ala
ska
Cal
iforn
ia Flo
rida
Mic
higa
nA
rizon
aM
aryl
and
New
Mex
ico
Nor
th C
arol
ina
Geo
rgia
Mis
siss
ippi
Ala
bam
aLo
uisi
ana
Sou
th C
arol
ina
01
23
45
Cluster Dendrogram
hclust (*, "complete")dist(scale(USArrests[−3]))
Hei
ght
Kurt Hornik 2006

Statististische Methoden
Vergleich mit der k-means Losung:
R> classes_hc2 <- cutree(hc2, 4)R> table(classes_kmns, classes_hc2)
classes_hc2classes_kmns 1 2 3 4
1 1 4 8 12 10 5 1 03 0 0 4 16
Kurt Hornik 2006

Statististische Methoden
R> stateplot(classes_hc2)R> title(main = "Clusters Found by Hierarchical Clustering\nAfter Scaling")
Clusters Found by Hierarchical ClusteringAfter Scaling
Kurt Hornik 2006

Statististische Methoden
Assoziationsregeln
Kurt Hornik 2006

Statististische Methoden
Assoziationsregeln
Ziel: finde jene Kombinationen der Werte von Merkmalen X1, . . . , Xp, die”spannend“
sind (haufig vorkommen, . . . ).
Anwendung vor allem in der Warenkorbanalyse (Market Basket Analysis): alle Xi sindbinar und entsprechen Transaktionsindikatoren (Item i gekauft (
”im Warenkorb“)
oder nicht).
Anwendbar aber auch auf beliebig skalierte Merkmale durch geeignete Binarisierung.
Im Prinzip Suche nach den Modi: in hochdimensionalen Raumen gibt es dafur meistzuwenig Beobachtungen (
”Fluch der Dimensionalitat“).
Kurt Hornik 2006

Statististische Methoden
Als Vereinfachung: statt spannender”Werte“ suche nach geeigneten Regionen, e.g.
Schnitte
R = X1 ∈ S1 ∩ · · · ∩Xp ∈ Spmit jeweils genau einem oder allen moglichen Werten eines Merkmals.
Falls alle Xi binar (sonst”dummy encoding“):
R↔ J = {j : Xj = 1}
Suchen spannende Item Sets J (Mengen von Items die gemeinsam gekauft werden)
Kurt Hornik 2006

Statististische Methoden
Haufige Item Sets
Support (auch: Pravalenz) T (J) des Item Set J: relative Haufigkeit der Beobach-tungen (Warenkorbe), die das Item Set J enthalten.
Association Rule Mining: suchen zunachst alle Item Sets mit hinreichend großemSupport, i.e., alle J mit T (J) ≥ t.
Statt aller 2p Item Sets sind dafur nur”wenige“ zu betrachten. Ausserdem: J1 ⊆
J2 ⇒ T (J1) ≥ T (J2), konnen daher schrittweise in l alle noch moglichen Item Setsmit l Elementen durchsuchen (
”Breadth-first“: Apriori Algorithmus).
Bekommen so die Frequent Item Sets.
Kurt Hornik 2006

Statististische Methoden
Von Item Sets zu Assoziationsregeln
Zerlegung
J =”antecedent“ A ∪
”consequent“ B
mit Interpretation:”aus A folgt B“, A⇒ B.
Wie”gut“ sind solche Regeln? Messung anhand von Qualitatsmaßen.
Confidence (auch: Predictability) einer Regel:
C(A⇒ B) =T (A⇒ B)
T (A)↔ Pr(B|A)
Expected Confidence: T (B) ↔ Pr(B)
Kurt Hornik 2006

Statististische Methoden
”Lift“ einer Regel:
L(A⇒ B) =C(A⇒ B)
T (B)=T (A⇒ B)
T (A)T (B)↔
Pr(A ∩B)
Pr(A)Pr(B)
Bei Mining von Assoziationsregeln: suche nur jene Regeln mit hinreichend großerConfidence, i.e.,
Finde alle Regeln mit T (A⇒ B) ≥ t und C(A⇒ B) ≥ c.
Integrationspotenzial in Query und Reporting Losungen, e.g.
alle Transaktionen in denen Item i die Konsequenz ist mit Konfidenz ≥ 80%und Support ≥ 2%.
Kurt Hornik 2006

Statististische Methoden
R: Assoziationsregeln
Datenaufbereitung: Kategorisierung und Binarisierung.
R> require("arules")Loading required package: arulesLoading required package: stats4Loading required package: Matrix[1] TRUER> AMOUNT_F <- cut(AMOUNT, c(0, 100, 200, 300, 500), labels = c("lo",+ "medlo", "medhi", "hi"))R> LAST_F <- cut(LAST, c(0, 4, 8, 12), labels = c("short", "medium",+ "long"))R> BOUGHT_ART_F <- factor(BOUGHT_ART)R> BT <- as(data.frame(CHOICE, GENDER, AMOUNT_F, LAST_F, BOUGHT_ART_F),+ "transactions")
Kurt Hornik 2006

Statististische Methoden
Zusammenfassung des erzeugten Transaktionsdatensatzes:
R> summary(BT)transactions as itemMatrix in sparse format with1300 rows (elements/itemsets/transactions) and13 columns (items)
most frequent items:LAST_F=short CHOICE=no BOUGHT_ART_F=FALSE GENDER=male
1000 900 873 844AMOUNT_F=medhi (Other)
470 2413
element (itemset/transaction) length distribution:5
1300
Min. 1st Qu. Median Mean 3rd Qu. Max.5 5 5 5 5 5
includes extended item information - examples:labels variables levels
1 CHOICE=no CHOICE no2 CHOICE=yes CHOICE yes
Kurt Hornik 2006

Statististische Methoden
Finden aller Assoziationsregeln mit Support ≥ 0.05 und Confidence ≥ 0.8:
R> rules <- apriori(BT, parameter = list(support = 0.05, confidence = 0.8))parameter specification:confidence minval smax arem aval originalSupport support minlen maxlen target
0.8 0.1 1 none FALSE TRUE 0.05 1 5 rulesext
FALSE
algorithmic control:filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithmversion 4.21 (2004.05.09) (c) 1996-2004 Christian Borgeltset item appearances ...[0 item(s)] done [0.00s].set transactions ...[13 item(s), 1300 transaction(s)] done [0.00s].sorting and recoding items ... [13 item(s)] done [0.01s].creating transaction tree ... done [0.00s].checking subsets of size 1 2 3 4 5 done [0.00s].writing ... [71 rule(s)] done [0.00s].creating S4 object ... done [0.00s].
Kurt Hornik 2006
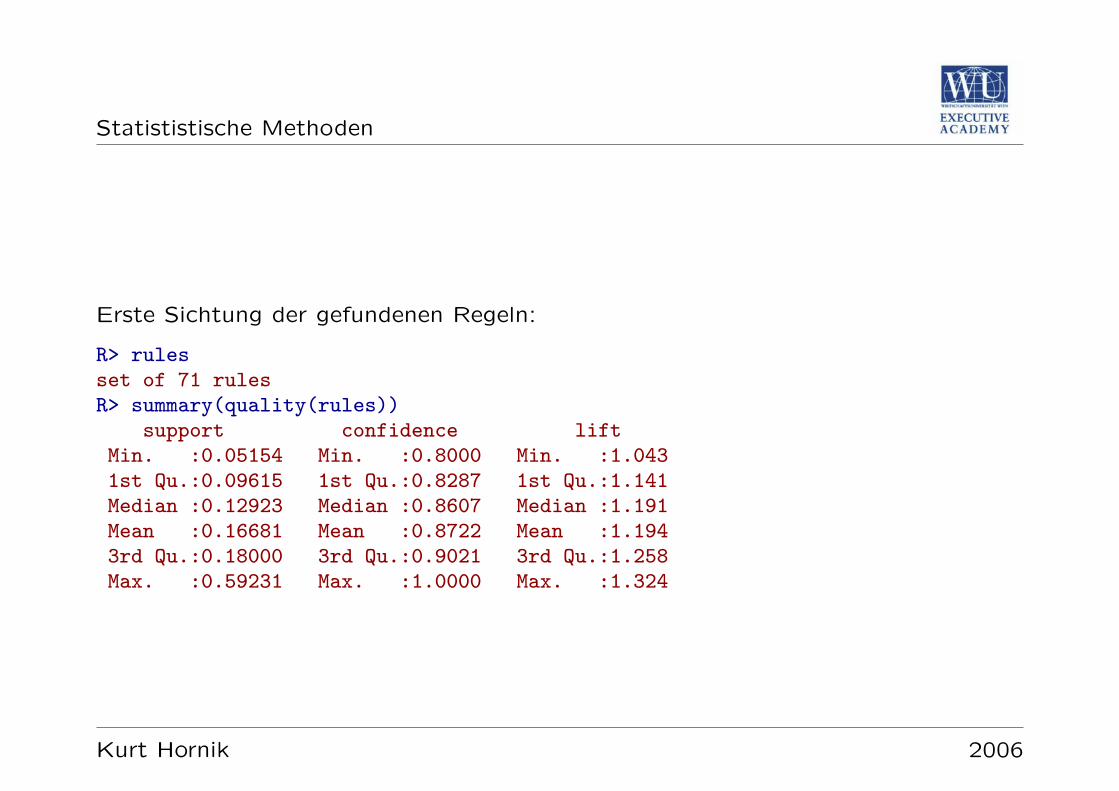
Statististische Methoden
Erste Sichtung der gefundenen Regeln:
R> rulesset of 71 rulesR> summary(quality(rules))
support confidence liftMin. :0.05154 Min. :0.8000 Min. :1.0431st Qu.:0.09615 1st Qu.:0.8287 1st Qu.:1.141Median :0.12923 Median :0.8607 Median :1.191Mean :0.16681 Mean :0.8722 Mean :1.1943rd Qu.:0.18000 3rd Qu.:0.9021 3rd Qu.:1.258Max. :0.59231 Max. :1.0000 Max. :1.324
Kurt Hornik 2006
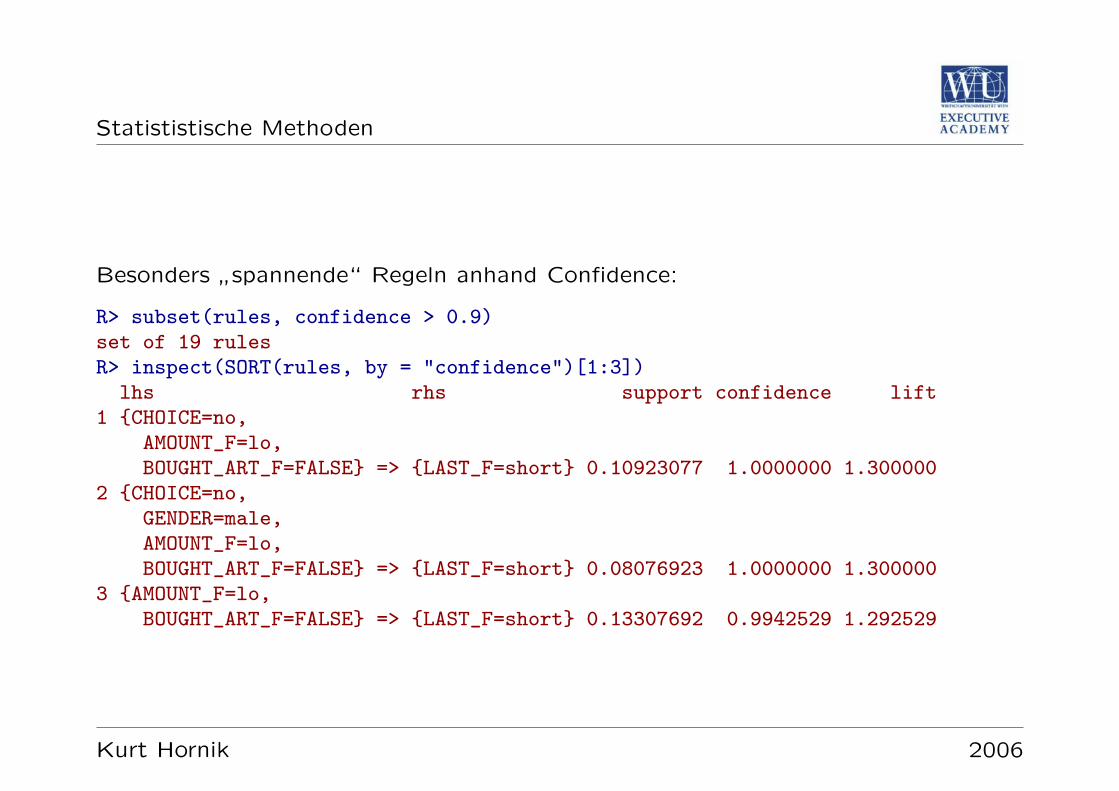
Statististische Methoden
Besonders”spannende“ Regeln anhand Confidence:
R> subset(rules, confidence > 0.9)set of 19 rulesR> inspect(SORT(rules, by = "confidence")[1:3])
lhs rhs support confidence lift1 {CHOICE=no,
AMOUNT_F=lo,BOUGHT_ART_F=FALSE} => {LAST_F=short} 0.10923077 1.0000000 1.300000
2 {CHOICE=no,GENDER=male,AMOUNT_F=lo,BOUGHT_ART_F=FALSE} => {LAST_F=short} 0.08076923 1.0000000 1.300000
3 {AMOUNT_F=lo,BOUGHT_ART_F=FALSE} => {LAST_F=short} 0.13307692 0.9942529 1.292529
Kurt Hornik 2006

Statististische Methoden
Besonders”spannende“ Regeln anhand Lift:
R> subset(rules, lift > 1.3)set of 3 rulesR> inspect(subset(rules, lift > 1.3))
lhs rhs support confidence lift1 {GENDER=male,
AMOUNT_F=medlo,BOUGHT_ART_F=FALSE} => {CHOICE=no} 0.12692308 0.9065934 1.309524
2 {CHOICE=no,GENDER=female,AMOUNT_F=medlo,LAST_F=short} => {BOUGHT_ART_F=FALSE} 0.05538462 0.8888889 1.323660
3 {GENDER=male,AMOUNT_F=medlo,LAST_F=short,BOUGHT_ART_F=FALSE} => {CHOICE=no} 0.11461538 0.9085366 1.312331
Kurt Hornik 2006
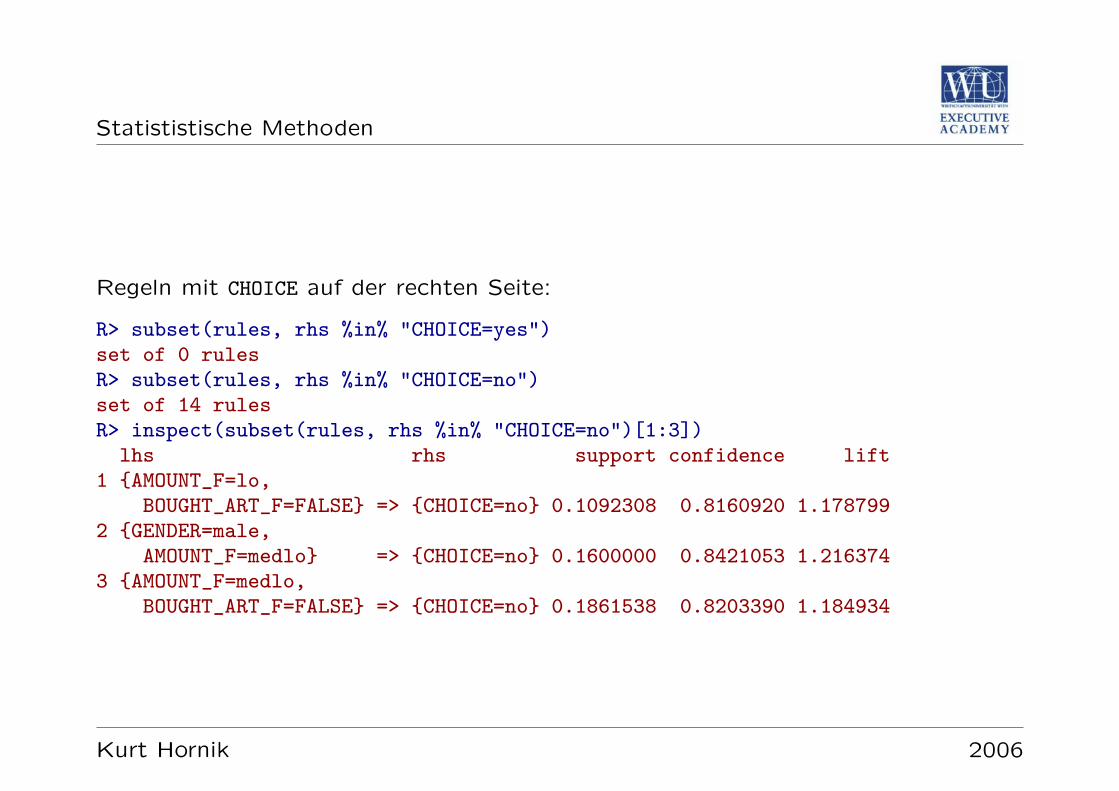
Statististische Methoden
Regeln mit CHOICE auf der rechten Seite:
R> subset(rules, rhs %in% "CHOICE=yes")set of 0 rulesR> subset(rules, rhs %in% "CHOICE=no")set of 14 rulesR> inspect(subset(rules, rhs %in% "CHOICE=no")[1:3])
lhs rhs support confidence lift1 {AMOUNT_F=lo,
BOUGHT_ART_F=FALSE} => {CHOICE=no} 0.1092308 0.8160920 1.1787992 {GENDER=male,
AMOUNT_F=medlo} => {CHOICE=no} 0.1600000 0.8421053 1.2163743 {AMOUNT_F=medlo,
BOUGHT_ART_F=FALSE} => {CHOICE=no} 0.1861538 0.8203390 1.184934
Kurt Hornik 2006

Statististische Methoden
Entscheidungsbaume
Kurt Hornik 2006

Statististische Methoden
Partitions- und Template-basiertes Lernen
Grundidee: ermittle”Output“ fur neuen
”Input“ x auf Basis der vorhandenen Daten
mit Inputs in einer Region mit/um x, e.g. durch Mittelbildung (Regression) oderMehrheitsentscheidung (Klassifikation).
Region um: e.g., k nachste Nachbarn (knn), gegebenenfalls”Quantisierung“ durch
Prototypen (LVQ)
Region mit: e.g., Zerlegung des Inputraums durch”achsenparallele“ Schnitte ⇒
Klassifikations-/Entscheidungs- und Regressionsbaume
Vergleiche: Fallbasiertes Schließen (Case-based Reasoning)
Kurt Hornik 2006

Statististische Methoden
Entscheidungsbaume
Target y kategorial mit Werten γ1, . . . , γK.
Fur Knoten n und Rn die entsprechende Region im Inputraum ist
pnk =1
Nn
∑xi∈Rn
I(yi = γk)
die relative Haufigkeit von Daten in Knoten n (Region Rn) mit Output γk.
Entscheidung innerhalb von n: jenes k wo pnk maximal (Mehrheitsentscheidung).
Kurt Hornik 2006

Statististische Methoden
Baume wachsen lassen
Idee: wollen Baum mit moglichst”reinen“ Endknoten (Blattern).
Maße fur Unreinheit (Impurity); Misklassifikationsrate; Gini Index (∑
k pnk(1− pnk)),Kreuzentropie (−
∑pnk log pnk). Im binaren Fall mit Haufigkeiten p und q = 1 − p:
1−max(p, q); 2pq, −p log p− q log q.
Suchen jene Region, wo wir die Reinheit durch Aufsplitten maximal verbessernkonnen.
Aufsplitten e.g. in der Form: xj ≤ s und xj > s fur ein metrisches (ordinales) Merkmalxj; sonst Wertemenge zerlegen. Aufhoren falls e.g. Regionen zu klein (Nn ≤ 5) oderrein genug.
Kurt Hornik 2006

Statististische Methoden
Baume zuruckstutzen
Cost complexity backward pruning: fur Teilbaum T sei |T | die Anzahl der Endknotenin T . Betrachten Komplexitatsmaß
Cα(T ) =∑
Endknoten n in T
Nn Impurity(Rn) + α|T |
Fur festes α eindeutig bestimmter kleinster Baum Tα mit minimalem Cα(T ).”Be-
stes“ α e.g. durch Kreuzvalidierung bestimmen.
Kurt Hornik 2006

Statististische Methoden
Diskussion
Entscheidungsbaume versus Systeme von Entscheidungsregeln
Interpretabilitat und Visualisierung;”bester“ Baum versus
”verstandlichster“ Baum
Aktuelle Trends: Zufallswalder (Random Forests) von Baumen
Kurt Hornik 2006

Statististische Methoden
R: Entscheidungsbaum
R> require("rpart")Loading required package: rpart[1] TRUER> dtm1 <- rpart(CHOICE ~ GENDER + AMOUNT + LAST + BOUGHT_ART, data = BBBClub)R> dtm1n= 1300
node), split, n, loss, yval, (yprob)* denotes terminal node
1) root 1300 400 no (0.6923077 0.3076923)2) BOUGHT_ART< 0.5 873 176 no (0.7983963 0.2016037) *3) BOUGHT_ART>=0.5 427 203 yes (0.4754098 0.5245902)
6) AMOUNT< 219.5 194 89 no (0.5412371 0.4587629)12) AMOUNT>=77.5 161 68 no (0.5776398 0.4223602)
24) GENDER=male 100 35 no (0.6500000 0.3500000) *25) GENDER=female 61 28 yes (0.4590164 0.5409836) *
13) AMOUNT< 77.5 33 12 yes (0.3636364 0.6363636) *7) AMOUNT>=219.5 233 98 yes (0.4206009 0.5793991) *
Kurt Hornik 2006

Statististische Methoden
R> plot(dtm1, uniform = TRUE)R> text(dtm1, pretty = TRUE, xpd = TRUE, use.n = TRUE)R> title(main = "Entscheidungsbaum fur CHOICE")
|BOUGHT_ART< 0.5
AMOUNT< 219.5
AMOUNT>=77.5
GENDER=male
no 697/176
no 65/35
yes28/33
yes12/21
yes98/135
Entscheidungsbaum für CHOICE
Kurt Hornik 2006

Statististische Methoden
Neurale Netze
Kurt Hornik 2006

Statististische Methoden
Mehrschichtperzeptrone (”Neurale Netze“)
Um 1990 waren”Neurale Netze“ die Erfolgsstory des maschinellen und parziell auch
des statistischen Lernens.
Biologische Motivation: im menschlichen Gehirn ∼ 1014−15 Neuronen die gleichzeitigarbeiten (Konnektionismus, Parallel Distributed Processing).
Abstraktion biologischer Neuronen als (Processing) Unit:
ofsl
iiii
w
w
w
1i
2i
ji
Kurt Hornik 2006

Statististische Methoden
Diese Units kann man zu Netzwerken kombinieren, e.g. vorwartsgerichtet und inSchichten: Eingabeschicht, ein oder mehrere verborgene Schichten zur internenBerechnung (
”hidden layers“), Ausgabeschicht.
Einfache Netzwerke: e.g.”Perzeptron“ (Rosenblatt, 1958)
Multi-layer Perzeptron mit einer verborgenen Schicht:
I H O
W1 W2
(I: Input Layer, H: Hidden Layer, O: Output Layer.)
Kurt Hornik 2006

Statististische Methoden
Approximationseigenschaften
Als Speziallfall (eine lineare Ausgabeunit, Hidden Units mit Output ψ(∑
i αixi − γ))ergeben sich Netze die Funktionen der Form
x 7→ o =H∑h=1
βhψ
(∑i
αhixi − γh
)mit geeigneter Aktivierungsfunktion ψ und Parametern (
”Gewichten“) θ =
(α11, . . . , αHp, β1, . . . , βH, γ1, . . . , γH), implementieren. I.e., x 7→ f(x, θ).
Welche Funktionen konnen so durch geeignete Wahl von θ annahernd dargestelltwerden? Bei hinreichend großem H alle (
”Neurale Netze sind universale Approxi-
matoren“)
Kurt Hornik 2006

Statististische Methoden
Back Propagation
Wie kann man (fur festes H) die Parameter θ geeignet wahlen? Fur Daten mitInput-Target Paaren (xi, yi) e.g. durch
E(θ) =n∑i=1
(yi − f(xi, θ))2 → min!
(nichtlineares Ausgleichsproblem).
Bei Verwendung eines einfachen Online-Gradientenverfahrens: (Error) Back Propa-gation (bei mehr als einer Zwischenschicht). Gradient kann rekursiv ruckwarts vonAusgabe- zur Eingabeschicht berechnet werden,
”Back Propagation Networks“.
Kurt Hornik 2006

Statististische Methoden
Lernen mit Mehrschichtperzeptronen
Beim Lernen gibt es eine Vielzahl zusatzlicher Aspekte:
• Verwendung anderer beziehungsweise besserer Lernverfahren zum Schatzen derModellparameter;
• Verwendung anderer Fehlerfunktionen bei der Schatzung (e.g., fur Klassifika-tionsaufgaben);
• Optimierung der expliziten Hyperparameter (vor allem Anzahl H der HiddenUnits);
• Optimierung der impliziten Hyperparameter (Aktivierungsfunktion ψ).
Kurt Hornik 2006

Statististische Methoden
Diskussion
Alleinvertretungsanspruch und Universalitatseigenschaft: viele”flexible“ Klassen pa-
rametrischer Modellfunktionen sind universal.
Fur quadratische Fehlerfunktionen sind Modelle die linear in den Parametern sindviel einfacher zu fitten.
Defizite von MLPs: Interpretabilitat, Visualisierbarkei, Reproduzierbarkeit, Komple-xitat der Modellanpassung (geht eigentlich nicht
”auf Knopfdruck“); Vorteile: per-
formen meist besser als klassische Verfahren (lineare und verallgemeinerte lineareModelle).
Kurt Hornik 2006

Statististische Methoden
R: Mehrschicht-Perzeptrone
R> require("nnet")Loading required package: nnet[1] TRUER> set.seed(111)R> nn1 <- nnet(CHOICE ~ I(AMOUNT/50) + GENDER + LAST + BOUGHT_ART,+ size = 3, skip = TRUE, rang = 0.03, trace = FALSE)R> summary(nn1)a 4-3-1 network with 23 weightsoptions were - skip-layer connections entropy fitting
b->h1 i1->h1 i2->h1 i3->h1 i4->h1-63.90 21.65 0.88 -0.96 30.17b->h2 i1->h2 i2->h2 i3->h2 i4->h2
-23.68 -23.17 76.34 26.21 280.74b->h3 i1->h3 i2->h3 i3->h3 i4->h3
415.49 -100.52 128.35 -71.23 1.21b->o h1->o h2->o h3->o i1->o i2->o i3->o i4->o0.46 -1.41 -1.11 -1.12 0.03 -0.31 0.00 2.33
Kurt Hornik 2006

Statististische Methoden
Modellierung
Kurt Hornik 2006

Statististische Methoden
Motivation
Grundlegende Fragen:
• Wozu bauen wir Modelle?
• Welche Eigenschaften sollen Modelle haben?
• Wie konnen wir verschiedene, miteinander in Wettbewerb stehende Modellemiteinander vergleichen?
Kurt Hornik 2006

Statististische Methoden
Wir bauen Modelle um . . .
• Ein vereinfachtes Bild der Wirklichkeit zu bekommen (Erklarungsmodelle)
• Auf Basis des Modells (dieses Bilds) Entscheidungen treffen zu konnen (e.g.,Vorhersagemodelle).
Bewertung von Gute muss berucksichtigen, welcher dieser Aspekte im Vordergrundsteht.
Kurt Hornik 2006

Statististische Methoden
Modellperformance
Entscheidungsrelevante Modelle sollen . . .
• Das zugrundeliegende Entscheidungsproblem moglichst gut losen
• In Einklang mit Theorie und Realitat (e.g.,”Stylized Facts“) stehen
• Lieber”einfacher als kompliziert“ sein (Modellkomplexitat)
• Lieber interpretabler als eine Black Box sein
weitere Kriterien, e.g. Akzeptanz, Kosten, . . .
Auswahl des besten Modells ist eigentlich mehrdimensionales Optimierungsproblem.
Soll sich der Performancevergleich ausschließlich auf das zugrundeliegende Entschei-dungsproblem beschranken?
Kurt Hornik 2006

Statististische Methoden
Entscheidungstheorie
Allgemein: fur Datum z treffen wir Entscheidung δ(z), ergibt Verlust L(δ(z)) undRisiko R(δ) gleich durchschnittlicher Verlust uber die Grundgesamtheit. Fur Datenz1, . . . , zn nennt man den durchschnittlichen Verlust
Rn(δ) =1
n
n∑i=1
L(δ(zi))
das empirische Risiko der Entscheidung δ.
Spezielles Entscheidungsproblem: Bauen von Vorhersagemodellen fur y auf der Basisder unabhangigen Merkmale in x (Uberwachtes Lernen; Supervised Learning). Manspricht (in diesem Kontext) von Regressions- und Klassifikationsaufgaben, falls ymetrisch beziehungsweise kategorial ist.
Kurt Hornik 2006

Statististische Methoden
Klassifikation
Wir zerlegen z = (x, y) in die Teile mit den unabhangigen und dem abhangigenMerkmal. Wird auf Basis von x die Klasse f(x) zugeordnet, so ist der entsprechendeVerlust
L(z) ⇔ L(y, f(x))
(”Cost of Misclassification“).
Im einfachsten Fall: 0/1-Loss (L(y, y) = 0 falls die Klassen gleich; sonst 1).
Allgemein: hat y k Kategorien, so bilden die Kosten fur Fehlklassifikation eine k× kMatrix mit Diagonale Null.
Kurt Hornik 2006

Statististische Methoden
Optimale Klassifikation
Fur 0/1-Loss ist fur die Grundgesamtheit die folgende Bayes-Entscheidung optimal:wahle jene Kategorie i von y, sodass P (y = i|x) maximal ist.
Allgemein: wahle die Klasse y so, dass
k∑i=1
L(i, y)P (y = i|x)
minimal wird.
Auf der Basis einer Stichprobe muss diese Entscheidung gelernt werden; dabeimuss man nicht unbedingt die bedingten Verteilungen genau lernen, sondern den
”Entscheidungsrand“.
Kurt Hornik 2006

Statististische Methoden
Empirische Risikominimierung
Offenbar wollen wir Entscheidungen mit moglichst kleinem Risiko treffen: wollenR(f) uber geeignete Klassen F von Modellen minimieren. I.e., wollen minf∈F R(f)bestimmen.
Allerdings kennen wir in der Praxis die Verteilung der Daten in der Grundgesamtheitnicht. Auf Basis einer Stichprobe z1, . . . , zn mit zi = (xi, yi) konnten wir versuchen,
Rn(f) =1
n
n∑i=1
L(yi, f(xi))
uber f ∈ F zu minimieren: Empirical Risk Minimization.
Problem: ist F”genugend groß“, kann das empirische Risiko immer Null gemacht
werden (e.g., Polynome beliebig großen Grades durch Datenpunkte legen). DieDaten werden
”auswendig gelernt“, die Generalisierungsfahigkeit ist schlecht.
Kurt Hornik 2006

Statististische Methoden
Risikoschatzung
Allgemeiner: das”wahre Risiko“ wird bei der Minimierung von Rn(f) systematisch
unterschatzt.
Abhilfe: wenn beliebig viele Daten zur Verfugung stehen, einen Teil der Datenverwenden um das
”Modell zu schatzen“, und einen anderen, um dann das wahre
Risiko zu schatzen. I.e.,
Eigener Test Datensatz fur”Model Assessment“
Werden verschiedene Modelle (ineinander geschachtelt oder vielleicht sogar”kom-
plett verschieden“ eingesetzt): jedes Modell auf einem Teil der Daten schatzen undfur den Performancevergleich
Eigener Validierungs Datensatz fur”Model Selection“
E.g., Split der Daten in Training, Validierung und Test im Verhaltnis 50 : 25 : 25.
Kurt Hornik 2006

Statististische Methoden
Risikominimierung mit allen Daten
In der Praxis sind oft nicht genug Daten fur eine Zerlegung in Training, Validierungund Test vorhanden.
Eine Strategie: Verbesserung der Schatzung des Risikos durch geeignete explizi-te Korrekturterme oder geeignete Kontrolle der Komplexitat der Modelle (Idee:einfache Modelle konnen nicht auswendig lernen).
Andere Idee: Daten fur Training und Validierung auseinanderhalten, aber geeignet
”rezyklieren“.
Kurt Hornik 2006

Statististische Methoden
Kreuzvalidierung
Sogenannte k-fache Kreuzvalidierung (k-fold Cross Validation):
• Indexmenge {1, . . . , n} in k Teile I1, . . . , Ik zerlegen
• Fur j = 1, . . . , k alle I· ausser Ij zum trainieren und Ij zum testen verwenden
• Aus diesen Ergebnissen den Durchschnitt bilden:
RkCVn (f) =
1
n
n∑i=1
L(yi, f(−j(i))(x)),
wobei j(i) die Nummer jenes I aus der Zerlegung ist, in das i fallt, und f (−j)
das Modell fur die Trainingsdaten die nicht aus Ij kommen.
Modellselektion auf Basis der Minimierung von RkCVn , Schatzung dann mit allen
Daten.
Kurt Hornik 2006

Statististische Methoden
Bootstrap Methoden
Bootstrap: Ziehe B-mal aus Daten Z = (z1, . . . , zn) mit Zurucklegen.
Idee: schatze Risiko jeweils auf Basis der Daten die nicht gezogen wurden, undmittle uber die Bootstrap Stichproben:
RBn =
1
n
n∑i=1
1
|I−i|
∑b∈I−1
L(yi, fb(xi))
Besser sind geeignete Kombinationen mit dem empirischen Risiko, e.g., die”0.632
Regel“
.368 ∗minf∈F
Rn(f) + 0632 ∗ RBn
Kurt Hornik 2006

Statististische Methoden
R: Unterstutzungscode
Funktion um den Prediction Error zu berechnen: L(yes,no) = 1, L(no, yes) = w
R> n_of_cases <- length(CHOICE)R> p_of_purchase <- sum(CHOICE == "yes")/n_of_casesR> PE <- function(p, w = 1) {+ tab <- table(p, CHOICE)+ if (NROW(tab) == 1)+ return(w * p_of_purchase)+ m <- match(rownames(tab), colnames(tab))+ if (all(!is.na(m)))+ tab <- tab[m, ]+ (tab[2, 1] + w * tab[1, 2])/n_of_cases+ }
Kurt Hornik 2006

Statististische Methoden
R: Sehr einfacher Modellvergleich
Wenn wir der Einfachheit halber die”besten“ gefundenen Modelle anhand des
Prediction Error vergleichen (siehe die vorhergehenden Seiten dafur”wie man es
wirklich machen sollte“):
R> PE(predict(lrm6, type = "response") > 0.5)[1] 0.2761538R> PE(predict(dtm1, type = "class"))[1] 0.2684615R> PE(predict(nn1, type = "class"))[1] 0.2623077
Kurt Hornik 2006

Statististische Methoden
Methodenwahl
Welches Lernverfahren soll man tatsachlich wahlen? Methodenpluralismus und Ent-scheidungsnot.
Generelle Empfehlungen versus Bestimmung der besten verfugbaren Losung eineskonkreten Lernproblems.
Frage: was genau ist das zu losende Lernproblem?
Gute (Performance, . . . ) versus Stabilitat von Losungen.
Benchmarkingdatensatze und -wettbewerbe fur typische Lernprobleme des DataMining, e.g. UCI Machine Learning und KDD Repositorien.
Kurt Hornik 2006

Statististische Methoden
error
bagging
bruto
lm
mars
mart
nnet
ppr
randomForest
rpart
svm
0 0.2 0.4 0.6 0.8 1
BostonHousing Friedman1
0 0.2 0.4 0.6 0.8 1
Friedman2 Friedman3
0 0.2 0.4 0.6 0.8 1
Ozone SLID
bagging
bruto
lm
mars
mart
nnet
ppr
randomForest
rpart
svm
abalone autompg
0 0.2 0.4 0.6 0.8 1
autos cpu
0 0.2 0.4 0.6 0.8 1
cpuSmall servo
0 0.2 0.4 0.6 0.8 1
Kurt Hornik 2006
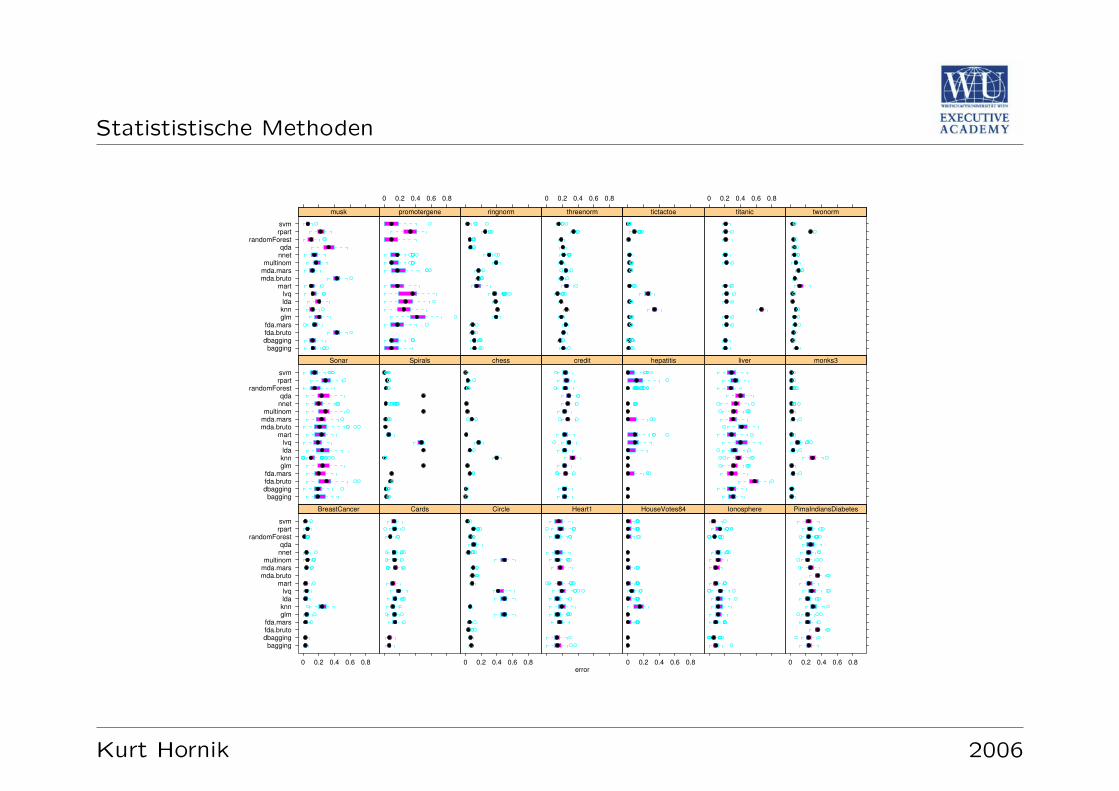
Statististische Methoden
error
baggingdbaggingfda.brutofda.mars
glmknnldalvq
martmda.brutomda.marsmultinom
nnetqda
randomForestrpartsvm
0 0.2 0.4 0.6 0.8
BreastCancer Cards
0 0.2 0.4 0.6 0.8
Circle Heart1
0 0.2 0.4 0.6 0.8
HouseVotes84 Ionosphere
0 0.2 0.4 0.6 0.8
PimaIndiansDiabetes
baggingdbaggingfda.brutofda.mars
glmknnldalvq
martmda.brutomda.marsmultinom
nnetqda
randomForestrpartsvm
Sonar Spirals chess credit hepatitis liver monks3
baggingdbaggingfda.brutofda.mars
glmknnldalvq
martmda.brutomda.marsmultinom
nnetqda
randomForestrpartsvm
musk promotergene
0 0.2 0.4 0.6 0.8
ringnorm threenorm
0 0.2 0.4 0.6 0.8
tictactoe titanic
0 0.2 0.4 0.6 0.8
twonorm
Kurt Hornik 2006

Statististische Methoden
Koordinaten
Kurt HornikDepartment fur Statistik und MathematikWirtschaftsuniversitat WienAugasse 2–6, A-1090 Wien
Tel: +43/1/313-36x4756Fax: +43/1/313-36x774Email: [email protected]: http://www.wu-wien.ac.at/cstat/hornik
Kurt Hornik 2006



![Literaturverzeichnis - link.springer.com978-3-642-40311-8/1.pdfLiteraturverzeichnis Dimitriadou, E., Hornik, K., Leisch, F., Meyer, A. & Weingessel, A. (2012). e1071: Misc FunctionsoftheDepartmentofStatistics(e1071),TUWien[Software].](https://static.fdokument.com/doc/165x107/5ea9079045731a5ac4059eab/literaturverzeichnis-link-978-3-642-40311-81pdf-literaturverzeichnis-dimitriadou.jpg)


