
Untersuchungen zur Implementierung digitaler Filter auf...
96
Untersuchungen zur Implementierung digitaler Filter auf FPGAs von Alfred Marganitz
-
Upload
hoangduong -
Category
Documents
-
view
212 -
download
0
Transcript of Untersuchungen zur Implementierung digitaler Filter auf...

Untersuchungen zur
Implementierung digitaler Filter auf
FPGAs
von
Alfred Marganitz

Allan V. Oppenheim, MIT:Zur digitalen Signalverarbeitung benötigt man einen ADU, DAU und einen Signalprozessor um dasselbe zu erreichen, wozu ein Widerstand und Kondensator genügt.

Inhalt1. Strukturen und Design digitaler Filter
2. FPGA
3. Fixed-point-Arithmetik konstanter Wortlänge- Addition- Multiplikation- Booth-Algorithmus
4. FIR-Filter- direkte Form- direkte Form mit Partialsummenbildung- transponierte direkte Form- verteilte Arithmetik
5. Wellendigitalfilter- Elemente- Abzweig-Wellendigitalfilter- Brücken-Wellendigitalfilter- WDF vs. FIR und IIR
6. Zusammenfassung

1. Strukturen und Design digitaler Filter
digitales Filter
(Toleranzschema)
H(f) : Frequenzgang
h(k) : Impulsantwort
FIR-Filter
Parks-McClellan-Algorithmus
analoges Bezugsfilter
(Toleranzschema)‘
H(p)
bilineareTransformation
H(z) : ÜbertragungsfunktionTustin-Formel
IIR-Filter
LC-FilterAbzweig-WellendigitalfilterWellenvariablen, Adaptoren
Allpaß-Dekomposition
Brücken-Wellendigitalfilter
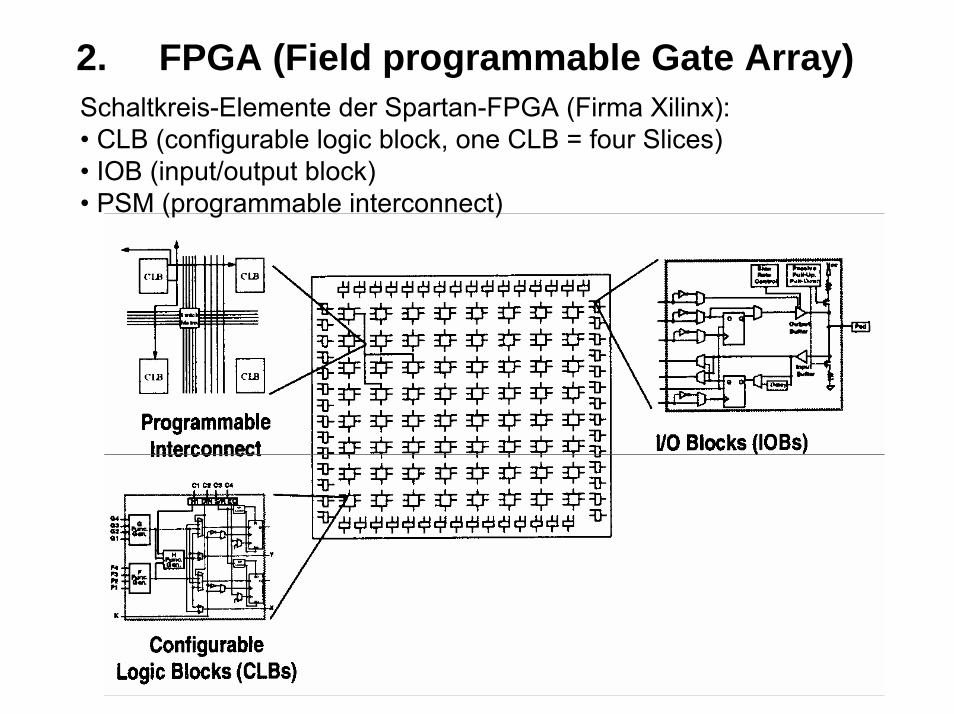
2. FPGA (Field programmable Gate Array)Schaltkreis-Elemente der Spartan-FPGA (Firma Xilinx):• CLB (configurable logic block, one CLB = four Slices)• IOB (input/output block)• PSM (programmable interconnect)
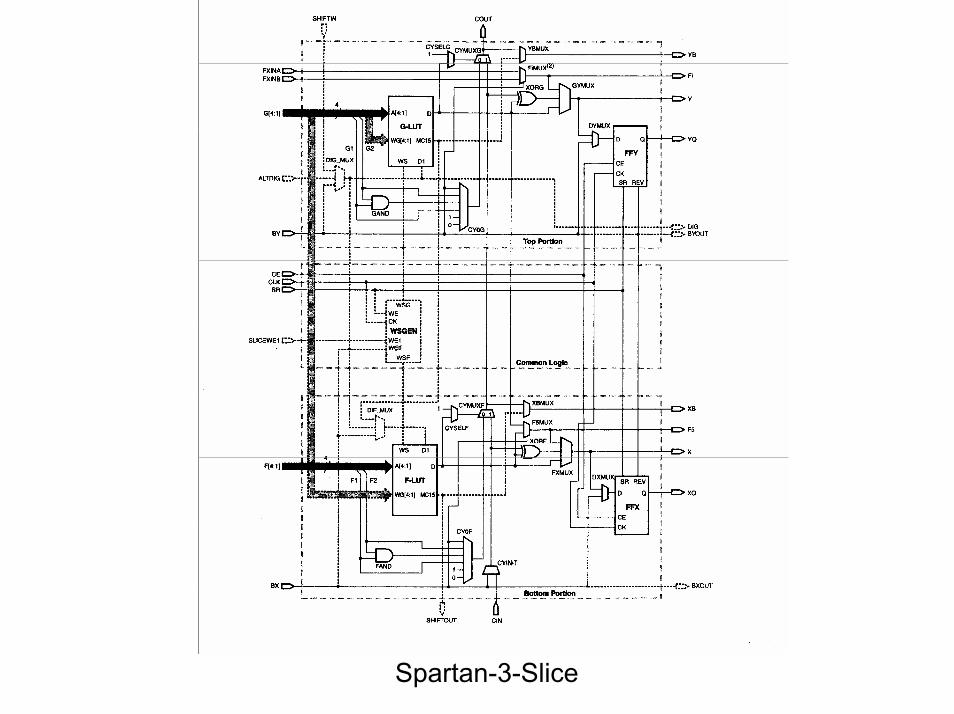
Spartan-3-Slice
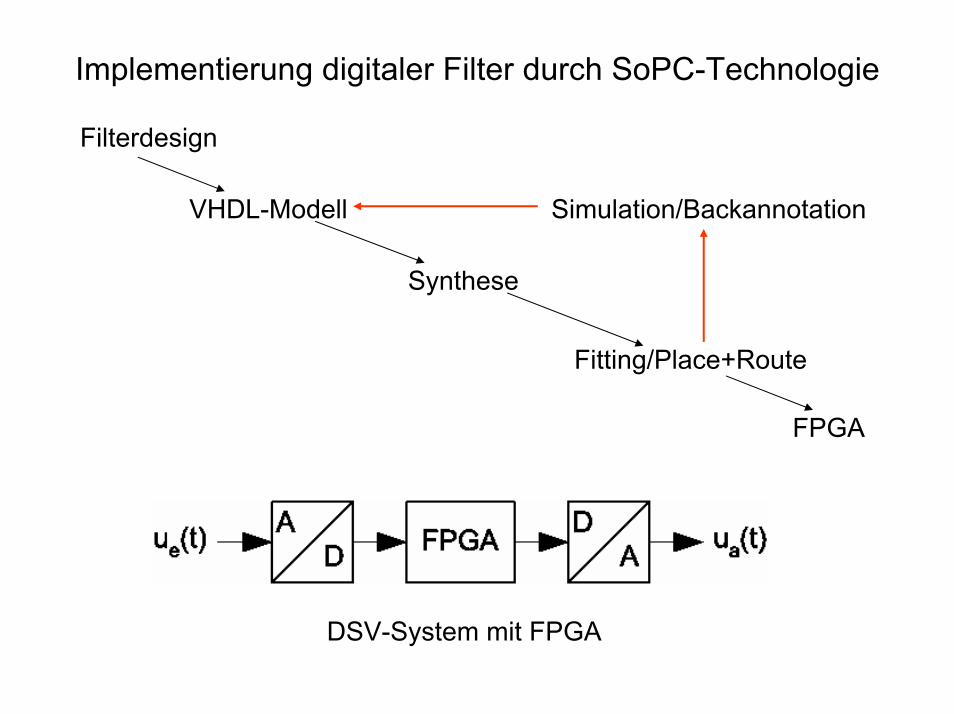
Implementierung digitaler Filter durch SoPC-Technologie
Filterdesign
VHDL-Modell
Synthese
Fitting/Place+Route
FPGA
Simulation/Backannotation
DSV-System mit FPGA
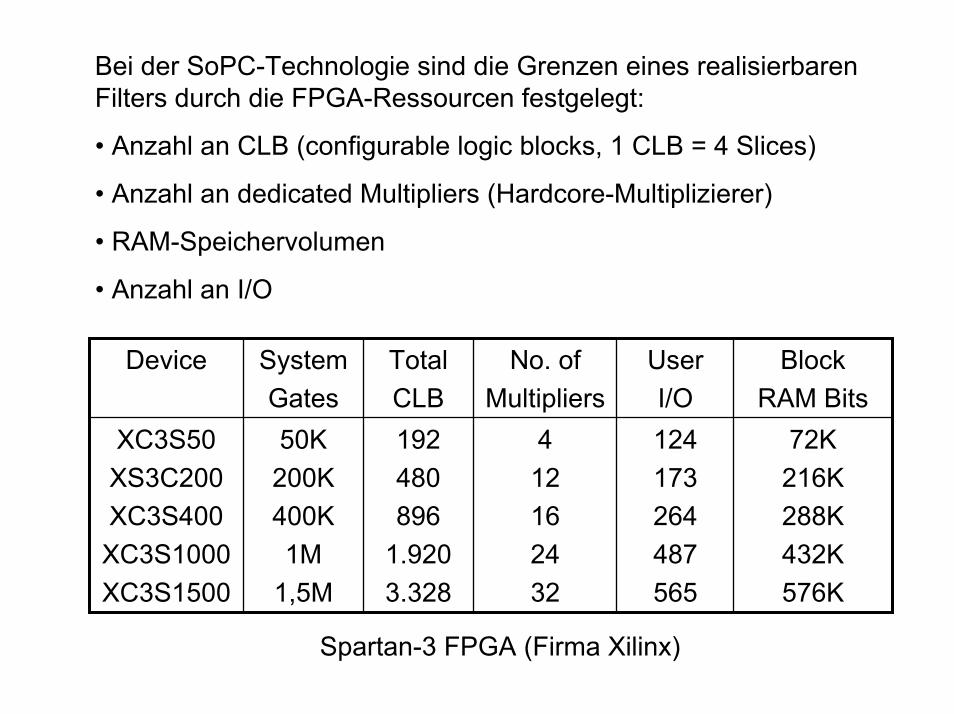
Bei der SoPC-Technologie sind die Grenzen eines realisierbaren Filters durch die FPGA-Ressourcen festgelegt:
• Anzahl an CLB (configurable logic blocks, 1 CLB = 4 Slices)
• Anzahl an dedicated Multipliers (Hardcore-Multiplizierer)
• RAM-Speichervolumen
• Anzahl an I/O
Device SystemGates
TotalCLB
No. ofMultipliers
UserI/O
BlockRAM Bits
XC3S50XS3C200XC3S400
XC3S1000XC3S1500
50K200K400K1M
1,5M
192480896
1.9203.328
412162432
124173264487565
72K216K288K432K576K
Spartan-3 FPGA (Firma Xilinx)

3. Fixed-Point-Arithmetik konstanter Wortlänge
Probleme bei arithmetischen Operationen mit Festkomma-zahlen:
• beschränkter Zahlenbereich
• beschränkte Genauigkeit
• Overflow-Fehler bei Addition
• Reduktionsfehler bei Multiplikation

(i) n-Bit-Komplementzahlen
a) ganze Zahlen
1n0.n
1n0.n
1n
00
3n3n
2n2n
1n1n0.n
2Z 12Z2
2a...2a2a2aZ−−−
−−
−−
−−
≤⇒−≤≤−
⇒⋅++⋅+⋅+⋅−=
b) gebrochene Zahlen
1Z 21Z1-
2a...2a2aa2ZZ
1)-1.(n1n
1)-1.(n
1n0
23n
12n1n1n
0.n)1n.(1
≤⇒−≤≤
⇒⋅++⋅+⋅+−==
+−
+−−−
−−−−−

(ii) Addition von 8-Bit-Komplementzahlen
1b ,a 1.77.1 ≤
1S 7.1 ≤
Allg. gilt: [ ]B7.17.17.1 baS +=
Wenn: Fehler-Overflow baS 1ba 7.17.11.77.17.1 ⇒+≠⇒>+

(iii) Fortlaufende n-fache Addition von 8-Bit-Komplementzahlen
Wenn: SaaS 1Smit ;aS und 1an
0B
n
01.7
n
0==⎥
⎦
⎤⎢⎣
⎡=⇒≤=≤ ∑∑∑
=νν
=νν
=ννν
Für eine beliebige Teilsumme: ∑=ν
ν=k
0a)k(S ; mit 0 < k < n gilt i.a.:
)k(Saa)k(Sk
0B
k
07.1 =≠⎥
⎦
⎤⎢⎣
⎡= ∑∑
=νν
=νν
Satz:
Bei einer fortlaufenden Addition von Komplementzahlen im 1.k-Format kompensieren sich die Overflow-Fehler genau dann, wenn der Betrag der Endsumme auf den Wert 1 beschränkt ist.

(iv) Multiplikation von 8-Bit-Komplementzahlen
Multiplikation fester Wortlänge von signed Integers im 1.7-Format
7.17.12.14
70.8
70.8
1416.0
0.80.80.16
bap
2b
2a
2p
bap
⋅=
⇒⋅=
⇒⋅=
Reduktion des 16-Bit-Produktwertes P2.14 → P1.7 auf 8 Bit durch:
• Truncate
• Round
• Round zero mean error

(v) Reduktionsfehler bei Fixed-Point-Multiplikation
(a) Truncate
Werte128 Bit 7 ⇒
02- PP -714.21.7 ≤ε<⇒−=εFehler:
Erwartungswert des Fehlers:
[ ] ∑∑=ν
−−−
=ννν −≈⋅−=⋅ν⋅−=⋅ε=ε
127
0
15147127
0
0039,0212722pE

(b) Round
Abrunden: ε = P1.7 – P2.14
Aufrunden: ε = P1.7 +2-7– P2.14
8-814.21.7 22- PP −≤ε<⇒−=εFehler:
Erwartungswert des Fehlers:
[ ] ( ) 1563
1
127
64
147147127
022222pE −
=ν =ν
−−−−
=ννν =⎥
⎦
⎤⎢⎣
⎡⋅ν−+⋅ν−⋅=⋅ε=ε ∑ ∑∑

Truncate Round Round zero mean error
p := signed(a) * signed(b);pt := p(14 downto 7);d := "0000000"&p(6);pr := pt + d;y <= std_logic_vector(pr);
p := signed(a) * signed(b);pt := p(14 downto 7);h := p(6 downto 0);d := "0000000"&p(6);if h = 64 and p(7) = ‘1' then
pr := pt;else
pr := pt + d;end if;y <= std_logic_vector(pr);
-2-8 < ε < 2-8
E[ ε ] = 01 8x8-Mul1 8x8-Add11 SlicesDelay: 9,37 ns
-2-8 < ε < 2-8
E[ ε ] = 2-15
1 8x8-Mul1 8x8-Add5 SlicesDelay: 7,73 ns
p := signed(a)*signed(b);y := p(14 downto 7);
-2-7 < ε < 0E[ ε ] = -127·2-15
1 8x8-Mul
Delay: 4,76 ns

(vi) Signed Integers im Booth-Format
0:amit ; 2)aa(2)aa(2)aa(
2a2a2a2a2a2a2a
2a2a2az
1-0
101
012
12
00
0
00
00
0
11
11
11
22
00
11
22
=⋅+−+⋅+−+⋅+−=
⋅+⋅−⋅+⋅−⋅+⋅+⋅−=
⋅+⋅+⋅−=
−
==44344214434421
∑∑∑−
=ν
νν
−
=ν
ν−νν
−
=ν
νν
−
−ννν
⋅β=⋅+−=⋅+⋅=
+−∈+−=β1n
0
1n
01
2n
0
1n1-n
1
22)aa(2a2-az
:Integers signedBit -nfür gilt 1,0 ,1aa: :Mit
(vii) Multiplikation von signed integers nach dem Booth-Algorithmus
ShiftAdd 2MDMD2MDMRP1n
0 MD,0,MD
1n
0+⇒⋅⋅β=⋅⎟
⎠
⎞⎜⎝
⎛⋅β=⋅= ∑∑
−
=ν
ν
+−∈
ν
−
=ν
νν 43421

Beispiel: Multiplikation von zwei 4-bit signed integers nach dem Booth-Algorithmus
1−=β
1+=β
0=β
1−=β
→ LUT ablegen

Ressourcen-Bedarf eines n-Bit-Booth-MultiplizierersRadix signed Integer Darstellung im Booth-Format LUT-
UmfangAdd
2
3
4
5
4·n
8·n
16·n
32·n
n∑−
=ν
ν−νν ⋅+−
1n
0 Werte4
1 2)aa(43421
∑−⋅
=ν
ν⋅−ν⋅ν⋅+ν⋅ ⋅++⋅−
1n
0
2
Werte8
12212
21
2)aaa2(4444 34444 21
∑−⋅
=ν
ν⋅−ν⋅ν⋅+ν⋅+ν⋅ ⋅++⋅+⋅−
1n
0
3
Werte16
1331323
31
2)aaa2a4(444444 3444444 21
∑−⋅
=ν
ν⋅−ν⋅ν⋅+ν⋅+ν⋅+ν⋅ ⋅++⋅+⋅+⋅−
1n
0
4
Werte32
144142434
41
2)aaa2a4a8(44444444 344444444 21
2n
3n
4n

VHDL-Modell Radix-2-Booth-Algorithmus
constant zero : signed(7 downto 0) := X"00";type table is array(0 to 3) of signed(7 downto 0);beginprocess(x,y)variable p_16 : signed(15 downto 0);variable md, y_neg : signed(7 downto 0);variable adr : std_logic_vector(1 downto 0);variable adr_bit : bit_vector(1 downto 0);variable adr_int : integer;variable table : table;begin----------------------- Multiplikand-Tabelle anlegen ----------------------
y_neg := zero-signed(y);table(0) := zero; -- 0table(1) := signed(y); -- MDtable(2) := y_neg; -- -MDtable(3) := zero; -- 0
----------------------------- Add/Shift -----------------------------------p_16 := X"0000";for i in 0 to 7 loop
if i = 0 thenadr := x(0)&"0";
elseadr := x(i)&x(i-1);
end if;adr_bit := to_bitvector(adr);adr_int := bv2int(adr_bit);md := table(adr_int); -- Table Fetchp_16 := p_16+md&"00000000"; -- Addp_16 := p_16(15)&p_16(15 downto 1); -- Shift
end loop;p <= std_logic_vector(p_16);
end process;

VHDL-Modell Radix-3-Booth-Algorithmusconstant zero : signed(8 downto 0) := "000000000";type tabelle is array(0 to 7) of signed(8 downto 0);process(x,y)variable p_16 : signed(15 downto 0);variable mr, y_9, y_9_2,y_9_neg,y_9_2_neg : signed(8 downto 0);variable adr : std_logic_vector(2 downto 0);variable adr_bit : bit_vector(2 downto 0);variable adr_int : integer;variable table : tabelle;begin
y_9 := signed(y(7)&y); y_9_2_neg := zero – y_p_2;y_9_2 := y_9(7 downto 0)&"0"; y_9_2_neg := zero – y_p_2;table(0) := zero; -- 0table(1) := y_9; -- MDtable(2) := y_9; -- MDtable(3) := y_9_2; -- 2MDtable(4) := y_9_2_neg; -- -2MDtable(5) := y_9_neg; -- -MDtable(6) := y_9_neg; -- -MDtable(7) := zero; -- 0p_16 := X"0000";for i in 0 to 3 loop
if i = 0 thenadr := x(1)&x(0)&"0";
elseadr := x(2*i+1)&x(2*i)&x(2*i-1);
end if;adr_bit := to_bitvector(adr);adr_int := bv2int(adr_bit);mr := table(adr_int);p_16 := p_16+(mr&"0000000");if i <= 2 then
p_16 := p_16(15)&p_16(15)&p_16(15 downto 2);else
p_16 := p_16(15)&p_16(15 downto 1);end if;
end loop;p <= std_logic_vector(p_16);
end process;

Syntheseergebnisse 8x8-Booth-Multiplizierer
Variable · Variable Konstante · Variable
Rad2 Rad3 Rad4 Rad5 Rad2 Rad3 Rad4 Rad5
Slices4-LUT32x11-ROM16x10-ROM16-Add11-Add10-Add9-Add8-AddTCLK(ns)
68123
--7---1
32,38
5493--3--1-
17,56
102162
--2-6--
18,95
202320
--113---
23,83
2956--7----
23,65
1729--3----
12,88
2229-32----
10,17
19282-1----
6,94
Macros

Path-Delay 8x8-Booth-Multiplizierer
2 3 4 5 0
5
10
15
20
25
30
35TCLK(ns)
Var x Var
Const x Var
Hardcore-8x8-MUL
Radix

Ressourcen-Bedarf eines 8x8-Booth-Multiplizierers
2 3 4 5 0
50
100
150
200
Radix
Slices
Var x Var
Const x Var
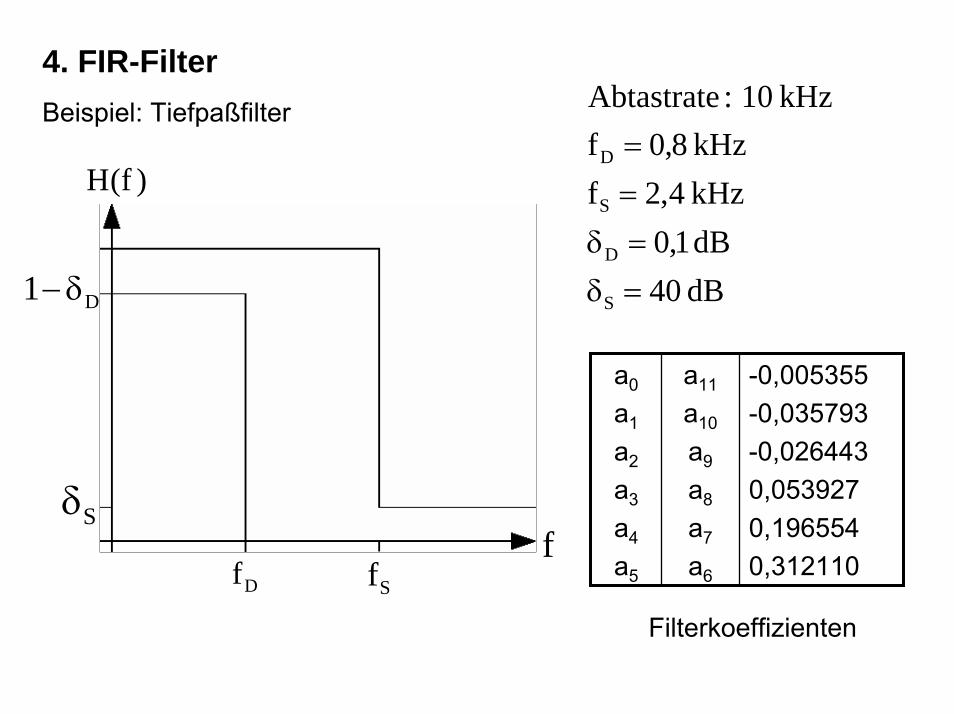
4. FIR-FilterBeispiel: Tiefpaßfilter
dB 40dB 1,0kHz 4,2fkHz 8,0f
kHz 10 :Abtastrate
S
D
S
D
=δ=δ==
)f(H
Df Sf
D1 δ−
Sδf
a0
a1
a2
a3
a4
a5
a11
a10
a9
a8
a7
a6
-0,005355-0,035793-0,0264430,0539270,1965540,312110
Filterkoeffizienten

Das Filter wurde jeweils in Form der vier Strukturen:
• direkte Form
• direkte Form mit Teilsummenbildung
• transponierte Form
• direkte Form mit Teilsummenbildung und verteilter Arithmetik
auf einem FPGA (Spartan-3, Firma Xilinx) implementiert. Dabei wurden die:
• Signalwerte und Filterkoeffizienten als 8-Bit signed integersim 1.7-Format dargestellt,
• Multiplikationen mit den Hardcore-Multipliers des FPGA durchgeführt.

4.1 Direkte Form
∑=ν
ν ν−⋅=11
0)k(xa)k(y :ngleichungDifferenze
VHDL-Modell: if clk‘event and clk = ‘1‘ thenx(0) <= x_in;y <= std_logic_vector(sop(14 downto 7));for i in 11 downto 1 loop
x(i) <= x(i-1);end loop;
end if;sop := 0for i in 11 downto 0 loop
sop := sop + coeff(i)*x(i);end loop;

library IEEE;use IEEE.STD_LOGIC_1164.ALL;use IEEE.STD_LOGIC_ARITH.ALL;use IEEE.STD_LOGIC_UNSIGNED.ALL;
entity fir isgeneric (N : integer :=11);port (x_in : in std_logic_vector(7 downto 0);
clk : in std_logic;y : out std_logic_vector(7 downto 0));
end fir;
architecture behavioral of fir istype tap_line is array (0 to N) of std_logic_vector(7 downto 0);signal x : tap_line;type table is array(0 to N) of signed(7 downto 0);constant coeff : table := (X"FF",X"FB",X“FD",X"07",X"19",X"28",
X"28",X"19",X"07",X"FD",X"FB", X"FF“);beginprocess(clk)variable sop : signed(15 downto 0);begin
if (clk'event and clk='1') thenfor i in N downto 1 loop
x(i) <= x(i-1);end loop;x(0) <= x_in;y <= std_logic_vector(sop(14 downto 7));
end if;sop := X"0000";for i in 0 to N loop
sop := sop + coeff(i)*signed(x(i));end loop;
end process;end behavioral;

4.2 Direkte Form mit Partialsummenbildung
Aufgrund der symmetrischen Koeffizienten lassen sich die 6 Partial-Summensignale bilden:
5 0für );11k(x)k(xS ≤ν≤ν+−+ν−=ν

Damit ergibt sich die Differenzengleichung des Filters zu:
( )∑∑=ν
ν=ν
νν ν+−+ν−⋅=⋅=5
0
5
0)11k(x)k(xaSa)k(y
VHDL-Modell:sop := 0;for i in 0 to 5 loop
sop := sop + coeff(i)*(x(i) + x(11-i));end loop;y <= std_logic_vector(sum(14 downto 7));

4.3 Transponierte FormMit dem Umkehrtheorem läßt sich die direkte Form in die transponierte Form umwandeln.
Hierfür lauten die Differenzengleichungen:
)1k(v)k(xay(k)10i1für );1k(v)k(xa)k(v
)k(xa)k(v
10
1iii
1111
−+⋅=≤≤−+⋅=
⋅=
−

VHDL-Modell mit Hardcore-Multiplikation
process(clk)begin
if clk‘event and clk = ‘1‘;x_int := signed(x);y <= std_logic_vector(v(0));for i in 1 to 11 loop
u(i) := v(i);end loop;
end if;for i in 0 to 11 loop
if i = 11 thenop_16 := a(i)*x_int;v(i) := op_16(14 downto 7);
elseop_16 := a(i)*x_int;v(i) := u(i+1)+op_16(14 downto 7);
end if;end loop;
end process;

VHDL-Modell mit Softcore-Multiplikation
constant coeff : coeff_table := ( ("0"&X"00","1"&X"F3","1"&X"F3","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a0("0"&X"00","1"&X"FB","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"), -- a1("0"&X"00","1"&X"FD","1"&X"FD","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a2("0"&X"00","0"&X"07","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"), -- a3("0"&X"00","0"&X"19","1"&X"F3","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a4("0"&X"00","0"&X"28","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"), -- a5("0"&X"00","0"&X"27","1"&X"F3","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a6 ("0"&X"00","0"&X"17","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"), -- a7("0"&X"00","0"&X"09","1"&X"F3","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a8("0"&X"00","1"&X"FA","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"), -- a9("0"&X"00","1"&X"F4","1"&X"F3","1"&X"E6","0"&X"1A","0"&X"0D","0"&X"0D","0"&X"00"), -- a10("0"&X"00","1"&X"F5","1"&X"FB","1"&X"F6","0"&X"0A","0"&X"05","0"&X"05","0"&X"00"));-- a11process(clk)begin
if (clk'event and clk='1') thenx_int := signed(x);y <= std_logic_vector(v(0));for i in 1 to 11 loop
u(i) := v(i);end loop;
end if;for i in 0 to 11 loop
if i = 0 thenop_16 := b3_mul(std_logic_vector(x_int),i,coeff);v(i) := op_16(14 downto 7);
elseop_16 := b3_mul(std_logic_vector(x_int),i,coeff);v(i) := u(i+1)+op_16(14 downto 7);
end if;end loop;
end process;

4.4 Prinzip der verteilten ArithmetikBeispiel:
ν=ν
ν ⋅= ∑ xay2
0
Für 4-Bit-Zahlen im 1.3-Format gilt:
[ ]⎩⎨⎧
=µ≤µ≤+
=α⋅µ⋅α== µ=µ
−µµ∑ 3für 1;-
20für ;1:mit ;2)(x x(0) x(1) x(2))3(xx
3
0
3
∑ ∑∑ ∑=µ =ν
νν−µ
µ=ν =µ
−µνµν µ⋅⋅⋅α=⋅µ⋅α⋅=
3
0
2
0
32
0
3
0
3 )(xa22)(xay
( ) 33
0 0,1 )( xda Werte;8
221100 2)(xa)(xa)(xay −µ
=µ ∈µ
µ ⋅µ⋅+µ⋅+µ⋅⋅α=∑ν
444444 3444444 21
Legt man diese 8 Werte in einer LUT ab, so ergibt sich folgende Struktur:


4.5 FIR-Filter mit verteilter Arithmetik
Geht man davon aus, daß die 6 Signalwerte Sν als 9-Bit-Zahlen im 2.7-Format dargestellt werden, so gilt hierfür:
( )s(0) s(1) s(2) s(3) s(4) s(5) s(6) )7(s )8(sS =
∑=µ
µ−µ
µ⎩⎨⎧
=µ≤µ≤+
=α⋅µ⋅α=8
0
7
8für 1;-70für ;1
:mit ;2)(sS

Damit ergibt sich die Differenzengleichung des FIR-Filters zu:
( )∑
∑ ∑ ∑∑
∑
=µ
−µµ
=ν =µ
−µν
=ννµ
=µ
−µνµν
=ννν
⋅µ⋅+µ⋅+µ⋅+µ⋅+µ⋅+µ⋅⋅α=
⋅µ⋅⋅α=⋅µ⋅α⋅=
⋅=
8
0
7
Werte64
554433221100
5
0
8
0
75
0
8
0
7
5
0
2)(sa)(sa)(sa)(sa)(sa)(sa
2)(s a2)(sa
Say
444444444444 3444444444444 21
Legt man die 64 Werte in einer LUT ab, so beträgt deren
Speichervolumen = 64·8 = 512 Bit

Dieses Speichervolumen läßt sich verringern, wenn man die Differenzen-gleichung:
( )∑=µ
−µµ ⋅µ⋅+µ⋅+µ⋅+µ⋅+µ⋅+µ⋅⋅α=
8
0
7
Werte64
554433221100 2)(sa)(sa)(sa)(sa)(sa)(sa y444444444444 3444444444444 21
umformt zu:
( )
( )
2)(sa)(sa)(sa
2)(sa)(sa)(say
78
0 Werte8
554433
78
0 Werte8
221100
−µ
=µµ
−µ
=µµ
⋅µ⋅+µ⋅+µ⋅⋅α+
+⋅µ⋅+µ⋅+µ⋅⋅α=
∑
∑
44444 344444 21
44444 344444 21
Die jeweiligen 8 Werte werden in zwei LUT abgelegt. Damit ergibt sich ein
Speichervolumen = 2·8·8 = 128 Bit
was einer Verringerung auf 25 % entspricht. Allerdings vergrößert sich der Bedarf an arithmetischen Operationen um eine 8-Bit-Addition.


Synthesis Report FIR-Filter 11. Ordnung
Hardcore-Multiplikation
Form Slices 4-LUT
HardMul
6-bit-Add
8-bit-Add
16-bit-Add
ROM CLK (ns)
direktdirekt p.Sdir.transp.
14212357
16512388
12612
---
-612
116-
---
20,4017,898,45
Form Slices 4-LUT
3-bit-Add
6-bit-Add
8-bit-Add
16-bit-Add
ROM CLK (ns)
direktdir.transp.vert. Arith.
346275133
525416229
847-
--5
-116
47361
--
64x8
28,0315,1022,29
Softcore-Multiplikation (Rad-3-Booth)

Synthesis Report FIR-Filter 11. Ordnung
50 100 150 200 250 300 3505
10
15
20
25
30
Slices →
↑TCLK(ns)
transp. HM
direkt HM
direkt part. Sum. HM
direkt SM
transp. SM
vert. Arithm.

5. WellendigitalfilterProblem bei der Diskretisierung analoger Filter:
verzögerungsfreie Schleife
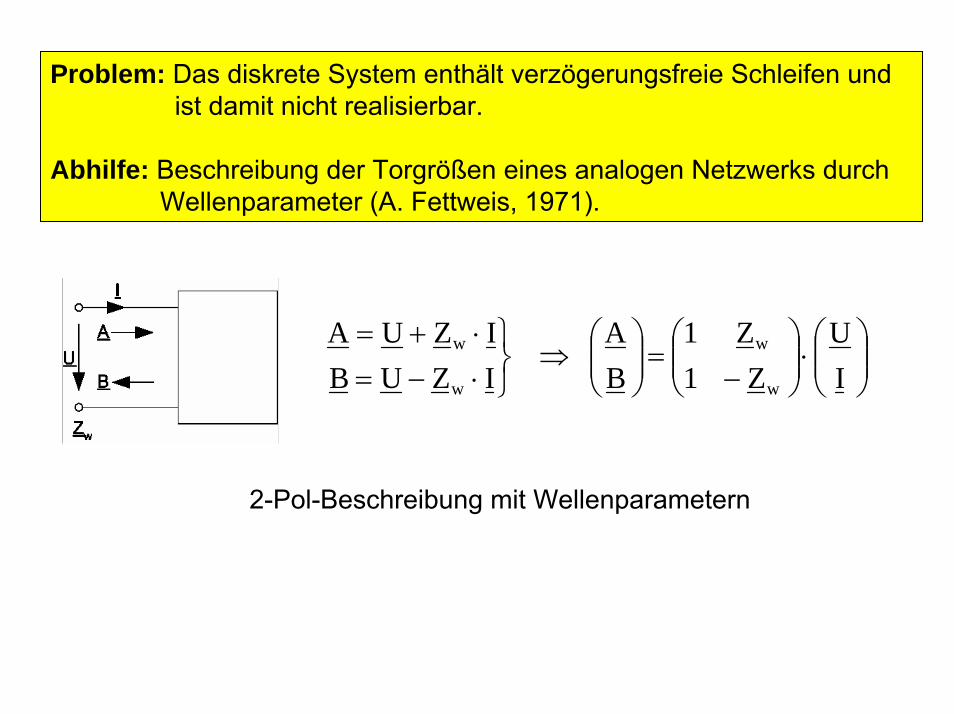
Problem: Das diskrete System enthält verzögerungsfreie Schleifen und ist damit nicht realisierbar.
Abhilfe: Beschreibung der Torgrößen eines analogen Netzwerks durch Wellenparameter (A. Fettweis, 1971).
⎟⎟⎠
⎞⎜⎜⎝
⎛⋅⎟⎟⎠
⎞⎜⎜⎝
⎛−
=⎟⎟⎠
⎞⎜⎜⎝
⎛⇒
⎭⎬⎫
⋅−=⋅+=
IU
Z1Z1
BA
IZUBIZUA
w
w
w
w
2-Pol-Beschreibung mit Wellenparametern

Beispiel: Kondensator als diskretes System mit Wellenvariablen
IZUBIZUA
w
w
⋅−=⋅+=
⇒⋅
=⋅ω⋅
= Cp
ICj
IU :mit
⇒⋅=⋅⋅⋅+⋅⋅−
=⇒⋅⎟⎟⎠
⎞⎜⎜⎝
⎛−
⋅=
⋅⎟⎟⎠
⎞⎜⎜⎝
⎛+
⋅=
TCR :mit ; CRp1CRp1
AB
IZCp
1B
IZCp
1A
a21
00
0
w
w
⇒+−
⋅⋅=⋅⋅+⋅⋅−
= 1z1zf2p :mit ;
Tp1Tp1
AB
aa2
1a2
1
1)-a(k b(k) z)z(A)z(B 1 =⇔= −
reflektierte Welle einfallende Welle, Ta verz.
z -1a(k) b(k)
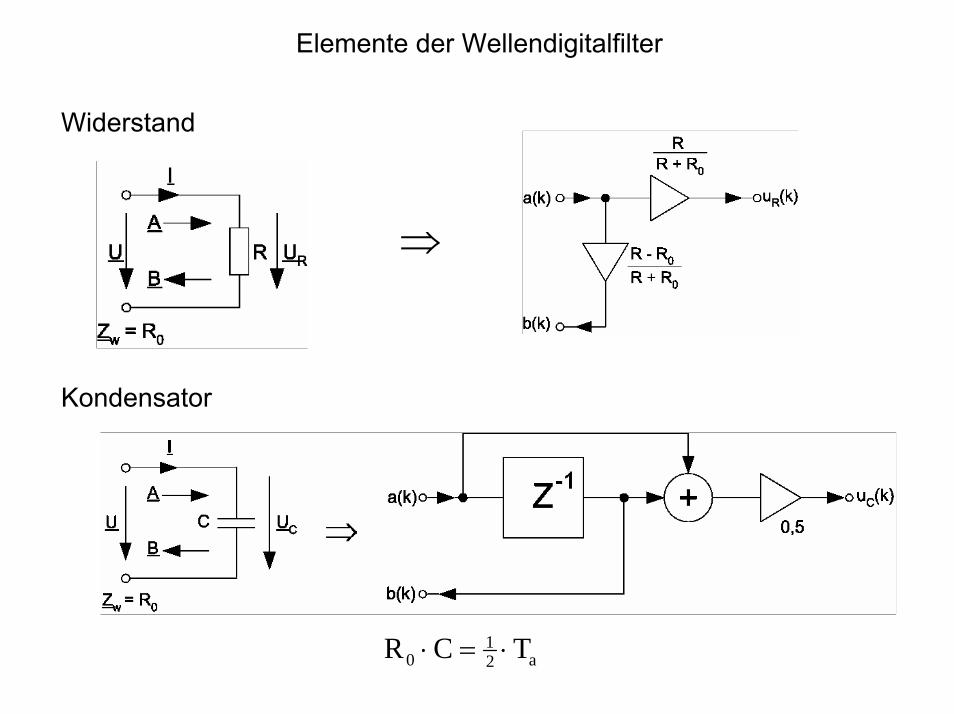
Elemente der Wellendigitalfilter
Widerstand
⇒
Kondensator
a21
0 TCR ⋅=⋅

Induktivität
a21
0
TRL
⋅=
Spannungsquelle mit Innenwiderstand
0
0
RRR2+⋅
0
0
RRRR
+−

3-Tor-Serienadaptor
321
3
1
III
0U
==
=∑=ν
ν
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛⋅⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−−−−−−−−−
=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛∈ν
++⋅
= νν
)k(a)k(a)k(a
r1rrrr1rrrr1
)k(b)k(b)k(b
:gilt 1,2,3 ;RRR
R2r :Mit
3
2
1
333
222
111
3
2
1
3w2w1w
w
Da r1 + r2 + r3 = 2, ergibt sich mit r3 =1:
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛⋅⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−−−−−−−
=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
)k(a)k(a)k(a
0111rr1rrrr1
)k(b)k(b)k(b
3
2
1
3
2
1
womit Port 3 reflexionsfrei ist.

3-Tor-Paralleladaptor
∑=ν
ν =
==3
1
321
0I
UUU
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛⋅⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−−
−=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛∈ν
++
⋅= ν
ν
)k(a)k(a)k(a
1gggg1gggg1g
)k(b)k(b)k(b
:gilt 1,2,3 ;2
g :Mit
3
2
1
321
321
321
3
2
1
R1
R1
R1
R1
3w2w1w
w
Da g1 + g2 + g3 = 2, ergibt sich mit g3 =1:
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛⋅⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−−−−
=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
)k(a)k(a)k(a
0g1g1gg1g11g
)k(b)k(b)k(b
3
2
1
3
2
1
womit Port 3 reflexionsfrei ist.
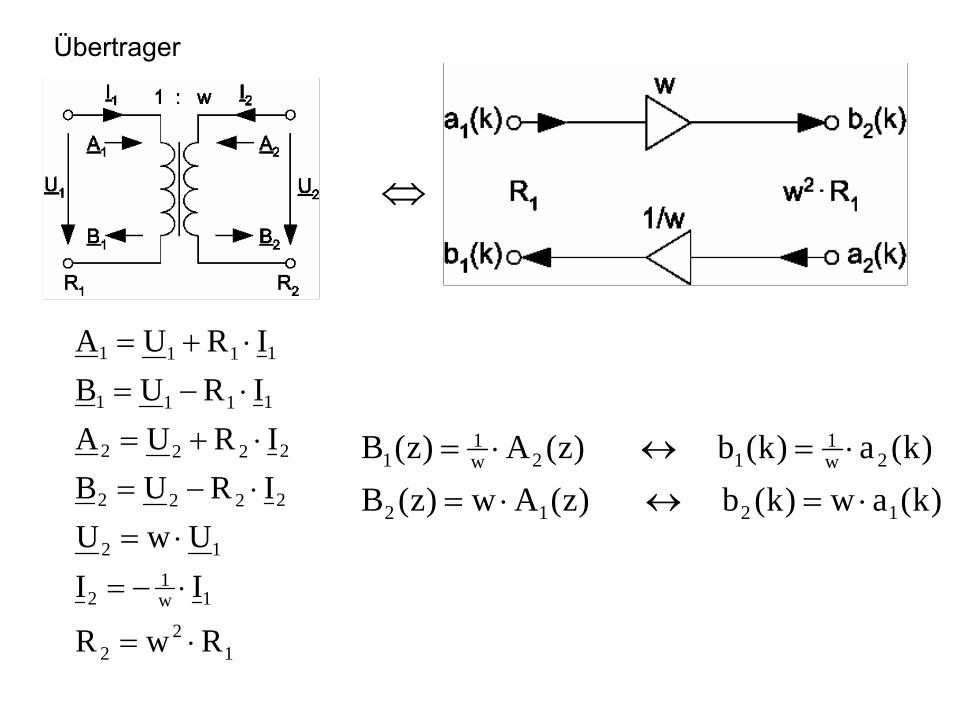
Übertrager
⇔
12
2
1w1
2
12
2222
2222
1111
1111
RwR
IIUwU
IRUB IRUA
IRUBIRUA
⋅=
⋅−=
⋅=⋅−=⋅+=⋅−=⋅+=
)k(aw)k(b )z(Aw)z(B)k(a)k(b )z(A)z(B
1212
2w1
12w1
1
⋅=↔⋅=
⋅=↔⋅=

Regeln• Zusammengeschaltete Tore müssen gleichen Wellenwiderstand zeigen.• Im Netz dürfen keine verzögerungsfreie Schleifen entstehen.

1. Beispiel: Tiefpaßfilter
)f(H
Df Sf
D1 δ−
Sδf
dB 40dB 1,0kHz 4,2fkHz 8,0f
kHz 10 :Abtastrate
S
D
S
D
=δ=δ==

)f(H
Df Sf
D1 δ−
Sδf
21
21
1
1
z65339,0z32483,11zz074257,01
z5882,01z03262.003262,0)z(H −−
−−
−
−
⋅+⋅−+⋅+
⋅⋅−
⋅+=
Allpaß-Dekomposition
Toleranzschema:
LC-Netzwerk
Abzweig-WDF Brücken-WDF

A) Abzweig-Wellendigitalfilter
LC-Netzwerk: C1 = 192,8 nFC2 = 10,31 nFC3 = C1L = 211,7 mH
P-Adaptormit C1
S-Adaptor
P-Adaptormit C3
P-Adaptormit C2, L
A-WDF:

Das WDF hat zwei Eingangssignale x1, x2 und zwei Ausgangssignale y1, y2. Definiert man die vier Übertragungsfunktionen:

Das WDF hat zwei Eingangssignale x1, x2 und zwei Ausgangssignale y1, y2. Definiert man die vier Übertragungsfunktionen:
XYH und
XY H
XYH und
XY H
0x2
222
0x2
112
0x1
221
0x1
111
11
22
==
==
==
==
21122211 HH und HH ==⇒
Weiterhin sind die Übertragungsfunktionen paarweise leistungskom-plementär. Es besteht die Beziehung (Feldkeller-Gesetz):
1)f(H)f(H)f(H)f(H 222
212
221
211 =+=+

0 1000 2000 3000 4000 50000
0.2
0.4
0.6
0.8
1
f/Hz
|H(f)
|/dB
)f(H211
)f(H221
Komplementäre Frequenzgänge des WDF

Skalierung bei Festkomma-Arithmetik
Forderung: Für ein beliebiges auf |x(k)| < 1 beschränktes Eingangssignal müssen alle internen Signale vi(k) des Systems ebenfalls auf |vi(k)| < 1 beschränkt sein.
Skalierung-Schmalband : )(Hmax
d)(HlimH :NormL
Skalierung-Breitband : )k(hh :Norm
de)(X)(H)k(v :IFT
)k(x)k(h)k(v :tzFaltungssa
i
pi2
1pi
ki1i1
kji2
1i
ii
p1
Ω=
⎟⎟⎠
⎞⎜⎜⎝
⎛Ω⋅Ω⋅=−
=−
Ω⋅⋅Ω⋅Ω⋅=
∗=
∫
∑
∫
π
π−π⋅∞→∞∞
∞
−∞=
⋅Ω⋅π
π−π⋅
l

0 5 10 15 20 25 30
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
7866,2)k(hh0k
212 ==∑∞
=
0 1000 2000 3000 4000 50000
0.5
1
1.5
2
2.5
1016,2)f(Hmax 2 =
h2
c = 1/2,7866 = 0,3589 c = 1/2,1016 = 0,4758

Übertrager
Abzweig-WDF mit Skalierung

Modellierung des Abzweig-Wellendigitalfilters
p_adaptor_1 p_adaptor_2
s_adaptor

VHDL-Modell des Tiefpaß-Abzweig-Wellendigitalfilterscomponent p_adaptor_1 generic(g : signed(7 downto 0));
port(a1, a2, a3 : in std_logic_vector(7 downto 0);b1, b2, b3 : out std_logic_vector(7 downto 0));
end component;component s_adaptor port(a1, a2, a3 : in std_logic_vector(7 downto 0);
b1, b2, b3 : out std_logic_vector(7 downto 0));end component;component p_adaptor_2 port(a1, a2, a3 : in std_logic_vector(7 downto 0);
b1, b2, b3 : out std_logic_vector(7 downto 0));end component;signal x_in,c1_in,l1,l_in,c2_in,c1_out,c2_out : std_logic_vector(7 downto 0);signal c3_out,l_out,c3_in,s1,s2,dy,r1,r2,h1,h2,y_out : std_logic_vector(7 downto 0);constant zero : std_logic_vector(7 downto 0) := X"00";beginu1: p_adaptor_1 generic map (X"1A") port map (x_in,c1_out,r2,dy,c1_in,h1);u2: s_adaptor port map (h1,s2,r1,r2,s1,h2);u3: p_adaptor_2 port map (h2,c3_out,zero,r1,c3_in,y_out);u4: p_adaptor_1 generic map(X"3C") port map (c2_out,l_out,s1,c2_in,l1,s2);process(clk,x)variable l_s : signed(7 downto 0);begin
if clk'event and clk='1' thenx_in <= x;c1_out <= c1_in;c2_out <= c2_in;c3_out <= c3_in;l_out <= l_in;y <= y_out;
end if;l_s := signed(zero)-signed(l1);l_in <= std_logic_vector(l_s);
end process;

B) Brücken-Wellendigitalfilter
(i) Allpaß-Dekomposition der Übertragungsfunktion:
Unter bestimmten Voraussetzungen läßt sich die Übertragungsfunktion H(z) eines diskreten Systems N-ter Ordnung darstellen durch:
[ ])z(B)z(A)z(H 21 +⋅=
A(z) und B(z) sind dabei zwei stabile Allpaßfilter mit |A(Ω)|=|B(Ω)|=1; für 0 < Ω < π, wobei für:
(i) N ungerade, A(z) und B(z) reelle Koeffizienten und N = nA+nB
(ii) N gerade, A(z) und B(z) komplexe Koeffizienten und nA = nB = N/2
Bemerkung:
(i) Butterworth-, Tchebycheff- und Cauer-Filter erfüllen die Vorausset-zungen.
(ii) Die Polstellen von H(z) sind über die sog. pole interlace property mit denen von A(z) und B(z) verknüpft.
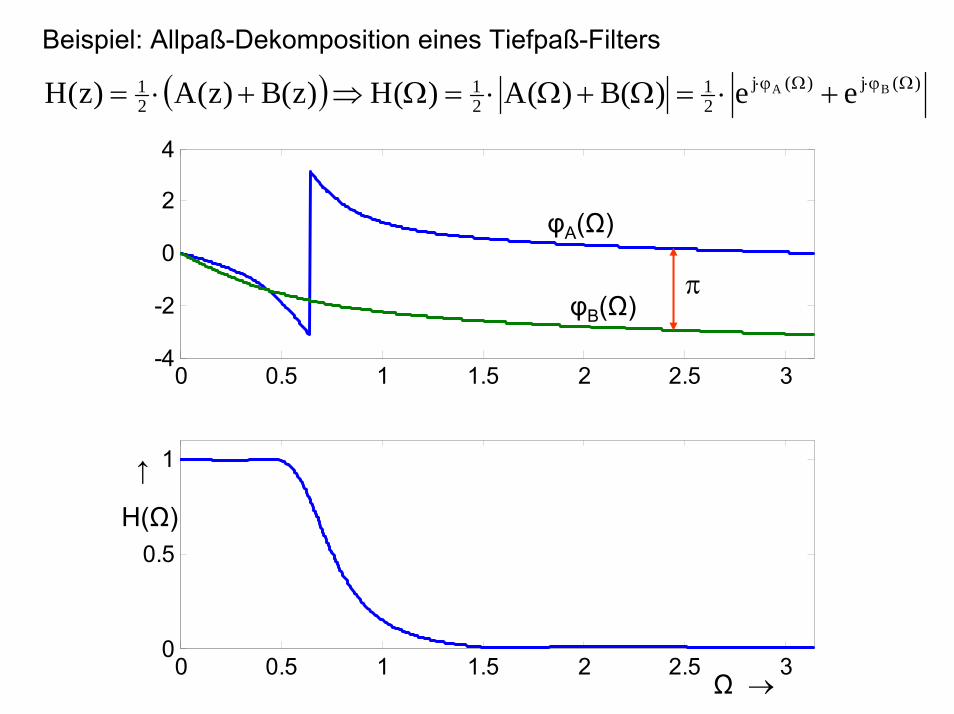
Beispiel: Allpaß-Dekomposition eines Tiefpaß-Filters
0 0.5 1 1.5 2 2.5 3-4
-2
0
2
4
0 0.5 1 1.5 2 2.5 30
0.5
1
( ) )(j)(j21
21
21 BA ee)(B)(A)(H)z(B)z(A)z(H Ωϕ⋅Ωϕ⋅ +⋅=Ω+Ω⋅=Ω⇒+⋅=
Ω →
φA(Ω)
φB(Ω)
↑
H(Ω)
π

Bemerkung:
Bildet man mit den Allpaßfiltern A(z), B(z) die Übertragungsfunktionen:
( )( ))z(B)z(A:)z(H~ )ii(
)z(B)z(A:)z(H )i(
21
21
−⋅=
+⋅=
so sind die zugehörigen Amplitudengänge leistungskomplementär. Es gilt somit:
π≤Ω≤=Ω+Ω 0 für ;1)(H~)(H22

Polstellen-Interlace-Konfiguration
Setzt sich eine Übertragungsfunktion H(z) n-ter Ordnung, mit n ungerade, aus zwei Allpaßfiltern A(z), B(z) zusammen, so sind die Polstellen der beiden Allpaßfilter gemäß einer Interlace-Konfiguration vollständig in den n Polstellen von H(z) enthalten.
Ordnet man die n Polstellen von H(z):
n321j ... :daß so n,1,...,mit ;erp v Θ<<Θ<Θ<Θ=ν⋅= Θ
νν
dann gilt: (i) Pole A(z): p1, p3, …, pn (ii) Pole B(z): p2, p4, …, pn-1
Definiert man: ( ) ( )
)zp1()z(D )ii( ; )zp1()z(D )i( 1k2
1n
1kB
11k2
1n
1kA
21
21
−−
=
−−
+
=
⋅−=⋅−= ΠΠ
)z(D)z(Dz)z(B
)z(D)z(Dz)z(A
B
B)1n(
A
A)1n( 21
21
⋅=⋅= −⋅−+⋅−dann gilt:
giert)(parakonju )z(D:(z)D :mit 1−∗=

(ii) Allpaß-Dekomposition des Tiefpaßfilters
21
21
1
1
z6534,0z3248,11zz0743,01
z5882,01z0326.00326,0)z(H −−
−−
−
−
⋅+⋅−+⋅+
⋅⋅−
⋅+=
-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Real Part
Imag
inar
y P
art
z5882,01z5882,0)z(B 1
1
−
−
⋅−+−
=
21
21
z6534,0z3248,11zz3248,16534,0A(z) −−
−−
⋅+⋅−+⋅−
=
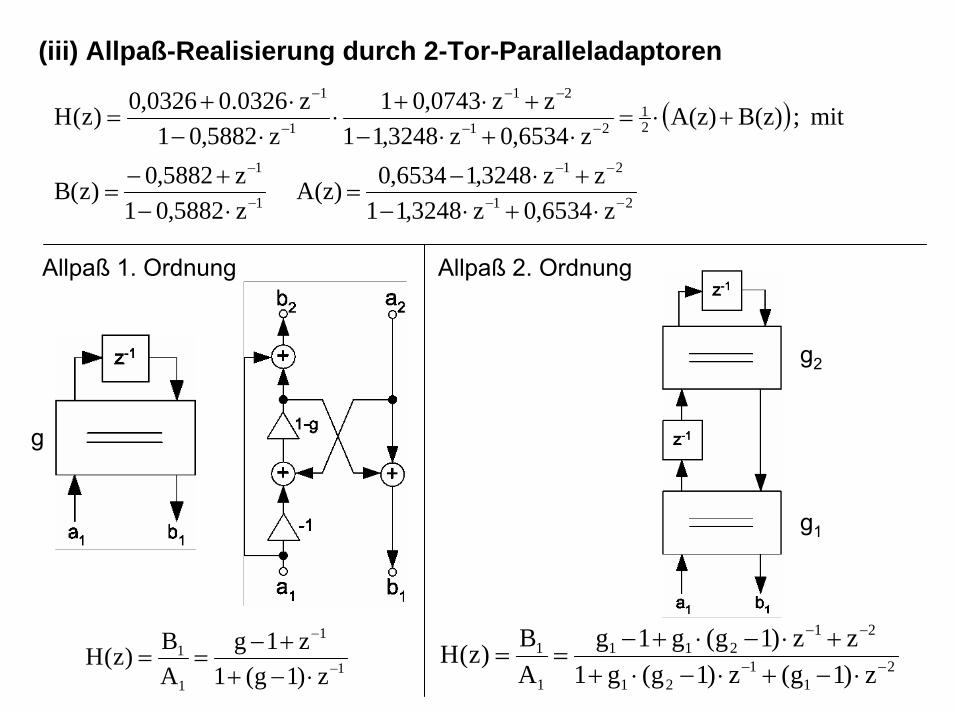
(iii) Allpaß-Realisierung durch 2-Tor-Paralleladaptoren
( )
21
21
1
1
21
21
21
1
1
z6534,0z3248,11zz3248,16534,0A(z)
z5882,01z5882,0)z(B
mit ; B(z)A(z)z6534,0z3248,11
zz0743,01z5882,01
z0326.00326,0)z(H
−−
−−
−
−
−−
−−
−
−
⋅+⋅−+⋅−
=⋅−+−
=
+⋅=⋅+⋅−
+⋅+⋅
⋅−⋅+
=
Allpaß 1. Ordnung Allpaß 2. Ordnung
1
1
1
1
z)1g(1z1g
AB)z(H −
−
⋅−++−
== 21
121
21211
1
1
z)1g(z)1g(g1zz)1g(g1g
AB)z(H −−
−−
⋅−+⋅−⋅++⋅−⋅+−
==
g2
g1
g

(iv) Struktur des Brücken-WDF:
x(k)y(k) : Tiefpaß
Hochpaß : )k(y~
g = 0,4118
g = 1,6534
g = 0,1987 Component
21
21
z6534,0z3248,11zz3248,16534,0A(z) −−
−−
⋅+⋅−+⋅−
=
z5882,01z5882,0)z(B 1
1
−
−
⋅−+−
=

VHDL-Modell des Tiefpaß-Brücken-Wellendigitalfilters
architecture structural of b_wdf iscomponent p_adaptor generic(g : signed(7 downto 0));
port(a1,a2 : in std_logic_vector(7 downto 0);b1,b2 : out std_logic_vector(7 downto 0));
end component;signal x_in,v1,v2,v3,u1,u2,u3,u4,y1,y2,y_out : std_logic_vector(7 downto 0);signal u1,u2,u3,u4,y1,y2,y_out : std_logic_vector(7 downto 0);beginp1: p_adaptor generic map(X"3D") port map(x_in,v1,y1,u1);p2: p_adaptor generic map(X"C3") port map(x_in,u4,y2,u2);p3: p_adaptor generic map(X"57") port map(v2,v3,u4,u3);process(clk)variable y_s : signed(7 downto 0);begin
if clk'event and clk='1' thenx_in <= x;v1 <= u1;v2 <= u2;v3 <= u3;y <= y_out;
end if;y_s := signed(y1) + signed(y2);y_out <= std_logic_vector(y_s);
end process;end structural;

WDF vs. FIR 11. Ordnung
0 1000 2000 3000 4000 5000-80
-70
-60
-50
-40
-30
-20
-10
0
f/Hz
H(f)
/dB
FIR 11. Ordnung
WDF
Amplitudengang

0 200 400 600 800 1000-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
f/Hz
H(f)
/dB
FIR
WDF
Amplitudengang im Durchlaßbereich

Tiefpaß Synthesis Report mit dem FPGA XC3 C200
Form Slices 4-LUT
8x8-Mul
6-bit-Add
8-bit-Add
16-bit-Add
ROM CLK (ns)
direktPart. Sum.transpon.vert. Arith.A-WDFB-WDF
15212355
1337552
16712389
2291380
1055-63
---5--
-61161910
13611--
---
64x8--
19,9717,899,56
22,2958,5725,29
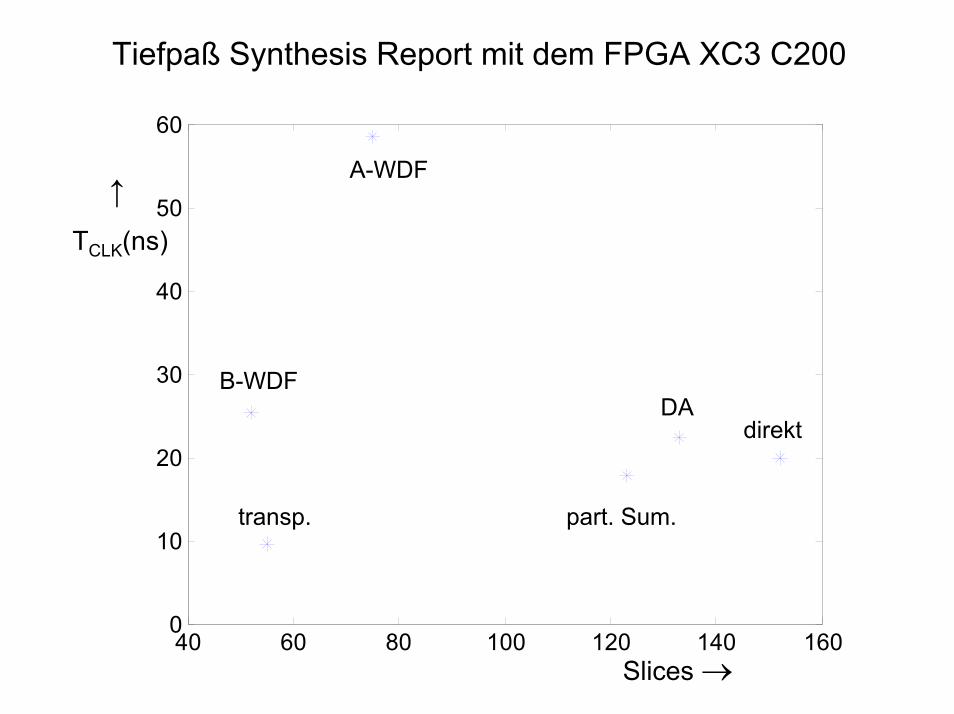
Tiefpaß Synthesis Report mit dem FPGA XC3 C200
40 60 80 100 120 140 1600
10
20
30
40
50
60
A-WDF
part. Sum.
DAdirekt
transp.
B-WDF
Slices →
↑TCLK(ns)

Beispiel 2: Bandpaßfilter
H(f)/dB
0.1
-0.1
-40
f/kHz1 1.6 2.1 3
FIR N = 46
IIR N = 6
Toleranzschema des digitalen Bandpaßfilters mit fa = 10 kHz

A) Bandpaß-Abzweig-Wellendigitalfilter
LC-Netzwerk
P2 mit L1
P1 mit C1
S1 S2
P3 mit C2, L2 P4 mit C3, L3
P6 mit C4
P5 mit L4A-WDF

VHDL-Modell des Bandpaß-Abzweig-Wellendigitalfiltersp1: p_adaptor_1 generic map(X"18") port map (x_in,c1_out,r1,dy,c1_in,h1);p2: p_adaptor_1 generic map(X“5E") port map (h1,l1_out,r2,r1,l1,h2);p3: p_adaptor_1 generic map(X"0C") port map (l2_out,c2_out,p3_in,l2,c2_in,p3_out);p4: p_adaptor_1 generic map(X“2C") port map (l3_out,c3_out,p4_in,l3,c3_in,p4_out);p5: p_adaptor_1 generic map(X“19") port map (h4,l4_out,r5,r4,l4,h5);p6: p_adaptor_2 port map (h5,c4_out,zero,r5,c4_in,y_out);s1: s_adaptor generic map(X"0D") port map (h2,p3_out,zero,r2,p3_in,h3);s2: s_adaptor generic map(X"52")port map (h3,p4_out,r4,r3,p4_in,h4);process(clk,x)variable l1_s,l2_s,l3_s,l4_s : signed(7 downto 0);begin
if clk'event and clk='1' thenx_in <= x;c1_out <= c1_in;c2_out <= c2_in;c3_out <= c3_in;c4_out <= c4_in;l1_out <= l1_in;l2_out <= l2_in;l3_out <= l3_in;l4_out <= l4_in;y <= y_out;
end if;l1_s := signed(zero)-signed(l1);l1_in <= std_logic_vector(l1_s);l2_s := signed(zero)-signed(l2);l2_in <= std_logic_vector(l2_s);l3_s := signed(zero)-signed(l3);l3_in <= std_logic_vector(l3_s);l4_s := signed(zero)-signed(l4);l4_in <= std_logic_vector(l4_s);
end process;

B) IIR-Bandpaßfilter
21
21
21
21
21
2
z8806.0z0557.11z2561,0z4059,02561,0
z8605.0z3983.01z2561,0z1138,02561,0
z7242.0z6933.01z2561,02561,0)z(H
:gsfunktionÜbertragun
−−
−−
−−
−−
−−
−
⋅+⋅−⋅+⋅−
⋅⋅+⋅−
⋅+⋅+⋅
⋅+⋅−⋅−
=
x(k) y(k)
Component

VHDL-Modell des IIR-Bandpaßfilters
architecture structural of iir_bandpass iscomponent biquad generic(a0,a1,a2,b1,b2 : signed(11 downto 0));
port(input: in std_logic_vector(7 downto 0);clk: in std_logic;output: out std_logic_vector(7 downto 0));
end component;signal x_in, y_out, v1, v2 : std_logic_vector(7 downto 0);beginbq1: biquad generic map(X"20C",X"000",X"DF4",X"A74",X"5CB")
port map (x_in,clk,v1);bq2: biquad generic map(X"20C",X"0E9",X"20C",X"CD0",X"6E2")
port map (v1,clk,v2);bq3: biquad generic map(X"106",X"E61",X"106",X"BC7",X"386")
port map (v2,clk,y_out);process(clk)begin
if clk'event and clk='1' thenx_in <= x;y <= y_out;
end if;end process;end structural;

C) Allpaß-Dekomposition von Bandpaßfiltern
Tiefpaß-Bandpaß-Transformation
[ ] [ ]1,...,2n ;erp n 1,..., ;erp
)z(B)z(A)z(H )z(B)z(A)z(H :TB2Tjj
BPBP21
BPTPTP21
TP
=µ⋅=→=ν⋅=
+⋅=→+⋅=−µν Θ⋅
µµΘ⋅
νν
Beispiel: 2n = 6
*1
*2
*3321
654321
p p p p p p
Θ<Θ<Θ<Θ<Θ<Θ
321
321 p p pΘ<Θ<Θ
Tiefpaß:
Bandpaß:
A(z)B(z)
Bei der TP2BP-Transformation bleibt die Polstellen-Interlace-Konfigu-ration erhalten

Tiefpaß Bandpaß
-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
6
Real PartIm
agin
ary
Par
t-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
3
Real Part
Imag
inar
y P
art

D) Bandpaß-Brücken-Wellendigitalfilter
Polstellen von H(z):0.1992 + 0.9060i0.1992 - 0.9060i0.5279 + 0.7759i0.5279 - 0.7759i0.3466 + 0.7772i 0.3466 - 0.7772i
-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Real Part
Imag
inar
y P
art
[ ])z(B)z(Az8806.0z0557.11
z2561,0z4059,02561,0
z8605.0z3983.01z2561,0z1138,02561,0
z7242.0z6933.01z2561,02561,0)z(H
21
21
21
21
21
21
2
+⋅=⋅+⋅−
⋅+⋅−
⋅⋅+⋅−
⋅+⋅+⋅
⋅+⋅−⋅−
=
−−
−−
−−
−−
−−
−

-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Real Part
Imag
inar
y P
art
Allpaß-Dekomposition des Bandpaßfilters

-1 -0.5 0 0.5 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Real Part
Imag
inar
y P
art
21
21
21
21
z8605.0z3983.01zz3983.08605.0
z8806.0z0557.11zz0557.18806.0)z(A
−−
−−
−−
−−
⋅+⋅−+⋅−
⋅⋅+⋅−
+⋅−=
21
21
z7242.0z6933.01zz6933.07242.0)z(B −−
−−
⋅+⋅−+⋅−
=
Allpaß-Dekomposition des Bandpaßfilters

Bandpaß-Brücken-Wellendigitalfilter
x(k)Bandsperre : )k(y~Bandpaß : )k(y
1.8806
0.4386 0.7859
1.8605
1.7242
0.5979
21
21
21
21
z8605.0z3983.01zz3983.08605.0
z8806.0z0557.11zz0557.18806.0)z(A
−−
−−
−−
−−
⋅+⋅−+⋅−
⋅⋅+⋅−
+⋅−=
21
21
z7242.0z6933.01zz6933.07242.0)z(B −−
−−
⋅+⋅−+⋅−
=
Component

VHDL-Modell des Bandpaß-Brücken-Wellendigitalfilters
architecture structural of bruecken_wdf_bp iscomponent p_adaptor generic(g : signed(7 downto 0));
port(a1,a2 : in std_logic_vector(7 downto 0);b1,b2 : out std_logic_vector(7 downto 0));
end component;signal x_in,v1,v2,v3,v4,v5,v6,v7,v8,v9 : std_logic_vector(7 downto 0);signal u1,u2,u3,u4,u5,u6,u7,y1,y2,y_out : std_logic_vector(7 downto 0);beginp1: p_adaptor generic map(X"2D") port map(x_in,v1,u2,u1);p2: p_adaptor generic map(X"1A") port map(v2,v3,v1,u3);p3: p_adaptor generic map(X"FA") port map(u2,v4,y1,v5);p4: p_adaptor generic map(X"45") port map(u4,u5,v4,v6);p5: p_adaptor generic map(X"Af") port map(x_in,v9,y2,v7);p6: p_adaptor generic map(X"2F") port map(u6,v8,v9,u7);process(clk)variable y_s : signed(7 downto 0);begin
if clk'event and clk='1' thenx_in <= x;v2 <= u1;v3 <= u3;u4 <= v5;u5 <= v6;u6 <= v7;v8 <= u7;y <= y_out;
end if;y_s := signed(y1) + signed(y2);y_out <= std_logic_vector(y_s);
end process;end structural;

0 1000 2000 3000 4000 5000-80
-70
-60
-50
-40
-30
-20
-10
0
10
f/Hz
|H(f)
|/dB
4-Bit Koeffizientenohne Quantisierung
WDF-Amplitudengang

1600 1700 1800 1900 2000 2100-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
f/Hz
|H(f)
|/dB
8-Bit-Koeffizientenohne Quantisierung
WDF-Durchlaßbereich

1600 1700 1800 1900 2000 2100-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
f/Hz
|H(f)
|/dB
7-Bit-Koeffizientenohne Quantisierung
WDF-Durchlaßbereich
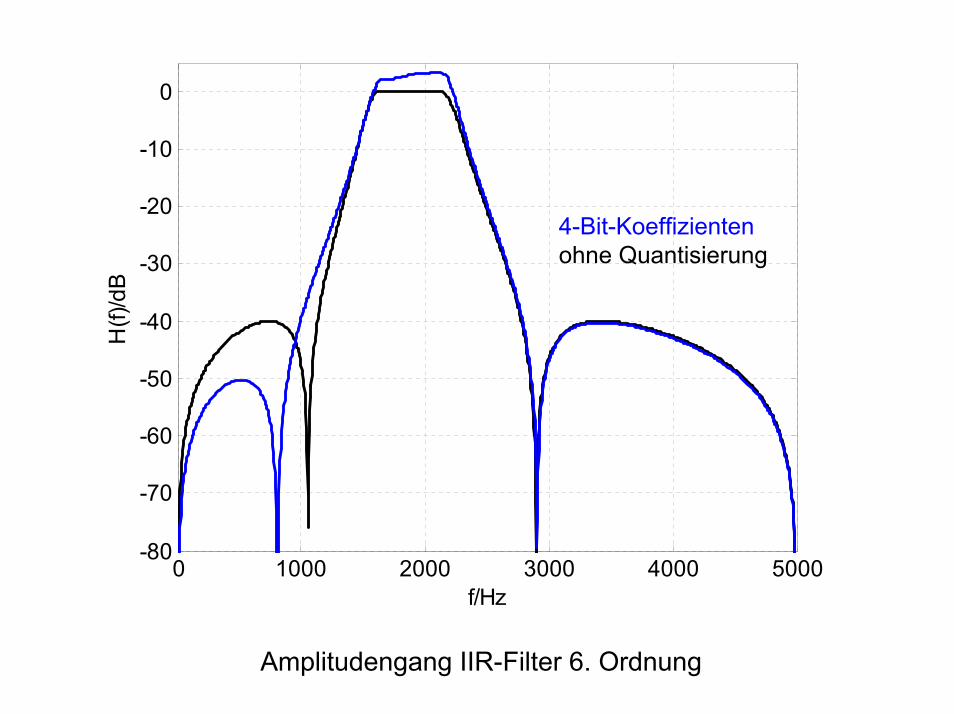
0 1000 2000 3000 4000 5000-80
-70
-60
-50
-40
-30
-20
-10
0H
(f)/d
B
f/Hz
4-Bit-Koeffizientenohne Quantisierung
Amplitudengang IIR-Filter 6. Ordnung

1600 1700 1800 1900 2000 2100-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
f/Hz
H(f)
/dB 11-Bit-Koeffizienten
ohne Quantisierung
Durchlaßbereich IIR-Filter 6. Ordnung

1600 1700 1800 1900 2000 2100-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
f/Hz
H(f)
/dB
10-Bit-Koeffizientenohne Quantisierung
Durchlaßbereich IIR-Filter 6. Ordnung

Synthesis Report eines Filters 6. Ordnung mit FPGA xxxC3
Macro/Features A-WDF B-WDF IIRMult 18x18 9 6 15Add/Sub 8 Bit 44 19 -Add/Sub 20 Bit - - 118-Bit-Register 10 8 84-LUT 350 152 209Slices 192 99 120TCLK(ns) 83,08 35,74 46,98Anzahl Koeffizienten 9 6 15Koeff.-Quantisierung 8 Bit 8 Bit 12 BitStabilität unbedingt bedingt bedingt
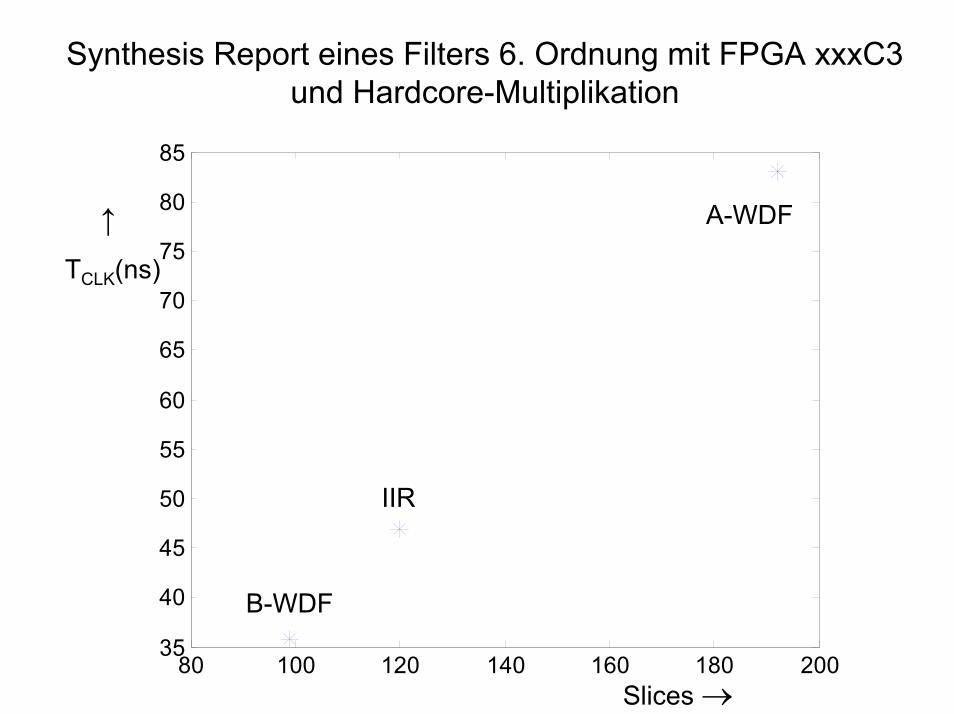
Synthesis Report eines Filters 6. Ordnung mit FPGA xxxC3 und Hardcore-Multiplikation
80 100 120 140 160 180 20035
40
45
50
55
60
65
70
75
80
85
Slices →
↑TCLK(ns)
B-WDF
IIR
A-WDF

WDF vs. IIR N. Ordnung mit Softcore-Multiplikation (Rad-3-Booth)
2 3 4 5 6 7 8 9 100
100
200
300
400
500
600
700
↑
Slices
N →
A-WDF
IIR
B-WDF

Wellendigitalfilter vs. IIR-Filter
• Ein Abzweig-Wellendigitalfilter ist prinzipiell stabil
• Bei einem Abzweig-Wellendigitalfilter treten keine Grenzzyklen auf
• Die Synthese von Abzweig-Wellendigitalfilter ist aufwendig, da entsprechende softwaregestützte Tools nicht existieren
• Die Eigenschaft der Allpaß-Dekomposition ist invariant gegenüber Frequenztransformationen
• Wellendigitalfilter benötigen weniger Multiplizierer
• Wellendigitalfilter benötigen erheblich mehr Addierer
• Wellendigitalfilter benötigen eine geringere Koeffizienten-Worlänge
• Mit Radix-3-Booth-Multiplizierern benötigt ein Brücken-Wellen-digitalfilter eine geringere Slice-Anzahl

5. Zusammenfassung
• Die Synthese-Performance wird entscheidend durch die Filterstruk-tur beeinflußt.
• Bei den FIR-Filtern zeigt die transponierter Form die beste Performance.
• Mit verteilter Arithmetik lassen sich FIR-Filter ohne die Verwendung von Multiplikations-Operationen implementieren.
• Brücken-Wellendigitalfilter weisen gegenüber IIR-Filtern eine deutlich bessere Performance auf.
• Der Radix-Booth-Multiplizierer ist eine Alternative zu dem Hardcore-Multiplizierer.
• In der Radix-3-Form benötigt der Booth-Multiplizierer die geringsten FPGA-Ressorcen.


















