
Transformieren, Manipulieren, Kuratieren: Technologien für die Wissensarbeit im Netz
24
KOOP-LITERA International – 20. Juni 2017 Transformieren, Manipulieren, Kuratieren: Technologien für die Wissensarbeit im Netz Georg Rehm [email protected] DFKI GmbH, Berlin KOOP-LITERA international
-
Upload
georg-rehm -
Category
Technology
-
view
69 -
download
2
Transcript of Transformieren, Manipulieren, Kuratieren: Technologien für die Wissensarbeit im Netz

KOOP-LITERA International – 20. Juni 2017
Transformieren, Manipulieren, Kuratieren: Technologien für die Wissensarbeit im Netz
Georg [email protected] GmbH, Berlin
KOOP-LITERAinternational

Überblick• Was ist digitale Kuratierung? • BMBF-Projekt Digitale Kuratierungstechnologien• Beispiel: Die Mendelsohn-Briefe• Schlussfolgerungen• Beobachtungen und Empfehlungen
KOOP-LITERA 2017 – 20. Juni 2017 2

Was ist digitale Kuratierung?
KOOP-LITERA 2017 – 20. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information
Information
3

Was ist digitale Kuratierung?
KOOP-LITERA 2017 – 20. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information? ?
??Information
4
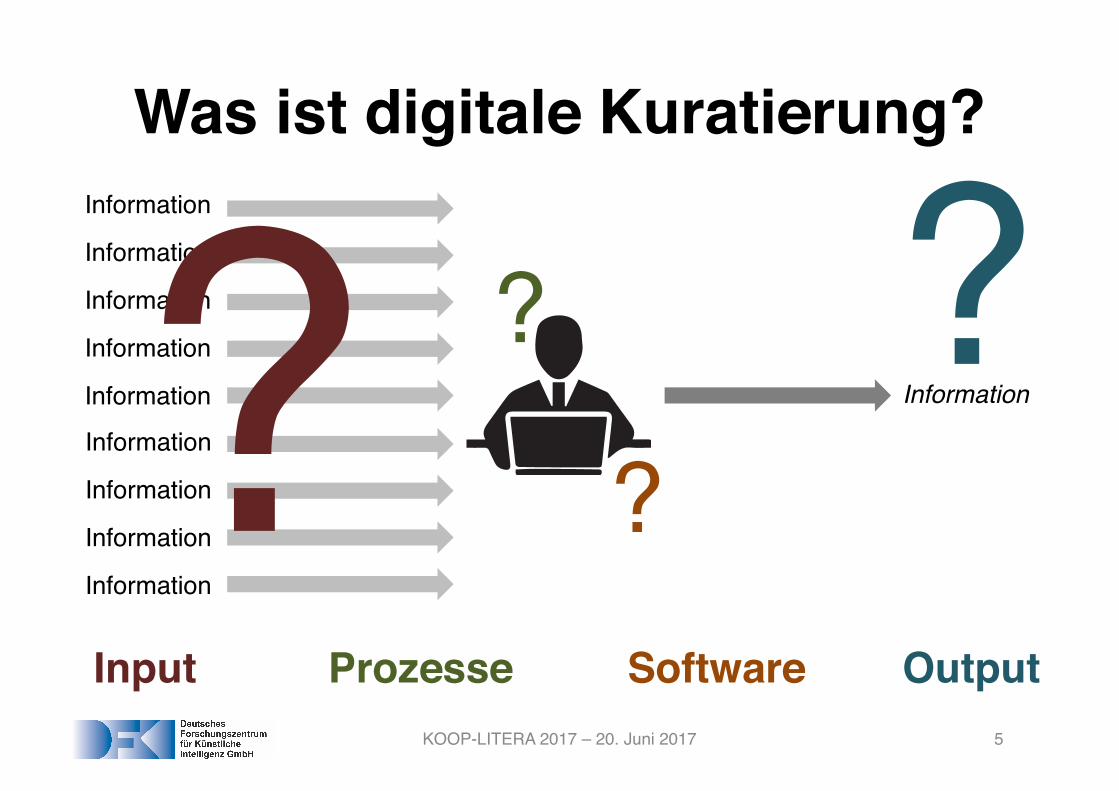
Was ist digitale Kuratierung?
KOOP-LITERA 2017 – 20. Juni 2017
Information
Information
Information
Information
Information
Information
Information
Information
Information? Information
OutputInput SoftwareProzesse
?
??
5
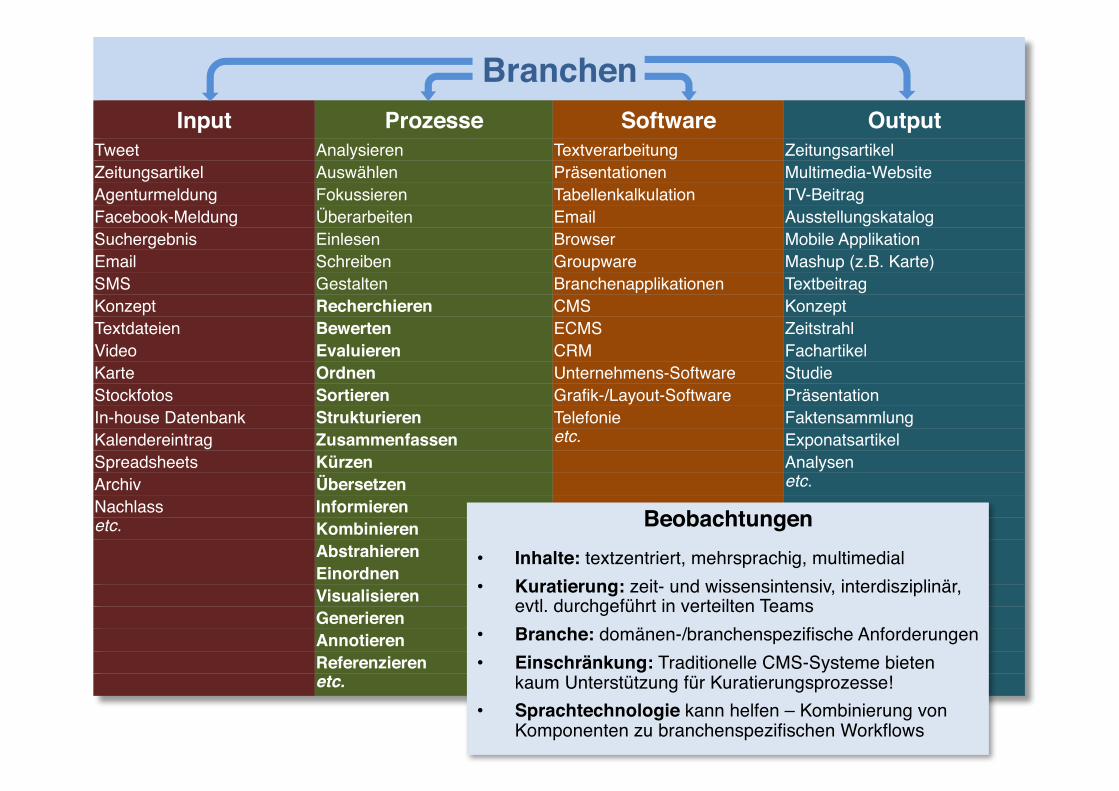
BranchenInput Prozesse Software Output
Tweet Analysieren Textverarbeitung ZeitungsartikelZeitungsartikel Auswählen Präsentationen Multimedia-WebsiteAgenturmeldung Fokussieren Tabellenkalkulation TV-BeitragFacebook-Meldung Überarbeiten Email AusstellungskatalogSuchergebnis Einlesen Browser Mobile Applikation Email Schreiben Groupware Mashup (z.B. Karte)SMS Gestalten Branchenapplikationen TextbeitragKonzept Recherchieren CMS KonzeptTextdateien Bewerten ECMS ZeitstrahlVideo Evaluieren CRM FachartikelKarte Ordnen Unternehmens-Software StudieStockfotos Sortieren Grafik-/Layout-Software PräsentationIn-house Datenbank Strukturieren Telefonie FaktensammlungKalendereintrag Zusammenfassen etc. ExponatsartikelSpreadsheets Kürzen AnalysenArchiv Übersetzen etc.Nachlass Informierenetc. Kombinieren
AbstrahierenEinordnenVisualisierenGenerierenAnnotierenReferenzierenetc.
Beobachtungen• Inhalte: textzentriert, mehrsprachig, multimedial• Kuratierung: zeit- und wissensintensiv, interdisziplinär,
evtl. durchgeführt in verteilten Teams• Branche: domänen-/branchenspezifische Anforderungen• Einschränkung: Traditionelle CMS-Systeme bieten
kaum Unterstützung für Kuratierungsprozesse!• Sprachtechnologie kann helfen – Kombinierung von
Komponenten zu branchenspezifischen Workflows

DKT Kick-off-Veranstaltung – 25. September 2015
Georg Rehm und Felix Sasaki. “Digital Curation Technologies.” In Proceedings of the 19th Annual Conference of the European Association for Machine Translation (EAMT 2016), Riga, Lettland, Mai 2016
Georg Rehm und Felix Sasaki. “Digitale Kuratierungstechnologien – Verfahren für die effiziente Verarbeitung, Erstellung und Verteilung qualitativ hochwertiger Medieninhalte.” In Proceedings der Frühjahrstagung der Gesellschaft für Sprachtechnologie und Computerlinguistik (GSCL 2015), S. 138-139, Duisburg, 2015
• Unterstützung und Optimierung digitaler Kuratierung durch Sprach- und Wissenstechnologien
• Entwicklung innovativer Prototypen bei den KMU-Partnern• Weiterentwicklung der DFKI-Technologien und Transfer mittels
Plattform für digitale Kuratierungstechnologien
Sprach- und Wissenstechnologien
Kuratierungstechnologien
Branchentechnologien
Plat
tform
tech
nolo
gie
Branchenlösungen
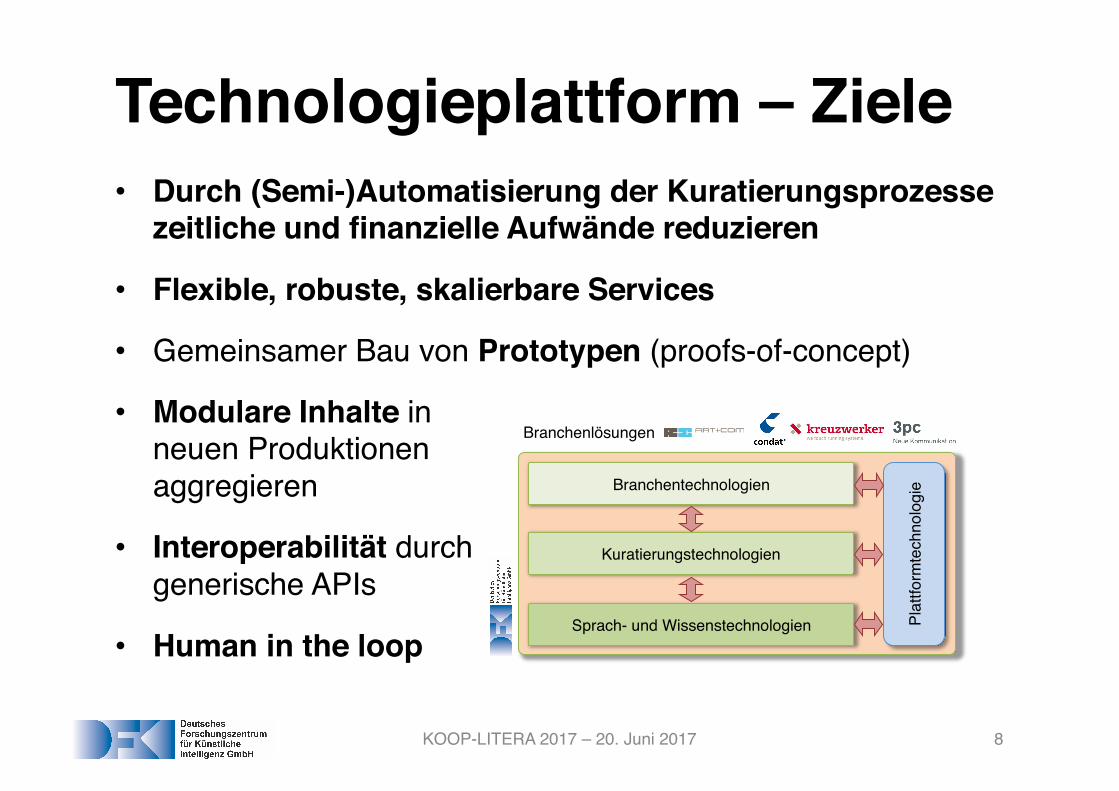
Technologieplattform – Ziele• Durch (Semi-)Automatisierung der Kuratierungsprozesse
zeitliche und finanzielle Aufwände reduzieren
• Flexible, robuste, skalierbare Services
• Gemeinsamer Bau von Prototypen (proofs-of-concept)
• Modulare Inhalte in neuen Produktionen aggregieren
• Interoperabilität durch generische APIs
• Human in the loop
KOOP-LITERA 2017 – 20. Juni 2017
Sprach- und Wissenstechnologien
Kuratierungstechnologien
Branchentechnologien
Plat
tform
tech
nolo
gie
Branchenlösungen
8

Aktueller Stand• Plattform: Services und Service-Workflows• Implementierte Kuratierungsservices:
– Named Entity Recognition – e-entityrecognition e-service – Geolocation – e-entityrecognition, Visualisierung– Temporal Analyser – e-entityrecognition, Visualisierung– Classification – e-classification e-service– Clustering – e-clustering e-service– Textzusammenfassen– e-summarisation e-service– Maschinelle Übersetzung – e-translation e-service– Sentiment Analysis – work in progress– Event Extraction – work in progress– Semantic Storytelling – work in progress
• Kuratierungs-Dashboard: Erster Prototyp
KOOP-LITERA 2017 – 20. Juni 2017 9

NER, Linking, Geolokalisierung
KOOP-LITERA 2017 – 20. Juni 2017
...In the Viking colony of Iceland, an extraordinary vernacular literature blossomed in the 12th through 14th centuries......The ships were scuttled there in the 11th century, to block anavigation channel and thusprotect Roskilde, thenCopenhagen from seaborne assault......Viking Age inscriptions havealso been discovered on theManx runestones on theIsle of Man.…
Plain Text NIF-Anreicherung Visualisierunghttp://api.digitale-kuratierung.de/api/e-nlp/namedEntityRecognition?analysis=ner http://http://dev.digitale-kuratierung.de/admini/pages/geolocalization.php
• Modus 1: Modell-basiert (für Domänen, für die annotierte Trainingsdaten verfügbar sind)
• Modus 2: Wörterbuch-basiert (für Domänen, für die lediglich Namenslisten verfügbar sind)
• Basiert auf OpenNLP (mit NIF-Integration)
• Entity-Linking durch SPARQL-Querys auf DBPedia.• Für Lokationen werden GPS-Koordinaten bezogen. • Es werden Durchschnittsangaben berechnet auf
Dokumentebene (über alle Lokationen), um diese auf einer Karte visualisieren zu können.
Geolokalisierung als visuelles Zusammenfassen!
10
KOOP-LITERA 2017 – 20. Juni 2017
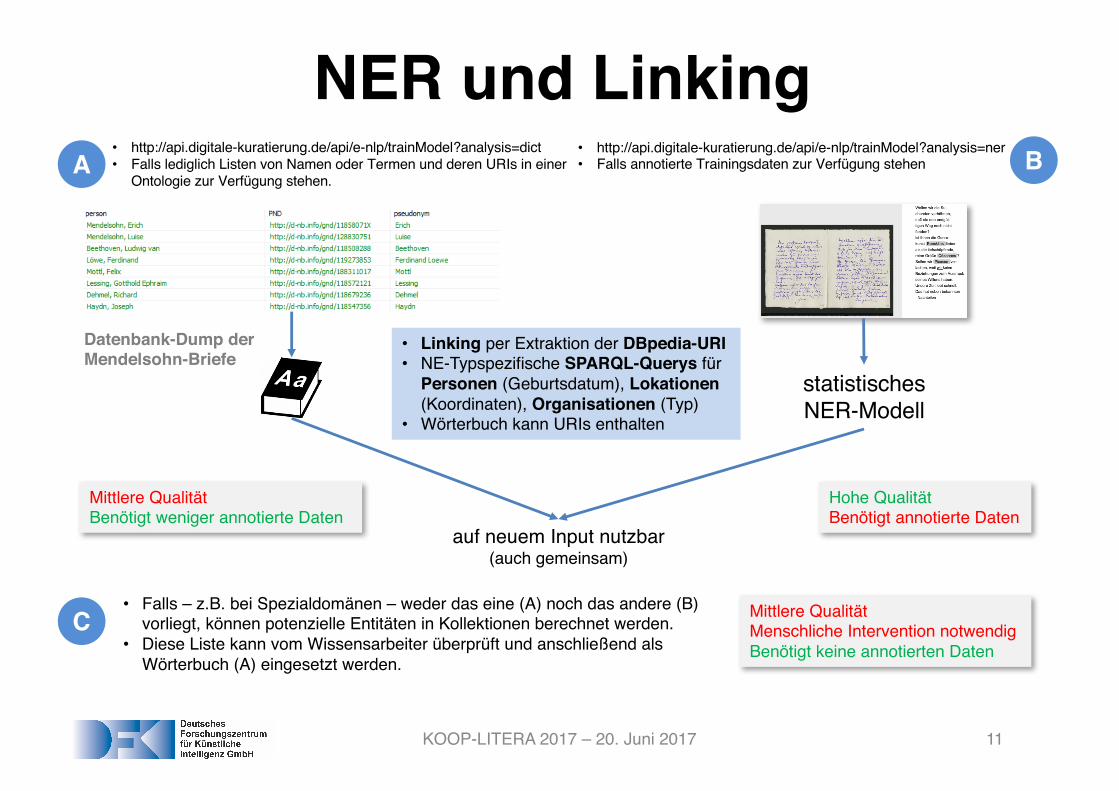
NER und Linking• http://api.digitale-kuratierung.de/api/e-nlp/trainModel?analysis=dict• Falls lediglich Listen von Namen oder Termen und deren URIs in einer
Ontologie zur Verfügung stehen.
• http://api.digitale-kuratierung.de/api/e-nlp/trainModel?analysis=ner• Falls annotierte Trainingsdaten zur Verfügung stehen
auf neuem Input nutzbar(auch gemeinsam)
statistischesNER-Modell
Datenbank-Dump der Mendelsohn-Briefe
Hohe QualitätBenötigt annotierte Daten
Mittlere QualitätBenötigt weniger annotierte Daten
• Falls – z.B. bei Spezialdomänen – weder das eine (A) noch das andere (B) vorliegt, können potenzielle Entitäten in Kollektionen berechnet werden.
• Diese Liste kann vom Wissensarbeiter überprüft und anschließend als Wörterbuch (A) eingesetzt werden.
Mittlere Qualität Menschliche Intervention notwendigBenötigt keine annotierten Daten
A B
C
• Linking per Extraktion der DBpedia-URI• NE-Typspezifische SPARQL-Querys für
Personen (Geburtsdatum), Lokationen (Koordinaten), Organisationen (Typ)
• Wörterbuch kann URIs enthalten
11
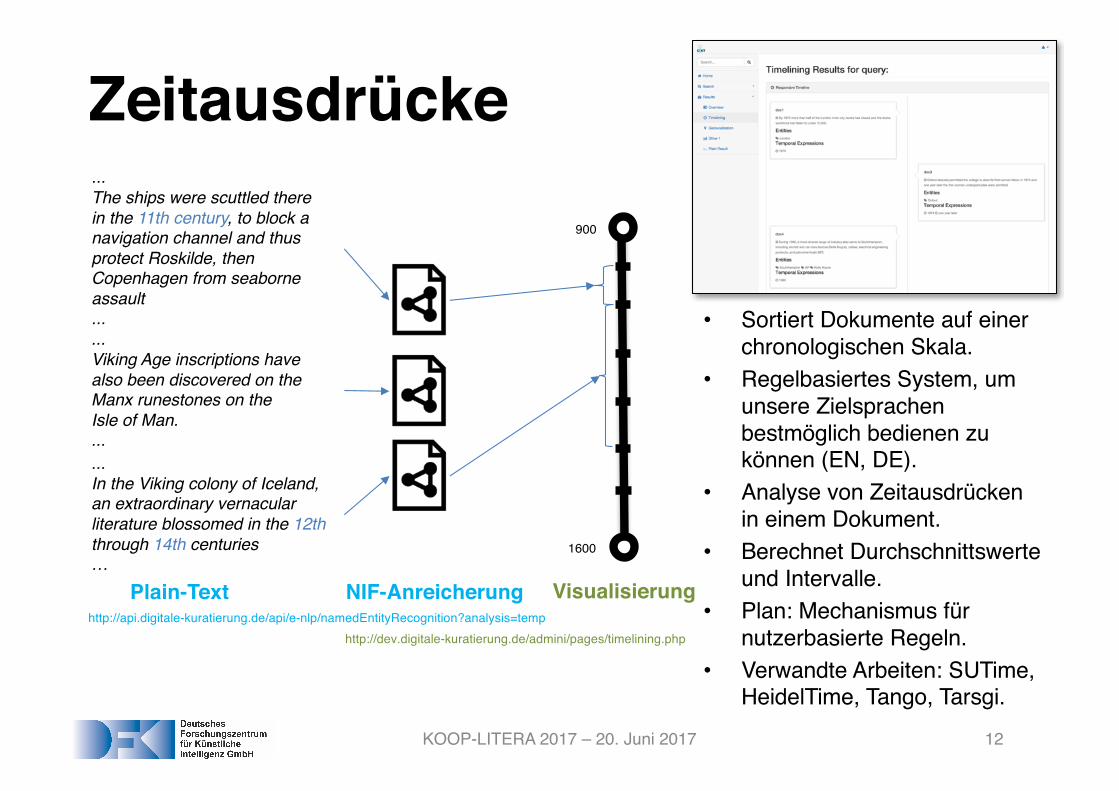
KOOP-LITERA 2017 – 20. Juni 2017
Zeitausdrücke...The ships were scuttled there in the 11th century, to block anavigation channel and thusprotect Roskilde, thenCopenhagen from seaborne assault......Viking Age inscriptions havealso been discovered on theManx runestones on theIsle of Man.......In the Viking colony of Iceland, an extraordinary vernacular literature blossomed in the 12ththrough 14th centuries…
900
1600
http://api.digitale-kuratierung.de/api/e-nlp/namedEntityRecognition?analysis=temphttp://dev.digitale-kuratierung.de/admini/pages/timelining.php
Plain-Text NIF-Anreicherung Visualisierung
• Sortiert Dokumente auf einer chronologischen Skala.
• Regelbasiertes System, um unsere Zielsprachen bestmöglich bedienen zu können (EN, DE).
• Analyse von Zeitausdrücken in einem Dokument.
• Berechnet Durchschnittswerte und Intervalle.
• Plan: Mechanismus für nutzerbasierte Regeln.
• Verwandte Arbeiten: SUTime, HeidelTime, Tango, Tarsgi.
12

Semantic Storytelling• Wichtige Wunschfunktionalität bei allen KMU-Partnern:
Semantic Storytelling• Eingabe: Kohärente, in sich geschlossene Kollektion• Ausgabe: Semantisch angereicherte Kollektion• Idee: Multiple Rezeptionspfade ermöglichen• Semantic Storytelling: Identifizierung, Ranking und
Empfehlung sinnvoller Hypertextpfade• Es gibt noch zahlreiche Herausforderungen ...
KOOP-LITERA 2017 – 20. Juni 2017 13
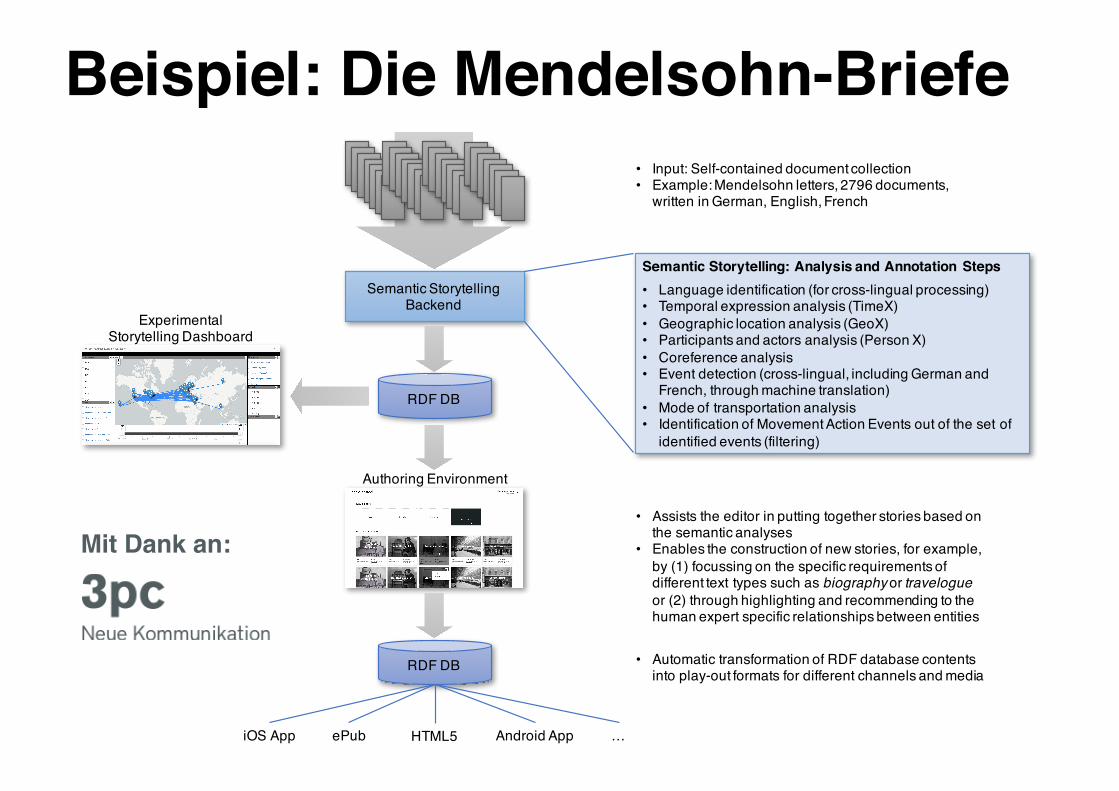
RDF DB
RDF DB
Semantic Storytelling Backend
Authoring Environment
iOS App Android AppHTML5ePub …
• Input: Self-contained document collection• Example: Mendelsohn letters, 2796 documents,
written in German, English, French
• Assists the editor in putting together stories based on the semantic analyses
• Enables the construction of new stories, for example, by (1) focussing on the specific requirements of different text types such as biography or travelogue or (2) through highlighting and recommending to the human expert specific relationships between entities
• Automatic transformation of RDF database contents into play-out formats for different channels and media
Semantic Storytelling: Analysis and Annotation Steps• Language identification (for cross-lingual processing)• Temporal expression analysis (TimeX)• Geographic location analysis (GeoX)• Participants and actors analysis (Person X)• Coreference analysis• Event detection (cross-lingual, including German and
French, through machine translation)• Mode of transportation analysis• Identification of Movement Action Events out of the set of
identified events (filtering)
ExperimentalStorytelling Dashboard
Beispiel: Die Mendelsohn-Briefe
Mit Dank an:

KOOP-LITERA 2017 – 20. Juni 2017 15
Beispiel: Die Mendelsohn-Briefe
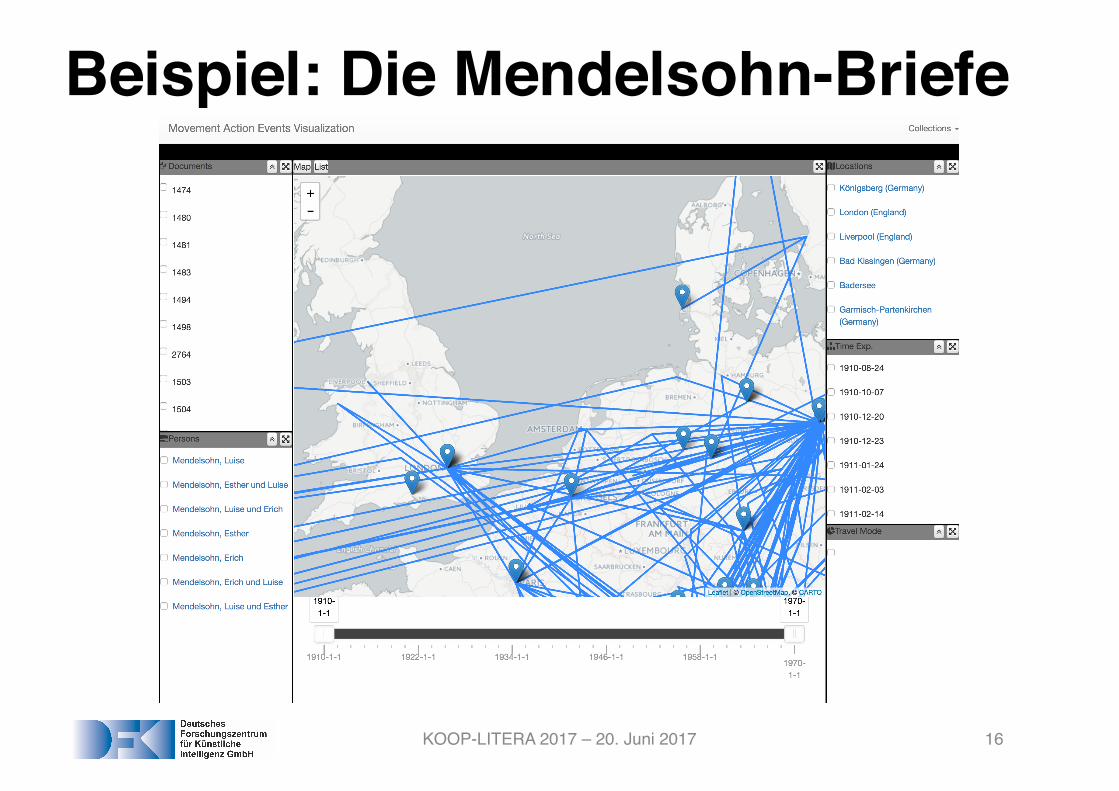
KOOP-LITERA 2017 – 20. Juni 2017 16
Beispiel: Die Mendelsohn-Briefe
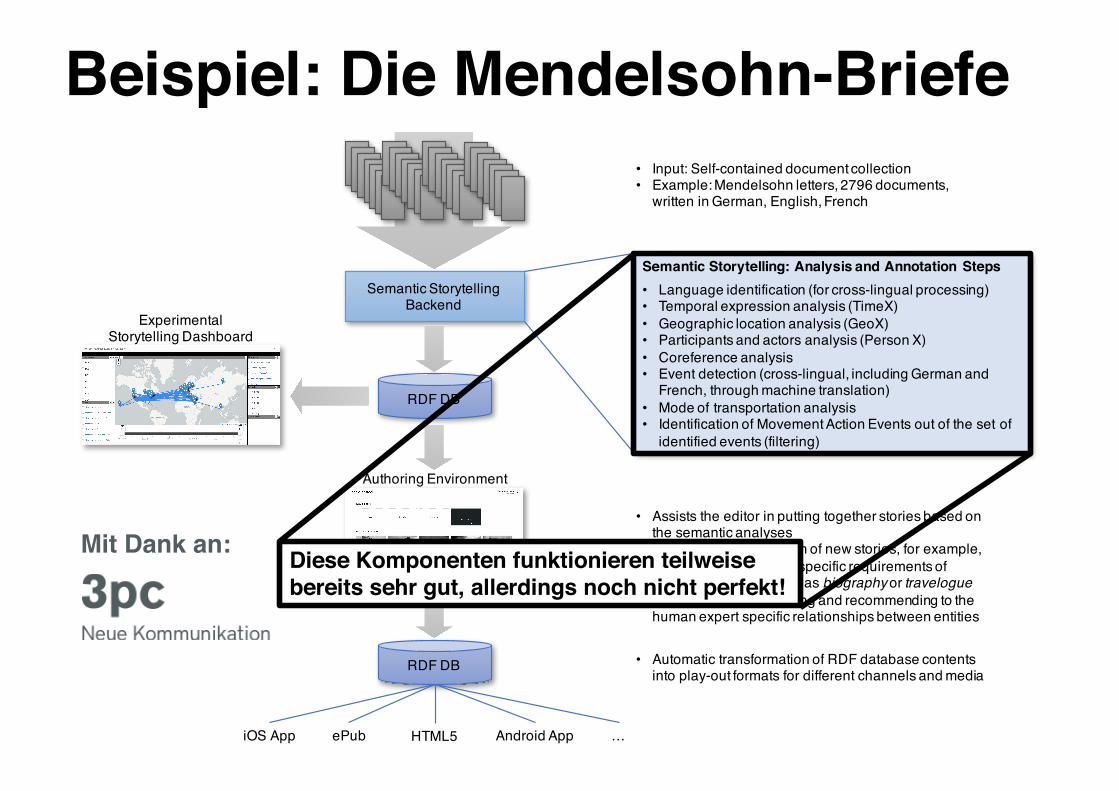
RDF DB
RDF DB
Semantic Storytelling Backend
Authoring Environment
iOS App Android AppHTML5ePub …
• Input: Self-contained document collection• Example: Mendelsohn letters, 2796 documents,
written in German, English, French
• Assists the editor in putting together stories based on the semantic analyses
• Enables the construction of new stories, for example, by (1) focussing on the specific requirements of different text types such as biography or travelogue or (2) through highlighting and recommending to the human expert specific relationships between entities
• Automatic transformation of RDF database contents into play-out formats for different channels and media
Semantic Storytelling: Analysis and Annotation Steps• Language identification (for cross-lingual processing)• Temporal expression analysis (TimeX)• Geographic location analysis (GeoX)• Participants and actors analysis (Person X)• Coreference analysis• Event detection (cross-lingual, including German and
French, through machine translation)• Mode of transportation analysis• Identification of Movement Action Events out of the set of
identified events (filtering)
ExperimentalStorytelling Dashboard
Beispiel: Die Mendelsohn-Briefe
Mit Dank an: Diese Komponenten funktionieren teilweisebereits sehr gut, allerdings noch nicht perfekt!

Kuratierungstechnologien• Kuratierungstechnologien: Verfahren zur semantischen
Datenanreicherung, die auf KI-Technologien basieren• KI-Technologien: Symbolische Verfahren, statistische
Verfahren, maschinelles Lernen, Deep Learning• Entscheidend für Abdeckung und Präzision: Große
Mengen repräsentativer, hochqualitativer Trainingsdaten• Anwendung auf inhärent idiosynkratische Daten-
sammlungen wie z.B. Nachlässe ist ambitioniert• Manuelle Anpassungen und Nacharbeit notwendig, da
Präzision und Performanz eines menschlichen Archivars nicht erreicht werden können
KOOP-LITERA 2017 – 20. Juni 2017 18

KI – Reality Check• Künstliche Intelligenz
– Beeindruckende Durchbrüche in den vergangenen Jahren
– Basieren u.a. auf sehr großen Datenmengen
– Entwicklung disruptiver, revolutionärer KI-Tools für die Arbeit mit Nachlässen ist nicht zu erwarten
– Aber: Standardwerkzeuge wie NER, Mapping werden kontinuierlich verbessert
• Arbeit mit Nachlässen– Hochgradig spezifische
Datensammlungen und Anwendungsfälle
– Anforderung: Hohe Präzision der Annotation sowie der Metadaten
– Eher kleine und sehr spezielle Datenmengen
– Prognose: Mittelfristige Entwicklung adaptiver Workbenches für interaktive Annotationen
KOOP-LITERA 2017 – 20. Juni 2017 19

Schlussfolgerungen• Kuratierungstechnologien unterstützen Wissensarbeiter
– auch Archivare – beim Verarbeiten digitaler Inhalte.• Kuratierungstechnologien werden benötigt, um digitale
Nachlässe tief semantisch zu erschließen.• Ziele: Bessere und einfachere Nutzbarkeit der Daten;
Findbarkeit; Kontextualisierung und Visualisierung (Karten, Zeitstrahl, Verknüpfung, LOD etc.).
• Prognose: Einbettung von KI in smarte Archiv-Tools, die die effiziente Bearbeitung (d.h. Kuratierung) generischer digitaler Nachlässe durch Experten erlauben.
• Dabei wird bis auf Weiteres gelten: Human in the loop.
KOOP-LITERA 2017 – 20. Juni 2017 20
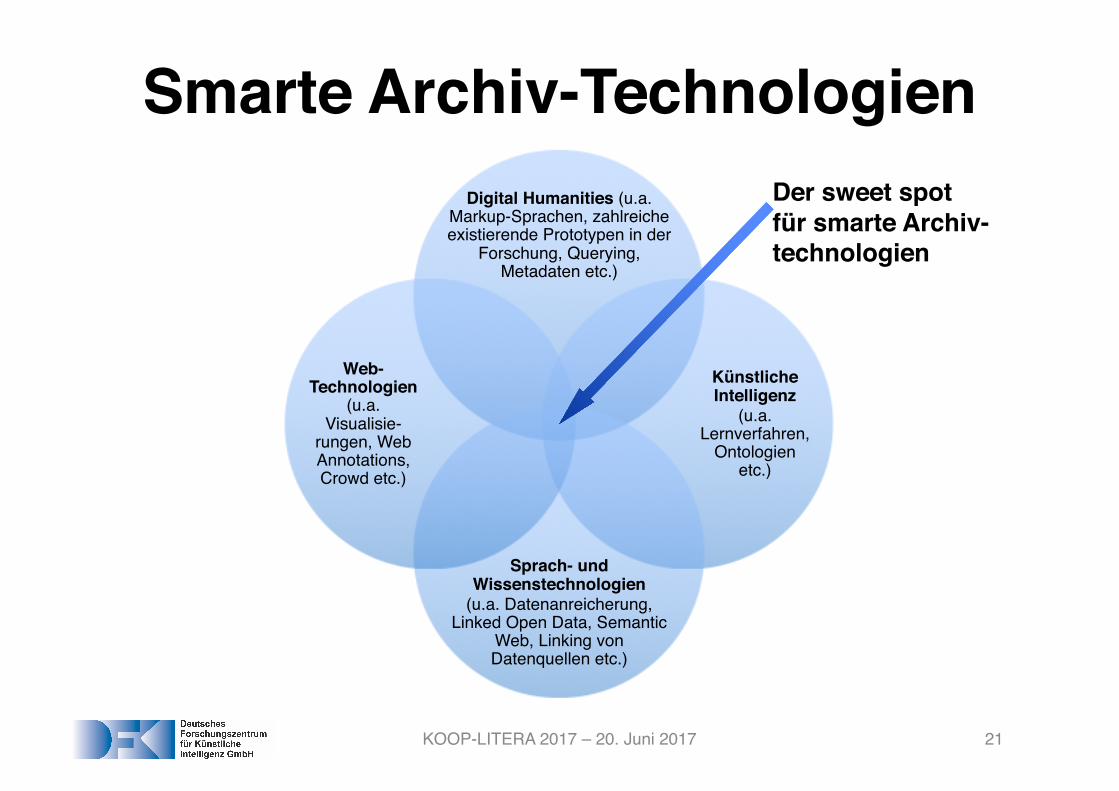
Smarte Archiv-Technologien
KOOP-LITERA 2017 – 20. Juni 2017 21
Digital Humanities (u.a. Markup-Sprachen, zahlreicheexistierende Prototypen in der
Forschung, Querying, Metadaten etc.)
KünstlicheIntelligenz
(u.a. Lernverfahren,
Ontologienetc.)
Sprach- und Wissenstechnologien
(u.a. Datenanreicherung, Linked Open Data, Semantic
Web, Linking von Datenquellen etc.)
Web-Technologien
(u.a. Visualisie-
rungen, Web Annotations, Crowd etc.)
Der sweet spotfür smarte Archiv-technologien

Beobachtungen• Großer Bedarf an zu entwickelnder Technologie• Derzeit kaum Fördergelder für Themen wie LZA,
Nachhaltigkeit, Preservation etc. • LZA wird im DH-Kontext bereits seit Jahren besprochen,
könnte aber selbst noch intensiver agieren• Lösungen für LZA können Mehrwert generieren, z.B. in
Bezug auf Datenqualität, Apps, Geschäftsmodelle etc.• LZA ist Ländersache – Räder werden oft neu erfunden• Selbstverständlich existieren digitale Nachlässe.
Materialität ist kein Kriterium für Qualität.
KOOP-LITERA 2017 – 20. Juni 2017 22

Empfehlungen• Mut zur Lücke: Nicht die volle inhaltliche Erschließung
z.B. eines Nachlasses anstreben. Stattdessen früh publizieren und kontinuierlich und gemeinsam mit der Crowd an der Verbesserung von Annotationen arbeiten.
• Linking, Linking, Linking: Intensive Nutzung verfügbarer semantischer Vokabulare zur Auszeichnung von Daten, um die eigenen Digitalisate sichtbar zu machen.
• Allianzen schmieden: LZA als internationale Aufgabe, Verbindung zu EU-Infrastrukturen und Initiativen aufbauen (CLARIN, Europeana, META-NET etc.)
• Europa benötigt eine LZA-Digitalstrategie!• Europäische Web-Archivmaschine – z.B. Archive.eu?
KOOP-LITERA 2017 – 20. Juni 2017 23

Vielen Dank!http://www.digitale-kuratierung.de
KOOP-LITERA 2017 – 20. Juni 2017 24
Georg Rehm. Eine Strategie zur Förderung der digitalen Langzeitarchivierung. In: Paul Klimpel, Jürgen Keiper (Hrsg.), Was bleibt? Nachhaltigkeit der Kultur in der Digitalen Welt. Eine Publikation des Internet und Gesellschaft-Co:llaboratorye.V., S. 199-214. iRights.Media, Berlin, September 2013. Abschlussbericht der 8. Initiative des Internet und Gesellschaft-Co:llaboratory e.V.


















