
Untersuchung d¨unnbesetzter QR-Verfahren bei der ... · de des steilsten Abstieges, die Methode...
88
Technische Universit¨ at M¨ unchen Institut f¨ ur Informatik Untersuchung d¨ unnbesetzter QR-Verfahren bei der Berechnung d¨ unnbesetzter approximativer Inverser Diplomarbeit im Fach Informatik Andreas Roy Aufgabensteller : Univ.-Prof. Dr. Thomas Huckle Betreuer : Dipl.-Tech. Math. Alexander Kallischko Abgabedatum : 15. 06. 2007
Transcript of Untersuchung d¨unnbesetzter QR-Verfahren bei der ... · de des steilsten Abstieges, die Methode...

Technische Universitat Munchen
Institut fur Informatik
Untersuchung dunnbesetzter QR-Verfahren
bei der Berechnung
dunnbesetzter approximativer Inverser
Diplomarbeit im Fach Informatik
Andreas Roy
Aufgabensteller : Univ.-Prof. Dr. Thomas Huckle
Betreuer : Dipl.-Tech. Math. Alexander Kallischko
Abgabedatum : 15. 06. 2007

ii
Erklarung zur Diplomarbeit
Ich versichere, dass ich diese Diplomarbeit selbstandig verfasst und nur dieangegebenen Quellen und Hilfsmittel verwendet habe.
Garching, den 15.06.2007

iii
Wenn der Weise stets dumm erscheint,konnen seine Fehler nicht enttauschenund sein Erfolg ist eine angenehmeUberraschung
Levi bar Alphaus, Die Bibel nach Biff

iv

v
Inhaltsverzeichnis
Vorwort 1
1 Grundlagen 3
1.1 Lineare Gleichungsysteme . . . . . . . . . . . . . . . . . . . . . 31.2 Kondition und Vorkonditionierung . . . . . . . . . . . . . . . . . 7
1.2.1 Jacobi- und Gauss-Seidel-Vorkonditionierer . . . . . . . . 81.2.2 SPAI -Vorkonditionierer . . . . . . . . . . . . . . . . . . 9
1.3 Lineare Ausgleichsrechnung . . . . . . . . . . . . . . . . . . . . 131.3.1 Losung mittels Normalengleichung . . . . . . . . . . . . 141.3.2 Losung mittels Orthogonalisierungsverfahren . . . . . . . 15
1.3.2.1 Householder-Reflektion . . . . . . . . . . . . . . 161.3.2.2 Givens-Rotation . . . . . . . . . . . . . . . . . 181.3.2.3 Gram-Schmidt-Verfahren . . . . . . . . . . . . 20
2 Modifikationen bei der Berechnung des SPAI 23
2.1 Dunnbesetzte Verfahren . . . . . . . . . . . . . . . . . . . . . . 232.1.1 Dunnbesetzte Speicherstrukturen . . . . . . . . . . . . . 262.1.2 Dunnbesetzte Methoden . . . . . . . . . . . . . . . . . . 27
2.1.2.1 Minimum-Degree mit Eliminationsgraphen . . . 282.1.2.2 Minimum-Degree mit Quotientengraphen . . . . 29
2.1.3 Concise Sparse Package . . . . . . . . . . . . . . . . . . . 342.2 QR-Updates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.2.1 Einfugen neuer Spalten . . . . . . . . . . . . . . . . . . . 392.2.2 Einfugen neuer Zeilen . . . . . . . . . . . . . . . . . . . . 412.2.3 QR-Updates im SPAI . . . . . . . . . . . . . . . . . . . 43
2.2.3.1 Implementierung . . . . . . . . . . . . . . . . . 462.3 QR-Zerlegung in einfacher Prazision mit iterativer Nachverfei-
nerung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3 Numerische Ergebnisse 61
3.1 LAPACK versus CSparse . . . . . . . . . . . . . . . . . . . . . . 613.1.1 Bandmatrizen . . . . . . . . . . . . . . . . . . . . . . . . 613.1.2 Permutierte Bandmatrizen . . . . . . . . . . . . . . . . . 63

vi Inhaltsverzeichnis
3.1.3 A - Testreihen . . . . . . . . . . . . . . . . . . . . . . . . 643.1.4 Vorpermutation durch AMD oder reverse Cuthill-McKee 67
3.2 QR-Updates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 693.2.1 Extremfalle des Patternupdates . . . . . . . . . . . . . . 703.2.2 Patternupdates mit Orsirr 2 und Sherman2 . . . . . . . 713.2.3 Patternupdates mit Pores 2 als Ausgangspattern . . . . 72
3.3 Float versus Double . . . . . . . . . . . . . . . . . . . . . . . . . 73
4 Zusammenfassung und Ausblick 79
Literaturverzeichnis 81

1
Vorwort
[...]Das indirecte Verfahren laßt sichhalb im Schlaf ausfuhren, oder mankann wahrend dessen an andere Dingedenken.[...]
Brief von Gauss an Gerling, 1823
Das Losen linearer Gleichungssysteme gehort zu den wichtigsten Methodenin der Mathematik. Das einfachste Verfahren zum Losen solcher Systeme wur-de 263 nach Christus von Liu Hui 263 in seinem Werk “Mathematik in neunBuchern” niedergeschrieben. Einen Popularitatsschub hat das Verfahren durchdie Beschreibung von Carl Friedrich Gauss (1777-1855) erhalten. Der nachGauss benannte Algorithmus besteht aus 2 Schritten:
• Vorwartselimination,
• Rucksubstitution.
Die Vorwartselimination bringt die Matrix mit Hilfe von Zeilenvertauschungenund Additionen geeigneter Vielfacher von Zeilen in obere Dreiecksform. DieRuckwartssubstitution bestimmt sukzessive alle Losungskomponenten, sodassnach diesem Schritt die exakte Losung des Gleichungssystems vorliegt. DerNachteil des Algorithmus ist neben der hohen Laufzeit von O(n3), wobei nder Matrixdimension entspricht, der Verlust der Dunnbesetztheit bei grossendunnbesetzten Matrizen im Verlauf der Vorwartselimination und die “Exakt-heit” der Losung. Haufig ist man mit einem Ergebnis zufrieden, das auf ei-ner gewissen Anzahl von Nachkommastellen genau ist. Um die Nachteile zuumgehen, bieten sich iterative Verfahren an. Bei diesen Verfahren wird ausge-hend von einer Startlosung mittels Fixpunktiteration neue bessere Losungengesucht, bis das Residuum der gefundenen Losung unter eine gewunschte ε-Schranke fallt. Die Konvergenz der iterativen Verfahren ist von der Konditiondes Gleichungssystems abhangig. Um eine schnelle Konvergenz bzw. uberhauptKonvergenz zu erhalten, muss bei den Gleichungsystemen die Kondition ver-bessert werden. Dies wird durch den Einsatz von Vorkonditionierern erreicht.

2 0 Vorwort
Die Auswahl der Vorkonditionierer bzw. der Vorkonditionierverfahren ist man-nigfaltig. In dieser Arbeit wird dem Sparse Approximate Inverse Vorkonditio-nierer, kurz SPAI , mit Hilfe verschiedener Techniken zu mehr Performanz ver-holfen. Der Performanzgewinn soll mittels Ersetzung der herkommlichen QR-Zerlegung durch dunnbesetzte QR-Zerlegung und QR-Updates erreicht werden.Eine weitere Performanzsteigerung wird von der float-basierten Rechnung er-wartet, bei der alle Rechnungen im float-Datentyp durchgefuhrt werden. An-schliessend wird mit Hilfe von Nachverfeinerungsschritten die Genauigkeit desErgebnisses erhoht, sodass diese das ungefahre Niveau des double-Datentypserreicht.

3
1 Grundlagen
Die Themen, die dieses Kapitel behandelt, liefern den mathematischen Hinter-grund der vorliegenden Arbeit. Der Startpunkt durch das Grundlagenkapitelsind lineare Gleichungssysteme und wie man sie lost. Anschliessend wird auf dieKondition von Gleichungssystemen eingegangen und wie man diese durch Vor-konditionierung verbessert. Konkret wird dabei die SPAI -Vorkonditionierungbetrachtet. Die Vorkonditionierung bestimmt durch die Verwendung der QR-Zerlegung das letzte Thema dieses Kapitels, die lineare Ausgleichsrechnungmit ihren Losungsmoglichkeiten.
1.1 Lineare Gleichungsysteme
Der Hintergrund regiert den Vorder-grund
Gottfried Niebaum, 1841 - 1902
In vielen Bereichen der Forschung und Praxis treten lineare Gleichungssytemeder Form
a11x1 + a12x2 + . . . a1nxn = b1
a21x1 + a22x2 + . . . a2nxn = b2...
......
an1x1 + an2x2 + . . . annxn = bn
kurz Ax = b auf, mit A ∈ Rn×n, x ∈ R
n und b ∈ Rn. Diese Aufgabenstel-
lung schnell und effizient zu losen ist eine Hauptaufgabe in der Mathematikund Informatik. Das beruhmteste Verfahren zum Losen linearer Gleichungs-systeme ist der Gauss-Algorithmus. Hier wird das System mittels Additionenvon geeigneten Vielfachen einer Zeile auf eine andere Zeile in ein aquivalenteseinfacheres System transformiert. Ziel der Umformung ist die Erzeugung eines

4 1 Grundlagen
Gleichungssystems in Zeilenstufenform. Nach der Umformung kann das Systemmit Hilfe von
xn =bn
ann
und xi =bi −
∑n
j=i+1 aijxj
aii
mit i = n − 1, . . . , 1 (1.1)
gelost werden. Das Verfahren benotigt zum Losen des Gleichungssystems
#F lops =2n3
3.
Die Anzahl der Flops kann verringert werden, wenn die Matrix A symmetrischpositiv definit, kurz spd, ist. In diesem Fall kann das Cholesky-Verfahren nachAndre-Louis Cholesky (1875-1918) angewandt werden.Bei diesem Verfahren verwendet man eine eindeutige Zerlegung
A = LDLT ,
wobei L eine untere Dreiecksmatrix ist, deren Werte auf der Diagonalen denWert Eins annehmen. D ist eine Diagonalmatrix mit positiven Eintragen. DieseZerlegung existiert fur alle spd Matrizen. Aufgrund der positiven Eintrage kanndie Matrix D zerlegt werden in
D = D12 D
12 mit D
12 =
√
dii fur i = 1 . . . n. (1.2)
Mit Hilfe von (1.2) kann man die Cholesky-Zerlegung bestimmen.
A = GGT mit G = LD12 . (1.3)
Die Zerlegung kann man gewinnbringend zur Losung des GleichungssystemsAx = b verwenden. Bei vorhandener Cholesky-Zerlegung lost man
y = GT x
b = Gy,
da b = Gy = G(GT x) = Ax gilt. Die Anzahl der benotigten Flops fur dasCholesky-Verfahren betragt
#F lops =n3
3
und damit nur halb soviele wie beim Gauss-Verfahren. Die beiden vorange-gangenen Verfahren werden auch als direkte Loser bezeichnet. Der Nachteildieser Verfahren ist, dass sie fur grosse dunnbesetzte Matrizen, wie sie beim

1.1 Lineare Gleichungsysteme 5
Losen von partiellen Differentialgleichungen nach einer entsprechenden Diskre-tisierung haufig vorkommen, recht unpraktikabel sind, da sie die dunnbesetzteStruktur der Matrix A bei der Berechnung nicht ausnutzen sondern zerstoren.Eine andere Klasse von Gleichungssystemlosern sind die iterativen Verfahren.Diese Methoden berechnen uber xk+1 = φ(xk) = Sxk +c, wobei S ein Splittingder Matrix A ist, einen Fixpunkt. Dieser Fixpunkt ist gleichzeitig Losung desGleichungsystems Ax = b. Damit das Verfahren konvergiert muss der Spek-tralradius von S kleiner als 1 sein [DH93, Seite 257].Ausgehend von einer Startlosung x(0) wird eine Folge von Losungen berechnet,wobei
x(0) → x(1) → . . . → limi→∞
x(i) = x
ist. Bei iterativen Verfahren wird die Losung so lange berechnet bis die Normdes Residuum r(i), mit r(i) = b − Axi, eine ε-Schranke unterschreitet. Die ite-rativen Verfahren unterteilen sich in Relaxations- und Krylovraumverfahren.Die Relaxationsverfahren gehen dabei von einer Startlosung x(0) aus und be-stimmen mit Hilfe der Iterationsfunktion φ(x) eine Folge von neuen genauerenLosungen. Das einfachste Verfahren sei hier kurz dargestellt, das Richardson-Verfahren. Es verwendet als Iterationsfunktion
φ(x) = b + (I − A)x. (1.4)
Das fuhrt auf die Iterationsvorschrift
x(k+1) = x(k) + (b − Ax(k)) = φ(x(k)).
Betrachtet man (b − Ax(k)) als Residuum r, dann wird bei diesem Verfahrendas Residuum als Korrektur zur Verbesserung der Naherung x(k) verwendet.Die Iterationsfunktion (1.4) lasst sich mit
b = Ax = (A + I − I)x
= Ax + Ix − Ix
= (A − I)x + x
begrunden. Das Verfahren konvergiert gegen die gesuchte Losung, wenn
‖ A − I ‖2< 1. (1.5)
Der Beweis befindet sich in [HS06, Seite 250]. Durch (1.5) ist das Verfahrennur sinnvoll fur eine Ausgangsmatrix A, die nahe an der Einheitsmatrix I liegt.Dieses Verfahren ist der Ausgangspunkt fur erfolgversprechendere Verfahrenbei denen die Matrix A nicht nahe an der Einheitsmatrix I liegen muss, um

6 1 Grundlagen
zu konvergieren.Ein anderer Ansatz, um das Gleichungssystem Ax − b zu losen, ist die Mini-mierung der Funktion
f(x) =1
2xT Ax − bT x
f ′(x) = Ax − b.(1.6)
Voraussetzung dafur ist, dass A spd ist. Die Funktion aus (1.6) kann als Pa-raboloid interpretiert werden.
x y
z
1.0
-1.0
1.0
-1.0
1.0
2.0
3.0
-1.0
x y
z
1.0
-1.01.0
-1.0
1.0
2.0
3.0
-1.0 x y
z
1.0
-1.0
1.0
-1.0
1.0
2.0
3.0
-1.0
Abbildung 1.1: Darstellung eines Paraboloiden sowie der Hohenlinien des Paraboloiden
Die Losung von (1.6) ist gekennzeichnet dadurch, dass die Ableitung an dieserStelle Null ist. Ausgehend von einem Punkt auf dem Paraboloid sucht man dasMinimum des Paraboloiden. Das lasst sich als iteratives Verfahren der Form
x(k+1) = x(k) + a(k)d(k) (1.7)
beschreiben, mit d(k) als k-te Suchrichtung und a(k) als Lange der Suchrichtungd(k). Die einzelnen Strategien zum Losen des Problems, wie z.B. die Metho-de des steilsten Abstieges, die Methode der konjugierten Richtungen und dieMethode der konjugierten Gradienten, unterscheiden sich durch die Bestim-mung der Suchrichtung. Das Verfahren des steilsten Abstieges verwendet dennegativen Gradienten −∇f(x) als Suchrichtung. Siehe [HS06, Seiten 254-257].Die Methode der konjugierten Gradienten (CG-Verfahren) benutzt statt dernegativen Gradienten Suchrichtungen, die A-orthogonal zueinander sind. ZweiVektoren p, q ∈ R
n sind A-orthogonal, wenn 〈p, Aq〉 = 0 gilt [HS06, Seite

1.2 Kondition und Vorkonditionierung 7
257]. Die A-orthogonalen Suchrichtungen spannen den Raum Uk auf, der proIteration um einen Basisvektor vergrossert wird [DH93, Seite 271].
Uk = span{r(0), Ar(0), . . . , Ak−1r(0)} fur k = 1, · · · , n. (1.8)
Der Raum Uk wird auch als Krylovraum bezeichnet. In der Iteration k wird imRaum x0 +Uk die beste Approximation gesucht. Nach spatestens n Iterationenentspricht die Approximation xn der gesuchten Losung, da dann im gesamtenRaum die Losung gesucht wird.Die Gradientenverfahren konvergieren schnell gegen die Losung, wenn der Pa-raboloid wenig verzerrt ist. Der Idealfall wird in der Abbildung 1.1 gezeigt.Hierbei bilden die Hohenlinien des Paraboloiden konzentrische Kreise um denNullpunkt. Unter diesem Umstand kann die Losung in einer Iteration berech-net werden. Der Grad der Verzerrung des Paraboloiden wird durch die Kon-dition der Ausgangsmatrix A bestimmt. Wie man die Kondition der Matrixverbessern kann, wird im folgenden Abschnitt beschrieben.
1.2 Kondition und Vorkonditionierung
just dropped in to see what conditionmy condition was in...
Mickey Newbury, 1940 - 2002
Um auftretende Fehler einer Problemstellung analysieren zu konnen, bedarfes eines Maßstabes, der festlegt wie stark sich Storungen der Eingabedatenauf die Losung des Problems auswirken. Um den Zusammenhang zu beschrei-ben, wurde der Begriff der Kondition eines Problems und damit einhergehenddie Konditionszahl eingefuhrt. Die Konditionszahl κ(A) einer Matrix A lautet
κ(A) :=
max‖x‖=1
‖ Ax ‖
min‖x‖=1
‖ Ax ‖ . (1.9)
und bestimmt den Grad der Verzerrung der Normkugel nach Anwendung derMatrix A. Fur Matrizen mit einer existierenden Inversen A−1 kann (1.9) um-geformt werden zu der kurzen pragnanten Darstellung
κ(A) =‖ A ‖‖ A−1 ‖ .
Siehe [DH93, Seite 35]. Um die Kondition der Matrix A zu verbessern, bietensich Vorkonditionierer an. Unter Vorkonditionierung eines Gleichungssystemsversteht man in der numerischen Mathematik die Umformung eines Systems

8 1 Grundlagen
Ax = b in ein aquivalentes System, das eine bessere Kondition aufweist. Dabeikann zwischen einer Linksvorkonditionierung (1.10), einer Rechtsvorkonditio-nierung (1.11) und einer beidseitigen Vorkonditionierung (1.12) unterschiedenwerden:
M−1Ax = M−1b (1.10)
AM−1y = b, x = M−1y (1.11)
M−11 AM−1
2 y = M−11 b, x = M−1
2 y (1.12)
Fur die Vorkonditioniermatrix M verwendet man nicht-singulare Matrizen,die A bzw. A−1 approximieren. Die Transformation verbessert dann fur dieeingesetzten iterativen Methoden die Kondition des Problems, wodurch einebessere Konvergenzgeschwindigkeit bzw. uberhaupt erst Konvergenz erreichtwird. Ziel ist es, ein M zu finden, so dass
κ(M−1A) � κ(A).
Trotz des ersichtlichen Vorteils des schnelleren Losens muss darauf geachtetwerden, dass dieser Vorteil nicht durch den zusatzlichen Aufwand aufgeho-ben wird. Auf die Losung hat die Vorkonditionierung keine Auswirkungen.Uberlicherweise wird das Produkt der Matrix A mit der Matrix M−1 nie expli-zit gebildet, stattdessen beschrankt man sich auf die einzelnen Vektorprodukte.Am Beispiel des CG-Verfahrens lasst sich die Auswirkung der Kondition aufdie Konvergenz gut veranschaulichen. Fur das CG-Verfahren gilt
‖ x∗ − xk ‖A≤ 2
(√κ − 1√κ + 1
)k
‖ x∗ − x0 ‖A , k = 1, 2, . . . , n, (1.13)
wobei κ = cond(A) = λmax(A)λmin(A)
, die Energienorm ‖ x ‖A=√
xT Ax und x∗ der
exakten Losung entspricht. Fur die Herleitung von (1.13) siehe [DH93, Seiten273-274].
Je kleiner der Faktor√
κ−1√κ+1
ist, desto schneller wird der Fehler ‖ x∗−xk ‖A ver-
ringert, d.h. man erhalt eine bessere Konvergenzgeschwindigkeit, wenn κ(M−1A)moglichst nahe an Eins liegt.
1.2.1 Jacobi- und Gauss-Seidel-Vorkonditionierer
Ein einfach zu implementierender Vorkonditionierer ist der Jacobi-Vorkonditi-onierer. Diese Methode verwendet als Vorkonditioniermatrix M = D, wobei D

1.2 Kondition und Vorkonditionierung 9
der Diagonalen der Matrix A entspricht. Im Falle der Linksvorkonditionierungverwendet man folgendes Gleichungssystem:
(D−1A)x = (D−1b). (1.14)
Wendet man die Jacobi-Vorkonditionierung auf das Richardson-Verfahren (1.4)an, erhalt man
φ(x) = D−1b + (I − D−1A)x. (1.15)
Als hinreichende Bedingung fur die Konvergenz von (1.15) gilt, dass A striktdiagonal dominant ist, d.h
|aii| >
n∑
i6=j
|aij | mit i = 1, . . . , n
[Saa00, Seite 111]. Eine weitere einfache Moglichkeit ist der Gauss-Seidel-Vorkonditionierer. Dieser verwendet als Vorkonditioniermatrix
M = (L + D), (1.16)
wobei D der Diagonalen von A und L der unteren Dreiecksmatrix von A ent-spricht. Analog zum Jacobi-Vorkonditionierer lautet das Gleichungssystem
((D + L)−1A)x = ((D + L)−1b) (1.17)
und auf das Richardson-Verfahren angewandt
φ(x) = (D + L)−1b + (I − (D + L)−1A)x. (1.18)
Mit Hilfe der Gauss-Seidel-Vorkonditionierung konvergiert das Verfahren furjede Matrix A, die spd ist. Der Beweis lasst sich in [DH93, Seiten 259-260]finden.
1.2.2 SPAI-Vorkonditionierer
1997 wurde von Grote und Huckle in [GH97] ein Vorkonditionierer vorgestellt,der eine dunnbesetzte approximierte Inverse erzeugt und diese Inverse als Vor-konditioniermatrix verwendet. Im Folgenden wird dieser Vorkonditionierer alsSPAI bezeichnet. Neben der Verbesserung der Kondition einer Matrix ist einweiteres Hauptmerkmal des Verfahrens die leichte Parallelisierbarkeit. Fur dieBerechnung der approximierten Inversen M ≈ A−1 wird neben der Ausgangs-matrix A ∈ R
n×n ein Muster (Pattern) P benotigt, das der Besetztheit von Mentspricht. Das Pattern P enthalt die Positionen an denen M Eintrage haben

10 1 Grundlagen
darf.Die SPAI -Methode erzeugt eine Matrix M fur die AM ≈ I gilt. Um ei-ne gute Approximation der Inversen zu berechnen, minimiert das Verfahren‖ AM − I ‖F . Die Norm
‖ A ‖F=
√
√
√
√
m∑
i=1
n∑
j=1
aij (1.19)
einer Matrix A wird als Frobenius-Norm bezeichnet. Der Vorteil bei der Ver-wendung der Frobenius-Norm liegt in der einfachen Parallisierbarkeit der Be-rechnung:
‖ AM − I ‖2F=
n∑
k=1
‖ (AM − I)ek ‖22 , (1.20)
wobei ek dem k-ten Einheitsvektor entspricht. Die Umformung (1.20) fuhrt dasAusgangsproblem auf n Minimierungsprobleme der Form
minmk
‖ Amk − ek ‖2 mit k = 1 . . . n (1.21)
zuruck. Aufgrund der Unabhangigkeit der Summanden beim Berechnen derNorm, konnen die Minimierungsaufgaben parallel gelost werden. Ausgehendvom Muster P werden die Besetztheitsstrukturen der einzelnen mk bestimmt.Das vorgegebene Muster kann mit Hilfe des Patternupdates um zusatzlicheEintrage erweitert werden bis die Norm ‖ Amk−ek ‖2 kleiner als eine gewahlteε-Schranke ist oder die maximale Besetztheit erreicht wurde. Durch die Vorga-ben des Pattern P ergibt sich die Moglichkeit das Minimierungsproblem (1.21)zu reduzieren und die Werte des Vektors mk effizient zu bestimmen.
minmk
‖ Amk − ek ‖2 → minmk
‖ Akmk − ek ‖2 . (1.22)
Um Ak, mk und ek zu erzeugen, sind zwei Indexmengen Ik und Jk notig. Inder Menge Jk sind alle Indizes j aufgefuhrt, fur die gilt mk(j) 6= 0. Die Redu-zierung von mk auf die Indizes j liefert mk.Die Eintrage i der Menge Ik entsprechen den Zeilenindizes der Matrix A, dieA(i,Jk) 6= 0 erfullen. Die Eliminierung aller Nullzeilen der Matrix A(.,Jk) lie-fert Ak. Durch die Beschrankung des Einheitsvektors auf die Menge Ik entstehtek
A(Ik,Jk) = Ak
ek(Ik) = ek.

1.2 Kondition und Vorkonditionierung 11
Das folgende Beispiel soll den Vorgang verdeutlichen:
A =
5 0 7 3.5 00 0.06 0 0 67.80 5.75 1.25 0.53 04 0 0 3 0
9.9 5.3 10.2 0 2.3
, P =
∗ 0 ∗ ∗ 00 ∗ 0 0 ∗0 ∗ ∗ ∗ 0∗ 0 0 ∗ 0∗ ∗ ∗ 0 ∗
Die Besetztheitstruktur des Vektors m1 entspricht dem ersten Vektor von P .Die Indexmenge J1 entspricht
J1 = {1, 4, 5}
Die Matrix A, eingeschrankt auf die Spalten der Menge J1, wird durch dieEintrage mit Balken dargestellt
A(.,J1) =
5 0 7 3.5 00 0.06 0 0 ¯67.80 5.75 1.25 ¯0.53 04 0 0 3 0
9.9 5.3 10.2 0 2.3
.
Die Menge I1 der Zeilenindizes umfasst
I1 = {1, 2, 3, 4, 5}.
Mit Hilfe der beiden Mengen kann die Matrix A1 bestimmt werden.
A1 = A(I1,J1)
5 3.5 00 0 67.80 0.53 04 3 0
9.9 0 2.3
.
Die restlichen Ak, mk und ek werden analog gebildet.Das Losen der einzelnen Minimierungsprobleme (1.22) erfolgt mit Hilfe der QR-Zerlegung. Das Verfahren der QR -Zerlegung wird im Kapitel 1.3.2 behandelt:
minmk
‖ Amk − ek ‖2 = minmk
‖ QRmk − ek ‖2
= minmk
‖ Rmk − QT ek ‖2 .(1.23)
Die Losung fur (1.23) ist mk = R−1QT ek. Die Gesamtheit aller Losungen mk,k = 1, . . . , n liefert eine approximierte Inverse M von A.

12 1 Grundlagen
Um die Approximation der Inversen zu verbessern, kann das Pattern erwei-tert werden. Die Vergrosserung des Pattern und die daraus resultierende Ver-besserung der Approximation der Inversen kann man als Verringerung von‖ AM − I ‖F auffassen. Um die Norm ‖ AM − I ‖F zu verringern, mussendie einzelnen Minimierungsprobleme (1.21) gelost werden. Ausgangspunkt derweiteren Verringerung der Norm ist das Residuum rk
rk = Amk − ek. (1.24)
Zur besseren Ubersicht wird das weitere Verfahren exemplarisch fur einen Spal-tenvektor mk beschrieben. Auf allen anderen Spalten lasst sich das Verfahrenanalog anwenden. Fur die Verbesserung werden zwei neue Indexmengen L undN benotigt. Die Menge L umfasst alle Indizes l fur die gilt rk(l) 6= 0. Fur allel ∈ L werden alle Indizes g bestimmt fur die gilt A(l, g) 6= 0 und g /∈ J . Alle ge-fundenen g werden zur jeweiligen Menge Nl zusammengefasst. Die Menge allerIndizes J , die zu einer Verbesserung beitragen konnen, lasst sich formulierenals
J =⋃
l∈LNl. (1.25)
Im Falle des obigen Beispiels fur k = 1 und einem Residuum, bei dem alleElemente ungleich Null sind, wurde die Menge J sich aus der Vereinigung derIndizes der Eintrage mit Balken zusammensetzen
P =
∗ 0 ∗ ∗ 00 ∗ 0 0 ∗0 ∗ ∗ ∗ 0∗ 0 0 ∗ 0∗ ∗ ∗ 0 ∗
, J = {2, 3}.
Aus dieser Menge wird der Index gesucht, der ‖ rk ‖2 am starksten verringert.Man erhalt das Minimierungsproblem
minµj
‖ Amk − ek + µjA(I, .)ej ‖22 = min
µj
‖ Amk − ek + µj aj ‖22
= minµj
‖ rk + µj aj ‖22 , ∀j ∈ J .
(1.26)
Das Minimierungsproblem (1.26) kann, unter Verwendung der Eigenschaftendes Skalarproduktes, wie folgt gelost werden:
‖ rk + µjaj ‖22 =‖ rk ‖2
2 +2µj〈rk, aj〉 + µ2j ‖ aj ‖2
2
⇒ d
dµj
‖ rk + µjaj ‖22 = 2〈rk, aj〉 + 2µj ‖ aj ‖2
2!= 0,

1.3 Lineare Ausgleichsrechnung 13
mit der Losung µj = − rTk
aj
‖aj‖22. Mit den berechneten µj konnen die neuen Resi-
duen berechnet werden. Die w Indizes aus j ∈ J , die die kleinsten Residuenerzeugen, werden der Menge J hinzugefugt. Mit der vergrosserten IndexmengeJ werden die Losungen von (1.21) erneut berechnet. Wenn das Ergebnis von(1.21) die vorgebene ε-Schranke nicht erreicht und die maximale Besetztheitnoch nicht erreicht wurde, kann das Patternupdate solange durchgefuhrt wer-den, bis eine der beiden Bedingungen erfullt wird.Die Residuen ‖ rk + µaj ‖2
2 verbessern sich aufgrund der Tatsache, dass
‖ rk + µaj ‖22 = ‖ rk ‖2
2 −2
⟨
rk,rTk aj
‖ aj ‖22
aj
⟩
+
∥
∥
∥
∥
rTk aj
‖ aj ‖22
aj
∥
∥
∥
∥
2
2
= ‖ rk ‖22 −2
rTk aj
‖ aj ‖22
rTk aj +
(rTk aj)
2
‖ aj ‖42
‖ aj ‖22
= ‖ rk ‖22 −
(rTk aj)
2
‖ aj ‖22
gilt. Weitere Informationen unter [GH97, Seiten 840-842].
1.3 Lineare Ausgleichsrechnung
I wish to God these calculations had be-en executed by steam
Charles Babbage, 1821
Wie im vorherigen Abschnitt gezeigt, verwendet der SPAI die lineare Aus-gleichsrechnung in Form der QR-Zerlegung, um die einzelnen Spaltenvektorenmk zu berechnen. Der folgende Abschnitt befasst sich mit der linearen Aus-gleichsrechnung im Allgemeinen. Anschliessend werden verschiedene Moglich-keiten zum Losen linearer Ausgleichsprobleme betrachtet.In vielen Bereichen werden durch Messungen und Beobachtungen Sachverhaltebeschrieben. Diese Sachverhalte sollen mit Hilfe einer Gesetzmassigkeit ausge-druckt werden, d.h. man sucht ein mathematisches Modell, das die Daten ambesten approximiert. Von den Messungen ausgehend erhalt man m Messwer-te, welche in einem Vektor zusammengefasst werden. Die gesuchten Modell-parameter werden in einen zweitem Vektor der Lange n untergebracht. DerZusammenhang zwischen Modellparameter und den Messwerten wird durcheine Matrix beschrieben. Man erhalt das lineare Gleichungssystem Ax = b,wobei A ∈ R
m×n, x ∈ Rn und b ∈ R
m ist, sowie m > n. Das uberbestimmteGleichungssystem hat im Normalfall keine eindeutige Losung, man mochte

14 1 Grundlagen
aber das Gleichungssystem mit einem moglichst kleinen Fehler losen. Daherversucht man das Residuum r = Ax − b zu minimieren. Das fuhrt zu demMinimierungsproblem
minx∈Rn
‖ Ax − b ‖2 . (1.27)
Statt der 2-Norm kann auch eine andere Norm, wie die 1-Norm oder die∞-Norm, verwendet werden. Die Verwendung der genannten Normen fuhrtauf andere Problemstellungen, wie das Standardproblem der linearen Opti-mierung (Verwendung der 1-Norm) oder das Problem der TschebyscheffschenAusgleichsrechnung (Verwendung der ∞-Norm). Siehe [DH93, Seite 70]. DasProblem (1.27) lasst sich auf mehreren Wegen losen. Eine Moglichkeit ist dasLosen mit Hilfe der Normalengleichung, eine andere Moglichkeit lost das Pro-blem mittels Orthogonalisierungsverfahren.
1.3.1 Losung mittels Normalengleichung
Das Verfahren zum Losen des linearen Ausgleichsproblems mit Hilfe der Nor-malengleichung verwendet als Ausgangspunkt die Aquivalenz der beiden Mi-nimierungsprobleme
minx∈Rn
‖ Ax − b ‖2 und minx∈Rn
‖ Ax − b ‖22 ,
d.h. der Losungsvektor x ist bei beiden Problemen identisch, wobei A ∈ Rm×n,
der Rang(A) = n und b ∈ Rm. Ausgehend von der quadrierten Form kann man
folgenden Zusammenhang herstellen
minx∈Rn
‖ Ax − b ‖22 = 〈Ax − b, Ax − b〉
= (Ax − b)T (Ax − b)
= xT AT Ax − 2xT AT b + bT b.
(1.28)
Das Ergebnis der Umformung (1.28) ist eine quadratische Gleichung und stellteinen nach oben geoffneten Paraboloiden dar. Durch Ableiten der Gleichungnach x und Nullsetzen kann die Losung des ursprunglichen Minimierungspro-blems bestimmt werden. Das fuhrt auf
2ATAx − 2AT b = 0 bzw. AT Ax = AT b, (1.29)
wobei AT Ax = AT b als Normalengleichung bezeichnet wird. Das entstandeneGleichungssystem ist symmetrisch und kann mit der in Kapitel 1.1 beschriebe-nen Cholesky-Zerlegung gelost werden. Das Verfahren liefert den Losungsvektor

1.3 Lineare Ausgleichsrechnung 15
x fur (1.27) [Sch93, Seiten 297-298]. Dieser Algorithmus benotigt zum Losendes Systems
#Flops = (m + n/3)n2. (1.30)
Der Nachteil dieser Methode ist im Allgemeinen die Verschlechterung der Kon-dition des Problems. Es kann gezeigt werden, dass die Konditionκ(AT A) = κ(A)2 ist [DH93, Seite 73].Im folgenden Abschnitt werden Verfahren behandelt, die (1.27) losen aber kei-ne Verschlechterung der Kondition des Problems wie die Normalengleichungzur Folge haben.
1.3.2 Losung mittels Orthogonalisierungsverfahren
Diese Methode nutzt die Zerlegung A = QR aus, wobei A ∈ Rm×n, Q ∈
Rm×m eine orthogonale Matrix, d.h. QT Q = I, und R ∈ R
m×n eine obereDreiecksmatrix ist, so dass gilt
QT A =
∗ · · · ∗. . .
...∗
0
=
(
R
0
)
. (1.31)
Der Vorteil dieser Zerlegung liegt in der Invarianz von Q bezuglich der 2-Norm,d.h die Kondition bleibt damit unverandert.
‖ Qy ‖2=‖ y ‖2 , mit ‖ Q ‖2= 1 (1.32)
Um (1.32) zu zeigen, betrachtet man die quadrierte Form von ‖ Qy ‖2:
‖ Qy ‖22= 〈Qy, Qy〉 = 〈QT Qy, y〉 = 〈y, y〉 =‖ y ‖2
2 .
Fur die Kondition giltκ(QA) = κ(A). (1.33)
Weitere Informationen zu (1.33) siehe [DH93, Seite 77].Die Normalengleichung (1.29) hingegen verschlechtert die Kondition. Der Nach-teil der Orthogonalisierungsverfahren ist jedoch der hohere Aufwand, der beider QR-Zerlegung geleistet werden muss. Darauf wird in den verschiedenenMethoden zur QR-Zerlegung genauer eingegangen.Auf das lineare Ausgleichsproblem angewandt, ergibt sich folgender Zusam-menhang:
minx∈Rn
‖ Ax − b ‖2= minx∈Rn
‖ QRx − b ‖2= minx∈Rn
‖ Rx − QT b ‖2 , (1.34)

16 1 Grundlagen
wobei QT b =(
b1b2
)
, b1 ∈ Rn und b2 ∈ R
m−n.
Die Losung des Minimierungsproblems (1.34) ist x = R−1b1. Dies zeigt sich in
‖ Ax − b ‖2 = ‖ QT (Ax − b) ‖2
=
∥
∥
∥
∥
(
Rx
0
)
−(
b1
b2
)∥
∥
∥
∥
2
= ‖ Rx − b1 ‖2 + ‖ b2 ‖2 .
(1.35)
Der erste Summand in (1.35) verschwindet genau dann, wenn x = R−1b1 ist.Der minimale Abstand bzw. Wert des Residuums r = Ax − b ist festgelegtdurch ‖ b2 ‖2.Im Folgenden werden drei Methoden der QR-Zerlegung beschrieben. Die wich-tigsten Verfahren sind die Householder-Reflektion, die Givens-Rotation unddas Gram-Schmidt-Verfahren. Bei der Householder-Reflektion und der Givens-Rotation wird die Matrix Q nicht explizit aufgebaut. Die Gram-Schmidt-Methode hingegen konstruiert die Matrix Q verfahrensbedingt.
1.3.2.1 Householder-Reflektion
Die Householder-Reflektion wurde von Alston Scott Householder im Jahr 1958vorgestellt. Es handelt sich dabei um eine Spiegelung des Vektors a an einerEbene l, die durch den Ursprung verlauft, sodass der Vektor auf ein Vielfacheseines Einheitsvektors gespiegelt wird:
v
1
2
1 2 3
a
e1 αe1
l
−2vT avT v
Abbildung 1.2: Spiegelung eines Vektor a an einer Ebene auf ein Vielfaches des Einheits-vektors
Bei der Householder-Reflektion wird eine Matrix der Form
H =
(
I − 2vvT
vTv
)
(1.36)

1.3 Lineare Ausgleichsrechnung 17
verwendet. Den Vektor
v = a + αe1 (1.37)
bezeichnet man als Householder-Vektor. Das Ziel der Reflektion ist das Er-zeugen eines Vielfachen vom ersten Einheitsvektor durch Elimination von Ein-tragen des Ausgangsvektors a. Es soll gelten
Ha = αe1
Ha =
(
I − 2vvT
vTv
)
a = a − 2vT a
vT vv
= a − 2(a + αe1)
T a
(a + αe1)T (a + αe1)(a + αe1)
=
(
1 − 2aT a + 2αa1
aT a + 2αa1 + α2
)
x − 2α(a + αe1)a
(a + αe1)T (a + αe1)e1. (1.38)
Der Minuend aus Gleichung (1.38) wird Null, wenn α =‖ a ‖2 entspricht. DerVektor a wird somit auf ein Vielfaches des ersten Einheitsvektors abgebildet.Fur den Householder-Vektor v ergibt sich daraus v = a− ‖ a ‖2 e1. Umeventuell auftretende Ausloschung zu verhindern, wenn a nahe an e1 liegt,bestimmt man
v =−(a2
2 + · · ·+ a2n)
a1+ ‖ a ‖2. (1.39)
In der QR-Zerlegung wird fur jeden Spaltenvektor von A, der Reihe nach dieHouseholder-Matrix aufgebaut und auf A angewandt. Startpunkt des Verfah-rens ist der erste Spaltenvektor von A. Mit diesem Vektor wird die Householder-Matrix bestimmt und auf A angewandt. Im nachsten Schritt nimmt man denzweiten Spaltenvektor des neu entstandenen A und verfahrt analog. Dies wirdbis zum letzten Vektor wiederholt. Durch diese Vorgangsweise wird die Aus-gangsmatrix A Schritt fur Schritt in die obere Dreiecksmatrix R uberfuhrt.
A =
∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗
→ H1A =
∗ ∗ ∗ ∗0 ∗ ∗ ∗0 ∗ ∗ ∗0 ∗ ∗ ∗
→ · · · → R
Die Matrix Q setzt sich aus dem Produkt der einzelnen Householder-Matrizenzusammen. Damit ergibt sich
H1H2 · · ·Hn = Q.

18 1 Grundlagen
Q wird in der Praxis fur gewohnlich nicht explizit aufgebaut, stattdessen wer-den die einzelnen Householder-Vektoren gespeichert. Platz fur die Householder-Vektoren bieten die Elemente des Ausgangsvektors die eliminiert wurden, da-mit das erste Element nicht mit dem jeweiligen Diagonalelement kollidiert, wirdder Vektor so umgeformt bzw. so erzeugt, dass das erste Element den WertEins enthalt. Die Kosten fur die QR-Zerlegung mittels Householder-Reflektionbetragen
#F lops = 4n2(m − n/3).
1.3.2.2 Givens-Rotation
Bei den Givens-Rotationen (nach Walace Givens 1958) handelt es sich umDrehungen in der Ebene. Mit Hilfe der Rotationen konnen die einzelnen Rich-tungskomponenten des Vektors a eliminiert werden, sodass am Ende der Vek-tor auf ein Vielfaches des ersten Einheitsvektor e1 gedreht wird. Abbildung 1.3stellt den einfachsten Fall dar. Hier genugt es den Vektor a ∈ R
2 mit einereinzigen Drehung um den Winkel θ auf den Einheitsvektor zu drehen.
1
2
1 2 3
a
e1
θ
αe1
Abbildung 1.3: Drehung eines Vektors a auf ein Vielfaches des Einheitsvektors
Um die Drehung des Vektors a auf ein Vielfaches αe1 des Einheitsvektors e1
durchzufuhren, verwendet man das Gleichungssystem
(
cos θ sin θ− sin θ cos θ
) (
a1
a2
)
= α
(
1
0
)
.
Die Givens-Rotation arbeitet im Vergleich zur Householder-Reflektion selek-tiver. Man wahlt die einzelnen Eintrage der Matrix bzw. des Vektors, die aufNull gesetzt werden sollen, aus und eliminiert sie Schritt fur Schritt. Um denEintrag der i-ten Spalten und k-ten Zeile zu eliminieren, verwendet man die

1.3 Lineare Ausgleichsrechnung 19
Matrix Gij:
Gij =
1 · · · 0 · · · 0 · · · 0...
. . ....
......
0 · · · c · · · s · · · 0 i...
.... . .
......
0 · · · −s · · · c · · · 0 j...
......
. . ....
0 · · · 0 · · · 0 · · · 1i j
.Um die Werte fur c (Cosinus) und s (Sinus) zu wahlen, betrachtet man folgen-des Gleichungssystem
(
c −ss c
) (
xi
xj
)
=
(
cxi − sxj
sxi + cxj
)
. (1.40)
Fur die beiden Gleichungen aus (1.40) soll gelten, dass
sxi + cxj = yj = 0 (1.41)
und
cxi − sxj = yi =√
x2i + x2
j . (1.42)
Die Gleichung (1.42) muss gelten, da die Givens-Rotation die Norm erhaltensoll. Alle Werte ausser yi und yj bleiben unverandert, deshalb muss der Anteilvon xj zu yi hinzugefugt werden. Durch Kombination der Gleichungen (1.41)und (1.42) lasst sich der Wert fur c und s einfach bestimmen.
c =xi
√
x2i + x2
j
und s = − xj√
x2i + x2
j
. (1.43)
Fur eine stabilere und vor einem Uberlauf geschutzte Methode zur Berechnungder Givens-Rotation siehe [GvL96, Seite 216]. Wahrend der QR-Zerlegung,wendet man die Givens-Rotationen auf alle Elemente unterhalb der Diagonalenvon A an, deren Wert ungleich Null ist und eliminiert diese.
A =
∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗
= G12A =
∗ ∗ ∗ ∗0 ∗ ∗ ∗∗ ∗ ∗ ∗∗ ∗ ∗ ∗
= · · ·
= G12G13G14 · G23G24 · G34R

20 1 Grundlagen
Die Matrix Q resultiert aus dem Produkt aller Givens-Rotationen. Wie schonbeim Householder-Verfahren wird Q nicht explizit berechnet, stattdessen be-rechnet man nur eine einfache Gleitkommazahl k fur jede Rotation und spei-chert diesen Wert an der Stelle, die in der Ausgangsmatrix eliminiert wurde.Es ergibt sich somit kein hoherer Speicheraufwand fur die Givens-Rotationenund die Givens-Rotationen Gij lassen sich schnell rekonstruieren [GvL96, Sei-ten 217-218].Der Aufwand fur die Anwendung der Givens-Rotationen, wahrend der QR-Zerlegung, auf eine vollbesetzte Matrix A ∈ R
m×n betragt
3n2(m − n/3) Flops. (1.44)
Das Householder-Verfahren ist im Vergleich zum Givens-Verfahren um einDrittel schneller.Kostensenkend in Bezug auf die Laufzeit des Verfahrens kann sich der Einsatzder Givens-Rotationen bei dunnbesetzten Matrizen auswirken. Ein Standard-beispiel ist die Faktorisierung einer sogenannten Hessenberg Matrix
∗ ∗ ∗ ∗ ∗∗ ∗ ∗ ∗ ∗0 ∗ ∗ ∗ ∗0 0 ∗ ∗ ∗0 0 0 ∗ ∗
,
bei der die Kosten auf#F lops = 3n2
sinken, da nur die (n − 1) Subdiagonalelemente eliminiert werden mussen.Neben der punktweisen Auswahl der Transformationen und den geringerenKosten bei einigen dunnbesetzten Problemen ist die freiwahlbare Ausfuhr-ungsreihenfolge der Givens-Rotationen ein weiterer Vorteil, d.h. man kann dieDrehung eines Vektors a ∈ R
n auf den ersten Einheitsvektors auf mehrerenWegen erreichen.
G1n · · ·G13G12a = αe1 oder
G12G23 · · ·Gn−1,na = αe1
1.3.2.3 Gram-Schmidt-Verfahren
Als drittes Verfahren zur Orthogonalisierung wird das Gram-Schmidt-Ver-fahren betrachtet. Bei diesem Verfahren wird die Matrix Q explizit erstellt,wodurch das Verfahren mehr Speicherplatz als die Householder- bzw. Givens-Methode benotigt. Das allgemeine Gram-Schmidt-Verfahren hat schlechte nu-merische Eigenschaften, welche zum Verlust der Orthogonalitat, wahrend der

1.3 Lineare Ausgleichsrechnung 21
Orthogonalisierung, fuhren konnen. Das allgemeine Verfahren verwendet mannur mit Reorthogonalisierungsschritten. Im Folgenden wird nur das modifizier-te Gram-Schmidt-Verfahren (MGS ) naher untersucht. Bei diesem Verfahrenwurden die schlechten numerischen Eigenschaften entfernt durch die Anderungdes Zeitpunktes der Normierung im Algorithmus. Hierbei wird die Ausgangs-matrix A ∈ R
m×n in die Matrix Q ∈ Rm×n uberfuhrt.
A → A(1) → · · · → A(n) = Q
Fur die einzelnen Matrizen A(k) k ≤ n gilt
A(k) = (q1, q2, · · · , qk−1, a(k)k , · · · , a(k)
n ),
wobei die Vektoren (q1, · · · , qk−1) zueinander orthogonal sind. Die restlichen
Vektoren (a(k)k , · · · , a
(k)n ) mussen im weiteren Verlauf noch orthogonalisiert wer-
den. Vor der eigentlichen Orthogonalisierung der k-ten Spalte erfolgt erst eineNormierung der Spalte:
qk =a
(k)k
‖ a(k)k ‖2
Der Wert ‖ a(k)k ‖2 wird als Diagonalelement rkk in der Matrix R gespeichert.
Nach der Normierung von qk erfolgt die Orthogonalisierung mit den Vektoren(a
(k)k+1, · · · , a
(k)n )
rkj = 〈qT , a(k)j 〉
a(k+1)j = aj − rkjqk,
wobei j = k + 1, · · · , n.Der Algorithmus zur QR-Zerlegung mittels Gram-Schmidt kostet
#F lops = 2mn2. (1.45)
Der Vorgang lasst sich auf 2 Arten durchfuhren, je nachdem ob die MatrixR zeilenweise oder spaltenweise aufgebaut wird. Die beiden Arten werden imFolgenden kurz schematisch skizziert. Das zeilenweise MGS:
A →
......
...q1 a2 a3 · · ·...
......
→
......
...q1 q2 a3 · · ·...
......
· · · = Q
∗ ∗ ∗ · · ·0 0 0 · · ·...
...... 0
→
∗ ∗ ∗ · · ·0 ∗ ∗ · · ·0 0 0 0...
...... 0
· · · = R.

22 1 Grundlagen
Die Berechnung des spaltenweisen MGS verlauft:
A →
......
...q1 a2 a3 · · ·...
......
→
......
...q1 q2 a3 · · ·...
......
· · · = Q
∗ 0 0 · · ·0 0 0 · · ·...
...... 0
→
∗ ∗ 0 · · ·0 ∗ 0 · · ·0 0 0 0...
...... 0
· · · = R.
Die entsprechenden Algorithmen zur Berechung des zeilen- bzw. spaltenweisenMGS und weitere Informationen finden sich in [Bjo96, Seite 62].Im anschliessenden Kapitel wird beschrieben, wie man dunnbesetzte Verfahreneinsetzen kann, um die QR-Faktorisierung einer dunnbesetzten Matrix effizi-ent durchzufuhren. Weiterhin wird eine Moglichkeit aufgezeigt, wie man einevorhandene Zerlegung einer Matrix A verwenden und anpassen muss, wennman der Matrix A Zeilen bzw. Spalten hinzufugt. Der Vorteil dieser Methodeist, dass die QR-Zerlegung nicht mehr komplett neu berechnet werden muss,sondern die schon vorhandene Zerlegung wieder verwendet werden kann.

23
2 Modifikationen bei der
Berechnung des SPAI
Haufig wird der SPAI -Vorkonditionierer auf dunnbesetzte Matrizen angewen-det, weshalb die entstehenden Matrizen Ai, siehe 1.2.2, ebenfalls haufig dunn-besetzt sind. Daher bietet es sich an, die intern verwendete QR-Zerlegungmittels dunnbesetzter Verfahren durchzufuhren. Der Abschnitt 2.1 behandeltdieses Thema. Eine weitere Verbesserung der Laufzeit des SPAI kann durchOptimierung des Patternupdates erreicht werden. Um die Approximation derInversen, die der SPAI berechnet, zu verbessern, wird das Ausgangspatternum neue Spalten erweitert, siehe dazu Abschnitt 1.2.2. Da die vorherige Zer-legung vorliegt, kann durch das QR-Update-Verfahren auf einfache Art undWeise die Zerlegung aktualisiert werden. Die Vorgehensweise wird in Abschnitt2.2 beschrieben. Ein anderer Ansatz zur Optimierung des SPAI ist die QR-Zerlegung und das Losen des Least-Squares-Problemes auf Basis des Datentypsfloat durchzufuhren und dann die Genauigkeit der Losung mit Hilfe iterativerNachverfeinerung zu erhohen.
2.1 Dunnbesetzte Verfahren
[...]Immer und immer wieder bitte ich:weniger Zahlen, dafur gescheitere.[...]
Wladimir Iljitsch Uljanow, 1921
Um lineare Gleichungssysteme der Form Ax = b mit Hilfe von Rechnern zulosen, kann man selbst Loser programmieren oder auf Bibliotheken zuruckgrei-fen. Eine der meist verwendeten Bibliotheken ist das Lineare Algebra Package,kurz LAPACK genannt. Die Bibliothek und die dazugehorige Dokumentationist auf www.netlib.org/lapack verfugbar. Sie realisiert Fortran77-Routinen zumLosen von linearen Gleichungssystemen, Least Squares Problemen, Eigenwert-problemen und Singularwertproblemen. In den Routinennamen ist festgelegtmit welcher Genauigkeit bzw. welchem Datentyp gerechnet wird. Die Genau-igkeit bzw. der Datentyp wird mit dem ersten Buchstaben des verwendeten

24 2 Modifikationen bei der Berechnung des SPAI
Funktionsnamen bestimmt. Es stehen zur Auswahl:
d = doppelte Genauigkeit, reells = einfache Genauigkeit, reellz = doppelte Genauigkeit, komplexc = einfache Genauigkeit, komplex
Allgemein lauten die Funktionen xFunktion(Parameter 1, . . . , Parameter n),wobei x ∈ {d, s, z, c} ist. Im SPAI werden hauptsachlich die Routinen xgeqrf,xormqr und xtrtrs verwendet, da mit ihnen die QR-Zerlegung, die Anwendungvon QT auf einen Vektor und Rx = QT b realisiert werden konnen. Die Funk-tionen werden im Folgenden kurz vorgestellt. Weitere Information finden sichunter [ABB+99].
xgeqrf Mit dieser Funktion wird die Zerlegung der Matrix A ∈ Rm×n
in A = QR durchgefuhrt. Die Zerlegung wird, wie in Ab-schnitt 1.3.2.1 beschrieben, ausgefuhrt. Die Matrix Q wirdnicht explizit aufgebaut, sondern in Form der Householder-Vektoren unterhalb der Diagonalen von A gespeichert. hi,j
entspricht der i-ten Komponente im j-ten Householder-Vektor.
R1,1 R1,2 · · · R1,n
h2,1 R2,2...
......
. . . Rn,n
hn+1,1 hn,2 . . . h2,n
......
...hm,1 hm−1,2 . . . hm−n,n
Die Funktion uberschreibt die Ursprungsmatrix A mit derZerlegung.
xormqr Mit xormqr wird Q bzw. QT , auf eine Matrix C bzw. einenVektor b angewandt. Die Anwendung von Q = H1 · H2 . . .Hn
auf C erfolgt intern durch die Anwendung der Householder-Matrix Hi fur i = 1, ..., n auf C.
xtrtrs xtrtrs lost das System Ax = b durch Rucksubstitution, wobeiA in Form einer oberen Dreiecksmatrix vorliegt. Das Ergebnisder Rucksubstitution liegt am Ende in den ersten n Eintragenvon b vor.
Die einzelnen Parameter der Funktionen xgeqrf, xormqr und xtrtrs sind auf

2.1 Dunnbesetzte Verfahren 25
http://www.netlib.org/lapack dokumentiert und konnen dort nachgelesen wer-den.In LAPACK werden die Matrizen immer voll gespeichert, d.h. es werden alleWerte inklusive der Nullen in einem eindimensionalen Feld abgelegt. Da Fort-ran mehrdimensionale Strukturen im Gegensatz zu C spaltenweise speichert,ist das LAPACK-Speicherformat fur Matrizen ebenfalls spaltenweise. Die Ma-trix
A =
a11 a12 a13
a21 a22 a23
a31 a32 a33
a41 a42 a43
a51 a52 a53
ist intern als folgendes Feld realisiert:
a11a21 a31 a41 a51 a12 a22 a32 a42 a52 a13 a23 a33 a43 a53
Nachfolgend wird der Algorithmus zur Losung eines Least-Squares-Problemesmittels LAPACK grob skizziert. Die Zerlegung wird in einer C-Struktur QRSgespeichert. Die Struktur speichert neben der Zerlegung die Matrixdimension,die Startindizes der Matrixspalten, die gewahlten Zeilen, die gewahlten Spal-ten und noch weitere Steuerinformationen.
Data : Matrix A, Vektor b, Zeilen, Spalten, gewahlte Zeilen, gewahlteSpalten
Result : Losung x
Initialisierung der VariablenQRC qrc anlegen und initialisieren
Losen von Ax = bZerlegen der Matrix mit Hilfe von xgeqrfAnwenden von QT auf b durch xormqrLosen von Rx = QT b mit dtrtrs
Speichern der Informationenqrc→Zerlegung = QR-Zerlegungqrc→beta = beta = Beta-Vektor der ZerlegungBestimmen der Anfangsindizes der Spaltenqrc→Anfangsindizes = Anfangsindizes
Algorithmus 1 : Losen eines Least-Squares-Problemes in LAPACK

26 2 Modifikationen bei der Berechnung des SPAI
Dieses Verfahren funktioniert bei vollen und bei dunnbesetzten Matrizen, wo-bei es sich eher fur volle Matrizen eignet, da der Speicherplatzbedarf bei vollenMatrizen nicht reduziert werden kann. Bei dunnbesetzten Matrizen wird jedocheine Menge Speicherplatz dazu verwendet, Nullen zu speichern. Da Nullen kei-ne Informationen enthalten, ist dieser Speicherplatz unnotiger Weise belegt.Im nachsten Abschnitt werden Speicherstrukturen und Verfahren angegeben,die keine unnotigen Nullen speichern und verwenden. An diese Speicherstruk-turen mussen auch die jeweiligen Implementierungen der Verfahren angepasstwerden.
2.1.1 Dunnbesetzte Speicherstrukturen
Der SPAI wird haufig auf dunnbesetzte Matrizen A angewendet, sodass auchdie dabei vorkommenden Matrizen A, siehe Abschnitt 1.2.2, dunnbesetzt sind.Daher ist es angebracht nur die Nichtnull-Elemente zu speichern, um Spei-cherplatz zu sparen. Es gibt verschiedene Speicherformate, um eine Matrixdunnbesetzt zu speichern. Die einfachste Methode, ist die Matrix in Tripletformzu speichern. Hier werden drei Vektoren benotigt. Ein Vektor zum Speichernder Werte, ein Vektor fur die Spaltenindizes und ein Vektor fur die Zeilenindi-zes. Insgesamt belaufen sich die Speicherkosten auf O(3 · nz(A)) anstatt vonO(m · n) im vollen Fall. Der Wert nz(A) entspricht der Anzahl der Elementeder Matrix A, die ungleich Null sind.Ein verbessertes Verfahren ist das Compress Sparse Column Verfahren, kurzCSC . Hierbei werden zwei Vektoren x und i der Lange nz(A) benotigt und eindritter Vektor p der Lange n+1. n entspricht der Anzahl der Spaltenvektoren.Der Vektor x enthalt die numerischen Werte und i die jeweilige Zeilenindizes.Die Eintrage der Matrix werden spaltenweise gespeichert. Der Vektor p enthaltden Startindex der Matrixspalten.
A =
5 3.5 0 6.20 0 67.8 0.10 0.53 0 04 3 0 0
9.9 0 2.3 10 1.2 0 0
In CSC gespeichert ergeben sich folgende Vektoren:
x = {5, 4, 9.9, 3.5, 0.53, 3, 1.2, 67.8, 2.3, 6.2, 0.1, 1}i = {1, 4, 5, 1, 3, 4, 6, 2, 5, 1, 2, 5}p = {0, 4, 8, 10, 13}.

2.1 Dunnbesetzte Verfahren 27
Weitere Speicherstrukturen sind Compress Sparse Row , welches analog zu CSCaufgebaut ist, das Modified Sparse Row (MSR) und das Ellpack-Itpack-Schema.Informationen zu den letztgenannten Speicherschemen finden sich in [Saa00,Seiten 85-86].
2.1.2 Dunnbesetzte Methoden
Beim Wechsel vom LAPACK-Speicherschema, bei dem alle Elemente der Ma-trix, auch die Nullen explizit gespeichert, hin zur Verwendung dunnbesetzterSpeicherschema mussen die ursprunglich verwendeten Funktionen angepasstwerden. Die Methode c = Ab, wobei A ∈ R
m×n im LAPACK-Format gespei-chert ist, lautet:
for i = 0 . . .m dofor j = 0 . . . n do
c[i] += A[i · m + j] · b[j] ;end
end
Algorithmus 2 : c = Ab im vollbesetzten Speicherschema
Dieser Algorithmus fur c = Ab benotigt O(mn) Schritte zur Berechnung von c.Nachfolgend derselbe Algorithmus abgewandelt fur die Verwendung einer imCSR-Format gespeicherten Matrix A ∈ R
m×n:
for k = 0 . . . n − 1 dofor j = p[i] . . . p[i + 1] − 1 do
c[k] += x[j] · b[i[j]] ;end
end
Algorithmus 3 : c = Ab mit CSC -Schema
Hier wird die Berechnung in O(nz(A)) Schritten durchgefuhrt, nachteilig wirktsich jedoch die indirekte Indizierung der Elemente von b auf die Laufzeit aus.Im Allgemeinen ist man bei dunnbesetzten Methoden, wie auch bei Verfahrenmit vollen Matrizen, auf eine hohe Effizienz aus. Daher versucht man bei Fak-torisierungen von Matrizen so wenig Fill-In wie moglich zu erzeugen, um einengroßtmoglichen Nutzen aus dem dunnbesetzten Speicherschema zu ziehen. Fill-In ist die verfahrensbedingte Erzeugung von Nichtnullkomponenten, die beim

28 2 Modifikationen bei der Berechnung des SPAI
Start des Verfahrens Null waren. Um den Fill-In bei einer Zerlegung zu ver-ringern, sucht man eine Permutationen P der Matrix, sodass bei einer Fakto-risierung moglichst wenig Fill-In entsteht. Dieses Problem ist NP-vollstandig.Der Beweis findet sich in [Yan81]. Daher verwendet man Heuristiken. EineMoglichkeit, eine solche Permutation P zu finden, besteht in graphentheore-tischen Verfahren. Eine Methode ist das Minimum-Degree-Verfahren, das zurKlasse der Greedy-Algorithmen gehort. Im Folgenden werden zwei Variantendes Verfahrens naher vorgestellt.
2.1.2.1 Minimum-Degree mit Eliminationsgraphen
Das Pattern der Nichtnulleintrage einer symmetrischen Matrix A ∈ Rn×n kann
als Graph G = G0 = (V, E) aufgefaßt werden, wobei V = V0 = {1 . . . n} derKnotenmenge entspricht und E der Kantenmenge. Eine Kante (i, j) ist genaudann in E enthalten, wenn die Komponente aij 6= 0 ist, aij ∈ A. Um Schleifenzu vermeiden, gilt zusatzlich i 6= j.Wahrend der Faktorisierung wird im Eliminationsschritt b der Knoten k ∈Vb−1 aus Gb entfernt. Gb entspricht dem Graphen nach dem b-ten Schritt.Alle Knoten, die adjazent zum entfernten Knoten k sind, werden durch neueKanten miteinander verbunden und bilden einen vollstandigen Untergraphen,eine Clique. Diese neuen Kanten werden der Menge E b−1 hinzugefugt.
E b = E b−1 ∪ Eneu mit Eneu enthalt die neuen Kanten
Vb = Vb−1 \ {k}
Die neuen Kanten, die E b hinzugefugt werden entsprechen dem Fill-In imSchritt b. Um den Fill-In zu verringern, wird immer das Element k der MengeVb−1 gewahlt mit minimalem Grad d(k). d(k) ist die Anzahl der Kanten desKnoten k. Die Reihenfolge der gewahlten Komponenten am Ende der Fakto-risierung entspricht der gesuchten Permutation P . Im Folgenden Beispiel wirddas Verfahren fur die ersten drei Schritte gezeigt. Ausgehend von folgenderBesetztheitsstruktur Pattern(A) ergibt sich der Graph G0:
Pattern(A) =
∗ 0 0 ∗ 0 0 ∗0 ∗ 0 0 ∗ ∗ ∗0 0 ∗ ∗ 0 0 0∗ 0 ∗ ∗ 0 0 00 ∗ 0 0 ∗ ∗ ∗0 ∗ ∗ 0 ∗ ∗ 0∗ ∗ 0 0 ∗ 0 ∗
2
7
14
56
3
G0

2.1 Dunnbesetzte Verfahren 29
In Abbildung 2.1 wird das schrittweise Entfernen von Knoten und Einfugenneuer Kanten dargestellt. Im ersten Eliminationsschritt wird der Knoten 1 alsPivotelement gewahlt, im zweiten Schritt der Knoten 3, im dritten Schritt derKnoten 4 usw. Der Vorgang wird solange durchgefuhrt bis nur noch ein Ele-ment vorhanden ist. Dann ist die Elimination abgeschlossen. Die Reihenfolgeder entfernten Knoten entspricht dabei der Permutation P .
6 7
2
5
43
G1
6 7
2
5
4
G2
6 7
2
5
G3
Abbildung 2.1: Schrittweise Elimination von Knoten aus dem Graphen
Die gestrichelten Linien entsprechen den neu eingefugten Kanten pro Elimina-tionsschritt. Das Verfahren liefert nicht die optimale Losung aber eine obereGrenze fur den Fill-In, der durch das b-te Pivotelelement verursacht wird,[ADD96, Seiten 887-888]. Der Nachteil bei dieser Methode ist, dass keine Aus-sagen im Voraus getroffen werden konnen, wieviel Fill-In in der Matrix erzeugtwird und somit wieviel Platz wahrend Berechnung fur den Graph benotigtwird. Das folgende Quotientengraph-Verfahren hingegen kommt mit einer fes-ten vorausberechenbaren Speichermenge aus.
2.1.2.2 Minimum-Degree mit Quotientengraphen
Mit Hilfe des Quotientengraphen werden die oben beschriebenen Cliquen nichtexplizit gebildet, d.h. es werden keine neuen Kanten eingefugt sondern die Cli-quen durch Knotenmengen beschrieben.Der Quotientengraph ist definiert als G
b = (Vb, Vb, E b, E b), wobei Vb der Men-ge der Knoten des Graphen entspricht, die noch nicht bis zum b-ten Schrittentfernt wurden. Die Knoten, die bis zum b-ten Schritt entfernt wurden, sindin der Menge Vb enthalten. Die Menge der Kanten im Graph G
b wird ebenfalls

30 2 Modifikationen bei der Berechnung des SPAI
in zwei Teilmengen aufgeteilt:
E b ⊆ Vb × Vb
E b ⊆ Vb × Vb
Der Quotientengraph G0 entspricht dem Eliminationsgraph G0, d.h. V0 und
E0 sind leere Mengen.Die einzelnen Knoten k ∈ Vb des Graphen werden durch zwei weitere Mengencharakterisiert:
Ak = {j | (k, j) ∈ E},T k = {j | (k : j) ∈ E}.
Ak entspricht der Menge der Knoten w ∈ Vb die adjazent mit k in Gb sind.
Analog dazu ist T k definiert. Die Menge Le des Elementes e ∈ Vb enthalt dieKnoten k ∈ Vb, die adjazent zu e sind:
Le = {k | (k, e) ∈ E}.
Der Grad dk des Knoten k lasst sich bestimmen mit
dk =
∣
∣
∣
∣
∣
Lk = (Ak ∪⋃
e∈Tk
Le) \ k
∣
∣
∣
∣
∣
(2.1)
Bei der Elimination des b-ten Pivotelements wird das p ∈ Vb mit minimalemdk entfernt und die Mengen
Vb = Vb−1 \ p
Vb = Vb−1 ∪ p
verringert bzw. erweitert. Die Mengen E b und E b werden durch Ak, Tk fur allek ∈ Vb sowie Le fur alle e ∈ Vb dargestellt.Die adjazenten Knoten k zum Knoten p werden nicht mit neuen Kanten ver-bunden wie im Eliminationsgraphen, sondern durch die Menge
Lp = (Ap ∪⋃
e∈Tp
Le) \ p
reprasentiert. Die existierenden Kanten im Graph Gb zwischen den Knoten
r, s ∈ Lp werden aus der Menge E entfernt, da die Information redundant ist.Betrachtet man den Eliminationsgraphen Gb, entsprechen die Eintrage vonLp genau den Knoten, die eine neue Clique nach dem Entfernen von p in Gb

2.1 Dunnbesetzte Verfahren 31
bilden. Die Kante zwischen r und s im Gb wird durch Entfernen von s aus Ar
und r aus As erreicht:
Ak = (Ak \ Lp) \ p, ∀k ∈ Lp.
Die Menge Ak enthalt alle Eintrage der Spalte k der Ausgangsmatrix A, diebis zum b-ten Schritt nicht verandert wurden.Alle Elemente der Menge V, die adjazent mit dem Knoten p waren, werden mitp vereinigt. Alle Referenzen der verschmolzenen Elemente in den verschiedenenTk werden auf p gesetzt. In allen Mengen Tk mit k ∈ V und k adjazent zu pwird p eingetragen:
Tk = (Tk \ Tp) ∪ p, ∀k ∈ Lp
Zuletzt werden Ap, Tp und alle Le mit e ∈ Tp entfernt.Das folgende Beispiel wurde aus [ADD96, Seiten 889-891] entnommen und dieersten vier Schritte etwas ausfuhrlicher durchgefuhrt.Ausgangspunkt ist die Besetztheitsstruktur einer Matrix A:
Pattern(A) =
∗ ∗ ∗∗ ∗ ∗ ∗
∗ ∗ ∗ ∗∗ ∗ ∗ ∗
∗ ∗ ∗ ∗ ∗∗ ∗ ∗ ∗
∗ ∗ ∗ ∗ ∗ ∗ ∗∗ ∗ ∗ ∗ ∗
∗ ∗ ∗ ∗ ∗ ∗∗ ∗ ∗ ∗
(2.2)
Der Quotientengraph G0 entspricht, wie oben erwahnt, dem Eliminationsgra-
phen G0. Im Folgenden werden nur die Mengen dargestellt, die sich wahrendder Elimination andern. Die durchgezogenen Linien stellen die Kanten von Edar. Die gestrichelten Linien entsprechen den Elementen von E . Die durchge-zogenen Kreise entsprechen den Elementen der Menge V. Die Elemente derMenge V werden durch gestrichelte Kreise dargestellt. Die Abbildung 2.2 zeigtden zum Pattern(A) (2.2), gehorenden Quotientengraphen G
0. In den Men-gen Ai sind die jeweiligen adjazenten Knoten aufgefuhrt. Alle anderen Mengenentsprechen der leeren Menge.

32 2 Modifikationen bei der Berechnung des SPAI
10 8 4 1
9 7 3 6
5
2A1 = {6, 1}A2 = {5, 6, 9}A3 = {5, 6, 7}A4 = {1, 7, 8}A5 = {2, 3, 7, 9}A6 = {1, 2, 3}A7 = {3, 4, 5, 8, 9, 10}A8 = {4, 7, 9, 10}A9 = {2, 5, 7, 8, 10}A10 = {7, 8, 9}
Li = ∅, i ∈ 1 . . . 10Ti = ∅, i ∈ 1 . . . 10
Abbildung 2.2: Ausgangsgraph G0 zur Beispielmatrix (2.2)
G1
A4 = {7, 8} T4 = {1}A6 = {2, 3} T6 = {1}L1 = {4, 6}
10 8 4 1
9 7 3 6
5
2 G2
A5 = {3, 7} T5 = {2}A6 = {3} T6 = {1, 2}A9 = {7, 8, 10} T9 = {2}L2 = {5, 6, 9}
10 8 4 1
9 7 3 6
5
2
G3
A5 = ∅ T5 = {2, 3}A6 = ∅ T6 = {1, 2, 3}A7 = {4, 8, 9, 10} T7 = {3}L3 = {5, 6, 7}
10 8 4 1
9 7 3 6
5
2 G4
A6 = ∅ T6 = {2, 3, 4}A7 = {9, 10} T7 = {3, 4}A8 = {9, 10} T8 = {4}L4 = {6, 7, 8}
10 8 4
9 7 3 6
5
2
Abbildung 2.3: Eliminationsschritte im Quotientengraphen

2.1 Dunnbesetzte Verfahren 33
In den ersten drei Schritten der Abbildung 2.3 wurden nur Knoten aus derMenge V in die Menge V verschoben, sowie redundante Kanten entfernt. Imvierten Schritt werden die Knoten 1 und 4 miteinander verschmolzen.Ein Verbesserung des Minimum-Degree-Verfahren lasst sich durch die Einfuh-rung von Superknoten erreichen. Superknoten entsprechen mehreren Knotenaus V fur die gilt:
Lr ∪ {r} = Ls ∪ {s} r, s ∈ V. (2.3)
Diese Knoten haben den selben Grad, sowie die selben Nachbarn. Sollte einerder Knoten als Pivotelement ausgewahlt werden, konnen die anderen ebenfallsentfernt werden, ohne zusatzlichen Fill-In zu verursachen. Daher konnen alleKnoten, die (2.3) erfullen zu einem Knoten verschmolzen werden. Die Verwen-dung von Supervariablen reduziert den Aufwand der Gradberechnung nach(2.1). Siehe [ADD96, Seiten 891-892].Durch Verwendung der Approximation
di = |Ai| + |Lk \ {i}| +∑
e∈Ei\{k}|Le \ Lk| , k = aktuelles Pivotelement (2.4)
statt der Gradberechnung (2.1) kann das Verfahren weiter beschleunigt werden.Die Laufzeit fur die Approximation belauft sich nach [Dav06, Seite 102] auf
(O(|Ai| + |Ti|), (2.5)
was geringer als die Berechnung von (2.1) ist. Dieses Verfahren wird als Ap-proximate Minimum Degree, kurz AMD bezeichnet.Die Abbildung 2.4 zeigt die Matrix Pores 2 der Harwell-Boeing Collection,zu finden unter http://math.nist.gov/MatrixMarket . Bild 2.4(a) zeigt die Po-res 2 und Bild 2.4(b) stellt die mit Hilfe des AMD-Verfahrens entstandenepermutierte Matrix Pores 2 dar.
Das Bild 2.5(a) entspricht der Matrix L der LU -Zerlegung von der Ma-trix Pores 2 . Bild 2.5(b) zeigt ebenfalls die Matrix L, jedoch wurde die LU -Zerlegung auf die permutierte Pores 2 angewandt. Es ist deutlich erkennbar,dass die Permutation mittels AMD zu einer erheblichen Reduktion des Fill-Ins bei der LU -Zerlegung beitragt. Hier stehen 125094 Nichtnullelemente derMatrix L bei der LU -Zerlegung der Pores 2 24784 Nichtnullelemente im per-mutierten Fall gegenuber.

34 2 Modifikationen bei der Berechnung des SPAI
(a) (b)
0 200 400 600 800 1000 1200
0
200
400
600
800
1000
1200
nz = 96130 200 400 600 800 1000 1200
0
200
400
600
800
1000
1200
nz = 9613
(a) (b)
Abbildung 2.4: Die Matrix Pores 2 Original und permutiert
(a) (b)
(a) (b)
Abbildung 2.5: Matrix L der LU -Zerlegung der Pores 2 (Original / permutiert mit AMD)
2.1.3 Concise Sparse Package
Fur die Verwendung dunnbesetzter Verfahren im SPAI muss die QR-Zerle-gung, das Anwenden von QT auf b sowie die Rucksubstitution an das jeweiligeSpeicherschema angepasst werden.Es gibt mehrere Pakete, die diese Funktionalitat umgesetzt haben, so z.B.
• SPOOLES www.netlib.org/linalg/spooles
• MA49 www.cse.clrc.ac.uk/nag/hsl
• CSparse www.cise.ufl.edu/research/sparse
In der vorliegenden Arbeit wurde die CSparse-Bibliothek fur die dunnbesetztenVerfahren verwendet. Als Speicherformat verwendet es das CSC -Speichersche-ma und realisiert neben den normalen Matrix-Vektor Operationen auch die

2.1 Dunnbesetzte Verfahren 35
Cholesky-, die LU - und die QR-Zerlegung. Um eine Permutation fur minima-len Fill-In zu berechnen, verwendet CSparse das in Abschnitt 2.1.2.2 beschrie-bene AMD-Verfahren. Die fur den Kontext dieser Diplomarbeit in Bezug aufdie QR-Zerlegung wichtigen Funktionen sind cs happly, cs sqr und cs qr .Die Funktion cs happly(cs *V, int i, double beta, double *x) wendet den i-tenHouseholder-Reflektor auf den Vektor x an. Die Householder-Vektoren sindin einer unteren Dreiecksmatrix gespeichert, ahnlich zu der Speicherung inLAPACK. Die einzelnen Householder-Vektoren sind jedoch nicht dahingehendnormiert, dass die erste Komponente Eins ist. Weiterhin wird die untere Drei-ecksmatrix im CSC -Format gespeichert.Mit cs sqr(int order, cs *A, int qr) wird die symbolische QR-Zerlegung durch-gefuhrt. Der Parameter order dient dazu, welche Anordnung der Matrix fur dieZerlegung verwendet werden soll. Es bietet sich die ursprungliche Anordnungan, also unveranderte Anordnung der einzelnen Komponenten. In dem Fallist der Wert des Parameters Null. Die zweite Moglichkeit ist die Verwendungder Anordnung, welche mit dem Approximate-Minimum-Degree Verfahren derMatrix C = AT A berechnet wurde. Der Parameter qr kann mit Null oder Einsbelegt werden. Im vorliegenden Fall ist jedoch nur der Wert Eins interessant.Mit ihm wird die eventuell gefundene Permutation, abhangig von Parameterorder , auf A angewendet, ein Eliminationsbaum aufgebaut sowie eine Zeilen-permutation gefunden, mit der sichergestellt wird, dass in jedem Eliminati-onsschritt die Diagonalelemente ungleich Null sind. Weitere Informationen zurAnalyse der Matrizen, Beispiele sowie der dazugehorige Quellcode finden sichin [Dav06, Seiten 38-41, 71-76].Die letzte Funktion cs qr(cs *A, css *S) fuhrt die numerische Zerlegung derMatrix anhand der Ergebnisse, die in der symbolischen Zerlegung gewonnenwurden, durch. Das Ergebnis der Zerlegung sind zwei separat gespeicherteMatrizen. Eine obere Dreiecksmatrix R sowie eine untere Dreiecksmatrix V ,welche die Householder-Vektoren enthalt. Beide Matrizen sind im CSC -Formatgespeichert. Siehe [Dav06, Seiten 76-78].Um ein Least-Squares-Problem Ax = b mit A ∈ R
m×n, b ∈ Rm und x ∈ R
n zulosen, verwendet CSparse folgenden Algorithmus

36 2 Modifikationen bei der Berechnung des SPAI
Input : Anordnung order, Matrix A, Vektor bOutput : Losung von Ax = bbegin
Analyse der Matrix A durch cs sqrnumerische Zerlegung A mit cs qrggf. Umpermutieren des Vektor bAnwenden der Householder-Matrizen auf b durch Anwendung voncs happlyLosen des Gleichungssystemsggf. Permutation des Losungsvektors
end
Algorithmus 4 : Losen eines Minimierungsproblemes mit CSparse
Fur das Losen des Gleichungssystemes und das Permutieren der rechten Sei-te b und des Losungsvektors x stellt die CSparse-Bibliothek Funktionen zurVerfugung.Die nachfolgenden Graphen zeigen erste numerische Ergebnisse. Hierbei wurdeuntersucht, inwiefern sich der zusatzliche Aufwand auf die Rechenzeit auswirkt.Es wurden Least-Squares-Probleme gelost, bei der schrittweise die Besetzt-heitsstruktur erhoht wurde, um eine erste Abschatzung zu bekommen, bis zuwelchem Fullgrad sich dunnbesetzte Verfahren lohnen. Naturlich hangen dieAussagen immer von den Matrizengrossen und der Matrixstruktur ab. In dervorliegenden Untersuchung wurde eine 100 × 100 Matrix verwendet, bei derbeliebige Diagonalen, Horizontalen und Vertikalen hinzugefugt wurden, um dieBesetztheit der Matrix in Prozentschritten sukzessive zu erhohen. Der dabeiverwendete Vektor b entspricht dem ersten Einheitsvektor.Die Abbildung 2.6 zeigt vier der verwendeten Matrizen.
(Matrix 3%) (Matrix 9%)
0 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 3040 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 901
Matrix 3% Matrix 9%

2.1 Dunnbesetzte Verfahren 37
(a) (b)
0 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 14050 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 2010
Matrix 14% Matrix 20%
Abbildung 2.6: Testmatrizen fur die Falle 3%, 9%, 14% und 20% Besetztheit
3% 5% 7% 9% 11% 13% 15% 17% 19% 21%
0.001
0.002
0.003
CSAMD
CSNOR
LAPACK
u u u
+ + +
q q q
u uu
u
u
u
uu
u uu u u u u u
u u
+ +
+ + + ++
+ + + + + + + + + + +
q q
q q q q q q q q q q q q q q q q
Abbildung 2.7: Laufzeitvergleich CSparse/LAPACK an den erstellten Testmatrizen mitsteigender Besetztheit
Anhand des Graphen in Abbildung 2.7 ist ersichtlich, dass alle drei Verfah-ren, CSparse mit AMD , CSparse mit naturlicher Anordnung und LAPACK,ihre Berechtigung haben. Bei sehr dunnbesetzten Matrizen hat CSparse mitangewendetem AMD klare Vorteile. Diese schwinden jedoch mit zunehmendenBesetztheitsgrad. Mit hoherer Besetztheit lohnt sich das CSparse-Verfahrenmit der Verwendung der ursprunglichen Anordnung der Matrix. Bei weiteremErhohen der Besetztheit der Matrix sollte das LAPACK-Verfahren verwendetwerden. Anhand der relativ konstanten Zeiten der Zerlegung mittels LAPACKkann man erkennen, dass die Besetztheit der Matrix eine wesentlich kleine-re Rolle auf die Ausfuhrungszeiten hat, als bei den dunnbesetzten Verfahren.Der Nachteil am LAPACK-Verfahren ist die explizite Speicherung der Nullen.So kann bei einer entsprechend grossen dunnen Matrix Speicherplatzmangelauftreten, wahrend die dunnbesetzten Verfahren mit dieser Matrix problemlos

38 2 Modifikationen bei der Berechnung des SPAI
umgehen konnen. Die richtige Wahl des Verfahrens ist neben der Besetztheitauch von der Struktur der Matrizen abhangig. Das lasst sich anhand der weite-ren Untersuchungen mit permutierten Matrizen, Bandmatrizen sowie verschie-denen im SPAI verwendeten Matrizen A im Abschnitt 3.1 zeigen. Die nachstenAbschnitte behandeln die Moglichkeit, die QR-Zerlegung von Matrizen wieder-zuverwenden und die Ursprungsmatrizen um Spalten und Zeilen zu erweitern.Statt die erweiterte Matrix unnotigerweise erneut komplett zu zerlegen, kanndie Zerlegung aktualisiert werden.
2.2 QR-Updates
[...]Wenn du etwas so machst, wie dues seit zehn Jahren gemacht hast, dannsind die Chancen recht groß, daß du esfalsch machst.[...]
Charles Kettering, amerikan. Ing.,
1876-1958
In Kapitel 1.2.2 wurde beschrieben, wie mit Hilfe von Patternupdates die Ap-proximation der Inversen verbessert werden kann. Dazu werden die Spaltender Menge J der bisherigen Menge der Spalten J hinzugefugt. Die Matrix des(j + 1)-ten Update A(j+1) wird verbreitert. Zusatzlich wird die Zeilenmenge Ium die Menge I erweitert, wobei
I = {i|A(i, J ) 6= 0 mit i = 1 . . . n und i /∈ I}.
n steht fur die Dimension der Ausgangsmatrix. Durch die Erweiterung derMatrix A(j) entsteht ein neues Minimierungsproblem, welches sich wieder mitHilfe der QR-Zerlegung losen lasst. Anstatt die Matrix A(j+1) erneut komplettzu faktorisieren, wird bei dem Verfahren der QR-Updates die vorherige Zer-legung A(j) = Q(j)R(j) verwendet, um die neue Zerlegung zu bestimmen. DieQR-Updates bieten die Moglichkeit neue Spalten und Zeilen in eine vorhan-dene Zerlegung einzufugen bzw. zu entfernen, ohne die komplette Zerlegungerneut zu berechnen.Im Fall des Patternupdates des SPAI -Vorkonditionierers werden nur Spaltenund Zeilen in die bestehende Matrix eingefugt. Das Verfahren zum Hinzufugenvon Zeilen und Spalten wird im Folgenden erlautert. Informationen zum Ent-fernen von Spalten aus der Matrix A finden sich in [GvL96, Seiten 608-609]sowie in [HL, Seiten 26-32]. Das Entfernen von Zeilen aus A wird in [GvL96,

2.2 QR-Updates 39
Seite 611] und [HL, Seiten 7-12] naher beschrieben.
2.2.1 Einfugen neuer Spalten
Die Matrix A = [a1, a2, . . . an], mit der Zerlegung A = QR soll um den Vektorv ∈ R
m in der Spalte k erweitert werden, wobei gilt 1 ≤ k ≤ n + 1.
Aakt = [A(1 : m, 1 : k − 1), v, A(1 : m, k − 1 : n)]
Um das zu erreichen, mussen Q und R erweitert und angepasst werden. Durchdas Anwenden von
R = QT Aakt
erhalt man R. Zum besseren Verstandnis ergibt sich fur m = 6, n = 4 undk = 3 folgende Matrix R. Die × stehen fur die neuen Eintrage in der Matrix.
R =
∗ ∗ × ∗ ∗0 ∗ × ∗ ∗0 0 × ∗ ∗0 0 × 0 ∗0 0 × 0 00 0 × 0 0
Diese Matrix lasst sich mit Hilfe von Householder-Reflektionen oder Givens-Rotationen in eine obere Dreiecksmatrix transformieren. In diesem Fall ist dieAnwendung von Givens-Rotationen zu bevorzugen, da dadurch der temporareFill-In im Vergleich zur Anwendung von Householder-Matrizen nicht vorhan-den ist. Zur Verdeutlichung der Transformation wird die obige Matrix R mitHilfe der Rotationen G3
5,6, G34,5, G
33,4 auf Zeilenstufenform gebracht, mit Gk
i,j
als Rotation in der k-ten Spalten um die Komponenten i und j. Die Eintragemit Querstrich sollen die Komponenten der jeweiligen Matrix hervorheben, diewahrend der Anwendung der Givens-Rotationen verandert werden.
˜R = G35,6R =
∗ ∗ × ∗ ∗0 ∗ × ∗ ∗0 0 × ∗ ∗0 0 × 0 ∗0 0 × 0 00 0 0 0 0
−→ ˜R = G34,5
˜R =
∗ ∗ × ∗ ∗0 ∗ × ∗ ∗0 0 × ∗ ∗0 0 × 0 ∗0 0 0 0 ∗0 0 0 0 0

40 2 Modifikationen bei der Berechnung des SPAI
Rakt = G33,4
˜R =
∗ ∗ × ∗ ∗0 ∗ × ∗ ∗0 0 × ∗ ∗0 0 0 ∗ ∗0 0 0 0 ∗0 0 0 0 0
Fur die Matrix Qakt ergibt sich
Qakt = Q · (Gkm−1,m)T · . . . · (Gk
n,n+1)T .
In diesem Fall kostet das Verfahren zum Aktualisieren der QR-Zerlegung O(mn)flops, wahrend die komplette Neuberechnung O(m3) kosten wurde.Eine weitere Moglichkeit, k Spalten in eine bestehende Zerlegung einzufugen,ist die k neuen Spaltenvektoren mit Hilfe einer Permutation P an den rech-ten Rand der Matrix zu permutieren. Die neuen Positionen der Vektoren sindn + 1 . . . n + k. Analog zum vorangegangen Verfahren sei R = QT AaktP . Dieresultierende Matrix R muss auf Zeilenstufenform gebracht werden:
Rperm = RP =
∗ ∗ ∗ ∗ ×0 ∗ ∗ ∗ ×0 0 ∗ ∗ ×0 0 0 ∗ ×0 0 0 0 ×0 0 0 0 ×
.
Die permutierte Matrix Rperm kann mit deutlich weniger Givens-Rotationenbzw. Householder-Reflektionen in Zeilenstufenform gebracht werden. Im obi-gen Beispiel reicht eine Operation aus:
Rakt = G55,6Rperm =
∗ ∗ ∗ ∗ ×0 ∗ ∗ ∗ ×0 0 ∗ ∗ ×0 0 0 ∗ ×0 0 0 0 ×0 0 0 0 0
.
Aus Sicht der Implementierung ist dieses Verfahren leichter umzusetzen alsdie Methode, bei der Spalten an der richtigen Postion eingefugt werden. DaMatrizen im CSR- oder LAPACK-Format in Form eines Feldes gespeichertwerden, kann man die neuen Spaltenvektoren einfach an das letzte Elementanhangen, anstatt aufwendig die neuen Spalten in die Speicherstruktur ein-zufugen. Um die richtige Reihenfolge der Komponenten des Losungsvektors

2.2 QR-Updates 41
zu erhalten, muss die Permutation nach dem Losen des neuen Gleichungssys-tems auf den Losungsvektor angewendet werden. Das neue GleichungssystemAaktxakt = b mit der Spaltenpermutation P lasst sich losen mit
AaktPP Txakt = b, y = P T xakt
AaktPy = b.(2.6)
Die Losung von (2.6) wird mit dem QR-Verfahren bestimmt. Die richtige Rei-henfolge der Komponenten des Losungsvektors ergibt sich durch xakt = Py.
2.2.2 Einfugen neuer Zeilen
In die Ausgangsmatrix A mit der Zerlegung A = QR soll ein neuer Zeilenvektorv ∈ R
n eingefugt werden.
Aakt =
A(1 : k − 1, 1 : n)v
A(k + 1 : m, 1 : n)
Fur Aakt lasst sich ein Permutationsmatrix P finden, sodass
PAakt =
(
vA
)
gilt. Um die Faktorisierungen von A anzupassen, wird analog zum Einfugenneuer Spalten QT auf Aakt angewendet. Dafur wird die Matrix Q erweitert zu
Qerw =
(
1 00 Q
)
,
sodass
QTerwPAakt =
(
vR
)
= R.
Die Matrix R ist eine Hessenberg Matrix, die wie in Abschnitt 1.3.2.2 beschrie-ben, durch Givens-Rotationen auf Zeilenstufenform gebracht wird. Die darausentstehende Matrix ist Rakt. Die Matrix Qakt entsteht aus dem Produkt vonQerw mit den verwendeten Givens-Rotationen,
Qakt = Qerw · (G11,2)
T · (G22,3)
T · (Gnn,n+1)
T ,
sodassPAakt = QaktRakt

42 2 Modifikationen bei der Berechnung des SPAI
gilt.Eine weitere Moglichkeit neue Zeilen zu A hinzuzufugen, entsteht bei der Ver-wendung einer weiteren Permutation P2. Statt die neuen Zeilenvektoren an dieerste Zeile der Matrix zu permutieren, kann man diese auch unter die letzteZeile der Matrix anhangen. Die neue Matrix hat dann die folgende Gestalt:
P2Aakt =
(
Av
)
.
Um Rakt und Qakt zu erstellen, wird das obige Verfahren analog angewandtmit anderen Givens-Rotationen und einer anderen Matrix Qerw2, wobei
Qerw2 =
(
Q 00 1
)
.
Das folgende schematische Beispiel zeigt das Zeilenupdate. Ausgangspunkt istdie Matrix A ∈ R
4×3 mit der Faktorisierung A = QR. Der Matrix A solleine Zeile an der zweiten Position hinzugefugt werden. Aakt sei die um einezusatzliche zweite Zeile erweiterte Matrix von A, Qerw2, die wie oben beschrie-ben, erweiterte Matrix Q und P2 die Permutation, die die neue Zeile an dasuntere Ende der Matrix Aakt permutiert. Auf Aakt wird die Permutation P2 undQT
erw2 angewandt. Im Folgenden markieren × die neuen Eintrage. VeranderteEintrage werden mit einem Balken dargestellt.
QTerw2P2Aakt = R =
∗ ∗ ∗0 ∗ ∗0 0 ∗0 0 0× × ×
Durch die Anwendung der Givens-Rotationen G11,5, G2
2,5 und G33,5 wird R in
Zeilenstufenform gebracht.
G11,5R = ˜R =
∗ ∗ ∗0 ∗ ∗0 0 ∗0 0 00 × ×
−→ G22,5
˜R =˜R =
∗ ∗ ∗0 ∗ ∗0 0 ∗0 0 00 0 ×
−→
G33,5
˜R = Rakt =
∗ ∗ ∗0 ∗ ∗0 0 ∗0 0 00 0 0

2.2 QR-Updates 43
Die neue orthogonale Matrix Qakt ergibt sich aus dem Produkt von Qerw2
mit den Givensrotationen (G11,5)
T , (G22,5)
T und (G33,5)
T . Die Permutationen Pder Matrix Aakt haben keinen Einfluss auf die Losung des GleichungssystemsAaktxakt = bakt, da
PQaktRaktx = Pbakt
Raktx = QTaktP
T Pbakt
Raktx = QTaktbakt.
2.2.3 QR-Updates im SPAI
Wie am Anfang des Abschnittes 1.2.2 beschrieben, setzt sich die Matrix des(j + 1)-ten Updates A(j+1) aus der Menge der gewahlten Zeilen I ∪ I undder Menge der gewahlten Spalten J ∪ J zusammen. Beim Aufbau der neuenMatrix A(j+1) sind die Zeilen der Menge I konstruktionsbedingt nur in denSpalten von J verschieden von Null. Um die Zeilen von I in die Zerlegungeinzubauen bietet sich an, die neuen Zeilen unten an die Matrix anzuhangen.Die neuen Spalten werden an den rechten Rand der Matrix, aufgrund derim Abschnitt 2.2.1 beschriebenen Grunde, permutiert. Das neu zu losendeGleichungssystem entspricht
PLA(j+1)PRP TR mj+1
k = PLb(j+1). (2.7)
PL und PR fuhren die gewunschten Permutationen durch. Somit ergibt sich furdie neue Matrix
A(j+1)perm = PLA(j+1)PR =
(
A(j)perm A(I, J )
0 A(I, J )
)
, A = Ausgangsmatrix (2.8)
Die Matrix A(I, J ) lasst sich aufteilen in A1(I1, J ) und A2(I2, J ). Hierbeientspricht I1 den ersten p Komponenten von I, wobei p der Anzahl der Spal-ten von R(j) entspricht. I2 entspricht den restlichen Zeilen von I. Um dievorhandene QR-Zerlegung A
(j)perm = Q(j)R(j) an die neue Matrix anzupassen,
wird Q(j) erweitert zu
Q(j)erw =
(
Q(j) 00 Iz
)
,
wobei z der Anzahl der Elemente in I entspricht. Die erweiterte Matrix (Q(j)erw)T
wird anschliessend auf A angewandt.
(Q(j)erw)T A(j+1)
perm =
R(j) (Q(j)erw1)
T A1(I1, J )
0 (Q(j)erw2)
T A2(I2, J )
0 A(I, J )
= R (2.9)

44 2 Modifikationen bei der Berechnung des SPAI
Die Aufteilung von (Q(j)erw)T in (Q
(j)erw1)
T und (Q(j)erw2)
T entspricht keiner neu-en Zerlegung sondern dient zur Veranschaulichung des Sachverhaltes. DurchDefinition von
B1 := (Q(j)erw1)
T A1(I1, J )
sowie dem Zusammenfassen von
B2 :=
(
(Q(j)erw2)
T A2(I2, J )
A(I, J )
)
ergibt sich
R =
(
R(j) B1
0 B2
)
.
Die folgende Darstellung 2.8 soll den Sachverhalt von (2.8) und (2.9) visuali-sieren. Der Zusatz perm der Matrix A(j) wurde aus Darstellungsgrunden weg-gelassen. Das Bild 2.8 (a) zeigt die Matrix A(j) ∈ R
m×n, die um einen Blockneuer Spalten und Zeilen, der A(I ∪ I,J ) ∈ R
k×p entspricht, erweitert wurde.Die Graphik 2.8 (b) zeigt die Struktur von R.
n p
m
k
A(j) A(I,J )
A(I,J )
A(j+1) = R =∗
......
∗ . . .
. . . ∗
......
∗
0...0
. . .
. . .
0...0
......
∗
...∗ . . .
. . .
. . .
. . .
......
∗
∗∗ ∗
∗...∗
n
k−n
Rj
B1
B2
. . .∗ ∗. . .∗
∗. . .∗
∗ . . ....∗
0
...∗
...∗ . . .
. . ....∗
......
...∗
(a) (b)
Abbildung 2.8: Die Matrix Aj+1 (a), sowie die Matrix (Qj)T Aj+1 (b)
Um R in Zeilenstufenform zu bringen, muss die QR-Zerlegung von B2 mit Hil-fe von Householder-Reflektoren oder Givens-Rotationen durchgefuhrt werden.Das fuhrt auf
R(j+1) =
(
R(j) B1
0 R
)
, (2.10)
wobei
R = QB2.

2.2 QR-Updates 45
Die orthogonale Matrix Q(j+1) fur das (j + 1) Update setzt sich aus den Ma-
trizen Q(j)erw und Q zusammen.
Q(j+1) =
(
Q(j) 00 Iz
) (
Ip 00 Q
)
mit p = Rang(Rk) (2.11)
Mit Hilfe der Matrix R(j+1) und Q(j+1) kann eine erweiterte Losung mk durchLosen von (2.12) bestimmt werden.
R(j+1)m(j+1)k = (Q(j+1))T b(j+1) (2.12)
Der Losungsvektor m(j+1)k wird um die Anzahl der neuen Spalten erweitert.
Der Vektor b(j+1) vergrossert sich um die Anzahl der neuen Zeilen. Nach demLosen von (2.12) muss die richtige Reihenfolge der Komponenten von m
(j+1)k
durch Anwendung der Permutation PR hergestellt werden.Der Vorgang des QR-Updates wahrend des Patternupdates soll das nachfolgen-de schematische Beispiel verdeutlichen. Die Zeilen- und Spaltenpermutationenwerden der Ubersichtlichkeit halber weggelassen. Die vorkommenden Indizesan den Matrix- bzw. Vektorkomponenten geben den jeweiligen Zeilenindex derKomponente an. Die Matrix A ∈ R
5×3 lasst sich zerlegen in A = QR, wobeiQ ∈ R
5×5 und R ∈ R5×3. Der Matrix A sollen zwei neue Spalten mit insgesamt
drei neuen Zeilen hinzugefugt werden, nachfolgend als B bezeichnet. Die ersteSpalte hat zwei zusatzliche Zeilen und die zweite Spalte eine neue Zeile.
A =
∗1 ∗1 ∗1
02 ∗2 02
∗3 03 ∗3
∗4 ∗4 ∗4
05 ∗5 ∗5
B =
∗1 ∗1
02 ∗2
∗3 03
∗4 ∗4
05 ∗5
∗6 06
∗7 ∗7
08 ∗8
Auf die ersten funf Komponenten von B wird QT angewandt.
B =
~1 ~1
~2 ~2
~3 ~3
~4 ~4
~5 ~5
= QT
∗1 ∗1
02 ∗2
∗3 03
∗4 ∗4
05 ∗5
Die ersten drei Zeilen von B entsprechen der Submatrix B1. Aus den Zeilenvier und funf von B und den restlichen Zeilen sechs, sieben und acht aus B

46 2 Modifikationen bei der Berechnung des SPAI
wird die Submatrix B2 gebildet, die anschliessend in B2 = QR zerlegt wird.
B1 =
~1 ~1
~2 ~2
~3 ~3
B2 =
~4 ~4
~5 ~5
∗6 06
∗7 ∗7
08 ∗8
Nach den vorangegangenen Schritten konnen die neuen Matrizen R(1) nach(2.10) und Q(1) nach (2.11) bestimmt werden und mit (2.12) eine entsprechendeerweiterte Losung mk berechnet werden.
2.2.3.1 Implementierung
Die Methode der QR-Updates wurde nach den Erkenntnissen aus Abschnitt 2.1mit Hilfe von LAPACK-Funktionen, unter Verwendung der CSparse-Bibliothekund als Mischform, also mit LAPACK-Funktionen und CSparse-Funktionen,realisiert. Fur die Implementierung der Funktionen existieren zwei C-Struk-turen, die die QR-Zerlegung der Matrix, die bisher verwendeten Permutatio-nen und aktuelle Dimensionen enthalten. Die Struktur QRL speichert die Zer-legung im LAPACK-Format, wahrend die andere Struktur QRC die Zerlegungim CSC-Format speichert. Beide Strukturen speichern neben den jeweiligenFormaten auch zusatzliche Informationen, die zum QR-Update benotigt wer-den. Die Implementierung wird im Folgenden grob beschrieben und dabei auf-tretende Probleme naher erlautert.Um die Zerlegung zu aktualisieren, also ein QR-Update durchzufuhren, beno-tigt man die Werte der neu hinzuzufugenden Spalten der Ausgangsmatrix A.Diese liegen im Feld sub spaltenweise gespeichert vor. Das Feld b enthalt dieWerte der rechten Seite. Weitere notige Informationen sind die Anzahl der neuhinzukommenden Spalten, die Originalposition der neuen Spalten und welcheneuen Zeilen hinzugefugt werden.
Data : QR-Zerlegung *QR, *sub, *b, Anzahl der neuen Spalten,*GewahltenNeuenSpalten, *neueZeilen
Result : die neue aktualisierte Zerlegung ist in QR gespeichert, dieersten n Eintrage von b enthalten die Losung
Nachfolgend wird zunachst das Vorgehen mit Hilfe des LAPACK-Paketes dar-gestellt. Anschliessend wird das Verfahren der QR-Updates mittels CSparsebeschrieben. Das letzte implementierte Verfahren ist ein Hybrid-Verfahren,welches LAPACK und CSparse Funktionen verwendet, um die Zerlegung zu

2.2 QR-Updates 47
aktualisieren. Den Abschluss des Abschnitt bildet ein erster Laufzeitvergleichder drei Methoden.
QR-Updates mit LAPACKDer erste Schritt ist der Aufbau der Submatrix bzw. die Auswahl der Werte derin A(k) gewahlten Zeilen aus sub sowie die Werte der neuen Zeilen aus sub, dasssind die Zeilenindizes in sub die noch nicht in der alten Auswahl vorhandensind und deren Werte ungleich Null sind. Bei Benutzung von LAPACK werdendie Werte von sub direkt hinter das letzte Element der vorherigen Zerlegungin permutierter Reihenfolge angefugt, genugend Platz vorausgesetzt.
for i = 0....#neueSpalten do
for j = 0....Azeilen do
B[index++] = sub[i · Azeilen + Zeilenpermutation[j]] ;endfor j = 0....#neueZeilen do
B[index++] = sub[i · Azeilen + neueZeilen[j]] ;end
end
Algorithmus 5 : Extrahieren der neuen Komponenten
B entspricht hierbei einem Zeiger auf das erste Elemente nach der letzten Kom-ponenten der vorherigen Zerlegung. Die Felder Zeilenpermutation und neue-Zeilen enthalten die bisher gewahlten Zeilen- bzw. die hinzukommenden neuenZeilenindizes. Schematisch kann das wie folgt dargestellt werden:Die Zerlegung einer Matrix A(k) ∈ R
m×n soll um zwei Spaltenvektoren w undd erweitert werden. Der Vektor w hat k zusatzliche Zeilen und Vektor d eineweitere neue Zeile:

48 2 Modifikationen bei der Berechnung des SPAI
A(k+1) =
R1,1 R1,2 · · · R1,n wp,1 dp,1
H2,1 R2,2...
......
......
. . . Rn,n wp,n dp,n
Hn+1,1 Hn,2 . . . H2,n wp,n+1 dp,n+1...
......
......
Hm,1 Hm−1,2 . . . Hm−n,n wp,m dp,m
wneu,1 dneu,1...
...wneu,k dneu,k
0 dneu,k+1
(2.13)
Die Indizes p und neu stehen fur die Permutation der Zeilen bzw. fur die neu-en Zeilen. Intern wird die Erweiterung als folgendes Feld realisiert. Unter demFeld sind die jeweiligen Indexgrenzen der Vektoren aufgefuhrt:
R1,1 . . .Hm,1 R1,2 . . .Hm−1,2 · · · wp,1 . . . wneu,k 0 dp,1 . . . dneu,k+1
1 m 2m 4m + k 5m + 2k + 1
In (2.13) sieht man, dass durch das Einfugen der neuen Spalten und Zeilendie Speicherstruktur, mit der LAPACK arbeitet, zerstort wird. Die LAPACK-Funktionen xormqr fur QT b und xtrts zum Losen von Rx = b, wobei x ∈ {d, s}ist, konnen nicht mehr angewandt werden, da sie mit vollen Matrizen arbeiten.Um diese Funktionen trotzdem verwenden zu konnen, kann die Speicherstruk-tur durch Einfugen von Nullen aufgefullt werden. Dieses Auffullen ist sehraufwendig, da die Vektoren im Hauptspeicher wahrend des Updates an anderePositionen kopiert werden mussen. Die zu (2.13) aufgefullte Struktur wurdewie folgt aussehen:
Ak+1 =
R1,1 R1,2 · · · R1,n wp,1 dp,1
H2,1 R2,2...
......
......
. . . Rn,n wp,n dp,n
Hn+1,1 Hn,2 . . . H2,n wp,n+1 dp,n+1...
......
......
Hm,1 Hm−1,2 . . . Hm−n,n wp,m dp,m
0 0 0 0 wneu,1 dneu,1...
......
......
...0 0 0 0 wneu,k dneu,k
0 0 0 0 0 dneu,k+1
(2.14)

2.2 QR-Updates 49
Die interne Darstellung entsprache dann:
R1,1 . . .Hm,1 0 . . . 0 R1,2 . . .Hm−1,2 0 . . . 0 . . . wp,1 . . . wneu,k 0
1 m 2m + k 4(m + k)
Statt die Matrix mit Nullen aufzufullen, lasst sich die Unterfunktion xlarf vonxormqr auch auf die Struktur (2.13) anwenden. Die Funktion xlarf wendeteinen Householder-Reflektor H auf eine gegebene Matrix B ∈ R
m×n von linkerSeite oder von rechter Seite an. Dieser Householder-Reflektor H entspricht derForm
H = I − τ · v · vT . (2.15)
Die Matrix I entspricht der Einheitsmatrix mit der Dimension m, τ ∈ R undder Vektor v ∈ R
m×1. Der Vorteil der Funktion xlarf ist, dass die Householder-Vektoren an beliebigen Adressen im Speicher liegen konnen. Man ubergibt alsParameter die jeweilige Anfangsadresse des Householder-Vektors vi, wobei derIndex i ∈ 1 . . .#Spalten von A(k), den Wert τ , die Anfangsadresse der MatrixB, wieviele Zeilen und Spalten von C benutzt werden, ein Feld fur temporareBerechnungen und weitere Steuerparameter. Die Funktion xlarf berechnet dieAnwendung von (2.15) auf B. Die Dokumentation des Befehls xlarf findet sichauf http://www.netlib.org/lapack. Die neuen Spalten und die zusatzlichen neu-en Zeilen werden im weiteren als B bezeichnet.Nach der Erweiterung der Matrix A muss, wie in Abschnitt 2.2.3 beschrieben,QT auf die neuen Spaltenvektoren angewendet werden. Dies erfolgt mit Hilfeder oben beschriebenen xlaft Funktion. Da sich die Zeilendimension der Ma-trix pro Update andern kann, wird das Anwenden der einzelnen Householder-Reflektoren blockweise nach Updatesschritte eingeteilt.
dims = 0;Zeilen = 0;for i = 0 . . .#Update do
Zeilen = Zeilen + # Zeilen im i-ten Update;for j = dims . . .dims + #neue Spalten pro i-tem Update do
Anwenden von xlarf;Andern der Startadresse vom v um Zeilen + 1 ;Andern der Startadresse vom B um 1;
enddims = dims + #neue Spalten pro i-tem Update
end
Algorithmus 6 : Anwenden der Householder-Matrizen
Nach der Anwendung von QT auf B muss analog nach (2.10) die Zerlegung

50 2 Modifikationen bei der Berechnung des SPAI
von B2 durchgefuhrt werden. Hier kann weiterhin auf die LAPACK-Funktionxgeqrf zuruckgegriffen werden. Bei der Zerlegung muss beachtet werden, dassdie richtige Anfangsadresse S von B2 ubergeben wird und wieviele Elementej jeweils ubersprungen werden mussen, um den nachsten Vektor von B2 zuerreichen. Sei B ∈ R
m×n. Die Submatrix B1 umfasst von den n Spalten dieersten k Zeilen, wobei k die Anzahl der Spalten von A(k) ist. Die SubmatrixB2 entspricht restlichen den m−k Zeilen von B. Die folgende Graphik soll denSachverhalt verdeutlichen:
k n − k
V ektor B11 V ektor B21 V ektor B12 . . . V ektor B1n V ektor B2n
S j
Die Bezeichner B1i und B2i entsprechen jeweils dem i-ten Vektor von B1 bzw.B2. Vom Beginn des ersten Vektors B21 der Submatrix zum nachsten Vektormussen m Elemente ubersprungen werden.Der nachste Schritt ist die Aktualisierung der Speicherstruktur QRL. Es wirddie neue Spalten- und Zeilendimension von A(k+1) gespeichert, welche Zeilenund Spalten hinzugekommen sind. Der letzte Schritt des QR-Update ist dieBerechnung der neuen Losung von
A(k+1)x = b(k+1) mit A(k+1) = Q(k+1)R(k+1)
Dazu wird, analog zur Anwendung von QT auf B mit Hilfe der LAPACK-Funktion xlarf, (Q(k+1))T auf bk+1 angewandt. Das Losen des neu entstandenenGleichungssystemes kann aufgrund der nicht mit Nullen aufgefullten Struk-tur nicht mit der LAPACK-Funktion xtrtrs gelost werden. Daher wurde dieRucksubstition mit
xnneu=
bnneu
anneunneu
xi =bi −
∑nneu
j=i+1 aijxj
aii
, mit i = nneu − 1, nneu − 2, . . . , 1
durchgefuhrt. Das Feld Spaltenindex enthalt die Anfangsindizes der einzelnenSpalten von Ak+1.

2.2 QR-Updates 51
Zwischenergebnis = 0;for i =nneu − 1 . . . 0 do
for j =i + 1 . . . nneu − 1 do
Zwischenergebnis + = A(k+1)[spaltenindex[j] + i] · b(k+1)[j];end
b(k+1)[i] = (b(k+1)[i] - Zwischenergebnis) /A(k+1)[spaltenindex[i] + i];Zwischenergebnis = 0;
end
Algorithmus 7 : Rucksubstitution im LAPACK-Speicherschema
Den Abschluss des QR-Updates bildet die Permutation des Ergebnisvektors,die die richtige Reihenfolge der xi herstellt.
QR-Updates mit CSparseUm QR-Updates mit CSparse durchzufuhren, vollfuhrt man dieselben Schrit-te wie mit den LAPACK-Funktionen. Die Probleme ergeben sich hier wiederdurch die Speicherung der Zerlegung. Wie in Abschnitt 2.1.3 beschrieben wer-den Q und R getrennt im CSC-Format gespeichert. Daher mussen beim QR-Update beide Matrizen angepasst werden. Ausgangspunkt ist wiederum dieAuswahl der bisher im aktuellen A(k) gewahlten Zeilen aus dem sub-Feld unddie damit verbundene Erstellung der Submatrix B. Aufgrund der Aufsplittungder Matrizen Q und R kann die Auswahl nicht einfach an die vorherige Zerle-gung angehangt werden. Die Auswahl wird in einem Puffer B gespeichert.Nach der Auswahl der Werte und dem damit verbundenen Erstellen von Berfolgt das Anwenden (Q(k))T auf B. Hierbei kann auf die in Abschnitt 2.1.3beschriebene Funktion cs happly zuruckgegriffen werden, welche die Funktio-nalitat der xlarf LAPACK-Funktion aufweist. Um die Zerlegung von B2 mitder cs qr-Funktion durchzufuhren, muss B2 in CSC-Format vorliegen, d.h B2
besteht aus den drei Feldern x, i und p.

52 2 Modifikationen bei der Berechnung des SPAI
ahat spalten = # Spalten von A(k);ahat zeilen = # Zeilen von A(k);zaehler = 0;zaehler2 = 1;for k =0 . . .neue Spalten − 1 do
zaehler3 = 0 ;for j = ahat spalten . . . ahat zeilen − 1 do
if B[j] 6= 0 thenB2 → x[zaehler] = B[j];B2 → i[zaehler] = zaehler3;zaehler++;
endzaehler3++;
endfor j = 0 . . .#neue Zeilen − 1 do
if sub[k · ahat zeilen + neueZeilen[j]] 6= 0 thenB2 → x[zaehler] = sub[k · ahat zeilen + neueZeilen[j];B2 → i[zaehler] = zaehler3;zaehler++;
endzaehler3++;
endB2 → p[zaehler2] = zaehler ;zaehler2++;B2 += ahat zeilen;
end
Algorithmus 8 : Aufbau des B2 Blockes im CSC-Format
Im Algorithmus 8 wird B2 spaltenweise gefullt. Das Feld sub enthalt, analog zuden vorherigen Algorithmen, die Werte der neuen Spalten und Zeilen. Die ein-zelnen Zahlervariablen dienen zur Positionsbestimmung in den verschiedenenFeldern der CSR-Struktur. Nach der Erstellung von B2 erfolgt die Zerlegungvon B2 durch Analyse mit der Funktion cs sqr und anschliessend die numeri-sche Zerlegung mittels cs qr. Nach der Zerlegung von B2 wird die ursprunglicheZerlegung, welche in der Speicherstruktur QRC hinterlegt ist, aktualisiert.Hierbei konnen an die Felder Q → x und R → x der ursprunglichen Zerlegungdie Werte der neuen Zerlegung angehangen werden. Einzig die Index-Felder iund p mussen noch angepasst werden. Weiterhin werden auch die sonstigenWerte der QRC, analog zum LAPACK-Verfahren aktualisiert. Nachdem das

2.2 QR-Updates 53
QR-Update durchgefuhrt wurde, kann die neue Losung von
A(k+1)x = b(k+1) mit A(k+1) = Q(k+1)R(k+1)
berechnet werden.
QR-Updates als Hybrid-Verfahren aus LAPACK- und CSparse-Funk-tionenDie letzte Version der QR-Updates ist eine Version, die aus einer Vereinigungbeider Welten, CSparse und LAPACK, besteht. Die Ausgangszerlegung vonA(k) wird mit CSparse durchgefuhrt, dadurch liegt die Zerlegung im CSC-Format gespeichert vor. Die Werte der bisher gewahlten Zeilen, sowie die neu-en Zeilen werden analog zum CSparse-Methode, aus sub extrahiert und an dierichtige Stelle in die Submatrix B eingetragen. Danach wird QT mit Hilfe derCSparse-Funktion cs happly berechnet. Die entstehende Submatrix B sollteein relativ dichtes Besetztheitsschema aufweisen. Die Besetztheitstruktur ei-nes Vektor x der auf die Householder-Matrix H angewandt wird, bleibt nurdann erhalten, wenn folgendes gilt:Sei Px das Pattern des Vektors x und Pv das Pattern vom Householder-Vektorv. Fur das neue Pattern Px gilt:
Px = Px ,wenn gilt Px ∩ Pv = ∅Px = Px ∪ Pv ,wenn gilt Px ∩ Pv 6= ∅ (2.16)
Das kann man anhand der Konstruktion der Householder-Matrix leicht nach-vollziehen. Die Householder-Matrix H wird konstruiert mit
H = I − τ · v · vT . (2.17)
Die entstehende Matrix aus v · vT hat genau an den Spalten dasselbe Pat-tern wie v in den die Komponenten von vT ungleich Null sind. Alle anderenSpalten sind Nullvektoren. Die Multiplikation mit einem Skalar τ andert dieBesetztheit von v · vT nicht. Durch die Subtraktion von I − τ · v · vT werdendie bisherigen Nullspalten durch den jeweiligen Einheitsvektor ek ersetzt, wenndie k-te Spalte eine Nullspalte war.
v =
∗0∗∗0
v · vT =
∗ 0 ∗ ∗ 00 0 0 0 0∗ 0 ∗ ∗ 0∗ 0 ∗ ∗ 00 0 0 0 0
H =
∗ 0 ∗ ∗ 00 1 0 0 0∗ 0 ∗ ∗ 0∗ 0 ∗ ∗ 00 0 0 0 1

54 2 Modifikationen bei der Berechnung des SPAI
Bei der Matrix-Vektor Multiplikation zwischen der Householder-Matrix H unddem Vektor x, wobei die Schnittmenge der Pattern von x und von v gleichNull ist, konnen Werte ungleich Null nur in den Einheitsvektoren der MatrixH entstehen und dort auch nur in den Komponenten, die ungleich Null sind.
x =
0∗00∗
Hx =
∗ 0 ∗ ∗ 00 1 0 0 0∗ 0 ∗ ∗ 0∗ 0 ∗ ∗ 00 0 0 0 1
·
0∗00∗
=
0∗00∗
Sollte die Schnittmenge beider Pattern ungleich Null sein, dann werden imErgebnisvektor in den Komponenten, die im Pattern von v liegen Eintrageungleich Null erzeugt und zusatzlich Eintrage fur die Komponente vom Patternvon x.
x =
∗∗000
Hx =
∗ 0 ∗ ∗ 00 1 0 0 0∗ 0 ∗ ∗ 0∗ 0 ∗ ∗ 00 0 0 0 1
·
∗∗000
=
∗∗∗∗0
Diesem Umstand zur Folge kann es Vorteile bringen, die Zerlegung von B2 mitHilfe der LAPACK-Funktion xgeqrf durchzufuhren. Insgesamt spart man sichhierbei die Erstellung von B2 im CSC-Format. Nach der Zerlegung von B2
muss A(k) zu A(k+1) aktualisiert werden. Danach kann wie im CSparse-Updatebeschrieben weiter vorgegangen werden.
Laufzeittests mit der Matrix Pores 2
Im folgenden Test wurde der SPAI mit der Einheitsmatrix I als Pattern aufdie Matrix Pores 2 angewandt. Es wurden vier Patternupdates durchgefuhrt,wobei jeweils sieben Spalten zu den jeweiligen Ai hinzugenommen wurden. DieGraphik 2.9 zeigt Matrizen A1k
, die wahrend des Patternupdates entstehen.
Die Darstellung 2.10 zeigt die drei implementierten Methoden verglichen mitder Referenzmethode. Die Referenzmethode lost das Minimierungsproblem mitder wahrend des k-ten Updateschrittes entstandenen vollstandig gespeichertenAik . Alle anderen Methoden verwenden die beschriebenen QR-Update Metho-den. Die Hybrid-Methode wird im weiteren Verlauf als lacs, die QR-Updatedie mit Hilfe von LAPACK arbeitet als laup und die CSparse-Methode als cscs

2.2 QR-Updates 55
0 1 2
0
1
2
3
4
5
6
7
8
9
nz = 80 5 10 15
0
5
10
15
20
25
30
35
nz = 1360 10 20 30
0
10
20
30
40
50
60
nz = 248
A10 A11 A12
Abbildung 2.9: Verschiedene A1ider Pores 2
bezeichnet. Die Referenzmethode wird ref abgekurzt. Die Abbildung 2.10 (a)zeigt die Dauer der einzelnen Updateschritte von A1. Die Graphik 2.10 (b)stellt den Vergleich der Gesamtzeiten der einzelnen Verfahren dar.Anhand der Abbildungen 2.10 kann man erkennen, dass sich die Verfahrenmit QR-Updates im Vergleich zu dem Referenzverfahren mit steigender An-zahl der Updateschritte immer lohnen. Bei nur einem Updateschritt ist dasReferenzverfahren noch schneller, da sich der Verwaltungsaufwand der QR-Updates Verfahren verhaltnismassig stark auf die eigentliche Berechnungszeitauswirkt. Dieser Vorsprung des Referenzverfahren egalisiert sich jedoch schonim nachsten Update. Ab diesem Punkt lohnt sich der Einsatz der Verfahrenlacs, laup und cscs. Weitere Tests, die diese Vermutungen belegen, finden sichim Abschnitt 3.2.Im anschliessenden Abschnitt wird ein weiteres Verfahren untersucht, um dasLosen von Least-Squares-Problem zu beschleunigen. Die Berechnungen werdenhier im float Datentyp durchgefuhrt und dann mit Hilfe einer iterativen Nach-verfeinerung verbessert. Das sollte zumindest in der Theorie zu einem weiterenSpeedup beitragen konnen.
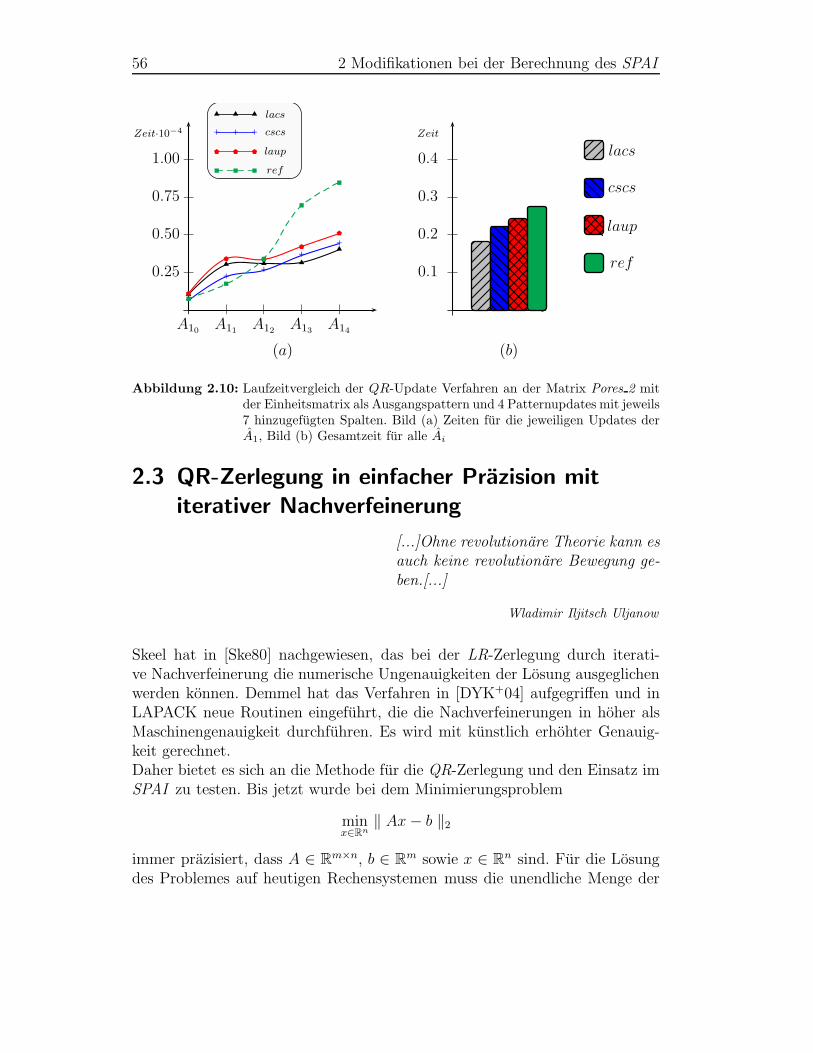
56 2 Modifikationen bei der Berechnung des SPAI
A10 A11 A12 A13 A14
0.25
0.50
0.75
1.00
lacs
cscs
laup
ref
u u u
+ + +
q q q
r r r
Zeit·10−4
u
u u u
u
+
++
++
q
q q
q
q
r
r
r
r
r
0.2
0.1
0.3
0.4
Zeit
lacs
cscs
laup
ref
(a) (b)
Abbildung 2.10: Laufzeitvergleich der QR-Update Verfahren an der Matrix Pores 2 mitder Einheitsmatrix als Ausgangspattern und 4 Patternupdates mit jeweils7 hinzugefugten Spalten. Bild (a) Zeiten fur die jeweiligen Updates derA1, Bild (b) Gesamtzeit fur alle Ai
2.3 QR-Zerlegung in einfacher Prazision mit
iterativer Nachverfeinerung
[...]Ohne revolutionare Theorie kann esauch keine revolutionare Bewegung ge-ben.[...]
Wladimir Iljitsch Uljanow
Skeel hat in [Ske80] nachgewiesen, das bei der LR-Zerlegung durch iterati-ve Nachverfeinerung die numerische Ungenauigkeiten der Losung ausgeglichenwerden konnen. Demmel hat das Verfahren in [DYK+04] aufgegriffen und inLAPACK neue Routinen eingefuhrt, die die Nachverfeinerungen in hoher alsMaschinengenauigkeit durchfuhren. Es wird mit kunstlich erhohter Genauig-keit gerechnet.Daher bietet es sich an die Methode fur die QR-Zerlegung und den Einsatz imSPAI zu testen. Bis jetzt wurde bei dem Minimierungsproblem
minx∈Rn
‖ Ax − b ‖2
immer prazisiert, dass A ∈ Rm×n, b ∈ R
m sowie x ∈ Rn sind. Fur die Losung
des Problemes auf heutigen Rechensystemen muss die unendliche Menge der

2.3 QR-Zerlegung in einfacher Prazision mit iterativer Nachverfeinerung 57
reellen Zahlen durch die endliche Menge der Zahlen, die im Rechensystem dar-stellbar sind, approximiert werden. Die Darstellung reeller Zahlen in Rechnernerfolgt mit Gleitkommazahlen. Den Aufbau einer Gleitkommazahl kann manschematisch wie folgt darstellen:
v Exponent Mantisse
v entspricht hierbei dem Vorzeichen. Der Wert einer Gleitkommazahl ergibtsich zu
(−1)V orzeichen · Mantisse · basisExponent.
Die Gleitkommazahlen lassen in Programmiersprachen meisten in Gleitkom-mazahlen mit einfacher Prazision, float genannt, und Gleitkommazahlen mitdoppelter Genauigkeit, double genannt, unterteilen. In der Programmierspra-che C gibt es zusatzlich den Datentyp long double.Der Datentyp float hat fur die Zahldarstellung 32 Bit zur Verfugung, wobei 1Bit auf das Vorzeichen entfallt, 8 Bit auf die Darstellung des Exponenten und23 Bit fur die Matisse zur Verfugung stehen. Mit dem Datentyp float kann maneine 6-stellige Genauigkeit erreichen. Fur wissenschaftliche Anwendungen istdas jedoch zu ungenau. In diesen Bereichen verwendet man den Datentyp dou-ble mit dem ein 15-stellige Genauigkeit erreicht werden kann. Hierbei belegtder Exponent 11 Bit und die Mantisse 52 Bits. Das Vorzeichenbit bleibt un-verandert. Aufgrund der geringen Genauigkeit des float Datentyp wurden dieBerechungen bisher in double durchgefuhrt, d.h die Eingangsdaten, die MatrixA und der Vektor b, sowie der Ergebnisvektor x liegen in doppelter Prazisionvor.Die Idee der QR-Zerlegung in einfacher Prazision mit iterativer Nachverfei-nerung ist die geringere Grosse des Datentyps float auszunutzen, um zu ei-ner schnelleren Losung zu kommen, mit dem Nachteil der Ungenauigkeit derLosung. Die ungenaue Losung soll mit Hilfe iterativer Verbesserung ausgegli-chen werden. Der Geschwindigkeitsvorteil des float Datentyps ist durch dieHardware begrundet, auf einer X-86-Architektur ist die Grosse des Datenbus32 Bit, d.h. in einem Schritt kann ein float vom Arbeitspeicher zum Rechenwerkubertragen werden, wahrend fur double-Werte zwei Schritte benotigt werden.Um diesen Vorteil auszunutzen, mussen die Eingangsdaten in den Datentypfloat konvertiert werden. Hierbei geht naturlich die Genauigkeit der Ausgangs-daten verloren. Diese Typumwandlung wird auch als cast bezeichnet.
A = castfloat(A)
b = castfloat(b),

58 2 Modifikationen bei der Berechnung des SPAI
mit A und b in einfacher Genauigkeit. Dann lost man
minx∈Rn
‖ Ax − b ‖2 ,
wobei die Losung x in einfacher Genauigkeit vorliegt. Fur A gilt weiterhinA = QR. Der folgende Schritt zur Erhohung der Genauigkeit der Losung,benotigt die Matrizen Q, R sowie den Vektor x.
Q = castdouble(Q)
R = castdouble(R)
b = castdouble(b).
Q, R und x entsprechen den in den Datentyp double zuruckkonvertierten Wer-ten von Q, R und x. Die Genauigkeit der Losung von x laßt sich durch iterativesAnwenden der folgenden Schritte
r = b − Axk−1
4x = R−1QT r
xk = xk−1 + 4x
(2.18)
verbessern, wobei der Startvektor x0 = x ist. Der erste Schritt ist die Bestim-mung des Residuum r der aktuellen Losung xk. Der folgende Schritt bestimmtdie Korrektur 4x, durch die die aktuelle Losung xk−1 verbessert wird. Dieneue verbesserte Losung lautet xk. Die iterativen Verbesserungen werden so-lange durchgefuhrt bis die Fehlernorm geringer als ein festzulegender Fehlerist.Die Iterationszahlen der folgenden Tabelle 2.1 wurden mit dem BICGStab-Verfahren und den drei Testmatrizen Pores 2, Sherman2 und Orsirr 2 in Mat-lab, siehe www.mathworks.com berechnet. Es wurde jeweils ein Gleichungssys-tem mit einer zufalligen rechten Seite gelost. Das relative Residuum wurde bei1.0e− 8 festgelegt. Die Testmatrizen wurden mit dem SPAI vorkonditioniert.Es wurden zwei Berechnungen gemacht. Bei der Vorkonditionierung der ers-ten Berechnung wurde der Datentyp double verwendet. Im zweiten Lauf wurdedie Vorkonditionierung in float mit vier Nachverfeinerungsschritten berechnet.Die Tabelle 2.1 zeigt, dass die auf float basierende Variante des SPAI ahnlicheIterationszahlen liefert wie die double Version. Die in Abschnitt 3.3 beobach-teten numerischen Ungenauigkeiten entsprechen den Beobachtungen Demmelsin [DYLE07], in dem das Nachverfeinerungsschema fur Least-Squares-Problemdiskutiert wird. Fur einen endgultigen Einsatz im SPAI sollte daher eine ent-sprechende Erweiterung von LAPACK abgewartet werden. Im anschliessenden

2.3 QR-Zerlegung in einfacher Prazision mit iterativer Nachverfeinerung 59
Tabelle 2.1: MATLAB-BICGStab-Vergleichstest an verschiedenen Testmatrizen mitSPAI -Vorkonditionierung in float mit vier Nachverfeinerungsschritten und indouble
Matrix A Pattern Iterationen double Iterationen floatSherman2 A2 24 22Pores 2 A3 55 60Orsirr 2 A 131 134
Kapitel 3 im Abschnitt 3 finden sich Tests und Ergebnisse zur QR-Zerlegungin einfacher Prazision mit iterativer Nachverfeinerung.

60 2 Modifikationen bei der Berechnung des SPAI

61
3 Numerische Ergebnisse
In den folgenden Abschnitten werden die numerischen Ergebnisse vorgestellt.Die Ausstattung des Testrechners umfasst
• Prozessor: Intel Pentium D
• Taktrate: 2800 MHz
• RAM: 3096 MB
• Compiler: GCC 4.1.1
• LAPACK: LAPACK 3.1.1
• CSparse: CSparse 2.0.6
• OS: Linux.
3.1 LAPACK versus CSparse
In diesem Kapitel werden Least-Squares-Probleme mit verschiedenen Besetzt-heitsstrukturen getestet, um herauszufinden, wann sich der Einsatz von dunn-besetzten Verfahren lohnt.
3.1.1 Bandmatrizen
Der erste Test wird mit Bandmatrizen durchgefuhrt. Die Werte der Matri-zen wurden zufallig gewahlt. Ausgangspunkt der Testreihe ist eine 100 × 100Matrix mit besetzter Hauptdiagonale sowie den ersten beiden Nebendiagona-len. Die Matrix ist zu 3% gefullt. Dieser Ausgangsmatrix werden sukzessiveDiagonalen zugefuhrt, sodass sich die Bandbreite der Matrix erhoht. Nach je-der 3%-igen Erhohung wird ein Least-Squares-Problem mit der Matrix gelost,mit LAPACK, mit CSparse unter Verwendung der AMD-Permutation und mitCSparse und der Verwendung der naturlichen Anordnung. Der Vektor b desLeast-Squares-Problems ist der erste Einheitsvektor.
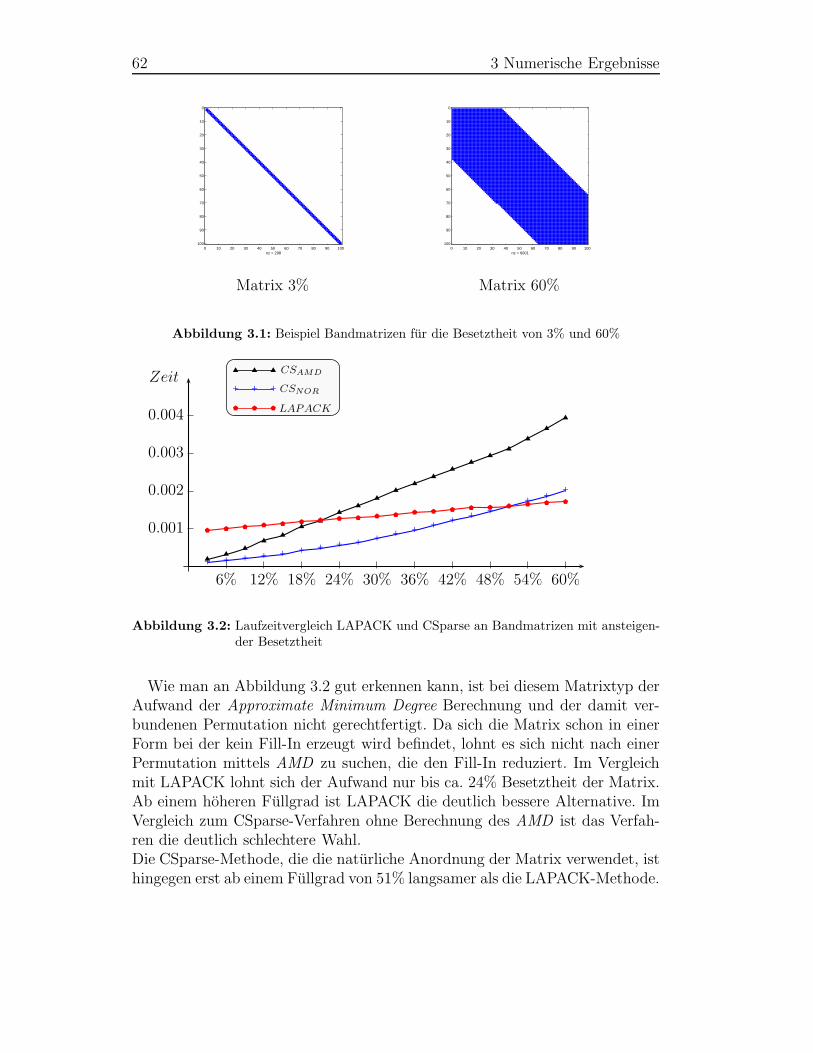
62 3 Numerische Ergebnisse
(a) (b)
0 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 2980 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 6001
Matrix 3% Matrix 60%
Abbildung 3.1: Beispiel Bandmatrizen fur die Besetztheit von 3% und 60%
6% 12% 18% 24% 30% 36% 42% 48% 54% 60%
0.001
0.002
0.003
0.004
ZeitCSAMD
CSNOR
LAPACK
u u u
+ + +
q q q
+ + + + + + + + + + + + + + + + + + + +
uu
uu
uu
uu
uu
uu
uu
uu
u
u
u
u
q q q q q q q q q q q q q q q q q q q q
Abbildung 3.2: Laufzeitvergleich LAPACK und CSparse an Bandmatrizen mit ansteigen-der Besetztheit
Wie man an Abbildung 3.2 gut erkennen kann, ist bei diesem Matrixtyp derAufwand der Approximate Minimum Degree Berechnung und der damit ver-bundenen Permutation nicht gerechtfertigt. Da sich die Matrix schon in einerForm bei der kein Fill-In erzeugt wird befindet, lohnt es sich nicht nach einerPermutation mittels AMD zu suchen, die den Fill-In reduziert. Im Vergleichmit LAPACK lohnt sich der Aufwand nur bis ca. 24% Besetztheit der Matrix.Ab einem hoheren Fullgrad ist LAPACK die deutlich bessere Alternative. ImVergleich zum CSparse-Verfahren ohne Berechnung des AMD ist das Verfah-ren die deutlich schlechtere Wahl.Die CSparse-Methode, die die naturliche Anordnung der Matrix verwendet, isthingegen erst ab einem Fullgrad von 51% langsamer als die LAPACK-Methode.

3.1 LAPACK versus CSparse 63
Bei solchen Matrizen stellt diese Methode im Vergleich zur LAPACK-Methodeeine sehr gute Alternative dar, besonders bei einem sehr dunnen Pattern. Furreine Bandmatrizen, wie die vorliegenden, gibt es effizientere Speicherschemataund speziell an die Bandstruktur angepasste Verfahren.
3.1.2 Permutierte Bandmatrizen
Bei diesem Testlauf wurden die Bandmatrizen des vorherigen Abschnittes 3.1.1durch die Anwendung zwei verschiedener zufalliger Permutationen geandert.
(a) (b)
0 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 2980 10 20 30 40 50 60 70 80 90 100
0
10
20
30
40
50
60
70
80
90
100
nz = 6001
Matrix 3% Matrix 60%
Abbildung 3.3: Permutierte Bandmatrizen mit einer Besetztheit von 3% und 60%
6% 12% 18% 24% 30% 36% 42% 48% 54% 60%
0.001
0.002
0.003
0.004
ZeitCSAMD
CSNOR
LAPACK
u u u
+ + +
q q q
uu
uu
uu
uu
uu
u
u
u
uu
uu
u
u u
++
++
+ + + ++ + + + + + + + + + + +
qq q q q q q q q q q q q q q q q q q q
Abbildung 3.4: Laufzeitvergleich LAPACK und CSparse an permutierten Bandmatrizen
Wie zu erwarten war, weist die LAPACK-Methode erneut eine relativ kon-stante Laufzeit auf. Bei diesen Matrizen zeigt sich im Vergleich zum Abschnitt

64 3 Numerische Ergebnisse
3.1.1 der Vorteil des AMD . Die permutierte Matrix wird durch die Anwendungdes AMD in eine Matrix transformiert, die einen wesentlich geringeren Fill-Inbesitzt. Die CSAMD-Methode erweist sich dadurch fur dunnbesetzte Matrizenbis zu einer Besetztheit von 24% als die Methode mit der geringsten Laufzeit,der drei zur Wahl stehenden Verfahren. Mit weiter ansteigender Besetztheit istdie LAPACK-Methode die Methode mit der geringsten Laufzeit. Sollte mannur dunnbesetzte Verfahren auswahlen, dann ist die CSAMD-Methode bis zueiner Besetztheit von ca. 40% die zu wahlende Methode. Ab dieser Besetztheitlohnt sich der Aufwand des AMD im Vergleich zum CSnor nicht mehr.
3.1.3 A - Testreihen
Bei diesen Tests werden Least-Squares-Probleme des SPAI mit verschiedenenReihen von Ai, i ∈ (1, . . . , n) berechnet und die jeweiligen Zeiten aufaddiert.Der Wert n entspricht der Dimension der Ausgangsmatrix A. Die A-Reihenwurden wie in Abschnitt 1.2.2 aus Matrizen mit verschiedenen Besetztheits-graden und verschiedenen Pattern erstellt. Die Ausgangsmatrizen der erstenTestreihen sind permutierte Bandmatrizen mit der Dimension 1000 × 1000.
Matrizen A Die Ursprungsmatrix und Pattern bestehen jeweils aus 5 Dia-gonalen. Die Besetztheit der einzelnen Ai betragt ca. 54.6%.Die entstandenen Matrizen Ai haben die Grosse 11 × 6.
Matrizen B Die Ausgangsmatrix besteht aus 20 Diagonalen und das Pat-tern aus 5 Diagonalen. Dabei wurden Matrizen Ai erstellt diezu ca. 80.77% besetzt sind. Die Grosse der Matrizen betragt26 × 6.
Matrizen C Diese Matrizen wurden erzeugt aus einer Ursprungsmatrixmit 5 Diagonalen und einem Pattern aus 20 Diagonalen. DieBesetztheit der einzelnen Ai betragt ca. 23.6%. Die Grosseder einzelnen Ai betragt 26 × 21.
Matrizen D Die Gruppe dieser Matrizen wurde aus einer Ursprungsma-trix mit 200 Diagonalen und einem Pattern mit 5 Diagonalenerstellt. Die Besetztheit der einzelnen Matrizen Ai betragt ca.99.7%. Hier schwanken die Matrixgrosse zwischen 163×6 und206 × 6.
Die Auswertung der Graphen 3.5 zeigt, dass sich die dunnbesetzten Verfahrenbei den Ai lohnen, die durch dunnbesetzte Matrizen und wesentlich starker

3.1 LAPACK versus CSparse 65
0.025
0.012
0.037
0.050
Zeit
Matrizen A Matrizen B
0.10
0.05
0.15
0.20
Zeit
Matrizen C Matrizen D
CSAMD CSNOR LAPACK
Abbildung 3.5: Laufzeitvergleich verschiedener Matrix/Pattern Kombinationen
besetzte Pattern entstanden sind, also vergleichsweise grosse A mit wenigenEintragen. Fur den Matrixtyp D und B ist das LAPACK-Verfahren die deut-lich bessere Wahl. Die anschliessenden Tests wurden mit Matrizen der Harwell-Boeing-Collection durchgefuhrt.
0 100 200 300 400 500 600 700 800
0
100
200
300
400
500
600
700
800
nz = 5970
Pores 2 Sherman2 Orsirr 2
Abbildung 3.6: Darstellung der verschiedenen Testmatrizen
Die Harwell-Boeing-Collection bietet Testmatrizen fur lineare Systeme, Least-Squares-Probleme, sowie fur Eigenwertprobleme. Die ausgewahlten Matrizenzeigt Abbildung 3.6. Es sind die Pores 2, Sherman2 und Orsirr 2 , welche auchin [GH97] als Testmatrizen hergenommen wurden. Es wurden erneut alle Ai
nach Abschnitt 1.2.2 berechnet und mit allen berechneten A-Matrizen wurdedas Least-Squares-Problem gelost und wiederum die Zeiten fur jede Methodeaddiert.

66 3 Numerische Ergebnisse
Pores 2 Die Matrix hat die Dimension 1224 × 1224, davon sind9613 Element verschieden von Null. Die Kondition dieserMatrix betragt 1.09e + 08. Um die Kondition der MatrixA = Pores 2 zu verbessern, sodass das darauf angewan-dete iterative Verfahren BICGSTAB, mit einer zufalligenrechten Seite und der Forderung das relative Residuum sollkleiner als 1e−8 sein, konvergiert, muss das SPAI -PatternA3 entsprechen. Fur das Pattern A bzw. A2 konvergiert dasVerfahren nicht. Die einzelnen Ai sind zu ca. 4 − 10% be-setzt. Die Dimensionen der Matrizen schwanken zwischen62 × 38 und 268 × 118.
Sherman2 Fur diese Matrix A = Sherman2 gilt das gleiche, wie furdie Pores 2 . Wieder soll BICGSTAB verwendet werden,mit einer zufalligen rechten Seite und der Abruchbedin-gung, dass das relative Residuum kleiner als 1e − 8 seinsoll. Bei dieser Matrix reicht das Pattern A2. Fur das Pat-tern A konvergiert das Verfahren nicht. Die Ai bestehenaus ca. 10−20% Nichtnullelementen. Die Dimensionen derMatrizen schwanken im Bereich von 62×38 und 268×118.Die Ausgangsmatrix hat eine Dimension von 1080 × 1080und 23094 Nichtnullelemente. Bei dieser Matrix betragt deiKondition 9.64e + 11
Orsirr 2 Die letzte Matrix A = Orsirr 2 gilt analog das selbe wiefur die vorausgehenden Matrizen. Hier reicht als Pattern Aaus. Die Besetztheit der einzelnen Matrizen Ai liegt zwi-schen 28 − 44%. Die Dimension der einzelnen Matrizen istim Bereich von 14 × 5 bis 27 × 7. Die Orsirr 2 ist diekleinste der drei Testmatrizen. Sie hat eine Dimension von886 × 886 und 5970 Nichtnullelemente und ein Konditionvon 6.32e + 04.
Die Auswertung der Berechnungen ist in Abbildung 3.7 dargestellt. Bei diesenMatrizen erweisen sich die dunnbesetzten Verfahren als sehr konkurrenzfahigim Vergleich zum vollbesetzten Verfahren mittels LAPACK-Funktionen. Be-sonders hervorzuheben ist der Pores 2 -Fall. Hier ist das CSparse-Verfahrenmit AMD-Permutation um den Faktor 3 schneller als die LAPACK-Methode.Insgesamt bestatigen diese Tests die vorherige Vermutung, dass sich die Verfah-ren die auf die CSparse-Bibliothek aufbauen, bei Matrizen die mit einem gros-

3.1 LAPACK versus CSparse 67
1.0
0.5
1.5
2.0
Zeit
Pores 2 Sherman2
0.10
0.05
0.15
0.20
Zeit
Orsirr 2
CSAMD CSNOR LAPACK
Abbildung 3.7: Laufzeitvergleich der verschiedenen Verfahren fur das Losen der Minimie-
rungsproblem aller Ai der Ausgangsmatrix A = Pores 2 mit Ausgangspat-tern A3, der Ausgangsmatrix A = Sherman2 mit Startpattern A2 und derMatrix A = Orsirr 2 mit Pattern A
sen Pattern erstellt wurden, in den vorliegenden Fallen A2 und A3, die deutlichbessere Wahl sind. Abstufend kann man sagen, das fur Matrizen Ai mit einerBesetztheit bis zu 10% sich der Aufwand des AMD-Verfahren mit Permutati-on lohnt. Mit steigendem Fullgrad sollte dann auf die CSparse-Methode ohneAMD zuruckgegriffen werden und letztendlich auf LAPACK.
3.1.4 Vorpermutation durch AMD oder reverse
Cuthill-McKee
Im letzten Abschnitt wurde verdeutlicht, dass dunnbesetzte Verfahren mit an-gewendetem AMD besonders bei Matrizen Ai, die aus einer dunnbesetztenMatrix A und einem wesentlich starker besetzten Pattern, z.B. A3, erstelltwurden, zu einer geringeren Ausfuhrungszeit fuhrt. Um sich den Aufwand derjeweiligen Anwendung des AMD und der zusatzlichen Permutationen der ein-zelnen Ai eventuell zu sparen, wird in diesem Abschnitt die Auswirkung einerVorpermutation der Ursprungsmatrix A durch den AMD oder reverse Cuthill-McKee untersucht. Der Cuthill-McKee-Algorithmus ordnet die Nichtnullele-mente so an, dass sie naher an der Diagonalen der Matrix liegen. Er verrin-gert die Bandbreite der Matrix. Dieses Verfahren baut wiederum auf einenGraphen auf. Beginnend bei einem gewahltem Startknoten wird der Graphim aufsteigenden Grad durchlaufen und dabei nummeriert. Diese Nummerie-rung entspricht der neuen Eliminationsreihenfolge. Der reverse Cuthill-McKee-Algorithmus startet mit dem letzten Element des Cuthill-McKee-Algorithmus,

68 3 Numerische Ergebnisse
da es haufig eine schmalere Bandbreite liefert als der Originalalgorithmus. DerAlgorithmus und ein verdeutlichendes Beispiel findet sich in [Saa00, Seiten90-92].
0 200 400 600 800 1000 1200
0
200
400
600
800
1000
1200
nz = 9613
Pores 2 Pores 2 AMD Pores 2 RCM
Abbildung 3.8: Permutationen der Matrix Pores 2
Abbildung 3.9 zeigt einen Vergleich der Zeiten fur die Matrix Pores 2 beider Verwendung einer nicht vorpermutierten Ursprungsmatrix, einer mit AMDvorpermutierten Ausgangsmatrix und einer mit der reverse Cuthill-McKee vor-permutierten Matrix. Fur den Test wurden wieder alle A extrahiert und mitjeder Ai das Minimierungsproblem gelost. Das Ausgangspattern war die A3,wobei A der Matrix entspricht. Von der vorausgehenden Permutation AMD
1.0
0.5
1.5
2.0
Zeit
Pores 2 Pores 2 AMD Pores 2 RCM
CSAMD CSNOR LAPACK
Abbildung 3.9: Laufzeitvergleich der Pores 2 mit den Laufzeiten der permutierten Pores 2
beim Losen der Minimierungsprobleme aller Ai
oder reverse Cuthill-McKee profitiert besonders das CSparse-Verfahren ohneAnwendung des AMD . Die Ausfuhrungszeit ist um den Faktor drei schnellerals ohne Permutation der Ausgangsmatrix. Die beiden anderen Verfahren ge-winnen hauptsachlich bei der Vorpermutation mittels reverse Cuthill-McKee.

3.2 QR-Updates 69
Um den Effekt zu uberprufen wurden die Matrizen Orsirr 2 und Sherman2ebenfalls vorpermutiert und der Test wiederholt. Das Pattern ist in diesemFall A2. Das Ergebnis fur die Matrix Sherman2 ist in Abbildung 3.10 dar-gestellt. Die Beschleunigung durch eine vorausgehende Permutationen ist beibeiden Matrizen minimal. Hier muss uberpruft werden, ob der Aufwand desAMD bzw. reverse Cuthill-McKee Verfahrens nicht den Geschwindigkeitsvor-teil egalisiert. Zusammenfasssend kann man sagen, dass durch VorpermutationLaufzeitgewinne erreicht werden konnen. Es muss jedoch fur jeden Fall gepruftwerden, ob es wirklich Vorteile bringt.
1.0
0.5
1.5
2.0
Zeit
Sherman2 Sherman2 AMDSherman2 RCM
CSAMD CSNOR LAPACK
Abbildung 3.10: Laufzeitvergleich der Sherman2 mit den Laufzeiten der permutierten
Sherman2 beim Losen der Minimierungsprobleme aller Ai
3.2 QR-Updates
Im abschliessenden Beispiel in Sektion 2.2 wurde gezeigt, wie sich die QR-Updates in einem Standardfall verhalten. In diesem Abschnitt werden die ex-tremen Fallen untersucht, um zu zeigen, ob das QR-Update sich auch die-sen Situationen lohnt. Dazu wurde der folgende Fall betrachtet: pro A wer-den 30 Patternupdates mit jeweils einer neuen hinzugefugten Spalte gemacht.Der zweite Extremtest wird mit einem Patternupdate pro A durchgefuhrt beidem 30 Spalten hinzugefugt werden. Die Tests werden mit der Matrix Pores 2durchgefuhrt. Das Ausgangspattern der Tests ist die Einheitsmatrix. Ansch-liessend wird mit den Matrizen Orsirr 2 und Sherman2 ein in der Praxis haufigauftretender Fall, namlich vier Patternupdates zu je sieben neu gewahlten Spal-ten getestet. Der letzte Test dieses Abschnittes wird mit einem Pattern, dasder Besetztheitsstruktur der Ausgangsmatrix entspricht durchgefuhrt. Hier ist

70 3 Numerische Ergebnisse
die Ausgangsmatrix erneut die Pores 2 . Es werden wieder vier Patternupdatesgemacht mit je sieben hinzugefugten Spalten.
3.2.1 Extremfalle des Patternupdates
Beim ersten Test werden 30 Patternupdates vorgenommen und Ai um jeweilseine neue Spalte erweitert. Die Abbildung 3.11 stellt die Dauer der einzelnenPatternupdates, inklusive des Losens des neuen Least-Squares-Problemes, furdie einzelnen Matrizen A1k
, k = 1 . . . 30 der Ausgangsmatrix Pores 2 dar. Hier
A10 A14 A18 A112 A116 A120 A124 A128
0.50
1.00
1.50
2.00
lacs
cscs
laup
ref
u u u
+ + +
q q q
r r r
Zeit·10−4
u
u u u u u u u uu u u u u u u
+ + + + + + + + + + + + + + + +q
q
qq q q q q
q q qq
q q q
q
r
r
rr
r rr
r
r
r
rr
r r
rr
Abbildung 3.11: Laufzeitvergleich des QR-Update 30 Patternupdates mit Hinzunahme
einer Spalte an der A1 der Pores 2 . Das Startpattern entspricht der Ein-heitsmatrix
erweisen sich die QR-Update Methoden der Referenzmethode als uberlegen.Fur diese Konstellation eignen sich, wie man den Zeiten erkennen kann, dieHybrid-Methode lacs und die reine CSparse-Methode cscs. An den Zeiten derReferenzmethode kann man erkennen, dass die Zerlegung der einzelnen A unddas anschliessende Losen des Minimierungsproblemes im Laufe der Patternup-dates wesentlich teurer ist als die Aktualisierung der schon vorhandenen Zerle-gung mit anschliessendem Losen. Diese Tatsache spiegelt sich in den Gesamt-zeiten wider. Siehe Abbildung 3.12 (a). Bei diesem Szenario ist die Hybrid-Methode oder die CSparse-Methode den Methoden, die nur auf LAPACK auf-bauen, vorzuziehen.Der nachste Test befasst sich mit dem genauen Gegenstuck zur aktuellen Si-tuation. Es wird nur ein Patternupdate gemacht, jedoch 30 Spalten neu zurMatrix Ai hinzugenommen. Damit wird den QR-Update Methoden der grosse

3.2 QR-Updates 71
1.0
0.5
1.5
Zeit
30 Updates(a)
lacs
cscs
laup
ref
0.2
0.1
0.3
Zeit
1 Update(b)
Abbildung 3.12: Laufzeitvergleich der Extremfalle der Pores 2 . Bild (a) 30 Updates miteiner neuen Spalte, Bild (b) ein Update mit 30 neuen Spalten
Vorteil genommen. Die hinzukommende Teilmatrix ist ahnlich dimensioniertwie daraus resultierende Matrix. Daher sollte die Referenzmethode bessereLaufzeiten liefern wie die Methoden lacs, cscs und laup. Der Vergleich der Me-thoden in diesem ungunstigen Szenario ist in Abbildung 3.12 (b) dargestellt.Selbst bei diesem ungunstigen Fall sind die QR-Updates konkurrenzfahig, d.h.QR-Updates konnen auch in diesem Fall eingesetzt werden, wenn kleine Ver-schlechterung der Laufzeit nicht weiter ins Gewicht fallen.
3.2.2 Patternupdates mit Orsirr 2 und Sherman2
Dieser Abschnitt soll zeigen, das die QR-Updates auch bei den zwei anderenTestmatrizen funktionieren und nicht wie die Vorpermutation der Matrix nurauf einen Typ beschrankt ist. Bei Matrizen Orsirr 2 und Sherman2 wird einStandardfall durchgerechnet, d.h. es werden vier Patternupdates durchgefuhrtund jeweils sieben Zeilen hinzugenommen. Die Abbildung 3.13 (a) zeigt diebenotigte Zeit fur die einzelnen Patternupdates und das Losen der jeweiligenMinimierungsprobleme der einzelnen Matrizen A1i
der Ausgangsmatrix Sher-man2 . Die Darstellung 3.13 (b) zeigt analog dazu die Zeiten der Updates vonA1 der Ausgangsmatrix Orsirr 2 . Die Verfahren lacs, cscs und laup sowie dieReferenzmethode verhalten sich bei diesen Matrizen analog zu bisherigen Er-kenntnissen.Der folgende Test verwendet ein anderes Ausgangspattern als die bisherigenTests. Mit diesem Test soll gezeigt werden, dass die QR-Update Methodennicht nur fur das Diagonalpattern Laufzeitvorteile bringen.

72 3 Numerische Ergebnisse
A10 A11 A12 A13 A14
0.25
0.50
0.75
1.00
Zeit·10−4
u
u
u
u
u
+
+
+
+
+
q
q
q
q
q
r
r
r
r
r
A10 A11 A12 A13 A14
0.25
0.50
0.75
1.00
lacs
cscs
laup
ref
u u u
+ + +
q q q
r r r
Zeit·10−4
u
uu
u
u
+
+
++
+
q
q q
q
q
r
r
r
r
r
(a) (b)
Abbildung 3.13: Laufzeitvergleich mit Orsirr 2 Bild(b) und Sherman2 Bild(a) mit derEinheitsmatrix als Ausgangspattern und 4 Patternupdates mit jeweils 7hinzugefugten Spalten
3.2.3 Patternupdates mit Pores 2 als Ausgangspattern
Dieser Test verwendet als Ausgangsmatrix erneut die Pores 2 . Zum Erzeugen
A10 A11 A12 A13 A14
1.00
2.00
3.00
4.00
lacs
cscs
laup
ref
u u u
+ + +
q q q
r r r
Zeit·10−4
uu u
u
u
++
+ ++
q
q qq
q
r
r
rr
r
0.2
0.1
0.3
Zeit
Gesamtzeit
(b)(a)
lacs
cscs
laup
ref
Abbildung 3.14: Laufzeitvergleich beim Berechnen der Minimierungsprobleme mit derPores 2 als Ausgangsmatrix und der Besetztheit der Pores 2 als Aus-gangspattern und vier Patternupdates mit 7 hinzugefugten Spalten. Bild(a) zeigt die Zeiten der einzelnen A1 und Bild (b) die Gesamtzeit aller A

3.3 Float versus Double 73
der A wurde jedoch als Pattern die Besetztheitsstruktur von Pores 2 gewahlt,dadurch bestehen die Ai0 nicht nur aus einem Vektor sondern sind Matrizender Dimension 20× 8 und hoher. Die Abbildung 3.14(a) zeigt erneut den Zeit-verlauf der Updates der A1 wahrend 3.14(b) die Gesamtzeit aller auftretendenUpdates darstellt. Auch hier zeigt sich die Verbesserung der Laufzeit der QR-Updates gegenuber der Referenzmethode uberaus deutlich. Von daher kannman davon ausgehen, dass das Verfahren der QR-Updates zur allgemeinenLaufzeitverbesserung des SPAI beitragen kann.
3.3 Float versus Double
Die anschliessenden Tests wurden teilweise auf einem zweiten System durch-gefuhrt, da die Ergebnisse auf dem ursprungliche System kein klares Bild lie-ferten. Das zweite System, System B unterscheidet sich im wesentlichen imBereich der Hardware vom Ausgangssystem A:
• Prozessor: Intel Pentium M
• Taktrate: 1600 MHz
• RAM: 1024 MB
• Compiler: GCC 4.1.2
• LAPACK: LAPACK 3.1.1
• OS: Linux.
Der erste Test wurde mit quadratischen Zufallsmatrizen durchgefuhrt, derenDimension sukzessive in Zehnerschritten erhoht wurde. Es wurde pro Matrixein Minimierungsproblem mit dem ersten Einheitsvektor als rechte Seite gelost.In der float Berechnung wurden vier Nachverfeinerungsschritte durchgefuhrt.In Abbildung 3.15 wurde das Laufzeitverhaltnis zwischen der Berechnung ineinfacher Genauigkeit mit iterativer Nachverfeinerung und der Berechnung indoppelter Genauigkeit dargestellt.Wie man in Abbildung 3.15 erkennen kann, schwankt das Laufzeitverhaltniszwischen der Berechnung in float mit iterativer Nachverfeinerung und der aufdem Datentyp double basierenden Berechnung mit der Dimension der Matrix.Die Beobachtung bei diesem Test ist, dass das Verhaltnis sich mit ansteigen-der Dimension bis zu einem bestimmten Punkt der Eins annahert und ab einerbestimmten Matrixdimension wieder vergrossert. Dieses sinkende und wiederansteigende Verhalten ist auch der Grund fur das zweite Testsystem. Auf die-sem System bestatigt sich, wie man an Abbildung 3.15 erkennen kann, das
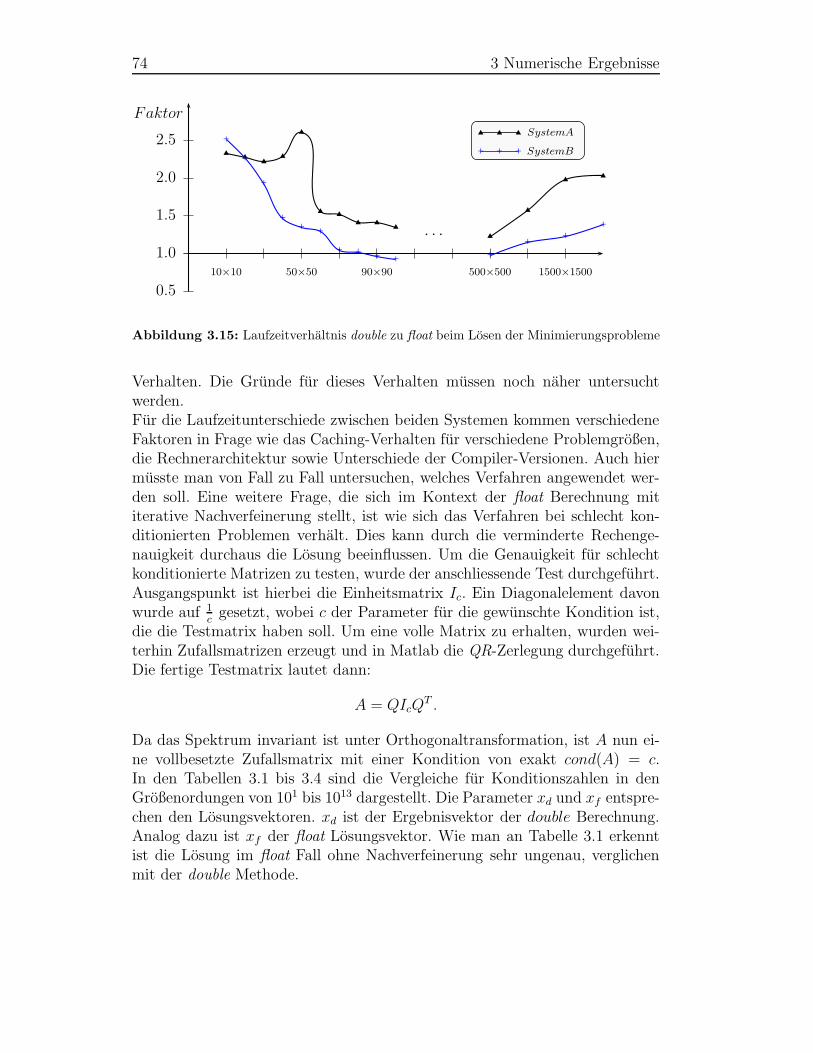
74 3 Numerische Ergebnisse
10×10 50×50 90×90 500×500 1500×1500
1.0
0.5
1.5
2.0
2.5
Faktor
uu
uu
u
u uu u
u
+
+
+
++ +
+ + + +
u
u
uu
++ +
+· · ·
SystemA
SystemB
u u u
+ + +
Abbildung 3.15: Laufzeitverhaltnis double zu float beim Losen der Minimierungsprobleme
Verhalten. Die Grunde fur dieses Verhalten mussen noch naher untersuchtwerden.Fur die Laufzeitunterschiede zwischen beiden Systemen kommen verschiedeneFaktoren in Frage wie das Caching-Verhalten fur verschiedene Problemgroßen,die Rechnerarchitektur sowie Unterschiede der Compiler-Versionen. Auch hiermusste man von Fall zu Fall untersuchen, welches Verfahren angewendet wer-den soll. Eine weitere Frage, die sich im Kontext der float Berechnung mititerative Nachverfeinerung stellt, ist wie sich das Verfahren bei schlecht kon-ditionierten Problemen verhalt. Dies kann durch die verminderte Rechenge-nauigkeit durchaus die Losung beeinflussen. Um die Genauigkeit fur schlechtkonditionierte Matrizen zu testen, wurde der anschliessende Test durchgefuhrt.Ausgangspunkt ist hierbei die Einheitsmatrix Ic. Ein Diagonalelement davonwurde auf 1
cgesetzt, wobei c der Parameter fur die gewunschte Kondition ist,
die die Testmatrix haben soll. Um eine volle Matrix zu erhalten, wurden wei-terhin Zufallsmatrizen erzeugt und in Matlab die QR-Zerlegung durchgefuhrt.Die fertige Testmatrix lautet dann:
A = QIcQT .
Da das Spektrum invariant ist unter Orthogonaltransformation, ist A nun ei-ne vollbesetzte Zufallsmatrix mit einer Kondition von exakt cond(A) = c.In den Tabellen 3.1 bis 3.4 sind die Vergleiche fur Konditionszahlen in denGroßenordungen von 101 bis 1013 dargestellt. Die Parameter xd und xf entspre-chen den Losungsvektoren. xd ist der Ergebnisvektor der double Berechnung.Analog dazu ist xf der float Losungsvektor. Wie man an Tabelle 3.1 erkenntist die Losung im float Fall ohne Nachverfeinerung sehr ungenau, verglichenmit der double Methode.

3.3 Float versus Double 75
Tabelle 3.1: MATLAB-Vergleichstest fur float QR-Zerlegung mit Matrizen A ∈ R1000×1000
in aufsteigender Konditionszahl und 0 Nachverfeinerungsschritten
cond(A) ‖Axd − b‖2 ‖Axf − b‖2‖xd−xf‖2
‖xd‖2
1.0e+01 5.26e-14 7.77e-06 4.13e-071.0e+02 6.42e-14 9.26e-06 1.67e-061.0e+03 5.63e-13 7.14e-05 6.33e-061.0e+04 4.73e-12 6.01e-04 1.46e-041.0e+05 4.74e-11 5.64e-03 9.20e-041.0e+06 5.09e-10 6.10e-02 6.96e-031.0e+07 1.72e-09 2.08e-01 1.05e-021.0e+08 4.51e-08 2.12e+00 6.31e-011.0e+09 4.08e-07 2.29e+00 9.49e-011.0e+10 5.82e-06 6.30e+00 9.92e-011.0e+11 4.73e-05 1.89e+01 9.97e-011.0e+12 3.56e-04 5.91e+00 1.00e-001.0e+13 4.41e-03 2.37e+01 1.00e-00
An der Tabelle 3.2 lasst sich der Effekt der Nachverfeinerung sehr gut beob-achten. Die beiden Fehlernormen entsprechen sich ungefahr bis zu einer Ma-trixkondition von 1.0e + 08. Die Nachverfeinerung verbessert also wirklich diefloat Losung und erhoht die Genauigkeit signifikant. Ab einer Kondition von1.0e + 09 bringt die Nachverfeinerung keine nennenswerte Verbesserung mehr.Die Tabellen 3.3 und 3.4 zeigen denselben Test fur Ausgangsmatrizen der Di-mension 1000× 500. Tests mit Matrizen der Dimension 1000× 500 zeigen, wieman in den Tabellen nachprufen kann, daß die Nachverfeinerungsschritte kaumeine nennenswerte Verbesserung der Fehlernormen bringen. Um das Verfahrenallgemein einsetzen zu konnen bedarf es noch weiterer Untersuchungen in die-sem Bereich, wie sich die hohen relativen Fehlernormen auf die beim SPAIentstehende Vorkonditioniermatrix auswirken.Das anschliessende Kapitel soll die Ergebnisse der Diplomarbeit zusammen-fassen und einen Ausblick geben, wie man die Laufzeit des SPAI noch weiterverringern konnte.

76 3 Numerische Ergebnisse
Tabelle 3.2: MATLAB-Vergleichstest fur float QR-Zerlegung mit Matrizen A ∈ R1000×1000
in aufsteigender Konditionszahl und 4 Nachverfeinerungsschritten
cond(A) ‖Axd − b‖2 ‖Axf − b‖2‖xd−xf‖2
‖xd‖2
1.0e+01 5.10e-14 2.64e-14 2.80e-151.0e+02 7.74e-14 3.82e-14 2.23e-151.0e+03 3.63e-13 1.43e-13 2.02e-141.0e+04 5.53e-12 2.29e-12 1.25e-121.0e+05 9.41e-11 4.28e-11 8.18e-121.0e+06 2.22e-10 9.02e-11 1.03e-101.0e+07 1.71e-09 1.06e-08 5.32e-101.0e+08 4.16e-09 4.44e-08 1.46e-091.0e+09 2.08e-07 2.98e+00 1.53e+001.0e+10 9.14e-06 2.07e+01 1.09e+001.0e+11 4.41e-05 4.37e+00 9.96e-011.0e+12 4.56e-04 7.24e+00 9.99e-011.0e+13 5.34e-03 6.49e+00 1.00e+00
Tabelle 3.3: MATLAB-Vergleichstest fur float QR-Zerlegung mit Matrizen A ∈ R1000×500
in aufsteigender Konditionszahl und 0 Nachverfeinerungsschritten
cond(A) ‖Axd − b‖2 ‖Axf − b‖2‖xd−xf‖2
‖xd‖2
1.0e+01 6.51e+00 6.51e+00 3.56e-071.0e+02 6.27e+00 6.27e+00 1.88e-051.0e+03 6.27e+00 6.27e+00 1.15e-041.0e+04 6.67e+00 6.67e+00 9.14e-041.0e+05 6.57e+00 6.57e+00 5.37e-021.0e+06 6.55e+00 6.55e+00 6.80e-011.0e+07 6.31e+00 6.32e+00 2.06e+001.0e+08 6.87e+00 6.88e+00 1.02e+001.0e+09 6.55e+00 6.55e+00 9.96e-011.0e+10 6.38e+00 6.40e+00 9.99e-011.0e+11 6.45e+00 6.45e+00 1.00e-001.0e+12 6.34e+00 6.37e+00 1.00e-001.0e+13 6.61e+00 6.61e+00 1.00e+00
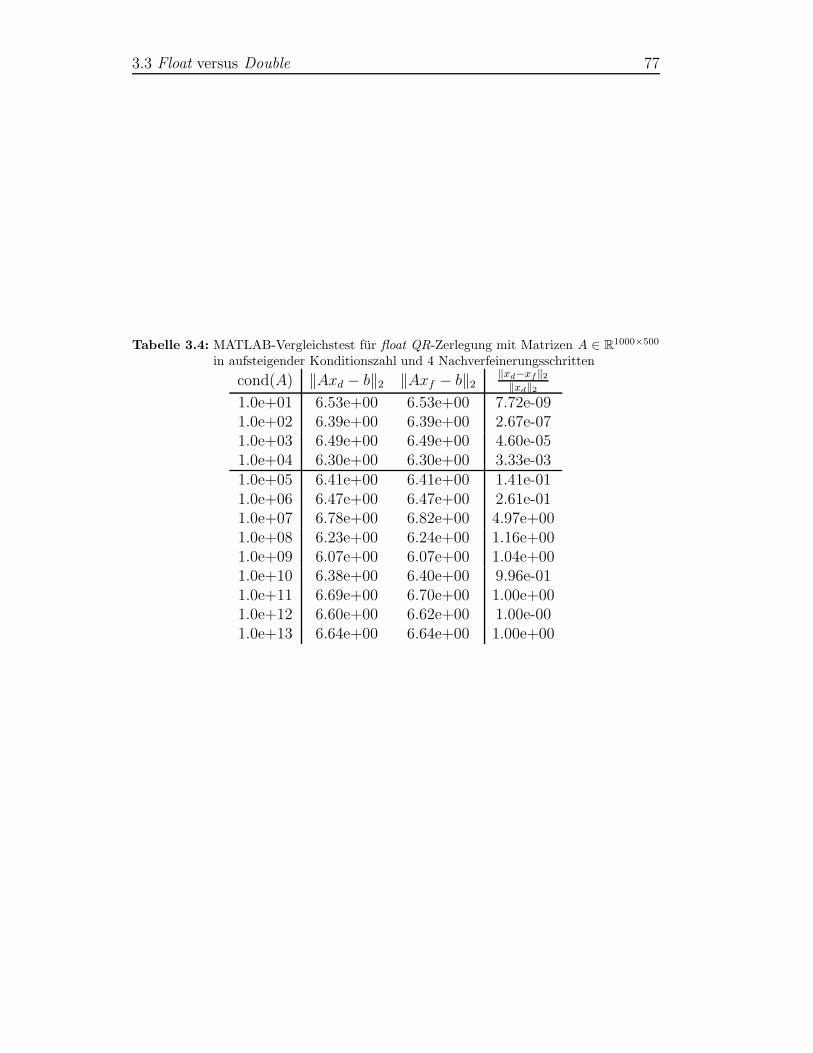
3.3 Float versus Double 77
Tabelle 3.4: MATLAB-Vergleichstest fur float QR-Zerlegung mit Matrizen A ∈ R1000×500
in aufsteigender Konditionszahl und 4 Nachverfeinerungsschritten
cond(A) ‖Axd − b‖2 ‖Axf − b‖2‖xd−xf‖2
‖xd‖2
1.0e+01 6.53e+00 6.53e+00 7.72e-091.0e+02 6.39e+00 6.39e+00 2.67e-071.0e+03 6.49e+00 6.49e+00 4.60e-051.0e+04 6.30e+00 6.30e+00 3.33e-031.0e+05 6.41e+00 6.41e+00 1.41e-011.0e+06 6.47e+00 6.47e+00 2.61e-011.0e+07 6.78e+00 6.82e+00 4.97e+001.0e+08 6.23e+00 6.24e+00 1.16e+001.0e+09 6.07e+00 6.07e+00 1.04e+001.0e+10 6.38e+00 6.40e+00 9.96e-011.0e+11 6.69e+00 6.70e+00 1.00e+001.0e+12 6.60e+00 6.62e+00 1.00e-001.0e+13 6.64e+00 6.64e+00 1.00e+00

78 3 Numerische Ergebnisse

79
4 Zusammenfassung und Ausblick
Zum Losen grosser linearer Gleichungsysteme konnen iterative Verfahren ein-gesetzt werden. Damit diese nach wenigen Schritten eine brauchbare Losungliefern, muss die Kondition der Iterationsmatrix moglichst klein sein. Um dieKondition einer Matrix zu verringern werden Vorkonditionierer eingesetzt. Inder vorliegenden Diplomarbeit wurde versucht, die Laufzeit des Vorkonditio-nierers SPAI zu verbessern.Dazu wird im ersten Kapitel die Grundlage gebildet. Es werden explizit einigeVorkonditionierer angesprochen, sowie das Losen von Minimierungsproblemenmittels Householder-Reflektion, Givens-Rotation oder dem Gram-Schmidt-Ver-fahren.Das zweite Kapitel befasst sich mit moglichen Modifikationen. Hierbei wurdendunnbesetzte Verfahren, QR-Updates, sowie die Moglichkeit der QR-Zerlegungim Datentyp float mit iterativer Nachverfeinerung besprochen. Dabei wurdegenauer auf die Verhinderung von Fill-In durch Minimum-Degree-Methodeneingegangen. Im Unterkapitel QR-Updates wurden die verschiedenen Moglich-keiten der Updates untersucht, die Implementierung dieser Methoden beschrie-ben und auf Hindernisse hingewiesen.Das dritte Kapitel umfasst umfangreiche Tests und numerische Ergebnisse zuden einzelnen Modifikationen. Ein wichtiges Ergebnis ist, dass man differen-zieren muss, wann dunnbesetzte Verfahren einsetzt werden. Grosse Vorteilegegenuber der vollbesetzten Verfahren wurde bei Matrizen Ai gezeigt, die beider Berechnung des SPAI fur eine dunnbesetzte Ausgangsmatrix unter Anwen-dung eines wesentlich starker besetzten Pattern entstehen. Besonders grosseUnterschiede ergaben sich bei der Anwendung auf die Ai der Matrix Pores 2und mit dem Pattern A3. Weitere Tests, mit einer Vorpermutation der Aus-gangsmatrix, fuhrten nur in einem Fall zu nennenswerter Laufzeitverringerung.Hier sollte von Fall zu Fall entschieden werden, ob eine man eine zusatzliche,den Fill-In reduzierende, Permutation anwendet.Die QR-Updates haben in ausfuhrlichen Tests gezeigt, dass sich eine Hybrid-Implementierung aus LAPACK und CSparse als besonders effizient erweist. DieLaufzeit der Referenzimplementierung, die die komplette Zerlegung durchfuhrt,konnte nahezu in jedem Szenario unterboten werden. Beim Standardfall, ei-nem Ausgangspattern, welches der Besetztheitsstruktur der Einheitsmatrix

80 4 Zusammenfassung und Ausblick
entspricht, jeweils vier Patternupdates und pro Update werden sieben Spal-ten hinzugefugt war die Hybrid-Methode ingesamt um den Faktor 1.7 schnel-ler als die Referenzmethode. Die schlechteste Situation fur die QR-Updatesist jeweils nur ein Patternupdate mit einer grossen Anzahl neuer Spalten. Indiesem Fall war die Laufzeit der Referenzmethode jedoch nur ein wenig klei-ner. Das Verhaltnis der Ausfuhrungszeiten zwischen Referenzmethode und derHybrid-Methode betrug 0.91. Abschliessend kann zu den QR-Updates gesagtwerden, dass die Vorteile dieser Methode uberwiegen und somit ein Einsatz imSPAI -Algorithmus empfohlen werden kann. Die letzte getestete Modifikationwar die float basierte QR-Zerlegung mit schrittweiser Nachverfeinerung. Die-se sollte jedoch mit Vorsicht genossen werden. Tests haben gezeigt, dass einSpeedup moglich ist aber die verminderte Genauigkeit kann bei schlecht kon-ditionierten Problemen einen nicht unerheblichen Einfluss auf die Genauigkeitder Losung haben. Hier bedarf es weiterer Untersuchungen, um eine aussage-kraftige Wertung abzugeben.In der vorliegenden Arbeit wurde mit der Optimierung des Algorithmus ver-sucht die Laufzeit des SPAI zu verbessern. Weitere Laufzeitverbesserungenkonnen durch Programmcodeoptimierung, wie z.B. SSE erreicht werden, wel-che bis jetzt noch nicht forciert wurde. Eine weitere Moglichkeit der Optimie-rung ist das Ausnutzen von Cacheeffekten wahrend der Vorkonditionierung furstark strukturierte Matrizen, wie sie bei PDE-Diskretisierungen haufig auftre-ten.

81
Literaturverzeichnis
[ABB+99] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Don-garra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenny,and D. Sorensen. LAPACK Users Guide 3.th Edition. SIAM, Phil-adelphia, 1999.
[ADD96] Patrick Amstoy, Timothy Davis, and Iain Duff. An approximateminimum degree ordering algorithm. SIAM Journal Matrix Ana-lysis and Application, 17(4):886 – 905, 1996.
[Bjo96] A. Bjorck. Numerical Methods for Least Squares Problems. SIAM,Philadelphia, 1996.
[Dav06] Timothy Davis. Direct Methods for Sparse Linear Systems. SIAM,2006.
[DH93] P. Deuflhard and A. Hohmann. Numerische Mathematik I 2. Auf-lage. Walter de Gruyter & Co., 1993.
[DYK+04] J. Demmel, Y.Hidan, W. Kahan, X. Li, S. Mukherjee, and E.Riedy.Error bounds from extra precise iterative refinement. Technicalreport, University of California at Berkley, 2004.
[DYLE07] J. Demmel, Y.Hida, X. Li, and E.Riedy. Extra-precise iterativerefinement for overdetermined least squares problems. Technicalreport, University of California at Berkley, 2007.
[GH97] Marcus Grote and Thomas Huckle. Parallel preconditioning withsparse approximate inverses. SIAM Journal on Scientific Compu-ting, 18(3):838–853, 1997.
[GvL96] G. H. Golub and C. F. van Loan. Matrix Computations 3rd Edition.The Johns Hopkins University Press, Baltimore and London, 1996.
[HL] Sven Hammarling and Craig Lucas. Updating the qr factorizationand the least squares problem. Technical report, Department ofMathematics, University of Manchester, M13 9PL, England.

82 Literaturverzeichnis
[HS06] Thomas Huckle and Stefan Schneider. Numerische Methoden2.Auflage. Springer Verlag, Berlin and Heidelberg, 2006.
[Saa00] Yousef Saad. Iterative Methods for Sparse Linear Systems 2.Editi-on. SIAM, Philadelphia, 2000.
[Sch93] H. R. Schwarz. Numerische Mathematik 3. Auflage. B. G. Teubner,Stuttgart, 1993.
[Ske80] Robert Skeel. Iterative refinement implies numerical stability forgaussian elimination. Mathematics of Computation, 35(151):817 –832, 1980.
[Yan81] Mihalis Yannakakis. Computing the minium fill-in is np-complete.SIAM Journal on Algebraic and Discrete Methods, 1(1):77–79,1981.


















